flowchart TD
MP["mixed precision<br/>(hız + bellek)"]:::cyan
FP16["fp16<br/>(yarı hassasiyet)"]:::cyan
AUTO["autocast<br/>(fp16 ileri geçiş)"]:::cyan
SCALER["GradScaler<br/>(küçük gradyanı koru)"]:::rose
CB["MixedPrecisionCB /<br/>Accelerate (HuggingFace,<br/>çoklu GPU)"]:::cyan
MP --> FP16
FP16 --> AUTO
FP16 --> SCALER
AUTO --> CB
SCALER --> CB
ST["style transfer"]:::cyan
OPT["girdiyi OPTIMIZE et<br/>(TensorModel: ağırlık değil piksel)"]:::rose
VGG["VGG16 özellikleri"]:::cyan
CONTENT["content loss<br/>(aktivasyon MSE)"]:::cyan
STYLE["style loss<br/>(Gram matrisi MSE)"]:::rose
BUILDER["builder dersi:<br/>'optimize the input'"]:::rose
ST --> OPT
OPT --> VGG
VGG --> CONTENT
VGG --> STYLE
CONTENT --> BUILDER
STYLE --> BUILDER
classDef cyan fill:#cffafe,stroke:#0891b2,stroke-width:2px,color:#1e293b;
classDef rose fill:#ffe4e6,stroke:#e11d48,stroke-width:2px,color:#1e293b;
23 Ders 20 — Mixed Precision ve Style Transfer (Mixed Precision and Style Transfer)
ETAP 6’nın (Sıfırdan Diffusion A) iki pratik konusu, tek dersin altında. Önce Howard’ın elinde mixed precision: eğitimi fp16 (yarı hassasiyet) ile hızlandırıp belleği azaltmak — hem sıfırdan bir MixedPrecision callback’iyle (autocast + GradScaler) hem HuggingFace Accelerate ile. Sonra Johno ve Tanishq’le style transfer: bir görüntüyü, ağırlıkları değil görüntünün kendisini optimize ederek başka bir resmin stiline dönüştürmek. İkinci konunun builder dersi büyük: gradient descent yalnızca model ağırlıkları için değildir — kaybı tanımla, hedefi parametre yap, optimize et. Tek cümleyle: mixed precision fp16 ile eğitimi hızlandırıp belleği azaltır (autocast + GradScaler, bir callback); style transfer ise gradient descent’i ağırlıklar yerine bir görüntü üzerinde çalıştırır — VGG16 ara katman özellikleri içeriği, Gram matrisi (kanal korelasyonları) stili ölçer, ikisinin MSE kaybı pikselleri yeni bir resme dönüştürür.
NotBölüm bilgisi
- Ders sayfası (video): course.fast.ai — Lesson 20: Mixed Precision & Style Transfer (~106 dk)
- Seri: Practical Deep Learning for Coders — Part 2, Ders 20
- Playlist: Part 2 — Foundations to Stable Diffusion (2022)
- Notebook: course22p2 — miniai/accel.py + nbs/16A_StyleTransfer
- Okuma süresi: ~38 dk
- Hocalar: Howard (mixed precision) + Jonathan Whitaker / Johno + Tanishq Abraham (style transfer)
- 🔗 ETAP 6 (Sıfırdan Diffusion A): Ders 19’da DDPM’i sıfırdan kurduk; diffusion artık kara kutu değil. Ders 20 iki pratik aracı ekler. Birincisi mixed precision — ağır diffusion eğitimlerini (L21+) hızlandırmanın standart yolu, miniai’ye bir callback olarak girer. İkincisi style transfer — Ders 9’da “piksel üzerinde gradient descent” diye tanıdığımız sezginin saf, doğrudan hâli: bu kez ağırlık değil, görüntünün kendisi optimize edilir.
23.1 Bu Derste Ne Var?
İki ayrı pratik konu, tek dersin altında. Önce mixed precision — eğitimi fp16 (yarı hassasiyet) ile hızlandırıp belleği azaltmak; hem sıfırdan bir callback ile hem HuggingFace Accelerate ile. Sonra style transfer — bir görüntüyü, ağırlıkları değil görüntünün kendisini optimize ederek başka bir resmin stiline dönüştürmek. İkinci konu, gradient descent’in ağırlıklar dışında da kullanılabileceğini gösteren zarif bir örnektir.
Üç temel fikir bu dersin omurgasını kurar:
- Mixed precision — fp16 hesaplama daha hızlı ve daha az bellekli; bir
MixedPrecision/AccelerateCBcallback’iyle eklenir (autocast + GradScaler) (mixed precision → callback). - Görüntüyü optimize etme — style transfer’da model bir
TensorModel’dir; öğrenilen ağırlık değil, görüntünün pikselleridir (optimize the input). - VGG16 özellikleri + Gram matrisi — içerik, ara katman aktivasyonlarıyla; stil ise bu özelliklerin Gram matrisi (korelasyonları) ile ölçülür (VGG16 → content loss → Gram).
“if you Google for PyTorch mixed precision… with autocast device equals ‘cuda’ type equals float16, get your predictions and call your loss.” — Howard, 3:01
Şekil 28.1 bu iki konuyu tek bir kavram haritasında birleştirir: üstte mixed precision (fp16 ile hız + bellek, autocast ileri geçişi yarı-hassasiyette çalıştırır, GradScaler küçük gradyanları korur, MixedPrecisionCB / Accelerate çoklu GPU’ya kadar uzanır); altta style transfer (ağırlığı değil girdiyi — pikselleri — optimize et, VGG16 özelliklerinden content + style/Gram kaybı türet). GradScaler, girdiyi optimize et ve ‘optimize the input’ builder dersi rose ile işaretlidir: dersin asıl çekirdeği, optimizasyon hedefinin ağırlık olmak zorunda olmadığıdır.
İpucuBuilder Notu — İki Konu, Bir Çatı: Hızlandırma ve Optimizasyon Genelliği
- Geriye (Ders 16-18): Mixed precision yine bir callback (miniai); Ders 16 callback sistemi sayesinde eğitime tek satırla eklenir. Style transfer ise standart bir Learner’ın farklı bir kullanımıdır — verisiz bir optimizasyon problemine uyarlanmış.
- Geriye (Ders 17): Style transfer’da VGG16 özellikleri hook fikriyle çıkarılır — Ders 17’nin hook altyapısı burada işe yarar.
- İleriye (Ders 21-25): Mixed precision, ağır diffusion eğitimlerini (L21+) hızlandırmak için standart; style transfer ise “optimize the input” fikrinin (Ders 9 pixel gradient) güzel bir örneği.
- Tek cümle: Mixed precision fp16 ile eğitimi hızlandırır; style transfer ise gradient descent’i ağırlıklar yerine bir görüntü üzerinde çalıştırarak, VGG16 özellikleri (içerik) ve Gram matrisi (stil) kayıplarıyla bir resmi yeniden çizer.
23.2 1. Mixed Precision Nedir?
Varsayılan eğitim fp32 (32-bit) sayılarla yapılır. Mixed precision, hesabın çoğunu fp16 (16-bit) ile yapar: daha hızlı (modern GPU’lar fp16’da çok daha verimli) ve daha az bellek. “Mixed” çünkü bazı hassas işlemler (kayıp birikimi, ağırlık güncellemeleri) fp32’de kalır. Sonuç: aynı GPU’da daha büyük model/batch ve daha hızlı eğitim.
Şekil 23.2 sorunun ve çözümün özünü gerçek hesaplamayla gösterir: fp16’nın aralığı dardır (max ≈ 65504), fp32’ye kıyasla küçücüktür. Bu yüzden çok küçük bir gradyan (örn. 1e-8) fp16’da 0’a yuvarlanır — underflow, kaybolur. GradScaler bunu kurtarır: gradyanı büyük bir çarpanla (×4096) ölçekler, böylece fp16 aralığına girer; optimizer adımından önce aynı çarpana geri böler. Sağ paneldeki log-ölçekli çubuklar, fp16’nın dar aralığını (hassasiyet ödünü) fp32 yanında görselleştirir.
Kod
d = E.fp16_precision_demo()
small = d["small_val"]
underflow = d["fp16_underflow"]
scale = d["scale"]
scaled = d["scaled"]
scaled_back = d["scaled_back"]
fp16_max = d["fp16_max"]
fp32_max = d["fp32_max"]
fig, (ax, axr) = plt.subplots(
1, 2, figsize=(10.5, 5.0), gridspec_kw={"width_ratios": [2.6, 1.0]}
)
# ---- Sol panel: GradScaler akışı (3 adım, dikey) ----
ax.set_xlim(0, 10)
ax.set_ylim(0, 10)
ax.axis("off")
# Adım 1 — UNDERFLOW (rose): küçük gradyan fp16'da kaybolur
viz.boxed_node(ax, 5.0, 8.4, 8.6, 1.7,
f"küçük gradyan {small:.0e} → fp16'da {underflow:.0f}\n"
f"(UNDERFLOW, kaybolur)",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_ROSE_500,
fontsize=11, lw=2.2)
# Adım 2 — GradScaler ölçekle (cyan): temsil edilebilir hale gelir
viz.boxed_node(ax, 5.0, 5.0, 8.6, 1.7,
f"GradScaler ×{scale:.0f} → fp16'da {scaled:.1e}\n"
f"(temsil edilir, kurtuldu)",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_CYAN_800,
fontsize=11, lw=2.2)
# Adım 3 — optimizer'dan önce geri böl
viz.boxed_node(ax, 5.0, 1.7, 8.6, 1.5,
f"optimizer'dan önce ÷{scale:.0f} → {scaled_back:.0e} geri",
fc=COL_WHITE, ec=COL_CYAN_700, tc=COL_TEXT,
fontsize=10.5, lw=1.8)
# Oklar (akış aşağı)
viz.arrow_between(ax, (5.0, 7.55), (5.0, 5.85), color=COL_ACCENT, lw=2.4)
viz.arrow_between(ax, (5.0, 4.15), (5.0, 2.45), color=COL_PRIMARY, lw=2.4)
ax.text(5.0, 6.78, "ölçekle", ha="center", va="center",
fontsize=9.5, color=COL_ACCENT, weight="bold")
ax.text(5.0, 3.38, "geri böl", ha="center", va="center",
fontsize=9.5, color=COL_PRIMARY, weight="bold")
ax.set_title("Mixed precision: GradScaler küçük gradyanı kurtarır",
fontsize=12, color=COL_TEXT, weight="bold", pad=10)
# ---- Sağ panel: fp16 vs fp32 aralık (log eksen) ----
axr.set_title("aralık (max)", fontsize=11, color=COL_TEXT, weight="bold", pad=10)
ranges = [fp16_max, fp32_max]
labels = ["fp16", "fp32"]
cols = [COL_ROSE_400, COL_PRIMARY]
ypos = [0, 1]
axr.barh(ypos, ranges, color=cols, height=0.5, zorder=3, log=True)
axr.set_yticks(ypos)
axr.set_yticklabels(labels, color=COL_TEXT, fontsize=11, weight="bold")
axr.set_xlim(1, 1e40)
axr.invert_yaxis()
viz.apply_style(axr)
axr.grid(True, axis="x", alpha=0.2, color=COL_SLATE_400)
axr.grid(False, axis="y")
axr.text(fp16_max, 0, f" {fp16_max:.0f}", va="center", ha="left",
color=COL_ROSE_500, fontsize=9.5, weight="bold")
axr.text(fp32_max, 1, f" {fp32_max:.0e}", va="center", ha="left",
color=COL_CYAN_800, fontsize=9.5, weight="bold")
axr.text(0.5, -0.62,
f"fp16 max {fp16_max:.0f} ≪ fp32 max {fp32_max:.0e}\n"
"dar aralık → hassasiyet ödünü",
transform=axr.transAxes, ha="center", va="top",
fontsize=9.5, color=COL_TEXT)
plt.tight_layout()
plt.show()
İpucuBuilder Notu — Mixed Precision: Production’da Neredeyse Her Zaman Açık
- İleriye (Ders 21): Diffusion eğitimleri büyük ve yavaş; mixed precision onları kaldırılabilir kılar — production’da neredeyse her zaman açıktır.
- Sezgi: “Mixed” kelimesi bir dengeyi anlatır: hesabın ağır kısmı (matris çarpımları, evrişimler) fp16’da hızlanır, ama hassasiyet kritik birkaç adım (kayıp birikimi, ağırlık güncellemesi) fp32’de tutulur. Hız fp16’dan, kararlılık fp32’den gelir — ikisinin en iyisi.
23.3 2. MixedPrecision Callback (Sıfırdan)
Mixed precision’ın PyTorch karşılığı iki parçadır: autocast (ileri geçişi fp16’da çalıştırır) ve GradScaler (fp16’da kaybolan küçük gradyanları ölçekleyerek korur). miniai’de bunlar bir TrainCB alt sınıfında toplanır — her eğitim adımı kancasına (before_batch, after_loss, backward, step) tek bir callback müdahale eder.
class MixedPrecision(TrainCB):
order = DeviceCB.order+10
def before_fit(self, learn): self.scaler = torch.cuda.amp.GradScaler()
def before_batch(self, learn):
self.autocast = torch.autocast("cuda", dtype=torch.float16)
self.autocast.__enter__()
def after_loss(self, learn): self.autocast.__exit__(None, None, None)
def backward(self, learn): self.scaler.scale(learn.loss).backward()
def step(self, learn):
self.scaler.step(learn.opt)
self.scaler.update()Şekil 23.3 callback’in eğitim döngüsüne nasıl oturduğunu şematik gösterir: üstte miniai eğitim döngüsünün kancaları (before_batch → forward → after_loss → backward → step), altta her kancada MixedPrecision’ın eylemi — autocast aç (fp16), ileri geçiş, autocast kapa, scaler.scale(loss).backward() (gradyan ölçekli), scaler.step + update (ölçek geri). Mesaj net: fp16 hesap + GradScaler tek bir callback’te toplanır (Ders 16 sistemi), Accelerate aynısını çoklu GPU/TPU ile yapar.
Kod
fig, ax = plt.subplots(figsize=(11.5, 5))
ax.set_xlim(0, 11.5)
ax.set_ylim(0, 5)
ax.axis("off")
fig.patch.set_facecolor(COL_WHITE)
# Üst sıra: eğitim döngüsü kancaları (miniai). Alt sıra: her kancada MixedPrecision eylemi.
xs = [1.35, 3.55, 5.75, 7.95, 10.15]
y_hook = 3.95
y_act = 1.55
bw, bh = 1.95, 0.92
hooks = [
"before_batch",
"forward",
"after_loss",
"backward",
"step",
]
acts = [
"autocast(fp16) AÇ",
"ileri geçiş\n(fp16, hızlı)",
"autocast KAPA",
"scaler.scale(loss)\n.backward()\n(gradyan ölçekli)",
"scaler.step(opt)\n+ scaler.update()\n(ölçek geri)",
]
# Üst sıra — eğitim döngüsü kancaları (cyan kutular)
for x, h in zip(xs, hooks):
boxed_node(ax, x, y_hook, bw, bh, h,
fc=COL_BG, ec=COL_PRIMARY, tc=COL_CYAN_800, fontsize=10.5)
# Kancalar arası ileri yön okları
for x0, x1 in zip(xs[:-1], xs[1:]):
arrow_between(ax, (x0 + bw / 2, y_hook), (x1 - bw / 2, y_hook),
color=COL_CYAN_700, lw=2.0)
# Alt sıra — MixedPrecision eylemleri (rose kutular)
for x, a in zip(xs, acts):
boxed_node(ax, x, y_act, bw, bh + 0.34, a,
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT,
fontsize=8.6, weight="normal")
# her kancadan kendi eylemine dikey bağ
arrow_between(ax, (x, y_hook - bh / 2), (x, y_act + (bh + 0.34) / 2),
color=COL_ROSE_500, lw=1.8, mutation_scale=14, shrink=4)
# Şerit etiketleri
ax.text(0.12, y_hook, "eğitim\ndöngüsü", ha="left", va="center",
fontsize=9.5, color=COL_CYAN_700, weight="bold")
ax.text(0.12, y_act, "MixedPrecision\ncallback", ha="left", va="center",
fontsize=9.5, color=COL_ACCENT, weight="bold")
# Alt annotate — sistem özeti
ax.text(5.75, 0.30,
"fp16 hesap + GradScaler tek bir callback'te (Ders 16 sistemi); "
"Accelerate aynısı + çoklu GPU/TPU",
ha="center", va="center", fontsize=9.5, color=COL_CYAN_800,
style="italic")
plt.tight_layout()
plt.show()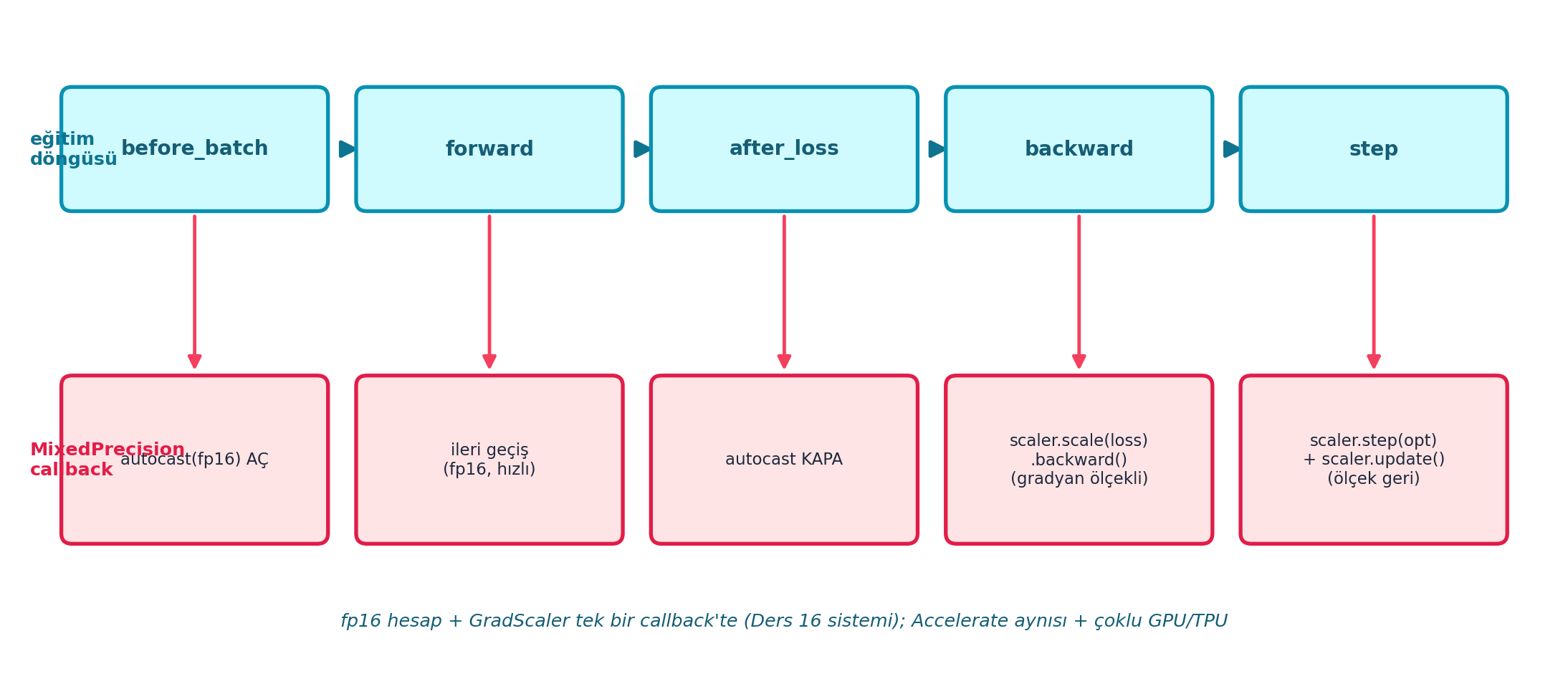
İpucuBuilder Notu — Callback: Eğitim Adımının Her Parçasına Müdahale
- Geriye (Ders 16): Eğitim adımının her parçasına (
before_batch,after_loss,backward,step) callback ile müdahale — Ders 16’nın callback sisteminin gücü tam burada. Çekirdek döngüye hiç dokunmadan, fp16 mantığı dışarıdan takılır. - Sezgi: Dört kanca dört rol üstlenir:
before_batchautocast’i açar (ileri geçiş fp16 olur),after_lossautocast’i kapatır (kayıp birikimi fp32’ye döner),backwardgradyanı ölçekler (underflow’u önler),stepölçeği geri alıp adımı atar. Her biri tek satır — karmaşıklık callback sınırında kapsüllenmiştir.
23.4 3. HuggingFace Accelerate
Aynı işi (ve dahasını — çoklu GPU, TPU) HuggingFace Accelerate kütüphanesi yapar. Tek bir Accelerator nesnesi modeli, optimizer’ı ve veri yükleyicileri sarar; acc.prepare ile hazırlanır, acc.backward ile geri yayılır. miniai’de yine bir callback (AccelerateCB).
from accelerate import Accelerator
class AccelerateCB(TrainCB):
order = DeviceCB.order+10
def __init__(self, n_inp=1, mixed_precision="fp16"):
super().__init__(n_inp=n_inp)
self.acc = Accelerator(mixed_precision=mixed_precision)
def before_fit(self, learn):
learn.model,learn.opt,learn.dls.train,learn.dls.valid = self.acc.prepare(
learn.model, learn.opt, learn.dls.train, learn.dls.valid)
def backward(self, learn): self.acc.backward(learn.loss)“Accelerate is a library that provides this single Accelerator that does things to accelerate your training loops. And one of the things it does is mixed precision training.” — Howard, 7:50
İpucuBuilder Notu — Accelerate: Production Standardı, Hâlâ Bir Callback
- İleriye (production): Accelerate çoklu GPU/TPU eğitimini tek API’ye indirir; production diffusion eğitiminin standart aracı. miniai’ye bir callback olarak girer — kuplaj yok.
- Sezgi: Accelerate’in zarafeti, mixed precision’ı tek bir detaydan ibaret kılmasıdır:
Accelerator(mixed_precision="fp16")der, gerisini (autocast, GradScaler, çoklu cihaz dağıtımı) kütüphane halleder. miniai açısından bu yine yalnızca iki kanca özelleşmiş birTrainCB’dir —before_fit(prepare) vebackward(acc.backward). Sıfırdan yazdığımızMixedPrecisionile production-grade Accelerate, miniai’ye aynı kapıdan girer.
23.5 4. Sneaky Trick: GPU’yu Meşgul Tutmak
Howard küçük bir hile gösterir: küçük modellerde GPU çoğu zaman boş bekler (CPU veri hazırlarken). Bir DataLoader’ı tekrarlayan bir sarmalayıcıyla (MultDL) batch’leri üst üste besleyerek GPU’yu meşgul tutmak, küçük işlerde belirgin hızlanma sağlar.
İpucuBuilder Notu — GPU Doygunluğu: Sık Göz Ardı Edilen Darboğaz
- İleriye (production): “GPU’yu aç tutma” (data pipeline darboğazını giderme) production performansının sık göz ardı edilen tarafıdır; profil çıkarmak değerlidir.
- Sezgi: Mixed precision hesabı hızlandırır, ama hesap GPU’ya hiç ulaşmıyorsa fayda etmez. Küçük modellerde darboğaz GPU değil, veri hazırlama (CPU) olabilir; GPU her batch’in gelmesini bekler. Önce nerede beklenildiğini ölçmek (profil), sonra doğru yeri optimize etmek mühendisliğin temel disiplinidir.
23.6 5. Style Transfer’a Giriş
İkinci konu (Johno): style transfer — klasik bir AI sanat tekniği. Bir “içerik” görüntüsünü (örn. bir fotoğraf) alıp, başka bir görüntünün (örn. bir tablo) stiline dönüştürmek. Mona Lisa’yı farklı sanatçıların fırça darbeleriyle yeniden çizmek gibi.
“we’re going to try to change the style so that the style looks like the style of some other picture. And the way we’re going to be doing that is by doing an optimization.” — Johno, 26:59
İpucuBuilder Notu — Style Transfer: Ders 9 Sezgisinin Saf Hâli
- Geriye (Ders 9): Ders 9’da diffusion’ı “piksel üzerinde gradient descent” sezgisiyle anlamıştık; style transfer aynı fikrin doğrudan, saf hâli. Diffusion’da o sezgi U-Net, scheduler, latent uzay katmanlarının altında gizliydi; burada hiçbir ara katman olmadan, doğrudan piksellere uygulanır.
- Sezgi: “Görüntünün stilini değiştir” gibi öznel bir hedefin matematiksel bir kayba çevrilebilmesi, dersin asıl numarasıdır — bu kayıp tanımlandıktan sonra gerisi tanıdık: gradient descent.
23.7 6. Görüntüyü Optimize Etmek (Ağırlık Değil)
Anahtar fikir: burada ağırlıkları değil, görüntünün kendisini optimize ederiz. Görüntü, öğrenilebilir bir parametre olan bir TensorModel’dir. Gradient descent her adımda pikselleri, kaybı azaltacak yönde günceller — yani çıktı doğrudan optimize edilen görüntüdür.
class TensorModel(nn.Module):
def __init__(self, t):
super().__init__()
self.t = nn.Parameter(t.clone())
def forward(self, x=0): return self.tŞekil 23.4 bu çekirdeği gerçek hesaplamayla kanıtlar (FLAGSHIP): üst satırda pikseller rastgele gürültüden başlar (adım 0), gradient descent adımlarıyla (5, 20, 60) hedefe yakınsar, son kare hedefle neredeyse ayırt edilemez; altta MSE kaybı 0.35’ten 0’a düşer. Vurgu: optimize edilen şey ağırlık değil, görüntünün pikselleridir. Style transfer aynı mekanizmayı VGG/Gram kaybıyla yapar — yöntem aynı, hedef farklı.
Kod
d = E.optimize_input_demo()
snaps = d["snapshots"]
target = d["target"]
loss = d["loss_curve"]
fig = plt.figure(figsize=(12, 6))
gs = fig.add_gridspec(2, 5, height_ratios=[1.15, 1.0], hspace=0.42, wspace=0.22)
# ----- ÜST satır: piksellerin gürültüden hedefe dönüşümü -----
panels = [
(snaps[0], "başlangıç (rastgele)", COL_SLATE_400),
(snaps[5], "adım 5", COL_CYAN_400),
(snaps[20], "adım 20", COL_PRIMARY),
(snaps[60], "son (hedefe yakınsadı)", COL_CYAN_700),
(target, "hedef", COL_ACCENT),
]
for j, (img, title, ec) in enumerate(panels):
ax = fig.add_subplot(gs[0, j])
ax.imshow(img, cmap="gray", vmin=0, vmax=1, interpolation="nearest")
ax.set_title(title, fontsize=10.5, color=COL_TEXT, weight="bold", pad=6)
ax.set_xticks([]); ax.set_yticks([])
for sp in ax.spines.values():
sp.set_color(ec); sp.set_linewidth(2.4)
# ----- ALT: loss eğrisi (MSE düşüşü) -----
axl = fig.add_subplot(gs[1, :])
steps = np.arange(loss.size)
axl.plot(steps, loss, color=COL_PRIMARY, linewidth=2.6, zorder=3)
axl.fill_between(steps, loss, color=COL_PRIMARY, alpha=0.10, zorder=1)
axl.scatter([0], [loss[0]], color=COL_SLATE_400, s=55, zorder=4)
axl.scatter([loss.size - 1], [loss[-1]], color=COL_ACCENT, s=55, zorder=4)
axl.set_xlabel("gradient descent adımı", fontsize=10.5)
axl.set_ylabel("MSE kayıp", fontsize=10.5)
axl.set_title("kayıp: pikseller hedefe yakınsadıkça düşer (0.35 → 0)",
fontsize=11, color=COL_CYAN_800, weight="bold", pad=6)
apply_style(axl)
axl.annotate("ağırlık DEĞİL görüntünün pikselleri optimize edilir (TensorModel)\n"
"style transfer bunu VGG/Gram kaybıyla yapar — yöntem aynı, hedef farklı",
xy=(loss.size * 0.32, loss[int(loss.size * 0.32)]),
xytext=(loss.size * 0.40, loss.max() * 0.62),
fontsize=9.8, color=COL_TEXT, weight="bold",
ha="left", va="center",
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG_ROSE,
ec=COL_ACCENT, lw=1.6),
arrowprops=dict(arrowstyle="-|>", color=COL_ACCENT, lw=2.0))
plt.tight_layout()
plt.show()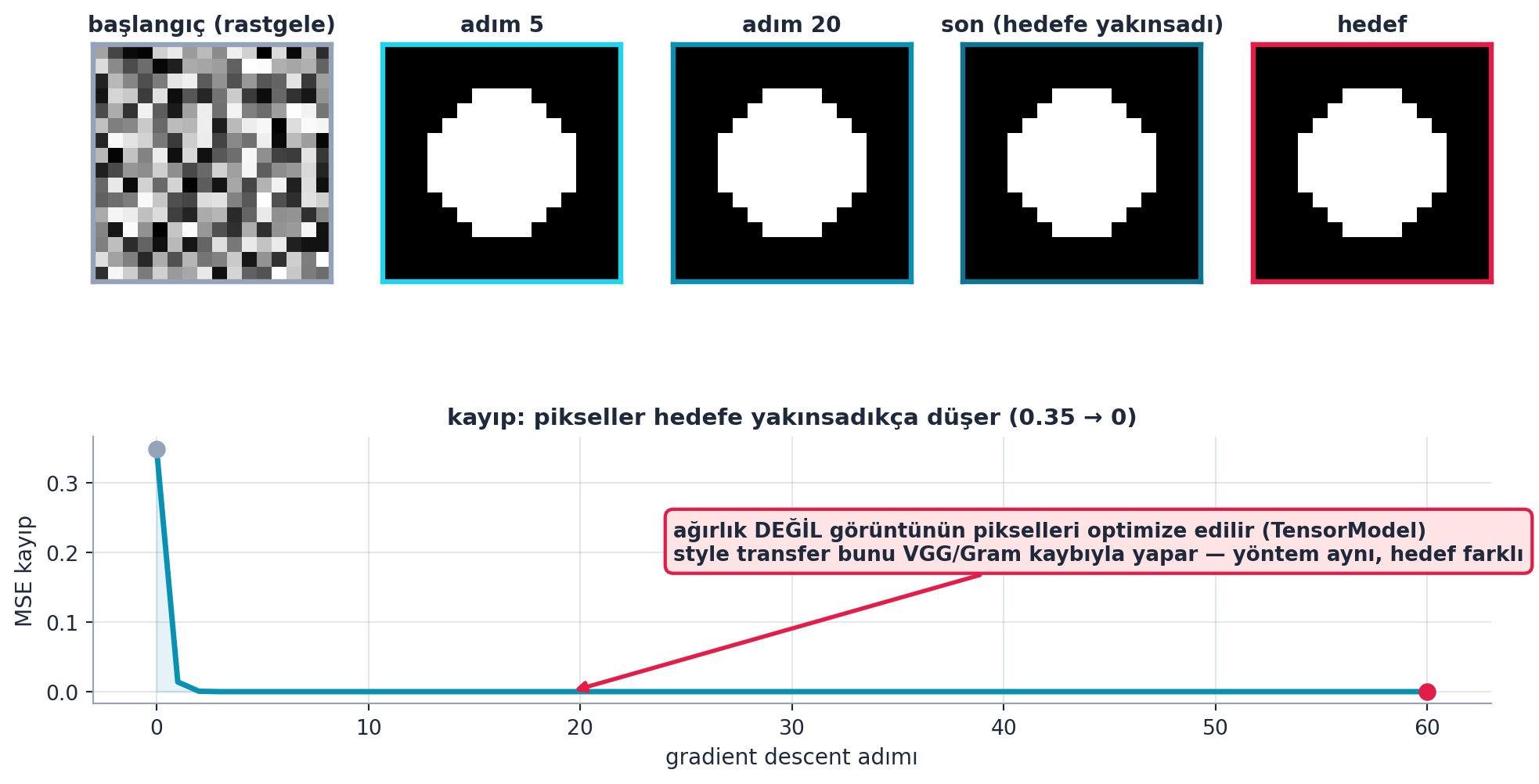
ÖnemliBuilder Notu — Optimize the Input: Aynı Mekanizma, Farklı Hedef (MERKEZÎ)
- Geriye (Ders 3/5): Gradient descent’i ağırlık öğrenmek için kullanmıştık; burada aynı mekanizma bir görüntüyü “öğreniyor”. Optimizasyon hedefi değişti, yöntem aynı.
nn.Parameterneyi sararsa onu optimize edersin — bu satır dersin tüm derinliğinin kaynağıdır. - Sezgi:
TensorModel’inforward’ı girdisini yok sayıp parametresini geri döndürür — yani “model” aslında optimize edilen görüntünün ta kendisidir. Geri yayılım kaybın gradyanını bu piksellere taşır, optimizer onları günceller. Normal eğitimde veri sabit/ağırlık değişkendi; burada ağırlık (VGG16) sabit/görüntü değişken. Mekanizma birebir aynı, roller takas edildi.
23.8 7. Optimizasyon Döngüsü: Dummy Learner
Görüntüyü optimize etmek için miniai Learner kullanılır — ama veri yok (optimize edilen tek şey görüntü). Bu yüzden uzunluğu sabit bir “kukla” DataLoader (LengthDataset) kurulur; her “batch” aslında aynı görüntü üzerinde bir optimizasyon adımıdır. İlerlemeyi ImageLogCB görselleştirir.
class LengthDataset():
def __init__(self, length=1): self.length=length
def __len__(self): return self.length
def __getitem__(self, idx): return 0,0
İpucuBuilder Notu — Dummy Learner: miniai Verisiz Bile Çalışır
- Geriye (Ders 16): miniai Learner o kadar esnek ki, “verisiz” bir optimizasyon problemine bile uyarlanabiliyor — callback sistemi ve gevşek bağlılık sayesinde. Eğitim döngüsünün hiçbir parçasını değiştirmeden, sadece veriyi “boş” kılarsın.
- Sezgi:
LengthDatasether__getitem__çağrısında(0, 0)döndürür — gerçek bir veri yok, sadece döngünün dönmesi için bir sayaç. miniai açısından bu sıradan bir eğitim; ama her “batch” aynı görüntü üzerinde bir gradient descent adımıdır. Çekirdek sade tutulduğu için, “verisiz optimizasyon” bile özel bir kod gerektirmez.
23.9 8. VGG16 ile Özellik Çıkarma
İçeriği ve stili ölçmek için ham pikseller yetmez; anlamsal özellikler gerekir. Önceden eğitilmiş bir VGG16 ağının ara katman aktivasyonları kullanılır: alt katmanlar kenar/doku, üst katmanlar nesne/yapı yakalar. calc_features istenen katmanların çıktısını toplar.
vgg16 = timm.create_model('vgg16', pretrained=True).to(def_device).features
def calc_features(imgs, target_layers=(18, 25)):
x = normalize(imgs)
feats = []
for i, layer in enumerate(vgg16[:max(target_layers)+1]):
x = layer(x)
if i in target_layers: feats.append(x.clone())
return feats
İpucuBuilder Notu — VGG16 Özellikleri: Ders 17 Hook Fikri
- Geriye (Ders 17): Ara katman aktivasyonlarını yakalamak = Ders 17’nin hook fikri; burada doğrudan katmanları gezerek aynı şeyi yaparız. Hook’la ağa “dışarıdan dinleme cihazı” takmak yerine, katmanları tek tek dolaşıp istediklerimizi toplayan basit bir döngü kullanılır — aynı amaç, daha açık kod.
- Sezgi: VGG16’nın katman derinliği bir soyutlama merdivenidir: alt katmanlar piksel-yakın (kenar, doku, renk geçişi), üst katmanlar anlam-yakın (nesne parçası, yapı). Bu yüzden içerik (yapı) üst katmanlarda, stil (doku) hem alt hem üst katmanlarda ölçülür —
target_layersseçimi neyi ölçtüğünü belirler.
23.10 9. Content Loss: İçeriği Korumak
İçerik kaybı, optimize edilen görüntünün VGG16 özelliklerinin, içerik görüntüsünün özelliklerine yakın olmasını sağlar — basit bir MSE: ara katman aktivasyon haritaları arasındaki kare fark. Böylece çıktı, içerik görüntüsünün yapısını (ne olduğunu) korur.
class ContentLossToTarget():
def __init__(self, target_im, target_layers=(18, 25)):
with torch.no_grad():
self.target_features = calc_features(target_im, target_layers)
def __call__(self, input_im):
return sum((f1-f2).pow(2).mean() for f1, f2 in
zip(calc_features(input_im, self.target_layers), self.target_features))Şekil 23.5 content ve style kaybının farkını şematik gösterir: ortada ön-eğitimli (donuk) VGG16 ara katman özellikleri, iki dala ayrılır. Üst dal content loss — özellik haritası MSE, konum korunur, “ne nerede” = yapı/içerik. Alt dal style loss — Gram matrisi MSE, konum atılır, “hangi özellik birlikte” = doku/stil. Toplam = content + ağırlık·style; gradient descent görüntüyü ikisini birden sağlayacak yönde iter.
Kod
fig, ax = plt.subplots(figsize=(11.5, 5.5))
ax.set_xlim(0, 11.5)
ax.set_ylim(0, 5.5)
ax.axis("off")
fig.patch.set_facecolor(COL_WHITE)
# Merkez: ön-eğitimli VGG16 ara katman özellikleri (donuk). İki dal: content + style.
xc, yc = 3.05, 2.75
bw, bh = 2.55, 1.18
# Merkez kutu — VGG16 ara katman özellikleri (nötr slate, ağırlık donuk)
boxed_node(ax, xc, yc, bw, bh,
"VGG16\n(ön-eğitimli, donuk)\nara katman özellikleri",
fc=COL_BG, ec=COL_CYAN_800, tc=COL_CYAN_800,
fontsize=10.0, lw=2.4)
# Üst dal — CONTENT loss (cyan): özellik haritası MSE, konum korunur
xb, y_top, y_bot = 8.35, 4.10, 1.40
bw2, bh2 = 5.4, 1.5
boxed_node(ax, xb, y_top, bw2, bh2,
"CONTENT loss — özellik haritası MSE\n(konum korunur)\n"
"→ 'ne nerede' = yapı / içerik",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_CYAN_800,
fontsize=9.6, lw=2.2)
# Alt dal — STYLE loss (rose): Gram matrisi MSE, konum atılır
boxed_node(ax, xb, y_bot, bw2, bh2,
"STYLE loss — Gram matrisi MSE\n(konum atılır)\n"
"→ 'hangi özellik birlikte' = doku / stil",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT,
fontsize=9.6, lw=2.2)
# Merkezden iki dala oklar
arrow_between(ax, (xc + bw / 2, yc + 0.30), (xb - bw2 / 2, y_top),
color=COL_CYAN_700, lw=2.2)
arrow_between(ax, (xc + bw / 2, yc - 0.30), (xb - bw2 / 2, y_bot),
color=COL_ROSE_500, lw=2.2)
# Sol annotate — katman derinliği notu
ax.text(0.12, yc, "alt katman: doku\nüst katman: yapı",
ha="left", va="center", fontsize=9.0, color=COL_CYAN_700,
weight="bold")
# Alt annotate — toplam kayıp ve optimize-the-input
ax.text(5.75, 0.30,
"toplam = content + ağırlık·style; gradient descent görüntüyü "
"ikisini birden sağlayacak yönde iter",
ha="center", va="center", fontsize=9.5, color=COL_CYAN_800,
style="italic")
plt.tight_layout()
plt.show()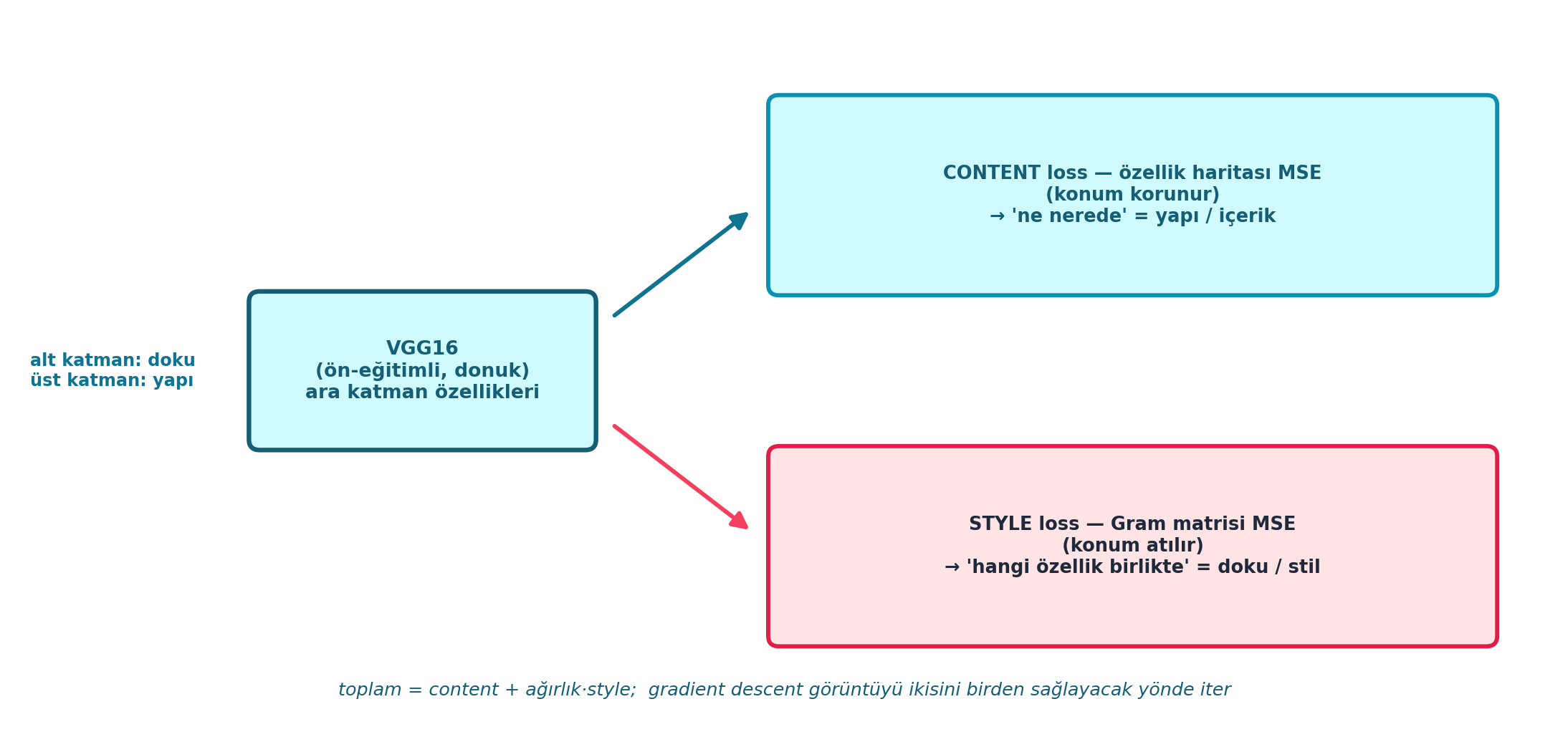
İpucuBuilder Notu — Content Loss: Yine MSE, Ama Özellik Uzayında
- Geriye (Ders 5): Yine MSE — ama piksellerde değil, anlamsal özelliklerde. “Ne” karşılaştırması özellik uzayında yapılır. Piksel MSE’si iki resmi “aynı yerde aynı renk mi?” diye karşılaştırırdı; özellik MSE’si “aynı nesneler, aynı yapı var mı?” diye karşılaştırır.
- Sezgi: İçeriği piksel düzeyinde zorlamak çıktıyı içerik görüntüsünün birebir kopyasına hapsederdi — stil değişemezdi. Özellik uzayında ölçmek esneklik tanır: “köpek burada, gökyüzü orada” korunur (üst katman aktivasyonları benzer), ama her pikselin tam rengi serbest kalır — böylece stil, içeriği bozmadan değişebilir.
23.11 10. Gram Matrisi: Stili Ölçmek
Stil, “nerede ne var” değil, “hangi özellikler birlikte görülüyor” sorusudur. Bunu Gram matrisi yakalar: bir katmanın özellik kanallarının birbirleriyle korelasyonu (her kanal çiftinin iç çarpımı). Konumdan bağımsız olduğu için stili (doku, renk, fırça darbesi) içerikten ayırır.
def calc_grams(img, target_layers=(1, 6, 11, 18, 25)):
return L(torch.einsum('chw, dhw -> cd', x, x) / (x.shape[-2]*x.shape[-1])
for x in calc_features(img, target_layers))Şekil 23.6 Gram matrisini gerçek hesaplamayla gösterir: solda korelasyonlu kanalları olan bir stilin Gram matrisi — kanal 0 ile kanal 1 birlikte ateşlediği için Gram[0,1] parlak; ortada bağımsız kanalların matrisi — köşegen-dışı ≈ 0; sağda açıklama: Gram[i,j] = kanal i ile j’nin korelasyonu (einsum 'chw,dhw→cd', h ve w toplanır). Gram konum bilgisini atar (h, w üzerinden toplanır), bu yüzden stili içerikten ayırır.
Kod
d = E.gram_matrix_demo()
gramA, gramB, C = d["gramA"], d["gramB"], d["C"]
fig, (axA, axB, axT) = plt.subplots(1, 3, figsize=(11.5, 4.8),
gridspec_kw={"width_ratios": [1.0, 1.0, 1.15]})
vmax = max(abs(gramA).max(), abs(gramB).max())
labels = [f"k{i}" for i in range(C)]
def draw_gram(ax, G, title):
im = ax.imshow(G, cmap="gray", vmin=-vmax, vmax=vmax)
ax.set_title(title, color=COL_CYAN_700, fontsize=11.5, weight="bold", pad=8)
ax.set_xticks(range(C)); ax.set_yticks(range(C))
ax.set_xticklabels(labels, color=COL_TEXT, fontsize=9)
ax.set_yticklabels(labels, color=COL_TEXT, fontsize=9)
ax.set_xlabel("kanal j", color=COL_TEXT, fontsize=9.5)
ax.set_ylabel("kanal i", color=COL_TEXT, fontsize=9.5)
for i in range(C):
for j in range(C):
v = G[i, j]
tc = COL_TEXT if v > 0 else COL_WHITE
ax.text(j, i, f"{v:.2f}", ha="center", va="center",
fontsize=8.5, color=tc, weight="bold")
for sp in ax.spines.values():
sp.set_color(COL_SLATE_400)
return im
draw_gram(axA, gramA, "stil A (kanal 0-1 korelasyonlu)")
# korelasyonlu girdiyi vurgula
axA.add_patch(plt.Rectangle((-0.5, 0.5), 1, 1, fill=False,
ec=COL_ACCENT, lw=2.6, zorder=5))
axA.add_patch(plt.Rectangle((0.5, -0.5), 1, 1, fill=False,
ec=COL_ACCENT, lw=2.6, zorder=5))
axA.annotate("Gram[0,1] parlak:\nk0 ile k1 birlikte ateşler",
xy=(1, 0), xytext=(2.3, -0.9), fontsize=8.5, color=COL_ACCENT,
weight="bold", ha="center",
arrowprops=dict(arrowstyle="-|>", color=COL_ACCENT, lw=1.8))
draw_gram(axB, gramB, "stil B (bağımsız kanallar)")
axB.text(1.5, 3.95, "köşegen-dışı ≈ 0\n(kanallar bağımsız)", ha="center",
va="top", fontsize=8.5, color=COL_CYAN_800, weight="bold")
# SAĞ panel: açıklama
axT.axis("off")
axT.set_xlim(0, 1); axT.set_ylim(0, 1)
axT.text(0.5, 0.94, "Gram[i,j] =\nkanal i ile j'nin korelasyonu",
ha="center", va="top", fontsize=11, color=COL_CYAN_700, weight="bold")
axT.text(0.5, 0.70, "einsum 'chw,dhw → cd'\n(= fr · frᵀ, h ve w toplanır)",
ha="center", va="top", fontsize=10, color=COL_TEXT, family="monospace")
viz.boxed_node(axT, 0.5, 0.40, 0.92, 0.20,
"konumdan BAĞIMSIZ\n→ stil / doku",
fc=COL_BG, ec=COL_PRIMARY, fontsize=10.5)
axT.text(0.5, 0.16,
"korelasyonlu kanallar → yüksek Gram girdisi;\n"
"Gram konum bilgisini atar (h,w toplanır)\n"
"→ stili içerikten ayırır",
ha="center", va="top", fontsize=8.8, color=COL_TEXT)
fig.suptitle("Gram matrisi: kanal korelasyonları stili yakalar",
color=COL_CYAN_800, fontsize=12.5, weight="bold", y=1.00)
plt.tight_layout()
plt.show()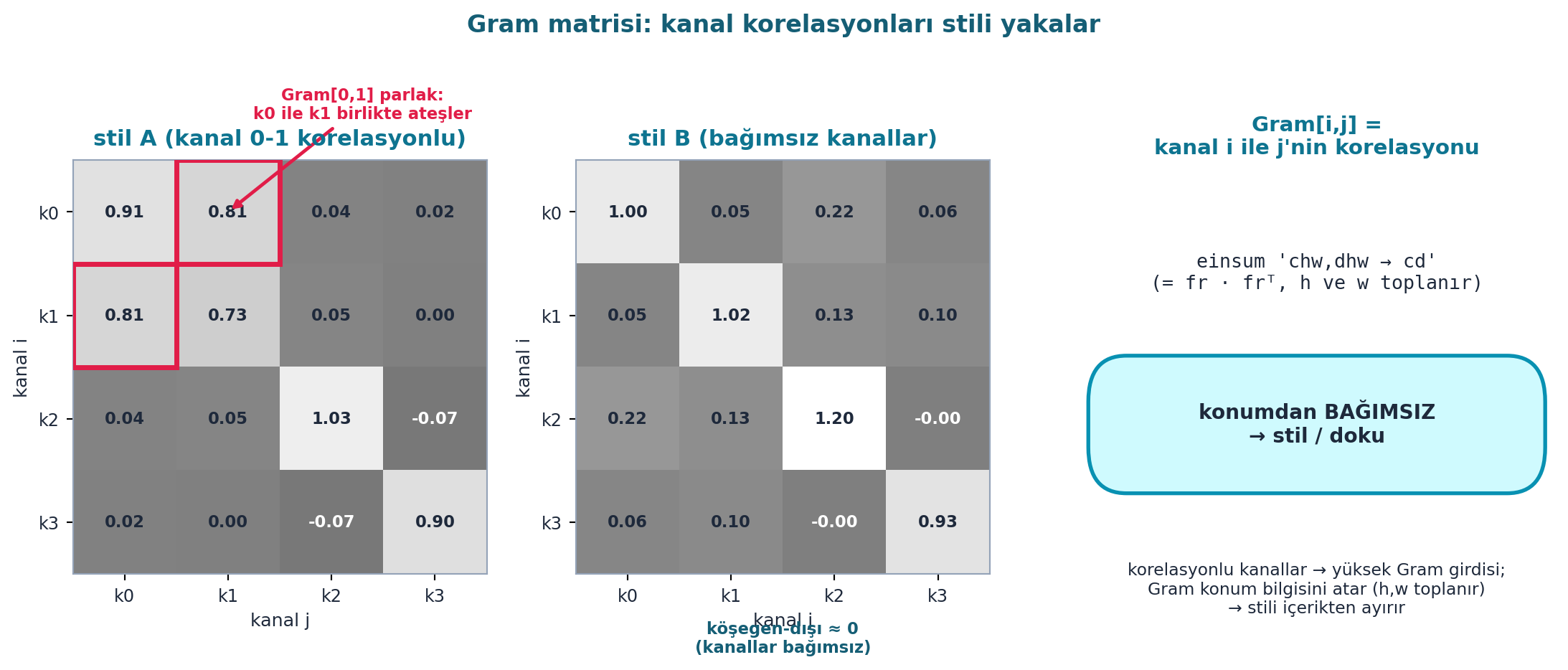
İpucuBuilder Notu — Gram Matrisi: Ders 11-12 einsum’un Zarif Uygulaması
- Geriye (Ders 12/11):
einsum('chw,dhw->cd')= kanallar arası iç çarpım (özellik korelasyon matrisi); Ders 11-12’de kurduğumuz einsum/matmul’un zarif bir uygulaması. Aynı einsum gramerini orada matris çarpımı için kullanmıştık; burada kanal korelasyonu için. - Sezgi: Gram matrisinin konumdan bağımsız olmasının sırrı einsum’un indekslerinde gizli:
'chw,dhw->cd'’dehvew(uzamsal boyutlar) çıktıda yok — yani üzerlerinden toplanıp atılırlar. Geriye sadece kanal-kanal (cd) ilişkisi kalır. Bu yüzden bir fırça darbesi resmin neresinde olursa olsun, aynı kanal korelasyonunu üretir — stil “nerede”den bağımsızdır.
23.12 11. Style Loss ve Birleşim
Stil kaybı, optimize edilen görüntünün Gram matrislerinin, stil görüntüsünün Gram matrislerine yakın olmasıdır (yine MSE). Toplam kayıp = içerik kaybı + stil kaybı (ağırlıklı). Gradient descent pikselleri ikisini birden azaltacak yönde iter: içeriği koru, stili eşleştir.
class StyleLossToTarget():
def __init__(self, target_im, target_layers=(1, 6, 11, 18, 25)):
with torch.no_grad(): self.target_grams = calc_grams(target_im, target_layers)
def __call__(self, input_im):
return sum((f1-f2).pow(2).mean() for f1, f2 in
zip(calc_grams(input_im, self.target_layers), self.target_grams))Şekil 23.7 tüm style transfer hattını şematik gösterir: solda içerik ve stil görüntüsünden hedef özellikler + Gram hesaplanır; ortada optimize edilen görüntü (TensorModel, başta gürültü) donuk VGG16’dan geçer; sağda content + style loss üretilir; gradient descent pikselleri günceller ve döngü geri besler. Anahtar mesaj: ağırlık donuk, görüntü optimize edilir; tüm bu hat, verisiz bir dummy Learner ile miniai döngüsü üstünde çalışır.
Kod
fig, ax = plt.subplots(figsize=(12, 5.5))
ax.set_xlim(0, 12)
ax.set_ylim(0, 5.5)
ax.axis("off")
fig.patch.set_facecolor(COL_WHITE)
# ---- Girdiler (sol): içerik + stil görüntüsü -> hedef özellikler/Gram ----
boxed_node(ax, 1.25, 4.55, 2.05, 0.85, "içerik görüntüsü",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_CYAN_800, fontsize=9.5)
boxed_node(ax, 1.25, 2.35, 2.05, 0.85, "stil görüntüsü",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_CYAN_800, fontsize=9.5)
boxed_node(ax, 3.85, 3.45, 2.05, 1.05,
"hedef özellikler\n+ Gram hesapla",
fc=COL_CYAN_50, ec=COL_CYAN_700, tc=COL_CYAN_800,
fontsize=9.0, weight="normal")
arrow_between(ax, (1.25 + 2.05 / 2, 4.55), (3.85, 3.45 + 0.32),
color=COL_CYAN_700, lw=1.8, shrink=8)
arrow_between(ax, (1.25 + 2.05 / 2, 2.35), (3.85, 3.45 - 0.32),
color=COL_CYAN_700, lw=1.8, shrink=8)
# ---- Optimize edilen görüntü (TensorModel, başta gürültü) ----
boxed_node(ax, 3.85, 1.05, 2.25, 0.95,
"optimize edilen görüntü\n(TensorModel, başta gürültü)",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT,
fontsize=8.4, weight="normal")
# ---- VGG16 (orta) ----
boxed_node(ax, 6.85, 3.45, 1.85, 1.05, "VGG16\n(donuk)",
fc=COL_CYAN_50, ec=COL_CYAN_800, tc=COL_CYAN_800, fontsize=10.0)
# hedef özellikler -> VGG16
arrow_between(ax, (3.85 + 2.05 / 2, 3.45), (6.85 - 1.85 / 2, 3.45),
color=COL_CYAN_700, lw=1.8, shrink=8)
# optimize edilen görüntü -> VGG16 (alt-sağ köşeden)
arrow_between(ax, (3.85 + 2.25 / 2, 1.05), (6.85 - 1.85 / 2, 3.45 - 0.34),
color=COL_ROSE_500, lw=1.9, shrink=8)
# ---- content + style loss ----
boxed_node(ax, 9.55, 3.45, 2.25, 1.05,
"content loss (içerikle)\n+ style loss (stille)",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT,
fontsize=8.6, weight="normal")
arrow_between(ax, (6.85 + 1.85 / 2, 3.45), (9.55 - 2.25 / 2, 3.45),
color=COL_CYAN_700, lw=1.8, shrink=8)
# ---- gradient descent: pikselleri güncelle (geri besleme döngüsü) ----
boxed_node(ax, 9.55, 1.05, 2.25, 0.95,
"gradient descent:\npikselleri güncelle",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_CYAN_800,
fontsize=8.8, weight="normal")
arrow_between(ax, (9.55, 3.45 - 0.52), (9.55, 1.05 + 0.48),
color=COL_ROSE_500, lw=1.9, shrink=6)
# döngü: gradyan -> optimize edilen görüntüye geri (pikselleri ittir)
arrow_between(ax, (9.55 - 2.25 / 2, 1.05), (3.85 + 2.25 / 2, 1.05),
color=COL_ROSE_500, lw=2.0, shrink=8,
connectionstyle="arc3,rad=0.16")
ax.text(6.70, 0.40, "döngü: GÖRÜNTÜ optimize edilir, ağırlık donuk",
ha="center", va="center", fontsize=8.6, color=COL_ACCENT,
style="italic")
# ---- Sonuç (sağ) ----
boxed_node(ax, 11.15, 4.85, 1.55, 0.78,
"sonuç:\niçerik + stil",
fc=COL_CYAN_50, ec=COL_CYAN_800, tc=COL_CYAN_800,
fontsize=8.4, weight="bold")
arrow_between(ax, (9.55 + 2.25 / 2, 3.45 + 0.30), (11.15, 4.85 - 0.30),
color=COL_CYAN_700, lw=1.8, shrink=8,
connectionstyle="arc3,rad=-0.18")
# ---- Üst annotate ----
ax.text(6.0, 5.30,
"ağırlık donuk, GÖRÜNTÜ optimize edilir; "
"dummy Learner (verisiz) ile miniai döngüsü",
ha="center", va="center", fontsize=9.5, color=COL_CYAN_800,
weight="bold")
plt.tight_layout()
plt.show()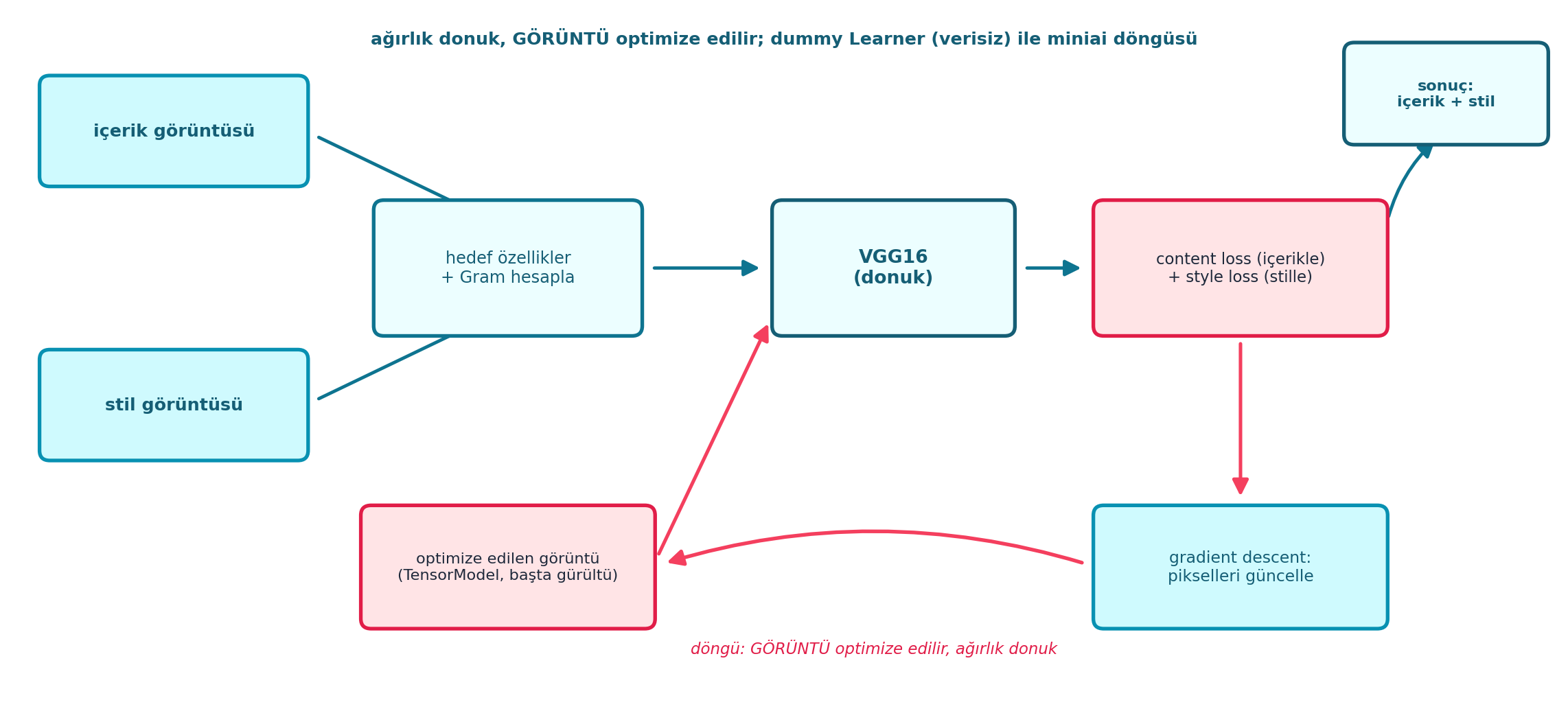
İpucuBuilder Notu — Birleşim: Loss Tasarımı Üretken Modellemenin Sanatı
- İleriye: İçerik + stil kaybının dengesi (ağırlıklar) sonucu belirler; “loss tasarımı” üretken modellemenin sanatıdır (diffusion guidance’ta tekrar görülür). Stil ağırlığı çok yüksekse içerik kaybolur (sadece doku), çok düşükse stil görünmez (sadece içerik).
- Sezgi: İki kaybın aynı pikseller üzerinde çekişmesi, sonucu belirler: content loss pikselleri “yapıyı koru” yönüne, style loss “dokuyu eşleştir” yönüne iter. Optimizer ikisinin ağırlıklı toplamını azaltır — yani dengede, içeriği tanınabilir ama stili yeni bir görüntü ortaya çıkar. Bu denge bir hiperparametredir; tasarımcının elindedir.
23.13 12. Builder İçgörüsü: Optimizasyon Hedefi Değişebilir
Bu dersin en derin builder dersi: gradient descent yalnızca model ağırlıkları için değildir. Aynı mekanizmayla bir girdiyi (görüntüyü), bir gömüyü (embedding), hatta bir prompt’u optimize edebilirsin. Style transfer, “kaybı tanımla, optimize edilecek şeyi parametre yap, gerisini gradient descent halletsin” esnekliğinin saf gösterimidir.
ÖnemliBuilder Notu — Optimize the Input: Dersin Kalbi (MERKEZÎ)
- İleriye (Ders 9A guidance): Diffusion’da “classifier-free guidance” ve custom guidance da aynı fikir — örnekleme sırasında bir kaybı optimize ederek üretimi yönlendirmek. Style transfer’da görüntüyü, guidance’ta diffusion ara durumunu optimize edersin; mekanizma birebir aynıdır.
- Çekirdek ders: Normal eğitim “veriyi sabit tut, ağırlığı öğren” derdi. Bu ders tersini gösterdi: “ağırlığı sabit tut (VGG16 donuk), girdiyi öğren”. Genelleme şudur —
nn.Parameterneyi sararsa, gradient descent onu optimize eder. Hedef ağırlık, görüntü, embedding, prompt ya da bir diffusion ara durumu olabilir. Yöntem değişmez. - Sezgi: Bu içgörünün gücü, modern üretken yaratıcılığın çoğunu tek bir reçeteye indirmesidir: textual inversion bir embedding’i, DreamBooth birkaç ağırlığı, custom guidance bir ara görüntüyü optimize eder — hepsi “kaybı tanımla → hedefi parametre yap → optimize et”. Bir kez bu çerçeveyi gördüğünde, yeni teknikleri “neyi optimize ediyorlar?” sorusuyla anında çözebilirsin.
23.14 13. miniai Köprüsü
Her iki konu da miniai üstünde çalışır. Mixed precision bir callback (MixedPrecision/AccelerateCB); style transfer standart bir Learner + özel kayıp + TensorModel. Foundations’ta kurduğumuz esnek altyapı, birbirinden çok farklı iki problemi (eğitim hızlandırma, görüntü optimizasyonu) aynı çatı altında çözüyor.
İpucuBuilder Notu — miniai: Çekirdeği Sade Tut, Davranışı Callback ile Genişlet
- Geriye (Ders 16): “Çekirdeği sade tut, davranışı callback ile genişlet” ilkesinin meyvesi: mixed precision = bir callback, style transfer = Learner’ın farklı bir kullanımı. İki tamamen farklı problem, aynı sade çekirdeğe bağlanır.
- Sezgi: Bu derste miniai’ye eklenen iki yetenek de çekirdek döngüye tek satır dokunmaz: mixed precision bir
TrainCBalt sınıfıyla (callback), style transfer ise verinin “boş”, modelinTensorModel, kaybın özel olduğu sıradan birfitçağrısıyla girer. L16’da callback mimarisini bu kadar özenle kurmanın ödülü tam burada görünür.
23.15 14. NYU Köprüsü: Özellik Uzayında Çalışmak
Style transfer’ın özünde, önceden eğitilmiş bir ağın özellik temsillerini kullanmak var — NYU Deep Learning’in (LeCun) merkezî temalarından biri. İçerik (özellik aktivasyonları) ve stil (Gram korelasyonları), bir ağın öğrendiği temsilin ne kadar zengin olduğunu gösterir. Bu, transfer learning ve self-supervised temsil öğrenmeyle (NYU) aynı sezgiye dayanır.
İpucuBuilder Notu — NYU: Önceden Eğitilmiş Özelliklerin Yaratıcı Kullanımı
- Geriye (NYU): Önceden eğitilmiş özelliklerin yeniden kullanımı; style transfer bunun yaratıcı bir uygulamasıdır. NYU’da bir ağın iç temsillerinin transfer learning ve SSL için ne kadar değerli olduğunu görmüştük.
- Sezgi: VGG16 sınıflandırma için eğitilmişti, style transfer’ı hiç bilmez. Ama öğrendiği ara temsiller o kadar genel ki, hiç amaçlanmamış bir görevde (içerik/stil ayrımı) doğrudan işe yarar. Bu, “iyi bir temsil görevden bağımsız zengindir” NYU sezgisinin somut kanıtıdır — aynı özellikler hem sınıflandırma hem sanat için kullanılabilir.
23.16 15. Kapanış
Ders 20 iki pratik araç verdi: mixed precision (fp16 ile hızlı, az bellekli eğitim — bir callback) ve style transfer (görüntüyü optimize etme, VGG16 özellikleri + Gram matrisi). İkincisinin builder dersi büyük: gradient descent ağırlıklarla sınırlı değil; kaybı tanımla, hedefi parametre yap, optimize et. miniai her iki problemi de zarifçe kaldırdı.
Şekil 23.8 dersin sentezidir: merkezde çekirdek fikir — optimize-the-input, gradient descent ağırlıkla sınırlı değil (kaybı tanımla → hedefi parametre yap → optimize et); sağda “neyi optimize ederiz?” örnekleri (ağırlık, görüntü/style transfer, embedding/textual inversion, prompt, diffusion ara durumu/9A custom guidance); solda önceki ders köprüleri (mixed precision → L16 callback, VGG16 → L17 hook, Gram einsum → L11-12); alt-solda Ders 9 diffusion = aynı fikrin saf hâli. Sentez: L20 = optimize-the-input genelliği + mixed precision hızlandırma, ikisi de miniai üstünde.
Kod
fig, ax = plt.subplots(figsize=(12.5, 6.5))
ax.set_xlim(0, 12.5)
ax.set_ylim(0, 6.5)
ax.axis("off")
# --- MERKEZ: çekirdek fikir (büyük vurgu) ---
cx, cy = 6.25, 3.35
boxed_node(
ax, cx, cy, 4.4, 1.55,
"L20: optimize-the-input\n"
"gradient descent ağırlıkla\n"
"SINIRLI DEĞİL\n"
"kaybı tanımla → hedefi\n"
"parametre yap → optimize et",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT,
fontsize=11.5, lw=2.6,
)
# --- SAĞ: "neyi optimize ediyoruz?" örnekleri (rose) ---
examples = [
("ağırlık\n(normal eğitim)", 11.05, 5.75),
("GÖRÜNTÜ\n(style transfer, bu ders)", 11.05, 4.30),
("embedding\n(textual inversion)", 11.05, 2.85),
("prompt", 11.05, 1.55),
("diffusion ara durumu\n(Ders 9A custom guidance)", 11.05, 0.45),
]
for txt, ex, ey in examples:
boxed_node(ax, ex, ey, 2.7, 1.0, txt,
fc=COL_BG_ROSE, ec=COL_ROSE_500, tc=COL_TEXT,
fontsize=8.8, lw=1.8)
arrow_between(ax, (cx + 2.2, cy + 0.15 * (ey - cy) / 1.4), (ex - 1.35, ey),
color=COL_ROSE_400, lw=2.0)
# --- SOL: köprüler (cyan) — hangi önceki ders bileşeni ---
bridges = [
("mixed precision\n→ Ders 16 callback", 1.55, 5.55),
("VGG16 features\n→ Ders 17 hook", 1.55, 4.05),
("Gram einsum\n→ Ders 11-12", 1.55, 2.55),
]
for txt, bx, by in bridges:
boxed_node(ax, bx, by, 2.7, 1.0, txt,
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT,
fontsize=8.8, lw=1.8)
arrow_between(ax, (bx + 1.35, by), (cx - 2.2, cy + 0.18 * (by - cy)),
color=COL_CYAN_400, lw=2.0)
# --- ALT-SOL: Ders 9 diffusion = aynı fikrin saf hâli (vurgu) ---
boxed_node(
ax, 2.4, 0.75, 3.9, 1.05,
"Ders 9 diffusion = piksel gradient\n"
"sezgisi burada SAF hâliyle",
fc=COL_CYAN_50, ec=COL_CYAN_700, tc=COL_CYAN_800,
fontsize=9.2, lw=2.2,
)
arrow_between(ax, (3.4, 1.25), (cx - 1.7, cy - 0.78),
color=COL_CYAN_700, lw=2.2)
# --- başlık şeritleri ---
ax.text(11.05, 6.40, "neyi optimize ederiz?", ha="center", va="center",
fontsize=10.5, color=COL_ACCENT, weight="bold")
ax.text(1.55, 6.40, "önceki ders köprüleri", ha="center", va="center",
fontsize=10.5, color=COL_CYAN_700, weight="bold")
plt.tight_layout()
plt.show()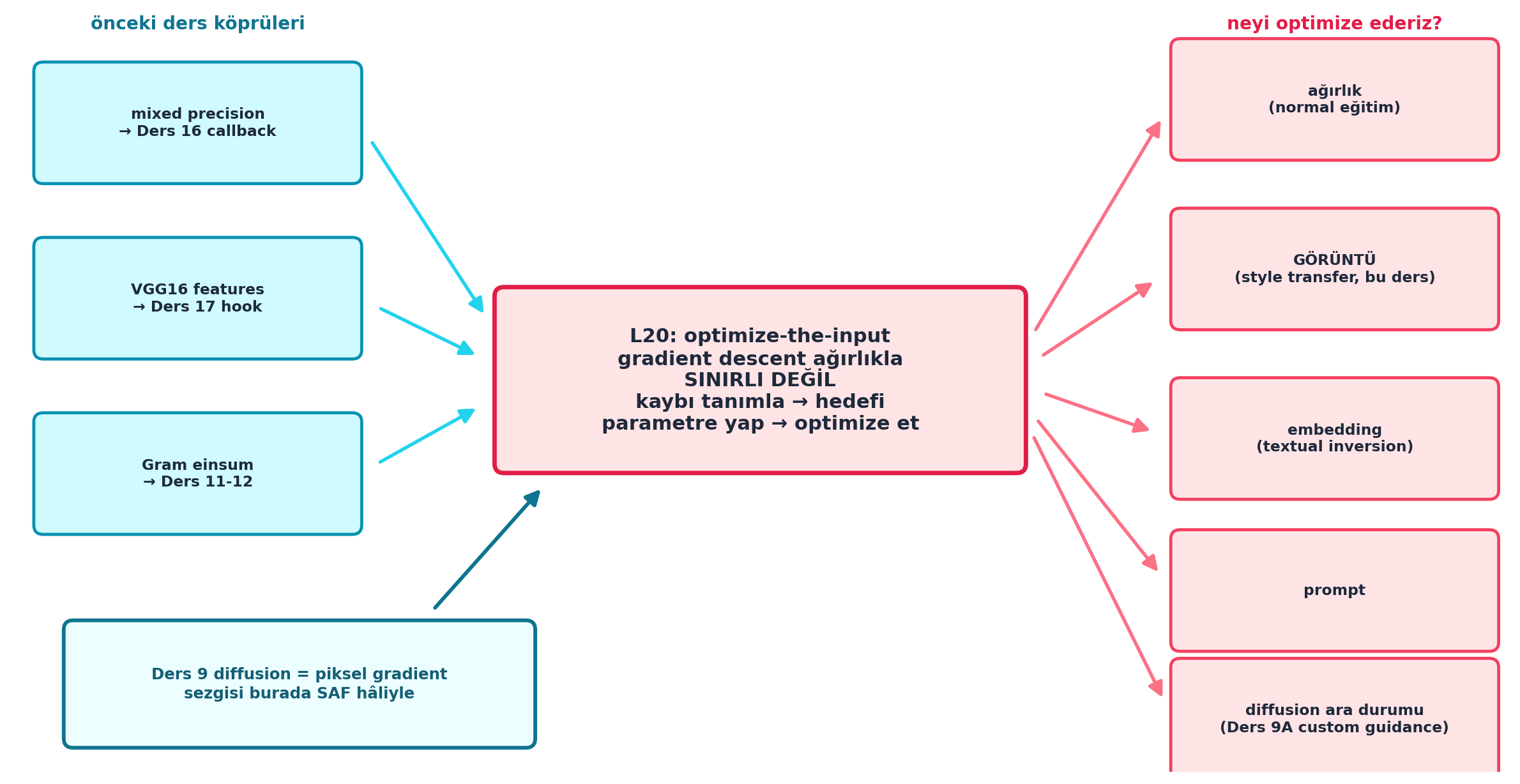
İpucuBuilder Notu — Kapanış: Gradient Descent Bir Araç, Neye Uygularsan O
- İleriye (Ders 21): Mixed precision artık elimizde; Ders 21 ağır diffusion eğitimlerini W&B ile izler, FID/KID ile ölçer ve DDIM ile hızlandırır.
- Sezgi: Bu dersten sonra “gradient descent neyi öğrenir?” sorusunun cevabı netleşti: ne
nn.Parameterile sararsan onu. Ağırlıklar yalnızca en sık karşılaşılan hedef; görüntü, embedding, prompt da aynı mekanizmayla optimize edilir. Bu genellik, diffusion guidance’tan textual inversion’a modern üretken yaratıcılığın temelidir.
23.17 Bu Dersin Özeti
- Mixed precision: Hesabı fp16’da yap (hız + bellek); hassas kısımlar fp32’de — “mixed” (mixed precision).
- MixedPrecision callback:
autocast(fp16 ileri geçiş) +GradScaler(küçük gradyanları koru); miniai TrainCB (callback). - Accelerate: HuggingFace tek API’si — çoklu GPU/TPU + mixed precision;
acc.prepare+acc.backward(Accelerate). - Style transfer: Bir görüntüyü, başka bir resmin stiline dönüştürme; optimizasyonla (giriş).
- Görüntüyü optimize etme: Model bir
TensorModel(öğrenilen ağırlık değil, piksellerdir); gradient descent pikselleri günceller (optimize the input). - VGG16 özellikleri: İçerik, ara katman aktivasyonlarıyla; alt katman doku, üst katman yapı (VGG16).
- Content loss / Style loss: İçerik = özellik MSE; stil = Gram matrisi (kanal korelasyonları) MSE (content, Gram).
- Builder dersi: Gradient descent ağırlıklarla sınırlı değil — girdi, gömü, prompt da optimize edilebilir (builder içgörüsü).
ÖnemliTek Bir Cümle
Mixed precision fp16 ile eğitimi hızlandırıp belleği azaltır (autocast + GradScaler, bir callback); style transfer ise gradient descent’i ağırlıklar yerine bir görüntü üzerinde çalıştırır — VGG16 ara katman özellikleri içeriği, Gram matrisi (kanal korelasyonları) ise stili ölçer, ikisinin MSE kaybı pikselleri yeni bir resme dönüştürür.
23.18 Kontrol Soruları
NotSoru 1: Mixed precision nedir ve neden GradScaler gerekir?
Cevap:
Mixed precision, eğitim hesabının çoğunu fp16 (16-bit kayan nokta) ile yapmaktır — modern GPU’larda çok daha hızlı ve daha az bellek kullanır. “Mixed” denmesinin sebebi, hassasiyet gerektiren bazı işlemlerin (örn. kayıp ve ağırlık güncellemeleri) fp32’de tutulmasıdır. Sorun: fp16’nın dar aralığında, çok küçük gradyanlar sıfıra yuvarlanıp (underflow) kaybolabilir. GradScaler bunu çözer: geri yayılımdan önce kaybı büyük bir çarpanla ölçekler (böylece gradyanlar fp16 aralığında kalır), optimizer adımından önce gradyanları geri ölçekler. Yani scaler.scale(loss).backward() + scaler.step(opt) + scaler.update(). autocast ileri geçişi fp16’da çalıştırır; GradScaler gradyanların hayatta kalmasını sağlar. (Şekil 23.2 küçük gradyanın underflow’unu ve GradScaler’ın kurtarışını gösterir.)
NotSoru 2: Style transfer’da ne optimize edilir? Bu, normal eğitimden nasıl farklıdır?
Cevap:
Normal eğitimde model ağırlıkları optimize edilir (veri sabit, ağırlık değişir). Style transfer’da tam tersi: görüntünün pikselleri optimize edilir, ağırlıklar (VGG16) donuktur. Model bir TensorModel’dir — tek parametresi optimize edilen görüntüdür (nn.Parameter). Her gradient descent adımı, kaybı (içerik + stil) azaltacak yönde pikselleri günceller. Yani çıktı, eğitilmiş bir ağ değil, doğrudan optimize edilmiş görüntünün kendisidir. Bu, gradient descent’in genelliğini gösterir: “neyi parametre yaparsan onu öğrenir”. Aynı mekanizma (geri yayılım + optimizer) hedefi değiştirir — ağırlık yerine görüntü. (Şekil 23.4 piksellerin gürültüden hedefe yakınsamasını gerçek hesaplamayla gösterir.)
NotSoru 3: İçerik ve stil neden farklı şekilde (özellik vs Gram matrisi) ölçülür?
Cevap:
İçerik “ne nerede” sorusudur — görüntünün yapısı, nesneleri, kompozisyonu. Bu, VGG16’nın ara katman aktivasyon haritalarıyla doğrudan ölçülür (konum bilgisi korunur): iki görüntünün özellik haritaları benzerse içerikleri benzerdir. Stil ise “ne nerede”den bağımsızdır — doku, renk paleti, fırça darbesi her yere yayılmıştır. Bunu Gram matrisi yakalar: bir katmanın özellik kanallarının birbirleriyle korelasyonu (einsum('chw,dhw->cd')). Gram matrisi konumu yok sayar (h, w boyutları üzerinden toplanır), sadece “hangi özellikler birlikte aktive oluyor”u tutar. Bu yüzden stili içerikten ayırabilir: içerik kaybı yapıyı korur, stil kaybı (Gram) dokuyu eşleştirir. (Şekil 23.6 korelasyonlu kanalların parlak Gram girdisi ürettiğini, Şekil 23.5 iki kaybın farkını gösterir.)
NotSoru 4: Bu ders gradient descent hakkında hangi derin builder dersini verir?
Cevap:
Gradient descent ağırlık öğrenmekle sınırlı değildir — bir kayıp fonksiyonu tanımlayıp optimize edilecek şeyi bir nn.Parameter yaptığın sürece, herhangi bir şeyi optimize edebilirsin. Style transfer’da bu bir görüntüdür (pikseller). Ama aynı fikirle bir gömü (embedding), bir prompt, ya da diffusion örneklemesinde bir ara durum optimize edilebilir. Builder içgörüsü: “kaybı tanımla → hedefi parametre yap → gerisini gradient descent halletsin”. Bu genellik, Ders 9’daki diffusion sezgisinden (piksel üzerinde gradient descent), Ders 9A’daki custom guidance’a, modern textual inversion/DreamBooth gibi tekniklere kadar uzanır. Gradient descent bir araçtır; onu neye uyguladığın sana kalmış. (Şekil 23.8 bu genelliği — ağırlık/görüntü/embedding/prompt — sentezler.)
23.19 Egzersizler
Egzersiz 1 (Direkt uygulama). Bir modeli MixedPrecision (veya AccelerateCB) callback’iyle eğit; eğitim süresini ve GPU bellek kullanımını fp32 ile karşılaştır (§2, §3).
Egzersiz 2 (İki-aşamalı). TensorModel + ContentLossToTarget ile sadece içerik kaybını optimize et; çıktının içerik görüntüsüne yakınsadığını gözle (Şekil 23.4’in yakınsamasını üret — §6, §9).
Egzersiz 3 (Edge case). Style loss ağırlığını çok yüksek/çok düşük yap; içerik-stil dengesinin sonucu nasıl değiştirdiğini gör (§11).
Egzersiz 4 (Kavramsal). Gram matrisi neden konumdan bağımsızdır? einsum('chw,dhw->cd')’de h ve w boyutlarına ne olur? (§10)
Egzersiz 5 (Sonraki dersin habercisi — Ders 21). DDPM örnekleri ürettik ama “iyi mi” nasıl ölçeriz? Üretilen görüntülerin kalitesini sayısal olarak ölçmenin (gerçek dağılıma yakınlık) nasıl mümkün olduğunu düşün (§15).
23.20 Sonraki: Ders 21 İçin Hazırlık
Ders 21: Deney Takibi, FID/KID ve DDIM
Ders 20 mixed precision ve style transfer verdi. Ders 21 üç konu işler: deney takibi (Weights & Biases callback), üretilen görüntü kalitesini ölçen FID/KID metrikleri (Fréchet/Kernel Inception Distance — Inception özellikleri + kovaryans + matris karekökü) ve DDIM (DDPM’i çok daha az adımda, deterministik örnekleyen hızlandırma).
Ana konular (Ders 21):
- W&B ile deney takibi (callback)
- FID/KID: üretilen görüntü kalitesi metriği
- Inception ağı + kovaryans + Fréchet mesafesi
- DDIM: hızlı, deterministik örnekleme
UyarıDers 21 Öncesi Yapılacak
- Bu dersin egzersizlerini çöz (özellikle 1 ve 2 — mixed precision + content loss).
- DDPM modelini mixed precision ile eğit, hızlanmayı gözle.
- Ders 19 sampling döngüsünü tekrar oku (DDIM onu hızlandıracak).
23.21 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Howard’da |
|---|---|---|
| Mixed precision | fp16 hesap (hız + bellek); hassas kısım fp32 | 0:06 |
autocast |
İleri geçişi fp16’da çalıştıran context manager | 3:17 |
GradScaler |
fp16’da kaybolan küçük gradyanları ölçekleyip korur | 3:23 |
| Accelerate | HuggingFace çoklu GPU/TPU + mixed precision API’si | 7:34 |
AccelerateCB |
acc.prepare + acc.backward; miniai callback | 11:05 |
| Style transfer | Görüntüyü başka resmin stiline dönüştürme | 20:38 |
TensorModel |
Optimize edilen görüntü (ağırlık değil, piksel) | 24:25 |
| VGG16 features | Ön-eğitimli ağın ara katman aktivasyonları | 35:04 |
| Content loss | Özellik haritası MSE; içeriği (yapıyı) korur | 47:24 |
| Gram matrisi | Kanal korelasyonları (einsum chw,dhw→cd); stili ölçer | 56:08 |
| Style loss | Gram matrisi MSE; dokuyu/stili eşleştirir | 56:08 |
| Optimize the input | Gradient descent ağırlık yerine girdiye uygulanır | 26:59 |
23.22 ML Bağlantıları Özeti
İpucuBuilder Notu — 6 ML Köprüsü: Hızlandırma + Optimizasyon Genelliği
Bu ders iki pratik aracı (mixed precision, style transfer) önceki derslerin altyapısına bağlar ve “optimize the input” genelliğini ortaya koyar; köprülerin özeti:
- Mixed precision → Ders 16 callback; eğitime tek satırla eklenir (miniai) (callback).
- VGG16 features → Ders 17 hook fikri; ara katman aktivasyonları yakalama (VGG16).
- Gram matrisi (einsum) → Ders 11-12 einsum/matmul; kanal korelasyon matrisi (Gram).
- Content/style loss → Ders 5 MSE; özellik uzayında karşılaştırma (content, style).
- Optimize the input → Ders 9 diffusion (piksel gradient) + 9A custom guidance; gradient descent’in genelliği (builder içgörüsü).
- Ön-eğitimli özellikler → NYU temsil öğrenme; transfer learning’in yaratıcı kullanımı (NYU köprü).
ÖnemliBu dersten tek bir şey alıp gideceksen
Bu dersten iki şey alıp gideceksin. Birincisi pratik: mixed precision (fp16 + autocast + GradScaler, bir callback) eğitimi hızlandırır ve belleği azaltır — ağır diffusion işleri için vazgeçilmez. İkincisi kavramsal ve daha derin: gradient descent ağırlıklarla sınırlı değil. Style transfer’da bir görüntünün piksellerini optimize ettik; VGG16 özellikleri içeriği, Gram matrisi stili ölçtü. “Kaybı tanımla, hedefi parametre yap, optimize et” — bu esneklik, diffusion guidance’tan textual inversion’a tüm modern üretken yaratıcılığın temelidir.