flowchart LR
A["Bağlam patlaması<br/>say-tablosu üstel büyür"] --> B["Embedding tablosu C<br/>id → küçük vektör"]
B --> C["MLP: birleştir<br/>.view ile concat"]
C --> D["gizli tanh katmanı<br/>@W1 + b1"]
D --> E["çıktı logitleri<br/>@W2 + b2"]
E --> F["F.cross_entropy<br/>NLL + sayısal kararlı"]
F --> G["minibatch + lr + split<br/>düzgün eğitim hattı"]
G --> H["örnekle<br/>yeni isim üret"]
style B fill:#f1f5f9,stroke:#475569,stroke-width:2px
style D fill:#eef2ff,stroke:#6366f1,stroke-width:2px
style F fill:#eef2ff,stroke:#6366f1,stroke-width:2px
style H fill:#e0e7ff,stroke:#1e293b,stroke-width:3px
4 makemore 2 — MLP (Bengio 2003)
Bağlamı say-tablosunda tutmak üstel patlar; her karakteri öğrenilen bir vektöre gömüp (embedding) bir MLP’den geçir — aynı ‘sonraki karakteri tahmin et’ problemi, bu kez ölçeklenebilir
NotBölüm bilgisi
- Karpathy’nin videosu: YouTube — Building makemore Part 2: MLP (≈76 dk)
- Seri: Neural Networks: Zero to Hero — Ders 3
- Hoca: Andrej Karpathy
- Kaynak repo: github.com/karpathy/makemore
- Okuma süresi: ≈30 dk
4.1 Bu Derste Ne Var?
Ders 2’de bigram modelini kurduk — ama yalnızca tek karaktere bakıyordu ve bağlamı büyütmek istediğimizde sayım tablosu üstel patlıyordu (\(27^3\), \(27^4\), …). Bu derste çözümü kuruyoruz: 2003 tarihli ünlü Bengio ve ark. makalesini izleyerek bir çok katmanlı algılayıcı (MLP) dil modeli.
“In the last lecture we implemented the bigram language model, and we implemented it both using counts and also using a super simple neural network that had a single linear layer.” — Karpathy, 0:00
Büyük fikir: karakterleri sayım tablosunda tutmak yerine, her karakteri küçük bir vektöre (embedding) gömeriz; birkaç karakterlik bağlamı bu vektörlerle bir gizli tanh katmanından geçirip bir sonraki karakteri tahmin ederiz. Sayım patlaması yok — çünkü artık sayıyor değil, öğreniyoruz (gradient descent).
Dersin üç büyük fikri:
- Embedding arama tablosu C — Ders 2’deki “one-hot @ W = satır seçimi” gözlemi burada somutlaşır: her karakter id’si, C tablosunun bir satırı (küçük bir vektör).
- MLP (Bengio 2003) — bağlam vektörlerini birleştir → gizli
tanhkatmanı → çıktı logitleri → softmax. Ders 1’in Neuron/Layer/MLP’sinin gerçek bir dil modeli hâli. - Eğitim pratikleri —
F.cross_entropy, minibatch SGD, öğrenme oranı taraması, train/dev/test bölmesi: ilk kez “düzgün” bir eğitim hattı.
İpucuBuilder Notu — Embedding, Ders 2’nin Ödülü
Geriye (Ders 1-2 + Stat 110):
- Embedding = Ders 2’nin ödülü. Ders 2’de “one-hot @ W, W’nin bir satırını seçer” demiştik; embedding tablosu C tam olarak budur — one-hot çarpımı israfı olmadan, id ile doğrudan satır seçimi.
- MLP = Ders 1. Gizli
tanhkatmanı + çıktı katmanı, micrograd’da kurduğumuz Neuron/Layer/MLP’nin tensör hâli;tanhtürevi (\(1 - \tanh^2\)) aynı. - Cross-entropy = Ders 2 NLL.
F.cross_entropy, Ders 2’de elle yazdığımız NLL’in sayısal-kararlı ve hızlı PyTorch hâli (Stat 110 MLE). - Minibatch / overfitting = Ders 1. Ders 1 §9 mini-batch SGD (varyans \(\propto 1/B\)) ve §10 overfitting/regularization burada gerçek veride uygulanır.
İleriye: Bu MLP, serinin geri kalanının iskeleti. Ders 4’te tam bu ağın aktivasyon/gradyan istatistiklerini düzeltip BatchNorm ekleyeceğiz; Ders 5’te aynı ağın backward’ını elle yazacağız. Embedding fikri ise doğrudan GPT’nin token embedding tablosuna gider.
Tek cümleyle: Bağlamı sayım tablosunda tutmak üstel patlar; bunun yerine her karakteri öğrenilen bir vektöre gömüp (embedding) bir MLP’den geçirmek, aynı “sonraki karakteri tahmin et” problemini ölçeklenebilir kılar.
4.2 Bigram’ın Sınırı ve Bağlam Patlaması
Ders 2’nin bigram modeli yalnızca bir önceki karaktere bakardı. Daha iyi tahmin için daha çok bağlam gerek — örneğin son 3 karaktere bakmak. Ama sayım yaklaşımıyla bu felaket: 3 karakter bağlamı için tablo \(27 \times 27 \times 27 = 19\,683\) satır; 10 karakter için \(27^{10}\) (\(\approx 200\) trilyon) — imkânsız. Her ek karakter, tabloyu 27 kat büyütür ve çoğu hücre hiç görülmez (sıfır sayım).
Çözüm: sayım yerine öğrenme. Karakterleri ayrık tablo hücreleri olarak değil, sürekli bir uzayda vektörler olarak temsil edersek, model benzer karakterleri (örn. sesli harfler) birbirine yakın yerleştirip genelleyebilir. İşte Bengio 2003’ün fikri.
İpucuBuilder Notu — Ayrık Tablo → Sürekli Uzay
Geriye (Ders 2): Bu, Ders 2’nin son egzersizinin (\(27^n\) patlaması) cevabı. Sayım, parametreyi veriye “ezberletir”; öğrenilen embedding ise genelleme yapar.
İleriye: “Ayrık tablo → sürekli vektör uzayı” geçişi, tüm modern NLP’nin temelidir (word2vec, GPT embedding’leri). Bağlamı büyütmenin maliyeti artık üstel değil, doğrusal/parametrik.
4.3 Bengio 2003 Makalesi
Karpathy makaleyi ekranda açar. Bu, sinir ağlarıyla dil modellemeyi öneren ilk makale değil ama en etkililerinden:
“So I have the paper pulled up here. Now this isn’t the very first paper that proposed the use of MLPs or neural networks to predict the next character or token in a sequence, but it’s definitely one that was very influential around that time.” — Karpathy, 2:01
Makalenin mimarisi: her kelime (Bengio’da kelime, bizde karakter) bir arama tablosundan (lookup table, \(C\)) küçük bir vektöre çevrilir. Bağlamdaki tüm vektörler birleştirilip bir gizli katmana, oradan da tüm sözlük üzerinde bir softmax çıktısına gider. Karpathy bu vektörlerin (embedding) eğitim sırasında backprop ile öğrenildiğini vurgular: benzer anlamlı öğeler uzayda birbirine yaklaşır.
İpucuBuilder Notu — Bengio = Transformer’ın İskeleti
İleriye: Bengio 2003 mimarisi — embedding + gizli katman + softmax — 20 yıl sonra transformer’ın da iskeletidir; transformer yalnızca “bağlamı birleştirme” kısmını (concatenation) dikkat mekanizmasıyla (Ders 7) değiştirir. Temel fikir aynı kalır.
4.4 Eğitim Veri Setini Kurmak (block_size)
Önce veriyi MLP’ye uygun hâle getiririz. block_size, kaç önceki karaktere bakacağımız (bağlam uzunluğu). Karpathy 3 ile başlar: “3 karakter gör, 4.’yü tahmin et.” Her isim, kayan bir pencereyle birçok (bağlam → hedef) örneğine bölünür.
block_size = 3 # kac karaktere bakarak tahmin ediyoruz
def build_dataset(words):
X, Y = [], []
for w in words:
context = [0] * block_size # '...' ile basla (hepsi nokta)
for ch in w + '.':
ix = s2i[ch]
X.append(context) # girdi: son 3 karakter id
Y.append(ix) # hedef: sonraki karakter
context = context[1:] + [ix] # pencereyi kaydir
return torch.tensor(X), torch.tensor(Y)
X, Y = build_dataset(words) # X: (n, 3), Y: (n,)context = context[1:] + [ix] satırı pencereyi kaydırır: en eski karakteri atar, yeni karakteri ekler. Örneğin “emma” için: ... -> e, ..e -> m, .em -> m, emm -> a, mma -> . — yani 5 örnek. X’in her satırı 3 tamsayı id, Y ise hedef id. Tüm isimlere uygulandığında veri seti 228.146 örneğe ulaşır (X şekli \((228146, 3)\), Y şekli \((228146,)\)).
Kod
import torch
import matplotlib.pyplot as plt
from matplotlib.patches import Rectangle, FancyArrowPatch
# Determinizm: figür yalnızca build_dataset'in sabit çıktısına dayanır (rastgelelik
# yok); ilke gereği yine de tohumu sabitliyoruz (apply_style KULLANILMAZ — şema).
torch.manual_seed(SEED)
# ---------------------------------------------------------------------------
# GERÇEK veri: 'emma' kelimesini build_dataset(block_size=3) ile 5 örneğe böl.
# X[k] = son 3 karakterin id'leri, Y[k] = sonraki karakterin id'si.
# Beklenen: ...→e(5), ..e→m(13), .em→m(13), emm→a(1), mma→.(0).
# ---------------------------------------------------------------------------
Xe, Ye = build_dataset(["emma"], block_size=3) # X (5,3) int, Y (5,) int
X_ids = Xe.tolist() # 5 satır, her biri 3 id
Y_ids = Ye.tolist() # 5 hedef id
n_satir = len(X_ids) # 5
block = 3 # block_size
fig, ax = plt.subplots(figsize=(11, 6))
fig.patch.set_facecolor(COL_WHITE)
ax.set_facecolor(COL_WHITE)
# ---------------------------------------------------------------------------
# Yerleşim (eksen birimleri). Soldan sağa: 3 bağlam hücresi | ok | hedef hücresi.
# Satırlar üstten alta dizilir (satır 0 en üstte).
# ---------------------------------------------------------------------------
hucre = 0.9 # bir bağlam/hedef hücresinin kenarı
bosluk = 0.18 # bağlam hücreleri arası boşluk
ctx_x0 = 0.6 # ilk bağlam hücresinin sol kenarı
ctx_genislik = block * hucre + (block - 1) * bosluk
ok_x0 = ctx_x0 + ctx_genislik + 0.35 # okun başlangıcı
ok_x1 = ok_x0 + 1.1 # okun bitişi
hedef_x = ok_x1 + 0.35 # hedef hücrenin sol kenarı
satir_yuk = hucre + 0.55 # satırlar arası dikey adım
def hucre_y(r):
"""r. satırın (0 üstte) hücre alt-kenarı y konumu."""
return (n_satir - 1 - r) * satir_yuk
# ---------------------------------------------------------------------------
# Her satırı çiz: 3 bağlam hücresi + ok + hedef. En sağdaki bağlam hücresi
# (yeni eklenen) indigo çerçeveyle, bir önceki satırdan ATILAN karakter soluk
# slate kutuyla (sol dışında) gösterilir.
# ---------------------------------------------------------------------------
for r in range(n_satir):
y = hucre_y(r)
ctx = X_ids[r] # bu satırın 3 bağlam id'si
hedef = Y_ids[r]
# --- 3 bağlam hücresi ---
for c in range(block):
cx = ctx_x0 + c * (hucre + bosluk)
cid = ctx[c]
ch = i2s[cid]
nokta = (cid == 0) # '.' başlangıç token'ı mı?
yeni = (c == block - 1) # en sağ hücre = bu adımda eklenen yeni karakter
# Dolgu: '.' -> slate-100 (COL_BG), gerçek harf -> indigo (COL_ACCENT).
if nokta:
fc = COL_BG
txt_col = COL_PRIMARY
else:
fc = COL_ACCENT
txt_col = COL_WHITE
# Çerçeve: yeni eklenen hücre koyu indigo + kalın (vurgu).
ec = COL_INDIGO_600 if yeni else COL_SLATE_400
lw = 2.8 if yeni else 1.1
ax.add_patch(Rectangle((cx, y), hucre, hucre, facecolor=fc,
edgecolor=ec, linewidth=lw, zorder=3))
ax.text(cx + hucre / 2, y + hucre / 2, ch, ha="center", va="center",
fontsize=18, color=txt_col, weight="bold", zorder=4)
# id altsimgesi (küçük, hücre altında)
ax.text(cx + hucre / 2, y - 0.04, f"id {cid}", ha="center", va="top",
fontsize=8, color=COL_SLATE_400, zorder=4)
# --- ATILAN karakter: bir sonraki adımda pencereden düşecek en sol karakter ---
# (Son satır hariç; her satırın en solundaki karakter bir SONRAKI satırda atılır.)
if r < n_satir - 1:
drop_id = ctx[0]
drop_ch = i2s[drop_id]
dcx = ctx_x0 - 0.02
# En sol hücrenin üzerine soluk "atılacak" işareti (kesik kontur)
ax.add_patch(Rectangle((ctx_x0, y), hucre, hucre, facecolor="none",
edgecolor=COL_SLATE_400, linewidth=1.4,
linestyle=(0, (3, 2)), zorder=5))
# --- ok (bağlam -> hedef) ---
ymid = y + hucre / 2
ax.add_patch(FancyArrowPatch(
(ok_x0, ymid), (ok_x1, ymid),
arrowstyle="-|>", mutation_scale=20,
color=COL_PRIMARY, linewidth=2.0, zorder=3,
))
# --- hedef hücresi (sonraki karakter) ---
h_ch = i2s[hedef]
h_nokta = (hedef == 0)
h_fc = COL_BG if h_nokta else COL_ACCENT
h_txt = COL_PRIMARY if h_nokta else COL_WHITE
ax.add_patch(Rectangle((hedef_x, y), hucre, hucre, facecolor=h_fc,
edgecolor=COL_INDIGO_600, linewidth=2.4, zorder=3))
ax.text(hedef_x + hucre / 2, y + hucre / 2, h_ch, ha="center", va="center",
fontsize=18, color=h_txt, weight="bold", zorder=4)
ax.text(hedef_x + hucre / 2, y - 0.04, f"id {hedef}", ha="center", va="top",
fontsize=8, color=COL_SLATE_400, zorder=4)
# ---------------------------------------------------------------------------
# Sütun başlıkları (en üst satırın üstünde)
# ---------------------------------------------------------------------------
y_baslik = hucre_y(0) + hucre + 0.30
ax.text(ctx_x0 + ctx_genislik / 2, y_baslik,
"bağlam (son 3 karakter)", ha="center", va="bottom",
fontsize=12, color=COL_TEXT, weight="bold")
ax.text(hedef_x + hucre / 2, y_baslik, "hedef", ha="center", va="bottom",
fontsize=12, color=COL_INDIGO_600, weight="bold")
# Kayma yönü açıklaması (sol kenarda, dikey ok aşağı)
ax.annotate(
"", xy=(ctx_x0 - 0.45, hucre_y(n_satir - 1) + hucre / 2),
xytext=(ctx_x0 - 0.45, hucre_y(0) + hucre / 2),
arrowprops=dict(arrowstyle="-|>", color=COL_INDIGO_400, lw=2.0),
)
ax.text(ctx_x0 - 0.62, (hucre_y(0) + hucre_y(n_satir - 1) + hucre) / 2,
"pencere kayar", ha="center", va="center", rotation=90,
fontsize=10.5, color=COL_INDIGO_400, weight="bold")
# Alt açıklama: yeni vs atılan hücre lejantı.
ax.text((ctx_x0 + hedef_x + hucre) / 2, hucre_y(n_satir - 1) - 0.95,
"indigo dolu = gerçek harf · slate dolu = '.' başlangıç token'ı · "
"kalın indigo çerçeve = yeni eklenen · kesik çerçeve = bir sonraki adımda atılacak",
ha="center", va="center", fontsize=9.5, color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.5", fc=COL_BG, ec=COL_ACCENT, lw=1.3))
ax.set_xlim(ctx_x0 - 1.2, hedef_x + hucre + 0.6)
ax.set_ylim(hucre_y(n_satir - 1) - 1.7, y_baslik + 0.5)
ax.set_aspect("equal")
ax.axis("off")
ax.set_title("'emma' → 5 (bağlam → hedef) örneği: block_size=3 kayan pencere",
color=COL_TEXT, fontsize=13, pad=10)
plt.tight_layout()
plt.show()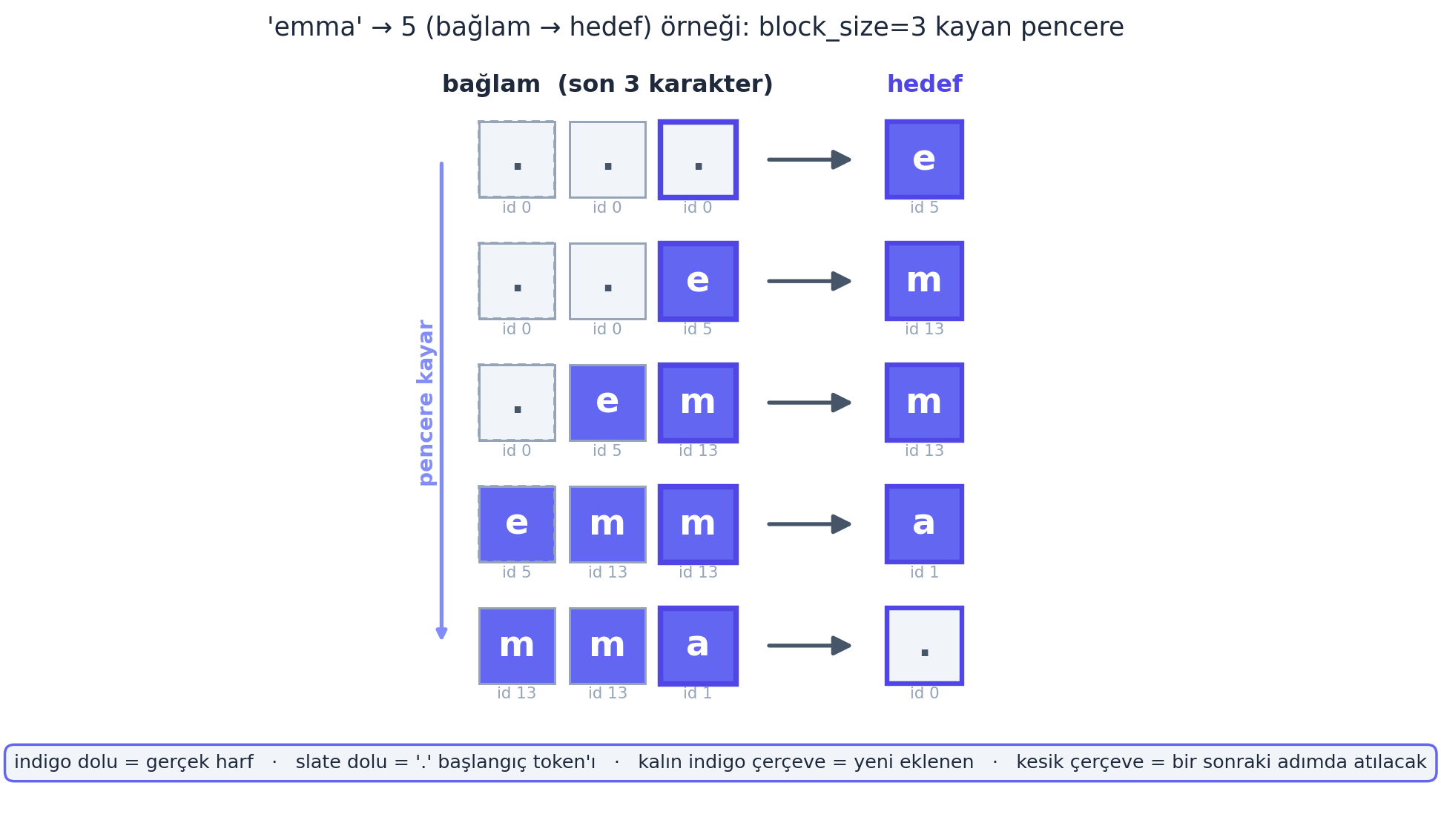
block_size kayan pencere: ‘emma’ kelimesi build_dataset(block_size=3) ile 5 (bağlam → hedef) örneğine bölünür. Her satır 3 hücreli bağlamı (s2i: .\(=0\), a\(=1\), e\(=5\), m\(=13\)) ve hedef karakteri gösterir: ...\(\to\)e, ..e\(\to\)m, .em\(\to\)m, emm\(\to\)a, mma\(\to\). — yani \(5\) örnek. Pencere her adımda sağa kayar: en sağdaki yeni hücre (indigo) eklenir, en soldaki atılan karakter (soluk slate) düşer. . başlangıç token’ları slate-100 dolgulu, gerçek harfler indigo dolguludur.
İpucuBuilder Notu — Kayan Pencere = Veri Yükleyicinin Çekirdeği
İleriye: Bu kayan bağlam penceresi, her dil modelinin veri yükleyicisinin çekirdeği. GPT’de block_size yüzlerce/binlerce token olur (Ders 7’de context length). Bağlamı sabit tutmak (fixed-context) MLP’nin sınırı; transformer bunu uzun bağlama taşır.
4.5 Embedding Arama Tablosu C
Şimdi Ders 2’nin ödülü. Her karakter id’sini küçük bir vektöre gömeriz. C bir matris: 27 satır (her karakter), her satır küçük bir vektör (örn. 2 boyutlu). Bir id’nin embedding’i = C’nin o satırı.
C = torch.randn((27, 2)) # 27 karakter, her biri 2-boyutlu vektor
emb = C[X] # (n, 3, 2): her ornek icin 3 karakterin embedding'iC[X] PyTorch’un güzel bir özelliği: X bir tamsayı tensörü \((n, 3)\), C[X] her id’yi C’nin ilgili satırıyla değiştirir → sonuç \((n, 3, 2)\). Bu, Ders 2’deki “one-hot @ W = satır seçimi”nin doğrudan, verimli hâli — one-hot çarpımı yapmadan id ile indeksleme.
“There’s also a lookup table that they call C. This lookup table is a matrix…” — Karpathy, 6:17
Kod
import torch
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.patches import Rectangle, FancyArrowPatch
# Deterministik C (Karpathy'nin meşhur tohumu) — figür her render'da aynı.
torch.manual_seed(SEED)
N_EMBED = 10 # ANA modelle aynı embedding boyutu
params = init_params(n_embed=N_EMBED, n_hidden=200, seed=SEED)
C = params[0].detach() # (27, n_embed) embedding tablosu
C_np = C.numpy()
# Tek bir bağlam örneği: 'emma' kayan penceresinden '.em' satırı -> [0, 5, 13].
Xrow = build_dataset(["emma"])[0][2] # tensor([0, 5, 13]) = .em
ids = Xrow.tolist() # [0, 5, 13]
emb = C[Xrow] # (3, n_embed): bu örneğin embedding'i
emb_np = emb.numpy()
# id -> görüntülenecek karakter etiketi ('.'=0, e=5, m=13)
labels = [i2s[i] for i in ids] # ['.', 'e', 'm']
fig, ax = plt.subplots(figsize=(11, 5))
fig.patch.set_facecolor(COL_WHITE)
ax.set_facecolor(COL_WHITE)
# ---------------------------------------------------------------------------
# Yerleşim koordinatları. Soldan sağa: X (3 id) | C tablosu (27 x n_embed) | sonuç (3 x n_embed)
# ---------------------------------------------------------------------------
hucre = 0.30 # bir hücre kenarı
id_x = 0.55 # X id sütununun x konumu (dikey 3'lük)
C_x0 = 2.7 # C ızgarasının sol kenarı
C_x1 = C_x0 + N_EMBED * hucre # C ızgarasının sağ kenarı
res_x = C_x1 + 2.7 # sonuç ızgarasının sol kenarı (geniş aralık)
res_x1 = res_x + N_EMBED * hucre # sonuç ızgarasının sağ kenarı
y_top = VOCAB * hucre # C sütununun üst kenarı (0..27 satır)
# C imshow için tutarlı renk ölçeği (slate/Greys)
vlim = float(np.abs(C_np).max())
# ---------------------------------------------------------------------------
# SOL: X satırı = 3 tamsayı id (dikey kutu dizisi). 'emma' -> .em = [0, 5, 13]
# ---------------------------------------------------------------------------
# id kutularını ferah dikey aralıkla, C ızgarasının dikey ortasına hizala.
id_box = 0.42 # id kutusu biraz büyük (okunaklı)
id_gap = 0.55 # kutular arası dikey aralık (oklar ayrışsın)
y_blok_top = y_top * 0.74 # üst id kutusunun üst kenarı
id_centers_y = []
for k, (idv, lab) in enumerate(zip(ids, labels)):
y = y_blok_top - k * id_gap - id_box
id_centers_y.append(y + id_box / 2)
ax.add_patch(Rectangle(
(id_x, y), id_box, id_box,
facecolor=COL_ACCENT, edgecolor=COL_INDIGO_600, linewidth=1.6, zorder=3,
))
ax.text(id_x + id_box / 2, y + id_box / 2, str(idv), ha="center", va="center",
fontsize=11, color=COL_WHITE, weight="bold", zorder=4)
# karakter etiketi (kutu solunda)
ax.text(id_x - 0.10, y + id_box / 2, f"`{lab}`", ha="right", va="center",
fontsize=9.5, color=COL_PRIMARY)
ax.text(id_x + id_box / 2, y_blok_top + 0.16, "bağlam X", ha="center", va="bottom",
fontsize=11, color=COL_TEXT, weight="bold")
y_blok_bot = y_blok_top - 2 * id_gap - id_box # alt id kutusunun alt kenarı
ax.text(id_x + id_box / 2, y_blok_bot - 0.14, r"`.em` $=[0,5,13]$", ha="center",
va="top", fontsize=9, color=COL_INDIGO_600)
# ---------------------------------------------------------------------------
# ORTA: C ağırlık matrisi (27 x n_embed) imshow; seçilen 3 satır indigo vurgulu
# ---------------------------------------------------------------------------
extent = [C_x0, C_x1, y_top - VOCAB * hucre, y_top] # [sol, sağ, alt, üst]
ax.imshow(C_np, cmap="Greys", extent=extent, aspect="auto",
origin="upper", alpha=0.85, zorder=2, vmin=-vlim, vmax=vlim)
# ızgara dış çerçevesi
ax.add_patch(Rectangle((C_x0, y_top - VOCAB * hucre), N_EMBED * hucre, VOCAB * hucre,
facecolor="none", edgecolor=COL_SLATE_400, linewidth=1.0, zorder=3))
ax.text((C_x0 + C_x1) / 2, y_top + 0.32, "embedding tablosu", ha="center", va="bottom",
fontsize=11, color=COL_TEXT, weight="bold")
ax.text((C_x0 + C_x1) / 2, y_top + 0.05, r"$C$ ($27 \times n_{embed}$)", ha="center",
va="bottom", fontsize=9.5, color=COL_PRIMARY)
# Seçilen 3 satırı indigo dikdörtgenle vurgula + id'den satıra ok çiz
row_centers_y = []
for k, idv in enumerate(ids):
row_y = y_top - (idv + 1) * hucre # üstten idv. satır
row_centers_y.append(row_y + hucre / 2)
ax.add_patch(Rectangle((C_x0, row_y), N_EMBED * hucre, hucre,
facecolor="none", edgecolor=COL_INDIGO_600,
linewidth=2.4, zorder=4))
# id kutusundan C'deki ilgili satıra ok
arrow = FancyArrowPatch(
(id_x + id_box + 0.03, id_centers_y[k]),
(C_x0 - 0.03, row_y + hucre / 2),
connectionstyle="arc3,rad=0.0", arrowstyle="-|>", mutation_scale=13,
color=COL_INDIGO_600, linewidth=1.5, zorder=5,
)
ax.add_patch(arrow)
# satır id etiketi (ızgara sağında)
ax.text(C_x1 + 0.08, row_y + hucre / 2, f"satır {idv}", ha="left", va="center",
fontsize=8, color=COL_INDIGO_600, weight="bold")
# n_embed sütun göstergesi (alt eksen)
ax.text((C_x0 + C_x1) / 2, y_top - VOCAB * hucre - 0.18,
r"$n_{embed}$ sütun", ha="center", va="top", fontsize=8.5, color=COL_PRIMARY)
# ---------------------------------------------------------------------------
# SAĞ: sonuç (3 x n_embed) = her id'nin çekilen embedding satırı (indigo çerçeve).
# Dikeyde C ızgarasının ortasına hizalanır; her satır hücresi okunaklı (res_cell).
# ---------------------------------------------------------------------------
res_cell = 0.42 # sonuç satır yüksekliği
res_h = 3 * res_cell # toplam yükseklik
res_top = y_top / 2 + res_h / 2 # C ortasına hizalı üst kenar
res_bot = res_top - res_h
res_cy = (res_top + res_bot) / 2 # sonuç bloğunun dikey merkezi
# = işareti (C ile sonuç arası) — sonuç bloğunun yüksekliğinde, etiketlerle çakışmaz
ax.text((C_x1 + res_x) / 2 + 0.1, res_cy, r"$=$", ha="center", va="center",
fontsize=22, color=COL_PRIMARY, weight="bold")
res_extent = [res_x, res_x1, res_bot, res_top]
ax.imshow(emb_np, cmap="Greys", extent=res_extent, aspect="auto",
origin="upper", alpha=0.85, zorder=2, vmin=-vlim, vmax=vlim)
ax.add_patch(Rectangle((res_x, res_bot), N_EMBED * hucre, res_h,
facecolor="none", edgecolor=COL_INDIGO_600, linewidth=2.4, zorder=4))
# her sonuç satırının başına karakter etiketi
for k, lab in enumerate(labels):
ry = res_top - (k + 0.5) * res_cell
ax.text(res_x - 0.12, ry, f"`{lab}`", ha="right", va="center",
fontsize=9.5, color=COL_INDIGO_600, weight="bold")
ax.text((res_x + res_x1) / 2, res_top + 0.12, "sonuç", ha="center", va="bottom",
fontsize=11, color=COL_TEXT, weight="bold")
ax.text((res_x + res_x1) / 2, res_bot - 0.16,
r"$C[X]$ — şekil $(3, n_{embed})$", ha="center", va="top",
fontsize=9.5, color=COL_INDIGO_600)
# Alt açıklama: çarpma değil, satır çekme (embedding'in özü).
ax.text((id_x + res_x1) / 2, -0.95,
r"$C[X]$ = one-hot $@\, W$ satır seçiminin verimli hâli (18.06 baz vektörü), çarpım masrafı yok",
ha="center", va="center", fontsize=10.5, color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.5", fc=COL_BG, ec=COL_ACCENT, lw=1.4))
ax.set_xlim(-0.5, res_x1 + 1.2)
ax.set_ylim(-1.6, y_top + 0.95)
ax.set_aspect("equal")
ax.axis("off")
ax.set_title(r"$C[X]$ satır seçimi: id $\rightarrow$ embedding vektörü", color=COL_TEXT, fontsize=12)
plt.tight_layout()
plt.show()
.em \(= [0, 5, 13]\)) doğrudan \(C\)’nin (\(27 \times n_{embed}\)) o satırlarını indeksleyerek çeker — sonuç \((3, n_{embed})\). Bu, Ders 2’deki one-hot \(@\,W\) satır seçiminin verimli hâlidir (18.06 baz vektörü): one-hot vektörü kurup çarpmak yok, çarpım masrafı yok. Tüm batch için \(C[X]\) şekli \((n, 3, n_{embed})\) olur.
İpucuBuilder Notu — C[X] = Verimli Satır Seçimi
Geriye (Ders 2 + 18.06): C[X], Ders 2’deki xenc @ W’nin (one-hot ile satır seçimi) verimli karşılığı — aynı işlem, çarpım masrafı yok (18.06: baz vektörüyle çarpım = satır seçimi). C’nin satırları eğitim sırasında backprop ile öğrenilir.
İleriye: Embedding tablosu, GPT’nin wte (word token embedding) tablosunun ta kendisi (Ders 10). Öğrenilen embedding uzayında benzer token’lar kümelenir — §13’te bunu gözle göreceğiz.
4.6 Gizli Katman ve tensör .view()
Embedding’leri \((n, 3, 2)\) gizli katmana vermeden önce düzleştirmek gerekir: 3 karakterin 2’şer boyutlu vektörünü tek bir 6-boyutlu vektörde birleştir → \((n, 6)\). Karpathy bunun için .view() kullanır ve tensör iç yapısına (storage/strides) kısa bir gezinti yapar.
W1 = torch.randn((6, 100)) # giris 6 (=3*2), gizli 100 noron
b1 = torch.randn(100)
h = torch.tanh(emb.view(-1, 6) @ W1 + b1) # (n, 100), gizli aktivasyonemb.view(-1, 6) embedding’i \((n, 3, 2)\) → \((n, 6)\) yeniden şekillendirir. .view() veriyi kopyalamaz, yalnızca aynı bellek üzerindeki “görünümü” değiştirir (storage + strides) — bu yüzden çok ucuzdur. Sonra @ W1 + b1 (lineer katman) ve tanh (Ders 1’in aktivasyonu) ile gizli katman aktivasyonu h elde edilir.
“There are usually many ways of implementing what you’d like to do in torch, and some of them will be faster, better, shorter, etc.” — Karpathy, 19:54
İpucuBuilder Notu — .view() = Bellek Düzeni Farkındalığı
Geriye (Ders 1 + 18.06): emb.view(-1,6) @ W1 + b1, Ders 1’in \(Wx + b\) lineer katmanı (18.06 matris çarpımı); tanh ise Ders 1’in aktivasyonu (türevi \(1 - \tanh^2\)). .view()’in kopyalamadan çalışması, tensör bellek düzeni (contiguous storage + strides) bilgisidir.
İleriye: .view() / .reshape(), tüm tensör kodunda her gün kullanılır (batch boyutlarını ayarlamak, attention’da head’leri ayırmak — Ders 7/10). Bellek-düzeni farkındalığı (contiguous vs view) production performansında önemlidir.
4.7 Çıktı Katmanı ve NLL
Gizli katmandan (100 boyut) çıktıya: 27 karakterin her biri için bir logit üretmeliyiz. İkinci bir lineer katman:
W2 = torch.randn((100, 27))
b2 = torch.randn(27)
logits = h @ W2 + b2 # (n, 27)Sonra Ders 2’deki softmax + NLL’in birebir aynısı: logitleri üstel al (counts), normalize et (probs), doğru hedeflerin olasılığının ortalama negatif log’unu al:
counts = logits.exp()
probs = counts / counts.sum(1, keepdim=True) # softmax
loss = -probs[torch.arange(len(Y)), Y].log().mean() # ortalama NLLBu, Ders 2’deki tek-katmanlı ağın kaybıyla aynı yapı — fark, arada bir gizli tanh katmanı olması (yani artık derin bir ağ). Aşağıdaki şema tüm forward akışını uçtan uca toplar.
Kod
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
# Bengio 2003 MLP forward akış şeması: soldan sağa kutu-ok diyagramı.
# Motor/eğitim çalıştırmaz; ANA modelin (n_embed=10, n_hidden=200) GERÇEK
# şekilleri L3 çekirdeğinden okunur (init_params + forward ile doğrulanmış):
# C (27,10) -> emb=C[X] (n,3,10) -> view (n,30) -> tanh(@W1+b1) (n,200)
# -> @W2+b2 logits (n,27) -> F.cross_entropy -> NLL.
# Determinist (şema; rastgelelik yok ama ilke gereği sabit tohum).
torch.manual_seed(SEED)
# ANA model boyutlarını çekirdekten doğrula (uydurma yok): C, W1, b1, W2, b2.
_params = init_params(n_embed=10, n_hidden=200)
_C, _W1, _b1, _W2, _b2 = _params
n_emb = _C.shape[1] # 10
n_in = _W1.shape[0] # 30 = 3 * 10
n_hid = _W1.shape[1] # 200
n_out = _W2.shape[1] # 27 = VOCAB
fig, ax = plt.subplots(figsize=(11, 5))
fig.patch.set_facecolor(COL_WHITE)
ax.set_facecolor(COL_WHITE)
# ---------------------------------------------------------------------------
# Ana akış kutuları (soldan sağa). highlight=True -> indigo vurgu (tanh, NLL).
# ---------------------------------------------------------------------------
box_w, box_h = 1.78, 1.16
y0 = 3.3 # ana akış satırı y'si
xs = [1.2, 3.4, 5.6, 7.8, 10.0, 12.2] # 6 kutu merkezi x
dugumler = [
{"x": xs[0], "ust": "$X$", "orta": "girdi id", "sekil": f"(n, {BLOCK_SIZE})", "hl": False},
{"x": xs[1], "ust": "$C[X]$", "orta": "embedding", "sekil": f"(n, {BLOCK_SIZE}, {n_emb})", "hl": False},
{"x": xs[2], "ust": ".view", "orta": "birleştir", "sekil": f"(n, {n_in})", "hl": False},
{"x": xs[3], "ust": r"$\tanh(@W_1{+}b_1)$", "orta": "gizli", "sekil": f"(n, {n_hid})", "hl": True},
{"x": xs[4], "ust": "$@W_2{+}b_2$", "orta": "logitler", "sekil": f"(n, {n_out})", "hl": False},
{"x": xs[5], "ust": "cross_entropy", "orta": "softmax + NLL", "sekil": "skaler", "hl": True},
]
for d in dugumler:
if d["hl"]: # indigo vurgu (Ders 1 köprüsü)
ec, lw, fc = COL_INDIGO_600, 2.8, "#eef2ff"
else: # standart slate akış kutusu
ec, lw, fc = COL_PRIMARY, 2.2, COL_BG
box = FancyBboxPatch(
(d["x"] - box_w / 2, y0 - box_h / 2), box_w, box_h,
boxstyle="round,pad=0.02,rounding_size=0.12",
fc=fc, ec=ec, linewidth=lw, zorder=3,
)
ax.add_patch(box)
ust_col = COL_INDIGO_600 if d["hl"] else COL_TEXT
ax.text(d["x"], y0 + box_h * 0.27, d["ust"], ha="center", va="center",
fontsize=11.5, color=ust_col, weight="bold", zorder=5)
ax.text(d["x"], y0 - box_h * 0.02, d["orta"], ha="center", va="center",
fontsize=9.5, color=COL_PRIMARY, style="italic", zorder=5)
# Gerçek şekil (ANA model) — kutunun altında, slate metin
ax.text(d["x"], y0 - box_h * 0.62, d["sekil"], ha="center", va="center",
fontsize=9.5, color=COL_SLATE_800, family="monospace",
weight="bold", zorder=5)
# ---------------------------------------------------------------------------
# Ana akış okları (indigo, soldan sağa veri akışı).
# ---------------------------------------------------------------------------
for a, b in zip(dugumler[:-1], dugumler[1:]):
start = (a["x"] + box_w / 2 + 0.04, y0)
end = (b["x"] - box_w / 2 - 0.04, y0)
arrow = FancyArrowPatch(
start, end, arrowstyle="-|>", mutation_scale=18,
color=COL_ACCENT, linewidth=2.2,
connectionstyle="arc3,rad=0.0", zorder=2,
)
ax.add_patch(arrow)
# ---------------------------------------------------------------------------
# Parametre kutuları (C, W1, b1, W2, b2) — slate çerçeve, ilgili katmana bağlı.
# C -> C[X] (embedding tablosu)
# W1,b1 -> tanh gizli katman
# W2,b2 -> logit çıktı katmanı
# ---------------------------------------------------------------------------
pb_w, pb_h = 1.62, 0.56
y_pu = 1.55 # üst parametre satırı (W'ler)
y_pl = 0.78 # alt parametre satırı (b'ler)
# C tek başına (embedding tablosu) -> C[X] kutusu; W1/b1 -> tanh; W2/b2 -> logit.
# Aynı katmanın iki parametresi dikeyde istiflenir (yatay çakışma yok).
param_kutu = [
{"x": xs[1], "y": y_pu, "etiket": "$C$", "sekil": f"({n_out},{n_emb})", "hedef": xs[1]},
{"x": xs[3], "y": y_pu, "etiket": "$W_1$", "sekil": f"({n_in},{n_hid})", "hedef": xs[3]},
{"x": xs[3], "y": y_pl, "etiket": "$b_1$", "sekil": f"({n_hid},)", "hedef": xs[3]},
{"x": xs[4], "y": y_pu, "etiket": "$W_2$", "sekil": f"({n_hid},{n_out})", "hedef": xs[4]},
{"x": xs[4], "y": y_pl, "etiket": "$b_2$", "sekil": f"({n_out},)", "hedef": xs[4]},
]
for p in param_kutu:
box = FancyBboxPatch(
(p["x"] - pb_w / 2, p["y"] - pb_h / 2), pb_w, pb_h,
boxstyle="round,pad=0.02,rounding_size=0.10",
fc=COL_WHITE, ec=COL_PRIMARY, linewidth=1.8, zorder=4,
)
ax.add_patch(box)
ax.text(p["x"] - pb_w * 0.24, p["y"], p["etiket"], ha="center", va="center",
fontsize=11, color=COL_TEXT, weight="bold", zorder=5)
ax.text(p["x"] + pb_w * 0.16, p["y"], p["sekil"], ha="center", va="center",
fontsize=8, color=COL_SLATE_800, family="monospace", zorder=5)
# Yalnızca üst satır parametresinden akış kutusuna ince slate ok çiz
# (alt b kutusu üst W kutusunun hemen altında; tek ok katmanı işaret eder).
if p["y"] == y_pu:
arrow = FancyArrowPatch(
(p["x"], p["y"] + pb_h / 2 + 0.02),
(p["hedef"], y0 - box_h / 2 - 0.02),
arrowstyle="-|>", mutation_scale=12,
color=COL_SLATE_400, linewidth=1.3,
connectionstyle="arc3,rad=0.0", zorder=1,
)
ax.add_patch(arrow)
ax.text(xs[2], y_pl, "öğrenilen\nparametreler",
ha="center", va="center", fontsize=9.5, color=COL_PRIMARY,
style="italic", zorder=5)
# ---------------------------------------------------------------------------
# Başlık + kısa açıklama
# ---------------------------------------------------------------------------
ax.text(6.7, 5.05,
f"MLP forward (Bengio 2003): ANA model — embedding {n_emb}, "
f"giriş {n_in}, gizli {n_hid}, çıktı {n_out}",
ha="center", va="center", fontsize=12.5, color=COL_TEXT,
weight="bold", zorder=5)
ax.set_xlim(-0.2, 13.6)
ax.set_ylim(0.0, 5.5)
ax.set_aspect("equal")
ax.axis("off")
plt.tight_layout()
plt.show()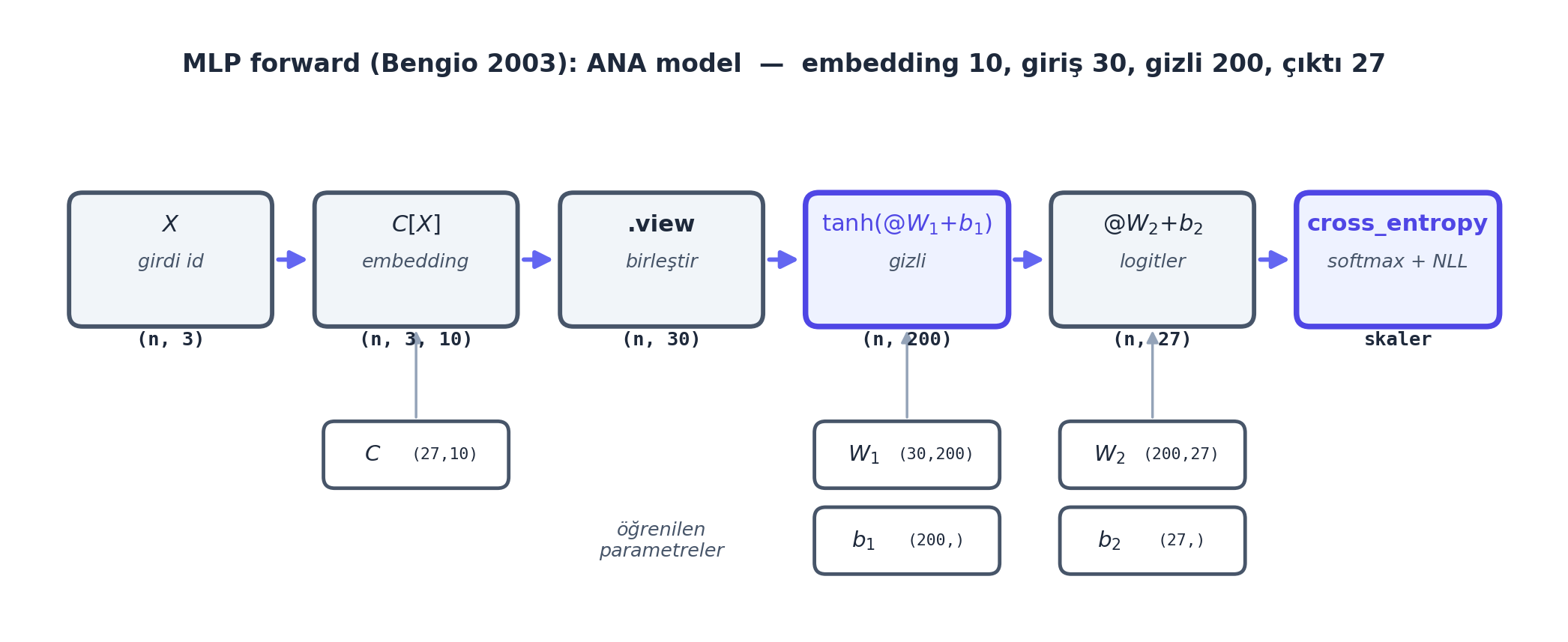
.view ile birleştir (n,30) \(\to\) gizli \(\tanh(@W_1+b_1)\) (n,200) \(\to\) çıktı \(@W_2+b_2\) logitler (n,27) \(\to\) F.cross_entropy ile NLL. Parametre kutuları (\(C, W_1, b_1, W_2, b_2\)) slate çerçeveyle ilgili katmana bağlanır; \(\tanh\) ve cross-entropy düğümleri indigo vurgulu (Ders 1 köprüsü: aktivasyon + NLL).
İpucuBuilder Notu — Çıktı + NLL, Ders 2’nin Tekrarı
Geriye (Ders 1-2): Çıktı katmanı + softmax + NLL, Ders 2’nin birebir tekrarı; tek fark girdinin embedding + gizli katmandan gelmesi. h @ W2 + b2 yine Ders 1’in lineer katmanı.
4.8 F.cross_entropy ve Neden Kullanılır
Elle yazdığımız counts = logits.exp(); probs = ...; loss = -...log().mean() zinciri çalışır ama PyTorch bunu tek bir fonksiyonda toplar: F.cross_entropy. Karpathy bunun sadece kısalık için değil, iki ciddi nedenle tercih edildiğini vurgular:
“That’s why there is a functional.cross_entropy function in PyTorch to calculate this much more [efficiently].” — Karpathy, 33:03
loss = F.cross_entropy(logits, Y) # tek satir, daha hizli + kararliİki kazanç: (1) Verimlilik — PyTorch ara tensörleri (counts, probs) bellekte oluşturmaz, işlemleri tek bir füzyonlu çekirdekte yapar, backward’ı daha basit/hızlıdır. (2) Sayısal kararlılık — büyük bir logit (örn. 100) için logits.exp() taşar (inf → nan). F.cross_entropy içeride logitlerden maksimumu çıkarır (softmax bu kaydırmaya karşı değişmezdir), böylece üstel hiçbir zaman taşmaz.
Kod
import torch
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
# §7 sayısal kararlılık: aynı logit vektörü iki yoldan softmax'a sokulur.
# NAİF : doğrudan logits.exp() -> büyük logit (100) için e^100 = inf -> nan.
# KARARLI: önce max (100) çıkar -> exp asla taşmaz; softmax(z)=softmax(z-c).
torch.manual_seed(SEED) # determinizm (figür sabit logitlerle çalışır; ilke gereği tohum)
# Karpathy'nin §7'de uyardığı tipik durum: bir logit çok büyük (örn. 100).
logits = torch.tensor([1.0, 2.0, 100.0])
etiket = ["$z_0=1$", "$z_1=2$", "$z_2=100$"]
x = np.arange(len(logits))
# --- NAİF yol: çıkarma yok, doğrudan exp ---
counts_naif = logits.exp() # [e^1, e^2, e^100] -> son terim inf
softmax_naif = counts_naif / counts_naif.sum() # inf/inf = nan
# --- KARARLI yol: maksimumu çıkar, sonra exp (F.cross_entropy'nin içeride yaptığı) ---
c = logits.max() # c = 100
counts_kararli = (logits - c).exp() # [e^-99, e^-98, e^0=1] -> taşma yok
softmax_kararli = counts_kararli / counts_kararli.sum() # [~0, ~0, ~1]
# Kanıt: kararlı softmax ile F.softmax (PyTorch'un kararlı uygulaması) birebir aynı.
softmax_torch = F.softmax(logits, dim=0)
# Bar değerleri (naif counts taşar; çizimde inf'i tepe değere kırparak göster).
counts_naif_list = counts_naif.tolist() # [2.718..., 7.389..., inf]
counts_kararli_list = counts_kararli.tolist() # [~0, ~0, 1.0]
fig, (ax_l, ax_r) = plt.subplots(1, 2, figsize=(11, 4.5))
fig.suptitle(
"`F.cross_entropy` içeride maksimumu çıkarır → exp asla taşmaz",
fontsize=13, color=COL_TEXT, y=1.02, weight="bold",
)
# --- SOL panel: NAİF (çıkarma yok) — taşma, indigo uyarı ---
apply_style(ax_l)
# inf bar'ı görünür kılmak için: sonlu terimleri gerçek yükseklikte, taşan
# terimi eksenin tepesine kadar uzat (yukarı oklu "patlama" izlenimi).
sonlu = [v if np.isfinite(v) else 0.0 for v in counts_naif_list]
tepe = max(v for v in sonlu) if any(s > 0 for s in sonlu) else 1.0
ust = tepe * 1.6 # eksen üst sınırı
bar_naif = [v if np.isfinite(v) else ust for v in counts_naif_list] # inf -> tavana değer
renkler_naif = [COL_INDIGO_400, COL_INDIGO_400, COL_INDIGO_600]
ax_l.bar(x, bar_naif, color=renkler_naif, width=0.6,
edgecolor=COL_WHITE, linewidth=1.0, zorder=3)
ax_l.set_title("NAİF — `logits.exp()` (çıkarma yok)", fontsize=12, color=COL_TEXT)
ax_l.set_xlabel("logit", fontsize=11)
ax_l.set_ylabel("`logits.exp()`", fontsize=11)
ax_l.set_xticks(x)
ax_l.set_xticklabels(etiket, fontsize=10.5)
ax_l.set_ylim(0, ust)
# Sonlu terimleri gerçek değerleriyle, taşan terimi 'inf' olarak etiketle.
for xi, v in zip(x, counts_naif_list):
if np.isfinite(v):
ax_l.text(xi, v + tepe * 0.04, f"{v:.1f}", ha="center", va="bottom",
fontsize=10, color=COL_TEXT, weight="bold", zorder=5)
else:
# Taşan bara yukarı ok + 'e^100 = inf' etiketi (sınırsız büyüme izlenimi).
ax_l.annotate("", xy=(xi, ust * 0.99), xytext=(xi, ust * 0.78),
arrowprops=dict(arrowstyle="-|>", color=COL_WHITE, lw=2.2),
zorder=6)
ax_l.text(xi, ust * 0.63, r"$e^{100} = \infty$", ha="center", va="center",
fontsize=12, color=COL_WHITE, weight="bold", zorder=6)
# Naif yolun çöktüğünü gösteren açık metin (Karpathy'nin uyarısı).
ax_l.text(0.42, 0.40,
"logits.exp() = [2.7, 7.4, inf]\n"
"softmax = inf / inf = nan\n"
"→ kayıp bozulur",
transform=ax_l.transAxes, ha="center", va="center", fontsize=10.5,
color=COL_INDIGO_600, family="monospace",
bbox=dict(boxstyle="round,pad=0.5", fc=COL_BG, ec=COL_INDIGO_600, lw=1.6))
# --- SAĞ panel: KARARLI (max çıkar) — taşma yok, slate güvenli ---
apply_style(ax_r)
ax_r.bar(x, counts_kararli_list, color=COL_PRIMARY, width=0.6,
edgecolor=COL_WHITE, linewidth=1.0, zorder=3)
ax_r.set_title("KARARLI — `(logits - max).exp()`", fontsize=12, color=COL_TEXT)
ax_r.set_xlabel("logit $-\\ c$ (max $c = 100$ çıkarıldı)", fontsize=11)
ax_r.set_ylabel("`(logits - max).exp()`", fontsize=11)
ax_r.set_xticks(x)
ax_r.set_xticklabels(["$-99$", "$-98$", "$0$"], fontsize=10.5)
ax_r.set_ylim(0, 1.3)
for xi, v in zip(x, counts_kararli_list):
gosterim = f"{v:.3g}"
ax_r.text(xi, v + 0.04, gosterim, ha="center", va="bottom",
fontsize=10, color=COL_TEXT, weight="bold", zorder=5)
# Kararlı softmax sonucu (taşma yok, F.softmax ile birebir aynı).
sm = softmax_kararli.tolist()
ax_r.text(0.5, 0.62,
f"softmax ≈ [{sm[0]:.2g}, {sm[1]:.2g}, {sm[2]:.2g}]\n"
"taşma yok → kayıp sağlam\n"
"= F.softmax (birebir aynı)",
transform=ax_r.transAxes, ha="center", va="center", fontsize=10.5,
color=COL_PRIMARY, family="monospace",
bbox=dict(boxstyle="round,pad=0.5", fc=COL_BG, ec=COL_PRIMARY, lw=1.6))
# Alt not: softmax kaydırmaya karşı değişmezdir (matematiksel gerekçe).
fig.text(0.5, -0.04,
"softmax kaydırmaya karşı değişmezdir: "
"$\\mathrm{softmax}(z) = \\mathrm{softmax}(z - c)$ "
"→ maksimumu çıkarmak sonucu değiştirmez, yalnızca taşmayı önler.",
ha="center", va="center", fontsize=10.5, color=COL_PRIMARY, style="italic")
plt.tight_layout()
plt.show()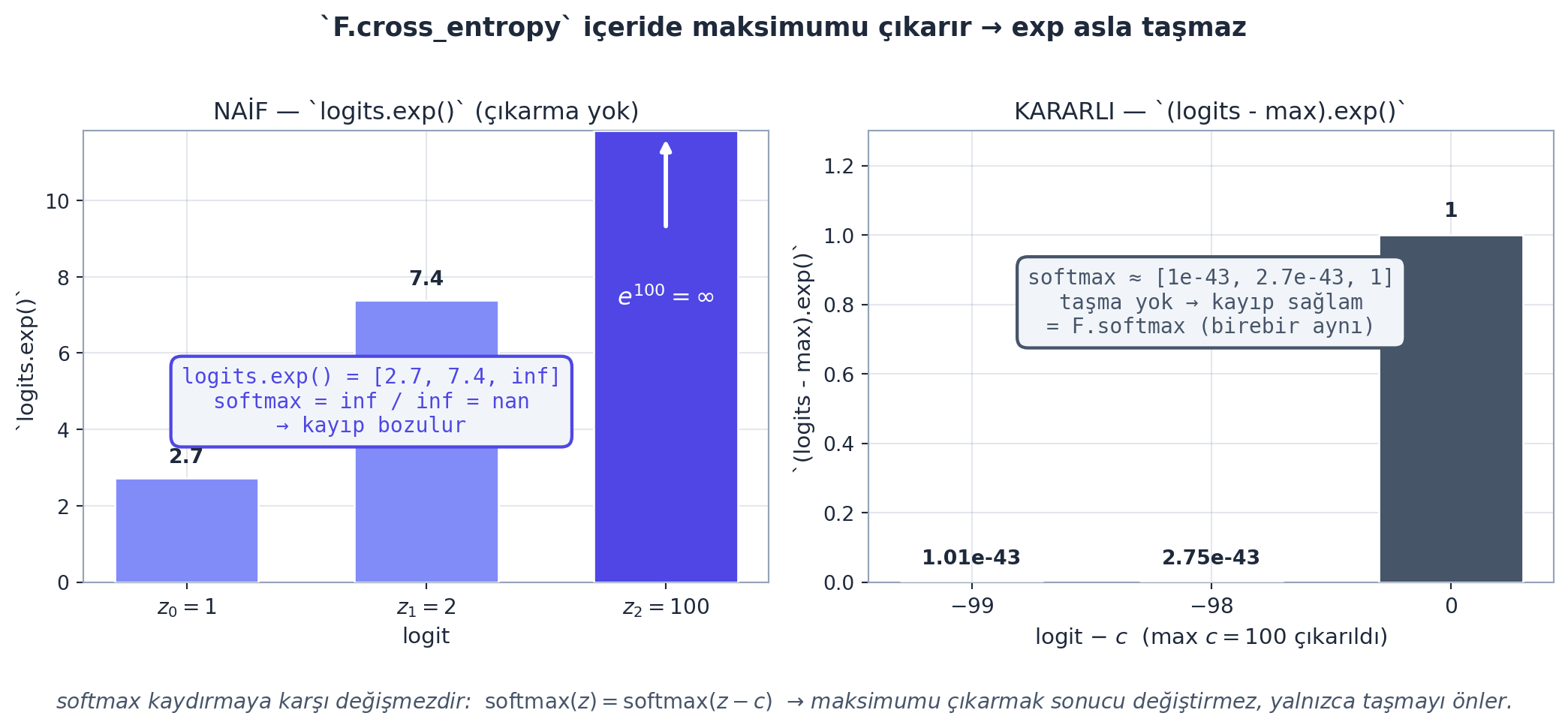
F.cross_entropy sayısal kararlılık: sol (indigo uyarı): büyük logitler \([1, 2, 100]\) için naif logits.exp() → en büyük üs taşar (\(e^{100} = \infty\)), ardından \(\infty/\infty = \mathrm{nan}\); softmax çöker. Sağ (slate güvenli): aynı logitlerden maksimum \(c = 100\) çıkarılınca \([-99, -98, 0]\) olur; exp() artık \([\approx 0,\ \approx 0,\ 1]\) verir, taşma yok, softmax \(\approx [0,\ 0,\ 1]\). Softmax kaydırmaya karşı değişmez olduğundan (\(\mathrm{softmax}(z) = \mathrm{softmax}(z - c)\)) sonuç matematiksel olarak aynıdır. F.cross_entropy bu çıkarmayı içeride yapar — bu yüzden elle yazılan zincirin aksine asla taşmaz.
İpucuBuilder Notu — Füzyon + Sayısal Kararlılık
Geriye (Ders 2 + Stat 110): F.cross_entropy, Ders 2’de elle yazdığımız NLL’in ta kendisi (Stat 110 MLE), yalnızca sayısal-kararlı ve füzyonlu. “Softmax max çıkarmaya karşı değişmez” özelliği: \(\mathrm{softmax}(z) = \mathrm{softmax}(z - c)\).
İleriye: Bu “ara değerleri materyalize etme, füzyonlu kernel kullan” fikri, production’da operator fusion’ın (Ders 10: torch.compile, FlashAttention) çekirdeğidir. Sayısal kararlılık (max çıkarma) her ciddi softmax implementasyonunda vardır.
4.9 Eğitim Döngüsü ve Tek Batch’e Overfit
Şimdi eğitiriz — Ders 1-2’deki aynı döngü (forward → zero_grad → backward → update), ama artık birden çok parametre (C, W1, b1, W2, b2).
parameters = [C, W1, b1, W2, b2]
for p in parameters:
p.requires_grad = True
for _ in range(200):
# forward
emb = C[X]
h = torch.tanh(emb.view(-1, 6) @ W1 + b1)
logits = h @ W2 + b2
loss = F.cross_entropy(logits, Y)
# backward
for p in parameters:
p.grad = None # zero_grad
loss.backward()
# update
for p in parameters:
p.data += -0.1 * p.gradKarpathy önce bir akıl-sağlığı kontrolü yapar: çok küçük bir veri parçasına (örn. tek bir batch, 32 örnek) modeli kasten aşırı uydurur (overfit). Loss neredeyse 0’a inerse, ağ öğrenebiliyor demektir — mimaride/kodda temel bir hata yok. (Loss tam 0 olmaz çünkü aynı bağlamın farklı hedefleri olabilir.)
İpucuBuilder Notu — Önce Küçük Veriye Overfit Et
Geriye (Ders 1): Döngü Ders 1 micrograd’ın aynısı; tek fark parametre listesinin uzaması ve p.grad = None ile zero_grad. Tek-batch’e overfit, Ders 1’deki “ağ öğreniyor mu?” kontrolünün pratiği.
İleriye: “Önce küçük bir veriye overfit et” her ML mühendisinin ilk sanity-check’idir: öğrenemiyorsa veri/loss/mimaride bug var demektir. Production debug’ın standart ilk adımı.
4.10 Minibatch SGD
Tüm veri seti (228 binden fazla örnek) üzerinde her adımda forward/backward yapmak yavaş. Çözüm Ders 1’den tanıdık: minibatch — her adımda rastgele küçük bir örnek kümesi (örn. 32) seç, gradyanı onun üzerinde hesapla.
ix = torch.randint(0, X.shape[0], (32,)) # rastgele 32 ornek indeksi
emb = C[X[ix]] # sadece bu batch
# ... forward/backward/update yalnizca X[ix], Y[ix] uzerindeMinibatch gradyanı, tam gradyanın gürültülü ama tarafsız bir tahminidir. Adımlar biraz “yanlış yönde” olabilir ama çok daha hızlı atılır — pratikte yaklaşık doğru yönde çok sayıda hızlı adım, az sayıda mükemmel adımdan iyidir.
İpucuBuilder Notu — Gürültülü Ama Hızlı
Geriye (Ders 1 + Stat 110): Bu, Ders 1 §9’un birebir uygulaması: minibatch gradyanı = tam gradyanın Monte Carlo tahmini; varyans \(\propto 1/B\) (Stat 110 örneklem ortalaması). torch.randint ile rastgele örnekleme.
İleriye: Tüm büyük-ölçek eğitim minibatch’le yapılır; batch boyutu throughput/bellek dengesidir (Ders 10: gradient accumulation, DDP — minibatch’in dağıtık hâli).
4.11 İyi Bir Öğrenme Oranı Bulmak
Öğrenme oranını (lr) elle tahmin etmek yerine Karpathy prensipli bir yöntem gösterir: bir tarama (sweep). lr’yi geniş bir aralıkta (örn. \(10^{-3}\) ile \(10^{0}\) arası) üstel olarak dene, her biri için loss’u kaydet, loss-vs-lr grafiğini çiz, vadinin dibini (en hızlı düşüş) seç.
lre = torch.linspace(-3, 0, 1000) # ussel aralik
lrs = 10**lre # lr = 10^exp (0.001 .. 1.0)
# her adimda bir lr dene, loss'u kaydet, sonra loss-vs-exp cizBizim taramamızda vadinin dibi gerçekte üs \(\approx -0{,}77\)’de, yani \(\mathrm{lr} \approx 10^{-0{,}77} \approx 0{,}17\) çıkar. İyi lr bulunduktan sonra, eğitimin sonlarına doğru lr azaltılır (decay) — büyük adımlarla yaklaş, küçük adımlarla yerleş.
Kod
import torch
import matplotlib.pyplot as plt
# Determinizm: aynı tarama her render'da (Karpathy'nin meşhur tohumu).
torch.manual_seed(SEED)
# ---------------------------------------------------------------------------
# Öğrenme oranı taraması (Karpathy imza). ANA model (n_embed=10, n_hidden=200),
# eğitim bölmesi üzerinde 1000 adım; her adımda 10^-3 .. 10^0 arası bir lr.
# lr_exp[i] = o adımın 10 tabanlı üssü; losses[i] = o adımın minibatch loss'u.
# ---------------------------------------------------------------------------
Xtr, Ytr, Xdev, Ydev, Xte, Yte = split_data()
lr_exp, losses = lr_sweep(
Xtr, Ytr, n_steps=1000, lr_exp_lo=-3.0, lr_exp_hi=0.0,
n_embed=10, n_hidden=200, seed=SEED,
)
lr_exp_t = torch.tensor(lr_exp)
losses_t = torch.tensor(losses)
# ---------------------------------------------------------------------------
# Kayan-ortalama (pencere 50): gürültüyü yumuşatıp vadiyi görünür kılar.
# Vadi dibi = en düşük 50-pencere ortalamasının merkez adımı (verify (d) ile aynı).
# ---------------------------------------------------------------------------
W = 50
kernel = torch.ones(W) / W
smooth = torch.nn.functional.conv1d(
losses_t.view(1, 1, -1), kernel.view(1, 1, -1)
).view(-1) # uzunluk = 1000 - W + 1
smooth_x = lr_exp_t[W // 2 : W // 2 + smooth.shape[0]]
# En düşük pencere ortalaması -> vadi dibi üssü (GERÇEK ölçüm; ~ -0.766)
best_rel = int(torch.argmin(smooth).item())
opt_exp = smooth_x[best_rel].item()
opt_lr = 10 ** opt_exp
first_loss = losses[0] # taze init, en küçük lr (~28.71)
last_loss = losses[-1] # en büyük lr, ıraksama (~18.31)
# ---------------------------------------------------------------------------
# Çizim
# ---------------------------------------------------------------------------
fig, ax = plt.subplots(figsize=(10, 5.5))
fig.patch.set_facecolor(COL_WHITE)
apply_style(ax)
# Ham (gürültülü) loss — slate ince çizgi
ax.plot(lr_exp, losses, color=COL_PRIMARY, linewidth=0.9, alpha=0.55,
zorder=2, label="ham minibatch loss")
# Kayan-ortalama — indigo, daha kalın
ax.plot(smooth_x.tolist(), smooth.tolist(), color=COL_ACCENT, linewidth=2.4,
zorder=4, label=f"kayan ortalama (pencere {W})")
# Vadi dibi — indigo dikey çizgi + anotasyon
ax.axvline(opt_exp, color=COL_INDIGO_600, linewidth=2.0, linestyle="--",
zorder=5)
y_lo, y_hi = min(losses), max(losses)
ax.annotate(
f"optimal lr $\\approx 10^{{{opt_exp:.2f}}} \\approx {opt_lr:.2f}".replace(".", "{,}") + "$",
xy=(opt_exp, y_lo + (y_hi - y_lo) * 0.10),
xytext=(opt_exp + 0.55, y_lo + (y_hi - y_lo) * 0.42),
fontsize=11, color=COL_INDIGO_600, weight="bold",
arrowprops=dict(arrowstyle="-|>", color=COL_INDIGO_600, lw=1.6),
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG, ec=COL_INDIGO_600, lw=1.3),
zorder=6,
)
# İlk loss anotasyonu (taze init, hokey sopası — küçük lr)
ax.annotate(
f"ilk loss $\\approx {first_loss:.2f}".replace(".", "{,}") + "$\n(taze init)",
xy=(lr_exp[0], first_loss),
xytext=(lr_exp[0] + 0.10, first_loss - (y_hi - y_lo) * 0.10),
fontsize=9.5, color=COL_TEXT, ha="left", va="top",
arrowprops=dict(arrowstyle="-|>", color=COL_SLATE_400, lw=1.3),
zorder=6,
)
# Son loss anotasyonu (büyük lr, ıraksama)
ax.annotate(
f"son loss $\\approx {last_loss:.2f}".replace(".", "{,}") + "$\n(lr çok büyük)",
xy=(lr_exp[-1], last_loss),
xytext=(lr_exp[-1] - 0.10, last_loss + (y_hi - y_lo) * 0.06),
fontsize=9.5, color=COL_TEXT, ha="right", va="bottom",
arrowprops=dict(arrowstyle="-|>", color=COL_SLATE_400, lw=1.3),
zorder=6,
)
ax.set_xlabel("öğrenme oranı üssü $\\log_{10}(\\mathrm{lr})$", fontsize=11)
ax.set_ylabel("minibatch loss", fontsize=11)
ax.set_title(
"Öğrenme oranı taraması — loss-vs-lr vadisi (vadi dibi = en iyi lr)",
fontsize=12.5, color=COL_TEXT, pad=10,
)
ax.set_xlim(-3.05, 0.35)
ax.legend(loc="upper center", fontsize=9.5, framealpha=0.95)
plt.tight_layout()
plt.show()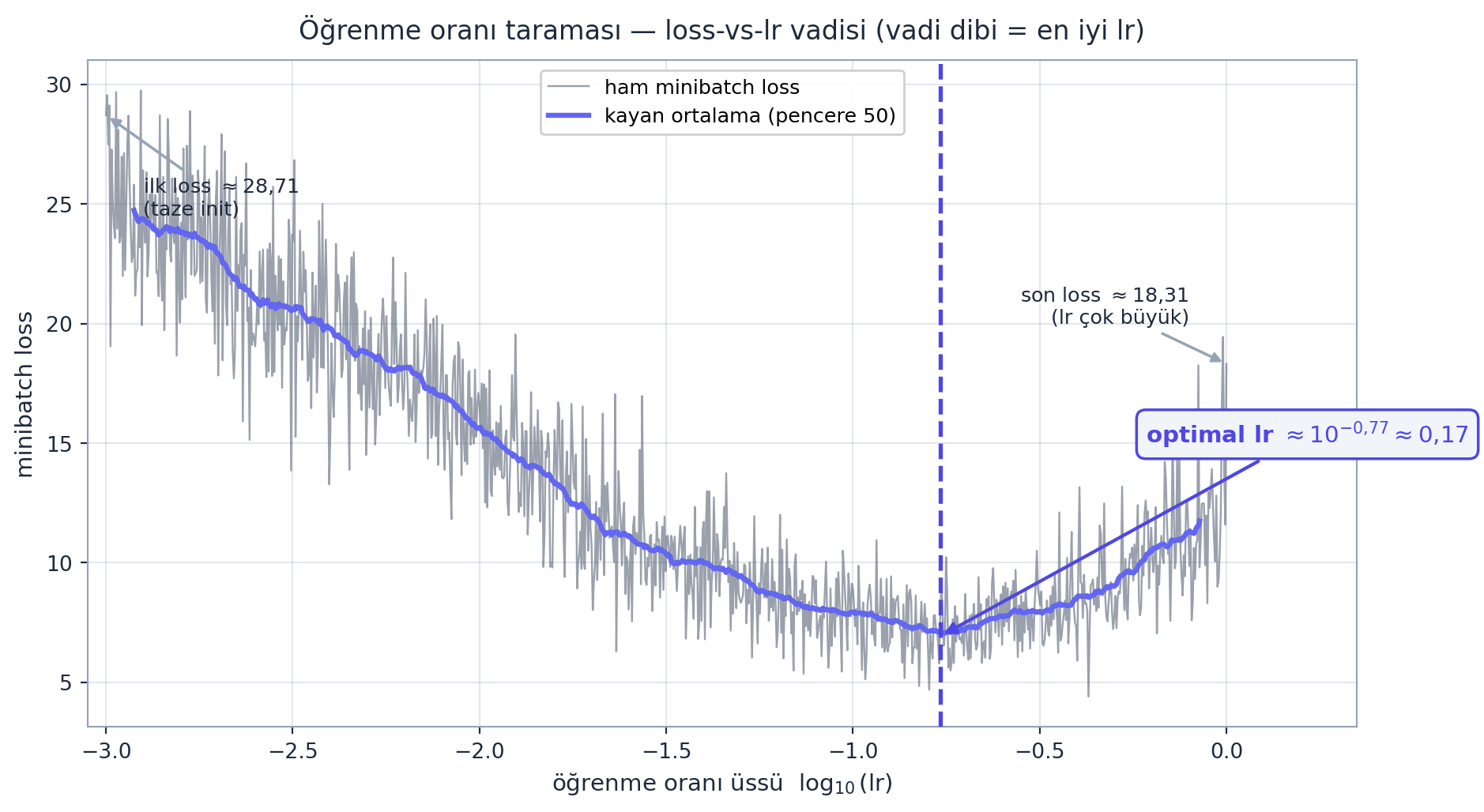
İpucuBuilder Notu — lr Taraması → LR Schedule
Geriye (Ders 1): lr, Ders 1 §8’in \(\eta\)’sı — çok büyük ıraksar, çok küçük yavaş. Tarama, “çok küçük/çok büyük arası dengeyi” deneysel bulma yöntemi.
İleriye: lr taraması ve lr decay (sonlara doğru azaltma), production’da learning rate schedule’a dönüşür: warmup + cosine/linear decay (Ders 10). Hyperparameter araması (Optuna, ablation) bunun otomatik hâli.
4.12 Train / Dev / Test Bölmesi
Şimdiye dek tek bir veri seti kullandık — ama bu tehlikeli: model veriyi ezberleyebilir (overfitting) ve yeni veride başarısız olur. Çözüm, veriyi üçe bölmek:
“We have the training split, the dev/validation split, and the test split.” — Karpathy, 54:35
import random
random.shuffle(words)
n1 = int(0.8 * len(words)) # %80 egitim
n2 = int(0.9 * len(words)) # %10 dev, %10 test
Xtr, Ytr = build_dataset(words[:n1]) # train: ogren
Xdev, Ydev = build_dataset(words[n1:n2]) # dev: hyperparametre ayarla
Xte, Yte = build_dataset(words[n2:]) # test: yalnizca en sonda, bir kez- Train (%80): Parametreleri öğrenmek için. (Bizde 182.546 örnek.)
- Dev/validation (%10): Hyperparametreleri (ağ boyutu, lr, embedding boyutu) ayarlamak için. (22.840 örnek.)
- Test (%10): Yalnızca en sonda, bir kez — gerçek genelleme performansı. Sık bakarsan ona da overfit edersin. (22.760 örnek.)
Tanı: train loss ≈ dev loss ise model yetersiz (underfitting — daha büyük ağ gerek); train loss ≪ dev loss ise aşırı öğrenme (overfitting — düzenlileştirme/daha çok veri gerek).
İpucuBuilder Notu — Üçlü Bölme = Standart Protokol
Geriye (Ders 1 + Stat 110): Train/dev/test ve under/overfitting, Ders 1 §10’un pratiği; bias-variance dengesi (Stat 110 Ders 34). “Test setine sık bakma” = ona bilgi sızdırma (data leakage).
İleriye: Bu üçlü bölme, tüm ML’in standart protokolüdür. Production’da dev set üzerinde model seçimi + test set ile final değerlendirme; LLM’lerde ayrıca held-out benchmark’lar (Ders 10: HellaSwag).
4.13 Ölçeklendirme: Daha Büyük Ağ
Loss’u daha da düşürmek için ağı büyütürüz: daha çok gizli nöron, daha yüksek boyutlu embedding. Karpathy gizli katmanı ve embedding boyutunu artırıp yeniden eğitir.
Önemli gözlem: bazen darboğaz embedding boyutudur. 2 boyutlu embedding, 27 karakterin ilişkilerini sıkıştırmak için fazla küçük olabilir; boyutu artırmak (örn. 10) loss’u düşürür. Ama her büyütme bir denge: daha çok parametre = daha iyi uyum ama daha yavaş eğitim + overfitting riski (dev loss’u izle).
Bizim ANA modelimiz (\(n_{embed}=10\), \(n_{hidden}=200\), 40.000 adım, \(\mathrm{lr}=0{,}1\), 30.000. adımda decay) şu final değerleri verir: train \(\approx 2{,}24\), dev \(\approx 2{,}28\), test \(\approx 2{,}27\). Dev, train’den yalnızca \(+0{,}0372\) yüksek — bu, hafif bir overfit ama sağlıklı bir denge. Aşağıdaki figür hem eğitim eğrisini (lr decay düşüşü görünür) hem de üç bölmenin final karşılaştırmasını gösterir.
Kod
import torch
import matplotlib.pyplot as plt
# Deterministik eğitim: aynı tohum -> aynı loss eğrisi + aynı final değerler.
torch.manual_seed(SEED)
# Train/dev/test bölmesi (80/10/10, sabit shuffle tohumu).
Xtr, Ytr, Xdev, Ydev, Xte, Yte = split_data()
# ANA model: n_embed=10, n_hidden=200. 40000 adım, lr=0.1, 30000.de decay (lr*=0.1).
N_STEPS = 40000
DECAY_AT = 30000
params_main, loss_gecmisi = train_mlp(
Xtr, Ytr, steps=N_STEPS, lr=0.1, batch_size=32,
n_embed=10, n_hidden=200, seed=SEED,
lr_decay_at=DECAY_AT, lr_decay=0.1,
)
# Final loss'lar (no_grad, F.cross_entropy = ortalama NLL) — GERÇEK değerler.
train_loss = evaluate(params_main, Xtr, Ytr) # ~2.2397
dev_loss = evaluate(params_main, Xdev, Ydev) # ~2.2769
test_loss = evaluate(params_main, Xte, Yte) # ~2.2700
# Minibatch loss çok gürültülüdür; kayan-pencere ortalamasıyla hafifçe düzleştir.
def _duzlestir(seri, pencere=200):
out, toplam = [], 0.0
from collections import deque
buf = deque()
for v in seri:
buf.append(v)
toplam += v
if len(buf) > pencere:
toplam -= buf.popleft()
out.append(toplam / len(buf))
return out
loss_smooth = _duzlestir(loss_gecmisi, pencere=200)
adim_no = list(range(1, N_STEPS + 1))
fig, (ax_l, ax_r) = plt.subplots(1, 2, figsize=(11, 5))
# --- SOL panel: minibatch loss eğrisi + lr decay işareti ---
apply_style(ax_l)
# Ham minibatch loss çok soluk (gürültü), düzleştirilmiş eğri belirgin (slate).
ax_l.plot(adim_no, loss_gecmisi, color=COL_SLATE_400, linewidth=0.6,
alpha=0.35, zorder=1, label="ham minibatch loss")
ax_l.plot(adim_no, loss_smooth, color=COL_PRIMARY, linewidth=2.2,
zorder=3, label="düzleştirilmiş (200 adım)")
# lr decay noktası: 30000. adımda dikey indigo çizgi + görünür düşüş.
ax_l.axvline(DECAY_AT, color=COL_ACCENT, linewidth=2.0, linestyle="--",
zorder=4, label=f"lr decay ($\\times 0{{,}}1$) — adım {DECAY_AT}")
# Decay sonrası düşüşü vurgulayan anot.
ax_l.annotate(
"lr $\\times 0{,}1$\ngörünür düşüş",
xy=(DECAY_AT, loss_smooth[DECAY_AT - 1]),
xytext=(DECAY_AT - 14500, loss_smooth[DECAY_AT - 1] + 0.45),
color=COL_INDIGO_600, fontsize=10, va="center", ha="center",
arrowprops=dict(arrowstyle="->", color=COL_INDIGO_600, lw=1.4), zorder=6,
)
ax_l.set_xlabel("Minibatch adımı", fontsize=12)
ax_l.set_ylabel("Kayıp (loss) = minibatch NLL", fontsize=12)
ax_l.set_title("Eğitim kaybı eğrisi — 40000 adım minibatch SGD", fontsize=12)
ax_l.set_xlim(0, N_STEPS)
# y-aralığını yerleşik bölgeye sıkıştır: erken keskin düşüş + decay sonrası
# görünür kayma okunur kalsın (tam 28'lik başlangıç ölçeği bunu ezerdi).
ax_l.set_ylim(1.9, 3.6)
ax_l.legend(loc="upper right", fontsize=9, framealpha=0.95)
# --- SAĞ panel: final train / dev / test bar karşılaştırması ---
apply_style(ax_r)
etiketler = ["train", "dev", "test"]
degerler = [train_loss, dev_loss, test_loss]
# train = slate (referans), dev = indigo (vurgu, overfit kanıtı), test = açık indigo.
renkler = [COL_PRIMARY, COL_ACCENT, COL_INDIGO_400]
x = list(range(3))
ax_r.bar(x, degerler, color=renkler, width=0.6,
edgecolor=COL_WHITE, linewidth=1.2, zorder=3)
# Bar üstü değer etiketleri (GERÇEK final loss'lar).
for xi, v in zip(x, degerler):
ax_r.text(xi, v + 0.006, f"{v:.4f}".replace(".", ","),
ha="center", va="bottom", fontsize=10.5, color=COL_TEXT,
weight="bold", zorder=5)
# dev - train farkı (hafif overfit) anotu.
fark = dev_loss - train_loss
ax_r.annotate(
"", xy=(1, dev_loss), xytext=(1, train_loss),
arrowprops=dict(arrowstyle="<->", color=COL_INDIGO_600, lw=1.6), zorder=6,
)
ax_r.text(
1.30, (train_loss + dev_loss) / 2,
f"dev $-$ train\n$= {fark:+.4f}".replace(".", ",") + "$\n(hafif overfit)",
ha="left", va="center", fontsize=9.5, color=COL_INDIGO_600,
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG, ec=COL_INDIGO_600, lw=1.2),
zorder=6,
)
ax_r.set_xticks(x)
ax_r.set_xticklabels(etiketler, fontsize=11)
ax_r.set_ylabel("final kayıp (ortalama NLL)", fontsize=12)
ax_r.set_title("Final train vs dev vs test loss", fontsize=12)
# Farkı görünür kılmak için sıkı y-aralığı (değerler 2,24–2,28 bandında).
ax_r.set_ylim(2.20, dev_loss + 0.03)
fig.suptitle(
"ANA model (n_embed=10, n_hidden=200): eğitim eğrisi + train/dev/test karşılaştırması",
fontsize=12.5, color=COL_TEXT, y=1.02,
)
plt.tight_layout()
plt.show()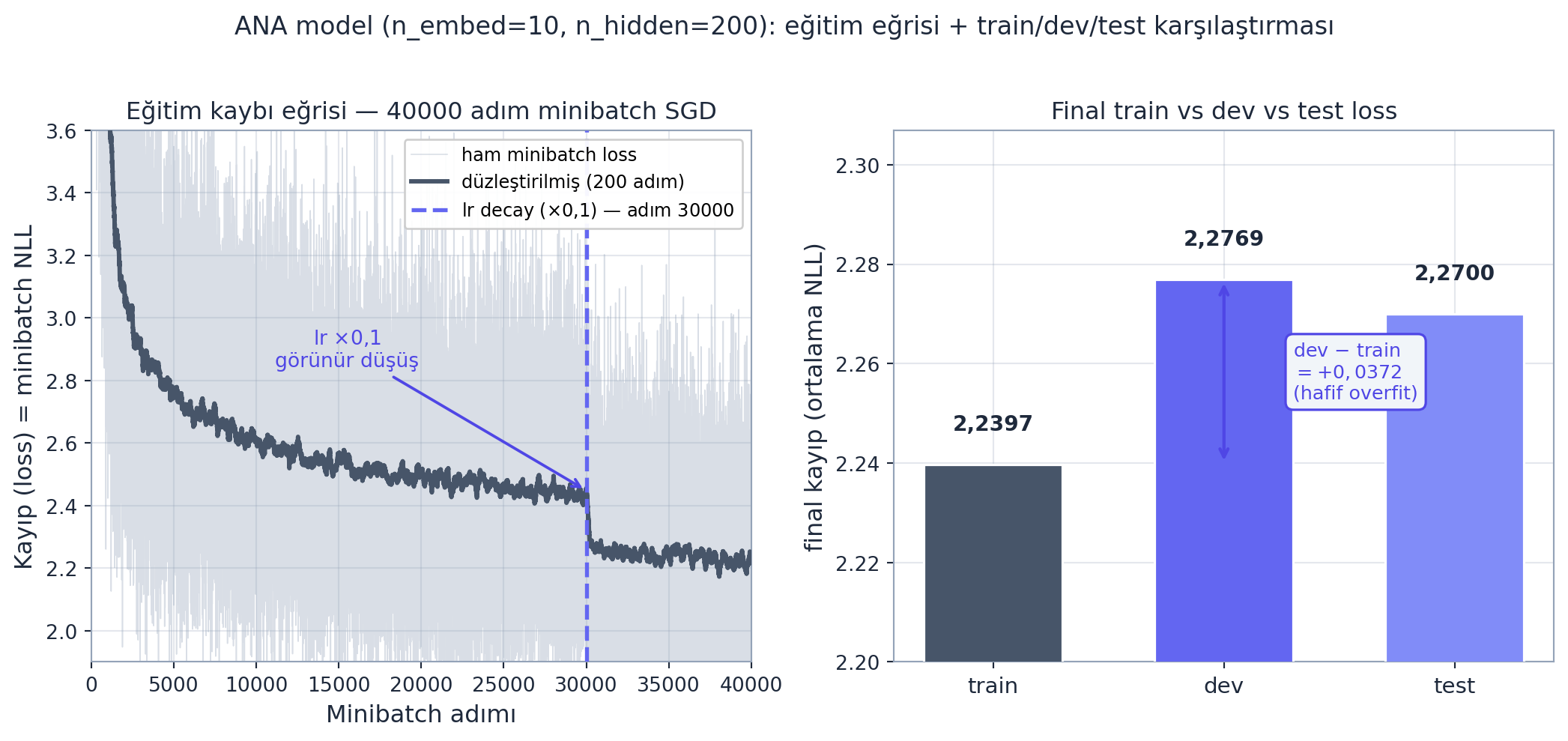
İpucuBuilder Notu — Darboğaz Nerede?
İleriye: “Darboğaz nerede?” sorusu (embedding mi, gizli katman mı, veri mi) production model tasarımının özüdür. Parametre sayısını ölçeklemek (genişlik/derinlik/embedding) doğrudan scaling laws’a (Ders 6/10) bağlanır: model boyutu vs veri vs compute dengesi.
4.14 Embedding’leri Görselleştirme
2 boyutlu embedding’lerin güzel yanı: doğrudan çizilebilirler. Karpathy 27 karakteri bir scatter plot’ta gösterir — ve model kimse söylemeden anlamlı yapı öğrenmiştir: sesli harfler (a, e, i, o, u) birbirine yakın kümelenir, . token’ı kendi başına bir köşede durur.
Bunu kendi GÖRSEL modelimizde (\(n_{embed}=2\)) ölçtük: sesli harflerin ortalama ikili uzaklığı \(0{,}8481\), tüm harflerin ortalaması ise \(1{,}0131\) (oran \(\approx 0{,}837 < 1\)) — yani sesli harfler birbirine, rastgele bir harf çiftine göre belirgin biçimde daha yakın. Dürüst not: bu tohumda ‘u’ bir aykırı değerdir (sesli ailesinden kopup yukarıda g/l/p ile durur); figür bunu olduğu gibi gösterir, sahte bir “mükemmel 5’li küme” çizmez. Yine de kümelenme gerçektir — model a/e/i/o’yu kimse söylemeden birbirine yaklaştırmıştır.
Bu, embedding’in neden güçlü olduğunun görsel kanıtı: model, “benzer davranan karakterleri” sürekli bir uzayda birbirine yaklaştırarak genelleme yapar — say-tablosunun asla yapamayacağı bir şey.
Kod
import torch
import matplotlib.pyplot as plt
# ---------------------------------------------------------------------------
# GÖRSEL model: n_embed=2 (2B embedding doğrudan çizilebilir), n_hidden=100.
# 30000 minibatch adımı — sesli harf kümelenmesi görünene dek yeterli.
# Deterministik (train_mlp içinde torch.manual_seed/Generator SEED sabit) —
# render her seferinde AYNI scatter'ı üretir.
# ---------------------------------------------------------------------------
torch.manual_seed(SEED)
Xtr, Ytr, Xdev, Ydev, Xte, Yte = split_data()
params, _ = train_mlp(
Xtr, Ytr, steps=30000, lr=0.1, batch_size=32,
n_embed=2, n_hidden=100,
)
C = params[0].detach() # (27, 2) öğrenilen embedding tablosu
# Kümelenme kanıtı: sesli ort-ikili-uzaklık vs tüm-harf ort (gerçek ölçüm).
vowel_mean, all_mean = vowel_clustering(C) # 0.8481 < 1.0131
oran = vowel_mean / all_mean # ~0.837
fig, ax = plt.subplots(figsize=(9, 8))
fig.patch.set_facecolor(COL_WHITE)
apply_style(ax)
# Sesli harf indeksleri (vurgu) vs diğerleri (slate). '.' ayrı çizilir.
vowel_idx = {s2i[v] for v in VOWELS} # {a, e, i, o, u}
dot_idx = s2i["."] # 0
# --- noktaları çiz: her karakteri kendi konumuna + etiket ---
for i in range(C.shape[0]):
x, y = C[i, 0].item(), C[i, 1].item()
ch = i2s[i]
if i == dot_idx:
# '.' token'ı: köşede, koyu slate kare ile ayrıştır.
ax.scatter(x, y, s=240, marker="s", color=COL_TEXT,
edgecolor=COL_WHITE, linewidth=1.4, zorder=4)
ax.annotate(
"'.' token'ı (köşe)",
xy=(x, y), xytext=(x - 0.30, y + 0.42),
ha="right", va="bottom", fontsize=10, color=COL_TEXT, weight="bold",
arrowprops=dict(arrowstyle="-|>", color=COL_TEXT, lw=1.3),
)
ax.text(x, y, ".", ha="center", va="center", fontsize=14,
color=COL_WHITE, weight="bold", zorder=5)
elif i in vowel_idx:
# Sesli harf: indigo vurgu (büyük daire).
ax.scatter(x, y, s=320, color=COL_ACCENT, edgecolor=COL_INDIGO_600,
linewidth=1.6, zorder=4, alpha=0.95)
ax.text(x, y, ch, ha="center", va="center", fontsize=13,
color=COL_WHITE, weight="bold", zorder=5)
else:
# Diğer harfler: soluk slate (arka plan).
ax.scatter(x, y, s=210, color=COL_SLATE_400, edgecolor=COL_WHITE,
linewidth=1.0, zorder=2, alpha=0.85)
ax.text(x, y, ch, ha="center", va="center", fontsize=11,
color=COL_TEXT, zorder=3)
# --- 'u' aykırı değerini dürüstçe işaretle (sesli ama yukarıda g/l/p ile) ---
ux, uy = C[s2i["u"], 0].item(), C[s2i["u"], 1].item()
ax.annotate(
"'u' aykırı değer\n(g, l, p ile yukarıda)",
xy=(ux, uy), xytext=(ux - 1.05, uy + 0.15),
ha="right", va="center", fontsize=9.5, color=COL_INDIGO_600, weight="bold",
arrowprops=dict(arrowstyle="-|>", color=COL_INDIGO_600, lw=1.4),
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG, ec=COL_INDIGO_600, lw=1.2),
)
# --- kümelenme kanıtı metin kutusu (gerçek ölçülmüş sayılar) ---
ax.text(
0.03, 0.97,
"Kümelenme kanıtı (ort-ikili-uzaklık):\n"
f" sesli (a,e,i,o,u): {vowel_mean:.4f}\n"
f" tüm harfler : {all_mean:.4f}\n"
f" oran : {oran:.3f} < 1 → kümelenme",
transform=ax.transAxes, ha="left", va="top", fontsize=9.5,
color=COL_TEXT, family="monospace",
bbox=dict(boxstyle="round,pad=0.5", fc=COL_BG, ec=COL_ACCENT, lw=1.4),
)
# --- lejant (sesli vurgu vs diğer) ---
from matplotlib.lines import Line2D
lejant = [
Line2D([0], [0], marker="o", color="none", markerfacecolor=COL_ACCENT,
markeredgecolor=COL_INDIGO_600, markersize=13,
label="sesli harf (a,e,i,o,u)"),
Line2D([0], [0], marker="o", color="none", markerfacecolor=COL_SLATE_400,
markeredgecolor=COL_WHITE, markersize=11, label="diğer harf"),
Line2D([0], [0], marker="s", color="none", markerfacecolor=COL_TEXT,
markeredgecolor=COL_WHITE, markersize=11, label="'.' token'ı"),
]
ax.legend(handles=lejant, loc="upper right", fontsize=9.5, framealpha=0.95)
# Üst kenara pay bırak: g/p en üstte (~2,35); lejant onların üstünde durur.
ymin, ymax = ax.get_ylim()
ax.set_ylim(ymin, ymax + 0.55)
ax.set_xlabel("embedding boyutu 1 ($C[:, 0]$)", fontsize=11)
ax.set_ylabel("embedding boyutu 2 ($C[:, 1]$)", fontsize=11)
ax.set_title(
"Öğrenilen 2B embedding: sesli harfler kümelenir ('u' aykırı), '.' köşede",
color=COL_TEXT, fontsize=12.5, pad=12,
)
ax.axhline(0, color=COL_SLATE_400, linewidth=0.7, alpha=0.5, zorder=1)
ax.axvline(0, color=COL_SLATE_400, linewidth=0.7, alpha=0.5, zorder=1)
plt.tight_layout()
plt.show()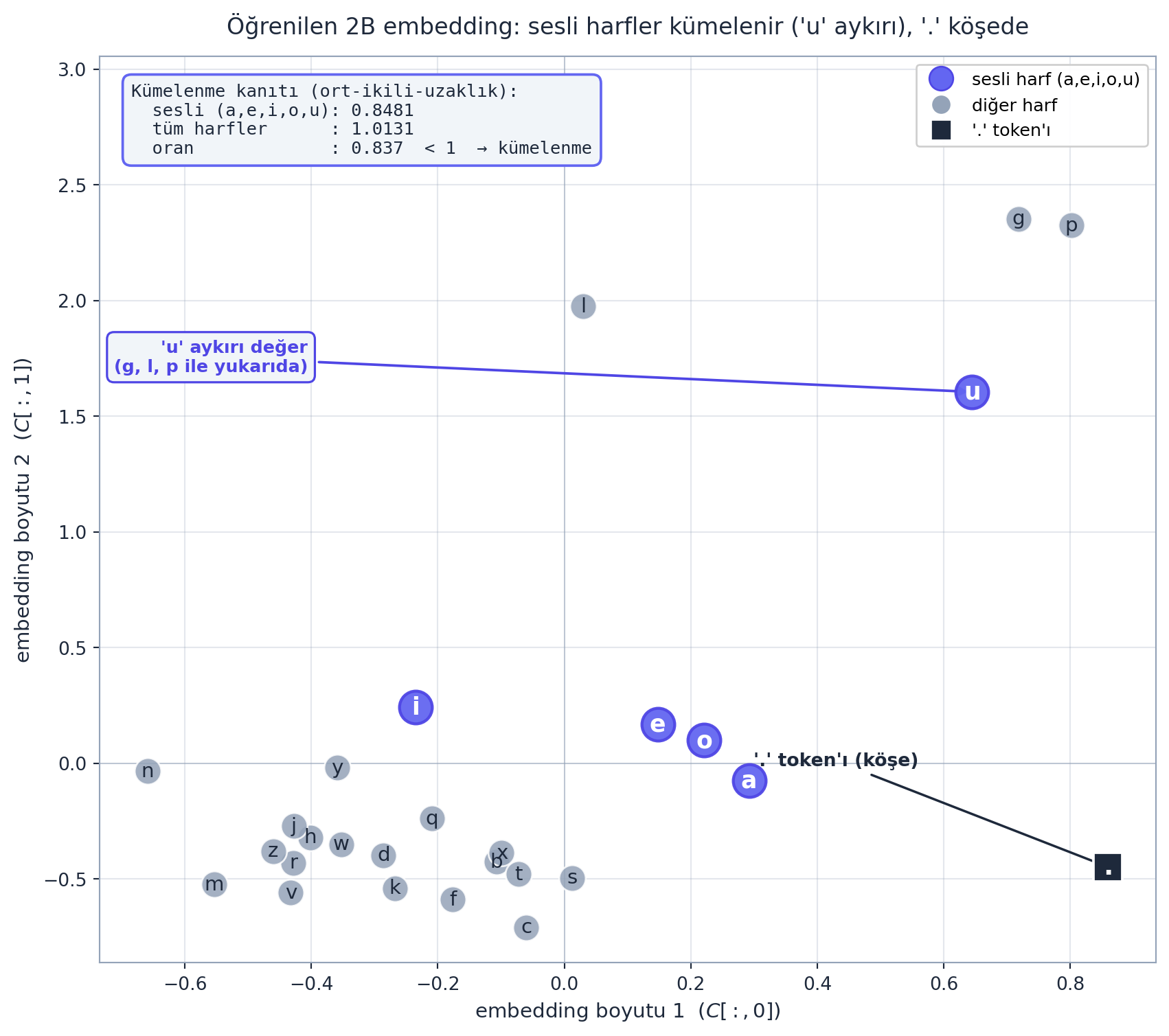
. token’ı sağ-alt köşede (\(+0{,}86, -0{,}45\)) tek başına durur. DÜRÜSTLÜK: bu tohumda ‘u’ bir aykırı değerdir (\(+0{,}64, +1{,}61\)) — sesli ailesinden kopup yukarıda g/l/p ile durur; figür bunu olduğu gibi gösterir, sahte ‘mükemmel 5’li küme’ çizmez. Yine de kümelenme gerçektir: sesli ortalama-ikili-uzaklık \(0{,}8481 <\) tüm-harf ortalaması \(1{,}0131\) (oran \(\approx 0{,}837\)) — model kimse söylemeden a/e/i/o’yu birbirine yaklaştırmıştır.
İpucuBuilder Notu — Embedding Geometrisi = Anlamsal Yapı
İleriye: Öğrenilen embedding uzayında anlamsal yapı, tüm modern NLP’nin temel gözlemidir (word2vec’in “king − man + woman ≈ queen”i). GPT’nin token embedding’leri de aynı şekilde yapı öğrenir, yalnızca çok daha yüksek boyutta. Embedding görselleştirme (t-SNE, PCA) production’da model anlamanın standart aracı.
4.15 Sonuç ve Örnekleme
Eğitilen MLP’den isim örneklemek, Ders 2’deki döngünün aynısı — yalnızca bir satır olasılık tablosu yerine MLP’nin forward’ı kullanılır:
context = [0] * block_size
while True:
emb = C[torch.tensor([context])]
h = torch.tanh(emb.view(1, -1) @ W1 + b1)
logits = h @ W2 + b2
probs = F.softmax(logits, dim=1)
ix = torch.multinomial(probs, num_samples=1, generator=g).item()
context = context[1:] + [ix] # pencereyi kaydir
if ix == 0:
breakÜretilen isimler bigram’dan belirgin biçimde daha iyidir — 3 karakterlik bağlam, tek karaktere göre çok daha gerçekçi diziler verir. Karpathy çalıştırılabilir Colab notebook’unu paylaşır.
İpucuBuilder Notu — Örnekleme = GPT’nin Üretim İskeleti
İleriye: Örnekleme döngüsü (bağlamı kaydır → forward → softmax → multinomial → tekrarla), GPT’nin metin üretiminin birebir iskeleti (autoregressive generation). Tek fark: MLP sabit bağlam, GPT uzun bağlam + dikkat.
4.16 Bu Dersin Özeti
- Bigram’ın bağlam patlaması (\(27^n\)) çözümü: say-tablosu yerine öğrenilen embedding + MLP (Bengio 2003).
- block_size bağlam uzunluğunu belirler;
build_datasetkayan pencereyle (bağlam → hedef) örnekleri üretir (“emma” → 5 örnek; tüm veri → 228.146 örnek). - Embedding tablosu C:
C[X]ile id → vektör (Ders 2’nin “one-hot @ W = satır seçimi”nin verimli hâli; backprop ile öğrenilir). - MLP: embedding’i
.view()ile düzleştir → gizlitanhkatmanı (W1, b1) → çıktı logitleri (W2, b2) → softmax. - F.cross_entropy: Ders 2’nin NLL’i; daha hızlı (füzyonlu) + sayısal kararlı (max çıkarma, exp taşmasını önler).
- Eğitim döngüsü Ders 1’in aynısı (forward → zero_grad → backward → update); önce tek batch’e overfit ederek sanity-check.
- Minibatch SGD (
torch.randint): gürültülü ama hızlı gradyan tahmini (varyans \(\propto 1/B\)). - Öğrenme oranı taraması (
torch.linspace, loss-vs-lr): vadinin dibi gerçekte üs \(\approx -0{,}77\) (\(\mathrm{lr} \approx 0{,}17\)); sonra decay. - Train/dev/test bölmesi (80/10/10); test’e yalnızca bir kez bak. ANA model final train \(\approx 2{,}24\), dev \(\approx 2{,}28\) (hafif overfit). Embedding’ler anlamlı yapı öğrenir (sesli harfler kümelenir: \(0{,}8481 < 1{,}0131\)).
ÖnemliTek Bir Cümle
Bağlamı say-tablosunda tutmak üstel patlar; her karakteri öğrenilen bir vektöre (embedding) gömüp bir MLP’den geçirmek, aynı “sonraki karakteri tahmin et” problemini ölçeklenebilir kılar — ve model, kimse söylemeden benzer karakterleri (sesli harfler) embedding uzayında birbirine yaklaştırarak genelleme öğrenir.
4.17 Kontrol Soruları
NotSoru 1: block_size = 3 ile, ‘an’ kelimesi build_dataset’te hangi (bağlam → hedef) örneklerine bölünür? (s2i: . = 0, a = 1, n = 14)
Bağlam [0, 0, 0] (üç nokta) ile başlar, her adımda kayar. “an” + bitiş .:
[0, 0, 0] → 1(...→ a)[0, 0, 1] → 14(..a→ n)[0, 1, 14] → 0(.an→ .)
Cevap: 3 örnek. Her satır 3 tamsayı id (girdi bağlam), hedef ise bir sonraki karakterin id’sidir. context = context[1:] + [ix] her adımda en eski karakteri atıp yenisini ekler (kayan pencere).
NotSoru 2: Elle yazılan counts = logits.exp(); probs = …; loss = -…log().mean() yerine neden F.cross_entropy(logits, Y) tercih edilir? İki neden.
Cevap: (1) Verimlilik: F.cross_entropy ara tensörleri (counts, probs) bellekte oluşturmaz; işlemleri tek bir füzyonlu çekirdekte yapar ve backward’ı daha basit/hızlıdır. (2) Sayısal kararlılık: Büyük bir logit (örn. 100) için logits.exp() taşar (inf → nan, loss bozulur). F.cross_entropy içeride logitlerden maksimumu çıkarır — softmax bu kaydırmaya karşı değişmez olduğu için (\(\mathrm{softmax}(z) = \mathrm{softmax}(z-c)\)) sonuç aynı kalır ama üstel asla taşmaz. Matematiksel olarak elle yazılanla aynı, ama pratikte güvenli ve hızlı.
NotSoru 3: C şekli (27, 2), X şekli (n, 3) ise C[X] hangi şekli verir? Gizli katmana vermeden önce neden .view(-1, 6) gerekir?
Cevap: C[X] şekli \((n, 3, 2)\) — her örnek (\(n\)), 3 karakter, her karakter 2-boyutlu embedding. Ama gizli katman düz bir vektör bekler: 3 karakterin 2’şer boyutunu birleştirip 6-boyutlu tek vektör. emb.view(-1, 6) bunu yapar → \((n, 6)\). .view() veriyi kopyalamaz, yalnızca aynı bellekteki görünümü (storage + strides) değiştirir — bu yüzden ucuzdur. -1, “bu boyutu otomatik hesapla” demek (burada \(n\)).
NotSoru 4: (Builder) C[X] (embedding arama) ile Ders 2’deki xenc @ W (one-hot çarpımı) neden aynı işlemdir? 18.06 ile bağla.
Cevap: Ders 2’de bir id’yi one-hot vektöre çevirip W ile çarpıyorduk; bir one-hot (baz vektörü \(e_i\)) ile matris çarpımı, W’nin \(i\)’inci satırını seçer (18.06 Ders 30). C[X] ise aynı satırı doğrudan indeksleyerek seçer — one-hot vektörü oluşturup çarpma masrafına girmeden. İkisi de “id → matrisin o satırı” yapar; embedding sadece verimli (büyük sözlüklerde 50.000-boyutlu one-hot çarpımı israfından kaçınır). Bu yüzden embedding tablosu = öğrenilen bir satır-arama matrisidir; GPT’nin wte tablosu da budur.
4.18 Egzersizler
Egzersiz 1 (Veri setini kur). build_dataset’i block_size = 3 ile yaz, tüm isimlere uygula. X.shape ve Y.shape yazdır (X: \((n, 3)\), Y: \((n,)\); bizde \(n = 228146\)). Birkaç örneği i2s ile geri çevirip “bağlam → hedef” olarak elle doğrula.
Egzersiz 2 (MLP’yi kur, tek batch’e overfit). C (\(27 \times 2\)), W1/b1, W2/b2 ile MLP’yi kur. Çok küçük bir veri parçasına (örn. ilk 32 örnek) kasten overfit et — loss’un neredeyse 0’a indiğini gözlemle. Bu, ağın öğrenebildiğinin (kodun doğru olduğunun) sanity-check’idir.
Egzersiz 3 (Öğrenme oranı taraması). torch.linspace(-3, 0, 1000) ile lr üslerini, 10**lre ile lr’leri üret. Her adımda bir lr dene, loss’u kaydet, loss-vs-üs grafiğini çiz. “Vadinin dibini” (en hızlı düşüş) bul — bizde üs \(\approx -0{,}77\), yani \(\mathrm{lr} \approx 0{,}17\). Bu lr ile tam eğitim yap.
Egzersiz 4 (Train/dev/test). Veriyi 80/10/10 böl (build_dataset ile üç ayrı set). Eğit, sonra train loss ve dev loss’u karşılaştır (bizde train \(\approx 2{,}24\), dev \(\approx 2{,}28\)). İkisi yakınsa underfitting (ağı büyüt), train ≪ dev ise overfitting. Gizli katmanı/embedding’i büyütüp dev loss’un nasıl değiştiğine bak.
Egzersiz 5 (Sonraki dersin habercisi). Ağı eğitmeye başladığında ilk iterasyonun loss’u kaçtır? (a) Model başlangıçta hiçbir şey bilmiyorsa, 27 karaktere eşit (uniform) olasılık vermeli — bu durumda loss \(\approx -\log(1/27) \approx 3{,}30\) olmalı. (b) Ama rastgele başlatılmış W2 ile ilk loss çok daha yüksek çıkar (bizim ölçümümüzde \(\approx 26{,}0\)); neden? (İpucu: rastgele logitler aşırı uçlarda → model “kendinden emin ama yanlış”.) İlk birkaç adım sadece bu aşırı logitleri ezmekle geçer (“hokey-sopası” loss eğrisi). Bu israfı nasıl önlersin? Bu soru, Ders 4’te (makemore 3: aktivasyonlar, gradyanlar, BatchNorm) başlangıç (initialization) ve aktivasyon istatistiklerini düzeltmeyi motive eder.
4.19 Sonraki Ders İçin Hazırlık
Ders 4: makemore 3 — Aktivasyonlar, Gradyanlar ve BatchNorm — Andrej Karpathy
Bu derste MLP’yi kurduk ve eğittik — ama “çalışıyor” ile “iyi çalışıyor” arasında fark var. Ders 4’te tam bu ağın içine bakacağız: başlangıçtaki loss neden çok yüksek (Egzersiz 5), tanh aktivasyonları neden “doyuyor” (saturation) ve ölü nöronlar oluşuyor, gradyanlar katmanlar arası nasıl akıyor. Kaiming (He) başlatması ile ağırlıkları doğru ölçekleyip, Batch Normalization’ı sıfırdan kuracağız.
Ana konular:
- Başlangıç loss’unu düzeltme (logitleri 0’a yakın başlatma).
- Doymuş tanh, ölü nöron, Kaiming init (fan-in ölçeklemesi).
- Batch Normalization: aktivasyonları normalize etme + running istatistikler.
UyarıDers 4 Öncesi Yapılacak
- Egzersizleri çöz — özellikle 5 (ilk loss neden yüksek?).
- Bu dersteki MLP kodunu hazır tut; Ders 4 doğrudan bunun üstüne kurar.
- “Embedding = öğrenilen satır-arama” ve “F.cross_entropy = kararlı NLL” cümlelerini hatırla.
4.20 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Karpathy’de |
|---|---|---|
| Bağlam patlaması | Say-tablosu bağlamla üstel büyür (\(27^n\)); çözüm öğrenilen embedding | 0m00 |
| Bengio 2003 | MLP dil modeli makalesi: embedding + gizli katman + softmax | 1m48 |
| block_size | Bağlam uzunluğu; kayan pencereyle (bağlam → hedef) örnek üretir | 9m01 |
| Embedding tablosu C | C[X] ile id → vektör; Ders 2 one-hot @ W satır seçiminin verimli hâli | 12m19 |
| .view() reshape | Tensörü kopyalamadan yeniden şekillendirme (storage + strides görünümü) | 18m35 |
| Gizli tanh katmanı | emb.view(-1,6) @ W1 + b1, sonra tanh; Ders 1’in lineer katmanı + aktivasyon | 18m35 |
| F.cross_entropy | Ders 2 NLL’in füzyonlu + sayısal-kararlı hâli (max çıkarır, exp taşmaz) | 32m50 |
| Tek batch’e overfit | Küçük veriye loss≈0; ağın öğrenebildiğinin sanity-check’i | 37m56 |
| Minibatch SGD | torch.randint ile rastgele batch; gürültülü ama hızlı gradyan (varyans ∝ 1/B) | 41m28 |
| Öğrenme oranı taraması | torch.linspace ile lr üs taraması; loss-vs-lr vadisi (üs ≈ −0,77); sonra decay | 45m39 |
| Train / dev / test | 80/10/10; train=öğren, dev=ayarla, test=bir kez; train ≈2,24 dev ≈2,28 | 53m20 |
| Embedding görselleştirme | 2B scatter; model sesli harfleri kümeler (0,8481 < 1,0131) | 1h05m |
4.21 ML Builder Bağlantıları
İpucu9 köprü
- Embedding C[X] → Ders 2 “one-hot @ W = satır seçimi” + 18.06 baz vektörü. İleriye: GPT’nin
wtetoken embedding tablosu (Ders 10). - MLP (gizli tanh) → Ders 1 Neuron/Layer/MLP + tanh türevi (\(1 - \tanh^2\)). İleriye: transformer’ın feed-forward bloğu (Ders 7).
- F.cross_entropy → Ders 2 NLL + Stat 110 MLE; füzyon + sayısal kararlılık. İleriye: operator fusion (Ders 10 torch.compile).
- .view() / reshape → tensör storage/strides. İleriye: attention’da head ayırma/birleştirme (Ders 7/10).
- Minibatch SGD → Ders 1 §9 + Stat 110 varyans \(\propto 1/B\). İleriye: DDP, gradient accumulation (Ders 10).
- lr taraması + decay → Ders 1 §8 \(\eta\). İleriye: learning rate schedule, warmup+cosine (Ders 10).
- Train/dev/test → Ders 1 §10 overfitting + Stat 110 bias-variance. İleriye: held-out benchmark (Ders 10 HellaSwag).
- Embedding’de anlamsal yapı → öğrenilen temsil (sesli harf kümesi). İleriye: word2vec, GPT embedding geometrisi.
- block_size sabit bağlam → MLP’nin sınırı. İleriye: transformer’ın uzun bağlamı + dikkat (Ders 7).
4.22 Karpathy’nin Önerdiği Kaynaklar
Karpathy’nin bu ders için verdiği kaynaklar:
- Ders notebook’u: makemore_part2_mlp.ipynb — dersin adım adım kodu.
- cs231n NumPy/Python rehberi: cs231n.github.io/python-numpy-tutorial — tensör/indeksleme temelleri.
- PyTorch başlangıç: Tensors + Deep Learning with PyTorch.
- Ders Colab notebook’u: Google Colab — çalıştırılabilir ortam.
ÖnemliBu dersten tek bir şey alıp gideceksen
Bağlamı say-tablosunda tutmak üstel patlar (\(27^n\)); bunun yerine her karakteri öğrenilen bir vektöre (embedding) gömüp bir MLP’den geçirmek, aynı “sonraki karakteri tahmin et” problemini ölçeklenebilir kılar. Embedding tablosu C, Ders 2’deki “one-hot @ W = satır seçimi”nin ta kendisidir — ve model, kimse söylemeden benzer karakterleri embedding uzayında kümeleyerek genelleme öğrenir.