---
title: "Yeni Sınırlar"
subtitle: "Universal approximation + OOD + adversarial + diffusion + LLM — sınırlar ve modern cepheler"
---
::: {.callout-note title="Bölüm bilgisi"}
- **Lecture videosu:** [YouTube — Lecture 6: New Frontiers](https://www.youtube.com/watch?v=ev7cLSd-ySE&list=PLtBw6njQRU-rwp5__7C0oIVt26ZgjG9NI&index=6) (≈56 dk)
- **Edition:** 2026 • **Hoca:** Ava Soleimany (Amini + Ava'nın son çekirdek dersi)
- **Kaynak:** [introtodeeplearning.com](https://introtodeeplearning.com)
- **Okuma süresi:** ≈34 dk
:::
## Bu Derste Ne Var? {#sec-bu-derste}
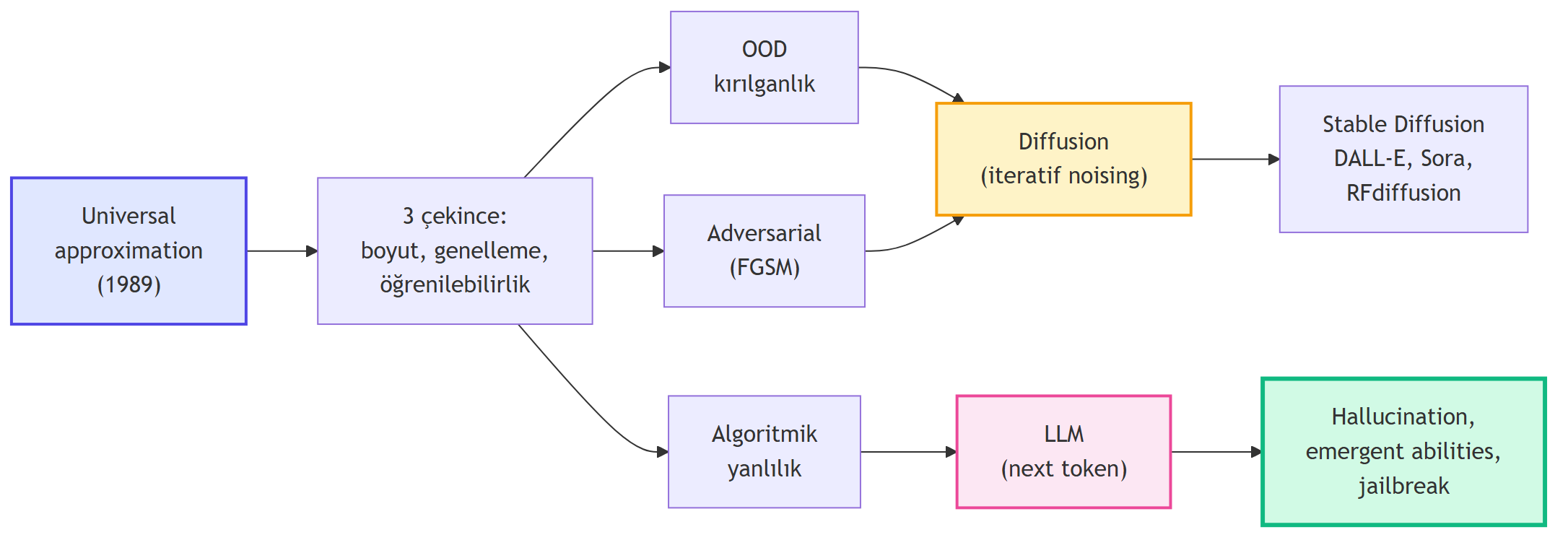
Bu, Amini ve Ava'nın son çekirdek dersi — "ne kadar yol kat ettik" ile "neresi hâlâ açık" arasında dürüst bir bilanço. Modern derin öğrenmenin gücünün yanında **somut sınırlarını** da görenin dersi. İki paralel akarsudan oluşuyor: önce yetenek-sınır-fırsat üçlemesi (universal approximation, genelleme, OOD, adversarial, bias), sonra bu sınırların aşılmasına yön verecek iki modern cephe — **diffusion modelleri** ve **büyük dil modelleri (LLM)**.
> *"the goal is ultimately that these stay as technology... that we as humans can use to accelerate our own creative process... and our own limitations can be augmented by the capabilities the models possess."* — Ava, 54:30
**Dersin üç büyük fikri:**
1. **Universal approximation + çekinceler** — tek katmanlı bir ağ herhangi bir sürekli fonksiyonu yaklaşıklayabilir, ama boyut, genelleme ve öğrenilebilirlik **garantili değildir**.
2. **Açık sınırlar** — OOD (dağılım dışı), adversarial saldırılar, algoritmik yanlılık; her biri açık bir araştırma cephesi.
3. **Modern cepheler** — diffusion modelleri (iteratif gürültü-giderme) ve LLM (next token + ölçek), bu sınırların bir kısmını aşıyor ama yeni soruları (hallucination, kalibrasyon, emergent) gündeme getiriyor.
{#fig-concept-map fig-align="center" width=85%}
::: {.callout-tip title="Builder Notu — ML Köprüleri"}
Bu ders kursun tüm dersleriyle iki yönde bağlanır: her dersin **sınırlarını** gösterir (Ders 1 generalizing, Ders 3 CNN adversarial, Ders 4 GAN/VAE → diffusion, Ders 5 RL'in OOD problemi), bir yandan **modern çözümlerini** sunar.
- **Universal approximation çekincesi** → Calculus süreklilik; Stat 110 bias-variance (Ders 34, Basu).
- **Adversarial perturbation** → Calculus zincir kuralının **ters yönü** (Ders 4) — ağırlıklar yerine girdiye gradient.
- **Diffusion forward noising** → Stat 110 Markov zinciri (Ders 31); her adım Normal gürültü.
- **Diffusion reverse denoising** → Stat 110 koşullu dağılım; MSE = Gauss MLE (Ders 13).
- **LLM next token** → Ders 2 sequence + Ders 1 cross-entropy + Stat 110 multinomial.
- **Hallucination zorunluluğu** → Stat 110 kalibrasyon ve beklenen değer (Ders 9).
**İleriye:** **score-based** modeller, **flow matching**, **consistency models** (tek-adım diffusion), **Stable Diffusion** latent diffusion, **Chinchilla scaling laws**, **RAG** + **agentic AI**, **reasoning models** (o1/R1), **AlphaFold 3 / RFdiffusion** (Ders 8), **calibration** araştırması.
:::
## Universal Approximation Teoremi (ve Çekinceler) {#sec-universal}
1989'da önerilen bir teorem var: **Universal Approximation Theorem**. Şöyle der: tek bir gizli katmanlı bir ileri-beslemeli (feed-forward) sinir ağı, **herhangi bir sürekli fonksiyonu** istenen bir hassasiyetle yaklaşıklayabilir. Yani derin ağların "derin" olmasına gerek bile yok — teoride tek katman yeter.
Kulağa şaşırtıcı geliyor, ama üç önemli **çekince** var:
- **Boyut garantisi yok:** O tek katmanın kaç nörondan oluşması gerektiği tanımlı değil; pratikte astronomik sayılar olabilir.
- **Genelleme garantisi yok:** Teorem yalnızca "yaklaşıkça oluşturulabilir" der; o yaklaşıklayıcının **görülmemiş veride** iyi çalışacağını göstermez.
- **Öğrenilebilirlik garantisi yok:** Bu yaklaşıklayıcının eğitimle bulunabileceği de garanti edilmez.
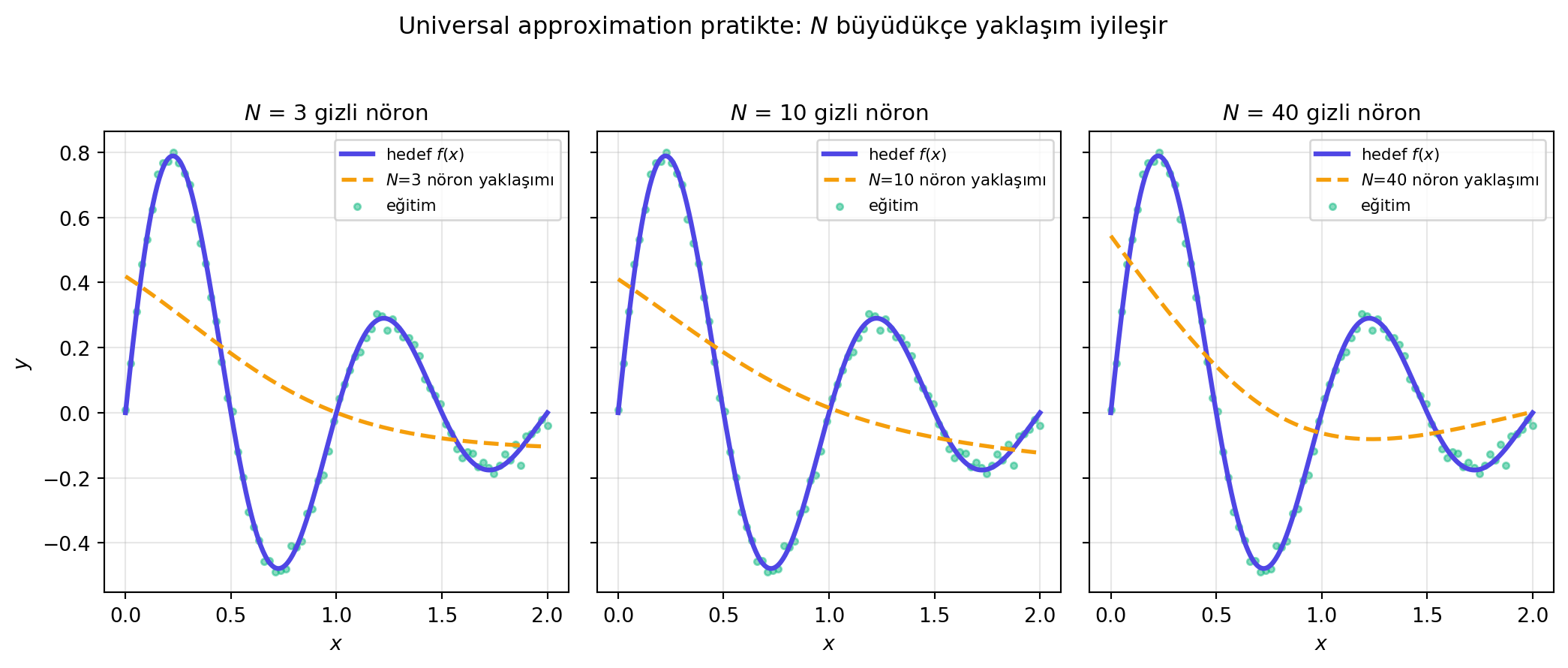
```{python}
#| label: fig-universal-approx
#| fig-cap: "Universal approximation pratikte: tek gizli katmanlı bir ağ ($N$ nöron, sigmoid + linear) hedef bir sürekli fonksiyonu ($\\sin(2\\pi x) \\cdot \\exp(-x)$) ne kadar iyi yaklaşıklıyor? $N$ büyüdükçe yaklaşım iyileşir."
#| fig-width: 11
#| fig-height: 4.5
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)
def target(x):
return np.sin(2 * np.pi * x) * np.exp(-x)
x = np.linspace(0, 2, 400)
y_true = target(x)
x_train = np.linspace(0, 2, 80)
y_train = target(x_train) + 0.02 * np.random.randn(80)
def sigmoid(z):
return 1.0 / (1.0 + np.exp(-np.clip(z, -50, 50)))
def fit_1hidden_mlp(x_tr, y_tr, N, epochs=2500, lr=0.05):
W1 = np.random.randn(N) * 1.5
b1 = np.random.randn(N) * 2.0
W2 = np.random.randn(N) * 0.3
b2 = 0.0
for _ in range(epochs):
z1 = np.outer(x_tr, W1) + b1
h = sigmoid(z1)
y_hat = h @ W2 + b2
err = y_hat - y_tr
gW2 = h.T @ err / len(x_tr)
gb2 = err.mean()
gh = np.outer(err, W2)
gz1 = gh * h * (1 - h)
gW1 = (gz1 * x_tr[:, None]).mean(axis=0)
gb1 = gz1.mean(axis=0)
W1 -= lr * gW1; b1 -= lr * gb1
W2 -= lr * gW2; b2 -= lr * gb2
return W1, b1, W2, b2
def predict(x_in, params):
W1, b1, W2, b2 = params
h = sigmoid(np.outer(x_in, W1) + b1)
return h @ W2 + b2
fig, axes = plt.subplots(1, 3, figsize=(11, 4.5), sharey=True)
for ax, N in zip(axes, [3, 10, 40]):
params = fit_1hidden_mlp(x_train, y_train, N)
y_pred = predict(x, params)
ax.plot(x, y_true, color='#4f46e5', linewidth=2.4, label='hedef $f(x)$')
ax.plot(x, y_pred, color='#f59e0b', linewidth=2.0, linestyle='--', label=f'$N$={N} nöron yaklaşımı')
ax.scatter(x_train, y_train, s=10, color='#10b981', alpha=0.5, label='eğitim')
ax.set_title(f'$N$ = {N} gizli nöron', fontsize=11)
ax.set_xlabel('$x$'); ax.grid(alpha=0.3)
if ax is axes[0]:
ax.set_ylabel('$y$')
ax.legend(fontsize=8)
fig.suptitle('Universal approximation pratikte: $N$ büyüdükçe yaklaşım iyileşir', y=1.02, fontsize=12)
plt.tight_layout()
plt.show()
```
Yani teori "olabilir" der; pratik ise "kolay mı, sağlam mı, doğru veriyle mi" sorularının bahsidir.
> *"there's no guarantee on the size of that layer... and perhaps even more important... no guarantees on the generalization capacity of such a model."* — Ava, 9:50
::: {.callout-tip title="Builder Notu — Yaklaşıklayabilir mi vs Genelleyebilir mi?"}
**Geriye (Calculus + Stat 110):** Universal approximation, **fonksiyon yaklaşıklaması** kuramının bir parçası — Calculus'un Taylor serisi (Ders 11) sezgisinin sonsuz parametreli versiyonu. "Yaklaşıklayabilir ama genelleyebilir mi?" sorusu, Stat 110'un bias-variance ikilemini (Ders 34, Basu'nun fili: yansız ≠ iyi) klasik makine öğrenmesinin diline taşır.
**İleriye:** Modern **ölçekleme yasaları** (Kaplan, Chinchilla) bu teoremin çekincelerine **veri-model-compute** üçlüsü üzerinden cevap arar — yeterli ölçeğe ulaşınca yetenekler **emergent** olarak ortaya çıkar (@sec-llm-frontiers). Bu yasalar bir builder'ın model boyutu, batch size, training steps kararlarının temelidir.
:::
## Genelleme Sorunu: Eğitim ≠ Anlama {#sec-generalization}
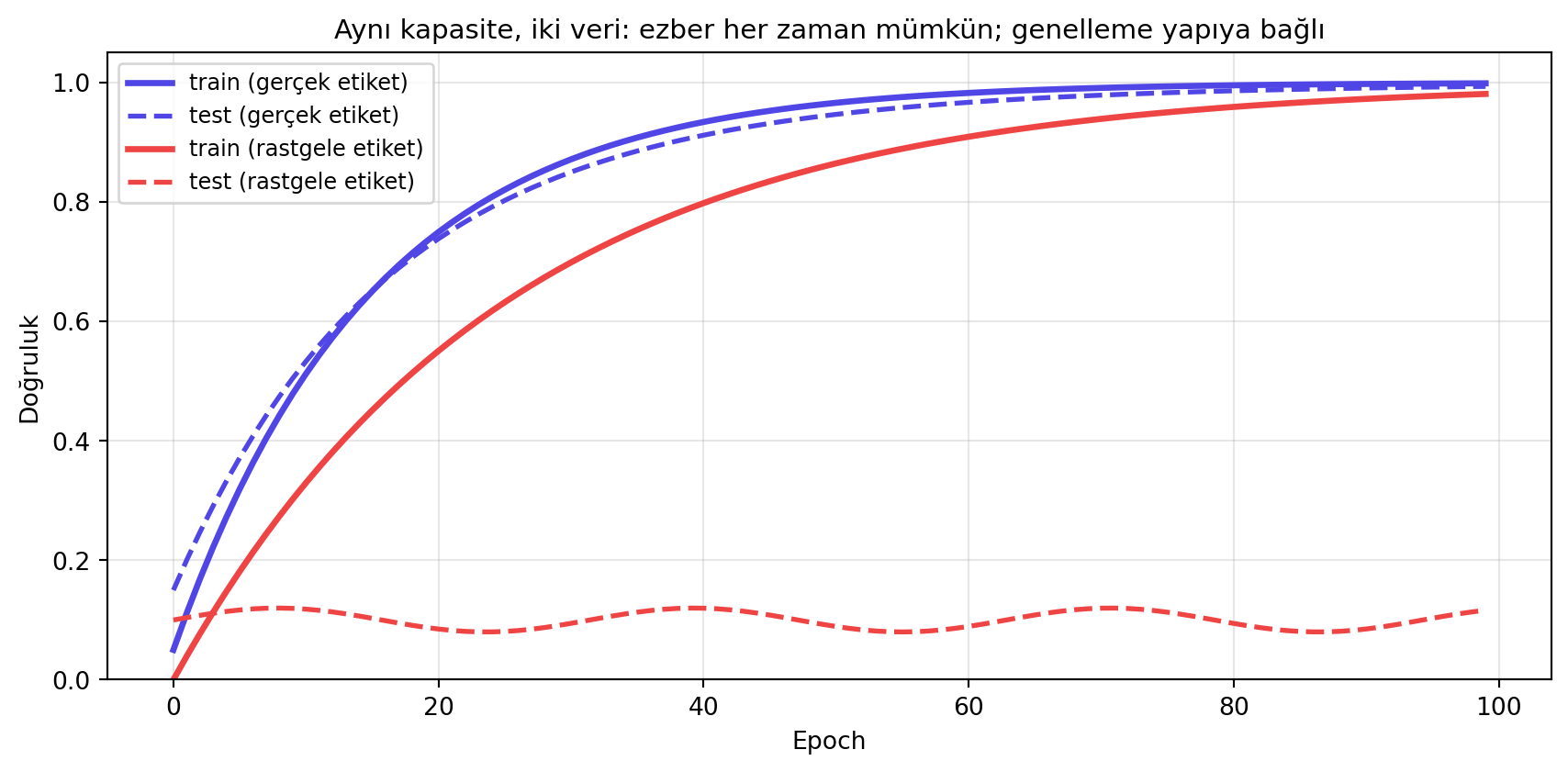
Universal approximation der ki: "bir fonksiyon yaklaşıklayıcısı var". Ama bu yaklaşıklayıcı, gerçekten **anlıyor mu** yoksa sadece eğitim verisini **ezberliyor mu**? Bu sorunun en şaşırtıcı cevabı bir 2017 makalesinden geldi: *Understanding Deep Neural Networks Requires Rethinking Generalization*.
Deney basit ama yıkıcı: ImageNet veri setindeki her görüntü için, etiketleri **rastgele yeniden atadılar** — K sınıflı bir zar attılar, her görüntüye o zar değerini etiket yaptılar. Yani "kedi" etiketli bir görüntü artık "uçak" veya "buzdolabı" olabilir; semantik bağ tümden koptu.
Sonra bu rastgele-etiketli veriyle bir CNN eğittiler. Beklenti: model hiçbir şey öğrenemez. **Gerçeklik:** eğitim seti üzerinde yine **neredeyse %100 doğruluk** elde ettiler. Tabii ki test setinde başarı sıfıra yakın çıktı — çünkü öğrenecek hiçbir desen yoktu, sadece ezber vardı.
```{python}
#| label: fig-memorize
#| fig-cap: "Rastgele etiket deneyinin sezgisi: yeterli kapasiteli bir ağ, anlamlı veriyi de rastgele veriyi de eğitimde %100'e kadar fit edebilir; ama test doğruluğu yalnızca verinin **yapısal sinyali** olduğunda yüksektir."
#| fig-width: 9
#| fig-height: 4.5
fig, ax = plt.subplots(figsize=(9, 4.5))
epoch = np.arange(0, 100)
train_real = 1.0 - 0.95 * np.exp(-epoch / 15)
test_real = 1.0 - 0.7 * np.exp(-epoch / 15) - 0.15 * np.exp(-epoch / 30)
train_rand = 1.0 - 1.0 * np.exp(-epoch / 25)
test_rand = 0.1 + 0.02 * np.sin(epoch / 5)
ax.plot(epoch, train_real, color='#4f46e5', linewidth=2.5, label='train (gerçek etiket)')
ax.plot(epoch, test_real, color='#4f46e5', linestyle='--', linewidth=2.0, label='test (gerçek etiket)')
ax.plot(epoch, train_rand, color='#ef4444', linewidth=2.5, label='train (rastgele etiket)')
ax.plot(epoch, test_rand, color='#ef4444', linestyle='--', linewidth=2.0, label='test (rastgele etiket)')
ax.set_xlabel('Epoch'); ax.set_ylabel('Doğruluk')
ax.set_title('Aynı kapasite, iki veri: ezber her zaman mümkün; genelleme yapıya bağlı', fontsize=11)
ax.legend(fontsize=9)
ax.grid(alpha=0.3)
ax.set_ylim(0, 1.05)
plt.tight_layout()
plt.show()
```
Bu deneyin mesajı: sinir ağları **muazzam kapasiteli** fonksiyon yaklaşıklayıcılarıdır; rastgele bir eşlemeyi bile ezberleyebilirler. Genelleme bu kapasiteden değil, **verinin yapısından** ve doğru endüktif önyargılardan gelir.
::: {.callout-tip title="Builder Notu — Kapasite ≠ Anlama"}
**Geriye (Stat 110):** Bu, **bias-variance** ikilemi (Stat 110 Ders 34) ve **Basu'nun fili** sezgisinin derin öğrenme versiyonu. Modelin kapasitesi (variance kaynağı) ile veri yapısının kaliteli sinyali (bias düşüren faktör) arasındaki dengeyi anlamak, bir builder için temel beceridir.
**İleriye:** Bu bulgu, modern derin öğrenmenin neden **regularization, data augmentation, pre-training, transfer learning** etrafında bu kadar yoğunlaştığını açıklar. Ayrıca **lottery ticket hypothesis** ve **double descent** gibi çağdaş araştırma damarlarının da kökeni budur.
:::
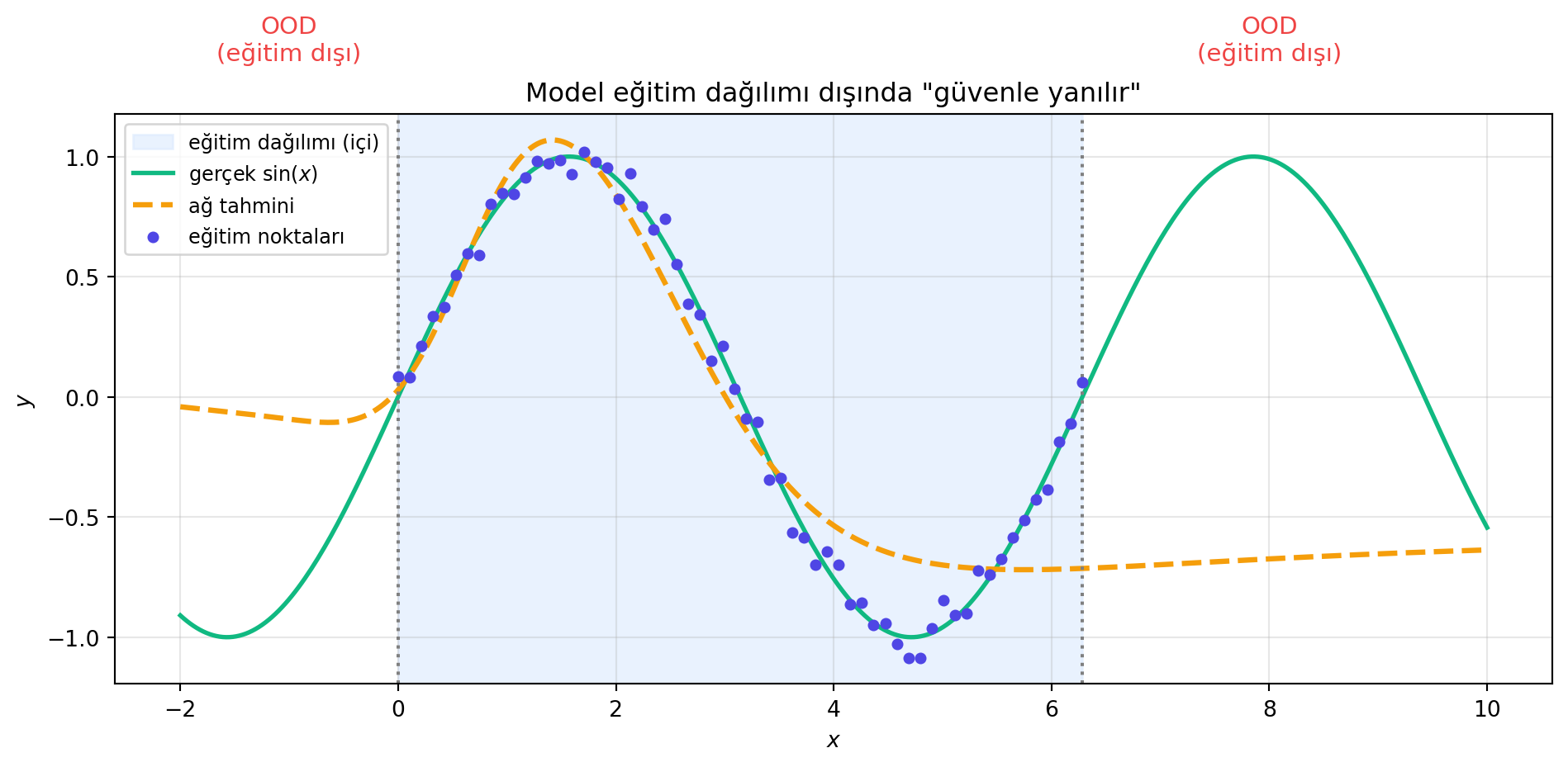
## Dağılım Dışı (OOD) ve Veri Kalitesinin Bedeli {#sec-ood}
Bir model yalnızca eğitim **dağılımı içinde** güvenilirdir. Yeni veri o dağılımdan saparsa (out-of-distribution, OOD), tahminler hızla bozulur. Trajik bir örnek: bir otonom aracın kazası. Sürücü haftalardır arabanın aynı yerde inşaat bariyerine doğru kaydığını bildiriyordu. Soruşturma açığa çıkardı — eğitim verisindeki o sokağın görüntülerinde inşaat bariyeri **yoktu**, daha sonra konulmuştu. Yani gerçek dünyadaki nesne, modelin eğitim dağılımı **dışındaydı**.
OOD problemi iki kardeş kavramla iç içe geçer:
- **Veri çeşitliliği:** Eğitim setinde temsil edilmeyen durumlar test zamanında ortaya çıkar.
- **Belirsizlik tahmini (uncertainty):** Model bir tahmini yaparken **ne kadar emin** olduğunu bilebilmeli. Otonom araç, biyoloji, tıp gibi güvenlik-kritik alanlarda "emin değilim, insan müdahalesi gerek" diyebilen modellere ihtiyaç var.
```{python}
#| label: fig-ood-shift
#| fig-cap: "Eğitim dağılımının kapsadığı bölgede model güvenli (mavi); dışına çıkıldıkça (turuncu) tahmin güveni hızla düşer. OOD detection bu boşluğu izleyen ek bir mekanizmadır."
#| fig-width: 10
#| fig-height: 5
np.random.seed(7)
x_train = np.linspace(0, 2 * np.pi, 60)
y_train = np.sin(x_train) + 0.05 * np.random.randn(60)
x_full = np.linspace(-2, 10, 400)
params = fit_1hidden_mlp(x_train, y_train, N=20, epochs=3000, lr=0.05)
y_pred = predict(x_full, params)
fig, ax = plt.subplots(figsize=(10, 5))
ax.axvspan(0, 2 * np.pi, color='#dbeafe', alpha=0.6, label='eğitim dağılımı (içi)')
ax.plot(x_full, np.sin(x_full), color='#10b981', linewidth=2.0, label='gerçek $\\sin(x)$')
ax.plot(x_full, y_pred, color='#f59e0b', linewidth=2.4, linestyle='--', label='ağ tahmini')
ax.scatter(x_train, y_train, color='#4f46e5', s=18, label='eğitim noktaları', zorder=4)
ax.axvline(0, color='gray', linestyle=':')
ax.axvline(2 * np.pi, color='gray', linestyle=':')
ax.text(-1.0, 1.4, 'OOD\n(eğitim dışı)', color='#ef4444', fontsize=11, ha='center')
ax.text(8.0, 1.4, 'OOD\n(eğitim dışı)', color='#ef4444', fontsize=11, ha='center')
ax.set_xlabel('$x$'); ax.set_ylabel('$y$')
ax.set_title('Model eğitim dağılımı dışında "güvenle yanılır"', fontsize=12)
ax.legend(fontsize=9)
ax.grid(alpha=0.3)
plt.tight_layout()
plt.show()
```
::: {.callout-tip title="Builder Notu — Belirsizlik Bilinçli Üretim"}
**Geriye (Stat 110):** OOD problemi, Stat 110'un **dağılım kayması** (covariate shift) ve **belirsizlik altında karar** çerçevesinin doğrudan uygulamasıdır. "Modelin emin olup olmadığını ölçmek" Stat 110'un **kalibrasyon** ve **posterior** kavramlarına bağlanır.
**İleriye:** **MC Dropout**, **deep ensembles**, **deep evidential regression**, **conformal prediction** modern belirsizlik tahmin çerçeveleridir. Üretimde: modelin **OOD detektörü** ile zorunlu eşlenik göndermesi (insan müdahalesi tetikleyici) hayat kurtarıcı bir tasarım kararıdır.
:::
## Adversarial Saldırılar: Gradient'i Girdiye Karşı {#sec-adversarial}
CNN'lerin görü performansı insan-üstü düzeylere ulaştı. Ama 2014'ten beri biliyoruz ki: bir görüntüye **insan gözünün ayırt edemeyeceği** kadar küçük bir gürültü eklemek, modeli tamamen yanlış sınıflandırmaya itebilir. "Panda" görüntüsüne minicik bir perturbasyon ekle → CNN "gibbon" diyor, %99 güvenle.
Mekanizma zariftir. Ders 1'de **gradient descent**'i öğrendik: ağırlıkları, **kayıp $J$'yi azaltacak** şekilde güncelliyorduk. Adversarial saldırı bunu **tersine çevirir**: ağırlıklar sabit, ama **girdiyi** kaybı **artıracak** yönde değiştir. Klasik bir formülasyon (FGSM — Fast Gradient Sign Method):
$$
x_{\text{adv}} = x + \epsilon \cdot \text{sign}\!\left(\nabla_x J(\theta,\, x,\, y)\right)
$$
Burada $\epsilon$ çok küçük bir adım büyüklüğüdür; gradient'in işaretine doğru atılan tek bir adım yeter.
```{python}
#| label: fig-fgsm-stylized
#| fig-cap: "FGSM stilize gösterimi: orijinal görüntü (sol), $\\epsilon \\cdot \\text{sign}(\\nabla_x J)$ perturbasyonu (orta, görselleştirme için büyütülmüş), adversarial sonuç (sağ). Modelin tahmini panda → gibbon."
#| fig-width: 12
#| fig-height: 4
np.random.seed(1)
H, W = 64, 64
xx, yy = np.meshgrid(np.linspace(-1, 1, W), np.linspace(-1, 1, H))
body = np.exp(-(xx**2 + (yy * 1.2)**2) / 0.4)
left_eye = np.exp(-((xx + 0.32)**2 + (yy + 0.18)**2) / 0.005)
right_eye = np.exp(-((xx - 0.32)**2 + (yy + 0.18)**2) / 0.005)
panda = 0.85 * body - 0.7 * (left_eye + right_eye)
panda = (panda - panda.min()) / (panda.max() - panda.min())
noise = np.sin(8 * xx) * np.cos(8 * yy) + 0.5 * np.sin(15 * xx + 3 * yy)
sign_noise = np.sign(noise)
eps = 0.05
adv = np.clip(panda + eps * sign_noise, 0, 1)
fig, axes = plt.subplots(1, 3, figsize=(12, 4))
axes[0].imshow(panda, cmap='gray', vmin=0, vmax=1)
axes[0].set_title('orijinal $x$\nağ: "panda" %99', fontsize=11)
axes[0].axis('off')
axes[1].imshow(sign_noise, cmap='RdBu', vmin=-1, vmax=1)
axes[1].set_title(r'$\epsilon \cdot \mathrm{sign}(\nabla_x J)$' + '\n(görselleştirme için büyütülmüş)', fontsize=11)
axes[1].axis('off')
axes[2].imshow(adv, cmap='gray', vmin=0, vmax=1)
axes[2].set_title('adversarial $x + \\epsilon \\cdot$sign$(\\nabla_x J)$\nağ: "gibbon" %99', fontsize=11)
axes[2].axis('off')
fig.suptitle('FGSM: girdiye küçük bir perturbasyon, modele tamamen başka bir sınıf gösterir', y=1.02, fontsize=12)
plt.tight_layout()
plt.show()
```
> *"how can we modify the input such that it yields a very very large change... increase the loss function to then yield this adversarial perturbation."* — Ava, 25:42
İş daha da derinleşti: MIT CSAIL ekibi **3 boyutlu fiziksel nesneler** üretti — kaplumbağa görünümlü 3B baskılar, CNN'lere her açıdan "tüfek" gibi görünüyordu.
::: {.callout-tip title="Builder Notu — Türev, Senin İçin Silah Olabilir"}
**Geriye (Calculus + Ders 1):** Adversarial saldırı, Calculus Ders 4'ün **zincir kuralını ters yönde** kullanmaktır — backprop'un öğrettiği aynı türev mekaniği, kötü niyetli bir girdi üreteci için silah olur. $\nabla_x J$ ile **girdiye göre gradient** Ders 1'de yapmadığımız bir hesap; çıkış parametrik değil girdi parametrik. Calculus aynı.
**İleriye:** Savunma araştırma cephesi geniş: **adversarial training**, **randomized smoothing**, **certified defenses**. Üretimde adversarial robustness, özellikle güvenlik-kritik sistemler (otonom araç, biyometri, finansal dolandırıcılık) için artık tasarım gereksinimidir.
:::
## Algoritmik Yanlılık ve Sınırların Fırsata Dönüşmesi {#sec-bias}
Modeller eğitim verisindeki **yapısal yanlılıkları** öğrenir; sonra bunları üretir, hatta amplifiye eder. Ava'nın gösterdiği bir örnek: gri-renkli köpek fotoğraflarını otomatik renklendiren bir model, bir köpeğin dilini yanlış renklerle boyamış. Sebep basit — eğitim verisindeki köpekler ağırlıklı olarak dilini dışarı çıkarmış pozlarda fotoğraflandığı için model şekli ile rengi karıştırdı.
Daha ciddi örnekler: yüz tanıma sistemlerinin az temsil edilen ten tonlarında zayıf performans (Joy Buolamwini'nin çığır açan çalışmaları); kredi puanlama, işe alım, ceza adalet sistemlerinde algoritmik **adaletsizlik**. Ders 4'teki **VAE-tabanlı debiasing** tam da bu probleme bir teknik cevaptı; ama yanlılık yalnızca teknik bir sorun değil — toplumsal bir adalet sorunudur.
Ava'nın çağrısı: bu sınırları **fırsat olarak** görmek. Her sınır — uncertainty, interpretability, bias, robustness — açık bir araştırma cephesidir; bir builder olarak "bu sınırla yaşamak" yerine "bu sınırı aşmak için ne yapabilirim" sorusunu sormak.
::: {.callout-tip title="Builder Notu — Fairness Mühendisliği"}
**Geriye (Stat 110):** Bias = veri dağılımı ile gerçek nüfus dağılımı arasındaki uyumsuzluk; Stat 110'un Simpson paradoksu ve confounder kavramlarının (Ders 6) doğrudan modern karşılığı.
**İleriye:** **Fairness metrics** (demographic parity, equalized odds), **causal inference** tabanlı debiasing, **counterfactual fairness**, **interpretability** araçları (SHAP, LIME, integrated gradients). Üretimde **model card'lar** ve **datasheet'ler** standart hâle geldi. Ders 12 (AI için Hipokrat Yemini) bu konuyu derinden işleyecek.
:::
## Diffusion Modelleri: Çekirdek Fikir {#sec-diffusion-core}
Ders 4'te VAE ve GAN'i gördük. Her iki yöntem de tek bir geçişte (one-shot) yeni örnek üretmeye çalışıyordu. Sorunları belli: GAN'lerde **mode collapse** ve eğitim kararsızlığı, VAE'lerde **bulanık örnekler**. Bugünün en çarpıcı üretken modelleri (Stable Diffusion, DALL-E 3, Sora, Imagen) **diffusion modelleri** ailesinden geliyor; çekirdek fikir basit ama derin:
> *"rather than doing generation in a single shot, what if we can decompose the problem into iterative generations that make the task easier?"* — Ava, 32:02
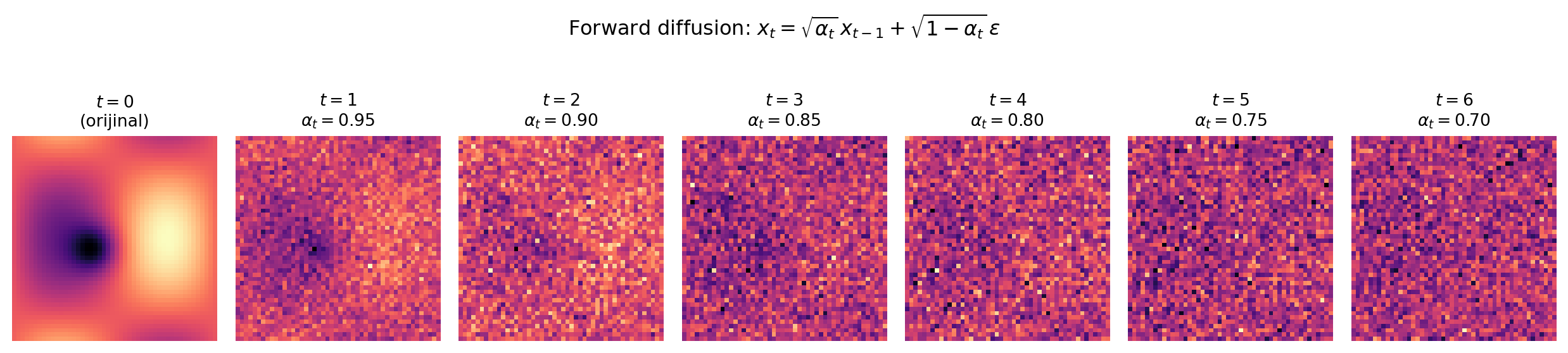
Yani: tek seferde gerçekçi bir görüntü üretmek zor; **adım adım** üretmek kolay. Diffusion bunu iki süreçten oluşan bir paradigmayla yapar:
- **İleri (forward) gürültüleme süreci:** Veriyi al, üzerine **adım adım** küçük miktarda Gaussian gürültü ekle. $T$ adım sonra ($T = 1000$ gibi) görüntü tamamen kayboluyor, geriye saf rastgele gürültü kalıyor. Bu süreç **deterministiktir**, öğrenilmez.
- **Geri (reverse) gürültü-giderme (denoising) süreci:** Bu sefer **gürültüden geriye doğru** git. Saf gürültüyle başla, her adımda biraz gürültüyü kaldır, sonunda anlamlı bir örnek elde et. Bu süreç **öğrenilir** — sinir ağı, her adımda "eklenmiş olan gürültüyü tahmin etmeyi" öğrenir.
```{python}
#| label: fig-diffusion-forward
#| fig-cap: "Diffusion forward süreci: orijinal görüntüden saf Gaussian gürültüye 6 adım. Her adımda küçük bir gürültü eklenir; $T$ sonunda yapısal sinyal kaybolur."
#| fig-width: 13
#| fig-height: 3
np.random.seed(3)
H, W = 48, 48
xx, yy = np.meshgrid(np.linspace(-1, 1, W), np.linspace(-1, 1, H))
img = 0.5 + 0.4 * np.sin(3 * xx) * np.cos(2 * yy) - 0.5 * np.exp(-((xx + 0.2)**2 + (yy - 0.1)**2) / 0.05)
img = (img - img.min()) / (img.max() - img.min())
T = 6
betas = np.linspace(0.05, 0.3, T)
alphas = 1 - betas
fig, axes = plt.subplots(1, T + 1, figsize=(13, 3))
axes[0].imshow(img, cmap='magma', vmin=0, vmax=1)
axes[0].set_title('$t = 0$\n(orijinal)', fontsize=10)
axes[0].axis('off')
current = img.copy()
for t in range(T):
noise = np.random.randn(H, W)
current = np.sqrt(alphas[t]) * current + np.sqrt(betas[t]) * noise
axes[t + 1].imshow(current, cmap='magma')
axes[t + 1].set_title(f'$t = {t + 1}$\n$\\alpha_t = {alphas[t]:.2f}$', fontsize=10)
axes[t + 1].axis('off')
fig.suptitle('Forward diffusion: $x_t = \\sqrt{\\alpha_t}\\,x_{t-1} + \\sqrt{1-\\alpha_t}\\,\\epsilon$', y=1.05, fontsize=12)
plt.tight_layout()
plt.show()
```
::: {.callout-tip title="Builder Notu — Iteratif Modellemenin Gücü"}
**Geriye (Stat 110 + Ders 4):** Forward gürültüleme süreci, doğrudan bir **Markov zinciridir** (Stat 110 Ders 31): $x_t$ yalnızca $x_{t-1}$'e bağlıdır. Her geçiş bir Normal dağılıma yapılan bir adımdır. Reverse süreç ise koşullu dağılımları öğrenir.
**İleriye:** Modern devamları: **DDIM** (deterministik, daha az adımda örnekleme), **latent diffusion** (Stable Diffusion — piksel uzayında değil sıkıştırılmış latent uzayda), **consistency models** (tek-adım sample), **score-based generative models** (sürekli zaman SDE).
:::
## Diffusion Matematiği ve Eğitim {#sec-diffusion-math}
Forward sürecin matematiği basittir. Her adımda $x_{t-1}$'i biraz "zayıflat" ve Gaussian gürültü ekle:
$$
x_t = \sqrt{\alpha_t}\, x_{t-1} + \sqrt{1 - \alpha_t}\, \epsilon, \qquad \epsilon \sim \mathcal{N}(0,\, I)
$$
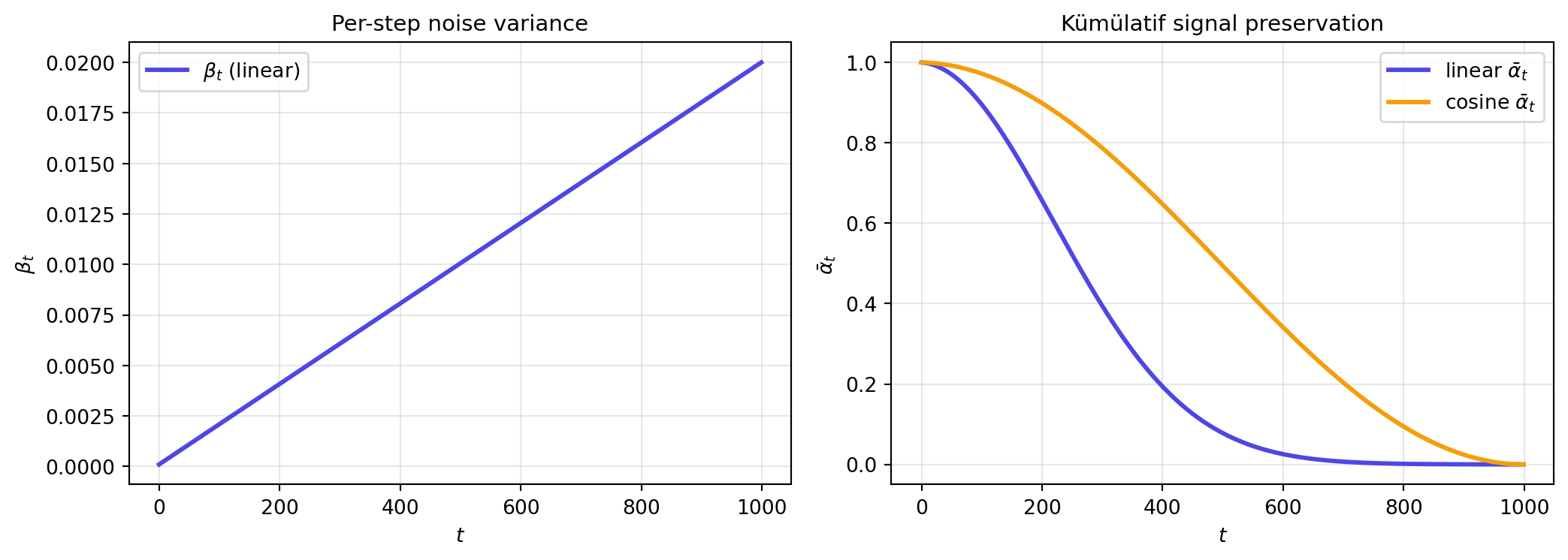
Burada $\alpha_t \in (0, 1)$ bir **gürültü programıdır** (noise schedule). $T$ büyük seçilirse, $x_T$ neredeyse saf Gaussian gürültü olur: $x_T \approx \mathcal{N}(0, I)$.
Sinir ağının görevi **geri yönlü**: $x_t$ verildiğinde, bu adımda **eklenen gürültüyü** $\epsilon$'yu tahmin etmek. Ağa $\epsilon_\theta(x_t, t)$ diyelim. Eğitim hedefi:
$$
L(\theta) = \mathbb{E}_{x_0,\, t,\, \epsilon}\!\left[\left\| \epsilon - \epsilon_\theta(x_t,\, t) \right\|^2\right]
$$
```python
# Diffusion egitim adimi (PyTorch sahte-kodu)
import torch, torch.nn.functional as F
def diffusion_train_step(model, x0, T=1000):
B = x0.size(0)
t = torch.randint(0, T, (B,), device=x0.device)
eps = torch.randn_like(x0)
alpha_bar_t = alpha_bars[t].view(-1, 1, 1, 1)
x_t = torch.sqrt(alpha_bar_t) * x0 + torch.sqrt(1 - alpha_bar_t) * eps
eps_pred = model(x_t, t) # U-Net tahmini
return F.mse_loss(eps_pred, eps) # Gauss MLE = MSE
```
> *"predicting the difference which is the noise is a very very effective way to train these diffusion models."* — Ava, 36:21
Üretim (inference) basit: $x_T \sim \mathcal{N}(0, I)$ örnekle → adım adım denoise → $t = 0$'da yeni bir $x_0$ elde et. Genellikle $T = 1000$ adım, ama DDIM ile 50 adıma kadar inebilir.
```{python}
#| label: fig-noise-schedule
#| fig-cap: "Gürültü programı: linear vs cosine. $\\beta_t$ (per-step variance) ve kümülatif $\\bar{\\alpha}_t$ ($T$ sonunda 0'a yakın). Cosine schedule modern DDPM/Stable Diffusion'da yaygın."
#| fig-width: 11
#| fig-height: 4
T = 1000
t_arr = np.arange(T)
beta_lin = np.linspace(1e-4, 0.02, T)
alpha_lin = 1 - beta_lin
alpha_bar_lin = np.cumprod(alpha_lin)
s = 0.008
f = np.cos(((t_arr / T) + s) / (1 + s) * np.pi / 2) ** 2
alpha_bar_cos = f / f[0]
fig, axes = plt.subplots(1, 2, figsize=(11, 4))
axes[0].plot(t_arr, beta_lin, color='#4f46e5', linewidth=2.2, label=r'$\beta_t$ (linear)')
axes[0].set_xlabel('$t$'); axes[0].set_ylabel(r'$\beta_t$')
axes[0].set_title('Per-step noise variance', fontsize=11)
axes[0].grid(alpha=0.3); axes[0].legend(fontsize=10)
axes[1].plot(t_arr, alpha_bar_lin, color='#4f46e5', linewidth=2.2, label='linear $\\bar{\\alpha}_t$')
axes[1].plot(t_arr, alpha_bar_cos, color='#f59e0b', linewidth=2.2, label='cosine $\\bar{\\alpha}_t$')
axes[1].set_xlabel('$t$'); axes[1].set_ylabel(r'$\bar{\alpha}_t$')
axes[1].set_title('Kümülatif signal preservation', fontsize=11)
axes[1].grid(alpha=0.3); axes[1].legend(fontsize=10)
plt.tight_layout()
plt.show()
```
::: {.callout-tip title="Builder Notu — Gauss MLE = MSE"}
**Geriye (Stat 110 + Ders 4):** MSE loss, **Gauss gürültü altında maximum likelihood** ile eşdeğerdir (Stat 110 Ders 13 Normal) — yani diffusion eğitimi olasılıksal olarak optimal. Forward süreç bir Markov zinciri; reverse'de Bayes teoremiyle gerçek tersi türetilebilir. Reparameterization trick (Ders 4 VAE) burada da kullanılır.
**İleriye:** **Score matching**, **classifier-free guidance**, **flow matching**, **consistency models** diffusion'ın daha hızlı varyantları — bir builder olarak bu cephe çok hızlı evriliyor.
:::
## Çok-Modal Diffusion: Text-to-Image ve Moleküler Tasarım {#sec-multimodal}
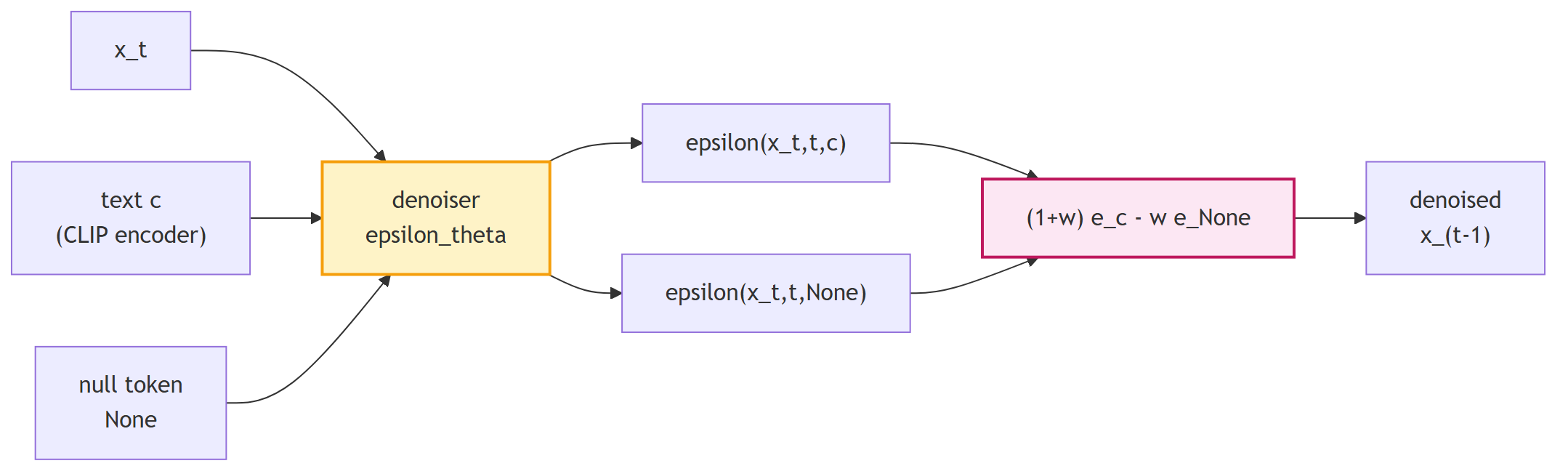
Diffusion'un asıl gücü **koşullu üretimde** ortaya çıkar. "Bir kedi resmi üret" yetersiz; "uzayda gezegen yüzeyinde yürüyen turuncu bir kedi" istemek istersin. Bu **text-to-image** kabiliyeti için diffusion'ın reverse adımına bir **rehber sinyal** enjekte ederiz:
1. **Metin embedding'i:** Bir dil modelinin (CLIP gibi) text encoder'ı ile metni vektöre çevir.
2. **Conditional reverse:** Denoising adımında bu vektörü modele ek girdi olarak ver; $\epsilon_\theta$ artık $\epsilon_\theta(x_t, t, c)$ — $c$ metin koşulu.
3. **Classifier-free guidance:** Eğitimde modeli hem koşullu hem koşulsuz öğret; üretimde iki tahmini birleştir:
$$
\hat{\epsilon}_\theta(x_t, t, c) = (1 + w)\,\epsilon_\theta(x_t, t, c) - w\,\epsilon_\theta(x_t, t, \varnothing)
$$
{#fig-cfg fig-align="center" width=85%}
Sonuç: Stable Diffusion, DALL-E 3, Imagen, Sora gibi modellerin temel mekaniği bu.
Daha derinde: diffusion **modaliteden bağımsız**. Görüntü = sürekli piksel değerleri; protein = sürekli 3B atom koordinatları; molekül = atomlar + bağlar. **RFdiffusion** ve **AlphaFold 3** gibi modeller, diffusion'ı protein yapı tasarımına uyguladı. Ders 8'de Christopher Bishop bu cepheyi derinden işleyecek.
::: {.callout-tip title="Builder Notu — Guidance Scale Trade-off'u"}
**Geriye (Ders 2 + 18.06):** Text embedding doğrudan Ders 2'nin embedding teknolojisidir; CLIP gibi modeller görüntü ve metin embedding'lerini **aynı vektör uzayına** projeksiyona oturtur (18.06 Ders 15). Guidance ise olasılıksal modellemede koşulun etkisini ayarlayan klasik bir Bayes hilesi (Stat 110 Ders 4 koşullu olasılık).
**İleriye:** **Image editing**, **ControlNet**, **personalization** (DreamBooth, LoRA), **multi-view 3D**. Üretimde diffusion'un **inference maliyeti** ($T$ adım) en büyük darboğaz; **consistency models** ve **distilled diffusion** bu cephede aktif.
:::
## LLM'lerin Temelleri: Next Token Prediction {#sec-llm-foundations}
GPT, Gemini, Claude, Llama — hepsinin temelinde aynı çekirdek görev var: **bir sonraki token'ı tahmin et**. Bir LLM, devasa bir metin korpusu üzerinde eğitilmiş çok büyük bir transformer ağıdır. Pipeline:
1. **Tokenization:** Ham metni alt-kelime parçalarına böl (BPE).
2. **Embedding:** Indeksleri öğrenilmiş bir vektör tablosundan embedding'lere çevir.
3. **Transformer ileri geçiş:** Token dizisini transformer'a ver, her pozisyon için bir sonraki token'ın **olasılık dağılımını** üret (vocab boyutunda softmax).
4. **Cross-entropy loss:** Gerçek bir sonraki token ile tahmin edilen olasılık dağılımını karşılaştır:
$$
L(\theta) = -\sum_{t} \log\, p_\theta\!\left(x_t \,\big|\, x_{<t}\right)
$$
Yani LLM eğitimi devasa bir **sınıflandırma görevidir**, her pozisyonda $K$ sınıf ($K$ = vocab boyutu, genelde 50K–200K) üzerinden softmax + cross-entropy.
> *"this is a classification problem... we can look at the true next token and the predicted probabilities over the possible next tokens and compute a cross entropy loss using this."* — Ava, 48:09
```python
# LLM egitim hedefi (PyTorch sahte-kodu)
import torch.nn.functional as F
# logits shape: (batch, seq_len, vocab_size)
# targets shape: (batch, seq_len) -- bir token kaydirilmis
logits = model(input_ids)
loss = F.cross_entropy(
logits.view(-1, vocab_size),
targets.view(-1),
)
loss.backward()
```
Bu görevin gücü iki çarpan: (a) **ölçek** — GPT-3 = 175 milyar parametre; (b) **veri** — internet ölçeğinde metin. Liquid AI gibi şirketler ise 2B parametreli **küçük modellerin** dikkatli eğitimle rekabet edebileceğini gösterdi (Ders 9'da Mathias Lechner anlatacak).
Base LLM next-token tahmin eder ama yardımcı değildir. Üzerine: (a) **instruction tuning**, (b) **RLHF** (Ders 5). Sonuç: ChatGPT'nin gördüğün asistan davranışı.
::: {.callout-tip title="Builder Notu — Self-Supervised'un Saf Hâli"}
**Geriye:** Aynı çekirdek mekanik tüm kursta tekrar tekrar geçer — Ders 2 (sequence + transformer + self-attention) + Ders 1 (cross-entropy + softmax) + Stat 110 (Bernoulli/multinomial). **Self-supervised** doğa: etiket gerekmiyor, veri kendi sinyalidir.
**İleriye:** **RAG**, **agentic AI**, **reasoning models** (o1, R1). Üretim tarafında **KV cache**, **flash attention**, **speculative decoding**, **quantization** bir LLM'in throughput'unu belirleyen anahtar tekniklerdir.
:::
## Hallucination, Kalibrasyon, Emergent Abilities {#sec-llm-frontiers}
LLM'lerin en görünür sorunu **halüsinasyon**: model olağanüstü güvenli bir tonla, gerçek dışı bilgi üretir. Yakın tarihli bir çalışma şaşırtıcı bir tespit yaptı: **iyi kalibre edilmiş bir LLM, halüsinasyon ürettiği bir sınırı zorunlu olarak aşar**. Sezgi: dilin doğası gereği, hangi token'ı seçeceğin üzerinde bir olasılık dağılımı vardır; modelin bu dağılımın altındaki **doğru olmayan** bir token'ı sıfırlamasının istatistiksel maliyeti, kalibrasyonun kendisini bozmaktır.
LLM'lerin diğer açık sınırları:
- **Jailbreak'ler** — adversarial saldırıların dil versiyonu (Ders 7'de Doug Blank canlı gösterecek).
- **Uzun-vadeli planlama ve mantık** — **reasoning** modelleri (o1, R1) **chain-of-thought** ile RL'yi birleştiriyor.
- **Belirsizlik** — modelin "bilmediğini söylemesi" hâlâ büyük ölçüde çözümsüz.
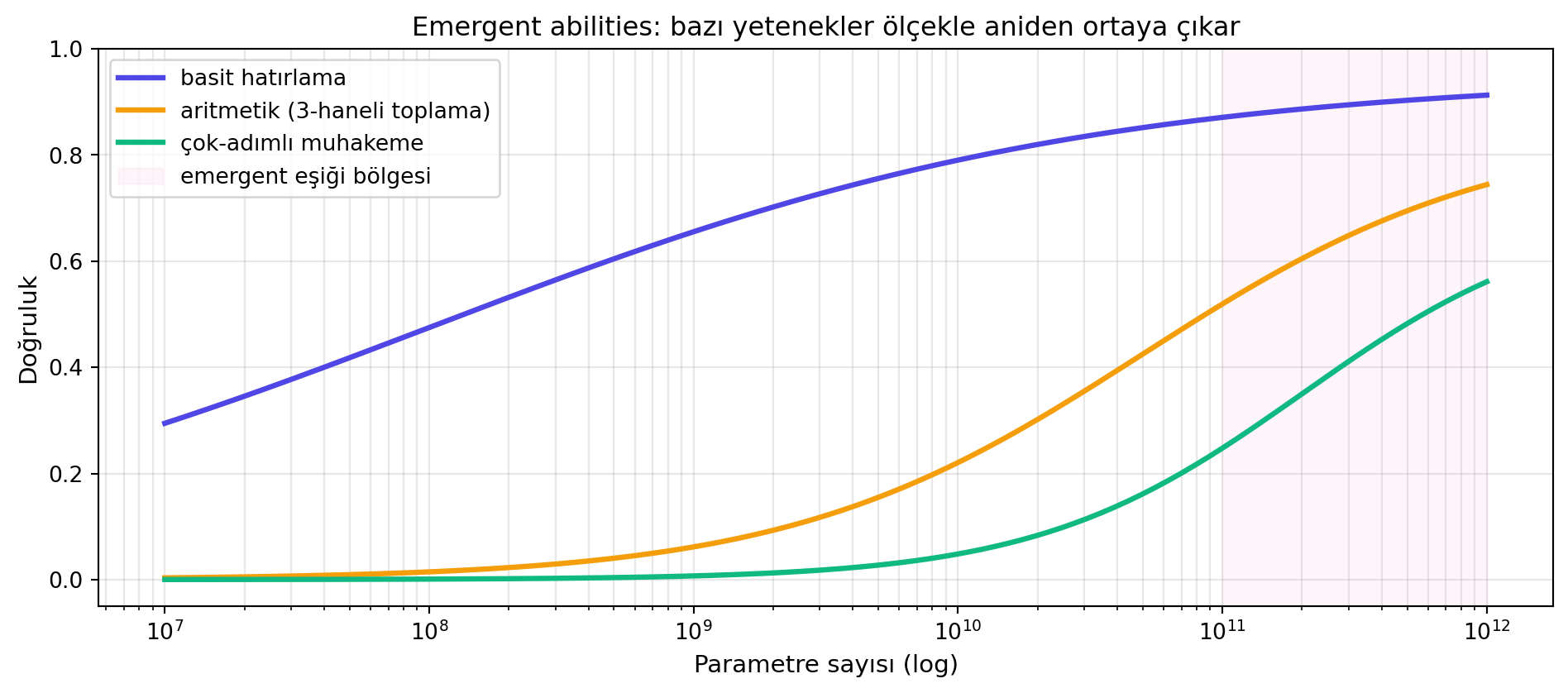
Ama tersine bir keşif de var: **emergent abilities** (ortaya çıkan yetenekler). Modeli yeterince büyütünce, daha küçük versiyonlarda **hiç olmayan** yetenekler aniden belirir — aritmetik, çok-adımlı muhakeme, kod yazma. Kaplan ve Chinchilla **scaling laws** bu olguyu sayısallaştırdı.
```{python}
#| label: fig-emergent
#| fig-cap: "Emergent abilities şematik: bazı yetenekler (çok-adımlı muhakeme) model ölçeğiyle sürekli değil, **adım fonksiyonu** gibi sıçramalarla ortaya çıkar — küçük modelde sıfır, eşik aşılınca aniden yüksek doğruluk."
#| fig-width: 10
#| fig-height: 4.5
n_params = np.logspace(7, 12, 200)
def emergent(N, threshold, sharpness=0.6):
return 1 / (1 + np.exp(-sharpness * (np.log10(N) - np.log10(threshold))))
basit_ezber = emergent(n_params, threshold=1e8, sharpness=0.8) * 0.95
aritmetik = emergent(n_params, threshold=5e10, sharpness=1.5) * 0.85
multistep = emergent(n_params, threshold=2e11, sharpness=2.0) * 0.7
fig, ax = plt.subplots(figsize=(10, 4.5))
ax.semilogx(n_params, basit_ezber, color='#4f46e5', linewidth=2.4, label='basit hatırlama')
ax.semilogx(n_params, aritmetik, color='#f59e0b', linewidth=2.4, label='aritmetik (3-haneli toplama)')
ax.semilogx(n_params, multistep, color='#10b981', linewidth=2.4, label='çok-adımlı muhakeme')
ax.axvspan(1e11, 1e12, color='#fce7f3', alpha=0.4, label='emergent eşiği bölgesi')
ax.set_xlabel('Parametre sayısı (log)', fontsize=11)
ax.set_ylabel('Doğruluk', fontsize=11)
ax.set_title('Emergent abilities: bazı yetenekler ölçekle aniden ortaya çıkar', fontsize=12)
ax.legend(fontsize=10, loc='upper left')
ax.grid(alpha=0.3, which='both')
ax.set_ylim(-0.05, 1.0)
plt.tight_layout()
plt.show()
```
> *"the goal is ultimately that these stay as technology, right? That we as humans can use to accelerate our own creative process and our own capabilities in ways that the models can't."* — Ava, 54:30
Ava'nın bitirici çağrısı: AI'yı **kendi yerine geçen** bir şey olarak değil, **kendi sınırlarını genişleten bir teknoloji** olarak görmek.
::: {.callout-tip title="Builder Notu — Kalibrasyon Üzerine"}
**Geriye (Stat 110):** Hallucination, doğrudan Stat 110'un **kalibrasyon** kavramıyla ilgilidir (Ders 9 beklenen değer, Ders 17 MLE). İyi kalibre edilmiş bir model, %80 güven verdiği iddialarda gerçekten %80 doğruluk gösterir.
**İleriye:** **RAG**, **inference-time scaling** (o1 tarzı), **tool use / function calling**, **constitutional AI**. Ders 7'de Doug Blank tam olarak "production'da AI'yı nasıl ölçer ve yönetiriz" konusunu işleyecek.
:::
## Bu Dersin Özeti {#sec-ozet}
1. **Universal approximation teoremi**: tek katmanlı bir ağ herhangi bir sürekli fonksiyonu yaklaşıklayabilir, ama **boyut, genelleme ve öğrenilebilirlik** garantili değildir.
2. **Genelleme paradoksu:** Bir CNN, **rastgele etiketlere** bile tam doğrulukla fit edebilir; genelleme kapasiteden değil **verinin yapısından** gelir.
3. **OOD** modelleri kırılgan yapar; gerçek dünyada veri çeşitliliği ve **belirsizlik tahmini** kritik.
4. **Adversarial saldırılar:** gradient'i girdiye karşı kullanarak modeller insan-görünmez perturbasyonlarla yanıltılır. FGSM: $x_{\text{adv}} = x + \epsilon \cdot \text{sign}(\nabla_x J)$.
5. **Algoritmik yanlılık:** veri yanlılığı modele yansır; debiasing teknik bir cevap ama toplumsal sorumluluk daha geniş.
6. **Diffusion modelleri:** "tek atımda üretmek" yerine **iteratif gürültü ekle / kaldır**. Forward süreç deterministik (Markov), reverse öğrenilir.
7. **Diffusion eğitimi:** her adımda eklenen gürültüyü MSE ile tahmin et — Gauss MLE. Modern Stable Diffusion, DALL-E 3, Sora bu omurgayı kullanır.
8. **Çok-modallık:** text-to-image (classifier-free guidance), protein ve molekül tasarımı (RFdiffusion, AlphaFold 3) — Ders 8 ile köprü.
9. **LLM'lerin çekirdek görevi**: next token prediction + cross-entropy (Ders 1 + Ders 2 mekaniği). Ölçek ve veri güç çarpanları.
10. **Hallucination, jailbreak, planlama** açık cepheler; **emergent abilities** ölçekle gelen kabiliyet sıçramaları. Hedef: AI'yı insan yeteneğini **artıran** teknoloji olarak görmek.
::: {.callout-important title="Tek bir cümle"}
Derin öğrenme bir sihir değil bir teknolojidir — universal approximation gücüne sahip ama OOD, adversarial ve önyargı sınırları olan; ve diffusion (iteratif gürültü-giderme) ile LLM (next token + ölçek) gibi modern cepheler bu sınırların bir kısmını aşarken yeni soruları (halüsinasyon, kalibrasyon, emergent yetenekler) gündeme getiriyor.
:::
## Kontrol Soruları {#sec-sorular}
::: {.callout-note collapse="true" title="Soru 1: Diffusion forward sürecinde $x_{t-1} = 2$, $\\alpha_t = 0,9$, $\\epsilon = 0,5$ verilsin. $x_t$'yi hesapla."}
**Cevap:** Formülü uygula:
$$
x_t = \sqrt{\alpha_t}\, x_{t-1} + \sqrt{1 - \alpha_t}\, \epsilon = \sqrt{0,9}\cdot 2 + \sqrt{0,1}\cdot 0,5
$$
Sayısal olarak: $\sqrt{0,9} \approx 0{,}949$, $\sqrt{0,1} \approx 0{,}316$. Yani $x_t \approx 0{,}949 \cdot 2 + 0{,}316 \cdot 0{,}5 \approx 2{,}056$.
Yorum: bir önceki değer (2) hafifçe "söndürüldü" ve üzerine küçük bir Gaussian gürültü eklendi. Reverse'de modelin öğrenmesi gereken şey **eklenen $0{,}158$**'lik gürültü payı; $\epsilon_\theta(x_t, t)$'nin yaklaşık $0{,}5$ tahmin etmesi beklenir. Çıkarınca $x_{t-1}$'i geri kazanır.
:::
::: {.callout-note collapse="true" title="Soru 2: Diffusion ve VAE/GAN arasındaki temel paradigma farkı nedir?"}
**Cevap:** Temel fark **iteratif vs tek-atımlık**. VAE ve GAN, latent'ten (veya gürültüden) **tek bir geçişle** veri üretmeye çalışır — bu çok zor bir öğrenme görevidir. Diffusion ise problemi **$T$ küçük adıma** parçalar; her adımda yalnızca "biraz gürültü kaldırma" öğrenilir, ki bu çok daha kolaydır.
**Kararlı eğitim:** GAN'in iki rakip ağ + min-max oyunu (Ders 4) doğası gereği kararsızdır. Diffusion tek bir ağı **MSE loss** ile eğitir — standart supervised eğitim; mode collapse yok.
**Yüksek kalite + çeşitlilik:** Forward süreç tüm veri dağılımını gürültüye "yayar"; reverse süreç dağılımın her köşesinden örnek üretebilir. VAE'lerde bulanıklık ve GAN'lerde mode collapse yokken, diffusion hem keskin hem çeşitli örnekler üretebilir. Bedel: $T$ adımlık çıkarım maliyeti.
:::
::: {.callout-note collapse="true" title="Soru 3: FGSM'de neden sadece gradient'in işareti alınır, büyüklüğü değil?"}
**Cevap:** Sezgi: amaç loss'u **artırmak**, **ne kadar artırılacağı** $\epsilon$ ile sabitlenmiştir. Gradient'in **işareti**, $J$'yi en hızlı artıran yönü söyler (en dik çıkış, Calculus Ders 6). Büyüklüğü ise konuma göre değişir; eğer büyüklüğü kullansaydık adım büyüklüğü kontrolsüz olur, perturbasyonun "insan-görünmez" sınırını aşardı. **Sadece işaret + sabit küçük $\epsilon$** alarak perturbasyonu **$L_\infty$ normunda** sınırlı tutarız (her piksel maksimum $\epsilon$ değişir).
**Zincir kuralı bağlantısı:** $\nabla_x J$, $J$'nin $x$'e göre türevidir. Backprop bu türevi, çıkıştan (loss'tan) girişe ($x$'e) kadar **zincir kuralıyla** geri taşıyabilir — aynı backprop mekaniği. Yalnızca **hangi parametreye** göre türev aldığımız değişti: ağırlıklara değil, girdiye.
:::
::: {.callout-note collapse="true" title="Soru 4: (Builder) İyi kalibre edilmiş LLM'ler neden zorunlu olarak halüsinasyon üretir?"}
**Cevap:** Sezgi: LLM her token pozisyonunda bir **olasılık dağılımı** üretir. Eğer model **iyi kalibre edilmiş** ise (Stat 110 Ders 9), bu dağılımın altındaki olasılıklar gerçeği yansıtır. Modelden örnek aldığında bu dağılımdan çekiş yapar; **doğru olmayan** bir token çekme olasılığı sıfır değildir. "Sadece tepe değeri ver" (greedy) yapsan kalibrasyonu bozarsın. Yani **istatistiksel bir trade-off** var: kalibrasyon ve sıfır halüsinasyon **birlikte mümkün değildir**.
**Builder stratejisi:** (1) **RAG** — modeli ezbere bırakma, harici bilgi tabanına bağla. (2) **Tool use** — model hesap yapacaksa hesap makinesi, gerçek arayacaksa arama motoru çağırsın. (3) **Self-consistency** — aynı sorunun $N$ kez sample'ını alıp ortak olanı seç. (4) **Calibrated confidence display** — modelin emin olmadığı yerlerde "emin değilim" çıktısı eğit. (5) Production'da insan-müdahale yolu açık tut. Halüsinasyon **bir bug değil bir feature** — onunla başa çıkmak modelin değil, **sistemin** sorumluluğu.
:::
## Egzersizler {#sec-egzersizler}
**Egzersiz 1 (FGSM saldırısı).** Pretrained bir ResNet (torchvision) ile bir görüntüyü sınıflandır, doğru tahmini gözle. Sonra FGSM ile küçük bir perturbasyon ($\epsilon \approx 0{,}01$) uygula ve aynı modelin artık yanlış sınıflandırdığını göster.
```python
import torch, torch.nn.functional as F
def fgsm(x, y_true, model, eps):
x = x.clone().detach().requires_grad_(True)
loss = F.cross_entropy(model(x), y_true)
loss.backward()
return (x + eps * x.grad.sign()).clamp(0, 1).detach()
# orijinal: model(x).argmax() = dogru sinif
# x_adv = fgsm(x, y_true, model, 0.01)
# model(x_adv).argmax() = artik yanlis
```
**Egzersiz 2 (Diffusion forward simülasyonu).** Bir MNIST görüntüsünü al; $\alpha_t$ programı (linear veya cosine) tanımla; $T = 100$ adımda forward gürültüleme uygula. Her 20 adımda görüntüyü kaydet ve göster. Son adımda görüntü saf Gaussian gürültüye dönüşmeli.
**Egzersiz 3 (Reverse adımı, elle).** Eğitilmiş bir $\epsilon_\theta$ verildiğini varsay. Bir noisy görüntü $x_t$ ve $\epsilon_\theta(x_t, t)$ tahmini elinde. $\alpha_t = 0{,}9$ ile **bir reverse adımının** matematiğini el ile yaz: $x_{t-1}$'i nasıl bulursun? (İpucu: forward denklemini $\epsilon$ için çöz, sonra tahmin edilen $\epsilon$ ile çıkar.)
**Egzersiz 4 (Stable Diffusion local).** `diffusers` kütüphanesi ile Stable Diffusion'ı lokal çalıştır. Birkaç prompt dene; **classifier-free guidance scale**'i değiştir (örn. 1, 5, 10, 20). Yüksek scale prompt'a daha sıkı bağlanır ama çeşitlilik düşer — trade-off'u gözle.
```python
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2-1")
for scale in [1.0, 5.0, 10.0, 20.0]:
img = pipe("an astronaut riding a horse", guidance_scale=scale).images[0]
img.save(f"out_{scale}.png")
```
**Egzersiz 5 (Sonraki dersin habercisi).** Ders 7 — Douglas Blank, Comet ML — *The Three Laws of AI* başlığıyla AI'yı **production'da deploy etmenin** zorluklarını işleyecek. Eğitilmiş bir modeli kullanıcılara ulaştırma sürecinde **hangi sorunlar** ortaya çıkar? (a) Latency vs throughput trade-off'u; (b) model drift (zaman içinde performans düşüşü); (c) A/B test, eval, izleme; (d) model versiyonlama, rollback. Her biri için kısa bir paragraf hazırla.
## Sonraki Ders İçin Hazırlık {#sec-sonraki}
**Ders 7: Yapay Zekânın Üç Yasası (The Three Laws of AI)** — Douglas Blank, Comet ML Head of Research (Misafir Ders)
Bir model eğitmek başka, onu **production'da çalışır halde tutmak** başkadır. Doug Blank uzun yıllardır MLOps cephesinin önde gelenlerinden — Comet ML deney izleme, model registry, LLM eval platformu sunan bir şirket. Ders'in adı "Üç Yasa" — production AI sistemlerinin uymak zorunda olduğu üç ilke etrafında dönecek (deney izleme, eval/monitoring, dağıtım).
**Ana konular:**
- Deney takibi: hangi hyperparameter hangi sonucu verdi?
- Model registry ve versiyonlama.
- LLM eval — "daha iyi" ne demek?
- Production drift ve monitoring.
::: {.callout-warning title="Ders 7 öncesi yapılacak"}
- Egzersizleri çöz — özellikle 1 (FGSM) ve 4 (Stable Diffusion local).
- Halüsinasyonu kalibrasyon ile kendi cümlenle açıkla; bu, Ders 7'nin LLM eval bölümünde tekrar karşına çıkacak.
- Ana cümleyi tekrar oku: *"Derin öğrenme bir teknoloji, sınırları olan; diffusion ve LLM bu sınırları aşan modern cepheler."*
:::
## Anahtar Kavramlar (Cheat Sheet) {#sec-cheat-sheet}
| Kavram | Tanım | Ava'da |
|--------|-------|--------|
| **Universal approximation** | 1989 teoremi: tek gizli katmanlı bir ağ herhangi bir sürekli fonksiyonu yaklaşıklayabilir | 9m00 |
| **Universal approx. çekincesi** | Boyut, genelleme ve öğrenilebilirlik garantili değil | 10m07 |
| **Rastgele etiket deneyi** | CNN rastgele etiketleri bile ezberler → genelleme verinin yapısından gelir | 11m24 |
| **OOD** | Eğitim dağılımı dışındaki örnekler; modelin kırılma noktası | 17m06 |
| **Uncertainty** | "Bilmediğini bilebilmek"; safety-critical için kritik | 22m35 |
| **Adversarial attack** | Girdiye küçük perturbasyon, modeli yanıltır; gradient'i girdiye karşı kullan | 23m39 |
| **FGSM** | $x_{\text{adv}} = x + \epsilon \cdot \text{sign}(\nabla_x J)$ | 25m42 |
| **Algoritmik yanlılık** | Veri yanlılığının modele yansıması; fairness sorunu | 27m02 |
| **Diffusion modeli** | İteratif gürültü ekleme + gürültü-giderme; modern üretken paradigma | 31m13 |
| **Forward noising** | $x_t = \sqrt{\alpha_t}\,x_{t-1} + \sqrt{1-\alpha_t}\,\epsilon$; deterministik Markov | 32m33 |
| **Reverse denoising** | NN $\epsilon_\theta(x_t, t)$ ile gürültüyü tahmin et, çıkar; öğrenilir | 34m32 |
| **Diffusion loss (MSE)** | $L = \mathbb{E}[\|\epsilon - \epsilon_\theta(x_t, t)\|^2]$; Gauss MLE | 36m21 |
| **Classifier-free guidance** | Koşullu + koşulsuz tahminleri karıştırarak prompt etkisini güçlendir | 40m37 |
| **LLM** | Çok büyük transformer + çok büyük metin korpusu; next token prediction | 43m30 |
| **Next token prediction** | Vocab üzerinde softmax + cross-entropy; Ders 1'in sınıflandırma loss'u | 44m48 |
| **Tokenization** | Metni alt-kelime parçalarına böl; BPE | 45m22 |
| **Hallucination** | LLM güvenle yanlış üretir; iyi kalibre edilmiş modellerde istatistiksel olarak kaçınılmaz | 51m32 |
| **Emergent abilities** | Ölçek eşiği aşıldığında aniden ortaya çıkan yetenekler (scaling laws) | 53m14 |
## ML Builder Bağlantıları {#sec-ml-baglantilar}
::: {.callout-tip title="9 köprü"}
1. **Universal approximation çekincesi** → Stat 110 bias-variance (Ders 34 Basu) + Calculus sürekli yaklaşıklayıcılar (Taylor Ders 11). İleriye: scaling laws (Kaplan, Chinchilla).
2. **Rastgele etiket / genelleme** → kapasite ≠ anlama; modern regularization, transfer learning, foundation models. İleriye: lottery ticket, double descent.
3. **OOD + belirsizlik** → Stat 110 kalibrasyon, posterior (Ders 4, Ders 9). İleriye: MC Dropout, deep ensembles, conformal prediction.
4. **Adversarial FGSM** → Calculus zincir kuralının ters yönde kullanımı (Ders 4); $\nabla_x J$ girdiye karşı türev. İleriye: adversarial training, randomized smoothing.
5. **Diffusion forward** → Stat 110 Markov zinciri (Ders 31) + Normal (Ders 13) + reparameterization (Ders 4). İleriye: score-based, flow matching, latent diffusion.
6. **Diffusion loss (MSE on noise)** → Stat 110 Gauss MLE (Ders 13). İleriye: classifier-free guidance, consistency models, distilled diffusion.
7. **Moleküler diffusion** → biology/chemistry'ye taşıma; Ders 8 (AI for Science, Chris Bishop) doğrudan bu cephe.
8. **LLM next token + cross-entropy** → Ders 1 cross-entropy + Ders 2 sequence + Stat 110 multinomial. İleriye: instruction tuning, RLHF, reasoning models.
9. **Hallucination + kalibrasyon** → Stat 110 Ders 9 beklenen değer, kalibre tahmin teorisi. İleriye: RAG, tool use, constitutional AI.
:::
::: {.callout-important title="Bu dersten tek bir şey alıp gideceksen"}
Modern derin öğrenmenin gücü gerçek ama sınırları da gerçek — universal approximation "olabilir" der, OOD ve adversarial "kırılganlık" der, halüsinasyon "istatistiksel zorunluluk" der. Diffusion ve LLM gibi modern paradigmalar, problemi parçalara bölmek ve ölçeklemekle bu sınırların bir kısmını aşarken yeni sorular ortaya çıkarıyor. Bir builder olarak: sınırları **fırsat olarak gör**, modelleri **insan yeteneğini artıran teknoloji** olarak konumlandır.
:::