flowchart TD
TEL["telemetri<br/>(hooks / ActivationStats)"] --> GOR["sorunu GÖR:<br/>aktivasyon patlar / söner"]
GOR --> MAT["varyans / kovaryans matematiği"]
MAT --> FORM["Var(y) ≈ n·Var(a)·Var(x)"]
FORM --> ILKE["TEK İLKE:<br/>varyansı sabit tut"]
ILKE --> INIT["çözüm 1: başlatma"]
INIT --> XAV["Xavier<br/>(1/√n)"]
XAV --> KAI["Kaiming<br/>(√(2/n), ReLU için)"]
ILKE --> NORM["çözüm 2: normalizasyon"]
NORM --> NIN["girdiyi normalize et"]
NORM --> GRELU["GeneralReLU"]
NORM --> LN["LayerNorm"]
NORM --> BN["BatchNorm<br/>(running mean, train/eval)"]
ILKE --> KARP["Karpathy makemore 3<br/>= birebir aynı"]
classDef cyan fill:#cffafe,stroke:#0891b2,stroke-width:2px,color:#1e293b;
classDef rose fill:#ffe4e6,stroke:#e11d48,stroke-width:2px,color:#1e293b;
class TEL,GOR,MAT,FORM,ILKE,INIT,XAV,NORM,NIN,GRELU,LN cyan;
class KAI,BN,KARP rose;
20 Ders 17 — Başlatma / Normalizasyon (Initialization/normalization)
Temeller B’nin teknik zirvesi: derin ağların neden eğitilmesinin zor olduğunu ve bunu çözen iki büyük fikri kurmak — doğru başlatma (initialization) ve normalizasyon. Howard önce ağın içine hook’larla bakar (her katmanın aktivasyon istatistikleri), sorunu (aktivasyonların patlaması/sönmesi) gözle görür, sonra matematiğini (varyans/kovaryans) kurup Xavier ve Kaiming init’i türetir; ardından BatchNorm/LayerNorm’u sıfırdan yazar. Tek cümleyle: derin ağ eğitiminin sırrı aktivasyon varyansını katmandan katmana sabit tutmaktır — bunu başlatma (Kaiming) baştan, normalizasyon (BatchNorm) sürekli sağlar. Ve bu, Karpathy’nin makemore 3’te elle keşfettiği şeyin tam fast.ai karşılığıdır.
NotBölüm bilgisi
- Ders sayfası (video): course.fast.ai — Lesson 17: Initialization/normalization (~116 dk)
- Seri: Practical Deep Learning for Coders — Part 2, Ders 17
- Playlist: Part 2 — Foundations to Stable Diffusion (2022)
- Notebook: course22p2 — nbs/10_activations + nbs/11_initializing
- Okuma süresi: ~42 dk
- 🔗 Temeller B’nin teknik zirvesi (ETAP 5): Ders 16’da esnek Learner’ı (miniai) kurduk; eğitim altyapısı hazır. Ders 17 o altyapıyla asıl zorluğa döner: derin ağların neden eğitilmesinin zor olduğu (aktivasyonların patlaması/sönmesi) ve callback-tabanlı çözümleri — hook’lar, init, norm. Bu ders Karpathy makemore 3’ün birebir fast.ai karşılığıdır.
20.1 Bu Derste Ne Var?
Temeller B’nin teknik zirvesi: derin ağların neden eğitilmesinin zor olduğunu ve bunu çözen iki büyük fikri kurmak — doğru başlatma (initialization) ve normalizasyon. Howard önce ağın içine hook’larla bakar (her katmanın aktivasyon istatistikleri), sorunu (aktivasyonların patlaması/sönmesi) gözle görür, sonra matematiğini (varyans/kovaryans) kurup Xavier ve Kaiming init’i türetir; ardından BatchNorm/LayerNorm’u sıfırdan yazar.
Üç temel fikir bu dersin omurgasını kurar:
- Telemetri (hooks) — eğitim sırasında her katmanın aktivasyon ortalama/std’sini izlemek; sorunu görmek çözmenin ilk adımıdır (telemetri → hook → ActivationStats).
- Başlatma (Kaiming init) — ağırlıkları öyle ölçekle ki aktivasyon varyansı katmandan katmana sabit kalsın; patlama/sönme önlenir (Xavier → Kaiming).
- Normalizasyon (BatchNorm/LayerNorm) — aktivasyonları her adımda yeniden merkezleyip ölçekleyerek eğitimi sağlamlaştır (LayerNorm → BatchNorm).
“I’m really excited about what we’re going to look at over the next lesson or two.” — Howard, 0:07
Şekil 28.1 bu yolculuğu tek bir yol haritasında birleştirir: solda telemetri (hooks → sorunu gör → varyans/kovaryans matematiği), ortada tek ilke (varyansı sabit tut), sağda iki çözüm — başlatma (Xavier 1/√n → Kaiming √(2/n)) ve normalizasyon (girdi normalize / GeneralReLU / LayerNorm / BatchNorm). Kaiming, BatchNorm ve Karpathy makemore 3 köprüsü rose ile işaretlidir: bu ders, Karpathy’nin bottom-up kurduğu şeyin top-down karşılığıdır.
İpucuBuilder Notu — Temeller B’nin Zirvesi: Telemetri → Matematik → Çözüm
- Geriye (Karpathy makemore 3): Bu ders, Karpathy’nin makemore 3’te elle keşfettiği her şeyin fast.ai karşılığı: aktivasyon istatistiklerini izleme, Kaiming init ile varyans koruma, BatchNorm. İki kurs burada birebir buluşur — Howard top-down (önce hook’la gör), Karpathy bottom-up (önce elle türet).
- İleriye (Ders 18-25): Sağlam init + norm olmadan derin ağlar (ResNet, U-Net, diffusion) eğitilemez; bu ders sonraki her şeyin önkoşulu.
- Tek cümle: Derin ağ eğitiminin sırrı, aktivasyon varyansını katmandan katmana sabit tutmaktır — bunu başlatma (Kaiming) baştan, normalizasyon (BatchNorm) sürekli sağlar.
20.2 1. Telemetri: Ağın İçine Bakmak
Howard’ın ilk hamlesi tedavi değil teşhis: eğitim sırasında her katmanın çıktısının ortalama ve standart sapmasını izlemek. “Sorunu göremezsen çözemezsin.” Bunun için miniai’ye bir HooksCallback ve ActivationStats eklendi — Ders 16’nın callback altyapısı üstüne kuruludur.
Şekil 20.2 bu izleme mekanizmasını gösterir: model katmanlarına register_forward_hook ile bir kanca takılır, ActivationStats callback’i her katman çıktısının ortalama/std/histogramını biriktirir, sonra bunları color_dim (aktivasyon histogramının zaman içindeki evrimi) ve dead_chart (ölü ünite oranı) ile görselleştirir. Karpathy makemore 3 de tam bu histogramları çizer.
Kod
fig, ax = plt.subplots(figsize=(11, 5))
ax.set_xlim(0, 11)
ax.set_ylim(0, 5)
ax.axis("off")
fig.patch.set_facecolor(COL_WHITE)
ax.set_facecolor(COL_WHITE)
# --- Sol: model (katmanlar) ---
boxed_node(ax, 1.55, 3.4, 2.5, 1.15,
"model\n(katmanlar)",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT, fontsize=11)
# küçük katman dilimleri (görsel ima)
for i, yy in enumerate((3.85, 3.4, 2.95)):
boxed_node(ax, 1.55, yy, 2.0, 0.30, "",
fc=COL_CYAN_50, ec=COL_CYAN_400, lw=1.2, fontsize=8)
# --- register_forward_hook (rose) ---
boxed_node(ax, 4.6, 3.4, 2.55, 1.05,
"register_\nforward_hook",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT, fontsize=10.5)
# --- ActivationStats callback ---
boxed_node(ax, 7.9, 3.4, 3.05, 1.35,
"ActivationStats\ncallback\nher katman çıktısının\nort / std / histogram'ı",
fc=COL_BG, ec=COL_CYAN_700, tc=COL_TEXT, fontsize=9.5)
# --- iki çıktı grafiği (alt) ---
boxed_node(ax, 6.35, 1.05, 2.9, 1.0,
"color_dim\naktivasyon histogramı\n(zaman içinde)",
fc=COL_CYAN_50, ec=COL_PRIMARY, tc=COL_TEXT, fontsize=9.0)
boxed_node(ax, 9.7, 1.05, 2.3, 1.0,
"dead_chart\nölü ünite oranı",
fc=COL_BG_ROSE, ec=COL_ROSE_500, tc=COL_TEXT, fontsize=9.0)
# --- oklar ---
arrow_between(ax, (2.85, 3.4), (3.30, 3.4), color=COL_ACCENT, lw=2.2) # model -> hook
arrow_between(ax, (5.90, 3.4), (6.35, 3.4), color=COL_PRIMARY, lw=2.2) # hook -> stats
arrow_between(ax, (7.55, 2.72), (6.70, 1.58), color=COL_CYAN_700, lw=2.0) # stats -> color_dim
arrow_between(ax, (8.55, 2.72), (9.50, 1.58), color=COL_CYAN_700, lw=2.0) # stats -> dead_chart
# --- annotate: sorunu GÖRMEDEN çözemezsin ---
ax.text(5.5, 4.78,
"Sorunu GÖRMEDEN çözemezsin: kötü init'te grafik patlamayı/çökmeyi gösterir · Ders 16 callback altyapısı üstüne",
ha="center", va="center", fontsize=9.5, style="italic",
color=COL_CYAN_800,
bbox=dict(boxstyle="round,pad=0.4", fc=COL_CYAN_50,
ec=COL_SLATE_300, lw=1.0))
# --- Karpathy köprü notu ---
ax.text(2.55, 0.55,
"↪ Karpathy makemore 3 de aynı histogramları çizer",
ha="left", va="center", fontsize=9.0, weight="bold",
color=COL_ACCENT)
plt.tight_layout()
plt.show()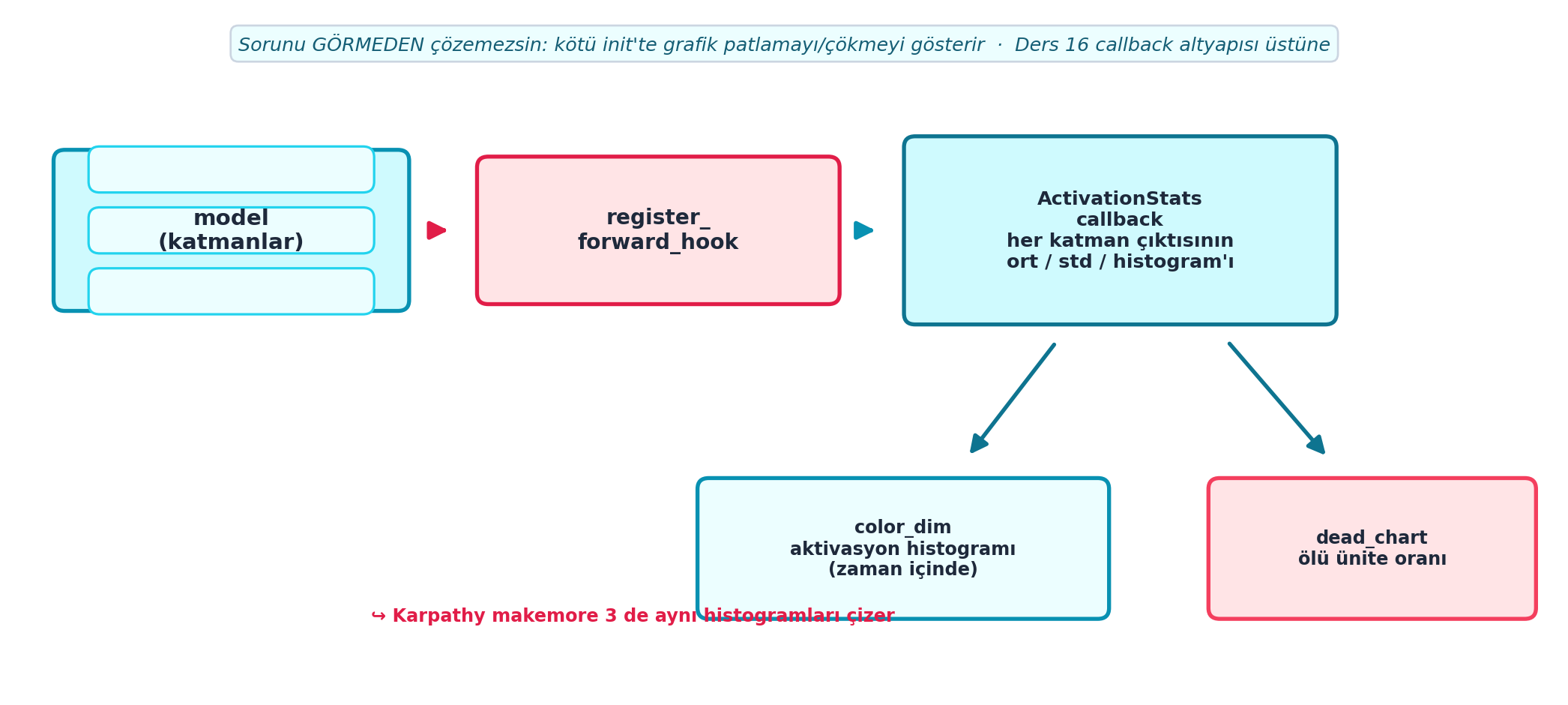
İpucuBuilder Notu — Telemetri: Önce Teşhis, Sonra Tedavi
- Geriye (Ders 16): Telemetri bir callback’tir; Ders 16’da kurduğumuz Learner+callback sistemi olmadan bu izleme mümkün değildi —
ActivationStatsHooksCallback’ten türer. - Sezgi: Howard’ın tüm dersi tek bir mühendislik refleksine dayanır: bir sorunu çözmeden önce onu ölçülebilir kıl. Aktivasyon std’sini her katmanda izlemek, patlama/sönmeyi soyut bir korku olmaktan çıkarıp bir grafiğe indirger — artık düzeltmenin işe yarayıp yaramadığını gözle görebiliriz.
20.3 2. Hook Nedir?
Hook, PyTorch’un bir katmana iliştirilen ve o katman her çalıştığında (forward/backward) otomatik tetiklenen bir fonksiyondur. register_forward_hook ile katmanın çıktısını yakalayıp kaydedebiliriz — modeli değiştirmeden içine bakarız.
class Hook():
def __init__(self, m, f): self.hook = m.register_forward_hook(partial(f, self))
def remove(self): self.hook.remove()
def __del__(self): self.remove()
def append_stats(hook, mod, inp, outp):
if not hasattr(hook,'stats'): hook.stats = ([],[])
acts = to_cpu(outp)
hook.stats[0].append(acts.mean())
hook.stats[1].append(acts.std())
İpucuBuilder Notu — Hook: Modeli Değiştirmeden İçine Bakma
- İleriye: Hook deseni her derin öğrenme framework’ünde vardır (PyTorch hooks, TF callbacks); model içini gözlemlemenin standart yolu. Aynı
register_forward_hookileride Grad-CAM, feature extraction, debugging için de kullanılır. - Sezgi:
append_statsyalnızca üç satır: çıktının ortalamasını ve std’sini ilgili kancanınstatslistesine ekler.partial(f, self)ile kanca nesnesi fonksiyona bağlanır — böylece her katmanın kendi istatistik geçmişi olur. Modelin forward koduna tek satır eklemeden tüm aktivasyonları izleyebiliriz.
20.4 3. ActivationStats: Renkli Boyut ve Ölü Üniteler
Hook’larla topladığımız istatistikleri görselleştiririz: color_dim (her katmanın aktivasyon histogramının zamanla evrimi — “renkli boyut” grafiği) ve dead_chart (sıfır kalan, yani “ölü” ünitelerin oranı). Kötü init’te bu grafikler aktivasyonların önce patlayıp sonra çöktüğünü açıkça gösterir.
class ActivationStats(HooksCallback):
def __init__(self, mod_filter=fc.noop): super().__init__(append_stats, mod_filter)
def color_dim(self, figsize=(11,5)): ...
def dead_chart(self, figsize=(11,5)): ...
İpucuBuilder Notu — color_dim: Karpathy ile Aynı Teşhis Grafiği
- Geriye (Karpathy makemore 3): Karpathy de aynı şeyi yapar — katman aktivasyonlarının histogramını çizip “ölü” nöronları (saturated tanh) gösterir. Aynı teşhis, aynı grafik; sadece Howard’ın aracı
ActivationStatscallback’i, Karpathy’ninki elle yazılmış döngü. - Sezgi:
color_dimzamanı (eğitim adımları) bir eksene, aktivasyon değerlerinin histogramını öteki eksene koyar; renk yoğunluğu o değerin ne sıklıkta görüldüğüdür. Sağlıklı bir katmanda histogram sabit ve dolu; kötü init’te önce yukarı patlar, sonra hepsi sıfıra (ölü) çöker — bozulmanın tam ne zaman başladığını gözle yakalarsın.
20.5 4. Sorun: Aktivasyonların Patlaması/Sönmesi
Basit bir deney sorunu çıplak gösterir: rastgele bir matrisi 50 kez çarp. Standart normal ağırlıkla aktivasyonlar nan’a patlar; çok küçük ağırlıkla (×0.01) sıfıra söner. İkisi de eğitimi imkânsız kılar.
x = torch.randn(200, 100)
for i in range(50): x = x @ torch.randn(100,100)
x[0:5,0:5] # nan — patladı
x = torch.randn(200, 100)
for i in range(50): x = x @ (torch.randn(100,100) * 0.01)
x[0:5,0:5] # 0 — söndüŞekil 20.3 bu deneyi gerçek hesaplamayla çizer (FLAGSHIP): 50 katman boyunca aktivasyon std’si log skalada izlenir. Standart normal ağırlık eğrisi (\(\sigma \to \infty\), nan) yukarı patlar; ×0.01 eğrisi (\(\sigma \to 0\)) tabana söner; Kaiming √(2/n) + ReLU eğrisi ise \(\sigma \approx 1\) hedefinde stabil kalır. Üç eğri tek bir gerçeği gösterir: kötü init eğitimi imkânsız kılar, doğru init varyansı sabit tutar.
Kod
d = E.variance_experiment_demo()
layers = np.array(d["layers"], dtype=float)
# inf/0 sentinellerini log-y skalada çizilebilir sınırlara kırp
TOP, BOT = 1e12, 1e-12 # patlama tavanı / sönme tabanı
def clip_for_log(vals):
arr = np.array(vals, dtype=float)
arr = np.where(np.isinf(arr) | (arr > TOP), TOP, arr)
arr = np.where(arr <= 0.0, BOT, arr)
arr = np.clip(arr, BOT, TOP)
return arr
std_standard = clip_for_log(d["std_standard"])
std_small = clip_for_log(d["std_small"])
std_kaiming = clip_for_log(d["std_kaiming"])
fig, ax = plt.subplots(figsize=(11, 6))
# 1'de referans çizgisi (ideal: varyans korunur, std ≈ 1)
ax.axhline(1.0, color=COL_SLATE_400, lw=1.2, ls="--", zorder=1)
ax.text(layers[-1], 1.0, " hedef σ ≈ 1", color=COL_SLATE_400,
fontsize=9.5, va="bottom", ha="right")
# Patlama tavanı / sönme tabanı bantları
ax.axhline(TOP, color=COL_ROSE_400, lw=0.8, ls=":", zorder=1)
ax.axhline(BOT, color=COL_SLATE_300, lw=0.8, ls=":", zorder=1)
# 3 eğri
ax.plot(layers, std_standard, color=COL_ACCENT, lw=2.4, marker="o", ms=3.5,
label="standart normal → PATLAR (∞ / nan)", zorder=4)
ax.plot(layers, std_small, color=COL_SLATE_400, lw=2.0, marker="s", ms=3.0,
label="×0.01 → SÖNER (→ 0)", zorder=3)
ax.plot(layers, std_kaiming, color=COL_PRIMARY, lw=3.2, marker="D", ms=3.5,
label="Kaiming √(2/n) + ReLU → STABİL (σ ≈ 1)", zorder=5)
# Patlama oku (rose, yukarı)
ai = int(np.argmax(std_standard >= TOP)) if np.any(std_standard >= TOP) else len(layers) - 1
ax.annotate("patlar: aktivasyon ∞ → nan",
xy=(layers[ai], TOP), xytext=(layers[ai] - 16, TOP * 1e-3),
color=COL_ACCENT, fontsize=10, weight="bold",
arrowprops=dict(arrowstyle="-|>", color=COL_ACCENT, lw=2.0))
# Sönme oku (slate, aşağı)
si = int(np.argmax(std_small <= BOT)) if np.any(std_small <= BOT) else len(layers) - 1
ax.annotate("söner: aktivasyon → 0",
xy=(layers[si], BOT), xytext=(layers[si] + 3, BOT * 1e3),
color=COL_CYAN_800, fontsize=10, weight="bold",
arrowprops=dict(arrowstyle="-|>", color=COL_SLATE_400, lw=2.0))
# Stabil bölge notu
ax.annotate("kötü init: patlar (nan) veya söner (0) → eğitim imkânsız;\nKaiming varyansı sabit tutar",
xy=(layers[len(layers) // 2], 1.0),
xytext=(2, 1e6),
color=COL_CYAN_700, fontsize=10.5, weight="bold",
ha="left", va="center",
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG, ec=COL_PRIMARY, lw=1.5))
ax.set_yscale("log")
ax.set_ylim(BOT * 0.3, TOP * 3)
ax.set_xlim(-1, layers[-1] + 1)
ax.set_xlabel("katman (derinlik)")
ax.set_ylabel("aktivasyon std (σ, log skala)")
ax.set_title("Varyans korunumu: 50 katman boyunca aktivasyon std", color=COL_TEXT, weight="bold")
apply_style(ax)
ax.legend(loc="lower left", framealpha=0.95, fontsize=9.5)
plt.tight_layout()
plt.show()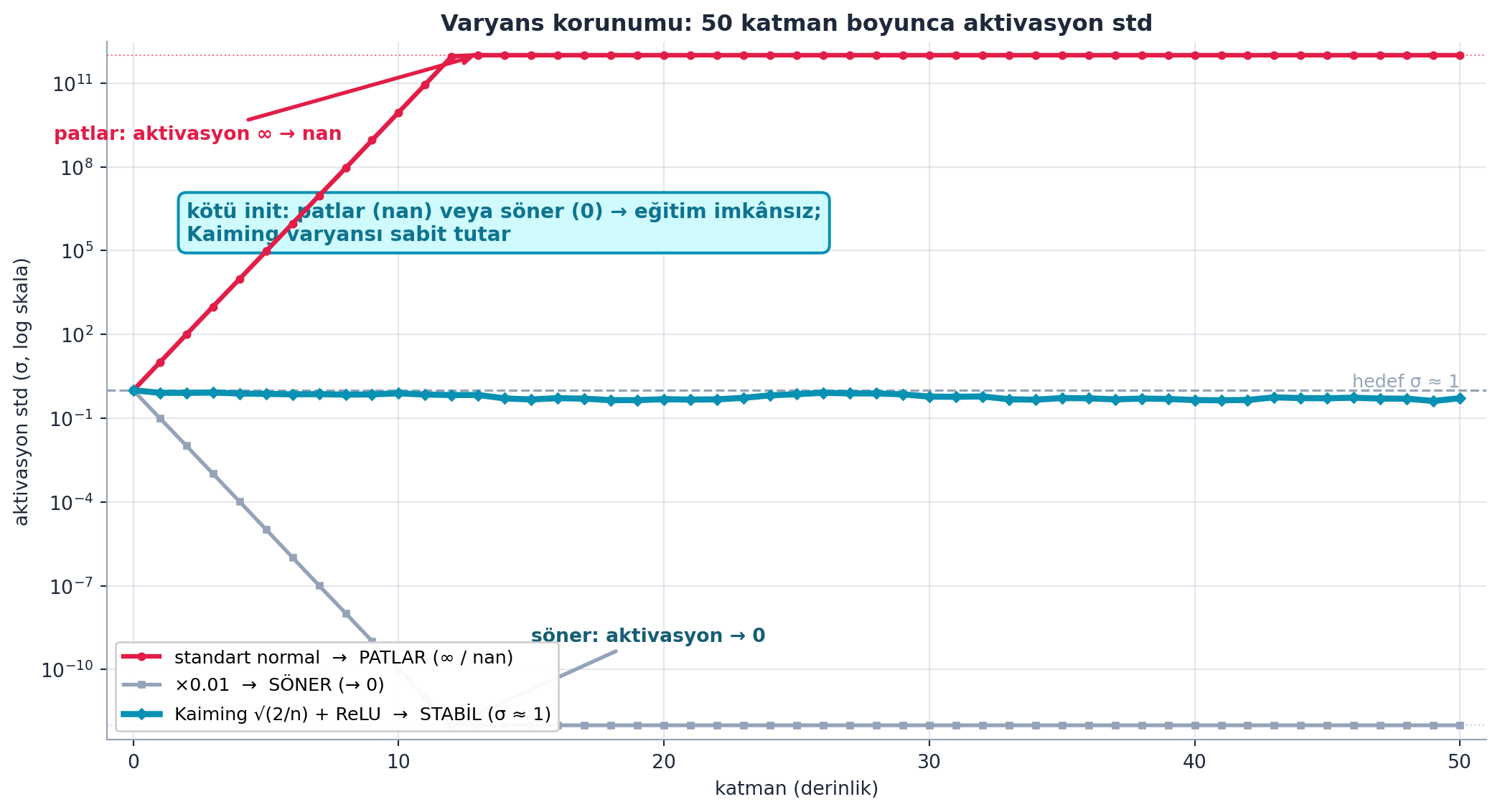
İpucuBuilder Notu — Patlama/Sönme: Derin Öğrenmenin Tarihsel Duvarı
- İleriye: Bu, derin ağ tarihinin (2012 öncesi) eğitilememe sorununun ta kendisi; çözümü (init) derin öğrenmeyi mümkün kıldı. AlexNet öncesi derin ağların “çalışmaması” büyük ölçüde bu varyans patlaması/sönmesiydi.
- Sezgi: 50 katman = 50 kez çarpma; her çarpma varyansı bir çarpanla ölçekler. Çarpan 1’den büyükse 50. kuvvete üssel patlama, küçükse üssel sönme. Tam 1 olması gereken bir denge — ve bu dengeyi tesadüfen tutturamazsın, ağırlık ölçeğini bilinçli ayarlaman gerekir.
20.6 5. Varyans ve Standart Sapma
Sorunun matematiği varyans: verinin yayılımının ölçüsü. Varyans, ortalamadan farkların karesinin ortalamasıdır: \(\mathrm{Var}(X) = \mathrm{ort}((x_i - \mu)^2)\) (burada “ort” ortalama). Standart sapma \(\sigma = \sqrt{\mathrm{Var}}\), veriyle aynı birime döner. Pratik özdeşlik: \(\mathrm{Var}(X) = \mathrm{ort}(X^2) - \mathrm{ort}(X)^2\) (hesabı kolaylaştırır).
t = torch.tensor([1.,2.,4.,18])
m = t.mean()
(t-m).pow(2).mean() # varyans
(t-m).pow(2).mean().sqrt() # std
(t*t).mean() - (m*m) # aynı varyans, kısa yol
İpucuBuilder Notu — Varyans: Ağırlık Ölçeklemenin Dili
- Geriye (Stat 110): Varyans/std olasılığın temel dağılım ölçüleri; burada ağırlık ölçeklemenin dilini verir. \(\mathrm{Var}(X) = E[X^2] - E[X]^2\) özdeşliği Stat 110’da kanıtlanan klasik sonuç.
- Sezgi: Karelerin ortalamasından ortalamanın karesini çıkaran kısa yol (\(E[X^2] - \mu^2\)), tek geçişte varyans hesaplamayı sağlar — veriyi iki kez dolaşmana gerek kalmaz. Init türetmesinde sıfır-ortalama varsayımıyla (\(\mu = 0\)) varyans doğrudan \(E[X^2]\)’e indirgenir, bu da formülleri sadeleştirir.
20.7 6. Kovaryans
İki değişkenin birlikte değişimini ölçen kovaryans: \(\mathrm{Cov}(X,Y) = \mathrm{ort}((X - \mu_X)(Y - \mu_Y)) = \mathrm{ort}(XY) - \mu_X \cdot \mu_Y\). İlişkisiz değişkenlerde ≈ 0. Varyans, X’in kendisiyle kovaryansıdır: \(\mathrm{Var}(X) = \mathrm{Cov}(X,X)\). Bu kavram, init türetmesinde “ağırlık ve girdi bağımsız” varsayımını kullanmak için gerekir.
cov = (t*v).mean() - t.mean()*v.mean()
cov / (t.std() * v.std()) # korelasyon = ölçeklenmiş kovaryans
İpucuBuilder Notu — Kovaryans: Bağımsızlık Varsayımının Anahtarı
- Geriye (18.06/18.065): Kovaryans matrisi lineer cebirin ve PCA’nın temeli; burada bağımsızlık varsayımını sağlar. Strang’ın 18.065’inde kovaryans matrisi \(A^T A\) formundaydı; aynı kavram.
- Sezgi: Init türetmesinin can damarı şudur: ağırlık \(a_i\) ile girdi \(x_i\) bağımsız ve sıfır ortalamalı ise, çarpımlarının çapraz terimleri (kovaryans) ortalama ≈ 0 olur ve düşer. İşte bu yüzden \(\mathrm{Var}(y) \approx n \cdot \mathrm{Var}(a) \cdot \mathrm{Var}(x)\) formülü temiz çıkar — kovaryans, “neden bu terimleri atabiliyoruz?” sorusunun cevabıdır.
20.8 7. Xavier / Glorot Başlatma
Anahtar gözlem: \(y = \sum a_i x_i\) (n girdi üzerinden) çıktısının varyansı, bağımsız sıfır-ortalamalı \(a_i\), \(x_i\) için n ile çarpılır: \(\mathrm{Var}(y) \approx n \cdot \mathrm{Var}(a) \cdot \mathrm{Var}(x)\). Bir katman varyansı n katına çıkarıyorsa, 50 katmanda \(n^{50}\) — işte patlama. Çözüm: ağırlıkları √n ile böl, yani \(\mathrm{Var}(a) = 1/n\). Bu Xavier (Glorot) init’tir; çıktı varyansını girdiye eşit tutar.
mean,sqr = 0.,0.
for i in range(100):
x = torch.randn(100); a = torch.randn(512, 100)
y = a @ x
mean += y.mean().item(); sqr += y.pow(2).mean().item()
mean/100, sqr/100 # ortalama ≈ 0, kare-ortalama ≈ 100 = girdi sayısı
w1 = torch.randn(100,50) / sqrt(100) # Glorot: √n ile böl“So that’s the reason why we need this math dot square root 100.” — Howard, 32:45
Şekil 20.4 bu türetmenin mantığını şema olarak verir: merkezde \(\mathrm{Var}(y) \approx n \cdot \mathrm{Var}(a) \cdot \mathrm{Var}(x)\) formülü ve “\(a_i, x_i\) bağımsız, sıfır ortalama → kovaryans ≈ 0” varsayımı. Sol kol (rose, sorun): her katman varyansı n katına çıkarır → 50 katmanda \(n^{50}\) = patlama. Sağ kol (cyan, çözüm): \(\mathrm{Var}(a) = 1/n\) (Xavier) ya da \(2/n\) (Kaiming) → çıktı varyansı = girdi varyansı, sabit kalır.
Kod
fig, ax = plt.subplots(figsize=(11, 5))
# --- MERKEZ formül: bir katmanın varyans korunumu --------------------------
# y = Σ aᵢ·xᵢ (n girdi), bağımsızlık varsayımıyla Var(y) ≈ n·Var(a)·Var(x)
boxed_node(ax, 5.0, 4.05, 6.6, 1.05,
"y = Σ aᵢ·xᵢ (n girdi)\nVar(y) ≈ n · Var(a) · Var(x)",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_CYAN_800,
fontsize=14, lw=2.4)
# bağımsızlık varsayımı notu (formülün hemen altında)
ax.text(5.0, 3.28,
"varsayım: aᵢ, xᵢ bağımsız ve sıfır ortalama → kovaryans ≈ 0",
ha="center", va="center", fontsize=9, color=COL_SLATE_400,
style="italic")
# --- Sol: her katman n KATINA çıkarır → PATLAMA ----------------------------
boxed_node(ax, 2.35, 2.0, 4.0, 0.95,
"bir katman varyansı\nn KATINA çıkarır",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_ROSE_500,
fontsize=10.5, lw=2.0)
boxed_node(ax, 2.35, 0.55, 4.0, 0.9,
"50 katmanda n⁵⁰ = PATLAMA\n(σ → ∞ ya da σ → 0)",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_ROSE_500,
fontsize=10.5, lw=2.0)
# formülden sola/aşağı: ölçeklenme zinciri (rose = sorun)
arrow_between(ax, (3.5, 3.55), (2.35, 2.5), color=COL_ACCENT, lw=2.2,
connectionstyle="arc3,rad=0.12")
arrow_between(ax, (2.35, 1.5), (2.35, 1.02), color=COL_ACCENT, lw=2.2)
# --- Sağ: çözüm → çıktı varyansı = girdi varyansı (SABİT) -------------------
boxed_node(ax, 7.65, 2.0, 4.2, 0.95,
"çözüm: Var(a) = 1/n (Xavier)\nya da 2/n (Kaiming, ReLU)",
fc=COL_CYAN_50, ec=COL_PRIMARY, tc=COL_CYAN_800,
fontsize=10.5, lw=2.0)
boxed_node(ax, 7.65, 0.55, 4.2, 0.9,
"çıktı varyansı = girdi varyansı\n(n·(1/n)·Var(x) = Var(x) — SABİT)",
fc=COL_CYAN_50, ec=COL_PRIMARY, tc=COL_CYAN_800,
fontsize=10.5, lw=2.0)
# formülden sağa/aşağı: çözüm zinciri (cyan = doğru)
arrow_between(ax, (6.5, 3.55), (7.65, 2.5), color=COL_PRIMARY, lw=2.2,
connectionstyle="arc3,rad=-0.12")
arrow_between(ax, (7.65, 1.5), (7.65, 1.02), color=COL_PRIMARY, lw=2.2)
# --- Patlama / sabit karşıtlığını ok ile vurgula ---------------------------
ax.annotate("Var(a)=1/n → n çarpanını TAM söndürür",
xy=(5.55, 0.55), xytext=(4.95, 1.62),
ha="center", va="center", fontsize=9, color=COL_TEXT, weight="bold",
arrowprops=dict(arrowstyle="-|>", color=COL_SLATE_400, lw=1.6,
connectionstyle="arc3,rad=0.0"))
ax.text(2.35, 2.78, "PATLAMA", ha="center", va="center",
fontsize=10, color=COL_ACCENT, weight="bold")
ax.text(7.65, 2.78, "SABİT (korunur)", ha="center", va="center",
fontsize=10, color=COL_CYAN_700, weight="bold")
ax.set_xlim(0.0, 10.0)
ax.set_ylim(-0.05, 4.75)
ax.axis("off")
plt.tight_layout()
plt.show()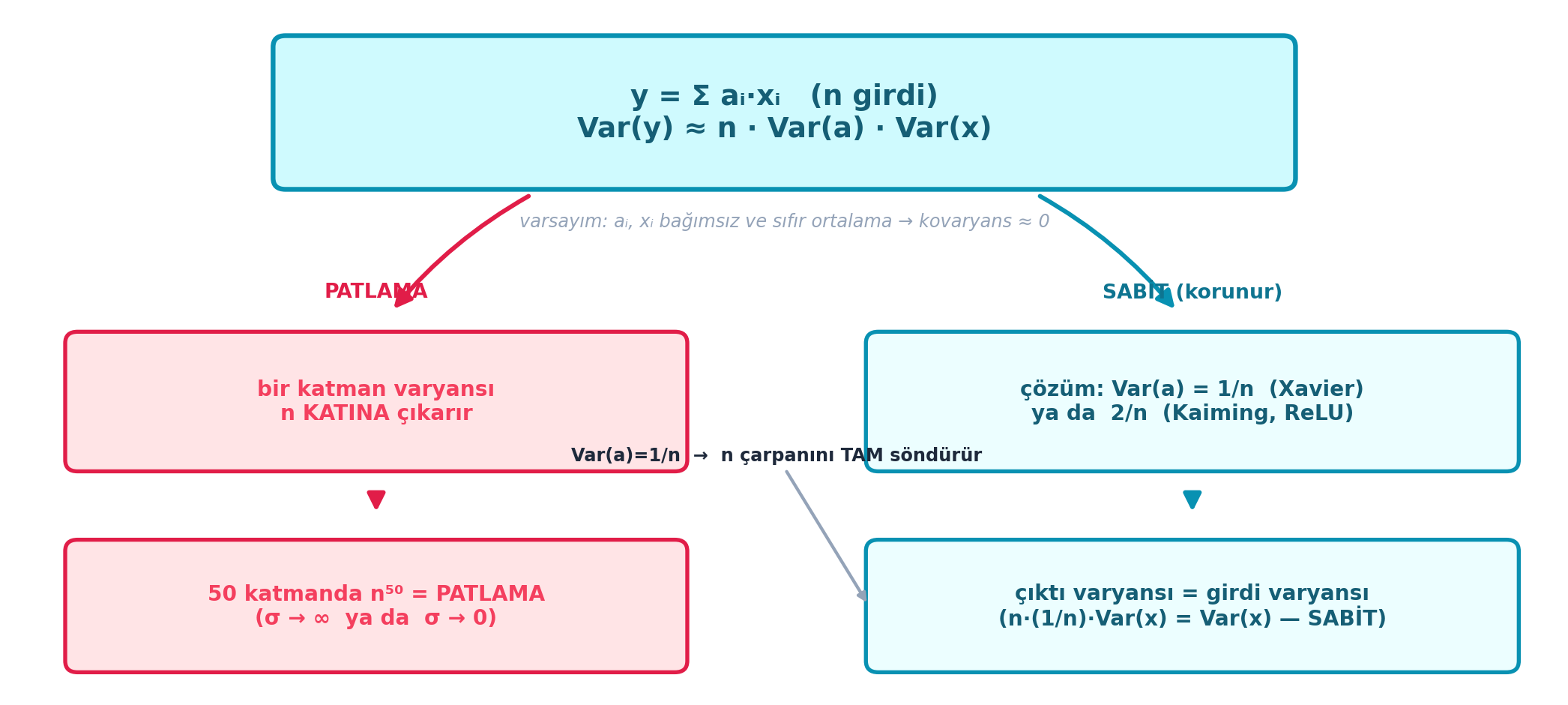
İpucuBuilder Notu — Glorot: Karpathy’nin Elle Bulduğu « Kar-Tanesi »
- Geriye (Karpathy makemore 3): Karpathy “kar-tanesi” sabitini (gain/√fan_in) elle bulup ağırlıkları ölçekler — bu tam olarak Glorot init’in türetilmesi. Karpathy önce sezgiyle \(0.2\) gibi bir sabit dener, sonra √fan_in’in neden doğru olduğunu görür; Howard aynı sonucu varyans cebrinden türetir.
- Sezgi: Formülün kalbi tek bir kelimede: n. Çıktı, n tane çarpımın toplamıdır; bağımsız terimlerin toplamının varyansı, varyansların toplamıdır → n çarpanı buradan gelir. √n ile bölmek tam olarak bu n’i geri söndürür: \(n \cdot (1/n) \cdot \mathrm{Var}(x) = \mathrm{Var}(x)\). Girdi varyansı çıktıya değişmeden geçer.
20.9 8. ReLU Sorunu ve Kaiming (He) Başlatma
Xavier, ReLU’yu hesaba katmaz. ReLU negatifleri sıfırlar → aktivasyonların ~yarısını siler → varyansı yarıya indirir. Telafi için varyansı iki katına ölçekle: \(\mathrm{Var}(a) = 2/n\), yani \(\sqrt{2/n}\) ile böl. Bu Kaiming (He) init’tir; ReLU’lu derin ağların standardı. Deney: 50 katman ReLU + √(2/100) ile aktivasyonlar sağ kalır.
x = torch.randn(200, 100)
for i in range(50): x = relu(x @ (torch.randn(100,100) * sqrt(2/100)))
x[0:5,0:5] # patlamadı, sönmedi — Kaiming init işe yaradı“rectified linear units, which is not something that Xavier Glorot looked at.” — Howard, 33:23
Şekil 20.5 ReLU’nun varyans üzerindeki etkisini gerçek hesaplamayla gösterir: solda standart normal girdi (\(E[x^2] \approx 1.0\), simetrik), sağda relu(x) çıktısı (\(E[\mathrm{relu}^2] \approx 0.5\) — negatifler sıfırda yığılır). ReLU karesel-ortalamayı yarılar; bu yüzden Kaiming √(2/n) (Xavier’in √2 katı telafisi) varyansı korur. Şekil 20.6 ise ReLU’lu 30-katman ağda iki init’i yarıştırır: Xavier (1/√n) varyansı söndürür (→0), Kaiming (√(2/n)) sabit (~1) tutar.
Kod
d = E.relu_variance_demo()
ms_before, ms_after = d["ms_before"], d["ms_after"]
x = np.random.default_rng(1).standard_normal(300000)
y = np.maximum(x, 0.0)
fig, (axL, axR) = plt.subplots(1, 2, figsize=(11, 4.8))
bins = np.linspace(-4.5, 4.5, 90)
# SOL: standart normal x (simetrik, cyan) — E[x²] ≈ 1
axL.hist(x, bins=bins, color=COL_PRIMARY, alpha=0.85, edgecolor=COL_WHITE, linewidth=0.2)
axL.axvline(0, color=COL_SLATE_400, lw=1.0, ls="--")
axL.set_title("girdi x ~ N(0, 1)", color=COL_CYAN_800, fontsize=12, weight="bold")
axL.set_xlabel("değer", fontsize=10)
axL.set_ylabel("frekans", fontsize=10)
axL.text(0.04, 0.93, f"E[x²] = {ms_before:.2f}", transform=axL.transAxes,
fontsize=13, weight="bold", color=COL_CYAN_800,
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG, ec=COL_PRIMARY, lw=1.5))
apply_style(axL)
# SAĞ: relu(x) (negatifler 0'da yığılır, rose) — E[relu²] ≈ 0.5
axR.hist(y, bins=bins, color=COL_ACCENT, alpha=0.85, edgecolor=COL_WHITE, linewidth=0.2)
axR.axvline(0, color=COL_SLATE_400, lw=1.0, ls="--")
axR.set_title("relu(x) = max(0, x)", color=COL_ROSE_500, fontsize=12, weight="bold")
axR.set_xlabel("değer", fontsize=10)
axR.text(0.55, 0.93, f"E[relu²] = {ms_after:.2f}", transform=axR.transAxes,
fontsize=13, weight="bold", color=COL_ACCENT,
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG_ROSE, ec=COL_ACCENT, lw=1.5))
# negatifler 0'da yığılır oku
axR.annotate("negatifler\n→ 0'da yığılır", xy=(0.0, 0.62), xycoords=("data", "axes fraction"),
xytext=(-3.6, 0.62), textcoords=("data", "axes fraction"),
fontsize=9.5, color=COL_ROSE_500, weight="bold", va="center", ha="center",
arrowprops=dict(arrowstyle="-|>", color=COL_ROSE_500, lw=1.8))
apply_style(axR)
# ORTADA "÷2" oku (sol histogramdan sağa)
fig.subplots_adjust(wspace=0.34)
fig.text(0.503, 0.55, "÷2", ha="center", va="center", fontsize=20, weight="bold",
color=COL_CYAN_700,
bbox=dict(boxstyle="circle,pad=0.32", fc=COL_WHITE, ec=COL_CYAN_700, lw=2.2))
fig.text(0.503, 0.40, "→", ha="center", va="center", fontsize=22, weight="bold",
color=COL_CYAN_700)
# Alt açıklama: neden Kaiming √(2/n)
fig.text(0.5, 0.005,
"ReLU negatifleri sıfırlar → karesel-ortalama yarılanır (E[x²]: 1.0 → 0.5) · "
"bu yüzden Kaiming √(2/n) (Xavier'in √2 katı telafisi) varyansı korur",
ha="center", va="bottom", fontsize=9.5, color=COL_TEXT, style="italic")
plt.tight_layout(rect=(0, 0.05, 1, 1))
plt.show()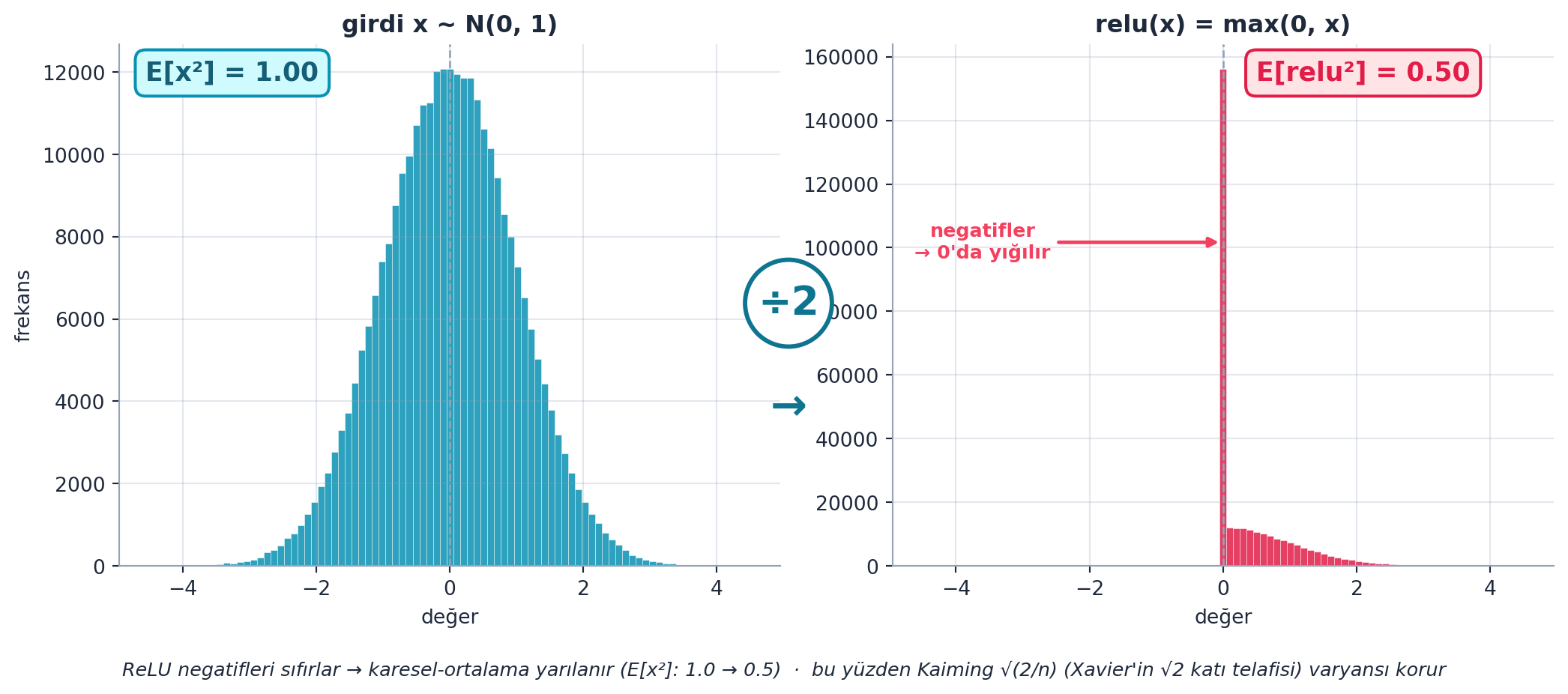
Kod
d = E.init_comparison_demo()
layers = np.array(d["layers"])
std_x = np.array(d["std_xavier"])
std_k = np.array(d["std_kaiming"])
# söndürme görünür olsun diye 0'ı taban değerle değiştir (log-y için)
floor = 1e-3
std_x_plot = np.clip(std_x, floor, None)
std_k_plot = np.clip(std_k, floor, None)
fig, ax = plt.subplots(figsize=(10, 5))
ax.plot(layers, std_k_plot, color=COL_PRIMARY, lw=2.6, marker="o", ms=4,
label="Kaiming √(2/n) → sabit ~1")
ax.plot(layers, std_x_plot, color=COL_ACCENT, lw=2.6, marker="s", ms=4,
label="Xavier 1/√n → söner (→0)")
ax.set_yscale("log")
ax.axhline(1.0, color=COL_SLATE_400, lw=1.2, ls="--", zorder=1)
ax.text(layers[-1], 1.0, " hedef σ ≈ 1", color=COL_CYAN_800,
fontsize=9.5, va="bottom", ha="right", weight="bold")
# Xavier'ın söndüğü bölgeyi işaretle
xi = int(len(layers) * 0.55)
ax.annotate(
"Xavier ReLU yarılamasını\ntelafi etmez → varyans söner",
xy=(layers[xi], std_x_plot[xi]),
xytext=(layers[xi] - 2, 0.012),
color=COL_ACCENT, fontsize=10, weight="bold", ha="center",
arrowprops=dict(arrowstyle="-|>", color=COL_ACCENT, lw=1.8),
)
# Kaiming'in sabitliğini işaretle
ki = int(len(layers) * 0.72)
ax.annotate(
"Kaiming √2 faktörüyle\nvaryansı korur",
xy=(layers[ki], std_k_plot[ki]),
xytext=(layers[ki] - 6, 3.2),
color=COL_CYAN_800, fontsize=10, weight="bold", ha="center",
arrowprops=dict(arrowstyle="-|>", color=COL_PRIMARY, lw=1.8),
)
ax.set_title("ReLU'lu 30-katman ağda aktivasyon std: Xavier söner, Kaiming sabit",
fontsize=12.5, weight="bold", pad=12)
ax.set_xlabel("katman derinliği")
ax.set_ylabel("aktivasyon std (σ) — log skala")
ax.set_xlim(layers[0], layers[-1])
ax.legend(loc="lower left", frameon=True, fontsize=10.5)
apply_style(ax)
# alt vurgu: ReLU'lu derin ağ için Kaiming şart
fig.text(0.5, -0.02,
"ReLU'lu derin ağ için Kaiming ŞART — Xavier varyansı katman katman söndürür, sinyal kaybolur",
ha="center", color=COL_CYAN_700, fontsize=10, weight="bold")
plt.tight_layout()
plt.show()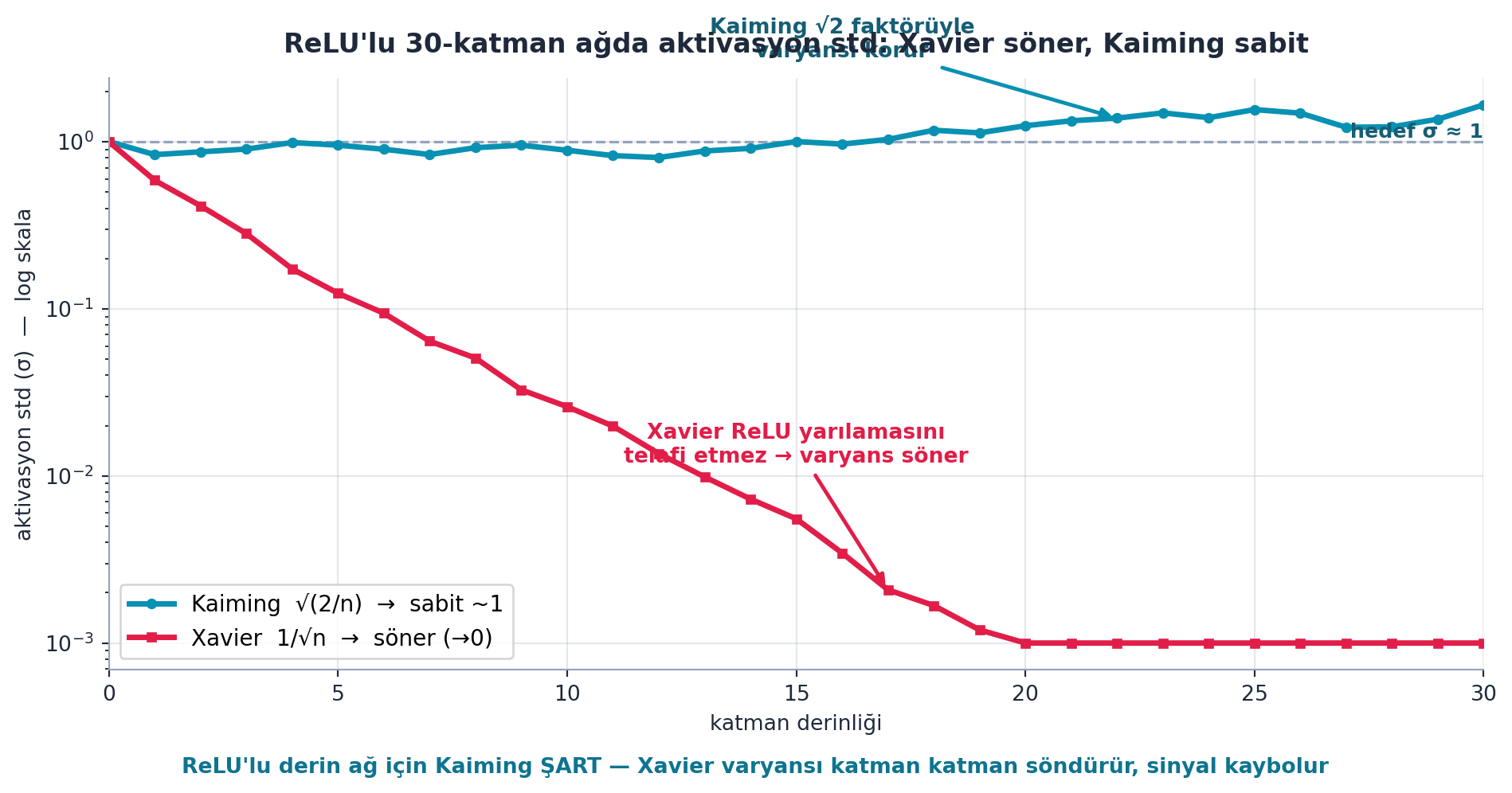
ÖnemliBuilder Notu — Kaiming = Karpathy makemore 3’ün TAM OMURGASI (MERKEZÎ)
- Geriye (Karpathy makemore 3) — MERKEZÎ: Karpathy makemore 3’ün tüm omurgası budur: aktivasyon istatistiklerini izle → varyansın katmandan katmana bozulduğunu gör → Kaiming gain (\(\sqrt{2/n}\)) ile ağırlıkları ölçekle → düzeldiğini doğrula. Karpathy tanh için gain’i \(5/3\) olarak elle bulur; ReLU için bu \(\sqrt{2}\)’dir. Aynı fikir, farklı aktivasyon.
- İki yol, tek fizik: Howard top-down (önce hook’la sorunu gör, sonra matematikle türet), Karpathy bottom-up (önce elle deneyerek türet, sonra histogramla gör) — ikisi de aynı sonuca varır: varyans korunumu. Builder için bu eşitlik dersin kalbidir:
init.kaiming_normal_’in altındaki büyü = Karpathy’nin satır satır yazdığı şey. - Sezgi: ReLU sinyalin yarısını (negatifleri) attığı için varyans yarıya iner; √2 ile çarpmak (yani 1/n yerine 2/n) bu kaybı önceden telafi eder. Telafi katmanın çıkışında değil, ağırlığın başlangıcında yapılır — bu yüzden “başlatma” sorunudur.
20.10 9. init Fonksiyonunu Uygulamak
PyTorch’ta model.apply(fn) her alt-modüle bir fonksiyon uygular. Kaiming init’i tüm conv katmanlarına böyle uygularız. init.kaiming_normal_ PyTorch’un hazır Kaiming başlatıcısıdır.
def init_weights(m):
if isinstance(m, (nn.Conv1d,nn.Conv2d,nn.Conv3d)): init.kaiming_normal_(m.weight)
model.apply(init_weights)
İpucuBuilder Notu — model.apply: Ağaç Gezme Deseni
- İleriye:
model.applyağaç gezme (tree traversal) deseni; tüm katmanlara toplu işlem uygulamanın standart yolu. Aynı desenle ağırlık dondurma, ağırlık paylaşımı, custom init hep tek satırda uygulanır. - Sezgi:
isinstancekontrolü init’i yalnızca conv katmanlarına uygular — BatchNorm veya bias gibi farklı başlatma isteyen modülleri atlar. Bu seçicilik önemlidir: her katman tipi kendi doğru init’ini ister, hepsine aynı şeyi uygulamak yeni bir hata kaynağıdır.
20.11 10. Girdi Normalizasyonu
İlk katmanın girdisi de doğru ölçekte olmalı: veriyi ortalaması 0, std’si 1 olacak şekilde normalize et (\(x' = (x - \mu) / \sigma\)). Bunu bir callback (BatchTransformCB) ile her batch’e uygularız — eğitim ve doğrulamada tutarlı.
xmean,xstd = xb.mean(), xb.std()
class BatchTransformCB(Callback):
def __init__(self, tfm, on_train=True, on_val=True): fc.store_attr()
def before_batch(self, learn):
if (self.on_train and learn.training) or (self.on_val and not learn.training):
learn.batch = self.tfm(learn.batch)
İpucuBuilder Notu — Girdi Normalizasyonu: Zincirin İlk Halkası
- Geriye (Ders 16): Yine bir callback; girdi normalizasyonu çekirdek döngüden ayrı, yeniden kullanılabilir —
BatchTransformCBDers 16’nınbefore_batchkancasına takılır. - Sezgi: Kaiming init katmanların varyansını korur ama bu, ilk girdinin zaten σ ≈ 1 olduğunu varsayar. Girdi normalizasyonu o varsayımı sağlar: zincirin başını doğru ölçeğe oturtursan, init zincirin geri kalanını korur. Eğitim/doğrulamada aynı μ, σ kullanmak kritiktir — yoksa model gördüğü dağılımdan farklı bir dağılımda test edilir.
20.12 11. GeneralReLU: 0-Ortalamalı Aktivasyon
ReLU çıktısı hep ≥ 0 olduğundan aktivasyon ortalaması pozitife kayar — bu da bir tür içsel kayma. Howard GeneralRelu ile çözer: küçük bir negatif eğim (leak) ekler ve çıktıyı bir sabit (sub) kadar aşağı kaydırarak ortalamayı ~0’a çeker.
class GeneralRelu(nn.Module):
def __init__(self, leak=None, sub=None, maxv=None):
super().__init__()
self.leak,self.sub,self.maxv = leak,sub,maxv
def forward(self, x):
x = F.leaky_relu(x,self.leak) if self.leak is not None else F.relu(x)
if self.sub is not None: x -= self.sub
if self.maxv is not None: x.clamp_max_(self.maxv)
return x
İpucuBuilder Notu — GeneralReLU: Ortalamayı Sıfıra Çekmek
- Geriye (Karpathy makemore): Karpathy de “tanh çıktısının ortalaması sıfırdan kaymış” sorununu tartışır; aktivasyon ortalamasını 0’a çekmek ortak temadır. İki kursta da hedef aynı: sadece varyansı değil, ortalamayı da kontrol altında tutmak.
- Sezgi: ReLU’nun iki gizli problemi var: (1) negatif girdiler için gradyan tam sıfır (ölü nöron), (2) çıktı hep pozitif (ortalama kayar).
leakbirinciyi çözer (küçük negatif eğim → gradyan akar),subikinciyi (sabit kaydırma → ortalama ~0).maxvise üstten kırparak patlamayı sınırlar. Üç küçük müdahale, üç ayrı dert.
20.13 12. LSUV: Veriye Bağlı Başlatma
Init’i formülle değil veriyle ayarlamak: LSUV (Layer-wise Sequential Unit Variance). Bir batch’i ağdan geçir, her katmanın çıktısının ortalama/std’sini hook’la ölç, sonra ağırlık ve bias’ı çıktı ortalaması 0 / std 1 olana dek kaydır-ölçekle. Karmaşık mimarilerde formül bilinmese bile çalışır.
İpucuBuilder Notu — LSUV: Formülü Bilmiyorsan Veriden Öğren
- İleriye: LSUV, “doğru init formülünü bilmiyorsan veriden öğren” fikri; modern mimarilerde (transformer init) hâlâ değerli. Karmaşık bloklar (attention, residual) için kapalı-form varyans formülü türetmek zordur — LSUV bunu deneysel olarak çözer.
- Sezgi: Kaiming bir formül (matematikten gelen ölçek); LSUV bir prosedür (veriden gelen ölçek). LSUV hook’ları (§2) kullanarak gerçek bir batch’in gerçek aktivasyon std’sini ölçer ve ağırlığı tam o std’ye bölerek çıktıyı 1’e zorlar. Formül yanılabileceği yerde (özel aktivasyon, karmaşık blok) veri yanılmaz.
20.14 13. LayerNorm: En Basit Normalizasyon
Howard normalizasyona en sade olandan başlar: LayerNorm. Her örnek için, kendi aktivasyonlarının ortalama/varyansıyla normalize eder (batch’ten bağımsız). Tüm fikir tek bir küçük modüldür; öğrenilebilir mult (γ) ve add (β) ağa ölçeği geri kazanma esnekliği verir.
class LayerNorm(nn.Module):
def __init__(self, dummy, eps=1e-5):
super().__init__()
self.eps = eps
self.mult = nn.Parameter(tensor(1.))
self.add = nn.Parameter(tensor(0.))
def forward(self, x):
m = x.mean((1,2,3), keepdim=True)
v = x.var ((1,2,3), keepdim=True)
x = (x-m) / ((v+self.eps).sqrt())
return x*self.mult + self.add“the whole thing is this code. What is layer normalization? Well, we can create a module.” — Howard, 1:07:11
İpucuBuilder Notu — LayerNorm: Transformer’ların Standart Normu
- İleriye (Ders 24, transformer): LayerNorm, transformer’ların standart normalizasyonudur; attention dersinde tekrar karşımıza çıkar. Karpathy’nin nanoGPT’sinde de her transformer bloğunda LayerNorm vardır.
- Sezgi: LayerNorm her örneği kendi içinde normalize eder — batch’teki diğer örneklerle hiç konuşmaz. Bu onu batch boyutuna duyarsız kılar (batch=1 bile çalışır), train/eval ayrımına gerek bırakmaz. Öğrenilebilir γ ve β, normalizasyonun ağı fazla kısıtlamasını önler: ağ gerekirse ölçeği/kaymayı geri kazanabilir. Tek modül, tek forward — Howard’ın vurgusu “the whole thing is this code”.
20.15 14. BatchNorm: Çalışan İstatistikler
BatchNorm her kanalı, mini-batch’in ortalama/varyansıyla normalize eder. Kritik incelik: eğitimde batch istatistiği kullanılır ve bir çalışan ortalama (running mean/variance) lerp_ (üssel hareketli ortalama) ile biriktirilir; çıkarımda (eval) bu biriken istatistik kullanılır. register_buffer ile saklanan bu değerler parametre değildir (gradyan almaz) ama modelle kaydedilir.
Normalizasyon: \(\hat{x} = (x - \mu) / \sqrt{\sigma^2 + \varepsilon}\), ardından \(y = \gamma \cdot \hat{x} + \beta\).
class BatchNorm(nn.Module):
def __init__(self, nf, mom=0.1, eps=1e-5):
super().__init__()
self.mom,self.eps = mom,eps
self.mults = nn.Parameter(torch.ones (nf,1,1))
self.adds = nn.Parameter(torch.zeros(nf,1,1))
self.register_buffer('vars', torch.ones(1,nf,1,1))
self.register_buffer('means', torch.zeros(1,nf,1,1))
def update_stats(self, x):
m = x.mean((0,2,3), keepdim=True)
v = x.var ((0,2,3), keepdim=True)
self.means.lerp_(m, self.mom)
self.vars.lerp_ (v, self.mom)
return m,v
def forward(self, x):
if self.training:
with torch.no_grad(): m,v = self.update_stats(x)
else: m,v = self.means,self.vars
x = (x-m) / (v+self.eps).sqrt()
return x*self.mults + self.adds“Batch Normalization was such an important paper.” — Howard, 1:04:26
Şekil 20.7 BatchNorm’un en kritik inceliğini gerçek hesaplamayla gösterir: eğitim boyunca batch ortalaması (cyan, oynak zigzag) her mini-batch’te zıplar; running mean (rose, kalın, lerp_ üssel hareketli) ise yumuşakça gerçek ortalamaya yakınsar. Çıkarımda (eval) batch istatistiği yerine bu biriken running değer kullanılır. register_buffer ile saklanan running mean, parametre değildir (gradyan almaz) ama modelle kaydedilir.
Kod
d = E.batchnorm_running_demo()
steps = np.asarray(d["steps"])
batch_means = np.asarray(d["batch_means"])
running_means = np.asarray(d["running_means"])
true_mean = d["true_mean"]
final_running = d["final_running"]
fig, ax = plt.subplots(figsize=(10.5, 5))
# Gerçek ortalama: yatay kesik referans çizgisi
ax.axhline(true_mean, color=COL_SLATE_400, linestyle="--", linewidth=1.6,
zorder=1, label=f"gerçek ortalama (μ = {true_mean:.1f})")
# Batch ortalaması: soluk cyan, OYNAK zigzag
ax.plot(steps, batch_means, color=COL_CYAN_400, linewidth=1.6, alpha=0.85,
marker="o", markersize=3.5, zorder=2,
label="batch ortalaması (her mini-batch'te oynak)")
# Running mean (lerp): rose kalın, YUMUŞAK yakınsar
ax.plot(steps, running_means, color=COL_ACCENT, linewidth=3.0, zorder=3,
label=f"running ort (lerp_, üssel hareketli) → {final_running:.2f}")
apply_style(ax)
ax.set_xlabel("eğitim adımı (mini-batch)")
ax.set_ylabel("aktivasyon ortalaması")
ax.set_title("BatchNorm running mean: eğitim vs çıkarım (eval)", color=COL_TEXT, weight="bold")
ax.set_xlim(steps.min() - 0.5, steps.max() + 0.5)
ax.legend(loc="upper right", framealpha=0.95, fontsize=9.5)
# Açıklayıcı annotate: EĞİTİM → ÇIKARIM mantığı
ax.annotate(
"EĞİTİM: gürültülü batch istatistiği;\n"
"running ort (üssel hareketli, lerp_)\n"
"yumuşakça yakınsar →\n"
"ÇIKARIM (eval): batch yerine\n"
"running kullanılır",
xy=(steps[-1], running_means[-1]),
xytext=(steps[-1] * 0.46, true_mean - 1.55),
fontsize=9.5, color=COL_TEXT,
ha="left", va="top",
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG_ROSE,
ec=COL_ROSE_400, linewidth=1.4),
arrowprops=dict(arrowstyle="-|>", color=COL_ROSE_500, linewidth=1.6,
connectionstyle="arc3,rad=-0.2"),
zorder=4,
)
# register_buffer notu
ax.text(0.012, 0.035,
"register_buffer ile saklanır (parametre değil, gradyan almaz)",
transform=ax.transAxes, fontsize=8.8, color=COL_CYAN_800,
style="italic", ha="left", va="bottom",
bbox=dict(boxstyle="round,pad=0.3", fc=COL_CYAN_50,
ec=COL_CYAN_400, linewidth=1.0))
plt.tight_layout()
plt.show()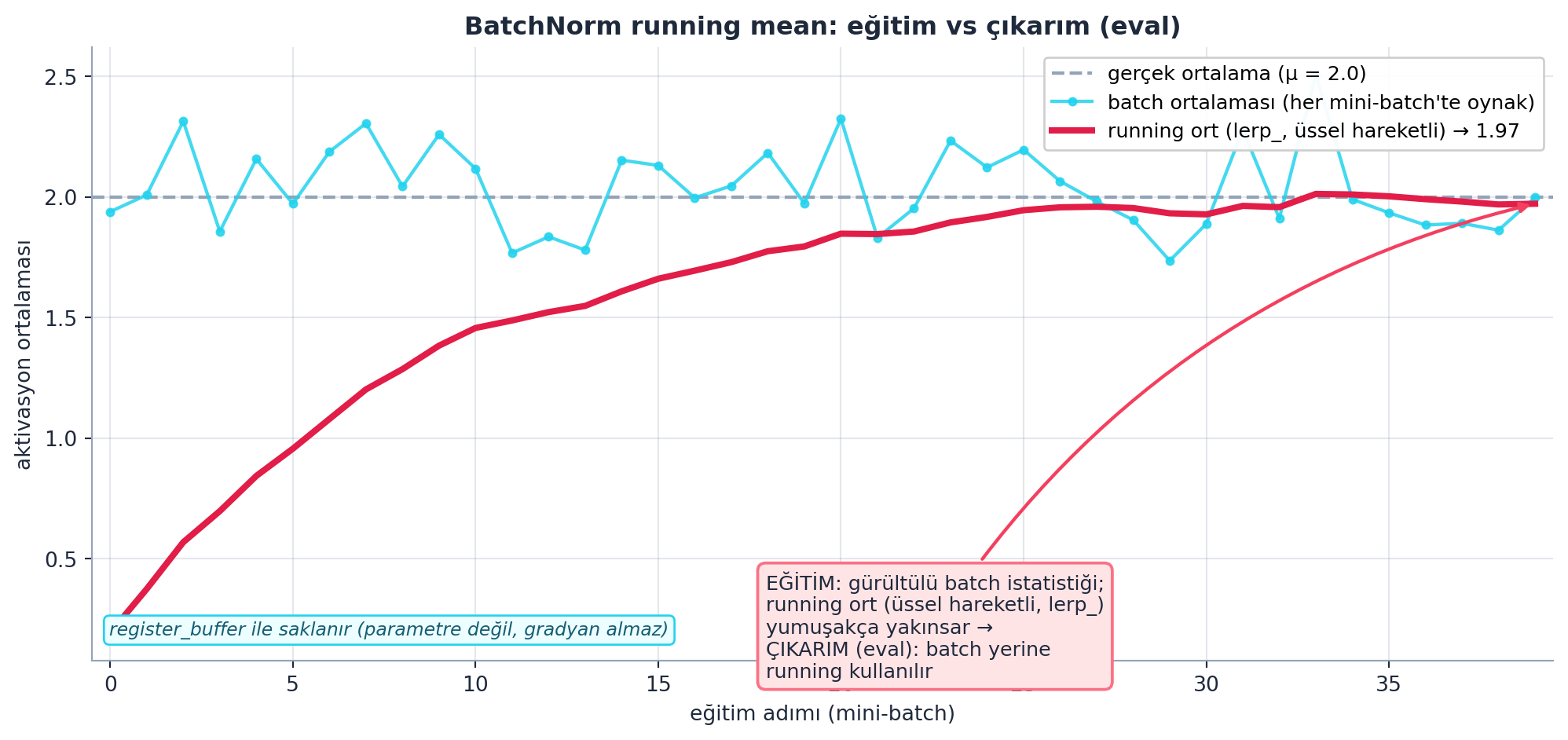
ÖnemliBuilder Notu — BatchNorm running_mean = Karpathy makemore 3’ün En Öğretici Noktası (MERKEZÎ)
- Geriye (Karpathy makemore 3) — MERKEZÎ: Karpathy BatchNorm’u tam bu detaylarla (batch istatistiği vs running mean, train/eval ayrımı, “BatchNorm batch’leri bağlar” tuhaflığı) sıfırdan kurar.
running_mean/running_varayrımı iki kursta da en kafa karıştırıcı ama en öğretici noktadır. Karpathy’ninbnmean_running/bnstd_runningdeğişkenleri = Howard’ınregister_buffer’lımeans/vars’ı. - Sezgi (varyans korunumu sentezi): BatchNorm, init’in yaptığını sürekli yapar. Kaiming varyansı bir kez (başlangıçta) sabitler; eğitim ilerledikçe ağırlıklar değişip varyansı yine bozabilir. BatchNorm her forward’da aktivasyonu yeniden σ ≈ 1’e zorlar — yani varyans korunumunu her adımda yeniler. İkisi aynı ilkenin iki uygulamasıdır: biri statik (init), öteki dinamik (norm).
- Tuzak:
lerp_(m, mom)üssel hareketli ortalamadır;no_gradiçinde, çünkü running istatistik gradyan akışına girmemeli (sadece izleyici).model.eval()çağırmayı unutmak → eval’de batch istatistiği kullanılır → tek örnekte saçma sonuç. Bu, production’da en sık yapılan BatchNorm hatasıdır.
20.16 15. BatchNorm vs LayerNorm — Gümüş Kurşun Değil
BatchNorm devrimdi (çok daha yüksek learning rate, hızlı eğitim) ama bedeli var: batch örneklerini birbirine bağlar, küçük batch’te bozulur, train/eval farkı karmaşıklık yaratır. LayerNorm bunlardan kaçınır (örnek-içi normalize). Howard’ın uyarısı: normalizasyon yardımcıdır ama her derde deva değildir.
“they’re still very helpful, but they’re not a silver bullet, as it turns out.” — Howard, 1:15:30
İpucuBuilder Notu — Norm Seçimi: Göreve Göre Karar
- İleriye: Modern mimariler norm seçimini (BatchNorm/LayerNorm/GroupNorm/RMSNorm) göreve göre yapar; “hangi norm” kararı production’da önemlidir. CNN’lerde genelde BatchNorm, transformer’larda LayerNorm, küçük-batch görüntüde GroupNorm.
- Sezgi: BatchNorm’un gücü ve zayıflığı aynı kökten: batch’i kullanır. Bu hızlı eğitim sağlar (batch istatistiği bedava bir regularizasyon getirir) ama örnekleri birbirine bağlar — bir örneğin çıktısı batch’teki diğerlerine bağlı hale gelir, küçük/değişken batch’te bozulur. LayerNorm bu bağı kesip her örneği yalıtır; bedeli, BatchNorm’un sağladığı batch-düzeyi regularizasyonu kaybetmektir. “Gümüş kurşun yok” — her seçimin bir bedeli var.
20.17 16. Kapanış
Ders 17, derin ağ eğitiminin en derin teknik sorununu çözdü: aktivasyonların patlaması/sönmesi. Yol: hook’larla teşhis → varyans/kovaryans matematiği → Xavier (1/√n) ve Kaiming (√(2/n)) init → girdi normalizasyonu + GeneralReLU → LSUV → LayerNorm ve BatchNorm sıfırdan. Hepsinin altında tek ilke var: varyansı sabit tut. Bu, Karpathy makemore 3’ün fast.ai karşılığı ve sonraki tüm derin mimarilerin (ResNet, diffusion) önkoşuludur.
Şekil 20.8 dersin sentezidir (Karpathy köprüsü merkezde): solda L17/Howard pipeline’ı (hook telemetri → varyans matematiği → Kaiming init → BatchNorm) top-down, sağda Karpathy makemore 3 pipeline’ı (aktivasyon histogramı → gain’i elle türet → BatchNorm sıfırdan → kararlı derin ağ) bottom-up. İki yol ortada tek ilkede buluşur: varyans korunumu. Altta üç köprü: varyans/kovaryans → Stat 110 + 18.06, Kaiming → init.kaiming_normal_ altındaki büyü, BatchNorm running_mean → Ders 18+ / diffusion önkoşulu.
Kod
fig, ax = plt.subplots(figsize=(12.5, 6))
ax.set_xlim(0, 12.5)
ax.set_ylim(0, 6)
ax.axis("off")
ax.set_facecolor(COL_WHITE)
# --- Başlık şeritleri (iki kurs) -------------------------------------------
ax.text(2.6, 5.72, "L17 (Howard, top-down)", ha="center", va="center",
fontsize=12, weight="bold", color=COL_ACCENT)
ax.text(9.9, 5.72, "Karpathy makemore 3 (bottom-up)", ha="center", va="center",
fontsize=12, weight="bold", color=COL_CYAN_700)
# --- SOL sütun: L17 / Howard (rose) — yukarıdan aşağı pipeline ---------------
left_nodes = [
"hook telemetri\n(aktivasyon std izle)",
"varyans matematiği\n(katman katman korunum)",
"Kaiming init\n√(2/n) — ReLU telafisi",
"BatchNorm\n(normalize + running)",
]
left_y = [5.05, 4.0, 2.95, 1.9]
for txt, yy in zip(left_nodes, left_y):
boxed_node(ax, 2.6, yy, 3.4, 0.72, txt, fc=COL_BG_ROSE, ec=COL_ACCENT,
tc=COL_TEXT, fontsize=9.5, lw=2.0)
for y0, y1 in zip(left_y[:-1], left_y[1:]):
arrow_between(ax, (2.6, y0), (2.6, y1), color=COL_ROSE_500, lw=2.0, shrink=18)
# --- SAĞ sütun: Karpathy makemore 3 (cyan) — bottom-up pipeline -------------
right_nodes = [
"aktivasyon histogramı\n(katman katman bak)",
"gain'i elle türet\n(5/3, √2 ... deneyerek)",
"BatchNorm sıfırdan\n(mean/var elle yaz)",
"kararlı derin ağ\n(varyans sabit kalır)",
]
right_y = [5.05, 4.0, 2.95, 1.9]
for txt, yy in zip(right_nodes, right_y):
boxed_node(ax, 9.9, yy, 3.4, 0.72, txt, fc=COL_CYAN_50, ec=COL_PRIMARY,
tc=COL_TEXT, fontsize=9.5, lw=2.0)
for y0, y1 in zip(right_y[:-1], right_y[1:]):
arrow_between(ax, (9.9, y0), (9.9, y1), color=COL_PRIMARY, lw=2.0, shrink=18)
# --- ORTA: tek ilke vurgusu -------------------------------------------------
boxed_node(ax, 6.25, 3.5, 3.0, 1.35,
"tek ilke:\nVARYANS\nKORUNUMU", fc=COL_ACCENT, ec=COL_CYAN_800,
tc=COL_WHITE, fontsize=14, lw=2.6)
# her iki kurstan ORTAK ilkeye ok (varyans korunumu)
arrow_between(ax, (4.3, 4.0), (5.05, 3.7), color=COL_ROSE_500, lw=2.4,
shrink=10, connectionstyle="arc3,rad=-0.12")
arrow_between(ax, (8.2, 4.0), (7.45, 3.7), color=COL_PRIMARY, lw=2.4,
shrink=10, connectionstyle="arc3,rad=0.12")
ax.text(6.25, 4.62, "varyans korunumu", ha="center", va="center",
fontsize=9, style="italic", color=COL_CYAN_800)
# --- ALT köprüler (3 referans bağlantısı) ----------------------------------
bridges = [
"varyans / kovaryans → Stat 110 + 18.06",
"Kaiming → init.kaiming_normal_ altındaki büyü",
"BatchNorm running_mean → Ders 18+ / diffusion önkoşulu",
]
bx = [2.6, 6.25, 9.9]
for txt, xx in zip(bridges, bx):
boxed_node(ax, xx, 0.62, 3.55, 0.66, txt, fc=COL_WHITE, ec=COL_SLATE_400,
tc=COL_CYAN_800, fontsize=8.2, lw=1.4, weight="normal")
# orta ilke + iki pipeline'dan alt köprülere ince ok
arrow_between(ax, (2.6, 1.54), (2.6, 0.95), color=COL_SLATE_400, lw=1.3, shrink=10)
arrow_between(ax, (6.25, 2.82), (6.25, 0.95), color=COL_SLATE_400, lw=1.3, shrink=10)
arrow_between(ax, (9.9, 1.54), (9.9, 0.95), color=COL_SLATE_400, lw=1.3, shrink=10)
ax.text(6.25, 5.78, "iki yol, tek fizik", ha="center", va="center",
fontsize=10.5, weight="bold", color=COL_CYAN_800)
plt.tight_layout()
plt.show()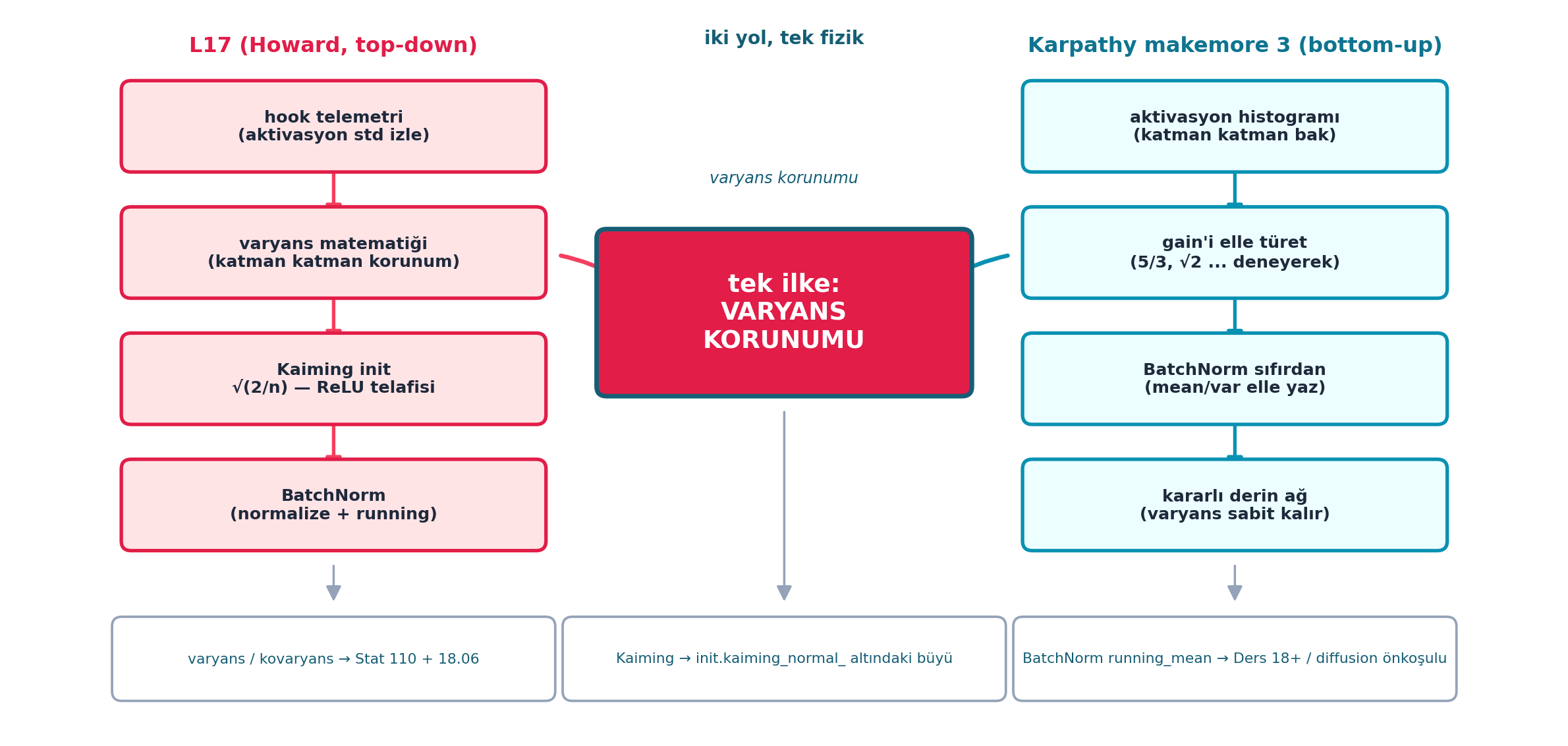
İpucuBuilder Notu — Kapanış: Sırada Hızlandırma ve ResNet
- İleriye (Ders 18): Sağlam init+norm hazır; Ders 18 hızlandırılmış optimizer’ları (momentum, Adam) ve ResNet’i (skip connection) bunun üstüne kurar. Init varyansı bir kez sabitler, norm sürekli; ResNet’in skip bağlantısı ise sinyalin derin ağda hiç bozulmadan akmasını sağlayan üçüncü mekanizmadır.
- Sezgi: Bu derste derin ağları eğitilebilir kıldık — patlama/sönme duvarını aştık. Sıradaki dersler eğitimi hızlandırır (daha iyi optimizer) ve derinleştirir (residual). Üç mekanizma (init + norm + skip) birlikte, modern derin öğrenmenin (ResNet’ten diffusion’a) çalışmasının temelidir.
20.18 Bu Dersin Özeti
- Telemetri (hooks): Eğitim sırasında her katmanın aktivasyon ortalama/std’sini izle; sorunu görmeden çözemezsin (telemetri).
- Sorun: Kötü init’te aktivasyonlar derin ağda ya
nan’a patlar ya sıfıra söner — eğitim imkânsız (sorun). - Varyans korunumu: \(y = \sum a_i x_i\) çıktı varyansı girdi sayısı n ile çarpılır (\(\mathrm{Var}(y) \approx n \cdot \mathrm{Var}(a) \cdot \mathrm{Var}(x)\)); n katmanda üssel bozulma (Xavier).
- Xavier (Glorot): Ağırlığı √n ile böl (\(\mathrm{Var}(a) = 1/n\)) → çıktı varyansı = girdi varyansı (Xavier).
- Kaiming (He): ReLU varyansı yarılar; √(2/n) ile böl → ReLU’lu derin ağların standardı (Kaiming).
- Girdi normalizasyonu + GeneralReLU: Girdiyi 0-ortalama/1-std yap; ReLU çıktısını 0-ortalamaya kaydır (girdi norm, GeneralReLU).
- LayerNorm: Her örneği kendi istatistiğiyle normalize eder; tek modül, batch’ten bağımsız (LayerNorm).
- BatchNorm: Batch istatistiğiyle normalize;
running_mean/running_var(register_buffer,lerp_) çıkarımda kullanılır; train/eval farkı kritik. Yardımcı ama gümüş kurşun değil (BatchNorm).
ÖnemliTek Bir Cümle
Derin ağ eğitiminin sırrı aktivasyon varyansını katmandan katmana sabit tutmaktır; bunu başlatma (Xavier 1/√n, ReLU için Kaiming √(2/n)) baştan, normalizasyon (LayerNorm/BatchNorm) eğitim boyunca sağlar — ve bu, Karpathy’nin makemore 3’te elle keşfettiği şeyin tam fast.ai karşılığıdır.
20.19 Kontrol Soruları
NotSoru 1: Aktivasyonların patlaması/sönmesi nedir ve neden olur?
Cevap:
Derin bir ağda her katman çıktısının varyansı, girdi sayısı n ile orantılı değişir: \(\mathrm{Var}(y) \approx n \cdot \mathrm{Var}(a) \cdot \mathrm{Var}(x)\). Eğer ağırlıklar çok büyükse her katman varyansı büyütür ve birçok katman sonra aktivasyonlar nan’a patlar; çok küçükse her katman küçültür ve aktivasyonlar sıfıra söner. İkisinde de gradyanlar bozulur (patlayan/kaybolan gradyan) ve eğitim imkânsız hâle gelir. Howard bunu 50 kez matris çarpma deneyiyle gösterir: standart normal ağırlık → nan, ×0.01 → 0. Çözüm, ağırlıkları varyans sabit kalacak şekilde ölçeklemek (Xavier/Kaiming init). (Şekil 20.3 üç eğriyle patlama/sönme/stabili gösterir.)
NotSoru 2: Xavier ile Kaiming init arasındaki fark nedir? Neden ReLU için Kaiming?
Cevap:
Xavier (Glorot) init, ağırlıkları √n ile böler (\(\mathrm{Var}(a) = 1/n\)), böylece doğrusal bir katmanın çıktı varyansı girdi varyansına eşit kalır. Ama ReLU’yu hesaba katmaz. ReLU negatif değerleri sıfırlar, yani aktivasyonların yaklaşık yarısını siler ve varyansı yarıya indirir. Bunu telafi etmek için Kaiming (He) init varyansı iki katına ölçekler: \(\mathrm{Var}(a) = 2/n\), yani √(2/n) ile böler. Sonuç: ReLU’lu derin ağlarda aktivasyon varyansı katmandan katmana korunur. Modern ReLU tabanlı ağların standardı Kaiming’dir; PyTorch’ta init.kaiming_normal_ ile uygulanır. (Şekil 20.5 ReLU’nun E[x²]’yi yarıladığını, Şekil 20.6 Xavier’in söndüğünü/Kaiming’in sabit kaldığını gösterir.)
NotSoru 3: BatchNorm eğitim ve çıkarım (eval) modunda neden farklı davranır? running_mean nedir?
Cevap:
Eğitimde BatchNorm her mini-batch’in kendi ortalama/varyansını kullanarak normalize eder — ama bu istatistik batch’ten batch’e oynar. Çıkarımda tek bir örnek olabilir (batch istatistiği anlamsız) ve sonuç deterministik olmalı. Çözüm: eğitim sırasında running_mean/running_var adlı bir çalışan (üssel hareketli) ortalama lerp_ ile biriktirilir (register_buffer ile saklanır — parametre değildir, gradyan almaz ama modelle kaydedilir). Eval modunda batch istatistiği yerine bu biriken running istatistik kullanılır. Bu train/eval ayrımı BatchNorm’un en kritik ve en sık hata yapılan noktasıdır (model.eval() çağırmayı unutmak yanlış sonuç verir). (Şekil 20.7 batch ortalamasının oynak, running ortalamanın yumuşak yakınsadığını gösterir.)
NotSoru 4: Bu ders Karpathy’nin makemore 3’üyle nasıl ilişkilidir? (builder bağlantısı)
Cevap:
İkisi de aynı problemi, aynı yöntemle, zıt yönlerden çözer. Karpathy makemore 3 (bottom-up): aktivasyon histogramlarını elle çizer, derin ağda istatistiğin bozulduğunu görür, Kaiming gain’i (√(2/n)) elle türetip ağırlıkları ölçekler, sonra BatchNorm’u sıfırdan (batch istatistiği vs running_mean, train/eval) kurar. Howard L17 (top-down): önce miniai hook’larıyla ActivationStats telemetrisini gösterir, sorunu grafik üzerinde tespit eder, varyans/kovaryans matematiğini kurup Xavier→Kaiming’i türetir, LayerNorm/BatchNorm’u yazar. Sonuç aynı tek ilkedir: varyans korunumu. Builder için bu, “kütüphanenin (init.kaiming_normal_, nn.BatchNorm2d) altındaki büyü = Karpathy’nin elle kurduğu şey” eşitliğinin en net örneğidir. (Şekil 20.8 iki pipeline’ı tek ilkede buluşturur.)
20.20 Egzersizler
Egzersiz 1 (Direkt uygulama). torch.randn(200,100)’ü 50 kez rastgele matrisle çarp; standart normal, ×0.01 ve ×√(2/100) ağırlıkla sonucu karşılaştır (patlama/sönme/sağ kalma — Şekil 20.3’in üç eğrisini kendi sayımınla doğrula — §4).
Egzersiz 2 (İki-aşamalı). Bir modele ActivationStats hook callback’i ekle, kötü init (varsayılan) ve Kaiming init ile eğit; color_dim grafiklerini karşılaştır (§3, §8).
Egzersiz 3 (Edge case). BatchNorm’u kendin yaz; aynı modeli model.train() ve model.eval() modunda çalıştır, running_mean kullanımının çıktıyı nasıl değiştirdiğini gözle (Şekil 20.7’in mantığını kendi kodunla üret — §14).
Egzersiz 4 (Kavramsal). Neden running_mean/running_var parametre değil de register_buffer ile tanımlanır? Gradyan alsaydı ne olurdu? (§14)
Egzersiz 5 (Sonraki dersin habercisi — Ders 18). Kaiming init aktivasyon varyansını sabitler; bir sonraki ders optimizer’ı (momentum/Adam) ele alır. Momentum’un gradyanları neden “yumuşattığını” düşün (§16).
20.21 Sonraki: Ders 18 İçin Hazırlık
Ders 18: Hızlandırılmış SGD ve ResNet (Accelerated SGD & ResNet)
Ders 17 sağlam init + normalizasyon kurdu. Ders 18, eğitimi hızlandıran iki şeyi ele alır: gelişmiş optimizer’lar (momentum, RMSProp, Adam — sıfırdan, Excel’de başlayarak) ve ResNet (skip connection / residual bağlantı) ile çok daha derin ağları eğitebilme.
Ana konular (Ders 18):
- SGD’den momentum’a, oradan Adam’a (sıfırdan)
- Learning rate scheduling (OneCycle)
- ResNet ve residual (skip) bağlantılar
- Daha derin ağları sağlamca eğitmek
UyarıDers 18 Öncesi Yapılacak
- Bu dersin egzersizlerini çöz (özellikle 2 ve 3 — telemetri + BatchNorm train/eval).
- Kaiming init + BatchNorm’lu bir CNN’i Fashion-MNIST’te eğit, ActivationStats ile izle.
- Ana cümleyi tekrar oku: “Sır, varyansı katmandan katmana sabit tutmaktır.”
20.22 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Howard’da |
|---|---|---|
| Hook | Katmana iliştirilen, çalışınca tetiklenen fonksiyon (telemetri) | 2:51 |
| ActivationStats | Aktivasyon ort/std/histogram izleyen callback | 5:32 |
color_dim / dead_chart |
Renkli boyut histogramı / ölü ünite grafiği | 5:42 |
| Varyans | ort((x − μ)²); yayılım ölçüsü | 21:21 |
| Kovaryans | ort(XY) − μₓ·μᵧ; birlikte değişim | 26:01 |
| Xavier / Glorot init | √n ile böl (Var = 1/n); doğrusal katman için | 29:33 |
| Kaiming / He init | √(2/n) ile böl; ReLU için (varyans korur) | 35:27 |
init.kaiming_normal_ |
PyTorch hazır Kaiming başlatıcısı | 36:52 |
| GeneralReLU | leak + sub ile 0-ortalamalı ReLU | 50:58 |
| LayerNorm | Örnek-içi normalize; batch’ten bağımsız | 1:06:39 |
| BatchNorm | Batch istatistiğiyle normalize; running_mean eval’de |
1:04:26 |
register_buffer |
Parametre olmayan ama modelle kaydedilen durum | 1:04:26 |
20.23 ML Bağlantıları Özeti
İpucuBuilder Notu — 6 ML Köprüsü: Varyans Korunumu + Karpathy makemore 3
Bu ders derin ağ eğitiminin en derin sorununu (patlama/sönme) çözer ve varyans korunumu ilkesiyle Karpathy makemore 3’e birebir köprü atar; köprülerin özeti:
- Varyans korunumu → Karpathy makemore 3’ün omurgası; init+norm’un tek ilkesi (Kaiming, BatchNorm).
- Kaiming init → ReLU ağların standardı;
init.kaiming_normal_altındaki türetme (Kaiming). - Hooks/telemetri → model içini gözlemleme; her framework’te (PyTorch/TF) standart (hook).
- Varyans/kovaryans → Stat 110 olasılık + 18.06 lineer cebir köprüsü (varyans, kovaryans).
- BatchNorm running_mean → train/eval ayrımı; production’da en sık hata kaynağı (BatchNorm).
- LayerNorm → transformer’ların (Ders 24) standart normalizasyonu (LayerNorm).
ÖnemliBu dersten tek bir şey alıp gideceksen
Derin ağ eğitiminin sırrı varyansı katmandan katmana sabit tutmaktır. Aktivasyonlar patlar veya söner çünkü her katman varyansı n ile ölçekler; çözüm ağırlıkları doğru başlatmak (ReLU için Kaiming √(2/n)) ve aktivasyonları sürekli normalize etmektir (BatchNorm/LayerNorm). Bunu hook’larla gördük, matematikle türettik, sıfırdan kurduk — ve bu, Karpathy’nin makemore 3’te elle keşfettiği şeyin tam karşılığıdır. Artık init.kaiming_normal_ ve nn.BatchNorm2d’nin altında ne olduğunu biliyoruz.