---
title: "LLM Sonrası-Eğitim (Post-Training)"
subtitle: "Base modelden asistana — SFT, LoRA, DPO, model merging ve test-time compute"
---
::: {.callout-note title="Bölüm bilgisi"}
- **Lecture videosu:** [YouTube — Lecture 10: LLM Post-Training](https://www.youtube.com/watch?v=_HfdncCbMOE&list=PLtBw6njQRU-rwp5__7C0oIVt26ZgjG9NI&index=17) (≈57 dk)
- **Edition:** 2025 misafir • **Hoca:** Maxime Labonne (Liquid AI, "LLM Engineer's Handbook" yazarı)
- **Kaynak:** [introtodeeplearning.com](https://introtodeeplearning.com) + [Liquid AI](https://www.liquid.ai)
- **Okuma süresi:** ≈35 dk
:::
## Bu Derste Ne Var? {#sec-bu-derste}
Ders 6'da gördük: bir LLM'in **base** (ön-eğitilmiş) hâli yalnızca **bir sonraki token'ı tahmin eder** — soru cevaplayamaz, talimat izleyemez, asistan gibi davranamaz. ChatGPT, Claude, Gemini gibi bugünün yardımsever asistanlarına dönüşmesi için **post-training** (sonrası-eğitim) gerekir. Bu ders tam olarak bu pipeline'ı — aşamalar, algoritmalar, veri, değerlendirme — açıyor.
> *"the goal of post-training is turning a base model into a useful assistant. To do that, we have two main steps: supervised fine-tuning and preference alignment."* — Maxime Labonne, 1:38
**Dersin üç büyük fikri:**
1. **Post-training = SFT + Preference Alignment.** Base modeli iki ana aşamayla (format öğretme + tercih hizalama) asistana çeviren disiplin.
2. **İyi veri = doğruluk + çeşitlilik + karmaşıklık.** Modern endüstri sırrı: fark **mimari değil, veridir**. Pre-training'de "daha çok daha iyi", post-training'de **az ama kaliteli** kazanır.
3. **Test-time compute scaling.** Inference sırasında daha çok hesap = küçük model bile büyük modeli geçebilir (Llama 3.2 1B > Llama 3.1 70B mümkün).
{#fig-concept-map fig-align="center" width=85%}
> *"good data... three dimensions. Accuracy, diversity, complexity... they can be applied throughout the entire pipeline."* — Maxime, 11:05
::: {.callout-tip title="Builder Notu — ML Köprüleri"}
Bu ders kursun ileriye köprülerinin LLM cephesinden en somut buluşma noktası.
**Geriye:**
- **SFT loss** → Ders 1 cross-entropy + Ders 6 next-token prediction.
- **Preference alignment** → Ders 5 RLHF'nin pratiği; PPO Ders 5'te tanışıldı.
- **DPO** → Stat 110 maximum likelihood (Ders 17) + Bradley-Terry tercih modeli (Ders 8 Bernoulli).
- **LoRA** → 18.06 low-rank approximation; SVD (Ders 29) sezgisinin pratiği.
- **Model merging (SLERP)** → 18.06 vektör uzayı interpolasyonu; küre üzerinde spherical linear interpolation.
- **Çeşitlilik (diversity)** → Stat 110 entropy / dağılım şekli (Ders 12).
- **LLM-as-judge** → Ders 7 Doug Blank dersinin merkez konusu, burada eğitim cephesi.
- **PRM** → Ders 5 reward model'in adım-bazında versiyonu.
**İleriye:** GRPO (DeepSeek-R1), ORPO, KTO, RLAIF, Constitutional AI; synthetic data + distillation; TRL (HuggingFace), Axolotl, Unsloth; vLLM + SGLang; Arena-Hard, MT-Bench, AlpacaEval; DoRA, AdaLoRA.
**Tek cümleyle:** Post-training, base modeli **format öğretme** (SFT), **tercih öğretme** (preference alignment) ve **birleştirme** (merging) ile asistana çeviren bir veri-zekası disiplinidir.
:::
## Post-Training Nedir? Base'den Asistana {#sec-post-training-nedir}
Ders 6'da gördük: pre-training, devasa metin korpusu (trilyonlarca token) üzerinde **bir sonraki token tahmini** yapan bir transformer öğretir. Sonuç: **base model**, dilin istatistiksel yapısını öğrenmiş; ama soru sorsan "sana yardımcı olması" gerektiğini bilmiyor. Yalnızca metni **devam ettiriyor**.
Post-training, bu base modeli **asistan** hâline getiren aşamaların toplamı. Maxime Labonne'a göre iki ana adım:
- **(1) Supervised Fine-Tuning (SFT) — öğretici fine-tune:** Modeli, **(talimat, cevap) çiftleriyle** eğit. Bir kullanıcı sorusu ve bir doğru cevap gösterilir; model bu kalıbı öğrenir. Ayrıca **chat template** (system + user + assistant rolleri) öğrenilir. Sonuç: instruction following + diyalog formatı.
- **(2) Preference Alignment — tercih hizalama:** SFT'den çıkan model talimatları izler ama her zaman istediğimiz **ton, format, kalitede** olmayabilir. Bu aşamada model **çifteler** görür: aynı soruya **kabul edilmiş** (chosen) ve **reddedilmiş** (rejected) iki cevap. Kabul edileni üretme olasılığını artır, reddedileni azalt.
```{python}
#| label: fig-post-train-data
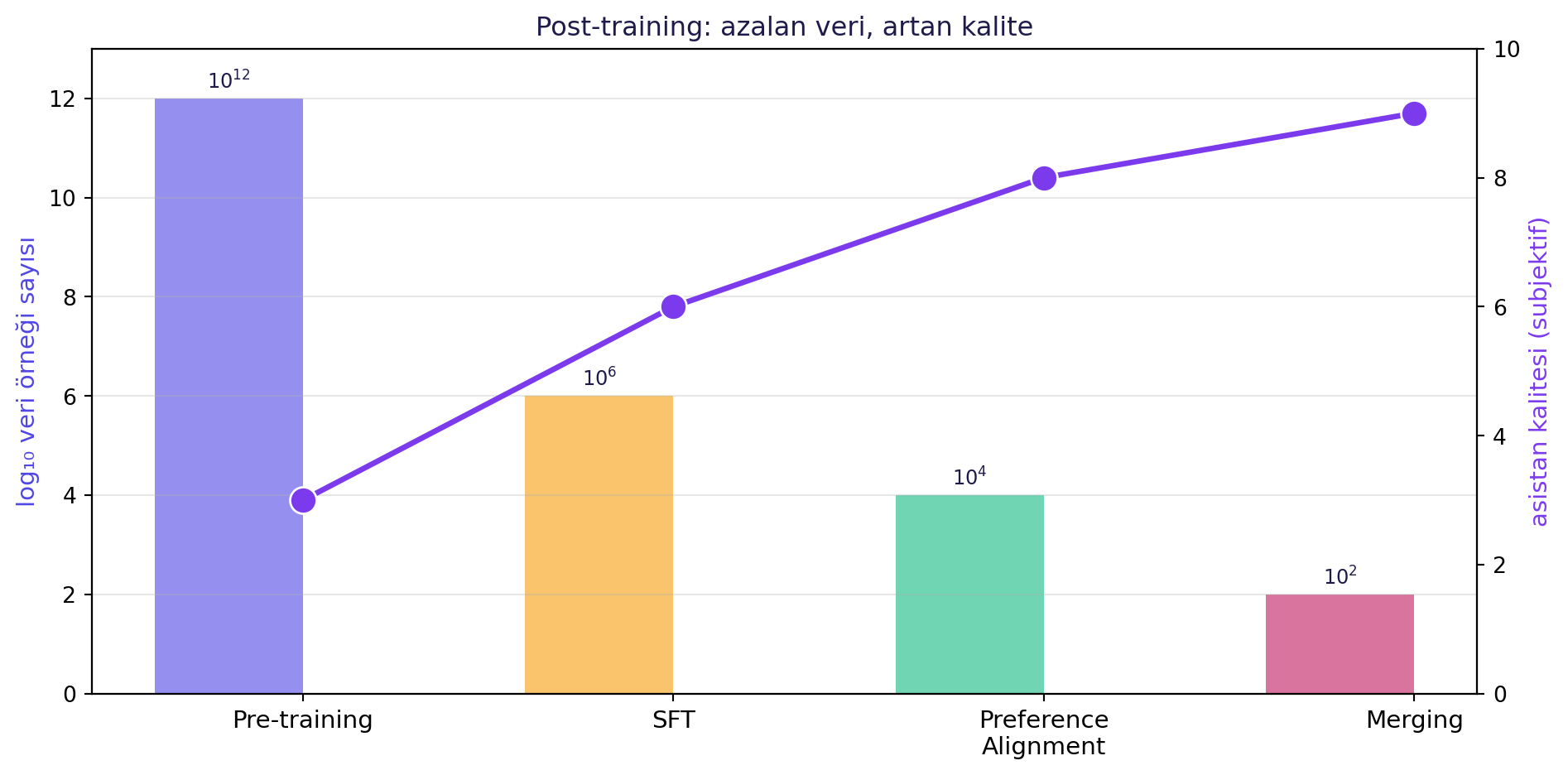
#| fig-cap: "Post-training boyunca azalan veri, artan kalite. Pre-training trilyonlarca token; SFT yüz binlerce-milyonlarca örnek; preference alignment on binler."
#| fig-width: 10
#| fig-height: 5
import numpy as np
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(10, 5))
stages = ['Pre-training', 'SFT', 'Preference\nAlignment', 'Merging']
data_sizes = [1e12, 1e6, 1e4, 1e2]
quality = [3, 6, 8, 9]
colors = ['#4f46e5', '#f59e0b', '#10b981', '#be185d']
x = np.arange(len(stages))
ax2 = ax.twinx()
ax.bar(x - 0.2, np.log10(data_sizes), 0.4, color=colors, alpha=0.6, label='log₁₀(veri boyutu)')
ax2.plot(x, quality, '-o', color='#7c3aed', linewidth=2.5, markersize=12,
markeredgecolor='white', label='kalite skoru')
ax.set_xticks(x)
ax.set_xticklabels(stages, fontsize=11)
ax.set_ylabel('log₁₀ veri örneği sayısı', fontsize=11, color='#4f46e5')
ax2.set_ylabel('asistan kalitesi (subjektif)', fontsize=11, color='#7c3aed')
ax.set_title('Post-training: azalan veri, artan kalite', fontsize=12, color='#1e1b4b')
ax.grid(alpha=0.3, axis='y')
ax.set_ylim(0, 13)
ax2.set_ylim(0, 10)
for xi, q, ds in zip(x, quality, data_sizes):
ax.text(xi - 0.2, np.log10(ds) + 0.2, f'10$^{{{int(np.log10(ds))}}}$',
ha='center', fontsize=9, color='#1e1b4b')
plt.tight_layout()
plt.show()
```
Eğitim **veri ölçeği farkları:** pre-training trilyonlarca token; SFT yüz binlerce-milyonlarca örnek; preference alignment on binler. Yani pipeline boyunca **azalan veri, artan kalite**.
::: {.callout-tip title="Builder Notu"}
**Geriye:** SFT teknik olarak yine bir cross-entropy minimizasyonudur (Ders 1) — "verilen prompt + cevabın yarısı koşulu altında kalanı tahmin et". Yalnızca **veri** değişmiş; mimari ve loss aynı. Preference alignment ise Ders 5'in RLHF'sinin pratik aşamasıdır.
**İleriye:** Bugün pre-training'den daha **çeşitli model** ailesi (Llama, Qwen, Mistral, Liquid) post-training farkıyla rekabet ediyor. Bir builder olarak: eğer bir base model yeterince "şeffafça açık" ise, domain'inize özgü post-training ile kısa zamanda **özel asistan** üretebilirsiniz. Tek bir builder + iyi veri + Unsloth/Axolotl yetiyor.
:::
## İyi Veri = Doğruluk + Çeşitlilik + Karmaşıklık {#sec-iyi-veri}
Maxime'in altını çizdiği en kritik nokta: **post-training kalitesini veri belirler**. Pre-training'de "daha çok daha iyi" hâkimken, post-training'de **az ama kaliteli** kazanır. Kalitenin üç boyutu var:
**(1) Doğruluk (Accuracy):** Cevap soruyla ilgili ve doğru mu?
- Kod cevapları için **unit testler** koş.
- Matematik için bir **çözücü** (Wolfram, sympy) ile çapraz kontrol.
- Doğal dil için **LLM-as-judge** veya regex-tabanlı kontroller.
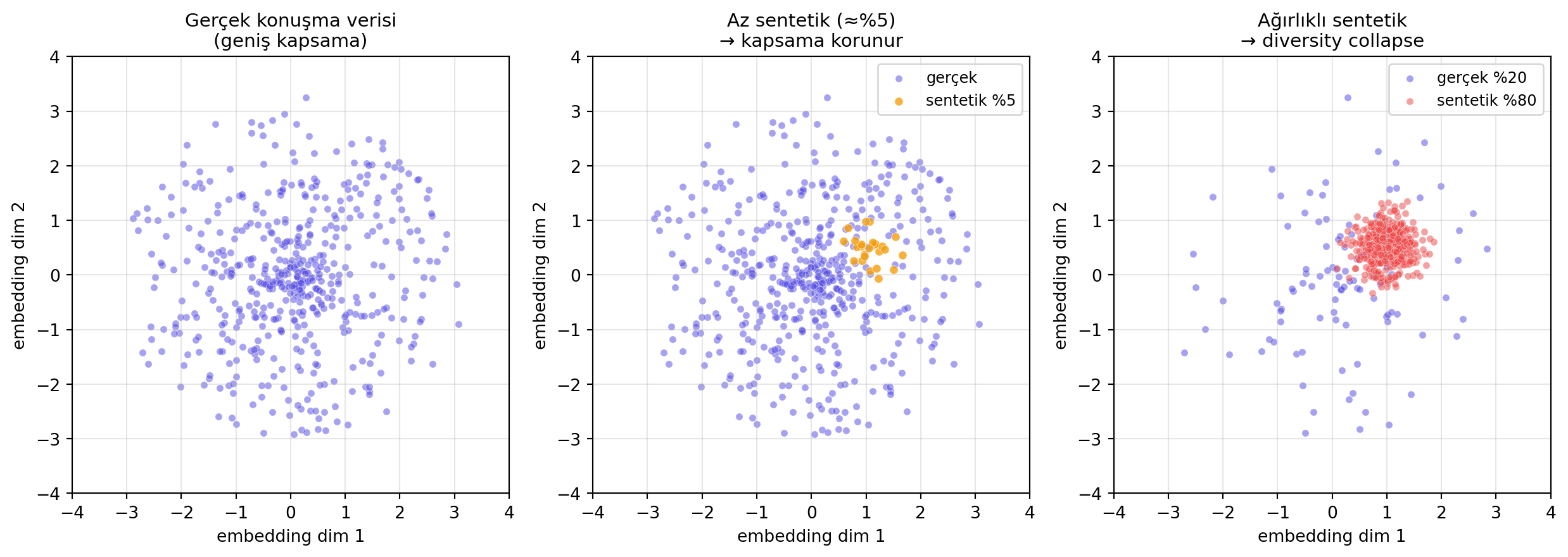
**(2) Çeşitlilik (Diversity):** Veri seti kullanıcının yapacağı tüm sorgu uzayını mümkün olduğunca kaplamalı. Sentetik veri burada **iki yönlü**: az miktarda eklerse çeşitliliği artırır, ama tamamen sentetik veri seti **diversity collapse** yapar.
**(3) Karmaşıklık (Complexity):** Modelin **uzun, detaylı, chain-of-thought** cevapları öğrenmesi. Kısa cevaplar reasoning'i geliştirmez.
```{python}
#| label: fig-diversity-collapse
#| fig-cap: "Çeşitlilik vs collapse. Sol: gerçek konuşma verisi geniş kapsama. Orta: az sentetik ekleme — kapsama korunur. Sağ: ağırlıklı sentetik — dağılım çöker (mode collapse)."
#| fig-width: 13
#| fig-height: 4.5
rng = np.random.default_rng(42)
fig, axes = plt.subplots(1, 3, figsize=(13, 4.5))
n = 500
theta = rng.uniform(0, 2*np.pi, n)
r = rng.uniform(0, 3, n)
x_real = r * np.cos(theta) + rng.normal(0, 0.2, n)
y_real = r * np.sin(theta) + rng.normal(0, 0.2, n)
axes[0].scatter(x_real, y_real, c='#4f46e5', alpha=0.5, s=18, edgecolor='white', linewidth=0.3)
axes[0].set_title('Gerçek konuşma verisi\n(geniş kapsama)', fontsize=11)
syn_mode = rng.normal([1, 0.5], 0.3, (25, 2))
axes[1].scatter(x_real, y_real, c='#4f46e5', alpha=0.5, s=18,
edgecolor='white', linewidth=0.3, label='gerçek')
axes[1].scatter(syn_mode[:, 0], syn_mode[:, 1], c='#f59e0b', alpha=0.8, s=25,
edgecolor='white', linewidth=0.3, label='sentetik %5')
axes[1].legend(fontsize=9, loc='upper right')
axes[1].set_title('Az sentetik (≈%5)\n→ kapsama korunur', fontsize=11)
syn_heavy = rng.normal([1, 0.5], 0.3, (400, 2))
small_idx = rng.choice(n, 100, replace=False)
axes[2].scatter(x_real[small_idx], y_real[small_idx], c='#4f46e5', alpha=0.5, s=18,
edgecolor='white', linewidth=0.3, label='gerçek %20')
axes[2].scatter(syn_heavy[:, 0], syn_heavy[:, 1], c='#ef4444', alpha=0.5, s=18,
edgecolor='white', linewidth=0.3, label='sentetik %80')
axes[2].legend(fontsize=9, loc='upper right')
axes[2].set_title('Ağırlıklı sentetik\n→ diversity collapse', fontsize=11)
for ax in axes:
ax.set_xlim(-4, 4)
ax.set_ylim(-4, 4)
ax.set_aspect('equal')
ax.grid(alpha=0.3)
ax.set_xlabel('embedding dim 1')
ax.set_ylabel('embedding dim 2')
plt.tight_layout()
plt.show()
```
Bu üç boyut **eş zamanlı** ölçülmeli; biri zayıfsa fine-tune sonucu zayıf olur. Maxime'in "data %33" tahmini buradan geliyor.
::: {.callout-tip title="Builder Notu"}
**Geriye (Stat 110):** "Çeşitlilik" tam olarak Stat 110'un **entropy** ve **dağılımın genişliği** kavramıdır. Düşük-entropi veri seti = tek mod-luk, yüksek-entropi veri seti = geniş kapsama.
**İleriye:** **DataComp**, **Curator**, **Distilabel**, **NeMo Curator** modern veri pipeline framework'leri. Phi serisi tamamen synthetic. **Data engineering**, model engineering'den daha kritik olabilir.
:::
## Veri Üretim Pipeline'ı ve Chat Template {#sec-veri-pipeline}
Post-training veri seti **bulunmaz**, **inşa edilir**. Tipik pipeline:
1. **Seed data:** Ham metin, mevcut talimat/cevap veri setleri, gerçek kullanıcı sorguları.
2. **Refine:** Soru veya cevap eksiklerini doldur (back-translation).
3. **Score & Filter:** Heuristic kurallar + **LLM-as-judge**.
4. **Decontaminate:** Test set leakage'i önle.
Tüm bu veri sonunda modele **chat template** ile sunulur:
```text
<|im_start|>system
You are a math tutor.<|im_end|>
<|im_start|>user
Solve: 2x + 5 = 11<|im_end|>
<|im_start|>assistant
Subtract 5: 2x = 6. Divide by 2: x = 3.<|im_end|>
```
Special tokenlar `<|im_start|>` ve `<|im_end|>` mesaj sınırlarını işaretler. **System/user/assistant** rolleri model için kim konuşuyor sinyalini taşır. SFT'nin asıl başarısının kaynağı tam olarak modele bu **konuşma yapısını** öğretmektir.
::: {.callout-tip title="Builder Notu"}
**Geriye (Ders 6):** Chat template tokenları **embedding tablosuna eklenmiş yeni semboller**. Model bunları sıradan kelimeler gibi öğrenir; ama görevleri yapısaldır.
**İleriye:** Farklı modellerin farklı chat templatesi var (ChatML, Llama-2, Llama-3, Mistral, Gemma). `tokenizer.apply_chat_template()` (HuggingFace) doğru template'i otomatik uygular.
:::
## SFT Teknikleri: Full Fine-Tune, LoRA, QLoRA {#sec-sft-teknikleri}
SFT'yi mekanik olarak yapmanın üç ana yolu var:
**(1) Full fine-tuning** — modelin **tüm parametrelerini** yeniden eğit. **Maksimum kalite**; fakat **VRAM yıkıcıdır** (70B için ~2 TB).
**(2) LoRA** (Low-Rank Adaptation) — modelin mevcut ağırlıklarını **dondur**; küçük bir **adaptör matrisi** ekleyip yalnızca onu eğit:
$$
W' = W + \alpha \cdot B A, \qquad B \in \mathbb{R}^{d \times r},\ A \in \mathbb{R}^{r \times k},\ r \ll \min(d, k)
$$
$r$ genellikle 8, 16, 32; $W$ ise 4096×4096 olabilir. Sonuç: toplam parametrenin **~%0.5'i** eğitilir.
**(3) QLoRA** (Quantized LoRA) — modeli yine dondur ama **4-bit quantize** edilmiş hâlde belleğe yükle. Bellek 70B model için bile tek GPU'ya iner. Bedel: **~%5 kalite kaybı**.
```{python}
#| label: fig-lora-rank
#| fig-cap: "LoRA low-rank decomposition. 4096×4096 ağırlık (16.7M parametre), iki küçük matrisin çarpımıyla yaklaşıklanır. r=8 için: 65K parametre, %0.39 oranı, 256× daha az parametre eğitilir."
#| fig-width: 12
#| fig-height: 5
import matplotlib.patches as patches
fig, ax = plt.subplots(figsize=(12, 5))
ax.add_patch(patches.Rectangle((0.5, 1), 3, 3, facecolor='#4f46e5', alpha=0.6, edgecolor='#1e1b4b', linewidth=2))
ax.text(2, 2.5, 'W\n(4096×4096)\n16.7M param', ha='center', va='center', color='white', fontsize=12, weight='bold')
ax.text(2, 0.5, 'tam fine-tune\n16,777,216 param', ha='center', fontsize=10, color='#1e1b4b')
ax.text(4.3, 2.5, '+', fontsize=30, ha='center', va='center', color='#be185d', weight='bold')
ax.add_patch(patches.Rectangle((4.8, 1.5), 0.6, 2, facecolor='#f59e0b', alpha=0.7, edgecolor='#92400e', linewidth=2))
ax.text(5.1, 2.5, 'B', ha='center', va='center', color='white', fontsize=14, weight='bold')
ax.text(5.1, 1.3, '4096×8', ha='center', fontsize=9, color='#92400e')
ax.text(5.1, 0.9, '32,768', ha='center', fontsize=9, color='#92400e')
ax.text(5.8, 2.5, '×', fontsize=24, ha='center', va='center', color='#be185d', weight='bold')
ax.add_patch(patches.Rectangle((6.2, 2.3), 2, 0.4, facecolor='#10b981', alpha=0.7, edgecolor='#064e3b', linewidth=2))
ax.text(7.2, 2.5, 'A', ha='center', va='center', color='white', fontsize=14, weight='bold')
ax.text(7.2, 2.0, '8×4096', ha='center', fontsize=9, color='#064e3b')
ax.text(7.2, 1.6, '32,768', ha='center', fontsize=9, color='#064e3b')
ax.text(8.5, 2.5, '=', fontsize=24, ha='center', va='center', color='#1e1b4b', weight='bold')
ax.text(9.5, 3, 'LoRA toplam:', ha='center', fontsize=11, color='#1e1b4b', weight='bold')
ax.text(9.5, 2.5, '65,536 param', ha='center', fontsize=14, color='#be185d', weight='bold')
ax.text(9.5, 2.0, '(%0.39 oran)', ha='center', fontsize=10, color='#be185d')
ax.text(9.5, 1.4, '~256× daha az', ha='center', fontsize=10, color='#7c3aed', style='italic')
ax.set_xlim(0, 11)
ax.set_ylim(0, 5)
ax.set_aspect('equal')
ax.axis('off')
ax.set_title('LoRA rank decomposition: W güncellemesini iki küçük matrisin çarpımıyla yaklaşıklamak',
fontsize=12, color='#1e1b4b')
plt.tight_layout()
plt.show()
```
Maxime'in karar ağacı:
- LLM şirketisin → **full fine-tune**.
- Domain-specific + ciddi GPU → **LoRA**.
- Tek GPU'luk hobici/start-up → **QLoRA**.
> *"if you can afford doing LoRA fine-tuning I would recommend LoRA fine-tuning. Most of the time full fine-tuning is actually a bit too much."* — Maxime, 23:19
::: {.callout-tip title="Builder Notu"}
**Geriye (18.06):** LoRA'nın ardındaki fikir doğrudan **SVD'dir** (Ders 29). Büyük matris W, en önemli birkaç tekil değerle yaklaşıklanabilir. Eğitim sırasındaki güncelleme $\Delta W$, tipik olarak düşük-ranklıdır.
**İleriye:** **DoRA**, **AdaLoRA**, **rsLoRA**, **PiSSA** varyantları. **PEFT** kütüphanesi (HuggingFace) standart implementasyonları sunar. **Multi-LoRA serving** (vLLM) tek base modele yüzlerce LoRA adaptör servisi mümkün kılar.
:::
## Preference Alignment: PPO ve DPO {#sec-preference-alignment}
SFT modelin **format ve göreve** uyumu öğretir; ama **insan tercihlerine** hizalanmasını sağlamaz. Bu, ikinci aşama olan **preference alignment**'ın işidir.
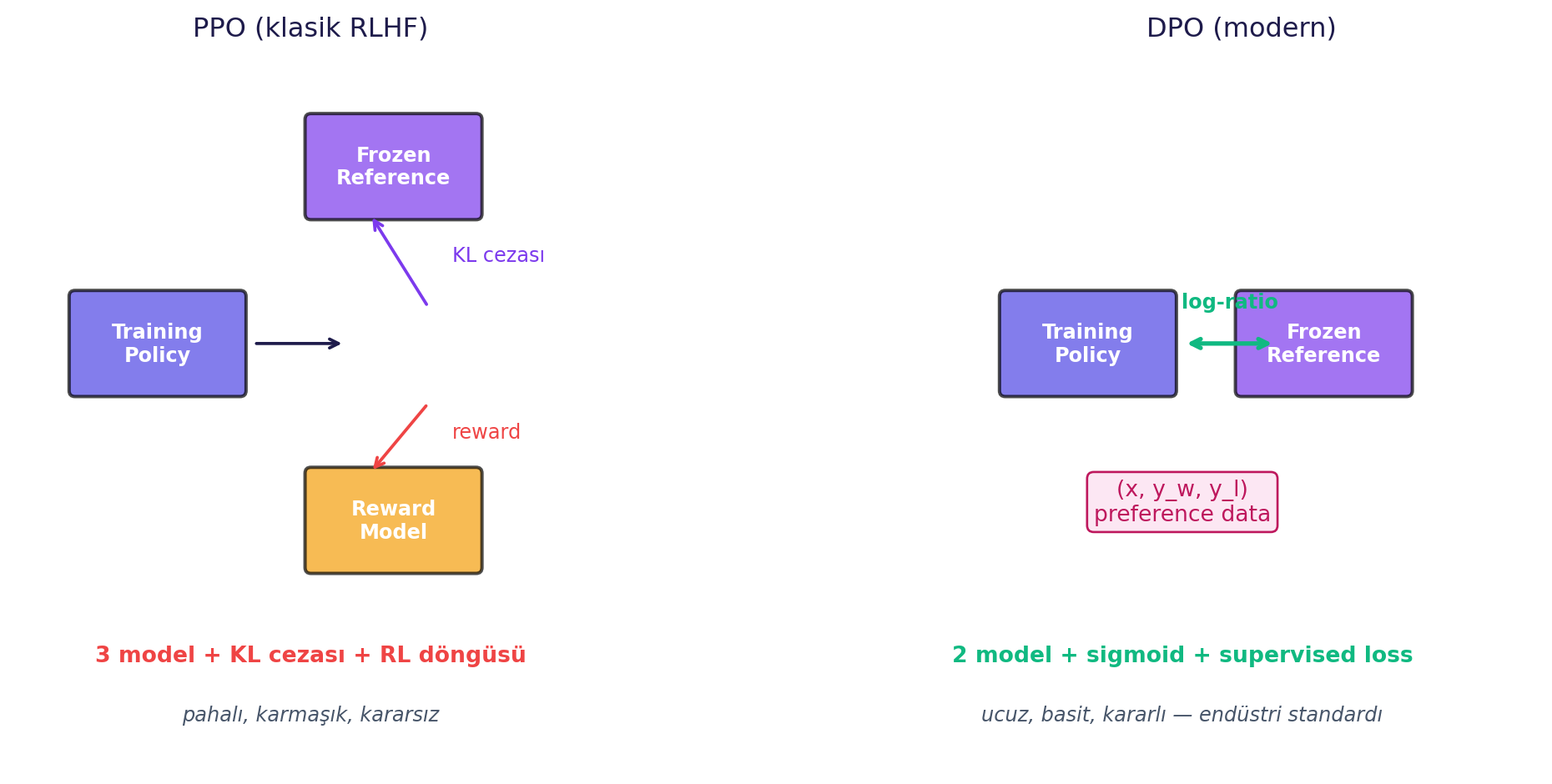
**PPO** (Proximal Policy Optimization) — Ders 5'in RLHF'sinde gördüğümüz klasik algoritma. Üç ayrı model birden gerekir: frozen base + training policy + reward model. Eğitim döngüsü: policy cevap üretir → reward puanlar → policy güncellenir + KL ceza.
**DPO** (Direct Preference Optimization) — 2023'te önerilen zarif sadeleştirme. RLHF'nin optimal politikasının **kapalı-form çözümü** vardır; reward model **olmadan** ifade edilebilir:
$$
L_{\text{DPO}} = -\mathbb{E}_{(x,\, y_w,\, y_l)}\!\left[\log \sigma\!\left(\beta \log \tfrac{\pi_\theta(y_w \mid x)}{\pi_{\text{ref}}(y_w \mid x)} - \beta \log \tfrac{\pi_\theta(y_l \mid x)}{\pi_{\text{ref}}(y_l \mid x)}\right)\right]
$$
$y_w$ = chosen, $y_l$ = rejected, $\beta$ = KL etkisinin gücü.
```{python}
#| label: fig-ppo-vs-dpo
#| fig-cap: "PPO (3 model + RL döngüsü) vs DPO (2 model + cross-entropy benzeri loss). DPO daha az pahalı, daha kararlı."
#| fig-width: 13
#| fig-height: 5
fig, axes = plt.subplots(1, 2, figsize=(13, 5))
ax = axes[0]
models = [
(1, 3, 'Training\nPolicy', '#4f46e5'),
(3, 4.5, 'Frozen\nReference', '#7c3aed'),
(3, 1.5, 'Reward\nModel', '#f59e0b'),
]
for x, y, label, c in models:
ax.add_patch(patches.FancyBboxPatch((x-0.5, y-0.4), 1.4, 0.8, boxstyle="round,pad=0.05",
facecolor=c, alpha=0.7, edgecolor='black', linewidth=1.5))
ax.text(x+0.2, y, label, ha='center', va='center', color='white', fontsize=9, weight='bold')
ax.annotate('', xy=(2.8, 3), xytext=(2, 3), arrowprops=dict(arrowstyle='->', color='#1e1b4b', lw=1.4))
ax.annotate('', xy=(3, 1.9), xytext=(3.5, 2.5), arrowprops=dict(arrowstyle='->', color='#ef4444', lw=1.4))
ax.text(3.7, 2.2, 'reward', fontsize=9, color='#ef4444')
ax.annotate('', xy=(3, 4.1), xytext=(3.5, 3.3), arrowprops=dict(arrowstyle='->', color='#7c3aed', lw=1.4))
ax.text(3.7, 3.7, 'KL cezası', fontsize=9, color='#7c3aed')
ax.text(2.5, 0.3, '3 model + KL cezası + RL döngüsü', ha='center', fontsize=10, weight='bold', color='#ef4444')
ax.text(2.5, -0.2, 'pahalı, karmaşık, kararsız', ha='center', fontsize=9, style='italic', color='#475569')
ax.set_title('PPO (klasik RLHF)', fontsize=12, color='#1e1b4b')
ax.set_xlim(0, 5)
ax.set_ylim(-0.6, 5.5)
ax.set_aspect('equal')
ax.axis('off')
ax = axes[1]
models2 = [
(1, 3, 'Training\nPolicy', '#4f46e5'),
(3, 3, 'Frozen\nReference', '#7c3aed'),
]
for x, y, label, c in models2:
ax.add_patch(patches.FancyBboxPatch((x-0.5, y-0.4), 1.4, 0.8, boxstyle="round,pad=0.05",
facecolor=c, alpha=0.7, edgecolor='black', linewidth=1.5))
ax.text(x+0.2, y, label, ha='center', va='center', color='white', fontsize=9, weight='bold')
ax.annotate('', xy=(2.8, 3), xytext=(2, 3), arrowprops=dict(arrowstyle='<->', color='#10b981', lw=2))
ax.text(2.4, 3.3, 'log-ratio', fontsize=9, color='#10b981', ha='center', weight='bold')
ax.text(2, 1.5, '(x, y_w, y_l)\npreference data', ha='center', fontsize=10, color='#be185d',
bbox=dict(boxstyle='round', facecolor='#fce7f3', edgecolor='#be185d'))
ax.text(2, 0.3, '2 model + sigmoid + supervised loss', ha='center', fontsize=10, weight='bold', color='#10b981')
ax.text(2, -0.2, 'ucuz, basit, kararlı — endüstri standardı', ha='center', fontsize=9, style='italic', color='#475569')
ax.set_title('DPO (modern)', fontsize=12, color='#1e1b4b')
ax.set_xlim(0, 5)
ax.set_ylim(-0.6, 5.5)
ax.set_aspect('equal')
ax.axis('off')
plt.tight_layout()
plt.show()
```
> *"DPO is less costly because you only have two models to load. It's faster, it's cheaper to use, but the quality is slightly lower. I would recommend using DPO over PPO unless you are OpenAI."* — Maxime, 25:15
100+ varyant arasında DPO bugün **gerçek-dünya endüstri standardı**. **GRPO** (DeepSeek-R1), **ORPO**, **KTO** modern varyantlar.
::: {.callout-tip title="Builder Notu"}
**Geriye (Ders 5 + Stat 110):** DPO'nun türetimi, RLHF amaç fonksiyonunun KL kısıtı altında **Bradley-Terry tercih modelinin** maximum likelihood çözümüdür. $\sigma$ sigmoidi ikili tercih olasılığını verir.
**İleriye:** **TRL** (HuggingFace) tüm bu algoritmaları standart API ile sunar. **OpenRLHF**, **OpenInstruct** açık-kaynak büyük-ölçek frameworks. **Constitutional AI** tercih verisini insan değil modelin **kendi-eleştirisinden** üretir.
:::
## Training Parametreleri ve İzleme {#sec-training-params}
Maxime'in pratik tavsiye listesi:
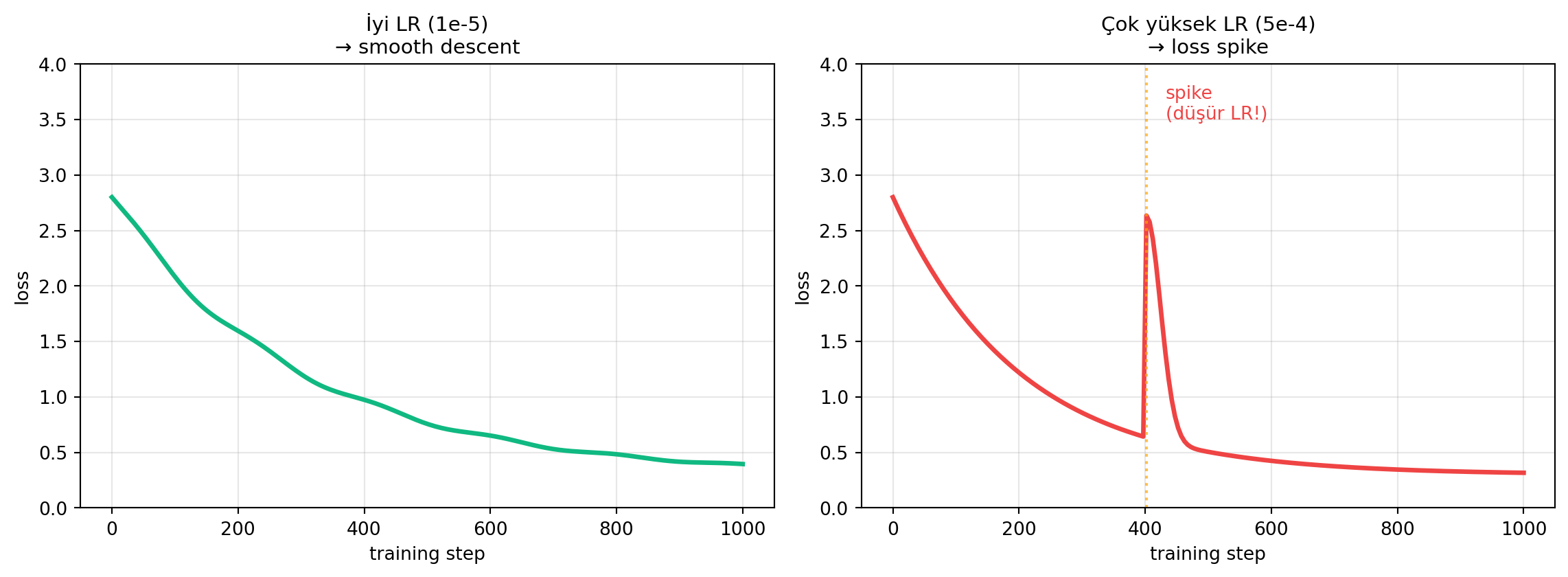
- **Learning rate (en kritik):** SFT için $1 \times 10^{-5} - 5 \times 10^{-5}$. DPO için daha düşük.
- **Batch size + max length:** VRAM tüketimini doğrudan belirler. **Gradient accumulation**.
- **Epochs:** Tipik 3-5. Validation loss izle.
- **Optimizer:** **AdamW** standart.
- **Attention:** **Flash Attention** pratikte zorunlu.
```{python}
#| label: fig-lr-spike
#| fig-cap: "Learning rate seçimi loss eğrisinde görünür. Çok yüksek LR (sağ) ilk yumuşak düşüş sonrası ani spike yapar; doğru LR (sol) smooth düşer."
#| fig-width: 12
#| fig-height: 4.5
steps = np.linspace(0, 1000, 200)
loss_good = 2.5 * np.exp(-steps / 300) + 0.3 + 0.05 * np.sin(steps / 30) * np.exp(-steps / 500)
loss_bad = 2.5 * np.exp(-steps / 200) + 0.3
spike_start = 80
spike = np.zeros_like(steps)
spike[spike_start:] = 2 * np.exp(-(steps[spike_start:] - steps[spike_start])**2 / 1000)
loss_bad = loss_bad + spike
fig, axes = plt.subplots(1, 2, figsize=(12, 4.5))
axes[0].plot(steps, loss_good, color='#10b981', linewidth=2.5)
axes[0].set_title('İyi LR (1e-5)\n→ smooth descent', fontsize=11)
axes[0].set_xlabel('training step')
axes[0].set_ylabel('loss')
axes[0].grid(alpha=0.3)
axes[0].set_ylim(0, 4)
axes[1].plot(steps, loss_bad, color='#ef4444', linewidth=2.5)
axes[1].set_title('Çok yüksek LR (5e-4)\n→ loss spike', fontsize=11)
axes[1].set_xlabel('training step')
axes[1].set_ylabel('loss')
axes[1].grid(alpha=0.3)
axes[1].set_ylim(0, 4)
axes[1].axvline(steps[spike_start], color='orange', linestyle=':', alpha=0.7)
axes[1].text(steps[spike_start] + 30, 3.5, 'spike\n(düşür LR!)', fontsize=10, color='#ef4444')
plt.tight_layout()
plt.show()
```
> *"bad learning rate is the one with the loss spike... after smooth descent, immediately after that we see the loss spike."* — Maxime, 28:07
Yardımcı kütüphaneler: **TRL** (HuggingFace), **Axolotl** (YAML config), **Unsloth** (tek GPU).
::: {.callout-tip title="Builder Notu"}
**Geriye (Ders 1):** Tüm bu parametreler Ders 1'in eğitim çevriminin doğrudan uzantısı. Yalnızca "validation loss izleme" eklendi.
**İleriye:** **Cosine LR schedule** + **linear warmup** standart. **W&B, Comet, MLflow** izleme. **Optuna** veya **Ray Tune** ile sistematik arama.
:::
## Model Merging: SLERP ve DARE-TIES {#sec-model-merging}
Modern post-training'in en zarif numarası: **iki ya da daha çok modelin parametrelerini ortalayıp, sonuçta her ikisinin de güçlü yönlerini taşıyan yeni model üretmek**.
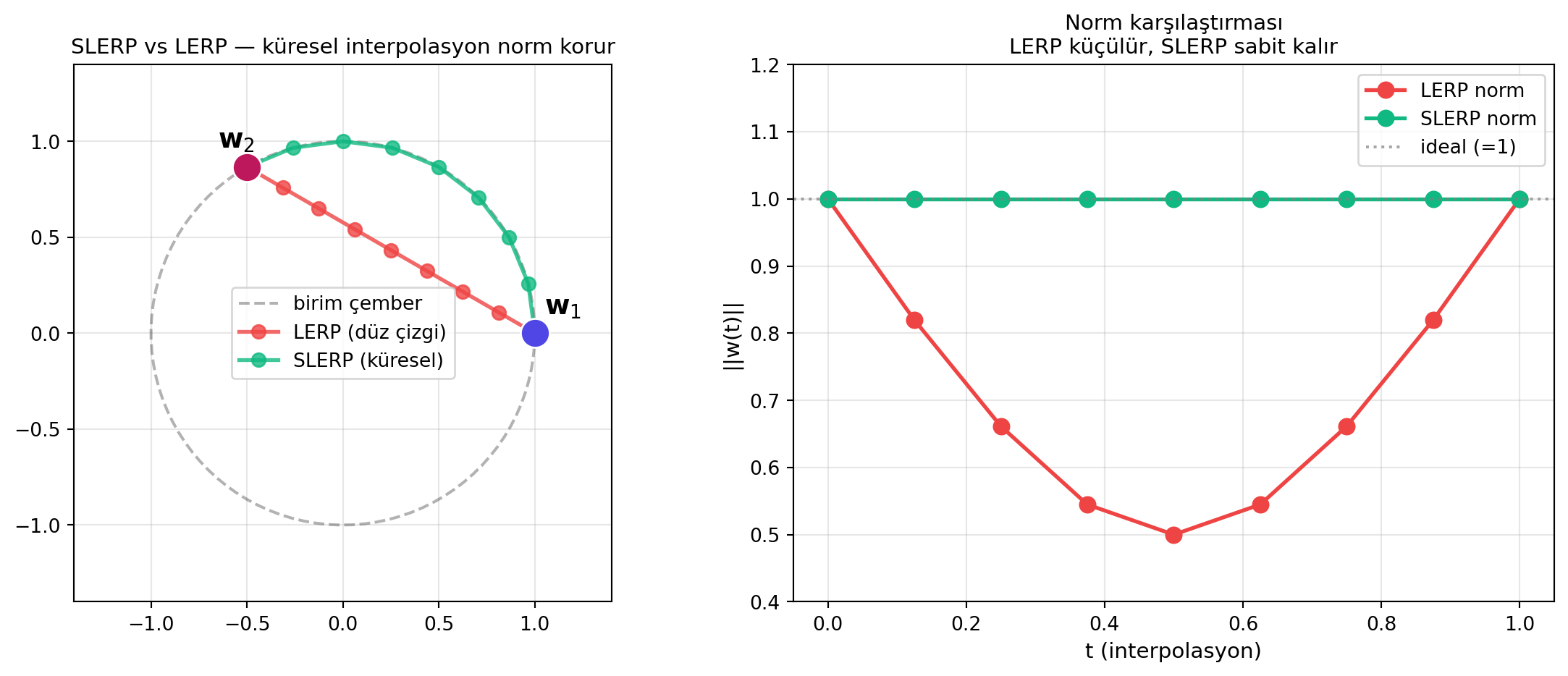
SLERP (Spherical Linear Interpolation) sezgisi: iki model vektörünü düz çizgide değil, **küre üzerinde** karıştır:
$$
\text{SLERP}(\mathbf{w}_1,\, \mathbf{w}_2,\, t) = \frac{\sin((1-t)\theta)}{\sin\theta}\, \mathbf{w}_1 + \frac{\sin(t\theta)}{\sin\theta}\, \mathbf{w}_2
$$
```{python}
#| label: fig-slerp
#| fig-cap: "SLERP: iki model vektörü arasında küre üzerinde geodezik interpolasyon. Düz lineer (LERP) küreyi keser ve normu küçültür; SLERP normu korur."
#| fig-width: 12
#| fig-height: 5
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
ax = axes[0]
theta = np.linspace(0, 2*np.pi, 100)
ax.plot(np.cos(theta), np.sin(theta), 'k--', alpha=0.3, label='birim çember')
w1 = np.array([1, 0])
w2 = np.array([np.cos(2*np.pi/3), np.sin(2*np.pi/3)])
ts = np.linspace(0, 1, 9)
lerp_pts = np.array([(1-t)*w1 + t*w2 for t in ts])
omega = np.arccos(np.dot(w1, w2))
slerp_pts = np.array([
(np.sin((1-t)*omega)/np.sin(omega))*w1 + (np.sin(t*omega)/np.sin(omega))*w2
for t in ts
])
ax.plot(lerp_pts[:, 0], lerp_pts[:, 1], '-o', color='#ef4444', linewidth=2, markersize=7,
label='LERP (düz çizgi)', alpha=0.8)
ax.plot(slerp_pts[:, 0], slerp_pts[:, 1], '-o', color='#10b981', linewidth=2, markersize=7,
label='SLERP (küresel)', alpha=0.8)
ax.plot(*w1, 'o', color='#4f46e5', markersize=15, markeredgecolor='white', zorder=5)
ax.plot(*w2, 'o', color='#be185d', markersize=15, markeredgecolor='white', zorder=5)
ax.text(w1[0]+0.05, w1[1]+0.1, '$\\mathbf{w}_1$', fontsize=14, weight='bold')
ax.text(w2[0]-0.15, w2[1]+0.1, '$\\mathbf{w}_2$', fontsize=14, weight='bold')
ax.set_xlim(-1.4, 1.4)
ax.set_ylim(-1.4, 1.4)
ax.set_aspect('equal')
ax.legend(fontsize=10)
ax.grid(alpha=0.3)
ax.set_title('SLERP vs LERP — küresel interpolasyon norm korur', fontsize=11)
ax = axes[1]
lerp_norms = np.linalg.norm(lerp_pts, axis=1)
slerp_norms = np.linalg.norm(slerp_pts, axis=1)
ax.plot(ts, lerp_norms, '-o', color='#ef4444', linewidth=2, markersize=8, label='LERP norm')
ax.plot(ts, slerp_norms, '-o', color='#10b981', linewidth=2, markersize=8, label='SLERP norm')
ax.axhline(1.0, color='gray', linestyle=':', alpha=0.7, label='ideal (=1)')
ax.set_xlabel('t (interpolasyon)', fontsize=11)
ax.set_ylabel('||w(t)||', fontsize=11)
ax.set_title('Norm karşılaştırması\nLERP küçülür, SLERP sabit kalır', fontsize=11)
ax.legend(fontsize=10)
ax.grid(alpha=0.3)
ax.set_ylim(0.4, 1.2)
plt.tight_layout()
plt.show()
```
**DARE-TIES** ise üç+ modeli birleştirebilir:
- **DARE** (Drop And REscale): bir modelin parametrelerinin rastgele kısmını sıfırla, geri kalanı yeniden-ölçekle.
- **TIES** (TrIm, Elect Sign, & Sum): yalnızca **en büyük** parametreleri tut; çelişen işaretler için **sign consensus**.
Pratik kural: **aynı mimari + aynı boyut + aynı precision** modellerini birleştir.
**Kullanım örneği — dil-özel model:** Llama 3 base'i Fince üzerinde continual pre-training + SFT + DPO ile eğit → "Fince'de iyi, başka her şeyde berbat" (catastrophic forgetting). Çözüm: bu Fince modeli **Llama-3-instruct** ile **merge** et. Sonuç: **Fince'de iyi + her şeyde iyi** model.
Araç: **MergeKit** (open-source).
::: {.callout-tip title="Builder Notu"}
**Geriye (18.06):** SLERP, birim küre üzerindeki vektörler arası geodezik. Aynı zamanda **Riemann ortalaması** kavramının basit hâli.
**İleriye:** **Mixture of Adapters**, **ModelSoup**, **FrankenMoE**, **Distillation + Merging** kombinasyonları. Liquid AI ve Mistral merge'i ürün geliştirme stratejilerinin parçası yaptı.
:::
## Evaluation: Üç Yaklaşım, Hepsi Eksik {#sec-evaluation}
Maxime şunu kabul ediyor: "LLM evaluation çalışmıyor, ne yaptığımızı bilmiyoruz." Üç ana yaklaşım var:
**(1) Otomatik benchmarklar:** MMLU, GSM8K, HumanEval. **Güçlü:** ölçeklenebilir, ucuz. **Zayıf:** "gerçek hayatta böyle kullanılmıyor" + **leak** riski.
**(2) İnsan değerlendirmesi (Chatbot Arena):** Elo skor. **Güçlü:** doğru sinyal. **Zayıf:** pahalı, biased (uzun > kısa, kendinden emin > tereddütlü, markdown > düz metin).
**(3) LLM-as-judge:** Bir LLM diğer LLM'in çıktısını yargılar. **Güçlü:** insan kadar nüanslı + ölçeklenebilir. **Zayıf:** yargıç model insan biaslarını taşır + kendine has biases (kendi çıktısını tercih etme).
> *"human preferences are not correlated with automated benchmarks... you can be really good on MMLU and really bad in terms of human preferences and vice versa. This is why these two approaches are complementary."* — Maxime, 45:39
::: {.callout-tip title="Builder Notu"}
**Geriye (Ders 7):** LLM-as-judge tam olarak Doug Blank'ın Comet/Opik dersindeki temadır. Burada Maxime aynı tekniği **eğitim cephesinde** kullanıyor.
**İleriye:** **MT-Bench**, **AlpacaEval 2**, **Arena-Hard**, **HELM**, **AGIEval**, **BBH**. **Inspect AI**, **HumanityLastExam**, **GPQA** frontier modelleri test ediyor. Eval'i CI/CD'ye entegre et.
:::
## Test-Time Compute Scaling {#sec-test-time-compute}
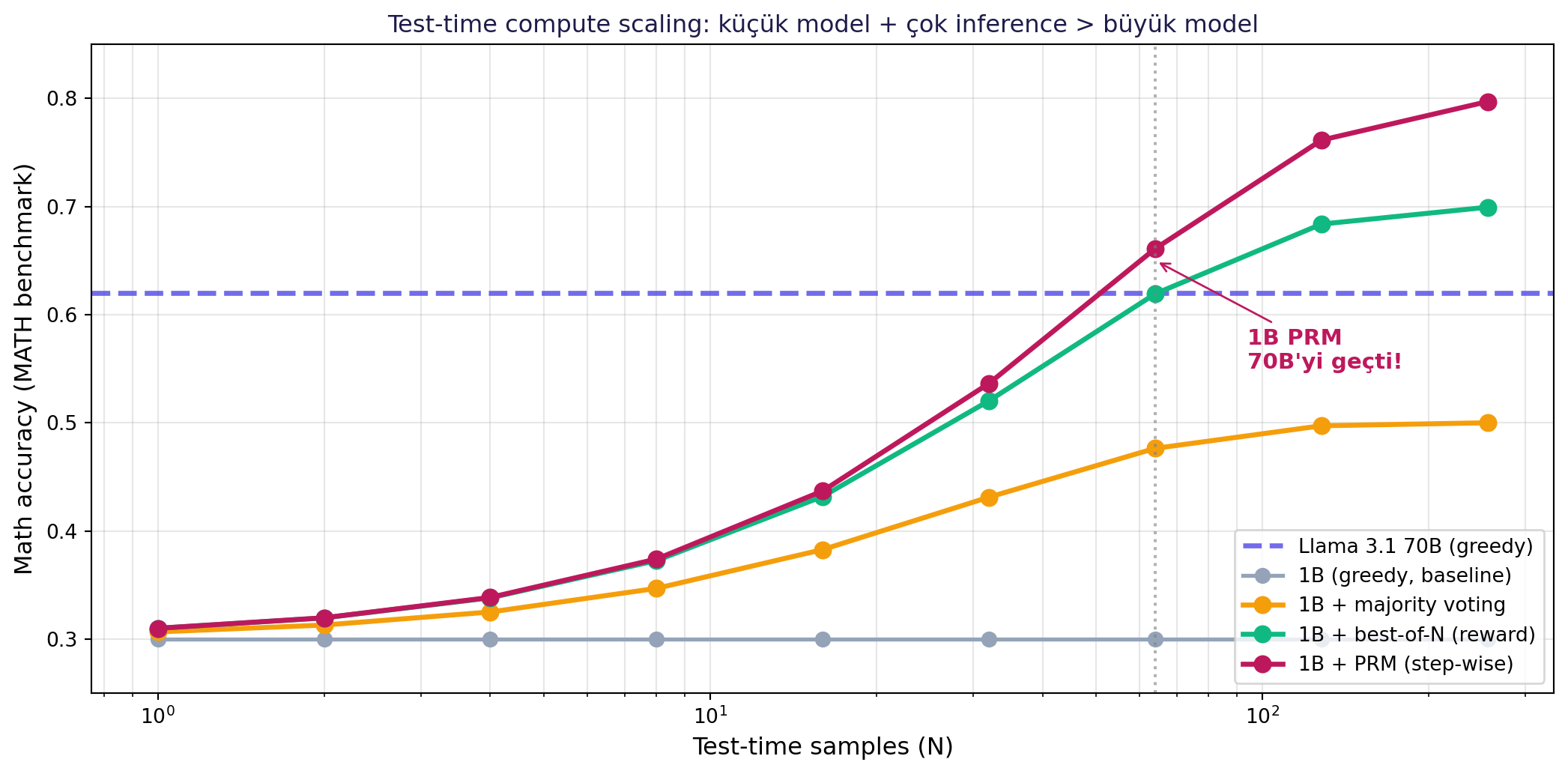
Post-training'in en son cephesi: **inference sırasında daha çok hesap kullanmak**. Yeni düşünce: "inference sırasında compute büyütürsem **küçük model bile** büyük modelin üzerine çıkabilir."
Üç giderek karmaşıklaşan strateji:
**(1) Majority voting:** Model'e aynı soruyu N kez sor. En sık çıkan cevabı seç.
**(2) Best-of-N:** N farklı cevap üret + **reward model** her cevabı puanlasın + en yüksek skorluyu seç.
**(3) Process Reward Models (PRM):** Cevabı bir bütün olarak puanlamak yerine, **adım adım** puanla. Düşük puanlı adımı **at**, yüksek puanlıyı **genişlet**. Beam search benzeri tree-search.
```{python}
#| label: fig-test-time-scaling
#| fig-cap: "Test-time compute scaling. N (sample sayısı) arttıkça doğruluk artar. Llama 3.2 1B + PRM yeterli N ile Llama 3.1 70B'yi geçer (HuggingFace deneyi)."
#| fig-width: 11
#| fig-height: 5.5
n_samples = np.array([1, 2, 4, 8, 16, 32, 64, 128, 256])
acc_70b = 0.62
acc_1b_greedy = 0.30 * np.ones_like(n_samples, dtype=float)
acc_1b_majority = 0.30 + 0.20 * (1 - np.exp(-n_samples / 30))
acc_1b_bon = 0.30 + 0.40 * (1 - np.exp(-n_samples / 40))
acc_1b_prm = 0.30 + 0.50 * (1 - np.exp(-n_samples / 50))
fig, ax = plt.subplots(figsize=(11, 5.5))
ax.axhline(acc_70b, color='#4f46e5', linestyle='--', linewidth=2.5, label='Llama 3.1 70B (greedy)', alpha=0.8)
ax.plot(n_samples, acc_1b_greedy, '-o', color='#94a3b8', linewidth=2, markersize=7, label='1B (greedy, baseline)')
ax.plot(n_samples, acc_1b_majority, '-o', color='#f59e0b', linewidth=2.5, markersize=8, label='1B + majority voting')
ax.plot(n_samples, acc_1b_bon, '-o', color='#10b981', linewidth=2.5, markersize=8, label='1B + best-of-N (reward)')
ax.plot(n_samples, acc_1b_prm, '-o', color='#be185d', linewidth=2.5, markersize=8, label='1B + PRM (step-wise)')
crossover_idx = np.argmax(acc_1b_prm > acc_70b)
if crossover_idx > 0:
ax.axvline(n_samples[crossover_idx], color='gray', linestyle=':', alpha=0.6)
ax.annotate('1B PRM\n70B\'yi geçti!', xy=(n_samples[crossover_idx], 0.65),
xytext=(n_samples[crossover_idx]+30, 0.55),
arrowprops=dict(arrowstyle='->', color='#be185d'),
fontsize=11, color='#be185d', weight='bold')
ax.set_xscale('log')
ax.set_xlabel('Test-time samples (N)', fontsize=12)
ax.set_ylabel('Math accuracy (MATH benchmark)', fontsize=12)
ax.set_title('Test-time compute scaling: küçük model + çok inference > büyük model',
fontsize=12, color='#1e1b4b')
ax.legend(fontsize=10, loc='lower right')
ax.grid(alpha=0.3, which='both')
ax.set_ylim(0.25, 0.85)
plt.tight_layout()
plt.show()
```
> *"the score that you get is pretty much the probability that this step will give you the right answer in the end... we iteratively get better and better steps."* — Maxime, 51:32
**Çarpıcı sonuç:** HuggingFace çalışmasında **Llama 3.2 1B/3B**, yeterli test-time compute ile **Llama 3.1 8B/70B'yi geçti** matematik benchmarklarında. Bu, **reasoning models** (OpenAI o1, DeepSeek R1, Claude extended thinking) sınıfının temelidir.
::: {.callout-tip title="Builder Notu"}
**Geriye (Stat 110 + Ders 5):** Majority voting tam olarak **Monte Carlo örneklem**. PRM ise Ders 5'in reward model'inin **adım-bazlı** versiyonu.
**İleriye:** **AlphaGo-style MCTS** + LLM (AlphaProof), **Reasoning models** DPO + GRPO + PRM kombinasyonları, **Self-Consistency**, **Reward hacking** aktif araştırma. Küçük modeller + test-time compute, frontier API maliyetinin %1'i ile karşılaştırılabilir kalite üretebilir.
:::
## Post-Training Döngüsü: %33-%33-%33 {#sec-doengue}
Maxime dersi bir formülasyonla bitiriyor: post-training emeği üç eşit parçaya ayrılır.
- **Veri (%33):** Seed seç, refine, score+filter, dedup ve decontaminate.
- **Eğitim (%33):** SFT → preference alignment → opsiyonel model merging.
- **Evaluation (%33):** Otomatik benchmark + insan + LLM-judge **birlikte**.
Ve hepsi bir **döngü**'dür:
> *"when you evaluate the model, you do not only evaluate the fine-tuning process. What you evaluate the most is actually the data and the quality of the data: the mixture, the diversity, complexity, and the accuracy of your training data."* — Maxime, 58:13
Bu, post-training endüstrisinin gerçek sırrıdır: model mimarisi, eğitim kodu, hyperparameter'lar — hepsi büyük ölçüde **standart**. Farkı yaratan **veri**.
## Bu Dersin Özeti {#sec-ozet}
1. **Post-training:** base modeli asistana çevirir. İki ana aşama: **SFT** (format öğret) + **preference alignment** (tercih hizala).
2. **İyi veri** üç boyutludur: **doğruluk + çeşitlilik + karmaşıklık**. Pre-training'de "daha çok daha iyi", post-training'de **az ama kaliteli** kazanır.
3. **Veri üretim pipeline'ı:** seed → refine → score/filter → dedup/decontaminate.
4. **Chat template** modele konuşma yapısını öğretir; SFT'nin asıl marifeti budur.
5. **SFT teknikleri:** full fine-tune, **LoRA** (low-rank adaptör), **QLoRA** (4-bit + adaptör).
6. **Preference alignment:** **PPO** (3 model, klasik) vs **DPO** (2 model, modern standart). 100+ varyant.
7. **Training params:** LR (en kritik), batch size, gradient accumulation, AdamW, FlashAttention.
8. **Model merging:** SLERP (2 model, küresel) + DARE-TIES (çoklu, sparse + sign consensus).
9. **Evaluation:** otomatik benchmark + insan + LLM-as-judge üçlüsü; insan tercihi ile otomatik benchmark **korele değildir**.
10. **Test-time compute scaling:** majority voting → best-of-N → PRM. Llama 3.2 1B yeterli inference ile 70B'yi geçebilir.
::: {.callout-important}
Post-training, base modeli SFT (format) + preference alignment (tercih) + opsiyonel merging (yetenek toplama) ile asistana çevirir; modern endüstri sırrı şudur: fark **mimari değil, veri**dir.
:::
## Kontrol Soruları {#sec-kontrol}
::: {.callout-note collapse="true" title="Soru 1 — LoRA parametre hesabı"}
Bir LLM'in 4096-boyutlu bir lineer katmanı ($W \in \mathbb{R}^{4096 \times 4096}$, ~16.7M parametre) için LoRA rank r=8 ile kaç parametre eğitilir?
**Cevap:** LoRA, W güncellemesini $W' = W + \alpha \cdot B \cdot A$ olarak parçalar:
- $A \in \mathbb{R}^{8 \times 4096}$ = 32,768 parametre
- $B \in \mathbb{R}^{4096 \times 8}$ = 32,768 parametre
- **Toplam adaptör = 65,536 parametre**
Tam fine-tune: $4096^2$ = 16,777,216 parametre. **Oran: %0.39** — LoRA bu katman için **256× daha az** parametre eğitir. Bellek, optimizer states ve gradient'lerin hesaba katılmasıyla VRAM düşüşü daha da büyük olur.
:::
::: {.callout-note collapse="true" title="Soru 2 — SFT vs Preference Alignment veri yapısı"}
SFT için **(prompt, cevap)** çiftleri yeter; preference alignment için **(prompt, chosen, rejected)** üçlü gerekir. Neden?
**Cevap:** SFT'nin görevi **format ve görev öğretmek**: "bu prompt'a şu cevap iyidir." Tek hedef cevap yeter; cross-entropy ile olasılığı maksimize edilir.
Preference alignment'ın görevi **göreli tercih öğretmek**: "A cevabı B'den iyi." Bu öğretim için **karşılaştırma** zorunlu — modelin "hangi yönde" güncelleneceğini bilmek için kontrast lazım. DPO loss'unda net görünür: chosen/rejected log-ratio farkına sigmoid uygulanır. Bradley-Terry tercih modelinin MLE'si.
:::
::: {.callout-note collapse="true" title="Soru 3 — Diversity collapse paradoksu"}
Sentetik veri "az miktarda eklenirse çeşitliliği arttırır, çok eklenirse diversity collapse'a yol açar." Neden?
**Cevap:** Bir LLM kendi eğitim dağılımından örnek üretir — sentetik veri **modelin kendi geçmişinin** yansımasıdır.
- **Az miktarda (≤%10-20):** Veri setindeki **boşlukları doldurur**. Data augmentation gibi.
- **Çok miktarda (>%50):** Model giderek **kendi dağılımını** öğrenir. Aradaki entropi gittikçe daralır — **model collapse** (Shumailov ve ark., Nature 2024).
**Builder dersi:** sentetik veri destek olarak kullan, omurga olarak değil. 1:5 (sentetik:gerçek) güvenli; >1:1 risklidir.
:::
::: {.callout-note collapse="true" title="Soru 4 — Hangi eval ne zaman?"}
**Cevap:** Her birinin maliyet/kalite/ölçeklenebilirlik dengesi farklı:
- **Otomatik (MMLU, GSM8K):** İlk hızlı eleme + CI/CD regresyon. Belirli yetenekler.
- **İnsan:** Ürün lansman öncesi + production izleme. Subjektif kalite. Pahalı + biased.
- **LLM-as-judge:** Eğitim sırasında her checkpoint + scaled evaluation. Multi-judge consensus + insan örneklem ile valide et.
**Genel asistan:** Üçü de gerek. **Domain-specific (örn. tıbbi):** Custom domain benchmark + domain uzmanı + LLM-judge kalibrasyonu.
:::
::: {.callout-note collapse="true" title="Soru 5 — DPO neden PPO'dan basit?"}
**Cevap:** PPO 3 model gerektirir (training policy + frozen reference + reward model) ve **RL döngüsü** çalıştırır. Karmaşık, pahalı, kararsız.
DPO'nun türetimi RLHF amaç fonksiyonunun KL kısıtı altında kapalı-form çözümünü gösterir; reward model **olmadan** ifade edilebilir. Yalnızca 2 model + standart supervised cross-entropy-benzeri loss yeter. RL döngüsü yok, gradient stable, eğitim ucuz.
:::
## Egzersizler {#sec-egzersiz}
**Egzersiz 1 — Mini SFT (TRL + LoRA).** HuggingFace TRL + PEFT ile küçük bir base modeli (Qwen2.5-0.5B, Llama-3.2-1B) basit bir instruction dataset üzerinde LoRA ile SFT yap. Base vs SFT modeline aynı 5 soruyu sor.
```python
from trl import SFTTrainer, SFTConfig
from peft import LoraConfig
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-0.5B")
tok = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-0.5B")
peft_config = LoraConfig(r=8, lora_alpha=16, target_modules=["q_proj","v_proj"])
trainer = SFTTrainer(model=model, tokenizer=tok, train_dataset=dataset,
peft_config=peft_config, args=SFTConfig(num_train_epochs=3))
trainer.train()
```
**Egzersiz 2 — DPO loss elle.** Bir (prompt, chosen, rejected) üçlüsü ver; frozen reference ve training model log-olasılıklarını hesapla; DPO loss'u Python'da elle yaz.
```python
import torch, torch.nn.functional as F
def dpo_loss(pi_chosen, pi_rejected, ref_chosen, ref_rejected, beta=0.1):
pi_logratio = pi_chosen - pi_rejected
ref_logratio = ref_chosen - ref_rejected
logits = beta * (pi_logratio - ref_logratio)
return -F.logsigmoid(logits).mean()
```
**Egzersiz 3 — Çeşitlilik ölçümü.** İki veri seti hazırla (biri tek-konu, biri çok-konulu). Her örneği sentence-transformer ile embed et. (a) Varyansı hesapla. (b) Pairwise mesafelerin ortalamasını al. Çok-konulu setin daha yüksek olduğunu gözle.
**Egzersiz 4 — Test-time compute.** Küçük bir matematik dataset (GSM8K'dan 50 soru) üzerinde Qwen 1.5B: Greedy / Majority (10 sample) / Best-of-N (10 sample + reward). Doğruluk %'lerini karşılaştır.
**Egzersiz 5 — Ders 11 hazırlığı.** Ders 11 LLM ve Ajanları işleyecek. (a) Bir LLM'in araç çağırma yeteneği nasıl post-training ile öğretilir? Tool-use SFT veri seti örnekleri ara. (b) Modern agent framework'leri (LangChain, CrewAI, MCP) tarayan kısa bir özet hazırla.
## Sonraki Ders İçin Hazırlık {#sec-sonraki}
**Ders 11: Büyük Dil Modelleri ve Ajanlar (LLMs & Agents)** — 2025 misafir.
Ders 10 base modeli asistana çevirdi; Ders 11 asistanı **autonomous ajan**a çevirir. Tool kullanım, planlama, hafıza, çoklu-adım reasoning.
::: {.callout-warning}
**Ders 11 öncesi yapılacak:** Egzersizleri çöz — özellikle 1 (SFT) ve 4 (test-time compute). DPO vs PPO farkını kendi cümlenle anlat. Ana cümleyi tekrar oku: "Post-training, base modeli SFT + preference alignment + opsiyonel merging ile asistana çevirir."
:::
## Anahtar Kavramlar (Cheat Sheet) {#sec-cheat}
| Kavram | Tanım | Maxime'de |
|--------|-------|-----------|
| Post-training | Pre-training sonrası: base'i asistana çevirme | 1m10 |
| SFT | (prompt, cevap) çiftleriyle format + görev öğretimi | 1m45 |
| Preference alignment | (prompt, chosen, rejected) ile tercih hizalama | 2m20 |
| 3 boyutlu veri kalitesi | Doğruluk + Çeşitlilik + Karmaşıklık | 8m43 |
| Diversity collapse | Çok sentetik = dağılım daralması | 10m23 |
| Chat template | im_start/im_end + system/user/assistant rolleri | 18m06 |
| Full fine-tune | Tüm parametreler güncellenir; en pahalı | 20m59 |
| LoRA | $W' = W + \alpha BA$; %0.5 parametre eğitilir | 21m47 |
| QLoRA | 4-bit + LoRA; tek GPU'da 70B fine-tune | 22m43 |
| PPO | Klasik RLHF, 3 model + KL ceza | 23m47 |
| DPO | Reward-modelsiz, kapalı-form; 2 model; standart | 24m57 |
| SLERP | Küresel lineer interpolasyon; iki model merge | 31m44 |
| DARE-TIES | Çoklu merge: drop+rescale + sign consensus | 32m16 |
| MMLU vs Arena | Otomatik vs insan; **korele değil** | 43m41 |
| LLM-as-judge | LLM diğer LLM'i puanlar; biases taşır | 46m41 |
| Majority voting | N cevap → en sık olanı seç | 50m03 |
| Best-of-N + PRM | Reward ile adım puanla; küçük > büyük olabilir | 50m45 |
## ML Builder Bağlantıları {#sec-baglantilar}
::: {.callout-tip title="8 köprü"}
1. **SFT loss** → Ders 1 cross-entropy + Ders 6 next-token prediction.
2. **Preference alignment** → Ders 5 RLHF + Stat 110 Bernoulli/Bradley-Terry (Ders 8) + Ders 17 MLE.
3. **LoRA** → 18.06 low-rank approximation + SVD (Ders 29). DoRA, AdaLoRA varyantları.
4. **DPO** → Stat 110 closed-form MLE; RL'siz preference optimization.
5. **Model merging (SLERP)** → 18.06 vektör uzayı + Riemann geometrisi (küre üzerinde interpolasyon).
6. **Diversity** → Stat 110 entropy + Ders 4 generative dağılım kapsama.
7. **LLM-as-judge** → Ders 7 Doug Blank dersinin eğitim cephesi karşılığı.
8. **Test-time compute + PRM** → Stat 110 Monte Carlo + Ders 5 reward model + Ders 6 reasoning models (o1, R1).
:::
::: {.callout-important}
**Bu dersten tek bir şey alıp gideceksen:** post-training, base modeli **SFT + preference alignment** ikilisiyle asistana çevirir; modern endüstri sırrı **mimari değil veri**dir — doğruluk + çeşitlilik + karmaşıklık üçlüsünü tutturduğun veri seti, hangi algoritmayı seçersen seç iyi modeli üretir. Ve evaluation senin pusuludur: ölçemediğin şeyi optimize edemezsin.
:::