---
title: "Derin Bilgisayarlı Görü"
subtitle: "Convolution + ReLU + pooling — kenardan nesneye uzanan hiyerarşi"
---
::: {.callout-note title="Bölüm bilgisi"}
- **Lecture videosu:** [YouTube — Lecture 3: Deep Computer Vision](https://www.youtube.com/watch?v=pqIcoskUuWs&list=PLtBw6njQRU-rwp5__7C0oIVt26ZgjG9NI&index=3) (≈57 dk)
- **Edition:** 2026 • **Hoca:** Alexander Amini
- **Kaynak:** [introtodeeplearning.com](https://introtodeeplearning.com)
- **Okuma süresi:** ≈32 dk
:::
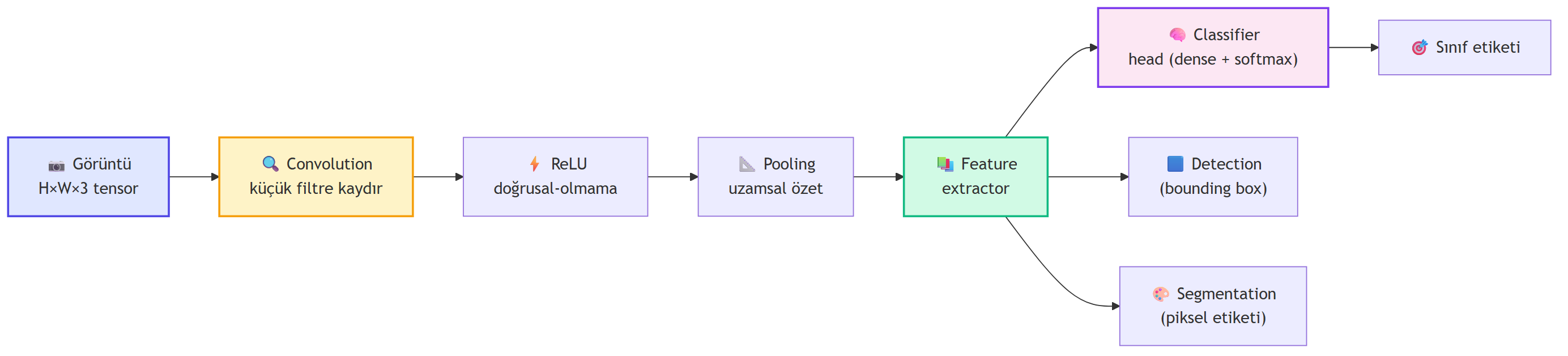
## Bu Derste Ne Var? {#sec-bu-derste}
Ders 1 sabit boyutlu vektör veriyi, Ders 2 dizileri işledi. Sırada en zengin modalite: **görüntüler**. İnsanlar için görü öyle doğaldır ki **tümüyle hafife alırız** — ama bir bilgisayar için piksellerden anlam çıkarmak çetin bir problemdir. Bugünkü kameralar, otonom araçlar, tıbbi görüntüleme, telefonundaki yüz tanıma — hepsi bu derste anlatacağımız bir tek mimariye dayanır: **convolutional neural network (CNN)**.
> *"sight and vision these are one of the most important human senses... vision is so much more than just recognizing... it's actually about understanding the dynamics of your scene."* — Amini, 0:24
**Dersin yolculuğu:**
1. **Görüntü = sayılar matrisi** — grayscale 2B, RGB 2B × 3 kanal.
2. **Hiyerarşik öznitelikler** — düşük (kenar/köşe) → orta (şekil) → yüksek (nesne).
3. **Convolution** — aynı küçük filtreyi görüntünün her yamasında kaydırmak: uzamsal yapıyı koruyan **weight sharing**.
4. **CNN'in üç operasyonu** — convolution + nonlinearity (ReLU) + pooling.
5. **Ötesi** — aynı öznitelikler nesne tespiti, semantik segmentasyon, otonom kontrol için tekrar kullanılır.
{#fig-concept-map fig-align="center" width=85%}
::: {.callout-tip title="Builder Notu — ML Köprüleri"}
Bu ders, önceki üç kursla özellikle 18.06 ve Calculus üzerinden derinden bağlanır:
- **Görüntü = matris** → 18.06 — grayscale 2B matris, RGB üç kanalın üst üste binmesi (tensor).
- **Convolution** → 18.06 lineer operatör; **öteleme-değişmez** (translation-equivariant) bir dönüşüm. Filtre · yama = 18.06 iç çarpım (Ders 1, 15).
- **Kenar tespiti filtreleri** → Calculus türev. Sobel/Laplacian, yoğunluk gradient'ini, yani görüntünün türevini hesaplar (Calculus Ders 2, 10).
- **Hiyerarşi (kenar → şekil → nesne)** → Calculus Ders 4 zincir kuralı / fonksiyon bileşkesi; backprop bu bileşkenin türevidir.
- **Pooling** → yerel özetleme; Stat 110 sıra istatistikleri (max → Ders 25) ve beklenen değer (avg → Ders 9).
- **Multiple filters → çıktı volume** → 18.06 paralel lineer projeksiyonlar yığını.
İleriye köprüler: vision transformer (ViT), object detection (YOLO/R-CNN), segmentation (U-Net), self-driving multi-modal füzyon, mobile/on-device quantization.
:::
## Görü Nedir? Ne Görüyoruz? {#sec-goru-nedir}
Amini dersi bir gözlemle açıyor: görü, **"ne'nin nerede olduğuna bakarak bilmek"** olarak tanımlanır; ama gerçek görü bundan çok daha fazlasıdır. Bir trafik sahnesini düşün: ikisi de "araba" olan iki nesne tanımlayabilirsin, ama yol kenarındaki park edilmiş olan ile yayalar için duran biri tamamen farklı dinamiklere sahiptir. Birinin **biraz sonra hareket edeceğini** sezmek de görünün parçasıdır.
> *"vision is so much more than just recognizing an image... it's actually about understanding the dynamics of your scene of your environment."* — Amini, 0:53
Derin öğrenme bu zengin anlamayı çeşitli uygulamalara taşıdı: yüz algılama/tanıma, otonom sürüş (Amini'nin MIT/Toyota arabası uçtan-uca CV ile sürülür), sağlık (röntgen/MR taramalarından kanser tespiti), erişilebilirlik, robotik, biyoloji.
::: {.callout-tip title="Builder Notu — Sahneyi Anlamak"}
**Geriye:** "Sahneyi anlamak" sezgisi, yalnızca pikselleri eşleştirmek yerine **yapısal ilişkiler** kurmaktır — bu, 18.06'nın "vektörler arası geometri" diline ve Stat 110'un nedensellik/koşullu olasılık çerçevesine bağlanır.
**İleriye:** Görü artık tek-modalite değil; modern sistemler görüntü + dil + sensör füzyonu yapar (CLIP, Gemini görsel modeller). Bu dersin convolutional omurgası, bu sistemlerin görü tarafında hâlâ yaygındır; transformer (ViT) ise rekabette öne geçiyor.
:::
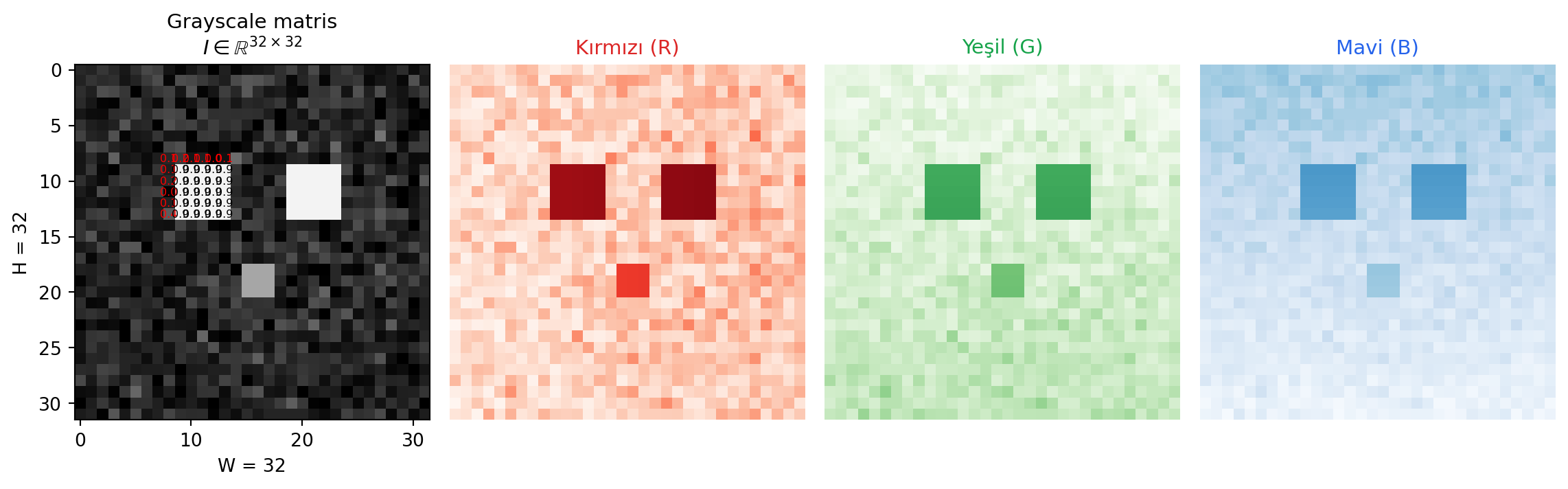
## Görüntü Bilgisayara Nasıl Görünür? {#sec-goruntu-matris}
Bilgisayarın gözü yoktur; gördüğü tek şey **sayılardır**. Bir grayscale görüntü, bilgisayar için bir **2B matristir**: her hücrede o pikselin **parlaklığı** (0 koyu, 1 parlak) yazar.
$$
I \in \mathbb{R}^{H \times W}
$$
Renkli görüntüler için bu matrisi **üç kanala** (kırmızı, yeşil, mavi) genişletiriz. Üç adet $H \times W$ matrisi üst üste binince üç boyutlu bir tensor olur:
$$
I \in \mathbb{R}^{H \times W \times 3}
$$
```{python}
#| label: fig-goruntu-matris
#| fig-cap: "Sentetik bir 'kedi yüzü' örneği. Sol: grayscale matris (parlaklık değerleri). Sağ: RGB üç kanal — kırmızı, yeşil, mavi ayrı ayrı."
#| fig-width: 12
#| fig-height: 4.5
import numpy as np
import matplotlib.pyplot as plt
rng = np.random.default_rng(0)
# Sentetik bir "kedi" benzeri imge: 2 göz + burun
H = W = 32
img = 0.15 + 0.1 * rng.standard_normal((H, W))
# arka plan
yy, xx = np.mgrid[0:H, 0:W]
# Sol göz
img[(yy - 11) ** 2 + (xx - 11) ** 2 < 9] = 0.95
# Sağ göz
img[(yy - 11) ** 2 + (xx - 21) ** 2 < 9] = 0.95
# Burun
img[(yy - 19) ** 2 + (xx - 16) ** 2 < 4] = 0.65
img = np.clip(img, 0, 1)
# RGB kanal sentezi
R = img * 0.9 + 0.1 * (xx / W)
G = img * 0.6 + 0.2 * (yy / H)
B = img * 0.4 + 0.3 * (1 - yy / H)
rgb = np.stack([R, G, B], axis=-1)
rgb = np.clip(rgb, 0, 1)
fig, axes = plt.subplots(1, 4, figsize=(12, 4.5))
# Grayscale + sayısal değerler
ax = axes[0]
im = ax.imshow(img, cmap='gray', vmin=0, vmax=1)
ax.set_title('Grayscale matris\n$I \\in \\mathbb{R}^{32 \\times 32}$', fontsize=11)
# Sayısal değerleri yazdır (sub-grid)
sub = img[8:14, 8:14]
for i in range(sub.shape[0]):
for j in range(sub.shape[1]):
ax.text(8 + j, 8 + i, f'{sub[i,j]:.1f}', ha='center', va='center',
fontsize=6, color='red' if sub[i,j] < 0.5 else 'black')
ax.set_xlabel(f'W = {W}'); ax.set_ylabel(f'H = {H}')
# R kanalı
for ax, channel, cmap_name, title, color in zip(
axes[1:], [R, G, B], ['Reds', 'Greens', 'Blues'],
['Kırmızı (R)', 'Yeşil (G)', 'Mavi (B)'],
['#dc2626', '#16a34a', '#2563eb']
):
ax.imshow(channel, cmap=cmap_name, vmin=0, vmax=1)
ax.set_title(title, fontsize=11, color=color)
ax.axis('off')
plt.tight_layout()
plt.show()
```
Yani senin gördüğün bir köpek fotoğrafı, bilgisayar için $H \times W \times 3$ boyutlu bir sayı kümesidir — başka bir şey değil.
::: {.callout-tip title="Builder Notu — Pipeline'ın Başı"}
**Geriye (18.06):** Grayscale görüntü tam olarak bir matris (Ders 1); RGB ise 3 kanalın istiflenmesidir. CNN'in tüm işlemleri (convolution, pooling, lineer katmanlar) bu tensorler üzerinde tanımlı lineer cebir operasyonlarıdır.
**İleriye:** Pratikte ham piksel değerlerini doğrudan ağa vermek nadiren ideal — **normalization** (kanal başına ortalama-sapma çıkarma) eğitim kararlılığını artırır. PyTorch'ta `torchvision.transforms` bu işi yapar.
:::
## Sınıflandırma ve Hiyerarşik Öznitelikler {#sec-hiyerarsi}
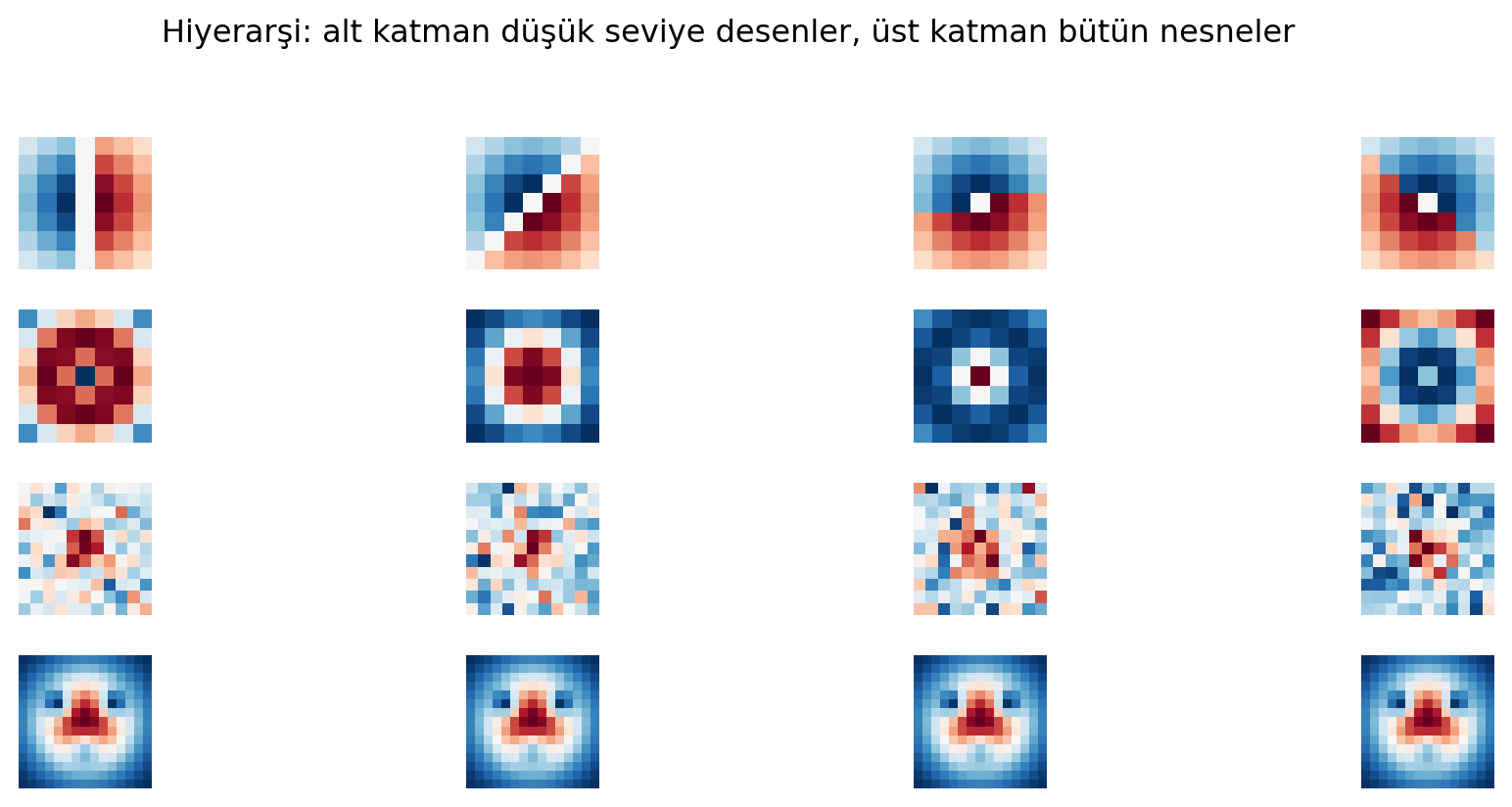
Görü için klasik bir görev: bir görüntüyü bir **sınıfa** ata. 2B görüntüden, sabit boyutlu 1B kategori vektörüne git. Peki ağ neye bakarak karar verir? İnsan olarak şöyle yaparsın: önce çizgileri, sonra köşeleri, sonra göz/burun/ağız gibi yapıları, en sonunda yüzü ararsın. Ağ da aynı **hiyerarşiyi** kurar — ama farkla: bu hiyerarşiyi sen elle tanımlamazsın, ağ **veriden öğrenir**.
- **Düşük seviye** (alt katmanlar): kenar, köşe, renk yamaları.
- **Orta seviye**: göz, tekerlek, kapı kolu gibi parça desenleri.
- **Yüksek seviye** (üst katmanlar): yüz, araba, ev gibi nesneler.
```{python}
#| label: fig-hiyerarsi
#| fig-cap: "Öznitelik hiyerarşisi: düşük seviye (kenarlar) → orta (basit şekiller) → yüksek (nesne parçaları). Her katmanın önceki üzerine kurulan örnek filtre örüntüleri."
#| fig-width: 12
#| fig-height: 4.5
rng = np.random.default_rng(2)
# Katman 1: kenar/yönlü filtreler
def edge_filter(angle, size=7):
yy, xx = np.mgrid[-size//2+1:size//2+1, -size//2+1:size//2+1]
rot = np.cos(np.deg2rad(angle)) * xx + np.sin(np.deg2rad(angle)) * yy
return np.sign(rot) * np.exp(-(yy**2 + xx**2) / 10)
# Katman 2: köşeler, dalgalar
def corner_filter(t, size=7):
yy, xx = np.mgrid[-size//2+1:size//2+1, -size//2+1:size//2+1]
r = np.sqrt(xx**2 + yy**2)
return np.sin(t + r * 0.6) * np.exp(-r**2 / 12)
# Katman 3: küçük göz-benzeri yamalar
def eye_like(seed, size=11):
yy, xx = np.mgrid[-size//2+1:size//2+1, -size//2+1:size//2+1]
r2 = xx**2 + yy**2
base = np.exp(-r2 / 4)
rngl = np.random.default_rng(seed)
base += 0.3 * rngl.standard_normal((size, size))
return base
# Katman 4: tam yüz (kompozit)
def face(seed, size=15):
yy, xx = np.mgrid[-size//2+1:size//2+1, -size//2+1:size//2+1]
base = np.exp(-(xx**2 + yy**2) / 30)
base -= 0.6 * np.exp(-((xx + 3)**2 + (yy + 2)**2) / 2)
base -= 0.6 * np.exp(-((xx - 3)**2 + (yy + 2)**2) / 2)
base -= 0.4 * np.exp(-(xx**2 + (yy - 3)**2) / 3)
return base
fig, axes = plt.subplots(4, 4, figsize=(12, 4.5),
gridspec_kw={'wspace': 0.1, 'hspace': 0.3})
layers = [
(edge_filter, [0, 45, 90, 135], 'Katman 1 — kenarlar', '#4f46e5'),
(corner_filter, [0, 1.2, 2.4, 3.8], 'Katman 2 — basit şekiller', '#f59e0b'),
(eye_like, [1, 2, 3, 4], 'Katman 3 — parçalar (göz/burun)', '#10b981'),
(face, [10, 20, 30, 40], 'Katman 4 — nesneler (yüz)', '#7c3aed'),
]
for row, (fn, args, title, color) in enumerate(layers):
for col, a in enumerate(args):
ax = axes[row, col]
ax.imshow(fn(a), cmap='RdBu_r')
ax.axis('off')
if col == 0:
ax.set_ylabel(title, fontsize=10, color=color, rotation=0,
ha='right', va='center', labelpad=80, weight='bold')
plt.suptitle('Hiyerarşi: alt katman düşük seviye desenler, üst katman bütün nesneler',
fontsize=12, y=1.02)
plt.tight_layout()
plt.show()
```
::: {.callout-tip title="Builder Notu — Fonksiyon Bileşkesi"}
**Geriye (Calculus):** Öznitelik hiyerarşisi, **fonksiyon bileşkesidir** — Calculus Ders 4'ün zincir kuralı zemini: $f_3(f_2(f_1(x)))$. Derin ağ tam olarak bu bileşkedir; backprop, gradient'i bu bileşkeden geriye taşır.
**İleriye:** Bu hiyerarşi modern modellerin de iskeleti: ResNet, VGG, EfficientNet. **Transfer learning** bu yüzden çalışır — bir görevde öğrenilen düşük seviye filtreler başka göreve taşınabilir (ImageNet → tıbbi görüntü).
:::
## Dense Ağ Neden Görüntüde Çöker? {#sec-dense-coker}
Ders 1'in fully connected (dense) ağı 1B girdi bekler. 2B bir görüntüyü vermek için "flatten" ederiz — satırları arka arkaya dizip tek bir uzun vektöre çeviririz. İşte iki büyük problem buradan başlar:
**Problem 1 — Uzamsal bilgi ölür.** Görüntüde yan yana iki piksel anlamlı bir ilişkiye sahiptir; ama flatten edip 1B'ye çekince bu komşuluk bilgisi tümden kaybolur. Ağ "komşu piksel" diye bir kavram bilmeden öğrenmeye çalışır.
> *"just by doing this one operation, even though in theory this could be learned... you've really killed... so much of the learning capacity of this model just by flattening this input."* — Amini, 12:55
**Problem 2 — Parametre patlaması.** $100 \times 100$'lük küçük bir görüntü bile 10.000 boyutlu girdi vektörüdür. 1000 nöronlu bir gizli katmanla = 10 milyon parametre. RGB ve gerçek boyutlarda ($224 \times 224 \times 3$) bu sayı yüzlerce milyona çıkar.
$$
\text{params (ilk katman)} = (H \cdot W \cdot C) \times \text{hidden}
$$
::: {.callout-tip title="Builder Notu — Yapısal Önyargı"}
**Geriye (18.06):** Parametre sayısı doğrudan matris boyutlarından gelir. "Uzamsal yapıyı koru" fikri, kanonik bazın yapısını yok etmemek demektir.
**İleriye:** Aynı parametre patlaması derdi modern büyük modellerin de temel kısıtıdır; çözüm hep "yapısal sınırlama" (weight sharing, low-rank, sparsity, MoE). CNN'in convolution'ı bu çözümün **prototipidir** — milyonlar yerine onlarca öğrenilebilir ağırlık.
:::
## Convolution: Yerel Yamalar ve Filtreler {#sec-convolution}
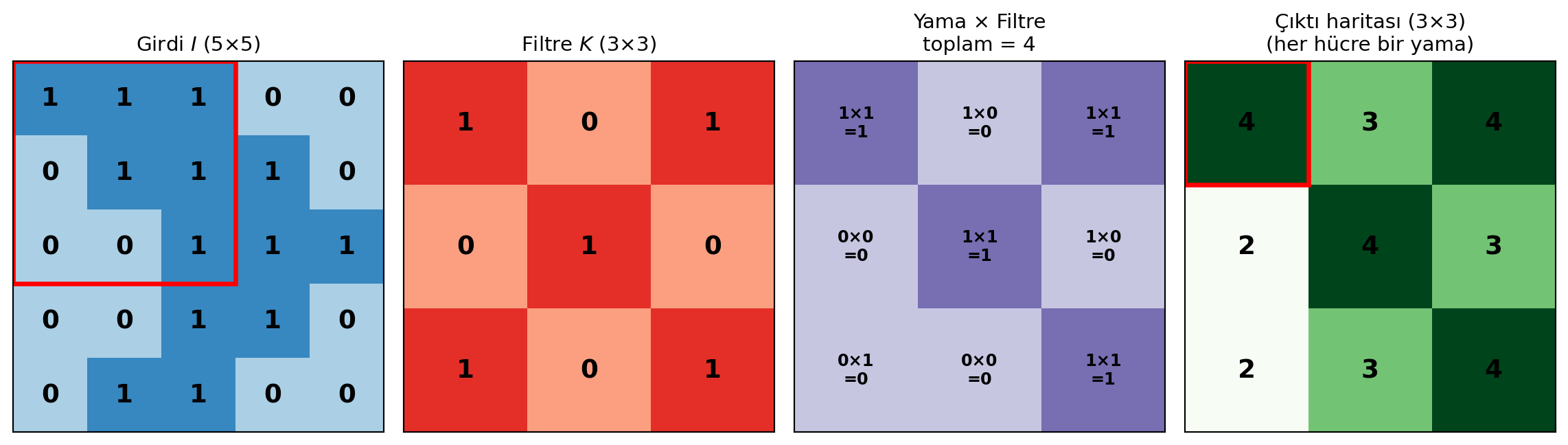
Çözüm fikir olarak basittir: görüntüyü 1B'ye çekme; **uzamsal yapısını koru**. Bir sonraki katmanın bir nöronunu görüntünün **her pikseline** değil, yalnızca küçük bir **yamasına** (patch) bağla. Aynı görüntüde tek bir yama yetmez; aynı küçük filtreyi görüntü boyunca **kaydırarak** uygularız — her konumda **aynı ağırlıkları** kullanırız.
> *"this operation that I just described to you, this patch-based operation where we look at every patch as opposed to the entire image — this is called the convolution."* — Amini, 21:24
Bir filtre, küçük bir ağırlık matrisidir (örn. $3 \times 3 = 9$ ağırlık). Her konumda, yamanın piksellerini filtre ağırlıklarıyla **eleman-eleman çarpıp** toplarız. Matematiksel olarak:
$$
(I * K)(x,\, y) = \sum_{i,\, j} I(x+i,\, y+j) \cdot K(i,\, j)
$$
```{python}
#| label: fig-conv-step
#| fig-cap: "Convolution adım adım: 5×5 girdiyi 3×3 filtre ile tara. Her konumda 3×3 yama × filtre eleman-eleman çarpılır ve toplanır → 3×3 çıktı haritası."
#| fig-width: 12
#| fig-height: 4.5
I = np.array([
[1, 1, 1, 0, 0],
[0, 1, 1, 1, 0],
[0, 0, 1, 1, 1],
[0, 0, 1, 1, 0],
[0, 1, 1, 0, 0],
], dtype=float)
K = np.array([
[1, 0, 1],
[0, 1, 0],
[1, 0, 1],
], dtype=float)
# Çıktı haritası
Ho, Wo = I.shape[0] - K.shape[0] + 1, I.shape[1] - K.shape[1] + 1
O = np.zeros((Ho, Wo))
for i in range(Ho):
for j in range(Wo):
O[i, j] = (I[i:i+3, j:j+3] * K).sum()
fig, axes = plt.subplots(1, 4, figsize=(12, 4.5))
# 1) Girdi
ax = axes[0]
ax.imshow(I, cmap='Blues', vmin=-1, vmax=2)
for i in range(I.shape[0]):
for j in range(I.shape[1]):
ax.text(j, i, f'{int(I[i,j])}', ha='center', va='center',
fontsize=14, weight='bold')
ax.set_title('Girdi $I$ (5×5)', fontsize=11)
ax.set_xticks([]); ax.set_yticks([])
# Yamayı vurgula (sol-üst)
from matplotlib.patches import Rectangle
ax.add_patch(Rectangle((-0.5, -0.5), 3, 3, fill=False, edgecolor='red', lw=2.5))
# 2) Filtre
ax = axes[1]
ax.imshow(K, cmap='Reds', vmin=-1, vmax=2)
for i in range(K.shape[0]):
for j in range(K.shape[1]):
ax.text(j, i, f'{int(K[i,j])}', ha='center', va='center',
fontsize=14, weight='bold')
ax.set_title('Filtre $K$ (3×3)', fontsize=11)
ax.set_xticks([]); ax.set_yticks([])
# 3) Adım: yamayı filtre ile çarp
ax = axes[2]
patch = I[:3, :3]
prod = patch * K
ax.imshow(prod, cmap='Purples', vmin=-1, vmax=2)
for i in range(3):
for j in range(3):
ax.text(j, i, f'{int(patch[i,j])}×{int(K[i,j])}\n={int(prod[i,j])}',
ha='center', va='center', fontsize=9, weight='bold')
ax.set_title(f'Yama × Filtre\ntoplam = {int(prod.sum())}', fontsize=11)
ax.set_xticks([]); ax.set_yticks([])
# 4) Çıktı haritası
ax = axes[3]
ax.imshow(O, cmap='Greens', vmin=O.min(), vmax=O.max())
for i in range(O.shape[0]):
for j in range(O.shape[1]):
ax.text(j, i, f'{int(O[i,j])}', ha='center', va='center',
fontsize=14, weight='bold')
ax.set_title('Çıktı haritası (3×3)\n(her hücre bir yama)', fontsize=11)
ax.set_xticks([]); ax.set_yticks([])
ax.add_patch(Rectangle((-0.5, -0.5), 1, 1, fill=False, edgecolor='red', lw=2.5))
plt.tight_layout()
plt.show()
```
Sonuçta ortaya çıkan 2B haritaya **özellik haritası** (feature map) denir: filtrenin görüntünün hangi konumlarında "tetiklendiğini" söyler.
```{python}
#| label: fig-sobel-edges
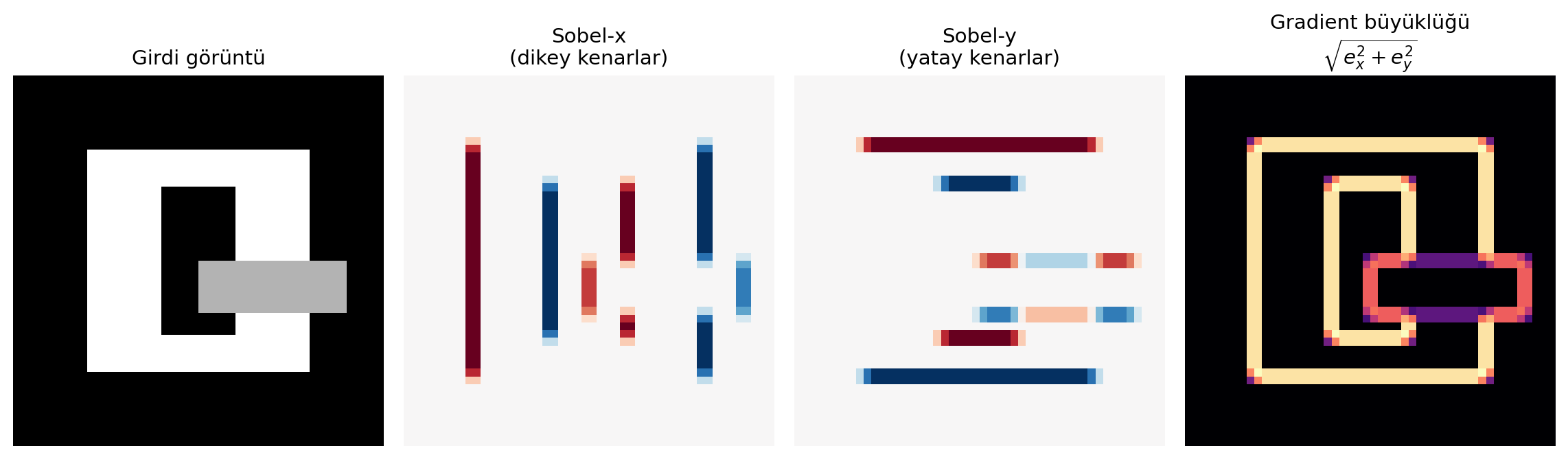
#| fig-cap: "Klasik kenar filtreleri = öğrenilebilir türev. Sobel-x dikey kenarları, Sobel-y yatay kenarları öne çıkarır."
#| fig-width: 12
#| fig-height: 4
# Sentetik bir geometrik şekil
img = np.zeros((50, 50))
img[10:40, 10:40] = 1.0 # iç kare
img[15:35, 20:30] = 0.0 # iç boşluk
img[25:32, 25:45] = 0.7 # küçük dikdörtgen
Kx = np.array([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]])
Ky = Kx.T
def conv2d(I, K):
Hi, Wi = I.shape
Hk, Wk = K.shape
Ho, Wo = Hi - Hk + 1, Wi - Wk + 1
out = np.zeros((Ho, Wo))
for i in range(Ho):
for j in range(Wo):
out[i, j] = (I[i:i+Hk, j:j+Wk] * K).sum()
return out
ex = conv2d(img, Kx)
ey = conv2d(img, Ky)
mag = np.sqrt(ex**2 + ey**2)
fig, axes = plt.subplots(1, 4, figsize=(12, 4))
axes[0].imshow(img, cmap='gray'); axes[0].set_title('Girdi görüntü', fontsize=11)
axes[1].imshow(ex, cmap='RdBu_r'); axes[1].set_title('Sobel-x\n(dikey kenarlar)', fontsize=11)
axes[2].imshow(ey, cmap='RdBu_r'); axes[2].set_title('Sobel-y\n(yatay kenarlar)', fontsize=11)
axes[3].imshow(mag, cmap='magma'); axes[3].set_title('Gradient büyüklüğü\n$\\sqrt{e_x^2 + e_y^2}$', fontsize=11)
for ax in axes:
ax.axis('off')
plt.tight_layout()
plt.show()
```
> *"convolution preserves the spatial relationships between pixels by learning these image features in small patches."* — Amini, 21:30
::: {.callout-tip title="Builder Notu — Convolution = Öğrenilebilir Türev"}
**Geriye (18.06 + Calculus):** Convolution, bir **lineer operatördür** ve **öteleme-değişmez** — görüntüyü kaydırırsan, çıktısı da aynı kadar kayar. Daha keskin bir köprü: kenar tespiti filtreleri (Sobel, Laplacian) tam olarak **Calculus türevidir** — piksel yoğunluğunun uzamsal gradient'ini hesaplarlar. Yani convolution = öğrenilebilir türev operatörü. Ders 2'de RNN aynı $W$'yi **zaman boyunca** paylaşıyordu; CNN aynı filtreyi **uzam boyunca** paylaşır.
**İleriye:** Pratikte convolution'ın iki parametre seti: filtre boyutu ve **stride** + **padding**. PyTorch'ta `nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)`. Dilated/depthwise/grouped convolution varyantları farklı verimlilik-ifade dengelerini hedefler (MobileNet, EfficientNet).
:::
## CNN'in Üç Operasyonu: Conv + ReLU + Pool {#sec-uc-operasyon}
Convolution, üç işlemden ilki. CNN'in mimarisi, her tekrar bloğunda üç adımı sırayla uygular:
**(1) Convolution.** Az önce gördük — küçük filtreyi her yamada uygula, feature map'leri üret.
**(2) Doğrusal-olmama (genelde ReLU).** Convolution lineer bir işlemdir; üst üste binerse tek bir lineer operatöre çöker. Her convolution sonrası bir ReLU geçirerek doğrusal-olmama katarız:
$$
\text{ReLU}(z) = \max(0,\, z)
$$
Sezgisel olarak bu, bir **eşik** gibi davranır: negatif tepki = 0; pozitif tepki = olduğu gibi geç.
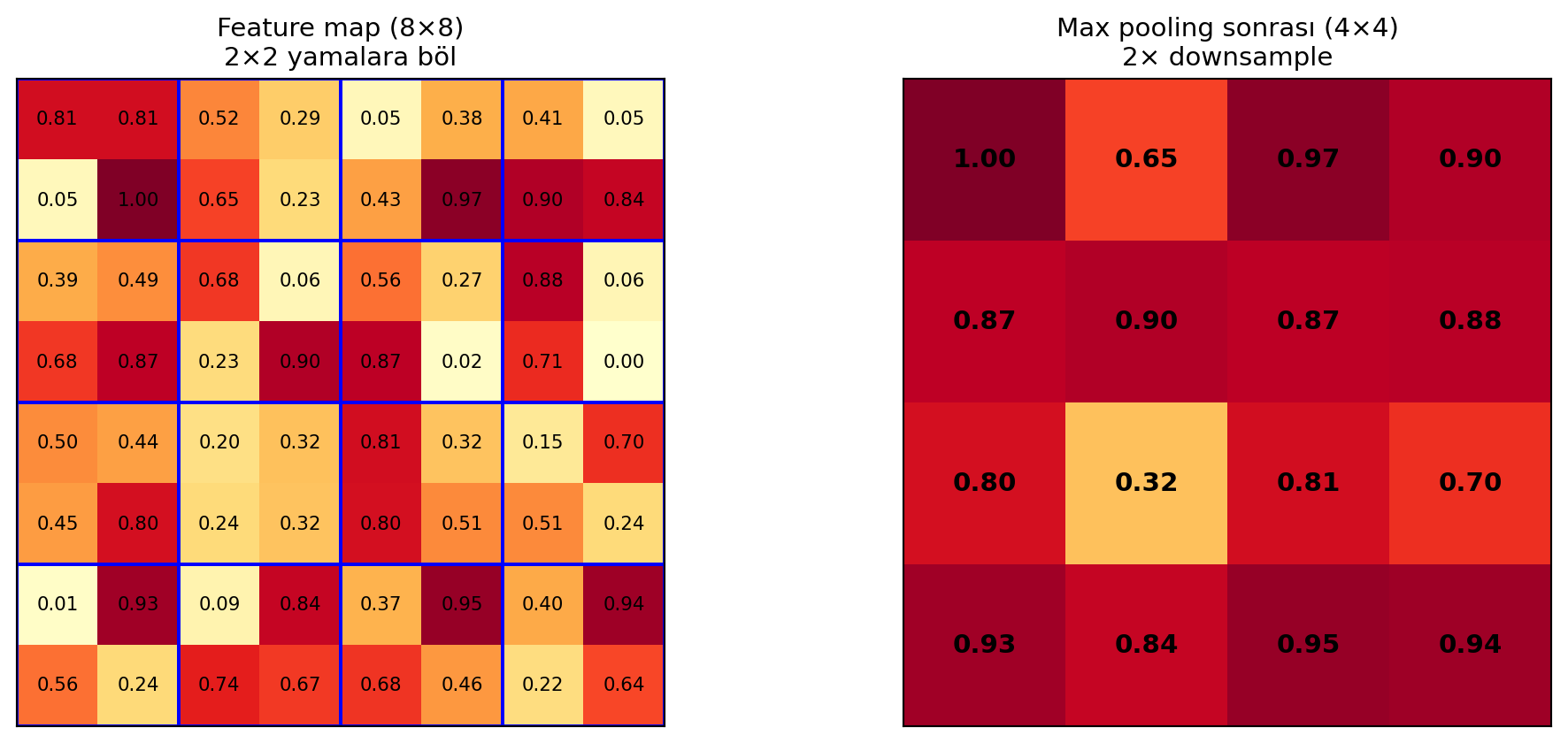
**(3) Pooling — örnekleme.** Bir feature map'i alıp uzamsal olarak küçültür (downsample). En yaygın yöntem **max pooling**: her küçük (örn. $2 \times 2$) yamada **maksimum** değeri tut, kalanı at.
```{python}
#| label: fig-pooling
#| fig-cap: "Max pooling 2×2: her yamadan maksimum değer tutulur. Feature map H ve W boyutlarında 2× küçülür; kanal sayısı değişmez."
#| fig-width: 11
#| fig-height: 4.5
rng = np.random.default_rng(5)
fm = rng.uniform(0, 1, (8, 8))
def maxpool(x, k=2):
H, W = x.shape
out = np.zeros((H // k, W // k))
for i in range(H // k):
for j in range(W // k):
out[i, j] = x[i*k:(i+1)*k, j*k:(j+1)*k].max()
return out
pooled = maxpool(fm, 2)
fig, axes = plt.subplots(1, 2, figsize=(11, 4.5))
ax = axes[0]
ax.imshow(fm, cmap='YlOrRd', vmin=0, vmax=1)
for i in range(8):
for j in range(8):
ax.text(j, i, f'{fm[i,j]:.2f}', ha='center', va='center', fontsize=8)
# 2x2 yamayı çiz
from matplotlib.patches import Rectangle
for i in range(0, 8, 2):
for j in range(0, 8, 2):
ax.add_patch(Rectangle((j - 0.5, i - 0.5), 2, 2,
fill=False, edgecolor='blue', lw=1.5))
ax.set_title('Feature map (8×8)\n2×2 yamalara böl', fontsize=11)
ax.set_xticks([]); ax.set_yticks([])
ax = axes[1]
ax.imshow(pooled, cmap='YlOrRd', vmin=0, vmax=1)
for i in range(4):
for j in range(4):
ax.text(j, i, f'{pooled[i,j]:.2f}', ha='center', va='center', fontsize=11, weight='bold')
ax.set_title('Max pooling sonrası (4×4)\n2× downsample', fontsize=11)
ax.set_xticks([]); ax.set_yticks([])
plt.tight_layout()
plt.show()
```
Pooling neden işe yarar?
- **Hiyerarşi tetiklenir:** Pooling ile görüntü küçülünce, aynı küçük filtre bir sonraki katmanda **daha geniş** uzamsal bölgeyi görür — yani **alıcı alan** derinlikle büyür.
- **Uzamsal değişmezlik:** Küçük kaymalara dayanıklılık.
- **Hesap/bellek tasarrufu:** Daha küçük tensorler.
> *"the whole point of what we're doing here is to learn this hierarchy."* — Amini, 37:42
::: {.callout-tip title="Builder Notu — Pooling = Sıra İstatistiği"}
**Geriye (Stat 110 + Calculus):** Max pooling, bir bölgenin **maksimum sıra istatistiğidir** (Stat 110 Ders 25); average pooling ise bölgenin **beklenen değeridir** (Ders 9). "Filtre + ReLU + pooling"in bileşkesi, Calculus Ders 4 zincir kuralının somut bir uygulamasıdır.
**İleriye:** Modern mimariler max pooling yerine sıklıkla **stride'lı convolution** (örn. stride=2) kullanır — downsampling'i öğrenilebilir hâle getirir. **Global average pooling** sınıflandırma kafasından önce uzamsal boyutu tek bir vektöre indirir.
:::
## Tam CNN Mimarisi: Feature Extractor + Classifier {#sec-cnn-mimari}
Üç operasyonu bir araya getirip uçtan uca bir görüntü sınıflandırıcı kuralım. Bir CNN iki belirgin parçaya ayrılır:
**Parça 1 — Feature extractor:** Conv + ReLU + Pool blokları üst üste istiflenir. Erken bloklar küçük desenleri, derin bloklar karmaşık parçaları yakalar. Her blokta filtre sayısı genelde artar (32 → 64 → 128), uzamsal boyut pooling ile küçülür.
**Parça 2 — Classifier head:** Yüksek seviye özellikleri **flatten** edip (veya global average pool'a verip) fully connected katmanlardan geçirir. Çıkışta sınıf sayısı kadar nöron + **softmax** ile olasılık dağılımı üretir.
{#fig-cnn-arch fig-align="center" width=85%}
PyTorch'ta küçük bir CNN:
```python
import torch.nn as nn
cnn = nn.Sequential(
# ---- feature extractor ----
nn.Conv2d(3, 32, kernel_size=3, padding=1), nn.ReLU(),
nn.MaxPool2d(2), # H,W -> H/2, W/2
nn.Conv2d(32, 64, kernel_size=3, padding=1), nn.ReLU(),
nn.MaxPool2d(2), # /2 yeniden
nn.Conv2d(64, 128, kernel_size=3, padding=1), nn.ReLU(),
nn.AdaptiveAvgPool2d(1), # global average pooling
# ---- classifier head ----
nn.Flatten(),
nn.Linear(128, 10), # 10 sinif
# softmax cross-entropy ile birlikte gelir (nn.CrossEntropyLoss)
)
```
Eğitim döngüsünde forward pass + cross-entropy + `loss.backward()` + optimizer.step() — yani Ders 1'in eğitim mekaniğinin aynısı, yalnızca model gövdesi değişti.
::: {.callout-tip title="Builder Notu — Transfer Learning"}
**Geriye:** Mimari, Ders 1'in (loss, gradient descent, backprop) ve Ders 2'nin (weight sharing) sezgilerini görüye uyarlar. Convolutional katmanları **basitçe lokal dot product katmanları** olarak görmek (18.06 Ders 30), CNN'i "sihirli" görmekten uzaklaştırır.
**İleriye:** Modern CNN'ler bu çekirdeğe **residual bağlantılar** (ResNet), **batch normalization**, **depthwise/grouped convolution** ekler. **Transfer learning:** ImageNet üzerinde önceden eğitilmiş feature extractor'ı al, classifier head'i kendi görevin için yeniden eğit — az veride bir builder'ın varsayılan başlangıcıdır.
:::
## Convolution'ın Ötesinde: Detection, Segmentation, Control {#sec-otesi}
CNN'in en güzel yanı: **feature extractor genel amaçlıdır**. Bir görevden öğrendiği düşük/orta seviye filtreleri, çok farklı görevler için tekrar kullanabilirsin — yalnızca **head'i** değiştirirsin.
> *"very general-purpose feature learning across an image... outputs of all these convolutional layers are very general purpose features that can be reused."* — Amini, 44:25
Birkaç klasik görev:
- **Nesne tespiti (object detection).** Görüntüdeki her nesnenin **bounding box** (x, y, h, w) ve sınıfını ver. Modern: Faster R-CNN, YOLO, DETR — uçtan-uca türevlenebilir kutu önerisi.
- **Semantik segmentasyon.** Her **piksele** bir sınıf ata. Mimari **encoder-decoder**: küçült (conv+pool), sonra **upsampling** ile geri büyüt. U-Net bu desenin en bilinen örneği.
- **Otonom kontrol.** Çoklu kamera özelliklerini birleştir, çıktıda araç komutlarını (direksiyon, gaz/fren) **dağılım** olarak öğren — bir kavşakta hem sola hem sağa dönmek mümkündür; çok-modlu olasılık dağılımı.
::: {.callout-tip title="Builder Notu — Tek Omurga, Çok Head"}
**Geriye (18.06):** "Feature extractor + değişen head" deseni, paylaşılan bir gösterim alt-uzayı üzerine farklı projeksiyon kafaları koymaktır (18.06 Ders 15 projeksiyon).
**İleriye:** Bu desen modern **multi-task learning**'in iskeletidir; tek bir omurga + birden çok task-specific head (Tesla HydraNet, Meta SAM). **Foundation model** çağında "pre-train edilmiş omurga + küçük head'ler" yaklaşımı standart.
:::
## CNN'in Bugünü ve Yarını {#sec-bugun-yarin}
Convolution yalnızca 2B görüntüye özgü değil. Aynı "yerel filtre + weight sharing" fikri:
- **1B** üzerinde: ses dalgaları, EKG/EEG, hatta dil dizileri (1D conv RNN'lere bir alternatiftir).
- **3B** üzerinde: video (zaman dahil) ve hacimsel taramalar (MR, CT).
Görü tarafında en büyük rakip — ve yer yer yeni baskın mimari — **Vision Transformer (ViT)**: görüntüyü küçük yamalara (örn. $16 \times 16$) böl, her yamayı bir **token** olarak gör, Ders 2'de gördüğümüz self-attention'ı bu tokenlere uygula. Yeterince veri olduğunda ViT genellikle CNN'i yakalar veya geçer; ama az veri ve hesap rejimlerinde CNN'in **yerleşik öneliği** (locality, weight sharing) hâlâ kazandırır.
::: {.callout-tip title="Builder Notu — İki Dersin Buluşması"}
**Geriye:** ViT, **Ders 2'nin attention'ını görüye uygulamaktır** — bu kursun en güçlü iki dersinin (RNN→attention ve CNN) son adımda buluştuğu yer.
**İleriye:** Self-supervised ön-eğitim devrimi (DINO, MAE, CLIP) ile CNN/ViT artık görsel **foundation model**'lerin omurgası. Bir builder olarak "baştan eğit" yerine "hazır omurga + transfer" varsayılan başlangıç olmalı.
:::
## Bu Dersin Özeti {#sec-ozet}
1. **Görü**, sadece tanıma değil — sahne dinamiklerini ve nedensel ilişkileri anlamaktır.
2. **Görüntü = sayılar matrisi:** grayscale $H \times W$, RGB $H \times W \times 3$ tensor.
3. **Dense ağ görüntüde çöker:** flatten uzamsal bilgiyi yok eder ve parametre patlar.
4. **Convolution:** küçük bir filtreyi her yamada uygula (weight sharing); yerel alıcı alan korunur.
5. **Feature map**, filtrenin görüntü boyunca tetiklendiği yerleri gösterir (dot product büyüklüğü).
6. **CNN'in üç operasyonu:** convolution + ReLU + pooling. Pooling, alıcı alanı derinlikle büyütür → öznitelik hiyerarşisi doğal olarak çıkar.
7. **Mimari iki parça:** feature extractor + classifier head. Eğitim, Ders 1'in cross-entropy + gradient descent + backprop'unun aynısıdır.
8. **Aynı omurga, farklı görevler:** detection, segmentation, kontrol; head değişir, feature extractor genelde aynı kalır.
9. **Convolution 1B ve 3B'ye genişler;** modern alternatif olarak Vision Transformer (Ders 2'nin attention'ı görüde).
::: {.callout-important title="Tek bir cümle"}
Convolutional neural network, aynı küçük filtreyi tüm uzamsal konumlarda paylaşan bir lineer operatörün (convolution), bir doğrusal-olmamanın (ReLU) ve bir özetleme adımının (pooling) istiflenmesidir — ve bu üçlü, kenardan nesneye uzanan öznitelik hiyerarşisini veriden öğrenir.
:::
## Kontrol Soruları {#sec-sorular}
::: {.callout-note collapse="true" title="Soru 1: Dikey kenar filtresi $K = [[-1, 0, 1], [-1, 0, 1], [-1, 0, 1]]$ ve girdi $I = [[0,1,1,1],[0,1,1,1],[0,1,1,1],[0,1,1,1]]$ ile sol-üst (0,0) konumdaki convolution çıktısı nedir?"}
**Cevap:** (0,0) konumundaki $3 \times 3$ yama: $[[0,1,1],[0,1,1],[0,1,1]]$. Eleman-eleman çarpıp topla:
$$
(0)(-1) + (1)(0) + (1)(1) + (0)(-1) + (1)(0) + (1)(1) + (0)(-1) + (1)(0) + (1)(1) = 3
$$
Sonuç **+3** (güçlü pozitif). Filtre "soldan koyu, sağdan parlak" desenini arıyor; bu yamada da soldan koyu (0'lar) sağdan parlak (1'ler) geçiş var → filtre **tetikleniyor**. Bu filtre aslında piksel yoğunluğunun **uzamsal türevidir** (Calculus Ders 2/10) — convolution = öğrenilebilir türev.
:::
::: {.callout-note collapse="true" title="Soru 2: $224 \times 224 \times 3$ RGB görüntüyü flatten edip 1000 nöronlu fully connected katmana bağlarsan ilk katmanda kaç parametre? Aynı görev için 32 filtreli $3 \times 3$ conv katmanı kaç parametre?"}
**Cevap:** **Fully connected:** girdi $224 \cdot 224 \cdot 3 = 150\,528$; ilk katman ağırlıkları $150\,528 \times 1000 \approx$ **150 milyon** parametre.
**Conv katmanı:** $32 \times (3 \times 3 \times 3) + 32 = 32 \cdot 27 + 32 =$ **896 parametre**. Yüz binlerce kat daha az.
Aradaki farkın iki kaynağı: (1) **weight sharing** — aynı filtre tüm uzamsal konumlarda; (2) **yerellik** — her nöron yalnızca küçük yamaya bağlı. Bu yapısal önyargılar, görüntülerin doğal istatistiklerine (komşu pikseller ilişkilidir, desenler uzamda kayabilir) uyar.
:::
::: {.callout-note collapse="true" title="Soru 3: Max vs average pooling farkı nedir? Pooling alıcı alanı (receptive field) nasıl büyütür?"}
**Cevap:** **Max pooling**, yerel yamadaki **maksimum** aktivasyonu tutar — "buralarda filtre tetiklendi mi?" sorusuna keskin cevap; küçük kaymalara doğal dayanıklı. **Average pooling** ise yamanın **ortalamasını** alır — yumuşak özetleme.
**Alıcı alan büyümesi:** Pooling feature map'i 2× küçültür. Aynı $3 \times 3$ filtreyi sonraki katmanda uygularsan, o filtrenin "gördüğü" bölge orijinal görüntüde artık $\sim 6 \times 6$'ya karşılık gelir. Birkaç katman sonra küçük filtreler büyük bölgeleri özetler — kenardan şekle, şekilden nesneye hiyerarşi doğal olarak çıkar.
:::
::: {.callout-note collapse="true" title="Soru 4: (Builder) Vision Transformer (ViT) convolution'ı tamamen attention ile değiştirir. CNN'in hangi yapısal önyargısını kaybeder, hangi avantajı kazanır?"}
**Cevap:** ViT görüntüyü küçük yamalara böler, her yamayı bir **token** olarak ele alır; Ders 2'nin self-attention'ını ($\mathbf{Q}\mathbf{K}^\top$ + softmax) bu token dizisine uygular.
**Kaybedilen:** CNN'in iki yapısal önyargısı — **yerellik** ve **öteleme-değişmezlik** — ViT'te açıkça yoktur; büyük veriden öğrenmesi gerekir. Bu yüzden az veriyle CNN'i yenmekte zorlanır.
**Kazanılan:** **Küresel ilişkiler** en alttan itibaren kurulur; attention daha **paralelleştirilebilir**. Yeterli veri ve hesap olduğunda ViT genellikle daha iyi ölçeklenir.
:::
::: {.callout-note collapse="true" title="Soru 5: ReLU'yu CNN'den çıkarırsan ne olur? Neden doğrusal-olmama derinliğin olmazsa olmazıdır?"}
**Cevap:** ReLU'suz CNN, art arda lineer (convolution) operatörlerden oluşur. İki lineer operatörün bileşkesi yine lineerdir (18.06): $W_2(W_1 x) = (W_2 W_1) x = W' x$. Yani kaç convolution katmanı istiflersen istifle, sonuç tek bir lineer filtreye çöker. Modelin ifade gücü dramatik azalır — yalnızca lineer ayrılabilir desenleri yakalayabilir; "kenar → şekil → nesne" hiyerarşisi imkânsız. Bu yüzden her conv sonrası bir doğrusal-olmama şarttır.
:::
## Egzersizler {#sec-egzersizler}
**Egzersiz 1 (Convolution'ı elle kur).** NumPy ile 2B convolution'ı sıfırdan yaz. Sobel x-yön kenar filtresi $K = [[-1,0,1],[-2,0,2],[-1,0,1]]$ kullan; küçük bir gri görüntüye uygula ve sonucu görselleştir.
```python
import numpy as np
def conv2d(I, K):
Hi, Wi = I.shape
Hk, Wk = K.shape
Ho, Wo = Hi - Hk + 1, Wi - Wk + 1
out = np.zeros((Ho, Wo))
for i in range(Ho):
for j in range(Wo):
out[i, j] = (I[i:i+Hk, j:j+Wk] * K).sum() # eleman carpim + toplam
return out
K = np.array([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]]) # Sobel x
I = np.random.rand(6, 6)
print(conv2d(I, K))
```
**Egzersiz 2 (Dense vs CNN parametre sayısı).** MNIST ($28 \times 28$) için iki model parametre sayısını karşılaştır: (a) Flatten → Dense(128) → Dense(10); (b) Conv2d(1, 32, 3) → MaxPool → Conv2d(32, 64, 3) → MaxPool → Flatten → Dense(10). Hangi mimaride kaç parametre var? Bölüm 5'te tartıştığımız "parametre patlaması" argümanını sayılarla doğrula.
**Egzersiz 3 (Alıcı alan hesabı).** Bir CNN şu sırada: Conv $3 \times 3$ (stride 1) → Conv $3 \times 3$ (stride 1) → MaxPool $2 \times 2$ (stride 2) → Conv $3 \times 3$ (stride 1). Son katmanın bir nöronunun orijinal girdideki alıcı alanı kaç piksele karşılık gelir? (İpucu: her conv $+2$, her stride-2 pool $2 \times$ ölçeklendirme yapar.)
**Egzersiz 4 (Tiny CNN — PyTorch).** PyTorch ile küçük bir CNN tanımla ve rastgele bir $32 \times 32$ RGB tensorle forward pass yap. Çıktının şekli ve toplam parametre sayısını yazdır.
```python
import torch
import torch.nn as nn
cnn = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, padding=1), nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, kernel_size=3, padding=1), nn.ReLU(),
nn.MaxPool2d(2),
nn.AdaptiveAvgPool2d(1),
nn.Flatten(),
nn.Linear(64, 10),
)
x = torch.randn(1, 3, 32, 32) # 1 batch, 3 kanal, 32x32
y = cnn(x)
print("cikti :", y.shape)
print("toplam :", sum(p.numel() for p in cnn.parameters()))
```
**Egzersiz 5 (Sonraki dersin habercisi).** Bu derste **ayırt edici (discriminative)** bir model kurduk: $P(\text{sınıf} \mid \text{görüntü})$ öğreniyor. Ders 4'te **üretken (generative)** modeller var: $P(\text{görüntü})$ öğrenip yeni görüntüler **üretiyor**. (a) Bir kediyi tanımak ile yeni bir kedi resmi yaratmak — hangisinin daha büyük bir bilgi gerektireceğini açıkla. (b) $28 \times 28$ grayscale bir görüntünün taşıyabileceği toplam piksel kombinasyonu sayısını hesapla ($256^{28 \cdot 28}$); bu uzayda "gerçekçi rakam" alt kümesinin oranı hakkında ne söyleyebilirsin? Bu, Ders 4'ün **manifold hipotezi**nin habercisidir.
## Sonraki Ders İçin Hazırlık {#sec-sonraki}
**Ders 4: Derin Üretken Modelleme (Deep Generative Modeling)** — Ava Soleimany
Şimdiye kadar her ders **tahmin** yaptı. Ders 4 farklı bir soruyu cevaplıyor: "Yeni bir şey **üretebilir miyim**?" Yeni yüz, yeni cümle, yeni protein. Bunun için modelin verinin dağılımı $P(x)$'i öğrenmesi ve örnekleme yapması gerekir.
**Ana konular:**
- Discriminative vs generative ayrımı; ne öğreniyoruz?
- **Autoencoder** ve **Variational Autoencoder (VAE)**: verinin gizli (latent) uzayını öğrenmek.
- **Generative Adversarial Networks (GAN)**: üretici vs ayırıcı oyunu.
- **Diffusion** modelleri: gürültüyü adım adım geri çevirerek üretmek.
::: {.callout-warning title="Ders 4 öncesi yapılacak"}
- Egzersizleri çöz — özellikle 4 (tiny CNN) ve 5 (manifold hipotezi sezgisi).
- CNN'in feature extractor + head ayrımını kendi cümlenle anlat; bu ayrım Ders 4'teki encoder-decoder mimarisinin habercisi.
- Ana cümleyi tekrar oku: *"CNN, weight sharing + locality ile öznitelik hiyerarşisini veriden öğrenen mimari."*
:::
## Anahtar Kavramlar (Cheat Sheet) {#sec-cheat-sheet}
| Kavram | Tanım | Amini'de |
|--------|-------|----------|
| **Görüntü tensoru** | Grayscale $H \times W$ matrisi; RGB $H \times W \times 3$ tensor | 4m42 |
| **Hiyerarşik öznitelik** | Düşük (kenar) → orta (şekil) → yüksek (nesne); veriden öğrenilir | 7m23 |
| **Flatten problemi** | 2B'yi 1B'ye sıkıştırmak uzamsal bilgiyi yok eder + param patlatır | 12m55 |
| **Yerel alıcı alan** | Bir nöronun yalnızca küçük yamaya bağlı olması | 14m58 |
| **Convolution** | Aynı filtreyi her yamada uygulamak: weight sharing + lokallik | 21m24 |
| **Filtre / Kernel** | Küçük öğrenilebilir ağırlık matrisi (örn. $3 \times 3$) | 17m05 |
| **Feature map** | Filtrenin girdide hangi konumlarda tetiklendiğinin haritası | 23m38 |
| **Stride / padding** | Adım büyüklüğü / kenar dolgusu — çıktı boyutunu belirler | 23m15 |
| **ReLU (CNN'de)** | Negatif aktivasyonları 0'a eşik; her conv sonrası uygulanır | 33m55 |
| **Max pooling** | Yerel yamanın maksimumunu al; uzamsal downsampling | 35m13 |
| **Alıcı alan büyümesi** | Pooling + derinlik, küçük filtrelerin geniş bölgeleri görmesini sağlar | 38m00 |
| **CNN mimari** | Feature extractor (conv+pool yığını) + classifier head | 40m52 |
| **Multiple filters** | Bir katmanda $N$ filtre → $N$ feature map; çıktı bir volume | 32m26 |
| **Object detection** | Bounding box + sınıf; uçtan uca türevlenebilir öneriler | 45m54 |
| **Semantic segmentation** | Piksel bazında sınıf etiketi; encoder-decoder (U-Net) | 51m20 |
| **1D / 3D conv** | Sıra (ses) ve hacim (video, MR) için aynı operatör | 40m32 |
## ML Builder Bağlantıları {#sec-ml-baglantilar}
::: {.callout-tip title="9 köprü"}
1. **Görüntü tensoru** → 18.06 matris/tensor temsili; çoklu kanal = üst üste binmiş matrisler. İleriye: normalization, transform pipeline.
2. **Convolution = öğrenilebilir lineer operatör** → 18.06 lineer dönüşüm (Ders 30); öteleme-değişmez yapı. İleriye: `nn.Conv2d`, depthwise/grouped varyantlar.
3. **Filtre · yama = dot product** → 18.06 iç çarpım, projeksiyon (Ders 1, 15); Ders 2'deki attention'la aynı çekirdek. İleriye: hibrit attention+conv mimariler.
4. **Kenar/sharpening filtreleri** → Calculus uzamsal türev (Ders 2, 10) — Sobel = birinci türev, Laplacian = ikinci türev. CNN bunları **öğrenir**.
5. **Hiyerarşi (kenar → şekil → nesne)** → Calculus Ders 4 fonksiyon bileşkesi / zincir kuralı; backprop bu bileşkenin türevini akıtır.
6. **Weight sharing** → 18.06 yapısal sınırlama; Ders 2'deki zaman ekseni weight sharing'in uzamsal kardeşi.
7. **Pooling (max / avg)** → Stat 110 sıra istatistikleri (max → Ders 25) ve beklenen değer (avg → Ders 9).
8. **Feature extractor + head deseni** → 18.06 paylaşılan alt-uzay + farklı projeksiyon kafaları. İleriye: multi-task learning, foundation models, transfer learning.
9. **ViT geçişi** → Ders 2'nin attention'ı görüde; iki büyük dersin buluşması. İleriye: foundation görsel modeller, self-supervised pre-training (DINO, MAE, CLIP).
:::
::: {.callout-important title="Bu dersten tek bir şey alıp gideceksen"}
CNN bir mimari değil, üç ilkenin somutlaşmasıdır — **weight sharing** (aynı filtre her yerde), **yerellik** (her nöron sadece yakın piksellere bakar) ve **derinlikle büyüyen alıcı alan** (pooling + composition). Bu üçü, görüntülerin doğal istatistiklerine uyan yapısal önyargılardır; dense ağın yapamadığı şeyi yapabilmesinin sebebi tam olarak budur. Aynı çekirdek, attention çağında bile altta yaşamaya devam ediyor.
:::