flowchart TD
L18["Ders 18: Üç Hızlandırma"]
L18 --> OPT["Optimizer evrimi"]
L18 --> LR["LR scheduling"]
L18 --> RES["ResNet"]
OPT --> SGD["SGD"]
SGD --> MOM["+ momentum<br/>(gradyan EMA)"]
MOM --> RMS["+ RMSProp<br/>(kare-gradyan EMA)"]
RMS --> ADAM["Adam<br/>(ikisi + bias düzeltme)"]
LR --> COS["cosine annealing"]
LR --> CYC["1-cycle<br/>(super-convergence)"]
RES --> DEG["degradation sorunu"]
DEG --> SKIP["skip connection<br/>out = F(x) + x"]
SKIP --> BLOCK["ResBlock"]
SKIP --> KARP["Karpathy nanoGPT:<br/>x = x + attn(x)<br/>residual stream = aynı skip"]
BLOCK --> CLOSE["Temeller B BİTER:<br/>matmul → backprop → Learner<br/>→ init/norm → optimizer → ResNet"]
classDef cyan fill:#cffafe,stroke:#0891b2,stroke-width:2px,color:#1e293b;
classDef rose fill:#ffe4e6,stroke:#e11d48,stroke-width:2px,color:#1e293b;
class L18,OPT,SGD,MOM,RMS,LR,COS,CYC,RES,DEG,BLOCK,CLOSE cyan;
class ADAM,SKIP,KARP rose;
21 Ders 18 — Hızlandırılmış SGD ve ResNet (Accelerated SGD & ResNet)
Temeller B’nin ve ‘from the foundations’ omurgasının finali: eğitimi hızlandıran iki büyük fikir. Önce optimizer’lar — Howard Excel’de gradient descent’ten başlayıp SGD → momentum → RMSProp → Adam’ı sıfırdan kurar. Sonra learning rate scheduling (cosine annealing, 1-cycle super-convergence). Son olarak ResNet — skip connection (out = F(x) + x) ile çok daha derin ağları eğitebilme. Tek cümleyle: Adam, gradyanın ve kare-gradyanın üssel ortalamalarını birleştiren adaptif optimizer’dır; ResNet ise katmanın çıktısına girdisini ekleyerek (out = F(x) + x) derin ağları eğitilebilir kılan mimari fikirdir — ve bu skip connection, Karpathy’nin nanoGPT’sindeki her transformer bloğunun (x = x + attn(x)) residual belkemiğidir.
NotBölüm bilgisi
- Ders sayfası (video): course.fast.ai — Lesson 18: Accelerated SGD & ResNet (~126 dk)
- Seri: Practical Deep Learning for Coders — Part 2, Ders 18
- Playlist: Part 2 — Foundations to Stable Diffusion (2022)
- Notebook: course22p2 — nbs/12_accel_sgd + nbs/13_resnet
- Okuma süresi: ~40 dk
- 🔗 Temeller B’nin finali (ETAP 5): Ders 17’de sağlam init + normalizasyon kurduk (varyans korunumu). Ders 18 onun üstüne eğitimi hızlandıran iki büyük fikri koyar: gelişmiş optimizer’lar (momentum → Adam, sıfırdan) ve ResNet (skip connection). Bununla “from the foundations” omurgası tamamlanır: matmul → backprop → Learner/callback → init/norm → optimizer → ResNet.
21.1 Bu Derste Ne Var?
Temeller B’nin finali ve ETAP’ın kapanışı: eğitimi hızlandıran iki büyük fikir. Önce optimizer’lar — Howard Excel’de gradient descent’ten başlayıp SGD → momentum → RMSProp → Adam’ı sıfırdan kurar. Sonra learning rate scheduling (cosine annealing, 1-cycle). Son olarak ResNet — skip connection ile çok daha derin ağları eğitebilme. Part 2’nin “from the foundations” omurgası burada tamamlanır.
Üç temel fikir bu dersin omurgasını kurar:
- Optimizer evrimi — SGD’ye momentum (gradyan ortalaması) eklenir, ona kare-gradyan ölçeklemesi (RMSProp) eklenir; ikisi birleşince Adam çıkar (SGD → momentum → RMSProp → Adam).
- LR scheduling — learning rate’i eğitim boyunca değiştirmek (warmup + azaltma); 1-cycle ile hızlı, sağlam eğitim (cosine → 1-cycle).
- ResNet (skip connection) — katmanın çıktısına girdisini ekle (
out = F(x) + x); derin ağları eğitilebilir kılar (degradation → skip → ResBlock).
“We’re going to start today in Microsoft Excel.” — Howard, 0:00
Şekil 28.1 bu üç hızlandırma eksenini tek bir yol haritasında birleştirir: optimizer evrimi (SGD→momentum→RMSProp→Adam), öğrenme oranı çizelgeleme (cosine + 1-cycle) ve ResNet skip connection. Adam, skip connection ve Karpathy nanoGPT köprüsü rose ile işaretlidir: skip connection out = F(x) + x, Karpathy’nin residual stream’iyle (x = x + attn(x)) birebir aynıdır.
İpucuBuilder Notu — Üç Hızlandırma: Optimizer, Scheduling, Mimari
- Geriye (Ders 17): Sağlam init + normalizasyon (Ders 17) hazır; bu ders onun üstüne optimizer ve mimari hızlandırması koyar. Ders 17 derin ağları eğitilebilir kıldı; Ders 18 onları hızlı ve derin yapar.
- İleriye (Karpathy nanoGPT) — MERKEZÎ: ResNet’in
+ xskip connection’ı, Karpathy’nin nanoGPT’sinde her transformer bloğunun belkemiğidir (residual stream). Ders 24’te (attention) tekrar karşımıza çıkar. - Tek cümle: Adam, gradyan ve kare-gradyan ortalamalarını birleştiren adaptif optimizer’dır; ResNet ise skip connection (
out = F(x) + x) ile derin ağları eğitilebilir kılan mimari fikirdir.
21.2 1. Excel’de Gradient Descent
Howard optimizer’lara en somut yerden başlar: bir Excel tablosunda lineer regresyonu gradient descent ile çözmek. Her satır bir adım; her hücre bir gradyan hesabı. Soyut formül yerine, ağırlıkların adım adım nasıl güncellendiğini gözle görürsün — sonra aynı mantığı koda taşırız. Excel, optimizer evrimini (SGD → momentum → RMSProp → Adam) yan yana hücrelerde görselleştirmek için ideal bir laboratuvardır: her varyasyonun ham gradyanı nasıl başka türlü işlediğini satır satır izlersin.
İpucuBuilder Notu — Excel: Optimizer’ı En Somut Hâliyle Görmek
- Geriye (Ders 3/5): Gradient descent’i Ders 3-5’te kurmuştuk; burada optimizer varyasyonlarını görselleştirmek için Excel kullanılıyor — kod yerine hücreler, her güncellemenin etkisini çıplak gösterir.
- Sezgi: Bir algoritmayı anlamanın en hızlı yolu, onu kodlamadan önce gözle izlenebilir bir tabloya dökmektir. Excel’de momentum hücresi “önceki ortalamanın bir kısmı + yeni gradyanın bir kısmı” olarak görünür; soyut EMA formülü birden somutlaşır.
21.3 2. Basit SGD (Sıfırdan)
En temel optimizer: her parametreyi gradyanı yönünde küçük bir adım (lr) kadar güncelle. Howard’ın SGD sınıfı bunu iki parçaya ayırır: opt_step (gradyan adımı) ve reg_step (weight decay). Bu ayrım, alt sınıfların yalnızca opt_step’i değiştirmesine izin verir — momentum, RMSProp ve Adam hep bu sınıftan türeyecek.
class SGD:
def __init__(self, params, lr, wd=0.):
params = list(params); fc.store_attr(); self.i = 0
def step(self):
with torch.no_grad():
for p in self.params:
self.reg_step(p); self.opt_step(p)
self.i += 1
def opt_step(self, p): p -= p.grad * self.lr
def reg_step(self, p):
if self.wd != 0: p *= 1 - self.lr*self.wd
def zero_grad(self):
for p in self.params: p.grad.data.zero_()Şekil 21.2 üç optimizer’ın (SGD, Momentum, Adam) kötü-koşullu bir vadideki yörüngelerini gerçek hesaplamayla çizer (FLAGSHIP): dar vadide (dik yön ≫ sığ yön) SGD dik yönde zikzak salınır, momentum bu salınımı söndürür, Adam ise parametre-başına adaptif ölçekler. Bu basit kuadratikte hepsi yakınsar — fark yörünge karakterindedir, bir “kazanan” iddia edilmez. Bu figür §2-5 boyunca kuracağımız optimizer evriminin görsel özetidir.
Kod
d = E.optimizer_trajectory_demo()
X, Y, Z, paths = d["X"], d["Y"], d["Z"], d["paths"]
fig, ax = plt.subplots(figsize=(10, 6))
# Kötü-koşullu (dar vadi) kuadratik yüzeyin kontur haritası — cyan colormap
levels = np.linspace(Z.min(), Z.max() * 0.65, 18)
ax.contour(X, Y, Z, levels=levels, cmap="cool", linewidths=0.9, alpha=0.75)
# Her optimizer farklı renk + stil ile (nokta + çizgi)
styles = {
"SGD": dict(color=COL_ACCENT, marker="o", ls="-", label="SGD"),
"Momentum": dict(color=COL_CYAN_800, marker="s", ls="-", label="Momentum"),
"Adam": dict(color=COL_ROSE_500, marker="^", ls="--", label="Adam"),
}
for name, st in styles.items():
tr = paths[name]
ax.plot(tr[:, 0], tr[:, 1], color=st["color"], ls=st["ls"], lw=2.0,
marker=st["marker"], ms=4.5, mfc=st["color"], mec=COL_WHITE,
mew=0.6, alpha=0.95, zorder=4, label=st["label"])
# Minimum (0,0) işaretli
ax.plot(0, 0, marker="*", ms=20, color=COL_CYAN_700, mec=COL_WHITE,
mew=1.0, zorder=6)
ax.annotate("minimum (0,0)", xy=(0, 0), xytext=(2.2, -2.6),
color=COL_CYAN_800, fontsize=10, weight="bold",
arrowprops=dict(arrowstyle="->", color=COL_CYAN_700, lw=1.4))
# DÜRÜST anlatı — "kazanan" iddia ETME, fark yörünge karakterinde
ax.annotate(
"Dar vadi (dik yön b≫a): SGD dik yönde ZİKZAK salınır;\n"
"momentum salınımı söndürür; Adam parametre-başına adaptif ölçekler.\n"
"Bu basit kuadratikte hepsi yakınsar — fark YÖRÜNGE KARAKTERİNDE.",
xy=(0.5, 0.985), xycoords="axes fraction", ha="center", va="top",
fontsize=9.5, color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.45", fc=COL_BG, ec=COL_PRIMARY, lw=1.4))
ax.set_xlabel("parametre 1 (sığ yön — düz vadi tabanı)")
ax.set_ylabel("parametre 2 (dik yön — dar vadi)")
ax.set_xlim(X.min(), X.max())
ax.set_ylim(Y.min(), Y.max())
apply_style(ax)
ax.legend(loc="lower right", framealpha=0.95, edgecolor=COL_SLATE_300)
plt.tight_layout()
plt.show()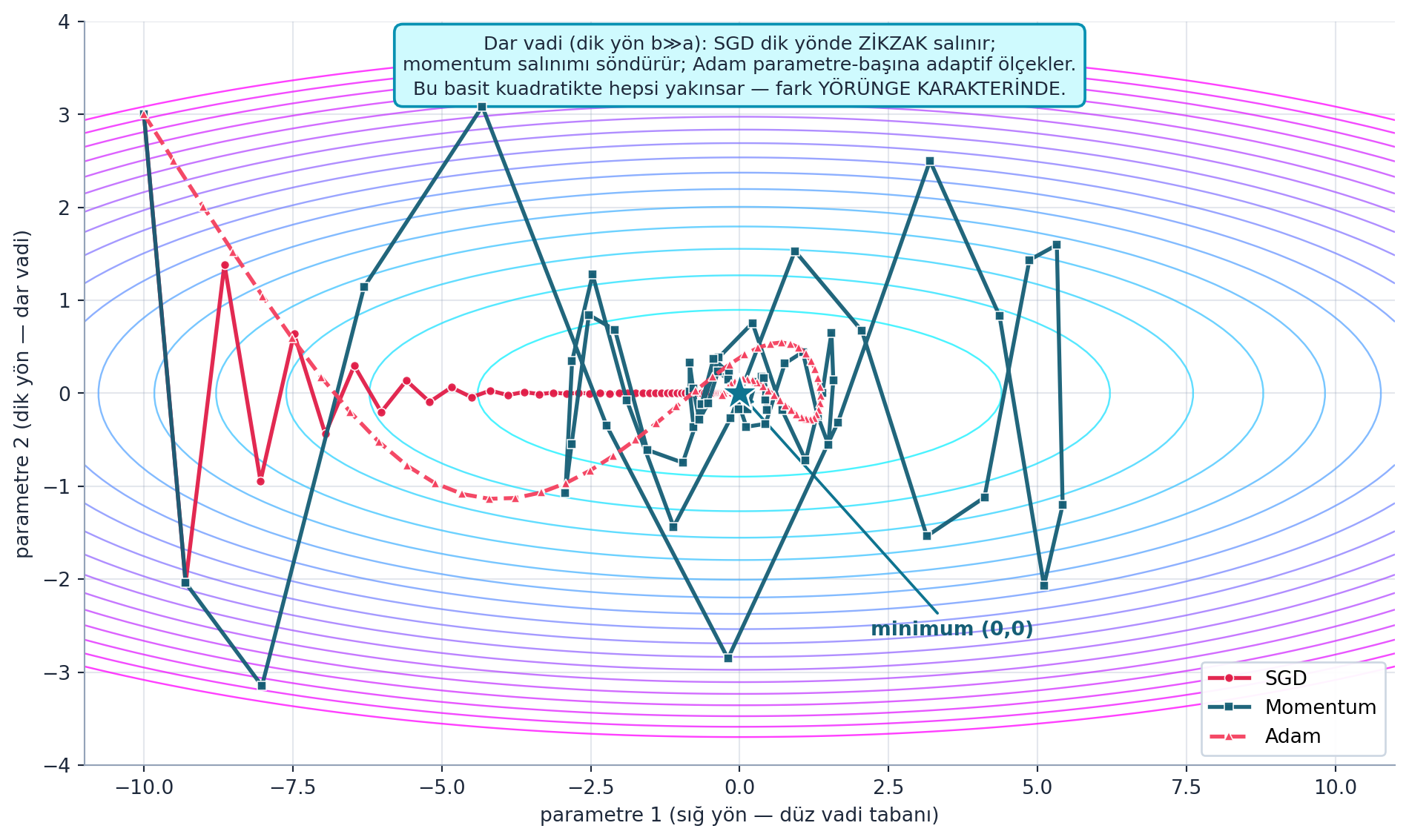
İpucuBuilder Notu — SGD: opt_step / reg_step Ayrımı
- Geriye (Ders 16): Ders 16’da
opt.step()/opt.zero_grad()çağırmıştık; işte o optimizer’ın sıfırdan hâli. Artık kütüphaneninoptim.SGD’sinin içinde ne olduğunu satır satır biliyoruz. - Sezgi:
opt_step(gradyan adımı) ilereg_step(weight decay) ayrımı bir tasarım kararıdır: alt sınıflar yalnızca nasıl adım atılacağını (opt_step) değiştirir, weight decay mantığını dokunmadan miras alır. Momentum/RMSProp/Adam bu yüzden üç-dört satırda yazılabilir.
21.4 3. Momentum
Saf SGD gürültülü gradyanlarda zikzak çizer. Momentum çözüm: ham gradyan yerine gradyanların üssel hareketli ortalamasını (EMA) kullan: grad_avg ← mom·grad_avg + (1−mom)·grad. Tutarlı yönde hızlanır, gürültüyü yumuşatır. Momentum, SGD’den türer ve yalnızca opt_step’i geçersiz kılar.
class Momentum(SGD):
def __init__(self, params, lr, wd=0., mom=0.9):
super().__init__(params, lr=lr, wd=wd); self.mom=mom
def opt_step(self, p):
if not hasattr(p, 'grad_avg'): p.grad_avg = torch.zeros_like(p.grad)
p.grad_avg = p.grad_avg*self.mom + p.grad*(1-self.mom)
p -= self.lr * p.grad_avgŞekil 21.3 momentum’un özünü gerçek hesaplamayla gösterir: ham gradyan (soluk, gürültülü zigzag) etrafında EMA (cyan, kalın) yumuşakça gerçek yönü izler. Geçmişi üssel ortalayarak gürültü varyansı ~1.4’ten ~0.07’ye iner; tutarlı yön korunur. Momentum, “geçmişi üssel unutarak ortalama al” desenidir.
Kod
d = E.ema_smoothing_demo()
steps = d["steps"]
raw_grad = d["raw_grad"]
ema_grad = d["ema_grad"]
true_signal = d["true_signal"]
fig, ax = plt.subplots(figsize=(10, 4.8))
# Ham gradyan: soluk, gürültülü zigzag
ax.plot(steps, raw_grad, color=COL_SLATE_400, lw=1.3, alpha=0.85,
label="ham gradyan (gürültülü)", zorder=2)
# Gerçek yön: rose kesik referans
ax.plot(steps, true_signal, color=COL_ACCENT, lw=2.2, ls="--",
label="gerçek yön", zorder=3)
# EMA (momentum): cyan kalın, yumuşak
ax.plot(steps, ema_grad, color=COL_PRIMARY, lw=3.0,
label="EMA (momentum)", zorder=4)
apply_style(ax)
ax.set_xlabel("adım")
ax.set_ylabel("gradyan")
ax.set_title("Momentum = gradyanların EMA'sı: gürültü sönümlenir, yön kalır",
color=COL_TEXT, fontsize=12, weight="bold")
ax.legend(loc="upper right", framealpha=0.95, edgecolor=COL_SLATE_300, fontsize=9.5)
ax.annotate(
"momentum geçmişi üssel ortalar →\ngürültü azalır, tutarlı yön kalır\n"
"(gürültü varyansı ~1.4→0.07)",
xy=(steps[int(len(steps) * 0.62)], ema_grad[int(len(steps) * 0.62)]),
xytext=(steps[int(len(steps) * 0.30)], float(raw_grad.max()) * 0.92),
fontsize=9.5, color=COL_CYAN_800, weight="bold",
ha="left", va="center",
arrowprops=dict(arrowstyle="-|>", color=COL_CYAN_700, lw=1.8,
shrinkA=4, shrinkB=8),
bbox=dict(boxstyle="round,pad=0.4", fc=COL_CYAN_50,
ec=COL_PRIMARY, lw=1.2),
)
plt.tight_layout()
plt.show()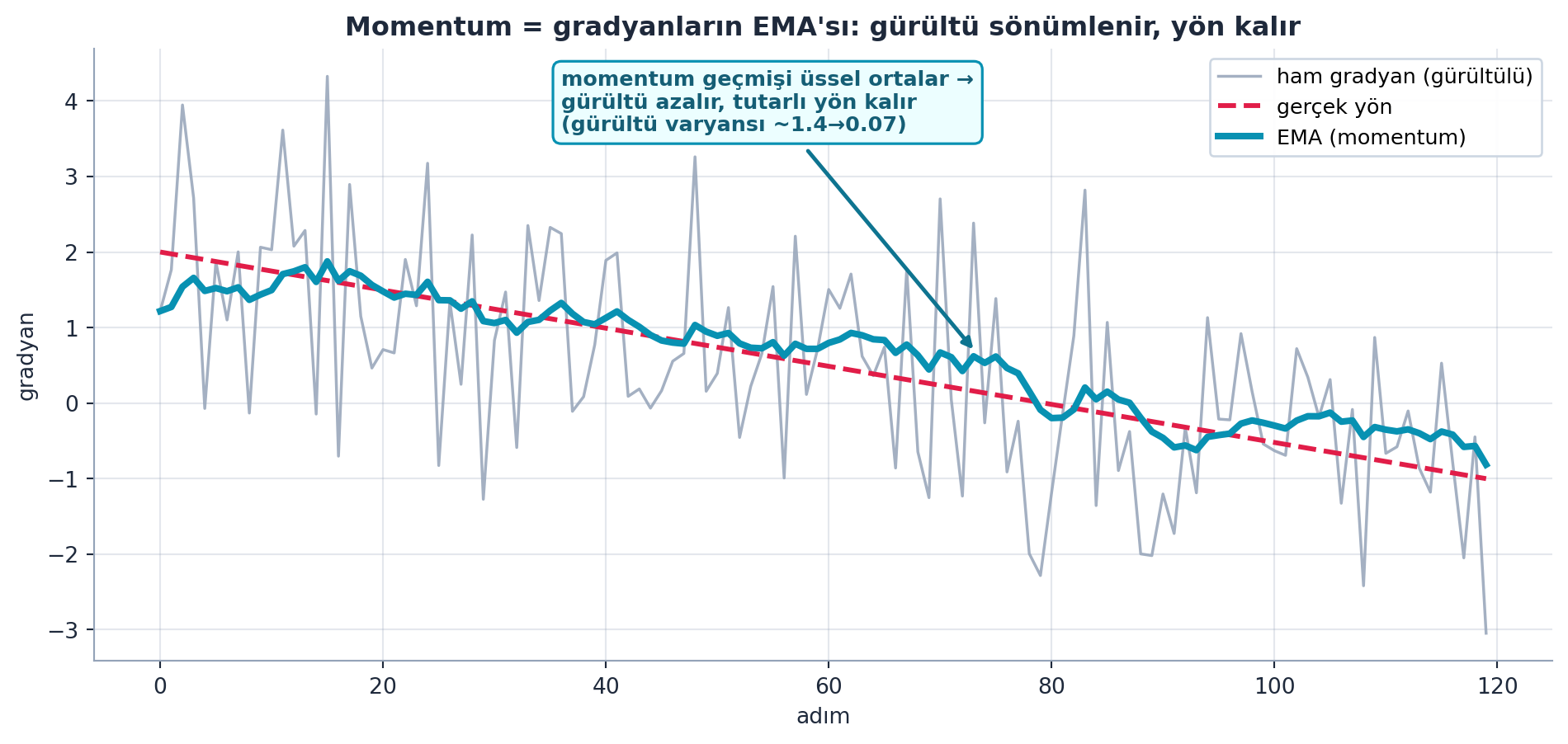
İpucuBuilder Notu — Momentum: EMA Deseni Her Yerde
- İleriye: EMA deseni her yerde — momentum, BatchNorm running_mean (Ders 17), Adam. “Geçmişi üssel unutarak ortalama al” temel araçtır; aynı
lerp_/EMA fikrini Ders 17’de BatchNorm’unrunning_mean’inde de gördük. - Sezgi:
grad_avg, son birkaç adımın gradyanlarının ağırlıklı ortalamasıdır — eski adımlar üssel olarak unutulur (mom=0.9 ise her adımda eski ortalamanın %90’ı kalır). Gürültü rastgele yönde olduğu için ortalamada birbirini götürür; gerçek (tutarlı) yön ise üst üste binerek güçlenir. Sonuç: daha düz, daha hızlı iniş.
21.5 4. RMSProp
Farklı parametrelerin farklı ölçekte gradyanları olabilir. RMSProp her parametreye adaptif bir adım verir: kare-gradyanların EMA’sını (sqr_avg) tut, gradyanı √sqr_avg ile böl. Büyük gradyanlı parametre küçük adım, küçük gradyanlı büyük adım atar. \(\varepsilon\) bölmede sıfıra bölünmeyi önler.
class RMSProp(SGD):
def __init__(self, params, lr, wd=0., sqr_mom=0.99, eps=1e-5):
super().__init__(params, lr=lr, wd=wd); self.sqr_mom,self.eps = sqr_mom,eps
def opt_step(self, p):
if not hasattr(p, 'sqr_avg'): p.sqr_avg = p.grad**2
p.sqr_avg = p.sqr_avg*self.sqr_mom + p.grad**2*(1-self.sqr_mom)
p -= self.lr * p.grad/(p.sqr_avg.sqrt() + self.eps)
İpucuBuilder Notu — RMSProp: Adam’ın Diğer Yarısı
- İleriye: “Parametre-başına adaptif learning rate” fikri Adam’ın yarısıdır; ε bölmede sıfıra bölünmeyi önler. Adam bu adaptif ölçeklemeyi momentum’la birleştirecek.
- Sezgi: Momentum gradyanın yönünü (birinci moment) ortalar; RMSProp gradyanın büyüklüğünü (ikinci moment, kare) ortalar. Bir parametre sürekli büyük gradyan alıyorsa
sqr_avgbüyür, ona bölünce adım küçülür — böylece tek bir global learning rate, her parametrenin kendi ölçeğine otomatik uyarlanır. Bu, farklı ölçekli parametreleri tek lr’yle eğitmeyi mümkün kılar.
21.6 5. Adam: Momentum + RMSProp
Adam, momentum (gradyan EMA’sı) ile RMSProp’u (kare-gradyan EMA’sı) birleştirir, üstüne bias düzeltmesi ekler (başlangıçta sıfırdan başlayan EMA’lar düşük tahmin verir; ilk adımlarda 1−βⁱ ile düzeltilir). Bugün en yaygın optimizer’dır.
class Adam(SGD):
def __init__(self, params, lr, wd=0., beta1=0.9, beta2=0.99, eps=1e-5):
super().__init__(params, lr=lr, wd=wd)
self.beta1,self.beta2,self.eps = beta1,beta2,eps
def opt_step(self, p):
if not hasattr(p, 'avg'): p.avg = torch.zeros_like(p.grad.data)
if not hasattr(p, 'sqr_avg'): p.sqr_avg = torch.zeros_like(p.grad.data)
p.avg = self.beta1*p.avg + (1-self.beta1)*p.grad
unbias_avg = p.avg / (1 - (self.beta1**(self.i+1)))
p.sqr_avg = self.beta2*p.sqr_avg + (1-self.beta2)*(p.grad**2)
unbias_sqr_avg = p.sqr_avg / (1 - (self.beta2**(self.i+1)))
p -= self.lr * unbias_avg / (unbias_sqr_avg + self.eps).sqrt()Şekil 21.4 bias düzeltmesini gerçek hesaplamayla gösterir: düzeltilmemiş EMA sıfırdan başlar ve ilk adımda gerçek değerin çok altında kalır (~0.09, yanlı); \(1-\beta^i\) ile bölünen düzeltilmiş EMA ise ilk adımdan itibaren doğru ölçektedir (~0.92). Bias düzeltmesi, EMA’nın sıfır-başlangıç yanlılığını telafi eder ve ısınma gecikmesini kaldırır.
Kod
d = E.adam_bias_demo()
steps = d["steps"]
unc = d["uncorrected"]
cor = d["corrected"]
true_val = d["true_val"]
fig, ax = plt.subplots(figsize=(10, 4.8))
apply_style(ax)
# Gerçek değer — gri kesik yatay
ax.axhline(true_val, color=COL_SLATE_400, ls="--", lw=1.8, zorder=2,
label=f"gerçek değer = {true_val:.1f}")
# Düzeltilmemiş EMA (sıfırdan başlar, yavaş yükselir) — rose
ax.plot(steps, unc, color=COL_ACCENT, lw=2.4, marker="o", ms=4,
markevery=3, zorder=4,
label="düzeltilmemiş EMA (sıfırdan başlar)")
# Düzeltilmiş (1−βⁱ ile) — cyan, ilk adımdan ~gerçek değerde
ax.plot(steps, cor, color=COL_PRIMARY, lw=2.6, marker="s", ms=4,
markevery=3, zorder=5,
label="düzeltilmiş (1−βⁱ bölmesi)")
# İlk adımları vurgula: düzeltilmemiş düşük, düzeltilmiş doğru
ax.annotate(
"EMA sıfırdan başlar → ilk adımlar DÜŞÜK (yanlı)",
xy=(steps[0], unc[0]), xytext=(7.5, 0.30),
fontsize=9.5, color=COL_ACCENT, weight="bold",
ha="left", va="center",
arrowprops=dict(arrowstyle="-|>", color=COL_ROSE_500, lw=1.8,
shrinkA=4, shrinkB=4, connectionstyle="arc3,rad=-0.25"),
)
ax.annotate(
"1−βⁱ telafi eder → ilk adımdan doğru ölçek\n(ısınma gecikmesi yok)",
xy=(steps[0], cor[0]), xytext=(7.5, 1.18),
fontsize=9.5, color=COL_CYAN_700, weight="bold",
ha="left", va="center",
arrowprops=dict(arrowstyle="-|>", color=COL_PRIMARY, lw=1.8,
shrinkA=4, shrinkB=4, connectionstyle="arc3,rad=0.25"),
)
# İlk adım sayısal etiketleri
ax.scatter([steps[0], steps[0]], [unc[0], cor[0]],
s=55, color=[COL_ACCENT, COL_PRIMARY],
edgecolors=COL_WHITE, linewidths=1.4, zorder=6)
ax.text(steps[0] - 0.4, unc[0], f"{unc[0]:.2f}", ha="right", va="center",
fontsize=9, color=COL_ACCENT, weight="bold")
ax.text(steps[0] - 0.4, cor[0], f"{cor[0]:.2f}", ha="right", va="center",
fontsize=9, color=COL_CYAN_700, weight="bold")
ax.set_xlabel("adım i")
ax.set_ylabel("EMA tahmini (gradyan ortalaması)")
ax.set_title("Adam bias düzeltmesi: ham EMA vs 1−βⁱ ile düzeltilmiş",
fontsize=12, weight="bold")
ax.set_xlim(-1.5, steps[-1] + 1)
ax.set_ylim(-0.05, 1.35)
ax.legend(loc="lower right", fontsize=9.5, framealpha=0.95)
plt.tight_layout()
plt.show()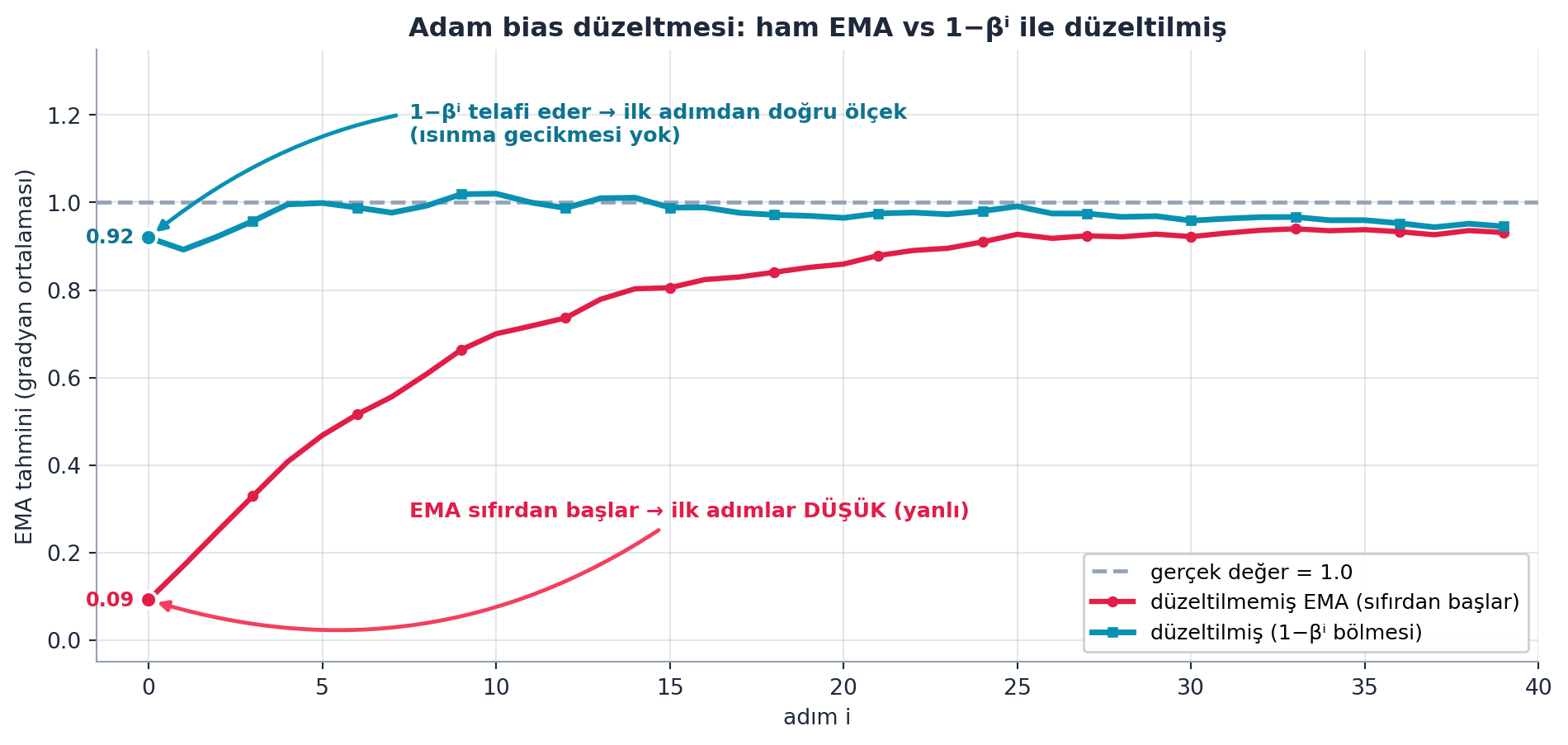
İpucuBuilder Notu — Adam: Optimizer Özü Köprüsü
- Geriye (Karpathy nanoGPT/Zero-to-Hero): Karpathy eğitim döngülerini
AdamWile sürer — yani optimizer’ın özü “gradyanın ortalaması (momentum) + ölçeklemesi (RMSProp)” iki kursta da aynıdır. Howard’ın sıfırdan yazdığıAdamsınıfı aynı iki momenti (birinci:avg, ikinci:sqr_avg) birleştirir; PyTorch’unAdamW’sinin içini açar. - Sezgi: Adam = momentum + RMSProp + bias düzeltmesi.
avgmomentum’u verir (yönü ortalar),sqr_avgRMSProp’u verir (büyüklüğü ortalar),unbias_*bölmeleri ise sıfırdan başlamanın getirdiği ilk-adım yanlılığını siler. \(\beta^i \to 0\) olunca düzeltme kaybolur — yani sadece başta etki eder.
21.7 6. Learning Rate Annealing
Sabit learning rate optimal değildir: başta büyük adım (hızlı ilerleme), sonda küçük adım (ince ayar) gerekir. Annealing = learning rate’i eğitim boyunca kademeli azaltmak. Howard önce Excel’de, sonra PyTorch’ta gösterir. Bu, optimizer’ın ne kadar adım atacağını zaman içinde uyarlar — optimizer’ın nasıl adım attığına (momentum/Adam) ek, ortogonal bir hızlandırma kaldıracıdır.
İpucuBuilder Notu — Annealing: Zaman İçinde Adım Boyu
- Geriye (Ders 3): Ders 3’te “learning rate çok büyük/küçük” sorununu görmüştük; annealing bunu zamana yayar — başta yüksek (hızlı kaba arama), sonda düşük (hassas yerleşme).
- Sezgi: Optimizer’ın yön seçimi (momentum, adaptif ölçek) ile adım boyu çizelgesi (annealing) iki ayrı eksendir; ikisi bağımsız ayarlanabilir. İyi bir reçete genellikle ikisini birlikte kullanır: Adam (yön) + cosine/1-cycle (adım boyu).
21.8 7. PyTorch Optimizer ve Scheduler Nasıl Çalışır?
Howard PyTorch’un kendi optimizer ve scheduler API’sini açar: optimizer param_groups üzerinde çalışır, scheduler her adımda optimizer’ın learning rate’ini günceller. Sıfırdan kurduğumuz mantığın PyTorch karşılığını görmek, kütüphaneyi demistifiye eder.
def sched_lrs(sched, steps):
lrs = [sched.get_last_lr()]
for i in range(steps):
sched.optimizer.step(); sched.step()
lrs.append(sched.get_last_lr())
plt.plot(lrs)
İpucuBuilder Notu — PyTorch API: Yeniden Kur, Sonra Kullan
- Geriye (Ders 10): “Yeniden kur, sonra kullan” — artık PyTorch optimizer/scheduler’ı kara kutu değil, içini biliyoruz.
optim.Adamvelr_scheduler.OneCycleLR, §2-5’te elle yazdığımız sınıfların üretim sürümüdür. - Sezgi: Scheduler, optimizer’ın
param_groups’undakilrdeğerini her.step()’te dışarıdan değiştiren ayrı bir nesnedir — optimizer’ı sarmalamaz, ona müdahale eder. Bu gevşek bağlama sayesinde herhangi bir optimizer’ı herhangi bir scheduler’la eşleştirebilirsin.
21.9 8. Scheduler Callback
Learning rate scheduling de bir callback’tir (Ders 16). BaseSchedCB scheduler’ı kurar; BatchSchedCB her batch’te, EpochSchedCB her epoch’ta adım atar. Eğitim döngüsü değişmez; scheduling ayrı bir eklenti.
class BaseSchedCB(Callback):
def __init__(self, sched): self.sched = sched
def before_fit(self, learn): self.schedo = self.sched(learn.opt)
def _step(self, learn):
if learn.training: self.schedo.step()
class BatchSchedCB(BaseSchedCB):
def after_batch(self, learn): self._step(learn)
İpucuBuilder Notu — Scheduler Callback: Ders 16 Altyapısı İş Başında
- Geriye (Ders 16) — köprü: Ders 16’nın callback sistemi tam burada işe yarar; scheduling çekirdek döngüye dokunmadan eklenir.
BatchSchedCB,after_batchkancasına takılan üç satırlık bir eklentidir. - Sezgi: Eğitim döngüsünü hiç değiştirmeden yeni bir davranış (her batch’te LR güncelle) eklemek, callback mimarisinin asıl ödülüdür. Aynı kanca noktasına ActivationStats (Ders 17), kayıt tutma ve scheduling birlikte takılabilir — birbirinden habersiz, birbirini bozmadan.
21.10 9. Cosine Annealing
Yaygın bir program: learning rate’i bir kosinüs eğrisi boyunca yüksekten sıfıra düşür. Yumuşak, kademeli azalma eğitimin sonunda ince ayara izin verir. PyTorch’ta CosineAnnealingLR.
tmax = epochs * len(dls.train)
sched = partial(lr_scheduler.CosineAnnealingLR, T_max=tmax)Şekil 21.5 iki programı gerçek hesaplamayla yan yana çizer: solda cosine annealing (LR yüksekten 0’a yumuşak, pürüzsüz iniş), sağda 1-cycle (LR warmup ile yükselir sonra düşer; momentum tersi yönde hareket eder). Bu figür §9-10’un görsel karşılaştırmasıdır; cosine pürüzsüz tek-yönlü iniş, 1-cycle ise warmup’lı çift-fazlı bir döngüdür.
Kod
d = E.lr_schedule_demo()
t = d["t"]
cosine = d["cosine"]
oc_lr = d["onecycle_lr"]
oc_mom = d["onecycle_mom"]
fig, (axc, axo) = plt.subplots(1, 2, figsize=(11.5, 4.8))
# --- SOL: cosine annealing (yüksek → 0) ---
axc.plot(t, cosine, color=COL_PRIMARY, lw=2.6, label="LR (cosine)")
axc.fill_between(t, 0, cosine, color=COL_BG, alpha=0.55, zorder=0)
axc.set_title("Cosine annealing", color=COL_CYAN_700, fontsize=12, weight="bold")
axc.set_xlabel("eğitim adımı")
axc.set_ylabel("learning rate")
axc.set_ylim(-0.03, 1.08)
apply_style(axc)
axc.annotate("yüksek → 0\n(yumuşak, pürüzsüz iniş)",
xy=(t[int(len(t) * 0.5)], cosine[int(len(t) * 0.5)]),
xytext=(t[int(len(t) * 0.18)], 0.30),
fontsize=9.5, color=COL_TEXT, weight="bold",
arrowprops=dict(arrowstyle="-|>", color=COL_CYAN_700, lw=1.6))
# --- SAĞ: 1-cycle — LR (cyan) + momentum tersi (rose, ikiz eksen) ---
axo.plot(t, oc_lr, color=COL_PRIMARY, lw=2.6, label="LR (1-cycle)")
axo.set_title("1-cycle (super-convergence)", color=COL_CYAN_700, fontsize=12, weight="bold")
axo.set_xlabel("eğitim adımı")
axo.set_ylabel("learning rate", color=COL_PRIMARY)
axo.set_ylim(-0.03, 1.08)
axo.tick_params(axis="y", colors=COL_PRIMARY)
apply_style(axo)
axm = axo.twinx()
axm.plot(t, oc_mom, color=COL_ACCENT, lw=2.6, ls="--", label="momentum")
axm.set_ylabel("momentum", color=COL_ACCENT)
axm.set_ylim(0.80, 0.98)
axm.tick_params(axis="y", colors=COL_ACCENT)
axm.spines["top"].set_visible(False)
axm.spines["right"].set_color(COL_ROSE_400)
# warmup tepe konumu (yüksek LR + düşük momentum penceresi)
warm = int(len(t) * 0.3)
axo.axvline(warm, color=COL_SLATE_400, lw=1.0, ls=":", zorder=0)
axo.annotate("warmup↑ sonra anneal↓",
xy=(warm, oc_lr[warm]),
xytext=(t[int(len(t) * 0.42)], 0.32),
fontsize=9.2, color=COL_PRIMARY, weight="bold",
arrowprops=dict(arrowstyle="-|>", color=COL_PRIMARY, lw=1.5))
axo.annotate("yüksek LR döneminde düşük momentum\n= istikrar (super-convergence)",
xy=(warm, 0.86), xytext=(t[int(len(t) * 0.30)], 0.92),
fontsize=9.2, color=COL_ACCENT, weight="bold",
ha="left", va="top",
bbox=dict(boxstyle="round,pad=0.3", fc=COL_BG_ROSE,
ec=COL_ROSE_400, lw=1.2),
arrowprops=dict(arrowstyle="-|>", color=COL_ACCENT, lw=1.5))
# Ders 17 köprü notu
axo.text(0.5, -0.30,
"Ders 17 sağlam init + BatchNorm, 1-cycle'ın yüksek LR'sini kaldırır",
transform=axo.transAxes, ha="center", va="top",
fontsize=8.8, color=COL_CYAN_800, style="italic")
# birleşik gösterge (LR + momentum)
lines = axo.get_lines()[:1] + axm.get_lines()[:1]
axo.legend(lines, [ln.get_label() for ln in lines],
loc="upper right", fontsize=9, frameon=False)
plt.tight_layout()
plt.show()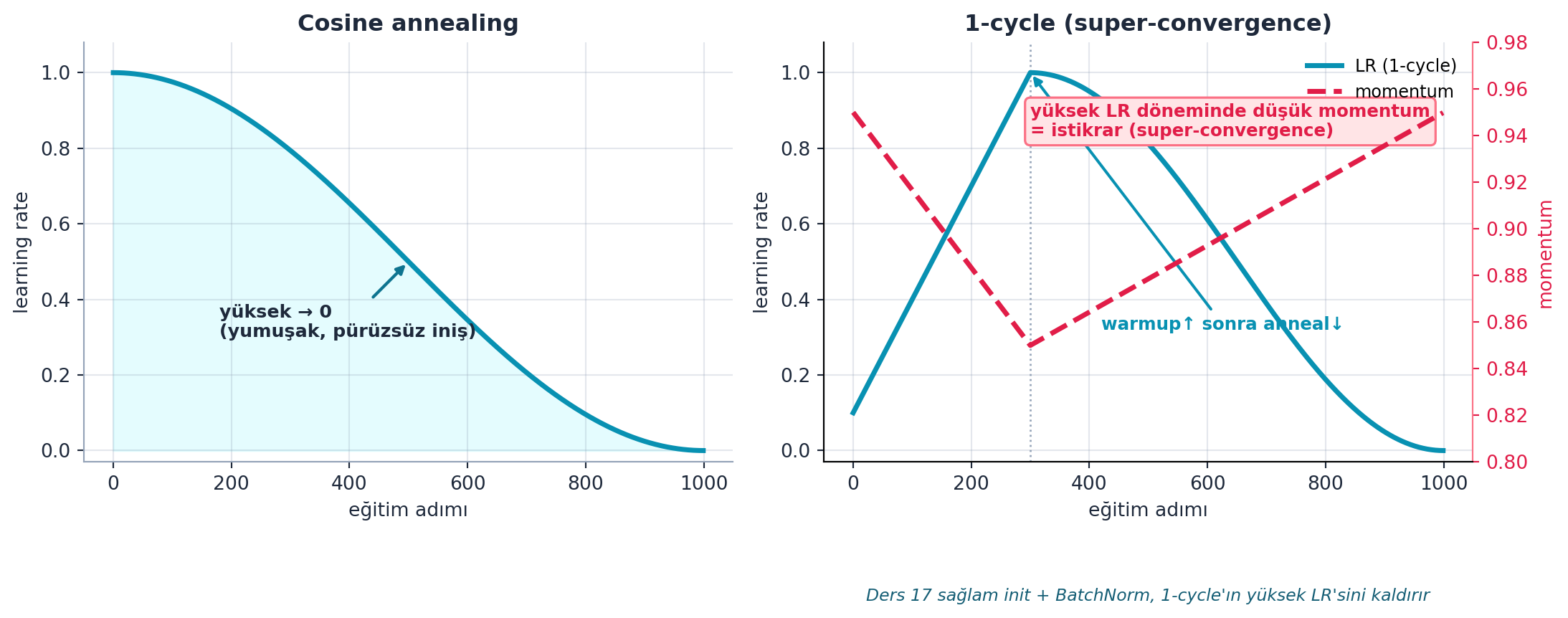
İpucuBuilder Notu — Cosine: Modern Standardın Programı
- İleriye: Cosine annealing modern eğitimin (transformer’lar dahil) standart programıdır; warmup’la birlikte kullanılır. Karpathy nanoGPT eğitiminde de warmup + cosine decay tipik reçetedir.
- Sezgi: Kosinüs eğrisi başta yavaş, ortada hızlı, sonda yine yavaş düşer — yani yüksek LR’de yeterince zaman geçirir (kaba arama), sonra giderek nazikleşerek (ince ayar) sıfıra yaklaşır. Doğrusal azalmaya kıyasla bu “yumuşak iniş” pratikte daha sağlam yakınsama verir.
21.11 10. 1-Cycle Learning Rate
Howard’ın favorisi: 1-cycle. Learning rate düşük başlar, yükselir (warmup), sonra düşer; momentum ise tam tersi (yüksek → düşük → yüksek). Yüksek LR döneminde düşük momentum istikrar sağlar. Sonuç: çok hızlı ve sağlam eğitim (“super-convergence”).
sched = partial(lr_scheduler.OneCycleLR, max_lr=lr, total_steps=tmax)
xtra = [BatchSchedCB(sched), rec]“the learning rate is starting very low and going up to high and then down again. But the momentum is starting high…” — Howard, 43:46
İpucuBuilder Notu — 1-cycle: Ders 17 Olmadan Çökerdi
- Geriye (Ders 17): 1-cycle yüksek LR’yi sağlam init + BatchNorm sayesinde kaldırabilir; Ders 17 olmadan bu hızlanma çökerdi. Yüksek LR döneminde aktivasyon varyansı kontrol altında tutulmazsa eğitim patlar — init + norm o güvenliği verir.
- Sezgi: LR ve momentum’un ters hareketi kasıtlıdır: yüksek LR döneminde (büyük adımlar) momentum düşürülür ki sistem aşırı ivmelenip savrulmasın; düşük LR döneminde (küçük adımlar) momentum yükseltilir ki ilerleme yavaşlamasın. Bu denge, çok kısa sürede yüksek doğruluk getiren “super-convergence”in sırrıdır.
21.12 11. ResNet Sorunu: Derin Ağ Neden Kötüleşir?
“Deep Residual Learning” makalesinin gözlemi: 56 katmanlı ağ, 20 katmanlının üst-kümesi olmalı (fazla katmanlar identity olsa hiçbir şey bozulmaz). Yani derin ağ en az sığ kadar iyi olmalı — ama pratikte daha kötü eğitildi. Sorun ifade gücü değil, eğitilebilirlik.
“This is in a paper called ‘Deep Residual Learning for Image Recognition’ that introduced ResNets.” — Howard, 1:01:34
Şekil 21.6 degradation’ı iki panelde gösterir: solda beklenti (56-katman ağ, 20-katmanın üst-kümesidir — fazla 36 katman identity olursa kötüleşemez), sağda gerçek (ResNet öncesi: düz 56-katman, düz 20-katmandan daha kötü eğitilir). Skip connection eklenince derin ResNet en düşük hataya iner — sorunun ifade gücü değil eğitilebilirlik olduğunu kanıtlar.
Kod
fig, (axL, axR) = plt.subplots(1, 2, figsize=(10.5, 5.5))
# ---------------------------------------------------------------------------
# SOL panel — BEKLENTİ: 56-katman ⊇ 20-katman üst-kümesi
# (fazla katmanlar identity olursa kötüleşemez → en az o kadar iyi olmalı)
# ---------------------------------------------------------------------------
axL.set_xlim(0, 10)
axL.set_ylim(0, 10)
axL.axis("off")
axL.set_title("BEKLENTİ (mantık)", color=COL_CYAN_800, fontsize=12.5, weight="bold")
# içteki kutu = 20-katman, dıştaki kutu = 56-katman (üst-küme görseli)
boxed_node(axL, 5.0, 5.2, 8.4, 7.0, "", fc=COL_BG, ec=COL_PRIMARY, lw=2.2)
boxed_node(axL, 4.2, 4.6, 4.4, 3.6, "20-katman\nağ", fc=COL_WHITE,
ec=COL_CYAN_700, tc=COL_CYAN_800, lw=2.0, fontsize=10.5)
axL.text(7.3, 7.6, "56-katman ağ", ha="center", va="center",
fontsize=11, weight="bold", color=COL_CYAN_800)
axL.text(5.0, 1.5,
"fazla 36 katman = identity\n→ 20-katmanı kapsar\n→ en az o kadar iyi olmalı",
ha="center", va="center", fontsize=9.8, color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.4", fc=COL_CYAN_50, ec=COL_PRIMARY, lw=1.3))
# ---------------------------------------------------------------------------
# SAĞ panel — GERÇEK (ResNet öncesi): düz 56-katman, 20-katmandan DAHA KÖTÜ
# illüstratif eğitim-hatası eğrileri (şematik)
# ---------------------------------------------------------------------------
ep = np.linspace(0, 1, 100) # normalize edilmiş eğitim ilerlemesi (illüstratif)
# düz-sığ (20-katman): düşük hataya iner (rose-açık)
err_plain_shallow = 0.10 + 0.55 * np.exp(-3.6 * ep)
# düz-derin (56-katman): eğitilebilirlik bozuk → sığdan DAHA YÜKSEK platoya oturur (rose)
err_plain_deep = 0.22 + 0.55 * np.exp(-2.6 * ep)
# ResNet-derin (56-katman + skip): EN DÜŞÜK hataya iner (cyan)
err_resnet_deep = 0.04 + 0.55 * np.exp(-4.2 * ep)
apply_style(axR)
axR.plot(ep, err_plain_deep, color=COL_ACCENT, lw=2.6,
label="düz 56-katman (derin)")
axR.plot(ep, err_plain_shallow, color=COL_ROSE_400, lw=2.4, ls="--",
label="düz 20-katman (sığ)")
axR.plot(ep, err_resnet_deep, color=COL_PRIMARY, lw=2.8,
label="ResNet 56-katman (skip)")
axR.set_title("GERÇEK (ölçüm — ResNet öncesi)", color=COL_CYAN_800,
fontsize=12.5, weight="bold")
axR.set_xlabel("eğitim ilerlemesi", fontsize=10.5)
axR.set_ylabel("eğitim hatası", fontsize=10.5)
axR.set_ylim(0, 0.72)
axR.set_xticks([])
axR.legend(loc="upper right", fontsize=9.2, framealpha=0.95)
# "düz derin > düz sığ" paradoksu (degradation): derin olan DAHA KÖTÜ
axR.annotate("düz derin > düz sığ\n(sorun ifade gücü DEĞİL,\neğitilebilirlik)",
xy=(0.62, err_plain_deep[62]), xytext=(0.30, 0.62),
fontsize=9.2, color=COL_ACCENT, weight="bold", ha="center",
arrowprops=dict(arrowstyle="-|>", color=COL_ACCENT, lw=1.8))
# skip connection çözer → derin ResNet en iyi
axR.annotate("skip connection eğitilebilirliği\nçözer → derin ResNet en iyi",
xy=(0.78, err_resnet_deep[78]), xytext=(0.40, 0.13),
fontsize=9.2, color=COL_CYAN_800, weight="bold", ha="center",
arrowprops=dict(arrowstyle="-|>", color=COL_PRIMARY, lw=1.8))
plt.tight_layout()
plt.show()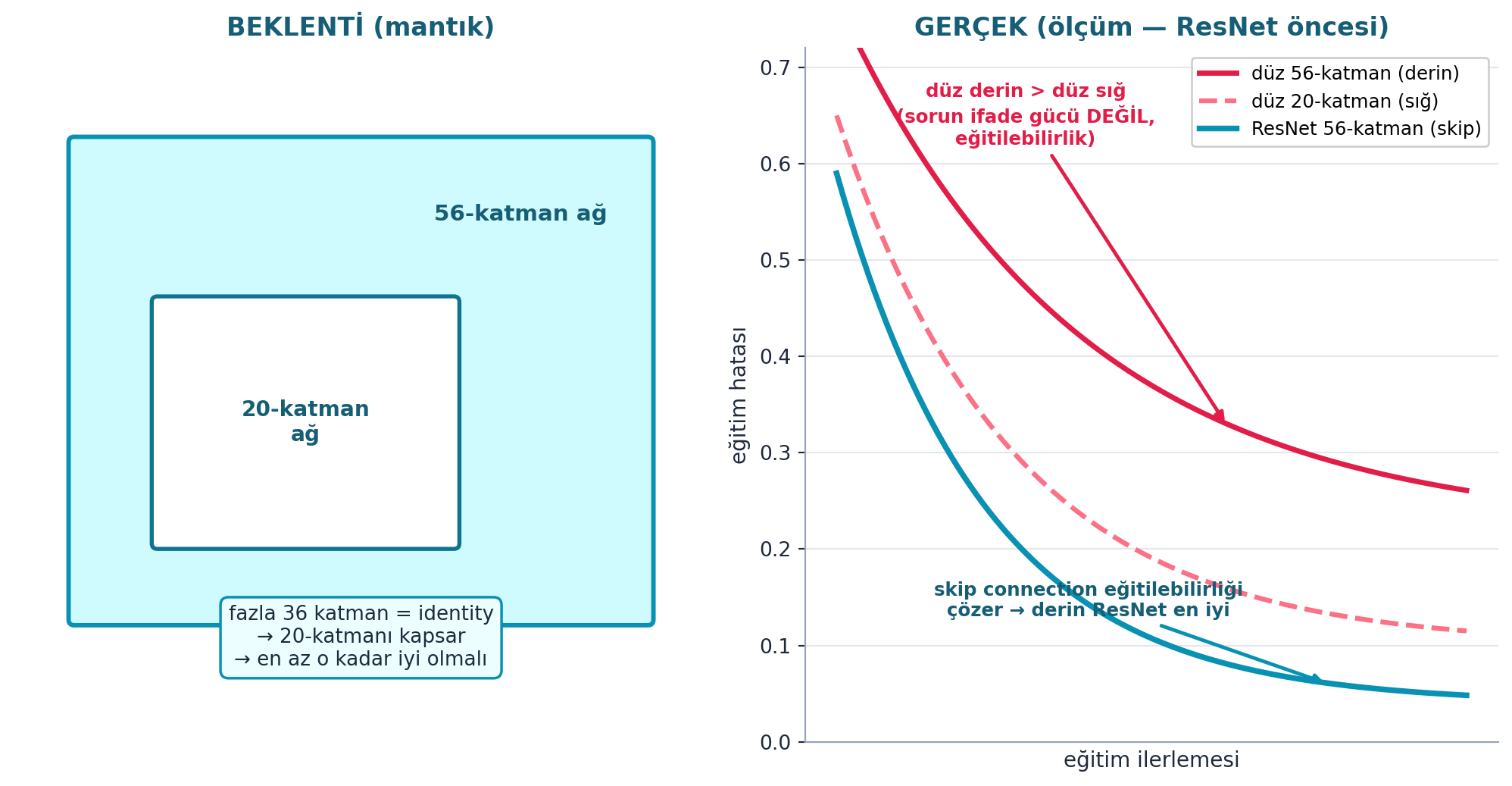
İpucuBuilder Notu — Degradation: Init/Norm Sorununun Mimari Boyutu
- Geriye (Ders 17): Derin ağın eğitilememesi = init/norm sorununun mimari boyutu; ResNet bunu farklı bir açıdan çözer. Ders 17 sinyali katman içinde (varyans korunumu) korur; ResNet sinyali katmanlar arasında (skip yolu) korur.
- Sezgi: Paradoks şu: derin ağ teoride sığ ağı kapsar (fazla katmanları identity yaparak), dolayısıyla asla daha kötü olamamalı. Ama optimizasyon o identity çözümünü bulamıyor — gradyan derin yığında bozuluyor. Sorun modelin yapabileceği değil, eğitimin onu bulabilmesi. ResNet identity’yi varsayılan hâle getirerek bu aramayı kolaylaştırır.
21.13 12. Skip Connection: out = F(x) + x
ResNet’in fikri tek satır: katmanın çıktısına girdisini geri ekle: \(out = F(x) + x\). Böylece katmanın yapması gereken, tüm dönüşüm değil, sadece artık (residual) — girdiden sapma. Eğer hiçbir şey öğrenmesi gerekmiyorsa \(F(x) = 0\) yapması (identity) kolaydır. Bu, gradyanın derin ağda doğrudan akmasını da sağlar.
“let’s add what’s called a skip connection where instead of just being out equals… conv1… conv2.” — Howard, 1:04:36
Şekil 21.7 skip connection’ı şema olarak gösterir (FLAGSHIP): girdi x iki yola ayrılır — ana yol F(x) (conv → norm → act → conv → norm, artığı öğrenir) ve skip yolu (x doğrudan, identity); ikisi + düğümünde toplanır (out = F(x) + x), sonra aktivasyondan geçer. Kanal/stride değişirse skip yolu 1×1 conv (idconv) + AvgPool ile boyut eşitlenir. + x terimi gradyanın doğrudan akmasını sağlar (gradyan otoyolu).
Kod
fig, ax = plt.subplots(figsize=(11, 6))
ax.set_xlim(0, 11)
ax.set_ylim(0, 6)
ax.axis("off")
ax.set_facecolor(COL_WHITE)
# --- Düğümler (akış: girdi → F(x) ana yol + identity skip → toplam → act → out) ---
# girdi x (sol)
boxed_node(ax, 1.4, 3.0, 1.7, 0.9, "girdi\nx",
fc=COL_BG, ec=COL_PRIMARY, fontsize=11)
# ana yol F(x): conv-norm-act-conv-norm (cyan, ortada üst banttan)
boxed_node(ax, 4.7, 4.3, 3.4, 1.5,
"F(x)\nconv → norm → act\n→ conv → norm",
fc=COL_CYAN_50, ec=COL_PRIMARY, tc=COL_CYAN_800,
fontsize=10, lw=2.2)
# toplama düğümü "+"
boxed_node(ax, 7.7, 3.0, 0.85, 0.85, "+",
fc=COL_WHITE, ec=COL_TEXT, tc=COL_TEXT, fontsize=18, lw=2.4)
# act (toplam sonrası aktivasyon)
boxed_node(ax, 9.0, 3.0, 1.15, 0.9, "act",
fc=COL_BG, ec=COL_PRIMARY, fontsize=11)
# out
boxed_node(ax, 10.3, 3.0, 1.15, 0.9, "out",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT, fontsize=11)
# --- Oklar ---
# girdi → F(x) (yukarı dallanma, cyan ana yol)
arrow_between(ax, (1.4, 3.45), (4.7, 3.55),
color=COL_PRIMARY, lw=2.2,
connectionstyle="arc3,rad=0.18")
# F(x) → + (aşağı, ana yol toplama düğümüne iner)
arrow_between(ax, (6.0, 3.95), (7.55, 3.30),
color=COL_PRIMARY, lw=2.2,
connectionstyle="arc3,rad=0.18")
# girdi → + : skip yolu (rose, kavisli ok ana yolu ATLAR, identity)
arrow_between(ax, (2.25, 2.75), (7.45, 2.78),
color=COL_ACCENT, lw=2.6,
connectionstyle="arc3,rad=-0.30")
# + → act → out
arrow_between(ax, (8.12, 3.0), (8.42, 3.0), color=COL_TEXT, lw=2.0)
arrow_between(ax, (9.57, 3.0), (9.72, 3.0), color=COL_TEXT, lw=2.0)
# --- Etiketler / annotate ---
# skip yolu etiketi (rose)
ax.text(4.7, 1.55, "x doğrudan (identity) — skip yolu",
ha="center", va="center", fontsize=10.5, weight="bold",
color=COL_ACCENT)
# ana yol etiketi
ax.text(4.7, 5.45, "ana yol (artığı öğrenir)",
ha="center", va="center", fontsize=10, weight="bold",
color=COL_CYAN_700)
# çekirdek sezgi annotate kutusu (sol alt)
ax.text(
0.35, 0.55,
"katman sadece ARTIĞI öğrenir (residual = F(x), girdiden sapma);\n"
"gerekirse F(x)=0 (identity geçişi) kolay + "+ "+ x gradyanın\n"
"doğrudan akmasını sağlar (gradyan otoyolu) → derin ağ eğitilebilir",
ha="left", va="center", fontsize=9.5, color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.5", fc=COL_CYAN_50,
ec=COL_SLATE_300, lw=1.2),
)
# boyut/stride notu (sağ üst)
ax.text(
10.85, 5.45,
"kanal/stride değişirse skip:\n1×1 conv (idconv) + AvgPool\nile boyut eşitlenir",
ha="right", va="center", fontsize=8.8, color=COL_SLATE_400,
style="italic",
)
# out = F(x) + x formül etiketi (toplam düğümü üstü)
ax.text(7.7, 3.75, "out = F(x) + x", ha="center", va="center",
fontsize=10, weight="bold", color=COL_TEXT)
plt.tight_layout()
plt.show()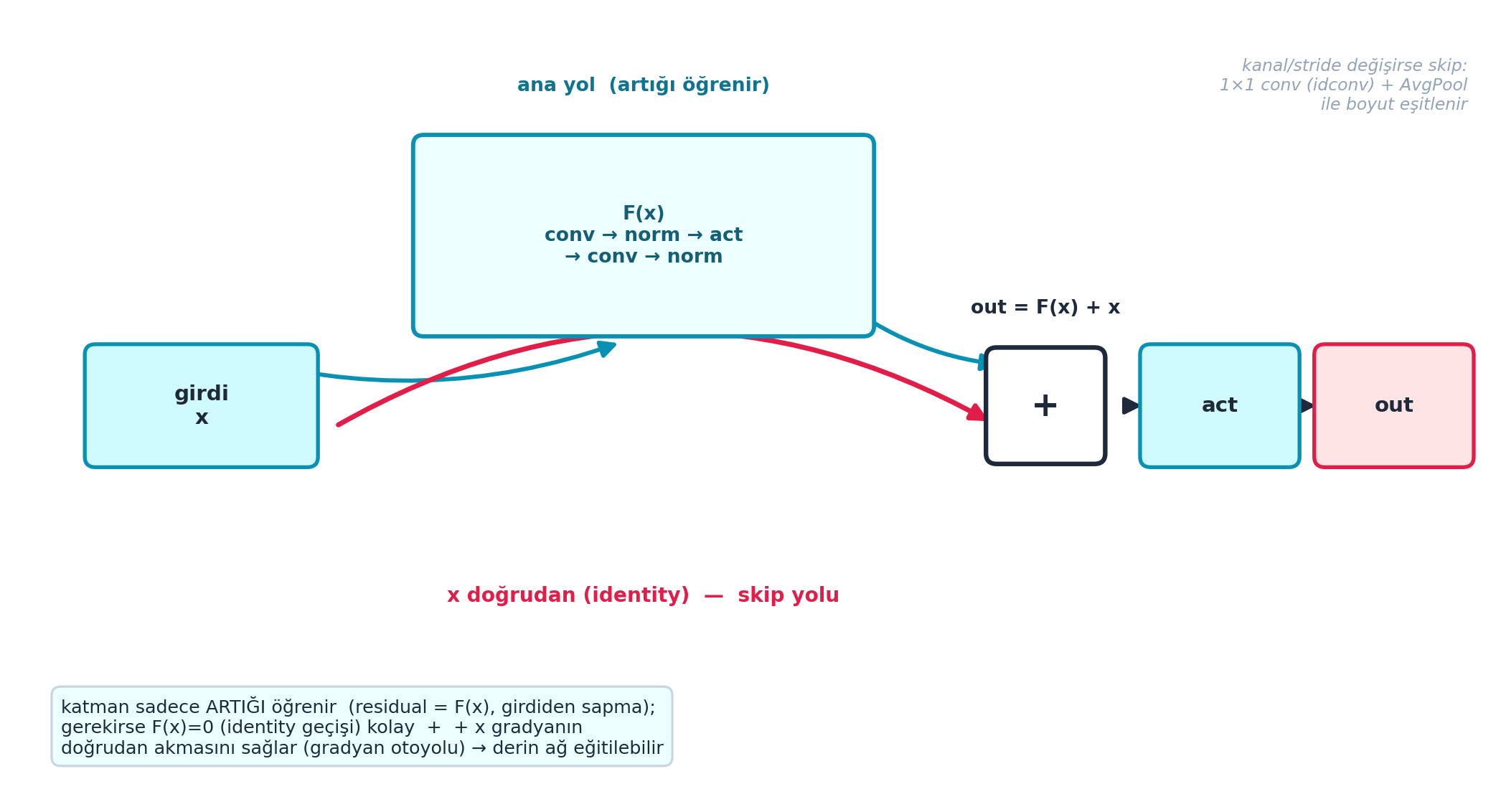
ÖnemliBuilder Notu — Skip Connection = Karpathy nanoGPT’nin Belkemiği (MERKEZÎ)
- İleriye (Karpathy nanoGPT) — MERKEZÎ: Bu
+ x, Karpathy’nin nanoGPT’sinde her transformer bloğunun belkemiğidir:x = x + attention(x),x = x + mlp(x). “Residual stream” derin transformer’ları eğitilebilir kılan tam bu fikirdir. ResNet (2015) → Transformer (2017) → GPT doğrudan miras zinciridir. - İki satır, tek fizik: Ders 18’de sıfırdan yazdığımız
ResBlock.forward’dakiself.convs(x) + ...ifadesi ile Karpathy’nin GPT bloğundakix + self.attn(x)aynı matematiksel fikirdir: bilgi blok boyunca değiştirilmeden akar (residual stream), her blok yalnızca bir artık katkı ekler. 96+ katmanlı GPT’lerin eğitilebilmesinin nedeni budur. - Sezgi:
+ xteriminin türevi 1’dir; yani geri yayılımda gradyan,Fne yaparsa yapsın, skip yolu üzerinden derin ağda hiç sönmeden doğrudan geriye akar. Bu “gradyan otoyolu”, katlanan çarpımların gradyanı yok etmesini engeller — Ders 17’nin varyans korunumuna mimari bir ek.
21.14 13. ResBlock Sıfırdan
ResBlock: iki conv’lu bir blok (convs) + skip yolu. Kanal sayısı değişirse skip yolu 1×1 conv (idconv) ile eşitlenir; stride 2 ise girdi AvgPool2d ile küçültülür. forward tek satır: iki conv’un çıktısı + (ölçeklenmiş) girdi, sonra aktivasyon.
def _conv_block(ni, nf, stride, act=act_gr, norm=None, ks=3):
return nn.Sequential(conv(ni, nf, stride=1, act=act, norm=norm, ks=ks),
conv(nf, nf, stride=stride, act=None, norm=norm, ks=ks))
class ResBlock(nn.Module):
def __init__(self, ni, nf, stride=1, ks=3, act=act_gr, norm=None):
super().__init__()
self.convs = _conv_block(ni, nf, stride, act=act, ks=ks, norm=norm)
self.idconv = fc.noop if ni==nf else conv(ni, nf, ks=1, stride=1, act=None)
self.pool = fc.noop if stride==1 else nn.AvgPool2d(2, ceil_mode=True)
self.act = act()
def forward(self, x): return self.act(self.convs(x) + self.idconv(self.pool(x)))
İpucuBuilder Notu — ResBlock: Önceki Derslerin Birleşimi
- Geriye (Ders 15/17):
conv,act_gr(GeneralReLU),norm(BatchNorm) — hepsi önceki derslerden; ResBlock onları birleştirir. Ders 17’nin BatchNorm’u ve GeneralReLU’su burada ana yolun (F(x)) yapıtaşları olur. - Sezgi:
forwardsatırının zarafeti şurada:self.convs(x)artığı (F(x)) üretir,self.idconv(self.pool(x))skip yolunu girdiyle aynı kanal/boyuta getirir, ikisi toplanır, sonraactuygulanır.ni==nfvestride==1durumlarındaidconv/poolbirernoop’tur — yani değişim yokken skip yolu saf identity’dir; tam da §12’nin istediği davranış.
21.15 14. ResNet Modeli ve Sonuç
ResBlock’ları üst üste dizerek tam ResNet kurulur (her blokta kanal artar, stride ile boyut düşer). Sonuçta aynı eğitim bütçesiyle, düz CNN’den belirgin daha yüksek doğruluk — skip connection’ın eğitilebilirlik kazancı.
def get_model(act=nn.ReLU, nfs=(8,16,32,64,128,256), norm=nn.BatchNorm2d):
layers = [ResBlock(1, 8, stride=1, act=act, norm=norm)]
layers += [ResBlock(nfs[i], nfs[i+1], act=act, norm=norm, stride=2) for i in range(len(nfs)-1)]
layers += [nn.Flatten(), nn.Linear(nfs[-1], 10, bias=False), nn.BatchNorm1d(10)]
return nn.Sequential(*layers).to(def_device)
İpucuBuilder Notu — get_model: Mimari Sonraki Tüm Derslere Taşınır
- İleriye (Ders 19-25): ResNet blokları, diffusion’ın U-Net’inde de temel yapıtaşıdır; bu mimari sonraki tüm derslere taşınır. Ders 19+’da DDPM eğitiminde gördüğümüz U-Net, ResBlock’lardan inşa edilecek.
- Sezgi:
get_modelbir desentir: girişte tek bir stride-1 blok, sonra her adımda kanalı iki katına çıkarıp (8→16→32...) stride-2 ile uzamsal boyutu yarıya indiren bloklar, sonda flatten + lineer + BatchNorm1d. Bu “kanalı büyüt, boyutu küçült” piramidi neredeyse tüm CNN sınıflandırıcıların ortak iskeletidir.
21.16 15. ETAP Kapanışı: Temeller Tamamlandı
Ders 18, “from the foundations” yolculuğunun teknik finalidir. Adam (optimizer), 1-cycle (scheduling) ve ResNet (mimari) ile artık modern bir derin ağı sıfırdan, sağlamca eğitebilecek tüm parçalara sahibiz: matmul → backprop → Learner/callback → init/norm → optimizer → ResNet. Bundan sonrası (Ders 19+) bu temel üstünde sıfırdan diffusion.
İpucuBuilder Notu — ETAP Kapanışı: miniai Tam Donanımlı
- İleriye (Ders 19): miniai artık tam donanımlı; Ders 19 bu altyapıyla DDPM (denoising diffusion) eğitmeye başlar — Part 2’nin ikinci diffusion bloğu. Optimizer + scheduling + ResNet üçlüsü, diffusion eğitiminin altyapısıdır.
- Sezgi: “From the foundations” sözünün anlamı tam burada netleşir: hiçbir parça (matmul, backward, Learner, init, norm, optimizer, ResBlock) kara kutu değil — her birini sıfırdan yazdık ve birleştirdik. Artık
nn,optim,lr_schedulerçağırdığında altında ne döndüğünü biliyorsun; bu, sonraki derslerin (diffusion) güveninin temelidir.
21.17 16. Kapanış
Ders 18 eğitimi hızlandıran üç fikri kurdu: optimizer evrimi (SGD → momentum → RMSProp → Adam, hepsi gradyan/kare-gradyan EMA’sının katmanlanması), LR scheduling (cosine annealing, 1-cycle super-convergence) ve ResNet (skip connection out = F(x) + x ile derin ağ eğitilebilirliği). Bu, Temeller B’nin ve “from the foundations” omurgasının finalidir.
Şekil 21.8 dersin sentezidir (Karpathy köprüsü merkezde): ortada rose omurga, skip connection’ın miras zincirini gösterir — ResNet (2015) out = F(x) + x → Transformer (2017) x = x + attn(x), x = x + mlp(x) (residual stream) → GPT / nanoGPT (96+ katman, eğitilebilir). Solda cyan köprüler (Adam → standart optimizer, 1-cycle → super-convergence, EMA → momentum/BatchNorm/Adam aynı araç), sağda ResBlock → diffusion U-Net. Tek fikir, üç çağ: 2015 → 2017 → bugün.
Kod
fig, ax = plt.subplots(figsize=(12.5, 6.5))
ax.set_xlim(0, 12.5)
ax.set_ylim(0, 6.5)
ax.axis("off")
ax.set_facecolor(COL_WHITE)
ax.text(6.25, 6.22, "L18 = skip connection miras zinciri (out = F(x) + x)",
ha="center", va="center", fontsize=12.5, weight="bold", color=COL_CYAN_800)
# --- ORTA omurga (rose): ResNet → Transformer → GPT miras zinciri ------------
spine_nodes = [
"ResNet (2015)\nout = F(x) + x\n(skip connection)",
"Transformer (2017)\nx = x + attn(x)\nx = x + mlp(x)\n(residual stream)",
"GPT / nanoGPT\n96+ katman\neğitilebilir",
]
spine_y = [5.05, 3.25, 1.45]
for txt, yy in zip(spine_nodes, spine_y):
boxed_node(ax, 6.25, yy, 3.6, 1.15, txt, fc=COL_BG_ROSE, ec=COL_ACCENT,
tc=COL_TEXT, fontsize=9.8, lw=2.4)
for y0, y1 in zip(spine_y[:-1], spine_y[1:]):
arrow_between(ax, (6.25, y0), (6.25, y1), color=COL_ROSE_500, lw=2.6, shrink=20)
# Karpathy köprüsü vurgusu (omurganın ortasına, MERKEZÎ)
ax.text(6.25, 2.30,
"Ders 18'in ResBlock + x = Karpathy nanoGPT x + attn(x) AYNI fikir",
ha="center", va="center", fontsize=8.6, style="italic",
weight="bold", color=COL_ACCENT)
# --- SOL köprüler (cyan): optimizer / scheduling / EMA -----------------------
left_bridges = [
"Adam →\nbugünkü standart optimizer\n(momentum + RMSProp + bias)",
"1-cycle →\nsuper-convergence\n(Ders 17 init+norm sayesinde)",
"EMA →\nmomentum = BatchNorm running\n= Adam aynı araç",
]
left_y = [5.05, 3.25, 1.45]
for txt, yy in zip(left_bridges, left_y):
boxed_node(ax, 2.25, yy, 3.5, 1.05, txt, fc=COL_CYAN_50, ec=COL_PRIMARY,
tc=COL_TEXT, fontsize=8.6, lw=2.0, weight="normal")
arrow_between(ax, (4.0, yy), (4.45, yy), color=COL_PRIMARY, lw=2.0, shrink=8)
# --- SAĞ köprü (cyan): ResBlock → diffusion U-Net ----------------------------
boxed_node(ax, 10.25, 3.25, 3.5, 1.15,
"ResBlock →\ndiffusion U-Net yapıtaşı\n(Ders 19+)",
fc=COL_CYAN_50, ec=COL_PRIMARY, tc=COL_TEXT, fontsize=9.0,
lw=2.0, weight="normal")
arrow_between(ax, (8.05, 3.25), (8.5, 3.25), color=COL_PRIMARY, lw=2.0, shrink=8)
ax.text(2.25, 6.0, "köprüler (cyan): araç miras", ha="center", va="center",
fontsize=9, weight="bold", color=COL_CYAN_700)
ax.text(6.25, 0.55, "tek fikir, üç çağ: 2015 → 2017 → bugün",
ha="center", va="center", fontsize=10, weight="bold", color=COL_ACCENT)
plt.tight_layout()
plt.show()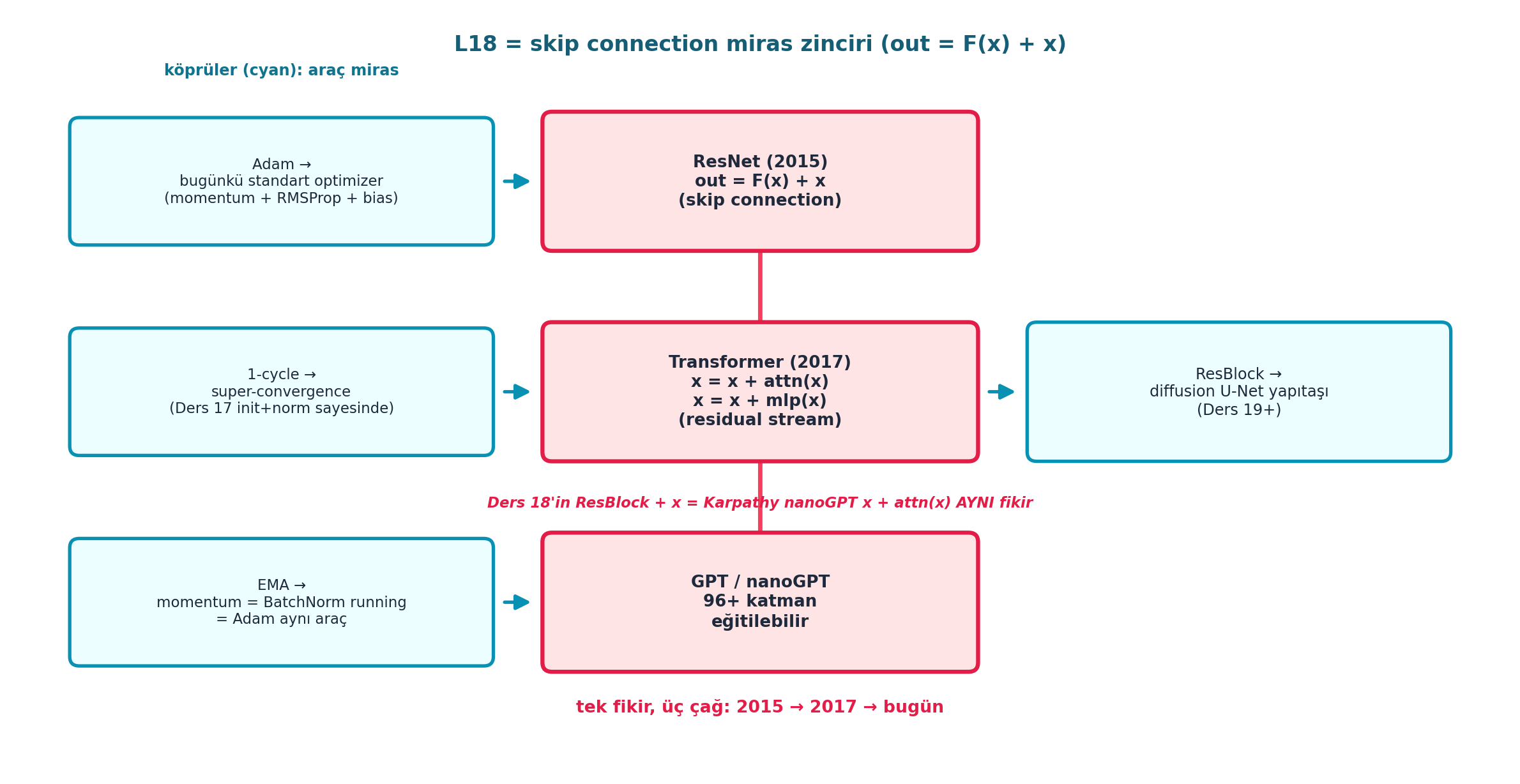
İpucuBuilder Notu — Kapanış: ResNet’ten Transformer’a Tek Belkemik
- İleriye: Adam + OneCycle bugün de standart eğitim reçetesidir; ResNet skip connection ise ResNet’ten transformer’a (Karpathy nanoGPT) tüm derin mimarinin temelidir. Ders 24 (attention) bu
+ x’i transformer bloğunda tekrar kuracak. - Sezgi: Bu dersin iki büyük fikri (Adam, ResNet) bağımsız görünür ama ikisi de sinyali koru ilkesinin farklı yüzleridir: Adam gradyanın bilgisini (yön + ölçek) EMA’larla korur; ResNet sinyali (ileri) ve gradyanı (geri) skip yoluyla korur. Ders 17’nin varyans korunumuyla birlikte, üçü “derin ağda sinyali bozmadan akıt” ilkesini tamamlar.
21.18 Bu Dersin Özeti
- SGD: Her parametreyi gradyanı yönünde lr kadar güncelle;
opt_step+reg_step(weight decay) ayrımı (SGD). - Momentum: Ham gradyan yerine gradyanların EMA’sı (
grad_avg ← mom·grad_avg + (1−mom)·grad); zikzakı yumuşatır (momentum). - RMSProp: Kare-gradyan EMA’sıyla parametre-başına adaptif adım; gradyanı
√sqr_avgile böl (RMSProp). - Adam: Momentum + RMSProp + bias düzeltmesi (1−βⁱ); en yaygın optimizer (Adam).
- LR scheduling: Learning rate’i zamanla değiştir (cosine annealing); callback olarak eklenir (cosine).
- 1-cycle: LR düşük→yüksek→düşük, momentum tersi; super-convergence (hızlı, sağlam eğitim) (1-cycle).
- ResNet sorunu: Derin ağ sığ ağın üst-kümesi olmalı ama eğitilemiyordu — sorun eğitilebilirlik (degradation).
- Skip connection: out = F(x) + x; katman sadece artığı (residual) öğrenir, gradyan doğrudan akar — ResNet’ten transformer’a tüm derin mimarinin temeli (skip).
ÖnemliTek Bir Cümle
Adam, gradyanın ve kare-gradyanın üssel ortalamalarını birleştirip parametre-başına adaptif adım atan optimizer’dır; ResNet ise katmanın çıktısına girdisini ekleyerek (out = F(x) + x) derin ağları eğitilebilir kılan mimari fikirdir — ve bu skip connection, Karpathy’nin nanoGPT’sindeki her transformer bloğunun residual belkemiğidir.
21.19 Kontrol Soruları
NotSoru 1: Momentum, RMSProp ve Adam arasındaki ilişki nedir?
Cevap:
Üçü aynı desenin (üssel hareketli ortalama, EMA) katmanlanmasıdır. Momentum, ham gradyan yerine gradyanların EMA’sını kullanır (grad_avg ← mom·grad_avg + (1−mom)·grad) — tutarlı yönde hızlanır, gürültüyü yumuşatır. RMSProp, kare-gradyanların EMA’sını (sqr_avg) tutar ve gradyanı √sqr_avg’a bölerek her parametreye adaptif (kendi ölçeğine uygun) bir adım verir. Adam, bu ikisini birleştirir: hem gradyan EMA’sı (momentum gibi) hem kare-gradyan EMA’sı (RMSProp gibi) kullanır, üstüne bir bias düzeltmesi ekler. Yani Adam = momentum + RMSProp + bias correction; bugün en yaygın optimizer budur. (Şekil 21.2 üç optimizer’ın yörünge karakterini gösterir.)
NotSoru 2: Adam’daki ‘bias düzeltmesi’ (1−βⁱ) ne işe yarar?
Cevap:
Adam’ın EMA’ları (avg, sqr_avg) sıfırdan başlatılır. İlk adımlarda bu ortalamalar gerçek değerin çok altında kalır (sıfıra doğru “yanlı”/biased). Örneğin ilk adımda avg = (1−β₁)·grad ≈ 0.1·grad — gerçek gradyanın onda biri. Bias düzeltmesi bunu telafi eder: avg’ı (1 − β₁ⁱ⁺¹) ile böler. Başlangıçta bu bölen küçüktür (örn. 0.1), bu yüzden tahmini büyütür; adım sayısı i arttıkça βⁱ → 0 olur ve bölen 1’e yaklaşır (düzeltme kaybolur). Sonuç: optimizer ilk adımlardan itibaren doğru ölçekte güncelleme yapar, ısınma gecikmesi olmaz. (Şekil 21.4 düzeltilmemiş EMA’nın ilk adımda düşük, düzeltilmişin doğru olduğunu gösterir.)
NotSoru 3: ResNet’in çözdüğü sorun nedir ve skip connection nasıl çözer?
Cevap:
Sorun degradation: teoride 56 katmanlı bir ağ, 20 katmanlının üst-kümesidir (fazla 36 katman identity yapsa hiçbir şey bozulmaz), dolayısıyla en az o kadar iyi olmalıdır. Ama pratikte daha derin ağ daha kötü eğitiliyordu — sorun ifade gücü değil, eğitilebilirlikti (gradyan derin ağda bozuluyor). Skip connection çözümü tek satır: out = F(x) + x. Katmanın öğrenmesi gereken artık tüm dönüşüm değil, sadece residual (girdiden sapma); hiçbir şey gerekmiyorsa F(x)=0 yapmak (yani identity) kolaydır. Ayrıca + x sayesinde gradyan, ara katmanları atlayarak doğrudan geriye akabilir (gradyan otoyolu). Böylece çok daha derin ağlar sağlamca eğitilir. (Şekil 21.6 beklenti vs gerçek panellerini, Şekil 21.7 akış şemasını gösterir.)
NotSoru 4: Skip connection ile Karpathy’nin nanoGPT’si arasındaki bağ nedir? (builder bağlantısı)
Cevap:
ResNet’in out = F(x) + x skip connection’ı, modern transformer’ların — ve Karpathy’nin nanoGPT’sinin — belkemiğidir. Her transformer bloğunda iki residual bağlantı vardır: x = x + attention(x) ve x = x + mlp(x). Buna “residual stream” denir: bilgi blok boyunca değiştirilmeden akar, her blok sadece bir artık katkı ekler. Bu, ResNet’te (2015) keşfedilen tam fikrin transformer’a (2017) taşınmış hâlidir; çok derin (96+ katman) GPT’lerin eğitilebilmesinin nedeni budur. Builder için bağ net: Ders 18’de sıfırdan yazdığımız ResBlock.forward’daki self.convs(x) + ... ifadesiyle, Karpathy’nin GPT bloğundaki x + self.attn(x) aynı matematiksel fikirdir. ResNet → Transformer → GPT doğrudan miras zinciridir. (Şekil 21.8 bu miras zincirini gösterir.)
21.20 Egzersizler
Egzersiz 1 (Direkt uygulama). SGD, Momentum ve Adam’ı kendin yaz; aynı modeli üçüyle eğit, kayıp eğrilerini karşılaştır (Şekil 21.2’nin yörünge karakterini kendi sayımınla doğrula — §2, §5).
Egzersiz 2 (İki-aşamalı). Bir BatchSchedCB ile OneCycleLR kullanarak modeli eğit; learning rate ve momentum’un eğitim boyunca nasıl değiştiğini çiz (sched_lrs — §8, §10).
Egzersiz 3 (Edge case). ResBlock’u yaz; ni != nf (kanal değişimi) ve stride=2 durumlarında idconv ve pool’un boyutları nasıl eşitlediğini doğrula (§13).
Egzersiz 4 (Kavramsal). Skip connection (out = F(x) + x) gradyanın derin ağda neden daha iyi aktığını açıkla; + x teriminin türevi nedir? (§12)
Egzersiz 5 (Sonraki dersin habercisi — Ders 19). ResNet blokları diffusion’ın U-Net’inde kullanılır. Bir görüntüye kademeli gürültü ekleyip sonra bir ağa onu geri tahmin ettirmenin (denoising) nasıl bir eğitim hedefi olduğunu düşün (§15).
21.21 Sonraki: Ders 19 İçin Hazırlık
Ders 19: DDPM ve Dropout (DDPM and Dropout)
Ders 18 “from the foundations” temellerini tamamladı (optimizer + scheduling + ResNet). Ders 19, ikinci diffusion bloğunu başlatır: DDPM (Denoising Diffusion Probabilistic Models) — bir görüntüye kademeli gürültü ekleyip (forward process, Ders 9B matematiği) bir ağa gürültüyü tahmin ettirerek sıfırdan diffusion model eğitmek. Artık miniai tam donanımlı.
Ana konular (Ders 19):
- DDPM forward/reverse process (sıfırdan)
- Gürültü tahmini eğitim hedefi
- U-Net mimarisi (ResNet bloklarıyla)
- Dropout düzenlileştirme
UyarıDers 19 Öncesi Yapılacak
- Bu dersin egzersizlerini çöz (özellikle 1 ve 3 — optimizer + ResBlock).
- Adam + OneCycle + ResNet’li bir modeli Fashion-MNIST’te eğit, en iyi doğruluğu hedefle.
- Ders 9B’nin (diffusion matematiği) forward process formülünü tekrar oku.
21.22 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Howard’da |
|---|---|---|
| SGD | Gradyan yönünde lr kadar adım; en temel optimizer | 1:43 |
| Momentum | Gradyanların EMA’sı; zikzakı yumuşatır | 11:01 |
| RMSProp | Kare-gradyan EMA’sıyla parametre-başına adaptif adım | 15:37 |
| Adam | Momentum + RMSProp + bias düzeltmesi | 16:41 |
grad_avg / sqr_avg |
Gradyan ve kare-gradyan hareketli ortalamaları | 11:01 |
| Bias düzeltmesi | EMA’nın sıfır-başlangıç yanlılığını (1−βⁱ) ile telafi | 16:41 |
| LR annealing | Learning rate’i zamanla azaltma | 23:02 |
| Cosine annealing | LR’yi kosinüs eğrisiyle düşürme | 40:15 |
| 1-cycle | LR düşük→yüksek→düşük, momentum tersi (super-convergence) | 42:24 |
| ResNet / degradation | Derin ağ sığın üst-kümesi ama eğitilemiyordu | 1:01:34 |
| Skip connection | out = F(x) + x; sadece artığı öğren, gradyan akar | 1:04:36 |
ResBlock / idconv |
İki conv + skip; 1×1 conv kanal eşitler | 1:07:00 |
21.23 ML Bağlantıları Özeti
İpucuBuilder Notu — 6 ML Köprüsü: Hızlandırma + Karpathy nanoGPT Residual
Bu ders eğitimi hızlandıran iki büyük fikri (Adam, ResNet) kurar ve skip connection ile Karpathy nanoGPT residual stream’ine birebir köprü atar; köprülerin özeti:
- Adam → momentum + RMSProp birleşimi; bugünkü standart optimizer (Adam).
- EMA deseni → momentum, BatchNorm running_mean (Ders 17), Adam — hepsi aynı araç (momentum).
- 1-cycle → super-convergence; sağlam init+norm (Ders 17) sayesinde mümkün (1-cycle).
- Skip connection → Karpathy nanoGPT residual stream (
x = x + attn(x)); ResNet→Transformer mirası (skip). - ResBlock → diffusion U-Net’inin (Ders 19+) temel yapıtaşı (ResBlock).
- Excel’de SGD → optimizer’ı en somut hâliyle görselleştirme (Ders 3 gradient descent köprüsü) (Excel).
ÖnemliBu dersten tek bir şey alıp gideceksen
İki büyük hızlandırma fikri. Adam, gradyanın ve kare-gradyanın hareketli ortalamalarını birleştirerek her parametreye akıllı, adaptif bir adım verir — SGD→momentum→RMSProp→Adam, hepsi aynı EMA desenin katmanlanmasıdır. ResNet, katmanın çıktısına girdisini ekleyerek (out = F(x) + x) derin ağları eğitilebilir kılar; katman tüm dönüşümü değil sadece artığı öğrenir, gradyan doğrudan akar. Bu + x, ResNet’ten transformer’a (Karpathy nanoGPT x = x + attn(x)) tüm modern derin mimarinin belkemiğidir. Temeller tamamlandı — sıradaki sıfırdan diffusion.