flowchart LR
A["Bigram baseline<br/>yalniz son token"] --> B["Matematik hilesi<br/>gecmis ortalamasi = matmul"]
B --> C["Self-attention<br/>Q / K / V, veriye-bagli"]
C --> D["Olcekli + nedensel maske<br/>softmax(QK/sqrt d), causal"]
D --> E["Multi-head + Feed-Forward<br/>iletisim + dusunme"]
E --> F["Residual + LayerNorm<br/>derin egitilebilir"]
F --> G["Decoder-only GPT<br/>autoregressive uretim"]
style C fill:#eef2ff,stroke:#6366f1,stroke-width:2px
style E fill:#eef2ff,stroke:#6366f1,stroke-width:2px
style G fill:#e0e7ff,stroke:#1e293b,stroke-width:3px
8 Sıfırdan GPT — Self-Attention ve Transformer
WaveNet’in sabit ağacı yerine öğrenilen iletişim: her token bir sorgu (query) ve anahtar (key) yayınlar, yakınlıklar softmax’lanır, değerler (value) ağırlıklı toplanır — bunun üzerine feed-forward, residual ve LayerNorm eklenince ChatGPT’yi çalıştıran GPT mimarisi ortaya çıkar
NotBölüm bilgisi
- Karpathy’nin videosu: YouTube — Let’s build GPT: from scratch, in code, spelled out (≈116 dk)
- Seri: Neural Networks: Zero to Hero — Ders 7 (serinin doruğu)
- Hoca: Andrej Karpathy
- Kaynak repo: github.com/karpathy/nanoGPT · ng-video-lecture
- Okuma süresi: ≈34 dk
8.1 Bu Derste Ne Var?
makemore serisi bitti. Bu derste doğrudan transformer’a — ChatGPT’yi çalıştıran mimariye — geçiyoruz. tiny Shakespeare veri setinde, karakter-düzeyli bir GPT’yi sıfırdan kuracağız. Bu, serinin doruğu: Ders 9 (tokenizer) ve Ders 10 (GPT-2) buna dayanır.
Büyük fikir, WaveNet’in sabit ağacı yerine öğrenilen iletişim: her token, bağlamdaki diğer token’lardan hangilerine ne kadar bakacağını kendisi öğrenir (self-attention). Sabit hiyerarşi yok; her token kendi “sorgusunu” yayınlar, diğerlerinin “anahtar”larıyla eşleşir, ve bulduğu “değer”leri ağırlıklı toplar.
“Now we get the crux of self-attention — this is probably the most important part of this video to understand.” — Karpathy, 1:01:58
Dersin üç büyük fikri:
- Bigram’dan transformer’a — tiny Shakespeare, karakter tokenizer, bigram baseline (seriye bağlanış), sonra dikkat eklemek.
- Self-attention — query/key/value, ölçekli nokta-çarpım dikkati: token’ların öğrenilen, veriye-bağlı iletişimi.
- Tam transformer bloğu — multi-head attention + feed-forward + residual bağlantılar + pre-norm LayerNorm + dropout.
İpucuBuilder Notu — Geriye Ders 1-6, İleriye Ders 8-10
Geriye (Ders 1-6):
- Bigram baseline = Ders 2. Transformer’a, Ders 2’nin bigram’ından başlarız (
nn.Embedding+ cross-entropy +generate) — sonra üzerine dikkat ekleriz. - Modüller = Ders 6.
nn.Module/Sequentialdeseni (Ders 6’da olgunlaşan) ile blokları istifleriz. - LayerNorm = Ders 4. Ders 4’te BatchNorm’u kurmuş, transformer’ın neden LayerNorm (her örneği bağımsız normalize) tercih ettiğini görmüştük.
- Residual + FFN gradyanı = Ders 5. backprop ninja sayesinde residual bağlantının gradyanı neden kolay akıttığını derinden anlıyoruz.
İleriye (Ders 8-10): Bu char-GPT, GPT-2’nin (Ders 10) küçük kardeşi — aynı mimari, daha küçük ölçek + karakter tokenizer (Ders 9’da gerçek BPE). Self-attention, tüm modern LLM’lerin (GPT, Claude, Llama) çekirdeği. Ders 8 (State of GPT) bu modelin nasıl asistana çevrildiğini anlatır.
Tek cümleyle: Transformer, token’ların birbirine öğrenilen ağırlıklarla baktığı (self-attention) bir iletişim mekanizmasıdır; bunun üzerine feed-forward, residual ve LayerNorm eklenince ChatGPT’yi çalıştıran GPT mimarisi ortaya çıkar.
8.2 Giriş: ChatGPT, Transformer ve nanoGPT
Karpathy ChatGPT’yle başlar: dil modelleri dünyayı salladı. Altındaki mimari transformer (2017, “Attention is All You Need”). Hedef: bu mimariyi sıfırdan, karakter-düzeyli bir dil modeli olarak kurmak — nanoGPT’nin eğitim versiyonu.
GPT’nin açılımı: Generatively Pretrained Transformer. “Transformer” mimari; “pretrained” devasa metin üzerinde “bir sonraki token’ı tahmin et” ile eğitilmiş (Ders 2-6’nın aynı çerçevesi, dev ölçekte). Bu derste mimariyi (transformer) kuruyoruz; ChatGPT’yi asistana çeviren ek aşamalar (SFT/RLHF) Ders 8’in konusu.
İpucuBuilder Notu — En Etkili Makale
İleriye: “Attention is All You Need” (Vaswani 2017), modern yapay zekânın en etkili makalesi. Bu derste kuracağımız mimari, GPT-2/3/4, Claude, Llama’nın hepsinin temelidir — yalnızca ölçek (parametre, veri, bağlam) değişir.
8.3 Veri ve Karakter Tokenizer
Veri: tiny Shakespeare (Shakespeare metinlerinin tek bir dosyası, ~1 MB). Önce metni modele verilebilir sayılara çeviririz — tokenization. Bu derste en basit yol: karakter-düzeyli tokenizer. Metindeki benzersiz karakterleri (\(65\) tane) sıralayıp her birine bir tamsayı atarız (Ders 2’nin s2i/i2s’i).
chars = sorted(list(set(text))) # 65 benzersiz karakter
stoi = {ch: i for i, ch in enumerate(chars)}
itos = {i: ch for i, ch in enumerate(chars)}
encode = lambda s: [stoi[c] for c in s] # metin -> id listesi
decode = lambda l: ''.join(itos[i] for i in l) # id listesi -> metin
data = torch.tensor(encode(text), dtype=torch.long)Karpathy bunun naif bir tokenizer olduğunu vurgular: \(65\) karakter = küçük sözlük, uzun diziler. Gerçek GPT’ler byte-pair encoding (BPE) kullanır — bu Ders 9’un konusu. Şimdilik karakter yeter. Bizim veri setimizde \(1.115.394\) karakter var; \(\%90\) eğitim (\(1.003.854\)), \(\%10\) doğrulama (\(111.540\)).
İpucuBuilder Notu — s2i/i2s Buradan Geliyor
Geriye (Ders 2): Karakter tokenizer, Ders 2’nin s2i/i2s arama tablolarının ta kendisi. “Metin → tamsayı → model” zinciri her dil modelinin ilk adımı.
İleriye: Naif karakter tokenizer → Ders 9’da gerçek BPE (tiktoken/sentencepiece): daha büyük sözlük, daha kısa diziler, daha verimli. Tokenizer seçimi modelin verimliliğini doğrudan etkiler.
8.4 Veri Yükleyici: Bloklar, Zaman Boyutu, Batch’ler
Modeli sabit uzunlukta parçalarla (block) eğitiriz. block_size (bağlam uzunluğu) kadar karakter al; her konum, bir sonrakini tahmin eder. Yani tek bir blok bile block_size adet (bağlam → hedef) örneği taşır — bu, modele küçük ve büyük bağlamları aynı anda görmeyi öğretir.
block_size = 8
batch_size = 32
def get_batch(split):
data = train_data if split == 'train' else val_data
ix = torch.randint(len(data) - block_size, (batch_size,)) # rastgele baslangic
x = torch.stack([data[i:i+block_size] for i in ix]) # (B, T) girdi
y = torch.stack([data[i+1:i+block_size+1] for i in ix]) # (B, T) hedef (1 kaydirilmis)
return x, yİki boyut: B (batch — paralel diziler) ve T (time/zaman — bloktaki konumlar). x[b, t]’nin hedefi y[b, t] = x[b, t+1]. Bu (B, T) yapısı, transformer’ın çalışacağı zemin.
İpucuBuilder Notu — Zaman Boyutu (T) Dikkatin Kalbi
Geriye (Ders 3-6): Bağlam penceresi (block_size), Ders 3’ten beri tanıdık; (B, T) tensör yapısı, Ders 6’nın (B, T, C)’sinin embedding’siz hâli. get_batch, Ders 3’ün minibatch örneklemesinin (torch.randint) dizi versiyonu.
İleriye: Bu “zaman boyutu” (T), transformer’ın kalbi: dikkat, T boyutundaki token’lar arası iletişimdir. GPT-2’de T=1024, modern modellerde yüz binlerce (Ders 10).
8.5 Bigram Baseline
Transformer’a sıçramadan önce, Ders 2’nin bigram modelini PyTorch’ta yeniden kurarız — baseline (kıyas noktası). nn.Embedding (token → logits doğrudan), cross-entropy loss, ve metin üreten generate().
class BigramLanguageModel(nn.Module):
def __init__(self, vocab_size):
super().__init__()
self.token_embedding_table = nn.Embedding(vocab_size, vocab_size) # her token -> logits
def forward(self, idx, targets=None):
logits = self.token_embedding_table(idx) # (B, T, vocab_size)
loss = None
if targets is not None:
B, T, C = logits.shape
loss = F.cross_entropy(logits.view(B*T, C), targets.view(B*T))
return logits, loss
def generate(self, idx, max_new_tokens):
for _ in range(max_new_tokens):
logits, _ = self(idx)
logits = logits[:, -1, :] # son zaman adimi
probs = F.softmax(logits, dim=-1)
idx_next = torch.multinomial(probs, num_samples=1)
idx = torch.cat((idx, idx_next), dim=1) # diziye ekle
return idxBu, Ders 2’nin bigram’ı: yalnızca son token’a bakıp sonrakini tahmin eder (bağlamı kullanmaz). Üretilen metin Shakespeare’e benzemez — ama transformer’ın üzerine kurulacağı iskelet hazır. Bizim ölçümümüzde bigram’ın final doğrulama kaybı \(2{,}4809\) (rastgele tahmin temeli \(-\ln(1/65) = 4{,}1744\)).
İpucuBuilder Notu — Her Şey Ders 2’den Tanıdık
Geriye (Ders 2-3): nn.Embedding = Ders 2-3’ün lookup tablosu; cross-entropy = Ders 2 NLL; generate = Ders 2’nin örnekleme döngüsü (multinomial). Hepsi tanıdık, yalnızca dizi (B, T) boyutunda.
İleriye: generate döngüsü (forward → softmax → multinomial → ekle → tekrarla), her LLM’in autoregressive metin üretiminin birebir iskeleti — GPT-4 de böyle üretir, yalnızca model devasa.
8.6 Eğitim ve Script’e Taşıma
Bigram’ı eğitiriz: optimizer olarak AdamW (Ders 4’te bahsedilen adaptif optimizer), ve gürültüyü azaltmak için estimate_loss (birkaç batch’in ortalama train/val loss’u, torch.no_grad + eval modu).
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-3)
for step in range(max_iters):
xb, yb = get_batch('train')
logits, loss = model(xb, yb)
optimizer.zero_grad(set_to_none=True) # Ders 1 zero_grad
loss.backward() # Ders 5: arkasinda ne var biliyoruz
optimizer.step()Döngü Ders 1’den beri aynı (forward → zero_grad → backward → update); tek fark optimizer nesnesinin güncellemeyi yapması. Karpathy kodu bir Jupyter hücresinden bir Python script’ine taşır (gerçek geliştirme).
İpucuBuilder Notu — Döngü Ders 1’den Beri Aynı
Geriye (Ders 1-5): Eğitim döngüsü Ders 1 micrograd’ın aynısı; optimizer.zero_grad = Ders 1 zero_grad, loss.backward() = Ders 5’te elle yazdığımız şey (artık arkasını biliyoruz), AdamW = Ders 4’te bahsedilen adaptif optimizer.
İleriye: AdamW + estimate_loss + train/val izleme, production eğitiminin standart iskeleti; Ders 10’da buna learning rate schedule, gradient clipping, mixed precision eklenir.
8.7 Matematik Hilesi: Geçmişi Matris Çarpımıyla Ortalama
Self-attention’a girmeden önce, kalbindeki bir numarayı kurarız. Bir token, yalnızca kendinden önceki token’larla iletişebilmeli (geleceği göremez — buna nedensel/causal denir).
“A fifth token would like to communicate with [past] tokens… but not the 6th, 7th, 8th.” — Karpathy, 43:23
En basit iletişim: geçmiş token’ların ortalamasını al (bag-of-words). Bu ortalamayı bir for döngüsüyle yapmak yavaş; numara, onu bir matris çarpımı olarak yapmak:
“The trick in self-attention: matrix multiply as weighted aggregation.” — Karpathy, 47:07
Alt-üçgensel (lower-triangular) bir ağırlık matrisi wei kur (her satır, o konuma kadar olan token’lara eşit ağırlık, gerisi \(0\)), normalize et; xbow = wei @ x her token için geçmişin ortalamasını verir. Daha esnek bir biçim: gelecek konumları \(-\infty\) ile maskeleyip softmax uygula → otomatik olarak normalize alt-üçgensel ağırlıklar:
tril = torch.tril(torch.ones(T, T))
wei = torch.zeros((T, T))
wei = wei.masked_fill(tril == 0, float('-inf')) # gelecek -> -sonsuz
wei = F.softmax(wei, dim=-1) # satir-normalize aglik
xbow = wei @ x # gecmisin agirlikli toplamisoftmax(-∞) = 0 olduğundan, gelecek token’lar sıfır ağırlık alır (nedensellik). Şu an ağırlıklar sabit (eşit ortalama); birazdan onları öğrenilen, veriye-bağlı hâle getireceğiz — işte self-attention.
Kod
import matplotlib.pyplot as plt
import numpy as np
raw = CM_RAW.numpy() # (8,8) ham yakınlık
soft = CM_SOFT.numpy() # (8,8) maske + softmax sonrası
fig, axes = plt.subplots(1, 2, figsize=(11, 5))
m = float(np.abs(raw).max())
im0 = axes[0].imshow(raw, cmap=CMAP_DIVERGE, vmin=-m, vmax=m)
axes[0].set_title("Ham yakınlık $QK^\\top$ (maskesiz)", color=COL_TEXT)
fig.colorbar(im0, ax=axes[0], fraction=0.046, pad=0.04)
im1 = axes[1].imshow(soft, cmap=CMAP_INDIGO, vmin=0.0, vmax=1.0)
axes[1].set_title("Maske $(-\\infty)$ + softmax → alt-üçgensel", color=COL_TEXT)
fig.colorbar(im1, ax=axes[1], fraction=0.046, pad=0.04)
for ax in axes:
ax.set_xlabel("anahtar (token)", color=COL_TEXT)
ax.set_ylabel("sorgu (token)", color=COL_TEXT)
ax.set_xticks(range(8)); ax.set_yticks(range(8))
# sağ panelde sıfır (gelecek) hücrelerine çentik
for i in range(8):
for j in range(8):
if j > i:
axes[1].text(j, i, "0", ha="center", va="center", fontsize=8, color=COL_SLATE_400)
plt.tight_layout()
plt.show()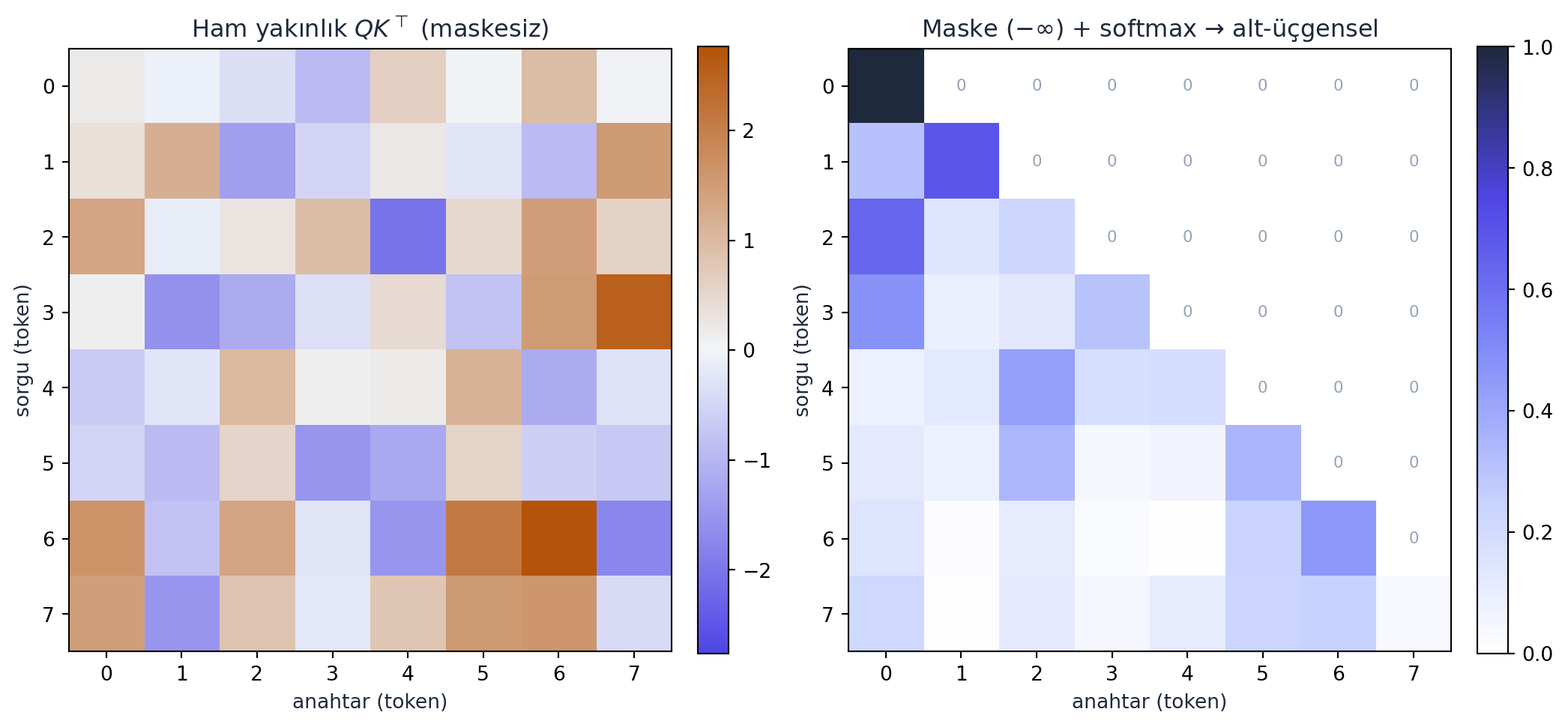
İpucuBuilder Notu — Ortalama = Matris Çarpımı
Geriye (18.06 + Ders 6): “Ortalama = matris çarpımı” (normalize tril ile), Ders 6’nın batched matmul’unun bir uygulaması (18.06 matris çarpımı). softmax = Ders 2-3’ün üstel-normalize’ı. \(-\infty\) maskeleme, nedenselliği zarif biçimde kodlar.
İleriye: Bu causal mask (tril + \(-\infty\) + softmax), her decoder transformer’ın (GPT) kalbinde vardır — model gelecekten “kopya çekemez”. FlashAttention (Ders 10) bu maskelemeyi verimli yapar.
8.8 Çekirdek: Tek Self-Attention Başı (Q/K/V)
İşte videonun en önemli anı — sabit ortalamayı öğrenilen, veriye-bağlı iletişime çeviriyoruz. Her token iki vektör yayınlar: bir query (sorgu) ve bir key (anahtar).
“[Each token emits] a query and a key. The query roughly speaking is ‘what am I looking for’, and the key is ‘what do I contain’.” — Karpathy, 1:04:06
İki token’ın yakınlığı (affinity), query’sinin diğerinin key’iyle nokta-çarpımıdır. Bu, sabit değil — token’ların içeriğine bağlı (veriye-bağlı).
“The affinities between tokens are not going to be constant zero, they’re going to be data dependent.” — Karpathy, 57:25
Üç projeksiyon (Q, K, V), bir nedensel maske, bir softmax, ve değerlerin (V) ağırlıklı toplamı:
\[ Q = x W_Q, \quad K = x W_K, \quad V = x W_V \] \[ \text{wei} = Q K^\top \;\;\xrightarrow{\text{maskele} + \text{softmax}}\;\; \text{out} = \text{softmax}(\text{wei}) \, V \]
head_size = 16
key = nn.Linear(C, head_size, bias=False)
query = nn.Linear(C, head_size, bias=False)
value = nn.Linear(C, head_size, bias=False)
k = key(x) # (B, T, head_size) "ne iceriyorum"
q = query(x) # (B, T, head_size) "ne ariyorum"
wei = q @ k.transpose(-2, -1) # (B, T, T) yakinliklar
wei = wei.masked_fill(tril == 0, float('-inf')) # nedensel maske
wei = F.softmax(wei, dim=-1) # agirlik dagilimi
v = value(x) # (B, T, head_size) "ne iletecegim"
out = wei @ v # (B, T, head_size) agirlikli toplamSezgi: her token sorgusunu yayınlar; içeriği o sorguya uyan geçmiş token’lar yüksek ağırlık alır; o token’ların değerleri ağırlıklı toplanır. Artık iletişim sabit değil, içeriğe göre öğreniliyor. Aşağıda, eğitilmiş GPT’mizin ilk başının gerçek ağırlık matrisini görüyoruz — alt-üçgensel (nedensel) ve öğrenilmiş:
Kod
import matplotlib.pyplot as plt
att = ATT_HEADS[0].numpy() # (16, 16) eğitilmiş block[0] head[0]
labels = ["\\n" if c == "\n" else ("␣" if c == " " else c) for c in ATT_CHARS]
fig, ax = plt.subplots(figsize=(8, 6.8))
im = ax.imshow(att, cmap=CMAP_INDIGO, vmin=0.0, vmax=float(att.max()))
ax.set_xticks(range(len(labels)))
ax.set_yticks(range(len(labels)))
ax.set_xticklabels(labels, fontsize=8.5)
ax.set_yticklabels(labels, fontsize=8.5)
ax.set_xlabel("anahtar (key) — bakılan geçmiş token", color=COL_TEXT)
ax.set_ylabel("sorgu (query) — bakan token", color=COL_TEXT)
ax.set_title("Self-attention ağırlıkları — alt-üçgensel, nedensel (head 0)", color=COL_TEXT)
cb = fig.colorbar(im, ax=ax, fraction=0.046, pad=0.04)
cb.set_label("ağırlık (softmax)", color=COL_TEXT)
plt.tight_layout()
plt.show()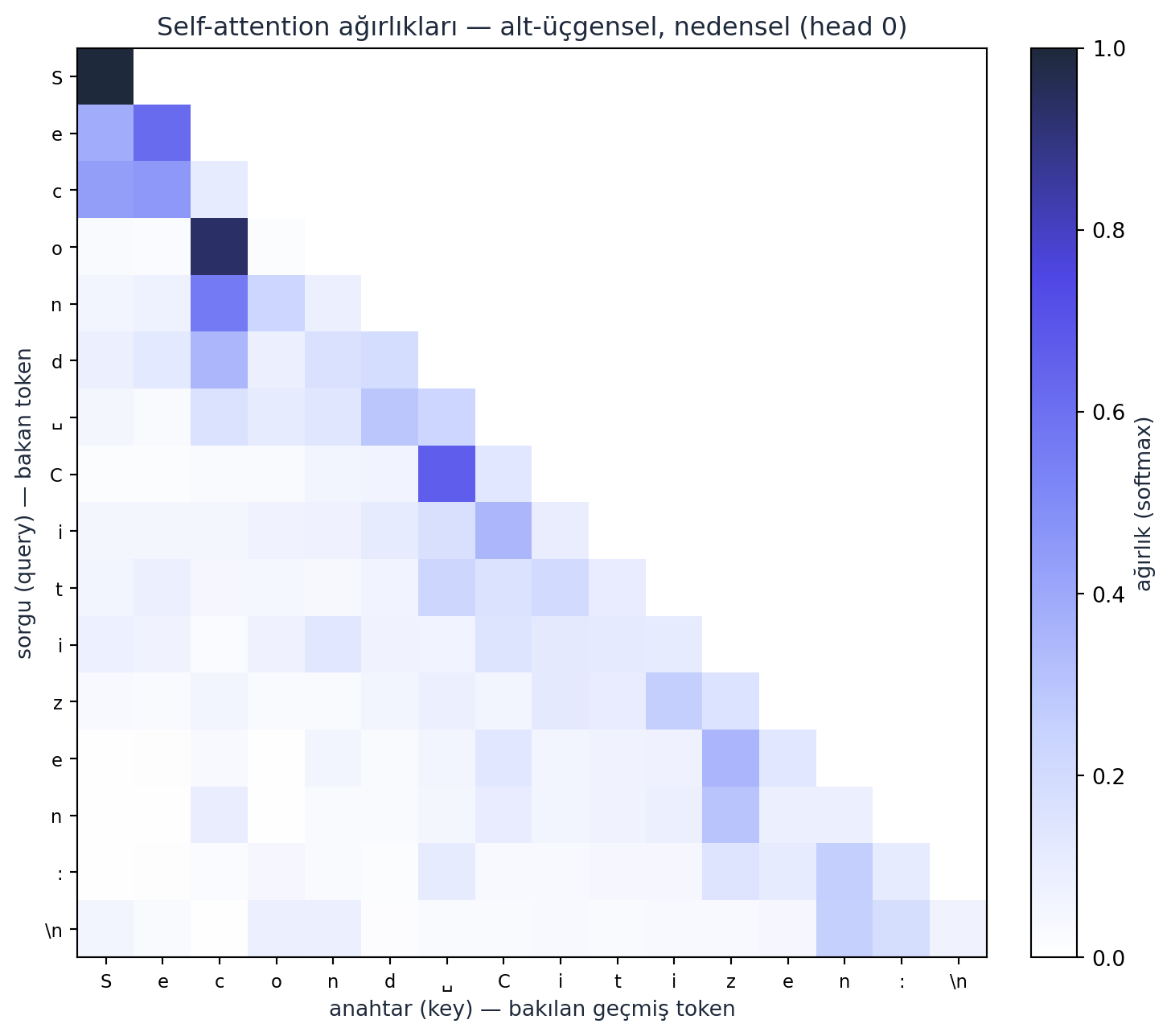
İpucuBuilder Notu — Q·Kᵀ = Nokta-Çarpım Benzerliği
Geriye (18.06 + Stat 110 + Ders 6): \(Q K^\top\) = nokta-çarpım benzerliği (18.06); softmax sonrası ağırlıklı toplam = koşullu beklenti sezgisi (Stat 110: ağırlıklar olasılık gibi). Üç projeksiyon (\(W_Q/W_K/W_V\)) = Ders 6’nın lineer katmanları.
İleriye: Bu tek baş, GPT’nin temel taşı. Self-attention’ın \(O(T^2)\) maliyeti (her token çifti) uzun bağlamda darboğaz; FlashAttention (Ders 10) bunu bellek-verimli yapar. Q/K/V çerçevesi, cross-attention (encoder-decoder) ve retrieval’a da genişler.
İpucuBuilder Notu — NYU H12 ile Köprü
Çapraz kurs (NYU Derin Öğrenme, H12 — Mike Lewis, NLP): NYU dersi de self-attention’ı (self-attention matrisi, nedensel maske, konum kodlama) işler — ama aynı kavramı farklı bir çerçeveden: orada attention bir matris operasyonu olarak NLP bağlamında sunulur, burada Karpathy “her token bir sorgu yayınlar” sezgisiyle sıfırdan kurar. İkisi aynı \(\text{softmax}(QK^\top/\sqrt{d_k})V\) formülüne iner — biri sezgi-önce, biri matris-önce.
8.9 Dikkat Üzerine Notlar ve Ölçekli Dikkat
Karpathy self-attention hakkında birkaç kritik not düşer:
- Dikkatin konum kavramı yoktur. Self-attention, token’ları bir küme gibi görür (permütasyona değişmez) — “5. token” ile “2. token” arasındaki sıra bilgisi yok. Bu yüzden token embedding’ine bir konum embedding’i (positional encoding) eklenir:
x = token_emb + pos_emb. - Her örnek bağımsız. Batch’teki diziler birbirine bakmaz (BatchNorm’un aksine — Ders 4).
- Encoder vs decoder. Nedensel maske (tril) varsa decoder (GPT — gelecek gizli); maske yoksa encoder (her token herkese bakar).
- Self vs cross attention. Q/K/V aynı kaynaktan gelirse self-attention; Q farklı bir kaynaktan gelirse cross-attention (çeviri gibi).
En önemli not: ölçekleme.
“Note 6: scaled self-attention — why divide by sqrt(head_size)?” — Karpathy, 1:16:51
Yakınlıkları (\(Q \cdot K^\top\)) head boyutunun kareköküne böleriz:
\[ \text{Attention}(Q, K, V) = \text{softmax}\!\left(\frac{Q K^\top}{\sqrt{d_k}}\right) V \]
Neden? Head boyutu (\(d_k\)) büyüdükçe \(Q \cdot K^\top\)’nin varyansı büyür; softmax’a çok büyük değerler girerse softmax doygunlaşır (neredeyse one-hot, tek bir token’a tüm ağırlık) → gradyan akmaz (Ders 4 doygunluk!). \(\sqrt{d_k}\)’ye bölmek varyansı \(\approx 1\)’de tutar, softmax yumuşak kalır. Ölçümümüzde: head_size \(=16\) için ham \(Q \cdot K^\top\) std \(\approx 4{,}295\) → ölçekli \(\approx 1{,}074\); head_size \(=100\) için ham \(\approx 10{,}093\) → ölçekli \(\approx 1{,}009\).
Aşağıda konum embedding’ini — dikkatin “uzaysızlığını” telafi eden mekanizmayı — sinüzoidal (klasik) ve öğrenilen (bizim GPT) biçimleriyle görüyoruz:
Kod
import matplotlib.pyplot as plt
sin_pe = SIN_PE.numpy() # (block_size, n_embd)
learned = LEARNED_PE.numpy() # (block_size, n_embd)
fig, axes = plt.subplots(1, 2, figsize=(11, 5))
im0 = axes[0].imshow(sin_pe, cmap=CMAP_DIVERGE, aspect="auto", vmin=-1, vmax=1)
axes[0].set_title("Sinüzoidal (analitik, Vaswani 2017)", color=COL_TEXT)
fig.colorbar(im0, ax=axes[0], fraction=0.046, pad=0.04)
lim = float(abs(learned).max())
im1 = axes[1].imshow(learned, cmap=CMAP_DIVERGE, aspect="auto", vmin=-lim, vmax=lim)
axes[1].set_title("Öğrenilen (bizim GPT'mizin pos_emb'i)", color=COL_TEXT)
fig.colorbar(im1, ax=axes[1], fraction=0.046, pad=0.04)
for ax in axes:
ax.set_xlabel("embedding boyutu (C)", color=COL_TEXT)
ax.set_ylabel("konum (T)", color=COL_TEXT)
plt.tight_layout()
plt.show()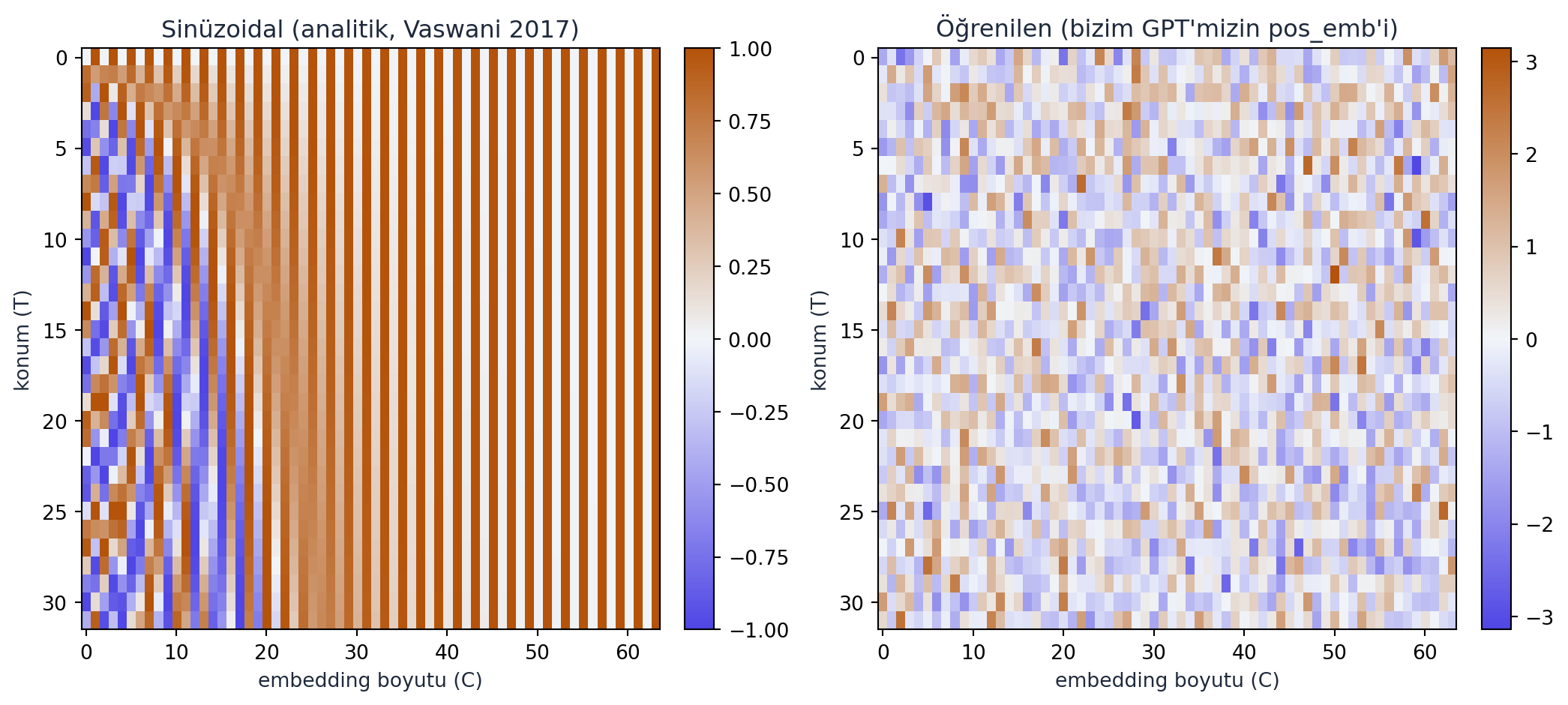
İpucuBuilder Notu — √dₖ = Varyans Kontrolü (Ders 4 Ruhu)
Geriye (Ders 4 + Stat 110): \(\sqrt{d_k}\) ölçeklemesi, Stat 110 varyans muhasebesi (Ders 4 Kaiming’le aynı ruh: varyansı kontrol et); doygun softmax = Ders 4’ün doymuş aktivasyonu (gradyan ölür). Positional encoding, dikkatin “uzaysız” oluşunu telafi eder.
İleriye: Scaled dot-product attention, “Attention is All You Need”in tam formülü. Pozisyon kodlaması (öğrenilen, sinüzoidal, RoPE) modern modellerde aktif araştırma; decoder-only (GPT) tasarımı tüm üretken LLM’lerin standardı.
8.10 Multi-Head Attention ve Feed-Forward
Multi-head attention. Tek bir dikkat başı tek tür ilişki yakalar. Karpathy birden çok başı (head) paralel çalıştırır, çıktılarını birleştirir (concat). Her baş farklı bir ilişki türü öğrenir (biri sözdizimi, biri anlam, vb.) — tıpkı birden çok filtre gibi.
class MultiHeadAttention(nn.Module):
def __init__(self, num_heads, head_size):
super().__init__()
self.heads = nn.ModuleList([Head(head_size) for _ in range(num_heads)])
self.proj = nn.Linear(num_heads * head_size, n_embd) # residual'a geri projeksiyon
def forward(self, x):
out = torch.cat([h(x) for h in self.heads], dim=-1) # baslari birlestir
return self.proj(out)Aşağıda eğitilmiş GPT’mizin ilk bloğundaki dört başın gerçek ağırlık matrisleri — her biri farklı bir örüntü öğrenmiş:
Kod
import matplotlib.pyplot as plt
fig, axes = plt.subplots(2, 2, figsize=(10, 9.2))
vmax = max(float(h.numpy().max()) for h in ATT_HEADS)
for i, ax in enumerate(axes.flat):
a = ATT_HEADS[i].numpy()
im = ax.imshow(a, cmap=CMAP_INDIGO, vmin=0.0, vmax=vmax)
ax.set_title(f"Baş {i+1}", color=COL_TEXT, fontsize=12)
ax.set_xticks([]); ax.set_yticks([])
ax.set_xlabel("anahtar →", color=COL_TEXT, fontsize=9)
ax.set_ylabel("sorgu ↓", color=COL_TEXT, fontsize=9)
fig.suptitle("4 dikkat başı — her biri farklı bir ilişki örüntüsü öğrenir",
color=COL_TEXT, fontsize=13)
fig.colorbar(im, ax=axes.ravel().tolist(), fraction=0.046, pad=0.04, label="ağırlık")
plt.show()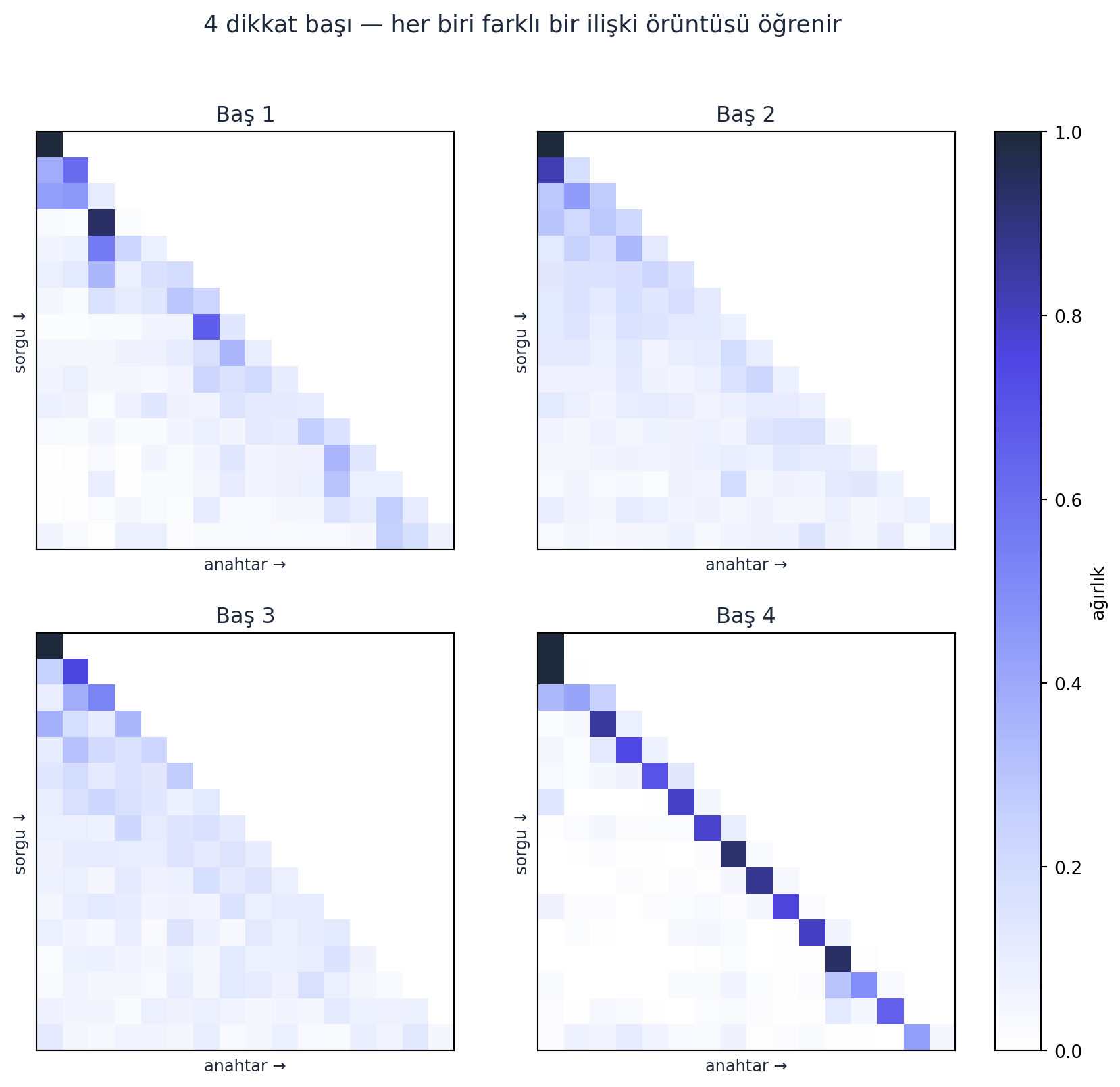
Feed-forward. Dikkat iletişimdir (token’lar bilgi toplar); ama topladıkları bilgiyi tek tek işlemeleri de gerekir. Bu, her token’a ayrı ayrı uygulanan küçük bir MLP (genelde \(4\times\) genişleme):
“Self-attention is the communication; then once they’ve gathered the data, they need to think on that data individually — and that’s [the feed-forward].” — Karpathy, 1:26:06
class FeedForward(nn.Module):
def __init__(self, n_embd):
super().__init__()
self.net = nn.Sequential(
nn.Linear(n_embd, 4 * n_embd), # 4x genisleme
nn.ReLU(),
nn.Linear(4 * n_embd, n_embd), # residual'a geri
)
def forward(self, x):
return self.net(x)Yani transformer bloğu iki adımdır: iletişim (multi-head attention) + düşünme (feed-forward).
İpucuBuilder Notu — FFN = Ders 1-6’nın MLP’si
Geriye (Ders 1-6): FeedForward = Ders 1-6’nın MLP’si (Linear → nonlin → Linear); multi-head = Ders 6’nın paralel-matmul fikri. “İletişim + düşünme” ayrımı, transformer bloğunun temel ritmidir.
İleriye: \(4\times\) genişleme + GELU (Ders 10), her transformer FFN’inin standardı. Multi-head, GPT-2’de 12 baş, büyük modellerde onlarca; başların ne öğrendiği (interpretability) aktif araştırma. Modern modellerde FFN, parametrelerin çoğunu tutar (MoE bunu seyrekleştirir).
8.11 Bloklar ve Residual Bağlantılar
Bir transformer bloğu = multi-head attention + feed-forward. Gücü için bunları üst üste istifleriz (derinlik). Ama derin ağlarda gradyan akışı zorlaşır (Ders 4 vanishing gradient). Çözüm: residual (artık) bağlantılar. Her alt-katmanın çıktısını girdisine ekleriz (bypass): x = x + attention(x), x = x + ffn(x). Bu “artık yol” (residual pathway), gradyanın derin ağda doğrudan akmasını sağlar (toplama gradyanı aynen geçirir — Ders 1!).
\[ x \leftarrow x + \text{MultiHead}(x), \qquad x \leftarrow x + \text{FeedForward}(x) \]
“Residual connections.” — Karpathy, 1:26:46
class Block(nn.Module):
def __init__(self, n_embd, n_head):
super().__init__()
self.sa = MultiHeadAttention(n_head, n_embd // n_head)
self.ffwd = FeedForward(n_embd)
def forward(self, x):
x = x + self.sa(x) # residual: iletisim
x = x + self.ffwd(x) # residual: dusunme
return xBaşlangıçta bu katkılar küçük tutulur ki blok “kimlik fonksiyonuna yakın” başlasın — derin ağ kolay öğrensin.
İpucuBuilder Notu — Residual = Ders 1 Toplama Gradyanı
Geriye (Ders 1 + Ders 4): Residual’ın gücü doğrudan Ders 1: toplama gradyanı aynen geçirir (yerel türev \(1\)). Bu yüzden x + f(x)’in gradyanı, derin ağda bile sönmeden akar. Ders 4’te ResNet örneğinde görmüştük; transformer da aynı fikri kullanır. Ders 5’te backward’ı elle yazdığımız için bu akışın neden işlediğini sezgisel biliyoruz.
İleriye: Residual bağlantılar, 100+ katmanlı ağları (GPT-3: 96 katman) eğitilebilir kılan temel. “Residual stream” (Ders 10), modern interpretability’nin de merkezi kavramı.
8.12 LayerNorm (Pre-Norm) ve Dropout
Derin transformer’ı kararlı eğitmek için iki ek: LayerNorm ve dropout.
“…this Norm is referring to something called LayerNorm.” — Karpathy, 1:32:58
LayerNorm, Ders 4’ün BatchNorm’una benzer (normalize + scale/shift) ama her örneği bağımsız normalize eder — batch’teki diğer örneklere bakmaz (BatchNorm’un “örnekleri bağlama” sorunu yok, Ders 4). Özellik (feature) boyutunda normalize eder. Modern transformer’lar pre-norm kullanır: LayerNorm, alt-katmandan önce uygulanır.
def forward(self, x):
x = x + self.sa(self.ln1(x)) # pre-norm: once normalize, sonra attention
x = x + self.ffwd(self.ln2(x)) # pre-norm: once normalize, sonra ffn
return xDropout (Ders 1), ölçeklerken (daha çok parametre) overfitting’i önler: eğitimde aktivasyonların bir kısmını rastgele kapatır. Aşağıda tam transformer bloğunun yapısı — iki pre-norm + iki residual yolu:
Kod
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
NL = chr(10)
fig, ax = plt.subplots(figsize=(9, 7.5))
ax.set_xlim(0, 10); ax.set_ylim(0, 11); ax.axis("off")
def box(x, y, w, h, text, fc=COL_BG, ec=COL_PRIMARY, lw=2.0, tc=COL_TEXT, fs=11):
ax.add_patch(FancyBboxPatch((x-w/2, y-h/2), w, h,
boxstyle="round,pad=0.02,rounding_size=0.12", fc=fc, ec=ec, lw=lw, zorder=2))
ax.text(x, y, text, ha="center", va="center", color=tc, fontsize=fs, weight="bold", zorder=3)
def arrow(x0, y0, x1, y1, color=COL_SLATE_400, lw=2.0):
ax.add_patch(FancyArrowPatch((x0, y0), (x1, y1), arrowstyle="-|>",
mutation_scale=16, color=color, lw=lw, zorder=1))
CX = 4.2
box(CX, 0.8, 3.0, 0.7, "girdi x (B, T, C)", fc="#ffffff", ec=COL_SLATE_400)
box(CX, 2.4, 2.6, 0.7, "LayerNorm (ln1)", fc=COL_BG, ec=COL_PRIMARY)
box(CX, 4.0, 3.4, 0.95, "Multi-Head" + NL + "Self-Attention", fc="#eef2ff", ec=COL_INDIGO_600, lw=2.4)
box(CX, 5.5, 1.0, 0.7, "+", fc="#e0e7ff", ec=COL_INDIGO_600, lw=2.2, fs=16)
box(CX, 7.0, 2.6, 0.7, "LayerNorm (ln2)", fc=COL_BG, ec=COL_PRIMARY)
box(CX, 8.6, 3.4, 0.95, "Feed-Forward" + NL + "(4× genişleme)", fc="#eef2ff", ec=COL_INDIGO_600, lw=2.4)
box(CX, 10.1, 1.0, 0.7, "+", fc="#e0e7ff", ec=COL_INDIGO_600, lw=2.2, fs=16)
for y0, y1 in [(1.15, 2.05), (2.75, 3.5), (4.5, 5.15), (5.85, 6.65), (7.35, 8.1), (9.1, 9.75)]:
arrow(CX, y0, CX, y1)
ax.annotate("", xy=(CX+0.5, 5.5), xytext=(CX+0.5, 1.6),
arrowprops=dict(arrowstyle="-|>", color=COL_ACCENT, lw=2.0, connectionstyle="arc3,rad=0.45"), zorder=1)
ax.text(CX+2.75, 3.6, "residual" + NL + "(iletişim)", ha="center", va="center",
color=COL_ACCENT, fontsize=10, style="italic")
ax.annotate("", xy=(CX+0.5, 10.1), xytext=(CX+0.5, 6.1),
arrowprops=dict(arrowstyle="-|>", color=COL_ACCENT, lw=2.0, connectionstyle="arc3,rad=0.45"), zorder=1)
ax.text(CX+2.75, 8.2, "residual" + NL + "(düşünme)", ha="center", va="center",
color=COL_ACCENT, fontsize=10, style="italic")
ax.text(CX, 10.95, "Transformer bloğu (pre-norm)", ha="center", va="center",
color=COL_TEXT, fontsize=13, weight="bold")
plt.tight_layout()
plt.show()
İpucuBuilder Notu — LayerNorm = BatchNorm’un Per-Örnek Hâli
Geriye (Ders 1 + Ders 4): LayerNorm = Ders 4 BatchNorm’un per-örnek hâli (Ders 4’te “transformer LayerNorm tercih eder” demiştik — işte burada). Dropout = Ders 1’in regularization’ı. Pre-norm, residual yolunu temiz tutar (gradyan akışı için).
İleriye: LayerNorm (ve türevi RMSNorm), her modern LLM’de var; pre-norm vs post-norm tasarım kararı eğitim kararlılığını etkiler (Ders 10). Dropout, büyük modellerde bazen kaldırılır (yeterli veri varsa).
İpucuBuilder Notu — fast.ai L24 ile Köprü (gelecekte)
Çapraz kurs (fast.ai, L24 — Jeremy Howard): [tahmin] Howard’ın transformer anlatımı self-attention’ı “matris çarpımı olarak dikkat” (matmul’lerin dizilişi) diliyle işler — Karpathy’nin “her token bir sorgu yayınlar” sezgisiyle aynı \(\text{softmax}(QK^\top/\sqrt{d_k})V\)’ye iner. fast.ai kursunun render’ı henüz L24’e ulaşmadı; bu köprü, fast.ai L24 hazır olduğunda detaylandırılacak.
8.13 Encoder, Decoder ve nanoGPT’ye Dönüş
Kurduğumuz GPT, decoder-only bir transformer: nedensel maske (tril) sayesinde her token yalnızca geçmişe bakar — metin üretmek için (autoregressive). Orijinal “Attention is All You Need” hem encoder (maskesiz, çeviri girdisi için) hem decoder içeriyordu; GPT yalnızca decoder’ı kullanır.
Bizim tam GPT’miz (\(4\) baş, \(3\) blok, \(n_{embd}=64\), \(159.937\) parametre) tiny Shakespeare’de eğitildiğinde, doğrulama kaybı bigram’ın \(2{,}4809\)’undan \(1{,}9281\)’e iner — tek dikkat başı ekleyince hafif (\(2{,}4359\)), tüm bileşenler (multi-head + feed-forward + residual + LayerNorm) istiflenince belirgin düşüş:
Kod
import matplotlib.pyplot as plt
import numpy as np
def smooth(h, k=100):
h = np.array(h, dtype=float)
n = (len(h) // k) * k
return h[:n].reshape(-1, k).mean(axis=1)
fig, (axL, axR) = plt.subplots(1, 2, figsize=(11, 5))
axL.plot(smooth(bigram_hist), color=COL_SLATE_400, lw=2, label=f"Bigram (val {bigram_final['val']:.4f})".replace(".", ","))
axL.plot(smooth(sh_hist), color=COL_INDIGO_400, lw=2, label=f"Tek dikkat başı (val {sh_final['val']:.4f})".replace(".", ","))
axL.plot(smooth(gpt_hist), color=COL_INDIGO_600, lw=2.2, label=f"Tam GPT (val {gpt_final['val']:.4f})".replace(".", ","))
apply_style(axL)
axL.set_xlabel("eğitim adımı (×100)"); axL.set_ylabel("eğitim kaybı (loss)")
axL.set_title("Eğitim eğrileri — düzleştirilmiş", color=COL_TEXT)
axL.legend(fontsize=9, loc="upper right")
names = ["Bigram", "Tek baş", "Tam GPT"]
vals = [bigram_final["val"], sh_final["val"], gpt_final["val"]]
cols = [COL_SLATE_400, COL_INDIGO_400, COL_INDIGO_600]
bars = axR.bar(names, vals, color=cols, width=0.6, zorder=3)
axR.axhline(UNIFORM_LOSS, color=COL_PRIMARY, ls="--", lw=1.3, zorder=2)
axR.text(2.4, UNIFORM_LOSS, f" rastgele {UNIFORM_LOSS:.3f}".replace(".", ","),
va="center", ha="left", color=COL_PRIMARY, fontsize=9)
apply_style(axR)
axR.set_ylabel("final doğrulama (val) loss")
axR.set_title("Final val loss — düşük daha iyi", color=COL_TEXT)
axR.set_ylim(0, 4.6)
for b, v in zip(bars, vals):
axR.text(b.get_x()+b.get_width()/2, v+0.07, f"{v:.4f}".replace(".", ","),
ha="center", va="bottom", color=COL_TEXT, fontsize=10, weight="bold")
plt.tight_layout()
plt.show()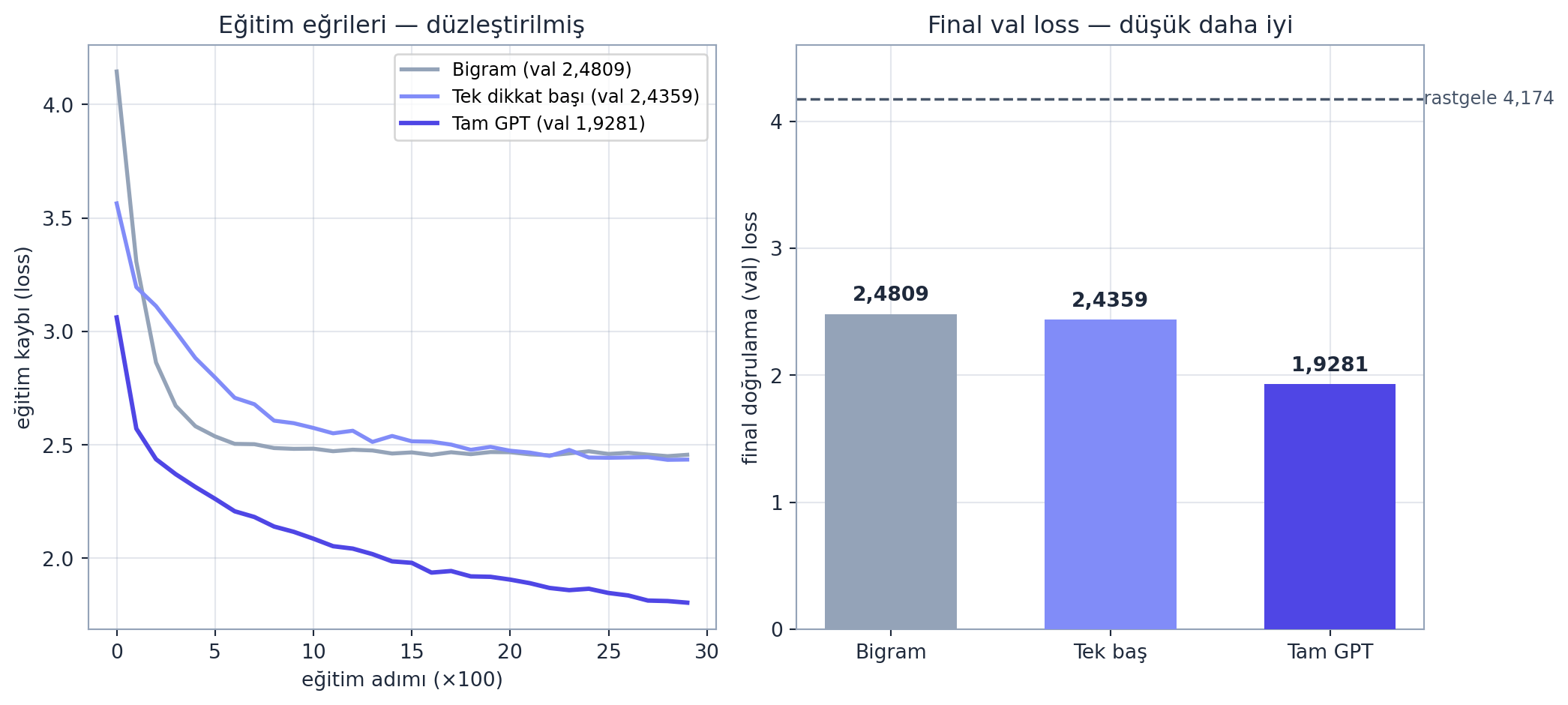
Asıl çarpıcı kanıt üretilen metinde: eğitimden önce saf gürültü, sonra Shakespeare-vari yapı (karakter adları, diyalog düzeni) — hiçbir kural verilmeden, yalnızca “bir sonraki karakteri tahmin et” hedefiyle:
Kod
import matplotlib.pyplot as plt
import textwrap
def wrap(s, width=40, maxlines=16):
lines = []
for seg in s.strip(chr(10)).split(chr(10)):
lines.extend(textwrap.wrap(seg, width) if seg else [""])
return chr(10).join(lines[:maxlines])
before = wrap(GEN_BEFORE, 40)
after = wrap(GEN_AFTER, 40)
fig, axes = plt.subplots(1, 2, figsize=(11, 6))
for ax, title, txt, ec in [
(axes[0], "EĞİTİM ÖNCESİ (rastgele model)", before, COL_SLATE_400),
(axes[1], "EĞİTİM SONRASI (3000 adım)", after, COL_INDIGO_600),
]:
ax.axis("off")
ax.add_patch(plt.Rectangle((0.04, 0.04), 0.92, 0.84, transform=ax.transAxes,
fc="#ffffff", ec=ec, lw=2.0))
ax.text(0.5, 0.95, title, transform=ax.transAxes, ha="center", va="top",
color=ec, fontsize=12, weight="bold")
ax.text(0.09, 0.83, txt, transform=ax.transAxes, ha="left", va="top",
color=COL_TEXT, fontsize=9, family="monospace")
fig.suptitle("Aynı model, eğitimden önce ve sonra — \"sonraki karakteri tahmin et\"",
color=COL_TEXT, fontsize=13)
plt.tight_layout()
plt.show()
LEONCESTER:, BUCY:), satır yapısı, kelime-benzeri parçalar. Model hiçbir kural verilmeden, yalnızca “bir sonraki karakteri tahmin et” hedefiyle dilin yapısını öğrendi. (Deterministik üretim.)
Bu char-GPT, nanoGPT’nin küçük kardeşi. Ölçeklendirip (daha çok blok/baş/embedding, daha uzun bağlam, gerçek tokenizer) GPT-2’ye ulaşırız — Ders 10’un konusu. Ve ChatGPT? O, böyle pretrain edilmiş bir GPT’nin üstüne SFT + RLHF eklenmiş hâli — Ders 8’in (State of GPT) konusu.
İpucuBuilder Notu — WaveNet’in Sabit Ağacından Öğrenilen Dikkate
Geriye (Ders 6): WaveNet sabit bir ağaç kurar — hangi token’ın hangisiyle birleşeceği önceden bellidir. Transformer bunu yeniden organize eder: sabit ağaç yerine her token her tokena öğrenilen ağırlıklarla bakar (attention). Aynı “uzun bağlamı verimli işle” probleminin daha esnek (ama \(O(T^2)\) ile daha pahalı) çözümü.
İleriye: Decoder-only GPT, tüm üretken LLM’lerin (GPT, Claude, Llama, Gemini) iskeleti. Encoder-only (BERT) sınıflandırma/anlama için; encoder-decoder (T5) çeviri için. Bu char-GPT’den GPT-2’ye (Ders 10) yol: aynı mimari, devasa ölçek + BPE tokenizer (Ders 9).
8.14 Bu Dersin Özeti
- GPT = decoder-only transformer; tiny Shakespeare’de karakter-düzeyli kurarız (Ders 9’da gerçek BPE).
- Veri (B, T) bloklar hâlinde; her konum sonrakini tahmin eder. Bigram baseline (Ders 2) başlangıç noktası (val \(2{,}4809\)).
- Matematik hilesi: geçmişin ağırlıklı toplamı = normalize alt-üçgensel matrisle matmul; nedensellik \(-\infty\) maske + softmax ile.
- Self-attention çekirdeği: her token bir query (ne arıyorum) ve key (ne içeriyorum) yayınlar; yakınlık = \(Q \cdot K^\top\) (veriye-bağlı); softmax sonrası value’ların ağırlıklı toplamı.
- Ölçekli dikkat: \(Q \cdot K^\top / \sqrt{d_k}\) — softmax doygunluğunu önler (varyans kontrolü, Ders 4).
- Multi-head: paralel başlar (farklı ilişkiler), concat; feed-forward: iletişim sonrası bireysel düşünme (\(4\times\) MLP).
- Residual bağlantılar: \(x = x + \text{alt-katman}(x)\); toplama gradyanı aynen geçirir (Ders 1) → derin ağda gradyan akar.
- LayerNorm (pre-norm): her örneği bağımsız normalize (Ders 4 BatchNorm’un per-örnek hâli); dropout ölçeklerken regularization.
- Konum embedding’i (dikkatin uzaysızlığını telafi); GPT decoder-only; ölçekle → GPT-2 (Ders 10), + SFT/RLHF → ChatGPT (Ders 8). Bizim GPT’miz val \(2{,}4809 \to 1{,}9281\).
ÖnemliTek Bir Cümle
Transformer, token’ların birbirine öğrenilen, veriye-bağlı ağırlıklarla baktığı (\(\text{query} \cdot \text{key} \to \text{softmax} \to \text{value}\)’ların ağırlıklı toplamı) bir iletişim mekanizmasıdır; bunun üzerine feed-forward (bireysel düşünme), residual bağlantılar (gradyan akışı) ve LayerNorm eklenince, ChatGPT’yi çalıştıran GPT mimarisi ortaya çıkar.
8.15 Kontrol Soruları
NotSoru 1: Self-attention’da, softmax’tan önce yakınlık matrisinin (wei) üst-üçgen kısmı neden −∞ ile maskelenir? softmax(−∞) ne verir ve bu neyi sağlar?
Cevap: \(\text{softmax}(-\infty) = 0\) (\(e^{-\infty} = 0\)). Üst-üçgen, bir token’ın gelecekteki token’lara olan yakınlığıdır; bunları \(-\infty\) yapıp softmax’tan geçirince o konumlar sıfır ağırlık alır. Böylece her token yalnızca kendinden önceki (ve kendisi) token’lardan bilgi toplar — nedensellik (causal). Bu, GPT’nin metin üretebilmesi için şart: model eğitimde “gelecekten kopya çekemez”, yoksa bir sonraki karakteri tahmin etmek anlamsızlaşır (cevabı zaten görmüş olur). Maske olmasaydı (encoder), her token herkese bakardı — anlama görevleri için uygun ama üretim için değil.
NotSoru 2: Matematik Hilesi bölümündeki bag-of-words ortalaması ile Self-Attention bölümündeki self-attention arasındaki temel fark nedir? Ne değişti?
Cevap: Bag-of-words’te ağırlıklar sabit ve eşitti: her geçmiş token’a aynı ağırlık (basit ortalama, wei normalize tril). Self-attention’da ağırlıklar öğrenilen ve veriye-bağlı: her token bir query (ne arıyorum) ve key (ne içeriyorum) yayınlar; ağırlık = query·key benzerliği. Yani “şu an ararken hangi geçmiş token ilgimi çekiyor” sorusunun cevabı, token’ların içeriğine göre dinamik olarak hesaplanır. Ayrıca value projeksiyonu eklendi: token ne ilettiğini (value) de ayrı öğrenir. Sabit ortalama → öğrenilen, içeriğe-duyarlı ağırlıklı toplam.
NotSoru 3: Yakınlıklar neden √(head_size)’a bölünür (ölçekli dikkat)? Bölünmezse ne olur?
Cevap: \(Q \cdot K^\top\), head_size kadar terimin toplamıdır; head_size büyüdükçe bu çarpımın varyansı büyür (Stat 110: bağımsız terimlerin toplamının varyansı terim sayısıyla artar — ölçümümüzde head_size \(16 \to 100\)’de ham std \(4{,}295 \to 10{,}093\)). Çok büyük değerler softmax’a girerse, softmax doygunlaşır — neredeyse one-hot olur. Doygun softmax’ın gradyanı \(\approx 0\)’dır (Ders 4 doymuş aktivasyon!), öğrenme durur. \(\sqrt{\text{head\_size}}\)’a bölmek, varyansı \(\approx 1\)’de tutar → softmax yumuşak (ağırlıklar dağılmış) kalır, gradyanlar akar. Bu, Ders 4’teki Kaiming init’le aynı ruh: varyansı kontrol et.
NotSoru 4: (Builder) Residual bağlantı (x = x + f(x)) derin transformer’ı neden eğitilebilir kılar? Ders 1 zincir kuralıyla bağla.
Cevap: x = x + f(x)’in x’e göre gradyanı, Ders 1’in toplama kuralıdır: toplama gradyanı her iki dala da aynen (yerel türev \(1\) ile) geçirir. Yani gradyan, f boyunca aktığı gibi, doğrudan (\(1\) katsayısıyla) da geriye akar — bir “otoyol” (residual pathway). Derin ağda (100+ katman), normal yolda gradyan her katmanda yerel türevlerle çarpıla çarpıla sönebilir (vanishing, Ders 4); ama residual’ın \(+1\) yolu gradyanı sönmeden en derine taşır. Bu yüzden GPT-3 gibi 96-katmanlı ağlar eğitilebilir. Başlangıçta f’nin katkısı küçük tutulur → blok “kimliğe yakın” başlar, ağ kademeli öğrenir.
8.16 Egzersizler
Egzersiz 1 (Nedensel maske). torch.tril ile alt-üçgensel matris kur. Bir yakınlık matrisini (rastgele) üst-üçgenden \(-\infty\) ile maskele, F.softmax(dim=-1) uygula. Sonucun alt-üçgensel olduğunu ve her satırın toplamının \(1\) olduğunu (wei.sum(-1)) doğrula. wei @ x’in geçmişin ağırlıklı toplamını verdiğini gör.
Egzersiz 2 (Tek dikkat başı). Q/K/V projeksiyonlarını (nn.Linear(C, head_size, bias=False)) kur. wei = q @ k.transpose(-2,-1), maskele, softmax, out = wei @ v. Çıktı şeklinin \((B, T, \text{head\_size})\) olduğunu doğrula. Maskeyi kaldırırsan (encoder) farkı gözlemle.
Egzersiz 3 (Ölçeklemenin etkisi). head_size’ı büyük seç (örn. \(100\)). \(Q \cdot K^\top\)’nin (a) ölçeksiz ve (b) \(/\sqrt{\text{head\_size}}\) ile std’sini ölç. Softmax çıktısının ölçeksizde doygunlaştığını (neredeyse one-hot), ölçeklide yumuşak kaldığını gözlemle.
Egzersiz 4 (Tam GPT). Block (multi-head + FFN + residual + pre-norm LayerNorm) kur, birkaçını istifle, token + positional embedding ekle. tiny Shakespeare’de eğit (AdamW), generate ile metin üret. Loss’un bigram baseline’dan (\(\approx 2{,}5\)) belirgin düştüğünü ve üretilen metnin Shakespeare-vari olduğunu gözlemle.
Egzersiz 5 (Sonraki dersin habercisi). Bu derste bir GPT’yi pretrain ettik: “bir sonraki token’ı tahmin et”. Ama ChatGPT sadece metni sürdürmez — talimatları izler, yardımcı yanıtlar verir, “yapamam” der. (a) Ham bir pretrain edilmiş GPT (yalnızca internet metnini taklit eden) neden doğrudan iyi bir asistan değildir? (b) Onu yardımcı bir asistana çevirmek için hangi ek eğitim aşamaları gerekir (ipucu: insan örnekleri + insan tercihleri)? Bu sorular, Ders 8’de (GPT’nin Hâli / State of GPT) pretrain → SFT → ödül modeli → RLHF pipeline’ını motive eder.
8.17 Sonraki Ders İçin Hazırlık
Ders 8: GPT’nin Hâli (State of GPT) — Andrej Karpathy (Microsoft Build 2023)
Bu derste GPT mimarisini kurduk ve pretrain ettik. Ders 8 farklı bir ders: canlı kodlama yok, kavramsal bir konferans konuşması. Karpathy, ham bir pretrain edilmiş GPT’nin ChatGPT gibi bir asistana nasıl dönüştürüldüğünü (4-aşamalı pipeline) ve bu asistanların nasıl etkili kullanılacağını (prompt engineering) kuş bakışı anlatır.
Ana konular:
- 4-aşamalı eğitim hattı: pretraining → SFT (gözetimli ince ayar) → ödül modeli → RLHF.
- Base model vs assistant model; “token simülatörü” zihniyeti.
- Prompt mühendisliği: chain-of-thought, self-consistency, tool use, RAG.
UyarıDers 8 Öncesi Yapılacak
- Egzersizleri çöz — özellikle 4 (tam GPT’yi eğit) ve 5 (asistan sezgisi).
- “GPT = pretrain edilmiş decoder transformer” cümlesini hatırla; Ders 8 bunun üstüne gelen aşamaları anlatır.
- Not: Ders 8 seri akışının dışında bir “kuş bakışı” — kod yerine kavram.
8.18 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Karpathy’de |
|---|---|---|
| GPT / transformer | Decoder-only transformer; “bir sonraki token’ı tahmin et” ile pretrain | 0m00 |
| (B, T) bloklar | Batch × zaman; her konum sonrakini tahmin eder (block_size bağlam) |
14m27 |
| Nedensel maske (tril) | Üst-üçgen \(-\infty\) + softmax → \(0\); token yalnızca geçmişe bakar | 42m13 |
| query / key / value | Q: ne arıyorum, K: ne içeriyorum, V: ne iletiyorum | 1h04m |
| Self-attention | \(\text{softmax}(Q \cdot K^\top / \sqrt{d_k}) \cdot V\); öğrenilen, veriye-bağlı toplam | 1h01m |
| Ölçekli dikkat (\(\sqrt{d_k}\)) | \(Q \cdot K^\top\)’yi \(\sqrt{\text{head\_size}}\)’a böl; softmax doygunluğunu önler | 1h16m |
| Positional encoding | Dikkatin uzaysızlığını telafi; token_emb + pos_emb |
1h11m |
| Multi-head attention | Paralel başlar (farklı ilişkiler), concat + projeksiyon | 1h21m |
| Feed-forward (\(4\times\)) | İletişim sonrası bireysel düşünme; Linear→nonlin→Linear | 1h24m |
| Residual bağlantı | \(x = x + \text{alt-katman}(x)\); toplama gradyanı geçirir (Ders 1) → derin akış | 1h26m |
| LayerNorm (pre-norm) | Her örneği bağımsız normalize (BatchNorm’un per-örnek hâli) | 1h32m |
| Decoder-only | Nedensel maskeli GPT (üretim); encoder maskesiz (anlama) | 1h42m |
8.19 ML Builder Bağlantıları
İpucu9 köprü — Transformer
- Bigram baseline → Ders 2 bigram (
nn.Embedding+ cross-entropy + generate). İleriye: her LLM’in autoregressive üretimi. - Self-attention (\(Q \cdot K^\top\)) → 18.06 nokta-çarpım + Stat 110 ağırlıklı/koşullu beklenti. İleriye: tüm LLM’lerin çekirdeği.
- Ölçekli dikkat (\(\sqrt{d_k}\)) → Ders 4 varyans kontrolü/doygunluk. İleriye: FlashAttention (Ders 10).
- Nedensel maske → Ders 6 tril + softmax. İleriye: KV cache, verimli decoding.
- Multi-head (paralel) → Ders 6 batched matmul. İleriye: GPU paralelliği, throughput.
- Feed-forward (\(4\times\)) → Ders 1-6 MLP. İleriye: parametrelerin çoğu burada; MoE seyrekleştirir.
- Residual bağlantı → Ders 1 toplama gradyanı + Ders 4 ResNet. İleriye: residual stream (Ders 10), interpretability.
- LayerNorm → Ders 4 BatchNorm’un per-örnek hâli. İleriye: RMSNorm, pre/post-norm tasarımı.
- Decoder-only GPT → tüm üretken LLM iskeleti. İleriye: GPT-2 (Ders 10), + SFT/RLHF → ChatGPT (Ders 8). Çapraz: NYU H12 (Lewis) attention, fast.ai L24 (Howard) matris-dili.
8.20 Karpathy’nin Önerdiği Kaynaklar
Karpathy’nin bu ders için verdiği kaynaklar:
- Ders deposu: github.com/karpathy/ng-video-lecture — dersin tam kodu.
- nanoGPT: github.com/karpathy/nanoGPT — production-ölçek versiyon (Ders 10).
- Attention is All You Need: arxiv 1706.03762 — Vaswani ve ark. 2017, transformer makalesi.
- GPT-3 makalesi: arxiv 2005.14165 — Brown ve ark. 2020, “Language Models are Few-Shot Learners”.
ÖnemliBu dersten tek bir şey alıp gideceksen
Transformer, token’ların birbirine öğrenilen, veriye-bağlı ağırlıklarla baktığı bir iletişim mekanizmasıdır — her token bir query (ne arıyorum) ve key (ne içeriyorum) yayınlar, yakınlıklar softmax’lanır, value’lar ağırlıklı toplanır. Bunun üzerine feed-forward (bireysel düşünme), residual (gradyan akışı) ve LayerNorm eklenince ChatGPT’yi çalıştıran GPT mimarisi çıkar. makemore’un sabit ağacı yerine, artık iletişim öğreniliyor.