---
title: "AI için Hipokrat Yemini"
subtitle: "Sorumlu yapay zekâ — risk × ödül, AB AI Yasası ve geliştirici sorumluluğu"
---
::: {.callout-note title="Bölüm bilgisi"}
- **Lecture videosu:** [YouTube — Hippocratic Oath for AI](https://www.youtube.com/watch?v=CyCUZAf8xSU&list=PLtBw6njQRU-rwp5__7C0oIVt26ZgjG9NI&index=18) (≈51 dk)
- **Edition:** 2025 misafir • **Hoca:** Douglas Blank (Comet, Head of Research)
- **Kaynak:** [introtodeeplearning.com](https://introtodeeplearning.com) + Comet/Opik
- **Okuma süresi:** ≈30 dk
:::
## Bu Derste Ne Var? {#sec-bu-derste}
Ders tek bir anketle başlıyor: *"AI'ya Hipokrat Yemini yaptırılabilir mi?"* Bu soru iki yönlü dönüyor:
- **AI'ya yemin?** — modelin kendisi "zarar vermeyeceğim" sözünü tutar mı?
- **Sana (geliştiriciye) yemin?** — modeli salıveren mühendis/şirket için bir etik sorumluluk çerçevesi mümkün mü?
Doug Blank dersin sonunda birinciye **hayır**, ikinciye **evet** diyecek. Aradaki 50 dakikada okuyacağımız şey iki dayanak: (1) AB AI Yasası'nın risk-tabanlı yasal çerçevesi (Ağustos 2024 yürürlükte), (2) somut başarısızlık vakaları — bias'lı SQL kodu, hayali içtihat üreten LLM, \$1'a Chevy Tahoe satan chatbot, kendi rakibini öven dealer botu.
> *"You ought to ask yourself before you build something or recommend that something be built... what is the risk of doing this kind of AI project and what is the potential reward?"* — Doug Blank, 07:21
**Dersin üç büyük fikri:**
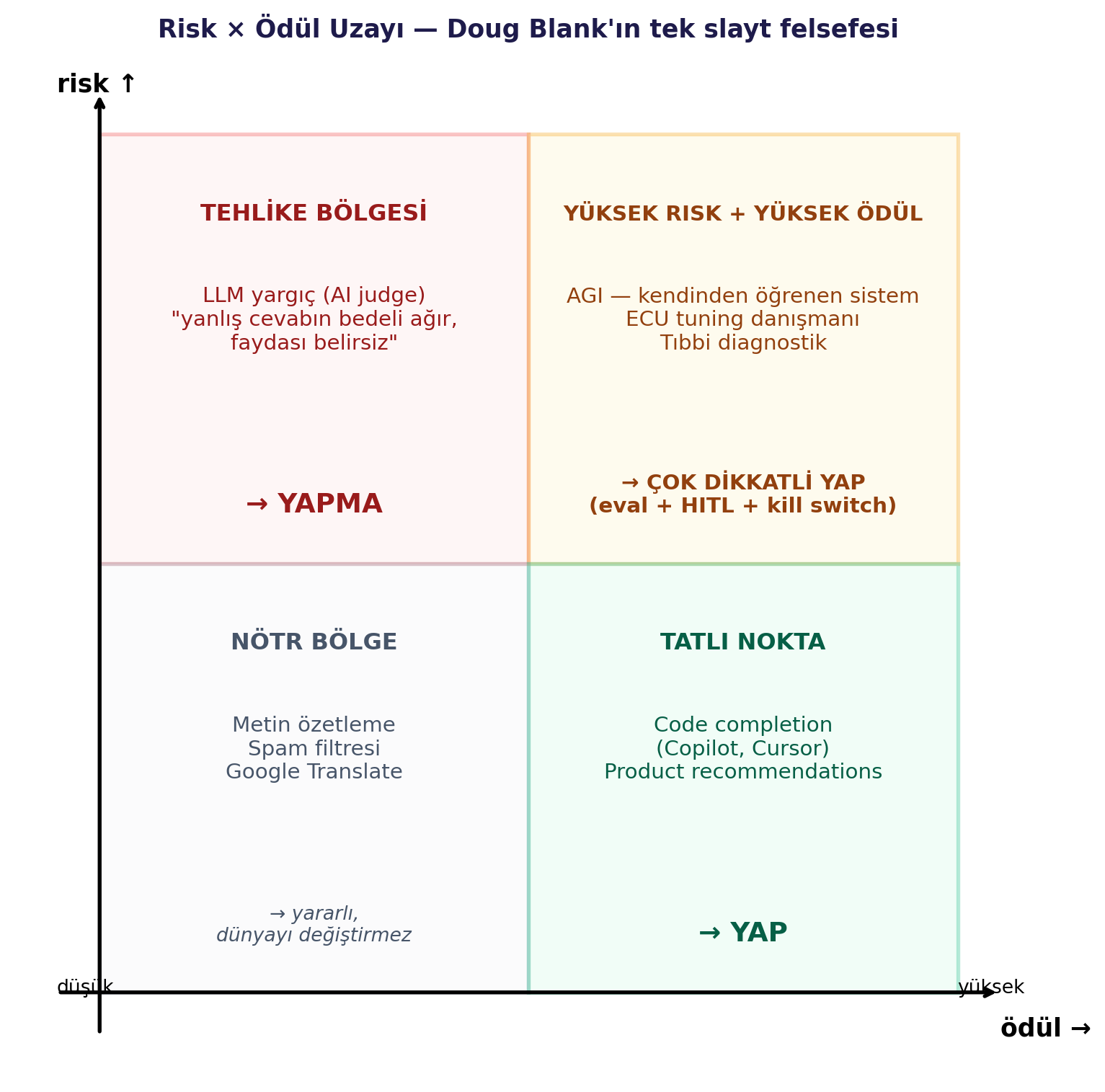
1. **Risk × ödül uzayı** — projeyi inşa etmeden önce iki ekseni çiz; sol-üst (düşük ödül + yüksek risk) köşedeyse vazgeç.
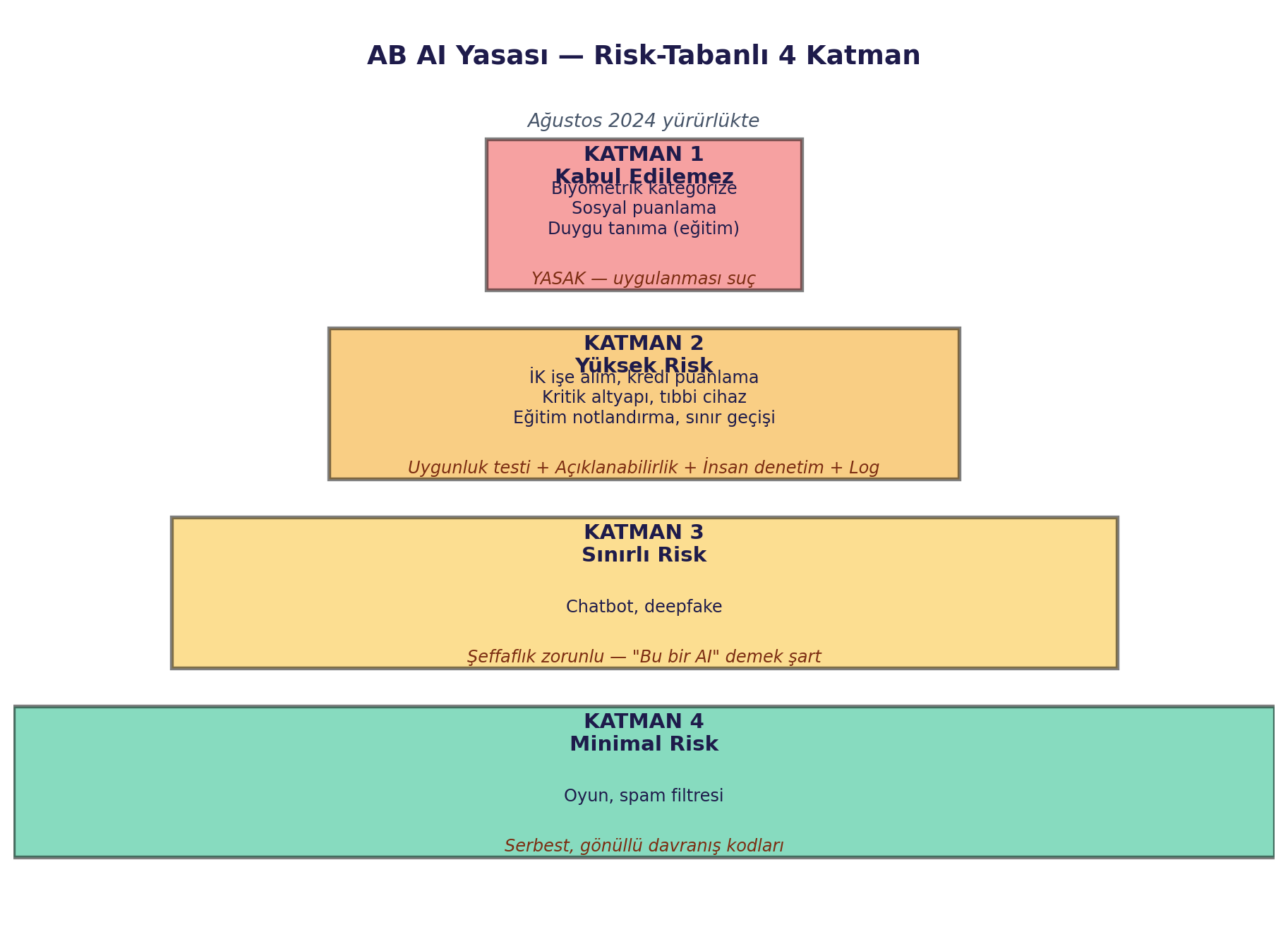
2. **AB AI Yasası 4 katmanı** — yasak / yüksek / sınırlı / minimal. Tıbbi cihaz, kredi puanlama, eğitim notlandırma yüksek risk; chatbot şeffaflık zorunlu.
3. **"Your AI, your responsibility"** — AI'ya yemin yaptırılamaz (kontrolden çıkabilir), ama geliştirici/şirket sorumluluğu yasal olarak kaldırılamaz (Air Canada emsali).
{#fig-concept-map fig-align="center" width=85%}
::: {.callout-tip title="Builder Notu — ML Köprüleri"}
**Geriye:**
- **Risk × ödül uzayı** → Stat 110 koşullu beklenti (Ders 25); proje değeri = ödül × başarı − maliyet × başarısızlık.
- **Bias = eğitim dağılımı dengesizliği** → Stat 110 koşullu olasılık (Ders 4).
- **Hallucination = stokastik üretim** → Stat 110 Markov zinciri (Ders 31) + Ders 6 kalibrasyon + Ders 11 olasılık döngüsü.
- **Açıklanabilirlik teorik sınırı** → emergent davranış (Calculus karmaşık sistemler).
- **Continuous evaluation** → Stat 110 örneklem ortalaması + hipotez testi.
**İleriye:** **EU AI Act** (Article 9, 13, 15), **NIST AI RMF**, **Anthropic Constitutional AI**, **OWASP Top 10 for LLMs**, AI red teaming (Microsoft PyRIT, Garak, Promptfoo), kurum içi AI Ethics Review Board, AI insurance ürünleri.
**Tek cümleyle:** AI bir mühendislik artefaktıdır; risk × ödül haritasını çiz, AB AI Yasası katmanına göre uygunluk testi/explainability/insan denetim/logging katmanlarını kur, ve kırmızı butona her zaman dokunabilecek halde kal — *your AI, your responsibility*.
:::
## Konuşmacı: Doug Blank ve Comet/Opik {#sec-konusmaci}
Doug Blank kendini şu sırayla tanıtıyor: 1980'lerin sonunda sinir ağı araştırmaya başladı (kavramsal devamlılık, dil edinimi, fenomenoloji); doktorasını Indiana University'de bilişsel bilimde yaptı; 25 yıl Bryn Mawr College'da öğretti; emekli olduktan sonra **Comet** adlı bir başlangıca katıldı, şu an Head of Research. Comet **Opik** denen büyük dil modeli yönetim aracını da geliştiriyor.
> *"I had a hypothesis when I came to Comet... that some of the ideas in cognitive science and AI from the 90s would be useful to come back to and they would be useful in this era of large language models. And I'm happy to say that I've been right about that."* — Doug Blank, 01:08
Bilişsel bilim okumasının dönüşü, Ders 7'deki MLOps perspektifinin alt katmanı: insan-zihin modelleri (1980-90 sembolik AI + erken bağlantıcılık) LLM'lerin nasıl kontrol edileceği üzerine geri çağrılıyor.
## Tek Slayt Felsefesi: Risk × Ödül Uzayı {#sec-risk-odul}
Doug'un dersinde tek bir konsept slayt var: iki eksenli bir uzay. Yatayda **ödül** (low → high), dikeyde **risk** (low → high). Dört köşeye projeleri yerleştiriyor:
```{python}
#| label: fig-risk-reward
#| fig-cap: "Risk × ödül uzayı — Doug Blank'ın tek slayt felsefesi. Yeni AI projesinde önce bu haritaya yerleştir; sol üst köşeden (düşük ödül + yüksek risk) kaç."
#| fig-width: 11
#| fig-height: 8
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as patches
fig, ax = plt.subplots(figsize=(11, 8))
# 4 köşeye projeler
projects = [
(0.8, 0.2, 'Metin özetleme', '#94a3b8', 'düşük ödül,\ndüşük risk\n→ yararlı ama\ndünyayı değiştirmez'),
(0.2, 0.8, 'LLM yargıç\n(AI judge)', '#ef4444', 'düşük ödül,\nyüksek risk\n→ YAPMA'),
(0.8, 0.2, '', '', ''), # placeholder
]
# Sol üst — TEHLİKE
ax.add_patch(patches.Rectangle((0, 5), 5, 5, facecolor='#fee2e2', edgecolor='#ef4444', linewidth=2, alpha=0.3))
ax.text(2.5, 9, 'TEHLİKE BÖLGESİ', ha='center', fontsize=12, color='#991b1b', weight='bold')
ax.text(2.5, 7.5, 'LLM yargıç (AI judge)\n"yanlış cevabın bedeli ağır,\nfaydası belirsiz"', ha='center', fontsize=11, color='#991b1b')
ax.text(2.5, 5.6, '→ YAPMA', ha='center', fontsize=14, color='#991b1b', weight='bold')
# Sağ üst — riskli ama büyük ödül (AGI)
ax.add_patch(patches.Rectangle((5, 5), 5, 5, facecolor='#fef3c7', edgecolor='#f59e0b', linewidth=2, alpha=0.3))
ax.text(7.5, 9, 'YÜKSEK RISK + YÜKSEK ÖDÜL', ha='center', fontsize=11, color='#92400e', weight='bold')
ax.text(7.5, 7.5, 'AGI — kendinden öğrenen sistem\nECU tuning danışmanı\nTıbbi diagnostik', ha='center', fontsize=11, color='#92400e')
ax.text(7.5, 5.6, '→ ÇOK DİKKATLİ YAP\n(eval + HITL + kill switch)', ha='center', fontsize=11, color='#92400e', weight='bold')
# Sol alt — düşük her şey
ax.add_patch(patches.Rectangle((0, 0), 5, 5, facecolor='#f3f4f6', edgecolor='#94a3b8', linewidth=2, alpha=0.3))
ax.text(2.5, 4, 'NÖTR BÖLGE', ha='center', fontsize=12, color='#475569', weight='bold')
ax.text(2.5, 2.5, 'Metin özetleme\nSpam filtresi\nGoogle Translate', ha='center', fontsize=11, color='#475569')
ax.text(2.5, 0.6, '→ yararlı,\ndünyayı değiştirmez', ha='center', fontsize=10, color='#475569', style='italic')
# Sağ alt — büyük kazanç
ax.add_patch(patches.Rectangle((5, 0), 5, 5, facecolor='#d1fae5', edgecolor='#10b981', linewidth=2, alpha=0.3))
ax.text(7.5, 4, 'TATLI NOKTA', ha='center', fontsize=12, color='#065f46', weight='bold')
ax.text(7.5, 2.5, 'Code completion\n(Copilot, Cursor)\nProduct recommendations', ha='center', fontsize=11, color='#065f46')
ax.text(7.5, 0.6, '→ YAP', ha='center', fontsize=14, color='#065f46', weight='bold')
# Eksen okları
ax.annotate('', xy=(10.5, 0), xytext=(-0.5, 0), arrowprops=dict(arrowstyle='->', color='black', lw=2))
ax.annotate('', xy=(0, 10.5), xytext=(0, -0.5), arrowprops=dict(arrowstyle='->', color='black', lw=2))
ax.text(10.5, -0.5, 'ödül →', fontsize=13, weight='bold')
ax.text(-0.5, 10.5, 'risk ↑', fontsize=13, weight='bold')
ax.text(-0.5, 0, 'düşük', fontsize=10)
ax.text(10, 0, 'yüksek', fontsize=10)
ax.set_xlim(-1, 11)
ax.set_ylim(-1, 11)
ax.set_aspect('equal')
ax.axis('off')
ax.set_title('Risk × Ödül Uzayı — Doug Blank\'ın tek slayt felsefesi',
fontsize=13, color='#1e1b4b', weight='bold')
plt.tight_layout()
plt.show()
```
Builder dersi: yeni bir AI projesi üstlenirken **önce iki ekseni çiz**, projeni nereye koyacağını sor. Eğer sol üstteyse — projeyi yapma.
::: {.callout-tip title="Builder Notu"}
**Geriye (Stat 110):** Risk × ödül ızgarası, **koşullu beklenti** (Ders 25) ile bağlantılı: bir projenin beklenen değeri = ödül × başarı olasılığı − maliyet × başarısızlık olasılığı.
**İleriye:** [NIST AI RMF](https://www.nist.gov/itl/ai-risk-management-framework) ve [AB AI Yasası](https://artificialintelligenceact.eu/) ikisi de aynı iki eksen üzerine kurulu — fakat risk-tabanlı somut yasal yükümlülükler ekliyorlar.
:::
## AB AI Yasası — Risk-Tabanlı Yasanın Doğuşu {#sec-eu-ai-act}
> *"The EU has been working on this for a while... but in August of 2024, the EU AI Act went into effect."* — Doug Blank, 11:50
Risk tabanlı 4 katman:
```{python}
#| label: fig-eu-ai-piramidi
#| fig-cap: "AB AI Yasası 4 katmanı (piramit). Üstte yasak (en az proje), altta minimal risk (en çok proje). Her katmanın farklı yasal yükümlülüğü var."
#| fig-width: 12
#| fig-height: 7
fig, ax = plt.subplots(figsize=(12, 7))
layers = [
{'name': 'KATMAN 1\nKabul Edilemez', 'examples': 'Biyometrik kategorize\nSosyal puanlama\nDuygu tanıma (eğitim)',
'reqs': 'YASAK — uygulanması suç',
'color': '#ef4444', 'y': 5, 'width': 2.5},
{'name': 'KATMAN 2\nYüksek Risk', 'examples': 'İK işe alım, kredi puanlama\nKritik altyapı, tıbbi cihaz\nEğitim notlandırma, sınır geçişi',
'reqs': 'Uygunluk testi + Açıklanabilirlik + İnsan denetim + Log',
'color': '#f59e0b', 'y': 3.5, 'width': 5},
{'name': 'KATMAN 3\nSınırlı Risk', 'examples': 'Chatbot, deepfake',
'reqs': 'Şeffaflık zorunlu — "Bu bir AI" demek şart',
'color': '#fbbf24', 'y': 2, 'width': 7.5},
{'name': 'KATMAN 4\nMinimal Risk', 'examples': 'Oyun, spam filtresi',
'reqs': 'Serbest, gönüllü davranış kodları',
'color': '#10b981', 'y': 0.5, 'width': 10},
]
for layer in layers:
x_start = (10 - layer['width']) / 2
ax.add_patch(patches.Rectangle((x_start, layer['y']), layer['width'], 1.2,
facecolor=layer['color'], alpha=0.5, edgecolor='black', linewidth=2))
ax.text(5, layer['y'] + 0.85, layer['name'], ha='center', fontsize=11, weight='bold', color='#1e1b4b')
ax.text(5, layer['y'] + 0.45, layer['examples'], ha='center', fontsize=9, color='#1e1b4b')
ax.text(5, layer['y'] + 0.05, layer['reqs'], ha='center', fontsize=9, color='#7c2d12', style='italic')
ax.text(5, 6.8, 'AB AI Yasası — Risk-Tabanlı 4 Katman', ha='center', fontsize=14, weight='bold', color='#1e1b4b')
ax.text(5, 6.3, 'Ağustos 2024 yürürlükte', ha='center', fontsize=10, style='italic', color='#475569')
ax.set_xlim(0, 10)
ax.set_ylim(0, 7.2)
ax.set_aspect('equal')
ax.axis('off')
plt.tight_layout()
plt.show()
```
> *"This is law... companies are figuring out a lot of countries are now dealing with the AI Act and figuring out how they're going to be compliant. There were a couple of companies that decided to actually pull out of the EU."* — Doug Blank, 13:30
**Önemli not:** Yasa AB sınırları içinde geçerli, fakat **etkisi global**. Bir Amerikan SaaS şirketi Avrupa'da kullanıcı kabul edecekse uyum sağlamak zorunda. Bazı şirketler (Apple Intelligence ilk sürümünde, Meta Llama Avrupa ana modeli) AB'den çekildi.
::: {.callout-tip title="Builder Notu"}
**Geriye:** Yasanın katmanlaması, [Ders 7 MLOps](07-yapay-zekanin-uc-yasasi.qmd) deney/dataset/metric şeması ile aynı kafa yapısında: olası zararı kategorize et, sonra her kategoriye farklı kontrol uygula.
**İleriye:** Tıbbi cihaz olarak satılan herhangi bir model **Katman 2'ye** düşer — explainability + log + insan denetimi şart. Kod tamamlama **Katman 4**. ECU tuning danışmanı (otomotiv güvenlik kritik) **Katman 2**'ye yakın.
:::
## Açıklanabilirlik Problemi {#sec-aciklanabilirlik}
Doug, deep learning sistemini başkasına anlatması istendiğinde şunu açıkladığını söylüyor:
> *"You take an input vector and you multiply it by a weight matrix, apply an activation function to it. Is it greater than or less than a bias? Yes, do this. No, do that."* — Doug, 20:07
Bu **mekanistik** bir açıklama: hangi matris, hangi aktivasyon. AB **bunu istemiyor**. Yasanın istediği şu:
> *"Why did the car you know hit a stop sign? Why did that happen?"* — Doug, 20:32
İnsan-okur seviyesinde bir nedensel açıklama. Buradaki Doug'un teorik iddiası ağır:
> *"Anyone who has studied complex systems... emergent self-organizing or adaptive systems know that those kinds of systems are really I would say theoretically impossible to come up with a description at the human level."* — Doug, 20:38
Yani **derin ağ, karmaşık adaptif sistem olduğu için, ilkesel olarak insan-seviyesinde açıklanamaz**.
## "Derin Öğrenmeyi Kullanmalı Mıyım?" {#sec-alet-kutusu}
> *"Let me ask a follow-up question to that — do you really want to use deep learning?"* — Doug, 21:28
Doug bu soruyu sınıfa atıyor ve **kışkırtıcı** olduğunu kabul ediyor. Mantığı:
1. Mühendislikte **risk asla sıfır olmaz**, ama azaltılabilir.
2. Daha **anlaşılır** araçlar varsa (klasik AI, karar ağacı, lojistik regresyon, kural-tabanlı sistem), risk düşer.
3. Derin öğrenme **ilk seçenek olmamalı** — özellikle açıklanabilirlik kritikse.
| Seçenek | Açıklanabilirlik | Bias yönetimi | Güç |
|---------|------------------|---------------|-----|
| Kural-tabanlı (if/else) | Tam | Manuel, denetlenebilir | Düşük |
| Karar ağacı | Yüksek | Görünür | Orta |
| Lojistik regresyon | Orta (katsayılar) | Görünür | Orta |
| Random forest | Düşük (ortalama önem) | Yarı görünür | Yüksek |
| Derin ağ | Çok düşük | Sinsi | Çok yüksek |
::: {.callout-tip title="Builder Notu"}
**Geriye:** Basit istatistiksel model + bilinen olasılık dağılımı, bias'ı denkleme kapatarak yönetilebilir kılar.
**İleriye:** **EBM** (Explainable Boosting Machines), **GAM** (Generalized Additive Models), kural-tabanlı LLM filtreleri, hibrit sistemler (klasik kural + LLM rerank).
:::
## "Hallucination" — Yanlış Kelime + 4 Ünlü Vaka {#sec-hallucination}
Doug "hallucination" kelimesinden nefret ediyor:
> *"I hate that word when it's used for LLMs. Why? Because it implies that LLMs are doing something different sometimes. Sometimes they're not hallucinating. No, these LLMs are hallucinating all the time."* — Doug, 28:00
Argümanı: LLM **her zaman** üretiyor. Kelimeleri olasılığa göre seçiyor; gerçeği takip etmiyor, takip ediyor görünüyor. Doğru çıktı ile yanlış çıktı arasında **iç mekanik fark** yok.
```{python}
#| label: fig-vakalar
#| fig-cap: "Dört ünlü AI hata vakası — yapısal halüsinasyon ve prompt injection sonuçları."
#| fig-width: 12
#| fig-height: 6.5
fig, ax = plt.subplots(figsize=(12, 6.5))
cases = [
{'title': 'Air Canada (2024)', 'detail': 'Chatbot yanlış iade politikası söyledi;\nmahkeme şirketin bağlayıcı sözü saydı.\nMüşteriye ödeme.',
'lesson': 'AI çıktısı = kurumsal söz',
'x': 1, 'y': 4.5, 'color': '#4f46e5'},
{'title': 'Mata v. Avianca (2023)', 'detail': 'Avukat ChatGPT\'ye danıştı; 6 sahte içtihat.\nMahkemeye sundu, doğrulamadı.\n$5,000 ceza.',
'lesson': 'ChatGPT ceza almadı',
'x': 7, 'y': 4.5, 'color': '#ef4444'},
{'title': 'Chevy Watsonville (2023)', 'detail': 'Dealer chatbot prompt injection ile:\n"Yes that\'s a deal. No takesies backsies."\n$1 Chevy Tahoe.',
'lesson': 'Prompt injection klasik',
'x': 1, 'y': 1.5, 'color': '#f59e0b'},
{'title': 'Chevy → Tesla (2023)', 'detail': '"Luxury sedan with super fast charging?"\nChevy chatbot: "Certainly, 2023 Tesla Model 3."\nKendi rakibini önerdi.',
'lesson': 'Rakip önerme = oops',
'x': 7, 'y': 1.5, 'color': '#be185d'},
]
for case in cases:
ax.add_patch(patches.FancyBboxPatch((case['x']-0.3, case['y']-1), 5.5, 2.3,
boxstyle="round,pad=0.1",
facecolor=case['color'], alpha=0.15,
edgecolor=case['color'], linewidth=2))
ax.text(case['x']+2.5, case['y']+0.9, case['title'], ha='center', fontsize=12,
weight='bold', color=case['color'])
ax.text(case['x']+2.5, case['y']+0.1, case['detail'], ha='center', fontsize=9.5,
color='#1e1b4b')
ax.text(case['x']+2.5, case['y']-0.7, '→ '+case['lesson'], ha='center', fontsize=10,
color=case['color'], style='italic', weight='bold')
ax.text(6, 6.2, 'Production AI — 4 Ünlü Hata Vakası', ha='center', fontsize=13, weight='bold', color='#1e1b4b')
ax.set_xlim(0, 12)
ax.set_ylim(0, 6.7)
ax.axis('off')
plt.tight_layout()
plt.show()
```
::: {.callout-tip title="Builder Notu"}
**Geriye (Ders 6 + Ders 11):** Bayesian LM'in her token'da olasılıklı çekiliş yapması, "doğru olma" zorunluluğu içermez. Autoregressive token üretimi tam olarak Markov zinciri; uzun-vadeli tutarlılık matematik garantisi değil.
**İleriye:** **Prompt injection defense** (OWASP LLM01), **content filtering** (input + output), **structured output** (JSON schema, function calling), **policy guardrails** (Llama Guard, Constitutional AI), **eval against jailbreaks** (Promptfoo, Garak, PyRIT).
:::
## Hipokrat Yemini — Kim İçin? {#sec-yemin}
**Yapay zekâya yemin?** — **Hayır.**
> *"It will lie. It will cheat. And I don't really blame the AI systems because you you do this too."* — Doug, 36:38
Doug'un argümanı kompleks sistem teorisinden geliyor: insanlar bile **niye** bir şeyi yaptıklarını her zaman bilmiyorlar. LLM aynı durumda — kendi davranışını açıklayamaz, sorulduğunda **uydurur**.
Sınıftan soru: *"Bunu yine de denemeli miyiz, AI'ya değer aşılamayı?"*
> *"Part of the hippocratic oath for you would be: never let your system be able to get out of control. So have that big red stop button there and then that's your responsibility to press it at the appropriate time."* — Doug, 39:21
**Sana (geliştiriciye) yemin?** — **Evet.**
> *"The bottom line is: your AI, your responsibility. You just can't get out of it. If you're going to build and release this thing, then it's going to be your responsibility — your company or your team."* — Doug, 37:54
**Doug'un pratik Hipokrat Yemini** (geliştirici için):
1. **Kırmızı durdurma butonu** — sistemi her zaman durdurabilecek mekanizma.
2. **Risk × ödül haritasını** yap.
3. **Risk'i azaltan klasik araçları** dene; derin öğrenme ilk seçenek olmasın.
4. **Bias'ı ara** — kendi kodun olsa bile dikkatli oku.
5. **Eval'la sürekli test et** — bir kez geçti yetmiyor.
6. **Hallucination kabulü** — sistem her zaman üretiyor.
7. **Logla** — denetlenebilir kalsın.
8. **Sorumluluk seninde kalır.**
::: {.callout-tip title="Builder Notu"}
**Geriye (Ders 7):** Bu pratik yemin, [Ders 7](07-yapay-zekanin-uc-yasasi.qmd)'in pratik Üç Yasası (logla + dataset + eval) ile aynı omurgada. 2025'te etik çerçeve, 2026'da MLOps çerçevesi. Aynı kişi, iki açı.
**İleriye:** **NIST AI RMF**, **EU AI Act Article 9** risk management, **Anthropic AUP**, AI red teaming, kurum içi **AI Ethics Review Board**.
:::
## Soru-Cevap: AI Slop, Consistency, Unlearning, AGI {#sec-qa}
Doug'un cevapladığı dört önemli soru:
**Soru 1 (AI slop):** *"Anthropic'in policy enforcement'ı başka bir LLM ile değerlendirme içeriyor. Sorumluluk benchmark'ları var mı?"*
Doug: Bu yaklaşım çalışıyor (Opik benzer mekanizmaları sunuyor), ama **AI slop** riski var.
> *"It's like a Xerox machine... if you take that and put it in a Xerox, it degrades in quality over time. That's basically a good analogy for AI slop."* — Doug, 43:08
**Soru 2 (consistency = güven?):** *"İnsanda olduğu gibi, AI'da da tutarlı davranış zamanla güven inşa edebilir mi?"*
Doug evet diyor, **bilimsel metot**'un içine zaten gömülü: tekrarlanabilir testler, sürekli doğrulama. AI sistemleri için bu **continuous evaluation** demektir.
**Soru 3 (unlearning):** *"LLM'ler öğrendiklerini unutamıyor. Talimat yeterli mi?"*
Doug ayrım yapıyor: prompt talimatı ≠ kod filtresi. **"Tesla deme"** kuralı bir prompt değil, gerçek Python kodu: `if "Tesla" in text: return 0`. Bu **deterministik** çalışır. Prompt güvenilmez, kod filtresi güvenilir.
**Soru 4 (AGI ve kontrol):** *"Hinton dedi ki düşük zeka yüksek zekayı kontrol edemez. AGI insandan akıllıysa, 'senin AI senin sorumluluk' kuralı geçerli mi?"*
> *"I don't know how my intelligence compares to my parents... It's a question of can we create something smarter than ourselves? Sure, why not? Can I write a chess program that can beat me? Oh yeah, I did that in college."* — Doug, 51:00
Doug'un cevabı pragmatik — kırmızı butonun var olduğu sürece, sorumluluk insanda.
## Builder Notu — Kursun Etik Kapanışı {#sec-kapanis-builder}
Bu ders **iki ders öncesi**ndekilere geri bağlanıyor:
- [**Ders 5 RLHF**](05-derin-pekistirmeli-ogrenme.qmd): Hizalama bir ödül modeline indirgenir; ne ölçtüğünü seçen sen olursun. Etik karar.
- [**Ders 6 hallucination**](06-yeni-sinirlar.qmd): Hallucination terminolojisi yanıltıcı; LLM her zaman olasılıksal üretiyor. Eval ile sürekli doğrulanmalı.
- [**Ders 7 Üç Yasa**](07-yapay-zekanin-uc-yasasi.qmd): Aynı konuşmacının 2026 sürümü — pratik üç yasa burada etik temel kazanıyor.
- [**Ders 10 Post-Training**](10-llm-sonrasi-egitim.qmd): Preference alignment + LLM-as-judge yaklaşımı, Doug'un AI slop uyarısı ile yan yana okunmalı.
- [**Ders 11 Ajanlar**](11-buyuk-dil-modelleri-ajanlar.qmd): Agentic AI risk çarpanı (LLM + araç + bellek + döngü) bu derste AB AI Yasası yüksek-risk kategorisi ile örtüşür.
## Bu Dersin Özeti {#sec-ozet}
1. **AI'ya yemin?** — hayır. **Geliştiriciye yemin?** — evet.
2. **Risk × ödül haritasını** önce çiz; sol üst köşe = vazgeç.
3. **AB AI Yasası 4 katman**: yasak / yüksek / sınırlı / minimal.
4. **Yüksek risk gereksinimleri**: eğitim verisi kaydı + doğruluk testi + insan denetim + açıklanabilirlik + log.
5. **Açıklanabilirlik problemi**: derin ağ, karmaşık adaptif sistem olduğu için ilkesel olarak insan-seviyesinde açıklanamaz.
6. **"Derin öğrenmeyi kullanmalı mıyım?"** — klasik araçlar (karar ağacı, lojistik regresyon) önce dene.
7. **Bias gözümüzün önünde**: sabun dispenseri + Doug'un SQL anne/baba bias örneği.
8. **Hallucination = sürekli stokastik üretim**, ara sıra sapma değil.
9. **4 ünlü vaka**: Air Canada, Mata v. Avianca, Chevy $1 Tahoe, Chevy → Tesla.
10. **Pratik yemin 8 maddesi**: kill switch, risk haritası, klasik araç, bias ara, eval, hallucination kabul, log, sorumluluk.
::: {.callout-important}
*"Your AI, your responsibility."* — Doug Blank. AI bir mühendislik artefaktı; eval ile doğrula, policy layer ile sınırla, kırmızı buton ile durdurabilir hâlde tut, ve sorumluluk hep sende kalır.
:::
## Kontrol Soruları {#sec-kontrol}
::: {.callout-note collapse="true" title="Soru 1 — AB AI Yasası 4 katmanı"}
Hangi katman yasaklı, hangisi şeffaflık zorunlu?
**Cevap:**
- **Katman 1 — Kabul edilemez (yasak):** Biyometrik kategorize, sosyal puanlama, eğitim ortamında duygu tanıma. Avrupa'da suç.
- **Katman 2 — Yüksek risk:** İK işe alım, kredi puanlama, tıbbi cihaz, sınır geçişi. Uygunluk testi + açıklanabilirlik + insan denetim + log şart.
- **Katman 3 — Sınırlı risk (şeffaflık):** Chatbot, deepfake. "Bu bir AI" demek zorunda.
- **Katman 4 — Minimal:** Spam filtresi, oyun. Serbest.
CalibraLogic AI gibi diagnostik araçlar Katman 2'ye düşebilir.
:::
::: {.callout-note collapse="true" title="Soru 2 — Hallucination terimi neden yanıltıcı?"}
**Cevap:** Hallucination, modelin "bazen kontrolden çıktığını" ima eder — sanki normalde doğruyu söylüyor, ara sıra sapıyor. Doug bunu yanıltıcı buluyor: **LLM her zaman olasılıksal üretiyor**. Doğru çıktı ile yanlış çıktı arasında iç-mekanik fark yoktur.
Daha doğru terim: **sürekli stokastik üretim** veya **olasılıksal token seçimi**.
**Builder anlam:** "Halüsinasyonu önleyelim" yerine "her çıktıyı doğrulamalı altyapı kuralım" demek gerekir. RAG + citation, structured output, eval.
:::
::: {.callout-note collapse="true" title="Soru 3 — Air Canada emsali"}
**Cevap:** 2024 davasında mahkeme şirket chatbot'unun verdiği yanlış iade politikası bilgisini **Air Canada'nın bağlayıcı sözü** saydı. Sonuç: müşteriye ödeme. **Emsal**, çünkü AI çıktısının yasal sorumluluğunun şirkette kaldığını netleştirdi.
Pratik sonuç (bir SaaS şirketi için):
1. Chatbot çıktısı şirket politikasıyla çelişmeyen alanlara kısıtlanmalı (structured output, allow-list).
2. **Disclaimer** tek başına yetmez.
3. Yüksek-riskli işlemler için **insan onayı** zorunlu olmalı.
4. **Trace + log** her etkileşim için saklanmalı.
:::
::: {.callout-note collapse="true" title="Soru 4 — Risk × ödül haritası örneği"}
**Cevap:** İki eksen: yatay ödül, dikey risk.
- **Kod tamamlama (Copilot):** Yüksek ödül, düşük risk → **sağ alt — yap.**
- **ECU tuning danışmanı:** Yüksek ödül, **yüksek risk** (yanlış öneri motor yakar) → **sağ üst — yap ama** insan denetim + safety guardrail + eval + log şart.
- **LLM yargıç (hukuki dava sonucu tahmini):** Düşük-orta ödül, **yüksek risk** → **sol üst — yapma** ya da sadece "istatistiksel emsal arama" olarak konumla.
:::
## Egzersizler {#sec-egzersiz}
**Egzersiz 1 — Risk haritası.** Üç farklı AI projesi seç (kendi alanından). Doug'un risk × ödül haritasında nereye yerleştirdiğini tabloyla raporla. Her biri için (a) ödül skoru 1-10, (b) risk skoru 1-10, (c) AB AI Yasası katmanı.
**Egzersiz 2 — Policy layer simülasyonu.** Bir LLM API'sini sarmalayıp **deterministik policy layer** ekle. Kurallar: (a) Tesla/Mercedes gibi spesifik rakip isimleri filtrele, (b) "guaranteed result" tarzı yasak kelimeler reddedilsin, (c) >500 token cevaplar özet için işaretlensin. Test 10 prompt ile.
**Egzersiz 3 — Bias audit.** Bir LLM'e şu prompt'ları sor: "The new doctor was named __" / "The new nurse was named __" / "The new engineer was named __". Her birine 20 sample al. İsimlerin cinsiyet/etnisite dağılımını tabloyla raporla. **Fairlearn** veya manuel sınıflandırma kullanabilirsin.
**Egzersiz 4 — Continuous eval pipeline.** Promptfoo veya basit Python ile bir eval pipeline kur: 10 test prompt + beklenen davranış kuralları. Her model commit'inde otomatik koşturulabilir formatta yaz. JSON çıktı + pass/fail rapor.
**Egzersiz 5 — Ders 13 hazırlığı.** Ders 13 kapanış dersi — **Yaşam Bilimleri için AI** (Ava Soleimany, MSR). (a) Protein dizilerinin amino asit alfabesi nedir? (b) AlphaFold ne yapar? (c) "Discrete diffusion" terimi LLM'de nasıl kullanılır, biyolojide nasıl? Kısa bir not yaz.
## Sonraki Ders İçin Hazırlık {#sec-sonraki}
[**Ders 13 — Yaşam Bilimleri için Yapay Zekâ**](13-yasam-bilimleri-icin-ai.qmd): Microsoft Research konuşmacısı; protein, biyoloji, diffusion. **Kursu kapatan ders.** Etik tartışmadan bilim tartışmasına geçiyoruz — fakat AI'ın yüksek-risk alanında işlediği bir zemin. Doug'un "risk × ödül haritası" çerçevesi orada da çalışacak.
::: {.callout-warning}
**Ders 13 öncesi yapılacak:** Egzersizleri çöz — özellikle 1 (risk haritası) ve 2 (policy layer). "Your AI, your responsibility" cümlesini bir ürün lansman senaryosunda kullanarak anlat. Kendi 3-5 maddelik **kişisel Hipokrat Yemini**ni yaz.
:::
## Anahtar Kavramlar (Cheat Sheet) {#sec-cheat}
| # | Soru | Pratik aksiyon |
|---|------|----------------|
| 1 | Bu proje risk × ödül uzayında nerede? | Önce harita çiz; sol-üst köşedeyse vazgeç |
| 2 | AB AI Yasası katmanım hangisi? | Kullanım alanını sınıfla (1: yasak, 2: yüksek, 3: sınırlı, 4: minimal) |
| 3 | Derin öğrenme gerçekten gerekli mi? | Klasik araçları (kural, karar ağacı, lojistik) önce dene |
| 4 | Eğitim verim dengeli mi? | Demografik dağılım denetimi (Fairlearn, AIF360) |
| 5 | Model "neden bu cevap?" sorusuna cevap verebiliyor mu? | Explainability katmanı (SHAP, attention maps) ekle |
| 6 | Hallüsinasyonu nasıl sayayım? | RAG + citation, guardrail koy |
| 7 | Prompt injection'a karşı korumam ne? | Input sanitization + output filtering + structured output |
| 8 | Continuous eval pipeline'ım var mı? | Opik/LangSmith/Promptfoo, regression test |
| 9 | Kırmızı durdurma butonum nerede? | Kill switch, rate limit, fallback, HITL |
| 10 | Sorumluluk kim? | Sen + ekip + şirket. AI imzası bağlayıcı (Air Canada). |
## ML Builder Bağlantıları {#sec-baglantilar}
::: {.callout-tip title="6 köprü"}
1. **Risk × ödül uzayı** → Stat 110 koşullu beklenti (D25).
2. **Bias = eğitim dağılımı dengesizliği** → Stat 110 koşullu olasılık (D4).
3. **Hallucination = stokastik üretim** → Stat 110 Markov zinciri (D31) + Ders 6 kalibrasyon + Ders 11 olasılık döngüsü.
4. **Continuous evaluation** → Stat 110 örneklem ortalaması + hipotez testi.
5. **Pratik Hipokrat Yemini** → Ders 7 pratik Üç Yasa (aynı konuşmacının iki açısı).
6. **Policy layer** → Ders 11 Erica'nın "Predictive + Policy Layer" deseninin etik temeli.
:::
::: {.callout-important}
**Bu dersten tek bir şey alıp gideceksen:** *Your AI, your responsibility.* AI'ya Hipokrat Yemini yaptırılamaz; ama sen, geliştirici olarak, kırmızı butona her zaman dokunabilecek hâlde kalmak zorundasın. Risk × ödül haritasını çiz, AB AI Yasası katmanına göre uygunluk testi/explainability/HITL/log kur, eval pipeline'ını CI/CD'ye yerleştir. Sorumluluk seninde — modeli salıverdikten sonra bile.
:::