---
title: "Derin Üretken Modelleme"
subtitle: "VAE ve GAN — verinin dağılımını öğrenip oradan örnek almak"
---
::: {.callout-note title="Bölüm bilgisi"}
- **Lecture videosu:** [YouTube — Lecture 4: Deep Generative Modeling](https://www.youtube.com/watch?v=R8V8CbuxryI&list=PLtBw6njQRU-rwp5__7C0oIVt26ZgjG9NI&index=4) (≈50 dk)
- **Edition:** 2026 • **Hoca:** Ava Soleimany
- **Kaynak:** [introtodeeplearning.com](https://introtodeeplearning.com)
- **Okuma süresi:** ≈30 dk
:::
## Bu Derste Ne Var? {#sec-bu-derste}
Şimdiye dek tüm dersler **tahmin** yaptı: bir görüntüye etiket, bir cümlenin sonrasına kelime. Bu ders bambaşka bir soruyu cevaplıyor: "Yeni bir şey **üretebilir miyim**?" Yeni bir yüz, yeni bir cümle, yeni bir protein. Bunun için modelin verinin **olasılık dağılımını** $P(x)$ öğrenmesi ve oradan **örnek alması** gerekir. Ava dersi bir gösterimle açıyor: üç yüz fotoğrafı gösterip soruyor — "hangisi gerçek?". Bu yıl ilk kez, Gemini'nın ürettiği sahte yüzler gerçeğinden ayırt edilemez hâle geldi.
> *"how can we learn distributions of data so that we can model that distribution and also sample from it to produce new instances?"* — Ava, 0:52
**Dersin üç büyük fikri:**
1. **Gözetimsiz öğrenme + latent değişkenler** — etiket yok; verinin **gizli (latent) eksenlerini** öğren.
2. **Autoencoder → VAE** — veriyi alt-boyutlu bir $Z$'ye sıkıştır, geri çıkar; sonra $Z$'yi olasılıksallaştır ki **örnek alabilesin**.
3. **GAN** — gürültüden gerçekçiye uzanan bir üretici ağ, bir de onu kandırmaya çalışan ayırıcı; adversarial bir oyun.
{#fig-concept-map fig-align="center" width=85%}
::: {.callout-tip title="Builder Notu — ML Köprüleri"}
Bu ders Stat 110 olasılık temelini doğrudan kullanır — köprüler organik:
- **Generative model = $P(x)$ öğrenmek** → Stat 110 dağılım modelleme (Ders 12 PDF, Ders 13 Normal).
- **Autoencoder bottleneck (Z)** → 18.06 boyut indirgeme; PCA'nın doğrusal-olmayan akrabası (SVD, Ders 29).
- **Reconstruction loss (MSE)** → Stat 110 Gauss gürültü varsayımının maximum likelihood karşılığı (Ders 13).
- **Reparameterization trick** — $z = \mu + \sigma \cdot \varepsilon$, $\varepsilon \sim \mathcal{N}(0,1)$ — Stat 110 konum-ölçek ailesi (Ders 14) + Calculus zincir kuralı (Ders 4).
- **KL divergence** → Stat 110 koşullu olasılık / entropy (Ders 4); cross-entropy'nin (Ders 1) "iki dağılımı yakınlaştır" kardeşi.
- **GAN ayırıcısı** → Ders 1 cross-entropy sınıflandırıcısı. **Min-max oyun** → Calculus eyer noktası (Ders 10).
İleriye köprüler: **diffusion modelleri**, score-based modelleri, **ELBO** (Jensen eşitsizliği), foundation görsel modeller (DALL-E, Stable Diffusion, Sora), VQ-VAE.
:::
## Generative Modelleme: Tahmin Etmek Yerine Üretmek {#sec-generative}
Ders 1-3 hep **denetimli öğrenme** yapıyordu: girdi $X$ ile etiket $Y$ çiftleri verilir; ağ $X \to Y$ fonksiyonunu öğrenir.
Generative modelleme **gözetimsizdir**: yalnızca veri var, etiket yok. Hedef, verinin **alta yatan dağılımını** öğrenmek — ya yoğunluk tahmini ($P(x)$ nedir?) ya da örnek üretimi ($P$'den nasıl örnek alırım?).
Bu neden önemli?
- **Örnek üretimi:** GPT (yeni metin), DALL-E/Nano Banana (yeni görüntü), Sora (yeni video), AlphaFold (yeni protein).
- **Yanlılık giderme (debiasing):** Veri dağılımını öğrenip nadir örnekleri öne çıkararak modeli daha adil hâle getirmek.
- **Aykırı değer tespiti:** Veri dağılımı dışına düşen girdileri yakalamak.
- **Yoğunluk tahmini:** Bir noktanın olasılığını hesaplamak — güvenilirlik, kalibrasyon.
> *"the use cases are far beyond... hyperrealistic images... debiasing... outlier detection... sample generation."* — Ava, 6:15
::: {.callout-tip title="Builder Notu — Foundation Modellerin Kalbi"}
**Geriye (Stat 110):** "Dağılımını öğren" hedefi doğrudan Stat 110'un ana sorusudur — PDF/CDF (Ders 12), maximum likelihood (Ders 17), Bayes inference (Ders 4).
**İleriye:** "Veri dağılımını öğren" bugünün foundation modellerinin (GPT, Claude, Gemini, Stable Diffusion) hedefidir; ölçekleme yasaları (Chinchilla) ve büyük veri ile derinden öğrenilen dağılım, modern generative AI'ın özeti.
:::
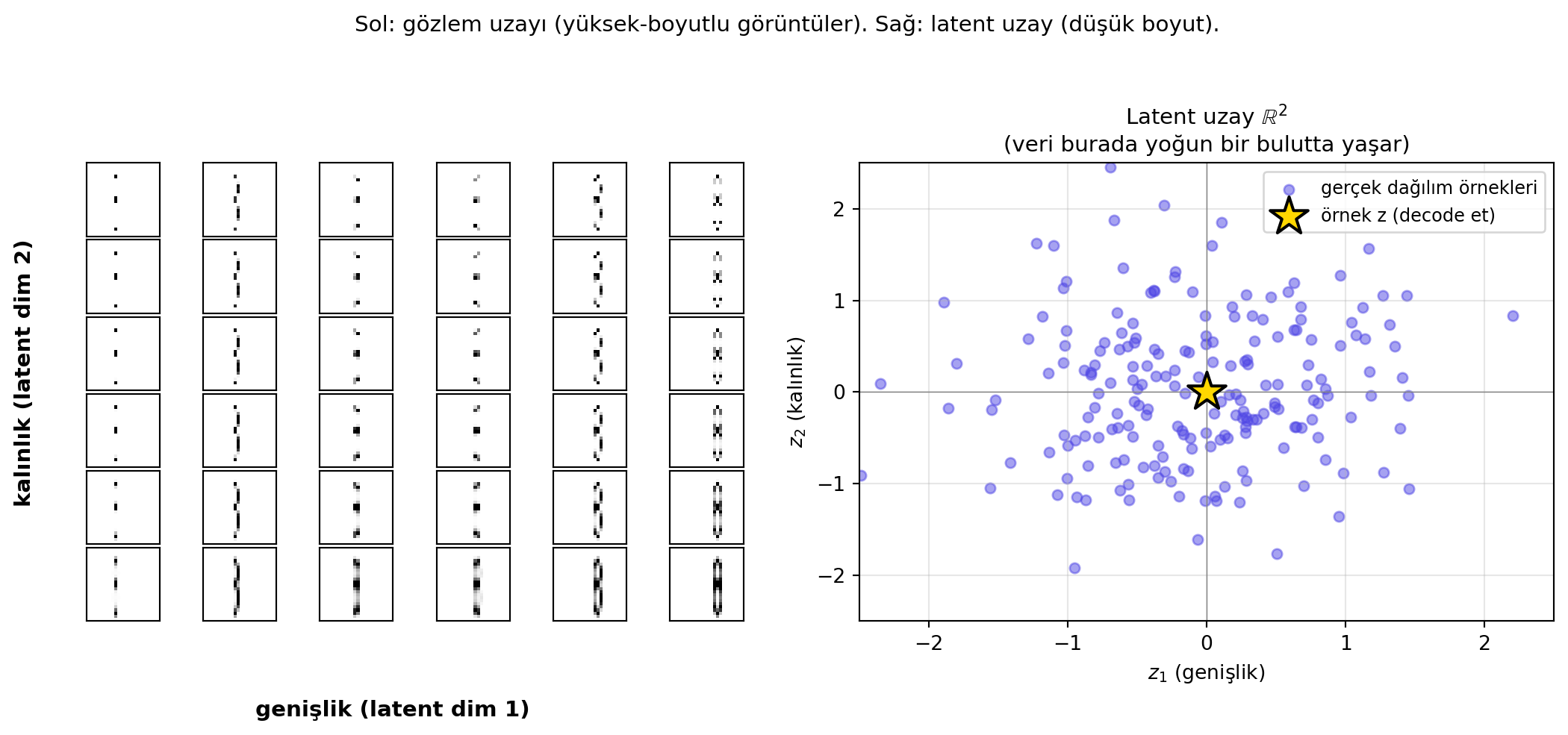
## Latent Variable Sezgisi: Platon'un Mağarası {#sec-latent}
Ava bu kavramı Platon'un Devlet adlı eserindeki **mağara miti** ile açıyor. Mahkûmlar zincirlenmiş, bir duvara bakar; arkalarındaki ateş, geçen nesnelerin gölgelerini duvara düşürür. Mahkûmlar nesneleri doğrudan göremez — yalnızca onların **gölgelerini** görür. Yine de, görünen gölgelerin **arkasında** bir şeylerin olduğunu sezerler.
Latent değişken modellemenin felsefesi tam budur: gözlemlediğimiz veri (yüzler, resimler) yüksek boyutludur, ama bu varyasyonu yaratan **temel eksenler** çok daha azdır — yüz örneğinde: yaş, cinsiyet, ifade, gözlük, ışıklandırma. Bu az sayıda gizli ekseni **latent değişkenler** $Z$ olarak adlandırırız.
```{python}
#| label: fig-latent-manifold
#| fig-cap: "Manifold hipotezi: yüksek-boyutlu veri (sentetik el yazısı '8'), düşük-boyutlu bir latent uzayda (genişlik × kalınlık) yaşar."
#| fig-width: 11
#| fig-height: 5
import numpy as np
import matplotlib.pyplot as plt
rng = np.random.default_rng(0)
# Latent eksenler: genişlik (-1..1), kalınlık (0.4..1.6)
n_grid = 6
W_lat = np.linspace(-1, 1, n_grid)
T_lat = np.linspace(0.4, 1.6, n_grid)
def draw_eight(ax, w, t):
"""Sentetik '8' rakamı — genişlik w, kalınlık t."""
H = 24
img = np.zeros((H, H))
yy, xx = np.mgrid[0:H, 0:H]
cx = H / 2 + w * 3
for cy, ry in [(8, 4), (16, 5)]:
r2 = ((xx - cx) / (1 + 0.3 * w))**2 + ((yy - cy) / ry)**2
ring = np.exp(-(r2 - 1)**2 / (0.04 / t**2))
img += ring
img = np.clip(img, 0, 1)
ax.imshow(img, cmap='gray_r')
ax.set_xticks([]); ax.set_yticks([])
fig = plt.figure(figsize=(11, 5))
# Sol: grid of 8s
gs = fig.add_gridspec(1, 2, width_ratios=[1, 1])
inner = gs[0].subgridspec(n_grid, n_grid, wspace=0.05, hspace=0.05)
for i, t in enumerate(T_lat):
for j, w in enumerate(W_lat):
ax = fig.add_subplot(inner[n_grid-1-i, j])
draw_eight(ax, w, t)
fig.text(0.25, 0.02, 'genişlik (latent dim 1)', ha='center', fontsize=11, weight='bold')
fig.text(0.01, 0.5, 'kalınlık (latent dim 2)', va='center', rotation=90, fontsize=11, weight='bold')
# Sağ: latent uzay scatter
ax = fig.add_subplot(gs[1])
n_pts = 200
zs = rng.standard_normal((n_pts, 2)) * 0.8
ax.scatter(zs[:, 0], zs[:, 1], c='#4f46e5', s=25, alpha=0.5, label='gerçek dağılım örnekleri')
ax.scatter(0, 0, marker='*', s=400, c='gold', edgecolor='black', linewidth=1.5, label='örnek z (decode et)', zorder=5)
ax.axhline(0, color='gray', lw=0.5); ax.axvline(0, color='gray', lw=0.5)
ax.set_xlim(-2.5, 2.5); ax.set_ylim(-2.5, 2.5)
ax.set_xlabel('$z_1$ (genişlik)'); ax.set_ylabel('$z_2$ (kalınlık)')
ax.set_title('Latent uzay $\\mathbb{R}^2$\n(veri burada yoğun bir bulutta yaşar)', fontsize=11)
ax.legend(fontsize=9); ax.grid(alpha=0.3)
plt.suptitle('Sol: gözlem uzayı (yüksek-boyutlu görüntüler). Sağ: latent uzay (düşük boyut).',
fontsize=11, y=1.0)
plt.tight_layout(rect=[0.03, 0.03, 1, 0.98])
plt.show()
```
::: {.callout-tip title="Builder Notu — Manifold Hipotezi"}
**Geriye (18.06):** Latent uzay sezgisi, **yüksek-boyutlu veriyi düşük-boyutlu bir alt-uzayda yaklaşıklamak** demektir — 18.06'nın PCA / SVD'sinin (Ders 29) doğrusal kuzeni. PCA, varyansı koruyan en iyi *lineer* projeksiyonu bulur; autoencoder bunun doğrusal-olmayan, derin versiyonudur.
**İleriye:** "Manifold hipotezi" — gerçekçi yüksek-boyutlu veriler, çok daha düşük-boyutlu bir manifold üzerinde yaşar. Bu hipotez generative modellerin neden çalışabildiğinin matematiksel açıklamasıdır.
:::
## Autoencoder: Sıkıştır ve Geri Çıkar {#sec-autoencoder}
Latent eksenlere etiketsiz nasıl ulaşırız? Çok zarif bir fikir: ağa kendi girdisini **yeniden inşa etmesini** öğretelim.
- **Encoder** $E_\phi$: girdi $x$'i alır, düşük-boyutlu latent $z$'ye sıkıştırır.
- **Decoder** $D_\theta$: $z$'den orijinali yeniden kurar: $\hat{x} = D_\theta(z)$.
Eğitim sinyali yalnızca girdinin kendisidir — etiket yok. Kayıp fonksiyonu, orijinal ile yeniden-inşanın farkı:
$$
L(\theta, \phi) = \| x - D_\theta(E_\phi(x)) \|^2
$$
Bu, piksel-bazlı bir uzaklıktır (MSE). $z$'nin boyutu küçük olduğundan, ağ verinin **özünü** sıkıştırmak zorunda kalır — bottleneck katman.
{#fig-autoencoder fig-align="center" width=85%}
> *"perhaps we can task the model to actually reconstruct or regenerate the data itself and use this as a signal to train the model."* — Ava, 13:32
::: {.callout-tip title="Builder Notu — Doğrusal Olmayan PCA"}
**Geriye (18.06 + Stat 110):** Autoencoder, **doğrusal-olmayan PCA**'dır. PCA en iyi *lineer* alt-uzayı bulurken autoencoder derin katmanlarla doğrusal-olmayan bir manifold yaklaşıklığı yapar. MSE loss ise Stat 110'da Normal gürültü varsayımının maximum likelihood karşılığıdır (Ders 13).
**İleriye:** Modern türleri: **denoising autoencoder** (girdiyi bozup geri çıkarmayı öğrenmek — diffusion'a köprü), **VQ-VAE** (kesikli latent — DALL-E gibi modellerde token uzayı).
:::
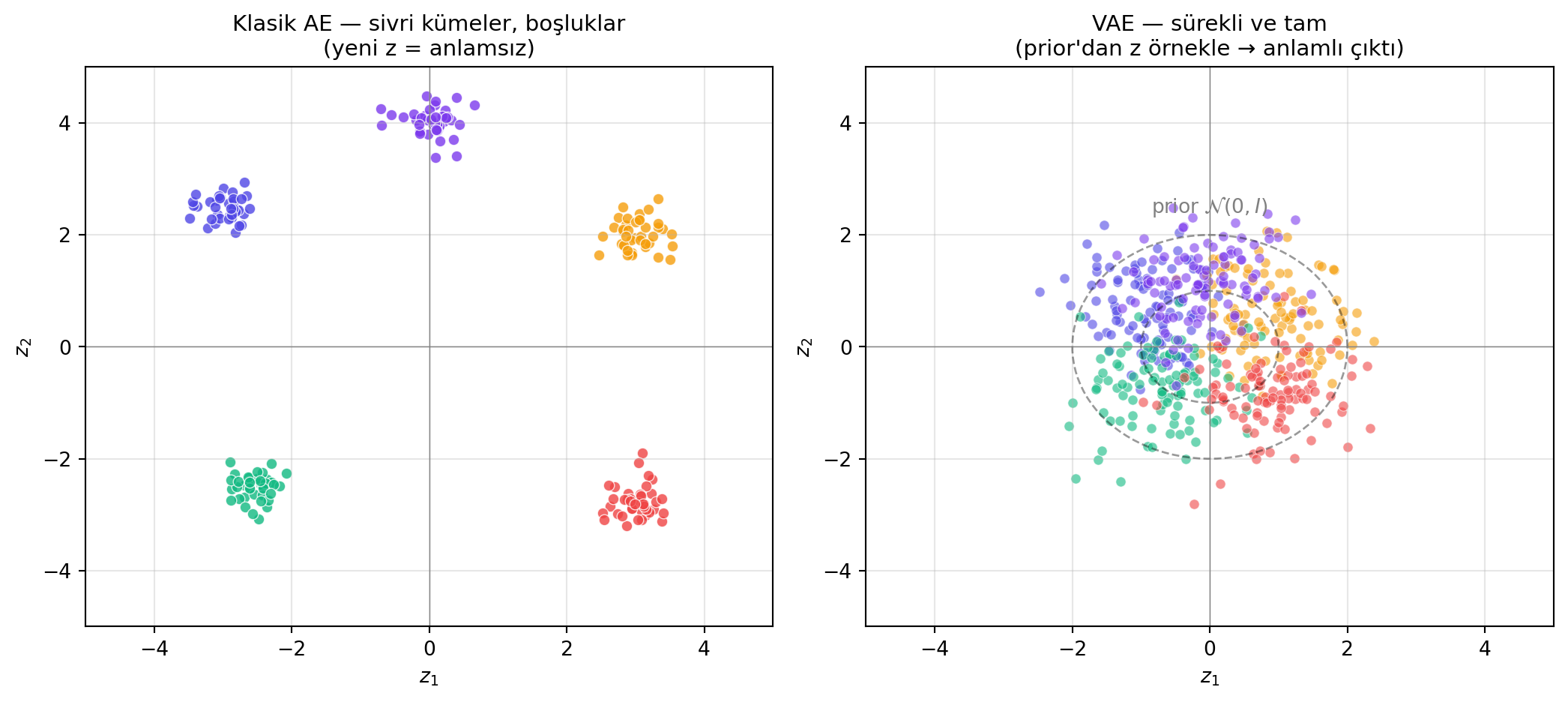
## Autoencoder'ın Sınırı: Örnekleme Yok {#sec-ae-limit}
Sıradan autoencoder güzel bir gösterim öğrenir, ama **örnek üretmek için yetersizdir**. Sebep: tamamen **deterministiktir**. Aynı girdi her geçtiğinde aynı $z$'yi, aynı $\hat{x}$'i verir; latent uzayda "gez ve yeni şey üret" şansı yoktur. Üstelik latent uzayın **boşlukları** vardır — eğitim verisinin yansıdığı noktaların arasında kalan bölgelerden örnek alırsan, decoder bunu mantıklı bir çıktıya çeviremez.
İhtiyacımız olan: latent uzayı bir **dağılım** olarak öğrenmek. Bu fikir, **VAE** (Variational Autoencoder) ile somutlaşıyor.
## VAE: Olasılıksal Twist {#sec-vae}
VAE'nin temel fikri: encoder'ı **tek bir $z$** üreten deterministik bir katman yerine, **bir olasılık dağılımının parametrelerini** üreten bir katman yap. En yaygın seçim Normal: her bir latent değişken için bir **ortalama** $\mu$ ve bir **standart sapma** $\sigma$ üret. Sonra bu dağılımdan örnekleyerek $z$ elde et:
$$
q_\phi(z \mid x) = \mathcal{N}\!\left(z;\; \mu_\phi(x),\; \sigma_\phi^2(x)\right)
$$
Decoder ise verilen $z$'den orijinal uzayda bir dağılım üretir: $p_\theta(x \mid z)$.
> *"instead of taking that deterministic layer Z we can replace that with a sampling operation... we now learn a mean and a variance for each latent variable."* — Ava, 18:38
```{python}
#| label: fig-latent-scatter
#| fig-cap: "VAE latent uzayı: prior'a (N(0, I)) çekilmiş, sınıflara göre kümelenen ama sürekli bir bulut. Yeni z örneklemek = yeni veri üretmek."
#| fig-width: 11
#| fig-height: 5
rng = np.random.default_rng(11)
fig, axes = plt.subplots(1, 2, figsize=(11, 5))
# Sol: klasik AE — kümelenmiş, boşluklu
ax = axes[0]
centers = np.array([[-3, 2.5], [3, 2.0], [-2.5, -2.5], [3, -2.8], [0, 4]])
colors_5 = ['#4f46e5', '#f59e0b', '#10b981', '#ef4444', '#7c3aed']
for c, col in zip(centers, colors_5):
pts = c + rng.standard_normal((40, 2)) * 0.25
ax.scatter(pts[:, 0], pts[:, 1], c=col, s=30, alpha=0.8, edgecolor='white', lw=0.5)
ax.set_xlim(-5, 5); ax.set_ylim(-5, 5)
ax.set_xlabel('$z_1$'); ax.set_ylabel('$z_2$')
ax.set_title('Klasik AE — sivri kümeler, boşluklar\n(yeni z = anlamsız)', fontsize=11)
ax.axhline(0, color='gray', lw=0.5); ax.axvline(0, color='gray', lw=0.5)
ax.grid(alpha=0.3)
# Sağ: VAE — N(0, I) prior'a yaslı, sürekli
ax = axes[1]
# KL → prior'a doğru sürükler
for c, col in zip(centers * 0.3, colors_5):
pts = c + rng.standard_normal((100, 2)) * 0.6
ax.scatter(pts[:, 0], pts[:, 1], c=col, s=25, alpha=0.6, edgecolor='white', lw=0.4)
# Standart Normal prior konturu
theta = np.linspace(0, 2 * np.pi, 100)
for r in [1, 2]:
ax.plot(r * np.cos(theta), r * np.sin(theta), 'k--', alpha=0.4, lw=1)
ax.text(0, 2.4, 'prior $\\mathcal{N}(0, I)$', ha='center', fontsize=10, color='gray')
ax.set_xlim(-5, 5); ax.set_ylim(-5, 5)
ax.set_xlabel('$z_1$'); ax.set_ylabel('$z_2$')
ax.set_title('VAE — sürekli ve tam\n(prior\'dan z örnekle → anlamlı çıktı)', fontsize=11)
ax.axhline(0, color='gray', lw=0.5); ax.axvline(0, color='gray', lw=0.5)
ax.grid(alpha=0.3)
plt.tight_layout()
plt.show()
```
VAE iki terimli bir kayıp ile eğitilir:
$$
L(\phi, \theta) = \underbrace{- \mathbb{E}_{q_\phi(z \mid x)}\!\left[\log p_\theta(x \mid z)\right]}_{\text{yeniden-inşa}} + \underbrace{D_{KL}\!\left(q_\phi(z \mid x) \,\|\, p(z)\right)}_{\text{düzenlileştirme}}
$$
**(1) Yeniden-inşa terimi:** "latent'ten örnek aldığında girdiyi geri alabiliyor musun?"
**(2) Düzenlileştirme terimi (KL divergence):** öğrenilen latent dağılımı $q_\phi(z|x)$ ile bir **prior** $p(z)$ arasındaki uzaklığı ölçer. En yaygın prior **standart Normal** $\mathcal{N}(0, I)$'dır. İki temel özelliği teşvik eder:
- **Süreklilik:** Latent uzayda yakın noktalar, anlamca da yakın çıktılara decode olur.
- **Tamlık:** Uzayın her noktasından mantıklı bir örnek üretilebilir.
::: {.callout-tip title="Builder Notu — KL = İki Dağılım Yakınlığı"}
**Geriye (Stat 110):** KL divergence, **iki dağılım arasındaki bilgi-teorik uzaklık** — Stat 110'un koşullu olasılık / entropy çerçevesinin (Ders 4) tabii bir uzantısı. Cross-entropy'nin (Ders 1) iki dağılımı yakınlaştırma niyetinin daha genel formüdür.
**İleriye:** İki-terimli loss yapısı, sonraki tüm olasılıksal generative modellerin (ELBO, score matching, flow matching) şablonudur. KL'nin nasıl ölçekleneceği (β-VAE'de $\beta$ katsayısı) **disentanglement** araştırmasının kalbidir.
:::
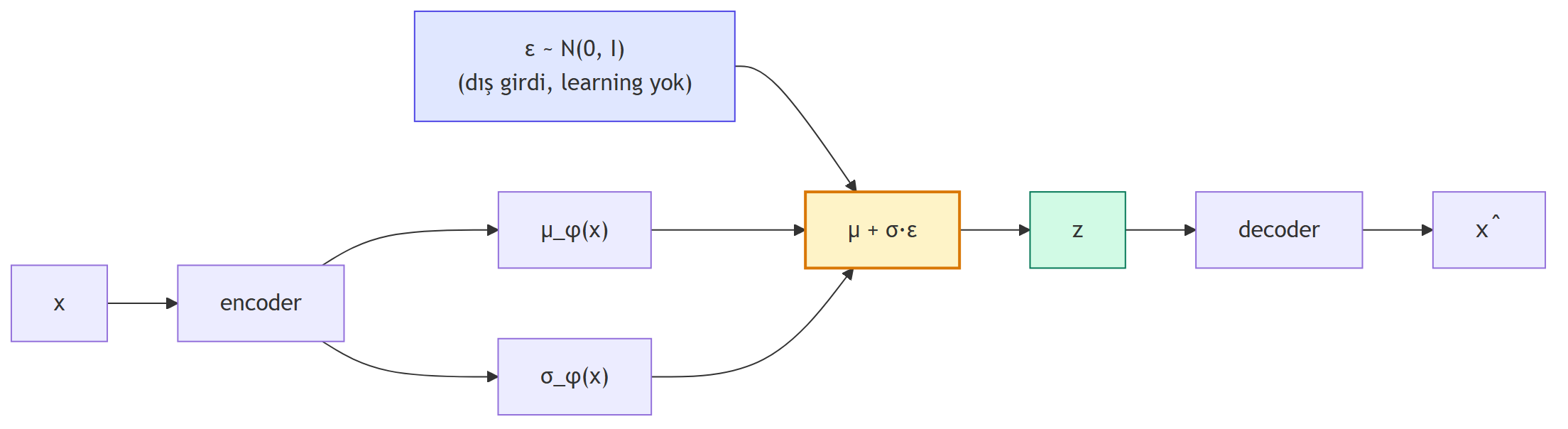
## Reparameterization Trick: Stokastik Düğümden Backprop {#sec-reparam}
VAE'yi gradient descent ile eğiteceğiz — ama latent katmanın **örnekleme** içeriyor: $z \sim \mathcal{N}(\mu, \sigma^2)$. Gradient bu stokastik düğümden **geçemez** (rastgelelik üzerinden türev tanımsız). Çözüm zarif:
$$
z = \mu + \sigma \cdot \varepsilon, \qquad \varepsilon \sim \mathcal{N}(0, I)
$$
Stokastikliği $z$'den **dışarı it**; sabit bir $\varepsilon$'a yerleştir. Artık $z$, $\mu$ ve $\sigma$'nın **deterministik** bir fonksiyonudur. Gradient'ler şimdi $\mu$ ve $\sigma$ üzerinden rahatça geriye akar.
{#fig-reparam fig-align="center" width=85%}
Bu hile **reparameterization trick** olarak bilinir ve VAE'nin uçtan-uca türevlenebilir olmasını sağlayan ana fikirdir.
::: {.callout-tip title="Builder Notu — Konum-Ölçek Ailesi"}
**Geriye (Stat 110 + Calculus):** Bu, Stat 110 Ders 14'ün **konum-ölçek ailesinin** kullanımıdır: $X = \mu + \sigma Z$ formundaki bir Normal'i, standart Normal'den oluştur. Calculus zincir kuralı (Ders 4) sayesinde, $\partial L / \partial \mu$ ve $\partial L / \partial \sigma$ kanalları artık doğrudan hesaplanabilir.
**İleriye:** Reparameterization trick, modern olasılıksal derin öğrenmenin temel taşıdır — variational inference, Bayesian neural networks, normalizing flows, ve bir ölçüde diffusion. Bir builder olarak "rastgelelik var ama backprop lazım" durumunda ilk düşüneceğin örüntüdür.
:::
## GAN: Üretici-Ayırıcı Oyunu {#sec-gan}
Bazen latent gösterim umurumuzda değildir; yalnızca **yeni örnek** istiyoruzdur. GAN doğrudan **gürültüden gerçekçi örneklere** giden bir ağ öğrenir.
Yapı çok zarif — iki rakip ağ:
- **Generator (üretici) G:** Bir gürültü vektörü $z \sim p(z)$ alır (genelde Gaussian) ve sahte bir örnek $G(z)$ üretir. Hedef: gerçekten ayırt edilemez olsun.
- **Discriminator (ayırıcı) D:** Bir örnek alır (gerçek veya $G$'den) ve **gerçek mi sahte mi** sınıflandırır. Hedef: doğru tahmin oranını maksimize etmek.
İkili **rekabet eder**. Resmî kayıp, bir **min-max** oyunudur:
$$
\min_G\; \max_D\; V(D,\, G) = \mathbb{E}_{x \sim p_{\text{data}}}\!\left[\log D(x)\right] + \mathbb{E}_{z \sim p_z}\!\left[\log\!\left(1 - D(G(z))\right)\right]
$$
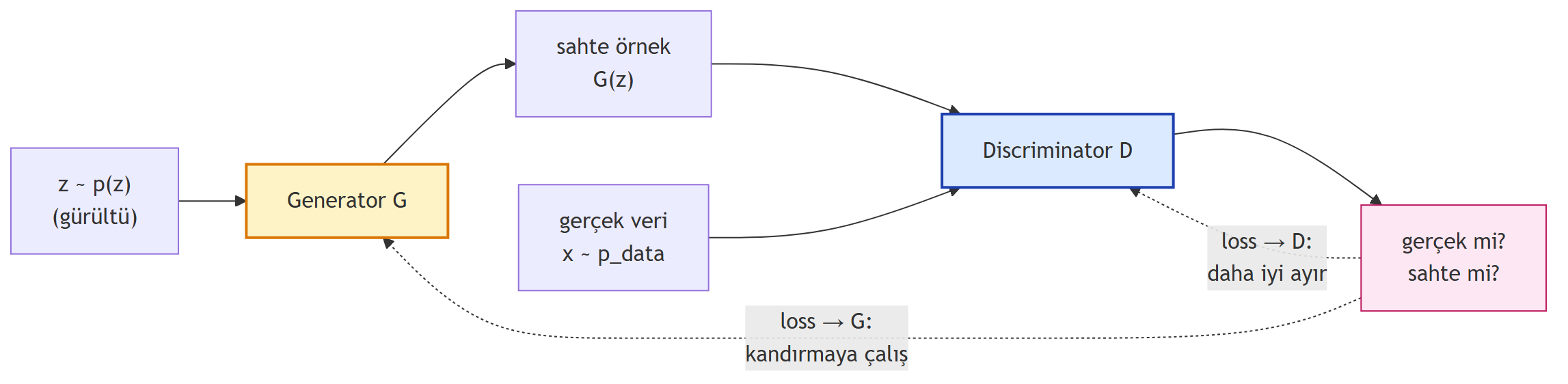{#fig-gan fig-align="center" width=85%}
> *"can we make this generative model by pitting two separate neural networks... against each other and having them compete in a loss function that captures this notion of competition."* — Ava, 36:04
```{python}
#| label: fig-gan-quality
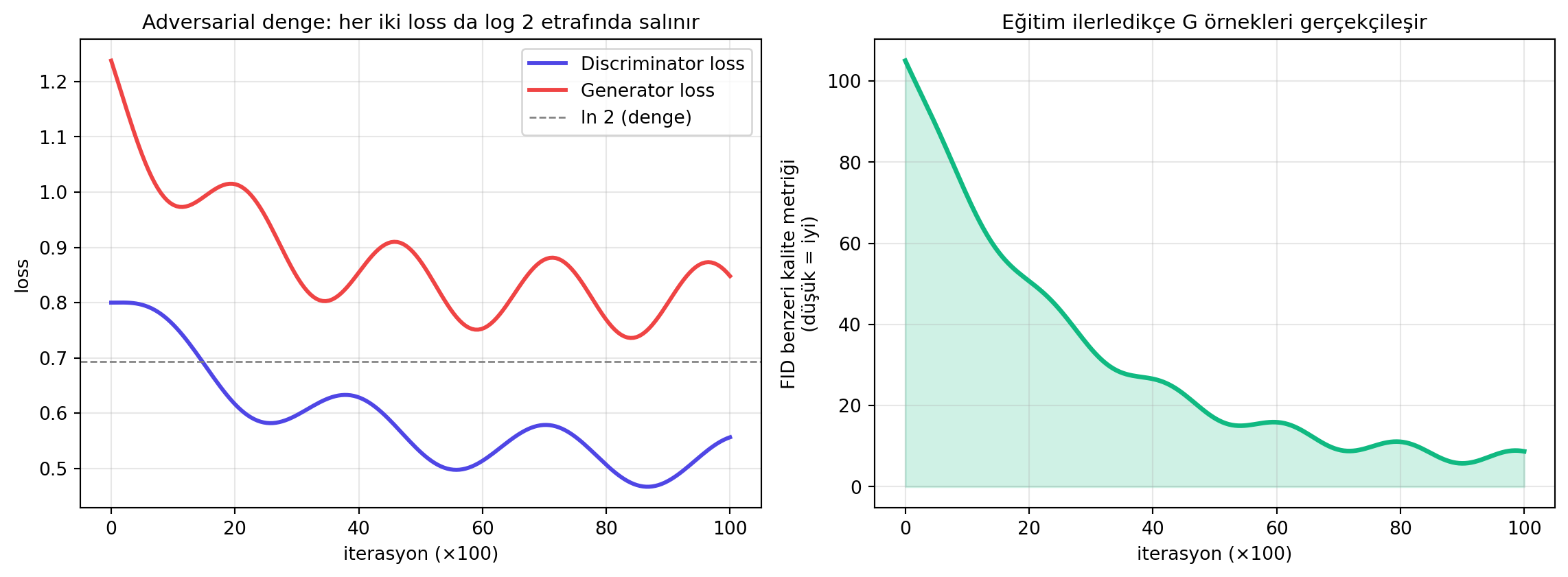
#| fig-cap: "GAN eğitiminde G ve D'nin loss'ları (sentetik): denge noktasında her ikisi de log 2'ye yakın salınır; G'nin örnekleri zamanla gerçeğe yaklaşır."
#| fig-width: 12
#| fig-height: 4.5
iters = np.linspace(0, 100, 200)
D_loss = 0.5 + 0.3 * np.exp(-iters / 30) + 0.05 * np.sin(iters / 5)
G_loss = 0.8 + 0.4 * np.exp(-iters / 20) + 0.07 * np.cos(iters / 4 + 1)
fig, axes = plt.subplots(1, 2, figsize=(12, 4.5))
ax = axes[0]
ax.plot(iters, D_loss, color='#4f46e5', lw=2.2, label='Discriminator loss')
ax.plot(iters, G_loss, color='#ef4444', lw=2.2, label='Generator loss')
ax.axhline(np.log(2), color='gray', lw=1, ls='--', label='ln 2 (denge)')
ax.set_xlabel('iterasyon (×100)')
ax.set_ylabel('loss')
ax.set_title('Adversarial denge: her iki loss da log 2 etrafında salınır', fontsize=11)
ax.legend(fontsize=10); ax.grid(alpha=0.3)
# Sağ: kalite eğrisi (örnek "FID" benzeri)
ax = axes[1]
quality = 100 * np.exp(-iters / 25) + 5 + 2 * np.sin(iters / 3)
ax.plot(iters, quality, color='#10b981', lw=2.5)
ax.fill_between(iters, quality, alpha=0.2, color='#10b981')
ax.set_xlabel('iterasyon (×100)')
ax.set_ylabel('FID benzeri kalite metriği\n(düşük = iyi)')
ax.set_title('Eğitim ilerledikçe G örnekleri gerçekçileşir', fontsize=11)
ax.grid(alpha=0.3)
plt.tight_layout()
plt.show()
```
Pratikte GAN eğitimi **kararsızdır**: G ve D'den biri çok güçlenirse diğeri sinyal alamaz (vanishing gradients), bazen G yalnızca birkaç moda yaslanır (**mode collapse**). Bu yüzden WGAN, spectral normalization, two-time-scale update gibi iyileştirmeler çıkmıştır.
::: {.callout-tip title="Builder Notu — D Bir Sınıflandırıcı"}
**Geriye (Stat 110 + Ders 1 + Calculus):** **D bir Ders 1 sınıflandırıcısıdır** — cross-entropy minimize ediyor, çıkışta bir Bernoulli olasılığı veriyor (Stat 110 Ders 8). **Min-max** Calculus'un **eyer noktası** problemidir (Ders 10): bir değişkene göre maksimum, diğerine göre minimum; Hessian indefinittir.
**İleriye:** GAN'ler bir dönemin baskın üretici modeliydi (StyleGAN, BigGAN); bugün birçok alanda **diffusion** modelleri öne geçti. Yine de GAN'lerin hızlı tek-adım örneklemesi belirli üretim hattlarında hâlâ kullanımda.
:::
## Diffusion'a Geçiş: Gürültüden Gerçeğe Adım Adım {#sec-diffusion}
GAN'in standart formu "gürültü → veri" haritalar. Bu dersin sonrasında gelen büyük adım **diffusion modelleri**: latent uzaya sıkıştırmak yerine, **gerçek veriye gürültü ekleyip** bu eklemeyi geri çevirmeyi adım adım öğrenen modeller. Bugünün Stable Diffusion, DALL-E 3, Sora, Imagen gibi modelleri bu yaklaşıma dayanır.
```{python}
#| label: fig-diffusion-forward
#| fig-cap: "Diffusion forward process: veri (t=0) → adım adım Gaussian gürültü ekle → t=T'de saf gürültü. Reverse process bu yolu geri öğrenir."
#| fig-width: 13
#| fig-height: 3.2
# Sentetik bir "rakam" oluştur
def synth_digit():
img = np.zeros((28, 28))
yy, xx = np.mgrid[0:28, 0:28]
# Bir "3" benzeri
img += np.exp(-(((xx - 12)**2 + (yy - 8)**2) / 6))
img += np.exp(-(((xx - 14)**2 + (yy - 14)**2) / 4))
img += np.exp(-(((xx - 12)**2 + (yy - 20)**2) / 6))
return np.clip(img, 0, 1)
img0 = synth_digit()
T = 6
betas = np.linspace(0.05, 0.4, T)
alpha_bars = np.cumprod(1 - betas)
rng = np.random.default_rng(4)
fig, axes = plt.subplots(1, T + 1, figsize=(13, 3.2))
# t=0 (clean)
axes[0].imshow(img0, cmap='gray_r', vmin=0, vmax=1)
axes[0].set_title('$t=0$\n(gerçek)', fontsize=10)
axes[0].axis('off')
# Forward steps
img_t = img0.copy()
for t in range(T):
sqrt_ab = np.sqrt(alpha_bars[t])
sqrt_1m = np.sqrt(1 - alpha_bars[t])
noise = rng.standard_normal(img0.shape)
img_t = sqrt_ab * img0 + sqrt_1m * noise
axes[t + 1].imshow(img_t, cmap='gray_r', vmin=-2, vmax=2)
axes[t + 1].set_title(f'$t={t+1}$', fontsize=10)
axes[t + 1].axis('off')
# Üst başlık: oklar
fig.suptitle('Forward (gürültü ekle) → ← Reverse (gürültüyü öğrenip geri çevir)',
fontsize=10)
plt.tight_layout()
plt.show()
```
::: {.callout-tip title="Builder Notu — Üç Yaklaşımı Karşılaştır"}
**İleriye:** Bir builder olarak "hangi model ne için iyi?" sorusunun cevabı:
- Hızlı tek-adım üretim → **GAN**
- Yorumlanabilir latent → **VAE**
- En yüksek kalite + esnek koşullama → **Diffusion** (bugün baskın)
Detayları **Ders 6 (New Frontiers)** kapsayacak.
:::
## Bu Dersin Özeti {#sec-ozet}
1. **Generative modelleme**, etiketsiz veriden $P(x)$ öğrenip oradan **yeni örnek** alır.
2. Kullanımları: örnek üretimi, debiasing, outlier tespiti, yoğunluk tahmini.
3. **Latent değişkenler** $Z$, verinin temel varyasyon eksenlerini taşıyan gizli koordinatlardır.
4. **Autoencoder:** encoder $x \to z$, decoder $z \to \hat{x}$; kayıp $= \|x - \hat{x}\|^2$; etiket gerekmez.
5. AE örnekleme için yetersiz — **deterministiktir**, latent uzay sürekli/tam değildir.
6. **VAE:** encoder $z$ yerine bir **Normal dağılımın** $\mu, \sigma$'sını üretir; $z = \text{sample} \to$ decoder.
7. **VAE loss = reconstruction + KL.** KL terimi, latent dağılımı standart Normal prior'a yakınlaştırır → süreklilik + tamlık.
8. **Reparameterization trick:** $z = \mu + \sigma \cdot \varepsilon$, $\varepsilon \sim \mathcal{N}(0, I)$. Stokastiği dışarı atar.
9. İyi eğitilmiş VAE latent eksenleri **yorumlanabilirdir**; perturbasyon, kontrollü değişim üretir.
10. **GAN:** Generator $G$ gürültüden örnek üretir; Discriminator $D$ gerçek vs sahte sınıflandırır. **Min-max** oyunu.
11. **Diffusion** modelleri bugün baskın; Ders 6'da göreceğiz.
::: {.callout-important title="Tek bir cümle"}
Generative modelleme, verinin dağılımını öğrenip oradan örnek almak demektir; VAE bunu *latent uzayı olasılıksal kılarak* (Stat 110 Normal + reparameterization trick) yapar, GAN ise *gürültüden gerçekçiye* iki ağın adversarial yarışıyla yapar — ikisi de günümüz üretken AI'nın temel taşlarıdır.
:::
## Kontrol Soruları {#sec-sorular}
::: {.callout-note collapse="true" title="Soru 1: Klasik autoencoder ile VAE arasındaki yapısal fark nedir? Neden klasik AE örnek üretmek için yetersizdir?"}
**Cevap:** Yapısal fark **ortadaki latent katmandadır**. Klasik AE'de encoder doğrudan tek bir vektör $z$ üretir (deterministik); VAE'de encoder bir **dağılımın parametrelerini** üretir: $\mu$ ve $\sigma$. Sonra $z$, bu dağılımdan örneklenir.
Klasik AE örnek üretmek için yetersizdir çünkü: (1) **Deterministik** — varyasyon yok. (2) Latent uzay üzerinde **bir dağılım yok** — "yeni $z$" üretmenin sistematik yolu yok; uzayda boşluklar var, oradan örnek alırsan decoder anlamsız çıktı verir. VAE bunu Normal prior ile latent uzayı **sürekli ve tam** yaparak çözer.
:::
::: {.callout-note collapse="true" title="Soru 2: VAE loss'unun KL terimi olmasaydı ne olurdu? Neden standart Normal prior seçilir?"}
**Cevap:** KL'siz bir VAE'de encoder, latent uzayda her örneği **birbirinden uzak**, **çok sivri** (küçük $\sigma$) dağılımlara yerleştirme eğilimine girer — böylece reconstruction kolaylaşır ama latent uzay parçalanır: noktalar arası boşluklar olur, prior'dan örnek aldığında decoder anlamsız çıktı verir.
**Standart Normal prior** $\mathcal{N}(0, I)$ seçilir çünkü: (a) merkezde toplar (tek bağlantılı bölge), (b) varyansları benzer tutar (sivrilik engellenir), (c) örnekleme çok kolay, (d) Stat 110 konum-ölçek özellikleri reparameterization trick'i mümkün kılar.
:::
::: {.callout-note collapse="true" title="Soru 3: Reparameterization trick'in mekaniği: $z = \mu + \sigma \cdot \varepsilon$ formülü neden $\partial L / \partial \mu$ ve $\partial L / \partial \sigma$'yı hesaplanabilir kılar?"}
**Cevap:** Klasik VAE'de $z$ doğrudan $\mathcal{N}(\mu, \sigma^2)$'den örnekleniyordu — hesaplama grafiğinde **stokastik düğüm**. Bu düğümden gradient geçmez. Reparameterization yeniden yazar:
$$
z = \mu + \sigma \cdot \varepsilon, \qquad \varepsilon \sim \mathcal{N}(0,\, I)
$$
Şimdi $\varepsilon$ dış bağımsız girdidir; $z$ ise $\mu$ ve $\sigma$'nın **deterministik** fonksiyonudur. Zincir kuralı:
$$
\frac{\partial L}{\partial \mu} = \frac{\partial L}{\partial z} \cdot 1, \qquad \frac{\partial L}{\partial \sigma} = \frac{\partial L}{\partial z} \cdot \varepsilon
$$
Her iki kanal da deterministik; gradient akar. Stat 110 Ders 14'ün **konum-ölçek ailesi** ($X = \mu + \sigma Z$) sezgisi tam olarak budur.
:::
::: {.callout-note collapse="true" title="Soru 4: (Builder) GAN'in min-max kaybında neden discriminator maksimize, generator minimize eder? Cross-entropy ile bağla."}
**Cevap:** Discriminator **bir Ders 1 sınıflandırıcısıdır** — gerçek/sahte için cross-entropy minimize ediyor. Cross-entropy:
$$
L_D = -\,\mathbb{E}_{x \sim p_{\text{data}}}[\log D(x)] - \mathbb{E}_{z \sim p_z}[\log(1 - D(G(z)))]
$$
Bu loss'u minimize etmek = ifadeyi negatif çevirip maksimize etmek (D'nin maksimize ettiği $V(D, G)$). Generator ise D'nin sahteleri ayırt etmesini **zorlaştırmak** ister → aynı ifadeyi **minimize** etmeye çalışır. Sonuçta D maksimize, G minimize → **min-max oyun**. Calculus açısından **eyer noktası** problemidir (Ders 10) — bu yüzden eğitim kararsız.
:::
::: {.callout-note collapse="true" title="Soru 5: Latent traversal nedir ve neden 'iyi' bir VAE'nin göstergesidir?"}
**Cevap:** **Latent traversal**, eğitilmiş bir VAE'de tek bir latent ekseni $z_i$'yi (örn. $-3$'ten $+3$'e) tarayarak değiştirip diğerlerini sabit tutmaktır. Sonra her değerde decode ederek görüntüleri yan yana koyarsın.
İyi bir VAE'de bu tarama **yumuşak ve kontrollü** bir değişim üretir: yüz örneğinde bir ekseni artırdıkça yaş değişir, bir başkası gülümseme açar, bir başkası gözlük ekler. Bu, latent uzayın anlamlı ve sürekli olduğunun kanıtıdır.
KL terimi olmadan eğitilmiş bir AE'de traversal "atlamalı" olur — bir noktadan diğerine geçiş anlamsız ara değerlerden geçer. Süreklilik özelliği, latent uzayın gerçekten verinin manifoldunu öğrendiğini gösterir.
:::
## Egzersizler {#sec-egzersizler}
**Egzersiz 1 (Klasik AE'yi kur).** MNIST üzerinde küçük bir autoencoder eğit (encoder 784→256→32, decoder 32→256→784). Loss = MSE. (a) Bir test örneğini geçir, yeniden inşayı orijinaliyle yan yana göster; (b) eğitimde *görülmemiş* bir gürültü vektörünü decoder'a ver, çıktının anlamsız olduğunu gözlemle — bu, sıradan AE'nin neden örnek üretemediğinin pratik kanıtıdır.
```python
import torch.nn as nn
encoder = nn.Sequential(nn.Linear(784, 256), nn.ReLU(), nn.Linear(256, 32))
decoder = nn.Sequential(nn.Linear(32, 256), nn.ReLU(), nn.Linear(256, 784), nn.Sigmoid())
# train: minimize ||x - decoder(encoder(x))||^2
```
**Egzersiz 2 (AE'yi VAE'ye çevir).** Egzersiz 1'in encoder'ını iki başlı yap: $\mu_\phi(x)$ ve $\log \sigma_\phi^2(x)$. $z = \mu + \sigma \cdot \varepsilon$, $\varepsilon \sim \mathcal{N}(0, I)$ ile **reparameterize** et. Loss = reconstruction + KL. Kapalı-form KL:
$$
D_{KL}\!\left(\mathcal{N}(\mu,\, \sigma^2) \,\Big\|\, \mathcal{N}(0,\, 1)\right) = \tfrac{1}{2}\!\left(\mu^2 + \sigma^2 - \log \sigma^2 - 1\right)
$$
Eğitim sonrası: prior'dan $z \sim \mathcal{N}(0, I)$ örnekle, decoder'a ver → MNIST benzeri yeni rakamlar üretmeli.
**Egzersiz 3 (Latent traversal).** Eğitilmiş VAE'de tek bir latent ekseni $z_i$'yi (örn. $-3, -2, \ldots, +3$) tarayarak değiştir, diğerlerini sabit tut. Her değerde decode edip görüntüleri yan yana koy. Aynı ekseni değiştirdiğinde çıktının **yumuşak** kayması, latent uzayın sürekli olduğunun göstergesidir.
**Egzersiz 4 (Tiny GAN).** MNIST için 100-boyutlu gürültüden $28 \times 28$ piksel üreten bir küçük $G$ ve görüntü → {gerçek, sahte} ikili sınıflandırıcı $D$ yaz. Alternatif güncelleme (1 adım $D$, 1 adım $G$) ile birkaç bin iterasyon eğit. Eğitim sırasında: (a) $G$'nin örneklerini her $N$ adımda kaydet, kalitenin nasıl arttığını gözle; (b) **mode collapse** belirtisi ara.
```python
import torch
import torch.nn as nn
G = nn.Sequential(
nn.Linear(100, 256), nn.ReLU(),
nn.Linear(256, 784), nn.Tanh(),
)
D = nn.Sequential(
nn.Linear(784, 256), nn.LeakyReLU(0.2),
nn.Linear(256, 1), # sigmoid BCEWithLogitsLoss ile birlesir
)
# Alternatif: D step (gercek + sahte ayir), G step (D'yi kandir)
```
**Egzersiz 5 (Sonraki dersin habercisi).** Bu dersin generative modelleri, etiketsiz veriden dağılım öğrendi. Ders 5'in derin **pekiştirmeli öğrenmesi** (RL) farklı bir paradigmadır: **ödül** sinyali vardır. Bir ajan, eylemleri sonucu ödülleri toplar; amaç toplam ödülü maksimize etmektir. (a) Bir oyunda "strateji öğrenmek" ile bir görüntü-etiket çiftlerinden "sınıflandırma öğrenmek" arasındaki farkı, eğitim sinyali ve geri besleme açısından yaz. (b) Ajan-çevre döngüsünü (state → action → reward → new state) küçük bir diyagramla taslakla.
## Sonraki Ders İçin Hazırlık {#sec-sonraki}
**Ders 5: Derin Pekiştirmeli Öğrenme (Deep Reinforcement Learning)** — Alexander Amini
Şimdiye kadar gördüğümüz tüm öğrenme paradigmalarında eğitim sinyali sabit verilerden geliyordu. RL'de farklı bir yapı var: bir **ajan**, bir **çevre** ile etkileşir; her adımda bir eylem yapar, çevreden bir **ödül** ve yeni bir durum alır. Ajanın amacı, uzun vadeli toplam ödülü maksimize eden bir **politika** öğrenmektir. Bu, AlphaGo, ChatGPT'nin RLHF aşaması ve robotik kontrolün temel paradigmasıdır.
**Ana konular:**
- Ajan-çevre etkileşimi; durum, eylem, ödül.
- Politika ve değer fonksiyonu.
- Q-learning, deep Q-network (DQN).
- Policy gradient, REINFORCE.
::: {.callout-warning title="Ders 5 öncesi yapılacak"}
- Egzersizleri çöz — özellikle 2 (VAE) ve 5 (ajan-çevre diyagramı).
- VAE'nin reparameterization trick'ini kendi cümlenle anlat — RL'nin policy gradient yöntemlerinde de "stokastik bir aksiyondan backprop" derdi çıkacak.
- Ana cümleyi tekrar oku: *"Generative modelleme = veri dağılımını öğrenip oradan örnek almak."*
:::
## Anahtar Kavramlar (Cheat Sheet) {#sec-cheat-sheet}
| Kavram | Tanım | Ava'da |
|--------|-------|--------|
| **Supervised vs Unsupervised** | $X \to Y$ eşlemesi vs etiketsiz veriden yapı | 3m01 |
| **Generative model** | Verinin dağılımı $P(x)$'i öğrenip örnek alabilen model | 3m32 |
| **Density estimation** | Bir noktanın $P(x)$ değerini hesaplamak | 4m46 |
| **Sample generation** | $P(x)$'ten yeni veri örnekleri çekmek | 5m22 |
| **Latent değişken ($Z$)** | Verinin temel varyasyon eksenleri | 9m59 |
| **Autoencoder** | Encoder $x \to z$ + decoder $z \to \hat{x}$ | 12m08 |
| **Bottleneck** | Latent uzayın boyutu küçük → sıkıştırma | 16m09 |
| **Reconstruction loss** | $\|x - \hat{x}\|^2$ | 14m38 |
| **VAE** | Encoder $\mu, \sigma$ üretir; $z$ örneklenir | 18m38 |
| **KL divergence** | İki dağılım arasındaki mesafe; latent ↔ prior | 21m50 |
| **Normal prior** | $\mathcal{N}(0, I)$; süreklilik + tamlık için | 24m02 |
| **Reparameterization trick** | $z = \mu + \sigma \cdot \varepsilon$, $\varepsilon \sim \mathcal{N}(0, I)$ | 28m32 |
| **Latent traversal** | Tek bir latent boyutu varyasyona uğratmak | 32m50 |
| **GAN** | Generator + Discriminator adversarial oyun | 33m38 |
| **Min-max objective** | $\min_G \max_D V(D, G)$ | 39m49 |
| **Mode collapse** | $G$ yalnızca birkaç modu üretmeye sıkışır | 42m17 |
| **CycleGAN** | Eşleşmemiş domain-to-domain çeviri | 44m50 |
## ML Builder Bağlantıları {#sec-ml-baglantilar}
::: {.callout-tip title="8 köprü"}
1. **$P(x)$ öğrenmek** → Stat 110 dağılım modelleme (Ders 12 PDF, Ders 13 Normal). İleriye: foundation modeller, RLHF reward modeli.
2. **Autoencoder bottleneck** → 18.06 boyut indirgeme, PCA / SVD (Ders 29); doğrusal-olmayan akrabası. İleriye: VQ-VAE, denoising AE → diffusion.
3. **Reconstruction (MSE)** → Stat 110 Gauss noise varsayımı (Ders 13) altında MLE. İleriye: perceptual loss, LPIPS.
4. **VAE Normal prior + KL** → Stat 110 Normal'in geometrisi (Ders 13-14) + Ders 4 koşullu olasılık / entropy. İleriye: β-VAE disentanglement.
5. **Reparameterization trick** → Stat 110 konum-ölçek ailesi (Ders 14: $X = \mu + \sigma Z$) + Calculus zincir kuralı (Ders 4). İleriye: Bayesian deep learning, normalizing flows.
6. **GAN discriminator** → Ders 1 cross-entropy sınıflandırıcı + Stat 110 Bernoulli (Ders 8). **Min-max** → Calculus eyer noktası (Ders 10). İleriye: WGAN, spectral normalization.
7. **CycleGAN** → İki manifold arası invertible eşleme (18.06 ters dönüşüm). İleriye: image-to-image foundation modelleri.
8. **Manifold hipotezi** → Yüksek-boyutlu verinin düşük-boyutlu manifold üzerinde yaşaması; tüm üretken modellemenin matematiksel zemini. İleriye: diffusion modelleri (Ders 6), score-based models, ELBO + Jensen (Stat 110 Ders 28).
:::
::: {.callout-important title="Bu dersten tek bir şey alıp gideceksen"}
Generative modelleme "tahmin et" yerine "üret" der; modelin verinin **dağılımını** öğrenmesini ve oradan **örnek almasını** ister. VAE bunu *olasılıksal latent uzay* (Stat 110 Normal + reparameterization trick) ile yapar; GAN ise *iki ağın adversarial oyunu* ile yapar. Her iki paradigma da bugünün üretken AI'sının (DALL-E, Stable Diffusion, GPT) iskeletini oluşturdu; modern diffusion modelleri ise bu fikirleri bir adım öteye taşıdı — Ders 6'da göreceğiz.
:::