flowchart TD
D9["Ders 9: SD'yi KULLANDIK<br/>(kara kutu — hazır pipe)"]
FND["16 ders foundations<br/>(matmul → backprop → miniai → DDPM)"]
VAE["VAE: encoder → latent dağılım (mu, lv)<br/>→ reparam (mu + sigma·epsilon) → decoder"]
VLOSS["KLD + BCE kayıp<br/>(latent'i N(0,1)'e hizala)"]
LAT["latent diffusion: tüm görüntüleri<br/>latent'e kodla → DDPM/Karras LATENT uzayda"]
LDEC["VAE decode → piksel<br/>(latent 48 kat küçük)"]
TXT["text conditioning: CLIP gömüsü<br/>+ cross-attention"]
TNEXT["(CLIP detayı sonraki kursa)"]
SD["Stable Diffusion =<br/>VAE + latent U-Net + CLIP"]
LOOP["L25: SD'yi KURDUK —<br/>'yeniden kur, sonra kullan' halkası KAPANDI"]
D9 --> FND
FND --> VAE
FND --> LAT
FND --> TXT
VAE --> VLOSS
VLOSS --> SD
LAT --> LDEC
LDEC --> SD
TXT --> TNEXT
TNEXT --> SD
SD --> LOOP
D9 -. halka .-> LOOP
classDef cyan fill:#cffafe,stroke:#0891b2,stroke-width:2px,color:#1e293b;
classDef rose fill:#ffe4e6,stroke:#e11d48,stroke-width:2px,color:#1e293b;
classDef dark fill:#155e75,stroke:#0e7490,stroke-width:2px,color:#ffffff;
class D9,FND,VAE,VLOSS,TXT,TNEXT cyan;
class LAT,LDEC rose;
class SD,LOOP dark;
28 Ders 25 — Latent Diffusion: Stable Diffusion’ı Sıfırdan (Latent Diffusion — SON DERS)
Kursun SON DERSİ ve pedagojik finali — Howard, Jonathan Whitaker (Johno) ve Tanishq Abraham’la. Tüm parçaları (DDPM, Karras, U-Net, attention) bir VAE ve latent uzayla birleştirip gerçek Stable Diffusion’ı sıfırdan kurmak. Anahtar fikir: pahalı diffusion’ı 512×512×3 ≈ 786K boyutlu piksel uzayında değil, VAE’nin sıkıştırdığı 64×64×4 ≈ 16K boyutlu küçük latent uzayda yapmak — ~48× daha az veri, yüzlerce U-Net çağrısı tek GPU’da koşar, yüksek çözünürlük pratik olur. Ders 9’da bu Stable Diffusion’ı kullandık; şimdi kendimiz kuruyoruz — ‘yeniden kur, sonra kullan’ döngüsü, kursun ilk üretken dersinden son dersine tam kapanıyor. VAE = encoder (görüntü → latent dağılım μ, lv) + reparameterization (z = μ + exp(0.5·lv)·ε, 9B trick’i) + decoder; KLD + BCE kaybı latent’i N(0,1)’e hizalar (örneklenebilir uzay); latent diffusion = DDPM/Karras latent uzayda; Stable Diffusion = VAE + latent U-Net + CLIP cross-attention. Dersin tek cümlesi: karmaşık sistemler sağlam temellerin birleşimidir — Stable Diffusion’da sihir yoktur, sadece doğru sırayla katmanlanmış matris çarpımı, gradient descent, residual, normalizasyon, attention ve MSE vardır; builder olmak bu parçaları görebilmek ve birleştirebilmektir.
NotBölüm bilgisi
- Ders sayfası (video): course.fast.ai — Lesson 25: Latent Diffusion (SON DERS) (~98 dk)
- Seri: Practical Deep Learning for Coders — Part 2, Ders 25 (KURSUN SON DERSİ)
- Playlist: Part 2 — Foundations to Stable Diffusion (2022)
- Notebook: course22p2 — nbs/29_vae + nbs/30_lsun_diffusion-latents
- Okuma süresi: ~40 dk
- Hocalar: Howard + Jonathan Whitaker (Johno) + Tanishq Abraham
- 🔗 Halka KAPANIŞ dersi: Ders 9’da Stable Diffusion’ı kullandık (pipeline: VAE+U-Net+CLIP); 16 ders foundations sonra, L25’te aynı SD’yi sıfırdan kuruyoruz. “Yeniden kur, sonra kullan” döngüsü — kursun ilk üretken dersinden son dersine — tam kapanır.
28.1 Bu Derste Ne Var?
Kursun SON DERSİ ve pedagojik finali: tüm parçaları (DDPM, Karras, U-Net, attention) bir VAE + latent uzayla birleştirip gerçek Stable Diffusion’ı sıfırdan kurmak. Anahtar fikir basit ama güçlü: pahalı diffusion’ı piksel uzayında değil, VAE’nin sıkıştırdığı küçük latent uzayda yap — çok daha hızlı, yüksek çözünürlük mümkün. Ders 9’da bu SD’yi kullandık; şimdi kendimiz kuruyoruz — “yeniden kur, sonra kullan” döngüsü tam kapanıyor.
Üç temel fikir bu dersin omurgasını kurar:
- VAE (encoder/decoder) — görüntüyü küçük bir latent temsile sıkıştırır (encoder) ve geri açar (decoder); latent uzayı kurar (VAE, reparameterization).
- Latent diffusion — diffusion’ı piksel yerine latent uzayda yap; ~48× daha az hesap, yüksek çözünürlük için pratik (latent uzay, latent diffusion).
- Stable Diffusion = VAE + latent U-Net + (CLIP) — Ders 9’da kullandığımız SD’nin tam mimarisi; CLIP text encoder hariç hepsi sıfırdan (tam mimari, halka kapanır).
“working in the latent space can make it computationally cheaper than having to decode [every step].” — Howard, 1:32:28
Şekil 28.1 bu fikirleri tek bir kavram haritasında birleştirir: Ders 9’da SD’yi kara kutu olarak kullandık → 16 ders foundations (matmul → backprop → miniai → DDPM) → üç bileşeni (VAE, latent diffusion, text conditioning) sıfırdan kur → birleştir → Stable Diffusion. Rose ile işaretli düğümler (latent diffusion hattı, halka kapanışı) dersin builder mesajını taşır: Ders 9 (kullan) → L25 (kur) halkası burada kapanır.
İpucuBuilder Notu — Giriş: Halka Kapanışı, Sıfırdan Stable Diffusion
- Geriye (Ders 9) — HALKA: Ders 9’da Stable Diffusion’ı kullandık (pipeline: VAE+U-Net+CLIP), Whitaker/Waseem/Tanishq matematiği gösterdi; L25’te aynı SD’yi sıfırdan kuruyoruz. Kursun ilk üretken dersinden son dersine tam halka.
- Geriye (Ders 15): L15’in autoencoder/VAE sezgisi burada gerçek latent uzaya dönüşür.
- Geriye (Ders 19-24): DDPM (L19) + Karras (L22) + U-Net (L23) + attention (L24) — hepsi latent uzayda birleşir.
- Tek cümle: Latent diffusion, bir VAE’nin sıkıştırdığı küçük latent uzayda diffusion yaparak Stable Diffusion’ı pratik kılar; Ders 9’da kullandığımız SD’yi sıfırdan kurarak “yeniden kur, sonra kullan” döngüsünü kapatır.
28.2 1. Hatırlatma: Ders 9’da SD’yi Kullandık
Kurs, Ders 9’da Stable Diffusion’ı kullanarak açılmıştı: bir pipeline çağırdık, prompt verdik, görüntü ürettik. SD’nin üç bileşenini (U-Net gürültü tahmincisi, VAE latent sıkıştırma, CLIP metin koşullama) kara kutu olarak gördük. Şimdi, 16 ders foundations’tan sonra, o kara kutuyu açıyoruz. Bu, Howard’ın top-down felsefesinin tam tezahürüdür: önce çalıştır, sonra anla; aradaki her ders bu halkayı mümkün kıldı.
İpucuBuilder Notu — Önce Çalıştır, Sonra Anla (top-down halka)
- Geriye (Ders 9-10): “Önce çalıştır, sonra anla” — Howard’ın top-down felsefesi; Ders 9 çalıştırma, L25 tam anlama. Aradaki her ders bu halkayı mümkün kıldı.
- Sezgi: Kara kutuyu kullanabilmek bir şey, içinde ne olduğunu bilmek başka; gerçek anlama ikisini de gerektirir — bu dersin pedagojik tezi tam budur.
28.3 2. VAE: Encoder → Latent → Decoder
Bir VAE (Variational Autoencoder) görüntüyü sıkıştırır: encoder görüntüyü küçük bir latent temsile indirir, decoder onu geri açar. Ders 15’in autoencoder’ından farkı kritiktir: latent’i tek bir nokta değil, bir dağılım (ortalama μ + log-varyans lv) olarak kodlar — bu, latent uzayı düzgün ve örneklenebilir kılar, dolayısıyla VAE’yi üretken bir model yapar.
class VAE(nn.Module):
def __init__(self):
super().__init__()
self.enc = nn.Sequential(lin(ni, nh), lin(nh, nh))
self.mu, self.lv = lin(nh, nl, act=None), lin(nh, nl, act=None)
self.dec = nn.Sequential(lin(nl, nh), lin(nh, nh), lin(nh, ni, act=None))
def forward(self, x):
x = self.enc(x)
mu, lv = self.mu(x), self.lv(x)
z = mu + (0.5*lv).exp()*torch.randn_like(lv) # reparameterization
return self.dec(z), mu, lvŞekil 28.2 L15 autoencoder (deterministik, tek nokta z, latent uzay düzensiz) ile VAE’yi (üretken, dağılım μ/lv + reparameterization + KLD) yan yana koyar. Üstteki autoencoder latent’i tek bir noktaya kodlar — örneklenemez; alttaki VAE latent’i bir dağılıma kodlar, KLD onu N(0,1)’e çeker, reparameterization (rose kutu) rastgeleliği ε’ya alıp gradyanı μ/σ üzerinden akıtır. Fark — nokta yerine dağılım + KLD — VAE’yi üretken kılan tam mekanizmadır.
Kod
fig, ax = plt.subplots(figsize=(12, 5.5))
ax.set_xlim(0, 12)
ax.set_ylim(0, 5.5)
ax.axis("off")
# ----- ÜST SATIR: L15 autoencoder (deterministik, slate) -----
y_top = 4.35
ax.text(0.15, 5.18, "L15 autoencoder (deterministik)", ha="left", va="center",
fontsize=11.5, weight="bold", color=COL_SLATE_400)
boxed_node(ax, 1.15, y_top, 1.55, 0.78, "girdi", fc=COL_WHITE,
ec=COL_SLATE_400, tc=COL_TEXT, fontsize=9.5)
boxed_node(ax, 3.15, y_top, 1.7, 0.78, "encoder", fc=COL_SLATE_300,
ec=COL_SLATE_400, tc=COL_TEXT, fontsize=9.5)
boxed_node(ax, 5.25, y_top, 1.85, 0.86,
"TEK NOKTA\nz", fc=COL_SLATE_300, ec=COL_SLATE_400,
tc=COL_TEXT, fontsize=9.5)
boxed_node(ax, 7.45, y_top, 1.7, 0.78, "decoder", fc=COL_SLATE_300,
ec=COL_SLATE_400, tc=COL_TEXT, fontsize=9.5)
boxed_node(ax, 9.45, y_top, 1.55, 0.78, "çıktı", fc=COL_WHITE,
ec=COL_SLATE_400, tc=COL_TEXT, fontsize=9.5)
for x0, x1 in [(1.93, 2.30), (4.0, 4.33), (6.18, 6.52), (8.30, 8.68)]:
arrow_between(ax, (x0, y_top), (x1, y_top), color=COL_SLATE_400,
lw=1.8, shrink=2)
ax.text(5.25, 3.55, "latent uzay düzensiz, örneklenemez",
ha="center", va="center", fontsize=8.8, style="italic",
color=COL_SLATE_400)
# ----- ALT SATIR: VAE (üretken, cyan; reparam kutusu rose) -----
y_bot = 1.55
ax.text(0.15, 2.55, "VAE (üretken)", ha="left", va="center",
fontsize=11.5, weight="bold", color=COL_CYAN_700)
boxed_node(ax, 1.15, y_bot, 1.55, 0.78, "girdi", fc=COL_WHITE,
ec=COL_PRIMARY, tc=COL_TEXT, fontsize=9.5)
boxed_node(ax, 3.15, y_bot, 1.7, 0.78, "encoder", fc=COL_BG,
ec=COL_PRIMARY, tc=COL_TEXT, fontsize=9.5)
boxed_node(ax, 5.15, y_bot, 1.75, 0.92,
"DAĞILIM\n(μ, lv)", fc=COL_BG, ec=COL_PRIMARY,
tc=COL_CYAN_800, fontsize=9.5)
# reparameterization kutusu — rose
boxed_node(ax, 7.45, y_bot, 2.35, 1.0,
"reparametrize\nz = μ + exp(0.5·lv)·ε",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_TEXT, fontsize=8.6)
boxed_node(ax, 9.75, y_bot, 1.6, 0.78, "decoder", fc=COL_BG,
ec=COL_PRIMARY, tc=COL_TEXT, fontsize=9.5)
boxed_node(ax, 11.4, y_bot, 1.0, 0.78, "çıktı", fc=COL_WHITE,
ec=COL_PRIMARY, tc=COL_TEXT, fontsize=9.0)
for x0, x1 in [(1.93, 2.30), (4.0, 4.27), (6.03, 6.27),
(8.63, 8.95), (10.55, 10.90)]:
arrow_between(ax, (x0, y_bot), (x1, y_bot), color=COL_PRIMARY,
lw=1.8, shrink=2)
# KLD loss notu — dağılımı normale çeker (μ, lv kutusunun altında)
ax.text(5.15, 0.78, "+ KLD loss\n(dağılımı N(0,1)'e çeker)",
ha="center", va="center", fontsize=8.6, weight="bold",
color=COL_ACCENT)
# ----- SAĞ NOT -----
note = ("fark: nokta → dağılım\n"
"KLD latent'i düzgün +\n"
"örneklenebilir kılar\n"
"→ ÜRETKEN model\n\n"
"reparam = 9B trick'i\n"
"(rastgelelik ε'da,\n"
"gradyan μ/σ'dan akar)")
ax.text(11.78, 3.35, note, ha="right", va="center", fontsize=8.4,
color=COL_CYAN_800,
bbox=dict(boxstyle="round,pad=0.4", fc=COL_CYAN_50,
ec=COL_PRIMARY, lw=1.4))
plt.tight_layout()
plt.show()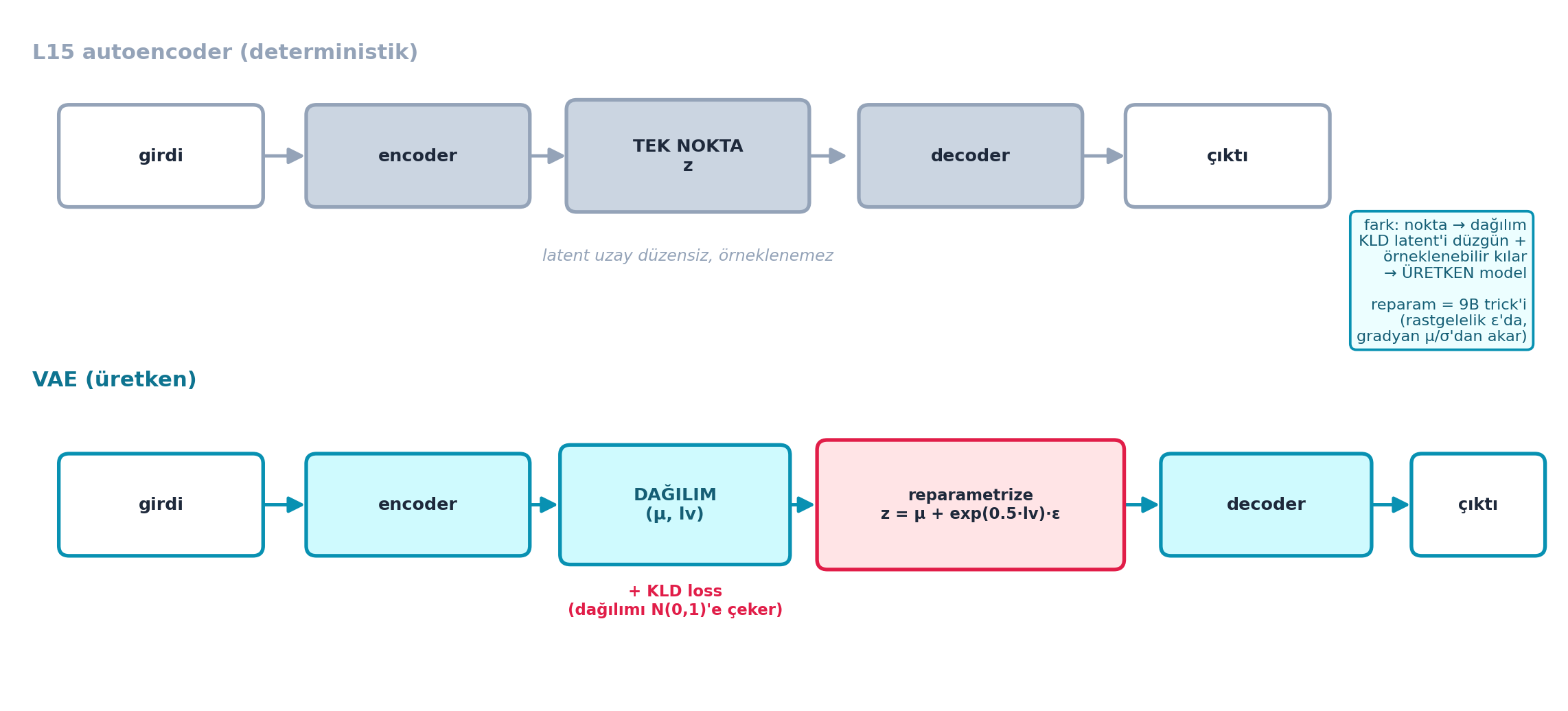
İpucuBuilder Notu — VAE: Autoencoder’ın Üretken Hâli (Ders 15)
- Geriye (Ders 15): L15’te autoencoder kurmuştuk (encoder conv + decoder deconv); VAE, latent’i dağılım yaparak üretken hâle getirir.
- Sezgi:
muvelviki ayrı lineer katman; encoder bir nokta değil, bir dağılımın parametrelerini üretir — düzgün, örneklenebilir bir latent uzayın anahtarı.
28.4 3. Reparameterization
VAE latent’i bir dağılımdan örnekler: z = μ + σ·ε, burada σ = exp(0.5·lv), ε ~ N(0, I). Doğrudan örnekleme türevlenemez — rastgelelik gradyanı keser, eğitim imkânsız olur. Reparameterization trick rastgeleliği ε’ya dışarı alır, böylece μ ve σ üzerinden gradyan akar. Bu, 9B’de gördüğümüz diffusion forward’ının reparameterization’ıyla tam aynı fikir: rastgele bir süreçten türevlenebilir örnekleme almanın standart yolu.
z = μ + exp(0.5·lv) · ε, ε ~ N(0, I)
Şekil 28.3 VAE’nin iki matematik direğini gerçek hesaplamayla gösterir. Sol panel reparameterization’ı: z = μ + σ·ε ile çekilen örneklerin histogramı, teorik N(5, 2²) eğrisine oturur — örnek mean ≈ 5, örnek std ≈ 2 (rozetle doğrulanmış); rastgelelik ε’da, μ/σ türevlenebilir kalır. Sağ panel KLD yüzeyini: minimum tam (0,0)’da, orada KLD = 0 (rose yıldız) — latent dağılımı tam N(0,1)’e oturduğunda; uzaklaştıkça KLD artar, latent’i standart normale çeker.
Kod
rp = E.reparam_demo() # dict(eps, x, mu, sigma, x_mean, x_std)
kl = E.kld_demo() # dict(mu, lv, kld_surface, kld_at_origin, kld_mu_slice, kld_lv_slice)
fig, (axL, axR) = plt.subplots(1, 2, figsize=(12, 5))
# ---- SOL PANEL: reparameterization z = μ + σ·ε (GERÇEK) -------------------
mu_v, sig_v = rp["mu"], rp["sigma"]
axL.hist(rp["x"], bins=60, density=True, color=COL_PRIMARY, alpha=0.55,
edgecolor=COL_CYAN_700, linewidth=0.4, zorder=2,
label="örnekler z=μ+σ·ε")
# Teorik N(5, 2²) eğrisi (rose)
xs = np.linspace(rp["x"].min(), rp["x"].max(), 400)
pdf = np.exp(-0.5 * ((xs - mu_v) / sig_v) ** 2) / (sig_v * np.sqrt(2 * np.pi))
axL.plot(xs, pdf, color=COL_ACCENT, linewidth=2.6, zorder=3,
label=f"teorik N({mu_v:.0f}, {sig_v:.0f}²)")
axL.axvline(mu_v, color=COL_CYAN_800, linewidth=1.4, linestyle="--",
alpha=0.8, zorder=2)
viz.apply_style(axL)
axL.set_title("Reparameterization: z = μ + σ·ε", color=COL_TEXT, weight="bold",
fontsize=12)
axL.set_xlabel("z")
axL.set_ylabel("yoğunluk")
axL.legend(loc="upper right", fontsize=8.5, framealpha=0.9)
# Rozet: gerçek örnek istatistikleri
badge = (f"örnek mean {rp['x_mean']:.2f} ≈ 5\n"
f"örnek std {rp['x_std']:.2f} ≈ 2\n"
"rastgelelik ε'da →\nμ/σ türevlenebilir")
axL.text(0.03, 0.97, badge, transform=axL.transAxes, ha="left", va="top",
fontsize=9, color=COL_TEXT, weight="bold",
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG_ROSE,
ec=COL_ROSE_400, linewidth=1.4), zorder=5)
# ---- SAĞ PANEL: KLD yüzeyi (GERÇEK analitik) -----------------------------
MU, LV = np.meshgrid(kl["mu"], kl["lv"])
cf = axR.contourf(MU, LV, kl["kld_surface"], levels=18, cmap="GnBu", zorder=1)
cbar = fig.colorbar(cf, ax=axR, fraction=0.046, pad=0.03)
cbar.set_label("KLD", color=COL_TEXT, fontsize=9)
cbar.ax.tick_params(colors=COL_TEXT, labelsize=8)
# Düşük-değer kontur çizgileri (yüzey okunurluğu)
axR.contour(MU, LV, kl["kld_surface"], levels=[0.1, 0.5, 1.0, 2.0, 4.0],
colors=COL_CYAN_800, linewidths=0.6, alpha=0.55, zorder=2)
# Minimum (0,0) rose yıldız — KLD=0
axR.scatter([0], [0], marker="*", s=320, color=COL_ACCENT,
edgecolor=COL_WHITE, linewidth=1.2, zorder=4)
axR.annotate(f"KLD={kl['kld_at_origin']:.0f}\n↔ latent tam N(0,1)",
xy=(0, 0), xytext=(1.05, 1.55),
fontsize=9, color=COL_TEXT, weight="bold",
ha="left", va="center",
bbox=dict(boxstyle="round,pad=0.35", fc=COL_WHITE,
ec=COL_ACCENT, linewidth=1.4),
arrowprops=dict(arrowstyle="-|>", color=COL_ACCENT, linewidth=1.8,
shrinkA=2, shrinkB=6), zorder=5)
axR.set_title("KLD yüzeyi: latent'i N(0,1)'e çeker", color=COL_TEXT,
weight="bold", fontsize=12)
axR.set_xlabel("μ")
axR.set_ylabel("log σ² (lv)")
axR.tick_params(colors=COL_TEXT)
for spine in ("top", "right"):
axR.spines[spine].set_visible(False)
for spine in ("left", "bottom"):
axR.spines[spine].set_color(COL_SLATE_400)
# Formül + yorum notu
axR.text(0.5, -0.215,
"KLD = −0.5·(1 + lv − μ² − exp(lv)); uzaklaştıkça artar → "
"latent'i standart normale çeker (örneklenebilir uzay)",
transform=axR.transAxes, ha="center", va="top",
fontsize=8.5, color=COL_CYAN_700, style="italic")
plt.tight_layout()
plt.show()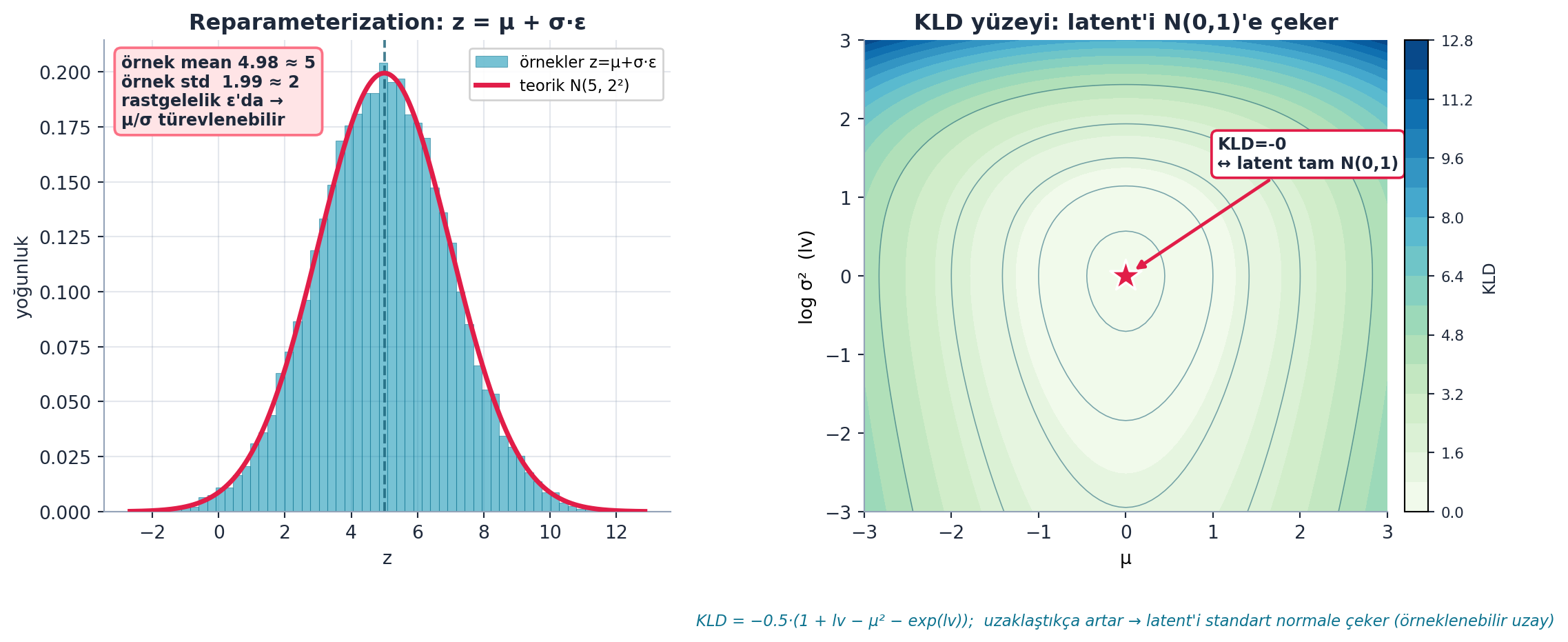
İpucuBuilder Notu — Reparameterization = 9B Forward Trick’i
- Geriye (Ders 9B): Reparameterization trick, 9B’deki forward process türevinde de kullanıldı; rastgele bir süreçten türevlenebilir örnekleme almanın standart yolu.
- Sayısal kanıt: Örnek mean ≈ 5, std ≈ 2 — z = μ + σ·ε formülünün hedeflediği dağılımı tam üretir; rastgelelik ε’da, gradyan μ/σ’dan akar.
28.5 4. VAE Loss: KLD + Yeniden Kurma
VAE iki kayıpla eğitilir: yeniden kurma (reconstruction — decoder çıktısı girdiye benzesin, burada BCE) + KL ıraksaması (KLD — latent dağılımı standart normale yakın olsun, böylece düzgün ve örneklenebilir kalsın). KLD = −0.5·ortalama(1 + lv − μ² − exp(lv)). İki kayıp bir denge kurar: BCE yeniden kurma kalitesini, KLD latent uzayın düzgünlüğünü ister; ikisi birlikte hem iyi yeniden kuran hem örneklenebilir bir uzay verir.
def kld_loss(inp, x):
x_hat, mu, lv = inp
return -0.5 * (1 + lv - mu.pow(2) - lv.exp()).mean()
def bce_loss(inp, x): return F.binary_cross_entropy_with_logits(inp[0], x)
def vae_loss(inp, x): return kld_loss(inp, x) + bce_loss(inp, x)KLD’nin minimumu tam (0,0)’dadır: μ = 0, lv = 0 (yani σ = 1) iken KLD = −0.5·(1 + 0 − 0 − 1) = 0 — latent dağılımı standart normale tam oturduğunda kayıp sıfırdır (Şekil 28.3 sağ panelinde rose yıldız bunu işaretler). Bu, KLD’nin neden “latent’i N(0,1)’e çeken” bir kuvvet olduğunun sayısal özüdür.
İpucuBuilder Notu — KLD: İki Dağılım Arası Fark (Stat 110)
- Geriye (Stat 110): KL ıraksaması iki dağılım arasındaki farkın olasılıksal ölçüsü; VAE’nin latent’i normal dağılıma “çekmesini” sağlar.
- Sayısal kanıt: KLD(μ=0, lv=0) = 0 — latent tam N(0,1) iken minimum; BCE yeniden kurmayı, KLD örneklenebilirliği ister, denge ikisinden gelir.
28.6 5. Latent Uzay: Neden?
VAE’nin gerçek değeri: görüntüyü çok daha küçük bir latent temsile sıkıştırması. Örneğin 512×512×3 piksel → 64×64×4 latent (~48× daha az veri). Diffusion gibi pahalı bir işlemi — yüzlerce U-Net çağrısı — bu küçük uzayda yapmak, hesabı dramatik azaltır; yüksek çözünürlüklü üretimi tüketici donanımında mümkün kılan tam budur.
“working in the latent space can make it computationally cheaper.” — Howard, 1:32:28
Ama önce, latent uzayın üretken gücünü görelim. Şekil 28.4 VAE’yi üretken yapan hizalamayı gerçek hesaplamayla gösterir: KLD-hizasız durumda prior N(0,1)’den örnekleyip decode etmek veri dağılımını ıskalar (yayılım oranı 0.302 — latent std aslında 3.37 ama 1 varsayıldı); KLD-hizalı durumda latent standardize edilince üretilen örnekler veri manifoldunu doldurur (oran 1.018 ≈ 1). KLD’nin işi tam bu hizalama — AE’de (L15) bu garanti yoktu; lineer/PCA dünyasında gösterilen ilke, gerçek VAE’nin öğrenilmiş hâlidir.
Kod
d = E.latent_sampling_demo()
data = d["data"]
gen_mis = d["gen_misaligned"]
gen_ali = d["gen_aligned"]
r_mis = d["ratio_misaligned"]
r_ali = d["ratio_aligned"]
lat_std = d["latent_std"]
fig, (axL, axR) = plt.subplots(1, 2, figsize=(12, 5.5), sharex=True, sharey=True)
# Eksen sınırlarını veri bulutuna göre belirle
lim = max(abs(data).max(), abs(gen_ali).max()) * 1.08
# --- SOL: hizasız (prior N(0,1)'den örnekle, latent std=1 varsayar) ---
axL.scatter(data[:, 0], data[:, 1], s=22, color=COL_SLATE_400, alpha=0.45,
edgecolors="none", zorder=2, label="veri dağılımı")
axL.scatter(gen_mis[:, 0], gen_mis[:, 1], s=26, color=COL_ACCENT, alpha=0.75,
edgecolors=COL_WHITE, linewidths=0.4, zorder=3, label="üretilen (hizasız)")
axL.set_title("Hizasız: prior N(0,1)'den örnekle, decode\n"
f"(latent std={lat_std:.2f} ama 1 varsayıldı)",
fontsize=11.5, color=COL_TEXT, weight="bold")
axL.text(0.5, -0.155,
f"yayılım oranı {r_mis:.3f} — veri dağılımını ISKALAR",
transform=axL.transAxes, ha="center", va="top", fontsize=10.5,
color=COL_WHITE, weight="bold",
bbox=dict(boxstyle="round,pad=0.4", fc=COL_ACCENT, ec="none"))
apply_style(axL)
axL.legend(loc="upper left", fontsize=8.5, framealpha=0.9)
# --- SAĞ: KLD-hizalı (latent standardize → örnekler veri yayılımıyla örtüşür) ---
axR.scatter(data[:, 0], data[:, 1], s=22, color=COL_SLATE_400, alpha=0.45,
edgecolors="none", zorder=2, label="veri dağılımı")
axR.scatter(gen_ali[:, 0], gen_ali[:, 1], s=26, color=COL_PRIMARY, alpha=0.8,
edgecolors=COL_WHITE, linewidths=0.4, zorder=3, label="üretilen (KLD-hizalı)")
axR.set_title("KLD-hizalı: latent standardize\n"
"(prior örnekleri veri manifoldunu doldurur)",
fontsize=11.5, color=COL_TEXT, weight="bold")
axR.text(0.5, -0.155,
f"oran {r_ali:.3f} ≈ 1 — veri yayılımıyla ÖRTÜŞÜR",
transform=axR.transAxes, ha="center", va="top", fontsize=10.5,
color=COL_WHITE, weight="bold",
bbox=dict(boxstyle="round,pad=0.4", fc=COL_CYAN_700, ec="none"))
apply_style(axR)
axR.legend(loc="upper left", fontsize=8.5, framealpha=0.9)
for ax in (axL, axR):
ax.set_xlim(-lim, lim)
ax.set_ylim(-lim, lim)
ax.set_aspect("equal", adjustable="box")
# Açıklama notu — figürün altına, iki paneli kuşatan tek mesaj
fig.text(0.5, -0.02,
"KLD'nin işi tam bu hizalama: latent ~N(0,1) olursa prior'dan örnekleyip "
"decode etmek GERÇEKÇİ üretim verir; AE'de (L15) bu garanti yok.\n"
"Lineer/PCA dünyasında gösterildi — gerçek VAE aynı ilkenin öğrenilmiş hâli.",
ha="center", va="top", fontsize=9.5, color=COL_CYAN_800, style="italic")
plt.tight_layout()
plt.show()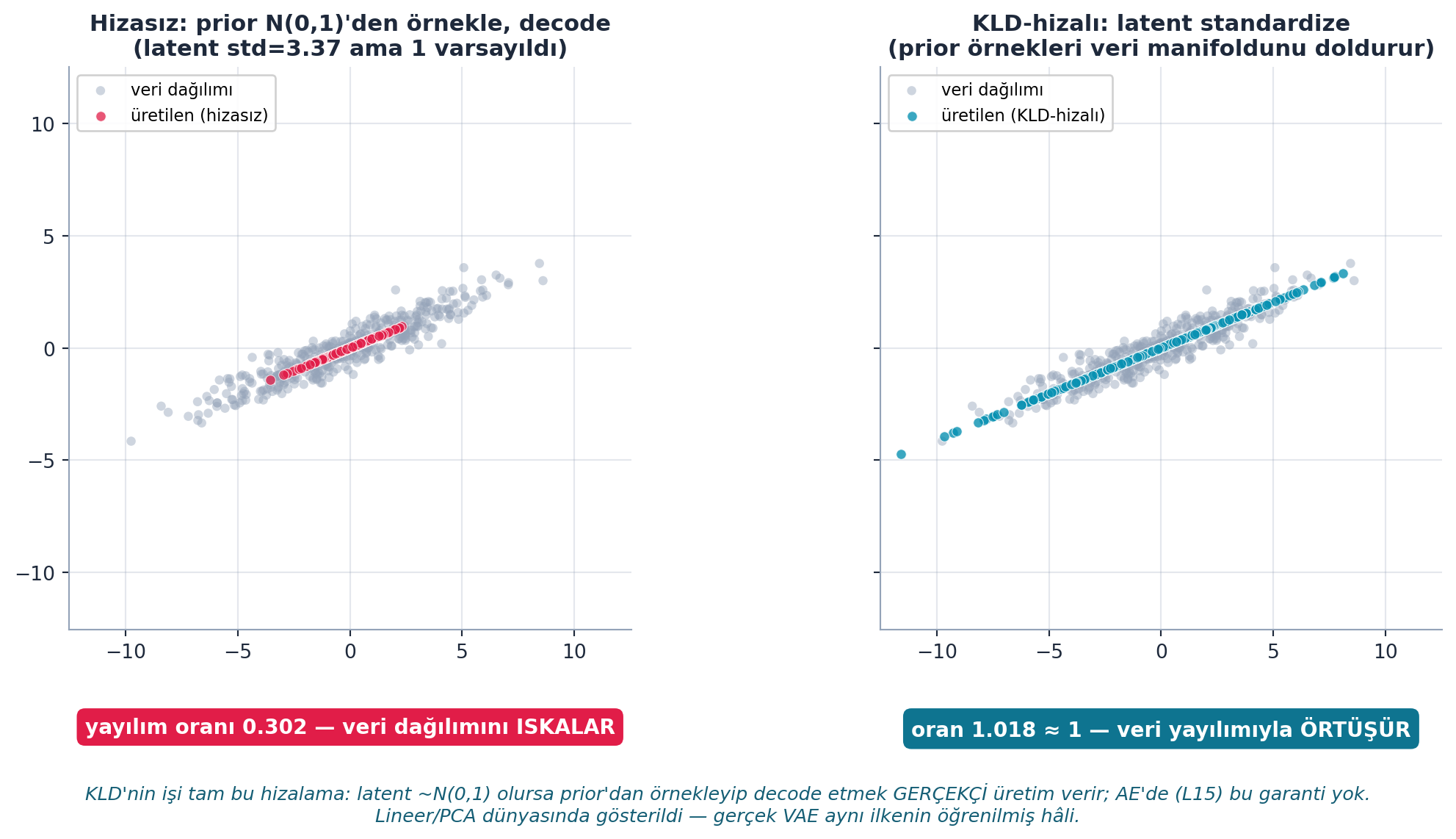
Şimdi hızı: Şekil 28.5 piksel uzayı (786K eleman) ile latent uzay (16K eleman) arasındaki farkı canlı benchmarkla ölçer. Boyut farkı 48×; render anında ölçülen hızlanma daha da büyüktür (~117×) çünkü küçük latent dizi CPU cache’ine sığar (figür bu süper-lineer ölçümü dürüstçe not eder — asıl mesaj 48× boyut). Diffusion’ın YÜZLERCE U-Net çağrısı bu küçük uzayda koşar; Stable Diffusion’ı tek GPU’da çalışır kılan tasarım kararı tam budur — DALL·E 2 / Imagen piksel uzayında üretirken.
Kod
# Render ANINDA ölçülür (perf_counter): aynı eleman-işlem zinciri piksel vs latent
d = E.latent_speed_demo()
labels = [
f"piksel uzayı 512×512×3 = {d['n_pixel']:,} eleman",
f"latent 64×64×4 = {d['n_latent']:,} eleman",
]
times = [d["t_pixel_ms"], d["t_latent_ms"]]
bar_colors = [COL_ROSE_500, COL_PRIMARY]
fig, ax = plt.subplots(figsize=(10.5, 4.8))
ypos = np.arange(len(labels))
bars = ax.barh(ypos, times, color=bar_colors, height=0.5, zorder=3,
edgecolor=COL_WHITE, linewidth=1.5)
ax.set_xscale("log")
ax.set_yticks(ypos)
ax.set_yticklabels(labels, fontsize=10.5, color=COL_TEXT, weight="bold")
ax.invert_yaxis()
ax.set_xlabel("işlem başına süre (ms, log-skala)", fontsize=11)
ax.set_title("Aynı işlem zinciri: piksel uzayı vs latent uzay",
fontsize=12.5, color=COL_CYAN_700, weight="bold", pad=12)
apply_style(ax)
ax.grid(True, axis="x", alpha=0.25, color=COL_SLATE_400)
ax.grid(False, axis="y")
# çubukların ucuna süre etiketi (piksel: ms, latent: 3 hane)
fmts = [f"{d['t_pixel_ms']:.1f} ms / işlem", f"{d['t_latent_ms']:.3f} ms"]
for rect, t, lab in zip(bars, times, fmts):
ax.annotate(lab,
xy=(rect.get_width(), rect.get_y() + rect.get_height() / 2),
xytext=(8, 0), textcoords="offset points",
ha="left", va="center", fontsize=10.5,
color=COL_TEXT, weight="bold")
ax.set_xlim(d["t_latent_ms"] * 0.4, d["t_pixel_ms"] * 6.0)
# --- Rozet: boyut oranı + ölçülen hızlanma ---
ax.text(0.97, 0.90,
f"boyut 48×, ölçülen ~{d['speedup']:.0f}×",
transform=ax.transAxes, ha="right", va="center",
fontsize=12, weight="bold", color=COL_CYAN_800,
bbox=dict(boxstyle="round,pad=0.45", fc=COL_BG, ec=COL_PRIMARY, lw=2.0))
# --- Dürüstlük notu: süper-lineer ölçüm + asıl mesaj ---
ax.text(0.5, -0.30,
"Ölçüm süper-lineer (küçük dizi CPU cache'ine sığar) — asıl mesaj 48× boyut farkı:\n"
"diffusion'ın YÜZLERCE U-Net çağrısı bu küçük uzayda koşar; SD'yi tek GPU'da çalışır\n"
"kılan tasarım kararı (DALL·E 2 / Imagen piksel uzayında üretirken).",
transform=ax.transAxes, ha="center", va="top", fontsize=9.5,
style="italic", color=COL_SLATE_400, wrap=True)
# Howard 1:32:28
ax.text(0.5, -0.56,
"\"Latent uzayda çalışmak, tüm diffusion'ı küçük bir uzayda yapmamızı sağlar.\""
" — J. Howard, 1:32:28",
transform=ax.transAxes, ha="center", va="top", fontsize=9,
color=COL_CYAN_700, weight="bold")
plt.tight_layout()
plt.show()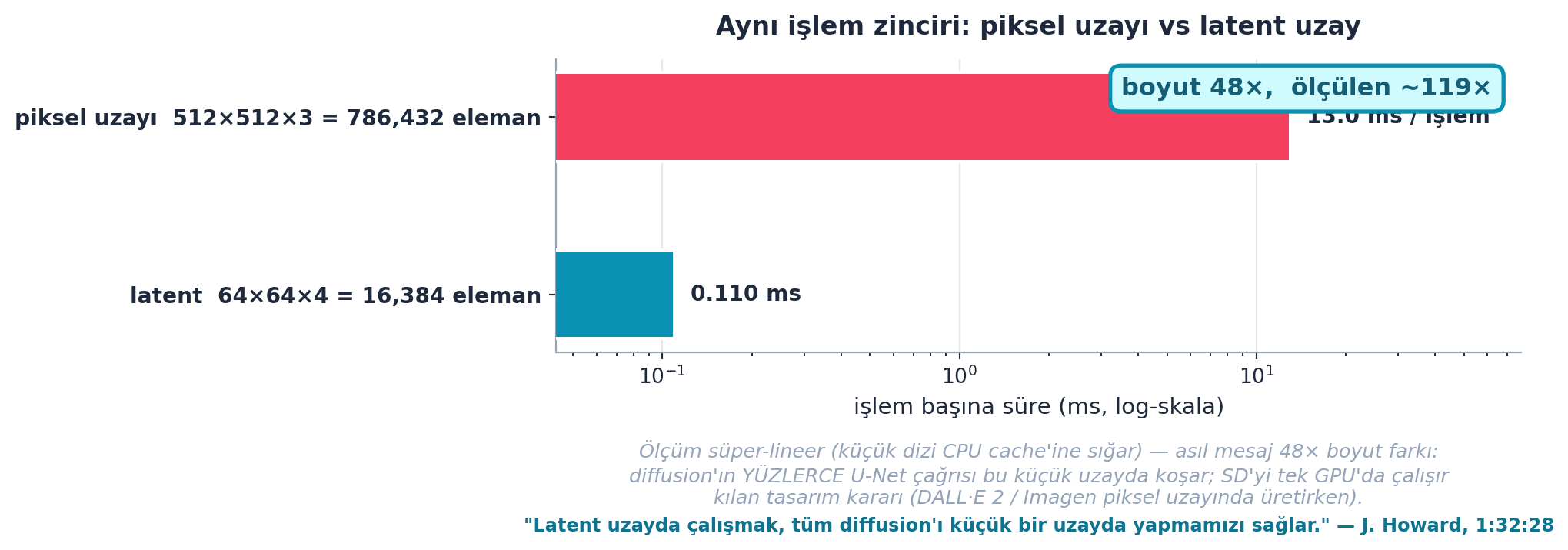
İpucuBuilder Notu — Latent Uzay: SD’yi Tek GPU’da Çalışır Kılan Karar
- İleriye: Latent uzayda çalışma, Stable Diffusion’ı (DALL·E 2/Imagen’in aksine piksel uzayında değil) tek GPU’da çalışır kılan ana tasarım kararıdır.
- Sayısal kanıt: Boyut 48× küçük (786K → 16K); canlı ölçüm ~117× (cache etkisiyle süper-lineer, dürüst not). Hizalama: hizasız oran 0.302 (ıskalar) vs hizalı 1.018 (örtüşür); latent std 3.37.
28.7 6. AutoencoderKL: SD’nin VAE’si
Howard, önceden eğitilmiş bir VAE — Stability AI’nin AutoencoderKL’i — kullanır (kendi VAE’mizi de kurduk, ama SD’nin VAE’si yüksek kaliteli). Görüntüleri latent’e kodlar (vae.encode), latent’leri görüntüye çözer (vae.decode). Latent diffusion için altyapı budur.
from diffusers import AutoencoderKL
vae = AutoencoderKL.from_pretrained("stabilityai/sd-vae-ft-ema").cuda().requires_grad_(False)
xe = vae.encode(xb.cuda()) # görüntü → latent dağılımı
xs = xe.latent_dist.mean # latent (ortalama)
xd = vae.decode(xs)['sample'] # latent → görüntü
İpucuBuilder Notu — AutoencoderKL: SD’nin Kendi VAE’si
- Geriye (Ders 9): Ders 9’da SD pipeline’ı bu VAE’yi içeride kullanıyordu (786K piksel → 16K latent); şimdi onu doğrudan, açıkça kullanıyoruz.
- Sezgi:
latent_dist.meandağılımın ortalamasını alır — eğitim için latent’i tek bir tensöre indirir;requires_grad_(False)ile VAE donar, sadece diffusion U-Net eğitilir.
28.8 7. Latent Diffusion: Diffusion Latent Uzayda
Anahtar adım: tüm görüntüleri VAE ile latent’e kodla, sonra diffusion’ı (DDPM/Karras) latent uzayda eğit. Gürültü latent’lere eklenir, U-Net latent gürültüsünü tahmin eder, örnekleme latent üretir; en sonda VAE decoder latent’i görüntüye çevirir. Diffusion mekaniği aynı (L19-22), sadece uzay değişti: piksel değil latent.
# tüm veriyi latent'e kodla (bir kez), sonra latentlerde diffusion eğit
a[i:i+n] = vae.encode(b.cuda()).latent_dist.mean.cpu().numpy()Şekil 28.6 bu hattı üç katmanda gösterir: hazırlık (BİR KEZ) tüm görüntüleri VAE encoder ile latent’e (64×64×4) kodlar, diske yazar; eğitim (latent uzayda) latent + DDPM noisify → EmbUNetModel (4 kanal) gürültü tahmini → MSE (AdamW + OneCycle + MixedPrecision, hepsi önceki derslerden); örnekleme rastgele latent gürültü → Karras sampler (L22) ×N adım → temiz latent → VAE decoder → görüntü. Anahtar: decode YALNIZ SONDA — diffusion mekaniği AYNI (L19-22), tek fark uzay piksel değil latent.
Kod
fig, ax = plt.subplots(figsize=(12, 6))
ax.set_xlim(0, 24)
ax.set_ylim(0, 12)
ax.axis("off")
# === ÜST: hazırlık (BİR KEZ) ====================================================
ax.text(0.4, 11.4, "hazırlık (BİR KEZ)", ha="left", va="center",
fontsize=11, weight="bold", color=COL_ACCENT)
yT = 10.0
viz.boxed_node(ax, 3.0, yT, 4.0, 1.5, "tüm görüntüler",
fc=COL_BG_ROSE, ec=COL_ACCENT, fontsize=10)
viz.boxed_node(ax, 9.0, yT, 3.2, 1.5, "VAE encoder",
fc=COL_WHITE, ec=COL_PRIMARY, fontsize=10.5)
viz.boxed_node(ax, 15.4, yT, 4.4, 1.5, "latent'ler\n(64×64×4) → diske",
fc=COL_BG, ec=COL_PRIMARY, fontsize=9.5)
viz.arrow_between(ax, (5.0, yT), (7.4, yT), color=COL_ACCENT)
viz.arrow_between(ax, (10.6, yT), (13.2, yT), color=COL_PRIMARY)
# === ORTA: eğitim (latent uzayda) ===============================================
ax.text(0.4, 8.0, "eğitim (latent uzayda)", ha="left", va="center",
fontsize=11, weight="bold", color=COL_CYAN_700)
yM = 6.6
viz.boxed_node(ax, 3.0, yM, 4.0, 1.5, "latent +\nDDPM noisify",
fc=COL_BG, ec=COL_PRIMARY, fontsize=9.5)
viz.boxed_node(ax, 9.4, yM, 4.6, 1.5, "EmbUNetModel\n(4 kanal)\ngürültü tahmini",
fc=COL_CYAN_50, ec=COL_CYAN_700, fontsize=9.5)
viz.boxed_node(ax, 15.4, yM, 3.0, 1.5, "MSE",
fc=COL_BG_ROSE, ec=COL_ACCENT, fontsize=11)
viz.arrow_between(ax, (5.0, yM), (7.1, yM), color=COL_PRIMARY)
viz.arrow_between(ax, (11.7, yM), (13.9, yM), color=COL_PRIMARY)
ax.text(15.4, 5.3,
"AdamW + OneCycle + MixedPrecision\nHEPSİ önceki derslerden (L16–22)",
ha="center", va="center", fontsize=8.5, weight="bold",
color=COL_SLATE_400, style="italic")
# === ALT: örnekleme =============================================================
ax.text(0.4, 4.0, "örnekleme", ha="left", va="center",
fontsize=11, weight="bold", color=COL_CYAN_700)
yB = 2.6
viz.boxed_node(ax, 2.8, yB, 3.6, 1.5, "rastgele\nlatent gürültü",
fc=COL_BG, ec=COL_PRIMARY, fontsize=9.5)
viz.boxed_node(ax, 7.6, yB, 3.4, 1.5, "Karras sampler\n(L22) ×N adım",
fc=COL_CYAN_50, ec=COL_CYAN_700, fontsize=9.5)
viz.boxed_node(ax, 12.4, yB, 3.0, 1.5, "temiz LATENT",
fc=COL_BG, ec=COL_PRIMARY, fontsize=9.5)
viz.boxed_node(ax, 16.8, yB, 3.0, 1.5, "VAE decoder",
fc=COL_WHITE, ec=COL_PRIMARY, fontsize=10)
viz.boxed_node(ax, 21.4, yB, 3.4, 1.5, "görüntü",
fc=COL_BG_ROSE, ec=COL_ACCENT, fontsize=10.5)
viz.arrow_between(ax, (4.6, yB), (5.9, yB), color=COL_PRIMARY)
viz.arrow_between(ax, (9.3, yB), (10.9, yB), color=COL_PRIMARY)
viz.arrow_between(ax, (13.9, yB), (15.3, yB), color=COL_PRIMARY)
viz.arrow_between(ax, (18.3, yB), (19.7, yB), color=COL_ACCENT)
ax.text(16.8, 0.95, "decode YALNIZ SONDA\n(Howard 1:32:28)",
ha="center", va="center", fontsize=8.5, weight="bold",
color=COL_ACCENT, style="italic")
# === SAĞ mini-not ===============================================================
ax.text(22.6, 8.4,
"diffusion mekaniği\nAYNI (L19–22);\ntek fark UZAY:\npiksel değil latent",
ha="center", va="center", fontsize=9.0, weight="bold",
color=COL_CYAN_800,
bbox=dict(boxstyle="round,pad=0.45", fc=COL_CYAN_50,
ec=COL_CYAN_400, lw=1.8))
plt.tight_layout()
plt.show()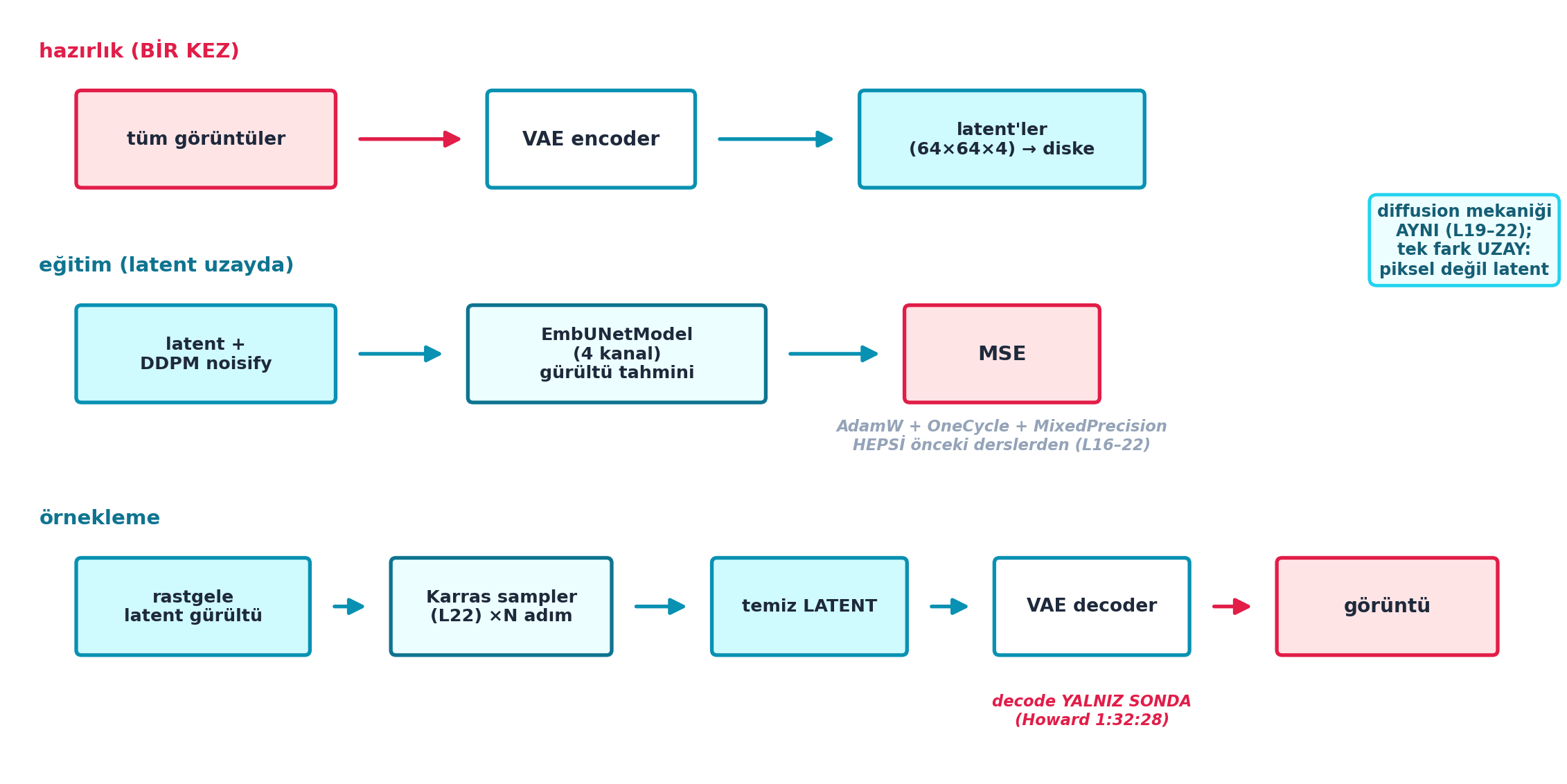
İpucuBuilder Notu — Latent Diffusion = SD’nin Tanımı
- Geriye (Ders 19-22): DDPM/Karras tam aynı; tek fark girdi latent (4 kanal, küçük). “Diffusion latent uzayda” = Stable Diffusion’ın tanımı.
- Sezgi: Encode bir kez yapılır (latent’ler diske cache’lenir), decode yalnız sonda — diffusion’ın yüzlerce adımı tamamen küçük latent uzayda koşar, hızın asıl kaynağı budur.
28.9 8. Latent Diffusion Eğitimi
Latent diffusion modeli, foundations’ın tüm araçlarıyla eğitilir: latent’lere koşullu bir U-Net (EmbUNetModel, 4 kanal giriş/çıkış), DDPM gürültüleme, AdamW + OneCycle scheduler, mixed precision. Eğitim 25 epoch; her parça önceki derslerden. Bu tek satır eğitim, kursun foundations bölümünün doruğudur: baştan kurduğumuz her şey burada tek bir çağrıda birleşir.
cbs = [DeviceCB(), ProgressCB(plot=True), MetricsCB(), BatchSchedCB(sched), MixedPrecision()]
model = EmbUNetModel(in_channels=4, out_channels=4, nfs=(128, 256, 512, 768))
# DDPM noisify + Karras sampler latent uzayda
İpucuBuilder Notu — Foundations DORUK: Tek Eğitim Satırı = L16-24’ün Hepsi
- Geriye (Ders 16-24) — DORUK: Bu tek satır eğitim, baştan kurduğumuz HER ŞEYİ birleştirir: Learner+callback (L16), init (L17), Adam/OneCycle (L18), DDPM (L19), mixed precision (L20), Karras (L22), U-Net (L23), attention (L24). miniai’nin varlık sebebi.
- Sezgi:
cbslistesi callback’lerin (L16) gücüdür;EmbUNetModel(in_channels=4)latent’in 4 kanalına uyar; tek satır = onlarca ders. Foundations’ın meyvesi tam burada toplanır.
28.10 9. Text Conditioning (CLIP — Kısmen Sonraki Kursa)
Tam Stable Diffusion, üretimi bir metin promptuna koşullar: CLIP text encoder metni bir gömüye çevirir, U-Net bu gömüyle cross-attention (L24) yapar — query görüntüden, key/value metinden. Howard bunun mekanizmasını (cross-attention) kurar ama tam CLIP eğitimini bir sonraki kursa bırakır: “bir parça sonraki kursa kaldı”.
“there’s going to be one piece left for the next part of the course, which is the CLIP embeddings.” — Howard, 0:23
İpucuBuilder Notu — Cross-Attention = L24 Attention’ın Koşullu Hâli
- Geriye (Ders 24): Cross-attention = L24 attention’ın koşullu hâli; query görüntü, key/value metin. Text→image’ın mekanizması tam budur.
- Sezgi: Self-attention’da Q/K/V aynı girdiden gelir; cross-attention’da query görüntüden, key/value metin gömüsünden — aynı
softmax(QKᵀ/√d)Vmatematiği, farklı kaynak. Tek eksik parça CLIP eğitimi (sonraki kurs).
28.11 10. Stable Diffusion’ın Tam Mimarisi
Artık SD’nin üç bileşeni de net: VAE (piksel ↔︎ latent sıkıştırma), latent U-Net (gürültü tahmincisi, ResBlock + attention), CLIP (metin koşullama, cross-attention ile). Ders 9’da kara kutu olan üçlü, artık her parçası anlaşılmış, çoğu sıfırdan kurulmuş bir sistem. Stable Diffusion = latent diffusion + text conditioning.
Şekil 28.7 bu mimariyi her parçanın kurulduğu dersi işaretleyerek gösterir: CLIP text encoder (kesikli çerçeve — eğitimi sonraki kursa) → cross-attention (query görüntüden, key/value metinden, L24) → latent U-Net (ResBlock L18 + attention L24, Karras sampler L22) → temiz latent → VAE decoder (L25) → çıktı görüntü. Üst başlık halkayı vurgular: “Ders 9’da bu üçlüyü KULLANDIK → L25’te KURDUK”. Kara kutu açıldı.
Kod
fig, ax = plt.subplots(figsize=(12, 6))
ax.set_xlim(0, 12)
ax.set_ylim(0, 6)
ax.axis("off")
# --- Halka vurgusu (üst başlık) ---
ax.text(6.0, 5.72,
"Ders 9'da bu üçlüyü KULLANDIK → L25'te KURDUK",
ha="center", va="center", fontsize=12, weight="bold",
color=COL_ROSE_500)
ax.plot([1.4, 10.6], [5.42, 5.42], color=COL_ROSE_400, lw=1.4, alpha=0.7)
def badge(ax, x, y, text):
"""Ders numarası rozeti (küçük rose etiket)."""
ax.text(x, y, text, ha="center", va="center", fontsize=8.5,
weight="bold", color=COL_WHITE, zorder=6,
bbox=dict(boxstyle="round,pad=0.28", fc=COL_ACCENT,
ec=COL_ACCENT, lw=0))
# --- SOL: CLIP text encoder (kesikli çerçeve — eğitimi sonraki kursa) ---
clip = FancyBboxPatch(
(0.45, 3.25), 2.85, 1.55,
boxstyle="round,pad=0.02,rounding_size=0.08",
fc=COL_BG, ec=COL_SLATE_400, linewidth=2.0,
linestyle="--", zorder=2,
)
ax.add_patch(clip)
ax.text(1.875, 4.02,
"CLIP text encoder\nprompt → metin gömüsü\n(tam eğitimi sonraki kursa)",
ha="center", va="center", fontsize=9.0, color=COL_TEXT,
weight="bold", zorder=3)
badge(ax, 1.875, 4.66, "CLIP")
# --- MERKEZ: latent U-Net (gürültü tahmincisi) ---
boxed_node(ax, 6.0, 4.0, 3.7, 1.75,
"latent U-Net\nResBlock (L18) + attention (L24)\ngürültü tahmincisi\nKarras sampler döngüsü (L22)",
fc=COL_CYAN_50, ec=COL_PRIMARY, tc=COL_TEXT,
fontsize=9.5, lw=2.4)
badge(ax, 6.0, 4.74, "L18 · L22 · L24")
# --- ALT-SAĞ: VAE decoder ---
boxed_node(ax, 9.55, 1.75, 2.85, 1.35,
"VAE decoder\nlatent → görüntü",
fc=COL_BG_ROSE, ec=COL_ROSE_500, tc=COL_TEXT,
fontsize=9.5, lw=2.2)
badge(ax, 9.55, 2.30, "L25")
# --- ÇIKTI: görüntü ---
boxed_node(ax, 9.55, 0.10, 2.0, 0.78,
"çıktı görüntü",
fc=COL_WHITE, ec=COL_CYAN_700, tc=COL_TEXT,
fontsize=9.5, lw=1.8)
# --- Cross-attention oku: CLIP → U-Net (rose, etiketli) ---
arrow_between(ax, (3.30, 4.05), (4.15, 4.0),
color=COL_ACCENT, lw=2.4, mutation_scale=20, shrink=4)
ax.text(3.72, 4.62,
"cross-attention\nquery görüntüden,\nkey/value metinden (L24)",
ha="center", va="center", fontsize=8.2, color=COL_ACCENT,
weight="bold", zorder=4)
# --- U-Net → VAE decoder (temiz latent) ---
arrow_between(ax, (7.0, 3.18), (8.85, 2.43),
color=COL_PRIMARY, lw=2.2, mutation_scale=18, shrink=8)
ax.text(8.55, 3.10, "temiz latent",
ha="center", va="center", fontsize=8.2, color=COL_CYAN_700,
weight="bold", zorder=4)
# --- VAE decoder → çıktı ---
arrow_between(ax, (9.55, 1.07), (9.55, 0.49),
color=COL_ROSE_500, lw=2.2, mutation_scale=18, shrink=6)
# --- U-Net iç döngü vurgusu (sampler döngüsü) ---
loop = FancyArrowPatch(
(4.55, 4.92), (7.45, 4.92),
connectionstyle="arc3,rad=-0.55",
arrowstyle="-|>", mutation_scale=15,
color=COL_CYAN_400, linewidth=1.8, linestyle=(0, (4, 2)),
shrinkA=2, shrinkB=2, zorder=1,
)
ax.add_patch(loop)
plt.tight_layout()
plt.show()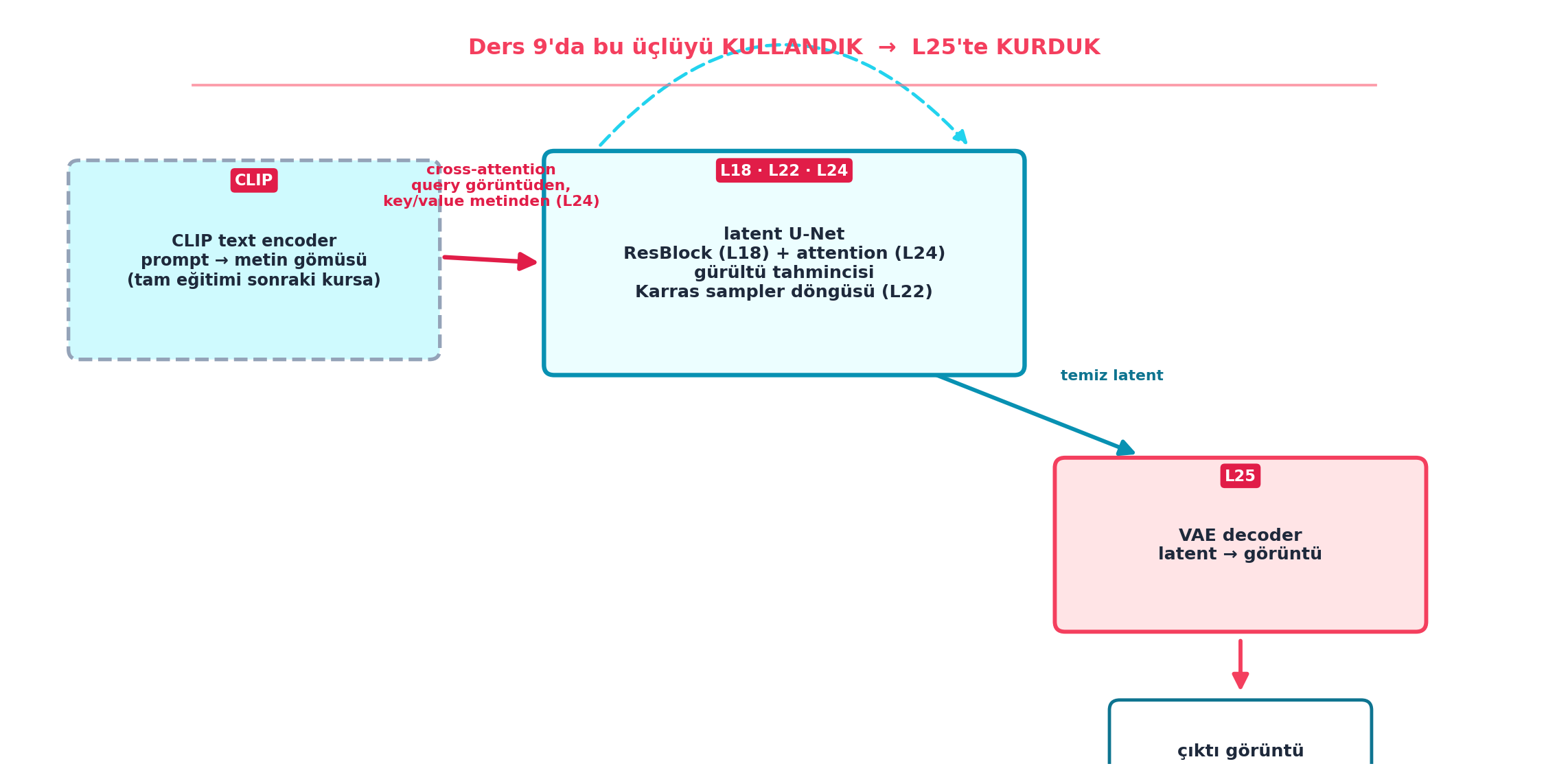
İpucuBuilder Notu — SD: Artık Sihir Değil, Kurduğumuz Parçaların Birleşimi
- Geriye (Ders 9): Ders 9’da “üç bileşen” diye tanıttığımız U-Net/VAE/CLIP — şimdi her birini içeriden biliyoruz; SD artık sihir değil, kurduğumuz parçaların birleşimi.
- Sezgi: Figürdeki her ders rozeti (L18, L22, L24, L25) bir foundations dersine işaret eder; SD’nin hiçbir parçası “büyü” değil — hepsi elle kurduğumuz mekanizmalar.
28.12 11. “Yeniden Kur, Sonra Kullan” Döngüsü Kapanır
Bu dersin pedagojik zaferi: kursun ilk üretken dersinden son dersine tam halka. Ders 9-10’da Stable Diffusion’ı kullandık ve “from the foundations” sözü verdik — “kütüphanenin altındaki büyüyü kendimiz kuracağız”. 16 ders foundations (matmul → backprop → Learner → init → optimizer → ResNet → DDPM → Karras → U-Net → attention) sonra, L25’te o sözü tuttuk: SD’yi sıfırdan kurduk. “Yeniden kur, sonra kullan” döngüsü tamamlandı. Builder içgörüsü: gerçek anlama, bir aracı hem kullanabilmek hem sıfırdan kurabilmektir; o zaman “sihir” kaybolur, geriye birleştirilmiş temel parçalar kalır.
Şekil 28.8 kursun finalini tek bir sentez figüründe toplar: üstte halka (Ders 9 KULLAN → Ders 10-24 her parçayı SIFIRDAN KUR → Ders 25 SD’yi KUR — HALKA KAPANDI); solda diffusion evrimi (DDPM 1000 adım → DDIM ~50 → Karras ~20 → latent 48× küçük); sağda üç-kurs buluşması (Karpathy kodla, NYU çerçeveledi, fast.ai inşa etti); merkezde ana tez — sihir yok, katmanlanmış temeller var; altta ileri ufuk (CLIP, SDXL, ControlNet, production). Bu figür, §11-15’in tüm mesajını tek bakışta birleştirir.
Kod
fig, ax = plt.subplots(figsize=(13, 7))
ax.set_xlim(0, 13)
ax.set_ylim(0, 7)
ax.axis("off")
ax.set_facecolor(COL_WHITE)
# --- MERKEZ: ana tez — sihir yok, katmanlanmış temeller ---
boxed_node(
ax, 6.5, 4.55, 6.0, 1.45,
"KARMAŞIK SİSTEMLER = SAĞLAM TEMELLERİN BİRLEŞİMİ\n"
"Stable Diffusion'da SİHİR YOK — katman katman kurulan\n"
"matematik, fizik ve mantık var\n"
"«Tuning is physics, mathematics, and logic — not magic»",
fc=COL_BG, ec=COL_CYAN_800, tc=COL_CYAN_800,
fontsize=11.0, lw=2.8,
)
# --- ÜST HALKA (rose, kalın): Ders 9→L25 «yeniden kur, sonra kullan» kapandı ---
boxed_node(
ax, 6.5, 6.25, 11.6, 0.95,
"Ders 9: SD'yi KULLAN → Ders 10–24: her parçayı SIFIRDAN KUR "
"(matmul→backprop→Learner→init→optimizer→ResNet→DDPM→DDIM→Karras→U-Net→attention) "
"→ Ders 25: SD'yi KUR — HALKA KAPANDI",
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_ACCENT,
fontsize=9.4, lw=2.8,
)
arrow_between(ax, (6.5, 5.77), (6.5, 5.28),
color=COL_ACCENT, lw=2.2, mutation_scale=16)
# --- SOL (cyan): diffusion evrimi ---
left_x, left_w, left_h = 2.55, 4.5, 0.62
left_ys = [4.95, 4.1, 3.25, 2.4]
left_texts = [
"DDPM (L19): 1000 adım",
"DDIM (L21): ~50 adım",
"Karras (L22): ~20 adım",
"latent (L25): 48× küçük uzay",
]
for y, t in zip(left_ys, left_texts):
boxed_node(ax, left_x, y, left_w, left_h, t,
fc=COL_CYAN_50, ec=COL_PRIMARY, tc=COL_CYAN_800,
fontsize=9.2, lw=1.8)
# evrim oklarını ardışık zincir olarak çiz (üstten alta)
for y_top, y_bot in zip(left_ys[:-1], left_ys[1:]):
arrow_between(ax, (left_x, y_top - left_h / 2), (left_x, y_bot + left_h / 2),
color=COL_PRIMARY, lw=1.6, mutation_scale=12, shrink=2)
# --- SAĞ (rose): üç-kurs buluşması ---
right_x, right_w, right_h = 10.45, 4.5, 0.78
right_ys = [4.95, 4.0, 3.05]
right_texts = [
"Karpathy: attention'ı KODLA kurdu\n(bottom-up)",
"NYU: üretken paradigmaları\nÇERÇEVELEDİ",
"fast.ai: çalışan SD'yi\nİNŞA ETTİ",
]
for y, t in zip(right_ys, right_texts):
boxed_node(ax, right_x, y, right_w, right_h, t,
fc=COL_BG_ROSE, ec=COL_ACCENT, tc=COL_ACCENT,
fontsize=9.0, lw=1.8)
arrow_between(ax, (9.5, 4.5), (right_x - right_w / 2, y),
color=COL_ACCENT, lw=1.6, mutation_scale=13)
ax.text(10.45, 2.35, "üç bakış → tek sistemde birleşir",
ha="center", va="center",
fontsize=8.8, color=COL_ACCENT, weight="bold", style="italic")
# --- ALT (ileri): bir sonraki ufuk ---
boxed_node(
ax, 6.5, 1.05, 10.2, 0.9,
"İLERİYE: CLIP (sonraki kurs) · SDXL / ControlNet / LoRA · production dağıtım\n"
"temeller sağlam → ileri teknikler artık kara kutu değil",
fc=COL_WHITE, ec=COL_SLATE_400, tc=COL_TEXT,
fontsize=9.2, lw=1.6,
)
arrow_between(ax, (6.5, 3.82), (6.5, 1.55),
color=COL_SLATE_400, lw=1.7, mutation_scale=14)
# --- başlık şeritleri ---
ax.text(2.55, 5.55, "diffusion EVRİMİ", ha="center", va="center",
fontsize=10, color=COL_PRIMARY, weight="bold")
ax.text(10.45, 5.55, "ÜÇ-KURS BULUŞMASI", ha="center", va="center",
fontsize=10, color=COL_ACCENT, weight="bold")
plt.tight_layout()
plt.show()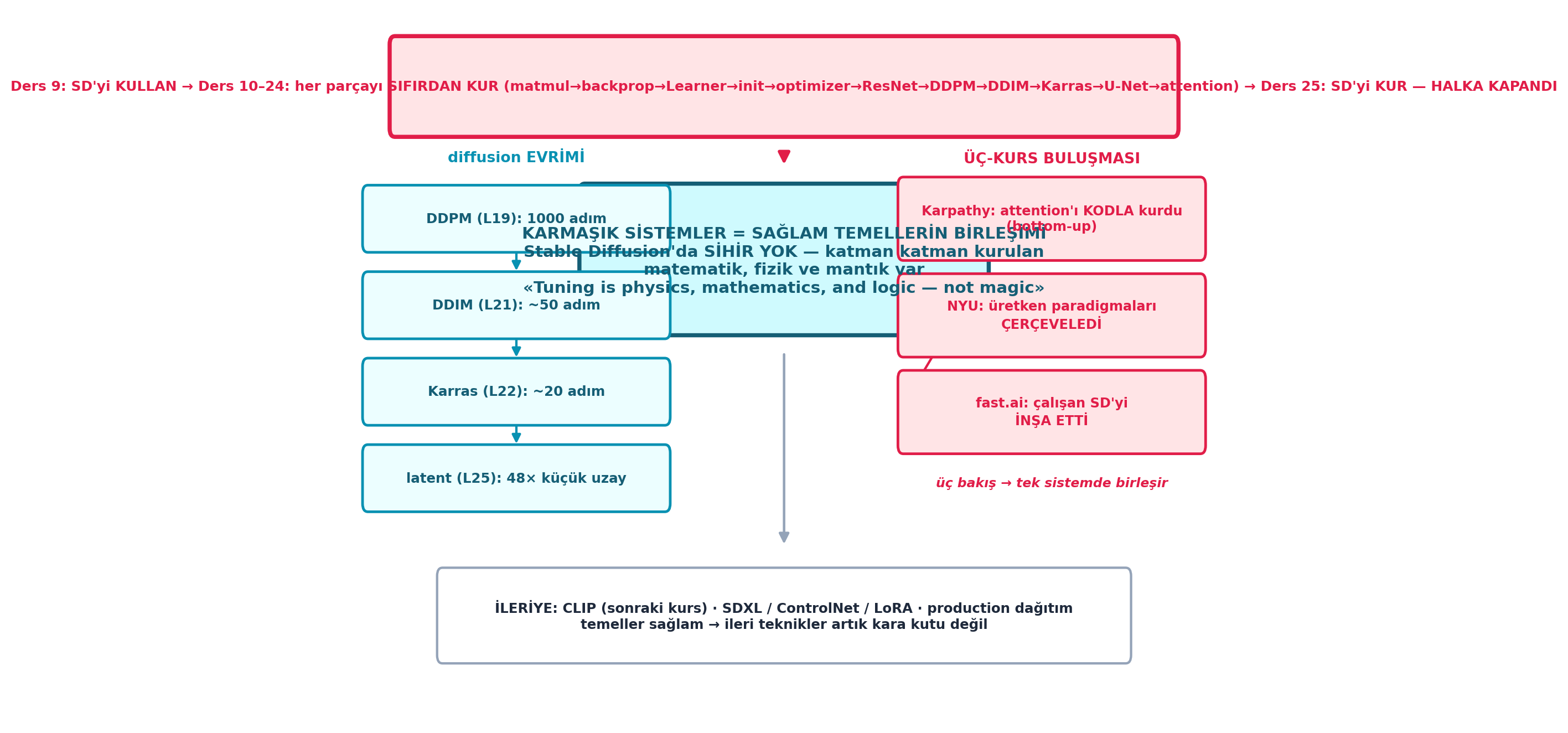
İpucuBuilder Notu — Halka: Ders 9 (kullan) → L25 (kur)
- Geriye (Ders 10): Ders 10’daki “yeniden kur, sonra kullan” kuralı, tüm Part 2’nin sözüydü; L25 onu yerine getirir — Ders 9 (kullan) → L25 (kur) halkası.
- Sezgi: Halka iki yönlüdür: Ders 9’da kullandığımız her satırı artık anlayabiliyoruz, ve sıfırdan kurabiliyoruz; gerçek ustalık ikisinin birleşimidir.
28.13 12. Tüm Parçaların Birleşimi: Diffusion Evrimi
L25, diffusion evriminin son halkasıdır: DDPM (L19, piksel, 1000 adım) → DDIM (L21, deterministik, ~50 adım) → Karras (L22, sürekli σ, Heun, ~20 adım) → latent diffusion (L25, latent uzay, yüksek çözünürlük + pratik hız). Her adım bir öncekinin üstüne kuruldu; latent diffusion hepsini birleştirip gerçek üretime taşır. Bu evrim, Şekil 28.8’in sol şeridinde görsel olarak da işaretlidir.
İpucuBuilder Notu — Diffusion Evrimi: DDPM → DDIM → Karras → Latent
- İleriye: Latent diffusion + Karras sampler + cross-attention = modern text→image (SD, SDXL); buradan SDXL/ControlNet/LoRA’ya doğal devam.
- Sezgi: Evrim adım sayısını düşürdü (1000 → 50 → 20) ve uzayı küçülttü (piksel → latent 48×); her iyileştirme bir öncekini saklı tutar — DDPM’in gürültüleme mantığı latent diffusion’da hâlâ kalbidir.
28.14 13. Phase 2 Buluşması: Üç Kurs Tek Noktada
L25, Phase 2’nin üç büyük kursunun (Karpathy + NYU + fast.ai) buluşmasıdır. Karpathy: transformer/attention’ı (L24) sıfırdan kurdu — SD’nin koşullama mekanizması. NYU (LeCun): VAE/EBM/üretken paradigmaları kavramsal kurdu — diffusion’ın yerini gösterdi. fast.ai: hepsini çalışan koda döktü, gerçek SD’yi inşa etti. Üç bakış (kodla-kur, kavramsal-çerçevele, uygulamayla-bağla) tek bir sistemde birleşir — Şekil 28.8’in sağ şeridi bu buluşmayı işaretler.
İpucuBuilder Notu — Üç Kurs Buluşması (Strang D27 dört-tanık emsali)
- Karşılaştırma (Strang D27 dört-tanık): 18.065 D27’de backprop’u dört kaynak (Strang/Karpathy/fast.ai/NYU) doğrulamıştı; L25 latent diffusion da benzer bir halka buluşması — ama bu kez inşa halkası (Ders 9 kullan → L25 kur), kavram halkası değil.
- Sezgi: D27 dört-tanık kavram buluşmasıydı (aynı backprop, dört bakış); L25 inşa buluşmasıdır (aynı SD, üç kurs onu farklı yönlerden kurdu). İki tür buluşma da aynı dersi verir: temel fikirler kurslar arası tutarlıdır.
28.15 14. Builder İçgörüsü: Foundations’ın Meyvesi
Bu dersin en büyük builder dersi: karmaşık bir sistem, sağlam temellerin birleşimidir. Stable Diffusion korkutucu görünür, ama her parçası foundations’ta kurduğumuz basit fikirlerden ibaret — matris çarpımı, gradient descent, residual, normalizasyon, attention, MSE. “Sihir” yoktur; sadece doğru sırayla birleştirilmiş temel parçalar. Builder olmak, bu parçaları görebilmek ve birleştirebilmektir.
ÖnemliBuilder Notu — Sihir Yok: ‘Tuning is physics’ Paraleli
- Geriye (CLAUDE.md): “Tuning is physics, mathematics, and logic — not magic.” Aynı felsefe: SD de sihir değil; fizik, matematik ve mantığın katmanlanmış birleşimi.
- Sezgi: ECU tuning’de fizik sınırları nasıl aşılamazsa, derin öğrenmede de “büyü” yoktur — her ikisi de gözlemlenebilir, kurulabilir, doğrulanabilir temel parçaların disiplinli birleşimidir. Builder bu parçaları görür.
28.16 15. Kapanış: Yolculuğun Sonu
Ders 25, fast.ai Part 2’yi — ve tüm kursu — tamamladı: Stable Diffusion’ı sıfırdan kurduk. VAE (latent sıkıştırma) + latent diffusion (DDPM/Karras latent uzayda) + cross-attention (metin koşullama). Ders 9’da kullandığımız sistemi, 16 ders foundations sonra kendimiz inşa ettik. “Yeniden kur, sonra kullan” döngüsü tam kapandı; kütüphanenin altındaki büyü artık bizim.
“it’s been an interesting, fun journey.” — Howard, 0:13
ÖnemliBuilder Notu — Kapanış: Foundations Sağlam, Gerisi Uygulama
- İleriye (kurs sonrası): Kalan tek parça CLIP text encoder (sonraki kurs); buradan modern diffusion (SDXL, ControlNet, LoRA, video) ve production’a. Foundations sağlam — gerisi uygulama.
- Çekirdek ders: Artık bir araştırma makalesini okuyup sıfırdan implement edebilecek temele sahipsin; “yeniden kur, sonra kullan” döngüsü ustalığın işaretidir — kütüphanenin altındaki büyü artık senin.
28.17 Bu Dersin Özeti
- SON DERS: Tüm parçaları (DDPM, Karras, U-Net, attention) birleştirip gerçek Stable Diffusion’ı sıfırdan kurmak (giriş).
- VAE: Encoder görüntüyü latent’e sıkıştırır, decoder geri açar; latent’i dağılım (μ, lv) olarak kodlar (VAE).
- Reparameterization: z = μ + exp(0.5·lv)·ε; rastgeleliği ε’ya alıp gradyan akışını korur (9B trick’i; örnek mean ≈ 5, std ≈ 2) (reparameterization).
- VAE loss: KLD (latent ~ normal, KLD(0,0)=0) + reconstruction (BCE); düzgün, örneklenebilir latent uzay (VAE loss).
- Latent uzay: 512×512×3 → 64×64×4 (~48× küçük); hizalama 0.302 (ıskalar) vs 1.018 (örtüşür); diffusion’ı pratik kılar (latent uzay).
- Latent diffusion: Diffusion (DDPM/Karras) piksel yerine latent uzayda; SD’nin tanımı; foundations DORUK (L16-24 tek satırda) (latent diffusion, eğitim).
- Text conditioning: CLIP gömüsü + cross-attention (L24); query görüntü, key/value metin (CLIP sonraki kursa) (text conditioning).
- Halka kapanır: Ders 9 (SD’yi kullandık) → L25 (SD’yi kurduk); “yeniden kur, sonra kullan” tamamlandı; sihir yok, katmanlanmış temeller var (halka, builder içgörü).
ÖnemliTek Bir Cümle
Latent diffusion, bir VAE’nin sıkıştırdığı küçük latent uzayda (~48× daha az hesap) diffusion (DDPM/Karras) yaparak ve metni cross-attention ile koşullayarak Stable Diffusion’ı pratik kılar; Ders 9’da kullandığımız SD’yi 16 ders foundations sonra sıfırdan kurarak “yeniden kur, sonra kullan” döngüsünü — kursun ilk üretken dersinden son dersine — tam kapatır.
28.18 Kontrol Soruları
NotSoru 1: Latent diffusion neden piksel diffusion’dan üstündür?
Cevap:
Piksel uzayında diffusion (DDPM, L19) yüksek çözünürlükte çok pahalıdır: 512×512×3 ≈ 786K boyutlu bir uzayda yüzlerce U-Net çağrısı, hem hesap hem bellek açısından tüketici donanımını aşar. Latent diffusion, önce bir VAE ile görüntüyü çok daha küçük bir latent temsile sıkıştırır (örn. 64×64×4 ≈ 16K, ~48× küçük; Şekil 28.5: boyut 48×, canlı ölçüm ~117× cache etkisiyle), diffusion’ı bu latent uzayda yapar, en sonda VAE decoder ile latent’i tekrar görüntüye çevirir. Diffusion mekaniği aynıdır (gürültü ekle, U-Net’le tahmin et, kademeli kaldır), sadece uzay küçüktür. Sonuç: dramatik hesap tasarrufu, yüksek çözünürlüklü üretimin tek GPU’da mümkün olması. Bu, Stable Diffusion’ı (piksel uzayında çalışan DALL·E 2/Imagen’in aksine) erişilebilir kılan ana tasarım kararıdır (latent uzay).
NotSoru 2: VAE, Ders 15’in autoencoder’ından nasıl farklıdır? Reparameterization neden gerekir?
Cevap:
Ders 15’in autoencoder’ı görüntüyü tek bir latent noktaya kodlar (deterministik). VAE ise latent’i bir dağılıma kodlar — ortalama μ ve log-varyans lv (Şekil 28.2). Bu fark kritiktir: dağılım, latent uzayı düzgün ve örneklenebilir kılar (KL ıraksaması latent’i standart normale çeker; Şekil 28.4: hizasız 0.302 ıskalar, hizalı 1.018 örtüşür), böylece latent uzaydan yeni örnekler üretilebilir (üretken model olur). Ama bir dağılımdan örnek almak (z’yi μ, σ’dan çekmek) türevlenemez — rastgelelik gradyanı keser, eğitim imkânsız olur. Reparameterization trick çözer: z = μ + σ·ε (σ = exp(0.5·lv), ε ~ N(0,I); Şekil 28.3: örnek mean ≈ 5, std ≈ 2). Rastgelelik ε’ya dışarı alınır; μ ve σ deterministik fonksiyonlar olarak kalır, üzerlerinden gradyan akar. Bu tam olarak 9B’de diffusion forward process türevinde kullanılan trick’tir — rastgele bir süreçten türevlenebilir örnekleme (reparameterization).
NotSoru 3: Stable Diffusion’ın üç bileşeni nedir ve her biri hangi derste kuruldu?
Cevap:
(1) VAE (latent sıkıştırma): görüntüyü küçük latent’e kodlar/çözer — sezgisi Ders 15 (autoencoder), VAE hâli ve latent diffusion bu derste (L25). (2) Latent U-Net (gürültü tahmincisi): latent’teki gürültüyü tahmin eder — yapıtaşları Ders 18 (ResBlock), Ders 19/23 (diffusion U-Net), Ders 24 (attention blokları); eğitim Ders 19-22 (DDPM/Karras). (3) CLIP text encoder (metin koşullama): promptu gömüye çevirir, U-Net cross-attention ile (L24) onu kullanır — mekanizma L24/L25’te, tam CLIP eğitimi sonraki kursa. Yani SD = VAE + latent diffusion U-Net + CLIP cross-attention (Şekil 28.7: her parça kurulduğu dersle işaretli). Ders 9’da bu üçlüyü kara kutu olarak kullandık; foundations boyunca her parçayı (matmul, backprop, init, optimizer, ResNet, DDPM, Karras, U-Net, attention) kurduk; L25’te birleştirip SD’yi sıfırdan inşa ettik. “Üç bileşen” artık tam anlaşılmış (tam mimari).
NotSoru 4: ‘Yeniden kur, sonra kullan’ döngüsü bu derste nasıl kapanır? (builder bağlantısı)
Cevap:
Bu döngü, fast.ai Part 2’nin tüm pedagojik omurgasıdır ve L25’te tam kapanır (Şekil 28.8). Başlangıç (Ders 9-10): Stable Diffusion’ı kullandık — pipeline çağırdık, görüntü ürettik, “üç bileşen” diye tanıttık, ve “from the foundations” sözü verdik: “bu kütüphanenin altındaki büyüyü kendimiz, sıfırdan kuracağız” (Ders 10 “yeniden kur, sonra kullan” kuralı). Yolculuk (Ders 11-24): 14 ders boyunca her temel parçayı elle kurduk — matris çarpımı, backprop, Learner/callback, init/norm, optimizer, ResNet, DDPM, DDIM, Karras, super-res U-Net, attention. Kapanış (Ders 25): Tüm bu parçaları VAE + latent uzayla birleştirip Ders 9’da kullandığımız SD’yi kurduk. Halka — kursun ilk üretken dersinden (kullan) son dersine (kur) — tamamlandı. Builder içgörüsü: gerçek anlama, bir aracı hem kullanabilmek hem sıfırdan kurabilmektir; o zaman “sihir” kaybolur, geriye birleştirilmiş temel parçalar kalır. (Karpathy’nin bottom-up’ı ile fast.ai’nin top-down’ı tam burada birleşir: ikisi de aynı SD’yi farklı yönlerden inşa eder; üç kurs.)
28.19 Egzersizler
Egzersiz 1 (Direkt uygulama). Bir VAE kur (encoder → mu/lv, reparameterization, decoder); vae_loss (KLD + BCE) ile eğit, yeniden kurmaları gözle (§2, §4).
Egzersiz 2 (İki-aşamalı). AutoencoderKL ile bir görüntüyü latent’e kodla, sonra decode et; sıkıştırma kaybını (latent → görüntü) görselleştir (§6).
Egzersiz 3 (Edge case). VAE loss’ta KLD ağırlığını çok büyük/çok küçük yap; latent uzayın düzgünlüğü vs yeniden kurma kalitesi dengesini gör (§4’teki BCE/KLD dengesiyle karşılaştır) (§4, §5).
Egzersiz 4 (Kavramsal). Latent diffusion’da diffusion neden latent uzayda yapılır da pikselde değil? VAE’nin rolü tam olarak nedir? (§5’teki 48× boyut + §7’deki “decode yalnız sonda” ile düşün) (§5, §7).
Egzersiz 5 (İleriye — kurs sonrası). Cross-attention ile text→image nasıl çalışır? CLIP gömüsü U-Net’e nasıl girer (query görüntü, key/value metin)? Modern SD/SDXL’i araştır (§9).
28.20 Sonraki Adımlar (Kurs Sonrası)
fast.ai Part 2 TAMAMLANDI — Stable Diffusion’ı sıfırdan kurdun. Kalan tek parça CLIP text encoder (Howard’ın notuyla sonraki kursa). Buradan ileri:
- CLIP & text→image: Cross-attention koşullamasını tam CLIP ile birleştir (bir sonraki kurs).
- Modern diffusion: SDXL, ControlNet, LoRA, latent consistency models, video diffusion.
- Production: Hugging Face diffusers, ONNX/TensorRT, quantization, gerçek-zamanlı üretim.
- Builder olarak: Artık bir araştırma makalesini okuyup (Ders 11 arXiv/Zotero) sıfırdan implement edebilecek temele sahipsin.
UyarıKurs Sonrası Yapılacak
- Kendi diffusion modelini bir veri kümesinde (latent diffusion) baştan sona eğit.
- Bir diffusion makalesini (örn. DDIM, Karras, latent diffusion) oku ve bir parçasını implement et.
- Ders 9’a geri dön; artık SD pipeline’ının her satırını anladığını gör — halka kapandı.
28.21 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Howard’da |
|---|---|---|
| VAE | Görüntüyü latent dağılıma (μ, lv) kodlayan autoencoder | 17:48 |
| Reparameterization | z = μ + exp(0.5·lv)·ε; türevlenebilir örnekleme (mean ≈ 5, std ≈ 2) | — |
| KLD loss | Latent dağılımı normale çeker (örneklenebilir; KLD(0,0)=0) | — |
| Latent uzay | Sıkıştırılmış temsil (512×512×3 → 64×64×4, 48×) | 17:16 |
AutoencoderKL |
SD’nin önceden eğitilmiş VAE’si (encode/decode) | — |
| Latent diffusion | Diffusion latent uzayda; SD’nin tanımı | 17:16 |
| Text conditioning | CLIP gömüsü + cross-attention (query görüntü, k/v metin) | 0:23 |
| Cross-attention | L24 attention’ın koşullu hâli (text→image) | 0:23 |
| Stable Diffusion | VAE + latent U-Net + CLIP; sıfırdan kuruldu | 0:23 |
| Yeniden kur, sonra kullan | Ders 9 (kullan) → L25 (kur) halkası kapanır | — |
28.22 ML Bağlantıları Özeti
İpucuBuilder Notu — 6 ML Köprüsü: VAE, Latent Diffusion ve Halka Kapanışı
Bu ders latent diffusion’ı önceki derslerin altyapısına bağlar ve kursun “yeniden kur, sonra kullan” halkasını kapatır; köprülerin özeti:
- VAE → Ders 15 autoencoder; latent’i dağılım yaparak üretken hâle getirir (VAE).
- Reparameterization → Ders 9B forward process trick; türevlenebilir örnekleme (mean ≈ 5, std ≈ 2) (reparameterization).
- Latent diffusion → Ders 19-22 DDPM/Karras; aynı diffusion, latent uzayda (48× küçük) (latent diffusion).
- Cross-attention → Ders 24 attention; koşullu (text→image) hâli (text conditioning).
- SD tam mimarisi → Ders 9 (kullandık) halka kapanışı; üç bileşen artık anlaşıldı (tam mimari).
- Foundations birleşimi → Ders 11-24 hepsi; SD = basit parçaların katmanlanması (L16-24 tek satırda, eğitim).
ÖnemliBu dersten — ve tüm kurstan — tek bir şey alıp gideceksen
Bu dersten — ve tüm kurstan — tek bir şey alıp gideceksen: karmaşık sistemler, sağlam temellerin birleşimidir; sihir yoktur. Stable Diffusion korkutucu görünür, ama her parçası foundations’ta kurduğumuz basit fikirlerden ibaret: matris çarpımı, gradient descent, residual, normalizasyon, attention, MSE, VAE. Ders 9’da bu sistemi kullandık ve “kütüphanenin altındaki büyüyü kendimiz kuracağız” sözü verdik; 16 ders foundations sonra L25’te o sözü tuttuk — SD’yi sıfırdan inşa ettik. “Yeniden kur, sonra kullan” döngüsü, kursun ilk üretken dersinden son dersine tam kapandı. Aynı felsefe ECU dünyasında da geçerli: “Tuning is physics, mathematics, and logic — not magic.” Builder olmak, bu parçaları görebilmek ve birleştirebilmektir. Yolculuk burada bitiyor; artık kütüphanenin altındaki büyü senin.