flowchart TD
P1["Part 1: top-down DL<br/>(8 ders bitti)"]:::cyan
P2["Part 2: Foundations →<br/>Stable Diffusion<br/>(sıfırdan kur)"]:::cyan
P1 --> P2
SD(["Stable Diffusion"]):::rose
P2 --> SD
UNET["U-Net: gürültü tahmincisi<br/>(CNN, Ders 8)"]:::cyan
VAE["VAE: latent sıkıştırma<br/>786K → 16K (~48×)"]:::cyan
CLIP["CLIP: metin koşullama<br/>(embedding, Ders 7)"]:::cyan
SD --> UNET
SD --> VAE
SD --> CLIP
CORE(["Çekirdek sezgi:<br/>Diffusion = pikselleri geçerlilik<br/>gradyanı yönünde ittir<br/>(= gradient descent, Ders 3)"]):::rose
SD -.-> CORE
UNET -.-> CORE
INF["Inference düğmeleri"]:::cyan
SD --> INF
STEPS["num_inference_steps<br/>(ayrıklaştırma inceliği)"]:::cyan
GUIDE["guidance_scale<br/>(prompt'a sadakat ↑)"]:::cyan
NEG["negative_prompt<br/>(istenmeyen yön ⊖)"]:::cyan
IMG["img2img<br/>(gürültüden değil görüntüden)"]:::cyan
INF --> STEPS
INF --> GUIDE
INF --> NEG
INF --> IMG
classDef cyan fill:#cffafe,stroke:#0e7490,stroke-width:2px,color:#1e293b;
classDef rose fill:#ffe4e6,stroke:#e11d48,stroke-width:2.5px,color:#1e293b;
10 Ders 9 — Stable Diffusion (Part 2 Başlangıcı)
Part 2’nin ilk dersi yönü değiştirir: Part 1 pratik derin öğrenmeyi top-down verdi, Part 2 ‘deep learning foundations to Stable Diffusion’ — her şeyi sıfırdan kurup Stable Diffusion’a varacak. Ama bu ilk ders yine top-down başlar: önce Stable Diffusion’la oynarız (prompt → görüntü, guidance scale, negative prompt, img2img, textual inversion), sonra nasıl çalıştığını sezgisel açarız. Çekirdek fikir: ‘bir şeyin ne kadar geçerli bir görüntü olduğunu’ söyleyen sihirli bir fonksiyonun pixel gradyanı yönünde pikselleri ittirmek — gürültüden görüntü doğar. Üç bileşen: U-Net (gürültü tahmincisi), VAE (latent sıkıştırma 786K → 16K), CLIP (metin koşullama)
NotBölüm bilgisi
- Howard’ın videosu: course.fast.ai — Lesson 9: Stable Diffusion (~135 dk)
- Seri: Practical Deep Learning for Coders — Part 2, Ders 9 (Part 2 BAŞLANGICI)
- Hoca: Jeremy Howard
- Playlist: Part 2 — Foundations to Stable Diffusion (2022)
- Notebook: diffusion-nbs — stable_diffusion
- Okuma süresi: ~40 dk
10.1 Bu Derste Ne Var?
Part 2’nin ilk dersine geldik (Howard’ın numaralandırmasıyla Lesson 9, çünkü Part 1 sekiz dersti). Yön değişiyor: Part 1 pratik derin öğrenmeyi top-down verdi; Part 2’nin tam adı “deep learning foundations to Stable Diffusion” — her şeyi sıfırdan kurup Stable Diffusion’a varacak. Ama bu ilk ders yine top-down başlar: önce Stable Diffusion’la oynarız, sonra nasıl çalıştığını sezgisel olarak açarız.
Üç temel fikir bu dersin omurgasını kurar:
- Stable Diffusion’ı kullanmak —
StableDiffusionPipelineile prompt → görüntü;guidance_scale,negative_prompt, img2img, textual inversion ve DreamBooth gibi araçlarla üretimi yönlendirme (Oynayalım → Pipeline). - Diffusion’ın sezgisi — “bir şeyin ne kadar geçerli bir görüntü olduğunu” söyleyen sihirli bir fonksiyon hayal et; pikselleri o fonksiyonun gradyanı yönünde ittir → gürültüden görüntü doğar (Sihirli API → Pixel Gradyanı).
- Üç bileşen — U-Net (gürültü tahmincisi), VAE/autoencoder (latent sıkıştırma: 786K → 16K), CLIP (metin koşullama) (U-Net → VAE → CLIP).
“We’re certainly not going to be spending all of our time seeing how to do important things; we’ll be doing generative modely fun things, and understanding lots of details.” — Howard, 0:45
Şekil 28.1 bu üç fikri tek bir yol haritasında birleştirir: Part 1’in (top-down, 8 ders) bittiği yerden Part 2’nin “önce kullan, sonra sıfırdan kur” stratejisine, oradan Stable Diffusion’ın üç bileşenine (U-Net + VAE + CLIP) ve çıkarım düğmelerine (num_inference_steps, guidance_scale, negative_prompt, img2img) uzanır — rose vurgulu “Stable Diffusion” ve “Çekirdek sezgi” düğümleri dersin doruğudur.
İpucuBuilder Notu — Üç Tanıdık Parça: Diffusion’ın Gradient Descent Kökü
- Geriye (Ders 3/8 + Karpathy): Diffusion’ın çekirdeği gradient descent’tir (Ders 3) — ama bu kez ağırlıkları değil pikselleri günceller;
f.backward()aynı autograd. U-Net bir CNN’dir (Ders 8); üretim, embedding’leri (Ders 7-8) kullanan CLIP ile koşullanır. - İleriye (Part 2 / NYU §4.J): Part 2’nin geri kalanı (L11-25) U-Net, VAE ve scheduler’ı sıfırdan kurar. Diffusion, NYU’nun enerji-tabanlı modelleri (EBM) ve self-supervised learning fikriyle akrabadır — “geçerlilik skoru” bir enerji fonksiyonu sezgisidir.
- Tek cümle: Stable Diffusion, metinle koşullanmış bir gürültü-giderme döngüsüdür; bugün kullanırız, Part 2 boyunca sıfırdan kurarız.
10.2 Stable Diffusion’la Oynayalım
Howard dersi top-down açar: önce modeli kullanırız. Hugging Face diffusers kütüphanesiyle, bir prompt’tan görüntü üreten hazır bir pipeline yükleriz. “Hepimiz oynamak için sabırsızlanıyoruz” der; mekanik sonra gelir. Bu, Part 2’nin “önce kullan, sonra sıfırdan kur” stratejisidir — konsept haritasının sol kolunda gördüğümüz “önce kullanım” adımı.
“Because we’re all dying to play with it, right?” — Howard, 1:42
İpucuBuilder Notu — Önce Çalışan Sonuç: Part 1 Top-Down Ruhunun Devamı
- Geriye (Ders 1): Top-down ruhu Ders 1 ile aynı; önce çalışan sonuç, sonra derinlik — modelin ne yaptığını görmeden iç mekaniğine inmeyiz.
- İleriye (bu ders): Bugün önce
pipe()’ı çağırıp görüntü üreteceğiz, dersin ikinci yarısında (Sihirli API) o “sihrin” aslında tanıdık gradient descent olduğunu açacağız.
10.3 Kaynaklar ve Compute
Howard diffusion-nbs repo’sunu (oynamak için notebook’lar), Lexica gibi prompt galerilerini ve compute seçeneklerini (Colab, Paperspace, kendi makinen) tanıtır. Part 2, Part 1’den daha fazla GPU gerektirir; diffusion modelleri ağırdır.
“Part 2 requires quite a bit more compute than Part 1.” — Howard, 12:15
İpucuBuilder Notu — Compute Maliyeti: Latent Uzayın Varlık Sebebi
- İleriye (production / VAE): Diffusion compute-yoğundur; latent uzayda çalışmak (sonraki bölümlerde VAE ile) bu maliyeti ~48× düşürür. “Pahalı işi küçük uzayda yap” disiplini, Stable Diffusion’ı pratik kılan anahtardır.
- İleriye (Ders 14):
fp16(yarı hassasiyet) bellek tasarrufu da aynı maliyet mücadelesinin parçasıdır; Part 2 Ders 14’te derinleşir.
10.4 StableDiffusionPipeline
İlk kod: hazır bir pipeline yükle, bir prompt ver, görüntü al. from_pretrained modeli (CompVis/stable-diffusion-v1-4) indirir; fp16 bellek için yarı hassasiyet kullanır. Bu, dersin geri kalanında açacağımız “yüksek seviye” arayüzdür — düşük seviye pipeline bunun içini gösterir.
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4", variant="fp16",
torch_dtype=torch.float16).to("cuda")
prompt = "a photograph of an astronaut riding a horse"
pipe(prompt).images[0]
İpucuBuilder Notu — from_pretrained = Transfer Learning’in Üretken Hâli
- Geriye (Ders 2):
from_pretrained= transfer learning; başkasının (CompVis) devasa GPU’larla eğittiği modeli indirip kullanırız — Ders 2’deki “önceden eğitilmiş modeli al, kendi işine uydur” fikrinin üretken model hâli. - İleriye (Ders 14):
fp16(mixed precision) bellek ve hız için yarı hassasiyet kullanır; Part 2 Ders 14’te neden işe yaradığı ve nasıl kurulduğu derinleşir.
10.5 num_inference_steps
Diffusion, gürültüden görüntüyü adım adım çıkarır. num_inference_steps kaç adımda çıkaracağını belirler: az adım hızlı ama kaba, çok adım yavaş ama kaliteli. torch.manual_seed aynı başlangıç gürültüsünü sabitler, böylece adım sayısının etkisini tek başına gözleyebiliriz.
torch.manual_seed(1024)
pipe(prompt, num_inference_steps=3).images[0] # hizli, kaba
pipe(prompt, num_inference_steps=16).images[0] # yavas, kaliteliŞekil 10.2 bu dengeyi gerçek bir yörünge üstünde gösterir: gürültü-giderme süreci sürekli bir hedef yörüngeye yaklaşır, num_inference_steps ise bu yörüngeyi kaç parçaya böldüğümüzdür. 3 adım yörüngeyi köşeli ve kaba yaklaşıklar (hızlı), 16 adım daha düzgün, 50 adım hedefle neredeyse örtüşür (yavaş). Yani parametre, gürültü-giderme yörüngesinin ayrıklaştırma inceliğidir — her adım pratikte bir U-Net çağrısıdır.
Kod
d = E.denoise_quality_demo()
t_fine, target, steps_dict = d["t_fine"], d["target"], d["steps_dict"]
# Az → çok adım: kabadan düzgüne. 3 kaba (rose), 16 orta, 50 hedefe oturur (cyan).
step_styles = {
3: dict(color=COL_ACCENT, ls="--", lw=2.4, ms=9, marker="o", label="3 adım — kaba/hızlı"),
16: dict(color=COL_ROSE_400, ls="-.", lw=2.0, ms=6.5, marker="s", label="16 adım — orta"),
50: dict(color=COL_PRIMARY, ls="-", lw=2.0, ms=4, marker="^", label="50 adım — düzgün/yavaş"),
}
fig, axes = plt.subplots(1, 3, figsize=(9, 5), sharex=True, sharey=True)
for ax, nstep in zip(axes, (3, 16, 50)):
viz.apply_style(ax)
# düzgün hedef yörünge (ince cyan referans çizgisi)
ax.plot(t_fine, target, color=COL_CYAN_400, lw=1.4, alpha=0.85,
zorder=2, label="hedef yörünge")
# nstep adımlı parçalı (Euler benzeri) yaklaşım
tn, yn = steps_dict[nstep]
st = step_styles[nstep]
ax.plot(tn, yn, color=st["color"], linestyle=st["ls"], lw=st["lw"],
marker=st["marker"], markersize=st["ms"],
markerfacecolor=COL_WHITE, markeredgecolor=st["color"],
markeredgewidth=1.6, zorder=4, label=f"{nstep} adımlı yaklaşım")
ax.set_title(st["label"], color=COL_TEXT, fontsize=11, weight="bold")
ax.set_xlabel("gürültü-giderme ilerlemesi", fontsize=9.5)
ax.legend(loc="lower right", fontsize=8.0, framealpha=0.92)
axes[0].set_ylabel("görüntü durumu (gürültü → görüntü)", fontsize=9.5)
# Az adım = kaba/hızlı (sol) → çok adım = düzgün/yavaş (sağ) annotate
axes[0].annotate("az adım: kaba ama hızlı\n(yörüngeyi köşeli yaklaşıklar)",
xy=(0.55, target[int(0.55 * (len(target) - 1))]),
xytext=(0.18, 0.18), fontsize=8.2, color=COL_ACCENT, weight="bold",
ha="left", va="center")
axes[2].annotate("çok adım: hedefle\nneredeyse örtüşür",
xy=(0.62, target[int(0.62 * (len(target) - 1))]),
xytext=(0.30, 0.30), fontsize=8.2, color=COL_CYAN_700, weight="bold",
ha="left", va="center")
plt.tight_layout()
plt.show()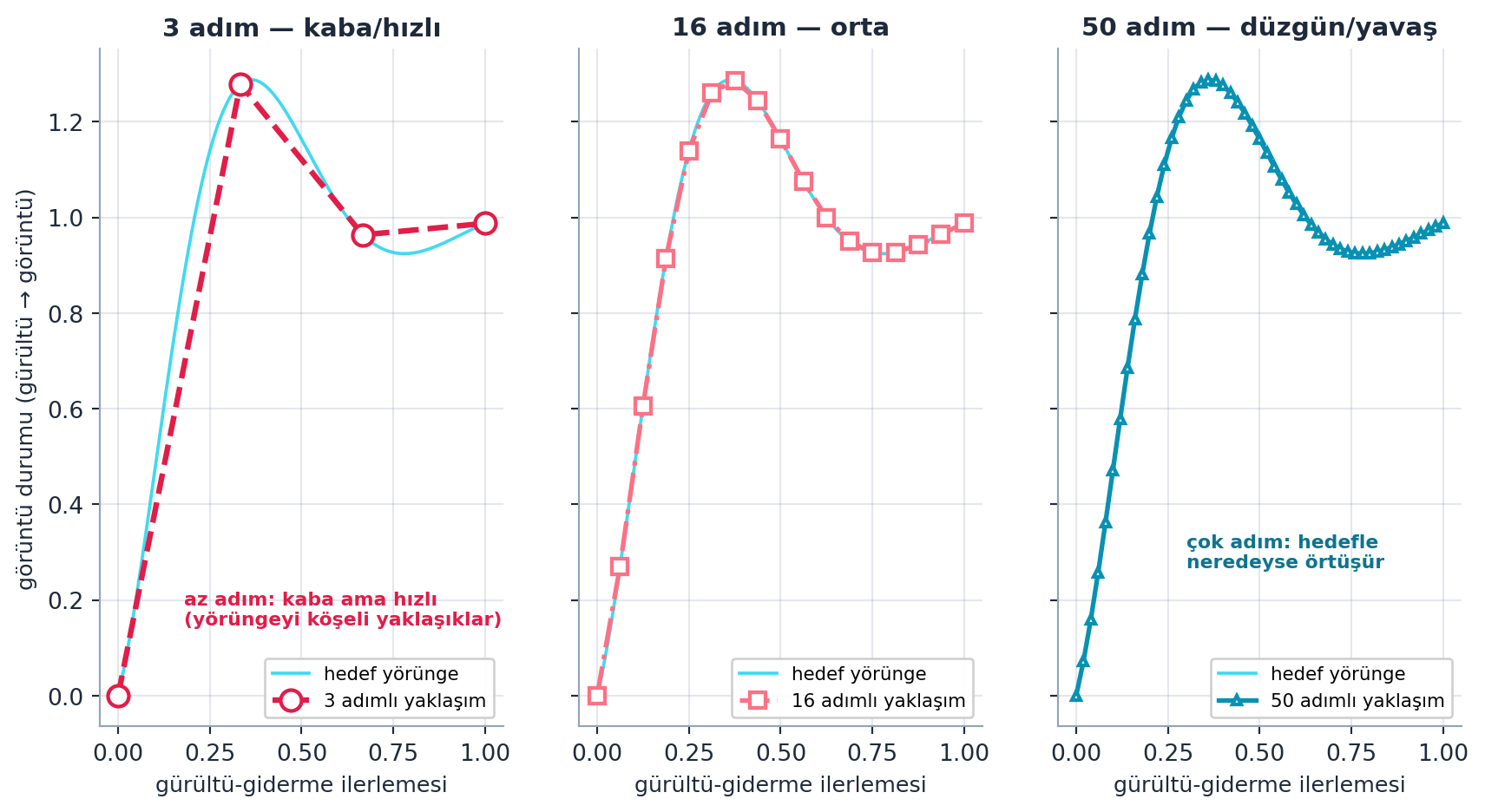
İpucuBuilder Notu — Adım Sayısı = Yörünge Ayrıklaştırması (DDIM’in Hedefi)
- Geriye (Ders 3): Az adımla kaba, çok adımla düzgün yaklaşma, Ders 3’teki gradient descent’in learning-rate/adım sayısı dengesinin ikizidir — büyük adım hızlı ama kaba, küçük adım yavaş ama hassas.
- İleriye (Ders 21 DDIM): Adım sayısını azaltıp kaliteyi korumak Part 2’nin (DDIM, Ders 21) ana hedeflerindendir; Şekil 10.2’in “50 adım ≈ 3 adımın kalitesi” hayali tam bu araştırma yönüdür.
10.6 guidance_scale (Classifier-Free Guidance)
guidance_scale, modelin prompt’a ne kadar “sıkı” uyacağını ayarlar. Düşük → yaratıcı ama prompt’tan uzak; yüksek → prompt’a sadık ama bazen aşırı. Bu, classifier-free guidance (CFG)’ın parametresidir: koşullu (prompt’lu) ve koşulsuz (boş prompt’lu) tahmini harmanlar.
images = concat(pipe(prompts, guidance_scale=g).images for g in [1.1, 3, 7, 14])“That’s what guidance scale does — you can think of the guidance scale as how strongly should we apply the prompt.” — Howard, 40:00
Şekil 10.3 CFG’nin vektör aritmetiğini somutlaştırır. Sol panel formülü gösterir: tahmin \(= \text{uncond} + s\cdot(\text{cond} - \text{uncond})\) — ölçek \(s\) büyüdükçe tahmin vektörü koşulsuz noktadan koşullu yöne, hatta ötesine taşar. Sağ panel dengeyi gösterir: yüksek \(s\) daha sadık (prompt’a uyum ↑) ama daha az çeşitli (varyasyon ↓). İkisi birlikte, neden çok yüksek guidance’ın aşırı doygun/yapay görüntüler verdiğini açıklar.
Kod
d = E.guidance_cfg_demo()
uncond, cond, preds = d["uncond"], d["cond"], d["preds"]
scales = d["scales"]
s_curve, fidelity, diversity = d["s_curve"], d["fidelity"], d["diversity"]
fig, (axL, axR) = plt.subplots(1, 2, figsize=(11.5, 4.8))
# ---- SOL panel: CFG vektör aritmetiği -------------------------------------
# Yön çizgisi (uncond -> cond ve ötesi), referans olarak soluk
far = uncond + max(scales) * (cond - uncond)
axL.plot([uncond[0], far[0]], [uncond[1], far[1]],
color=COL_SLATE_400, lw=1.0, ls="--", zorder=1)
# uncond ve cond noktaları
axL.scatter(*uncond, s=130, color=COL_CYAN_700, zorder=4, edgecolors=COL_WHITE, linewidths=1.5)
axL.scatter(*cond, s=130, color=COL_ACCENT, zorder=4, edgecolors=COL_WHITE, linewidths=1.5)
axL.annotate("uncond", uncond, textcoords="offset points", xytext=(-6, -16),
ha="right", fontsize=10.5, weight="bold", color=COL_CYAN_700)
# pred noktaları: her ölçek için uncond'dan o noktaya ok zinciri
prev = uncond
scale_cols = [COL_CYAN_400, COL_PRIMARY, COL_CYAN_700, COL_ACCENT]
for s, col in zip(scales, scale_cols):
p = preds[float(s)]
arrow_between(axL, prev, p, color=col, lw=2.2, shrink=6, mutation_scale=15, zorder=2)
axL.scatter(*p, s=95, color=col, zorder=4, edgecolors=COL_WHITE, linewidths=1.2)
lbl = "cond (s=1)" if s == 1.0 else f"s={int(s)}"
dy = 14 if s != 1.0 else -16
axL.annotate(lbl, p, textcoords="offset points", xytext=(8, dy),
ha="left", fontsize=9.5, weight="bold", color=col)
prev = p
axL.set_title("CFG vektör aritmetiği: uncond + s·(cond − uncond)",
fontsize=11, color=COL_TEXT, weight="bold")
axL.set_xlabel("gürültü-tahmin bileşeni 1")
axL.set_ylabel("gürültü-tahmin bileşeni 2")
viz.apply_style(axL)
axL.set_aspect("equal", adjustable="datalim")
# ---- SAĞ panel: sadakat ↑ / çeşitlilik ↓ denge eğrileri --------------------
axR.plot(s_curve, fidelity, color=COL_PRIMARY, lw=2.6, label="sadakat (prompt'a uyum) ↑")
axR.plot(s_curve, diversity, color=COL_ACCENT, lw=2.6, label="çeşitlilik (varyasyon) ↓")
# ölçek işaretleri (sol panelle bağ)
for s in scales:
axR.axvline(s, color=COL_SLATE_400, lw=0.8, ls=":", alpha=0.6, zorder=1)
axR.annotate("düşük s:\nyaratıcı / uzak", xy=(2.0, np.exp(-0.16 * 2.0)),
xytext=(3.0, 0.78), fontsize=9.5, color=COL_ACCENT, weight="bold",
arrowprops=dict(arrowstyle="->", color=COL_ROSE_400, lw=1.4))
axR.annotate("yüksek s:\nsadık / aşırı", xy=(13.0, 1.0 - np.exp(-0.32 * 13.0)),
xytext=(8.4, 0.40), fontsize=9.5, color=COL_CYAN_700, weight="bold",
arrowprops=dict(arrowstyle="->", color=COL_CYAN_400, lw=1.4))
axR.set_title("Guidance ölçeği dengesi", fontsize=11, color=COL_TEXT, weight="bold")
axR.set_xlabel("guidance ölçeği s")
axR.set_ylabel("göreli düzey (0–1)")
axR.set_xlim(s_curve.min(), s_curve.max())
axR.set_ylim(0, 1.05)
axR.legend(loc="center right", fontsize=9.5, framealpha=0.95)
viz.apply_style(axR)
plt.tight_layout()
plt.show()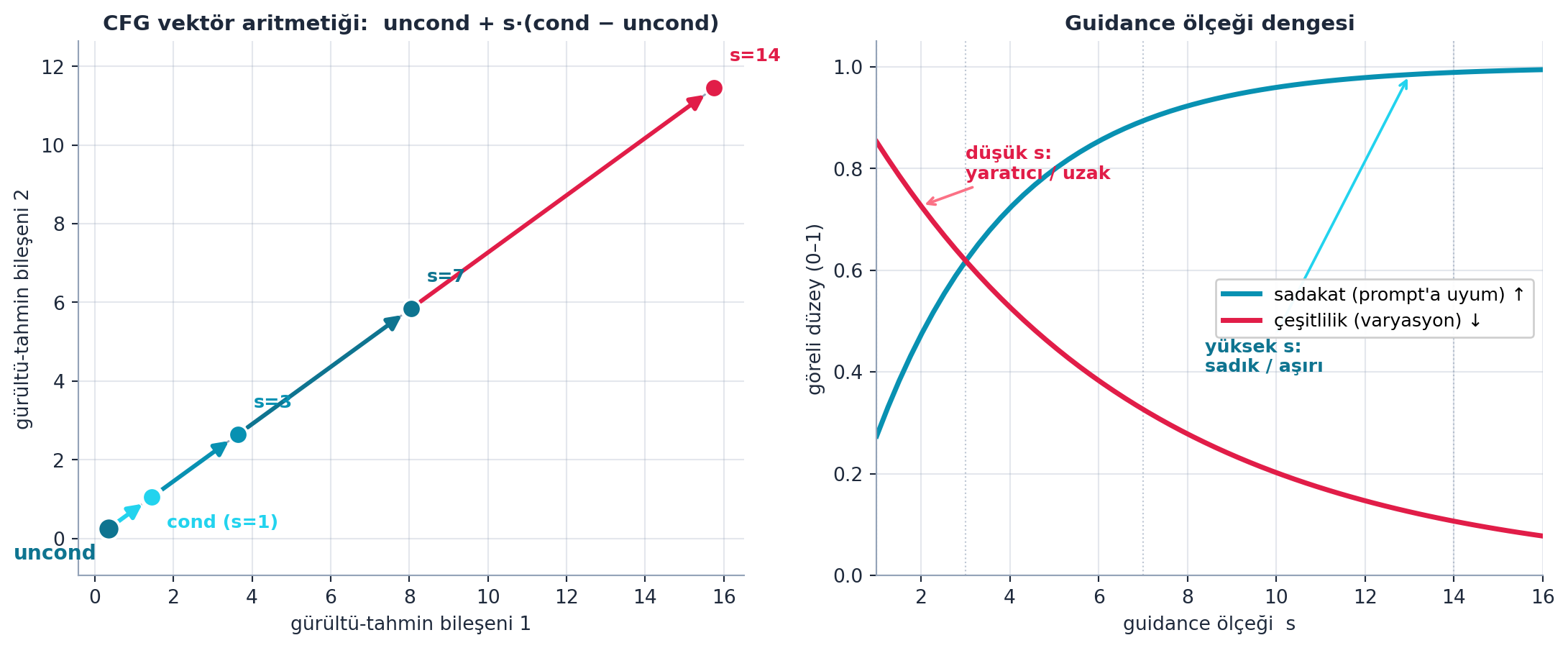
İpucuBuilder Notu — CFG = Koşullu ile Koşulsuz Arası Vektör Aritmetiği
- Geriye (Ders 7 dot product): CFG’nin “koşullu − koşulsuz” yönü, Ders 7’deki vektör aritmetiğinin üretken hâlidir — iki tahmin arasındaki farkı bir yön olarak alıp ölçekleriz.
- İleriye (Ders 10/9A): Classifier-free guidance’ın tam matematiği Ders 9A (Whitaker) ve Ders 10’da açılır (§4.I); Şekil 10.3’in sadakat/çeşitlilik eğrileri o derslerde formel hâle gelir.
10.7 negative_prompt
negative_prompt ile modele “şunu İSTEME” deriz: çıktıyı belirtilen kavramdan uzaklaştırır. Howard “blue” negatif prompt’uyla mavi tonları çıkarır. CFG açısından bu, guidance yönünü tersine çevirmektir — istenen yöne itmek yerine istenmeyen yönden çekmek.
torch.manual_seed(1000)
pipe(prompt, negative_prompt="blue").images[0] # mavi tonlardan uzaklas
İpucuBuilder Notu — Negatif Prompt = Guidance Yönünün Tersi
- Geriye (guidance): Negatif prompt, classifier-free guidance’ın yönünü tersine çeviren bir kavramdır — “cond − uncond” yerine “uncond − unwanted” yönüne iter; aynı vektör aritmetiği, ters işaret.
- İleriye (9A): Ders 9A’da Whitaker bunu derinleştirir: negatif prompt’u ve embedding interpolasyonunu latent uzayda elle kontrol eder.
10.8 img2img: Görüntüden Görüntü
Sıfır gürültü yerine bir başlangıç görüntüsünden başlayabiliriz: model onu kısmen gürültüleyip prompt’a göre yeniden çizer. strength ne kadar değiştireceğini belirler (0 = aynı, 1 = tamamen yeniden). Bu, num_inference_steps yörüngesine baştan değil ortadan girmek gibidir — gürültü-giderme döngüsünü saf gürültüyle değil, kısmen gürültülenmiş bir görüntüyle başlatırız.
from diffusers import StableDiffusionImg2ImgPipeline
images = pipe(prompt="Wolf howling at the moon, photorealistic 4K",
image=init_image, strength=0.8, num_inference_steps=50).images
İpucuBuilder Notu — img2img: Stil Aktarımı ve Düzenlemenin Temeli
- İleriye (production): img2img, stil aktarımı ve düzenlemenin (inpainting, DiffEdit) temelidir; başlangıç görüntüsünü kısmen gürültüleyip yeniden çizme fikri Ders 10’da derinleşir.
- Geriye (num_inference_steps):
strength, gürültü-giderme yörüngesine hangi noktadan gireceğimizi belirler — düşükstrengthorijinale yakın kalır, yüksekstrengthneredeyse sıfırdan üretir.
10.9 Textual Inversion ve DreamBooth
İki güçlü özelleştirme yöntemi: Textual inversion tek bir yeni embedding eğitir (yeni bir kavrama/stile bir “kelime” öğretir); DreamBooth modeli birkaç fotoğrafla ince ayarlar (örn. belirli bir kişiyi/nesneyi). İkisi de modele yeni bir şey öğretir — biri tek bir embedding satırını, diğeri model ağırlıklarını günceller.
“Textual Inversion is where we actually fine-tune just a single embedding… we add that token to the text model and then train the embedding.” — Howard, 40:00
İpucuBuilder Notu — Textual Inversion = Tek Bir Embedding Satırını Eğitmek
- Geriye (Ders 7-8): Textual inversion = tek bir embedding’i (arama tablosu satırını) eğitmek; embedding’in arama tablosu olduğu bilgisi (Ders 7-8) doğrudan işler — yeni “kelime”, CLIP sözlüğüne eklenen yeni bir satırdır.
- İleriye (production): DreamBooth modelin tamamını birkaç görselle ince ayarlar; ikisi de transfer learning’in üretken modellere taşınmış hâlidir.
10.10 Stable Diffusion Nasıl Çalışır: Sihirli API
Şimdi sezgiye geçiyoruz. Howard “el yazısı rakam üreten” basit bir örnekle açıklar. Bir sihirli API hayal et: ona bir görüntü verirsin, sana “bunun el yazısı bir rakam olma olasılığı”nı döner (örn. 0.98 veya 0.02). Bu fonksiyona sahipsek, onu görüntü üretmek için kullanabiliriz. Bu, dersin ikinci yarısının çekirdek kurgusudur — sonraki bölümde (Pixel Gradyanı) bu fonksiyonun gradyanını alıp üretime çevireceğiz.
“You pass an image into this magic API, and it returns the probability that this thing is a handwritten digit.” — Howard, 47:00
İpucuBuilder Notu — Görüntü = Sayı + Bir Skor Fonksiyonu
- Geriye (Ders 1): “Görüntü = sayı” (Ders 1) artı bir skor fonksiyonu — tanıdık parçalar; sihirli API yalnızca “bu görüntü ne kadar geçerli?” sorusuna bir sayı döndüren bir fonksiyondur.
- İleriye (Pixel Gradyanı): Bu fonksiyona sahipsek, onun gradyanını alıp pikselleri “daha geçerli” yöne itebiliriz — sıradaki bölümün konusu.
10.11 Pixel Gradyanı → Gürültü Giderme
Anahtar fikir: bu sihirli fonksiyonun, her pikselle ilgili gradyanını alırız — “bu pikseli biraz değiştirsem, rakam olma olasılığı ne kadar artar?”. Sonra her pikseli bu gradyan yönünde azıcık ittirirsek, görüntü biraz daha “rakam gibi” olur. Bunu tekrarlarsak, gürültüden bir rakam doğar. İşte diffusion budur — ama ağırlıkları değil pikselleri günceller.
# Kavram (gercek SD bunu U-Net ile yapar):
# pikselleri "daha gecerli goruntu" yonunde ittir
# x = x - c * gradient(P(x gecerli), x) # her adimda biraz gurultu gider“We’ve calculated the gradient of the probability that X3 is a handwritten digit with respect to the pixels of X3. We take every pixel and subtract a little bit times its gradient.” — Howard, 49:41
Şekil 10.4 bu çekirdeği gerçek hesaplamayla gösterir: arka plandaki geçerlilik alanı \(P(x)\) (yüksek = geçerli görüntü bölgesi), iki rose yıldız iki geçerli görüntü (mod), ve gürültülü bir başlangıçtan yıldızlardan birine inen score-ascent yörüngesi. Her küçük ok, score \(\nabla \log P\) yönüdür; ardışık adımlarla en yakın geçerli moda yaklaşırız. Diffusion’ın özü tam budur — ağırlık değil, pikselin kendisi güncellenir.
Kod
d = E.pixel_gradient_demo()
X, Y, field, traj, modes = d["X"], d["Y"], d["field"], d["traj"], d["modes"]
fig, ax = plt.subplots(figsize=(7.5, 6))
# Geçerlilik alanı P(x): cyan colormap ile contourf (yüksek P = geçerli görüntü bölgesi)
cf = ax.contourf(X, Y, field, levels=16, cmap="GnBu", alpha=0.92, zorder=0)
ax.contour(X, Y, field, levels=8, colors=[COL_CYAN_700], linewidths=0.6,
alpha=0.45, zorder=1)
cb = fig.colorbar(cf, ax=ax, fraction=0.046, pad=0.03)
cb.set_label("P(x) — geçerlilik (yoğunluk)", color=COL_TEXT, fontsize=9.5)
cb.ax.tick_params(colors=COL_TEXT, labelsize=8)
# İki mod = iki geçerli görüntü (rose yıldız + etiket)
ax.scatter(modes[:, 0], modes[:, 1], marker="*", s=520, c=[COL_ACCENT],
edgecolors=COL_WHITE, linewidths=1.6, zorder=6)
for i, m in enumerate(modes):
ax.annotate("geçerli görüntü", xy=(m[0], m[1]),
xytext=(m[0] + 0.25, m[1] + 0.45),
fontsize=9.5, color=COL_ACCENT, weight="bold", zorder=7)
# Score-ascent yörüngesi: rose çizgi + noktalar
ax.plot(traj[:, 0], traj[:, 1], "-", color=COL_ACCENT, lw=2.0, alpha=0.85,
zorder=4)
ax.scatter(traj[:, 0], traj[:, 1], s=22, c=[COL_ROSE_400],
edgecolors=COL_ACCENT, linewidths=0.8, zorder=5)
# Ardışık noktalar arası küçük oklar: score (∇log P) yönü
step = 3
for i in range(0, len(traj) - step, step):
viz.arrow_between(ax, tuple(traj[i]), tuple(traj[i + step]),
color=COL_ACCENT, lw=1.4, mutation_scale=12,
shrink=3, zorder=5)
# Başlangıç (gürültü) ve son (geçerli) noktaları etiketle
p_start, p_end = traj[0], traj[-1]
ax.scatter(*p_start, s=130, c=[COL_WHITE], edgecolors=COL_ACCENT,
linewidths=2.2, zorder=8)
ax.annotate("gürültü\n(başlangıç)", xy=tuple(p_start),
xytext=(p_start[0] - 0.15, p_start[1] + 0.30),
fontsize=10, color=COL_TEXT, weight="bold", ha="center", zorder=9)
ax.annotate("geçerli\n(son)", xy=tuple(p_end),
xytext=(p_end[0] + 0.55, p_end[1] - 0.75),
fontsize=10, color=COL_CYAN_700, weight="bold", ha="center",
zorder=9,
arrowprops=dict(arrowstyle="-|>", color=COL_CYAN_700, lw=1.4))
# Score yön açıklaması (tek etiket)
mid = traj[len(traj) // 3]
ax.annotate("score (∇log P) yönü", xy=tuple(mid),
xytext=(mid[0] - 0.1, mid[1] + 0.85),
fontsize=9, color=COL_ACCENT, style="italic", zorder=9)
ax.set_title("Geçerlilik alanı + score-ascent: gürültüden görüntüye",
color=COL_TEXT, fontsize=12.5, weight="bold", pad=10)
ax.set_xlabel("piksel ekseni 1", color=COL_TEXT, fontsize=10)
ax.set_ylabel("piksel ekseni 2", color=COL_TEXT, fontsize=10)
ax.tick_params(colors=COL_TEXT)
for sp in ("top", "right"):
ax.spines[sp].set_visible(False)
for sp in ("left", "bottom"):
ax.spines[sp].set_color(COL_SLATE_400)
ax.set_aspect("equal", adjustable="box")
plt.tight_layout()
plt.show()Matematiksel olarak bu yön bir score’dur: olasılık yoğunluğunun logaritmasının gradyanı, \(\nabla_x \log p(x)\). Score yüksek olasılıklı bölgelere doğru işaret eder; pikselleri o yönde adım adım iterek gürültüden geçerli bir görüntüye varırız.
İpucuBuilder Notu — Bu, Loss Yerine Skor Üstünde Gradient Descent
- Geriye (Ders 3/5): Bu, gradient descent’in ta kendisidir (Ders 3) — ama loss yerine “geçerlilik skoru”, ağırlık yerine piksel;
f.backward()(Ders 5) aynı autograd mekanizmasıdır. - İleriye (Part 2): Bu “sihirli fonksiyon”u sıfırdan kuracağız (L15-L25); o, gürültü tahmin eden bir sinir ağı (U-Net)dir. Score \(\nabla \log p\) fikri, NYU’nun enerji-tabanlı modelleriyle (sentez figürü) akrabadır.
10.12 U-Net: Gürültü Tahmincisi
Pratikte “sihirli fonksiyon” bir sinir ağıdır ve adı U-Net’tir — Stable Diffusion’ın ilk bileşeni. Girdisi gürültülü bir görüntü; çıktısı o görüntüdeki gürültünün tahmini (veya gürültüsüz hâli). Gürültüyü çıkarıp tekrarlayarak görüntü oluşur. Pixel gradyanı bölümündeki “score” işte bu ağın çıktısıdır.
“This is the first component of Stable Diffusion, it’s the U-Net. The input to the U-Net is a somewhat noisy image, and from the input we end up with the un-noisy image.” — Howard, 1:00:00
İpucuBuilder Notu — U-Net = CNN’in Encoder-Decoder Hâli
- Geriye (Ders 8): U-Net bir CNN mimarisidir (Ders 8 convolution); encoder-decoder + skip bağlantıları. Conv katmanlarıyla görüntüyü küçültüp büyütür — simple_cnn yığınının simetrik, üretken hâli.
- İleriye (Ders 19/23): U-Net, Part 2 Ders 19 ve 23’te sıfırdan kurulur (§4.I); attention ile koşullama orada eklenir.
10.13 Autoencoder / VAE: Latent Sıkıştırma
Sorun: 512×512×3 bir görüntü = 786.432 sayı; U-Net’i bu kadar pikselle eğitmek çok pahalı. Çözüm bir autoencoder (VAE): görüntüyü 64×64×4 = 16.384 sayıya sıkıştırır (encoder), sonra geri açar (decoder). U-Net’i bu küçük latent uzayda çalıştırırız — ~48× daha az veri. Stable Diffusion’ı latent diffusion yapan şey budur.
“We’ve compressed it from 786,432 to 16,384. We’ve created a very powerful compression algorithm. Why on earth would we train our U-Net with 786,432 pixels?” — Howard, 1:10:00
Şekil 10.5 bu sıkıştırmayı gerçek sayılarla gösterir: sol panel piksel uzayı (786.432) ile latent uzayı (16.384) log-skalada karşılaştırır — ~48× fark; sağ panel VAE encode → latent diffusion → decode akışını şematize eder. U-Net pahalı işi pikselde değil, bu ~48× küçük latent uzayda yapar.
Kod
d = E.latent_compression_demo()
pixels, latents, ratio = d["pixels"], d["latents"], d["ratio"]
fig, (axL, axR) = plt.subplots(1, 2, figsize=(11.5, 4.8))
# --- SOL: piksel vs latent eleman sayısı (log-skala, fark çok büyük) ---
labels = ["Piksel uzayı\n512×512×3", "Latent uzay\n64×64×4"]
values = [pixels, latents]
colors = [COL_ACCENT, COL_PRIMARY]
bars = axL.bar(labels, values, color=colors, width=0.58, zorder=3,
edgecolor=COL_WHITE, linewidth=1.5)
axL.set_yscale("log")
axL.set_ylabel("eleman sayısı (log-skala)")
axL.set_title("Görüntü kaç sayıdan oluşur?", color=COL_TEXT, weight="bold")
for b, v in zip(bars, values):
axL.text(b.get_x() + b.get_width() / 2, v * 1.18, f"{v:,}".replace(",", "."),
ha="center", va="bottom", color=COL_TEXT, fontsize=11, weight="bold")
axL.set_ylim(top=pixels * 4)
viz.apply_style(axL)
axL.grid(True, axis="y", alpha=0.2, color=COL_SLATE_400)
axL.grid(False, axis="x")
# ~48× sıkıştırma oku/annotate (iki bar arasında)
axL.annotate(
f"~{ratio:.0f}× sıkıştırma",
xy=(1, latents), xytext=(0.5, pixels * 0.42),
ha="center", va="center", fontsize=11.5, weight="bold", color=COL_CYAN_700,
arrowprops=dict(arrowstyle="-|>", color=COL_CYAN_700, lw=2.0,
connectionstyle="arc3,rad=-0.25"),
)
# --- SAĞ: VAE encode→latent diffusion→decode şematik ---
axR.set_xlim(0, 10)
axR.set_ylim(0, 10)
axR.axis("off")
axR.set_title("U-Net latent uzayda çalışır", color=COL_TEXT, weight="bold")
y0 = 6.2
viz.boxed_node(axR, 1.5, y0, 2.4, 1.9, "512×512×3\ngörüntü\n(786.432)",
fc=COL_BG_ROSE, ec=COL_ACCENT, fontsize=9.5)
viz.boxed_node(axR, 5.0, y0, 1.9, 1.25, "VAE\nencoder",
fc=COL_WHITE, ec=COL_PRIMARY, fontsize=10)
viz.boxed_node(axR, 8.4, y0, 2.4, 1.9, "64×64×4\nlatent\n(16.384)",
fc=COL_BG, ec=COL_PRIMARY, fontsize=9.5)
viz.boxed_node(axR, 5.0, 2.0, 1.9, 1.25, "VAE\ndecoder",
fc=COL_WHITE, ec=COL_PRIMARY, fontsize=10)
viz.boxed_node(axR, 1.5, 2.0, 2.4, 1.9, "512×512×3\ngörüntü\n(786.432)",
fc=COL_BG_ROSE, ec=COL_ACCENT, fontsize=9.5)
viz.arrow_between(axR, (2.7, y0), (4.05, y0))
viz.arrow_between(axR, (5.95, y0), (7.2, y0))
viz.arrow_between(axR, (8.4, 5.25), (5.7, 2.55), color=COL_PRIMARY)
viz.arrow_between(axR, (4.05, 2.0), (2.7, 2.0))
# latent kutusunun üstünde U-Net'in burada çalıştığı notu
axR.text(8.4, 8.55, f"U-Net burada çalışır\n(~{ratio:.0f}× ucuz)",
ha="center", va="center", fontsize=9.5, weight="bold",
color=COL_CYAN_700,
bbox=dict(boxstyle="round,pad=0.3", fc=COL_CYAN_50, ec=COL_CYAN_400, lw=1.5))
viz.arrow_between(axR, (8.4, 8.0), (8.4, 7.2), color=COL_CYAN_400, lw=1.6)
plt.tight_layout()
plt.show()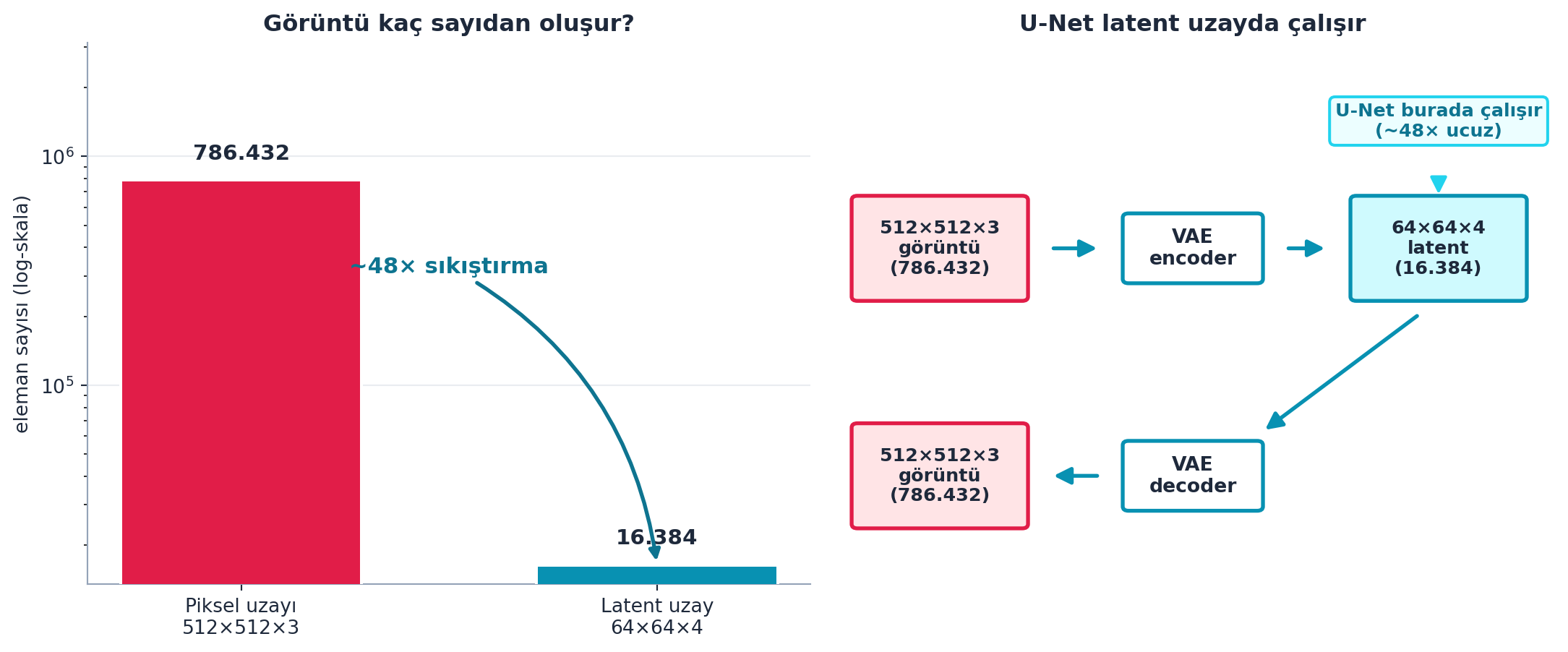
İpucuBuilder Notu — Latent Uzayda Çalış: Pahalı İşi Küçük Temsilde Yap
- Geriye (6.S191 / Ders 8): VAE, 6.S191 Ders 4’te kavramsaldır; autoencoder Ders 8’de geçti. “Latent uzayda çalışmak” = pahalı işlemi düşük boyutlu, anlamlı bir temsilde yapmak — aynı verimlilik mantığı embedding ve quantization’da da geçerli.
- İleriye (Ders 25/29): VAE, Part 2 Ders 25/29’da sıfırdan kurulur (§4.I “latent diffusion”); encoder/decoder ve reconstruction loss orada açılır.
10.14 CLIP: Metin Koşullama
Üçüncü bileşen: CLIP. Prompt’u (metni) U-Net’in anlayacağı bir embedding’e çevirir. CLIP, metin ve görüntüyü ortak bir uzaya gömecek şekilde eğitilmiştir; böylece “astronaut riding a horse” metni, üretimi o yöne koşullar. U-Net her gürültü-giderme adımında bu embedding’i girdi olarak alır.
from transformers import CLIPTokenizer, CLIPTextModel
tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14")
text_encoder = CLIPTextModel.from_pretrained("openai/clip-vit-large-patch14").to("cuda")
İpucuBuilder Notu — CLIP = Embedding’in Çok-Modal Hâli
- Geriye (Ders 4/7): CLIP metni tokenize edip (Ders 4) embedding’e çevirir (Ders 7); metin-görüntü ortak uzayı, Ders 8’deki embedding mesafesinin çok-modal hâlidir — “yakın embedding = benzer anlam” burada metin ile görüntü arasında geçerlidir.
- İleriye (Part 2): CLIP’in attention ile U-Net’i nasıl koşullandırdığı (cross-attention) Part 2’de açılır; metin embedding’i, gürültü-giderme döngüsünün her adımına yön verir.
10.15 Latent + Scheduler + Noise Schedule
Üretim, latent uzayda rastgele gürültüyle başlar (64×64×4). Scheduler her adımda ne kadar gürültü kaldırılacağını yöneten noise schedule’ı (\(\beta\), \(\bar{\alpha}\) dizileri) belirler. U-Net her adımda gürültüyü tahmin eder, scheduler onu kısmen çıkarır; bu döngü görüntüyü oluşturur.
torch.manual_seed(100)
latents = torch.randn((batch_size, unet.in_channels, height//8, width//8)).half().to("cuda")
scheduler.set_timesteps(num_inference_steps) # noise schedule adimlariÜretim bu noise schedule’ın tersine gider. İleri (forward) süreç temiz bir görüntüye adım adım gürültü ekler: \[x_t = \sqrt{\bar{\alpha}_t}\,x_0 + \sqrt{1-\bar{\alpha}_t}\,\varepsilon\] burada \(x_0\) temiz görüntü, \(\varepsilon\) saf gürültü, \(\bar{\alpha}_t\) ise \(t\) adımında ne kadar sinyal korunduğunu belirler. Şekil 10.6 bu ileri süreci gösterir: üst panel DDPM lineer noise schedule’ında \(\bar{\alpha}_t\) ve sinyal/gürültü katsayılarını (\(\sqrt{\bar{\alpha}_t}\), \(\sqrt{1-\bar{\alpha}_t}\)), alt satır da temiz \(x_0\)’dan saf gürültüye giden gerçek \(x_t\) karelerini çizer. Stable Diffusion üretimi bu okun tersidir — saf gürültüden başlayıp \(\bar{\alpha}_t\)’yi geri tırmanır.
Kod
import matplotlib.gridspec as gridspec
sched = E.noise_schedule_demo()
fwd = E.forward_diffusion_demo()
frames = fwd["frames"]
snap_ts = [t for (t, _ab, _img) in frames]
fig = plt.figure(figsize=(12, 6))
gs = gridspec.GridSpec(2, len(frames), height_ratios=[1.35, 1.0],
hspace=0.42, wspace=0.12)
# ÜST PANEL — noise schedule: ᾱ_t + sinyal/gürültü katsayıları √ᾱ, √(1−ᾱ)
ax_top = fig.add_subplot(gs[0, :])
t = sched["t"]
ax_top.plot(t, sched["alpha_bar"], color=COL_PRIMARY, lw=2.6,
label=r"$\bar{\alpha}_t$ (sinyal-koruma)", zorder=4)
ax_top.plot(t, sched["sqrt_ab"], color=COL_CYAN_400, lw=2.0, ls="--",
label=r"$\sqrt{\bar{\alpha}_t}$ (sinyal katsayısı)", zorder=3)
ax_top.plot(t, sched["sqrt_1mab"], color=COL_ACCENT, lw=2.0, ls="--",
label=r"$\sqrt{1-\bar{\alpha}_t}$ (gürültü katsayısı)", zorder=3)
# snapshot t'lerini dikey işaretle (alt satırdaki karelere bağlanır)
for tt in snap_ts:
ax_top.axvline(tt, color=COL_SLATE_400, lw=1.0, ls=":", alpha=0.85, zorder=1)
ab_here = float(sched["alpha_bar"][tt])
ax_top.scatter([tt], [ab_here], color=COL_CYAN_700, s=28, zorder=5)
ax_top.text(tt, 1.04, f"t={tt}", ha="center", va="bottom",
fontsize=8.5, color=COL_TEXT, weight="bold")
ax_top.set_xlim(0, len(t) - 1)
ax_top.set_ylim(-0.02, 1.12)
ax_top.set_xlabel("difüzyon adımı t (temiz → gürültü)")
ax_top.set_ylabel("katsayı")
ax_top.set_title("DDPM lineer noise schedule — ileri (forward) sürecin sinyal/gürültü karışımı",
fontsize=11.5, weight="bold")
viz.apply_style(ax_top)
ax_top.legend(loc="center right", fontsize=9, framealpha=0.9)
# ALT SATIR — forward diffusion kareleri (gerçek x_t snapshot'ları)
for i, (tt, ab, img) in enumerate(frames):
ax = fig.add_subplot(gs[1, i])
ax.imshow(img, cmap="gray", interpolation="nearest")
ax.set_xticks([]); ax.set_yticks([])
ax.set_title(f"t={tt}, ᾱ={ab:.2f}", fontsize=9.5, color=COL_TEXT, weight="bold")
for spine in ax.spines.values():
spine.set_edgecolor(COL_PRIMARY if i == 0 else
(COL_ACCENT if i == len(frames) - 1 else COL_SLATE_400))
spine.set_linewidth(2.2 if i in (0, len(frames) - 1) else 1.0)
if i == 0:
ax.set_xlabel("temiz x₀", fontsize=9.5, color=COL_CYAN_700, weight="bold")
elif i == len(frames) - 1:
ax.set_xlabel("saf gürültü", fontsize=9.5, color=COL_ACCENT, weight="bold")
plt.tight_layout()
plt.show()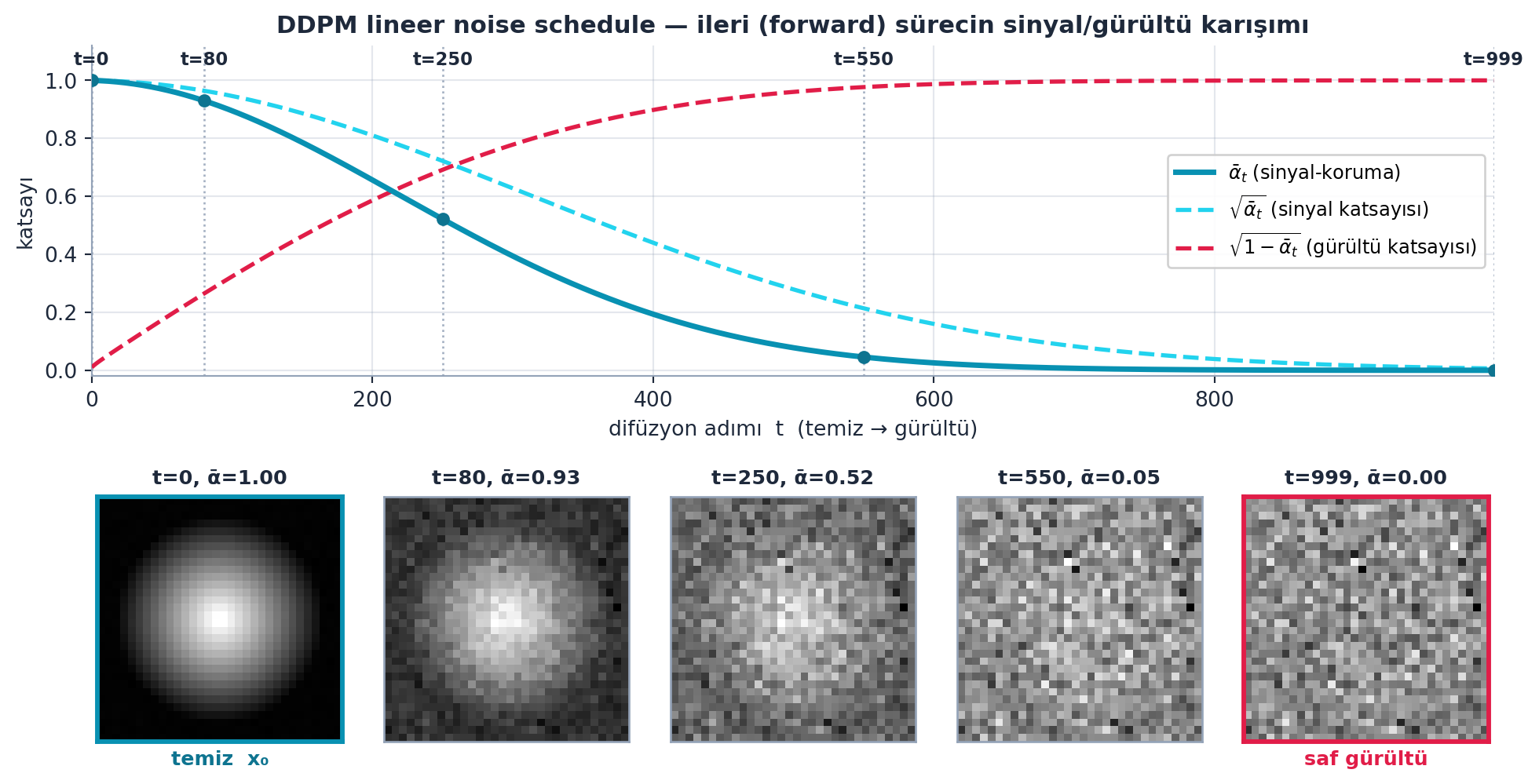
İpucuBuilder Notu — Noise Schedule: DDPM/DDIM/Karras’ın Çekirdeği
- İleriye (Ders 19-22): Noise schedule, DDPM (Ders 19) ve DDIM (Ders 21) ile Karras (Ders 22) Part 2’de sıfırdan kurulur (§4.I); Şekil 10.6’un lineer schedule’ı orada gelişmiş schedule’larla karşılaştırılır.
- Geriye (num_inference_steps):
scheduler.set_timestepstam olarak num_inference_steps bölümündeki ayrıklaştırmayı kurar — kaç adımda gürültü kaldırılacağı bu noise schedule’dan okunur.
10.16 Düşük Seviye Pipeline
Howard hazır pipe()’ın içini açar — beş adım: (1) tokenizer + CLIP prompt’u embedding’e çevirir; (2) classifier-free guidance için boş prompt embedding’i de hazırlanır; (3) latent rastgele gürültüyle başlar; (4) döngüde U-Net gürültüyü tahmin eder, scheduler çıkarır; (5) VAE decoder latent’i görüntüye açar.
# Classifier-free guidance: kosullu + kosulsuz embedding
text_emb = text_encoder(text_input.input_ids.to("cuda"))[0].half()
uncond_emb = text_encoder(uncond_input.input_ids.to("cuda"))[0].half()
emb = torch.cat([uncond_emb, text_emb])
# latent gurultu -> dongude U-Net + scheduler -> VAE decode
latents = torch.randn((len(prompts), unet.in_channels, height//8, width//8)).half().to("cuda")
latents = latents * scheduler.init_noise_sigmaŞekil 10.7 bu beş adımı tek bir çıkarım hattında birleştirir — bu derslerin flagship diyagramıdır. Solda CLIP metni embedding’e çevirir (ve CFG için boş prompt’tan uncond embedding hazırlanır); merkezde latent uzayda rastgele gürültü, rose vurgulu “× N adım” döngüsünde U-Net + scheduler ile temizlenir (CLIP embedding’i döngüyü koşullar); sağda VAE decoder temizlenmiş latent’i 512×512×3 görüntüye açar. Üç bileşen tek bir akışta: CLIP yön verir, U-Net+scheduler latent’te gürültü giderir, VAE açar.
Kod
fig, ax = plt.subplots(figsize=(12, 6.5))
ax.set_xlim(0, 12)
ax.set_ylim(0, 6.5)
ax.axis("off")
# --- (SOL) Metin koşullama zinciri: prompt -> CLIP -> metin embedding ---
viz.boxed_node(ax, 1.55, 5.55, 2.5, 0.95,
'metin istemi\n"astronaut riding\na horse"',
fc=COL_WHITE, ec=COL_CYAN_700, tc=COL_TEXT, fontsize=9.0)
viz.boxed_node(ax, 1.55, 4.05, 2.4, 0.95,
"CLIP\nmetin → embedding",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_CYAN_800, fontsize=9.5)
viz.boxed_node(ax, 1.55, 2.75, 2.4, 0.8,
"metin embedding\n(koşullu)",
fc=COL_CYAN_50, ec=COL_PRIMARY, tc=COL_TEXT, fontsize=8.8)
# (ÜST-AYRI) classifier-free guidance: boş prompt -> uncond embedding
viz.boxed_node(ax, 1.55, 6.15, 2.5, 0.62,
'boş istem "" → uncond embedding',
fc=COL_BG_ROSE, ec=COL_ROSE_400, tc=COL_TEXT,
fontsize=7.6, lw=1.5)
viz.arrow_between(ax, (1.55, 5.07), (1.55, 4.55), color=COL_PRIMARY)
viz.arrow_between(ax, (1.55, 3.57), (1.55, 3.18), color=COL_PRIMARY)
# --- (MERKEZ) latent uzay: rastgele gürültü -> döngü -> temizlenmiş latent ---
# açık-cyan latent uzay zemini (döngüyü çevreler)
ax.add_patch(plt.Rectangle((3.55, 1.85), 5.05, 3.55, facecolor=COL_CYAN_50,
edgecolor=COL_CYAN_400, linewidth=1.4,
linestyle="--", zorder=0))
ax.text(6.07, 5.18, "latent uzay 64×64×4", ha="center", va="center",
fontsize=8.6, color=COL_CYAN_700, weight="bold", zorder=1)
viz.boxed_node(ax, 4.55, 4.45, 1.95, 0.9,
"rastgele\ngürültü latent",
fc=COL_WHITE, ec=COL_CYAN_700, tc=COL_TEXT, fontsize=8.6)
# DÖNGÜ kutusu (rose vurgulu) — içinde U-Net + scheduler
ax.add_patch(FancyBboxPatch((5.95, 2.35), 2.45, 2.65,
boxstyle="round,pad=0.02,rounding_size=0.10",
fc=COL_BG_ROSE, ec=COL_ACCENT, linewidth=2.4, zorder=1))
ax.text(7.17, 4.72, "× N adım", ha="center", va="center",
fontsize=9.0, color=COL_ACCENT, weight="bold", zorder=3)
viz.boxed_node(ax, 7.17, 4.05, 2.05, 0.78,
"U-Net:\ngürültü tahmin et",
fc=COL_WHITE, ec=COL_ACCENT, tc=COL_TEXT, fontsize=8.6, lw=1.8)
viz.boxed_node(ax, 7.17, 2.95, 2.05, 0.78,
"scheduler:\ngürültüyü kısmen çıkar",
fc=COL_WHITE, ec=COL_ROSE_400, tc=COL_TEXT, fontsize=8.2, lw=1.8)
# döngü içi akış (U-Net -> scheduler) ve geri besleme (scheduler -> U-Net)
viz.arrow_between(ax, (6.55, 3.66), (6.55, 3.34), color=COL_ACCENT, mutation_scale=14, shrink=6)
viz.arrow_between(ax, (7.85, 3.34), (7.85, 3.66), color=COL_ROSE_400,
mutation_scale=14, shrink=6, connectionstyle="arc3,rad=0.0",
style="-|>")
# gürültü latent -> döngü girişi
viz.arrow_between(ax, (5.52, 4.45), (5.95, 3.7), color=COL_CYAN_700)
# CLIP embedding U-Net'i KOŞULLAR (rose kesikli ok, soldan döngüye)
viz.arrow_between(ax, (2.78, 2.95), (6.12, 3.95), color=COL_ACCENT,
lw=1.8, style="-|>", connectionstyle="arc3,rad=-0.18")
ax.text(4.35, 2.18, "koşullar", ha="center", va="center",
fontsize=8.0, color=COL_ACCENT, style="italic", weight="bold", zorder=3)
# --- döngü çıkışı -> temizlenmiş latent -> VAE -> çıktı görüntü ---
viz.boxed_node(ax, 7.17, 1.42, 2.05, 0.7,
"temizlenmiş latent",
fc=COL_CYAN_50, ec=COL_PRIMARY, tc=COL_TEXT, fontsize=8.4)
viz.arrow_between(ax, (7.17, 2.55), (7.17, 1.77), color=COL_ACCENT)
viz.boxed_node(ax, 9.95, 1.42, 1.95, 0.8,
"VAE\ndecoder",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_CYAN_800, fontsize=9.5)
viz.arrow_between(ax, (8.22, 1.42), (8.97, 1.42), color=COL_PRIMARY)
viz.boxed_node(ax, 11.0, 3.55, 1.75, 1.4,
"çıktı görüntü\n512×512×3",
fc=COL_WHITE, ec=COL_CYAN_700, tc=COL_TEXT, fontsize=9.0)
viz.arrow_between(ax, (9.95, 1.82), (10.85, 2.85), color=COL_PRIMARY,
connectionstyle="arc3,rad=-0.18")
# --- üç bileşen lejantı (CLIP cyan / U-Net rose / VAE cyan) ---
ax.text(0.15, 0.42, "CLIP", fontsize=8.5, color=COL_CYAN_700, weight="bold")
ax.text(1.55, 0.42, "U-Net + scheduler", fontsize=8.5, color=COL_ACCENT, weight="bold")
ax.text(4.85, 0.42, "VAE", fontsize=8.5, color=COL_CYAN_700, weight="bold")
ax.text(0.15, 0.05, "(metin koşullama)", fontsize=7.2, color=COL_SLATE_400)
ax.text(1.55, 0.05, "(latent gürültü giderme, × N)", fontsize=7.2, color=COL_SLATE_400)
ax.text(4.85, 0.05, "(latent → piksel)", fontsize=7.2, color=COL_SLATE_400)
plt.tight_layout()
plt.show()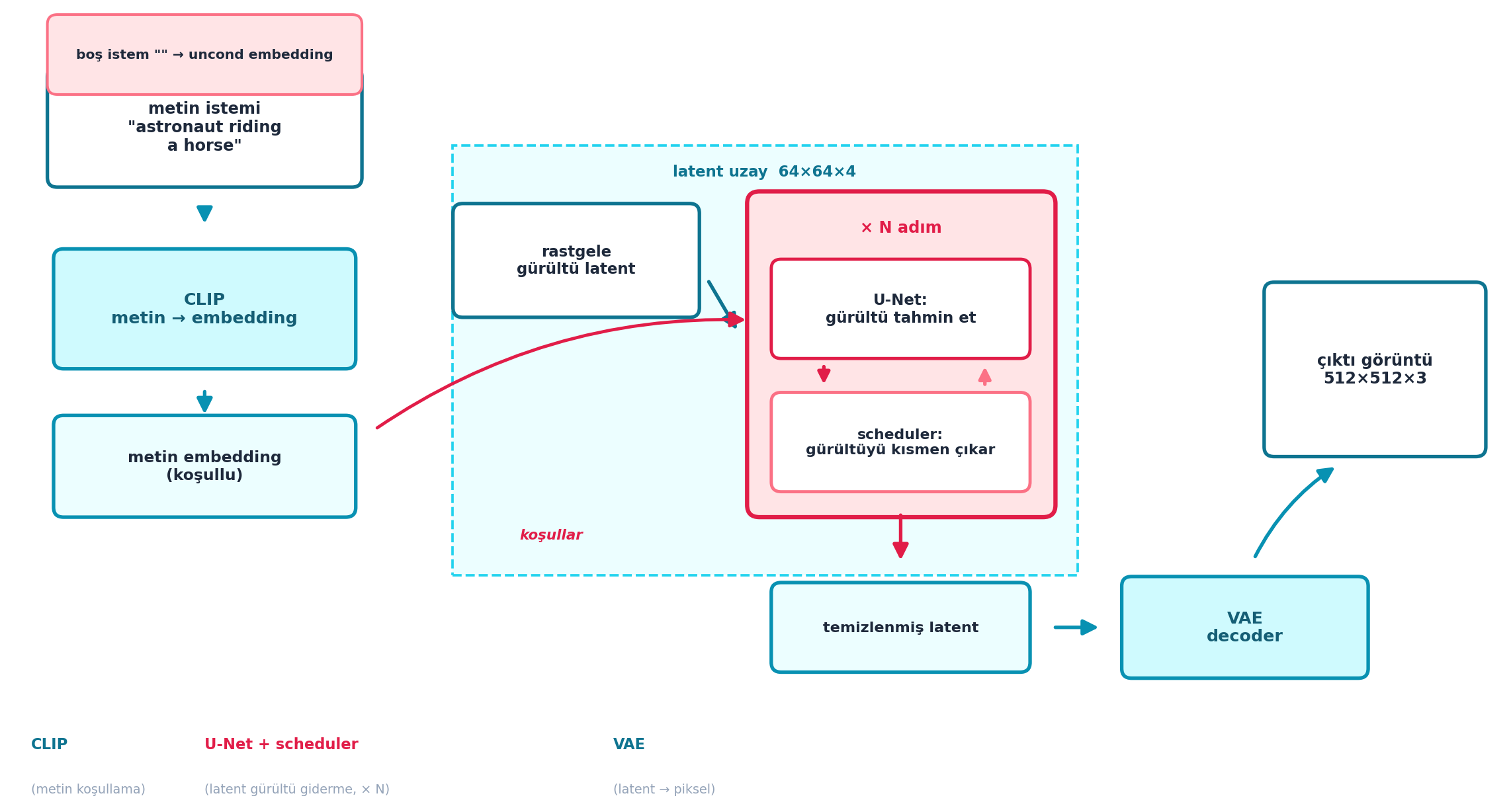
İpucuBuilder Notu — Beş Adım = Part 2’nin Yol Haritası
- İleriye (Part 2): Bu beş adım — CLIP, latent, U-Net döngüsü, scheduler, VAE — Part 2’nin geri kalanının yol haritasıdır; her biri sıfırdan kurulacak.
- Geriye (pipeline): Yüksek seviye
pipe()bu beş adımı tek satırda gizler; düşük seviye açılım, “framework sihir değil, bizim kuracağımızın temiz hâli” disiplinidir (Ders 8’deki “sıfırdan bil, hazırı güvenle kullan” ile aynı).
10.17 Kapanış
Ders 9 Part 2’yi top-down açtı: Stable Diffusion’ı kullandık (prompt, guidance, negative prompt, img2img, textual inversion) ve nasıl çalıştığını sezgisel olarak gördük — “bir şeyi daha geçerli yapan gradyan yönünde pikselleri ittir”. Üç bileşeni tanıdık: U-Net (gürültü tahmincisi), VAE (latent sıkıştırma), CLIP (metin koşullama). Part 2’nin geri kalanı bunları sıfırdan kuracak.
“In Part 2 we’re going to build our own everything from scratch, including our own calculus things.” — Howard, 0:45
Şekil 10.8 dersin sentezidir: Stable Diffusion sihir değil — her parçası Ders 3-8 ve NYU’dan tanıdık. Pixel gradyanı/score (Ders 3/5 gradient descent), U-Net (Ders 8 CNN), CLIP (Ders 4/7 tokenize + embedding), VAE (Ders 8 autoencoder + verimlilik), geçerlilik skoru (NYU §4.J enerji-tabanlı model). Yeni olan parçalar değil, bir araya getirilişleridir.
Kod
fig, ax = plt.subplots(figsize=(12, 6.5))
ax.set_xlim(0, 12)
ax.set_ylim(0, 10)
ax.axis("off")
# Başlık şeritleri
ax.text(2.7, 9.45, "Stable Diffusion parçası", ha="center", va="center",
fontsize=13, weight="bold", color=COL_ACCENT)
ax.text(9.3, 9.45, "Nereden geliyor (tanıdık)", ha="center", va="center",
fontsize=13, weight="bold", color=COL_CYAN_700)
# (SD parçası [rose], kaynak [cyan]) satırları — yukarıdan aşağıya
rows = [
("piksel gradyanı / score\n(∇log p)",
"Ders 3/5: gradient descent\n(ağırlık yerine piksel) · f.backward()"),
("U-Net",
"Ders 8: CNN\nencoder–decoder + skip bağlantı"),
("CLIP metin koşullama",
"Ders 4/7: tokenize + embedding\nmetin-görüntü ortak uzay"),
("VAE latent",
"Ders 8: autoencoder + verimlilik\n(pahalı işi küçük uzayda yap)"),
("geçerlilik skoru",
"NYU §4.J: enerji-tabanlı model\n(EBM) · self-supervised"),
]
bw_l, bw_r = 3.2, 4.2 # kutu genişlikleri (sol/sağ)
bh = 1.18 # kutu yüksekliği
xL, xR = 2.7, 9.3 # sütun merkezleri
y_top, y_gap = 8.35, 1.62 # ilk satır + satır aralığı
for i, (sd_part, source) in enumerate(rows):
y = y_top - i * y_gap
# SOL: SD parçası (rose dolgu/çerçeve)
viz.boxed_node(ax, xL, y, bw_l, bh, sd_part,
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT,
fontsize=10.5, lw=2.0)
# SAĞ: kaynak (cyan dolgu/çerçeve)
viz.boxed_node(ax, xR, y, bw_r, bh, source,
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT,
fontsize=9.5, lw=2.0)
# Ok: parça → kaynak
viz.arrow_between(ax, (xL + bw_l / 2, y), (xR - bw_r / 2, y),
color=COL_CYAN_400, lw=2.2, shrink=4)
# Alt sentez kutusu — birleşim mesajı
viz.boxed_node(ax, 6.0, 0.62, 11.0, 0.92,
"Stable Diffusion = tanıdık parçaların birleşimi · yeni olan: bunların bir araya getirilişi",
fc=COL_WHITE, ec=COL_CYAN_700, tc=COL_CYAN_700,
fontsize=11.0, lw=2.0)
plt.tight_layout()
plt.show()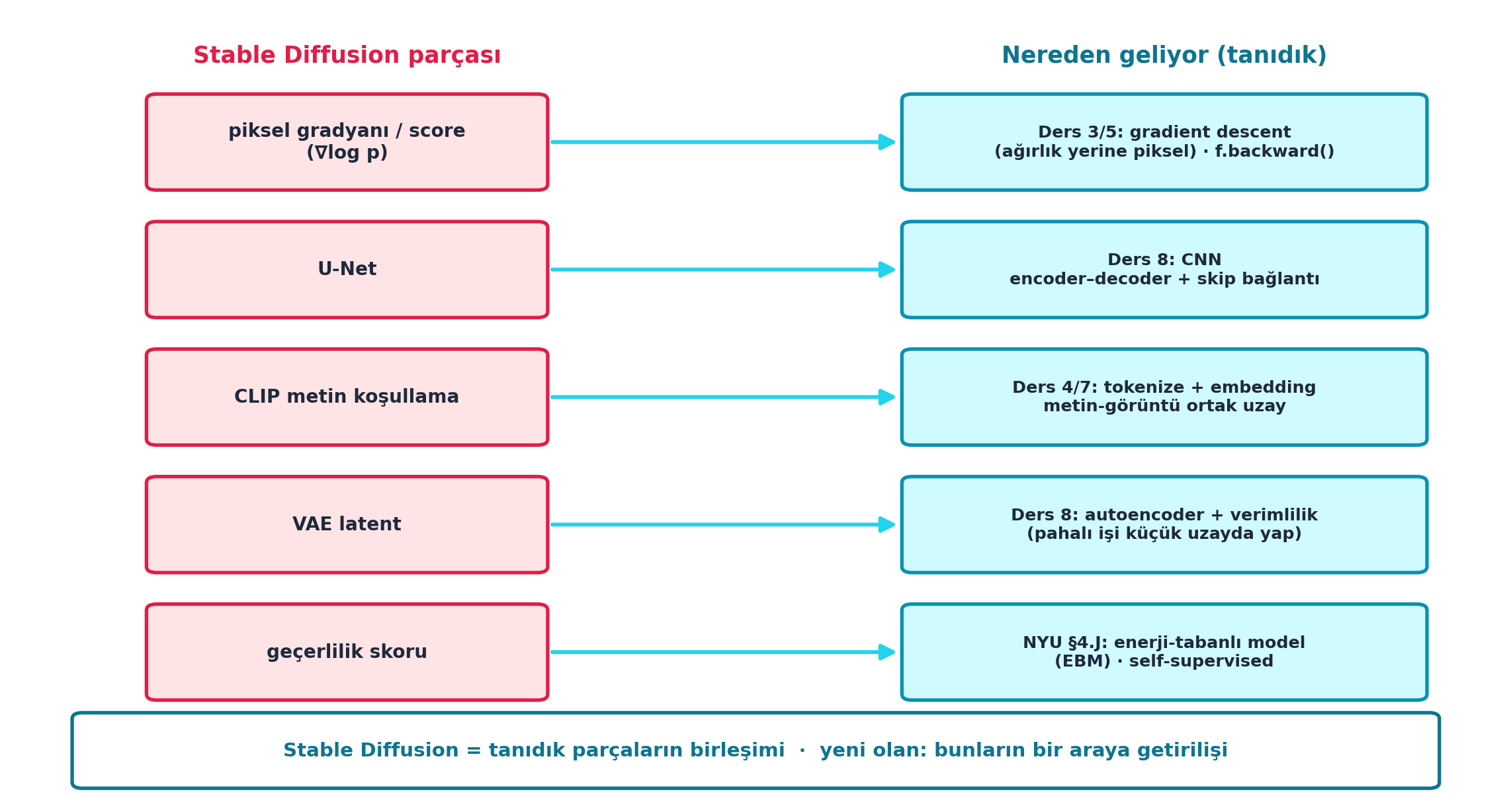
İpucuBuilder Notu — 9A/9B/10: Derinliğe İniş
- İleriye (Ders 9A/9B/10): Ders 9A (Whitaker) latent uzayı ve guidance’ı derinleştirir; Ders 9B (Waseem + Tanishq) diffusion’ın matematiğini; Ders 10 “from the foundations”a başlar — matmul’dan backprop’a.
- Geriye (tüm ders): Şekil 10.8’in beş satırı bu dersin her bölümünü (pixel gradyanı, U-Net, CLIP, VAE) tek bir “tanıdık parçalar” mesajında toplar.
10.18 Bu Dersin Özeti
- Part 2 top-down başlar: önce Stable Diffusion’ı kullan, sonra sıfırdan kur (Oynayalım, Pipeline).
StableDiffusionPipelineile prompt → görüntü;num_inference_stepskalite/hız,guidance_scaleprompt sadakati,negative_promptkaçınma (num_inference_steps, guidance, negative_prompt).- img2img bir başlangıç görüntüsünü prompt’a göre yeniden çizer; textual inversion/DreamBooth modele yeni kavram öğretir (img2img, textual inversion).
- Diffusion sezgisi: “bir görüntünün ne kadar geçerli olduğunu” söyleyen bir fonksiyonun pixel gradyanı yönünde ittirmek (sihirli API, pixel gradyanı).
- Bu, gradient descent’tir — ama ağırlıkları değil pikselleri günceller; gürültüden görüntü doğar (pixel gradyanı).
- U-Net gürültü tahmincisidir (SD’nin 1. bileşeni); girdi gürültülü görüntü, çıktı gürültüsüz tahmin (U-Net).
- VAE/autoencoder görüntüyü latent uzaya sıkıştırır (786K → 16K); U-Net orada çalışır (latent diffusion) (VAE).
- CLIP metni embedding’e çevirip üretimi koşullar; scheduler/noise schedule adım adım gürültü kaldırmayı yönetir (CLIP, scheduler).
ÖnemliTek Bir Cümle
Stable Diffusion, CLIP ile metne koşullanmış bir U-Net’in, VAE’nin sıkıştırdığı latent uzayda, rastgele gürültüyü adım adım giderek görüntü oluşturmasıdır — ve özünde bu, pikselleri “daha geçerli görüntü” yönünde ittiren bir gradient descent’tir.
10.19 Kontrol Soruları
NotSoru 1: Howard’ın ‘sihirli API’ örneği diffusion’ı nasıl açıklıyor? Bu, neyin sezgisidir?
Cevap:
Sihirli API, bir görüntü alıp “bunun geçerli bir görüntü (örn. el yazısı rakam) olma olasılığını” döndüren bir fonksiyondur. Eğer bu fonksiyonumuz varsa, onun her pikselle ilgili gradyanını alabiliriz — “bu pikseli değiştirsem olasılık ne kadar artar?”. Sonra her pikseli bu gradyan yönünde azıcık ittirip görüntüyü biraz daha “geçerli” yaparız; tekrarlarsak gürültüden görüntü doğar. Bu, gürültü giderme (denoising) sürecinin sezgisidir ve pratikte o “sihirli fonksiyon” bir sinir ağıdır (U-Net). Mekanizma gradient descent’tir — ama ağırlıklar yerine pikseller güncellenir. (Şekil 10.4 geçerlilik alanı + score-ascent yörüngesini gösterir.)
NotSoru 2: Stable Diffusion’ın üç bileşeni (U-Net, VAE, CLIP) ne işe yarar?
Cevap:
U-Net gürültü tahmincisidir: girdisi gürültülü bir (latent) görüntü, çıktısı o gürültünün tahmini; çıkarılınca görüntü netleşir. VAE (autoencoder) görüntüyü latent uzaya sıkıştırır (512×512×3 ≈ 786K sayı → 64×64×4 ≈ 16K) ve geri açar; U-Net bu küçük uzayda çalışır, ~48× daha ucuz (bu yüzden “latent diffusion”). CLIP prompt’u (metni) U-Net’in anlayacağı bir embedding’e çevirir; metin ve görüntüyü ortak uzaya gömdüğü için üretimi prompt yönünde koşullar. Üçü birlikte: CLIP yön verir, U-Net latent’te gürültü giderir, VAE sonucu görüntüye açar. (Şekil 10.7 üçünü tek hatta, Şekil 10.5 VAE sıkıştırmasını gösterir.)
NotSoru 3: guidance_scale ve num_inference_steps üretimi nasıl etkiler?
Cevap:
num_inference_steps gürültüden görüntüye kaç adımda gidileceğidir: az adım (örn. 3) hızlı ama kaba, çok adım (örn. 50) yavaş ama kaliteli — kalite/hız dengesi. guidance_scale (classifier-free guidance) modelin prompt’a ne kadar sıkı uyacağıdır: düşük değer yaratıcı ama prompt’tan uzak, yüksek değer prompt’a sadık ama bazen aşırı doygun/yapay. İkisi de üretim sırasında ayarlanır (modeli yeniden eğitmeden); birlikte kalite, hız ve prompt sadakati arasındaki dengeyi belirler. (Şekil 10.2 adım sayısını, Şekil 10.3 CFG dengesini gösterir.)
NotSoru 4: Neden U-Net’i piksel uzayında değil latent uzayında çalıştırırız? (builder bağlantısı)
Cevap:
512×512×3 bir görüntü ~786.000 sayıdır; U-Net’i milyonlarca böyle görüntüyle, her adımda bu kadar pikselle eğitmek/çalıştırmak devasa compute ister. VAE görüntüyü ~16.000 sayılık bir latent’e sıkıştırdığından (≈48× az), U-Net’i bu küçük uzayda çalıştırmak çok daha ucuz ve hızlıdır — kalite neredeyse korunur çünkü VAE algısal olarak önemli bilgiyi tutar. Builder açısından bu, Stable Diffusion’ı pratik kılan anahtar fikirdir (“latent diffusion”): pahalı işlemi düşük boyutlu, anlamlı bir temsilde yapmak — aynı verimlilik mantığı embedding ve quantization’da da geçerli. (Bkz. VAE, Şekil 10.5.)
10.20 Egzersizler
Egzersiz 1 (Direkt uygulama). diffusion-nbs repo’sunu aç, StableDiffusionPipeline ile kendi prompt’larını üret; torch.manual_seed’i sabitleyip tekrarlanabilirliği gözle.
Egzersiz 2 (İki-aşamalı). Aynı prompt + seed ile num_inference_steps’i 3, 16, 50 yap; guidance_scale’i 1, 7, 14 yap; kalite/sadakat farkını karşılaştır.
Egzersiz 3 (Edge case). negative_prompt ile bir kavramı (örn. renk, nesne) çıkarmayı dene; img2img’de strength’i 0.2 ve 0.9 yapıp farkı gözle.
Egzersiz 4 (Kavramsal). El yazısı rakam örneğini kâğıt üstünde izle: bir “geçerlilik fonksiyonu” + pixel gradyanı ile gürültüden rakam nasıl doğar, adım adım açıkla.
Egzersiz 5 (Sonraki dersin habercisi — 9A). Latent uzayda iki prompt embedding’i arasında interpolasyon yapıp ara görüntüler üretmeyi araştır (Whitaker Ders 9A).
10.21 Sonraki: Ders 9A İçin Hazırlık
Ders 9A: Stable Diffusion Derinlemesine (Jonathan Whitaker)
Ders 9 Stable Diffusion’ı kullanıp sezgisini verdi. Ders 9A (misafir: Jonathan Whitaker) latent uzaya ve guidance’a derinlemesine iner: latent’lerle oynama, classifier-free guidance’ın içi, embedding interpolasyonu.
Ana konular (Ders 9A):
- Latent uzay ve VAE ile kodlama/çözme
- Classifier-free guidance’ın mekaniği
- Embedding interpolasyonu ve negative prompts
- Pipeline’ı parça parça kurma
UyarıDers 9A Öncesi Yapılacak
- Bu dersin egzersizlerini çöz (özellikle 1 ve 4 — pipeline’la oyna, sezgiyi izle).
diffusion-nbsnotebook’unu kendi compute’unda çalıştır.- Ana cümleyi tekrar oku: “Diffusion = pikselleri geçerlilik gradyanı yönünde ittirmek.”
10.22 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Howard’da |
|---|---|---|
| StableDiffusionPipeline | Prompt’tan görüntü üreten hazır diffusers pipeline’ı | 20:48 |
num_inference_steps |
Gürültüden görüntüye adım sayısı (kalite/hız) | 21:38 |
| guidance_scale | Prompt’a sadakat (classifier-free guidance) | 40:00 |
| negative_prompt | Çıktıyı belirtilen kavramdan uzaklaştırma | 40:10 |
| img2img | Başlangıç görüntüsünü prompt’a göre yeniden çizme | 41:16 |
| Textual inversion | Tek bir embedding eğitip yeni kavram öğretme | 40:00 |
| Sihirli API sezgisi | Geçerlilik skorunun pixel gradyanı ile gürültü giderme | 47:00 |
| U-Net | Gürültü tahmincisi; SD’nin 1. bileşeni | 1:00:00 |
| VAE / autoencoder | Görüntüyü latent’e sıkıştırma (786K → 16K) | 1:10:00 |
| CLIP | Metni embedding’e çevirip üretimi koşullama | 1:00:00 |
| Latent | Sıkıştırılmış görüntü temsili (64×64×4) | 1:10:00 |
| Scheduler / noise schedule | Her adımda kaldırılacak gürültüyü yöneten dizi | 1:00:00 |
10.23 ML Bağlantıları Özeti
İpucuBuilder Notu — 6 ML Köprüsü: Stable Diffusion’ın Kökleri
Bu ders, Stable Diffusion’ı kullanmaktan üç bileşenine ve gradient descent köküne uzanır; köprülerin özeti:
- Diffusion = pixel gradient descent → Ders 3/5’in gradient descent’i, ağırlık yerine piksel üstünde;
f.backward()aynı autograd (pixel gradyanı). - U-Net → CNN (Ders 8); encoder-decoder + skip; Part 2’de sıfırdan (Ders 19/23) (U-Net).
- VAE / latent diffusion → 6.S191 Ders 4 + Ders 8 autoencoder; pahalı işlemi küçük uzayda yapma verimliliği (VAE).
- CLIP → metin tokenize (Ders 4) + embedding (Ders 7); metin-görüntü ortak uzayı (çok-modal) (CLIP).
- guidance / negative prompt → üretimi yönlendirme; Ders 9A/10’da matematik (guidance, negative_prompt).
- NYU (§4.J) → diffusion, enerji-tabanlı modeller (EBM) ve self-supervised learning ile akraba; “geçerlilik skoru” = enerji fonksiyonu sezgisi (sentez).
ÖnemliBu dersten tek bir şey alıp gideceksen
Stable Diffusion sihir değil, üç tanıdık parçanın birleşimidir — bir CNN (U-Net) gürültüyü tahmin eder, bir autoencoder (VAE) işi küçük bir latent uzaya taşır, CLIP metinle yön verir. Özü ise Ders 3’ten beri bildiğin gradient descent’tir: bir şeyi “daha geçerli” yapan yönde adım at. Bugün kullandık; Part 2 boyunca her parçasını sıfırdan kuracağız.