---
title: "Bilim için Yapay Zekâ"
subtitle: "Emulator paradigması + No Free Lunch + geometric DL + Aurora + MatterGen + Skala"
---
::: {.callout-note title="Bölüm bilgisi"}
- **Lecture videosu:** [YouTube — Lecture 8: AI for Science](https://www.youtube.com/watch?v=rZACoZD8AG8&list=PLtBw6njQRU-rwp5__7C0oIVt26ZgjG9NI&index=8) (≈59 dk)
- **Edition:** 2026 misafir • **Hoca:** Christopher Bishop, Microsoft Technical Fellow + AI for Science kurucusu
- **Kaynak:** [introtodeeplearning.com](https://introtodeeplearning.com) + [bishopbook.com](https://bishopbook.com)
- **Okuma süresi:** ≈35 dk
:::
## Bu Derste Ne Var? {#sec-bu-derste}
Bu ders, kursun **bilim cephesine** dönüşüdür. Chris Bishop, 30 yıllık makine öğrenmesi veterani ve Microsoft'un AI for Science girisiminin kurucusu; konuya çarpıcı bir gözlemle giriyor: **dünyamız matematiğin diliyle yazılmış**. Elektronun manyetik momentini fizik teorisinden hesapladığımızda, deneyle 13 anlamlı basamak hassasiyetinde uyuşuyor. Maddenin, atmosferin, kimyanın denklemleri bilinmektedir; sorun **çözmenin** çok pahalı olmasıdır.
> *"the most extraordinary thing that science has ever uncovered is the fact that our world is described by mathematics... and it's very simple mathematics."* — Chris Bishop, 1:30
Bu pahalı-çözüm sorununa karşı AI iki kapı açıyor: (a) deneye yardımcı olmak (yorum, otomasyon, veri analizi), ve (b) bu dersin odağı — **AI emulator**: simulatorden çok daha hızlı (genellikle 1000×'dan fazla) ama benzer doğrulukta bir sinir ağı yaklaşıklayıcısı.
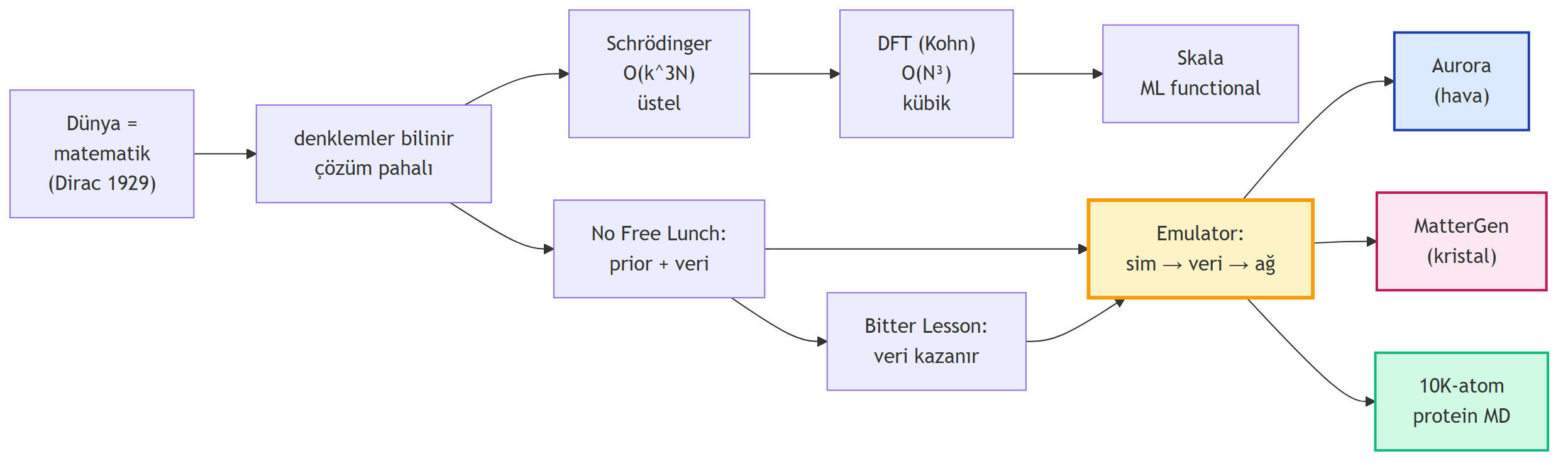
**Dersin üç büyük fikri:**
1. **Üçüncü oracle** — bilimsel keşif döngüsüne (hipotez → deney → gözlem) 1960'larda simülasyon eklendi; şimdi AI emulator üçüncü kapıyı açıyor.
2. **No Free Lunch + Bitter Lesson uzlaşması** — bilim **prior-zengin** ama veri-fakir; LLM **veri-zengin** ama prior-fakir. Çözüm: denklemden veri üret, veriyle eğit.
3. **Emulator paradigması, üç vitrin** — Aurora (hava foundation), MatterGen (kristal diffusion), Skala (kuantum kimyası ML functional); biyoloji cephesi 10K-atom MD'yi mümkün kılıyor.
{#fig-concept-map fig-align="center" width=85%}
::: {.callout-tip title="Builder Notu — ML Köprüleri"}
Bu ders kursun en zarif **köprü** dersidir — Ders 1-7'nin tümü bilimsel keşif sahnesine çıkıyor:
- **Diffusion modelleri** (Ders 4 + 6) artık kristal/molekül üretimi için MatterGen olarak yeniden yorumlanıyor.
- **Foundation modeller** (Ders 6 LLM mantığı) hava + iklim verilerine genelleniyor (Aurora).
- **Inductive bias** (Stat 110 prior, Ders 4) bilim bağlamında öğrenmeyle birleşiyor.
- **Supervised learning** (Ders 1) sentetik veriyle (simulator çıktıları) eğitilen emulator olarak yeniden yükleniyor.
- **GNN / message passing** Skala'da kullanılıyor (Ders 3 conv'un grafik versiyonu).
- **18.06 boyut indirgeme** (PCA, SVD) DFT'nin Schrödinger 3N → 3 boyut sezgisiyle birebir.
**İleriye:** **AlphaFold 2/3**, **RFdiffusion** (Baker Nobel 2024), **Materials Project + MatterGen**, **Aurora**, **Microsoft Discovery Platform**, **e3nn**, **MACE**, **NequIP**, **EquiformerV2**. Ders 13 (AI for Life Sciences) bu cepheyi biyoloji odaklı derinleştirecek.
**Tek cümleyle:** AI for Science, **denklem çözücü** olarak çok pahalı simulatorlerin yerine **simulatordan eğitilmiş sinir ağı yaklaşıklayıcılar (emulator) koyma** disiplinidir; sonuç 1000× hızlanma.
:::
## Dünya = Matematik (ve Çözülemeyen Denklem İronisi) {#sec-math-world}
Bishop dersi insanların bilime borcu olan en garip keşifle açıyor: **dünyamız matematiğin diliyle yazılmış**. Bir kağıt üzerinde işaretler yaparak geleceği tahmin edebiliyoruz — bu kendi başına şaşırtıcı. Ayrıca, kullanılan matematik şaşırtıcı biçimde basit: Maxwell denklemleri, Schrödinger denklemi, Newton yasaları.
Maddenin yapısı (atomlar, moleküller), atmosferin dinamiği, ilacın protein ile bağlanması — hepsi için temel denklemler **bilinmektedir**. Yine de yeni bir ilaç bilgisayarda tasarlanamıyor. Çünkü:
> *"the underlying physical laws necessary for the mathematical theory of a large part of physics and the whole of chemistry are thus completely known. The difficulty is only that the exact application of these laws leads to equations much too complicated to be soluble."* — Paul Dirac, 1929 (Bishop, 3:25)
Yani problem teori-eksikliği değil, **hesaplama karşıtı**. Schrödinger denklemi için maliyet **üstel olarak elektron sayısıyla** büyür; 100 elektronlu küçücük bir kafein molekülü bile doğrudan çözülemiyor.
::: {.callout-tip title="Builder Notu — Pahalı Çözümün Modern Cevabı"}
**Geriye (Calculus + 18.06):** "Basit denklem ama çözüm pahalı" durumu, tüm kursun arka planı. Calculus diferansiyel denklemler ve 18.06 boyut sorunu bilimsel hesaplamanın her günü.
**İleriye:** Bu ironiye AI'nın önerdiği tek bir güçlü cevap **emulator** — denklem çözmek yerine önceden çözülmüş örnekleri **öğrenip yaklaşık tahmin et**. Bu sezgi, tüm dersin omurgası olacak; Microsoft Aurora (hava), MatterGen (kristal), AlphaFold (protein) hepsi bu desenin farklı alanlarda uygulaması.
:::
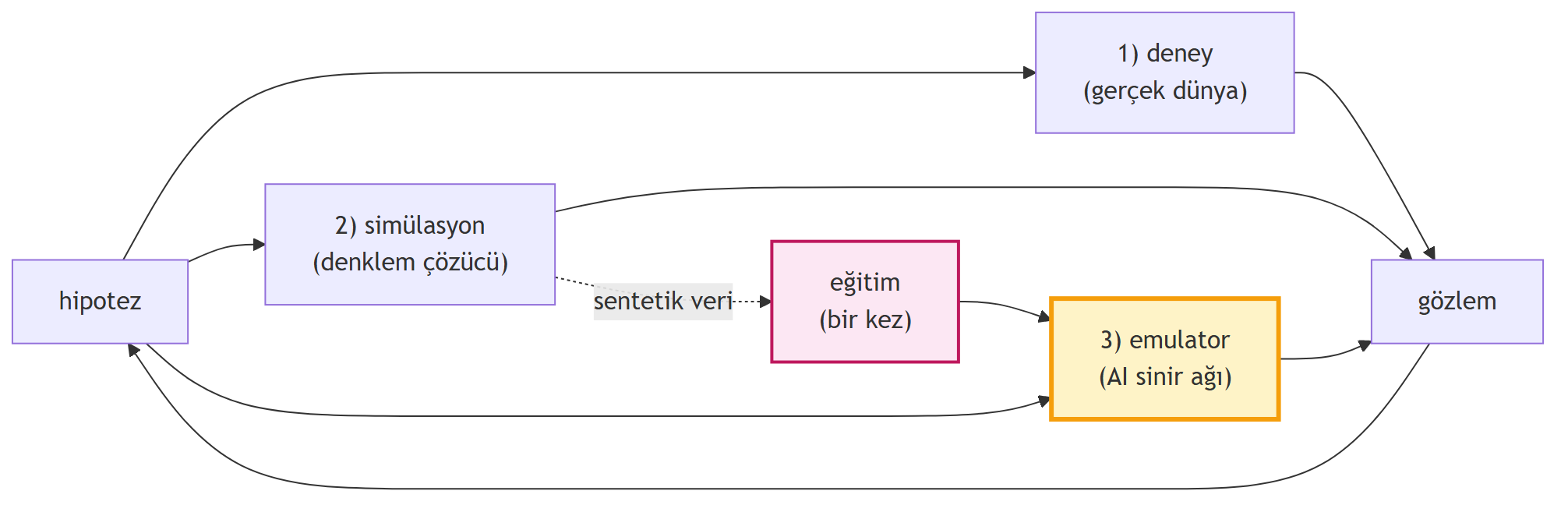
## Bilimsel Keşif Döngüsü ve AI'nın Üçüncü Kapısı {#sec-third-oracle}
Bilim, yüzyıllardır aynı döngüyü çalıştırıyor: bir bilim insanı hipotez kurar → deneyle test eder → gözlem yapar → hipotezi rafine eder.
**1960'larda dijital bilgisayarlar** bu döngüye ikinci bir kapı ekledi: **simülasyon**. Pahalı ama esnek bir "oracle". Ancak Schrödinger denklemi gibi temel denklemler için simülasyon **ölçeklenmez** — küçük sistemlerde çalışır, gerçek dünya boyutunda patlar.
**AI devrimi** üçüncü bir kapıyı açıyor — Bishop'un odaklandığı: **AI emulator**. Mantığı basit ama güçlü: önce simülatörü kullanarak pahalı bir veri seti üret (binlerce çözüm), sonra bir sinir ağını bu sentetik veriyle eğit, ve nihayet eğitilmiş ağı (emulator) binlerce kez kullan. Emulator, simülatörün **sıkıştırılmış neural surrogate'idir**; tipik olarak **1000× daha hızlı**.
> *"the AI emulator provides a third pathway, a third kind of oracle to use within this scientific discovery loop."* — Bishop, 7:21
{#fig-discovery-cycle fig-align="center" width=85%}
::: {.callout-tip title="Builder Notu — Sentetik Supervised"}
**Geriye (Ders 1):** Emulator paradigması saf **supervised learning'dir** — sadece veri **simülatörden sentetik** olarak gelir, gerçek dünyadan değil. Loss, optimizer, gradient descent aynı.
**İleriye:** Aynı desen robotikte **sim-to-real** ile (Ders 5 RL), oyun motorlarında, fizik motoru emulator'lerinde (Nvidia Omniverse) görüldü. Bu paradigmanın sınırı **dağılım dışı** (Ders 6 OOD) — simülator hangi koşulları kapsadıysa emulator orada güçlü, ötesinde değil.
:::
## No Free Lunch ve İndüktif Yanlılık {#sec-no-free-lunch}
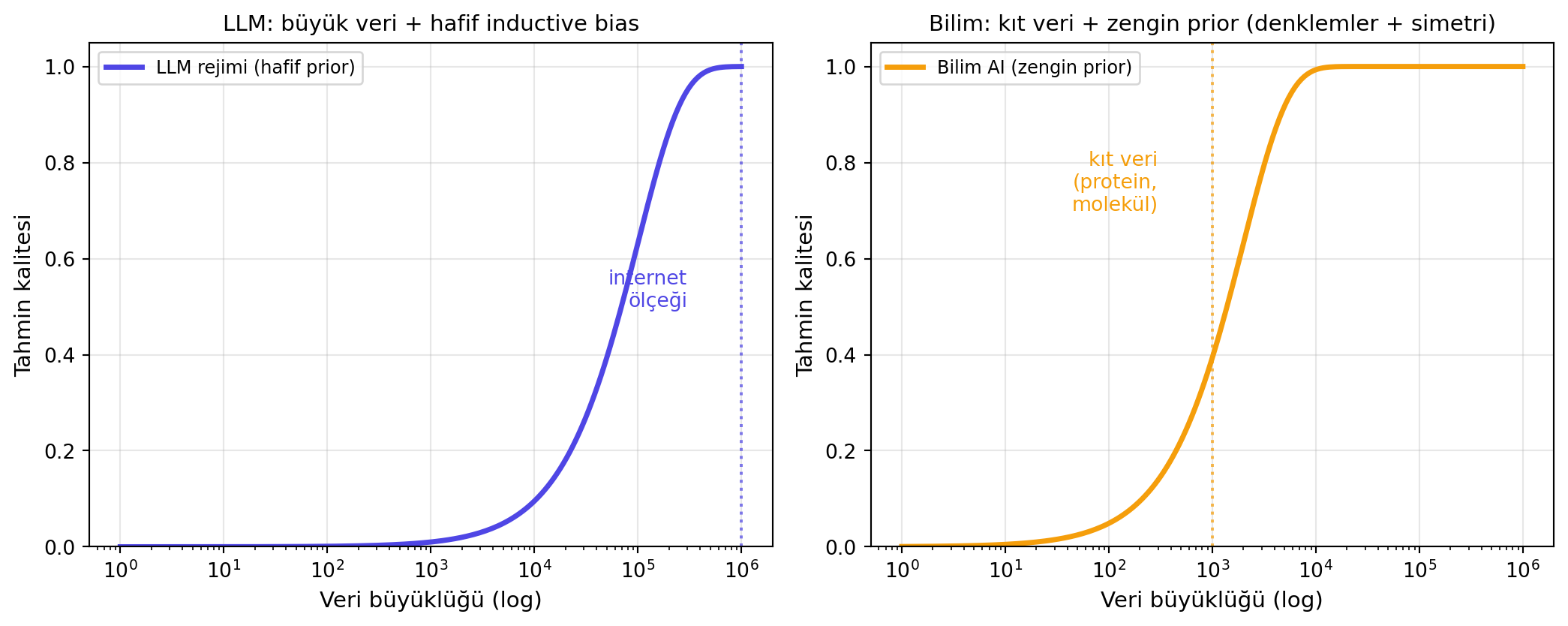
Makine öğrenmesinin kalbinde **No Free Lunch Theorem** var: **veriden tek başına öğrenemezsin**. Tahmin = veri × **varsayımlar** (eş anlamlı: prior knowledge, inductive bias).
Bishop bu prensibi iki uç örnek üzerinden konumlandırıyor:
- **LLM rejimi:** Devasa veri (internet ölçeği) + **hafif** inductive bias.
- **Bilim rejimi:** Veri **kıt ve pahalıdır** (bir öğrenci bir protein yapısını çözmek için yıl harcayabilir). Buna karşın **inductive bias çok zengindir** — dünyayı tanımlayan denklemler biliniyor.
Bilim için bu inductive bias üç tipte gelir:
- **Denklemler kendisi** (Schrödinger, Newton, Maxwell): bilinen kesin teorik yapı.
- **Simetri / değişmezlik (invariance):** Vakumdaki bir molekülü döndürürsen enerjisi değişmez.
- **Eş-değişmezlik (equivariance):** Molekülün manyetik momenti molekülle birlikte dönmeli.
- **Korunum yasaları:** Enerji, momentum, yük, kütle.
```{python}
#| label: fig-noo-free-lunch
#| fig-cap: "İki rejim: LLM (sol — büyük veri ile hafif prior'ı kapatır) ve bilim AI (sağ — zengin prior ile az veriyi kapatır). Tahmin = veri × prior; ikisinden biri zayıfsa diğeri tam doldurmalı."
#| fig-width: 11
#| fig-height: 4.5
import numpy as np
import matplotlib.pyplot as plt
fig, axes = plt.subplots(1, 2, figsize=(11, 4.5))
veri = np.logspace(0, 6, 200)
# LLM rejimi: prior zayıf, veri büyük
prior_llm = 0.1
quality_llm = 1 - np.exp(-veri * prior_llm / 1e4)
# Bilim rejimi: prior güçlü, veri az
prior_sci = 5.0
quality_sci = 1 - np.exp(-veri * prior_sci / 1e4)
axes[0].semilogx(veri, quality_llm, color='#4f46e5', linewidth=2.6, label='LLM rejimi (hafif prior)')
axes[0].axvline(1e6, color='#4f46e5', linestyle=':', alpha=0.7)
axes[0].text(3e5, 0.5, 'internet\nölçeği', color='#4f46e5', fontsize=10, ha='right')
axes[0].set_xlabel('Veri büyüklüğü (log)', fontsize=11)
axes[0].set_ylabel('Tahmin kalitesi', fontsize=11)
axes[0].set_title('LLM: büyük veri + hafif inductive bias', fontsize=11)
axes[0].legend(fontsize=9)
axes[0].grid(alpha=0.3)
axes[0].set_ylim(0, 1.05)
axes[1].semilogx(veri, quality_sci, color='#f59e0b', linewidth=2.6, label='Bilim AI (zengin prior)')
axes[1].axvline(1e3, color='#f59e0b', linestyle=':', alpha=0.7)
axes[1].text(3e2, 0.7, 'kıt veri\n(protein,\nmolekül)', color='#f59e0b', fontsize=10, ha='right')
axes[1].set_xlabel('Veri büyüklüğü (log)', fontsize=11)
axes[1].set_ylabel('Tahmin kalitesi', fontsize=11)
axes[1].set_title('Bilim: kıt veri + zengin prior (denklemler + simetri)', fontsize=11)
axes[1].legend(fontsize=9)
axes[1].grid(alpha=0.3)
axes[1].set_ylim(0, 1.05)
plt.tight_layout()
plt.show()
```
Bu **simetri-eş-değişme** sezgisi modern bir alt-alanın temeli oldu: **Geometric Deep Learning** — ağ mimarisini fiziksel bilginin gereksinimlerine göre özel tasarlamak.
> *"in LLMs we use data — lots of data — but the inductive bias is fairly lightweight... in science, data is scarce, expensive. But uniquely in science we have this very rich inductive bias. We know the equations."* — Bishop, 9:05
::: {.callout-tip title="Builder Notu — Equivariant Mimari"}
**Geriye (Stat 110 + Ders 4):** Inductive bias = Stat 110'un **prior'ıdır**. LLM eğitimi bir tür **veri-baskın posterior**; bilim AI'sı **prior-baskın inference**. Ders 4'ün **VAE prior'ı (Normal)** mimarinin endüktif yanlılığına bir örnektir.
**İleriye:** Geometric deep learning yetkin bir builder cephesidir: **e3nn**, **MACE**, **NequIP**, **EquiformerV2** kütüphaneleri. Materyal ve molekül AI'sının gerçek üretim aracıdır. **AlphaFold 2/3'ün** mimarisi de bu prensiplere göre tasarlanmıştır.
:::
## Bitter Lesson: Veri Sonunda Kazanır {#sec-bitter-lesson}
Bishop, kendi alanının en önemli derslerinden birini şöyle tanıtıyor: *"every single one of you by the end of today should take five minutes and go and read this blog."* Söz konusu blog, Rich Sutton'un 2019'da yazdığı **The Bitter Lesson**.
Sutton'un gözlemi acımasız: AI tarihi boyunca araştırmacılar **akıllıca prior knowledge** baking ile sistemlerini geliştirmeyi denediler. Her seferinde **bir başka grup geldi**, daha fazla veri + daha çok compute kullandı, ve onları **geçti**. Bilgisayar hızı üstel olarak büyüdüğü için (Moore Yasası), nihayetinde "daha çok veri + daha çok parametre + daha basit bir model" karmaşık prior'lardan üstün geliyor.
> *"over the years, many people have improved the performance of machine learning systems by baking in additional prior knowledge. But they've always lost out to somebody else who simply had more data."* — Bishop, 12:19
Bu, bilim AI'sı için bir paradoks yaratıyor — denklemleri tasarımdan **atmak istemiyoruz**, ama veri-baskın yaklaşımların kazandığını da biliyoruz.
Çözüm: **iki yaklaşımı birleştir.** Bishop'un emülatör paradigması tam olarak bu sentezdir — "denklemlerden veri **üret**, sonra veriyle veri-baskın bir ağ eğit".
::: {.callout-tip title="Builder Notu — Prior'ı Veriye Çevirmek"}
**Geriye (Ders 6):** Bitter Lesson, **scaling laws** ile aynı ailedendir; Ders 6'da gördüğümüz "emergent abilities scale ile gelir" gözlemi bunun derin öğrenme versiyonudur. Bir builder için: prior'larını dataset'e yazıp (data augmentation, sentetik veri) sonra büyük modele bırakmak, çoğu zaman elle mimariye gömmekten daha verimlidir.
**İleriye:** "Sentetik veri" çağı yeni başlıyor: **synthetic data augmentation** LLM eğitiminde standart; **kendinden öğrenen sistemler** (AlphaZero — Ders 5 self-play) aynı mantıkta. "Veri üret + öğren" yeni paradigmanın motoru.
:::
## Emülatör Paradigması: Sentez {#sec-emulator}
Bitter Lesson ile inductive bias zenginliğini uzlaştıran Bishop'un formülü iki aşamalıdır:
**Aşama 1 — Sentetik veri üretimi:** Klasik simülatörü (Schrödinger çözücü, fizik motoru, hava modeli) kullanarak **binlerce çözüm üret**. Bu pahalıdır, ama **bir kez** yapılır.
**Aşama 2 — Emulator eğitimi:** Bu sentetik veriyle bir sinir ağı eğit. Tek bir A100 yeterli olabilir.
**Sonuç:** Eğitilmiş emulator, simülatörden tipik olarak **1000× daha hızlı**, bazen çok daha fazla.
> *"that trained emulator is much faster than the simulator. And typically I would say more than three orders of magnitude... a factor of a thousand is quite transformational."* — Bishop, 18:39
Emülator yaklaşımının yapısal avantajları:
- **Mükemmel etiketli veri:** simülatör çıktısı tam olarak ne istediğinizi hesaplıyor; manuel etiketleme yok.
- **Gizlilik yok:** veriler matematiktendir; PII problemi yok.
- **Sınırsız veri:** compute olduğu sürece veri üretilebilir.
- **Atıl compute kullanımı:** Microsoft gibi şirketler küresel data center'larında atıl GPU saatlerini bu üretime ayırabilir.
- **Genelleme:** doğru tasarımla, eğitim dağılımı dışında da güzel çalışabilir.
::: {.callout-tip title="Builder Notu — Bir Kez Eğit, Bin Kez Kullan"}
**Geriye:** Emülator paradigması = **sentetik supervised learning + yapısal kısıt**. Aynı temel mekanik Ders 1'inkidir; yalnızca veri kaynağı simülatordür.
**İleriye:** Bu paradigma birçok alanda kullanım buluyor: hava tahmini (Aurora, GraphCast — DeepMind), molekül enerjisi (MatterSim, NequIP), akışkanlar mekaniği, plazma fiziği, malzeme keşfi. Bir builder olarak: pahalı klasik bir hesabın varsa, emülator paradigmasını düşün; eğitim bir kez, kullanım sonsuz.
:::
## Hava Tahmini Emülatörü: Aurora Foundation Model {#sec-aurora}
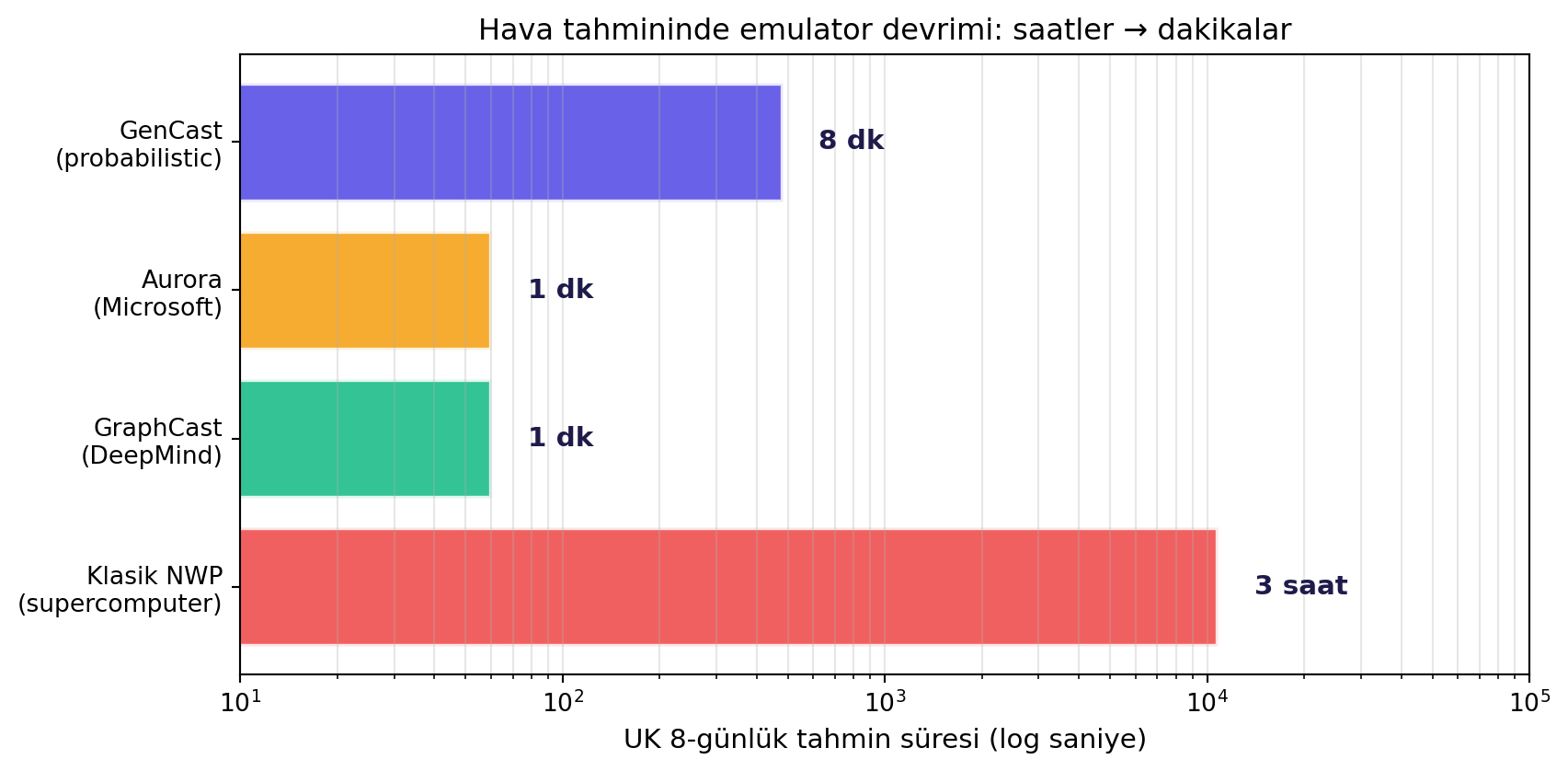
Hava tahmini (numerical weather prediction, NWP), emülator paradigmasının olgun bir uygulaması. Klasik bir NWP modeli atmosferdeki kısmi diferansiyel denklemleri çözer, dünyayı 3B grid'e ayırır, çok ince zaman adımlarında integre eder. Her bir tahmin koşusu **supercomputer cluster** üzerinde **saatler** sürer.
Bishop'un Microsoft AI4Science ekibi **Aurora**'yı geliştirdi — bir tek simülatör emülatörü değil, çoklu simülatör, çoklu ölçek, çoklu zaman skalası verisiyle eğitilmiş bir **foundation model**:
> *"we've trained an emulator on very diverse data... from many different simulators, different length scales, different resolutions, different time scales... to force the model to learn more fundamentally about the dynamics of the Earth's system."* — Bishop, 21:08
Foundation model olduğu için **fine-tune** edilebilir. Pratik bir örnek: **azot oksit kirlilik akışı** tahmini. Sadece kirlilik verisi yetersiz. Çözüm: önce Aurora'yı geniş hava verisiyle eğit (foundation), sonra dar kirlilik verisiyle fine-tune et. Sonuç: **state-of-the-art** pollution forecast.
**Pratik sonuç:** "UK 8-günlük hava tahminini tek A100 GPU'da 1 dakika".
```{python}
#| label: fig-aurora-speed
#| fig-cap: "Hava tahmininde simulator vs emulator: klasik NWP saatler/günler süren supercomputer iş; Aurora aynı tahmini tek A100 GPU'da dakikalar içinde üretir (log ölçek)."
#| fig-width: 9
#| fig-height: 4.5
methods = ['Klasik NWP\n(supercomputer)', 'GraphCast\n(DeepMind)', 'Aurora\n(Microsoft)', 'GenCast\n(probabilistic)']
times_s = [3 * 3600, 60, 60, 480]
colors = ['#ef4444', '#10b981', '#f59e0b', '#4f46e5']
fig, ax = plt.subplots(figsize=(9, 4.5))
bars = ax.barh(methods, times_s, color=colors, edgecolor='white', linewidth=2, alpha=0.85)
ax.set_xscale('log')
for bar, t in zip(bars, times_s):
if t >= 3600:
text = f'{t // 3600} saat'
elif t >= 60:
text = f'{t // 60} dk'
else:
text = f'{t} sn'
ax.text(t * 1.3, bar.get_y() + bar.get_height() / 2, text,
va='center', fontsize=11, weight='bold', color='#1e1b4b')
ax.set_xlabel('UK 8-günlük tahmin süresi (log saniye)', fontsize=11)
ax.set_title('Hava tahmininde emulator devrimi: saatler → dakikalar', fontsize=12)
ax.grid(axis='x', alpha=0.3, which='both')
ax.set_xlim(10, 1e5)
plt.tight_layout()
plt.show()
```
::: {.callout-tip title="Builder Notu — Foundation Model Mantığı"}
**Geriye (Ders 6 + Ders 2):** Aurora bir **foundation modeldir** — Ders 6'nın LLM'leri gibi geniş eğitim + spesifik fine-tune. Mimari büyük ölçüde transformer-türevi (Ders 2 self-attention). "Token" yerine "yer-zaman patch'leri" var.
**İleriye:** DeepMind'ın **GraphCast** (graph neural network ile hava), **GenCast** (probabilistic forecasting), **NeuralGCM** (Google) bu cephenin diğer önemli oyuncuları. **Climate emulator'lar** (uzun zaman ölçeği), **mevsim tahmini**, **atmospheric chemistry** açık problemler.
:::
## Moleküler Tasarım: MatterGen ve Üç Yönlü Tradeoff {#sec-mattergen}
Bishop'un ekibinin bir diğer ürünü **MatterGen** — diffusion modeli, kristaller için. Ders 4 ve Ders 6'nın diffusion mekanizması (forward noising + reverse denoising) **moleküler yapı uzayına** uyarlanmış:
- Eğitim verisi: bilinen kararlı kristal yapılar.
- Forward süreç: atomic koordinatlara, hücre parametrelerine, atom tiplerine adım adım Gaussian gürültü ekle.
- Reverse süreç: bir sinir ağı (geometric DL prensipleriyle eşi-değişmez) gürültüyü kaldırarak rastgele başlangıçtan kararlı kristal yapı üretir.
**Conditional diffusion:** istenen özelliklere (elektronik, manyetik, mekanik) göre üretim. "Düşük nadir-toprak içerikli güçlü mıknatıs üret" → MatterGen aday yapılar verir. Daha sonra **MatterSim** bu adayların özelliklerini hızlıca hesaplar.
Buradaki büyük resim: ilaç ve materyal tasarımı bir **dev arama problemidir**. Bishop ilaç-benzeri küçük organik moleküllerin uzayının ≈$10^{60}$ olduğunu söylüyor — güneş sistemindeki atom sayısı kadar.
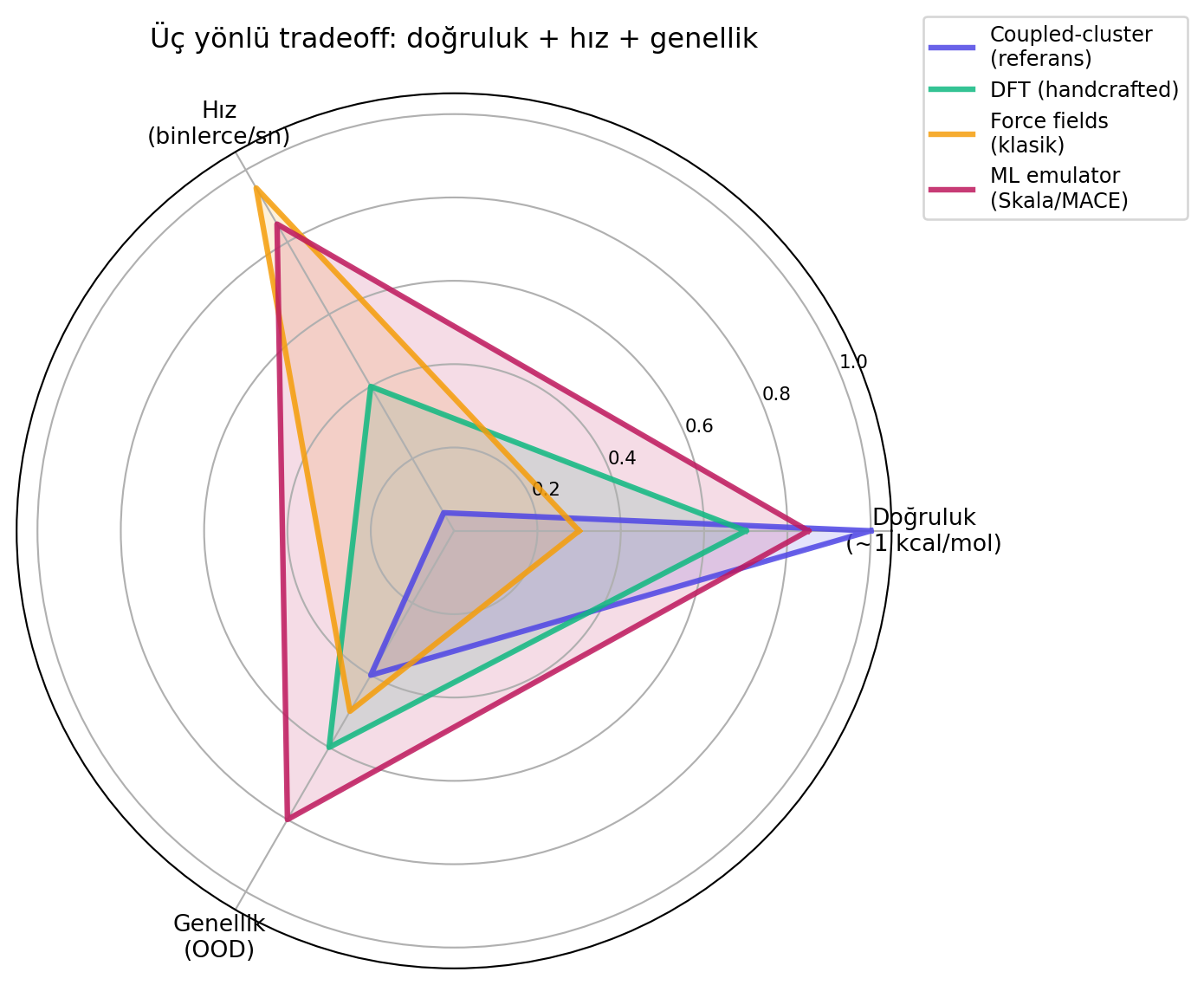
**Üç yönlü tradeoff:** Bishop'un anahtar grafiği — molekül modellemede üç eksen var: **doğruluk** (kimyasal doğruluk ≈1 kcal/mol), **hız**, **genellik**.
```{python}
#| label: fig-three-way-tradeoff
#| fig-cap: "MatterSim üç-yönlü tradeoff: doğruluk + hız + genellik. Klasik metodlar ikisini sağlar; ML emulator üçünü dengeleyen tek aday."
#| fig-width: 8
#| fig-height: 6
fig, ax = plt.subplots(figsize=(8, 6), subplot_kw=dict(projection='polar'))
categories = ['Doğruluk\n(~1 kcal/mol)', 'Hız\n(binlerce/sn)', 'Genellik\n(OOD)']
N = len(categories)
angles = [n / N * 2 * np.pi for n in range(N)] + [0]
methods_scores = {
'Coupled-cluster\n(referans)': ([1.0, 0.05, 0.4], '#4f46e5'),
'DFT (handcrafted)': ([0.7, 0.4, 0.6], '#10b981'),
'Force fields\n(klasik)': ([0.3, 0.95, 0.5], '#f59e0b'),
'ML emulator\n(Skala/MACE)': ([0.85, 0.85, 0.8], '#be185d'),
}
for label, (scores, color) in methods_scores.items():
values = scores + scores[:1]
ax.plot(angles, values, color=color, linewidth=2.4, label=label, alpha=0.85)
ax.fill(angles, values, color=color, alpha=0.15)
ax.set_xticks(angles[:-1])
ax.set_xticklabels(categories, fontsize=10)
ax.set_ylim(0, 1.05)
ax.set_yticks([0.2, 0.4, 0.6, 0.8, 1.0])
ax.set_yticklabels(['0.2', '0.4', '0.6', '0.8', '1.0'], fontsize=8)
ax.set_title('Üç yönlü tradeoff: doğruluk + hız + genellik', fontsize=12, pad=20)
ax.legend(loc='upper right', bbox_to_anchor=(1.35, 1.1), fontsize=9)
plt.tight_layout()
plt.show()
```
> *"You could have any two of those, no problem at all, but you need all three. And they trade off against each other."* — Bishop, 27:04
::: {.callout-tip title="Builder Notu — Conditional Diffusion Geri Dönüşü"}
**Geriye:** MatterGen, Ders 4 VAE/GAN'ın ve Ders 6 diffusion'unun moleküler kuzenidir; mekanik birebir aynı ($\mu$, $\sigma$, $\epsilon$, denoising loss), domain farklı. Aynı zamanda **conditional diffusion** kullanır — text-to-image'in (Ders 6) materials versiyonu ("property-to-material").
**İleriye:** **RFdiffusion** (David Baker, protein tasarımı — 2024 Nobel Kimya!), **Boltz** (Open AlphaFold alternatifi), **DiffDock**. Bir builder olarak ilaç ve materyal endüstrisi yakın geleceğin en sıcak AI uygulama alanlarındandır; geometric DL + diffusion + emulator üçlüsü temel beceri seti.
:::
## Schrödinger Denkleminin Sessiz Eziyeti {#sec-schrodinger}
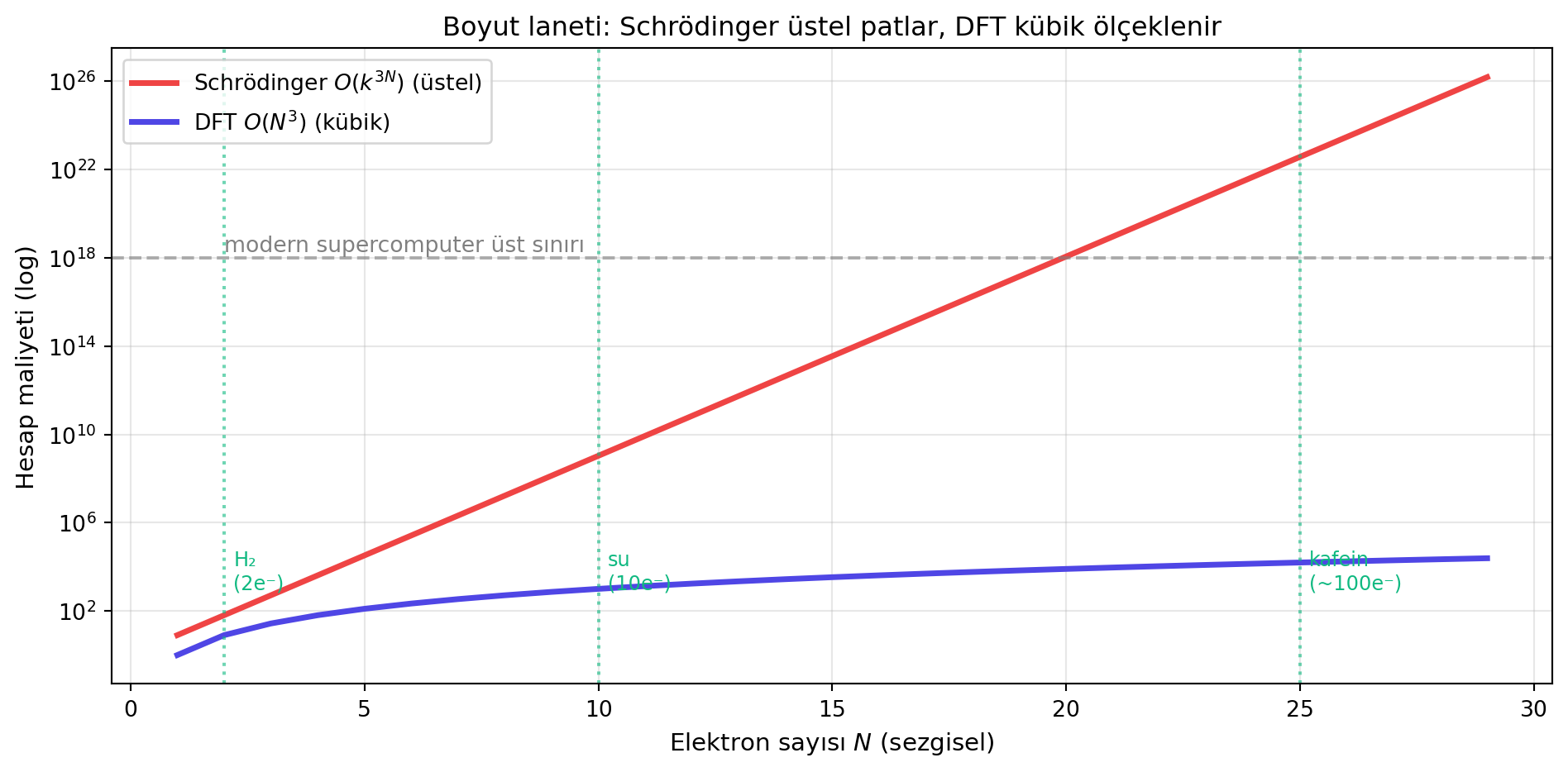
Bishop dersin en güzel hikâyesini Schrödinger denklemiyle başlatıyor. Maddeyi atomik seviyede tanımlayan temel denklem — bilim insanları için **kutsaldır**, çünkü deneyle 13 anlamlı basamak uyuşan o denklem buradan türetilir. Ama bir özelliği var: **çözümü acı verici biçimde pahalı**.
Denklemin bilinmeyeni **dalga fonksiyonu $\Psi$** (psi). Sistem $N$ elektrondan oluşuyorsa, $\Psi$ **$3N$-boyutlu uzayda** tanımlı bir fonksiyondur:
$$
\Psi(\mathbf{x}_1,\, \mathbf{x}_2,\, \ldots,\, \mathbf{x}_N)
$$
Kafein molekülü 100 elektron içerir → $\Psi$ **300-boyutlu** bir fonksiyondur. Bu uzayda denklemi sayısal çözmek için 3B'yi grid'e böl: 1B 1000 nokta, 2B $1000^2$ = 1 milyon, 3B 1 milyar, … $N$ boyutta **üstel olarak patlar**:
$$
\text{maliyet} \propto k^{3N}
$$
```{python}
#| label: fig-curse-3n
#| fig-cap: "Schrödinger denkleminin boyut laneti: maliyet $k^{3N}$ üstel; bilinen tüm bilgisayar kapasitesi çok küçük moleküllerin bile altında kalır. DFT (mavi) kübik ölçeklenmeyle bu duvarı kırar."
#| fig-width: 10
#| fig-height: 5
N = np.arange(1, 30)
schrodinger_cost = np.power(2.0, 3 * N)
dft_cost = N ** 3
fig, ax = plt.subplots(figsize=(10, 5))
ax.semilogy(N, schrodinger_cost, color='#ef4444', linewidth=2.6, label=r'Schrödinger $O(k^{3N})$ (üstel)')
ax.semilogy(N, dft_cost, color='#4f46e5', linewidth=2.6, label=r'DFT $O(N^3)$ (kübik)')
ax.axhline(1e18, color='gray', linestyle='--', alpha=0.6)
ax.text(2, 2e18, 'modern supercomputer üst sınırı', fontsize=10, color='gray')
ax.axvline(2, color='#10b981', linestyle=':', alpha=0.6)
ax.text(2.2, 1e3, 'H₂\n(2e⁻)', fontsize=9, color='#10b981')
ax.axvline(10, color='#10b981', linestyle=':', alpha=0.6)
ax.text(10.2, 1e3, 'su\n(10e⁻)', fontsize=9, color='#10b981')
ax.axvline(25, color='#10b981', linestyle=':', alpha=0.6)
ax.text(25.2, 1e3, 'kafein\n(~100e⁻)', fontsize=9, color='#10b981')
ax.set_xlabel('Elektron sayısı $N$ (sezgisel)', fontsize=11)
ax.set_ylabel('Hesap maliyeti (log)', fontsize=11)
ax.set_title('Boyut laneti: Schrödinger üstel patlar, DFT kübik ölçeklenir', fontsize=12)
ax.legend(fontsize=10, loc='upper left')
ax.grid(alpha=0.3, which='both')
plt.tight_layout()
plt.show()
```
> *"the cost grows exponentially with the number of electrons and that means that this tiny molecule which is a lot smaller than many drug molecules is already out of reach."* — Bishop, 30:14
Bu, AI'nın çözmesi gereken **gerçek**, **iyi tanımlı** bir problem.
::: {.callout-tip title="Builder Notu — Boyut Laneti Saldırıları"}
**Geriye (18.06 + Stat 110):** Bu, klasik **boyut laneti**dir (curse of dimensionality) — Stat 110 yüksek-boyutlu uzayların hacminin patlaması; 18.06 grid'in boyut ekseninde üstel büyümesi.
**İleriye:** Boyut lanetine karşı modern yaklaşımlar: **Monte Carlo** (Stat 110 örnekleme), **importance sampling**, **variational methods**, ve bu dersin öne çıkardığı **ML emulator**. Hepsi aynı sorunun farklı saldırılarıdır.
:::
## DFT'nin Nobel'li Sihri ve Microsoft Skala {#sec-dft-skala}
1965'te Walter Kohn (Nobel Kimya 1998) inanılmaz bir şey keşfetti: dalga fonksiyonu $\Psi$'yu **hesaplamamıza gerek yok**. Çünkü ihtiyacımız olan her şey — enerji, kuvvet, yoğunluk — **elektron yoğunluğundan** hesaplanabilir. Elektron yoğunluğu yalnızca **3-boyutlu** bir fonksiyondur:
$$
\rho(\mathbf{r}) = \int |\Psi(\mathbf{r},\, \mathbf{x}_2,\, \ldots,\, \mathbf{x}_N)|^2\, d\mathbf{x}_2 \cdots d\mathbf{x}_N
$$
Bu **kesin** bir dönüşümdür. **Üstel** maliyetli problemi **kübik** maliyetli probleme indirger:
$$
\text{Schrödinger} \sim O(k^{3N}) \quad\longrightarrow\quad \text{DFT (Density Functional Theory)} \sim O(N^3)
$$
Bu mantığa **Density Functional Theory (DFT)** denir; bilimde en çok atıf alan konulardan biri, ulusal supercomputer iş yükünün üçte birini kapsar.
Ama bir küçük kötü haber: DFT'nin **exchange-correlation functional**'ı ($E_{xc}[\rho]$) var. Kohn bunun **evrensel** olduğunu kanıtladı, ama analitik formülünü yazamadı. 60 yıldır 800+ **el-yapımı yaklaşıklık** önerildi.
> *"there is a single exchange correlation functional that describes the whole of molecular space... one universal exchange correlation functional. He wasn't however able to write down an explicit analytical form."* — Bishop, 34:32
Bishop'un AI4Science ekibi 3+ yıldır bu probleme **machine learning ile saldırıyor** — proje adı **Skala** (İtalyanca "merdiven" = ladder):
- **Mimari:** elektron yoğunluğu milyonlarca nokta bulutu; doğrudan üstüne ağ koymak ölçeklenmez. Bu yüzden **message passing** — nokta bulutundan atom merkezlerine, atomlar arası, sonra geri noktalara. Geometric DL prensiplerine sahip eş-değişmez bir GNN.
- **Veri:** üç yıl boyunca **yüksek doğruluklu kuantum kimyası simülasyonları** koşuldu — daha önce kamuya açık tüm verinin **10 katı**.
- **Sonuç:** Skala, **kübik ölçeklenmeyle** **kimyasal doğruluk**a ulaşıyor.
::: {.callout-tip title="Builder Notu — Skala = Boyut İndirgeme + Message Passing"}
**Geriye (18.06 + Ders 4):** DFT'nin $\Psi$'dan $\rho$'ya geçişi, **kesin boyut indirgemedir** — 18.06'nın "information-preserving projection" idealinin fiziksel bir karşılığı. Skala'nın message passing mimarisi Ders 3'ün convolution'unun graph versiyonudur (Graph Neural Networks).
**İleriye:** ML potential / ML force fields cephesi: **NequIP**, **MACE**, **Allegro**, **GemNet**, **PaiNN**, **Equiformer**. **Materials Genome Initiative** ve **Open Catalyst Project** bu modellerin endüstriyel veri setleridir.
:::
## Biyolojiye Uzanmak: 10K-Atom Protein Dinamiği {#sec-md}
Bishop dersi son büyük adımla bitiriyor — emulator paradigması ne kadar büyük problemlere ölçeklenebilir? Biyoloji **devasa** ve **karmaşık**. Tek bir slayttaki özet: DNA → RNA → amino asit dizisi → protein → 3B yapı → **işlev**.
DNA dizilemesi: çözülmüş. Protein 3B yapısı: büyük ölçüde çözülmüş (AlphaFold + Baker Nobel'leri 2024). Geriye en önemli soru kalıyor: **işlev**. Çünkü işlev statik yapıdan değil **dinamikten** gelir.
Klasik **molecular dynamics (MD)** simülasyonu: her atomun konum ve hızını adım adım Newton'un 2. yasasına göre güncelle. İki büyük zorluk var:
1. **Kuvvet hesabı:** her adımda kuvvetler kuantum fiziğinden gelir (DFT veya Schrödinger). Yani her adım pahalı.
2. **Sıralılık laneti:** Atomik titreşimler femtosaniye ölçeğinde ($10^{-15}$ s); ilginç biyoloji (protein katlanması) milisaniye ölçeğinde ($10^{-3}$ s). Yani **$10^{12}$–$10^{15}$ ardışık adım** gerekir.
> *"this is intrinsically sequential. So it's sort of a double whammy. It's a really really hard problem."* — Bishop, 43:43
**Bishop'un çözümü hiyerarşik emulator:** atomları doğrudan tekil olarak modellemek yerine, **parçalara grupla**. Her parçanın diğeriyle etkileşim kuvvetlerini DFT ile hesapla (sentetik veri). Bu çiftler üzerinde bir emulator eğit. Sonuç: **10K atomlu proteinler** için MD mümkün hale geldi.
Bir adım daha ileri: dynamics'i tamamen atla — emulator ve deneysel veriyle **equilibrium dağılımından doğrudan örnek al**. Bishop ekibinin **Science** dergisinin kapağında yayınlanan makalesi tam olarak budur.
::: {.callout-tip title="Builder Notu — Hiyerarşik Kompozisyon"}
**Geriye:** Bu hiyerarşik yaklaşım, kursun her dersindeki **kompozisyon** prensibinin (Calculus zincir kuralı, CNN katmanları, transformer'ın çoklu attention head'leri) bilim cephesindeki en olgun örneğidir.
**İleriye:** **Boltzmann Generator** (Frank Noé), **molecular flow matching**, **Diffusion-based MD**, **DiG** cephesin ileri kollarıdır. Ders 13'te (AI for Life Sciences) bu cephe biyoloji odaklı derinleştirilecek.
:::
## Bu Dersin Özeti {#sec-ozet}
1. **Dünya = matematik** + denklemler basit ama çözümü pahalı (Dirac, 1929). Elektron manyetik momenti 13 anlamlı basamak doğruluk.
2. **Bilimsel keşif döngüsü:** hipotez → deney → gözlem → rafine. 1960'larda **simülasyon** (2. oracle); şimdi **AI emulator** (3. oracle).
3. **No Free Lunch:** veriden tek başına öğrenilmez, **prior + veri** gerek. LLM rejimi: çok veri + hafif prior. Bilim: kıt veri + zengin prior.
4. **Geometric DL:** invariance, equivariance, korunum yasalarını mimariye gömmek (e3nn, MACE, NequIP).
5. **Bitter Lesson:** kurnaz prior'lar uzun vadede çok-veriye + büyük compute'a yenik düşer.
6. **Çözüm = Emulator paradigması:** simülatordan sentetik veri üret → ağı eğit → emulator'ı (1000× daha hızlı) kullan.
7. **Hava tahmini (Aurora):** UK 8-günlük tahmin 1 dakikada tek A100'de. Foundation model + fine-tune.
8. **Moleküler tasarım:** MatterGen (diffusion ile kristal üretim, koşullu) + MatterSim (özellik tahmini emulator).
9. **Üç yönlü tradeoff:** doğruluk + hız + genellik — hepsini birden istemek zor; kimyasal doğruluk 1 kcal/mol eşiği.
10. **Schrödinger → DFT → Skala:** Walter Kohn'un Nobel'li keşfi ($3N$ → 3 boyut, kesin), 60 yıl handcrafted functional'lar; Microsoft Skala ML ile evrensel functional'a yöneliyor. Biyoloji cephesi: 10K-atom protein dinamiği artık mümkün.
::: {.callout-important title="Tek bir cümle"}
AI for Science, bilinen ama çözülmesi pahalı denklemlerin yerine **simülatorden eğitilmiş sinir ağı yaklaşıklayıcıları (emulator)** koymanın disiplinidir — Bitter Lesson ile No Free Lunch'ı uzlaştıran zarif sentez. Sonuç 1000× hızlanma, ilaç keşfinin, malzeme tasarımının, hava tahmininin yeniden tanımı.
:::
## Kontrol Soruları {#sec-sorular}
::: {.callout-note collapse="true" title="Soru 1: AI for Science neden klasik simülatörü tamamen değil de emülator paradigmasıyla 'sıkıştırıp' kullanır?"}
**Cevap:** Klasik simülatör (DFT, Schrödinger çözücü, NWP) **fizik açısından kesindir** ama **iteratif** ve **kübik-üstel** ölçeklenir. Emülator, simülatorden alınan **sentetik veriyle eğitilmiş bir sinir ağıdır**; bir kerelik eğitilir, sonra **forward pass = sabit zaman** maliyetiyle çağrılır. Tipik kazanım **1000×** hızlanma.
**Avantajlar:** Hız (gerçek-zaman ölçeği uygulamaları); sınırsız sentetik veri (compute-bound); mükemmel etiket; gizlilik yok; foundation model olarak fine-tune edilebilir.
**Kısıtlar:** **Dağılım dışı (OOD) zayıflık** (Ders 6) — simülator hangi koşulları örneklediyse emulator orada güçlü; **sentetik verinin kalitesi** simülatorin doğruluğuyla sınırlı; **bir kez eğitim pahalı** — bir kez yapıp binlerce kez kullanma mantığı sadece yüksek-tekrar kullanım rejimlerinde anlamlı.
:::
::: {.callout-note collapse="true" title="Soru 2: No Free Lunch 'prior + veri' der; Bitter Lesson 'çok veri kazanır' der. Emülator paradigmasında nasıl uzlaşır?"}
**Cevap:** Görünür çelişki: prior bilgi (denklemler, simetri) ile büyük veri tartışılıyor. **Emülator paradigması iki yaklaşımı birleştirir**:
1. **Prior'ı veriye dönüştür:** Denklemleri "mimariye gömmek" (geometric DL) yerine, denklemleri **kullanarak veri üret**. Schrödinger'in tam çözümünden milyonlarca örnek üret; bu artık "veri".
2. **Veriyi büyüt:** Üretilen sentetik veri sınırsızdır (compute izin verdiği sürece). Bitter Lesson burada devreye girer — büyük veri + büyük model + çok compute = en iyi sonuç.
Sonuç: **prior bilgisi, mimari kısıtlama olarak değil, veri zenginliği olarak** dahil edilir. Mimari büyük ölçüde genel kalır (Bitter Lesson'a uygun); ama gördüğü veri, fizik tarafından kalibre edilmiş özel veridir.
Bonus: "data augmentation" sezgisi tam burada — bir molekülü 100 kez döndürüp etiketleyerek modeli rotasyon-değişmez hâle getirmek, simetriyi mimariye gömmekten genellikle daha kolay ve etkilidir.
:::
::: {.callout-note collapse="true" title="Soru 3: DFT, Schrödinger denklemini kesin olarak 3N boyuttan 3 boyuta indirir. Bu nasıl mümkün, ve neden hâlâ DFT zoo var?"}
**Cevap:** Kohn'un içgörüsü: enerji ve diğer fiziksel özellikler dalga fonksiyonu $\Psi$'nun tamamına ihtiyaç duymaz, **yalnızca elektron yoğunluğu $\rho(r)$'ye bağımlıdır**. $\rho$ tek bir 3B fonksiyondur ($3N$ değil). Bu kesin bir matematiksel eşdeğerliktir — yaklaşıklık değil.
Sonuç: maliyet **üstel** ($k^{3N}$) → **kübik** ($N^3$). Kohn 1998'de Nobel Kimya aldı.
**Ama bir küçük catch:** DFT denklemleri **exchange-correlation functional** $E_{xc}[\rho]$ içerir — küçük ama kritik bir terim. Kohn bu functional'ın **evrensel** olduğunu kanıtladı, ama analitik formülünü **yazamadı**. Pratikte 800+ **el-yapımı yaklaşıklık** geliştirildi:
- Bazıları belirli kimyaya (organik moleküller) iyi, başkasına (geçiş metalleri) kötü.
- Bazıları ucuz (cubic), bazıları doğru (yüksek mertebeden ölçeklenme).
Microsoft'un **Skala** projesi: bu evrensel functional'ı **machine learning ile öğrenmeye** çalışıyor — point cloud (yoğunluk) + atom-merkez message passing + büyük yüksek-doğruluk veri seti.
:::
::: {.callout-note collapse="true" title="Soru 4: (Builder) Tüm bu modeller hangi kurs derslerinin pratik karşılığıdır? Bir builder hangi alt-cepheyi öğrenmeli?"}
**Cevap:** **Kurs eşleştirmesi:**
- **MatterGen** → Ders 4 + Ders 6 diffusion modelleri (kristal koşullu üretim).
- **MatterSim** → Ders 1 supervised + geometric DL (özellik tahmini emulator).
- **Aurora** → Ders 6 LLM foundation model paradigması + Ders 2 transformer.
- **Skala** → Ders 1 supervised + Ders 3 convolution'un graph versiyonu (message passing) + Ders 4 generative learning prensipleri.
- **AlphaFold** → Ders 2 attention + Ders 3 CNN + Ders 6 diffusion (AlphaFold 3'te).
**Bir builder hangi alt-cepheyi öğrenmeli?** Üç **en aktif** kol:
1. **Geometric / Equivariant Deep Learning:** **e3nn**, **MACE**, **NequIP**, **EquiformerV2** kütüphaneleri.
2. **ML potentials / Force fields:** atomik kuvvetleri öğrenen ağlar (MD'nin emulator'ü). Open Catalyst Project, Materials Project veri setleri.
3. **Diffusion for science:** RFdiffusion (Baker, 2024 Nobel!), Boltz, DiffDock.
Bir builder olarak bu alanlara erken giriş demek **az rekabet + yüksek etki** demek; ChatGPT'nin doyuma yaklaştığı yerde science AI yeni başlıyor.
:::
## Egzersizler {#sec-egzersizler}
**Egzersiz 1 (Mini emülator paradigması).** Basit fizik bir sistem seç — ör. **basit sarkaç**. (a) Analitik veya küçük zaman-adımlı sayısal simülator yaz: $\theta(t)$ için Newton 2. yasası. (b) Bu simülatorden 10.000 başlangıç-koşul, sonuç-konum çifti üret. (c) Küçük bir MLP eğit: girdi $(\theta_0, \omega_0, t)$, çıktı $\theta(t)$. (d) Eğitim sonrası emulator'ın hızını ve doğruluğunu simulatorle karşılaştır.
```python
import numpy as np
def simulate(theta0, omega0, t, g=9.81, L=1.0, dt=1e-4):
theta, omega = theta0, omega0
steps = int(t / dt)
for _ in range(steps):
omega += -(g/L) * np.sin(theta) * dt
theta += omega * dt
return theta
# Sentetik veri uret, sonra MLP egit. Emulator = forward pass.
```
**Egzersiz 2 (Foundation model fine-tune).** HuggingFace `transformers` ile ön-eğitilmiş bir text-classification modelini al (örn. `distilbert-base`). Küçük bir veri seti hazırla. (a) Sıfırdan eğit (no pre-training) → kötü sonuç. (b) Foundation modelden fine-tune → çok daha iyi. Aurora'nın hava + kirlilik pattern'ını text-classification için yaşa.
**Egzersiz 3 (Schrödinger 1D kutu içinde parçacık).** Quantum mechanics'in en basit problemi: 1B kutuda parçacık. Analitik çözüm: $\psi_n(x) = \sqrt{2/L} \sin(n\pi x/L)$, enerji $E_n = n^2 \pi^2 \hbar^2/(2mL^2)$. (a) NumPy ile dalga fonksiyonunu ve enerjileri analitik hesapla. (b) Aynı problemi grid-bazlı (finite difference) sayısal çöz. (c) Bishop'un sezgisi: bir MLP'yi $(x, n) \to \psi_n(x)$ eşlemesine eğitirsen, $n=11$'i hiç görmemişken bile çözebilir mi?
**Egzersiz 4 (Geometric DL hello world).** PyTorch + `e3nn` kütüphanesini kur. Küçük bir molekülde (örn. su, H₂O) atomic koordinatlardan **rotasyon-değişmez** bir enerji tahmincisi eğit. Aynı molekülü rastgele döndür → enerjinin değişmediğini gözlemle. Bu, mimariye gömülmüş simetrinin görsel ispatıdır.
**Egzersiz 5 (Sonraki dersin habercisi).** Ders 9 — **Mathias Lechner, Liquid AI Co-founder & CTO** — *Secrets to Massively Parallel Training*. Bishop'un bahsettiği eğitim **bir tek GPU'da** olabiliyordu (emulator küçüktü). LLM eğitimi ise **binlerce GPU'ya yayılan distributed training**. (a) Veri paralelizmi (DDP), model paralelizmi (tensor + pipeline + sequence parallelism) ve **ZeRO** optimizasyonlarının ne olduğunu kısaca araştır. (b) **Liquid AI**'nın 2B parametreli modelleri GPT-4'ten daha iyi performans nasıl gösteriyor?
## Sonraki Ders İçin Hazırlık {#sec-sonraki}
**Ders 9: Devasa Paralel Eğitimin Sırları (Secrets to Massively Parallel Training)** — Mathias Lechner, Liquid AI Co-founder & CTO (Misafir Ders)
Bishop science cephesinde **küçük modelleri çok kullanmaktan** bahsetti; Lechner üretim cephesinde **büyük modelleri etkin eğitmekten** konuşacak. Liquid AI, Ders 1'in açılışında Amini'nin gösterdiği "telefonda offline çalışan 2B model GPT-4'ü geçti" modelini yapan ekip.
**Ana konular (beklenti):**
- Distributed training paradigmaları (DDP, FSDP, tensor parallelism, pipeline parallelism).
- ZeRO, gradient checkpointing, mixed precision (FP16/BF16/FP8).
- Veri verimi: "compute-optimal" vs "data-optimal" eğitim (Chinchilla scaling laws).
- Liquid neural network mimarisi.
::: {.callout-warning title="Ders 9 öncesi yapılacak"}
- Egzersizleri çöz — özellikle 1 (mini emülator) ve 4 (geometric DL).
- Bitter Lesson'u kendi cümlenle anlat: prior bilgi → veri'ye nasıl dönüştürülür?
- Ana cümleyi tekrar oku: *"Bilim için AI = denklem yerine emulator; bitter lesson + no free lunch sentezi."*
:::
## Anahtar Kavramlar (Cheat Sheet) {#sec-cheat-sheet}
| Kavram | Tanım | Bishop'ta |
|--------|-------|-----------|
| **Dünya = matematik** | Doğa basit denklemlerle 13 anlamlı basamak doğrulukta tarif ediliyor | 1m30 |
| **Dirac ironisi** | Denklemler bilinir ama çözümleri pratikte çoğunlukla ulaşılmaz | 3m25 |
| **3. oracle (emulator)** | Deney + simülasyon yanına AI emulator: 1000× daha hızlı yaklaşıklayıcı | 7m21 |
| **No Free Lunch** | Veri tek başına öğretmez; mutlaka prior/inductive bias gerekir | 8m13 |
| **LLM rejimi** | Bol veri + hafif prior (attention) | 8m54 |
| **Bilim rejimi** | Kıt veri + zengin prior (denklemler + simetri + korunum) | 9m05 |
| **Invariance / Equivariance** | Rotasyonda enerji sabit (inv) / vektör döner (equiv); geometric DL'in temeli | 10m14 |
| **Bitter Lesson** | Sutton 2019: kurnaz prior'lar uzun vadede çok-veriye yenik düşer | 12m19 |
| **Emülator paradigması** | Simülator → sentetik veri → eğit → 1000× daha hızlı emulator | 13m32 |
| **Aurora foundation model** | Çeşitli simulator verisiyle eğitilmiş hava modeli + fine-tune | 20m58 |
| **MatterGen** | Diffusion ile koşullu kristal üretim (Ders 4/6'nın materyal versiyonu) | 23m26 |
| **MatterSim** | Materyal özelliği tahmini emulator (binlerce candidate hızlı tarama) | 26m11 |
| **Üç-yönlü tradeoff** | Doğruluk + hız + genellik; herhangi 2'si kolay, 3'ü zor | 27m04 |
| **Chemical accuracy** | ~1 kcal/mol — laboratuvar yerine geçebilecek eşik | 27m42 |
| **Schrödinger eziyeti** | $\Psi$ $3N$-boyutlu; maliyet üstel ($k^{3N}$) | 30m14 |
| **DFT (Walter Kohn)** | $\rho(r)$ ile değiştir → kübik maliyet; kesin eşitlik; Nobel 1998 | 30m57 |
| **Exchange-correlation functional** | DFT'nin küçük ama kritik universal terimi; 800+ handcrafted, ML'in hedefi | 33m51 |
| **Skala** | Microsoft'un ML-öğrenilmiş universal functional girişimi | 37m25 |
| **Curse of sequentiality** | MD'de femtosaniye adımları + ms ölçekli olaylar | 42m40 |
| **10K-atom MD** | Hiyerarşik emulator ile büyük protein dinamikleri artık mümkün | 44m48 |
## ML Builder Bağlantıları {#sec-ml-baglantilar}
::: {.callout-tip title="9 köprü"}
1. **Emülator paradigması** → Ders 1 supervised learning + sentetik veri. İleriye: ML potentials, sim-to-real (Ders 5 RL'e köprü).
2. **No Free Lunch + inductive bias** → Stat 110 prior (Ders 4 koşullu) + Ders 4 VAE prior. İleriye: meta-learning, Bayesian deep learning.
3. **Geometric DL (invariance/equivariance)** → 18.06 lineer dönüşümün simetrileri; fiziksel uzay geometrisi. İleriye: e3nn, MACE, EquiformerV2.
4. **Bitter Lesson** → Ders 6 scaling laws ile aynı aile; veri + compute kazandırır. İleriye: synthetic data augmentation, kendinden öğrenen sistemler.
5. **Aurora foundation model** → Ders 6 LLM foundation paradigmasının yer-zaman versiyonu + Ders 2 transformer. İleriye: GraphCast, GenCast, NeuralGCM.
6. **MatterGen diffusion** → Ders 4 + Ders 6 diffusion'un kristal yapı uzayına uyarlanması; conditional generation.
7. **DFT (Kohn 1965)** → 18.06 boyut indirgeme'nin kesin fiziksel örneği ($3N$ → 3 boyut, kayıpsız).
8. **Skala (ML universal functional)** → Ders 1 supervised + Ders 3 convolution'un graph versiyonu (GNN, message passing) + büyük sentetik veri seti.
9. **10K-atom MD emulator** → kompozisyonun (Calculus zincir kuralı) bilim cephesindeki en olgun örneği: hiyerarşik abstraction.
:::
::: {.callout-important title="Bu dersten tek bir şey alıp gideceksen"}
AI for Science, **bilinen denklemlerin pahalı çözümlerinin yerine sinir ağı yaklaşıklayıcıları (emulator) koyma** disiplinidir; Bitter Lesson ile No Free Lunch arasındaki sentez. Aurora'dan MatterGen'e, Skala'dan AlphaFold'a kadar tüm modern science AI'sının çekirdek mantığı budur. Ve en güzel kısmı: bu cephe henüz **çok genç** — bir builder olarak bugün girersen, ChatGPT'nin doyumdan saatler içinde uzaklaşan bir alana giriyorsun.
:::