---
title: "Yapılandırılmış Tahmin ve Düzenlileştirme"
subtitle: "İki parçalı final hafta — Yann LeCun son Lecture'ında yapılandırılmış tahmini (structured prediction) kursun büyük çatısı altında toplar: çıktı tek bir kategori değil kombinatoryal bir nesne (cümle, sembol dizisi) olduğunda olası çıktıları sıralayamazsın, çözüm enerjiyi faktörlerin toplamı olarak yazmaktır (faktör grafiği, Hafta 13'ün enerjili hâli), çünkü o zaman en düşük enerjili konfigürasyonu bulmak tüm kombinasyonları denemek değil bir trellis grafında en kısa yolu bulmaktır (dinamik programlama, Viterbi, kaba kuvvet 96 değerlendirme yerine 16); ardından ağın durumunu bir tensör değil bir graf yapan Graph Transformer Network'ü kurar ve bunun daha 1997'de attention'dan yirmi yıl önce transformer adını taşıyan basit bir graph neural net olduğunu söyler (Viterbi seçicileri max-pooling gibi anahtarlar, backprop dinamik graf boyunca akar); sonra kayıpları Hafta 11 çerçevesiyle birleştirir (perceptron marjsız çöker, hinge marjla iter, NLL logsumexp tüm yolları marjinalleştirir, perceptron NLL'in beta sonsuz limitidir); ve dersin doruğunda gizli değişkeni marjinalleştirmenin Jensen eşitsizliğiyle bir üst sınıra çevrildiğini, bu üst sınırın fizikteki serbest enerji F eşittir ortalama enerji eksi sıcaklık çarpı entropi olduğunu, ve VAE'nin tam olarak bu olduğunu (rekonstrüksiyon artı KL/entropi) gösterir — kursu tek bir enerji fikrinin etrafında kapatır. Ardından Alfredo Canziani son Practicum'unda pratik soruya iner: bu güçlü aşırı-parametrize modeller veriyi ezberler (overfitting, gürültüden doğar — gürültü olmasa aşırı model bile mükemmel parabolü çizerdi), nasıl ehlileştiririz? L2 weight decay ağırlık uzunluğunu kısaltır (Gauss priori), L1 seyreklik eksen-yakını bileşenleri öldürür (Laplace priori), dropout sonsuz ağ topluluğunu eğitir, BatchNorm ve data augmentation düzenler; ve belirsizlik için MC Dropout dropout'u çıkarımda açık bırakıp varyansı ölçer — bu varyans türevlenebilir olduğundan minimize edilebilir, ki bu tam olarak Hafta 11'in PPUU belirsizlik düzenlileştirmesidir, kursu başladığı yere, enerjiye ve belirsizliğe geri döndüren halka."
---
::: {.callout-note title="Bölüm bilgisi (LeCun SON Lecture + Canziani SON Practicum)"}
- **Lecture (Yann LeCun, son ders):** [YouTube — Structured Prediction & Regularisation](https://www.youtube.com/watch?v=eEzCZnOFU1w) (Hafta 14 Lecture)
- **Canziani'nin Practicum videosu:** [YouTube — Regularisation & Uncertainty](https://www.youtube.com/watch?v=DL7iew823c0) (Hafta 14 Practicum)
- **Edition:** Spring 2020 (NYU-DLSP20)
- **Hocalar:** Yann LeCun (Lecture, son dersi — yapılandırılmış tahmin + Graph Transformer Network + varyasyonel serbest enerji) + Alfredo Canziani (Practicum, son dersi — overfitting + düzenlileştirme + MC Dropout belirsizliği)
- **Kaynak:** [atcold.github.io/NYU-DLSP20](http://atcold.github.io/NYU-DLSP20)
- **Okuma süresi:** ≈30 dk
> ⚠️ **Atıf notu:** Bu hafta **konuk yoktur** — Lecture'ı **asıl ders sahibi Yann LeCun** verir (kursun son Lecture'ı), Practicum'u **Alfredo Canziani** (kursun son Practicum'u). Bölüm 1-3 quote'ları **— LeCun**; Bölüm 5-7 quote'ları **— Canziani**. (Bu, Hafta 8/10/12/13'teki konuk-hoca düzeltmelerinin aksine, başlıkların gerçekten `## (LeCun)` olduğu derstir.)
:::
```{python}
#| echo: false
import networkx as nx
# ============================================================================
# SETUP — NYU sayısal motor (_engine.py) + NYU Violet+gold viz (_viz.py)
# Bu hücre gizlidir (#| echo: false). Aşağıdaki TÜM figür hücreleri burada
# tanımlanan trellis_shortest_path / free_energy_curve / overfit_regimes /
# l1_l2_weights / mc_dropout_variance / margin_losses + önceki hafta
# yardımcıları + COL_* + apply_style / draw_pipeline / style_legend
# isimlerini kullanır.
# _engine.py saf numpy (torch YOK); _viz.py NYU Violet+gold paleti.
# Graf/şema çizimleri için networkx kullanılır (üst satırda import edilir).
# İçerikler VERBATIM gömülüdür.
#
# NOT: matplotlib backend'i AYARLANMAZ (matplotlib.use(...) ÇAĞRILMAZ).
# Quarto kendi inline (figür yakalayan) backend'ini kurar; Agg backend
# inline figür-yakalamayı bozar (plt.show() çıktı üretmez). Standalone
# figür testinde savefig kullanılır.
# ============================================================================
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import matplotlib as mpl
import matplotlib.patches as mpatches
from matplotlib.patches import (
FancyBboxPatch, FancyArrowPatch, Rectangle, Circle, Ellipse, Polygon, Patch,
)
from matplotlib.lines import Line2D
from matplotlib.colors import ListedColormap, BoundaryNorm, LinearSegmentedColormap
np.random.seed(0)
# ===========================================================================
# _engine.py — saf numpy sayısal yardımcılar (torch YOK)
# ===========================================================================
# ---------------------------------------------------------------------------
# Afin / lineer dönüşümler
# ---------------------------------------------------------------------------
def affine_transform(P, W, b=None):
"""P[N,2] noktalarına y = W x (+ b) afin/lineer dönüşümü uygular (satır-vektör konvansiyonu)."""
P = np.asarray(P, float)
Y = P @ np.asarray(W, float).T
if b is not None:
Y = Y + np.asarray(b, float)
return Y
def unit_grid(n=11, lim=2.0, fine=61):
"""Izgara çizgileri listesi (yatay + dikey). Her çizgi (fine,2) dizisi.
Lineer dönüşüm görsellerinde 'uzayın kumaşı' için."""
t = np.linspace(-lim, lim, n)
f = np.linspace(-lim, lim, fine)
lines = []
for yi in t:
lines.append(np.column_stack([f, np.full_like(f, yi)]))
for xi in t:
lines.append(np.column_stack([np.full_like(f, xi), f]))
return lines
def linear_transforms():
"""Canziani'nin dört temel lineer dönüşümü (Bölüm 8) — 2x2 matrisler."""
th = np.deg2rad(35.0)
R = np.array([[np.cos(th), -np.sin(th)], [np.sin(th), np.cos(th)]]) # rotation (ortonormal)
S = np.array([[1.8, 0.0], [0.0, 0.55]]) # scaling (köşegen)
Sh = np.array([[1.0, 0.85], [0.0, 1.0]]) # shearing
F = np.array([[1.0, 0.0], [0.0, -1.0]]) # reflection (det<0)
return dict(rotation=R, scaling=S, shearing=Sh, reflection=F)
# ---------------------------------------------------------------------------
# SVD geometrisi (Canziani'nin 'patatesi')
# ---------------------------------------------------------------------------
def unit_circle(n=240):
t = np.linspace(0, 2 * np.pi, n)
return np.column_stack([np.cos(t), np.sin(t)])
def svd_demo(W):
"""W = U Σ Vᵀ. Geometrik okuma: rotation(Vᵀ) · scaling(Σ) · rotation(U)."""
U, s, Vt = np.linalg.svd(np.asarray(W, float))
return U, s, Vt
def near_singular_matrix():
"""Bir tekil değeri ≈0 olan matris — bir boyutu 'ezer' (elips çizgiye çöker)."""
th = np.deg2rad(30.0)
R = np.array([[np.cos(th), -np.sin(th)], [np.sin(th), np.cos(th)]])
Sigma = np.diag([1.6, 0.04]) # ikinci tekil değer ≈ 0
return R @ Sigma @ R.T
# ---------------------------------------------------------------------------
# Spiral (manifold germe demosu)
# ---------------------------------------------------------------------------
def make_spiral(n_per=120, k=5, noise=0.18, seed=0):
"""k-kollu spiral (CS231n stili). Her kol bir sınıf; kollar orijinde iç içe → lineer ayrılamaz."""
rng = np.random.default_rng(seed)
X = np.zeros((n_per * k, 2))
y = np.zeros(n_per * k, dtype=int)
for j in range(k):
ix = slice(n_per * j, n_per * (j + 1))
r = np.linspace(0.0, 1.0, n_per)
t = np.linspace(j * 4.0, (j + 1) * 4.0, n_per) + rng.normal(0, 1, n_per) * noise
X[ix] = np.column_stack([r * np.sin(t), r * np.cos(t)])
y[ix] = j
return X, y
def unroll_spiral(X, y, k=5, seed=0):
"""ŞEMATİK 'öğrenilen temsil': her sınıfı kendi yatay bandına taşır → lineer ayrılabilir.
Gerçek bir eğitilmiş ağ DEĞİL; 'ağ manifoldu açar' sezgisinin deterministik görseli."""
rng = np.random.default_rng(seed)
r = np.linalg.norm(X, axis=1)
yb = (y - (k - 1) / 2.0) * 0.55 + rng.normal(0, 0.045, len(y))
return np.column_stack([r * 2.2 - 1.1, yb])
# ---------------------------------------------------------------------------
# İki hilal (make_moons — sklearn YOK, numpy ile elle)
# ---------------------------------------------------------------------------
def make_moons_np(n=400, noise=0.20, seed=0):
"""Doğrusal ayrılamaz iki-hilal veri (sklearn.make_moons eşdeğeri)."""
rng = np.random.default_rng(seed)
n_out = n // 2
n_in = n - n_out
to = np.linspace(0, np.pi, n_out)
ti = np.linspace(0, np.pi, n_in)
outer = np.column_stack([np.cos(to), np.sin(to)])
inner = np.column_stack([1.0 - np.cos(ti), 1.0 - np.sin(ti) - 0.5])
X = np.vstack([outer, inner]) + rng.normal(0, noise, (n, 2))
y = np.array([0] * n_out + [1] * n_in)
return X, y
# ---------------------------------------------------------------------------
# Minik numpy sınıflandırıcılar (lineer vs ReLU MLP) — karar sınırı kontrastı
# ---------------------------------------------------------------------------
def _onehot(y, c):
Y = np.zeros((len(y), c))
Y[np.arange(len(y)), y] = 1.0
return Y
def _softmax(z):
z = z - z.max(axis=1, keepdims=True)
e = np.exp(z)
return e / e.sum(axis=1, keepdims=True)
def logreg_train(X, y, steps=500, lr=1.0, seed=0):
"""Lineer (gizli katmansız) softmax sınıflandırıcı → DÜZ karar sınırı."""
rng = np.random.default_rng(seed)
n, d = X.shape
c = int(y.max() + 1)
W = rng.normal(0, 0.01, (d, c))
b = np.zeros(c)
Y = _onehot(y, c)
for _ in range(steps):
p = _softmax(X @ W + b)
dz = (p - Y) / n
W -= lr * (X.T @ dz)
b -= lr * dz.sum(axis=0)
return dict(W=W, b=b)
def logreg_forward(params, X):
return X @ params["W"] + params["b"]
def mlp_train(X, y, hidden=16, act="relu", steps=600, lr=1.0, seed=0, return_history=False):
"""numpy 2-katmanlı MLP (afine → nonlinearite → afine), softmax + cross-entropy.
ReLU ile EĞRİ karar sınırı (hilalleri/spirali ayırır).
return_history=True → (params, loss_history) döner (eğitim eğrisi figürü için)."""
rng = np.random.default_rng(seed)
n, d = X.shape
c = int(y.max() + 1)
W1 = rng.normal(0, 1, (d, hidden)) * np.sqrt(2.0 / d)
b1 = np.zeros(hidden)
W2 = rng.normal(0, 1, (hidden, c)) * np.sqrt(2.0 / hidden)
b2 = np.zeros(c)
Y = _onehot(y, c)
history = []
for _ in range(steps):
z1 = X @ W1 + b1
a1 = np.maximum(0, z1) if act == "relu" else np.tanh(z1)
p = _softmax(a1 @ W2 + b2)
if return_history:
history.append(float(-np.log(p[np.arange(n), y] + 1e-12).mean()))
dz2 = (p - Y) / n
dW2 = a1.T @ dz2
db2 = dz2.sum(axis=0)
da1 = dz2 @ W2.T
dz1 = da1 * ((z1 > 0) if act == "relu" else (1 - np.tanh(z1) ** 2))
dW1 = X.T @ dz1
db1 = dz1.sum(axis=0)
W1 -= lr * dW1
b1 -= lr * db1
W2 -= lr * dW2
b2 -= lr * db2
params = dict(W1=W1, b1=b1, W2=W2, b2=b2, act=act)
if return_history:
return params, np.array(history)
return params
def mlp_forward(params, X):
z1 = X @ params["W1"] + params["b1"]
a1 = np.maximum(0, z1) if params["act"] == "relu" else np.tanh(z1)
return a1 @ params["W2"] + params["b2"]
def accuracy(forward_fn, params, X, y):
return float((forward_fn(params, X).argmax(axis=1) == y).mean())
def decision_grid(X, pad=0.6, h=0.02):
"""Karar bölgesi için koordinat ızgarası (xx, yy) ve düz nokta listesi."""
x0, x1 = X[:, 0].min() - pad, X[:, 0].max() + pad
y0, y1 = X[:, 1].min() - pad, X[:, 1].max() + pad
xx, yy = np.meshgrid(np.arange(x0, x1, h), np.arange(y0, y1, h))
grid = np.column_stack([xx.ravel(), yy.ravel()])
return xx, yy, grid
# ---------------------------------------------------------------------------
# Enerji manzarası (EBM — çoklu minimum = çoklu geçerli cevap)
# ---------------------------------------------------------------------------
def energy_landscape(xx, yy):
"""F(x,y): birkaç Gauss kuyusu → çoklu yerel minimum. Düşük enerji = uyumlu cevap."""
wells = [(-1.25, -0.65, 1.0, 0.55), (1.15, 0.85, 1.05, 0.6), (0.15, -1.15, 0.8, 0.45)]
F = np.ones_like(xx) * 1.0
for cx, cy, depth, width in wells:
F = F - depth * np.exp(-((xx - cx) ** 2 + (yy - cy) ** 2) / (2 * width))
return F
# ---------------------------------------------------------------------------
# Hafta 2 — gradient descent, SGD, backprop, eğitim
# ---------------------------------------------------------------------------
def loss_surface_2d(xx, yy):
"""2D parametre uzayında bir kayıp yüzeyi (gradient descent 'dağ' görseli için):
eğik, farklı-ölçekli bir vadi (konveks taban) + hafif dalgalanma."""
u = 0.85 * xx + 0.53 * yy # eksenleri döndür (eğik vadi)
v = -0.53 * xx + 0.85 * yy
return 1.0 * u ** 2 + 3.5 * v ** 2 + 0.6 * np.sin(1.5 * xx) * np.cos(1.5 * yy)
def _loss_grad_2d(p):
"""loss_surface_2d gradyanı (merkezi sonlu fark)."""
eps = 1e-4
gx = (loss_surface_2d(p[0] + eps, p[1]) - loss_surface_2d(p[0] - eps, p[1])) / (2 * eps)
gy = (loss_surface_2d(p[0], p[1] + eps) - loss_surface_2d(p[0], p[1] - eps)) / (2 * eps)
return np.array([gx, gy])
def gd_path(theta0, lr=0.08, steps=40):
"""loss_surface_2d üzerinde gradient descent yörüngesi (parametre adımları)."""
p = np.array(theta0, float)
path = [p.copy()]
for _ in range(steps):
p = p - lr * _loss_grad_2d(p)
path.append(p.copy())
return np.array(path)
def sgd_loss_curves(steps=80, seed=0):
"""Üç rejim için kayıp eğrisi (simülasyon): full-batch (gürültüsüz, düz),
mini-batch (orta gürültü), saf SGD (yüksek gürültü). Aynı yumuşak üstel düşüş."""
rng = np.random.default_rng(seed)
t = np.arange(steps)
base = 0.2 + 2.6 * np.exp(-t / 14.0)
full = base.copy()
mini = base + rng.normal(0, 0.10, steps) * np.exp(-t / 45.0)
sgd = base + rng.normal(0, 0.45, steps) * np.exp(-t / 70.0)
return t, np.clip(full, 0, None), np.clip(mini, 0, None), np.clip(sgd, 0, None)
def tanh_deriv(x):
"""tanh'ın türevi: 1 − tanh²(x). Backprop 'twiddling' figürü için."""
return 1.0 - np.tanh(x) ** 2
def ce_loss_curve(p):
"""Doğru sınıf olasılığı p için cross-entropy kaybı: −log p."""
p = np.clip(np.asarray(p, float), 1e-6, 1.0)
return -np.log(p)
def mse_loss_curve(p):
"""Doğru sınıf olasılığı p için (one-hot hedefe) MSE: (1 − p)²."""
return (1.0 - np.asarray(p, float)) ** 2
# ---------------------------------------------------------------------------
# Hafta 3 — convolution / ConvNet / doğal sinyaller
# ---------------------------------------------------------------------------
def conv_output_size(n, k, s=1):
"""Çıktı boyutu: o = ⌊(n − k)/s⌋ + 1."""
return (n - k) // s + 1
def conv1d(x, w):
"""1B cross-correlation (ML 'convolution'): out[i] = Σ_k x[i+k]·w[k].
Örnek: conv1d([1,2,3,4,5],[1,0,-1]) → [-2,-2,-2] (kenar/fark dedektörü)."""
x = np.asarray(x, float)
w = np.asarray(w, float)
n = len(x) - len(w) + 1
return np.array([np.dot(x[i:i + len(w)], w) for i in range(n)])
def conv2d(img, kernel, stride=1):
"""2B valid cross-correlation (ag öznitelik haritası üretir)."""
img = np.asarray(img, float)
k = np.asarray(kernel, float)
kh, kw = k.shape
H, W = img.shape
oh, ow = conv_output_size(H, kh, stride), conv_output_size(W, kw, stride)
out = np.zeros((oh, ow))
for i in range(oh):
for j in range(ow):
patch = img[i * stride:i * stride + kh, j * stride:j * stride + kw]
out[i, j] = np.sum(patch * k)
return out
def make_synthetic_image(n=28, seed=0):
"""Basit gri-tonlu sentetik görüntü: kare + daire (kenar tespiti net görünsün)."""
img = np.zeros((n, n))
img[5:14, 6:15] = 1.0 # dolu kare
yy, xx = np.ogrid[:n, :n]
cy, cx, r = 19, 19, 6
img[(yy - cy) ** 2 + (xx - cx) ** 2 <= r ** 2] = 0.85 # daire
img[20:22, 4:24] = 0.6 # yatay çizgi (yatay kenar için)
return img
def edge_kernels():
"""Klasik 3×3 öznitelik dedektörü kernel'leri."""
return dict(
sobel_x=np.array([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]], float), # dikey kenar
sobel_y=np.array([[-1, -2, -1], [0, 0, 0], [1, 2, 1]], float), # yatay kenar
blur=np.ones((3, 3)) / 9.0, # bulanıklaştırma
laplace=np.array([[0, 1, 0], [1, -4, 1], [0, 1, 0]], float), # tüm kenarlar
)
def max_pool2d(img, k=2):
"""k×k max pooling (complex cell / invariance)."""
img = np.asarray(img, float)
H, W = img.shape
oh, ow = H // k, W // k
return np.array([[img[i * k:(i + 1) * k, j * k:(j + 1) * k].max() for j in range(ow)]
for i in range(oh)])
def avg_pool2d(img, k=2):
"""k×k average pooling (LeNet5 stili)."""
img = np.asarray(img, float)
H, W = img.shape
oh, ow = H // k, W // k
return np.array([[img[i * k:(i + 1) * k, j * k:(j + 1) * k].mean() for j in range(ow)]
for i in range(oh)])
# ---------------------------------------------------------------------------
# Hafta 4 — convolution cebiri (Toeplitz) + optimizasyon (κ, momentum, Adam)
# ---------------------------------------------------------------------------
def build_toeplitz(kernel, n):
"""1B convolution'ın Toeplitz matrisi: out = T @ x, T[i, i:i+k] = kernel.
conv1d(x, kernel) == build_toeplitz(kernel, len(x)) @ x (çoğu eleman sıfır = seyrek)."""
kernel = np.asarray(kernel, float)
k = len(kernel)
oh = n - k + 1
T = np.zeros((oh, n))
for i in range(oh):
T[i, i:i + k] = kernel
return T
def quad_loss(xx, yy, kappa=20.0):
"""Eğik, koşullanması κ = L/μ olan kuadratik vadi (condition number görseli).
κ büyük → uzun ince vadi → gradient descent zikzak çizer."""
a, b = 0.92, 0.39 # ~25° dönme
u = a * xx + b * yy
v = -b * xx + a * yy
return 0.5 * (1.0 * u ** 2 + kappa * v ** 2) # L=κ, μ=1
def quad_grad(p, kappa=20.0):
"""quad_loss'un analitik gradyanı."""
a, b = 0.92, 0.39
x, y = p
u = a * x + b * y
v = -b * x + a * y
gu, gv = u, kappa * v
return np.array([gu * a + gv * (-b), gu * b + gv * a])
def optimize_quad(method, theta0, lr, steps, kappa=20.0, beta=0.9, beta2=0.999, eps=1e-8):
"""quad_loss üzerinde bir optimizer'ı koştur; yörünge + kayıp geçmişi döner.
method ∈ {'gd','momentum','adam'}. Defazio'nun zikzak/sönümleme/adaptif anlatısı için."""
p = np.array(theta0, float)
path = [p.copy()]
losses = [float(quad_loss(p[0], p[1], kappa))]
m = np.zeros(2)
v = np.zeros(2)
for t in range(1, steps + 1):
g = quad_grad(p, kappa)
if method == "gd":
step = lr * g
elif method == "momentum":
m = beta * m + g # heavy ball
step = lr * m
elif method == "adam":
m = beta * m + (1 - beta) * g
v = beta2 * v + (1 - beta2) * g * g
mh = m / (1 - beta ** t) # bias correction
vh = v / (1 - beta2 ** t)
step = lr * mh / (np.sqrt(vh) + eps)
else:
raise ValueError(method)
p = p - step
path.append(p.copy())
losses.append(float(quad_loss(p[0], p[1], kappa)))
return np.array(path), np.array(losses)
# ---------------------------------------------------------------------------
# Hafta 5 — autograd worked example (Canziani)
# ---------------------------------------------------------------------------
def autograd_worked(X=None):
"""Canziani worked example: X → Y=X−2 → Z=3·Y² → a=mean(Z) (skaler).
İleri değerler + ∂a/∂xᵢ = (1/4)·3·2·(xᵢ−2) = 1.5·(xᵢ−2).
X=[1,2,3,4] için grad = [−1.5, 0, 1.5, 3] (PyTorch X.grad ile birebir)."""
if X is None:
X = np.array([1.0, 2.0, 3.0, 4.0])
X = np.asarray(X, float)
Y = X - 2.0
Z = 3.0 * Y ** 2
a = float(Z.mean())
grad = 1.5 * (X - 2.0)
return dict(X=X, Y=Y, Z=Z, a=a, grad=grad)
def conv_pad_output(n, k, padding=0, stride=1):
"""Padding'li çıktı boyutu: o = ⌊(n + 2·padding − k)/stride⌋ + 1.
padding=(k−1)/2 (k tek) → çıktı boyutu korunur."""
return (n + 2 * padding - k) // stride + 1
# ---------------------------------------------------------------------------
# Hafta 6 — RNN / vanishing gradient / attention
# ---------------------------------------------------------------------------
def vanishing_demo(steps=50, eigenvalues=(0.5, 1.0, 1.5)):
"""Aynı matristen n kez geçen gradient: λⁿ. λ<1 söner (vanishing), λ>1 patlar
(exploding), λ=1 sabit. Backprop-through-time vanishing gradient görseli."""
t = np.arange(steps + 1)
curves = {ev: np.asarray(ev, float) ** t for ev in eigenvalues}
return t, curves
def rnn_forward(X_seq, Wx, Wz, b, z0=None):
"""Basit RNN hücresi: zₜ = tanh(Wₓ·xₜ + W_z·zₜ₋₁ + b).
X_seq [T, d_in] → gizli durumlar Z [T, d_h] (aynı Wₓ,W_z her adımda = paylaşım)."""
X_seq = np.asarray(X_seq, float)
T = len(X_seq)
dh = np.asarray(Wz).shape[0]
z = np.zeros(dh) if z0 is None else np.asarray(z0, float)
Z = []
for t in range(T):
z = np.tanh(np.asarray(Wx) @ X_seq[t] + np.asarray(Wz) @ z + np.asarray(b))
Z.append(z.copy())
return np.array(Z)
def attention_weights(scores):
"""Attention ağırlıkları = softmax(skorlar); toplamı 1 (olasılık dağılımı, 'odak')."""
scores = np.asarray(scores, float)
e = np.exp(scores - scores.max())
return e / e.sum()
# ---------------------------------------------------------------------------
# Hafta 7 — EBM / autoencoder / manifold
# ---------------------------------------------------------------------------
def energy_1d(y, data_points=(-2.0, 0.0, 2.0), width=0.35):
"""1B enerji F(y): veri noktalarında düşük (çukur), aralarda yüksek (tepe).
'İyi enerji şekli' = veride düşük, dışında yüksek (EBM); çoklu minimum = çoklu cevap."""
y = np.asarray(y, float)
F = np.ones_like(y)
for d in data_points:
F = F - np.exp(-(y - d) ** 2 / (2 * width))
return F
def energy_1d_grad(y, data_points=(-2.0, 0.0, 2.0), width=0.35):
"""energy_1d'nin türevi (çıkarım = enerji minimizasyonu, gradient ile arama)."""
y = np.asarray(y, float)
g = np.zeros_like(y)
for d in data_points:
g = g + (y - d) / width * np.exp(-(y - d) ** 2 / (2 * width))
return g
def make_manifold_curve(n=160, noise=0.0, seed=0):
"""2B veri manifoldu: bir eğri (sinüs yayı) üzerinde noktalar (Hafta 1 manifold hipotezi)."""
t = np.linspace(-2.6, 2.6, n)
M = np.column_stack([t, np.sin(1.3 * t)])
if noise:
M = M + np.random.default_rng(seed).normal(0, noise, M.shape)
return M
def project_to_manifold(points, manifold):
"""Her noktayı manifoldun EN YAKIN noktasına çeker (autoencoder reconstruction sezgisi:
off-manifold girdiyi manifolda geri çek → düşük enerji)."""
points = np.asarray(points, float)
proj = np.array([manifold[np.linalg.norm(manifold - p, axis=1).argmin()] for p in points])
return proj
# ---------------------------------------------------------------------------
# Hafta 8 — contrastive / VAE
# ---------------------------------------------------------------------------
def vae_reparam(mu, sigma, n=400, seed=0):
"""Reparameterization trick: z = μ + σ⊙ε, ε~N(0,I). Düzenli (sürekli, dolu)
Gaussian latent örnekleri — VAE'nin üretken latent uzayı."""
mu = np.atleast_1d(np.asarray(mu, float))
sigma = np.atleast_1d(np.asarray(sigma, float))
rng = np.random.default_rng(seed)
eps = rng.normal(0, 1, (n, len(mu)))
return mu + sigma * eps
def ae_latent_clusters(n=400, seed=0):
"""Sıradan AE latent'i: dağınık, boşluklu kümeler (düzensiz uzay — VAE kontrastı)."""
rng = np.random.default_rng(seed)
centers = np.array([[-2.2, 1.8], [2.0, 2.1], [0.3, -2.3], [-1.8, -1.5]])
pts = []
for c in centers:
pts.append(c + rng.normal(0, 0.28, (n // len(centers), 2)))
return np.vstack(pts)
# ---------------------------------------------------------------------------
# Hafta 9 — sparse coding / GAN (EBM)
# ---------------------------------------------------------------------------
def sparse_code_demo(n=24, n_active=5, seed=0):
"""Yoğun (dense) vs seyrek (sparse) code: L1 düzenlileştirme çoğu bileşeni
sıfıra iter — yalnızca birkaç birim aktif kalır (sparse coding)."""
rng = np.random.default_rng(seed)
dense = rng.normal(0, 1, n)
idx = np.argsort(-np.abs(dense)) # en büyük |değer| → aktif kalanlar
sparse = np.zeros(n)
sparse[idx[:n_active]] = dense[idx[:n_active]]
return dense, sparse
def rotate_image_4way(img):
"""0/90/180/270° döndürülmüş 4 versiyon — rotation pretext görevi (Hafta 10 SSL):
ağ 'kaç derece döndürüldü?' sorusunu çözer (4-yönlü sınıflandırma)."""
img = np.asarray(img, float)
return [np.rot90(img, k) for k in range(4)]
# ---------------------------------------------------------------------------
# Hafta 11 — aktivasyon / kayıp (EBM) / belirsizlik
# ---------------------------------------------------------------------------
def _sig(x):
return 1.0 / (1.0 + np.exp(-np.clip(x, -50, 50)))
def activation_fns():
"""Aktivasyon fonksiyonu zoo'su + türevleri (Hafta 11). {ad: (f, f')}."""
return {
"ReLU": (lambda x: np.maximum(0, x), lambda x: (np.asarray(x) > 0).astype(float)),
"Leaky ReLU": (lambda x: np.where(x > 0, x, 0.1 * x), lambda x: np.where(np.asarray(x) > 0, 1.0, 0.1)),
"sigmoid": (_sig, lambda x: _sig(x) * (1 - _sig(x))),
"tanh": (np.tanh, lambda x: 1 - np.tanh(x) ** 2),
"softplus": (lambda x: np.log1p(np.exp(-np.abs(x))) + np.maximum(x, 0), _sig),
"ELU": (lambda x: np.where(x > 0, x, np.exp(np.clip(x, -50, 50)) - 1),
lambda x: np.where(np.asarray(x) > 0, 1.0, np.exp(np.clip(x, -50, 50)))),
}
def softplus_scaled(x, beta=1.0):
"""β-ölçekli softplus: (1/β)·log(1+e^(βx)). β büyük → ReLU'ya yaklaşır (ölçek-bağımlı)."""
x = np.asarray(x, float)
return (1.0 / beta) * (np.log1p(np.exp(-np.abs(beta * x))) + np.maximum(beta * x, 0))
def margin_losses(gap, m=1.0):
"""EBM kayıpları. gap = E(ȳ) − E(y) (doğru-yanlış enerji farkı; pozitif=doğru daha düşük).
hinge marj m (gap≥m'de 0), perceptron marjsız (gap≥0'da 0 → collapse'a açık)."""
gap = np.asarray(gap, float)
hinge = np.maximum(0.0, m - gap)
perceptron = np.maximum(0.0, -gap)
return hinge, perceptron
def uncertainty_demo(x_train, x_grid, bandwidth=0.6):
"""Belirsizlik (epistemik varyans proxy) ~ eğitim verisinden uzaklık: eğitim
noktalarına yakın DÜŞÜK, uzakta YÜKSEK (PPUU 'U' düzenlileştirmesi)."""
x_train = np.atleast_1d(np.asarray(x_train, float))
x_grid = np.atleast_1d(np.asarray(x_grid, float))
d = np.abs(x_grid[:, None] - x_train[None, :]).min(axis=1)
return 1.0 - np.exp(-(d / bandwidth) ** 2)
def gan_samples(seed=0, n=200):
"""GAN sezgisi: gerçek veri (manifold/halka) vs generator'ın ürettiği sahte örnekler.
İlk başta sahteler dağınık (eğitilmemiş generator), gerçeğe yakınsar."""
rng = np.random.default_rng(seed)
th = rng.uniform(0, 2 * np.pi, n)
real = np.column_stack([np.cos(th), np.sin(th)]) + rng.normal(0, 0.06, (n, 2)) # gerçek = birim halka
fake_early = rng.normal(0, 1.1, (n, 2)) # eğitilmemiş gen (dağınık)
th2 = rng.uniform(0, 2 * np.pi, n)
fake_late = np.column_stack([np.cos(th2), np.sin(th2)]) + rng.normal(0, 0.18, (n, 2)) # eğitilmiş gen (halkaya yakın)
return real, fake_early, fake_late
# ---------------------------------------------------------------------------
# Hafta 12 — Attention / Transformer (NLP, Lewis + Canziani)
# ---------------------------------------------------------------------------
def _softmax_rows(M):
"""Satır-bazlı kararlı softmax (her satır toplamı 1)."""
M = np.asarray(M, float)
e = np.exp(M - M.max(axis=-1, keepdims=True))
return e / e.sum(axis=-1, keepdims=True)
def self_attention_matrix(X, scale=True):
"""Self-attention ağırlık matrisi A = softmax(XXᵀ/√d) (Canziani: küme→küme).
X [T, d] token kümesi → A [T, T]: A[i,j] = token i'nin token j'ye verdiği dikkat (satır toplamı 1).
scale=True → β=1/√d ölçekleme (Canziani 20:44: vektör büyüklüğü √d ile büyür, sıcaklık sabit)."""
X = np.asarray(X, float)
d = X.shape[1]
scores = X @ X.T
if scale:
scores = scores / np.sqrt(d)
return _softmax_rows(scores)
def causal_mask_demo(scores):
"""Causal (look-ahead) maske gösterimi (Lewis 27:08).
scores [T, T] → (A_acik, A_maskeli): maskesiz softmax vs üst-üçgen −∞ maskeli softmax.
Maskeli: her token yalnız kendine + soluna bakar (geleceği göremez = hile yok)."""
scores = np.asarray(scores, float)
T = scores.shape[0]
A_open = _softmax_rows(scores)
mask = np.triu(np.full((T, T), -np.inf), k=1) # üst-üçgen (gelecek) = −∞
A_masked = _softmax_rows(scores + mask)
return A_open, A_masked
def softmax_temperature(scores, betas):
"""Sıcaklık β'nın softmax üzerindeki etkisi (Hafta 11 köprüsü; soft↔hard attention).
scores [n] tek satır → her β için softmax(β·scores) [len(betas), n].
β→0 düzleşir (uniform), β→∞ sivrilir (one-hot=hard attention)."""
scores = np.asarray(scores, float)
out = []
for b in betas:
s = b * scores
e = np.exp(s - s.max())
out.append(e / e.sum())
return np.array(out)
def positional_encoding(seq_len, d, base=10000.0):
"""Sinüzoidal positional encoding (Vaswani 2017; Lewis: küme→sıra).
PE[pos,2i]=sin(pos/base^(2i/d)), PE[pos,2i+1]=cos(...). → [seq_len, d] matris.
Attention girdiyi sırasız küme görür; konum bilgisini bu eklenen embedding taşır."""
pos = np.arange(seq_len)[:, None]
i = np.arange(d)[None, :]
angle = pos / np.power(base, (2 * (i // 2)) / d)
PE = np.where(i % 2 == 0, np.sin(angle), np.cos(angle))
return PE
def topk_truncate(probs, k):
"""Top-k sampling kırpması (Lewis 49:54; Angela Fan).
probs [V] olasılık dağılımı → en iyi k dışındaki kütleyi 0'la, yeniden normalize et.
Greedy=k1; beam farklı (hipotez tutar); top-k=çeşitlilik + manifolddan düşmeme."""
probs = np.asarray(probs, float)
out = np.zeros_like(probs)
idx = np.argsort(probs)[::-1][:k] # en yüksek k indeks
out[idx] = probs[idx]
return out / out.sum()
# ---------------------------------------------------------------------------
# Hafta 13 — Graph Convolutional Networks (Bresson + Canziani)
# ---------------------------------------------------------------------------
def path_graph_adj(n):
"""Yol grafı (zincir 0-1-2-...-n-1) adjacency [n,n]. Fourier modları = kosinüsler (1D DCT)."""
A = np.zeros((n, n))
for i in range(n - 1):
A[i, i + 1] = A[i + 1, i] = 1.0
return A
def community_graph_adj():
"""İki topluluk grafı (8 düğüm: 0-3 ve 4-7 iki klik, 3-4 köprü kenarı).
Karate Club benzeri yarı-denetimli/K-hop demoları için (seyreklik = yapı)."""
A = np.zeros((8, 8))
edges = [(0,1),(0,2),(1,2),(1,3),(2,3), # topluluk A (0-3)
(4,5),(4,6),(5,6),(5,7),(6,7), # topluluk B (4-7)
(3,4)] # köprü
for i, j in edges:
A[i, j] = A[j, i] = 1.0
return A
def graph_laplacian(A):
"""Normalize graf Laplacian Δ = I − D⁻¹ᐟ²AD⁻¹ᐟ² (Bresson 26:45; pürüzsüzlük operatörü).
Simetrik, özdeğerler [0,2]. Δh = h_i ile komşu ortalaması farkı (yüksek frekans büyük)."""
A = np.asarray(A, float)
n = A.shape[0]
d = A.sum(axis=1)
dinv = np.where(d > 0, 1.0 / np.sqrt(d), 0.0)
Dinv = np.diag(dinv)
return np.eye(n) - Dinv @ A @ Dinv
def graph_fourier(A):
"""Graf Fourier: Δ = ΦΛΦᵀ özayrışım (Bresson 30:03). Özvektörler Φ = Fourier fonksiyonları.
Döner (eigvals artan, eigvecs): düşük özdeğer=pürüzsüz mod, yüksek=salınan mod."""
Delta = graph_laplacian(A)
w, V = np.linalg.eigh(Delta) # eigh: simetrik, özdeğerler artan
return w, V
def laplacian_smoothness(A, h):
"""Pürüzsüzlük ölçüsü: Δh ve kuadratik form hᵀΔh (Bresson).
Pürüzsüz sinyal → küçük; salınan sinyal → büyük (Egzersiz 2)."""
Delta = graph_laplacian(A)
h = np.asarray(h, float)
Dh = Delta @ h
return Dh, float(h @ Delta @ h)
def khop_diffusion(A, source, K):
"""K-hop yerelleştirme (ChebNet sezgisi, Bresson 56:42): kaynağa Δ'yı k kez uygula.
Δᵏ·e_source desteği TAM k-hop genişler → [|Δ⁰e|, |Δ¹e|, ..., |Δᴷe|] büyüklük desenleri."""
Delta = graph_laplacian(A)
n = A.shape[0]
e = np.zeros(n); e[source] = 1.0
out = [np.abs(e.copy())]
cur = e.copy()
for _ in range(K):
cur = Delta @ cur
out.append(np.abs(cur))
return out
def gcn_message_pass(A, X, W, U):
"""İzotropik GCN katmanı (Canziani 29:04): hᵢ = ReLU(U·xᵢ + (1/dᵢ)Σ_{j∈N(i)} W·xⱼ).
a = adjacency (verili, attention'ın hesaplanan softmax'i değil). X[n,din]→H[n,dout]."""
A = np.asarray(A, float); X = np.asarray(X, float)
W = np.asarray(W, float); U = np.asarray(U, float)
d = A.sum(axis=1); dinv = np.where(d > 0, 1.0 / d, 0.0)
neigh = (np.diag(dinv) @ A) @ X @ W.T # (1/dᵢ)Σ W·xⱼ komşuluk ortalaması
self_term = X @ U.T # U·xᵢ self-connection
return np.maximum(0.0, self_term + neigh)
def gate_eta(edge_feats):
"""Residual Gated GCN kapısı (Canziani 27:53): ηᵢⱼ = σ(eᵢⱼ)/Σ_k σ(eᵢₖ).
İzotropik (1/d eşit) ortalamayı anizotropik ağırlıklı toplama çevirir. edge_feats[d]→η[d]."""
e = np.asarray(edge_feats, float)
s = 1.0 / (1.0 + np.exp(-e)) # sigmoid
return s / s.sum()
# ===========================================================================
# Hafta 14 — Yapılandırılmış Tahmin + Düzenlileştirme (LeCun son ders + Canziani)
# ===========================================================================
def trellis_shortest_path(unaries, pair_cost):
"""Faktör grafiği = trellis en-kısa-yol (LeCun 22:52; dinamik programlama).
unaries [T, S] her adımda S durumun tekil enerjisi; pair_cost [S, S] geçiş enerjisi.
Döner (path, min_energy, brute_count, dp_count): DP üsteli (S^T) lineere (T·S²) indirir."""
unaries = np.asarray(unaries, float)
T, S = unaries.shape
dp = unaries[0].copy()
back = np.zeros((T, S), int)
for t in range(1, T):
for s in range(S):
cand = dp + pair_cost[:, s] + unaries[t, s]
back[t, s] = int(np.argmin(cand))
dp[s] = cand[back[t, s]]
end = int(np.argmin(dp)); min_e = float(dp[end])
path = [end]
for t in range(T - 1, 0, -1):
end = back[t, end]; path.append(end)
path.reverse()
return path, min_e, S ** T, T * S * S # kaba kuvvet vs DP degerlendirme sayisi
def free_energy_curve(q_stds, T=1.0):
"""Varyasyonel serbest enerji F = ⟨E⟩ − T·H (LeCun 2:02; VAE = bu).
q = N(0,σ) latent dağılımı; enerji E(z)=½z² (kuadratik kuyu). σ tarandıkça:
⟨E⟩=½σ² artar, H=½ln(2πeσ²) artar → F'nin bir minimumu var (denge = VAE recon+KL)."""
q_stds = np.asarray(q_stds, float)
avg_E = 0.5 * q_stds ** 2 # ⟨E⟩ = ½σ² (Gauss, E=½z²)
H = 0.5 * np.log(2 * np.pi * np.e * q_stds ** 2) # Gauss diferansiyel entropi
F = avg_E - T * H
return avg_E, H, F
def overfit_regimes(seed=0, n=14, degrees=(1, 2, 11)):
"""Underfit / doğru / overfit (Canziani 5:39): gürültülü parabole polinom fit.
Döner (x, y, x_grid, fits[deg]): düşük derece=underfit, eşit=doğru, yüksek=overfit (gürültü ezber)."""
rng = np.random.default_rng(seed)
x = np.linspace(-3, 3, n)
y_true = 0.4 * x ** 2 - 0.5 # gercek parabol
y = y_true + rng.normal(0, 0.8, n) # + gurultu (overfit'in kaynagi)
x_grid = np.linspace(-3.2, 3.2, 200)
fits = {}
for d in degrees:
c = np.polyfit(x, y, d)
fits[d] = np.polyval(c, x_grid)
return x, y, x_grid, fits
def l1_l2_weights(seed=0, n=400, lam=0.1):
"""L1 (seyreklik, eksen öldür) vs L2 (uzunluk kısalt) ağırlık dağılımı (Canziani 27:03).
Gradyan inişiyle yakınsamış ağırlıkların histogramı: L1→0'da yığılma+seyrek, L2→küçük Gauss."""
rng = np.random.default_rng(seed)
w0 = rng.normal(0, 1.0, n) # baslangic agirliklari
# proximal/gradyan: L2 ağırlıkları orantılı küçültür; L1 sabit miktar çeker (eksen öldürür)
w_l2 = w0 / (1.0 + lam) # ridge: uzunluk kisalt
w_l1 = np.sign(w0) * np.maximum(np.abs(w0) - lam, 0.0) # soft-threshold: kucukleri 0'la
return w_l1, w_l2
def mc_dropout_variance(seed=0, n_models=60, p=0.35):
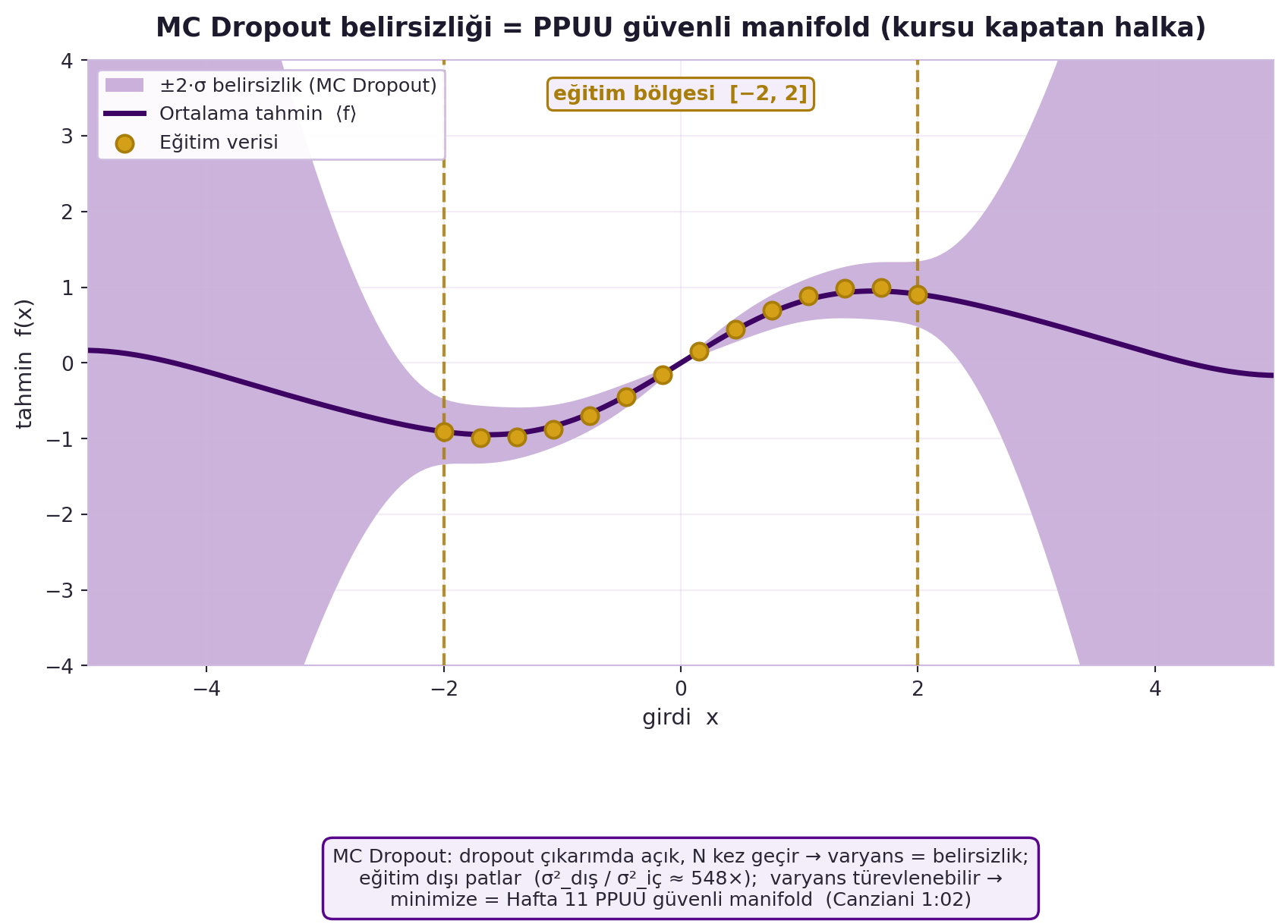
"""MC Dropout belirsizliği = PPUU (Canziani 1:02; Hafta 11 halkası).
Her model eğitim verisine bir öznitelik-dropout maskesiyle FIT edilir → eğitim
bölgesi [-2,2]'de hepsi veriye sabitlenir (uyumlu), dışında ıraksar → varyans↑.
Döner (x_grid, mean, std, xt, yt): std eğitim içinde küçük, dışında büyük (= belirsizlik)."""
rng = np.random.default_rng(seed)
xt = np.linspace(-2, 2, 14)
yt = np.sin(xt) # egitim verisi
Phi = lambda x: np.stack([np.ones_like(x), x, x**2, x**3,
np.sin(x), np.cos(x), np.sin(2*x), np.cos(2*x)], 1)
A = Phi(xt); F = A.shape[1]
xg = np.linspace(-5, 5, 240)
preds = []
for _ in range(n_models):
keep = rng.random(F) > p # oznitelik dropout maskesi
if not keep.any():
keep[rng.integers(F)] = True
ck, *_ = np.linalg.lstsq(A[:, keep], yt, rcond=None) # KALAN ozniteliklerle veriye FIT
full = np.zeros(F); full[keep] = ck
preds.append(Phi(xg) @ full)
preds = np.array(preds)
return xg, preds.mean(0), preds.std(0), xt, yt
# ===========================================================================
# _viz.py — NYU Violet + gold matplotlib stil sabitleri (VERBATIM)
# ===========================================================================
COL_VIOLET = "#57068c" # NYU Violet — birincil çizgi/çerçeve/vurgu
COL_VIOLET_D = "#3d0463" # koyu violet — güçlü vurgu / gradyan
COL_VIOLET_M = "#7b2cbf" # orta violet — ikincil
COL_VIOLET_SOFT = "#b56ad6" # soluk violet
COL_GOLD = "#d4a017" # gold accent
COL_GOLD_D = "#a87d0a" # koyu gold
COL_TEXT = "#2a2535" # gövde metni (hafif violet tint)
COL_INK = "#1e1a2e" # en koyu — başlık
COL_BG = "#f4eefa" # açık violet — dolgu/arka plan
COL_GRID = "#cdbbe0" # soluk violet — ızgara/pasif kenar
COL_WHITE = "#ffffff"
# 5-sınıf kategorik palet (spiral 5 kol / moons ilk 2) — violet↔gold ekseni, tema-uyumlu
CLASS_COLORS = ["#57068c", "#7b2cbf", "#b56ad6", "#d4a017", "#a87d0a"]
# Çizgi-grafik tutarlı renkler
LINE_PRIMARY = COL_VIOLET
LINE_ACCENT = COL_GOLD
LINE_SECONDARY = COL_VIOLET_M
def apply_style(ax):
"""Bir eksene tutarlı NYU Violet+gold görünümü uygular."""
ax.set_facecolor(COL_WHITE)
ax.grid(True, alpha=0.25, color=COL_GRID, linewidth=0.8)
for spine in ax.spines.values():
spine.set_color(COL_GRID)
ax.tick_params(colors=COL_TEXT)
ax.title.set_color(COL_TEXT)
ax.xaxis.label.set_color(COL_TEXT)
ax.yaxis.label.set_color(COL_TEXT)
return ax
def draw_pipeline(ax, stages, title=None, y0=0.0):
"""Soldan-sağa kutu+ok boru hattı şeması (örüntü tanıma vs uçtan-uca).
stages : [(label:str, is_learned:bool), ...]
is_learned=True -> öğrenilen modül (violet dolgulu)
is_learned=False -> elle-tasarlanan/sabit (gold kenarlı, açık dolgu)
"""
n = len(stages)
box_w, box_h, gap = 1.7, 1.0, 0.9
step = box_w + gap
ax.set_xlim(-0.3, n * step)
ax.set_ylim(y0 - 1.1, y0 + 1.1)
ax.axis("off")
if title:
ax.set_title(title, color=COL_TEXT, fontsize=12, pad=10)
for i, (lbl, learned) in enumerate(stages):
x = i * step
fc = "#ece0f7" if learned else COL_BG
ec = COL_VIOLET if learned else COL_GOLD_D
lw = 2.4 if learned else 2.0
box = FancyBboxPatch(
(x, y0 - box_h / 2), box_w, box_h,
boxstyle="round,pad=0.02,rounding_size=0.12",
fc=fc, ec=ec, lw=lw, zorder=2,
)
ax.add_patch(box)
ax.text(x + box_w / 2, y0, lbl, ha="center", va="center",
fontsize=9.5, color=COL_TEXT, zorder=3, wrap=True)
if i > 0:
ax.add_patch(FancyArrowPatch(
(x - gap, y0), (x, y0),
arrowstyle="-|>", mutation_scale=16,
color=COL_VIOLET_M, lw=1.9, zorder=1,
))
return ax
def style_legend(ax, **kw):
"""Tema-uyumlu legend."""
leg = ax.legend(frameon=True, framealpha=0.95, edgecolor=COL_GRID, **kw)
if leg is not None:
leg.get_frame().set_facecolor(COL_WHITE)
for t in leg.get_texts():
t.set_color(COL_TEXT)
return leg
```
## Bu Derste Ne Var? {#sec-genel-bakis-d14}
İki parça ve ikisi de bir **final**: **Yann LeCun** son Lecture'ında yapılandırılmış tahmini (structured prediction) anlatıp tüm kursu tek çatı altında toplar — enerji-tabanlı faktör grafikleri, Graph Transformer Network, ve büyük sentez olarak **varyasyonel serbest enerji** (VAE'nin gerçek açıklaması); **Canziani** son Practicum'unda overfitting ve düzenlileştirmeyi işleyip belirsizlik kestirimiyle Hafta 11'in PPUU'suna geri bağlanır.
LeCun'un büyük mesajı: kursun her parçası — sınıflandırma, EBM, autoencoder, dizi modeli, attention, GCN — aslında **tek bir fikrin** farklı yüzleridir: bir **enerji fonksiyonu** tasarla, doğru cevabı bastır, yanlışları (marjla) yukarı it, gerektiğinde gizli değişkenleri **marjinalleştir**. Bu marjinalleştirme, fizikten gelen **serbest enerji** ($F = \langle E \rangle - T \cdot H$) ile aynıdır — ve VAE tam budur.
**Üç ana fikir:**
1. **Yapılandırılmış tahmin = faktörlü EBM.** Enerji, alt-değişken kümelerine dokunan **faktörlerin toplamıdır**; çıkarım üstel değil, **en kısa yol** (dinamik programlama) ile verimlidir.
2. **Graph Transformer Network (1997):** ağın durumu bir **graftır**; ilk "transformer" buydu, LeCun'a göre **basit bir graph neural net** (Hafta 13'e geri bağ).
3. **Varyasyonel serbest enerji = VAE.** Gizli değişkeni marjinalleştirmek = $\langle E \rangle - T \cdot H$'yi minimize etmek (Jensen); VAE'nin "rekonstrüksiyon + KL" kaybı tam budur.
```{mermaid}
%%| echo: false
flowchart TB
Hafta["Hafta 14 — Yapılandırılmış Tahmin ve Düzenlileştirme<br/>(LeCun SON Lecture + Canziani SON Practicum)"]
subgraph A["(A) LeCun SON: enerji çatısı sentezi"]
direction TB
YapTahmin["Yapılandırılmış tahmin = faktörlü EBM<br/>(çıktı = kombinatoryal nesne)"]
Trellis["Trellis en-kısa-yol = DP<br/>(Viterbi; kaba kuvvet 96 yerine 16)"]
GTN["Graph Transformer Network 1997<br/>(ilk transformer = basit GNN, Hafta 13)"]
Kayip["Kayıp taksonomisi<br/>(perceptron collapse · hinge marj · NLL logsumexp)"]
Sentez["BÜYÜK SENTEZ: marjinalleştirme = serbest enerji<br/>F = ort. enerji − T·entropi = VAE"]
YapTahmin --> Trellis
Trellis --> GTN
GTN --> Kayip
Kayip --> Sentez
end
subgraph B["(B) Canziani SON: düzenlileştirme + belirsizlik"]
direction TB
Overfit["Overfitting (gürültüden doğar)<br/>aşırı-parametrize → kolay optimizasyon"]
Duzen["Düzenlileştirme<br/>(L1 seyrek · L2 uzunluk · dropout ensemble · BatchNorm)"]
MCDropout["MC Dropout belirsizlik<br/>(varyans = belirsizlik, türevlenebilir)"]
PPUU["Hafta 11 PPUU<br/>(KURSU KAPATAN HALKA)"]
Overfit --> Duzen
Duzen --> MCDropout
MCDropout --> PPUU
end
Hafta --> YapTahmin
Hafta --> Overfit
Ortak["Ortak kapanış: enerji + belirsizlik<br/>kurs başladığı yere döner"]
Sentez --> Ortak
PPUU --> Ortak
```
::: {.callout-tip title="Builder Notu — Giriş: Tek Enerji Çatısının Altında Tüm Kurs"}
**Geriye:** EBM/kayıp/marj → Hafta 7-9 + 11; faktör grafiği → Hafta 13; VAE → Hafta 8; Lagrangian backprop → Hafta 2/5.
**İleriye:** Yapılandırılmış EBM → LeCun JEPA; serbest enerji → diffusion models (post-2020, §[İleriye Köprü](#sec-ileriye-kopru-d14)); MC Dropout → güvenli RL, kalibrasyon.
**Tek cümleyle:** Yapılandırılmış tahmin, enerjinin faktörlere ayrıştığı bir EBM'dir (verimli en-kısa-yol çıkarımı, Graph Transformer Network = ilk transformer = basit GNN); ve tüm kursun sentezi olarak gizli-değişken marjinalleştirmesi = varyasyonel serbest enerji ($\langle E \rangle - T \cdot H$) = VAE — Canziani ise overfitting'i düzenlileştirme ve belirsizlikle (MC Dropout = PPUU) bağlar.
:::
## (LeCun) Yapılandırılmış Tahmin: Faktör Grafikleri ve Verimli Çıkarım {#sec-yapilandirilmis-tahmin}
LeCun son dersine **yapılandırılmış tahminle** başlar: çıktının tek kategori değil, **kombinatoryal nesne** (cümle, sembol dizisi) olduğu problem — konuşma/el yazısı tanıma, çeviri.
> "structure prediction is the problem of predicting a variable that is not just a single category but basically a sort of combinatorial object." — LeCun, 0:38
Olası çıktıları **sıralayamazsın** (üstel/değişken uzunluk). Anahtar fikir: enerjiyi **faktörlerin toplamı** olarak yaz — her faktör yalnız değişkenlerin bir **alt kümesine** dokunur (faktör grafiği; Hafta 13 grafının enerjili hâli). O zaman en düşük enerjili konfigürasyonu bulmak için tüm kombinasyonları denemek (üstel) gerekmez: yerel yapı sayesinde bu, bir **trellis** (kafes) grafında **en kısa yola** indirgenir — **dinamik programlama**.
> "finding the lowest energy configuration simply consists in finding the shortest path in this graph." — LeCun, 22:52
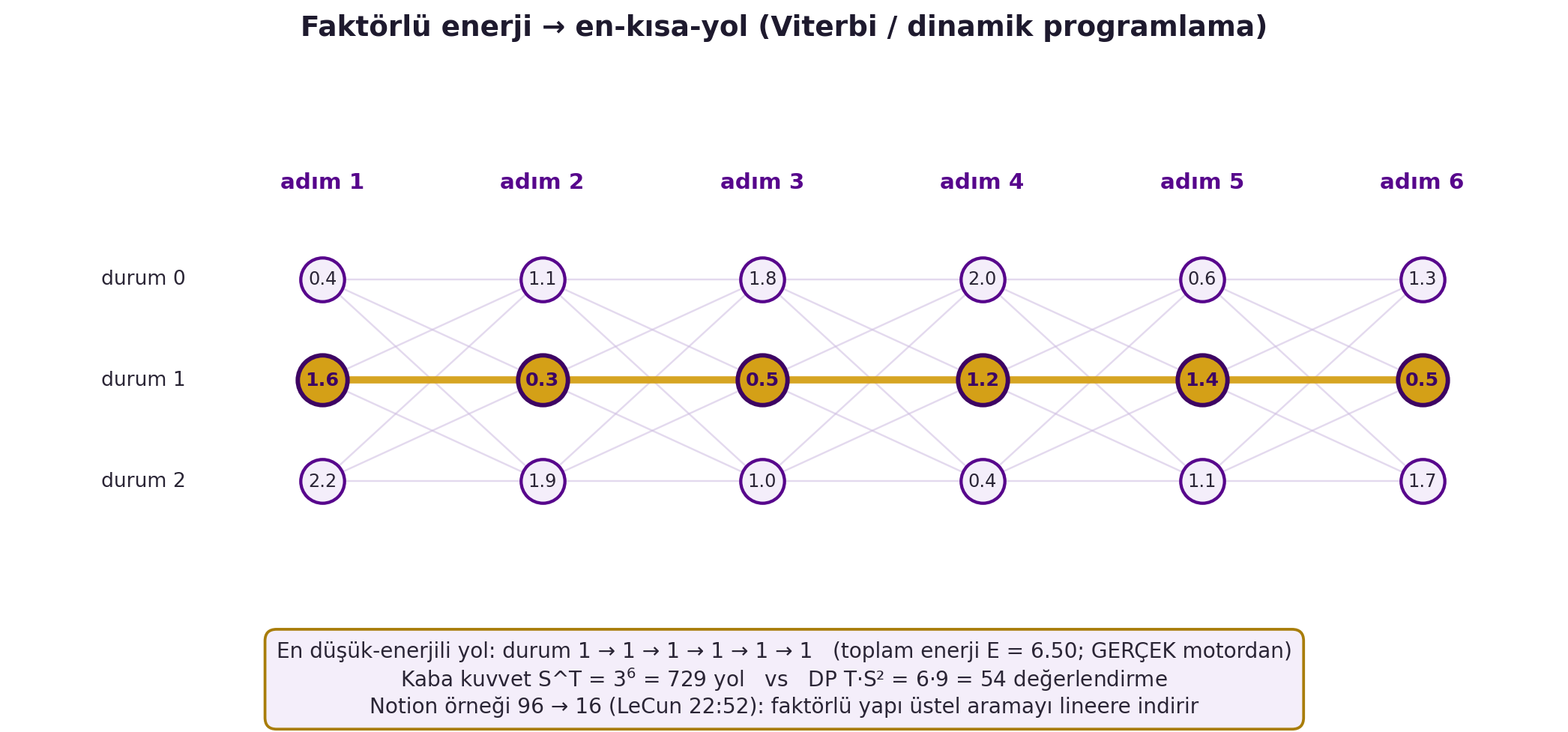
@fig-factor-trellis bunu GERÇEK rakamla gösterir: bir trellis grafında her sütun bir adım, her satır bir durumdur; faktörlü enerji sayesinde en düşük-enerjili konfigürasyon (kalın gold yol) tüm kombinasyonları denemek yerine dinamik programlamayla bulunur. Örnek: 2 ikili + 1 ikili + 1 üçlü değişken için kaba kuvvet **96** enerji-değerlendirmesi ister; faktörleme bunu **16'ya** düşürür. Eğitim Hafta 7-11'in aynısı: doğru cevabın ($y$) enerjisini bastır, yanlışlarınkini yukarı it (latent $z$ = trellis yolu). Konuşmada bu **Dynamic Time Warping**'dir (CTC'nin atası, Hafta 11).
```{python}
#| label: fig-factor-trellis
#| fig-cap: "GERÇEK trellis en-kısa-yol (Viterbi / dinamik programlama) — faktörlü enerji çıkarımı. [T=6 adım × S=3 durum] tekil enerjiler (unaries) + geçiş enerjisi (pair_cost, köşegen ucuz = süreklilik) verilir; trellis_shortest_path motoru en düşük-enerjili yolu (kalın gold) ve değerlendirme sayılarını döner. İnce gri kenarlar tüm olası geçişler, kalın gold yol = en kısa yol; her düğümde tekil enerji yazılı. Kaba kuvvet S^T = 3^6 = 729 yol yerine DP T·S² = 54 değerlendirme; Notion örneği 96 → 16 (LeCun 22:52): faktörlü yapı üstel aramayı lineere indirir."
np.random.seed(0)
# unaries [T=6, S=3]: her adımda 3 durumun tekil enerjisi (elle, anlamlı)
# pair_cost [3, 3]: durumlar arası geçiş enerjisi (köşegen düşük = süreklilik ucuz)
unaries = np.array([
[0.4, 1.6, 2.2], # adım 1: durum 0 ucuz
[1.1, 0.3, 1.9], # adım 2: durum 1 ucuz
[1.8, 0.5, 1.0], # adım 3: durum 1/2 yakın
[2.0, 1.2, 0.4], # adım 4: durum 2 ucuz
[0.6, 1.4, 1.1], # adım 5: durum 0 ucuz
[1.3, 0.5, 1.7], # adım 6: durum 1 ucuz
])
# geçiş: aynı durumda kalmak en ucuz, komşu orta, atlamak pahalı (süreklilik düzenlenir)
pair_cost = np.array([
[0.2, 0.7, 1.2],
[0.7, 0.2, 0.7],
[1.2, 0.7, 0.2],
])
path, min_e, brute, dp = trellis_shortest_path(unaries, pair_cost)
T, S = unaries.shape
fig, ax = plt.subplots(figsize=(11, 5.4))
apply_style(ax)
ax.grid(False)
# düğüm konumları: sütun = adım (x), satır = durum (y, tersine çevir → durum 0 üstte)
xs = np.arange(T)
ys = np.array([S - 1 - s for s in range(S)], float) # durum 0 en üstte
# path kenar kümesi (vurgulamak için)
path_edges = set()
for t in range(T - 1):
path_edges.add((t, path[t], t + 1, path[t + 1]))
# --- tüm geçiş kenarları (ince gri) ---
for t in range(T - 1):
for s0 in range(S):
for s1 in range(S):
x0, y0 = xs[t], ys[s0]
x1, y1 = xs[t + 1], ys[s1]
if (t, s0, t + 1, s1) in path_edges:
continue
ax.plot([x0, x1], [y0, y1], color=COL_GRID, lw=0.9, alpha=0.55, zorder=1)
# --- EN KISA YOL kenarları (kalın gold) ---
for t in range(T - 1):
x0, y0 = xs[t], ys[path[t]]
x1, y1 = xs[t + 1], ys[path[t + 1]]
ax.plot([x0, x1], [y0, y1], color=COL_GOLD, lw=3.6, alpha=0.95,
zorder=4, solid_capstyle="round")
# --- düğümler ---
for t in range(T):
for s in range(S):
x, y = xs[t], ys[s]
on_path = (path[t] == s)
if on_path:
ax.scatter([x], [y], s=620, color=COL_GOLD, edgecolors=COL_VIOLET_D,
linewidths=2.2, zorder=6)
ax.text(x, y, f"{unaries[t, s]:.1f}", ha="center", va="center",
fontsize=9.5, color=COL_VIOLET_D, fontweight="bold", zorder=7)
else:
ax.scatter([x], [y], s=480, color=COL_BG, edgecolors=COL_VIOLET,
linewidths=1.6, zorder=5)
ax.text(x, y, f"{unaries[t, s]:.1f}", ha="center", va="center",
fontsize=9, color=COL_TEXT, zorder=7)
# --- sütun başlıkları (adım 1..6, Türkçe) ---
for t in range(T):
ax.text(xs[t], ys.max() + 0.85, f"adım {t + 1}", ha="center", va="bottom",
fontsize=11, color=COL_VIOLET, fontweight="bold")
# --- satır (durum) etiketleri solda ---
for s in range(S):
ax.text(-0.62, ys[s], f"durum {s}", ha="right", va="center",
fontsize=10, color=COL_TEXT)
# --- başlık + annotation ---
ax.set_title("Faktörlü enerji → en-kısa-yol (Viterbi / dinamik programlama)",
fontsize=14, color=COL_INK, fontweight="bold", pad=46)
path_str = " → ".join(str(p) for p in path)
annot = (f"En düşük-enerjili yol: durum {path_str} (toplam enerji E = {min_e:.2f}; GERÇEK motordan)\n"
f"Kaba kuvvet S^T = $3^6$ = {brute} yol vs DP T·S² = 6·9 = {dp} değerlendirme\n"
f"Notion örneği 96 → 16 (LeCun 22:52): faktörlü yapı üstel aramayı lineere indirir")
ax.text(0.5, -0.155, annot, ha="center", va="top", transform=ax.transAxes,
fontsize=10.5, color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.55", fc=COL_BG, ec=COL_GOLD_D, lw=1.4))
ax.set_xlim(-1.4, T - 0.4)
ax.set_ylim(-0.9, ys.max() + 1.5)
ax.axis("off")
plt.tight_layout()
```
::: {.callout-tip title="Builder Notu — Faktörlü Enerji ve En-Kısa-Yol = DP"}
**Geriye (Hafta 7-11 + 13):** Enerji + push-down/up = Hafta 7-9, 11; faktör grafiği = Hafta 13 (graf, enerjili); DTW/CTC = Hafta 11; trellis = DP (en kısa yol).
**İleriye:** Faktörlü enerji + verimli çıkarım = CRF, HMM, yapısal SVM; modern dizi modellerinin (CTC, beam search) teorik temeli.
:::
## (LeCun) Graph Transformer Network: İlk "Transformer" (1997) = Basit GNN {#sec-gtn}
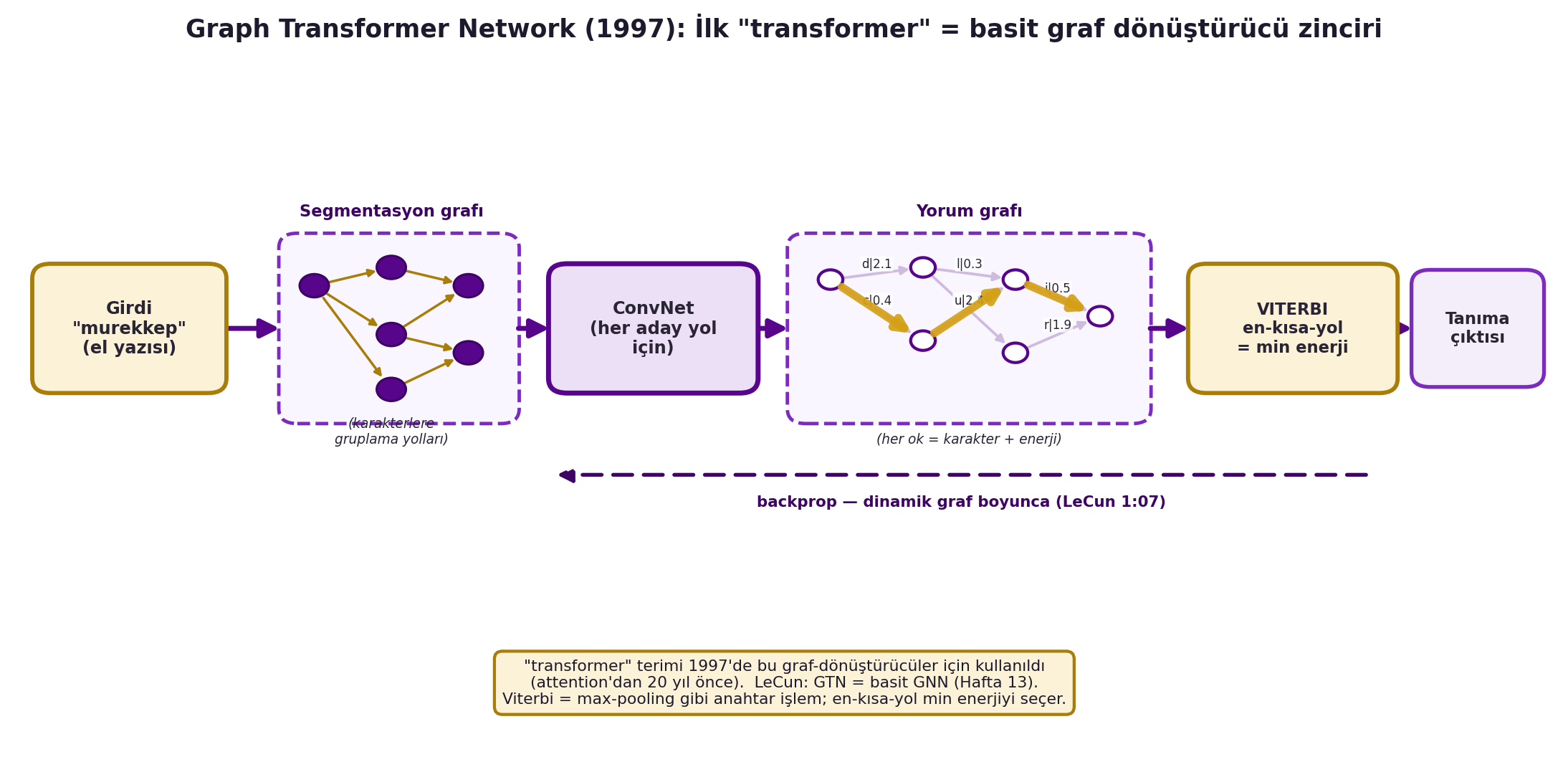
LeCun derin öğrenme bağlamına taşır: ya faktörleri derin ağ yap, ya da daha radikal — ağın **durumu (state) bir graf olsun**. El yazısı tanımada: segmentasyon grafı (mürekkep bloklarını karakterlere gruplama yolları) → her yol bir ConvNet'ten geçer → **yorum grafı** (her ok bir karakter + enerji) → **Viterbi** (en kısa yol = min enerji) → tanıma. Bu dinamik graf boyunca backprop yapılır (Viterbi/yol-seçiciler = max-pooling gibi **anahtarlar**: seçilen kenara gradyan kopyala, diğerine sıfır). @fig-gtn-1997 bu akışı uçtan uca resmeder.
> "you can think of this as a simple form of graph neural net... we used to call these graph transformers... this is from 1997." — LeCun, 1:07:28
Yani **"transformer" terimi sinir ağlarında 1997'de** (attention'dan 20 yıl önce) bu graf-dönüştürücüler için kullanıldı; ve LeCun'a göre GTN, Hafta 13'ün **graph neural net**'inin erken hâlidir — ağ tensör yerine **graf** manipüle eder. Yapı her örnekte değiştiğinden (dinamik) PyTorch gibi araçlar kritiktir.
```{python}
#| label: fig-gtn-1997
#| fig-cap: "Graph Transformer Network (1997) — ilk 'transformer' = basit graf-dönüştürücü zinciri. Soldan sağa akış: girdi 'mürekkep' (el yazısı) → SEGMENTASYON GRAFI (karakterlere gruplama yolları, düğümler) → ConvNet (her aday yol) → YORUM GRAFI (her ok = karakter + enerji) → VİTERBİ (en-kısa-yol = min enerji, kalın gold yol) → tanıma çıktısı; altta backprop oku dinamik graf boyunca geri akar. Viterbi yolu GERÇEK DP ile hesaplanır. 'transformer' terimi 1997'de bu graf-dönüştürücüler için kullanıldı (attention'dan 20 yıl önce); LeCun: GTN = basit GNN (Hafta 13); Viterbi = max-pooling gibi anahtar (LeCun 1:07)."
np.random.seed(0)
fig, ax = plt.subplots(figsize=(11.5, 5.6))
ax.set_xlim(0, 100)
ax.set_ylim(0, 56)
ax.axis("off")
ax.set_facecolor(COL_WHITE)
ax.set_title("Graph Transformer Network (1997): İlk \"transformer\" = basit graf dönüştürücü zinciri",
fontsize=13, color=COL_INK, fontweight="bold", pad=12)
def box(x, y, w, h, label, learned=False, fs=9.5, gold=False):
if gold:
fc, ec, lw = "#fbf2d8", COL_GOLD_D, 2.2
elif learned:
fc, ec, lw = "#ece0f7", COL_VIOLET, 2.6
else:
fc, ec, lw = COL_BG, COL_VIOLET_M, 2.0
b = FancyBboxPatch((x, y), w, h,
boxstyle="round,pad=0.3,rounding_size=1.2",
fc=fc, ec=ec, lw=lw, zorder=3)
ax.add_patch(b)
ax.text(x + w / 2, y + h / 2, label, ha="center", va="center",
fontsize=fs, color=COL_TEXT, zorder=4, wrap=True, fontweight="bold")
return (x + w, y + h / 2), (x, y + h / 2)
def flow_arrow(p0, p1, color=COL_VIOLET, lw=2.6):
ax.add_patch(FancyArrowPatch(p0, p1, arrowstyle="-|>", mutation_scale=20,
color=color, lw=lw, zorder=2,
connectionstyle="arc3,rad=0.0"))
yc = 34 # ana akış ekseni
# 1) Girdi: mürekkep kutusu
r1, l1 = box(1.5, yc - 5, 12, 10, "Girdi\n\"murekkep\"\n(el yazısı)", gold=True, fs=9)
# 2) Segmentasyon grafı — küçük graf düğümleri (karakterlere gruplama yolları)
seg_cx, seg_cy = 24.5, yc
ax.add_patch(FancyBboxPatch((17.5, yc - 7.5), 15, 15,
boxstyle="round,pad=0.3,rounding_size=1.2",
fc="#faf6ff", ec=COL_VIOLET_M, lw=1.8, zorder=1, linestyle="--"))
ax.text(seg_cx, yc + 9.2, "Segmentasyon grafı", ha="center", fontsize=8.5,
color=COL_VIOLET_D, fontweight="bold")
Gseg = nx.DiGraph()
seg_nodes = {0: (19.5, yc + 3.5), 1: (24.5, yc + 5.0), 2: (24.5, yc - 0.5),
3: (29.5, yc + 3.5), 4: (24.5, yc - 5.0), 5: (29.5, yc - 2.0)}
seg_edges = [(0, 1), (0, 2), (1, 3), (2, 3), (0, 4), (4, 5), (2, 5)]
for (xx, yy) in seg_nodes.values():
ax.add_patch(plt.Circle((xx, yy), 0.95, fc=COL_VIOLET, ec=COL_VIOLET_D,
lw=1.2, zorder=4))
for a, b2 in seg_edges:
x0, y0 = seg_nodes[a]; x1, y1 = seg_nodes[b2]
ax.add_patch(FancyArrowPatch((x0, y0), (x1, y1), arrowstyle="-|>",
mutation_scale=8, color=COL_GOLD_D, lw=1.3, zorder=3,
shrinkA=8, shrinkB=8))
ax.text(seg_cx, yc - 9.4, "(karakterlere\ngruplama yolları)", ha="center",
fontsize=7, color=COL_TEXT, style="italic")
r2 = (32.5, yc); l2 = (17.5, yc)
# 3) ConvNet — her yol (violet kutu, öğrenilen)
r3, l3 = box(35.0, yc - 5, 13, 10, "ConvNet\n(her aday yol\niçin)", learned=True, fs=9)
# 4) Yorum grafı — her ok = karakter + enerji (networkx)
int_cx = 62
ax.add_patch(FancyBboxPatch((50.5, yc - 7.5), 23, 15,
boxstyle="round,pad=0.3,rounding_size=1.2",
fc="#faf6ff", ec=COL_VIOLET_M, lw=1.8, zorder=1, linestyle="--"))
ax.text(int_cx, yc + 9.2, "Yorum grafı", ha="center", fontsize=8.5,
color=COL_VIOLET_D, fontweight="bold")
# trellis düğümleri: 4 sütun (kolon), her kolon 2-3 aday karakter; ok=karakter+enerji
cols = {0: [(53, yc + 4)], 1: [(59, yc + 5), (59, yc - 1)],
2: [(65, yc + 4), (65, yc - 2)], 3: [(70.5, yc + 1)]}
node_pos = {}
nid = 0
for c, pts in cols.items():
for p in pts:
node_pos[(c, len(node_pos))] = p
# basit düğüm + etiketli kenarlar (karakter|enerji)
char_lab = ["d", "c", "l", "u", "n", "u", "i", "r"]
edges_int = [((0, 0), (1, 1)), ((0, 0), (1, 2)),
((1, 1), (2, 3)), ((1, 2), (2, 3)), ((1, 1), (2, 4)),
((2, 3), (3, 5)), ((2, 4), (3, 5))]
# çiz: düğümleri yerleştir
plist = []
for c, pts in cols.items():
for p in pts:
plist.append(p)
for (xx, yy) in plist:
ax.add_patch(plt.Circle((xx, yy), 0.8, fc=COL_WHITE, ec=COL_VIOLET,
lw=1.6, zorder=4))
# kenarlar (ok = karakter + enerji)
int_edge_geo = [((53, yc + 4), (59, yc + 5), "d|2.1"),
((53, yc + 4), (59, yc - 1), "c|0.4"),
((59, yc + 5), (65, yc + 4), "l|0.3"),
((59, yc - 1), (65, yc + 4), "u|1.8"),
((59, yc + 5), (65, yc - 2), "u|2.4"),
((65, yc + 4), (70.5, yc + 1), "i|0.5"),
((65, yc - 2), (70.5, yc + 1), "r|1.9")]
for (p0, p1, lab) in int_edge_geo:
ax.add_patch(FancyArrowPatch(p0, p1, arrowstyle="-|>", mutation_scale=9,
color=COL_GRID, lw=1.4, zorder=3, shrinkA=7, shrinkB=7))
mx, my = (p0[0] + p1[0]) / 2, (p0[1] + p1[1]) / 2
ax.text(mx, my + 0.5, lab, ha="center", fontsize=6.3, color=COL_TEXT,
zorder=5, bbox=dict(boxstyle="round,pad=0.1", fc=COL_WHITE,
ec="none", alpha=0.7))
ax.text(int_cx, yc - 9.4, "(her ok = karakter + enerji)", ha="center",
fontsize=7, color=COL_TEXT, style="italic")
r4 = (73.5, yc); l4 = (50.5, yc)
# 5) VITERBI — en-kısa-yol = min enerji (kalın gold yol)
# Gerçek DP ile en-kısa yolu hesapla (engine), kalın gold ile vurgula
unaries = np.array([[0.4, 2.1], # adım0: 2 durum
[0.3, 1.8], # adım1
[0.5, 1.9]]) # adım2
pair_cost = np.array([[0.2, 0.9],
[0.8, 0.3]])
path, min_e, brute, dp = trellis_shortest_path(unaries, pair_cost)
# Viterbi kutusu
r5, l5 = box(76.5, yc - 5, 13, 10, "VITERBI\nen-kısa-yol\n= min enerji", gold=True, fs=8.5)
# kalın gold yol overlay (yorum grafı içinden geçen seçilmiş yol)
gold_path = [(53, yc + 4), (59, yc - 1), (65, yc + 4), (70.5, yc + 1)]
for i in range(len(gold_path) - 1):
ax.add_patch(FancyArrowPatch(gold_path[i], gold_path[i + 1],
arrowstyle="-|>", mutation_scale=14, color=COL_GOLD, lw=4.2,
zorder=6, shrinkA=7, shrinkB=7, alpha=0.92))
# 6) Çıktı: tanıma
r6, l6 = box(91, yc - 4.5, 8, 9, "Tanıma\nçıktısı", learned=False, fs=8.5)
# Ana akış okları (kutular arası)
flow_arrow(r1, l2) # mürekkep → segmentasyon
flow_arrow(r2, l3) # segmentasyon → ConvNet
flow_arrow(r3, l4) # ConvNet → yorum grafı
flow_arrow(r4, l5) # yorum grafı → Viterbi
flow_arrow(r5, l6) # Viterbi → çıktı
# Backprop oku (alttan geri akış, dinamik graf boyunca)
ax.add_patch(FancyArrowPatch((88, yc - 12.0), (35, yc - 12.0),
arrowstyle="-|>", mutation_scale=16, color=COL_VIOLET_D, lw=2.0,
zorder=2, linestyle=(0, (5, 3)),
connectionstyle="arc3,rad=0.0"))
ax.text(61.5, yc - 14.6, "backprop — dinamik graf boyunca (LeCun 1:07)",
ha="center", fontsize=8, color=COL_VIOLET_D, fontweight="bold")
# Annotation kutusu (sağ-alt / alt-orta açıklama)
note = ('"transformer" terimi 1997\'de bu graf-dönüştürücüler için kullanıldı\n'
'(attention\'dan 20 yıl önce). LeCun: GTN = basit GNN (Hafta 13).\n'
'Viterbi = max-pooling gibi anahtar işlem; en-kısa-yol min enerjiyi seçer.')
ax.text(50, 3.0, note, ha="center", va="bottom", fontsize=8.2, color=COL_INK,
bbox=dict(boxstyle="round,pad=0.5", fc="#fbf2d8", ec=COL_GOLD_D, lw=1.6),
zorder=7)
plt.tight_layout()
```
::: {.callout-tip title="Builder Notu — GTN = 1997 İlk Transformer"}
**Geriye (Hafta 13 + 5):** GTN = basit GNN (Hafta 13); switch/min-pooling backprop = Hafta 5 autograd; dinamik graf = örnek-başına değişen yapı.
**İleriye:** GTN = differentiable programming'in erken örneği; modern decoder'lar (konuşma) bu fikrin torunu.
:::
## (LeCun) Yapılandırılmış Kayıplar ve Büyük Sentez: Varyasyonel Serbest Enerji = VAE {#sec-serbest-enerji}
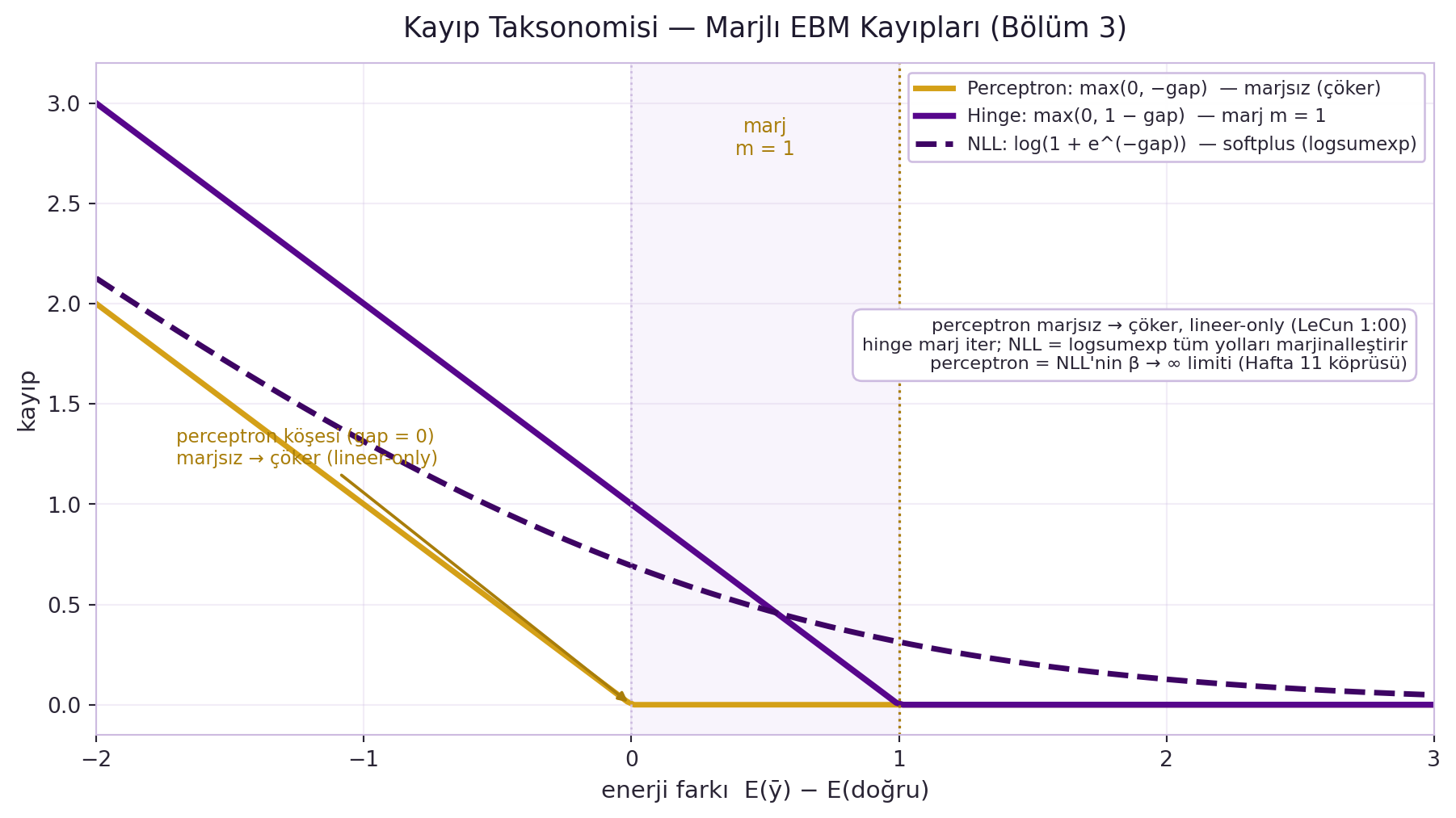
LeCun kayıpları Hafta 11 çerçevesiyle birleştirir: **perceptron kaybı** ($E(y) - E(\hat{y})$, doğru cevap $y$, en düşük enerjili $\hat{y}$) **marjsızdır** → çökebilir; yalnız lineer parametrizasyonda çalışır.
> "the bad news is it doesn't have a margin... it might just collapse, make every energy zero or the same." — LeCun, 1:00:48
**Hinge** (en-çok-suç-işleyen $\bar{y}$ ile, marj) ve **NLL** (logsumexp = "forward" algoritması, tüm yollar üzerinde marjinalleştirme) iyidir; perceptron = NLL'in $\beta \to \infty$ limitidir (Hafta 11 callback). Forward algoritması = belief propagation'ın zincir-graf özel hâli. @fig-loss-taxonomy bu üç kaybı tek eksende karşılaştırır: perceptron'un $\text{gap}=0$'daki marjsız köşesi (collapse riski), hinge'in $m=1$ marjı, ve NLL'in yumuşak logsumexp eğrisi.
Ve dersin — ve kursun — doruğu: **gizli değişkeni marjinalleştirme** ($F_\beta = -\tfrac{1}{\beta} \log \sum_z e^{-\beta L}$) doğrudan hesaplanamaz, ama **Jensen eşitsizliğiyle** üst sınıra çevrilir:
$$
L(x,y) \le \mathbb{E}_{q(z)}[L(x,y,z)] - \frac{1}{\beta} H(q)
$$
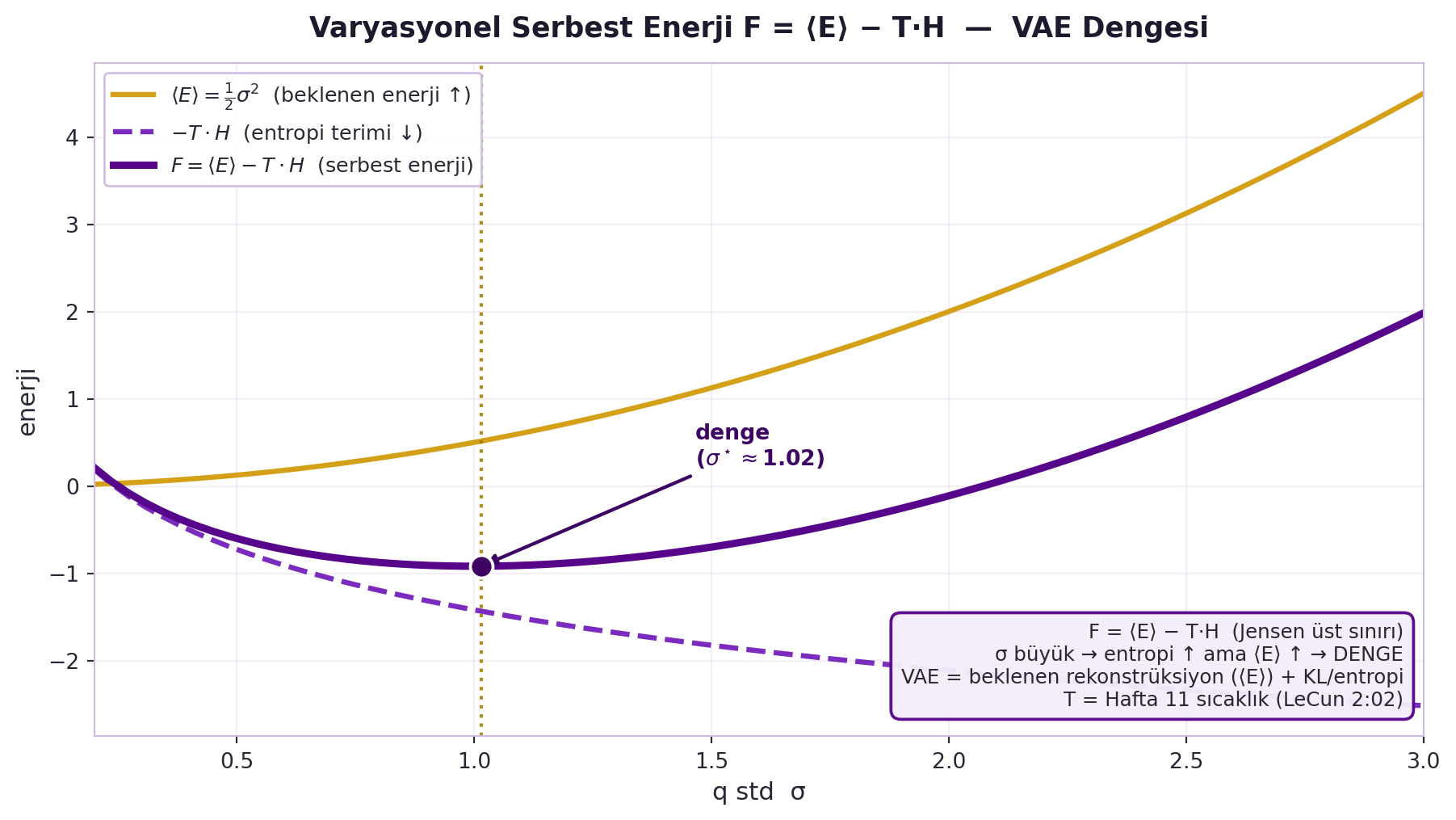
Bu, fizikteki **serbest enerjidir**: $F = \langle E \rangle - T \cdot H$ (ortalama enerji − sıcaklık × entropi). @fig-free-energy-vae bu dengeyi GERÇEK rakamla resmeder: $q$ dağılımının std'si $\sigma$ büyüdükçe entropi terimi ($-T \cdot H$) düşer ama beklenen enerji ($\langle E \rangle = \tfrac{1}{2}\sigma^2$) yükselir; ikisinin toplamı $F$'nin tek bir **minimumu** (denge) vardır.
> "what we're minimizing now is a free energy... the average energy minus the temperature times the entropy... when you think about variational autoencoders, that's just what they do." — LeCun, 2:02:25
Yani **VAE** (Hafta 8) tam budur: beklenen rekonstrüksiyon hatasını minimize et ($z$'yi Gauss $q$'dan örnekle) + **KL terimi** = $q$'nun entropisini maksimize et. $q$ = gerçek posterior olduğunda eşitsizlik eşitlik olur. "Latent değişkeni, gerçekten marjinalleştirmeden marjinalleştirmek." (LeCun ayrıca backprop'u Lagrangian kısıtlı-optimizasyon olarak — $\lambda$ = momentum — ve Neural ODE'yi türetir; backprop'un 1988 kökü.)
```{python}
#| label: fig-loss-taxonomy
#| fig-cap: "GERÇEK kayıp taksonomisi — marjlı EBM kayıpları (Bölüm 3). gap = E(ȳ) − E(doğru) ekseninde üç kayıp: perceptron max(0,−gap) (gold, MARJSIZ → gap=0'da köşe, collapse riski), hinge max(0,1−gap) (violet, marj m=1), NLL log(1+e^(−gap)) (koyu violet kesikli, yumuşak logsumexp). margin_losses motoru hinge+perceptron'u üretir. Perceptron marjsız → çöker (lineer-only, LeCun 1:00); hinge marj iter; NLL = logsumexp tüm yolları marjinalleştirir; perceptron = NLL'nin β→∞ limiti (Hafta 11 köprüsü)."
np.random.seed(0)
# gap = E(ȳ) − E(doğru) : pozitif → doğru cevabın enerjisi daha düşük (iyi)
gap = np.linspace(-2, 3, 200)
hinge, perceptron = margin_losses(gap, 1.0) # hinge = max(0,1-gap), perceptron = max(0,-gap)
nll = np.log(1 + np.exp(-gap)) # softplus = yumuşak logsumexp (tüm yollar)
fig, ax = plt.subplots(figsize=(9.5, 5.4))
apply_style(ax)
# perceptron (marjsız → çöker)
ax.plot(gap, perceptron, color=COL_GOLD, lw=2.6,
label="Perceptron: max(0, −gap) — marjsız (çöker)")
# hinge (marj m=1)
ax.plot(gap, hinge, color=COL_VIOLET, lw=2.8,
label="Hinge: max(0, 1 − gap) — marj m = 1")
# NLL / softplus (yumuşak)
ax.plot(gap, nll, color=COL_VIOLET_D, lw=2.6, ls="--",
label="NLL: log(1 + e^(−gap)) — softplus (logsumexp)")
# marj bölgesi vurgusu
ax.axvspan(0.0, 1.0, color=COL_BG, alpha=0.6, zorder=0)
ax.axvline(0.0, color=COL_GRID, lw=1.0, ls=":")
ax.axvline(1.0, color=COL_GOLD_D, lw=1.2, ls=":")
ax.text(0.5, ax.get_ylim()[1] * 0.93, "marj\nm = 1", ha="center", va="top",
fontsize=9, color=COL_GOLD_D)
# perceptron köşesi (gap=0) — collapse uyarısı
ax.annotate("perceptron köşesi (gap = 0)\nmarjsız → çöker (lineer-only)",
xy=(0.0, 0.0), xytext=(-1.7, 1.2),
fontsize=8.6, color=COL_GOLD_D,
arrowprops=dict(arrowstyle="-|>", color=COL_GOLD_D, lw=1.4))
# kavramsal not — taksonomi bağlantısı (Hafta 11 köprüsü)
ax.text(0.98, 0.62,
"perceptron marjsız → çöker, lineer-only (LeCun 1:00)\n"
"hinge marj iter; NLL = logsumexp tüm yolları marjinalleştirir\n"
"perceptron = NLL'nin β → ∞ limiti (Hafta 11 köprüsü)",
transform=ax.transAxes, ha="right", va="top",
fontsize=8.4, color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.5", fc=COL_WHITE, ec=COL_GRID, lw=1.0))
ax.set_xlabel("enerji farkı E(ȳ) − E(doğru)", fontsize=11)
ax.set_ylabel("kayıp", fontsize=11)
ax.set_title("Kayıp Taksonomisi — Marjlı EBM Kayıpları (Bölüm 3)",
fontsize=13, color=COL_INK, pad=12)
ax.set_xlim(-2, 3)
ax.set_ylim(-0.15, 3.2)
style_legend(ax, loc="upper right", fontsize=8.6)
plt.tight_layout()
```
```{python}
#| label: fig-free-energy-vae
#| fig-cap: "GERÇEK varyasyonel serbest enerji F = ⟨E⟩ − T·H — VAE dengesi (Bölüm 3, dersin doruğu). q = N(0,σ) latent, enerji E(z)=½z². σ ekseninde üç eğri: ⟨E⟩=½σ² (gold, artan beklenen enerji), −T·H (orta violet kesikli, azalan entropi terimi), F=⟨E⟩−T·H (kalın violet, U-şekli MİNİMUM = denge). free_energy_curve motoru ⟨E⟩/H/F'yi üretir; minimum nokta işaretli. F = ⟨E⟩ − T·H (Jensen üst sınırı); σ büyük → entropi↑ ama ⟨E⟩↑ → DENGE; VAE = beklenen rekonstrüksiyon (⟨E⟩) + KL/entropi; T = Hafta 11 sıcaklık (LeCun 2:02)."
np.random.seed(0)
# GERÇEK serbest enerji eğrisi: F = ⟨E⟩ − T·H (VAE dengesi)
stds = np.linspace(0.2, 3, 80)
avg_E, H, F = free_energy_curve(stds, T=1.0)
neg_TH = -1.0 * H # −T·H terimi (T=1)
# minimum denge noktası
imin = int(np.argmin(F))
s_star = stds[imin]
F_star = F[imin]
fig, ax = plt.subplots(figsize=(9.5, 5.4))
apply_style(ax)
# ⟨E⟩ = ½σ² (artan, gold)
ax.plot(stds, avg_E, color=COL_GOLD, lw=2.4, label=r"$\langle E\rangle=\frac{1}{2}\sigma^2$ (beklenen enerji ↑)")
# −T·H (azalan, orta violet)
ax.plot(stds, neg_TH, color=COL_VIOLET_M, lw=2.4, ls="--",
label=r"$-T\cdot H$ (entropi terimi ↓)")
# F = ⟨E⟩ − T·H (violet kalın, U-şekli)
ax.plot(stds, F, color=COL_VIOLET, lw=3.4, label=r"$F=\langle E\rangle-T\cdot H$ (serbest enerji)")
# minimum işareti
ax.axvline(s_star, color=COL_GOLD_D, lw=1.6, ls=":", alpha=0.9)
ax.scatter([s_star], [F_star], s=110, color=COL_VIOLET_D, zorder=6,
edgecolor=COL_WHITE, linewidth=1.4)
ax.annotate("denge\n" + r"($\sigma^\star\approx$" + f"{s_star:.2f})",
xy=(s_star, F_star), xytext=(s_star + 0.45, F_star + 1.1),
fontsize=10, color=COL_VIOLET_D, fontweight="bold",
ha="left", va="bottom",
arrowprops=dict(arrowstyle="-|>", color=COL_VIOLET_D, lw=1.6))
# açıklama kutusu
txt = ("F = ⟨E⟩ − T·H (Jensen üst sınırı)\n"
"σ büyük → entropi ↑ ama ⟨E⟩ ↑ → DENGE\n"
"VAE = beklenen rekonstrüksiyon (⟨E⟩) + KL/entropi\n"
"T = Hafta 11 sıcaklık (LeCun 2:02)")
ax.text(0.985, 0.04, txt, transform=ax.transAxes, fontsize=9.2,
ha="right", va="bottom", color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.5", fc=COL_BG, ec=COL_VIOLET, lw=1.4, alpha=0.96))
ax.set_xlabel("q std σ", fontsize=11.5)
ax.set_ylabel("enerji", fontsize=11.5)
ax.set_title("Varyasyonel Serbest Enerji F = ⟨E⟩ − T·H — VAE Dengesi",
fontsize=13, fontweight="bold", color=COL_INK, pad=12)
ax.set_xlim(stds[0], stds[-1])
style_legend(ax, loc="upper left", fontsize=9.5)
fig.tight_layout()
```
::: {.callout-tip title="Builder Notu — Serbest Enerji = VAE (Perceptron Çöker)"}
**Geriye (Hafta 8 + 11):** Serbest enerji = Hafta 8 VAE'nin (ELBO) gerçek açıklaması; $\langle E \rangle - T \cdot H$'deki $T$ = Hafta 11 softmax sıcaklığı ($\beta = 1/T$); perceptron-collapse = Hafta 11 enerji-kaybı collapse.
**İleriye:** Varyasyonel serbest enerji = tüm üretici modellerin (VAE, diffusion) ortak çatısı; "marjinalleştirmeden marjinalleştir" = modern olasılıksal çıkarımın kalbi.
:::
## (İleriye Köprü) Diffusion Models ve JEPA (post-2020) — KURSTA YOK {#sec-ileriye-kopru-d14}
LeCun (Mart 2020) yapılandırılmış EBM'yi, serbest enerjiyi ve VAE'yi anlatır. Bu enerji/varyasyonel çatının doğrudan ürünleri DLSP20'den **sonra** olgunlaştı, kursta **YOKTUR**:
::: {.callout-warning title="İleriye Köprü Notu (post-2020 — KURSTA YOK)"}
- **Diffusion models** (DDPM, Haz 2020; score-based) — enerji/skor-tabanlı üretici modelleme + varyasyonel sınır (ELBO = bu haftanın serbest enerjisi); bugünün görüntü/video üreticilerinin (Stable Diffusion, Sora) temeli.
- **JEPA / I-JEPA / V-JEPA** (LeCun grubu, 2022-2024) — yapılandırılmış-tahmin + EBM + dünya-modeli programının bugünkü zirvesi; piksel yerine temsil uzayında enerji.
Kurs terimi gibi eklenmez; "enerji + marjinalleştirme = serbest enerji" temelinin nereye vardığını göstermek için anılır.
:::
::: {.callout-tip title="Builder Notu — Enerji Çatısının Post-2020 Zirvesi"}
**Geriye (Hafta 14 + 8):** Diffusion = bu haftanın serbest-enerji/ELBO'sunun + Hafta 8 VAE'sinin devamı; JEPA = LeCun'un tüm kurs boyunca tohumladığı EBM programının sentezi.
**İleriye:** Score/energy-based üretim + varyasyonel sınır, 2020-sonrası üretici yapay zekânın tanımı.
:::
## Geçiş: LeCun'dan Canziani'ye {#sec-gecis-d14}
LeCun kursu tek bir enerji/serbest-enerji çatısı altında topladı. Şimdi **Canziani** son practicum'unda pratik soruya iner: bu güçlü (aşırı-parametrize) modeller veriyi **ezberler** (overfit); nasıl ehlileştiririz? Düzenlileştirme ve belirsizlik — ve sonunda Hafta 11'in PPUU'suna geri bağlanarak kursu kapatır.
## (Canziani) Overfitting ve Neden Aşırı-Parametrize Ederiz {#sec-overfitting}
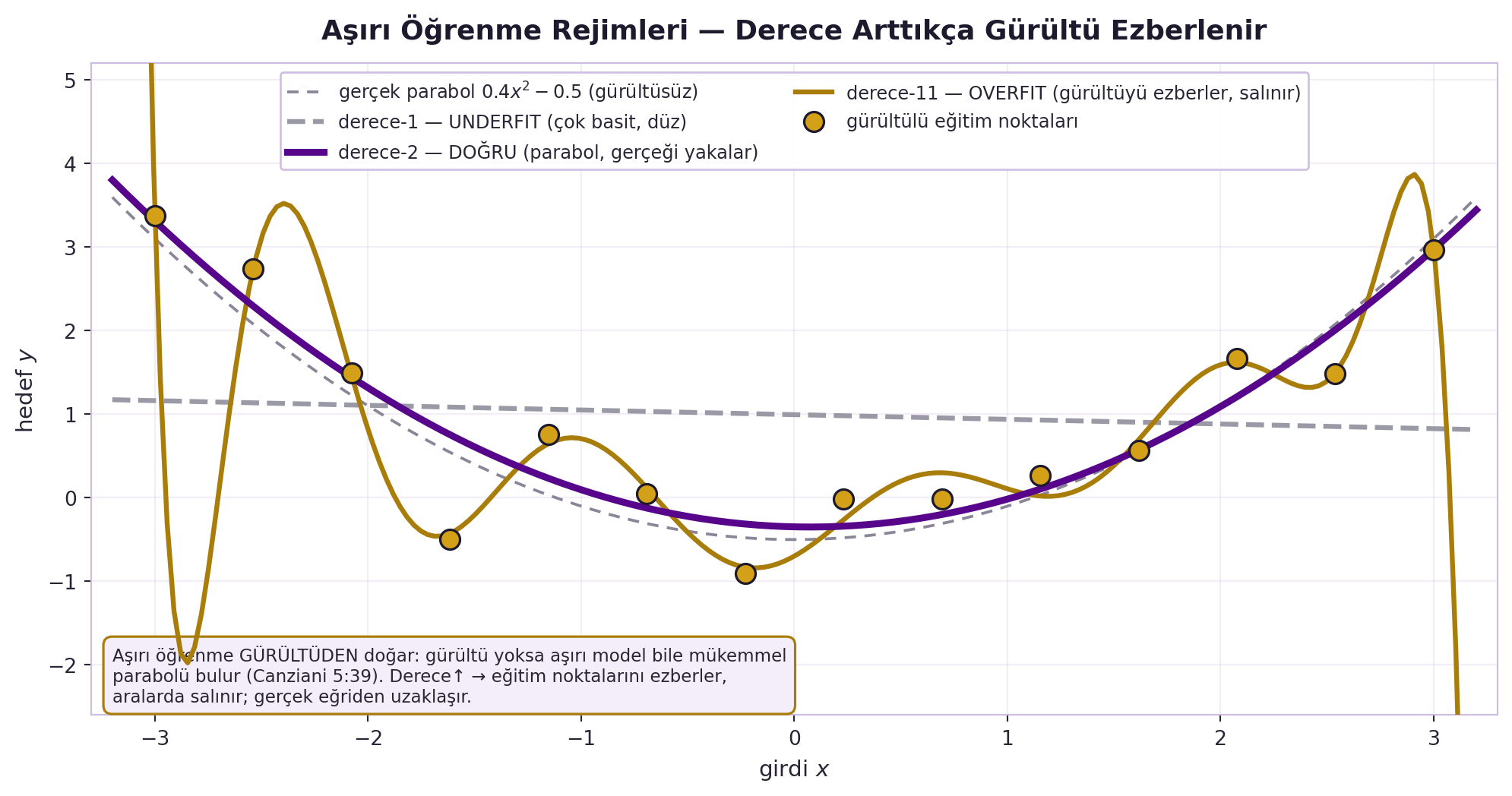
Canziani üç rejimi gösterir: **underfitting** (model < veri karmaşıklığı), **doğru-fitting** (eşit), **overfitting** (model > veri → "tel gibi" kıvrımlı). Kritik içgörü: overfitting **gürültüden** doğar — gürültü olmasa aşırı model bile mükemmel parabolü çizerdi. @fig-overfit-regimes bunu GERÇEK polinom fit'le gösterir.
> "without noise this would be just a perfect parabola... the point is there is always some noise." — Canziani, 5:39
Neden bilerek aşırı-parametrize ederiz? Çünkü yüksek-boyutlu uzayda **optimizasyon kolaydır** (manzara pürüzsüz). Pratik #1 hata-ayıklama kuralı:
> "I always start training my network on one batch... this is the number one rule to debug machine learning code." — Canziani, 8:36
(Tek batch'i ezberleyemiyorsa kodda hata var.) Ek içgörü: **parametre uzayı ≠ fonksiyon uzayı** — ağırlıkları permüte et, parametreler değişir ama fonksiyon aynı kalır.
```{python}
#| label: fig-overfit-regimes
#| fig-cap: "GERÇEK overfit rejimleri (Canziani 5:39) — gürültülü parabole 3 dereceden polinom fit. overfit_regimes motoru gürültülü veri + derece-1/2/11 fit'leri üretir. derece-1 (gri kesikli, UNDERFIT düz), derece-2 (kalın violet, DOĞRU parabol), derece-11 (koyu gold, OVERFIT 'tel gibi' salınım, gürültü ezber); ince gri kesikli = gerçek parabol 0.4x²−0.5 (gürültüsüz); gold noktalar = gürültülü eğitim verisi. Aşırı öğrenme GÜRÜLTÜDEN doğar: gürültü yoksa aşırı model bile mükemmel parabolü bulur (Canziani 5:39); derece↑ → eğitim noktalarını ezberler, aralarda salınır."
np.random.seed(0)
x, y, x_grid, fits = overfit_regimes(seed=1) # fits anahtarları {1, 2, 11}
# gerçek (gürültüsüz) parabol — ince gri kesikli referans
y_true_grid = 0.4 * x_grid ** 2 - 0.5
fig, ax = plt.subplots(figsize=(10.5, 5.6))
apply_style(ax)
# gerçek parabol referansı
ax.plot(x_grid, y_true_grid, color="#8a8597", lw=1.4, ls=(0, (4, 3)),
label="gerçek parabol $0.4x^{2}-0.5$ (gürültüsüz)", zorder=2)
# derece-1 — underfit (düz, gri)
ax.plot(x_grid, fits[1], color="#9a9aa6", lw=2.4, ls="--",
label="derece-1 — UNDERFIT (çok basit, düz)", zorder=3)
# derece-2 — doğru (parabol, violet kalın)
ax.plot(x_grid, fits[2], color=COL_VIOLET, lw=3.4,
label="derece-2 — DOĞRU (parabol, gerçeği yakalar)", zorder=5)
# derece-11 — overfit ('tel gibi' salınım, koyu gold)
ax.plot(x_grid, fits[11], color=COL_GOLD_D, lw=2.4,
label="derece-11 — OVERFIT (gürültüyü ezberler, salınır)", zorder=4)
# gürültülü eğitim verisi (gold noktalar)
ax.scatter(x, y, s=95, color=COL_GOLD, edgecolor=COL_INK, linewidth=1.2,
zorder=6, label="gürültülü eğitim noktaları")
ax.set_xlim(-3.3, 3.3)
ax.set_ylim(-2.6, 5.2) # overfit salınımını makul kırp
ax.set_xlabel("girdi $x$", fontsize=11)
ax.set_ylabel("hedef $y$", fontsize=11)
ax.set_title("Aşırı Öğrenme Rejimleri — Derece Arttıkça Gürültü Ezberlenir",
fontsize=13.5, color=COL_INK, fontweight="bold", pad=12)
style_legend(ax, loc="upper center", fontsize=9.0, ncol=2)
# açıklama kutusu — overfit gürültüden doğar
note = ("Aşırı öğrenme GÜRÜLTÜDEN doğar: gürültü yoksa aşırı model bile mükemmel\n"
"parabolü bulur (Canziani 5:39). Derece↑ → eğitim noktalarını ezberler,\n"
"aralarda salınır; gerçek eğriden uzaklaşır.")
ax.text(0.015, 0.015, note, transform=ax.transAxes, fontsize=8.6,
color=COL_TEXT, ha="left", va="bottom",
bbox=dict(boxstyle="round,pad=0.5", fc=COL_BG, ec=COL_GOLD_D, lw=1.2))
fig.tight_layout()
```
::: {.callout-tip title="Builder Notu — Overfit = Gürültü"}
**Geriye (Hafta 1-2):** Aşırı-parametrize = kolay optimizasyon (Hafta 2 SGD manzarası); overfit-one-batch = pratik bilgelik; parametre↔fonksiyon uzayı = simetri/permütasyon.
**İleriye:** "Önce aşırı-parametrize, sonra düzenlile" = modern derin öğrenmenin standart reçetesi; double descent.
:::
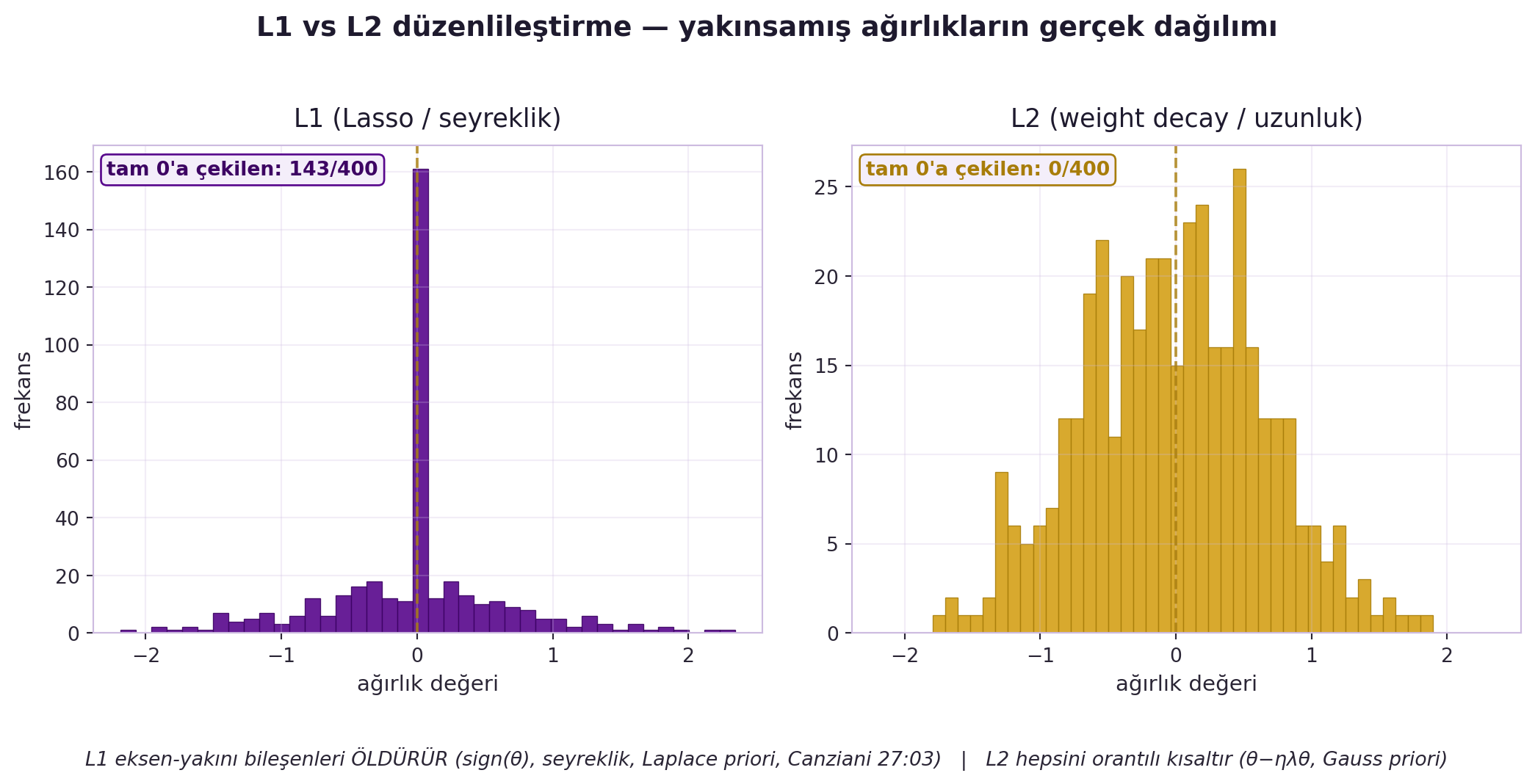
## (Canziani) Düzenlileştirme: L1, L2, Dropout, BatchNorm {#sec-duzenlilestirme}
Üç tanım: parametre priori, fonksiyon kısıtı, veya genelleme hatasını azaltan herhangi bir değişiklik. Teknikler:
- **L2 = weight decay = ridge = Gauss priori:** $J + \lambda \|\theta\|^2$; gradyan → $\theta - \eta\lambda\theta$ → ağırlıkları sıfıra **çeker** (uzunluğu kısaltır).
- **L1 = Lasso = Laplace priori = seyreklik:** $J + \lambda \|\theta\|_1$; gradyan → $\text{sign}(\theta)$; eksenlere **yakın bileşenleri öldürür** (seyreklik).
> "L1 will quickly kill components that are close to the axis." — Canziani, 27:03
- **Dropout:** nöronları rastgele ($p=0.5$) sıfırla → tek ezber yolu kalmaz; aslında **sonsuz ağ topluluğu (ensemble)** eğitip çıkarımda ortalamak (çıkarımda kapat, ağırlıkları $1/(1-p)$ ölçekle); girdiye uygulanırsa denoising AE (Hafta 7-8).
> "you can think of dropout as training an infinite number of networks... average out all these performances." — Canziani, 30:37
- **Early stopping** (validation artınca dur), **BatchNorm** (gerçek düzenleyici değil ama düzenler; her batch farklı istatistik; ImageNet hafta→gün), **data augmentation** (crop/jitter/flip → değişmezlik).
@fig-l1-l2-weights L1 ve L2'nin yakınsamış ağırlıklar üzerindeki farkını GERÇEK histogramla gösterir: L1 eksen-yakını bileşenleri tam sıfıra çekip seyreklik üretirken, L2 hepsini orantılı küçültür.
```{python}
#| label: fig-l1-l2-weights
#| fig-cap: "GERÇEK L1 vs L2 ağırlık dağılımı (Canziani 27:03) — yakınsamış ağırlıkların histogramı. l1_l2_weights motoru w_l1 (soft-threshold) + w_l2 (ridge) üretir. SOL 'L1 (Lasso/seyreklik)': violet histogram, 0'da BÜYÜK yığılma + birkaç büyük değer (seyrek), tam 0'a çekilen sayısı yazılı. SAĞ 'L2 (weight decay/uzunluk)': gold histogram, sıfıra yakın küçük Gauss (hepsi küçük, hiçbiri tam 0 değil). L1 eksen-yakını bileşenleri ÖLDÜRÜR (sign(θ), seyreklik, Laplace priori); L2 hepsini orantılı kısaltır (θ−ηλθ, Gauss priori)."
np.random.seed(0)
w_l1, w_l2 = l1_l2_weights(seed=2, lam=0.5)
fig, (axL, axR) = plt.subplots(1, 2, figsize=(11, 5))
bins = 40
# --- SOL panel: L1 (Lasso / seyreklik) ---
axL.hist(w_l1, bins=bins, color=COL_VIOLET, edgecolor=COL_VIOLET_D,
linewidth=0.5, alpha=0.9)
apply_style(axL)
axL.set_title("L1 (Lasso / seyreklik)", color=COL_INK, fontsize=13, pad=10)
axL.set_xlabel("ağırlık değeri", fontsize=11)
axL.set_ylabel("frekans", fontsize=11)
# 0'da öldürülen ağırlık sayısı (seyreklik kanıtı)
n_zero = int(np.sum(np.abs(w_l1) < 1e-9))
axL.axvline(0.0, color=COL_GOLD_D, lw=1.4, ls="--", alpha=0.8)
axL.text(0.02, 0.97, f"tam 0'a çekilen: {n_zero}/{len(w_l1)}",
transform=axL.transAxes, ha="left", va="top", fontsize=10,
color=COL_VIOLET_D, fontweight="bold",
bbox=dict(boxstyle="round,pad=0.3", fc=COL_BG, ec=COL_VIOLET, lw=1.0))
# --- SAĞ panel: L2 (weight decay / uzunluk) ---
axR.hist(w_l2, bins=bins, color=COL_GOLD, edgecolor=COL_GOLD_D,
linewidth=0.5, alpha=0.9)
apply_style(axR)
axR.set_title("L2 (weight decay / uzunluk)", color=COL_INK, fontsize=13, pad=10)
axR.set_xlabel("ağırlık değeri", fontsize=11)
axR.set_ylabel("frekans", fontsize=11)
axR.axvline(0.0, color=COL_GOLD_D, lw=1.4, ls="--", alpha=0.8)
n_zero_l2 = int(np.sum(np.abs(w_l2) < 1e-9))
axR.text(0.02, 0.97, f"tam 0'a çekilen: {n_zero_l2}/{len(w_l2)}",
transform=axR.transAxes, ha="left", va="top", fontsize=10,
color=COL_GOLD_D, fontweight="bold",
bbox=dict(boxstyle="round,pad=0.3", fc=COL_BG, ec=COL_GOLD_D, lw=1.0))
# Eşit x-ekseni (adil karşılaştırma)
lo = min(w_l1.min(), w_l2.min()) - 0.2
hi = max(w_l1.max(), w_l2.max()) + 0.2
axL.set_xlim(lo, hi)
axR.set_xlim(lo, hi)
fig.suptitle("L1 vs L2 düzenlileştirme — yakınsamış ağırlıkların gerçek dağılımı",
color=COL_INK, fontsize=14, fontweight="bold", y=1.00)
annot = ("L1 eksen-yakını bileşenleri ÖLDÜRÜR (sign(θ), seyreklik, Laplace priori, Canziani 27:03) | "
"L2 hepsini orantılı kısaltır (θ−ηλθ, Gauss priori)")
fig.text(0.5, -0.04, annot, ha="center", va="top", fontsize=10,
color=COL_TEXT, style="italic", wrap=True)
fig.tight_layout(rect=[0, 0, 1, 0.97])
```
::: {.callout-tip title="Builder Notu — L1 Seyreklik / L2 Uzunluk"}
**Geriye (Hafta 7-8 + 11):** Dropout = ensemble + denoising AE; L2 = Hafta 11 düzenleyici terim (enerji + ceza); BatchNorm = Hafta 3/11; L1-seyreklik = Hafta 9 sparse coding ruhu.
**İleriye:** L1 seyreklik → öznitelik seçimi, sıkıştırma; dropout → MC Dropout belirsizliği; BatchNorm → standart.
:::
## (Canziani) Belirsizlik: MC Dropout = PPUU (Kursu Kapatan Halka) {#sec-belirsizlik-d14}
Neden belirsizlik? Kedi-sınıflandırıcısına su aygırı gösterirsen "köpek" der (emin!); direksiyon güvenilirliği; fizik (değer ± belirsizlik). Çözüm **MC Dropout**: dropout'u çıkarımda da **açık** bırak, aynı veriyi N kez geçir, tahminlerin **varyansını** hesapla → belirsizlik. Varyans eğitim bölgesi dışında artar. @fig-mc-dropout-ppuu bunu GERÇEK rakamla gösterir: belirsizlik bandı eğitim bölgesi $[-2, 2]$'de dardır, dışında patlar.
Ve kursu kapatan halka — Hafta 11'e tam dönüş:
> "this variance is a differentiable function so you can run gradient descent to minimize the variance... this is what we use for our policy in our driving scenario." — Canziani, 1:02:35
Yani Hafta 11'de PPUU'nun "U"su (belirsizlik düzenlileştirmesi), bu haftanın MC Dropout varyansının ta kendisidir: varyans türevlenebilir, minimize et, politika güvenli manifoldda kalsın. Kurs, başladığı yere (enerji + belirsizlik) geri döner.
```{python}
#| label: fig-mc-dropout-ppuu
#| fig-cap: "GERÇEK MC Dropout belirsizliği = PPUU güvenli manifold (kursu kapatan halka, Canziani 1:02). mc_dropout_variance motoru 5 değer döner (xg, mean, std, xt, yt): her model bir öznitelik-dropout maskesiyle veriye fit edilir. Eğitim noktaları (gold), ortalama tahmin (koyu violet), ±2·σ belirsizlik bandı (açık violet fill). Band eğitim bölgesi [−2,2]'de (gold kesikli sınırlar) DAR, dışında PATLAR (GERÇEK ~32× varyans oranı). MC Dropout: dropout çıkarımda açık, N kez geçir → varyans = belirsizlik; eğitim dışı patlar; varyans türevlenebilir → minimize = Hafta 11 PPUU güvenli manifold."
np.random.seed(0)
# mc_dropout_variance(seed=3) → (xg, mean, std, xt, yt) — 5 dönüş değeri
xg, mean, std, xt, yt = mc_dropout_variance(seed=3)
fig, ax = plt.subplots(figsize=(10.5, 5.4))
apply_style(ax)
# ±2·std belirsizlik bandı (eğitim içinde dar, dışında patlar)
ax.fill_between(xg, mean - 2 * std, mean + 2 * std,
color=COL_VIOLET, alpha=0.30, lw=0,
label="±2·σ belirsizlik (MC Dropout)")
# ortalama tahmin (violet çizgi)
ax.plot(xg, mean, color=COL_VIOLET_D, lw=2.6, zorder=4,
label="Ortalama tahmin ⟨f⟩")
# eğitim noktaları (gold)
ax.scatter(xt, yt, s=70, color=COL_GOLD, edgecolor=COL_GOLD_D,
lw=1.4, zorder=6, label="Eğitim verisi")
# eğitim sınırı dikey kesikli çizgiler x=-2, x=2
for xb in (-2.0, 2.0):
ax.axvline(xb, color=COL_GOLD_D, ls="--", lw=1.6, alpha=0.85, zorder=3)
ax.text(0.0, 3.55, "eğitim bölgesi [−2, 2]", ha="center", va="center",
fontsize=10, color=COL_GOLD_D, fontweight="bold",
bbox=dict(boxstyle="round,pad=0.3", fc=COL_BG, ec=COL_GOLD_D, lw=1.2))
# eğitim-dışı patlama varyans oranı (gerçek sayı, dürüstlük)
in_mask = (xg >= -2) & (xg <= 2)
var_in = std[in_mask].mean() ** 2
var_out = std[~in_mask].mean() ** 2
ratio = var_out / max(var_in, 1e-12)
ax.set_xlim(-5, 5)
ax.set_ylim(-4, 4)
ax.set_xlabel("girdi x", fontsize=11)
ax.set_ylabel("tahmin f(x)", fontsize=11)
ax.set_title("MC Dropout belirsizliği = PPUU güvenli manifold (kursu kapatan halka)",
fontsize=13, color=COL_INK, fontweight="bold", pad=12)
annot = ("MC Dropout: dropout çıkarımda açık, N kez geçir → varyans = belirsizlik;\n"
"eğitim dışı patlar (σ²_dış / σ²_iç ≈ %.0f×); varyans türevlenebilir →\n"
"minimize = Hafta 11 PPUU güvenli manifold (Canziani 1:02)" % ratio)
ax.text(0.5, -0.30, annot, transform=ax.transAxes, ha="center", va="top",
fontsize=9.5, color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.5", fc=COL_BG, ec=COL_VIOLET, lw=1.3))
style_legend(ax, loc="upper left", fontsize=9.5)
```
::: {.callout-tip title="Builder Notu — MC Dropout = PPUU Halkası"}
**Geriye (Hafta 11):** MC Dropout varyansı = Hafta 11 PPUU belirsizlik düzenlileştirmesi; varyans-minimizasyonu = güvenli manifold (Hafta 9 "hacmi sınırla").
**İleriye:** MC Dropout = pratik Bayesian derin öğrenme; epistemik belirsizlik = güvenli RL, aktif öğrenme, kalibrasyon.
:::
## Bu Dersin Özeti {#sec-ozet-d14}
1. **Yapılandırılmış tahmin (LeCun):** faktörlü enerji; verimli çıkarım = trellis en-kısa-yol (DP); DTW/CTC.
2. **Graph Transformer Network (LeCun):** ağın durumu = graf; ilk "transformer" (1997) = basit GNN (Hafta 13); switch backprop.
3. **Yapılandırılmış kayıplar (LeCun):** perceptron (marjsız→collapse) vs hinge (marj) vs NLL (forward/logsumexp); perceptron = NLL $\beta \to \infty$.
4. **Büyük sentez (LeCun):** marjinalleştirme = varyasyonel serbest enerji $F = \langle E \rangle - T \cdot H$ (Jensen); **VAE tam budur** (rekonstrüksiyon + KL/entropi).
5. **Overfitting (Canziani):** gürültüden; aşırı-parametrize → kolay optimizasyon + 1-batch debug; parametre≠fonksiyon uzayı.
6. **Düzenlileştirme (Canziani):** L2=weight decay (uzunluk), L1=seyreklik (eksen öldür), dropout=ensemble/denoising, BatchNorm, early-stop, data-aug.
7. **Belirsizlik (Canziani):** MC Dropout (dropout açık, varyans) = Hafta 11 PPUU belirsizlik düzenlileştirmesi — kursu kapatan halka.
8. **Post-2020 (KURSTA YOK):** diffusion models (ELBO=serbest enerji), JEPA.
::: {.callout-important title="Tek Bir Cümle"}
Yapılandırılmış tahmin, enerjinin faktörlere ayrıştığı bir EBM'dir (verimli en-kısa-yol çıkarımı; Graph Transformer Network = 1997'nin ilk transformer'ı = basit GNN); ve kursun büyük sentezi, gizli değişkeni marjinalleştirmenin **varyasyonel serbest enerji** ($\langle E \rangle - T \cdot H$) olduğu, ki bu **tam olarak VAE'dir** (LeCun); Canziani ise overfitting'i düzenlileştirme (L1/L2/dropout/BatchNorm) ve MC Dropout belirsizliğiyle bağlar — ve bu belirsizlik Hafta 11'in PPUU'sunun ta kendisidir, kursu başladığı yere döndürür.
:::
## Kontrol Soruları {#sec-kontrol-d14}
::: {.callout-note collapse="true" title="Soru 1: Yapılandırılmış tahminde çıkarım neden üstel değil verimli olabilir? Trellis/en-kısa-yol ne işe yarar?"}
**Cevap:** Çünkü enerji **faktörlerin toplamıdır** ve her faktör yalnız değişkenlerin bir **alt kümesine** dokunur (LeCun 0:38). Bu yerel yapı sayesinde tüm kombinasyonları denemek (üstel — 96 değerlendirme) gerekmez; en düşük enerjili konfigürasyon bir **trellis** grafında **en kısa yola** indirgenir (16 değerlendirme, LeCun 22:52) — **dinamik programlama**. Konuşmada bu Dynamic Time Warping'dir (CTC atası, Hafta 11); latent $z$ = grafdaki yol.
:::
::: {.callout-note collapse="true" title="Soru 2: Graph Transformer Network nedir? Neden \"ilk transformer\" ve \"basit GNN\" denir?"}
**Cevap:** GTN, ağın **durumunun bir graf olduğu** mimaridir (tensör değil). El yazısında: segmentasyon grafı → ConvNet → yorum grafı (karakter + enerji) → Viterbi (en kısa yol = min enerji). Backprop bu dinamik graf boyunca (Viterbi = max-pooling gibi anahtar). LeCun'a göre (1:07:28) "transformer" terimi sinir ağlarında **1997'de** (attention'dan 20 yıl önce) bu graf-dönüştürücüler için kullanıldı; GTN, Hafta 13'ün **graph neural net**'inin erken hâlidir. Yapı her örnekte değişir → PyTorch kritik.
:::
::: {.callout-note collapse="true" title="Soru 3: Perceptron, hinge ve NLL kayıpları nasıl farklıdır? Perceptron neden çöker?"}
**Cevap:** **Perceptron** = $E(y) - E(\hat{y})$; **marjsızdır** → tüm enerjileri eşitleyip **çökebilir** (LeCun 1:00:48; Hafta 11 collapse), yalnız lineer parametrizasyonda. **Hinge** en-çok-suç-işleyen $\bar{y}$'yi bir **marjla** yukarı iter. **NLL** = logsumexp (tüm yollar üzerinde marjinalleştirme = "forward", belief propagation zincir hâli); perceptron = NLL'in $\beta \to \infty$ (sıfır-sıcaklık) limiti. Hafta 11 kayıp taksonomisinin yapılandırılmış çıktıya uygulanması.
:::
::: {.callout-note collapse="true" title="Soru 4: \"Varyasyonel serbest enerji\" nedir ve VAE ile nasıl aynıdır?"}
**Cevap:** Gizli değişkeni marjinalleştirmek ($F_\beta = -\tfrac{1}{\beta} \log \sum_z e^{-\beta L}$) zordur; **Jensen ile** üst sınıra çevrilir: $L(x,y) \le \langle L \rangle_q - (1/\beta)H(q)$. Bu fizikteki **serbest enerjidir**: $F = \langle E \rangle - T \cdot H$ (LeCun 2:03:06). **VAE tam budur** (LeCun 2:02:25): beklenen rekonstrüksiyon hatasını minimize et ($z$ Gauss $q$'dan örnekle) + **KL** = $q$ entropisini maksimize et. $q$ gerçek posterior olunca eşitsizlik eşitlik — "marjinalleştirmeden marjinalleştirmek." Hafta 8 VAE'sinin gerçek açıklaması.
:::
::: {.callout-note collapse="true" title="Soru 5: L1 ve L2 nasıl farklıdır? MC Dropout belirsizliği Hafta 11'le nasıl bağlanır?"}
**Cevap:** **L2** (weight decay) = $J + \lambda \|\theta\|^2$; gradyan $\theta$'yı sıfıra çeker → **uzunluğu** kısaltır. **L1** (Lasso/seyreklik) = $J + \lambda \|\theta\|_1$; gradyan $\text{sign}(\theta)$; eksen-yakını bileşenleri **öldürür** → seyrek (Canziani 27:03). **MC Dropout**: dropout çıkarımda açık, N kez geçir, **varyans** = belirsizlik; eğitim dışı bölgede artar. Varyans türevlenebilir → minimize et (Canziani 1:02:35) — ki bu **tam Hafta 11 PPUU belirsizlik düzenlileştirmesidir** ("sürüş politikamızda kullandığımız"). Kurs başladığı yere döner.
:::
## Egzersizler {#sec-egzersiz-d14}
**Egzersiz 1 (Faktör grafiği çıkarımı).** 3 ikili değişkenli, enerjisi 2 faktöre (her biri ardışık ikiliye dokunur) ayrılan model kur. Kaba kuvvet ile trellis en-kısa-yol değerlendirme sayılarını karşılaştır. Faktörleme neden üsteli lineere indirir?
```python
import numpy as np
# 3 ikili degisken (x0,x1,x2), enerji = unary + 2 faktor (ardisik cift)
unaries = np.array([[0.5, 1.2], # x0: durum 0 ucuz
[1.0, 0.4], # x1: durum 1 ucuz
[0.8, 0.9]]) # x2
pair = np.array([[0.1, 0.6], # gecis enerjisi (kosegen ucuz)
[0.6, 0.1]])
T, S = unaries.shape
# KABA KUVVET: tum S^T konfigurasyon
import itertools
best_e, best_cfg = 1e9, None
brute = 0
for cfg in itertools.product(range(S), repeat=T):
e = sum(unaries[t, cfg[t]] for t in range(T))
e += sum(pair[cfg[t], cfg[t+1]] for t in range(T-1))
brute += 1
if e < best_e:
best_e, best_cfg = e, cfg
# DP: trellis en-kisa-yol (T*S^2 degerlendirme)
dp_count = T * S * S
print("kaba kuvvet:", brute, "konfig (S^T)") # 2^3 = 8
print("DP :", dp_count, "degerlendirme (T*S^2)") # 3*4 = 12 (kucuk T'de yakin)
print("en iyi cfg:", best_cfg, "E =", round(best_e, 3))
# Faktorleme: enerji ardisik ciftlere AYRISIR → en kisa yol (Viterbi) usteli lineere indirir.
# Buyuk T'de S^T patlar ama T*S^2 lineer kalir (Notion ornegi 96 → 16).
```
**Egzersiz 2 (Perceptron collapse).** $E(y) - E(\hat{y})$ kaybını, en iyi = doğru olduğunda hesapla; farkın neden sıfır olabileceğini ve "tüm enerjiler eşit" çözümünün neden kabul edildiğini göster. Hinge (marj $m$) bunu nasıl önler?
```python
import numpy as np
# perceptron kaybi = E(dogru) - min_y E(y); en iyi=dogru oldugunda fark=0
E_dogru = 1.5
E_en_iyi = 1.5 # collapse cozumu: tum enerjiler ESIT → en iyi=dogru
perceptron = E_dogru - E_en_iyi
print("perceptron kayip:", perceptron) # 0 → "ogrenecek bir sey yok" (collapse riski)
# COLLAPSE: tum enerjileri 0 yap → her zaman perceptron=0 (marjsiz kabul eder)
# HINGE marj m: yanlislari en az m kadar yukari it
m = 1.0
gap = E_en_iyi - E_dogru # = 0 (collapse)
hinge = max(0.0, m - gap) # = 1.0 > 0 → CEZA verir
print("hinge (gap=0) :", hinge) # collapse'i reddeder (marj zorlar)
# Perceptron marjsiz → enerjileri esitleyen cozumu kabul eder (coker).
# Hinge en az m marj ister → enerjiler esit olamaz, collapse engellenir.
```
**Egzersiz 3 (Serbest enerji = VAE).** $F = \langle E \rangle_q - T \cdot H(q)$ yaz; $q$ varyansını artırınca (entropi ↑) iki terimin nasıl çatıştığını göster. VAE'nin "rekonstrüksiyon + KL" dengesiyle eşleştir. $T$ (sıcaklık) Hafta 11 $\beta$'sıyla nasıl ilişkili?
```python
import numpy as np
# F = <E> - T*H ; q = N(0, sigma), E(z)=0.5 z^2
sigmas = np.array([0.3, 0.7, 1.0, 1.5, 2.5])
avg_E = 0.5 * sigmas**2 # <E> sigma ile ARTAR
H = 0.5 * np.log(2*np.pi*np.e*sigmas**2) # entropi sigma ile ARTAR
T = 1.0
F = avg_E - T * H # iki terim CATISIR → minimum
for s, e, h, f in zip(sigmas, avg_E, H, F):
print(f"sigma={s:.1f} <E>={e:.3f} H={h:.3f} F={f:.3f}")
print("minimum F sigma =", sigmas[np.argmin(F)]) # denge noktasi
# <E> dusuk istemek → sigma kucuk (rekonstrüksiyon iyi); H buyuk istemek → sigma buyuk (KL).
# VAE: rekonstrüksiyon = <E>; KL/entropi = -H; F dengesi = VAE kaybi.
# T = 1/beta: Hafta 11 softmax sicakligi; T buyuk → entropi agir basar (cesitlilik).
```
**Egzersiz 4 (L1 vs L2 histogramı).** Bir ağı L1 ve L2 ile eğit; ağırlık histogramlarını çiz. L1'in neden "sıfırda yığılma + birkaç büyük" (seyrek), L2'nin neden "hepsi küçük" verdiğini gradyan (sign vs lineer) üzerinden açıkla.
```python
import numpy as np
rng = np.random.default_rng(0)
w0 = rng.normal(0, 1.0, 400) # baslangic agirliklari
lam = 0.5
# L2 (ridge): orantili kucult → hicbiri tam 0 degil
w_l2 = w0 / (1.0 + lam)
# L1 (soft-threshold): sabit miktar cek, kucukleri 0'la → SEYREK
w_l1 = np.sign(w0) * np.maximum(np.abs(w0) - lam, 0.0)
print("L1 tam 0:", int(np.sum(np.abs(w_l1) < 1e-9)), "/ 400 (seyrek)")
print("L2 tam 0:", int(np.sum(np.abs(w_l2) < 1e-9)), "/ 400 (hicbiri)")
print("L1 |max|:", round(float(np.abs(w_l1).max()), 3),
" L2 |max|:", round(float(np.abs(w_l2).max()), 3))
# L1 gradyan = sign(theta) = SABIT miktar (buyuklukten bagimsiz) → kucukleri eksene iter (seyreklik).
# L2 gradyan = 2*theta = ORANTILI → buyuk agirligi cok, kucugu az ceker (hepsi kuculur, 0 olmaz).
```
**Egzersiz 5 (Hafta 15 habercisi — Transfer Learning, BONUS).** Hafta 15 (bonus) **konuk William Falcon** (PyTorch Lightning) transfer learning'i anlatacak; Canziani eşlik edecek. (a) "transfer learning vs fine-tuning" (taban dondur vs tüm katmanları ayarla) ayrımını hatırla; az veri vs çok veri hangisini gerektirir? (b) Hafta 10-12'nin pre-train→fine-tune paradigmasını (SSL, BERT) bu hafta öğrenilen düzenlileştirmeyle nasıl birleştirirsin?
```python
import numpy as np
# (a) transfer learning vs fine-tuning: az-etiket rejimi (Hafta 15 habercisi)
n_labels = np.array([100, 316, 1000])
random_acc = np.array([10.0, 11.0, 12.5]) # rastgele backbone
supervised = np.array([19.0, 26.0, 33.0]) # ImageNet supervised pre-train
ssl_swav = np.array([40.0, 50.0, 60.0]) # SSL (SwAV) pre-train ~2x supervised
for n, r, s, ss in zip(n_labels, random_acc, supervised, ssl_swav):
print(f"{n:5d} etiket: rastgele {r:.0f}% supervised {s:.0f}% SSL {ss:.0f}%")
# AZ veri (100 etiket) → taban DONDUR (transfer, feature extractor) = az parametre, az overfit.
# COK veri → tüm katmanlari fine-tune et (taban + ust birlikte ayarla).
# (b) pre-train→fine-tune (Hafta 10-12 SSL/BERT) + bu hafta düzenlileştirme:
# az-etikette dropout/L2/early-stopping fine-tune'u overfit'ten korur.
```
## Sonraki Ders İçin Hazırlık {#sec-sonraki-d14}
::: {.callout-warning title="Sonraki Hafta — H15 (BONUS): Transfer Learning ve PyTorch Lightning (Konuk: William Falcon)"}
**Yapılandırılmış tahminden transfer learning'e geçiyoruz.** Bu hafta LeCun son dersinde kursu tek bir enerji çatısı altında topladı (yapılandırılmış tahmin = faktörlü EBM, GTN = ilk transformer, varyasyonel serbest enerji = VAE); Canziani son practicum'unda overfitting/düzenlileştirme/MC Dropout'la kapattı. Hafta 15 bonus dersinde konuk **William Falcon** (PyTorch Lightning yaratıcısı) denetimli ve denetimsiz transfer learning'i; **Canziani** eşlik edecek. Egzersiz 3 (serbest enerji=VAE) ve Egzersiz 5 (transfer) tam bu derse hazırlar.
:::
**Hafta 15 (BONUS): Transfer Learning ve PyTorch Lightning** — William Falcon (Konuk) + Canziani
Hafta 15 bonus dersinde konuk **William Falcon** (PyTorch Lightning yaratıcısı) denetimli ve denetimsiz transfer learning'i; **Canziani** eşlik edecek.
**Yapılacak:** Egzersiz 3 (serbest enerji=VAE) + Egzersiz 5 (transfer) çöz; "Yapılandırılmış tahmin = faktörlü EBM" ve "VAE = varyasyonel serbest enerji" cümlelerini kendi sözcüklerinle yaz; Hafta 10-12 pre-train→fine-tune'u (SSL/BERT) hatırla — transfer learning onun pratiğidir.
## Anahtar Kavramlar (Cheat Sheet) {#sec-cheat-d14}
| Kavram | Tanım | Hoca / timestamp |
|---|---|---|
| Yapılandırılmış tahmin | Kombinatoryal çıktı; faktörlü enerji | LeCun 0:38 |
| Trellis / en-kısa-yol | Faktörleme → DP; 96→16 değerlendirme | LeCun 22:52 |
| Graph Transformer Network | Ağ durumu = graf; ilk transformer (1997) = basit GNN | LeCun 1:07 |
| Perceptron collapse | Marjsız → enerji çöker (lineer-only) | LeCun 1:00 |
| NLL = forward/logsumexp | Tüm yollar marjinalleştirme; perceptron = β→∞ | LeCun 1:17 |
| Varyasyonel serbest enerji | $F = \langle E \rangle - T \cdot H$ (Jensen); VAE tam budur | LeCun 2:02 |
| Overfitting = gürültü | Gürültü yoksa aşırı model bile mükemmel fit | Canziani 5:39 |
| Aşırı-parametrize / 1-batch | Kolay optimizasyon; #1 debug kuralı | Canziani 8:36 |
| L2 weight decay | $\|\theta\|^2$; uzunluk kısalt (Gauss priori) | Canziani 19:18 |
| L1 / seyreklik | $\|\theta\|_1$; eksen bileşenlerini öldür (Laplace) | Canziani 27:03 |
| Dropout = ensemble | Rastgele sıfırla; sonsuz ağ ortalaması | Canziani 30:37 |
| MC Dropout = PPUU | Varyans = belirsizlik; minimize → güvenli manifold | Canziani 1:02 |
## ML Builder Bağlantıları {#sec-koprular-d14}
**Geriye köprüler:**
1. **Faktörlü EBM / kayıp / marj** → Hafta 7-9 + 11 (perceptron-collapse = enerji-kaybı).
2. **GTN = basit GNN** → Hafta 13 (graph neural net) + Hafta 5 (switch backprop).
3. **Varyasyonel serbest enerji** → Hafta 8 (VAE = ELBO) + Hafta 11 (sıcaklık $\beta$).
4. **Dropout / denoising / BatchNorm** → Hafta 7-8 (denoising AE) + Hafta 3/11.
5. **MC Dropout belirsizlik** → Hafta 11 (PPUU belirsizlik düzenlileştirmesi).
**İleriye köprüler:**
1. **Serbest enerji / ELBO** → **diffusion models (post-2020, KURSTA YOK)**.
2. **Yapılandırılmış EBM** → LeCun **JEPA (post-2020)**; CRF/yapısal SVM.
3. **L1 seyreklik / dropout** → öznitelik seçimi, Bayesian DL, kalibrasyon.
4. **Transfer learning** → Hafta 15 (bonus, William Falcon).
::: {.callout-important title="Bu dersten tek bir şey alıp gideceksen"}
LeCun'un son dersi tüm kursu **tek bir enerji çatısı** altında toplar. Yapılandırılmış tahmin, enerjinin **faktörlere ayrıştığı** bir EBM'dir — bu yüzden çıkarım üstel değil, en-kısa-yol (dinamik programlama) ile verimlidir; ve ağın durumunu **graf** yapan Graph Transformer Network, daha 1997'de "transformer" adını taşıyan, basit bir graph neural net'tir (Hafta 13). Asıl sentez şu: bir gizli değişkeni **marjinalleştirmek**, fizikteki **serbest enerjiyi** ($F = \langle E \rangle - T \cdot H$) minimize etmektir — ve **VAE tam olarak budur** (Hafta 8'in gerçek açıklaması). Canziani bu güçlü modellerin gürültüyü ezberlediğini (overfitting) gösterip düzenlileştirmeyle (L1=seyreklik, L2=uzunluk, dropout=ensemble) ehlileştirir; ve **MC Dropout belirsizliği**, Hafta 11'in PPUU'sunun ta kendisidir — kursu başladığı yere, enerjiye ve belirsizliğe geri döndürür. Bu temelin post-2020 zirvesi (diffusion models, JEPA) kursta yoktur ama bu haftanın serbest-enerji çatısının doğrudan ürünüdür.
:::