---
title: "Derin Dizi Modelleme"
subtitle: "RNN, BPTT ve attention — geçmişi bellekte tutan iki paradigma"
---
::: {.callout-note title="Bölüm bilgisi"}
- **Lecture videosu:** [YouTube — Lecture 2: Deep Sequence Modeling](https://www.youtube.com/watch?v=d02VkQ9MP44&list=PLtBw6njQRU-rwp5__7C0oIVt26ZgjG9NI&index=2) (≈57 dk)
- **Edition:** 2026 • **Hoca:** Ava Soleimany
- **Kaynak:** [introtodeeplearning.com](https://introtodeeplearning.com)
- **Okuma süresi:** ≈34 dk
:::
## Bu Derste Ne Var? {#sec-bu-derste}
Ders 1'deki ağlar **sabit boyutlu, sırasız** veri işliyordu. Ama dünyadaki pek çok şey bir **dizidir**: metin (kelime dizisi), ses (dalga dizisi), video (kare dizisi), finans, biyoloji. Ava dersi tek bir sezgiyle açıyor: havada giden bir topun bir sonraki konumunu tahmin et. Geçmişini bilmeden tahmin bir **zardır**; ama geçmiş yörüngeyi verirsem problem kolaylaşır. Dizi modellemenin özü budur: **geçmişi bellekte tutup geleceği tahmin etmek.**
> *"sequence modeling... is a very very powerful and general paradigm that has become super relevant today especially with the onset of these very powerful language models."* — Ava, 0:16
**Dersin üç büyük fikri:**
1. **RNN (recurrent neural network)** — bir **iç durum** ($h_t$) tutup adım adım diziyi işleyen ağ.
2. **Dili sayıya çevirmek** — tokenization, embedding ve dizi modellemenin 4 tasarım kriteri.
3. **Attention ve transformer** — recurrence'ı tamamen atıp diziye **global** bakan, GPT'leri çalıştıran mekanizma.
{#fig-concept-map fig-align="center" width=85%}
::: {.callout-tip title="Builder Notu — ML Köprüleri"}
Bu ders, önceki üç kursun üstüne kurulu — hatta en zarif köprüler burada:
- **RNN recurrence ($h_t$, $h_{t-1}$'e bağlı)** → aynı fonksiyonun tekrar tekrar uygulanması = Calculus iterated map / sabit nokta (Ders 12) + Stat 110 Markov durumu (Ders 31).
- **BPTT** → Calculus zincir kuralının (Ders 4) **zaman boyunca** uygulanması.
- **Vanishing/exploding gradient** → aynı $\mathbf{W}$ matrisinin tekrar çarpılması; spektral yarıçap (18.06 özdeğer, Ders 21) + contraction ($\|f'\| < 1$, Calculus Ders 12) ile birebir.
- **Attention skoru $\mathbf{Q}\mathbf{K}^\top$** → 18.06 dot product / projeksiyon (Ders 15) + cosine benzerlik; attention ağırlığı = bir tür koşullu olasılık (Stat 110 Ders 4).
- **Softmax** → Calculus $e^x$ (Ders 5) + Stat 110 multinomial / yeniden-normalleştirme (Ders 20).
İleriye köprüler: tokenization/BPE, embedding tabloları, gradient clipping, KV cache, FlashAttention, transformer scaling, multi-head attention.
:::
## Dizi Verisi ve Neden Farklı? {#sec-dizi-verisi}
Ders 1'in **feed-forward** (ileri beslemeli) ağları sabit sayıda girdi alıyordu. Dizi verisi farklıdır: **zamana yayılmıştır** ve parçaları birbirine bağlıdır. Top örneği tam da bunu gösterir — tek bir an yetmez, geçmiş gerekir.
Dizi verisi her yerde: konuşma (ses dalgaları), metin (karakter/kelime dizisi), tıbbi sinyaller, finansal zaman serileri, biyolojik diziler (protein/DNA), hareket, video, hava durumu.
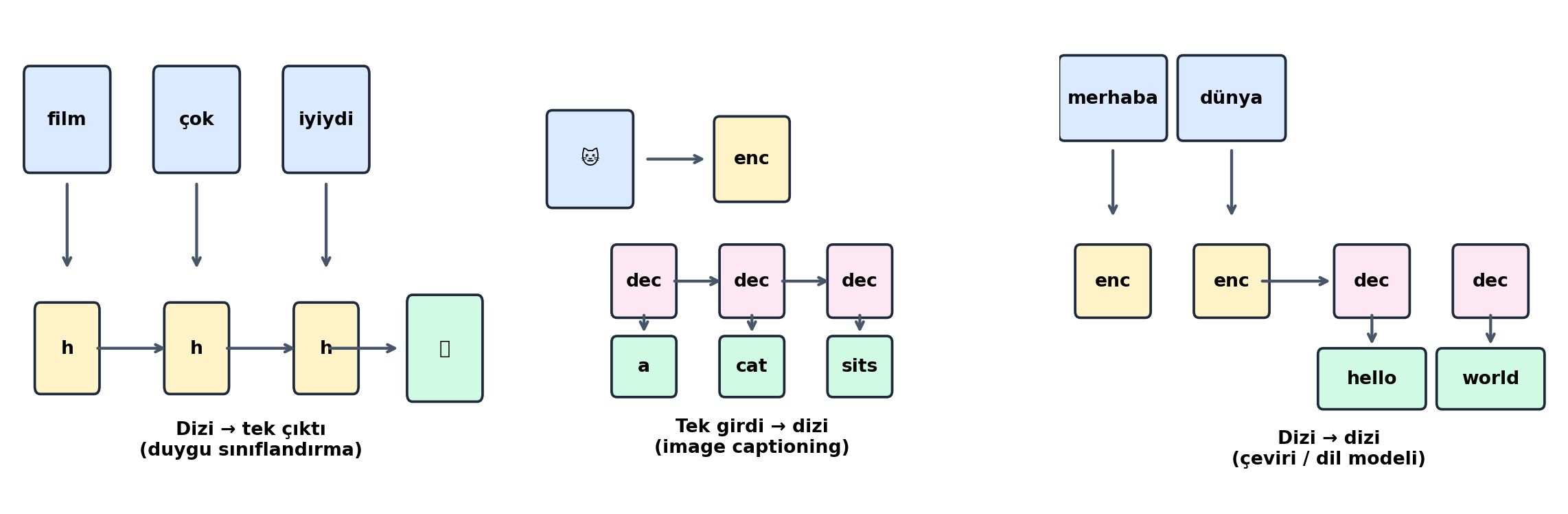
Dizi modellemede üç temel görev tipi var:
- **Dizi → tek çıktı:** Bir tweet'e duygu etiketi (sınıflandırma).
- **Tek girdi → dizi:** Bir görsele açıklama üretmek (image captioning).
- **Dizi → dizi:** Bir dili başka dile çevirmek; çoğu dil modeli görevi böyledir.
```{python}
#| label: fig-gorev-tipleri
#| fig-cap: "Dizi modellemenin üç görev tipi: dizi→tek (sınıflandırma), tek→dizi (üretim), dizi→dizi (çeviri)."
#| fig-width: 12
#| fig-height: 4
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as mp
fig, axes = plt.subplots(1, 3, figsize=(12, 4))
def draw_box(ax, x, y, txt, color, w=0.7, h=0.6):
rect = mp.FancyBboxPatch((x - w/2, y - h/2), w, h, boxstyle="round,pad=0.05",
facecolor=color, edgecolor='#1e293b', linewidth=1.4)
ax.add_patch(rect)
ax.text(x, y, txt, ha='center', va='center', fontsize=10, weight='bold')
def draw_arrow(ax, x0, y0, x1, y1):
ax.annotate('', xy=(x1, y1), xytext=(x0, y0),
arrowprops=dict(arrowstyle='->', color='#475569', lw=1.6))
# 1) Dizi -> tek
ax = axes[0]
for i, w in enumerate(['film', 'çok', 'iyiydi']):
draw_box(ax, 0.5 + i*1.2, 2.5, w, '#dbeafe')
draw_arrow(ax, 0.5 + i*1.2, 2.1, 0.5 + i*1.2, 1.5)
for i in range(3):
draw_box(ax, 0.5 + i*1.2, 1.0, 'h', '#fef3c7', w=0.5, h=0.5)
if i < 2:
draw_arrow(ax, 0.75 + i*1.2, 1.0, 1.45 + i*1.2, 1.0)
draw_arrow(ax, 2.9, 1.0, 3.6, 1.0)
draw_box(ax, 4.0, 1.0, '👍', '#d1fae5', w=0.6, h=0.6)
ax.text(2.2, 0.3, 'Dizi → tek çıktı\n(duygu sınıflandırma)', ha='center', fontsize=10, weight='bold')
ax.set_xlim(0, 4.6); ax.set_ylim(0, 3.2)
ax.axis('off')
# 2) Tek -> dizi
ax = axes[1]
draw_box(ax, 0.5, 2.0, '🐱', '#dbeafe', w=0.7, h=0.7)
draw_arrow(ax, 1.0, 2.0, 1.6, 2.0)
draw_box(ax, 2.0, 2.0, 'enc', '#fef3c7', w=0.6, h=0.6)
for i, w in enumerate(['a', 'cat', 'sits']):
draw_box(ax, 1.0 + i*1.0, 1.0, 'dec', '#fce7f3', w=0.5, h=0.5)
draw_box(ax, 1.0 + i*1.0, 0.3, w, '#d1fae5', w=0.5, h=0.4)
draw_arrow(ax, 1.0 + i*1.0, 0.75, 1.0 + i*1.0, 0.55)
if i < 2:
draw_arrow(ax, 1.25 + i*1.0, 1.0, 1.75 + i*1.0, 1.0)
ax.text(2.0, -0.4, 'Tek girdi → dizi\n(image captioning)', ha='center', fontsize=10, weight='bold')
ax.set_xlim(0, 4.6); ax.set_ylim(-0.8, 3.2)
ax.axis('off')
# 3) Dizi -> dizi
ax = axes[2]
for i, w in enumerate(['merhaba', 'dünya']):
draw_box(ax, 0.5 + i*1.1, 2.5, w, '#dbeafe', w=0.9)
draw_arrow(ax, 0.5 + i*1.1, 2.1, 0.5 + i*1.1, 1.5)
draw_box(ax, 0.5 + i*1.1, 1.0, 'enc', '#fef3c7', w=0.6, h=0.5)
draw_arrow(ax, 1.85, 1.0, 2.55, 1.0)
for i, w in enumerate(['hello', 'world']):
draw_box(ax, 2.9 + i*1.1, 1.0, 'dec', '#fce7f3', w=0.6, h=0.5)
draw_box(ax, 2.9 + i*1.1, 0.2, w, '#d1fae5', w=0.9, h=0.4)
draw_arrow(ax, 2.9 + i*1.1, 0.75, 2.9 + i*1.1, 0.45)
ax.text(2.5, -0.5, 'Dizi → dizi\n(çeviri / dil modeli)', ha='center', fontsize=10, weight='bold')
ax.set_xlim(0, 4.6); ax.set_ylim(-0.8, 3.2)
ax.axis('off')
plt.tight_layout()
plt.show()
```
::: {.callout-tip title="Builder Notu — Görev Tipini Önce Belirle"}
**Geriye:** "Dizi = zamana yayılmış, parçaları bağımlı veri" tanımı, Stat 110'daki **stokastik süreç** fikriyle (Ders 31, Markov zinciri) aynı zeminde: bir adımdaki durum öncekine bağlıdır. Fark şu: Markov'da geçiş olasılıkları sabittir; RNN bu geçiş fonksiyonunu **öğrenir**.
**İleriye:** Görev tipini doğru tanımlamak (seq→one, one→seq, seq→seq) bir builder için ilk karardır; mimari, loss ve veri hazırlığı bu seçime göre şekillenir. Bugün bu görevlerin çoğu tek bir transformer omurgasıyla (encoder/decoder) ele alınıyor.
:::
## RNN: İç Durum ve Recurrence {#sec-rnn}
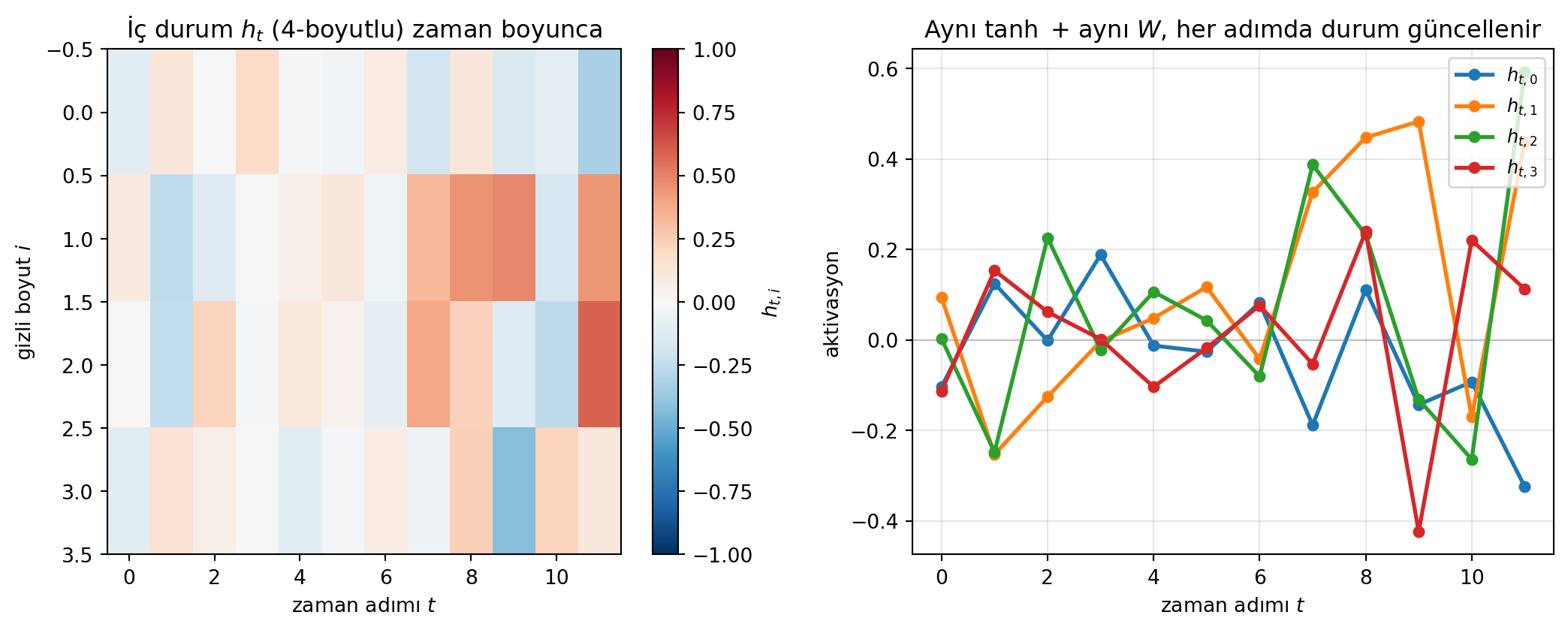
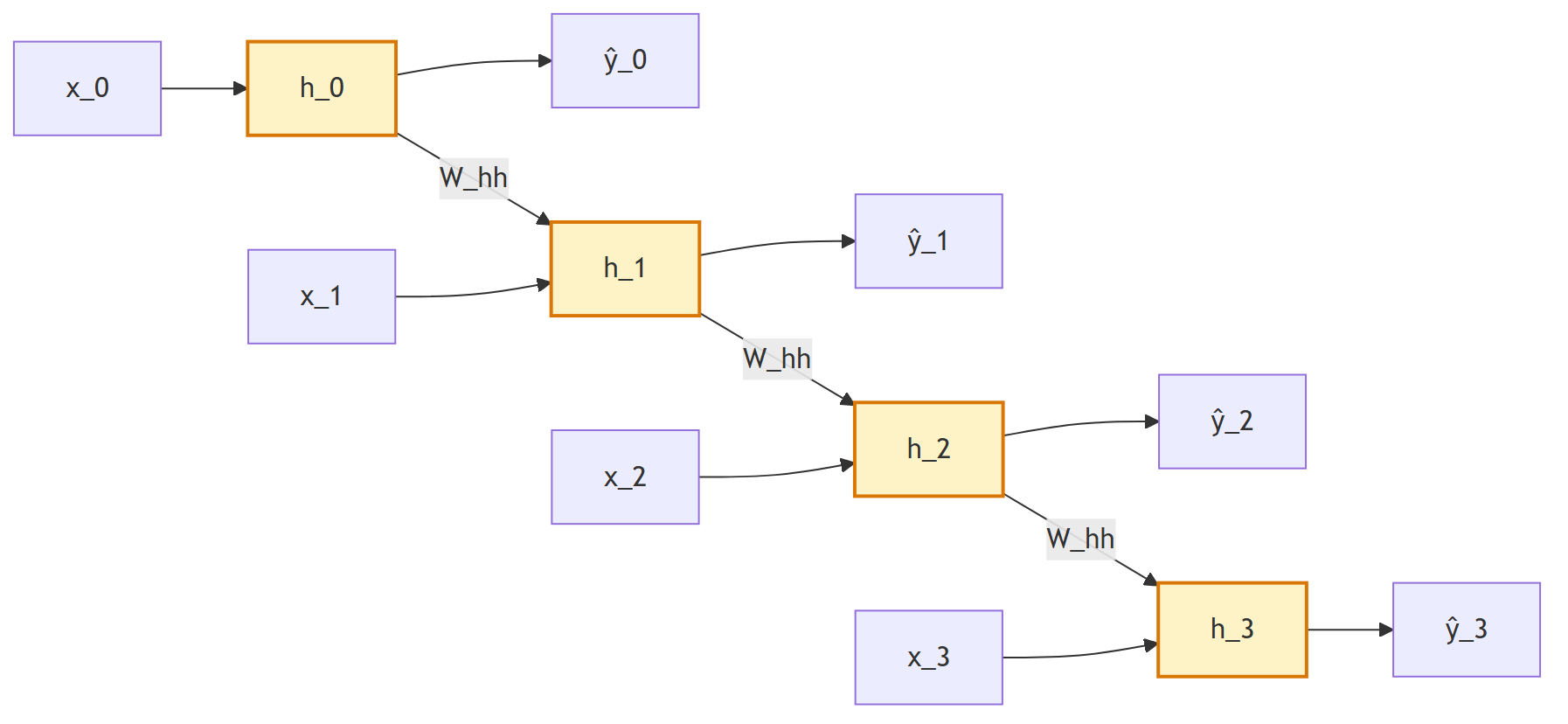
Ders 1'in perceptron'unu hatırla: girdileri ağırlıklarla çarp, topla, aktivasyondan geçir → $\hat{y}$. Diziyi bu ağa **zaman adımı zaman adımı** verirsek ($t=0$'da $x_0$ → ağ → $\hat{y}_0$; …), adımlar **birbirinden kopuk** kalır. Dizinin özü adımların ilişkili olmasıdır; bu yüzden ağa bir **bellek** kazandırmalıyız.
İç durum fikrini formelleştirelim. $h_t$, bir **recurrence relation** (yineleme bağıntısı) ile tanımlanır: her adımda durum, mevcut girdi ve önceki durumun bir fonksiyonu olarak güncellenir:
$$
h_t = f_W(x_t,\, h_{t-1})
$$
Burada $f_W$, bir ağırlık kümesi $W$ ile parametrelenmiş bir fonksiyondur. Kritik nokta: **aynı fonksiyon ve aynı ağırlıklar her zaman adımında kullanılır** (weight sharing). Tahmin de bu durumdan üretilir.
{#fig-rnn-unroll fig-align="center" width=85%}
> *"this core idea of maintaining an internal state h(t), updating it per individual time steps and using that to inform the predicted output is the core intuitive idea behind... recurrent neural networks or RNNs."* — Ava, 13:23
Recurrence relation'ı somutlaştıralım. İç durum güncellemesi: önceki durum ve mevcut girdi, **iki ayrı ağırlık matrisiyle** çarpılır, toplanır ve aktivasyondan (genelde $\tanh$) geçer:
$$
h_t = \tanh\!\left(W_{hh}\, h_{t-1} + W_{xh}\, x_t\right)
$$
Çıktı tahmini ise durumu bir başka ağırlık matrisiyle dönüştürür:
$$
\hat{y}_t = W_{hy}\, h_t
$$
Bu üç matris ($W_{hh}, W_{xh}, W_{hy}$) **öğrenilir** ve her adımda aynısı kullanılır. Her adımda bir tahmin ürettiğimiz için her adımda bir loss hesaplayıp toplam loss elde ederiz:
$$
L = \sum_{t} L_t
$$
Pratikte RNN hücresini sıfırdan yazmazsın; framework'lerde hazırdır:
```python
import torch.nn as nn
# girdi boyutu 10, gizli durum 20, 1 katman
rnn = nn.RNN(input_size=10, hidden_size=20, batch_first=True)
# x: (batch, zaman_adimi, ozellik), h0: baslangic durumu
y, hn = rnn(x, h0) # y: her adimdaki cikti, hn: son gizli durum
```
```{python}
#| label: fig-rnn-state
#| fig-cap: "Küçük bir RNN'in iç durumunun zamanla evrilmesi. Aynı W'ler kullanılır; durum vektörü dizinin geçmişini sıkıştırır."
#| fig-width: 11
#| fig-height: 4.5
rng = np.random.default_rng(0)
H, D, T = 4, 2, 12
Whh = rng.standard_normal((H, H)) * 0.4
Wxh = rng.standard_normal((H, D)) * 0.4
xs = rng.standard_normal((T, D)) * 0.5
hs = np.zeros((T, H))
h = np.zeros(H)
for t in range(T):
h = np.tanh(Whh @ h + Wxh @ xs[t])
hs[t] = h
fig, axes = plt.subplots(1, 2, figsize=(11, 4.5))
# Sol: durum heatmap
ax = axes[0]
im = ax.imshow(hs.T, aspect='auto', cmap='RdBu_r', vmin=-1, vmax=1)
ax.set_xlabel('zaman adımı $t$')
ax.set_ylabel('gizli boyut $i$')
ax.set_title('İç durum $h_t$ (4-boyutlu) zaman boyunca')
plt.colorbar(im, ax=ax, label='$h_{t,i}$')
# Sağ: her boyut bir eğri
ax = axes[1]
for i in range(H):
ax.plot(range(T), hs[:, i], '-o', linewidth=2, markersize=5, label=f'$h_{{t,{i}}}$')
ax.axhline(0, color='gray', linewidth=0.6, alpha=0.5)
ax.set_xlabel('zaman adımı $t$')
ax.set_ylabel('aktivasyon')
ax.set_title('Aynı $\\tanh$ + aynı $W$, her adımda durum güncellenir')
ax.legend(fontsize=9, loc='upper right')
ax.grid(alpha=0.3)
plt.tight_layout()
plt.show()
```
::: {.callout-tip title="Builder Notu — Weight Sharing ve Seri Darboğaz"}
**Geriye (Calculus + 18.06):** Recurrence relation, **aynı fonksiyonun tekrar tekrar uygulanmasıdır** — tam olarak Calculus Ders 12'deki iterated map / sabit nokta sezgisi ($x_{n+1} = f(x_n)$). Bu tekrarın kararlı mı yoksa patlayıcı mı olduğu, $f$'nin türevine bağlıdır ($\|f'\|<1$ çekici, $>1$ itici). "Aynı $W$'yi her adımda kullanmak" (weight sharing), 18.06'daki tek bir lineer dönüşümün tekrar uygulanmasıdır.
**İleriye:** Weight sharing parametre sayısını sabit tutar (dizi ne kadar uzasa da $W$ aynı) — bu verimlidir; ama adımların sırayla işlenmesi zorunluluğu, RNN'i **parallelize edilemez** kılar. Bu darboğaz, GPU çağında attention'ın neden kazandığının ana sebebidir.
:::
## Dili Sayıya Çevirmek: Embedding {#sec-embedding}
Dizi modellemenin amiral görevi **sonraki kelime tahmini**dir (next word prediction) — tüm dil modellerinin temeli. "this morning I took my cat for a ___" cümlesinde bir sonraki kelimeyi tahmin et. Ama ilk sorun: sinir ağları **sayılarla** çalışır, kelimelerle değil.
İlk adım **tokenization**: kelimeleri (veya parçalarını) tam sayı indekslerine eşle. Sonra indeksleri vektöre çevirmenin iki yolu:
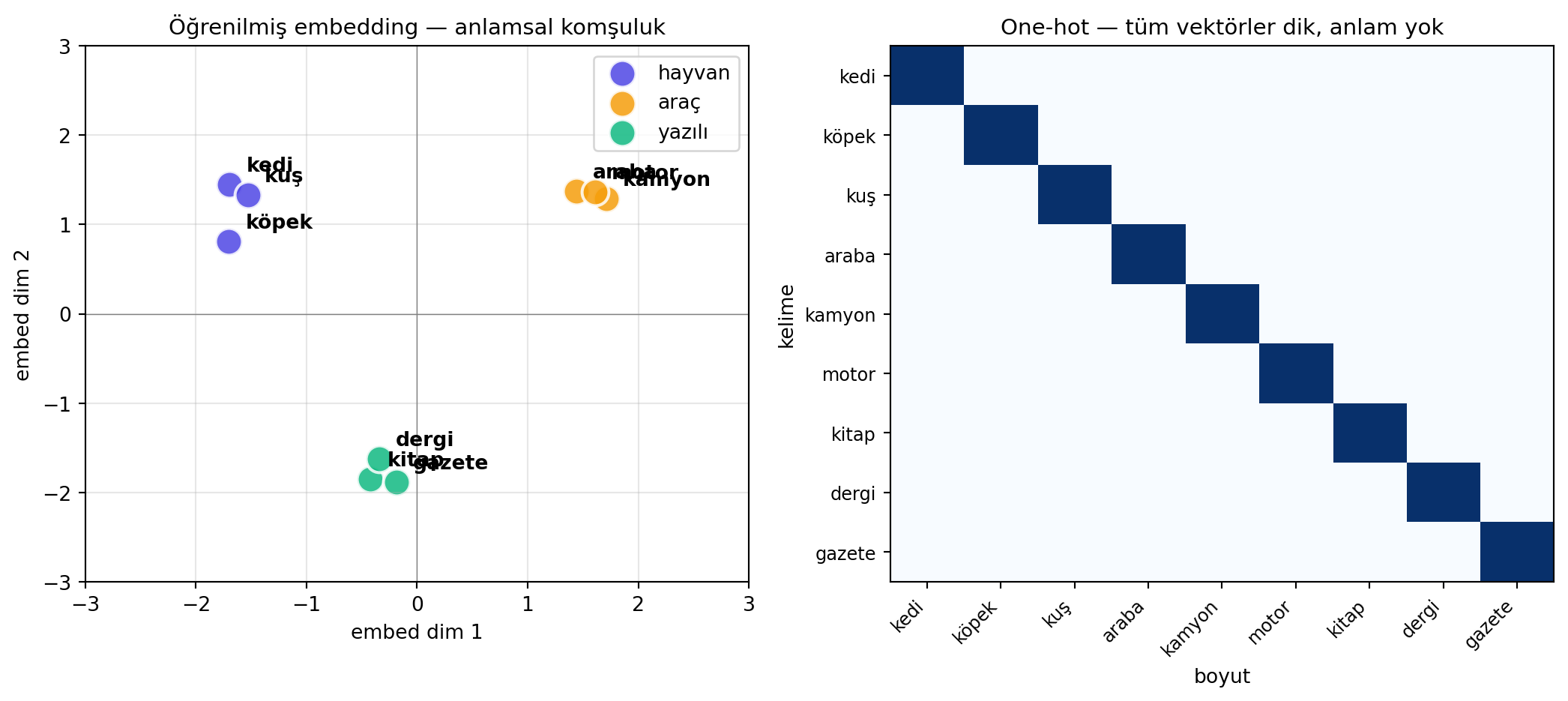
- **Naif: one-hot.** Her kelime, tek biti 1 (gerisi 0) sabit uzunlukta vektör. Sorun: hiçbir **anlam** taşımaz.
- **Akıllı: öğrenilmiş embedding.** Kelimeleri, **anlamsal** ilişkileri yakalayacak biçimde bir vektör uzayına gömeriz: "learning" ile "education" yakın, "learning" ile "tennis" uzak.
```{python}
#| label: fig-embedding-scatter
#| fig-cap: "Öğrenilmiş embedding vs one-hot. Solda anlamsal komşuluk (yakın anlamlar yakın vektörler); sağda one-hot — her vektör hepsine eşit uzaklıkta dik."
#| fig-width: 11
#| fig-height: 5
rng = np.random.default_rng(1)
words = ['kedi', 'köpek', 'kuş', 'araba', 'kamyon', 'motor', 'kitap', 'dergi', 'gazete']
groups = [0, 0, 0, 1, 1, 1, 2, 2, 2] # hayvan / araç / yazı
centers = np.array([[-1.8, 1.2], [1.6, 1.2], [-0.2, -1.8]])
emb = np.array([centers[g] + rng.standard_normal(2) * 0.3 for g in groups])
fig, axes = plt.subplots(1, 2, figsize=(11, 5))
ax = axes[0]
colors = ['#4f46e5', '#f59e0b', '#10b981']
labels = ['hayvan', 'araç', 'yazılı']
for g in range(3):
mask = np.array(groups) == g
ax.scatter(emb[mask, 0], emb[mask, 1], c=colors[g], s=180, alpha=0.85,
edgecolor='white', linewidth=1.5, label=labels[g])
for i, w in enumerate(words):
ax.annotate(w, emb[i] + 0.15, fontsize=10, weight='bold')
ax.set_xlim(-3, 3); ax.set_ylim(-3, 3)
ax.set_xlabel('embed dim 1'); ax.set_ylabel('embed dim 2')
ax.set_title('Öğrenilmiş embedding — anlamsal komşuluk', fontsize=11)
ax.legend(fontsize=10); ax.grid(alpha=0.3)
ax.axhline(0, color='gray', lw=0.5); ax.axvline(0, color='gray', lw=0.5)
ax = axes[1]
oh = np.eye(len(words))
ax.imshow(oh, cmap='Blues', aspect='auto')
ax.set_xticks(range(len(words)))
ax.set_xticklabels(words, rotation=45, ha='right', fontsize=9)
ax.set_yticks(range(len(words)))
ax.set_yticklabels(words, fontsize=9)
ax.set_title('One-hot — tüm vektörler dik, anlam yok', fontsize=11)
ax.set_xlabel('boyut'); ax.set_ylabel('kelime')
plt.tight_layout()
plt.show()
```
::: {.callout-tip title="Builder Notu — Embedding = Anlamı Öğrenen Baz"}
**Geriye (18.06):** Embedding, bir kelimeyi **vektör uzayına** yerleştirmektir; anlamsal yakınlık = vektörlerin dot product / mesafe yakınlığı (18.06 Ders 1, 15). One-hot vektörler ise 18.06'nın **standart baz vektörleridir** (birbirine dik, eşit uzaklıkta — bu yüzden anlam taşımaz). Embedding tam olarak bu dikliği kırıp anlamlı geometriyi öğrenir.
**İleriye:** Pratikte tokenization **BPE** (byte-pair encoding) gibi alt-kelime şemalarıyla yapılır; embedding'ler büyük bir **lookup table** olarak öğrenilir (`nn.Embedding`). Bir LLM'in girdi tarafının tamamı budur; vocab boyutu × embedding boyutu, parametre bütçesinin önemli kısmıdır.
:::
## Dizi Modellemenin 4 Tasarım Kriteri {#sec-4-kriter}
Sonraki kelime tahmini üzerinden, herhangi bir dizi mimarisinin karşılaması gereken dört kriteri çıkarabiliriz:
1. **Sayısal gösterim (+ anlam).** Veriyi sayıya çevir, anlamı yakalayarak — yani embedding.
2. **Değişken uzunluk.** Kısa, orta, uzun cümle — hepsini işleyebilmeli. Feed-forward ağlar burada **çöker**; RNN doğal olarak başa çıkar.
3. **Uzun-menzilli bağımlılıklar.** Cümlenin başındaki bir bilgi, çok sonraki bir kelimeyi belirleyebilir.
4. **Sıra önemli.** Kelime sırası anlamı tümden değiştirir.
> *"The food was good, not bad at all, means great... But if we flip the order of the words... we've completely flipped the meaning. The exact words are the same. Order matters."* — Ava, 29:51
RNN'ler bu kriterlere kısmen cevap verir: değişken uzunluğu iç durumla, sırayı adım adım işlemeyle, bağımlılıkları weight sharing'le ele alır.
::: {.callout-tip title="Builder Notu — Sıra Bilgisi Bir Bilgidir"}
**Geriye:** Kriter 1 (embedding) doğrudan 18.06 vektör uzayı; kriter 4 (sıra) ise permütasyonun anlamı değiştirmesi — bunu attention'da **positional embedding** ile geri kazanacağız.
**İleriye:** Bu dört kriter, bir builder için yeni bir dizi mimarisini değerlendirme **checklist'idir**: "Değişken uzunluğu nasıl ele alıyor? Uzun bağımlılığı? Sırayı? Sayısal gösterimi?"
:::
## BPTT ve Vanishing Gradient {#sec-bptt}
Ders 1'de feed-forward ağı backprop ile eğitmiştik. RNN'de bir ek boyut var: **zaman**. Her adımda bir loss var; toplam loss'u minimize etmek için gradient'i hem ağ içinde hem de **zaman adımları boyunca** geriye yaymalıyız. Bu algoritmanın adı **backpropagation through time (BPTT)**.
> *"this is the formulation of this algorithm for training RNNs called back propagation through time because error is flowing back through time from where we are currently in the sequence back to the beginning."* — Ava, 32:30
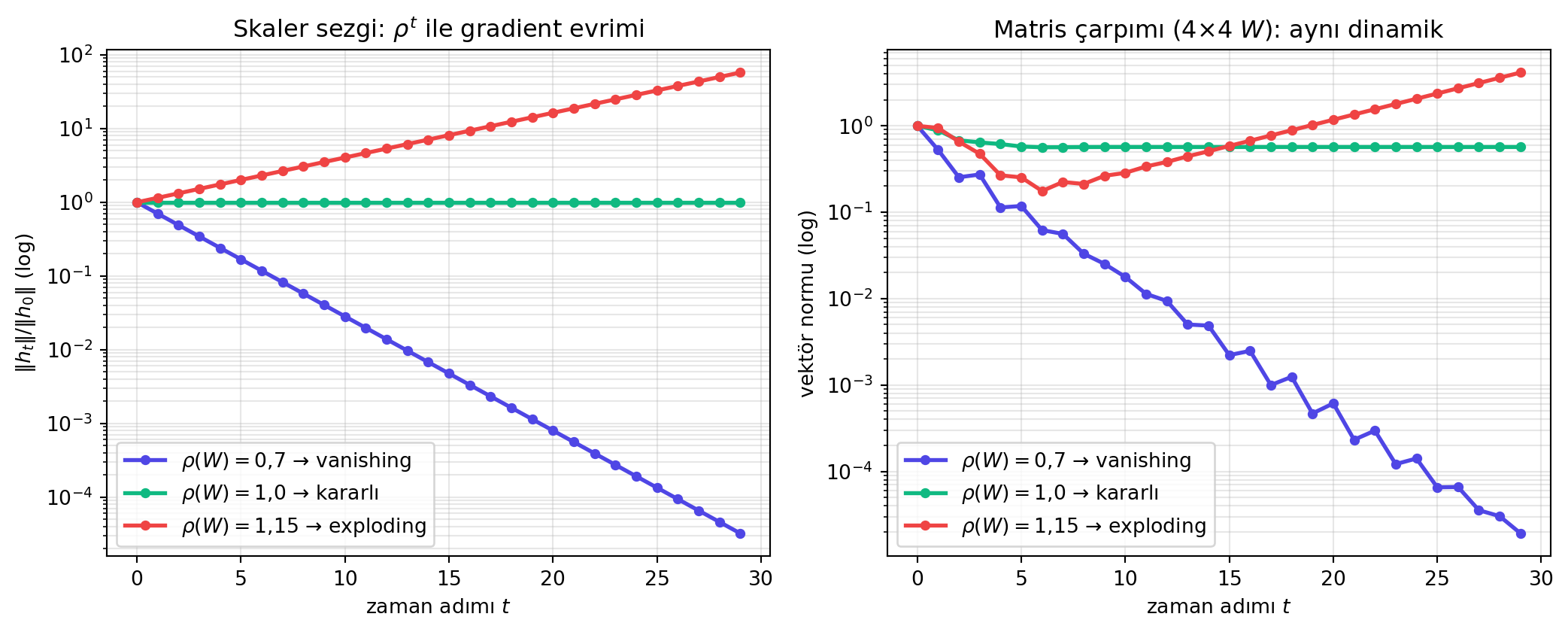
BPTT'nin teknik derdi: gradient'i $t=0$'a kadar geri taşımak, **aynı $W_{hh}$ matrisinin tekrar tekrar çarpılmasını** gerektirir:
$$
\frac{\partial h_t}{\partial h_0} = \prod_{k=1}^{t} \frac{\partial h_k}{\partial h_{k-1}}
$$
Bu tekrarlı çarpımın sonucu $W_{hh}$'nin "büyüklüğüne" bağlıdır:
- Değerler **büyükse** → çarpım hızla patlar: **exploding gradient**. Çözüm: **gradient clipping**.
- Değerler **küçükse** → çarpım sıfıra büzülür: **vanishing gradient**. Sinyal kaybolur.
```{python}
#| label: fig-spektral
#| fig-cap: "Aynı matrisin tekrar çarpılması: spektral yarıçap > 1 patlar, < 1 söner. Vanishing/exploding gradient'in özdeğer kökeni."
#| fig-width: 11
#| fig-height: 4.5
T = 30
configs = [
(0.7, '$\\rho(W) = 0{,}7$ → vanishing', '#4f46e5'),
(1.0, '$\\rho(W) = 1{,}0$ → kararlı', '#10b981'),
(1.15, '$\\rho(W) = 1{,}15$ → exploding', '#ef4444'),
]
fig, axes = plt.subplots(1, 2, figsize=(11, 4.5))
ax = axes[0]
ts = np.arange(T)
for rho, label, c in configs:
norms = rho ** ts
ax.plot(ts, norms, '-o', color=c, linewidth=2, markersize=4, label=label)
ax.set_yscale('log')
ax.set_xlabel('zaman adımı $t$')
ax.set_ylabel('$\\|h_t\\| / \\|h_0\\|$ (log)')
ax.set_title('Skaler sezgi: $\\rho^t$ ile gradient evrimi')
ax.legend(fontsize=10); ax.grid(alpha=0.3, which='both')
ax = axes[1]
rng = np.random.default_rng(7)
for rho, label, c in configs:
W = rng.standard_normal((4, 4))
eigs = np.abs(np.linalg.eigvals(W))
W = W * (rho / eigs.max())
v = rng.standard_normal(4); v /= np.linalg.norm(v)
norms = [1.0]
for _ in range(T - 1):
v = W @ v
norms.append(np.linalg.norm(v))
ax.plot(ts, norms, '-o', color=c, linewidth=2, markersize=4, label=label)
ax.set_yscale('log')
ax.set_xlabel('zaman adımı $t$')
ax.set_ylabel('vektör normu (log)')
ax.set_title('Matris çarpımı (4×4 $W$): aynı dinamik')
ax.legend(fontsize=10); ax.grid(alpha=0.3, which='both')
plt.tight_layout()
plt.show()
```
> *"if the values of this weight matrix are large, things can blow up very quickly, a problem that we call exploding gradients... the inverse problem... is known as the vanishing gradient problem."* — Ava, 33:33
Vanishing gradient'in gerçek bedeli: model **uzun-menzilli bağımlılıkları** yakalayamaz. Bunu hafifletmek için Schmidhuber ekibinin **LSTM** mimarisi (kapılarla bilgi akışını düzenler) tasarlandı.
::: {.callout-tip title="Builder Notu — Özdeğer Olgusu"}
**Geriye (18.06 + Calculus):** Aynı matrisin tekrar çarpılması, o matrisin **özdeğerlerine** bakar (18.06 Ders 21): en büyük özdeğerin mutlak değeri (spektral yarıçap $\rho$) 1'den büyükse çarpım patlar, küçükse söner — tıpkı Calculus Ders 12'deki sabit nokta kararlılığı. Yani vanishing/exploding gradient, doğrudan bir **özdeğer** olgusudur.
**İleriye:** Gradient clipping bugün de standart bir eğitim hilesidir. LSTM/GRU kapıları, residual bağlantılar ve normalization, hepsi "sinyali derinlik/zaman boyunca koru" probleminin farklı çözümleridir.
:::
## RNN'in Limitleri ve Attention'a Geçiş {#sec-limitler}
RNN güçlü, ama üç temel sınırı var:
- **Encoding bottleneck:** Tüm geçmişi tek bir $h_t$ vektörüne sıkıştırırız — dizi uzadıkça bu darboğaz olur.
- **Parallelize edilemez:** Veriyi adım adım işlemek zorunludur; GPU'nun paralel gücünü kullanamaz.
- **Bellek sorunu:** Vanishing gradient yüzünden uzun bağımlılıklar kaybolur.
İdealde diziye **global** bakmak, **paralel** işlemek ve **uzun bellek** istiyoruz. Peki recurrence'ı tamamen **atsak**? Naif fikir: tüm zaman noktalarını tek bir vektörde birleştir, dense ağa ver. Ama bu (a) dizi uzadıkça ölçeklenmez, (b) **sıra bilgisini yok eder**, (c) hangi parçanın önemli olduğunu seçemez. Eksik olan tam da bu: ağın, dizinin **önemli parçalarını kendi başına bulması**.
> *"can we devise mathematically a way for the network to learn how to pick up and identify those dependencies locally and also globally that are going to be important... this is the notion of attention."* — Ava, 42:21
::: {.callout-tip title="Builder Notu — Paralelleştirilebilirlik = Devrim"}
**Geriye:** "Hepsini birleştir" yaklaşımının sıra bilgisini yok etmesi, 4. kriteri ihlal eder — bu yüzden attention'da sırayı **positional embedding** ile geri katmamız gerekecek.
**İleriye:** "Parallelize edilebilirlik" bir akademik ayrıntı değil, transformer devriminin **motorudur**: RNN'in sıralı zinciri GPU'da boştur, attention ise tüm adımları aynı anda işler → yüksek throughput. Bedeli: attention'ın dizi uzunluğuyla $O(n^2)$ maliyeti (FlashAttention'ın doğduğu yer).
:::
## Self-Attention ve Transformer {#sec-attention}
Attention'ın sezgisi: bir girdinin **hangi parçalarına dikkat edileceğini** öğrenmek. Bunu bir **arama** problemi gibi düşün (YouTube benzetmesi): elinde bir **query** (sorgu: "deep learning"), her videonun bir **key**'i (başlık) ve bir **value**'su (videonun kendisi) var. Query ile key'lerin benzerliğini hesaplar, en ilgili value'yu çekersin.
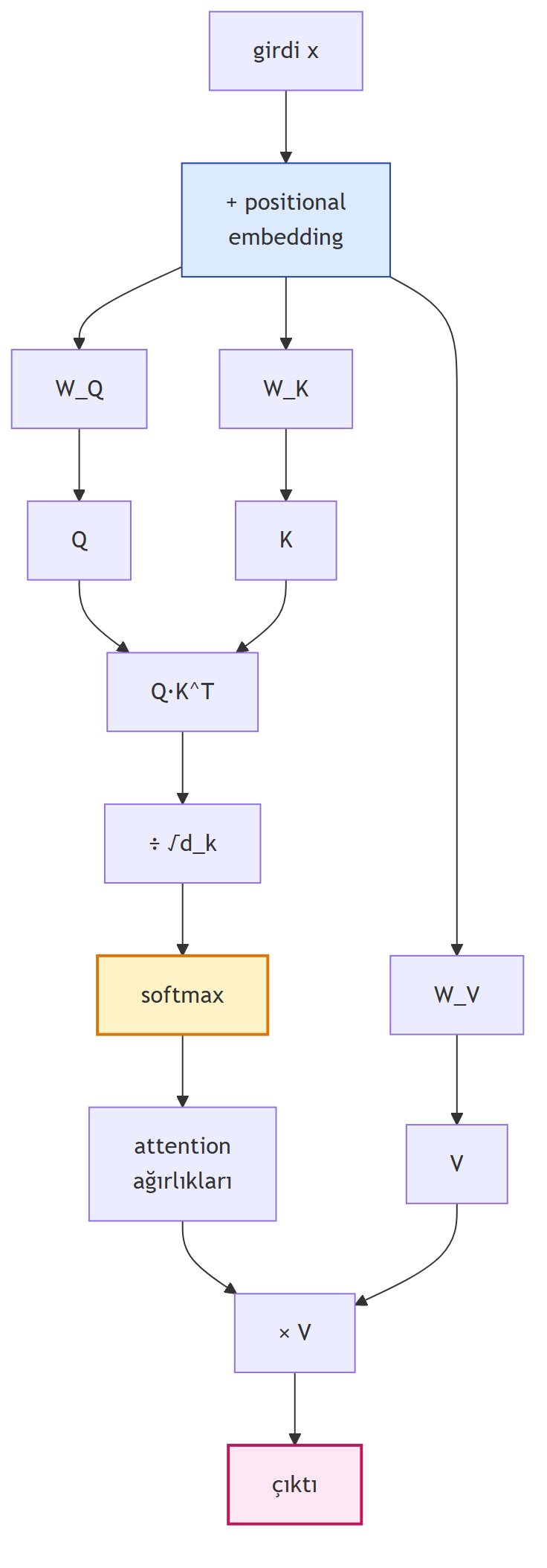
Self-attention bunu bir dizinin **kendi içinde** yapar. Adımlar:
1. **Positional embedding:** Recurrence'ı attığımız için sırayı kaybetmemek adına, girdiye konum bilgisini katan bir gömme eklenir.
2. **Q, K, V üret:** Aynı girdi embedding'i, **üç ayrı öğrenilmiş katmandan** geçirilerek query (Q), key (K) ve value (V) matrislerine dönüştürülür.
3. **Benzerlik skoru:** Q ile K'nın hizalanmasını **dot product** ile ölç; ölçek faktörüyle böl. Bu, vektörlerin ne kadar aynı yöne baktığını veren **cosine similarity**'dir.
4. **Softmax:** Skorları 0–1 arasına sıkıştırıp **attention ağırlıklarına** çevir.
5. **Değeri çek:** Bu ağırlıkları V ile çarp → çıktı.
Hepsini tek bir formülde toplarsak:
$$
\text{Attention}(Q,\, K,\, V) = \text{softmax}\!\left(\frac{Q K^\top}{\sqrt{d_k}}\right) V
$$
Softmax, skorları bir olasılık dağılımına çevirir:
$$
\text{softmax}(z)_i = \frac{e^{z_i}}{\sum_j e^{z_j}}
$$
{#fig-transformer-block fig-align="center" width=85%}
```{python}
#| label: fig-attention-heatmap
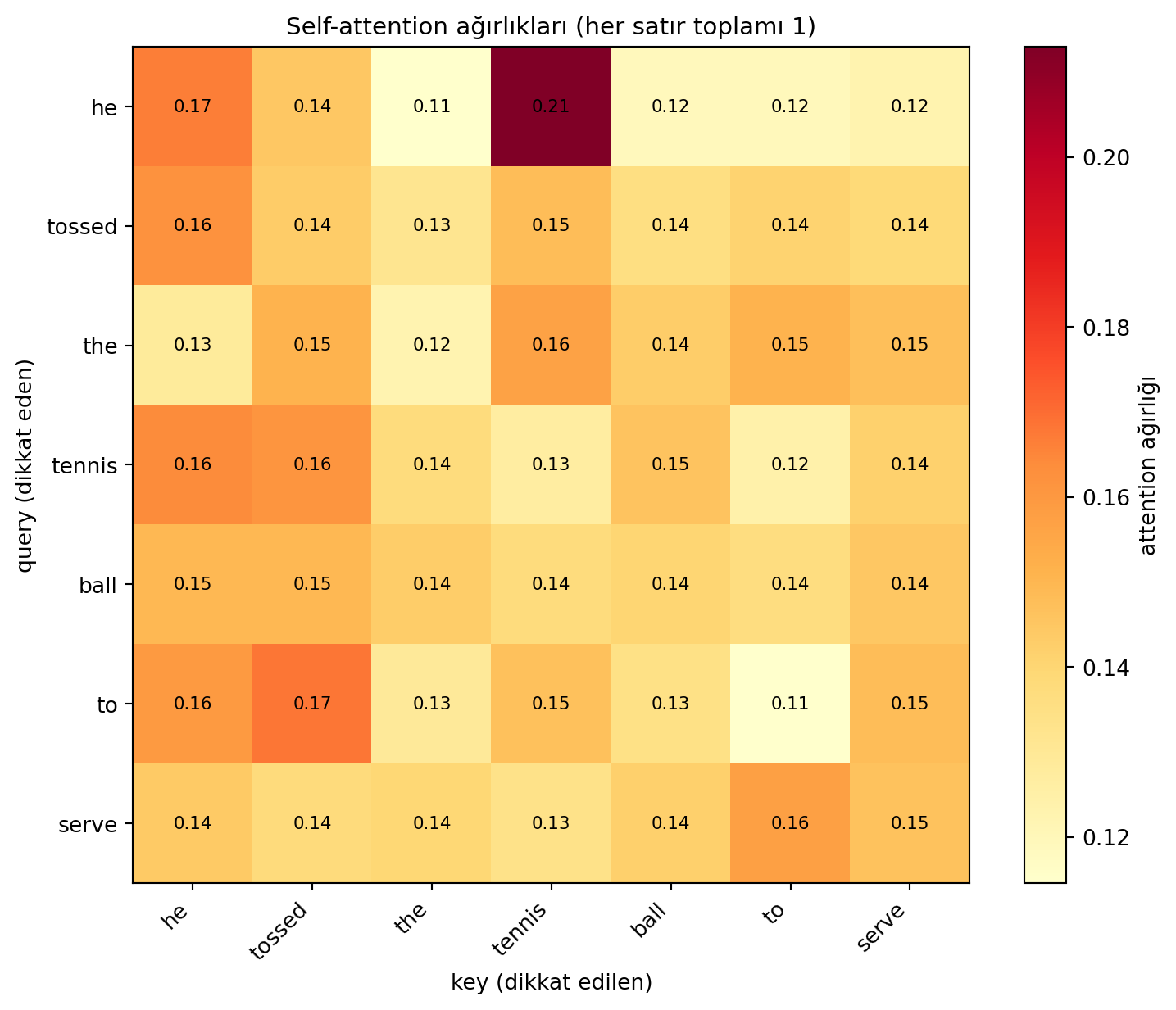
#| fig-cap: "Self-attention ağırlık matrisi. 'ball' ile 'tossed' ve 'serve' yüksek skor alır — ilişkili kelimeler dot product ile öne çıkar."
#| fig-width: 8
#| fig-height: 6.5
tokens = ['he', 'tossed', 'the', 'tennis', 'ball', 'to', 'serve']
n = len(tokens)
rng = np.random.default_rng(3)
d = 16
emb = rng.standard_normal((n, d)) * 0.3
emb[4] = emb[1] * 0.5 + emb[5] * 0.4 + rng.standard_normal(d) * 0.1
emb[6] = emb[4] * 0.6 + rng.standard_normal(d) * 0.15
WQ = rng.standard_normal((d, d)) * 0.3
WK = rng.standard_normal((d, d)) * 0.3
Q = emb @ WQ
K = emb @ WK
def softmax(z, axis=-1):
e = np.exp(z - z.max(axis=axis, keepdims=True))
return e / e.sum(axis=axis, keepdims=True)
scores = Q @ K.T / np.sqrt(d)
A = softmax(scores)
fig, ax = plt.subplots(figsize=(8, 6.5))
im = ax.imshow(A, cmap='YlOrRd', aspect='equal')
ax.set_xticks(range(n)); ax.set_xticklabels(tokens, rotation=45, ha='right')
ax.set_yticks(range(n)); ax.set_yticklabels(tokens)
ax.set_xlabel('key (dikkat edilen)')
ax.set_ylabel('query (dikkat eden)')
ax.set_title('Self-attention ağırlıkları (her satır toplamı 1)', fontsize=11)
for i in range(n):
for j in range(n):
ax.text(j, i, f'{A[i,j]:.2f}', ha='center', va='center', fontsize=8,
color='white' if A[i,j] > 0.25 else 'black')
plt.colorbar(im, ax=ax, label='attention ağırlığı')
plt.tight_layout()
plt.show()
```
> *"we take the dot-product between the query and the key and scale it... this is also known as the cosine similarity."* — Ava, 50:19
Bu işlem bir **attention head**'dir; birden çok head'i istifleyerek (multi-head attention) farklı ilişki örüntüleri aynı anda öğrenilir. Attention, **transformer** mimarisinin temel yapı taşıdır — GPT, BERT gibi modellerdeki "T" tam olarak transformer'dır. Üstelik son derece paralelleştirilebilir.
> *"what's really powerful is that it's very very parallelizable."* — Ava, 54:02
::: {.callout-tip title="Builder Notu — Dot Product Çekirdek, $O(n^2)$ Bedel"}
**Geriye (18.06 + Stat 110 + Calculus):** Attention'ın kalbi **dot product**'tır ($\mathbf{Q}\mathbf{K}^\top$) — iki vektörün hizasını ölçen 18.06 işlemi (Ders 1, 15); $\sqrt{d_k}$ ile bölmek onu cosine benzerliğe yaklaştırır. Softmax sonrası **attention ağırlıkları**, bir **koşullu olasılık dağılımıdır** (Stat 110 Ders 4); softmax skorları toplamı 1 olan bir dağılıma **yeniden-normalleştirir** (Ders 20) ve içindeki $e^x$ Calculus Ders 5'tir.
**İleriye:** $\mathbf{Q}\mathbf{K}^\top$ matrisi dizi uzunluğunda **$O(n^2)$** bellek/hesap ister — uzun-bağlamın temel zorluğu; **FlashAttention** bunu bellek-verimli hesaplar. Çıkarımda geçmiş K ve V'ler **KV cache**'te saklanıp tekrar hesaplanmaz (otoregresif üretimin hız sırrı).
:::
## Bu Dersin Özeti {#sec-ozet}
1. **Dizi verisi** zamana yayılmıştır ve parçaları bağımlıdır; görev tipleri: dizi→tek, tek→dizi, dizi→dizi.
2. **RNN** bir iç durum ($h_t$) tutup her adımda günceller; geçmişi bellek olarak taşır.
3. **Recurrence:** $h_t = \tanh(W_{hh} h_{t-1} + W_{xh} x_t)$, $\hat{y}_t = W_{hy} h_t$; üç matris öğrenilir ve her adımda paylaşılır.
4. Dili **tokenization + embedding** ile sayısal, anlamı yakalayan vektörlere çeviririz.
5. Dizi modellemenin **4 kriteri**: sayısal gösterim, değişken uzunluk, uzun-menzilli bağımlılık, sıra.
6. RNN'ler **BPTT** (backpropagation through time) ile eğitilir — zincir kuralı zaman boyunca.
7. BPTT'de aynı $W_{hh}$ tekrar çarpılır → **vanishing/exploding gradient** (özdeğer olgusu); LSTM kapıları bunu hafifletir.
8. RNN'in limitleri (encoding bottleneck, paralel değil, kısa bellek) **attention**'a yol açtı.
9. **Self-attention:** Q, K, V üret; benzerliği $\mathbf{Q}\mathbf{K}^\top$ ile ölç, softmax ile ağırlığa çevir, V ile çarp. Bu, **transformer**'ın temel yapı taşıdır ve paraleldir.
::: {.callout-important title="Tek bir cümle"}
Dizi modelleme, geçmişi tek bir gizli durumda biriktiren RNN'den, diziye global bakıp önemli ilişkileri $\mathbf{Q}\mathbf{K}^\top$ dot product + softmax ile bulan attention'a uzanan bir yolculuktur — ve bu son adım, bugünün tüm büyük dil modellerinin omurgasıdır.
:::
## Kontrol Soruları {#sec-sorular}
::: {.callout-note collapse="true" title="Soru 1: Bir RNN değişken uzunlukta cümleleri (2 kelime de, 20 kelime de) işleyebilir, ama Ders 1'in feed-forward ağı işleyemez. Neden?"}
**Cevap:** Feed-forward ağ **sabit sayıda girdi** bekler — giriş katmanının boyutu mimaride sabittir; 2 kelimelik ve 20 kelimelik cümleyi aynı ağa veremezsin. RNN ise diziyi **adım adım** işler: aynı hücreyi (aynı $W$'leri) her kelime için tekrar uygular ve bilgiyi iç durum $h_t$'de taşır. Dizi ne kadar uzun olursa o kadar çok adım atılır, ama parametre sayısı değişmez. "Weight sharing + adım adım işleme", değişken uzunluğu doğal olarak çözer.
:::
::: {.callout-note collapse="true" title="Soru 2: BPTT'de aynı $W_{hh}$ matrisi neden vanishing veya exploding gradient'e yol açar?"}
**Cevap:** Gradient'i $t$ adımı geriye taşımak, kabaca $W_{hh}$'ye bağlı türevlerin **$t$ kez çarpılması** demektir. Basit bir skaler sezgisi: çarpan 0,5 ise 10 adım sonra $0{,}5^{10} \approx 0{,}001$ (söner, **vanishing**); çarpan 1,5 ise $1{,}5^{10} \approx 57$ (patlar, **exploding**). Matris hâlinde bu çarpanın rolünü **spektral yarıçap** $\rho$ oynar: $\rho < 1$ ise gradient söner, $\rho > 1$ ise patlar. Çözüm: exploding için gradient clipping, vanishing için LSTM/GRU kapıları.
:::
::: {.callout-note collapse="true" title="Soru 3: Self-attention'da Q, K, V ne işe yarar? Benzerlik neden dot product ile ölçülür ve softmax ne yapar?"}
**Cevap:** Bir **arama** gibi düşün: **Q** (query) ne aradığını, **K** (key) her öğenin etiketini, **V** (value) çekilecek asıl içeriği temsil eder; üçü de aynı girdiden üç ayrı öğrenilmiş katmanla üretilir. Benzerlik **dot product** ($\mathbf{Q}\mathbf{K}^\top$) ile ölçülür çünkü dot product iki vektörün ne kadar **aynı yöne baktığını** verir (hizalanma = ilişki; 18.06 projeksiyon). $\sqrt{d_k}$ ile ölçeklenir. **Softmax** bu ham skorları toplamı 1 olan, 0–1 arası **attention ağırlıklarına** çevirir — her key'e ne kadar dikkat edileceğinin bir dağılımı. Son olarak bu ağırlıklarla V çarpılır.
:::
::: {.callout-note collapse="true" title="Soru 4: (Builder) Attention neden paralelleştirilebilirken RNN değildir? Production'da somut sonucu nedir?"}
**Cevap:** RNN, $h_t$'yi hesaplamak için **$h_{t-1}$'e ihtiyaç duyar** — adımlar zorunlu olarak sıralıdır. Attention ise tüm $\mathbf{Q}\mathbf{K}^\top$ skorlarını **aynı anda** (tek matris çarpımıyla) hesaplar. GPU'lar büyük matris çarpımlarında muazzam paraleldir; dolayısıyla attention donanımı doyurur, RNN ise boş bırakır. **Production sonucu:** transformer'lar çok daha yüksek **throughput** ile eğitilir; çıkarımda geçmiş K/V değerleri **KV cache**'te saklanır. Bedeli, attention'ın dizi uzunluğunda $O(n^2)$ maliyetidir.
:::
::: {.callout-note collapse="true" title="Soru 5: Embedding ile one-hot arasındaki fark nedir? Hangisi anlamlı geometriyi öğrenir?"}
**Cevap:** **One-hot** vektörler birbirine **dik** (orthogonal) standart baz vektörleridir; herhangi iki kelime arasındaki cosine benzerlik tam **0**'dır. "kedi" ile "köpek", "kedi" ile "araba" kadar uzaktır — hiçbir anlamsal yapı yok. **Embedding** ise öğrenilebilir bir lookup table'dır; eğitim sırasında sık birlikte geçen kelimeler birbirine yakın yerleştirilir (Stat 110 koşullu olasılık + 18.06 vektör geometrisi). Sonuçta "kedi" ile "köpek" yakın, "kedi" ile "araba" uzak çıkar. Anlamlı geometri, dik bazı kırarak doğar.
:::
## Egzersizler {#sec-egzersizler}
**Egzersiz 1 (RNN hücresini elle kur).** NumPy ile bir RNN hücresinin ileri geçişini yaz: $h_t = \tanh(W_{hh} h_{t-1} + W_{xh} x_t)$. 4 adımlık rastgele girdi ver, her adımdaki $h_t$'yi yazdır.
```python
import numpy as np
def rnn_step(x_t, h_prev, Wxh, Whh, b):
return np.tanh(Whh @ h_prev + Wxh @ x_t + b) # durum guncelleme
np.random.seed(0)
H, D = 3, 2
Whh = np.random.randn(H, H) * 0.5
Wxh = np.random.randn(H, D) * 0.5
b = np.zeros(H)
h = np.zeros(H)
for t, x in enumerate(np.random.randn(4, D)):
h = rnn_step(x, h, Wxh, Whh, b)
print(f"t={t} h={np.round(h, 3)}")
```
**Egzersiz 2 (Embedding ve cosine similarity).** PyTorch `nn.Embedding` ile küçük bir embedding tablosu kur. İki kelimenin embedding vektörleri arasındaki **cosine similarity**'yi hesapla. Sonra aynı kelimeleri one-hot ile temsil edip cosine similarity'lerine bak (0 çıkar). Anlamı 18.06'nın dik baz vektörleri ile açıkla.
**Egzersiz 3 (Spektral yarıçap ve gradient).** $2 \times 2$ bir $W$ matrisi seç. (a) Özdeğerlerini hesapla (`np.linalg.eigvals`). (b) Bir vektörü $W$ ile 20 kez çarp, normunu kaydet. $\rho > 1$ iken patladığını, $< 1$ iken söndüğünü göster ve vanishing/exploding gradient ile ilişkilendir.
**Egzersiz 4 (Self-attention'ı PyTorch ile).** Küçük bir dizi için scaled dot-product attention'ı PyTorch ile yaz. Attention matrisini yazdır; her satırının toplamının 1 olduğunu doğrula.
```python
import torch
import torch.nn.functional as F
torch.manual_seed(0)
n, d = 5, 8
Q = torch.randn(n, d)
K = torch.randn(n, d)
V = torch.randn(n, d)
scores = Q @ K.T / d ** 0.5 # Q . K^T / sqrt(d_k)
A = F.softmax(scores, dim=-1) # attention agirligi (satir toplami 1)
out = A @ V
print("satir toplami =", A.sum(dim=-1)) # ~1.0
print("cikti sekli =", out.shape)
```
**Egzersiz 5 (Sonraki dersin habercisi).** Ders 3 görü (vision) üzerine. Bir görüntü, piksellerden oluşan 2B bir ızgaradır. (a) Görüntüyü düz vektöre açıp (flatten) dense ağa vermenin neden israf olduğunu açıkla. (b) Aynı küçük filtreyi görüntünün her yamasında **paylaşma** (weight sharing) fikrini taslakla — bu, Ders 3'teki **convolution**'ın çekirdeğidir ve RNN'deki weight sharing ile aynı ruhtadır.
## Sonraki Ders İçin Hazırlık {#sec-sonraki}
**Ders 3: Derin Bilgisayarlı Görü (Deep Computer Vision)** — Alexander Amini
Bu derste diziyi işledik; sırada **görüntüler** var. Bir görüntü, uzamsal yapısı olan 2B bir piksel ızgarasıdır. Ders 3, görüntüleri işleyen **convolutional neural network**'leri (CNN) anlatacak: aynı filtreyi görüntü boyunca kaydırarak (weight sharing) kenar, köşe, nesne gibi hiyerarşik özellikleri öğrenmek.
**Ana konular:**
- Convolution: yerel yamalar üzerinde paylaşılan filtreler.
- Özellik hiyerarşisi (kenar → şekil → nesne).
- Pooling, CNN mimarileri ve uygulamalar.
::: {.callout-warning title="Ders 3 öncesi yapılacak"}
- Egzersizleri çöz — özellikle 4 (self-attention) ve 5 (görüntü/convolution sezgisi).
- Attention formülünü kendi cümlenle anlat: "$\mathbf{Q}\mathbf{K}^\top$ ile benzerlik, softmax ile ağırlık, V ile içerik."
- Ana cümleyi tekrar oku: *"RNN geçmişi tek bir duruma sıkıştırır; attention diziye global bakar."*
:::
## Anahtar Kavramlar (Cheat Sheet) {#sec-cheat-sheet}
| Kavram | Tanım | Ava'da |
|--------|-------|--------|
| **Dizi verisi** | Zamana yayılmış, parçaları bağımlı veri | 2m33 |
| **RNN** | İç durum tutup diziyi adım adım işleyen ağ | 13m23 |
| **Gizli durum ($h_t$)** | Geçmişi taşıyan, her adımda güncellenen bellek vektörü | 11m01 |
| **Recurrence relation** | $h_t = \tanh(W_{hh} h_{t-1} + W_{xh} x_t)$; aynı $W$ her adımda | 14m00 |
| **Weight sharing** | Aynı ağırlıkların her zaman adımında kullanılması | 15m00 |
| **Tokenization** | Kelimeleri sayısal indekslere eşleme | 24m08 |
| **Embedding** | Kelimeleri anlamı yakalayan vektör uzayına gömme | 25m42 |
| **One-hot** | Tek bit 1, gerisi 0; anlam taşımayan naif gösterim | 26m31 |
| **BPTT** | Backpropagation through time; gradient zaman boyunca geriye | 32m30 |
| **Vanishing/exploding gradient** | Tekrarlı $W_{hh}$ çarpımı sinyali söndürür/patlatır | 33m33 |
| **LSTM** | Kapılarla durum akışını kontrol eden RNN türevi | 36m18 |
| **Encoding bottleneck** | Tüm geçmişi tek $h_t$'ye sıkıştırma sınırı | 38m49 |
| **Attention** | Dizinin önemli parçalarını öğrenip seçme mekanizması | 42m21 |
| **Q / K / V** | Query, key, value; aramada sorgu / etiket / içerik | 44m31 |
| **Scaled dot-product** | $\text{softmax}(\mathbf{Q}\mathbf{K}^\top / \sqrt{d_k})\mathbf{V}$ | 50m19 |
| **Positional embedding** | Sırayı recurrence olmadan koruyan konum gömmesi | 47m43 |
| **Transformer** | Attention head'lerinden kurulu, paralel mimari (GPT/BERT) | 43m05 |
## ML Builder Bağlantıları {#sec-ml-baglantilar}
::: {.callout-tip title="8 köprü"}
1. **RNN recurrence ($h_t = f(x_t, h_{t-1})$)** → Calculus iterated map / sabit nokta (Ders 12) + Stat 110 Markov durumu (Ders 31). İleriye: durumlu modeller, streaming inference.
2. **RNN durum güncellemesi ($\tanh$, iki matris)** → Ders 1 perceptron + 18.06 matris-vektör çarpımı. İleriye: `nn.RNN/LSTM/GRU`.
3. **Embedding** → 18.06 vektör uzayı, dot product benzerliği; one-hot = standart baz. İleriye: BPE tokenizer, `nn.Embedding` tabloları.
4. **BPTT** → Calculus zincir kuralı (Ders 4) zaman boyunca. İleriye: truncated BPTT, bellek-hesap dengesi.
5. **Vanishing/exploding gradient** → 18.06 özdeğer/spektral yarıçap (Ders 21) + Calculus contraction (Ders 12). İleriye: gradient clipping, LSTM kapıları, residual.
6. **Attention skoru $\mathbf{Q}\mathbf{K}^\top$** → 18.06 dot product / projeksiyon (Ders 15), cosine benzerlik. İleriye: FlashAttention, $O(n^2)$, uzun-bağlam.
7. **Softmax (attention ağırlığı)** → Calculus $e^x$ (Ders 5) + Stat 110 koşullu olasılık / multinomial (Ders 4, 20). İleriye: masked / causal attention.
8. **Transformer paralelliği** → matris çarpımı GPU paraleli (18.06). İleriye: throughput, KV cache, multi-head, ViT / protein modelleri (Ders 3, 8).
:::
::: {.callout-important title="Bu dersten tek bir şey alıp gideceksen"}
Dizi modellemenin iki büyük fikri var — RNN "geçmişi bir gizli durumda biriktir, adım adım işle" der; attention ise "diziye global bak, önemli ilişkileri $\mathbf{Q}\mathbf{K}^\top$ + softmax ile bul" der. İkincisi paralelleştirilebilir olduğu için GPU çağında kazandı ve bugünün tüm büyük dil modellerinin temelini oluşturdu. Mekanizmanın kalbi yine tanıdık: dot product, özdeğer, koşullu olasılık ve zincir kuralı.
:::