---
title: "Evrişimli Ağlar (ConvNets) ve Doğal Sinyaller"
subtitle: "NYU'nun iki hocalı ritmi: LeCun convolution'ın *neden*ini verir — doğal dünya kompozisyoneldir, kökü görsel kortekstedir (Hubel-Wiesel → LeNet5); Canziani bunu sistematikleştirir — doğal sinyallerin üç özelliği (stationarity, locality, compositionality) doğrudan üç mimari karara (parameter sharing, sparsity, hiyerarşi) çevrilir"
---
::: {.callout-note title="Bölüm bilgisi"}
- **LeCun'un Lecture videosu:** [YouTube — Lecture 03: Convolution operator and deep ConvNets](https://www.youtube.com/watch?v=FW5gFiJb-ig) (≈98 dk)
- **Canziani'nin Practicum videosu:** [YouTube — Practicum 03: Properties of natural signals](https://www.youtube.com/watch?v=kwPWpVverkw) (≈48 dk)
- **Edition:** Spring 2020 (NYU-DLSP20)
- **Hocalar:** Yann LeCun (Lecture, teorik) + Alfredo Canziani (Practicum, pratik)
- **Kaynak:** [atcold.github.io/NYU-DLSP20](http://atcold.github.io/NYU-DLSP20)
- **Okuma süresi:** ≈30 dk
:::
```{python}
#| echo: false
# ============================================================================
# SETUP — NYU sayısal motor (_engine.py) + NYU Violet+gold viz (_viz.py)
# Bu hücre gizlidir (#| echo: false). Aşağıdaki TÜM figür hücreleri burada
# tanımlanan conv1d / conv2d / conv_output_size / make_synthetic_image /
# edge_kernels / max_pool2d / avg_pool2d + COL_* + apply_style /
# draw_pipeline / style_legend / CLASS_COLORS isimlerini kullanır.
# _engine.py saf numpy (torch YOK); _viz.py NYU Violet+gold paleti.
# İçerikler VERBATIM gömülüdür.
#
# NOT: matplotlib backend'i AYARLANMAZ (matplotlib.use(...) ÇAĞRILMAZ).
# Quarto kendi inline (figür yakalayan) backend'ini kurar; Agg backend
# inline figür-yakalamayı bozar (plt.show() çıktı üretmez). Standalone
# figür testinde savefig kullanılır.
# ============================================================================
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from matplotlib.patches import (
FancyBboxPatch, FancyArrowPatch, Rectangle, Circle, Patch,
)
# ===========================================================================
# _engine.py — saf numpy sayısal yardımcılar (torch YOK)
# ===========================================================================
# ---------------------------------------------------------------------------
# Afin / lineer dönüşümler
# ---------------------------------------------------------------------------
def affine_transform(P, W, b=None):
"""P[N,2] noktalarına y = W x (+ b) afin/lineer dönüşümü uygular (satır-vektör konvansiyonu)."""
P = np.asarray(P, float)
Y = P @ np.asarray(W, float).T
if b is not None:
Y = Y + np.asarray(b, float)
return Y
def unit_grid(n=11, lim=2.0, fine=61):
"""Izgara çizgileri listesi (yatay + dikey). Her çizgi (fine,2) dizisi.
Lineer dönüşüm görsellerinde 'uzayın kumaşı' için."""
t = np.linspace(-lim, lim, n)
f = np.linspace(-lim, lim, fine)
lines = []
for yi in t:
lines.append(np.column_stack([f, np.full_like(f, yi)]))
for xi in t:
lines.append(np.column_stack([np.full_like(f, xi), f]))
return lines
def linear_transforms():
"""Canziani'nin dört temel lineer dönüşümü (Bölüm 8) — 2x2 matrisler."""
th = np.deg2rad(35.0)
R = np.array([[np.cos(th), -np.sin(th)], [np.sin(th), np.cos(th)]]) # rotation (ortonormal)
S = np.array([[1.8, 0.0], [0.0, 0.55]]) # scaling (köşegen)
Sh = np.array([[1.0, 0.85], [0.0, 1.0]]) # shearing
F = np.array([[1.0, 0.0], [0.0, -1.0]]) # reflection (det<0)
return dict(rotation=R, scaling=S, shearing=Sh, reflection=F)
# ---------------------------------------------------------------------------
# SVD geometrisi (Canziani'nin 'patatesi')
# ---------------------------------------------------------------------------
def unit_circle(n=240):
t = np.linspace(0, 2 * np.pi, n)
return np.column_stack([np.cos(t), np.sin(t)])
def svd_demo(W):
"""W = U Σ Vᵀ. Geometrik okuma: rotation(Vᵀ) · scaling(Σ) · rotation(U)."""
U, s, Vt = np.linalg.svd(np.asarray(W, float))
return U, s, Vt
def near_singular_matrix():
"""Bir tekil değeri ≈0 olan matris — bir boyutu 'ezer' (elips çizgiye çöker)."""
th = np.deg2rad(30.0)
R = np.array([[np.cos(th), -np.sin(th)], [np.sin(th), np.cos(th)]])
Sigma = np.diag([1.6, 0.04]) # ikinci tekil değer ≈ 0
return R @ Sigma @ R.T
# ---------------------------------------------------------------------------
# Spiral (manifold germe demosu)
# ---------------------------------------------------------------------------
def make_spiral(n_per=120, k=5, noise=0.18, seed=0):
"""k-kollu spiral (CS231n stili). Her kol bir sınıf; kollar orijinde iç içe → lineer ayrılamaz."""
rng = np.random.default_rng(seed)
X = np.zeros((n_per * k, 2))
y = np.zeros(n_per * k, dtype=int)
for j in range(k):
ix = slice(n_per * j, n_per * (j + 1))
r = np.linspace(0.0, 1.0, n_per)
t = np.linspace(j * 4.0, (j + 1) * 4.0, n_per) + rng.normal(0, 1, n_per) * noise
X[ix] = np.column_stack([r * np.sin(t), r * np.cos(t)])
y[ix] = j
return X, y
def unroll_spiral(X, y, k=5, seed=0):
"""ŞEMATİK 'öğrenilen temsil': her sınıfı kendi yatay bandına taşır → lineer ayrılabilir.
Gerçek bir eğitilmiş ağ DEĞİL; 'ağ manifoldu açar' sezgisinin deterministik görseli."""
rng = np.random.default_rng(seed)
r = np.linalg.norm(X, axis=1)
yb = (y - (k - 1) / 2.0) * 0.55 + rng.normal(0, 0.045, len(y))
return np.column_stack([r * 2.2 - 1.1, yb])
# ---------------------------------------------------------------------------
# İki hilal (make_moons — sklearn YOK, numpy ile elle)
# ---------------------------------------------------------------------------
def make_moons_np(n=400, noise=0.20, seed=0):
"""Doğrusal ayrılamaz iki-hilal veri (sklearn.make_moons eşdeğeri)."""
rng = np.random.default_rng(seed)
n_out = n // 2
n_in = n - n_out
to = np.linspace(0, np.pi, n_out)
ti = np.linspace(0, np.pi, n_in)
outer = np.column_stack([np.cos(to), np.sin(to)])
inner = np.column_stack([1.0 - np.cos(ti), 1.0 - np.sin(ti) - 0.5])
X = np.vstack([outer, inner]) + rng.normal(0, noise, (n, 2))
y = np.array([0] * n_out + [1] * n_in)
return X, y
# ---------------------------------------------------------------------------
# Minik numpy sınıflandırıcılar (lineer vs ReLU MLP) — karar sınırı kontrastı
# ---------------------------------------------------------------------------
def _onehot(y, c):
Y = np.zeros((len(y), c))
Y[np.arange(len(y)), y] = 1.0
return Y
def _softmax(z):
z = z - z.max(axis=1, keepdims=True)
e = np.exp(z)
return e / e.sum(axis=1, keepdims=True)
def logreg_train(X, y, steps=500, lr=1.0, seed=0):
"""Lineer (gizli katmansız) softmax sınıflandırıcı → DÜZ karar sınırı."""
rng = np.random.default_rng(seed)
n, d = X.shape
c = int(y.max() + 1)
W = rng.normal(0, 0.01, (d, c))
b = np.zeros(c)
Y = _onehot(y, c)
for _ in range(steps):
p = _softmax(X @ W + b)
dz = (p - Y) / n
W -= lr * (X.T @ dz)
b -= lr * dz.sum(axis=0)
return dict(W=W, b=b)
def logreg_forward(params, X):
return X @ params["W"] + params["b"]
def mlp_train(X, y, hidden=16, act="relu", steps=600, lr=1.0, seed=0, return_history=False):
"""numpy 2-katmanlı MLP (afine → nonlinearite → afine), softmax + cross-entropy.
ReLU ile EĞRİ karar sınırı (hilalleri/spirali ayırır).
return_history=True → (params, loss_history) döner (eğitim eğrisi figürü için)."""
rng = np.random.default_rng(seed)
n, d = X.shape
c = int(y.max() + 1)
W1 = rng.normal(0, 1, (d, hidden)) * np.sqrt(2.0 / d)
b1 = np.zeros(hidden)
W2 = rng.normal(0, 1, (hidden, c)) * np.sqrt(2.0 / hidden)
b2 = np.zeros(c)
Y = _onehot(y, c)
history = []
for _ in range(steps):
z1 = X @ W1 + b1
a1 = np.maximum(0, z1) if act == "relu" else np.tanh(z1)
p = _softmax(a1 @ W2 + b2)
if return_history:
history.append(float(-np.log(p[np.arange(n), y] + 1e-12).mean()))
dz2 = (p - Y) / n
dW2 = a1.T @ dz2
db2 = dz2.sum(axis=0)
da1 = dz2 @ W2.T
dz1 = da1 * ((z1 > 0) if act == "relu" else (1 - np.tanh(z1) ** 2))
dW1 = X.T @ dz1
db1 = dz1.sum(axis=0)
W1 -= lr * dW1
b1 -= lr * db1
W2 -= lr * dW2
b2 -= lr * db2
params = dict(W1=W1, b1=b1, W2=W2, b2=b2, act=act)
if return_history:
return params, np.array(history)
return params
def mlp_forward(params, X):
z1 = X @ params["W1"] + params["b1"]
a1 = np.maximum(0, z1) if params["act"] == "relu" else np.tanh(z1)
return a1 @ params["W2"] + params["b2"]
def accuracy(forward_fn, params, X, y):
return float((forward_fn(params, X).argmax(axis=1) == y).mean())
def decision_grid(X, pad=0.6, h=0.02):
"""Karar bölgesi için koordinat ızgarası (xx, yy) ve düz nokta listesi."""
x0, x1 = X[:, 0].min() - pad, X[:, 0].max() + pad
y0, y1 = X[:, 1].min() - pad, X[:, 1].max() + pad
xx, yy = np.meshgrid(np.arange(x0, x1, h), np.arange(y0, y1, h))
grid = np.column_stack([xx.ravel(), yy.ravel()])
return xx, yy, grid
# ---------------------------------------------------------------------------
# Enerji manzarası (EBM — çoklu minimum = çoklu geçerli cevap)
# ---------------------------------------------------------------------------
def energy_landscape(xx, yy):
"""F(x,y): birkaç Gauss kuyusu → çoklu yerel minimum. Düşük enerji = uyumlu cevap."""
wells = [(-1.25, -0.65, 1.0, 0.55), (1.15, 0.85, 1.05, 0.6), (0.15, -1.15, 0.8, 0.45)]
F = np.ones_like(xx) * 1.0
for cx, cy, depth, width in wells:
F = F - depth * np.exp(-((xx - cx) ** 2 + (yy - cy) ** 2) / (2 * width))
return F
# ---------------------------------------------------------------------------
# Hafta 2 — gradient descent, SGD, backprop, eğitim
# ---------------------------------------------------------------------------
def loss_surface_2d(xx, yy):
"""2D parametre uzayında bir kayıp yüzeyi (gradient descent 'dağ' görseli için):
eğik, farklı-ölçekli bir vadi (konveks taban) + hafif dalgalanma."""
u = 0.85 * xx + 0.53 * yy # eksenleri döndür (eğik vadi)
v = -0.53 * xx + 0.85 * yy
return 1.0 * u ** 2 + 3.5 * v ** 2 + 0.6 * np.sin(1.5 * xx) * np.cos(1.5 * yy)
def _loss_grad_2d(p):
"""loss_surface_2d gradyanı (merkezi sonlu fark)."""
eps = 1e-4
gx = (loss_surface_2d(p[0] + eps, p[1]) - loss_surface_2d(p[0] - eps, p[1])) / (2 * eps)
gy = (loss_surface_2d(p[0], p[1] + eps) - loss_surface_2d(p[0], p[1] - eps)) / (2 * eps)
return np.array([gx, gy])
def gd_path(theta0, lr=0.08, steps=40):
"""loss_surface_2d üzerinde gradient descent yörüngesi (parametre adımları)."""
p = np.array(theta0, float)
path = [p.copy()]
for _ in range(steps):
p = p - lr * _loss_grad_2d(p)
path.append(p.copy())
return np.array(path)
def sgd_loss_curves(steps=80, seed=0):
"""Üç rejim için kayıp eğrisi (simülasyon): full-batch (gürültüsüz, düz),
mini-batch (orta gürültü), saf SGD (yüksek gürültü). Aynı yumuşak üstel düşüş."""
rng = np.random.default_rng(seed)
t = np.arange(steps)
base = 0.2 + 2.6 * np.exp(-t / 14.0)
full = base.copy()
mini = base + rng.normal(0, 0.10, steps) * np.exp(-t / 45.0)
sgd = base + rng.normal(0, 0.45, steps) * np.exp(-t / 70.0)
return t, np.clip(full, 0, None), np.clip(mini, 0, None), np.clip(sgd, 0, None)
def tanh_deriv(x):
"""tanh'ın türevi: 1 − tanh²(x). Backprop 'twiddling' figürü için."""
return 1.0 - np.tanh(x) ** 2
def ce_loss_curve(p):
"""Doğru sınıf olasılığı p için cross-entropy kaybı: −log p."""
p = np.clip(np.asarray(p, float), 1e-6, 1.0)
return -np.log(p)
def mse_loss_curve(p):
"""Doğru sınıf olasılığı p için (one-hot hedefe) MSE: (1 − p)²."""
return (1.0 - np.asarray(p, float)) ** 2
# ---------------------------------------------------------------------------
# Hafta 3 — convolution / ConvNet / doğal sinyaller
# ---------------------------------------------------------------------------
def conv_output_size(n, k, s=1):
"""Çıktı boyutu: o = ⌊(n − k)/s⌋ + 1."""
return (n - k) // s + 1
def conv1d(x, w):
"""1B cross-correlation (ML 'convolution'): out[i] = Σ_k x[i+k]·w[k].
Örnek: conv1d([1,2,3,4,5],[1,0,-1]) → [-2,-2,-2] (kenar/fark dedektörü)."""
x = np.asarray(x, float)
w = np.asarray(w, float)
n = len(x) - len(w) + 1
return np.array([np.dot(x[i:i + len(w)], w) for i in range(n)])
def conv2d(img, kernel, stride=1):
"""2B valid cross-correlation (ag öznitelik haritası üretir)."""
img = np.asarray(img, float)
k = np.asarray(kernel, float)
kh, kw = k.shape
H, W = img.shape
oh, ow = conv_output_size(H, kh, stride), conv_output_size(W, kw, stride)
out = np.zeros((oh, ow))
for i in range(oh):
for j in range(ow):
patch = img[i * stride:i * stride + kh, j * stride:j * stride + kw]
out[i, j] = np.sum(patch * k)
return out
def make_synthetic_image(n=28, seed=0):
"""Basit gri-tonlu sentetik görüntü: kare + daire (kenar tespiti net görünsün)."""
img = np.zeros((n, n))
img[5:14, 6:15] = 1.0 # dolu kare
yy, xx = np.ogrid[:n, :n]
cy, cx, r = 19, 19, 6
img[(yy - cy) ** 2 + (xx - cx) ** 2 <= r ** 2] = 0.85 # daire
img[20:22, 4:24] = 0.6 # yatay çizgi (yatay kenar için)
return img
def edge_kernels():
"""Klasik 3×3 öznitelik dedektörü kernel'leri."""
return dict(
sobel_x=np.array([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]], float), # dikey kenar
sobel_y=np.array([[-1, -2, -1], [0, 0, 0], [1, 2, 1]], float), # yatay kenar
blur=np.ones((3, 3)) / 9.0, # bulanıklaştırma
laplace=np.array([[0, 1, 0], [1, -4, 1], [0, 1, 0]], float), # tüm kenarlar
)
def max_pool2d(img, k=2):
"""k×k max pooling (complex cell / invariance)."""
img = np.asarray(img, float)
H, W = img.shape
oh, ow = H // k, W // k
return np.array([[img[i * k:(i + 1) * k, j * k:(j + 1) * k].max() for j in range(ow)]
for i in range(oh)])
def avg_pool2d(img, k=2):
"""k×k average pooling (LeNet5 stili)."""
img = np.asarray(img, float)
H, W = img.shape
oh, ow = H // k, W // k
return np.array([[img[i * k:(i + 1) * k, j * k:(j + 1) * k].mean() for j in range(ow)]
for i in range(oh)])
# ===========================================================================
# _viz.py — NYU Violet + gold matplotlib stil sabitleri ve yardımcıları
# ===========================================================================
COL_VIOLET = "#57068c" # NYU Violet — birincil çizgi/çerçeve/vurgu
COL_VIOLET_D = "#3d0463" # koyu violet — güçlü vurgu / gradyan
COL_VIOLET_M = "#7b2cbf" # orta violet — ikincil
COL_VIOLET_SOFT = "#b56ad6" # soluk violet
COL_GOLD = "#d4a017" # gold accent
COL_GOLD_D = "#a87d0a" # koyu gold
COL_TEXT = "#2a2535" # gövde metni (hafif violet tint)
COL_INK = "#1e1a2e" # en koyu — başlık
COL_BG = "#f4eefa" # açık violet — dolgu/arka plan
COL_GRID = "#cdbbe0" # soluk violet — ızgara/pasif kenar
COL_WHITE = "#ffffff"
# 5-sınıf kategorik palet (spiral 5 kol / moons ilk 2) — violet↔gold ekseni, tema-uyumlu
CLASS_COLORS = ["#57068c", "#7b2cbf", "#b56ad6", "#d4a017", "#a87d0a"]
# Çizgi-grafik tutarlı renkler
LINE_PRIMARY = COL_VIOLET
LINE_ACCENT = COL_GOLD
LINE_SECONDARY = COL_VIOLET_M
def apply_style(ax):
"""Bir eksene tutarlı NYU Violet+gold görünümü uygular."""
ax.set_facecolor(COL_WHITE)
ax.grid(True, alpha=0.25, color=COL_GRID, linewidth=0.8)
for spine in ax.spines.values():
spine.set_color(COL_GRID)
ax.tick_params(colors=COL_TEXT)
ax.title.set_color(COL_TEXT)
ax.xaxis.label.set_color(COL_TEXT)
ax.yaxis.label.set_color(COL_TEXT)
return ax
def draw_pipeline(ax, stages, title=None, y0=0.0):
"""Soldan-sağa kutu+ok boru hattı şeması (örüntü tanıma vs uçtan-uca).
stages : [(label:str, is_learned:bool), ...]
is_learned=True -> öğrenilen modül (violet dolgulu)
is_learned=False -> elle-tasarlanan/sabit (gold kenarlı, açık dolgu)
"""
n = len(stages)
box_w, box_h, gap = 1.7, 1.0, 0.9
step = box_w + gap
ax.set_xlim(-0.3, n * step)
ax.set_ylim(y0 - 1.1, y0 + 1.1)
ax.axis("off")
if title:
ax.set_title(title, color=COL_TEXT, fontsize=12, pad=10)
for i, (lbl, learned) in enumerate(stages):
x = i * step
fc = "#ece0f7" if learned else COL_BG
ec = COL_VIOLET if learned else COL_GOLD_D
lw = 2.4 if learned else 2.0
box = FancyBboxPatch(
(x, y0 - box_h / 2), box_w, box_h,
boxstyle="round,pad=0.02,rounding_size=0.12",
fc=fc, ec=ec, lw=lw, zorder=2,
)
ax.add_patch(box)
ax.text(x + box_w / 2, y0, lbl, ha="center", va="center",
fontsize=9.5, color=COL_TEXT, zorder=3, wrap=True)
if i > 0:
ax.add_patch(FancyArrowPatch(
(x - gap, y0), (x, y0),
arrowstyle="-|>", mutation_scale=16,
color=COL_VIOLET_M, lw=1.9, zorder=1,
))
return ax
def style_legend(ax, **kw):
"""Tema-uyumlu legend."""
leg = ax.legend(frameon=True, framealpha=0.95, edgecolor=COL_GRID, **kw)
if leg is not None:
leg.get_frame().set_facecolor(COL_WHITE)
for t in leg.get_texts():
t.set_color(COL_TEXT)
return leg
```
## Bu Derste Ne Var? {#sec-genel-bakis-d3}
Hafta 2'nin sonunda bir sorun bırakmıştık: tam-bağlı (fully connected) bir ağ bir görüntüyü işlemek için onu uzun bir vektöre **düzleştirir** — ve bu, hem parametre sayısını patlatır hem de komşu piksellerin **uzamsal yapısını** yok eder. Bu hafta çözümü görüyoruz: **convolution** ve **evrişimli ağlar (ConvNets)**.
Yine iki hocalı. **Yann LeCun** (Lecture) convolution'ın *neden* doğru araç olduğunu anlatır: doğal dünya **kompozisyoneldir** (kenarlar köşeleri, köşeler nesneleri oluşturur) ve bu fikrin kökü **biyolojidedir** — görsel korteks (Hubel & Wiesel). Sonra **Alfredo Canziani** (Practicum) bunu somutlaştırır: doğal sinyallerin **üç özelliğini** (stationarity, locality, compositionality) tanımlar ve her birinin hangi mimari seçime (parameter sharing, sparsity) yol açtığını gösterir.
Bu haftanın üç ana fikri:
1. **Convolution = kayan pencere + paylaşılan ağırlıklar (kernel).** Aynı küçük filtreyi tüm görüntüde gezdirirsin; bu, parametreyi azaltır ve öteleme-değişmezlik kazandırır.
2. **ConvNet = convolution + nonlinearite + pooling**, hiyerarşik olarak istiflenir; çünkü dünya kompozisyoneldir.
3. **Mimari, verinin yapısından doğar:** locality → sparsity (seyrek bağlantı), stationarity → parameter sharing (ağırlık paylaşımı).
```{mermaid}
%%| echo: false
flowchart TB
subgraph Ozellik["Doğal sinyalin üç özelliği (Canziani)"]
direction LR
Stat["Stationarity<br/>(durağanlık):<br/>aynı desen her yerde"]
Loc["Locality<br/>(yerellik):<br/>bilgi yerel komşulukta"]
Comp["Compositionality<br/>(kompozisyonellik):<br/>parçalar bütünü kurar"]
end
subgraph Karar["Üç mimari karar (ConvNet)"]
direction LR
Share["Parameter Sharing:<br/>aynı kernel her konumda"]
Sparse["Sparsity:<br/>yalnızca yerel pencere"]
Hier["Hiyerarşi / Derinlik:<br/>katmanları istifle"]
end
Stat -- "türetir" --> Share
Loc -- "türetir" --> Sparse
Comp -- "türetir" --> Hier
Karar --> Ritim["ConvNet ritmi:<br/>convolution → nonlinearite → pooling"]
Ritim --> Biyoloji["Biyolojik kök (V1 görsel korteks):<br/>simple cell = convolution<br/>complex cell = pooling"]
```
::: {.callout-tip title="Builder Notu — Convolution: Hafta 2'nin Açık Sorusunu Kapatmak"}
**Geriye (önkoşul kurslar):**
- **Convolution = kayan iç çarpım** → 18.06 dot product / lineer operatör + Hafta 1 "filtre·yama" sezgisi.
- **Hiyerarşik öznitelik** → Hafta 1 (elle vs öğrenilen hiyerarşi) + Calculus fonksiyon bileşkesi.
- **Parameter sharing / öteleme-değişmezlik** → §4.J "equivariance vs invariance"; 18.06 öteleme-değişmez operatör.
**İleriye (production / research):**
- ConvNet omurgası → ResNet, U-Net, YOLO, ve görü foundation modelleri.
- "Veri yapısı → mimari" ilkesi → geometric deep learning (graf ağları, Hafta 13) ve transformer'ların (Hafta 12) tasarım felsefesi.
**Tek cümleyle:** Convolution, doğal sinyallerin yerel, tekrar eden, kompozisyonel yapısını sömüren bir kayan-filtre işlemidir; ConvNet bu filtreleri nonlinearite ve pooling ile hiyerarşik istifleyerek görüntüden öznitelikleri uçtan uca öğrenir.
:::
## (LeCun) Neden Tam-Bağlı Ağ Yetmez? {#sec-neden-fc-yetmez}
LeCun convolution'a, tam-bağlı ağın görüntüde neden başarısız olduğunu göstererek giriyor. Bir görüntüyü `nn.Linear`'a vermek için onu tek bir vektöre düzleştirmen gerekir. İki büyük sorun çıkar:
1. **Parametre patlaması.** 1000×1000×3 = 3 milyon girdiyi 1000 nöronlu bir katmana bağlamak 3 milyar ağırlık demektir — tek bir katmanda. Eğitilemez, belleğe sığmaz.
2. **Uzamsal yapı kaybı.** Düzleştirme, komşu piksellerin komşuluğunu yok eder; ağ "şu piksel şunun yanında" bilgisini baştan kaybeder. Oysa bir görüntüde anlam tam da bu yerel komşuluktadır.
Çözüm, görüntünün yapısını kullanan bir operatördür. LeCun'un cevabı: aynı küçük **yerel öznitelik dedektörünü** (filtre) tüm görüntüde gezdir, çıktılarını topla — ve **öteleme-değişmez** bir tespit elde et.
> "[you have] local feature detectors and then [you] sum up their activity, and what you get is an invariant detection." — LeCun, 25:41
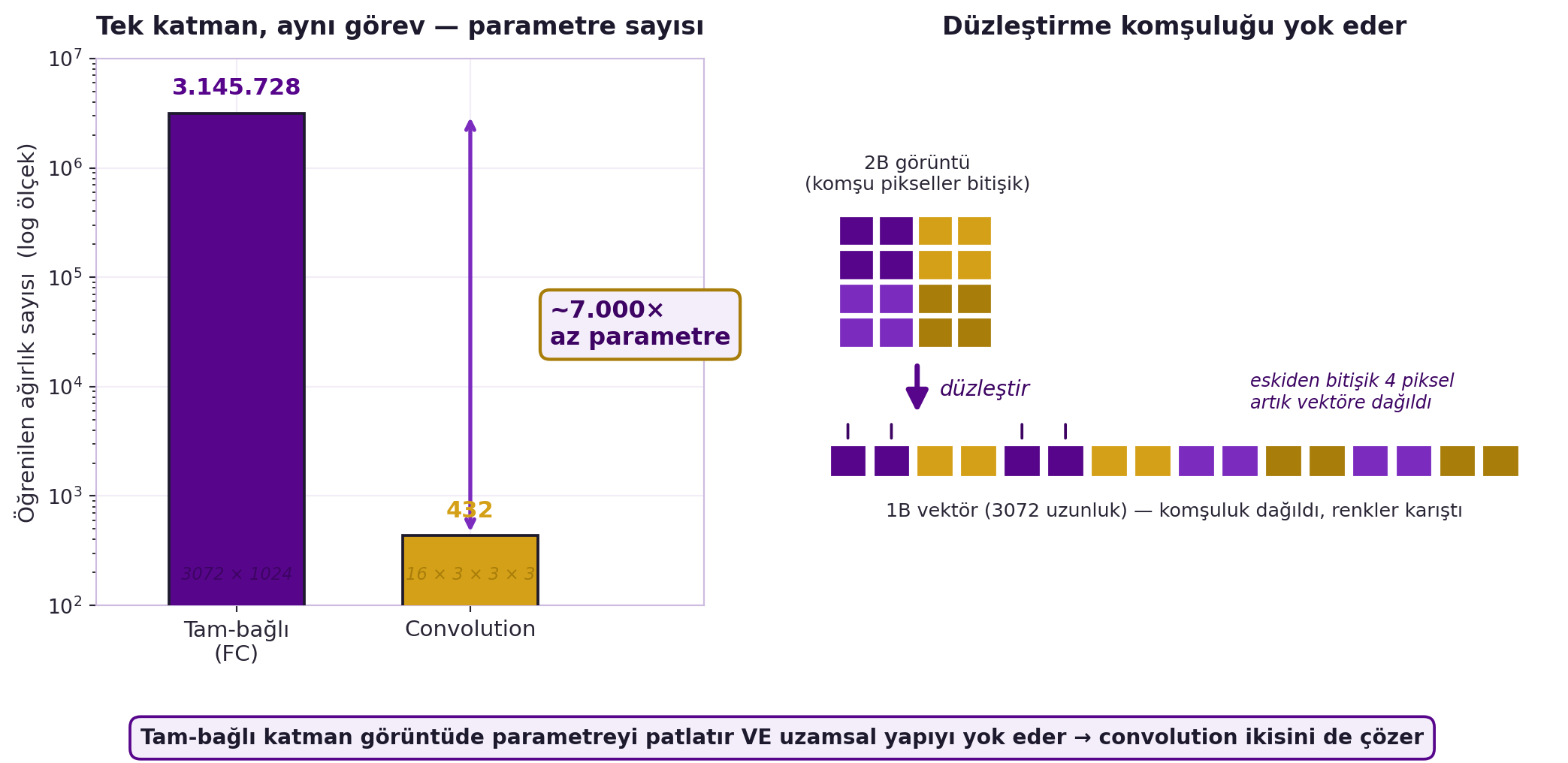
@fig-fc-vs-conv her iki sorunu da somutlaştırır: solda tam-bağlı katman convolution'a göre ~7000× fazla parametre ister, sağda düzleştirme komşu pikselleri 1B vektöre dağıtarak uzamsal yapıyı bozar — convolution ikisini birden çözer.
```{python}
#| label: fig-fc-vs-conv
#| fig-cap: "Tam-bağlı bir katman görüntü girdisinde parametreyi patlatır (3.145.728'e karşı 432, ~7000× fazla) ve düzleştirme komşu pikselleri 1B vektöre dağıtarak uzamsal yapıyı yok eder; convolution her iki sorunu da çözer."
np.random.seed(0)
# Parametre aritmetiği (Bölüm 1/9 — parametre patlaması)
# SOL panel: aynı katman, iki tasarım.
# Tam-bağlı (FC): 32×32×3 = 3072 girdi pikseli → 1024 gizli nöron
# => 3072 × 1024 = 3.145.728 ağırlık
# Convolution : 16 filtre × (3 girdi kanalı × 3×3 kernel) = 16×3×3×3 = 432 ağırlık
in_h, in_w, in_c = 32, 32, 3
n_in = in_h * in_w * in_c # 3072 düzleştirilmiş girdi
n_hidden = 1024 # gizli nöron
fc_params = n_in * n_hidden # 3.145.728
n_filters, k = 16, 3
conv_params = n_filters * in_c * k * k # 16×3×3×3 = 432
ratio = fc_params / conv_params # ≈ 7281 → "~7000x az"
fig, (axL, axR) = plt.subplots(
1, 2, figsize=(11, 5.0),
gridspec_kw={"width_ratios": [1.0, 1.25]},
)
fig.patch.set_facecolor(COL_WHITE)
# ----------------------------------------------------------------------
# SOL PANEL — parametre sayısı bar grafiği (LOG y-ekseni)
# ----------------------------------------------------------------------
apply_style(axL)
labels = ["Tam-bağlı\n(FC)", "Convolution"]
vals = [fc_params, conv_params]
bar_colors = [COL_VIOLET, COL_GOLD]
xpos = [0, 1]
bars = axL.bar(xpos, vals, width=0.58, color=bar_colors,
edgecolor=COL_INK, linewidth=1.4, zorder=3)
axL.set_yscale("log")
axL.set_ylim(1e2, 1e7)
axL.set_xticks(xpos)
axL.set_xticklabels(labels, fontsize=11)
axL.set_ylabel("Öğrenilen ağırlık sayısı (log ölçek)", fontsize=11)
axL.set_title("Tek katman, aynı görev — parametre sayısı",
fontsize=12.5, color=COL_INK, fontweight="bold", pad=12)
# bar üzerine kesin değerler
val_txt = [f"{fc_params:,}".replace(",", "."), f"{conv_params:,}".replace(",", ".")]
for x, v, t, c in zip(xpos, vals, val_txt, bar_colors):
axL.text(x, v * 1.35, t, ha="center", va="bottom",
fontsize=11.5, fontweight="bold", color=c, zorder=4)
# alt-açıklama: nereden geliyor
axL.text(0, 1.6e2, "3072 × 1024", ha="center", va="bottom",
fontsize=8.5, color=COL_VIOLET_D, style="italic", zorder=4)
axL.text(1, 1.6e2, "16 × 3 × 3 × 3", ha="center", va="bottom",
fontsize=8.5, color=COL_GOLD_D, style="italic", zorder=4)
# büyük fark annotation — iki barı bağlayan dikey çizgi + ok
axL.annotate(
"", xy=(1, conv_params), xytext=(1, fc_params),
arrowprops=dict(arrowstyle="<->", color=COL_VIOLET_M, lw=2.0),
zorder=2,
)
axL.text(
1.34, np.sqrt(fc_params * conv_params),
f"~{round(ratio/1000)*1000:,}×\naz parametre".replace(",", "."),
ha="left", va="center", fontsize=12, fontweight="bold",
color=COL_VIOLET_D, rotation=0,
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG, ec=COL_GOLD_D, lw=1.6),
zorder=5,
)
axL.set_xlim(-0.6, 2.0)
# ----------------------------------------------------------------------
# SAĞ PANEL — "düzleştirme uzamsal yapıyı bozar" şeması
# ----------------------------------------------------------------------
axR.set_xlim(0, 12)
axR.set_ylim(0, 10)
axR.axis("off")
axR.set_title("Düzleştirme komşuluğu yok eder",
fontsize=12.5, color=COL_INK, fontweight="bold", pad=12)
# küçük 4×4 görüntü ızgarası — komşu pikseller renkli kümeler
gn = 4
cell = 0.62
gx0, gy0 = 0.7, 4.7 # sol-alt köşe
# pikselleri renkli bölgelere ayır: 2×2 dört blok (komşuluk = ortak renk)
block_colors = np.array([
[COL_VIOLET, COL_VIOLET, COL_GOLD, COL_GOLD],
[COL_VIOLET, COL_VIOLET, COL_GOLD, COL_GOLD],
[COL_VIOLET_M, COL_VIOLET_M, COL_GOLD_D, COL_GOLD_D],
[COL_VIOLET_M, COL_VIOLET_M, COL_GOLD_D, COL_GOLD_D],
], dtype=object)
# satır indeksini görsel y ile eşleştir (üst satır = ilk satır)
pix_color = {}
for r in range(gn):
for c in range(gn):
x = gx0 + c * cell
y = gy0 + (gn - 1 - r) * cell
col = block_colors[r, c]
pix_color[(r, c)] = col
axR.add_patch(Rectangle((x, y), cell * 0.92, cell * 0.92,
facecolor=col, edgecolor=COL_WHITE,
linewidth=1.6, zorder=3))
axR.text(gx0 + gn * cell / 2, gy0 + gn * cell + 0.35,
"2B görüntü\n(komşu pikseller bitişik)", ha="center", va="bottom",
fontsize=9.5, color=COL_TEXT)
# ok aşağı doğru: "düzleştir (flatten)" — solda dikey
arr_x = gx0 + gn * cell / 2
axR.add_patch(FancyArrowPatch(
(arr_x, gy0 - 0.25), (arr_x, gy0 - 1.25),
arrowstyle="-|>", mutation_scale=22, color=COL_VIOLET, lw=2.6, zorder=4,
))
axR.text(arr_x + 0.35, gy0 - 0.75, "düzleştir",
ha="left", va="center", fontsize=10.5, style="italic",
color=COL_VIOLET_D)
# 1B uzun vektör — satır-sıralı (row-major) okuma → komşuluk dağılır
vec_y = 2.35
vcell = 11.0 / 16.0
vx0 = 0.55
order = [(r, c) for r in range(gn) for c in range(gn)] # row-major
for idx, (r, c) in enumerate(order):
x = vx0 + idx * vcell
axR.add_patch(Rectangle((x, vec_y), vcell * 0.86, vcell * 0.86,
facecolor=pix_color[(r, c)], edgecolor=COL_WHITE,
linewidth=1.2, zorder=3))
axR.text(6.0, vec_y - 0.45,
"1B vektör (3072 uzunluk) — komşuluk dağıldı, renkler karıştı",
ha="center", va="top", fontsize=9.5, color=COL_TEXT)
# vurgu: bir blok (violet) komşuları artık ayrık
# violet bloğun 1B'deki konumları: r in {0,1}, c in {0,1} -> idx = r*4 + c
viol_idx = [r * gn + c for r in range(2) for c in range(2)]
for idx in viol_idx:
x = vx0 + idx * vcell + vcell * 0.43
axR.add_patch(FancyArrowPatch(
(x, vec_y + vcell * 0.92), (x, vec_y + vcell * 0.92 + 0.40),
arrowstyle="-", color=COL_VIOLET_D, lw=1.4, zorder=5,
))
axR.text(7.2, vec_y + vcell * 0.92 + 0.55,
"eskiden bitişik 4 piksel\nartık vektöre dağıldı",
ha="left", va="bottom", fontsize=9.0, color=COL_VIOLET_D,
style="italic")
# alt mesaj kutusu
fig.text(0.5, -0.02,
"Tam-bağlı katman görüntüde parametreyi patlatır VE uzamsal yapıyı yok eder → convolution ikisini de çözer",
ha="center", va="top", fontsize=10.5, color=COL_INK, fontweight="bold",
bbox=dict(boxstyle="round,pad=0.5", fc=COL_BG, ec=COL_VIOLET, lw=1.4))
plt.tight_layout(rect=[0, 0.03, 1, 1])
```
::: {.callout-tip title="Builder Notu — Parametre Patlaması"}
**Geriye (Hafta 2):** Bu, Hafta 2 Egzersiz 5'in cevabıdır: 1000×1000 RGB için tam-bağlı ilk katman milyarlarca parametre ister; convolution bunu birkaç bine indirir (kernel paylaşımı).
**İleriye:** "Yapıyı sömür" ilkesi her modern mimaride var: convolution uzamsal yapıyı, attention diziyi/grafı, GNN graf yapısını sömürür.
:::
## (LeCun) Weight Sharing ve Convolution Operatörü {#sec-weight-sharing}
İki fikir convolution'ı kurar. Birincisi **weight sharing (ağırlık paylaşımı)**: bir ağırlık grubunu görüntünün her konumunda *aynen* kullanmaya zorlarsın.
> "you change all the copies of W at the same time, in a very simple manner — and that's called weight sharing: when two weights are forced to be [equal]." — LeCun, 12:06
İkincisi **convolution'ın tanımı**: küçük bir pencereyi (kernel) girdinin üzerinde kaydırıp her konumda bir iç çarpım hesaplamak.
> "an input window, and then swiping it over — that's a convolution." — LeCun, 26:49
1B durumda, sinyal $x$ ile kernel $w$'nin convolution'ı:
$$
(x * w)[i] = \sum_{k} x[i+k]\, w[k]
$$
Aynı $w$ her $i$ konumunda kullanılır (paylaşım). 2B/3B/4B kernel'lere genelleşir; çok-boyutlu kernel'e LeCun "kernel" der. (Teknik not: matematiksel convolution kernel'i ters okur; ML'de genelde ters okumadan kullanırız — buna aslında cross-correlation denir, ama pratikte "convolution" deriz.)
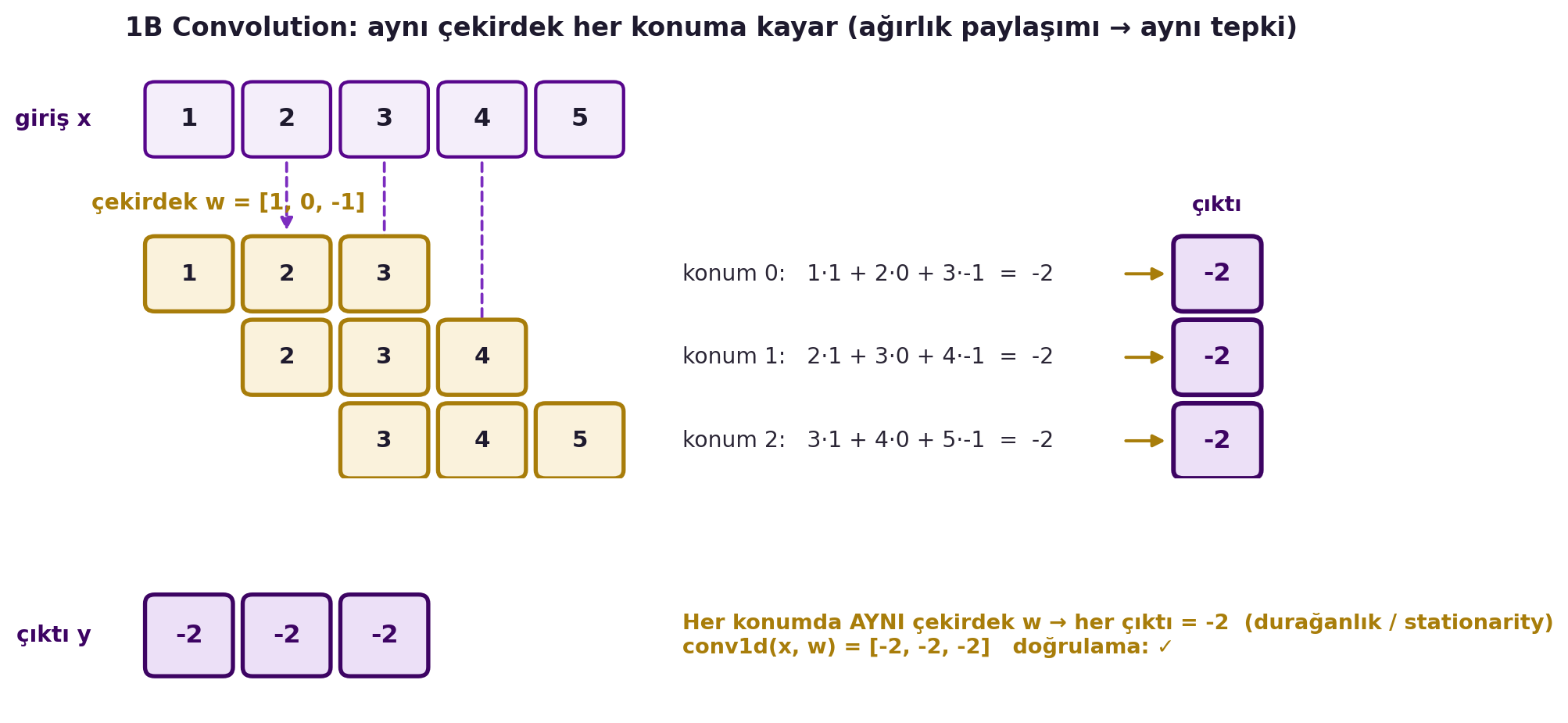
**Somut örnek.** $x = [1, 2, 3, 4, 5]$, kernel $w = [1, 0, -1]$ (basit bir kenar/fark dedektörü). Pencereyi kaydırarak her konumda iç çarpım: konum 0 → $1 \cdot 1 + 2 \cdot 0 + 3 \cdot (-1) = -2$; konum 1 → $2 \cdot 1 + 3 \cdot 0 + 4 \cdot (-1) = -2$; konum 2 → $3 \cdot 1 + 4 \cdot 0 + 5 \cdot (-1) = -2$. Çıktı $[-2, -2, -2]$: sinyal düzgün arttığı için fark dedektörü her yerde aynı yanıtı verir. İşte stationarity (aynı desen) + weight sharing (aynı kernel) birlikte: aynı yapı nerede olursa olsun aynı tepki. @fig-conv1d-sliding bu üç kayma konumunu ve her konumda aynı iç çarpımı somut olarak gösterir.
```{python}
#| label: fig-conv1d-sliding
#| fig-cap: "x=[1,2,3,4,5] sinyaline w=[1,0,-1] kenar dedektörünün üç konumda kaydırılması: her konumda aynı çekirdek aynı iç çarpımı (= -2) üretir, böylece ağırlık paylaşımı çıktı [-2,-2,-2] ile durağanlığı (stationarity) somutlaştırır."
# 1B convolution dersin SOMUT örneği: giriş sinyali ve kenar/fark dedektörü kernel
x = np.array([1, 2, 3, 4, 5], float)
w = np.array([1, 0, -1], float) # kenar/fark dedektörü
out = conv1d(x, w) # motor ile hesapla -> [-2,-2,-2]
n, k = len(x), len(w)
o = conv_output_size(n, k) # = 3 kayma konumu
fig, (axT, axB) = plt.subplots(
2, 1, figsize=(11.0, 5.6), height_ratios=[2.3, 0.8],
)
fig.subplots_adjust(hspace=0.30)
# Sabit yatay yerleşim sütunları (pencere kayma alanından SONRA başlar)
X_TXT = n + 0.55 # iç çarpım metni başlangıcı (tüm pencere konumlarından sağda)
X_OUT = n + 5.6 # çıktı hücresi sütunu
X_MAX = n + 7.4
# --- ÜST PANEL: kayan pencere + her konumda iç çarpım ---
axT.set_xlim(-0.7, X_MAX)
axT.set_ylim(-0.45, o + 1.55)
axT.axis("off")
axT.set_title(
"1B Convolution: aynı çekirdek her konuma kayar (ağırlık paylaşımı → aynı tepki)",
color=COL_INK, fontsize=12.5, pad=12, fontweight="bold",
)
cell_w = 0.86
y_sig = o + 0.85 # giriş sinyali satırı (üstte)
# Giriş sinyali x hücreleri (üst şerit)
for i, xi in enumerate(x):
box = FancyBboxPatch(
(i + (1 - cell_w) / 2, y_sig - cell_w / 2), cell_w, cell_w,
boxstyle="round,pad=0.02,rounding_size=0.10",
fc=COL_BG, ec=COL_VIOLET, lw=1.6, zorder=2,
)
axT.add_patch(box)
axT.text(i + 0.5, y_sig, f"{int(xi)}", ha="center", va="center",
fontsize=12, color=COL_INK, fontweight="bold", zorder=3)
axT.text(-0.5, y_sig, "giriş x", ha="right", va="center",
fontsize=10.5, color=COL_VIOLET_D, fontweight="bold")
# Kernel ağırlıkları etiketi
axT.text(-0.5, y_sig - 1.0, f"çekirdek w = [{int(w[0])}, {int(w[1])}, {int(w[2])}]",
ha="left", va="center", fontsize=10.5, color=COL_GOLD_D, fontweight="bold")
# Üç kayma konumu: her satırda pencere + iç çarpım hesabı + çıktı
row_gap = 1.0
for p in range(o): # p = kayma konumu 0,1,2
y_row = (o - 1 - p) * row_gap # en üstteki satır konum 0
seg = x[p:p + k]
# pencere kutucukları (gold vurgulu — aktif konum)
for j in range(k):
col = p + j
box = FancyBboxPatch(
(col + (1 - cell_w) / 2, y_row - cell_w / 2), cell_w, cell_w,
boxstyle="round,pad=0.02,rounding_size=0.10",
fc="#faf2dc", ec=COL_GOLD_D, lw=2.0, zorder=2,
)
axT.add_patch(box)
axT.text(col + 0.5, y_row, f"{int(seg[j])}", ha="center", va="center",
fontsize=11, color=COL_INK, fontweight="bold", zorder=3)
# kayan pencereyi sinyale bağlayan ok (kesik violet)
axT.add_patch(FancyArrowPatch(
(p + k / 2.0, y_sig - cell_w / 2 - 0.04),
(p + k / 2.0, y_row + cell_w / 2 + 0.04),
arrowstyle="-|>", mutation_scale=12,
color=COL_VIOLET_M, lw=1.4, ls=(0, (3, 2)), zorder=1,
))
# iç çarpım hesabı metni (sabit sütun — pencere kayma alanından sağda)
prod = " + ".join([f"{int(seg[j])}·{int(w[j])}" for j in range(k)])
val = int(out[p])
axT.text(
X_TXT, y_row,
f"konum {p}: {prod} = {val}",
ha="left", va="center", fontsize=10.6, color=COL_TEXT,
)
# çıktıya giden ok (hesaptan çıktı hücresine)
axT.add_patch(FancyArrowPatch(
(X_OUT - 0.55, y_row), (X_OUT - 0.06, y_row),
arrowstyle="-|>", mutation_scale=12, color=COL_GOLD_D, lw=1.5, zorder=1,
))
# çıktı hücresi (violet dolgulu, sağda)
box = FancyBboxPatch(
(X_OUT, y_row - cell_w / 2), cell_w, cell_w,
boxstyle="round,pad=0.02,rounding_size=0.10",
fc="#ece0f7", ec=COL_VIOLET_D, lw=2.2, zorder=2,
)
axT.add_patch(box)
axT.text(X_OUT + cell_w / 2, y_row, f"{val}", ha="center", va="center",
fontsize=12, color=COL_VIOLET_D, fontweight="bold", zorder=3)
axT.text(X_OUT + cell_w / 2, (o - 1) * row_gap + 0.7, "çıktı",
ha="center", va="bottom", fontsize=10, color=COL_VIOLET_D, fontweight="bold")
# --- ALT PANEL: çıktı sinyali tek satır (sonuç vektörü) + doğrulama ---
axB.set_xlim(-0.7, X_MAX)
axB.set_ylim(-0.7, 0.9)
axB.axis("off")
axB.text(-0.5, 0.1, "çıktı y", ha="right", va="center",
fontsize=10.5, color=COL_VIOLET_D, fontweight="bold")
for i, yi in enumerate(out):
box = FancyBboxPatch(
(i + (1 - cell_w) / 2, 0.1 - cell_w / 2), cell_w, cell_w,
boxstyle="round,pad=0.02,rounding_size=0.10",
fc="#ece0f7", ec=COL_VIOLET_D, lw=2.0, zorder=2,
)
axB.add_patch(box)
axB.text(i + 0.5, 0.1, f"{int(yi)}", ha="center", va="center",
fontsize=12, color=COL_VIOLET_D, fontweight="bold", zorder=3)
ok_match = np.allclose(out, conv1d(x, w))
axB.text(
n + 0.55, 0.1,
"Her konumda AYNI çekirdek w → her çıktı = -2 (durağanlık / stationarity)\n"
f"conv1d(x, w) = {out.astype(int).tolist()} doğrulama: {'✓' if ok_match else '✗'}",
ha="left", va="center", fontsize=10.2, color=COL_GOLD_D, fontweight="bold",
);
```
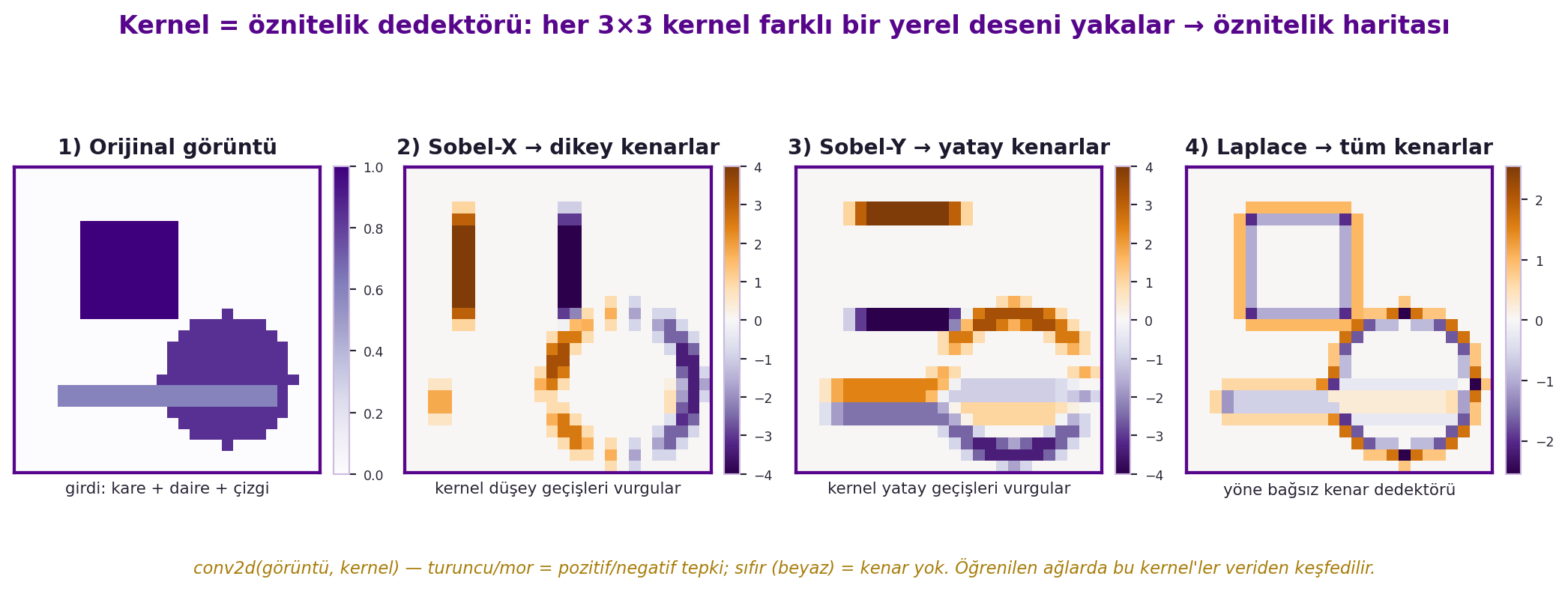
Bu yüzden convolution doğal olarak bir **öznitelik dedektörüdür**: kernel belli bir yerel deseni (kenar, köşe) arar; çıktısı yüksekse "burada o desen var" der. Yerel dedektörlerin çıktılarını topladığında, desenin konumundan görece bağımsız bir tespit elde edersin. @fig-conv2d-edge aynı fikri 2B'de gösterir: farklı kernel'ler aynı görüntüden farklı yerel desenleri (kenar yönlerini) çeker.
```{python}
#| label: fig-conv2d-edge
#| fig-cap: "Aynı sentetik görüntüye uygulanan dört farklı 3×3 kernel: Sobel-X dikey kenarları, Sobel-Y yatay kenarları, Laplace ise tüm kenarları yakalar — her kernel ayrı bir yerel deseni vurgulayan bir öznitelik haritası (feature map) üretir."
# Hafta 3 — Bölüm 2/5: kernel = öznitelik dedektörü
# Aynı görüntüye farklı 3×3 kernel'leri uygula → her biri farklı bir yerel
# deseni (kenar yönünü) yakalar. conv2d ile GERÇEK cross-correlation hesabı.
img = make_synthetic_image(28)
K = edge_kernels()
# Her kernel için öznitelik haritası (feature map) — gerçek conv2d hesabı
fmap_sx = conv2d(img, K["sobel_x"]) # dikey kenarlar
fmap_sy = conv2d(img, K["sobel_y"]) # yatay kenarlar
fmap_lp = conv2d(img, K["laplace"]) # tüm kenarlar
paneller = [
(img, "1) Orijinal görüntü", "Purples", None, "girdi: kare + daire + çizgi"),
(fmap_sx, "2) Sobel-X → dikey kenarlar", "PuOr_r", np.abs(fmap_sx).max(), "kernel düşey geçişleri vurgular"),
(fmap_sy, "3) Sobel-Y → yatay kenarlar", "PuOr_r", np.abs(fmap_sy).max(), "kernel yatay geçişleri vurgular"),
(fmap_lp, "4) Laplace → tüm kenarlar", "PuOr_r", np.abs(fmap_lp).max(), "yöne bağsız kenar dedektörü"),
]
fig, axes = plt.subplots(1, 4, figsize=(11.0, 3.6))
for ax, (data, baslik, cmap, vlim, altnot) in zip(axes, paneller):
if vlim is None: # orijinal görüntü 0..1
im = ax.imshow(data, cmap=cmap, vmin=0, vmax=1)
else: # kenar haritaları: 0 etrafında simetrik (işaret = kenar yönü)
im = ax.imshow(data, cmap=cmap, vmin=-vlim, vmax=vlim)
ax.set_title(baslik, color=COL_INK, fontsize=10.5, pad=7, fontweight="bold")
ax.set_xticks([]); ax.set_yticks([])
for spine in ax.spines.values():
spine.set_color(COL_VIOLET)
spine.set_linewidth(1.6)
ax.set_xlabel(altnot, color=COL_TEXT, fontsize=8.0, labelpad=4)
cb = fig.colorbar(im, ax=ax, fraction=0.046, pad=0.04)
cb.ax.tick_params(labelsize=6.5, colors=COL_TEXT)
cb.outline.set_edgecolor(COL_GRID)
fig.suptitle(
"Kernel = öznitelik dedektörü: her 3×3 kernel farklı bir yerel deseni yakalar → öznitelik haritası",
color=COL_VIOLET, fontsize=12.5, fontweight="bold", y=1.04,
)
# Alt mesaj şeridi
fig.text(0.5, -0.04,
"conv2d(görüntü, kernel) — turuncu/mor = pozitif/negatif tepki; sıfır (beyaz) = kenar yok. "
"Öğrenilen ağlarda bu kernel'ler veriden keşfedilir.",
ha="center", color=COL_GOLD_D, fontsize=8.5, style="italic")
fig.tight_layout(rect=[0, 0, 1, 0.99])
```
::: {.callout-tip title="Builder Notu — Kernel = Kayan İç Çarpım"}
**Geriye (18.06 + Hafta 1):** Kernel·yama iç çarpımı, 18.06 dot product'tır; her konumda aynı kernel, Hafta 1'in "filtre bir yamaya bakar" sezgisinin tüm görüntüye yayılmış hâli.
**İleriye:** Weight sharing parametreyi dramatik azaltır ve **öteleme-değişmezlik (equivariance)** kazandırır — nesne nerede olursa olsun aynı filtre onu yakalar. Donanımda convolution, optimize edilmiş bir GEMM/kernel çağrısıdır.
:::
## (LeCun) ConvNet'in Üç İşlemi: Conv, Nonlinearite, Pooling {#sec-uc-islem}
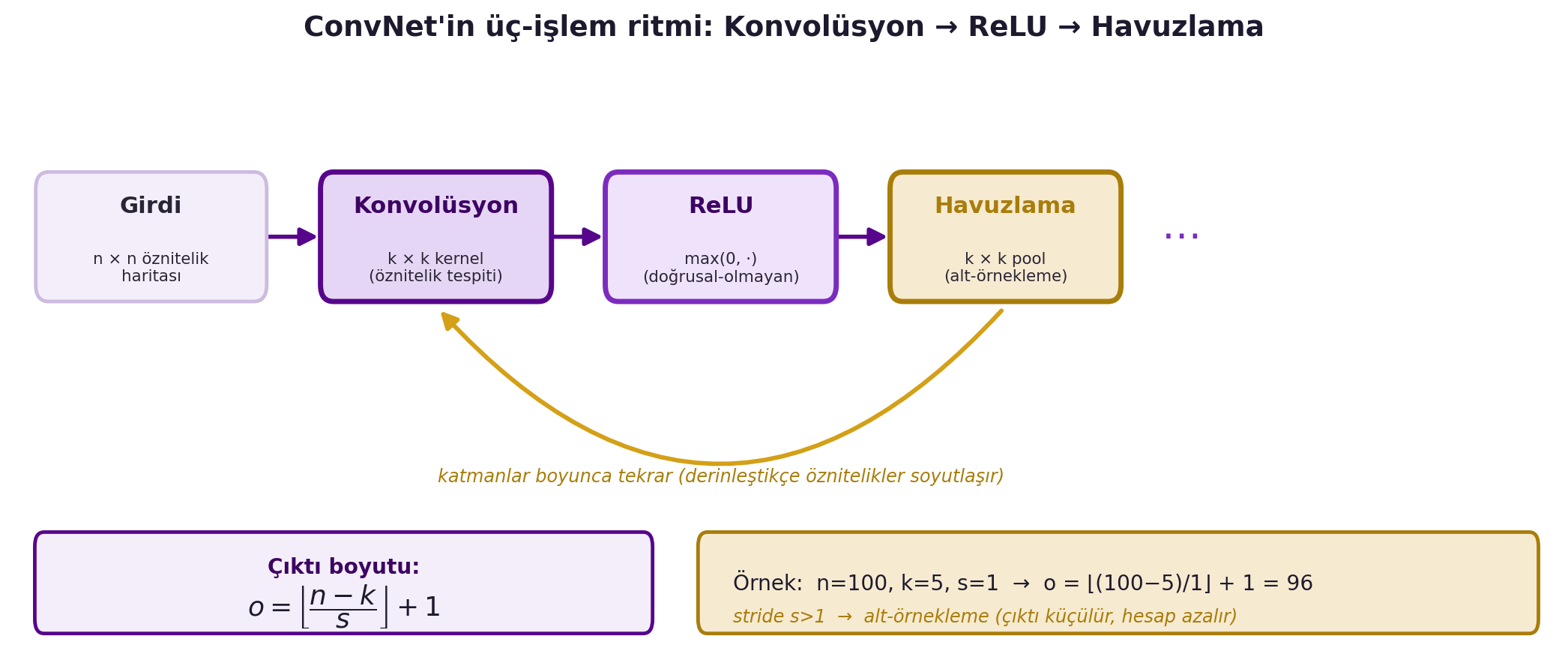
LeCun bir ConvNet'i üç işlemin dönüşümlü tekrarı olarak tanımlıyor:
> "[a convnet is an] alternation of linear operators [convolution] and pointwise non-linearity... and there's going to be a third type of operation called pooling, which is actually optional." — LeCun, 30:24
1. **Convolution** — yerel öznitelikleri çıkarır (paylaşılan kernel).
2. **Nonlinearite** (ReLU) — Hafta 1-2'deki gerekçeyle, doğrusal çöküşü önler.
3. **Pooling** (opsiyonel) — küçük bir pencerede özetler (örn. 2×2 ortalama/maksimum), çözünürlüğü düşürür ve küçük konum değişimlerine dayanıklılık katar.
Önemli bir ayar **stride** (adım): kernel'i 1 yerine $s$ piksel kaydırırsan çıktı küçülür. Girdi boyutu $n$, kernel $k$, stride $s$ için çıktı boyutu:
$$
o = \left\lfloor \frac{n - k}{s} \right\rfloor + 1
$$
Örneğin $n = 100$, $k = 5$, $s = 1$ → çıktı 96. Stride > 1, hem hesabı azaltır hem de pooling gibi alt-örnekleme (downsampling) yapar. @fig-convnet-three-ops bu üç-işlem ritmini ve çıktı boyutu formülünü tek şemada toplar.
```{python}
#| label: fig-convnet-three-ops
#| fig-cap: "ConvNet'in üç-işlem ritmi: her katman girdiyi Konvolüsyon (öznitelik tespiti) → ReLU (doğrusal-olmayan) → Havuzlama (alt-örnekleme) sırasıyla işler ve bu blok katmanlar boyunca tekrarlanır; çıktı boyutu o = ⌊(n−k)/s⌋ + 1 ile verilir (n=100, k=5, s=1 → 96)."
fig, (ax, axf) = plt.subplots(
2, 1, figsize=(11, 4.6), height_ratios=[2.7, 1.0]
)
fig.suptitle(
"ConvNet'in üç-işlem ritmi: Konvolüsyon → ReLU → Havuzlama",
color=COL_INK, fontsize=14, fontweight="bold", y=1.0,
)
# ---------------------------------------------------------------------------
# ÜST: üç-işlem boru hattı şeması (tekrar eden blok)
# ---------------------------------------------------------------------------
ax.set_xlim(0, 16.6)
ax.set_ylim(-2.15, 1.05)
ax.axis("off")
box_w, box_h = 2.45, 1.05
gap = 0.62
x = 0.25
# Renk şeması: conv=violet, ReLU=orta violet, pool=gold
# (op_label, alt_label, facecolor, edgecolor, text_color)
ops = [
("Girdi", "n × n öznitelik\nharitası", COL_BG, COL_GRID, COL_TEXT),
("Konvolüsyon", "k × k kernel\n(öznitelik tespiti)", "#e6d6f5", COL_VIOLET, COL_VIOLET_D),
("ReLU", "max(0, ·)\n(doğrusal-olmayan)", "#efe2fb", COL_VIOLET_M, COL_VIOLET_D),
("Havuzlama", "k × k pool\n(alt-örnekleme)", "#f6ead0", COL_GOLD_D, COL_GOLD_D),
]
centers = []
for i, (op, sub, fc, ec, tc) in enumerate(ops):
lw = 2.6 if i > 0 else 1.8
box = FancyBboxPatch(
(x, -box_h / 2), box_w, box_h,
boxstyle="round,pad=0.02,rounding_size=0.14",
fc=fc, ec=ec, lw=lw, zorder=2,
)
ax.add_patch(box)
ax.text(x + box_w / 2, 0.26, op, ha="center", va="center",
fontsize=11.5, fontweight="bold", color=tc, zorder=3)
ax.text(x + box_w / 2, -0.26, sub, ha="center", va="center",
fontsize=8.0, color=COL_TEXT, zorder=3, linespacing=1.15)
centers.append(x + box_w / 2)
if i > 0:
ax.add_patch(FancyArrowPatch(
(x - gap, 0), (x, 0),
arrowstyle="-|>", mutation_scale=18,
color=COL_VIOLET, lw=2.1, zorder=1,
))
x += box_w + gap
# "tekrar" geri-dönüş oku (Havuzlama çıktısı → bir sonraki Konvolüsyon),
# kutuların ALTINDAN dolaşır (etiket metnini kesmez)
ax.annotate(
"", xy=(centers[1], -box_h / 2 - 0.06), xytext=(centers[3], -box_h / 2 - 0.06),
arrowprops=dict(arrowstyle="-|>", color=COL_GOLD, lw=2.2,
connectionstyle="arc3,rad=-0.55", mutation_scale=17,
shrinkA=3, shrinkB=3),
zorder=4,
)
ax.text((centers[1] + centers[3]) / 2, -2.02,
"katmanlar boyunca tekrar (derinleştikçe öznitelikler soyutlaşır)",
ha="center", va="center", fontsize=9, style="italic",
color=COL_GOLD_D, zorder=3)
# devam noktaları → "…"
ax.text(x + 0.05, 0.0, "⋯", ha="center", va="center",
fontsize=20, color=COL_VIOLET_M, zorder=3)
# ---------------------------------------------------------------------------
# ALT: çıktı boyutu formülü + sayısal örnek (engine: conv_output_size)
# ---------------------------------------------------------------------------
axf.set_xlim(0, 16.6)
axf.set_ylim(0, 1)
axf.axis("off")
# Formül kutusu
fbox = FancyBboxPatch(
(0.25, 0.18), 6.6, 0.66,
boxstyle="round,pad=0.03,rounding_size=0.10",
fc=COL_BG, ec=COL_VIOLET, lw=1.8, zorder=2,
)
axf.add_patch(fbox)
axf.text(3.55, 0.62, "Çıktı boyutu:", ha="center", va="center",
fontsize=10.5, fontweight="bold", color=COL_VIOLET_D)
axf.text(3.55, 0.34, r"$o = \left\lfloor \dfrac{n - k}{s} \right\rfloor + 1$",
ha="center", va="center", fontsize=13.5, color=COL_INK)
# Sayısal örnek (engine'den hesaplanır — uydurma yok)
n_ex, k_ex, s_ex = 100, 5, 1
o_ex = conv_output_size(n_ex, k_ex, s_ex) # 96
ebox = FancyBboxPatch(
(7.4, 0.18), 9.0, 0.66,
boxstyle="round,pad=0.03,rounding_size=0.10",
fc="#f6ead0", ec=COL_GOLD_D, lw=1.8, zorder=2,
)
axf.add_patch(ebox)
axf.text(7.75, 0.51,
f"Örnek: n={n_ex}, k={k_ex}, s={s_ex} → o = ⌊(100−5)/1⌋ + 1 = {o_ex}",
ha="left", va="center", fontsize=10.5, color=COL_INK)
axf.text(7.75, 0.27,
"stride s>1 → alt-örnekleme (çıktı küçülür, hesap azalır)",
ha="left", va="center", fontsize=9.0, style="italic", color=COL_GOLD_D)
fig.tight_layout(rect=[0, 0, 1, 0.96])
```
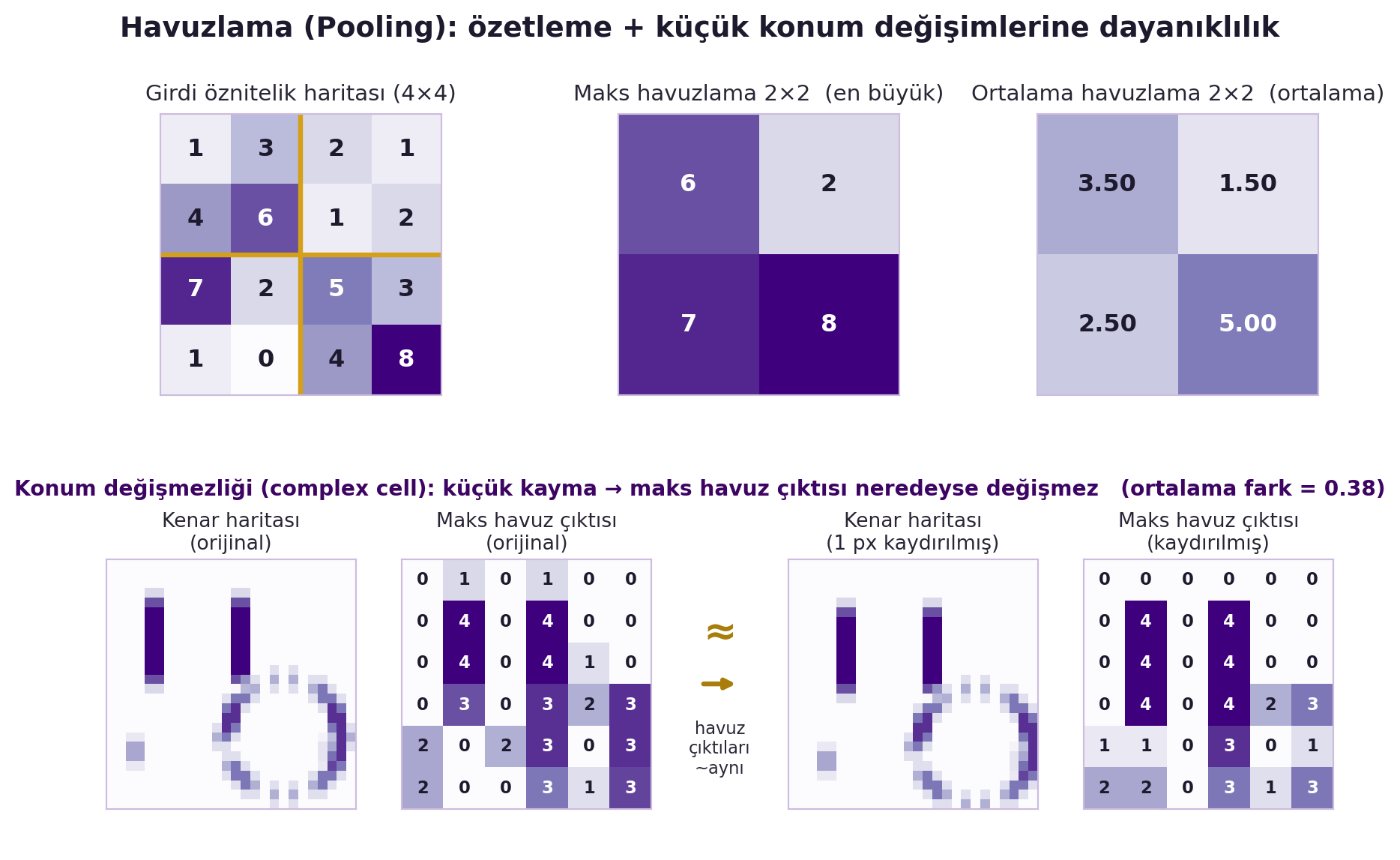
**Pooling'e biraz daha yakından.** Pooling, küçük bir pencerede (örn. 2×2) öznitelikleri özetler — en yaygın iki yol **max pooling** (penceredeki en güçlü yanıtı al) ve **average pooling** (ortalamasını al). LeNet5 ortalama pooling kullanıyordu; modern ağlar çoğunlukla max tercih eder. Pooling'in iki işlevi var: (1) çözünürlüğü düşürerek bir sonraki katmanın **daha geniş bir alanı** görmesini sağlar (etkin receptive field büyür); (2) bir öznitelliğin tam konumundaki küçük kaymalara **dayanıklılık (invariance)** katar — birazdan göreceğimiz "complex cell" fikrinin tam karşılığı. Yani conv "nerede" bilgisini korur (equivariance), pooling onu kasıtlı olarak biraz **bulanıklaştırır** (invariance); ikisinin dengesi, ConvNet'in hem konuma duyarlı hem konuma dayanıklı olmasını sağlar. @fig-pooling-invariance hem havuzlamanın özetlemesini hem de kaymaya dayanıklılığını sayısal olarak gösterir.
```{python}
#| label: fig-pooling-invariance
#| fig-cap: "Havuzlama (pooling) iki işi yapar: üstte 4×4 öznitelik haritasının 2×2 maks ve ortalama havuzlamayla özetlenmesi, altta ise küçük bir piksel kaymasına rağmen maks havuz çıktısının neredeyse değişmeden kalması (ortalama fark ≈ 0.38) gösterilerek complex cell konum değişmezliği örneklenir."
fig = plt.figure(figsize=(11, 6.6))
gs = fig.add_gridspec(2, 1, height_ratios=[1.0, 1.15], hspace=0.42)
# ---------------------------------------------------------------------------
# ÜST: 4x4 örnek ızgara -> 2x2 max pooling ve average pooling (sayılarla)
# ---------------------------------------------------------------------------
gs_top = gs[0].subgridspec(1, 3, width_ratios=[1.25, 1.0, 1.0], wspace=0.32)
ax_in = fig.add_subplot(gs_top[0])
ax_mx = fig.add_subplot(gs_top[1])
ax_av = fig.add_subplot(gs_top[2])
# 4x4 küçük öznitelik bloğu (öğretici tam sayılar)
G = np.array([
[1, 3, 2, 1],
[4, 6, 1, 2],
[7, 2, 5, 3],
[1, 0, 4, 8],
], float)
mx = max_pool2d(G, k=2) # her 2x2 blokun maksimumu
av = avg_pool2d(G, k=2) # her 2x2 blokun ortalaması
def draw_grid(ax, M, title, fmt, cmap="Purples", vmax=None):
vmax = M.max() if vmax is None else vmax
ax.imshow(M, cmap=cmap, vmin=0, vmax=vmax)
n = M.shape[0]
for i in range(n):
for j in range(n):
val = M[i, j]
# arka plan koyuysa beyaz, açıksa koyu metin
tc = COL_WHITE if val > 0.62 * vmax else COL_INK
ax.text(j, i, fmt.format(val), ha="center", va="center",
fontsize=12, color=tc, fontweight="bold")
ax.set_xticks([]); ax.set_yticks([])
ax.set_title(title, color=COL_TEXT, fontsize=11, pad=7)
for s in ax.spines.values():
s.set_color(COL_GRID)
return ax
# girdi: 2x2 blok sınırlarını altın çizgilerle vurgula
draw_grid(ax_in, G, "Girdi öznitelik haritası (4×4)", "{:.0f}", cmap="Purples")
for b in (1.5,): # tek iç bölme çizgisi (2x2 blok ayrımı)
ax_in.axhline(b, color=COL_GOLD, lw=2.4)
ax_in.axvline(b, color=COL_GOLD, lw=2.4)
draw_grid(ax_mx, mx, "Maks havuzlama 2×2 (en büyük)", "{:.0f}", cmap="Purples", vmax=G.max())
draw_grid(ax_av, av, "Ortalama havuzlama 2×2 (ortalama)", "{:.2f}", cmap="Purples", vmax=G.max())
# ---------------------------------------------------------------------------
# ALT: invariance — orijinal vs 1px kaydırılmış; max-pool çıktıları ~AYNI
# ---------------------------------------------------------------------------
gs_bot = gs[1].subgridspec(1, 5, width_ratios=[1, 1, 0.18, 1, 1], wspace=0.22)
ax_o = fig.add_subplot(gs_bot[0])
ax_op = fig.add_subplot(gs_bot[1])
ax_s = fig.add_subplot(gs_bot[3])
ax_sp = fig.add_subplot(gs_bot[4])
# sentetik görüntü -> Sobel-x kenar haritası (mutlak); sonra maks havuzlama
base = make_synthetic_image(n=28, seed=0)
ker = edge_kernels()["sobel_x"]
def edge_map(img):
return np.abs(conv2d(img, ker))
# orijinal
emap_o = edge_map(base)
pool_o = max_pool2d(emap_o, k=4) # büyük havuz: kaymaya dayanıklılığı görünür kıl
# 1 piksel sağa+aşağı kaydır (np.roll: küçük konum değişimi)
shifted = np.roll(np.roll(base, 1, axis=0), 1, axis=1)
emap_s = edge_map(shifted)
pool_s = max_pool2d(emap_s, k=4)
vmax_e = max(emap_o.max(), emap_s.max())
vmax_p = max(pool_o.max(), pool_s.max())
# kaymaya rağmen havuz çıktıları ne kadar benzer?
diff = np.abs(pool_o - pool_s).mean()
def show_img(ax, M, title, vmax, with_text=False):
ax.imshow(M, cmap="Purples", vmin=0, vmax=vmax)
ax.set_xticks([]); ax.set_yticks([])
ax.set_title(title, color=COL_TEXT, fontsize=10, pad=5)
for s in ax.spines.values():
s.set_color(COL_GRID)
if with_text:
n = M.shape[0]
for i in range(n):
for j in range(n):
v = M[i, j]
tc = COL_WHITE if v > 0.6 * vmax else COL_INK
ax.text(j, i, "{:.0f}".format(v), ha="center", va="center",
fontsize=8.5, color=tc, fontweight="bold")
return ax
show_img(ax_o, emap_o, "Kenar haritası\n(orijinal)", vmax_e)
show_img(ax_op, pool_o, "Maks havuz çıktısı\n(orijinal)", vmax_p, with_text=True)
show_img(ax_s, emap_s, "Kenar haritası\n(1 px kaydırılmış)", vmax_e)
show_img(ax_sp, pool_sp := pool_s, "Maks havuz çıktısı\n(kaydırılmış)", vmax_p, with_text=True)
# orta ince eksen: "kayma" oku + invariance mesajı
ax_mid = fig.add_subplot(gs_bot[2])
ax_mid.axis("off")
ax_mid.set_xlim(0, 1); ax_mid.set_ylim(0, 1)
ax_mid.annotate("", xy=(0.95, 0.5), xytext=(0.05, 0.5),
arrowprops=dict(arrowstyle="-|>", color=COL_GOLD_D, lw=2.4))
ax_mid.text(0.5, 0.66, "≈", ha="center", va="center",
fontsize=20, color=COL_GOLD_D, fontweight="bold")
ax_mid.text(0.5, 0.30, "havuz\nçıktıları\n~aynı", ha="center", va="center",
fontsize=8.5, color=COL_TEXT)
# alt grup başlığı (invariance vurgusu, sayısal kanıt)
fig.text(0.5, 0.485,
"Konum değişmezliği (complex cell): küçük kayma → maks havuz çıktısı neredeyse değişmez "
"(ortalama fark = {:.2f})".format(diff),
ha="center", va="center", fontsize=10.5, color=COL_VIOLET_D, fontweight="bold")
fig.suptitle("Havuzlama (Pooling): özetleme + küçük konum değişimlerine dayanıklılık",
fontsize=14, color=COL_INK, fontweight="bold", y=0.985);
```
::: {.callout-tip title="Builder Notu — Conv-Nonlin-Pool Ritmi"}
**Geriye (Hafta 2):** "Conv + nonlinearite" çifti, Hafta 2'nin "afin + nonlinearite" (döndür-ez) atomunun uzamsal versiyonudur — afin yerine ağırlık-paylaşımlı convolution.
**İleriye:** Modern ağlarda pooling yerini çoğunlukla strided convolution'a bıraktı; ama "çıkar → büz → özetle" ritmi her görü mimarisinde sürer (ResNet, ConvNeXt).
:::
## (LeCun) Hiyerarşik Temsil ve Kompozisyonel Dünya {#sec-hiyerarsi}
Neden katmanları **istifleriz**? Çünkü doğal dünya kompozisyoneldir: küçük parçalar birleşip daha büyük yapıları oluşturur.
> "we want to build hierarchical representations because the world is compositional... edges kind of assemble to form local features like corners and T-junctions [and so on]." — LeCun, 34:17
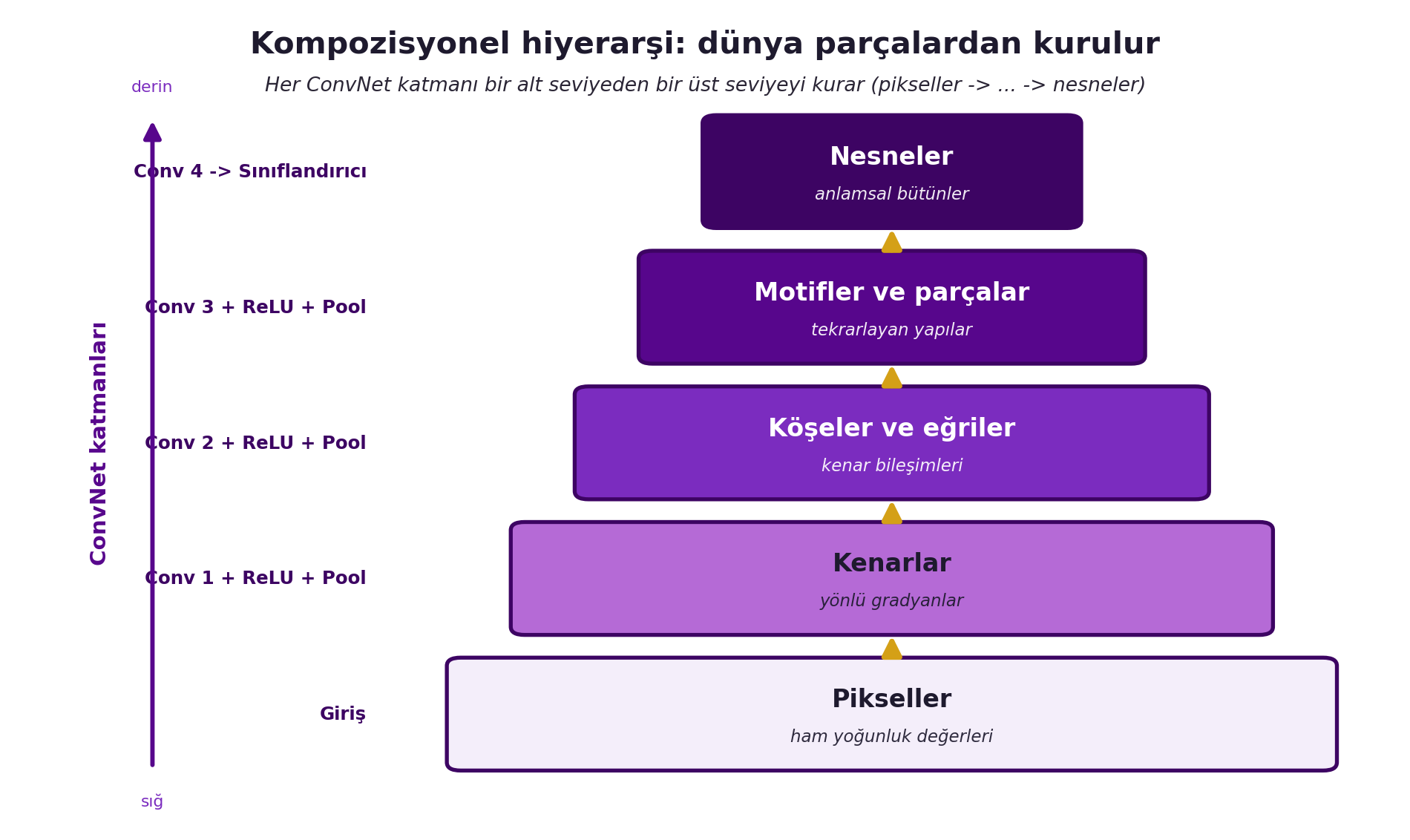
Yani: pikseller → kenarlar → köşeler/eğriler → motifler → nesne parçaları → nesneler. Her ConvNet katmanı bir alt seviyenin öznitelliklerini birleştirip bir üst seviyeyi kurar. LeCun'un vurgusu: bu hiyerarşi keyfi değil, **dünyanın kendi yapısını** yansıtır — ve belki de derin öğrenmenin neden bu kadar iyi çalıştığının sebebi budur. @fig-hierarchy bu piramidi pikselden nesneye kadar gösterir.
```{python}
#| label: fig-hierarchy
#| fig-cap: "Kompozisyonel hiyerarşi piramidi: bir ConvNet katman katman pikselleri kenarlara, kenarları köşelere/eğrilere, onları motiflere/parçalara ve en sonunda nesnelere dönüştürerek dünyanın parçalardan kurulu yapısını yeniden inşa eder."
levels = [
("Pikseller", "ham yoğunluk değerleri"),
("Kenarlar", "yönlü gradyanlar"),
("Köşeler ve eğriler", "kenar bileşimleri"),
("Motifler ve parçalar", "tekrarlayan yapılar"),
("Nesneler", "anlamsal bütünler"),
]
conv_labels = [
"Giriş",
"Conv 1 + ReLU + Pool",
"Conv 2 + ReLU + Pool",
"Conv 3 + ReLU + Pool",
"Conv 4 -> Sınıflandırıcı",
]
n = len(levels)
band_fc = [COL_BG, COL_VIOLET_SOFT, COL_VIOLET_M, COL_VIOLET, COL_VIOLET_D]
txt_col = [COL_INK, COL_INK, COL_WHITE, COL_WHITE, COL_WHITE]
fig, ax = plt.subplots(figsize=(10, 6))
ax.set_xlim(0, 10)
ax.set_ylim(0, 10)
ax.axis("off")
band_h = 1.35
gap = 0.32
y_bottom = 0.7
cx = 6.35
max_half = 3.2
min_half = 1.35
centers_y = []
for i, (title, sub) in enumerate(levels):
half = max_half - (max_half - min_half) * (i / (n - 1))
yb = y_bottom + i * (band_h + gap)
yc = yb + band_h / 2.0
centers_y.append(yc)
box = FancyBboxPatch(
(cx - half, yb), 2 * half, band_h,
boxstyle="round,pad=0.02,rounding_size=0.10",
fc=band_fc[i], ec=COL_VIOLET_D, lw=2.0, zorder=2,
)
ax.add_patch(box)
ax.text(cx, yc + 0.18, title, ha="center", va="center",
fontsize=12.5, fontweight="bold", color=txt_col[i], zorder=3)
ax.text(cx, yc - 0.28, sub, ha="center", va="center",
fontsize=8.6, style="italic", color=txt_col[i], zorder=3, alpha=0.92)
ax.text(2.55, yc, conv_labels[i], ha="right", va="center",
fontsize=9.2, color=COL_VIOLET_D, fontweight="bold", zorder=3)
for i in range(n - 1):
y_lo = centers_y[i] + band_h / 2.0 - 0.02
y_hi = centers_y[i + 1] - band_h / 2.0 + 0.02
ax.add_patch(FancyArrowPatch(
(cx, y_lo), (cx, y_hi),
arrowstyle="-|>", mutation_scale=20,
color=COL_GOLD, lw=2.6, zorder=4,
))
ax.add_patch(FancyArrowPatch(
(1.0, y_bottom), (1.0, centers_y[-1] + band_h / 2.0),
arrowstyle="-|>", mutation_scale=18,
color=COL_VIOLET, lw=2.2, zorder=3,
))
ax.text(0.62, (y_bottom + centers_y[-1] + band_h / 2.0) / 2.0, "ConvNet katmanları",
ha="center", va="center", rotation=90,
fontsize=11, color=COL_VIOLET, fontweight="bold", zorder=3)
ax.text(1.0, centers_y[-1] + band_h / 2.0 + 0.28, "derin",
ha="center", va="bottom", fontsize=8.2, color=COL_VIOLET_M)
ax.text(1.0, y_bottom - 0.30, "sığ",
ha="center", va="top", fontsize=8.2, color=COL_VIOLET_M)
ax.text(5.0, 9.62, "Kompozisyonel hiyerarşi: dünya parçalardan kurulur",
ha="center", va="center", fontsize=15.5, fontweight="bold", color=COL_INK)
ax.text(5.0, 9.12, "Her ConvNet katmanı bir alt seviyeden bir üst seviyeyi kurar "
"(pikseller -> ... -> nesneler)",
ha="center", va="center", fontsize=10, color=COL_TEXT, style="italic")
fig.tight_layout()
```
::: {.callout-tip title="Builder Notu — Kompozisyonel Dünya"}
**Geriye (Calculus + Hafta 1):** Katman istifleme = fonksiyon bileşkesi (Calculus zincir kuralı dünyası); hiyerarşik öznitelik, Hafta 1'in "düşük→orta→yüksek seviye özellik" sezgisinin somutlaşması.
**İleriye:** "Kompozisyonel hiyerarşi" fikri, transfer learning'in (önceki katmanlar genel, son katmanlar göreve özel) ve foundation modellerin temel gerekçesidir.
:::
## (LeCun) Biyoloji: Görsel Korteks, Hubel-Wiesel ve Complex Cells {#sec-biyoloji}
LeCun bu fikirlerin biyolojik kökenini anlatıyor. Görsel sinyal gözden beynin arkasındaki **birincil görsel kortekse (V1)** gider; oradan V2, V4, IT boyunca bir **hiyerarşi** (ventral pathway) izler.
> "this idea — hierarchy and local feature detection — comes from biology." — LeCun, 37:36
İki anahtar kavram, Hubel & Wiesel'in keşfi:
- **Receptive field (alıcı alan):** Bir nöronun yalnızca görsel alanın küçük bir bölgesine duyarlı olması. Bar o bölgenin dışına çıkınca nöron tepki vermez. Aynı işi yapan nöronlar tüm görsel alana **kopyalanmıştır** (bu, weight sharing'in biyolojik karşılığıdır).
- **Complex cells (karmaşık hücreler):** Bir öznitelliğin tam konumundaki küçük değişimlere **değişmez** (invariant) tepki verir — pooling'in biyolojik karşılığı.
Hubel & Wiesel aslında iki hücre tipi buldu: **simple cells** (basit hücreler) belirli bir konumda belirli bir yönelimdeki kenarlara tepki verir — convolution filtresinin biyolojik karşılığı; **complex cells** (karmaşık hücreler) ise aynı yönelimi *konumdan görece bağımsız* tanır (bir grup simple cell'in çıktısını özetler) — pooling'in karşılığı. Yani görsel korteksin "kenar bul, sonra konumu bulanıklaştır" ritmi, convolution + pooling ritminin ta kendisidir.
Bu fikirler 1980'lerde Fukushima'nın **neocognitron**'una, oradan LeCun'un ConvNet'ine ilham verdi. Neocognitron simple/complex cell katmanlarını taklit ediyordu ama backprop ile eğitilmiyordu; LeCun'un katkısı tam da bu yapıyı **uçtan uca gradient ile eğitilebilir** kılmaktı. Modelin bazı öznitelik dedektörleri elle tasarlanmış, bazıları öğrenilmişti — derin öğrenmenin "elle mühendislikten öğrenmeye" geçişinin (Hafta 1) görüdeki somut anı.
::: {.callout-tip title="Builder Notu — Görsel Korteks ↔ ConvNet"}
**Geriye (§4.J):** Receptive field + replikasyon = **equivariance** (öteleme-eşdeğişkenlik, convolution); complex cell = **invariance** (pooling). §4.J'deki "equivariance vs invariance" ayrımının biyolojik kökü budur.
**İleriye:** Görsel korteks ↔ ConvNet benzerliği, nörobilim-ML kesişiminin (NeuroAI) klasik örneğidir; ama modern ağlar artık biyolojiyi taklit etmekten çok mühendislik kısıtlarıyla şekillenir.
:::
## (LeCun) LeNet5: İlk ConvNet'ler {#sec-lenet5}
LeCun kendi tarihî ağını, **LeNet5**'i anlatıyor (el yazısı rakam tanıma). Yapı taşları bugünküyle aynı: strided convolution + pooling (2×2 ortalama) + nonlinearite, hiyerarşik istiflenmiş. Her katman bir **öznitelik haritaları (feature maps)** kümesi üretir; bir sonraki katman, önceki haritaların **kombinasyonlarını** algılamak için her biri farklı kernel'lerle convolve eder.
İlginç bir tarihsel ayrıntı: LeNet5'te öznitelik haritaları arasındaki bağlantı **tam değildi** — her harita önceki tüm haritalara bağlı değildi; belirli bir kombinasyon şeması vardı (hesabı azaltmak ve çeşitlilik için). Convolution kernel'ine bazen **filtre** de denir. En üstteki haritalar tek bir konuma indiğinde, bunlar artık çıktı sınıfları olur.
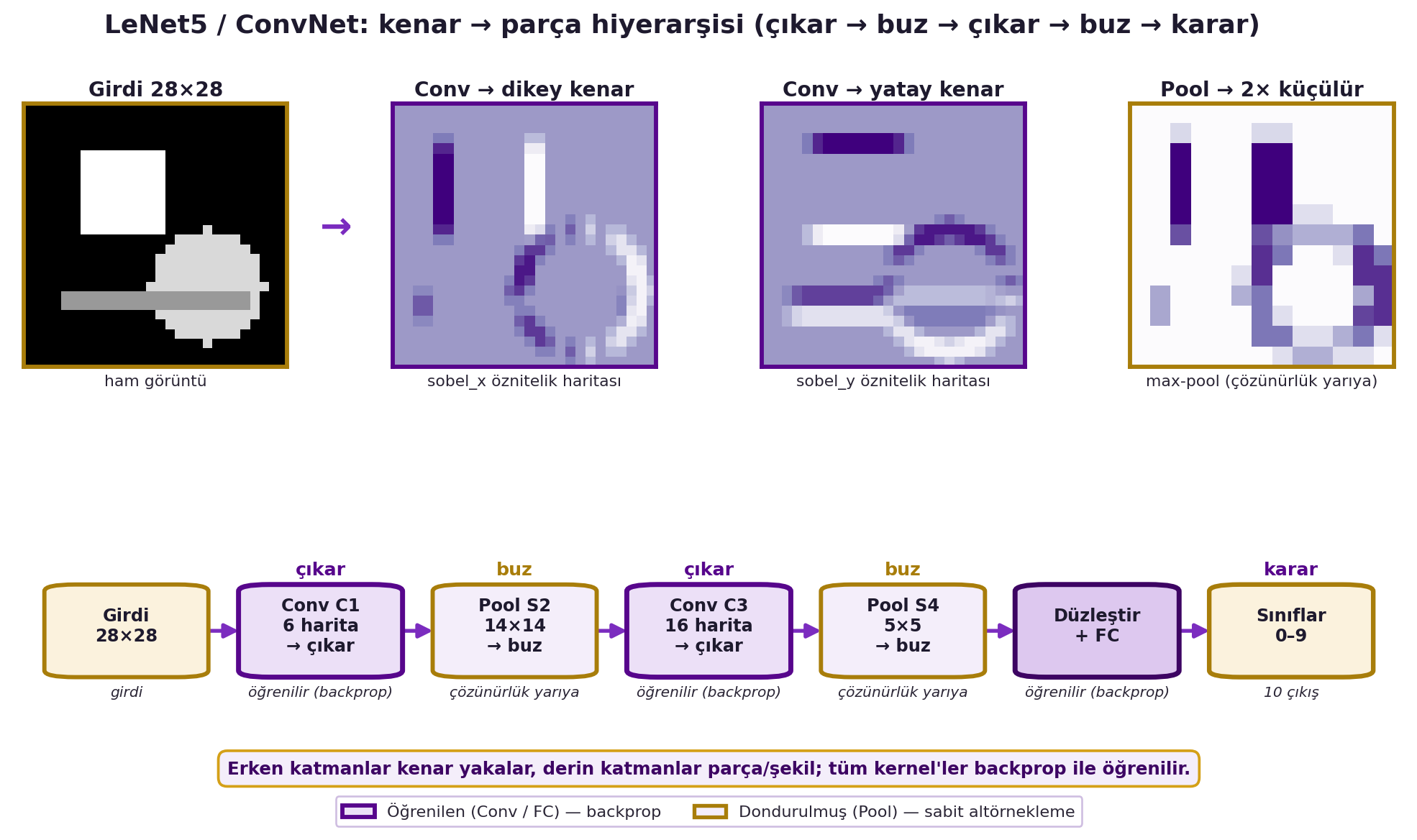
Akışı izlemek aydınlatıcı: giriş görüntüsü → convolution (birkaç öznitelik haritası) → pooling (çözünürlük yarıya) → tekrar convolution (önceki haritaların kombinasyonları, daha zengin öznitelikler) → tekrar pooling → ... → en sonunda haritalar 1×1'e indiğinde tam-bağlı bir sınıflandırıcı. Yani LeNet5, "çıkar → büz → çıkar → büz → karar ver" ritmidir. Erken katmanlar basit kenarları, derin katmanlar nesne-benzeri parçaları yakalar — Bölüm 4'teki kompozisyonel hiyerarşinin somut hâli. Dikkat: tüm bu yapı, Hafta 2'deki aynı backprop ile uçtan uca eğitilir; "elle tasarım" yalnızca *mimaridedir* (kernel boyutu, katman sayısı), ağırlıklar öğrenilir. @fig-lenet5 bu akışı gerçek öznitelik haritalarıyla gösterir.
```{python}
#| label: fig-lenet5
#| fig-cap: "LeNet5/ConvNet mimari akışı: girdi görüntüden conv katmanlarının ürettiği gerçek kenar öznitelik haritaları (üst), pooling ile çözünürlüğün yarıya inmesi ve çıkar→buz→çıkar→buz→karar ritmiyle düzleştirme-FC-sınıf akışı (alt); erken katmanlar kenar, derin katmanlar parça yakalar ve tüm kernel'ler backprop ile öğrenilir."
# --- Sentetik girdi + iki gerçek öznitelik haritası (conv2d + edge_kernels) ---
img = make_synthetic_image(28)
K = edge_kernels()
fmap_v = conv2d(img, K["sobel_x"]) # dikey kenar haritası
fmap_h = conv2d(img, K["sobel_y"]) # yatay kenar haritası
fmap_l = conv2d(img, K["laplace"]) # tüm kenarlar (derin katman sezgisi)
pool_v = max_pool2d(np.abs(fmap_v), 2) # çözünürlük yarıya (complex cell)
fig = plt.figure(figsize=(11.0, 6.2))
gs = fig.add_gridspec(
2, 4, height_ratios=[1.0, 1.15], hspace=0.42, wspace=0.30,
left=0.06, right=0.975, top=0.86, bottom=0.06,
)
# ----------------------------------------------------------------------
# ÜST SATIR — gerçek öznitelik haritaları (küçük imshow'lar)
# ----------------------------------------------------------------------
panels = [
(img, "Girdi 28×28", "gray", "ham görüntü"),
(fmap_v, "Conv → dikey kenar", "Purples", "sobel_x öznitelik haritası"),
(fmap_h, "Conv → yatay kenar", "Purples", "sobel_y öznitelik haritası"),
(pool_v, "Pool → 2× küçülür", "Purples", "max-pool (çözünürlük yarıya)"),
]
for col, (M, ttl, cmap, sub) in enumerate(panels):
ax = fig.add_subplot(gs[0, col])
ax.imshow(M, cmap=cmap, interpolation="nearest")
ax.set_title(ttl, fontsize=10.5, color=COL_INK, fontweight="bold", pad=4)
ax.set_xlabel(sub, fontsize=8.2, color=COL_TEXT)
ax.set_xticks([]); ax.set_yticks([])
edge = COL_GOLD_D if col == 0 else (COL_VIOLET if "Conv" in ttl else COL_GOLD_D)
for sp in ax.spines.values():
sp.set_color(edge); sp.set_linewidth(2.2)
# küçük ok: girdiden ilk conv haritasına 'çıkar' akışını ima et
fig.text(0.272, 0.715, "→", ha="center", va="center",
fontsize=20, color=COL_VIOLET_M, fontweight="bold")
# ----------------------------------------------------------------------
# ALT SATIR — LeNet5 / ConvNet akış şeması (tam genişlik)
# ----------------------------------------------------------------------
axf = fig.add_subplot(gs[1, :])
axf.axis("off")
axf.set_xlim(0, 100)
axf.set_ylim(0, 100)
# ritim: çıkar(conv) -> buz(pool) -> çıkar -> buz -> karar
# is_learned: conv & FC öğrenilir (violet dolgu), pool sabit/dondurulmuş (gold kenar)
stages = [
("Girdi\n28×28", "in", "girdi"),
("Conv C1\n6 harita\n→ çıkar", "conv", "öğrenilir (backprop)"),
("Pool S2\n14×14\n→ buz", "pool", "çözünürlük yarıya"),
("Conv C3\n16 harita\n→ çıkar", "conv", "öğrenilir (backprop)"),
("Pool S4\n5×5\n→ buz", "pool", "çözünürlük yarıya"),
("Düzleştir\n+ FC", "fc", "öğrenilir (backprop)"),
("Sınıflar\n0–9", "out", "10 çıkış"),
]
n = len(stages)
box_w, box_h = 11.2, 30.0
y0 = 52.0
margin = 2.5
total = 100 - 2 * margin
gap = (total - n * box_w) / (n - 1)
step = box_w + gap
style = {
"in": dict(fc="#fbf2dd", ec=COL_GOLD_D, lw=2.2),
"conv": dict(fc="#ece0f7", ec=COL_VIOLET, lw=2.6),
"pool": dict(fc=COL_BG, ec=COL_GOLD_D, lw=2.2),
"fc": dict(fc="#ddc8ef", ec=COL_VIOLET_D, lw=2.6),
"out": dict(fc="#fbf2dd", ec=COL_GOLD_D, lw=2.4),
}
centers = []
for i, (lbl, kind, sub) in enumerate(stages):
x = margin + i * step
cx = x + box_w / 2
centers.append(cx)
st = style[kind]
box = FancyBboxPatch(
(x, y0 - box_h / 2), box_w, box_h,
boxstyle="round,pad=0.3,rounding_size=2.2",
fc=st["fc"], ec=st["ec"], lw=st["lw"], zorder=3,
)
axf.add_patch(box)
axf.text(cx, y0 + 1.5, lbl, ha="center", va="center",
fontsize=9.0, color=COL_INK, zorder=4, fontweight="bold")
axf.text(cx, y0 - box_h / 2 - 5.5, sub, ha="center", va="center",
fontsize=7.6, color=COL_TEXT, zorder=4, style="italic")
if i > 0:
axf.add_patch(FancyArrowPatch(
(centers[i - 1] + box_w / 2, y0), (x, y0),
arrowstyle="-|>", mutation_scale=15,
color=COL_VIOLET_M, lw=2.0, zorder=2,
))
# ritim etiketleri (çıkar->buz->çıkar->buz->karar) üst banttan
rhythm = [("çıkar", 1), ("buz", 2), ("çıkar", 3), ("buz", 4), ("karar", 6)]
for word, idx in rhythm:
col = COL_VIOLET if word in ("çıkar", "karar") else COL_GOLD_D
axf.text(centers[idx], y0 + box_h / 2 + 5.0, word, ha="center", va="center",
fontsize=9.5, color=col, fontweight="bold", zorder=5)
# alt mesaj kutusu
axf.text(
50, 6.5,
"Erken katmanlar kenar yakalar, derin katmanlar parça/şekil; tüm kernel'ler backprop ile öğrenilir.",
ha="center", va="center", fontsize=9.2, color=COL_VIOLET_D, fontweight="bold",
bbox=dict(boxstyle="round,pad=0.5", fc=COL_BG, ec=COL_GOLD, lw=1.4),
)
# lejant (öğrenilen vs dondurulmuş)
handles = [
Patch(fc="#ece0f7", ec=COL_VIOLET, lw=2.2, label="Öğrenilen (Conv / FC) — backprop"),
Patch(fc=COL_BG, ec=COL_GOLD_D, lw=2.0, label="Dondurulmuş (Pool) — sabit altörnekleme"),
]
leg = axf.legend(handles=handles, loc="upper center", bbox_to_anchor=(0.5, 0.0),
ncol=2, fontsize=8.4, frameon=True, framealpha=0.95,
edgecolor=COL_GRID)
leg.get_frame().set_facecolor(COL_WHITE)
for t in leg.get_texts():
t.set_color(COL_TEXT)
fig.suptitle("LeNet5 / ConvNet: kenar → parça hiyerarşisi (çıkar → buz → çıkar → buz → karar)",
fontsize=13.5, color=COL_INK, fontweight="bold", y=0.965);
```
::: {.callout-tip title="Builder Notu — LeNet5 Soyağacı"}
**Geriye (Hafta 2):** LeNet5 de aynı "modül + maliyet + backprop" iskeletiyle eğitilir; tek fark, lineer modüllerin yerini ağırlık-paylaşımlı convolution modüllerinin almasıdır.
**İleriye:** LeNet5 (1998) → AlexNet (2012, Hafta 1'deki "ikinci devrim") → VGG/ResNet. Çekirdek aynı kaldı; ölçek, derinlik ve donanım değişti.
:::
## Geçiş: LeCun'dan Canziani'ye {#sec-gecis-d3}
LeCun convolution'ın *neden*ini verdi: kompozisyonel dünya, biyolojik hiyerarşi, ağırlık paylaşımı, LeNet5. Şimdi **Canziani** bunu sistematikleştiriyor: convolution'ı "icat etmek" yerine, doğal sinyallerin hangi **özelliklerinin** convolution'ı *zorunlu kıldığını* gösteriyor. Üç kelime: stationarity, locality, compositionality — ve her biri bir mimari kararına çevriliyor.
## (Canziani) Doğal Sinyallerin Üç Özelliği {#sec-uc-ozellik}
Canziani, convolutional ağların neden bu kadar iyi olduğunu doğal sinyallerin üç özelliğine bağlıyor (görüntü, ses, metin — "doğada olduğu için doğal sinyal").
1. **Stationarity (durağanlık):** Aynı tür desen, sinyal boyunca tekrar tekrar görünür. Bir kenar görüntünün her yerinde aynı kenardır.
2. **Locality (yerellik):** Bilgi yereldir — anlam, yakın komşu örneklerde toplanır, uzaktakilerle değil.
3. **Compositionality (kompozisyonellik):** Dünya açıklanabilir biçimde parçalardan kurulur; küçük yapılar birleşip büyükleri oluşturur (LeCun'un hiyerarşisi).
> "the key words for understanding convolutions [are]: stationarity, locality, compositionality." — Canziani, 0:58
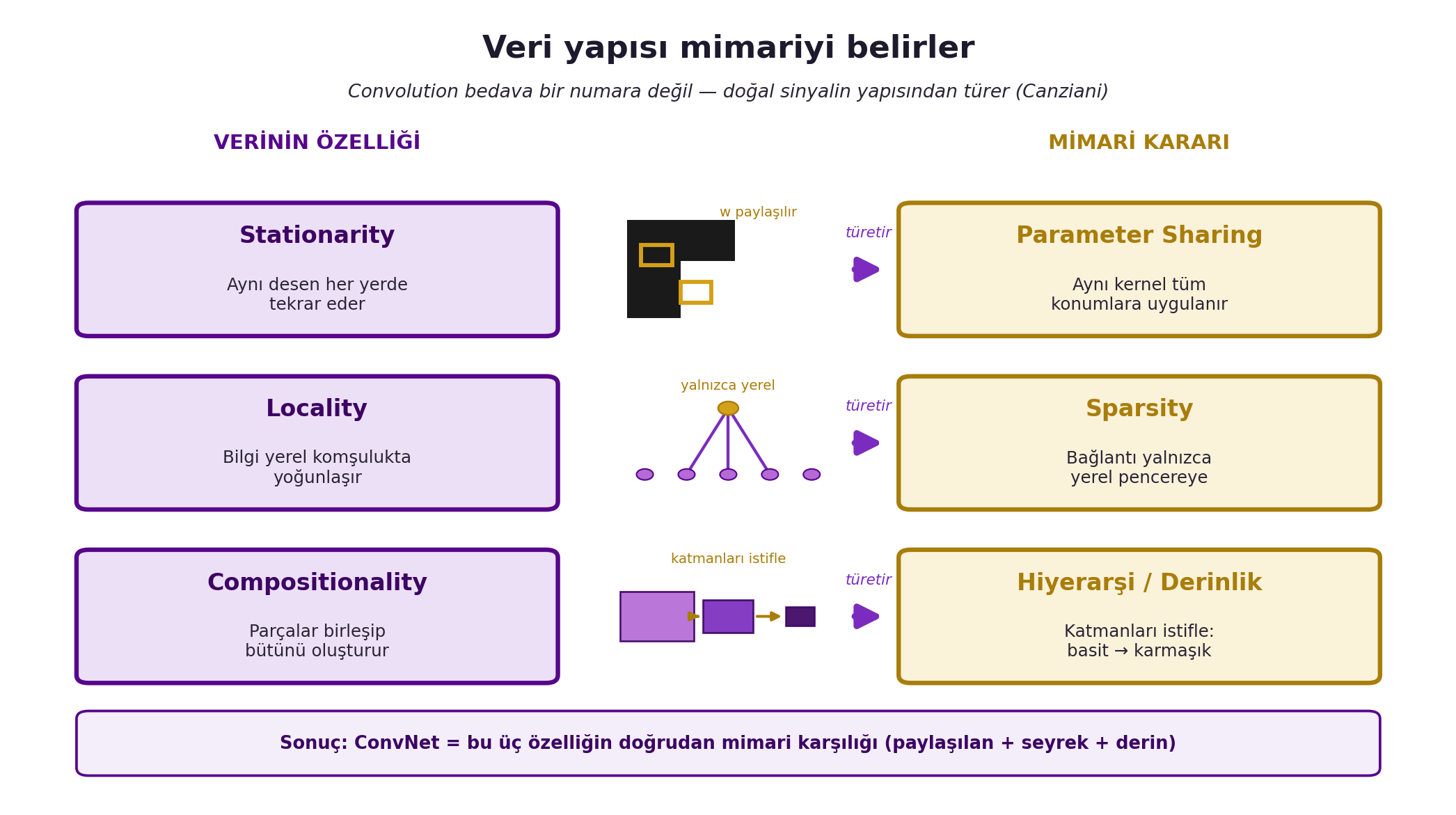
Canziani sezgiyi somutlaştırıyor: bir sinyali kendisiyle convolve edersen (flip + kaydır + iç çarpım) tekrar eden desenleri yakalarsın — durağanlığın matematiksel izi. @fig-three-properties bu üç özelliğin her birini bir mimari karara nasıl eşlediğini tek şemada toplar.
```{python}
#| label: fig-three-properties
#| fig-cap: "Canziani'nin doğal-sinyal özelliklerini ConvNet mimari kararlarına eşleyen üç satırlı şema: Stationarity→Parameter Sharing, Locality→Sparsity, Compositionality→Hiyerarşi/Derinlik — convolution'ın verinin yapısından türediğini gösterir."
fig, ax = plt.subplots(figsize=(11, 6.2))
ax.set_xlim(0, 12)
ax.set_ylim(0, 10)
ax.axis("off")
fig.patch.set_facecolor(COL_WHITE)
# --- başlık ---
ax.text(6, 9.55, "Veri yapısı mimariyi belirler", ha="center", va="center",
fontsize=17, fontweight="bold", color=COL_INK)
ax.text(6, 9.0, "Convolution bedava bir numara değil — doğal sinyalin yapısından türer (Canziani)",
ha="center", va="center", fontsize=10, color=COL_TEXT, style="italic")
# --- kolon başlıkları ---
ax.text(2.55, 8.35, "VERİNİN ÖZELLİĞİ", ha="center", va="center",
fontsize=11, fontweight="bold", color=COL_VIOLET)
ax.text(9.45, 8.35, "MİMARİ KARARI", ha="center", va="center",
fontsize=11, fontweight="bold", color=COL_GOLD_D)
# --- satır geometrisi ---
rows = [
("Stationarity", "Aynı desen her yerde\ntekrar eder",
"Parameter Sharing", "Aynı kernel tüm\nkonumlara uygulanır", "share"),
("Locality", "Bilgi yerel komşulukta\nyoğunlaşır",
"Sparsity", "Bağlantı yalnızca\nyerel pencereye", "local"),
("Compositionality", "Parçalar birleşip\nbütünü oluşturur",
"Hiyerarşi / Derinlik", "Katmanları istifle:\nbasit → karmaşık", "deep"),
]
y_centers = [6.75, 4.55, 2.35]
row_h = 1.65
left_x, left_w = 0.55, 4.0
icon_x, icon_w = 5.15, 1.7
right_x, right_w = 7.45, 4.0
def feature_box(x, yc, title, sub):
box = FancyBboxPatch((x, yc - row_h / 2), left_w, row_h,
boxstyle="round,pad=0.02,rounding_size=0.10",
fc="#ece0f7", ec=COL_VIOLET, lw=2.4, zorder=2)
ax.add_patch(box)
ax.text(x + left_w / 2, yc + 0.42, title, ha="center", va="center",
fontsize=12.5, fontweight="bold", color=COL_VIOLET_D, zorder=3)
ax.text(x + left_w / 2, yc - 0.32, sub, ha="center", va="center",
fontsize=9.2, color=COL_TEXT, zorder=3)
def decision_box(x, yc, title, sub):
box = FancyBboxPatch((x, yc - row_h / 2), right_w, row_h,
boxstyle="round,pad=0.02,rounding_size=0.10",
fc="#fbf2da", ec=COL_GOLD_D, lw=2.4, zorder=2)
ax.add_patch(box)
ax.text(x + right_w / 2, yc + 0.42, title, ha="center", va="center",
fontsize=12.5, fontweight="bold", color=COL_GOLD_D, zorder=3)
ax.text(x + right_w / 2, yc - 0.32, sub, ha="center", va="center",
fontsize=9.2, color=COL_TEXT, zorder=3)
def big_arrow(yc):
ax.add_patch(FancyArrowPatch((icon_x + icon_w + 0.18, yc), (right_x - 0.12, yc),
arrowstyle="-|>", mutation_scale=26,
color=COL_VIOLET_M, lw=3.4, zorder=4))
ax.text((icon_x + icon_w + right_x) / 2 + 0.03, yc + 0.46, "türetir",
ha="center", va="center", fontsize=8.0, color=COL_VIOLET_M,
style="italic", zorder=5)
# --- minik ikon/şema çizerleri (engine'den veri) ---
def icon_panel(yc):
"""ikon için temiz mini-eksen alanı; çerçeve döndürür (x0,x1,y0,y1)."""
pad_y = 0.62
return icon_x, icon_x + icon_w, yc - pad_y, yc + pad_y
def icon_share(yc):
# aynı 3x3 kernel iki farklı konuma uygulanıyor (stationarity → sharing)
x0, x1, y0, y1 = icon_panel(yc)
img = make_synthetic_image(12)
ax.imshow(img, cmap="gray", extent=[x0, x0 + 0.9, y0, y1],
aspect="auto", zorder=3, alpha=0.9)
k = edge_kernels()["sobel_x"]
for dx, dy in [(0.12, 0.42), (0.45, -0.05)]:
r = Rectangle((x0 + dx, y0 + 0.25 + dy), 0.26, 0.26,
fill=False, ec=COL_GOLD, lw=2.2, zorder=5)
ax.add_patch(r)
ax.text((x0 + x1) / 2 + 0.25, y1 + 0.02, "w paylaşılır",
ha="center", va="bottom", fontsize=7.4, color=COL_GOLD_D, zorder=5)
def icon_local(yc):
# tam-bağlı (her noktaya) vs seyrek (yerel pencere) bağlantı
x0, x1, y0, y1 = icon_panel(yc)
cx = (x0 + x1) / 2
out_y = y1 - 0.18
in_xs = np.linspace(x0 + 0.15, x1 - 0.15, 5)
out_node = (cx, out_y)
for ix in in_xs:
ax.add_patch(Circle((ix, y0 + 0.22), 0.07, fc=COL_VIOLET_SOFT,
ec=COL_VIOLET, lw=0.8, zorder=5))
ax.add_patch(Circle(out_node, 0.085, fc=COL_GOLD, ec=COL_GOLD_D, lw=0.9, zorder=6))
for ix in in_xs[1:4]:
ax.plot([ix, cx], [y0 + 0.22, out_y], color=COL_VIOLET_M, lw=1.6, zorder=4)
ax.text(cx, y1 + 0.02, "yalnızca yerel", ha="center", va="bottom",
fontsize=7.4, color=COL_GOLD_D, zorder=5)
def icon_deep(yc):
# istiflenmiş katmanlar: küçülen öznitelik haritaları (basit→karmaşık)
x0, x1, y0, y1 = icon_panel(yc)
sizes = [0.62, 0.42, 0.24]
xs = np.linspace(x0 + 0.25, x1 - 0.25, 3)
yc_mid = (y0 + y1) / 2
cols = [COL_VIOLET_SOFT, COL_VIOLET_M, COL_VIOLET_D]
for i, (xx, s, c) in enumerate(zip(xs, sizes, cols)):
ax.add_patch(Rectangle((xx - s / 2, yc_mid - s / 2), s, s,
fc=c, ec=COL_VIOLET_D, lw=1.0, zorder=5, alpha=0.92))
if i < 2:
ax.add_patch(FancyArrowPatch((xs[i] + sizes[i] / 2, yc_mid),
(xs[i + 1] - sizes[i + 1] / 2, yc_mid),
arrowstyle="-|>", mutation_scale=10,
color=COL_GOLD_D, lw=1.5, zorder=6))
ax.text((x0 + x1) / 2, y1 + 0.02, "katmanları istifle", ha="center",
va="bottom", fontsize=7.4, color=COL_GOLD_D, zorder=5)
icon_drawers = {"share": icon_share, "local": icon_local, "deep": icon_deep}
for (ftitle, fsub, dtitle, dsub, ikey), yc in zip(rows, y_centers):
feature_box(left_x, yc, ftitle, fsub)
icon_drawers[ikey](yc)
big_arrow(yc)
decision_box(right_x, yc, dtitle, dsub)
# --- alt mesaj şeridi ---
ax.add_patch(FancyBboxPatch((0.55, 0.35), 10.9, 0.78,
boxstyle="round,pad=0.02,rounding_size=0.10",
fc=COL_BG, ec=COL_VIOLET, lw=1.4, zorder=2))
ax.text(6, 0.74, "Sonuç: ConvNet = bu üç özelliğin doğrudan mimari karşılığı "
"(paylaşılan + seyrek + derin)",
ha="center", va="center", fontsize=9.6, color=COL_VIOLET_D,
fontweight="bold", zorder=3)
plt.tight_layout()
```
::: {.callout-tip title="Builder Notu — Üç Özellik = İnductive Bias"}
**Geriye (Hafta 1):** Compositionality, Hafta 1'deki manifold/hiyerarşi sezgisinin sinyal-yapısı diliyle ifadesidir; stationarity ve locality, görüntü verisinin neden 3-milyon-boyutlu uzayın minik bir bölgesinde yaşadığını açıklar.
**İleriye:** Bu üç özellik bir "tümevarımsal önyargı (inductive bias)" listesidir; bir veriye doğru mimariyi seçmek, o verinin hangi özellikleri taşıdığını sormakla başlar (Hafta 13 graf ağları, Hafta 8 Bishop'ın inductive bias tartışmasına köprü).
:::
## (Canziani) Özellikten Mimariye: Locality → Sparsity, Stationarity → Parameter Sharing {#sec-ozellikten-mimariye}
Canziani'nin en güçlü adımı: her özelliği bir mimari karara **çevirmek**.
- **Locality → sparsity (seyrek bağlantı).** Bilgi yerelse, bir çıktı nöronunun tüm girdiye bağlı olması gereksizdir; yalnızca küçük bir yerel pencereye bağlanır. Bu, tam-bağlı katmanın bağlantılarını dramatik azaltır.
- **Stationarity → parameter sharing (ağırlık paylaşımı).** Aynı desen her yerde görünüyorsa, onu yakalayan filtreyi her konumda yeniden öğrenmek gerekmez; aynı kernel tüm konumlarda paylaşılır.
Canziani mantığı tersinden de vurguluyor: özellik yoksa teknik de geçersizdir.
> "if my data doesn't show locality, can I use sparsity? No." — Canziani, 21:10
Yani sparsity ve parameter sharing "bedava" numaralar değil; doğrudan verinin yapısına dayanan, gerekçeli tasarım kararlarıdır. İkisi birlikte, tam-bağlı katmanı bir convolution katmanına dönüştürür.
::: {.callout-tip title="Builder Notu — Özellik → Mimari"}
**Geriye (Hafta 2):** Tam-bağlı katman ($Wx + b$) her girdiyi her çıktıya bağlardı; sparsity bunu yerel pencereye indirir, parameter sharing aynı $W$'yi her konumda kullanır. Convolution = "kısıtlanmış" bir lineer katmandır.
**İleriye:** "Doğru inductive bias = daha az parametre + daha iyi genelleme" denklemi, model verimliliğinin (data efficiency) temelidir; yanlış bias ise (örn. görüntüye saf MLP) veri ve compute israfıdır.
:::
## (Canziani) Kernel'ler: 1B, 2B, 3B ve Boyutlar {#sec-kernel-boyutlar}
Canziani kernel'i somutlaştırıyor: bir convolution katmanı bir **kernel topluluğudur**. 1B sinyalde (ses) kernel küçük bir ağırlık penceresidir; her kernel bağımsızdır, dolayısıyla paralel eğitilebilir. Çok kanallı durumda kernel boyutları şöyle okunur: kaç kernel (çıktı kanalı) × kalınlık (girdi kanalı) × pencere boyutu.
Örneğin 7 girdi kanalından 3 çıktı kanalı üreten 1B kernel'ler "2 kernel" gibi gruplanabilir; görüntüde (2B) kernel'ler 3 boyutlu olur (yükseklik × genişlik × girdi kanalı), ve katman bunlardan birden çok tutar. Her kernel bir öznitelik haritası üretir; haritalar üst üste binerek bir sonraki katmanın girdisi olur — LeCun'un LeNet5 anlattığı yapının ta kendisi.
Bu, hem **connection sparsity** (her çıktı yalnızca yerel pencereye bakar) hem **parameter sharing** (aynı kernel her konumda) sağlar; ikisi olmadan parametre sayısı yine patlardı.
**Sayılarla.** 32×32×3 bir görüntüyü düşün. Tam-bağlı bir katman 1024 çıktı üretmek isterse: $32 \cdot 32 \cdot 3 \cdot 1024 \approx$ **3,1 milyon** ağırlık. Aynı işi 16 adet 3×3 convolution kernel'i ile yaparsan: $16 \cdot (3 \cdot 3 \cdot 3) =$ **432** ağırlık (artı 16 bias). Yani convolution parametreyi binlerce kat azaltır — ve bu azalma "kalite kaybı" değil, doğru inductive bias'tır: parametreyi azaltmak aynı zamanda genelleme gücünü artırır, çünkü model verinin gerçek yapısına (yerel + durağan) uygun kısıtlanmıştır. Convolution çıktısının kanal sayısı kaç kernel kullandığınla belirlenir; her kernel girdinin tüm kanallarına bakar (kalınlık = girdi kanalı), tek bir öznitelik haritası üretir. Bu binlerce-kat azalma @fig-fc-vs-conv'de görselleştirilmiştir.
::: {.callout-tip title="Builder Notu — Kernel Topluluğu"}
**Geriye (18.06):** Kernel topluluğu = bir dizi yerel lineer operatör; çok-kanallı convolution, kanallar üzerinde toplanan iç çarpımlardır (18.06 matris-tensör işlemi).
**İleriye:** Kernel sayısı (genişlik) ve katman sayısı (derinlik) ConvNet'in kapasite eksenleridir; 1×1 convolution (kanal karıştırma), depthwise/separable convolution gibi varyantlar verimlilik için bunları yeniden düzenler.
:::
## (Canziani) Pratik: PyTorch'ta Bir ConvNet {#sec-pytorch-convnet}
Tüm bu fikirler PyTorch'ta birkaç satıra iner. Bir convolution katmanı `nn.Conv2d`, pooling `nn.MaxPool2d`; geri kalan Hafta 2'nin aynısı (forward → loss → backward → step). LeNet5-benzeri minik bir ağ:
```python
import torch
import torch.nn as nn
convnet = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=3, padding=1), nn.ReLU(), # 3 kanal -> 16 ozellik haritasi
nn.MaxPool2d(2), # cozunurluk yariya (invariance)
nn.Conv2d(16, 32, kernel_size=3, padding=1), nn.ReLU(), # 16 -> 32: kombinasyonlar
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(32 * 8 * 8, 10), # son siniflandirici
)
x = torch.randn(64, 3, 32, 32) # batch=64, 3x32x32 goruntu
y = convnet(x) # cikti: (64, 10) sinif skorlari
```
Dikkat edilecek noktalar: `nn.Conv2d(in_channels, out_channels, kernel_size)` ağırlık paylaşımını ve seyrek bağlantıyı otomatik yapar — sen yalnızca kanal sayılarını ve kernel boyutunu verirsin. `padding=1`, kenar etkilerini telafi eder (çıktı boyutunu korur). `Flatten` sadece en sonda, haritalar yeterince küçüldükten sonra çağrılır — Hafta 2'de yaptığımız erken düzleştirmenin (uzamsal yapı kaybı) tam tersi. Bu ağ da aynı `loss.backward()` + `optimizer.step()` döngüsüyle eğitilir; convolution sadece yeni bir modül tipidir.
::: {.callout-tip title="Builder Notu — nn.Conv2d Pratiği"}
**Geriye (Hafta 2):** Bu ağ Hafta 2'nin eğitim döngüsünün birebir aynısıyla eğitilir — convolution bir modül olduğundan backprop (LeCun'un Jacobian zinciri) onun için de otomatik çalışır.
**İleriye:** `nn.Conv2d` + `nn.BatchNorm2d` + residual bağlantı = modern ResNet bloğunun iskeleti; `padding`, `stride`, `dilation` parametreleri pratikte alıcı alanı (receptive field) ve çözünürlüğü ayarlamanın araçlarıdır.
:::
## Bu Dersin Özeti {#sec-ozet-d3}
1. **Tam-bağlı ağ görüntüde yetmez:** parametre patlar, uzamsal yapı kaybolur (Hafta 2 köprüsü).
2. **Convolution = kayan pencere (kernel) + ağırlık paylaşımı.** Aynı filtre tüm görüntüde gezer; iç çarpım hesaplar.
3. **ConvNet = convolution + nonlinearite + pooling** (opsiyonel), hiyerarşik istiflenir; stride alt-örnekleme yapar.
4. **Hiyerarşi, dünyanın kompozisyonelliğinden gelir:** pikseller → kenarlar → köşeler → nesneler.
5. **Biyolojik kök:** görsel korteks V1-V2-V4-IT; simple cell = conv (equivariance), complex cell = pooling (invariance); Hubel-Wiesel → neocognitron → LeNet5.
6. **Mimari, verinin yapısından doğar (Canziani):** locality → sparsity, stationarity → parameter sharing, compositionality → hiyerarşi/derinlik.
::: {.callout-important title="Tek Bir Cümle"}
Convolution, doğal sinyallerin yerel (locality), tekrar eden (stationarity) ve kompozisyonel yapısını sömüren, ağırlık-paylaşımlı bir kayan-filtre işlemidir; ConvNet bu filtreleri nonlinearite ve pooling ile hiyerarşik istifleyerek — tıpkı görsel korteks gibi — görüntüden öznitelikleri uçtan uca öğrenir.
:::
## Kontrol Soruları {#sec-kontrol-d3}
::: {.callout-note collapse="true" title="Soru 1: Bir görüntüyü tam-bağlı (nn.Linear) bir katmana vermek neden kötü bir fikirdir? Convolution iki sorunu nasıl çözer?"}
**Cevap:** İki sorun: (1) **parametre patlaması** — 1000×1000×3 girdiyi düzleştirip 1000 nörona bağlamak ~3 milyar ağırlık ister; (2) **uzamsal yapı kaybı** — düzleştirme komşu piksellerin komşuluğunu yok eder. Convolution ikisini de çözer: **parameter sharing** (aynı küçük kernel her konumda) parametreyi binlere indirir; **connection sparsity** (her çıktı yalnızca yerel pencereye bakar) uzamsal yapıyı korur. Convolution aslında ağırlıkları kısıtlanmış (paylaşımlı + seyrek) bir lineer katmandır.
:::
::: {.callout-note collapse="true" title="Soru 2: Convolution çıktı boyutu formülünü yaz. n = 32, k = 5, s = 1 için çıktı kaç olur? Stride'ı neden artırırsın?"}
**Cevap:** Çıktı boyutu:
$$
o = \left\lfloor \frac{n - k}{s} \right\rfloor + 1
$$
$n = 32$, $k = 5$, $s = 1$ → $o = \lfloor 27/1 \rfloor + 1 = 28$. Stride'ı artırmak ($s > 1$) çıktıyı küçültür: hem hesabı/belleği azaltır hem de pooling gibi alt-örnekleme (downsampling) yapar — çözünürlüğü düşürüp daha soyut, daha geniş kapsamlı öznitelikler kurar.
:::
::: {.callout-note collapse="true" title="Soru 3: Doğal sinyallerin üç özelliği nedir ve her biri hangi mimari karara çevrilir?"}
**Cevap:** (1) **Stationarity** (aynı desen her yerde tekrar eder) → **parameter sharing** (aynı kernel her konumda); (2) **Locality** (bilgi yereldir) → **sparsity** (her çıktı yalnızca yerel pencereye bağlanır); (3) **Compositionality** (parçalar büyükleri oluşturur) → **hiyerarşi/derinlik** (katmanları istifle). Canziani'nin uyarısı: özellik yoksa teknik geçersizdir — "data locality göstermiyorsa sparsity kullanamazsın" (21:10). Yani convolution, verinin yapısına dayanan gerekçeli bir tasarımdır.
:::
::: {.callout-note collapse="true" title="Soru 4: (Builder) Receptive field ve complex cell kavramları ConvNet'in hangi iki özelliğine karşılık gelir? §4.J terimleriyle bağla."}
**Cevap:** Hubel-Wiesel'in **receptive field**'ı (nöron yalnızca yerel bir bölgeye duyarlı, ve aynı dedektör tüm görsel alana kopyalanmış) = convolution'ın **equivariance**'ı (öteleme-eşdeğişkenlik): nesne nerede olursa olsun aynı kernel onu yakalar, çıktı da konumla birlikte kayar. **Complex cell** (öznitelliğin küçük konum değişimlerine değişmez tepkisi) = **pooling**'in sağladığı **invariance** (değişmezlik). §4.J: equivariance = konumla birlikte değişir; invariance = konumdan bağımsız. ConvNet ikisini de kullanır: conv equivariant, pooling invariant.
:::
## Egzersizler {#sec-egzersiz-d3}
**Egzersiz 1 (Convolution elle).** 1B bir sinyal $x = [1, 2, 3, 4, 5]$ ve kernel $w = [1, 0, -1]$ için convolution (cross-correlation) çıktısını elle hesapla, sonra `torch.nn.functional.conv1d` ile doğrula. Çıktı boyutunu formülle önceden tahmin et.
```python
import torch
import torch.nn.functional as F
x = torch.tensor([1., 2., 3., 4., 5.]).view(1, 1, -1) # (batch, kanal, uzunluk)
w = torch.tensor([1., 0., -1.]).view(1, 1, -1) # tek kernel
print(F.conv1d(x, w).flatten()) # -> [-2, -2, -2]
```
**Egzersiz 2 (Parametre karşılaştırması).** 32×32×3 girdi için: (a) 1024 çıktılı tam-bağlı katman kaç parametre? (b) 16 adet 3×3 kernel'li convolution katmanı kaç parametre? Aradaki farkı yorumla — parameter sharing + sparsity ne kazandırdı?
**Egzersiz 3 (Öteleme-değişmezlik).** Bir görüntüdeki nesneyi birkaç piksel kaydır. (a) Tam-bağlı bir ağda çıktı nasıl değişir? (b) Bir conv+pooling ağında? `nn.Conv2d` + `nn.MaxPool2d` ile küçük bir deney kur ve equivariance/invariance farkını gözlemle.
**Egzersiz 4 (Üç özellik).** Şu üç veriden hangisi locality/stationarity gösterir, hangisi göstermez, neden: (a) doğal görüntü, (b) tablo verisi (her sütun farklı bir özellik), (c) ses dalgası? Hangisi için convolution uygundur?
**Egzersiz 5 (Hafta 4 habercisi).** Convolution'ı bir matris çarpımı olarak yazabilir misin? (a) Küçük bir 1B convolution'ı, ağırlıkları kaydırarak doldurulmuş bir **Toeplitz matrisi** ile ifade et. (b) Bu, convolution'ın aslında "yapısı kısıtlanmış bir lineer katman" olduğunu gösterir — Hafta 4'te Canziani convolution'ı tam olarak lineer cebir diliyle (Toeplitz/dolaşım matrisleri) ele alacak. Neden bu bakış faydalı?
## Sonraki Ders İçin Hazırlık {#sec-sonraki-d3}
::: {.callout-warning title="Sonraki Hafta — H4: Konvolüsyonun Cebiri (Toeplitz) ve Optimizasyon"}
**Convolution'dan lineer cebire.** Bu hafta convolution'ın *ne* olduğunu ve *neden* gerektiğini gördük. Hafta 4'te Canziani convolution'ı **lineer cebir** diliyle (Toeplitz/dolaşım matrisleri olarak) açacak — Egzersiz 5'in "convolution = yapısı kısıtlanmış lineer katman" sezgisi tam burada formelleşir; LeCun ise optimizasyonu derinleştirecek (SGD'nin ötesinde Adam, momentum, normalization katmanları).
:::
**Hafta 4: Konvolüsyonun Cebiri ve Optimizasyon I-II** — Canziani (Lecture) + LeCun (Lecture)
Bu hafta convolution'ın *ne* olduğunu ve *neden* gerektiğini gördük. Hafta 4'te Canziani convolution'ı **lineer cebir** diliyle (Toeplitz/dolaşım matrisleri olarak) açacak; LeCun ise optimizasyonu derinleştirecek (SGD'nin ötesinde Adam, momentum, normalization katmanları).
**Hafta 4 öncesi yapılacak:**
- Egzersiz 2 (parametre karşılaştırması) ve Egzersiz 5 (convolution = Toeplitz matris) çöz.
- "Stationarity → parameter sharing, locality → sparsity" eşlemesini kendi sözcüklerinle yaz.
- Hafta 2'nin SGD'sini hatırla — Hafta 4'te onu Adam ve normalization ile geliştireceğiz.
## Anahtar Kavramlar (Cheat Sheet) {#sec-cheat-d3}
| Kavram | Tanım | Hoca / timestamp |
|---|---|---|
| Weight sharing | Aynı ağırlıkları her konumda kullanmaya zorlama | LeCun 12m06 |
| Convolution | Kernel'i girdide kaydırıp her konumda iç çarpım | LeCun 26m49 |
| Kernel / filtre | Convolution'ın küçük, paylaşılan ağırlık penceresi | LeCun 29m50 |
| ConvNet üç işlem | convolution + nonlinearite + pooling (opsiyonel) | LeCun 30m24 |
| Stride | Kernel'in kaydırma adımı; > 1 ise alt-örnekleme | LeCun 30m53 |
| Kompozisyonel hiyerarşi | Kenarlar → köşeler → nesneler; derinliğin sebebi | LeCun 34m17 |
| Receptive field | Nöronun duyarlı olduğu yerel bölge; equivariance | LeCun 44m15 |
| Simple / complex cell | Simple = conv (kenar), complex = pooling (invariance) | LeCun 45m29 |
| LeNet5 / feature map | İlk ConvNet; her kernel bir öznitelik haritası üretir | LeCun 49m05 |
| Stationarity | Aynı desen her yerde tekrar eder → parameter sharing | Canziani 4m29 |
| Locality | Bilgi yereldir → sparsity (seyrek bağlantı) | Canziani 6m53 |
| Compositionality | Parçalar büyükleri kurar → hiyerarşi/derinlik | Canziani 11m58 |
## ML Builder Bağlantıları {#sec-koprular-d3}
**Geriye köprüler (önkoşul kurslar):**
1. **Convolution = kayan iç çarpım** → 18.06 dot product / lineer operatör + Hafta 1 filtre·yama.
2. **Hiyerarşi = fonksiyon bileşkesi** → Calculus zincir kuralı + Hafta 1 öznitelik hiyerarşisi.
3. **equivariance / invariance** → §4.J + 18.06 öteleme-değişmez operatör.
4. **ConvNet eğitimi** → Hafta 2 (modül + maliyet + backprop); convolution da bir modüldür.
5. **Kernel topluluğu = kanal üzerinde toplanan iç çarpımlar** → 18.06 matris-tensör.
**İleriye köprüler (production / research):**
1. **LeNet5 omurgası** → AlexNet, VGG, ResNet, ConvNeXt.
2. **inductive bias (üç özellik)** → geometric deep learning, transformer tasarım felsefesi.
3. **stride / pooling** → modern strided-conv downsampling, U-Net encoder-decoder.
4. **1×1 / depthwise convolution** → verimli mimariler (MobileNet, EfficientNet).
::: {.callout-important title="Bu dersten tek bir şey alıp gideceksen"}
Convolution sihir değildir — doğal sinyallerin üç özelliğinin (stationarity, locality, compositionality) doğrudan mimariye çevrilmesidir: aynı küçük filtreyi her yerde paylaş (stationarity → parameter sharing), yalnızca yerele bak (locality → sparsity), katmanları istifle (compositionality → hiyerarşi). LeCun bunu kompozisyonel dünya ve görsel korteksle motive eder, Canziani üç özellikten mimariyi türetir — ve LeNet5'ten bugünkü görü modellerine giden yol işte bu çekirdeğin üstünde durur.
:::