flowchart LR
A["Rastgele init<br/>kotu baslar"] --> B["Yuksek baslangic loss<br/>kendinden emin ama yanlis"]
A --> C["Doymus tanh<br/>olu noron, gradyan akmaz"]
B --> D["Cikti katmanini kucult<br/>logitler sifira yakin"]
C --> E["Kaiming baslatma<br/>varyansi koru"]
D --> F["Batch Normalization<br/>dagilimi zorla dayat"]
E --> F
F --> G["Modullestir<br/>Linear / BatchNorm1d / Tanh"]
G --> H["Teshis<br/>aktivasyon + gradyan + update:data"]
style D fill:#eef2ff,stroke:#6366f1,stroke-width:2px
style E fill:#eef2ff,stroke:#6366f1,stroke-width:2px
style F fill:#e0e7ff,stroke:#1e293b,stroke-width:3px
style H fill:#e0e7ff,stroke:#1e293b,stroke-width:3px
5 makemore 3 — Aktivasyonlar, Gradyanlar ve BatchNorm
Bir ağı eğitilebilir kılmak yalnızca mimari değildir; aktivasyon ve gradyan istatistiklerini de doğru ayarlamaktır — doğru başlatma (Kaiming) sinyali katmanlar boyunca korur, Batch Normalization onu zorla dayatır
NotBölüm bilgisi
- Karpathy’nin videosu: YouTube — Building makemore Part 3: Activations & Gradients, BatchNorm (≈116 dk)
- Seri: Neural Networks: Zero to Hero — Ders 4
- Hoca: Andrej Karpathy
- Kaynak repo: github.com/karpathy/makemore
- Okuma süresi: ≈34 dk
5.1 Bu Derste Ne Var?
Ders 3’te MLP’yi kurduk ve çalıştırdık. Ama “çalışıyor” ile “iyi çalışıyor” aynı şey değil. Bu derste tam o ağın içine bakarız: ağırlıklar nasıl başlatılmalı, aktivasyonlar ve gradyanlar katmanlar arasında nasıl akmalı, ve neden derin ağları “sağlıklı” tutmak başlı başına bir mühendislik.
“In the last lecture we implemented the multilayer perceptron along the lines of Bengio 2003 for character-level language modeling.” — Karpathy, 0:00
Büyük fikir: rastgele başlatılan bir ağ genelde kötü başlar — ya aşırı kendinden emin (yanlış), ya aktivasyonlar doymuş (gradyan akmıyor). Bunu önce elle (Kaiming başlatma), sonra otomatik bir mekanizmayla (Batch Normalization) düzeltiriz. Son olarak kodu PyTorch-tarzı modüllere dönüştürüp ağı teşhis araçlarıyla (histogramlar) izleriz.
Dersin üç büyük fikri:
- Başlatma (initialization) — başlangıç loss’unu düzelt (logitleri 0’a yakın başlat), doymuş
tanh’ı önle, ağırlıkları Kaiming ile ölçekle. - Batch Normalization — aktivasyonları batch üzerinden normalize ederek eğitimi sağlamlaştıran katman; running istatistikler, ölçekle-kaydır, epsilon.
- Teşhis ve PyTorch-laştırma — kodu modüllere (Linear/BatchNorm1d/Tanh) böl, aktivasyon/gradyan histogramlarıyla ağın sağlığını izle.
İpucuBuilder Notu — Ders 3’ün TAM Ağını Mercek Altına Almak
Geriye (Ders 1-3 + Stat 110):
- Bu, Ders 3’ün TAM ağı. Yeni model yok; aynı MLP’yi (embedding + gizli
tanh+ softmax) mercek altına alıyoruz. - Başlangıç loss’u = Ders 3 Egzersiz 5. “Neden ilk loss 26, oysa \(\log(27)\approx 3{,}3\) olmalı?” sorusunun cevabı burada (hokey-sopası eğrisi).
- Doymuş
tanh= Ders 1.tanh’ın türevi \(1-\tanh^2\); çıktı \(\pm 1\)’e yapışınca türev \(0\) olur → gradyan akmaz (ölü nöron). - Kaiming + BatchNorm = Stat 110. Başlatma, aktivasyon varyansını katmanlar arası korumakla ilgili (Stat 110 varyans/Normal); BatchNorm ise standardizasyon (z-skoru: \((x-\mu)/\sigma\)).
İleriye: Başlatma ve normalizasyon, derin ağları eğitilebilir kılan iki temel. BatchNorm 2015’te derin ağ devrimini (ResNet) mümkün kıldı; Ders 7’de transformer’ın tercih ettiği LayerNorm’u göreceğiz. “Aktivasyon/gradyan istatistiklerini izle” alışkanlığı production debug’ının çekirdeği.
Tek cümleyle: Bir ağı eğitilebilir kılmak, yalnızca mimariyi değil aktivasyon ve gradyan istatistiklerini de doğru ayarlamaktır — doğru başlatma (Kaiming) ve normalizasyon (BatchNorm) bunu sağlar.
5.2 Neden Aktivasyon ve Gradyan İstatistiği?
Ders 3’ün MLP’si çalışıyordu ama Karpathy daha derine iner: rastgele başlatılan ağırlıklar, ağın içindeki sayıları (aktivasyonlar) ve onların gradyanlarını kötü bir hâle sokabilir. Çok büyük/küçük aktivasyonlar, doygunluk, akıp giden veya patlayan gradyanlar — bunlar eğitimi yavaşlatır veya tamamen durdurur.
“If you’re well-versed in the dark arts of backpropagation and have an intuitive sense of how these gradients flow through a neural net, [you’ll understand why this matters].” — Karpathy, 15:04
Bu ders, “ağ çalışıyor” ile “ağ sağlıklı öğreniyor” arasındaki farkı görmeyi ve düzeltmeyi öğretir.
İpucuBuilder Notu — İç İstatistikleri İzle
İleriye: “İç istatistikleri izle” yaklaşımı — aktivasyon dağılımları, gradyan normları, update:data oranı — her ciddi eğitim hattında (W&B, TensorBoard) standarttır. Modelin “neden öğrenmiyor” sorusunun cevabı genelde bu istatistiklerdedir.
5.3 Başlangıç Loss’unu Düzeltme
Ders 3 Egzersiz 5’in cevabı: eğitimin ilk iterasyonunda loss çok yüksek (bizim ölçümümüzde \(\approx 26{,}01\)) çıkıyordu, oysa “hiçbir şey bilmeyen” bir model 27 karaktere eşit olasılık verip \(-\log(1/27) \approx 3{,}30\) loss almalı. Sorun: rastgele başlatılan W2/b2, aşırı uç logitler üretiyor — ağ “kendinden emin ama yanlış”.
“The network is very confidently wrong.” — Karpathy, 5:57
Bu, hokey-sopası loss eğrisine yol açar: ilk birkaç iterasyon yalnızca bu aşırı logitleri ezmekle geçer (boşa giden eğitim).
“In the hockey stick, the very first few iterations of the loss… the optimization is just squashing down the logits and then rearranging.” — Karpathy, 11:48
Çözüm: logitleri başlangıçta 0’a yakın yap. Çıktı katmanını küçült: W2 *= 0.01, b2 *= 0. Böylece başlangıç logitleri \(\approx 0\) → softmax \(\approx\) uniform → ilk loss \(\approx 3{,}3\) (beklenen). Hokey-sopası kaybolur, eğitim baştan verimli.
# Karpathy §2: cikti katmanini kucult -> logitler ~0 -> ilk loss ~log(27)
W2 = torch.randn((n_hidden, vocab_size)) * 0.01 # ham randn yerine kucuk
b2 = torch.zeros(vocab_size) # b2 = 0 (uc logit yok)
# ilk loss artik ~3.3 (uniform beklenen), hokey-sopasi kaybolurKod
import math
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
# Deterministik: aynı tohum -> aynı başlangıç loss + aynı eğri.
torch.manual_seed(SEED)
# Train/dev/test bölmesi (80/10/10, sabit shuffle tohumu).
Xtr, Ytr, Xdev, Ydev, Xte, Yte = split_data()
LOG27 = math.log(VOCAB) # uniform (hiçbir şey bilmeyen) modelin beklenen NLL'i ≈ 3,30
# ---------------------------------------------------------------------------
# SOL panel verisi: ilk-iterasyon (tüm-veri) loss — Karpathy §2 demosu.
# fix'siz: ham randn W2/b2 -> uç logitler -> "kendinden emin ama yanlış" -> YÜKSEK
# fix'li : W2*=0.01, b2=0 -> logitler ≈ 0 -> softmax ≈ uniform -> ≈ log(27)
# (starting_loss çekirdek fonksiyonu; GERÇEK değerler: 26,01 ve 3,31.)
# ---------------------------------------------------------------------------
sl_bad = starting_loss(Xtr, Ytr, fix_output=False) # ≈ 26,01
sl_fix = starting_loss(Xtr, Ytr, fix_output=True) # ≈ 3,31
# ---------------------------------------------------------------------------
# SAĞ panel verisi: ilk N_CURVE minibatch adımında loss eğrisi. starting_loss ile
# AYNI tek-gizli MLP'yi (ham randn vs fix'li çıktı) birebir kurar ve kısa eğitir.
# fix'siz -> hokey-sopası (yüksekten keskin düşüş); fix'li -> baştan ≈ 3,3 düz.
# Çekirdeğin train()'i modüler/Kaiming ağı eğitir; burada §2 demosuna sadık kalmak
# için starting_loss'un ham-randn MLP'sini birebir eğiten yerel döngü kullanılır.
# ---------------------------------------------------------------------------
N_CURVE = 200
N_EMBD, N_HIDDEN, LR, BS = 10, 200, 0.1, 32
def _curve_demo(fix_output, steps=N_CURVE, n_embd=N_EMBD, n_hidden=N_HIDDEN,
lr=LR, batch_size=BS, seed=SEED):
"""starting_loss'un tek-gizli ham-randn MLP'sini kısa eğit; minibatch loss
geçmişini döndür. fix_output=True -> W2*=0.01, b2=0 (logitler ≈ 0)."""
g = torch.Generator().manual_seed(seed)
C = torch.randn((VOCAB, n_embd), generator=g)
W1 = torch.randn((BLOCK_SIZE * n_embd, n_hidden), generator=g)
b1 = torch.randn(n_hidden, generator=g)
W2 = torch.randn((n_hidden, VOCAB), generator=g) # ham randn -> uç logitler
b2 = torch.randn(VOCAB, generator=g)
if fix_output:
W2 = W2 * 0.01 # logitleri 0'a yaklaştır
b2 = b2 * 0.0 # b2 = 0
params = [C, W1, b1, W2, b2]
for p in params:
p.requires_grad = True
gb = torch.Generator().manual_seed(seed)
n = Xtr.shape[0]
hist = []
for _ in range(steps):
ix = torch.randint(0, n, (batch_size,), generator=gb)
Xb, Yb = Xtr[ix], Ytr[ix]
emb = C[Xb].view(Xb.shape[0], -1)
h = torch.tanh(emb @ W1 + b1)
logits = h @ W2 + b2
loss = F.cross_entropy(logits, Yb)
hist.append(loss.item())
for p in params:
p.grad = None
loss.backward()
for p in params:
p.data += -lr * p.grad
return hist
hist_bad = _curve_demo(fix_output=False)
hist_fix = _curve_demo(fix_output=True)
# Minibatch loss gürültülüdür; hokey-sopası şeklini netleştirmek için kayan-pencere
# ortalamasıyla hafifçe düzleştir (ham eğri soluk arka planda kalır).
def _duzlestir(seri, pencere=10):
from collections import deque
out, toplam, buf = [], 0.0, deque()
for v in seri:
buf.append(v)
toplam += v
if len(buf) > pencere:
toplam -= buf.popleft()
out.append(toplam / len(buf))
return out
hist_bad_s = _duzlestir(hist_bad, pencere=8)
hist_fix_s = _duzlestir(hist_fix, pencere=8)
adim = list(range(1, N_CURVE + 1))
fig, (ax_l, ax_r) = plt.subplots(1, 2, figsize=(11, 5))
# --- SOL panel: ilk-iterasyon loss bar karşılaştırması ---
apply_style(ax_l)
etiketler = ["fix'siz\n(ham randn $W_2/b_2$)", "fix'li\n($W_2\\times 0{,}01$, $b_2=0$)"]
degerler = [sl_bad, sl_fix]
renkler = [COL_PRIMARY, COL_ACCENT] # fix'siz slate, fix'li indigo
x = [0, 1]
ax_l.bar(x, degerler, color=renkler, width=0.58,
edgecolor=COL_WHITE, linewidth=1.2, zorder=3)
# log(27) uniform referans çizgisi (indigo kesik) + etiket.
ax_l.axhline(LOG27, color=COL_INDIGO_600, linewidth=1.8, linestyle="--", zorder=4)
ax_l.text(1.46, LOG27, "$\\log(27)\\approx 3{,}30$\n(uniform beklenen)",
ha="right", va="bottom", fontsize=9, color=COL_INDIGO_600, zorder=6)
# Bar üstü GERÇEK değer etiketleri (Türkçe ondalık {,}).
for xi, v in zip(x, degerler):
ax_l.text(xi, v + 0.5, f"{v:.2f}".replace(".", ","),
ha="center", va="bottom", fontsize=12, color=COL_TEXT,
weight="bold", zorder=5)
# fix oranı anotu (fix'siz kaç kat yüksek).
ax_l.text(0.0, sl_bad - 3.2,
f"$\\approx {sl_bad/sl_fix:.0f}\\times$\ndaha yüksek".replace(".", ","),
ha="center", va="top", fontsize=9.5, color=COL_WHITE, weight="bold",
zorder=6)
ax_l.set_xticks(x)
ax_l.set_xticklabels(etiketler, fontsize=10)
ax_l.set_ylabel("ilk-iterasyon kayıp (ortalama NLL)", fontsize=12)
ax_l.set_title("Başlangıç loss'u: fix'siz vs fix'li", fontsize=12)
ax_l.set_ylim(0, sl_bad + 3.5)
# --- SAĞ panel: ilk 200 minibatch adımı loss eğrisi (hokey-sopası vs düz) ---
apply_style(ax_r)
# Ham eğriler soluk (gürültü), düzleştirilmiş eğriler belirgin.
ax_r.plot(adim, hist_bad, color=COL_SLATE_400, linewidth=0.7, alpha=0.35, zorder=1)
ax_r.plot(adim, hist_fix, color=COL_INDIGO_400, linewidth=0.7, alpha=0.40, zorder=1)
ax_r.plot(adim, hist_bad_s, color=COL_PRIMARY, linewidth=2.3, zorder=3,
label="fix'siz — hokey-sopası")
ax_r.plot(adim, hist_fix_s, color=COL_ACCENT, linewidth=2.3, zorder=3,
label="fix'li — baştan düz")
# log(27) referans çizgisi (fix'li bu band civarında başlar).
ax_r.axhline(LOG27, color=COL_INDIGO_600, linewidth=1.4, linestyle="--",
zorder=2, alpha=0.8)
ax_r.text(N_CURVE, LOG27 + 0.5, "$\\log(27)\\approx 3{,}30$", ha="right",
va="bottom", fontsize=9, color=COL_INDIGO_600, zorder=5)
# fix'siz başlangıç (uç logitler) anotu.
ax_r.annotate(
"fix'siz: uç logitleri\nezmekle geçer\n(boşa eğitim)",
xy=(3, hist_bad_s[2]),
xytext=(58, hist_bad_s[2] - 2.5),
color=COL_PRIMARY, fontsize=9.5, va="center", ha="left",
arrowprops=dict(arrowstyle="->", color=COL_PRIMARY, lw=1.4), zorder=6,
)
# fix'li düz başlangıç anotu.
ax_r.annotate(
"fix'li: ilk adımdan\n$\\approx 3{,}3$ civarında",
xy=(N_CURVE * 0.72, hist_fix_s[int(N_CURVE * 0.72) - 1]),
xytext=(N_CURVE * 0.40, LOG27 + 4.0),
color=COL_INDIGO_600, fontsize=9.5, va="center", ha="center",
arrowprops=dict(arrowstyle="->", color=COL_INDIGO_600, lw=1.4), zorder=6,
)
ax_r.set_xlabel("Minibatch adımı", fontsize=12)
ax_r.set_ylabel("kayıp (minibatch NLL)", fontsize=12)
ax_r.set_title(f"İlk {N_CURVE} adım: hokey-sopası vs düz", fontsize=12)
ax_r.set_xlim(1, N_CURVE)
ax_r.set_ylim(0, max(hist_bad) * 1.05)
ax_r.legend(loc="upper right", fontsize=9.5, framealpha=0.95)
fig.suptitle(
"Başlangıç loss'u: çıktı katmanını küçültmek (fix) hokey-sopasını yok eder",
fontsize=12.5, color=COL_TEXT, y=1.02,
)
plt.tight_layout()
plt.show()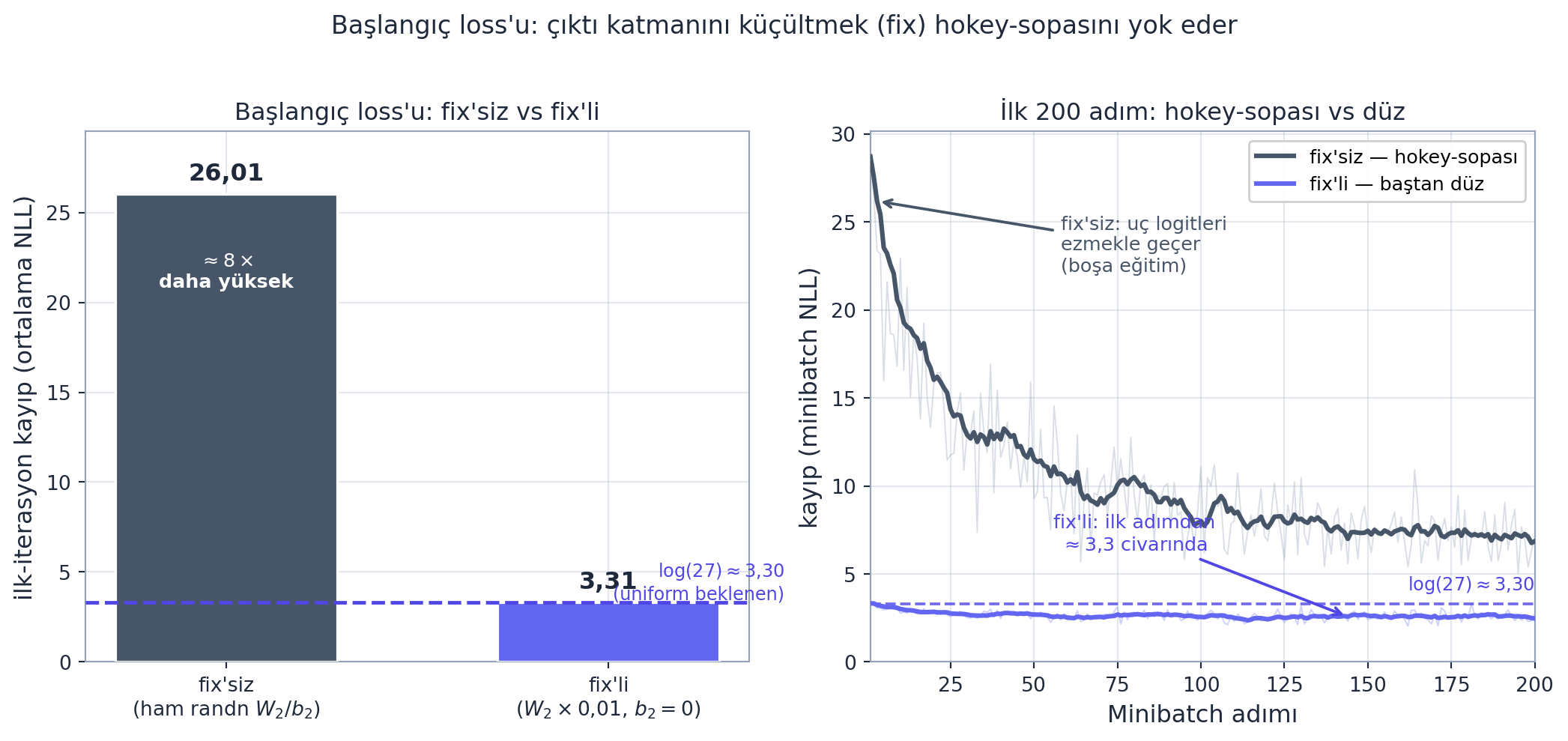
İpucuBuilder Notu — Başlangıç Loss’u = İlk Sanity-Check
Geriye (Stat 110 + Ders 3): Beklenen başlangıç loss’u \(-\log(1/n) = \log(n)\) (uniform dağılımın NLL’i, Stat 110). Bu, “modelin sağlıklı başladığını” doğrulayan ilk göstergedir — Ders 3 Egzersiz 5’in tam cevabı.
İleriye: “Başlangıç loss’u beklenen değere yakın mı?” production’da modelin doğru kurulduğunu gösteren ilk sanity-check’tir. Yanlışsa, eğitimin ilk %5’i boşa gider.
5.4 Doymuş tanh ve Ölü Nöron
Logit sorununu çözdük; şimdi gizli katmana bakalım. tanh, girdisini \(-1\) ile \(+1\) arasına sıkıştırır. Eğer aktivasyon-öncesi değerler (pre-activation) çok büyük/küçükse, tanh çıktısı \(\pm 1\)’e yapışır — buna doygunluk (saturation) denir.
Sorun şu: tanh’ın türevi \(1 - \tanh^2\)’dir (Ders 1). Çıktı \(\pm 1\)’e yapışınca türev \(\approx 0\) olur → o nörondan gradyan akmaz → o nöron öğrenemez. Karpathy bunu bir histogramla gösterir: rastgele büyük başlatmada gizli aktivasyonların çoğu \(\pm 1\)’de toplanır (doymuş). Aşağıdaki figürde kötü init (gizli Linear kazancı \(\times 5\)) ile doygunluk oranı \(\approx \%79{,}1\), Kaiming init ile yalnızca \(\approx \%19{,}5\).
# Bir batch ileri gecir, gizli tanh ciktilarinin histogramini incele
h = torch.tanh(emb @ W1 + b1) # (batch, n_hidden) aktivasyon
saturation = (h.abs() > 0.97).float().mean() # |h|>0.97 doygunluk orani
# kotu init -> ~%79 doymus; Kaiming -> ~%20 (saglikli)Kod
import torch
import matplotlib.pyplot as plt
# Deterministik: aynı tohum -> aynı batch -> aynı histogram + aynı doygunluk %.
torch.manual_seed(SEED)
# Train/dev/test bölmesi (80/10/10, sabit shuffle tohumu).
Xtr, Ytr, Xdev, Ydev, Xte, Yte = split_data()
# Bir batch (1000 örnek, tohumlu) — Karpathy'nin tek-geçiş aktivasyon histogramı.
g = torch.Generator().manual_seed(SEED)
ix = torch.randint(0, Xtr.shape[0], (1000,), generator=g)
Xb = Xtr[ix]
# --- İKİ varyant (tek gizli katman, n_hidden=200; _verify_L4 §b ile birebir) ---
# Kötü init: gizli Linear kazancını şişir (bad_init=5 -> büyük W -> doygun tanh).
C_bad, layers_bad = build_model(n_embd=10, n_hidden=200, n_layer=2,
fix_output=False, use_bn=False, bad_init=5.0,
seed=SEED)
# Kaiming init: gizli Linear gain=5/3 (naif değil; bad_init=1).
C_good, layers_good = build_model(n_embd=10, n_hidden=200, n_layer=2,
fix_output=False, use_bn=False, bad_init=1.0,
seed=SEED)
# Tanh çıktıları (düzleştirilmiş) + doygunluk oranı (|h|>0,97) — GERÇEK ölçüm.
h_bad = tanh_outputs(C_bad, layers_bad, Xb)[0].flatten().numpy()
h_good = tanh_outputs(C_good, layers_good, Xb)[0].flatten().numpy()
sat_bad = tanh_saturation(C_bad, layers_bad, Xb)[0] * 100.0 # ~79,1
sat_good = tanh_saturation(C_good, layers_good, Xb)[0] * 100.0 # ~19,5
bins = torch.linspace(-1, 1, 61).numpy() # tanh çıktısı [-1, 1]
SAT_THRESH = 0.97 # doygunluk eşiği
fig, (ax_l, ax_r) = plt.subplots(1, 2, figsize=(11, 5), sharey=True)
# ---------------------------------------------------------------------------
# SOL panel: KÖTÜ init — slate dolu histogram, ±1 doymuş uçlar indigo vurgulu.
# ---------------------------------------------------------------------------
apply_style(ax_l)
counts_bad, edges_bad, patches_bad = ax_l.hist(
h_bad, bins=bins, color=COL_PRIMARY, edgecolor=COL_WHITE,
linewidth=0.4, zorder=3,
)
# ±1 yakınındaki (|h|>0,97) doymuş çubukları indigo ile boya (vurgu).
for patch, left in zip(patches_bad, edges_bad[:-1]):
bin_center = left + (edges_bad[1] - edges_bad[0]) / 2.0
if abs(bin_center) > SAT_THRESH:
patch.set_facecolor(COL_ACCENT)
patch.set_zorder(4)
# Doygunluk eşik çizgileri (±0,97).
for xthr in (-SAT_THRESH, SAT_THRESH):
ax_l.axvline(xthr, color=COL_INDIGO_600, linewidth=1.4, linestyle="--",
alpha=0.8, zorder=5)
# Doygunluk yüzdesi anotu (kutu içinde, GERÇEK ölçüm).
ax_l.text(
0.0, ax_l.get_ylim()[1] * 0.92,
"doygunluk ($|h|>0{,}97$)\n$\\approx \\%" + f"{sat_bad:.1f}".replace(".", "{,}") + "$",
ha="center", va="top", fontsize=11, color=COL_INDIGO_600, weight="bold",
bbox=dict(boxstyle="round,pad=0.5", fc=COL_BG, ec=COL_INDIGO_600, lw=1.4),
zorder=6,
)
ax_l.set_xlabel("gizli tanh çıktısı $h$", fontsize=12)
ax_l.set_ylabel("nöron-değer sayısı", fontsize=12)
ax_l.set_title("Kötü init (kazanç $\\times 5$) — doymuş", fontsize=12)
ax_l.set_xlim(-1.02, 1.02)
# ---------------------------------------------------------------------------
# SAĞ panel: KAIMING init — indigo dolu histogram, 0 civarında yayılmış.
# ---------------------------------------------------------------------------
apply_style(ax_r)
ax_r.hist(h_good, bins=bins, color=COL_ACCENT, edgecolor=COL_WHITE,
linewidth=0.4, zorder=3)
# Doygunluk eşik çizgileri (±0,97) — kıyas için aynı işaret.
for xthr in (-SAT_THRESH, SAT_THRESH):
ax_r.axvline(xthr, color=COL_INDIGO_600, linewidth=1.4, linestyle="--",
alpha=0.8, zorder=5)
ax_r.text(
0.0, ax_r.get_ylim()[1] * 0.92,
"doygunluk ($|h|>0{,}97$)\n$\\approx \\%" + f"{sat_good:.1f}".replace(".", "{,}") + "$",
ha="center", va="top", fontsize=11, color=COL_INDIGO_600, weight="bold",
bbox=dict(boxstyle="round,pad=0.5", fc=COL_BG, ec=COL_INDIGO_600, lw=1.4),
zorder=6,
)
ax_r.set_xlabel("gizli tanh çıktısı $h$", fontsize=12)
ax_r.set_title("Kaiming init (kazanç $5/3$) — yayılmış", fontsize=12)
ax_r.set_xlim(-1.02, 1.02)
fig.suptitle(
"Gizli tanh çıktıları: kötü init (doymuş) vs Kaiming init (yayılmış)",
fontsize=12.5, color=COL_TEXT, y=1.02,
)
plt.tight_layout()
plt.show()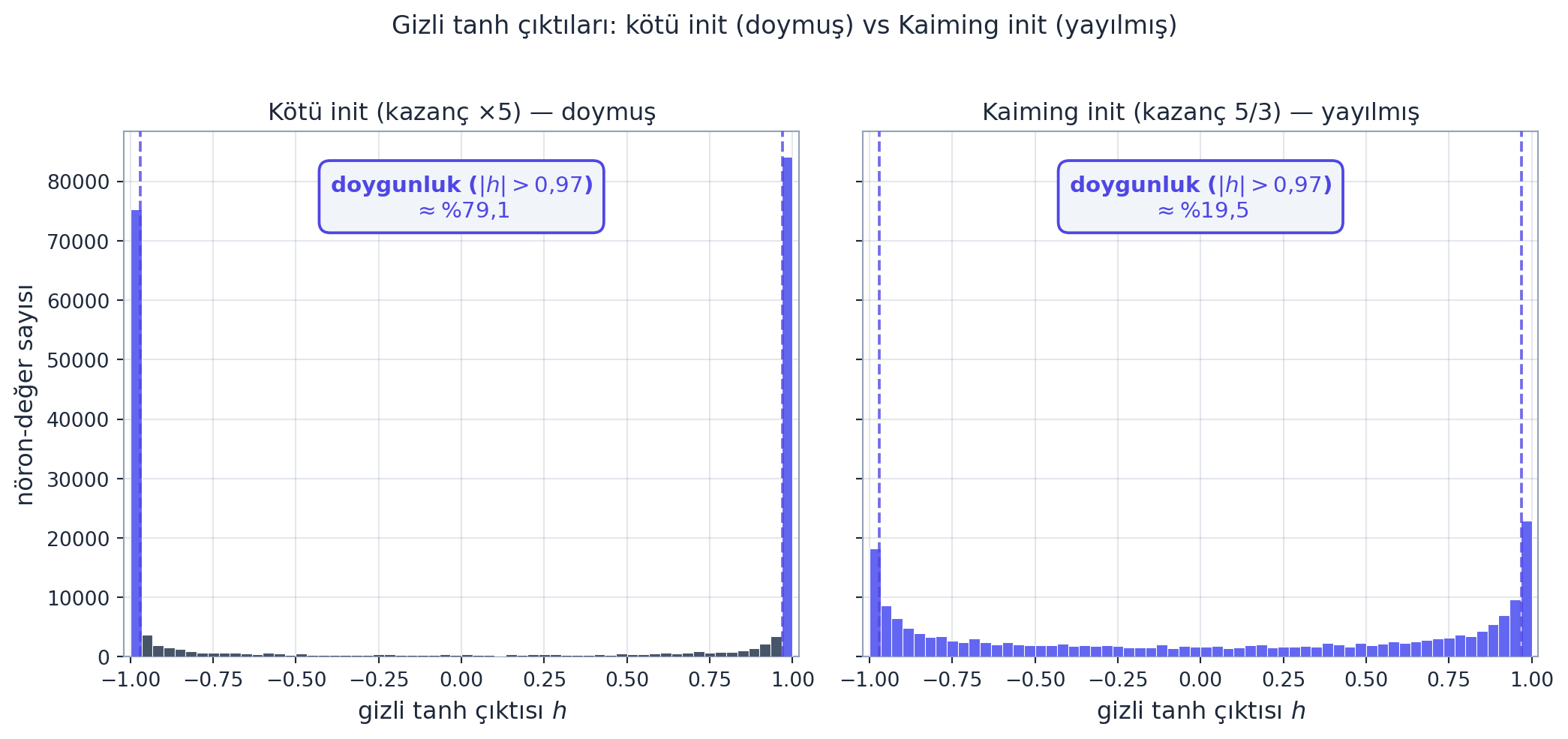
tanh aktivasyonlarının histogramı (bir batch, \(n_{hidden}=200\) nöron). Sol (slate): kötü init (gizli Linear kazancı \(\times 5\)) — değerler \(\pm 1\)’de yığılmış (doymuş); doygunluk (\(|h| > 0{,}97\)) oranı \(\approx \%79{,}1\) (\(\pm 1\) uçları indigo vurgulu). Doymuş tanh’ın türevi \(1-\tanh^2 \approx 0\), gradyan akmaz. Sağ (indigo): Kaiming init (tanh kazancı \(5/3\)) — dağılım \(0\) civarında yayılmış (aktif, eğimli bölge); doygunluk oranı \(\approx \%19{,}5\). Aynı tohum (SEED), aynı batch; deterministik.
“We have what’s called a dead neuron… it’s kind of like a permanent brain damage in the mind of a network.” — Karpathy, 19:26
Bir nöron tüm batch boyunca hep doymuşsa (hep \(\pm 1\)), hiç gradyan almaz, asla güncellenmez — kalıcı olarak ölüdür. Aşağıdaki harita bunu somutlaştırır: bir sütun (nöron) tüm batch boyunca koyu (doymuş) ise o nöron ölüdür. Çözüm: aktivasyon-öncesini 0 civarında (tanh’ın aktif, eğimli bölgesinde) tutmak. Bunu da W1 ağırlıklarını küçülterek yaparız (örn. W1 *= 0.2). Ama “ne kadar küçük?” sorusunun prensipli cevabı bir sonraki bölümde: Kaiming init.
Kod
import torch
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import LinearSegmentedColormap
from matplotlib.patches import Rectangle
# Deterministik: aynı tohum -> aynı kötü-init ağı + aynı batch -> aynı harita.
torch.manual_seed(SEED)
# Train bölmesi (80/10/10, sabit shuffle tohumu).
Xtr, Ytr, Xdev, Ydev, Xte, Yte = split_data()
# Kötü init ağı (bad_init=5): gizli Linear kazancı 5x şişirilir -> aktivasyon-
# öncesi büyür -> tanh ±1'e yapışır (doygunluk). BN YOK, fix_output YOK.
C, layers = build_model(n_embd=10, n_hidden=100, block_size=BLOCK_SIZE,
n_layer=2, fix_output=False, use_bn=False,
bad_init=5.0, gain=TANH_GAIN, seed=SEED)
# İlk (tek) gizli tanh katmanının çıktısı bir batch üzerinde: (batch, n_hidden).
# Küçük batch (24): "tüm batch boyunca doymuş" = ölü nöron koşulunu okunur kılar
# (her satır = bir örnek). Daha büyük batch'te bir nöronun her örnekte doyması
# istatistiksel olarak güçleşir; 24 satırda ölü nöron net görünür.
BATCH = 24
ix = torch.randint(0, Xtr.shape[0], (BATCH,),
generator=torch.Generator().manual_seed(SEED))
Xb = Xtr[ix]
H = tanh_outputs(C, layers, Xb)[0].numpy() # ilk tanh katmanı (batch, n_hidden)
THRESH = 0.97
sat_mask = np.abs(H) > THRESH # bool: doymuş hücreler
sat_per_neuron = sat_mask.mean(axis=0) # sütun (nöron) başına doygunluk oranı
genel_sat = sat_mask.mean() # toplam doygunluk oranı
# Ölü nöron: TÜM batch boyunca doymuş (sütun tamamen koyu) -> oran == 1.0.
dead_neurons = np.where(sat_per_neuron >= 1.0 - 1e-9)[0]
n_batch, n_neuron = H.shape
# ---------------------------------------------------------------------------
# Slate -> koyu-slate ısı haritası: |h| büyüdükçe (doyguna yaklaştıkça) koyu.
# (apply_style imshow'a uygulanmaz.)
# ---------------------------------------------------------------------------
cmap_sat = LinearSegmentedColormap.from_list(
"slate_sat", [COL_WHITE, COL_BG, COL_SLATE_400, COL_PRIMARY, COL_TEXT])
fig = plt.figure(figsize=(11, 5))
fig.patch.set_facecolor(COL_WHITE)
# Üstte ince doygunluk-oranı çubuğu + altta ana ısı haritası (paylaşılan x).
gs = fig.add_gridspec(2, 1, height_ratios=[1, 6], hspace=0.08)
ax_bar = fig.add_subplot(gs[0])
ax_hm = fig.add_subplot(gs[1], sharex=ax_bar)
# --- üst panel: nöron-başı doygunluk oranı çubuğu ---
bar_renk = [COL_INDIGO_600 if i in dead_neurons else COL_ACCENT
for i in range(n_neuron)]
ax_bar.bar(np.arange(n_neuron), sat_per_neuron, width=1.0,
color=bar_renk, zorder=3)
ax_bar.axhline(1.0, color=COL_INDIGO_600, linewidth=0.9, linestyle=":",
alpha=0.7, zorder=2)
ax_bar.set_ylim(0, 1.05)
ax_bar.set_yticks([0, 1])
ax_bar.set_yticklabels(["0", "1"], fontsize=8)
ax_bar.set_ylabel("doygunluk\noranı", fontsize=8.5, color=COL_TEXT)
ax_bar.tick_params(colors=COL_TEXT, labelbottom=False)
ax_bar.set_facecolor(COL_WHITE)
for spine in ax_bar.spines.values():
spine.set_color(COL_SLATE_400)
ax_bar.set_title(
f"Doygunluk haritası — kötü init (bad_init=5): genel doygunluk "
f"%{genel_sat * 100:.1f}, ölü nöron sayısı {len(dead_neurons)}",
fontsize=12, color=COL_TEXT, pad=8)
# --- alt panel: batch x nöron |tanh| ısı haritası ---
im = ax_hm.imshow(np.abs(H), cmap=cmap_sat, aspect="auto",
vmin=0, vmax=1, interpolation="nearest")
# Ölü nöron sütunlarını indigo çerçeveyle vurgula (kalıcı brain damage).
for j in dead_neurons:
ax_hm.add_patch(Rectangle((j - 0.5, -0.5), 1, n_batch,
fill=False, edgecolor=COL_INDIGO_600,
linewidth=2.2, zorder=5))
if len(dead_neurons) > 0:
j0 = int(dead_neurons[0])
ax_hm.annotate(
"ölü nöron\n(türev $1-\\tanh^2 \\approx 0$ → gradyan akmaz)",
xy=(j0, n_batch * 0.5),
xytext=(min(j0 + 16, n_neuron - 2), n_batch * 0.5),
color=COL_INDIGO_600, fontsize=9, va="center", ha="left",
arrowprops=dict(arrowstyle="->", color=COL_INDIGO_600, lw=1.6),
bbox=dict(boxstyle="round,pad=0.35", fc=COL_WHITE,
ec=COL_INDIGO_600, lw=1.2), zorder=6)
ax_hm.set_xlabel("gizli nöron (sütun)", fontsize=12, color=COL_TEXT)
ax_hm.set_ylabel("batch örneği (satır)", fontsize=12, color=COL_TEXT)
ax_hm.tick_params(colors=COL_TEXT)
for spine in ax_hm.spines.values():
spine.set_color(COL_SLATE_400)
# Renk çubuğu: koyu = doymuş (|tanh| → 1).
cbar = fig.colorbar(im, ax=[ax_bar, ax_hm], fraction=0.025, pad=0.02)
cbar.set_label("$|\\tanh|$ (koyu = doymuş)", fontsize=10, color=COL_TEXT)
cbar.ax.tick_params(colors=COL_TEXT)
cbar.outline.set_edgecolor(COL_SLATE_400)
plt.show()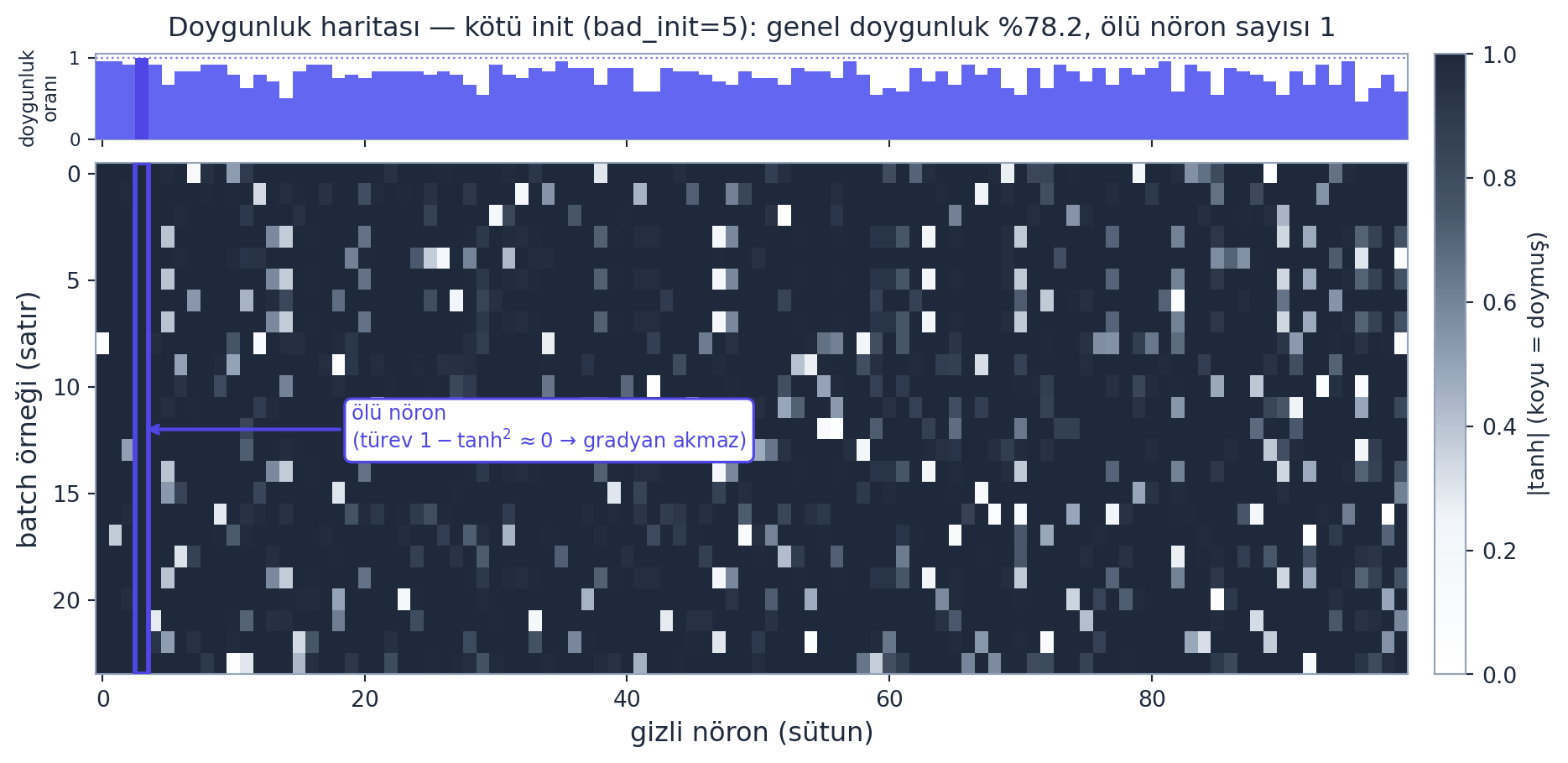
İpucuBuilder Notu — Ölü Nöron Ders 1’in tanh Türevidir
Geriye (Ders 1): Ölü nöron, doğrudan Ders 1’in tanh türevinden (\(1 - o^2\)) çıkar: \(o = \pm 1\) → türev \(0\) → zincir kuralında o nöronun gradyanı sıfırlanır. ReLU’da karşılığı: girdi hep negatifse çıktı hep \(0\), türev hep \(0\) → ölü ReLU.
İleriye: Doygunluk/ölü nöron, derin ağ eğitiminin klasik sorunudur. Çözümler: dikkatli init (Kaiming), normalizasyon (BatchNorm/LayerNorm), residual bağlantılar (Ders 7). Modern aktivasyonlar (GELU, SiLU) da bu yüzden tercih edilir.
5.5 Kaiming (He) Başlatması
Ağırlıkları “ne kadar küçük” başlatmalı? Rastgele tahmin yerine prensipli bir formül var: Kaiming (He) başlatması (He ve ark. 2015, “Delving Deep into Rectifiers”).
“Calculating the init scale: Kaiming init.” — Karpathy, 27:53
Fikir: her katmanın çıktısının varyansı, girdisinin varyansıyla aynı kalmalı — böylece sinyal katmanlar boyunca ne patlar ne söner. Bunu sağlayan ölçek, ağırlık standart sapmasını fan-in (girdi bağlantı sayısı) ve aktivasyona özgü bir kazanç (gain) ile ayarlar:
\[ \text{std} = \frac{\text{gain}}{\sqrt{n_{in}}} \]
Burada \(n_{in}\) = fan-in (katmana giren bağlantı sayısı). Kazanç aktivasyona bağlıdır: tanh için \(5/3\), ReLU için \(\sqrt{2}\) (ReLU negatifleri kestiği için varyansı telafi eder).
W1 = torch.randn((n_in, n_hidden)) * (5/3) / (n_in**0.5) # Kaiming (tanh)Bu ölçekle başlatınca aktivasyonlar 0 civarında, iyi yayılmış (ne doymuş ne çökmüş) kalır — gradyanlar sağlıklı akar. Aşağıdaki figür 6 katmanlı derin bir yığında bunu kanıtlar: naif init (gain \(=1\)) katman-katman söner (\(0{,}617 \to 0{,}320\)), Kaiming (gain \(=5/3\)) korunur (\(0{,}750 \to 0{,}654\), \(\approx 0{,}65\) düzlükte oturur).
Kod
import torch
import matplotlib.pyplot as plt
# Determinizm: aynı tohum -> aynı katman std'leri (Karpathy'nin meşhur tohumu).
torch.manual_seed(SEED)
# ---------------------------------------------------------------------------
# Derin yığın için bir minibatch (verify (c) ile birebir aynı: 1000 örnek).
# 6 katmanlı MLP (BN'siz) -> 5 gizli tanh katmanı; her tanh çıktısının std'si
# sırayla ölçülür. gain=5/3 (Kaiming) varyansı korur; gain=1 (naif) söndürür.
# ---------------------------------------------------------------------------
Xtr, Ytr, Xdev, Ydev, Xte, Yte = split_data()
g = torch.Generator().manual_seed(SEED)
ix = torch.randint(0, Xtr.shape[0], (1000,), generator=g)
Xb = Xtr[ix]
# GERÇEK std değerleri (_verify_L4.py §c ile aynı çağrı, aynı sayı).
std_kaim = activation_std_per_layer(Xb, n_embd=10, n_hidden=200, n_layer=6,
gain=TANH_GAIN, seed=SEED) # ≈0,65-0,75 düz
std_naif = activation_std_per_layer(Xb, n_embd=10, n_hidden=200, n_layer=6,
gain=1.0, seed=SEED) # söner 0,62->0,32
katman = list(range(1, len(std_kaim) + 1)) # katman indeksi 1..5
# ---------------------------------------------------------------------------
# Çizim
# ---------------------------------------------------------------------------
fig, ax = plt.subplots(figsize=(11, 5))
fig.patch.set_facecolor(COL_WHITE)
apply_style(ax)
# İdeal-koruma referansı: std = 1,0 (varyans hiç kaybolmadan korunsa).
ax.axhline(1.0, color=COL_SLATE_400, linewidth=1.6, linestyle="--",
zorder=2, label="ideal koruma ($\\mathrm{std}=1{,}0$)")
# naif (gain=1): aşağı eğimli, söner -> slate.
ax.plot(katman, std_naif, color=COL_PRIMARY, linewidth=2.4, marker="o",
markersize=8, markerfacecolor=COL_PRIMARY, markeredgecolor=COL_WHITE,
markeredgewidth=1.3, zorder=4, label="naif init (gain $=1$) — söner")
# Kaiming (gain=5/3): ~0,65-0,75 düz, korunur -> indigo.
ax.plot(katman, std_kaim, color=COL_ACCENT, linewidth=2.6, marker="s",
markersize=8, markerfacecolor=COL_ACCENT, markeredgecolor=COL_WHITE,
markeredgewidth=1.3, zorder=5, label="Kaiming init (gain $=5/3$) — korunur")
# --- işaretçi başına gerçek std değeri anote (Türkçe ondalık {,}) ---
for x, s in zip(katman, std_kaim):
ax.annotate(f"{s:.3f}".replace(".", ","),
xy=(x, s), xytext=(0, 11), textcoords="offset points",
ha="center", va="bottom", fontsize=9, color=COL_INDIGO_600,
weight="bold", zorder=6)
for x, s in zip(katman, std_naif):
ax.annotate(f"{s:.3f}".replace(".", ","),
xy=(x, s), xytext=(0, -16), textcoords="offset points",
ha="center", va="top", fontsize=9, color=COL_PRIMARY,
weight="bold", zorder=6)
# Sönme yönünü vurgulayan ok anotu (naif eğrisi boyunca aşağı).
ax.annotate(
"naif: varyans\nher katmanda kısılır",
xy=(katman[-1], std_naif[-1]),
xytext=(katman[-1] - 1.6, std_naif[-1] - 0.16),
color=COL_PRIMARY, fontsize=9.5, ha="center", va="center",
arrowprops=dict(arrowstyle="-|>", color=COL_PRIMARY, lw=1.4),
bbox=dict(boxstyle="round,pad=0.35", fc=COL_BG, ec=COL_PRIMARY, lw=1.1),
zorder=7,
)
# Korunma vurgusu (Kaiming düzlüğü).
ax.annotate(
"Kaiming: $\\approx 0{,}65$\ndüzlükte oturur",
xy=(katman[2], std_kaim[2]),
xytext=(katman[2] + 0.55, std_kaim[2] + 0.20),
color=COL_INDIGO_600, fontsize=9.5, ha="center", va="center",
arrowprops=dict(arrowstyle="-|>", color=COL_INDIGO_600, lw=1.4),
bbox=dict(boxstyle="round,pad=0.35", fc=COL_BG, ec=COL_INDIGO_600, lw=1.1),
zorder=7,
)
ax.set_xlabel("Gizli katman indeksi (derin yığın)", fontsize=12)
ax.set_ylabel("tanh aktivasyon std'si", fontsize=12)
ax.set_title(
"Aktivasyon std katmanlar arası — naif (söner) vs Kaiming (korunur)",
fontsize=12.5, color=COL_TEXT, pad=10,
)
ax.set_xticks(katman)
ax.set_xlim(0.6, len(std_kaim) + 0.4)
ax.set_ylim(0.0, 1.15)
ax.legend(loc="lower left", fontsize=9.5, framealpha=0.95)
plt.tight_layout()
plt.show()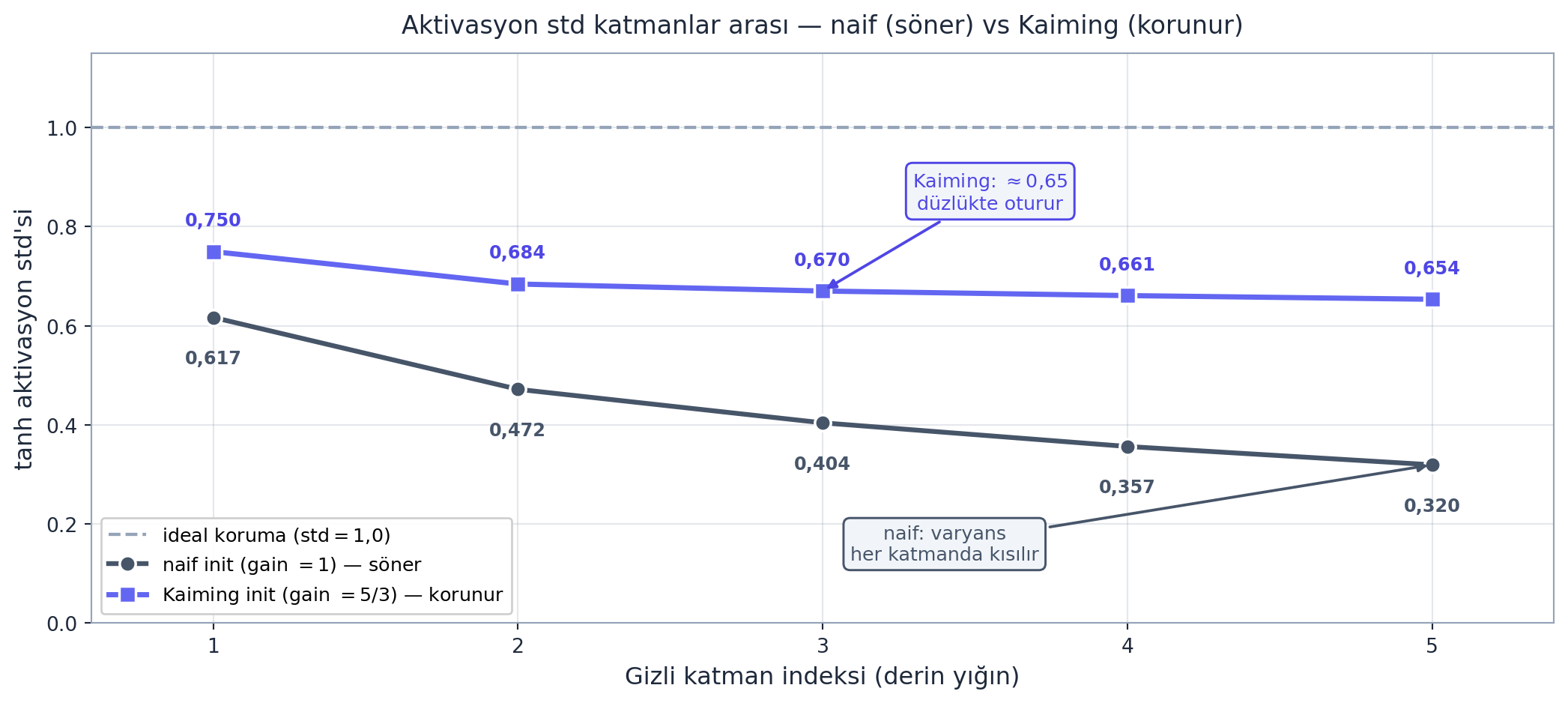
activation_std_per_layer).
İpucuBuilder Notu — fast.ai L17 Köprüsü: Varyans Korunumu → Kaiming → BatchNorm
Çapraz-ders (Phase 2): fast.ai L17 (Temeller B: aktivasyonlar/init) ile AYNI kavram: varyans korunumu → Kaiming gain (tanh \(5/3\), ReLU \(\sqrt{2}\)) → BatchNorm. Howard ConvNet üzerinden (Xavier/Kaiming + BatchNorm running_mean/register_buffer), Karpathy MLP üzerinden — aynı matematik, farklı çatı. İki ders aynı zinciri kurar: “aktivasyon varyansını katman boyunca koru, init yetmezse normalizasyonla zorla dayat.”
Geriye (Stat 110): Kaiming, tamamen varyans muhasebesidir (Stat 110): bir lineer kombinasyonun varyansı, terim sayısı (fan-in) ile büyür; bunu \(1/\sqrt{n_{in}}\) ile telafi ederiz. gain ise aktivasyonun varyansı ne kadar daralttığını (tanh kontraktiftir) dengeler.
İleriye: Kaiming/Xavier init, her derin ağ kütüphanesinin varsayılanıdır (PyTorch nn.init.kaiming_normal_). Ama BatchNorm/LayerNorm geldikten sonra init’e hassasiyet azalır — bir sonraki konu tam da bu.
5.6 Batch Normalization: Fikir
Kaiming init işe yarar ama kırılgandır: ağ derinleştikçe, her katmanın aktivasyon dağılımını doğru tutmak giderek zorlaşır. 2015’te çıkan radikal fikir: init’le uğraşma — istediğin dağılımı zorla.
“Normalization layers like batch normalization, layer normalization, group normalization…” — Karpathy, 36:41
Batch Normalization’ın sezgisi: gizli katmanın aktivasyon-öncesi değerlerinin (pre-activation) kabaca Gaussian (ortalama 0, standart sapma 1) olmasını istiyoruz — o zaman doğrudan öyle yap. Her eğitim adımında, batch üzerinden istatistikleri hesapla ve aktivasyonları normalize et. Bu, “doğru init’i bulma” problemini büyük ölçüde ortadan kaldırır.
İpucuBuilder Notu — BatchNorm = Stat 110 Standardizasyonu
Geriye (Stat 110): “Bir dağılımı ortalama 0, std 1 yap” tam olarak standardizasyondur (z-skoru: \(z = (x - \mu)/\sigma\), Stat 110). BatchNorm bunu ağın içinde, her katmanda yapar.
İleriye: Normalizasyon katmanları (Batch/Layer/Group/RMSNorm) modern derin öğrenmenin vazgeçilmezi. Transformer LayerNorm kullanır (Ders 7); fikir hep aynı: aktivasyon dağılımını kontrol altında tut.
5.7 Batch Normalization: İmplementasyon
BatchNorm, gizli aktivasyon-öncesi hpreact’i batch boyutu üzerinden normalize eder. Her nöron için batch’in ortalaması \(\mu_B\) ve varyansı \(\sigma^2_B\) hesaplanır; sonra normalize edilir:
\[ \hat{x}_i = \frac{x_i - \mu_B}{\sqrt{\sigma_B^2 + \epsilon}}, \qquad y_i = \gamma \, \hat{x}_i + \beta \]
Önemli ayrıntı: normalize edip bırakmayız. Ölçekle ($= $ bngain) ve kaydır ($= $ bnbias) ekleriz — bunlar öğrenilen parametrelerdir. Neden? Çünkü ağ bazen normalize-edilmemiş bir dağılım isteyebilir; \(\gamma/\beta\) ona normalizasyonu “geri alma” özgürlüğü verir. Başlangıçta \(\gamma=1\), \(\beta=0\) (saf normalize).
# hpreact: (batch, n_hidden) aktivasyon-oncesi
bnmean = hpreact.mean(0, keepdim=True) # batch ortalamasi
bnstd = hpreact.std(0, keepdim=True) # batch std
hpreact = bngain * (hpreact - bnmean) / bnstd + bnbias # normalize + olcekle/kaydir
h = torch.tanh(hpreact) # sonra aktivasyonbngain (\(\gamma\), başlangıçta 1’ler) ve bnbias (\(\beta\), başlangıçta 0’lar) öğrenilen parametrelerdir. Normalize edilen hpreact artık 0 civarında, iyi yayılmış → tanh doymaz, gradyanlar akar. Aşağıdaki şema akışın her aşamasındaki gerçek dağılımı gösterir: önce geniş/kayık (\(\mu\approx -0{,}33\), std \(\approx 4{,}99\)), normalize sonrası \(\mu\approx 0\) std \(\approx 1\), tanh sonrası \([-1,1]\) aralığına yayılmış (std \(\approx 0{,}63\)).
Kod
import torch
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
# BatchNorm forward şeması: ÜST bantta soldan sağa 4 kutu (hpreact -> normalize ->
# scale/shift -> tanh); ALT bantta her aşamanın o batch'teki GERÇEK dağılımı.
# Sayılar uydurma DEĞİL: BN'li bir modelin ilk gizli Linear çıktısı (hpreact) bir
# batch için hesaplanır, BatchNorm adımları (normalize, gamma*xhat+beta, tanh) elle
# uygulanıp gerçek std/ortalama ölçülür. Determinist (sabit tohum).
torch.manual_seed(SEED)
# ---------------------------------------------------------------------------
# GERÇEK batch: BN'li model kur, ilk gizli Linear çıktısını (hpreact) al.
# bad_init>1 -> hpreact bilerek geniş/kayık (BatchNorm'un düzelttiği durum).
# ---------------------------------------------------------------------------
Xtr_b, Ytr_b, _, _, _, _ = split_data()
_C_bn, _layers_bn = build_model(n_embd=10, n_hidden=100, n_layer=2,
fix_output=False, use_bn=True, bad_init=3.0,
seed=SEED)
g_b = torch.Generator().manual_seed(SEED)
ix_b = torch.randint(0, Xtr_b.shape[0], (1000,), generator=g_b) # 1000'lik batch
Xb_bn = Xtr_b[ix_b]
with torch.no_grad():
_emb = _C_bn[Xb_bn].view(Xb_bn.shape[0], -1)
_lin0 = _layers_bn[0] # ilk gizli Linear (BN öncesi)
hpre = _lin0(_emb) # (1000, n_hidden) aktivasyon-öncesi
EPS = 1e-5
mu = hpre.mean(0, keepdim=True)
var = hpre.var(0, keepdim=True)
xhat = (hpre - mu) / torch.sqrt(var + EPS) # normalize (standardizasyon)
gamma, beta = 1.0, 0.0 # BatchNorm başlangıcı
y_bn = gamma * xhat + beta # ölçekle/kaydır (başlangıçta = xhat)
h_out = torch.tanh(y_bn) # aktivasyon
# Histogram verileri (gerçek, tüm batch x tüm nöron düzleştirilmiş).
d_pre = hpre.flatten().numpy()
d_hat = xhat.flatten().numpy()
d_scl = y_bn.flatten().numpy()
d_out = h_out.flatten().numpy()
# Aşama altı anote için gerçek istatistikler (caption ile birebir tutarlı).
def _tr(v): # math-mode Türkçe ondalık: 0.00 -> 0{,}00
return f"{v:.2f}".replace(".", "{,}")
mu_pre, sd_pre = float(hpre.mean()), float(hpre.std())
mu_hat, sd_hat = float(xhat.mean()), float(xhat.std())
mu_out, sd_out = float(h_out.mean()), float(h_out.std())
fig = plt.figure(figsize=(11, 5.5))
fig.patch.set_facecolor(COL_WHITE)
# ---------------------------------------------------------------------------
# ÜST BANT: şematik eksen (figür-oranı). Boxes + oklar + açıklama burada;
# 0..1 normalize koordinat -> histogram sütun merkezleriyle hizalı.
# ---------------------------------------------------------------------------
ax = fig.add_axes([0.0, 0.46, 1.0, 0.54])
ax.set_xlim(0, 1)
ax.set_ylim(0, 1)
ax.set_facecolor(COL_WHITE)
ax.axis("off")
# 4 sütun merkezi (figür-oranı x). Histogram insetleri de bu merkezleri kullanır.
col_cx = [0.135, 0.380, 0.625, 0.870]
inset_w = 0.205 # histogram inset genişliği (figür)
box_w, box_h = 0.205, 0.46 # şematik eksen koordinatında kutu
y_box = 0.56
dugumler = [
{"x": col_cx[0], "ust": r"$h_{pre}$", "orta": "aktivasyon-öncesi", "alt": "(n, n_hidden)", "hl": False},
{"x": col_cx[1], "ust": r"$\dfrac{x-\mu_B}{\sqrt{\sigma_B^2+\epsilon}}$", "orta": "normalize", "alt": r"$\hat{x}$ ($\mu{=}0$, std$=1$)", "hl": True},
{"x": col_cx[2], "ust": r"$\gamma\,\hat{x}+\beta$", "orta": "ölçekle / kaydır", "alt": r"$\gamma{=}1$, $\beta{=}0$", "hl": False},
{"x": col_cx[3], "ust": r"$\tanh$", "orta": "aktivasyon", "alt": r"$[-1,\,1]$", "hl": False},
]
# x ekseni eşit ölçek değil (geniş figür) -> kutuları transform=ax.transData ile
# çiz ama en/boy oranını korumak için box_w/box_h figür-oranına göre seçildi.
for d in dugumler:
if d["hl"]:
ec, lw, fc = COL_INDIGO_600, 2.8, "#eef2ff"
else:
ec, lw, fc = COL_PRIMARY, 2.2, COL_BG
box = FancyBboxPatch(
(d["x"] - box_w / 2, y_box - box_h / 2), box_w, box_h,
boxstyle="round,pad=0.01,rounding_size=0.04",
fc=fc, ec=ec, linewidth=lw, zorder=3, mutation_aspect=0.42,
)
ax.add_patch(box)
ust_col = COL_INDIGO_600 if d["hl"] else COL_TEXT
ax.text(d["x"], y_box + box_h * 0.27, d["ust"], ha="center", va="center",
fontsize=13 if not d["hl"] else 11.5, color=ust_col,
weight="bold", zorder=5)
ax.text(d["x"], y_box - box_h * 0.06, d["orta"], ha="center", va="center",
fontsize=10, color=COL_PRIMARY, style="italic", zorder=5)
ax.text(d["x"], y_box - box_h * 0.32, d["alt"], ha="center", va="center",
fontsize=8.5, color=COL_SLATE_800, zorder=5)
# Akış okları (indigo, soldan sağa) — kutular arası boşlukta.
for a, b in zip(dugumler[:-1], dugumler[1:]):
arrow = FancyArrowPatch(
(a["x"] + box_w / 2 + 0.008, y_box), (b["x"] - box_w / 2 - 0.008, y_box),
arrowstyle="-|>", mutation_scale=16, color=COL_ACCENT, linewidth=2.2,
connectionstyle="arc3,rad=0.0", zorder=2,
)
ax.add_patch(arrow)
# Başlık (üst) + epsilon/standardizasyon açıklaması (kutuların hemen altında).
ax.text(0.5, 0.93, "Batch Normalization ileri akışı — bir batch'in gerçek "
"dağılımı her aşamada", ha="center", va="center", fontsize=12.5,
color=COL_TEXT, weight="bold", zorder=5)
ax.text(0.5, 0.135,
r"normalize $=$ standardizasyon (Stat 110 z-skoru) · payda kararlılığı "
r"$\epsilon=10^{-5}$ · başlangıç $\gamma{=}1$, $\beta{=}0$ (saf normalize) · "
r"$\tanh$ aktivasyonu $[-1,1]$'e sıkıştırır",
ha="center", va="center", fontsize=9.5, color=COL_TEXT, zorder=5,
bbox=dict(boxstyle="round,pad=0.5", fc=COL_BG, ec=COL_ACCENT, lw=1.3))
# Her kutudan kendi histogramına ince slate bağlantı oku (şematik eksende, aşağı).
for d in dugumler:
arrow = FancyArrowPatch(
(d["x"], y_box - box_h / 2 - 0.01), (d["x"], 0.30),
arrowstyle="-|>", mutation_scale=10, color=COL_SLATE_400,
linewidth=1.1, connectionstyle="arc3,rad=0.0", zorder=2,
)
ax.add_patch(arrow)
# ---------------------------------------------------------------------------
# ALT BANT: her aşamanın altında küçük dağılım histogramı (gerçek batch).
# inset eksenler figür-oranında; sütun merkezleriyle hizalı.
# ---------------------------------------------------------------------------
hist_specs = [
{"data": d_pre, "col": COL_PRIMARY,
"title": f"$\\mu\\approx {_tr(mu_pre)}$, std$\\approx {_tr(sd_pre)}$", "clip": None},
{"data": d_hat, "col": COL_INDIGO_600,
"title": f"$\\mu\\approx {_tr(mu_hat)}$, std$\\approx {_tr(sd_hat)}$", "clip": None},
{"data": d_scl, "col": COL_INDIGO_400,
"title": r"$\gamma\hat{x}+\beta$ ($=\hat{x}$)", "clip": None},
{"data": d_out, "col": COL_ACCENT,
"title": f"$\\mu\\approx {_tr(mu_out)}$, std$\\approx {_tr(sd_out)}$", "clip": (-1.05, 1.05)},
]
inset_h = 0.30
inset_y = 0.085
for cx, spec in zip(col_cx, hist_specs):
iax = fig.add_axes([cx - inset_w / 2, inset_y, inset_w, inset_h])
apply_style(iax)
iax.hist(spec["data"], bins=40, color=spec["col"], alpha=0.85,
edgecolor=COL_WHITE, linewidth=0.3)
iax.axvline(0, color=COL_SLATE_400, linewidth=1.0, zorder=1) # 0 referans
iax.set_yticks([])
iax.tick_params(axis="x", labelsize=7.5)
iax.set_title(spec["title"], fontsize=9, color=COL_TEXT, pad=3)
if spec["clip"] is not None:
iax.set_xlim(*spec["clip"])
plt.show()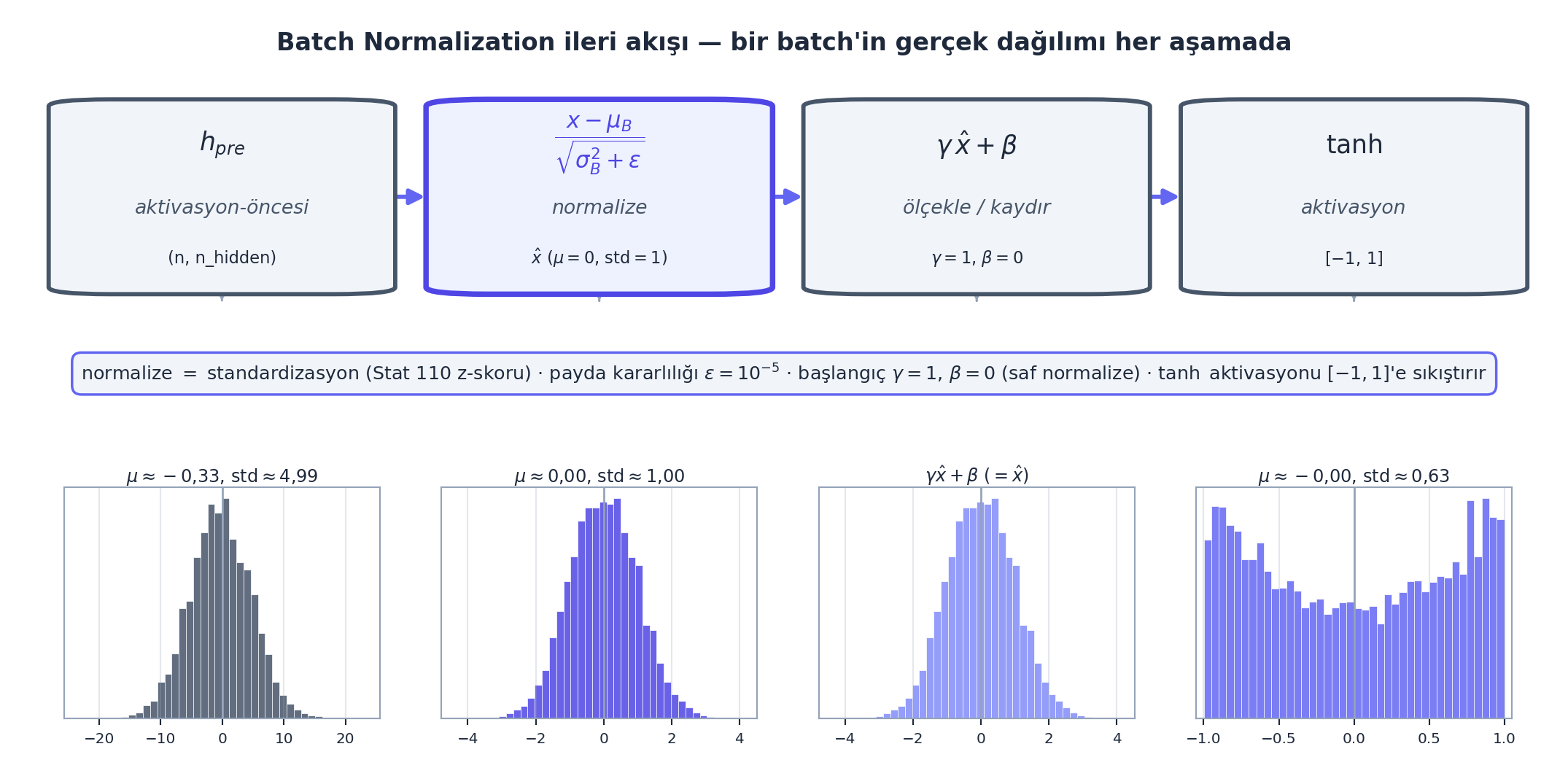
İpucuBuilder Notu — Normalize + Öğrenilen Scale/Shift Deseni
Geriye (Stat 110 + Ders 1): Normalize formülü \((x - \mu)/\sigma\) doğrudan Stat 110 standardizasyonu; \(\gamma/\beta\) ise konum-ölçek dönüşümü (\(X = \mu + \sigma Z\)). \(\gamma=1\)/\(\beta=0\) başlatmak, BatchNorm’un başta saf-normalize, sonra gerekirse öğrenip uyarlamasını sağlar.
İleriye: \(\gamma\) (scale) ve \(\beta\) (shift), her normalizasyon katmanında (LayerNorm dahil) vardır. “Normalize et, sonra öğrenilen scale/shift ile geri-alma özgürlüğü ver” deseni tüm modern mimarilerde tekrarlanır.
5.8 BatchNorm Test Zamanı ve Running İstatistikler
BatchNorm’un bir sorunu var: eğitimde batch’in ortalama/std’sini kullanır. Ama test zamanında tek bir örnek tahmin etmek isteyebilirsin — batch yok, ortalama/std hesaplanamaz. Çözüm: eğitim boyunca istatistikleri yürüyen (running) bir ortalamayla biriktir, test zamanında onları kullan.
“[We estimate] the mean and standard deviation in a running manner during training of the neural net.” — Karpathy, 56:11
with torch.no_grad(): # bu istatistikler gradyan TASIMAZ
bnmean_running = 0.999 * bnmean_running + 0.001 * bnmean
bnstd_running = 0.999 * bnstd_running + 0.001 * bnstdBu bir üstel hareketli ortalamadır (EMA): her adımda mevcut tahmini biraz günceller. Test zamanında bu sabit bnmean_running/bnstd_running kullanılır (batch’e ihtiyaç kalmaz). Ayrıca: BatchNorm, bir örneğin çıktısını batch’teki diğer örneklere bağlar (istatistikler ortak) — bu küçük bir “jitter” (gürültü) katar ve hafif bir regularization etkisi yapar.
İpucuBuilder Notu — Buffer + Train/Eval Modu
Geriye (Stat 110 + Calculus): Running mean/std, Stat 110’daki çevrimiçi ortalama tahmini; EMA katsayısı (\(0{,}999\)) Calculus’taki üstel sönümün ayrık hâli. torch.no_grad: bu istatistikler öğrenilen parametre değil, tampon (buffer) — gradyan taşımaz.
İleriye: Running stats / buffer kavramı tüm normalizasyon katmanlarında var. Train/eval modu ayrımı (model.train() / model.eval()) tam da bu yüzden kritik: BatchNorm eval’de running stats kullanır, dropout eval’de kapanır.
5.9 BatchNorm Detayları: epsilon ve Spurious Bias
İki ince nokta:
epsilon (\(\epsilon\)): Bölme paydasında varyansa küçük bir \(\epsilon\) eklenir: \(\sqrt{\sigma^2 + \epsilon}\). Neden? Bir batch’te bir nöronun varyansı sıfıra çok yakınsa (tüm örnekler aynı), \(\sqrt{\sigma} \approx 0\) olur ve bölme patlar (inf/nan). \(\epsilon\) (örn. \(10^{-5}\)) bunu önler.
Spurious (gereksiz) bias: BatchNorm aktivasyondan ortalamayı çıkarır. Ama bir önceki lineer katmanın bias’ı b1 de aktivasyona sabit bir kayma ekler — ve bu kayma, BatchNorm’un ortalama-çıkarma adımında tam olarak iptal olur. Yani b1 hiçbir işe yaramaz (gradyanı bile garip davranır). Çözüm: BatchNorm’dan önceki katmanda bias’ı kaldır (zaten $= $ bnbias onun işini görür).
İpucuBuilder Notu — bias=False + epsilon = nan-Önleyici Ayrıntılar
İleriye: “BatchNorm’dan önceki Linear’da bias=False” kuralı, PyTorch’ta da standarttır (nn.Linear(..., bias=False) + nn.BatchNorm1d). \(\epsilon\) ise her normalizasyon katmanının sayısal-kararlılık parametresidir. Bu küçük ayrıntılar, “neden gradyanım nan oldu” hatalarının sık kaynağıdır.
5.10 BatchNorm Nereye Oturur + ResNet Örneği
BatchNorm tipik olarak şu sırayla kullanılır: Lineer katman → BatchNorm → doğrusal-olmama (örn. Linear → BatchNorm1d → Tanh). Karpathy gerçek bir örnek olarak ResNet-50’yi gösterir: derin görü ağlarında bu Linear/Conv → BatchNorm → ReLU bloğu tekrar tekrar istiflenir, üstüne residual (artık) bağlantılar eklenir.
Karpathy BatchNorm hakkında dürüst bir uyarı da yapar:
“No one likes this layer. It causes a huge amount of bugs, and intuitively it’s because it is coupling examples in the forward pass of a neural net.” — Karpathy, 1:17:13
Yani BatchNorm güçlü ama tuzaklı: örnekleri batch içinde birbirine bağladığı için (bir örneğin çıktısı diğerlerine bağlı) çok sayıda ince bug’a yol açar. Bu yüzden modern mimariler (özellikle transformer) çoğunlukla LayerNorm’u tercih eder — o, her örneği bağımsız normalize eder.
İpucuBuilder Notu — Conv→BN→ReLU + Residual
İleriye: BatchNorm → LayerNorm geçişi, Ders 7’de transformer’da somutlaşır. ResNet’in “Conv→BN→ReLU + residual” bloğu, derin öğrenmenin en etkili tasarım desenlerinden; residual bağlantıları Ders 7’de (transformer) yeniden göreceğiz. “BatchNorm örnekleri bağlar” sorunu, neden inference’ta running stats’a geçildiğinin de sebebi.
5.11 PyTorch Katman İçleri (Linear, BatchNorm1d)
Karpathy elle kurduğumuz katmanları PyTorch’un gerçek katmanlarıyla karşılaştırır: torch.nn.Linear ve torch.nn.BatchNorm1d. PyTorch’un dokümantasyonunu açıp, bizim yazdığımızla birebir aynı olduğunu gösterir — sadece daha çok ayar (kwarg) ile.
nn.Linear(fan_in, fan_out, bias=True): tam olarak x @ W + b; ağırlıkları varsayılan olarak Kaiming-benzeri bir dağılımla başlatır.
nn.BatchNorm1d(dim, eps=1e-5, momentum=0.1, affine=True, track_running_stats=True):
eps: payda kararlılığı (bkz. BatchNorm Detayları).momentum: running istatistiklerin EMA katsayısı (bkz. Running İstatistikler).affine: \(\gamma\) (scale) ve \(\beta\) (shift) öğrenilsin mi (bkz. İmplementasyon).track_running_stats: running mean/std tutulsun mu (bkz. Running İstatistikler).
Yani kurduğumuz her parça PyTorch’ta bir kwarg’a karşılık geliyor — “kara kutu” değil, anladığımız mekanizma.
İpucuBuilder Notu — Önce Sıfırdan Kur, Sonra Kütüphaneyle Eşleştir
Geriye (Ders 1): Bu, Ders 1’in “micrograd’ı PyTorch ile karşılaştır” anının tekrarı: önce sıfırdan kur, sonra kütüphaneyle eşleştir. nn.Linear = Ders 1’in \(Wx + b\)’si; nn.BatchNorm1d = bu derste kurduğumuz normalize+scale+shift+running.
İleriye: Kütüphane katmanlarının kwarg’larını “anlayarak” kullanmak, production’da doğru tasarım kararları (bias var/yok, eval modu, momentum) vermeni sağlar — kopyala-yapıştır yerine.
5.12 Kodu PyTorch-laştırma (Modüller)
Karpathy kodu, PyTorch’un torch.nn tarzında Lego bloklarına (modüller) böler. Her modül bir __call__ (forward) ve parameters() metoduna sahip — Ders 1’deki Neuron/Layer/MLP arabiriminin aynısı.
class Linear:
def __init__(self, fan_in, fan_out, bias=True):
self.weight = torch.randn((fan_in, fan_out)) / fan_in**0.5 # Kaiming
self.bias = torch.zeros(fan_out) if bias else None
def __call__(self, x):
self.out = x @ self.weight
if self.bias is not None:
self.out = self.out + self.bias
return self.out
def parameters(self):
return [self.weight] + ([] if self.bias is None else [self.bias])
class BatchNorm1d:
def __init__(self, dim, eps=1e-5, momentum=0.1):
self.eps = eps; self.momentum = momentum; self.training = True
self.gamma = torch.ones(dim); self.beta = torch.zeros(dim)
self.running_mean = torch.zeros(dim); self.running_var = torch.ones(dim)
def __call__(self, x):
if self.training:
xmean = x.mean(0, keepdim=True)
xvar = x.var(0, keepdim=True)
else:
xmean = self.running_mean; xvar = self.running_var
xhat = (x - xmean) / torch.sqrt(xvar + self.eps) # normalize
self.out = self.gamma * xhat + self.beta # olcekle/kaydir
if self.training:
with torch.no_grad():
self.running_mean = (1-self.momentum)*self.running_mean + self.momentum*xmean
self.running_var = (1-self.momentum)*self.running_var + self.momentum*xvar
return self.out
def parameters(self):
return [self.gamma, self.beta]
class Tanh:
def __call__(self, x):
self.out = torch.tanh(x)
return self.out
def parameters(self):
return []
# katmanlari istifle (torch.nn.Sequential gibi)
layers = [Linear(n_embd*block_size, n_hidden, bias=False), BatchNorm1d(n_hidden), Tanh(),
Linear(n_hidden, vocab_size)]Her modül self.out’u saklar (birazdan teşhis için), training bayrağı BatchNorm’un train/eval davranışını ayırır. Bu yapı, torch.nn.Module API’sinin birebir taklididir.
İpucuBuilder Notu — call + parameters() = Ders 1’in Arabirimi
Geriye (Ders 1): __call__ + parameters() arabirimi, Ders 1’in Neuron/Layer/MLP’sinin ta kendisi; artık katmanlar (Linear/BatchNorm1d/Tanh) ayrı bloklar. bias=False (BatchNorm’dan önce) §spurious-bias dersidir.
İleriye: Bu modülerlik, torch.nn.Module’un tasarım felsefesi: her katman forward + parameters sunar, istiflenebilir. Tüm modern ağlar (transformer dahil) bu Lego-blok yaklaşımıyla kurulur.
5.13 Diagnostik: Aktivasyon ve Gradyan Histogramları
Modüller self.out sakladığı için artık ağın sağlığını görselleştirebiliriz. Karpathy iki temel histogram çizer:
Aktivasyon histogramları (ileri geçiş): Her tanh katmanının çıktı dağılımını çiz. İyi bir ağda dağılım 0 civarında, makul yayılmış olmalı; \(\pm 1\)’de yığılma (doygunluk) veya hep-0 (ölü) kötüdür. “Doygunluk yüzdesi” (\(|\text{aktivasyon}| > 0{,}97\) olanların oranı) bir sağlık metriğidir.
Gradyan histogramları (geri geçiş): Her katmanın gradyan dağılımını çiz. Katmanlar arası gradyan büyüklükleri birbirine yakın olmalı; derinleştikçe sönüyorsa (vanishing) veya büyüyorsa (exploding) ağ dengesizdir. Kaiming init + BatchNorm tam da bunu dengeler. Aşağıdaki figür bunu ölçer: BN’siz ağda katman-başı gradyan std uçlarda yüksek-ortada düşük (dengesiz, max/min spread \(\approx 4{,}2\times\)), BN’li ağda çok daha düz (dengeli, spread \(\approx 2{,}1\times\)).
“If you’re well-versed in the dark arts of backpropagation and have an intuitive sense of how these gradients flow through a neural net…” — Karpathy, 15:04
Kod
import torch
import matplotlib.pyplot as plt
# Determinizm: aynı tohum -> aynı eğitim -> aynı katman gradyan std'leri.
torch.manual_seed(SEED)
# Train/dev/test bölmesi (80/10/10, sabit shuffle tohumu).
Xtr, Ytr, Xdev, Ydev, Xte, Yte = split_data()
# ---------------------------------------------------------------------------
# İki 6-katmanlı derin ağ (BN'in faydası derinde görünür), makul Kaiming init.
# _verify_L4 §d/§e ile birebir: 20000 adım, lr=0.1. Sonra tek minibatch backward
# ile her gizli Linear weight gradyanının std'si (gradient_per_layer) ölçülür.
# ---------------------------------------------------------------------------
N_STEPS = 20000
# BN'siz (Kaiming, makul init) — dengesiz gradyan dağılımı.
C_bnsiz, layers_bnsiz = build_model(n_embd=10, n_hidden=100, n_layer=6,
fix_output=True, use_bn=False, bad_init=1.0,
seed=SEED)
train(C_bnsiz, layers_bnsiz, Xtr, Ytr, steps=N_STEPS, lr=0.1, seed=SEED)
# BN'li (Kaiming, makul init) — dengeli gradyan dağılımı.
C_bnli, layers_bnli = build_model(n_embd=10, n_hidden=100, n_layer=6,
fix_output=True, use_bn=True, bad_init=1.0,
seed=SEED)
train(C_bnli, layers_bnli, Xtr, Ytr, steps=N_STEPS, lr=0.1, seed=SEED)
# Katman-başı gradyan std (her gizli + çıktı Linear için) — GERÇEK değerler.
gstd_bnsiz = gradient_per_layer(C_bnsiz, layers_bnsiz, Xtr, Ytr, seed=SEED)
gstd_bnli = gradient_per_layer(C_bnli, layers_bnli, Xtr, Ytr, seed=SEED)
# Denge ölçütü: max/min oranı (1'e yakın = dengeli, büyük = dengesiz).
spread_bnsiz = max(gstd_bnsiz) / min(gstd_bnsiz)
spread_bnli = max(gstd_bnli) / min(gstd_bnli)
# Linear katman indeksleri (1..6).
katmanlar = list(range(1, len(gstd_bnsiz) + 1))
fig, ax = plt.subplots(figsize=(11, 5))
apply_style(ax)
# --- BN'siz (slate): dengesiz, uçlarda yüksek ---
ax.plot(katmanlar, gstd_bnsiz, color=COL_PRIMARY, linewidth=2.4,
marker="o", markersize=9, markerfacecolor=COL_PRIMARY,
markeredgecolor=COL_WHITE, markeredgewidth=1.4, zorder=4,
label=rf"BN'siz — dengesiz (spread $\approx {f'{spread_bnsiz:.1f}'.replace('.', '{,}')}\times$)")
# --- BN'li (indigo): dengeli, daha düz ---
ax.plot(katmanlar, gstd_bnli, color=COL_ACCENT, linewidth=2.4,
marker="s", markersize=9, markerfacecolor=COL_ACCENT,
markeredgecolor=COL_WHITE, markeredgewidth=1.4, zorder=5,
label=rf"BN'li — dengeli (spread $\approx {f'{spread_bnli:.1f}'.replace('.', '{,}')}\times$)")
# Her noktanın değer etiketi (bilimsel gösterim, Türkçe ondalık).
def _fmt_sci(v):
"""1,11e-2 -> '$1{,}11\\cdot10^{-2}$' biçimi (math-mode Türkçe ondalık)."""
s = f"{v:.2e}" # '1.11e-02'
mant, exp = s.split("e")
mant = mant.replace(".", "{,}") # math-mode ondalık ayraç
exp = int(exp) # -2
return rf"${mant}\cdot10^{{{exp}}}$"
# BN'siz etiketler (üstte, slate).
for x, v in zip(katmanlar, gstd_bnsiz):
ax.annotate(_fmt_sci(v), xy=(x, v), xytext=(0, 11),
textcoords="offset points", ha="center", va="bottom",
fontsize=8.0, color=COL_PRIMARY, zorder=6)
# BN'li etiketler (altta, indigo).
for x, v in zip(katmanlar, gstd_bnli):
ax.annotate(_fmt_sci(v), xy=(x, v), xytext=(0, -13),
textcoords="offset points", ha="center", va="top",
fontsize=8.0, color=COL_INDIGO_600, zorder=6)
# Spread oranlarını vurgulayan anot kutusu (sağ üst, başlık/etiketlerden uzak).
ax.text(
0.985, 0.80,
"max/min spread:\n"
rf"BN'siz $\approx {f'{spread_bnsiz:.1f}'.replace('.', '{,}')}\times$ (dengesiz)" + "\n"
rf"BN'li $\approx {f'{spread_bnli:.1f}'.replace('.', '{,}')}\times$ (dengeli)",
transform=ax.transAxes, ha="right", va="top", fontsize=10, color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.5", fc=COL_BG, ec=COL_ACCENT, lw=1.4), zorder=7,
)
ax.set_yscale("log")
ax.set_xticks(katmanlar)
ax.set_xlabel("Linear katman indeksi (giriş → çıkış)", fontsize=12)
ax.set_ylabel("Weight gradyan std (log ölçek)", fontsize=12)
ax.set_title(
"Katman-başı gradyan std: BN'li (dengeli) vs BN'siz (dengesiz)",
fontsize=13, pad=10,
)
ax.set_xlim(0.6, len(katmanlar) + 0.4)
ax.legend(loc="upper left", fontsize=9.5, framealpha=0.95)
plt.tight_layout()
plt.show()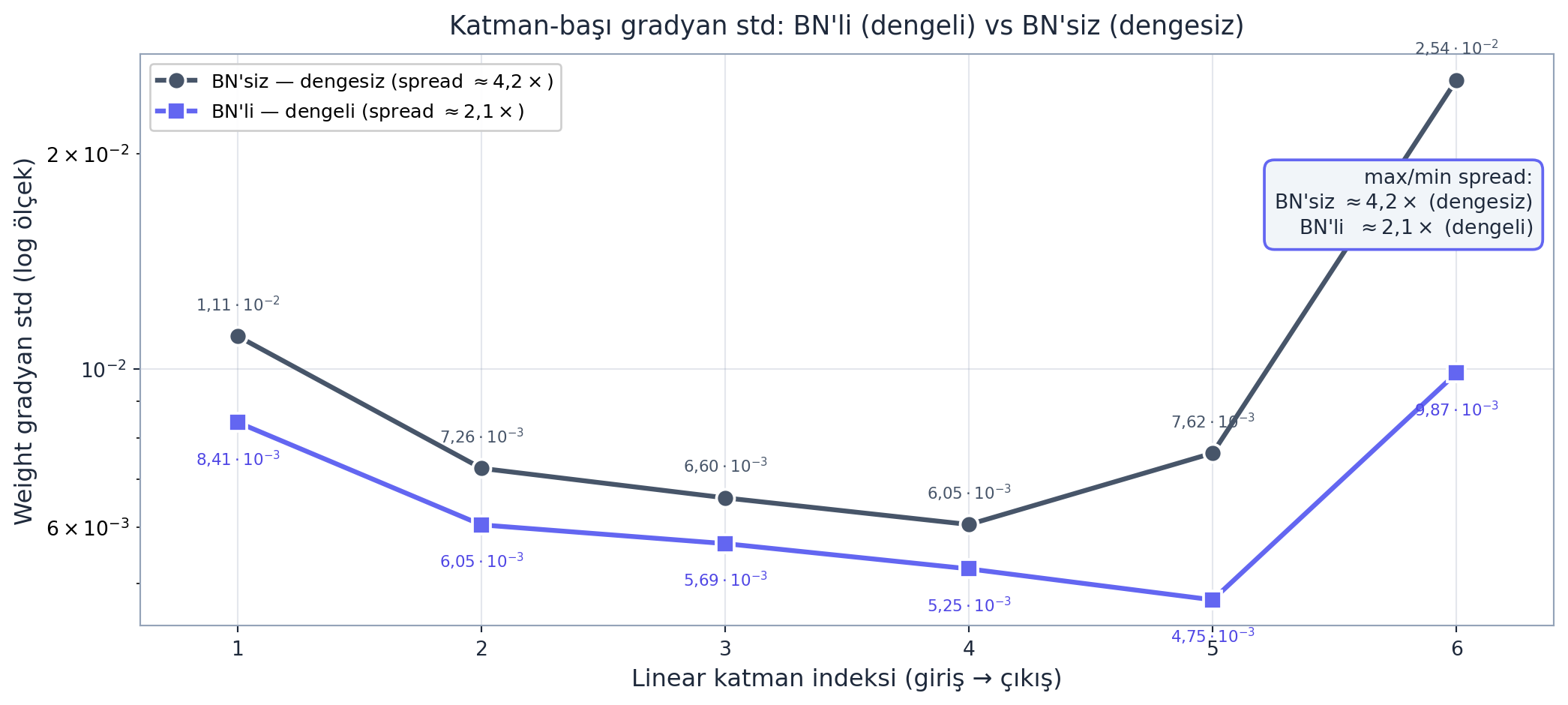
gradient_per_layer, _verify_L4 §e).
Aynı 6 katmanlı ağ üzerinde, BatchNorm’un iki kazancını birlikte de görebiliriz: makul init’te hafif iyileşme + kötü init’e karşı dayanıklılık.
Kod
import torch
import matplotlib.pyplot as plt
# Determinizm: aynı tohum -> aynı eğitim eğrileri + aynı final loss değerleri.
torch.manual_seed(SEED)
# Train/dev bölmesi (80/10/10, sabit shuffle tohumu).
Xtr, Ytr, Xdev, Ydev, Xte, Yte = split_data()
# 6 katmanlı derin ağ; BN faydası derinde belirginleşir. _verify_L4.py (d) ile
# birebir aynı çağrılar -> birebir aynı sayılar (prose = caption = verify).
N_STEPS = 20000
# (1) BN'siz, Kaiming (makul init)
C1, L1 = build_model(n_embd=10, n_hidden=100, n_layer=6, fix_output=True,
use_bn=False, bad_init=1.0, seed=SEED)
hist1 = train(C1, L1, Xtr, Ytr, steps=N_STEPS, lr=0.1, seed=SEED)
tr1, dv1 = evaluate(C1, L1, Xtr, Ytr), evaluate(C1, L1, Xdev, Ydev) # dev ~2,2031
# (2) BN'li, Kaiming (makul init)
C2, L2 = build_model(n_embd=10, n_hidden=100, n_layer=6, fix_output=True,
use_bn=True, bad_init=1.0, seed=SEED)
hist2 = train(C2, L2, Xtr, Ytr, steps=N_STEPS, lr=0.1, seed=SEED)
tr2, dv2 = evaluate(C2, L2, Xtr, Ytr), evaluate(C2, L2, Xdev, Ydev) # dev ~2,1858
# (3) BN'li, KASTEN kötü init (x5) — BN yine de kurtarmalı
C3, L3m = build_model(n_embd=10, n_hidden=100, n_layer=6, fix_output=True,
use_bn=True, bad_init=5.0, seed=SEED)
hist3 = train(C3, L3m, Xtr, Ytr, steps=N_STEPS, lr=0.1, seed=SEED)
tr3, dv3 = evaluate(C3, L3m, Xtr, Ytr), evaluate(C3, L3m, Xdev, Ydev) # dev ~2,2330
# (4) BN'siz, KASTEN kötü init (x5) — BN olmadan kötü init zorlanır
C4, L4m = build_model(n_embd=10, n_hidden=100, n_layer=6, fix_output=True,
use_bn=False, bad_init=5.0, seed=SEED)
hist4 = train(C4, L4m, Xtr, Ytr, steps=N_STEPS, lr=0.1, seed=SEED)
tr4, dv4 = evaluate(C4, L4m, Xtr, Ytr), evaluate(C4, L4m, Xdev, Ydev) # dev ~2,5318
# Türkçe ondalık biçimleyici (4 hane). Bare-text (bar etiketi) için düz virgül.
def _tr(x):
return f"{x:.4f}".replace(".", ",")
# Math-mode ($...$) için Türkçe ondalık: korunan {,} (matematik modunda sıkı aralık).
def _tr_math(x):
return f"{x:.4f}".replace(".", "{,}")
fig, (ax_l, ax_r) = plt.subplots(1, 2, figsize=(11, 5))
# ===========================================================================
# SOL panel: 4 senaryonun gruplanmış train/dev bar'ları.
# BN'li çubuklar indigo, BN'siz çubuklar slate. train soluk, dev koyu.
# ===========================================================================
apply_style(ax_l)
# Senaryo sırası: ekseni "BN'siz vs BN'li" ve "Kaiming vs kötü-init" okur kılar.
senaryolar = ["BN'siz\nKaiming", "BN'li\nKaiming", "BN'li\nkötü-init ×5",
"BN'siz\nkötü-init ×5"]
train_v = [tr1, tr2, tr3, tr4]
dev_v = [dv1, dv2, dv3, dv4]
# BN'li (2,3) -> indigo; BN'siz (1,4) -> slate. train = soluk ton, dev = koyu ton.
bn_li = [False, True, True, False]
train_renk = [COL_SLATE_400 if not b else COL_INDIGO_400 for b in bn_li]
dev_renk = [COL_PRIMARY if not b else COL_ACCENT for b in bn_li]
x = list(range(4))
w = 0.38
xb_train = [xi - w / 2 for xi in x]
xb_dev = [xi + w / 2 for xi in x]
ax_l.bar(xb_train, train_v, width=w, color=train_renk, edgecolor=COL_WHITE,
linewidth=1.0, zorder=3, label="train")
ax_l.bar(xb_dev, dev_v, width=w, color=dev_renk, edgecolor=COL_WHITE,
linewidth=1.0, zorder=3, label="dev")
# Bar üstü dev değer etiketleri (GERÇEK final loss, Türkçe ondalık).
for xi, v in zip(xb_dev, dev_v):
ax_l.text(xi, v + 0.006, _tr(v), ha="center", va="bottom",
fontsize=9.5, color=COL_TEXT, weight="bold", zorder=5)
for xi, v in zip(xb_train, train_v):
ax_l.text(xi, v + 0.006, _tr(v), ha="center", va="bottom",
fontsize=8.5, color=COL_SLATE_800, zorder=5)
# BN'siz kötü-init'in patlamasını vurgulayan anot.
ax_l.annotate(
"BN'siz kötü-init\npatlar",
xy=(xb_dev[3], dev_v[3]), xytext=(xb_dev[3] - 0.05, dev_v[3] + 0.16),
color=COL_PRIMARY, fontsize=9, ha="center", va="bottom",
arrowprops=dict(arrowstyle="-|>", color=COL_PRIMARY, lw=1.3),
bbox=dict(boxstyle="round,pad=0.3", fc=COL_BG, ec=COL_PRIMARY, lw=1.0),
zorder=6,
)
ax_l.set_xticks(x)
ax_l.set_xticklabels(senaryolar, fontsize=9)
ax_l.set_ylabel("final kayıp (ortalama NLL)", fontsize=12)
ax_l.set_title("4 senaryo: final train/dev loss (BN'li indigo · BN'siz slate)",
fontsize=11.5)
# y-aralığı: tüm bar'lar (≈2,15–2,53) + üst anot/etiket payı görünür kalsın.
ax_l.set_ylim(2.10, 2.78)
ax_l.legend(loc="upper left", fontsize=9.5, framealpha=0.95)
# ===========================================================================
# SAĞ panel: BN'li kötü-init vs BN'siz kötü-init eğitim loss eğrisi.
# Kötü-inite dayanıklılık kanıtı: BN'li düşük platoya iner, BN'siz yüksekte
# takılır. BN kazancı (dev) +0,2988; BN-kötü ≈ BN-Kaiming (dev fark +0,0472).
# ===========================================================================
apply_style(ax_r)
# Minibatch loss gürültülüdür; kayan-pencere ortalamasıyla hafifçe düzleştir.
def _duzlestir(seri, pencere=200):
from collections import deque
out, toplam, buf = [], 0.0, deque()
for v in seri:
buf.append(v)
toplam += v
if len(buf) > pencere:
toplam -= buf.popleft()
out.append(toplam / len(buf))
return out
adim = list(range(1, N_STEPS + 1))
h3_s = _duzlestir(hist3, pencere=200) # BN'li kötü-init
h4_s = _duzlestir(hist4, pencere=200) # BN'siz kötü-init
# BN'siz kötü-init (slate): yüksekte takılır.
ax_r.plot(adim, hist4, color=COL_SLATE_400, linewidth=0.6, alpha=0.30, zorder=1)
ax_r.plot(adim, h4_s, color=COL_PRIMARY, linewidth=2.2, zorder=3,
label="BN'siz kötü-init ×5")
# BN'li kötü-init (indigo): düşük platoya iner.
ax_r.plot(adim, hist3, color=COL_INDIGO_400, linewidth=0.6, alpha=0.30, zorder=2)
ax_r.plot(adim, h3_s, color=COL_ACCENT, linewidth=2.4, zorder=4,
label="BN'li kötü-init ×5")
# BN'li Kaiming dev referansı: BN-kötü ona neredeyse eşit (init'e duyarsızlık).
ax_r.axhline(dv2, color=COL_INDIGO_600, linewidth=1.4, linestyle=":",
zorder=2, label=f"BN'li Kaiming dev $= {_tr_math(dv2)}$")
# Son platodaki dev kazancı: BN'siz kötü-dev - BN'li kötü-dev = +0,2988.
kazanc = dv4 - dv3
x_an = int(N_STEPS * 0.82)
ax_r.annotate(
"", xy=(x_an, dv3), xytext=(x_an, dv4),
arrowprops=dict(arrowstyle="<->", color=COL_INDIGO_600, lw=1.6), zorder=6,
)
ax_r.text(
x_an - 700, (dv3 + dv4) / 2,
"BN kazancı (dev)\n$= " + _tr_math(kazanc).lstrip("+") + "$",
ha="right", va="center", fontsize=9.5, color=COL_INDIGO_600,
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG, ec=COL_INDIGO_600, lw=1.2),
zorder=7,
)
# BN-kötü ≈ BN-Kaiming farkı anotu (init'e dayanıklılık).
fark_bn = dv3 - dv2
ax_r.annotate(
"BN'li kötü-init $\\approx$ BN'li Kaiming\n(dev farkı yalnızca $+" + _tr(fark_bn) + "$)",
xy=(int(N_STEPS * 0.62), h3_s[int(N_STEPS * 0.62) - 1]),
xytext=(int(N_STEPS * 0.42), dv2 - 0.30),
color=COL_INDIGO_600, fontsize=9, ha="center", va="center",
arrowprops=dict(arrowstyle="-|>", color=COL_INDIGO_600, lw=1.3),
bbox=dict(boxstyle="round,pad=0.35", fc=COL_BG, ec=COL_ACCENT, lw=1.1),
zorder=7,
)
ax_r.set_xlabel("Minibatch adımı", fontsize=12)
ax_r.set_ylabel("Kayıp (loss) = minibatch NLL", fontsize=12)
ax_r.set_title("Kötü-inite dayanıklılık — BN'li (iner) vs BN'siz (takılır)",
fontsize=11.5)
ax_r.set_xlim(0, N_STEPS)
# y-aralığı: erken keskin düşüş (~3,3) + iki platonun ayrışması okunur kalsın.
ax_r.set_ylim(2.05, 3.55)
ax_r.legend(loc="upper right", fontsize=9, framealpha=0.95)
fig.suptitle(
"BatchNorm'un iki kazancı: hafif iyileşme (Kaiming) + kötü-inite dayanıklılık",
fontsize=12.5, color=COL_TEXT, y=1.02,
)
plt.tight_layout()
plt.show()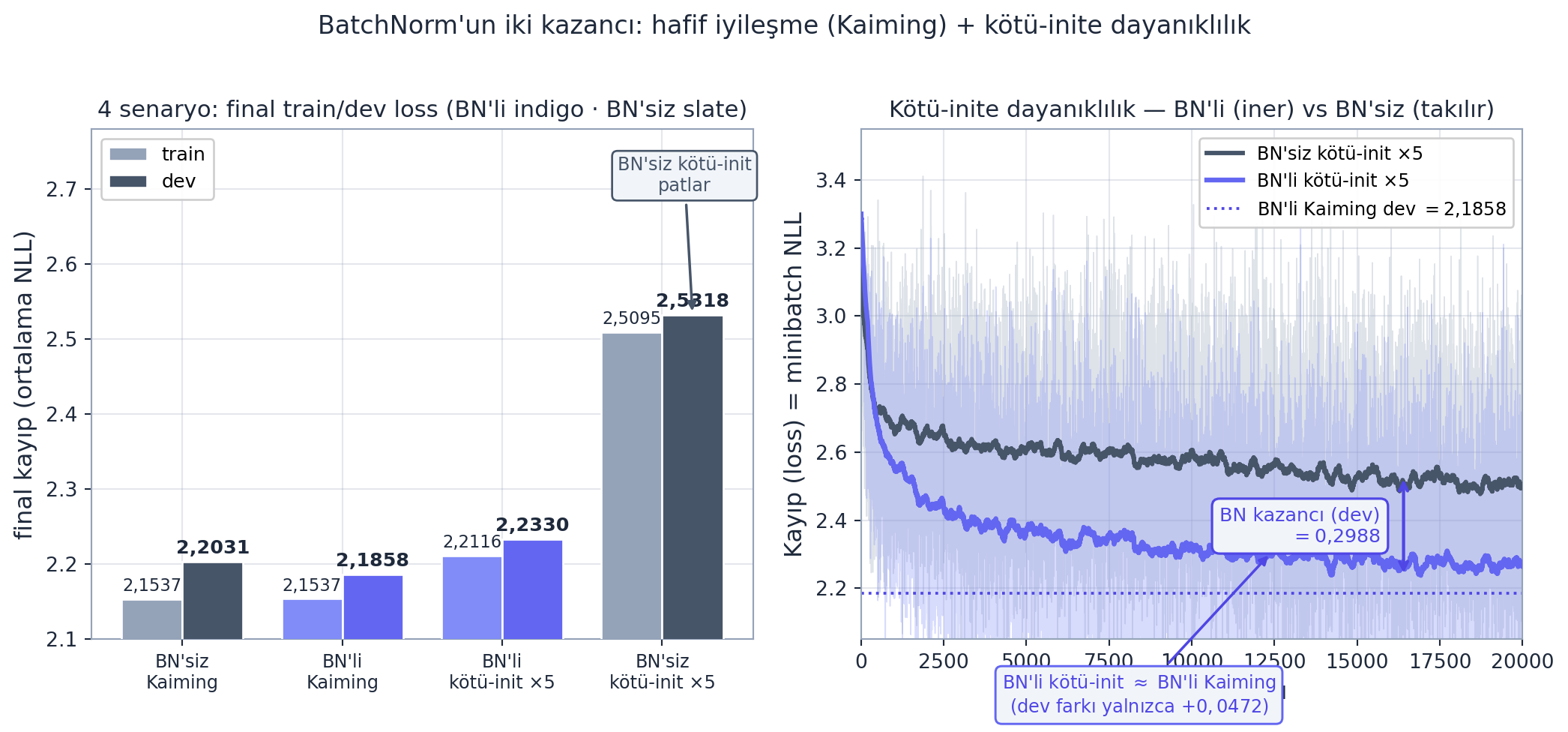
evaluate/train).
İpucuBuilder Notu — Gradyan Akışı = Ders 1 Zincir Kuralı
Geriye (Ders 1): Gradyan akışı, Ders 1’in backprop zincir kuralıdır; her katmanda gradyan yerel türevle çarpılır, bu yüzden kötü init/aktivasyon gradyanı katlanarak söndürür/patlatır. Histogram, bunu gözle görmenin yolu.
İleriye: Aktivasyon/gradyan histogramları, W&B/TensorBoard’da standart izleme panelleridir. “Gradyan normu katmanlar arası dengeli mi” sorusu, derin ağ debug’ının ilk adımı.
5.14 Diagnostik: update:data Oranı
Üçüncü ve en kullanışlı metrik: update:data oranı. Her parametre için, bir adımdaki güncellemenin büyüklüğünü (\(\text{lr} \times\) grad’ın std’si) parametrenin kendi std’sine böl, \(\log_{10}\)’unu al.
Kaba kural: bu oran \(\approx -3\) (yani \(10^{-3}\)) olmalı — her adımda parametreler kendi büyüklüklerinin binde biri kadar değişir. Çok yüksekse (örn. \(-1\)) öğrenme oranı fazla büyük (kararsız); çok düşükse (örn. \(-5\)) ağ neredeyse öğrenmiyor. Bizim ölçümümüzde medyan \(\approx -2{,}14\) (aralık \([-2{,}99,\, -1{,}89]\)) — sağlıklı \(-3\) bandının üst sınırında. Bu oran, öğrenme oranını ayarlamanın Ders 3’teki taramadan daha prensipli bir yoludur.
with torch.no_grad(): # olcum; gradyan tasimaz
ud = (lr * p.grad.std() / p.data.std()).log10() # update:data orani (log10)
# kaba kural: ud ~ -3 (binde bir). cok yuksek -> lr buyuk; cok dusuk -> ogrenmiyor
İpucuBuilder Notu — update:data = lr’nin İnce Ayarı
Geriye (Ders 3): Bu, Ders 3’teki lr taramasının daha ince hâli: lr’yi loss eğrisine değil, parametre-güncelleme oranına göre ayarla. torch.no_grad ile ölçülür (gradyan taşımaz).
İleriye: update:data oranı (ve gradyan normu izleme), büyük model eğitiminde standart sağlık göstergesi — lr schedule ve gradient clipping kararları buna dayanır (Ders 10).
5.15 Linear-Collapse Notu ve Sonuç
Karpathy bir kenar not düşer: eğer katmanlar arasına doğrusal-olmama koymazsan (sadece Linear’lar), tüm derin ağ tek bir lineer katmana çöker (Ders 1’deki aynı gözlem: lineer \(\circ\) lineer \(=\) lineer). Doğrusal-olmama (tanh/ReLU) derinliği anlamlı kılan şeydir.
Sonuç olarak: doğru init (Kaiming) + normalizasyon (BatchNorm), derin bir ağı “eğitilebilir” yapar. Aktivasyon/gradyan/update istatistiklerini izlemek ise ağın sağlığını teşhis etmenin yoludur — “çalışıyor” ile “iyi öğreniyor” arasındaki fark budur.
İpucuBuilder Notu — Linear-Collapse = Ders 1 Kontrol Sorusu 2
Geriye (Ders 1): Linear-collapse, Ders 1 Kontrol Sorusu 2’nin tekrarı: aktivasyon olmadan $W_2(W_1 x) = (W_2 W_1)x = $ tek lineer katman (18.06 bileşke).
İleriye: Init + normalizasyon + residual bağlantılar (Ders 7), 100+ katmanlı ağları (ResNet, transformer) eğitilebilir kılan üçlü. Modern mimari tasarımı büyük ölçüde “gradyanı sağlıklı akıt” mühendisliğidir.
5.16 Bu Dersin Özeti
- Aktivasyon ve gradyan istatistikleri önemlidir: kötü init, doygunluk veya patlayan/sönen gradyan eğitimi durdurur.
- Başlangıç loss’unu düzelt: çıktı katmanını küçült (
W2 *= 0.01,b2 = 0) → logitler \(\approx 0\) → ilk loss \(\approx \log(27) \approx 3{,}3\) (bizde fix’siz \(26{,}01\), fix’li \(3{,}31\); hokey-sopası kaybolur). - Doymuş
tanh/ ölü nöron: çıktı \(\pm 1\)’e yapışınca türev (\(1-\tanh^2\)) \(\approx 0\) → gradyan akmaz (kötü init doygunluğu \(\approx \%79{,}1\) vs Kaiming \(\approx \%19{,}5\)). Aktivasyon-öncesini 0 civarında tut. - Kaiming init: std \(= \text{gain} / \sqrt{n_{in}}\); gain
tanhiçin \(5/3\), ReLU için \(\sqrt{2}\). Aktivasyon varyansını katmanlar arası korur (Kaiming son katman std \(0{,}654\) vs naif \(0{,}320\)). - BatchNorm: aktivasyonları batch üzerinden normalize (\(\hat{x} = (x-\mu)/\sqrt{\sigma^2+\epsilon}\)) + öğrenilen ölçekle/kaydır (\(\gamma\), \(\beta\)).
- Running stats: test zamanı için EMA ile mean/std biriktir (
torch.no_grad, buffer); train/eval modu ayrımı. - epsilon (payda kararlılığı) + spurious bias (BatchNorm öncesi Linear’da bias=False).
- Kodu modüllere böl (Linear/BatchNorm1d/Tanh,
torch.nngibi);self.outile teşhis (gradyan std BN’li spread \(\approx 2{,}1\times\) vs BN’siz \(\approx 4{,}2\times\); update:data \(\approx 10^{-2{,}1}\)). - BatchNorm güçlü ama tuzaklı (örnekleri bağlar; kötü init’te bile dev \(2{,}2330\) vs BN’siz \(2{,}5318\)); transformer LayerNorm tercih eder (Ders 7).
ÖnemliTek Bir Cümle
Bir ağı eğitilebilir kılmak yalnızca mimariyi değil, aktivasyon ve gradyan istatistiklerini de doğru ayarlamaktır: doğru başlatma (Kaiming) ve normalizasyon (BatchNorm) sinyali katmanlar boyunca sağlıklı akıtır — ve bu istatistikleri izlemek (histogramlar, update:data oranı), “çalışıyor” ile “iyi öğreniyor” arasındaki farkı görmenin yoludur.
5.17 Kontrol Soruları
NotSoru 1: 27 karakterli bir dil modeli, eğitimin başında ‘hiçbir şey bilmiyorsa’ ilk loss kaç olmalı? Neden? Pratikte 26 gibi çok daha yüksek çıkarsa sebebi nedir?
Hiçbir şey bilmeyen model, 27 karaktere eşit (uniform) olasılık verir: her birine \(1/27\). Loss = ortalama NLL: \[
\text{loss} = -\log\left(\frac{1}{27}\right) = \log(27) \approx 3{,}30
\] Cevap: \(\approx 3{,}3\) olmalı. Pratikte bizim ölçümümüzde \(\approx 26{,}01\) çıktı; çünkü rastgele başlatılan W2/b2 aşırı uç logitler üretiyor — model “kendinden emin ama yanlış”, bazı karakterlere çok yüksek/düşük olasılık atıyor. Bu, ilk birkaç iterasyonu boşa harcayan hokey-sopası loss eğrisine yol açar. Çözüm: W2 *= 0.01, b2 = 0 ile logitleri 0’a yakın başlat → ilk loss \(\approx 3{,}31\) (uniform beklenenin tam üstünde).
NotSoru 2: Kaiming init ile BatchNorm, ikisi de aktivasyon istatistiklerini düzeltir. Aralarındaki temel fark nedir?
Cevap: Kaiming init yalnızca başlangıçta ağırlıkları doğru ölçekleyerek aktivasyon varyansını 1 civarında tutmaya çalışır — ama eğitim ilerledikçe ağırlıklar değişir ve istatistik kayabilir; derin ağda doğru ayarlamak kırılgandır. BatchNorm ise her adımda, her ileri geçişte aktivasyonları aktif olarak normalize eder — yani “doğru dağılımı umut etmek” yerine “zorla dayatmak”. BatchNorm init’e hassasiyeti büyük ölçüde ortadan kaldırır (bu yüzden çok kullanışlı): bizim ölçümümüzde kasten kötü init (\(\times 5\)) ile bile BN’li ağ dev \(2{,}2330\) verirken (BN’li Kaiming \(2{,}1858\)’e neredeyse eşit), BN’siz kötü-init dev \(2{,}5318\)’e patlar. Ama BatchNorm örnekleri batch içinde birbirine bağlar (bug kaynağı, jitter). İkisi birlikte de kullanılır: makul init + BatchNorm.
NotSoru 3: ‘Ölü nöron’ ne zaman oluşur ve neden ‘kalıcı’ olabilir? tanh türevi ile bağla.
Cevap: tanh’ın türevi \(1 - \tanh^2\)’dir (Ders 1). Bir nöronun aktivasyon-öncesi değeri çok büyük/küçükse, tanh çıktısı \(\pm 1\)’e yapışır (doygunluk) → türev \(\approx 0\). Eğer bir nöron tüm batch boyunca hep doymuşsa, geri yayılımda hep \(\approx 0\) gradyan alır → ağırlıkları asla güncellenmez → öğrenemez. “Kalıcı” çünkü güncellenmeyince doygunluktan çıkamaz; bir kısır döngü (Karpathy’nin deyişiyle “permanent brain damage”). Önlem: dikkatli init (Kaiming) veya BatchNorm ile aktivasyon-öncesini 0 civarında tutmak. (ReLU’da karşılığı: girdi hep negatif → çıktı hep 0 → ölü ReLU.)
NotSoru 4: (Builder) BatchNorm’un normalize adımı (x − μ)/√(σ²+ε) Stat 110’daki hangi kavramdır? Neden ek olarak öğrenilen γ (scale) ve β (shift) eklenir?
Cevap: Normalize adımı tam olarak standardizasyondur (Stat 110 z-skoru): \(z = (x - \mu)/\sigma\), ortalamayı 0, std’yi 1 yapar. BatchNorm bunu batch istatistikleriyle, ağın içinde yapar. \(\gamma\) ve \(\beta\) neden? Çünkü her zaman ortalama-0-std-1 istemeyebiliriz — ağ bazen farklı bir ölçek/konum isteyebilir (örn. tanh’ı belli bir bölgede kullanmak). \(\gamma\) (scale) ve \(\beta\) (shift), öğrenilen parametrelerdir ve modele normalizasyonu kısmen veya tamamen geri alma özgürlüğü verir (Stat 110 konum-ölçek dönüşümü: \(X = \mu + \sigma Z\)). Başlangıçta \(\gamma=1\), \(\beta=0\) (saf normalize); eğitimle ağ ne istediğini öğrenir. Yani BatchNorm “0-1 yap, ama gerekirse değiştirmene izin ver” der.
5.18 Egzersizler
Egzersiz 1 (Başlangıç loss’unu düzelt). Ders 3 MLP’sini al, ilk iterasyonun loss’unu yazdır (bizde \(\approx 26{,}01 \gg 3{,}3\)). Sonra W2 *= 0.01 ve b2 = 0 (veya b2 *= 0) yap, ilk loss’u tekrar ölç — \(\approx \log(27) \approx 3{,}31\) çıkmalı. Loss eğrilerini karşılaştır: hokey-sopası kayboldu mu?
Egzersiz 2 (tanh doygunluğunu gör). Gizli katman aktivasyonlarının (h = tanh(...)) histogramını çiz. (a) Büyük W1 ile: çoğu değer \(\pm 1\)’de mi (doymuş)? (b) W1’i küçült (örn. Kaiming), histogramın 0 civarında yayıldığını gözlemle. \(|h| > 0{,}97\) olanların yüzdesini (doygunluk oranı) hesapla (bizde kötü init \(\approx \%79{,}1\), Kaiming \(\approx \%19{,}5\)).
Egzersiz 3 (Kaiming init). std = gain / fan_in**0.5 (tanh için gain \(= 5/3\)) ile W1’i başlat. Ağ derinleştikçe (birkaç gizli katman) her katmanın aktivasyon std’sinin \(\approx 1\) civarında kaldığını doğrula — naif (Kaiming’siz) init ile karşılaştır (std katmanlar boyunca söner/patlar; bizde Kaiming son katman \(0{,}654\), naif \(0{,}320\)).
Egzersiz 4 (BatchNorm kur). Modüller bölümündeki BatchNorm1d modülünü kur, gizli katmandan sonra ekle (Linear → BatchNorm1d → Tanh, Linear’da bias=False). Eğit, loss’u Kaiming-only ile karşılaştır. Sonra kasten kötü bir init dene (W1’i çok büyük) — BatchNorm’un ağı yine de kurtardığını (init’e duyarsızlık; bizde BN’li kötü-init dev \(2{,}2330\) vs BN’siz kötü-init \(2{,}5318\)) gözlemle. model.eval() ile running stats’ı test et.
Egzersiz 5 (Sonraki dersin habercisi). Ders 2’den beri loss.backward() çağırıp gradyanları PyTorch’un autograd’ına bırakıyoruz. Ama bu ağın (embedding + Linear + BatchNorm + tanh + cross_entropy) her parametresinin gradyanını PyTorch tam olarak nasıl hesaplıyor, gerçekten biliyor musun? (a) cross_entropy’nin logitlere göre gradyanını elle türetmeyi dene (ipucu: softmax \(-\) one-hot). (b) BatchNorm’un backward’ının neden zor olduğunu düşün (\(\mu\) ve \(\sigma\) tüm batch’e bağlı). Bu sorular, Ders 5’te (makemore 4: backprop ninja) loss.backward()’ı kaldırıp her gradyanı tensör düzeyinde elle yazmayı motive eder — backprop’u gerçekten anlamak için.
5.19 Sonraki Ders İçin Hazırlık
Ders 5: makemore 4 — Backprop Ninjası (Elle Geri Yayılım) — Andrej Karpathy
Bu derste loss.backward() bizim için tüm gradyanları hesaplıyordu — bir kara kutu gibi. Ders 5’te o kutuyu açıyoruz: bu MLP+BatchNorm ağının backward’ını PyTorch autograd olmadan, tensör düzeyinde elle yazacağız. Karpathy’nin deyişiyle backprop “sızdıran bir soyutlama” (leaky abstraction) — körü körüne .backward() çağırmak, ince bug’ları gözden kaçırmana yol açabilir.
Ana konular:
- “Backprop is a leaky abstraction”: neden elle backward yazmak öğretici.
- Atomik hesaplama grafiği boyunca elle backward (cross_entropy, tanh, BatchNorm, matmul, embedding).
- Analitik cross-entropy ve BatchNorm gradyanları (tek satırlık formüller).
UyarıDers 5 Öncesi Yapılacak
- Egzersizleri çöz — özellikle 5 (cross_entropy gradyanını elle türet: softmax \(-\) one-hot).
- Ders 1’in micrograd backward’ını hatırla: her işlemin yerel türevi, zincir kuralıyla geriye taşınır.
- “Aktivasyon/gradyan istatistiklerini izle” ve “Kaiming + BatchNorm” cümlelerini hatırla.
5.20 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Karpathy’de |
|---|---|---|
| Başlangıç loss’u | Beklenen \(\approx \log(\text{vocab})\); logitleri 0’a yakın başlat (W2 küçült, b2=0) | 4m16 |
| Hokey-sopası eğrisi | İlk iterasyonlar aşırı logitleri ezmekle geçer; kötü init belirtisi | 11m48 |
| Doymuş tanh | Çıktı \(\pm 1\)’e yapışır; türev \((1-\tanh^2)\approx 0\); gradyan akmaz | 13m04 |
| Ölü nöron | Tüm batch’te doymuş nöron hiç güncellenmez (kalıcı) | 19m26 |
| Kaiming (He) init | std \(=\) gain \(/ \sqrt{n_{in}}\); gain tanh\(\to 5/3\), ReLU\(\to \sqrt{2}\); varyansı korur | 27m53 |
| Batch Normalization | Aktivasyonu batch’te normalize: \((x-\mu)/\sqrt{\sigma^2+\epsilon}\), sonra \(\gamma\hat{x}+\beta\) | 40m43 |
| Running stats (EMA) | Test için mean/std biriktir (buffer, torch.no_grad); train/eval modu | 54m02 |
| epsilon + spurious bias | \(\epsilon\) payda kararlılığı; BatchNorm öncesi Linear’da bias gereksiz (=False) | 1h00m |
| \(\gamma\) (scale) / \(\beta\) (shift) | Öğrenilen ölçekle-kaydır; normalizasyonu geri-alma özgürlüğü | 40m43 |
| Modülleştirme | Linear/BatchNorm1d/Tanh blokları (call, parameters); torch.nn gibi | 1h18m |
| Aktivasyon/gradyan histogramı | Doygunluk % ve katmanlar arası gradyan dengesi teşhisi | 1h26m |
| update:data oranı | \(\log_{10}(\text{lr}\cdot\text{grad\_std} / \text{param\_std}) \approx -3\) olmalı; lr sağlık metriği | 1h26m |
5.21 ML Builder Bağlantıları
İpucu9 köprü — BatchNorm
- Başlangıç loss’u → Stat 110 uniform NLL \(= \log(n)\) + Ders 3 Egzersiz 5. İleriye: model sanity-check.
- Doymuş tanh / ölü nöron → Ders 1 tanh türevi \((1-\tanh^2)=0\). İleriye: ReLU/GELU, residual bağlantılar.
- Kaiming init → Stat 110 varyans/Normal dağılım + fast.ai L17 varyans korunumu (aynı matematik, farklı çatı). İleriye: PyTorch nn.init, derin ağ eğitilebilirliği.
- BatchNorm = standardizasyon → Stat 110 z-skoru \((x-\mu)/\sigma\). İleriye: LayerNorm (Ders 7), RMSNorm.
- Running stats (EMA) → Stat 110 çevrimiçi ortalama + Calculus üstel sönüm. İleriye: train/eval modu, model.eval().
- Modülleştirme → Ders 1 Neuron/Layer/MLP arabirimi. İleriye: torch.nn.Module, tüm modern mimariler.
- Gradyan akışı/histogram → Ders 1 backprop zincir kuralı. İleriye: vanishing/exploding gradient, gradient clipping (Ders 10).
- update:data oranı → Ders 3 lr taraması. İleriye: learning rate schedule, gradient norm izleme (Ders 10).
- Linear-collapse → Ders 1 Kontrol Sorusu 2 (lineer \(\circ\) lineer \(=\) lineer, 18.06). İleriye: derinliğin neden doğrusal-olmama gerektirdiği.
5.22 Karpathy’nin Önerdiği Kaynaklar
Karpathy’nin bu ders için verdiği kaynaklar:
- Kaiming (He) init makalesi: arxiv 1502.01852 — “Delving Deep into Rectifiers” (He ve ark. 2015).
- Batch Normalization makalesi: arxiv 1502.03167 — Ioffe & Szegedy 2015.
- Ek kaynak: arxiv 2105.07576.
- Ders Colab notebook’u: Google Colab — çalıştırılabilir ortam.
ÖnemliBu dersten tek bir şey alıp gideceksen
Bir ağı eğitilebilir kılmak yalnızca mimariyi değil, aktivasyon ve gradyan istatistiklerini de doğru ayarlamaktır. Doğru başlatma (Kaiming) sinyali katmanlar boyunca korur; Batch Normalization onu zorla dayatır; ve aktivasyon/gradyan/update istatistiklerini izlemek, “ağ çalışıyor” ile “ağ sağlıklı öğreniyor” arasındaki farkı görmenin tek yoludur.