---
title: "Sparse Coding, Dünya Modelleri ve GAN"
subtitle: "İki hocalı hafta — EBM serisinin üçüncü ve son dersi. Yann LeCun (Lecture) Hafta 7-8'i birleştiren güçlü bir ilke verir: non-contrastive (mimari) yöntemlerin ortak özü, latent değişkenin bilgi kapasitesini azaltarak düşük-enerji uzayının hacmini sınırlamaktır — bottleneck (Hafta 7), VAE'de gürültü/varyans (Hafta 8) ve sparse coding (bu hafta) hepsi aynı amaca hizmet eder. Ardından sparse coding'i, group/structural sparsity'yi ve araştırma programının kalbi olan dünya modellerini (belirsiz geleceği öngören latent-variable EBM) anlatır. Alfredo Canziani (Practicum) ise GAN'ı (üretken çekişmeli ağ) gösterir ve onu dersin omurgasıyla tutarlı biçimde bir EBM olarak çerçeveler: generator latent gürültüden sahte örnek üretir, cost network (enerji ağı) gerçeğe düşük, sahteye yüksek enerji verir; generator negatifleri öğrenerek üretir — yani GAN, akıllı/adaptif negatif üreteçli contrastive bir EBM'dir."
---
::: {.callout-note title="Bölüm bilgisi"}
- **LeCun'un Lecture videosu:** [YouTube — Energy-based models III: sparse coding, world models, GANs](https://www.youtube.com/watch?v=Pgct8PKV7iw) (≈118 dk)
- **Canziani'nin Practicum videosu:** [YouTube — Generative adversarial networks](https://www.youtube.com/watch?v=xYc11zyZ26M) (≈75 dk)
- **Edition:** Spring 2020 (NYU-DLSP20)
- **Hocalar:** Yann LeCun (Lecture, teorik) + Alfredo Canziani (Practicum, pratik)
- **Kaynak:** [atcold.github.io/NYU-DLSP20](http://atcold.github.io/NYU-DLSP20)
- **Okuma süresi:** ≈22 dk
:::
```{python}
#| echo: false
# ============================================================================
# SETUP — NYU sayısal motor (_engine.py) + NYU Violet+gold viz (_viz.py)
# Bu hücre gizlidir (#| echo: false). Aşağıdaki TÜM figür hücreleri burada
# tanımlanan sparse_code_demo / gan_samples / energy_landscape / energy_1d
# + önceki hafta yardımcıları + COL_* + apply_style / draw_pipeline /
# style_legend / CLASS_COLORS isimlerini kullanır.
# _engine.py saf numpy (torch YOK); _viz.py NYU Violet+gold paleti.
# İçerikler VERBATIM gömülüdür.
#
# NOT: matplotlib backend'i AYARLANMAZ (matplotlib.use(...) ÇAĞRILMAZ).
# Quarto kendi inline (figür yakalayan) backend'ini kurar; Agg backend
# inline figür-yakalamayı bozar (plt.show() çıktı üretmez). Standalone
# figür testinde savefig kullanılır.
# ============================================================================
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from matplotlib.patches import (
FancyBboxPatch, FancyArrowPatch, Rectangle, Circle, Ellipse, Polygon, Patch,
)
from matplotlib.lines import Line2D
from matplotlib.colors import ListedColormap, BoundaryNorm, LinearSegmentedColormap
np.random.seed(0)
# ===========================================================================
# _engine.py — saf numpy sayısal yardımcılar (torch YOK)
# ===========================================================================
# ---------------------------------------------------------------------------
# Afin / lineer dönüşümler
# ---------------------------------------------------------------------------
def affine_transform(P, W, b=None):
"""P[N,2] noktalarına y = W x (+ b) afin/lineer dönüşümü uygular (satır-vektör konvansiyonu)."""
P = np.asarray(P, float)
Y = P @ np.asarray(W, float).T
if b is not None:
Y = Y + np.asarray(b, float)
return Y
def unit_grid(n=11, lim=2.0, fine=61):
"""Izgara çizgileri listesi (yatay + dikey). Her çizgi (fine,2) dizisi.
Lineer dönüşüm görsellerinde 'uzayın kumaşı' için."""
t = np.linspace(-lim, lim, n)
f = np.linspace(-lim, lim, fine)
lines = []
for yi in t:
lines.append(np.column_stack([f, np.full_like(f, yi)]))
for xi in t:
lines.append(np.column_stack([np.full_like(f, xi), f]))
return lines
def linear_transforms():
"""Canziani'nin dört temel lineer dönüşümü (Bölüm 8) — 2x2 matrisler."""
th = np.deg2rad(35.0)
R = np.array([[np.cos(th), -np.sin(th)], [np.sin(th), np.cos(th)]]) # rotation (ortonormal)
S = np.array([[1.8, 0.0], [0.0, 0.55]]) # scaling (köşegen)
Sh = np.array([[1.0, 0.85], [0.0, 1.0]]) # shearing
F = np.array([[1.0, 0.0], [0.0, -1.0]]) # reflection (det<0)
return dict(rotation=R, scaling=S, shearing=Sh, reflection=F)
# ---------------------------------------------------------------------------
# SVD geometrisi (Canziani'nin 'patatesi')
# ---------------------------------------------------------------------------
def unit_circle(n=240):
t = np.linspace(0, 2 * np.pi, n)
return np.column_stack([np.cos(t), np.sin(t)])
def svd_demo(W):
"""W = U Σ Vᵀ. Geometrik okuma: rotation(Vᵀ) · scaling(Σ) · rotation(U)."""
U, s, Vt = np.linalg.svd(np.asarray(W, float))
return U, s, Vt
def near_singular_matrix():
"""Bir tekil değeri ≈0 olan matris — bir boyutu 'ezer' (elips çizgiye çöker)."""
th = np.deg2rad(30.0)
R = np.array([[np.cos(th), -np.sin(th)], [np.sin(th), np.cos(th)]])
Sigma = np.diag([1.6, 0.04]) # ikinci tekil değer ≈ 0
return R @ Sigma @ R.T
# ---------------------------------------------------------------------------
# Spiral (manifold germe demosu)
# ---------------------------------------------------------------------------
def make_spiral(n_per=120, k=5, noise=0.18, seed=0):
"""k-kollu spiral (CS231n stili). Her kol bir sınıf; kollar orijinde iç içe → lineer ayrılamaz."""
rng = np.random.default_rng(seed)
X = np.zeros((n_per * k, 2))
y = np.zeros(n_per * k, dtype=int)
for j in range(k):
ix = slice(n_per * j, n_per * (j + 1))
r = np.linspace(0.0, 1.0, n_per)
t = np.linspace(j * 4.0, (j + 1) * 4.0, n_per) + rng.normal(0, 1, n_per) * noise
X[ix] = np.column_stack([r * np.sin(t), r * np.cos(t)])
y[ix] = j
return X, y
def unroll_spiral(X, y, k=5, seed=0):
"""ŞEMATİK 'öğrenilen temsil': her sınıfı kendi yatay bandına taşır → lineer ayrılabilir.
Gerçek bir eğitilmiş ağ DEĞİL; 'ağ manifoldu açar' sezgisinin deterministik görseli."""
rng = np.random.default_rng(seed)
r = np.linalg.norm(X, axis=1)
yb = (y - (k - 1) / 2.0) * 0.55 + rng.normal(0, 0.045, len(y))
return np.column_stack([r * 2.2 - 1.1, yb])
# ---------------------------------------------------------------------------
# İki hilal (make_moons — sklearn YOK, numpy ile elle)
# ---------------------------------------------------------------------------
def make_moons_np(n=400, noise=0.20, seed=0):
"""Doğrusal ayrılamaz iki-hilal veri (sklearn.make_moons eşdeğeri)."""
rng = np.random.default_rng(seed)
n_out = n // 2
n_in = n - n_out
to = np.linspace(0, np.pi, n_out)
ti = np.linspace(0, np.pi, n_in)
outer = np.column_stack([np.cos(to), np.sin(to)])
inner = np.column_stack([1.0 - np.cos(ti), 1.0 - np.sin(ti) - 0.5])
X = np.vstack([outer, inner]) + rng.normal(0, noise, (n, 2))
y = np.array([0] * n_out + [1] * n_in)
return X, y
# ---------------------------------------------------------------------------
# Minik numpy sınıflandırıcılar (lineer vs ReLU MLP) — karar sınırı kontrastı
# ---------------------------------------------------------------------------
def _onehot(y, c):
Y = np.zeros((len(y), c))
Y[np.arange(len(y)), y] = 1.0
return Y
def _softmax(z):
z = z - z.max(axis=1, keepdims=True)
e = np.exp(z)
return e / e.sum(axis=1, keepdims=True)
def logreg_train(X, y, steps=500, lr=1.0, seed=0):
"""Lineer (gizli katmansız) softmax sınıflandırıcı → DÜZ karar sınırı."""
rng = np.random.default_rng(seed)
n, d = X.shape
c = int(y.max() + 1)
W = rng.normal(0, 0.01, (d, c))
b = np.zeros(c)
Y = _onehot(y, c)
for _ in range(steps):
p = _softmax(X @ W + b)
dz = (p - Y) / n
W -= lr * (X.T @ dz)
b -= lr * dz.sum(axis=0)
return dict(W=W, b=b)
def logreg_forward(params, X):
return X @ params["W"] + params["b"]
def mlp_train(X, y, hidden=16, act="relu", steps=600, lr=1.0, seed=0, return_history=False):
"""numpy 2-katmanlı MLP (afine → nonlinearite → afine), softmax + cross-entropy.
ReLU ile EĞRİ karar sınırı (hilalleri/spirali ayırır).
return_history=True → (params, loss_history) döner (eğitim eğrisi figürü için)."""
rng = np.random.default_rng(seed)
n, d = X.shape
c = int(y.max() + 1)
W1 = rng.normal(0, 1, (d, hidden)) * np.sqrt(2.0 / d)
b1 = np.zeros(hidden)
W2 = rng.normal(0, 1, (hidden, c)) * np.sqrt(2.0 / hidden)
b2 = np.zeros(c)
Y = _onehot(y, c)
history = []
for _ in range(steps):
z1 = X @ W1 + b1
a1 = np.maximum(0, z1) if act == "relu" else np.tanh(z1)
p = _softmax(a1 @ W2 + b2)
if return_history:
history.append(float(-np.log(p[np.arange(n), y] + 1e-12).mean()))
dz2 = (p - Y) / n
dW2 = a1.T @ dz2
db2 = dz2.sum(axis=0)
da1 = dz2 @ W2.T
dz1 = da1 * ((z1 > 0) if act == "relu" else (1 - np.tanh(z1) ** 2))
dW1 = X.T @ dz1
db1 = dz1.sum(axis=0)
W1 -= lr * dW1
b1 -= lr * db1
W2 -= lr * dW2
b2 -= lr * db2
params = dict(W1=W1, b1=b1, W2=W2, b2=b2, act=act)
if return_history:
return params, np.array(history)
return params
def mlp_forward(params, X):
z1 = X @ params["W1"] + params["b1"]
a1 = np.maximum(0, z1) if params["act"] == "relu" else np.tanh(z1)
return a1 @ params["W2"] + params["b2"]
def accuracy(forward_fn, params, X, y):
return float((forward_fn(params, X).argmax(axis=1) == y).mean())
def decision_grid(X, pad=0.6, h=0.02):
"""Karar bölgesi için koordinat ızgarası (xx, yy) ve düz nokta listesi."""
x0, x1 = X[:, 0].min() - pad, X[:, 0].max() + pad
y0, y1 = X[:, 1].min() - pad, X[:, 1].max() + pad
xx, yy = np.meshgrid(np.arange(x0, x1, h), np.arange(y0, y1, h))
grid = np.column_stack([xx.ravel(), yy.ravel()])
return xx, yy, grid
# ---------------------------------------------------------------------------
# Enerji manzarası (EBM — çoklu minimum = çoklu geçerli cevap)
# ---------------------------------------------------------------------------
def energy_landscape(xx, yy):
"""F(x,y): birkaç Gauss kuyusu → çoklu yerel minimum. Düşük enerji = uyumlu cevap."""
wells = [(-1.25, -0.65, 1.0, 0.55), (1.15, 0.85, 1.05, 0.6), (0.15, -1.15, 0.8, 0.45)]
F = np.ones_like(xx) * 1.0
for cx, cy, depth, width in wells:
F = F - depth * np.exp(-((xx - cx) ** 2 + (yy - cy) ** 2) / (2 * width))
return F
# ---------------------------------------------------------------------------
# Hafta 2 — gradient descent, SGD, backprop, eğitim
# ---------------------------------------------------------------------------
def loss_surface_2d(xx, yy):
"""2D parametre uzayında bir kayıp yüzeyi (gradient descent 'dağ' görseli için):
eğik, farklı-ölçekli bir vadi (konveks taban) + hafif dalgalanma."""
u = 0.85 * xx + 0.53 * yy # eksenleri döndür (eğik vadi)
v = -0.53 * xx + 0.85 * yy
return 1.0 * u ** 2 + 3.5 * v ** 2 + 0.6 * np.sin(1.5 * xx) * np.cos(1.5 * yy)
def _loss_grad_2d(p):
"""loss_surface_2d gradyanı (merkezi sonlu fark)."""
eps = 1e-4
gx = (loss_surface_2d(p[0] + eps, p[1]) - loss_surface_2d(p[0] - eps, p[1])) / (2 * eps)
gy = (loss_surface_2d(p[0], p[1] + eps) - loss_surface_2d(p[0], p[1] - eps)) / (2 * eps)
return np.array([gx, gy])
def gd_path(theta0, lr=0.08, steps=40):
"""loss_surface_2d üzerinde gradient descent yörüngesi (parametre adımları)."""
p = np.array(theta0, float)
path = [p.copy()]
for _ in range(steps):
p = p - lr * _loss_grad_2d(p)
path.append(p.copy())
return np.array(path)
def sgd_loss_curves(steps=80, seed=0):
"""Üç rejim için kayıp eğrisi (simülasyon): full-batch (gürültüsüz, düz),
mini-batch (orta gürültü), saf SGD (yüksek gürültü). Aynı yumuşak üstel düşüş."""
rng = np.random.default_rng(seed)
t = np.arange(steps)
base = 0.2 + 2.6 * np.exp(-t / 14.0)
full = base.copy()
mini = base + rng.normal(0, 0.10, steps) * np.exp(-t / 45.0)
sgd = base + rng.normal(0, 0.45, steps) * np.exp(-t / 70.0)
return t, np.clip(full, 0, None), np.clip(mini, 0, None), np.clip(sgd, 0, None)
def tanh_deriv(x):
"""tanh'ın türevi: 1 − tanh²(x). Backprop 'twiddling' figürü için."""
return 1.0 - np.tanh(x) ** 2
def ce_loss_curve(p):
"""Doğru sınıf olasılığı p için cross-entropy kaybı: −log p."""
p = np.clip(np.asarray(p, float), 1e-6, 1.0)
return -np.log(p)
def mse_loss_curve(p):
"""Doğru sınıf olasılığı p için (one-hot hedefe) MSE: (1 − p)²."""
return (1.0 - np.asarray(p, float)) ** 2
# ---------------------------------------------------------------------------
# Hafta 3 — convolution / ConvNet / doğal sinyaller
# ---------------------------------------------------------------------------
def conv_output_size(n, k, s=1):
"""Çıktı boyutu: o = ⌊(n − k)/s⌋ + 1."""
return (n - k) // s + 1
def conv1d(x, w):
"""1B cross-correlation (ML 'convolution'): out[i] = Σ_k x[i+k]·w[k].
Örnek: conv1d([1,2,3,4,5],[1,0,-1]) → [-2,-2,-2] (kenar/fark dedektörü)."""
x = np.asarray(x, float)
w = np.asarray(w, float)
n = len(x) - len(w) + 1
return np.array([np.dot(x[i:i + len(w)], w) for i in range(n)])
def conv2d(img, kernel, stride=1):
"""2B valid cross-correlation (ag öznitelik haritası üretir)."""
img = np.asarray(img, float)
k = np.asarray(kernel, float)
kh, kw = k.shape
H, W = img.shape
oh, ow = conv_output_size(H, kh, stride), conv_output_size(W, kw, stride)
out = np.zeros((oh, ow))
for i in range(oh):
for j in range(ow):
patch = img[i * stride:i * stride + kh, j * stride:j * stride + kw]
out[i, j] = np.sum(patch * k)
return out
def make_synthetic_image(n=28, seed=0):
"""Basit gri-tonlu sentetik görüntü: kare + daire (kenar tespiti net görünsün)."""
img = np.zeros((n, n))
img[5:14, 6:15] = 1.0 # dolu kare
yy, xx = np.ogrid[:n, :n]
cy, cx, r = 19, 19, 6
img[(yy - cy) ** 2 + (xx - cx) ** 2 <= r ** 2] = 0.85 # daire
img[20:22, 4:24] = 0.6 # yatay çizgi (yatay kenar için)
return img
def edge_kernels():
"""Klasik 3×3 öznitelik dedektörü kernel'leri."""
return dict(
sobel_x=np.array([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]], float), # dikey kenar
sobel_y=np.array([[-1, -2, -1], [0, 0, 0], [1, 2, 1]], float), # yatay kenar
blur=np.ones((3, 3)) / 9.0, # bulanıklaştırma
laplace=np.array([[0, 1, 0], [1, -4, 1], [0, 1, 0]], float), # tüm kenarlar
)
def max_pool2d(img, k=2):
"""k×k max pooling (complex cell / invariance)."""
img = np.asarray(img, float)
H, W = img.shape
oh, ow = H // k, W // k
return np.array([[img[i * k:(i + 1) * k, j * k:(j + 1) * k].max() for j in range(ow)]
for i in range(oh)])
def avg_pool2d(img, k=2):
"""k×k average pooling (LeNet5 stili)."""
img = np.asarray(img, float)
H, W = img.shape
oh, ow = H // k, W // k
return np.array([[img[i * k:(i + 1) * k, j * k:(j + 1) * k].mean() for j in range(ow)]
for i in range(oh)])
# ---------------------------------------------------------------------------
# Hafta 4 — convolution cebiri (Toeplitz) + optimizasyon (κ, momentum, Adam)
# ---------------------------------------------------------------------------
def build_toeplitz(kernel, n):
"""1B convolution'ın Toeplitz matrisi: out = T @ x, T[i, i:i+k] = kernel.
conv1d(x, kernel) == build_toeplitz(kernel, len(x)) @ x (çoğu eleman sıfır = seyrek)."""
kernel = np.asarray(kernel, float)
k = len(kernel)
oh = n - k + 1
T = np.zeros((oh, n))
for i in range(oh):
T[i, i:i + k] = kernel
return T
def quad_loss(xx, yy, kappa=20.0):
"""Eğik, koşullanması κ = L/μ olan kuadratik vadi (condition number görseli).
κ büyük → uzun ince vadi → gradient descent zikzak çizer."""
a, b = 0.92, 0.39 # ~25° dönme
u = a * xx + b * yy
v = -b * xx + a * yy
return 0.5 * (1.0 * u ** 2 + kappa * v ** 2) # L=κ, μ=1
def quad_grad(p, kappa=20.0):
"""quad_loss'un analitik gradyanı."""
a, b = 0.92, 0.39
x, y = p
u = a * x + b * y
v = -b * x + a * y
gu, gv = u, kappa * v
return np.array([gu * a + gv * (-b), gu * b + gv * a])
def optimize_quad(method, theta0, lr, steps, kappa=20.0, beta=0.9, beta2=0.999, eps=1e-8):
"""quad_loss üzerinde bir optimizer'ı koştur; yörünge + kayıp geçmişi döner.
method ∈ {'gd','momentum','adam'}. Defazio'nun zikzak/sönümleme/adaptif anlatısı için."""
p = np.array(theta0, float)
path = [p.copy()]
losses = [float(quad_loss(p[0], p[1], kappa))]
m = np.zeros(2)
v = np.zeros(2)
for t in range(1, steps + 1):
g = quad_grad(p, kappa)
if method == "gd":
step = lr * g
elif method == "momentum":
m = beta * m + g # heavy ball
step = lr * m
elif method == "adam":
m = beta * m + (1 - beta) * g
v = beta2 * v + (1 - beta2) * g * g
mh = m / (1 - beta ** t) # bias correction
vh = v / (1 - beta2 ** t)
step = lr * mh / (np.sqrt(vh) + eps)
else:
raise ValueError(method)
p = p - step
path.append(p.copy())
losses.append(float(quad_loss(p[0], p[1], kappa)))
return np.array(path), np.array(losses)
# ---------------------------------------------------------------------------
# Hafta 5 — autograd worked example (Canziani)
# ---------------------------------------------------------------------------
def autograd_worked(X=None):
"""Canziani worked example: X → Y=X−2 → Z=3·Y² → a=mean(Z) (skaler).
İleri değerler + ∂a/∂xᵢ = (1/4)·3·2·(xᵢ−2) = 1.5·(xᵢ−2).
X=[1,2,3,4] için grad = [−1.5, 0, 1.5, 3] (PyTorch X.grad ile birebir)."""
if X is None:
X = np.array([1.0, 2.0, 3.0, 4.0])
X = np.asarray(X, float)
Y = X - 2.0
Z = 3.0 * Y ** 2
a = float(Z.mean())
grad = 1.5 * (X - 2.0)
return dict(X=X, Y=Y, Z=Z, a=a, grad=grad)
def conv_pad_output(n, k, padding=0, stride=1):
"""Padding'li çıktı boyutu: o = ⌊(n + 2·padding − k)/stride⌋ + 1.
padding=(k−1)/2 (k tek) → çıktı boyutu korunur."""
return (n + 2 * padding - k) // stride + 1
# ---------------------------------------------------------------------------
# Hafta 6 — RNN / vanishing gradient / attention
# ---------------------------------------------------------------------------
def vanishing_demo(steps=50, eigenvalues=(0.5, 1.0, 1.5)):
"""Aynı matristen n kez geçen gradient: λⁿ. λ<1 söner (vanishing), λ>1 patlar
(exploding), λ=1 sabit. Backprop-through-time vanishing gradient görseli."""
t = np.arange(steps + 1)
curves = {ev: np.asarray(ev, float) ** t for ev in eigenvalues}
return t, curves
def rnn_forward(X_seq, Wx, Wz, b, z0=None):
"""Basit RNN hücresi: zₜ = tanh(Wₓ·xₜ + W_z·zₜ₋₁ + b).
X_seq [T, d_in] → gizli durumlar Z [T, d_h] (aynı Wₓ,W_z her adımda = paylaşım)."""
X_seq = np.asarray(X_seq, float)
T = len(X_seq)
dh = np.asarray(Wz).shape[0]
z = np.zeros(dh) if z0 is None else np.asarray(z0, float)
Z = []
for t in range(T):
z = np.tanh(np.asarray(Wx) @ X_seq[t] + np.asarray(Wz) @ z + np.asarray(b))
Z.append(z.copy())
return np.array(Z)
def attention_weights(scores):
"""Attention ağırlıkları = softmax(skorlar); toplamı 1 (olasılık dağılımı, 'odak')."""
scores = np.asarray(scores, float)
e = np.exp(scores - scores.max())
return e / e.sum()
# ---------------------------------------------------------------------------
# Hafta 7 — EBM / autoencoder / manifold
# ---------------------------------------------------------------------------
def energy_1d(y, data_points=(-2.0, 0.0, 2.0), width=0.35):
"""1B enerji F(y): veri noktalarında düşük (çukur), aralarda yüksek (tepe).
'İyi enerji şekli' = veride düşük, dışında yüksek (EBM); çoklu minimum = çoklu cevap."""
y = np.asarray(y, float)
F = np.ones_like(y)
for d in data_points:
F = F - np.exp(-(y - d) ** 2 / (2 * width))
return F
def energy_1d_grad(y, data_points=(-2.0, 0.0, 2.0), width=0.35):
"""energy_1d'nin türevi (çıkarım = enerji minimizasyonu, gradient ile arama)."""
y = np.asarray(y, float)
g = np.zeros_like(y)
for d in data_points:
g = g + (y - d) / width * np.exp(-(y - d) ** 2 / (2 * width))
return g
def make_manifold_curve(n=160, noise=0.0, seed=0):
"""2B veri manifoldu: bir eğri (sinüs yayı) üzerinde noktalar (Hafta 1 manifold hipotezi)."""
t = np.linspace(-2.6, 2.6, n)
M = np.column_stack([t, np.sin(1.3 * t)])
if noise:
M = M + np.random.default_rng(seed).normal(0, noise, M.shape)
return M
def project_to_manifold(points, manifold):
"""Her noktayı manifoldun EN YAKIN noktasına çeker (autoencoder reconstruction sezgisi:
off-manifold girdiyi manifolda geri çek → düşük enerji)."""
points = np.asarray(points, float)
proj = np.array([manifold[np.linalg.norm(manifold - p, axis=1).argmin()] for p in points])
return proj
# ---------------------------------------------------------------------------
# Hafta 8 — contrastive / VAE
# ---------------------------------------------------------------------------
def vae_reparam(mu, sigma, n=400, seed=0):
"""Reparameterization trick: z = μ + σ⊙ε, ε~N(0,I). Düzenli (sürekli, dolu)
Gaussian latent örnekleri — VAE'nin üretken latent uzayı."""
mu = np.atleast_1d(np.asarray(mu, float))
sigma = np.atleast_1d(np.asarray(sigma, float))
rng = np.random.default_rng(seed)
eps = rng.normal(0, 1, (n, len(mu)))
return mu + sigma * eps
def ae_latent_clusters(n=400, seed=0):
"""Sıradan AE latent'i: dağınık, boşluklu kümeler (düzensiz uzay — VAE kontrastı)."""
rng = np.random.default_rng(seed)
centers = np.array([[-2.2, 1.8], [2.0, 2.1], [0.3, -2.3], [-1.8, -1.5]])
pts = []
for c in centers:
pts.append(c + rng.normal(0, 0.28, (n // len(centers), 2)))
return np.vstack(pts)
# ---------------------------------------------------------------------------
# Hafta 9 — sparse coding / GAN (EBM)
# ---------------------------------------------------------------------------
def sparse_code_demo(n=24, n_active=5, seed=0):
"""Yoğun (dense) vs seyrek (sparse) code: L1 düzenlileştirme çoğu bileşeni
sıfıra iter — yalnızca birkaç birim aktif kalır (sparse coding)."""
rng = np.random.default_rng(seed)
dense = rng.normal(0, 1, n)
idx = np.argsort(-np.abs(dense)) # en büyük |değer| → aktif kalanlar
sparse = np.zeros(n)
sparse[idx[:n_active]] = dense[idx[:n_active]]
return dense, sparse
def gan_samples(seed=0, n=200):
"""GAN sezgisi: gerçek veri (manifold/halka) vs generator'ın ürettiği sahte örnekler.
İlk başta sahteler dağınık (eğitilmemiş generator), gerçeğe yakınsar."""
rng = np.random.default_rng(seed)
th = rng.uniform(0, 2 * np.pi, n)
real = np.column_stack([np.cos(th), np.sin(th)]) + rng.normal(0, 0.06, (n, 2)) # gerçek = birim halka
fake_early = rng.normal(0, 1.1, (n, 2)) # eğitilmemiş gen (dağınık)
th2 = rng.uniform(0, 2 * np.pi, n)
fake_late = np.column_stack([np.cos(th2), np.sin(th2)]) + rng.normal(0, 0.18, (n, 2)) # eğitilmiş gen (halkaya yakın)
return real, fake_early, fake_late
# ===========================================================================
# _viz.py — NYU Violet + gold matplotlib stil sabitleri ve yardımcıları
# ===========================================================================
COL_VIOLET = "#57068c" # NYU Violet — birincil çizgi/çerçeve/vurgu
COL_VIOLET_D = "#3d0463" # koyu violet — güçlü vurgu / gradyan
COL_VIOLET_M = "#7b2cbf" # orta violet — ikincil
COL_VIOLET_SOFT = "#b56ad6" # soluk violet
COL_GOLD = "#d4a017" # gold accent
COL_GOLD_D = "#a87d0a" # koyu gold
COL_TEXT = "#2a2535" # gövde metni (hafif violet tint)
COL_INK = "#1e1a2e" # en koyu — başlık
COL_BG = "#f4eefa" # açık violet — dolgu/arka plan
COL_GRID = "#cdbbe0" # soluk violet — ızgara/pasif kenar
COL_WHITE = "#ffffff"
# 5-sınıf kategorik palet (spiral 5 kol / moons ilk 2) — violet↔gold ekseni, tema-uyumlu
CLASS_COLORS = ["#57068c", "#7b2cbf", "#b56ad6", "#d4a017", "#a87d0a"]
# Çizgi-grafik tutarlı renkler
LINE_PRIMARY = COL_VIOLET
LINE_ACCENT = COL_GOLD
LINE_SECONDARY = COL_VIOLET_M
def apply_style(ax):
"""Bir eksene tutarlı NYU Violet+gold görünümü uygular."""
ax.set_facecolor(COL_WHITE)
ax.grid(True, alpha=0.25, color=COL_GRID, linewidth=0.8)
for spine in ax.spines.values():
spine.set_color(COL_GRID)
ax.tick_params(colors=COL_TEXT)
ax.title.set_color(COL_TEXT)
ax.xaxis.label.set_color(COL_TEXT)
ax.yaxis.label.set_color(COL_TEXT)
return ax
def draw_pipeline(ax, stages, title=None, y0=0.0):
"""Soldan-sağa kutu+ok boru hattı şeması (örüntü tanıma vs uçtan-uca).
stages : [(label:str, is_learned:bool), ...]
is_learned=True -> öğrenilen modül (violet dolgulu)
is_learned=False -> elle-tasarlanan/sabit (gold kenarlı, açık dolgu)
"""
n = len(stages)
box_w, box_h, gap = 1.7, 1.0, 0.9
step = box_w + gap
ax.set_xlim(-0.3, n * step)
ax.set_ylim(y0 - 1.1, y0 + 1.1)
ax.axis("off")
if title:
ax.set_title(title, color=COL_TEXT, fontsize=12, pad=10)
for i, (lbl, learned) in enumerate(stages):
x = i * step
fc = "#ece0f7" if learned else COL_BG
ec = COL_VIOLET if learned else COL_GOLD_D
lw = 2.4 if learned else 2.0
box = FancyBboxPatch(
(x, y0 - box_h / 2), box_w, box_h,
boxstyle="round,pad=0.02,rounding_size=0.12",
fc=fc, ec=ec, lw=lw, zorder=2,
)
ax.add_patch(box)
ax.text(x + box_w / 2, y0, lbl, ha="center", va="center",
fontsize=9.5, color=COL_TEXT, zorder=3, wrap=True)
if i > 0:
ax.add_patch(FancyArrowPatch(
(x - gap, y0), (x, y0),
arrowstyle="-|>", mutation_scale=16,
color=COL_VIOLET_M, lw=1.9, zorder=1,
))
return ax
def style_legend(ax, **kw):
"""Tema-uyumlu legend."""
leg = ax.legend(frameon=True, framealpha=0.95, edgecolor=COL_GRID, **kw)
if leg is not None:
leg.get_frame().set_facecolor(COL_WHITE)
for t in leg.get_texts():
t.set_color(COL_TEXT)
return leg
```
## Bu Derste Ne Var? {#sec-genel-bakis-d9}
Bu hafta **EBM serisinin üçüncü ve son dersi**. **Yann LeCun** Hafta 7-8'i birleştiren bir ilke veriyor (non-contrastive yöntemlerin ortak özü: düşük-enerji uzayının hacmini sınırlamak), **sparse coding**'i ve **dünya modellerini (world models)** anlatıyor. **Alfredo Canziani** ise **GAN**'ı (üretken çekişmeli ağ) gösteriyor — ve onu, dersin omurgasıyla tutarlı biçimde, bir **EBM** olarak çerçeveliyor.
::: {.callout-warning title="⚠️ Terminoloji notu (NYU sinyatürü)"}
Canziani GAN'daki "discriminator" terimini kullanmıyor; LeCun'u izleyerek ona **cost network (maliyet/enerji ağı)** diyor. Yani GAN, dersin EBM diline çevrilmiş: cost = enerji, generator negatifleri üretir.
:::
Bu haftanın üç ana fikri:
1. **Non-contrastive yöntemler tek ilkede birleşir:** düşük-enerji bölgesinin **hacmini sınırla**. Sparsity, gürültü ekleme (VAE), bottleneck — hepsi aynı amaca hizmet eder.
2. **Dünya modeli (world model):** geleceği belirsizlik altında öngören bir EBM; LeCun'un araştırma programının kalbi.
3. **GAN = contrastive EBM:** generator sahte örnekler (negatifler) üretir; cost network gerçeğe düşük, sahteye yüksek enerji verir; generator cost'u düşürerek (kandırarak) öğrenir.
```{mermaid}
%%| echo: false
flowchart TB
EBM["EBM serisi 3/3 = enerji şekillendirme<br/>(Hafta 7 çerçeve → Hafta 8 yöntem → Hafta 9 birleşim)"]
subgraph A["(A) Non-contrastive birleştirici ilke"]
direction TB
Kapasite["Kapasiteyi azalt<br/>→ düşük-enerji HACMİNİ sınırla"]
Bottleneck["Bottleneck (Hafta 7)<br/>darboğaz"]
VAE["VAE / gürültü (Hafta 8)<br/>varyans kısıtı"]
Sparsity["Sparsity / L1 (Hafta 9)<br/>az aktif birim"]
Kapasite --> Bottleneck
Kapasite --> VAE
Kapasite --> Sparsity
end
subgraph B["(B) Dünya modeli = latent EBM"]
direction TB
Belirsiz["Belirsiz gelecek<br/>(bir duruma çok sonraki)"]
CokluMin["Çoklu minimum enerji<br/>(latent z belirsizliği yakalar)"]
Belirsiz --> CokluMin
end
subgraph C["(C) GAN = contrastive EBM"]
direction TB
Generator["Generator<br/>(latent → sahte x̂)"]
Cost["Cost network = enerji ağı<br/>(gerçeğe düşük / sahteye yüksek)"]
Cekisme["Çekişme (min-max)<br/>generator cost'u düşürür"]
OgrNeg["Öğrenilen negatif<br/>(adaptif, elle değil)"]
Generator --> Cost
Cost --> Cekisme
Cekisme --> OgrNeg
end
EBM --> Kapasite
EBM --> Belirsiz
EBM --> Generator
```
::: {.callout-tip title="Builder Notu — EBM Serisi Tek Çatıda Kapanır"}
**Geriye (önkoşul kurslar):**
- **Düşük-enerji hacmini sınırla** → Hafta 7 bottleneck + Hafta 8 VAE/gürültü + bu hafta sparsity (üçü aynı ilke).
- **Sparse coding (L1)** → 18.06 (seyrek temsil) + Stat 110 (Laplace prior).
- **GAN = cost/enerji + generator** → Hafta 7 EBM + Hafta 8 contrastive (generator = öğrenilen negatif üretici).
**İleriye (production / research):**
- World model → LeCun'un JEPA programı (post-2020 ileriye köprü); model-based RL, planning.
- GAN → CycleGAN, StyleGAN; ve diffusion (modern üretken modeller).
**Tek cümleyle:** Non-contrastive EBM yöntemleri (sparsity, VAE, bottleneck) düşük-enerji uzayının hacmini sınırlayarak çalışır; GAN ise contrastive bir EBM'dir — generator negatifleri *öğrenerek* üretir, cost network onları yukarı iter.
:::
## (LeCun) EBM Serisi 3/3 ve Birleştirici İlke {#sec-birlestirici}
LeCun dersi "EBM'nin üçüncü parçası" diye açıyor (sparse coding, GAN'a kısa giriş, world models).
> "this is the third part of the lecture on energy based models... sparse coding... GANs very briefly... learning world models." — LeCun, 0:00
Önce Hafta 7-8'i birleştiren güçlü bir ilke veriyor. Hatırla: contrastive yöntemler negatifte enerji yukarı basar; non-contrastive yöntemler **yapıyla** kısıtlar. LeCun şimdi non-contrastive ailenin **ortak özünü** söylüyor: latent değişkenin (code) **bilgi kapasitesini azaltırsan**, düşük enerji alabilen uzayın **hacmini** azaltırsın.
> "if you reduce the information capacity of the latent variable... as a consequence you also minimize the volume of space that can take low energy." — LeCun, 16:00
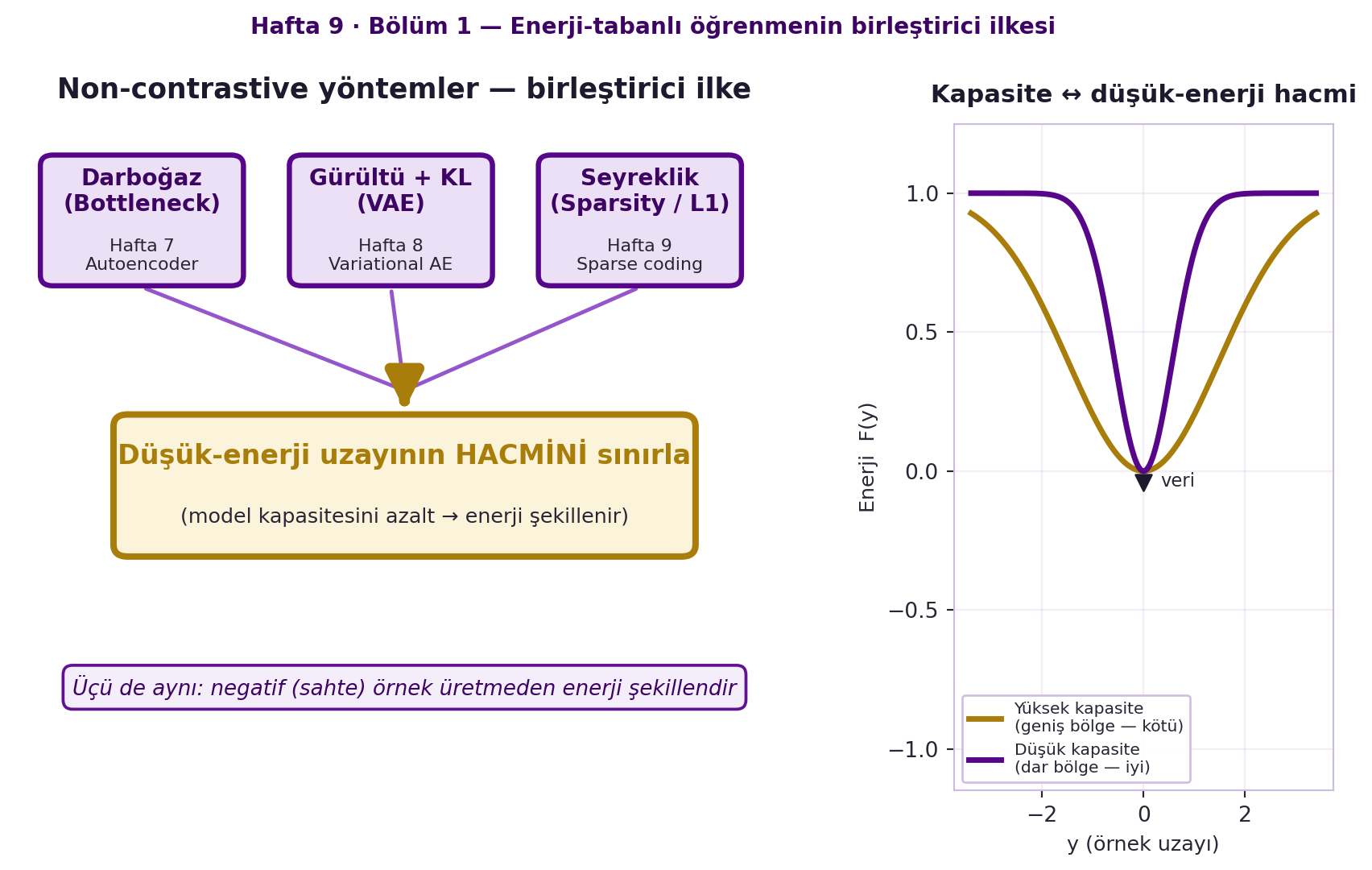
Bu yüzden bottleneck (Hafta 7), VAE'de gürültü/varyans (Hafta 8) ve sparsity (bu hafta) **aynı şeyi yapar**: düşük-enerji hacmini sınırlar. Veriye düşük enerji verirsen, kapasite sınırlı olduğu için gerisi otomatik yükselir — negatif örnek üretmeden. @fig-unifying-principle bu birleştirici ilkeyi şematize ediyor: üç yöntem (bottleneck, VAE-gürültü, sparsity) tek bir oka iner ("düşük-enerji hacmini sınırla"), ve sağdaki küçük görsel sezgiyi pekiştirir — yüksek kapasite geniş bir düşük-enerji bölgesi (kötü), düşük kapasite veriye sıkıca oturan dar bir bölge (iyi) bırakır.
```{python}
#| label: fig-unifying-principle
#| fig-cap: "Hafta 9 Bölüm 1 — Enerji-tabanlı öğrenmenin birleştirici (non-contrastive) ilkesi. Üç farklı yöntem — darboğaz/autoencoder (Hafta 7), gürültü + KL ile VAE (Hafta 8) ve seyreklik/L1 sparse coding (Hafta 9) — tek bir ilkeye iner: düşük-enerji uzayının HACMİNİ sınırlamak, yani model kapasitesini azaltarak enerji manzarasını şekillendirmek. Üçü de negatif (sahte) örnek üretmeden çalışır. Sağdaki küçük görsel sezgiyi pekiştirir: yüksek kapasite geniş bir düşük-enerji bölgesi (kötü, her şeye düşük enerji verir) yaratırken, düşük kapasite veriye sıkıca oturan dar bir bölge (iyi) bırakır."
fig = plt.figure(figsize=(11, 5.6))
gs = fig.add_gridspec(1, 3, width_ratios=[2.05, 0.05, 1.0], wspace=0.18)
# ---------------------------------------------------------------------------
# SOL: birleştirici ilke şeması (3 yöntem → tek ok → tek sonuç kutusu)
# ---------------------------------------------------------------------------
axL = fig.add_subplot(gs[0, 0])
axL.set_xlim(0, 10)
axL.set_ylim(0, 10)
axL.axis("off")
axL.set_title("Non-contrastive yöntemler — birleştirici ilke",
color=COL_INK, fontsize=13, fontweight="bold", pad=12)
# Üç yöntem kutusu (yan yana, violet)
methods = [
("Darboğaz\n(Bottleneck)", "Hafta 7\nAutoencoder"),
("Gürültü + KL\n(VAE)", "Hafta 8\nVariational AE"),
("Seyreklik\n(Sparsity / L1)", "Hafta 9\nSparse coding"),
]
box_w, box_h = 2.55, 1.9
xs = [0.35, 3.55, 6.75]
y_top = 7.6
centers_top = []
for (lbl, sub), x in zip(methods, xs):
box = FancyBboxPatch(
(x, y_top), box_w, box_h,
boxstyle="round,pad=0.03,rounding_size=0.16",
fc="#ece0f7", ec=COL_VIOLET, lw=2.4, zorder=2,
)
axL.add_patch(box)
cx = x + box_w / 2
axL.text(cx, y_top + box_h - 0.52, lbl, ha="center", va="center",
fontsize=10.5, color=COL_VIOLET_D, fontweight="bold", zorder=3)
axL.text(cx, y_top + 0.42, sub, ha="center", va="center",
fontsize=8.3, color=COL_TEXT, zorder=3)
centers_top.append(cx)
# Tek BÜYÜK ok: üç kutu → tek sonuç kutusu (huni)
y_arrow_top = y_top - 0.05
y_result_top = 3.55
y_result_h = 2.05
result_cx = 5.0
join_y = 5.95
for cx in centers_top:
axL.add_patch(FancyArrowPatch(
(cx, y_arrow_top), (result_cx, join_y + 0.05),
arrowstyle="-", color=COL_VIOLET_M, lw=1.8,
connectionstyle="arc3,rad=0.0", zorder=1, alpha=0.8,
))
axL.add_patch(FancyArrowPatch(
(result_cx, join_y), (result_cx, y_result_top + y_result_h + 0.05),
arrowstyle="-|>", mutation_scale=34, color=COL_GOLD_D, lw=5.0, zorder=2,
))
# Tek sonuç kutusu (gold)
res_w = 7.4
res_box = FancyBboxPatch(
(result_cx - res_w / 2, y_result_top), res_w, y_result_h,
boxstyle="round,pad=0.04,rounding_size=0.18",
fc="#fbf3da", ec=COL_GOLD_D, lw=3.0, zorder=2,
)
axL.add_patch(res_box)
axL.text(result_cx, y_result_top + y_result_h - 0.55,
"Düşük-enerji uzayının HACMİNİ sınırla",
ha="center", va="center", fontsize=12.5, color=COL_GOLD_D,
fontweight="bold", zorder=3)
axL.text(result_cx, y_result_top + 0.55,
"(model kapasitesini azalt → enerji şekillenir)",
ha="center", va="center", fontsize=9.5, color=COL_TEXT, zorder=3)
# Annotation: üçü de aynı
axL.text(result_cx, 1.55,
"Üçü de aynı: negatif (sahte) örnek üretmeden enerji şekillendir",
ha="center", va="center", fontsize=9.8, color=COL_VIOLET_D,
style="italic", zorder=3,
bbox=dict(boxstyle="round,pad=0.45", fc=COL_BG, ec=COL_VIOLET,
lw=1.4, alpha=0.95))
# ---------------------------------------------------------------------------
# SAĞ: yüksek kapasite (geniş düşük-enerji) vs düşük kapasite (dar bölge)
# ---------------------------------------------------------------------------
axR = fig.add_subplot(gs[0, 2])
apply_style(axR)
axR.set_title("Kapasite ↔ düşük-enerji hacmi",
color=COL_INK, fontsize=11.5, fontweight="bold", pad=10)
yy = np.linspace(-3.4, 3.4, 600)
F_high = energy_1d(yy, data_points=(0.0,), width=2.2)
F_low = energy_1d(yy, data_points=(0.0,), width=0.32)
axR.plot(yy, F_high, color=COL_GOLD_D, lw=2.6,
label="Yüksek kapasite\n(geniş bölge — kötü)")
axR.plot(yy, F_low, color=COL_VIOLET, lw=2.6,
label="Düşük kapasite\n(dar bölge — iyi)")
thr = -0.4
axR.fill_between(yy, F_high, thr, where=(F_high < thr),
color=COL_GOLD, alpha=0.18, zorder=0)
axR.fill_between(yy, F_low, thr, where=(F_low < thr),
color=COL_VIOLET, alpha=0.20, zorder=0)
axR.scatter([0.0], [F_low.min() - 0.04], s=55, color=COL_INK,
zorder=5, marker="v")
axR.annotate("veri", (0.0, F_low.min() - 0.04), textcoords="offset points",
xytext=(8, -2), fontsize=8.5, color=COL_TEXT)
axR.set_xlabel("y (örnek uzayı)", fontsize=9.5)
axR.set_ylabel("Enerji F(y)", fontsize=9.5)
axR.set_ylim(-1.15, 1.25)
style_legend(axR, loc="lower left", fontsize=7.6)
fig.suptitle("Hafta 9 · Bölüm 1 — Enerji-tabanlı öğrenmenin birleştirici ilkesi",
color=COL_VIOLET_D, fontsize=10.5, y=1.005, fontweight="bold");
```
::: {.callout-tip title="Builder Notu — Kapasite = Hacim"}
**Geriye (Hafta 7-8):** Bu, Hafta 7 (bottleneck) + Hafta 8 (VAE gürültü) + bu hafta (sparsity) üçlüsünü tek cümlede birleştirir: "düşük-enerji hacmini sınırla". Kapasite kısıtı = düzenlileştirme (Hafta 1 regularization).
**İleriye:** "Kapasiteyi sınırla → düşük-enerji hacmini sınırla" ilkesi, modern non-contrastive SSL'in (VICReg'in covariance terimi, post-2020) teorik temelidir.
:::
## (LeCun) Sparse Coding ve Group/Structural Sparsity {#sec-sparse}
**Sparse coding**: bir girdiyi, az sayıda aktif birimle (seyrek code) temsil et. Bir L1 düzenlileştirici, code'un çoğu bileşenini sıfıra iter — yalnızca birkaçı aktif kalır. Bu, kapasiteyi sınırlamanın (Bölüm 1) bir yoludur.
LeCun bunu **group sparsity** ve **structural sparsity** ile genişletiyor: birimleri gruplar (örn. 2B topolojide 16×16 matris, ya da bir graf/ağaç) hâlinde düzenle; düzenlileştirici en az sayıda **grubu** açık tutmaya çalışır.
> "[the sparsity regularizer] tends to turn off the maximum number of groups... the system [imposes] sparsity on groups." — LeCun, 8:01
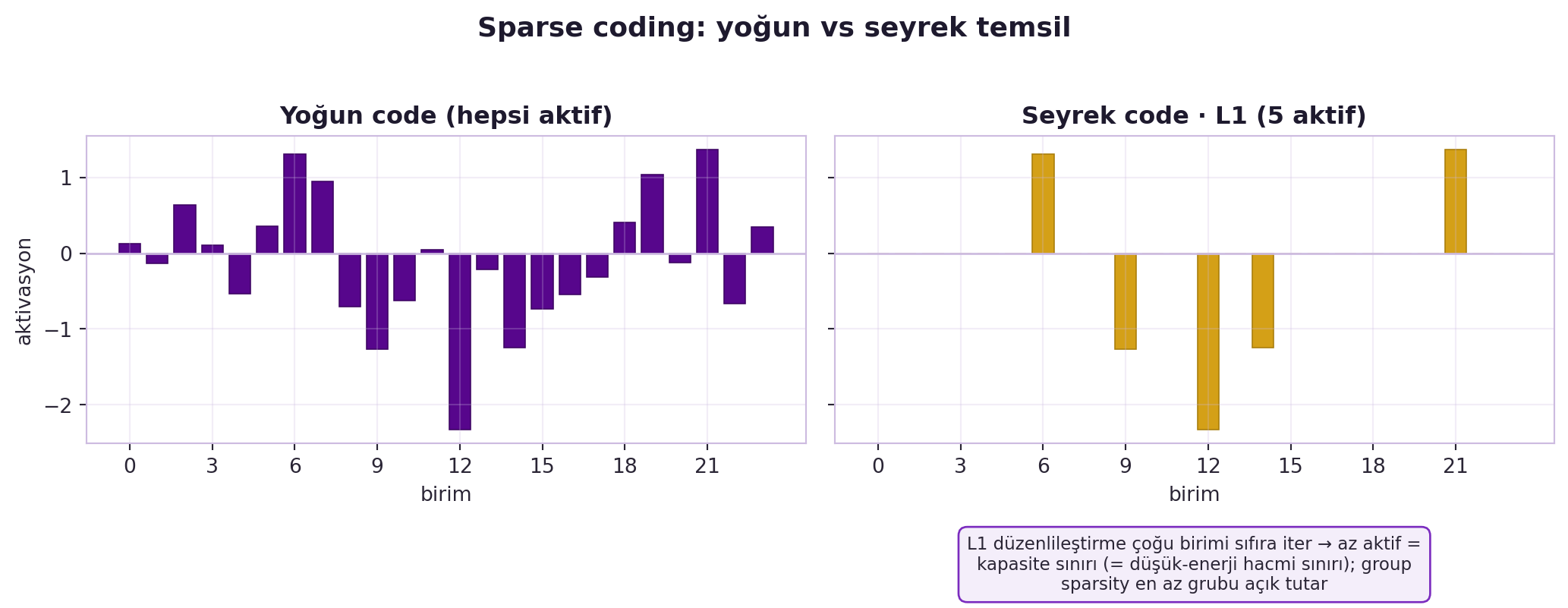
Gruplar 2B topolojide organize edilirse, yan yana birimler birlikte aktif olur — bu, complex cell'lere (Hafta 3) benzer bir yapı öğrenir. @fig-sparse-coding aynı temsili yoğun (24 birimin hepsi aktif) ve seyrek (yalnızca 5 birim aktif) biçimde gösteriyor: L1 düzenlileştirme aktivasyonların çoğunu sıfıra iter, kapasiteyi — yani düşük-enerji hacmini — sınırlar.
```{python}
#| label: fig-sparse-coding
#| fig-cap: "Sparse coding: aynı temsil yoğun (solda, 24 birimin hepsi aktif) ve seyrek (sağda, yalnızca 5 birim aktif) biçimde. L1 düzenlileştirme aktivasyonların çoğunu sıfıra iter; az sayıda aktif birim modelin kapasitesini — yani düşük-enerji hacmini — sınırlar (EBM bakışı). Group sparsity en az grubu açık tutarak yapılı bir seyreklik dayatır."
dense, sparse = sparse_code_demo(24, 5)
n = len(dense)
x = np.arange(n)
fig, (axL, axR) = plt.subplots(1, 2, figsize=(11, 4.6), sharey=True)
# SOL — Yoğun code
apply_style(axL)
axL.bar(x, dense, color=COL_VIOLET, edgecolor=COL_VIOLET_D, linewidth=0.6, width=0.78)
axL.axhline(0, color=COL_GRID, linewidth=1.0, zorder=1)
axL.set_title("Yoğun code (hepsi aktif)", color=COL_INK, fontsize=12, fontweight="bold")
axL.set_xlabel("birim", color=COL_TEXT)
axL.set_ylabel("aktivasyon", color=COL_TEXT)
axL.set_xticks(x[::3])
# SAĞ — Seyrek code (L1)
apply_style(axR)
active_mask = sparse != 0.0
bar_colors = [COL_GOLD if a else COL_GRID for a in active_mask]
bar_alphas = [1.0 if a else 0.35 for a in active_mask]
bars = axR.bar(x, sparse, color=bar_colors, edgecolor=COL_GOLD_D, linewidth=0.6, width=0.78)
for b, a in zip(bars, bar_alphas):
b.set_alpha(a)
axR.axhline(0, color=COL_GRID, linewidth=1.0, zorder=1)
n_active = int(active_mask.sum())
axR.set_title(f"Seyrek code · L1 ({n_active} aktif)", color=COL_INK, fontsize=12, fontweight="bold")
axR.set_xlabel("birim", color=COL_TEXT)
axR.set_xticks(x[::3])
axR.annotate(
"L1 düzenlileştirme çoğu birimi sıfıra iter → az aktif =\n"
"kapasite sınırı (= düşük-enerji hacmi sınırı); group\n"
"sparsity en az grubu açık tutar",
xy=(0.5, -0.30), xycoords="axes fraction", ha="center", va="top",
fontsize=8.6, color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.5", fc=COL_BG, ec=COL_VIOLET_M, lw=1.0),
)
fig.suptitle("Sparse coding: yoğun vs seyrek temsil", color=COL_INK,
fontsize=13.5, fontweight="bold", y=1.0)
fig.tight_layout(rect=[0, 0.02, 1, 0.97])
```
::: {.callout-tip title="Builder Notu — Sparse = Az Aktif"}
**Geriye (18.06 + Stat 110 + Hafta 3):** Seyrek temsil = az sayıda baz vektörle ifade (18.06); L1 düzenlileştirme = Laplace prior (Stat 110). Group sparsity'nin öğrendiği topoloji, Hafta 3'ün complex cell organizasyonunu andırır.
**İleriye:** Sparsity, yorumlanabilir temsil (interpretable features) ve verimli (seyrek) ağların temelidir; mixture-of-experts'in (seyrek aktivasyon) uzak akrabası.
:::
## (LeCun) Dünya Modelleri (World Models) {#sec-world-model}
LeCun araştırma programının kalbine değiniyor: **dünya modelleri**. Bir dünya modeli, mevcut durumdan ve eylemden **geleceği öngörür** — ama gelecek belirsizdir (bir duruma birçok olası sonraki durum). Bu yüzden dünya modeli doğal olarak bir **EBM**'dir: olası gelecek durumlara düşük enerji, olanaksızlara yüksek enerji verir; belirsizliği latent değişkenlerle modeller.
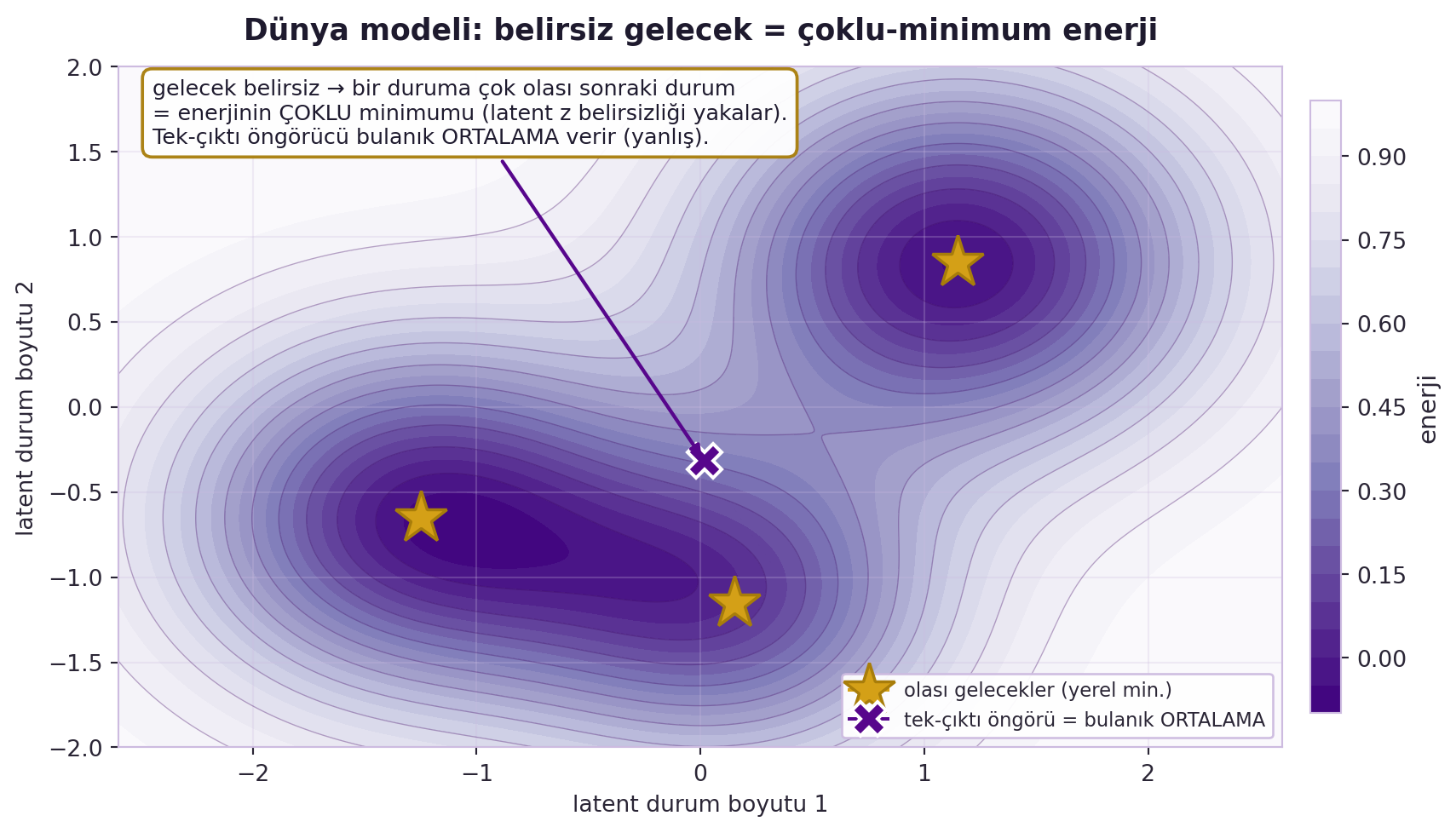
Bu, Hafta 7'nin latent-variable EBM'sinin zaman/öngörü hâlidir: y (gelecek) belirsizdir, z (latent) belirsizliği yakalar. Tahminin belirsizliğini bir enerji manzarasıyla temsil etmek, tek-çıktılı bir öngörücünün yapamadığı şeydir (bulanık ortalama yerine olası gelecekler). @fig-world-model bu farkı bir enerji manzarasında gösteriyor: çoklu yerel minimum (gold yıldızlar) olası gelecekleri, violet X ise tek-çıktı öngörücünün ürettiği — hiçbir gerçek geleceğe karşılık gelmeyen — bulanık ortalamayı temsil eder.
```{python}
#| label: fig-world-model
#| fig-cap: "Dünya modeli, belirsiz geleceği latent enerji-tabanlı modelle yakalar: mevcut bir durumdan birden çok olası sonraki durum bulunduğu için enerji manzarasının çoklu yerel minimumu (gold yıldızlar) vardır. Tek-çıktı veren öngörücü tüm bu olasılıkların ortalamasını alır (violet X) ve hiçbir gerçek geleceğe karşılık gelmeyen, manifold dışı bulanık bir tahmin üretir. Latent değişken z bu belirsizliği temsil ederek modelin tek bir bulanık ortalama yerine ayrık geçerli gelecekleri ayırt etmesini sağlar."
xx, yy = np.meshgrid(np.linspace(-2.6, 2.6, 320), np.linspace(-2.0, 2.0, 320))
F = energy_landscape(xx, yy)
fig, ax = plt.subplots(figsize=(9.5, 5.2))
cf = ax.contourf(xx, yy, F, levels=24, cmap="Purples_r")
cs = ax.contour(xx, yy, F, levels=10, colors=COL_VIOLET_D, linewidths=0.5, alpha=0.35)
cb = fig.colorbar(cf, ax=ax, shrink=0.9, pad=0.02)
cb.set_label("enerji", color=COL_TEXT, fontsize=11)
cb.ax.tick_params(colors=COL_TEXT)
cb.outline.set_edgecolor(COL_GRID)
# energy_landscape kuyu merkezleri (çoklu olası gelecek = çoklu minimum)
wells = [(-1.25, -0.65), (1.15, 0.85), (0.15, -1.15)]
for k, (cx, cy) in enumerate(wells):
ax.plot(cx, cy, marker="*", markersize=24, color=COL_GOLD,
markeredgecolor=COL_GOLD_D, markeredgewidth=1.3, zorder=5,
label="olası gelecekler (yerel min.)" if k == 0 else None)
# Tek-çıktı öngörücünün verdiği "ortalama" — minimumların ağırlık merkezi (manifold dışı)
mean_pt = np.mean(wells, axis=0)
ax.plot(*mean_pt, marker="X", markersize=15, color=COL_VIOLET,
markeredgecolor=COL_WHITE, markeredgewidth=1.5, zorder=6,
label="tek-çıktı öngörü = bulanık ORTALAMA")
ax.annotate(
"gelecek belirsiz → bir duruma çok olası sonraki durum\n"
"= enerjinin ÇOKLU minimumu (latent z belirsizliği yakalar).\n"
"Tek-çıktı öngörücü bulanık ORTALAMA verir (yanlış).",
xy=mean_pt, xytext=(-2.45, 1.55),
fontsize=9.5, color=COL_INK,
bbox=dict(boxstyle="round,pad=0.45", fc=COL_WHITE, ec=COL_GOLD_D, lw=1.4, alpha=0.95),
arrowprops=dict(arrowstyle="-|>", color=COL_VIOLET, lw=1.6),
zorder=7,
)
apply_style(ax)
ax.set_title("Dünya modeli: belirsiz gelecek = çoklu-minimum enerji",
color=COL_INK, fontsize=13, weight="bold", pad=12)
ax.set_xlabel("latent durum boyutu 1", color=COL_TEXT)
ax.set_ylabel("latent durum boyutu 2", color=COL_TEXT)
ax.set_xlim(-2.6, 2.6)
ax.set_ylim(-2.0, 2.0)
style_legend(ax, loc="lower right", fontsize=8.5)
fig.tight_layout()
```
::: {.callout-tip title="Builder Notu — Dünya Modeli = Latent EBM"}
**Geriye (Hafta 7 + 6):** Dünya modeli = latent-variable EBM (Hafta 7) + dizi/öngörü (Hafta 6); belirsiz gelecek = enerji fonksiyonunun birden çok minimumu.
**İleriye:** World model, LeCun'un bugünkü **JEPA** programının (post-2020 ileriye köprü) ve model-based RL / planning'in merkezidir — cevabı üretmek yerine enerji üzerinden *planla*.
:::
## Geçiş: LeCun'dan Canziani'ye {#sec-gecis-d9}
LeCun non-contrastive ilkeyi (düşük-enerji hacmini sınırla), sparse coding'i ve world model'leri kurdu — ve GAN'a kısaca değindi ("yarın Alfredo'dan daha çok duyacaksınız"). Şimdi **Canziani** GAN'ı açıyor. Kritik olan: Canziani GAN'ı sıfırdan **EBM diliyle** anlatıyor — "discriminator" yerine **cost network** (enerji ağı) diyor. Böylece GAN, Hafta 7-8'in enerji çerçevesine tam oturuyor: generator negatifleri üretir, cost network enerjiyi şekillendirir.
## (Canziani) GAN: Generator + Cost Network (= Enerji) {#sec-gan-cost}
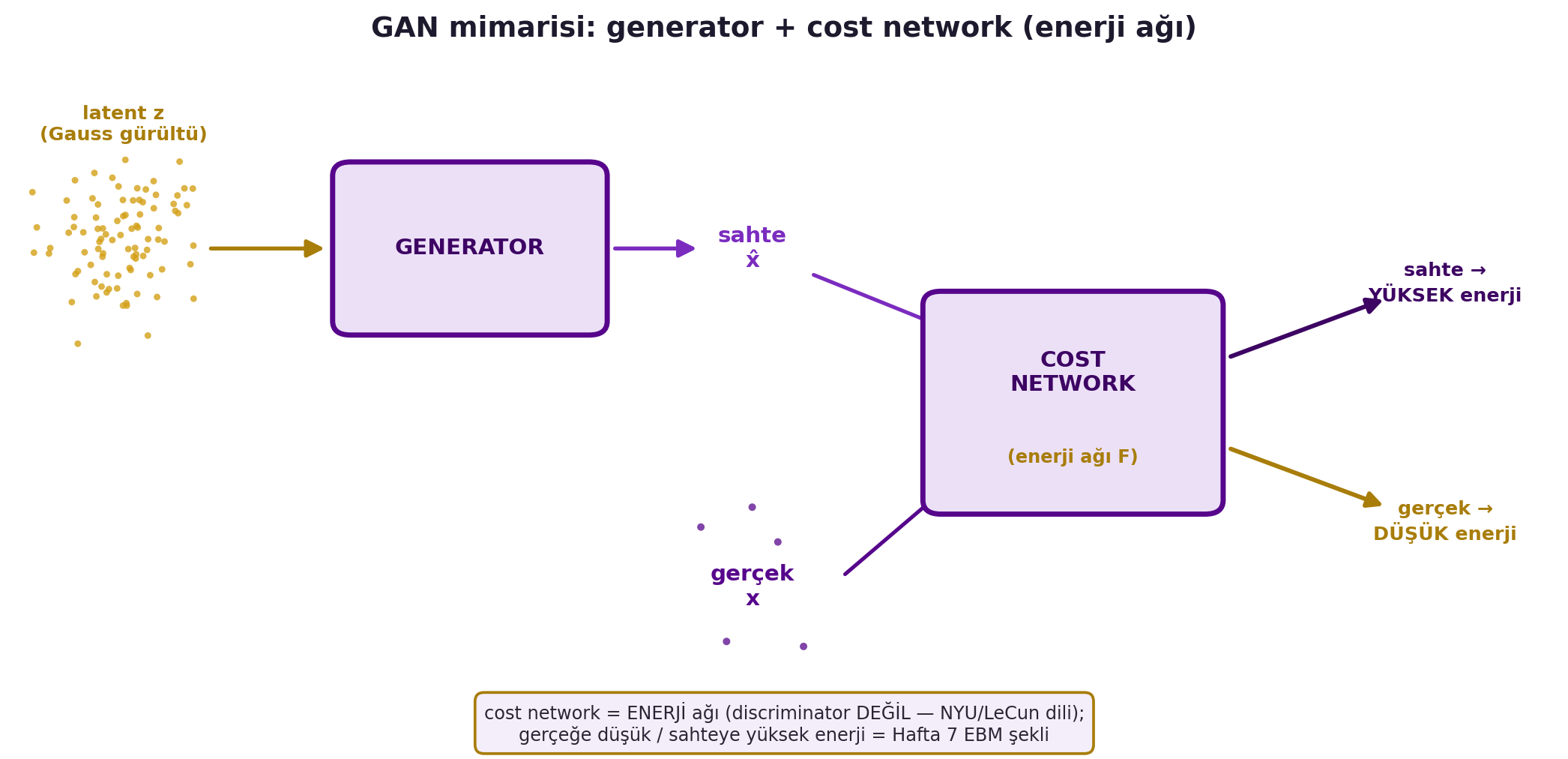
Canziani GAN'ı iki parçayla kuruyor. Bir **generator**, bir latent z (Gaussian örneği) alıp sahte bir örnek $\hat{x}$ üretir. Bir **cost network** (klasik adıyla discriminator — ama Canziani/LeCun bunu yanlış bulup "cost network" der) her girdiye bir maliyet (enerji) atar.
> "in the classical formulation of a GAN we have a discriminator — [but] discriminators are just plain wrong, at least following Yann... we have this cost network." — Canziani, 2:37
Cost network gerçek (pembe) örneklere **düşük** maliyet, sahte (mavi, generator'dan gelen $\hat{x}$) örneklere **yüksek** maliyet verir. Yani cost = enerji: gerçek veride düşük, sahtede yüksek — tam Hafta 7'nin EBM şekli. @fig-gan-architecture bu mimariyi gösteriyor: latent gürültü z (gold bulut) generator'dan geçip sahte $\hat{x}$ üretir; hem gerçek x hem sahte $\hat{x}$ cost network'e girer ve ağ gerçeğe düşük, sahteye yüksek enerji atar.
```{python}
#| label: fig-gan-architecture
#| fig-cap: "GAN mimarisi: latent gürültü z (Gauss bulutu) generator'dan geçerek sahte x̂ üretir; hem gerçek x hem sahte x̂ cost network'e (enerji ağı F) girer. Ağ gerçeğe DÜŞÜK, sahteye YÜKSEK enerji atar — bu, Hafta 7'deki EBM enerji şeklinin ta kendisidir. NYU/LeCun dilinde bu modül 'discriminator' değil 'cost network' olarak adlandırılır."
fig, ax = plt.subplots(figsize=(11, 5.4))
ax.set_xlim(0, 12)
ax.set_ylim(0, 6.8)
ax.axis("off")
ax.set_title("GAN mimarisi: generator + cost network (enerji ağı)",
color=COL_INK, fontsize=14, fontweight="bold", pad=14)
# ---- latent z: Gaussian bulut (gold) ----
rng_z = np.random.default_rng(0)
zc = rng_z.normal(0, 1, (90, 2))
zc[:, 0] = 0.85 + 0.30 * zc[:, 0]
zc[:, 1] = 5.0 + 0.42 * zc[:, 1]
ax.scatter(zc[:, 0], zc[:, 1], s=11, color=COL_GOLD, alpha=0.8, zorder=3, edgecolors="none")
ax.text(0.85, 6.2, "latent z\n(Gauss gürültü)", ha="center", va="center",
fontsize=9.5, color=COL_GOLD_D, fontweight="bold")
# ---- GENERATOR kutusu ----
gen = FancyBboxPatch((2.5, 4.1), 2.1, 1.7,
boxstyle="round,pad=0.02,rounding_size=0.14",
fc="#ece0f7", ec=COL_VIOLET, lw=2.6, zorder=2)
ax.add_patch(gen)
ax.text(3.55, 4.95, "GENERATOR", ha="center", va="center",
fontsize=11, color=COL_VIOLET_D, fontweight="bold", zorder=3)
# z -> generator oku
ax.add_patch(FancyArrowPatch((1.5, 4.95), (2.45, 4.95),
arrowstyle="-|>", mutation_scale=18, color=COL_GOLD_D, lw=2.0, zorder=1))
# ---- sahte örnek x̂ ----
ax.text(5.75, 4.95, "sahte\nx̂", ha="center", va="center", fontsize=11,
color=COL_VIOLET_M, fontweight="bold", zorder=3)
ax.add_patch(FancyArrowPatch((4.65, 4.95), (5.35, 4.95),
arrowstyle="-|>", mutation_scale=18, color=COL_VIOLET_M, lw=2.0, zorder=1))
# ---- gerçek örnek x (violet) ----
ax.text(5.75, 1.55, "gerçek\nx", ha="center", va="center", fontsize=11,
color=COL_VIOLET, fontweight="bold", zorder=3)
ax.scatter([5.35, 5.55, 5.95, 6.15, 5.75], [2.15, 1.0, 2.0, 0.95, 2.35],
s=14, color=COL_VIOLET, alpha=0.75, zorder=3, edgecolors="none")
# ---- COST NETWORK (enerji ağı) ----
cost = FancyBboxPatch((7.1, 2.3), 2.3, 2.2,
boxstyle="round,pad=0.02,rounding_size=0.14",
fc="#ece0f7", ec=COL_VIOLET, lw=2.6, zorder=2)
ax.add_patch(cost)
ax.text(8.25, 3.7, "COST\nNETWORK", ha="center", va="center",
fontsize=11, color=COL_VIOLET_D, fontweight="bold", zorder=3)
ax.text(8.25, 2.85, "(enerji ağı F)", ha="center", va="center",
fontsize=9, color=COL_GOLD_D, fontweight="bold", zorder=3)
# sahte x̂ -> cost network
ax.add_patch(FancyArrowPatch((6.2, 4.7), (7.45, 4.05),
arrowstyle="-|>", mutation_scale=16, color=COL_VIOLET_M, lw=1.9, zorder=1))
# gerçek x -> cost network
ax.add_patch(FancyArrowPatch((6.45, 1.65), (7.45, 2.75),
arrowstyle="-|>", mutation_scale=16, color=COL_VIOLET, lw=1.9, zorder=1))
# ---- maliyet / enerji çıktıları ----
# gerçeğe DÜŞÜK enerji (gold ok aşağı/düşük)
ax.add_patch(FancyArrowPatch((9.45, 2.95), (10.7, 2.35),
arrowstyle="-|>", mutation_scale=16, color=COL_GOLD_D, lw=2.2, zorder=1))
ax.text(11.15, 2.2, "gerçek →\nDÜŞÜK enerji", ha="center", va="center",
fontsize=9.5, color=COL_GOLD_D, fontweight="bold", zorder=3)
# sahteye YÜKSEK enerji (violet ok yukarı/yüksek)
ax.add_patch(FancyArrowPatch((9.45, 3.85), (10.7, 4.45),
arrowstyle="-|>", mutation_scale=16, color=COL_VIOLET_D, lw=2.2, zorder=1))
ax.text(11.15, 4.6, "sahte →\nYÜKSEK enerji", ha="center", va="center",
fontsize=9.5, color=COL_VIOLET_D, fontweight="bold", zorder=3)
# ---- annotation kutusu ----
ann = ("cost network = ENERJİ ağı (discriminator DEĞİL — NYU/LeCun dili);\n"
"gerçeğe düşük / sahteye yüksek enerji = Hafta 7 EBM şekli")
ax.text(6.0, 0.18, ann, ha="center", va="center", fontsize=9,
color=COL_TEXT, zorder=4,
bbox=dict(boxstyle="round,pad=0.5", fc=COL_BG, ec=COL_GOLD_D, lw=1.4))
plt.tight_layout()
```
::: {.callout-tip title="Builder Notu — Cost Network ≠ Discriminator"}
**Geriye (Hafta 7):** Cost network = enerji fonksiyonu (LeCun'un diyagramında "cost" karesi, skaler çıktı); gerçeğe düşük, sahteye yüksek = Hafta 7'nin "veride düşük, dışında yüksek" şekli.
**İleriye:** GAN'ın "cost network" çerçevesi, EBM-tabanlı üretken modellere ve modern critic/reward modellerine (RLHF) köprüdür.
:::
## (Canziani) GAN Eğitimi: Çekişme (Generator Kandırır) {#sec-gan-egitim}
GAN eğitimi bir **çekişmedir (adversarial)**: iki ağ birbirine karşı oynar.
- **Cost network** öğrenir: gerçek örneklere düşük, sahtelere yüksek maliyet ver (enerjiyi doğru şekle sok).
- **Generator** öğrenir: cost network'ün **düşük** maliyet vereceği örnekler üret — yani onu kandır, sahtelerini "gerçek gibi" göster.
> "the cost network will be trained to have low cost for inputs that are [real] and high cost for inputs that are [fake]... [the generator] is going to be enforced to have a low cost [for its outputs]." — Canziani, 5:23 / 7:18
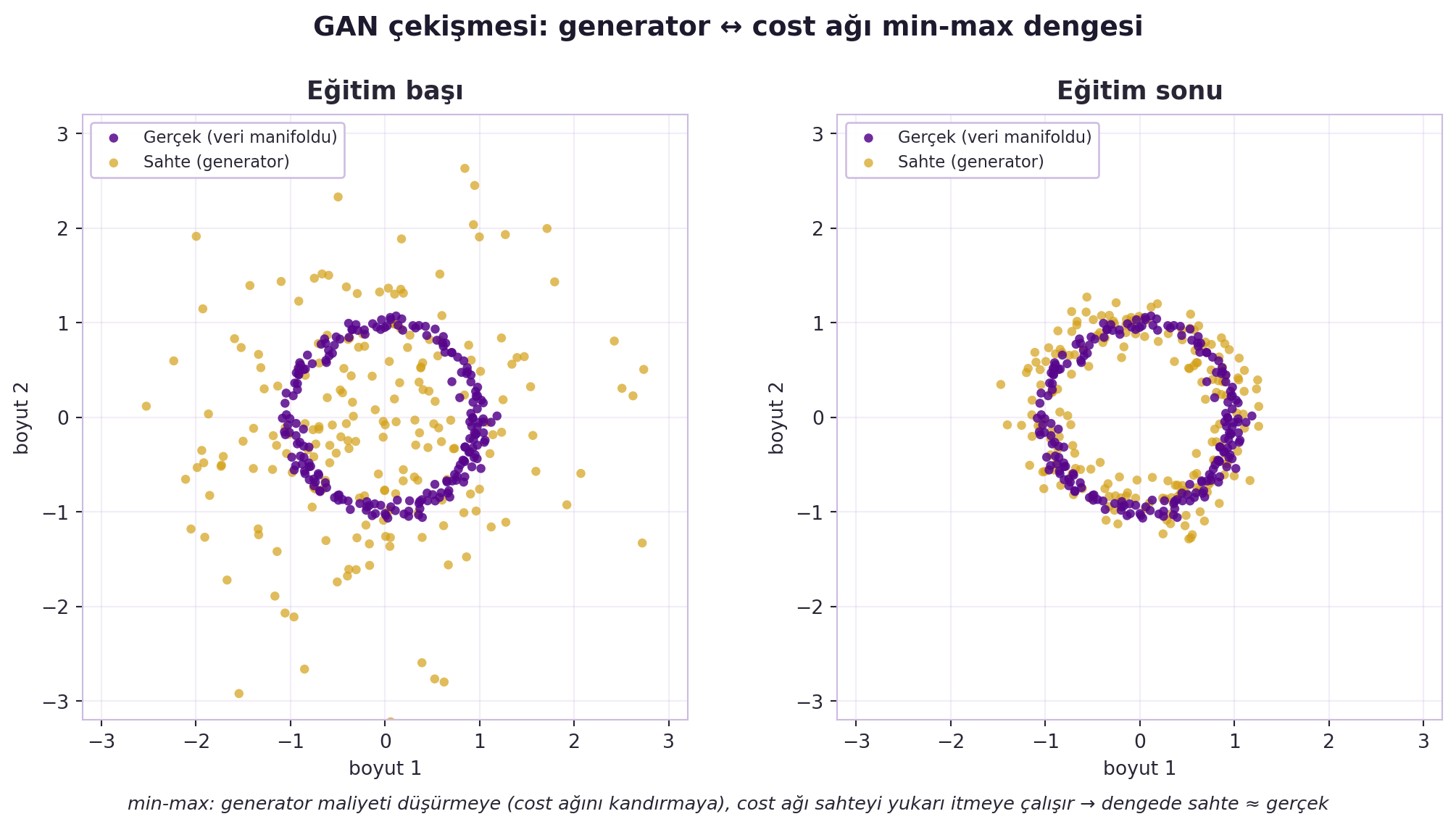
Bu min-max dansı: generator cost'u düşürmeye, cost network sahteyi yukarı itmeye çalışır. Dengede generator, gerçeğe çok benzeyen örnekler üretir. Klasik GAN amacı, Hafta 1-2'nin cross-entropy'siyle (gerçek/sahte ikili sınıflandırma) yazılır. @fig-gan-training bu çekişmeyi gösteriyor: solda eğitim başında sahte örnekler (gold) dağınık bir buluttur, sağda eğitim sonunda gerçek veri manifolduna (violet halka) yakınsar.
```{python}
#| label: fig-gan-training
#| fig-cap: "GAN çekişmesi (min-max): solda eğitim başında generator'ın ürettiği sahte örnekler (gold) dağınık bir buluttur ve gerçek veri manifoldundan (violet birim halka) uzaktır; sağda eğitim sonunda sahte örnekler halkaya yakınsar (sahte ≈ gerçek). Generator maliyeti düşürmeye (cost ağını kandırmaya), cost ağı ise sahteyi yukarı itmeye çalışır; denge bu iki kuvvetin eşitlendiği noktadır."
real, fake_early, fake_late = gan_samples(0, 200)
fig, (axL, axR) = plt.subplots(1, 2, figsize=(11, 5.4))
# --- SOL: Eğitim başı ---
axL.scatter(real[:, 0], real[:, 1], s=22, color=COL_VIOLET, alpha=0.85,
edgecolors="none", label="Gerçek (veri manifoldu)", zorder=3)
axL.scatter(fake_early[:, 0], fake_early[:, 1], s=22, color=COL_GOLD, alpha=0.7,
edgecolors="none", label="Sahte (generator)", zorder=2)
axL.set_title("Eğitim başı", color=COL_INK, fontsize=13, fontweight="bold", pad=8)
axL.set_xlabel("boyut 1")
axL.set_ylabel("boyut 2")
axL.set_xlim(-3.2, 3.2)
axL.set_ylim(-3.2, 3.2)
axL.set_aspect("equal")
apply_style(axL)
style_legend(axL, loc="upper left", fontsize=8.5)
# --- SAĞ: Eğitim sonu ---
axR.scatter(real[:, 0], real[:, 1], s=22, color=COL_VIOLET, alpha=0.85,
edgecolors="none", label="Gerçek (veri manifoldu)", zorder=3)
axR.scatter(fake_late[:, 0], fake_late[:, 1], s=22, color=COL_GOLD, alpha=0.7,
edgecolors="none", label="Sahte (generator)", zorder=2)
axR.set_title("Eğitim sonu", color=COL_INK, fontsize=13, fontweight="bold", pad=8)
axR.set_xlabel("boyut 1")
axR.set_ylabel("boyut 2")
axR.set_xlim(-3.2, 3.2)
axR.set_ylim(-3.2, 3.2)
axR.set_aspect("equal")
apply_style(axR)
style_legend(axR, loc="upper left", fontsize=8.5)
# --- min-max çekişme açıklaması ---
fig.text(0.5, -0.02,
"min-max: generator maliyeti düşürmeye (cost ağını kandırmaya), cost ağı sahteyi "
"yukarı itmeye çalışır → dengede sahte ≈ gerçek",
ha="center", va="top", fontsize=9.5, color=COL_TEXT,
style="italic", wrap=True)
fig.suptitle("GAN çekişmesi: generator ↔ cost ağı min-max dengesi",
color=COL_INK, fontsize=14, fontweight="bold", y=1.02)
fig.tight_layout()
```
::: {.callout-tip title="Builder Notu — Min-Max Çekişme"}
**Geriye (Hafta 1-2):** Cost network'ün gerçek/sahte ayrımı = Hafta 1 cross-entropy (Bernoulli/ikili sınıflandırma); min-max = Calculus eyer noktası (saddle point).
**İleriye:** GAN eğitimi kararsızdır (mode collapse, dengesizlik); WGAN, spectral normalization gibi teknikler bunu yumuşatır.
:::
## (Canziani) GAN = Contrastive EBM {#sec-gan-ebm}
İşte dersin birleştirici fikri: GAN, bir **contrastive EBM**'dir. Hafta 8'de contrastive yöntemlerin negatif örnek ürettiğini görmüştük — ama oradaki negatifler elle (augmentation/rastgele) üretiliyordu. GAN'da **generator, negatifleri öğrenerek üretir**: cost network'ün en çok kandığı (en düşük enerjili sahte) örnekleri arar. Yani GAN = "akıllı negatif üreteçli" contrastive EBM.
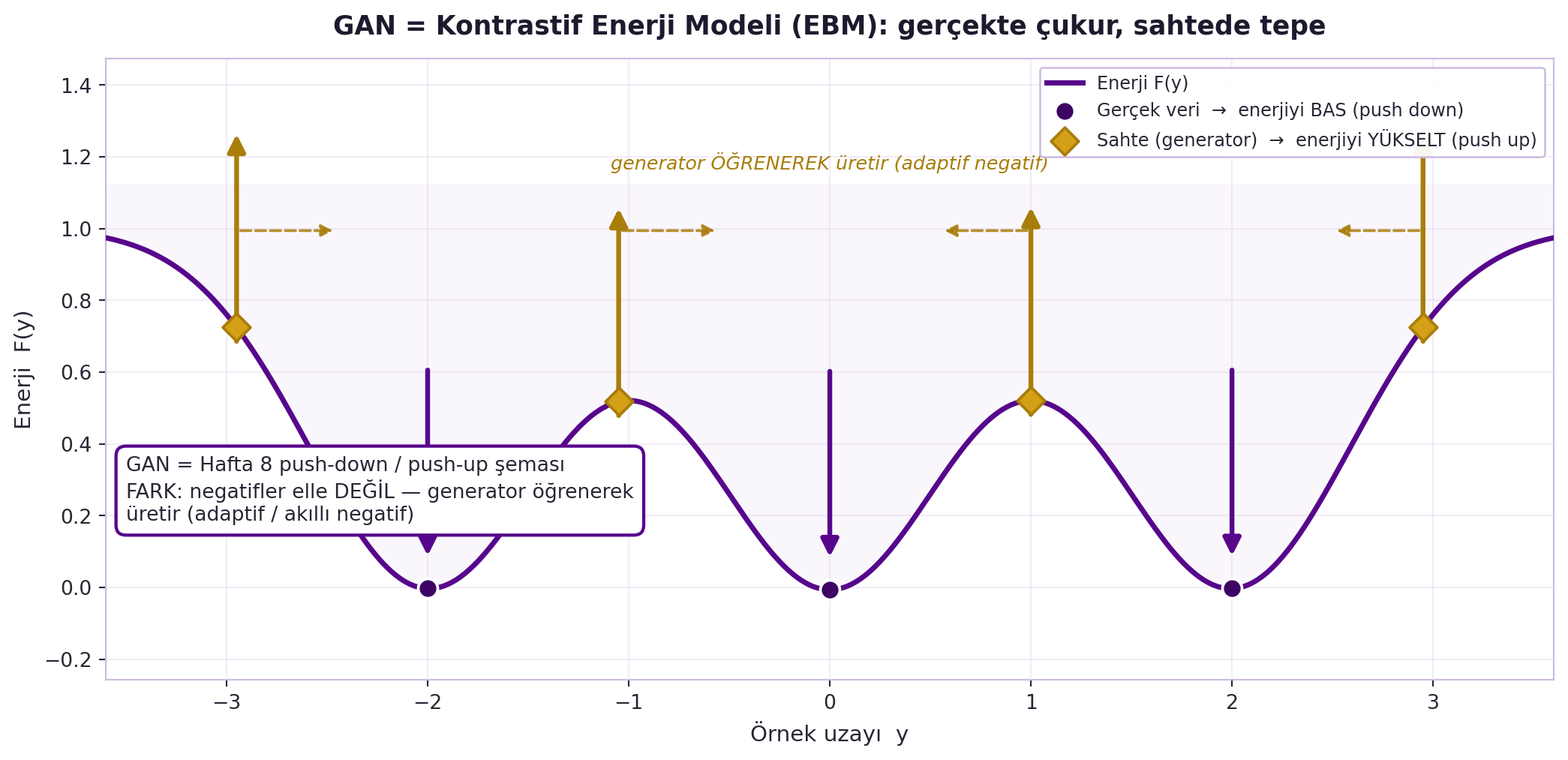
Cost network gerçeğe düşük enerji (push down), generator'ın sahtelerine yüksek enerji (push up) verir — Hafta 8'in push-down/push-up'ı, ama negatifler artık sabit değil, **rakip bir ağ tarafından adaptif üretiliyor**. Bu, GAN'ı dersin EBM omurgasına tam oturtur. @fig-gan-contrastive-ebm bunu enerji eğrisi üzerinde gösteriyor: gerçek veri noktalarında çukur (violet, push-down), generator'ın sahtelerinde tepe (gold, push-up); kesikli yatay oklar ise generator'ın öğrenerek sahteleri çukurlara doğru taşıdığını (adaptif negatif) vurgular.
```{python}
#| label: fig-gan-contrastive-ebm
#| fig-cap: "GAN, kontrastif bir enerji modeli (EBM) olarak. Enerji eğrisi F(y) gerçek veri noktalarında çukur (violet noktalar, aşağı oklar = push-down), generator'ın ürettiği sahte noktalarda tepe yapar (gold elmaslar, yukarı oklar = push-up). Kesikli yatay oklar adaptifliği gösterir: Hafta 8'deki sabit/elle negatiflerin aksine generator, sahteleri öğrenerek çukurlara doğru taşır (akıllı/adaptif negatif)."
np.random.seed(0)
# --- Veri (gerçek) ve enerji eğrisi -------------------------------------
data_points = (-2.0, 0.0, 2.0) # gerçek veri noktaları
y = np.linspace(-3.6, 3.6, 700)
F = energy_1d(y, data_points=data_points, width=0.35)
# Generator'ın ürettiği SAHTE noktalar: başta enerji çukurlarının DIŞINDA
# (yüksek enerji bölgeleri), öğrendikçe gerçeğe doğru kayıyor (adaptif).
fake_start = np.array([-2.95, -1.05, 1.0, 2.95]) # erken: tepelerde
fake_end = np.array([-2.45, -0.55, 0.55, 2.5]) # öğrenince: çukurlara kayar
fig, ax = plt.subplots(figsize=(11, 5.4))
apply_style(ax)
# Enerji eğrisi
ax.plot(y, F, color=COL_VIOLET, lw=2.6, zorder=3, label="Enerji F(y)")
ax.fill_between(y, F, F.max() + 0.15, color=COL_BG, alpha=0.45, zorder=1)
# Gerçek veri: çukur diplerinde, violet "push down" (aşağı ok)
for d in data_points:
fd = float(energy_1d(np.array([d]), data_points=data_points, width=0.35)[0])
ax.scatter([d], [fd], s=95, color=COL_VIOLET_D, edgecolor=COL_WHITE,
linewidth=1.4, zorder=6)
ax.add_patch(FancyArrowPatch((d, fd + 0.62), (d, fd + 0.08),
arrowstyle="-|>", mutation_scale=18,
color=COL_VIOLET, lw=2.4, zorder=5))
# Gerçek veri legend etiketi (tek seferlik proxy)
ax.scatter([], [], s=95, color=COL_VIOLET_D, edgecolor=COL_WHITE,
linewidth=1.4, label="Gerçek veri → enerjiyi BAS (push down)")
# Sahte (generator) noktalar: tepelerde, gold "push up" (yukarı ok)
for fs in fake_start:
fv = float(energy_1d(np.array([fs]), data_points=data_points, width=0.35)[0])
ax.scatter([fs], [fv], s=95, marker="D", color=COL_GOLD,
edgecolor=COL_GOLD_D, linewidth=1.4, zorder=6)
ax.add_patch(FancyArrowPatch((fs, fv - 0.05), (fs, fv + 0.55),
arrowstyle="-|>", mutation_scale=18,
color=COL_GOLD_D, lw=2.4, zorder=5))
ax.scatter([], [], s=95, marker="D", color=COL_GOLD, edgecolor=COL_GOLD_D,
linewidth=1.4, label="Sahte (generator) → enerjiyi YÜKSELT (push up)")
# Adaptiflik: generator ÖĞRENEREK sahteleri çukura doğru taşır (yatay ok)
for fs, fe in zip(fake_start, fake_end):
ax.add_patch(FancyArrowPatch((fs, F.max() + 0.02), (fe, F.max() + 0.02),
arrowstyle="-|>", mutation_scale=12,
color=COL_GOLD_D, lw=1.4, ls="--",
alpha=0.85, zorder=4))
ax.text(0.0, F.max() + 0.18, "generator ÖĞRENEREK üretir (adaptif negatif)",
ha="center", va="bottom", fontsize=9.5, color=COL_GOLD_D, style="italic")
# Açıklama kutusu
ax.text(
-3.5, F.min() + 0.18,
"GAN = Hafta 8 push-down / push-up şeması\n"
"FARK: negatifler elle DEĞİL — generator öğrenerek\n"
"üretir (adaptif / akıllı negatif)",
ha="left", va="bottom", fontsize=10, color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.5", fc=COL_WHITE, ec=COL_VIOLET, lw=1.6),
zorder=8,
)
ax.set_title("GAN = Kontrastif Enerji Modeli (EBM): gerçekte çukur, sahtede tepe",
fontsize=13, color=COL_INK, pad=12, fontweight="bold")
ax.set_xlabel("Örnek uzayı y", fontsize=11)
ax.set_ylabel("Enerji F(y)", fontsize=11)
ax.set_xlim(-3.6, 3.6)
ax.set_ylim(F.min() - 0.25, F.max() + 0.5)
style_legend(ax, loc="upper right", fontsize=9)
plt.tight_layout()
```
::: {.callout-tip title="Builder Notu — GAN = Öğrenilen Negatif"}
**Geriye (Hafta 8):** GAN = contrastive EBM (push down gerçek, push up sahte); fark, negatiflerin öğrenilen bir generator'dan gelmesi. Hafta 8 contrastive + Hafta 7 enerji = GAN.
**İleriye:** "Öğrenilen negatif üreteci" fikri, modern üretken modellerin ve adversarial eğitimden RLHF reward-model'e uzanan tekniklerin ortak teması.
:::
## Bu Dersin Özeti {#sec-ozet-d9}
1. **Non-contrastive birleştirici ilke:** latent kapasitesini azalt → düşük-enerji uzayının hacmini sınırla. Sparsity, gürültü (VAE), bottleneck — hepsi aynı (Hafta 7-8-9 birleşir).
2. **Sparse coding:** az aktif birimle temsil (L1); group/structural sparsity en az grubu açık tutar.
3. **Dünya modeli:** belirsiz geleceği öngören latent-variable EBM (LeCun programının kalbi).
4. **GAN:** generator (latent → sahte $\hat{x}$) + cost network (= enerji; gerçeğe düşük, sahteye yüksek). "Discriminator" yerine "cost network" (NYU/LeCun dili).
5. **GAN eğitimi = çekişme:** cost network sahteyi yukarı iter, generator cost'u düşürür (kandırır); min-max.
6. **GAN = contrastive EBM:** generator negatifleri *öğrenerek* üretir — Hafta 8 contrastive'in adaptif-negatifli hâli.
::: {.callout-important title="Tek Bir Cümle"}
EBM serisinin son dersi her şeyi tek çatıda topluyor: non-contrastive yöntemler (sparsity, VAE, bottleneck) düşük-enerji uzayının hacmini sınırlayarak enerjiyi şekillendirir; GAN ise contrastive bir EBM'dir — generator negatifleri öğrenerek üretir, cost network (enerji) gerçeğe düşük, sahteye yüksek değer vererek onu hizaya sokar.
:::
## Kontrol Soruları {#sec-kontrol-d9}
::: {.callout-note collapse="true" title="Soru 1: Non-contrastive yöntemleri (sparsity, VAE, bottleneck) birleştiren ilke nedir? LeCun bunu nasıl ifade eder?"}
**Cevap:** Üçü de aynı şeyi yapar: **latent değişkenin (code) bilgi kapasitesini azaltır → düşük enerji alabilen uzayın hacmini sınırlar** (LeCun 16:00). Kapasite sınırlıysa, veriye düşük enerji verdiğinde geri kalan otomatik olarak yükselir — negatif örnek üretmeden. Bottleneck (Hafta 7) code'u küçültür; VAE (Hafta 8) gürültü/varyansla kapasiteyi sınırlar; sparsity (bu hafta) çoğu birimi sıfıra iter. Hepsi "düşük-enerji hacmini sınırla" ilkesinin farklı uygulamalarıdır — contrastive'in (negatif itme) alternatifi.
:::
::: {.callout-note collapse="true" title="Soru 2: Dünya modeli neden bir EBM'dir? Tek-çıktılı bir öngörücüden farkı nedir?"}
**Cevap:** Dünya modeli mevcut durum + eylemden **geleceği öngörür**, ama gelecek **belirsizdir** (bir duruma birçok olası sonraki durum). Tek-çıktılı bir öngörücü bunları tek bir çıktıya — genelde bulanık bir ortalamaya — sıkıştırır (yanlış). EBM ise olası geleceklere **düşük enerji**, olanaksızlara **yüksek enerji** verir; belirsizliği **latent değişkenle** ($z$) yakalar (Hafta 7 latent-variable EBM). Yani dünya modeli = öngörü + latent-variable EBM; birden çok geçerli gelecek = enerjinin birden çok minimumu.
:::
::: {.callout-note collapse="true" title="Soru 3: Canziani neden 'discriminator' yerine 'cost network' diyor? GAN'ın iki parçası ne yapar?"}
**Cevap:** Çünkü GAN'ı dersin **EBM diline** çeviriyor: "cost network" bir **enerji fonksiyonudur** — Canziani/LeCun "discriminator" terimini yanlış bulur (2:37). İki parça: **Generator** latent bir z (Gaussian örneği) alıp sahte örnek $\hat{x}$ üretir; **cost network** her girdiye bir enerji (maliyet) atar — gerçeğe (pembe) düşük, sahteye (mavi, generator'dan) yüksek. Yani cost = enerji, ve "gerçeğe düşük/sahteye yüksek" tam Hafta 7'nin EBM şeklidir.
:::
::: {.callout-note collapse="true" title="Soru 4: (Builder) GAN neden bir contrastive EBM'dir? Hafta 8'in contrastive yöntemlerinden farkı nedir?"}
**Cevap:** GAN, Hafta 8'in **push-down/push-up**'ını yapar: cost network gerçeğe düşük enerji (push down), generator'ın sahtelerine yüksek enerji (push up) verir. Bu yüzden bir **contrastive EBM**'dir. **Fark:** Hafta 8'de negatifler elle/sabit üretiliyordu (augmentation, rastgele); GAN'da negatifleri **generator öğrenerek, adaptif üretir** — cost network'ün en çok kandığı (en düşük enerjili) sahteleri arar. Yani GAN = "akıllı/öğrenilen negatif üreteçli" contrastive EBM; min-max çekişme bu adaptif negatif üretiminin sonucudur.
:::
## Egzersizler {#sec-egzersiz-d9}
**Egzersiz 1 (Kapasite = hacim).** Bir autoencoder'ın code boyutunu 32 → 8 → 2 küçült. Her durumda reconstruction kalitesi ve "düşük enerji alan uzay" nasıl değişir? "Kapasiteyi sınırla = düşük-enerji hacmini sınırla" ilkesini gözlemle.
```python
import numpy as np
# Kapasite (code boyutu) kuculdukce "dusuk enerji alan uzay" daralir.
# Sema: genis code -> her seyi yeniden kurabilir (genis dusuk-enerji = kotu);
# dar code -> sadece veriyi kurabilir (dar dusuk-enerji = iyi).
def low_energy_width(code_dim, data_dim=32):
# kabaca: dusuk-enerji hacmi ~ code kapasitesiyle orantili (sezgi)
return code_dim / data_dim
for code in (32, 8, 2):
w = low_energy_width(code)
print(f"code={code:2d} -> dusuk-enerji hacmi ~ {w:.3f} "
f"({'genis=kotu' if w > 0.5 else 'dar=iyi (kapasite sinirli)'})")
# code=32 -> hacim ~1.0 (her sey dusuk = kotu); code=2 -> dar (veriye oturur = iyi)
```
**Egzersiz 2 (Sparse coding).** Bir code'a L1 düzenlileştirme ekle (loss += λ·$\lVert\text{code}\rVert_1$). λ'yı artırınca kaç birim aktif kalıyor? Group sparsity (birimleri gruplayıp grup-normuna L1) ne farklı yapar?
```python
import numpy as np
# L1 yumusatma (soft-threshold): code = sign(z) * max(|z| - lam, 0)
# lam buyudukce daha cok birim sifira gider (aktif birim sayisi DUSER).
def soft_threshold(z, lam):
return np.sign(z) * np.maximum(np.abs(z) - lam, 0.0)
rng = np.random.default_rng(0)
z = rng.normal(0, 1, 24) # ham code (yogun)
for lam in (0.0, 0.5, 1.0, 1.5):
code = soft_threshold(z, lam)
n_active = int(np.count_nonzero(code))
print(f"lambda={lam:.1f} -> aktif birim = {n_active:2d} / 24")
# lambda buyudukce aktif birim DUSER (L1 cogu birimi sifira iter)
# group sparsity: birimleri gruplara ayir, grup-normuna L1 -> EN AZ grubu acik tut
```
**Egzersiz 3 (GAN = cost network).** Küçük bir GAN kur (generator + "cost network"/discriminator). Cost network'ün gerçek/sahte örneklere verdiği değerleri eğitim boyunca izle: gerçek düşük, sahte yüksek mi? Bunun Hafta 7 enerji şekliyle ilişkisini açıkla.
```python
import torch
import torch.nn as nn
# Generator: gurultu z -> sahte ornek ; Cost network: ornek -> enerji (skaler)
G = nn.Sequential(nn.Linear(8, 32), nn.ReLU(), nn.Linear(32, 2))
Cost = nn.Sequential(nn.Linear(2, 32), nn.ReLU(), nn.Linear(32, 1)) # = enerji agi
real = torch.randn(64, 2) * 0.1 + torch.tensor([1.0, 0.0]) # gercek veri (manifold)
z = torch.randn(64, 8)
fake = G(z) # sahte ornekler
E_real = Cost(real).mean() # gercege DUSUK olmali
E_fake = Cost(fake).mean() # sahteye YUKSEK olmali
# cost network kaybi: gercegi bas (dusur), sahteyi yukselt -> Hafta 7 EBM sekli
cost_loss = E_real - E_fake # minimize et: E_real kucuk, E_fake buyuk
# generator kaybi: cost'u DUSUR (kandir) -> E_fake'i kucult
gen_loss = Cost(G(z)).mean()
print("cost(gercek)=enerji DUSUK, cost(sahte)=enerji YUKSEK -> Hafta 7 enerji sekli")
```
**Egzersiz 4 (Mode collapse).** GAN'ını eğit; generator'ın hep aynı birkaç örneği üretmeye başladığını (mode collapse) gözlemlemeye çalış. Bu, "generator cost'u kandırmanın kolay yolunu buldu" olarak nasıl yorumlanır?
```python
import torch
# Mode collapse: generator cost'u kandirmanin KOLAY yolunu bulur ->
# tum z'leri ayni (dusuk-enerjili) cikti'ya esler (cesitlilik kaybolur).
def mode_collapse_score(samples):
# cikti cesitliligi: dusukse -> collapse (hep ayni ornek)
return samples.std(dim=0).mean().item()
healthy = torch.randn(200, 2) # cesitli cikti (saglikli)
collapsed = torch.randn(200, 2) * 0.02 + 1.0 # neredeyse tek nokta (collapse)
print(f"saglikli cesitlilik = {mode_collapse_score(healthy):.3f}")
print(f"collapse cesitlilik = {mode_collapse_score(collapsed):.3f}")
# collapse: generator tek bir "cost'u kandiran" noktayi bulup oraya yiginlasti
# -> cesitlilik ~0; min-max dengesi bozuldu (WGAN/spectral norm bunu yumusatir)
```
**Egzersiz 5 (Hafta 10 habercisi — görüde SSL).** Hafta 8'de contrastive SSL'i (pozitif/negatif çift) gördük. Hafta 10'da **konuk Ishan Misra** bunu görüde derinleştirecek (pretext görevler, PIRL, ClusterFit). (a) Etiketsiz görüntülerden bir "pretext görevi" (örn. döndürme açısını tahmin et) nasıl gözetim sinyali üretir? (b) Bu, etiketli veri pahalı olduğunda neden değerlidir?
```python
import torch
# (a) Pretext gorevi: ETIKETSIZ goruntuyu dondur, ACIYI tahmin ettir.
# Donme acisi "bedava etiket" uretir -> oz-denetimli gozetim sinyali.
def make_rotation_task(img):
angles = [0, 90, 180, 270] # 4 sinif (bedava etiket)
k = torch.randint(0, 4, (1,)).item()
rotated = torch.rot90(img, k, dims=[-2, -1]) # k*90 derece dondur
return rotated, k # (girdi, otomatik etiket)
img = torch.rand(3, 32, 32)
rot, label = make_rotation_task(img)
print(f"pretext etiketi (donme sinifi) = {label} -> ag bunu tahmin ederek ogrenir")
# (b) etiketli veri PAHALI; pretext gorevi etiketi BEDAVA uretir (oz-denetim)
# -> bol etiketsiz veriyle on-egitim, sonra az etiketle ince-ayar (Hafta 10)
```
## Sonraki Ders İçin Hazırlık {#sec-sonraki-d9}
::: {.callout-warning title="Sonraki Hafta — H10: Görüde Öz-Denetimli Öğrenme (SSL) ve PPUU (Konuk: Ishan Misra)"}
**SSL görüye iniyor.** Bu hafta EBM serisini kapattık: non-contrastive birleştirici ilke (kapasite → düşük-enerji hacmi), sparse coding, dünya modelleri ve GAN (= contrastive EBM, öğrenilen negatif). Hafta 10'da **konuk hoca Ishan Misra** (Facebook AI Research) görüde öz-denetimli öğrenmeyi anlatacak (pretext görevler, ClusterFit, **PIRL**); Canziani ise belirsizlik altında öngörü/politika öğrenmeyi (PPUU) — dünya modellerinin pratiğini — gösterecek. Egzersiz 3 (GAN cost network) ve Egzersiz 5 (pretext görev) tam bu derse hazırlar.
:::
**Hafta 10: Görüde Öz-Denetimli Öğrenme (SSL) ve PPUU** — Konuk: Ishan Misra (Lecture) + Canziani (Practicum)
Hafta 10'da **konuk hoca Ishan Misra** (Facebook AI Research) görüde öz-denetimli öğrenmeyi anlatacak: pretext görevler, ClusterFit, **PIRL**. Canziani ise belirsizlik altında öngörü/politika öğrenmeyi (PPUU) — dünya modellerinin pratiğini — gösterecek.
**Hafta 10 öncesi yapılacak:**
- Egzersiz 3 (GAN cost network) ve Egzersiz 5 (pretext görev) çöz.
- "GAN = contrastive EBM (öğrenilen negatif)" ve "non-contrastive = düşük-enerji hacmini sınırla" cümlelerini kendi sözcüklerinle yaz.
- Hafta 8 contrastive SSL'i hatırla — Hafta 10 onu görüye uygular.
## Anahtar Kavramlar (Cheat Sheet) {#sec-cheat-d9}
| Kavram | Tanım | Hoca / timestamp |
|---|---|---|
| Düşük-enerji hacmini sınırla | Non-contrastive'in ortak ilkesi (kapasite azalt) | LeCun 16m00 |
| Sparse coding | Az aktif birimle temsil; L1 düzenlileştirme | LeCun 0m33 |
| Group / structural sparsity | En az sayıda grubu açık tut; topolojik organizasyon | LeCun 8m01 |
| Dünya modeli (world model) | Belirsiz geleceği öngören latent-variable EBM | LeCun 0m22 |
| GAN | Generator (latent→sahte) + cost network (enerji) | Canziani 1m55 |
| Cost network (≠ discriminator) | Enerji ağı; gerçeğe düşük, sahteye yüksek | Canziani 2m37 |
| GAN eğitimi (çekişme) | Cost sahteyi yukarı iter, generator cost'u düşürür | Canziani 5m23 |
| GAN = contrastive EBM | Generator negatifleri öğrenerek üretir | Canziani / LeCun |
## ML Builder Bağlantıları {#sec-koprular-d9}
**Geriye köprüler (önkoşul kurslar):**
1. **Düşük-enerji hacmini sınırla** → Hafta 7 bottleneck + Hafta 8 VAE + bu hafta sparsity (birleşim).
2. **Sparse coding (L1)** → 18.06 seyrek temsil + Stat 110 Laplace prior.
3. **Cost network = enerji** → Hafta 7 EBM + Hafta 1 cross-entropy (gerçek/sahte).
4. **Min-max** → Calculus eyer noktası (saddle point).
5. **GAN = contrastive EBM** → Hafta 8 push-down/push-up (öğrenilen negatif).
**İleriye köprüler (production / research):**
1. **World model** → LeCun JEPA programı (post-2020), model-based RL/planning.
2. **GAN** → CycleGAN, StyleGAN, WGAN; diffusion (modern üretken).
3. **Sparse / structural** → yorumlanabilir temsil, mixture-of-experts (seyrek aktivasyon).
4. **Öğrenilen negatif** → adversarial eğitim, RLHF reward model.
::: {.callout-important title="Bu dersten tek bir şey alıp gideceksen"}
EBM serisi tek çatıda kapanır — non-contrastive yöntemler (sparsity, VAE, bottleneck) hep aynı şeyi yapar: düşük-enerji uzayının hacmini sınırlamak; GAN ise contrastive bir EBM'dir, ama negatiflerini elle değil, bir generator'la **öğrenerek** üretir, ve cost network (LeCun'un dilinde "discriminator" değil, enerji ağı) gerçeğe düşük, sahteye yüksek enerji vererek onu hizaya sokar. Dünya modelleri de aynı çerçevenin geleceğe bakan hâlidir — ve LeCun'un bugünkü araştırmasının (JEPA) tohumudur.
:::