flowchart TD
SR["süper çözünürlük: düşük çözünürlük → yüksek çözünürlük<br/>(eksik detay UYDURULUR = üretken)"]
COND["koşullu üretim:<br/>çıktı girdiye koşullanır"]
MODEL["TinyUnet<br/>(ResBlock aşağı + yukarı + çapraz bağlantılar)"]
PROB["loss sorunu: pixel MSE<br/>→ geçerli çıktıların ORTALAMASI<br/>→ bulanık"]
PERC["perceptual loss:<br/>özellik uzayında karşılaştır (cmodel)"]
COMB["comb_loss = pixel + özellik bölü on"]
ATTN["koşullama → attention (L24)"]
T2I["metin-görüntü (L25)"]
SR --> COND
COND --> MODEL
MODEL --> PROB
PROB --> PERC
PERC --> COMB
COMB --> ATTN
ATTN --> T2I
classDef cyan fill:#ecfeff,stroke:#0891b2,stroke-width:2px,color:#1e293b;
classDef rose fill:#ffe4e6,stroke:#e11d48,stroke-width:2px,color:#1e293b;
class SR,MODEL,PROB,COMB,T2I cyan;
class COND,PERC,ATTN rose;
26 Ders 23 — Super-Resolution (Süper Çözünürlük)
SON ETAP’ın (ETAP 7) açılışı — Howard, Jonathan Whitaker (Johno) ve Tanishq Abraham’la. Düşük çözünürlüklü bir görüntüden yüksek çözünürlük üretmek; bu, üretimi bir girdiye koşullamanın (conditional generation) en sade örneği ve koşullu diffusion’a doğrudan köprü. Anahtar ders şu: piksel MSE keskin görüntü vermez (bulanıklaştırır), çünkü tek bir düşük çözünürlüklü girdiye karşılık birçok geçerli keskin çıktı vardır ve MSE bunların ortalamasını ödüllendirir. Çözüm, Ders 20’den tanıdığımız perceptual (feature) loss — çıktıyı ve hedefi önceden eğitilmiş bir ağın özellik uzayında karşılaştırmak; bu, style transfer’ın content loss’unun birebir aynısıdır. Üç temel fikir: super-res = koşullu üretim (bir U-Net düşük→yüksek dönüşümünü öğrenir), pixel loss bulanıklaştırır, perceptual loss keskinliği geri kazandırır. Model sıfırdan kurulan bir U-Net (TinyUnet): L18’in ResBlock’larından + L19’un U-Net yapısından. Dersin builder içgörüsü tek cümlede: doğru loss doğru sonucu belirler — «neyi optimize ettiğin» (loss) çoğu zaman «nasıl optimize ettiğinden» (mimari) kritiktir. SON ETAP burada başlar; sıradaki attention (L24) ve text→image (L25) ile gerçek Stable Diffusion’a yaklaşıyoruz.
NotBölüm bilgisi
- Ders sayfası (video): course.fast.ai — Lesson 23: Super-resolution (~101 dk)
- Seri: Practical Deep Learning for Coders — Part 2, Ders 23
- Playlist: Part 2 — Foundations to Stable Diffusion (2022)
- Notebook: course22p2 — nbs/25_superres (+ Tiny ImageNet U-Net)
- Okuma süresi: ~38 dk
- Hocalar: Howard + Jonathan Whitaker (Johno) + Tanishq Abraham
- 🔗 SON ETAP (ETAP 7) açılışı: ETAP 6’da diffusion’ı baştan sona kurduk — DDPM (L19), iyileştirilmiş eğitim (L20), FID/DDIM (L21), cosine/Karras (L22). Artık temel diffusion bizim. SON ETAP artık “nasıl çalışır”ı değil “ne yapabiliriz”i soruyor: super-res (L23) → attention (L24) → latent diffusion (L25). Ders 23, koşullu üretimin en sade örneğiyle bu kapıyı açar.
26.1 Bu Derste Ne Var?
SON ETAP’ın açılışı: super-resolution — düşük çözünürlüklü bir görüntüden yüksek çözünürlüklü üretmek. Bu, üretimi bir girdiye koşullamanın (conditional generation) ilk örneğidir ve koşullu diffusion’a doğrudan köprüdür. Anahtar ders: piksel MSE keskin görüntü vermez (bulanıklaştırır); çözüm, Ders 20’den tanıdığımız perceptual (feature) loss — çıktıyı özellik uzayında karşılaştırmak.
Üç temel fikir bu dersin omurgasını kurar:
- Super-resolution = koşullu üretim — çıktı, düşük çözünürlüklü girdiye koşullanır; bir U-Net düşük→yüksek dönüşümünü öğrenir (super-res nedir, koşullu üretim).
- Pixel loss bulanıklaştırır — MSE birçok olası keskin çıktının ortalamasını alır, sonuç pürüzlü; keskinlik için yetersiz (pixel loss).
- Perceptual loss — çıktı ve hedefi önceden eğitilmiş bir ağdan geçirip özellik uzayında karşılaştır; doku ve keskinliği geri kazandırır (perceptual loss).
“we want to use perceptual loss. And I think it was John who taught us about perceptual loss.” — Howard, 1:15:00
Şekil 28.1 bu üç fikri tek bir kavram haritasında birleştirir: super-res (düşük çözünürlük → yüksek çözünürlük; eksik detay uydurulur = üretken) → koşullu üretim (çıktı girdiye koşullanır) → TinyUnet (ResBlock aşağı + yukarı + çapraz bağlantılar) → loss sorunu (pixel MSE = geçerli çıktıların ortalaması = bulanık) → perceptual loss (özellik uzayında karşılaştır, cmodel) → comb_loss (pixel + özellik/10) → koşullama L24 attention ve L25 text→image kapısını açar. Rose ile işaretli düğümler (koşullu üretim, perceptual loss, attention) dersin iki çekirdek mesajını taşır: koşullama ve özellik uzayında karşılaştırma.
İpucuBuilder Notu — Giriş: SON ETAP, Koşullama ve Perceptual Loss
- Geriye (Ders 20) — köprü: Perceptual loss, Ders 20’deki style transfer’ın content loss’unun birebir aynısı — özellik uzayında MSE. Aynı fikir, yeni problem.
- Geriye (Ders 18-19): Super-res U-Net (TinyUnet), L18’in ResBlock’larından + L19’un U-Net yapısından kurulu.
- İleriye (Ders 24-25): Super-res = koşullu üretim; koşullama, latent diffusion’ın (L25) text→image’ının temeli; attention (L24) bu koşullamayı güçlendirir.
- Tek cümle: Super-resolution, bir U-Net’i düşük çözünürlüklü girdiye koşullayarak yüksek çözünürlük üretir; keskinlik için piksel MSE değil, özellik uzayında perceptual loss kullanılır.
26.2 1. Super-Resolution Nedir?
Super-resolution, düşük çözünürlüklü (örn. 32×32) bir görüntüyü alıp yüksek çözünürlüklü (örn. 64×64) versiyonunu üretmektir. Eksik detayları “uydurmak” gerekir — bu yüzden bir üretken problemdir. Çıktı düşük çözünürlüklü girdiye koşullanır: model serbestçe üretmez, verilen görüntüyü büyütür.
Buradaki incelik küçültme sırasında bilginin gerçekten kaybolmasıdır. Bir 2× pool, ince dokuları ve kenarları siler; geriye dönüş bilineer interpolasyonla yapılamaz, çünkü interpolasyon var olanı yayar, yeni detay üretmez. Şekil 26.2 bunu gerçek hesaplamayla gösterir: 2× downsample sonrası yüksek-frekans (HF) enerjisi orijinalin yalnızca %6’sına düşer (216→13), bilineer geri büyütmenin görüntüye karşı MSE’si 0’ın üstündedir (bilgi kayıp). Nearest büyütme bloklu, bilineer yumuşak ama detaysız — ikisi de kaybolan dokuyu geri getiremez. Demek ki super-res, modelin öğrendiği görüntü dağılımından makul detay üretmesini ister.
Kod
d = E.superres_downup_demo()
orig, low = d["orig"], d["low"]
up_n, up_b = d["up_nearest"], d["up_bilinear"]
mse = d["mse_bilinear"]
hf_o, hf_b, ratio = d["hf_orig"], d["hf_bilinear"], d["hf_ratio"]
panels = [
(orig, "orijinal (32×32, detaylı)", COL_CYAN_700),
(low, "düşük çözünürlük (16×16, 2× pool)", COL_SLATE_400),
(up_n, "nearest büyütme (bloklu)", COL_ROSE_400),
(up_b, "bilinear büyütme (yumuşak ama detaysız)", COL_ACCENT),
]
fig, axes = plt.subplots(1, 4, figsize=(12, 4))
for ax, (im, title, tc) in zip(axes, panels):
ax.imshow(im, cmap="gray", vmin=0.0, vmax=1.0, interpolation="nearest")
ax.set_title(title, fontsize=10.5, color=tc, weight="bold", pad=8)
ax.set_xticks([]); ax.set_yticks([])
for sp in ax.spines.values():
sp.set_edgecolor(COL_SLATE_300)
# Rozet — gerçek ölçümler
badge = (f"bilinear MSE {mse:.4f} > 0 (bilgi KAYIP)\n"
f"yüksek-frekans enerjisi %{ratio*100:.0f}'ya düştü "
f"({hf_o:.0f}→{hf_b:.0f})")
fig.text(0.5, 1.02, badge, ha="center", va="bottom", fontsize=10.5,
color=COL_TEXT, weight="bold",
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG_ROSE,
ec=COL_ACCENT, lw=1.8))
# Annotate — kavramsal çıkarım
note = ("interpolasyon detay ÜRETMEZ, var olanı yayar; kaybolan detayı geri "
"getirmek = makul detay UYDURMAK = üretken problem; çıktı girdiye KOŞULLANIR")
fig.text(0.5, -0.06, note, ha="center", va="top", fontsize=10,
color=COL_CYAN_800, style="italic", wrap=True)
plt.tight_layout(rect=(0, 0.0, 1, 0.93))
İpucuBuilder Notu — Super-Res Bir Üretken Problemdir
- İçgörü: Küçültme bilgiyi yok eder (HF enerji %6’ya düşer); kaybolanı geri getirmek = makul detayı uydurmak = üretken problem. Basit büyütme (nearest/bilinear) detay üretmez, var olanı yayar.
- İleriye (Ders 25): “Çıktıyı bir girdiye koşullama” fikri, latent diffusion’da metni (text→image) koşullamanın temeli; super-res en sade koşullu üretim örneği.
26.3 2. Tiny ImageNet’e Geçiş
Fashion-MNIST super-res için fazla basit (zaten net). Howard daha zengin, gerçek görüntülere — Tiny ImageNet’e — geçer. Bu, perceptual loss’un farkını gerçekten görebilmek için gerekli: gerçek dokular, kenarlar, detaylar. MNIST’te bir karakterin keskin/bulanık farkı zaten zor görülür; gerçek doku üzerinde perceptual loss’un kazandırdığı keskinlik çıplak gözle ayırt edilebilir.
“we’re going to move on to Tiny Imagenet… I want to show [the difference].” — Howard, 6:06
İpucuBuilder Notu — Gerçek Veri: Foundations + Uygulama Birleşir
- Geriye (Ders 1-8): Gerçek görüntü verisiyle çalışmak Part 1’in DataBlock/DataLoaders altyapısını kullanır; foundations + uygulama birleşir.
- Sezgi: Bir tekniğin değerini görmek için onu zorlayacak veri gerekir. MNIST’in keskin/bulanık farkı görünmez; Tiny ImageNet’in gerçek dokusu perceptual loss’un katkısını gözle ölçülebilir kılar.
26.4 3. Super-Res U-Net (TinyUnet)
Model bir U-Net’tir, sıfırdan kurulur (TinyUnet): bir aşağı yol (down path, ResBlock’larla küçülterek özellik çıkarır) ve bir yukarı yol (up path, büyüterek görüntüyü yeniden kurar). L18’in ResBlock’u temel yapıtaşıdır.
class TinyUnet(nn.Module):
def __init__(self, act=act_gr, nfs=(32,64,128,256,512,1024), norm=nn.BatchNorm2d):
super().__init__()
self.start = ResBlock(3, nfs[0], stride=1, act=act, norm=norm)
self.dn = nn.ModuleList([ResBlock(nfs[i], nfs[i+1], act=act, norm=norm, stride=2)
for i in range(len(nfs)-1)])
self.up = nn.ModuleList([up_block(nfs[i], nfs[i-1]) for i in range(len(nfs)-1, 0, -1)])Şekil 26.3 mimariyi şematik gösterir: solda DOWN PATH (stride-2 ResBlock’larla 3→32→64→128→256→512→1024, uzamsal olarak küçülerek özellik çıkarır), sağda UP PATH (up_block’larla 1024→512→…→3, büyüterek yüksek çözünürlüğü yeniden kurar), ortada çapraz bağlantılar (cross connection). U-Net = encoder-decoder + skip; down özellik çıkarır, up yeniden kurar, skip inceliği korur.
Kod
fig, ax = plt.subplots(figsize=(11.5, 6.0))
ax.set_xlim(0, 11.5)
ax.set_ylim(0, 6.0)
ax.axis("off")
# Sütun başlıkları
ax.text(2.6, 5.72, "DOWN PATH", ha="center", va="center", fontsize=12.5,
weight="bold", color=COL_CYAN_800)
ax.text(8.9, 5.72, "UP PATH", ha="center", va="center", fontsize=12.5,
weight="bold", color=COL_CYAN_800)
ax.text(5.75, 5.72, "cross\nconnection", ha="center", va="center",
fontsize=9.5, weight="bold", color=COL_ACCENT)
# ----------------------------------------------------------------------------
# SOL — down path (yukarıdan aşağıya küçülen seviyeler; nfs=32→1024)
# ----------------------------------------------------------------------------
down_levels = [
(5.05, "ResBlock 3→32\n(stride 1)"),
(4.10, "ResBlock 32→64\n(stride 2)"),
(3.15, "ResBlock 64→128\n(stride 2)"),
(2.20, "ResBlock 128→256\n(stride 2)"),
(1.25, "…→512→1024\n(en küçük çözünürlük)"),
]
down_w = [3.0, 2.7, 2.4, 2.1, 1.9] # her seviye daralır (uzamsal küçülme)
for (y, txt), w in zip(down_levels, down_w):
boxed_node(ax, 2.6, y, w, 0.74, txt, fc=COL_BG, ec=COL_PRIMARY,
fontsize=8.8)
# down path okları (aşağı doğru)
for y_top in (5.05, 4.10, 3.15, 2.20):
arrow_between(ax, (2.6, y_top - 0.40), (2.6, y_top - 0.93),
color=COL_PRIMARY, shrink=2)
# ----------------------------------------------------------------------------
# SAĞ — up path (aşağıdan yukarıya büyüyen seviyeler; geri kurma)
# ----------------------------------------------------------------------------
up_levels = [
(1.25, "up_block 1024→512\n(yeniden büyüt)"),
(2.20, "up_block 512→256"),
(3.15, "up_block 256→128"),
(4.10, "up_block 128→64"),
(5.05, "çıktı 64→3\n(yüksek çözünürlük)"),
]
up_w = [1.9, 2.1, 2.4, 2.7, 3.0] # yukarı çıktıkça genişler (geri büyüme)
for (y, txt), w in zip(up_levels, up_w):
fc = COL_CYAN_50 if y == 5.05 else COL_BG
ec = COL_CYAN_700 if y == 5.05 else COL_PRIMARY
boxed_node(ax, 8.9, y, w, 0.74, txt, fc=fc, ec=ec, fontsize=8.8)
# up path okları (yukarı doğru)
for y_bot in (1.25, 2.20, 3.15, 4.10):
arrow_between(ax, (8.9, y_bot + 0.40), (8.9, y_bot + 0.93),
color=COL_PRIMARY, shrink=2)
# ----------------------------------------------------------------------------
# ORTA — cross connections (her seviyeden karşısına yatay kesikli rose ok)
# detay down'dan up'a DOĞRUDAN taşınır
# ----------------------------------------------------------------------------
cross_ys = [5.05, 4.10, 3.15, 2.20, 1.25]
cross_x0 = [2.6 + w / 2 + 0.05 for w in down_w]
cross_x1 = [8.9 - w / 2 - 0.05 for w in up_w]
for y, x0, x1 in zip(cross_ys, cross_x0, cross_x1):
ax.annotate("", xy=(x1, y), xytext=(x0, y),
arrowprops=dict(arrowstyle="-|>", color=COL_ACCENT,
lw=1.8, linestyle=(0, (5, 3)),
mutation_scale=14, shrinkA=2, shrinkB=2),
zorder=1)
ax.text(5.75, 1.25 + 0.46, "detay → doğrudan", ha="center", va="bottom",
fontsize=8.0, style="italic", color=COL_ACCENT)
# Alt not — cross connection = U-Net'in özü
ax.text(5.75, 0.42,
"cross connection = Ders 18 skip'in U-Net hâli; down özellik çıkarır, "
"up yeniden kurar, skip inceliği korur",
ha="center", va="center", fontsize=9.2, weight="bold", color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.45", fc=COL_BG_ROSE, ec=COL_ACCENT,
lw=1.4))
plt.tight_layout()
plt.show()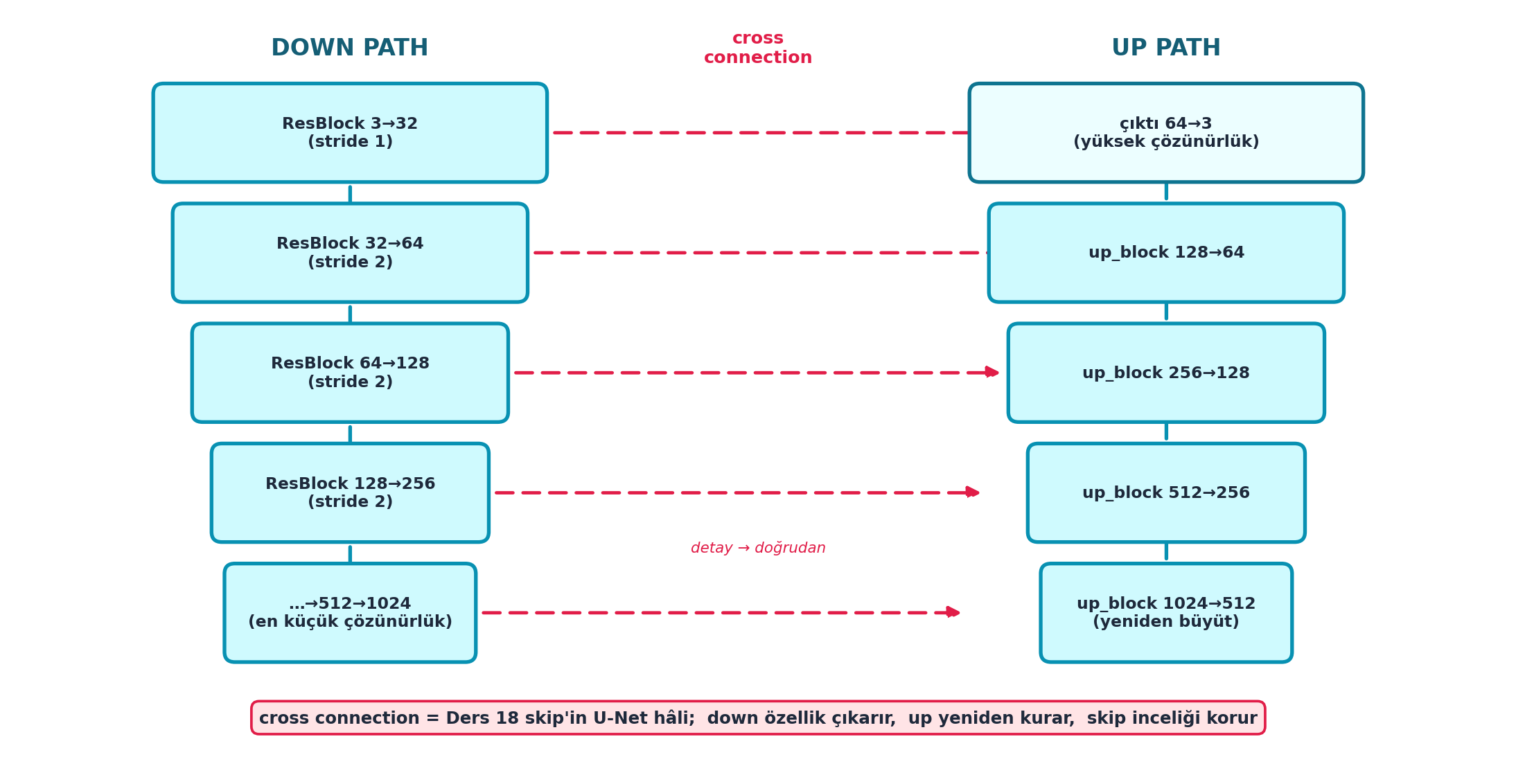
İpucuBuilder Notu — TinyUnet = Ders 18 ResBlock + Ders 19 U-Net
- Geriye (Ders 18): Aşağı yol = stride-2 ResBlock’lar (L18); yukarı yol bunları tersine çevirir. U-Net = encoder-decoder + skip.
- Geriye (Ders 19): Diffusion U-Net’inin yapısı burada yeniden kullanılır; aynı encoder-decoder iskeleti, yeni görev (super-res).
26.5 4. Cross Connections (U-Net Skip)
U-Net’in gücü cross connection’lardadır: aşağı yoldaki her seviyenin çıktısı, yukarı yolda aynı seviyeye eklenir (skip). Böylece ince detaylar (down path’te kaybolan) up path’e doğrudan taşınır. Bu, L18’in skip connection’ının U-Net mimarisindeki hâlidir.
Sezgi şu: down path görüntüyü sıkıştırırken yüksek-frekans detayları (kenarlar, dokular) eritir; up path bunları sıfırdan yeniden üretmek zorunda kalsa zorlanırdı. Cross connection, down path’in henüz erimemiş erken-seviye özelliklerini up path’in karşılık gelen seviyesine doğrudan köprüler — detay yeniden icat edilmek yerine taşınır.
İpucuBuilder Notu — Cross Connection = Skip’in U-Net Hâli
- Geriye (Ders 18): Cross connection = skip connection
out = F(x) + x’in U-Net versiyonu; gradyan ve detay akışını korur. - Sezgi: Down path’te kaybolan ince detay, cross connection’la up path’e doğrudan taşınır — model onu yeniden üretmek zorunda kalmaz; bu, super-res kalitesinin temel taşı.
26.6 5. Pixel Loss’un Yetersizliği
İlk deneme: çıktı ile hedef arasında piksel MSE. Sorun: bir düşük çözünürlüklü girdiye karşılık birçok geçerli yüksek çözünürlüklü çıktı vardır; MSE bunların ortalamasını alır — sonuç bulanık, keskinlikten yoksun. Piksel benzerliği “iyi görüntü” demek değildir.
Şekil 26.4 bu FLAGSHIP içgörüyü gerçek hesaplamayla kanıtlar. Aynı düşük çözünürlüklü girdiye karşılık 50 geçerli keskin çıktı kurulur (kenar konumu örnekler arası kayar). MSE-optimal tahmin matematiksel olarak bu 50 çıktının ortalamasıdır — çünkü ortalama, tüm olasılıklara olan kare hatayı en aza indirir. Sonuç: tek bir keskin örneğin dik kenar basamağı, ortalamada yayvan bir rampaya dönüşür. Keskinlik ölçüsü max|∇x| 1.000’den 0.340’a düşer — yani 2.9× kayıp. Matematiksel olarak optimal olan çözüm, görsel olarak yanlıştır: keskin desenler birbirini siler, bulanıklık kalır.
Kod
d = E.pixel_blur_demo()
s0 = d["samples"][0]
s1 = d["samples"][1]
avg = d["mse_optimal"]
prof_single = d["edge_profiles"]["single"]
prof_avg = d["edge_profiles"]["avg"]
sh_single = d["sharpness_single"]
sh_avg = d["sharpness_avg"]
n = avg.shape[0]
fig = plt.figure(figsize=(12, 6.5))
gs = fig.add_gridspec(2, 3, height_ratios=[1.0, 0.85], hspace=0.42, wspace=0.22)
# --- Üst satır: üç görüntü (gri colormap) ---
imgs = [
(s0, "geçerli keskin çıktı #1", COL_PRIMARY),
(s1, "geçerli keskin çıktı #2", COL_PRIMARY),
(avg, "MSE-optimal tahmin = 50 çıktının ORTALAMASI", COL_ACCENT),
]
for j, (im, title, edge) in enumerate(imgs):
ax = fig.add_subplot(gs[0, j])
ax.imshow(im, cmap="gray", vmin=0.0, vmax=1.0, interpolation="nearest")
ax.set_title(title, color=edge, fontsize=10.5, weight="bold", pad=6)
ax.set_xticks([]); ax.set_yticks([])
for sp in ax.spines.values():
sp.set_edgecolor(edge); sp.set_linewidth(2.2)
# --- Alt panel: kenar profilleri (tek keskin örnek vs ortalama) ---
axp = fig.add_subplot(gs[1, :])
cols = np.arange(n)
axp.step(cols, prof_single, where="mid", color=COL_PRIMARY, linewidth=2.6,
label="tek keskin örnek (dik basamak)")
axp.plot(cols, prof_avg, color=COL_ACCENT, linewidth=2.8,
label="50 çıktının ortalaması (yayvan rampa)")
axp.fill_between(cols, prof_avg, step=None, color=COL_BG_ROSE, alpha=0.55, zorder=0)
axp.set_xlim(0, n - 1)
axp.set_ylim(-0.08, 1.15)
axp.set_xlabel("piksel sütunu (kenar profili — satır n/2)")
axp.set_ylabel("yoğunluk")
viz.apply_style(axp)
axp.legend(loc="upper left", fontsize=9.5, framealpha=0.92)
# Keskinlik rozeti
axp.text(0.985, 0.90,
"max|∇x|: 1.000 → 0.340\n(2.9× kayıp)",
transform=axp.transAxes, ha="right", va="top",
fontsize=10.5, weight="bold", color=COL_CYAN_800,
bbox=dict(boxstyle="round,pad=0.45", fc=COL_CYAN_50,
ec=COL_ACCENT, linewidth=1.8))
# Açıklama anotasyonu
axp.text(0.5, -0.42,
"Tek düşük-çöz girdiye karşılık BİRÇOK geçerli keskin çıktı var (kenar konumu belirsiz);\n"
"MSE hepsinin ortalamasını ödüllendirir — keskin desenler birbirini siler = bulanıklık.\n"
"Matematiksel olarak optimal, görsel olarak yanlış.",
transform=axp.transAxes, ha="center", va="top",
fontsize=10, color=COL_TEXT)
plt.tight_layout()
plt.show()
İpucuBuilder Notu — Pixel MSE Ortalamayı Ödüllendirir
- İçgörü: Tek girdiye karşılık çok geçerli keskin çıktı var; MSE hepsinin ortalamasını ödüllendirir (kare hatayı minimize eder) — keskin desenler birbirini siler, keskinlik 1.000→0.340 (2.9× kayıp).
- Geriye (Ders 21): Ders 21’de öğrendik — piksel karşılaştırması anlamsal kaliteyi yakalamaz; aynı sorun super-res’te bulanıklık olarak çıkar.
26.7 6. Perceptual (Feature) Loss
Çözüm perceptual loss: çıktıyı ve hedefi önceden eğitilmiş bir ağdan (içerik modeli) geçir, özellik uzayında karşılaştır. Özellikler dokuyu ve yapıyı kodlar; bu uzayda yakınlık, keskin ve gerçekçi çıktı demektir. Bu, Ders 20’deki style transfer’ın content loss’unun birebir aynısıdır.
Şekil 26.5 ilkeyi gerçek hesaplamayla gösterir (özellik burada elle tanımlı — kenar enerjisi Σ|∇|² — ama ilke gerçek perceptual loss’la aynı). Üç görüntü: hedef (keskin, dokulu), aday A (1px kaymış keskin kopya — görsel olarak doğru), aday B (bulanık — yapı yerinde, doku ölü). Piksel MSE A’yı 0.0308, B’yi 0.0179 ölçer; yani MSE bulanık B’yi seçer (YANLIŞ) — çünkü 1px kayma her piksele büyük hata yazar, bulanıklık ise hatayı yumuşatır. Kenar-enerji özelliği ise tersini yapar: hedefe özellik farkı A için 0.40, B için 60.92 — özellik uzayı keskin A’yı seçer (DOĞRU). İşte perceptual loss’un özü: karşılaştırmayı piksel piksel değil, özellik uzayında yap.
“we want to use perceptual loss.” — Howard, 1:15:00
Kod
d = E.perceptual_vs_pixel_demo()
target = d["target"]
cand_sharp = d["cand_sharp"]
cand_blur = d["cand_blur"]
fig = plt.figure(figsize=(12, 6.5))
gs = fig.add_gridspec(2, 3, height_ratios=[1.15, 0.85], hspace=0.42, wspace=0.28)
# --- ÜST: üç görüntü (hedef / kaymış-keskin / bulanık) -----------------------
imgs = [
(target, "hedef (keskin, dokulu)", COL_CYAN_700),
(cand_sharp, "aday A: 1px kaymış KESKİN kopya\n(görsel doğru)", COL_ROSE_500),
(cand_blur, "aday B: bulanık\n(yapı yerinde, doku ölü)", COL_CYAN_700),
]
for i, (img, title, tc) in enumerate(imgs):
ax = fig.add_subplot(gs[0, i])
ax.imshow(img, cmap="gray", vmin=0.0, vmax=1.0, interpolation="nearest")
ax.set_title(title, color=tc, fontsize=10.5, weight="bold", pad=6)
ax.set_xticks([]); ax.set_yticks([])
for s in ax.spines.values():
s.set_color(COL_SLATE_400); s.set_linewidth(1.2)
# --- ALT SOL: pixel-MSE → bulanığı seçer (YANLIŞ), rose çerçeve ---------------
axL = fig.add_subplot(gs[1, 0:1])
axL.set_xlim(0, 1); axL.set_ylim(0, 1); axL.axis("off")
axL.add_patch(plt.Rectangle((0.02, 0.03), 0.96, 0.94, transform=axL.transAxes,
fill=True, fc=COL_BG_ROSE, ec=COL_ACCENT, lw=2.4,
zorder=0))
axL.text(0.5, 0.86, "pixel-MSE (piksel-piksel kare hata)", ha="center",
va="center", color=COL_ACCENT, fontsize=11, weight="bold")
axL.text(0.5, 0.62, f"A (kaymış-keskin) = {d['mse_sharp']:.4f}", ha="center",
va="center", color=COL_TEXT, fontsize=10.5)
axL.text(0.5, 0.46, f"B (bulanık) = {d['mse_blur']:.4f}", ha="center",
va="center", color=COL_TEXT, fontsize=10.5)
axL.text(0.5, 0.24,
f"A={d['mse_sharp']:.4f} > B={d['mse_blur']:.4f}\n→ MSE BULANIĞI seçer (YANLIŞ)",
ha="center", va="center", color=COL_ACCENT, fontsize=10.5, weight="bold")
# --- ALT ORTA+SAĞ: kenar-enerji özelliği → keskini seçer (DOĞRU), cyan çerçeve -
axR = fig.add_subplot(gs[1, 1:3])
axR.set_xlim(0, 1); axR.set_ylim(0, 1); axR.axis("off")
axR.add_patch(plt.Rectangle((0.015, 0.03), 0.97, 0.94, transform=axR.transAxes,
fill=True, fc=COL_CYAN_50, ec=COL_PRIMARY, lw=2.4,
zorder=0))
axR.text(0.5, 0.88, "kenar-enerji özelliği: Σ|∇|² (doku/keskinlik istatistiği)",
ha="center", va="center", color=COL_CYAN_700, fontsize=11, weight="bold")
axR.text(0.30, 0.66, f"enerji(hedef) = {d['feat_target']:.1f}", ha="center",
va="center", color=COL_TEXT, fontsize=10)
axR.text(0.30, 0.52, f"enerji(A keskin) = {d['feat_sharp']:.1f}", ha="center",
va="center", color=COL_TEXT, fontsize=10)
axR.text(0.30, 0.38, f"enerji(B bulanık) = {d['feat_blur']:.1f}", ha="center",
va="center", color=COL_TEXT, fontsize=10)
axR.text(0.74, 0.60, f"|fark| A = {d['featdiff_sharp']:.2f}", ha="center",
va="center", color=COL_CYAN_800, fontsize=10.5, weight="bold")
axR.text(0.74, 0.44, f"|fark| B = {d['featdiff_blur']:.2f}", ha="center",
va="center", color=COL_CYAN_800, fontsize=10.5, weight="bold")
axR.text(0.5, 0.18,
f"|fark| A={d['featdiff_sharp']:.2f} ≪ B={d['featdiff_blur']:.2f}"
" → özellik KESKİNİ seçer (DOĞRU)",
ha="center", va="center", color=COL_PRIMARY, fontsize=10.5, weight="bold")
# --- DÜRÜSTLÜK notu (figür altı) ---------------------------------------------
fig.text(0.5, -0.01,
"Özellik burada ELLE tanımlı (kenar enerjisi Σ|∇|²); gerçek perceptual loss "
"öğrenilmiş ağ (cmodel) özellikleri kullanır —\nİLKE aynı: karşılaştırmayı "
"özellik uzayında yap (= Ders 20 content loss, Ders 21 FID).",
ha="center", va="top", color=COL_SLATE_400, fontsize=8.8, style="italic")
plt.tight_layout()
plt.show()
İpucuBuilder Notu — Perceptual Loss = Ders 20 Content Loss (KÖPRÜ)
- Geriye (Ders 20) — merkezî köprü: Style transfer’da içeriği özellik uzayında ölçmüştük; super-res’te keskinliği aynı şekilde ölçüyoruz. Perceptual loss = özellik uzayında MSE — birebir aynı teknik.
- Sezgi: Pixel MSE 1px kaymış keskini cezalandırıp bulanığı seçer (0.0308 > 0.0179); özellik uzayı doğru sıralar (0.40 ≪ 60.92). “İyi görüntü” tanımı piksellerde değil, özelliklerde yapılır.
- Dürüstlük notu: Figürdeki özellik elle (kenar enerjisi); gerçek perceptual loss öğrenilmiş ağ (cmodel) özelliklerini kullanır — ilke aynı.
26.8 7. cmodel: Özellik Modeli
Perceptual loss için bir özellik modeli (cmodel) gerekir — burada Tiny ImageNet’te özel eğitilmiş bir sınıflandırıcı. Çıktı ve hedef bu modelden geçirilip ara özellikleri karşılaştırılır. (Style transfer’da VGG16 kullanmıştık; burada veriye uygun özel bir model.)
cmodel = torch.load('models/inettiny-custom-25').cuda()
UyarıGüvenlik Builder Notu — torch.load (2022 kodu)
- Yukarıdaki çağrı Howard’ın 2022 hâli;
torch.loadweights_onlybelirtmez. Eski PyTorch varsayılanındatorch.loadmodeli unpickle eder — bu, dosyanın içine gömülmüş keyfi kodu çalıştırabilir (güvenilmeyen checkpoint = uzaktan kod yürütme riski). - Modern PyTorch (2.6+) artık
weights_only=True’yı varsayılan yapar; yalnızca tensör ağırlıklarını yükler, keyfi kodu çalıştırmaz. Eski sürümde bunu elle ver:torch.load(path, weights_only=True)(tam model nesnesi değil,state_dictyüklenir). - Pratik: Güvenilmeyen kaynaktan gelen
.pt/.pthdosyalarını aslaweights_only=Falseile açma; mümkünsestate_dict+ bilinen mimari kullan. (Bu not zenginleştirme katmanıdır; üstteki Notion kodu 2022 orijinali olarak korunmuştur.)
İpucuBuilder Notu — cmodel: Veriye Uygun Özellik Modeli
- Geriye (Ders 20): Style transfer VGG16 kullandı; super-res kendi veri kümesinde eğitilmiş bir model kullanır — özellikler göreve daha uygun.
- Sezgi: Özellikleri çıkaran ağ ne kadar veriye uygunsa, “iyi görüntü” tanımı o kadar isabetli olur; genel VGG yerine Tiny ImageNet sınıflandırıcısı bu görevin dokusunu daha iyi tanır.
26.9 8. comb_loss: Pixel + Feature
Pratik çözüm ikisini birleştirir: piksel MSE (genel yapı doğru olsun) + perceptual loss (keskin/gerçekçi detay). comb_loss çıktının ve hedefin özelliklerini karşılaştırır, piksel MSE ile toplar (ağırlıklı).
def comb_loss(inp, tgt):
with torch.no_grad(): tgt_feat = cmodel(tgt).float()
inp_feat = cmodel(inp).float()
feat_loss = F.mse_loss(inp_feat, tgt_feat)
return F.mse_loss(inp, tgt) + feat_loss/10Şekil 26.6 bu birleşimi şematik gösterir: U-Net çıktısı (inp) ve hedef (tgt) iki yola girer — doğrudan piksel MSE (genel yapı doğru olsun) ve cmodel ara özellikleri üzerinden perceptual MSE (doku/keskinlik). İkisi comb_loss = pixel + feat/10 olarak birleşir. Hedef özellikleri no_grad altında (sabit), /10 denge ağırlığıdır — Ders 20’nin content+style birleşimi gibi. Mesaj: loss tasarımı sonucu belirler.
Kod
fig, ax = plt.subplots(figsize=(11.5, 5.2))
ax.set_xlim(0, 11.5)
ax.set_ylim(0, 5.2)
ax.axis("off")
# --- Girdiler (sol) ---
boxed_node(ax, 1.45, 4.05, 2.5, 0.95,
"U-Net çıktısı\n(inp)",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_CYAN_800, fontsize=10.5)
boxed_node(ax, 1.45, 1.15, 2.5, 0.95,
"hedef\n(tgt)",
fc=COL_BG_ROSE, ec=COL_ROSE_500, tc=COL_TEXT, fontsize=10.5)
# --- Yol 1: doğrudan piksel MSE (cyan) ---
boxed_node(ax, 5.55, 2.95, 3.4, 1.05,
"F.mse_loss(inp, tgt)\npiksel: genel yapı doğru",
fc=COL_CYAN_50, ec=COL_PRIMARY, tc=COL_CYAN_800, fontsize=10)
arrow_between(ax, (2.7, 3.95), (3.85, 3.20), color=COL_PRIMARY, lw=2.2,
connectionstyle="arc3,rad=-0.12")
arrow_between(ax, (2.7, 1.25), (3.85, 2.70), color=COL_PRIMARY, lw=2.2,
connectionstyle="arc3,rad=0.12")
# --- Yol 2: cmodel özellikleri → perceptual MSE (rose) ---
boxed_node(ax, 5.55, 0.70, 4.1, 1.0,
"cmodel: Tiny ImageNet sınıflandırıcı (donuk)\n→ ara özellikler",
fc=COL_SLATE_300, ec=COL_SLATE_400, tc=COL_TEXT, fontsize=9.3,
lw=1.8)
arrow_between(ax, (2.7, 3.85), (3.55, 1.05), color=COL_ROSE_500, lw=2.2,
connectionstyle="arc3,rad=-0.05")
arrow_between(ax, (2.7, 1.05), (3.5, 0.78), color=COL_ROSE_500, lw=2.2,
connectionstyle="arc3,rad=0.0")
boxed_node(ax, 9.55, 0.70, 3.3, 1.0,
"F.mse_loss(feat)\nperceptual: doku/keskinlik",
fc=COL_BG_ROSE, ec=COL_ROSE_500, tc=COL_TEXT, fontsize=10)
arrow_between(ax, (7.6, 0.70), (7.9, 0.70), color=COL_ROSE_500, lw=2.2)
# --- Toplam (sağ üst) ---
boxed_node(ax, 9.55, 3.55, 3.3, 1.1,
"comb_loss\n= pixel + feat/10",
fc=COL_BG, ec=COL_CYAN_700, tc=COL_CYAN_800, fontsize=11.5,
lw=2.6)
arrow_between(ax, (7.25, 2.95), (8.45, 3.40), color=COL_PRIMARY, lw=2.2,
connectionstyle="arc3,rad=0.10")
arrow_between(ax, (10.05, 1.20), (9.95, 3.00), color=COL_ROSE_500, lw=2.2,
connectionstyle="arc3,rad=-0.18")
# --- Not (alt) ---
ax.text(5.75, 4.78,
"LOSS TASARIMI sonucu belirler: neyi optimize ettiğin, "
"nasıl optimize ettiğinden kritik",
ha="center", va="center", fontsize=10.5, color=COL_CYAN_800,
weight="bold")
ax.text(5.75, 2.12,
"tgt özellikleri no_grad (hedef sabit) • /10 = denge ağırlığı "
"• Ders 20 content+style birleşimi gibi",
ha="center", va="center", fontsize=8.8, color=COL_TEXT, style="italic")
plt.tight_layout()
plt.show()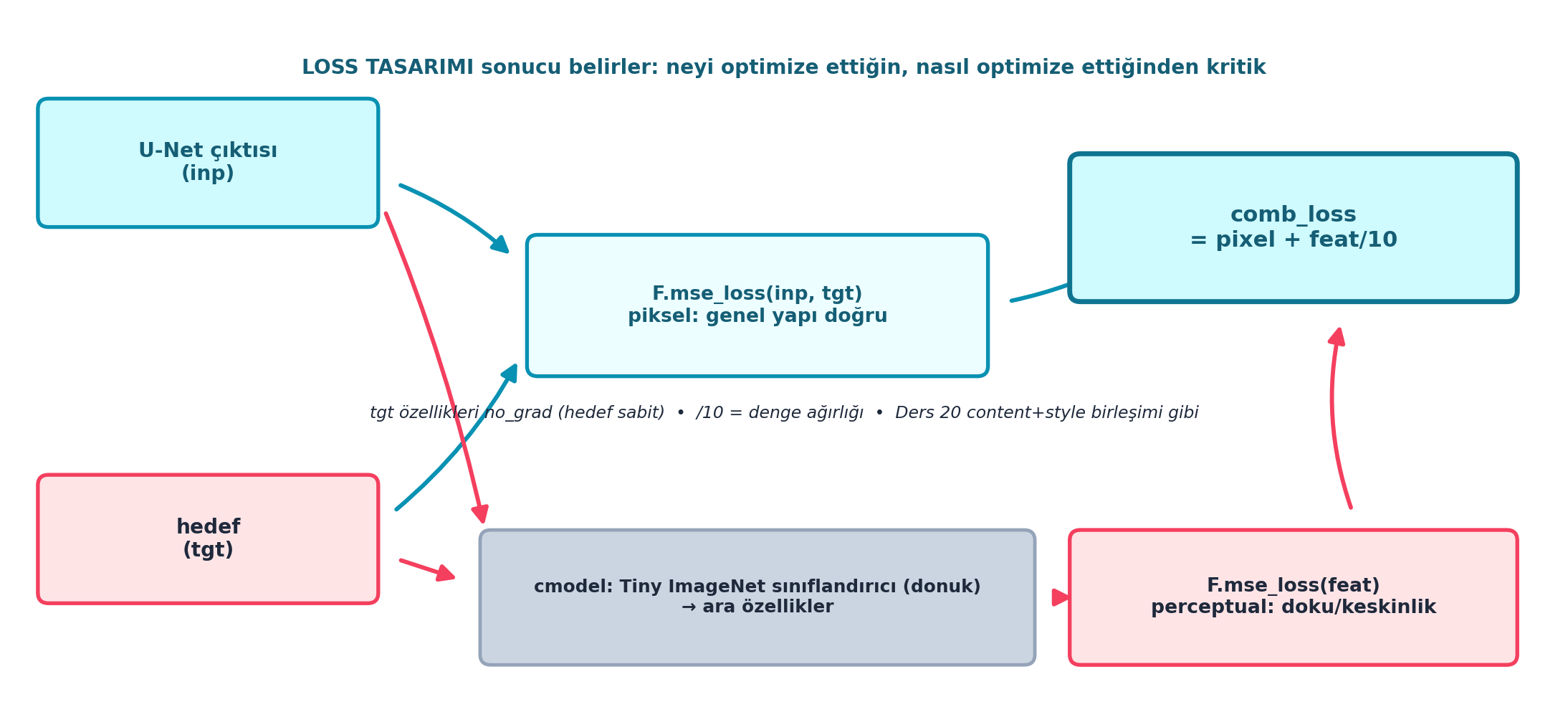
İpucuBuilder Notu — comb_loss: İki Loss’un Dengesi
- Geriye (Ders 20): İçerik + stil kaybını birleştirmek gibi; burada piksel + özellik kaybı. “Loss tasarımı” sonucu belirler.
- Sezgi: Piksel MSE genel yapıyı (renk, konum) doğru tutar, perceptual loss detayı keskinleştirir;
/10ağırlığı ikisini dengeler — yalnız perceptual artefakt üretebilir, yalnız piksel bulanıklaştırır.
26.10 9. Eğitim ve Keskinlik
comb_loss ile eğitilen super-res U-Net, saf piksel MSE’ye göre belirgin daha keskin çıktı verir. Perceptual loss, modelin “doğru piksel değeri” yerine “doğru görünen doku” üretmesini teşvik eder. Sonuç: gerçekçi, keskin yüksek çözünürlük. §5’teki bulanıklık (keskinlik 1.000→0.340) ile §6’daki doğru sıralama (özellik 0.40 ≪ 60.92) birleştiğinde, comb_loss’un neden işe yaradığı netleşir: piksel terimi yapıyı, özellik terimi keskinliği tutar.
“we’re doing all this from scratch.” — Howard, 45:09
İpucuBuilder Notu — Keskinlik: Perceptual Loss’un Meyvesi
- İçgörü: comb_loss modeli “doğru görünen doku” üretmeye iter; saf piksel MSE’nin bulanıklığını aşar.
- İleriye: Aynı perceptual loss fikri, GAN’lar ve modern super-res/restorasyon modellerinde standarttır.
26.11 10. Super-Resolution = Koşullu Üretim
Daha derin bir bakış: super-res, çıktıyı bir girdiye (düşük çözünürlüklü görüntü) koşullayan bir üretken modeldir. Model serbestçe değil, verilen koşula göre üretir. Bu, koşullu üretimin (conditional generation) en sade örneğidir ve sonraki derslerin (text→image) temelidir.
Şekil 26.7 koşullamanın üç-aşamalı ilerlemesini şematik gösterir: SUPER-RES (L23, koşul = düşük-çöz görüntü → U-Net → yüksek-çöz, en sade koşullama) → ATTENTION (L24, konumlar arası ilişki + dış bilgiyle etkileşim, cross-attention) → TEXT→IMAGE (L25, koşul = metin/CLIP gömüsü → cross-attention → Stable Diffusion). Üstte vurgu: koşullama, üretken modeli kontrol edilebilir kılar (serbest üretimden işe yarar üretime). Altta: diffusion da koşullanabilir — L19 DDPM + koşul = SD upscaler / inpainting.
Kod
fig, ax = plt.subplots(figsize=(12, 5))
ax.set_xlim(0, 12)
ax.set_ylim(0, 5)
ax.axis("off")
# Üstte vurgu başlığı
ax.text(6, 4.72,
"koşullama = üretken modeli KONTROL EDİLEBİLİR kılar "
"(serbest üretimden → işe yarar üretime)",
ha="center", va="center", fontsize=11.5, weight="bold",
color=COL_CYAN_800)
# 3 aşama kutusu (soldan sağa)
w, h, ymid = 3.4, 2.3, 2.5
xs = [2.0, 6.0, 10.0]
boxed_node(ax, xs[0], ymid, w, h,
"SUPER-RES (L23)\n\nkoşul = düşük-çöz GÖRÜNTÜ\n→ U-Net →\nyüksek-çöz çıktı\n\n(en sade koşullama)",
fc=COL_BG, ec=COL_PRIMARY, tc=COL_TEXT, fontsize=9.5)
boxed_node(ax, xs[1], ymid, w, h,
"ATTENTION (L24)\n\nkonumlar arası ilişki\n+ dış bilgiyle etkileşim\n(cross-attention\nmekanizması)",
fc=COL_CYAN_50, ec=COL_CYAN_700, tc=COL_TEXT, fontsize=9.5)
boxed_node(ax, xs[2], ymid, w, h,
"TEXT→IMAGE (L25)\n\nkoşul = METİN\n(CLIP gömüsü)\n→ cross-attention →\nStable Diffusion",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT, fontsize=9.5)
# Aşamalar arası oklar
arrow_between(ax, (xs[0] + w / 2, ymid), (xs[1] - w / 2, ymid),
color=COL_CYAN_700, lw=2.4, mutation_scale=22, shrink=6)
arrow_between(ax, (xs[1] + w / 2, ymid), (xs[2] - w / 2, ymid),
color=COL_ROSE_500, lw=2.4, mutation_scale=22, shrink=6)
# Alt not
ax.text(6, 0.55,
"diffusion da koşullanabilir: L19 DDPM + koşul = SD upscaler / inpainting",
ha="center", va="center", fontsize=10, style="italic",
color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.4", fc=COL_WHITE,
ec=COL_SLATE_400, lw=1.2))
plt.tight_layout()
plt.show()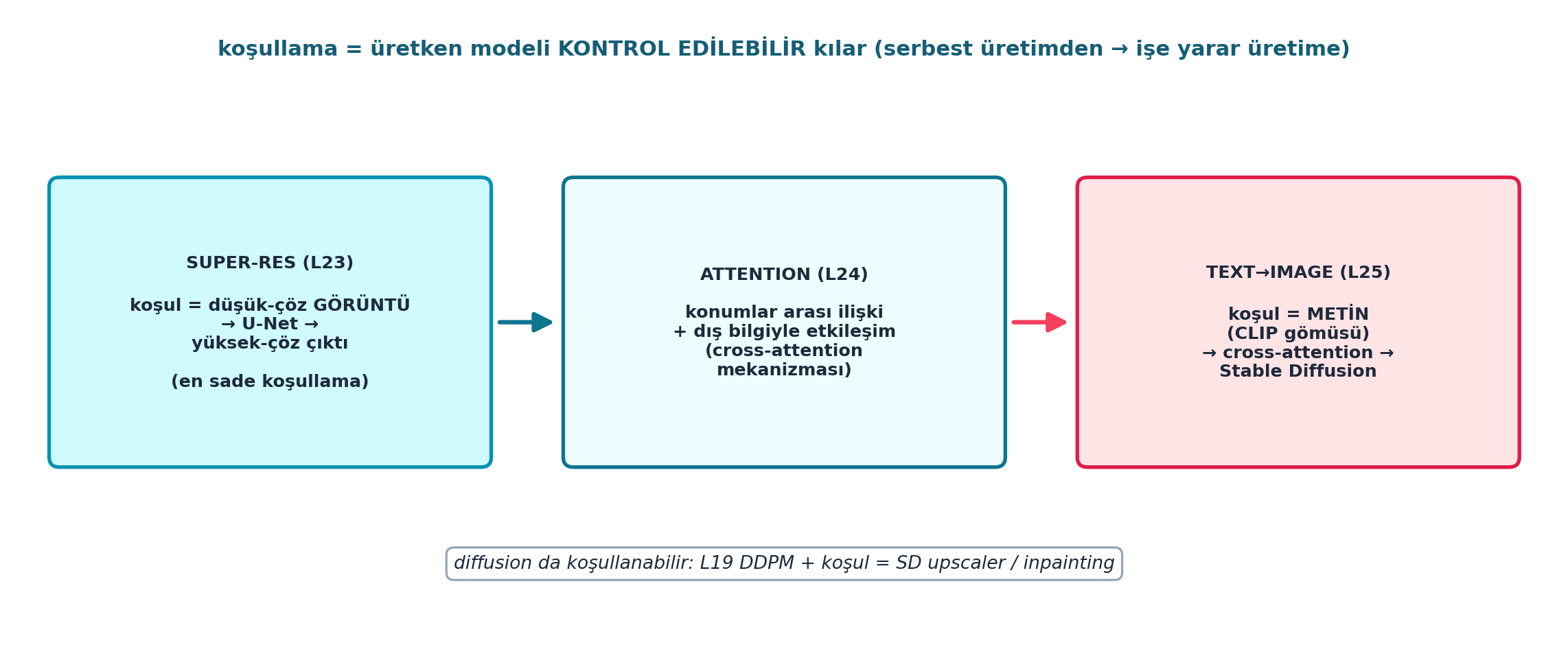
İpucuBuilder Notu — Koşullama: Kontrol Edilebilir Üretim
- İleriye (Ders 24-25): Koşullama mekanizması — bir girdiyi U-Net’e besleyip çıktıyı yönlendirmek — attention (L24) ve text conditioning (L25) ile genişler.
- Sezgi: Koşullama, üretken modeli “kontrol edilebilir” kılan mekanizmadır; serbest üretimden (DDPM koşulsuz örnekleme) işe yarar üretime (super-res, text→image) geçiş.
26.12 11. Diffusion’a Köprü: Koşullu Diffusion Super-Res
Super-res aynı zamanda bir diffusion problemi olarak da kurulabilir: düşük çözünürlüklü görüntüye koşullanmış bir diffusion modeli, gürültüden yüksek çözünürlük üretir. Bu, DDPM’i (L19) koşullu hâle getirmenin doğal yoludur ve modern super-res diffusion’ın (örn. SD upscaler) temelidir.
İpucuBuilder Notu — Koşullu DDPM: Super-Res, Inpainting, Text→Image
- Geriye (Ders 19-22): DDPM/Karras altyapısı koşullu hâle gelince super-res, inpainting, text→image hepsi mümkün; super-res en sade koşullama.
- Sezgi: L19’da kurduğumuz koşulsuz DDPM’e bir koşul (düşük-çöz görüntü) eklemek yeterli; aynı örnekleme döngüsü, koşula göre yönlendirilmiş üretim verir.
26.13 12. Builder İçgörüsü: Loss Tasarımı
Bu dersin builder dersi: doğru loss, doğru sonucu belirler. Piksel MSE “matematiksel olarak doğru” ama görsel olarak yanlış (bulanık) çıktı verir; perceptual loss insanın algıladığı kaliteyi hedefler. Üretken modellemede “neyi optimize ettiğin” (loss), “nasıl optimize ettiğinden” (mimari) çoğu zaman daha kritiktir.
Bu içgörü dersin merkezidir: aynı TinyUnet mimarisi, loss’a göre tamamen farklı çıktı verir — piksel MSE ile bulanık (keskinlik 1.000→0.340), comb_loss ile keskin. Mimari sabit, sonucu değiştiren loss tasarımı. Perceptual loss’un Ders 20 content loss’uyla birebir aynı olması da bunu pekiştirir: “neyi optimize edeceğin” sorusunun cevabı, görevden göreve taşınabilen güçlü bir araçtır.
İpucuBuilder Notu — Loss = Test Yazılabilir Hedef Tanımı
- Geriye (CLAUDE.md): “Test yazılabilir bir hedef tanımı” — loss tam olarak budur; hedefi yanlış tanımlarsan (piksel MSE) model yanlış şeyi optimize eder.
- Merkezî ders: “Doğru loss doğru sonucu belirler” — perceptual loss = Ders 20 content loss BİREBİR; «neyi optimize ettiğin» mimariden kritik. Aynı model + farklı loss = farklı sonuç (bulanık vs keskin).
26.14 13. miniai Köprüsü
Super-res yine miniai üstünde: TinyUnet bir nn.Module, comb_loss özel bir kayıp, eğitim standart Learner + callback’lerle. Foundations’ın esnek altyapısı, yeni bir problemi (super-res) minimum kodla çözüyor.
İpucuBuilder Notu — miniai: Yeni Problem, Aynı Altyapı
- Geriye (Ders 16): Yeni problem = yeni model + yeni loss; eğitim altyapısı (Learner, callback, Adam, OneCycle) değişmeden kalır.
- Sezgi: ETAP 4-5’te kurduğumuz Learner çerçevesi super-res’te de aynen çalışır — yalnız model (TinyUnet) ve loss (comb_loss) değişir; altyapının yeniden kullanılabilirliği foundations’ın amacıdır.
26.15 14. NYU/Foundations Köprüsü
Perceptual loss’un özü, önceden eğitilmiş bir ağın temsillerini (representations) kullanmaktır — NYU Deep Learning’in (LeCun) merkezî teması. Bir ağın öğrendiği özellikler o kadar zengindir ki, “iyi görüntü” tanımı bile o uzayda yapılabilir. Bu, transfer learning ve temsil öğrenmenin yaratıcı bir uygulamasıdır.
İpucuBuilder Notu — Temsil Öğrenme: Özellik Uzayının Gücü
- Geriye (NYU + Ders 20-21): Özellik uzayı (perceptual loss, FID, style transfer) tüm bu derslerin ortak aracı — temsil öğrenmenin gücü.
- Sezgi: Bir ağın öğrendiği temsiller o kadar zengindir ki, kalite ölçütü (perceptual loss), benzerlik ölçütü (FID), içerik ölçütü (style transfer) hepsi o uzayda tanımlanabilir.
26.16 15. Kapanış
Ders 23, SON ETAP’ı super-resolution ile açtı: bir U-Net’i (sıfırdan, ResBlock’larla) düşük çözünürlüğe koşullayarak yüksek çözünürlük üretmek. Anahtar ders, perceptual loss — piksel MSE’nin bulanıklığını, özellik uzayında karşılaştırma ile aşmak. Super-res, koşullu üretimin en sade örneği; sonraki derslerin (attention, text→image) köprüsü.
Şekil 26.8 bu kapanışı dersin sentezi olarak çerçeveler: merkezde çekirdek mesaj — doğru loss, doğru sonucu belirler (pixel MSE matematiksel doğru ama görsel yanlış/bulanık; perceptual loss insanın algıladığı kaliteyi hedefler). Solda geriye köprüler: perceptual loss = Ders 20 content loss (birebir), özellik uzayı = Ders 21 FID/Inception, TinyUnet = Ders 18 ResBlock + Ders 19 U-Net, piksel karşılaştırma yetersiz = Ders 21 dersi. Sağda ileriye: koşullu diffusion (SD upscaler), attention → L24, text→image → L25. Altta: CLAUDE.md köprüsü — “test yazılabilir hedef tanımı” = loss tam olarak budur.
Kod
fig, ax = plt.subplots(figsize=(12.5, 6.5))
ax.set_xlim(0, 12.5)
ax.set_ylim(0, 6.5)
ax.axis("off")
ax.set_facecolor(COL_WHITE)
# --- MERKEZ: ana mesaj ---
boxed_node(
ax, 6.25, 4.45, 5.6, 1.55,
"DOĞRU LOSS, DOĞRU SONUCU BELİRLER\n"
"pixel MSE matematiksel doğru ama görsel yanlış (bulanık)\n"
"perceptual loss insanın algıladığı kaliteyi hedefler",
fc=COL_BG, ec=COL_CYAN_800, tc=COL_CYAN_800,
fontsize=11.5, lw=2.6,
)
# --- SOL KÖPRÜLER (cyan): geriye doğru kurslar arası bağ ---
left_x, left_w, left_h = 2.35, 4.3, 0.62
left_ys = [5.85, 5.05, 4.25, 3.45]
left_texts = [
"perceptual loss = Ders 20 content loss\n(BİREBİR aynı teknik)",
"özellik uzayı = Ders 21 FID/Inception",
"TinyUnet = Ders 18 ResBlock + Ders 19 U-Net",
"piksel karşılaştırma yetersiz = Ders 21 dersi",
]
for y, t in zip(left_ys, left_texts):
boxed_node(ax, left_x, y, left_w, left_h, t,
fc=COL_CYAN_50, ec=COL_PRIMARY, tc=COL_CYAN_800,
fontsize=8.6, lw=1.8)
arrow_between(ax, (left_x + left_w / 2, y), (3.6, 4.55),
color=COL_PRIMARY, lw=1.6, mutation_scale=13)
# --- SAĞ İLERİ (rose): ileriye doğru dersler ---
right_x, right_w, right_h = 10.15, 4.0, 0.66
right_ys = [5.7, 4.75, 3.8]
right_texts = [
"koşullu diffusion (SD upscaler)",
"attention → L24",
"text→image → L25",
]
for y, t in zip(right_ys, right_texts):
boxed_node(ax, right_x, y, right_w, right_h, t,
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_ACCENT,
fontsize=9.2, lw=1.8)
arrow_between(ax, (8.9, 4.55), (right_x - right_w / 2, y),
color=COL_ACCENT, lw=1.7, mutation_scale=14)
# --- ALT: CLAUDE.md köprüsü ---
boxed_node(
ax, 6.25, 1.35, 9.4, 0.95,
"CLAUDE.md köprüsü: «test yazılabilir hedef tanımı» = loss tam olarak budur\n"
"(hedefi sayıyla tanımla → optimize et; yanlış loss = yanlış hedef = yanlış sonuç)",
fc=COL_WHITE, ec=COL_SLATE_400, tc=COL_TEXT,
fontsize=9.6, lw=1.6,
)
arrow_between(ax, (6.25, 3.68), (6.25, 1.83),
color=COL_SLATE_400, lw=1.6, mutation_scale=14)
# --- başlık şeritleri ---
ax.text(2.35, 6.28, "← GERİYE: kurslar-arası köprü", ha="center", va="center",
fontsize=10, color=COL_PRIMARY, weight="bold")
ax.text(10.15, 6.28, "İLERİYE: koşullu üretim →", ha="center", va="center",
fontsize=10, color=COL_ACCENT, weight="bold")
plt.tight_layout()
plt.show()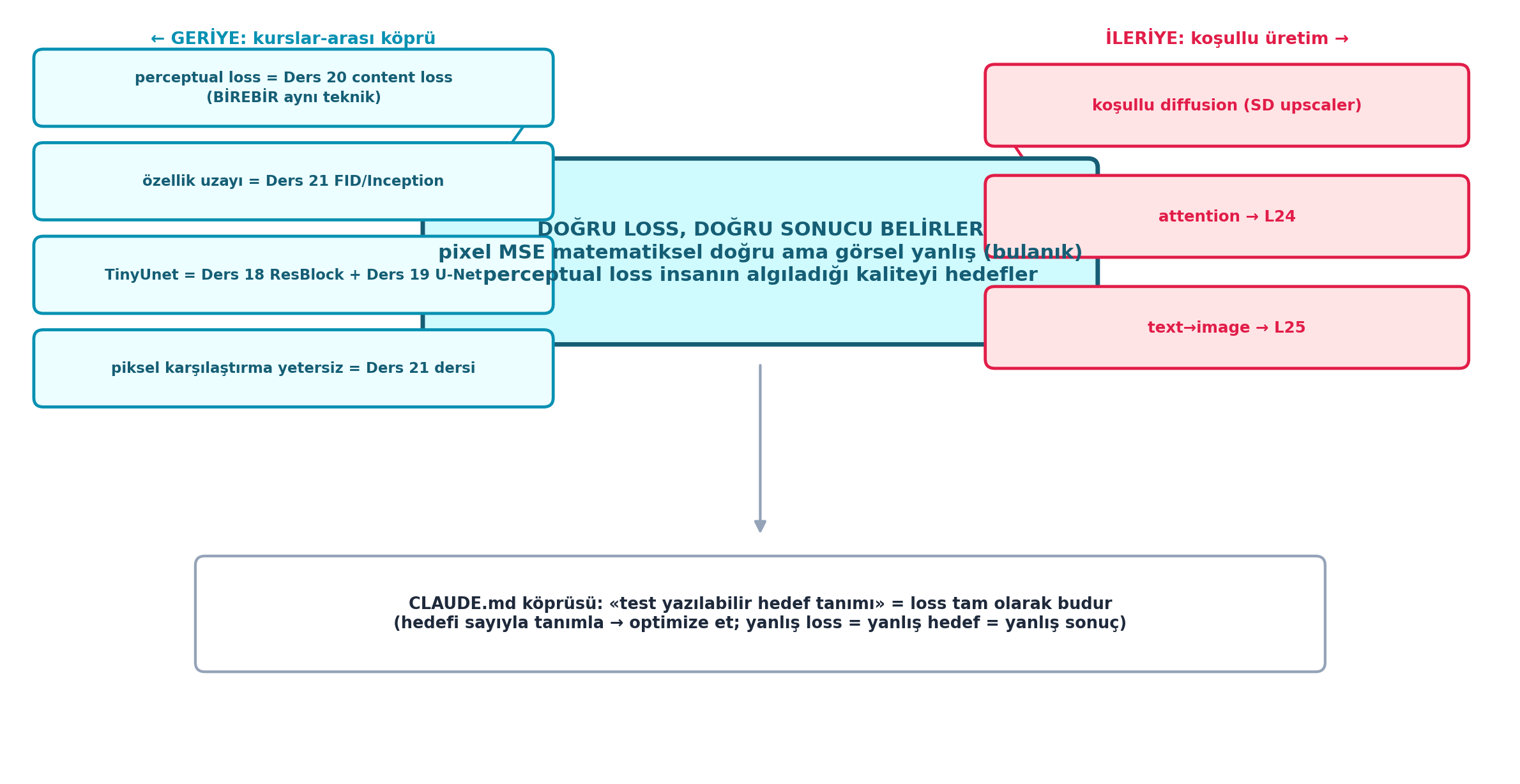
ÖnemliBuilder Notu — Kapanış: SON ETAP Başladı
- İleriye (Ders 24): Koşullama elimizde; Ders 24 attention’ı sıfırdan kurar — U-Net’e güçlü bir koşullama ve ilişkilendirme mekanizması ekler (Karpathy nanoGPT köprüsü).
- Çekirdek ders: Doğru loss her şeyi belirler — super-res’i piksel MSE ile eğitirsen bulanık (keskinlik 1.000→0.340); perceptual loss (Ders 20 content loss’unun aynısı) keskinliği geri getirir. Super-res = koşullu üretimin en sade örneği, attention ve text→image’a köprü.
26.17 Bu Dersin Özeti
- Super-resolution: Düşük çözünürlüklü görüntüden yüksek çözünürlük üretme; eksik detayları “uydurma” (HF enerji küçültmede %6’ya düşer) (super-res nedir).
- Koşullu üretim: Çıktı düşük çözünürlüklü girdiye koşullanır; serbest üretim değil (koşullu üretim).
- Tiny ImageNet: Gerçek görüntüler (MNIST yetersiz); perceptual loss’un farkını görmek için (Tiny ImageNet).
- TinyUnet: Sıfırdan U-Net (ResBlock down path + up path + cross connections) (TinyUnet).
- Pixel loss bulanıklaştırır: MSE birçok geçerli çıktının ortalamasını alır; keskinlik 1.000→0.340 (2.9× kayıp) (pixel loss).
- Perceptual loss: Çıktı ve hedefi özellik uzayında (önceden eğitilmiş cmodel) karşılaştır; özellik keskini seçer (0.40 ≪ 60.92) (perceptual loss).
- comb_loss: Piksel MSE + perceptual loss/10 (ağırlıklı); yapı + detay birlikte (comb_loss).
- Builder dersi: Doğru loss doğru sonucu belirler; “neyi optimize ettiğin” mimariden kritik (loss tasarımı).
ÖnemliTek Bir Cümle
Super-resolution, bir U-Net’i (sıfırdan, ResBlock’larla kurulu) düşük çözünürlüklü girdiye koşullayarak yüksek çözünürlük üretir; piksel MSE bulanıklaştırdığı için (keskinlik 1.000→0.340) keskinlik, Ders 20’nin perceptual loss’uyla (özellik uzayında karşılaştırma, özellik 0.40 ≪ 60.92) sağlanır — ve bu, koşullu üretimin en sade örneği olarak attention ve text→image’a köprüdür.
26.18 Kontrol Soruları
NotSoru 1: Super-resolution neden bir üretken (generative) problemdir, basit bir büyütme değil?
Cevap:
Düşük çözünürlüklü bir görüntüde bilgi kaybolmuştur — küçültme sırasında ince detaylar (dokular, kenarlar) silinir (Şekil 26.2: HF enerji %6’ya düşer). Bunları geri getirmek, kaybolan bilgiyi “uydurmaktır”: tek bir düşük çözünürlüklü girdiye karşılık birçok geçerli yüksek çözünürlüklü çıktı vardır. Basit interpolasyon (bilineer büyütme) bulanık sonuç verir çünkü detay üretmez, sadece var olanı yayar (figürde bilinear MSE > 0, detay geri gelmez). Gerçek super-resolution, modelin öğrendiği görüntü dağılımından makul detaylar üretmesini gerektirir — bu yüzden üretken bir problemdir. Çıktı düşük çözünürlüklü girdiye koşullanır (serbest üretim değil), ama yine de eksik detayı yaratıcı biçimde doldurur.
NotSoru 2: Pixel MSE neden bulanık çıktı verir? Perceptual loss bunu nasıl çözer?
Cevap:
Bir düşük çözünürlüklü girdiye karşılık birçok eşit derecede geçerli keskin çıktı vardır (örn. bir dokunun tam piksel düzeni belirsiz). Piksel MSE, bu olasılıkların ortalamasını alan çıktıyı ödüllendirir — çünkü ortalama, tüm olasılıklara olan kare hatayı en aza indirir. Ama keskin detayların ortalaması bulanıktır (farklı keskin desenler birbirini siler — Şekil 26.4’de keskinlik 1.000→0.340, 2.9× kayıp). Sonuç: matematiksel olarak “en iyi” MSE çözümü, görsel olarak yumuşak/pürüzlü. Perceptual loss çözer çünkü çıktıyı piksel piksel değil, önceden eğitilmiş bir ağın özellik uzayında karşılaştırır. Bu uzayda “keskin doku var mı” gibi anlamsal özellikler kodlanır (Şekil 26.5: özellik uzayı keskini seçer, fark 0.40 ≪ 60.92, oysa piksel MSE bulanığı seçer 0.0179 < 0.0308); ortalama almak yerine, çıktının gerçekçi doku/yapıya sahip olmasını teşvik eder. Sonuç keskin ve gerçekçi.
NotSoru 3: Perceptual loss ile Ders 20’nin style transfer’ı arasındaki bağ nedir?
Cevap:
İkisi aynı tekniktir: önceden eğitilmiş bir ağın özellik uzayında MSE. Ders 20’deki style transfer’da content loss, optimize edilen görüntünün VGG16 özelliklerinin içerik görüntüsünün özelliklerine yakın olmasını sağlıyordu — yani içeriği özellik uzayında ölçüyordu. Super-res’teki perceptual loss tam olarak budur: super-res çıktısının özelliklerini, yüksek çözünürlüklü hedefin özelliklerine yaklaştırır (F.mse_loss(cmodel(inp), cmodel(tgt))). Tek fark: style transfer’da görüntü optimize ediliyordu (ağırlık sabit), super-res’te U-Net ağırlıkları optimize ediliyor (perceptual loss bir eğitim kaybı olarak). Builder içgörüsü: “özellik uzayında karşılaştırma” — style transfer, FID (L21), super-res perceptual loss — hepsi aynı güçlü fikrin farklı uygulamaları.
NotSoru 4: Super-resolution neden ‘koşullu üretim’ olarak görülür ve sonraki derslere nasıl bağlanır? (builder bağlantısı)
Cevap:
Super-resolution’da model serbestçe üretmez (DDPM’in koşulsuz örneklemesi gibi); çıktısını düşük çözünürlüklü girdiye koşullar — verilen görüntüyü büyütür. Bu, koşullu üretimin (conditional generation) en sade örneğidir: “şu girdiye göre üret”. Aynı koşullama fikri sonraki derslerin temelidir (Şekil 26.7): Ders 24’te attention, U-Net’in girdinin farklı bölgelerini ilişkilendirmesini ve dış bilgiyle (koşulla) etkileşmesini sağlar; Ders 25’te text conditioning, çıktıyı bir metin promptuna koşullar (text→image). Yani super-res (görüntüye koşullama) → attention (ilişkilendirme/cross-attention) → text→image (metne koşullama) doğal bir ilerlemedir. Builder için: koşullama, üretken modeli “kontrol edilebilir” kılan mekanizmadır — serbest üretimden işe yarar üretime geçiş.
26.19 Egzersizler
Egzersiz 1 (Direkt uygulama). Bir super-res U-Net’i sadece piksel MSE ile eğit; çıktının bulanık olduğunu gözle (keskinlik kaybını §5’teki 1.000→0.340 ile karşılaştır) (§5).
Egzersiz 2 (İki-aşamalı). Aynı modeli comb_loss (piksel + perceptual) ile eğit; iki çıktıyı keskinlik açısından karşılaştır (§8, §9).
Egzersiz 3 (Edge case). comb_loss’taki perceptual ağırlığını (feat_loss/10) değiştir (örn. /1, /100); keskinlik-doğruluk dengesinin nasıl kaydığını gör (§8).
Egzersiz 4 (Kavramsal). Perceptual loss neden özellik uzayında MSE kullanır da piksel MSE’yi tamamen atmaz? İkisinin birlikte rolü nedir (piksel yapıyı, özellik keskinliği)? (§6, §8)
Egzersiz 5 (Sonraki dersin habercisi — Ders 24). Super-res U-Net girdinin yerel bölgelerine bakar (convolution). Görüntünün uzak bölgelerini birbiriyle ilişkilendirmek (örn. simetri) için nasıl bir mekanizma gerekir, düşün (attention) (§10).
26.20 Sonraki: Ders 24 İçin Hazırlık
Ders 24: Attention ve Transformer Blokları
Ders 23 super-res ile koşullu üretimi açtı. Ders 24 attention’ı sıfırdan kurar — convolution’ın yerel bakışını aşıp görüntünün (veya dizinin) tüm bölgelerini birbiriyle ilişkilendiren mekanizma. Self-attention (Q/K/V), multi-head attention ve U-Net’e attention ekleme. Karpathy’nin nanoGPT’sinde sıfırdan kurduğu attention’ın fast.ai/miniai’da yeniden inşası.
Ana konular (Ders 24):
- Self-attention (query, key, value; softmax(QKᵀ/√d)V)
- Multi-head attention
- Attention’ı U-Net’e ekleme
- Transformer bloğu (residual + attention)
UyarıDers 24 Öncesi Yapılacak
- Bu dersin egzersizlerini çöz (özellikle 1 ve 2 — pixel vs perceptual loss).
- Ders 18’in residual (skip) bağlantısını tekrar oku (attention + residual = transformer bloğu).
- Karpathy nanoGPT’deki self-attention’ı hatırla (bu ders onu yeniden kuracak).
26.21 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Howard’da |
|---|---|---|
| Super-resolution | Düşük çözünürlükten yüksek çözünürlük üretme | 6:18 |
| Koşullu üretim | Çıktı bir girdiye (düşük-çöz) koşullanır | 6:18 |
| Tiny ImageNet | Gerçek görüntü kümesi (MNIST yetersiz) | 6:06 |
TinyUnet |
Sıfırdan U-Net (ResBlock down/up + cross) | — |
| Cross connection | U-Net skip; detay down→up taşır | 20:06 |
| Pixel loss bulanıklığı | MSE çıktıların ortalamasını alır → pürüzlü (1.000→0.340) | — |
| Perceptual loss | Özellik uzayında MSE (keskinlik geri gelir) | 1:15:00 |
cmodel |
Perceptual loss için özellik (içerik) modeli | — |
comb_loss |
Piksel MSE + perceptual loss/10 (ağırlıklı) | — |
| Loss tasarımı | Doğru loss = doğru sonuç (mimariden kritik) | — |
26.22 ML Bağlantıları Özeti
İpucuBuilder Notu — 6 ML Köprüsü: Loss, U-Net ve Temsil Öğrenme
Bu ders super-res’i önceki derslerin altyapısına bağlar ve “doğru loss doğru sonucu belirler” felsefesini ortaya koyar; köprülerin özeti:
- Perceptual loss → Ders 20 style transfer content loss; özellik uzayında MSE (BİREBİR aynı teknik) (perceptual loss).
- TinyUnet → Ders 18 ResBlock + Ders 19 diffusion U-Net; encoder-decoder + skip (TinyUnet).
- Cross connection → Ders 18 skip connection; U-Net detay akışı (cross connections).
- Koşullu üretim → Ders 25 text→image; super-res en sade koşullama örneği (koşullu üretim).
- Özellik uzayı → NYU temsil öğrenme + Ders 21 FID; “iyi” tanımı özelliklerde (NYU köprüsü).
- Loss tasarımı → CLAUDE.md “test yazılabilir hedef”; üretkende loss = hedef tanımı (loss tasarımı).
ÖnemliBu dersten tek bir şey alıp gideceksen
Bu dersten tek bir şey alıp gideceksen: doğru loss her şeyi belirler. Super-resolution’ı piksel MSE ile eğitirsen bulanık çıktı alırsın (keskinlik 1.000→0.340, 2.9× kayıp) — çünkü MSE birçok geçerli keskin çıktının ortalamasını ödüllendirir. Çözüm, çıktıyı önceden eğitilmiş bir ağın özellik uzayında karşılaştıran perceptual loss (Ders 20’nin style transfer content loss’unun aynısı; figürde özellik keskini doğru seçer, fark 0.40 ≪ 60.92). Super-res ayrıca koşullu üretimin en sade örneği — çıktıyı bir girdiye koşullama — ve bu, sonraki derslerin (attention ile ilişkilendirme, text→image koşullama) köprüsü. SON ETAP başladı; sıradaki attention ile gerçek Stable Diffusion’a yaklaşıyoruz.