---
title: "Derin Pekiştirmeli Öğrenme"
subtitle: "Q-learning ve policy gradient — ödül sinyaliyle karar öğrenmek"
---
::: {.callout-note title="Bölüm bilgisi"}
- **Lecture videosu:** [YouTube — Lecture 5: Deep Reinforcement Learning](https://www.youtube.com/watch?v=1ij3dweHu-0&list=PLtBw6njQRU-rwp5__7C0oIVt26ZgjG9NI&index=5) (≈59 dk)
- **Edition:** 2026 • **Hoca:** Alexander Amini
- **Kaynak:** [introtodeeplearning.com](https://introtodeeplearning.com)
- **Okuma süresi:** ≈34 dk
:::
## Bu Derste Ne Var? {#sec-bu-derste}
Şimdiye kadar iki paradigma gördük: **denetimli** (X-Y çiftleri, Ders 1-3) ve **gözetimsiz** (sadece X, Ders 4). Üçüncü önemli aile **pekiştirmeli öğrenmedir (RL)**: ne etiket, ne sadece veri — bir **ödül sinyali** vardır. Bir **ajan**, bir **çevre** ile etkileşir; her adımda bir **eylem** yapar, karşılığında yeni bir **durum** ve bir **ödül** alır. Hedef: uzun vadeli toplam ödülü maksimize eden bir **politika** öğrenmek.
Bu paradigma, AlphaGo'nun insan şampiyonları yenmesinden ChatGPT'nin **RLHF** ile hizalanmasına, robot kontrolünden otonom sürüşe kadar geniş bir alanın motorudur. Özelliği: öğrenme **etkileşim sırasında** olur — insanların dünyayı öğrenmesine en yakın paradigma.
> *"in the reinforcement learning world we actually have neither [labels nor unlabeled data]... we are actively collecting data while the model is learning... much more similar to how we as humans also learn."* — Amini, 1:01
**Dersin yolculuğu:**
1. **RL'in anatomisi** — ajan, çevre, eylem, durum, ödül, toplam getiri, iskonto.
2. **Q fonksiyonu ve politika** — "bu durumda şu eylemi yaparsam ne kadar ödül beklerim?"
3. **Deep Q-Learning (DQN)** — Bellman hedefiyle Q'yu öğren; Atari 2015 devrimi.
4. **Policy Gradient (REINFORCE)** — dolaylı yerine doğrudan politika öğren.
5. **Sürekli eylem uzayları** — Gaussian politika (VAE reparameterization ile akraba).
6. **AlphaGo ve RLHF** — gerçek dünya ölçeğindeki uygulamalar.
{#fig-concept-map fig-align="center" width=85%}
::: {.callout-tip title="Builder Notu — ML Köprüleri"}
Bu ders, Stat 110 ve Calculus'un "karar verme" diline kavuşması:
- **Total return + iskonto faktörü $\gamma$** → Calculus Ders 11 **geometrik seri** ve Stat 110 geometrik dağılım (Ders 8) — üstel sönümle geleceği azaltır.
- **Q fonksiyonu = beklenen toplam ödül** → Stat 110 koşullu beklenti (Ders 25); $Q(s, a) = \mathbb{E}[R_t \mid s, a]$.
- **Bellman denklemi** → Stat 110 **ilk-adım analizi** (Ders 7) ve Calculus Ders 12 **iterated map / sabit nokta**.
- **Policy gradient kaybı ($-\log \pi \cdot R$)** → Stat 110 maximum likelihood (Ders 17) + Ders 1 cross-entropy; ödülle ağırlıklı.
- **Sürekli politika (Gaussian)** → Stat 110 Normal (Ders 13-14) — VAE'nin Ders 4'teki reparameterization paralelliği.
İleriye köprüler: **RLHF** (ChatGPT/Claude hizalama), AlphaZero/MuZero, actor-critic, PPO/A2C, sim2real, world models.
:::
## Üçüncü Paradigma: Etiket Değil, Ödül {#sec-3-paradigma}
Makine öğrenmesindeki üç büyük paradigmayı yan yana koymak yararlı:
- **Denetimli:** $(x, y)$ çiftleri — girdi ve etiket. Hedef $X \to Y$ eşlemesi.
- **Gözetimsiz:** sadece $x$'ler — hedef dağılım / yapı çıkarmak.
- **Pekiştirmeli:** veri $(s, a, r)$ üçlülerinden oluşur — durum, eylem, ödül. Etiket yok; bir ajan çevrede dolanıp **kendi verisini toplar**.
Elma örneği yardımcı olur: denetimlide "bu elmadır" diye etiketli foto verilir; gözetimsizde sadece yüzlerce elma fotoğrafı; RL'de **elmayı yiyip uzun yaşamak** güzel bir geri besleme verir, ajan da "elma yemek iyi" sonucuna ulaşır — etiket olmadan, deneyimle.
RL'nin kalbi **zaman boyunca toplam ödülü maksimize etmektir**. Robotik, oyun, otonom sürüş ve son dönemde **LLM hizalaması (RLHF)** bu paradigmanın yansımalarıdır.
::: {.callout-tip title="Builder Notu — RLHF Yolculuğu"}
**Geriye (Stat 110):** RL'nin "karar verme + belirsizlik + beklenti" üçlüsü, Stat 110'un doğrudan uygulamasıdır. Bir kararın iyiliğini **beklenen toplam ödülle** ölçeriz.
**İleriye:** "Ödül sinyaliyle öğren" fikri, modern LLM'lerin **RLHF** aşamasının omurgasıdır — insan tercihleri (beğeni/beğenmeme) bir ödül modeli eğitir, RL ile LLM "kullanıcı dostu" hâle getirilir.
:::
## RL'in Anatomisi: Ajan, Çevre, Eylem, Durum, Ödül {#sec-anatomi}
RL'in beş parça sözlüğü — tüm algoritmaların ortak iskeleti:
- **Ajan (agent):** Eylemi yapan; drone, Super Mario, bir robot, sen.
- **Çevre (environment):** Ajan'ın içinde yaşadığı dünya.
- **Eylem (action) $a$:** Ajan'ın çevreye gönderdiği şey. Tanımlı bir **eylem uzayı** $\mathcal{A}$ vardır — ayrık (sol/sağ/dur) veya sürekli (direksiyon açısı).
- **Durum (state) $s$:** Çevrenin ajan'a verdiği geri besleme.
- **Ödül (reward) $r$:** Yapılan eylemin **iyiliğini** sayısallaştıran skaler.
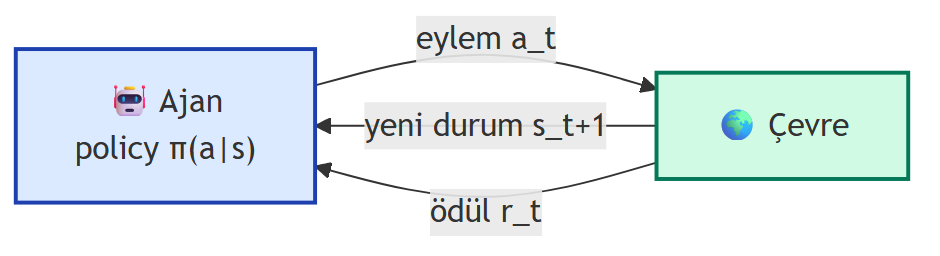{#fig-agent-env-loop fig-align="center" width=85%}
Ajan'ın hedefi **uzun vadeli toplam ödül** (return). Bunu **iskontolanmış** olarak yazarız:
$$
R_t = \sum_{k=0}^{\infty} \gamma^k\, r_{t+k} = r_t + \gamma\, r_{t+1} + \gamma^2\, r_{t+2} + \cdots
$$
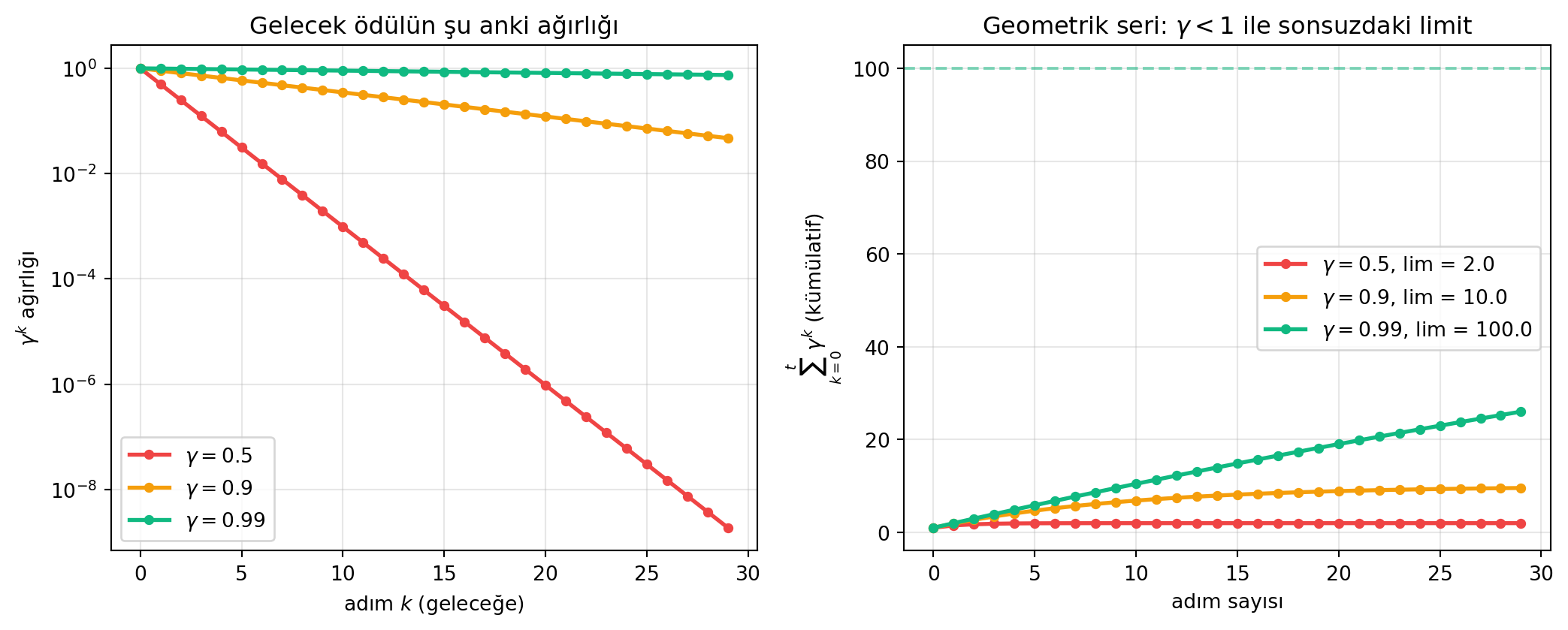
$\gamma \in [0, 1)$ **iskonto faktörüdür**: gelecekteki ödülleri günümüze indirger. Sezgi: "5 dolar bugün" mü, "5 dolar bir yıl sonra" mı? Bugün. $\gamma$ matematiksel olarak bu tercihi kodlar; ayrıca sonsuz toplamın **yakınsamasını** garantiler.
> *"the total reward... is the sum of all rewards starting from the current time t... but oftentimes useful to also discount some of the future things."* — Amini, 9:14
```{python}
#| label: fig-gamma-decay
#| fig-cap: "İskonto faktörü γ farklı değerlerle gelecekteki ödüllerin etkisi. γ=0 miyop; γ→1 uzun-vadeli (ama yakınsama zor)."
#| fig-width: 11
#| fig-height: 4.5
import numpy as np
import matplotlib.pyplot as plt
T = 30
ks = np.arange(T)
gammas = [(0.5, '#ef4444'), (0.9, '#f59e0b'), (0.99, '#10b981')]
fig, axes = plt.subplots(1, 2, figsize=(11, 4.5))
ax = axes[0]
for g, c in gammas:
ax.plot(ks, g ** ks, '-o', color=c, lw=2, markersize=4,
label=f'$\\gamma = {g}$')
ax.set_xlabel('adım $k$ (geleceğe)')
ax.set_ylabel('$\\gamma^k$ ağırlığı')
ax.set_title('Gelecek ödülün şu anki ağırlığı')
ax.legend(fontsize=10); ax.grid(alpha=0.3)
ax.set_yscale('log')
# Sağ: kümülatif return
ax = axes[1]
rewards = np.ones(T) * 1.0
for g, c in gammas:
cum = np.cumsum(g ** ks * rewards)
ax.plot(ks, cum, '-o', color=c, lw=2, markersize=4,
label=f'$\\gamma = {g}$, lim = ${1/(1-g):.1f}$')
ax.axhline(1 / (1 - 0.99), color='#10b981', ls='--', alpha=0.5)
ax.set_xlabel('adım sayısı')
ax.set_ylabel('$\\sum_{k=0}^t \\gamma^k$ (kümülatif)')
ax.set_title('Geometrik seri: $\\gamma < 1$ ile sonsuzdaki limit')
ax.legend(fontsize=10); ax.grid(alpha=0.3)
plt.tight_layout()
plt.show()
```
::: {.callout-tip title="Builder Notu — $\\gamma$ Bir Tasarım Kararı"}
**Geriye (Calculus + Stat 110):** $R_t$ formülü tam olarak **geometrik bir seridir** — Calculus Ders 11 ($\gamma < 1 \to$ seri yakınsar). $\gamma$ = bir tür **üstel sönüm** (Calculus Ders 5: $e^x$ decay). Stat 110 açısından $\gamma$ "şimdi" ile "sonra" arasındaki **zaman tercih faktörüdür**.
**İleriye:** $\gamma$ ayarı bir hyperparameter savaşıdır: küçük $\gamma$ ($\sim 0{,}9$) miyoplaştırır; büyük $\gamma$ ($\sim 0{,}99$) uzun-vadeli planlama ister ama eğitim varyansını artırır. ChatGPT'nin RLHF aşamasında ödüller anında olduğu için $\gamma$ daha az önemlidir; satrançta ise kritiktir.
:::
## Q Fonksiyonu: Bir Durumdan Beklenen Toplam Ödül {#sec-q-fonksiyon}
RL'in en merkezi nesnesi **Q fonksiyonu**:
$$
Q(s,\, a) = \mathbb{E}\!\left[R_t \,\Big|\, s_t = s,\; a_t = a\right]
$$
Sözel olarak: "Eğer $s$ durumundayken $a$ eylemini yaparsan (ve sonra makul davranırsan), ne kadar toplam ödül beklerim?"
Q'nun büyüsü: **Q'yu biliyorsan, optimal eylem trivialdir:**
$$
a^* = \arg\max_a\; Q(s,\, a)
$$
Yani RL'in tüm zorluğu "Q'yu bilmiyoruz, ondan **öğrenelim**" cümlesindedir.
```{python}
#| label: fig-q-table
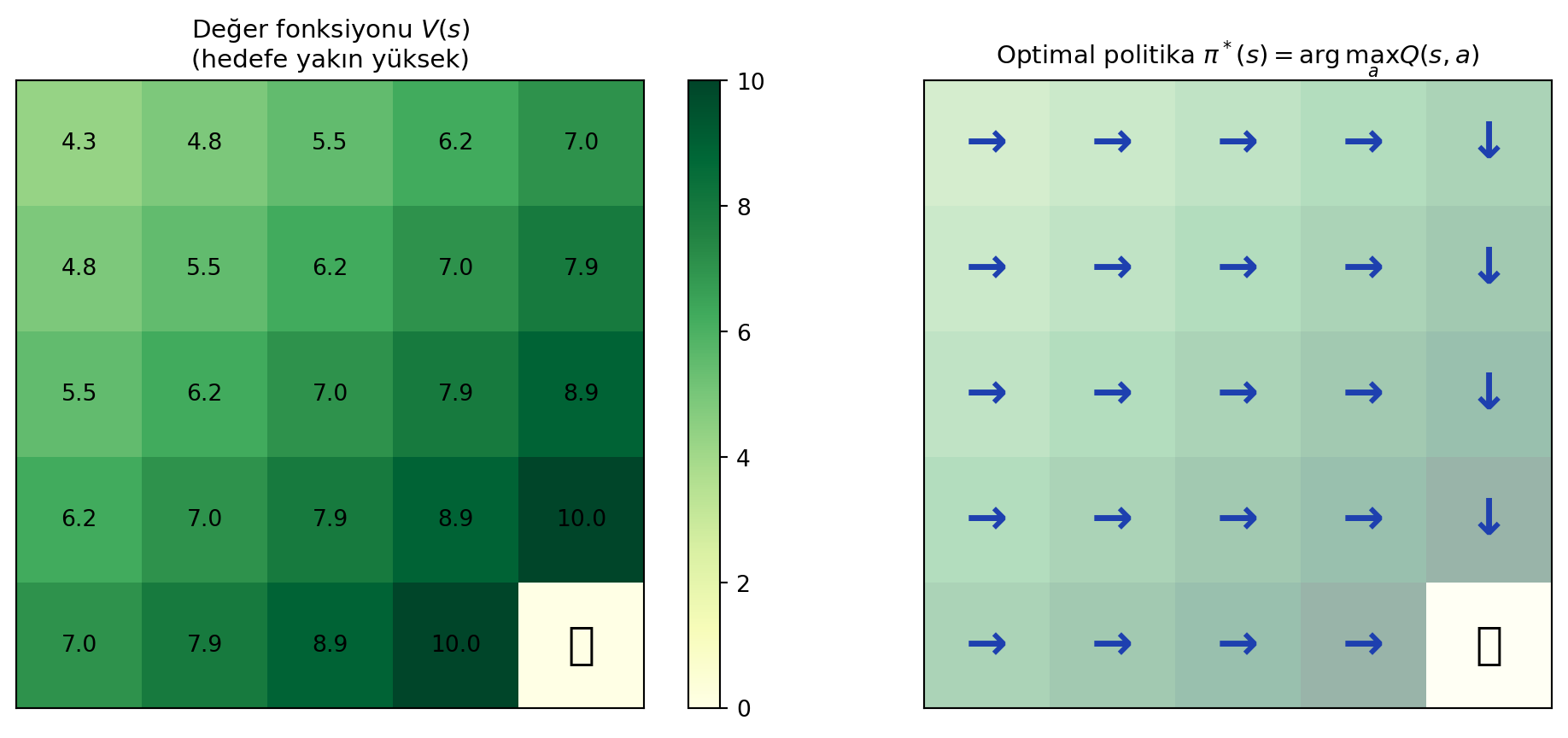
#| fig-cap: "Küçük bir grid-world için Q-tablosu (heatmap). Her hücrede 4 eylem (kuzey, doğu, güney, batı) için bir Q değeri. Hedefe yakın hücrelerde Q yüksek."
#| fig-width: 11
#| fig-height: 4.5
# 5x5 grid-world: alt-sağ köşede hedef (+10), aksi 0
N = 5
goal = (4, 4)
def value_iter(N, goal, gamma=0.9, iters=100):
V = np.zeros((N, N))
actions = [(-1, 0), (0, 1), (1, 0), (0, -1)]
for _ in range(iters):
V_new = V.copy()
for i in range(N):
for j in range(N):
if (i, j) == goal:
V_new[i, j] = 0
continue
best = -np.inf
for di, dj in actions:
ni, nj = max(0, min(N-1, i+di)), max(0, min(N-1, j+dj))
r = 10.0 if (ni, nj) == goal else -0.1
best = max(best, r + gamma * V[ni, nj])
V_new[i, j] = best
V = V_new
return V
V = value_iter(N, goal)
# Q için: en iyi eylemi politika olarak çıkar
actions = [(-1, 0), (0, 1), (1, 0), (0, -1)]
arrows = ['↑', '→', '↓', '←']
gamma = 0.9
policy = np.zeros((N, N), dtype=int)
for i in range(N):
for j in range(N):
if (i, j) == goal:
policy[i, j] = -1
continue
best, ba = -np.inf, 0
for ai, (di, dj) in enumerate(actions):
ni, nj = max(0, min(N-1, i+di)), max(0, min(N-1, j+dj))
r = 10.0 if (ni, nj) == goal else -0.1
q = r + gamma * V[ni, nj]
if q > best:
best, ba = q, ai
policy[i, j] = ba
fig, axes = plt.subplots(1, 2, figsize=(11, 4.5))
# Sol: V(s) heatmap
ax = axes[0]
im = ax.imshow(V, cmap='YlGn')
for i in range(N):
for j in range(N):
if (i, j) == goal:
ax.text(j, i, '🎯', ha='center', va='center', fontsize=20)
else:
ax.text(j, i, f'{V[i,j]:.1f}', ha='center', va='center', fontsize=10)
ax.set_title('Değer fonksiyonu $V(s)$\n(hedefe yakın yüksek)', fontsize=11)
ax.set_xticks([]); ax.set_yticks([])
plt.colorbar(im, ax=ax)
# Sağ: optimal politika (oklar)
ax = axes[1]
ax.imshow(V, cmap='YlGn', alpha=0.4)
for i in range(N):
for j in range(N):
if (i, j) == goal:
ax.text(j, i, '🎯', ha='center', va='center', fontsize=20)
else:
ax.text(j, i, arrows[policy[i, j]], ha='center', va='center',
fontsize=22, color='#1e40af', weight='bold')
ax.set_title('Optimal politika $\\pi^*(s) = \\arg\\max_a Q(s, a)$',
fontsize=11)
ax.set_xticks([]); ax.set_yticks([])
plt.tight_layout()
plt.show()
```
::: {.callout-tip title="Builder Notu — Q = Koşullu Beklenti"}
**Geriye (Stat 110):** Q tam olarak Stat 110 Ders 25'in **koşullu beklenti** kavramıdır — $\mathbb{E}[Y \mid X = x]$. **argmax** ise Calculus Ders 10'un ekstrema problemine inanır.
**İleriye:** Q fonksiyonunu **tüm eylemler için aynı anda** çıkartmak verimli mimari kararıdır (input state → vector of Q values per action). Bu, DQN'in standart yapısıdır.
:::
## Policy: Hangi Eylem? {#sec-policy}
Q fonksiyonu "durum + eylem → değer" verir. Ajan'ın asıl ihtiyacı **politikadır**. İki temel form:
$$
\pi(s) = \arg\max_a\; Q(s,\, a) \qquad \text{(deterministik, değer-tabanlı)}
$$
$$
\pi(a \mid s) \qquad \text{(stokastik, dağılım — politika-tabanlı)}
$$
Birinci yol Q'dan türeyen deterministik bir politikadır. İkinci yol her eylem için bir **olasılık** atar; ajan örnekler. Stokastik olmak iki avantaj sağlar: (1) **keşif** doğal olarak gelir, (2) çoklu-modlu durumları muhafaza eder.
Bu, RL'in temel ikiliğidir:
- **Value learning:** Q'yu öğren, argmax ile politikayı türet.
- **Policy learning:** Politikayı doğrudan öğren, Q'ya hiç değme.
## Deep Q-Learning: Q'yu Bir Ağ ile Öğrenmek {#sec-dqn}
Q'yu nasıl öğreneceğiz? Bir sinir ağı ile. **DQN**: girdi olarak $s$ al, çıkışta **her olası eylem için bir Q değeri** üret.
Eğitim hedefi: **Bellman optimality equation**:
$$
Q^*(s,\, a) = r + \gamma\, \max_{a'}\; Q^*(s',\, a')
$$
Sözel olarak: "Optimal Q, **anlık ödül** + iskonto edilmiş **bir sonraki durumdaki en iyi Q** olmalıdır." Bu özyinelemeli tanım, RL'in matematiksel kalbidir.
Loss:
$$
L(\theta) = \left( \underbrace{r + \gamma\, \max_{a'} Q_\theta(s',\, a')}_{\text{Bellman hedefi}} - \underbrace{Q_\theta(s,\, a)}_{\text{ağın tahmini}} \right)^2
$$
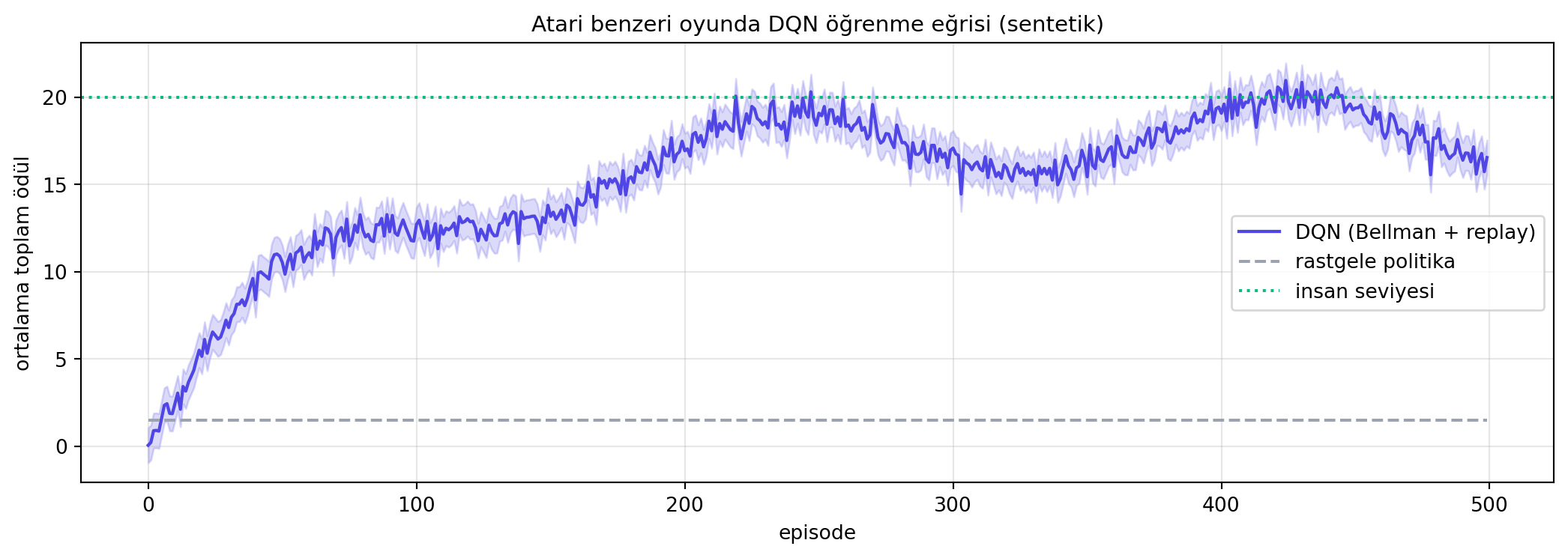
2015'te DeepMind, Atari oyunları üzerinde tam olarak bunu yaptı — girdi olarak ham piksel ekranını alan bir CNN'in çıktısına Q değerleri koydu, Bellman ile eğitti. Sonuç: **50'den fazla Atari oyununda insan seviyesini geçen** tek bir algoritma.
```{python}
#| label: fig-dqn-curve
#| fig-cap: "DQN'in tipik öğrenme eğrisi (sentetik): başta rastgele politika, sonra Bellman güncellemeleriyle artan ortalama dönüş."
#| fig-width: 11
#| fig-height: 4
eps = np.arange(500)
# Sentetik öğrenme eğrisi
mean_return = 0 + 18 * (1 - np.exp(-eps / 80)) + 2 * np.sin(eps / 30) + 0.5 * np.random.default_rng(0).standard_normal(500)
random_baseline = np.ones_like(eps) * 1.5
fig, ax = plt.subplots(figsize=(11, 4))
ax.plot(eps, mean_return, color='#4f46e5', lw=1.6, label='DQN (Bellman + replay)')
ax.fill_between(eps, mean_return - 1, mean_return + 1, color='#4f46e5', alpha=0.2)
ax.plot(eps, random_baseline, color='#9ca3af', lw=1.5, ls='--', label='rastgele politika')
ax.axhline(20, color='#10b981', lw=1.5, ls=':', label='insan seviyesi')
ax.set_xlabel('episode')
ax.set_ylabel('ortalama toplam ödül')
ax.set_title('Atari benzeri oyunda DQN öğrenme eğrisi (sentetik)', fontsize=11)
ax.legend(fontsize=10); ax.grid(alpha=0.3)
plt.tight_layout()
plt.show()
```
::: {.callout-tip title="Builder Notu — Bellman = Sabit Nokta"}
**Geriye (Stat 110 + Calculus):** Bellman, Stat 110 Ders 7'deki **ilk-adım analizinin** (kumarbazın iflası) genel formudur. Calculus açısından özyinelemeli yapı, Ders 12'nin **iterated map / sabit nokta** problemidir: $Q^*$ tam olarak $TQ = r + \gamma \max Q$ operatörünün sabit noktasıdır. $\gamma < 1$ olduğu için $T$ büzücü (contraction) bir operatördür — Banach sabit-nokta teoremi yakınsamayı garantiler.
**İleriye:** Saf DQN bugün nadiren çıplak kullanılır. **Replay buffer**, **target network** (Double DQN), **prioritized replay** standart eğitim hilelerindendir.
:::
## Q-Learning'in Sınırları {#sec-q-limit}
DQN zarif ama iki ciddi kısıtı var:
**(1) Ayrık eylem uzayı zorunluluğu.** Q ağı her eylem için **ayrı bir çıktı kafası** ister. Sürekli kontrol (örn. direksiyon açısı = 23,7°) yapamazsın.
**(2) Deterministik (argmax) politika.** "Hep maksimumu seç" stratejisi, çevre stokastikse veya birden çok eşit-iyi seçenek varsa sorun çıkarır. Üstelik **keşif** için bilerek rastgelelik eklemen gerekir (ε-greedy gibi hilelerle).
Bu iki kısıt, bizi farklı bir yaklaşıma götürür: **politikayı doğrudan öğrenmek**.
## Policy Gradient: Doğrudan Politika Öğrenmek {#sec-policy-gradient}
Q'ya hiç bakmadan, doğrudan politikayı öğrenelim. Politika ağı, durumu alır ve eylem uzayında **bir olasılık dağılımı** üretir:
$$
\pi_\theta(a \mid s)
$$
Ajan bu dağılımdan örnekler: $a \sim \pi_\theta(\cdot \mid s)$. **REINFORCE** algoritmasının özü:
1. **Rollout:** Rastgele başlatılan politika ile bir bölüm oyna.
2. Yol boyunca $(s, a, r)$ üçlülerini kaydet.
3. Her $t$ için $R_t$ hesapla.
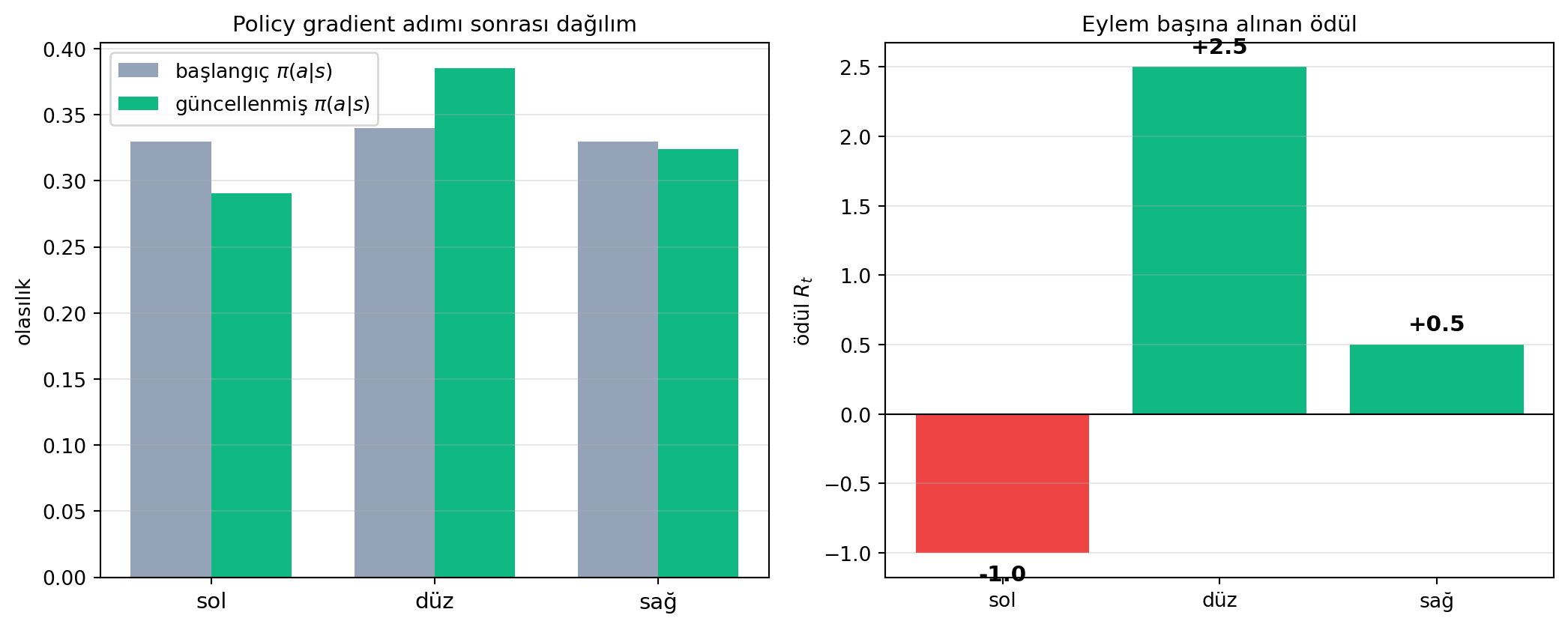
4. **Loss:** Yüksek-ödüllü eylemlerin olasılığını artır, düşüklerini azalt:
$$
L(\theta) = -\sum_t \log \pi_\theta(a_t \mid s_t)\, \cdot\, R_t
$$
5. SGD adımı at; tekrarla.
**Sezgi:**
- Yüksek ödüllü eylem → loss çok negatif → ağ "aynısını yapsın" yönünde güncellenir.
- Düşük ödüllü eylem → "bunu azalt" yönünde güncellenir.
```{python}
#| label: fig-policy-grad-intuition
#| fig-cap: "Policy gradient sezgisi: yüksek ödüllü eylemler 'olabilir' yapılır (yukarı), düşükler 'olabilir değil' yapılır (aşağı). Loss = -Σ log π · R."
#| fig-width: 11
#| fig-height: 4.5
# Sentetik dağılım
actions = ['sol', 'düz', 'sağ']
init_probs = np.array([0.33, 0.34, 0.33])
rewards = np.array([-1.0, +2.5, +0.5]) # düz iyi, sol kötü
# Bir adım policy gradient sonrası ağırlıklarda artış/azalış
delta = 0.18 * rewards / np.abs(rewards).max()
new_probs = init_probs * np.exp(delta)
new_probs = new_probs / new_probs.sum()
fig, axes = plt.subplots(1, 2, figsize=(11, 4.5))
ax = axes[0]
x = np.arange(3)
ax.bar(x - 0.18, init_probs, 0.36, color='#94a3b8', label='başlangıç $\\pi(a|s)$')
ax.bar(x + 0.18, new_probs, 0.36, color='#10b981', label='güncellenmiş $\\pi(a|s)$')
ax.set_xticks(x); ax.set_xticklabels(actions, fontsize=11)
ax.set_ylabel('olasılık')
ax.set_title('Policy gradient adımı sonrası dağılım', fontsize=11)
ax.legend(fontsize=10); ax.grid(alpha=0.3, axis='y')
ax = axes[1]
colors_r = ['#ef4444' if r < 0 else '#10b981' for r in rewards]
ax.bar(actions, rewards, color=colors_r)
ax.axhline(0, color='black', lw=0.8)
ax.set_ylabel('ödül $R_t$')
ax.set_title('Eylem başına alınan ödül', fontsize=11)
ax.grid(alpha=0.3, axis='y')
for i, r in enumerate(rewards):
ax.text(i, r + (0.1 if r > 0 else -0.2), f'{r:+.1f}', ha='center', fontsize=11, weight='bold')
plt.tight_layout()
plt.show()
```
> *"decrease the probability of ever doing anything that we did close to an accident. We'll increase the probability of doing things that we did away from the accident."* — Amini, 44:30
::: {.callout-tip title="Builder Notu — Maximum Likelihood + Ödül Ağırlığı"}
**Geriye (Stat 110 + Calculus):** $-\log \pi(a|s)$ ifadesi, Stat 110'un **maximum log-likelihood'unun** (Ders 17) negatifidir. $R_t$ ile çarpılması bunu **ödüle göre ağırlıklandırmaktır** — iyi sonuçlu örneklere daha çok güven.
**İleriye:** REINFORCE varyansı yüksektir. Çözüm: **baseline** çıkar, "advantage" $A(s, a) = R_t - b(s)$ kullan → **actor-critic**. **PPO** (Proximal Policy Optimization), politika güncellemelerini bir güven bölgesine sınırlayarak kararlılık sağlar — ChatGPT'nin RLHF aşamasında kullanılan algoritmadır.
:::
## Sürekli Eylem Uzayları: Gaussian Politika {#sec-surekli}
Ayrık eylemlerde $\pi(a \mid s)$ bir kategorel dağılımdır. Sürekli eylemde (direksiyon açısı, robot eklem açısı) olası eylem sayısı sonsuzdur. Çözüm: politika ağı bir **sürekli dağılımın parametrelerini** üretir. En yaygın seçim **Gaussian**:
$$
\pi_\theta(a \mid s) = \mathcal{N}\!\left(a;\; \mu_\theta(s),\; \sigma_\theta^2(s)\right)
$$
Backprop için sorun aynı: stokastik düğüm. Çözüm aynı: **reparameterization** (Ders 4 VAE'sinden tanıdığın hile):
$$
a = \mu_\theta(s) + \sigma_\theta(s) \cdot \varepsilon, \qquad \varepsilon \sim \mathcal{N}(0, 1)
$$
$\varepsilon$'u dışarı kanalla, $\mu$ ve $\sigma$ üzerinden gradient akıt.
> *"we're going to learn a mean and a variance that defines that distribution... sample from that distribution to infer one possible action."* — Amini, 39:18
::: {.callout-tip title="Builder Notu — VAE Akrabası"}
**Geriye (Stat 110 + Ders 4):** Gaussian politika, Stat 110 Ders 13-14'ün Normal'ini RL bağlamında giyer. Reparameterization, Ders 4'ün VAE'sinin RL'e aktarımı.
**İleriye:** Sürekli kontrolde modern standartlar **DDPG**, **SAC** (Soft Actor-Critic — maksimum entropi ile keşfi teşvik), **TD3**. "Maksimum entropi" çerçevesi (SAC) Stat 110'un entropy'sini doğrudan loss'a katar.
:::
## Self-Play, AlphaGo ve RLHF {#sec-real-world}
Gerçek dünyada her şeyi denemek tehlikelidir — bir otonom araba öğrenmek için defalarca **çarpmak** zorunda mı? Hayır. Çözüm iki taraflıdır: **simülasyon** ve **self-play**.
**Self-play:** Bir ajan kendine karşı oynar; her oyun bir eğitim örneği üretir. **AlphaGo** bunu çok güzel gösterdi:
1. Şampiyon insan oyun kayıtlarından **taklit öğrenme** ile başlangıç ağı kur.
2. Bu ağı kendine karşı oynatarak self-play; RL ile geliştir.
3. Bir **değer ağı** $V$ öğren ve Monte Carlo Tree Search ile birleştir.
Daha sonra **AlphaZero**, insan taklit aşamasını **atıp** sıfırdan self-play ile süper-insanseviye performansa ulaştı.
**RLHF — Modern LLM Hizalama:** Modern büyük dil modellerinin en kritik **eğitim sonrası** aşaması RL'dir:
{#fig-rlhf fig-align="center" width=85%}
> *"those likes versus dislikes, those thumbs ups or thumbs down that you give when talking to a chatbot are exactly training a reward model for a reinforcement learning algorithm to maximize."* — Amini, 54:46
ChatGPT'nin "yardımsever, zararsız, dürüst" davranışının nereden geldiği, AlphaGo'nun Go'yu nasıl çözdüğü ile **aynı** algoritmik ailedendir — sadece çevre farklı (oyun → dil) ve ödül modeli farklı (oyun sonucu → insan tercihi).
::: {.callout-tip title="Builder Notu — Kursun Birleştiği Yer"}
**Geriye:** RLHF, kursun parçalarını birleştirir: **Reward model = Ders 1 sınıflandırıcı + Stat 110 Bernoulli**. **PPO politika güncellemesi = policy gradient + güven-bölgesi kısıtı**. **Self-attention'lı LLM = Ders 2**.
**İleriye:** Modern alternatifler: **DPO** (Direct Preference Optimization — RL'siz), **Constitutional AI**, **RLAIF**.
:::
## Bu Dersin Özeti {#sec-ozet}
1. **RL üçüncü paradigmadır:** etiket de yok, sadece veri de yok; **ödül sinyali** vardır.
2. **Beş parça:** ajan, çevre, eylem, durum, ödül.
3. **Total return** $R_t = \sum_k \gamma^k r_{t+k}$ ($\gamma < 1$ yakınsama + tercih).
4. **Q fonksiyonu** $Q(s, a)$, bir (durum, eylem) çiftinden beklenen toplam ödüldür.
5. Q'yu bilirsen optimal eylem trivialdir: $a^* = \arg\max_a Q(s, a)$.
6. **Policy** $\pi(s)$ veya $\pi(a \mid s)$ ajan'ın davranışıdır.
7. **Deep Q-Learning (DQN):** NN state'i alır, her eyleme Q üretir; **Bellman optimality** target ile eğitilir.
8. **Bellman = ilk-adım analizi + sabit nokta**; $\gamma$ büzücü operatör → yakınsama garantili.
9. Q-learning'in sınırı: **ayrık eylem** + **deterministik politika**.
10. **Policy gradient (REINFORCE):** Politikayı doğrudan öğren; kayıp $-\log \pi(a|s) \cdot R_t$.
11. **Sürekli eylem:** Gaussian politika; reparameterization ile backprop.
12. **Gerçek dünya zorlukları:** simülasyon + self-play (AlphaGo, AlphaZero).
13. **RLHF**, modern LLM hizalamasının motoru.
::: {.callout-important title="Tek bir cümle"}
Pekiştirmeli öğrenme, bir ajanın etkileşim ve ödül sinyali yoluyla davranış öğrenmesidir; iki temel yol vardır — Q'yu öğrenip argmax al (DQN, Bellman ile) ya da politikayı doğrudan optimize et (policy gradient) — ve her ikisi de Stat 110'un beklenti diliyle yazılmış Calculus optimizasyonudur.
:::
## Kontrol Soruları {#sec-sorular}
::: {.callout-note collapse="true" title="Soru 1: $\\gamma = 0{,}9$ ile, sıralı ödüller $r_0 = 2, r_1 = 3, r_2 = 5, r_3 = 0, \\ldots$ olarak gelsin. $R_0$'ı hesapla. $\\gamma = 1$ ve $\\gamma = 0$ olsaydı?"}
**Cevap:** Tanım:
$$
R_0 = \sum_{k=0}^{\infty} \gamma^k\, r_k = 2 + (0{,}9)(3) + (0{,}9)^2(5) + 0 + \cdots
$$
$0{,}9^2 = 0{,}81$, $0{,}81 \times 5 = 4{,}05$; toplam **$R_0 = 2 + 2{,}7 + 4{,}05 = 8{,}75$**.
**$\gamma = 1$:** $R_0 = 2 + 3 + 5 = 10$. Gelecek ödüller tam değeriyle sayılır.
**$\gamma = 0$:** $R_0 = 2$ (yalnızca $r_0$). Tüm gelecek ödüller görmezden gelinir — model **miyop** olur.
Bu, $\gamma$'nın "şimdiki değer" sezgisini somutlaştırır (Calculus Ders 11 geometrik seri).
:::
::: {.callout-note collapse="true" title="Soru 2: Bir otonom arabada direksiyon açısını öğrenmek için Q-learning neden yetersizdir? Policy gradient nasıl çözer?"}
**Cevap:** Direksiyon açısı **sürekli** bir değişkendir. Q-learning ağı **her eylem için ayrı çıktı kafası** ister — sonsuz eylemli uzayda bu imkânsızdır. Açıları bin'lere bölmek mümkün ama kabadır.
**Policy gradient** doğrudan bir **olasılık dağılımı** öğrenir: ağ $\mu_\theta(s)$ ve $\sigma_\theta(s)$ üretir, ajan $a \sim \mathcal{N}(\mu, \sigma^2)$'den örnekler. Sonsuz değerli uzayda bile, dağılımı iki parametre ile temsil etmek yeterlidir; reparameterization ($a = \mu + \sigma \cdot \varepsilon$) ile gradient akar. Bonus: $\sigma$ doğal olarak **keşif miktarını** kontrol eder.
:::
::: {.callout-note collapse="true" title="Soru 3: Bellman optimality denklemi neden RL'in matematiksel kalbidir? 'Sabit nokta' yorumunu açıkla."}
**Cevap:** Bellman:
$$
Q^*(s,\, a) = r + \gamma\, \max_{a'}\, Q^*(s',\, a')
$$
Karar verme problemini **bir adım + kalan problem** olarak böler — Stat 110 Ders 7'nin ilk-adım analizinin genel formu.
**Sabit nokta yorumu:** Bellman, bir $T$ operatörü tanımlar: $(TQ)(s, a) = r + \gamma \max_{a'} Q(s', a')$. Optimal $Q^*$ tam olarak $T$'nin sabit noktasıdır: $TQ^* = Q^*$ (Calculus Ders 12). $\gamma < 1$ olduğu için $T$ büzücü bir operatördür (iki Q tahmini arasındaki mesafe $T$ uygulandığında küçülür — Banach sabit-nokta teoremi). Bu, herhangi bir başlangıçtan iterasyonla $Q^*$'ya yakınsamayı **matematiksel olarak garanti eder**.
:::
::: {.callout-note collapse="true" title="Soru 4: (Builder) RLHF'in üç ana bileşeni nedir? Reward model bu kursun hangi önceki derslerine bağlanır?"}
**Cevap:** **RLHF üç bileşen:**
1. **Ön-eğitim:** LLM, internet metinlerinde next-word prediction ile — Ders 2'nin sequence modeling'i.
2. **Reward model:** İnsanların tercih oylarından eğitilen bir model. Bir yanıt verildiğinde "insanların ne kadar beğeneceğini" tahmin eder.
3. **RL fine-tune:** LLM, reward modelin verdiği ödülü maksimize edecek şekilde **PPO** ile yeniden eğitilir.
**Reward model bağlantıları:**
- **Ders 1 cross-entropy:** Reward model, ikili tercihleri sınıflandırır → tam olarak Ders 1'in sigmoid + cross-entropy mekanizması.
- **Stat 110 Bernoulli (Ders 8):** Tercihler Bernoulli ile modellenir — Bradley-Terry modeli ($P(A > B) = \sigma(r_A - r_B)$).
- **Stat 110 maximum likelihood (Ders 17):** Reward modelin eğitimi, gözlenen tercihlerin olabilirliğini maksimize etmektir.
:::
::: {.callout-note collapse="true" title="Soru 5: Exploration vs exploitation ikilemi nedir? Saf argmax politikası neden bu ikilemde başarısız olur?"}
**Cevap:** **Exploration (keşif):** Yeni eylemleri deneyip dünya hakkında daha çok şey öğrenmek. **Exploitation (sömürü):** Şimdiye kadar öğrendiğin en iyi eylemi seçip ödülü maksimize etmek. Bu ikisi çatışır — yeni şey denemek için bilineni bırakmak gerek.
**Saf argmax (deterministik) politika** her durumda Q'su en yüksek eylemi seçer; rastgelelik yok. Sorun: ajan başta yanlış bir tahmin yapmışsa (örn. yanlış bir eylemi yüksek değerli sanmışsa), o eyleme sıkışır ve daha iyi alternatifleri **asla** denemez. Çünkü argmax onları seçmez → ödül görmez → değer güncellenmez → seçilmez. Bir sömürü tuzağıdır.
Çözüm: ε-greedy (her adımda ε olasılıkla rastgele eylem), softmax-Q, upper-confidence-bound (UCB), Thompson sampling — hepsi keşfi sistematik biçimde teşvik eden mekanizmalar.
:::
## Egzersizler {#sec-egzersizler}
**Egzersiz 1 (Tablo Q-learning, elle).** 3 durumlu, 2 eylemli küçük bir MDP: $S = \{A, B, C\}$, eylemler $\{\text{sol}, \text{sağ}\}$, geçişler: A--sağ→B (r=0), A--sol→C (r=0), B--sağ→C (r=10), C son durum. $\gamma = 0{,}9$. Q'yu sıfır başlatıp Bellman güncellemesini elle birkaç kez uygula; $Q^*(A, \text{sağ})$ ve $Q^*(A, \text{sol})$ neye yakınsıyor? Hangi politika optimal?
**Egzersiz 2 (REINFORCE — CartPole).** PyTorch ve `gymnasium` ile CartPole-v1 üzerinde REINFORCE'u uygula. Politika ağı: state (4 boyut) → 2-class softmax. Birkaç yüz bölümde ortalama dönüşün artışını gözle.
```python
import torch
import torch.nn as nn
import torch.nn.functional as F
policy = nn.Sequential(nn.Linear(4, 64), nn.ReLU(), nn.Linear(64, 2))
opt = torch.optim.Adam(policy.parameters(), lr=1e-2)
# rollout sonrasi (states, actions, returns) elinde olsun
logits = policy(states)
log_probs = F.log_softmax(logits, dim=-1).gather(1, actions.unsqueeze(1)).squeeze()
loss = -(log_probs * returns).mean()
opt.zero_grad(); loss.backward(); opt.step()
```
**Egzersiz 3 ($\gamma$ tarama).** Aynı CartPole'da $\gamma \in \{0{,}5, 0{,}9, 0{,}99, 1{,}0\}$ için ayrı ayrı eğit; ortalama dönüşün öğrenme eğrisini karşılaştır. $\gamma$ küçük → ne olur? $\gamma = 1$ → sonsuz horizonda toplam patlar mı? Sonucu Calculus Ders 11 ile ilişkilendir.
**Egzersiz 4 (Sürekli politika).** `Pendulum-v1` (sürekli eylem: tork $\in \mathbb{R}$) için Gaussian politika eğit. Ağ $\mu_\theta(s)$ ve $\log \sigma_\theta(s)$ üretsin. Eylem örneklemeyi reparameterization ile yap. Eğitim sırasında $\sigma$'nın nasıl evrildiğini izle.
**Egzersiz 5 (Sonraki dersin habercisi).** Ders 6 "Yeni Sınırlar": mevcut derin öğrenmenin başarısız olduğu yerleri inceleyecek. Şu sorulara birer paragraf cevap hazırla:
(a) Bir LLM, eğitim verisinde olmayan tamamen yeni bir konuda neden zayıflayabilir? (genelleme, **dağılım dışı** OOD)
(b) Bir CNN, görüntüye küçük bir gürültü eklendiğinde neden yanılabilir? (adversarial robustness)
(c) Modern büyük modellerin enerji ve hesap maliyeti neden bir sınırdır? (verimlilik, scaling laws)
(d) Ödülü bir builder olarak nasıl tanımlarsın, ve yanlış tanımlanmış ödül (reward hacking) ne kadar tehlikeli olabilir?
## Sonraki Ders İçin Hazırlık {#sec-sonraki}
**Ders 6: Yeni Sınırlar (New Frontiers)** — Alexander Amini + Ava Soleimany
Şimdiye kadar gördüklerimiz olağanüstü — ama derin öğrenmenin sınırları da gerçek. Ders 6, son birkaç yılın frontier konularını ve mevcut yöntemlerin **başaramadıklarını** ele alacak: diffusion modelleri (Ders 4'ün üretken devamı), bias ve fairness, robustness, dağılım dışı genelleme, scaling laws.
**Ana konular:**
- **Diffusion modelleri:** Stable Diffusion, DALL-E, Sora'nın matematiği.
- **Generalization ve robustness:** OOD, adversarial examples.
- **Bias, fairness, alignment:** Ders 5 RLHF ve Ders 12 AI etiğinin köprüsü.
- **Scaling laws ve verimlilik:** Chinchilla, model boyutu vs veri vs hesap.
::: {.callout-warning title="Ders 6 öncesi yapılacak"}
- Egzersizleri çöz — özellikle 2 (REINFORCE), 4 (sürekli politika), 5 (frontier soruları).
- Bölüm 5'in Bellman denklemini kendi cümlenle anlat: "$Q^*$ nedir, neden contraction yakınsıyor?"
- Ana cümleyi tekrar oku: *"RL = ödül sinyaliyle etkileşimsel öğrenme."*
:::
## Anahtar Kavramlar (Cheat Sheet) {#sec-cheat-sheet}
| Kavram | Tanım | Amini'de |
|--------|-------|----------|
| **3. paradigma** | Etiket de değil, sadece veri de değil — ödül sinyali | 4m08 |
| **Ajan / çevre** | Eylem yapan / etkileşilen dünya | 5m54 |
| **Eylem ($a$), Durum ($s$), Ödül ($r$)** | RL üçlüsü; her $t$ adımında üretilir | 7m01 |
| **Total return $R_t$** | $R_t = \sum_k \gamma^k r_{t+k}$ | 9m14 |
| **İskonto $\gamma$** | $\gamma \in [0,1)$; gelecek ödülü azaltır | 9m51 |
| **Q fonksiyonu** | $Q(s, a) = \mathbb{E}[R_t \mid s, a]$ | 13m17 |
| **Policy $\pi$** | $\pi(s)$ deterministik veya $\pi(a \mid s)$ stokastik | 15m23 |
| **Argmax politika** | $a^* = \arg\max_a Q(s, a)$ | 14m38 |
| **Deep Q-Network (DQN)** | NN state → Q vector per action | 24m54 |
| **Bellman optimality** | $Q^*(s,a) = r + \gamma \max_{a'} Q^*(s', a')$ | 26m43 |
| **Q-learning sınırı** | Ayrık eylem zorunlu; argmax → stokastik çevrede zayıf | 32m53 |
| **Policy gradient** | $-\sum \log \pi \cdot R_t$ (REINFORCE) | 34m54 |
| **Sürekli politika** | $\pi(a \mid s) = \mathcal{N}(\mu_\theta, \sigma_\theta^2)$ | 37m55 |
| **Exploration vs exploitation** | Yeni denemek mi, bilineni sömürmek mi? | 48m09 |
| **Self-play / AlphaGo** | Ajan kendine karşı oynar | 52m00 |
| **RLHF** | İnsan tercihleri → reward model → PPO ile LLM hizalama | 54m46 |
## ML Builder Bağlantıları {#sec-ml-baglantilar}
::: {.callout-tip title="8 köprü"}
1. **Total return + $\gamma$** → Calculus Ders 11 geometrik seri + Stat 110 Ders 8 geometrik dağılım. İleriye: finansal NPV, hayat bilimi diskontosu.
2. **Q fonksiyonu** → Stat 110 koşullu beklenti (Ders 25); ajan kararı bu beklentinin argmax'ı (Calculus Ders 10).
3. **Bellman denklemi** → Stat 110 ilk-adım analizi (Ders 7) + Calculus Ders 12 iterated map / sabit nokta. İleriye: dinamik programlama, optimal kontrol.
4. **Policy gradient ($-\log \pi \cdot R$)** → Stat 110 max-likelihood (Ders 17) + Ders 1 cross-entropy. İleriye: PPO, A2C, baselines.
5. **Sürekli politika (Gaussian)** → Stat 110 Normal (Ders 13-14) + reparameterization (Ders 4 VAE'sinden).
6. **Self-play (AlphaGo)** → Stat 110 Markov zinciri (Ders 31); durağan strateji dinamiği. İleriye: AlphaZero, MuZero.
7. **Exploration vs exploitation** → Stat 110 belirsizlik altında karar; multi-armed bandit; Thompson sampling Bayes posteriori.
8. **RLHF** → Ders 1 cross-entropy + Stat 110 Bernoulli (Bradley-Terry preference model); ChatGPT/Claude'un hizalama mekanizması.
:::
::: {.callout-important title="Bu dersten tek bir şey alıp gideceksen"}
RL, etiket olmadan **ödül sinyaliyle** öğrenen üçüncü paradigmadır; iki temel yolu vardır — değeri öğrenip argmax al (DQN, Bellman ile) ya da politikayı doğrudan optimize et (REINFORCE, policy gradient). Her ikisi de Stat 110'un beklenti diliyle yazılmış Calculus optimizasyonudur. Aynı çekirdek, Atari'den AlphaGo'ya ve ChatGPT'nin RLHF'sine kadar modern AI'nın **karar verme** ekseninin tamamını oluşturuyor.
:::