---
title: "Devasa Paralel Eğitimin Sırları"
subtitle: "Scaling laws + bellek bütçesi + DDP + ZeRO + tensor/pipeline/sequence/MoE parallelism"
---
::: {.callout-note title="Bölüm bilgisi"}
- **Lecture videosu:** [YouTube — Lecture 9: Secrets to Massively Parallel Training](https://www.youtube.com/watch?v=UZZD9d9YqnQ&list=PLtBw6njQRU-rwp5__7C0oIVt26ZgjG9NI&index=9) (≈53 dk)
- **Edition:** 2026 misafir • **Hoca:** Mathias Lechner, Liquid AI Co-founder & CTO
- **Kaynak:** [introtodeeplearning.com](https://introtodeeplearning.com) + [Liquid AI](https://www.liquid.ai)
- **Okuma süresi:** ≈34 dk
:::
## Bu Derste Ne Var? {#sec-bu-derste}
Kursun en **production-mühendislik** odaklı dersi. Bishop, Ders 8'de bilim cephesinden **küçük modelleri çok kullanmaktan** söz etti; Lechner ise modern AI'ın diğer cephesinden — **devasa modelleri etkin ölçeklendirmekten** — konuşuyor. Liquid AI, Ders 1'in açılışında Amini'nin gösterdiği "telefonda offline çalışan 2B model GPT-4'ü benchmark'larda geçiyor" demosunun arkasındaki ekip.
> *"today I'm going to talk about massively parallel training, specifically how we at Liquid AI scale training runs up to thousands of GPUs."* — Mathias Lechner, 1:09
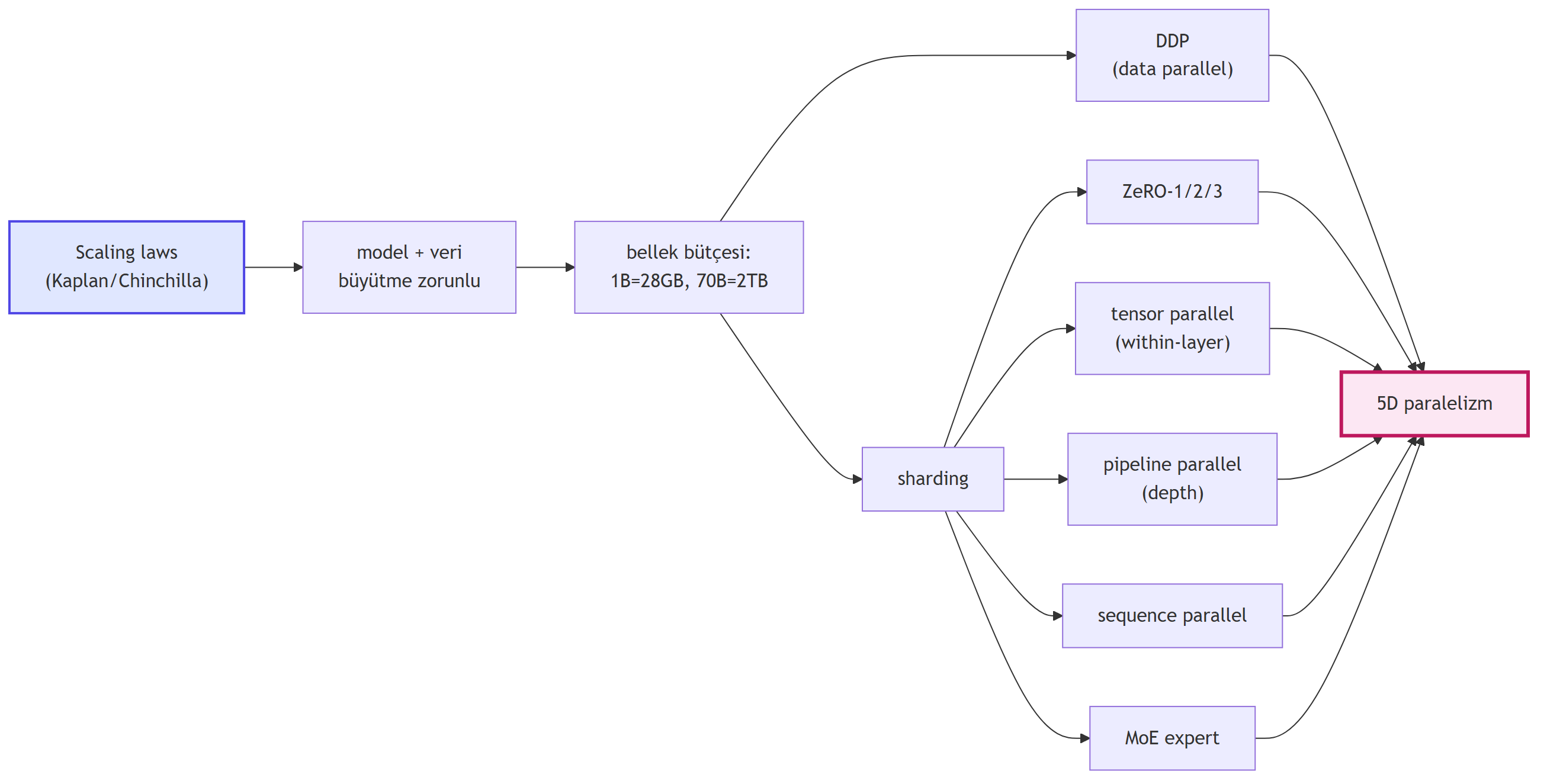
**Dersin üç büyük fikri:**
1. **Scaling laws + ironi** — daha çok veri + daha büyük model = daha iyi loss; ama inference maliyeti baskın olduğunda modeller **küçülmek** zorunda (GPT-3 175B → LFM 2.5 1.2B).
2. **Bellek bütçesi sharding zorunluluğu** — 1B model = 28 GB; 70B model = 2 TB tek GPU'da imkânsız. Cevap: paylaştır (shard).
3. **5D paralelizm** — data + tensor + pipeline + sequence + expert (MoE). Modern cluster training'in mühendislik dili.
{#fig-concept-map fig-align="center" width=85%}
::: {.callout-tip title="Builder Notu — ML Köprüleri"}
Bu ders, kursun **İleriye** köprülerinin Big Tech tarafının haritası. Bir builder, training cluster'ı yoksa bile bu yöntemlerin **küçük ölçekli versiyonlarını** (tek GPU'da gradient accumulation, mixed precision, optimizer offload) kullanacaktır.
- **DDP** → Ders 1 SGD'nin paralel döngüsü; all-reduce mean = Stat 110 örneklem ortalaması.
- **Batch size genelleme erozyonu** → Ders 1 mini-batch + Stat 110 varyans $\propto 1/B$.
- **Activation checkpointing** → Ders 1 backprop'un hafıza-hesap takası; Calculus zincir kuralının parçalı yeniden hesaplanması.
- **Pipeline / tensor / sequence parallel** → 18.06 matris çarpımının satır/sütun parçalanması.
- **MoE** → Ders 4 generative + Ders 2 routing; structured sparsity.
- **Cluster scale-up/scale-out** → 18.06 lineer sistem yerişimı; matris-vektor iş yükü coğrafi ayrıştırma.
**İleriye köprüler:** **DeepSpeed** + **FSDP** + **Megatron-LM** + **JAX/Flax**, **FlashAttention**, **PagedAttention** (vLLM), **TPU/Trainium**, **Triton** GPU kernel, **Mosaic Composer**, **NeMo**. **Liquid Foundation Models (LFM 2)** mimarisi: convolution + attention + recurrent karışık yapı.
**Tek cümleyle:** Ölçekleme yasaları modeli büyütmeye iter, donanım sınırları modeli bölmeye zorlar; data/tensor/pipeline/sequence/MoE paralelizmleri bu iki kuvvetin **mühendislik uzlaşması**dır.
:::
## Ölçekleme Zorunluluğu: GPU'nun Doğuşu ve Scaling Laws {#sec-scaling}
Lechner dersi tarihten başlıyor. **2011** — AlexNet, ImageNet yarışmasını uçtan-uca **iki Nvidia GTX 580 GPU** üzerinde eğitilmiş bir konvolüsyonel ağla kazandı. Neden GPU? Çünkü sinir ağı eğitimi büyük ölçüde **matris çarpımıdır**:
$$
x \cdot W : \quad \underbrace{(256 \times 4096)}_{\text{batch} \times \text{features}} \cdot \underbrace{(4096 \times 4096)}_{W} = (256 \times 4096)
$$
Bu tek çarpım ≈8 milyar FLOP. 2011'de tipik bir CPU ≈0.1 TFLOPS üretiyordu; bir gaming GPU (GTX 580) bunun ≈16 katı. Şimdi (H100) yine **~1000×** daha hızlı.
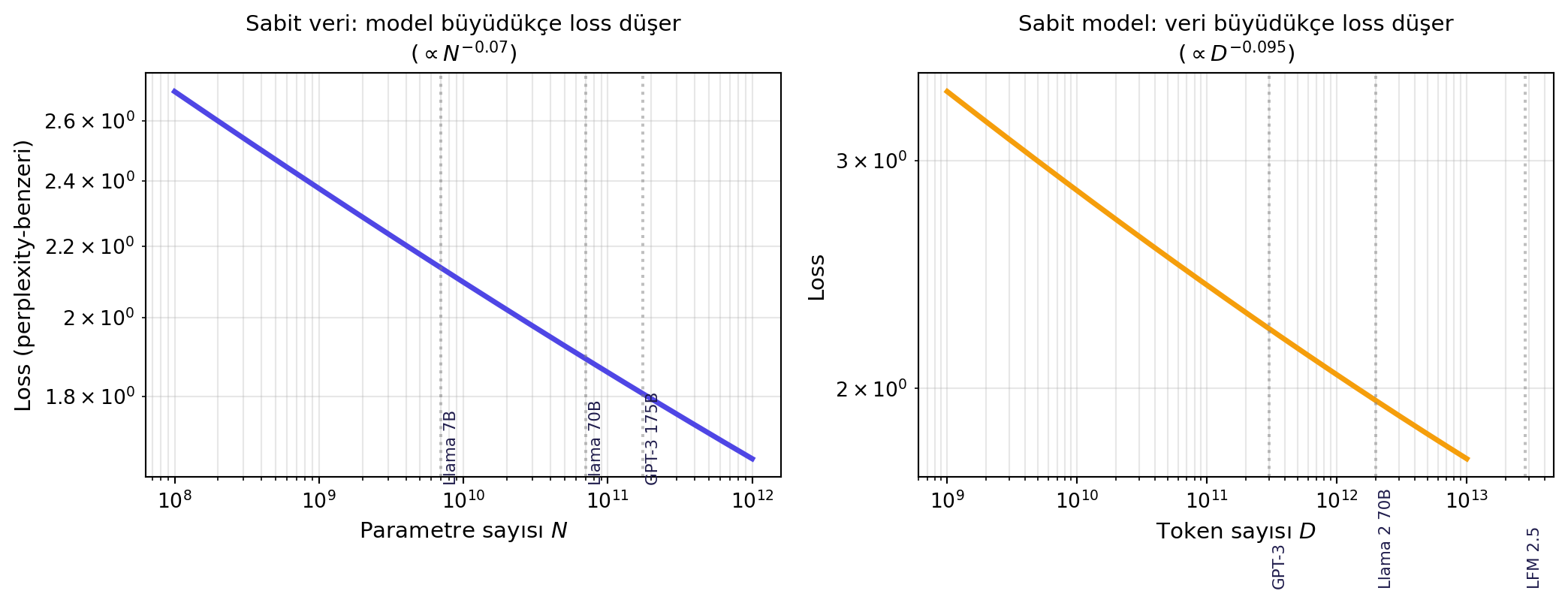
Meta'nın Llama 2 (2023) eğitim eğrileri net gösteriyor: daha çok veri → daha düşük loss, monoton; aynı veri + daha büyük model = daha iyi sonuç. Bu gözlemler **scaling laws** olarak resmileştirildi (Kaplan 2020, Chinchilla 2022).
> *"more training data means a better loss... larger model on same data means a lower loss."* — Lechner, 5:31
```{python}
#| label: fig-scaling-laws
#| fig-cap: "Scaling laws sezgisi: loss, hem parametre sayısı hem token sayısı ile bir **güç yasası** ilişkisi gösterir. Sol — sabit veri ile farklı model boyutları; sağ — sabit model ile farklı veri büyüklüğü."
#| fig-width: 11
#| fig-height: 4.5
import numpy as np
import matplotlib.pyplot as plt
fig, axes = plt.subplots(1, 2, figsize=(11, 4.5))
N = np.logspace(8, 12, 200)
loss_N = 0.5 + 8.0 * N ** (-0.07)
axes[0].loglog(N, loss_N, color='#4f46e5', linewidth=2.6)
axes[0].set_xlabel('Parametre sayısı $N$', fontsize=11)
axes[0].set_ylabel('Loss (perplexity-benzeri)', fontsize=11)
axes[0].set_title('Sabit veri: model büyüdükçe loss düşer\n($\\propto N^{-0.07}$)', fontsize=11)
axes[0].grid(alpha=0.3, which='both')
for N_mark, label in [(7e9, 'Llama 7B'), (7e10, 'Llama 70B'), (1.75e11, 'GPT-3 175B')]:
axes[0].axvline(N_mark, color='gray', linestyle=':', alpha=0.5)
axes[0].text(N_mark * 1.05, 1.6, label, rotation=90, fontsize=8, color='#1e1b4b', va='bottom')
D = np.logspace(9, 13, 200)
loss_D = 0.6 + 20.0 * D ** (-0.095)
axes[1].loglog(D, loss_D, color='#f59e0b', linewidth=2.6)
axes[1].set_xlabel('Token sayısı $D$', fontsize=11)
axes[1].set_ylabel('Loss', fontsize=11)
axes[1].set_title('Sabit model: veri büyüdükçe loss düşer\n($\\propto D^{-0.095}$)', fontsize=11)
axes[1].grid(alpha=0.3, which='both')
for D_mark, label in [(3e11, 'GPT-3'), (2e12, 'Llama 2 70B'), (2.8e13, 'LFM 2.5')]:
axes[1].axvline(D_mark, color='gray', linestyle=':', alpha=0.5)
axes[1].text(D_mark * 1.05, 1.4, label, rotation=90, fontsize=8, color='#1e1b4b', va='bottom')
plt.tight_layout()
plt.show()
```
Sonuç: **ölçeklendirme artık tercih değil, zorunluluk.** Endüstri yalnızca modeli değil, hem modeli hem veriyi büyütmek zorunda.
::: {.callout-tip title="Builder Notu — Roofline Profilleme"}
**Geriye (Ders 6 + Stat 110):** Scaling laws, Ders 6'da Ava'nın bahsettiği **emergent abilities** olgusunun nicel zeminidir. Power-law ilişkileri Stat 110'un da çeşitli yerlerinde görülür.
**İleriye:** Bir builder olarak: **compute-bound** mu yoksa **memory-bound** mu olduğun, mimari ve donanım seçiminin temelidir. GPU üzerinde **roofline model** profillemesi (Nsight Systems, PyTorch Profiler), neyi optimize edeceğini gösterir.
:::
## Sezgi-Dışı: Modeller Küçülüyor (İnference Maliyeti Hâkim) {#sec-inference-dominance}
Scaling laws "daha büyük model her zaman daha iyi" diyor. Ama endüstri verileri farklı bir hikâye anlatıyor:
| Model | Yıl | Parametre | Token |
|-------|-----|-----------|-------|
| GPT-3 | 2020 | 175B | 300B |
| Llama 2 70B | 2023 | 70B | 2T |
| LFM 2.5 1.2B | 2025 | 1.2B | 28T |
Modeller hem **küçülüyor** hem **çok daha çok veriyle eğitiliyor**. Neden? Çünkü scaling laws yalnızca **eğitim maliyetini** anlatır. Ama bir modelin gerçek toplam maliyeti **eğitim + ömür boyu çıkarım (inference)** toplamıdır. ChatGPT'nin milyarlarca kullanıcısı olduğunda, inference maliyeti eğitim maliyetini **birkaç gün içinde** geçer.
> *"the inference cost dominates the compute. If you look at the lifetime of a model, the training portion is actually only a small portion."* — Lechner, 8:09
Pratik kanıt: GPT-3 modelinin weight'leri Lechner'in laptopuna sığmıyor; LFM 2.5 1.2B ise Raspberry Pi'de çalışıyor — telefonda offline çalışıyor (Ders 1 açılış demosu).
Bu, **Chinchilla scaling laws**'un da öğrettiği şey: "compute-optimal" model boyutu, veri ve compute tüketimini birlikte düşünür. "Daha çok veriyle daha küçük modeli daha uzun eğitmek" sıklıkla daha iyi sonuç verir.
::: {.callout-tip title="Builder Notu — Toplam Yaşam-Döngüsü Maliyeti"}
**Geriye (Ders 6):** Bu, Ders 6'nın sonunda işaret edilen ölçek-yetenek-maliyet trilemmasının pratik karşılığıdır.
**İleriye:** **Quantization** (FP8, INT8, INT4, GPTQ, AWQ), **distillation**, **pruning**, **MoE**, **architecture search** (Liquid'ın liquid neural networks gibi yeni mimarileri). Bir builder olarak: **toplam yaşam-döngüsü maliyetini** modelle 1-1 eşle; eğitim ucuz olsa bile inference pahalı modeli prod'a çıkarmayın.
:::
## Data Parallelism (DDP): Doğal Paralelliği Sömürmek {#sec-ddp}
İlk ve en doğal ölçeklendirme yöntemi: **veri paralelliği**. SGD'nin güzel bir özelliği var — bir batch'teki her bir örneğin gradient'i **diğerlerinden bağımsız** hesaplanır:
$$
\nabla L = \frac{1}{B}\sum_{i=1}^{B}\nabla \mathcal{L}_i
$$
Bu, paralelleştirme için altın bir fırsat: $N$ GPU'ya **modelin tam bir kopyasını** koy, batch'i $N$ parçaya böl, her GPU kendi parçasının gradient'ini bağımsız hesaplasın, sonra **tek bir senkronizasyon adımında** (all-reduce) ortalamayı al.
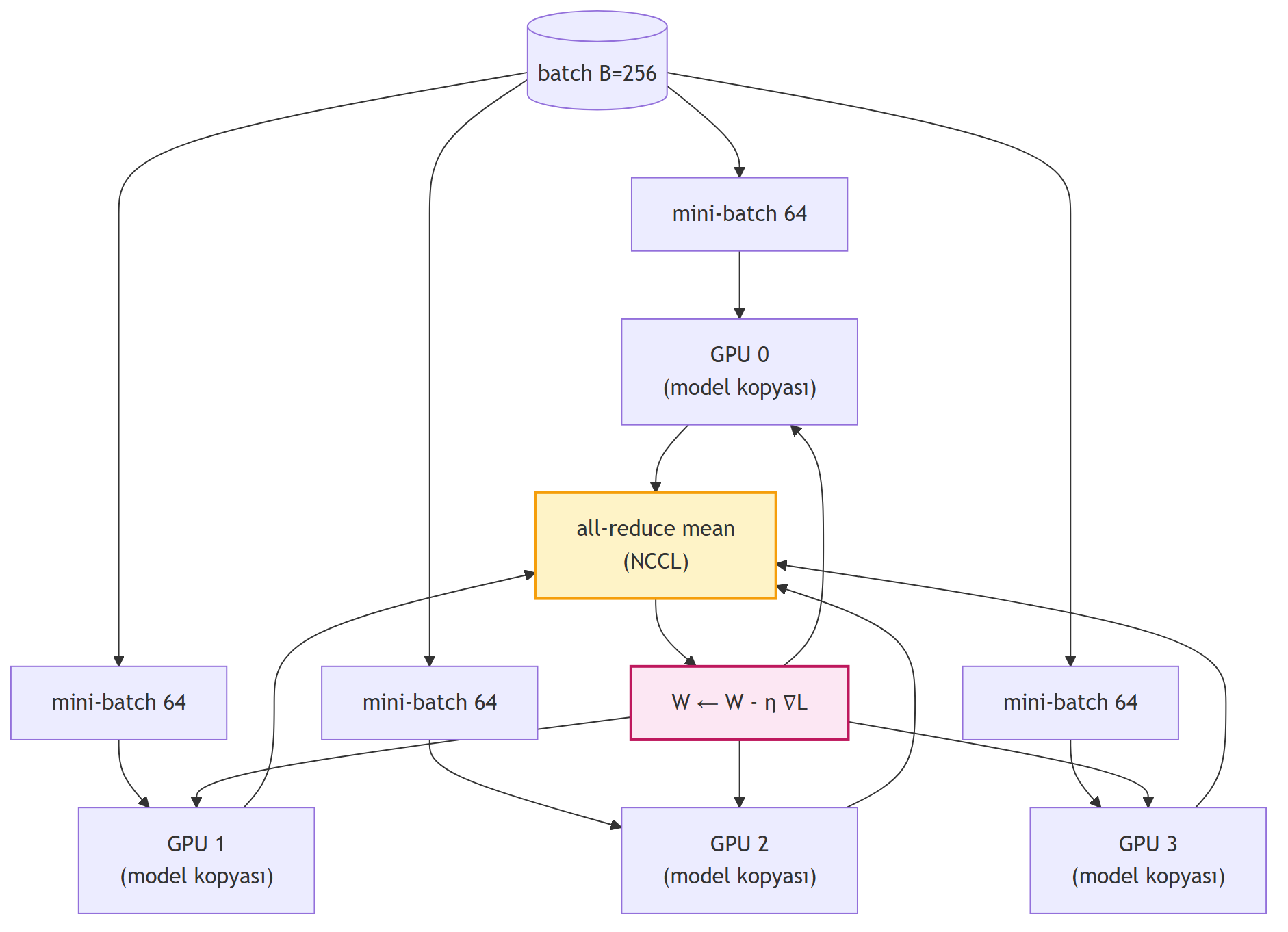{#fig-ddp fig-align="center" width=85%}
**Avantajlar:** Compute-heavy kısım tamamen paralel; communication yalnızca sonda bir kez; lineer ölçeklenir.
**Sınırı:** "effective batch size" arttıkça **genelleme** zarar görür. Çok büyük batch'lerle eğitilen modeller, küçük batch'le eğitilenlerin gerisinde kalır (test setinde). Bu, **loss landscape**'in optimizasyon dinamikleri ile ilgilidir.
> *"batch size scaling is the most naive way to scale, but there's a limitation, and we need to think about how to scale throughput without scaling batch size."* — Lechner, 11:09
Yani DDP **gerekli** ama **yetmez**.
::: {.callout-tip title="Builder Notu — LR Scaling"}
**Geriye (Stat 110):** Mini-batch gradient = full-batch gradient'in tarafsız tahmincisi — Stat 110 Ders 9 örneklem ortalaması. Varyans $\propto 1/B$ ifadesi DDP'nin de tabanıdır.
**İleriye:** Pratikte **linear LR scaling** (batch size 2× → LR 2×, belirli sınırlara kadar), **LR warmup**, **LAMB optimizer** bu trade-off'u idare eder. **Gradient accumulation** (küçük microbatch'lerin gradient'lerini biriktir, sonra bir adım at) ise tek GPU'da "sanal" büyük batch elde etmenin yoludur.
:::
## GPU Bellek Bütçesi: 1B Bile Sıkıyor {#sec-memory}
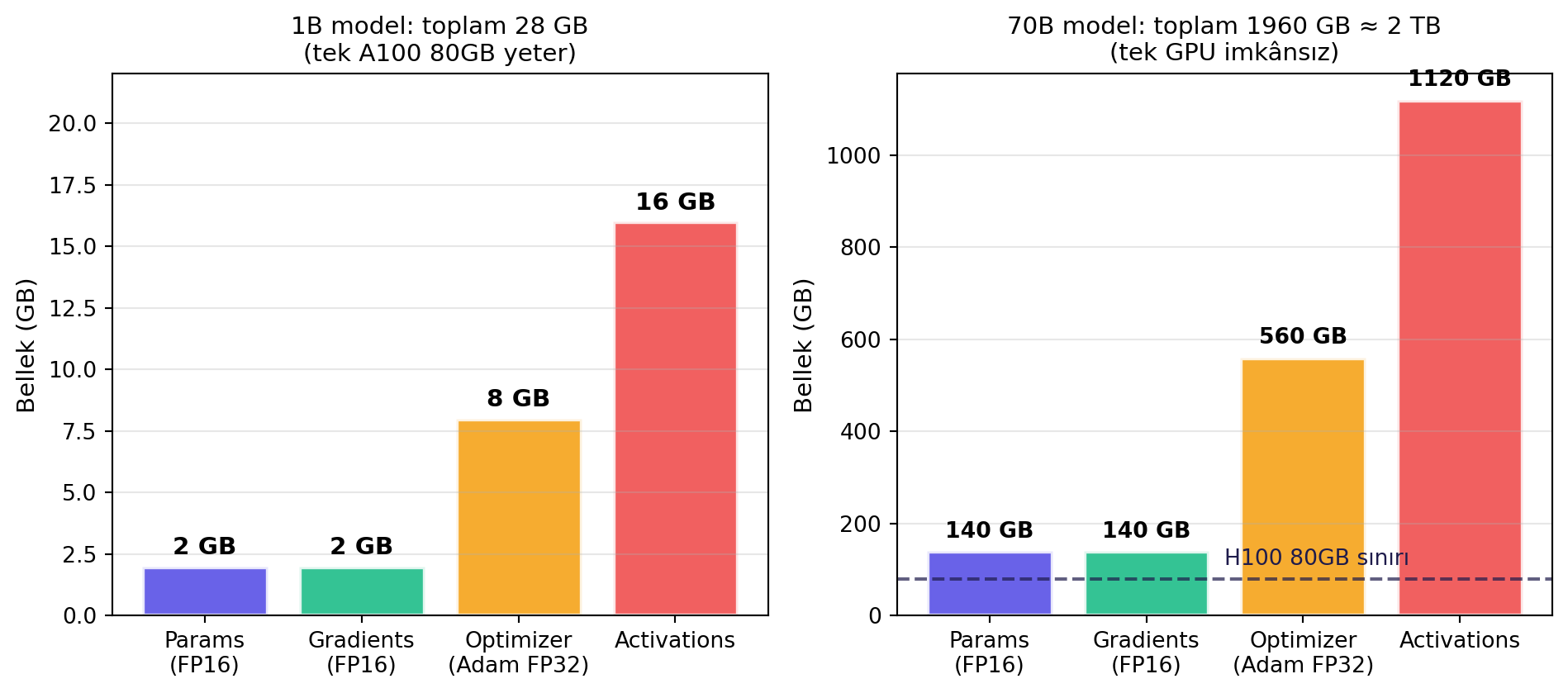
Lechner çok somut bir hesap yapıyor — **1 milyar parametreli** bir modeli batch size 16, 256 katman, 1k hidden boyutla eğitmek için bellekte ne kadar yer gerekiyor?
```{python}
#| label: fig-memory-budget
#| fig-cap: "1B parametreli modelin bellek dökümü: 28 GB toplam (1×A100/H100 yeter). 70B model 70× ölçeklenince 2 TB — tek GPU'da imkânsız → sharding zorunlu."
#| fig-width: 10
#| fig-height: 4.5
fig, axes = plt.subplots(1, 2, figsize=(10, 4.5))
categories = ['Params\n(FP16)', 'Gradients\n(FP16)', 'Optimizer\n(Adam FP32)', 'Activations']
sizes_1b = [2, 2, 8, 16]
colors = ['#4f46e5', '#10b981', '#f59e0b', '#ef4444']
axes[0].bar(categories, sizes_1b, color=colors, edgecolor='white', linewidth=2, alpha=0.85)
for i, v in enumerate(sizes_1b):
axes[0].text(i, v + 0.5, f'{v} GB', ha='center', fontsize=11, weight='bold')
axes[0].set_ylabel('Bellek (GB)', fontsize=11)
axes[0].set_title(f'1B model: toplam {sum(sizes_1b)} GB\n(tek A100 80GB yeter)', fontsize=11)
axes[0].grid(axis='y', alpha=0.3)
axes[0].set_ylim(0, 22)
sizes_70b = [s * 70 for s in sizes_1b]
axes[1].bar(categories, sizes_70b, color=colors, edgecolor='white', linewidth=2, alpha=0.85)
for i, v in enumerate(sizes_70b):
axes[1].text(i, v + 30, f'{v} GB', ha='center', fontsize=10, weight='bold')
axes[1].axhline(80, color='#1e1b4b', linestyle='--', alpha=0.7)
axes[1].text(1.5, 110, 'H100 80GB sınırı', fontsize=10, color='#1e1b4b')
axes[1].set_ylabel('Bellek (GB)', fontsize=11)
axes[1].set_title(f'70B model: toplam {sum(sizes_70b)} GB ≈ 2 TB\n(tek GPU imkânsız)', fontsize=11)
axes[1].grid(axis='y', alpha=0.3)
plt.tight_layout()
plt.show()
```
Dört kalem:
- **Parameters (FP16):** 1B × 2 byte = **2 GB**.
- **Gradients (FP16):** Aynı boyutta = **2 GB**.
- **Optimizer states (Adam, FP32):** 1B × 4 byte × 2 moment = **8 GB**.
- **Activations:** ≈ **16 GB**.
$$
\text{toplam bellek} \approx \underbrace{2 + 2}_{\text{params + grads}} + \underbrace{8}_{\text{optimizer}} + \underbrace{16}_{\text{activations}} = 28\text{ GB}
$$
**1 milyar parametre için 28 GB.** Llama 2 70B veya GPT-4-class modeller için: $70 \times 28 \approx 2$ TB. Tek GPU'da yok.
> *"if you extrapolate this to a 70 billion parameter model, this would require 2 terabytes... there's no way we can fit this. So we need to have better strategies to reduce the memory requirements of training."* — Lechner, 13:09
::: {.callout-tip title="Builder Notu — Mixed Precision"}
**Geriye:** Bu hesap, Ders 1'deki backprop mekaniğinin (Calculus zincir kuralı + activation saklama) somut bellek karşılığıdır.
**İleriye:** **Mixed precision training**: parameters BF16, master copy FP32 — bellek/sayısal-doğruluk trade-off'u. **FP8 training** (H100 + Hopper): yeni jenerasyon ekstra bellek tasarrufu. **Quantization-aware training**: production için bellek-doğruluk dengesini eğitim sırasında öğren.
:::
## Activation Checkpointing + CPU Offload {#sec-checkpoint}
Activation belleği toplamın yarısından fazlasını kaplıyordu. İlk savunma: **activation checkpointing**. Forward'da her katmanın aktivasyonunu saklamak yerine, **her $N$ katmanda bir** sakla; aradakileri **at**. Backward'da gradient ihtiyaç duyduğunda, saklanmayanları **tekrar hesapla**.
> *"activation checkpointing is a trade-off compute to memory... in this scenario we see a 4× reduction in memory. In practice it's a lot."* — Lechner, 14:30
Tipik tasarruf: 4× bellek azalma, ~1.3× compute artışı.
İkinci savunma: **CPU offload**. GPU belleği yetmiyorsa, az kullanılan veriyi **CPU RAM'e** veya **NVMe disk'e** sürün. Bedel: **bandwidth**. GPU'nun kendi HBM'i ~3 TB/s; CPU'ya geçen PCIe bus ~30 GB/s (100× yavaş). Yani offload **niş** kullanımdadır.
::: {.callout-tip title="Builder Notu — FlashAttention"}
**Geriye:** Activation checkpointing = Calculus zincir kuralının **lazy evaluation** versiyonu — gerektiğinde yeniden hesapla.
**İleriye:** **FlashAttention** ve **PagedAttention** modern attention implementasyonları aynı bellek-compute takasını attention için yapar. Production'da: tek GPU'da büyük model fine-tune'u için **bitsandbytes** (8-bit Adam) + **PEFT** (LoRA) + activation checkpointing standart kombinasyondur.
:::
## GPU Küme Mimarisi: NVLink + InfiniBand {#sec-cluster}
Bin GPU'lu eğitim küme'leri nasıl yapılandırılır?
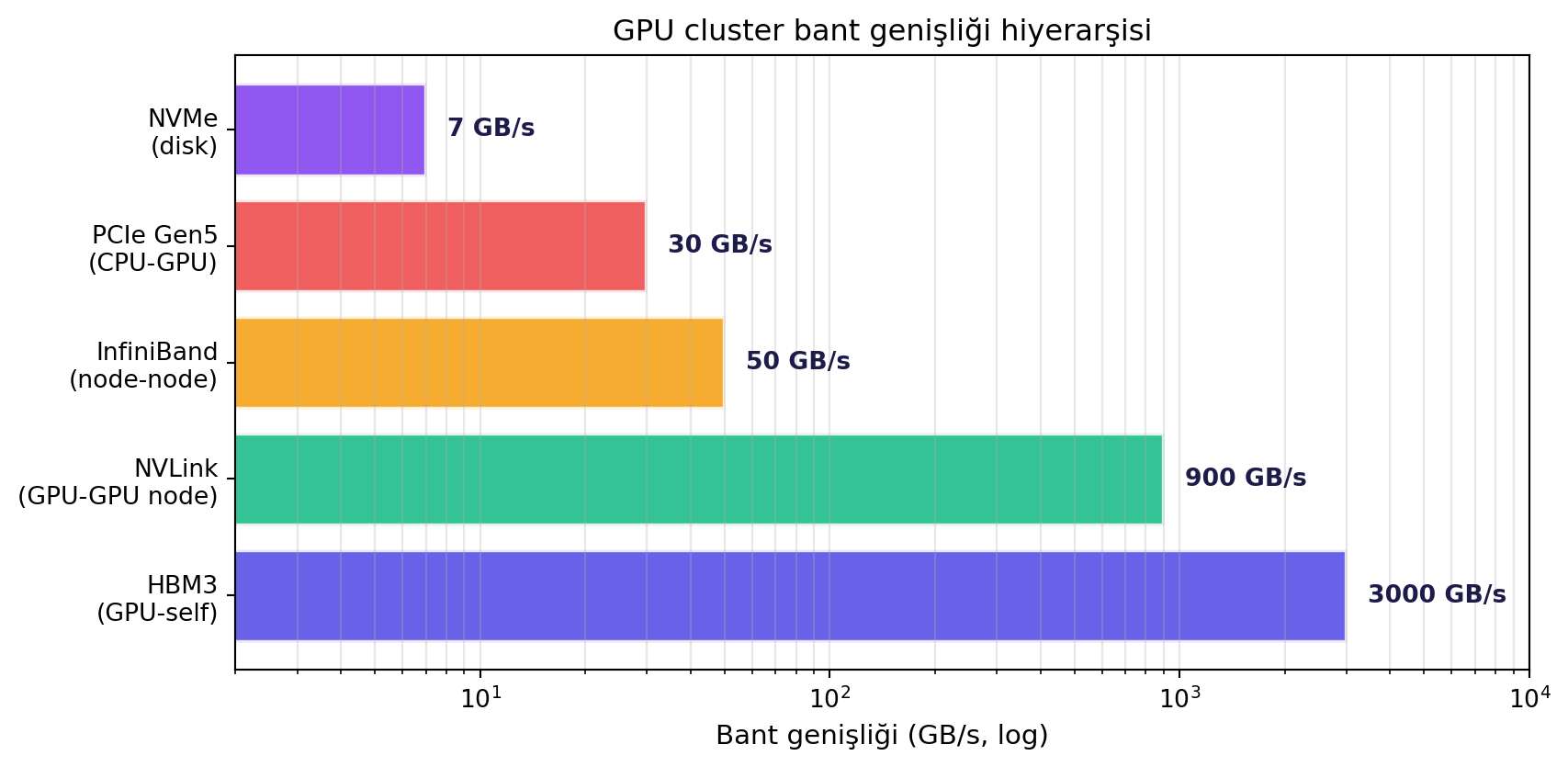
**Tek bir node:**
- 1 CPU + **8 GPU** (typical Nvidia DGX H100).
- Her GPU'nun kendi **HBM** (~3 TB/s).
- 8 GPU birbirine **NVLink** ile bağlı (~900 GB/s).
- CPU node'un kontrolünü tutar; PCIe ile GPU'lara bağlı (~30 GB/s, **çok daha yavaş**).
- Bu yapı **"scale up"** denir.
**Çoklu node:**
- Aynı yapıdan $N$ node birbirine bağlanır.
- Node'lar arası **InfiniBand** veya RoCE ağı (~400 Gb/s = 50 GB/s).
- **RDMA** (Remote Direct Memory Access) kritik.
- Bu yapı **"scale out"** denir.
```{python}
#| label: fig-bandwidth
#| fig-cap: "Bant genişliği hiyerarşisi (log ölçek): HBM > NVLink > InfiniBand > PCIe > Disk. Bu hiyerarşi, paralelizm stratejisi seçiminin fiziksel temelidir."
#| fig-width: 9
#| fig-height: 4.5
links = ['HBM3\n(GPU-self)', 'NVLink\n(GPU-GPU node)', 'InfiniBand\n(node-node)', 'PCIe Gen5\n(CPU-GPU)', 'NVMe\n(disk)']
bandwidth = [3000, 900, 50, 30, 7]
colors = ['#4f46e5', '#10b981', '#f59e0b', '#ef4444', '#7c3aed']
fig, ax = plt.subplots(figsize=(9, 4.5))
bars = ax.barh(links, bandwidth, color=colors, edgecolor='white', linewidth=2, alpha=0.85)
ax.set_xscale('log')
for bar, bw in zip(bars, bandwidth):
ax.text(bw * 1.15, bar.get_y() + bar.get_height() / 2, f'{bw} GB/s',
va='center', fontsize=10, weight='bold', color='#1e1b4b')
ax.set_xlabel('Bant genişliği (GB/s, log)', fontsize=11)
ax.set_title('GPU cluster bant genişliği hiyerarşisi', fontsize=12)
ax.grid(axis='x', alpha=0.3, which='both')
ax.set_xlim(2, 10000)
plt.tight_layout()
plt.show()
```
Bant genişliği hiyerarşisi: $\text{HBM} > \text{NVLink} > \text{InfiniBand (RDMA)} > \text{PCIe} > \text{Disk}$.
::: {.callout-tip title="Builder Notu — Topology-Aware"}
**Geriye (18.06):** Matris çarpımı $W \cdot x$, hangi GPU çiftleri arasında hangi veri akacaksa, ona göre paylaştırılır. 18.06'nın **block matrix multiplication**'ı bu mantığın matematiksel temelidir.
**İleriye:** Bant genişliği hiyerarşisini bilmek, kendi mimarinizi tasarlarken **"hangi tensor nerede yaşamalı"** sorusunu doğru yanıtlamayı sağlar. **NVSHMEM**, **DeepEP**, **NCCL** modern GPU communication kütüphaneleridir; **collective operations** (all-reduce, all-gather, reduce-scatter) bunların API'leridir.
:::
## Sharding Stratejileri: Modeli Parçalara Bölmek {#sec-sharding}
DDP modelin **tam kopyasını** her GPU'ya yerleştiriyordu. Büyük modellerde bu mümkün değil — modelin kendisini, gradient'ini, optimizer state'ini **paylaştırmak** gerekiyor.
Genel takas:
$$
\text{daha az bellek per GPU} \;\Longleftrightarrow\; \text{daha çok haberleşme}
$$
Hangi şeyi sharding ettiğine göre stratejiler:
- **Optimizer sharding (ZeRO Stage 1):** Sadece optimizer state'leri böl.
- **Pipeline parallelism:** Modeli **katman ekseninde** böl.
- **Tensor parallelism:** **Katman içinde** böl.
- **Sequence parallelism:** Diziyi token ekseninde böl.
- **Expert parallelism (MoE):** Mixture-of-Experts mimarilerinde uzman ağlarını farklı GPU'lara dağıt.
Her strateji belirli bir bellek-haberleşme dengesine sahip; pratikte **birleştirilir**. Buna **3D / 5D paralelizm** denir.
> *"the key trade-off here is in a way that we reduce the memory that each device must hold but it adds communication overhead."* — Lechner, 19:53
{#fig-sharding-flow fig-align="center" width=85%}
::: {.callout-tip title="Builder Notu — 5D Paralelizm"}
**Geriye (18.06):** Tensor parallelism doğrudan blok matris çarpımının paralelleştirilmesidir (18.06 Ders 30); kolon vs satır parçalanma seçimi, ara sonuçların hangi GPU'da kalacağını belirler.
**İleriye:** Modern training cluster'larda **5D parallelism** (data + tensor + pipeline + sequence + expert) eş zamanlı çalışır. **DeepSpeed ZeRO config** veya **FSDP wrap policy** yazmak, bu beş eksen kararının somut hâlidir.
:::
## Pipeline ve Tensor Parallelism: Detaylar {#sec-pipeline-tensor}
**Pipeline parallelism (depth-wise split)** — modeli **derinlik ekseninde** parçala. Örnek: 64-katmanlı bir transformer, 4 GPU'ya. GPU0: katmanlar 0–15, GPU1: 16–31, vb. Sonra forward'da GPU0 hesaplar, GPU1 hesaplarken GPU0 boşta.
Bu **pipeline bubble** problemini doğurur. 4 GPU'lu sistemde ortalama %25 yararlanım = %75 boşa.
**Çözüm: microbatching.** Bir batch'i daha küçük parçalara böl; GPU0 birinci microbatch'i bitirince ikinciye geçer (pipeline başlar). F1 yarış pisti gibi.
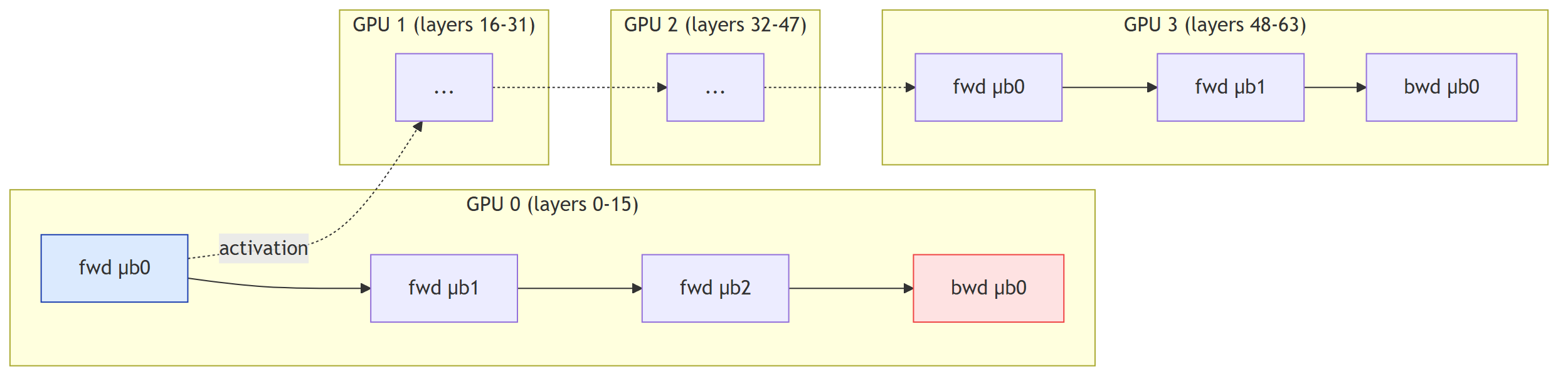{#fig-pipeline fig-align="center" width=85%}
**Tensor parallelism (within-layer split)** — bir tek katmanı parçala. $W$ matrisini ya **sütun** ya **satır** boyunca böl. Transformer MLP iki ardışık linear katmandır. **İlk katmanı column parallel + ikinci katmanı row parallel** yaparsan, ara çıktıyı (sharded) GPU'lar arası taşımaya gerek kalmaz — yalnızca **son adımda tek bir all-reduce**:
$$
\underbrace{x \xrightarrow{\text{column-parallel } W_1} h \xrightarrow{\text{GELU}} h'}_{\text{sharded ortada}} \xrightarrow{\text{row-parallel } W_2} \underbrace{y}_{\text{all-reduce}}
$$
**Sonuç:** İki katmanlık MLP, tek bir haberleşme adımıyla tensor-parallel koşar.
::: {.callout-tip title="Builder Notu — Column + Row Stack"}
**Geriye (18.06):** Tensor parallelism, **blok matris çarpımının** doğrudan paralelleştirilmesidir (18.06 Ders 30). Column vs row tercih, hangi tensor'ın hangi cihazda kalacağını belirleyen tasarımsal bir karardır.
**İleriye:** **Sequence parallelism** ile birleştirilebilir (Megatron-LM "sequence parallelism"); attention'da Q, K, V matrisleri için ayrı kararlar gerekebilir.
:::
## Sequence Parallelism ve Mixture of Experts {#sec-moe}
**Sequence parallelism** — diziyi token boyutunda parçala. 8k bağlam → 2k token / 4 GPU. MLP, LayerNorm gibi **zaman-bağımsız** katmanlar haberleşme gerektirmez. Ama **attention** her token'ı her token'a bakmasını gerektirdiği için karmaşıktır: **ring attention**, **DeepSpeed-Ulysses** bunu çözer.
**Mixture of Experts (MoE)** — fikir: bir transformer FFN'in içine birden çok "uzman" (sub-FFN) koy. Bir **router**, her token için hangi uzman(lar)ın aktif olacağına karar verir; aktif olmayanlar **sıfır** kabul edilir. Yani **kapasite** (toplam parametre) büyür ama **compute** (token başına aktif parametre) küçük kalır.
LFM2 8B-A1B örneği: 8.3B parametreli model, ama token başına yalnızca **1.5B aktif**.
> *"so it runs with the inference speed of a 1.5 billion model but has the capacity of an 8 billion model."* — Lechner, 29:21
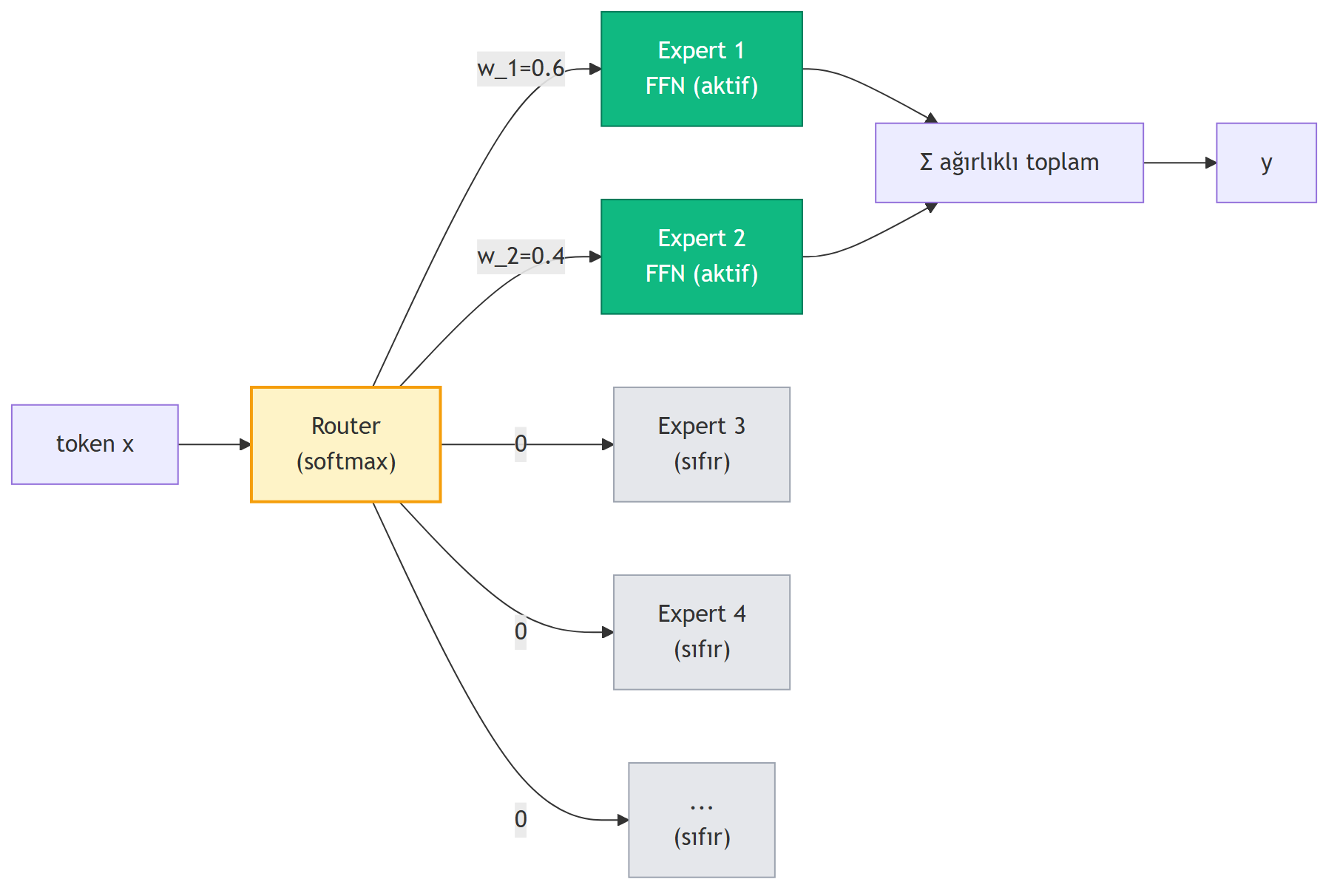{#fig-moe fig-align="center" width=85%}
**MoE'nin iki sorunu:**
1. **Eğitim kararsızlığı (load balancing):** Router naif olarak tüm token'ları aynı bir uzmana yönlendirebilir; o uzman büyür, diğerleri **eğitilmez**.
2. **GPU dengesizliği:** Aynı problem GPU seviyesinde — bazı GPU'lar yüklü, diğerleri idle.
> *"if the load balancing doesn't work and all tokens get routed to expert 0 and expert 1, it means GPU 1 has all the load and the rest are idling."* — Lechner, 30:14
::: {.callout-tip title="Builder Notu — MoE Cephesi"}
**Geriye (Ders 2):** Sequence parallelism, Ders 2'deki self-attention'ın hesaplama yapısının ($n^2$ complexity) bellek-boyutlanmadaki somut karşılığıdır. MoE ise Ders 4'ün generative mantığı + Ders 2'nin token-routing'inin birleşimidir.
**İleriye:** MoE bugünün frontier modellerinde standart: GPT-4 (16-expert), Mixtral (8-expert), DeepSeek-v3 (256-expert), LFM2-A1B. **Token routing** dinamikleri (top-k routing, expert choice routing) aktif araştırma cephesi. Sequence parallelism için **FlashAttention v2/v3**, **xFormers**, **vLLM PagedAttention** referans implementasyonlardır.
:::
## Frameworks: DeepSpeed, FSDP, Megatron-LM, JAX {#sec-frameworks}
Yukarıdaki paralelizm teknikleri kavramsal güzeller ama pratikte yüzlerce GPU'da bunları doğru senkronize etmek **zorlu mühendislik** problemidir.
**DeepSpeed (Microsoft)** — "ZeRO" ailesi:
- **Stage 1:** Optimizer state'leri shard et.
- **Stage 2:** Gradient'leri de shard et.
- **Stage 3:** Parameter'ları da shard et.
**FSDP (Fully Sharded Data Parallel, Meta)** — PyTorch native ZeRO-3 muadili:
```python
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
model = FSDP(MyModel(), sharding_strategy=ShardingStrategy.FULL_SHARD)
# ... normal training loop ...
```
**Megatron-LM (Nvidia)** — `ColumnParallelLinear`, `RowParallelLinear` katmanları; tensor + pipeline parallel built-in.
**JAX / Flax (Google)** — TPU üzerinde dominant. `pmap`, `pjit`, `shard_map` API'leri.
> *"each company wants to do their own stuff in a way. There's one company missing here — it's Google. It's because they are using JAX and not PyTorch."* — Lechner, 34:46
**Liquid AI'nın kendi yaklaşımı:** Hepsini birleştirir + custom optimizasyonlar. Sırrı: hibrit mimari (convolution + attention + recurrence), 2B parametrede 28T token, dikkatli scheduling.
::: {.callout-tip title="Builder Notu — Küçük Başla"}
**Geriye (Ders 7):** Bu framework manzarası, Ders 7 MLOps'unun training tarafıdır.
**İleriye:** Bir builder olarak: küçük başla. Önce single-GPU DDP, sonra FSDP, sonra ihtiyaç olursa Megatron-LM. **Mosaic Composer** (Databricks), **NeMo** (Nvidia), **Levanter** (JAX, Stanford) gibi yüksek-seviye orchestrator'lar bu karmaşıklığı sarar.
:::
## Bu Dersin Özeti {#sec-ozet}
1. **GPU + scaling laws:** AlexNet 2011'den bu yana GPU 1000×, ve scaling laws (Kaplan/Chinchilla) **veri + model + compute** üçlüsünün gücünü resmileştirdi.
2. **Sezgi-dışı:** modeller küçülüyor (GPT-3 175B → LFM 2.5 1.2B), çünkü **inference maliyeti** eğitim maliyetini aşar; toplam yaşam-döngüsünde küçük + iyi-eğitilmiş model kazanır.
3. **Data parallelism (DDP):** SGD'nin doğal paralelliği; replicate model, distribute batch, all-reduce sonda. Sınır: batch size genelleme erozyonu.
4. **Bellek bütçesi:** params + grads + optimizer + activations = 1B model için 28 GB; 70B için 2 TB. Tek GPU'da imkânsız → sharding zorunlu.
5. **Activation checkpointing:** bellek-compute takası, 4× bellek tasarrufu.
6. **CPU offload:** bandwidth darboğazı, niş kullanım.
7. **Cluster mimarisi:** NVLink scale-up + InfiniBand scale-out + RDMA; bant genişliği hiyerarşisi paralelizm seçimini belirler.
8. **Sharding paralelizmleri:** optimizer (ZeRO-1), pipeline (depth + microbatching), tensor (within-layer column/row), sequence, expert (MoE) — production'da hepsi birlikte.
9. **Pipeline bubble** microbatching ile çözülür; tensor parallel'da column + row stack tek all-reduce ile MLP çalıştırır.
10. **MoE** kapasiteyi compute'tan ayırır; load balancing kritik. **Frameworks:** DeepSpeed/FSDP/Megatron-LM/JAX.
::: {.callout-important title="Tek bir cümle"}
Devasa paralel eğitim, scaling laws'ın "daha çok" emrini donanım sınırları içine sığdırma sanatıdır — **modeli, gradient'i, optimizer'ı, sequence'ı, hatta uzmanları** bin GPU'ya parçalayıp tek bir öğrenme adımı gibi göstermek; data parallelism temel, sharding stratejileri (optimizer, pipeline, tensor, sequence, MoE) ölçek sınırlarını aşan mühendislik.
:::
## Kontrol Soruları {#sec-sorular}
::: {.callout-note collapse="true" title="Soru 1: DDP 'lineer ölçeklenir' demiştik. Pratikte sınır nerede?"}
**Cevap:** DDP'nin compute kısmı gerçekten doğrusal ölçeklenir. Sınır iki yerden gelir:
1. **All-reduce maliyeti:** GPU sayısı arttıkça gradient senkronizasyonu büyür. $N$ GPU üzerinde all-reduce kabaca $O(N)$ veri taşır (ring all-reduce). NVLink/InfiniBand bant genişliği doyduğunda, compute hızlanmayı haberleşme yutar.
2. **Effective batch size erozyonu:** $N$ GPU × batch_per_GPU = effective batch. Çok büyük batch (örn. >32K) genelleme performansını düşürür. Stat 110: küçük batch gradient'inin **varyansı** modeli daha iyi regularize eder.
Pratik çözümler: **gradient accumulation**, **LR scaling** (batch ile birlikte LR'yi büyüt), **LARS/LAMB** optimizer'ları, **warmup**.
:::
::: {.callout-note collapse="true" title="Soru 2: 1B parametreli modelin Adam ile eğitiminde toplam bellek 28 GB. 70B için neden tek GPU'ya sığmaz?"}
**Cevap:** 1B model, batch 16, 256 katman, 1k hidden için kalemler:
| Kalem | Hesap | Boyut |
|-------|-------|-------|
| Parameters (FP16) | 1B × 2 byte | 2 GB |
| Gradients (FP16) | 1B × 2 byte | 2 GB |
| Optimizer (Adam, FP32, 2 moment) | 1B × 4 × 2 byte | 8 GB |
| Activations | batch × layers × hidden | ~16 GB |
| **Toplam** | | **28 GB** |
70B için kabaca 70× extrapole ederiz: ~**2 TB**. En büyük modern GPU bellek (H100 80 GB, B200 192 GB, MI300X 256 GB) bunun çok altında. Yani **fiziksel olarak imkânsızdır** tek GPU'ya sığdırmak. Bu yüzden:
- Optimizer states shard et (ZeRO-1): −8/$N$ GB.
- Gradient shard et (ZeRO-2): −2/$N$ GB ekstra.
- Parameter shard et (ZeRO-3 / FSDP): −2/$N$ GB ekstra.
- Activation checkpointing: 16 → 4 GB (4× azalma).
Tüm bunlarla, **64 GPU üzerinde**, 70B model ortalama ~30 GB / GPU'ya sığar.
:::
::: {.callout-note collapse="true" title="Soru 3: Transformer MLP'de neden column-parallel + row-parallel stack tek all-reduce ile çalışır?"}
**Cevap:** Anahtar: ara hidden vektörünün **sharded** kalmasıdır.
- **İlk katman (column parallel):** Girdi $x$ her GPU'da replicated. $W_1$'in sütunları GPU'lara dağıtılır. Her GPU $x \cdot W_{1,\text{kendi sütunu}}$ hesaplar → çıktı **sharded** (ara hidden $h$'in farklı parçaları farklı GPU'larda).
- **GELU:** Element-wise, sharded $h$ üzerinde **lokal** çalışır. Haberleşme yok.
- **İkinci katman (row parallel):** Girdi $h$ zaten sharded. $W_2$'nin satırları GPU'lara dağıtılır. Her GPU kendi parçasını çarpar → **kısmi sonuçlar**. Bunları toplamak için tek **all-reduce**.
Sonuç: iki linear katman + bir nonlinearity, **bir tek all-reduce** ile tensor-parallel koşar. İletişim minimum, GPU'lar maksimum yararlanım. Bu desen Megatron-LM'in MLP block implementasyonunun temelidir; bugün hemen her büyük transformer eğitiminde kullanılır.
:::
::: {.callout-note collapse="true" title="Soru 4: (Builder) MoE ne zaman seç, ne zaman dense tercih et?"}
**Cevap:** **MoE'yi seç:**
- **Inference cost** kritikse ve kalite şart: aynı kalite için çok daha az aktif FLOP. LFM2-A1B örneği: 8B kapasite + 1.5B inference hızı.
- **Çok-domain** model: farklı uzmanlar farklı işlerde uzmanlaşır.
- Eğitim **compute bütçesi** parametre bütçesini aşmıyor.
**Dense'i seç:**
- **Yüksek-throughput inference**: dense FLOP'lar daha **predictable** ve **donanım-verimlidir** (matrix multiply optimal). MoE routing GPU'da "sparse-style" işlemler getirir.
- **Eğitim kararlılığı**: MoE'nin load balancing problemi gerçektir; deneyimsiz ekipler için tehlikeli.
- **Bellek budget'i tight**: MoE inference için tüm uzmanları bellekte tutman gerek (sadece compute aktif değil), bu "effective param count" gibi bellek isteminin yanılgısıdır.
- **Distillation** hedefiyse: dense modeli distill etmek MoE'yi distill etmekten çok daha kolay.
Pratik öneri: önce dense scaling laws ile sınırlarını öğren, sonra MoE'ye geç. Open-source: Mixtral (8×7B), DBRX, DeepSeek-v3 öğrenmeye iyi başlangıç noktaları.
:::
## Egzersizler {#sec-egzersizler}
**Egzersiz 1 (Minimal DDP).** PyTorch `torch.distributed` ile **tek makinede** 2-süreç DDP eğitimi yaz. MNIST gibi küçük bir veri seti yeter. `torchrun --nproc_per_node=2 train.py` ile başlat.
```python
import torch, torch.nn as nn, torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
dist.init_process_group(backend='nccl')
rank = dist.get_rank()
model = MyModel().cuda(rank)
ddp_model = DDP(model, device_ids=[rank])
# normal training loop — DDP gradient'leri otomatik all-reduce eder
```
**Egzersiz 2 (FSDP wrap policy).** Aynı modeli FSDP ile sar; `ShardingStrategy.FULL_SHARD` (ZeRO-3 muadili) ve `NO_SHARD` (DDP eşdeğeri) ayarlarını karşılaştır. (a) Her GPU'da bellek tüketimini `torch.cuda.memory_allocated()` ile ölç. (b) Adım süresi (latency) nasıl değişir?
**Egzersiz 3 (Bellek bütçesi hesabı).** Llama 2 7B için tahmini eğitim belleğini hesapla. Varsayımlar: FP16 params + grads, Adam (FP32 m + v), 4K context, batch 4. (a) Activation checkpointing kullanmadan bellek? (b) Activation checkpointing ile? (c) Tek H100 80 GB'a sığar mı?
```python
def memory_budget(num_params, hidden, layers, batch, seq_len, dtype_bytes=2):
params = num_params * dtype_bytes
grads = num_params * dtype_bytes
optimizer = num_params * 4 * 2 # Adam: m + v in FP32
activations = batch * seq_len * hidden * layers * 4 * dtype_bytes
return {
'params_GB': params/1e9,
'grads_GB': grads/1e9,
'opt_GB': optimizer/1e9,
'acts_GB': activations/1e9,
}
print(memory_budget(7e9, 4096, 32, 4, 4096))
```
**Egzersiz 4 (Mixed precision).** PyTorch'ta `torch.amp.autocast` ile bfloat16 eğitim yap. (a) Standart FP32 ile karşılaştır: throughput, bellek, doğruluk. (b) NaN/Inf görür müsün? `GradScaler` ne işe yarar?
**Egzersiz 5 (Sonraki dersin habercisi).** **Ders 10** — 2025 misafir, **LLM Post-Training**: bir base LLM'i nasıl ChatGPT/Claude gibi asistana çevirirsin? Üç aşamayı araştır: (a) **Instruction tuning** (SFT — supervised fine-tuning) — insan-yazılı talimatlardan öğrenme; (b) **RLHF** (Reinforcement Learning from Human Feedback) — Ders 5'ten hatırla; (c) **DPO** (Direct Preference Optimization) — RL'siz, doğrudan tercih optimizasyonu. Her aşama için bir paragraf hazırla.
## Sonraki Ders İçin Hazırlık {#sec-sonraki}
**Ders 10: LLM Sonrası-Eğitim (LLM Post-Training)** — 2025 misafir konuşmacı
Base LLM next-token tahmin eder (Ders 6); ama "yardımsever, zararsız, dürüst" davranan bir asistana dönüşmesi için **post-training** aşamaları gerekir. SFT, RLHF, DPO bu üçlünün direkleridir. Lechner'in bahsettiği LFM 2.5 1.2B gibi modeller, etkili post-training sayesinde küçükken bile rekabetçi olabilir.
**Ana konular (beklenen):**
- SFT (supervised fine-tuning) — instruction following.
- Reward model — Ders 5'in RLHF'sinin temeli.
- PPO, DPO, GRPO — modern alignment algoritmaları.
- Constitutional AI ve aktif hizalama cepheleri.
::: {.callout-warning title="Ders 10 öncesi yapılacak"}
- Egzersizleri çöz — özellikle 3 (bellek bütçesi) ve 5 (post-training stages).
- DDP + FSDP + sharding hiyerarşisini kendi cümlenle anlat — bir builder olarak hangi durumda hangisini seçersin?
- Ana cümleyi tekrar oku: *"Devasa paralel eğitim, scaling laws'ın 'daha çok' emrini donanım sınırları içine sığdırma sanatıdır."*
:::
## Anahtar Kavramlar (Cheat Sheet) {#sec-cheat-sheet}
| Kavram | Tanım | Lechner'de |
|--------|-------|------------|
| **GPU eğitiminin doğuşu** | AlexNet 2011, 2 GPU, derin öğrenme devrimini tetikledi | 2m21 |
| **Scaling laws** | Loss = veri ve parametre sayısının güç yasası fonksiyonu | 5m31 |
| **Inference dominance** | Model ömründe inference maliyeti eğitimin ötesine geçer → küçük model trendi | 8m09 |
| **Data parallelism (DDP)** | Modeli replicate et, batch'i böl, sonda all-reduce | 9m55 |
| **Batch size limit** | Çok büyük effective batch genelleme erozyonuna yol açar | 11m09 |
| **Bellek bütçesi** | 1B model = 28 GB (params + grads + optimizer + activations) | 13m06 |
| **Activation checkpointing** | Belleği 4× azalt, ekstra forward pass maliyetiyle | 14m30 |
| **CPU offload** | Az kullanılan veriyi CPU RAM'e gönder; bandwidth darboğazı | 15m23 |
| **NVLink scale-up** | Tek node içinde 8 GPU yüksek-bant bağlantı (~900 GB/s) | 17m51 |
| **InfiniBand scale-out** | Node'lar arası ağ (~50 GB/s) + RDMA | 18m23 |
| **Optimizer sharding (ZeRO-1)** | Optimizer state'leri böl; reduce-scatter + all-gather | 20m12 |
| **Pipeline parallelism** | Depth-wise split + microbatching ile bubble'ı azalt | 22m05 |
| **Tensor parallelism** | Within-layer split (W column/row); MLP'de tek all-reduce | 24m32 |
| **Sequence parallelism** | Token ekseninde böl; uzun bağlam eğitimi (ring attention) | 26m26 |
| **Mixture of Experts** | Router + uzmanlar; kapasite vs compute ayrılması; load balancing kritik | 27m51 |
| **DeepSpeed / FSDP / Megatron / JAX** | 4 ana sharding framework'ü; PyTorch + Microsoft/Meta/Nvidia, Google JAX | 30m44 |
## ML Builder Bağlantıları {#sec-ml-baglantilar}
::: {.callout-tip title="8 köprü"}
1. **DDP** → Ders 1 SGD doğal paralelliği + Stat 110 örneklem ortalaması (Ders 9). İleriye: gradient accumulation, large-batch LR scaling.
2. **Bellek bütçesi** → Ders 1 backprop'un Calculus zincir kuralı sonucu activation saklama. İleriye: mixed precision (FP16/BF16/FP8), quantization.
3. **Activation checkpointing** → Calculus zincir kuralı parçalı yeniden hesaplama; bellek-compute trade-off.
4. **Cluster scale-up/out** → 18.06 blok matris çarpımı + topology-aware kararlar.
5. **Tensor parallelism** → 18.06 Ders 30 matris çarpım faktörleri; column + row stacking transformer MLP için optimal.
6. **Sequence parallelism** → Ders 2 attention'ın $O(n^2)$ maliyetinin paralelleştirilmesi; FlashAttention/PagedAttention modern karşılığı.
7. **MoE** → Ders 4 generative + Ders 2 token routing; structured sparsity.
8. **Scaling laws + küçük model trendi** → Ders 6'nın emergent abilities + Bishop'un Bitter Lesson sezgisinin nicel hâli. İleriye: Chinchilla, compute-optimal training.
:::
::: {.callout-important title="Bu dersten tek bir şey alıp gideceksen"}
Modern AI'ın işleyen sırrı, scaling laws + cluster mühendisliğinin uzlaşmasıdır. Scaling laws "daha çok" der; donanım "sığmıyor" der; **5 boyutlu paralelizm** (data, tensor, pipeline, sequence, expert) bu iki kuvvetin arasında kalan zarif mühendislik diliyle ölçeği kazandırır. Bir builder olarak: küçük başla (DDP), ihtiyaç olursa katmanlama (FSDP → tensor parallel → pipeline parallel), ve toplam yaşam-döngüsü maliyetini eğitim kadar inference'da da düşün.
:::