---
title: "Gradient Descent, Backprop ve Yapay Sinir Ağları"
subtitle: "NYU'nun iki hocalı ritmi: LeCun cebirle 'eğitmek = bir kaybı gradient descent ile küçültmek, gradient'i backprop = zincir kuralı hesaplar' der, Canziani geometriyle 'ağ döndür-ez dizisidir' diye gösterip Hafta 1'in spiral ağını gerçekten eğitir"
---
::: {.callout-note title="Bölüm bilgisi"}
- **LeCun'un Lecture videosu:** [YouTube — Lecture 02: Backpropagation and architectural components](https://www.youtube.com/watch?v=d9vdh3b787Y) (≈103 dk)
- **Canziani'nin Practicum videosu:** [YouTube — Practicum 02: Training a neural network](https://www.youtube.com/watch?v=WAn6lip5oWk) (≈57 dk)
- **Edition:** Spring 2020 (NYU-DLSP20)
- **Hocalar:** Yann LeCun (Lecture, teorik) + Alfredo Canziani (Practicum, pratik)
- **Kaynak:** [atcold.github.io/NYU-DLSP20](http://atcold.github.io/NYU-DLSP20)
- **Okuma süresi:** ≈30 dk
:::
```{python}
#| echo: false
# ============================================================================
# SETUP — NYU sayısal motor (_engine.py) + NYU Violet+gold viz (_viz.py)
# Bu hücre gizlidir (#| echo: false). Aşağıdaki TÜM figür hücreleri burada
# tanımlanan loss_surface_2d / gd_path / sgd_loss_curves / tanh_deriv /
# ce_loss_curve / mse_loss_curve / make_spiral / affine_transform /
# linear_transforms / logreg_train / mlp_train / mlp_forward / decision_grid /
# accuracy + COL_* + apply_style / draw_pipeline / style_legend / CLASS_COLORS
# isimlerini kullanır. _engine.py saf numpy (torch YOK); _viz.py NYU Violet+gold
# paleti. İçerikler VERBATIM gömülüdür.
#
# NOT: matplotlib backend'i AYARLANMAZ (matplotlib.use(...) ÇAĞRILMAZ).
# Quarto kendi inline (figür yakalayan) backend'ini kurar; Agg backend
# inline figür-yakalamayı bozar (plt.show() çıktı üretmez). Standalone
# figür testinde savefig kullanılır.
# ============================================================================
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
# ===========================================================================
# _engine.py — saf numpy sayısal yardımcılar (torch YOK)
# ===========================================================================
# ---------------------------------------------------------------------------
# Afin / lineer dönüşümler
# ---------------------------------------------------------------------------
def affine_transform(P, W, b=None):
"""P[N,2] noktalarına y = W x (+ b) afin/lineer dönüşümü uygular (satır-vektör konvansiyonu)."""
P = np.asarray(P, float)
Y = P @ np.asarray(W, float).T
if b is not None:
Y = Y + np.asarray(b, float)
return Y
def unit_grid(n=11, lim=2.0, fine=61):
"""Izgara çizgileri listesi (yatay + dikey). Her çizgi (fine,2) dizisi.
Lineer dönüşüm görsellerinde 'uzayın kumaşı' için."""
t = np.linspace(-lim, lim, n)
f = np.linspace(-lim, lim, fine)
lines = []
for yi in t:
lines.append(np.column_stack([f, np.full_like(f, yi)]))
for xi in t:
lines.append(np.column_stack([np.full_like(f, xi), f]))
return lines
def linear_transforms():
"""Canziani'nin dört temel lineer dönüşümü (Bölüm 8) — 2x2 matrisler."""
th = np.deg2rad(35.0)
R = np.array([[np.cos(th), -np.sin(th)], [np.sin(th), np.cos(th)]]) # rotation (ortonormal)
S = np.array([[1.8, 0.0], [0.0, 0.55]]) # scaling (köşegen)
Sh = np.array([[1.0, 0.85], [0.0, 1.0]]) # shearing
F = np.array([[1.0, 0.0], [0.0, -1.0]]) # reflection (det<0)
return dict(rotation=R, scaling=S, shearing=Sh, reflection=F)
# ---------------------------------------------------------------------------
# SVD geometrisi (Canziani'nin 'patatesi')
# ---------------------------------------------------------------------------
def unit_circle(n=240):
t = np.linspace(0, 2 * np.pi, n)
return np.column_stack([np.cos(t), np.sin(t)])
def svd_demo(W):
"""W = U Σ Vᵀ. Geometrik okuma: rotation(Vᵀ) · scaling(Σ) · rotation(U)."""
U, s, Vt = np.linalg.svd(np.asarray(W, float))
return U, s, Vt
def near_singular_matrix():
"""Bir tekil değeri ≈0 olan matris — bir boyutu 'ezer' (elips çizgiye çöker)."""
th = np.deg2rad(30.0)
R = np.array([[np.cos(th), -np.sin(th)], [np.sin(th), np.cos(th)]])
Sigma = np.diag([1.6, 0.04]) # ikinci tekil değer ≈ 0
return R @ Sigma @ R.T
# ---------------------------------------------------------------------------
# Spiral (manifold germe demosu)
# ---------------------------------------------------------------------------
def make_spiral(n_per=120, k=5, noise=0.18, seed=0):
"""k-kollu spiral (CS231n stili). Her kol bir sınıf; kollar orijinde iç içe → lineer ayrılamaz."""
rng = np.random.default_rng(seed)
X = np.zeros((n_per * k, 2))
y = np.zeros(n_per * k, dtype=int)
for j in range(k):
ix = slice(n_per * j, n_per * (j + 1))
r = np.linspace(0.0, 1.0, n_per)
t = np.linspace(j * 4.0, (j + 1) * 4.0, n_per) + rng.normal(0, 1, n_per) * noise
X[ix] = np.column_stack([r * np.sin(t), r * np.cos(t)])
y[ix] = j
return X, y
def unroll_spiral(X, y, k=5, seed=0):
"""ŞEMATİK 'öğrenilen temsil': her sınıfı kendi yatay bandına taşır → lineer ayrılabilir.
Gerçek bir eğitilmiş ağ DEĞİL; 'ağ manifoldu açar' sezgisinin deterministik görseli."""
rng = np.random.default_rng(seed)
r = np.linalg.norm(X, axis=1)
yb = (y - (k - 1) / 2.0) * 0.55 + rng.normal(0, 0.045, len(y))
return np.column_stack([r * 2.2 - 1.1, yb])
# ---------------------------------------------------------------------------
# İki hilal (make_moons — sklearn YOK, numpy ile elle)
# ---------------------------------------------------------------------------
def make_moons_np(n=400, noise=0.20, seed=0):
"""Doğrusal ayrılamaz iki-hilal veri (sklearn.make_moons eşdeğeri)."""
rng = np.random.default_rng(seed)
n_out = n // 2
n_in = n - n_out
to = np.linspace(0, np.pi, n_out)
ti = np.linspace(0, np.pi, n_in)
outer = np.column_stack([np.cos(to), np.sin(to)])
inner = np.column_stack([1.0 - np.cos(ti), 1.0 - np.sin(ti) - 0.5])
X = np.vstack([outer, inner]) + rng.normal(0, noise, (n, 2))
y = np.array([0] * n_out + [1] * n_in)
return X, y
# ---------------------------------------------------------------------------
# Minik numpy sınıflandırıcılar (lineer vs ReLU MLP) — karar sınırı kontrastı
# ---------------------------------------------------------------------------
def _onehot(y, c):
Y = np.zeros((len(y), c))
Y[np.arange(len(y)), y] = 1.0
return Y
def _softmax(z):
z = z - z.max(axis=1, keepdims=True)
e = np.exp(z)
return e / e.sum(axis=1, keepdims=True)
def logreg_train(X, y, steps=500, lr=1.0, seed=0):
"""Lineer (gizli katmansız) softmax sınıflandırıcı → DÜZ karar sınırı."""
rng = np.random.default_rng(seed)
n, d = X.shape
c = int(y.max() + 1)
W = rng.normal(0, 0.01, (d, c))
b = np.zeros(c)
Y = _onehot(y, c)
for _ in range(steps):
p = _softmax(X @ W + b)
dz = (p - Y) / n
W -= lr * (X.T @ dz)
b -= lr * dz.sum(axis=0)
return dict(W=W, b=b)
def logreg_forward(params, X):
return X @ params["W"] + params["b"]
def mlp_train(X, y, hidden=16, act="relu", steps=600, lr=1.0, seed=0, return_history=False):
"""numpy 2-katmanlı MLP (afine → nonlinearite → afine), softmax + cross-entropy.
ReLU ile EĞRİ karar sınırı (hilalleri/spirali ayırır).
return_history=True → (params, loss_history) döner (eğitim eğrisi figürü için)."""
rng = np.random.default_rng(seed)
n, d = X.shape
c = int(y.max() + 1)
W1 = rng.normal(0, 1, (d, hidden)) * np.sqrt(2.0 / d)
b1 = np.zeros(hidden)
W2 = rng.normal(0, 1, (hidden, c)) * np.sqrt(2.0 / hidden)
b2 = np.zeros(c)
Y = _onehot(y, c)
history = []
for _ in range(steps):
z1 = X @ W1 + b1
a1 = np.maximum(0, z1) if act == "relu" else np.tanh(z1)
p = _softmax(a1 @ W2 + b2)
if return_history:
history.append(float(-np.log(p[np.arange(n), y] + 1e-12).mean()))
dz2 = (p - Y) / n
dW2 = a1.T @ dz2
db2 = dz2.sum(axis=0)
da1 = dz2 @ W2.T
dz1 = da1 * ((z1 > 0) if act == "relu" else (1 - np.tanh(z1) ** 2))
dW1 = X.T @ dz1
db1 = dz1.sum(axis=0)
W1 -= lr * dW1
b1 -= lr * db1
W2 -= lr * dW2
b2 -= lr * db2
params = dict(W1=W1, b1=b1, W2=W2, b2=b2, act=act)
if return_history:
return params, np.array(history)
return params
def mlp_forward(params, X):
z1 = X @ params["W1"] + params["b1"]
a1 = np.maximum(0, z1) if params["act"] == "relu" else np.tanh(z1)
return a1 @ params["W2"] + params["b2"]
def accuracy(forward_fn, params, X, y):
return float((forward_fn(params, X).argmax(axis=1) == y).mean())
def decision_grid(X, pad=0.6, h=0.02):
"""Karar bölgesi için koordinat ızgarası (xx, yy) ve düz nokta listesi."""
x0, x1 = X[:, 0].min() - pad, X[:, 0].max() + pad
y0, y1 = X[:, 1].min() - pad, X[:, 1].max() + pad
xx, yy = np.meshgrid(np.arange(x0, x1, h), np.arange(y0, y1, h))
grid = np.column_stack([xx.ravel(), yy.ravel()])
return xx, yy, grid
# ---------------------------------------------------------------------------
# Enerji manzarası (EBM — çoklu minimum = çoklu geçerli cevap)
# ---------------------------------------------------------------------------
def energy_landscape(xx, yy):
"""F(x,y): birkaç Gauss kuyusu → çoklu yerel minimum. Düşük enerji = uyumlu cevap."""
wells = [(-1.25, -0.65, 1.0, 0.55), (1.15, 0.85, 1.05, 0.6), (0.15, -1.15, 0.8, 0.45)]
F = np.ones_like(xx) * 1.0
for cx, cy, depth, width in wells:
F = F - depth * np.exp(-((xx - cx) ** 2 + (yy - cy) ** 2) / (2 * width))
return F
# ---------------------------------------------------------------------------
# Hafta 2 — gradient descent, SGD, backprop, eğitim
# ---------------------------------------------------------------------------
def loss_surface_2d(xx, yy):
"""2D parametre uzayında bir kayıp yüzeyi (gradient descent 'dağ' görseli için):
eğik, farklı-ölçekli bir vadi (konveks taban) + hafif dalgalanma."""
u = 0.85 * xx + 0.53 * yy # eksenleri döndür (eğik vadi)
v = -0.53 * xx + 0.85 * yy
return 1.0 * u ** 2 + 3.5 * v ** 2 + 0.6 * np.sin(1.5 * xx) * np.cos(1.5 * yy)
def _loss_grad_2d(p):
"""loss_surface_2d gradyanı (merkezi sonlu fark)."""
eps = 1e-4
gx = (loss_surface_2d(p[0] + eps, p[1]) - loss_surface_2d(p[0] - eps, p[1])) / (2 * eps)
gy = (loss_surface_2d(p[0], p[1] + eps) - loss_surface_2d(p[0], p[1] - eps)) / (2 * eps)
return np.array([gx, gy])
def gd_path(theta0, lr=0.08, steps=40):
"""loss_surface_2d üzerinde gradient descent yörüngesi (parametre adımları)."""
p = np.array(theta0, float)
path = [p.copy()]
for _ in range(steps):
p = p - lr * _loss_grad_2d(p)
path.append(p.copy())
return np.array(path)
def sgd_loss_curves(steps=80, seed=0):
"""Üç rejim için kayıp eğrisi (simülasyon): full-batch (gürültüsüz, düz),
mini-batch (orta gürültü), saf SGD (yüksek gürültü). Aynı yumuşak üstel düşüş."""
rng = np.random.default_rng(seed)
t = np.arange(steps)
base = 0.2 + 2.6 * np.exp(-t / 14.0)
full = base.copy()
mini = base + rng.normal(0, 0.10, steps) * np.exp(-t / 45.0)
sgd = base + rng.normal(0, 0.45, steps) * np.exp(-t / 70.0)
return t, np.clip(full, 0, None), np.clip(mini, 0, None), np.clip(sgd, 0, None)
def tanh_deriv(x):
"""tanh'ın türevi: 1 − tanh²(x). Backprop 'twiddling' figürü için."""
return 1.0 - np.tanh(x) ** 2
def ce_loss_curve(p):
"""Doğru sınıf olasılığı p için cross-entropy kaybı: −log p."""
p = np.clip(np.asarray(p, float), 1e-6, 1.0)
return -np.log(p)
def mse_loss_curve(p):
"""Doğru sınıf olasılığı p için (one-hot hedefe) MSE: (1 − p)²."""
return (1.0 - np.asarray(p, float)) ** 2
# ===========================================================================
# _viz.py — NYU Violet + gold matplotlib stil sabitleri ve yardımcıları
# ===========================================================================
COL_VIOLET = "#57068c" # NYU Violet — birincil çizgi/çerçeve/vurgu
COL_VIOLET_D = "#3d0463" # koyu violet — güçlü vurgu / gradyan
COL_VIOLET_M = "#7b2cbf" # orta violet — ikincil
COL_VIOLET_SOFT = "#b56ad6" # soluk violet
COL_GOLD = "#d4a017" # gold accent
COL_GOLD_D = "#a87d0a" # koyu gold
COL_TEXT = "#2a2535" # gövde metni (hafif violet tint)
COL_INK = "#1e1a2e" # en koyu — başlık
COL_BG = "#f4eefa" # açık violet — dolgu/arka plan
COL_GRID = "#cdbbe0" # soluk violet — ızgara/pasif kenar
COL_WHITE = "#ffffff"
# 5-sınıf kategorik palet (spiral 5 kol / moons ilk 2) — violet↔gold ekseni, tema-uyumlu
CLASS_COLORS = ["#57068c", "#7b2cbf", "#b56ad6", "#d4a017", "#a87d0a"]
# Çizgi-grafik tutarlı renkler
LINE_PRIMARY = COL_VIOLET
LINE_ACCENT = COL_GOLD
LINE_SECONDARY = COL_VIOLET_M
def apply_style(ax):
"""Bir eksene tutarlı NYU Violet+gold görünümü uygular."""
ax.set_facecolor(COL_WHITE)
ax.grid(True, alpha=0.25, color=COL_GRID, linewidth=0.8)
for spine in ax.spines.values():
spine.set_color(COL_GRID)
ax.tick_params(colors=COL_TEXT)
ax.title.set_color(COL_TEXT)
ax.xaxis.label.set_color(COL_TEXT)
ax.yaxis.label.set_color(COL_TEXT)
return ax
def draw_pipeline(ax, stages, title=None, y0=0.0):
"""Soldan-sağa kutu+ok boru hattı şeması (örüntü tanıma vs uçtan-uca).
stages : [(label:str, is_learned:bool), ...]
is_learned=True -> öğrenilen modül (violet dolgulu)
is_learned=False -> elle-tasarlanan/sabit (gold kenarlı, açık dolgu)
"""
n = len(stages)
box_w, box_h, gap = 1.7, 1.0, 0.9
step = box_w + gap
ax.set_xlim(-0.3, n * step)
ax.set_ylim(y0 - 1.1, y0 + 1.1)
ax.axis("off")
if title:
ax.set_title(title, color=COL_TEXT, fontsize=12, pad=10)
for i, (lbl, learned) in enumerate(stages):
x = i * step
fc = "#ece0f7" if learned else COL_BG
ec = COL_VIOLET if learned else COL_GOLD_D
lw = 2.4 if learned else 2.0
box = FancyBboxPatch(
(x, y0 - box_h / 2), box_w, box_h,
boxstyle="round,pad=0.02,rounding_size=0.12",
fc=fc, ec=ec, lw=lw, zorder=2,
)
ax.add_patch(box)
ax.text(x + box_w / 2, y0, lbl, ha="center", va="center",
fontsize=9.5, color=COL_TEXT, zorder=3, wrap=True)
if i > 0:
ax.add_patch(FancyArrowPatch(
(x - gap, y0), (x, y0),
arrowstyle="-|>", mutation_scale=16,
color=COL_VIOLET_M, lw=1.9, zorder=1,
))
return ax
def style_legend(ax, **kw):
"""Tema-uyumlu legend."""
leg = ax.legend(frameon=True, framealpha=0.95, edgecolor=COL_GRID, **kw)
if leg is not None:
leg.get_frame().set_facecolor(COL_WHITE)
for t in leg.get_texts():
t.set_color(COL_TEXT)
return leg
```
## Bu Derste Ne Var? {#sec-genel-bakis-d2}
Hafta 1'de bir ağ *kurduk* ama eğitmedik — spiral noktaları hâlâ ayrılmamıştı. Bu hafta ağa **nasıl öğretileceğini** görüyoruz. Yine iki hocalı: önce **Yann LeCun** (Lecture) öğrenmenin motorunu — **gradient descent** ve **backpropagation**'ı — teorik olarak kurar; sonra **Alfredo Canziani** (Practicum) bunu PyTorch'ta uygular ve Hafta 1'in spiral ağını gerçekten eğitir.
LeCun'un büyük fikri tek cümlede: bir sinir ağı, **modüllerin** (her biri girdi → çıktı hesaplayan bir kutu) bir zinciridir; eğitmek, bir **kayıp (loss)** fonksiyonunu gradient descent ile küçültmektir; ve gradient'i hesaplamanın yolu **backpropagation = zincir kuralının modüllere uygulanması**dır. Canziani ise bir ağın aslında "döndür-ez" (rotation–squashing) dizisi olduğunu gösterir, sınıflandırma için doğru kaybın **cross-entropy** olduğunu açıklar ve eğitim döngüsünü koda döker.
Bu haftanın üç ana fikri:
1. **Eğitim = bir kaybı gradient descent ile küçültmek.** Ağ rastgele başlar; kayıp, tahmin ile gerçek arasındaki farktır.
2. **Backpropagation = zincir kuralı.** Gradient, çıktıdan girişe doğru **Jacobian matrisleriyle çarpılarak** taşınır; daha fazlası değil.
3. **Sınıflandırmanın kaybı cross-entropy'dir** (−log softmax), regresyonunki MSE.
```{mermaid}
%%| echo: false
flowchart TB
subgraph Dongu["Eğitim döngüsü (her adımda tekrar)"]
direction LR
Forward["forward (ileri geçiş):<br/>x → ŷ"]
Loss["kayıp (cross-entropy):<br/>ŷ ile y karşılaştır"]
Backward["backward (Jacobian zinciri):<br/>∂C çıktıdan girişe"]
Step["step:<br/>parametreyi güncelle (θ ← θ − η∇L)"]
Forward --> Loss --> Backward --> Step
Step -- "tekrar" --> Forward
end
Dongu --> LeCun["LeCun (teori):<br/>modül + Jacobian zinciri"]
Dongu --> Canziani["Canziani (pratik):<br/>döndür-ez + cross-entropy"]
```
::: {.callout-tip title="Builder Notu — Hafta 1'i Eğitmek: İki Yön"}
**Geriye (önkoşul kurslar):**
- **Backprop = zincir kuralı** → Phase 1 Calculus Ders 4 (zincir kuralı) + Karpathy micrograd (autograd'ı sıfırdan kurar — LeCun'un "module + Jacobian" çerçevesinin kod hâli).
- **Cross-entropy = −log olabilirlik** → Stat 110 Bernoulli/NLL + Phase 1 DL Ders 1 cross-entropy.
- **Gradient descent** → Phase 1 Calculus türev (Ders 2) + 18.06 gradient/Jacobian (matris dili).
**İleriye (production / research):**
- LeCun'un "module + Jacobian" çerçevesi tam olarak **PyTorch autograd**'ın iç mantığıdır (`loss.backward()`); ileride `torch.autograd`, gradient checkpointing.
- SGD'nin "noisy ama ucuz" doğası → modern büyük-ölçek eğitimin (mini-batch, gradient accumulation, DDP) temelidir.
**Tek cümleyle:** Bir ağı eğitmek, bir kaybı gradient descent ile küçültmektir; gradient'i de backpropagation — yani zincir kuralının modül-modül, Jacobian çarpımlarıyla uygulanması — hesaplar.
:::
## (LeCun) Modüller ve Maliyet Fonksiyonu {#sec-moduller}
LeCun derse modüler bakışla başlıyor: bir sinir ağı, birbirine bağlı **modüllerden** kuruludur. İki tür modül var:
1. **Fonksiyonel modüller** — girdiyi çıktıya çeviren işlemler (linear, ReLU, ...). LeCun bunları "mavi yuvarlak" kutular olarak çizer.
2. **Maliyet (cost) modülleri** — ağın en tepesine konur; tahmin $\hat{Y}$ ile gerçek $Y$'yi karşılaştırıp tek bir sayı (kayıp) üretir.
> "the C function compares Y and Y bar [Ŷ]... loss functions are things that we minimize." — LeCun, 1:43
Yani eğitim, bu maliyet modülünün çıktısını (kaybı) olabildiğince küçültmektir. Ağ rastgele başlatıldığından ilk tahminler kötüdür; kayıp büyüktür. Amaç, parametreleri kaybı düşürecek yönde ayarlamaktır. Bu modüler kurgu kursun geri kalanının da omurgasıdır: her yeni mimari (CNN, RNN, transformer), aynı "modülleri bağla, tepeye maliyet koy, eğit" iskeletine oturur.
::: {.callout-tip title="Builder Notu — Her Şey Modül"}
**Geriye (Karpathy):** "Her şey modül" görüşü, Karpathy'nin micrograd'daki `Value` nesnesiyle birebir: her işlem bir düğüm, her düğüm ileri (forward) hesaplar ve geri (backward) gradient taşır. LeCun cebirle, Karpathy kodla aynı soyutlamayı kurar.
**İleriye:** Modüler tasarım, PyTorch'un `nn.Module` API'sinin felsefesidir: karmaşık modeller küçük, yeniden kullanılabilir, türevlenebilir bloklardan kurulur.
:::
## (LeCun) Loss ve Gradient-Tabanlı Öğrenme {#sec-gradient}
Kaybı nasıl küçültürüz? **Gradient-tabanlı** yöntemlerle. Gradient, kaybın her parametreye göre değişim yönünü söyler; biz kaybı azaltmak için gradient'in **ters** yönünde küçük adımlar atarız. LeCun bunu dağ benzetmesiyle anlatıyor: sisli bir dağda en dik iniş yönünü bulup o yönde küçük bir adım atmak gibi — tüm manzarayı göremezsin, ama ayağının altındaki eğimi bilirsin.
> "gradient descent is like being in the mountain... you compute the gradient and take a small step downhill." — LeCun, 10:27
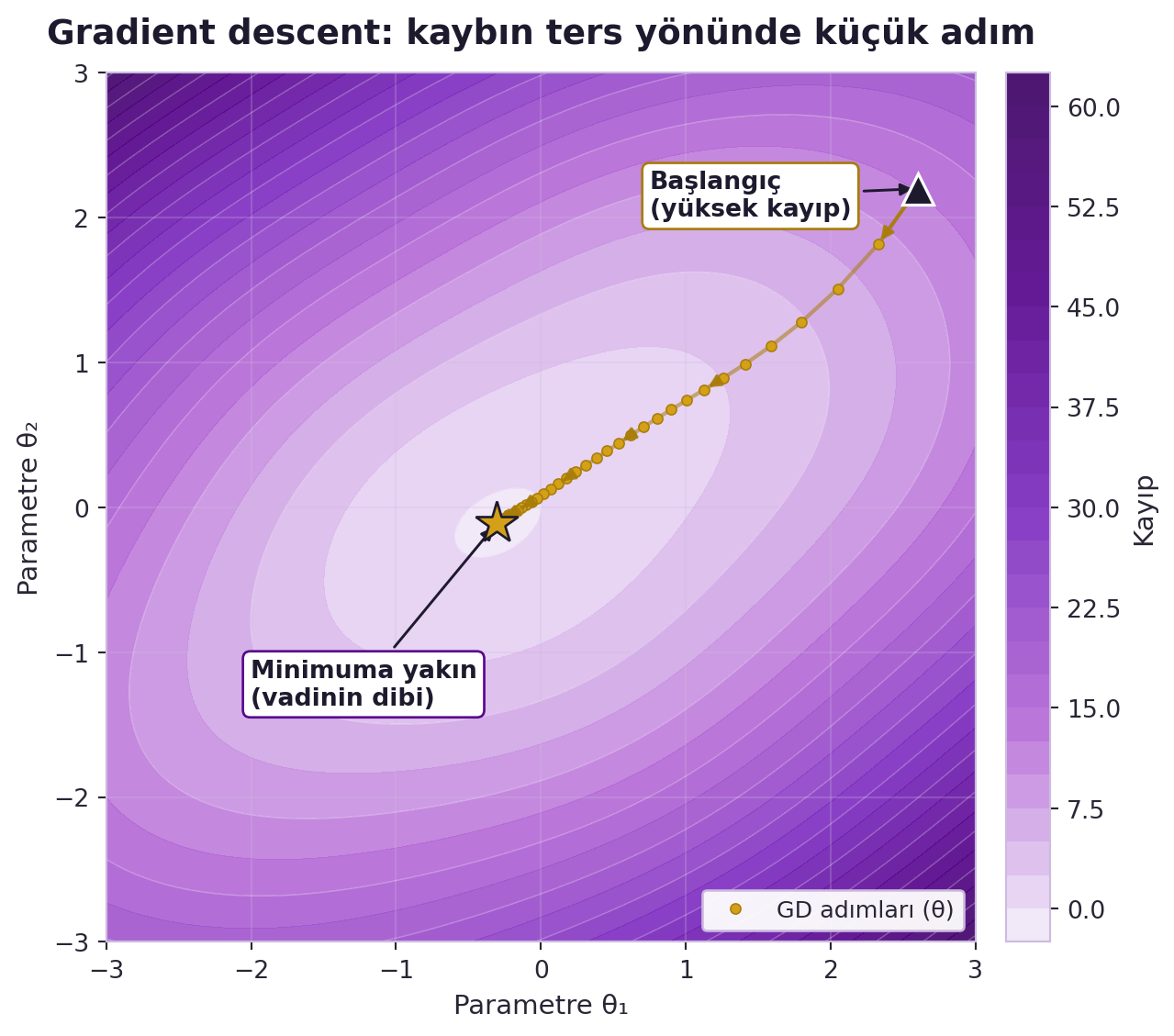
@fig-loss-landscape-gd bu "dağdan iniş" sezgisini somutlaştırır: yüksek-kayıp başlangıcından, kaybın ters yönünde küçük adımlarla vadinin dibine (minimuma) inilir.
```{python}
#| label: fig-loss-landscape-gd
#| fig-cap: "Eğik bir kayıp vadisi üzerinde gradient descent yörüngesi: parametreler yüksek-kayıp başlangıcından kaybın ters yönünde küçük adımlarla vadinin dibine (minimuma) iner — LeCun'un 'dağdan iniş' benzetmesi."
np.random.seed(0)
# Kayıp manzarası: 2D parametre uzayında eğik vadi (LeCun'un 'dağ' benzetmesi)
g = np.linspace(-3.0, 3.0, 400)
xx, yy = np.meshgrid(g, g)
Z = loss_surface_2d(xx, yy)
# Gradient descent yörüngesi: yüksek kayıptan minimuma 'dağdan iniş'
path = gd_path(theta0=[2.6, 2.2], lr=0.06, steps=60)
fig, ax = plt.subplots(figsize=(9.5, 6.0))
apply_style(ax)
# Tema-uyumlu colormap (açık violet → violet → koyu violet)
from matplotlib.colors import LinearSegmentedColormap
cmap = LinearSegmentedColormap.from_list(
"nyu_loss", [COL_BG, COL_VIOLET_SOFT, COL_VIOLET_M, COL_VIOLET, COL_VIOLET_D]
)
cf = ax.contourf(xx, yy, Z, levels=28, cmap=cmap, alpha=0.92)
# İnce kontur çizgileri — manzara hatlarını belirginleştir
ax.contour(xx, yy, Z, levels=14, colors=COL_WHITE, linewidths=0.5, alpha=0.35)
cbar = fig.colorbar(cf, ax=ax, pad=0.02, fraction=0.046)
cbar.set_label("Kayıp", color=COL_TEXT, fontsize=11)
cbar.ax.tick_params(colors=COL_TEXT)
cbar.outline.set_edgecolor(COL_GRID)
# GD yörüngesi: gold nokta-çizgi
ax.plot(path[:, 0], path[:, 1], "-", color=COL_GOLD_D, lw=1.6, alpha=0.55, zorder=4)
ax.plot(path[:, 0], path[:, 1], "o", color=COL_GOLD, ms=4.2,
mec=COL_GOLD_D, mew=0.6, zorder=5, label="GD adımları (θ)")
# Oklarla iniş yönünü göster (her birkaç adımda bir)
for i in range(0, len(path) - 1, 6):
ax.annotate(
"", xy=path[i + 1], xytext=path[i],
arrowprops=dict(arrowstyle="-|>", color=COL_GOLD_D, lw=1.4, alpha=0.9),
zorder=6,
)
# Başlangıç noktası (yüksek kayıp = dağın tepesi)
ax.plot(*path[0], "^", color=COL_INK, ms=13, mec=COL_WHITE, mew=1.2, zorder=7)
ax.annotate("Başlangıç\n(yüksek kayıp)", xy=path[0], xytext=(path[0][0] - 1.85, path[0][1] - 0.05),
color=COL_INK, fontsize=10, fontweight="bold", ha="left", va="center",
arrowprops=dict(arrowstyle="-|>", color=COL_INK, lw=1.1),
bbox=dict(boxstyle="round,pad=0.3", fc=COL_WHITE, ec=COL_GOLD_D, lw=1.0))
# Son nokta (minimuma yakın = vadinin dibi)
ax.plot(*path[-1], "*", color=COL_GOLD, ms=18, mec=COL_INK, mew=1.0, zorder=7)
ax.annotate("Minimuma yakın\n(vadinin dibi)", xy=path[-1], xytext=(path[-1][0] - 1.7, path[-1][1] - 1.25),
color=COL_INK, fontsize=10, fontweight="bold", ha="left",
arrowprops=dict(arrowstyle="-|>", color=COL_INK, lw=1.1),
bbox=dict(boxstyle="round,pad=0.3", fc=COL_WHITE, ec=COL_VIOLET, lw=1.0))
ax.set_title("Gradient descent: kaybın ters yönünde küçük adım",
color=COL_INK, fontsize=14, fontweight="bold", pad=12)
ax.set_xlabel("Parametre θ₁", fontsize=11)
ax.set_ylabel("Parametre θ₂", fontsize=11)
ax.set_xlim(-3.0, 3.0)
ax.set_ylim(-3.0, 3.0)
ax.set_aspect("equal")
style_legend(ax, loc="lower right", fontsize=9.5)
fig.tight_layout()
```
Bir uyarı: öğrenme **neredeyse her zaman** gradient-tabanlı optimizasyondur, ama kayıp yüzeyi non-convex olduğundan (Hafta 1, "nobody understands") yakınsama garantisi yoktur — yine de pratikte çalışır. LeCun ayrıca türevlenemeyen durumlar için bir trick'ten söz eder: maliyet modülünü türevlenebilir bir modülle yaklaşık temsil edip yine backprop kullanmak.
::: {.callout-tip title="Builder Notu — Dağda İniş (Gradient)"}
**Geriye (Calculus):** Gradient = çok değişkenli türev; gradient'in negatifi en dik iniş yönüdür (Phase 1 Calculus Ders 6). "Küçük adım" $\eta$ ile ölçeklenir — learning rate.
**İleriye:** Gradient-tabanlı optimizasyon tüm derin öğrenmenin motorudur; adımın nasıl atılacağı (Adam, momentum, normalization) Hafta 4'ün konusu.
:::
## (LeCun) SGD: "Descent Değil, Optimization" {#sec-sgd-d2}
Tam gradient'i tüm veri üzerinde hesaplamak pahalıdır. **Stokastik gradient descent (SGD)** gradient'i tek bir (veya küçük bir batch) örnek üzerinde tahmin eder — çok daha hızlı, ama gürültülü. LeCun'un meşhur düzeltmesi:
> "it shouldn't be called stochastic gradient descent, because it's not actually a descent algorithm — it should be called stochastic gradient optimization. It's very noisy." — LeCun, 17:10
Güncelleme kuralı: parametreyi, **örnek-başına kaybın** gradient'inin $\eta$ katı kadar geri al:
$$
\theta \leftarrow \theta - \eta\, \nabla_\theta \mathcal{L}(\theta)
$$
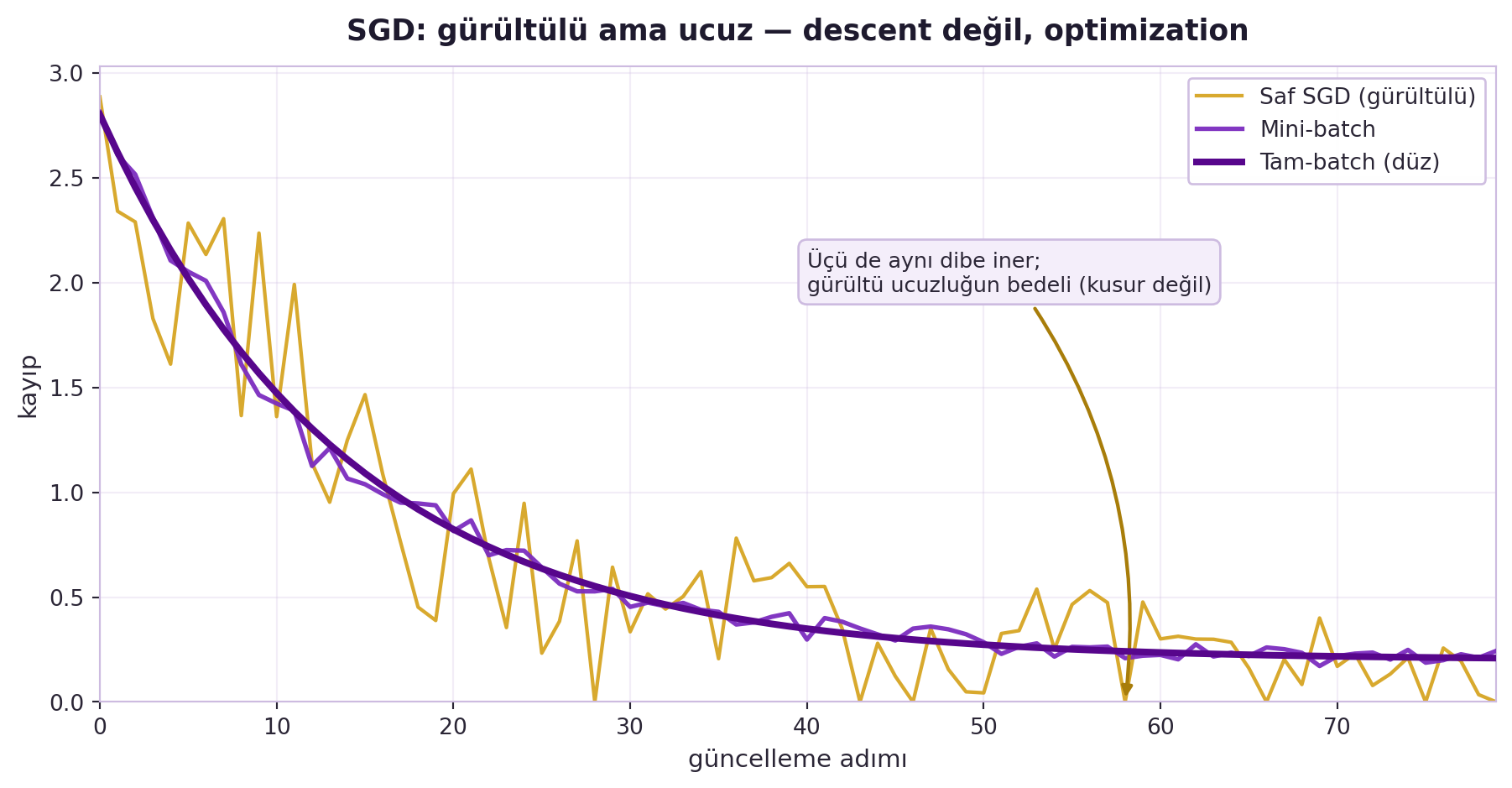
Gürültü kötü değildir: sığ yerel minimumlardan kaçmaya yardım eder ve aynı bütçeyle çok daha sık güncelleme demektir. Tam-batch gradient her adımda "doğru" yönü verir ama bir adım için tüm veriyi tarar; SGD "yaklaşık doğru" yönü verir ama saniyede yüzlerce adım atar — pratikte ikincisi kazanır. @fig-sgd-vs-gd üç rejimi tek eksende karşılaştırır.
```{python}
#| label: fig-sgd-vs-gd
#| fig-cap: "Tek eksende üç kayıp eğrisi: tam-batch düz inerken, mini-batch ve saf SGD aynı dibe iner ama artan gürültüyle — gürültü, ucuz güncellemelerin bedelidir, bir kusur değil."
np.random.seed(0)
t, full, mini, sgd = sgd_loss_curves(steps=80, seed=0)
fig, ax = plt.subplots(figsize=(9.5, 5.0))
apply_style(ax)
# Saf SGD — en gürültülü, en arkada (gold)
ax.plot(t, sgd, color=COL_GOLD, lw=1.6, alpha=0.9,
label="Saf SGD (gürültülü)", zorder=2)
# Mini-batch — orta gürültü (orta violet)
ax.plot(t, mini, color=COL_VIOLET_M, lw=2.0, alpha=0.95,
label="Mini-batch", zorder=3)
# Tam-batch — düz, gürültüsüz, en kalın, en önde (violet)
ax.plot(t, full, color=COL_VIOLET, lw=3.0,
label="Tam-batch (düz)", zorder=4)
ax.set_title("SGD: gürültülü ama ucuz — descent değil, optimization",
fontsize=13, color=COL_INK, pad=12, fontweight="bold")
ax.set_xlabel("güncelleme adımı", fontsize=11)
ax.set_ylabel("kayıp", fontsize=11)
ax.set_xlim(0, t.max())
ax.set_ylim(0, None)
# Mesaj annotasyonu: üçü de düşer; gürültü ucuzluğun bedeli
ax.annotate("Üçü de aynı dibe iner;\ngürültü ucuzluğun bedeli (kusur değil)",
xy=(58, sgd[58]), xytext=(40, 2.05),
fontsize=9.5, color=COL_TEXT,
ha="left", va="center",
arrowprops=dict(arrowstyle="-|>", color=COL_GOLD_D, lw=1.6,
connectionstyle="arc3,rad=-0.2"),
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG, ec=COL_GRID, lw=1.0))
style_legend(ax, loc="upper right", fontsize=10)
fig.tight_layout()
```
Üç uç noktayı karşılaştırmak aydınlatıcı:
- **Tam-batch (full-batch):** gradient'i tüm N örnek üzerinde hesapla. En doğru yön, ama bir tek güncelleme için tüm veriyi taradığından devasa veride imkânsız.
- **Tek örnek (saf SGD):** gradient'i tek bir rastgele örnek üzerinde hesapla. Çok hızlı ama çok gürültülü — yön çoğu zaman yanlış, ama ortalamada doğru.
- **Mini-batch (pratik standart):** gradient'i B örnekten (örn. 32, 64) oluşan bir batch üzerinde hesapla. Hız ile gürültü arasında ayarlanabilir denge. Modern donanım (GPU) zaten matris işlemlerini paralel yaptığından, mini-batch hem hızlı hem makul doğrudur.
Önemli nokta: gürültü "kusur" değil, bir özelliktir — non-convex bir yüzeyde stokastik dürtmeler, deterministik gradient descent'in takılacağı sığ çukurlardan modeli kurtarabilir.
::: {.callout-tip title="Builder Notu — SGD: Gürültü Bir Özellik"}
**Geriye (Stat 110):** Mini-batch gradient'i, gerçek gradient'in **tarafsız tahmincisidir** (örneklem ortalaması, Stat 110 Monte Carlo); varyans batch boyutuyla azalır ($\propto 1/B$).
**İleriye:** SGD'nin ucuzluğu, milyar-parametreli modelleri eğitilebilir kılar; batch size ↔ throughput dengesi, gradient accumulation ve dağıtık eğitimin (DDP) çekirdeğidir.
:::
## (LeCun) Backpropagation = Zincir Kuralı (Twiddling Sezgisi) {#sec-backprop}
Gradient descent'in kalbi $\partial C/\partial \theta$ terimiydi — ama onu nasıl hesaplarız? Cevap **backpropagation**, ve LeCun'un üstüne basa basa söylediği şey: bu, zincir kuralından (chain rule) başka bir şey değildir.
> "we're going to use chain rule — chain rule, if you remember from kindergarten..." — LeCun, 27:36
LeCun zincir kuralını "twiddling" (azıcık oynatma) sezgisiyle yeniden türetiyor: bir nonlinearite $z = h(s)$ düşün. Girdiyi azıcık ($ds$ kadar) oynatırsan, çıktı $dz = ds \cdot h'(s)$ kadar değişir. Bu da kaybı $dC = dz \cdot (\partial C/\partial z)$ kadar değiştirir. İkisini birleştirip $ds$'yi sadeleştirince:
$$
\frac{\partial C}{\partial s} = \frac{\partial C}{\partial z}\, h'(s)
$$
Yani biri sana kaybın $z$'ye göre türevini verirse, sen onu nonlinearitenin türeviyle çarpıp kaybın $s$'ye göre türevini elde edersin. Bir zincir boyunca bunu tekrarlarsın: gradyan'ı çıktıdan girişe, her $h$ fonksiyonunun türeviyle çarparak taşırsın. LeCun yarı şaka der ki tüm yaptığı zincir kuralını yeniden türetmektir:
> "I've done nothing more than rederiving chain rule. But it's a little more intuitive if you think of it in terms of twiddling things around." — LeCun, 32:01
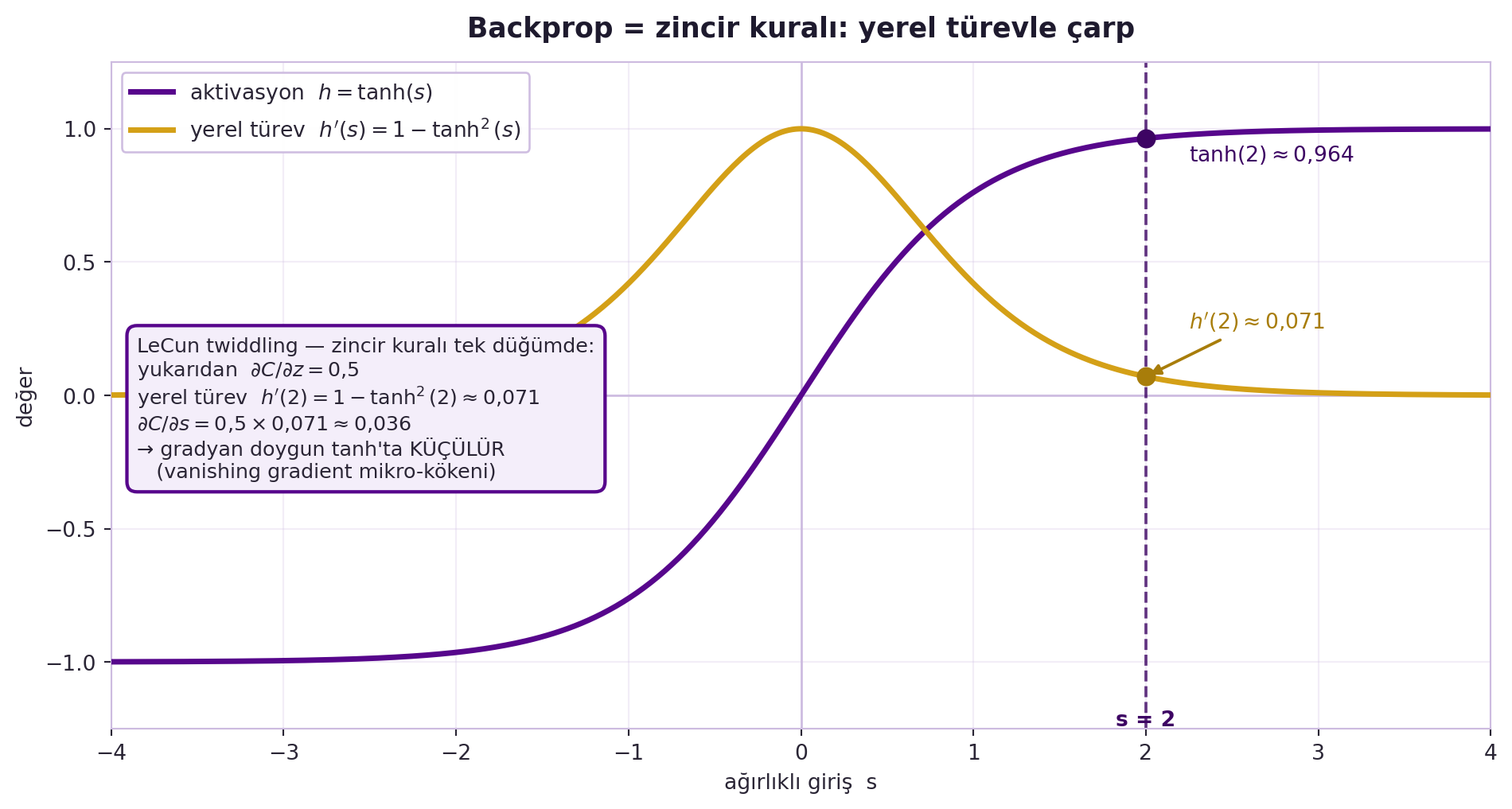
**Somut örnek.** Diyelim $s = 2$, $h = \tanh$, ve kaybın çıktıya göre türevi $\partial C/\partial z = 0{,}5$ olarak yukarıdan geldi. tanh'ın türevi $h'(s) = 1 - \tanh^2(s)$; $\tanh(2) \approx 0{,}964$ olduğundan $h'(2) \approx 1 - 0{,}929 = 0{,}071$. O hâlde $\partial C/\partial s = (\partial C/\partial z) \cdot h'(s) = 0{,}5 \times 0{,}071 \approx 0{,}036$. Yani yukarıdan gelen $0{,}5$'lik gradyan, doygun (saturated) tanh'tan geçince $0{,}036$'ya **küçülür** — bu, derin ağlarda vanishing gradient'in mikro-kökenidir (Hafta 4'te normalization/init bunu çözer). @fig-backprop-twiddling bu somut çarpımı tanh eğrisi ve yerel türevi üzerinde gösterir; backprop böyle, modülden modüle yerel türevi çarparak ilerler.
```{python}
#| label: fig-backprop-twiddling
#| fig-cap: "tanh(s) aktivasyonu ve yerel türevi h'(s)=1−tanh²(s); s=2 noktasında zincir kuralı somut çarpımı (∂C/∂z=0,5 × h'(2)≈0,071 = 0,036) doygun bölgede gradyanın nasıl küçüldüğünü — vanishing gradient'in mikro-kökenini — gösterir."
np.random.seed(0)
s = np.linspace(-4, 4, 400)
y_tanh = np.tanh(s)
y_dtanh = tanh_deriv(s) # h'(s) = 1 - tanh^2(s)
s0 = 2.0
t0 = np.tanh(s0) # ≈ 0.964
d0 = tanh_deriv(s0) # ≈ 0.071
dC_dz = 0.5 # yukarıdan gelen gradyan
dC_ds = dC_dz * d0 # ≈ 0.036
fig, ax = plt.subplots(figsize=(10, 5.4))
apply_style(ax)
# İki eğri
ax.plot(s, y_tanh, color=COL_VIOLET, lw=2.6, label=r"aktivasyon $h=\tanh(s)$", zorder=4)
ax.plot(s, y_dtanh, color=COL_GOLD, lw=2.6,
label=r"yerel türev $h'(s)=1-\tanh^2(s)$", zorder=4)
# Sıfır eksenleri
ax.axhline(0, color=COL_GRID, lw=1.0, zorder=1)
ax.axvline(0, color=COL_GRID, lw=1.0, zorder=1)
# s = 2 işaretleme
ax.axvline(s0, color=COL_VIOLET_D, lw=1.4, ls="--", alpha=0.8, zorder=2)
ax.plot([s0], [t0], "o", color=COL_VIOLET_D, ms=8, zorder=5)
ax.plot([s0], [d0], "o", color=COL_GOLD_D, ms=8, zorder=5)
ax.annotate(r"$\tanh(2)\approx0{,}964$", xy=(s0, t0), xytext=(s0 + 0.25, t0 - 0.02),
fontsize=10, color=COL_VIOLET_D, va="top", ha="left", zorder=6)
ax.annotate(r"$h'(2)\approx0{,}071$", xy=(s0, d0), xytext=(s0 + 0.25, d0 + 0.16),
fontsize=10, color=COL_GOLD_D, va="bottom", ha="left", zorder=6,
arrowprops=dict(arrowstyle="-|>", color=COL_GOLD_D, lw=1.4))
# s metni
ax.text(s0, -1.18, "s = 2", color=COL_VIOLET_D, fontsize=10, ha="center", va="top",
fontweight="bold")
# Annotation kutusu — LeCun twiddling somut örneği
box_txt = (
"LeCun twiddling — zincir kuralı tek düğümde:\n"
r"yukarıdan $\partial C/\partial z = 0{,}5$" + "\n"
r"yerel türev $h'(2)=1-\tanh^2(2)\approx0{,}071$" + "\n"
r"$\partial C/\partial s = 0{,}5\times0{,}071\approx0{,}036$" + "\n"
"→ gradyan doygun tanh'ta KÜÇÜLÜR\n"
" (vanishing gradient mikro-kökeni)"
)
ax.text(-3.85, -0.05, box_txt, fontsize=9.5, color=COL_TEXT, va="center", ha="left",
zorder=7,
bbox=dict(boxstyle="round,pad=0.5", fc=COL_BG, ec=COL_VIOLET, lw=1.6))
ax.set_xlim(-4, 4)
ax.set_ylim(-1.25, 1.25)
ax.set_xlabel("ağırlıklı giriş s")
ax.set_ylabel("değer")
ax.set_title("Backprop = zincir kuralı: yerel türevle çarp", fontsize=13,
color=COL_INK, fontweight="bold", pad=12)
style_legend(ax, loc="upper left")
fig.tight_layout()
```
::: {.callout-tip title="Builder Notu — Twiddling = Zincir Kuralı"}
**Geriye (Calculus + Karpathy):** Bu doğrudan Phase 1 Calculus Ders 4 zincir kuralıdır; "twiddling" = türevin "küçük dürtme $dx$" tanımı. Karpathy micrograd'da her düğümün `_backward` kapanışı tam olarak bu yerel türevi ($h'(s)$) saklar ve tersten çağırır (reverse-mode autodiff).
**İleriye:** PyTorch'ta `loss.backward()` bu zinciri otomatik yürütür; çok derin ağlarda zincirin uzaması vanishing/exploding gradient'e yol açar (Hafta 3-4 normalization/init).
:::
## (LeCun) Lineer Modülün Backprop'u: Ağırlıkları Tersten Kullanmak {#sec-lineer-backprop}
Nonlinearite modülünü gördük; ikinci tür **lineer modül**dür. Burada bir $z$ değişkeni, ağırlıklarıyla çarpılarak **birden çok** $s$ değişkenini besler (dallanma). $z$'yi azıcık oynatırsan, beslediği her $s$'i kendi ağırlığı kadar etkilersin; ve her $s$ kaybı etkiler. Küçük değişimlerde toplam etki, bu katkıların **toplamıdır**:
$$
\frac{\partial C}{\partial z} = \sum_i w_i\, \frac{\partial C}{\partial s_i}
$$
LeCun'un özlü ifadesi: ileri geçişte ağırlıkları "yukarı" kullanırsın, geri geçişte aynı ağırlıkları "aşağı" — gradyanların ağırlıklı toplamını alırsın.
> "when you back propagate through a neural net, you compute a weighted sum of the gradients using the weights backwards." — LeCun, 36:24
Yani ileri geçiş $s = Wz$, geri geçiş ise $\partial C/\partial z = W^\top (\partial C/\partial s)$ — aynı $W$ matrisi, transpozuyla. Backprop'un simetrisi tam burada.
::: {.callout-tip title="Builder Notu — Forward W, Backward Wᵀ"}
**Geriye (18.06):** İleri geçiş $W$ ile çarpma, geri geçiş $W^\top$ ile çarpmadır — 18.06'nın transpoz/iç çarpım dünyası. Dallanan değişkenin gradyanlarının toplanması, çok-değişkenli zincir kuralının (Calculus) doğrudan sonucudur.
**İleriye:** "Forward $W$, backward $W^\top$" simetrisi, her `nn.Linear` katmanının autograd implementasyonudur; özel katman yazarken bu çifti tanımlarsın.
:::
## (LeCun) Jacobian Formülasyonu ve Hesaplama Grafiği {#sec-jacobian}
LeCun backprop'u tek bir genel kurala indiriyor. Vektör değerli modüller için zincir kuralı **Jacobian matrisleriyle** yazılır. Bir modüller dizisinde, kaybın $k$. modülün girdisine göre gradient'i, bir sonraki gradient ile o modülün **Jacobian matrisinin** çarpımıdır:
$$
\frac{\partial C}{\partial z_k} = \frac{\partial C}{\partial z_{k+1}}\, \frac{\partial z_{k+1}}{\partial z_k}
$$
Jacobian matrisinin $ij$ elemanı, çıktının $i$. bileşeninin girdinin $j$. bileşenine kısmi türevidir. Backprop, çıktıdan girişe doğru bu Jacobian matrislerini **art arda çarpmaktan** ibarettir. Parametreli bir modülün **iki** Jacobian'ı vardır: biri girdiye göre (gradient'i bir önceki katmana taşır), biri ağırlıklara göre (o katmanın ağırlık gradient'ini verir). LeCun'un kapanışı:
> "that's all there is to backprop." — LeCun, 49:32
Bir ağı kavramsal olarak "linear–nonlinear çiftlerinin" istiflenmesi olarak görmek faydalı: $s_{k+1} = W_k z_k$, ardından $z_k = h(s_k)$. LeCun'un deyişiyle "bir katman, linear-nonlinear bir çifttir" (37:31) — ama modern ağlarda bu ayrım her zaman temiz değildir.
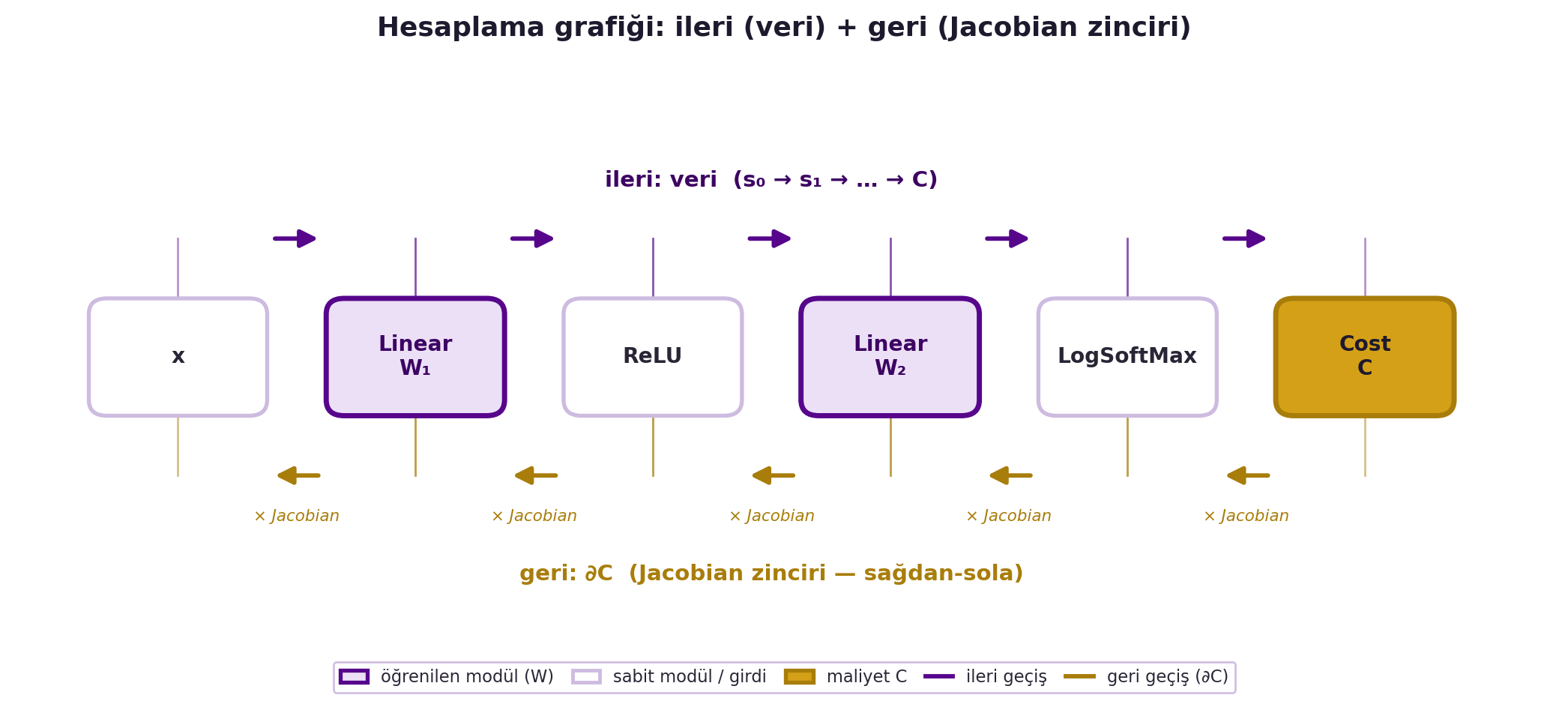
**Hesaplama grafiği ve genelleştirilmiş backprop.** LeCun bu fikri tek bir zincirden genel bir **hesaplama grafiğine** (computation graph) genelliyor. Bir ağ, modüllerin yönlü asiklik grafiğidir (DAG); ileri geçiş bu grafiği soldan-sağa hesaplar. Backprop ise aynı grafiği "türev grafiğine" çevirir: her modülün yerine Jacobian'ı geçer ve sinyalleri sağdan-sola taşır. @fig-computation-graph bu çift akışı tek bir grafik üzerinde gösterir: üstte ileri (veri), altta geri (Jacobian zinciri). Bu, modüllerin birden çok girdisi/çıktısı olduğunda da çalışır — dallanan bir değişkenin gradyanları toplanır (Bölüm 5'teki "ağırlıklı toplam" kuralı). Bu genellik sayesinde PyTorch, herhangi bir modül kombinasyonu için backward'ı otomatik üretir; sen yalnızca ileri geçişi tanımlarsın.
```{python}
#| label: fig-computation-graph
#| fig-cap: "x → Linear W₁ → ReLU → Linear W₂ → LogSoftMax → Cost C modül zincirinde ileri geçiş (violet, veri akışı) ile geri geçişin (gold, sağdan-sola ∂C Jacobian zinciri) aynı grafik üzerinde nasıl ters yönde aktığını gösteren hesaplama grafiği."
np.random.seed(0)
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
fig, ax = plt.subplots(figsize=(11, 5))
ax.set_xlim(-0.6, 11.4)
ax.set_ylim(-2.4, 2.6)
ax.axis("off")
ax.set_title("Hesaplama grafiği: ileri (veri) + geri (Jacobian zinciri)",
color=COL_INK, fontsize=13.5, fontweight="bold", pad=14)
# Modül zinciri: x -> [Linear W1] -> [ReLU] -> [Linear W2] -> [LogSoftMax] -> [Cost C]
nodes = [
("x", False), # girdi (gold kenarli, veri)
("Linear\nW₁", True), # ogrenilen (violet)
("ReLU", False), # sabit nonlinearite
("Linear\nW₂", True), # ogrenilen (violet)
("LogSoftMax", False), # sabit
("Cost\nC", None), # maliyet — gold dolgulu (farkli)
]
box_w, box_h, gap = 1.35, 1.0, 0.50
step = box_w + gap
y_box = 0.0
centers = []
for i, (lbl, kind) in enumerate(nodes):
x = i * step
cx = x + box_w / 2
centers.append(cx)
if kind is None: # Cost — gold dolgu, farkli
fc, ec, lw, tc = COL_GOLD, COL_GOLD_D, 2.6, COL_INK
elif kind: # ogrenilen modul — violet dolgu
fc, ec, lw, tc = "#ece0f7", COL_VIOLET, 2.6, COL_VIOLET_D
else: # sabit/girdi
fc, ec, lw, tc = COL_WHITE, COL_GRID, 2.0, COL_TEXT
box = FancyBboxPatch(
(x, y_box - box_h / 2), box_w, box_h,
boxstyle="round,pad=0.02,rounding_size=0.14",
fc=fc, ec=ec, lw=lw, zorder=3,
)
ax.add_patch(box)
ax.text(cx, y_box, lbl, ha="center", va="center",
fontsize=10.5, fontweight="bold", color=tc, zorder=4)
# --- UST satir: ileri ok (violet, soldan-saga) ---
y_fwd = box_h / 2 + 0.55
for i in range(len(centers) - 1):
ax.add_patch(FancyArrowPatch(
(centers[i] + box_w / 2 + 0.05, y_fwd),
(centers[i + 1] - box_w / 2 - 0.05, y_fwd),
arrowstyle="-|>", mutation_scale=18,
color=COL_VIOLET, lw=2.2, zorder=2,
))
# kutudan uste/uste-kutuya kisa baglantilar
ax.plot([centers[i], centers[i]], [box_h / 2, y_fwd], color=COL_VIOLET,
lw=1.0, alpha=0.45, zorder=1)
ax.plot([centers[i + 1], centers[i + 1]], [y_fwd, box_h / 2], color=COL_VIOLET,
lw=1.0, alpha=0.45, zorder=1)
ax.text((centers[0] + centers[-1]) / 2, y_fwd + 0.42,
"ileri: veri (s₀ → s₁ → … → C)", ha="center", va="bottom",
fontsize=11, fontweight="bold", color=COL_VIOLET_D, zorder=4)
# --- ALT satir: geri ok (gold, sagdan-sola) ---
y_bwd = -(box_h / 2 + 0.55)
for i in range(len(centers) - 1, 0, -1):
ax.add_patch(FancyArrowPatch(
(centers[i] - box_w / 2 - 0.05, y_bwd),
(centers[i - 1] + box_w / 2 + 0.05, y_bwd),
arrowstyle="-|>", mutation_scale=18,
color=COL_GOLD_D, lw=2.2, zorder=2,
))
ax.plot([centers[i], centers[i]], [-box_h / 2, y_bwd], color=COL_GOLD_D,
lw=1.0, alpha=0.5, zorder=1)
ax.plot([centers[i - 1], centers[i - 1]], [y_bwd, -box_h / 2], color=COL_GOLD_D,
lw=1.0, alpha=0.5, zorder=1)
# her geri-ok ustune Jacobian etiketi
midx = (centers[i] + centers[i - 1]) / 2
ax.text(midx, y_bwd - 0.30, "× Jacobian", ha="center", va="top",
fontsize=8.0, style="italic", color=COL_GOLD_D, zorder=4)
ax.text((centers[0] + centers[-1]) / 2, y_bwd - 0.78,
"geri: ∂C (Jacobian zinciri — sağdan-sola)", ha="center", va="top",
fontsize=11, fontweight="bold", color=COL_GOLD_D, zorder=4)
# Lejant: violet=ogrenilen modul, gold=maliyet / geri-yol
from matplotlib.patches import Patch
from matplotlib.lines import Line2D
handles = [
Patch(fc="#ece0f7", ec=COL_VIOLET, lw=2.0, label="öğrenilen modül (W)"),
Patch(fc=COL_WHITE, ec=COL_GRID, lw=1.8, label="sabit modül / girdi"),
Patch(fc=COL_GOLD, ec=COL_GOLD_D, lw=2.0, label="maliyet C"),
Line2D([0], [0], color=COL_VIOLET, lw=2.2, label="ileri geçiş"),
Line2D([0], [0], color=COL_GOLD_D, lw=2.2, label="geri geçiş (∂C)"),
]
leg = ax.legend(handles=handles, loc="lower center", bbox_to_anchor=(0.5, -0.13),
ncol=5, frameon=True, framealpha=0.95, edgecolor=COL_GRID,
fontsize=8.5, handlelength=1.6, columnspacing=1.1)
leg.get_frame().set_facecolor(COL_WHITE)
for t in leg.get_texts():
t.set_color(COL_TEXT)
fig.tight_layout()
```
Ayrıca bir ayrım: **çıkarım (inference)** yalnızca ileri geçiştir — ağ, girdiyi $\mathbb{R}^n$'den $\mathbb{R}^c$'ye ($n$ boyuttan $c$ sınıfa) eşleyen sabit bir fonksiyondur. **Eğitim (training)** ise ileri + geri geçiş + güncelleme döngüsüdür. Çıkarımda backprop yoktur; backprop sadece öğrenme için gereklidir.
::: {.callout-tip title="Builder Notu — Jacobian = Matris Zinciri"}
**Geriye (18.06):** Jacobian, bir vektör fonksiyonunun türev matrisidir; zincir = matris çarpımı (18.06 bileşke dönüşüm). Reverse-mode, bu çarpımları sağdan-sola yapar (verimli — çünkü kayıp skalerdir, soldan vektör küçük kalır).
**İleriye:** "İki Jacobian'lı modül" soyutlaması, her PyTorch katmanının `forward`/`backward` çiftidir; bu genel algoritma, çok-girişli/çok-çıkışlı modüllere de aynen uygulanır.
:::
## (LeCun) Aktivasyon ve LogSoftMax Modülleri {#sec-logsoftmax}
LeCun somut modül örnekleri veriyor. Çekirdek olanlar: **lineer** ve **ReLU** (pointwise nonlinearite). Sınıflandırma için kritik olan ise **LogSoftMax**: softmax bir skor vektörünü olasılık dağılımına çevirir (her eleman pozitif, toplamı 1); LogSoftMax bunun logaritmasıdır. Bu modül, ham skorları (logit) olasılığa çevirip kaybın hesaplanmasını sağlar — Canziani'nin Practicum'da kullanacağı cross-entropy'nin yapı taşıdır. NYU'da kullanılan modül listesi uzundur çünkü her görev (sınıflandırma, sıralama, gömme) kendi modülünü ister.
::: {.callout-tip title="Builder Notu — Softmax'ın Olasılık Köprüsü"}
**Geriye (Calculus + Stat 110):** Softmax = argmax'ın yumuşak, türevlenebilir hâli; $e^x$ (Calculus Ders 5) + multinomial dağılım (Stat 110). Log almak, çarpımları toplama çevirir ve sayısal kararlılık sağlar.
**İleriye:** Pratikte softmax + log + NLL tek bir kararlı işlemde birleştirilir (`F.cross_entropy`); ayrı yazmak taşma (overflow) riski taşır.
:::
## Geçiş: LeCun'dan Canziani'ye {#sec-gecis-d2}
LeCun makineyi kurdu — modüller, kayıp, gradient descent, backprop (twiddling → Jacobian zinciri), LogSoftMax. Şimdi **Canziani** bunları PyTorch'a indiriyor: önce bir ağın anatomisini "döndür-ez" diliyle yeniden anlatıyor, sonra Hafta 1'de kurduğumuz ama eğitmediğimiz spiral ağını **gerçekten eğitiyor**. LeCun "gradient nasıl hesaplanır"ı anlattı; Canziani "ağ neye benzer, kaybı nasıl seçer, eğitim döngüsünü nasıl yazarsın"ı gösteriyor.
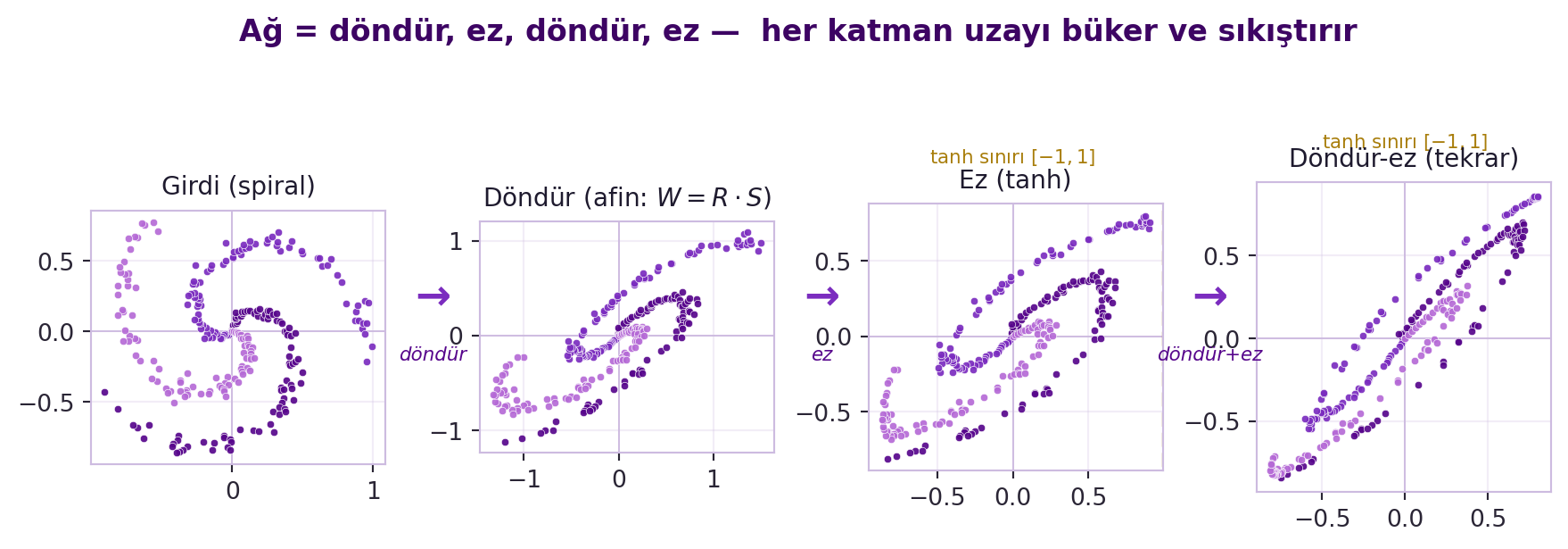
## (Canziani) Ağ Anatomisi: Döndür–Ez (Rotation–Squashing) {#sec-dondur-ez}
Canziani tam-bağlı (fully connected) bir ağı tek bir cümleye indiriyor. Girdi $x$ (alt, pembe) bir **afin dönüşümden** geçer, sonra bir **nonlineariteden** ($f$) — çıktısı gizli katman $h$ (yeşil, vektör, "gizli" çünkü dışarıdan görünmez). Sonra yine afin + nonlinearite → çıktı $\hat{y}$ (mavi). Canziani'nin metaforu:
> "an affine transformation — I call them rotations; a nonlinear function — I call squashing. So you just repeat rotation, squashing, rotation, squashing." — Canziani, 15:43
Yani bir ağ = **döndür, ez, döndür, ez...** Afin dönüşüm (matris + bias) uzayı döndürür/ölçekler/öteler; nonlinearite onu büker (ezme). Hafta 1'in geometrisinin doğrudan devamı. @fig-rotation-squashing aynı spiral nokta bulutuna sırayla döndürme ve ezme uygulayıp bu ritmi görselleştirir. Aktivasyon örnekleri: positive part (ReLU), sigmoid, tanh (sigmoid'in yeniden ölçeklenmiş hâli), soft(arg)max (argmax'ın yumuşak hâli).
```{python}
#| label: fig-rotation-squashing
#| fig-cap: "Canziani'nin 'döndür-ez' dizisi: aynı spiral nokta bulutuna sırayla afin döndürme (W=R·S) ve tanh ezme uygulanır — ağ, uzayı tekrar tekrar büküp [-1,1] kutusuna sıkıştıran bir döndür-ez-döndür-ez katman zinciridir."
np.random.seed(0)
# Girdi: küçük 3-kollu spiral (iç içe geçmiş nokta bulutu) — Hafta 1 geometri devamı
X0, y = make_spiral(n_per=90, k=3, noise=0.16, seed=0)
# Bölüm 8 lineer dönüşümleri: ağın "döndür" adımı = rotation @ scaling
T = linear_transforms()
W = T["rotation"] @ T["scaling"] # döndür-ölç (afin katman ağırlığı)
# Katman dizisi: döndür → ez → döndür → ez
X1 = affine_transform(X0, W) # (2) Döndür (afin)
X2 = np.tanh(X1) # (3) Ez (tanh, eleman-bazlı)
X3 = affine_transform(X2, W) # (4a) tekrar döndür
X4 = np.tanh(X3) # (4b) tekrar ez
panels = [
(X0, "Girdi (spiral)"),
(X1, "Döndür (afin: $W=R\\cdot S$)"),
(X2, "Ez (tanh)"),
(X4, "Döndür-ez (tekrar)"),
]
fig, axes = plt.subplots(1, 4, figsize=(11.0, 3.4))
fig.patch.set_facecolor(COL_WHITE)
for ax, (P, ttl) in zip(axes, panels):
apply_style(ax)
for c in range(3):
m = (y == c)
ax.scatter(P[m, 0], P[m, 1], s=10, color=CLASS_COLORS[c],
edgecolors=COL_WHITE, linewidths=0.25, alpha=0.92, zorder=3)
ax.set_title(ttl, fontsize=10.5, color=COL_INK, pad=7)
ax.set_aspect("equal", adjustable="box")
ax.axhline(0, color=COL_GRID, lw=0.7, zorder=0)
ax.axvline(0, color=COL_GRID, lw=0.7, zorder=0)
# "Ez" panellerinde tanh kutusunu (±1 sınır) göster — bulut nasıl sıkışıyor
for k in (2, 3):
axes[k].add_patch(plt.Rectangle((-1, -1), 2, 2, fill=False,
edgecolor=COL_GOLD_D, lw=1.6, ls="--", zorder=2))
axes[k].text(0.0, 1.12, "tanh sınırı $[-1,1]$", ha="center", va="bottom",
fontsize=8, color=COL_GOLD_D)
# Paneller arası ok + tekrar eden ritim etiketi
fig.subplots_adjust(wspace=0.32, top=0.78, bottom=0.08)
labels = ["döndür", "ez", "döndür+ez"]
for i, lab in enumerate(labels):
x_mid = (axes[i].get_position().x1 + axes[i + 1].get_position().x0) / 2.0
fig.text(x_mid, 0.50, "→", ha="center", va="center",
fontsize=18, color=COL_VIOLET_M, fontweight="bold")
fig.text(x_mid, 0.40, lab, ha="center", va="center",
fontsize=8, color=COL_VIOLET, style="italic")
fig.suptitle("Ağ = döndür, ez, döndür, ez — her katman uzayı büker ve sıkıştırır",
fontsize=12.5, color=COL_VIOLET_D, fontweight="bold", y=0.98);
```
Bir terminoloji tuzağı: Canziani bu ağı "üç katmanlı" sayar (girdi + gizli + çıktı nöron katmanı = 3); LeCun "iki katmanlı" der (programcı gibi sıfırdan + ağırlık matrisi sayısı). İkisi de aynı ağı kasteder — sadece sayma kuralı farklı.
::: {.callout-tip title="Builder Notu — Döndür-Ez = Hafta 1 Geometrisi"}
**Geriye (Hafta 1):** "Döndür-ez", Hafta 1'in "uzay kumaşını ger + nonlinearite ile bük" geometrisinin tam karşılığıdır. Afin = rotation/scaling/shearing/reflection + öteleme (18.06).
**İleriye:** Bu "katman = afin + nonlinearite" kalıbı, her derin mimarinin atomudur; residual bağlantılar ve normalization bu atomun üstüne eklenir.
:::
## (Canziani) Supervised Learning ve Sınıflandırma {#sec-supervised}
Canziani sınıflandırmayı (supervised learning) hatırlatarak başlıyor: kedi/köpek görüntülerini ayırmak gibi. Her örneğin bir **etiketi (label)** vardır; üç sınıf varsa üç etiket. Ağ, girdiyi alıp bir sınıf tahmini üretir; eğitim, tahmini doğru etikete yaklaştırır.
> "supervised learning, classification — this is going to be kind of a revise of stuff you've seen." — Canziani, 2:43
Canziani önemli bir geometrik gerekçe ekliyor: ağ neden girdiyi **yüksek-boyutlu bir ara temsile** ($D$, $\mathbb{R}^n$'den çok daha büyük) taşır? Çünkü yüksek boyutta noktalar birbirinden çok uzaktır; uzakta olanları "döndürerek" ayırmak kolaydır, sıkışık olanları kıpırdatmaya çalışınca hepsi birlikte hareket eder.
> "whenever you go in a very high dimensional space, everything's far apart... it's very easy to rotate stuff and get things to move a little bit." — Canziani, 24:35
::: {.callout-tip title="Builder Notu — Yüksek Boyutta Ayırmak Kolay"}
**Geriye (Hafta 1 + 18.06):** Sınıflandırma = uzayda noktaları ayrıştırma (manifold germe). "Yüksek-boyutta her şey uzak" gözlemi, Hafta 1'in 3-milyon-boyutlu uzay sezgisinin eğitime yansımasıdır.
**İleriye:** Etiketli veri pahalıdır — bu, kursun ilerleyen haftalarda öz-denetimli öğrenmeye (SSL, Hafta 8-10) neden yöneldiğinin sebebidir.
:::
## (Canziani) Cross-Entropy: Sınıflandırmanın Kaybı {#sec-cross-entropy}
Sınıflandırmada doğru kayıp nedir? Canziani örnek-başına kaybı tanımlıyor: doğru sınıfın softmax olasılığının **negatif logaritması**. Ağ doğru sınıfa yüksek olasılık verirse kayıp küçük, düşük verirse büyük olur.
> "this loss is also called cross entropy." — Canziani, 29:51
Doğru sınıf $c$ için örnek-başına cross-entropy:
$$
\mathcal{L}_{\text{CE}} = -\log \frac{e^{y_c}}{\sum_j e^{y_j}}
$$
Etiketler genelde **one-hot** kodlanır (doğru sınıf 1, ötekiler 0); cross-entropy, modelin olasılık dağılımını bu one-hot hedefe yaklaştırır. Tüm veri setinde minimize edilen, örnek-başına kayıpların ortalamasıdır (LeCun bunu büyük $L$ ile yazar).
::: {.callout-tip title="Builder Notu — CE = Negatif Log-Olabilirlik"}
**Geriye (Stat 110):** Cross-entropy doğrudan olasılıktan gelir: doğru sınıfın **negatif log-olabilirliğini** (NLL) minimize etmek = maximum likelihood (Stat 110 Bernoulli/multinomial). Yani kayıp "uydurma" değil, olasılık teoreminin sonucudur — KL ıraksamasını azaltmaya denktir.
**İleriye:** Sınıf dengesizliğinde ağırlıklı/focal loss; çok-etiketli problemlerde sigmoid + BCE. Kayıp seçimi bir mühendislik kararıdır.
:::
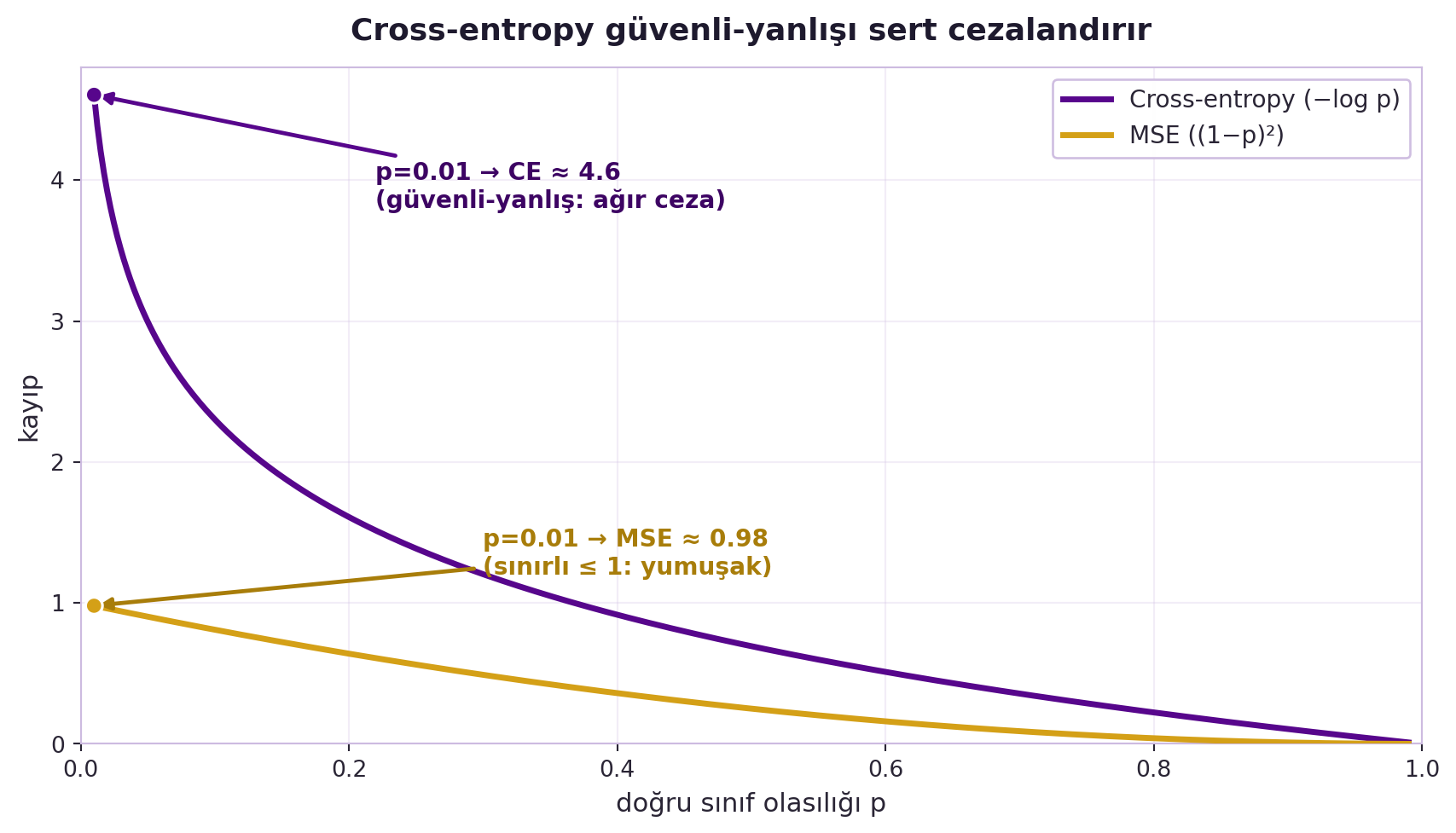
## (Canziani) Cross-Entropy vs MSE: Görev Kaybı Belirler {#sec-ce-vs-mse}
Canziani'ye sınıfta sorulan klasik soru: neden cross-entropy de MSE (ortalama kare hata) değil? Cevap: görev belirler. **Sınıflandırmada** çıktı bir olasılıktır → cross-entropy çalışır ve istatistiksel gerekçesi vardır. **Regresyonda** (sürekli değer tahmini) çıktı sürekli olur → MSE kullanılır.
> "if we talk about classification, we're going to be talking about classes and labels [cross-entropy]; [in regression] targets [MSE]." — Canziani, 49:12
@fig-cross-entropy-vs-mse iki kaybın doğru-sınıf olasılığı $p$ karşısındaki davranışını yan yana koyar: cross-entropy $p \to 0$'da patlar, MSE ise sınırlı kalır. Aynı eğitim döngüsünde tek değişen, kriterdir (criterion): sınıflandırma için `CrossEntropyLoss`, regresyon için `MSELoss`. Sözlük de değişir: sınıflandırmada "sınıf/etiket", regresyonda "hedef (target)".
```{python}
#| label: fig-cross-entropy-vs-mse
#| fig-cap: "Doğru sınıf olasılığı p düştükçe cross-entropy (−log p) patlar ama MSE ((1−p)²) en fazla 1'de kalır; bu yüzden cross-entropy sınıflandırmada güvenli-yanlış tahmini sert cezalandırır."
np.random.seed(0)
p = np.linspace(0.01, 0.99, 400)
ce = ce_loss_curve(p) # −log p
mse = mse_loss_curve(p) # (1 − p)²
fig, ax = plt.subplots(figsize=(9, 5.2))
apply_style(ax)
ax.plot(p, ce, color=COL_VIOLET, lw=2.6, label="Cross-entropy (−log p)", zorder=3)
ax.plot(p, mse, color=COL_GOLD, lw=2.6, label="MSE ((1−p)²)", zorder=3)
# p = 0.01'de iki kaybı işaretle/annotate
p0 = 0.01
ce0 = float(ce_loss_curve(p0)) # ≈ 4.6
mse0 = float(mse_loss_curve(p0)) # ≈ 0.98
ax.scatter([p0, p0], [ce0, mse0], s=55, zorder=5,
color=[COL_VIOLET, COL_GOLD], edgecolor=COL_WHITE, linewidth=1.2)
ax.annotate(f"p=0.01 → CE ≈ {ce0:.1f}\n(güvenli-yanlış: ağır ceza)",
xy=(p0, ce0), xytext=(0.22, 3.95),
color=COL_VIOLET_D, fontsize=10.5, fontweight="bold", va="center",
arrowprops=dict(arrowstyle="-|>", color=COL_VIOLET, lw=1.8))
ax.annotate(f"p=0.01 → MSE ≈ {mse0:.2f}\n(sınırlı ≤ 1: yumuşak)",
xy=(p0, mse0), xytext=(0.30, 1.35),
color=COL_GOLD_D, fontsize=10.5, fontweight="bold", va="center",
arrowprops=dict(arrowstyle="-|>", color=COL_GOLD_D, lw=1.8))
ax.set_xlim(0.0, 1.0)
ax.set_ylim(0.0, 4.8)
ax.set_xlabel("doğru sınıf olasılığı p", fontsize=11.5)
ax.set_ylabel("kayıp", fontsize=11.5)
ax.set_title("Cross-entropy güvenli-yanlışı sert cezalandırır",
fontsize=13.5, color=COL_INK, fontweight="bold", pad=12)
style_legend(ax, loc="upper right", fontsize=10.5)
fig.tight_layout()
```
::: {.callout-tip title="Builder Notu — Görev → Kayıp"}
**Geriye (Stat 110):** MSE, gürültünün Gaussian olduğu varsayımının maximum likelihood karşılığıdır; cross-entropy ise Bernoulli/multinomial'in. İki kayıp da aynı ilkeden (MLE) farklı dağılım varsayımlarıyla türer.
**İleriye:** "Görev → çıktı tipi → kayıp" zinciri, herhangi bir ML problemini kurarken ilk verilen karardır.
:::
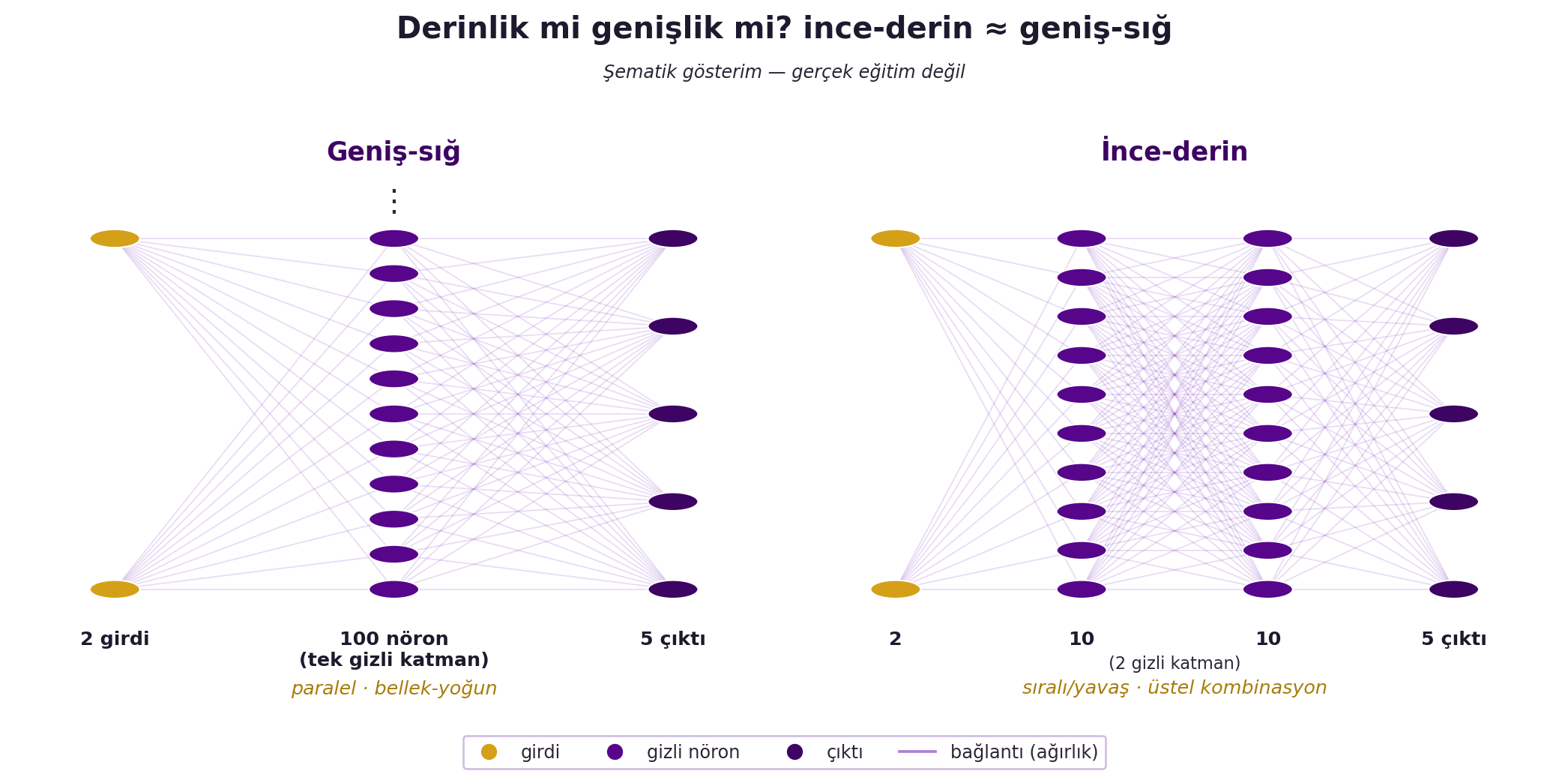
## (Canziani) Derinlik vs Genişlik {#sec-derinlik-genislik}
Canziani pratik bir tasarım sorusu açıyor: aynı ifade gücünü tek bir **geniş** katmanla mı (örn. 100 nöron) yoksa birkaç **derin** katmanla mı (örn. 10+10) elde etmeli? İlginç gözlem: derin istifleme, nöron kombinasyonlarını **üstel** olarak artırdığı için, ince ama derin bir ağ, geniş ama sığ bir ağa yakın güç sağlayabilir.
Tradeoff ise hesaplamada: **derin** ağda veri bağımlılığı vardır — alttaki katman bitmeden üstteki başlayamaz, yani daha sıralı (yavaş). **Geniş** ağ daha paralelleştirilebilir ama çok daha fazla nöron/bellek ister. @fig-depth-vs-width iki mimariyi şematik olarak yan yana koyar. Yani "derin mi geniş mi" sorusunun cevabı donanıma (paralellik) ve bellek bütçesine bağlıdır.
```{python}
#| label: fig-depth-vs-width
#| fig-cap: "İki ağ mimarisinin şematik karşılaştırması: solda geniş-sığ ağ (2 girdi → 100 nöronlu tek gizli katman → 5 çıktı, paralel ama bellek-yoğun), sağda ince-derin ağ (2 → 10 → 10 → 5, sıralı/yavaş ama üstel katman kombinasyonu) — derinliğin az nöronla geniş-sığ ağa denk ifade gücü sağladığını gösterir."
np.random.seed(0)
from matplotlib.patches import Circle, FancyBboxPatch
from matplotlib.lines import Line2D
def _layer_y(n, n_draw, lim=0.86):
"""n nöronlu bir katman için dikey y konumları. n_draw > n ise üst/altta
'noktalar' (…) ile kısaltılmış gösterim için gerçek çizilecek y'leri döndürür."""
if n <= n_draw:
ys = np.linspace(lim, -lim, n)
return ys, False
ys = np.linspace(lim, -lim, n_draw)
return ys, True
def draw_net(ax, layer_sizes, layer_draw, xlabels, edge_alpha=0.16, node_r=0.045):
"""Şematik ileri-beslemeli ağ. layer_sizes: gerçek nöron sayıları (etiket için);
layer_draw: her katmanda fiilen çizilen nöron sayısı (görsel kısaltma)."""
L = len(layer_sizes)
xs = np.linspace(0.0, 1.0, L)
ys_all, trunc_all = [], []
for n, nd in zip(layer_sizes, layer_draw):
ys, trunc = _layer_y(n, nd)
ys_all.append(ys)
trunc_all.append(trunc)
# bağlantılar (önce, nöronların arkasında)
for i in range(L - 1):
for ya in ys_all[i]:
for yb in ys_all[i + 1]:
ax.plot([xs[i], xs[i + 1]], [ya, yb],
color=COL_VIOLET_M, alpha=edge_alpha, lw=0.7, zorder=1)
# nöronlar
for i, (x, ys, trunc) in enumerate(zip(xs, ys_all, trunc_all)):
if i == 0:
fc = COL_GOLD # girdi katmanı = gold
elif i == L - 1:
fc = COL_VIOLET_D # çıktı katmanı = koyu violet
else:
fc = COL_VIOLET # gizli katman = NYU violet
for y in ys:
ax.add_patch(Circle((x, y), node_r, fc=fc, ec=COL_WHITE,
lw=0.8, zorder=3))
if trunc: # kısaltma noktaları (üstte)
ax.text(x, 0.965, "⋮", ha="center", va="bottom",
fontsize=15, color=COL_TEXT, zorder=3)
# katman boyut etiketi (altta)
ax.text(x, -1.06, xlabels[i], ha="center", va="top",
fontsize=9.5, color=COL_INK, fontweight="bold", zorder=3)
fig, axes = plt.subplots(1, 2, figsize=(11.0, 5.2))
fig.patch.set_facecolor(COL_WHITE)
# --- SOL: Geniş-sığ ag (2 -> 100 -> 5) ---
axL = axes[0]
axL.set_xlim(-0.18, 1.18)
axL.set_ylim(-1.42, 1.30)
axL.axis("off")
draw_net(axL,
layer_sizes=[2, 100, 5],
layer_draw=[2, 11, 5],
xlabels=["2 girdi", "100 nöron\n(tek gizli katman)", "5 çıktı"])
axL.text(0.5, 1.22, "Geniş-sığ", ha="center", va="bottom",
fontsize=13, fontweight="bold", color=COL_VIOLET_D)
axL.text(0.5, -1.30, "paralel · bellek-yoğun", ha="center", va="top",
fontsize=9.5, color=COL_GOLD_D, style="italic")
# --- SAG: İnce-derin ag (2 -> 10 -> 10 -> 5) ---
axR = axes[1]
axR.set_xlim(-0.18, 1.18)
axR.set_ylim(-1.42, 1.30)
axR.axis("off")
draw_net(axR,
layer_sizes=[2, 10, 10, 5],
layer_draw=[2, 10, 10, 5],
xlabels=["2", "10", "10", "5 çıktı"])
axR.text(0.5, 1.22, "İnce-derin", ha="center", va="bottom",
fontsize=13, fontweight="bold", color=COL_VIOLET_D)
axR.text(0.5, -1.30, "sıralı/yavaş · üstel kombinasyon", ha="center", va="top",
fontsize=9.5, color=COL_GOLD_D, style="italic")
axR.text(0.5, -1.18, "(2 gizli katman)", ha="center", va="top",
fontsize=8.5, color=COL_TEXT)
# Ortak legend (figür üstü)
handles = [
Line2D([0], [0], marker="o", color="w", markerfacecolor=COL_GOLD,
markeredgecolor=COL_WHITE, markersize=9, label="girdi"),
Line2D([0], [0], marker="o", color="w", markerfacecolor=COL_VIOLET,
markeredgecolor=COL_WHITE, markersize=9, label="gizli nöron"),
Line2D([0], [0], marker="o", color="w", markerfacecolor=COL_VIOLET_D,
markeredgecolor=COL_WHITE, markersize=9, label="çıktı"),
Line2D([0], [0], color=COL_VIOLET_M, lw=1.4, alpha=0.6, label="bağlantı (ağırlık)"),
]
leg = fig.legend(handles=handles, loc="lower center", ncol=4, frameon=True,
framealpha=0.95, edgecolor=COL_GRID, fontsize=9,
bbox_to_anchor=(0.5, -0.02))
leg.get_frame().set_facecolor(COL_WHITE)
for t in leg.get_texts():
t.set_color(COL_TEXT)
fig.suptitle("Derinlik mi genişlik mi? ince-derin ≈ geniş-sığ",
fontsize=15, fontweight="bold", color=COL_INK, y=1.00)
fig.text(0.5, 0.935, "Şematik gösterim — gerçek eğitim değil",
ha="center", va="top", fontsize=9, color=COL_TEXT, style="italic")
fig.tight_layout(rect=[0, 0.05, 1, 0.93])
```
::: {.callout-tip title="Builder Notu — Derinlik mi Genişlik mi"}
**Geriye (Hafta 1):** Geniş ara temsil, "yüksek boyutta her şey uzak → ayırması kolay" sezgisini kullanır; derinlik ise her katmanda yeni nonlineariteyle ifade gücünü üst üste bindirir.
**İleriye:** Derinlik/genişlik dengesi, modern ölçeklemenin (scaling laws), pipeline/tensor paralelliğinin ve bellek-throughput tradeoff'unun doğrudan konusudur — Hafta 4 ve sonrası.
:::
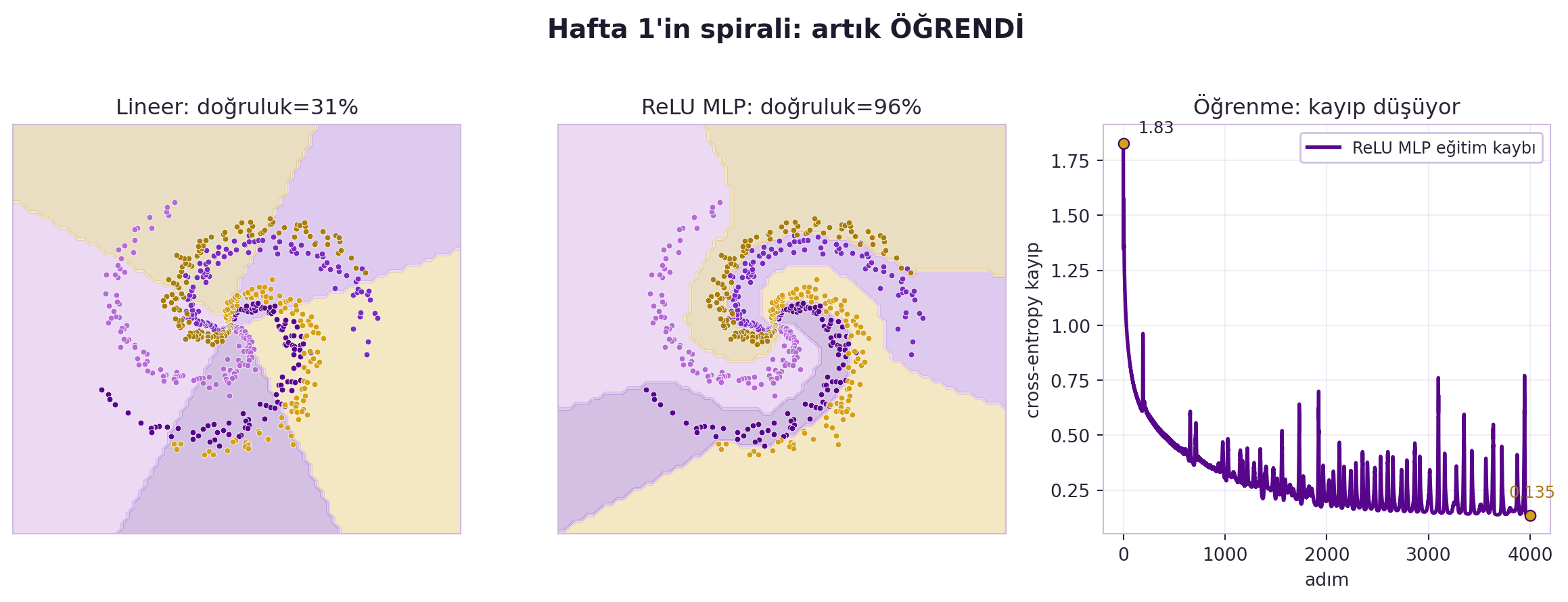
## (Canziani) PyTorch'ta Eğitim Döngüsü {#sec-egitim-dongusu}
Canziani teoriyi koda döküyor ve Hafta 1'in spiral ağını eğitiyor. Eğitim, parametreleri (ağırlık matrisleri) gradient descent ile güncellemektir:
> "how do you train a neural network? Gradient [methods]." — Canziani, 39:18
PyTorch'ta standart döngü: ileri geçiş → kaybı hesapla → `backward()` (LeCun'un Jacobian zinciri) → optimizer adımı.
```python
import torch
import torch.nn as nn
model = nn.Sequential(
nn.Linear(2, 100), nn.ReLU(), # dondur + ez (rotation + squashing)
nn.Linear(100, 5), # 5 sinif (spiral kollari)
)
criterion = nn.CrossEntropyLoss() # softmax + NLL birlikte
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
for epoch in range(1000):
y_pred = model(x) # ileri gecis (forward)
loss = criterion(y_pred, y) # cross-entropy
optimizer.zero_grad() # gradyanlari sifirla (Karpathy'nin meshur hatasi)
loss.backward() # backprop = Jacobian zinciri
optimizer.step() # theta <- theta - eta * grad
```
Döngü ilerledikçe kayıp düşer; eğitim sonunda spiral kolları lineer ayrılabilir hale gelir — Hafta 1'de göremediğimiz "öğrenme" işte budur. @fig-spiral-trained Hafta 1'in spiral ağını gerçekten eğitir: lineer sınıflandırıcı kolları ayıramaz, ReLU MLP ayırır, ve eğitim kaybı düşer. Canziani döngünün ilk ve son kayıp değerlerini karşılaştırarak ağın gerçekten öğrendiğini gösterir (örn. ilk kayıp yüksek, son kayıp 0.86 gibi düşük bir değere iner).
```{python}
#| label: fig-spiral-trained
#| fig-cap: "Hafta 1'in spirali artık eğitildi: lineer softmax sınıflandırıcı 5 kolu ayıramaz (%31), ReLU MLP manifoldu açarak kolları ayırır (%96) ve eğitim kaybı 4000 adımda 1,83'ten 0,135'e düşer."
np.random.seed(0)
# Hafta 1'in spirali — ortak veri
X, y = make_spiral(n_per=120, k=5, noise=0.18, seed=0)
xx, yy, grid = decision_grid(X, pad=0.6, h=0.04)
# Lineer (gizli katmansız softmax) — kolları AYIRAMAZ
lin = logreg_train(X, y, steps=800, seed=0)
acc_lin = accuracy(logreg_forward, lin, X, y)
Zlin = logreg_forward(lin, grid).argmax(axis=1).reshape(xx.shape)
# ReLU MLP — manifoldu açar, 5 kolu AYIRIR
mlp, hist = mlp_train(X, y, hidden=100, act="relu", steps=4000, lr=1.5, seed=0,
return_history=True)
acc_mlp = accuracy(mlp_forward, mlp, X, y)
Zmlp = mlp_forward(mlp, grid).argmax(axis=1).reshape(xx.shape)
from matplotlib.colors import ListedColormap
cmap = ListedColormap(CLASS_COLORS)
fig, (axL, axR, axC) = plt.subplots(1, 3, figsize=(12.2, 4.5))
# --- SOL: lineer karar bölgesi (kollar karışık) ---
axL.contourf(xx, yy, Zlin, levels=np.arange(-0.5, 5.5, 1.0), cmap=cmap, alpha=0.25)
for j in range(5):
m = y == j
axL.scatter(X[m, 0], X[m, 1], s=11, c=CLASS_COLORS[j], edgecolors=COL_WHITE,
linewidths=0.3, zorder=3)
axL.set_title(f"Lineer: doğruluk={acc_lin:.0%}", fontsize=12, color=COL_TEXT)
axL.set_xticks([]); axL.set_yticks([])
axL.set_xlim(xx.min(), xx.max()); axL.set_ylim(yy.min(), yy.max())
apply_style(axL)
# --- ORTA: ReLU MLP karar bölgesi (5 kol ayrılmış) ---
axR.contourf(xx, yy, Zmlp, levels=np.arange(-0.5, 5.5, 1.0), cmap=cmap, alpha=0.25)
for j in range(5):
m = y == j
axR.scatter(X[m, 0], X[m, 1], s=11, c=CLASS_COLORS[j], edgecolors=COL_WHITE,
linewidths=0.3, zorder=3)
axR.set_title(f"ReLU MLP: doğruluk={acc_mlp:.0%}", fontsize=12, color=COL_TEXT)
axR.set_xticks([]); axR.set_yticks([])
axR.set_xlim(xx.min(), xx.max()); axR.set_ylim(yy.min(), yy.max())
apply_style(axR)
# --- SAĞ: eğitim kayıp eğrisi ---
axC.plot(np.arange(len(hist)), hist, color=COL_VIOLET, lw=2.0,
label="ReLU MLP eğitim kaybı")
axC.scatter([0, len(hist) - 1], [hist[0], hist[-1]], s=34, color=COL_GOLD,
edgecolors=COL_VIOLET_D, linewidths=0.8, zorder=4)
axC.annotate(f"{hist[0]:.2f}", (0, hist[0]), textcoords="offset points",
xytext=(8, 6), fontsize=9, color=COL_TEXT)
axC.annotate(f"{hist[-1]:.3f}", (len(hist) - 1, hist[-1]), textcoords="offset points",
xytext=(-12, 10), fontsize=9, color=COL_GOLD_D)
axC.set_title("Öğrenme: kayıp düşüyor", fontsize=12, color=COL_TEXT)
axC.set_xlabel("adım"); axC.set_ylabel("cross-entropy kayıp")
apply_style(axC)
style_legend(axC, loc="upper right", fontsize=9)
fig.suptitle("Hafta 1'in spirali: artık ÖĞRENDİ", fontsize=14.5,
color=COL_INK, fontweight="bold", y=1.02)
fig.tight_layout()
```
::: {.callout-tip title="Builder Notu — Dört Satırlık Döngü"}
**Geriye (LeCun + Karpathy):** `loss.backward()` tam olarak LeCun'un Jacobian zinciridir; `zero_grad()` Karpathy'nin "her backward öncesi gradyanı sıfırla" dersidir (atlanırsa gradient yanlış birikir).
**İleriye:** Bu dört satırlık döngü (forward → loss → backward → step) tüm derin öğrenme eğitiminin iskeletidir; üstüne validation, checkpoint, LR schedule, mixed precision biner.
:::
## Bu Dersin Özeti {#sec-ozet-d2}
1. **Eğitim = kaybı gradient descent ile küçültmek.** Ağ modüllerden kuruludur; maliyet modülü tahmin ile gerçeği karşılaştırır.
2. **Gradient descent** kaybı gradient'in ters yönünde küçük adımlarla azaltır; **SGD** bunu tek örnek/batch üzerinde tahminle yapar ("descent değil, optimization" — gürültülü ama ucuz).
3. **Backpropagation = zincir kuralı.** "Twiddling" sezgisiyle: gradyan'ı çıktıdan girişe her modülün türeviyle çarparak taşırsın; vektörel hâlde bu **Jacobian matrislerinin çarpımıdır**. Lineer modülde "ağırlıkların tersten ağırlıklı toplamı" (forward $W$, backward $W^\top$). "That's all there is to backprop."
4. **Ağ = döndür-ez** (afin + nonlinearite) dizisidir; LogSoftMax/softmax skorları olasılığa çevirir.
5. **Cross-entropy** sınıflandırmanın kaybıdır (−log softmax = NLL); **MSE** regresyonunki. Görev kaybı belirler.
6. **Derinlik vs genişlik:** ince-derin ≈ geniş-sığ (üstel kombinasyon), ama derin = sıralı/yavaş, geniş = paralel/bellek-yoğun.
7. **PyTorch eğitim döngüsü:** forward → loss → zero_grad → backward → step. Hafta 1'in spiral ağı bununla eğitilip ayrılır.
::: {.callout-important title="Tek Bir Cümle"}
Bir ağı eğitmek, bir kaybı (sınıflandırmada cross-entropy) gradient descent ile küçültmektir; gradient'i backpropagation — zincir kuralının modül-modül Jacobian çarpımlarıyla uygulanması — hesaplar, ve tüm bu döngü PyTorch'ta forward → loss → backward → step'ten ibarettir.
:::
## Kontrol Soruları {#sec-kontrol-d2}
::: {.callout-note collapse="true" title="Soru 1: Backpropagation neyden ibarettir? 'Jacobian' kelimesini kullanarak açıkla."}
**Cevap:** Backprop, zincir kuralının modüllere uygulanmasıdır. Vektörel modüllerde gradient, çıktıdan girişe doğru her modülün **Jacobian matrisiyle** çarpılarak taşınır:
$$
\frac{\partial C}{\partial z_k} = \frac{\partial C}{\partial z_{k+1}}\, \frac{\partial z_{k+1}}{\partial z_k}
$$
Parametreli bir modülün iki Jacobian'ı vardır: girdiye göre olan gradient'i bir önceki katmana taşır; ağırlıklara göre olan o katmanın ağırlık gradient'ini verir. Lineer modülde bu "forward $W$, backward $W^\top$" simetrisidir. LeCun'un deyişiyle "that's all there is to backprop" (49:32). Karpathy bunu micrograd'da `_backward` kapanışlarıyla koda döker.
:::
::: {.callout-note collapse="true" title="Soru 2: LeCun neden 'SGD aslında bir descent algoritması değil' diyor? Gürültü neden kötü değildir?"}
**Cevap:** Çünkü SGD gradient'i tüm veri yerine tek bir (veya küçük batch) örnek üzerinde **tahmin eder**; bu tahmin gürültülüdür, dolayısıyla her adım kaybı garantili azaltmaz — bazen artırabilir. Bu yüzden LeCun "stochastic gradient optimization" demeyi tercih eder (17:10). Gürültü kötü değildir: (1) çok daha ucuz ve sık güncelleme demektir, (2) sığ yerel minimumlardan kaçmaya yardım eder. Stat 110 köprüsü: mini-batch gradient'i gerçek gradient'in tarafsız tahmincisidir, varyans $\propto 1/B$.
:::
::: {.callout-note collapse="true" title="Soru 3: Sınıflandırmada cross-entropy, regresyonda MSE kullanılır. Bu seçim neye dayanır? Cross-entropy formülünü yaz."}
**Cevap:** Görevin çıktı tipine ve onun altındaki olasılık varsayımına dayanır. Sınıflandırmada çıktı bir olasılık dağılımıdır; doğru sınıf $c$ için cross-entropy:
$$
\mathcal{L}_{\text{CE}} = -\log \frac{e^{y_c}}{\sum_j e^{y_j}}
$$
Bu, doğru sınıfın negatif log-olabilirliğidir (NLL) → maximum likelihood (Stat 110 multinomial). Regresyonda çıktı süreklidir; MSE, Gaussian gürültü varsayımının maximum likelihood karşılığıdır. İkisi de aynı ilkeden (MLE) farklı dağılımlarla türer — kayıp "uydurma" değildir.
:::
::: {.callout-note collapse="true" title="Soru 4: (Builder) PyTorch eğitim döngüsündeki dört adımı (forward, loss, backward, step) LeCun'un ve Karpathy'nin kavramlarıyla eşle. zero_grad() neden gerekli?"}
**Cevap:** **forward** = modüllerin ileri geçişi (LeCun'un fonksiyonel modülleri, "döndür-ez"); **loss** = maliyet modülü ($\hat{Y}$ ile $Y$ karşılaştırması, cross-entropy); **backward** = backpropagation, LeCun'un Jacobian zinciri (`loss.backward()`); **step** = gradient descent güncellemesi $\theta \leftarrow \theta - \eta\nabla L$. `zero_grad()` gereklidir çünkü PyTorch gradyanları varsayılan olarak **biriktirir** (toplar); her backward öncesi sıfırlanmazsa önceki adımların gradyanları yenisine eklenir ve eğitim bozulur — Karpathy'nin meşhur hatası.
:::
## Egzersizler {#sec-egzersiz-d2}
**Egzersiz 1 (Cross-entropy elle).** Bir skor vektörü (logit) için softmax'i NumPy ile hesapla, sonra doğru sınıfın −log olasılığını al. Aynı sonucu `torch.nn.functional.cross_entropy` ile karşılaştır.
```python
import numpy as np
def softmax(z): e = np.exp(z - z.max()); return e / e.sum()
z = np.array([2.0, 0.5, -1.0]); c = 0 # dogru sinif 0
p = softmax(z); print(-np.log(p[c])) # cross-entropy
```
**Egzersiz 2 (Spiral'ı eğit).** Hafta 1'de kurduğun spiral ağına (2 → 100 → ReLU → 5) `CrossEntropyLoss` + `SGD` ekle ve 1000 epoch eğit. Kayıp eğrisini çiz; ilk ve son kayıp değerlerini karşılaştır. Karar bölgelerinin nasıl ayrıştığını gözlemle.
**Egzersiz 3 (zero_grad'ı unut).** Eğitim döngüsünden `optimizer.zero_grad()` satırını sil ve eğit. Kaybın neden bozulduğunu açıkla (gradyan birikimi). Sonra geri ekle.
**Egzersiz 4 (CE vs MSE).** Aynı spiral verisinde (a) cross-entropy, (b) MSE (one-hot hedeflerle) ile eğit. Hangisi daha iyi/kararlı yakınsıyor? Neden cross-entropy sınıflandırma için doğru seçim?
**Egzersiz 5 (Hafta 3 habercisi — görüntüye geçiş).** Bu hafta girdi 2 sayıydı. Şimdi 28×28 piksellik bir rakam görüntüsünü düşün: `nn.Linear` ile işlemek için 784 boyuta düzleştirmen gerekir — ve uzamsal yapı (komşu pikseller) kaybolur. (a) 1000×1000 RGB için ilk linear katmanın kaç parametresi olurdu? (b) Bu "parametre patlaması" ve kaybolan uzamsal yapı, Hafta 3'te **convolution**'a neden ihtiyaç duyduğumuzu motive eder — neden?
## Sonraki Ders İçin Hazırlık {#sec-sonraki-d2}
::: {.callout-warning title="Sonraki Hafta — H3: Evrişimli Ağlar (ConvNets)"}
**Tam-bağlı ağdan doğal sinyallere.** Bu hafta tam-bağlı (fully connected) ağları eğittik. Hafta 3'te LeCun görüntü gibi **doğal sinyallerin** yapısını (yerel, hiyerarşik, öteleme-değişmez) ve bunu sömüren **convolution**'ı anlatacak; görsel korteksten LeNet5'e uzanacak. Canziani doğal sinyaller ve pooling'i PyTorch'ta gösterecek — Egzersiz 5'in "parametre patlaması" tam burada çözülür.
:::
**Hafta 3: Evrişimli Ağlar (ConvNets) ve Doğal Sinyaller** — LeCun (Lecture) + Canziani (Practicum)
Bu hafta tam-bağlı (fully connected) ağları eğittik. Hafta 3'te LeCun görüntü gibi **doğal sinyallerin** yapısını (yerel, hiyerarşik, öteleme-değişmez) ve bunu sömüren **convolution**'ı anlatacak; görsel korteksten LeNet5'e uzanacak. Canziani doğal sinyaller ve pooling'i PyTorch'ta gösterecek.
**Hafta 3 öncesi yapılacak:**
- Egzersiz 2'yi (spiral eğitimi) ve Egzersiz 5'i (görüntü/parametre patlaması) çöz.
- "Backprop = zincir kuralının Jacobian çarpımlarıyla uygulanması" cümlesini kendi sözcüklerinle yaz.
- Karpathy micrograd'ı (Phase 2) hatırla — `loss.backward()` orada elle nasıl kuruluyordu?
## Anahtar Kavramlar (Cheat Sheet) {#sec-cheat-d2}
| Kavram | Tanım | Hoca / timestamp |
|---|---|---|
| Modül | Girdi → çıktı hesaplayan blok; ağ modüllerden kurulur | LeCun 6m04 |
| Maliyet (cost) modülü | $\hat{Y}$ ile $Y$'yi karşılaştırıp kaybı üretir; tepeye konur | LeCun 1m43 |
| Gradient descent | Gradient'in ters yönünde küçük adım; dağda iniş | LeCun 10m27 |
| SGD | Gradient'i tek örnek/batch'te tahmin; gürültülü, ucuz | LeCun 17m10 |
| Backprop = zincir kuralı | Gradient'i çıktıdan girişe taşıma; twiddling sezgisi | LeCun 27m36 |
| Ağırlıkları tersten | Forward $W$, backward $W^\top$; gradyanların ağırlıklı toplamı | LeCun 36m24 |
| Jacobian matrisi | Vektör fonksiyonun türev matrisi; backprop = Jacobian çarpımları | LeCun 46m10 |
| Döndür-ez | Ağ = afin (rotation) + nonlinearite (squashing) dizisi | Canziani 15m43 |
| Cross-entropy (NLL) | Sınıflandırma kaybı: −log softmax (doğru sınıf) | Canziani 29m51 |
| MSE | Regresyon kaybı: ortalama kare hata | Canziani 48m46 |
| Derinlik vs genişlik | İnce-derin ≈ geniş-sığ; derin sıralı, geniş paralel | Canziani 25m21 |
| Eğitim döngüsü | forward → loss → zero_grad → backward → step | Canziani 39m18 |
## ML Builder Bağlantıları {#sec-koprular-d2}
**Geriye köprüler (önkoşul kurslar):**
1. **Backprop / zincir kuralı** → Calculus Ders 4 + Karpathy micrograd (`_backward`, autograd).
2. **Cross-entropy / NLL** → Stat 110 Bernoulli/multinomial log-olabilirlik (MLE).
3. **Jacobian / zincir = matris çarpımı + forward $W$ / backward $W^\top$** → 18.06 bileşke dönüşüm ve transpoz.
4. **SGD tarafsız tahmin** → Stat 110 örneklem ortalaması, varyans $\propto 1/B$.
5. **MSE = Gaussian MLE** → Stat 110 normal dağılım.
**İleriye köprüler (production / research):**
1. **module + Jacobian** → PyTorch `nn.Module` + `autograd` (`loss.backward()`).
2. **SGD ucuzluğu** → mini-batch, gradient accumulation, DDP.
3. **softmax+log+NLL birleşik** → `F.cross_entropy` (sayısal kararlılık).
4. **Derinlik/genişlik + eğitim döngüsü** → scaling laws, checkpoint, LR schedule, mixed precision.
::: {.callout-important title="Bu dersten tek bir şey alıp gideceksen"}
Bir ağı eğitmek sihir değildir — bir kaybı gradient descent ile küçültmektir; ve gradient'i hesaplayan backpropagation, zincir kuralının modül-modül Jacobian çarpımlarıyla uygulanmasından başka bir şey değildir. LeCun bunu Jacobian cebriyle kurar, Canziani PyTorch'ta dört satırda (forward → loss → backward → step) gösterir — ve Hafta 1'in eğitilmemiş spiral ağı işte böyle ayrışır.
:::