flowchart TD
L11(["L11 — Matris Çarpımı"])
%% SOL KOL — araştırma becerisi
RES["araştırma becerisi"]
ARX["arXiv (preprint)"]
ZOT["Zotero (not al)"]
PAP["makale oku<br/>(DiffEdit örneği)"]
L11 --> RES
RES --> ARX
ARX --> ZOT
ZOT --> PAP
%% SAĞ KOL — from the foundations
FND["from the foundations"]
RANK["tensör rank"]
ELEM["elementwise"]
FRO["Frobenius norm"]
BCAST["broadcasting<br/>(kural: sondan başa,<br/>eşit ya da 1)"]
BMM["broadcasting matmul<br/>(döngüsüz)"]
SPD["hız (einsum / @)<br/>→ Ders 12"]
L11 --> FND
FND --> RANK
RANK --> ELEM
ELEM --> FRO
FRO --> BCAST
BCAST --> BMM
BMM --> SPD
classDef cyan fill:#cffafe,stroke:#0e7490,stroke-width:1.5px,color:#155e75;
classDef rose fill:#ffe4e6,stroke:#e11d48,stroke-width:1.5px,color:#9f1239;
class L11,RES,ARX,ZOT,PAP,FND,RANK,ELEM,FRO,SPD cyan;
class BCAST,BMM rose;
14 Ders 11 — Matris Çarpımı (Matrix multiplication)
Part 2’nin üçüncü dersi iki beceri verir. İlk yarı bir araştırma becerisi öğretir: akademik makale (DiffEdit) okuma iş akışı — arXiv’den preprint, Zotero ile not. İkinci yarı « from the foundations »a döner ve Ders 10’un yavaş üç-döngü matris çarpımını broadcasting ile döngüsüz, yüzlerce kat hızlı hâle getirir. Anahtar fikir tek cümleyle: bir döngüyü kaldırmanın yolu broadcasting’dir — iş artık optimize C/GPU koduna devredilir.
NotBölüm bilgisi
- Ders sayfası (video): course.fast.ai — Lesson 11: Matrix multiplication (~108 dk)
- Seri: Practical Deep Learning for Coders — Part 2, Ders 11
- Playlist: Part 2 — Foundations to Stable Diffusion (2022)
- Notebook: course22p2 — nbs/01_matmul
- Okuma süresi: ~38 dk
- 🔁 İki kol: İlk yarı araştırma becerisi (arXiv → Zotero → DiffEdit), ikinci yarı « from the foundations » (matmul’u broadcasting ile döngüsüz hızlandır). Bu ders ETAP 4 (Temeller A) başıdır.
14.1 Bu Derste Ne Var?
Part 2’nin üçüncü dersi iki şey yapar. İlk yarı bir araştırma becerisi verir: akademik makale (DiffEdit) okuma iş akışı (arXiv + Zotero). İkinci yarı “from the foundations”a döner (dönüş) ve matris çarpımını broadcasting ile döngüsüz, hızlı hâle getirir.
Üç temel fikir bu dersin omurgasını kurar:
- Makale okuma iş akışı — arXiv’den preprint, Zotero ile not alma; DiffEdit gibi bir makaleyi adım adım anlama ve uygulama (makale akışı).
- Broadcasting — farklı şekilli tensörleri otomatik hizalayıp döngüsüz işleme; matris çarpımını Python döngüsünden kurtarmanın anahtarı (broadcasting → kurallar).
- Döngüsüz matmul — üç iç içe döngü yerine broadcasting ile tek döngü; optimize C/GPU koduna düşen, çok daha hızlı versiyon (broadcasting matmul → hız).
“Okay, so let’s move on with our From the Foundations now.” — Howard, 58:52
Şekil 28.1 bu yapıyı tek bir yol haritasında birleştirir: solda araştırma kolu (arXiv → Zotero → makale), sağda “from the foundations” temel zinciri (tensör rank → elementwise → Frobenius → broadcasting → broadcasting matmul → hız). İki kol L11’de birleşir.
İpucuBuilder Notu — İki Beceri, Tek Ders
- Geriye (Ders 5/10/18.06): Broadcasting Ders 5’te (Titanic) tanıtılmıştı; Ders 10’daki üç-döngü matmul’u burada broadcasting ile hızlandırıyoruz. matmul = 18.06’nın kalbi.
- İleriye (Ders 12 / NYU §4.J): einsum ve
@(Ders 12) matmul’u tamamlar; broadcasting tüm tensör hesabının (NYU dahil) verimlilik temeli. - Tek cümle: Broadcasting, döngüleri kaldırıp tensör işlemlerini optimize koda devretmenin yoludur; matris çarpımı bunun ilk büyük kazanımı.
14.2 1. Ders 10 Özeti ve Öğrenci İşleri
Howard haftanın öğrenci projeleriyle başlar ve bir SD tekniğini hatırlatır: guidance update’i, normların oranıyla ölçeklemek (çok büyük güncelleme adımı “çok ileri zıplar”). Ardından Ders 10’un “from the foundations” başlangıcını (Ders 10) özetler.
“It’s the third lesson in Part 2.” — Howard, 0:00
İpucuBuilder Notu — Köprü: SD’den Foundations’a
- Geriye (Ders 9A): guidance ölçekleme, CFG’nin pratik bir ince ayarı; “norm oranı” sezgisi büyük adımları frenler.
- Sezgi: Bu özet bir köprüdür — önceki dersin SD detaylarını kapatıp temel zincire (matmul) geçişi hazırlar.
14.3 2. DiffEdit: Diffusion ile Akıllı Düzenleme
Howard bir makale örneği seçer: DiffEdit — bir görüntüde yalnızca prompt’un işaret ettiği bölgeyi (örn. “köpek”i “at”a) değiştiren, gerisini koruyan bir yöntem. Bir referans metinle gürültü ekleyip-çıkararak hangi piksellerin değişeceğini bulur (maske), sonra yalnızca orayı yeniden üretir.
“We add noise to it, and then we denoise it using the reference text.” — Howard, 46:36
Şekil 14.2 bu üç adımı şematik gösterir: girdi görüntü (köpek) → referans metinle gürültüle-gider ve değişen pikselleri bul → bu farktan bir maske çıkar (yalnız köpek bölgesi) → yalnız maskeli bölgeyi yeniden üret (köpek → at) → çıktıda gerisi korunur.
Kod
fig, ax = plt.subplots(figsize=(12, 5))
ax.set_xlim(0, 12)
ax.set_ylim(0, 5)
ax.axis("off")
# ----- Akış kutuları -----
# 1) Girdi görüntü
boxed_node(ax, 1.5, 3.5, 2.3, 1.1,
"girdi görüntü\n(köpek)",
fc=COL_CYAN_50, ec=COL_CYAN_700, tc=COL_TEXT, fontsize=10)
# 2) Referans metinle gürültüle-gider → değişen pikselleri bul
boxed_node(ax, 5.0, 3.5, 3.0, 1.3,
"referans metinle\ngürültüle-gider →\nDEĞİŞEN pikselleri bul",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT, fontsize=9.5)
# 3) Maske: yalnız köpek bölgesi (vurgu — rose)
boxed_node(ax, 5.0, 1.2, 3.0, 1.1,
"MASKE\nyalnız köpek bölgesi",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT, fontsize=10)
# 4) Yalnız maskeli bölgeyi yeniden üret (at)
boxed_node(ax, 9.2, 3.5, 3.0, 1.3,
"yalnız maskeli bölgeyi\nyeniden üret\n(köpek → at)",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT, fontsize=9.5)
# 5) Çıktı
boxed_node(ax, 9.2, 1.2, 3.0, 1.1,
"çıktı (at)\ngerisi korunur",
fc=COL_CYAN_50, ec=COL_CYAN_700, tc=COL_TEXT, fontsize=10)
# ----- Oklar -----
arrow_between(ax, (2.65, 3.5), (3.5, 3.5)) # girdi → gürültüle-gider
arrow_between(ax, (5.0, 2.85), (5.0, 1.75), color=COL_ACCENT) # → maske (rose)
arrow_between(ax, (6.5, 1.4), (7.7, 2.95), color=COL_ACCENT) # maske → yeniden üret
arrow_between(ax, (6.5, 3.5), (7.7, 3.5)) # gürültüle-gider → yeniden üret
arrow_between(ax, (9.2, 2.85), (9.2, 1.75)) # yeniden üret → çıktı
# ----- Not -----
ax.text(6.0, 0.25,
"img2img + maskeleme = hedefli gürültü-giderme (Ders 9 gelişmişi)",
ha="center", va="center", fontsize=10, style="italic",
color=COL_CYAN_800, weight="bold")
plt.tight_layout()
plt.show()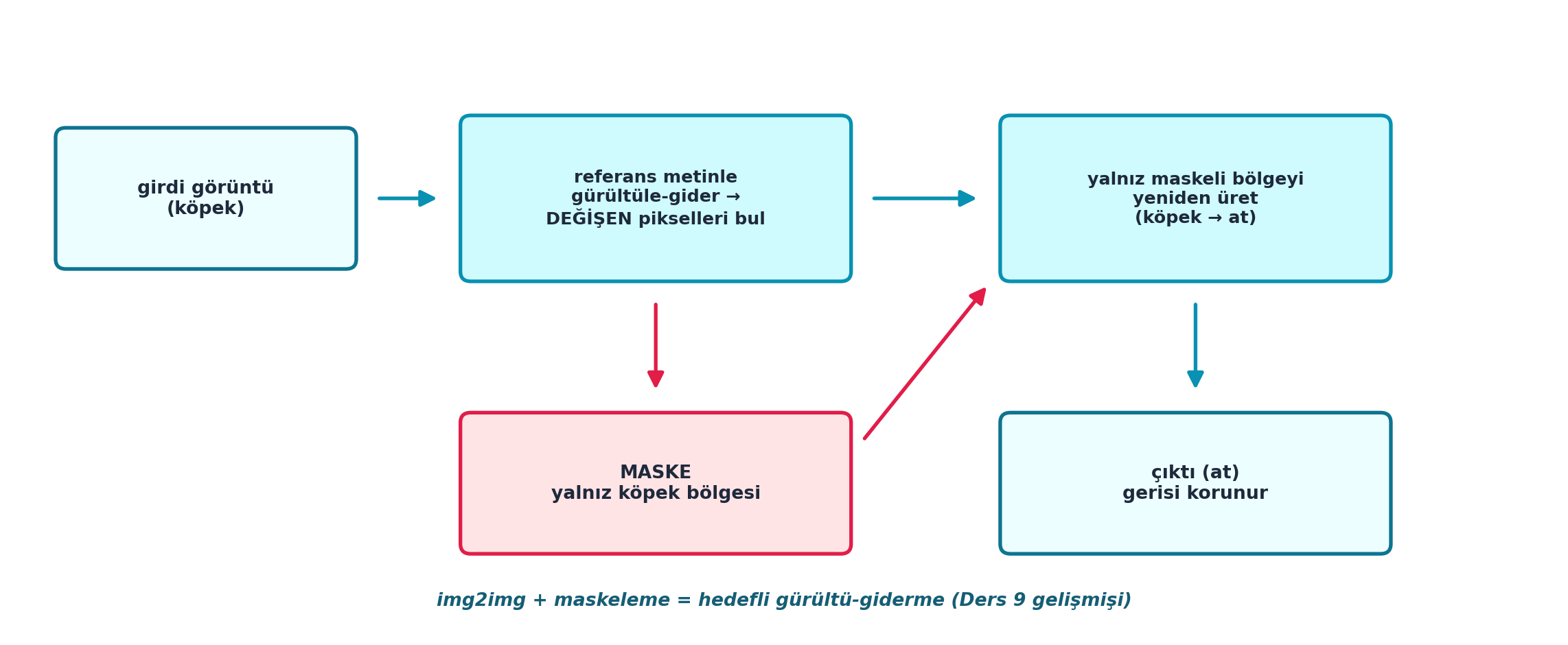
İpucuBuilder Notu — DiffEdit: Hedefli Gürültü-Giderme
- Geriye (Ders 9/9A): img2img + maskeleme; DiffEdit, gürültüleme-giderme döngüsünün hedefli kullanımıdır — maske, değişimi yalnızca istenen bölgeye sınırlar.
- Sezgi: Maske, “referans metinle gürültüleyip-giderince hangi pikseller değişiyor?” sorusunun cevabıdır; değişen yerler düzenlenecek bölgedir.
14.4 3. Akademik Makale Okuma İş Akışı
Howard değerli bir meta-beceri öğretir: makale okuma. Çoğu derin öğrenme bilgisi arXiv (preprint sunucusu) üzerindendir; hakem değerlendirmesini beklemek çok yavaştır. Howard’ın iş akışı: arXiv’den PDF → Zotero ile kaydet, üzerine not al, anla.
“arXiv is a preprint server… we use arXiv a lot. If you wait until it’s been peer reviewed, you’ll [wait too long].” — Howard, 13:22
İpucuBuilder Notu — Makale Okuma: Alanın Ucunda Kalmak
- İleriye (builder): Makale okuyabilmek, alandaki en yeni tekniklere erişimin tek yolu; hakemli yayını beklemek aylar/yıllar alır.
- Araç: Zotero gibi bir araçla sistemli okuma (kaydet + üzerine not al) kalıcı bilgi sağlar — “tüketici”den “üretici”ye geçişin anahtarı.
14.5 4. “From the Foundations”a Dönüş
Mola sonrası Howard foundations’a döner: matris çarpımını sıfırdan, ama bu kez hızlı kurmak. Ders 10’da üç döngü vardı (yavaş); şimdi döngüleri broadcasting ile kaldıracağız.
“Okay, so let’s move on with our From the Foundations now. Matrix multiplication from scratch.” — Howard, 58:52
İpucuBuilder Notu — Aynı matmul, Yeni Hedef: Hız
- Geriye (Ders 10): Aynı matmul; hedef yorumlanan Python döngülerini optimize tensör işlemlerine çevirmek.
- Sezgi: “Sıfırdan kur” kuralı geçerli — ama bu kez amaç doğruluğu değil, performansı sıfırdan kazanmak; iç döngüleri tensör ifadelerine devretmek.
14.6 5. Tensör Rank’ı
Önce terminoloji: bir tensörün rank’ı boyut sayısıdır. Rank 0 = skaler, rank 1 = vektör, rank 2 = matris (liste listesi), rank 3 = matrisler yığını. Broadcasting’i anlamak için rank ve şekil (shape) kavramı kritiktir.
“This here is a rank one tensor — it’s a vector. Whereas a rank two tensor is like a list of lists.” — Howard, 1:01:13
Şekil 14.3 bu dört rank’ı yan yana gösterir: skaler (rank 0, tek sayı), vektör (rank 1, 1B dizi), matris (rank 2, 2B ızgara), yığın (rank 3, üst üste matrisler). Her panelin başlığında gerçek shape yazılıdır — Ders 1’in H×W×3 görüntüsü rank 3’tür.
Kod
data = E.rank_tensors_demo()
items = data["items"]
fig, axes = plt.subplots(1, 4, figsize=(12, 4))
panel_titles = ["rank 0 = skaler", "rank 1 = vektör", "rank 2 = matris", "rank 3 = yığın"]
# --- Panel 0: skaler (rank 0) — tek sayı, kutu içinde ---
ax = axes[0]
ax.set_xlim(0, 1); ax.set_ylim(0, 1)
ax.axis("off")
rank, ad, shape, val = items[0]
boxed_node(ax, 0.5, 0.5, 0.5, 0.34, f"{float(val):.0f}",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_CYAN_800, fontsize=22, lw=2.4)
ax.set_title(f"{panel_titles[0]}\nshape={tuple(shape)}",
fontsize=11.5, color=COL_CYAN_700, weight="bold")
# --- Panel 1: vektör (rank 1) — 1B dizi, yatay hücre satırı ---
ax = axes[1]
ax.set_xlim(0, 1); ax.set_ylim(0, 1)
ax.axis("off")
rank, ad, shape, vec = items[1]
n = len(vec)
w = 0.92 / n
for i, value in enumerate(vec):
cx = 0.04 + w * (i + 0.5)
boxed_node(ax, cx, 0.5, w * 0.9, 0.30, f"{value:.0f}",
fc=COL_CYAN_50, ec=COL_PRIMARY, tc=COL_TEXT, fontsize=14, lw=2.0)
ax.set_title(f"{panel_titles[1]}\nshape={tuple(shape)}",
fontsize=11.5, color=COL_CYAN_700, weight="bold")
# --- Panel 2: matris (rank 2) — 2B ızgara, imshow + değerler ---
ax = axes[2]
rank, ad, shape, mat = items[2]
ax.imshow(mat, cmap="cividis", aspect="equal")
for (r, c), value in np.ndenumerate(mat):
ax.text(c, r, f"{value:.0f}", ha="center", va="center",
color=COL_WHITE, fontsize=14, weight="bold")
ax.set_xticks([]); ax.set_yticks([])
for spine in ax.spines.values():
spine.set_edgecolor(COL_PRIMARY); spine.set_linewidth(2.0)
ax.set_title(f"{panel_titles[2]}\nshape={tuple(shape)}",
fontsize=11.5, color=COL_CYAN_700, weight="bold")
# --- Panel 3: yığın (rank 3) — 2 matris üst üste, şematik derinlik ---
ax = axes[3]
ax.set_xlim(0, 1); ax.set_ylim(0, 1)
ax.axis("off")
rank, ad, shape, stack = items[3]
depth, rows, cols = stack.shape
# arkadan öne 'depth' adet ızgarayı kaydırarak çiz (üst üste yığın illüzyonu)
gw, gh = 0.42, 0.42 # bir ızgaranın genişlik/yükseklik
x0, y0 = 0.16, 0.20 # en arka ızgaranın sol-alt köşesi
dx, dy = 0.13, 0.14 # katmanlar arası kaydırma
cw, ch = gw / cols, gh / rows
for d in range(depth - 1, -1, -1): # arkadan öne
ox, oy = x0 + dx * d, y0 + dy * d
fc = COL_BG_ROSE if d == 0 else COL_CYAN_50
ec = COL_ACCENT if d == 0 else COL_SLATE_400
for r in range(rows):
for c in range(cols):
cell_x = ox + c * cw
cell_y = oy + (rows - 1 - r) * ch
ax.add_patch(plt.Rectangle((cell_x, cell_y), cw, ch,
fc=fc, ec=ec, lw=1.4, zorder=d + 1))
if d == 0: # yalnız ön katmanda değer yaz
ax.text(cell_x + cw / 2, cell_y + ch / 2, f"{stack[d, r, c]:.0f}",
ha="center", va="center", color=COL_TEXT,
fontsize=10, weight="bold", zorder=depth + 2)
ax.set_title(f"{panel_titles[3]}\nshape={tuple(shape)}",
fontsize=11.5, color=COL_CYAN_700, weight="bold")
fig.suptitle("rank = eksen/boyut sayısı · Ders 1'in H×W×3 görüntüsü rank 3",
fontsize=12.5, color=COL_TEXT, weight="bold", y=1.02)
plt.tight_layout()
plt.show()
İpucuBuilder Notu — Rank = Eksen Sayısı
- Geriye (Ders 1): Ders 1’deki “görüntü = H×W×3 tensör” rank 3’tür; rank = eksen sayısı, shape = her eksenin uzunluğu.
- Sezgi: Broadcasting tam olarak shape üstünde çalışır — hangi eksenlerin “eşit ya da 1” olduğunu rank ve shape belirler; bu yüzden önce bunlar tanımlanır.
14.7 6. Elementwise İşlemler
Aynı şekilli iki tensörde toplama, çarpma, karşılaştırma elementwise (eleman eleman) çalışır: a + b, a * b, a > b her konumu ayrı işler. Howard bunun optimize C kodunda paralel yapıldığını vurgular — Python döngüsü değil.
a + b # her konumu ayrı topla
a * b # her konumu ayrı çarp (NOT: matris çarpımı DEĞİL)
a > b # her konumu ayrı karşılaştır -> bool tensör
İpucuBuilder Notu — Elementwise: Tensör İşlemlerinin Temeli
- Geriye (Ders 5): Ders 5’teki
(indep * coeffs)elementwise çarpımdı; tensör işlemlerinin temeli. - Sezgi:
a * belementwise çarpımdır, dot product değil — paralel C koduna düştüğü için Python döngüsünden çok hızlıdır; broadcasting bunu farklı şekillere genişletir.
14.8 7. Frobenius Norm
Howard üretken modellemede sık görülecek bir kavramı tanıtır: Frobenius norm — bir matrisin tüm elemanlarının karelerinin toplamının karekökü:
\[\|A\|_F = \sqrt{\sum_{i,j} a_{ij}^2}\]
Korkutucu görünen sembol, aslında basit bir “elemanları karele, topla, karekök al” işlemidir.
“We’re going to learn about a new thing that looks kind of crazy called Frobenius norm… we’ll use that from time to time as we’re doing generative modeling.” — Howard, 1:19:58
Şekil 14.4 bunu gerçek hesaplama ile gösterir: solda matris \(A\), ortada her elemanı karelenmiş \(A^2\), sağda \(\sum a_{ij}^2\) toplamı ve karekökü; sonuç np.linalg.norm ile teyit edilir.
Kod
d = E.frobenius_demo()
A, sq = d["A"], d["sq"]
sq_sum, fro, np_fro = d["sq_sum"], d["fro"], d["np_fro"]
fig, (axL, axM, axR) = plt.subplots(1, 3, figsize=(12, 4.5),
gridspec_kw={"width_ratios": [1.0, 1.0, 1.1]})
# --- SOL: matris A (değerleri annotate) ---
axL.imshow(A, cmap="cividis", aspect="equal")
for i in range(A.shape[0]):
for j in range(A.shape[1]):
axL.text(j, i, f"{A[i, j]:.1f}", ha="center", va="center",
fontsize=9, weight="bold", color=COL_WHITE)
axL.set_title("A (5×5 matris)", color=COL_CYAN_700, fontsize=12, weight="bold")
axL.set_xticks([]); axL.set_yticks([])
for sp in axL.spines.values():
sp.set_edgecolor(COL_CYAN_700); sp.set_linewidth(2.0)
# --- ORTA: sq = A² (her elemanı karele) ---
axM.imshow(sq, cmap="Reds", aspect="equal")
for i in range(sq.shape[0]):
for j in range(sq.shape[1]):
axM.text(j, i, f"{sq[i, j]:.1f}", ha="center", va="center",
fontsize=9, weight="bold", color=COL_TEXT)
axM.set_title("A² (her elemanı karele)", color=COL_ACCENT, fontsize=12, weight="bold")
axM.set_xticks([]); axM.set_yticks([])
for sp in axM.spines.values():
sp.set_edgecolor(COL_ACCENT); sp.set_linewidth(2.0)
# --- SAĞ: Σ → √ hesabı + np teyit rozeti ---
axR.set_xlim(0, 1); axR.set_ylim(0, 1); axR.axis("off")
axR.text(0.5, 0.92, "Frobenius norm ‖A‖_F", ha="center", va="center",
fontsize=13, weight="bold", color=COL_CYAN_800)
axR.text(0.5, 0.72, f"Σ aᵢⱼ² = {sq_sum:.1f}", ha="center", va="center",
fontsize=15, weight="bold", color=COL_ACCENT,
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG_ROSE, ec=COL_ROSE_400, lw=1.8))
axR.annotate("", xy=(0.5, 0.50), xytext=(0.5, 0.62),
arrowprops=dict(arrowstyle="-|>", color=COL_PRIMARY, lw=2.2))
axR.text(0.5, 0.40, f"√ {sq_sum:.1f} = {fro:.2f}", ha="center", va="center",
fontsize=18, weight="bold", color=COL_CYAN_800,
bbox=dict(boxstyle="round,pad=0.45", fc=COL_BG, ec=COL_PRIMARY, lw=2.2))
axR.text(0.5, 0.18, f"✓ np.linalg.norm teyit: {np_fro:.2f}", ha="center", va="center",
fontsize=11, weight="bold", color=COL_WHITE,
bbox=dict(boxstyle="round,pad=0.35", fc=COL_CYAN_700, ec=COL_CYAN_800, lw=1.5))
axR.text(0.5, 0.04,
"matrisin tek-sayı büyüklüğü\n(vektör uzunluğunun matris hâli)",
ha="center", va="center", fontsize=9.5, style="italic", color=COL_SLATE_400)
plt.tight_layout()
plt.show()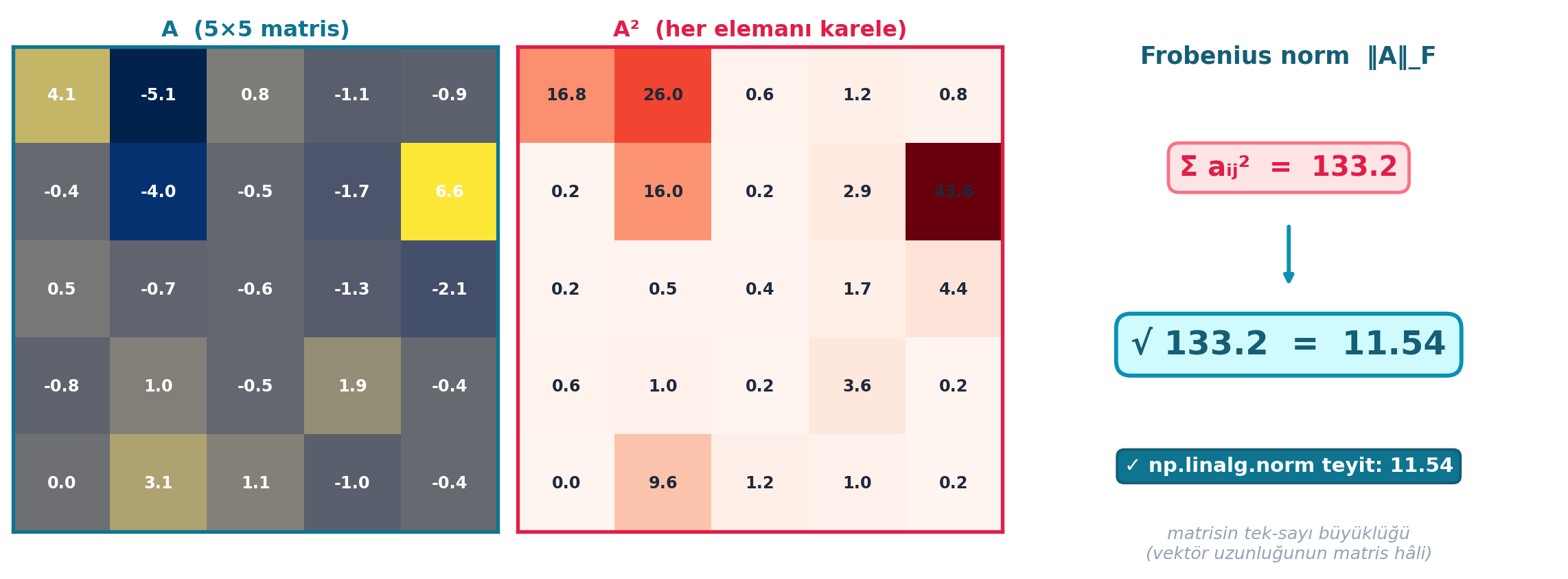
İpucuBuilder Notu — Frobenius: Matrisin Tek-Sayı Büyüklüğü
- Geriye (18.06 / Ders 8): Frobenius norm, bir matrisi tek bir “büyüklük” sayısına indirir; vektör uzunluğunun (Öklid normu) matris hâlidir.
- Sezgi: Sembol \(\sqrt{\Sigma a_{ij}^2}\) korkutur ama tarif basittir — karele, topla, karekök al; üretken modellemede iki tensörün “ne kadar farklı” olduğunu ölçerken sık geçer.
14.9 8. Broadcasting: Skaler ile
Broadcasting, farklı şekilli tensörleri otomatik hizalayıp işleme sokmaktır. En basiti skalerle: tensor * 2 skaleri tüm elemanlara uygular (sanki aynı şekle kopyalanmış gibi) — ama gerçek kopya oluşmaz, optimize biçimde yapılır.
“Now we’re going to get into something really fun, which is broadcasting.” — Howard, 1:24:00
İpucuBuilder Notu — Skaler Broadcast: En Basit Hâli
- Geriye (Ders 5): Ders 5’te broadcasting’i “891 kez kopyalanmış gibi” diye görmüştük; burada kuralları öğreniyoruz.
- Sezgi:
tensor * 2skaleri her elemana uyguluyormuş gibidir ama bellekte kopya oluşmaz — “sanki yayıldı” yalnızca kavramsaldır; gerçek iş optimize koddadır.
14.10 9. Boyut Ekleme: unsqueeze ve None
Broadcasting’i yönlendirmek için tensöre birim eksen ekleriz. unsqueeze(0) veya c[None, :] başa, unsqueeze(1) veya c[:, None] ortaya bir boyut ekler. Bu, hangi eksenlerin hizalanacağını kontrol etmenin yoludur.
c.unsqueeze(0), c[None, :] # bas tarafa birim eksen (1, n)
c.unsqueeze(1), c[:, None] # ortaya birim eksen (n, 1)
İpucuBuilder Notu — None: Eksen Yerleştirmenin Kontrolü
- İleriye (Ders 24):
Noneile eksen ekleme, broadcasting matmul’un ve attention’ın (Ders 24) anahtar tekniğidir. - Sezgi:
[None, :]ile[:, None]farkı, vektörün satır mı sütun mu olarak yayılacağını belirler; matmul’da satırı (n,1) yapmak için[:, None]kullanılır.
14.11 10. Vektör-Matris Broadcasting
Bir vektörü bir matrisle çarparken broadcasting devreye girer: vektör, matrisin her satırına (veya sütununa, eksen ekleyişine göre) uygulanır. Bu, “her satır için ayrı işlem” döngüsünü tek bir tensör işlemine çevirir.
İpucuBuilder Notu — Vektör-Matris: Döngüyü Tek İşleme İndirme
- Geriye (Ders 5): Ders 5’teki normalizasyon (her satırı vektöre bölme) bu broadcasting’di.
- Sezgi: “Her satır için ayrı uygula” bir Python döngüsü olurdu; broadcasting bu döngüyü silip işi tek tensör çağrısına devreder — okunabilirlik ve hız birlikte gelir.
14.12 11. Broadcasting Kuralları
Kural basittir: iki tensörün şekilleri sondan başa karşılaştırılır; her eksende boyutlar ya eşit olmalı ya da biri 1 olmalı (1 olan, diğerine “yayılır”). Eksen sayıları farklıysa eksik olan başa 1’lerle doldurulur.
“The rules of broadcasting are [worth knowing]; as long as the last axes match, it’ll broadcast over those axes.” — Howard, 1:24:00
Şekil 14.5 bu kuralı tablo ve görsel yayılma ile gösterir (FLAGSHIP): solda örnek şekiller için “uyumlu mu?” tablosu (eşit ya da biri 1 → ✓; aksi → HATA), sağda \((3,1)\) sütun × \((1,4)\) satır = \((3,4)\) yayılma çarpım tablosu — sütun yatay, satır dikey yayılır.
Kod
d = E.broadcasting_demo()
examples = d["examples"]
col, row, grid = d["col"], d["row"], d["grid"] # (3,1), (1,4), (3,4)
fig, (axL, axR) = plt.subplots(1, 2, figsize=(12, 5.5),
gridspec_kw={"width_ratios": [1.05, 1.0]})
# --------------------------------------------------------------------------
# SOL panel — broadcasting kuralı tablosu (her örnek bir satır)
# --------------------------------------------------------------------------
axL.set_xlim(0, 10)
axL.set_ylim(0, 10)
axL.axis("off")
axL.set_title("Broadcasting kuralı", fontsize=13, weight="bold",
color=COL_CYAN_800, pad=10)
# Kural başlığı (kutu içinde)
boxed_node(axL, 5.0, 9.0, 9.4, 1.05,
"kural: şekilleri SONDAN BAŞA hizala — her eksen\nEŞİT olmalı YA DA biri 1 (o eksen yayılır)",
fc=COL_CYAN_50, ec=COL_CYAN_700, tc=COL_CYAN_800,
fontsize=10.5, lw=2.0)
# Sütun başlıkları
axL.text(2.7, 7.85, "şekil A × şekil B", ha="center", va="center",
fontsize=10.5, weight="bold", color=COL_TEXT)
axL.text(7.0, 7.85, "→ çıktı", ha="center", va="center",
fontsize=10.5, weight="bold", color=COL_TEXT)
axL.plot([0.4, 9.6], [7.45, 7.45], color=COL_SLATE_300, lw=1.4, zorder=1)
# Her örnek bir satır
y0 = 6.7
dy = 1.55
for k, (desc, sa, sb, out, ok) in enumerate(examples):
yy = y0 - k * dy
fc = COL_CYAN_50 if ok else COL_BG_ROSE
ec = COL_CYAN_700 if ok else COL_ROSE_500
# satır kutusu (şekil A × şekil B)
boxed_node(axL, 2.7, yy, 4.4, 1.05, desc,
fc=fc, ec=ec, tc=COL_TEXT, fontsize=11, lw=1.8)
# ok + sonuç
arrow_between(axL, (5.0, yy), (5.9, yy), color=ec, lw=2.0,
mutation_scale=14, shrink=2)
if ok:
out_txt = "(" + ", ".join(str(v) for v in out) + ")"
axL.text(7.6, yy + 0.18, out_txt, ha="center", va="center",
fontsize=11.5, weight="bold", color=COL_CYAN_800)
axL.text(7.6, yy - 0.42, "✓ uyumlu", ha="center", va="center",
fontsize=9.5, weight="bold", color=COL_CYAN_700)
else:
axL.text(7.6, yy + 0.18, "HATA", ha="center", va="center",
fontsize=11.5, weight="bold", color=COL_ACCENT)
axL.text(7.6, yy - 0.42, "✗ 4 ≠ 5 (biri 1 değil)",
ha="center", va="center",
fontsize=9.0, weight="bold", color=COL_ROSE_500)
# --------------------------------------------------------------------------
# SAĞ panel — görsel yayılma: (3,1) sütun × (1,4) satır = (3,4) çarpım tablosu
# --------------------------------------------------------------------------
nr, nc = grid.shape # 3, 4
axR.set_title("görsel: (3,1) sütun × (1,4) satır = (3,4)",
fontsize=13, weight="bold", color=COL_CYAN_800, pad=10)
# imshow çarpım tablosu (cyan tonlu)
extent = (0, nc, 0, nr)
axR.imshow(grid[::-1], cmap="cividis", extent=extent,
aspect="auto", alpha=0.55, vmin=0, vmax=grid.max())
# ızgara çizgileri + hücre değerleri (col[i]*row[j])
for i in range(nr):
for j in range(nc):
cx, cy = j + 0.5, (nr - 1 - i) + 0.5
axR.text(cx, cy, f"{int(grid[i, j])}", ha="center", va="center",
fontsize=14, weight="bold", color=COL_TEXT, zorder=4)
axR.text(cx, cy - 0.30, f"{int(col[i, 0])}×{int(row[0, j])}",
ha="center", va="center", fontsize=8.0,
color=COL_CYAN_800, zorder=4)
for g in range(nc + 1):
axR.plot([g, g], [0, nr], color=COL_WHITE, lw=2.0, zorder=3)
for g in range(nr + 1):
axR.plot([0, nc], [g, g], color=COL_WHITE, lw=2.0, zorder=3)
# SOL kenar: (3,1) sütun vektörü [[1],[2],[3]]
for i in range(nr):
cy = (nr - 1 - i) + 0.5
boxed_node(axR, -0.75, cy, 0.85, 0.7, f"{int(col[i, 0])}",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_CYAN_800,
fontsize=12, lw=1.8)
# sütunun YATAY yayılması (broadcast) — sağa ok
arrow_between(axR, (-0.3, cy), (0.5, cy), color=COL_PRIMARY,
lw=1.6, mutation_scale=12, shrink=2, zorder=5)
axR.text(-0.75, nr + 0.55, "sütun\n(3,1)", ha="center", va="center",
fontsize=9.5, weight="bold", color=COL_CYAN_700)
# ÜST kenar: (1,4) satır vektörü [[1,2,3,4]]
for j in range(nc):
cx = j + 0.5
boxed_node(axR, cx, nr + 0.75, 0.7, 0.7, f"{int(row[0, j])}",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_ACCENT,
fontsize=12, lw=1.8)
# satırın DİKEY yayılması (broadcast) — aşağı ok
arrow_between(axR, (cx, nr + 0.35), (cx, nr - 0.35), color=COL_ACCENT,
lw=1.6, mutation_scale=12, shrink=2, zorder=5)
axR.text(nc + 0.45, nr + 0.75, "satır\n(1,4)", ha="center", va="center",
fontsize=9.5, weight="bold", color=COL_ROSE_500)
axR.set_xlim(-1.4, nc + 1.0)
axR.set_ylim(-0.4, nr + 1.4)
axR.set_xticks([])
axR.set_yticks([])
for spine in axR.spines.values():
spine.set_visible(False)
plt.tight_layout()
plt.show()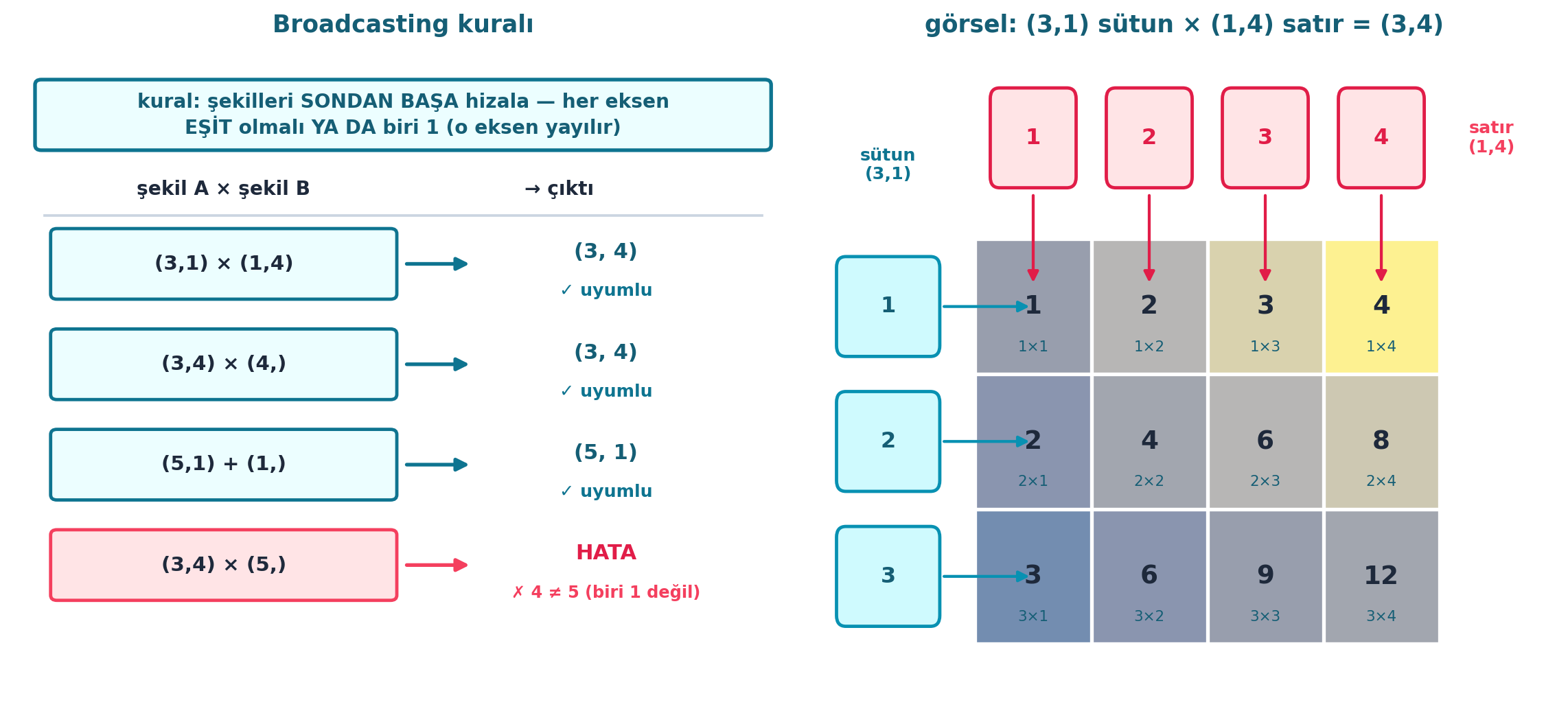
İpucuBuilder Notu — Kural: Sondan Başa, Eşit ya da 1
- Geriye (Ders 5 / §4.F): Bu kurallar NumPy/PyTorch’ta aynıdır; Karpathy §4.F’de broadcasting’i “sessiz hata kaynağı” olarak işaretler — kural bilinmezse yanlış sonuç sessizce çıkar.
- Sezgi: “Sondan başa” hizalama, eksen sayıları farklı tensörleri (örn. \((784,)\) ile \((5,784)\)) otomatik eşler; eksik eksen başa 1 olarak doldurulur ve oradan yayılır.
14.13 12. Broadcasting ile Matmul: Döngüleri Kaldırma
İşte kazanım: matmul’un en içteki döngüsünü (dot product) broadcasting ile kaldırırız. a[i,:,None] * b ifadesi, i. satırı tüm b sütunlarıyla aynı anda çarpar; .sum(dim=0) ise toplar. Üç döngüden tek döngüye iner.
def matmul(a, b):
(ar, ac), (br, bc) = a.shape, b.shape
c = torch.zeros(ar, bc)
for i in range(ar):
c[i] = (a[i,:,None] * b).sum(dim=0) # broadcast: tum sutunlar birden
return cBurada a[i,:,None] i. satırı \((784,1)\) yapar, b \((784,10)\) ile broadcast çarpılır \((784,10)\), .sum(dim=0) ise sütunları toplar \((10,)\) — i. satırın tüm çıktısı tek işlemde hesaplanır.
Şekil 14.6 bu akışı ve sonucu gösterir: üstte a[i,:,None] \((5,1)\) sütun × b \((5,3)\) → ara \((5,3)\) broadcast → sum(0) → c[i] \((3,)\); altta broadcasting sonucu ile numpy a @ b yan yana — np.allclose ile özdeş.
Kod
d = E.broadcasting_matmul_demo()
a, b = d["a"], d["b"]
c_bc, c_np = d["c_broadcast"], d["c_numpy"]
correct = d["correct"]
fig = plt.figure(figsize=(11, 5.5))
fig.patch.set_facecolor(COL_WHITE)
gs = fig.add_gridspec(2, 2, height_ratios=[1.0, 1.5], hspace=0.42, wspace=0.22)
# ----------------------------------------------------------------------------
# ÜST: broadcasting akış şeması (a[i,:,None] sütun × b → ara → sum(0) → c[i])
# ----------------------------------------------------------------------------
ax_top = fig.add_subplot(gs[0, :])
ax_top.set_xlim(0, 10)
ax_top.set_ylim(0, 2)
ax_top.axis("off")
ax_top.set_title("Broadcasting matmul: iç iki döngü (j, k) yok edildi",
fontsize=12.5, color=COL_CYAN_700, weight="bold", pad=6)
boxed_node(ax_top, 1.25, 1.0, 2.0, 1.05,
"a[i, :, None]\n(5, 1) sütun", fc=COL_BG, ec=COL_PRIMARY, fontsize=9.5)
boxed_node(ax_top, 4.0, 1.0, 1.9, 1.05,
"× b\n(5, 3)", fc=COL_CYAN_50, ec=COL_CYAN_700, fontsize=9.5)
boxed_node(ax_top, 6.7, 1.0, 2.0, 1.05,
"ara: (5, 3)\nbroadcast", fc=COL_BG_ROSE, ec=COL_ROSE_500, fontsize=9.5)
boxed_node(ax_top, 9.1, 1.0, 1.55, 1.05,
"sum(0)\n→ c[i] (3,)", fc=COL_WHITE, ec=COL_ACCENT, tc=COL_ACCENT, fontsize=9.5)
arrow_between(ax_top, (2.25, 1.0), (3.05, 1.0), color=COL_CYAN_700)
arrow_between(ax_top, (4.95, 1.0), (5.70, 1.0), color=COL_CYAN_700)
arrow_between(ax_top, (7.70, 1.0), (8.32, 1.0), color=COL_ACCENT)
ax_top.text(5.0, 0.18,
"tek döngü (i, satır) kalır; iç çarpım-toplam broadcasting'e devredildi",
ha="center", va="center", fontsize=9.5, color=COL_TEXT, style="italic")
# ----------------------------------------------------------------------------
# ALT: iki sonuç matrisi yan yana (broadcasting vs numpy @) — özdeş
# ----------------------------------------------------------------------------
vmin = min(c_bc.min(), c_np.min())
vmax = max(c_bc.max(), c_np.max())
def draw_mat(ax, M, title):
im = ax.imshow(M, cmap="cividis", vmin=vmin, vmax=vmax, aspect="auto")
ax.set_title(title, fontsize=11, color=COL_CYAN_800, weight="bold", pad=6)
ax.set_xticks(range(M.shape[1]))
ax.set_yticks(range(M.shape[0]))
ax.set_xticklabels([f"k{j}" for j in range(M.shape[1])], fontsize=8.5)
ax.set_yticklabels([f"i{i}" for i in range(M.shape[0])], fontsize=8.5)
ax.tick_params(length=0, colors=COL_TEXT)
for i in range(M.shape[0]):
for j in range(M.shape[1]):
ax.text(j, i, f"{M[i, j]:.2f}", ha="center", va="center",
fontsize=8.5, color=COL_WHITE, weight="bold")
for spine in ax.spines.values():
spine.set_color(COL_SLATE_400)
return im
ax_bc = fig.add_subplot(gs[1, 0])
ax_np = fig.add_subplot(gs[1, 1])
draw_mat(ax_bc, c_bc, "c = broadcasting matmul (4, 3)")
draw_mat(ax_np, c_np, "c = numpy a @ b (4, 3)")
# np.allclose rozeti — iki matris arasında
badge_fc = COL_BG if correct else COL_BG_ROSE
badge_ec = COL_PRIMARY if correct else COL_ACCENT
badge_tc = COL_CYAN_800 if correct else COL_ACCENT
fig.text(0.5, 0.075, f"np.allclose = {correct} (aynı sonuç)",
ha="center", va="center", fontsize=11, weight="bold", color=badge_tc,
bbox=dict(boxstyle="round,pad=0.45", fc=badge_fc, ec=badge_ec, lw=2.0))
plt.tight_layout(rect=(0, 0.05, 1, 1))
plt.show()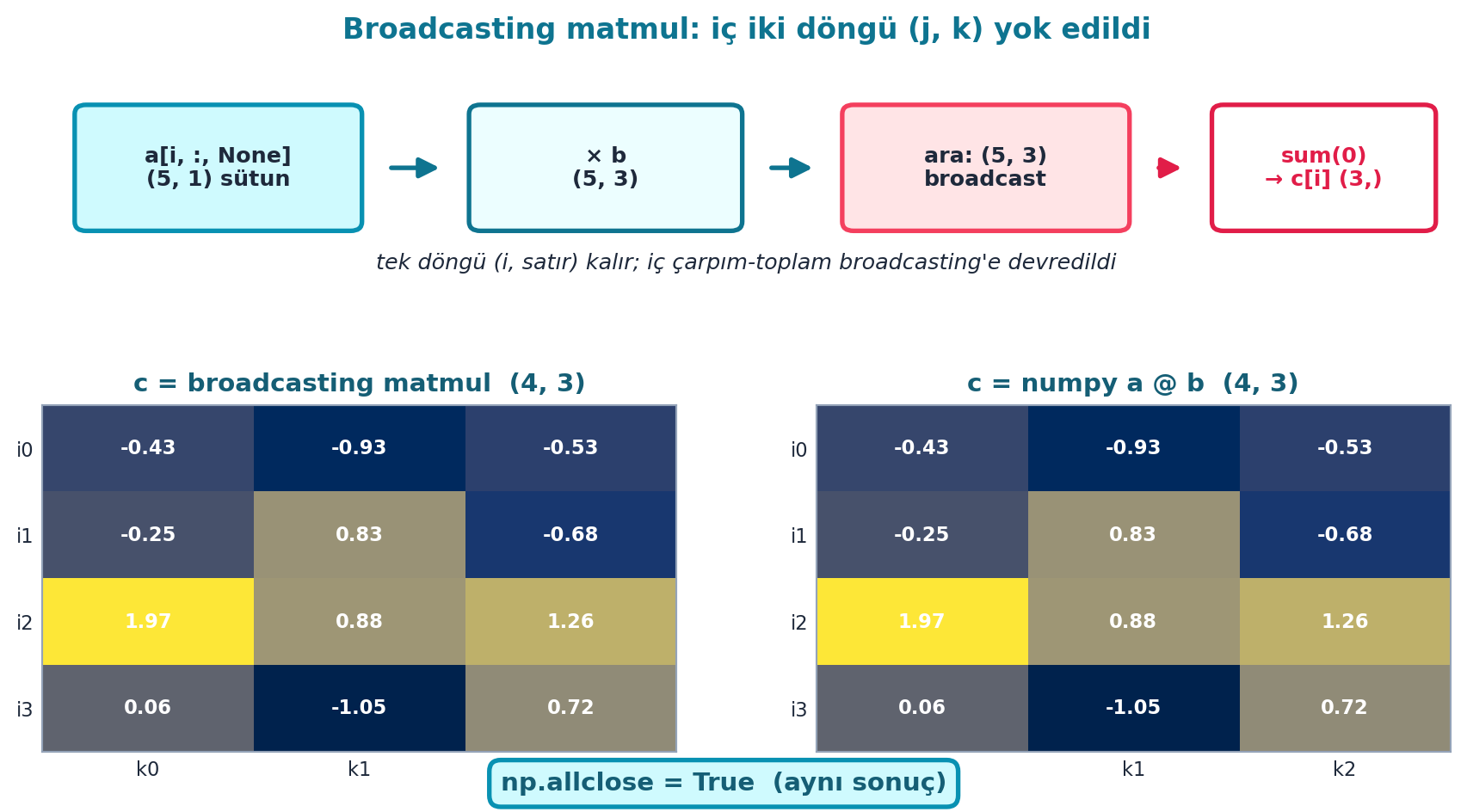
İpucuBuilder Notu — İç İki Döngü Broadcasting’e Devredildi
- Geriye (Ders 10): Ders 10’un üç döngüsü tek döngüye indi; iç iki döngü (j sütun, k dot product) broadcasting’e devredildi.
- Sezgi:
a[i,:,None]satırı dik bir sütun yapar ki tümbsütunlarıyla aynı anda hizalansın;.sum(dim=0)ile k ekseni toplanınca i. satırın bütün çıktısı tek tensör işleminde çıkar.
14.14 13. Broadcasting Matmul: Hız
Bu versiyon, Python döngülü matmul’dan yüzlerce kat hızlıdır: iç iş artık optimize C koduna (ve GPU’ya) düşer. Howard %timeit ile farkı gösterir — milisaniyeler yerine mikrosaniyeler.
Şekil 14.7 bu ilerlemeyi gerçek canlı benchmark ile ölçer: aynı matris çarpımı üç yöntemle — 3 iç içe döngü → broadcasting → numpy @ — her adım hızlanır, sonuçlar np.allclose ile özdeştir. Broadcasting döngüyü optimize koda devreder.
Kod
d = E.matmul_speed3_demo()
methods = ["3 iç içe\ndöngü", "broadcasting", "numpy @"]
times = [d["loop_ms"], d["broadcast_ms"], d["numpy_ms"]]
bar_colors = [COL_ROSE_500, COL_PRIMARY, COL_CYAN_800]
fig, (ax, axr) = plt.subplots(
1, 2, figsize=(11, 5), gridspec_kw={"width_ratios": [2.4, 1.0]}
)
# --- Sol: log-skala bar grafik ---
xpos = np.arange(len(methods))
bars = ax.bar(xpos, times, color=bar_colors, width=0.6, zorder=3,
edgecolor=COL_WHITE, linewidth=1.5)
ax.set_yscale("log")
ax.set_xticks(xpos)
ax.set_xticklabels(methods, fontsize=11, color=COL_TEXT, weight="bold")
ax.set_ylabel("süre (ms, log-skala)", fontsize=11)
ax.set_title("Aynı matris çarpımı, üç yöntem", fontsize=12.5,
color=COL_CYAN_700, weight="bold", pad=12)
apply_style(ax)
ax.grid(True, axis="y", alpha=0.25, color=COL_SLATE_400)
ax.grid(False, axis="x")
# barların üstüne ms etiketi
for rect, t in zip(bars, times):
ax.annotate(f"{t:.2f} ms",
xy=(rect.get_x() + rect.get_width() / 2, rect.get_height()),
xytext=(0, 5), textcoords="offset points",
ha="center", va="bottom", fontsize=10.5,
color=COL_TEXT, weight="bold")
# log-skalada üst başlık için biraz pay
ax.set_ylim(min(times) * 0.35, max(times) * 3.0)
# --- Sağ: hızlanma rozetleri + ilerleme notu ---
axr.axis("off")
axr.set_xlim(0, 1)
axr.set_ylim(0, 1)
boxed_node(axr, 0.5, 0.82, 0.92, 0.20,
f"broadcasting: {d['speedup_bc']:.0f}× hızlanma",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_CYAN_800, fontsize=11.5)
boxed_node(axr, 0.5, 0.58, 0.92, 0.20,
f"numpy @: {d['speedup_np']:.0f}× hızlanma",
fc=COL_CYAN_50, ec=COL_CYAN_800, tc=COL_CYAN_800, fontsize=11.5)
boxed_node(axr, 0.5, 0.34, 0.92, 0.20,
f"np.allclose hepsi = {d['correct']}\n(aynı sonuç)",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_ACCENT, fontsize=10.5)
axr.text(0.5, 0.10,
"Ders 10'un 3-döngüsü → broadcasting (Ders 11) → @ (Ders 12)",
ha="center", va="center", fontsize=9.5, style="italic",
color=COL_SLATE_400, wrap=True)
plt.tight_layout()
plt.show()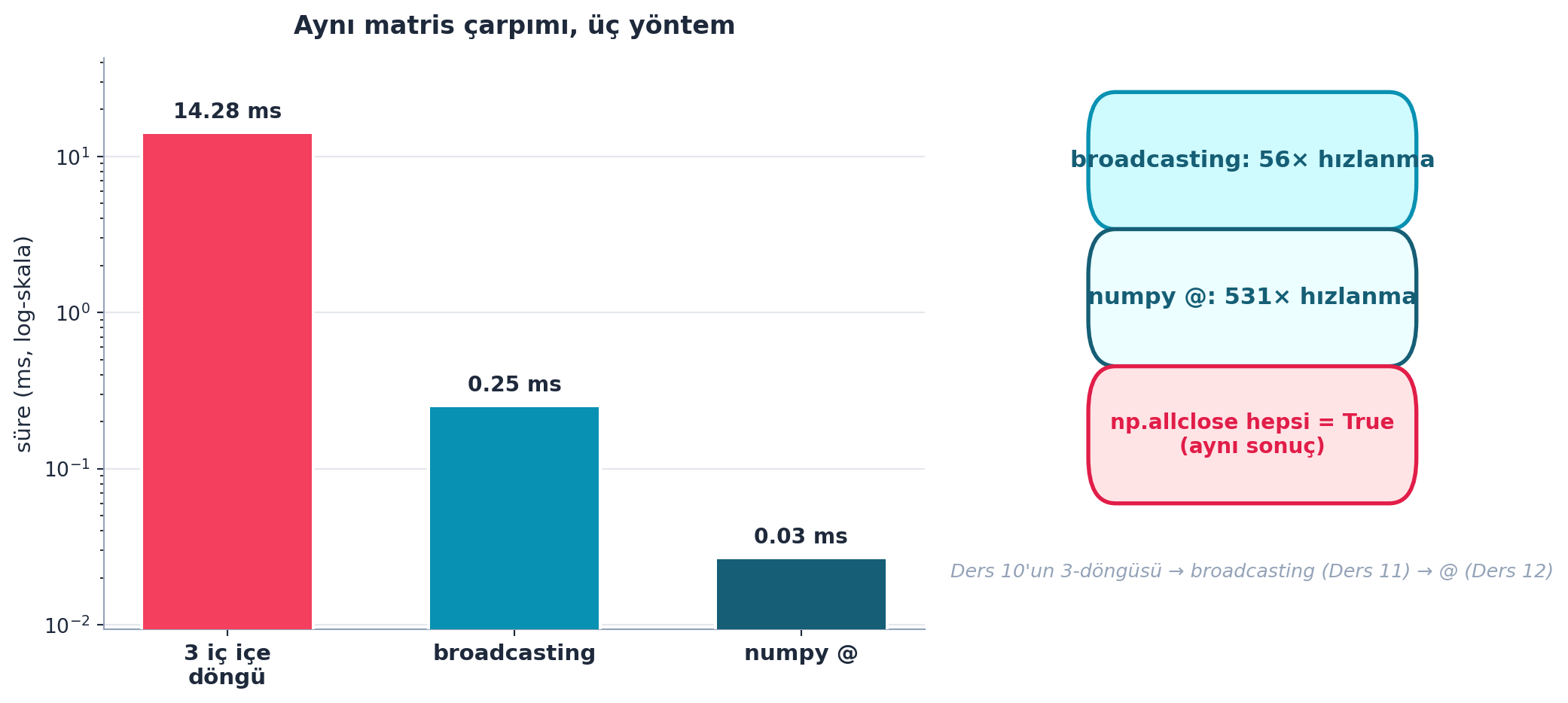
İpucuBuilder Notu — Döngüyü Tensör İşlemine Çevir
- İleriye: Bu, “döngüyü tensör işlemine çevir” ilkesi; tüm performanslı sayısal kodun temel desenidir.
- Builder ipucu: Hız kazanırken doğruluğu kaybetmediğini her zaman doğrula — benchmark’ın her yanı
np.allclose ✓veriyorsa kazanım gerçektir.
14.15 14. Neden Bu Kadar Hızlı?
Sebep: Python döngüsü her işlemi tek tek yorumlar; broadcasting ise tüm işlemi tek bir tensör çağrısında, derlenmiş ve paralelleştirilmiş (SIMD/GPU) koda devreder. Az sayıda Python çağrısı, çok sayıda paralel hesap.
“[This is] really slow.” — Howard, ~58:00 (döngülü matmul timing)
İpucuBuilder Notu — Hızın Kaynağı: Az Python, Çok Paralel Hesap
- Geriye (Ders 10): Numba bir fonksiyonu derliyordu; broadcasting ise PyTorch’un zaten derli C/CUDA çekirdeklerini kullanır — kod yazmadan hız.
- Sezgi: Python yorumlayıcısı her
c[i,j] += ...işlemini tek tek çalıştırır (yavaş); broadcasting bir komutla milyonlarca hesabı SIMD/GPU’ya devreder — “az Python çağrısı, çok paralel iş”.
14.16 15. İleriye: Einsum ve @
Howard sonraki adımı işaret eder: Einstein toplamı (einsum) ve PyTorch’un @ operatörü matmul’u daha da kısaltır ve hızlandırır (Ders 12). Sonunda a @ b tek karakterle, GPU’da en hızlı hâle gelir.
import torch
torch.einsum('ik,kj->ij', a, b) # tekrarlanan k toplanir -> matmul
a @ b # en kisa: GPU'da en hizli
İpucuBuilder Notu — einsum / @: Yolculuğun Son Adımı
- İleriye (Ders 12): einsum (
'ik,kj->ij') ve@, matmul yolculuğunun son adımlarıdır; oradan gerçek GPU GEMM’ine geçilir. - Sezgi: einsum’da tekrarlanan indeks (k) “bu eksen üzerinden topla” demektir;
@ise bunun en kısa yazılışıdır — broadcasting matmul’u bir kez anladıktan sonra@’i güvenle kullanırsın.
14.17 16. Kapanış
Ders 11 iki beceri verdi: makale okuma (arXiv + Zotero ile DiffEdit) ve broadcasting. Broadcasting, Ders 10’un yavaş üç-döngü matmul’unu optimize, döngüsüz bir tensör işlemine çevirdi — “from the foundations” omurgasının ilk büyük hız kazanımı.
Şekil 14.8 dersin sentezidir: solda L11’in parçaları (broadcasting, broadcasting matmul, Frobenius norm, tensör rank, makale okuma, DiffEdit), sağda her birinin nereden/nereye köprüsü — Ders 5+10 → döngüsüz hız, Ders 12 einsum/@ → GPU GEMM, 18.06 + üretken modelleme, Ders 1 H×W×3 tensör, builder meta-becerisi, Ders 9 img2img gelişmişi.
Kod
fig, ax = plt.subplots(figsize=(12, 6.5))
ax.set_xlim(0, 12)
ax.set_ylim(0, 6.5)
ax.axis("off")
# Başlık şeritleri
ax.text(2.3, 6.25, "L11'de", ha="center", va="center",
fontsize=13, weight="bold", color=COL_ROSE_500)
ax.text(8.7, 6.25, "nereden / nereye", ha="center", va="center",
fontsize=13, weight="bold", color=COL_CYAN_700)
# SOL: L11 parçaları (rose) — 6 kutu, dikey dizilim
left_x, lw, lh = 2.3, 3.3, 0.78
ys = [5.45, 4.45, 3.45, 2.45, 1.45, 0.55]
left_labels = [
"broadcasting",
"broadcasting\nmatmul",
"Frobenius norm",
"tensör rank",
"makale okuma\n(arXiv / Zotero)",
"DiffEdit",
]
for y, txt in zip(ys, left_labels):
boxed_node(ax, left_x, y, lw, lh, txt,
fc=COL_BG_ROSE, ec=COL_ROSE_500, tc=COL_ACCENT,
fontsize=10, lw=2.0)
# SAĞ: kaynak/hedef (cyan) — 6 kutu, sol kutularla hizalı
right_x, rw, rh = 8.9, 5.1, 0.82
right_labels = [
"Ders 5 (Titanic normalizasyon)\n+ Ders 10 (3-döngü matmul)\n→ döngüsüz hız",
"Ders 12 (einsum / @)\n→ GPU GEMM",
"18.06 + üretken\nmodellemede sık",
"Ders 1: görüntü = H×W×3 tensör",
"builder meta-becerisi:\nalanın ucunda kal",
"Ders 9 img2img gelişmişi\n(maske)",
]
for y, txt in zip(ys, right_labels):
boxed_node(ax, right_x, y, rw, rh, txt,
fc=COL_CYAN_50, ec=COL_CYAN_700, tc=COL_CYAN_800,
fontsize=9, lw=2.0)
# Oklar: her sol parça → ilgili kaynak/hedef
for y in ys:
arrow_between(ax, (left_x + lw / 2, y), (right_x - rw / 2, y),
color=COL_CYAN_400, lw=1.8, mutation_scale=15, shrink=4)
plt.tight_layout()
plt.show()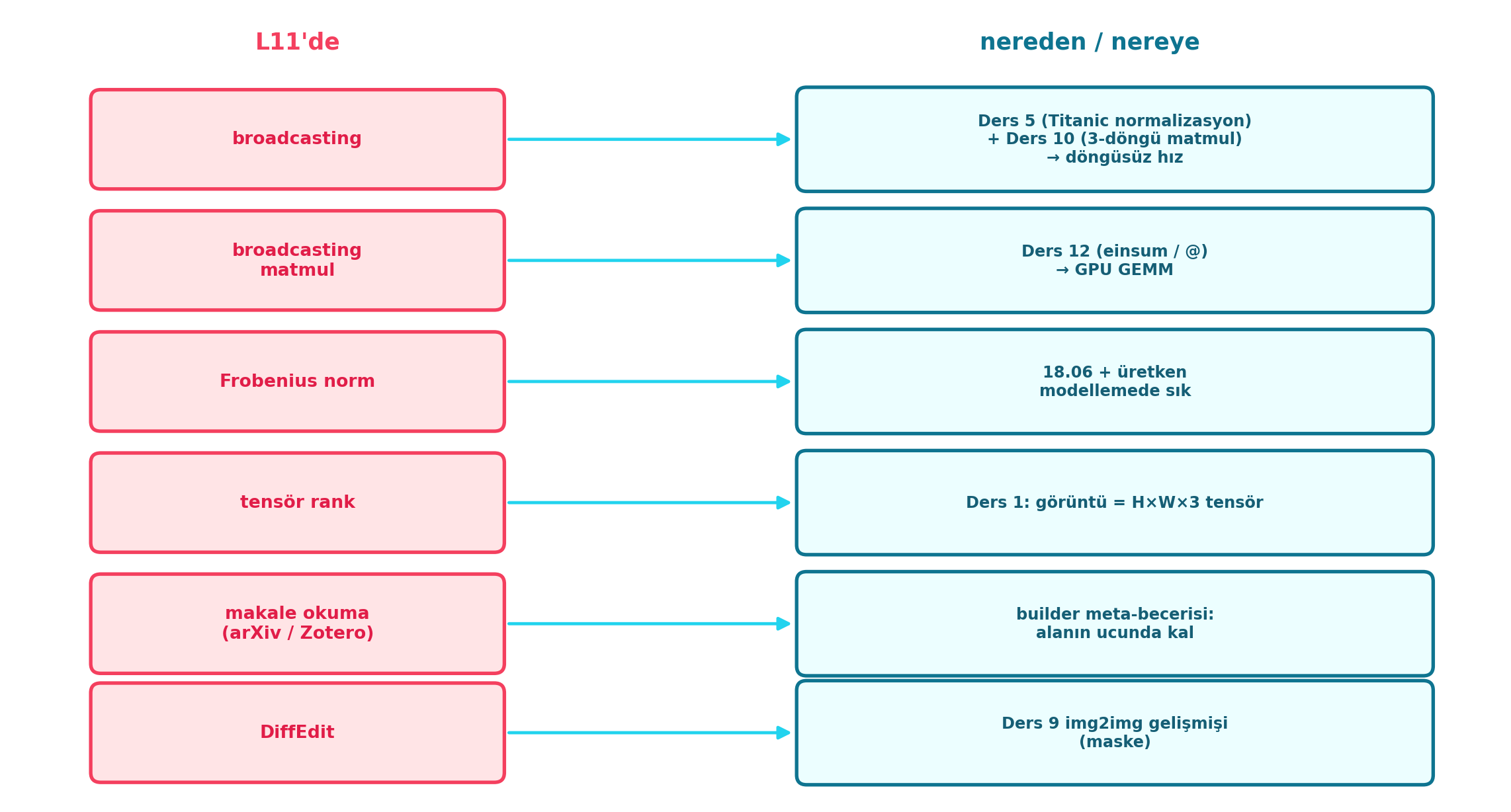
İpucuBuilder Notu — Foundations Zinciri İlerliyor
- İleriye (Ders 12-14): Ders 12 matmul’u einsum/@ ile bitirip mean shift’e geçer; Ders 13-14 backprop’u sıfırdan kurar.
- Tek cümle: Bir döngüyü kaldırmanın yolu broadcasting’dir; matmul bunun ilk büyük kazanımıydı, sıradaki parçalar (backprop, Learner, diffusion) aynı zincirde elle kurulacak.
14.18 Bu Dersin Özeti
- Makale okuma araştırmanın temel becerisi: arXiv’den preprint, Zotero ile not alma (DiffEdit örneği) (makale akışı).
- DiffEdit bir görüntüde yalnızca prompt’un işaret ettiği bölgeyi değiştirir (maske + hedefli gürültü-giderme) (DiffEdit).
- Tensörün rank’ı boyut sayısıdır (skaler/vektör/matris/yığın); broadcasting şekil üstünde çalışır (rank).
- Frobenius norm = \(\sqrt{\sum a_{ij}^2}\) (tüm elemanların kareleri toplamının karekökü); matrisin “büyüklüğü” (Frobenius).
- Broadcasting farklı şekilli tensörleri otomatik hizalar; kural: sondan başa, eksenler eşit ya da biri 1 (kurallar).
- unsqueeze/None ile birim eksen ekleyerek broadcasting yönlendirilir (unsqueeze).
- Broadcasting ile matmul iç döngüyü kaldırır:
c[i] = (a[i,:,None] * b).sum(dim=0)(broadcasting matmul). - Sonuç Python döngüsünden yüzlerce kat hızlı (optimize C/GPU); einsum ve
@(Ders 12) daha da ileri gider (hız, einsum).
ÖnemliTek Bir Cümle
Broadcasting, farklı şekilli tensörleri otomatik hizalayıp döngüleri optimize koda devretmenin yoludur; Ders 10’un yavaş üç-döngü matris çarpımını, tek döngülü ve yüzlerce kat hızlı bir tensör işlemine dönüştürür.
14.19 Kontrol Soruları
NotSoru 1: Broadcasting nedir ve kuralı nedir?
Cevap:
Broadcasting, farklı şekilli iki tensörü, küçük olanı büyük olana otomatik “yayarak” (kopyalıyormuş gibi, ama gerçek kopya oluşturmadan) elementwise işleme sokmaktır. Kural: şekiller sondan başa karşılaştırılır; her eksende ya boyutlar eşit olmalı ya da biri 1 olmalı (1 olan diğerine yayılır). Eksen sayıları farklıysa, eksik olanın başına 1’ler eklenir. Örneğin \((5,784)\) ile \((784,)\) çarpılınca vektör her satıra yayılır. Bu, açık döngü yerine tek bir optimize tensör işlemi sağlar. (Şekil 14.5 bu kuralı tablo ve görsel yayılma ile gösterir.)
NotSoru 2: Broadcasting matris çarpımını nasıl hızlandırır? Ders 10’un üç döngüsüne ne olur?
Cevap:
Ders 10’da matmul üç iç içe döngüydü (i, j, k) ve Python’da yavaştı. Broadcasting ile en içteki dot-product döngüsü (k) ve sütun döngüsü (j) kaldırılır: c[i] = (a[i,:,None] * b).sum(dim=0). Burada a[i,:,None] i. satırı \((784,1)\) yapar, b \((784,10)\) ile broadcast çarpılır \((784,10)\), .sum(dim=0) ise sütunları toplar \((10,)\) — i. satırın tüm çıktısı tek işlemde. Geriye tek döngü (i) kalır. Hesap artık optimize C/GPU koduna düştüğü için yüzlerce kat hızlanır. (Şekil 14.7 bu hızlanmayı gerçek benchmark’la gösterir.)
NotSoru 3: unsqueeze / None ne işe yarar ve broadcasting’le ilişkisi nedir?
Cevap:
unsqueeze(dim) veya [None] indeksleme, tensöre birim (1) eksen ekler — örneğin \((n,)\) vektörünü \((1,n)\) veya \((n,1)\) yapar. Bu, broadcasting’in hangi eksenlerde yayılacağını kontrol etmenin yoludur. Matmul’da a[i,:,None] satırı \((784,1)\) yapar ki \((784,10)\) matrisle hizalansın ve her sütunla çarpılsın. Birim eksen eklemeden broadcasting yanlış hizalanır veya hata verir. Bu teknik attention (Ders 24) gibi ileri konularda da merkezîdir. (Şekil 14.6 a[i,:,None] akışını gösterir.)
NotSoru 4: Akademik makale okuma neden bir builder becerisidir? (builder bağlantısı)
Cevap:
Derin öğrenme çok hızlı ilerler ve en yeni teknikler önce arXiv’de (preprint olarak, hakem değerlendirmesinden önce) yayımlanır; hakemli yayını beklemek aylar/yıllar alır. Bir builder olarak alanın ucunda kalmak istiyorsan makale okuyabilmen gerekir. Howard’ın iş akışı: arXiv’den PDF al, Zotero gibi bir araçla kaydet ve üzerine not alarak sistemli oku. DiffEdit örneğinde olduğu gibi, bir makaleyi okuyup adım adım uygulayabilmek, “tüketici”den “üretici”ye geçişin anahtarıdır. (Şekil 28.1 sol kol bu akışı gösterir.)
14.20 Egzersizler
Egzersiz 1 (Direkt uygulama). İki tensör oluştur (örn. \((5,784)\) ve \((784,)\)) ve unsqueeze/None ile farklı eksenlere birim boyut ekleyip broadcasting sonuçlarını gözle. (§9)
Egzersiz 2 (İki-aşamalı). Ders 10’un üç-döngü matmul’unu broadcasting versiyonuna (c[i] = (a[i,:,None]*b).sum(dim=0)) çevir; %timeit ile hız farkını ölç. (Şekil 14.7’ı kendi sayınla yeniden üret — §12-13)
Egzersiz 3 (Edge case). Şekilleri broadcast edilemeyen iki tensörü (örn. \((3,4)\) ve \((5,)\)) çarpmayı dene; hatayı oku ve kuralı neden ihlal ettiğini açıkla. (§11)
Egzersiz 4 (Kavramsal). Bir matrisin Frobenius norm’unu elle hesapla (elemanları karele, topla, karekök al); torch ile doğrula. (§7)
Egzersiz 5 (Sonraki dersin habercisi — Ders 12). torch.einsum('ik,kj->ij', a, b) ifadesinin matmul ile aynı sonucu verdiğini doğrula; tekrarlanan indeks (k) ne anlama geliyor düşün. (§15)
14.21 Sonraki: Ders 12 İçin Hazırlık
Ders 12: Mean Shift Kümeleme (Mean shift clustering)
Ders 11 matmul’u broadcasting ile hızlandırdı. Ders 12 önce matmul’u einsum ve @ ile bitirir (CLIP Interrogator demosuyla), sonra ilk tam “from foundations” algoritmasını kurar: mean shift clustering — etiketsiz veriyi kümelere ayıran bir yöntem.
Ana konular (Ders 12):
- Einstein toplamı (einsum) ve
@ - CLIP Interrogator (görüntüden prompt)
- Mean shift clustering (Gaussian kernel)
- Batched mean shift (GPU)
UyarıDers 12 Öncesi Yapılacak
- Bu dersin egzersizlerini çöz (özellikle 2 ve 5 — broadcasting matmul + einsum).
- Broadcasting kurallarını kendi cümlelerinle yaz.
- Ana cümleyi tekrar oku: “Broadcasting = döngüyü optimize koda devret.”
14.22 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Howard’da |
|---|---|---|
| arXiv | Preprint sunucusu; en yeni makaleler | 13:22 |
| Zotero | Makale kaydetme + not alma aracı | 15:03 |
| DiffEdit | Maske + hedefli gürültü-giderme ile bölgesel düzenleme | 46:36 |
| Rank | Tensörün boyut (eksen) sayısı | 1:01:13 |
| Elementwise | Aynı şekilli tensörlerde eleman eleman işlem | 1:01:13 |
| Frobenius norm | \(\sqrt{\sum a_{ij}^2}\); matris büyüklüğü | 1:19:58 |
| Broadcasting | Farklı şekilli tensörleri otomatik hizalama | 1:24:00 |
| Broadcasting kuralı | Sondan başa; eksen eşit ya da biri 1 | 1:24:00 |
| unsqueeze / None | Tensöre birim eksen ekleme | 1:24:00 |
| Broadcasting matmul | c[i] = (a[i,:,None]*b).sum(dim=0); döngüsüz |
59:15 |
| Makale okuma | arXiv + Zotero iş akışı; builder becerisi | 13:09 |
| einsum / @ (ileriye) | matmul’un en kısa/hızlı hâli (Ders 12) | 58:52 |
14.23 ML Bağlantıları Özeti
İpucuBuilder Notu — 6 ML Köprüsü: L11’in Tanıdık Kökleri
Bu ders araştırma becerisini ve foundations hızını her parçada tanıdık kavramlara bağlar; köprülerin özeti:
- Broadcasting → döngüsüz tensör hesabı; tüm performanslı sayısal kodun temeli (Ders 5/10) (broadcasting).
- Broadcasting matmul → üç döngü → tek döngü; optimize C/GPU’ya devir (broadcasting matmul).
- Frobenius norm → matris büyüklüğü (18.06); üretken modellemede sık (Frobenius).
- Makale okuma (arXiv/Zotero) → alandaki en yeni tekniklere erişim; builder meta-becerisi (makale akışı).
- DiffEdit → maske + hedefli gürültü-giderme; img2img’in (Ders 9) gelişmişi (DiffEdit).
- unsqueeze/None → eksen yönetimi; attention (Ders 24) ve broadcasting’in anahtarı (unsqueeze).
ÖnemliBu dersten tek bir şey alıp gideceksen
Bir döngüyü kaldırmanın yolu broadcasting’dir. Ders 10’un yavaş üç-döngü matris çarpımını, c[i] = (a[i,:,None]*b).sum(dim=0) ile tek döngüye ve yüzlerce kat hıza indirdik — çünkü iş artık optimize C/GPU koduna devredildi. Ayrıca bir builder becerisi öğrendik: makaleleri arXiv’den okuyup Zotero ile not alarak alanın ucunda kalmak.