flowchart LR
D["tablo veri<br/>(Titanic)"] --> P["dummy +<br/>normalize"]
P --> LM["lineer model<br/>(matris çarpımı @)"]
LM --> GD["gradient descent<br/>(katsayıları uydur)"]
GD --> SIG["sigmoid<br/>(0–1 olasılık)"]
SIG --> NN["sinir ağı<br/>(matris + ReLU + matris)"]
NN --> DEEP["derin ağ<br/>(katman listesi)"]
style D fill:#cffafe,stroke:#0891b2,stroke-width:2px
style LM fill:#cffafe,stroke:#0891b2,stroke-width:2px
style SIG fill:#cffafe,stroke:#0891b2,stroke-width:2px
style NN fill:#cffafe,stroke:#0891b2,stroke-width:2px
style DEEP fill:#ffe4e6,stroke:#e11d48,stroke-width:3px
6 Sıfırdan Model — Titanic’te Lineer Modelden Derin Ağa (From-scratch model)
Bir tablo veriyi (Titanic) sayıya çevir — eksik değer doldur, kategorikleri dummy variable’a çevir, normalize et — sonra önce bir lineer modeli (matris çarpımı + gradient descent), ardından sigmoid’i ve bir sinir ağını (matris + ReLU + matris) hiçbir model katmanı kütüphanesi olmadan, sadece tensör işlemleriyle sıfırdan kur; Howard’ın Excel’de gördüğü her şeyi Python’a taşıdığı, fast.ai’nin ’büyü’sünü çözen ders
NotBölüm bilgisi
- Howard’ın videosu: course.fast.ai — Lesson 5: From-scratch model (~103 dk)
- Seri: Practical Deep Learning for Coders — Part 1, Ders 5
- Hoca: Jeremy Howard
- Playlist: Practical Deep Learning Part 1 (2022)
- Notebook: course22 — 05-linear-model-and-neural-net-from-scratch
- Okuma süresi: ~35 dk
6.1 Bu Derste Ne Var?
Ders 3’te bir modelin gradient descent ile uydurulan esnek bir fonksiyon olduğunu görmüştük; Ders 4’te ise Hugging Face Trainer’ı kara kutu olarak kullandık. Ders 5 tekrar aşağı iner ve bunu gerçek bir tablo verisinde sıfırdan kurar: Titanic veri setinde önce bir lineer modeli, sonra bir sinir ağını — hiçbir hazır model katmanı kullanmadan, sadece tensör işlemleriyle. Howard Excel’de gördüğü her şeyi Python’a taşır.
Üç temel fikir:
- Tablo verisini sayıya çevirme — eksik değer doldurma, kategorik sütunları dummy variable’a (one-hot) çevirme, ölçekleri eşitleme (normalizasyon) (Titanic Verisi → Kategorik Veri → Normalizasyon).
- Lineer model = (girdi × katsayı) toplamı — bu bir matris çarpımıdır; gradient descent’le katsayıları uydururuz, türevi PyTorch hesaplar (Lineer Modeli Kurmak → Matris Çarpımı).
- Sinir ağı = matris çarpımı + ReLU + tekrar — lineer modeli iki katmana genişletip ReLU eklemek “sıfırdan derin öğrenme”yi tamamlar (Bir Sinir Ağı → Derin Ağa Genişletme).
“We’re going to build a couple of different types of tabular models from scratch.” — Howard, 0:13
Şekil 28.1 bu üç fikri tek bir haritada birleştirir: tablo veriden başlayıp dummy + normalize ile sayıya geçer, lineer modele (matris çarpımı) ulaşır, gradient descent ile katsayıları uydurur, sigmoid’le olasılığa çevirir ve son olarak matris + ReLU + matris ile sinir ağına, oradan da derin ağa (rose vurgulu) genişler.
İpucuBuilder Notu — Karpathy’nin Yolu, Howard’ın Diliyle
- Geriye (Ders 3 / Karpathy / 18.06): Ders 3’ün gradient descent’i burada gerçek veriye uygulanır;
@(matris çarpımı) 18.06’nın kalbidir; Karpathy makemore aynı “sıfırdan” ruhu — bu ders, fast.ai top-down’ın bir an için Karpathy bottom-up’a döndüğü yerdir. - İleriye (Ders 6): “Sıfırdan yapmak öğretir ama yavaştır” — bir sonraki ders framework’ün (fastai) neden gerekli olduğunu gösterir.
- Tek cümle: Bir sinir ağı, tablo verisinde bile yalnızca matris çarpımları, ReLU ve gradient descent’ten ibarettir.
6.2 Sıfırdan Tabular Model
Howard tablo (spreadsheet/veritabanı) verisine döner ve modeli sıfırdan kurar. Excel’in neredeyse her şeyi yapabildiğini ama pratikte Python kullandığımızı belirtir — Excel küçük örnekleri sezdirmek için iyidir, gerçek iş Python’da yapılır.
“Excel can do nearly everything we need to build a neural network, but we don’t tend to use Excel in practice — instead we use a programming language like Python.” — Howard, 1:30
İpucuBuilder Notu — Önce Elle Sez, Sonra Kodda Ölçekle
- İleriye: “Önce küçük ölçekte (Excel) sezgi, sonra kodda ölçek” — Howard’ın pedagojik deseni; karmaşık fikirleri elle görmek anlayışı kökleştirir. Aynı desen, sinir ağını sıfırdan kurarken zirvesine ulaşır.
- Geriye (Ders 4): Ders 4’te kütüphane (Hugging Face) merkezdeyken, burada bilinçli olarak kütüphaneyi bırakıp Learner/Trainer’ın içinde ne olduğunu elle açıyoruz.
6.3 Titanic Verisi ve Eksik Değerler
İlk iş veriyi hazırlamaktır. Gerçek veri eksik (NaN) değerler içerir. Howard satır veya sütun atmaz; bunun yerine eksik değerleri o sütunun moduyla (en sık değer) doldurur. Böylece hiç veri kaybetmeyiz.
“I don’t throw out rows and I don’t throw out columns.” — Howard, 14:54
Şekil 6.2 bu hazırlığın ilk iki adımını (eksik değeri doldur, kategorikleri dummy’ye çevir) ve üçüncü adımı (normalize) tek bir akışta gösterir — soldaki kırmızı NaN hücresi, ortada modla doldurulur.
Kod
fig = plt.figure(figsize=(12.0, 4.4))
fig.patch.set_facecolor(COL_WHITE)
ax = fig.add_axes([0.0, 0.0, 1.0, 1.0])
ax.set_xlim(0, 13)
ax.set_ylim(3.3, 10)
ax.axis("off")
# --- Yardımcı: küçük tablo çizici (başlıklar + hücreler) -------------------
def mini_table(ax, x0, y_top, col_w, headers, rows, header_fc, header_ec,
cell_fc=COL_WHITE, cell_ec=COL_SLATE_400, tc=COL_TEXT,
h_head=0.78, h_cell=0.72, fontsize=9.5, special=None):
"""Soldan x0'da, üstten y_top'ta bir tablo çizer. special: {(r,c): (fc,ec,tc)}."""
special = special or {}
n_cols = len(headers)
# başlık satırı
for c, head in enumerate(headers):
cx = x0 + c * col_w + col_w / 2.0
boxed_node(ax, cx, y_top, col_w * 0.94, h_head, head,
fc=header_fc, ec=header_ec, tc=tc,
fontsize=fontsize, lw=1.8, weight="bold")
# hücreler
for r, row in enumerate(rows):
ry = y_top - h_head - 0.10 - r * (h_cell + 0.10)
for c, val in enumerate(row):
cx = x0 + c * col_w + col_w / 2.0
fc, ec, vtc = special.get((r, c), (cell_fc, cell_ec, tc))
boxed_node(ax, cx, ry, col_w * 0.94, h_cell, val,
fc=fc, ec=ec, tc=vtc,
fontsize=fontsize, lw=1.6, weight="normal")
return n_cols
# --- Aşama başlıkları (üstte) ----------------------------------------------
ax.text(2.05, 9.55, "1) HAM TABLO", ha="center", va="center",
fontsize=11.5, weight="bold", color=COL_CYAN_800)
ax.text(6.5, 9.55, "2) DOLDUR + DUMMY", ha="center", va="center",
fontsize=11.5, weight="bold", color=COL_CYAN_800)
ax.text(11.0, 9.55, "3) NORMALİZE", ha="center", va="center",
fontsize=11.5, weight="bold", color=COL_ACCENT)
# ----------------------------------------------------------------------------
# 1) HAM TABLO: Sex / Embarked / Age (bir hücre NaN -> kırmızı)
# ----------------------------------------------------------------------------
headers1 = ["Sex", "Embark", "Age"]
rows1 = [
["male", "S", "22"],
["female", "C", "NaN"],
["male", "S", "38"],
]
# (1,2) hücresi = NaN -> rose vurgulu
special1 = {(1, 2): (COL_BG_ROSE, COL_ACCENT, COL_ACCENT)}
mini_table(ax, 0.55, 8.55, 1.05, headers1, rows1,
header_fc=COL_CYAN_50, header_ec=COL_PRIMARY, special=special1)
# ----------------------------------------------------------------------------
# 2) DOLDUR + DUMMY: NaN -> mod (yeşil-cyan vurgu), male -> is_male=1/is_female=0
# ----------------------------------------------------------------------------
headers2 = ["is_male", "is_fem", "Emb_S", "Age"]
rows2 = [
["1", "0", "1", "22"],
["0", "1", "0", "30"], # NaN -> mod (median) 30 ile dolduruldu
["1", "0", "1", "38"],
]
# doldurulan hücre (1,3) cyan vurgu (yeşil-ish/cyan = doldurma)
special2 = {(1, 3): (COL_BG, COL_CYAN_700, COL_CYAN_800)}
mini_table(ax, 4.85, 8.55, 0.95, headers2, rows2,
header_fc=COL_CYAN_50, header_ec=COL_PRIMARY, special=special2)
# ----------------------------------------------------------------------------
# 3) NORMALİZE: Age gibi büyük sütun /maks ile 0-1 aralığına
# ----------------------------------------------------------------------------
headers3 = ["is_male", "is_fem", "Emb_S", "Age÷mak"]
rows3 = [
["1", "0", "1", "0.58"],
["0", "1", "0", "0.79"],
["1", "0", "1", "1.00"],
]
# Age sütunu (c=3) tamamen rose vurgu (normalize edilen sütun)
special3 = {(r, 3): (COL_BG_ROSE, COL_ACCENT, COL_TEXT) for r in range(3)}
mini_table(ax, 9.15, 8.55, 0.95, headers3, rows3,
header_fc=COL_BG_ROSE, header_ec=COL_ACCENT, special=special3)
# --- Aşamalar arası oklar + etiketler --------------------------------------
arrow_between(ax, (3.85, 6.6), (4.80, 6.6), color=COL_PRIMARY, lw=2.6)
ax.text(4.30, 7.25, "doldur + dummy", ha="center", va="center",
fontsize=10.0, style="italic", weight="bold", color=COL_CYAN_700)
arrow_between(ax, (8.75, 6.6), (9.10, 6.6), color=COL_ACCENT, lw=2.6,
shrink=6, mutation_scale=14)
ax.text(8.95, 7.25, "normalize", ha="center", va="center",
fontsize=10.0, style="italic", weight="bold", color=COL_ACCENT)
# --- Alt-not ----------------------------------------------------------------
ax.text(6.5, 3.9,
"model yalnızca 0–1 aralığı sayı ister: kategorik metni 0/1'e, "
"büyük sayıyı maks'a böl",
ha="center", va="center", fontsize=10.5, style="italic",
weight="bold", color=COL_CYAN_800)
plt.show()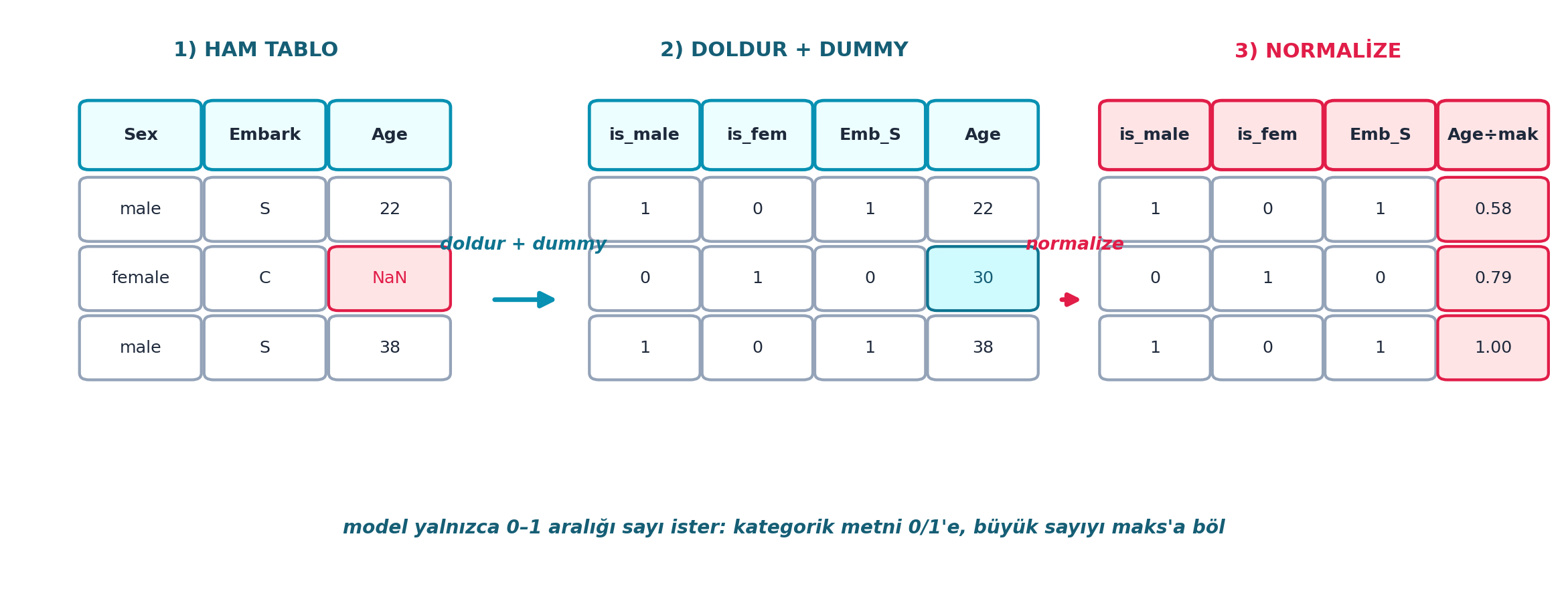
İpucuBuilder Notu — Atma, Doldur
- İleriye (production): Eksik değer stratejisi (doldur, işaretle, at) modeli ciddi etkiler; “at” çoğu zaman en kötüsüdür çünkü bilgi kaybeder. Şekil 6.2’in soldaki rose NaN hücresi, ortada modla doldurulup korunur — satır kaybetmeyiz.
- İleriye (Kategorik Veri): Doldurma sayısal sütun içindir; metin (kategorik) sütunları sayıya çevirmek için bambaşka bir araç (dummy variable) gerekir — sıradaki bölüm.
6.4 Kategorik Veri: Dummy Variable
Bir modeli “male” kelimesiyle veya “S” harfiyle çarpamayız — model sayı ister. Çözüm dummy variable (one-hot kodlama): her kategori için 0/1 değerli ayrı bir sütun. Cinsiyet, yolcu sınıfı, biniş limanı gibi kategorik alanlar bu şekilde sayısallaşır.
“We cannot multiply the letter ‘S’ by a coefficient. What we do is we create something called dummy variables.” — Howard, 19:09
Şekil 6.2’in ortadaki sütunu (is_male / is_fem / Emb_S) tam bu dönüşümü gösterir: tek Sex metni iki 0/1 sütununa açılır.
İpucuBuilder Notu — Her Kategori = Bir 0/1 Sütun
- Geriye (Python/pandas):
pd.get_dummieskategorik sütunları otomatik açar; “her kategori = bir 0/1 sütunu” temsili tüm tablo ML’inin temelidir. - İleriye (Lineer Modeli Kurmak): Her dummy sütununa model ayrı bir katsayı öğrenir; “is_male” sütununun katsayısı, cinsiyetin hayatta kalmaya etkisini doğrudan yakalar.
6.5 Ölçekleri Eşitlemek (Normalizasyon)
Sütunlar çok farklı büyüklüklerde olabilir — “Age” diğerlerinden çok daha büyüktür. Eğer normalize etmezsek, büyük sütun katsayıları domine eder. Howard her sütunu maksimumuna bölerek 0-1 aralığına çeker. Bu işlem broadcasting ile çok optimize biçimde yapılır.
“‘Age’ is much bigger than any of the other columns. So what we could do is divide by this vector, in a very optimized way.” — Howard, 35:22
Şekil 6.2’in en sağdaki rose sütunu (Age÷mak) bu adımı gösterir: 22/38 → 0.58, 38/38 → 1.00 gibi, tüm değerler 0–1 aralığına çekilir.
İpucuBuilder Notu — Ölçek Eşitlenmezse Büyük Sütun Domine Eder
- Geriye (Stat 110): Normalizasyon, özniteliklerin karşılaştırılabilir ölçekte olmasını sağlar; standardizasyonun basit hâli.
- İleriye (Broadcasting): “vektöre böl” ifadesi bir broadcasting işlemidir — 891 satırın hepsine aynı maks-vektörünü uygular; aynı mekanik birazdan lineer modelin kalbinde tekrar görünür.
6.6 Lineer Modeli Kurmak
Lineer model basittir: her sütunu bir katsayı ile çarp, satır boyunca topla. Howard katsayıları rastgele (-0.5 ile 0.5 arası) başlatır; tahmin = (girdi × katsayı) satır toplamı; kayıp = ortalama mutlak hata.
torch.manual_seed(442)
n_coeff = t_indep.shape[1]
coeffs = torch.rand(n_coeff) - 0.5 # rastgele baslangic katsayilari
preds = (t_indep * coeffs).sum(axis=1) # her satir icin agirlikli toplam
loss = torch.abs(preds - t_dep).mean() # ortalama mutlak hata
İpucuBuilder Notu — Quadratic’in Çok Değişkenli Hâli
- Geriye (Ders 3): Bu, Ders 3’teki quadratic’in çok değişkenli hâli; katsayılar = parametreler. Tek bir
a·x² + b·x + cyerine artık her sütunun bir katsayısı var. - Geriye (18.06): (girdi × katsayı) toplamı bir dot product; tüm satırlar için yapılınca matris-vektör çarpımı — bu eşitlik Matris Çarpımı bölümünde açıkça kurulacak.
6.7 Broadcasting
Howard t_indep * coeffs ifadesinin nasıl çalıştığını açıklar: 891×12’lik bir matrisi 12’lik bir vektörle çarpıyoruz. Broadcasting, vektörü her satıra otomatik uygular (sanki 891 kez kopyalanmış gibi) — hem kısa kod hem optimize C kodu, hatta GPU’da paralel.
“This is using the incredibly powerful technique of broadcasting. It’s as if this was broadcast 891 times. And that all happened in optimized C code.” — Howard, 46:55
İpucuBuilder Notu — Açık Döngü Yerine Yayılma
- Geriye (18.06 / NumPy): Broadcasting, farklı şekilli tensörleri hizalama kuralıdır; “son eksenler uyuşursa yayılır.” Aynı kural normalizasyondaki “vektöre böl” işlemini de optimize eder.
- İleriye: Açık
fordöngüsü yerine broadcasting, modern sayısal hesabın hız sırrıdır; aynı satır toplamı birazdan tek bir@ile matris çarpımına dönüşecek.
6.8 Gradient Descent Adımı
Ders 3’teki döngünün aynısı: katsayılara requires_grad_(), kaybı hesapla, backward() ile gradyanları al, katsayıları gradyanın tersine küçük adım kaydır, sonra gradyanı sıfırla (yoksa birikir).
loss = calc_loss(coeffs, t_indep, t_dep)
loss.backward()
with torch.no_grad():
coeffs.sub_(coeffs.grad * 0.1) # gradyanin tersine adim
coeffs.grad.zero_() # gradyani sifirla (birikmesin)“The one bit we don’t want to do from scratch is calculating derivatives — PyTorch does that for us.” — Howard, 39:44
İpucuBuilder Notu — grad.zero_() Karpathy’nin Meşhur Tuzağı
- Geriye (Karpathy):
grad.zero_()unutulursa gradyanlar birikir — Karpathy’nin meşhurzero_gradhatasının ta kendisi; aynı satır birazdan eğitim döngüsünde bir fonksiyona sarılır. - İleriye: “türevi PyTorch hesaplar” — sıfırdan yapmanın tek istisnası budur; geri kalan her şey (forward, loss, güncelleme) elle yazılır.
6.9 Eğitim Döngüsü
Howard adımları fonksiyonlara sarar: update_coeffs (adım + sıfırla), one_epoch (kayıp + backward + güncelle), train_model (katsayıları başlat + epoch’lar boyunca döndür). Bu, her ML eğitim döngüsünün iskeletidir.
def update_coeffs(coeffs, lr):
coeffs.sub_(coeffs.grad * lr); coeffs.grad.zero_()
def one_epoch(coeffs, lr):
loss = calc_loss(coeffs, trn_indep, trn_dep)
loss.backward()
with torch.no_grad(): update_coeffs(coeffs, lr)
def train_model(epochs=30, lr=0.01):
torch.manual_seed(442)
coeffs = init_coeffs()
for i in range(epochs): one_epoch(coeffs, lr=lr)
return coeffsŞekil 6.3 bu döngünün davranışını gerçek bir sıfırdan eğitimde gösterir: her epoch’ta loss düşer, accuracy yükselir — loss.backward() + coeffs -= grad·lr + grad.zero_() üçlüsünün sonucu.
Kod
gd = logistic_gd_demo()
epochs = gd["epochs"]
loss_hist = gd["loss_hist"]
acc_hist = gd["acc_hist"]
fig, ax = plt.subplots(figsize=(7.4, 4.6))
# Sol y-ekseni: loss (BCE) — cyan
l1, = ax.plot(epochs, loss_hist, color=COL_PRIMARY, linewidth=2.4,
label="loss (BCE)", zorder=3)
apply_style(ax)
ax.set_xlabel("epoch")
ax.set_ylabel("loss (BCE)", color=COL_PRIMARY)
ax.tick_params(axis="y", colors=COL_PRIMARY)
# Sag y-ekseni: accuracy — rose
ax2 = ax.twinx()
l2, = ax2.plot(epochs, acc_hist, color=COL_ACCENT, linewidth=2.4,
label="accuracy", zorder=3)
ax2.set_ylabel("accuracy", color=COL_ACCENT)
ax2.tick_params(axis="y", colors=COL_ACCENT)
ax2.spines["top"].set_visible(False)
ax2.set_facecolor("none")
ax.set_title("Sıfırdan eğitim: loss düşer, accuracy yükselir",
fontsize=12, weight="bold")
# Birlesik legend (iki eksenin cizgileri)
lines = [l1, l2]
ax.legend(lines, [ln.get_label() for ln in lines], loc="center right",
frameon=True, framealpha=0.95, edgecolor=COL_PRIMARY, fontsize=9)
# Egitim dongusu notu
ax.text(0.5, -0.205,
"loss.backward() + coeffs -= grad·lr + grad.zero_()",
transform=ax.transAxes, ha="center", va="top",
fontsize=9, color=COL_TEXT, style="italic")
plt.show()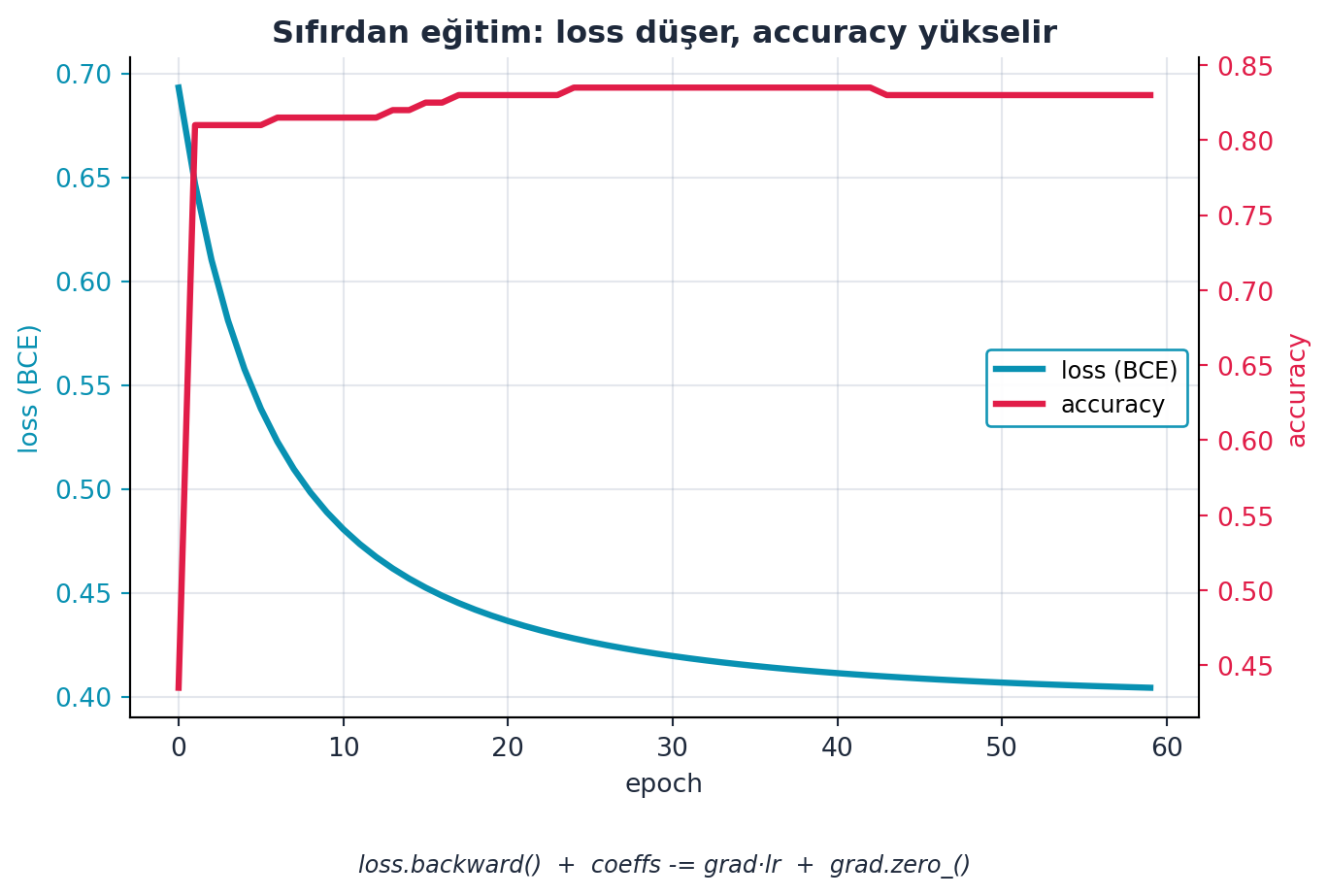
loss.backward() ile gradyan, coeffs -= grad·lr ile güncelleme, grad.zero_() ile sıfırlama.
İpucuBuilder Notu — Learner ve Trainer’ın Çıplak Hâli
- Geriye (Ders 1-4): fastai
Learnerve Hugging FaceTrainertam bu döngüyü senin için sarar; burada onu elle görüyoruz — Şekil 6.3’deki loss-aşağı / accuracy-yukarı eğrisi, o kara kutuların içinde olan biten şeydir. - İleriye (Sigmoid): Şekil 6.3’deki accuracy, çıktıyı bir sigmoid’den geçirince ek bir sıçrama yapar; sıradaki bölümler önce doğruluğu ölçmeyi, sonra sigmoid’i ekler.
6.10 Doğruluğu Ölçmek
Kayıp optimizasyon içindir; insan için doğruluk (accuracy) daha anlamlıdır. Howard tahmin 0.5’ten büyükse “hayatta kaldı” sayar ve gerçekle karşılaştırır. Validation set’te ölçülür (eğitimde değil).
def acc(coeffs):
return (val_dep.bool() == (calc_preds(coeffs, val_indep) > 0.5)).float().mean()
İpucuBuilder Notu — Loss Optimize İçin, Accuracy İnsan İçin
- Geriye (Ders 4): Metric (accuracy) ile loss (MAE) farkı; bu tam Ders 4’teki metric vs loss ayrımıdır — loss’a göre eğit, accuracy’ye göre yargıla.
- Geriye (Ders 4): Doğruluk yalnızca validation set’te ölçülür (overfitting kontrolü) — eğitim doğruluğu modelin gerçek başarısını söylemez.
6.11 Sigmoid
Lineer modelin çıktısı herhangi bir sayı olabilir, ama bir olasılık (0-1) istiyoruz. Çözüm sigmoid fonksiyonu: her sayıyı yumuşakça 0 ile 1 arasına sıkıştırır. Howard bunu ekleyince doğruluk 0.79’dan 0.82’ye çıkar.
“If you’re wondering why is my model not very good, often the thing you need is chucking it through a sigmoid.” — Howard, 51:00
def calc_preds(coeffs, indeps):
return torch.sigmoid((indeps * coeffs).sum(axis=1)) # ciktiyi 0-1'e sikistirŞekil 6.4 bu fonksiyonun S şeklini gösterir: büyük negatif girdi 0’a, büyük pozitif girdi 1’e yaklaşır, merkez \(s(0) = 0.5\). Matematiksel olarak \(s(x) = \dfrac{1}{1 + e^{-x}}\).
Kod
# GERÇEK hesaplama — sigmoid: s(x) = 1 / (1 + e^-x) (bkz. sigmoid_curve)
x, s = sigmoid_curve()
fig, ax = plt.subplots(figsize=(7.4, 4.7))
# asimptotlar: 0 ve 1 (ince yatay çizgiler)
ax.axhline(0.0, lw=1.0, color=COL_SLATE_400, ls="--", zorder=1)
ax.axhline(1.0, lw=1.0, color=COL_SLATE_400, ls="--", zorder=1)
# dikey eksen x=0
ax.axvline(0.0, lw=0.9, color=COL_SLATE_400, zorder=1)
# gölge bölgeler: x<0 → 0'a yaklaşır (rose), x>0 → 1'e yaklaşır (cyan)
ax.fill_between(x, 0.0, s, where=(x < 0), color=COL_BG_ROSE, alpha=0.55, zorder=0)
ax.fill_between(x, s, 1.0, where=(x > 0), color=COL_BG, alpha=0.55, zorder=0)
# sigmoid eğrisi — birincil cyan, kalın
ax.plot(x, s, lw=2.6, color=COL_PRIMARY, zorder=3)
# merkez noktası s(0) = 0.5
ax.scatter([0.0], [0.5], s=48, color=COL_ACCENT, zorder=5)
ax.annotate(
"s(0) = 0.5",
xy=(0.0, 0.5),
xytext=(1.6, 0.30),
fontsize=10.5, weight="bold", color=COL_ACCENT,
arrowprops=dict(arrowstyle="->", color=COL_ACCENT, lw=1.6),
)
# bölge etiketleri
ax.text(-5.6, 0.12, "büyük negatif → 0", fontsize=10, weight="bold",
color=COL_ACCENT, ha="center")
ax.text(5.4, 0.88, "büyük pozitif → 1", fontsize=10, weight="bold",
color=COL_CYAN_700, ha="center")
apply_style(ax)
ax.set_ylim(-0.08, 1.08)
ax.set_title("Sigmoid: herhangi bir sayıyı 0–1 olasılığına sıkıştırır",
fontsize=13, weight="bold", color=COL_CYAN_700)
ax.set_xlabel("girdi (z = X@w + b)")
ax.set_ylabel("olasılık")
# açıklama notu
ax.text(0.5, -0.30,
"büyük pozitif → 1, büyük negatif → 0; ikili sınıflandırmada çıkış aktivasyonu",
transform=ax.transAxes, ha="center", va="top",
fontsize=9.5, color=COL_TEXT, style="italic")
fig.tight_layout()
plt.show()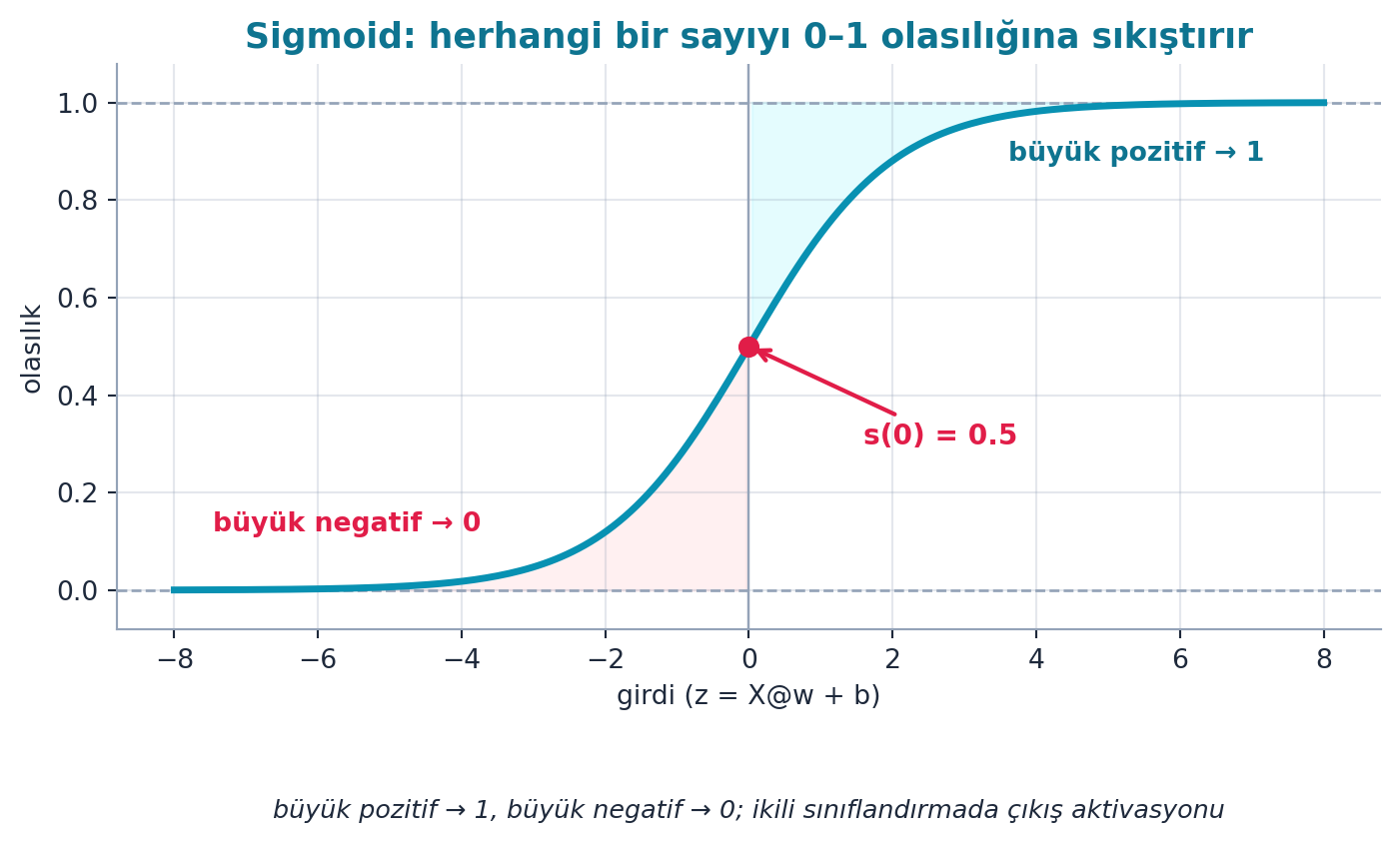
İpucuBuilder Notu — Çıkış Aktivasyonu Her Modelde Var
- Geriye (6.S191 / Calculus): Sigmoid, 6.S191 Ders 1’in aktivasyon fonksiyonu (§4.D); S şeklinde, eˣ tabanlı. Şekil 6.4’in merkez noktası \(s(0)=0.5\) tam karar eşiğidir.
- İleriye: Sınıflandırmada çıktıyı olasılığa çevirmek standarttır; ikili için sigmoid, çoklu için softmax. Bu sigmoid, sinir ağının ve derin ağın son adımında da yerini korur.
6.12 Kaggle’a Gönderme
Howard modeli test setine uygular ve tahminleri Kaggle formatında bir CSV’ye yazar. Sıfırdan kurulmuş bir lineer model bile makul bir sonuç verir — “from scratch” çalışıyor.
“Actually predicting who survived the Titanic. That’s cool — from scratch.” — Howard, 47:00
İpucuBuilder Notu — Deploy’un Kaggle Versiyonu
- Geriye (Ders 2): Bu, deploy’un Kaggle versiyonu — modeli yeni veride çalıştırıp çıktı üretme; eğittiğin model ancak yeni veriye uygulanınca değer üretir.
- İleriye (Matris Çarpımı): Bu noktaya kadar lineer model bir satır toplamıyla yazıldı; Howard birazdan onu tek bir
@operatörüne sadeleştirip sinir ağına zemin hazırlar.
6.13 Matris Çarpımı (@)
(indeps * coeffs).sum(axis=1) ifadesi aslında bir matris çarpımıdır. Python’ın @ operatörü tam bunu yapar (PyTorch tensörlerinde optimize biçimde). Howard kodu sadeleştirir ve sinir ağına hazırlanır.
val_indep @ coeffs # (indep * coeffs).sum(axis=1) ile ayni
def calc_preds(coeffs, indeps): return torch.sigmoid(indeps @ coeffs)“@ is an official Python operator. It means matrix-multiply. Because these are tensors, that will use PyTorch’s, and they’re exactly the same.” — Howard, 59:34
Şekil 6.5 bu eşitliği gerçek sayılarla gösterir: 6×4’lük bir X matrisi, 4’lük bir katsayı vektörüyle çarpılınca her satır için tek bir çıktı (X @ coeffs) üretir — (X * coeffs).sum(axis=1) ile birebir aynı.
Kod
mm = matmul_demo()
X = mm["X"] # (6, 4)
coeffs = mm["coeffs"] # (4,)
preds = mm["preds"] # (6,)
rows = mm["rows"] # 6 yolcu etiketi
cols = mm["cols"] # 4 özellik etiketi
n_rows, n_cols = X.shape
fig = plt.figure(figsize=(11.0, 5.0))
# SOL: X heatmap (geniş), ORTA: coeffs vektörü (dar) + '@', SAĞ: preds barh
gs = fig.add_gridspec(1, 3, width_ratios=[2.5, 0.9, 2.0], wspace=0.55)
ax_x = fig.add_subplot(gs[0, 0])
ax_c = fig.add_subplot(gs[0, 1])
ax_p = fig.add_subplot(gs[0, 2])
# SOL — X matrisi (6×4) imshow heatmap (cyan tonu: cividis)
im = ax_x.imshow(X, cmap="cividis", aspect="auto", vmin=0.0, vmax=1.0)
ax_x.set_xticks(range(n_cols))
ax_x.set_xticklabels(cols, color=COL_TEXT, fontsize=10)
ax_x.set_yticks(range(n_rows))
ax_x.set_yticklabels(rows, color=COL_TEXT, fontsize=9.5)
ax_x.set_title("X — girdi matrisi (6×4)", color=COL_CYAN_800,
fontsize=11.5, weight="bold", pad=8)
for i in range(n_rows):
for j in range(n_cols):
val = X[i, j]
tcol = COL_WHITE if val < 0.55 else COL_TEXT
ax_x.text(j, i, f"{val:.2f}", ha="center", va="center",
fontsize=9, color=tcol, weight="bold")
ax_x.tick_params(length=0)
for spine in ax_x.spines.values():
spine.set_visible(False)
# ORTA — coeffs vektörü (4,) dikey heatmap + '@' işareti
cvec = coeffs.reshape(-1, 1) # (4, 1) dikey
ax_c.imshow(cvec, cmap="RdBu_r", aspect="auto", vmin=-0.5, vmax=0.5)
ax_c.set_xticks([])
ax_c.set_yticks(range(n_cols))
ax_c.set_yticklabels(cols, color=COL_TEXT, fontsize=9)
ax_c.set_title("coeffs (4,)", color=COL_CYAN_800,
fontsize=11.5, weight="bold", pad=8)
for i in range(n_cols):
ax_c.text(0, i, f"{coeffs[i]:+.2f}", ha="center", va="center",
fontsize=9.5, color=COL_TEXT, weight="bold")
ax_c.tick_params(length=0)
for spine in ax_c.spines.values():
spine.set_visible(False)
fig.text(0.455, 0.5, "@", ha="center", va="center",
fontsize=30, color=COL_ACCENT, weight="bold")
fig.text(0.625, 0.5, "=", ha="center", va="center",
fontsize=30, color=COL_CYAN_700, weight="bold")
# SAĞ — preds (6,) yatay bar (diverging: + cyan, − rose)
y_pos = np.arange(n_rows)
bar_colors = [COL_PRIMARY if v >= 0 else COL_ACCENT for v in preds]
ax_p.barh(y_pos, preds, color=bar_colors, height=0.6, zorder=3)
ax_p.axvline(0.0, color=COL_SLATE_400, linewidth=1.0, zorder=2)
ax_p.set_yticks(y_pos)
ax_p.set_yticklabels(rows, color=COL_TEXT, fontsize=9.5)
ax_p.invert_yaxis()
ax_p.set_title("preds = X @ coeffs (6,)", color=COL_CYAN_800,
fontsize=11.5, weight="bold", pad=8)
ax_p.set_xlabel("ham çıktı (logit)", color=COL_TEXT, fontsize=9.5)
pad = 0.04
ax_p.set_xlim(preds.min() - pad - 0.06, preds.max() + pad + 0.06)
for i, v in enumerate(preds):
off = 0.012 if v >= 0 else -0.012
ha = "left" if v >= 0 else "right"
ax_p.text(v + off, i, f"{v:+.3f}", va="center", ha=ha,
color=COL_TEXT, fontsize=9, weight="bold")
apply_style(ax_p)
ax_p.grid(True, axis="x", alpha=0.2, color=COL_SLATE_400)
ax_p.grid(False, axis="y")
fig.suptitle("Lineer model = X @ coeffs (matris çarpımı)",
color=COL_CYAN_800, fontsize=14, weight="bold", y=1.02)
fig.text(0.5, -0.04,
"(girdi × katsayı) satır toplamı = matris-vektör çarpımı; "
"broadcasting/@ hızlandırır",
ha="center", va="center", fontsize=9.5, color=COL_TEXT, style="italic")
plt.show()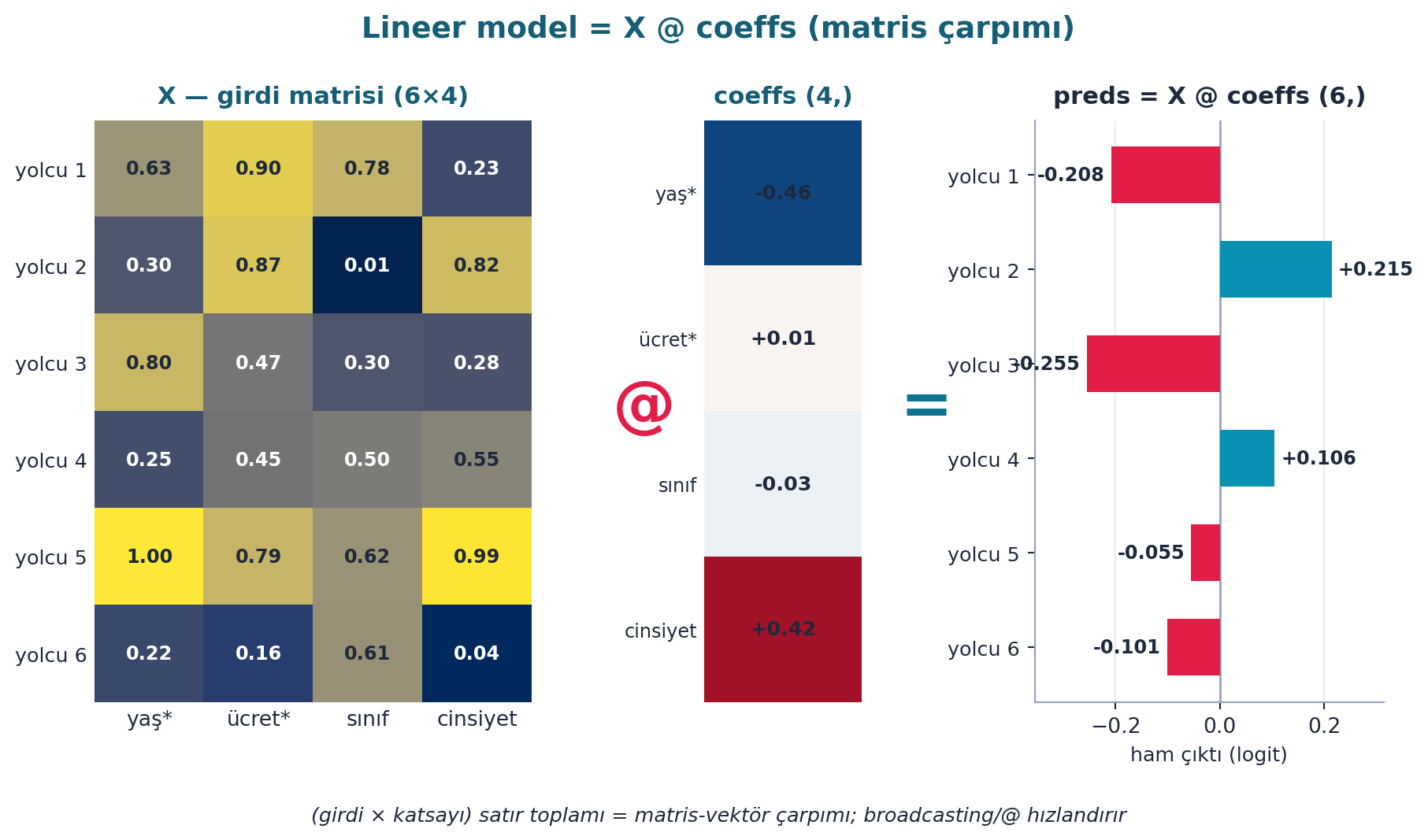
İpucuBuilder Notu — @ Lineer Cebrin Kalbi
- Geriye (18.06):
@= matris çarpımı, lineer cebirin kalbi; her sinir ağı katmanı bir matris çarpımıdır. Şekil 6.5’deki tek katsayı sütunu (4×1), birazdan bir matrise (4×20) genişleyecek. - İleriye (Bir Sinir Ağı): Vektörü “n×1 matris”e (sütun vektör) çevirmek, birden çok katsayı sütunu (yani gizli katman) eklemeye zemin hazırlar — sinir ağının tek satırlık adımı.
6.14 Bir Sinir Ağı
İşte zirve: matris çarpımına geçtikten sonra “çıldırıp” bir sinir ağı kurabiliriz. Tek katsayı sütunu yerine bir katsayı matrisi (n_coeff × n_hidden) kullanırız; her satır artık 20 değer (gizli aktivasyon) üretir. Bunları ReLU’dan geçirip ikinci bir katmanla tek çıktıya indirip sigmoid uygularız.
def init_coeffs(n_hidden=20):
layer1 = (torch.rand(n_coeff, n_hidden) - 0.5) / n_hidden
layer2 = torch.rand(n_hidden, 1) - 0.3
const = torch.rand(1)[0]
return layer1.requires_grad_(), layer2.requires_grad_(), const.requires_grad_()
import torch.nn.functional as F
def calc_preds(coeffs, indeps):
l1, l2, const = coeffs
res = F.relu(indeps @ l1) # 1. katman + ReLU (dogrusal-olmama)
res = res @ l2 + const # 2. katman -> tek cikti
return torch.sigmoid(res)“Now that we’ve done this using matrix-multiply, we can go crazy, and we can go ahead and create a neural network.” — Howard, 1:03:26
Şekil 6.6 lineer modelden sinir ağına ve derin ağa geçişi üç satırda gösterir: lineer = tek matris çarpımı; sinir ağı = matris @ + ReLU + matris @ + sigmoid (n_hidden=20 gizli birim); derin ağ = bu adımı bir katman listesinde tekrarlamak.
Kod
# SEMATIK: lineer model -> sinir agi -> derin ag evrimi (kavramsal mimari).
# Sahte sayi yok: yalnizca yapi/sekil etiketleri (n_hidden=20 birim notu).
fig, ax = plt.subplots(figsize=(11.0, 7.2))
fig.patch.set_facecolor(COL_WHITE)
ax.set_xlim(0, 22)
ax.set_ylim(0, 13)
ax.axis("off")
# satir merkez yukseklikleri (yukaridan asagiya)
Y1, Y2, Y3 = 11.0, 7.0, 2.6
H = 1.35 # kutu yuksekligi
GAP = 0.45 # ok ile kutu arasi acik
def lab(y, text):
"""Satir basligi (solda, koyu cyan)."""
ax.text(0.2, y + 1.55, text, ha="left", va="bottom",
fontsize=12.5, color=COL_CYAN_700, weight="bold")
def databox(x, y, w, text, fontsize=10.0):
"""Veri / agirlik kutusu — cyan."""
return boxed_node(ax, x, y, w, H, text,
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT,
fontsize=fontsize, lw=2.2)
def opbox(x, y, w, text):
"""ReLU / sigmoid gibi aktivasyon kutusu — rose vurgulu."""
return boxed_node(ax, x, y, w, H, text,
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT,
fontsize=10.0, lw=2.0)
def flow(x0, x1, y, color=COL_PRIMARY):
arrow_between(ax, (x0 + GAP, y), (x1 - GAP, y), color=color, lw=2.2)
# SATIR 1 — Lineer model: [girdi] @ [coeffs] -> [cikti]
lab(Y1, "1 · Lineer model")
databox(2.4, Y1, 3.0, "girdi\nx (n özellik)")
databox(7.4, Y1, 3.0, "@ katsayılar\nw (n×1)")
databox(13.0, Y1, 3.0, "çıktı\ntek sayı")
flow(3.9, 5.9, Y1)
flow(8.9, 11.5, Y1)
ax.text(5.4, Y1 + 0.55, "@", ha="center", va="bottom",
fontsize=13, color=COL_CYAN_700, weight="bold")
ax.text(15.3, Y1, "= tek matris\nçarpımı", ha="left", va="center",
fontsize=9.5, color=COL_SLATE_400, weight="bold", style="italic")
# SATIR 2 — Sinir agi: girdi @ w1 -> ReLU -> @ w2 -> sigmoid -> cikti
lab(Y2, "2 · Sinir ağı")
databox(2.2, Y2, 2.7, "girdi\nx (n)")
databox(6.0, Y2, 2.9, "@ katman 1\nw₁ (n×h)")
opbox(9.9, Y2, 2.4, "ReLU\nmax(0, ·)")
databox(13.7, Y2, 2.9, "@ katman 2\nw₂ (h×1)")
opbox(17.6, Y2, 2.4, "sigmoid\n0–1")
databox(20.9, Y2, 1.8, "çıktı")
flow(3.55, 4.55, Y2)
flow(7.45, 8.70, Y2)
flow(11.10, 12.25, Y2)
flow(15.15, 16.40, Y2)
flow(18.80, 20.00, Y2)
ax.text(9.9, Y2 - 1.45, "h = n_hidden = 20 gizli birim",
ha="center", va="top", fontsize=9.0, color=COL_ACCENT,
weight="bold", style="italic")
# SATIR 3 — Derin ag: girdi -> (@ + ReLU) x N -> cikti (+ sigmoid)
lab(Y3, "3 · Derin ağ")
databox(2.2, Y3, 2.7, "girdi\nx (n)")
layer_xs = [6.5, 10.7, 14.9]
sub = ["₁", "₂", "₃"] # Unicode altsimge (figur metni Unicode serbest)
prev_x_right = 3.55
for i, lx in enumerate(layer_xs):
bw = 3.0
# birlesik "@ + ReLU" blogu — ReLU iceren her katman rose vurgulu (accent cerceve)
boxed_node(ax, lx, Y3, bw, H, f"@ w{sub[i]} + ReLU",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT,
fontsize=10.5, lw=2.0)
flow(prev_x_right, lx - bw / 2, Y3)
prev_x_right = lx + bw / 2
databox(19.6, Y3, 2.8, "çıktı\n(+ sigmoid)")
flow(prev_x_right, 19.6 - 1.4, Y3)
# dongu/tekrar vurgu kutusu (rose noktali cerceve) — N katman bloklarini sarar
from matplotlib.patches import FancyBboxPatch
loop_box = FancyBboxPatch((4.7, Y3 - 1.35), 12.05, 2.7,
boxstyle="round,pad=0.05,rounding_size=0.15",
fc="none", ec=COL_ACCENT, lw=1.6, ls=(0, (5, 3)),
zorder=0)
ax.add_patch(loop_box)
ax.text(10.7, Y3 - 1.55, "(@ + ReLU) × N katman — for katman in katmanlar: x = ReLU(x @ wᵢ)",
ha="center", va="top", fontsize=9.0, color=COL_ACCENT,
weight="bold", style="italic")
# Alt not — ana fikir
ax.text(11.0, 0.15,
"sinir ağı = matris çarpımı + ReLU + matris çarpımı; "
"derin ağ = bu adımı tekrarla — hepsi sıfırdan",
ha="center", va="bottom", fontsize=10.5, color=COL_TEXT,
weight="bold",
bbox=dict(boxstyle="round,pad=0.5", fc=COL_BG, ec=COL_PRIMARY,
alpha=0.9, lw=1.5))
plt.tight_layout()
plt.show()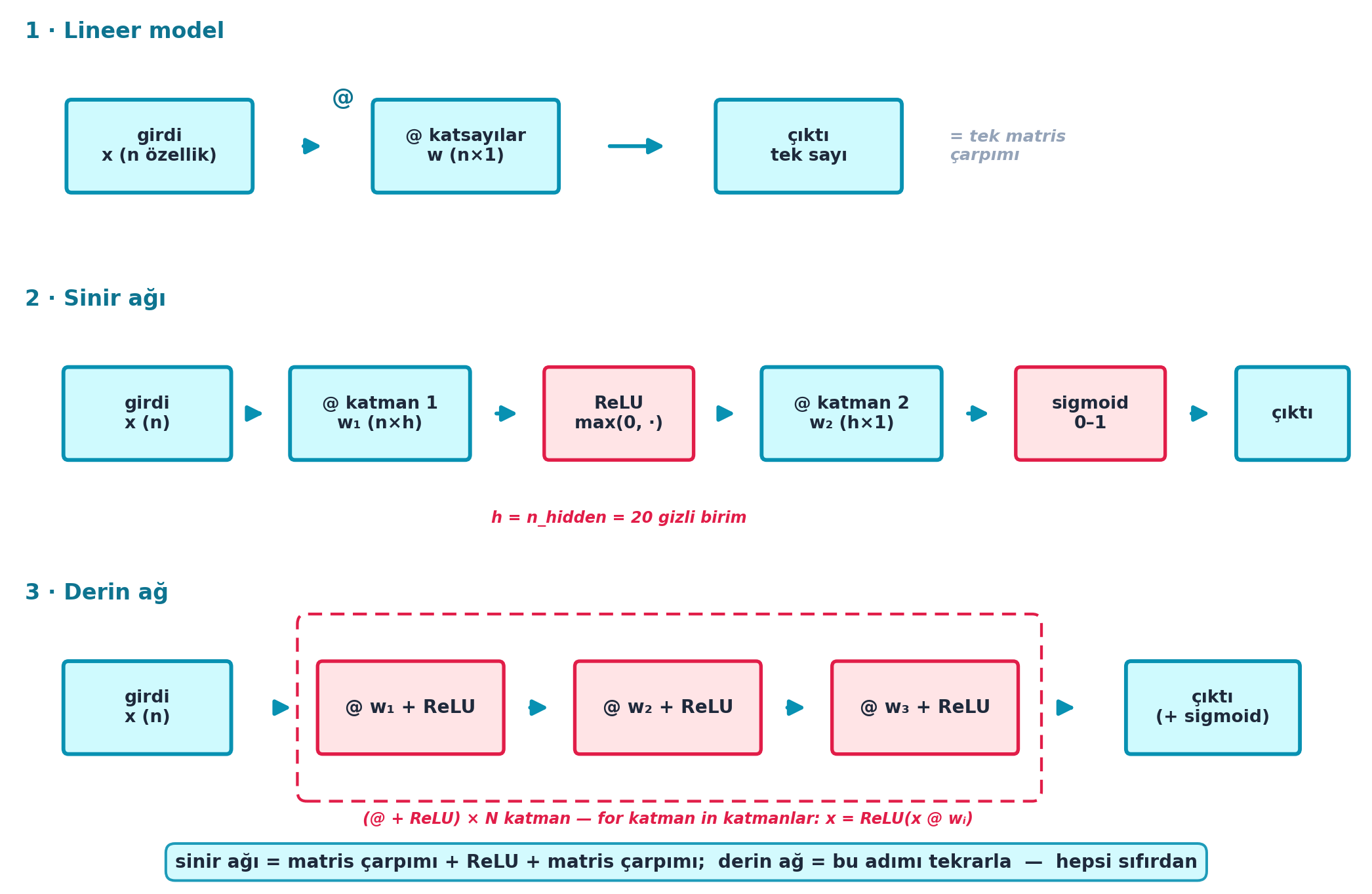
İpucuBuilder Notu — Bu Tam Ders 3’ün ReLU Toplamı
- Geriye (Ders 3): Bu tam Ders 3’ün “ReLU toplamı”dır — sadece matrislerle ifade edilmiş;
n_hidden=20yani 20 ReLU birimi. Şekil 6.6’ın 2. satırı (rose ReLU kutusu) bu dönüşümün tam görüntüsüdür. - Geriye (Karpathy): layer1/layer2/ReLU = Karpathy makemore MLP’sinin elle hâli; aynı
W1 @ x → ReLU → W2 @ ·zinciri.
6.15 Derin Ağa Genişletme
Howard son adımı atar: iki katman yerine istediğin kadar katman. Bir katman listesi üzerinde döngü kurar, her birinde matris çarpımı + (son hariç) ReLU uygular. Artık bu gerçek bir derin sinir ağıdır — hepsi sıfırdan.
def calc_preds(coeffs, indeps):
layers, consts = coeffs
n = len(layers)
res = indeps
for i, l in enumerate(layers):
res = res @ l + consts[i]
if i != n-1: res = F.relu(res) # son katman haric ReLU
return torch.sigmoid(res)Şekil 6.6’ın en alt satırı (rose noktalı çerçeveyle sarılan (@ + ReLU) × N bloğu) tam bu döngüyü gösterir: bir katman listesi üzerinde matris çarpımı + ReLU.
İpucuBuilder Notu — nn.Sequential’ın Özü
- İleriye: Bu döngü, PyTorch’un
nn.Sequential’ının özüdür; “katman listesi üzerinde matris çarpımı + aktivasyon” tüm derin ağların iskeleti — Şekil 28.1’in en sağdaki rose “derin ağ” düğümü buraya işaret eder. - Geriye (Sinir Ağı): İki katmanı genelleştirmenin tek farkı bir
fordöngüsüdür; mimari aynı (matris + ReLU), sadece tekrar sayısı değişken.
6.16 “Sıfırdan Derin Öğrenme” ve Framework
Howard büyük tabloyu kapatır: Titanic’te bir derin sinir ağını yalnızca tensör işlemleriyle, hiçbir model katmanı kütüphanesi olmadan kurduk. Ama elle yapmak zahmetlidir — katsayı başlatma, gradyan ölçeği, fiddly ayarlar. Bir sonraki ders neden framework (fastai) kullandığımızı gösterecek.
“When you do stuff by hand, everything does get more fiddly.” — Howard, 1:05:02
Şekil 6.7 bu kontrastı gösterir: solda elle yapılan 8 adımlık fiddly liste (başlat → normalize → matris çarpımı → sigmoid → loss → backward → grad.zero_ → adım), sağda aynı matematiği az ve sağlam kodla saran fastai Learner.
Kod
fig, (ax_l, ax_r) = plt.subplots(1, 2, figsize=(12, 6.2))
# --- SOL PANEL: Sıfırdan (elle) — uzun adım listesi (nötr/gri tonlar) ---
ax_l.set_title("Sıfırdan (elle)",
fontsize=13, color=COL_TEXT, weight="bold", pad=12)
ax_l.set_xlim(0, 10); ax_l.set_ylim(0, 10); ax_l.axis("off")
gx = 5.0
steps_l = [
"katsayıları başlat",
"normalize et",
"matris çarpımı (X @ w)",
"sigmoid",
"loss hesapla",
"backward (gradyan)",
"grad.zero_()",
"lr ile adım at",
]
ys = np.linspace(9.05, 1.65, len(steps_l))
bw, bh = 6.0, 0.78
for y, txt in zip(ys, steps_l):
boxed_node(ax_l, gx, y, bw, bh, txt,
fc=COL_SLATE_300, ec=COL_SLATE_400, tc=COL_TEXT,
fontsize=10.0, lw=1.8)
for y0, y1 in zip(ys[:-1], ys[1:]):
arrow_between(ax_l, (gx, y0), (gx, y1), color=COL_SLATE_400,
lw=1.6, shrink=8, mutation_scale=12)
ax_l.text(gx, 0.55, "fiddly, hataya açık, öğretici",
ha="center", va="center",
fontsize=11, color=COL_SLATE_400, style="italic", weight="bold")
# --- SAĞ PANEL: Framework (fastai Learner) — tek kompakt kutu (canlı cyan) ---
ax_r.set_title("Framework (fastai Learner)",
fontsize=13, color=COL_CYAN_700, weight="bold", pad=12)
ax_r.set_xlim(0, 10); ax_r.set_ylim(0, 10); ax_r.axis("off")
rx = 5.0
boxed_node(ax_r, rx, 5.35, 7.0, 2.4,
"Learner\n\ndls + model + fine_tune",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT,
fontsize=12.5, lw=2.6)
ax_r.text(rx, 0.55, "az kod, doğru başlatma/optimizer, hızlı",
ha="center", va="center",
fontsize=11, color=COL_ACCENT, style="italic", weight="bold")
# --- ORTA OK: "aynı matematik, daha az kod" (sol → sağ panel) ---
mid = fig.add_axes([0.0, 0.0, 1.0, 1.0], zorder=0)
arrow_between(mid, (0.485, 0.5), (0.515, 0.5),
color=COL_ACCENT, lw=2.6, mutation_scale=22, shrink=2)
mid.set_xlim(0, 1); mid.set_ylim(0, 1); mid.axis("off")
mid.text(0.5, 0.585, "aynı matematik,\ndaha az kod",
ha="center", va="bottom",
fontsize=10.5, color=COL_ACCENT, weight="bold")
plt.show()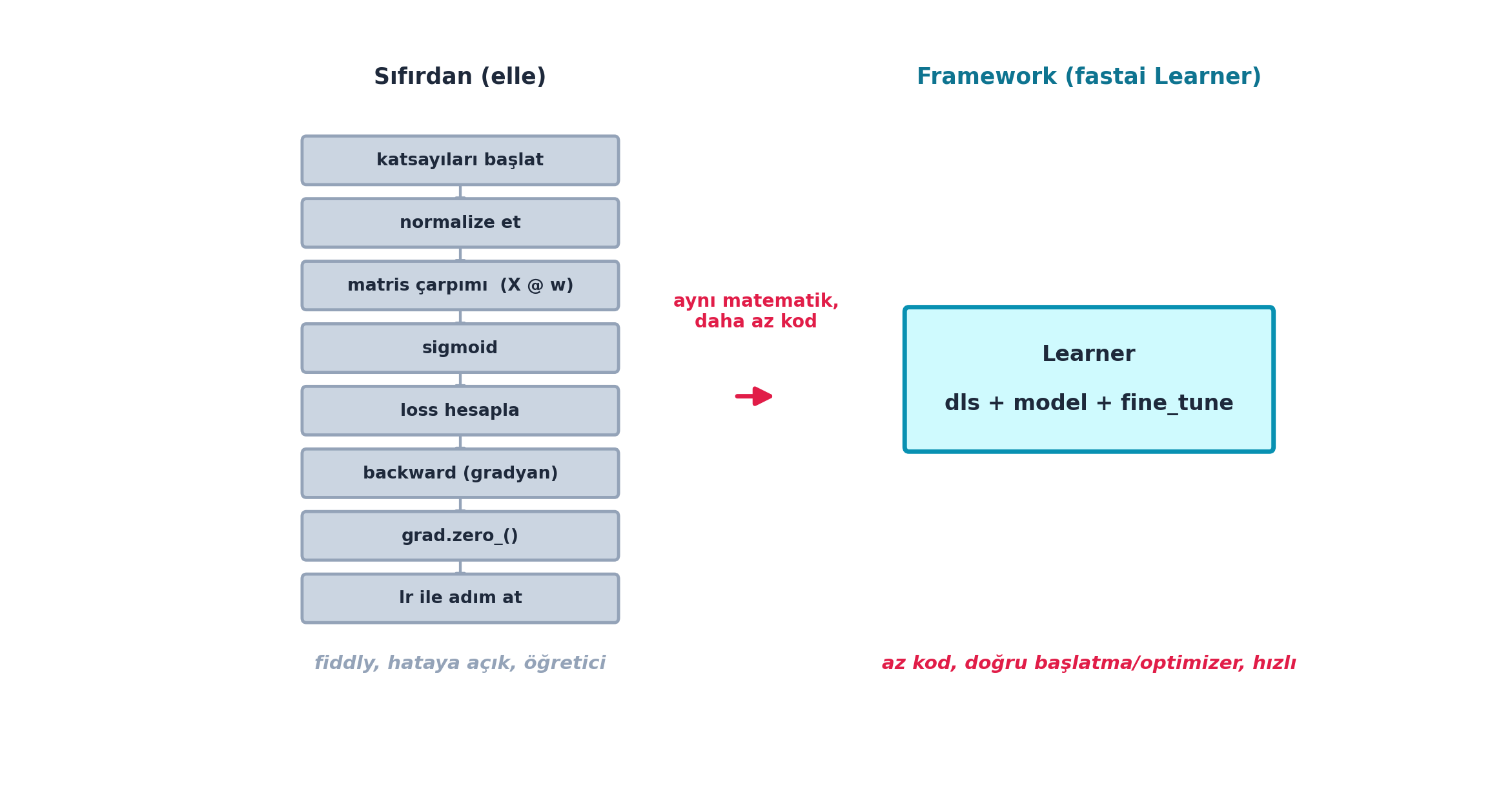
İpucuBuilder Notu — Sıfırdan Bilmek = Neyin Otomatikleştiğini Bilmek
- İleriye (Ders 6): Framework, başlatma/optimizer/veri yükleme gibi “fiddly” parçaları doğru ve hızlı yapar; sıfırdan bilmek ise neyi otomatikleştirdiğini anlamanı sağlar. Şekil 6.7’ün sol panelindeki 8 adım, sağdaki tek
Learnerkutusunun içinde gizlidir. - Geriye (Eğitim Döngüsü): Soldaki “backward → grad.zero_ → adım” üçlüsü, elle yazdığımız
one_epochfonksiyonunun ta kendisidir; framework onu görünmez kılar.
6.17 Kapanış
Ders 5, Ders 3’ün soyut çekirdeğini gerçek bir tablo verisinde somutlaştırdı: veri hazırlama (dummy + normalize) → lineer model (matris çarpımı + gradient descent) → sigmoid → sinir ağı (katman + ReLU) → derin ağ. Hiçbir sihir yok; sadece matris çarpımları, ReLU ve gradient descent.
Şekil 6.8 bu uçtan uca akışı tek bir şeritte özetler: Titanic CSV’den başlayıp dummy + normalize, X matrisi, matris çarpımı + katmanlar, ReLU, sigmoid ve sonunda hayatta-kalma olasılığına — hiçbir kütüphane katmanı olmadan.
Kod
fig = plt.figure(figsize=(12.6, 3.4))
fig.patch.set_facecolor(COL_WHITE)
ax = fig.add_axes([0.0, 0.0, 1.0, 1.0])
ax.set_xlim(0, 100)
ax.set_ylim(0, 26)
ax.axis("off")
yc = 14.0
bw, bh = 13.0, 8.6 # kutu genisligi / yuksekligi
# 7 kutu merkezi (eşit aralıklı zincir)
xs = [7.0, 22.0, 36.5, 51.0, 65.5, 80.0, 93.5]
# --- Veri hazırlama kutuları (cyan) ---
boxed_node(ax, xs[0], yc, bw, bh,
"tablo veri\n(Titanic CSV)",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT, fontsize=10, lw=2.2)
boxed_node(ax, xs[1], yc, bw, bh,
"dummy +\nnormalize\n(0–1)",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT, fontsize=10, lw=2.2)
boxed_node(ax, xs[2], yc, bw, bh,
"X matrisi\n(satır × özellik)",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT, fontsize=10, lw=2.2)
# --- Model kutuları (rose-vurgulu) ---
boxed_node(ax, xs[3], yc, bw + 1.4, bh,
"X @ coeffs\n(matris çarpımı\n+ katmanlar)",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT, fontsize=9.6, lw=2.4)
boxed_node(ax, xs[4], yc, bw, bh,
"ReLU\nmax(0, ·)",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT, fontsize=10, lw=2.4)
boxed_node(ax, xs[5], yc, bw, bh,
"sigmoid\n→ 0–1",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT, fontsize=10, lw=2.4)
# --- Çıktı kutusu (rose, dolu vurgu) ---
boxed_node(ax, xs[6], yc, bw, bh,
"olasılık →\nhayatta\nkaldı?",
fc=COL_ROSE_500, ec=COL_ACCENT, tc=COL_WHITE, fontsize=10, lw=2.4)
# --- Oklar (kutular arası) ---
# kutu yarı-genişlikleri değişebilir; X@coeffs biraz geniş
half = [bw / 2, bw / 2, bw / 2, (bw + 1.4) / 2, bw / 2, bw / 2, bw / 2]
for i in range(len(xs) - 1):
p0 = (xs[i] + half[i], yc)
p1 = (xs[i + 1] - half[i + 1], yc)
# veri-hazırlama bölümü cyan ok, model bölümü rose ok
col = COL_PRIMARY if i < 2 else COL_ACCENT
arrow_between(ax, p0, p1, color=col, lw=2.3, shrink=2, mutation_scale=15)
# --- Bölge etiketleri (üst) ---
ax.text((xs[0] + xs[2]) / 2, yc + bh / 2 + 3.6, "veri hazırlama",
ha="center", va="bottom", fontsize=10.5, color=COL_CYAN_800,
weight="bold")
ax.text((xs[3] + xs[5]) / 2, yc + bh / 2 + 3.6, "model (tensör işlemleri)",
ha="center", va="bottom", fontsize=10.5, color=COL_ACCENT,
weight="bold")
# --- Alt not ---
ax.text(50, 1.6,
"hiçbir kütüphane katmanı yok — sadece tensör işlemleri + gradient descent",
ha="center", va="center", fontsize=9.5, color=COL_SLATE_400,
weight="bold", style="italic")
plt.show()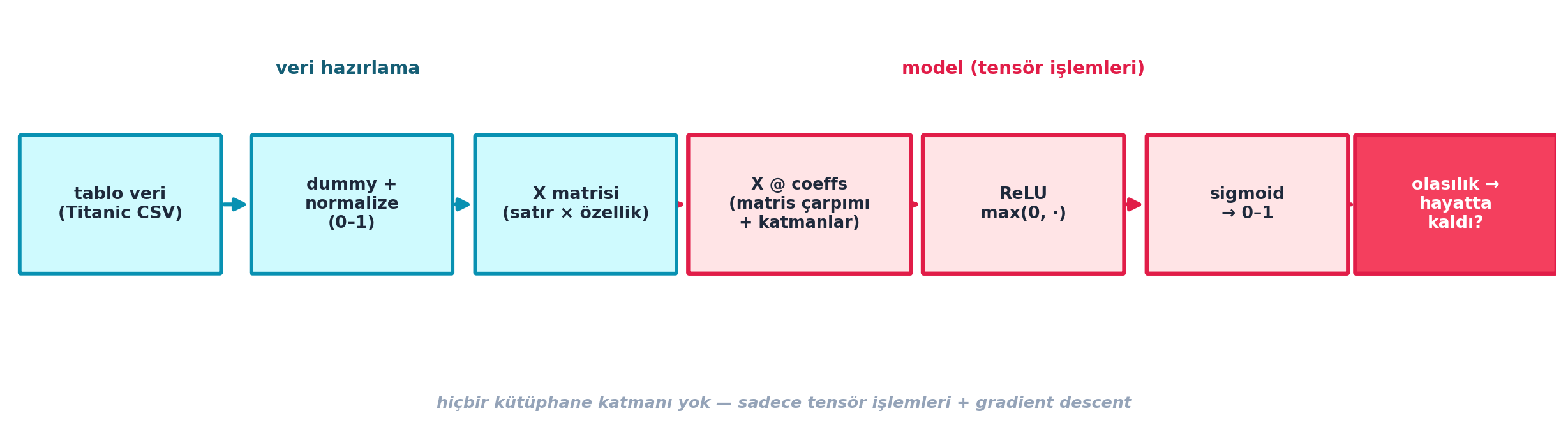
X @ coeffs + katmanlar) → ReLU → sigmoid → hayatta-kalma olasılığı. Hiçbir model katmanı kütüphanesi yok, sadece tensör işlemleri + gradient descent.
İpucuBuilder Notu — Top-Down ile Bottom-Up’ın Buluştuğu Yer
- Geriye (tüm seri): Bu, fast.ai top-down ile Karpathy bottom-up’ın buluştuğu yer — Howard burada bir an için Karpathy moduna geçip her şeyi elle kurar. Şekil 6.8’un soldan sağa cyan→rose şeridi, kavram haritasının doğrusal hâlidir.
- İleriye (Ders 6): Bu uçtan uca elle kurulan zincir, framework’le birkaç satıra inecek; ama “ne otomatikleşti?” sorusunun cevabı tam burada, Şekil 6.8’da görünür kalır.
6.18 Bu Dersin Özeti
- Tablo verisi önce sayıya çevrilir: eksik değerleri modla doldur, kategorikleri dummy variable’a çevir, sütunları normalize et (Titanic Verisi, Kategorik Veri, Normalizasyon).
- Lineer model = (girdi × katsayı) satır toplamı; katsayılar gradient descent’le uydurulur (Lineer Modeli Kurmak).
- Broadcasting bir vektörü tüm satırlara optimize biçimde uygular; açık döngüden çok daha hızlı (Broadcasting).
- Eğitim döngüsü: kayıp →
backward()→ katsayıları güncelle →grad.zero_(); PyTorch yalnızca türevi hesaplar (Gradient Descent Adımı, Eğitim Döngüsü). - Sigmoid çıktıyı 0-1 olasılığına sıkıştırır; sınıflandırmada doğruluğu artırır (Sigmoid).
- Matris çarpımı (
@) lineer katmanın özüdür; vektörü sütun matrise çevirmek gizli katman eklemeye zemin hazırlar (Matris Çarpımı). - Sinir ağı = matris çarpımı + ReLU + ikinci matris çarpımı;
n_hiddengizli birim sayısıdır (Bir Sinir Ağı). - Derin ağ = bu adımı katman listesi üzerinde tekrarlamak — hepsi sıfırdan, sadece tensör işlemleriyle (Derin Ağa Genişletme).
ÖnemliTek Bir Cümle
Bir derin sinir ağı, tablo verisinde bile, normalize edilmiş sayıların ardışık matris çarpımları + ReLU’dan geçirilip gradient descent ile katsayılarının uydurulmasından ibarettir — fast.ai’nin gizlediği “büyü” budur.
6.19 Kontrol Soruları
NotSoru 1: Kategorik bir sütunu (örn. cinsiyet) neden doğrudan modele veremeyiz? Çözüm nedir?
Cevap:
Model girdiyi bir katsayıyla çarpar; “male” veya “S” gibi metni sayıyla çarpamayız. Çözüm dummy variable (one-hot kodlama): her kategori için 0/1 değerli ayrı bir sütun açarız. Örneğin cinsiyet → “is_male” ve “is_female” sütunları (biri 1, diğeri 0). Böylece kategorik bilgi sayısal hâle gelir ve model her kategoriye ayrı bir katsayı öğrenebilir.
NotSoru 2: Lineer modeli sinir ağına dönüştüren tam olarak nedir? Ders 3’ün ’ReLU toplamı’yla bağlantısı nedir?
Cevap:
İki değişiklik: (1) tek katsayı vektörü yerine bir katsayı matrisi (n_coeff × n_hidden) kullanmak — her satır artık tek değil n_hidden (örn. 20) değer üretir; (2) bu değerleri ReLU’dan geçirip ikinci bir katmanla (matris çarpımı) tek çıktıya indirmek. Bu, Ders 3’teki “yeterince ReLU topla” fikrinin matrislerle ifade edilmiş hâlidir: 20 gizli birim = 20 ReLU; F.relu(indeps@l1) onları üretir, res@l2 toplar. Yani sinir ağı = matris çarpımı + ReLU + matris çarpımı.
NotSoru 3: grad.zero_() neden gereklidir? Atlanırsa ne olur?
Cevap:
PyTorch’ta backward() gradyanları mevcut .grad değerinin üstüne ekler (biriktirir), üzerine yazmaz. Her gradient descent adımından sonra grad.zero_() ile sıfırlamazsan, bir sonraki adımın gradyanı öncekilerle toplanır ve güncelleme yanlış (çok büyük) olur — model düzgün eğitilmez. Bu, Karpathy’nin de vurguladığı meşhur zero_grad hatasıdır; production eğitim döngülerinde de sık görülen bir bug kaynağıdır.
NotSoru 4: Sigmoid neden eklenir ve ne işe yarar? (builder bağlantısı)
Cevap:
Lineer modelin (veya son katmanın) çıktısı herhangi bir gerçek sayı olabilir (negatif, çok büyük). Ama ikili sınıflandırmada bir olasılık (0-1 arası) isteriz. Sigmoid her sayıyı yumuşakça 0 ile 1 arasına sıkıştırır (büyük pozitif → 1’e, büyük negatif → 0’a yakın). Howard’da bunu eklemek doğruluğu 0.79’dan 0.82’ye çıkardı. Builder açısından: çıktıyı görevin gerektirdiği aralığa eşleyen “çıkış aktivasyonu” her modelde standarttır — ikili için sigmoid, çok-sınıflı için softmax.
6.20 Egzersizler
Egzersiz 1 (Direkt uygulama). Titanic verisinde lineer modeli sıfırdan kur (coeffs, calc_preds, calc_loss) ve train_model ile eğit; doğruluğu validation set’te ölç.
Egzersiz 2 (İki-aşamalı). Sigmoid’i ekle/çıkar ve doğruluğun nasıl değiştiğini kıyasla; learning rate’i sigmoid’li/sigmoid’siz ayrı ayarla.
Egzersiz 3 (Edge case). grad.zero_() satırını kasıtlı olarak sil ve eğitimin nasıl bozulduğunu (loss’un patlaması) gözlemle.
Egzersiz 4 (Python ile doğrulama). (indeps * coeffs).sum(axis=1) ile indeps @ coeffs sonuçlarının birebir aynı olduğunu doğrula; broadcasting ile matris çarpımı arasındaki ilişkiyi açıkla.
Egzersiz 5 (Sonraki dersin habercisi). Aynı modeli fastai’nin tabular_learner’ı ile kur ve sıfırdan yazdığın kodla sonuçları/kod miktarını kıyasla (Ders 6 framework).
6.21 Sonraki Ders İçin Hazırlık
Ders 6: Rastgele Ormanlar (Random forests)
Ders 5’te her şeyi elle yaptık. Ders 6 önce framework’ün (fastai) değerini gösterir, sonra tamamen farklı ama çok güçlü bir model ailesini tanıtır: random forests ve gradient boosting — tablo verisinde sinir ağına güçlü bir alternatif.
Ana konular:
- Framework neden gerekli (fastai ile az kod)
- Karar ağaçları ve random forest
- Feature importance
- Out-of-bag hatası
UyarıDers 6 Öncesi Yapılacak
- Bu dersin egzersizlerini çöz (özellikle 1 ve 3 — sıfırdan eğit, zero_ hatasını gör).
- Titanic modelini kendi notebook’unda baştan kur.
- Ana cümleyi tekrar oku: “Sinir ağı = matris çarpımı + ReLU + gradient descent.”
6.22 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Howard’da |
|---|---|---|
| Eksik değer doldurma | NaN’ları modla (en sık değer) doldur, satır/sütun atma | 14:54 |
| Dummy variable | Kategoriyi 0/1 sütunlara açma (one-hot) | 19:09 |
| Normalizasyon | Sütunları benzer ölçeğe çekme (maks’a bölme) | 35:22 |
| Lineer model | (girdi × katsayı) satır toplamı | 26:53 |
| Broadcasting | Vektörü tüm satırlara optimize uygulama | 46:55 |
grad.zero_() |
Her adımdan sonra gradyanı sıfırlama (birikmesin) | 39:44 |
| Sigmoid | Çıktıyı 0-1 olasılığına sıkıştırma | 48:17 |
| Matris çarpımı (@) | Lineer katmanın özü; dot product’ların matrisi | 58:29 |
| Gizli katman (n_hidden) | Ara aktivasyonlar; ReLU’dan geçen ara çıktılar | 1:03:34 |
| Sinir ağı | matris çarpımı + ReLU + matris çarpımı | 1:03:34 |
| Derin ağ | Katman listesi üzerinde matris çarpımı + ReLU | 1:06:01 |
| accuracy | Tahmin > 0.5 ile gerçeğin eşleşme oranı (validation) | 46:11 |
6.23 ML Builder Bağlantıları
İpucuBuilder Notu — 6 ML Köprüsü
Bu ders, fast.ai top-down’ı bir an için Karpathy bottom-up’a çevirir: tablo veriyi sayıya çevirip sıfırdan bir derin ağ kurar. Köprülerin özeti:
- Sıfırdan model → fast.ai’nin gizlediği her şeyin elle hâli; Karpathy makemore ile aynı ruh (Sıfırdan Tabular Model).
- Matris çarpımı (@) → her sinir ağı katmanının özü (18.06); broadcasting ile birlikte hız sırrı (Matris Çarpımı, Broadcasting).
- Sinir ağı = matris + ReLU + matris → Ders 3’ün “ReLU toplamı”nın somut kodu (Bir Sinir Ağı).
- grad.zero_() → gradyan birikimi tuzağı; Karpathy’nin meşhur hatası, production bug kaynağı (Gradient Descent Adımı).
- Sigmoid/softmax → çıkış aktivasyonu; çıktıyı görevin aralığına eşler (Sigmoid).
- Dummy + normalizasyon → tablo verisini sayısallaştırmanın standart ön işlemi (Kategorik Veri, Normalizasyon).
ÖnemliBu dersten tek bir şey alıp gideceksen
Bu dersten tek bir şey alıp gideceksen: bir derin sinir ağında gizem yoktur. Veriyi sayıya çevir, ardışık matris çarpımlarından ReLU ile geçir, gradient descent ile katsayıları uydur. Howard bunu Titanic’te hiçbir kütüphane katmanı kullanmadan kurdu — fast.ai’nin “büyü”sü tam olarak budur, sadece daha az ve daha sağlam kodla.