---
title: "NLP, Transformer ve Attention"
subtitle: "İki parçalı hafta — konuk hoca Mike Lewis (Facebook AI Research, NLP/çeviri) Lecture'da derin öğrenmenin doğal dil işlemeyi nasıl dönüştürdüğünü anlatır: dil modelleme bir yoğunluk tahminidir ve tüm hüner bağlam kodlayıcıdadır; CNN sınırlı alıcı alanıyla, RNN tek vektöre sıkıştıran darboğazı ve yavaşlığıyla yetersizdir, Transformer ise her kelimenin her kelimeye doğrudan baktığı düşük-önyargılı bir modeldir, paralelleşir ve ölçeklenir; multi-head attention Q/K/V ile kurulur, causal maske geleceğe bakmayı engeller ve positional encoding sırayı geri verir; decoding tarafında greedy ile beam search exposure bias yüzünden bozulur, top-k sampling çeşitlilik getirir; ve öz-denetimli öğrenme dilin motorudur — word2vec'ten BERT'e boşluğu doldurma (masked-LM), pre-train ve fine-tune ile her göreve taşınan tek model, ölçek kraldır. Ardından Alfredo Canziani (Practicum) attention'ın altındaki basit matematiği kurar: Transformer dizilerle değil kümelerle çalışır, attention bir kümenin elemanlarını benzerlik skorlarıyla harmanlayan linear kombinasyondur, Q/K/V girdinin öğrenilen rotasyonlarıdır, encoder ile decoder bir autoencoder iskeleti oluşturur, autoregressive üretim look-ahead maskeyle eğitilir ve T×T attention matrisi küme büyüdükçe karesel olarak patlar."
---
::: {.callout-note title="Bölüm bilgisi (KONUK Mike Lewis + Canziani)"}
- **Konuk Lecture (Mike Lewis, FAIR):** [YouTube — Deep Learning for NLP](https://www.youtube.com/watch?v=6D4EWKJgNn0) (Hafta 12 Lecture)
- **Canziani'nin Practicum videosu:** [YouTube — Attention & the Transformer](https://www.youtube.com/watch?v=f01J0Dri-6k)
- **Edition:** Spring 2020 (NYU-DLSP20)
- **Hocalar:** Mike Lewis (Konuk Lecture, NLP/Transformer) + Alfredo Canziani (Practicum, attention matematiği) — Yann LeCun tartışmaya katılır (word2vec = basit GNN köprüsü)
- **Kaynak:** [atcold.github.io/NYU-DLSP20](http://atcold.github.io/NYU-DLSP20)
- **Okuma süresi:** ≈30 dk
> ⚠️ **Atıf notu:** Bu haftanın Lecture'ı **LeCun değil, konuk Mike Lewis** (FAIR, doğal dil işleme). Lecture quote'ları **— Lewis**; Practicum **— Canziani**; LeCun tartışmaya katılıp köprü kurduğunda **— LeCun**.
:::
```{python}
#| echo: false
# ============================================================================
# SETUP — NYU sayısal motor (_engine.py) + NYU Violet+gold viz (_viz.py)
# Bu hücre gizlidir (#| echo: false). Aşağıdaki TÜM figür hücreleri burada
# tanımlanan self_attention_matrix / causal_mask_demo / softmax_temperature /
# positional_encoding / topk_truncate + attention_weights + önceki hafta
# yardımcıları + COL_* + apply_style / draw_pipeline / style_legend /
# CLASS_COLORS isimlerini kullanır.
# _engine.py saf numpy (torch YOK); _viz.py NYU Violet+gold paleti.
# İçerikler VERBATIM gömülüdür.
#
# NOT: matplotlib backend'i AYARLANMAZ (matplotlib.use(...) ÇAĞRILMAZ).
# Quarto kendi inline (figür yakalayan) backend'ini kurar; Agg backend
# inline figür-yakalamayı bozar (plt.show() çıktı üretmez). Standalone
# figür testinde savefig kullanılır.
# ============================================================================
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from matplotlib.patches import (
FancyBboxPatch, FancyArrowPatch, Rectangle, Circle, Ellipse, Polygon, Patch,
)
from matplotlib.lines import Line2D
from matplotlib.colors import ListedColormap, BoundaryNorm, LinearSegmentedColormap
import networkx as nx
np.random.seed(0)
# ===========================================================================
# _engine.py — saf numpy sayısal yardımcılar (torch YOK)
# ===========================================================================
# ---------------------------------------------------------------------------
# Afin / lineer dönüşümler
# ---------------------------------------------------------------------------
def affine_transform(P, W, b=None):
"""P[N,2] noktalarına y = W x (+ b) afin/lineer dönüşümü uygular (satır-vektör konvansiyonu)."""
P = np.asarray(P, float)
Y = P @ np.asarray(W, float).T
if b is not None:
Y = Y + np.asarray(b, float)
return Y
def unit_grid(n=11, lim=2.0, fine=61):
"""Izgara çizgileri listesi (yatay + dikey). Her çizgi (fine,2) dizisi.
Lineer dönüşüm görsellerinde 'uzayın kumaşı' için."""
t = np.linspace(-lim, lim, n)
f = np.linspace(-lim, lim, fine)
lines = []
for yi in t:
lines.append(np.column_stack([f, np.full_like(f, yi)]))
for xi in t:
lines.append(np.column_stack([np.full_like(f, xi), f]))
return lines
def linear_transforms():
"""Canziani'nin dört temel lineer dönüşümü (Bölüm 8) — 2x2 matrisler."""
th = np.deg2rad(35.0)
R = np.array([[np.cos(th), -np.sin(th)], [np.sin(th), np.cos(th)]]) # rotation (ortonormal)
S = np.array([[1.8, 0.0], [0.0, 0.55]]) # scaling (köşegen)
Sh = np.array([[1.0, 0.85], [0.0, 1.0]]) # shearing
F = np.array([[1.0, 0.0], [0.0, -1.0]]) # reflection (det<0)
return dict(rotation=R, scaling=S, shearing=Sh, reflection=F)
# ---------------------------------------------------------------------------
# SVD geometrisi (Canziani'nin 'patatesi')
# ---------------------------------------------------------------------------
def unit_circle(n=240):
t = np.linspace(0, 2 * np.pi, n)
return np.column_stack([np.cos(t), np.sin(t)])
def svd_demo(W):
"""W = U Σ Vᵀ. Geometrik okuma: rotation(Vᵀ) · scaling(Σ) · rotation(U)."""
U, s, Vt = np.linalg.svd(np.asarray(W, float))
return U, s, Vt
def near_singular_matrix():
"""Bir tekil değeri ≈0 olan matris — bir boyutu 'ezer' (elips çizgiye çöker)."""
th = np.deg2rad(30.0)
R = np.array([[np.cos(th), -np.sin(th)], [np.sin(th), np.cos(th)]])
Sigma = np.diag([1.6, 0.04]) # ikinci tekil değer ≈ 0
return R @ Sigma @ R.T
# ---------------------------------------------------------------------------
# Spiral (manifold germe demosu)
# ---------------------------------------------------------------------------
def make_spiral(n_per=120, k=5, noise=0.18, seed=0):
"""k-kollu spiral (CS231n stili). Her kol bir sınıf; kollar orijinde iç içe → lineer ayrılamaz."""
rng = np.random.default_rng(seed)
X = np.zeros((n_per * k, 2))
y = np.zeros(n_per * k, dtype=int)
for j in range(k):
ix = slice(n_per * j, n_per * (j + 1))
r = np.linspace(0.0, 1.0, n_per)
t = np.linspace(j * 4.0, (j + 1) * 4.0, n_per) + rng.normal(0, 1, n_per) * noise
X[ix] = np.column_stack([r * np.sin(t), r * np.cos(t)])
y[ix] = j
return X, y
def unroll_spiral(X, y, k=5, seed=0):
"""ŞEMATİK 'öğrenilen temsil': her sınıfı kendi yatay bandına taşır → lineer ayrılabilir.
Gerçek bir eğitilmiş ağ DEĞİL; 'ağ manifoldu açar' sezgisinin deterministik görseli."""
rng = np.random.default_rng(seed)
r = np.linalg.norm(X, axis=1)
yb = (y - (k - 1) / 2.0) * 0.55 + rng.normal(0, 0.045, len(y))
return np.column_stack([r * 2.2 - 1.1, yb])
# ---------------------------------------------------------------------------
# İki hilal (make_moons — sklearn YOK, numpy ile elle)
# ---------------------------------------------------------------------------
def make_moons_np(n=400, noise=0.20, seed=0):
"""Doğrusal ayrılamaz iki-hilal veri (sklearn.make_moons eşdeğeri)."""
rng = np.random.default_rng(seed)
n_out = n // 2
n_in = n - n_out
to = np.linspace(0, np.pi, n_out)
ti = np.linspace(0, np.pi, n_in)
outer = np.column_stack([np.cos(to), np.sin(to)])
inner = np.column_stack([1.0 - np.cos(ti), 1.0 - np.sin(ti) - 0.5])
X = np.vstack([outer, inner]) + rng.normal(0, noise, (n, 2))
y = np.array([0] * n_out + [1] * n_in)
return X, y
# ---------------------------------------------------------------------------
# Minik numpy sınıflandırıcılar (lineer vs ReLU MLP) — karar sınırı kontrastı
# ---------------------------------------------------------------------------
def _onehot(y, c):
Y = np.zeros((len(y), c))
Y[np.arange(len(y)), y] = 1.0
return Y
def _softmax(z):
z = z - z.max(axis=1, keepdims=True)
e = np.exp(z)
return e / e.sum(axis=1, keepdims=True)
def logreg_train(X, y, steps=500, lr=1.0, seed=0):
"""Lineer (gizli katmansız) softmax sınıflandırıcı → DÜZ karar sınırı."""
rng = np.random.default_rng(seed)
n, d = X.shape
c = int(y.max() + 1)
W = rng.normal(0, 0.01, (d, c))
b = np.zeros(c)
Y = _onehot(y, c)
for _ in range(steps):
p = _softmax(X @ W + b)
dz = (p - Y) / n
W -= lr * (X.T @ dz)
b -= lr * dz.sum(axis=0)
return dict(W=W, b=b)
def logreg_forward(params, X):
return X @ params["W"] + params["b"]
def mlp_train(X, y, hidden=16, act="relu", steps=600, lr=1.0, seed=0, return_history=False):
"""numpy 2-katmanlı MLP (afine → nonlinearite → afine), softmax + cross-entropy.
ReLU ile EĞRİ karar sınırı (hilalleri/spirali ayırır).
return_history=True → (params, loss_history) döner (eğitim eğrisi figürü için)."""
rng = np.random.default_rng(seed)
n, d = X.shape
c = int(y.max() + 1)
W1 = rng.normal(0, 1, (d, hidden)) * np.sqrt(2.0 / d)
b1 = np.zeros(hidden)
W2 = rng.normal(0, 1, (hidden, c)) * np.sqrt(2.0 / hidden)
b2 = np.zeros(c)
Y = _onehot(y, c)
history = []
for _ in range(steps):
z1 = X @ W1 + b1
a1 = np.maximum(0, z1) if act == "relu" else np.tanh(z1)
p = _softmax(a1 @ W2 + b2)
if return_history:
history.append(float(-np.log(p[np.arange(n), y] + 1e-12).mean()))
dz2 = (p - Y) / n
dW2 = a1.T @ dz2
db2 = dz2.sum(axis=0)
da1 = dz2 @ W2.T
dz1 = da1 * ((z1 > 0) if act == "relu" else (1 - np.tanh(z1) ** 2))
dW1 = X.T @ dz1
db1 = dz1.sum(axis=0)
W1 -= lr * dW1
b1 -= lr * db1
W2 -= lr * dW2
b2 -= lr * db2
params = dict(W1=W1, b1=b1, W2=W2, b2=b2, act=act)
if return_history:
return params, np.array(history)
return params
def mlp_forward(params, X):
z1 = X @ params["W1"] + params["b1"]
a1 = np.maximum(0, z1) if params["act"] == "relu" else np.tanh(z1)
return a1 @ params["W2"] + params["b2"]
def accuracy(forward_fn, params, X, y):
return float((forward_fn(params, X).argmax(axis=1) == y).mean())
def decision_grid(X, pad=0.6, h=0.02):
"""Karar bölgesi için koordinat ızgarası (xx, yy) ve düz nokta listesi."""
x0, x1 = X[:, 0].min() - pad, X[:, 0].max() + pad
y0, y1 = X[:, 1].min() - pad, X[:, 1].max() + pad
xx, yy = np.meshgrid(np.arange(x0, x1, h), np.arange(y0, y1, h))
grid = np.column_stack([xx.ravel(), yy.ravel()])
return xx, yy, grid
# ---------------------------------------------------------------------------
# Enerji manzarası (EBM — çoklu minimum = çoklu geçerli cevap)
# ---------------------------------------------------------------------------
def energy_landscape(xx, yy):
"""F(x,y): birkaç Gauss kuyusu → çoklu yerel minimum. Düşük enerji = uyumlu cevap."""
wells = [(-1.25, -0.65, 1.0, 0.55), (1.15, 0.85, 1.05, 0.6), (0.15, -1.15, 0.8, 0.45)]
F = np.ones_like(xx) * 1.0
for cx, cy, depth, width in wells:
F = F - depth * np.exp(-((xx - cx) ** 2 + (yy - cy) ** 2) / (2 * width))
return F
# ---------------------------------------------------------------------------
# Hafta 2 — gradient descent, SGD, backprop, eğitim
# ---------------------------------------------------------------------------
def loss_surface_2d(xx, yy):
"""2D parametre uzayında bir kayıp yüzeyi (gradient descent 'dağ' görseli için):
eğik, farklı-ölçekli bir vadi (konveks taban) + hafif dalgalanma."""
u = 0.85 * xx + 0.53 * yy # eksenleri döndür (eğik vadi)
v = -0.53 * xx + 0.85 * yy
return 1.0 * u ** 2 + 3.5 * v ** 2 + 0.6 * np.sin(1.5 * xx) * np.cos(1.5 * yy)
def _loss_grad_2d(p):
"""loss_surface_2d gradyanı (merkezi sonlu fark)."""
eps = 1e-4
gx = (loss_surface_2d(p[0] + eps, p[1]) - loss_surface_2d(p[0] - eps, p[1])) / (2 * eps)
gy = (loss_surface_2d(p[0], p[1] + eps) - loss_surface_2d(p[0], p[1] - eps)) / (2 * eps)
return np.array([gx, gy])
def gd_path(theta0, lr=0.08, steps=40):
"""loss_surface_2d üzerinde gradient descent yörüngesi (parametre adımları)."""
p = np.array(theta0, float)
path = [p.copy()]
for _ in range(steps):
p = p - lr * _loss_grad_2d(p)
path.append(p.copy())
return np.array(path)
def sgd_loss_curves(steps=80, seed=0):
"""Üç rejim için kayıp eğrisi (simülasyon): full-batch (gürültüsüz, düz),
mini-batch (orta gürültü), saf SGD (yüksek gürültü). Aynı yumuşak üstel düşüş."""
rng = np.random.default_rng(seed)
t = np.arange(steps)
base = 0.2 + 2.6 * np.exp(-t / 14.0)
full = base.copy()
mini = base + rng.normal(0, 0.10, steps) * np.exp(-t / 45.0)
sgd = base + rng.normal(0, 0.45, steps) * np.exp(-t / 70.0)
return t, np.clip(full, 0, None), np.clip(mini, 0, None), np.clip(sgd, 0, None)
def tanh_deriv(x):
"""tanh'ın türevi: 1 − tanh²(x). Backprop 'twiddling' figürü için."""
return 1.0 - np.tanh(x) ** 2
def ce_loss_curve(p):
"""Doğru sınıf olasılığı p için cross-entropy kaybı: −log p."""
p = np.clip(np.asarray(p, float), 1e-6, 1.0)
return -np.log(p)
def mse_loss_curve(p):
"""Doğru sınıf olasılığı p için (one-hot hedefe) MSE: (1 − p)²."""
return (1.0 - np.asarray(p, float)) ** 2
# ---------------------------------------------------------------------------
# Hafta 3 — convolution / ConvNet / doğal sinyaller
# ---------------------------------------------------------------------------
def conv_output_size(n, k, s=1):
"""Çıktı boyutu: o = ⌊(n − k)/s⌋ + 1."""
return (n - k) // s + 1
def conv1d(x, w):
"""1B cross-correlation (ML 'convolution'): out[i] = Σ_k x[i+k]·w[k].
Örnek: conv1d([1,2,3,4,5],[1,0,-1]) → [-2,-2,-2] (kenar/fark dedektörü)."""
x = np.asarray(x, float)
w = np.asarray(w, float)
n = len(x) - len(w) + 1
return np.array([np.dot(x[i:i + len(w)], w) for i in range(n)])
def conv2d(img, kernel, stride=1):
"""2B valid cross-correlation (ag öznitelik haritası üretir)."""
img = np.asarray(img, float)
k = np.asarray(kernel, float)
kh, kw = k.shape
H, W = img.shape
oh, ow = conv_output_size(H, kh, stride), conv_output_size(W, kw, stride)
out = np.zeros((oh, ow))
for i in range(oh):
for j in range(ow):
patch = img[i * stride:i * stride + kh, j * stride:j * stride + kw]
out[i, j] = np.sum(patch * k)
return out
def make_synthetic_image(n=28, seed=0):
"""Basit gri-tonlu sentetik görüntü: kare + daire (kenar tespiti net görünsün)."""
img = np.zeros((n, n))
img[5:14, 6:15] = 1.0 # dolu kare
yy, xx = np.ogrid[:n, :n]
cy, cx, r = 19, 19, 6
img[(yy - cy) ** 2 + (xx - cx) ** 2 <= r ** 2] = 0.85 # daire
img[20:22, 4:24] = 0.6 # yatay çizgi (yatay kenar için)
return img
def edge_kernels():
"""Klasik 3×3 öznitelik dedektörü kernel'leri."""
return dict(
sobel_x=np.array([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]], float), # dikey kenar
sobel_y=np.array([[-1, -2, -1], [0, 0, 0], [1, 2, 1]], float), # yatay kenar
blur=np.ones((3, 3)) / 9.0, # bulanıklaştırma
laplace=np.array([[0, 1, 0], [1, -4, 1], [0, 1, 0]], float), # tüm kenarlar
)
def max_pool2d(img, k=2):
"""k×k max pooling (complex cell / invariance)."""
img = np.asarray(img, float)
H, W = img.shape
oh, ow = H // k, W // k
return np.array([[img[i * k:(i + 1) * k, j * k:(j + 1) * k].max() for j in range(ow)]
for i in range(oh)])
def avg_pool2d(img, k=2):
"""k×k average pooling (LeNet5 stili)."""
img = np.asarray(img, float)
H, W = img.shape
oh, ow = H // k, W // k
return np.array([[img[i * k:(i + 1) * k, j * k:(j + 1) * k].mean() for j in range(ow)]
for i in range(oh)])
# ---------------------------------------------------------------------------
# Hafta 4 — convolution cebiri (Toeplitz) + optimizasyon (κ, momentum, Adam)
# ---------------------------------------------------------------------------
def build_toeplitz(kernel, n):
"""1B convolution'ın Toeplitz matrisi: out = T @ x, T[i, i:i+k] = kernel.
conv1d(x, kernel) == build_toeplitz(kernel, len(x)) @ x (çoğu eleman sıfır = seyrek)."""
kernel = np.asarray(kernel, float)
k = len(kernel)
oh = n - k + 1
T = np.zeros((oh, n))
for i in range(oh):
T[i, i:i + k] = kernel
return T
def quad_loss(xx, yy, kappa=20.0):
"""Eğik, koşullanması κ = L/μ olan kuadratik vadi (condition number görseli).
κ büyük → uzun ince vadi → gradient descent zikzak çizer."""
a, b = 0.92, 0.39 # ~25° dönme
u = a * xx + b * yy
v = -b * xx + a * yy
return 0.5 * (1.0 * u ** 2 + kappa * v ** 2) # L=κ, μ=1
def quad_grad(p, kappa=20.0):
"""quad_loss'un analitik gradyanı."""
a, b = 0.92, 0.39
x, y = p
u = a * x + b * y
v = -b * x + a * y
gu, gv = u, kappa * v
return np.array([gu * a + gv * (-b), gu * b + gv * a])
def optimize_quad(method, theta0, lr, steps, kappa=20.0, beta=0.9, beta2=0.999, eps=1e-8):
"""quad_loss üzerinde bir optimizer'ı koştur; yörünge + kayıp geçmişi döner.
method ∈ {'gd','momentum','adam'}. Defazio'nun zikzak/sönümleme/adaptif anlatısı için."""
p = np.array(theta0, float)
path = [p.copy()]
losses = [float(quad_loss(p[0], p[1], kappa))]
m = np.zeros(2)
v = np.zeros(2)
for t in range(1, steps + 1):
g = quad_grad(p, kappa)
if method == "gd":
step = lr * g
elif method == "momentum":
m = beta * m + g # heavy ball
step = lr * m
elif method == "adam":
m = beta * m + (1 - beta) * g
v = beta2 * v + (1 - beta2) * g * g
mh = m / (1 - beta ** t) # bias correction
vh = v / (1 - beta2 ** t)
step = lr * mh / (np.sqrt(vh) + eps)
else:
raise ValueError(method)
p = p - step
path.append(p.copy())
losses.append(float(quad_loss(p[0], p[1], kappa)))
return np.array(path), np.array(losses)
# ---------------------------------------------------------------------------
# Hafta 5 — autograd worked example (Canziani)
# ---------------------------------------------------------------------------
def autograd_worked(X=None):
"""Canziani worked example: X → Y=X−2 → Z=3·Y² → a=mean(Z) (skaler).
İleri değerler + ∂a/∂xᵢ = (1/4)·3·2·(xᵢ−2) = 1.5·(xᵢ−2).
X=[1,2,3,4] için grad = [−1.5, 0, 1.5, 3] (PyTorch X.grad ile birebir)."""
if X is None:
X = np.array([1.0, 2.0, 3.0, 4.0])
X = np.asarray(X, float)
Y = X - 2.0
Z = 3.0 * Y ** 2
a = float(Z.mean())
grad = 1.5 * (X - 2.0)
return dict(X=X, Y=Y, Z=Z, a=a, grad=grad)
def conv_pad_output(n, k, padding=0, stride=1):
"""Padding'li çıktı boyutu: o = ⌊(n + 2·padding − k)/stride⌋ + 1.
padding=(k−1)/2 (k tek) → çıktı boyutu korunur."""
return (n + 2 * padding - k) // stride + 1
# ---------------------------------------------------------------------------
# Hafta 6 — RNN / vanishing gradient / attention
# ---------------------------------------------------------------------------
def vanishing_demo(steps=50, eigenvalues=(0.5, 1.0, 1.5)):
"""Aynı matristen n kez geçen gradient: λⁿ. λ<1 söner (vanishing), λ>1 patlar
(exploding), λ=1 sabit. Backprop-through-time vanishing gradient görseli."""
t = np.arange(steps + 1)
curves = {ev: np.asarray(ev, float) ** t for ev in eigenvalues}
return t, curves
def rnn_forward(X_seq, Wx, Wz, b, z0=None):
"""Basit RNN hücresi: zₜ = tanh(Wₓ·xₜ + W_z·zₜ₋₁ + b).
X_seq [T, d_in] → gizli durumlar Z [T, d_h] (aynı Wₓ,W_z her adımda = paylaşım)."""
X_seq = np.asarray(X_seq, float)
T = len(X_seq)
dh = np.asarray(Wz).shape[0]
z = np.zeros(dh) if z0 is None else np.asarray(z0, float)
Z = []
for t in range(T):
z = np.tanh(np.asarray(Wx) @ X_seq[t] + np.asarray(Wz) @ z + np.asarray(b))
Z.append(z.copy())
return np.array(Z)
def attention_weights(scores):
"""Attention ağırlıkları = softmax(skorlar); toplamı 1 (olasılık dağılımı, 'odak')."""
scores = np.asarray(scores, float)
e = np.exp(scores - scores.max())
return e / e.sum()
# ---------------------------------------------------------------------------
# Hafta 7 — EBM / autoencoder / manifold
# ---------------------------------------------------------------------------
def energy_1d(y, data_points=(-2.0, 0.0, 2.0), width=0.35):
"""1B enerji F(y): veri noktalarında düşük (çukur), aralarda yüksek (tepe).
'İyi enerji şekli' = veride düşük, dışında yüksek (EBM); çoklu minimum = çoklu cevap."""
y = np.asarray(y, float)
F = np.ones_like(y)
for d in data_points:
F = F - np.exp(-(y - d) ** 2 / (2 * width))
return F
def energy_1d_grad(y, data_points=(-2.0, 0.0, 2.0), width=0.35):
"""energy_1d'nin türevi (çıkarım = enerji minimizasyonu, gradient ile arama)."""
y = np.asarray(y, float)
g = np.zeros_like(y)
for d in data_points:
g = g + (y - d) / width * np.exp(-(y - d) ** 2 / (2 * width))
return g
def make_manifold_curve(n=160, noise=0.0, seed=0):
"""2B veri manifoldu: bir eğri (sinüs yayı) üzerinde noktalar (Hafta 1 manifold hipotezi)."""
t = np.linspace(-2.6, 2.6, n)
M = np.column_stack([t, np.sin(1.3 * t)])
if noise:
M = M + np.random.default_rng(seed).normal(0, noise, M.shape)
return M
def project_to_manifold(points, manifold):
"""Her noktayı manifoldun EN YAKIN noktasına çeker (autoencoder reconstruction sezgisi:
off-manifold girdiyi manifolda geri çek → düşük enerji)."""
points = np.asarray(points, float)
proj = np.array([manifold[np.linalg.norm(manifold - p, axis=1).argmin()] for p in points])
return proj
# ---------------------------------------------------------------------------
# Hafta 8 — contrastive / VAE
# ---------------------------------------------------------------------------
def vae_reparam(mu, sigma, n=400, seed=0):
"""Reparameterization trick: z = μ + σ⊙ε, ε~N(0,I). Düzenli (sürekli, dolu)
Gaussian latent örnekleri — VAE'nin üretken latent uzayı."""
mu = np.atleast_1d(np.asarray(mu, float))
sigma = np.atleast_1d(np.asarray(sigma, float))
rng = np.random.default_rng(seed)
eps = rng.normal(0, 1, (n, len(mu)))
return mu + sigma * eps
def ae_latent_clusters(n=400, seed=0):
"""Sıradan AE latent'i: dağınık, boşluklu kümeler (düzensiz uzay — VAE kontrastı)."""
rng = np.random.default_rng(seed)
centers = np.array([[-2.2, 1.8], [2.0, 2.1], [0.3, -2.3], [-1.8, -1.5]])
pts = []
for c in centers:
pts.append(c + rng.normal(0, 0.28, (n // len(centers), 2)))
return np.vstack(pts)
# ---------------------------------------------------------------------------
# Hafta 9 — sparse coding / GAN (EBM)
# ---------------------------------------------------------------------------
def sparse_code_demo(n=24, n_active=5, seed=0):
"""Yoğun (dense) vs seyrek (sparse) code: L1 düzenlileştirme çoğu bileşeni
sıfıra iter — yalnızca birkaç birim aktif kalır (sparse coding)."""
rng = np.random.default_rng(seed)
dense = rng.normal(0, 1, n)
idx = np.argsort(-np.abs(dense)) # en büyük |değer| → aktif kalanlar
sparse = np.zeros(n)
sparse[idx[:n_active]] = dense[idx[:n_active]]
return dense, sparse
def rotate_image_4way(img):
"""0/90/180/270° döndürülmüş 4 versiyon — rotation pretext görevi (Hafta 10 SSL):
ağ 'kaç derece döndürüldü?' sorusunu çözer (4-yönlü sınıflandırma)."""
img = np.asarray(img, float)
return [np.rot90(img, k) for k in range(4)]
# ---------------------------------------------------------------------------
# Hafta 11 — aktivasyon / kayıp (EBM) / belirsizlik
# ---------------------------------------------------------------------------
def _sig(x):
return 1.0 / (1.0 + np.exp(-np.clip(x, -50, 50)))
def activation_fns():
"""Aktivasyon fonksiyonu zoo'su + türevleri (Hafta 11). {ad: (f, f')}."""
return {
"ReLU": (lambda x: np.maximum(0, x), lambda x: (np.asarray(x) > 0).astype(float)),
"Leaky ReLU": (lambda x: np.where(x > 0, x, 0.1 * x), lambda x: np.where(np.asarray(x) > 0, 1.0, 0.1)),
"sigmoid": (_sig, lambda x: _sig(x) * (1 - _sig(x))),
"tanh": (np.tanh, lambda x: 1 - np.tanh(x) ** 2),
"softplus": (lambda x: np.log1p(np.exp(-np.abs(x))) + np.maximum(x, 0), _sig),
"ELU": (lambda x: np.where(x > 0, x, np.exp(np.clip(x, -50, 50)) - 1),
lambda x: np.where(np.asarray(x) > 0, 1.0, np.exp(np.clip(x, -50, 50)))),
}
def softplus_scaled(x, beta=1.0):
"""β-ölçekli softplus: (1/β)·log(1+e^(βx)). β büyük → ReLU'ya yaklaşır (ölçek-bağımlı)."""
x = np.asarray(x, float)
return (1.0 / beta) * (np.log1p(np.exp(-np.abs(beta * x))) + np.maximum(beta * x, 0))
def margin_losses(gap, m=1.0):
"""EBM kayıpları. gap = E(ȳ) − E(y) (doğru-yanlış enerji farkı; pozitif=doğru daha düşük).
hinge marj m (gap≥m'de 0), perceptron marjsız (gap≥0'da 0 → collapse'a açık)."""
gap = np.asarray(gap, float)
hinge = np.maximum(0.0, m - gap)
perceptron = np.maximum(0.0, -gap)
return hinge, perceptron
def uncertainty_demo(x_train, x_grid, bandwidth=0.6):
"""Belirsizlik (epistemik varyans proxy) ~ eğitim verisinden uzaklık: eğitim
noktalarına yakın DÜŞÜK, uzakta YÜKSEK (PPUU 'U' düzenlileştirmesi)."""
x_train = np.atleast_1d(np.asarray(x_train, float))
x_grid = np.atleast_1d(np.asarray(x_grid, float))
d = np.abs(x_grid[:, None] - x_train[None, :]).min(axis=1)
return 1.0 - np.exp(-(d / bandwidth) ** 2)
def gan_samples(seed=0, n=200):
"""GAN sezgisi: gerçek veri (manifold/halka) vs generator'ın ürettiği sahte örnekler.
İlk başta sahteler dağınık (eğitilmemiş generator), gerçeğe yakınsar."""
rng = np.random.default_rng(seed)
th = rng.uniform(0, 2 * np.pi, n)
real = np.column_stack([np.cos(th), np.sin(th)]) + rng.normal(0, 0.06, (n, 2)) # gerçek = birim halka
fake_early = rng.normal(0, 1.1, (n, 2)) # eğitilmemiş gen (dağınık)
th2 = rng.uniform(0, 2 * np.pi, n)
fake_late = np.column_stack([np.cos(th2), np.sin(th2)]) + rng.normal(0, 0.18, (n, 2)) # eğitilmiş gen (halkaya yakın)
return real, fake_early, fake_late
# ---------------------------------------------------------------------------
# Hafta 12 — Attention / Transformer (NLP, Lewis + Canziani)
# ---------------------------------------------------------------------------
def _softmax_rows(M):
"""Satır-bazlı kararlı softmax (her satır toplamı 1)."""
M = np.asarray(M, float)
e = np.exp(M - M.max(axis=-1, keepdims=True))
return e / e.sum(axis=-1, keepdims=True)
def self_attention_matrix(X, scale=True):
"""Self-attention ağırlık matrisi A = softmax(XXᵀ/√d) (Canziani: küme→küme).
X [T, d] token kümesi → A [T, T]: A[i,j] = token i'nin token j'ye verdiği dikkat (satır toplamı 1).
scale=True → β=1/√d ölçekleme (Canziani 20:44: vektör büyüklüğü √d ile büyür, sıcaklık sabit)."""
X = np.asarray(X, float)
d = X.shape[1]
scores = X @ X.T
if scale:
scores = scores / np.sqrt(d)
return _softmax_rows(scores)
def causal_mask_demo(scores):
"""Causal (look-ahead) maske gösterimi (Lewis 27:08).
scores [T, T] → (A_acik, A_maskeli): maskesiz softmax vs üst-üçgen −∞ maskeli softmax.
Maskeli: her token yalnız kendine + soluna bakar (geleceği göremez = hile yok)."""
scores = np.asarray(scores, float)
T = scores.shape[0]
A_open = _softmax_rows(scores)
mask = np.triu(np.full((T, T), -np.inf), k=1) # üst-üçgen (gelecek) = −∞
A_masked = _softmax_rows(scores + mask)
return A_open, A_masked
def softmax_temperature(scores, betas):
"""Sıcaklık β'nın softmax üzerindeki etkisi (Hafta 11 köprüsü; soft↔hard attention).
scores [n] tek satır → her β için softmax(β·scores) [len(betas), n].
β→0 düzleşir (uniform), β→∞ sivrilir (one-hot=hard attention)."""
scores = np.asarray(scores, float)
out = []
for b in betas:
s = b * scores
e = np.exp(s - s.max())
out.append(e / e.sum())
return np.array(out)
def positional_encoding(seq_len, d, base=10000.0):
"""Sinüzoidal positional encoding (Vaswani 2017; Lewis: küme→sıra).
PE[pos,2i]=sin(pos/base^(2i/d)), PE[pos,2i+1]=cos(...). → [seq_len, d] matris.
Attention girdiyi sırasız küme görür; konum bilgisini bu eklenen embedding taşır."""
pos = np.arange(seq_len)[:, None]
i = np.arange(d)[None, :]
angle = pos / np.power(base, (2 * (i // 2)) / d)
PE = np.where(i % 2 == 0, np.sin(angle), np.cos(angle))
return PE
def topk_truncate(probs, k):
"""Top-k sampling kırpması (Lewis 49:54; Angela Fan).
probs [V] olasılık dağılımı → en iyi k dışındaki kütleyi 0'la, yeniden normalize et.
Greedy=k1; beam farklı (hipotez tutar); top-k=çeşitlilik + manifolddan düşmeme."""
probs = np.asarray(probs, float)
out = np.zeros_like(probs)
idx = np.argsort(probs)[::-1][:k] # en yüksek k indeks
out[idx] = probs[idx]
return out / out.sum()
# ===========================================================================
# _viz.py — NYU Violet + gold matplotlib stil sabitleri ve yardımcıları
# ===========================================================================
COL_VIOLET = "#57068c" # NYU Violet — birincil çizgi/çerçeve/vurgu
COL_VIOLET_D = "#3d0463" # koyu violet — güçlü vurgu / gradyan
COL_VIOLET_M = "#7b2cbf" # orta violet — ikincil
COL_VIOLET_SOFT = "#b56ad6" # soluk violet
COL_GOLD = "#d4a017" # gold accent
COL_GOLD_D = "#a87d0a" # koyu gold
COL_TEXT = "#2a2535" # gövde metni (hafif violet tint)
COL_INK = "#1e1a2e" # en koyu — başlık
COL_BG = "#f4eefa" # açık violet — dolgu/arka plan
COL_GRID = "#cdbbe0" # soluk violet — ızgara/pasif kenar
COL_WHITE = "#ffffff"
# 5-sınıf kategorik palet (spiral 5 kol / moons ilk 2) — violet↔gold ekseni, tema-uyumlu
CLASS_COLORS = ["#57068c", "#7b2cbf", "#b56ad6", "#d4a017", "#a87d0a"]
# Çizgi-grafik tutarlı renkler
LINE_PRIMARY = COL_VIOLET
LINE_ACCENT = COL_GOLD
LINE_SECONDARY = COL_VIOLET_M
def apply_style(ax):
"""Bir eksene tutarlı NYU Violet+gold görünümü uygular."""
ax.set_facecolor(COL_WHITE)
ax.grid(True, alpha=0.25, color=COL_GRID, linewidth=0.8)
for spine in ax.spines.values():
spine.set_color(COL_GRID)
ax.tick_params(colors=COL_TEXT)
ax.title.set_color(COL_TEXT)
ax.xaxis.label.set_color(COL_TEXT)
ax.yaxis.label.set_color(COL_TEXT)
return ax
def draw_pipeline(ax, stages, title=None, y0=0.0):
"""Soldan-sağa kutu+ok boru hattı şeması (örüntü tanıma vs uçtan-uca).
stages : [(label:str, is_learned:bool), ...]
is_learned=True -> öğrenilen modül (violet dolgulu)
is_learned=False -> elle-tasarlanan/sabit (gold kenarlı, açık dolgu)
"""
n = len(stages)
box_w, box_h, gap = 1.7, 1.0, 0.9
step = box_w + gap
ax.set_xlim(-0.3, n * step)
ax.set_ylim(y0 - 1.1, y0 + 1.1)
ax.axis("off")
if title:
ax.set_title(title, color=COL_TEXT, fontsize=12, pad=10)
for i, (lbl, learned) in enumerate(stages):
x = i * step
fc = "#ece0f7" if learned else COL_BG
ec = COL_VIOLET if learned else COL_GOLD_D
lw = 2.4 if learned else 2.0
box = FancyBboxPatch(
(x, y0 - box_h / 2), box_w, box_h,
boxstyle="round,pad=0.02,rounding_size=0.12",
fc=fc, ec=ec, lw=lw, zorder=2,
)
ax.add_patch(box)
ax.text(x + box_w / 2, y0, lbl, ha="center", va="center",
fontsize=9.5, color=COL_TEXT, zorder=3, wrap=True)
if i > 0:
ax.add_patch(FancyArrowPatch(
(x - gap, y0), (x, y0),
arrowstyle="-|>", mutation_scale=16,
color=COL_VIOLET_M, lw=1.9, zorder=1,
))
return ax
def style_legend(ax, **kw):
"""Tema-uyumlu legend."""
leg = ax.legend(frameon=True, framealpha=0.95, edgecolor=COL_GRID, **kw)
if leg is not None:
leg.get_frame().set_facecolor(COL_WHITE)
for t in leg.get_texts():
t.set_color(COL_TEXT)
return leg
```
## Bu Derste Ne Var? {#sec-genel-bakis-d12}
Bu hafta iki parça: **konuk hoca Mike Lewis** (Facebook AI Research, NLP/çeviri) Lecture'da derin öğrenmenin doğal dil işlemeyi nasıl dönüştürdüğünü anlatıyor — dil modellemeden Transformer'a, decoding'den BERT'e; **Alfredo Canziani** (Practicum) ise attention'ın altında yatan matematiği (kümeler üzerinde linear kombinasyon, Q/K/V) ve Transformer encoder/decoder mimarisini koddan kuruyor.
Lewis'in büyük fikri: dile özel yapı **dayatmaktan vazgeç**; çok-ifadeli, düşük-önyargılı (low-bias) bir model (Transformer) al, çok metin göster, yapıyı kendisi öğrensin. Canziani: Transformer'ın görünür karmaşıklığının altında basit bir fikir var — attention, bir **kümenin** elemanlarını benzerlik skorlarıyla harmanlayan linear kombinasyondur.
Bu haftanın üç ana fikri:
1. **Transformer = her kelime her kelimeye doğrudan bakar.** RNN darboğazını (tek vektöre sıkıştır) ve CNN sınırlı alıcı alanını ortadan kaldırır; paralelleşir, ölçeklenir.
2. **Attention = kümeler üzerinde benzerlik-ağırlıklı linear kombinasyon.** Q/K/V = girdinin öğrenilen rotasyonları; tek doğrusalsızlık softmax; sıra bilgisi positional encoding.
3. **Öz-denetimli öğrenme dilin motorudur.** word2vec/BERT "boşluğu doldur" (cake metaforu); pre-train → fine-tune tek modeli her göreve taşır.
```{mermaid}
%%| echo: false
flowchart TB
Hafta["Hafta 12 = iki parça<br/>(Lewis: NLP/Transformer · Canziani: attention matematiği)"]
subgraph A["(A) Dil → Transformer → SSL — Lewis (Konuk)"]
direction TB
Baglam["Bağlam kodlayıcı evrimi<br/>CNN (sınırlı alan) → RNN (darboğaz + yavaş)<br/>→ TRANSFORMER (her kelime her kelimeye)"]
Multi["Multi-head attention<br/>Q/K/V + causal maske + positional encoding"]
Decode["Decoding<br/>greedy / beam / top-k · exposure bias"]
SSL["Öz-denetimli öğrenme<br/>word2vec → BERT (masked-LM = denoising) + cake"]
Baglam --> Multi
Multi --> Decode
Decode --> SSL
end
subgraph B["(B) Attention matematiği — Canziani"]
direction TB
Kume["Küme → küme<br/>(Transformer dizilerle değil kümelerle çalışır)"]
Lin["Attention = linear kombinasyon<br/>h = X·a · hard (one-hot) / soft"]
QKV["Q/K/V = öğrenilen rotasyonlar<br/>self vs cross-attention"]
EncDec["Encoder / decoder<br/>(autoencoder iskeleti)"]
Auto["Autoregressive + look-ahead maske<br/>→ T×T matris KARESEL patlar"]
Kume --> Lin
Lin --> QKV
QKV --> EncDec
EncDec --> Auto
end
Hafta --> Baglam
Hafta --> Kume
```
::: {.callout-tip title="Builder Notu — İki Hoca, Tek Fikir: Her Kelime Her Kelimeye Bakar"}
**Geriye (önkoşul + kurs):**
- **Bağlam kodlayıcı** → Hafta 6 (RNN/LSTM/attention/seq2seq); Transformer onun **tekrarlamasız** hâli.
- **Softmax / β** → Hafta 11 (attention katsayısı = softmax, sıcaklık); attention katsayısı 0'a yaklaşsın → giriş −∞.
- **SSL / cake / pretext** → Hafta 10 (Misra) + Hafta 7-8 (BERT masked-LM = denoising autoencoder).
**İleriye (production / research):**
- Transformer → tüm modern LLM (GPT/BERT/T5) omurgası; ViT, protein, multimodal.
- "word2vec = basit GNN" (LeCun) → Hafta 13 Graph ConvNets.
**Tek cümleyle:** Transformer, her kelimenin her kelimeye doğrudan baktığı, kümeler üzerinde benzerlik-ağırlıklı linear kombinasyon (attention) yapan düşük-önyargılı bir modeldir; öz-denetimli "boşluğu doldur" (BERT) ile etiketsiz metinden öğrenir, pre-train→fine-tune ile her dil görevine taşınır.
:::
## (Lewis — Konuk) Dil Modelleme ve Bağlam Kodlayıcının Evrimi {#sec-dil-modelleme}
Lewis dil modellemeyle başlıyor: metnin **yoğunluk tahmini** (her dizeye olasılık ata). Bu olasılık zincir kuralıyla çarpanlara ayrılır → bir dizi "önceki kelimelere bakıp **bir sonraki kelimeyi tahmin et**" sınıflandırması. Tüm hüner **bağlam kodlayıcıdadır** (context encoder); onun evrimi dersin omurgasıdır ("Bu Derste Ne Var" şemasında CNN → RNN → Transformer evrimi de buradadır):
- **CNN** (Bengio 2003; Dauphin 2016): hızlı, paralel — ama **sınırlı alıcı alan** (uzun-menzilli bağımlılığı yakalayamaz).
- **RNN**: ilkesel olarak sınırsız bağlam — ama tüm geçmişi **tek vektöre sıkıştırır** (darboğaz), gradyan kaybolur (Hafta 6), ardışık olduğu için **yavaştır**.
- **Transformer** (Vaswani 2017, "Attention is all you need"): ikisinin de sorununu çözer.
> "for self attention you can in principle put 100% attention on any word in the distant past... it avoids issues like vanishing gradients quite effectively." — Lewis, 31:43
Gücün kaynağı **her kelime çifti arasında doğrudan bağlantı**. Self-attention karesel olsa da tek bir büyük matris çarpımı olarak **paralel** hesaplanır → olağanüstü ölçeklenir (GPT-2 2019'da 2 milyar, sonra 17 milyar parametreye...).
::: {.callout-tip title="Builder Notu — Bağlam Kodlayıcı Evrimi"}
**Geriye (Hafta 6):** RNN darboğazı + vanishing gradient = LSTM'in savaştığı sorun; attention = seq2seq attention. Transformer onu **tekrarlama olmadan** yapar.
**İleriye:** "Her kelime her kelimeye bakar" = LLM'lerin temel hesaplama modeli; paralelleşme = GPU-çağı ölçeklemenin anahtarı.
:::
## (Lewis — Konuk) Multi-Head Attention, Maskeleme ve Positional Encoding {#sec-multihead}
Transformer bloğu iki alt-katmandan oluşur: **multi-head attention** + feedforward (MLP), her ikisi de **Add&Norm** (residual bağlantı + LayerNorm) ile sarılı. (LayerNorm, BatchNorm değil — batch boyutuna bağlı olmadığı için NLP'de tercih edilir.)
**Multi-head attention'ın** kalbi: her kelime için bir **query** ("önceki sıfat ne?"), bir **key** ("ben bir sıfatım") ve bir **value**. Query·key nokta çarpımı → softmax → önceki kelimeler üzerinde bir dağılım → value'ların ağırlıklı toplamı. "Multi-head" = bunu paralel olarak birden çok kez yapmak (aynı anda farklı şeyleri yakalar: hem "boynuzlu" hem "gümüş-beyaz" hem "bunlar → çoğul").
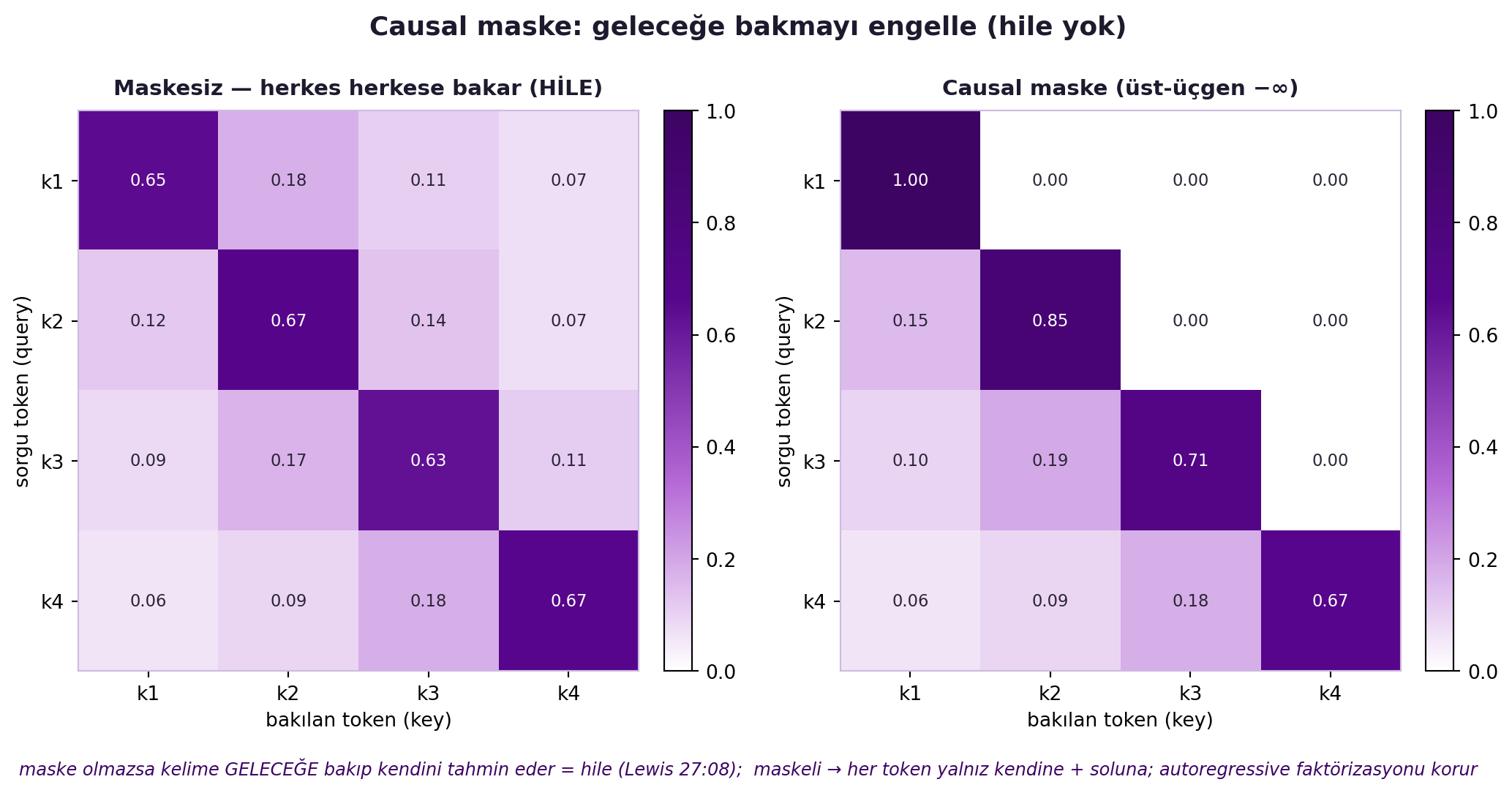
İki kritik detay var. Birincisi **causal maskeleme**: tüm zaman adımları aynı anda hesaplandığından, hiçbir şey kelimelerin **geleceğe bakmasını** engellemez (hile = kelimeyi kendisiyle tahmin etmek). @fig-causal-mask bu sorunu ve çözümünü iki panelde gösterir: maskesiz attention'da her token herkese bakar (hile), causal maske ise üst-üçgeni $-\infty$ yaparak her token'ı yalnız kendine ve soluna bakmaya zorlar.
> "if you're computing all the time steps at once there's nothing to stop words looking at the future... the solution here is self-attention masking." — Lewis, 27:08
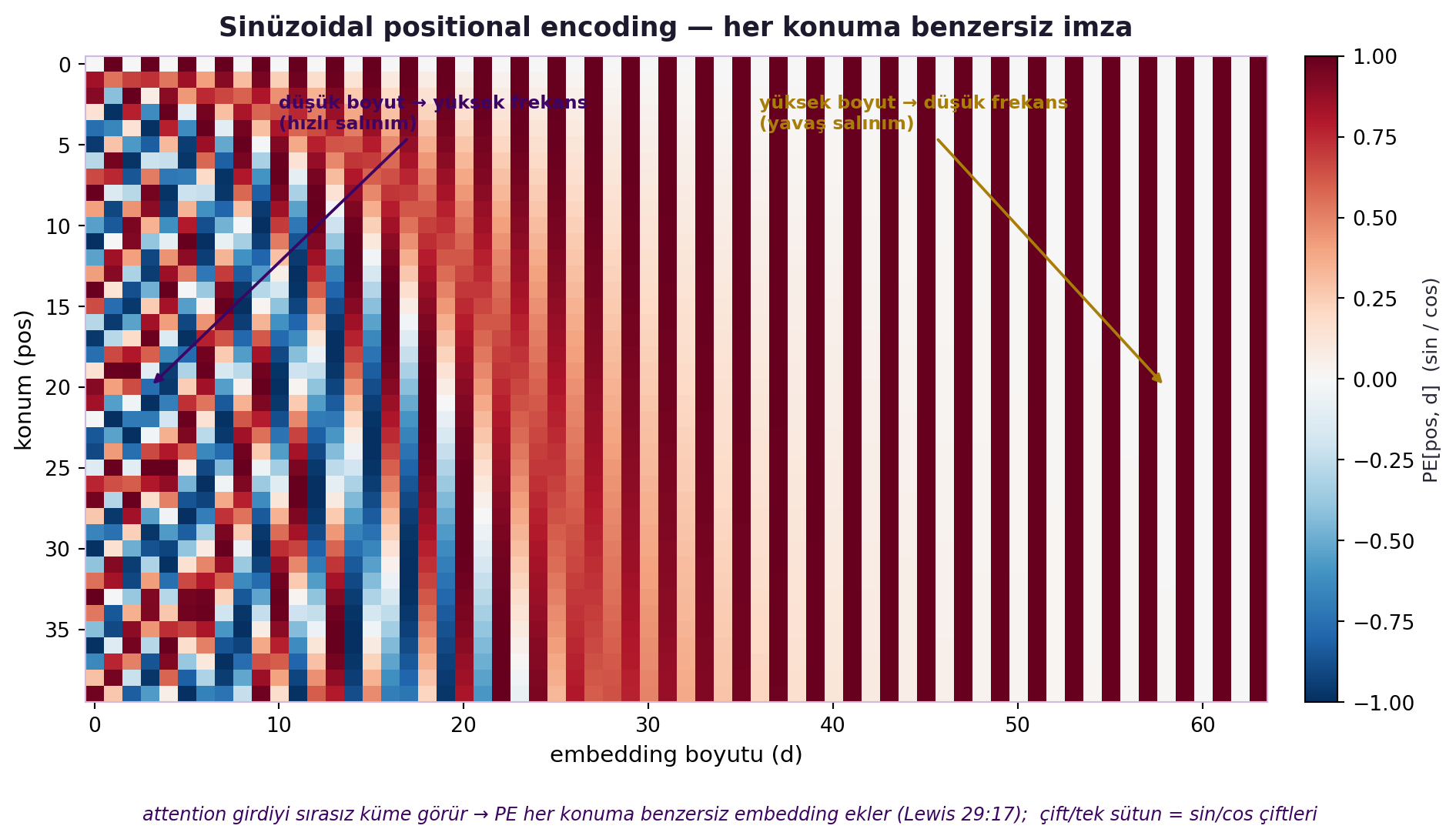
İkincisi **positional encoding**: attention girdiyi bir **küme** olarak görür (sırası yoktur). Dilde sıra önemlidir → her konuma ayrı bir embedding öğrenilip eklenir. @fig-positional-encoding klasik sinüzoidal kodlamayı gösterir: her konum, frekansları boyut boyunca değişen bir sinüs/kosinüs imzasıyla işaretlenir.
Diğer "hileler" de kritik: LayerNorm, **learning-rate warmup** (0'dan hedefe doğrusal ısınma), dikkatli initialization, label smoothing.
```{python}
#| label: fig-causal-mask
#| fig-cap: "Causal (look-ahead) maske, 2 panel — GERÇEK softmax çıktısı. 4 token için anlamlı bir skor matrisi (k1..k4) üzerinde causal_mask_demo çalıştırılır. SOL 'Maskesiz': her token herkese (geleceğe dâhil) bakabilir — bu eğitimde HİLE'dir çünkü model bir kelimeyi tahmin ederken cevabı (gelecek kelimeyi) görür. SAĞ 'Causal maske (üst-üçgen −∞)': üst-üçgen sıfırlanır (beyaz), her token yalnız kendine ve soluna bakar → autoregressive faktörizasyon korunur, hile yok (Lewis 27:08). Hücre değerleri yazılı; her satır toplamı 1."
scores = np.array([
[2.4, 1.1, 0.6, 0.2],
[0.9, 2.6, 1.0, 0.4],
[0.5, 1.2, 2.5, 0.8],
[0.3, 0.7, 1.4, 2.7],
])
A_open, A_masked = causal_mask_demo(scores)
tokens = ["k1", "k2", "k3", "k4"]
violet_cmap = LinearSegmentedColormap.from_list(
"violet_seq", [COL_WHITE, COL_VIOLET_SOFT, COL_VIOLET, COL_VIOLET_D]
)
fig, axes = plt.subplots(1, 2, figsize=(11, 5.0))
panels = [
(axes[0], A_open, "Maskesiz — herkes herkese bakar (HİLE)"),
(axes[1], A_masked, "Causal maske (üst-üçgen −∞)"),
]
for ax, A, title in panels:
im = ax.imshow(A, cmap=violet_cmap, vmin=0, vmax=1, aspect="equal")
ax.set_xticks(range(4)); ax.set_xticklabels(tokens, fontsize=10)
ax.set_yticks(range(4)); ax.set_yticklabels(tokens, fontsize=10)
ax.set_xlabel("bakılan token (key)", fontsize=10)
ax.set_ylabel("sorgu token (query)", fontsize=10)
ax.set_title(title, fontsize=11, color=COL_INK, fontweight="bold", pad=8)
for i in range(4):
for j in range(4):
v = A[i, j]
ax.text(j, i, f"{v:.2f}", ha="center", va="center", fontsize=8.5,
color=COL_WHITE if v > 0.45 else COL_TEXT)
for spine in ax.spines.values():
spine.set_color(COL_GRID)
fig.colorbar(im, ax=ax, fraction=0.046, pad=0.04)
fig.suptitle("Causal maske: geleceğe bakmayı engelle (hile yok)",
fontsize=13.5, color=COL_INK, fontweight="bold", y=1.02)
fig.text(0.5, -0.04,
"maske olmazsa kelime GELECEĞE bakıp kendini tahmin eder = hile (Lewis 27:08); "
"maskeli → her token yalnız kendine + soluna; autoregressive faktörizasyonu korur",
ha="center", va="top", fontsize=9, color=COL_VIOLET_D, style="italic")
fig.tight_layout()
```
```{python}
#| label: fig-positional-encoding
#| fig-cap: "Sinüzoidal positional encoding (Vaswani 2017) — GERÇEK PE matrisi (FLAGSHIP). positional_encoding(seq_len=40, d=64) → PE [40, 64] heatmap (diverging RdBu_r, [-1,1]). Klasik desen: embedding boyutu (sütun) arttıkça frekans düşer — düşük boyutlar hızlı salınır (sık çizgili), yüksek boyutlar yavaş (geniş bantlar); çift/tek sütunlar sin/cos çiftleridir. Her konum (satır) böylece benzersiz bir imza alır. Sezgi: attention girdiyi SIRASIZ küme görür; PE her konuma benzersiz bir konum imzası ekler (Lewis 29:17), böylece 'küme' yeniden 'sıraya' kavuşur."
PE = positional_encoding(seq_len=40, d=64)
fig, ax = plt.subplots(figsize=(10, 5.4))
im = ax.imshow(PE, cmap="RdBu_r", vmin=-1, vmax=1, aspect="auto")
ax.set_xlabel("embedding boyutu (d)", fontsize=11)
ax.set_ylabel("konum (pos)", fontsize=11)
ax.set_title("Sinüzoidal positional encoding — her konuma benzersiz imza",
fontsize=13, color=COL_INK, fontweight="bold", pad=10)
for spine in ax.spines.values():
spine.set_color(COL_GRID)
cbar = fig.colorbar(im, ax=ax, fraction=0.04, pad=0.03)
cbar.set_label("PE[pos, d] (sin / cos)", fontsize=9.5, color=COL_TEXT)
ax.annotate("düşük boyut → yüksek frekans\n(hızlı salınım)",
xy=(3, 20), xytext=(10, 4),
fontsize=8.8, color=COL_VIOLET_D, fontweight="bold",
arrowprops=dict(arrowstyle="-|>", color=COL_VIOLET_D, lw=1.4))
ax.annotate("yüksek boyut → düşük frekans\n(yavaş salınım)",
xy=(58, 20), xytext=(36, 4),
fontsize=8.8, color=COL_GOLD_D, fontweight="bold",
arrowprops=dict(arrowstyle="-|>", color=COL_GOLD_D, lw=1.4))
fig.text(0.5, -0.02,
"attention girdiyi sırasız küme görür → PE her konuma benzersiz embedding ekler "
"(Lewis 29:17); çift/tek sütun = sin/cos çiftleri",
ha="center", va="top", fontsize=9, color=COL_VIOLET_D, style="italic")
fig.tight_layout()
```
::: {.callout-tip title="Builder Notu — Maske = Hile Yok, Konum Eklenir"}
**Geriye (Hafta 11 + 6 + 3):** Softmax + β = Hafta 11 (katsayı 0'a yaklaşsın → giriş $-\infty$); residual = Hafta 3; attention = Hafta 6. Causal maske, autoregressive faktörizasyonu korur.
**İleriye:** Q/K/V + maske + positional encoding = her LLM'in değişmez iskeleti; uzun bağlam = karesel maliyetle savaş (sparse/lineer attention).
:::
## (Lewis — Konuk) Decoding ve Öz-Denetimli Öğrenme: word2vec'ten BERT'e {#sec-decoding-ssl}
**Decoding (çıkarım):** model her diziye olasılık atıyor — peki metni nasıl **üretiriz**? Tüm dizi üzerinde argmax üsteldir (hesaplanamaz). Pratik seçenekler:
- **Greedy:** her adımda en olası kelimeyi al — geri-izleme yok.
- **Beam search:** en iyi n hipotezi tut; ama büyük beam → bozuk/boş çıktılar.
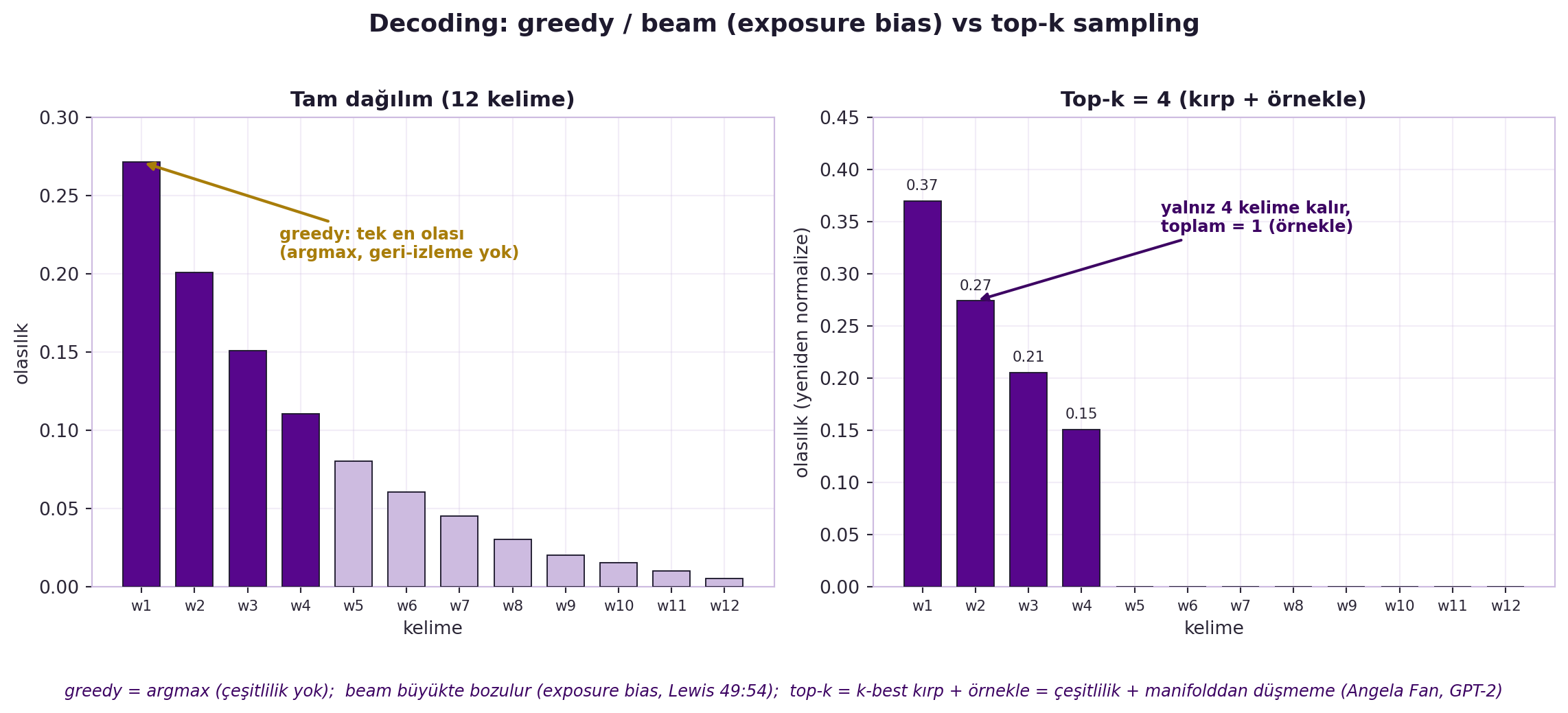
- **Sampling / Top-k** (Angela Fan): dağılımı k-best'e kırp, sonra örnekle → hem çeşitlilik hem "iyi dil manifoldundan" düşmeme. GPT-2'nin güzel örnekleri böyle üretildi.
@fig-topk-sampling bu farkı iki panelde gösterir: tam dağılımda greedy tek en olası kelimeyi seçerken, top-k=4 dağılımı dört en iyiye kırpıp yeniden normalize eder (sonra örnekler). Bozulmanın asıl sebebi **exposure bias**: eğitimde model kendi hatalarını hiç görmez (hep doğru önceki kelimeler verilir); test anında bir kötü adım atınca daha önce görmediği bir duruma düşer ve döngüye girer.
> "at training time we're typically not using a beam... we're not exposing the model to its own mistakes." — Lewis, 49:54
**Öz-denetimli öğrenme** dersin doruğu — Lewis, LeCun'un **cake (pasta)** metaforuna başvuruyor:
> "most of the learning we do has to be unsupervised... [supervised learning is] just being a little bit of icing on top of the cake." — Lewis, 1:09:43
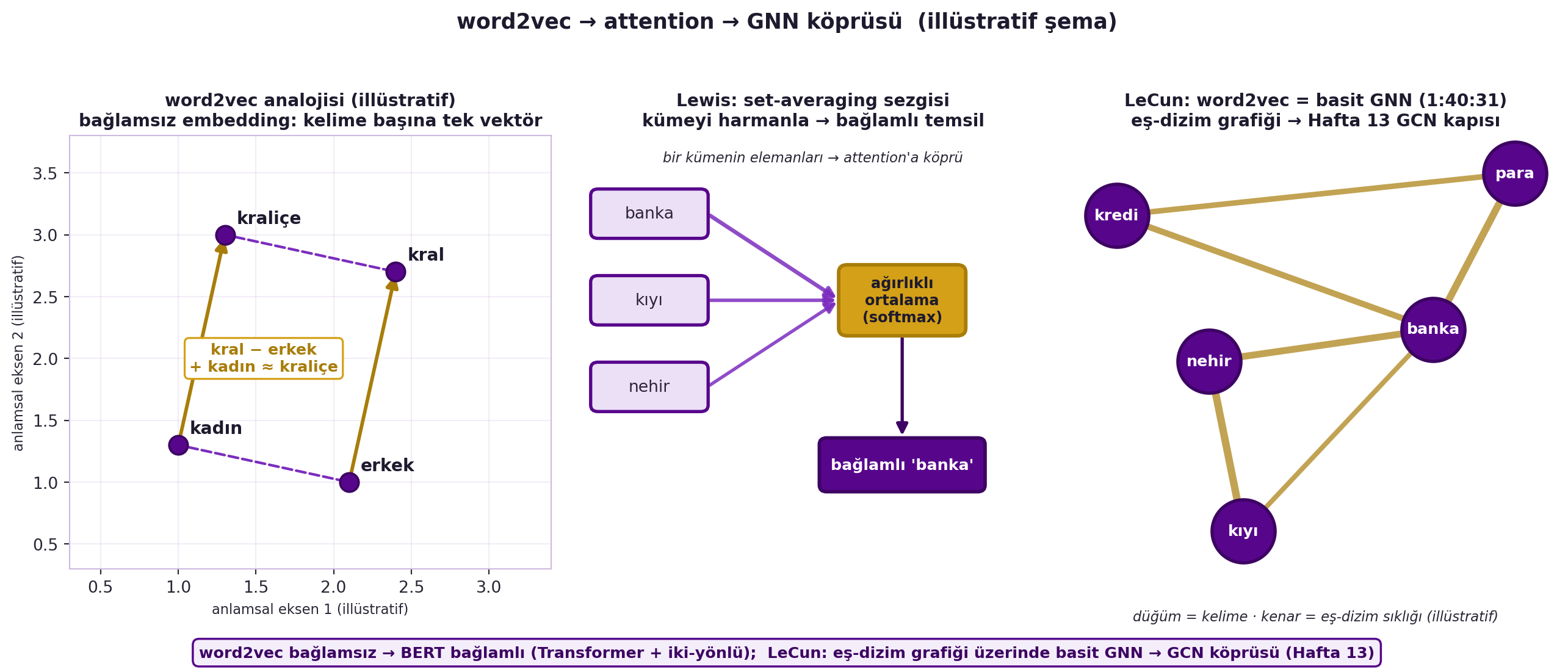
Evrim şöyle: **word2vec** (boşluğu doldur → kelime embedding; "kral − erkek + kadın ≈ kraliçe") ama bağlamdan **bağımsız** (kelime başına tek vektör). Sonra **GPT** (tek-yönlü dil modeli → fine-tune ile her görev), **ELMo** (iki-yönlü birleştirme) ve **BERT**:
> "bert basically looks quite a lot like word2vec, it's a fill-in-the-blanks task... the reason it works much better is [the transformer, more context, bidirectional]." — Lewis, 1:18:50
BERT, token'ların %15'ini maskeler ve doldurur — bu bir **denoising** görevidir (Hafta 7-8 denoising autoencoder). RoBERTa/BART/T5 bunu basitleştirip **ölçekler**. Özet: düşük-önyargı + iki-yönlü bağlam + **ölçek**.
LeCun tartışmaya katılıp bir sonraki haftaya köprü kuruyor:
> "you can view those self-supervised training systems [word2vec, BERT] as basically a very simple form of graph neural net... the graph is how often two words appear next to each other." — LeCun, 1:40:31
@fig-word2vec-bridge bu köprüyü resmeder: solda word2vec'in bağlamsız analoji düzlemi, ortada Lewis'in "kümeyi harmanla" (set-averaging) sezgisi (attention'a köprü), sağda LeCun'un eş-dizim grafiği üzerinde basit GNN yorumu (Hafta 13 GCN kapısı).
```{python}
#| label: fig-topk-sampling
#| fig-cap: "Top-k decoding, 2 panel — GERÇEK kırpma + yeniden normalize. 12 kelimelik azalan bir olasılık dağılımı üzerinde topk_truncate(probs, 4). SOL 'Tam dağılım (12 kelime)': gri/violet barlar; greedy = argmax (gold ok, tek en olası kelimeyi seçer, geri-izleme yok). SAĞ 'Top-k=4 (kırp + örnekle)': yalnız 4 bar (violet, toplamı 1'e yeniden normalize), geri kalan kütle 0. Sezgi: greedy tek-en-iyi (çeşitlilik yok); beam büyük beam'de bozulur (exposure bias: model kendi hatasını hiç görmez, Lewis 49:54); top-k = k-best kırp + örnekle → çeşitlilik + manifolddan düşmeme (Angela Fan, GPT-2)."
probs = np.array([0.27, 0.20, 0.15, 0.11, 0.08, 0.06,
0.045, 0.03, 0.02, 0.015, 0.01, 0.005])
probs = probs / probs.sum()
kept = topk_truncate(probs, 4)
V = len(probs)
x = np.arange(V)
labels = [f"w{i+1}" for i in range(V)]
fig, (axL, axR) = plt.subplots(1, 2, figsize=(12, 4.8))
# SOL — tam dağılım + greedy işareti
apply_style(axL)
colors_full = [COL_VIOLET if i < 4 else COL_GRID for i in range(V)]
axL.bar(x, probs, color=colors_full, edgecolor=COL_INK, linewidth=0.7, width=0.7, zorder=3)
g = int(np.argmax(probs))
axL.annotate("greedy: tek en olası\n(argmax, geri-izleme yok)",
xy=(g, probs[g]), xytext=(2.6, 0.21),
fontsize=9, color=COL_GOLD_D, fontweight="bold",
arrowprops=dict(arrowstyle="-|>", color=COL_GOLD_D, lw=1.6))
axL.set_xticks(x); axL.set_xticklabels(labels, fontsize=8, rotation=0)
axL.set_xlabel("kelime", fontsize=10)
axL.set_ylabel("olasılık", fontsize=10)
axL.set_title("Tam dağılım (12 kelime)", fontsize=11.5, color=COL_INK, fontweight="bold")
axL.set_ylim(0, 0.30)
# SAĞ — top-k=4 (kırpılmış + renormalize)
apply_style(axR)
colors_k = [COL_VIOLET if kept[i] > 0 else COL_GRID for i in range(V)]
axR.bar(x, kept, color=colors_k, edgecolor=COL_INK, linewidth=0.7, width=0.7, zorder=3)
for i in range(V):
if kept[i] > 0:
axR.text(i, kept[i] + 0.008, f"{kept[i]:.2f}", ha="center", va="bottom",
fontsize=8, color=COL_TEXT)
axR.set_xticks(x); axR.set_xticklabels(labels, fontsize=8)
axR.set_xlabel("kelime", fontsize=10)
axR.set_ylabel("olasılık (yeniden normalize)", fontsize=10)
axR.set_title("Top-k = 4 (kırp + örnekle)", fontsize=11.5, color=COL_INK, fontweight="bold")
axR.set_ylim(0, 0.45)
axR.annotate("yalnız 4 kelime kalır,\ntoplam = 1 (örnekle)",
xy=(1, kept[1]), xytext=(4.5, 0.34),
fontsize=9, color=COL_VIOLET_D, fontweight="bold",
arrowprops=dict(arrowstyle="-|>", color=COL_VIOLET_D, lw=1.5))
fig.suptitle("Decoding: greedy / beam (exposure bias) vs top-k sampling",
fontsize=13.5, color=COL_INK, fontweight="bold", y=1.02)
fig.text(0.5, -0.04,
"greedy = argmax (çeşitlilik yok); beam büyükte bozulur (exposure bias, Lewis 49:54); "
"top-k = k-best kırp + örnekle = çeşitlilik + manifolddan düşmeme (Angela Fan, GPT-2)",
ha="center", va="top", fontsize=9, color=COL_VIOLET_D, style="italic")
fig.tight_layout()
```
```{python}
#| label: fig-word2vec-bridge
#| fig-cap: "word2vec → attention → GNN köprüsü (illüstratif şema). SOL — word2vec analojisi: bağlamsız embedding'de her kelime tek vektördür; 'kral − erkek + kadın ≈ kraliçe' paralelkenarı bu doğrusal yapıyı gösterir (vektör konumları ILLÜSTRATIF, gerçek bir eğitilmiş embedding değil — yalnızca sezgi). ORTA — Lewis'in set-averaging sezgisi: bir bağlam kümesinin elemanları softmax ağırlıklarıyla harmanlanır (ağırlıklı ortalama) → bağlamlı temsil; bu, self-attention'ın çekirdeğine köprüdür (ok kalınlıkları self_attention_matrix ağırlıklarıyla orantılı). SAG — LeCun'un gözlemi (1:40:31): word2vec, kelimelerin düğüm, eş-dizim sıklığının kenar olduğu bir grafik üzerinde basit bir GNN gibidir (networkx eş-dizim grafiği; kenar ağırlıkları illüstratif) → Hafta 13 GCN kapısı. Özet: word2vec bağlamsız → BERT bağlamlı (Transformer + iki-yönlü); eş-dizim grafiği üzerinde basit GNN → GCN köprüsü."
fig, axes = plt.subplots(1, 3, figsize=(13.5, 5.2))
ax_l, ax_m, ax_r = axes
# --- SOL: word2vec analojisi (ILLUSTRATIF) ---
apply_style(ax_l)
king = np.array([2.4, 2.7]); queen = np.array([1.3, 3.0])
man = np.array([2.1, 1.0]); woman = np.array([1.0, 1.3])
pts = {"kral": king, "kraliçe": queen, "erkek": man, "kadın": woman}
for lbl, p in pts.items():
ax_l.scatter(*p, s=130, color=COL_VIOLET, edgecolor=COL_VIOLET_D,
linewidth=1.4, zorder=4)
ax_l.annotate(lbl, p, xytext=(7, 7), textcoords="offset points",
fontsize=10.5, color=COL_INK, fontweight="bold", zorder=5)
def _arrow(ax, a, b, color, lw=2.2, ls="-", style="-|>"):
ax.add_patch(FancyArrowPatch(a, b, arrowstyle=style, mutation_scale=15,
color=color, lw=lw, linestyle=ls, zorder=3))
_arrow(ax_l, man, king, COL_GOLD_D)
_arrow(ax_l, woman, queen, COL_GOLD_D)
_arrow(ax_l, man, woman, COL_VIOLET_M, lw=1.6, ls="--", style="-")
_arrow(ax_l, king, queen, COL_VIOLET_M, lw=1.6, ls="--", style="-")
ax_l.text(1.55, 2.0, "kral − erkek\n+ kadın ≈ kraliçe",
fontsize=9.5, color=COL_GOLD_D, ha="center", va="center", fontweight="bold",
bbox=dict(boxstyle="round,pad=0.3", fc=COL_WHITE, ec=COL_GOLD, lw=1.2))
ax_l.set_xlim(0.3, 3.4); ax_l.set_ylim(0.3, 3.8)
ax_l.set_title("word2vec analojisi (illüstratif)\nbağlamsız embedding: kelime başına tek vektör",
fontsize=10.5, color=COL_INK, fontweight="bold")
ax_l.set_xlabel("anlamsal eksen 1 (illüstratif)", fontsize=8.5)
ax_l.set_ylabel("anlamsal eksen 2 (illüstratif)", fontsize=8.5)
# --- ORTA: Lewis set-averaging sezgisi (attention'a köprü) ---
ax_m.set_xlim(0, 10); ax_m.set_ylim(0, 10); ax_m.axis("off")
ax_m.set_title("Lewis: set-averaging sezgisi\nkümeyi harmanla → bağlamlı temsil",
fontsize=10.5, color=COL_INK, fontweight="bold")
tokens = ["banka", "kıyı", "nehir"]
tok_xy = [(1.3, 8.2), (1.3, 6.2), (1.3, 4.2)]
for lbl, (tx, ty) in zip(tokens, tok_xy):
box = FancyBboxPatch((tx - 0.9, ty - 0.55), 2.4, 1.1,
boxstyle="round,pad=0.02,rounding_size=0.15",
fc="#ece0f7", ec=COL_VIOLET, lw=2.0, zorder=2)
ax_m.add_patch(box)
ax_m.text(tx + 0.3, ty, lbl, ha="center", va="center",
fontsize=10, color=COL_TEXT, zorder=3)
mix = (6.7, 6.2)
mbox = FancyBboxPatch((mix[0] - 1.15, mix[1] - 0.8), 2.6, 1.6,
boxstyle="round,pad=0.02,rounding_size=0.18",
fc=COL_GOLD, ec=COL_GOLD_D, lw=2.2, zorder=2)
ax_m.add_patch(mbox)
ax_m.text(mix[0] + 0.15, mix[1], "ağırlıklı\nortalama\n(softmax)",
ha="center", va="center", fontsize=9, color=COL_INK, fontweight="bold", zorder=3)
A = self_attention_matrix(np.array([[1.0, 0.2, 0.1],
[0.3, 1.0, 0.4],
[0.1, 0.5, 1.0]]))
w = A[0] # 1. token'ın (banka) bağlam ağırlıkları → ok kalınlığı
for (tx, ty), wi in zip(tok_xy, w):
ax_m.add_patch(FancyArrowPatch((tx + 1.5, ty), (mix[0] - 1.15, mix[1]),
arrowstyle="-|>", mutation_scale=13,
color=COL_VIOLET_M, lw=1.2 + 3.0 * wi,
zorder=1, alpha=0.85))
out = (6.7, 2.4)
obox = FancyBboxPatch((out[0] - 1.55, out[1] - 0.6), 3.4, 1.2,
boxstyle="round,pad=0.02,rounding_size=0.15",
fc=COL_VIOLET, ec=COL_VIOLET_D, lw=2.2, zorder=2)
ax_m.add_patch(obox)
ax_m.text(out[0] + 0.15, out[1], "bağlamlı 'banka'", ha="center", va="center",
fontsize=9.5, color=COL_WHITE, fontweight="bold", zorder=3)
ax_m.add_patch(FancyArrowPatch((mix[0] + 0.15, mix[1] - 0.8), (out[0] + 0.15, out[1] + 0.6),
arrowstyle="-|>", mutation_scale=14,
color=COL_VIOLET_D, lw=2.0, zorder=1))
ax_m.text(5.0, 9.4, "bir kümenin elemanları → attention'a köprü",
fontsize=8.5, color=COL_TEXT, ha="center", style="italic")
# --- SAG: LeCun word2vec = basit GNN (eş-dizim grafiği, networkx) ---
ax_r.axis("off")
ax_r.set_title("LeCun: word2vec = basit GNN (1:40:31)\neş-dizim grafiği → Hafta 13 GCN kapısı",
fontsize=10.5, color=COL_INK, fontweight="bold")
G = nx.Graph()
words = ["nehir", "banka", "para", "kıyı", "kredi"]
G.add_nodes_from(words)
edges = [("nehir", "banka", 0.8), ("nehir", "kıyı", 0.9), ("banka", "kıyı", 0.5),
("banka", "para", 0.85), ("banka", "kredi", 0.7), ("para", "kredi", 0.6)]
for u, v, ww in edges:
G.add_edge(u, v, weight=ww)
pos = nx.spring_layout(G, seed=3, k=1.6)
nx.draw_networkx_edges(G, pos, ax=ax_r,
width=[1.0 + 4.0 * G[u][v]["weight"] for u, v in G.edges()],
edge_color=COL_GOLD_D, alpha=0.7)
nx.draw_networkx_nodes(G, pos, ax=ax_r, node_size=1500,
node_color=COL_VIOLET, edgecolors=COL_VIOLET_D, linewidths=2.0)
nx.draw_networkx_labels(G, pos, ax=ax_r, font_size=9.5, font_color=COL_WHITE,
font_weight="bold")
ax_r.text(0.5, -0.12, "düğüm = kelime · kenar = eş-dizim sıklığı (illüstratif)",
transform=ax_r.transAxes, fontsize=8.5, color=COL_TEXT, ha="center", style="italic")
# --- Köprü özeti annotation ---
fig.text(0.5, -0.02,
"word2vec bağlamsız → BERT bağlamlı (Transformer + iki-yönlü); "
"LeCun: eş-dizim grafiği üzerinde basit GNN → GCN köprüsü (Hafta 13)",
ha="center", fontsize=9.5, color=COL_VIOLET_D, fontweight="bold",
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG, ec=COL_VIOLET, lw=1.3))
fig.suptitle("word2vec → attention → GNN köprüsü (illüstratif şema)",
fontsize=13, color=COL_INK, fontweight="bold", y=1.04)
fig.tight_layout()
```
::: {.callout-tip title="Builder Notu — Exposure Bias ve Cake = SSL"}
**Geriye (Hafta 10 + 7-8):** SSL / cake / pretext = Hafta 10 (Misra); BERT masked-LM = Hafta 7-8 denoising AE (gürültüyü geri al = enerji); word2vec analojisi = Hafta 1 temsil öğrenme.
**İleriye:** pre-train → fine-tune = tüm foundation model paradigması; LeCun'un graf yorumu = Hafta 13 GCN.
:::
## (İleriye Köprü) GPT-3'ten ChatGPT'ye — LLM Patlaması (post-2020) — KURSTA YOK {#sec-post2020-kopru}
Lewis (Mart 2020) en güçlü modeller olarak GPT-2, BERT, RoBERTa, BART/T5 ve top-k sampling'i anlatır — "100 milyar parametreli modeller geliyor" söylentisini aktarır. Aşağıdakiler DLSP20'den **sonra** geldi, kursta **YOKTUR** (yalnızca ileriye köprü):
::: {.callout-warning title="⚠️ İleriye Köprü Notu (post-2020 — KURSTA YOK)"}
- **GPT-3** (Mayıs 2020) — 175 milyar parametre; **in-context learning / few-shot** (Lewis'in "1-10 örnekle öğrenebilir miyiz?" sorusunun cevabı).
- **InstructGPT / RLHF** (2022), **ChatGPT** (Kasım 2022), **GPT-4** (2023), **LLaMA** (2023) — insan geri-bildirimiyle hizalama; Lewis'in "grounding / cherry" sorusunun pratik yanıtı.
- **FlashAttention** (2022), uzun-bağlam Transformer'lar — Lewis'in "512 token sınırı / koca bir kitabı modelleyebilir miyiz?" sorusunun devamı.
Bunlar kurs terimi gibi eklenmez; Lewis'in "ölçek en önemli şey" tezinin nereye vardığını göstermek için anılır.
:::
::: {.callout-tip title="Builder Notu — Ölçek Tezi Nereye Vardı"}
**Geriye (Hafta 12):** LLM patlaması = "düşük-önyargı + iki-yönlü + ölçek" tezinin doğrudan devamı; RLHF = Lewis'in "grounding" sorusunun yanıtı.
**İleriye:** in-context learning + RLHF = 2020-sonrası NLP'nin tanımı — ama hepsi 2017 Transformer + 2018 BERT temelinin üstünde durur.
:::
## Geçiş: Lewis'ten Canziani'ye {#sec-gecis-d12}
Lewis, Transformer'ın **neden** çalıştığını ve NLP'yi nasıl dönüştürdüğünü anlattı. Şimdi **Canziani** kaputu açıyor: attention'ın altında yatan basit matematiği (kümeler, linear kombinasyon, Q/K/V) ve Transformer encoder/decoder iskeletini PyTorch'ta kuruyor — görünür karmaşıklığın aslında "yemek tarifi arama" kadar sezgisel olduğunu gösteriyor.
## (Canziani) Attention = Kümeler Üzerinde Linear Kombinasyon {#sec-kume-linear}
Kilit çerçeve: Transformer **dizilerle değil, kümelerle** çalışır.
> "transformers are going to be something that maps sets to sets, they don't really deal with sequences." — Canziani, 0:49
**Self-attention:** gizli temsil $h$, kümenin ($X$) elemanlarının **linear kombinasyonudur**: $h = X \cdot a$. Katsayı $a$ iki türlü olabilir:
- **Hard attention:** $a$ tek-sıcak (one-hot) → kümeden **tek** bir eleman seçer.
- **Soft attention:** $a$ toplamı 1 → konveks kombinasyon (harman).
$a$ nereden gelir? Her $x_i$ ile sorgu $x$ arasındaki **benzerlik skorundan** (nokta çarpımı), softmax'ten:
$$
a = \text{softmax}\!\left(\frac{X^\top x}{\sqrt{d}}\right)
$$
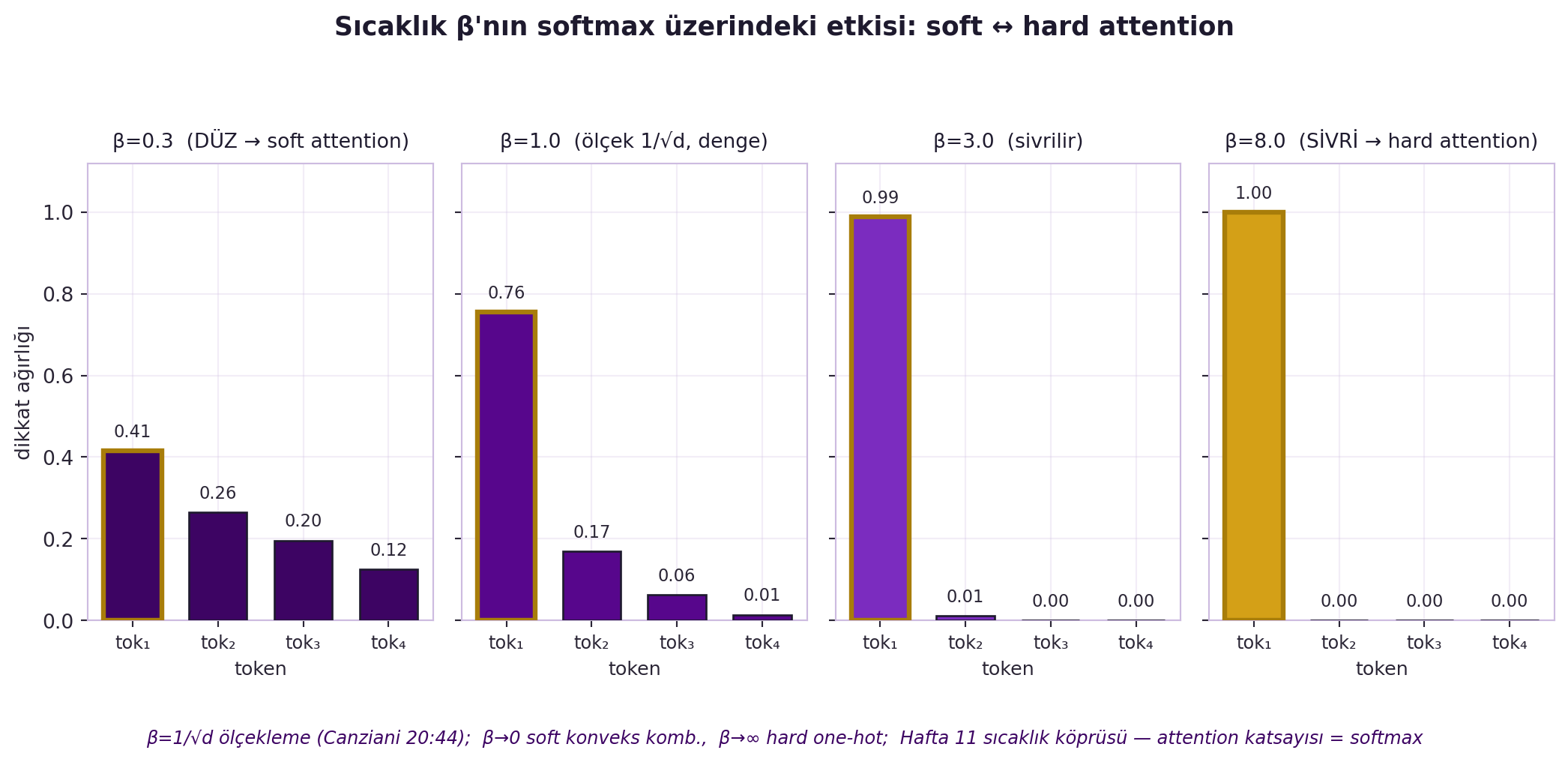
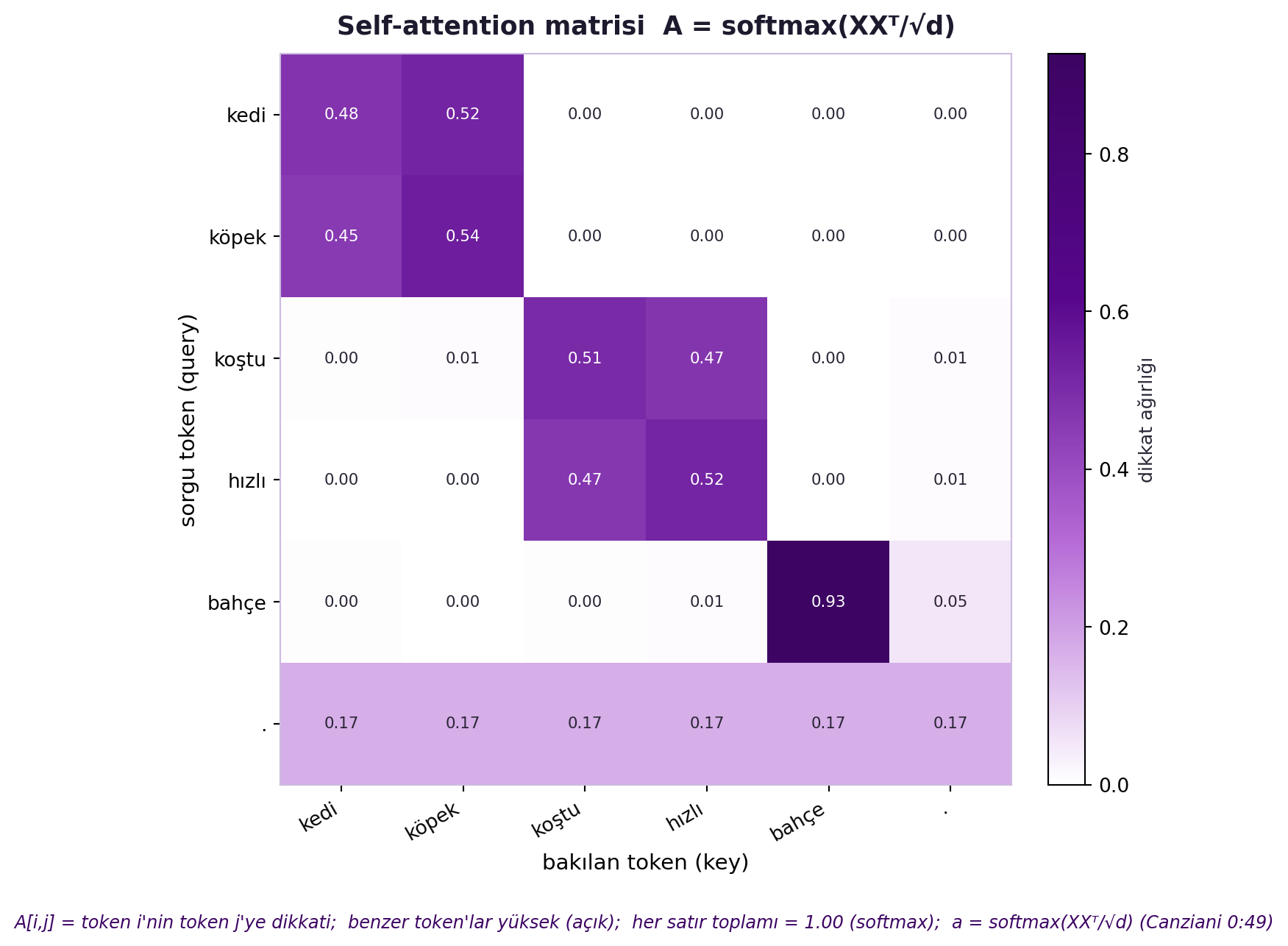
(Burada $\beta = 1/\sqrt{d}$ ölçeklemesi vardır: vektör büyüklüğü $\sqrt{d}$ ile büyür, sıcaklığı sabit tutmak için bölünür.) @fig-softmax-temperature bu $\beta$ ölçeklemesinin etkisini gösterir: $\beta$ küçükken dağılım düzleşir (soft attention, harman), $\beta$ büyürken sivrilir (hard attention, tek-seçim) — bu doğrudan Hafta 11 sıcaklık köprüsüdür. @fig-self-attention-matrix ise gerçek bir token kümesi üzerinde tüm $A$ matrisini hesaplar: benzer token'lar birbirine yüksek dikkat verir, her satır toplamı 1'dir.
**Key-value store** analojisi: YouTube'da "lazanya" yazarsın (**query**), bu tüm video başlıklarıyla (**keys**) karşılaştırılır, en yüksek skorlu videoyu (**value**) getirirsin.
> "you have one query, you check all the keys and find how matching the key is... and then you retrieve all those values." — Canziani, 19:07
```{python}
#| label: fig-softmax-temperature
#| fig-cap: "Sıcaklık β'nın softmax üzerindeki etkisi: soft ↔ hard attention. β küçük → düz (soft, harman); β büyük → sivri (hard, tek-seçim). β=1/√d ölçekleme = Hafta 11 sıcaklık köprüsü."
from matplotlib.colors import LinearSegmentedColormap
# Sabit skorlar (4 token) + 4 sıcaklık (β)
scores = np.array([3.0, 1.5, 0.5, -1.0])
betas = [0.3, 1.0, 3.0, 8.0]
W = softmax_temperature(scores, betas) # [4, 4], her satır toplamı 1
tokens = ["tok₁", "tok₂", "tok₃", "tok₄"]
n_tok = len(scores)
x = np.arange(n_tok)
# β renk gradyani: violet → gold
beta_cmap = LinearSegmentedColormap.from_list(
"violet_gold", [COL_VIOLET_D, COL_VIOLET, COL_VIOLET_M, COL_GOLD]
)
beta_colors = [beta_cmap(t) for t in np.linspace(0, 1, len(betas))]
beta_titles = [
"β=0.3 (DÜZ → soft attention)",
"β=1.0 (ölçek 1/√d, denge)",
"β=3.0 (sivrilir)",
"β=8.0 (SİVRİ → hard attention)",
]
fig, axes = plt.subplots(1, 4, figsize=(11, 4.6), sharey=True)
for k, ax in enumerate(axes):
apply_style(ax)
w = W[k]
bars = ax.bar(x, w, color=beta_colors[k], edgecolor=COL_INK,
linewidth=1.0, width=0.68, zorder=3)
# tek-seçim vurgusu: en yüksek ağırlığa gold kenar
bars[int(np.argmax(w))].set_edgecolor(COL_GOLD_D)
bars[int(np.argmax(w))].set_linewidth(2.4)
for xi, wi in zip(x, w):
ax.text(xi, wi + 0.025, f"{wi:.2f}", ha="center", va="bottom",
fontsize=8.5, color=COL_TEXT, zorder=4)
ax.set_title(beta_titles[k], fontsize=10, color=COL_INK, pad=8)
ax.set_xticks(x)
ax.set_xticklabels(tokens, fontsize=9)
ax.set_xlabel("token", fontsize=9.5)
ax.set_ylim(0, 1.12)
if k == 0:
ax.set_ylabel("dikkat ağırlığı", fontsize=10)
fig.suptitle(
"Sıcaklık β'nın softmax üzerindeki etkisi: soft ↔ hard attention",
fontsize=13, color=COL_INK, fontweight="bold", y=1.04,
)
note = ("β=1/√d ölçekleme (Canziani 20:44); β→0 soft konveks komb., "
"β→∞ hard one-hot; Hafta 11 sıcaklık köprüsü — attention katsayısı = softmax")
fig.text(0.5, -0.04, note, ha="center", va="top", fontsize=9,
color=COL_VIOLET_D, style="italic")
fig.tight_layout(rect=[0, 0, 1, 0.97])
plt.show()
```
```{python}
#| label: fig-self-attention-matrix
#| fig-cap: "Self-attention ağırlık matrisi A = softmax(XXᵀ/√d) — GERÇEK hesaplama (FLAGSHIP). 6 token'lık anlamlı bir embedding kümesi X (benzer kelimeler birbirine yakın yerleştirilmiş: 'kedi'/'köpek' yakın, 'koştu'/'hızlı' yakın, '.' uzak) → self_attention_matrix(X) → A [6,6] heatmap (violet). Satır = sorgu token, sütun = bakılan token; A[i,j] = token i'nin token j'ye verdiği dikkat. Benzer token'lar yüksek dikkat alır (açık renk); her satırın toplamı tam 1'dir (softmax). Bu, Canziani'nin 'küme → küme' görüşünün çekirdeğidir (0:49): attention bir kümenin elemanlarını benzerlik-ağırlıklı harmanlar."
# 6 token: anlamlı 2B embedding (benzer olanlar yakın)
tokens6 = ["kedi", "köpek", "koştu", "hızlı", "bahçe", "."]
X = np.array([
[ 2.2, 1.9], # kedi (canlı/hayvan kümesi)
[ 2.0, 2.2], # köpek (kediye yakın)
[-1.8, 1.6], # koştu (eylem kümesi)
[-2.1, 1.2], # hızlı (koştu'ya yakın, zarf)
[ 0.2, -2.0], # bahçe (mekan)
[ 0.0, 0.0], # . (nötr / uzak)
])
A = self_attention_matrix(X) # [6,6], satır toplamı 1
violet_cmap = LinearSegmentedColormap.from_list(
"violet_seq2", [COL_WHITE, COL_VIOLET_SOFT, COL_VIOLET, COL_VIOLET_D]
)
fig, ax = plt.subplots(figsize=(7.6, 6.4))
im = ax.imshow(A, cmap=violet_cmap, vmin=0, vmax=A.max(), aspect="equal")
ax.set_xticks(range(6)); ax.set_xticklabels(tokens6, fontsize=10, rotation=30, ha="right")
ax.set_yticks(range(6)); ax.set_yticklabels(tokens6, fontsize=10)
ax.set_xlabel("bakılan token (key)", fontsize=11)
ax.set_ylabel("sorgu token (query)", fontsize=11)
ax.set_title("Self-attention matrisi A = softmax(XXᵀ/√d)",
fontsize=13, color=COL_INK, fontweight="bold", pad=10)
for i in range(6):
for j in range(6):
v = A[i, j]
ax.text(j, i, f"{v:.2f}", ha="center", va="center", fontsize=8.0,
color=COL_WHITE if v > 0.30 else COL_TEXT)
for spine in ax.spines.values():
spine.set_color(COL_GRID)
cbar = fig.colorbar(im, ax=ax, fraction=0.046, pad=0.04)
cbar.set_label("dikkat ağırlığı", fontsize=9.5, color=COL_TEXT)
# satır toplamı 1 doğrulama notu
fig.text(0.5, -0.02,
"A[i,j] = token i'nin token j'ye dikkati; benzer token'lar yüksek (açık); "
f"her satır toplamı = 1.00 (softmax); a = softmax(XXᵀ/√d) (Canziani 0:49)",
ha="center", va="top", fontsize=9, color=COL_VIOLET_D, style="italic")
fig.tight_layout()
```
::: {.callout-tip title="Builder Notu — Küme→Küme"}
**Geriye (Hafta 11 + 6 + 1):** Softmax + β = Hafta 11; benzerlik = nokta çarpımı (Hafta 1); linear kombinasyon = ağırlıklı ortalama. Attention = Hafta 6 çekirdeği, "küme" diliyle yeniden anlatılmış.
**İleriye:** "Sets to sets" görüşü Transformer'ı görüntü (ViT), grafik ve protein gibi her veri türüne taşır.
:::
## (Canziani) Query-Key-Value ve Transformer Encoder/Decoder {#sec-qkv-encdec}
**Q, K, V** girdinin öğrenilen **rotasyonlarıdır**: $Q = W_Q x$, $K = W_K x$, $V = W_V x$. Attention'daki **tek eğitilebilir parametreler** bunlardır — attention yönelime (orientation) dayalıdır, softmax dışında doğrusalsızlık yoktur:
> "this attention thing is completely based on orientation... the only non-linearity is whenever you get the probability distribution." — Canziani, 22:05
Q ve K aynı boyutta olmalıdır (karşılaştırılırlar); V farklı olabilir ("tarifin içeriği"). İki tür attention vardır:
- **Self-attention:** Q, K, V hepsi aynı $X$'ten gelir (kendi kafanda bir tarif düşünmek).
- **Cross-attention:** Q girdiden/decoder'dan, K ve V başka yerden/encoder'dan gelir (tarif kitabına bakmak).
**Transformer = encoder + decoder** (bir autoencoder gibi). @fig-transformer-encoder-decoder bu iskeleti gösterir:
- **Encoder bloğu:** self-attention + "convolution" (kernel=1 olan 1D conv = kümenin her elemanına uygulanan MLP — Canziani "bu lineer katman değil, convolution'dır" diye ısrar eder) + Add&Norm.
- **Decoder bloğu:** encoder'ın yaptıklarına ek olarak **cross-attention** (query decoder'dan, key/value encoder'ın $H$ temsilinden).
IMDB film yorumu sınıflandırması (yalnız encoder) test doğruluğu **%83**'tür.
```{python}
#| label: fig-transformer-encoder-decoder
#| fig-cap: "Transformer encoder/decoder mimarisi (Q/K/V dâhil) — şema. SOL 'Encoder bloğu (×N)': girdi + PE → Multi-Head Self-Attention (Q/K/V aynı X'ten) → Add&Norm → 'Convolution' kernel=1 (= her elemana MLP) → Add&Norm → H. SAĞ 'Decoder bloğu (×N)': hedef + PE → Masked Self-Attention → Add&Norm → Cross-Attention (Q decoder'dan, K/V encoder H'sinden; gold ok) → Add&Norm → MLP → Add&Norm → softmax çıktı. Encoder + decoder = autoencoder iskeleti (Hafta 8); Q/K/V öğrenilen rotasyonlar = tek parametre; cross-attention dili soyutlar → dile-agnostik kavram (Canziani 1:03:44); kernel=1 conv = MLP (Hafta 3 1×1 conv)."
fig, ax = plt.subplots(figsize=(12, 7.2))
ax.set_xlim(0, 13); ax.set_ylim(0, 11.5); ax.axis("off")
ax.set_title("Transformer = Encoder + Decoder (autoencoder iskeleti)",
color=COL_INK, fontsize=14, fontweight="bold", pad=10)
def tbox(x, y, w, h, label, fc, ec, lw=2.0, fs=8.8, tc=None, dashed=False):
ls = (0, (5, 3)) if dashed else "solid"
b = FancyBboxPatch((x - w / 2, y - h / 2), w, h,
boxstyle="round,pad=0.02,rounding_size=0.10",
fc=fc, ec=ec, lw=lw, linestyle=ls, zorder=3)
ax.add_patch(b)
ax.text(x, y, label, ha="center", va="center", fontsize=fs,
color=tc or COL_TEXT, zorder=4, wrap=True)
def varrow(x, y0, y1, color=COL_VIOLET_M, lw=2.0):
ax.add_patch(FancyArrowPatch((x, y0), (x, y1), arrowstyle="-|>",
mutation_scale=15, color=color, lw=lw, zorder=2))
# ---- ENCODER (sol sütun, x=3) ----
xe = 3.2
ax.add_patch(FancyBboxPatch((xe - 2.0, 1.0), 4.0, 8.6,
boxstyle="round,pad=0.05,rounding_size=0.15",
fc=COL_BG, ec=COL_VIOLET, lw=1.6, linestyle=(0, (4, 2)), zorder=1))
ax.text(xe, 9.95, "Encoder bloğu (×N)", ha="center", fontsize=11.5,
color=COL_VIOLET_D, fontweight="bold")
tbox(xe, 1.7, 2.9, 0.85, "girdi + positional encoding", COL_BG, COL_GOLD_D, fs=8.2)
tbox(xe, 3.3, 3.3, 1.0, "Multi-Head\nSelf-Attention\n(Q/K/V aynı X'ten)", "#ece0f7", COL_VIOLET, lw=2.4, fs=8.2)
tbox(xe, 4.85, 2.2, 0.6, "Add & Norm", COL_WHITE, COL_VIOLET_M, fs=8.2)
tbox(xe, 6.3, 3.3, 1.0, "'Convolution' kernel=1\n(= her elemana MLP)", "#ece0f7", COL_VIOLET, lw=2.4, fs=8.2)
tbox(xe, 7.85, 2.2, 0.6, "Add & Norm", COL_WHITE, COL_VIOLET_M, fs=8.2)
tbox(xe, 9.0, 2.0, 0.7, "H (temsil)", COL_VIOLET, COL_VIOLET_D, fs=9.0, tc=COL_WHITE)
for y0, y1 in [(2.15, 2.78), (3.85, 4.52), (5.18, 5.78), (6.85, 7.52), (8.18, 8.62)]:
varrow(xe, y0, y1)
# ---- DECODER (sağ sütun, x=9.8) ----
xd = 9.8
ax.add_patch(FancyBboxPatch((xd - 2.1, 1.0), 4.2, 9.0,
boxstyle="round,pad=0.05,rounding_size=0.15",
fc="#faf4e6", ec=COL_GOLD_D, lw=1.6, linestyle=(0, (4, 2)), zorder=1))
ax.text(xd, 10.3, "Decoder bloğu (×N)", ha="center", fontsize=11.5,
color=COL_GOLD_D, fontweight="bold")
tbox(xd, 1.7, 2.9, 0.85, "hedef + positional encoding", COL_BG, COL_GOLD_D, fs=8.2)
tbox(xd, 3.2, 3.2, 0.95, "Masked\nSelf-Attention", "#ece0f7", COL_VIOLET, lw=2.4, fs=8.2)
tbox(xd, 4.55, 2.0, 0.55, "Add & Norm", COL_WHITE, COL_VIOLET_M, fs=8.0)
tbox(xd, 5.95, 3.5, 1.0, "Cross-Attention\n(Q decoder · K/V encoder H)", "#fbf2d6", COL_GOLD_D, lw=2.4, fs=8.0)
tbox(xd, 7.3, 2.0, 0.55, "Add & Norm", COL_WHITE, COL_VIOLET_M, fs=8.0)
tbox(xd, 8.4, 2.0, 0.6, "MLP + Add&Norm", COL_WHITE, COL_VIOLET_M, fs=8.0)
tbox(xd, 9.4, 1.9, 0.6, "softmax çıktı", COL_VIOLET, COL_VIOLET_D, fs=8.6, tc=COL_WHITE)
for y0, y1 in [(2.15, 2.7), (3.7, 4.27), (4.85, 5.42), (6.48, 6.99), (7.6, 8.08), (8.72, 9.08)]:
varrow(xd, y0, y1)
# encoder H → decoder cross-attention (gold ok)
ax.add_patch(FancyArrowPatch((xe + 1.05, 9.0), (xd - 1.78, 5.95),
arrowstyle="-|>", mutation_scale=18,
color=COL_GOLD_D, lw=2.6,
connectionstyle="arc3,rad=-0.18", zorder=5))
ax.text(6.5, 8.2, "encoder H →\ncross-attention\n(dile-agnostik kavram)",
ha="center", va="center", fontsize=8.2, color=COL_GOLD_D,
fontweight="bold", style="italic")
fig.text(0.5, 0.005,
"encoder + decoder = autoencoder iskeleti (Hafta 8); Q/K/V = öğrenilen rotasyon (tek param); "
"cross-attention dili soyutlar → dile-agnostik kavram (Canziani 1:03:44); kernel=1 conv = MLP (Hafta 3)",
ha="center", va="bottom", fontsize=8.8, color=COL_VIOLET_D, style="italic")
fig.tight_layout()
```
::: {.callout-tip title="Builder Notu — Q/K/V = Rotasyon"}
**Geriye (Hafta 8 + 3 + 1):** Encoder/decoder = Hafta 8 autoencoder mimarisi; residual + LayerNorm = Hafta 3; "convolution kernel=1" = Hafta 3 1×1 conv = MLP. Q/K/V rotasyonu = Hafta 1 lineer dönüşüm.
**İleriye:** Encoder-only (BERT) vs decoder-only (GPT) vs encoder-decoder (T5/çeviri) = LLM ailesinin üç dalı.
:::
## (Canziani) Autoregressive Üretim, Look-ahead Mask ve Karesel Maliyet {#sec-autoregressive}
Çeviri (cat → gato): decoder çıktıyı **autoregressive** üretir — bir kelime üretir, geri besler, sonrakini sorar. Her yeni girdi farklı bir **query** sorar; encoder'ın hangi bileşenine bakacağına decoder karar verir.
**Eğitim vs çıkarım:** çıkarım autoregressive (sıralı); eğitimde ise tüm dizi tek geçişte işlenir + **look-ahead mask** (geleceği görmeyi engeller — Lewis'in causal maskesinin aynısı). Cross-attention sayesinde encoder dili soyutlar — $H$ temsilleri **dile-agnostik kavramlardır**:
> "the H encoder are stripping off the language specific information, they are just concepts... the representation of the concept without the language attached." — Canziani, 1:03:44
Son bir uyarı — **$A$ matrisi tehlikelidir**: $T \times T$ boyutludur ($T$ = küme büyüklüğü). 1000 öğeli bir küme → milyon-boyutlu bir matris → karesel olarak **patlar**:
> "this is very dangerous... if you have many keys this stuff starts blowing up quickly." — Canziani, 53:01
Uzun diziler için Reformer/LSH/sparse attention gibi yöntemler gerekir.
::: {.callout-tip title="Builder Notu — Karesel Maliyet Patlar"}
**Geriye (Hafta 6 + 11):** Autoregressive = Hafta 6 dizi üretimi; look-ahead mask = Lewis'in causal maskesi; karesel maliyet = self-attention bedeli (Hafta 11 softmax).
**İleriye:** Dile-agnostik encoder = çok-dilli MT + multimodal hizalama; karesel maliyet = lineer/sparse attention araştırmasının itici gücü (Reformer, FlashAttention).
:::
## Bu Dersin Özeti {#sec-ozet-d12}
1. **Bağlam kodlayıcı evrimi (Lewis):** CNN (sınırlı alan) → RNN (darboğaz + yavaş + vanishing) → **Transformer** (her kelime her kelimeye, paralel, ölçeklenir).
2. **Multi-head attention (Lewis):** Q/K/V; causal mask (geleceği görme); positional encoding (küme → sıra); warmup / LayerNorm / label-smoothing.
3. **Decoding (Lewis):** greedy / beam (exposure bias → bozulma); top-k sampling (çeşitlilik).
4. **SSL = dilin motoru (Lewis):** word2vec (bağlamsız) → GPT (tek-yön) → ELMo → **BERT** (masked-LM = denoising); ölçek kraldır.
5. **Attention = küme linear kombinasyonu (Canziani):** $h = X \cdot a$; hard (one-hot) vs soft; $a = \text{softmax}(X^\top x/\sqrt{d})$; key-value store.
6. **Q/K/V + encoder/decoder (Canziani):** öğrenilen rotasyonlar; self vs cross; encoder + decoder = autoencoder iskeleti; IMDB %83.
7. **Autoregressive + maske + karesel maliyet (Canziani):** look-ahead mask; dile-agnostik kavram; $T \times T$ matris patlar.
8. **Post-2020 (KURSTA YOK):** GPT-3 / in-context, ChatGPT / RLHF, FlashAttention — "ölçek" tezinin devamı.
::: {.callout-important title="Tek Bir Cümle"}
Transformer, RNN'in darboğazını ve CNN'in sınırlı alıcı alanını ortadan kaldıran, her kelimenin her kelimeye doğrudan baktığı düşük-önyargılı bir modeldir; çekirdeği attention'dır — bir kümenin elemanlarını Q/K/V benzerlik skorlarıyla (softmax) harmanlayan linear kombinasyon — ve öz-denetimli "boşluğu doldur" (BERT) ile etiketsiz metinden öğrenip pre-train→fine-tune ile her dil görevine taşınır.
:::
## Kontrol Soruları {#sec-kontrol-d12}
::: {.callout-note collapse="true" title="Soru 1: RNN ve CNN'in hangi sorunlarını Transformer çözer? \"Her kelime her kelimeye bakar\" ne kazandırır?"}
**Cevap:** CNN **sınırlı alıcı alan** taşır (uzun-menzilli bağımlılığı yakalayamaz); RNN tüm geçmişi **tek vektöre sıkıştırır** (darboğaz), **vanishing gradient** sorunu yaşar (Hafta 6) ve ardışık olduğu için **yavaştır** (paralelleşmez). Transformer self-attention ile her kelimeyi her kelimeye **doğrudan** bağlar (Lewis 31:43): herhangi bir geçmişe kayıpsız erişim (darboğaz yok, vanishing büyük ölçüde yok) + tek bir matris çarpımı = **paralelleşir** → olağanüstü ölçekleme.
:::
::: {.callout-note collapse="true" title="Soru 2: Multi-head attention'da Q/K/V nedir? Causal mask neden gerekir, positional encoding neden eklenir?"}
**Cevap:** **Query** "ne arıyorum?", **key** kelimeyi etiketler, **value** içeriği taşır. Query·key → softmax → dağılım → value'ların ağırlıklı toplamı; **multi-head** = aynı anda farklı sorular sormak. **Causal mask** (üst-üçgen $-\infty$): tüm adımlar aynı anda hesaplanır, maske olmazsa kelimeler **geleceğe bakıp** hile yapar (Lewis 27:08). **Positional encoding**: attention girdiyi sırasız bir **küme** olarak görür; sıra bilgisi için her konuma bir embedding eklenir.
:::
::: {.callout-note collapse="true" title="Soru 3: Beam search neden bozuk çıktı üretir? \"Exposure bias\" nedir? Top-k sampling ne yapar?"}
**Cevap:** Büyük beam → boş/tekrarlı çıktılar. Sebep **exposure bias**: eğitimde hep doğru önceki kelimeler verilir, model kendi **hatalarını görmez** (Lewis 49:54); test anında bir kötü adımdan sonra görmediği bir duruma düşer ve döngüye girer. **Top-k** (Angela Fan): dağılımı en iyi k'ye kırpıp örnekler — çeşitlilik + "iyi dil manifoldundan" düşmeme. GPT-2 örnekleri böyle üretilir.
:::
::: {.callout-note collapse="true" title="Soru 4: BERT word2vec'ten neden daha iyi? \"Cake\" metaforu nedir? BERT hangi Hafta-7/8 fikriyle aynıdır?"}
**Cevap:** İkisi de "boşluğu doldur" görevidir; word2vec sığ bir linear projeksiyondur ve **bağlamsızdır** (kelime başına tek vektör). BERT büyük bir **Transformer** + **iki-yönlü** zengin etkileşim kullanır (Lewis 1:18:50) → bağlamlı temsil. **Cake** (LeCun): öğrenmenin çoğu denetimsizdir (pastanın kendisi), denetimli öğrenme = üstteki ince krema (1:09:43). BERT masked-LM = Hafta 7-8 **denoising autoencoder**: girdiyi boz (%15 maske), geri kur — gürültüyü gidermek = enerjiyi şekillendirmek.
:::
::: {.callout-note collapse="true" title="Soru 5: Canziani'ye göre attention özünde nedir? Q ve K neden aynı boyutta, V neden farklı olabilir?"}
**Cevap:** Attention = bir **kümenin** ($X$) **benzerlik-ağırlıklı linear kombinasyonu**: $h = X \cdot a$, $a = \text{softmax}(X^\top x/\sqrt{d})$ (Canziani 0:49, 19:07). Hard = one-hot (tek seçim), soft = konveks harman. Key-value: query tüm key'lerle karşılaştırılır, value'lar getirilir. **Q ve K aynı boyutta olmalıdır** çünkü nokta çarpımıyla **karşılaştırılırlar** (yönelim). **V farklı olabilir** çünkü o "tarifin içeriği"dir — karşılaştırılmaz, getirilir. Tek doğrusalsızlık softmax'tir (22:05).
:::
## Egzersizler {#sec-egzersiz-d12}
**Egzersiz 1 (Attention'ı elle hesapla).** 3 elemanlı bir küme {x₁, x₂, x₃} (2B) ve bir sorgu x verilsin. Skorları (xᵢ·x), softmax (β=1) katsayılarını ve h = Σ aᵢ xᵢ'yi hesapla. β büyüdükçe (hard'a doğru) h nasıl değişir?
```python
import numpy as np
# Attention = kumenin benzerlik-agirlikli LINEAR KOMBINASYONU: h = X^T a, a = softmax(beta * X x)
X = np.array([[1.0, 0.0], # x1
[0.0, 1.0], # x2
[0.8, 0.6]]) # x3 (x1'e yakin)
x = np.array([1.0, 0.2]) # sorgu
def softmax(z, beta=1.0):
z = beta * (z - z.max())
e = np.exp(z)
return e / e.sum()
skorlar = X @ x # her x_i ile sorgu nokta carpimi
for beta in [0.5, 1.0, 5.0]:
a = softmax(skorlar, beta) # katsayilar (toplam 1)
h = a @ X # linear kombinasyon
print(f"beta={beta}: a={np.round(a,3)} h={np.round(h,3)}")
# beta buyur -> a one-hot'a yaklasir (HARD) -> h tek bir x_i'ye yaklasir (en yuksek skorlu)
```
**Egzersiz 2 (Causal mask).** 4 kelimelik bir dizi için 4×4 attention skor matrisi çiz; causal mask (üst-üçgen −∞) uygula; softmax sonrası her satırın yalnız kendine + soluna ağırlık verdiğini göster. Maske olmasa neden "hile" olur?
```python
import numpy as np
def softmax_rows(M):
e = np.exp(M - M.max(axis=-1, keepdims=True))
return e / e.sum(axis=-1, keepdims=True)
scores = np.random.default_rng(0).normal(0, 1, (4, 4))
mask = np.triu(np.full((4, 4), -np.inf), k=1) # ust-ucgen (gelecek) = -inf
A = softmax_rows(scores + mask)
print(np.round(A, 2))
# Her satir yalniz kendine + soluna agirlik verir (ust-ucgen = 0).
# Maske OLMASA: kelime tahmin edilirken GELECEK kelimeyi gorur = cevabi kopyalar (HILE);
# maske autoregressive faktorizasyonu p(x1)p(x2|x1)p(x3|x1,x2)... korur.
```
**Egzersiz 3 (Q/K/V boyutları).** d=8, h=4 head'li multi-head attention'da W_Q / W_K / W_V boyutları nedir? Head'leri birleştiren son W neden gerekir? Q=K, V≠ örneğiyle açıkla.
```python
import numpy as np
d_model, n_head = 8, 4
d_head = d_model // n_head # 2 -> her head'in Q/K/V boyutu
# Her head icin: W_Q, W_K [d_model, d_head] (Q ve K AYNI boyut -> nokta carpimi);
# W_V [d_model, d_head] (V FARKLI olabilir, ama burada d_head)
print(f"d_model={d_model}, n_head={n_head}, d_head={d_head}")
print(f"W_Q, W_K, W_V her head icin: [{d_model}, {d_head}]")
print(f"head'leri birlestiren W_O: [{n_head*d_head}, {d_model}] = [{d_model}, {d_model}]")
# W_O GEREKLI: h head'in ciktilari concat edilir [n_head*d_head] -> d_model'e geri yansitilir.
# Q ve K aynı boyutta (karsilastirilir); V "tarifin icerigi" -> farkli olabilir.
```
**Egzersiz 4 (BERT = denoising).** Bir cümlenin %15'ini maskele, bir Transformer encoder ile doldur. Bunu Hafta 7-8 denoising autoencoder ile eşle: "maske" hangi gürültü, "doldur" hangi enerji-minimizasyonu? word2vec'ten farkı nedir?
```python
import numpy as np
cumle = ["kedi", "bahçede", "fareyi", "hızla", "kovaladı"]
rng = np.random.default_rng(1)
maske = rng.random(len(cumle)) < 0.15 # ~%15 token'i maskele
bozuk = [("[MASK]" if m else w) for w, m in zip(maske, cumle)]
print("orijinal:", cumle)
print("bozuk :", bozuk) # "maske" = denoising AE'deki GURULTU (Hafta 7-8)
# BERT = denoising AE: girdiyi boz (maske=gurultu), TRANSFORMER ile geri kur ("doldur").
# "Doldur" = dusuk-enerjili (olasi) cumleyi geri getir = enerjiyi sekillendir.
# word2vec farki: BAGLAMSIZ (kelime basina tek vektor); BERT bagalmli + iki-yonlu Transformer.
```
**Egzersiz 5 (Hafta 13 habercisi — Graph ConvNets).** Hafta 13'te **konuk Xavier Bresson** (NTU) GCN'leri anlatacak; Canziani practicum'u kuracak. (a) LeCun'un "word2vec = basit graph neural net (kelime eş-dizim grafiği)" yorumunu (1:40:31) düşün: bir cümleyi grafik olarak nasıl temsil edersin? (b) Görüntü (düzenli ızgara) ile molekül (düzensiz grafik) arasında "convolution"u genellemek neden zordur?
```python
import numpy as np
# (a) Cumle -> grafik: dugum = kelime, kenar = es-dizim (yan yana gelme) sikligi.
# LeCun: word2vec/BERT, bu graf uzerinde basit bir GNN gibi calisir (1:40:31).
kelimeler = ["nehir", "banka", "kiyi", "para"]
# komsuluk (es-dizim) matrisi (illustratif): nehir-banka-kiyi yakin, banka-para yakin
A = np.array([[0, 1, 1, 0],
[1, 0, 1, 1],
[1, 1, 0, 0],
[0, 1, 0, 0]])
derece = A.sum(1)
print("dugumler:", kelimeler)
print("dereceler (komsu sayisi):", derece)
# (b) Goruntude convolution SABIT bir izgarada kayar (her piksel ayni komsuluk yapisi);
# molekul/grafikte her dugumun KOMSU SAYISI farkli -> sabit kernel kaymaz.
# GCN bunu komsulardan mesaj-toplama (aggregate) ile cozer -> Hafta 13.
```
## Sonraki Ders İçin Hazırlık {#sec-sonraki-d12}
::: {.callout-warning title="Sonraki Hafta — H13: Graph Convolutional Networks (GCN) (Konuk: Xavier Bresson)"}
**Attention'dan grafiklere geçiyoruz.** Bu hafta Transformer'ı (her kelime her kelimeye), multi-head attention'ı (Q/K/V + causal mask + positional encoding), decoding'i (greedy/beam/top-k, exposure bias) ve SSL'i (word2vec → BERT, masked-LM = denoising) Lewis'le; attention'ın matematiğini, encoder/decoder iskeletini ve karesel maliyeti Canziani'yle kapattık. Hafta 13'te konuk **Xavier Bresson** (Nanyang Technological University, GNN uzmanı) convolution'u düzensiz grafiklere genelleyen GCN'leri (spektral + uzaysal) anlatacak; **Canziani** GCN practicum'u kuracak. Egzersiz 1 (attention elle) ve Egzersiz 5 (cümle → grafik) tam bu derse hazırlar.
:::
**Hafta 13: Graph Convolutional Networks (GCN)** — Xavier Bresson (Konuk Lecture) + Canziani (Practicum)
Hafta 13'te konuk **Xavier Bresson** (Nanyang Technological University, GNN uzmanı) convolution'u düzensiz grafiklere genelleyen GCN'leri (spektral + uzaysal) anlatacak; **Canziani** GCN practicum'u kuracak. LeCun'un bu haftaki "word2vec = basit GNN" köprüsü doğrudan o derse açılır.
**Hafta 13 öncesi yapılacak:**
- Egzersiz 1 (attention elle) ve Egzersiz 5 (cümle → grafik) çöz.
- "Attention = küme linear kombinasyonu" ve "BERT = denoising" cümlelerini kendi sözcüklerinle yaz.
- Hafta 3 ConvNet'in "locality + stationarity + compositionality" üçlüsünü hatırla — GCN bunları grafiklere taşır.
## Anahtar Kavramlar (Cheat Sheet) {#sec-cheat-d12}
| Kavram | Tanım | Hoca / timestamp |
|---|---|---|
| Dil modeli | Metin yoğunluk tahmini; zincir kuralı → next-word | Lewis 4:45 |
| CNN → RNN → Transformer | Sınırlı alan → darboğaz/yavaş → her kelime her kelimeye | Lewis 31:43 |
| Multi-head attention | Q/K/V; aynı anda farklı sorular; paralel | Lewis 23:58 |
| Causal mask | Üst-üçgen −∞; geleceğe bakmayı engeller | Lewis 27:08 |
| Positional encoding | Küme → sıra; her konuma embedding | Lewis 29:17 |
| Exposure bias / top-k | Kendi hatasını görmez → döngü; k-best örnekle | Lewis 49:54 |
| SSL / cake / BERT | word2vec → BERT; masked-LM = denoising; ölçek | Lewis 1:09 |
| Attention = küme lin. komb. | h = X·a; hard (one-hot) / soft | Canziani 1:45 |
| Key-value store | query → keys → values (lazanya analojisi) | Canziani 19:07 |
| Q/K/V rotasyon | W_Q/W_K/W_V; tek param; β=1/√d | Canziani 20:44 |
| Encoder/decoder | self + (cross) + Add&Norm; autoencoder iskeleti | Canziani 35:15 |
| Karesel maliyet (A: T×T) | Küme büyüdükçe patlar; Reformer/LSH | Canziani 53:01 |
## ML Builder Bağlantıları {#sec-koprular-d12}
**Geriye köprüler (önkoşul + kurs):**
1. **Bağlam kodlayıcı** → Hafta 6 (RNN/LSTM/attention/seq2seq); Transformer = tekrarlamasız hâli.
2. **Softmax / β** → Hafta 11 (attention katsayısı = softmax, sıcaklık).
3. **SSL / cake / BERT denoising** → Hafta 10 (pretext) + Hafta 7-8 (denoising AE).
4. **Encoder/decoder + residual** → Hafta 8 (autoencoder) + Hafta 3 (BatchNorm / 1×1 conv).
5. **Q/K/V = lineer dönüşüm** → Hafta 1-2 (lineer cebir, nokta çarpımı).
**İleriye köprüler (production / research):**
1. **Transformer** → tüm LLM (GPT/BERT/T5); ViT, protein, multimodal.
2. **SSL + ölçek** → **GPT-3 / ChatGPT / RLHF (post-2020, KURSTA YOK)**.
3. **word2vec = basit GNN (LeCun)** → Hafta 13 Graph ConvNets.
4. **Karesel maliyet** → sparse / lineer / FlashAttention; uzun-bağlam.
::: {.callout-important title="Bu dersten tek bir şey alıp gideceksen"}
Transformer'ın tüm sırrı **attention**'dır ve attention basittir — bir **kümenin** elemanlarını, Q/K/V benzerlik skorlarından (softmax) gelen katsayılarla harmanlayan bir **linear kombinasyon**. RNN darboğazını ve CNN sınırlı alıcı alanını ortadan kaldırıp her kelimeyi her kelimeye doğrudan bağlar (paralel, ölçeklenir). Dile özel yapı dayatmak yerine düşük-önyargılı modeli çok metinle besle (Lewis); öz-denetimli "boşluğu doldur" (BERT = Hafta 7-8 denoising) etiketsiz metinden öğrenir, pre-train→fine-tune her göreve taşır. LeCun'un köprüsü hazır: word2vec/BERT, kelime eş-dizim grafiği üzerinde **basit bir graph neural net** — bir sonraki haftanın (GCN) kapısı. Post-2020 zirvesi (GPT-3, ChatGPT, RLHF) kursta yoktur ama hepsi 2017 Transformer'ın üstünde durur.
:::