flowchart LR
T["metin<br/>(ham cümle)"] --> TOK["tokenization<br/>(subword)"]
TOK --> NUM["numericalization<br/>(input_ids)"]
NUM --> PM["pretrained dil modeli<br/>+ fine-tune"]
PM --> CLS["NLP sınıflandırması"]
VAL["validation / test set<br/>disiplini<br/>(overfitting'i yakala)"] --> CLS
style T fill:#cffafe,stroke:#0891b2,stroke-width:2px
style NUM fill:#cffafe,stroke:#0891b2,stroke-width:2px
style PM fill:#cffafe,stroke:#0891b2,stroke-width:2px
style VAL fill:#ffe4e6,stroke:#e11d48,stroke-width:3px
5 Doğal Dil İşleme — Metin, Tokenization ve Validation Disiplini (Natural Language Processing)
Metni token’lara böl, sayıya çevir (input_ids), pretrained bir dil modelini (deberta-v3-small) Hugging Face ile fine-tune et — ama asıl ustalık overfitting’i yakalayan doğru validation/test set’i kurmaktır; rastgele ayırmak çoğu zaman yanlıştır ve sessizce değer yok eder
NotBölüm bilgisi
- Howard’ın videosu: course.fast.ai — Lesson 4: Natural Language (NLP) (~95 dk)
- Seri: Practical Deep Learning for Coders — Part 1, Ders 4
- Hoca: Jeremy Howard
- Playlist: Practical Deep Learning Part 1 (2022)
- Notebook: course22 — Getting started with NLP (Hugging Face)
- Okuma süresi: ~35 dk
5.1 Bu Derste Ne Var?
Ders 1-3’te hep görüntülerle çalıştık; Ders 4 metne geçer. Howard bir Kaggle yarışması üzerinden (US Patent Phrase Matching — iki ifadenin anlamca ne kadar yakın olduğunu tahmin etme) NLP sınıflandırması kurar. Bu derste fastai değil, Hugging Face Transformers kullanılır. Ama dersin asıl kalbi mekanik değildir: ikinci yarı, tüm makine öğrenmesinin en kritik kavramına ayrılır — overfitting ve onu yakalayan validation/test set disiplini.
Üç temel fikir:
- Tokenization + numericalization — metni token’lara böl, sonra her token’ı sözlükteki konumuna (sayıya,
input_ids) çevir; modeller yalnızca sayıyla çalışır (Tokenization → Numericalization). - Pretrained dil modeli + fine-tune — görüntüdeki transfer learning aynen metne uygulanır;
deberta-v3-small’dan başla, kendi verine uyarla (Fine-tuning ve Transfer Learning). - İyi validation set = en kritik beceri — rastgele ayırmak çoğu zaman yanlıştır; modeli geleceği/yeni kişileri tahmin edecek şekilde test etmelisin, yoksa sessizce değer yok edersin (İyi Bir Validation Set Kurmak).
“In the real world outside of Kaggle you will often not even know that you overfit — you just destroy value for your organization silently.” — Howard, 54:19
Şekil 28.1 bu üç fikri, metinden başlayıp tokenization → numericalization → pretrained model + fine-tune zincirine ve ayrı bir kolda validation/test disiplinine uzanan tek bir haritada birleştirir.
İpucuBuilder Notu — Mekanik Kolay, Disiplin Zor
- Geriye (6.S191): NLP, 6.S191 Ders 2’deki dizi modelleme + transformer’ın pratik uygulamasıdır; “metin = token dizisi = sayı dizisi” — Howard burada o diziyi gerçek bir Kaggle problemine bağlar.
- İleriye (Part 2 / Karpathy): Tokenization Karpathy Ders 9’da (BPE) sıfırdan kurulur; Transformer Part 2 Ders 24’te. Bu derste ikisi de kara kutudur — Hugging Face Trainer hazır verir.
- Tek cümle: Metni sayıya çevirip pretrained bir modeli ince ayarlarsın; ama asıl ustalık doğru validation set’i kurmaktadır — gerisi birkaç satır.
5.2 Neden NLP için Farklı Kütüphane?
Howard bu derste fastai yerine Hugging Face Transformers kullanır. Sebebi: NLP’de transformer tabanlı modeller standart hâline geldi ve Transformers kütüphanesi bu ekosistemin merkezi. Howard, farklı bir kütüphane görmenin de öğretici olduğunu söyler — aynı kavramlar (tokenize, model, fine-tune) her yerde aynıdır.
“Why we’d be using a different library other than fast.ai.” — Howard, 1:13
İpucuBuilder Notu — Kavramlar Taşınır, API’ler Değişir
- İleriye: Tek bir kütüphaneye bağlı kalmamak builder için değerli; kavramlar taşınabilir, API’ler değişir. Hugging Face Trainer’ın fastai
Learner’ına ne kadar benzediğini birazdan göreceğiz — aynı fikir, farklı isim. - Geriye (Ders 3): Ders 3’te bir modelin “gradient descent ile uydurulan esnek bir fonksiyon” olduğunu kurmuştuk; o çekirdek kütüphaneden bağımsızdır — Transformers de aynı çekirdeği eğitir.
5.3 Fine-tuning ve Transfer Learning
NLP’de de fikir görüntüdekiyle aynıdır: sıfırdan eğitmeyiz, pretrained bir dil modelinden başlar, onu kendi görevimize ince ayarlarız. Howard, Zeiler-Fergus katman görselleştirmesini (Ders 3’teki gibi) hatırlatır: alt katmanlar genel, üst katmanlar göreve özel öznitelikler öğrenir.
“Finetuning a pretrained model.” — Howard, 3:25
Şekil 5.2 pretrained dil modelinin (genel dili öğrenmiş) fine_tune ile kendi görevimize (patent benzerliği) nasıl uyarlandığını gösterir — görüdeki vision_learner mantığının birebir aynısı.
Kod
# Transfer learning metne de uygulanır (ŞEMATİK / kavramsal akış — gerçek
# hesaplama yok). SOL: pretrained dil modeli (deberta-v3-small) → fine_tune →
# SAĞ: görev modeli (patent benzerlik skoru). Ders 1-3'teki vision_learner +
# fine_tune ile AYNI fikir; tek fark girdinin metin olması.
fig, ax = plt.subplots(figsize=(8.4, 3.1))
ax.set_xlim(0, 10)
ax.set_ylim(0, 4)
ax.axis("off")
# SOL: pretrained dil modeli (cyan kutu)
boxed_node(
ax, 2.35, 2.45, 3.7, 1.7,
"Pretrained dil modeli\n(deberta-v3-small)\ngenel dil, devasa metin",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_CYAN_700, fontsize=10.5, lw=2.2,
)
# SAĞ: görev modeli (rose kutu)
boxed_node(
ax, 7.65, 2.45, 3.5, 1.7,
"Görev modeli\n(patent benzerlik skoru)",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_ACCENT, fontsize=10.5, lw=2.2,
)
# OK: fine_tune (accent ile vurgulu)
arrow_between(ax, (4.2, 2.45), (5.9, 2.45), color=COL_ACCENT, lw=2.4,
mutation_scale=20, shrink=4)
ax.text(5.05, 2.95, "fine_tune", ha="center", va="center",
fontsize=11, color=COL_ACCENT, weight="bold", style="italic")
# ALT not: Ders 1-3 vision_learner ile aynı fikir
ax.text(
5.0, 0.62,
"Ders 1-3'teki vision_learner + fine_tune ile AYNI fikir; tek fark girdi metin",
ha="center", va="center", fontsize=10, color=COL_TEXT, style="italic",
)
ax.text(
5.0, 0.05,
"(transfer learning — görüntü → metin)",
ha="center", va="center", fontsize=8.5, color=COL_SLATE_400,
)
plt.show()fine_tune ile kendi görevimize (patent benzerliği) uyarlanır — görüdeki vision_learner mantığının aynısı.
İpucuBuilder Notu — Aynı Transfer, Yeni Modalite
- Geriye (Ders 1-3):
vision_learner+fine_tunemantığı; tek fark girdinin metin olması. Şekil 5.2’deki cyan→rose akışı, görüde gördüğümüz “genel öğren, sonra uyarla” zincirinin metin karşılığıdır. - İleriye (ULMFiT): NLP’ye transfer learning’i ilk getiren yöntem Howard’ın kendi icadı ULMFiT’tir; pretrained + fine-tune fikrinin metindeki köküdür.
5.4 Problem: US Patent Phrase Matching
Howard somut bir Kaggle yarışması seçer: iki patent ifadesinin (anchor ve target, bir bağlam içinde) anlamca ne kadar yakın olduğunu 0-1 arası bir skorla tahmin etme. Bu aslında bir regresyon problemidir (sürekli skor), ama NLP sınıflandırma altyapısıyla çözülür.
“US Patent Phrase to Phrase Matching Kaggle competition.” — Howard, 14:49
İpucuBuilder Notu — Benzerlik Skoru Her Yerde
- İleriye: “Benzerlik skoru” problemi semantic search, öneri sistemleri ve embedding tabanlı eşleştirmenin temelidir; bir kez kurduğun NLP sınıflandırıcı pek çok yere taşınır.
- İleriye (Metric vs Loss): Skor sürekli (regresyon) olduğu için metrik de süreklidir — bu yarışmada Pearson korelasyonu; sınıflandırma “doğruluk”undan farklı bir ölçü.
5.5 Veriyi Hazırlama
Model tek bir metin girdisi ister; Howard üç alanı (context, target, anchor) tek bir string’de birleştirir ve veriyi Hugging Face Dataset nesnesine çevirir.
df['input'] = 'TEXT1: ' + df.context + '; TEXT2: ' + df.target + '; ANC1: ' + df.anchor
from datasets import Dataset
ds = Dataset.from_pandas(df)
İpucuBuilder Notu — Yapıyı Modele İpucu Olarak Ver
- Geriye (Python): pandas DataFrame ile veri manipülasyonu; alanları işaretli (TEXT1/TEXT2/ANC1) birleştirmek modele yapıyı ipucu olarak verir — model, hangi parçanın ne olduğunu bu etiketlerden çıkarır.
- İleriye (Numericalization): Bu tek
inputstring’i birazdan tokenize edilipinput_ids’e dönüşecek; veri hazırlığı, tokenization’ın hammaddesidir.
5.6 Tokenization
Metni modele vermeden önce token’lara bölmek gerekir. En basit yol kelimelere bölmektir ama o zaman sözlük çok büyür ve nadir kelimeler sorun olur. Modern yöntem subword tokenization: kelimeleri sık geçen parçalara böler.
“We don’t want a vocabulary to be too big. So instead, nowadays, people tend to tokenize into something called subwords.” — Howard, 31:02
Kritik kural: tokenize ederken modeli eğitenlerle birebir aynı yöntemi kullanmalısın, yoksa farklı token’lar çıkar.
from transformers import AutoTokenizer
model_nm = 'microsoft/deberta-v3-small'
tokz = AutoTokenizer.from_pretrained(model_nm)
tokz.tokenize("A platypus is an ornithorhynchus anatinus.")
# platypus -> ['platypus'], ornithorhynchus -> ['or','ni','tho','rhynch','us']Şekil 5.3 tüm boru hattını tek bir resimde toplar: ham cümle → subword token’lar (ornithorhynchus → or·ni·tho·rhynch·us) → her token’ın sözlük konumu (input_ids).
Kod
fig = plt.figure(figsize=(11.0, 5.8))
fig.patch.set_facecolor(COL_WHITE)
ax = fig.add_axes([0.0, 0.0, 1.0, 1.0])
ax.set_xlim(0, 12)
ax.set_ylim(0, 10)
ax.axis("off")
# --- Aşama başlıkları (üstte) ---
ax.text(1.85, 9.5, "1) METİN", ha="center", va="center",
fontsize=11.5, weight="bold", color=COL_CYAN_800)
ax.text(6.0, 9.5, "2) TOKEN (subword)", ha="center", va="center",
fontsize=11.5, weight="bold", color=COL_CYAN_800)
ax.text(10.3, 9.5, "3) input_ids", ha="center", va="center",
fontsize=11.5, weight="bold", color=COL_ACCENT)
# --- SOL: cümle kutusu (beyaz, soluk kenar) ---
boxed_node(ax, 1.85, 5.2, 3.0, 4.6,
"\"A platypus\nis an\nornithorhynchus\nanatinus.\"",
fc=COL_WHITE, ec=COL_SLATE_400, tc=COL_TEXT,
fontsize=11.0, lw=2.0, weight="normal")
# --- ORTA: subword token kutucukları (Howard örneği) ---
# platypus -> ['platypus'] ; ornithorhynchus -> ['or','ni','tho','rhynch','us']
tokens = ["platypus", "or", "ni", "tho", "rhynch", "us"]
ids = [38, 14, 92, 207, 461, 15] # illüstratif sözlük konumları
ty = np.linspace(8.35, 1.75, len(tokens))
mid_x = 6.0
for tok, yy in zip(tokens, ty):
boxed_node(ax, mid_x, yy, 2.4, 0.82, f"'{tok}'",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT,
fontsize=10.5, lw=2.0, weight="bold")
# --- SAĞ: input_ids (rose, accent) ---
right_x = 10.3
for idv, yy in zip(ids, ty):
boxed_node(ax, right_x, yy, 1.5, 0.82, str(idv),
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT,
fontsize=11.5, lw=2.0, weight="bold")
# --- Aşamalar arası oklar + etiketler ---
# cümle -> token kutuları (tek geniş ok)
arrow_between(ax, (3.45, 5.2), (4.75, 5.2),
color=COL_PRIMARY, lw=2.6)
ax.text(4.1, 5.95, "tokenize", ha="center", va="center",
fontsize=10.5, style="italic", weight="bold", color=COL_CYAN_700)
# token -> input_ids (her satır için küçük ok)
for yy in ty:
arrow_between(ax, (mid_x + 1.25, yy), (right_x - 0.80, yy),
color=COL_ACCENT, lw=1.8, shrink=4, mutation_scale=12)
ax.text(8.55, 8.95, "numericalize", ha="center", va="center",
fontsize=10.5, style="italic", weight="bold", color=COL_ACCENT)
# --- Alt-not ---
ax.text(6.0, 0.55,
"model yalnızca sayıyla çalışır; eğiten ile AYNI tokenizer şart",
ha="center", va="center", fontsize=10.5, style="italic",
weight="bold", color=COL_CYAN_800)
plt.show()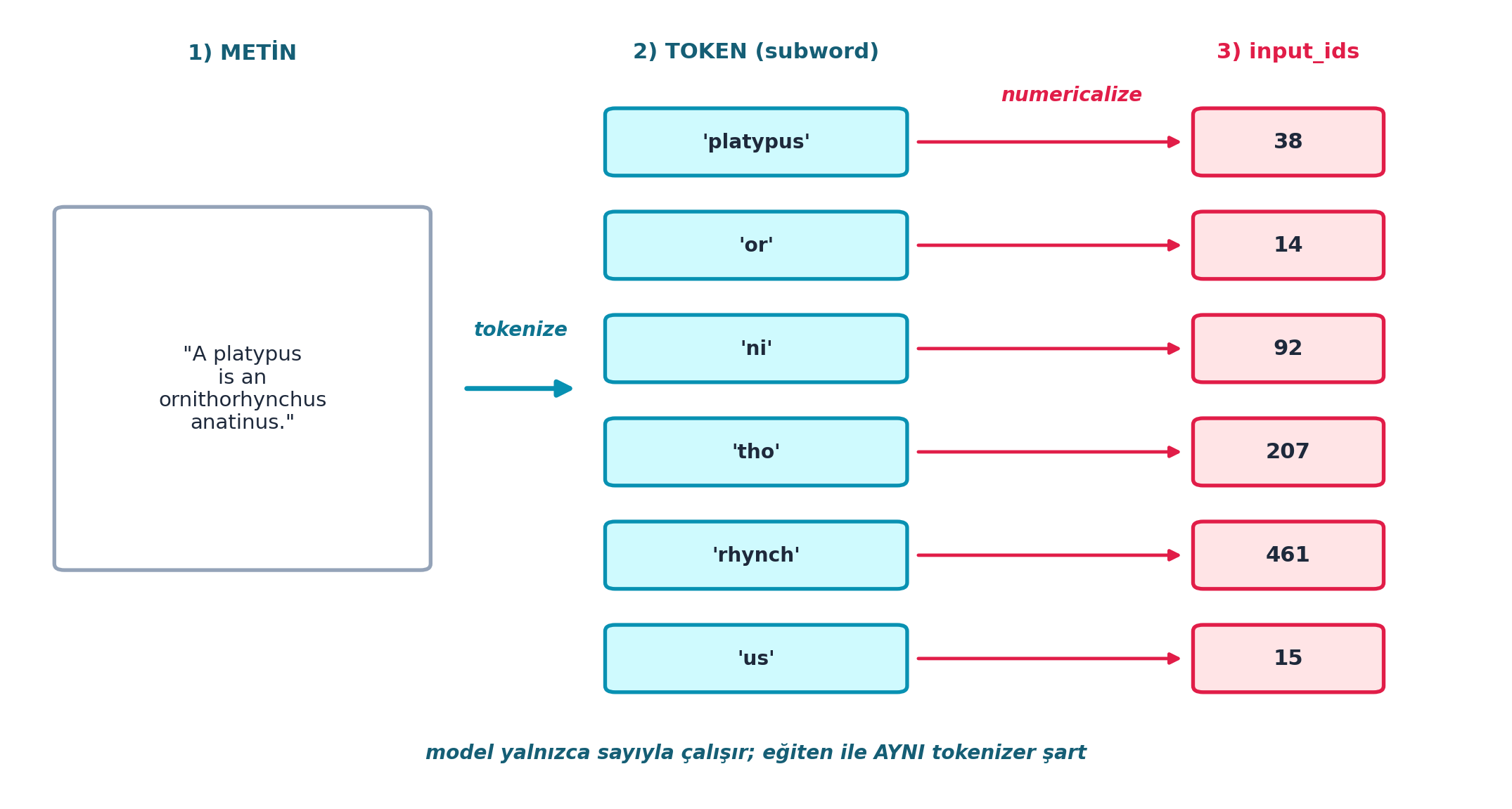
İpucuBuilder Notu — Neden Subword?
- İleriye (Karpathy Ders 9): Subword/BPE tokenization Karpathy’nin minbpe dersinde sıfırdan kurulur; “neden subword?” sorusu orada derinleşir — burada
AutoTokenizerhazır verir, orada elle örersin. - Pratik: Şekil 5.3’daki “eğiten ile AYNI tokenizer şart” uyarısı kritiktir; yanlış tokenizer, modelin öğrendiği sözlük konumlarıyla uyuşmaz ve çıktı anlamsızlaşır.
5.7 Vocabulary ve Hugging Face Model Hub
Vocabulary (sözlük), tüm benzersiz token’ların listesidir. Model seçimi tokenizer’ı da belirler — bu yüzden Howard önce modeli (deberta-v3-small) seçer. Hugging Face Model Hub binlerce pretrained model barındırır; AutoTokenizer doğru sözlüğü ve tokenize kurallarını otomatik indirir.
“When we say AutoTokenizer, it will download the vocabulary and the details about how this particular model tokenized the dataset.” — Howard, 35:57
İpucuBuilder Notu — Model + Tokenizer Ayrılmaz İkili
- İleriye: Model Hub, görüdeki timm’in NLP karşılığıdır; “doğru pretrained model + onun tokenizer’ı” ikilisi ayrılmaz. Ders 3’teki timm karşılaştırması görüde neyse, Model Hub metinde odur.
- Geriye (Tokenization):
AutoTokenizer.from_pretrained(model_nm)tek satırla doğru sözlüğü çeker — bu yüzden modeli seçmek tokenizer’ı da seçmektir.
5.8 Numericalization
Tokenization metni token’lara böler; numericalization her token’ı sözlükteki konumuna (bir sayıya, input_ids) çevirir. Model yalnızca bu sayılarla çalışır. Howard bir fonksiyon yazıp tüm veri setini toplu (batched) tokenize eder.
def tok_func(x): return tokz(x["input"])
tok_ds = ds.map(tok_func, batched=True)
tok_ds = tok_ds.rename_columns({'score': 'labels'}) # HF 'labels' bekler“These are the position in the vocabulary of each of the tokens in the string.” — Howard, 38:58
Şekil 5.3’ın sağ kolonu (rose input_ids kutuları) tam bu adımı gösterir: her token kutusu bir sayıya eşlenir.
İpucuBuilder Notu — Her Şey Sayıdır (Metin Sürümü)
- Geriye (Ders 1): “Her şey sayıdır” ilkesi — görüntü pikselleri gibi metin de token id’lerine dönüşür; modelin kapısı her zaman bir sayı dizisidir.
- Pratik: Hugging Face hedef sütununu
labelsadıyla arar; yeniden adlandırmazsan eğitim sessizce çalışmaz — bu, Trainer kurarken en sık yapılan hatadır.
5.9 ULMFiT
Howard, NLP için transfer learning’i ilk getiren kendi yöntemine değinir: ULMFiT. Önce büyük bir metin külliyatında bir dil modeli eğitilir (sonraki kelimeyi tahmin), sonra bu model hedef göreve ince ayarlanır. ULMFiT, büyük belgeleri (transformer’ların aksine) kolayca işleyebilir.
“ULMFiT fits large documents easily.” — Howard, 43:27
İpucuBuilder Notu — Transfer Learning’in NLP Kökü
- Geriye (Ders 1): ULMFiT, modern NLP devriminin iki temelinden biri (Ders 1’de Howard’ın icadı olarak geçti); RNN tabanlı, uzun belgelerde hâlâ avantajlı. Fine-tuning ve Transfer Learning bölümündeki fikrin tarihsel köküdür.
- İleriye: Transformer’lar kısa bağlamda üstün; ULMFiT uzun belgede; ikisi tamamlayıcı. “Tek doğru mimari” yoktur — bağlam uzunluğu kararı belirler.
5.10 Overfitting ve Underfitting
Dersin kalbi: bir model veriyi ne az ne çok öğrenmelidir. Howard bir polinom örneğiyle gösterir. 1. derece polinom (doğru) veriye yetersiz uyar — underfitting; sistematik olarak yanlıştır. 10. derece polinom eğitim verisini ezberler ama gerçek deseni kaçırır — overfitting. 2. derece tam isabettir.
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import make_pipeline
def plot_poly(degree):
model = make_pipeline(PolynomialFeatures(degree), LinearRegression())
model.fit(x, y); plt.scatter(x, y); plot_function(model.predict)
plot_poly(1) # underfit
plot_poly(10) # overfit
plot_poly(2) # tam isabet“We don’t want underfitting or overfitting. Underfitting is pretty easy to recognize; overfitting is a bit harder.” — Howard, 45:55
Şekil 5.4 aynı veriye üç farklı karmaşıklıkta polinom uydurur: derece 1 yetersiz (underfit), derece 2 tam isabet, derece 10 gürültüyü ezberler (overfit).
Kod
pf = poly_fit_demo((1, 2, 10))
titles = {
1: "derece 1 — underfit (yetersiz)",
2: "derece 2 — tam isabet",
10: "derece 10 — overfit (ezber)",
}
fig, axes = plt.subplots(1, 3, figsize=(12.6, 4.0))
for ax, d in zip(axes, (1, 2, 10)):
ax.scatter(pf["x"], pf["y"], color=COL_ACCENT, s=22, zorder=3,
edgecolors="white", linewidths=0.6, label="gürültülü veri")
ax.plot(pf["xs"], pf["fits"][d], color=COL_PRIMARY, lw=2.2, zorder=2,
label=f"derece {d} polinom")
ax.set_title(titles[d], fontsize=11.5, color=COL_TEXT, weight="bold")
ax.set_ylim(-3, 8)
ax.set_xlabel("x")
apply_style(ax)
axes[0].set_ylabel("y")
fig.suptitle("aynı veri, artan model karmaşıklığı", fontsize=12.5,
color=COL_TEXT, weight="bold", y=1.02)
fig.tight_layout()
plt.show()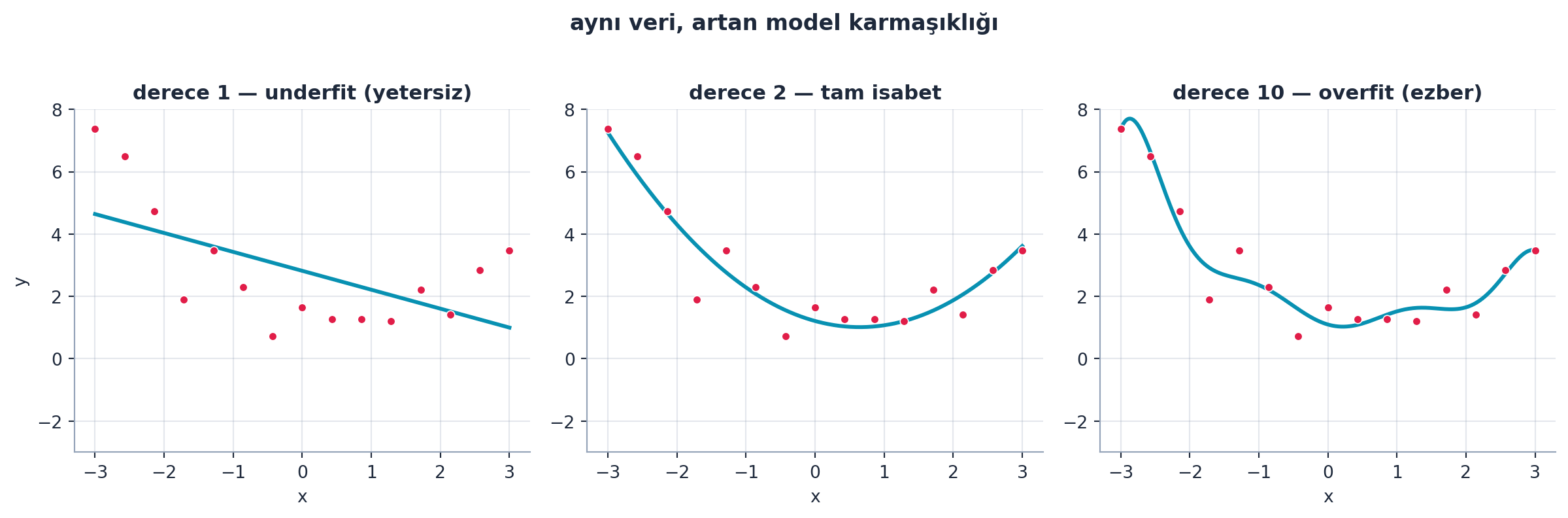
Aynı olguyu tek bir eğriyle özetlemenin yolu bias-variance dengesidir: model karmaşıklığı arttıkça train hatası hep düşer, ama validation hatası bir U çizer — en düşük noktası en iyi modeldir. Şekil 5.5 bunu gösterir.
Kod
# Bias-variance dengesi: model karmasikligi (polinom derecesi) arttikca
# train hatasi hep duser, validation hatasi U cizer (orta karmasiklikta en dusuk).
bv = bias_variance_demo()
degrees = bv["degrees"]
train_err = bv["train_err"]
valid_err = bv["valid_err"]
best = bv["best_degree"]
fig, ax = plt.subplots(figsize=(8.5, 4.6))
ax.plot(degrees, train_err, "o-", color=COL_PRIMARY, lw=2.2,
markersize=6, label="train hatası")
ax.plot(degrees, valid_err, "s-", color=COL_ACCENT, lw=2.2,
markersize=6, label="validation hatası")
ax.axvline(best, color=COL_SLATE_400, ls=":", lw=2.0,
label=f"en iyi (derece {best})")
# En iyi noktayi vurgula (validation minimumu)
best_idx = int(np.where(degrees == best)[0][0])
ax.scatter([best], [valid_err[best_idx]], color=COL_ACCENT, s=70, zorder=6,
edgecolor=COL_WHITE, linewidth=1.2)
# Bolgeler: solda underfit, sagda overfit
ax.annotate("underfit\n(yüksek bias)", xy=(degrees[0], valid_err[0]),
xytext=(1.2, valid_err[0] - 0.55), color=COL_TEXT,
fontsize=9, weight="bold", ha="left", va="top")
ax.annotate("overfit →\n(yüksek varyans)", xy=(degrees[-1], valid_err[-1]),
xytext=(degrees[-1] - 0.2, valid_err[-1]), color=COL_ACCENT,
fontsize=9, weight="bold", ha="right", va="top")
ax.set_xlabel("polinom derecesi (model karmaşıklığı)")
ax.set_ylabel("MSE")
ax.set_xticks(list(degrees))
ax.set_title("Bias-variance: en düşük validation orta karmaşıklıkta",
fontsize=12, weight="bold", color=COL_TEXT)
apply_style(ax)
ax.legend(loc="upper center", frameon=False, fontsize=9.5)
# Not: train hep duser; validation U cizer — overfit saginda yukselir
fig.text(0.5, -0.04,
"train hep düşer; validation U çizer — overfit sağında yükselir",
ha="center", va="top", fontsize=9, color=COL_TEXT, style="italic")
fig.tight_layout()
plt.show()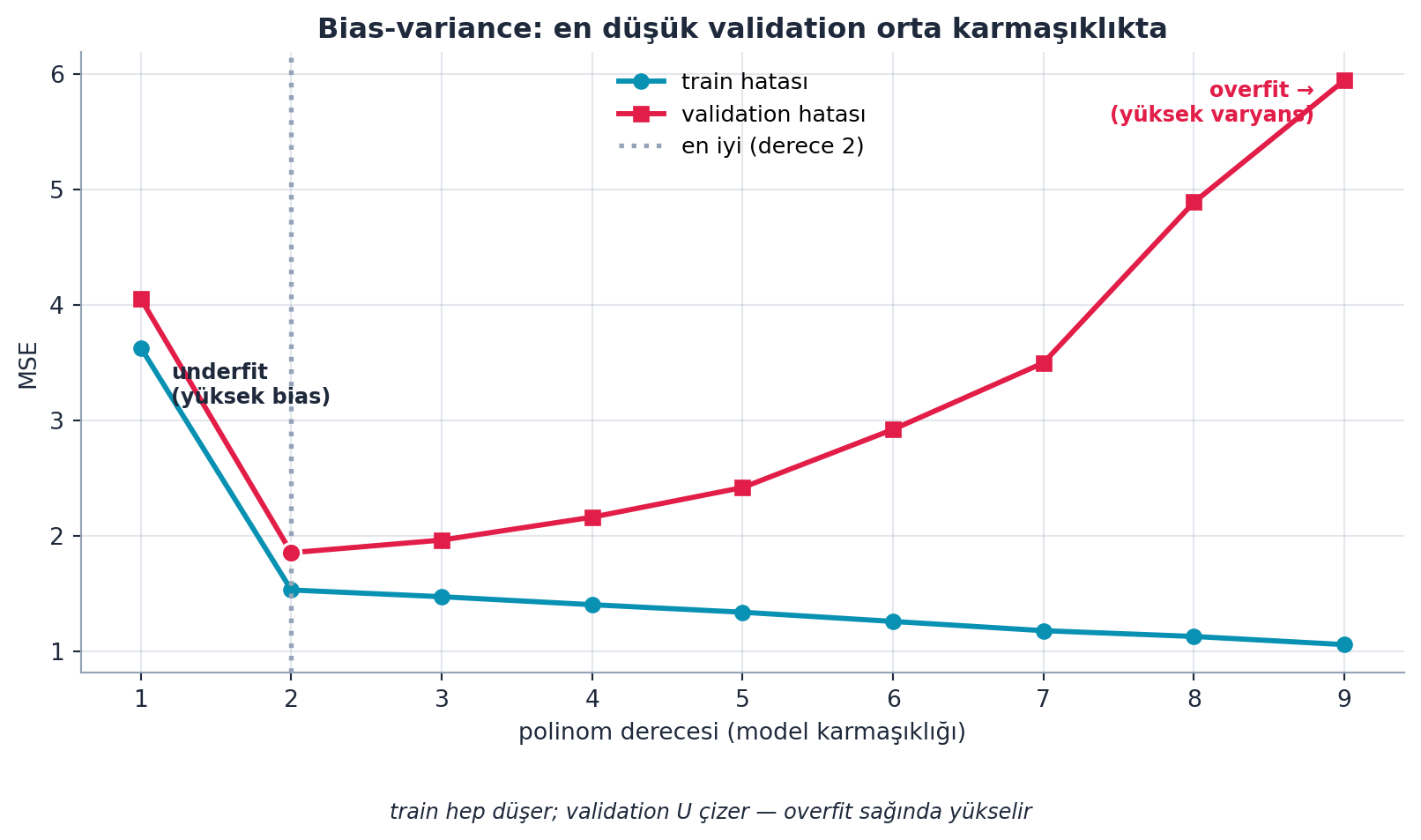
İpucuBuilder Notu — Underfit Kolay, Overfit Sinsi
- Geriye (Stat 110): Bias-variance dengesi; underfit = yüksek bias, overfit = yüksek variance. Şekil 5.5’taki U eğrisi tam bu istatistiksel dengeyi çizer — solu bias, sağı varyans.
- İleriye (Validation Set): Overfitting’i yakalamanın tek dürüst yolu validation set’tir — Şekil 5.4’teki derece-10 ezberini, ancak modelin görmediği veride ölçerek fark edersin; sıradaki bölüm bunu kurar.
5.11 Validation Set Neden Zorunlu?
Validation set, eğitimde kullanılmayan ama doğruluğu ölçmek için ayrılan veridir. Overfitting’i ancak modelin görmediği veride ölçerek yakalarsın. fastai bunu zorunlu kılar; çoğu kütüphane ise validation set’i atlamana izin vererek “ayağına sıkmanı” kolaylaştırır.
“Most libraries make it really easy to shoot yourself in the foot by not having a validation set. So fast.ai won’t even let you do that.” — Howard, 51:58
İpucuBuilder Notu — fastai Zorlar, Diğerleri İzin Verir
- Geriye (Ders 1):
RandomSplitter(valid_pct=0.2)tam bunu yapar; metrik yalnızca validation set’te ölçülür — Ders 1’de farkında olmadan kullandığın disiplin, burada açıkça gerekçelendirilir. - İleriye (İyi Bir Validation Set Kurmak): Validation set’in var olması yetmez; doğru kurulması gerekir — bir sonraki bölüm “rastgele ayırmak neden çoğu zaman yanlış” sorusunu açar.
5.12 İyi Bir Validation Set Kurmak
En kritik nokta: validation set’i rastgele ayırmak çoğu zaman yanlıştır. Zaman serisinde geleceği tahmin edeceksen, validation set son haftalar olmalı (ortadan rastgele değil). Modeli “geçmişi değil, geleceği” tahmin edecek şekilde test etmelisin.
“In a time series, you’re probably going to want to predict future dates. You should truncate and remove the last couple of weeks, testing whether you can predict the future, rather than the past.” — Howard, 53:17
Howard iki Kaggle örneği verir: dikkati dağılmış sürücü yarışmasında test set’te eğitimde olmayan kişiler vardı — iyi bir validation set de eğitimdekinden farklı kişiler içermeliydi. Balıkçılık yarışmasında ise model balığı değil tekneyi tanıyarak “kopya çekti.”
“Your validation set should contain photos of people that aren’t in the data you’re training your model on.” — Howard, 55:24
Şekil 5.6 aynı zaman serisini iki strateji ile ayırır: solda rastgele ayırma geleceği sızdırır (kötü — model komşu noktayı tanır), sağda son dönemi ayırmak geleceği tahmin etmeyi taklit eder (iyi).
Kod
# Aynı zaman serisi; iki farklı validation-split stratejisi yan yana
ts = timeseries_split_demo()
t = ts["t"]
y = ts["y"]
rmask = ts["random_valid"] # rastgele seçilmiş noktalar (KÖTÜ)
tmask = ts["timebased_valid"] # son %20 (İYİ)
fig, (ax_l, ax_r) = plt.subplots(1, 2, figsize=(11.0, 4.2), sharey=True)
# SOL — rastgele ayırma (KÖTÜ): gelecek sızar
ax_l.plot(t, y, color=COL_PRIMARY, lw=1.4, zorder=2, label="seri")
ax_l.scatter(t[rmask], y[rmask], color=COL_ACCENT, s=42, zorder=4,
edgecolor=COL_WHITE, linewidth=0.8, label="validation (rastgele)")
ax_l.set_title("rastgele ayırma — KÖTÜ", fontsize=12, weight="bold",
color=COL_ACCENT)
ax_l.set_xlabel("zaman")
ax_l.set_ylabel("değer")
ax_l.text(0.5, 1.02 * y.max(),
"gelecek sızar; model komşu noktayı ezberler",
ha="left", va="bottom", fontsize=9.5, color=COL_TEXT, style="italic")
apply_style(ax_l)
ax_l.legend(loc="lower right", frameon=False, fontsize=9)
# SAĞ — son-dönemi ayır (İYİ): geleceği test eder
t_split = t[tmask].min()
ax_r.axvspan(t_split - 0.5, t.max() + 0.5, color=COL_BG_ROSE, alpha=0.7,
zorder=1, label="validation bölgesi")
ax_r.plot(t, y, color=COL_PRIMARY, lw=1.4, zorder=2, label="seri")
ax_r.scatter(t[tmask], y[tmask], color=COL_ACCENT, s=42, zorder=4,
edgecolor=COL_WHITE, linewidth=0.8, label="validation (son %20)")
ax_r.axvline(t_split - 0.5, color=COL_SLATE_400, ls=":", lw=2.0, zorder=3)
ax_r.set_title("son-dönemi ayır — İYİ", fontsize=12, weight="bold",
color=COL_PRIMARY)
ax_r.set_xlabel("zaman")
ax_r.text(0.5, 1.02 * y.max(),
"geleceği test eder",
ha="left", va="bottom", fontsize=9.5, color=COL_TEXT, style="italic")
apply_style(ax_r)
ax_r.legend(loc="lower right", frameon=False, fontsize=9)
fig.suptitle("Zaman serisinde validation set: rastgele DEĞİL, son-dönem",
fontsize=12.5, weight="bold", color=COL_TEXT, y=1.03)
fig.tight_layout()
plt.show()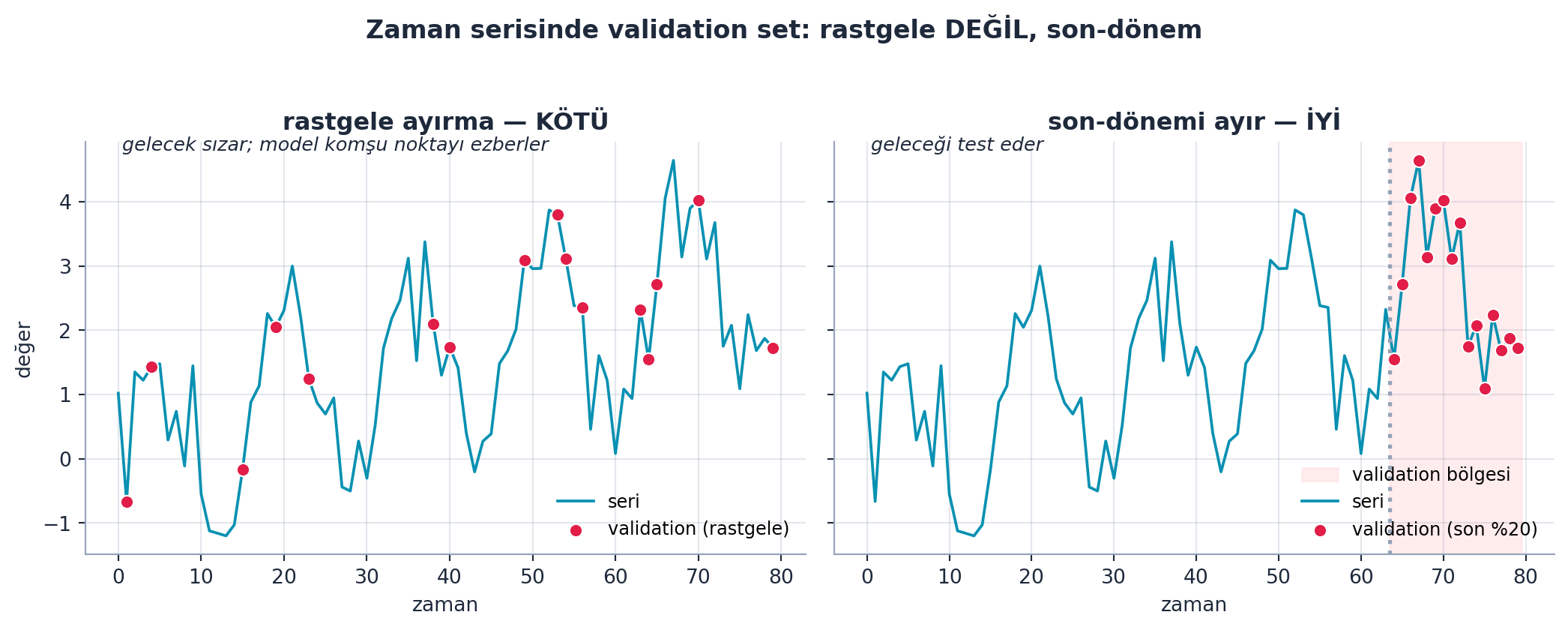
İpucuBuilder Notu — Validation = Gerçek Kullanımın Provası
- İleriye (production): Veri sızıntısı (data leakage) ve kötü validation set, gerçek dünyada sessiz başarısızlığın bir numaralı sebebidir.
train_test_split/random_splitterseni rastgele ayırmaya teşvik eder — Şekil 5.6’in sol paneli tam bu tuzağı gösterir; dikkatli ol. - Geriye (Overfitting): İyi validation set, Şekil 5.5’taki U eğrisinin minimumunu dürüst ölçmeni sağlar; kötü validation set o minimumu olduğundan iyi gösterir ve seni overfit bir modele yönlendirir.
5.13 Test Set
Test set, üçüncü bir ayrımdır: model geliştirirken doğruluğunu izlemek için bile kullanmazsın. Neden? Üç ay boyunca her gün iki model denersen 180 model denemiş olursun; bazıları validation set’te salt şans eseri iyi çıkar. Test set, “validation set üzerinde overfit” etmediğinden emin olmanı sağlar.
“A test set is basically another validation set, but you don’t even use it for tracking your accuracy while you build your model.” — Howard, 57:17
Howard acı gerçeği de söyler: üç ay çalışıp test set’te kötü sonuç alırsan, başa dönmekten başka çare yoktur — ama bilmek bilmemekten iyidir.
“If it’s terrible, honestly you have to go back to square one. Better to know than to not know.” — Howard, 58:44
Şekil 5.7 üç-yönlü ayrımı ve “validation üzerinde overfit” kavramını gösterir: çok sayıda denemeden biri validation’da şans eseri parlar; test set, hiç dokunulmadığından gerçek performansı söyler.
Kod
# fig-test-set — Uc-yonlu ayrim (train/validation/test) + 'validation uzerinde
# overfit' kavrami. KAVRAMSAL sema (gercek hesaplama yok) -> caption '(sematik)'.
# Notion Bolum 12 (Test Set): cok deneme -> bazilari validation'da SANS ESERI
# iyi cikar; test set gelistirme boyunca hic dokunulmadigindan panzehirdir.
fig, (ax_top, ax_bot) = plt.subplots(
2, 1, figsize=(8.4, 5.6), gridspec_kw={"height_ratios": [1.0, 2.2]}
)
# ---------------------------------------------------------------------------
# UST PANEL — yatay yigili bar: train %60 / validation %20 / test %20
# ---------------------------------------------------------------------------
ax_top.set_xlim(0, 100)
ax_top.set_ylim(0, 1)
ax_top.axis("off")
segments = [
("Train %60", 0, 60, COL_PRIMARY, COL_WHITE,
"model bu veriden ogrenir"),
("Validation %20", 60, 20, COL_ROSE_400, COL_TEXT,
"model secimi / ayar"),
("Test %20", 80, 20, COL_ACCENT, COL_WHITE,
"sona kadar dokunma"),
]
bar_y, bar_h = 0.32, 0.42
for name, x0, w, fc, tc, sub in segments:
ax_top.add_patch(
plt.Rectangle((x0, bar_y), w, bar_h, facecolor=fc,
edgecolor=COL_WHITE, linewidth=2.2, zorder=2)
)
ax_top.text(x0 + w / 2, bar_y + bar_h / 2, name, ha="center", va="center",
fontsize=10.5, weight="bold", color=tc, zorder=3)
ax_top.text(x0 + w / 2, bar_y - 0.16, sub, ha="center", va="center",
fontsize=8.0, color=COL_SLATE_400, style="italic", zorder=3)
ax_top.text(50, 0.93, "Uc-yonlu ayrim", ha="center", va="center",
fontsize=11.5, weight="bold", color=COL_CYAN_800)
# ---------------------------------------------------------------------------
# ALT PANEL — kavram: cok model denemesi -> bazilari validation'da sans eseri
# iyi (overfit). Test set = dokunulmayan final kontrol.
# ---------------------------------------------------------------------------
ax_bot.set_xlim(0, 100)
ax_bot.set_ylim(0, 100)
ax_bot.axis("off")
# Sol kume: cok sayida model denemesi (kucuk noktalar). Deterministik dagilim.
rng = np.random.default_rng(7)
n_models = 60
mx = rng.uniform(8, 40, n_models)
my = rng.uniform(20, 82, n_models)
ax_bot.scatter(mx, my, s=24, facecolor=COL_SLATE_300, edgecolor=COL_SLATE_400,
linewidth=0.5, zorder=2)
# Bir tanesi validation'da SANS ESERI iyi cikar (accent vurgu).
lucky_x, lucky_y = 30, 70
ax_bot.scatter([lucky_x], [lucky_y], s=140, facecolor=COL_ACCENT,
edgecolor=COL_WHITE, linewidth=1.6, zorder=4)
ax_bot.annotate(
"sans eseri\nvalidation'da iyi",
xy=(lucky_x, lucky_y), xytext=(8, 92),
fontsize=8.6, weight="bold", color=COL_ACCENT, ha="left", va="center",
arrowprops=dict(arrowstyle="-|>", color=COL_ACCENT, lw=1.6,
shrinkA=2, shrinkB=8), zorder=5,
)
ax_bot.text(24, 9, "cok sayida model denemesi", ha="center", va="center",
fontsize=9.2, weight="bold", color=COL_CYAN_700)
# Orta: validation 'kapisi' kutusu — denemeler buradan gecer.
boxed_node(ax_bot, 52, 52, 17, 22,
"Validation\nset\n\nmodel secimi",
fc=COL_BG_ROSE, ec=COL_ROSE_500, tc=COL_TEXT,
fontsize=8.8, lw=2.0)
# 'cok deneme -> validation sansi' uyari etiketi
ax_bot.text(52, 26, "cok deneme ->\nvalidation uzerinde overfit",
ha="center", va="center", fontsize=8.2, weight="bold",
color=COL_ROSE_500, style="italic")
# Sag: test set — dokunulmayan final kontrol (panzehir).
boxed_node(ax_bot, 84, 52, 19, 26,
"TEST set\n\ngelistirme boyunca\nDOKUNMA\n\n[ kilitli ]",
fc=COL_BG, ec=COL_ACCENT, tc=COL_CYAN_800,
fontsize=8.8, lw=2.6)
ax_bot.text(84, 26, "gercek performansi\nsoyleyen final kontrol",
ha="center", va="center", fontsize=8.2, weight="bold",
color=COL_ACCENT, style="italic")
# Oklar: denemeler -> validation -> (en sonda) test
arrow_between(ax_bot, (42, 52), (52, 52), color=COL_SLATE_400, lw=1.8,
shrink=10)
arrow_between(ax_bot, (61, 50), (74, 50), color=COL_ACCENT, lw=2.2,
shrink=12, style="-|>", connectionstyle="arc3,rad=-0.22")
ax_bot.text(67, 66, "sadece en\nsonda bir kez", ha="center", va="center",
fontsize=7.8, weight="bold", color=COL_ACCENT)
fig.suptitle("Train / Validation / Test — ve 'validation uzerinde overfit'",
fontsize=12.5, weight="bold", color=COL_CYAN_800, y=0.995)
fig.tight_layout(rect=(0, 0, 1, 0.97))
plt.show()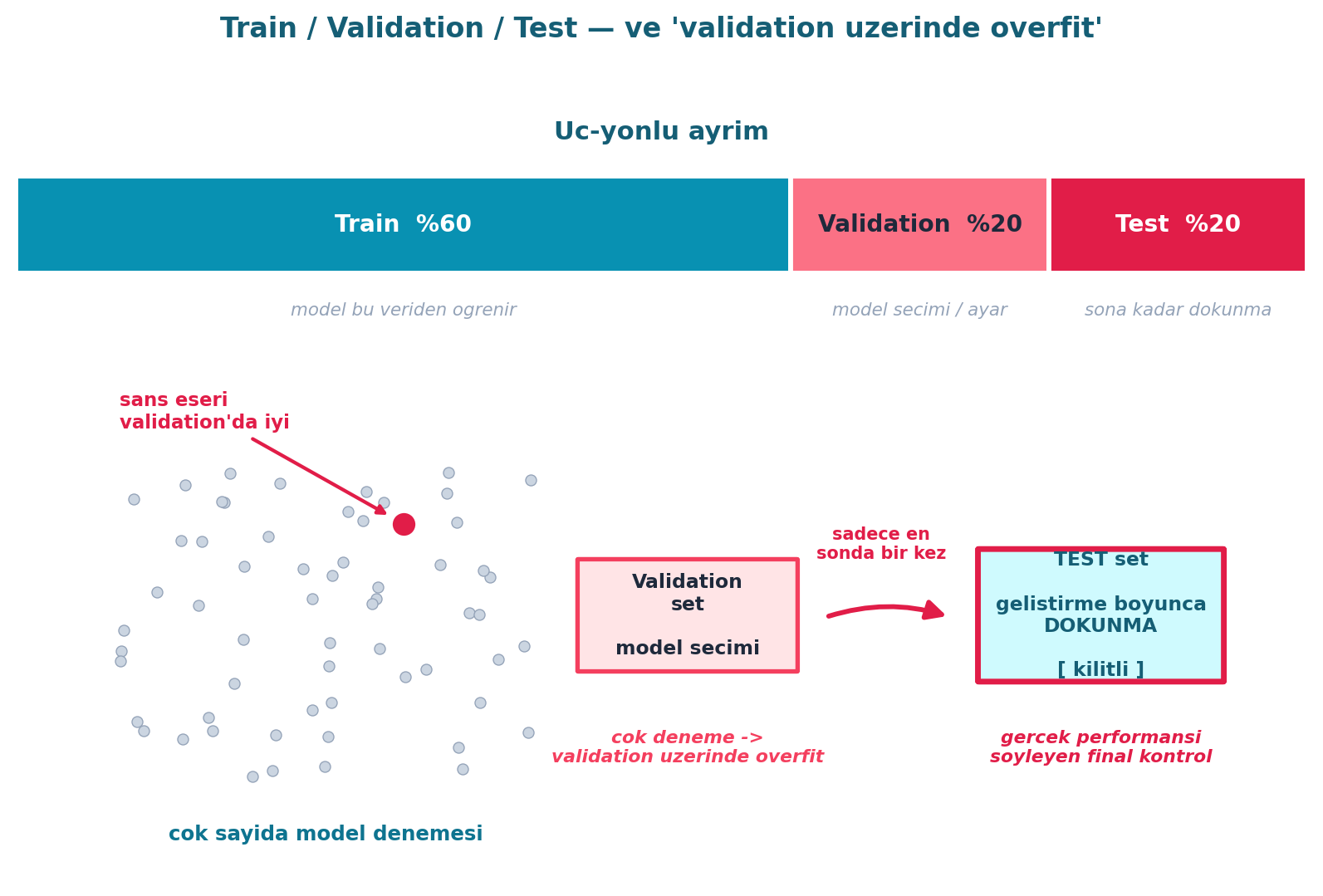
İpucuBuilder Notu — Çok Deneme = Şans Eseri Galip
- Geriye (Stat 110): Çok sayıda hipotez denenince şans eseri “anlamlı” sonuç çıkması = çoklu karşılaştırma problemi; test set bunun panzehiridir. Şekil 5.7’teki “şans eseri iyi” noktası tam bu istatistiksel tuzaktır.
- İleriye (Kaggle İş Akışı): Kaggle’ın gizli test set’i tam bu disiplini dayatır — yalnızca en sonda görürsün; bu yüzden Howard onu validation becerisi için en iyi antrenman alanı sayar.
5.14 Metric vs Loss
Loss, modelin optimize ettiği şeydir (gradient descent için pürüzsüz olmalı). Metric, insanın umursadığı şeydir (örn. doğruluk, korelasyon). İkisi farklı olabilir. Bu yarışmada metrik Pearson korelasyonudur (tahmin ile gerçek arasındaki doğrusal ilişki).
def corr(x, y): return np.corrcoef(x, y)[0][1]
def corr_d(eval_pred): return {'pearson': corr(*eval_pred)}“Metric versus loss.” — Howard, 59:05
Şekil 5.8 kontrastı görselleştirir: loss pürüzsüz ve türevlenebilirdir (gradient descent optimize eder), metric ise basamaklı/türevsizdir ama işin gerçek hedefidir.
Kod
ml = metric_vs_loss_demo()
p = ml["p"]
loss_smooth = ml["loss_smooth"]
metric_step = ml["metric_step"]
fig, (axL, axR) = plt.subplots(1, 2, figsize=(9.6, 4.4))
# SOL: loss — modelin optimize ettigi (purzsuz, turevlenebilir)
axL.plot(p, loss_smooth, color=COL_PRIMARY, linewidth=2.4, zorder=3)
apply_style(axL)
axL.set_title("loss — modelin optimize ettiği", fontsize=12, weight="bold")
axL.set_xlabel("model parametresi / eşiği")
axL.set_ylabel("loss")
axL.annotate("türevlenebilir →\ngradient descent kullanabilir",
xy=(0.55, 0.55), ha="center", va="center",
fontsize=9.5, color=COL_CYAN_700, weight="bold")
# SAG: metric — insanin umursadigi (basamakli, turevsiz)
axR.plot(p, metric_step, color=COL_ACCENT, linewidth=2.4,
drawstyle="steps-mid", zorder=3)
apply_style(axR)
axR.set_ylim(0.4, 1.0)
axR.set_title("metric — insanın umursadığı", fontsize=12, weight="bold")
axR.set_xlabel("model parametresi / eşiği")
axR.set_ylabel("metric (ör. doğruluk)")
axR.annotate("türevsiz/basamaklı → optimize EDİLEMEZ,\nama iş hedefi (ör. doğruluk, Pearson)",
xy=(0.72, 0.92), xytext=(0.5, 0.55),
ha="center", va="bottom", fontsize=9.5, color=COL_ACCENT,
weight="bold")
fig.suptitle("loss'a göre eğit, metric'e göre yargıla",
fontsize=12.5, weight="bold", color=COL_TEXT, y=1.02)
fig.tight_layout()
plt.show()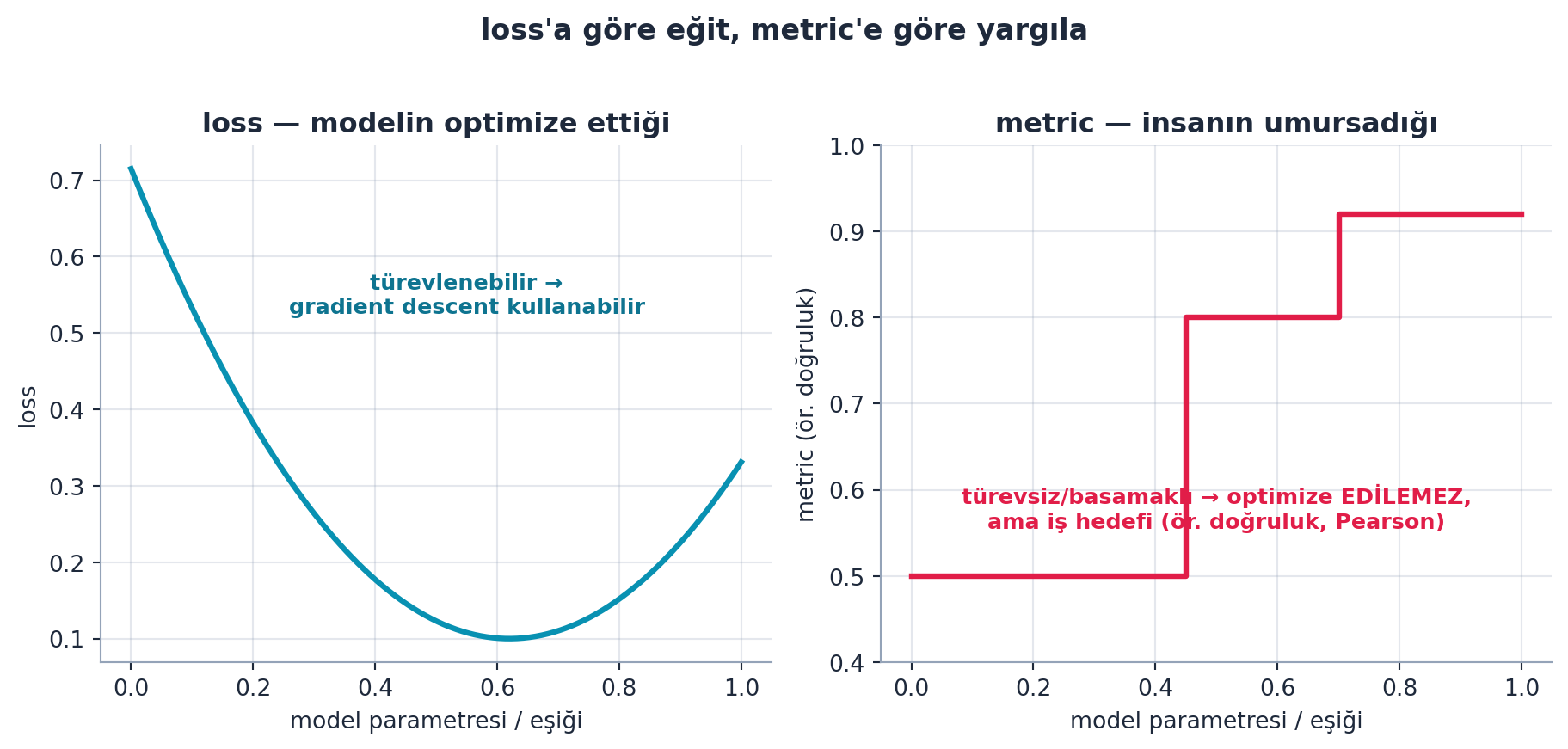
İpucuBuilder Notu — Eğit ve Yargıla Farklı Sayılarla
- İleriye: Loss optimize edilebilir olmalı; metric iş hedefini yansıtır. Pearson, aykırı değerlere duyarlıdır — Howard veri temizlemede bunu vurgular; Şekil 5.8’un basamaklı sağ paneli “neden doğrudan metric’i optimize edemeyiz” sorusunun cevabıdır.
- Geriye (Ders 3): Loss Ders 3’te gradient descent’in küçülttüğü pürüzsüz sayıydı; burada onun yanına “insanın umursadığı” metric’i koyup ikisini ayırıyoruz.
5.15 Hugging Face Trainer ile Eğitim
Her şey hazır olunca eğitim, Hugging Face Trainer ile birkaç satırdır: TrainingArguments hiperparametreleri (learning rate, batch size, epoch) tutar, Trainer model + veri + metrik’i birleştirir (fastai’nin Learner’ına çok benzer).
from transformers import TrainingArguments, Trainer
args = TrainingArguments('outputs', learning_rate=8e-5, warmup_ratio=0.1,
lr_scheduler_type='cosine', fp16=True, evaluation_strategy="epoch",
per_device_train_batch_size=128, num_train_epochs=4, weight_decay=0.01)
model = AutoModelForSequenceClassification.from_pretrained(model_nm, num_labels=1)
trainer = Trainer(model, args, train_dataset=dds['train'], eval_dataset=dds['test'],
tokenizer=tokz, compute_metrics=corr_d)
trainer.train()
İpucuBuilder Notu — Trainer ≈ Learner
- Geriye (Ders 1):
Trainer≈Learner;TrainingArguments≈ fastai’nin eğitim ayarları. Kavram aynı, API farklı — Neden Farklı Kütüphane? bölümündeki “kavramlar taşınır” iddiasının somut kanıtı. - İleriye (Part 2 Ders 18):
lr_scheduler_type='cosine'+warmup_ratio= OneCycle benzeri çizelge; learning rate yönetimi Part 2’de derinleşir. Ders 3’teki learning rate tartışmasının üretimdeki hâlidir.
5.16 Kaggle İş Akışı ve Pratik Özet
Howard, Kaggle’ı validation set becerisini geliştirmenin en iyi yeri olarak önerir: günde sınırlı gönderim + gizli test set, overfitting’i “iliklerinde hissetmeni” sağlar. Gerçek dünyada overfit ettiğini fark bile etmezsin; Kaggle’da birkaç kez “battıktan” sonra öğrenirsin.
“Kaggle competitions are a fantastic way to test your ability to create a good validation set.” — Howard, 53:39
İpucuBuilder Notu — Önce Validation Stratejisi, Sonra Model
- İleriye: “Önce başarı kriterini ve validation stratejisini tanımla, sonra modele başla” — goal-driven disiplin; sona değil başa konur. Ders 3’teki “başarı kriterini baştan tanımla” tavsiyesinin NLP’deki yankısıdır.
- Geriye (Test Set): Kaggle’ın gizli test set’i, Şekil 5.7’teki “dokunulmayan final kontrol” kutusunun gerçek hayattaki örneğidir — bu yüzden disiplin antrenmanı için ideal.
5.17 Kapanış
Ders 4 iki şeyi öğretti: (1) metni modele sokmanın mekaniği (tokenization → numericalization → pretrained model + fine-tune, Hugging Face ile), ve (2) tüm ML’in en kritik becerisi olan doğru validation/test set kurma. Mimari ve kütüphane değişse de bu ikinci ders her yerde geçerlidir.
İpucuBuilder Notu — Mekanik Eskir, Disiplin Kalır
- İleriye: Tokenizer ve Transformer Part 2’de (ve Karpathy’de) sıfırdan kurulacak; validation disiplini ise her projede taşınır — model değişir, “iyi validation set” sorusu hiç değişmez.
- Geriye (Bu Derste Ne Var?): Dersin başındaki üç fikir — tokenization, transfer learning, iyi validation set — burada tek bir cümlede kapanır.
5.18 Bu Dersin Özeti
- NLP’de fastai yerine Hugging Face Transformers kullanılır; kavramlar (tokenize, model, fine-tune) aynıdır (Neden Farklı Kütüphane?).
- Tokenization metni subword token’lara böler; modeli eğitenlerle aynı tokenizer kullanılmalıdır (Tokenization).
- Numericalization her token’ı sözlük konumuna (
input_ids) çevirir; model yalnızca sayıyla çalışır (Numericalization). - Transfer learning metne de uygulanır: pretrained model (deberta-v3-small) + fine-tune; ULMFiT bunun RNN tabanlı öncüsüdür (Fine-tuning, ULMFiT).
- Overfitting (ezber) ve underfitting (yetersiz) arasında denge gerekir; polinom derecesi bunu somutlaştırır (Overfitting ve Underfitting).
- Validation set overfitting’i yakalar; fastai onu zorunlu kılar (Validation Set Neden Zorunlu?).
- İyi validation set rastgele değildir — geleceği/yeni kişileri tahmin edecek şekilde kurulmalı; aksi halde sessizce değer yok edilir (İyi Bir Validation Set Kurmak).
- Test set üçüncü ayrımdır; validation üzerinde overfit etmediğini garantiler. Metric (insan hedefi) ile loss (model hedefi) farklıdır (Test Set, Metric vs Loss).
ÖnemliTek Bir Cümle
NLP’de metni token’lara bölüp sayıya çevirir ve pretrained bir modeli ince ayarlarsın; ama bir modelin gerçekten işe yarayıp yaramadığını yalnızca doğru kurulmuş bir validation/test set söyler — bu, tüm makine öğrenmesinin en kritik becerisidir.
5.19 Kontrol Soruları
NotSoru 1: Tokenization ile numericalization arasındaki fark nedir? Neden modeli eğitenlerle aynı tokenizer kullanılmalı?
Cevap:
Tokenization metni parçalara (subword token’lara) böler; numericalization her token’ı sözlükteki (vocabulary) konumuna, yani bir sayıya (input_ids) çevirir. İkisi birlikte metni modelin anlayacağı sayı dizisine dönüştürür. Aynı tokenizer şart çünkü her model belirli bir sözlük ve bölme kuralıyla eğitildi; farklı bir tokenizer farklı token’lar üretir ve modelin öğrendiği sözlük konumlarıyla uyuşmaz — sonuç anlamsız olur. AutoTokenizer.from_pretrained(model_nm) doğru olanı otomatik indirir.
NotSoru 2: Howard neden “rastgele bir validation set çoğu zaman yanlıştır” der? Bir örnek ver.
Cevap:
Çünkü validation set, modeli gerçekte nasıl kullanacağını taklit etmelidir. Zaman serisinde geleceği tahmin edeceksen, validation set son dönem olmalı (ortadan rastgele değil) — yoksa “geçmişi tahmin” etmeyi ölçersin, oysa geleceği tahmin edeceksin. Howard’ın dikkati dağılmış sürücü örneğinde test set eğitimde olmayan kişiler içeriyordu; rastgele ayırsaydın aynı kişinin bazı fotoğrafları hem eğitimde hem validation’da olur, model kişiyi tanıyıp aldatıcı yüksek skor verirdi. İyi validation set, eğitimden gerçekten farklı (gelecek/yeni kişi) örnekler içermelidir.
NotSoru 3: Test set neden validation set’ten ayrı gerekir? “Validation set üzerinde overfit” ne demektir?
Cevap:
Model geliştirirken yüzlerce varyant denersin ve her birini validation set’te ölçersin. Bu kadar çok deneme arasında bazıları salt şans eseri validation set’te iyi çıkar — sen de o modeli seçersin. Bu, “validation set üzerinde overfit”tir: validation skorunu kendi karar verme sürecinle dolaylı olarak ezberlemişsindir. Test set, geliştirme boyunca hiç dokunmadığın üçüncü bir ayrımdır; yalnızca en sonda bakarsın ve böylece gerçek performansı öğrenirsin. Kötü çıkarsa başa dönmek gerekir — ama bilmek bilmemekten iyidir.
NotSoru 4: Metric ile loss neden farklı olabilir? (builder bağlantısı)
Cevap:
Loss, gradient descent’in optimize ettiği şeydir; bu yüzden pürüzsüz ve türevlenebilir olmalı (örn. MSE, cross-entropy). Metric ise insanın/işin umursadığı şeydir (örn. doğruluk, Pearson korelasyonu, gelir) ve genellikle türevlenemez ya da optimize için uygun değildir. Bu yarışmada loss MSE benzeri, metric Pearson korelasyonudur. Builder açısından: modeli loss’a göre eğitirsin ama başarıyı metric’e göre yargılarsın — ikisini karıştırmak yanlış model seçimine yol açar.
5.20 Egzersizler
Egzersiz 1 (Direkt uygulama). Bir Hugging Face tokenizer yükle (AutoTokenizer.from_pretrained) ve kendi cümlelerini tokenize et; subword bölünmelerini ve input_ids’i incele.
Egzersiz 2 (İki-aşamalı). Kendi metin verinde context/target alanlarını tek bir input string’inde birleştir, Dataset’e çevir ve map ile tokenize et.
Egzersiz 3 (Edge case). plot_poly ile 1, 2, 5, 16 derece polinomları çiz; underfit→tam→overfit geçişini ve eğitim verisine ezberlemeyi gözlemle.
Egzersiz 4 (Validation tasarımı). Bir zaman serisi veride hem rastgele hem “son dönemi ayır” validation set kur; iki yaklaşımın aynı modeli nasıl farklı değerlendirdiğini açıkla.
Egzersiz 5 (Sonraki dersin habercisi). Bir Trainer kurup küçük bir veride birkaç epoch eğit; compute_metrics ile Pearson’u izle, validation skoru eğitim skorundan ayrışınca (overfit) durdur.
5.21 Sonraki Ders İçin Hazırlık
Ders 5: Sıfırdan Model (From-scratch model)
Ders 4’te Hugging Face Trainer’ı kara kutu olarak kullandık. Ders 5 tekrar aşağı iner: bir tablo verisi (Titanic) üzerinde önce lineer modeli ve sinir ağını sıfırdan kurar, sonra neden framework kullanmamız gerektiğini gösterir.
Ana konular:
- Tablo verisini hazırlama (eksik değer, kategorik kodlama)
- Lineer modeli sıfırdan (matris çarpımı + gradient descent)
- Sinir ağına genişletme
- Framework’ün değeri
UyarıDers 5 Öncesi Yapılacak
- Bu dersin egzersizlerini çöz (özellikle 4 — iyi validation set tasarla).
- Bir Kaggle yarışmasına gir ve gizli test set deneyimini yaşa.
- Ana cümleyi tekrar oku: “İyi validation set, ML’in en kritik becerisidir.”
5.22 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Howard’da |
|---|---|---|
| Tokenization | Metni subword token’lara bölme | 29:30 |
| Vocabulary | Tüm benzersiz token’ların listesi | 30:17 |
| Numericalization | Token’ı sözlük konumuna (input_ids) çevirme | 38:58 |
| AutoTokenizer | Modelin sözlüğünü ve tokenize kuralını indirir | 33:26 |
| ULMFiT | RNN tabanlı NLP transfer learning; uzun belgelere uygun | 43:27 |
| Underfitting | Yetersiz kapasite; sistematik yanlış | 45:55 |
| Overfitting | Eğitim verisini ezberleme; yeni veride kötü | 45:55 |
| Validation set | Eğitimde görülmeyen, doğruluk ölçen ayrım | 50:56 |
| İyi validation set | Rastgele değil; geleceği/yeni kişileri test eder | 52:32 |
| Test set | Geliştirmede kullanılmayan üçüncü gizli ayrım | 57:17 |
| Metric vs loss | İnsan hedefi vs modelin optimize ettiği pürüzsüz şey | 59:05 |
| Trainer | HF’in Learner’ı; model + veri + metrik | 59:05 |
5.23 ML Builder Bağlantıları
İpucuBuilder Notu — 6 ML Köprüsü
Bu ders, NLP mekaniğini (tokenization → numericalization → fine-tune) öğretir ama asıl dersi tüm ML’e taşınan validation/test disiplinidir; köprülerin özeti:
- Tokenization/numericalization → metni sayıya çeviren standart NLP ön işlemi; Karpathy Ders 9 (BPE) sıfırdan kurar (Tokenization).
- Transfer learning (metin) → pretrained dil modeli + fine-tune; ULMFiT öncüsü, modern Transformers standardı (Fine-tuning).
- Overfitting/underfitting → bias-variance dengesi (Stat 110); her modelde merkez sorun (Overfitting ve Underfitting).
- İyi validation set → production’da sessiz başarısızlığı önleyen tek savunma; data leakage’ın panzehiri (İyi Bir Validation Set Kurmak).
- Test set → çoklu deneme şansını eler; bilimsel değerlendirmenin temeli (Test Set).
- Metric vs loss → loss optimize edilebilir, metric iş hedefini yansıtır; model seçimini doğru metric belirler (Metric vs Loss).
ÖnemliBu dersten tek bir şey alıp gideceksen
Bu dersten tek bir şey alıp gideceksen: en gelişmiş model bile kötü bir validation set’le değersizdir. Metni sayıya çevirip pretrained bir modeli ince ayarlamak artık birkaç satır; asıl ustalık, modeli gerçek dünyada nasıl kullanacağını taklit eden bir validation/test set kurmaktır — yoksa overfit ettiğini fark bile etmeden değer yok edersin.