---
title: "Graph Convolutional Networks"
subtitle: "İki parçalı hafta — konuk hoca Xavier Bresson (Nanyang Technological University, GNN uzmanı) Lecture'da ConvNet'in başarısını üç doğal-sinyal varsayımına (locality, stationarity, compositionality) dayandırır ve bu varsayımları düzensiz grafiklere taşımanın iki yolunu kurar: template matching (uzaysal) ve convolution teoremi (spektral); uzaysal yolda düğümlerin sırası ve konumu olmadığından şablon eşleştirme anlamsızdır, çözüm tek bir şablon vektörünü tüm komşulukla eşleyip toplamaktır; spektral yolda graf Laplacian'ı pürüzsüzlüğü ölçer, özvektörleri graf Fourier fonksiyonlarını verir, ve ChebNet filtreyi Laplacian'ın polinomu olarak yazarak K-hop yerelleştirilmiş, eigendecomposition gerektirmeyen, gerçek graflar seyrek olduğu için lineer karmaşıklıkta bir convolution elde eder; uzaysal GCN'ler izotropik (tüm komşuya aynı ağırlık: Vanilla, GraphSAGE, GIN) ve anizotropik (komşulara farklı ağırlık: MoNet, GAT, GatedGCN) diye ayrışır, ve dersin doruğunda Bresson Transformer'ın tam-bağlı bir graf üzerinde GCN olduğunu, yani aslında bir küme sinir ağı olduğunu gösterir. Ardından Alfredo Canziani (Practicum) aynı birliği ters yönden kurar: GCN'i okuyunca aslında self-attention olduğunu fark eder, çünkü attention katsayıları hesaplanmak yerine adjacency matrisinden verilir; dereceye bölme, self-connection ve ReLU eklenince izotropik GCN çıkar; Residual Gated GCN'in kenar geçidi izotropik ortalamayı anizotropik ağırlıklı toplama çevirir; ve DGL ile mesaj, reduce, update_all fonksiyonları kurulup graf-seviye sınıflandırma (mean-pool sonra MLP) ile düğüm-seviye yarı-denetimli sınıflandırma (Karate Club, yalnız iki etiket grafın yapısı boyunca yayılır) gösterilir — her iki hoca da aynı sonuca varır: seyreklik yapıdır, ve graph convolution ile attention'ı ayıran tek şey grafın kendisidir."
---
::: {.callout-note title="Bölüm bilgisi (KONUK Xavier Bresson + Canziani)"}
- **Konuk Lecture (Xavier Bresson, NTU):** [YouTube — Graph Convolutional Networks](https://www.youtube.com/watch?v=Iiv9R6BjxHM) (Hafta 13 Lecture)
- **Canziani'nin Practicum videosu:** [YouTube — Graph Convolutional Networks](https://www.youtube.com/watch?v=2aKXWqkbpWg)
- **Edition:** Spring 2020 (NYU-DLSP20)
- **Hocalar:** Xavier Bresson (Konuk Lecture, spektral + uzaysal GCN) + Alfredo Canziani (Practicum, GCN = attention, Residual Gated GCN, DGL) — Yann LeCun tartışmaya katılır (öz-denetimli öğrenme = grafın sömürülmesi köprüsü)
- **Kaynak:** [atcold.github.io/NYU-DLSP20](http://atcold.github.io/NYU-DLSP20)
- **Okuma süresi:** ≈30 dk
> ⚠️ **Atıf notu:** Bu haftanın Lecture'ı **LeCun değil, konuk Xavier Bresson** (NTU, graph neural net dünyasının önde gelen isimlerinden). Doğrulama: LeCun (ders sahibi) tartışmada Bresson'a ismiyle hitap eder ("I can tell you, Xavier...", 1:50:06) ve onu "NTU'dan, graph neural net dünyasının önde gelen isimlerinden" diye tanıtır. Lecture quote'ları **— Bresson**; Practicum **— Canziani**; LeCun katıldığında **— LeCun**.
:::
```{python}
#| echo: false
import networkx as nx
# ============================================================================
# SETUP — NYU sayısal motor (_engine.py) + NYU Violet+gold viz (_viz.py)
# Bu hücre gizlidir (#| echo: false). Aşağıdaki TÜM figür hücreleri burada
# tanımlanan path_graph_adj / community_graph_adj / graph_laplacian /
# graph_fourier / laplacian_smoothness / khop_diffusion / gcn_message_pass /
# gate_eta + önceki hafta yardımcıları + COL_* + apply_style / draw_pipeline /
# style_legend / CLASS_COLORS isimlerini kullanır.
# _engine.py saf numpy (torch YOK); _viz.py NYU Violet+gold paleti.
# Graf çizimleri için networkx kullanılır (üst satırda import edilir).
# İçerikler VERBATIM gömülüdür.
#
# NOT: matplotlib backend'i AYARLANMAZ (matplotlib.use(...) ÇAĞRILMAZ).
# Quarto kendi inline (figür yakalayan) backend'ini kurar; Agg backend
# inline figür-yakalamayı bozar (plt.show() çıktı üretmez). Standalone
# figür testinde savefig kullanılır.
# ============================================================================
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import matplotlib as mpl
import matplotlib.patches as mpatches
from matplotlib.patches import (
FancyBboxPatch, FancyArrowPatch, Rectangle, Circle, Ellipse, Polygon, Patch,
)
from matplotlib.lines import Line2D
from matplotlib.colors import ListedColormap, BoundaryNorm, LinearSegmentedColormap
np.random.seed(0)
# ===========================================================================
# _engine.py — saf numpy sayısal yardımcılar (torch YOK)
# ===========================================================================
# ---------------------------------------------------------------------------
# Afin / lineer dönüşümler
# ---------------------------------------------------------------------------
def affine_transform(P, W, b=None):
"""P[N,2] noktalarına y = W x (+ b) afin/lineer dönüşümü uygular (satır-vektör konvansiyonu)."""
P = np.asarray(P, float)
Y = P @ np.asarray(W, float).T
if b is not None:
Y = Y + np.asarray(b, float)
return Y
def unit_grid(n=11, lim=2.0, fine=61):
"""Izgara çizgileri listesi (yatay + dikey). Her çizgi (fine,2) dizisi.
Lineer dönüşüm görsellerinde 'uzayın kumaşı' için."""
t = np.linspace(-lim, lim, n)
f = np.linspace(-lim, lim, fine)
lines = []
for yi in t:
lines.append(np.column_stack([f, np.full_like(f, yi)]))
for xi in t:
lines.append(np.column_stack([np.full_like(f, xi), f]))
return lines
def linear_transforms():
"""Canziani'nin dört temel lineer dönüşümü (Bölüm 8) — 2x2 matrisler."""
th = np.deg2rad(35.0)
R = np.array([[np.cos(th), -np.sin(th)], [np.sin(th), np.cos(th)]]) # rotation (ortonormal)
S = np.array([[1.8, 0.0], [0.0, 0.55]]) # scaling (köşegen)
Sh = np.array([[1.0, 0.85], [0.0, 1.0]]) # shearing
F = np.array([[1.0, 0.0], [0.0, -1.0]]) # reflection (det<0)
return dict(rotation=R, scaling=S, shearing=Sh, reflection=F)
# ---------------------------------------------------------------------------
# SVD geometrisi (Canziani'nin 'patatesi')
# ---------------------------------------------------------------------------
def unit_circle(n=240):
t = np.linspace(0, 2 * np.pi, n)
return np.column_stack([np.cos(t), np.sin(t)])
def svd_demo(W):
"""W = U Σ Vᵀ. Geometrik okuma: rotation(Vᵀ) · scaling(Σ) · rotation(U)."""
U, s, Vt = np.linalg.svd(np.asarray(W, float))
return U, s, Vt
def near_singular_matrix():
"""Bir tekil değeri ≈0 olan matris — bir boyutu 'ezer' (elips çizgiye çöker)."""
th = np.deg2rad(30.0)
R = np.array([[np.cos(th), -np.sin(th)], [np.sin(th), np.cos(th)]])
Sigma = np.diag([1.6, 0.04]) # ikinci tekil değer ≈ 0
return R @ Sigma @ R.T
# ---------------------------------------------------------------------------
# Spiral (manifold germe demosu)
# ---------------------------------------------------------------------------
def make_spiral(n_per=120, k=5, noise=0.18, seed=0):
"""k-kollu spiral (CS231n stili). Her kol bir sınıf; kollar orijinde iç içe → lineer ayrılamaz."""
rng = np.random.default_rng(seed)
X = np.zeros((n_per * k, 2))
y = np.zeros(n_per * k, dtype=int)
for j in range(k):
ix = slice(n_per * j, n_per * (j + 1))
r = np.linspace(0.0, 1.0, n_per)
t = np.linspace(j * 4.0, (j + 1) * 4.0, n_per) + rng.normal(0, 1, n_per) * noise
X[ix] = np.column_stack([r * np.sin(t), r * np.cos(t)])
y[ix] = j
return X, y
def unroll_spiral(X, y, k=5, seed=0):
"""ŞEMATİK 'öğrenilen temsil': her sınıfı kendi yatay bandına taşır → lineer ayrılabilir.
Gerçek bir eğitilmiş ağ DEĞİL; 'ağ manifoldu açar' sezgisinin deterministik görseli."""
rng = np.random.default_rng(seed)
r = np.linalg.norm(X, axis=1)
yb = (y - (k - 1) / 2.0) * 0.55 + rng.normal(0, 0.045, len(y))
return np.column_stack([r * 2.2 - 1.1, yb])
# ---------------------------------------------------------------------------
# İki hilal (make_moons — sklearn YOK, numpy ile elle)
# ---------------------------------------------------------------------------
def make_moons_np(n=400, noise=0.20, seed=0):
"""Doğrusal ayrılamaz iki-hilal veri (sklearn.make_moons eşdeğeri)."""
rng = np.random.default_rng(seed)
n_out = n // 2
n_in = n - n_out
to = np.linspace(0, np.pi, n_out)
ti = np.linspace(0, np.pi, n_in)
outer = np.column_stack([np.cos(to), np.sin(to)])
inner = np.column_stack([1.0 - np.cos(ti), 1.0 - np.sin(ti) - 0.5])
X = np.vstack([outer, inner]) + rng.normal(0, noise, (n, 2))
y = np.array([0] * n_out + [1] * n_in)
return X, y
# ---------------------------------------------------------------------------
# Minik numpy sınıflandırıcılar (lineer vs ReLU MLP) — karar sınırı kontrastı
# ---------------------------------------------------------------------------
def _onehot(y, c):
Y = np.zeros((len(y), c))
Y[np.arange(len(y)), y] = 1.0
return Y
def _softmax(z):
z = z - z.max(axis=1, keepdims=True)
e = np.exp(z)
return e / e.sum(axis=1, keepdims=True)
def logreg_train(X, y, steps=500, lr=1.0, seed=0):
"""Lineer (gizli katmansız) softmax sınıflandırıcı → DÜZ karar sınırı."""
rng = np.random.default_rng(seed)
n, d = X.shape
c = int(y.max() + 1)
W = rng.normal(0, 0.01, (d, c))
b = np.zeros(c)
Y = _onehot(y, c)
for _ in range(steps):
p = _softmax(X @ W + b)
dz = (p - Y) / n
W -= lr * (X.T @ dz)
b -= lr * dz.sum(axis=0)
return dict(W=W, b=b)
def logreg_forward(params, X):
return X @ params["W"] + params["b"]
def mlp_train(X, y, hidden=16, act="relu", steps=600, lr=1.0, seed=0, return_history=False):
"""numpy 2-katmanlı MLP (afine → nonlinearite → afine), softmax + cross-entropy.
ReLU ile EĞRİ karar sınırı (hilalleri/spirali ayırır).
return_history=True → (params, loss_history) döner (eğitim eğrisi figürü için)."""
rng = np.random.default_rng(seed)
n, d = X.shape
c = int(y.max() + 1)
W1 = rng.normal(0, 1, (d, hidden)) * np.sqrt(2.0 / d)
b1 = np.zeros(hidden)
W2 = rng.normal(0, 1, (hidden, c)) * np.sqrt(2.0 / hidden)
b2 = np.zeros(c)
Y = _onehot(y, c)
history = []
for _ in range(steps):
z1 = X @ W1 + b1
a1 = np.maximum(0, z1) if act == "relu" else np.tanh(z1)
p = _softmax(a1 @ W2 + b2)
if return_history:
history.append(float(-np.log(p[np.arange(n), y] + 1e-12).mean()))
dz2 = (p - Y) / n
dW2 = a1.T @ dz2
db2 = dz2.sum(axis=0)
da1 = dz2 @ W2.T
dz1 = da1 * ((z1 > 0) if act == "relu" else (1 - np.tanh(z1) ** 2))
dW1 = X.T @ dz1
db1 = dz1.sum(axis=0)
W1 -= lr * dW1
b1 -= lr * db1
W2 -= lr * dW2
b2 -= lr * db2
params = dict(W1=W1, b1=b1, W2=W2, b2=b2, act=act)
if return_history:
return params, np.array(history)
return params
def mlp_forward(params, X):
z1 = X @ params["W1"] + params["b1"]
a1 = np.maximum(0, z1) if params["act"] == "relu" else np.tanh(z1)
return a1 @ params["W2"] + params["b2"]
def accuracy(forward_fn, params, X, y):
return float((forward_fn(params, X).argmax(axis=1) == y).mean())
def decision_grid(X, pad=0.6, h=0.02):
"""Karar bölgesi için koordinat ızgarası (xx, yy) ve düz nokta listesi."""
x0, x1 = X[:, 0].min() - pad, X[:, 0].max() + pad
y0, y1 = X[:, 1].min() - pad, X[:, 1].max() + pad
xx, yy = np.meshgrid(np.arange(x0, x1, h), np.arange(y0, y1, h))
grid = np.column_stack([xx.ravel(), yy.ravel()])
return xx, yy, grid
# ---------------------------------------------------------------------------
# Enerji manzarası (EBM — çoklu minimum = çoklu geçerli cevap)
# ---------------------------------------------------------------------------
def energy_landscape(xx, yy):
"""F(x,y): birkaç Gauss kuyusu → çoklu yerel minimum. Düşük enerji = uyumlu cevap."""
wells = [(-1.25, -0.65, 1.0, 0.55), (1.15, 0.85, 1.05, 0.6), (0.15, -1.15, 0.8, 0.45)]
F = np.ones_like(xx) * 1.0
for cx, cy, depth, width in wells:
F = F - depth * np.exp(-((xx - cx) ** 2 + (yy - cy) ** 2) / (2 * width))
return F
# ---------------------------------------------------------------------------
# Hafta 2 — gradient descent, SGD, backprop, eğitim
# ---------------------------------------------------------------------------
def loss_surface_2d(xx, yy):
"""2D parametre uzayında bir kayıp yüzeyi (gradient descent 'dağ' görseli için):
eğik, farklı-ölçekli bir vadi (konveks taban) + hafif dalgalanma."""
u = 0.85 * xx + 0.53 * yy # eksenleri döndür (eğik vadi)
v = -0.53 * xx + 0.85 * yy
return 1.0 * u ** 2 + 3.5 * v ** 2 + 0.6 * np.sin(1.5 * xx) * np.cos(1.5 * yy)
def _loss_grad_2d(p):
"""loss_surface_2d gradyanı (merkezi sonlu fark)."""
eps = 1e-4
gx = (loss_surface_2d(p[0] + eps, p[1]) - loss_surface_2d(p[0] - eps, p[1])) / (2 * eps)
gy = (loss_surface_2d(p[0], p[1] + eps) - loss_surface_2d(p[0], p[1] - eps)) / (2 * eps)
return np.array([gx, gy])
def gd_path(theta0, lr=0.08, steps=40):
"""loss_surface_2d üzerinde gradient descent yörüngesi (parametre adımları)."""
p = np.array(theta0, float)
path = [p.copy()]
for _ in range(steps):
p = p - lr * _loss_grad_2d(p)
path.append(p.copy())
return np.array(path)
def sgd_loss_curves(steps=80, seed=0):
"""Üç rejim için kayıp eğrisi (simülasyon): full-batch (gürültüsüz, düz),
mini-batch (orta gürültü), saf SGD (yüksek gürültü). Aynı yumuşak üstel düşüş."""
rng = np.random.default_rng(seed)
t = np.arange(steps)
base = 0.2 + 2.6 * np.exp(-t / 14.0)
full = base.copy()
mini = base + rng.normal(0, 0.10, steps) * np.exp(-t / 45.0)
sgd = base + rng.normal(0, 0.45, steps) * np.exp(-t / 70.0)
return t, np.clip(full, 0, None), np.clip(mini, 0, None), np.clip(sgd, 0, None)
def tanh_deriv(x):
"""tanh'ın türevi: 1 − tanh²(x). Backprop 'twiddling' figürü için."""
return 1.0 - np.tanh(x) ** 2
def ce_loss_curve(p):
"""Doğru sınıf olasılığı p için cross-entropy kaybı: −log p."""
p = np.clip(np.asarray(p, float), 1e-6, 1.0)
return -np.log(p)
def mse_loss_curve(p):
"""Doğru sınıf olasılığı p için (one-hot hedefe) MSE: (1 − p)²."""
return (1.0 - np.asarray(p, float)) ** 2
# ---------------------------------------------------------------------------
# Hafta 3 — convolution / ConvNet / doğal sinyaller
# ---------------------------------------------------------------------------
def conv_output_size(n, k, s=1):
"""Çıktı boyutu: o = ⌊(n − k)/s⌋ + 1."""
return (n - k) // s + 1
def conv1d(x, w):
"""1B cross-correlation (ML 'convolution'): out[i] = Σ_k x[i+k]·w[k].
Örnek: conv1d([1,2,3,4,5],[1,0,-1]) → [-2,-2,-2] (kenar/fark dedektörü)."""
x = np.asarray(x, float)
w = np.asarray(w, float)
n = len(x) - len(w) + 1
return np.array([np.dot(x[i:i + len(w)], w) for i in range(n)])
def conv2d(img, kernel, stride=1):
"""2B valid cross-correlation (ag öznitelik haritası üretir)."""
img = np.asarray(img, float)
k = np.asarray(kernel, float)
kh, kw = k.shape
H, W = img.shape
oh, ow = conv_output_size(H, kh, stride), conv_output_size(W, kw, stride)
out = np.zeros((oh, ow))
for i in range(oh):
for j in range(ow):
patch = img[i * stride:i * stride + kh, j * stride:j * stride + kw]
out[i, j] = np.sum(patch * k)
return out
def make_synthetic_image(n=28, seed=0):
"""Basit gri-tonlu sentetik görüntü: kare + daire (kenar tespiti net görünsün)."""
img = np.zeros((n, n))
img[5:14, 6:15] = 1.0 # dolu kare
yy, xx = np.ogrid[:n, :n]
cy, cx, r = 19, 19, 6
img[(yy - cy) ** 2 + (xx - cx) ** 2 <= r ** 2] = 0.85 # daire
img[20:22, 4:24] = 0.6 # yatay çizgi (yatay kenar için)
return img
def edge_kernels():
"""Klasik 3×3 öznitelik dedektörü kernel'leri."""
return dict(
sobel_x=np.array([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]], float), # dikey kenar
sobel_y=np.array([[-1, -2, -1], [0, 0, 0], [1, 2, 1]], float), # yatay kenar
blur=np.ones((3, 3)) / 9.0, # bulanıklaştırma
laplace=np.array([[0, 1, 0], [1, -4, 1], [0, 1, 0]], float), # tüm kenarlar
)
def max_pool2d(img, k=2):
"""k×k max pooling (complex cell / invariance)."""
img = np.asarray(img, float)
H, W = img.shape
oh, ow = H // k, W // k
return np.array([[img[i * k:(i + 1) * k, j * k:(j + 1) * k].max() for j in range(ow)]
for i in range(oh)])
def avg_pool2d(img, k=2):
"""k×k average pooling (LeNet5 stili)."""
img = np.asarray(img, float)
H, W = img.shape
oh, ow = H // k, W // k
return np.array([[img[i * k:(i + 1) * k, j * k:(j + 1) * k].mean() for j in range(ow)]
for i in range(oh)])
# ---------------------------------------------------------------------------
# Hafta 4 — convolution cebiri (Toeplitz) + optimizasyon (κ, momentum, Adam)
# ---------------------------------------------------------------------------
def build_toeplitz(kernel, n):
"""1B convolution'ın Toeplitz matrisi: out = T @ x, T[i, i:i+k] = kernel.
conv1d(x, kernel) == build_toeplitz(kernel, len(x)) @ x (çoğu eleman sıfır = seyrek)."""
kernel = np.asarray(kernel, float)
k = len(kernel)
oh = n - k + 1
T = np.zeros((oh, n))
for i in range(oh):
T[i, i:i + k] = kernel
return T
def quad_loss(xx, yy, kappa=20.0):
"""Eğik, koşullanması κ = L/μ olan kuadratik vadi (condition number görseli).
κ büyük → uzun ince vadi → gradient descent zikzak çizer."""
a, b = 0.92, 0.39 # ~25° dönme
u = a * xx + b * yy
v = -b * xx + a * yy
return 0.5 * (1.0 * u ** 2 + kappa * v ** 2) # L=κ, μ=1
def quad_grad(p, kappa=20.0):
"""quad_loss'un analitik gradyanı."""
a, b = 0.92, 0.39
x, y = p
u = a * x + b * y
v = -b * x + a * y
gu, gv = u, kappa * v
return np.array([gu * a + gv * (-b), gu * b + gv * a])
def optimize_quad(method, theta0, lr, steps, kappa=20.0, beta=0.9, beta2=0.999, eps=1e-8):
"""quad_loss üzerinde bir optimizer'ı koştur; yörünge + kayıp geçmişi döner.
method ∈ {'gd','momentum','adam'}. Defazio'nun zikzak/sönümleme/adaptif anlatısı için."""
p = np.array(theta0, float)
path = [p.copy()]
losses = [float(quad_loss(p[0], p[1], kappa))]
m = np.zeros(2)
v = np.zeros(2)
for t in range(1, steps + 1):
g = quad_grad(p, kappa)
if method == "gd":
step = lr * g
elif method == "momentum":
m = beta * m + g # heavy ball
step = lr * m
elif method == "adam":
m = beta * m + (1 - beta) * g
v = beta2 * v + (1 - beta2) * g * g
mh = m / (1 - beta ** t) # bias correction
vh = v / (1 - beta2 ** t)
step = lr * mh / (np.sqrt(vh) + eps)
else:
raise ValueError(method)
p = p - step
path.append(p.copy())
losses.append(float(quad_loss(p[0], p[1], kappa)))
return np.array(path), np.array(losses)
# ---------------------------------------------------------------------------
# Hafta 5 — autograd worked example (Canziani)
# ---------------------------------------------------------------------------
def autograd_worked(X=None):
"""Canziani worked example: X → Y=X−2 → Z=3·Y² → a=mean(Z) (skaler).
İleri değerler + ∂a/∂xᵢ = (1/4)·3·2·(xᵢ−2) = 1.5·(xᵢ−2).
X=[1,2,3,4] için grad = [−1.5, 0, 1.5, 3] (PyTorch X.grad ile birebir)."""
if X is None:
X = np.array([1.0, 2.0, 3.0, 4.0])
X = np.asarray(X, float)
Y = X - 2.0
Z = 3.0 * Y ** 2
a = float(Z.mean())
grad = 1.5 * (X - 2.0)
return dict(X=X, Y=Y, Z=Z, a=a, grad=grad)
def conv_pad_output(n, k, padding=0, stride=1):
"""Padding'li çıktı boyutu: o = ⌊(n + 2·padding − k)/stride⌋ + 1.
padding=(k−1)/2 (k tek) → çıktı boyutu korunur."""
return (n + 2 * padding - k) // stride + 1
# ---------------------------------------------------------------------------
# Hafta 6 — RNN / vanishing gradient / attention
# ---------------------------------------------------------------------------
def vanishing_demo(steps=50, eigenvalues=(0.5, 1.0, 1.5)):
"""Aynı matristen n kez geçen gradient: λⁿ. λ<1 söner (vanishing), λ>1 patlar
(exploding), λ=1 sabit. Backprop-through-time vanishing gradient görseli."""
t = np.arange(steps + 1)
curves = {ev: np.asarray(ev, float) ** t for ev in eigenvalues}
return t, curves
def rnn_forward(X_seq, Wx, Wz, b, z0=None):
"""Basit RNN hücresi: zₜ = tanh(Wₓ·xₜ + W_z·zₜ₋₁ + b).
X_seq [T, d_in] → gizli durumlar Z [T, d_h] (aynı Wₓ,W_z her adımda = paylaşım)."""
X_seq = np.asarray(X_seq, float)
T = len(X_seq)
dh = np.asarray(Wz).shape[0]
z = np.zeros(dh) if z0 is None else np.asarray(z0, float)
Z = []
for t in range(T):
z = np.tanh(np.asarray(Wx) @ X_seq[t] + np.asarray(Wz) @ z + np.asarray(b))
Z.append(z.copy())
return np.array(Z)
def attention_weights(scores):
"""Attention ağırlıkları = softmax(skorlar); toplamı 1 (olasılık dağılımı, 'odak')."""
scores = np.asarray(scores, float)
e = np.exp(scores - scores.max())
return e / e.sum()
# ---------------------------------------------------------------------------
# Hafta 7 — EBM / autoencoder / manifold
# ---------------------------------------------------------------------------
def energy_1d(y, data_points=(-2.0, 0.0, 2.0), width=0.35):
"""1B enerji F(y): veri noktalarında düşük (çukur), aralarda yüksek (tepe).
'İyi enerji şekli' = veride düşük, dışında yüksek (EBM); çoklu minimum = çoklu cevap."""
y = np.asarray(y, float)
F = np.ones_like(y)
for d in data_points:
F = F - np.exp(-(y - d) ** 2 / (2 * width))
return F
def energy_1d_grad(y, data_points=(-2.0, 0.0, 2.0), width=0.35):
"""energy_1d'nin türevi (çıkarım = enerji minimizasyonu, gradient ile arama)."""
y = np.asarray(y, float)
g = np.zeros_like(y)
for d in data_points:
g = g + (y - d) / width * np.exp(-(y - d) ** 2 / (2 * width))
return g
def make_manifold_curve(n=160, noise=0.0, seed=0):
"""2B veri manifoldu: bir eğri (sinüs yayı) üzerinde noktalar (Hafta 1 manifold hipotezi)."""
t = np.linspace(-2.6, 2.6, n)
M = np.column_stack([t, np.sin(1.3 * t)])
if noise:
M = M + np.random.default_rng(seed).normal(0, noise, M.shape)
return M
def project_to_manifold(points, manifold):
"""Her noktayı manifoldun EN YAKIN noktasına çeker (autoencoder reconstruction sezgisi:
off-manifold girdiyi manifolda geri çek → düşük enerji)."""
points = np.asarray(points, float)
proj = np.array([manifold[np.linalg.norm(manifold - p, axis=1).argmin()] for p in points])
return proj
# ---------------------------------------------------------------------------
# Hafta 8 — contrastive / VAE
# ---------------------------------------------------------------------------
def vae_reparam(mu, sigma, n=400, seed=0):
"""Reparameterization trick: z = μ + σ⊙ε, ε~N(0,I). Düzenli (sürekli, dolu)
Gaussian latent örnekleri — VAE'nin üretken latent uzayı."""
mu = np.atleast_1d(np.asarray(mu, float))
sigma = np.atleast_1d(np.asarray(sigma, float))
rng = np.random.default_rng(seed)
eps = rng.normal(0, 1, (n, len(mu)))
return mu + sigma * eps
def ae_latent_clusters(n=400, seed=0):
"""Sıradan AE latent'i: dağınık, boşluklu kümeler (düzensiz uzay — VAE kontrastı)."""
rng = np.random.default_rng(seed)
centers = np.array([[-2.2, 1.8], [2.0, 2.1], [0.3, -2.3], [-1.8, -1.5]])
pts = []
for c in centers:
pts.append(c + rng.normal(0, 0.28, (n // len(centers), 2)))
return np.vstack(pts)
# ---------------------------------------------------------------------------
# Hafta 9 — sparse coding / GAN (EBM)
# ---------------------------------------------------------------------------
def sparse_code_demo(n=24, n_active=5, seed=0):
"""Yoğun (dense) vs seyrek (sparse) code: L1 düzenlileştirme çoğu bileşeni
sıfıra iter — yalnızca birkaç birim aktif kalır (sparse coding)."""
rng = np.random.default_rng(seed)
dense = rng.normal(0, 1, n)
idx = np.argsort(-np.abs(dense)) # en büyük |değer| → aktif kalanlar
sparse = np.zeros(n)
sparse[idx[:n_active]] = dense[idx[:n_active]]
return dense, sparse
def rotate_image_4way(img):
"""0/90/180/270° döndürülmüş 4 versiyon — rotation pretext görevi (Hafta 10 SSL):
ağ 'kaç derece döndürüldü?' sorusunu çözer (4-yönlü sınıflandırma)."""
img = np.asarray(img, float)
return [np.rot90(img, k) for k in range(4)]
# ---------------------------------------------------------------------------
# Hafta 11 — aktivasyon / kayıp (EBM) / belirsizlik
# ---------------------------------------------------------------------------
def _sig(x):
return 1.0 / (1.0 + np.exp(-np.clip(x, -50, 50)))
def activation_fns():
"""Aktivasyon fonksiyonu zoo'su + türevleri (Hafta 11). {ad: (f, f')}."""
return {
"ReLU": (lambda x: np.maximum(0, x), lambda x: (np.asarray(x) > 0).astype(float)),
"Leaky ReLU": (lambda x: np.where(x > 0, x, 0.1 * x), lambda x: np.where(np.asarray(x) > 0, 1.0, 0.1)),
"sigmoid": (_sig, lambda x: _sig(x) * (1 - _sig(x))),
"tanh": (np.tanh, lambda x: 1 - np.tanh(x) ** 2),
"softplus": (lambda x: np.log1p(np.exp(-np.abs(x))) + np.maximum(x, 0), _sig),
"ELU": (lambda x: np.where(x > 0, x, np.exp(np.clip(x, -50, 50)) - 1),
lambda x: np.where(np.asarray(x) > 0, 1.0, np.exp(np.clip(x, -50, 50)))),
}
def softplus_scaled(x, beta=1.0):
"""β-ölçekli softplus: (1/β)·log(1+e^(βx)). β büyük → ReLU'ya yaklaşır (ölçek-bağımlı)."""
x = np.asarray(x, float)
return (1.0 / beta) * (np.log1p(np.exp(-np.abs(beta * x))) + np.maximum(beta * x, 0))
def margin_losses(gap, m=1.0):
"""EBM kayıpları. gap = E(ȳ) − E(y) (doğru-yanlış enerji farkı; pozitif=doğru daha düşük).
hinge marj m (gap≥m'de 0), perceptron marjsız (gap≥0'da 0 → collapse'a açık)."""
gap = np.asarray(gap, float)
hinge = np.maximum(0.0, m - gap)
perceptron = np.maximum(0.0, -gap)
return hinge, perceptron
def uncertainty_demo(x_train, x_grid, bandwidth=0.6):
"""Belirsizlik (epistemik varyans proxy) ~ eğitim verisinden uzaklık: eğitim
noktalarına yakın DÜŞÜK, uzakta YÜKSEK (PPUU 'U' düzenlileştirmesi)."""
x_train = np.atleast_1d(np.asarray(x_train, float))
x_grid = np.atleast_1d(np.asarray(x_grid, float))
d = np.abs(x_grid[:, None] - x_train[None, :]).min(axis=1)
return 1.0 - np.exp(-(d / bandwidth) ** 2)
def gan_samples(seed=0, n=200):
"""GAN sezgisi: gerçek veri (manifold/halka) vs generator'ın ürettiği sahte örnekler.
İlk başta sahteler dağınık (eğitilmemiş generator), gerçeğe yakınsar."""
rng = np.random.default_rng(seed)
th = rng.uniform(0, 2 * np.pi, n)
real = np.column_stack([np.cos(th), np.sin(th)]) + rng.normal(0, 0.06, (n, 2)) # gerçek = birim halka
fake_early = rng.normal(0, 1.1, (n, 2)) # eğitilmemiş gen (dağınık)
th2 = rng.uniform(0, 2 * np.pi, n)
fake_late = np.column_stack([np.cos(th2), np.sin(th2)]) + rng.normal(0, 0.18, (n, 2)) # eğitilmiş gen (halkaya yakın)
return real, fake_early, fake_late
# ---------------------------------------------------------------------------
# Hafta 12 — Attention / Transformer (NLP, Lewis + Canziani)
# ---------------------------------------------------------------------------
def _softmax_rows(M):
"""Satır-bazlı kararlı softmax (her satır toplamı 1)."""
M = np.asarray(M, float)
e = np.exp(M - M.max(axis=-1, keepdims=True))
return e / e.sum(axis=-1, keepdims=True)
def self_attention_matrix(X, scale=True):
"""Self-attention ağırlık matrisi A = softmax(XXᵀ/√d) (Canziani: küme→küme).
X [T, d] token kümesi → A [T, T]: A[i,j] = token i'nin token j'ye verdiği dikkat (satır toplamı 1).
scale=True → β=1/√d ölçekleme (Canziani 20:44: vektör büyüklüğü √d ile büyür, sıcaklık sabit)."""
X = np.asarray(X, float)
d = X.shape[1]
scores = X @ X.T
if scale:
scores = scores / np.sqrt(d)
return _softmax_rows(scores)
def causal_mask_demo(scores):
"""Causal (look-ahead) maske gösterimi (Lewis 27:08).
scores [T, T] → (A_acik, A_maskeli): maskesiz softmax vs üst-üçgen −∞ maskeli softmax.
Maskeli: her token yalnız kendine + soluna bakar (geleceği göremez = hile yok)."""
scores = np.asarray(scores, float)
T = scores.shape[0]
A_open = _softmax_rows(scores)
mask = np.triu(np.full((T, T), -np.inf), k=1) # üst-üçgen (gelecek) = −∞
A_masked = _softmax_rows(scores + mask)
return A_open, A_masked
def softmax_temperature(scores, betas):
"""Sıcaklık β'nın softmax üzerindeki etkisi (Hafta 11 köprüsü; soft↔hard attention).
scores [n] tek satır → her β için softmax(β·scores) [len(betas), n].
β→0 düzleşir (uniform), β→∞ sivrilir (one-hot=hard attention)."""
scores = np.asarray(scores, float)
out = []
for b in betas:
s = b * scores
e = np.exp(s - s.max())
out.append(e / e.sum())
return np.array(out)
def positional_encoding(seq_len, d, base=10000.0):
"""Sinüzoidal positional encoding (Vaswani 2017; Lewis: küme→sıra).
PE[pos,2i]=sin(pos/base^(2i/d)), PE[pos,2i+1]=cos(...). → [seq_len, d] matris.
Attention girdiyi sırasız küme görür; konum bilgisini bu eklenen embedding taşır."""
pos = np.arange(seq_len)[:, None]
i = np.arange(d)[None, :]
angle = pos / np.power(base, (2 * (i // 2)) / d)
PE = np.where(i % 2 == 0, np.sin(angle), np.cos(angle))
return PE
def topk_truncate(probs, k):
"""Top-k sampling kırpması (Lewis 49:54; Angela Fan).
probs [V] olasılık dağılımı → en iyi k dışındaki kütleyi 0'la, yeniden normalize et.
Greedy=k1; beam farklı (hipotez tutar); top-k=çeşitlilik + manifolddan düşmeme."""
probs = np.asarray(probs, float)
out = np.zeros_like(probs)
idx = np.argsort(probs)[::-1][:k] # en yüksek k indeks
out[idx] = probs[idx]
return out / out.sum()
# ---------------------------------------------------------------------------
# Hafta 13 — Graph Convolutional Networks (Bresson + Canziani)
# ---------------------------------------------------------------------------
def path_graph_adj(n):
"""Yol grafı (zincir 0-1-2-...-n-1) adjacency [n,n]. Fourier modları = kosinüsler (1D DCT)."""
A = np.zeros((n, n))
for i in range(n - 1):
A[i, i + 1] = A[i + 1, i] = 1.0
return A
def community_graph_adj():
"""İki topluluk grafı (8 düğüm: 0-3 ve 4-7 iki klik, 3-4 köprü kenarı).
Karate Club benzeri yarı-denetimli/K-hop demoları için (seyreklik = yapı)."""
A = np.zeros((8, 8))
edges = [(0,1),(0,2),(1,2),(1,3),(2,3), # topluluk A (0-3)
(4,5),(4,6),(5,6),(5,7),(6,7), # topluluk B (4-7)
(3,4)] # köprü
for i, j in edges:
A[i, j] = A[j, i] = 1.0
return A
def graph_laplacian(A):
"""Normalize graf Laplacian Δ = I − D⁻¹ᐟ²AD⁻¹ᐟ² (Bresson 26:45; pürüzsüzlük operatörü).
Simetrik, özdeğerler [0,2]. Δh = h_i ile komşu ortalaması farkı (yüksek frekans büyük)."""
A = np.asarray(A, float)
n = A.shape[0]
d = A.sum(axis=1)
dinv = np.where(d > 0, 1.0 / np.sqrt(d), 0.0)
Dinv = np.diag(dinv)
return np.eye(n) - Dinv @ A @ Dinv
def graph_fourier(A):
"""Graf Fourier: Δ = ΦΛΦᵀ özayrışım (Bresson 30:03). Özvektörler Φ = Fourier fonksiyonları.
Döner (eigvals artan, eigvecs): düşük özdeğer=pürüzsüz mod, yüksek=salınan mod."""
Delta = graph_laplacian(A)
w, V = np.linalg.eigh(Delta) # eigh: simetrik, özdeğerler artan
return w, V
def laplacian_smoothness(A, h):
"""Pürüzsüzlük ölçüsü: Δh ve kuadratik form hᵀΔh (Bresson).
Pürüzsüz sinyal → küçük; salınan sinyal → büyük (Egzersiz 2)."""
Delta = graph_laplacian(A)
h = np.asarray(h, float)
Dh = Delta @ h
return Dh, float(h @ Delta @ h)
def khop_diffusion(A, source, K):
"""K-hop yerelleştirme (ChebNet sezgisi, Bresson 56:42): kaynağa Δ'yı k kez uygula.
Δᵏ·e_source desteği TAM k-hop genişler → [|Δ⁰e|, |Δ¹e|, ..., |Δᴷe|] büyüklük desenleri."""
Delta = graph_laplacian(A)
n = A.shape[0]
e = np.zeros(n); e[source] = 1.0
out = [np.abs(e.copy())]
cur = e.copy()
for _ in range(K):
cur = Delta @ cur
out.append(np.abs(cur))
return out
def gcn_message_pass(A, X, W, U):
"""İzotropik GCN katmanı (Canziani 29:04): hᵢ = ReLU(U·xᵢ + (1/dᵢ)Σ_{j∈N(i)} W·xⱼ).
a = adjacency (verili, attention'ın hesaplanan softmax'i değil). X[n,din]→H[n,dout]."""
A = np.asarray(A, float); X = np.asarray(X, float)
W = np.asarray(W, float); U = np.asarray(U, float)
d = A.sum(axis=1); dinv = np.where(d > 0, 1.0 / d, 0.0)
neigh = (np.diag(dinv) @ A) @ X @ W.T # (1/dᵢ)Σ W·xⱼ komşuluk ortalaması
self_term = X @ U.T # U·xᵢ self-connection
return np.maximum(0.0, self_term + neigh)
def gate_eta(edge_feats):
"""Residual Gated GCN kapısı (Canziani 27:53): ηᵢⱼ = σ(eᵢⱼ)/Σ_k σ(eᵢₖ).
İzotropik (1/d eşit) ortalamayı anizotropik ağırlıklı toplama çevirir. edge_feats[d]→η[d]."""
e = np.asarray(edge_feats, float)
s = 1.0 / (1.0 + np.exp(-e)) # sigmoid
return s / s.sum()
# ===========================================================================
# _viz.py — NYU Violet + gold matplotlib stil sabitleri ve yardımcıları
# ===========================================================================
COL_VIOLET = "#57068c" # NYU Violet — birincil çizgi/çerçeve/vurgu
COL_VIOLET_D = "#3d0463" # koyu violet — güçlü vurgu / gradyan
COL_VIOLET_M = "#7b2cbf" # orta violet — ikincil
COL_VIOLET_SOFT = "#b56ad6" # soluk violet
COL_GOLD = "#d4a017" # gold accent
COL_GOLD_D = "#a87d0a" # koyu gold
COL_TEXT = "#2a2535" # gövde metni (hafif violet tint)
COL_INK = "#1e1a2e" # en koyu — başlık
COL_BG = "#f4eefa" # açık violet — dolgu/arka plan
COL_GRID = "#cdbbe0" # soluk violet — ızgara/pasif kenar
COL_WHITE = "#ffffff"
# 5-sınıf kategorik palet (spiral 5 kol / moons ilk 2) — violet↔gold ekseni, tema-uyumlu
CLASS_COLORS = ["#57068c", "#7b2cbf", "#b56ad6", "#d4a017", "#a87d0a"]
# Çizgi-grafik tutarlı renkler
LINE_PRIMARY = COL_VIOLET
LINE_ACCENT = COL_GOLD
LINE_SECONDARY = COL_VIOLET_M
def apply_style(ax):
"""Bir eksene tutarlı NYU Violet+gold görünümü uygular."""
ax.set_facecolor(COL_WHITE)
ax.grid(True, alpha=0.25, color=COL_GRID, linewidth=0.8)
for spine in ax.spines.values():
spine.set_color(COL_GRID)
ax.tick_params(colors=COL_TEXT)
ax.title.set_color(COL_TEXT)
ax.xaxis.label.set_color(COL_TEXT)
ax.yaxis.label.set_color(COL_TEXT)
return ax
def draw_pipeline(ax, stages, title=None, y0=0.0):
"""Soldan-sağa kutu+ok boru hattı şeması (örüntü tanıma vs uçtan-uca).
stages : [(label:str, is_learned:bool), ...]
is_learned=True -> öğrenilen modül (violet dolgulu)
is_learned=False -> elle-tasarlanan/sabit (gold kenarlı, açık dolgu)
"""
n = len(stages)
box_w, box_h, gap = 1.7, 1.0, 0.9
step = box_w + gap
ax.set_xlim(-0.3, n * step)
ax.set_ylim(y0 - 1.1, y0 + 1.1)
ax.axis("off")
if title:
ax.set_title(title, color=COL_TEXT, fontsize=12, pad=10)
for i, (lbl, learned) in enumerate(stages):
x = i * step
fc = "#ece0f7" if learned else COL_BG
ec = COL_VIOLET if learned else COL_GOLD_D
lw = 2.4 if learned else 2.0
box = FancyBboxPatch(
(x, y0 - box_h / 2), box_w, box_h,
boxstyle="round,pad=0.02,rounding_size=0.12",
fc=fc, ec=ec, lw=lw, zorder=2,
)
ax.add_patch(box)
ax.text(x + box_w / 2, y0, lbl, ha="center", va="center",
fontsize=9.5, color=COL_TEXT, zorder=3, wrap=True)
if i > 0:
ax.add_patch(FancyArrowPatch(
(x - gap, y0), (x, y0),
arrowstyle="-|>", mutation_scale=16,
color=COL_VIOLET_M, lw=1.9, zorder=1,
))
return ax
def style_legend(ax, **kw):
"""Tema-uyumlu legend."""
leg = ax.legend(frameon=True, framealpha=0.95, edgecolor=COL_GRID, **kw)
if leg is not None:
leg.get_frame().set_facecolor(COL_WHITE)
for t in leg.get_texts():
t.set_color(COL_TEXT)
return leg
```
## Bu Derste Ne Var? {#sec-genel-bakis-d13}
Bu hafta iki parça: **konuk hoca Xavier Bresson** (Nanyang Technological University, GNN uzmanı) Lecture'da ConvNet'i düzensiz grafiklere genelleyen **graph convolutional network**'leri (spektral + uzaysal) anlatıyor; **Alfredo Canziani** (Practicum) GCN'in aslında Hafta 12'nin **self-attention**'ı olduğunu (yalnız bağlantılar verili) gösteriyor ve Residual Gated GCN'i DGL koddan kuruyor.
Büyük birleştirici fikir iki yönden gelir: Bresson **"Transformer = tam-bağlı bir graf üzerinde GCN'dir"** der; Canziani **"GCN = self-attention'dır, ama attention katsayıları hesaplanmaz, adjacency matrisinden verilir"** der. İkisi aynı gerçeğe varır: attention ve graph convolution **aynı işlemdir**; onları ayıran tek şey **seyreklik (sparsity)** — yani grafın kendisi.
Bu haftanın üç ana fikri:
1. **Convolution'u grafa genellemenin iki yolu:** template matching (uzaysal) ve convolution teoremi (spektral/Fourier). İkisi de farklı GCN sınıfları doğurur.
2. **Seyreklik = yapı.** Gerçek grafikler (beyin, web, molekül) seyrektir; ChebNet, Laplacian'ın kuvvetleriyle K-hop yerelleştirilmiş, **lineer** karmaşıklıkta convolution yapar.
3. **GCN ↔ attention birliği.** GCN = adjacency-verili attention (Canziani); Transformer = tam-bağlı GCN (Bresson) → attention ve graph conv aynı operasyon.
```{mermaid}
%%| echo: false
flowchart TB
Hafta["Hafta 13 = iki parça<br/>(Bresson: spektral + uzaysal GCN · Canziani: GCN = attention)"]
subgraph A["(A) ConvNet → Graf → Transformer — Bresson (Konuk)"]
direction TB
Varsayim["ConvNet 3 varsayım<br/>locality + stationarity + compositionality"]
IzgaraGraf["Izgara vs graf<br/>(düzenli grid → düzensiz graf: sıra/konum yok)"]
IkiYol["İKİ YOL<br/>template matching (uzaysal) · convolution teoremi (spektral)"]
Spektral["Spektral: Laplacian → Fourier → ChebNet<br/>(K-hop, lineer çünkü seyrek)"]
IzoAniso["Uzaysal: izotropik vs anizotropik<br/>(Vanilla/GIN · GAT/GatedGCN)"]
Transformer["Transformer = tam-bağlı GCN<br/>(küme sinir ağı)"]
Varsayim --> IzgaraGraf
IzgaraGraf --> IkiYol
IkiYol --> Spektral
IkiYol --> IzoAniso
IzoAniso --> Transformer
end
subgraph B["(B) GCN = attention — Canziani"]
direction TB
GcnAtt["GCN = attention<br/>(a = adjacency VERİLİ, hesaplanmaz)"]
Katman["dereceye böl + self-connection + ReLU<br/>(izotropik GCN katmanı)"]
Gated["Residual Gated GCN<br/>(kapı eta → anizotropi)"]
DGL["DGL: mesaj / reduce / update_all"]
Gorev["graf / düğüm sınıflandırma<br/>(yarı-denetimli, Karate Club)"]
GcnAtt --> Katman
Katman --> Gated
Gated --> DGL
DGL --> Gorev
end
Hafta --> Varsayim
Hafta --> GcnAtt
Ortak["Ortak sonuç: SEYREKLİK = YAPI<br/>(graph conv ile attention'ı ayıran tek şey grafın kendisi)"]
Transformer --> Ortak
Gorev --> Ortak
```
::: {.callout-tip title="Builder Notu — İki Hoca, Tek Fikir: Seyreklik = Yapı"}
**Geriye (önkoşul + kurs):**
- **ConvNet locality / stationarity / compositionality** → Hafta 3 (doğal sinyaller); Fourier / Laplacian / eigendecomposition → Hafta 3 + 18.06.
- **Self-attention / sets** → Hafta 12 (GCN onun adjacency-verili hâli).
- **Gate / softmax** → Hafta 6 (LSTM gating) + Hafta 12 (attention softmax).
**İleriye (production / research):**
- GCN → ilaç/protein (AlphaFold), öneri sistemleri, sosyal ağ, fizik.
- Anisotropic gate + edge features → Graph Transformers (post-2020, §[İleriye Köprü](#sec-ileriye-kopru-d13)).
**Tek cümleyle:** Graph convolution, ConvNet'in locality/stationarity/compositionality varsayımlarını düzensiz grafiklere taşır — ya template matching (uzaysal GCN) ya da spektral teori (Laplacian/Fourier, ChebNet) ile; ve özünde Hafta 12'nin attention'ıyla aynıdır: GCN = adjacency-verili attention, Transformer = tam-bağlı GCN.
:::
## (Bresson — Konuk) ConvNet'ten Graf'a: Convolution'un İki Tanımı {#sec-izgaradan-grafa}
Bresson ConvNet'in başarısının üç **varsayıma** dayandığını hatırlatır (Hafta 3'ün doğal-sinyal ilkeleri):
> "the main assumption is that your data is compositional... it is formed of patterns that are local (locality)... you have stationarity... and it is hierarchical." — Bresson, 2:54
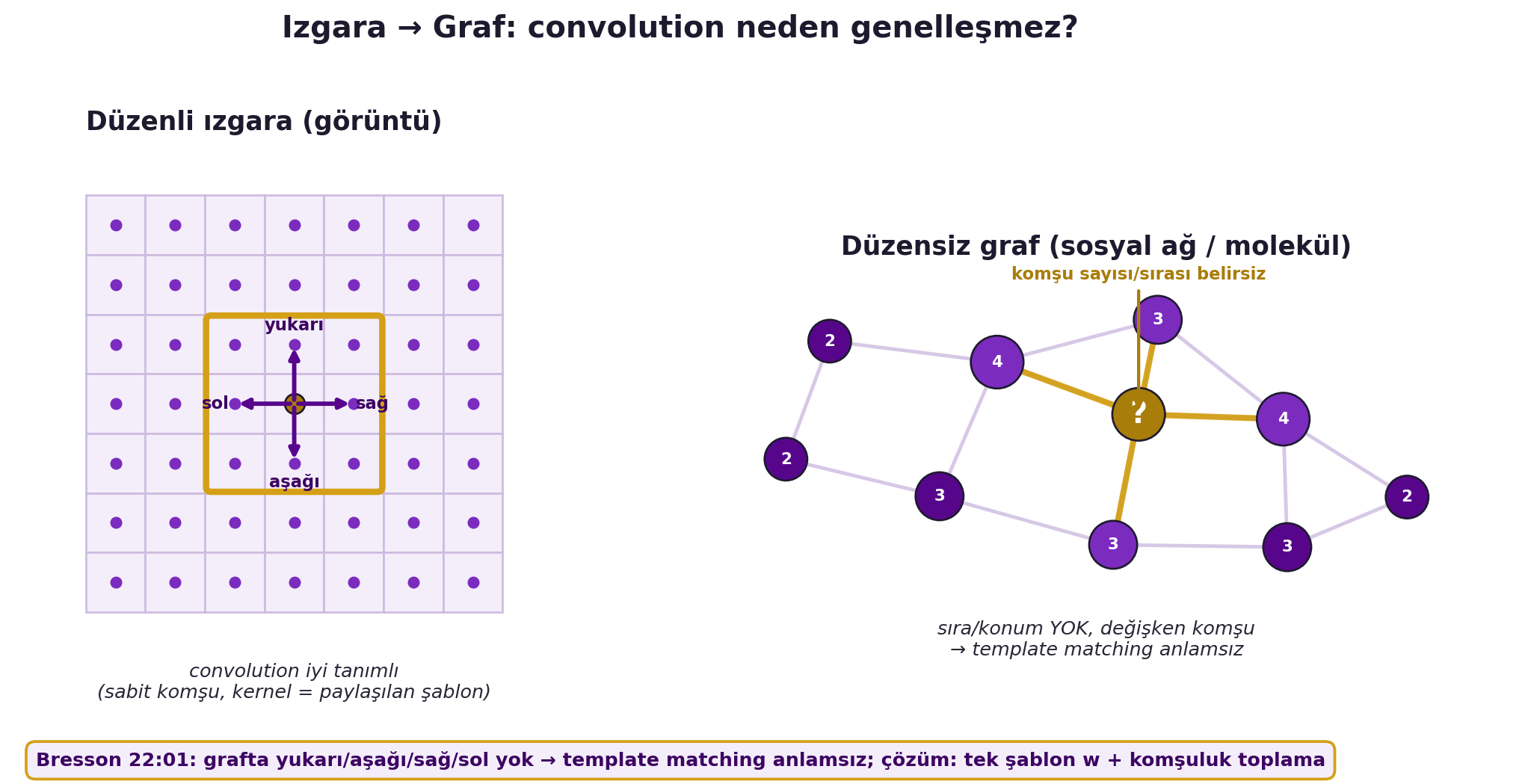
Görüntü/ses/metin **düzenli ızgaralardır** (2D/1D grid); ızgarada convolution iyi tanımlı ve hızlıdır. Ama sosyal ağ, beyin bağlantısı, molekül **ızgara değildir** — düzensiz **graflardır** (köşeler V, kenarlar E, adjacency A). @fig-grid-vs-graph bu çelişkiyi iki panelde gösterir: solda düzenli ızgarada her pikselin sabit komşuluğu ("yukarı/aşağı/sağ/sol") ve paylaşılan bir $3\times3$ kernel'i varken, sağda düzensiz grafta düğümlerin sırası, konumu ve komşu sayısı değişkendir. Convolution'u grafa nasıl genelleriz? İki yol:
1. **Template matching (uzaysal):** kernel'i kaydır, nokta çarpımı al. Ama grafta **iki sorun**: düğümlerin **sırası/konumu yok** (hangi komşu "sağ üst"?), komşu sayısı **değişken**.
> "on a graph you have no notion of where is up, where is down, where is right, where is left... so this matching generally has no meaning." — Bresson, 22:01
2. **Convolution teoremi (spektral):** convolution = Fourier uzayında nokta çarpımı. Ama grafta Fourier dönüşümünü yeniden tanımlamak gerek — ve hızlı olmalı.
```{python}
#| label: fig-grid-vs-graph
#| fig-cap: "Izgara → Graf: convolution neden genelleşmez? SOL 'Düzenli ızgara (görüntü)': 7x7 piksel ızgarası + merkez piksel üzerinde 3x3 kernel penceresi; yukarı/aşağı/sağ/sol komşular SABİT ve bellidir, convolution iyi tanımlı (kernel = paylaşılan şablon). SAĞ 'Düzensiz graf (sosyal ağ/molekül)': networkx ile değişken-dereceli düzensiz bir graf; odak düğümde '?' işareti ve 'komşu sayısı/sırası belirsiz' rozeti — düğümlerin sırası/konumu yok, komşu sayısı değişken, template matching anlamsız (çözüm: tek şablon w + komşuluk toplama, Bresson 22:01)."
np.random.seed(0)
fig, (axL, axR) = plt.subplots(1, 2, figsize=(12, 5.4))
# --------------------------- SOL: Düzenli ızgara ---------------------------
axL.set_title("Düzenli ızgara (görüntü)", color=COL_INK, fontsize=13, fontweight="bold", pad=12)
G = 7 # 7×7 piksel ızgarası
# piksel hücreleri
for i in range(G):
for j in range(G):
axL.add_patch(Rectangle((j, G - 1 - i), 1, 1,
facecolor=COL_BG, edgecolor=COL_GRID, lw=1.0, zorder=1))
# piksel merkez düğümleri
for i in range(G):
for j in range(G):
axL.plot(j + 0.5, G - 1 - i + 0.5, "o", ms=5,
color=COL_VIOLET_M, zorder=3)
# 3×3 kernel penceresi (merkez piksel 3,3)
ci, cj = 3, 3
kx, ky = cj - 1, G - 1 - (ci + 1) # sol-alt köşe
axL.add_patch(FancyBboxPatch((kx + 0.02, ky + 0.02), 3 - 0.04, 3 - 0.04,
boxstyle="round,pad=0.0,rounding_size=0.08",
facecolor="none", edgecolor=COL_GOLD, lw=3.2, zorder=4))
# merkez pikseli vurgula
axL.plot(cj + 0.5, G - 1 - ci + 0.5, "o", ms=10,
color=COL_GOLD_D, zorder=5, markeredgecolor=COL_INK, markeredgewidth=1.0)
# sabit komşu yönleri: yukarı / aşağı / sağ / sol (oklarla)
cx, cy = cj + 0.5, G - 1 - ci + 0.5
dirs = {"yukarı": (0, 1), "aşağı": (0, -1), "sağ": (1, 0), "sol": (-1, 0)}
for name, (dx, dy) in dirs.items():
axL.annotate("", xy=(cx + dx, cy + dy), xytext=(cx, cy),
arrowprops=dict(arrowstyle="-|>", color=COL_VIOLET, lw=2.2), zorder=6)
axL.text(cx + dx * 1.32, cy + dy * 1.32, name, ha="center", va="center",
fontsize=8.5, color=COL_VIOLET_D, fontweight="bold", zorder=7)
axL.text(G / 2, -0.85, "convolution iyi tanımlı\n(sabit komşu, kernel = paylaşılan şablon)",
ha="center", va="top", fontsize=9.5, color=COL_TEXT, fontstyle="italic")
axL.set_xlim(-1.2, G + 0.2)
axL.set_ylim(-1.7, G + 0.7)
axL.set_aspect("equal")
axL.axis("off")
# --------------------------- SAĞ: Düzensiz graf ---------------------------
axR.set_title("Düzensiz graf (sosyal ağ / molekül)", color=COL_INK, fontsize=13,
fontweight="bold", pad=12)
# değişken-derece düzensiz graf (community_graph_adj benzeri + ekstra düğümler)
Gr = nx.Graph()
edges = [(0, 1), (0, 2), (1, 2), (1, 3), (2, 4), (3, 4), (3, 5),
(4, 6), (5, 6), (5, 7), (6, 8), (7, 8), (4, 9), (9, 6), (2, 9)]
Gr.add_edges_from(edges)
pos = nx.spring_layout(Gr, seed=4, k=0.9, iterations=200)
degrees = dict(Gr.degree())
focus = 4 # '?' işaretli odak düğüm (değişken komşu)
neighbors = list(Gr.neighbors(focus))
# kenarlar
nx.draw_networkx_edges(Gr, pos, ax=axR, edge_color=COL_GRID, width=1.8, alpha=0.8)
# odak düğümün komşuluk kenarlarını vurgula (gold)
focus_edges = [(focus, nb) for nb in neighbors]
nx.draw_networkx_edges(Gr, pos, edgelist=focus_edges, ax=axR,
edge_color=COL_GOLD, width=3.0, alpha=0.95)
# düğüm boyutu = derece (değişken derece görünür olsun)
node_sizes = [220 + 120 * degrees[n] for n in Gr.nodes()]
node_colors = []
for n in Gr.nodes():
if n == focus:
node_colors.append(COL_GOLD_D)
elif n in neighbors:
node_colors.append(COL_VIOLET_M)
else:
node_colors.append(COL_VIOLET)
nx.draw_networkx_nodes(Gr, pos, ax=axR, node_size=node_sizes,
node_color=node_colors, edgecolors=COL_INK, linewidths=1.0)
# odak düğümde '?' işareti
fx, fy = pos[focus]
axR.text(fx, fy, "?", ha="center", va="center", fontsize=15,
color=COL_WHITE, fontweight="bold", zorder=10)
# komşulara küçük '?' rozeti — sıra/konum belirsiz
for nb in neighbors:
nbx, nby = pos[nb]
axR.annotate("", xy=(nbx, nby), xytext=(fx, fy),
arrowprops=dict(arrowstyle="-", color="none"))
axR.annotate("komşu sayısı/sırası belirsiz", xy=(fx, fy), xytext=(fx, fy + 0.42),
ha="center", va="bottom", fontsize=8.5, color=COL_GOLD_D, fontweight="bold",
zorder=11, arrowprops=dict(arrowstyle="-|>", color=COL_GOLD_D, lw=1.6))
# derece etiketleri (değişken derece vurgusu)
for n in Gr.nodes():
nx_, ny_ = pos[n]
if n != focus:
axR.text(nx_, ny_, str(degrees[n]), ha="center", va="center",
fontsize=8.0, color=COL_WHITE, fontweight="bold", zorder=10)
axR.text(0.5, -0.10, "sıra/konum YOK, değişken komşu\n→ template matching anlamsız",
transform=axR.transAxes, ha="center", va="top",
fontsize=9.5, color=COL_TEXT, fontstyle="italic")
axR.set_aspect("equal")
axR.axis("off")
axR.margins(0.12)
# --------------------------- Bresson annotation ---------------------------
fig.text(0.5, 0.015,
"Bresson 22:01: grafta yukarı/aşağı/sağ/sol yok → template matching anlamsız; "
"çözüm: tek şablon w + komşuluk toplama",
ha="center", va="bottom", fontsize=9.5, color=COL_VIOLET_D, fontweight="bold",
bbox=dict(boxstyle="round,pad=0.5", facecolor=COL_BG, edgecolor=COL_GOLD, lw=1.4))
fig.suptitle("Izgara → Graf: convolution neden genelleşmez?",
color=COL_INK, fontsize=15, fontweight="bold", y=0.99)
fig.tight_layout(rect=[0, 0.06, 1, 0.96])
```
::: {.callout-tip title="Builder Notu — Izgaradan Grafa"}
**Geriye (Hafta 3):** locality/stationarity/compositionality = Hafta 3 doğal sinyaller; ızgara convolution = Hafta 3 ConvNet; template matching = korelasyon.
**İleriye:** "Düzenli ızgaradan düzensiz grafa" = geometric deep learning'in temel motivasyonu; molekül/protein/sosyal-ağ.
:::
## (Bresson — Konuk) Spektral GCN: Laplacian, Fourier ve ChebNet {#sec-spektral-gcn}
Spektral yol için merkez operatör **graf Laplacian'ıdır** (normalize):
$$
\Delta = I - D^{-1/2} A\, D^{-1/2}
$$
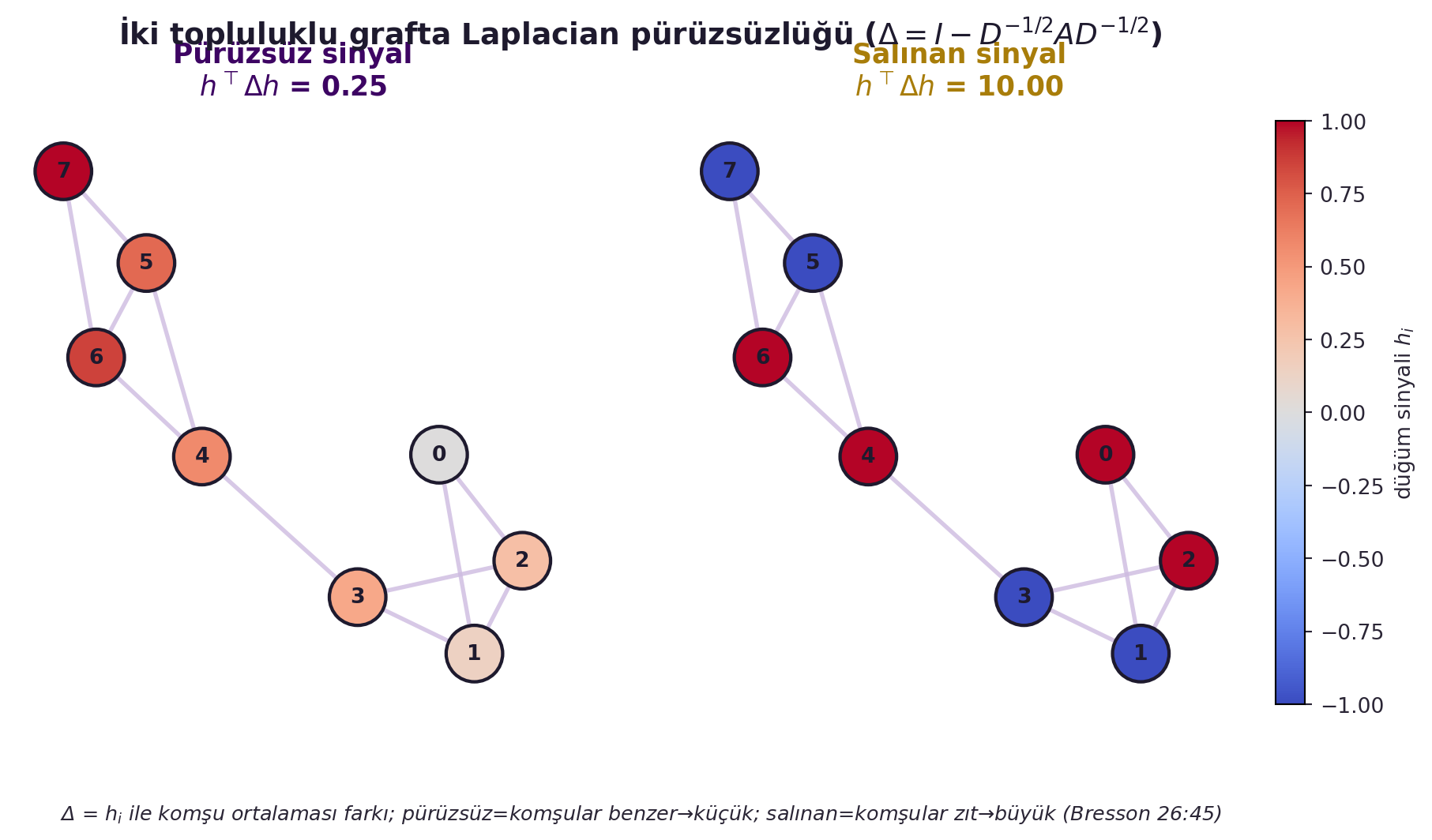
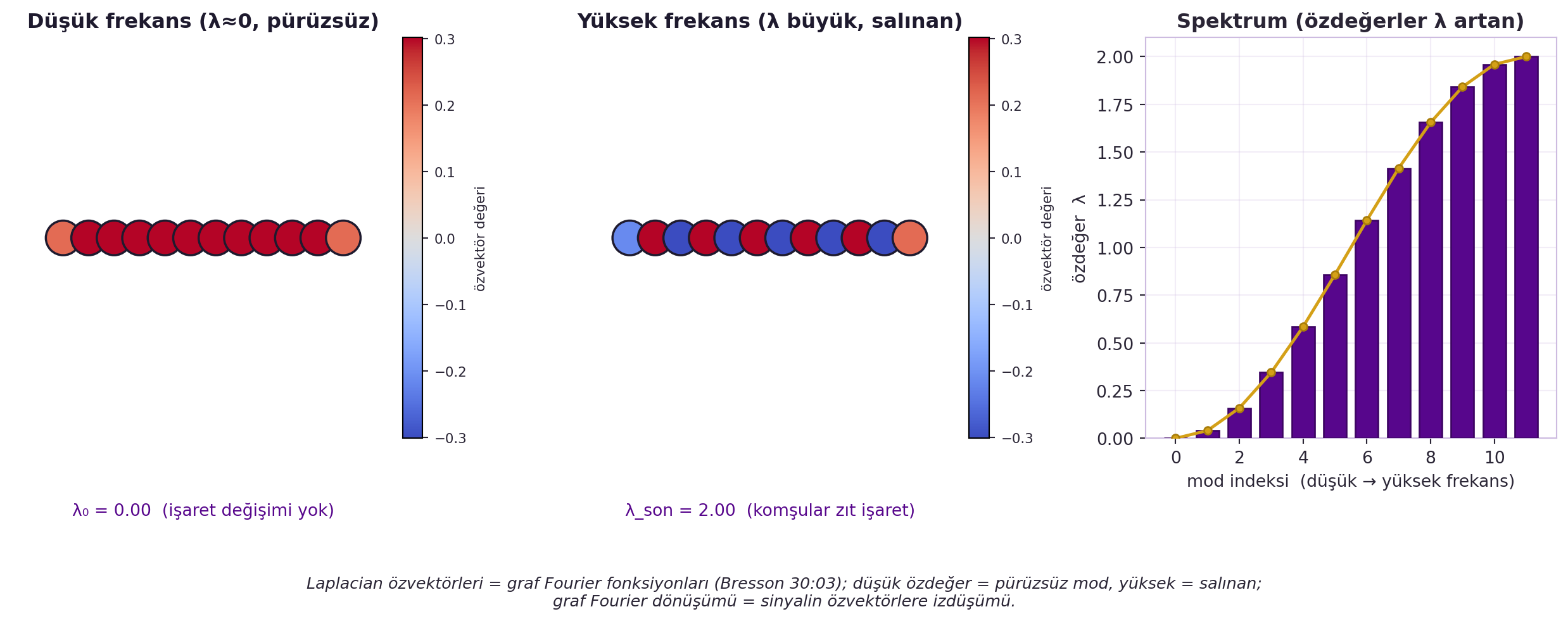
($D$ = derece köşegen matrisi.) Laplacian, bir fonksiyonun graf üzerindeki **pürüzsüzlüğünün ölçüsüdür** ($h_i$ ile komşularının ortalaması farkı). @fig-laplacian-smoothness bunu iki topluluklu bir grafta GERÇEK rakamla gösterir: yavaş-değişen (pürüzsüz) bir sinyalde kuadratik form $h^\top \Delta h$ küçük çıkar, komşular arasında zıt işaret alan (salınan) bir sinyalde büyük çıkar. **Özayrışımı** ($\Delta = \Phi \Lambda \Phi^\top$) graf **Fourier fonksiyonlarını** (özvektörler $\Phi$) ve **spektrumu** (özdeğerler $\Lambda$) verir. @fig-graph-fourier bu modları bir yol grafında resmeder: en küçük özdeğere ait özvektör neredeyse sabittir (pürüzsüz mod), en büyük özdeğere ait olan komşular arası kutuplaşır (salınan mod); graf Fourier dönüşümü = fonksiyonu bu özvektörlere izdüşürmek.
- **Vanilla spektral GCN** (Bruna, Zaremba, Szlam, **LeCun** 2014): spektral filtreyi backprop ile öğren. Sorun: uzaysal yerelleştirme garantisi yok, $N$ parametre, $O(N^2)$ ($\Phi$ yoğun).
- **Pürüzsüz filtreler (spline):** frekansta pürüzsüz = uzayda yerel (Heisenberg/Parseval) → $K$ parametre. Ama hâlâ $O(N^2)$.
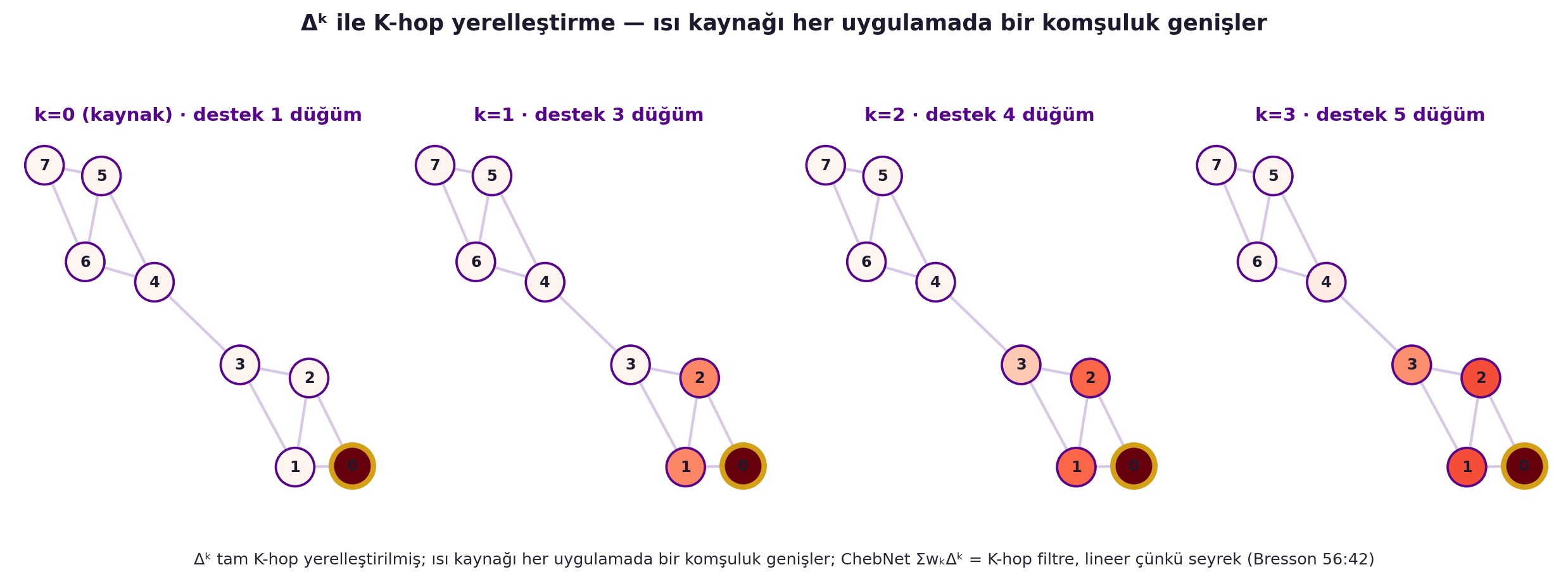
- **ChebNet** (Defferrard, **Bresson**, 2016): spektral filtre = **Laplacian'ın polinomu** ($\sum_k w_k \Delta^k$). $\Delta^k$ tam **K-hop yerelleştirilmiş**; özyinelemeli $x_k = \Delta \cdot x_{k-1}$. @fig-khop-chebnet bir "ısı kaynağını" alıp Laplacian'ı tekrar tekrar uygulayarak desteğin her adımda bir hop genişlediğini GERÇEK rakamla gösterir. Karmaşıklık = (kenar $\times$ K) = seyrek grafikler için **LİNEER** — eigendecomposition gerekmez!
> "every natural graph is usually sparse, because sparsity is structure." — Bresson, 56:42
ChebNet "spektral" denilse de hesaplama tamamen uzaysaldır (Laplacian çarpımları). MNIST sanity-check: %99, lineer karmaşıklık.
```{python}
#| label: fig-laplacian-smoothness
#| fig-cap: "İki topluluklu grafta Laplacian pürüzsüzlüğü — GERÇEK kuadratik form. A = community_graph_adj() (8 düğüm, 2 topluluk + köprü). SOL 'Pürüzsüz sinyal': düğümler yavaş-değişen bir sinyalle (coolwarm) renklendirilir, komşular benzer, hᵀΔh KÜÇÜK. SAĞ 'Salınan sinyal': düğümler alternatif +1/−1 alır, komşular zıt, hᵀΔh BÜYÜK. Başlıklarda motordan gelen GERÇEK değerler yazılı. Sezgi: Δh = h_i ile komşu ortalaması farkı; pürüzsüz=komşular benzer→küçük, salınan=komşular zıt→büyük (Bresson 26:45)."
np.random.seed(0)
# FLAGSHIP: GERÇEK Laplacian pürüzsüzlük (Bresson 26:45)
# A = 8 düğüm, 2 topluluk (0-3 ve 4-7, 3-4 köprü)
A = community_graph_adj()
G = nx.from_numpy_array(A)
# Sabit layout (iki panelde AYNI pozisyon)
pos = nx.spring_layout(G, seed=7, k=0.9)
# Pürüzsüz sinyal: yavaş-değişen (komşular benzer)
h_smooth = np.linspace(0.0, 1.0, 8)
_, q_smooth = laplacian_smoothness(A, h_smooth)
# Salınan sinyal: alternatif işaret (komşular zıt)
h_osc = np.array([1.0, -1.0, 1.0, -1.0, 1.0, -1.0, 1.0, -1.0])
_, q_osc = laplacian_smoothness(A, h_osc)
fig, (axL, axR) = plt.subplots(1, 2, figsize=(11, 5))
cmap = plt.cm.coolwarm
# --- SOL panel: Pürüzsüz sinyal ---
nx.draw_networkx_edges(G, pos, ax=axL, edge_color=COL_GRID, width=2.0, alpha=0.8)
nodesL = nx.draw_networkx_nodes(
G, pos, ax=axL, node_color=h_smooth, cmap=cmap,
vmin=-1, vmax=1, node_size=720, edgecolors=COL_INK, linewidths=1.6,
)
nx.draw_networkx_labels(G, pos, ax=axL, font_size=10, font_color=COL_INK,
font_weight="bold")
axL.set_title("Pürüzsüz sinyal\n" + r"$h^{\top}\Delta h$ = " + f"{q_smooth:.2f}",
color=COL_VIOLET_D, fontsize=13, fontweight="bold", pad=12)
axL.axis("off")
# --- SAĞ panel: Salınan sinyal ---
nx.draw_networkx_edges(G, pos, ax=axR, edge_color=COL_GRID, width=2.0, alpha=0.8)
nodesR = nx.draw_networkx_nodes(
G, pos, ax=axR, node_color=h_osc, cmap=cmap,
vmin=-1, vmax=1, node_size=720, edgecolors=COL_INK, linewidths=1.6,
)
nx.draw_networkx_labels(G, pos, ax=axR, font_size=10, font_color=COL_INK,
font_weight="bold")
axR.set_title("Salınan sinyal\n" + r"$h^{\top}\Delta h$ = " + f"{q_osc:.2f}",
color=COL_GOLD_D, fontsize=13, fontweight="bold", pad=12)
axR.axis("off")
# Ortak renk çubuğu
sm = plt.cm.ScalarMappable(cmap=cmap, norm=plt.Normalize(vmin=-1, vmax=1))
sm.set_array([])
cbar = fig.colorbar(sm, ax=[axL, axR], fraction=0.025, pad=0.03)
cbar.set_label("düğüm sinyali $h_i$", color=COL_TEXT, fontsize=10)
cbar.ax.tick_params(colors=COL_TEXT)
# Annotation
fig.text(
0.5, -0.02,
"Δ = $h_i$ ile komşu ortalaması farkı; pürüzsüz=komşular benzer→küçük; "
"salınan=komşular zıt→büyük (Bresson 26:45)",
ha="center", va="top", fontsize=9.5, color=COL_TEXT, style="italic",
)
fig.suptitle("İki topluluklu grafta Laplacian pürüzsüzlüğü "
r"($\Delta = I - D^{-1/2} A D^{-1/2}$)",
color=COL_INK, fontsize=14, fontweight="bold", y=1.02);
```
```{python}
#| label: fig-graph-fourier
#| fig-cap: "GERÇEK graf Fourier modları — yol grafı (path_graph_adj(12)) için Laplacian özvektörleri. SOL 'Düşük frekans (lambda≈0, pürüzsüz)': en küçük özdeğere ait özvektör neredeyse sabittir (işaret değişimi yok). ORTA 'Yüksek frekans (lambda büyük, salınan)': en büyük özdeğere ait özvektör komşular arası zıt işaret alır (kutuplaşma). SAĞ 'Spektrum': özdeğerler lambda artan sırada bar+çizgi. Sezgi: Laplacian özvektörleri = graf Fourier fonksiyonları (Bresson 30:03); düşük özdeğer=pürüzsüz mod, yüksek=salınan; graf Fourier dönüşümü = sinyalin özvektörlere izdüşümü."
np.random.seed(0)
# GERÇEK graf Fourier modları — yol grafı (path graph) için Laplacian özvektörleri.
P = path_graph_adj(12)
eigvals, V = graph_fourier(P) # (özdeğerler artan, özvektörler sütun)
# Düşük frekans modu (λ≈0, pürüzsüz) ve yüksek frekans modu (λ büyük, salınan)
low_mode = V[:, 0] # en küçük özdeğer → pürüzsüz (neredeyse sabit)
high_mode = V[:, -1] # en büyük özdeğer → komşular arası işaret değişimi (salınan)
# Path grafı için SABİT yatay düzen (her panelde aynı pozisyon)
G = nx.from_numpy_array(P)
n = P.shape[0]
pos = {i: (i, 0.0) for i in range(n)} # yatay zincir dizilimi
fig, axes = plt.subplots(1, 3, figsize=(13, 4.6))
fig.patch.set_facecolor(COL_WHITE)
# Her mod kendi simetrik renk ölçeğiyle gösterilir; düşük mod neredeyse tek-renk
# (pürüzsüz = işaret değişimi yok), yüksek mod komşular arası kutuplaşma (kırmızı↔mavi).
lim_lo = max(np.abs(low_mode).max(), 1e-9)
lim_hi = max(np.abs(high_mode).max(), 1e-9)
# --- SOL: düşük frekans modu ---
ax0 = axes[0]
nx.draw_networkx_edges(G, pos, ax=ax0, edge_color=COL_GRID, width=2.0)
nodes0 = nx.draw_networkx_nodes(
G, pos, ax=ax0, node_color=low_mode, cmap="coolwarm",
vmin=-lim_lo, vmax=lim_lo,
node_size=420, edgecolors=COL_INK, linewidths=1.3,
)
ax0.set_title("Düşük frekans (λ≈0, pürüzsüz)", color=COL_INK, fontsize=12, fontweight="bold")
ax0.text(0.5, -0.16, f"λ₀ = {eigvals[0]:.2f} (işaret değişimi yok)", transform=ax0.transAxes,
ha="center", va="top", fontsize=10, color=COL_VIOLET)
ax0.set_facecolor(COL_WHITE)
ax0.axis("off")
ax0.margins(0.12)
cb0 = fig.colorbar(nodes0, ax=ax0, fraction=0.05, pad=0.02)
cb0.ax.tick_params(labelsize=8, colors=COL_TEXT)
cb0.set_label("özvektör değeri", fontsize=8, color=COL_TEXT)
# --- ORTA: yüksek frekans modu ---
ax1 = axes[1]
nx.draw_networkx_edges(G, pos, ax=ax1, edge_color=COL_GRID, width=2.0)
nodes1 = nx.draw_networkx_nodes(
G, pos, ax=ax1, node_color=high_mode, cmap="coolwarm",
vmin=-lim_hi, vmax=lim_hi,
node_size=420, edgecolors=COL_INK, linewidths=1.3,
)
ax1.set_title("Yüksek frekans (λ büyük, salınan)", color=COL_INK, fontsize=12, fontweight="bold")
ax1.text(0.5, -0.16, f"λ_son = {eigvals[-1]:.2f} (komşular zıt işaret)", transform=ax1.transAxes,
ha="center", va="top", fontsize=10, color=COL_VIOLET)
ax1.set_facecolor(COL_WHITE)
ax1.axis("off")
ax1.margins(0.12)
cb1 = fig.colorbar(nodes1, ax=ax1, fraction=0.05, pad=0.02)
cb1.ax.tick_params(labelsize=8, colors=COL_TEXT)
cb1.set_label("özvektör değeri", fontsize=8, color=COL_TEXT)
# --- SAĞ: spektrum (özdeğerler artan) ---
ax2 = axes[2]
idx = np.arange(len(eigvals))
ax2.bar(idx, eigvals, color=COL_VIOLET, edgecolor=COL_VIOLET_D, width=0.72, zorder=3)
ax2.plot(idx, eigvals, "-o", color=COL_GOLD, markersize=4.5,
markeredgecolor=COL_GOLD_D, lw=1.8, zorder=4)
ax2.set_title("Spektrum (özdeğerler λ artan)", color=COL_INK, fontsize=12, fontweight="bold")
ax2.set_xlabel("mod indeksi (düşük → yüksek frekans)", fontsize=10)
ax2.set_ylabel("özdeğer λ", fontsize=10)
ax2.set_xticks(idx[::2])
apply_style(ax2)
# Açıklama notu (annotation)
note = ("Laplacian özvektörleri = graf Fourier fonksiyonları (Bresson 30:03); "
"düşük özdeğer = pürüzsüz mod, yüksek = salınan;\n"
"graf Fourier dönüşümü = sinyalin özvektörlere izdüşümü.")
fig.text(0.5, -0.04, note, ha="center", va="top", fontsize=9.5,
color=COL_TEXT, style="italic", wrap=True)
fig.tight_layout(rect=[0, 0.02, 1, 1])
```
```{python}
#| label: fig-khop-chebnet
#| fig-cap: "GERÇEK K-hop yerelleştirme (ChebNet) — Δᵏ ile ısı yayılımı. A = community_graph_adj(), kaynak = düğüm 0. 4 panel AYNI layout: her panelde düğümler |Δᵏe| büyüklüğüyle (Reds) renklendirilir, kaynak düğüm gold kenarla işaretli. Destek HER uygulamada bir hop genişler (panel başlıklarında GERÇEK aktif-düğüm sayısı). Sezgi: Δᵏ tam K-hop yerelleştirilmiş; ChebNet ΣwₖΔᵏ = K-hop filtre, lineer çünkü seyrek (Bresson 56:42)."
np.random.seed(0)
# Graf: iki topluluk (8 düğüm), kaynak = düğüm 0
A = community_graph_adj()
diff = khop_diffusion(A, 0, 3) # [|Δ⁰e|, |Δ¹e|, |Δ²e|, |Δ³e|]
# networkx grafı + SABİT layout (4 panelde aynı pos)
G = nx.from_numpy_array(A)
pos = nx.spring_layout(G, seed=7)
fig, axes = plt.subplots(1, 4, figsize=(13, 4.0))
titles = ["k=0 (kaynak)", "k=1", "k=2", "k=3"]
source = 0
for k, ax in enumerate(axes):
vals = diff[k]
vmax = vals.max() if vals.max() > 0 else 1.0
# kenarlar
nx.draw_networkx_edges(G, pos, ax=ax, edge_color=COL_GRID, width=1.6, alpha=0.8)
# düğümler — Δᵏe büyüklüğü ile renklendir (Reds)
nodes = nx.draw_networkx_nodes(
G, pos, ax=ax, node_color=vals, cmap="Reds",
vmin=0.0, vmax=vmax, node_size=520,
edgecolors=COL_VIOLET, linewidths=1.4,
)
# kaynak düğüm: kalın gold kenar (işaretli)
nx.draw_networkx_nodes(
G, pos, ax=ax, nodelist=[source], node_color=[vals[source]], cmap="Reds",
vmin=0.0, vmax=vmax, node_size=620,
edgecolors=COL_GOLD, linewidths=3.2,
)
# düğüm numaraları
nx.draw_networkx_labels(G, pos, ax=ax, font_size=9, font_color=COL_INK,
font_weight="bold")
# aktif (destek içindeki) düğüm sayısı
active = int(np.sum(vals > 1e-9))
ax.set_title(f"{titles[k]} · destek {active} düğüm",
color=COL_VIOLET, fontsize=11, fontweight="bold", pad=8)
ax.set_facecolor(COL_WHITE)
ax.axis("off")
fig.suptitle("Δᵏ ile K-hop yerelleştirme — ısı kaynağı her uygulamada bir komşuluk genişler",
color=COL_INK, fontsize=13, fontweight="bold", y=1.04)
annot = ("Δᵏ tam K-hop yerelleştirilmiş; ısı kaynağı her uygulamada bir komşuluk genişler; "
"ChebNet ΣwₖΔᵏ = K-hop filtre, lineer çünkü seyrek (Bresson 56:42)")
fig.text(0.5, -0.07, annot, ha="center", va="top", color=COL_TEXT,
fontsize=9.5, wrap=True)
plt.tight_layout(rect=[0, 0, 1, 0.97])
```
::: {.callout-tip title="Builder Notu — Laplacian = Pürüzsüzlük, Fourier ve ChebNet K-hop"}
**Geriye (Hafta 3 + 18.06):** Fourier = Hafta 3 spektral görüş; Laplacian özayrışımı = 18.06 eigendecomposition; pürüzsüz↔yerel = belirsizlik ilkesi.
**İleriye:** Spektral GCN → graf sinyal işleme, spektral clustering; ChebNet polinomu = mesaj-geçişin erken hâli.
:::
## (Bresson — Konuk) Uzaysal GCN: Isotropic, Anisotropic ve Transformer = Tam-Bağlı GCN {#sec-uzaysal-gcn}
Uzaysal yol template matching'i düğüm-yeniden-parametrizasyonuna **değişmez** kılar: tek şablon vektörü $w$'yi tüm komşularla eşleştir (komşuluk üzerinde topla). Matris formu: $H^{l+1} = f(A H^l W)$.
- **Isotropic GCN** (tüm komşulara aynı ağırlık): Vanilla GCN (Kipf-Welling 2016), GraphSAGE (merkez + komşuluk ayrı şablon), GIN (graf izomorfizmi). Komşuluk ortalaması; weight sharing; graf boyutundan bağımsız.
- **Anisotropic GCN** (komşulara **farklı** ağırlık): MoNet (GMM), **GAT** (Velickovic-Bengio, komşuluk üzerinde softmax attention), **GatedGCN** (Bresson-Laurent 2017, kenar-geçidi + açık kenar öznitelikleri). Sosyal ağda "republican vs democrat"ı aynı işlememelisin → anizotropi.
@fig-isotropic-anisotropic bu ayrımı GERÇEK rakamla gösterir: bir merkez düğüm + 4 komşu üzerinde, izotropik durumda tüm kenarlar eşit ağırlıklıdır ($\eta = 1/d$, "bulanıklaştır"), anizotropik durumda kapı $\eta_{ij} = \sigma(e_{ij})/\sum_k \sigma(e_{ik})$ her kenara farklı ağırlık verir (büyük öznitelikli kenar = kalın).
Dersin doruğu — Hafta 12'ye köprü:
> "a standard transformer is actually a special case of graph convolutional nets when the graph is fully connected... transformers are set neural networks." — Bresson, 1:19:39
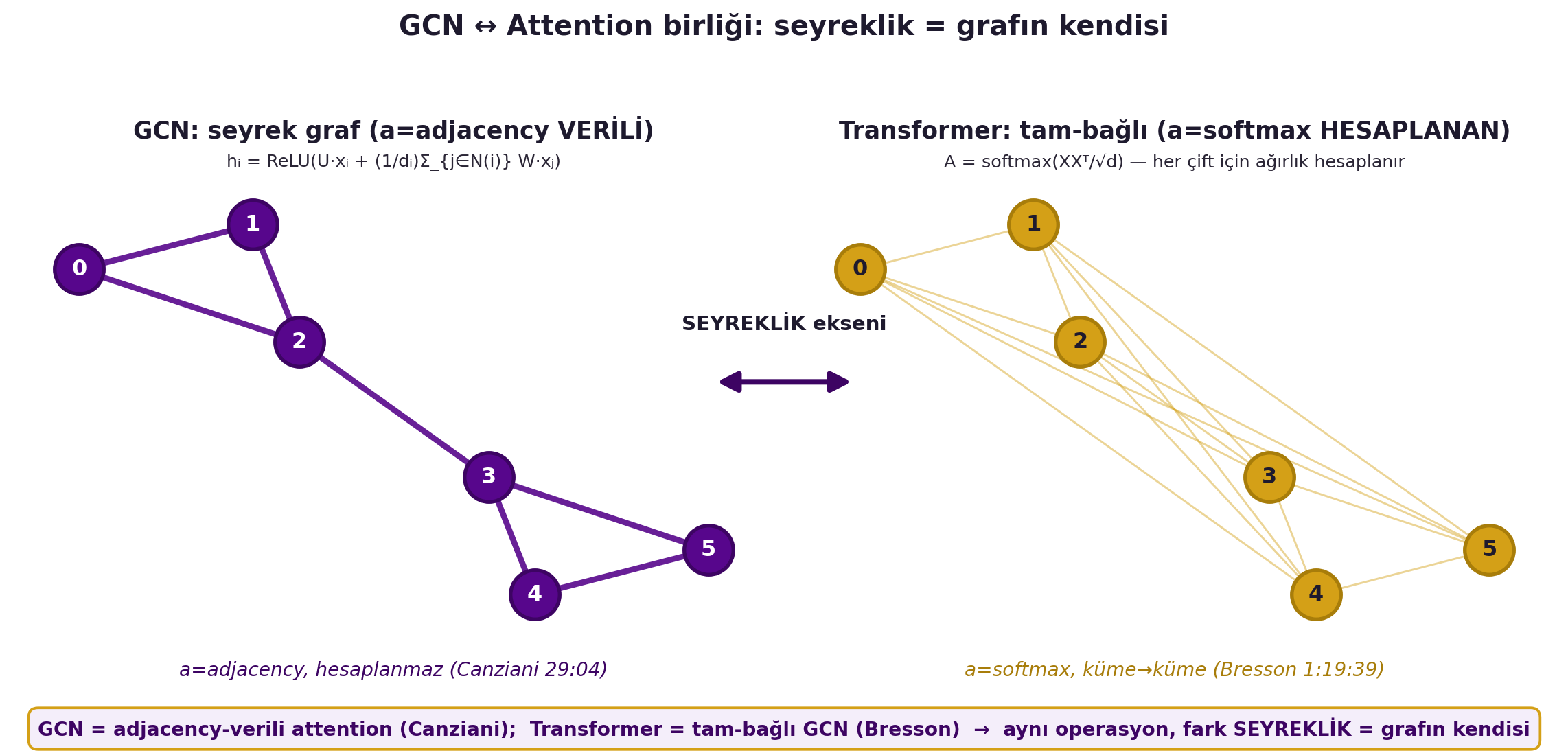
GAT denkleminde komşuluğu **tüm graf** yaparsan (tam-bağlı), tam olarak Hafta 12'nin Transformer'ını elde edersin. @fig-gcn-attention-unity bu birliği dersin doruk figürü olarak iki panelde gösterir: solda seyrek graf (a = adjacency VERİLİ), sağda aynı düğümlerin tam-bağlı hâli (a = softmax HESAPLANAN), ortada "seyreklik ekseni". Tam-bağlı olunca "graf" demek anlamsızlaşır (seyreklik = grafı ilginç yapan şey) — ona **küme** demek daha doğru. LeCun ekler: tüm öz-denetimli öğrenme bir graf yapısı (kelime eş-dizim, benzerlik grafiği) sömürür — "there is a very very strong connection between self-supervised learning and the graph view of a training set." — LeCun, 1:43:49
```{python}
#| label: fig-isotropic-anisotropic
#| fig-cap: "GERÇEK izotropik vs anizotropik komşu toplama (Residual Gated GCN, Canziani 27:53). Bir merkez düğüm i + 4 komşu (yıldız graf). SOL 'İzotropik (eta = 1/d eşit)': tüm kenarlar aynı kalınlık/renk, komşuluk ortalaması (Vanilla/GIN, 'bulanıklaştır'). SAĞ 'Anizotropik (kapı eta = sigma(e)/Σsigma(e))': gate_eta(edge_feats) ile kenar kalınlıkları FARKLI; büyük kenar-özniteliği → kalın kenar (GAT/GatedGCN). Kenar üstündeki eta değerleri motordan GERÇEK. Sezgi: kapı eta backprop ile hangi komşunun önemli olduğunu öğrenir — Hafta 6 LSTM kapı mekanizmasının grafiksel akrabası."
np.random.seed(0)
# GERÇEK izotropik vs anizotropik komşu toplama (Residual Gated GCN, Canziani 27:53).
# Bir merkez düğüm (i=0) + 4 komşu (j1..j4) = networkx yıldız grafı.
# Kenar öznitelikleri eᵢⱼ → gate_eta ile kapı η = σ(e)/Σσ(e).
edge_feats = np.array([2.0, 0.5, -1.0, -2.0])
eta = gate_eta(edge_feats) # σ(e)/Σσ(e) → [0.466, 0.329, 0.142, 0.063]
d = len(edge_feats)
iso = np.full(d, 1.0 / d) # izotropik: 1/d eşit ağırlık (komşuluk ortalaması)
G = nx.star_graph(d) # düğüm 0 merkez, 1..d yapraklar
# SABİT layout (iki panelde de AYNI pos): merkez ortada, komşular çember üzerinde
pos = {0: np.array([0.0, 0.0])}
ang = np.linspace(0.5 * np.pi, 0.5 * np.pi + 2 * np.pi, d, endpoint=False)
for k in range(d):
pos[k + 1] = np.array([np.cos(ang[k]), np.sin(ang[k])])
edges = [(0, k + 1) for k in range(d)]
fig, (axL, axR) = plt.subplots(1, 2, figsize=(12, 5.6))
# Anizotropik kenar rengi için violet→gold colormap (büyük η = koyu violet)
cmap = mpl.colors.LinearSegmentedColormap.from_list(
"vg", [COL_GOLD, COL_VIOLET_M, COL_VIOLET_D])
def draw_panel(ax, weights, title, anisotropic):
ax.set_title(title, color=COL_INK, fontsize=12.5, fontweight="bold", pad=12)
widths = weights * 16.0 + 0.8 # kenar kalınlığı η ile ORANTILI
if anisotropic:
norm = mpl.colors.Normalize(vmin=weights.min(), vmax=weights.max())
ecolors = [cmap(norm(w)) for w in weights] # her kenar FARKLI renk
else:
ecolors = [COL_VIOLET_M] * d # tüm kenarlar AYNI ('bulanıklaştır')
nx.draw_networkx_edges(G, pos, edgelist=edges, width=list(widths),
edge_color=ecolors, ax=ax, alpha=0.92)
# Merkez düğüm gold (hedef i), komşular violet
nx.draw_networkx_nodes(G, pos, nodelist=[0], node_color=COL_GOLD,
node_size=1300, edgecolors=COL_VIOLET_D,
linewidths=2.4, ax=ax)
nx.draw_networkx_nodes(G, pos, nodelist=[k + 1 for k in range(d)],
node_color=COL_VIOLET, node_size=950,
edgecolors=COL_VIOLET_D, linewidths=1.8, ax=ax)
lbl = {0: "i"}
for k in range(d):
lbl[k + 1] = f"j{k+1}"
nx.draw_networkx_labels(G, pos, labels=lbl, font_size=12,
font_color=COL_WHITE, font_weight="bold", ax=ax)
# Kenar üstüne GERÇEK η değerini yaz
for k in range(d):
px, py = pos[k + 1]
ax.text(0.46 * px, 0.46 * py, f"η={weights[k]:.3f}", fontsize=10,
ha="center", va="center", fontweight="bold",
color=COL_GOLD_D if anisotropic else COL_VIOLET_D,
bbox=dict(boxstyle="round,pad=0.18", fc=COL_WHITE,
ec=COL_GRID, lw=1.0, alpha=0.96))
# kenar özniteliği eᵢⱼ yaprak dışında
ax.text(1.34 * px, 1.34 * py, f"e={edge_feats[k]:+.1f}", fontsize=9,
ha="center", va="center", style="italic", color=COL_TEXT)
ax.set_xlim(-1.75, 1.75)
ax.set_ylim(-1.7, 1.75)
ax.set_aspect("equal")
ax.axis("off")
draw_panel(axL, iso, "İzotropik (η = 1/d eşit)\nVanilla GCN / GIN — komşu ortalaması", False)
draw_panel(axR, eta, "Anizotropik (kapı η = σ(e)/Σσ(e))\nGAT / GatedGCN — öğrenilen ağırlık", True)
annot = ("İzotropik: tüm komşular aynı ağırlık (komşuluk ortalaması, 'bulanıklaştır'). "
"Anizotropik: kapı η komşu önemini ayırır (büyük öznitelik → kalın kenar).\n"
"Kapı η backprop ile hangi komşunun önemli olduğunu öğrenir "
"(Canziani 27:53) — Hafta 6 LSTM kapı mekanizmasının grafiksel akrabası.")
fig.text(0.5, 0.02, annot, ha="center", va="bottom",
fontsize=9.3, color=COL_TEXT, wrap=True)
fig.suptitle("İzotropik ve Anizotropik Mesaj Geçişi — GCN'de Komşu Ağırlıklandırma",
color=COL_VIOLET_D, fontsize=14, fontweight="bold", y=0.99)
fig.tight_layout(rect=(0, 0.08, 1, 0.95))
```
```{python}
#| label: fig-gcn-attention-unity
#| fig-cap: "GCN ↔ Attention birliği: seyreklik = grafın kendisi (DERSİN DORUĞU). İki panel AYNI 6 düğüm, AYNI layout. SOL 'GCN: seyrek graf (a=adjacency VERİLİ)': birkaç kenarlı seyrek graf; a = adjacency, hesaplanmaz (Canziani 29:04). SAĞ 'Transformer: tam-bağlı (a=softmax HESAPLANAN)': aynı düğümler ama HER düğüm her düğüme bağlı (soluk yoğun kenarlar); a = softmax, küme→küme (Bresson 1:19:39). ORTADA çift-yönlü 'SEYREKLİK ekseni' oku. Sezgi: GCN = adjacency-verili attention (Canziani); Transformer = tam-bağlı GCN (Bresson), aynı operasyon, fark SEYREKLİK = grafın kendisi."
np.random.seed(0)
# 6 düğümlü ORTAK küme — iki panelde AYNI düğümler, AYNI sabit layout.
# SOL: GCN = seyrek graf (a=adjacency, VERİLİ, hesaplanmaz).
# SAĞ: Transformer = tam-bağlı (a=softmax, HESAPLANAN, küme→küme).
# Birlik: aynı operasyon (komşuluk üzerinden mesaj toplama); fark = SEYREKLİK.
N = 6
# Seyrek graf: birkaç kenar (iki küçük topluluk + köprü hissi)
sparse_edges = [(0, 1), (1, 2), (0, 2), (2, 3), (3, 4), (4, 5), (3, 5)]
G_sparse = nx.Graph()
G_sparse.add_nodes_from(range(N))
G_sparse.add_edges_from(sparse_edges)
# Tam-bağlı (transformer): aynı düğümler, HER düğüm her düğüme bağlı
G_full = nx.complete_graph(N)
# SABİT layout — iki panelde birebir aynı konum
pos = nx.spring_layout(G_sparse, seed=7, k=0.9)
fig, (axL, axR) = plt.subplots(1, 2, figsize=(12.0, 5.6))
fig.patch.set_facecolor(COL_WHITE)
# ---------------------------------------------------------------------------
# SOL panel — GCN: seyrek graf (a=adjacency VERİLİ)
# ---------------------------------------------------------------------------
axL.set_facecolor(COL_WHITE)
nx.draw_networkx_edges(G_sparse, pos, ax=axL, edge_color=COL_VIOLET,
width=3.2, alpha=0.9)
nx.draw_networkx_nodes(G_sparse, pos, ax=axL, node_color=COL_VIOLET,
node_size=720, edgecolors=COL_VIOLET_D, linewidths=2.0)
nx.draw_networkx_labels(G_sparse, pos, ax=axL, font_color=COL_WHITE,
font_size=12, font_weight="bold")
axL.set_title("GCN: seyrek graf (a=adjacency VERİLİ)",
color=COL_INK, fontsize=13, fontweight="bold", pad=26)
axL.text(0.5, -0.06, "a=adjacency, hesaplanmaz (Canziani 29:04)",
transform=axL.transAxes, ha="center", va="top",
color=COL_VIOLET_D, fontsize=10.5, fontstyle="italic")
axL.text(0.5, 1.035, r"hᵢ = ReLU(U·xᵢ + (1/dᵢ)Σ_{j∈N(i)} W·xⱼ)",
transform=axL.transAxes, ha="center", va="bottom",
color=COL_TEXT, fontsize=9.5)
axL.axis("off")
# ---------------------------------------------------------------------------
# SAĞ panel — Transformer: tam-bağlı (a=softmax HESAPLANAN)
# ---------------------------------------------------------------------------
axR.set_facecolor(COL_WHITE)
nx.draw_networkx_edges(G_full, pos, ax=axR, edge_color=COL_GOLD,
width=1.1, alpha=0.45)
nx.draw_networkx_nodes(G_full, pos, ax=axR, node_color=COL_GOLD,
node_size=720, edgecolors=COL_GOLD_D, linewidths=2.0)
nx.draw_networkx_labels(G_full, pos, ax=axR, font_color=COL_INK,
font_size=12, font_weight="bold")
axR.set_title("Transformer: tam-bağlı (a=softmax HESAPLANAN)",
color=COL_INK, fontsize=13, fontweight="bold", pad=26)
axR.text(0.5, -0.06, "a=softmax, küme→küme (Bresson 1:19:39)",
transform=axR.transAxes, ha="center", va="top",
color=COL_GOLD_D, fontsize=10.5, fontstyle="italic")
axR.text(0.5, 1.035, r"A = softmax(XXᵀ/√d) — her çift için ağırlık hesaplanır",
transform=axR.transAxes, ha="center", va="bottom",
color=COL_TEXT, fontsize=9.5)
axR.axis("off")
# ---------------------------------------------------------------------------
# ORTA — çift-yönlü ok + 'SEYREKLİK ekseni'
# ---------------------------------------------------------------------------
arrow = FancyArrowPatch(
(0.455, 0.5), (0.545, 0.5), transform=fig.transFigure,
arrowstyle="<|-|>", mutation_scale=22, lw=3.0,
color=COL_VIOLET_D, zorder=10,
)
fig.add_artist(arrow)
fig.text(0.5, 0.565, "SEYREKLİK ekseni", ha="center", va="bottom",
color=COL_INK, fontsize=11, fontweight="bold", zorder=11)
# Alt birlik anlatısı (flagship köprü)
fig.text(0.5, 0.015,
"GCN = adjacency-verili attention (Canziani); "
"Transformer = tam-bağlı GCN (Bresson) → "
"aynı operasyon, fark SEYREKLİK = grafın kendisi",
ha="center", va="bottom", color=COL_VIOLET_D, fontsize=10.5,
fontweight="bold",
bbox=dict(boxstyle="round,pad=0.5", fc=COL_BG, ec=COL_GOLD, lw=1.4))
fig.suptitle("GCN ↔ Attention birliği: seyreklik = grafın kendisi",
color=COL_INK, fontsize=15, fontweight="bold", y=1.0)
plt.tight_layout(rect=[0, 0.06, 1, 0.95])
```
::: {.callout-tip title="Builder Notu — Isotropic vs Anisotropic ve Transformer = Tam-Bağlı GCN"}
**Geriye (Hafta 12 + 6):** Anizotropi gate = Hafta 6 LSTM gating + Hafta 12 attention softmax; Transformer = tam-bağlı GCN = Hafta 12; SSL-graf = Hafta 10 + 12 (word2vec=GNN).
**İleriye:** GAT/GatedGCN → Graph Transformers (post-2020); izotropi-anizotropi = GNN tasarımının ana sınıflandırması.
:::
## (İleriye Köprü) Graph Transformers, AlphaFold, Geometric DL (post-2020) — KURSTA YOK {#sec-ileriye-kopru-d13}
Bresson (Mart 2020) GCN'i template matching + spektral teoriyle kurar; GAT/GatedGCN'i en güçlü anizotropik modeller olarak verir ve "düğümler için positional encoding nasıl bulunur = en önemli açık soru" der. Aşağıdakiler DLSP20'den **sonra** geldi, kursta **YOKTUR**:
::: {.callout-warning title="İleriye Köprü Notu (post-2020 — KURSTA YOK)"}
- **Graph Transformers** (Graphormer 2021, GraphGPS 2022) ve **Laplacian positional encoding** — Bresson'un "düğüm positional encoding açık sorusunun" cevabı; "Transformer = tam-bağlı GCN" fikrinin olgunlaşması.
- **AlphaFold 2** (2021) — protein katlanmasını attention/graf ile çözer; Bresson'un "protein yapısı çok zor ama öğrenebiliriz" probleminin pratik zaferi.
- **Geometric Deep Learning** (Bronstein ve ark., 2021) — CNN/GNN/Transformer'ı tek simetri/değişmezlik çerçevesinde birleştiren program.
Bunlar kurs terimi gibi eklenmez; "graf = yapı, attention = tam-bağlı graf" temelinin nereye vardığını göstermek için anılır.
:::
::: {.callout-tip title="Builder Notu — Açık Soru: Düğüm Positional Encoding"}
**Geriye (Hafta 12-13):** Graph Transformers = bu haftanın anizotropik GAT + Hafta 12 Transformer'ının birleşimi; positional encoding = Bresson'un açık sorusu.
**İleriye:** Geometric DL, tüm derin öğrenmeyi "veri üzerindeki simetriler" diliyle birleştirir — CNN (öteleme), GNN (permütasyon), Transformer (küme).
:::
## Geçiş: Bresson'dan Canziani'ye {#sec-gecis-d13}
Bresson convolution'u grafa **neden** ve **nasıl** genellediğimizi (spektral + uzaysal) anlattı ve "Transformer = tam-bağlı GCN" köprüsünü kurdu. Şimdi **Canziani** aynı birliği ters yönden gösterir: geçen haftanın self-attention'ından başlayıp, attention katsayılarını adjacency matrisiyle **değiştirerek** GCN'i türetir — ve Residual Gated GCN'i DGL ile koddan kurar.
## (Canziani) GCN = Attention, Ama Bağlantılar Verili {#sec-gcn-attention}
Canziani GCN literatürünü okuyunca şaşkınlığını paylaşır: bu zaten attention!
> "graph convolutional networks... I read them and oh, it's actually the same thing... it looks like attention to me." — Canziani, 10:50
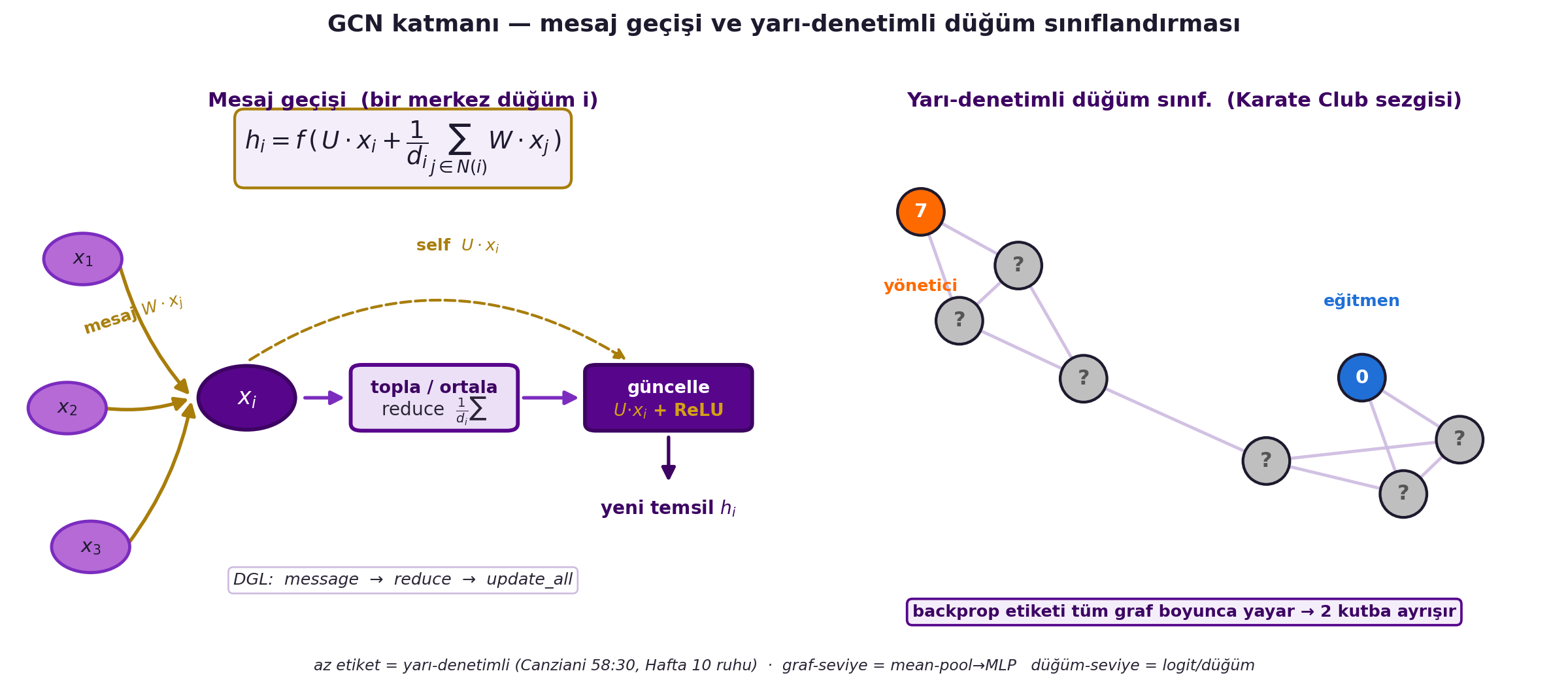
Hatırlatma (Hafta 12): self-attention'da $h = X \cdot a$, ve $a = \text{softmax}(\text{skorlar})$ sana **kime bakacağını** söyler (hesaplanır). GCN'de **$a$ = adjacency vektörüdür** — kendine gelen kenar varsa 1, yoksa 0 (verilir, hesaplanmaz). Gerisi otomatik:
- Dereceye böl ($a$'daki bir'lerin sayısı $d$): $h$ ölçeği komşu sayısıyla büyümesin → komşuluk **ortalaması**.
- Öğrenilen rotasyon $W$ ekle, **self-connection** ($U \cdot x$) ekle, nonlinearity (ReLU) ekle.
$$
h_i = f\!\left(U x_i + \frac{1}{d_i} \sum_{j \in N(i)} W x_j\right)
$$
Çok katman = yığ (her katman hâlâ bir **kümedir**, bağlantılar adjacency'den verili). @fig-gcn-message-pass solda bu mesaj-geçiş katmanını (komşulardan gelen mesajları topla/ortala, self-connection ile güncelle) bir şema olarak, sağda ise yarı-denetimli düğüm sınıflandırmasını gösterir.
> "the only difference between attention and this is that these connections are given to you by the adjacency matrix instead of being computed with attention." — Canziani, 29:04
```{python}
#| label: fig-gcn-message-pass
#| fig-cap: "GCN katmanı — mesaj geçişi ve yarı-denetimli düğüm sınıflandırması. SOL 'Mesaj geçişi (bir merkez düğüm i)': hᵢ = f(U·xᵢ + (1/dᵢ)Σ W·xⱼ) şeması — komşulardan mesaj (W·xⱼ) → topla/ortala (reduce 1/dᵢ Σ) → güncelle (U·xᵢ + ReLU) → yeni temsil hᵢ; DGL: message → reduce → update_all. SAĞ 'Yarı-denetimli düğüm sınıf. (Karate Club sezgisi)': iki topluluklu graf, yalnız 2 etiketli düğüm (0=eğitmen mavi, 7=yönetici turuncu), gerisi gri '?'; backprop etiketi tüm graf boyunca yayar → 2 kutba ayrışır. Sezgi: az etiket = yarı-denetimli (Canziani 58:30, Hafta 10 ruhu); graf-seviye = mean-pool→MLP, düğüm-seviye = logit/düğüm."
np.random.seed(0)
fig, (axL, axR) = plt.subplots(1, 2, figsize=(12.6, 5.4),
gridspec_kw={"width_ratios": [1.05, 1.0]})
fig.suptitle("GCN katmanı — mesaj geçişi ve yarı-denetimli düğüm sınıflandırması",
fontsize=13.5, color=COL_INK, fontweight="bold", y=0.99)
# ---------------------------------------------------------------------------
# SOL panel — Mesaj geçişi şeması (FancyArrow)
# ---------------------------------------------------------------------------
axL.set_xlim(0, 10)
axL.set_ylim(0, 10)
axL.axis("off")
axL.set_title("Mesaj geçişi (bir merkez düğüm i)", color=COL_VIOLET_D,
fontsize=11.5, pad=8, fontweight="bold")
# üst formül
axL.text(5.0, 9.45,
r"$h_i = f\,(\,U\cdot x_i + \dfrac{1}{d_i}\sum_{j\in N(i)} W\cdot x_j\,)$",
ha="center", va="center", fontsize=14, color=COL_INK,
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG, ec=COL_GOLD_D, lw=1.6))
# merkez düğüm i
cx, cy = 3.0, 4.6
center = Circle((cx, cy), 0.62, fc=COL_VIOLET, ec=COL_VIOLET_D, lw=2.2, zorder=5)
axL.add_patch(center)
axL.text(cx, cy, r"$x_i$", ha="center", va="center", color=COL_WHITE,
fontsize=13, zorder=6, fontweight="bold")
# komşu düğümler + mesaj okları (W·xⱼ)
neigh_pos = [(0.9, 7.3), (0.7, 4.4), (1.0, 1.7)]
for k, (nxp, nyp) in enumerate(neigh_pos):
nb = Circle((nxp, nyp), 0.5, fc=COL_VIOLET_SOFT, ec=COL_VIOLET_M, lw=1.8, zorder=5)
axL.add_patch(nb)
axL.text(nxp, nyp, r"$x_%d$" % (k + 1), ha="center", va="center",
color=COL_INK, fontsize=11, zorder=6)
# mesaj oku komşudan merkeze
axL.add_patch(FancyArrowPatch((nxp + 0.45, nyp), (cx - 0.7, cy),
arrowstyle="-|>", mutation_scale=16,
color=COL_GOLD_D, lw=2.0, zorder=3,
connectionstyle="arc3,rad=0.12"))
axL.text(1.55, 6.2, r"mesaj $W\cdot x_j$", ha="center", va="center",
color=COL_GOLD_D, fontsize=9.5, rotation=18, fontweight="bold")
# topla/ortala kutusu (reduce 1/dᵢ)
bx, by = 5.4, 4.6
red = FancyBboxPatch((bx - 1.05, by - 0.62), 2.1, 1.24,
boxstyle="round,pad=0.02,rounding_size=0.14",
fc="#ece0f7", ec=COL_VIOLET, lw=2.2, zorder=4)
axL.add_patch(red)
axL.text(bx, by + 0.18, "topla / ortala", ha="center", va="center",
color=COL_VIOLET_D, fontsize=10, zorder=5, fontweight="bold")
axL.text(bx, by - 0.26, r"reduce $\frac{1}{d_i}\sum$", ha="center", va="center",
color=COL_TEXT, fontsize=10.5, zorder=5)
# merkez+komşu birikimi → reduce
axL.add_patch(FancyArrowPatch((cx + 0.7, cy), (bx - 1.1, by),
arrowstyle="-|>", mutation_scale=16,
color=COL_VIOLET_M, lw=2.0, zorder=3))
# güncelle kutusu (update U·xᵢ + ReLU)
ux, uy = 8.4, 4.6
upd = FancyBboxPatch((ux - 1.05, uy - 0.62), 2.1, 1.24,
boxstyle="round,pad=0.02,rounding_size=0.14",
fc=COL_VIOLET, ec=COL_VIOLET_D, lw=2.2, zorder=4)
axL.add_patch(upd)
axL.text(ux, uy + 0.18, "güncelle", ha="center", va="center",
color=COL_WHITE, fontsize=10, zorder=5, fontweight="bold")
axL.text(ux, uy - 0.26, r"$U\!\cdot\! x_i$ + ReLU", ha="center", va="center",
color=COL_GOLD, fontsize=10, zorder=5, fontweight="bold")
axL.add_patch(FancyArrowPatch((bx + 1.1, by), (ux - 1.1, uy),
arrowstyle="-|>", mutation_scale=16,
color=COL_VIOLET_M, lw=2.0, zorder=3))
# çıktı hᵢ
axL.add_patch(FancyArrowPatch((ux, uy - 0.7), (ux, uy - 1.7),
arrowstyle="-|>", mutation_scale=16,
color=COL_VIOLET_D, lw=2.0, zorder=3))
axL.text(ux, uy - 2.15, r"yeni temsil $h_i$", ha="center", va="center",
color=COL_VIOLET_D, fontsize=10.5, fontweight="bold")
# self-connection oku (U·xᵢ kısayolu)
axL.add_patch(FancyArrowPatch((cx, cy + 0.7), (ux - 0.5, uy + 0.7),
arrowstyle="-|>", mutation_scale=13,
color=COL_GOLD_D, lw=1.6, zorder=2,
linestyle="--", connectionstyle="arc3,rad=-0.32"))
axL.text(5.7, 7.55, r"self $U\cdot x_i$", ha="center", va="center",
color=COL_GOLD_D, fontsize=9.5, fontweight="bold")
# DGL terminoloji notu
axL.text(5.0, 1.05, "DGL: message → reduce → update_all",
ha="center", va="center", color=COL_TEXT, fontsize=9.5,
style="italic",
bbox=dict(boxstyle="round,pad=0.3", fc=COL_WHITE, ec=COL_GRID, lw=1.0))
# ---------------------------------------------------------------------------
# SAG panel — Yarı-denetimli düğüm sınıflandırması (Karate Club sezgisi)
# ---------------------------------------------------------------------------
axR.set_title("Yarı-denetimli düğüm sınıf. (Karate Club sezgisi)",
color=COL_VIOLET_D, fontsize=11.5, pad=8, fontweight="bold")
axR.axis("off")
axR.set_xlim(-1.35, 1.35)
axR.set_ylim(-1.55, 1.45)
A = community_graph_adj() # 8 düğüm, 2 topluluk + köprü 3-4
G = nx.from_numpy_array(A)
pos = nx.spring_layout(G, seed=7, k=0.9) # SABIT layout
# kenarlar
nx.draw_networkx_edges(G, pos, ax=axR, edge_color=COL_GRID, width=1.8, alpha=0.9)
# düğüm renkleri: yalnız 2 etiketli, gerisi gri '?'
LABELED = {0: "#1f6fd6", 7: "#FF6A00"} # düğüm 0 mavi=eğitmen, düğüm 7 turuncu=yönetici
node_colors = []
for nd in G.nodes():
node_colors.append(LABELED.get(nd, "#bfbfbf"))
nx.draw_networkx_nodes(G, pos, ax=axR, node_color=node_colors,
node_size=720, edgecolors=COL_INK, linewidths=1.6)
# etiketler: etiketli düğümler isimli, gerisi '?'
for nd in G.nodes():
px, py = pos[nd]
if nd in LABELED:
txt = "0" if nd == 0 else "7"
axR.text(px, py, txt, ha="center", va="center", color=COL_WHITE,
fontsize=11, fontweight="bold", zorder=6)
else:
axR.text(px, py, "?", ha="center", va="center", color="#555555",
fontsize=12, fontweight="bold", zorder=6)
# rol açıklamaları
p0x, p0y = pos[0]
p7x, p7y = pos[7]
axR.annotate("eğitmen", (p0x, p0y), xytext=(p0x, p0y + 0.42),
ha="center", color="#1f6fd6", fontsize=9.5, fontweight="bold")
axR.annotate("yönetici", (p7x, p7y), xytext=(p7x, p7y - 0.46),
ha="center", color="#FF6A00", fontsize=9.5, fontweight="bold")
# yayılma oku açıklaması
axR.text(0.0, -1.42,
"backprop etiketi tüm graf boyunca yayar → 2 kutba ayrışır",
ha="center", va="center", color=COL_VIOLET_D, fontsize=9.5,
fontweight="bold",
bbox=dict(boxstyle="round,pad=0.32", fc=COL_BG, ec=COL_VIOLET, lw=1.4))
# alt-açıklama notu (tüm figür)
fig.text(0.5, 0.015,
"az etiket = yarı-denetimli (Canziani 58:30, Hafta 10 ruhu) · "
"graf-seviye = mean-pool→MLP düğüm-seviye = logit/düğüm",
ha="center", va="bottom", color=COL_TEXT, fontsize=8.8, style="italic")
fig.tight_layout(rect=[0, 0.045, 1, 0.965])
```
::: {.callout-tip title="Builder Notu — GCN = Verili Attention"}
**Geriye (Hafta 12):** $h = X \cdot a$ = Hafta 12 attention; $a$ = adjacency (verili) vs softmax (hesaplanan); dereceye bölme = $\sqrt{d}$ ölçeklemesi akrabası; self-connection + ReLU = standart katman.
**İleriye:** "Attention = öğrenilen graf, GCN = verili graf" ekseni, tüm geometric DL'in birleştirici görüşü.
:::
## (Canziani) Residual Gated GCN: Kenar Geçidi (η) ile Anisotropy {#sec-gated-gcn}
Uyguladıkları model **Residual Gated GCN** (Bresson & Laurent): kenarların da **öznitelikleri** ($e_j$) vardır. Vanilla GCN tüm komşuları aynı işler (izotropik, "her şeyi bulanıklaştır"); buradaki **kapı (gate) η** bunu kırar — gelen her mesajı, o kenarın temsiline göre **modüle eder**:
> "we're not going to be just averaging all these incoming values, we're going to be weighting them, modulating them based on what we think might be relevant." — Canziani, 27:53
Kapı, kenarların sigmoid'inin normalize hâlidir (soft-attention'ın kenar versiyonu):
$$
\eta_{ij} = \frac{\sigma(e_{ij})}{\sum_{k \in N(i)} \sigma(e_{ik})}
$$
Bu, izotropik ortalamayı **anizotropik** ağırlıklı toplama çevirir — hangi komşunun önemli olduğunu ağ backprop ile öğrenir. (Aynı kapı $\eta_{ij}=\sigma(e_{ij})/\sum_k \sigma(e_{ik})$, daha önce @fig-isotropic-anisotropic'te merkez düğüm η kapısı olarak GERÇEK rakamla resmedilmişti: izotropik eşit-ağırlık vs anizotropik öğrenilen-ağırlık.) Residual + BatchNorm ile sarılır.
::: {.callout-tip title="Builder Notu — Kenar Kapısı η"}
**Geriye (Hafta 6 + 11 + 12):** Kapı η = Hafta 6 LSTM gating + Hafta 12 softmax attention; sigmoid normalize = soft argmax akrabası; residual+BatchNorm = Hafta 3 + 11; izotropik ortalama = bilgi yok etme (blur).
**İleriye:** Kenar-öznitelikli anizotropik GCN = molekül (bağ türü), trafik, öneri; GatedGCN benchmark'larda izotropikleri geçer.
:::
## (Canziani) DGL Kodu, Graf vs Düğüm Sınıflandırma (Semi-Supervised) {#sec-dgl-gorevler}
Kod **DGL** (Deep Graph Library) ile: **mesaj fonksiyonu** (kenar UDF — source/destination/edge öznitelikleri) + **reduce fonksiyonu** (düğüm UDF — gelen mesajların mailbox'ı) + `update_all`. Veri: **MiniGCDataset** — 8 graf sınıfı (circle, star, wheel, lollipop, hypercube, grid, clique, circular ladder). Görev: **graf sınıflandırma** (değişken düğüm sayısı). Düğüm özniteliklerini **mean-pool** → MLP → 8-yönlü sınıflandırıcı.
İki görev tipi (her ikisi @fig-gcn-message-pass'in sağ panelinde resmedildi):
- **Graf-seviye:** tüm düğümleri ortala → MLP (graf başına tek etiket).
- **Düğüm-seviye:** her köşe için logit; örn. **Zachary Karate Club** (eğitmen=düğüm 0, yönetici=düğüm 33, yalnız 2 etiket) → **yarı-denetimli (semi-supervised)** düğüm sınıflandırma: etiketleri graf yapısı boyunca yay; temsiller çekilip ayrışır.
> "you only have a few labels... this is called semi-supervised learning." — Canziani, 58:30
Canziani'nin son vurgusu Bresson'unkiyle aynı: **seyreklik yapıdır** — herkes herkese bağlıysa adjacency tüm-bir olur ve attention'a dönersin; seyrek olunca graf "kimin kiminle bağlı olduğunu" söyler.
::: {.callout-tip title="Builder Notu — Seyreklik = Yapı"}
**Geriye (Hafta 10 + 12):** Mean-pool = değişken-boyut çözümü (Hafta 12 küme); semi-supervised = Hafta 10 (az etiket, SSL); $\sqrt{\text{boyut}}$ ölçekleme = Hafta 12 $\sqrt{d}$.
**İleriye:** Düğüm/kenar/graf görevleri = GNN'in dört temel problemi; mesaj-geçiş = tüm modern GNN kütüphanelerinin (DGL, PyG) çekirdeği.
:::
## Bu Dersin Özeti {#sec-ozet-d13}
1. **Convolution'u grafa genelle (Bresson):** template matching (uzaysal) — sıra/konum yok sorunu; convolution teoremi (spektral) — graf Fourier.
2. **Spektral GCN (Bresson):** Laplacian $\Delta = I - D^{-1/2}AD^{-1/2}$ (pürüzsüzlük); Fourier = özvektörler; **ChebNet** = Laplacian polinomu, K-hop, lineer (seyreklik = yapı).
3. **Uzaysal GCN (Bresson):** isotropic (Vanilla/GraphSAGE/GIN) vs anisotropic (GAT/GatedGCN); **Transformer = tam-bağlı GCN**.
4. **GCN = attention (Canziani):** $h = X \cdot a$; $a$ = adjacency (verili) vs softmax (hesaplanan); dereceye böl + self-connection + ReLU.
5. **Residual Gated GCN (Canziani):** kenar geçidi $\eta = \sigma(e)/\sum \sigma(e)$ → anizotropi; izotropik ortalamayı ağırlıklı toplama çevirir.
6. **DGL + görevler (Canziani):** mesaj/reduce/update_all; graf sınıflandırma (mean-pool→MLP); düğüm sınıflandırma (Karate Club, semi-supervised).
7. **Post-2020 (KURSTA YOK):** Graph Transformers + Laplacian PE, AlphaFold 2, Geometric DL.
::: {.callout-important title="Tek Bir Cümle"}
Graph convolution, ConvNet'in locality/stationarity/compositionality varsayımlarını düzensiz grafiklere taşır — ya template matching (uzaysal GCN: izotropik/anizotropik) ya da spektral teori (Laplacian/Fourier, ChebNet, lineer çünkü graflar seyrektir) ile; ve özünde Hafta 12'nin attention'ıyla aynı operasyondur: Canziani'ye göre GCN = adjacency-verili attention, Bresson'a göre Transformer = tam-bağlı GCN — ikisini ayıran tek şey seyrekliktir (grafın kendisi).
:::
## Kontrol Soruları {#sec-kontrol-d13}
::: {.callout-note collapse="true" title="Soru 1: Convolution'u grafa genellemenin iki yolu nedir? Template matching grafta neden doğrudan çalışmaz?"}
**Cevap:** (1) **Template matching (uzaysal):** kernel'i kaydır, nokta çarpımı → uzaysal GCN. (2) **Convolution teoremi (spektral):** Fourier uzayında nokta çarpımı → spektral GCN. Template matching grafta doğrudan çalışmaz çünkü düğümlerin **sırası/konumu yoktur** ("yukarı/aşağı/sağ/sol" yok, Bresson 22:01) — hangi komşunun şablonun hangi hücresine karşılık geldiği belirsiz; ayrıca komşu sayısı **değişken**. Çözüm: tek şablon $w$ (yeniden-parametrizasyona değişmez) + komşuluk üzerinde toplama.
:::
::: {.callout-note collapse="true" title="Soru 2: Graf Laplacian nedir, neyi ölçer? ChebNet neden lineer karmaşıklıkta çalışır?"}
**Cevap:** Normalize Laplacian $\Delta = I - D^{-1/2}AD^{-1/2}$; bir fonksiyonun graf üzerindeki **pürüzsüzlüğünü** ölçer ($h_i$ ile komşu ortalaması farkı). Özayrışımı ($\Delta = \Phi\Lambda\Phi^\top$) graf **Fourier fonksiyonlarını** (özvektörler) ve spektrumu verir. Vanilla spektral GCN $O(N^2)$ ($\Phi$ yoğun). **ChebNet** filtreyi Laplacian'ın **polinomu** ($\sum_k w_k \Delta^k$) olarak yazar: $\Delta^k$ tam K-hop yerelleştirilmiş, özyinelemeli $x_k = \Delta \cdot x_{k-1}$; karmaşıklık = kenar $\times$ K. Graflar **seyrek** olduğundan (kenar $\approx$ sabit$\times N$) bu **lineerdir** — eigendecomposition hiç gerekmez (Bresson 56:42).
:::
::: {.callout-note collapse="true" title="Soru 3: \"Transformer=tam-bağlı GCN\" ne demek? \"GCN=attention\" ile nasıl aynı gerçeğe varır?"}
**Cevap:** Bir GAT denkleminde komşuluğu **tüm graf** yaparsan (her düğüm her düğüme = tam-bağlı), Hafta 12'nin Transformer'ını elde edersin (Bresson 1:19:39). Tersinden Canziani: self-attention'da $h = X \cdot a$, $a$ hesaplanır; GCN'de **$a$ = adjacency** (verili, Canziani 29:04). İkisi aynı operasyon — **fark seyrekliktir**: GCN seyrek (graf verili), Transformer tam-bağlı (her şey her şeye, "küme"). Tam-bağlı olunca seyreklik kaybolur, ona graf değil **küme** demek doğrudur.
:::
::: {.callout-note collapse="true" title="Soru 4: Isotropic vs anisotropic GCN farkı nedir? Residual Gated GCN'deki kapı η ne yapar?"}
**Cevap:** **Isotropic** GCN tüm komşulara **aynı** ağırlık (komşuluk ortalaması — Vanilla/GraphSAGE/GIN); "her şeyi bulanıklaştırmak" gibi. **Anisotropic** komşulara **farklı** ağırlık (GAT, GatedGCN) — sosyal ağda farklı grupları aynı işlememek için. **Residual Gated GCN**'in kapısı $\eta = \sigma(e_{ij})/\sum \sigma(e_{ik})$ (kenar temsillerinin normalize sigmoid'i, Canziani 27:53), gelen mesajı kenara göre **modüle eder** → izotropik ortalamayı anizotropik ağırlıklı toplama çevirir; hangi komşunun önemli olduğunu backprop öğrenir. Hafta 6 LSTM gating + Hafta 12 attention akrabası.
:::
::: {.callout-note collapse="true" title="Soru 5: Graf-seviye ve düğüm-seviye sınıflandırma nasıl farklıdır? Karate Club neden \"semi-supervised\"dir?"}
**Cevap:** **Graf-seviye:** tüm düğümleri **mean-pool** → MLP → graf başına tek etiket (örn. MiniGCD 8 graf tipi). **Düğüm-seviye:** her köşe için ayrı logit (mean-pool yok) → düğüm başına etiket. **Karate Club** yarı-denetimlidir çünkü yalnız **2 etiket** var (eğitmen=0, yönetici=33); kayıp yalnız bu iki düğümde ama backprop bilgiyi **tüm graf yapısı boyunca yayar** (Canziani 58:30) → etiketsiz düğümlerin temsilleri iki kutba çekilip ayrışır. Hafta 10'un "az etiketle öğren" ruhu.
:::
## Egzersizler {#sec-egzersiz-d13}
**Egzersiz 1 (GCN = attention).** Hafta 12 self-attention'ı ($h = X \cdot a$, $a = \text{softmax}(X^\top x)$) yaz; sonra $a$'yı adjacency vektörüyle (1/0) değiştirip dereceye bölerek vanilla GCN'i türet. "Hesaplanan $a$" ile "verili $a$" farkı, GCN ile Transformer'ı nasıl ayırır?
```python
import numpy as np
# Hafta 12 self-attention: a HESAPLANIR (softmax skorlari)
X = np.array([[1.0, 0.0], # x1
[0.0, 1.0], # x2
[0.8, 0.6]]) # x3
x = X[0] # sorgu = x1
def softmax(z):
e = np.exp(z - z.max())
return e / e.sum()
a_attn = softmax(X @ x) # HESAPLANAN attention katsayilari
h_attn = a_attn @ X # h = X^T a (linear kombinasyon)
# GCN: a VERILIR (adjacency satiri), sonra dereceye bolunur (komsuluk ortalamasi)
a_adj = np.array([1.0, 1.0, 0.0]) # x1'in komsulari: x2 var, x3 yok (VERILI)
d = a_adj.sum() # derece
h_gcn = (a_adj / d) @ X # komsuluk ortalamasi
print("attention h:", np.round(h_attn, 3), " (a HESAPLANAN)")
print("gcn h :", np.round(h_gcn, 3), " (a VERILI = adjacency)")
# Fark: attention a'yi softmax ile HESAPLAR (kime bakacagini ogrenir);
# GCN a'yi adjacency'den ALIR (kim kime bagli VERILI). Transformer = tam-bagli GCN.
```
**Egzersiz 2 (Laplacian pürüzsüzlük).** Küçük grafta (5 düğüm) $\Delta = I - D^{-1/2}AD^{-1/2}$'yi elle hesapla. Sabit ve hızlı salınan sinyale uygula; pürüzsüz sinyalde $\Delta h$ küçük, salınanda büyük olduğunu göster. Neden "pürüzsüzlük ölçüsü"?
```python
import numpy as np
# 5 dugumlu yol grafi (zincir 0-1-2-3-4)
A = np.zeros((5, 5))
for i in range(4):
A[i, i + 1] = A[i + 1, i] = 1.0
d = A.sum(1)
Dinv = np.diag(1.0 / np.sqrt(d))
Delta = np.eye(5) - Dinv @ A @ Dinv # normalize Laplacian
h_smooth = np.array([1.0, 1.0, 1.0, 1.0, 1.0]) # sabit (puruzsuz)
h_osc = np.array([1.0, -1.0, 1.0, -1.0, 1.0]) # salinan
print("puruzsuz hDh:", round(float(h_smooth @ Delta @ h_smooth), 3)) # ~0 (kucuk)
print("salinan hDh:", round(float(h_osc @ Delta @ h_osc), 3)) # BUYUK
# Dh = h_i ile komsu ortalamasi farki; puruzsuzde komsular benzer -> kucuk,
# salinada komsular zit -> buyuk => "puruzsuzluk olcusu".
```
**Egzersiz 3 (K-hop yerelleştirme).** Bir düğüme "ısı kaynağı" (1, gerisi 0) koy. $\Delta$'yı 1/2/3 kez uygula; desteğin her seferinde bir hop genişlediğini göster. ChebNet'in $\sum_k w_k \Delta^k$'sı neden "tam K-hop yerelleştirilmiş"?
```python
import numpy as np
# 6 dugumlu yol grafi, isi kaynagi = dugum 0
A = np.zeros((6, 6))
for i in range(5):
A[i, i + 1] = A[i + 1, i] = 1.0
d = A.sum(1)
Delta = np.eye(6) - np.diag(1/np.sqrt(d)) @ A @ np.diag(1/np.sqrt(d))
e = np.zeros(6); e[0] = 1.0 # isi kaynagi (sadece dugum 0)
cur = e.copy()
for k in range(4):
aktif = int(np.sum(np.abs(cur) > 1e-9))
print(f"k={k}: destek {aktif} dugum") # destek her adimda bir hop genisler
cur = Delta @ cur
# Delta^k bir dugumden tam k-hop uzaktaki dugumlere erisir -> Sum w_k Delta^k = K-hop FILTRE.
# Seyrek grafta (kenar ~ sabit*N) maliyet kenar*K = LINEER (eigendecomposition yok).
```
**Egzersiz 4 (Anisotropy gate).** Bir düğümün 3 komşusu + kenar öznitelikleri olsun. $\eta = \sigma(e)/\sum \sigma(e)$ kapısını hesapla; büyük öznitelikli kenarın katkısının nasıl arttığını göster. İzotropik ($\eta = 1/d$) ile karşılaştır — anizotropi sosyal ağda neden gerekli?
```python
import numpy as np
edge_feats = np.array([2.0, 0.0, -2.0]) # 3 komsu, farkli kenar oznitelikleri
sig = 1.0 / (1.0 + np.exp(-edge_feats)) # sigmoid
eta = sig / sig.sum() # ANIZOTROPIK kapi
iso = np.full(3, 1.0 / 3) # IZOTROPIK (1/d esit)
print("anizotropik eta:", np.round(eta, 3)) # buyuk oznitelik -> buyuk agirlik
print("izotropik eta:", np.round(iso, 3)) # hepsi esit (bulanikilastir)
# Buyuk e_ij olan komsu daha cok katkida bulunur (kapi onu "secer").
# Sosyal agda: farkli gruplari (republican/democrat) AYNI islememek icin anizotropi gerekli.
```
**Egzersiz 5 (Hafta 14 habercisi — Yapılandırılmış Tahmin).** Hafta 14'te **LeCun** (son dersi) yapılandırılmış tahmini (structured prediction), enerji-tabanlı faktör grafiklerini, dizi etiketlemeyi; Canziani düzenlileştirmeyi anlatacak. (a) GCN'in "düğüm başına logit + graf yapısı boyunca yayma" fikrini, dizi etiketlemedeki "her token'a etiket + komşuluk tutarlılığı" ile ilişkilendir. (b) Bir CRF/faktör grafiği, bu haftanın graf yapısını Hafta 7-9 EBM enerjisiyle nasıl birleştirir?
```python
import numpy as np
# (a) GCN dugum-seviye: her dugum (token) icin logit + graf (komsuluk) tutarliligi.
# Dizi etiketleme = ZINCIR graf: her token bir dugum, komsu = yan token.
tokens = ["isim", "fiil", "isim", "edat"]
A_zincir = np.array([[0, 1, 0, 0], # her token sadece yan tokenlara bagli
[1, 0, 1, 0],
[0, 1, 0, 1],
[0, 0, 1, 0]])
print("dizi etiketleme = zincir graf, komsu sayisi:", A_zincir.sum(1))
# (b) CRF/faktor grafigi: unary enerji (her token-etiket) + pairwise enerji (komsu cift).
# Hafta 7-9 EBM: dusuk enerji = uyumlu (token+etiket+komsuluk); cikarim = enerji min.
# GCN graf yapisi = faktor grafiginin baglanti yapisi; Hafta 14 bunu EBM ile birlestirir.
```
## Sonraki Ders İçin Hazırlık {#sec-sonraki-d13}
::: {.callout-warning title="Sonraki Hafta — H14: Yapılandırılmış Tahmin ve Düzenlileştirme (LeCun SON ders + Canziani)"}
**Graflardan yapılandırılmış tahmine geçiyoruz.** Bu hafta convolution'u grafa genellemenin iki yolunu (template matching uzaysal + convolution teoremi spektral), Laplacian/Fourier/ChebNet'i, izotropik-anizotropik GCN'i ve "Transformer = tam-bağlı GCN" köprüsünü Bresson'la; "GCN = adjacency-verili attention"ı, Residual Gated GCN'i ve DGL ile graf/düğüm sınıflandırmayı Canziani'yle kapattık. Hafta 14'te **LeCun** son dersini verecek: yapılandırılmış tahmin, enerji-tabanlı faktör grafikleri, dizi etiketleme; **Canziani** overfitting ve düzenlileştirmeyi (son practicum) anlatacak. Egzersiz 1 (GCN=attention) ve Egzersiz 5 (graf → yapılandırılmış tahmin) tam bu derse hazırlar.
:::
**Hafta 14: Yapılandırılmış Tahmin (Structured Prediction) ve Düzenlileştirme** — LeCun (Lecture, son dersi) + Canziani (Practicum)
Hafta 14'te **LeCun** son dersini verecek: yapılandırılmış tahmin, enerji-tabanlı faktör grafikleri, dizi etiketleme; **Canziani** overfitting ve düzenlileştirmeyi (son practicum) anlatacak.
**Hafta 14 öncesi yapılacak:**
- Egzersiz 1 (GCN=attention) + Egzersiz 5 (graf → yapılandırılmış tahmin) çöz.
- "GCN = adjacency-verili attention" ve "Transformer = tam-bağlı GCN" cümlelerini kendi sözcüklerinle yaz.
- Hafta 7-9 EBM enerjisini hatırla — Hafta 14 faktör grafikleri o enerjiyi graf yapısıyla birleştirir.
## Anahtar Kavramlar (Cheat Sheet) {#sec-cheat-d13}
| Kavram | Tanım | Hoca / timestamp |
|---|---|---|
| ConvNet 3 varsayım | locality + stationarity + compositionality | Bresson 2:54 |
| Template matching grafta sorun | Düğüm sırası/konumu yok; değişken komşu | Bresson 22:01 |
| Graf Laplacian Δ | $I - D^{-1/2}AD^{-1/2}$; pürüzsüzlük ölçüsü | Bresson 26:45 |
| Graf Fourier | Laplacian özvektörleri = Fourier fonksiyonları | Bresson 30:03 |
| ChebNet | Laplacian polinomu; K-hop; lineer (seyrek) | Bresson 53:04 |
| Isotropic GCN | Tüm komşu aynı ağırlık (Vanilla/GraphSAGE/GIN) | Bresson 1:09 |
| Anisotropic GCN | Komşulara farklı ağırlık (GAT/GatedGCN) | Bresson 1:17 |
| Transformer = tam-bağlı GCN | Komşuluk = tüm graf → küme/attention | Bresson 1:19 |
| GCN = attention | $h = X \cdot a$; $a$ = adjacency (verili) | Canziani 29:04 |
| Gated GCN kapısı η | $\sigma(e)/\sum \sigma(e)$; izotropik → anizotropik | Canziani 27:53 |
| DGL mesaj/reduce | edge UDF + node UDF + update_all | Canziani 40:18 |
| Graf vs düğüm sınıflandırma | mean-pool→MLP vs logit/düğüm (semi-supervised) | Canziani 58:30 |
## ML Builder Bağlantıları {#sec-koprular-d13}
**Geriye köprüler:**
1. **ConvNet 3 varsayım** → Hafta 3 (doğal sinyaller: locality/stationarity/compositionality).
2. **Laplacian / Fourier / eigendecomposition** → Hafta 3 (spektral) + 18.06 lineer cebir.
3. **GCN = attention** → Hafta 12 (self-attention; $a$ verili vs hesaplanan).
4. **Gate η / residual / BatchNorm** → Hafta 6 (LSTM gate) + Hafta 3/11.
5. **Semi-supervised düğüm sınıflandırma** → Hafta 10 (az etiket, SSL).
**İleriye köprüler:**
1. **Anisotropic GCN + edge features** → **Graph Transformers + Laplacian PE (post-2020, KURSTA YOK)**.
2. **GCN protein/molekül** → **AlphaFold 2 (post-2020)**.
3. **Transformer = tam-bağlı GCN** → Geometric Deep Learning birleştirici program.
4. **Mesaj-geçiş** → DGL/PyG; tüm modern GNN kütüphaneleri.
::: {.callout-important title="Bu dersten tek bir şey alıp gideceksen"}
Graph convolution, ConvNet'i (locality/stationarity/compositionality) düzensiz grafiklere taşımaktır — ya template matching (uzaysal) ya da Laplacian/Fourier (spektral); ve gerçek graflar **seyrek** olduğundan ChebNet (Laplacian polinomu) bunu **lineer** zamanda yapar. Ama asıl içgörü birleştiricidir: **GCN ve attention aynı operasyondur**. Canziani'ye göre GCN = self-attention, ama attention katsayıları hesaplanmaz, **adjacency'den verilir**; Bresson'a göre Transformer = **tam-bağlı bir graf üzerinde GCN**. İkisini ayıran tek şey **seyrekliktir** — yani grafın kendisi; seyreklik yapıdır, yapı kimin kiminle bağlı olduğunu söyler. Bu temelin post-2020 zirvesi (Graph Transformers, AlphaFold, Geometric DL) kursta yoktur ama bu haftanın tohumlarının doğrudan ürünüdür.
:::