flowchart TD
EMB["embedding<br/>(collab / NLP / tablo)<br/>kategori → vektör"] --> CONV["convolution<br/>(kernel + kaydırma)<br/>kaydırılan dot product"]
CONV --> CNN["CNN<br/>conv + ReLU + pooling + BatchNorm<br/>boyut küçülür, kanal artar"]
style EMB fill:#cffafe,stroke:#0891b2,stroke-width:2px
style CONV fill:#cffafe,stroke:#0891b2,stroke-width:2px
style CNN fill:#ffe4e6,stroke:#e11d48,stroke-width:3px
9 Evrişimler / CNN — Convolution ve Embedding’in Her Yerdeliği (Convolutions)
Part 1’in son dersi iki şeyi tamamlar: önce Ders 7’nin embedding hikâyesini bitirir — embedding’i sıfırdan kurma, yorumlama, mesafeyle benzerlik ve embedding’in collaborative filtering’den NLP’ye, oradan tablo verisine (entity embeddings) taşınması: hepsi aynı ‘arama tablosu’; sonra dersin asıl başlığı convolution — küçük bir kerneli (filtre) görüntü üzerinde kaydırıp her konumda dot product alan, kenar gibi yerel desenleri yakalayan, tam bağlı ağa kıyasla çok az parametre kullanan işlem; ve CNN — conv + ReLU + pooling + BatchNorm yığını: her katman görüntüyü küçültürken kanalı artırır, sonunda tek bir tahmin kalır
NotBölüm bilgisi
- Howard’ın videosu: course.fast.ai — Lesson 8: Convolutions (CNNs) (~97 dk)
- Seri: Practical Deep Learning for Coders — Part 1, Ders 8 (FİNAL)
- Hoca: Jeremy Howard
- Playlist: Practical Deep Learning Part 1 (2022)
- Notebook: fastbook — 13_convolutions
- Okuma süresi: ~36 dk
9.1 Bu Derste Ne Var?
Part 1’in son dersi iki şeyi tamamlar. İlk yarı, Ders 7’nin embedding hikâyesini bitirir: embedding’i sıfırdan kurma, yorumlama, mesafeyle benzerlik, ve embedding’in NLP ile tablo verisine (entity embeddings) taşınması. İkinci yarı dersin başlığıdır: convolution — CNN’lerin, yani görüntü modellerinin temel işlemi.
Üç temel fikir:
- Embedding her yerde — collaborative filtering, NLP ve tablo verisi; hepsi aynı “arama tablosu”. Tablo verisinde kategorik sütunlar için embedding (entity embeddings) güçlü bir tekniktir (Embedding Her Yerde → Tablo İçin Embedding).
- Convolution = kaydırılan mini dot product — küçük bir filtreyi (kernel) görüntü üzerinde kaydırıp yerel desenleri (kenar) yakalama; tam bağlı ağa kıyasla çok az parametre (Convolution: Kenar Bulma → Filtreyi Kaydırma).
- CNN = conv + ReLU + pooling yığını — her katman görüntüyü küçültürken kanal sayısını artırır; sonunda tek bir tahmin kalır (simple_cnn → Pooling → BatchNorm).
“You can think of a convolution as being a sliding window of little mini dot products.” — Howard, 53:00
Şekil 28.1 bu üç fikri tek bir haritada birleştirir: her veri tipinde kategoriyi vektöre çeviren embedding’den, görüntü üzerinde kaydırılan convolution’a, oradan conv + ReLU + pooling + BatchNorm’dan oluşan CNN’e ilerler — rose vurgulu “CNN” düğümü dersin doruğudur.
İpucuBuilder Notu — İki Yarı, Tek Hikâye: Embedding’in Her Yerdeliği ve Convolution
- Geriye (Ders 1/3/7): Bu ders Ders 1’deki “görüntü = sayı”yı, Ders 3’teki Zeiler-Fergus öznitelik dedektörlerini ve Ders 7’deki embedding’i birleştirip somutlaştırır.
- İleriye (Part 2 / Karpathy): Convolution Part 2’de (Ders 15, 19) U-Net ve diffusion’ın temeli; entity embeddings modern tablo modellerinin standardı; Şekil 28.1’in rose “CNN” düğümü buradan büyür.
- Tek cümle: Convolution, az parametreyle yerel desen yakalayan kaydırmalı bir dot product’tır; embedding ise her veri tipinde kategoriyi vektöre çeviren arama tablosudur.
9.2 Part 1 Finali ve Embedding’i Sıfırdan Kurma
Howard son derse, Ders 7’nin embedding’ini sıfırdan kurarak başlar. PyTorch’un Embedding katmanı aslında basittir: eğitilecek bir parametre matrisi oluşturur ve onu küçük rastgele sayılarla doldurur.
def create_params(size):
# egitilecek bir parametre matrisi: kucuk normal rastgele sayilarla doldur
return nn.Parameter(torch.zeros(*size).normal_(0, 0.01))“This is the last lesson of Part One.” — Howard, 0:00
Bu, Ders 7’deki Embedding’in içini açar: gizem yok, sadece eğitilebilir bir tablo — embedding’in arama tablosu olduğu fikrinin kod hâli.
İpucuBuilder Notu — nn.Parameter: Gradient Descent’in Güncellediği Tablo
- Geriye (Ders 5/7):
nn.Parameter, gradient descent’in güncelleyeceği ağırlıklardır; embedding bunların bir arama tablosu hâli — Ders 7’de elle kurduğumuzEmbeddingtam bucreate_paramsile aynı işi yapar. - İleriye (Part 2):
nn.Parameterile saklanan bu ağırlıklar Part 2’de sıfırdan optimize edilir — matmul’dan backprop’a kadar her parametrenin gradyanı elle hesaplanıp güncellenecek;requires_gradmekanizması orada açılır.
9.3 Embedding Yorumlama
Eğitilmiş embedding’ler yorumlanabilir. Howard film faktörlerinin en düşük/en yüksek değerli olanlarına bakar ve hangi filmlerin uçlarda olduğunu görür — model, hiç söylenmeden, filmleri anlamlı eksenlerde (örn. klasik vs gişe) düzenlemiştir.
“What we could do is we could find which Movie-IDs [have the lowest factors], the names of those movies.” — Howard, 12:32
Bu, Ders 7’deki latent uzayın yorumlanabilirliğinin devamıdır: model, anlamı biz tanımlamadan eksenleri kendi keşfeder.
İpucuBuilder Notu — Latent Uzayı İncelemek = Yorumlanabilirlik
- Geriye (Ders 7): Bu, Ders 7’deki latent faktörlerin yorumlanabilirliğinin devamı; orada PCA ile gördüğümüz “klasik vs gişe” ekseni, burada en uç film faktörlerine bakarak doğrudan okunur.
- İleriye (yorumlanabilirlik): Öğrenilen latent uzayı incelemek, modelin “ne öğrendiğini” anlamanın güçlü bir yolu; “bu eksen ne demek?” sorusu modelin iç temsilini açar.
9.4 fastai’de Collab: EmbeddingDotBias
Ders 7’de sıfırdan kurduğumuz dot-product-bias modelini fastai hazır sunar: EmbeddingDotBias. collab_learner bunu otomatik kullanır — elle yazdığımız sınıfın kütüphane hâli.
“EmbeddingDotBias, so we can take a look at that.” — Howard, 18:11
İpucuBuilder Notu — Sıfırdan Bilmek, Hazırı Güvenle Kullanmak
- Geriye (Ders 7): Elle kurduğun
DotProductBias= fastai’ninEmbeddingDotBias’ı; sıfırdan bilmek, hazırı güvenle kullanmanı sağlar — “framework sihir değil, bizim yazdığımızın temiz hâli.” - İleriye (Part 2): Bu “önce sıfırdan, sonra hazırı” disiplini Part 2’nin omurgasıdır —
Learnerve optimizer dâhil her soyutlama “from the foundations” yeniden kurulup ancak sonra kütüphane hâliyle kullanılır.
9.5 Embedding Mesafesi
Embedding’ler bir uzayda nokta olduğundan, iki film arasındaki mesafeyi ölçebiliriz (Öklid mesafesine benzer, normalize edilmiş). Yakın embedding’ler benzer filmler demektir. Howard bir filme en yakını sorar ve “Dial M for Murder”a en yakın filmi bulur — mantıklı bir sonuç.
“Based on this embedding distance, the closest is ‘Dial M for Murder’, which makes a lot of sense.” — Howard, 23:16
Bu mesafe fikri embedding’in her yerdeliğine köprüdür: kategoriyi vektöre çeviren her tabloda “yakınlık = benzerlik” geçerlidir.
İpucuBuilder Notu — Semantic Search ve Vektör Veritabanlarının Çekirdeği
- Geriye (Ders 7 dot product): Mesafe, Ders 7’deki dot product’ın ikiz fikridir — dot product benzerliği büyütür, mesafe ise farkı ölçer; ikisi de embedding’leri aynı vektör uzayında karşılaştırır.
- İleriye (production): Embedding mesafesi, semantic search ve öneri sistemlerinin (“benzer ürünler”) çekirdeğidir; vektör veritabanlarının (Qdrant vb.) ve RAG sistemlerinin temel işlemi — içerikleri embedding’e çevir, en yakın komşuları ara.
9.6 Derin Öğrenme ile Collaborative Filtering
Dot product yerine, kullanıcı ve film embedding’lerini birleştirip bir sinir ağına besleyebiliriz. fastai bunu PyTorch’un hazır işlevleriyle kolaylaştırır; Ders 7’de sıfırdan yazdığımız yapının daha esnek hâli.
“A neural net exactly the same as the style that we created, but we’re using PyTorch’s functionality to do it more easily.” — Howard, 24:26
İpucuBuilder Notu — Sinir Ağı Tabanlı Collab: Daha Esnek
- Geriye (Ders 7): Bu, Ders 7’de sıfırdan yazdığımız collab modelinin sinir ağı varyantı; orada embedding’leri dot product’la birleştirmiştik, burada aynı embedding’ler concat edilip katmanlara beslenir.
- İleriye: Sinir ağı tabanlı collab, ek özellikleri (kullanıcı yaşı, tür) kolayca dâhil eder; saf dot product’tan daha esnektir — embedding’leri girdi olarak alıp katmanlarla işler.
9.7 NLP için Embedding
Embedding fikri metne de taşınır: her kelime/token bir embedding vektörüne çevrilir (Ders 4’teki tokenization + numericalization’ın devamı). Model, kelimeleri anlamlı bir vektör uzayında konumlandırır.
“Look up something in an array. And then, inside the model, we’re basically [working with those vectors].” — Howard, 30:28
Bu, “kelime id → vektör” — yani embedding’in arama tablosu fikrinin metne uygulanmış hâli; sonraki bölümdeki embedding’in her yerdeliğinin ikinci kolu.
İpucuBuilder Notu — Token Embedding’leri = Karpathy’nin İlk Katmanı
- Geriye (Ders 7 arama tablosu): “Kelime id → vektör”, Ders 7’deki embedding arama tablosunun metne uygulanmış hâli; kullanıcı/film id’si yerine token id’si aynı diziden satır çeker.
- İleriye (Karpathy): Token embedding’leri Karpathy makemore ve GPT’nin ilk katmanı; “kelime id → vektör” tam bu arama tablosu — dil modeli, bu embedding’leri attention ve MLP ile işleyerek sonraki token’ı tahmin eder.
9.8 Tablo İçin Embedding (Entity Embeddings)
En güçlü genelleme: tablo verisindeki kategorik sütunlar için embedding (entity embeddings). Mağaza, ürün, gün gibi kategoriler, dummy variable yerine öğrenilen vektörlerle temsil edilir. tabular_learner bunu otomatik yapar. Howard, Rossmann mağaza satış tahmini yarışmasında bu yöntemin (entity embeddings) yayımlanmış bir makaleye dönüştüğünü anlatır.
“It’s not just Collaborative Filtering and NLP but also Tabular Analysis.” — Howard, 30:28
Bu üçüncü kol — collaborative filtering, NLP ve tablo — sıradaki Embedding Her Yerde figürünü tamamlar: aynı mekanizma üç farklı veri tipinde.
İpucuBuilder Notu — Dummy Variable’dan Öğrenilen Vektöre
- Geriye (Ders 5/6): Ders 5’te kategorikler dummy variable, Ders 6’da ağaç için ham koddu; entity embeddings ise onları öğrenilen vektörlere çevirir — sinir ağının tablo gücü.
- İleriye (production): Entity embeddings, tablo derin öğrenmesinin standardı; kategorinin “anlamını” öğrenir (benzer mağazalar latent uzayda yakın olur).
9.9 Embedding Her Yerde
Dersin ilk yarısının özeti tek bir resimde toplanır: embedding her yerdedir. Collaborative filtering (kullanıcı/film id), NLP (kelime/token) ve tablo verisi (kategorik sütun) — üçü de aynı “arama tablosu”. Kategoriyi öğrenilen bir vektöre çeviren tek fikir, üç farklı alanda yeniden ortaya çıkar.
Şekil 9.2 bu birliği gösterir: merkezde embedding (rose vurgulu, “arama tablosu”), üç kola ayrılır — collaborative filtering, NLP ve tablo (entity embeddings) — hepsi aynı mekanizma.
Kod
# ---------------------------------------------------------------------------
# Embedding HER YERDE (ŞEMATİK / kavramsal — gerçek hesaplama yok).
# Ortada tek fikir: EMBEDDING = öğrenilen arama tablosu (rose vurgulu).
# Üç kola ayrılır (hepsi cyan): aynı mekanizma 3 farklı alanda.
# SOL : Collaborative filtering — kullanıcı/film id -> faktör vektörü
# ORTA : NLP — kelime/token -> vektör
# SAĞ : Tablo verisi — kategorik sütun -> entity embedding
# Ortadan üç kola arrow_between. Alt not: kategoriyi vektöre çeviren tek fikir.
# ---------------------------------------------------------------------------
fig = plt.figure(figsize=(11.6, 6.0))
fig.patch.set_facecolor(COL_WHITE)
ax = fig.add_axes([0.0, 0.0, 1.0, 1.0])
ax.set_xlim(0, 100)
ax.set_ylim(0, 56)
ax.axis("off")
# --- Merkez: EMBEDDING (öğrenilen arama tablosu) — rose vurgulu ---
cx, cy = 50.0, 41.0
cw, ch = 30.0, 10.0
boxed_node(ax, cx, cy, cw, ch,
"EMBEDDING\n(arama tablosu)",
fc=COL_ROSE_500, ec=COL_ACCENT, tc=COL_WHITE,
fontsize=13.5, lw=2.6)
ax.text(cx, cy + ch / 2 + 2.4,
"kategori → öğrenilen vektör",
ha="center", va="bottom", fontsize=10.5, color=COL_ACCENT,
weight="bold", style="italic")
# --- Üç kol (cyan): aynı mekanizma, 3 alan ---
by = 13.0 # kol kutuları y merkezi
bw, bh = 27.0, 13.0
xs = [18.0, 50.0, 82.0]
branch_texts = [
"Collaborative\nfiltering\n\nkullanıcı/film id\n→ faktör",
"NLP\n\n\nkelime/token\n→ vektör",
"Tablo\n\n\nkategorik sütun\n→ entity embedding",
]
branch_titles = ["öneri sistemi", "dil modeli", "yapılandırılmış veri"]
for x, txt in zip(xs, branch_texts):
boxed_node(ax, x, by, bw, bh, txt,
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT,
fontsize=10.5, lw=2.2, weight="normal")
# --- Oklar: merkezden üç kola (cyan) ---
for x in xs:
p0 = (cx + (x - cx) * 0.30, cy - ch / 2) # merkez alt kenarından açıl
p1 = (x, by + bh / 2) # kol üst kenarına
arrow_between(ax, p0, p1, color=COL_PRIMARY, lw=2.4,
shrink=4, mutation_scale=16)
# --- Kol üstü kısa etiket (hangi alan) ---
for x, t in zip(xs, branch_titles):
ax.text(x, by + bh / 2 + 1.2, t, ha="center", va="bottom",
fontsize=9.5, color=COL_CYAN_800, weight="bold")
# --- Alt not: tek fikir ---
ax.text(50, 2.4,
"aynı mekanizma: kategoriyi bir vektöre çeviren öğrenilen tablo",
ha="center", va="center", fontsize=11, color=COL_SLATE_400,
weight="bold", style="italic")
plt.show()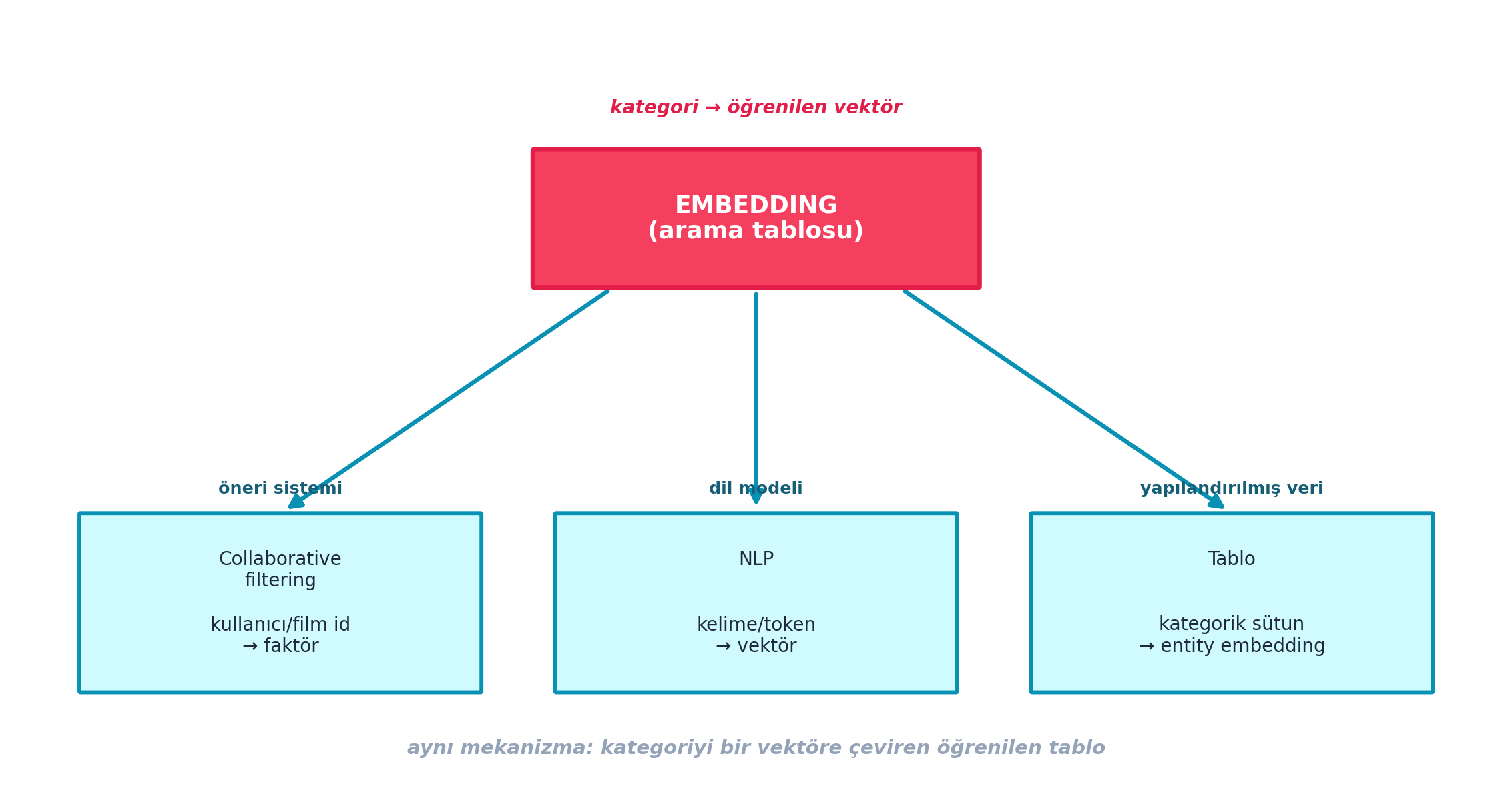
İpucuBuilder Notu — Tek Mekanizma, Üç Alan
- Geriye (Ders 4/6/7): Üç kol da daha önce ayrı ayrı gördüğümüz şeyler: NLP tokenization, tablo kategorikleri, collab latent faktörleri — Şekil 9.2 bunları tek fikirde birleştirir.
- İleriye (Karpathy / production): “Kategori → öğrenilen vektör” modern derin öğrenmenin her yerinde; öneri, dil modeli ve yapılandırılmış veri aynı arama tablosunu paylaşır.
9.10 Convolution: Kenar Bulma
İkinci yarı dersin başlığıdır. Howard convolution’ı bir kenar bulucu ile tanıtır. Küçük bir 3×3 matris (kernel) tasarlar: üst satır −1, alt satır +1. Bu kernel bir görüntü yamasıyla eleman eleman çarpılıp toplanınca, yatay kenar varsa büyük, yoksa küçük bir sayı verir.
top_edge = tensor([[-1, -1, -1],
[ 0, 0, 0],
[ 1, 1, 1]]).float() # yatay kenar bulucu kernel“How did I do this? I did this using something called a convolution.” — Howard, 44:33
Şekil 9.3 bu işlemi gerçek hesaplamayla gösterir: solda girdi görüntü, ortada 3×3 top_edge kerneli (üst −1, alt +1), sağda öznitelik haritası — kerneli her konuma kaydırıp dot product alınca yatay kenarlar büyük tepki verir. Bu, Ders 3’teki Zeiler-Fergus “öğrenilmiş kenar dedektörleri”nin elle kurulmuş hâlidir.
Kod
# GERÇEK hesaplama — numpy convolution (top_edge kerneli) (bkz. _engine.conv_kernel_demo)
ck = conv_kernel_demo()
image = ck["image"] # (16, 16)
kernel = ck["kernel"] # (3, 3) yatay kenar bulucu (top_edge)
fmap = ck["feature_map"] # (14, 14)
fig, axes = plt.subplots(1, 3, figsize=(10.6, 4.4))
ax_img, ax_ker, ax_fm = axes
# --- SOL: girdi görüntü (16x16) ---
ax_img.imshow(image, cmap="gray", vmin=0, vmax=1, interpolation="nearest")
ax_img.set_title("girdi görüntü (16×16)", fontsize=12, weight="bold", color=COL_CYAN_800, pad=10)
ax_img.set_xticks([]); ax_img.set_yticks([])
for s in ax_img.spines.values():
s.set_color(COL_CYAN_700); s.set_linewidth(1.5)
# --- ORTA: 3x3 kenar kerneli (top_edge), her hücrede değer ---
ax_ker.imshow(kernel, cmap="RdBu_r", vmin=-1, vmax=1, interpolation="nearest")
for i in range(kernel.shape[0]):
for j in range(kernel.shape[1]):
v = kernel[i, j]
ax_ker.text(j, i, f"{v:+.0f}", ha="center", va="center",
fontsize=16, weight="bold",
color=("#ffffff" if abs(v) > 0.5 else COL_TEXT))
ax_ker.set_title("3×3 kenar kerneli (top_edge)", fontsize=12, weight="bold", color=COL_CYAN_800, pad=10)
ax_ker.set_xticks([]); ax_ker.set_yticks([])
ax_ker.set_xticks(np.arange(-0.5, kernel.shape[1], 1), minor=True)
ax_ker.set_yticks(np.arange(-0.5, kernel.shape[0], 1), minor=True)
ax_ker.grid(which="minor", color="#ffffff", linewidth=2.0)
ax_ker.tick_params(which="minor", length=0)
for s in ax_ker.spines.values():
s.set_visible(False)
# --- SAĞ: öznitelik haritası (kenarlar vurgulu) ---
ax_fm.imshow(fmap, cmap="magma", interpolation="nearest")
ax_fm.set_title("öznitelik haritası (14×14)", fontsize=12, weight="bold", color=COL_CYAN_800, pad=10)
ax_fm.set_xticks([]); ax_fm.set_yticks([])
for s in ax_fm.spines.values():
s.set_color(COL_ACCENT); s.set_linewidth(1.5)
# --- Paneller arası işaretler: ⊛ kaydır+dot / = (panel-üstü annotate ile, gutter'a hizalı) ---
ax_img.annotate("⊛", xy=(1.10, 0.5), xycoords="axes fraction",
ha="center", va="center", fontsize=26, weight="bold",
color=COL_ACCENT, annotation_clip=False)
ax_img.annotate("kaydır\n+dot", xy=(1.10, 0.30), xycoords="axes fraction",
ha="center", va="center", fontsize=9.5, weight="bold",
color=COL_TEXT, annotation_clip=False)
ax_ker.annotate("=", xy=(1.12, 0.5), xycoords="axes fraction",
ha="center", va="center", fontsize=26, weight="bold",
color=COL_ACCENT, annotation_clip=False)
# Üst başlık + alt not
fig.suptitle("Convolution = kenar bulma", fontsize=14, weight="bold", color=COL_CYAN_700, y=1.00)
fig.text(0.5, 0.005,
"kerneli her konuma kaydır, dot product al → kenar varsa büyük tepki",
ha="center", va="bottom", fontsize=10.5, weight="bold", color=COL_TEXT)
fig.tight_layout(rect=(0, 0.05, 1, 0.94))
fig.subplots_adjust(wspace=0.28)
plt.show()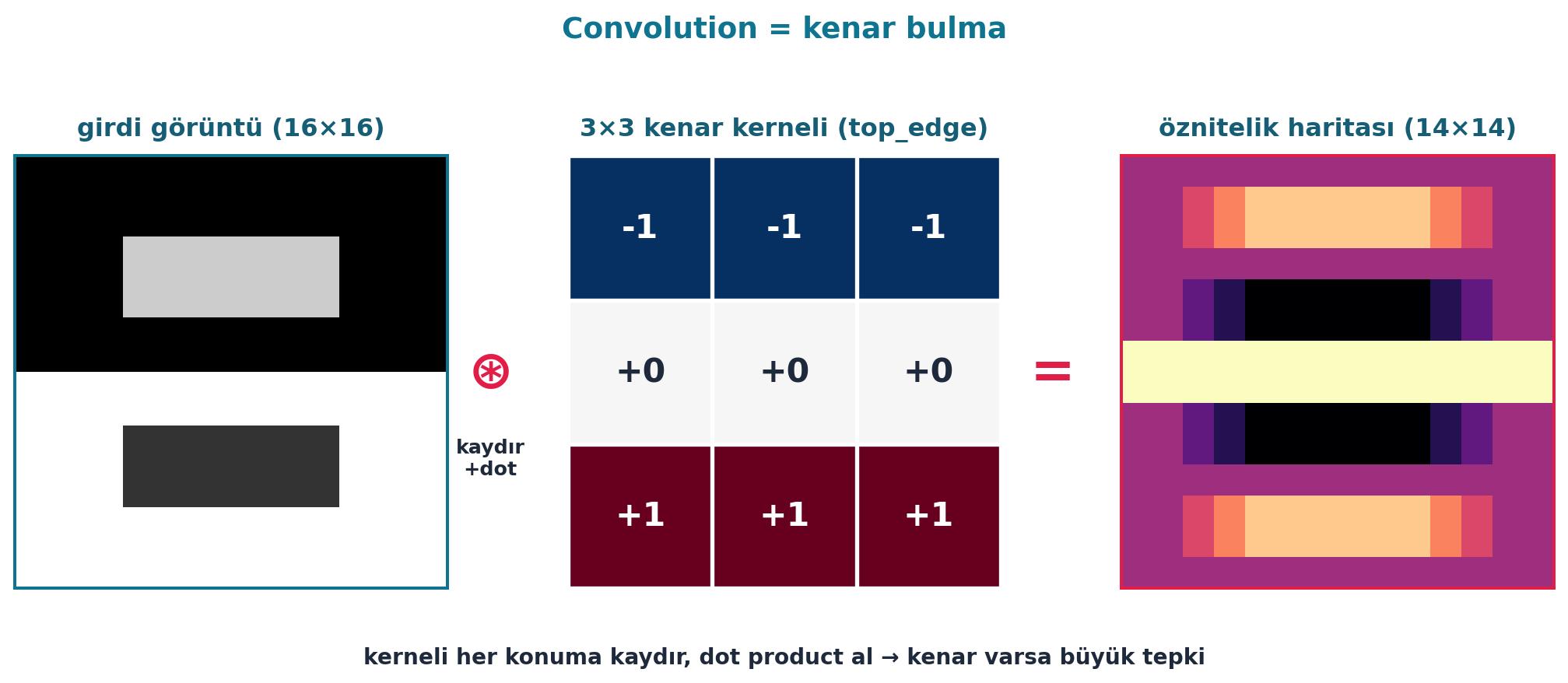
İpucuBuilder Notu — Elle Kernel vs Öğrenilen Kernel
- Geriye (Ders 3): Bu, Ders 3’teki Zeiler-Fergus “öğrenilmiş kenar dedektörleri”nin elle kurulmuş hâli; Şekil 9.3’in
top_edge’i bir insanın tasarladığı kernel — CNN bunları kendi öğrenir. - İleriye (Filtreyi Kaydırma): Tek bir konumda hesaplanan bu dot product, sıradaki bölümde tüm görüntüye kaydırılarak öznitelik haritasına dönüşür.
9.11 apply_kernel: Filtreyi Kaydırma
Bir convolution, bu kerneli görüntünün her konumuna kaydırarak uygular. Her konumda kernel ile o yamanın dot product’ı alınır; sonuç yeni bir “öznitelik haritası”dır (feature map). Howard bunu açıkça “kaydırılan mini dot product’lar” diye tanımlar.
def apply_kernel(row, col, kernel):
# (row,col) merkezli 3x3 yamayi kernel ile carpip topla
return (im3_t[row-1:row+2, col-1:col+2] * kernel).sum()
# kerneli tum konumlara kaydir -> oznitelik haritasi
rng = range(1, 27)
top_edge3 = tensor([[apply_kernel(i, j, top_edge) for j in rng] for i in rng])“You can think of a convolution as being a sliding window of little mini dot products. The size of this is called its kernel size — this is a 3 by 3 kernel.” — Howard, 53:00
Şekil 9.4 bu kaydırmayı şematik olarak gösterir: kernel (rose pencere) görüntü üzerinde her konuma kayar; her konumda kernel × yama bir tek sayı üretir, bu sayılar öznitelik haritasını oluşturur. Her konumdaki işlem bir dot product’tır — convolution, mekânsal olarak tekrarlanan dot product.
Kod
from matplotlib.patches import Rectangle
np.random.seed(0)
fig, ax = plt.subplots(figsize=(11, 5.6))
ax.set_xlim(0, 13.5)
ax.set_ylim(0, 8)
ax.set_aspect("equal")
ax.axis("off")
# --- SOL: 6x6 görüntü ızgarası ---
G = 6
cell = 0.78
x0, y0 = 0.6, 1.4
img_w = G * cell
ax.text(x0 + img_w / 2, y0 + G * cell + 0.45, "görüntü (6×6)",
ha="center", va="center", fontsize=11.5, color=COL_CYAN_700, weight="bold")
for r in range(G):
for c in range(G):
ax.add_patch(Rectangle(
(x0 + c * cell, y0 + (G - 1 - r) * cell), cell, cell,
fc=COL_CYAN_50, ec=COL_SLATE_300, lw=1.0, zorder=1))
def win_xy(r, c):
px = x0 + c * cell
py = y0 + (G - 1 - (r + 2)) * cell
return px, py
# 2 hayalet (soluk) kaydırılmış konum
ghost_positions = [(0, 1), (1, 3)]
for (gr, gc) in ghost_positions:
px, py = win_xy(gr, gc)
ax.add_patch(Rectangle(
(px, py), 3 * cell, 3 * cell,
fc="none", ec=COL_ROSE_400, lw=1.6, ls=(0, (4, 3)),
alpha=0.45, zorder=3))
# aktif kernel penceresi (rose, dolu vurgu)
ar, ac = 0, 0
apx, apy = win_xy(ar, ac)
ax.add_patch(Rectangle(
(apx, apy), 3 * cell, 3 * cell,
fc=COL_BG_ROSE, ec=COL_ACCENT, lw=3.0, alpha=0.85, zorder=4))
ax.text(apx + 1.5 * cell, apy + 3 * cell + 0.28, "kernel 3×3",
ha="center", va="center", fontsize=10, color=COL_ACCENT, weight="bold")
# kaydırma okları (pencere kayar)
arrow_between(ax, (apx + 1.5 * cell, apy + 1.5 * cell),
(win_xy(*ghost_positions[0])[0] + 1.5 * cell,
win_xy(*ghost_positions[0])[1] + 1.5 * cell),
color=COL_ROSE_500, lw=1.6, mutation_scale=12, shrink=2)
arrow_between(ax, (win_xy(*ghost_positions[0])[0] + 1.5 * cell,
win_xy(*ghost_positions[0])[1] + 1.5 * cell),
(win_xy(*ghost_positions[1])[0] + 1.5 * cell,
win_xy(*ghost_positions[1])[1] + 1.5 * cell),
color=COL_ROSE_500, lw=1.6, mutation_scale=12, shrink=2)
# --- ORTA: dot product kutusu + ana ok ---
mx = x0 + img_w + 1.55
boxed_node(ax, mx, 4.0, 2.0, 1.05,
"kernel × yama\n= tek sayı",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT,
fontsize=9.5, lw=2.0)
arrow_between(ax, (apx + 3 * cell, apy + 1.5 * cell), (mx - 1.0, 4.0),
color=COL_ACCENT, lw=2.2, mutation_scale=16, shrink=6)
# --- SAĞ: 4x4 öznitelik haritası ---
F = 4
fx0 = mx + 1.55
fy0 = y0 + cell
fmap_w = F * cell
ax.text(fx0 + fmap_w / 2, fy0 + F * cell + 0.45, "öznitelik haritası",
ha="center", va="center", fontsize=11.5, color=COL_CYAN_700, weight="bold")
for r in range(F):
for c in range(F):
is_active = (r == 0 and c == 0)
ax.add_patch(Rectangle(
(fx0 + c * cell, fy0 + (F - 1 - r) * cell), cell, cell,
fc=(COL_BG if is_active else COL_CYAN_50),
ec=(COL_PRIMARY if is_active else COL_SLATE_300),
lw=(2.6 if is_active else 1.0), zorder=(3 if is_active else 1)))
out_cx = fx0 + 0.5 * cell
out_cy = fy0 + (F - 1) * cell + 0.5 * cell
arrow_between(ax, (mx + 1.0, 4.0), (out_cx, out_cy),
color=COL_PRIMARY, lw=2.2, mutation_scale=16, shrink=6)
# --- ALT NOT ---
ax.text(6.75, 0.45,
"her konum bir dot product; pencere kayar → öznitelik haritası",
ha="center", va="center", fontsize=11, color=COL_ACCENT,
style="italic", weight="bold")
fig.tight_layout()
plt.show()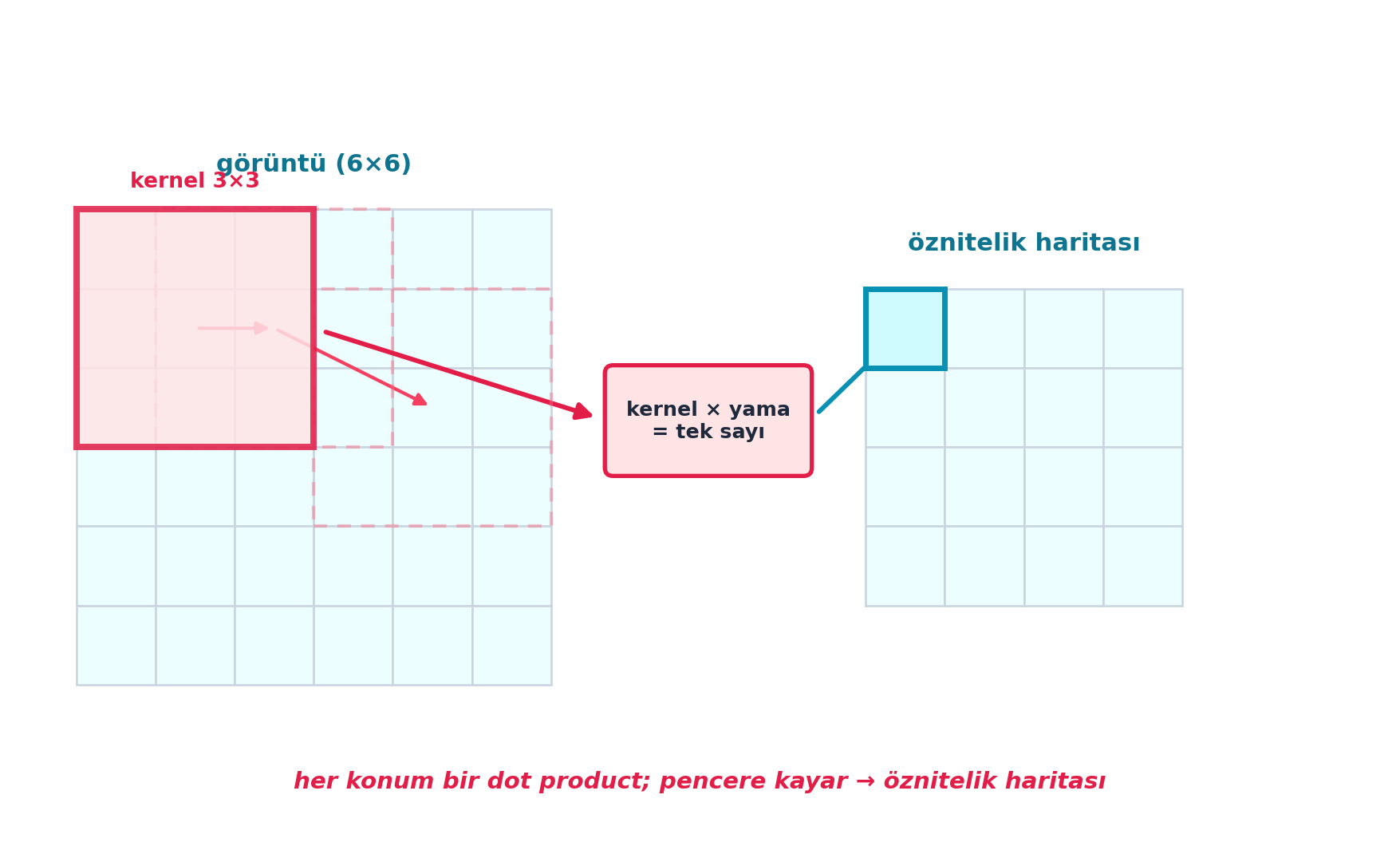
İpucuBuilder Notu — Convolution = Mekânsal Olarak Tekrarlanan Dot Product
- Geriye (18.06 / Ders 5): Her konumdaki işlem bir dot product; convolution = mekânsal olarak tekrarlanan dot product — Şekil 9.4’in her penceresi, 18.06’nın “satır × yama = skaler” işlemini bir kez daha çalıştırır.
- İleriye (F.conv2d): Bu açık döngü öğreticidir ama yavaştır; sıradaki bölüm aynı işlemi optimize biçimde yapar.
9.12 F.conv2d: Verimli Convolution
Elle döngü yavaştır; PyTorch F.conv2d aynı işlemi optimize biçimde, hatta birden çok kerneli (kanalı) ve tüm batch’i aynı anda yapar.
batch_features = F.conv2d(xb, edge_kernels) # tum batch + tum kerneller, optimizeBu, apply_kernel’in açık döngüsünü optimize çekirdek koda çevirir — sonuç aynı, hız çok daha yüksek (GPU’da paralel).
İpucuBuilder Notu — Açık Döngüyü Optimize Çekirdeğe Çevirmek
- Geriye (Ders 5): Broadcasting/matris çarpımı gibi,
conv2dde açık döngüyü optimize çekirdek koda çevirir (GPU’da paralel) — Ders 5’teki “döngü yerine matris işlemi” dersinin görüntü hâli. - İleriye:
F.conv2dbirden çok kerneli (kanalı) aynı anda uygular; her kanal farklı bir desen (yatay kenar, dikey kenar, köşe) öğrenir.
9.13 Neden CNN? Parametre Paylaşımı
Kritik avantaj: 28×28 bir görüntüyü tam bağlı bir katmana versek 784 ağırlık gerekirdi (her piksel için biri). Convolution ise aynı 3×3 kerneli (yalnızca 9 parametre) tüm görüntüde paylaşır. Bu hem parametre sayısını düşürür hem de “kenar her yerde kenardır” (öteleme-değişmezlik) bilgisini gömer.
“We don’t have 784 parameters, we only have nine parameters.” — Howard, 44:33
Şekil 9.5 bu karşıtlığı gösterir: solda tam bağlı katman (her piksele ayrı ağırlık → 784), sağda convolution (tek 3×3 kernel tüm görüntüde paylaşılır → 9). Aynı kernel her yerde → az parametre + öteleme-değişmezlik = görüntü için doğru inductive bias.
Kod
# Deterministik (figürde stokastik öğe yok ama kural gereği sabit).
# Sayılar SEMATİK kontrast: 28x28=784 ağırlık (tam bağlı) vs 3x3=9 parametre (conv).
np.random.seed(0)
FC_PARAMS = 28 * 28 # 784 — tam bağlı: her piksele ayrı ağırlık
CONV_PARAMS = 3 * 3 # 9 — convolution: tek 3x3 kernel, tüm görüntüde paylaşılır
fig = plt.figure(figsize=(12.2, 6.4))
# Üst sıra: iki kavram paneli (sol tam bağlı / sağ convolution)
# Alt: ortak bar karşılaştırması (784 vs 9)
ax_l = fig.add_axes([0.03, 0.40, 0.45, 0.55]) # sol panel
ax_r = fig.add_axes([0.52, 0.40, 0.45, 0.55]) # sağ panel
ax_b = fig.add_axes([0.10, 0.07, 0.80, 0.24]) # alt bar
# ----------------------------------------------------------------------------
# SOL PANEL — Tam bağlı katman: her piksel AYRI ağırlık (nötr/gri)
# ----------------------------------------------------------------------------
ax_l.set_title("Tam bağlı katman", fontsize=13.5, color=COL_TEXT,
weight="bold", pad=10)
ax_l.set_xlim(0, 10)
ax_l.set_ylim(0, 10)
ax_l.axis("off")
boxed_node(ax_l, 5.0, 8.0, 6.4, 1.5, "28×28 = 784 piksel",
fc=COL_SLATE_300, ec=COL_SLATE_400, tc=COL_TEXT,
fontsize=11.5, lw=1.8)
ax_l.annotate("", xy=(5.0, 5.45), xytext=(5.0, 7.2),
arrowprops=dict(arrowstyle="-|>", color=COL_SLATE_400, lw=2.0))
ax_l.text(5.0, 6.35, "her piksele AYRI ağırlık",
ha="center", va="center", fontsize=10.5,
color=COL_SLATE_400, style="italic", weight="bold")
boxed_node(ax_l, 5.0, 4.3, 5.6, 1.7, "784\nparametre",
fc=COL_SLATE_300, ec=COL_SLATE_400, tc=COL_TEXT,
fontsize=15, lw=2.0)
ax_l.text(5.0, 1.6, "her konum için\nbağımsız ağırlık (çok)",
ha="center", va="center", fontsize=10,
color=COL_SLATE_400, style="italic")
# ----------------------------------------------------------------------------
# SAĞ PANEL — Convolution: tek 3x3 kernel TÜM görüntüde PAYLAŞILIR (cyan+rose)
# ----------------------------------------------------------------------------
ax_r.set_title("Convolution", fontsize=13.5, color=COL_CYAN_700,
weight="bold", pad=10)
ax_r.set_xlim(0, 10)
ax_r.set_ylim(0, 10)
ax_r.axis("off")
boxed_node(ax_r, 5.0, 8.0, 6.4, 1.5, "3×3 kernel",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT,
fontsize=12, lw=2.4)
ax_r.annotate("", xy=(5.0, 5.45), xytext=(5.0, 7.2),
arrowprops=dict(arrowstyle="-|>", color=COL_ACCENT, lw=2.2))
ax_r.text(5.0, 6.35, "TÜM görüntüde PAYLAŞILIR",
ha="center", va="center", fontsize=10.5,
color=COL_ACCENT, style="italic", weight="bold")
boxed_node(ax_r, 5.0, 4.3, 5.6, 1.7, "9\nparametre",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT,
fontsize=15, lw=2.6)
ax_r.text(5.0, 1.6, "aynı kernel her yerde →\naz parametre + öteleme-değişmezlik",
ha="center", va="center", fontsize=10,
color=COL_CYAN_700, style="italic", weight="bold")
# ----------------------------------------------------------------------------
# ALT BAR — büyük sayı karşılaştırması (784 vs 9)
# ----------------------------------------------------------------------------
ax_b.barh([1], [FC_PARAMS], color=COL_SLATE_300, edgecolor=COL_SLATE_400,
height=0.62, zorder=3)
ax_b.barh([0], [CONV_PARAMS], color=COL_ACCENT, edgecolor=COL_ROSE_500,
height=0.62, zorder=3)
ax_b.set_yticks([1, 0])
ax_b.set_yticklabels(["Tam bağlı\n(784)", "Convolution\n(9)"],
fontsize=10.5, color=COL_TEXT, weight="bold")
ax_b.set_xlim(0, FC_PARAMS * 1.12)
ax_b.set_xlabel("parametre sayısı", fontsize=10.5, color=COL_TEXT)
ax_b.set_facecolor(COL_WHITE)
for spine in ("top", "right", "left"):
ax_b.spines[spine].set_visible(False)
ax_b.spines["bottom"].set_color(COL_SLATE_400)
ax_b.tick_params(colors=COL_TEXT, length=0)
ax_b.grid(True, axis="x", alpha=0.2, color=COL_SLATE_400)
# değer etiketleri
ax_b.text(FC_PARAMS + 12, 1, "784", va="center", ha="left",
fontsize=12.5, color=COL_TEXT, weight="bold")
ax_b.text(CONV_PARAMS + 12, 0, "9", va="center", ha="left",
fontsize=12.5, color=COL_ACCENT, weight="bold")
ax_b.text(FC_PARAMS * 0.55, 0.0,
f"≈ {FC_PARAMS // CONV_PARAMS}× daha az parametre",
va="center", ha="left", fontsize=10.5,
color=COL_CYAN_700, style="italic", weight="bold")
plt.show()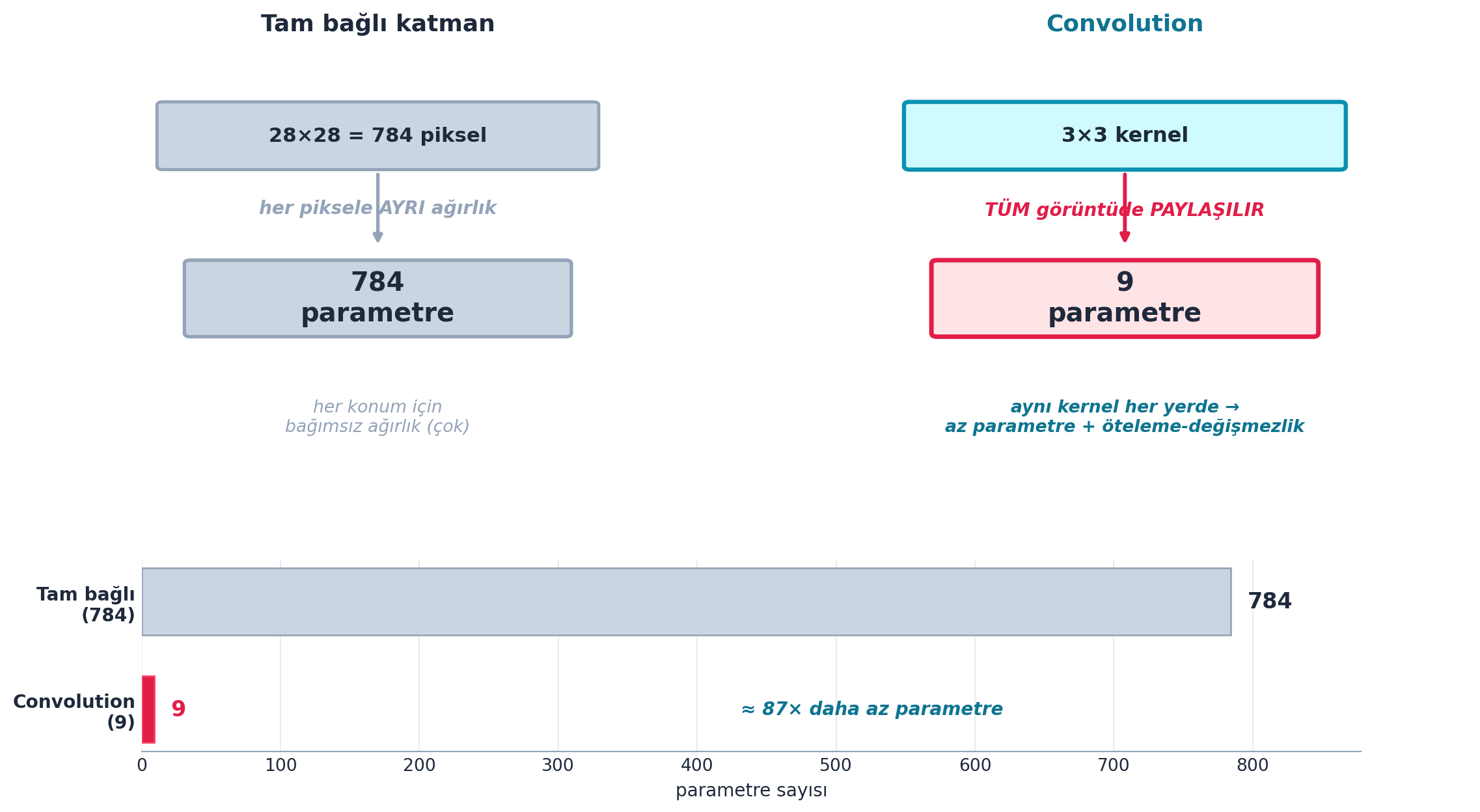
İpucuBuilder Notu — Paylaşım + Yerellik = Doğru Inductive Bias
- Geriye (Ders 5): Tam bağlı katman her piksele ayrı ağırlık verir; conv aynı ağırlığı paylaşır — daha az parametre, daha iyi genelleme. Şekil 9.5’in 784 → 9 karşıtlığı bu farkın somut hâli.
- İleriye (18.06): Parametre paylaşımı + yerel bağlantı = convolution’ı görüntü için doğru “inductive bias” yapan şey; modelin yapıya dair önbilgisini mimariye gömer.
9.14 simple_cnn Mimarisi
Bir CNN, conv + ReLU katmanlarının yığınıdır. Howard stride=2 kullanır: her katman görüntüyü yarıya indirirken (28→14→7→4→2→1) kanal sayısını artırır. Sonunda tek bir aktivasyon kalır ve Flatten ile tahmine dönüşür.
def conv(ni, nf, ks=3, act=True):
res = nn.Conv2d(ni, nf, stride=2, kernel_size=ks, padding=ks//2)
if act: res = nn.Sequential(res, nn.ReLU()) # conv + ReLU
return res
simple_cnn = sequential(
conv(1 , 4), # 14x14
conv(4 , 8), # 7x7
conv(8 , 16), # 4x4
conv(16, 32), # 2x2
conv(32, 2, act=False), # 1x1
Flatten(),
)
learn = Learner(dls, simple_cnn, loss_func=F.cross_entropy, metrics=accuracy)“A convolutional neural network is very, very, very simple.” — Howard, 45:00
Şekil 9.6 bu yığını şematik olarak gösterir: her conv + ReLU katmanı stride=2 ile boyutu yarılar (28→14→7→4→2→1) ve kanalı artırır (1→4→8→16→32→2); sonunda Flatten ile tek tahmine iner. Bu, Ders 3’ün “ReLU toplamı”nın mekânsal hâli; kayıp ise Ders 7’deki F.cross_entropy.
Kod
# SEMATIK: simple_cnn = conv + ReLU yigini (kavramsal mimari, gercek model yok).
# Sahte sayi yok: yalnizca yapi/sekil etiketleri (boyut + kanal).
fig, ax = plt.subplots(figsize=(12.6, 6.6))
fig.patch.set_facecolor(COL_WHITE)
ax.set_xlim(0, 26)
ax.set_ylim(0, 13)
ax.axis("off")
# Soldan saga katman zinciri. Her katman: stride=2 boyutu yarilar (28->14->7->4->2->1),
# kanal artar (1->4->8->16->32->2). Kutu boyutu kuculur, renk-yogunluk artar.
YC = 7.6 # zincir merkez yuksekligi
GAP = 0.35 # ok bosluğu
# katman: (x_merkez, kutu_yari_boyut h/2, kanal-yogunluk indeksi, ust_etiket, alt_etiket, tip)
# tip: "data" (cyan), "relu" (rose vurgulu), "out" (koyu cyan)
# kanal arttikca cyan tonu koyulasir -> "renk-yogunluk artar"
CYAN_RAMP = [COL_CYAN_400, COL_PRIMARY, COL_CYAN_700, COL_CYAN_700, COL_CYAN_800]
layers = [
# (x, half, fc, ec, ust, alt, tip)
(2.3, 2.30, COL_CYAN_50, COL_PRIMARY, "girdi", "28×28×1", "data"),
(6.6, 2.00, CYAN_RAMP[0], COL_PRIMARY, "conv+ReLU", "14×14×4", "relu"),
(10.4, 1.70, CYAN_RAMP[1], COL_PRIMARY, "conv+ReLU", "7×7×8", "relu"),
(13.8, 1.40, CYAN_RAMP[2], COL_PRIMARY, "conv+ReLU", "4×4×16", "relu"),
(16.7, 1.15, CYAN_RAMP[3], COL_PRIMARY, "conv+ReLU", "2×2×32", "relu"),
(19.3, 0.95, CYAN_RAMP[4], COL_CYAN_800,"conv", "1×1×2", "out"),
]
centers = []
for x, half, fc, ec, ust, alt, tip in layers:
w = 2.0 * half
h = 2.0 * half
# ReLU iceren conv katmanlari rose cerceve ile vurgulanir
if tip == "relu":
ec_use = COL_ACCENT
lw_use = 2.4
else:
ec_use = ec
lw_use = 2.4
# kanal arttikca metin rengi koyu cyan kutuda beyaza döner (okunabilirlik)
tc_use = COL_WHITE if fc in (COL_CYAN_700, COL_CYAN_800) else COL_TEXT
boxed_node(ax, x, YC, w, h, "",
fc=fc, ec=ec_use, tc=tc_use, lw=lw_use)
# ust etiket (katman tipi) — kutunun ustunde
ust_col = COL_ACCENT if tip == "relu" else COL_CYAN_700
ax.text(x, YC + half + 0.55, ust, ha="center", va="bottom",
fontsize=10.0, color=ust_col, weight="bold")
# alt etiket (boyut×kanal) — kutunun altinda
ax.text(x, YC - half - 0.45, alt, ha="center", va="top",
fontsize=10.5, color=COL_TEXT, weight="bold")
centers.append((x, half))
# katmanlar arasi oklar (kutu kenarindan kenara) — kucuk shrink, dar bosluklarda gorunur
for i in range(len(centers) - 1):
x0, h0 = centers[i]
x1, h1 = centers[i + 1]
arrow_between(ax, (x0 + h0 + GAP, YC), (x1 - h1 - GAP, YC),
color=COL_PRIMARY, lw=2.3, shrink=2, mutation_scale=15)
# son conv -> Flatten -> tahmin
x_last, h_last = centers[-1]
# Flatten kutusu
fx = 22.0
boxed_node(ax, fx, YC, 2.2, 1.5, "Flatten",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT, fontsize=10.5, lw=2.2)
arrow_between(ax, (x_last + h_last + GAP, YC), (fx - 1.1 - GAP, YC),
color=COL_PRIMARY, lw=2.3)
# tahmin kutusu
px = 24.6
boxed_node(ax, px, YC, 2.0, 1.5, "tahmin",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT, fontsize=10.5, lw=2.2)
arrow_between(ax, (fx + 1.1 + GAP, YC), (px - 1.0 - GAP, YC),
color=COL_PRIMARY, lw=2.3)
# Boyut akisi seridi (ust) — 28 -> 14 -> 7 -> 4 -> 2 -> 1
ax.text(10.7, 12.4,
"boyut: 28 → 14 → 7 → 4 → 2 → 1 (her katman stride=2 ile yarılar)",
ha="center", va="top", fontsize=10.5, color=COL_CYAN_800,
weight="bold", style="italic")
# Alt not — ana fikir
ax.text(13.0, 0.35,
"her katman: stride=2 boyutu yarılar, kanal sayısı artar; "
"sonunda Flatten ile tek tahmine iner — Ders 3'ün 'ReLU toplamı'nın mekânsal hâli",
ha="center", va="bottom", fontsize=10.5, color=COL_TEXT,
weight="bold",
bbox=dict(boxstyle="round,pad=0.5", fc=COL_BG, ec=COL_PRIMARY,
alpha=0.9, lw=1.5))
plt.tight_layout()
plt.show()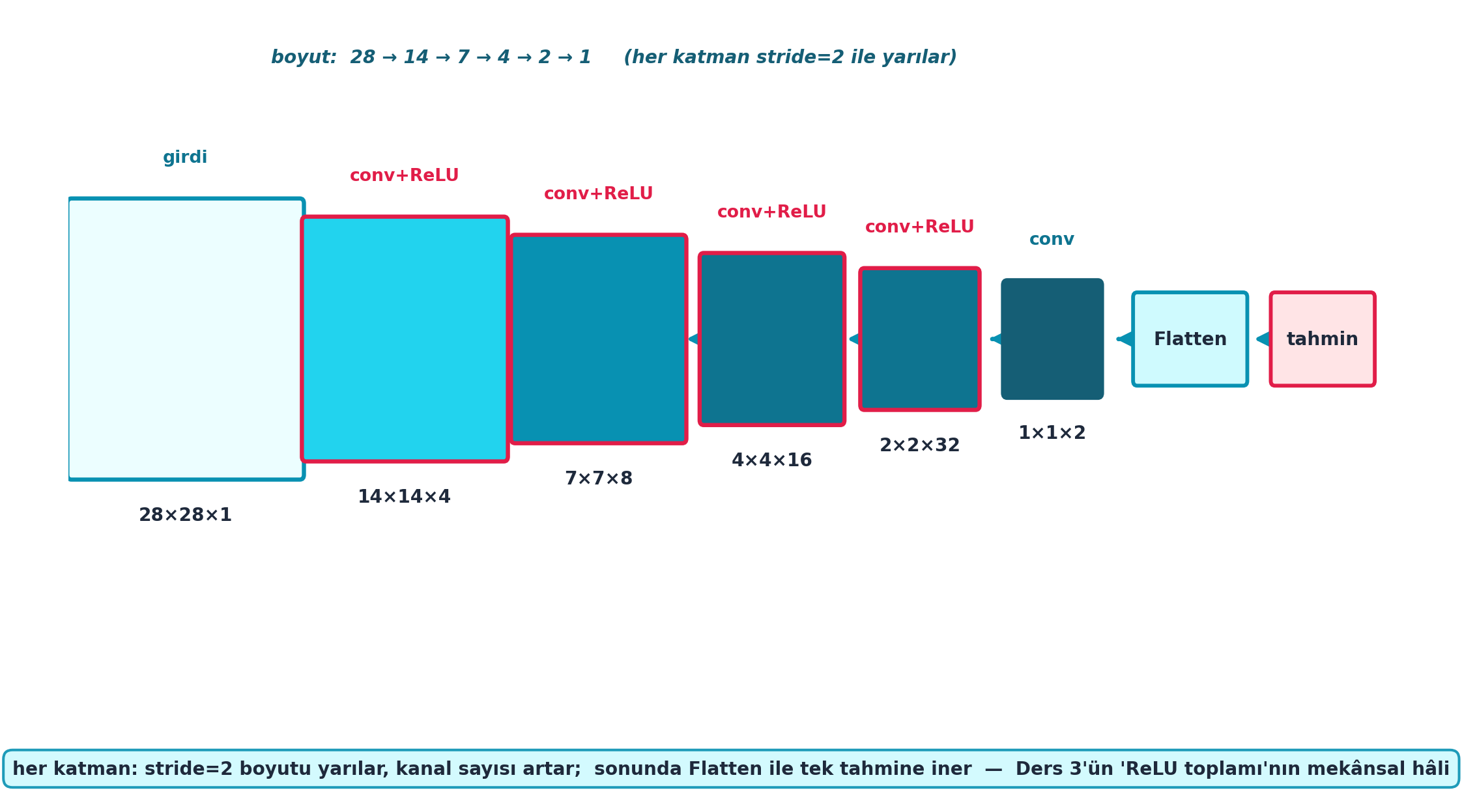
İpucuBuilder Notu — conv + ReLU = ’ReLU Toplamı’nın Mekânsal Hâli
- Geriye (Ders 3/5):
conv + ReLUyığını = Ders 3’ün “ReLU toplamı”nın mekânsal hâli;F.cross_entropy(Ders 7) sınıflandırma kaybı — Şekil 9.6’in son kutusu bu kayba bağlanır. - İleriye (Part 2): Bu basit yığın, Part 2’de ResNet ve U-Net gibi derin mimarilerin iskeletidir; stride’lı conv boyut indirgemenin temel aracı.
9.15 Pooling
Howard max pooling’e değinir: convolution gibi kaydırılan bir pencere, ama bu kez her penceredeki en büyük değeri alır. Bu, görüntüyü küçültür (çözünürlük düşer) ve özeti çıkarır. Modern ağlar genelde stride’lı conv veya pooling ile boyutu giderek azaltır.
“Max Pooling is kind of like a convolution — a sliding window — but this time [it takes the max]. With 2 by 2 max pooling we end up losing [resolution].” — Howard, 58:00
Şekil 9.7 bu işlemi gerçek hesaplamayla gösterir: 2×2 kaydırılan pencere her bölgenin en büyük değerini alır → 6×6 girdi 3×3’e iner. Çözünürlüğü düşürür, hesabı azaltır ve küçük kaymalara dayanıklılık (translation invariance) katar — simple_cnn’in stride’lı conv’una alternatif bir boyut indirgeme yolu.
Kod
from matplotlib.patches import Rectangle, FancyArrowPatch
mp = maxpool_demo()
inp = mp["inp"] # (6, 6) girdi
out = mp["out"] # (3, 3) çıktı = her 2x2 bloğun max'ı
n_in = inp.shape[0] # 6
n_out = out.shape[0] # 3
# Hangi bloğu vurgulayalım? — global max'ı içeren 2x2 bloğu seç (rose vurgu)
flat_max = np.argmax(out)
hi, hj = flat_max // n_out, flat_max % n_out # vurgulanan çıktı hücresi
fig = plt.figure(figsize=(11.5, 5.2))
gs = fig.add_gridspec(1, 3, width_ratios=[2.4, 0.7, 1.4], wspace=0.30)
ax_in = fig.add_subplot(gs[0, 0])
ax_ar = fig.add_subplot(gs[0, 1])
ax_out = fig.add_subplot(gs[0, 2])
# SOL — 6x6 girdi imshow (Blues), her hücrede değer
vmax = max(inp.max(), out.max())
ax_in.imshow(inp, cmap="Blues", vmin=0, vmax=vmax)
for i in range(n_in):
for j in range(n_in):
v = inp[i, j]
tcol = COL_WHITE if v > vmax * 0.6 else COL_TEXT
ax_in.text(j, i, f"{int(v)}", ha="center", va="center",
fontsize=11, color=tcol, weight="bold")
ax_in.set_title("girdi 6×6", color=COL_CYAN_800, fontsize=12.5,
weight="bold", pad=10)
ax_in.set_xticks([])
ax_in.set_yticks([])
for spine in ax_in.spines.values():
spine.set_visible(False)
# 2x2 blok ayrım çizgileri (cyan çerçeveler) — 3x3 = 9 blok
for bi in range(n_out):
for bj in range(n_out):
is_hi = (bi == hi and bj == hj)
ec = COL_ACCENT if is_hi else COL_PRIMARY
lw = 3.4 if is_hi else 2.0
rect = Rectangle((2 * bj - 0.5, 2 * bi - 0.5), 2, 2,
fill=False, edgecolor=ec, linewidth=lw, zorder=4)
ax_in.add_patch(rect)
# vurgulanan blokta max hücreyi işaretle (rose kesik çerçeve)
block = inp[2 * hi:2 * hi + 2, 2 * hj:2 * hj + 2]
mr, mc = np.unravel_index(np.argmax(block), block.shape)
gmr, gmc = 2 * hi + mr, 2 * hj + mc
sel = Rectangle((gmc - 0.5, gmr - 0.5), 1, 1, fill=False,
edgecolor=COL_ACCENT, linewidth=3.0, linestyle="--", zorder=5)
ax_in.add_patch(sel)
ax_in.set_xlim(-0.6, n_in - 0.4)
ax_in.set_ylim(n_in - 0.4, -0.6)
# ORTA — ok: "2×2 max → boyut yarılanır"
ax_ar.axis("off")
arrow = FancyArrowPatch((0.05, 0.5), (0.95, 0.5),
transform=ax_ar.transAxes,
arrowstyle="-|>", mutation_scale=26,
color=COL_CYAN_700, linewidth=2.6)
ax_ar.add_patch(arrow)
ax_ar.text(0.5, 0.66, "2×2 max", ha="center", va="bottom",
fontsize=12, color=COL_CYAN_800, weight="bold")
ax_ar.text(0.5, 0.34, "boyut\nyarılanır", ha="center", va="top",
fontsize=10.5, color=COL_TEXT, weight="bold")
# SAĞ — 3x3 çıktı imshow (Blues), her hücrede değer = ilgili bloğun max'ı
ax_out.imshow(out, cmap="Blues", vmin=0, vmax=vmax)
for i in range(n_out):
for j in range(n_out):
v = out[i, j]
tcol = COL_WHITE if v > vmax * 0.6 else COL_TEXT
ax_out.text(j, i, f"{int(v)}", ha="center", va="center",
fontsize=14, color=tcol, weight="bold")
ax_out.set_title("çıktı 3×3", color=COL_CYAN_800, fontsize=12.5,
weight="bold", pad=10)
ax_out.set_xticks([])
ax_out.set_yticks([])
for spine in ax_out.spines.values():
spine.set_visible(False)
# vurgulanan çıktı hücresini rose çerçevele
rect_o = Rectangle((hj - 0.5, hi - 0.5), 1, 1, fill=False,
edgecolor=COL_ACCENT, linewidth=3.4, zorder=4)
ax_out.add_patch(rect_o)
ax_out.set_xlim(-0.55, n_out - 0.45)
ax_out.set_ylim(n_out - 0.45, -0.55)
fig.suptitle("Max pooling (gerçek hesaplama) — 2×2 pencere her bloğun EN BÜYÜK değerini alır",
color=COL_CYAN_800, fontsize=13.5, weight="bold", y=1.02)
fig.text(0.5, -0.04,
"Kaydırılan pencerede EN BÜYÜK değer seçilir (kesik kırmızı: vurgulanan bloğun max'ı); "
"çözünürlüğü düşürür, özeti çıkarır.",
ha="center", va="center", fontsize=9.5, color=COL_TEXT, style="italic")
plt.show()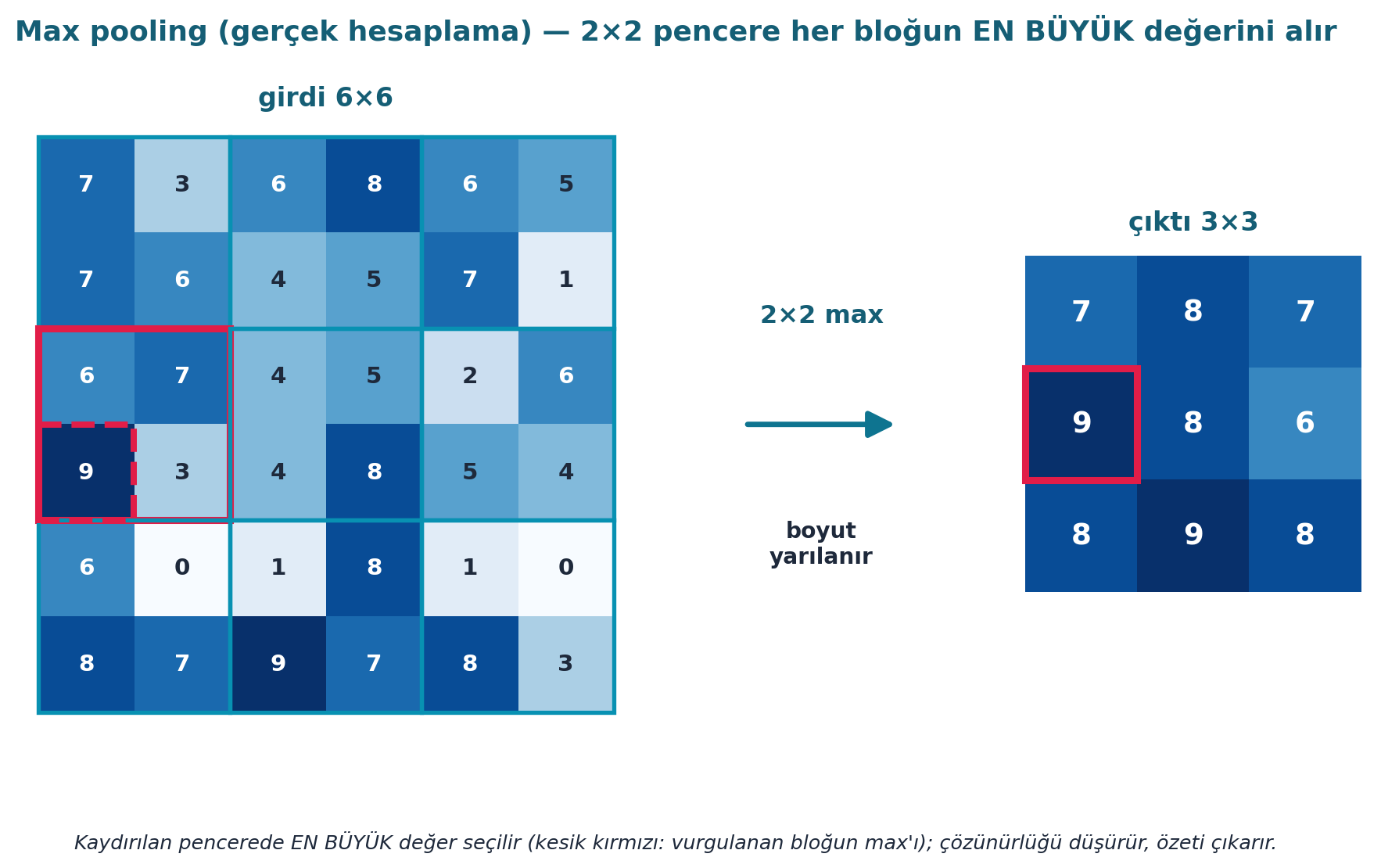
İpucuBuilder Notu — Max = En Güçlü Tepki, Ortalama = Beklenen Değer
- Geriye (Stat 110): Max pooling, bir bölgenin “en güçlü tepkisini” alır; ortalama pooling ise beklenen değeri. Şekil 9.7’in 6×6 → 3×3 indirgemesi, boyut indirgeme + öteleme dayanıklılığı sağlar.
- İleriye (simple_cnn): Modern ağlar boyutu ya max pooling ya stride’lı conv ile azaltır; ikisi de “kaydırılan pencere” fikrinin farklı kullanımı.
9.16 BatchNorm
Howard daha derin ve hızlı eğitim için conv katmanına BatchNorm (toplu normalizasyon) ekler: aktivasyonları batch üzerinden normalize ederek eğitimi kararlı ve hızlı kılar.
def conv(ni, nf, ks=3, act=True):
layers = [nn.Conv2d(ni, nf, stride=2, kernel_size=ks, padding=ks//2)]
if act: layers.append(nn.ReLU())
layers.append(nn.BatchNorm2d(nf)) # aktivasyonlari normalize et
return nn.Sequential(*layers)Şekil 9.8 bu normalizasyonu gerçek hesaplamayla gösterir: kaymış/geniş bir aktivasyon dağılımı (sol) ort≈0 std≈1’e (sağ) çekilir. Aktivasyon istatistiğini koruyarak eğitimi kararlı ve hızlı kılar; daha derin ağları eğitilebilir yapar.
Kod
# GERÇEK hesaplama: BatchNorm aktivasyonları batch üzerinden normalize eder.
bn = batchnorm_demo()
raw, normed = bn["raw"], bn["normed"]
raw_mean, raw_std = bn["raw_stats"] # kaymış/geniş (ort≈2.5 std≈1.8)
normed_mean, normed_std = bn["normed_stats"] # ort≈0 std≈1
fig, axes = plt.subplots(1, 2, figsize=(9.6, 4.2))
# SOL: BatchNorm ÖNCESİ — kaymış/geniş dağılım (soluk slate)
ax0 = axes[0]
ax0.hist(raw, bins=40, color=COL_SLATE_400, edgecolor="white", linewidth=0.4)
ax0.axvline(raw_mean, color=COL_TEXT, lw=1.8, ls="--", zorder=4)
apply_style(ax0)
ax0.set_title("BatchNorm ÖNCESİ: ort=%.1f std=%.1f" % (raw_mean, raw_std),
fontsize=11.5, color=COL_TEXT, weight="bold", pad=8)
ax0.set_xlabel("aktivasyon değeri", fontsize=10.5)
ax0.set_ylabel("frekans", fontsize=10.5)
# SAĞ: BatchNorm SONRASI — ortalanmış/standart dağılım (cyan)
ax1 = axes[1]
ax1.hist(normed, bins=40, color=COL_PRIMARY, edgecolor="white", linewidth=0.4)
ax1.axvline(normed_mean, color=COL_TEXT, lw=1.8, ls="--", zorder=4)
apply_style(ax1)
ax1.set_title(r"BatchNorm SONRASI: ort$\approx$0 std$\approx$1",
fontsize=11.5, color=COL_TEXT, weight="bold", pad=8)
ax1.set_xlabel("normalize aktivasyon", fontsize=10.5)
ax1.set_ylabel("frekans", fontsize=10.5)
# Üst başlık
fig.suptitle(r"BatchNorm: aktivasyonları ort=0 std=1'e normalize eder",
fontsize=13, color=COL_TEXT, weight="bold", y=1.02)
# Alt not
fig.text(0.5, -0.04,
"aktivasyon istatistiğini koruyup eğitimi kararlı/hızlı kılar; "
"Karpathy makemore'da sıfırdan",
ha="center", va="top", fontsize=9.5, color=COL_CYAN_700, style="italic")
fig.tight_layout()
plt.show()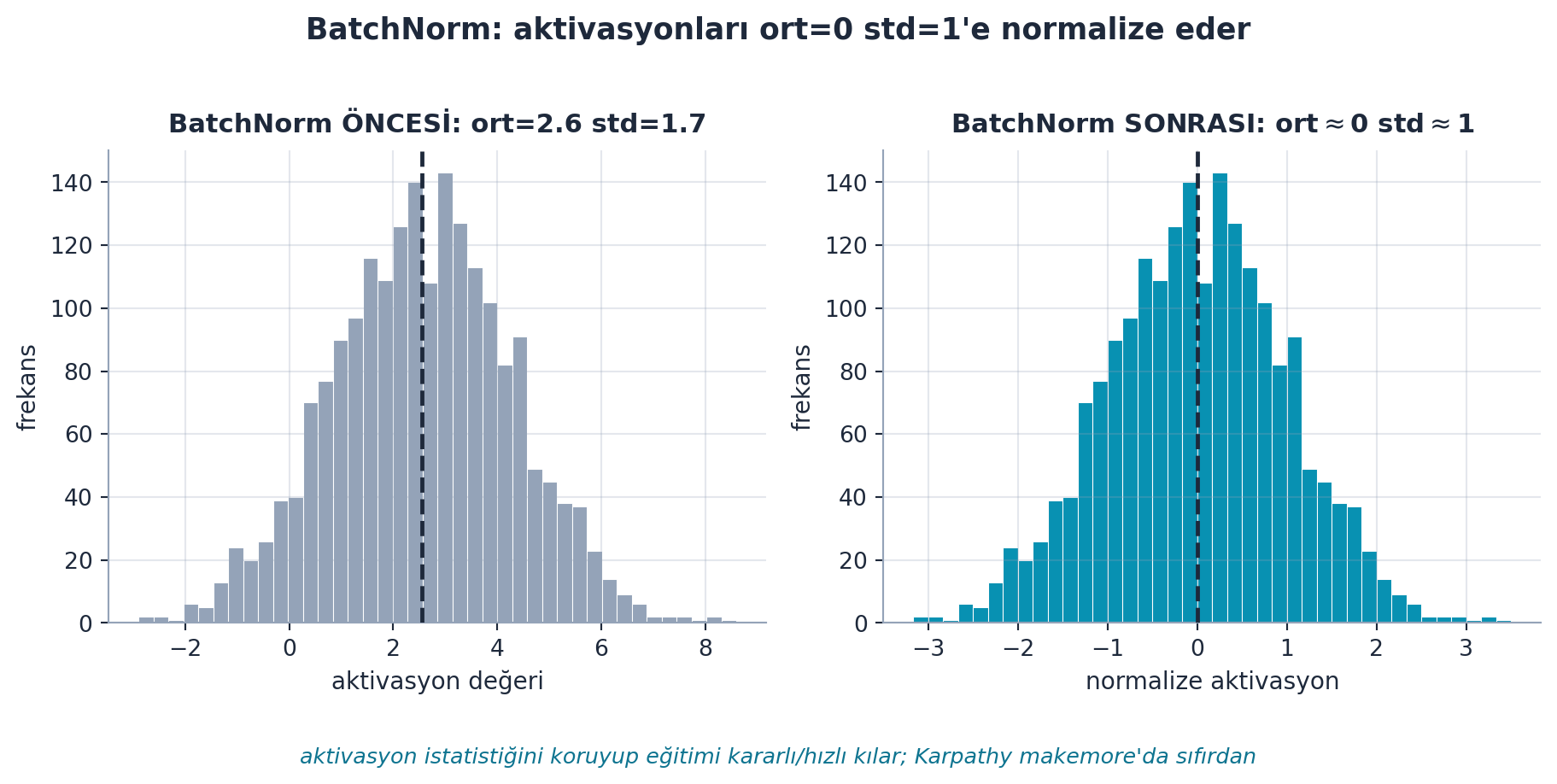
İpucuBuilder Notu — BatchNorm: Karpathy makemore’da Sıfırdan
- Geriye (§4.F / Karpathy): BatchNorm, Karpathy makemore Ders 4’te sıfırdan kurulur (§4.F); aktivasyon istatistiğini koruyup derin ağları eğitilebilir kılar — Şekil 9.8’un ort≈0 std≈1 çıktısı tam bu normalizasyon.
- İleriye (Part 2 Ders 17): Başlatma + normalizasyon, Part 2’de derinlemesine işlenecek; “neden bu kadar işe yarıyor?” sorusu hâlâ aktif bir araştırma konusu.
9.17 Serinin Kapanışı: Part 1 → Part 2
Howard Part 1’i kapatır. Ana mesajı tenacity (azim): çoğu insan erken vazgeçer; bir şeyi gerçekten “güzelce bitirmek” seni küçük bir azınlığa sokar. Howard kendi araçlarını (nbdev) bunu kolaylaştırmak için kurduğunu söyler.
“If you just keep going until something’s actually finished, that’s going to put you in a small minority. Most people don’t do that.” — Howard, 1:35:13
İpucuBuilder Notu — Top-Down’dan ’From the Foundations’a
- Geriye (Ders 1 / Part 1): Part 1 Ders 1’den beri “önce çalıştır, sonra derinleş” (top-down) izledi — çalışan modelden başlayıp parçalarını açtı; bu ders o yaklaşımın doruğu ve kapanışı.
- İleriye (Part 2): Part 1 pratik DL’i (top-down) verdi; Part 2 her şeyi sıfırdan kurup Stable Diffusion’a varacak — Karpathy ruhuna en yakın bölüm. Bu dersin convolution’ı ve BatchNorm’u orada sıfırdan yeniden kurulacak.
9.18 Kapanış
Part 1 burada bitti. Ders 8 embedding’i (collab, NLP, tablo) ve convolution’ı (CNN’lerin temeli) birleştirdi. Sekiz derste sıfırdan çalışan modeller kurduk, deploy ettik, hem ağaçları hem sinir ağlarını öğrendik. Howard’ın kapanış sözü bir davet:
“I hope you’ll join us in Part 2. Thanks very much, everybody. I really enjoyed this process.” — Howard, 1:36:04
İpucuBuilder Notu — Part 2 / Karpathy: Builder’ın Derinlik Katmanı
- Geriye (tüm Part 1 zinciri): Sekiz ders boyunca Ders 1’in çalışan modelinden bu dersin convolution ve embedding’in her yerdeliğine kadar kurduğumuz her parça, Şekil 28.1’in tek zincirinde toplanır — Part 2 bu zincirin üzerine inşa edilir.
- İleriye (Part 2 / Karpathy): Part 2 “from the foundations” omurgasıyla matmul’dan diffusion’a her şeyi sıfırdan kurar; Karpathy serisiyle birlikte builder’ın derinlik katmanı — Şekil 28.1’in embedding → convolution → CNN zinciri, Part 2’de tek tek parçalarına ayrılıp yeniden kurulacak.
9.19 Bu Dersin Özeti
- Embedding, PyTorch’ta sıfırdan kurulabilir: küçük rastgele sayılarla başlatılan, eğitilebilir bir parametre tablosu (Embedding’i Sıfırdan Kurma).
- Öğrenilen embedding’ler yorumlanabilir; faktörler ve aralarındaki mesafe benzerliği (örn. benzer filmler) ortaya çıkarır (Embedding Yorumlama, Embedding Mesafesi).
- Embedding fikri her yerde: collaborative filtering, NLP (kelime embedding) ve tablo verisi (entity embeddings) (Embedding Her Yerde, Tablo İçin Embedding).
- Convolution, küçük bir kerneli (filtre) görüntü üzerinde kaydırıp her konumda dot product alır — “kaydırılan mini dot product’lar” (Convolution: Kenar Bulma, Filtreyi Kaydırma).
- Aynı kernel tüm görüntüde paylaşılır: 784 yerine 9 parametre; az parametre + öteleme-değişmezlik (Parametre Paylaşımı).
- CNN = conv + ReLU (+ pooling/BatchNorm) yığını; her katman boyutu küçültür, kanalı artırır (simple_cnn).
- Pooling (örn. max) görüntüyü küçültüp özeti çıkarır; BatchNorm eğitimi kararlı ve hızlı kılar (Pooling, BatchNorm).
- Part 1, top-down yaklaşımla pratik derin öğrenmeyi verdi; Part 2 her şeyi sıfırdan kuracak (Serinin Kapanışı).
ÖnemliTek Bir Cümle
Convolution, az parametreyle yerel desenleri yakalayan, görüntü üzerinde kaydırılan bir dot product’tır; embedding ise collaborative filtering’den NLP’ye ve tablo verisine kadar her yerde kategoriyi öğrenilen bir vektöre çeviren arama tablosudur.
9.20 Kontrol Soruları
NotSoru 1: Convolution nedir ve neden tam bağlı bir katmandan çok daha az parametre kullanır?
Cevap:
Convolution, küçük bir kerneli (örn. 3×3 matris) görüntünün her konumuna kaydırıp her konumda kernel ile o yamanın dot product’ını alır; sonuç bir öznitelik haritasıdır (kenar, köşe gibi yerel desenleri yakalar). Az parametre kullanır çünkü aynı kernel tüm görüntüde paylaşılır: 28×28 bir görüntü için tam bağlı katman 784 ağırlık isterken, 3×3 convolution yalnızca 9 ağırlık kullanır. Bu paylaşım hem parametreyi düşürür hem de “bir kenar görüntünün her yerinde kenardır” (öteleme-değişmezlik) bilgisini gömer — görüntü için doğru inductive bias. (Şekil 9.3 kenar bulmayı, Şekil 9.5 784 → 9 karşıtlığını gösterir.)
NotSoru 2: ‘Embedding her yerdedir’ ne demek? Üç farklı kullanım alanı ver.
Cevap:
Embedding, bir kategoriyi (id’yi) öğrenilen bir vektöre çeviren arama tablosudur ve aynı fikir üç alanda kullanılır: (1) Collaborative filtering — kullanıcı ve ürün id’leri için latent faktör vektörleri (Ders 7); (2) NLP — her kelime/token için kelime embedding’i (Ders 4, Karpathy); (3) Tablo verisi — kategorik sütunlar (mağaza, ürün) için entity embeddings, dummy variable yerine öğrenilen vektörler (Rossmann örneği). Üçünde de mekanizma aynıdır: kategoriyi vektöre çeviren, gradient descent’le öğrenilen bir tablo. (Şekil 9.2 üç kolu tek mekanizmada gösterir.)
NotSoru 3: Pooling ve BatchNorm bir CNN’de ne işe yarar?
Cevap:
Pooling (örn. max pooling), convolution gibi kaydırılan bir penceredir ama her pencerede en büyük (max) değeri alır; bu, görüntüyü küçültür (çözünürlük düşer), hesabı azaltır ve küçük kaymalara dayanıklılık (translation invariance) katar. Modern ağlar bunu stride’lı conv ile de yapar. BatchNorm (toplu normalizasyon) ise her katmanın aktivasyonlarını batch üzerinden normalize eder; bu, aktivasyon istatistiğini koruyarak eğitimi kararlı ve çok daha hızlı kılar, daha derin ağları eğitilebilir yapar. (Şekil 9.7 pooling’i, Şekil 9.8 normalizasyonu gösterir.)
NotSoru 4: Embedding mesafesi neden kullanışlıdır? Üretimde nerede karşına çıkar? (builder bağlantısı)
Cevap:
Embedding’ler bir vektör uzayında nokta olduğundan, iki öğe arasındaki mesafe (Öklid benzeri) onların benzerliğini ölçer — yakın embedding’ler benzer öğeler demektir (Howard’ın örneğinde “Dial M for Murder”a en yakın filmler mantıklı çıktı). Builder açısından bu, modern semantic search ve öneri sistemlerinin (“benzer ürünler/filmler”) çekirdeğidir; içerikleri embedding’e çevirip en yakın komşuları aramak, vektör veritabanlarının (Qdrant, FAISS) ve RAG sistemlerinin temel işlemidir. (Bkz. Embedding Mesafesi.)
9.21 Egzersizler
Egzersiz 1 (Direkt uygulama). top_edge ve left_edge kernellerini kur, apply_kernel ile bir görüntüye uygula ve ürettikleri öznitelik haritalarını karşılaştır.
Egzersiz 2 (İki-aşamalı). simple_cnn’i (conv + ReLU yığını) kur ve MNIST benzeri bir veride F.cross_entropy ile eğit; her katmanın çıktı boyutunu (simple_cnn(xb).shape) izle.
Egzersiz 3 (Edge case). conv’a BatchNorm2d ekle/çıkar ve eğitim hızı/kararlılığı farkını gözlemle.
Egzersiz 4 (Python ile doğrulama). Bir tam bağlı katman (784 girdi) ile 3×3 conv’un parametre sayısını hesaplayıp karşılaştır; parametre paylaşımının etkisini açıkla.
Egzersiz 5 (Sonraki dersin habercisi — Part 2). Convolution’ın diffusion modellerinde (U-Net) nasıl kullanıldığını araştır; Part 2’de bunu sıfırdan kuracağız.
9.22 Sonraki: PART 2 İçin Hazırlık
Part 2: Deep Learning Foundations to Stable Diffusion
Part 1 bitti — pratik derin öğrenmeyi top-down öğrendin. Part 2 (Ders 9-25) yön değiştirir: önce Stable Diffusion’ı kullanır, sonra her şeyi sıfırdan (from the foundations) yeniden kurar — matris çarpımından backprop’a, Learner’dan diffusion’a. Karpathy ruhuna en yakın bölüm.
Ana konular (Part 2):
- Stable Diffusion ve diffusion modelleri
- Sıfırdan: matmul, backprop, Learner, init/norm
- DDPM, DDIM, U-Net, attention, latent diffusion
UyarıPart 2 Öncesi Yapılacak
- Part 1’in tüm egzersizlerini tamamla ve bir model deploy et.
- Bir şey üret ve forum’da paylaş (Howard’ın tavsiyesi: azim + bitirmek).
- Ana cümleyi tekrar oku: “Convolution = kaydırılan dot product; embedding = arama tablosu.”
9.23 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Howard’da |
|---|---|---|
| Embedding (sıfırdan) | Eğitilebilir, küçük rastgele başlatılan parametre tablosu | 7:43 |
| Embedding yorumlama | Faktörlere bakıp modelin öğrendiği eksenleri görme | 12:32 |
| Embedding mesafesi | Vektör uzayında yakınlık = benzerlik (öneri/arama) | 22:13 |
| Entity embeddings | Tablo kategorik sütunları için öğrenilen vektörler | 35:01 |
| Convolution | Kerneli kaydırarak her konumda dot product | 44:33 |
| Kernel | Küçük filtre matrisi (örn. 3×3 kenar bulucu) | 44:33 |
| Parametre paylaşımı | Aynı kernel her yerde; 784 yerine 9 parametre | 44:33 |
| F.conv2d | Optimize convolution (tüm batch + kanal) | 53:00 |
| simple_cnn | conv + ReLU yığını; boyut küçülür, kanal artar | 45:00 |
| Pooling | Kaydırmalı max/ortalama; boyut indirgeme | 58:00 |
| BatchNorm | Aktivasyonları normalize; kararlı/hızlı eğitim | 57:07 |
| stride | Kernelin adım büyüklüğü; görüntüyü küçültür | 45:00 |
9.24 ML Builder Bağlantıları
İpucuBuilder Notu — 6 ML Köprüsü
Bu ders, embedding’in her yerdeliğinden convolution’a ve CNN’e uzanır; köprülerin özeti:
- Convolution → görüntü için doğru inductive bias (paylaşım + yerellik); CNN/U-Net/diffusion’ın temeli (Part 2) (Convolution: Kenar Bulma, Parametre Paylaşımı).
- Embedding her yerde → collab + NLP + tablo (entity embeddings); kategoriyi vektöre çeviren ortak fikir (Embedding Her Yerde, Tablo İçin Embedding).
- Embedding mesafesi → semantic search, öneri, vektör veritabanları (Qdrant), RAG (Embedding Mesafesi).
- BatchNorm → Karpathy makemore’da sıfırdan (§4.F); derin ağ eğitimini kararlı kılar (BatchNorm).
- Parametre paylaşımı → az parametre + genelleme; modern mimarilerin verimlilik sırrı (Parametre Paylaşımı).
- Pooling/stride → boyut indirgeme; hesabı azaltıp soyutlama seviyesini artırma (Pooling, simple_cnn).
ÖnemliBu dersten ve Part 1’den tek bir şey alıp gideceksen
Bu dersten ve Part 1’den tek bir şey alıp gideceksen: derin öğrenmenin parçaları basittir ve hepsi birbirine bağlanır. Embedding bir arama tablosu, convolution kaydırılan bir dot product, model gradient descent’le uydurulan bir fonksiyondur. Howard’ın son tavsiyesi en değerlisi: bir şeyi gerçekten bitir ve paylaş — çoğu insan vazgeçer; sen vazgeçme. Part 2’de görüşmek üzere.