flowchart TD
L19["L19 — DDPM sıfırdan<br/>(saf piksel, latent yok)"]:::cyan
DROP["Dropout<br/>(düzenlileştirme, train/eval)"]:::cyan
L19 --> SCHED["β çizelgesi → α=1−β → ᾱ=∏α"]:::cyan
L19 --> FWD["forward process (KOLAY):<br/>xₜ=√ᾱ·x₀+√(1−ᾱ)·ε<br/>kapalı form"]:::rose
L19 --> REV["reverse process (ZOR):<br/>U-Net gürültü tahmin εθ"]:::cyan
SCHED --> FWD
FWD --> KEY["ANAHTAR İÇGÖRÜ:<br/>kayıp sadece MSE ‖ε−εθ‖²"]:::rose
REV --> KEY
KEY --> BRIDGE["9B matematiği → noisify kodu"]:::rose
BRIDGE --> CB["DDPMCB = miniai TrainCB + noisify"]:::cyan
CB --> GEN["üretim: saf gürültü →<br/>n_steps geriye<br/>(yinelemeli arıtma)"]:::cyan
REV --> GEN
KEY --> TRAIN["eğitim döngüsü:<br/>rastgele t, gürültüle, εθ tahmin et"]:::cyan
TRAIN --> CB
DROP --> TRAIN
classDef cyan fill:#cffafe,stroke:#0891b2,stroke-width:2px,color:#1e293b;
classDef rose fill:#ffe4e6,stroke:#e11d48,stroke-width:2px,color:#1e293b;
22 Ders 19 — DDPM ve Dropout (DDPM and Dropout)
ETAP 6’nın (Sıfırdan Diffusion A) açılışı ve Part 2’nin matematik zirvesi: DDPM’i (Denoising Diffusion Probabilistic Models) sıfırdan kurmak. Ders 9B’de Waseem ve Tanishq’in türettiği forward process matematiği, burada Howard’ın elinde çalışan koda dönüşür. Kısa bir Dropout ara konusundan sonra DDPM’in kalbi: bir görüntüye kapalı formülle gürültü ekle (forward, kolay), bir U-Net’e o gürültüyü tahmin ettir (reverse, zor), kayıp sadece MSE. Tek cümleyle: DDPM, bir görüntüye kapalı formülle (xₜ = √ᾱₜ·x₀ + √(1−ᾱₜ)·ε) gürültü ekleyip bir U-Net’e o gürültüyü MSE ile tahmin ettirerek eğitilen üretken modeldir; üretim, saf gürültüden başlayıp ağın tahmin ettiği gürültüyü adım adım kaldırarak imkânsız dönüşümü binlerce kolay adıma bölmektir — ve bu, 9B’de türetilen matematiğin miniai üstünde koda dökülmüş hâlidir.
NotBölüm bilgisi
- Ders sayfası (video): course.fast.ai — Lesson 19: DDPM and Dropout (~109 dk)
- Seri: Practical Deep Learning for Coders — Part 2, Ders 19
- Playlist: Part 2 — Foundations to Stable Diffusion (2022)
- Notebook: course22p2 — nbs/15_DDPM
- Okuma süresi: ~42 dk
- Hocalar: Howard + Tanishq Abraham + Jonathan Whitaker (Johno)
- 🔗 ETAP 6’nın başı (Sıfırdan Diffusion A): Ders 18’de “from the foundations” omurgası tamamlandı (matmul → backprop → Learner/callback → init/norm → optimizer → ResNet). miniai artık tam donanımlı. Ders 19 bu altyapıyla DDPM’i sıfırdan kurar — Ders 9B’nin diffusion matematiğini (forward process) Howard’ın elinde çalışan koda döker. Bu, Part 2’nin teori-pratik köprüsünün doruğudur.
22.1 Bu Derste Ne Var?
ETAP’ın ve Part 2’nin matematik zirvesi: DDPM’i (Denoising Diffusion Probabilistic Models) sıfırdan kurmak. Ders 9B’de Waseem ve Tanishq’in türettiği diffusion matematiği (forward process), burada Howard’ın elinde çalışan koda dönüşür. Önce kısa bir Dropout ara konusu, sonra DDPM’in kalbi: bir görüntüye kademeli gürültü ekle (forward), bir ağa o gürültüyü tahmin ettir (reverse), kayıp sadece MSE. miniai (L16-18) artık tam donanımlı — DDPM onu kullanır.
Üç temel fikir bu dersin omurgasını kurar:
- Forward process (kolay) — bir görüntüye kapalı formülle gürültü ekle: xₜ = √ᾱₜ · x₀ + √(1 − ᾱₜ) · ε. Tek adımda istenen gürültü seviyesi, ara adımları gezmeden (forward → noisify).
- Reverse process (zor) — gürültülü görüntüden gürültüyü kaldırmak; bir sinir ağı (U-Net) tarafından öğrenilir (reverse → sampling).
- Anahtar içgörü — ağ sadece eklenen gürültüyü (ε) tahmin eder; kayıp basit bir MSE’dir. Diffusion’ın tüm karmaşıklığı buna iner (anahtar içgörü).
“the forward direction is driven… really easily to make it something more noisy. And the reverse direction is incredibly difficult.” — Howard, 26:00
Şekil 28.1 bu üç ekseni tek bir yol haritasında birleştirir: kolay forward süreç (kapalı form gürültüleme), zor reverse süreç (U-Net gürültü tahmini) ve her şeyi tek bir MSE kaybına indirgeyen anahtar içgörü. forward formülü, MSE içgörüsü ve 9B → noisify köprüsü rose ile işaretlidir: bu dersin kalbi, Ders 9B’de türetilen matematiğin (xₜ=√ᾱ·x₀+√(1−ᾱ)·ε) miniai üstünde before_batch koduna dökülmesidir.
İpucuBuilder Notu — Üç Eksen: Kolay Forward, Zor Reverse, Tek MSE
- Geriye (Ders 9B): 9B’de Waseem/Tanishq forward process q(xₜ|xₜ₋₁) ve reparameterization’ı türetti; bu ders onu Howard’ın
before_batch’inde üç satır koda döküyor. Teori→kod köprüsünün en saf örneği. - Geriye (Ders 16-18): miniai Learner+callback (L16), Kaiming init (L17), ResBlock/U-Net (L18) — DDPM bu altyapıyı kullanır;
DDPMCB, miniaiTrainCB’den türer. - İleriye (Ders 20-25): DDPM temeldir; mixed precision (L20), DDIM (L21), Karras (L22), latent diffusion (L25) hep bunun üstüne kurulur.
- Tek cümle: DDPM, bir görüntüye kapalı formülle gürültü ekleyip bir ağa o gürültüyü MSE ile tahmin ettiren üretken modeldir; üretim, saf gürültüden başlayıp adım adım gürültüyü kaldırmaktır.
22.2 1. Dropout
Ders, kısa bir düzenlileştirme tekniğiyle açılır: Dropout. Eğitim sırasında her ileri geçişte aktivasyonların rastgele bir kısmını (örn. %10) sıfırlar; ağ tek bir nörona aşırı bağımlı olamaz, daha sağlam temsiller öğrenir. Çıkarımda kapatılır. Bir nn.Module olarak miniai modeline eklenir.
class Dropout(nn.Module):
def __init__(self, p): super().__init__(); self.p = p
def forward(self, x):
if not self.training: return x
dist = distributions.binomial.Binomial(probs=1-self.p)
return x * dist.sample(x.size()).to(x.device) * 1/(1-self.p)
İpucuBuilder Notu — Dropout: Train/Eval Ayrımı BatchNorm Gibi
- Geriye (§4.D): Dropout genel bir düzenlileştirme tekniğidir; burada miniai’ye sıfırdan eklenir. Eğitim/çıkarım ayrımı (
self.training) BatchNorm’daki (L17) ile aynı desendir: davranış eğitimde ve çıkarımda farklıdır. - Sezgi: Çıkarımda hiçbir aktivasyon düşürülmediği için, eğitimde hayatta kalan aktivasyonlar
1/(1−p)ile ölçeklenir — böylece beklenen toplam çıktı eğitim ile çıkarım arasında tutarlı kalır. Bu “inverted dropout” hilesi, çıkarımda fazladan iş yapmayı önler.
22.3 2. DDPM Nedir? (Saf Piksel Diffusion)
DDPM, en temel diffusion modelidir: latent VAE yok, doğrudan piksel uzayında çalışır (Stable Diffusion’ın aksine). Fikir 9B’den tanıdık: bir görüntüye kademeli gürültü ekleyen bir forward süreç ve onu tersine çeviren öğrenilmiş bir reverse süreç. Bu ders ikisini de sıfırdan kurar — “model hariç her şey”.
“DDPM doesn’t have the latent VAE thing and we’re not going to do [that here].” — Howard, 12:21
İpucuBuilder Notu — DDPM: En Sade Hâlinden Başla
- Geriye (Ders 9): Ders 9’da Stable Diffusion’ı (latent + U-Net + CLIP) kullandık; burada en sade hâlini (saf piksel, koşulsuz) sıfırdan kuruyoruz — “yeniden kur, sonra anla” kuralının diffusion’a uygulanışı.
- Sezgi: Latent uzayı (VAE), CLIP koşullamasını, guidance’ı bir kenara bırakıp çıplak çekirdeği — forward + reverse + MSE — izole etmek, diffusion’ın gerçekte ne olduğunu görmenin en temiz yoludur. Tüm o ek katmanlar (Ders 25’te dönecek) bu çekirdeği hızlandırır veya koşullar, ama özünü değiştirmez.
22.4 3. Forward Process: Gürültü Eklemek (Kolay Yön)
Forward süreç bir görüntüye adım adım gürültü ekler. Kritik kolaylık: t adımındaki gürültülü görüntüyü, tüm ara adımları gezmeden kapalı formülle doğrudan üretebilirsin:
\[x_t = \sqrt{\bar{\alpha}_t} \cdot x_0 + \sqrt{1 - \bar{\alpha}_t} \cdot \varepsilon, \qquad \varepsilon \sim \mathcal{N}(0, I)\]
Burada x₀ orijinal görüntü, ε standart normal gürültü, ᾱₜ ise t’ye kadarki gürültü çizelgesinin birikimli çarpımı. ᾱₜ büyükken görüntü temiz, küçükken neredeyse saf gürültü.
“the forward process, which is mostly just used for training.” — Howard, 23:58
Şekil 22.2 forward gürültülemeyi gerçek hesaplamayla üç gürültü seviyesinde (t=50/500/950) ayrıştırır (FLAGSHIP): her satır xₜ = √ᾱ·x₀ + √(1−ᾱ)·ε formülünü sinyal payı (√ᾱ·x₀) + gürültü payı (√(1−ᾱ)·ε) = xₜ olarak gösterir. t arttıkça √ᾱ azalır (sinyal solar), √(1−ᾱ) artar (gürültü baskınlaşır); t=950’de ᾱ≈0, görüntü saf gürültüye iner. Tüm bunlar tek formülle, tek adımda — ara adımları gezmeden.
Kod
import matplotlib.gridspec as gridspec
d = E.ddpm_noisify_demo() # GERÇEK: dict(x0, eps, frames=[(t, ᾱ, signal, noise, xt)...])
frames = d["frames"] # t = 50 / 500 / 950
vmax = float(max(np.abs(d["x0"]).max(), np.abs(d["eps"]).max()))
fig = plt.figure(figsize=(12, 8))
fig.patch.set_facecolor(COL_WHITE)
# 3 satır (t) × 7 sütun: [sinyal, "+", gürültü, "=", xₜ] — operatör sütunları dar
gs = gridspec.GridSpec(
3, 7, figure=fig,
width_ratios=[1.0, 0.32, 1.0, 0.32, 1.0, 0.0, 0.0],
hspace=0.32, wspace=0.18,
left=0.10, right=0.985, top=0.86, bottom=0.04,
)
col_titles = ["√ᾱ·x₀ (sinyal payı)", "√(1−ᾱ)·ε (gürültü payı)", "= xₜ"]
img_cols = [0, 2, 4]
def show(ax, arr, title=None, title_col=None):
ax.imshow(arr, cmap="gray", vmin=-vmax, vmax=vmax, interpolation="nearest")
ax.set_xticks([]); ax.set_yticks([])
for s in ax.spines.values():
s.set_color(COL_SLATE_400); s.set_linewidth(1.2)
if title is not None:
ax.set_title(title, fontsize=10.5, color=title_col or COL_TEXT,
weight="bold", pad=6)
for row, (t, ab, sig, noi, xt) in enumerate(frames):
# her sütunun rengi: sinyal=cyan, gürültü=rose, xₜ=koyu cyan
panels = [(sig, COL_CYAN_700), (noi, COL_ROSE_500), (xt, COL_CYAN_800)]
for k, (arr, tcol) in enumerate(panels):
ax = fig.add_subplot(gs[row, img_cols[k]])
show(ax, arr, title=(col_titles[k] if row == 0 else None), title_col=tcol)
if k == 0:
# satır başlığı: t ve ᾱ
ax.set_ylabel(f"t = {t}\nᾱ = {ab:.3f}", fontsize=11,
color=COL_TEXT, weight="bold", rotation=0,
ha="right", va="center", labelpad=42)
# operatör sütunları: "+" ve "="
for opcol, sym in ((1, "+"), (3, "=")):
axo = fig.add_subplot(gs[row, opcol])
axo.axis("off")
axo.text(0.5, 0.5, sym, ha="center", va="center",
fontsize=24, color=COL_SLATE_400, weight="bold")
# üst başlık + kapalı-form açıklaması
fig.text(0.10, 0.965, "Forward noising — sinyal/gürültü ayrışımı",
fontsize=14, color=COL_CYAN_800, weight="bold", ha="left", va="center")
fig.text(0.10, 0.905,
"xₜ = √ᾱ·x₀ + √(1−ᾱ)·ε: t↑ → sinyal √ᾱ azalır, gürültü √(1−ᾱ) artar; "
"kapalı formülle TEK adımda",
fontsize=10.5, color=COL_TEXT, ha="left", va="center")
# t=50 neredeyse temiz, t=950 saf gürültü — yorum etiketleri (sağ kenar)
fig.text(0.992, 0.74, "t=50: sinyal baskın\n(neredeyse temiz)",
fontsize=9, color=COL_CYAN_700, ha="right", va="center",
style="italic", rotation=90)
fig.text(0.992, 0.16, "t=950: ᾱ≈0\n(saf gürültü, sinyal ~0)",
fontsize=9, color=COL_ROSE_500, ha="right", va="center",
style="italic", rotation=90)
plt.tight_layout()
plt.show()
İpucuBuilder Notu — Forward: 9B’nin Kapalı Formu Burada
- Geriye (Ders 9B): Bu tam olarak 9B’deki forward process kapalı formülüdür (reparameterization ile türetilmişti); orada matematik, burada görsel ve birazdan (§7) kod. Tek satırlık formül, tüm forward sürecin özüdür.
- Sezgi: Forward sürecin “kolay” olmasının sebebi, t’ye kadarki gürültü birikiminin tek bir kapalı çarpıma (ᾱₜ) sıkıştırılabilmesidir. Adım adım q(xₜ|xₜ₋₁) uygulamak yerine, doğrudan q(xₜ|x₀)’a atlarsın — eğitimde rastgele t seçip o gürültü seviyesini tek hamlede üretmek bu yüzden mümkündür.
22.5 4. β Çizelgesi ve ᾱ
Gürültü miktarı bir β çizelgesi ile belirlenir: her adımda eklenen varyans, βₘᵢₙ’den βₘₐₓ’a doğrusal artar. Türetilen büyüklükler: αₜ = 1 − βₜ, ve ᾱₜ = ∏ₛ₌₁ᵗ αₛ (birikimli çarpım — t adımından sonra orijinal sinyalin ne kadar kaldığı). σₜ = √βₜ.
self.β = torch.linspace(self.βmin, self.βmax, self.n_steps)
self.α = 1. - self.β
self.ᾱ = torch.cumprod(self.α, dim=0)
self.σ = self.β.sqrt()Şekil 22.3 çizelgeyi gerçek hesaplamayla iki panelde çizer: solda βₜ (her adımda eklenen varyans, linear artar) ve σₜ=√βₜ; sağda ᾱₜ (birikimli çarpım — kalan sinyal, 1’den 0’a düşer) ile birlikte forward formülünün iki katsayısı √ᾱₜ (sinyal katsayısı) ve √(1−ᾱₜ) (gürültü katsayısı). Bu iki katsayının t boyunca makaslaması — biri inerken diğeri çıkar — forward gürültülemenin tüm dinamiğidir.
Kod
sch = E.ddpm_schedule_demo()
t = sch["t"]
beta = sch["beta"]
alpha_bar = sch["alpha_bar"]
sigma = sch["sigma"]
sqrt_ab = np.sqrt(alpha_bar) # sinyal katsayısı √ᾱ
sqrt_1mab = np.sqrt(1.0 - alpha_bar) # gürültü katsayısı √(1−ᾱ)
fig, (axL, axR) = plt.subplots(1, 2, figsize=(11.5, 4.8))
# ---- SOL PANEL: β_t (eklenen varyans) ve σ=√β ----------------------------
axL.plot(t, beta, color=COL_ACCENT, lw=2.6,
label=r"$\beta_t$ (eklenen varyans)", zorder=4)
axL.plot(t, sigma, color=COL_PRIMARY, lw=2.2, ls="--",
label=r"$\sigma_t=\sqrt{\beta_t}$ (gürültü std)", zorder=3)
axL.set_xlim(0, len(t) - 1)
axL.set_ylim(0, max(sigma.max(), beta.max()) * 1.18)
axL.set_xlabel("difüzyon adımı t")
axL.set_ylabel("değer")
axL.set_title("β çizelgesi (linear ↑)", fontsize=11.5, weight="bold")
viz.apply_style(axL)
axL.legend(loc="upper left", fontsize=9, framealpha=0.9)
axL.annotate("β her adımda eklenen varyans\n(linear artar: %.4f → %.2f)"
% (beta[0], beta[-1]),
xy=(len(t) * 0.62, beta[int(len(t) * 0.62)]),
xytext=(len(t) * 0.06, beta.max() * 0.92),
fontsize=8.6, color=COL_TEXT, weight="bold",
arrowprops=dict(arrowstyle="->", color=COL_ROSE_400, lw=1.4))
# ---- SAĞ PANEL: ᾱ_t (kalan sinyal) + √ᾱ + √(1−ᾱ) -------------------------
axR.plot(t, alpha_bar, color=COL_PRIMARY, lw=3.0,
label=r"$\bar{\alpha}_t=\prod(1-\beta)$ (kalan sinyal)", zorder=5)
axR.plot(t, sqrt_ab, color=COL_CYAN_400, lw=2.0, ls="--",
label=r"$\sqrt{\bar{\alpha}_t}$ (sinyal katsayısı)", zorder=4)
axR.plot(t, sqrt_1mab, color=COL_ACCENT, lw=2.0, ls="--",
label=r"$\sqrt{1-\bar{\alpha}_t}$ (gürültü katsayısı)", zorder=4)
axR.set_xlim(0, len(t) - 1)
axR.set_ylim(-0.02, 1.08)
axR.set_xlabel("difüzyon adımı t (temiz → gürültü)")
axR.set_ylabel("katsayı")
axR.set_title("ᾱ ve karışım katsayıları (1 → 0)", fontsize=11.5, weight="bold")
viz.apply_style(axR)
axR.legend(loc="center right", fontsize=8.6, framealpha=0.9)
axR.annotate("ᾱ = t adımından sonra\nKALAN sinyal (1 → 0)",
xy=(int(len(t) * 0.30), float(alpha_bar[int(len(t) * 0.30)])),
xytext=(len(t) * 0.34, 0.74),
fontsize=8.6, color=COL_TEXT, weight="bold",
arrowprops=dict(arrowstyle="->", color=COL_CYAN_700, lw=1.4))
plt.tight_layout()
plt.show()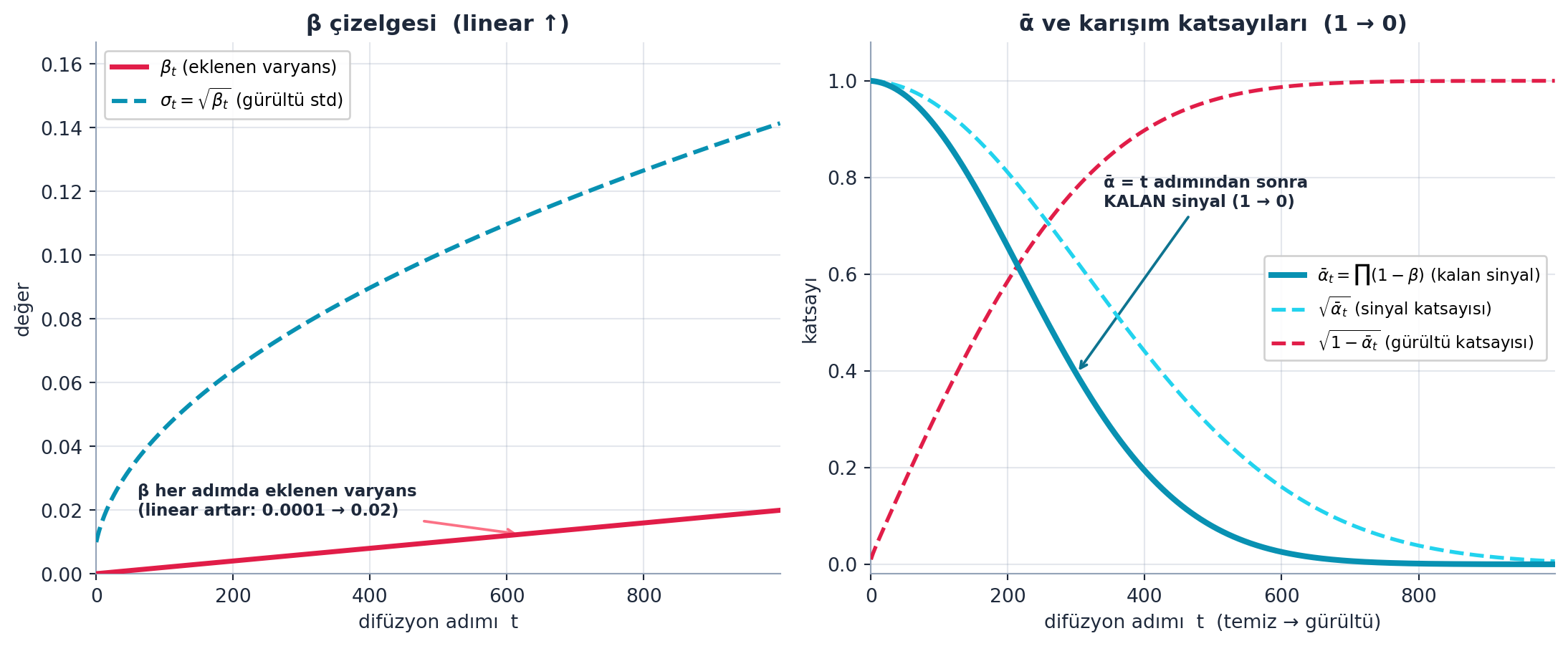
İpucuBuilder Notu — Çizelge: En Kritik Hiperparametre
- İleriye (Ders 22): β/ᾱ çizelgesi diffusion’ın en kritik hiperparametresidir; çizelgenin şekli (linear vs cosine) örnek kalitesini doğrudan etkiler. Ders 22 (Karras, cosine schedule) bunu yeniden tasarlar.
- Sezgi:
torch.cumprodtek satırda tüm sihri yapar: αₜ=1−βₜ değerlerinin birikimli çarpımı, ᾱₜ’yi verir — yani “ilk t adımda sinyalin ne kadarı hayatta kaldı?” sorusunun cevabı. β linear artarken ᾱ düzgün biçimde 1’den 0’a iner; bu sayede her t için forward formülünün katsayıları önceden hesaplanıp hazır tutulur (self.ᾱ[t]ile anında erişim).
22.6 5. Reverse Process: Gürültüyü Kaldırmak (Zor Yön)
Reverse süreç tersini yapar: gürültülü xₜ’den biraz daha az gürültülü xₜ₋₁’e geçer. Bu yön çok zordur — saf gürültüden anlamlı bir görüntüye gitmek. Çözüm: her adımı tahmin eden bir sinir ağı eğit. Üretim, saf gürültüden başlayıp bu adımı n_steps kez tekrarlamaktır.
“the reverse direction is incredibly difficult… Neural network. And we learn it during the training of the model.” — Howard, 26:00 / 34:24
İpucuBuilder Notu — Reverse: Öğrenilen Yön
- İleriye (Ders 21): Reverse süreç n_steps (örn. 1000) adım sürer — yavaş, her adım bir U-Net çağrısı. DDIM (Ders 21) aynı kaliteyi çok daha az adımda (~50) verir.
- Sezgi: Forward’ı kapalı formülle “atlayabilmemize” rağmen reverse’ü atlayamayız: tek bir gürültülü xₜ’ye karşılık sonsuz olası temiz x₀ vardır, dolayısıyla ters geçiş belirsizdir. Ağ bu belirsizliği, “bu seviyede tipik olarak hangi gürültü eklenmiş?” sorusunu öğrenerek küçük adımlarla çözer — her adım az gürültü kaldırdığı için belirsizlik yönetilebilir kalır.
22.7 6. Anahtar İçgörü: Kayıp Sadece MSE
DDPM’in tüm karmaşık matematiği (ELBO, KL ıraksamaları) pratikte tek bir şeye iner: ağ, eklenen gürültüyü tahmin eder ve kayıp, tahmin edilen gürültü ile gerçek gürültü arasındaki MSE’dir:
\[L = \| \varepsilon - \varepsilon_\theta(x_t, t) \|^2\]
Bu içgörü dersin kalbidir: diffusion’ı eğitmek, “şu görüntüye eklediğim gürültü neydi?” sorusunu MSE ile yanıtlamaktan ibarettir.
“This is just an MSE loss… what this neural network is doing is trying to predict that noise.” — Howard, 35:59 / 37:38
Şekil 22.4 anahtar içgörüyü gerçek hesaplamayla dört panelde gösterir (FLAGSHIP): x₀ (orijinal) → xₜ (gürültülü) → ε (eklenen gürültü, ağın tahmin hedefi) → x₀ geri (ε bilinince). Kritik nokta sağ panelde: ε bilindiğinde x₀ = (xₜ − √(1−ᾱ)·ε)/√ᾱ formülüyle kusursuz geri kazanılır (geri kazanım MSE ≈ 0). Yani diffusion, “eklenen gürültüyü tahmin et” regresyon problemine — Ders 5’in basit MSE’sine — indirgenir.
Kod
d = E.mse_noise_demo()
x0, xt, eps = d["x0"], d["xt"], d["eps"]
x0_rec = d["x0_recovered"]
t, ab, rmse = d["t"], d["ab"], d["recover_mse"]
panels = [
(x0, "x₀ (orijinal)", COL_CYAN_700),
(xt, f"xₜ (gürültülü, t={t})", COL_TEXT),
(eps, "ε (eklenen gürültü = AĞIN HEDEFİ)", COL_ACCENT),
(x0_rec, "x₀ geri (ε bilinince)", COL_CYAN_700),
]
fig, axes = plt.subplots(1, 4, figsize=(12, 4))
for ax, (im, title, tc) in zip(axes, panels):
ax.imshow(im, cmap="gray")
ax.set_title(title, fontsize=10.5, color=tc, weight="bold", pad=8)
ax.set_xticks([]); ax.set_yticks([])
for s in ax.spines.values():
s.set_edgecolor(COL_SLATE_300)
# Geri kazanım rozeti (kusursuz geri dönüş)
axes[3].text(
0.5, -0.16,
f"x₀=(xₜ−√(1−ᾱ)·ε)/√ᾱ → geri kazanım MSE={rmse:.0e} ≈ 0 (KUSURSUZ)",
transform=axes[3].transAxes, ha="center", va="top",
fontsize=8.6, color=COL_CYAN_800, weight="bold",
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG, ec=COL_PRIMARY, lw=1.6),
)
# Anahtar içgörü annotate (ε = ağın tahmin hedefi)
axes[2].annotate(
"ağ eklenen gürültüyü (ε) tahmin eder\n"
"kayıp = MSE(ε, εθ)\n"
"ε bilinince x₀ kusursuz geri gelir\n"
"→ diffusion = gürültü-tahmin REGRESYONU (Ders 5 MSE)",
xy=(0.5, -0.16), xycoords="axes fraction",
ha="center", va="top", fontsize=8.4, color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG_ROSE, ec=COL_ACCENT, lw=1.6),
)
fig.suptitle(
"DDPM ε-prediction: diffusion = gürültü-tahmin regresyonu (ε bilinince x₀ KUSURSUZ)",
fontsize=12, color=COL_TEXT, weight="bold", y=1.02,
)
plt.tight_layout()
plt.show()
İpucuBuilder Notu — MSE: Görkemli Modelin Basit Kalbi
- Geriye (Ders 5/13): MSE’yi Ders 5 ve 13’te kurmuştuk; diffusion gibi görkemli bir şeyin kalbinde aynı basit kayıp var. “Tuning is physics, not magic” ruhuyla, diffusion da sihir değildir — kalbinde sıradan bir regresyon kaybı yatar.
- Sezgi: ε’yu tahmin etmekle x₀’ı tahmin etmek matematiksel olarak denktir, çünkü forward formülü ikisini lineer bağlar: biri bilinince diğeri tek satırda çıkar (figürde gösterilen geri kazanım). Pratikte ε-prediction tercih edilir — gürültü her t’de aynı ölçekte (standart normal) olduğu için kayıp daha kararlı davranır.
22.8 7. noisify: Forward’ı Koda Dökmek
Forward process, eğitimde her batch’te uygulanır (before_batch): rastgele bir t adımı seç, kapalı formülle görüntüyü o seviyeye gürültüle, ağın hedefi eklenen ε olsun. Üç satır matematik, üç satır kod.
def before_batch(self, learn):
device = learn.batch[0].device
ε = torch.randn(learn.batch[0].shape, device=device) # gürültü
x0 = learn.batch[0] # orijinal görüntü
n = x0.shape[0]
t = torch.randint(0, self.n_steps, (n,), device=device, dtype=torch.long) # rastgele adım
ᾱ_t = self.ᾱ[t].reshape(-1, 1, 1, 1).to(device)
xt = ᾱ_t.sqrt()*x0 + (1-ᾱ_t).sqrt()*ε # forward kapalı form
learn.batch = ((xt, t), ε) # girdi: (gürültülü, t); hedef: ε
ÖnemliBuilder Notu — noisify: Teori→Kod Köprüsünün Zirvesi (MERKEZÎ)
- Geriye (Ders 9B) — köprü doruğu:
xt = ᾱ_t.sqrt()*x0 + (1-ᾱ_t).sqrt()*εsatırı, 9B’nin forward process formülünün (§3) birebir koda dökülmüş hâlidir. Block math forward formülü = bu tek satır. Bu, Part 2’nin teori-pratik köprüsünün doruğudur (§12 bu köprüyü açar). - İki satır, tek fizik: §3’teki \(x_t = \sqrt{\bar{\alpha}_t}\,x_0 + \sqrt{1-\bar{\alpha}_t}\,\varepsilon\) formülü ile koddaki
ᾱ_t.sqrt()*x0 + (1-ᾱ_t).sqrt()*εaynı matematiksel ifadedir — sadece notasyon değişti (√ᾱ →ᾱ_t.sqrt(), ε →ε). Notebook’un Unicode değişkenleri (β, α, ᾱ, ε) doğrudan 9B notasyonunu kodda korur. - Sezgi:
before_batch’in zarafeti: eğitim verisini yeniden tanımlar. Girdi artık temiz görüntü değil,(gürültülü görüntü, t adımı)ikilisidir; hedef de etiket değil, eklenen gürültü ε’dir. Böylece standart miniai eğitim döngüsü, hiç değişmeden, bir diffusion modeli eğitir.
22.9 8. U-Net: Gürültü Tahmincisi
Gürültüyü tahmin eden ağ bir U-Net’tir: girdisi gürültülü görüntü + zaman adımı t, çıktısı aynı şekilde bir görüntü (tahmin edilen gürültü). Bu derste hazır diffusers UNet2DModel kullanılır; mimarisi L18’in ResBlock’larından kuruludur (encoder-decoder + skip connections).
from diffusers import UNet2DModel
model = UNet2DModel(in_channels=1, out_channels=1, block_out_channels=(32, 64, 128, 128))“image and predict the noise. So the shapes of the input and the output are the same.” — Howard, 41:07
İpucuBuilder Notu — U-Net: Foundations Bloklarından Kurulu
- Geriye (Ders 18): U-Net’in iç yapıtaşı ResBlock’tur (L18); diffusion’ın ağı, foundations’ta sıfırdan kurduğumuz blokların birleşimidir. L18’in
out = F(x) + xskip connection’ı burada hem ResBlock içinde hem U-Net’in encoder-decoder skip’lerinde iki kez karşımıza çıkar. - İleriye (Ders 26): Ders 26’da U-Net’i
diffusers’tan hazır almak yerine, tıpkı ResBlock’u kurduğumuz gibi sıfırdan kuracağız — “yeniden kur, sonra kullan” zincirinin bir halkası daha. - Sezgi: Girdi ve çıktının aynı şekilde (örn. 1×28×28) olması bir tesadüf değil, görevin doğasıdır: ağ “her piksele eklenen gürültü neydi?” sorusunu yanıtlar, dolayısıyla çıktı da girdiyle aynı uzamsal boyutta bir gürültü haritasıdır. U-Net’in encoder-decoder + skip yapısı tam bu “aynı boyutta gir, aynı boyutta çık ama dönüştür” görevi için idealdir.
22.10 9. Eğitim Döngüsü: DDPMCB
Tüm DDPM mantığı bir callback’te toplanır: DDPMCB, miniai’nin TrainCB’sinden türer. before_batch gürültüleme yapar, predict U-Net’i çağırır. Eğitim, standart bir miniai Learner ile: MSE kayıp, Adam, OneCycle scheduler.
ddpm_cb = DDPMCB(n_steps=1000, beta_min=0.0001, beta_max=0.02)
cbs = [ddpm_cb, DeviceCB(), ProgressCB(plot=True), MetricsCB(), BatchSchedCB(sched)]
learn = Learner(model, dls, nn.MSELoss(), lr=lr, cbs=cbs, opt_func=optim.Adam)
learn.fit(epochs)Şekil 22.5 eğitimin yapısını şematik gösterir: ortada DDPMCB (miniai TrainCB’den türer — before_batch gürültüler, predict U-Net’i çağırır), çevresinde foundations’tan gelen tüm parçalar — Learner+callback (L16), Kaiming init+norm (L17), Adam+OneCycle (L18), ResBlock→U-Net (L18), MSE (L5/13). Mesaj net: diffusion eğitimi = miniai + tek bir gürültüleme callback’i.
Kod
fig, ax = plt.subplots(figsize=(12.0, 5.5))
fig.patch.set_facecolor(COL_WHITE)
ax.set_xlim(0, 120)
ax.set_ylim(0, 50)
ax.axis("off")
# =========================================================
# Başlık
# =========================================================
ax.text(60, 47.8, "diffusion eğitimi = miniai + tek bir gürültüleme callback'i",
ha="center", va="center", fontsize=12.5, color=COL_ACCENT, weight="bold")
# =========================================================
# ORTA — DDPMCB (miniai TrainCB'den türer) — rose çekirdek
# =========================================================
cx, cy = 60.0, 24.0
boxed_node(ax, cx, cy, 30.0, 16.0, "",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT, lw=2.6)
ax.text(cx, cy + 5.2, "DDPMCB", ha="center", va="center",
fontsize=13.5, color=COL_ACCENT, weight="bold")
ax.text(cx, cy + 2.0, "(miniai TrainCB'den türer)", ha="center", va="center",
fontsize=8.8, color=COL_TEXT, weight="bold", style="italic")
ax.text(cx, cy - 1.4, "before_batch:\nnoisify (forward)", ha="center", va="center",
fontsize=9.2, color=COL_TEXT, weight="bold")
ax.text(cx, cy - 5.2, "predict:\nU-Net çağır", ha="center", va="center",
fontsize=9.2, color=COL_TEXT, weight="bold")
# =========================================================
# ÇEVRE — foundations parçaları (cyan), DDPMCB'ye besleme okları
# =========================================================
# (etiket, ders, kutu-merkezi)
pieces = [
("Learner + callback\n(Ders 16)", (14.0, 40.0)),
("Kaiming init + norm\n(Ders 17)", (14.0, 24.0)),
("Adam + OneCycle\n(Ders 18)", (14.0, 8.0)),
("ResBlock → U-Net\n(Ders 18)", (106.0, 32.0)),
("MSE\n(Ders 5/13)", (106.0, 16.0)),
]
for text, (px, py) in pieces:
boxed_node(ax, px, py, 26.0, 8.6, text,
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT, fontsize=9.6, lw=2.2)
# foundations parçasından çekirdeğe ince cyan ok
arrow_between(ax, (px, py), (cx, cy), color=COL_CYAN_400, lw=1.8,
mutation_scale=14, shrink=18)
# =========================================================
# Vurgu — "yeniden kur sonra kullan" meyvesi
# =========================================================
ax.text(60, 5.0,
"miniai'yi bu yüzden özenle kurduk — \"yeniden kur, sonra kullan\" meyvesi: "
"tüm makine hazır, geriye yalnız tek callback kalıyor",
ha="center", va="center", fontsize=10.0, color=COL_CYAN_700,
weight="bold")
plt.tight_layout()
plt.show()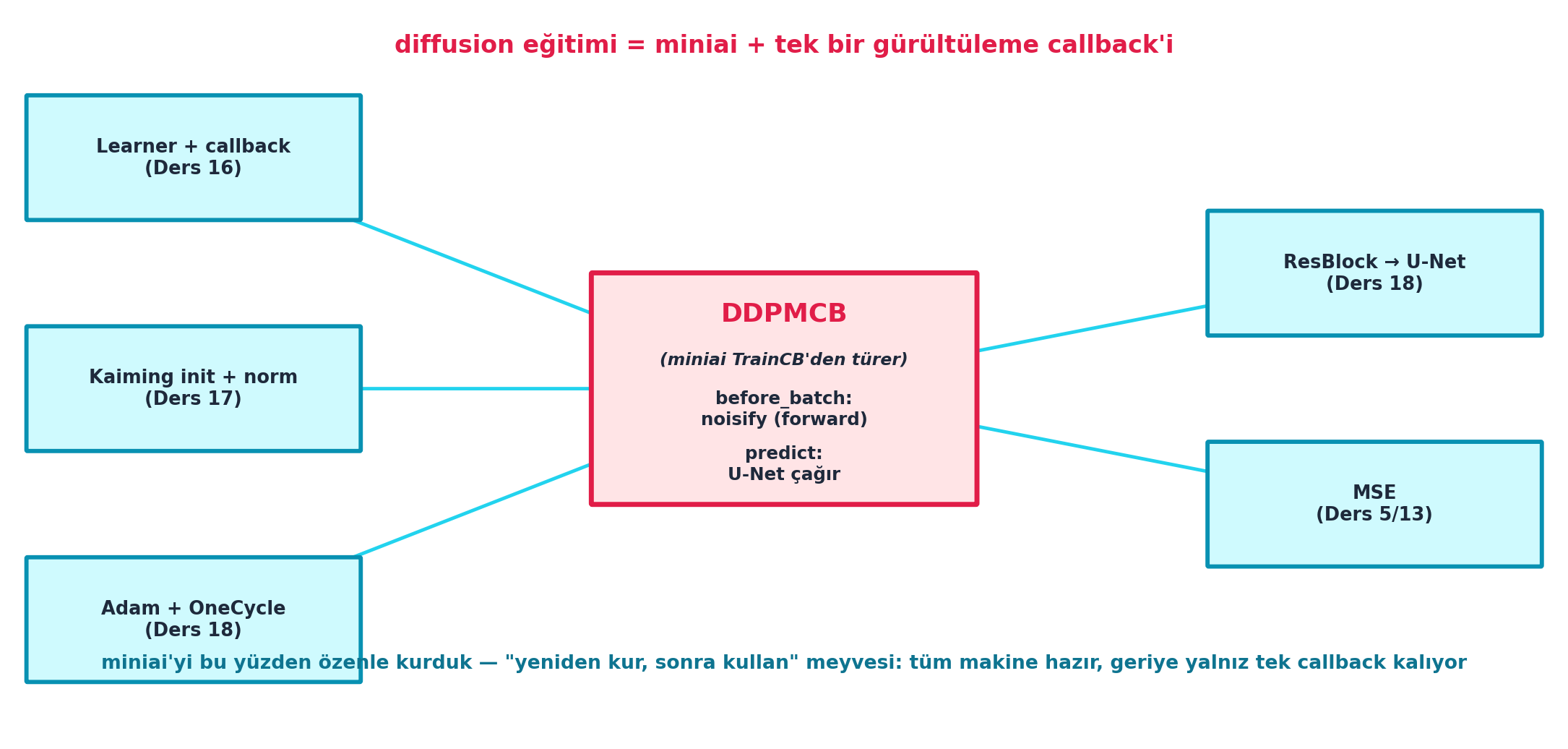
ÖnemliBuilder Notu — DDPMCB: Foundations’ın Tümü Burada Birleşir (MERKEZÎ)
- Geriye (Ders 16-18) — MERKEZÎ: DDPM, baştan kurduğumuz her şeyi birleştirir: Learner+callback (L16), Adam+OneCycle (L18), MSE. Diffusion eğitimi = miniai + bir callback. miniai’nin tam donanımlı olmasının sebebi tam buydu — diffusion gibi karmaşık bir modeli sağlam bir altyapı üstünde birkaç parçayla eğitebilmek.
- Sezgi:
DDPMCB’ninTrainCB’den türemesi tüm yükü taşır: eğitim döngüsünün geri kalanı (forward/backward/step) miras alınır, yalnızca iki kanca özelleşir —before_batch(gürültüleme) vepredict(U-Net çağrısı). Bu, L16’da callback mimarisini bu kadar özenle kurmanın asıl ödülüdür: yeni bir model ailesini (diffusion) çekirdek döngüye hiç dokunmadan eklersin.
22.11 10. Sampling: Reverse’ü Koda Dökmek
Üretim (sample): saf gürültüyle başla (x_t = randn), n_steps adım geriye git. Her adımda U-Net gürültüyü tahmin eder, ondan temiz görüntü tahminini (x_0_hat) çıkar, bir adım daha az gürültülü duruma geç. Son adımda temiz örnek elde edilir.
@torch.no_grad()
def sample(self, model, sz):
x_t = torch.randn(sz, device=device)
preds = []
for t in reversed(range(self.n_steps)):
z = torch.randn(x_t.shape) if t > 0 else torch.zeros(x_t.shape)
noise_pred = learn.model(x_t, t_batch).sample
x_0_hat = ((x_t - (1-self.ᾱ[t]).sqrt()*noise_pred)/self.ᾱ[t].sqrt()).clamp(-1,1)
x_t = x_0_hat*x0_coeff + x_t*xt_coeff + self.σ[t]*z
preds.append(x_t.cpu())
return preds“by predicting the noise and subtracting it out, we are going back to the distribution.” — Howard, 39:34
Şekil 22.6 sampling döngüsünü şematik gösterir: üstte kademeli gürültü→görüntü şeridi (saf gürültü x_T → yarı temizlenmiş → temiz örnek x₀), altta akış şeması — saf gürültüyle başla, for t in reversed(range(n_steps)) döngüsünde her adım U-Net gürültü tahmini (εθ) → temiz tahmin (x₀_hat) → bir adım az gürültülü (xₜ₋₁), ve geri besleme ile tekrar. n_steps bitince temiz örnek çıkar. Alt not, döngünün yavaşlığını (1000 adım) ve DDIM çözümünü (Ders 21, ~50 adım) hatırlatır.
Kod
import matplotlib.gridspec as gridspec
# Üst şerit için illüstratif kademeli gürültü→görüntü kareleri.
# ddpm_noisify_demo'nun gerçek noisify kareleri TERS sırada okunur
# (saf gürültü t=950 → yarı t=500 → temiz t=50): reverse sampling'in
# nereye gittiğini görselleştirir (yörünge şematiktir, gerçek değil).
nz = E.ddpm_noisify_demo(t_values=(50, 500, 950))
strip = [fr[4] for fr in nz["frames"]][::-1] # [saf gürültü, yarı, temiz]
strip_lbl = ["saf gürültü x_T", "yarı temizlenmiş", "temiz örnek x₀"]
fig = plt.figure(figsize=(12, 5.5))
gs = gridspec.GridSpec(2, 1, height_ratios=[1.0, 2.5], hspace=0.30)
# ----------------------------------------------------------------------------
# ÜST — kademeli gürültü→görüntü dizisi (illüstratif imshow şeridi)
# ----------------------------------------------------------------------------
gs_top = gridspec.GridSpecFromSubplotSpec(
1, 5, subplot_spec=gs[0], width_ratios=[1, 0.25, 1, 0.25, 1], wspace=0.05)
strip_cols = [0, 2, 4]
for k, (img, lbl) in enumerate(zip(strip, strip_lbl)):
ax = fig.add_subplot(gs_top[strip_cols[k]])
ax.imshow(img, cmap="gray", interpolation="nearest")
ax.set_xticks([]); ax.set_yticks([])
is_first, is_last = (k == 0), (k == len(strip) - 1)
ec = COL_ACCENT if is_first else (COL_CYAN_700 if is_last else COL_SLATE_400)
for sp in ax.spines.values():
sp.set_edgecolor(ec)
sp.set_linewidth(2.4 if (is_first or is_last) else 1.0)
tc = COL_ACCENT if is_first else (COL_CYAN_700 if is_last else COL_TEXT)
ax.set_title(lbl, fontsize=9.0, color=tc, weight="bold")
# kareler arası "gürültü gider" okları
for col in (1, 3):
axa = fig.add_subplot(gs_top[col]); axa.axis("off")
axa.annotate("", xy=(0.95, 0.5), xytext=(0.05, 0.5),
arrowprops=dict(arrowstyle="-|>", color=COL_PRIMARY, lw=2.2))
axa.text(0.5, 0.74, "gürültü gider", ha="center", va="bottom",
fontsize=7.6, color=COL_CYAN_700, style="italic")
# ----------------------------------------------------------------------------
# ALT — reverse sampling akış şeması (boxed_node + arrow_between)
# ----------------------------------------------------------------------------
ax = fig.add_subplot(gs[1])
ax.set_xlim(0, 12)
ax.set_ylim(0, 5.0)
ax.axis("off")
# (SOL) başlangıç: saf gürültü x_T = randn
viz.boxed_node(ax, 1.45, 2.5, 2.35, 1.05,
"saf gürültü\nx_T = randn(...)",
fc=COL_WHITE, ec=COL_ACCENT, tc=COL_TEXT, fontsize=9.0, lw=2.2)
# DÖNGÜ zemini (rose kesikli çerçeve) — for t in reversed(range(n_steps))
ax.add_patch(FancyBboxPatch((3.35, 0.45), 6.15, 4.20,
boxstyle="round,pad=0.02,rounding_size=0.08",
fc=COL_CYAN_50, ec=COL_ACCENT, linewidth=1.8,
linestyle="--", zorder=0))
ax.text(6.42, 4.30, "for t in reversed(range(n_steps)): ← her adım bir U-Net çağrısı",
ha="center", va="center", fontsize=8.8, color=COL_ACCENT,
weight="bold", style="italic", zorder=1)
# döngü adımları (üç kutu, soldan sağa)
viz.boxed_node(ax, 4.75, 2.95, 2.25, 0.92,
"U-Net gürültü\ntahmini εθ(xₜ, t)",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT, fontsize=8.6, lw=2.0)
viz.boxed_node(ax, 7.55, 2.95, 2.55, 0.92,
"temiz tahmin\nx₀_hat = (xₜ−√(1−ᾱ)·εθ)/√ᾱ",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_CYAN_800, fontsize=8.0, lw=2.0)
viz.boxed_node(ax, 6.42, 1.20, 3.05, 0.82,
"bir adım daha az gürültülü xₜ₋₁",
fc=COL_WHITE, ec=COL_CYAN_700, tc=COL_TEXT, fontsize=8.6, lw=1.8)
# döngü içi akış: εθ → x₀_hat → xₜ₋₁
viz.arrow_between(ax, (5.88, 2.95), (6.28, 2.95), color=COL_ACCENT,
mutation_scale=15, shrink=8)
viz.arrow_between(ax, (7.55, 2.49), (7.10, 1.61), color=COL_PRIMARY,
mutation_scale=15, shrink=8, connectionstyle="arc3,rad=0.12")
# geri besleme: xₜ₋₁ → bir sonraki adımda U-Net'e (tekrar)
viz.arrow_between(ax, (4.90, 1.20), (4.75, 2.49), color=COL_ROSE_400,
mutation_scale=15, shrink=8, connectionstyle="arc3,rad=0.18",
style="-|>")
ax.text(3.92, 2.00, "tekrar\n(xₜ ← xₜ₋₁)", ha="center", va="center",
fontsize=7.6, color=COL_ROSE_400, style="italic",
weight="bold", zorder=3)
# giriş: x_T → döngü
viz.arrow_between(ax, (2.63, 2.55), (3.62, 2.90), color=COL_ACCENT,
connectionstyle="arc3,rad=-0.10")
# (SAĞ) çıkış: temiz örnek x₀
viz.boxed_node(ax, 11.0, 2.5, 1.85, 1.05,
"temiz örnek\nx₀",
fc=COL_WHITE, ec=COL_CYAN_700, tc=COL_TEXT, fontsize=9.0, lw=2.2)
viz.arrow_between(ax, (8.83, 1.20), (10.55, 2.10), color=COL_CYAN_700,
connectionstyle="arc3,rad=-0.14")
ax.text(9.75, 0.95, "n_steps bitince", ha="center", va="center",
fontsize=7.8, color=COL_CYAN_700, style="italic", weight="bold")
# alt not: 1000 adım yavaş → DDIM
ax.text(6.0, 0.02, "1000 adım, her biri bir U-Net çağrısı (yavaş → DDIM Ders 21 ~50 adım)",
ha="center", va="bottom", fontsize=8.2, color=COL_SLATE_400, style="italic")
plt.tight_layout()
plt.show()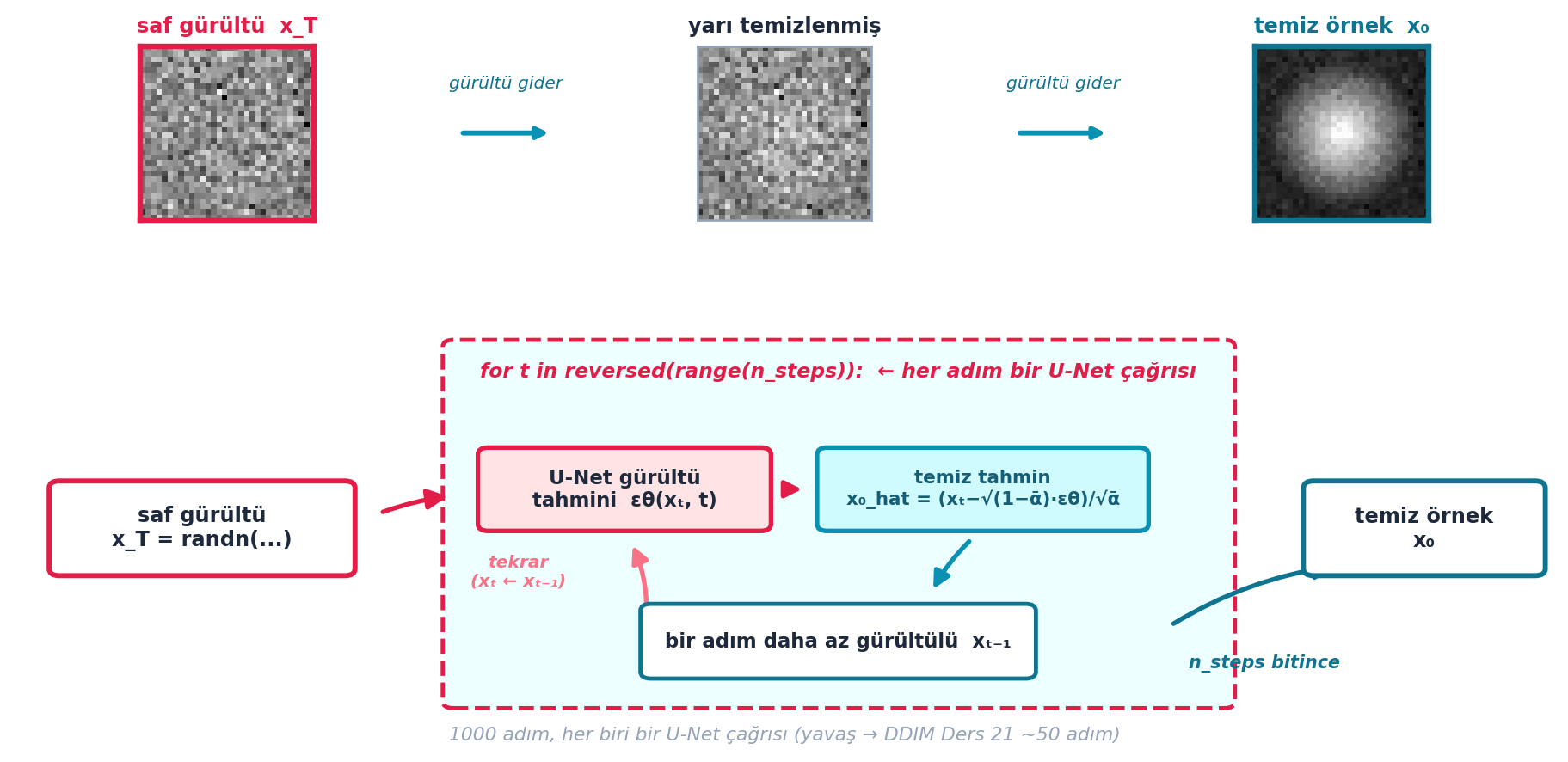
İpucuBuilder Notu — Sampling: Yavaş ama Doğru
- İleriye (Ders 21): Bu döngü 1000 adım sürer — bir görüntü için 1000 U-Net çağrısı, yavaş. DDIM (Ders 21) aynı kaliteyi ~50 adımda verir; aradaki fark üretim hızında devrim yaratır.
- Sezgi: Son adımda (t=0)
z = zerosolması bilinçlidir: ara adımlarda küçük rastgele gürültü (σₜ·z) eklemek üretimi çeşitlendirir, ama en son adımda gürültü eklemek nihai temiz örneği yeniden kirletirdi.x_0_hather adımda U-Net’in “şu anki en iyi temiz tahmini”dir; tam ona atlamak yerine bir adım kadar yaklaşmak (kısmi güncelleme), reverse sürecin küçük ve güvenli adımlarla ilerlemesini sağlar.
22.12 11. DDPM’in Üç Adımlı Eğitim Reçetesi
Howard her şeyi tek cümlede özetler: rastgele bir zaman adımı seç, görüntüye o kadar gürültü ekle, ağa gürültülü görüntü + adımı ver, eklenen gürültüyü MSE ile tahmin ettir. Bu kadar.
“we select a random timestep and then we add noise to our image… we pass the noisy image to a model as well as the timestep. And we are trying to predict the amount of noise… with the MSE loss.” — Howard, 43:55
İpucuBuilder Notu — Reçete: Önce Çalıştır, Sonra Anla
- Geriye (Ders 3): “Önce çalıştır, sonra anla” — karmaşık ELBO matematiğini bilmesen de bu üç adımlı reçeteyle diffusion eğitebilirsin; anlama sonra gelir. Howard kasıtlı olarak olasılıksal türevi atlar ve doğrudan çalışan koda gider.
- Sezgi: Reçetenin üç adımı doğrudan üç kod parçasına eşlenir: “rastgele t + gürültü ekle” →
before_batch(§7); “gürültülü + t’yi ağa ver” → U-Netpredict(§8); “gürültüyü MSE ile tahmin et” →nn.MSELoss()(§6). Üç cümle, üç satır, bir model.
22.13 12. 9B Matematiğinin Koda Dökülmesi
Bu ders, Part 2’nin teori-pratik köprüsünün doruğudur. Ders 9B’de Waseem ve Tanishq forward process q(xₜ|xₜ₋₁), Gaussian transitions, reparameterization ve forward’ın kapalı formunu türetti. Burada o matematik, before_batch’teki tek satıra (xt = ᾱ_t.sqrt()*x0 + (1-ᾱ_t).sqrt()*ε) iner. Notebook’un Unicode değişkenleri (β, α, ᾱ, ε, σ) doğrudan 9B notasyonunu yansıtır.
Köprüyü açık biçimde yan yana koyalım:
| 9B’de (matematik) | L19’da (kod) |
|---|---|
| \(x_t = \sqrt{\bar{\alpha}_t}\,x_0 + \sqrt{1-\bar{\alpha}_t}\,\varepsilon\) | xt = ᾱ_t.sqrt()*x0 + (1-ᾱ_t).sqrt()*ε |
| \(\bar{\alpha}_t = \prod_{s=1}^{t}(1-\beta_s)\) | self.ᾱ = torch.cumprod(self.α, dim=0) |
| \(L = \|\varepsilon - \varepsilon_\theta(x_t,t)\|^2\) | nn.MSELoss() |
| \(\varepsilon \sim \mathcal{N}(0, I)\) | ε = torch.randn(...) |
ÖnemliBuilder Notu — Köprü: Matematik Bilen Kodu, Kod Bilen Matematiği Anlar (MERKEZÎ)
- Geriye (Ders 9B) — köprü: 9B’nin block math forward process formülü = bu dersin
noisifykodu. Matematik bilen builder kodu, kod bilen builder matematiği anlar. Tablo bu eşlemeyi satır satır gösterir: her matematiksel ifade tam bir kod satırına karşılık gelir. - Sezgi: Bu eşlemenin değeri çift yönlüdür. 9B’yi izleyip türevi anlayan biri, koddaki
ᾱ_t.sqrt()*x0’ın neden doğru olduğunu bilir (reparameterization). Tersine, kodu önce gören biri (Howard’ın “önce çalıştır” yaklaşımı)cumprodverandn’ün ne yaptığını görüp matematiği geriye doğru sökebilir. İkisi de aynı tek gerçeğe — forward kapalı formuna — varır.
22.14 13. NYU Köprüsü: Üretken Paradigmalar
DDPM’i diğer üretken modellerle konumlandırmak (NYU Deep Learning, LeCun): VAE (NYU H8, autoencoder/EBM) verili bir latent’ten tek adımda üretir; GAN (NYU H9, contrastive EBM) bir ayırıcıya karşı üretir; diffusion ise üretimi yinelemeli arıtmaya (iterative refinement) böler — gürültüyü kademeli kaldırarak. DDPM’in noise-prediction hedefi, GAN’ın adversarial hedefine bir alternatiftir; daha kararlı eğitim verir.
İpucuBuilder Notu — NYU: Diffusion Üçüncü Büyük Alternatif
- Geriye (NYU H8-9): NYU’da EBM/VAE/GAN paradigmalarını gördük; diffusion bunların üçüncü büyük alternatifidir. NOT: BYOL/VICReg/MAE/JEPA gibi post-2020 yöntemler NYU DLSP20’de yoktu — diffusion da o kursta yalnızca kavramsaldı; burada sıfırdan kuruluyor.
- Sezgi: Üç paradigmayı ayıran şey, üretim kaç adımda olur: VAE tek decode adımında, GAN tek generator geçişinde, diffusion ise binlerce küçük denoising adımında üretir. Bu “çok adıma bölme”, diffusion’ın eğitimini GAN’a kıyasla daha kararlı kılar (adversarial denge yok, sadece bir MSE regresyonu) — pratikteki popülaritesinin temel sebeplerinden biri.
22.15 14. Neden DDPM Çalışır? (Yinelemeli Arıtma)
DDPM’in gücü, zor bir problemi (saf gürültüden görüntü) çok sayıda kolay probleme (bir adım daha az gürültü) bölmesidir. Her adımda ağ küçük, yapılabilir bir tahmin yapar; binlerce küçük adım birikince tek seferde imkânsız olan dönüşüm gerçekleşir. Bu “böl ve arıt” stratejisi, modern üretken modellemenin temel fikridir.
Şekil 22.7 bu içgörüyü iki panelde karşılaştırır: solda tek adım (imkânsız) — saf gürültüden temiz görüntüye tek dev sıçrama, öğrenilemez (dönüşüm çok büyük); sağda binlerce kolay adım (DDPM) — saf gürültü → biraz daha temiz → … → temiz, her adım küçük ve yapılabilir bir tahmin. DDPM’in gücü tam burada: imkânsız dönüşümü binlerce yapılabilir küçük adıma bölmek.
Kod
fig, (axL, axR) = plt.subplots(1, 2, figsize=(11.5, 5.0),
gridspec_kw={"width_ratios": [1.0, 1.55]})
# ----------------------------------------------------------------------------
# SOL — TEK ADIM (imkânsız): saf gürültü → temiz görüntü, tek dev ok
# ----------------------------------------------------------------------------
axL.set_xlim(0, 10); axL.set_ylim(0, 10); axL.axis("off")
axL.set_facecolor(COL_WHITE)
axL.text(5, 9.4, "TEK ADIM (imkânsız)", ha="center", va="center",
fontsize=12.5, weight="bold", color=COL_ACCENT)
boxed_node(axL, 5, 7.4, 5.2, 1.5, r"saf gürültü" "\n" r"$\mathcal{N}(0,\,I)$",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT, fontsize=11)
boxed_node(axL, 5, 2.3, 5.2, 1.5, "temiz görüntü\nx₀",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT, fontsize=11)
# tek dev ok (kalın, rose)
big = arrow_between(axL, (5, 6.55), (5, 3.15),
color=COL_ACCENT, lw=4.2, mutation_scale=34, shrink=6)
# kırmızı ✗ + "öğrenilemez" etiketi
axL.text(6.75, 4.85, "✗", ha="center", va="center",
fontsize=30, weight="bold", color=COL_ACCENT)
axL.annotate("öğrenilemez\n(dönüşüm çok büyük)",
xy=(5, 4.85), xytext=(8.6, 4.85),
ha="center", va="center", fontsize=9.5, weight="bold",
color=COL_ACCENT, style="italic",
arrowprops=dict(arrowstyle="-", color=COL_ROSE_400, lw=1.2))
# ----------------------------------------------------------------------------
# SAĞ — BİNLERCE KOLAY ADIM (DDPM): zincir, her adım küçük ok
# ----------------------------------------------------------------------------
axR.set_xlim(0, 12); axR.set_ylim(0, 10); axR.axis("off")
axR.set_facecolor(COL_WHITE)
axR.text(6, 9.4, "BİNLERCE KOLAY ADIM (DDPM)", ha="center", va="center",
fontsize=12.5, weight="bold", color=COL_CYAN_700)
# zincir kutuları: saf gürültü → biraz daha temiz → … → temiz
import matplotlib.colors as mcolors
rgb_rose = mcolors.to_rgb(COL_ROSE_400)
rgb_cyan = mcolors.to_rgb(COL_CYAN_400)
def _blend(c0, c1, t):
return tuple(c0[i] + (c1[i] - c0[i]) * t for i in range(3))
labels = ["saf\ngürültü", "biraz\ndaha temiz", "…", "neredeyse\ntemiz", "temiz\nx₀"]
n = len(labels)
xs = np.linspace(1.7, 10.3, n)
y_chain = 6.6
bw, bh = 1.9, 1.5
for i, lab in enumerate(labels):
t = i / (n - 1) # 0 (gürültü) → 1 (temiz)
if i == 0:
fc, ec, tc = COL_BG_ROSE, COL_ACCENT, COL_TEXT # saf gürültü
elif i == n - 1:
fc, ec, tc = COL_BG, COL_CYAN_700, COL_TEXT # temiz
else:
fc = mcolors.to_hex(_blend(rgb_rose, rgb_cyan, t)) # rose→cyan geçiş
ec, tc = COL_SLATE_400, COL_TEXT
boxed_node(axR, xs[i], y_chain, bw, bh, lab, fc=fc, ec=ec, tc=tc,
fontsize=9.5, lw=2.0)
# küçük yeşil/cyan oklar — her adım "bir adım az gürültü"
for i in range(n - 1):
arrow_between(axR, (xs[i], y_chain), (xs[i + 1], y_chain),
color=COL_CYAN_400, lw=2.4, mutation_scale=16, shrink=24)
axR.text(6, 5.18,
"her adım küçük: bir adım az gürültü = KOLAY tahmin",
ha="center", va="center", fontsize=10, weight="bold",
color=COL_CYAN_700)
# annotate: DDPM'in gücü (böl ve arıt)
axR.annotate(
"DDPM'in gücü: imkânsız dönüşümü\nbinlerce yapılabilir küçük adıma böler\n('böl ve arıt')",
xy=(6, 6.6), xytext=(6, 2.95),
ha="center", va="center", fontsize=10, weight="bold", color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.5", fc=COL_CYAN_50, ec=COL_CYAN_700, lw=1.4),
arrowprops=dict(arrowstyle="-|>", color=COL_CYAN_700, lw=1.6))
# alt not — modern üretken modelleme
fig.text(0.5, 0.015,
"yinelemeli arıtma — modern üretken modellemenin temel fikri",
ha="center", va="bottom", fontsize=10.5, weight="bold",
color=COL_CYAN_700)
plt.tight_layout(rect=(0, 0.05, 1, 1))
plt.show()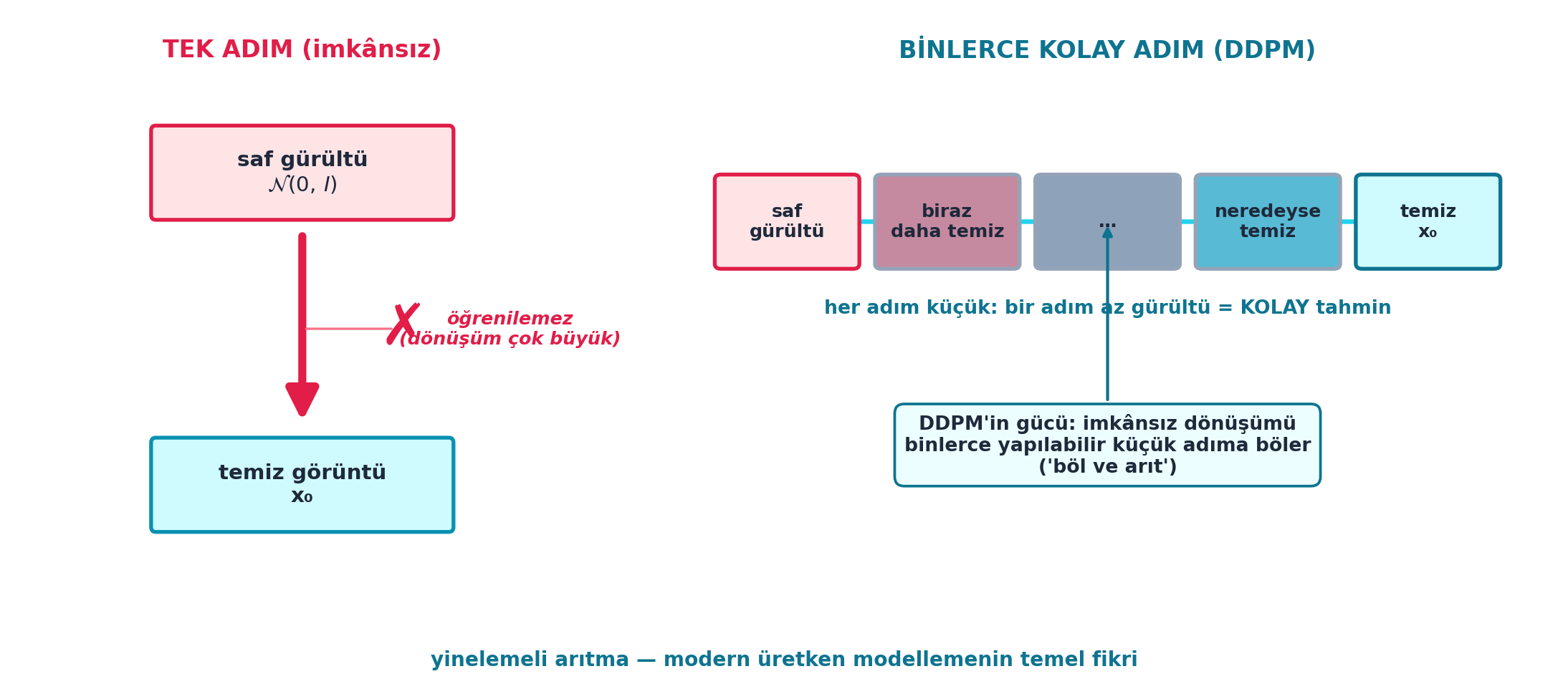
İpucuBuilder Notu — Yinelemeli Arıtma: Böl ve Arıt
- İleriye (Ders 25): Aynı yinelemeli arıtma, latent uzayda yapılınca (Ders 25) Stable Diffusion olur — daha hızlı, daha yüksek çözünürlük. Fikir değişmez, sadece piksel uzayı yerine sıkıştırılmış latent uzayda çalışır.
- Sezgi: Bir adımda gürültüden görüntüye gitmek imkânsızdır çünkü dağılımlar arası mesafe çok büyüktür — ağın öğrenmesi gereken eşleme aşırı karmaşık olurdu. Her adımı küçük tutarak (\(x_t \to x_{t-1}\), az gürültü farkı) her tahmin yerel ve kolay kalır; zorluk binlerce adıma yayılır. Bu, “büyük bir problemi yönetilebilir küçük parçalara böl” mühendislik ilkesinin üretken modellemedeki tezahürüdür.
22.16 15. Kapanış
Ders 19, Part 2’nin teori-pratik köprüsünü tamamladı: DDPM’i sıfırdan kurduk. Forward process (kapalı formülle gürültü ekle) + reverse process (U-Net ile gürültüyü tahmin et) + MSE kaybı + miniai eğitim döngüsü. 9B’nin matematiği koda döküldü; foundations’ta (L15-18) kurduğumuz her şey (Learner, callback, Adam, ResBlock/U-Net) burada birleşti. Diffusion artık kara kutu değil.
Şekil 22.8 dersin sentezidir: solda L19’da kurduğumuz parçalar (rose), sağda nereden geldikleri / nereye gittikleri (cyan). En üstte köprü doruğu — noisify (xₜ=√ᾱ·x₀+√(1−ᾱ)·ε) = Ders 9B forward process matematiğinin birebir kodu; altında MSE → Ders 5/13 regresyonu, DDPMCB/U-Net → Ders 16-18 miniai, üretken paradigma → NYU H8 VAE + H9 GAN yanında diffusion üçüncü alternatif, yinelemeli arıtma → Ders 25 latent diffusion. Sentez: L19 = 9B matematiğinin koda dökülüşü + MSE regresyonu + miniai.
Kod
fig, ax = plt.subplots(figsize=(12.5, 6.5))
ax.set_xlim(0, 12.5)
ax.set_ylim(0, 10)
ax.axis("off")
# Başlık şeritleri
ax.text(2.75, 9.45, "L19'da", ha="center", va="center",
fontsize=13, weight="bold", color=COL_ACCENT)
ax.text(9.55, 9.45, "Nereden / nereye", ha="center", va="center",
fontsize=13, weight="bold", color=COL_CYAN_700)
# (L19 parçası [rose], kaynak/hedef [cyan]) satırları — yukarıdan aşağıya
rows = [
("noisify\nxₜ=√ᾱ·x₀+√(1−ᾱ)·ε",
"Ders 9B forward process MATEMATİĞİ\n(Waseem/Tanishq türetti) → BİREBİR kod\n(köprü doruğu)"),
("MSE noise loss",
"Ders 5/13: MSE\ndiffusion'ın kalbinde basit regresyon"),
("DDPMCB / U-Net",
"Ders 16-18: miniai\n(Learner + Adam + ResBlock)"),
("üretken paradigma",
"NYU H8 VAE + H9 GAN\ndiffusion 3. alternatif (iterative refinement)"),
("yinelemeli arıtma",
"Ders 25: latent diffusion (SD)\naynı fikir, latent uzayda"),
]
bw_l, bw_r = 3.3, 4.7 # kutu genişlikleri (sol/sağ)
bh = 1.18 # kutu yüksekliği
xL, xR = 2.75, 9.55 # sütun merkezleri
y_top, y_gap = 8.35, 1.62 # ilk satır + satır aralığı
for i, (l19_part, source) in enumerate(rows):
y = y_top - i * y_gap
# SOL: L19 parçası (rose dolgu/çerçeve)
viz.boxed_node(ax, xL, y, bw_l, bh, l19_part,
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT,
fontsize=10.0, lw=2.0)
# SAĞ: kaynak/hedef (cyan dolgu/çerçeve)
viz.boxed_node(ax, xR, y, bw_r, bh, source,
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT,
fontsize=9.0, lw=2.0)
# Ok: parça → kaynak/hedef
viz.arrow_between(ax, (xL + bw_l / 2, y), (xR - bw_r / 2, y),
color=COL_CYAN_400, lw=2.2, shrink=4)
# Alt sentez kutusu — birleşim mesajı
viz.boxed_node(ax, 6.25, 0.62, 11.6, 0.92,
"L19 = 9B matematiğinin koda dökülüşü · forward→noisify + MSE regresyonu + miniai · VAE/GAN yanında diffusion 3. üretken paradigma",
fc=COL_WHITE, ec=COL_CYAN_700, tc=COL_CYAN_700,
fontsize=10.0, lw=2.0)
plt.tight_layout()
plt.show()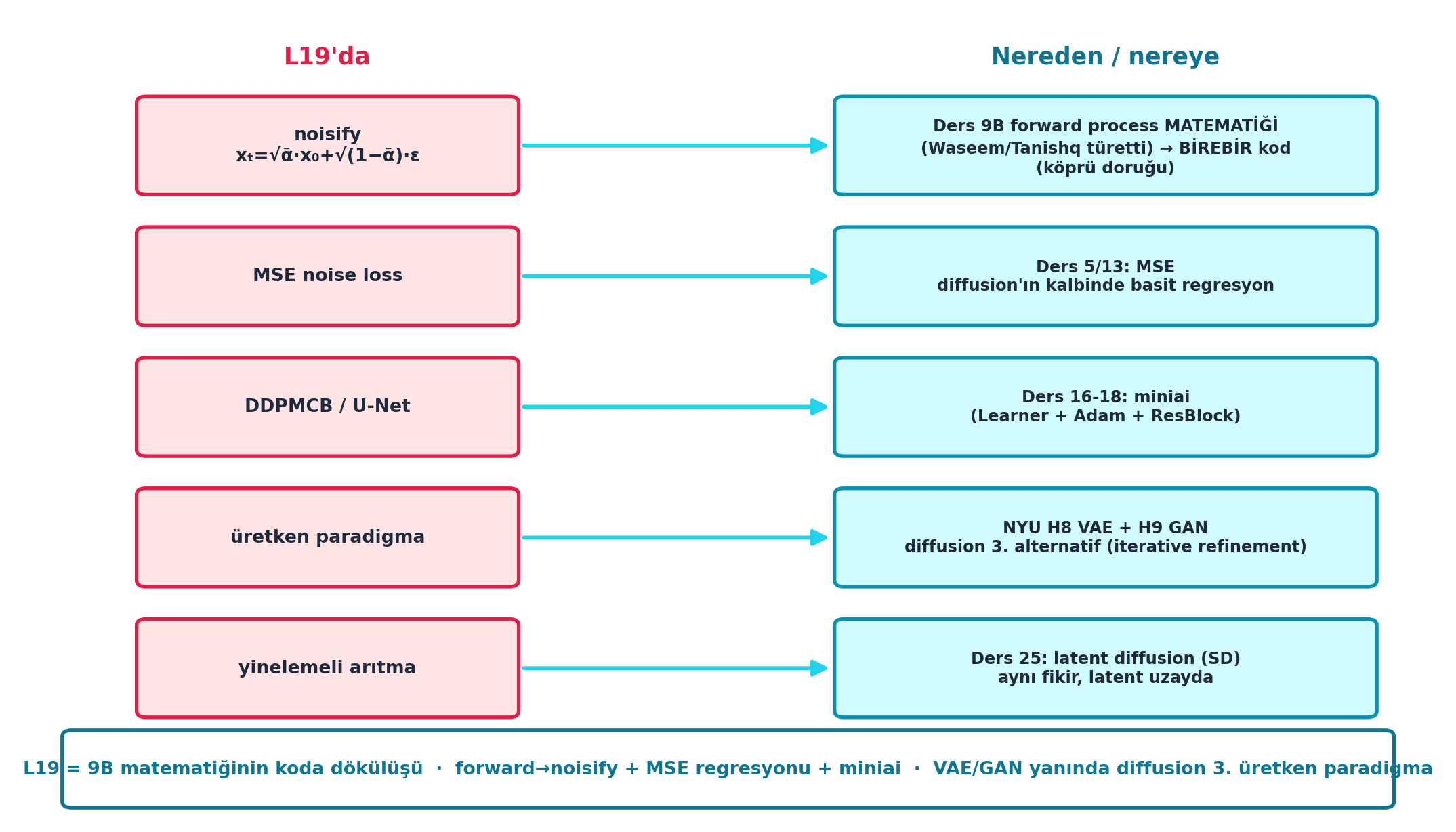
İpucuBuilder Notu — Kapanış: Diffusion Artık Kara Kutu Değil
- İleriye (Ders 20-22): DDPM temeldir; Ders 20 (mixed precision + style transfer), 21 (FID/KID metrikleri + DDIM hızlandırma), 22 (cosine schedule + Karras) hep bunun üstüne kurulur. ETAP 6’nın bu açılış dersi, gelecek tüm diffusion derslerinin çekirdeğini verir.
- Sezgi: Bu dersten sonra
diffuserskütüphanesini çağırdığında altında ne döndüğünü biliyorsun: forward formülü, ε-prediction, MSE, reverse sampling döngüsü. Tıpkı L18 sonrasıoptim.Adam’ın içini bilmek gibi — diffusion da artık demistifiye edilmiş bir araç, sihirli bir kara kutu değil. “From the foundations” yolculuğunun meyvesi tam budur.
22.17 Bu Dersin Özeti
- Dropout: Eğitimde aktivasyonların rastgele kısmını sıfırlayan düzenlileştirme; çıkarımda kapalı (BatchNorm gibi train/eval ayrımı) (Dropout).
- DDPM: Saf piksel diffusion (latent yok); forward (gürültü ekle) + reverse (gürültü kaldır) süreçleri (DDPM nedir).
- Forward (kolay): xₜ = √ᾱₜ · x₀ + √(1 − ᾱₜ) · ε; kapalı formülle tek adımda istenen gürültü seviyesi (forward).
- β çizelgesi: βₜ doğrusal artar; αₜ = 1 − βₜ, ᾱₜ = ∏ αₛ (birikimli çarpım, kalan sinyal) (çizelge).
- Reverse (zor): Gürültüden görüntüye; bir U-Net her adımı öğrenir, n_steps kez tekrarlanır (reverse).
- Anahtar içgörü: Ağ eklenen gürültüyü (ε) tahmin eder; kayıp = MSE(ε, εθ). Diffusion’ın tüm karmaşıklığı buna iner (MSE).
- DDPMCB: Tüm mantık miniai
TrainCB’den türeyen bir callback’te; eğitim = standart Learner + MSE + Adam + OneCycle (DDPMCB). - Sampling: Saf gürültüden başla, U-Net’le gürültüyü kademeli kaldır; zor problemi binlerce kolay adıma böl (sampling, yinelemeli arıtma).
ÖnemliTek Bir Cümle
DDPM, bir görüntüye kapalı formülle (xₜ = √ᾱₜ·x₀ + √(1−ᾱₜ)·ε) gürültü ekleyip bir U-Net’e o gürültüyü MSE ile tahmin ettirerek eğitilen üretken modeldir; üretim, saf gürültüden başlayıp ağın tahmin ettiği gürültüyü adım adım kaldırarak imkânsız dönüşümü binlerce kolay adıma bölmektir — ve bu, 9B’de türetilen matematiğin miniai üstünde koda dökülmüş hâlidir.
22.18 Kontrol Soruları
NotSoru 1: Forward process neden ‘kolay’, reverse process neden ’zor’dur?
Cevap:
Forward process bir görüntüye gürültü eklemektir — bu önemsizdir, sadece rastgele gürültü ekliyorsun. Üstelik kapalı formül sayesinde tüm ara adımları gezmeden, t adımındaki gürültülü görüntüyü tek hamlede üretebilirsin: xₜ = √ᾱₜ · x₀ + √(1 − ᾱₜ) · ε. Reverse process tersidir: saf gürültüden (veya gürültülü bir görüntüden) anlamlı, daha temiz bir görüntüye gitmek. Bu son derece zordur çünkü sonsuz olası “temiz görüntü” vardır ve hangi gürültünün eklendiğini bilmek gerekir. Çözüm: bu zor ters adımı bir sinir ağına (U-Net) öğretmek. Ağ “bu gürültülü görüntüye hangi gürültü eklenmiş?” sorusunu yanıtlar; o gürültüyü çıkararak bir adım geriye gideriz. (Şekil 22.2 forward’ın kolaylığını, Şekil 22.6 reverse’ün adım adım zorluğunu gösterir.)
NotSoru 2: DDPM’in kaybı neden ‘sadece MSE’ diye özetlenir?
Cevap:
DDPM’in tam teorik türevi olasılıksaldır (ELBO — evidence lower bound, KL ıraksamaları, Gaussian geçişler). Ama bu matematik sadeleştirildiğinde pratik eğitim hedefi tek bir şeye iner: ağ, görüntüye eklenen gürültüyü tahmin eder (εθ), ve kayıp, tahmin edilen gürültü ile gerçek eklenen gürültü arasındaki ortalama kare hatadır: L = ‖ε − εθ(xₜ, t)‖². Yani diffusion eğitmek, “şu görüntüye eklediğim ε neydi?” regresyon sorusunu MSE ile çözmektir. Howard’ın vurgusu tam buradadır: görkemli diffusion modellerinin kalbinde, Ders 5’te gördüğümüz basit MSE vardır — sihir değil. (Şekil 22.4 ε bilinince x₀’ın kusursuz geri kazanıldığını gösterir.)
NotSoru 3: ᾱₜ (alpha bar) nedir ve forward formülünde ne işe yarar?
Cevap:
ᾱₜ, gürültü çizelgesinin birikimli çarpımıdır: ᾱₜ = ∏ₛ₌₁ᵗ αₛ, burada αₛ = 1 − βₛ. Sezgisi: t adımından sonra orijinal sinyalin (görüntünün) ne kadarının “hayatta kaldığı”. Forward formülünde xₜ = √ᾱₜ · x₀ + √(1 − ᾱₜ) · ε iki katsayıyı belirler: √ᾱₜ orijinal görüntünün ağırlığı, √(1 − ᾱₜ) gürültünün ağırlığı. t küçükken ᾱₜ ≈ 1 (görüntü neredeyse temiz); t büyükken ᾱₜ ≈ 0 (neredeyse saf gürültü). Birikimli çarpım sayesinde herhangi bir t için gürültülü görüntüyü tek adımda hesaplayabiliriz — ara adımları tek tek uygulamaya gerek yok. Kod: self.ᾱ = torch.cumprod(self.α, dim=0). (Şekil 22.3 ᾱ’nın 1’den 0’a düşüşünü ve iki katsayının makaslamasını gösterir.)
NotSoru 4: DDPM, foundations derslerini (L16-18) nasıl kullanır? (builder bağlantısı)
Cevap:
DDPM, “from the foundations” yolculuğunda kurduğumuz her parçayı birleştirir. Ders 16 (Learner+callback): Tüm DDPM mantığı (DDPMCB) miniai’nin TrainCB’sinden türeyen bir callback’tir; eğitim döngüsü standart miniai Learner’dır. Ders 17 (init/norm): U-Net’in katmanları Kaiming init + normalizasyon kullanır, yoksa eğitilemezdi. Ders 18 (Adam/OneCycle/ResBlock): Eğitim Adam + OneCycle ile yapılır; U-Net’in iç yapıtaşı L18’in ResBlock’udur. Yani DDPM eğitimi = miniai + bir gürültüleme callback’i. Howard’ın L16-18’de miniai’yi bu kadar özenle kurmasının sebebi tam buydu: diffusion gibi karmaşık bir modeli, sağlam bir altyapı üstünde birkaç parçayla eğitebilmek. Bu, “yeniden kur, sonra kullan” kuralının meyvesidir. (Şekil 22.5 foundations parçalarının DDPMCB’de birleşimini gösterir.)
22.19 Egzersizler
Egzersiz 1 (Direkt uygulama). β çizelgesini (torch.linspace) kur, αₜ ve ᾱₜ’yi hesapla; ᾱₜ’nin t boyunca 1’den 0’a nasıl düştüğünü çiz (Şekil 22.3’nın ᾱ eğrisini kendi sayımınla doğrula — §4).
Egzersiz 2 (İki-aşamalı). before_batch gürültüleme kodunu bir görüntüye uygula; farklı t değerlerinde (örn. t=50, 500, 950) gürültülü görüntüyü görselleştir (Şekil 22.2’in sinyal/gürültü ayrışımını üret — §7).
Egzersiz 3 (Edge case). sample döngüsünü yaz; t=0’da z=0 (son adımda gürültü eklenmez) olmasının neden gerekli olduğunu açıkla (§10).
Egzersiz 4 (Kavramsal). Ağ neden gürültüyü (ε) tahmin eder de doğrudan temiz görüntüyü (x₀) tahmin etmez? İkisi matematiksel olarak nasıl ilişkili? (§6)
Egzersiz 5 (Sonraki dersin habercisi — Ders 20). DDPM eğitimi yavaş ve bellek-yoğun. Mixed precision (fp16) eğitimi nasıl hızlandırıp belleği nasıl azaltabilir, düşün (§15).
22.20 Sonraki: Ders 20 İçin Hazırlık
Ders 20: Mixed Precision ve Style Transfer
Ders 19 DDPM’i sıfırdan kurdu. Ders 20 iki konu işler: mixed precision (fp16/bf16 ile daha hızlı, daha az bellekli eğitim — HuggingFace Accelerate) ve style transfer (bir görüntüyü optimize ederek, VGG16 özellikleri + Gram matrisi style loss ile bir resmi başka bir stilde yeniden çizmek). Bu, optimizasyonu ağırlıklar yerine girdi görüntüsü üzerinde yapmanın güzel bir örneğidir.
Ana konular (Ders 20):
- MixedPrecision callback + HuggingFace Accelerate
- Görüntüyü optimize etme (ağırlık değil, piksel)
- VGG16 ile özellik çıkarma (hooks)
- Content loss + Style loss (Gram matrisi)
UyarıDers 20 Öncesi Yapılacak
- Bu dersin egzersizlerini çöz (özellikle 1 ve 2 — β çizelgesi + gürültüleme görselleştirme).
- DDPM’i Fashion-MNIST’te eğit,
sampleile örnek üret. - Ders 17’nin hook bölümünü tekrar oku (style transfer’da VGG16 özellikleri hook’la çıkarılır).
22.21 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Howard’da |
|---|---|---|
| DDPM | Saf piksel denoising diffusion; latent yok | 12:13 |
| Dropout | Aktivasyonların rastgele kısmını sıfırlama (düzenlileştirme) | 2:08 |
| Forward process | xₜ = √ᾱₜ·x₀ + √(1−ᾱₜ)·ε; gürültü ekleme (kolay) | 23:58 |
| Reverse process | Gürültüden görüntüye; U-Net öğrenir (zor) | 33:51 |
| β çizelgesi | βₘᵢₙ→βₘₐₓ doğrusal artan varyans | 40:26 |
| ᾱ (alpha bar) | ᾱₜ = ∏ αₛ; birikimli çarpım (kalan sinyal) | 47:06 |
| ε-prediction | Ağ eklenen gürültüyü tahmin eder (εθ) | 37:38 |
| MSE loss | ‖ε − εθ‖²; diffusion’ın tüm kaybı budur | 35:59 |
noisify / before_batch |
Forward’ı eğitimde uygulama | 40:26 |
| U-Net | Gürültü tahmincisi; girdi=çıktı şekli (ResBlock’lardan) | 41:16 |
DDPMCB |
miniai TrainCB’den türeyen DDPM callback’i | 56:07 |
| Sampling | Saf gürültüden n_steps geriye giderek üretim | 39:17 |
22.22 ML Bağlantıları Özeti
İpucuBuilder Notu — 6 ML Köprüsü: 9B Matematiği → Kod + miniai Sentezi
Bu ders, Ders 9B’de türetilen forward process matematiğini miniai üstünde koda döker ve diffusion’ı diğer üretken paradigmalar arasında konumlandırır; köprülerin özeti:
- Forward process → Ders 9B matematiği (Waseem/Tanishq); orada türev, burada
noisifykodu — köprü doruğu (noisify, 9B köprü). - MSE noise loss → Ders 5/13 MSE; diffusion’ın kalbinde basit regresyon (MSE).
- DDPMCB → Ders 16-18 miniai (Learner+callback+Adam+ResBlock); diffusion = miniai + bir callback (DDPMCB).
- U-Net → Ders 18 ResBlock’ları; diffusion ağı foundations bloklarından kurulu (U-Net).
- Üretken paradigmalar → NYU H8 VAE/EBM + H9 GAN; diffusion üçüncü büyük alternatif (iterative refinement) (NYU köprü).
- Yinelemeli arıtma → Ders 25 latent diffusion (Stable Diffusion); aynı fikir latent uzayda (yinelemeli arıtma).
ÖnemliBu dersten tek bir şey alıp gideceksen
Diffusion sihir değildir. Forward process bir görüntüye kapalı formülle gürültü ekler (kolay); reverse process bir U-Net’in tahmin ettiği gürültüyü kademeli kaldırır (zor, öğrenilmiş). Tüm karmaşık olasılık matematiği pratikte tek bir şeye iner — ağ eklenen gürültüyü tahmin eder, kayıp basit bir MSE’dir. 9B’de türetilen matematiği burada miniai üstünde koda döktük; foundations’ta kurduğumuz her parça (Learner, callback, Adam, ResBlock/U-Net) burada birleşti. Üretim, imkânsız bir dönüşümü binlerce kolay adıma bölmektir.