flowchart LR
A["Bolum A: nn.Module<br/>Ders 7 mimari, HF agirlik yukle"] --> B["Bolum B: Hiz<br/>1000ms -> 93ms"]
B --> C["Bolum C: Egitim hatti<br/>AdamW, schedule, DDP"]
C --> D["Veri + Eval<br/>FineWeb-EDU, HellaSwag"]
D --> E["Bolum D: Sonuc<br/>GPT-2'yi gecti"]
style A fill:#eef2ff,stroke:#6366f1,stroke-width:2px
style E fill:#e0e7ff,stroke:#1e293b,stroke-width:3px
11 GPT-2’yi (124M) Yeniden Üretmek — Serinin Finali
Ders 7’nin transformer mimarisini ve Ders 9’un tokenizer’ını alıp production ölçeğine taşımak; çalışan bir model ile GPT-2’yi geçen ciddi bir eğitim arasındaki farkın büyük kısmı mimari değil, hız (TF32’den FlashAttention’a) ve ölçek (DDP, gradient accumulation, kaliteli veri) mühendisliğidir — micrograd’dan başlayan yolculuğun finali
NotBölüm bilgisi
- Karpathy’nin videosu: YouTube — Let’s reproduce GPT-2 (124M) (≈241 dk — serinin en uzunu)
- Seri: Neural Networks: Zero to Hero — Ders 10 (FİNAL)
- Hoca: Andrej Karpathy
- Kaynak repo: github.com/karpathy/build-nanogpt · nanoGPT
- Okuma süresi: ≈50 dk (en uzun ders)
ÖnemliBu derste gerçek 124M eğitimi yok — gerçek-hesaplanabilir sayılar var
GPT-2 124M’i gerçekten eğitmek saatlerce çok-GPU gerektirir (bu render ortamında infeasible). Bu derste gerçek-hesaplanabilir sayıları üretiyoruz: parametre sayısı (\(124{,}4\)M — mimariyi kurup saydık), weight tying tasarrufu (\(38{,}6\)M), beklenen ilk loss (\(\ln 50257 = 10{,}82\)), residual init (\(0{,}02/\sqrt{2N}\)), LR schedule eğrisi. Hız süreleri (\(1000 \to 93\)ms) Karpathy’nin A100 ölçümüdür — figürde açıkça “A100 ölçümü” diye işaretlenir.
11.1 Bu Derste Ne Var?
Seri burada doruğuna ulaşıyor: gerçek bir GPT-2 (124M) modelini sıfırdan, OpenAI’nin orijinaliyle uyumlu biçimde yeniden üretiyoruz. Ders 7’de transformer mimarisini, Ders 9’da BPE tokenizer’ı kurmuştuk; bu ders ikisini birleştirip production ölçeğine taşıyor — yalnızca “çalışan” değil, hızlı ve ciddi bir eğitim hattıyla.
“Today we are going to reproduce the GPT-2 model, the 124 million [parameter version].” — Karpathy, 0:00
Ders dört bölüme ayrılır:
- Bölüm A — nn.Module: GPT-2’yi PyTorch’ta kur, OpenAI ağırlıklarını yükle, örnekle, eğitime başla (weight tying, init).
- Bölüm B — Hız: Aynı modeli hızlandır (\(1000\)ms → \(93\)ms): TF32, bfloat16, torch.compile, FlashAttention, “güzel sayılar”.
- Bölüm C — Eğitim hattı: AdamW, gradient clipping, LR schedule, weight decay, gradient accumulation, DDP (çok-GPU), FineWeb-EDU, HellaSwag.
- Bölüm D — Sonuçlar: Sabahki eğitim sonuçları, llm.c, ve serinin kapanışı.
Büyük fikir: “çalışan bir model” ile “production-kalite eğitim” arasındaki fark — ve bu farkın büyük kısmı mühendislik (hız, kararlılık, ölçek).
İpucuBuilder Notu — Tüm Seri Burada Birleşir
Geriye (bütün seri):
- Bölüm A = Ders 7. Tüm attention/FFN/residual/LayerNorm Ders 7’de inşa edildi; bu ders onları GPT-2 ölçeğine taşır (\(12\) katman, \(768\) boyut, \(124\)M parametre).
- Tokenizer = Ders 9. GPT-2 BPE tokenizer’ı (tiktoken
gpt2), Ders 9’da kurduğumuz encode/decode hattı. - Pretraining = Ders 8. Ders 8’in kavramsal anlattığı 1. aşamanın (pretraining) pratik gerçeği: gerçek veri, gerçek compute.
- Sentez = Ders 1-6. micrograd’ın autograd’ı, makemore’un dil modelleme çerçevesi — hepsi burada GPT-2’de buluşur.
Tek cümleyle: GPT-2’yi yeniden üretmek, Ders 7’nin transformer’ını + Ders 9’un tokenizer’ını alıp production ölçeğine taşımaktır — ve “çalışan model” ile “ciddi eğitim” arasındaki farkın büyük kısmı, mimari değil hız ve ölçek mühendisliğidir.
11.2 Giriş ve GPT-2 Checkpoint’ini İnceleme
Hedef: 2019’da OpenAI’nin yayımladığı GPT-2’nin 124 milyon parametreli (en küçük) versiyonunu yeniden üretmek. Önce orijinal OpenAI checkpoint’ini (HuggingFace üzerinden) inceleriz: model bir sözlük (state_dict) olarak gelir — ağırlık tensörleri ve adları. Bu adlar (wte, wpe, h.0.attn..., ln_f, lm_head) bizim kuracağımız yapıyı belirler.
GPT-2 124M mimarisi: 12 katman, 12 dikkat başı, 768 embedding boyutu, 1024 bağlam uzunluğu, 50257 token sözlük. Bu sayılar Ders 7’deki char-GPT’nin büyütülmüş hâli — aynı mimari, gerçek ölçek:
Kod
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
NL = chr(10)
fig, ax = plt.subplots(figsize=(9, 7.5))
ax.set_xlim(0, 10); ax.set_ylim(0, 11.5); ax.axis("off")
def box(x, y, w, h, t, fc, ec, fs=10.5, tc=None):
ax.add_patch(FancyBboxPatch((x-w/2, y-h/2), w, h, boxstyle="round,pad=0.02,rounding_size=0.12",
fc=fc, ec=ec, lw=2.2, zorder=2))
ax.text(x, y, t, ha="center", va="center", color=tc or COL_TEXT, fontsize=fs, weight="bold")
def arrow(x0, y0, x1, y1):
ax.add_patch(FancyArrowPatch((x0, y0), (x1, y1), arrowstyle="-|>", mutation_scale=15, color=COL_PRIMARY, lw=2.0, zorder=1))
CX = 3.6
box(CX, 0.8, 3.2, 0.7, "token id'leri (B, T)", "#ffffff", COL_SLATE_400)
box(CX, 2.3, 4.2, 0.85, "wte + wpe" + NL + "token + konum embedding", "#eef2ff", COL_INDIGO_400, fs=9.5)
box(CX, 4.6, 4.2, 1.3, "12 × Block" + NL + "(LayerNorm + Attention + MLP," + NL + "residual; 12 baş, 768)", "#eef2ff", COL_INDIGO_600, fs=9.5)
box(CX, 6.9, 3.0, 0.7, "ln_f (son LayerNorm)", "#eef2ff", COL_INDIGO_400, fs=9.5)
box(CX, 8.4, 3.0, 0.75, "lm_head" + NL + "(50257 logit)", "#eef2ff", COL_INDIGO_400, fs=9.5)
box(CX, 9.9, 3.2, 0.7, "olasılıklar (sonraki token)", "#dcfce7", "#15803d", tc="#15803d", fs=9.5)
for y0, y1 in [(1.15, 1.87), (2.72, 3.95), (5.25, 6.55), (7.25, 8.02), (8.77, 9.55)]:
arrow(CX, y0, CX, y1)
# Sag panel: ozet sayilar
bx = 7.3
ax.text(bx, 10.6, "GPT-2 124M", ha="center", color=COL_TEXT, fontsize=14, weight="bold")
specs = ["12 katman (block)", "12 dikkat başı", "768 embedding boyutu",
"1024 bağlam (block_size)", "50257 token sözlük", "", "≈ 124,4M parametre",
"(weight tying'li)"]
for i, s in enumerate(specs):
ax.text(bx, 9.7 - i * 0.62, s, ha="center", color=COL_INDIGO_600 if "124" in s else COL_TEXT,
fontsize=11 if "124" in s else 9.5, weight="bold" if "124" in s else "normal")
ax.text(CX, 11.15, "Ders 7 transformer'ı, GPT-2 ölçeği", ha="center", color=COL_TEXT, fontsize=12, weight="bold")
plt.tight_layout()
plt.show()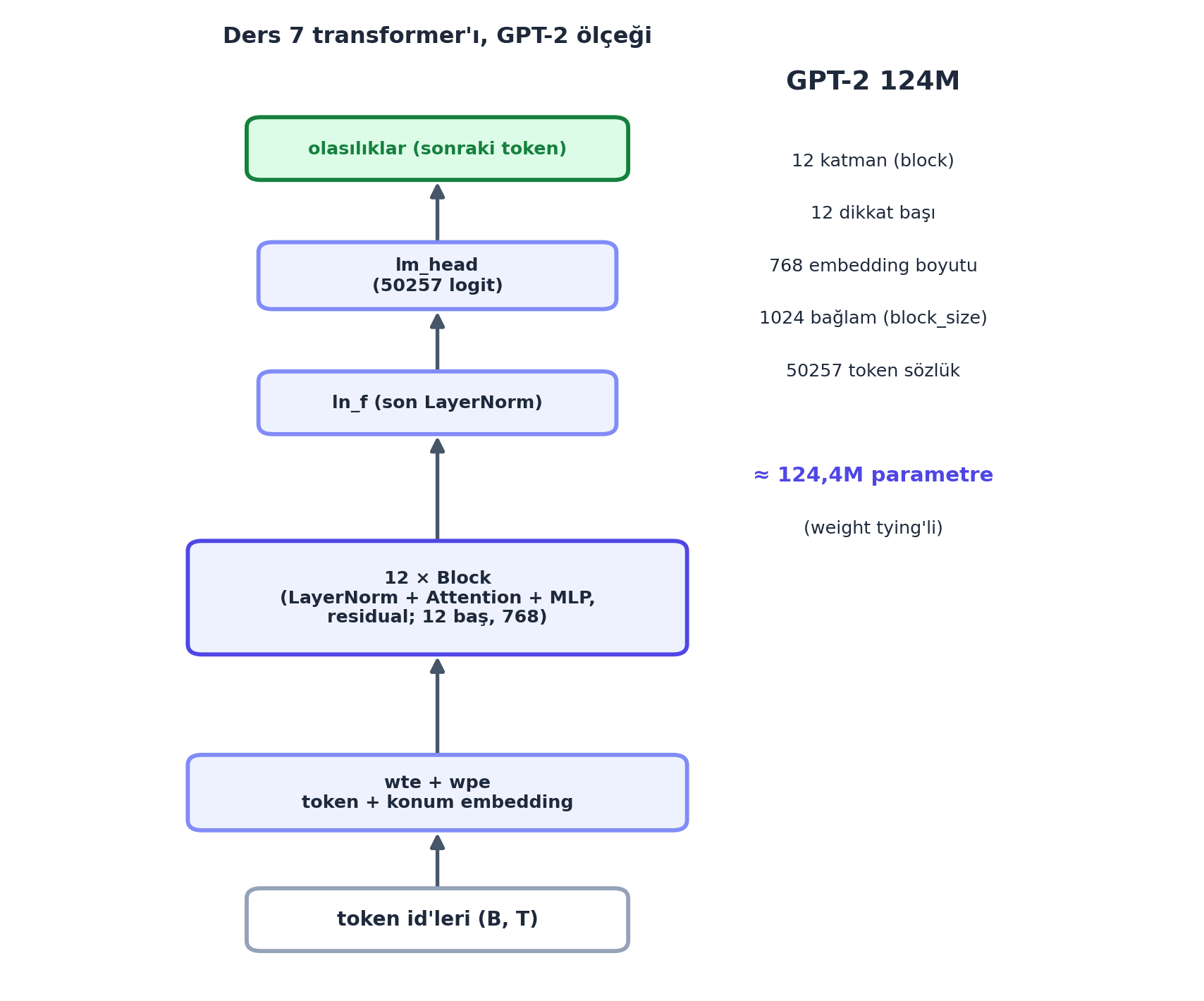
wte) + konum embedding (wpe) toplanır, \(12\) transformer bloğundan (\(12\) baş, \(768\) boyut) geçer, son LayerNorm (ln_f), sonra lm_head ile \(50257\) logit. Mimari Ders 7 ile birebir aynı — yalnızca isimler GPT-2 sözleşmesinde ve ölçek büyük. Toplam \(124{,}4\)M parametre (weight tying’li). Bu sayılar OpenAI checkpoint’iyle uyumlu.
İpucuBuilder Notu — Model = Adlandırılmış Ağırlık Sözlüğü
Geriye (Ders 7): OpenAI checkpoint’inin ağırlık adları (wte, wpe, attention, MLP, LayerNorm), Ders 7’de kurduğumuz bileşenlerin birebir adı. Bir model = ağırlık tensörlerinin adlandırılmış bir sözlüğü; mimariyi bu adlardan okuyabilirsin.
İleriye: “Önce referans checkpoint’i incele, sonra ona uyumlu kur” — production’da var olan bir modeli (LLaMA, Mistral) yüklemek/uyarlamak için standart ilk adım.
11.3 Bölüm A: GPT-2 nn.Module İmplementasyonu
GPT-2’yi PyTorch’ta kuruyoruz (Ders 7’nin mimarisini GPT-2 isimlendirmesiyle), OpenAI ağırlıklarını yüklüyoruz, örnekliyoruz, ve eğitime başlıyoruz.
11.3.1 nn.Module İskeleti
Modeli, OpenAI checkpoint’inin isimlendirmesine uyumlu kurarız: bir GPTConfig (hiperparametreler) ve bir GPT(nn.Module). Yapı Ders 7’nin aynısı, yalnızca isimler GPT-2 sözleşmesinde.
@dataclass
class GPTConfig:
block_size: int = 1024 # baglam uzunlugu
vocab_size: int = 50257 # BPE sozluk (Ders 9)
n_layer: int = 12 # transformer blok sayisi
n_head: int = 12 # dikkat basi
n_embd: int = 768 # embedding boyutu
class GPT(nn.Module):
def __init__(self, config):
super().__init__()
self.transformer = nn.ModuleDict(dict(
wte = nn.Embedding(config.vocab_size, config.n_embd), # token embedding
wpe = nn.Embedding(config.block_size, config.n_embd), # positional embedding
h = nn.ModuleList([Block(config) for _ in range(config.n_layer)]),
ln_f = nn.LayerNorm(config.n_embd), # son LayerNorm
))
self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)Block (Ders 7): pre-norm LayerNorm → CausalSelfAttention → residual, sonra LayerNorm → MLP → residual. GPT-2’nin MLP’si GELU (tanh yaklaşık biçimi) kullanır — Ders 7’deki ReLU yerine.
class MLP(nn.Module):
def __init__(self, config):
super().__init__()
self.c_fc = nn.Linear(config.n_embd, 4 * config.n_embd) # 4x genisleme
self.gelu = nn.GELU(approximate='tanh') # GPT-2 GELU
self.c_proj = nn.Linear(4 * config.n_embd, config.n_embd) # residual'a geriBu mimariyi kurup parametreleri saydığımızda \(124{,}4\)M çıkar — parametrelerin çoğu \(12\) blokta:
Kod
import matplotlib.pyplot as plt
names = [c[0] for c in PARAM_COMPONENTS]
vals = [c[1] for c in PARAM_COMPONENTS]
names_r = names[::-1]; vals_r = vals[::-1]
cols = [COL_INDIGO_600, COL_INDIGO_400, COL_ACCENT, COL_SLATE_400][::-1]
fig, ax = plt.subplots(figsize=(10, 4.8))
bars = ax.barh(range(len(vals_r)), vals_r, color=cols, zorder=3)
ax.set_yticks(range(len(names_r)))
ax.set_yticklabels(names_r, fontsize=9.5)
apply_style(ax)
ax.set_xlabel("parametre sayısı (milyon)")
ax.set_title(f"124,4M parametre nerede? (çoğu 12 blokta)", color=COL_TEXT)
for i, (b, v) in enumerate(zip(bars, vals_r)):
ax.text(v + 1.2, i, f"{v:.1f}M".replace(".", ","), va="center", color=COL_TEXT, fontsize=9.5, weight="bold")
ax.set_xlim(0, max(vals) * 1.18)
plt.tight_layout()
plt.show()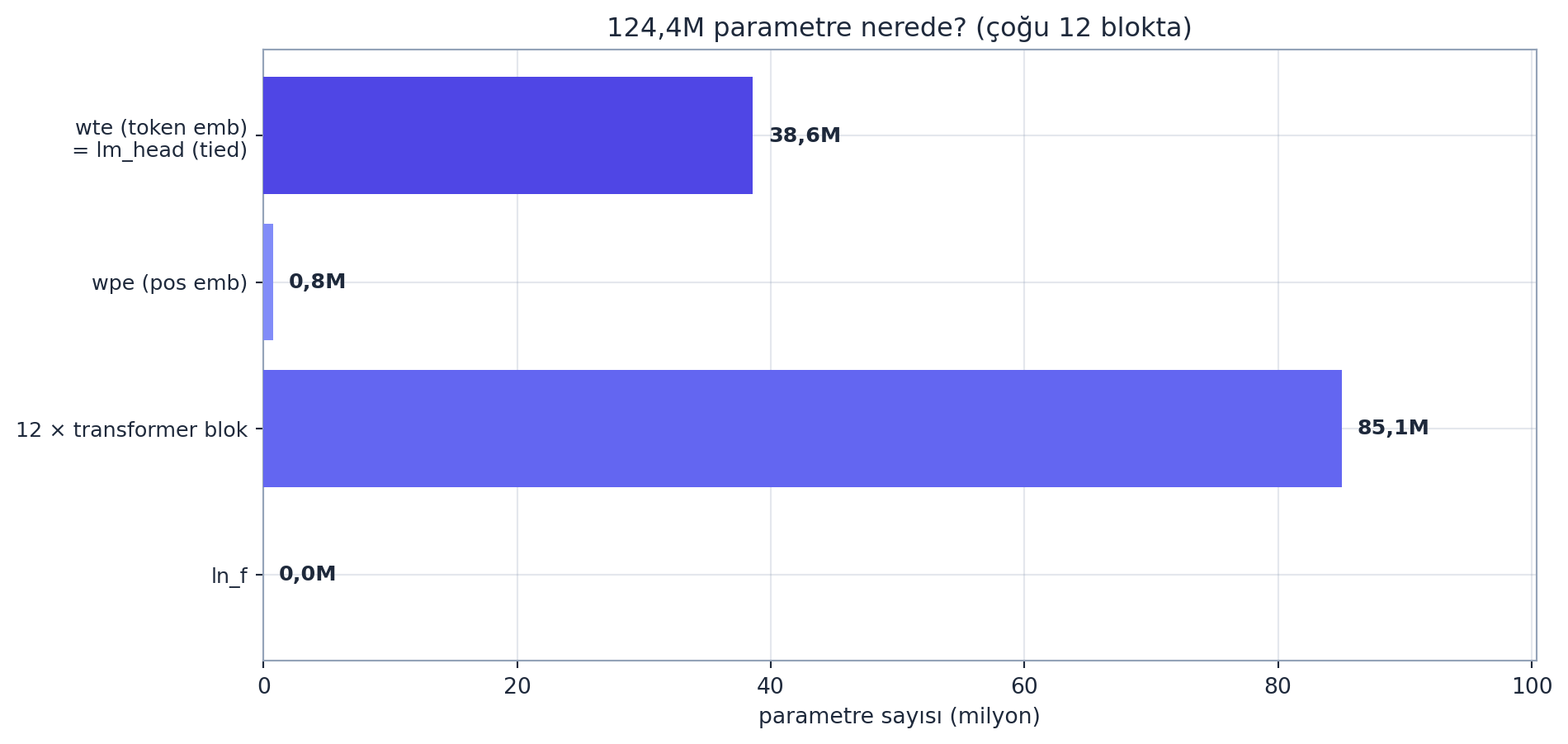
wte (\(\approx 38{,}6\)M) ikinci büyük; weight tying ile lm_head ile paylaşıldığı için iki kez sayılmaz. Konum embedding wpe (\(\approx 0{,}8\)M) ve son LayerNorm küçüktür. Toplam \(\approx 124{,}4\)M.
11.3.2 HuggingFace Ağırlıklarını Yükleme
Modeli kurduk; şimdi OpenAI’nin eğittiği ağırlıkları yükleriz (from_pretrained). Tek incelik: OpenAI bazı ağırlıkları (attention/MLP projeksiyonları) transpoze saklamış (eski TensorFlow Conv1D mirası); yüklerken .t() ile çeviririz.
@classmethod
def from_pretrained(cls, model_type):
transposed = ['attn.c_attn.weight', 'attn.c_proj.weight',
'mlp.c_fc.weight', 'mlp.c_proj.weight']
# ... her anahtar icin: transposed ise sd[k].t() kopyala, degilse dogrudanYükleme başarılıysa, modelimiz OpenAI GPT-2’nin tam kopyası — mimarimizin doğruluğunun kanıtı (Ders 1’in “micrograd = PyTorch” karşılaştırmasının GPT-2 ölçeğindeki hâli).
11.3.3 İleri Geçiş, Cross-Entropy ve Tek-Batch Overfit
İleri geçiş Ders 7’nin aynısı: wte + wpe, bloklar, ln_f, sonra lm_head. Hedef verilince cross-entropy:
def forward(self, idx, targets=None):
pos = torch.arange(0, idx.size(1), device=idx.device)
x = self.transformer.wte(idx) + self.transformer.wpe(pos) # token + konum
for block in self.transformer.h:
x = block(x)
logits = self.lm_head(self.transformer.ln_f(x)) # (B, T, vocab)
loss = None
if targets is not None:
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1))
return logits, lossRastgele başlatılmış modelde ilk loss \(\approx -\ln(1/50257) = \mathbf{10{,}82}\) olmalı (uniform, Ders 4’ün “beklenen başlangıç loss”u). Sonra Ders 3’ten tanıdık sanity-check: tek küçük batch’e kasten overfit et, loss \(\approx 0\)’a insin.
“[Batch] 4 and 32 right now, just because we’re debugging — we just want to have a single batch that’s very small, and all of this should now look familiar.” — Karpathy, 52:10
11.3.4 Weight Tying ve Başlatma
İki önemli detay, GPT-2’yi sadık üretmek için. Weight tying: token embedding (wte) ile dil-modeli başı (lm_head) aynı matrisi paylaşır.
“What’s happening here is a common weight tying scheme that actually comes from [the original paper].” — Karpathy, 1:07:58
self.transformer.wte.weight = self.lm_head.weight # ayni tensor (Ders 2: one-hot@W = satir secimi)Kod
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
NL = chr(10)
fig, ax = plt.subplots(figsize=(10, 4.8))
ax.set_xlim(0, 12); ax.set_ylim(0, 5.5); ax.axis("off")
def box(x, y, w, h, t, fc, ec, fs=10, tc=None):
ax.add_patch(FancyBboxPatch((x-w/2, y-h/2), w, h, boxstyle="round,pad=0.02,rounding_size=0.1",
fc=fc, ec=ec, lw=2.2, zorder=2))
ax.text(x, y, t, ha="center", va="center", color=tc or COL_TEXT, fontsize=fs, weight="bold")
# Giris yolu
box(1.6, 4.2, 2.4, 0.8, "token id" + NL + "(giriş)", "#ffffff", COL_SLATE_400, fs=9)
box(1.6, 1.3, 2.4, 0.8, "logitler" + NL + "(çıkış)", "#dcfce7", "#15803d", tc="#15803d", fs=9)
# Paylasilan matris (merkez)
box(6, 2.75, 3.2, 1.5, "PAYLAŞILAN MATRİS" + NL + "W (50257 × 768)" + NL + "wte.weight = lm_head.weight", "#eef2ff", COL_INDIGO_600, fs=10)
# Oklar
ax.add_patch(FancyArrowPatch((2.8, 4.0), (4.5, 3.1), arrowstyle="-|>", mutation_scale=15, color=COL_INDIGO_400, lw=2.0))
ax.text(3.5, 3.85, "wte: id → satır", color=COL_INDIGO_400, fontsize=9, style="italic")
ax.add_patch(FancyArrowPatch((4.5, 2.4), (2.8, 1.5), arrowstyle="-|>", mutation_scale=15, color=COL_ACCENT, lw=2.0))
ax.text(3.5, 1.65, "lm_head: vektör → logit", color=COL_ACCENT, fontsize=9, style="italic")
# Tasarruf
box(10.0, 2.75, 2.8, 1.6, "Tasarruf" + NL + "≈ 38,6M parametre" + NL + "(124M'in %31'i)", "#fef3c7", "#b45309", tc="#b45309", fs=9.5)
ax.add_patch(FancyArrowPatch((7.65, 2.75), (8.55, 2.75), arrowstyle="-|>", mutation_scale=15, color=COL_PRIMARY, lw=2.0))
ax.text(6, 5.1, "Weight tying: wte = lm_head (aynı matris, iki yön)", ha="center", color=COL_TEXT, fontsize=12, weight="bold")
plt.tight_layout()
plt.show()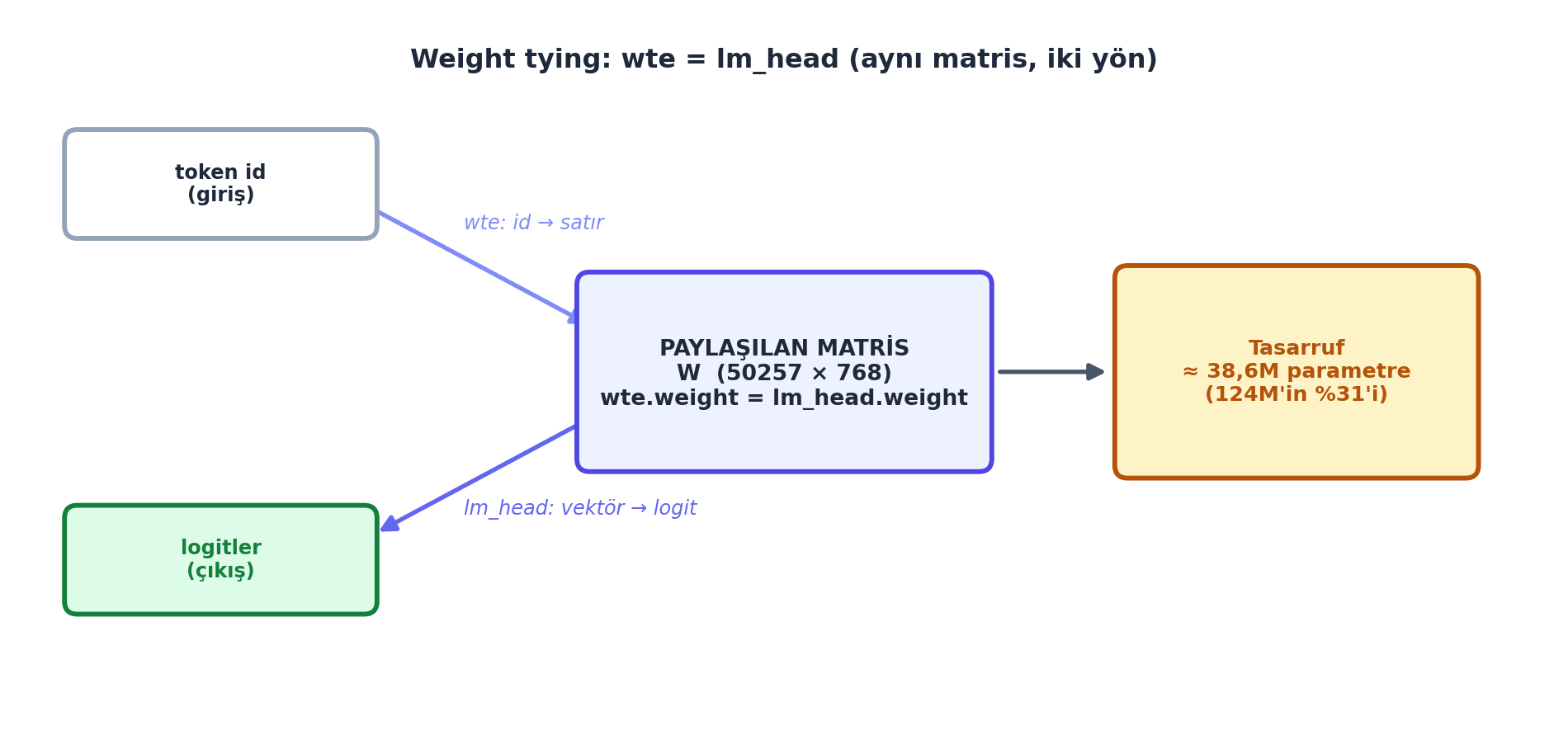
wte, giriş — id’den vektöre) ile dil-modeli başı (lm_head, çıkış — vektörden logitlere) aynı ağırlık matrisini paylaşır. İkisi de aynı “token ↔︎ vektör” eşlemesini yapar (biri ileri, biri ters — Ders 2: one-hot \(\times W\) = satır seçimi). Paylaşmak \(50257 \times 768 \approx 38{,}6\)M parametre tasarrufu sağlar (124M’lik modelin \(\%31\)’i!) ve genellemeyi iyileştirir.
Başlatma: GPT-2 ağırlıkları std\(=0{,}02\) normal ile başlatılır. Kritik ek: residual projeksiyonları katman sayısıyla ölçeklenir — residual akışına (Ders 7) her katman katkı eklediği için varyans katlanarak büyümesin:
\[ \text{std} = 0{,}02 \times \frac{1}{\sqrt{2N}} \]
Burada \(N\) = katman sayısı; \(2\) ise her blokta \(2\) residual ekleme (attention + MLP). \(N=12\) için bu \(\approx 0{,}00408\) (Ders 4 Kaiming’in residual’a özel hâli).
İpucuBuilder Notu — Weight Tying = Ders 2; Init Scaling = Ders 4
Geriye (Ders 2, 4, 7): Weight tying, Ders 2’nin “one-hot \(\times W\) = satır seçimi” gözleminden gelir (giriş ve çıkış aynı matris olabilir). Residual init scaling = Ders 4 varyans kontrolü, Ders 7 residual akışına uygulanmış (\(1/\sqrt{2N}\) ile her katmanın katkısı dengelenir).
İleriye: from_pretrained, tüm modern iş akışının temeli: hazır base model yükle, üstüne kendi ince ayarını (Ders 8 SFT/LoRA) ekle. Bu küçük detaylar (tying, init), “sadık reprodüksiyon” ile “yaklaşık” arasındaki farktır.
11.4 Bölüm B: Hız Optimizasyonları
GPT-2’yi kurduk, eğitebiliyoruz — ama yavaş (adım başına \(\approx 1000\)ms). Şimdi aynı modeli, sonucu değiştirmeden hızlandırıyoruz. Temel sorun:
“The workloads for training are memory bound — which means the tensor cores that do all these extremely fast multiplications [sit idle, waiting for data].” — Karpathy, 1:27:29
Yani GPU çoğu zaman “bellek-bağlı” (memory bound): hesap değil, veri taşıma darboğaz. Hızlandırma adımları (her biri veriyi azaltır veya turları birleştirir; süreler Karpathy’nin A100 ölçümü, illüstratif):
- TF32 (
set_float32_matmul_precision('high')): Tensor Cores, \(\approx 3\times\) matmul hızı → \(333\)ms. - bfloat16 (
torch.autocast): geniş üs aralığı (scaler’sız; fp16 scaler ister) → \(300\)ms. - torch.compile: kernel füzyonu + Python overhead kaldırma (HBM gidip-gelmeyi azaltır) → \(130\)ms.
- FlashAttention (
F.scaled_dot_product_attention): \(T \times T\) matrisini HBM’de hiç oluşturmaz (online softmax, \(O(T)\) bellek) → \(96\)ms. - Güzel sayılar: vocab \(50257 \to 50304\) (\(128\)’in katı; GPU hizalaması) → \(93\)ms.
torch.set_float32_matmul_precision('high') # TF32
with torch.autocast(device_type='cuda', dtype=torch.bfloat16): # bf16
logits, loss = model(x, y)
model = torch.compile(model) # kernel fuzyonu
y = F.scaled_dot_product_attention(q, k, v, is_causal=True) # FlashAttentionKod
import matplotlib.pyplot as plt
labels = [s[0] for s in SPEED]
ms = [s[1] for s in SPEED]
labels_r = labels[::-1]; ms_r = ms[::-1]
fig, ax = plt.subplots(figsize=(10, 5.5))
cols = [COL_INDIGO_600, COL_INDIGO_400, COL_ACCENT, COL_INDIGO_400, COL_INDIGO_600, COL_SLATE_400]
bars = ax.barh(range(len(ms_r)), ms_r, color=cols[::-1], zorder=3)
ax.set_yticks(range(len(labels_r)))
ax.set_yticklabels(labels_r, fontsize=10)
apply_style(ax)
ax.set_xlabel("adım başına süre (ms) — düşük daha hızlı")
ax.set_title(f"Hız: {ms[0]}ms → {ms[-1]}ms (≈{ms[0]/ms[-1]:.1f}×) — Karpathy A100 ölçümü".replace(".", ","), color=COL_TEXT)
for i, (b, v) in enumerate(zip(bars, ms_r)):
ax.text(v + 12, i, f"{v} ms", va="center", color=COL_TEXT, fontsize=9.5, weight="bold")
ax.set_xlim(0, max(ms) * 1.15)
plt.tight_layout()
plt.show()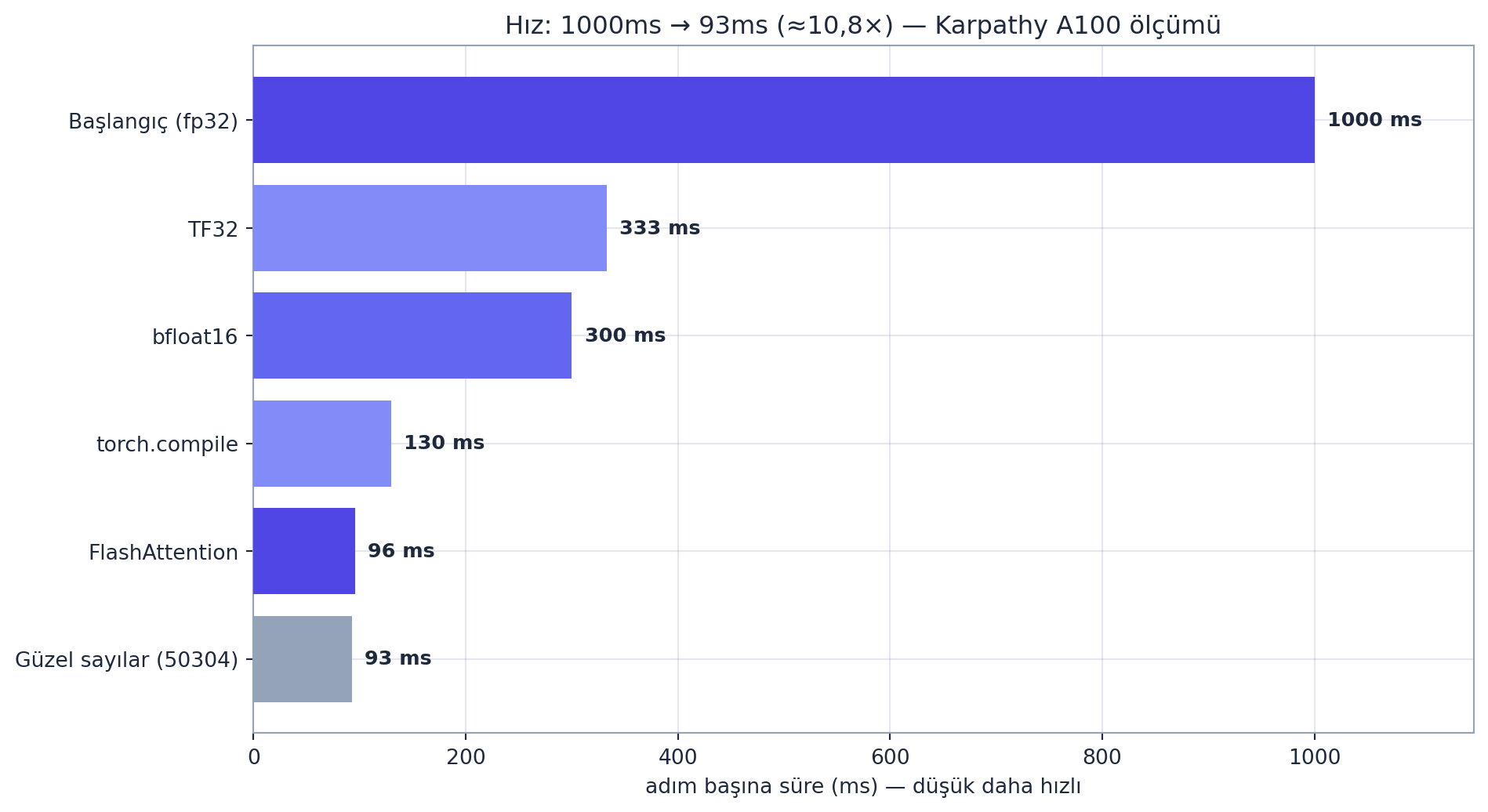
İpucuBuilder Notu — Hız = Ders 5 Füzyon Ruhu + Donanım
Geriye (Ders 5, 7): torch.compile/FlashAttention, Ders 5’teki “atomik graf yerine füzyonlu hesap” fikrinin donanım hâli — ara değerleri materyalize etme, tek geçişte hesapla. FlashAttention, Ders 7’nin \(\text{softmax}(QK^\top/\sqrt{d})V\) formülünü aynen yapar ama dev ara matrisi saklamaz.
İleriye: “Memory bound vs compute bound”, GPU performansının temel kavramı. Mixed precision (bf16) + torch.compile + FlashAttention, tüm modern büyük-model eğitiminin standardı; FP8, vLLM, TensorRT bir sonraki katman.
11.5 Bölüm C: Hiperparametreler, Eğitim Hattı ve DDP
GPT-2’yi kurduk (A) ve hızlandırdık (B). Şimdi ciddi bir eğitim hattı — GPT-3 makalesinin hiperparametreleri (GPT-2 belirsizdir).
AdamW + gradient clipping: betas \((0{,}9, 0{,}95)\), eps \(10^{-8}\); tüm gradyanların küresel normunu \(1{,}0\)’a kırp (kötü bir batch’in modeli sarsmasını önle).
optimizer = torch.optim.AdamW(model.parameters(), lr=6e-4, betas=(0.9, 0.95), eps=1e-8)
norm = torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0) # gradient clippingLearning rate schedule: başta warmup (lr’yi \(0\)’dan yükselt), sonra cosine decay (minimuma indir):
Kod
import matplotlib.pyplot as plt
steps = [s for (s, lr) in LR_CURVE]
lrs = [lr for (s, lr) in LR_CURVE]
fig, ax = plt.subplots(figsize=(10, 5))
ax.plot(steps, lrs, color=COL_INDIGO_600, lw=2.6, zorder=3)
ax.axvspan(0, LR_WARMUP, color=COL_ACCENT, alpha=0.12, zorder=1)
ax.axvline(LR_WARMUP, color=COL_ACCENT, ls="--", lw=1.3)
apply_style(ax)
ax.set_xlabel("eğitim adımı")
ax.set_ylabel("learning rate (η)")
ax.set_title("Warmup + cosine decay — büyük adımla ısın, küçükle yerleş", color=COL_TEXT)
ax.annotate("warmup\n(lineer)", xy=(LR_WARMUP/2, max(lrs)*0.5), ha="center",
color=COL_ACCENT, fontsize=9.5, weight="bold")
ax.annotate("cosine decay", xy=(LR_MAX_STEP*0.55, max(lrs)*0.55), ha="center",
color=COL_INDIGO_600, fontsize=9.5, weight="bold")
ax.annotate(f"η_max = 6e-4", xy=(LR_WARMUP, max(lrs)), xytext=(LR_WARMUP+1500, max(lrs)*0.97),
fontsize=9, color=COL_TEXT,
arrowprops=dict(arrowstyle="-|>", color=COL_SLATE_400, lw=1.2))
plt.tight_layout()
plt.show()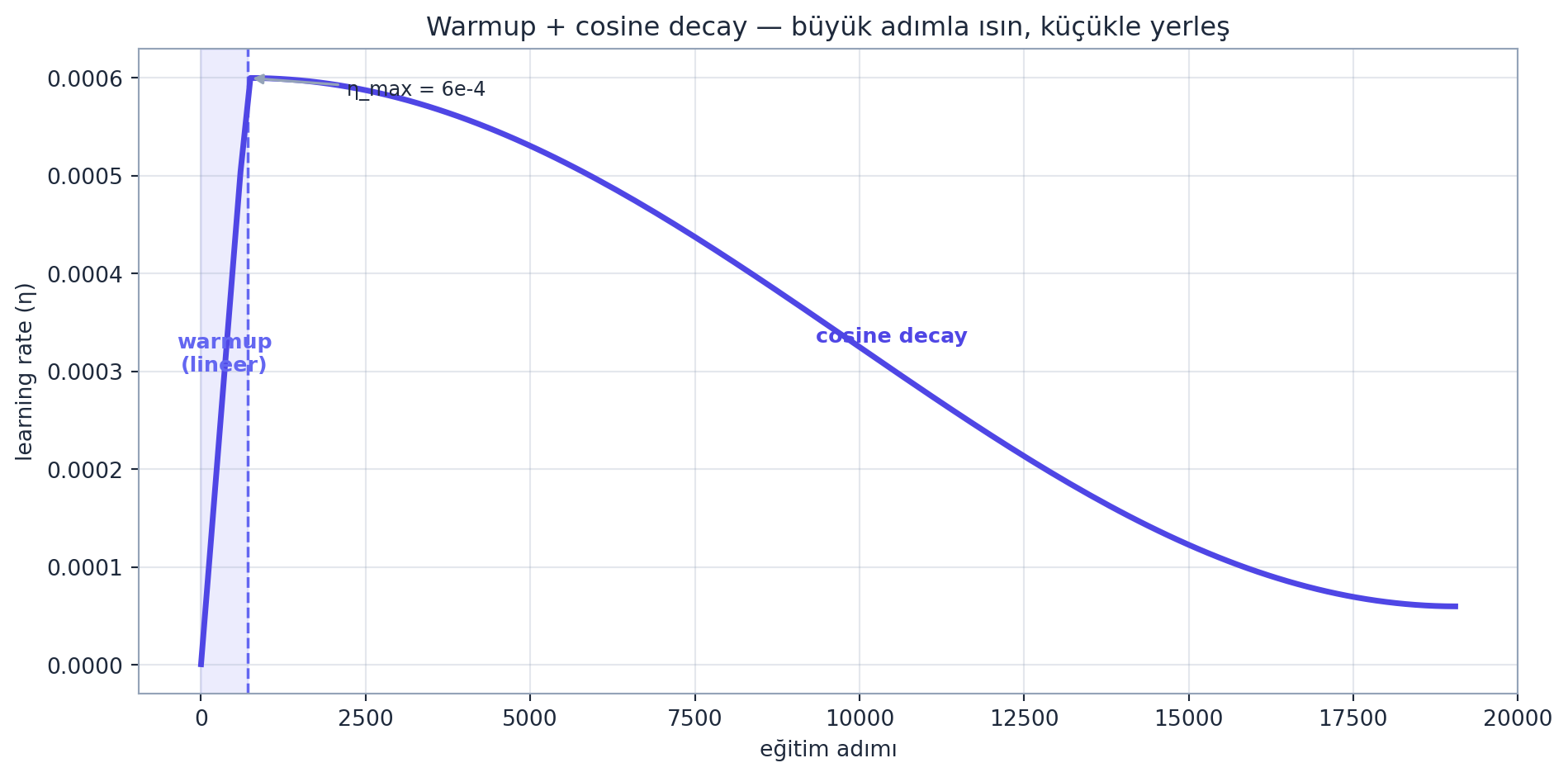
Weight decay (\(0{,}1\)): yalnızca 2 boyutlu ağırlıklara (matrisler, embedding’ler), bias/LayerNorm’a değil (Ders 2 L2 regularization). Gradient accumulation: GPT-3 batch başına \(\approx 0{,}5\)M token kullanır (tek GPU’ya sığmaz); büyük batch’i micro-batch’lere böl, gradyanları biriktir (Ders 1 +=!), loss’u grad_accum_steps’e böl (ortalamayı koru):
loss_accum = 0.0
for micro in range(grad_accum_steps):
x, y = loader.next_batch()
with torch.autocast(device_type='cuda', dtype=torch.bfloat16):
logits, loss = model(x, y)
loss = loss / grad_accum_steps # ortalamayi koru!
loss.backward() # gradyanlar BIRIKIR (Ders 1)
optimizer.step() # tum micro-batch'ler sonrasi tek adimDDP (DistributedDataParallel): modeli her GPU’ya kopyala, her GPU farklı veri dilimini işlesin, gradyanları ortala (all-reduce). Veri: FineWeb-EDU (kalite-filtreli eğitsel web, sample-10BT). Değerlendirme: validation loss (Ders 3 train/dev/test) + HellaSwag benchmark.
İpucuBuilder Notu — Gradient Accumulation = Ders 1 += ; DDP = Stat 110 Ortalama
Geriye (Ders 1-4): Eğitim döngüsü micrograd’ın aynısı; gradyan birikmesi = Ders 1 += (zero_grad’ı yalnız tam adımdan önce); /grad_accum_steps = ortalamayı koruma; AdamW + clip = Ders 4; LR decay = Ders 3 + Calculus (cosine); DDP all-reduce = Stat 110 örneklem ortalaması (her GPU bir alt-örnek). Weight decay = Ders 2 L2.
İleriye: Warmup + cosine, gradient clipping, seçici weight decay, gradient accumulation, DDP — neredeyse tüm modern LLM eğitiminin standardı. Daha büyük modeller için FSDP (model paralelliği), tensor/pipeline parallelism gelir.
11.6 Bölüm D: Sonuçlar ve Kapanış
Karpathy eğitimi gece boyunca (bir bulut GPU kümesinde, örn. \(8\times\) A100) koşturur ve sabah sonuçlara bakar. Sonuç çarpıcı: model yalnızca OpenAI’nin GPT-2 124M’ini geçmekle kalmaz, bazı ölçülerde GPT-3 124M’e bile yaklaşır — daha az token görmesine rağmen. Sebep: daha kaliteli veri (FineWeb-EDU) + iyi eğitim hattı (Bölüm B+C).
Yani 2019’da OpenAI’nin (kapalı) ürettiği bir modeli, sıfırdan, açık araçlarla, birkaç yüz dolarlık compute ile yeniden ürettik — ve geçtik. Karpathy ayrıca llm.c’yi tanıtır: aynı GPT-2 eğitimini PyTorch yerine ham C/CUDA ile yapan kod (Ders 1’in “her şey efficiency” + Ders 5’in “elle backward” felsefesinin en uç hâli).
İpucuBuilder Notu — Açık Reprodüksiyon Alanı Demokratikleştirir
İleriye: “Daha az token ama daha iyi veri/hat ile eski modeli geçmek”, scaling laws + veri kalitesi araştırmasının pratik kanıtı. build-nanogpt (commit-by-commit) + nanoGPT (production-temiz), kendi GPT’ni eğitmenin başlangıç noktası — artık tüm hat senin elinde: tokenizer → mimari → eğitim → değerlendirme.
11.7 Seri Kapanışı
Bu, Neural Networks: Zero to Hero serisinin son dersiydi. Yolculuk: bir skaler türevden (Ders 1 micrograd) gerçek bir dil modeline (Ders 10 GPT-2 124M) — her adım bir öncekinin üstüne kuruldu.
Kod
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
NL = chr(10)
fig, ax = plt.subplots(figsize=(11.5, 5))
n = len(JOURNEY)
ax.set_xlim(0, n * 2.0); ax.set_ylim(0, 5); ax.axis("off")
for i, (ls, title, desc) in enumerate(JOURNEY):
x = i * 2.0 + 1.0
last = (i == n - 1)
ax.add_patch(FancyBboxPatch((x-0.9, 1.7), 1.8, 1.7, boxstyle="round,pad=0.02,rounding_size=0.12",
fc="#e0e7ff" if last else "#eef2ff", ec=COL_INDIGO_600 if last else COL_INDIGO_400,
lw=3.0 if last else 2.0, zorder=2))
ax.text(x, 3.05, ls, ha="center", va="center", color=COL_ACCENT, fontsize=10, weight="bold")
ax.text(x, 2.6, title, ha="center", va="center", color=COL_TEXT, fontsize=10.5, weight="bold")
ax.text(x, 2.05, desc, ha="center", va="center", color=COL_SLATE_400, fontsize=7.8)
if i < n - 1:
ax.add_patch(FancyArrowPatch((x+0.9, 2.55), (x+1.1, 2.55), arrowstyle="-|>",
mutation_scale=14, color=COL_PRIMARY, lw=2.0, zorder=1))
ax.text(n, 4.4, "micrograd'dan GPT-2'ye — Neural Networks: Zero to Hero", ha="center",
color=COL_TEXT, fontsize=13, weight="bold")
ax.text(1.0, 0.9, "dL/dx (skaler türev)", ha="center", color=COL_SLATE_400, fontsize=8.5, style="italic")
ax.text(n*2.0 - 1.0, 0.9, "GPT-2 (124M dil modeli)", ha="center", color=COL_INDIGO_600, fontsize=8.5, style="italic", weight="bold")
ax.add_patch(FancyArrowPatch((1.0, 1.2), (n*2.0 - 1.0, 1.2), arrowstyle="-|>",
mutation_scale=16, color=COL_SLATE_400, lw=1.4, ls="--", zorder=0))
plt.tight_layout()
plt.show()
Calculus zincir kuralı (backprop), 18.06 matris çarpımı (her katman), Stat 110 olasılık (cross-entropy, varyans) — üç matematik kursu + \(10\) ders, tek bir GPT-2’de birleşti. Karpathy’nin tek mesajı baştan sona aynıydı: sinir ağları sihir değil; anlaşılabilir, kurulabilir, ve “gerisi sadece verimlilik”tir.
“Eternal glory goes to anyone who can get rid of [tokenization].” — Karpathy, Ders 9, 2:10:21 (serinin esprili ruhu)
İpucuBuilder Notu — Builder Yolu Açık
İleriye: Buradan: kendi modelini eğit, ince ayarla (Ders 8 SFT/LoRA), değerlendir (HellaSwag), modern teknikleri (FSDP, RLHF/DPO, reasoning) ekle, veya araştırmaya geç. micrograd’dan GPT-2’ye tüm hat artık senin.
11.8 Bu Dersin Özeti
- GPT-2 124M reprodüksiyonu: Ders 7 transformer + Ders 9 tokenizer + Ders 8 pipeline, production ölçeğinde (\(12\) katman, \(768\), \(50257\), \(\approx 124{,}4\)M parametre).
- Bölüm A (nn.Module): GPT-2’yi OpenAI isimlendirmesiyle kur, HF ağırlıklarını yükle (transpoze tuzağı), (B,T)+cross-entropy ile eğit, tek-batch overfit; weight tying (wte=lm_head, \(\approx 38{,}6\)M tasarruf) + residual init scaling (\(0{,}02/\sqrt{2N} \approx 0{,}00408\)).
- Bölüm B (hız, \(1000 \to 93\)ms): memory-bound; TF32 → bf16 → torch.compile → FlashAttention → güzel sayılar (\(50304\)). \(\approx 10{,}8\times\) (A100 ölçümü).
- Bölüm C (eğitim hattı): GPT-3 hiperparametreleri, AdamW + gradient clipping, warmup+cosine LR schedule, seçici weight decay, gradient accumulation (Ders 1
+=), DDP (all-reduce), FineWeb-EDU, validation + HellaSwag. - Bölüm D (sonuçlar): model GPT-2 124M’i geçti, GPT-3 124M’e yaklaştı (kaliteli veri + iyi hat); llm.c (ham C/CUDA); build-nanogpt.
- Büyük ders: “çalışan model” ile “ciddi eğitim” arasındaki fark çoğunlukla mimari değil, hız ve ölçek mühendisliğidir.
- Tüm seri burada birleşir: micrograd → makemore → transformer (Ders 7) → State of GPT (Ders 8) → tokenizer (Ders 9) → GPT-2 (Ders 10).
ÖnemliTek Bir Cümle
GPT-2’yi yeniden üretmek, Ders 7’nin transformer mimarisini ve Ders 9’un tokenizer’ını alıp production ölçeğine taşımaktır; ve “çalışan bir model” ile “GPT-2’yi geçen ciddi bir eğitim” arasındaki farkın büyük kısmı mimari değil, hız (\(1000 \to 93\)ms) ve ölçek (DDP, gradient accumulation, kaliteli veri) mühendisliğidir — micrograd’dan başlayan yolculuğun finali.
11.9 Kontrol Soruları
NotSoru 1: Weight tying nedir (wte = lm_head)? Neden yapılır, ne kazandırır? Ders 2 ile bağla.
Cevap: Weight tying, token embedding tablosu (wte, giriş: id → vektör) ile dil-modeli başının (lm_head, çıkış: vektör → logitler) aynı ağırlık matrisini paylaşmasıdır. Neden: ikisi de aynı “token ↔︎ vektör” eşlemesini yapar — biri ileri (Ders 2: id seçer \(W\)’nin satırını), biri ters. Kazanç: (1) \(\approx 38{,}6\)M parametre tasarrufu (vocab × n_embd \(= 50257 \times 768\) — \(124\)M’lik modelin \(\%31\)’i!); (2) daha iyi genelleme. Ders 2’deki “one-hot \(\times W\) = \(W\)’nin satırını seçer” gözleminin doğrudan sonucu: aynı \(W\), hem satır-seçimi (giriş) hem logit-üretimi (çıkış) için kullanılabilir.
NotSoru 2: Hız yolculuğunda (1000ms→93ms) en büyük kazançlar neden mümkün oldu? ‘Memory bound’ ne demek?
Cevap: Memory bound = darboğaz hesap değil, veri taşıma. GPU’nun Tensor Core’ları çok hızlı, ama veriyi yavaş HBM bellekten yeterince hızlı çekemeyince boşta beklerler. Bu yüzden en büyük kazançlar, veri taşımayı azaltan optimizasyonlardan geldi: TF32/bf16 (daha az byte → \(1000 \to 300\)ms), torch.compile (kernel füzyonu, HBM gidip-gelmeyi azalt → \(130\)ms), FlashAttention (\(T \times T\) matrisi HBM’de hiç oluşturma → \(96\)ms). Hepsi aynı matematiği yapar (sonuç değişmez), yalnızca donanımı daha verimli kullanır. Modern hızlandırma çoğunlukla “daha az hesap” değil, “belleği daha az meşgul et”.
NotSoru 3: Gradient accumulation’da loss neden grad_accum_steps’e bölünür? Bölünmezse ne olur?
Cevap: Cross-entropy, bir batch üzerinde ortalama alır (toplam değil). Büyük batch’i micro-batch’lere bölüp gradyanları topladığımızda, her micro-batch kendi içinde ortalama hesaplar; bunları toplayınca efektif olarak toplam elde ederiz, ortalama değil — yani gradyan \(\text{grad\_accum\_steps}\) kat büyük olur. loss = loss / grad_accum_steps ile her micro-batch’in katkısını ölçekleyerek, biriken gradyanın gerçek büyük-batch ortalamasına eşit olmasını sağlarız. Bölünmezse: efektif öğrenme oranı \(\text{grad\_accum\_steps}\) kat büyür (gradyan şişer), eğitim kararsızlaşır/ıraksar. (Gradyanların birikmesi = Ders 1’in += kuralı; bölme = ortalamayı koruma.)
NotSoru 4: (Builder) Bu ders, Ders 7’den (Sıfırdan GPT) gerçekte ne ekliyor? Mimari mi değişti?
Cevap: Mimari neredeyse aynı — Ders 7’nin transformer’ı (attention, FFN, residual, LayerNorm), yalnızca GPT-2 isimlendirmesi + büyük boyut (\(12\) katman, \(768\), \(124\)M) + GELU. Eklenen asıl şey mühendislik: (1) Sadakat (HF ağırlık yükleme, weight tying, doğru init); (2) Hız (TF32, bf16, torch.compile, FlashAttention — \(\approx 10\times\)); (3) Ölçek/kararlılık (LR schedule, gradient clipping, weight decay, gradient accumulation, DDP); (4) Veri/değerlendirme (FineWeb-EDU, HellaSwag). Yani Ders 7 “model nasıl çalışır”ı, Ders 10 “production’da nasıl ciddi eğitilir”i öğretir. “Çalışan model”den “GPT-2’yi geçen model”e fark, mimaride değil, bu mühendislik katmanlarındadır — serinin en büyük dersi.
11.10 Egzersizler
Egzersiz 1 (GPT-2’yi yükle ve çalıştır). from_pretrained('gpt2') ile OpenAI GPT-2’yi yükle (HuggingFace). Bir önek (“Hello, I’m a language model,”) ver, top-k örneklemeyle metin üret. Tutarlı çıktı = mimarin doğru. tiktoken gpt2 ile encode/decode et (Ders 9).
Egzersiz 2 (Sıfırdan eğit, overfit). Rastgele başlatılmış bir GPT(GPTConfig()) kur. İlk loss’un \(\approx \ln(50257) \approx 10{,}8\) olduğunu doğrula. Tek küçük batch’e overfit et (\(50\) adım), loss’un \(\approx 0\)’a indiğini gözlemle.
Egzersiz 3 (Hız ölçümü). Adım başına süreyi (ms) ölç (torch.cuda.synchronize() + zaman). Sırayla ekle: TF32, autocast(bfloat16), torch.compile, F.scaled_dot_product_attention (FlashAttention). Her birinin hızlanmasını ölç.
Egzersiz 4 (Eğitim hattı). LR schedule (warmup + cosine), gradient clipping (norm \(1{,}0\)), seçici weight decay, gradient accumulation ekle. FineWeb-EDU sample-10BT’nin bir parçasında eğit, validation loss’u izle. (Çok GPU varsa DDP ile dene.)
Egzersiz 5 (Seri finali — ne inşa edeceksin?). micrograd’dan (Ders 1) GPT-2’ye (Ders 10) tüm yolculuğu tamamladın. Şimdi kendi projen: (a) Kendi veri setinde (şiir, kod, kendi yazıların) bir nanoGPT eğit; (b) Bir base model’i kendi görevin için ince ayarla (Ders 8: SFT/LoRA); (c) llm.c’yi okuyup en alt seviyeyi gör. Artık tüm hat senin: tokenizer → mimari → eğitim → değerlendirme. Ne inşa edeceksin?
11.11 Sonraki Adımlar
Bu, serinin son dersiydi — “sonraki ders” yok, ama sonraki proje var. Karpathy’nin önerdiği yol:
build-nanogpt(commit-by-commit) venanoGPT(production-temiz) ile kendi GPT’ni eğit.- Bir base model’i kendi göreviniz için ince ayarla (Ders 8: SFT/LoRA).
llm.c’yi okuyup en alt seviyeyi (ham C/CUDA) gör.- Modern teknikleri ekle: FSDP, RLHF/DPO (Ders 8), reasoning (Ders 8 CoT’nin gelişmişi).
UyarıSeriden Sonra
- Üç matematik temelini (Calculus zincir kuralı, 18.06 matris çarpımı, Stat 110 olasılık) ve \(10\) dersi bir araya getirdin.
- “Sinir ağları sihir değil” — artık her katmanı sıfırdan kurabilir, production’a taşıyabilirsin.
- Builder yolu açık: kendi modelini eğit, değerlendir, paylaş.
11.12 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Karpathy’de |
|---|---|---|
| GPT-2 124M nn.Module | Ders 7 transformer, GPT-2 isimlendirmesi (wte/wpe/h/ln_f/lm_head); \(12\) katman, \(768\), \(50257\) | 13m49 |
| HF ağırlık yükleme | from_pretrained; state_dict kopyala, bazı tensörleri transpoze et (TF Conv1D) |
28m13 |
| Weight tying | wte = lm_head (aynı matris); \(\approx 38{,}6\)M tasarruf + genelleme | 1h06m |
| Residual init scaling | std \(= 0{,}02/\sqrt{2N} \approx 0{,}00408\); residual akış varyansını kontrol | 1h13m |
| TF32 (Tensor Cores) | set_float32_matmul_precision('high'); \(\approx 3\times\) matmul (\(1000 \to 333\)ms) |
1h28m |
| bfloat16 / autocast | Geniş üs aralığı (scaler’sız); fp16 scaler ister (\(300\)ms) | 1h39m |
| torch.compile | Kernel füzyonu + Python overhead kaldırma (\(130\)ms) | 1h48m |
| FlashAttention | \(T \times T\) matrisi HBM’de oluşturma; online softmax, \(O(T)\) bellek (\(96\)ms) | 2h00m |
| Güzel sayılar | vocab \(50257 \to 50304\) (\(128\)’in katı); GPU hizalaması (\(93\)ms) | 2h06m |
| AdamW + gradient clip | betas \((0{,}9, 0{,}95)\); küresel grad normu \(1{,}0\)’a kırp | 2h15m |
| LR schedule | warmup (lineer) + cosine decay (min \(\%10\)) | 2h21m |
| Gradient accumulation | Micro-batch’leri biriktir (Ders 1 +=), loss/accum böl; büyük batch taklidi |
2h34m |
| DDP (çok-GPU) | Modeli kopyala, gradyanları ortala (all-reduce); torchrun | 2h46m |
| FineWeb-EDU + HellaSwag | Kaliteli eğitsel veri + sağduyu benchmark’ı; val loss + benchmark izle | 3h10m |
11.13 ML Builder Bağlantıları
İpucu9 köprü — GPT-2 Reprodüksiyon
- GPT-2 nn.Module → Ders 7 transformer’ın production ölçeği. İleriye: GPT-3/4, LLaMA (aynı iskelet, daha büyük).
- HF ağırlık yükleme → Ders 9 model cerrahisi. İleriye: base model yükle + ince ayar (Ders 8).
- Weight tying → Ders 2 “one-hot \(\times W\) = satır seçimi”. İleriye: parametre verimliliği.
- Residual init scaling → Ders 4 Kaiming + Ders 7 residual akışı. İleriye: derin model kararlılığı.
- Mixed precision + torch.compile + FlashAttention → Ders 5 füzyon ruhu + donanım. İleriye: FP8, vLLM, TensorRT.
- AdamW + grad clip + LR schedule → Ders 1 optimizer + Ders 3-4 lr/clip. İleriye: büyük-model eğitiminin standardı.
- Gradient accumulation → Ders 1
+=+ Ders 3 minibatch. İleriye: büyük efektif batch. - DDP → Ders 1 SGD + Stat 110 örneklem ortalaması. İleriye: FSDP, tensor/pipeline parallelism.
- FineWeb-EDU + HellaSwag → Ders 3 train/dev/test + Ders 8 veri kalitesi. İleriye: veri pipeline’ı + lm-eval-harness.
11.14 Karpathy’nin Önerdiği Kaynaklar
Karpathy’nin bu ders için verdiği kaynaklar:
- build-nanogpt: github.com/karpathy/build-nanogpt — dersin commit-by-commit kodu.
- nanoGPT: github.com/karpathy/nanoGPT — production-temiz versiyon.
- llm.c: github.com/karpathy/llm.c — aynı eğitim, ham C/CUDA.
- Attention is All You Need: arxiv 1706.03762; GPT-3 makalesi: arxiv 2005.14165.
ÖnemliBu dersten — ve tüm seriden — tek bir şey alıp gideceksen
GPT-2’yi yeniden üretmek, Ders 7’nin transformer’ını ve Ders 9’un tokenizer’ını alıp production ölçeğine taşımaktır — ve “çalışan model” ile “GPT-2’yi geçen ciddi eğitim” arasındaki farkın büyük kısmı mimari değil, hız (\(1000\)ms\(\to 93\)ms) ve ölçek (DDP, gradient accumulation, kaliteli veri) mühendisliğidir. micrograd’dan başlayan yolculuk burada, gerçek bir GPT-2’de tamamlanır: sinir ağları sihir değil — anlaşılabilir, kurulabilir, ve gerisi sadece verimliliktir.