flowchart LR
A["dict {k: v}"] --> B["d[key], .get()"]
A --> C["methods<br/>.keys, .values, .items"]
A --> D["💎 state_dict"]
A --> E["Counter, defaultdict"]
F["set {1, 2, 3}"] --> G["Unique + O(1) lookup"]
G --> H["💎 NLP vocabulary"]
F --> I["union | intersect &"]
I --> J["➡️ Data leakage check"]
style D fill:#fce4ec,stroke:#c2185b,stroke-width:3px
style H fill:#fce4ec,stroke:#c2185b,stroke-width:3px
style J fill:#fce4ec,stroke:#c2185b,stroke-width:3px
8 Sözlükler ve Setler
{k: v} ve {a, b} — state_dict, vocab, data leakage check
NotBölüm bilgisi
- Mosh’un videosu: Chapter 19 (Dictionaries) (≈7 dk) + Mosh’un göstermediği: Set
- Bölüm aralığı: 2:07:20 — 2:14:16 (+ Set bu derste eklendi)
- Kaynaklar: Python docs — dict · Python docs — set
- Okuma süresi: ≈35 dk
8.1 Bu Derste Ne Var?
Python’un dört temel koleksiyon yapısının ikincisi ve üçüncüsünü öğreneceksin: dictionary (dict) ve set. Liste sıralı koleksiyondu (Ders 4); dict anahtar-değer eşlemesi, set ise unique elemanların sırasız koleksiyonu.
Dersin beş parçası:
- Dictionary (sözlük). —
{"anahtar": "değer"}. Mosh’un ay-isim dönüştürücüsü. - Dict erişim ve metodlar. —
dict[k],.get(),.keys(),.values(),.items(). - Set (küme). —
{1, 2, 3}. Unique elemanlar. - Set operasyonları. —
|,&,-,^. - Dört koleksiyon karşılaştırması. — list/tuple/dict/set.
İpucuBuilder Notu — Bu Dersin ML Köprüleri
- Dict = JSON config / hyperparameter config. ML eğitim kodlarının %90’ında
config = {"lr": 1e-3, "batch_size": 64, "epochs": 100}. JSON dosyaları zaten dict olarak yüklenir (json.load(...)). - Dict = PyTorch
model.state_dict(). Modelin tüm ağırlıkları ad-tensor map’i. Model kaydetme/yükleme bu dict üzerinden işler. - Dict = HuggingFace tokenizer vocab.
tokenizer.vocabher tokeni id’sine map’ler:{"hello": 7592, "world": 2088, ...}. LLM’lerin temeli bu dict’tir. - Set = unique label collection. ML’de “kaç tane benzersiz sınıf var?” →
len(set(labels)). Vocabulary oluşturma. - Set = duplicate filtering.
list(set(items))yinelenenleri ayıkla. - Set operations = data filtering venn. Train set vs val set vs test set kelime kesişimi, örütme kontrolü.
collections.Counter,defaultdict. Standartdict’in güçlü kardeşleri.Counter(labels)ML class imbalance kontrolü için günlük pratik.
8.2 Dictionary — Anahtar-Değer Eşlemesi
Mosh:
“bir sözlük python’da bilgi depolamamıza izin veren özel bir yapıdır. ne denir anahtar değer çiftleri.” — Mosh (Türkçe dublaj), 2:07:31
8.2.1 Günlük Hayat Analojisi
Mosh kelimenin kendisinden faydalanıyor: “sözlük” gibi.
“kelime benzersiz bir şekilde tanımlayana benzer Sözlüğün içinde, ve sonra değer gerçek tanım olacaktır.” — Mosh (Türkçe dublaj), 2:08:02
- Kelime → anahtar (key).
- Tanım → değer (value).
8.2.2 Motivasyon — Ay Kısaltma Dönüştürücüsü
List ile (kötü):
kisaltmalar = ["Jan", "Feb", "Mar", ...]
tam_isimler = ["January", "February", "March", ...]
idx = kisaltmalar.index("Mar")
print(tam_isimler[idx])İki ayrı liste, indekslerin denkleşmesini elle sağlaman gerek. Kırılgan.
Dict ile (iyi):
ay_donusumleri = {
"Jan": "January",
"Feb": "February",
"Mar": "March",
}
print(ay_donusumleri["Mar"]) # March8.2.3 Sentaks
“açık ve kapalı kıvrımlı parantez” — Mosh (Türkçe dublaj), 2:09:08
sozluk_adi = {
anahtar1: deger1,
anahtar2: deger2,
anahtar3: deger3,
}Küme parantezi { } ile. Her giriş anahtar: değer. Aralarında virgül.
8.2.4 Anahtar Kuralları
“anahtarların hepsinin benzersiz olması gerekiyor.” — Mosh (Türkçe dublaj), 2:10:15
Üç kural:
- Unique — aynı anahtar iki kere yazılamaz.
- Immutable tip — anahtar
str,int,float,tuple,bool,frozensetolabilir. List/dict/set olamaz. - Hashable — yukarıdaki kısıtlamanın teknik adı.
# OK:
d = {"key": 1} # str
d = {42: "answer"} # int
d = {(3, 5): "point"} # tuple (Ders 4'te bu nedenle tuple gerekiyordu!)
# YANLIS:
d = {[1, 2]: "list"} # TypeError: unhashable8.2.5 Dict ML’in DNA’sı
İpucuBuilder Notu — 10 ML Pattern
ML kodunda dict 10+ farklı yerde:
# 1. Hyperparameter config:
config = {"lr": 1e-3, "batch_size": 64, "device": "cuda"}
# 2. JSON yükleme:
import json
with open("config.json") as f:
cfg = json.load(f) # cfg bir dict!
# 3. Model state_dict:
import torch
state = model.state_dict() # OrderedDict[str, Tensor]
torch.save(state, "model.pt")
# 4. Tokenizer vocab:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
vocab = tokenizer.get_vocab() # dict[str, int]
print(vocab["hello"]) # 7592
# 5. Dataset sample:
sample = {"image": tensor, "label": 7, "path": "img.jpg"}
# 6. Metric tracking:
metrics = {"loss": [], "acc": [], "f1": []}
# 7. Model outputs (HuggingFace):
outputs = model(input_ids)
print(outputs.logits) # dict-like ciktiMosh’un “ay-isim dönüştürücüsü” mikro örneği, yukarıdaki tüm pattern’ların çekirdeği. Tek bir kavram, on farklı görünüm.
8.3 Dict Erişim — [] ve .get()
8.3.1 Bracket Access
ay_donusumleri = {
"Jan": "January",
"Feb": "February",
"Nov": "November",
}
ay_donusumleri["Nov"] # 'November'
ay_donusumleri["Luc"] # KeyError: 'Luc'8.3.2 .get() — Güvenli Erişim
“get işlevini kullanmanın nesi harika Aslında kullanmak istediğim varsayılan bir değer belirtebilirim. eğer bu anahtarlar bulamazsa” — Mosh (Türkçe dublaj), 2:12:22
ay_donusumleri.get("Nov") # 'November'
ay_donusumleri.get("Luc") # None (hata yok!)
ay_donusumleri.get("Luc", "Bilinmeyen") # 'Bilinmeyen'Pratik:
# Sert (anahtar olmalı):
lr = config["learning_rate"]
# Yumusak (default ile):
lr = config.get("learning_rate", 1e-3)ML hyperparameter okuma çoğu zaman .get(...) ile default’lu.
8.3.3 Ekle / Değiştir / Sil
kullanici = {"ad": "Deniz", "yas": 35}
kullanici["sehir"] = "Istanbul" # ekle
kullanici["yas"] = 36 # değiştir
del kullanici["sehir"] # sil
yas = kullanici.pop("yas") # sil ve değeri al8.3.4 in Üyelik
"Jan" in ay_donusumleri # True
"XYZ" in ay_donusumleri # Falsein dict için anahtarı kontrol eder.
8.4 Dict Metodları
ay = {"Jan": "January", "Feb": "February", "Mar": "March"}
# Anahtarlar / değerler / çiftler:
ay.keys() # dict_keys(['Jan', 'Feb', 'Mar'])
ay.values() # dict_values(['January', 'February', 'March'])
ay.items() # dict_items([('Jan', 'January'), ...])
# Iteration:
for anahtar, deger in ay.items():
print(f"{anahtar} -> {deger}")
# Birleştir:
a = {"x": 1, "y": 2}
b = {"y": 99, "z": 3}
a.update(b) # a artik {"x": 1, "y": 99, "z": 3}
# Modern (Python 3.9+):
c = a | b # yeni dict8.4.1 Dict Comprehension
kareler = {x: x**2 for x in range(1, 6)}
# {1: 1, 2: 4, 3: 9, 4: 16, 5: 25}
kullanici = {"ad": "Deniz", "yas": 35}
buyuk_dict = {k.upper(): str(v).upper() for k, v in kullanici.items()}8.5 Counter ve defaultdict — Dict’in Güçlü Kardeşleri
8.5.1 Counter — Sayma
from collections import Counter
labels = ["kedi", "kopek", "kedi", "kus", "kedi", "kopek"]
counter = Counter(labels)
# Counter({'kedi': 3, 'kopek': 2, 'kus': 1})
counter.most_common(2)
# [('kedi', 3), ('kopek', 2)]ML class imbalance kontrolü:
from collections import Counter
class_counts = Counter(dataset_labels)
for cls, count in class_counts.most_common():
pct = count / len(dataset_labels) * 100
print(f" {cls}: {count} ({pct:.1f}%)")8.5.2 defaultdict — Otomatik Initialize
from collections import defaultdict
# Normal dict (uzun):
gruplar = {}
for n in [1, 2, 3, 4, 5]:
grup = "cift" if n % 2 == 0 else "tek"
if grup not in gruplar:
gruplar[grup] = []
gruplar[grup].append(n)
# defaultdict (kısa):
gruplar = defaultdict(list)
for n in [1, 2, 3, 4, 5]:
grup = "cift" if n % 2 == 0 else "tek"
gruplar[grup].append(n)8.6 Set — Unique Elemanlar
Mosh göstermez ama Python ekosisteminin temel parçası.
8.6.1 Set Nedir?
Set: sırasız + unique elemanlar.
sayilar = {1, 2, 3, 4, 5}
print(type(sayilar)) # <class 'set'>
karisik = {1, 2, 2, 3, 3, 3, 4}
print(karisik) # {1, 2, 3, 4} - yinelenenler kaybolduListe ile farklar:
- Sıra yok —
set[0]çalışmaz. - Unique — yinelenenler otomatik filtrelenir.
8.6.2 Sentaks Tuzağı
# Boş set:
bos = set() # bos set
yine_bos = {} # boş DICT! (set değil)
# Dolu:
sayilar = {1, 2, 3}
# Liste'den (deduplication):
from_list = set([1, 2, 2, 3, 3, 4]) # {1, 2, 3, 4}{} boş dict, set() boş set — Python tasarım kararı.
8.6.3 Set Metodları
sayilar = {1, 2, 3}
sayilar.add(4) # {1, 2, 3, 4}
sayilar.add(2) # zaten var, hicbir sey olmaz
sayilar.remove(2) # {1, 3, 4}
sayilar.discard(100) # OK (remove → KeyError)
n = sayilar.pop() # rastgele eleman çıkar
len({1, 2, 3, 4, 5}) # 5
3 in {1, 2, 3} # True8.6.4 Set’in Süper Gücü — in O(1)
import time
n = 1_000_000
liste = list(range(n))
kume = set(liste)
# Liste'de arama: O(n)
start = time.time()
print(n - 1 in liste)
print(f"List: {time.time() - start:.4f}s")
# 0.0150s
# Set'te arama: O(1)
start = time.time()
print(n - 1 in kume)
print(f"Set: {time.time() - start:.7f}s")
# 0.0000003s50,000 kat hızlı. Set hash table kullanır.
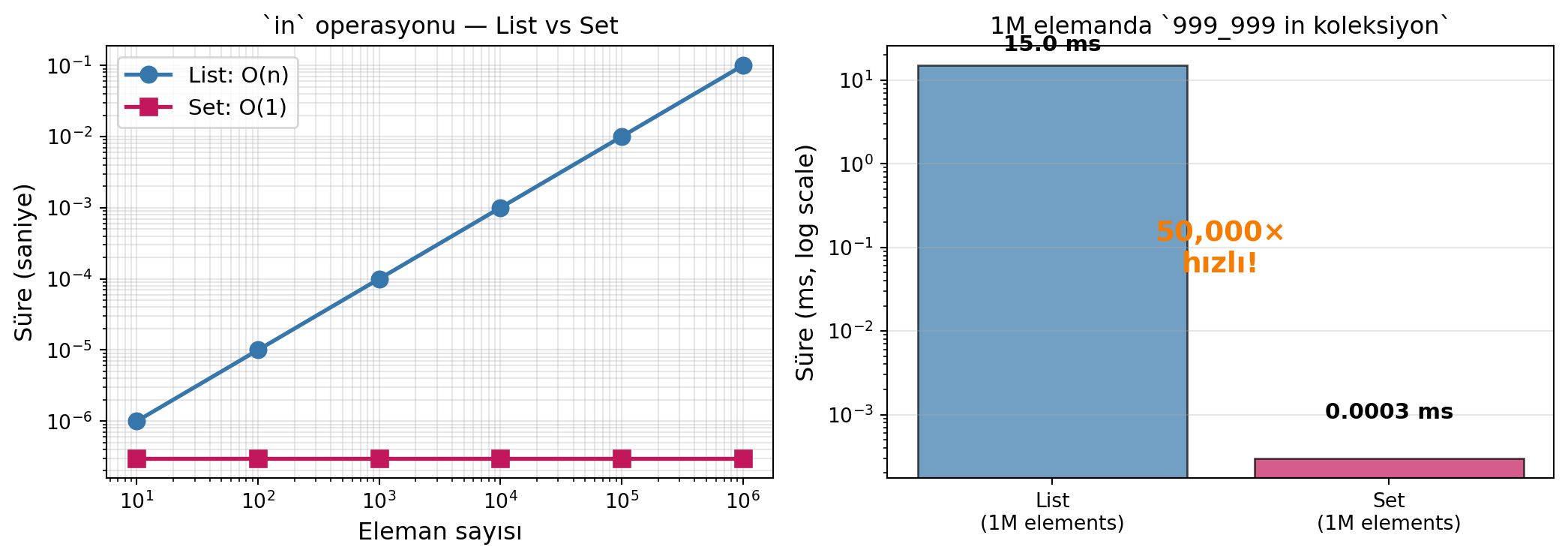
in operasyonu için 50K kat hız farkı
8.7 Set Operasyonları — Küme Matematiği
a = {1, 2, 3, 4, 5}
b = {4, 5, 6, 7, 8}
a | b # {1, 2, 3, 4, 5, 6, 7, 8} birleşim
a & b # {4, 5} kesişim
a - b # {1, 2, 3} fark
a ^ b # {1, 2, 3, 6, 7, 8} simetrik fark
# Alt-küme:
{1, 2} <= {1, 2, 3} # True
{1, 2} < {1, 2} # False (esit, oz degil)8.7.1 Vocabulary Oluşturma (NLP)
İpucuBuilder Notu — NLP Vocab
documents = [
"the cat sat on the mat",
"the dog ate the bone",
"a cat and a dog",
]
vocab = set()
for doc in documents:
vocab.update(doc.split())
print(f"Vocab size: {len(vocab)}") # 108.7.2 Train/Val/Test Data Leakage Check
ÖnemliBuilder Notu — Data Leakage
Üretim ML’inde kritik kontrol:
# Test ID'leri train'de var mı? (data leakage)
train_ids = set(train_df["id"])
test_ids = set(test_df["id"])
leakage = train_ids & test_ids
if leakage:
print(f"WARNING: {len(leakage)} ID train+test'te")
# Val'da train'de görünmemiş kelimeler:
train_vocab = set(...)
val_vocab = set(...)
unseen_val = val_vocab - train_vocabMilyon kayıt için saniyede biter.
8.8 Dört Koleksiyon — Karşılaştırma
| Özellik | list [1, 2] |
tuple (1, 2) |
dict {a: 1} |
set {1, 2} |
|---|---|---|---|---|
| Sıralı | Evet | Evet | Evet (3.7+) | Hayır |
| Değişebilir | Evet | Hayır | Evet | Evet |
| Yinelenen OK | Evet | Evet | Anahtar değil | Hayır |
| Erişim | l[i] |
t[i] |
d[key] |
in |
| Hashable mi? | Hayır | Evet | Hayır | Hayır (frozenset evet) |
| Sentaks | [a, b] |
(a, b) |
{a: 1} |
{a, b} |
8.8.1 Karar Akışı
Sıralı mı olmalı?
├── HAYIR → Set (unique + üyelik kontrolü hızlı)
└── EVET:
└── Anahtar-değer mi?
├── EVET → Dict
└── HAYIR:
└── Değişecek mi?
├── EVET → List
└── HAYIR → Tuple8.8.2 Pratik
# List:
losses = [0.5, 0.4, 0.3] # epoch sirasi onemli
friends = ["Kevin", "Karen"] # eklenebilir
# Tuple:
input_shape = (3, 224, 224) # tensor boyutu
rgb = (255, 0, 0) # sabit
# Dict:
config = {"lr": 1e-3, "batch_size": 64}
# Set:
seen_ids = {1, 5, 23, 7} # bir id gorduk mu?8.9 Bu Dersin Özeti
- Dict (
{}): anahtar-değer eşlemesi. Anahtarlar unique + hashable. - Erişim:
d[k]sert,.get(k, default)yumuşak. - Iteration:
.keys(),.values(),.items(). indict için anahtarı kontrol.- Set (
{...}/set()): unique + sırasız + hızlıin. - Set ops:
|,&,-,^. {}boş dict,set()boş set.Counter,defaultdict—collectionsgüçlü kardeşler.- ML eki: dict her yerde (config/state_dict/vocab), set vocab+dedup+filter için kritik.
ÖnemliTek Bir Cümle
Dict ({anahtar: değer}) anahtarla hızlı arama yapar — Mosh’un ay-isim örneği aslında PyTorch’taki model.state_dict(), HuggingFace tokenizer vocab’ı, ve JSON config dosyalarının ata-formudur; set ({1, 2, 3}) unique elemanları sırasız tutar ve in kontrolünü O(1)’e indirir — NLP vocabulary, label dedup, ve train/val data leakage kontrolünün günlük aracı.
8.10 Egzersizler
Egzersiz 1. Öğrenci sicil dict — 5 öğrenci, notlar list:
sicil = {
"Deniz": [85, 90, 78],
???
}
# (a) "Aylin" ekle, notları [95, 88, 92]
# (b) "Deniz"in notuna 80 ekle
# (c) "Mosh"un ortalaması
# (d) Tüm ortalamalarEgzersiz 2. Kelime sayma — manuel + Counter:
cumle = "the quick brown fox jumps over the lazy dog the dog naps"
# Manuel:
kelime_sayilari = {}
for kelime in cumle.split():
kelime_sayilari[kelime] = kelime_sayilari.get(kelime, 0) + 1
# Counter (tek satır):
from collections import Counter
sayilar = Counter(cumle.split())Egzersiz 3. Liste kesişim/fark — set ile:
a = [1, 2, 3, 4, 5, 6]
b = [4, 5, 6, 7, 8, 9]
kesisim_set = set(a) & set(b)
fark_set = set(a) - set(b)
print(kesisim_set) # {4, 5, 6}
print(fark_set) # {1, 2, 3}1 milyon eleman için hangisi pratik?
Egzersiz 4. ML config güvenli erişim:
config = {
"model": "resnet18",
"lr": 1e-3,
"batch_size": 64,
}
# Zorunlu:
model_name = config["model"]
lr = config["lr"]
# Opsiyonel:
epochs = config.get(???) # default 100
device = config.get(???) # default "cpu"
weight_decay = config.get(???) # default 0.0Egzersiz 5. (Builder eksen — model state JSON)
import json
model_state = {
"layer1.weight": [[0.1, 0.2], [0.3, 0.4]],
"layer1.bias": [0.0, 0.0],
"layer2.weight": [[0.5, 0.6], [0.7, 0.8]],
"layer2.bias": [0.1, 0.1],
}
# Kaydet:
with open("model.json", "w") as f:
json.dump(model_state, f)
# Yükle:
with open("model.json") as f:
loaded = json.load(f)
# Anahtar-shape print:
for name, weights in loaded.items():
if isinstance(weights[0], list):
shape = (len(weights), len(weights[0]))
else:
shape = (len(weights),)
print(f" {name}: shape={shape}")PyTorch torch.save / torch.load mekanizmasının JSON versiyonu.
8.11 Sonraki Ders İçin Hazırlık
Ders 8: Döngüler
Bu kursun en kritik dersi. Mosh dört chapter’da (While, Guessing Game, For, 2D Lists). for batch in dataloader: modern AI’nın ana motoru.
- Mosh’un Ch 20-22 ve Ch 24’ünü izle (2:14:16-2:52:44, ~38 dk).
- Şu cümleyi içselleştir: “Döngü = tekrar etme = bir grup veri üzerinde aynı işi yapma.”
İpucuBu dersten tek bir şey alıp gideceksen
Dict ({anahtar: değer}) anahtarla hızlı arama yapar — Mosh’un ay-isim örneği aslında PyTorch’taki model.state_dict(), HuggingFace tokenizer vocab’ı, ve JSON config dosyalarının ata-formudur; set ({1, 2, 3}) unique elemanları sırasız tutar ve in kontrolünü O(1)’e indirir — NLP vocabulary, label dedup, ve train/val data leakage kontrolünün günlük aracı; Python’un dört koleksiyon yapısı (list, tuple, dict, set) artık tam senin elinde, ve modern ML kodunun her satırı bu dördünden birinin üzerinde inşa edilmiş.