---
title: "Derin Öğrenmeye Giriş"
subtitle: "Perceptron + gradient descent + backpropagation — bir sinir ağının üç temel taşı"
---
::: {.callout-note title="Bölüm bilgisi"}
- **Lecture videosu:** [YouTube — Lecture 1: Intro to Deep Learning](https://www.youtube.com/watch?v=II4giR4vOOo&list=PLtBw6njQRU-rwp5__7C0oIVt26ZgjG9NI&index=1) (≈56 dk)
- **Edition:** 2026 • **Hoca:** Alexander Amini
- **Kaynak:** [introtodeeplearning.com](https://introtodeeplearning.com)
- **Okuma süresi:** ≈32 dk
:::
## Bu Derste Ne Var? {#sec-bu-derste}
Bu MIT 6.S191'in ilk dersi — bir haftalık yoğun derin öğrenme boot camp'inin temel taşı. Amini açılışta bir gözlemle başlıyor: alanın hızı baş döndürücü. 2015'te yüz görüntüsü üretimi ilkeldi; 2018'de sıçradı; 2020'de videoya, 2022'de (GPT-3.5/4) dile yayıldı. Hatta bugün, sadece **2 milyar parametreli**, telefonda tamamen çevrimdışı çalışan açık kaynak bir model, orijinal GPT-4'ü neredeyse her benchmark'ta geçebiliyor.
Ama asıl mesele şu tek fikirde: geleneksel makine öğrenmesi, bir görevi çözmek için **insan eliyle mühendislik** (hangi özelliklere bakılacağını elle tanımlamak) ister. Derin öğrenme bu kuralları **doğrudan veriden** öğrenir.
> *"Traditional machine learning algorithms really require a level of hand engineering... Deep learning is so exciting because it enables us to learn those rules that traditionally are driven by human engineering now by computers and by data."* — Amini, 13:03
**Dersin üç büyük fikri:**
1. **Perceptron (tek nöron)** — her sinir ağının yapı taşı. Üç adım: dot product + bias + doğrusal-olmayan aktivasyon.
2. **Nöronları katmana, katmanları derin ağlara istiflemek** — basit yapı taşından milyar parametreli hiyerarşik makineler.
3. **Eğitim** — loss fonksiyonu (hata) → gradient descent (loss'u azalt) → backpropagation (gradient'i hesapla).
{#fig-concept-map fig-align="center" width=85%}
::: {.callout-tip title="Builder Notu — ML Köprüleri"}
Bu derste önceki üç kursun (calculus, lineer cebir, olasılık) bu dersin **matematik temeli** olduğunu net göreceksin:
- **Perceptron = 18.06 dot product.** `Wx + b` tam olarak matris-vektör çarpımı + öteleme (18.06 Ders 30).
- **Gradient descent = Calculus türev.** "Eğimin ters yönünde küçük adım" = türevin tanımı (Calculus Ders 2).
- **Backpropagation = Calculus zincir kuralı.** Amini'nin kendi sözüyle *"nothing more than the chain rule"* (Calculus Ders 4).
- **Cross-entropy loss = Stat 110.** İki olasılık dağılımını eşleştirme (Stat 110 Ders 4, koşullu olasılık/entropy).
- **Dropout = Stat 110 Bernoulli.** Her nöronu $p$ olasılıkla "kapatmak" bir Bernoulli maskesidir (Stat 110 Ders 8).
İleriye köprüler de derse içkin: Amini'nin telefonda çalışan model demosu **quantization + on-device inference**; "vanilla SGD yerine neredeyse hep Adam" **adaptive optimizer**; batch size seçimi **throughput**; early stopping/checkpoint **MLOps** demektir.
:::
## AI vs ML vs DL: Üç İç İçe Halka {#sec-ai-ml-dl}
Önce kelimeleri yerine oturtalım, çünkü sık karıştırılıyorlar. Amini bunları iç içe geçmiş üç halka olarak tanımlıyor:
- **Yapay zekâ (AI):** Bir geleceği/kararı bilgilendirmek için bilgi işleyen algoritmalar kurma pratiği. Zekânın özü budur.
- **Makine öğrenmesi (ML):** AI'ın bir alt-kümesi; bilgiyi işleme adımlarını **açıkça programlamadan**, bunu veriden öğrenen kısım.
- **Derin öğrenme (DL):** ML'in bir alt-kümesi; bu öğrenmeyi özellikle **(derin) sinir ağları** ile yapan kısım.
```{python}
#| label: fig-ai-ml-dl
#| fig-cap: "Üç iç içe halka: AI ⊃ ML ⊃ DL. Her halka, bir öncekinin özel hâlidir."
#| fig-width: 9
#| fig-height: 6
import numpy as np
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(9, 6))
# Üç iç içe daire
circles = [
(3.2, '#e0e7ff', '#4338ca', 'Yapay Zekâ (AI)\nbilgi işleyen algoritmalar'),
(2.2, '#fef3c7', '#d97706', 'Makine Öğrenmesi (ML)\nveriden öğrenir'),
(1.2, '#fce7f3', '#be185d', 'Derin Öğrenme (DL)\nsinir ağı ile öğrenir'),
]
for r, fc, ec, label in circles:
circle = plt.Circle((0, 0), r, color=fc, ec=ec, linewidth=2.2, alpha=0.85)
ax.add_patch(circle)
ax.text(0, 2.7, 'AI', fontsize=18, weight='bold', ha='center', color='#1e1b4b')
ax.text(0, 1.7, 'ML', fontsize=16, weight='bold', ha='center', color='#92400e')
ax.text(0, 0, 'DL', fontsize=22, weight='bold', ha='center', color='#831843')
# Sağ tarafa açıklamalar
explanations = [
(3.5, 2.5, 'AI: kural tabanlı veya öğrenen\n algoritmalar (uzman sistemler dahil)'),
(3.5, 0.7, 'ML: kuralları açıkça\n programlamadan veriden öğrenir'),
(3.5, -1.5, 'DL: bu öğrenmeyi\n sinir ağları ile yapar'),
]
for x, y, txt in explanations:
ax.text(x, y, txt, fontsize=10, va='center', color='#1e293b')
ax.set_xlim(-4, 8)
ax.set_ylim(-4, 4)
ax.set_aspect('equal')
ax.axis('off')
ax.set_title('AI ⊃ ML ⊃ DL — her halka bir öncekinin özel hâli', fontsize=12, color='#1e1b4b')
plt.tight_layout()
plt.show()
```
> *"deep learning is nothing more than a subset of machine learning which focuses on the use of neural networks, specifically deep neural networks, to do this task of learning from data."* — Amini, 9:14
Peki neden "elle mühendislik" yerine veriden öğrenmek bu kadar güçlü? Bir yüzü tanımayı düşün. İnsan olarak nasıl yaparsın? Önce görüntüdeki çizgileri, sonra çizgilerin oluşturduğu köşeleri, sonra köşelerden göz/burun/ağız gibi yapıları, en sonunda bir yüzü ararsın. Derin öğrenme tam da bu **hiyerarşik** biçimde çalışır: düşük seviye özelliklerden (çizgi, kenar) orta seviye yapılara (köşe, eğri), oradan yüksek seviye nesnelere. Fark şu: bu özellik hiyerarşisini sen tanımlamazsın — ağ veriden kendi öğrenir.
Bu temel fikirler (1950'ler–1970'ler) yeni değil. Peki neden patlama **şimdi**? Amini üç nedene bağlıyor:
1. **Büyük veri (big data):** Bu algoritmalar veriyle beslenir; dünya hiç bu kadar çok veri üretmemişti.
2. **Donanım (hardware):** Nvidia/AMD GPU'ları paralel hesabı hızlandırdı.
3. **Yazılım (software):** TensorFlow/PyTorch gibi kütüphaneler büyük modelleri kurma/eğitme yeteneğini demokratikleştirdi.
::: {.callout-tip title="Builder Notu — Üç Tetikleyici"}
**Geriye:** "Özellikleri elle tanımlamak yerine veriden öğrenmek" fikri, kursun geri kalanının da omurgası. Hiyerarşik özellik öğrenme, sonraki derslerde CNN (görü) ve transformer (dil) olarak somutlaşacak.
**İleriye:** Amini'nin üç nedeni bir builder'ın günlük gerçeğidir. "Donanım" → GPU/TPU bellek ve throughput kısıtları (DGX Spark, H100, GB200 — Ders 9'da derinleşeceğiz); "yazılım" → PyTorch ekosistemi. Modern bir farkı da gösterdi: aynı yeteneğin **kenar cihaza (on-device)** inmesi — bu, ileride göreceğin quantization (INT8/FP8) ve verimli inference'ın ürünü.
:::
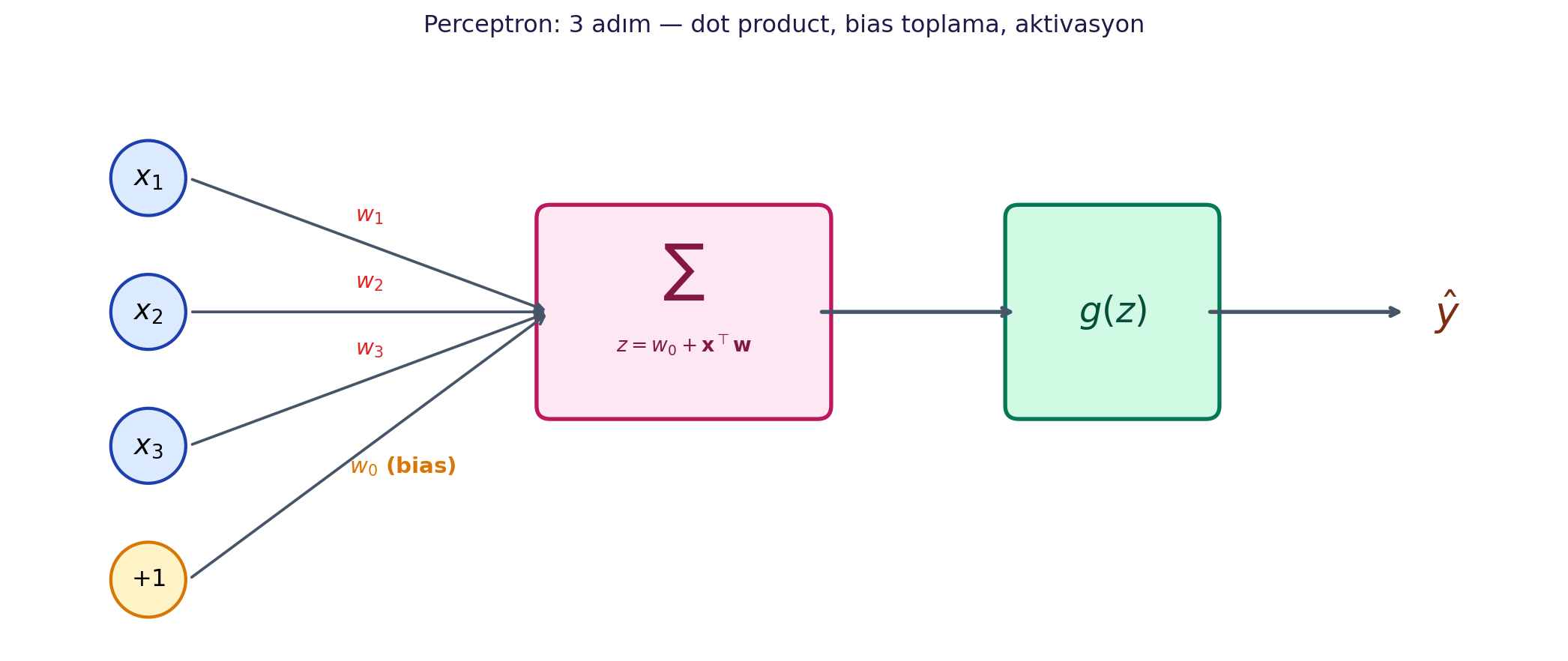
## Perceptron: Tek Nöron {#sec-perceptron}
Her sinir ağının en küçük yapı taşı tek bir nörondur — diğer adıyla **perceptron**. Önce bilginin nörondan nasıl *ileri* aktığını (forward propagation) görelim.
Nöronun $m$ tane girdisi var: $x_1, x_2, \ldots, x_m$. Nöron şunu yapar: her girdiyi kendi **ağırlığıyla** (weight) çarpar, hepsini toplar, sonuca bir sayı ekler ve çıkan tek sayıyı bir **aktivasyon fonksiyonundan** ($g$) geçirir. Eklenen o ekstra sayı **bias** terimidir ($w_0$): fonksiyonu yukarı/aşağı kaydırmaya yarar.
$$
\hat{y} = g\!\left(w_0 + \sum_{i=1}^{m} x_i w_i\right)
$$
$\mathbf{x}$ ve $\mathbf{w}$ birer $m$-boyutlu sayı listesi (vektör) olduğundan, bu ifadeyi lineer cebir diliyle çok daha derli toplu yazabiliriz. Toplam $\sum x_i w_i$ aslında $\mathbf{x}$ ile $\mathbf{w}$'nin **dot product'ıdır**:
$$
\hat{y} = g\!\left(w_0 + \mathbf{x}^\top \mathbf{w}\right)
$$
```{python}
#| label: fig-perceptron
#| fig-cap: "Perceptron: girdiler ağırlıkla çarpılıp toplanır, bias eklenir, aktivasyondan geçirilir. Üç adım."
#| fig-width: 11
#| fig-height: 5
import matplotlib.pyplot as plt
import matplotlib.patches as mp
fig, ax = plt.subplots(figsize=(11, 5))
# Girdiler (sol)
inputs = ['$x_1$', '$x_2$', '$x_3$']
weights = ['$w_1$', '$w_2$', '$w_3$']
y_positions = [3.5, 2.5, 1.5]
for x_in, w, y in zip(inputs, weights, y_positions):
ax.add_patch(plt.Circle((1.0, y), 0.28, color='#dbeafe', ec='#1e40af', lw=1.6))
ax.text(1.0, y, x_in, fontsize=14, ha='center', va='center', weight='bold')
ax.annotate('', xy=(4.0, 2.5), xytext=(1.3, y),
arrowprops=dict(arrowstyle='->', color='#475569', lw=1.4))
# Ağırlık etiketi
mid_x = (1.3 + 4.0) / 2
mid_y = (y + 2.5) / 2
ax.text(mid_x, mid_y + 0.18, w, fontsize=11, ha='center', color='#dc2626', weight='bold')
# Bias
ax.add_patch(plt.Circle((1.0, 0.5), 0.28, color='#fef3c7', ec='#d97706', lw=1.6))
ax.text(1.0, 0.5, '$+1$', fontsize=12, ha='center', va='center', weight='bold')
ax.annotate('', xy=(4.0, 2.5), xytext=(1.3, 0.5),
arrowprops=dict(arrowstyle='->', color='#475569', lw=1.4))
ax.text(2.5, 1.3, '$w_0$ (bias)', fontsize=11, color='#d97706', weight='bold')
# Nöron gövdesi
nucleus = mp.FancyBboxPatch((4.0, 1.8), 2.0, 1.4, boxstyle="round,pad=0.1",
facecolor='#fce7f3', edgecolor='#be185d', linewidth=2)
ax.add_patch(nucleus)
ax.text(5.0, 2.8, r'$\sum$', fontsize=22, ha='center', va='center', color='#831843', weight='bold')
ax.text(5.0, 2.2, '$z = w_0 + \\mathbf{x}^\\top\\mathbf{w}$', fontsize=10, ha='center', color='#831843')
# Aktivasyon
ax.annotate('', xy=(7.5, 2.5), xytext=(6.0, 2.5),
arrowprops=dict(arrowstyle='->', color='#475569', lw=2))
activation = mp.FancyBboxPatch((7.5, 1.8), 1.4, 1.4, boxstyle="round,pad=0.1",
facecolor='#d1fae5', edgecolor='#047857', linewidth=2)
ax.add_patch(activation)
ax.text(8.2, 2.5, '$g(z)$', fontsize=18, ha='center', va='center', color='#064e3b', weight='bold')
# Çıktı
ax.annotate('', xy=(10.4, 2.5), xytext=(8.9, 2.5),
arrowprops=dict(arrowstyle='->', color='#475569', lw=2))
ax.text(10.7, 2.5, r'$\hat{y}$', fontsize=20, ha='center', va='center', color='#7c2d12', weight='bold')
ax.set_xlim(0, 11.5)
ax.set_ylim(0, 4.5)
ax.set_aspect('equal')
ax.axis('off')
ax.set_title('Perceptron: 3 adım — dot product, bias toplama, aktivasyon', fontsize=12, color='#1e1b4b')
plt.tight_layout()
plt.show()
```
> *"you should remember how a single neuron works. And that's by doing a dot product, adding a bias, and applying a nonlinearity. It's really three steps."* — Amini, 24:44
Aktivasyondan **önceki** ham toplama ($w_0 + \mathbf{x}^\top \mathbf{w}$) genelde $z$ denir; çıktı ise $\hat{y} = g(z)$. Bu $z/\hat{y}$ ayrımı backpropagation'da (@sec-backprop) işimize yarayacak.
::: {.callout-tip title="Builder Notu — Linear Layer Hardware Karşılığı"}
**Geriye (18.06):** $w_0 + \mathbf{x}^\top \mathbf{w}$ tam olarak bir **matris-vektör çarpımı + öteleme**. Tek nöronda dot product; bir katmanda (@sec-noronlardan-aglara) $\mathbf{Wx + b}$ matris çarpımına dönüşür (18.06 Ders 30). Yani bir "linear layer", lineer cebirin temel işleminden başka bir şey değil.
**İleriye:** Bu tek satır her framework'te hazır: PyTorch'ta `nn.Linear`, TensorFlow'da `Dense`. Donanımda ise bu, bir **GEMM** (genelleştirilmiş matris çarpımı) çağrısıdır — GPU/TPU'lar tam olarak bunu hızlandırmak için tasarlanmıştır. Bir modelin FLOP'larının büyük kısmı bu çarpımlardadır.
:::
## Aktivasyon Fonksiyonları ve Doğrusal-Olmama {#sec-aktivasyon}
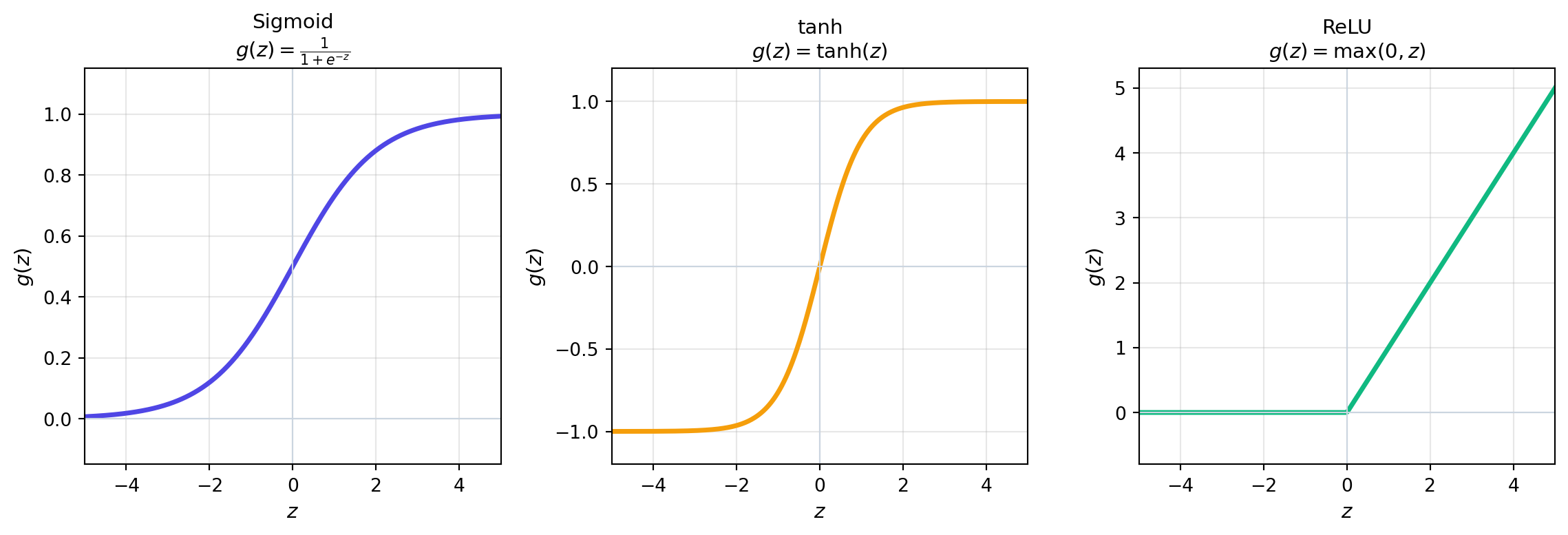
Aktivasyon fonksiyonu $g$, $x$-ekseninde herhangi bir reel sayıyı ($-\infty$ ile $+\infty$) alıp yeni bir sayıya **doğrusal olmayan** biçimde dönüştürür. İki yaygın örnek:
$$
g(z) = \frac{1}{1 + e^{-z}} \qquad \text{(sigmoid)}
$$
Sigmoid her girdiyi 0 ile 1 arasına sıkıştırır — bu yüzden olasılık üretmek için idealdir. Bir diğeri ReLU:
$$
g(z) = \max(0,\, z) \qquad \text{(ReLU)}
$$
ReLU çıktıyı 0 ile $+\infty$ arasında tutar; iki lineer parçanın arasına bir kırılma koyan, hesaplaması çok ucuz bir fonksiyondur.
```{python}
#| label: fig-aktivasyon
#| fig-cap: "Üç yaygın aktivasyon fonksiyonu. Sigmoid (0–1 olasılık), tanh (−1, +1 simetrik), ReLU (modern varsayılan)."
#| fig-width: 12
#| fig-height: 4.2
z = np.linspace(-5, 5, 400)
sigmoid = 1 / (1 + np.exp(-z))
tanh = np.tanh(z)
relu = np.maximum(0, z)
fig, axes = plt.subplots(1, 3, figsize=(12, 4.2))
for ax, y, name, color, formula in [
(axes[0], sigmoid, 'Sigmoid', '#4f46e5', r'$g(z) = \frac{1}{1+e^{-z}}$'),
(axes[1], tanh, 'tanh', '#f59e0b', r'$g(z) = \tanh(z)$'),
(axes[2], relu, 'ReLU', '#10b981', r'$g(z) = \max(0, z)$'),
]:
ax.plot(z, y, color=color, linewidth=2.6)
ax.axhline(0, color='#cbd5e0', linewidth=0.8)
ax.axvline(0, color='#cbd5e0', linewidth=0.8)
ax.set_title(f'{name}\n{formula}', fontsize=11)
ax.set_xlabel('$z$', fontsize=11)
ax.set_ylabel('$g(z)$', fontsize=11)
ax.grid(alpha=0.3)
ax.set_xlim(-5, 5)
axes[0].set_ylim(-0.15, 1.15)
axes[1].set_ylim(-1.2, 1.2)
axes[2].set_ylim(-0.8, 5.3)
plt.tight_layout()
plt.show()
```
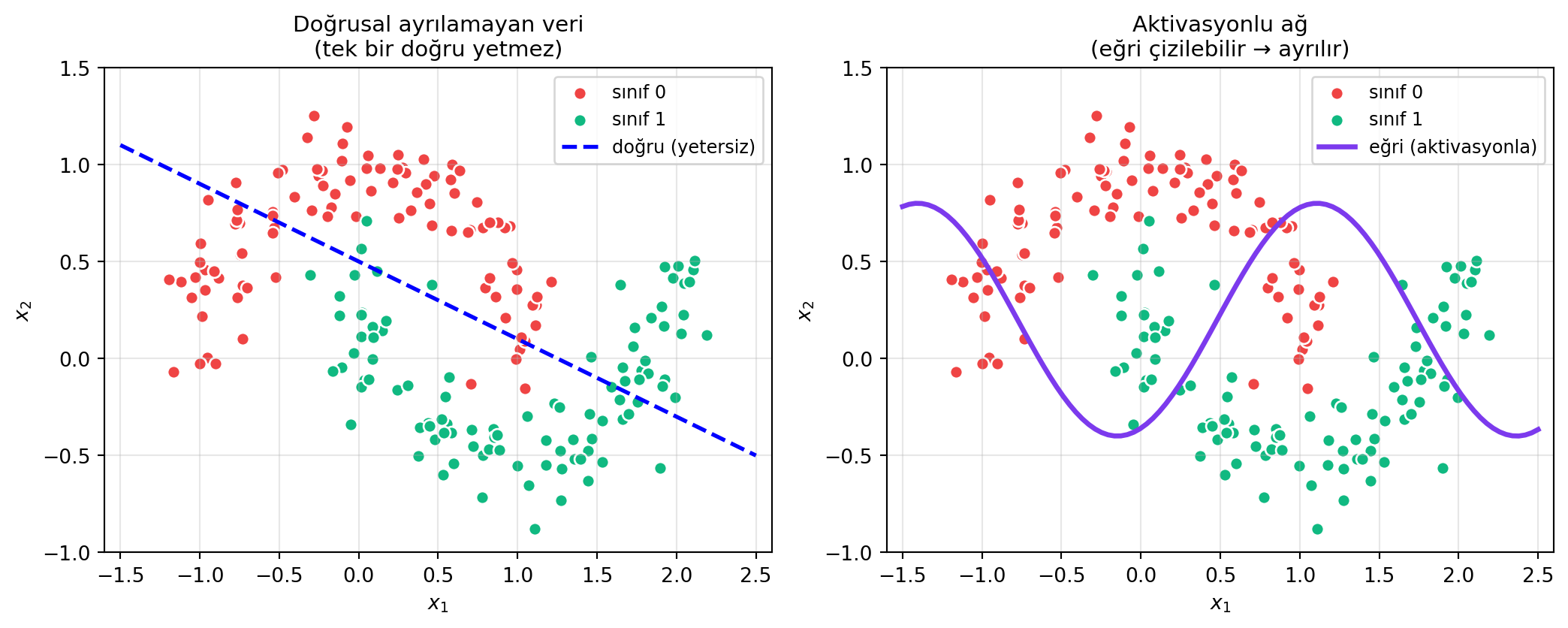
**Peki neden doğrusal-olmama şart?** Çünkü gerçek hayat doğrusal değildir.
> *"The point of an activation function is precisely to introduce nonlinearities into our model... real life is highly nonlinear. It's highly complex and dynamic."* — Amini, 19:50
Somut örnek: düzlemde yeşil ve kırmızı noktaları ayıran tek bir **doğru** çizmen istense, çoğu gerçek veride bu imkânsızdır — veri doğrusal olarak ayrılamaz. Ama **eğri** çizmene izin verilirse problem kolaylaşır.
```{python}
#| label: fig-karar-siniri
#| fig-cap: "Doğrusal ayrılamayan veri (sol) — tek bir doğru iki sınıfı ayıramaz. Doğrusal-olmama izniyle (sağ) eğri çizilebilir."
#| fig-width: 11
#| fig-height: 4.5
# make_moons benzeri sentetik veri (numpy ile, sklearn gerektirmez)
rng = np.random.default_rng(42)
n_per = 100
t = np.linspace(0, np.pi, n_per)
# Sınıf 0: üst yarım daire
x0 = np.column_stack([np.cos(t), np.sin(t)]) + 0.15 * rng.standard_normal((n_per, 2))
# Sınıf 1: alt yarım daire, kaydırılmış
x1 = np.column_stack([1.0 - np.cos(t), 0.5 - np.sin(t)]) + 0.15 * rng.standard_normal((n_per, 2))
X = np.vstack([x0, x1])
y_target = np.concatenate([np.zeros(n_per), np.ones(n_per)]).astype(int)
fig, axes = plt.subplots(1, 2, figsize=(11, 4.5))
# Sol: lineer (yetersiz)
ax = axes[0]
ax.scatter(X[y_target == 0, 0], X[y_target == 0, 1], c='#ef4444', s=40, label='sınıf 0', edgecolor='white')
ax.scatter(X[y_target == 1, 0], X[y_target == 1, 1], c='#10b981', s=40, label='sınıf 1', edgecolor='white')
# Yetersiz doğru
xx = np.linspace(-1.5, 2.5, 100)
ax.plot(xx, -0.4 * xx + 0.5, 'b--', linewidth=2, label='doğru (yetersiz)')
ax.set_title('Doğrusal ayrılamayan veri\n(tek bir doğru yetmez)', fontsize=11)
ax.set_xlabel('$x_1$'); ax.set_ylabel('$x_2$')
ax.legend(fontsize=9); ax.grid(alpha=0.3)
# Sağ: doğrusal-olmayan (yeterli)
ax = axes[1]
ax.scatter(X[y_target == 0, 0], X[y_target == 0, 1], c='#ef4444', s=40, label='sınıf 0', edgecolor='white')
ax.scatter(X[y_target == 1, 0], X[y_target == 1, 1], c='#10b981', s=40, label='sınıf 1', edgecolor='white')
# Sezgisel eğri (sin)
xx = np.linspace(-1.5, 2.5, 100)
yy = 0.6 * np.sin(2.5 * xx - 1.2) + 0.2
ax.plot(xx, yy, color='#7c3aed', linewidth=2.5, label='eğri (aktivasyonla)')
ax.set_title('Aktivasyonlu ağ\n(eğri çizilebilir → ayrılır)', fontsize=11)
ax.set_xlabel('$x_1$'); ax.set_ylabel('$x_2$')
ax.legend(fontsize=9); ax.grid(alpha=0.3)
for ax in axes:
ax.set_xlim(-1.6, 2.6)
ax.set_ylim(-1.0, 1.5)
plt.tight_layout()
plt.show()
```
**Somut hesap:** Eğitilmiş bir nöronu görselleştirelim. Diyelim $w_0 = 1$, $w_1 = 3$, $w_2 = -2$ olarak eğitildi ve yeni bir girdi geliyor: $(x_1, x_2) = (-1, 2)$. Aktivasyondan önceki $z$:
$$
z = 1 + (3)(-1) + (-2)(2) = 1 - 3 - 4 = -6
$$
$z = -6$ negatif → karar sınırının "sol" tarafındayız. Sigmoid'den geçince çok negatif bir $z$, 0,5'in altında, sıfıra yakın bir değer verir. Genel kural: karar sınırının solu aktivasyondan önce negatif (sigmoid sonrası $< 0{,}5$), sağı pozitif ($> 0{,}5$).
::: {.callout-tip title="Builder Notu — Aktivasyon Olmadan Derinlik Çöker"}
**Geriye (Calculus + 18.06):** Sigmoid = $1/(1+e^{-z})$; paydadaki $e^x$, Calculus Ders 5'in yıldızı (türevi kendisiyle orantılı — bu, backprop'ta gradient hesabını kolaylaştırır). Daha derin bir nokta: aktivasyon **olmasaydı**, üst üste binen katmanlar tek bir lineer dönüşüme çökerdi (18.06: lineer ∘ lineer = lineer). Doğrusal-olmama, derinliğin neden işe yaradığının matematiksel sebebidir.
**İleriye:** Bugün varsayılan aktivasyon çoğunlukla **ReLU** (ve türevleri GELU/SiLU); ucuz ve derin ağlarda vanishing gradient'i sigmoid'e göre azaltır. Sigmoid ise genelde son katmanda, ikili sınıflandırmada olasılık üretmek için kullanılır.
:::
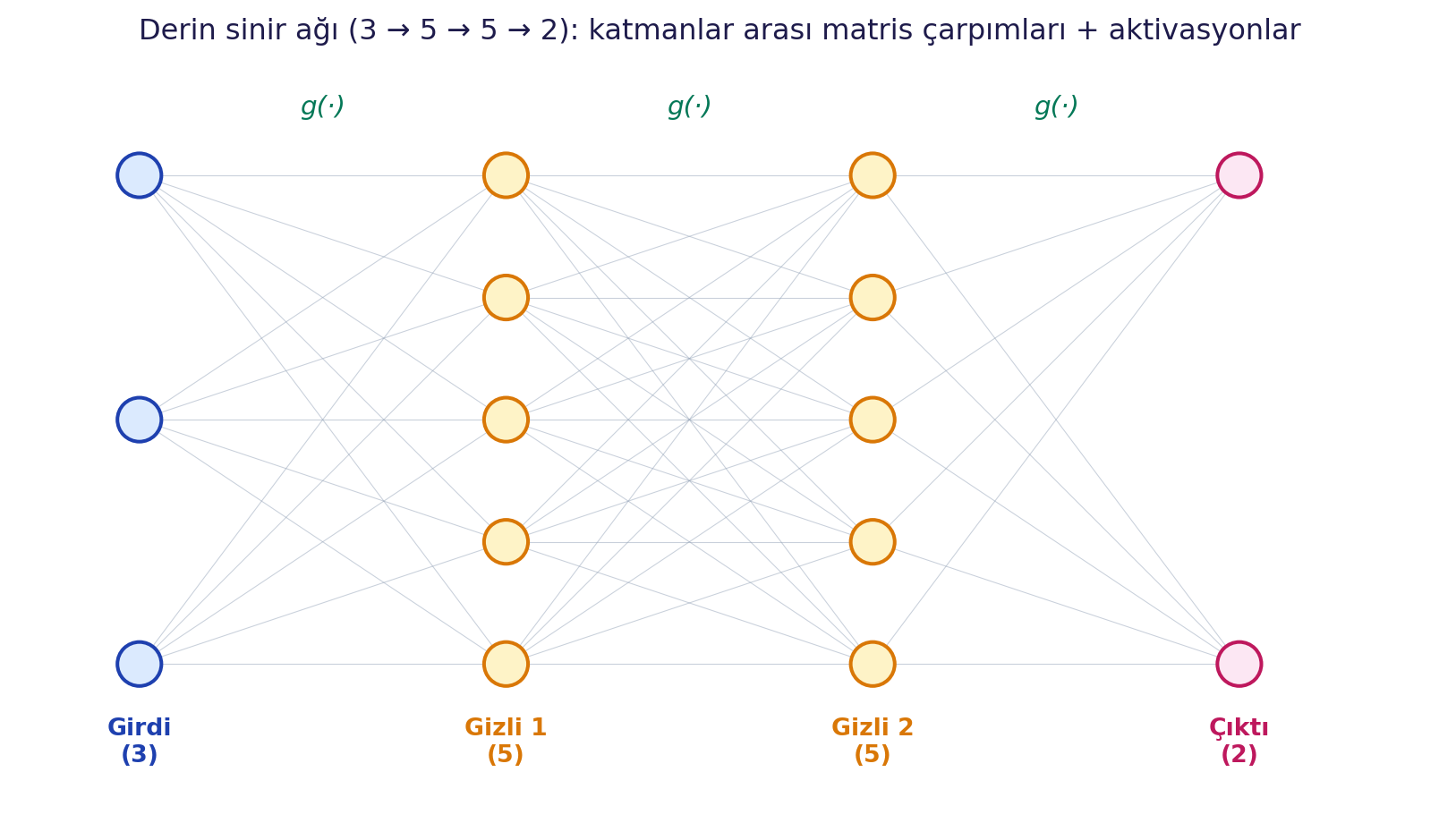
## Nöronlardan Derin Ağlara {#sec-noronlardan-aglara}
Tek nöronu anladıysan gerisi istifleme. Önce **çok çıktılı** bir katman: aynı girdileri gören iki nöron koy. İkisi de aynı $\mathbf{x}$'i görür ama her birinin **kendi bağımsız ağırlıkları** vardır; böylece iki farklı çıktı üretirler. Bir katmandaki tüm nöronların ağırlıklarını tek bir matris $\mathbf{W}$'de toplarsak:
$$
\mathbf{z} = \mathbf{W}\mathbf{x} + \mathbf{b}, \qquad \hat{\mathbf{y}} = g(\mathbf{z})
$$
Burada $\mathbf{W}$'nin boyutu (çıktı boyutu × girdi boyutu); her satırı bir nöronun ağırlık vektörüdür. Tek nörondaki dot product, bir katmanda **matris çarpımına** genişler. PyTorch'ta bu hazır gelir:
```python
import torch
import torch.nn as nn
# Tek bir lineer katman: 3 girdi -> 2 noron (cikti)
layer = nn.Linear(in_features=3, out_features=2)
x = torch.tensor([1.0, 2.0, 3.0])
z = layer(x) # z = W x + b (matris carpimi + bias)
y = torch.sigmoid(z) # dogrusal-olmayan aktivasyon
```
Şimdi **gizli katman** ekleyelim: girdi → gizli katman ($\mathbf{W}_1$) → çıktı ($\mathbf{W}_2$). Artık iki ayrı ağırlık matrisi var. Katmanları doğrusal-olmamalarla **üst üste istifleyince** derin ağ ortaya çıkar:
$$
\hat{\mathbf{y}} = g_L\!\left(\mathbf{W}_L \, g_{L-1}\!\left(\cdots g_1(\mathbf{W}_1 \mathbf{x} + \mathbf{b}_1)\cdots\right) + \mathbf{b}_L\right)
$$
```{python}
#| label: fig-derin-ag
#| fig-cap: "Derin sinir ağı: katmanlar üst üste, aralarında aktivasyon. Her ok bir ağırlık parametresi."
#| fig-width: 11
#| fig-height: 5
fig, ax = plt.subplots(figsize=(11, 5))
layers = [3, 5, 5, 2] # girdi, gizli1, gizli2, çıktı
layer_x = [1, 4, 7, 10]
layer_labels = ['Girdi\n(3)', 'Gizli 1\n(5)', 'Gizli 2\n(5)', 'Çıktı\n(2)']
layer_colors = ['#dbeafe', '#fef3c7', '#fef3c7', '#fce7f3']
layer_edges = ['#1e40af', '#d97706', '#d97706', '#be185d']
positions = []
for x, n, color, ec, label in zip(layer_x, layers, layer_colors, layer_edges, layer_labels):
ys = np.linspace(0.5, 4.5, n)
nodes = []
for y in ys:
ax.add_patch(plt.Circle((x, y), 0.18, color=color, ec=ec, lw=1.5, zorder=3))
nodes.append((x, y))
positions.append(nodes)
ax.text(x, -0.3, label, fontsize=10, ha='center', color=ec, weight='bold')
# Bağlantılar (ağırlıklar)
for L in range(len(positions) - 1):
for (x0, y0) in positions[L]:
for (x1, y1) in positions[L + 1]:
ax.plot([x0, x1], [y0, y1], color='#94a3b8', linewidth=0.4, alpha=0.5, zorder=1)
# Aktivasyon etiketleri
for x_mid in [2.5, 5.5, 8.5]:
ax.text(x_mid, 5.0, 'g(·)', fontsize=11, ha='center', color='#047857', style='italic')
ax.set_xlim(0, 11.5)
ax.set_ylim(-0.8, 5.5)
ax.set_aspect('equal')
ax.axis('off')
ax.set_title('Derin sinir ağı (3 → 5 → 5 → 2): katmanlar arası matris çarpımları + aktivasyonlar',
fontsize=12, color='#1e1b4b')
plt.tight_layout()
plt.show()
```
> *"a deep neural network is nothing more than a neural network that has more than usually three layers... going deeper and deeper across each of these layers."* — Amini, 30:18
Kodda bu sadece bir `Sequential` bloğu:
```python
model = nn.Sequential(
nn.Linear(3, 64), nn.ReLU(), # girdi -> gizli
nn.Linear(64, 64), nn.ReLU(), # gizli -> gizli (derinlik)
nn.Linear(64, 1) # gizli -> cikti
)
```
::: {.callout-tip title="Builder Notu — Genişlik, Derinlik, Parametre Sayısı"}
**Geriye (18.06):** Bir katman = bir **lineer dönüşüm** ($\mathbf{Wx}$) + öteleme ($\mathbf{b}$). Derin ağ, art arda lineer dönüşümler — ama aralarına doğrusal-olmama girmezse (18.06: bileşke lineer dönüşüm yine lineerdir) tüm derinlik tek bir $\mathbf{W}$'ye çökerdi.
**İleriye:** Genişlik (her katmandaki nöron sayısı) ve derinlik (katman sayısı), parametre sayısını ve dolayısıyla bellek + FLOP'u belirleyen iki tasarım eksenidir. Parametre sayımı = $\sum_l (\text{girdi}_l \times \text{çıktı}_l + \text{bias}_l)$ — bu sayı, modelin GPU'ya sığıp sığmayacağını doğrudan belirler.
:::
## Modeli Eğitmek: Loss Fonksiyonu {#sec-loss}
Somut bir problem: **bu dersi geçecek miyim?** İki girdi var — kaç ders dinledin ($x_1$) ve final projesine kaç saat ayırdın ($x_2$). Geçmiş öğrencilerin verisi elimizde. Sen (4 ders, 5 saat) noktasındasın. Ağa bu ikisini veriyoruz; çıktı: 0,1 yani %10 geçme olasılığı. Oysa gerçek cevap: geçtin (1). Ağ neden yanıldı?
Çünkü ağ **rastgele başlatıldı** — dünyayı hiç görmemiş bir bebek gibi. Şimdi ağa hatasını göstermeliyiz, ki bir dahaki sefere (4, 5) gördüğünde 1'e yakın tahmin etsin. Bu hatayı sayısallaştıran şeye **loss** (kayıp) denir: tahmin ile gerçek arasındaki sapma.
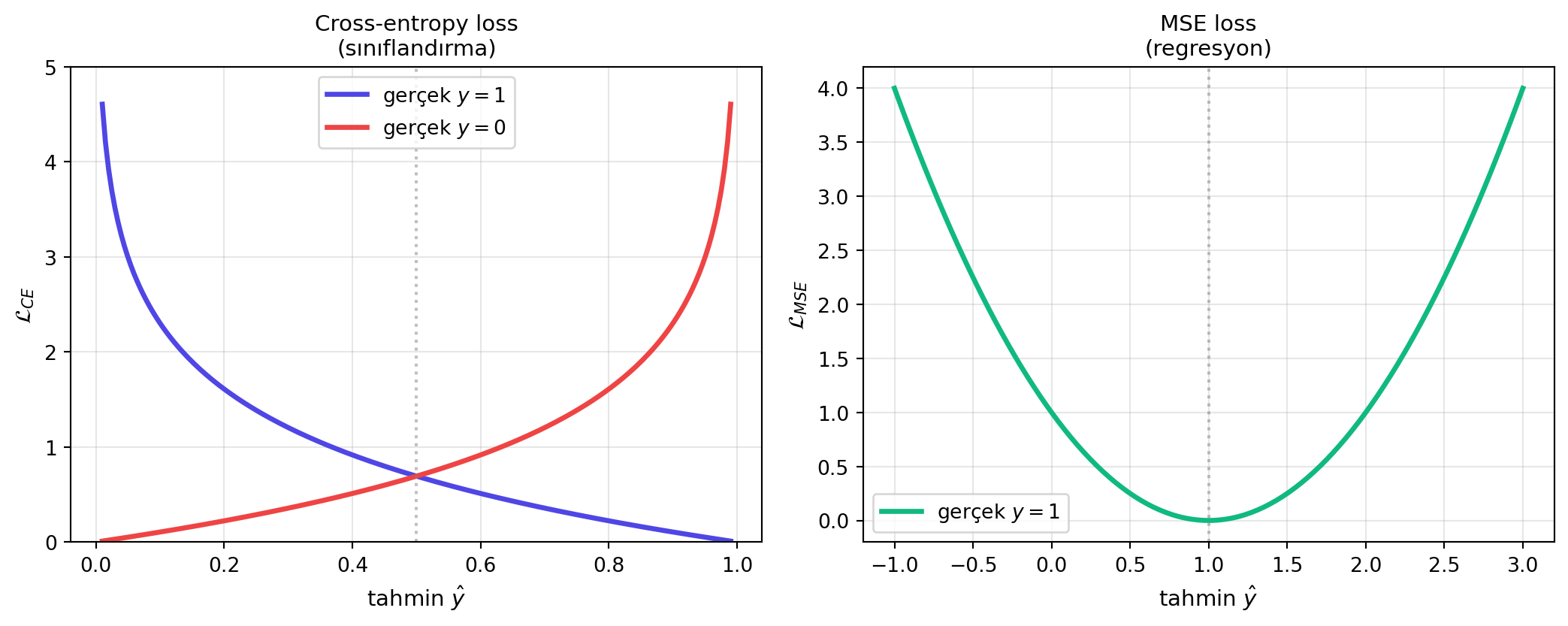
Loss'un biçimi göreve bağlıdır:
- **Sınıflandırma** (evet/hayır): çıktı bir olasılıktır (sigmoid ile 0–1). Burada **cross-entropy** loss kullanılır.
- **Regresyon** (sürekli değer: sıcaklık, not): çıktı sürekli olur; **MSE** (ortalama kare hata) kullanılır.
Eğitim, tüm veri setindeki ortalama loss'u (empirik loss $J(\mathbf{W})$) minimize eden ağırlıkları bulmaktır:
$$
J(\mathbf{W}) = \frac{1}{n} \sum_{i=1}^{n} \mathcal{L}\!\left(f(\mathbf{x}^{(i)};\, \mathbf{W}),\; y^{(i)}\right)
$$
İkili sınıflandırmada cross-entropy:
$$
\mathcal{L}_{\text{CE}} = -\frac{1}{n} \sum_{i=1}^{n} \left[\, y^{(i)} \log \hat{y}^{(i)} + (1 - y^{(i)}) \log(1 - \hat{y}^{(i)}) \,\right]
$$
Regresyonda MSE:
$$
\mathcal{L}_{\text{MSE}} = \frac{1}{n} \sum_{i=1}^{n} \left( y^{(i)} - \hat{y}^{(i)} \right)^2
$$
```{python}
#| label: fig-loss-fns
#| fig-cap: "İki temel loss: cross-entropy (sınıflandırma) ve MSE (regresyon). Cross-entropy 0/1'e yakın yanlış tahminleri çok sert cezalandırır."
#| fig-width: 11
#| fig-height: 4.5
fig, axes = plt.subplots(1, 2, figsize=(11, 4.5))
# Cross-entropy: y_true=1 sabit, y_pred [0, 1] arasında
y_pred = np.linspace(0.01, 0.99, 200)
ce_y1 = -np.log(y_pred) # gerçek=1: -log(ŷ)
ce_y0 = -np.log(1 - y_pred) # gerçek=0: -log(1-ŷ)
axes[0].plot(y_pred, ce_y1, color='#4f46e5', linewidth=2.5, label='gerçek $y = 1$')
axes[0].plot(y_pred, ce_y0, color='#ef4444', linewidth=2.5, label='gerçek $y = 0$')
axes[0].set_title('Cross-entropy loss\n(sınıflandırma)', fontsize=11)
axes[0].set_xlabel(r'tahmin $\hat{y}$', fontsize=11)
axes[0].set_ylabel(r'$\mathcal{L}_{CE}$', fontsize=11)
axes[0].legend(fontsize=10)
axes[0].grid(alpha=0.3)
axes[0].set_ylim(0, 5)
axes[0].axvline(0.5, color='gray', linestyle=':', alpha=0.5)
# MSE: y_true=1, y_pred [-1, 3] arasında
y_pred = np.linspace(-1, 3, 200)
mse = (1 - y_pred) ** 2
axes[1].plot(y_pred, mse, color='#10b981', linewidth=2.5, label='gerçek $y = 1$')
axes[1].set_title('MSE loss\n(regresyon)', fontsize=11)
axes[1].set_xlabel(r'tahmin $\hat{y}$', fontsize=11)
axes[1].set_ylabel(r'$\mathcal{L}_{MSE}$', fontsize=11)
axes[1].legend(fontsize=10)
axes[1].grid(alpha=0.3)
axes[1].axvline(1.0, color='gray', linestyle=':', alpha=0.5)
plt.tight_layout()
plt.show()
```
::: {.callout-tip title="Builder Notu — Loss = Maximum Likelihood"}
**Geriye (Stat 110):** Cross-entropy doğrudan olasılıktan gelir. $y \log \hat{y} + (1-y) \log(1-\hat{y})$ ifadesi, bir Bernoulli dağılımının **log-likelihood'udur** (Stat 110 Ders 8); cross-entropy'i minimize etmek = maximum likelihood = gerçek ile tahmin dağılımı arasındaki **KL ıraksamasını** azaltmak. MSE ise gürültünün Gaussian olduğu varsayımının maximum likelihood karşılığıdır (Stat 110 Ders 13).
**İleriye:** Loss seçimi bir mühendislik kararıdır: sınıf dengesizliğinde **focal loss**, çok-sınıflıda softmax + cross-entropy, üretken modellerde **ELBO** (Ders 4). $J(\mathbf{W})$'nin "tüm veri ortalaması" tanımı, bir sonraki adımda (mini-batch) neden tahminle yetineceğimizi de açıklar.
:::
## Gradient Descent: Loss'u Minimize Etmek {#sec-gradient-descent}
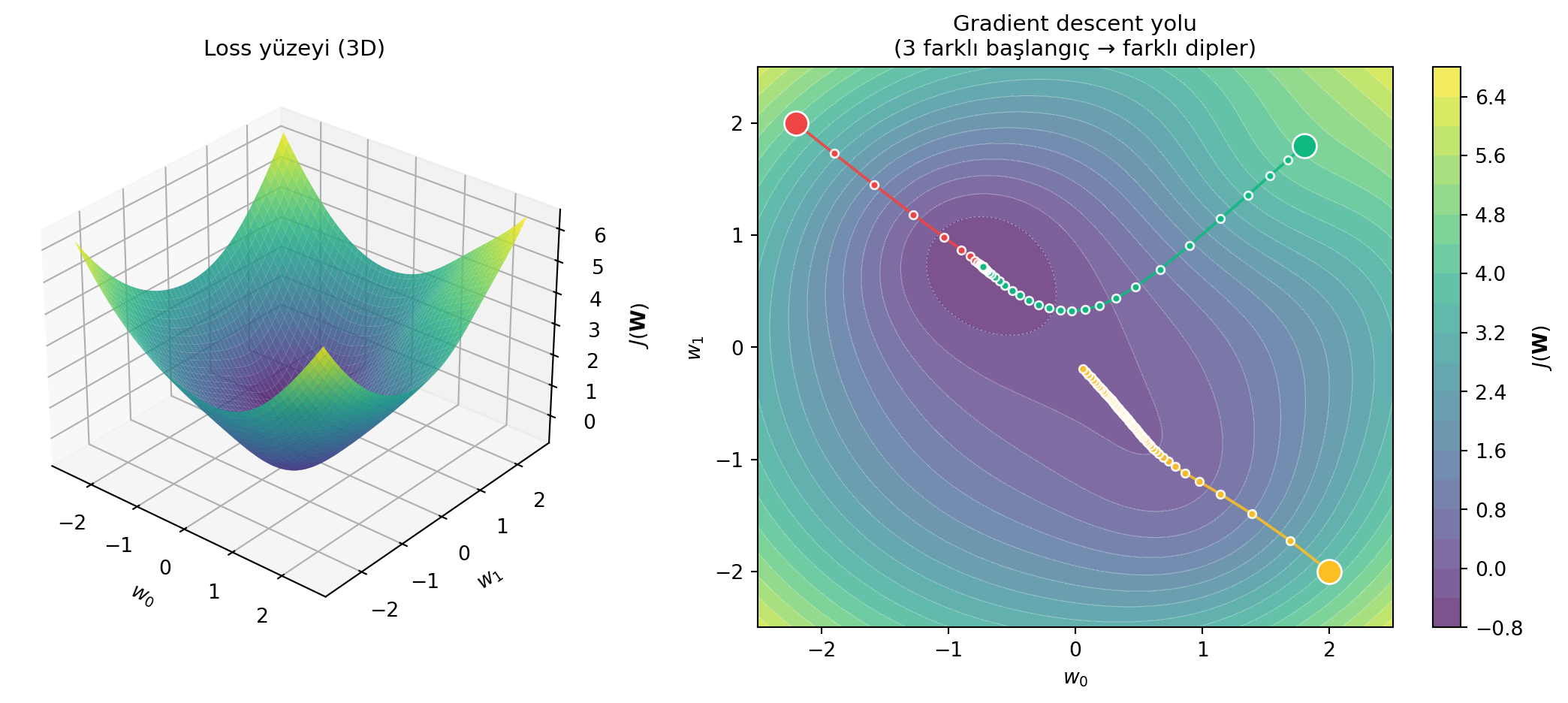
Loss $J(\mathbf{W})$, ağırlıkların bir fonksiyonudur — sonunda tek bir sayı (skaler) verir. İki parametreli bir ağı düşün ($w_0, w_1$): her ikili için bir loss değeri var; bunu yükseklik olarak çizersen ortaya bir **yüzey** çıkar. Amaç: en düşük loss'u veren ağırlıkları bulmak. Nasıl?
1. Ağırlıkları **rastgele başlat**.
2. Bulunduğun noktada **gradient'i** hesapla. Gradient, o yerel noktadaki eğimin *yukarı* yönünü söyler.
3. Biz aşağı inmek istiyoruz → gradient'in **negatifi** yönünde küçük bir adım at.
4. Yakınsayana kadar tekrarla.
$$
\mathbf{W} \leftarrow \mathbf{W} - \eta\, \frac{\partial J(\mathbf{W})}{\partial \mathbf{W}}
$$
> *"The gradient tells us the direction of the slope at that location... we want to go down. So we actually take the negative of the gradient and take a small step down."* — Amini, 37:52
```{python}
#| label: fig-loss-landscape
#| fig-cap: "Loss yüzeyi (sol) ve gradient descent yolu (sağ). Her ok gradient'in tersi yönünde küçük bir adım; algoritma bir dibe yakınsar — ille de en derin dibe değil."
#| fig-width: 12
#| fig-height: 5
from mpl_toolkits.mplot3d import Axes3D
# Bir non-convex loss yüzeyi
def loss(w0, w1):
return 0.5 * (w0**2 + w1**2) + 1.5 * np.exp(-((w0-1.5)**2 + (w1-1.5)**2)) \
- 1.5 * np.exp(-((w0+1.0)**2 + (w1-1.0)**2)) \
- 1.0 * np.exp(-((w0-1.0)**2 + (w1+1.5)**2))
def grad(w0, w1, h=1e-4):
return ((loss(w0+h, w1) - loss(w0-h, w1)) / (2*h),
(loss(w0, w1+h) - loss(w0, w1-h)) / (2*h))
w0_grid = np.linspace(-2.5, 2.5, 100)
w1_grid = np.linspace(-2.5, 2.5, 100)
W0, W1 = np.meshgrid(w0_grid, w1_grid)
L = loss(W0, W1)
fig = plt.figure(figsize=(12, 5))
# Sol: 3D yüzey
ax1 = fig.add_subplot(121, projection='3d')
ax1.plot_surface(W0, W1, L, cmap='viridis', alpha=0.85, edgecolor='none')
ax1.set_xlabel('$w_0$'); ax1.set_ylabel('$w_1$'); ax1.set_zlabel('$J(\\mathbf{W})$')
ax1.set_title('Loss yüzeyi (3D)', fontsize=11)
ax1.view_init(elev=30, azim=-50)
# Sağ: gradient descent yolu (contour üzerinde)
ax2 = fig.add_subplot(122)
contour = ax2.contourf(W0, W1, L, levels=20, cmap='viridis', alpha=0.7)
ax2.contour(W0, W1, L, levels=20, colors='white', linewidths=0.4, alpha=0.5)
# 3 farklı başlangıçtan GD
starts = [(-2.2, 2.0), (2.0, -2.0), (1.8, 1.8)]
colors = ['#ef4444', '#fbbf24', '#10b981']
eta = 0.12
for start, c in zip(starts, colors):
w0, w1 = start
path = [(w0, w1)]
for _ in range(60):
gw0, gw1 = grad(w0, w1)
w0 -= eta * gw0
w1 -= eta * gw1
path.append((w0, w1))
px, py = zip(*path)
ax2.plot(px, py, '-o', color=c, markersize=4, linewidth=1.4, alpha=0.9, markeredgecolor='white')
ax2.plot(start[0], start[1], 'o', color=c, markersize=12, markeredgecolor='white', zorder=5)
ax2.set_xlabel('$w_0$'); ax2.set_ylabel('$w_1$')
ax2.set_title('Gradient descent yolu\n(3 farklı başlangıç → farklı dipler)', fontsize=11)
plt.colorbar(contour, ax=ax2, label='$J(\\mathbf{W})$')
plt.tight_layout()
plt.show()
```
Bir dibe yakınsaması garantidir, ama bunun *en* derin dip olması garanti değildir — nereden başladığına bağlıdır.
::: {.callout-tip title="Builder Notu — Gradient, Yön ve İnit"}
**Geriye (Calculus):** Gradient, çok değişkenli türevdir. Tek değişkende türev = eğim (Calculus Ders 2); çok değişkende $\nabla J$, en dik *çıkış* yönünü gösterir, negatifini almak en dik *iniş*tir. $\eta$ ile atılan adım, türevin "küçük dürtme $dx$" sezgisinin pratiğe dökülmüş hâlidir. Yüzeyin neden birden çok dibi olduğu (non-convexlik) ikinci türevle/eğrilikle ilgilidir (Calculus Ders 10, Hessian).
**İleriye:** "Hangi dibe düşeceğin başlangıca bağlı" gözlemi, **weight initialization**'ın (Xavier/He) neden önemli olduğunu önceler. Yakınsama hızı ve kararlılığı, optimizer ve learning rate seçimine bağlıdır. Üretimde bu döngü, **checkpoint**'lerle izlenir ve durdurulur.
:::
## Backpropagation: Gradient'i Nasıl Hesaplarız? {#sec-backprop}
Gradient descent'in kalbi $\partial J / \partial \mathbf{W}$ terimiydi — ama onu **nasıl** hesaplarız? Bunun adı **backpropagation**.
En basit ağı al: $x \to$ tek nöron $\to \hat{y} \to$ loss $J$. $w_2$'nin loss'a etkisini, yani $\partial J / \partial w_2$'yi merak ediyoruz: *"$w_2$'yi azıcık değiştirsem $J$ ne kadar değişir?"* Zincir kuralıyla bunu iki parçaya ayırırız:
$$
\frac{\partial J}{\partial w_2} = \frac{\partial J}{\partial \hat{y}} \cdot \frac{\partial \hat{y}}{\partial w_2}
$$
Şimdi bir önceki katmanın ağırlığını, $w_1$'i istersek, zincir kuralını **bir kez daha** uygularız:
$$
\frac{\partial J}{\partial w_1} = \frac{\partial J}{\partial \hat{y}} \cdot \frac{\partial \hat{y}}{\partial z_1} \cdot \frac{\partial z_1}{\partial w_1}
$$
Daha derin bir ağda bu süreci tekrar tekrar uygularsın: gradient'leri çıktıdan başlayıp ağın topolojisi boyunca **geriye doğru** taşırsın, ta girişe kadar.
{#fig-backprop-flow fig-align="center" width=85%}
> *"that's the backprop algorithm. In theory, it's just an application of the chain rule... nothing more than the chain rule."* — Amini, 42:16
Teoride zincir kuralı; pratikte ise loss yüzeyi son derece **non-convex** olduğundan iş, başlatma ve regularization seçimlerine bağlı hâle gelir.
::: {.callout-tip title="Builder Notu — Reverse-Mode Autodiff"}
**Geriye (Calculus):** Backprop, **zincir kuralının** (Calculus Ders 4) katman katman uygulanmasından başka bir şey değil. Ders 4'te gördüğün "$dh$ terimlerinin sadeleşmesi" tam olarak **reverse-mode autodiff**'tir: gradient'i çıktıdan girişe doğru biriktirmek, ara türevleri yeniden hesaplamadan zincirler. Yüzeyin non-convexliği Calculus Ders 10 (Hessian) ile bağlanır.
**İleriye:** PyTorch'ta bu `loss.backward()` ile otomatik olur (`torch.autograd`). Bellek darboğazı olursa **gradient checkpointing** (ara aktivasyonları yeniden hesaplamak) devreye girer (Ders 9'da derinleşiriz). Çok derin ağlarda zincirin uzaması **vanishing/exploding gradient**'e yol açar — residual bağlantılar, normalization ve dikkatli init bunu çözer.
:::
## Pratik I: Learning Rate ve Optimizer'lar {#sec-learning-rate}
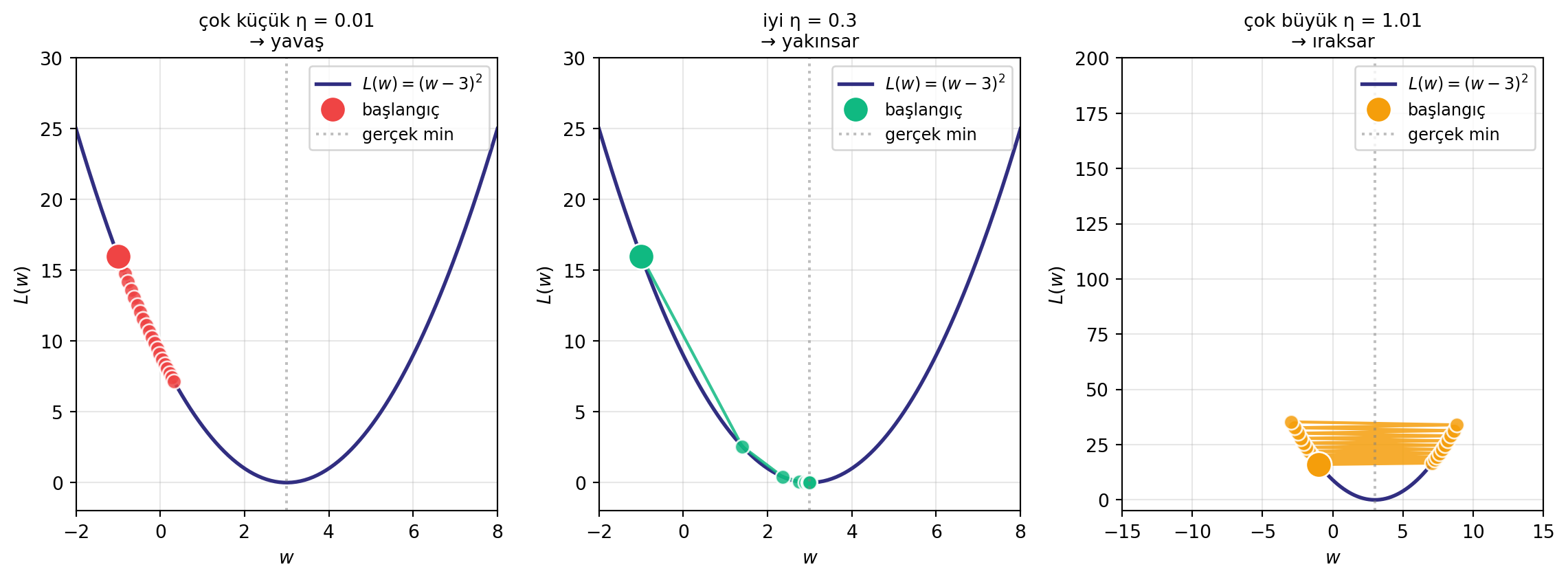
Gradient descent güncellemesinde "küçük bir adım at" demiştik. Peki **ne kadar** küçük? Adım büyüklüğü $\eta$'dır (learning rate) — gradient'i ne hızda takip ettiğin.
Bu sayıyı ayarlamak zordur:
- **Çok küçük $\eta$** → model sahte (sığ) bir yerel minimumda takılır, büyük minimumlara hiç ulaşamaz.
- **Çok büyük $\eta$** → minimumun üstünden atlarsın (overshoot), loss patlayabilir.
```{python}
#| label: fig-learning-rate
#| fig-cap: "Üç farklı learning rate. Çok küçük (sol) yavaş; ideal (orta) hızlı yakınsar; çok büyük (sağ) overshoot eder."
#| fig-width: 12
#| fig-height: 4.5
# Basit kuadratik L(w) = (w-3)^2
def loss_q(w): return (w - 3) ** 2
def grad_q(w): return 2 * (w - 3)
w_range = np.linspace(-2, 8, 200)
L_range = loss_q(w_range)
fig, axes = plt.subplots(1, 3, figsize=(12, 4.5))
configs = [
(0.01, 'çok küçük η = 0.01\n→ yavaş', '#ef4444'),
(0.3, 'iyi η = 0.3\n→ yakınsar', '#10b981'),
(1.01, 'çok büyük η = 1.01\n→ ıraksar', '#f59e0b'),
]
for ax, (eta, title, color) in zip(axes, configs):
ax.plot(w_range, L_range, color='#312e81', linewidth=2, label='$L(w) = (w-3)^2$')
w = -1.0
path_w = [w]
path_L = [loss_q(w)]
for _ in range(20):
w = w - eta * grad_q(w)
if abs(w) > 1e4: break
path_w.append(w)
path_L.append(loss_q(w))
ax.plot(path_w, path_L, 'o-', color=color, markersize=8, linewidth=1.6,
markeredgecolor='white', alpha=0.85)
ax.plot(path_w[0], path_L[0], 'o', color=color, markersize=14,
markeredgecolor='white', zorder=5, label='başlangıç')
ax.axvline(3, color='gray', linestyle=':', alpha=0.5, label='gerçek min')
ax.set_title(title, fontsize=10)
ax.set_xlabel('$w$'); ax.set_ylabel('$L(w)$')
ax.legend(fontsize=9, loc='upper right')
ax.grid(alpha=0.3)
if eta > 1:
ax.set_xlim(-15, 15); ax.set_ylim(-5, 200)
else:
ax.set_xlim(-2, 8); ax.set_ylim(-2, 30)
plt.tight_layout()
plt.show()
```
İdeali: sahte yerel minimumların üstünden atlayacak kadar büyük, ama global'e yakın dibe yerleşecek kadar dengeli bir $\eta$. Bunu sabit seçmek yerine **uyarlanabilir (adaptive) learning rate** kullanılır: gradient büyükken adımı küçült, küçükken **momentum** ile yerel minimumların üstünden taşı. İşte bu yüzden vanilla SGD yerine pratikte neredeyse her zaman **Adam, RMSprop, Adagrad, Adadelta** gibi optimizer'lar kullanılır.
::: {.callout-tip title="Builder Notu — Momentum = İvme"}
**Geriye (Calculus):** Momentum, fiziğin **ivme** sezgisinden gelir (Calculus Ders 10: ikinci türev); geçmiş gradient'lerin "hızını" biriktirip düz/sığ bölgelerde hareketi sürdürür. Uyarlanabilir adım ise yüzeyin yerel eğriliğine göre adımı ayarlamaktır.
**İleriye:** Bugün varsayılan başlangıç çoğunlukla **AdamW**'dir. Üstüne **learning rate schedule** biner: warmup + cosine/exponential decay (bu üstel sönüm tam da Calculus Ders 5'in $e^x$'i). $\eta$, batch size ile birlikte en kritik hyperparameter'lardandır; **Optuna** gibi araçlarla ve ablation çalışmalarıyla aranır.
:::
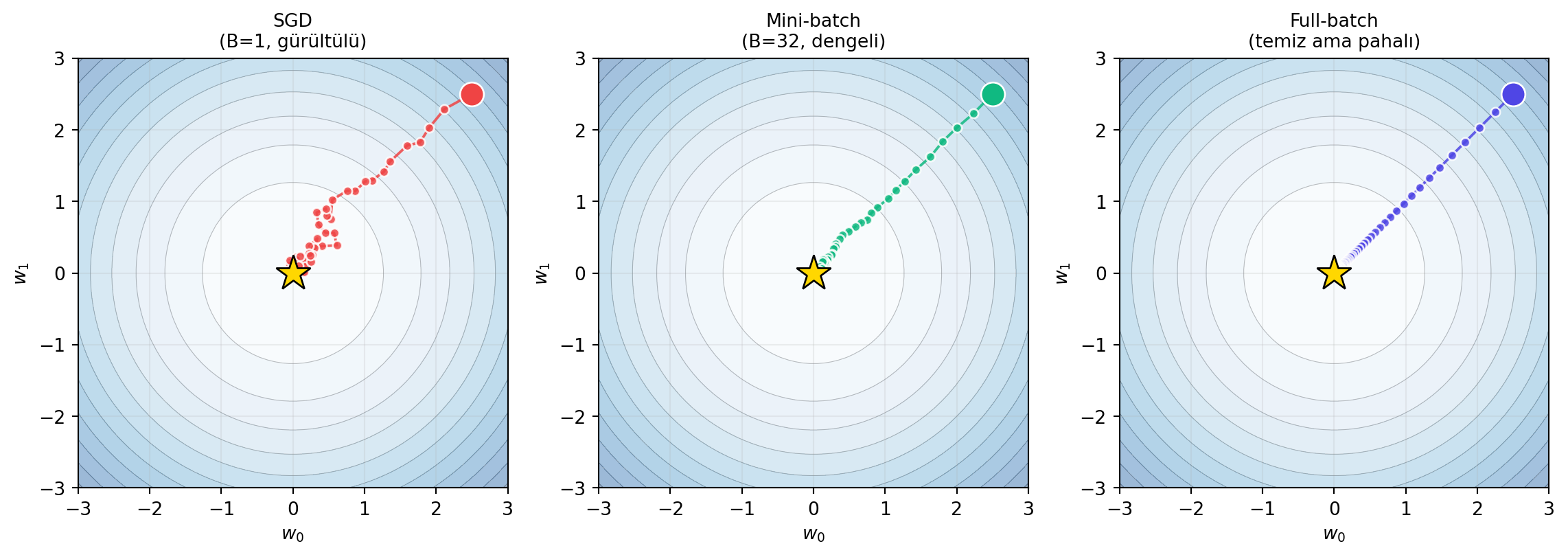
## Pratik II: SGD ve Mini-Batch {#sec-sgd}
Backprop pahalıdır: her parametre için, çıktıdan girişe kadar türev hesaplarsın — üstelik bunu veri setindeki **her nokta** için. Gerçek problemlerde tüm veri üzerinde her iterasyonda bunu yapmak mümkün değildir. Çözüm aşamalı:
- **SGD (stochastic gradient descent):** Gradient'i tüm veri yerine **tek bir rastgele nokta** üzerinde hesapla. Çok hızlı, ama çok gürültülü.
- **Mini-batch:** Gradient'i $B$ tane noktadan oluşan bir **batch** üzerinde hesapla. Yaygın batch size 32; büyük dil modellerinde milyonlar.
$$
\frac{\partial J}{\partial \mathbf{W}} \approx \frac{1}{B} \sum_{k=1}^{B} \frac{\partial \mathcal{L}_k}{\partial \mathbf{W}}
$$
```{python}
#| label: fig-sgd-vs-batch
#| fig-cap: "SGD (sol, gürültülü ama hızlı) vs mini-batch (orta, dengeli) vs full-batch (sağ, pahalı ama temiz). Aynı yüzey, üç farklı varyans profili."
#| fig-width: 12
#| fig-height: 4.5
np.random.seed(7)
# Basit 2D loss
def loss2d(w0, w1): return 0.5 * (w0**2 + w1**2)
def true_grad(w0, w1): return (w0, w1)
w0_grid = np.linspace(-3, 3, 60)
w1_grid = np.linspace(-3, 3, 60)
W0, W1 = np.meshgrid(w0_grid, w1_grid)
L = loss2d(W0, W1)
fig, axes = plt.subplots(1, 3, figsize=(12, 4.5))
noise_levels = [(0.8, 'SGD\n(B=1, gürültülü)'), (0.25, 'Mini-batch\n(B=32, dengeli)'), (0.0, 'Full-batch\n(temiz ama pahalı)')]
colors = ['#ef4444', '#10b981', '#4f46e5']
for ax, (noise, title), color in zip(axes, noise_levels, colors):
ax.contour(W0, W1, L, levels=12, colors='gray', linewidths=0.4, alpha=0.5)
ax.contourf(W0, W1, L, levels=12, cmap='Blues', alpha=0.4)
w0, w1 = 2.5, 2.5
path = [(w0, w1)]
for _ in range(40):
gw0, gw1 = true_grad(w0, w1)
gw0 += np.random.normal(0, noise)
gw1 += np.random.normal(0, noise)
w0 -= 0.1 * gw0
w1 -= 0.1 * gw1
path.append((w0, w1))
px, py = zip(*path)
ax.plot(px, py, '-o', color=color, markersize=5, linewidth=1.4, alpha=0.85,
markeredgecolor='white')
ax.plot(2.5, 2.5, 'o', color=color, markersize=13, markeredgecolor='white', zorder=5)
ax.plot(0, 0, '*', color='gold', markersize=20, markeredgecolor='black', zorder=5)
ax.set_title(title, fontsize=10)
ax.set_xlabel('$w_0$'); ax.set_ylabel('$w_1$')
ax.set_aspect('equal')
ax.grid(alpha=0.2)
ax.set_xlim(-3, 3); ax.set_ylim(-3, 3)
plt.tight_layout()
plt.show()
```
::: {.callout-tip title="Builder Notu — Batch ↔ Varyans Trade-off"}
**Geriye (Stat 110):** Mini-batch gradient'i, gerçek (tüm-veri) gradient'in **tarafsız tahmincisidir** — rastgele bir alt-kümenin ortalaması, Stat 110'daki örneklem ortalaması/Monte Carlo ile birebir aynı (Ders 9). "SGD gürültülü ama mini-batch daha doğru" gözlemi, tahmin varyansının batch boyutuyla azalmasıdır: varyans $\propto 1/B$ (Büyük Sayılar Yasası).
**İleriye:** Batch size, doğrudan **throughput vs bellek** dengesidir. Bellek yetmezse **gradient accumulation** (birkaç küçük batch'in gradient'ini toplayıp tek adım atmak) kullanılır. Büyük-batch eğitiminde learning rate'i buna göre ölçeklemek gerekir (linear/sqrt scaling). Ders 9'da bunu **distributed training** ile genelleştireceğiz.
:::
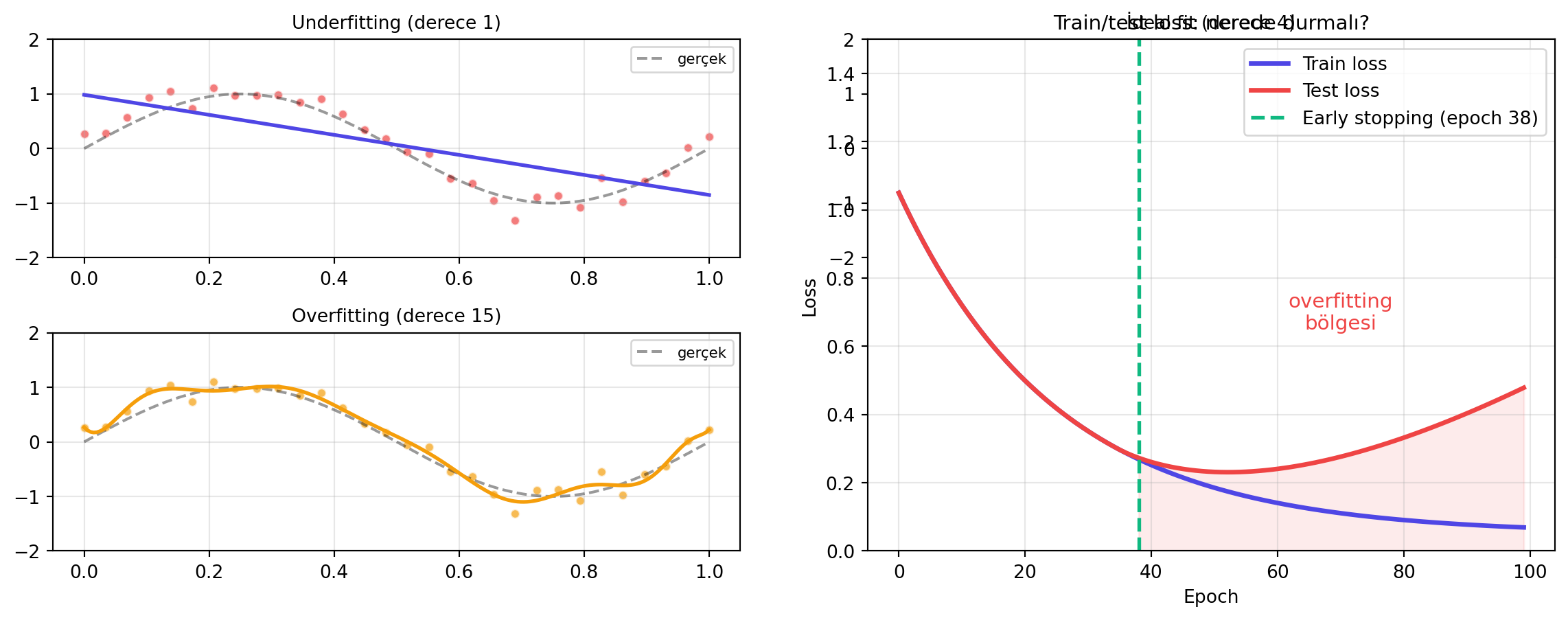
## Pratik III: Overfitting ve Regularization {#sec-overfitting}
**Overfitting:** Modelin eğitim verisinin ayrıntılarına fazla gömülüp, o veri dışına **genelleyemeyecek** kadar ezberlemesi. Karşıtı **underfitting**: yeterince ifade gücü olmayan bir modelin desenleri yakalayamaması. İdeal, ikisinin **ortasıdır**.
İki popüler regularization yolu:
- **Dropout:** Olasılıksal bir yöntem. Her iterasyonda gizli katman aktivasyonlarının bir kısmını (örn. $p = 0{,}5$) **rastgele kapat**. Hiçbir nöron tek bir yola güvenemez; ağ farklı yollar üzerinden çalışmayı öğrenir.
- **Early stopping:** Eğitim ve test loss'unu birlikte izle. Başta ikisi de düşer; bir noktadan sonra eğitim loss'u düşmeye devam ederken test loss'u **artmaya** başlar — overfitting buradan başlar. O noktadaki checkpoint'i seç.
```{python}
#| label: fig-overfitting
#| fig-cap: "Sol: underfitting (çok basit), iyi fit (denge), overfitting (ezber). Sağ: train/test loss eğrileri — test loss yükselmeye başladığı an early stopping."
#| fig-width: 12
#| fig-height: 5
np.random.seed(0)
x_data = np.linspace(0, 1, 30)
y_data = np.sin(2 * np.pi * x_data) + 0.15 * np.random.randn(30)
x_fine = np.linspace(0, 1, 200)
y_true = np.sin(2 * np.pi * x_fine)
# Üç model: derece 1, 4, 15
fig = plt.figure(figsize=(12, 5))
ax1 = fig.add_subplot(2, 2, 1)
p1 = np.poly1d(np.polyfit(x_data, y_data, 1))
ax1.plot(x_fine, y_true, 'k--', alpha=0.4, label='gerçek')
ax1.scatter(x_data, y_data, c='#ef4444', s=25, alpha=0.7, edgecolor='white')
ax1.plot(x_fine, p1(x_fine), color='#4f46e5', linewidth=2)
ax1.set_title('Underfitting (derece 1)', fontsize=10)
ax1.set_ylim(-2, 2); ax1.grid(alpha=0.3); ax1.legend(fontsize=8)
ax2 = fig.add_subplot(2, 2, 2)
p4 = np.poly1d(np.polyfit(x_data, y_data, 4))
ax2.plot(x_fine, y_true, 'k--', alpha=0.4, label='gerçek')
ax2.scatter(x_data, y_data, c='#10b981', s=25, alpha=0.7, edgecolor='white')
ax2.plot(x_fine, p4(x_fine), color='#10b981', linewidth=2)
ax2.set_title('İdeal fit (derece 4)', fontsize=10)
ax2.set_ylim(-2, 2); ax2.grid(alpha=0.3); ax2.legend(fontsize=8)
ax3 = fig.add_subplot(2, 2, 3)
p15 = np.poly1d(np.polyfit(x_data, y_data, 15))
ax3.plot(x_fine, y_true, 'k--', alpha=0.4, label='gerçek')
ax3.scatter(x_data, y_data, c='#f59e0b', s=25, alpha=0.7, edgecolor='white')
ax3.plot(x_fine, p15(x_fine), color='#f59e0b', linewidth=2)
ax3.set_title('Overfitting (derece 15)', fontsize=10)
ax3.set_ylim(-2, 2); ax3.grid(alpha=0.3); ax3.legend(fontsize=8)
# Sağ: train/test loss eğrisi
ax4 = fig.add_subplot(1, 2, 2)
epoch = np.arange(0, 100)
train_loss = 1.0 * np.exp(-epoch / 25) + 0.05
test_loss = 1.0 * np.exp(-epoch / 25) + 0.05 + 0.0008 * np.maximum(0, epoch - 35) ** 1.5
ax4.plot(epoch, train_loss, color='#4f46e5', linewidth=2.5, label='Train loss')
ax4.plot(epoch, test_loss, color='#ef4444', linewidth=2.5, label='Test loss')
early_stop = 38
ax4.axvline(early_stop, color='#10b981', linestyle='--', linewidth=2, label=f'Early stopping (epoch {early_stop})')
ax4.fill_between(epoch[early_stop:], 0, test_loss[early_stop:], color='#ef4444', alpha=0.1)
ax4.text(70, 0.65, 'overfitting\nbölgesi', fontsize=11, color='#ef4444', ha='center')
ax4.set_xlabel('Epoch'); ax4.set_ylabel('Loss')
ax4.set_title('Train/test loss: nerede durmalı?', fontsize=11)
ax4.legend(fontsize=10); ax4.grid(alpha=0.3)
ax4.set_ylim(0, 1.5)
plt.tight_layout()
plt.show()
```
> *"in dropout, all we do is that we randomly drop out some activations of the hidden layers with some probability... it's forcing it to not rely on any one pathway."* — Amini, 51:09
::: {.callout-tip title="Builder Notu — Dropout = Bernoulli Maskesi"}
**Geriye (Stat 110):** Dropout, her nöron için bir **Bernoulli(1−p) maskesidir** (Stat 110 Ders 8); inference'ta beklenen değeri korumak için ölçekleme (inverted dropout) yapılır — bu da beklenen değer (Ders 9) hesabıdır. Overfitting/underfitting ikilemi ise doğrudan **bias-variance** dengesidir (Stat 110 Ders 34).
**İleriye:** Dropout, weight decay (L2), early stopping ve data augmentation, üretimde standart regularization araçlarıdır. Early stopping'in dayandığı **train/validation/test ayrımı** ve **checkpoint** yönetimi, MLOps'un (W&B, model registry) çekirdeğidir — Ders 7'de (The Three Laws of AI, Comet ML) bunu derinleştireceğiz.
:::
## Bu Dersin Özeti {#sec-ozet}
1. Derin öğrenme, bir görevin kurallarını **elle tanımlamak yerine doğrudan veriden** öğrenir; AI ⊃ ML ⊃ DL.
2. Patlamanın üç nedeni: büyük veri, donanım (GPU), yazılım (PyTorch/TensorFlow).
3. **Perceptron** (tek nöron) üç adımdır: dot product + bias + doğrusal-olmayan aktivasyon — $\hat{y} = g(w_0 + \mathbf{x}^\top \mathbf{w})$.
4. **Aktivasyon fonksiyonu** doğrusal-olmama katar; o olmadan tüm katmanlar tek bir lineer dönüşüme çökerdi.
5. Nöronları katmana, katmanları (aralarına aktivasyon koyarak) **derin ağlara** istifleriz; bir katman $\mathbf{Wx + b}$ matris çarpımıdır.
6. **Loss** tahmin–gerçek sapmasıdır; sınıflandırmada cross-entropy, regresyonda MSE.
7. **Gradient descent** ağırlıkları gradient'in ters yönünde küçük adımlarla günceller.
8. **Backpropagation**, gradient'i hesaplar — özünde zincir kuralının çıktıdan girişe uygulanmasıdır.
9. Pratik: learning rate ve uyarlanabilir optimizer'lar (Adam), hesap için mini-batch (SGD), genelleme için regularization (dropout, early stopping).
::: {.callout-important title="Tek bir cümle"}
Bir sinir ağı, "dot product + bias + doğrusal-olmama" yapı taşının istiflenmesidir; onu eğitmek ise bir loss fonksiyonunu gradient descent ile minimize etmek, gradient'i de backpropagation (zincir kuralı) ile hesaplamaktan ibarettir — gerisi, bu çekirdeği veriye ve donanıma ölçeklemenin pratiğidir.
:::
## Kontrol Soruları {#sec-sorular}
::: {.callout-note collapse="true" title="Soru 1: w₀ = 0, w₁ = 1, w₂ = −1 ağırlıklı bir perceptron'a (sigmoid) (x₁, x₂) = (3, 1) girdisi veriliyor. z ve ŷ?"}
**Cevap:** Önce ham toplam:
$$
z = w_0 + w_1 x_1 + w_2 x_2 = 0 + (1)(3) + (-1)(1) = 2
$$
$z = 2$ pozitif → karar sınırının "sağ" tarafındayız. Sigmoid'den geçirince $\hat{y} = 1/(1 + e^{-2}) \approx 0{,}88$. Yani %88 — sigmoid çıktısı 0,5'in üzerinde, bu da $z > 0$ olmasıyla tutarlı.
:::
::: {.callout-note collapse="true" title="Soru 2: İki katmanlı ağda aktivasyonu kaldırırsan ne olur?"}
**Cevap:** Aktivasyon olmadan ağ $\hat{y} = \mathbf{W}_2(\mathbf{W}_1 \mathbf{x})$ hâline gelir. Matris çarpımı birleşmeli olduğundan:
$$
\mathbf{W}_2(\mathbf{W}_1 \mathbf{x}) = (\mathbf{W}_2 \mathbf{W}_1)\, \mathbf{x} = \mathbf{W}' \mathbf{x}
$$
İki katman **tek bir lineer katmana** çöker (18.06: iki lineer dönüşümün bileşkesi yine lineerdir). Kaç katman istiflersen istifle, sonuç tek bir $\mathbf{W}'\mathbf{x}$ kalır — model yalnızca doğrusal sınırlar çizebilir, doğrusal ayrılamayan veriyi (moons örneği) asla ayıramaz. Derinliğin işe yaramasının sebebi tam olarak katmanlar arasındaki doğrusal-olmamadır.
:::
::: {.callout-note collapse="true" title="Soru 3: Learning rate çok küçük/büyük seçilirse? Gradient descent neden 'en derin' dibi değil?"}
**Cevap:** **Çok küçük $\eta$:** Adımlar minik olur; eğitim yavaş ve sığ bir yerel minimumda takılabilir. **Çok büyük $\eta$:** Minimumun üstünden atlarsın (overshoot); loss sıçrar, hatta ıraksayıp patlayabilir. **Neden "bir" dibe:** Gradient yalnızca **yerel** eğim bilgisidir — bulunduğun noktada hangi yönün aşağı olduğunu söyler, tüm yüzeyi görmez. Bu yüzden nereden başladığına bağlı olarak en yakın dibe iner; loss yüzeyi non-convex olduğundan bu, global minimum olmak zorunda değildir.
:::
::: {.callout-note collapse="true" title="Soru 4: (Builder) Cross-entropy minimize = Maximum likelihood — neden?"}
**Cevap:** İkili etiket $y \in \{0, 1\}$ ve model tahmini $\hat{y} = P(y = 1)$ için, tek bir örneğin olasılığı bir **Bernoulli** dağılımıdır (Stat 110 Ders 8): $P(y) = \hat{y}^y (1-\hat{y})^{1-y}$. Bunun logaritması $y \log \hat{y} + (1-y) \log(1-\hat{y})$. Tüm veri üzerinde **log-likelihood'u maksimize etmek**, bu ifadenin negatifinin ortalamasını — yani tam olarak cross-entropy'yi — **minimize etmektir**:
$$
\mathcal{L}_{\text{CE}} = -\frac{1}{n} \sum_{i=1}^{n} \left[\, y^{(i)} \log \hat{y}^{(i)} + (1 - y^{(i)}) \log(1 - \hat{y}^{(i)}) \,\right]
$$
Yani cross-entropy minimize etmek = maximum likelihood = gerçek etiket dağılımıyla model dağılımı arasındaki **KL ıraksamasını azaltmak**. Loss "uydurma" bir hata ölçüsü değil; doğrudan olasılıktan türer.
:::
## Egzersizler {#sec-egzersizler}
**Egzersiz 1 (Perceptron'u elle kur).** Tek bir perceptron'un ileri geçişini NumPy ile sıfırdan yaz. Sonra PyTorch'ta `nn.Linear` + `torch.sigmoid` ile aynı sonucu doğrula.
```python
import numpy as np
def perceptron(x, w, b, g=lambda z: 1/(1+np.exp(-z))):
z = np.dot(x, w) + b # dot product + bias
return g(z) # aktivasyon
x = np.array([3.0, 1.0])
w = np.array([1.0, -1.0])
b = 0.0
print(perceptron(x, w, b)) # ~0.88 (Soru 1 ile ayni)
```
**Egzersiz 2 (Doğrusal-olmama neden şart?).** `sklearn.datasets.make_moons` ile doğrusal ayrılamayan bir veri seti üret. (a) Aktivasyonsuz (sadece `nn.Linear`'lar) bir ağ, (b) aralarında `nn.ReLU` olan bir ağ eğit. Karar sınırlarını çiz. Aktivasyonsuz ağın neden yalnızca düz bir çizgi çizebildiğini gözlemle.
**Egzersiz 3 (Learning rate süpürmesi).** Basit bir kuadratik loss $L(w) = (w - 3)^2$ üzerinde gradient descent'i elle uygula (gradient = $2(w - 3)$). $\eta \in \{0{,}01,\ 0{,}1,\ 0{,}5,\ 1{,}0,\ 1{,}01\}$ için 50 iterasyon koştur. Hangi $\eta$'da yavaş yakınsıyor, hangisinde ıraksıyor?
```python
import numpy as np
def gd(eta, steps=50, w0=10.0):
w, hist = w0, [w0]
for _ in range(steps):
grad = 2 * (w - 3) # dL/dw
w = w - eta * grad # gradient descent guncelleme
hist.append(w)
return hist
for eta in [0.01, 0.1, 0.5, 1.0, 1.01]:
print(eta, round(gd(eta)[-1], 4))
```
**Egzersiz 4 (Overfitting ve dropout).** Oyuncak verisi (`make_moons` veya XOR) için küçük bir MLP eğit. Veriyi train/test olarak ayır; her epoch iki loss'u kaydet. (a) Dropout'suz eğit, test loss'unun bir noktadan sonra arttığını gözlemle. (b) `nn.Dropout(0.5)` ekleyip karşılaştır. Early stopping noktasını grafikte işaretle.
**Egzersiz 5 (Sonraki dersin habercisi).** Bu derste gördüğün ağ, **sabit sayıda** girdi alıyor. Şimdi bir cümleyi düşün: "film harikaydı" 2 kelime, "film başından sonuna kadar harikaydı" 5 kelime. Değişken uzunlukta bir diziyi sabit girdili bir perceptron'a nasıl verirsin? (a) Naif bir fikir öner ve neden yetersiz olduğunu açıkla. (b) $x \to$ nöron $\to \hat{y} \to L$ minik ağı için $\partial L / \partial w$'yi zincir kuralıyla elle yaz. Bu iki gözlem, Ders 2'de **dizi modellerine** (RNN, attention) neden ihtiyaç duyduğumuzu motive eder.
## Sonraki Ders İçin Hazırlık {#sec-sonraki}
**Ders 2: Derin Dizi Modelleme (Deep Sequence Modeling)** — Ava Soleimany
Bu derste gördüğümüz ağlar yalnızca sabit boyutlu veriyle çalışıyordu. Ama dünyadaki pek çok şey bir **dizidir**: metin, ses, video. Ava, bu dizileri işleyen modelleri — RNN'lerden attention ve transformer'lara — anlatacak. GPT'leri çalıştıran mekanizma tam da budur.
**Ana konular:**
- Diziyi modelleme: değişken uzunluk ve sıra neden zorluk yaratır?
- RNN'ler ve gizli durum (hidden state); zaman içinde geri yayılım (BPTT).
- Attention ve transformer mimarisinin temeli.
::: {.callout-warning title="Ders 2 öncesi yapılacak"}
- Egzersizleri çöz — özellikle 4 (overfitting) ve 5 (dizi sezgisi).
- Backpropagation'ın "zincir kuralının geriye uygulanması" olduğunu kendi cümlenle yaz (Calculus Ders 4).
- Ana cümleyi tekrar oku: *"Bir sinir ağı, dot product + bias + doğrusal-olmama yapı taşının istiflenmesidir."*
:::
## Anahtar Kavramlar (Cheat Sheet) {#sec-cheat-sheet}
| Kavram | Tanım | Amini'de |
|--------|-------|----------|
| **Perceptron (nöron)** | $\hat{y} = g(w_0 + \mathbf{x}^\top \mathbf{w})$ — dot product + bias + aktivasyon | 24m44 |
| **Bias ($w_0$)** | Aktivasyon öncesi eklenen öteleme terimi | 17m15 |
| **Aktivasyon fonksiyonu** | Doğrusal-olmama katan $g$; derinliği anlamlı kılar | 19m50 |
| **Sigmoid** | $g(z) = 1/(1 + e^{-z})$; 0–1 olasılık | 18m41 |
| **ReLU** | $g(z) = \max(0, z)$; modern varsayılan | 19m29 |
| **Linear / Dense katman** | $\mathbf{Wx + b}$ matris çarpımı; PyTorch `nn.Linear` | 27m40 |
| **Derin ağ** | Aktivasyonlarla istiflenmiş çok sayıda katman | 30m18 |
| **Loss / $J(\mathbf{W})$** | Veri seti üzerinde ortalama hata | 33m35 |
| **Cross-entropy** | Sınıflandırma loss'u | 34m47 |
| **MSE** | Regresyon loss'u | 35m27 |
| **Gradient descent** | $\mathbf{W} \leftarrow \mathbf{W} - \eta \, \partial J / \partial \mathbf{W}$ | 38m40 |
| **Backpropagation** | Zincir kuralıyla çıktıdan girişe gradient | 42m16 |
| **Learning rate ($\eta$)** | Adım büyüklüğü | 43m27 |
| **SGD / mini-batch** | Gradient'i tek nokta / $B$ noktalık batch üzerinde tahmin | 46m50 |
| **Dropout** | Aktivasyonları $p$ olasılıkla kapatan regularization | 50m56 |
| **Early stopping** | Test loss yükselince eğitimi durdur | 53m01 |
## ML Builder Bağlantıları {#sec-ml-baglantilar}
::: {.callout-tip title="8 köprü"}
1. **Perceptron / linear layer ($\mathbf{Wx + b}$)** → 18.06 matris-vektör çarpımı ve dot product (Ders 30). İleriye: GEMM, GPU throughput.
2. **Aktivasyon (sigmoid)** → Calculus $e^x$ (Ders 5); doğrusal-olmama olmadan katmanlar tek lineer dönüşüme çöker (18.06 bileşke). İleriye: ReLU/GELU varsayılanları.
3. **Loss / $J(\mathbf{W})$ (cross-entropy)** → Stat 110 Bernoulli log-likelihood ve KL (Ders 4, 8); MSE → Gaussian gürültü (Ders 13). İleriye: göreve özel loss seçimi.
4. **Gradient descent** → Calculus türev/eğim (Ders 2) ve en dik iniş (gradient, Ders 6). İleriye: convergence, init.
5. **Backpropagation** → Calculus zincir kuralı (Ders 4) = reverse-mode autodiff; non-convex yüzey/eğrilik (Ders 10, Hessian). İleriye: `torch.autograd`, gradient checkpointing.
6. **Optimizer / momentum** → Calculus ivme (Ders 10). İleriye: AdamW, LR schedule ($e^x$ decay), Optuna.
7. **Mini-batch SGD** → Stat 110 örneklem ortalaması/Monte Carlo, varyans $\propto 1/B$ (Ders 9, 29). İleriye: batch size–throughput, gradient accumulation.
8. **Dropout** → Stat 110 Bernoulli maskesi + beklenen değer (Ders 8, 9); overfitting = bias-variance (Ders 34). İleriye: weight decay, MLOps checkpoint.
:::
::: {.callout-important title="Bu dersten tek bir şey alıp gideceksen"}
Bir sinir ağı sihir değildir — "dot product + bias + doğrusal-olmama" yapı taşının istiflenmesidir; eğitmek ise bir loss'u gradient descent ile minimize edip gradient'i backpropagation (zincir kuralı) ile hesaplamaktır. Bu mekaniğin her parçası, daha önce öğrendiğin calculus, lineer cebir ve olasılığın üstünde durur.
:::