---
title: "Enerji-Tabanlı Modeller (EBM) ve Autoencoder"
subtitle: "İki hocalı hafta — kursun teorik omurgası: Yann LeCun (Lecture) enerji-tabanlı modelleri (EBM) kurar; bir ağı tek çıktı veren fonksiyon olmaktan çıkarıp her olası cevaba bir uyumluluk skoru (enerji) atayan ve çıkarımı enerji minimizasyonu yapan bir çerçeveye dönüştürür — çoklu minimum, çoklu geçerli cevap. Alfredo Canziani (Practicum) autoencoder'ları gösterir — encoder, code, decoder, veri manifoldu — ve bir autoencoder'ın aslında bir EBM olduğunu ortaya koyar: manifold üzerinde düşük, dışında yüksek enerji (yeniden kurma hatası)."
---
::: {.callout-note title="Bölüm bilgisi"}
- **LeCun'un Lecture videosu:** [YouTube — Energy-based models I](https://www.youtube.com/watch?v=tVwV14YkbYs) (≈97 dk)
- **Canziani'nin Practicum videosu:** [YouTube — Autoencoders](https://www.youtube.com/watch?v=bggWQ14DD9M) (≈55 dk)
- **Edition:** Spring 2020 (NYU-DLSP20)
- **Hocalar:** Yann LeCun (Lecture, teorik) + Alfredo Canziani (Practicum, pratik)
- **Kaynak:** [atcold.github.io/NYU-DLSP20](http://atcold.github.io/NYU-DLSP20)
- **Okuma süresi:** ≈25 dk
:::
```{python}
#| echo: false
# ============================================================================
# SETUP — NYU sayısal motor (_engine.py) + NYU Violet+gold viz (_viz.py)
# Bu hücre gizlidir (#| echo: false). Aşağıdaki TÜM figür hücreleri burada
# tanımlanan energy_1d / energy_1d_grad / make_manifold_curve /
# project_to_manifold + önceki hafta yardımcıları + COL_* +
# apply_style / draw_pipeline / style_legend / CLASS_COLORS isimlerini kullanır.
# _engine.py saf numpy (torch YOK); _viz.py NYU Violet+gold paleti.
# İçerikler VERBATIM gömülüdür.
#
# NOT: matplotlib backend'i AYARLANMAZ (matplotlib.use(...) ÇAĞRILMAZ).
# Quarto kendi inline (figür yakalayan) backend'ini kurar; Agg backend
# inline figür-yakalamayı bozar (plt.show() çıktı üretmez). Standalone
# figür testinde savefig kullanılır.
# ============================================================================
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from matplotlib.patches import (
FancyBboxPatch, FancyArrowPatch, Rectangle, Circle, Polygon, Patch,
)
from matplotlib.lines import Line2D
from matplotlib.colors import ListedColormap, BoundaryNorm, LinearSegmentedColormap
np.random.seed(0)
# ===========================================================================
# _engine.py — saf numpy sayısal yardımcılar (torch YOK)
# ===========================================================================
# ---------------------------------------------------------------------------
# Afin / lineer dönüşümler
# ---------------------------------------------------------------------------
def affine_transform(P, W, b=None):
"""P[N,2] noktalarına y = W x (+ b) afin/lineer dönüşümü uygular (satır-vektör konvansiyonu)."""
P = np.asarray(P, float)
Y = P @ np.asarray(W, float).T
if b is not None:
Y = Y + np.asarray(b, float)
return Y
def unit_grid(n=11, lim=2.0, fine=61):
"""Izgara çizgileri listesi (yatay + dikey). Her çizgi (fine,2) dizisi.
Lineer dönüşüm görsellerinde 'uzayın kumaşı' için."""
t = np.linspace(-lim, lim, n)
f = np.linspace(-lim, lim, fine)
lines = []
for yi in t:
lines.append(np.column_stack([f, np.full_like(f, yi)]))
for xi in t:
lines.append(np.column_stack([np.full_like(f, xi), f]))
return lines
def linear_transforms():
"""Canziani'nin dört temel lineer dönüşümü (Bölüm 8) — 2x2 matrisler."""
th = np.deg2rad(35.0)
R = np.array([[np.cos(th), -np.sin(th)], [np.sin(th), np.cos(th)]]) # rotation (ortonormal)
S = np.array([[1.8, 0.0], [0.0, 0.55]]) # scaling (köşegen)
Sh = np.array([[1.0, 0.85], [0.0, 1.0]]) # shearing
F = np.array([[1.0, 0.0], [0.0, -1.0]]) # reflection (det<0)
return dict(rotation=R, scaling=S, shearing=Sh, reflection=F)
# ---------------------------------------------------------------------------
# SVD geometrisi (Canziani'nin 'patatesi')
# ---------------------------------------------------------------------------
def unit_circle(n=240):
t = np.linspace(0, 2 * np.pi, n)
return np.column_stack([np.cos(t), np.sin(t)])
def svd_demo(W):
"""W = U Σ Vᵀ. Geometrik okuma: rotation(Vᵀ) · scaling(Σ) · rotation(U)."""
U, s, Vt = np.linalg.svd(np.asarray(W, float))
return U, s, Vt
def near_singular_matrix():
"""Bir tekil değeri ≈0 olan matris — bir boyutu 'ezer' (elips çizgiye çöker)."""
th = np.deg2rad(30.0)
R = np.array([[np.cos(th), -np.sin(th)], [np.sin(th), np.cos(th)]])
Sigma = np.diag([1.6, 0.04]) # ikinci tekil değer ≈ 0
return R @ Sigma @ R.T
# ---------------------------------------------------------------------------
# Spiral (manifold germe demosu)
# ---------------------------------------------------------------------------
def make_spiral(n_per=120, k=5, noise=0.18, seed=0):
"""k-kollu spiral (CS231n stili). Her kol bir sınıf; kollar orijinde iç içe → lineer ayrılamaz."""
rng = np.random.default_rng(seed)
X = np.zeros((n_per * k, 2))
y = np.zeros(n_per * k, dtype=int)
for j in range(k):
ix = slice(n_per * j, n_per * (j + 1))
r = np.linspace(0.0, 1.0, n_per)
t = np.linspace(j * 4.0, (j + 1) * 4.0, n_per) + rng.normal(0, 1, n_per) * noise
X[ix] = np.column_stack([r * np.sin(t), r * np.cos(t)])
y[ix] = j
return X, y
def unroll_spiral(X, y, k=5, seed=0):
"""ŞEMATİK 'öğrenilen temsil': her sınıfı kendi yatay bandına taşır → lineer ayrılabilir.
Gerçek bir eğitilmiş ağ DEĞİL; 'ağ manifoldu açar' sezgisinin deterministik görseli."""
rng = np.random.default_rng(seed)
r = np.linalg.norm(X, axis=1)
yb = (y - (k - 1) / 2.0) * 0.55 + rng.normal(0, 0.045, len(y))
return np.column_stack([r * 2.2 - 1.1, yb])
# ---------------------------------------------------------------------------
# İki hilal (make_moons — sklearn YOK, numpy ile elle)
# ---------------------------------------------------------------------------
def make_moons_np(n=400, noise=0.20, seed=0):
"""Doğrusal ayrılamaz iki-hilal veri (sklearn.make_moons eşdeğeri)."""
rng = np.random.default_rng(seed)
n_out = n // 2
n_in = n - n_out
to = np.linspace(0, np.pi, n_out)
ti = np.linspace(0, np.pi, n_in)
outer = np.column_stack([np.cos(to), np.sin(to)])
inner = np.column_stack([1.0 - np.cos(ti), 1.0 - np.sin(ti) - 0.5])
X = np.vstack([outer, inner]) + rng.normal(0, noise, (n, 2))
y = np.array([0] * n_out + [1] * n_in)
return X, y
# ---------------------------------------------------------------------------
# Minik numpy sınıflandırıcılar (lineer vs ReLU MLP) — karar sınırı kontrastı
# ---------------------------------------------------------------------------
def _onehot(y, c):
Y = np.zeros((len(y), c))
Y[np.arange(len(y)), y] = 1.0
return Y
def _softmax(z):
z = z - z.max(axis=1, keepdims=True)
e = np.exp(z)
return e / e.sum(axis=1, keepdims=True)
def logreg_train(X, y, steps=500, lr=1.0, seed=0):
"""Lineer (gizli katmansız) softmax sınıflandırıcı → DÜZ karar sınırı."""
rng = np.random.default_rng(seed)
n, d = X.shape
c = int(y.max() + 1)
W = rng.normal(0, 0.01, (d, c))
b = np.zeros(c)
Y = _onehot(y, c)
for _ in range(steps):
p = _softmax(X @ W + b)
dz = (p - Y) / n
W -= lr * (X.T @ dz)
b -= lr * dz.sum(axis=0)
return dict(W=W, b=b)
def logreg_forward(params, X):
return X @ params["W"] + params["b"]
def mlp_train(X, y, hidden=16, act="relu", steps=600, lr=1.0, seed=0, return_history=False):
"""numpy 2-katmanlı MLP (afine → nonlinearite → afine), softmax + cross-entropy.
ReLU ile EĞRİ karar sınırı (hilalleri/spirali ayırır).
return_history=True → (params, loss_history) döner (eğitim eğrisi figürü için)."""
rng = np.random.default_rng(seed)
n, d = X.shape
c = int(y.max() + 1)
W1 = rng.normal(0, 1, (d, hidden)) * np.sqrt(2.0 / d)
b1 = np.zeros(hidden)
W2 = rng.normal(0, 1, (hidden, c)) * np.sqrt(2.0 / hidden)
b2 = np.zeros(c)
Y = _onehot(y, c)
history = []
for _ in range(steps):
z1 = X @ W1 + b1
a1 = np.maximum(0, z1) if act == "relu" else np.tanh(z1)
p = _softmax(a1 @ W2 + b2)
if return_history:
history.append(float(-np.log(p[np.arange(n), y] + 1e-12).mean()))
dz2 = (p - Y) / n
dW2 = a1.T @ dz2
db2 = dz2.sum(axis=0)
da1 = dz2 @ W2.T
dz1 = da1 * ((z1 > 0) if act == "relu" else (1 - np.tanh(z1) ** 2))
dW1 = X.T @ dz1
db1 = dz1.sum(axis=0)
W1 -= lr * dW1
b1 -= lr * db1
W2 -= lr * dW2
b2 -= lr * db2
params = dict(W1=W1, b1=b1, W2=W2, b2=b2, act=act)
if return_history:
return params, np.array(history)
return params
def mlp_forward(params, X):
z1 = X @ params["W1"] + params["b1"]
a1 = np.maximum(0, z1) if params["act"] == "relu" else np.tanh(z1)
return a1 @ params["W2"] + params["b2"]
def accuracy(forward_fn, params, X, y):
return float((forward_fn(params, X).argmax(axis=1) == y).mean())
def decision_grid(X, pad=0.6, h=0.02):
"""Karar bölgesi için koordinat ızgarası (xx, yy) ve düz nokta listesi."""
x0, x1 = X[:, 0].min() - pad, X[:, 0].max() + pad
y0, y1 = X[:, 1].min() - pad, X[:, 1].max() + pad
xx, yy = np.meshgrid(np.arange(x0, x1, h), np.arange(y0, y1, h))
grid = np.column_stack([xx.ravel(), yy.ravel()])
return xx, yy, grid
# ---------------------------------------------------------------------------
# Enerji manzarası (EBM — çoklu minimum = çoklu geçerli cevap)
# ---------------------------------------------------------------------------
def energy_landscape(xx, yy):
"""F(x,y): birkaç Gauss kuyusu → çoklu yerel minimum. Düşük enerji = uyumlu cevap."""
wells = [(-1.25, -0.65, 1.0, 0.55), (1.15, 0.85, 1.05, 0.6), (0.15, -1.15, 0.8, 0.45)]
F = np.ones_like(xx) * 1.0
for cx, cy, depth, width in wells:
F = F - depth * np.exp(-((xx - cx) ** 2 + (yy - cy) ** 2) / (2 * width))
return F
# ---------------------------------------------------------------------------
# Hafta 2 — gradient descent, SGD, backprop, eğitim
# ---------------------------------------------------------------------------
def loss_surface_2d(xx, yy):
"""2D parametre uzayında bir kayıp yüzeyi (gradient descent 'dağ' görseli için):
eğik, farklı-ölçekli bir vadi (konveks taban) + hafif dalgalanma."""
u = 0.85 * xx + 0.53 * yy # eksenleri döndür (eğik vadi)
v = -0.53 * xx + 0.85 * yy
return 1.0 * u ** 2 + 3.5 * v ** 2 + 0.6 * np.sin(1.5 * xx) * np.cos(1.5 * yy)
def _loss_grad_2d(p):
"""loss_surface_2d gradyanı (merkezi sonlu fark)."""
eps = 1e-4
gx = (loss_surface_2d(p[0] + eps, p[1]) - loss_surface_2d(p[0] - eps, p[1])) / (2 * eps)
gy = (loss_surface_2d(p[0], p[1] + eps) - loss_surface_2d(p[0], p[1] - eps)) / (2 * eps)
return np.array([gx, gy])
def gd_path(theta0, lr=0.08, steps=40):
"""loss_surface_2d üzerinde gradient descent yörüngesi (parametre adımları)."""
p = np.array(theta0, float)
path = [p.copy()]
for _ in range(steps):
p = p - lr * _loss_grad_2d(p)
path.append(p.copy())
return np.array(path)
def sgd_loss_curves(steps=80, seed=0):
"""Üç rejim için kayıp eğrisi (simülasyon): full-batch (gürültüsüz, düz),
mini-batch (orta gürültü), saf SGD (yüksek gürültü). Aynı yumuşak üstel düşüş."""
rng = np.random.default_rng(seed)
t = np.arange(steps)
base = 0.2 + 2.6 * np.exp(-t / 14.0)
full = base.copy()
mini = base + rng.normal(0, 0.10, steps) * np.exp(-t / 45.0)
sgd = base + rng.normal(0, 0.45, steps) * np.exp(-t / 70.0)
return t, np.clip(full, 0, None), np.clip(mini, 0, None), np.clip(sgd, 0, None)
def tanh_deriv(x):
"""tanh'ın türevi: 1 − tanh²(x). Backprop 'twiddling' figürü için."""
return 1.0 - np.tanh(x) ** 2
def ce_loss_curve(p):
"""Doğru sınıf olasılığı p için cross-entropy kaybı: −log p."""
p = np.clip(np.asarray(p, float), 1e-6, 1.0)
return -np.log(p)
def mse_loss_curve(p):
"""Doğru sınıf olasılığı p için (one-hot hedefe) MSE: (1 − p)²."""
return (1.0 - np.asarray(p, float)) ** 2
# ---------------------------------------------------------------------------
# Hafta 3 — convolution / ConvNet / doğal sinyaller
# ---------------------------------------------------------------------------
def conv_output_size(n, k, s=1):
"""Çıktı boyutu: o = ⌊(n − k)/s⌋ + 1."""
return (n - k) // s + 1
def conv1d(x, w):
"""1B cross-correlation (ML 'convolution'): out[i] = Σ_k x[i+k]·w[k].
Örnek: conv1d([1,2,3,4,5],[1,0,-1]) → [-2,-2,-2] (kenar/fark dedektörü)."""
x = np.asarray(x, float)
w = np.asarray(w, float)
n = len(x) - len(w) + 1
return np.array([np.dot(x[i:i + len(w)], w) for i in range(n)])
def conv2d(img, kernel, stride=1):
"""2B valid cross-correlation (ag öznitelik haritası üretir)."""
img = np.asarray(img, float)
k = np.asarray(kernel, float)
kh, kw = k.shape
H, W = img.shape
oh, ow = conv_output_size(H, kh, stride), conv_output_size(W, kw, stride)
out = np.zeros((oh, ow))
for i in range(oh):
for j in range(ow):
patch = img[i * stride:i * stride + kh, j * stride:j * stride + kw]
out[i, j] = np.sum(patch * k)
return out
def make_synthetic_image(n=28, seed=0):
"""Basit gri-tonlu sentetik görüntü: kare + daire (kenar tespiti net görünsün)."""
img = np.zeros((n, n))
img[5:14, 6:15] = 1.0 # dolu kare
yy, xx = np.ogrid[:n, :n]
cy, cx, r = 19, 19, 6
img[(yy - cy) ** 2 + (xx - cx) ** 2 <= r ** 2] = 0.85 # daire
img[20:22, 4:24] = 0.6 # yatay çizgi (yatay kenar için)
return img
def edge_kernels():
"""Klasik 3×3 öznitelik dedektörü kernel'leri."""
return dict(
sobel_x=np.array([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]], float), # dikey kenar
sobel_y=np.array([[-1, -2, -1], [0, 0, 0], [1, 2, 1]], float), # yatay kenar
blur=np.ones((3, 3)) / 9.0, # bulanıklaştırma
laplace=np.array([[0, 1, 0], [1, -4, 1], [0, 1, 0]], float), # tüm kenarlar
)
def max_pool2d(img, k=2):
"""k×k max pooling (complex cell / invariance)."""
img = np.asarray(img, float)
H, W = img.shape
oh, ow = H // k, W // k
return np.array([[img[i * k:(i + 1) * k, j * k:(j + 1) * k].max() for j in range(ow)]
for i in range(oh)])
def avg_pool2d(img, k=2):
"""k×k average pooling (LeNet5 stili)."""
img = np.asarray(img, float)
H, W = img.shape
oh, ow = H // k, W // k
return np.array([[img[i * k:(i + 1) * k, j * k:(j + 1) * k].mean() for j in range(ow)]
for i in range(oh)])
# ---------------------------------------------------------------------------
# Hafta 4 — convolution cebiri (Toeplitz) + optimizasyon (κ, momentum, Adam)
# ---------------------------------------------------------------------------
def build_toeplitz(kernel, n):
"""1B convolution'ın Toeplitz matrisi: out = T @ x, T[i, i:i+k] = kernel.
conv1d(x, kernel) == build_toeplitz(kernel, len(x)) @ x (çoğu eleman sıfır = seyrek)."""
kernel = np.asarray(kernel, float)
k = len(kernel)
oh = n - k + 1
T = np.zeros((oh, n))
for i in range(oh):
T[i, i:i + k] = kernel
return T
def quad_loss(xx, yy, kappa=20.0):
"""Eğik, koşullanması κ = L/μ olan kuadratik vadi (condition number görseli).
κ büyük → uzun ince vadi → gradient descent zikzak çizer."""
a, b = 0.92, 0.39 # ~25° dönme
u = a * xx + b * yy
v = -b * xx + a * yy
return 0.5 * (1.0 * u ** 2 + kappa * v ** 2) # L=κ, μ=1
def quad_grad(p, kappa=20.0):
"""quad_loss'un analitik gradyanı."""
a, b = 0.92, 0.39
x, y = p
u = a * x + b * y
v = -b * x + a * y
gu, gv = u, kappa * v
return np.array([gu * a + gv * (-b), gu * b + gv * a])
def optimize_quad(method, theta0, lr, steps, kappa=20.0, beta=0.9, beta2=0.999, eps=1e-8):
"""quad_loss üzerinde bir optimizer'ı koştur; yörünge + kayıp geçmişi döner.
method ∈ {'gd','momentum','adam'}. Defazio'nun zikzak/sönümleme/adaptif anlatısı için."""
p = np.array(theta0, float)
path = [p.copy()]
losses = [float(quad_loss(p[0], p[1], kappa))]
m = np.zeros(2)
v = np.zeros(2)
for t in range(1, steps + 1):
g = quad_grad(p, kappa)
if method == "gd":
step = lr * g
elif method == "momentum":
m = beta * m + g # heavy ball
step = lr * m
elif method == "adam":
m = beta * m + (1 - beta) * g
v = beta2 * v + (1 - beta2) * g * g
mh = m / (1 - beta ** t) # bias correction
vh = v / (1 - beta2 ** t)
step = lr * mh / (np.sqrt(vh) + eps)
else:
raise ValueError(method)
p = p - step
path.append(p.copy())
losses.append(float(quad_loss(p[0], p[1], kappa)))
return np.array(path), np.array(losses)
# ---------------------------------------------------------------------------
# Hafta 5 — autograd worked example (Canziani)
# ---------------------------------------------------------------------------
def autograd_worked(X=None):
"""Canziani worked example: X → Y=X−2 → Z=3·Y² → a=mean(Z) (skaler).
İleri değerler + ∂a/∂xᵢ = (1/4)·3·2·(xᵢ−2) = 1.5·(xᵢ−2).
X=[1,2,3,4] için grad = [−1.5, 0, 1.5, 3] (PyTorch X.grad ile birebir)."""
if X is None:
X = np.array([1.0, 2.0, 3.0, 4.0])
X = np.asarray(X, float)
Y = X - 2.0
Z = 3.0 * Y ** 2
a = float(Z.mean())
grad = 1.5 * (X - 2.0)
return dict(X=X, Y=Y, Z=Z, a=a, grad=grad)
def conv_pad_output(n, k, padding=0, stride=1):
"""Padding'li çıktı boyutu: o = ⌊(n + 2·padding − k)/stride⌋ + 1.
padding=(k−1)/2 (k tek) → çıktı boyutu korunur."""
return (n + 2 * padding - k) // stride + 1
# ---------------------------------------------------------------------------
# Hafta 6 — RNN / vanishing gradient / attention
# ---------------------------------------------------------------------------
def vanishing_demo(steps=50, eigenvalues=(0.5, 1.0, 1.5)):
"""Aynı matristen n kez geçen gradient: λⁿ. λ<1 söner (vanishing), λ>1 patlar
(exploding), λ=1 sabit. Backprop-through-time vanishing gradient görseli."""
t = np.arange(steps + 1)
curves = {ev: np.asarray(ev, float) ** t for ev in eigenvalues}
return t, curves
def rnn_forward(X_seq, Wx, Wz, b, z0=None):
"""Basit RNN hücresi: zₜ = tanh(Wₓ·xₜ + W_z·zₜ₋₁ + b).
X_seq [T, d_in] → gizli durumlar Z [T, d_h] (aynı Wₓ,W_z her adımda = paylaşım)."""
X_seq = np.asarray(X_seq, float)
T = len(X_seq)
dh = np.asarray(Wz).shape[0]
z = np.zeros(dh) if z0 is None else np.asarray(z0, float)
Z = []
for t in range(T):
z = np.tanh(np.asarray(Wx) @ X_seq[t] + np.asarray(Wz) @ z + np.asarray(b))
Z.append(z.copy())
return np.array(Z)
def attention_weights(scores):
"""Attention ağırlıkları = softmax(skorlar); toplamı 1 (olasılık dağılımı, 'odak')."""
scores = np.asarray(scores, float)
e = np.exp(scores - scores.max())
return e / e.sum()
# ---------------------------------------------------------------------------
# Hafta 7 — EBM / autoencoder / manifold
# ---------------------------------------------------------------------------
def energy_1d(y, data_points=(-2.0, 0.0, 2.0), width=0.35):
"""1B enerji F(y): veri noktalarında düşük (çukur), aralarda yüksek (tepe).
'İyi enerji şekli' = veride düşük, dışında yüksek (EBM); çoklu minimum = çoklu cevap."""
y = np.asarray(y, float)
F = np.ones_like(y)
for d in data_points:
F = F - np.exp(-(y - d) ** 2 / (2 * width))
return F
def energy_1d_grad(y, data_points=(-2.0, 0.0, 2.0), width=0.35):
"""energy_1d'nin türevi (çıkarım = enerji minimizasyonu, gradient ile arama)."""
y = np.asarray(y, float)
g = np.zeros_like(y)
for d in data_points:
g = g + (y - d) / width * np.exp(-(y - d) ** 2 / (2 * width))
return g
def make_manifold_curve(n=160, noise=0.0, seed=0):
"""2B veri manifoldu: bir eğri (sinüs yayı) üzerinde noktalar (Hafta 1 manifold hipotezi)."""
t = np.linspace(-2.6, 2.6, n)
M = np.column_stack([t, np.sin(1.3 * t)])
if noise:
M = M + np.random.default_rng(seed).normal(0, noise, M.shape)
return M
def project_to_manifold(points, manifold):
"""Her noktayı manifoldun EN YAKIN noktasına çeker (autoencoder reconstruction sezgisi:
off-manifold girdiyi manifolda geri çek → düşük enerji)."""
points = np.asarray(points, float)
proj = np.array([manifold[np.linalg.norm(manifold - p, axis=1).argmin()] for p in points])
return proj
# ===========================================================================
# _viz.py — NYU Violet + gold matplotlib stil sabitleri ve yardımcıları
# ===========================================================================
COL_VIOLET = "#57068c" # NYU Violet — birincil çizgi/çerçeve/vurgu
COL_VIOLET_D = "#3d0463" # koyu violet — güçlü vurgu / gradyan
COL_VIOLET_M = "#7b2cbf" # orta violet — ikincil
COL_VIOLET_SOFT = "#b56ad6" # soluk violet
COL_GOLD = "#d4a017" # gold accent
COL_GOLD_D = "#a87d0a" # koyu gold
COL_TEXT = "#2a2535" # gövde metni (hafif violet tint)
COL_INK = "#1e1a2e" # en koyu — başlık
COL_BG = "#f4eefa" # açık violet — dolgu/arka plan
COL_GRID = "#cdbbe0" # soluk violet — ızgara/pasif kenar
COL_WHITE = "#ffffff"
# 5-sınıf kategorik palet (spiral 5 kol / moons ilk 2) — violet↔gold ekseni, tema-uyumlu
CLASS_COLORS = ["#57068c", "#7b2cbf", "#b56ad6", "#d4a017", "#a87d0a"]
# Çizgi-grafik tutarlı renkler
LINE_PRIMARY = COL_VIOLET
LINE_ACCENT = COL_GOLD
LINE_SECONDARY = COL_VIOLET_M
def apply_style(ax):
"""Bir eksene tutarlı NYU Violet+gold görünümü uygular."""
ax.set_facecolor(COL_WHITE)
ax.grid(True, alpha=0.25, color=COL_GRID, linewidth=0.8)
for spine in ax.spines.values():
spine.set_color(COL_GRID)
ax.tick_params(colors=COL_TEXT)
ax.title.set_color(COL_TEXT)
ax.xaxis.label.set_color(COL_TEXT)
ax.yaxis.label.set_color(COL_TEXT)
return ax
def draw_pipeline(ax, stages, title=None, y0=0.0):
"""Soldan-sağa kutu+ok boru hattı şeması (örüntü tanıma vs uçtan-uca).
stages : [(label:str, is_learned:bool), ...]
is_learned=True -> öğrenilen modül (violet dolgulu)
is_learned=False -> elle-tasarlanan/sabit (gold kenarlı, açık dolgu)
"""
n = len(stages)
box_w, box_h, gap = 1.7, 1.0, 0.9
step = box_w + gap
ax.set_xlim(-0.3, n * step)
ax.set_ylim(y0 - 1.1, y0 + 1.1)
ax.axis("off")
if title:
ax.set_title(title, color=COL_TEXT, fontsize=12, pad=10)
for i, (lbl, learned) in enumerate(stages):
x = i * step
fc = "#ece0f7" if learned else COL_BG
ec = COL_VIOLET if learned else COL_GOLD_D
lw = 2.4 if learned else 2.0
box = FancyBboxPatch(
(x, y0 - box_h / 2), box_w, box_h,
boxstyle="round,pad=0.02,rounding_size=0.12",
fc=fc, ec=ec, lw=lw, zorder=2,
)
ax.add_patch(box)
ax.text(x + box_w / 2, y0, lbl, ha="center", va="center",
fontsize=9.5, color=COL_TEXT, zorder=3, wrap=True)
if i > 0:
ax.add_patch(FancyArrowPatch(
(x - gap, y0), (x, y0),
arrowstyle="-|>", mutation_scale=16,
color=COL_VIOLET_M, lw=1.9, zorder=1,
))
return ax
def style_legend(ax, **kw):
"""Tema-uyumlu legend."""
leg = ax.legend(frameon=True, framealpha=0.95, edgecolor=COL_GRID, **kw)
if leg is not None:
leg.get_frame().set_facecolor(COL_WHITE)
for t in leg.get_texts():
t.set_color(COL_TEXT)
return leg
```
## Bu Derste Ne Var? {#sec-genel-bakis-d7}
Bu hafta kursun **teorik omurgasına** giriyoruz: **Yann LeCun**'un en sevdiği konu, **enerji-tabanlı modeller (EBM)**. Hafta 1'de kısaca değinilen "cevaplar = enerji fonksiyonunun minimumları" fikri burada tam açılıyor. **Alfredo Canziani** ise Practicum'da **autoencoder**'ları gösteriyor — ve dersin sonunda göreceğin gibi, bir autoencoder aslında bir EBM'dir.
LeCun'un büyük fikri: bir ağı "girdi → tek çıktı" fonksiyonu olarak görmek kısıtlayıcıdır. Bunun yerine, her olası $(x, y)$ çiftine bir **enerji** (uyumsuzluk skoru) atayan bir $F(x, y)$ tanımla; **çıkarım**, verilen $x$ için enerjiyi **minimize** eden $y$'yi aramaktır. Canziani'nin autoencoder'ı bunun somut bir örneğidir: veri **manifoldu** üzerinde düşük, dışında yüksek "enerji" (yeniden kurma hatası).
Bu haftanın üç ana fikri:
1. **EBM = her cevaba bir enerji.** Tek çıktı yerine, uyumlu çiftlere düşük, uyumsuza yüksek skor; çıkarım = enerji minimizasyonu (birden çok cevap olabilir).
2. **Enerji ≠ kayıp.** Enerji çıkarımda kullanılır (hangi $y$?); kayıp eğitimde enerji fonksiyonunu şekillendirmek için.
3. **Autoencoder bir EBM'dir:** veri manifoldu üzerini yeniden kurar (düşük enerji), dışını manifolda geri çeker (yüksek enerji).
```{mermaid}
%%| echo: false
flowchart TB
subgraph LeCun["(A) EBM çerçevesi (LeCun)"]
direction LR
Enerji["Enerji = uyumluluk skoru<br/>her (x, y) çiftine F(x, y)"]
Cikarim["Çıkarım = argmin F<br/>(enerji minimizasyonu)"]
Sekil["Enerji ≠ kayıp<br/>veride düşük / dışında yüksek"]
Latent["Latent EBM<br/>F(x, y, z) — z yardımcı bilgi"]
Enerji --> Cikarim
Cikarim --> Sekil
Sekil --> Latent
end
subgraph Canziani["(B) Autoencoder (Canziani)"]
direction LR
AE["Encoder → code → decoder<br/>girdiyi yeniden kur"]
Manifold["Veri manifoldu<br/>(yalnızca üzerini kur)"]
Recon["Reconstruction = enerji<br/>manifoldda düşük, dışında yüksek"]
AEBM["Autoencoder = EBM"]
AE --> Manifold
Manifold --> Recon
Recon --> AEBM
end
Latent -. "code = latent z; AE = EBM'nin somut hâli" .-> AE
```
::: {.callout-tip title="Builder Notu — Tek Çıktıdan Enerjiye"}
**Geriye (önkoşul kurslar):**
- **Enerji = uyumluluk skoru** → Stat 110 (energy = −log p; Boltzmann, Hafta 8-9'da) + Hafta 1 EBM teaser.
- **Çıkarım = enerji minimizasyonu** → Calculus gradient descent (y yönünde) + implicit function (Calculus).
- **Manifold** → Hafta 1 manifold hipotezi + 18.06 altuzay.
**İleriye (production / research):**
- EBM → LeCun'un JEPA programı (post-2020 ileriye köprü); world models, planning.
- Autoencoder → VAE (Hafta 8), denoising AE, ve temsil öğrenme.
**Tek cümleyle:** Enerji-tabanlı model, her $(x, y)$ çiftine bir uyumluluk skoru (enerji) atar ve çıkarımı enerji minimizasyonu yapar; autoencoder bunun pratik bir hâlidir — veri manifoldu üzerine düşük enerji koyup dışını geri çeker.
:::
## (LeCun) EBM Nedir? Tek Çıktı Yerine Her Cevaba Enerji {#sec-ebm-nedir}
LeCun EBM'yi geniş bir çerçeve olarak açıyor: birçok öğrenme algoritması (olasılıksal modeller dahil) EBM'nin özel hâlidir.
> "energy based models — it's basically a framework through which we can express a lot of different learning algorithms... probabilistic methods are really kind of a special case of energy based models." — LeCun, 0:00
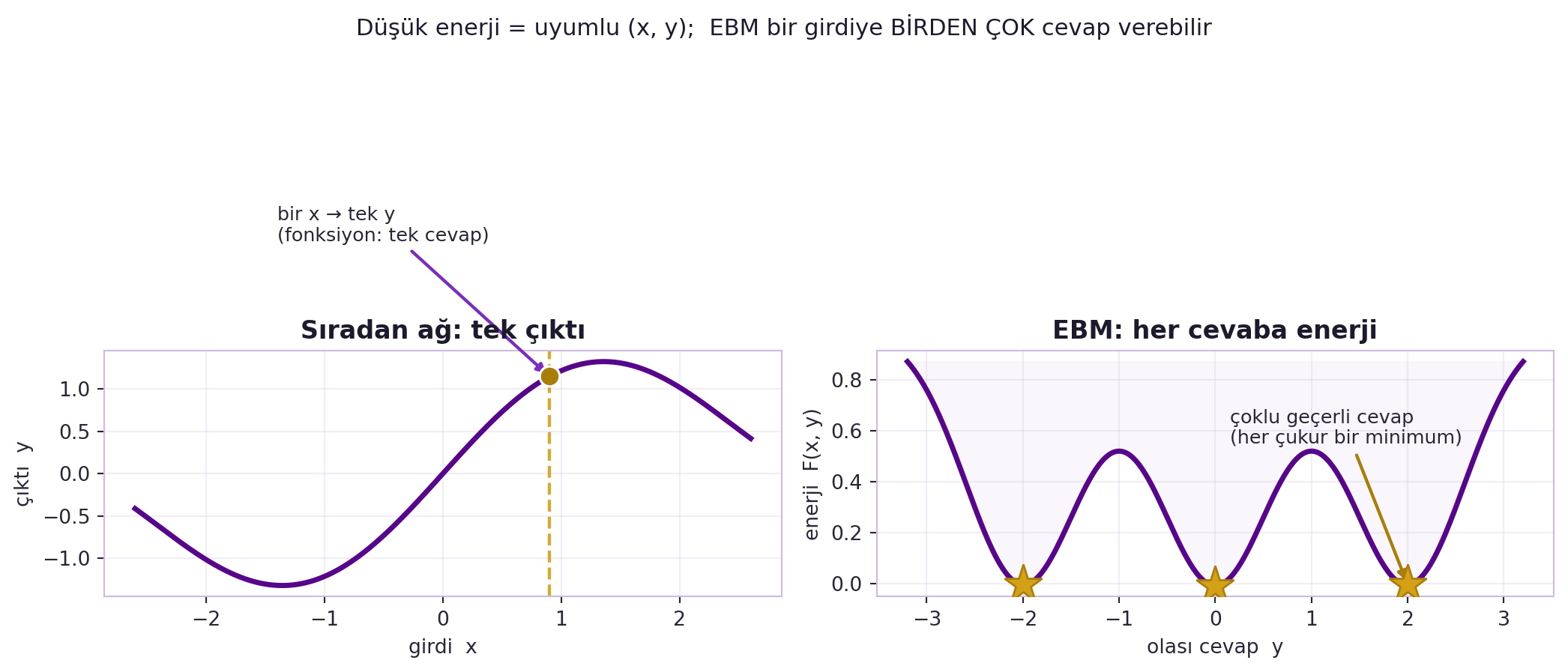
Fikir şu: sıradan bir ağ bir girdiye **tek** çıktı üretir. EBM ise her olası çıktıya bir **skor** verir — her olası sınıflandırmaya bir enerji. Düşük enerji = "bu $y$, bu $x$ ile uyumlu"; yüksek enerji = "uyumsuz". @fig-ebm-vs-function bu iki bakışı yan yana koyar: solda sıradan bir ağ (bir $x$'e tek $y$, dikey çizgi eğriyi tek noktada keser), sağda EBM'nin çoklu çukuru (her gold yıldız bir geçerli cevap).
> "all the values of Y that are compatible with this X have low energy, and all the values that are not compatible have higher energy." — LeCun, 7:52
Bu yüzden EBM bir **örtük (implicit) fonksiyondur**: $y$'yi doğrudan hesaplamaz; $y$'yi, $F(x, y)$'yi en küçük yapan değer olarak *tanımlar*. (Calculus benzetmesi: $x^2 + y^2 - 1 = 0$ örtük fonksiyonu, bir $x$'e birden çok uyumlu $y$ verir.)
```{python}
#| label: fig-ebm-vs-function
#| fig-cap: "Sıradan ağ ile enerji-tabanlı model (EBM) karşılaştırması. Solda sıradan bir ağ: girdi x ile çıktı y arasında bir fonksiyon — her x'e tek bir y düşer (dikey çizgi eğriyi tek noktada keser). Sağda EBM: her olası cevaba bir enerji F(x,y) atanır; düşük enerjili çukurlar uyumlu cevaplardır. energy_1d ile (-2, 0, 2) veri noktalarında üç çukur (gold yıldız) belirir — yani EBM bir girdiye birden çok geçerli cevap verebilir."
fig, (axL, axR) = plt.subplots(1, 2, figsize=(11, 4.6))
# ---- SOL: Sıradan ağ — tek çıktı (x → y fonksiyonu) ----
x = np.linspace(-2.6, 2.6, 300)
y = np.sin(1.3 * x) + 0.25 * x # her x'e TEK y
axL.plot(x, y, color=COL_VIOLET, lw=2.6, zorder=3)
# Bir x'te dikey çizgi → eğriyi TEK noktada keser
x0 = 0.9
y0 = np.sin(1.3 * x0) + 0.25 * x0
axL.axvline(x0, color=COL_GOLD, lw=1.6, ls="--", alpha=0.9, zorder=2)
axL.plot([x0], [y0], "o", color=COL_GOLD_D, ms=10, zorder=4,
markeredgecolor=COL_WHITE, markeredgewidth=1.2)
axL.annotate("bir x → tek y\n(fonksiyon: tek cevap)",
xy=(x0, y0), xytext=(x0 - 2.3, y0 + 1.6),
fontsize=9.5, color=COL_TEXT,
arrowprops=dict(arrowstyle="-|>", color=COL_VIOLET_M, lw=1.6))
apply_style(axL)
axL.set_title("Sıradan ağ: tek çıktı", color=COL_INK, fontsize=12.5, fontweight="bold")
axL.set_xlabel("girdi x", fontsize=10)
axL.set_ylabel("çıktı y", fontsize=10)
# ---- SAĞ: EBM — her cevaba enerji (çoklu minimum) ----
yy = np.linspace(-3.2, 3.2, 400)
data_pts = (-2.0, 0.0, 2.0)
F = energy_1d(yy, data_points=data_pts, width=0.35)
axR.plot(yy, F, color=COL_VIOLET, lw=2.6, zorder=3)
axR.fill_between(yy, F, F.max(), color=COL_BG, alpha=0.5, zorder=1)
# Minimumları gold yıldızla işaretle (= çoklu geçerli cevap)
for d in data_pts:
Fd = energy_1d(np.array([d]), data_points=data_pts, width=0.35)[0]
axR.plot([d], [Fd], marker="*", color=COL_GOLD, ms=20, zorder=5,
markeredgecolor=COL_GOLD_D, markeredgewidth=1.0)
axR.annotate("çoklu geçerli cevap\n(her çukur bir minimum)",
xy=(2.0, energy_1d(np.array([2.0]), data_points=data_pts, width=0.35)[0]),
xytext=(0.15, 0.55), fontsize=9.5, color=COL_TEXT,
arrowprops=dict(arrowstyle="-|>", color=COL_GOLD_D, lw=1.6))
apply_style(axR)
axR.set_title("EBM: her cevaba enerji", color=COL_INK, fontsize=12.5, fontweight="bold")
axR.set_xlabel("olası cevap y", fontsize=10)
axR.set_ylabel("enerji F(x, y)", fontsize=10)
fig.suptitle("Düşük enerji = uyumlu (x, y); EBM bir girdiye BİRDEN ÇOK cevap verebilir",
color=COL_INK, fontsize=11.5, y=1.005)
fig.tight_layout()
```
::: {.callout-tip title="Builder Notu — Örtük Fonksiyon = Calculus Akrabası"}
**Geriye (Hafta 1 + Calculus):** EBM, Hafta 1'de LeCun'un kısaca açtığı fikrin tam hâli. "Örtük fonksiyon" doğrudan Calculus'tan (bir denklemin örtük tanımladığı eğri). Olasılığa köprü: düşük enerji = yüksek olasılık (energy = −log p, sabite kadar — Stat 110).
**İleriye:** "Her cevaba skor" görüşü, modern üretken modellerin (enerji/score-based) ve LeCun'un dünya-modeli programının temelidir.
:::
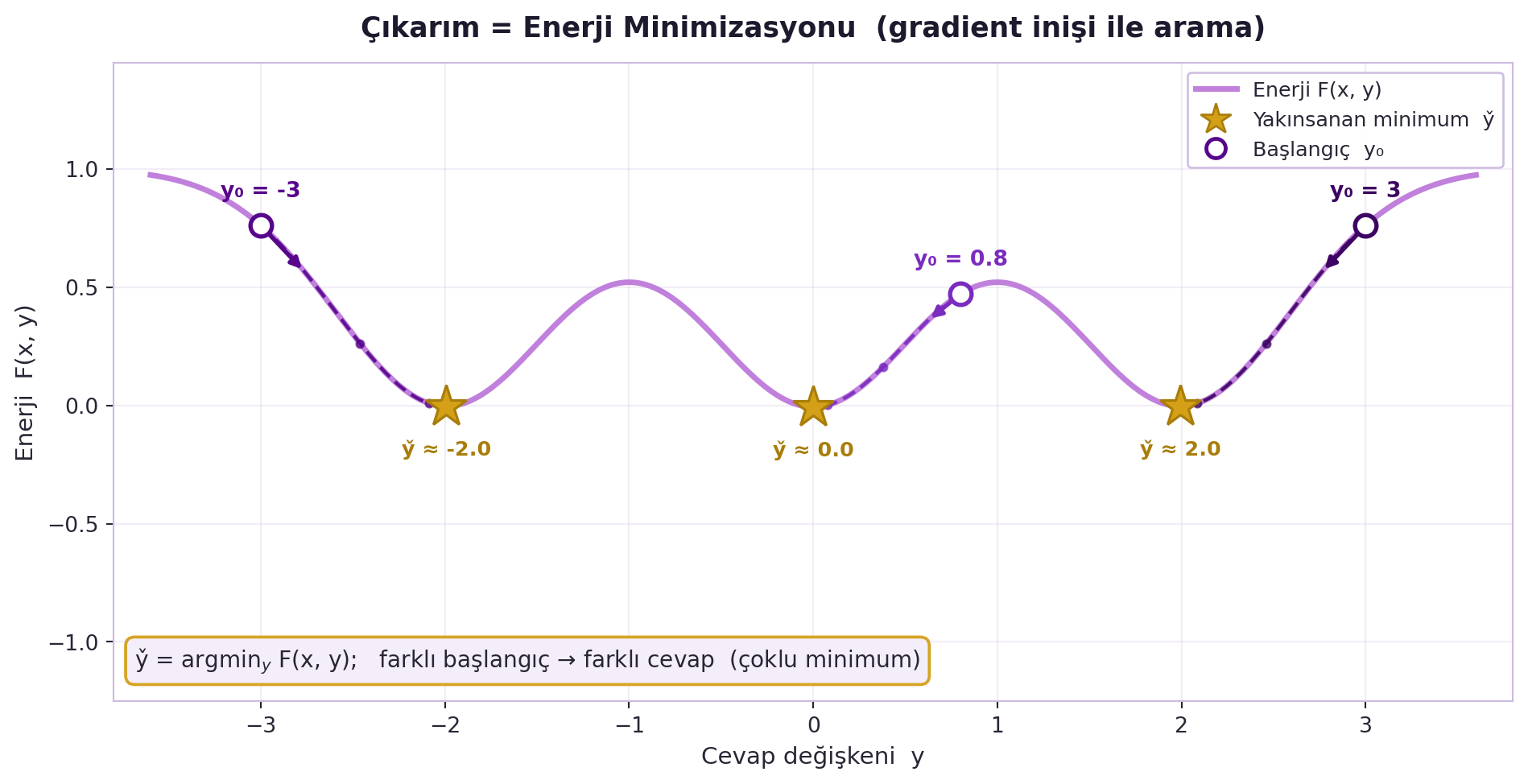
## (LeCun) Çıkarım = Enerji Minimizasyonu (Çoklu Cevap) {#sec-cikarim}
EBM'de **çıkarım (inference)** bir aramadır: verilen $x$ için, enerjiyi minimize eden $y$'yi bul.
$$
\check{y} = \arg\min_y F(x, y)
$$
Kritik fark: sonuç tek bir $y$ olmak zorunda değildir — enerji fonksiyonunun birden çok minimumu varsa, bir girdiye **birden çok geçerli cevap** verir (Hafta 6 Egzersiz 5'in cevabı: bir cümlenin birçok çevirisi). Çıkarım algoritması bu minimumu **gradient descent** ile arayabilir ($y$ yönünde enerjiyi aşağı in). @fig-inference-argmin tam bunu gösterir: aynı enerji eğrisi üzerinde üç farklı başlangıç noktası, `energy_1d_grad` ile en yakın çukura iner — farklı başlangıç, farklı geçerli cevap.
> "the inference procedure is going to find the Y that minimizes F(X,Y)... there might be multiple values." — LeCun, 8:06
LeCun ayrıca vurguluyor: standart çok-sınıflı sınıflandırma (Hafta 2) zaten örtük olarak EBM'dir — softmax skorları enerjidir, en yüksek skor = en düşük enerji.
```{python}
#| label: fig-inference-argmin
#| fig-cap: "Çıkarım = enerji minimizasyonu. Aynı enerji eğrisi F(x, y) üzerinde üç farklı başlangıç noktasından (y₀ = −3, 0.8, 3) gradient inişi (η = 0.05, ~150 adım) başlatılır; her yörünge nokta-çizgi ve yön okuyla en yakın yerel minimuma yakınsar (sırasıyla y̌ ≈ −2, 0, 2). Gold yıldızlar yakınsanan minimumları işaretler. Çoklu minimum = çoklu geçerli cevap: çıkarım y̌ = argmin_y F(x, y) başlangıca bağlıdır."
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(0)
# Bölüm 2: Çıkarım = enerji minimizasyonu (gradient ile arama).
# Aynı F(x,y), farklı başlangıç y₀ → farklı minimuma yakınsar (çoklu cevap).
data_points = (-2.0, 0.0, 2.0)
width = 0.35
# Enerji eğrisi (soluk violet)
y_grid = np.linspace(-3.6, 3.6, 600)
F_grid = energy_1d(y_grid, data_points, width)
fig, ax = plt.subplots(figsize=(10, 5.2))
apply_style(ax)
ax.plot(y_grid, F_grid, color=COL_VIOLET_SOFT, lw=2.6, alpha=0.85,
label="Enerji F(x, y)", zorder=2)
# Üç farklı başlangıç noktasından gradient descent yörüngesi
y0_list = [-3.0, 0.8, 3.0]
eta = 0.05
n_steps = 150
traj_colors = [COL_VIOLET, COL_VIOLET_M, COL_VIOLET_D]
for k, y0 in enumerate(y0_list):
ys = [y0]
y = y0
for _ in range(n_steps):
y = y - eta * float(energy_1d_grad(np.array([y]), data_points, width)[0])
ys.append(y)
ys = np.array(ys)
Fs = energy_1d(ys, data_points, width)
c = traj_colors[k]
# Yörünge: nokta-çizgi + her ~12. adımda işaret
ax.plot(ys, Fs, color=c, lw=1.6, ls=(0, (4, 2)), alpha=0.9, zorder=3)
ax.plot(ys[::12], Fs[::12], color=c, marker="o", ms=3.5, ls="none",
alpha=0.7, zorder=3)
# Başlangıç noktası (içi boş daire) + ok ile ilk yön
ax.plot(y0, float(energy_1d(np.array([y0]), data_points, width)[0]),
marker="o", ms=10, mfc=COL_WHITE, mec=c, mew=2.0, zorder=4)
ax.annotate("", xy=(ys[6], Fs[6]), xytext=(ys[0], Fs[0]),
arrowprops=dict(arrowstyle="-|>", color=c, lw=2.0,
shrinkA=6, shrinkB=2), zorder=4)
ax.text(y0, float(energy_1d(np.array([y0]), data_points, width)[0]) + 0.10,
f"y₀ = {y0:g}", ha="center", va="bottom", fontsize=10,
color=c, fontweight="bold", zorder=5)
# Varış minimumu: gold yıldız
ax.plot(ys[-1], Fs[-1], marker="*", ms=20, mfc=COL_GOLD, mec=COL_GOLD_D,
mew=1.2, zorder=6)
ax.text(ys[-1], Fs[-1] - 0.14, f"y̌ ≈ {ys[-1]:.1f}", ha="center", va="top",
fontsize=9.5, color=COL_GOLD_D, fontweight="bold", zorder=6)
# Yıldız + başlangıç için legend girişleri (tek seferlik)
ax.plot([], [], marker="*", ms=15, mfc=COL_GOLD, mec=COL_GOLD_D, mew=1.0,
ls="none", label="Yakınsanan minimum y̌", color=COL_GOLD)
ax.plot([], [], marker="o", ms=9, mfc=COL_WHITE, mec=COL_VIOLET, mew=1.8,
ls="none", label="Başlangıç y₀", color=COL_VIOLET)
ax.set_xlabel("Cevap değişkeni y", fontsize=11)
ax.set_ylabel("Enerji F(x, y)", fontsize=11)
ax.set_title("Çıkarım = Enerji Minimizasyonu (gradient inişi ile arama)",
fontsize=13, color=COL_INK, fontweight="bold", pad=12)
# Annotation kutusu — çoklu minimum vurgusu
ax.text(0.015, 0.04,
"y̌ = argmin$_y$ F(x, y); farklı başlangıç → farklı cevap (çoklu minimum)",
transform=ax.transAxes, fontsize=10.5, color=COL_TEXT, va="bottom",
ha="left",
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG, ec=COL_GOLD, lw=1.4,
alpha=0.95))
ax.set_xlim(-3.8, 3.8)
ax.set_ylim(-1.25, 1.45)
style_legend(ax, loc="upper right", fontsize=9.5)
plt.tight_layout()
```
::: {.callout-tip title="Builder Notu — Çıkarım = Arama"}
**Geriye (Hafta 2 + Calculus):** "En yüksek softmax = en düşük enerji" — Hafta 2 sınıflandırması bir EBM özel hâli. Gradient-tabanlı çıkarım, Calculus gradient descent'in *girdi/çıktı* (parametre değil) üzerinde uygulanmasıdır.
**İleriye:** "Çıkarım = optimizasyon" fikri, diffusion modelleri (Hafta 9 teaser) ve modern planlama/akıl yürütme yaklaşımlarının temelidir — cevabı hesaplamak yerine *ara*.
:::
## (LeCun) Enerji ≠ Kayıp; Enerji Fonksiyonunun Şekli {#sec-enerji-kayip}
Sık karışan bir nokta: **enerji, kayıp (loss) değildir.** Enerji **çıkarımda** kullanılır (hangi $y$?); kayıp ise **eğitimde** enerji fonksiyonunu doğru şekle sokmak için.
> "this energy function is not what we mean by [loss]... it's what we minimize during inference." — LeCun, 7:27
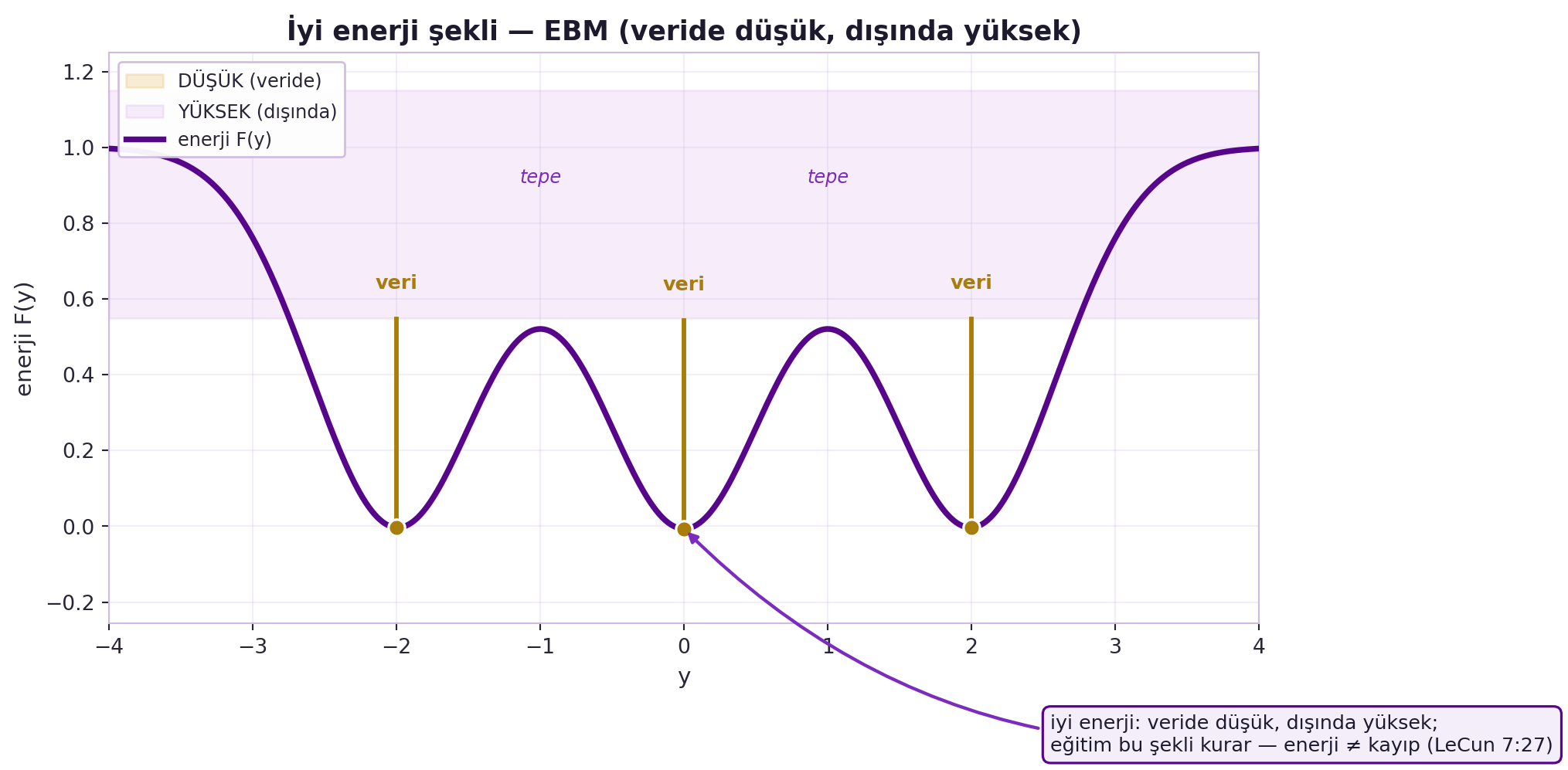
İyi bir enerji fonksiyonu şu şekle sahip olmalı: **veri noktalarında düşük, dışında yüksek**. Eğitim, $F$'yi bu şekle getirir — gerçek $(x, y)$ çiftlerine çukur (düşük enerji), uyumsuzlara tepe (yüksek enerji) koyar. @fig-energy-shape bu "iyi enerji şeklini" çiziyor: veri noktalarında ($y \in \{-2, 0, 2\}$) çukur, aralarda tepe. EBM eğitiminin tüm zorluğu budur: dışarıyı nasıl yükseltirsin? (Bu, Hafta 8'in contrastive vs non-contrastive ayrımının konusu.)
Grafiksel modeller (graphical models) de EBM'dir: enerji, alt-küme terimlerinin toplamı olarak ayrışır; bu yapıda verimli çıkarım algoritmaları vardır.
```{python}
#| label: fig-energy-shape
#| fig-cap: "İyi enerji şekli (EBM, Bölüm 3): `energy_1d` ile çizilen 1B enerji fonksiyonu F(y), veri noktalarında (y ∈ {−2, 0, 2}) düşük çukurlar, aralarda yüksek tepeler oluşturur. Gold dikey işaretler veriyi gösterir; eğitim bu şekli kurar — veride düşük, dışında yüksek. Enerji ≠ kayıp (LeCun 7:27)."
data_points = (-2.0, 0.0, 2.0)
y = np.linspace(-4, 4, 400)
F = energy_1d(y, data_points)
fig, ax = plt.subplots(figsize=(10, 5))
apply_style(ax)
# DÜŞÜK (veride) bölge: enerji eğrisinin altını çukurlarda gold ile dolgula
F_min = F.min()
ax.fill_between(y, F, F_min - 0.15, where=(F < -0.4), interpolate=True,
color=COL_GOLD, alpha=0.18, zorder=1, label="DÜŞÜK (veride)")
# YÜKSEK (dışında) bölge: tepe seviyelerini soluk violet ile vurgula
ax.axhspan(0.55, 1.15, color=COL_VIOLET_SOFT, alpha=0.12, zorder=0,
label="YÜKSEK (dışında)")
# Enerji eğrisi (violet)
ax.plot(y, F, color=COL_VIOLET, lw=2.8, zorder=4, label="enerji F(y)")
# Veri noktaları: dikey işaret + 'veri' etiketi, çukur diplerinde
for d in data_points:
Fd = float(energy_1d(np.array([d]), data_points)[0])
ax.plot([d, d], [Fd, Fd + 0.55], color=COL_GOLD_D, lw=2.2, zorder=5)
ax.plot(d, Fd, "o", color=COL_GOLD_D, ms=8, zorder=6,
markeredgecolor=COL_WHITE, markeredgewidth=1.2)
ax.text(d, Fd + 0.62, "veri", ha="center", va="bottom",
fontsize=9.5, color=COL_GOLD_D, fontweight="bold", zorder=6)
# Tepe (yüksek) bölgeleri — aralar yüksek
ax.text(-1.0, 0.92, "tepe", ha="center", va="center", fontsize=9,
color=COL_VIOLET_M, style="italic", zorder=6)
ax.text(1.0, 0.92, "tepe", ha="center", va="center", fontsize=9,
color=COL_VIOLET_M, style="italic", zorder=6)
# Annotation — enerji ≠ kayıp
ax.annotate(
"iyi enerji: veride düşük, dışında yüksek;\n"
"eğitim bu şekli kurar — enerji ≠ kayıp (LeCun 7:27)",
xy=(0.0, float(energy_1d(np.array([0.0]), data_points)[0])),
xytext=(2.55, -0.55),
fontsize=9.5, color=COL_INK,
ha="left", va="center",
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG, ec=COL_VIOLET, lw=1.2),
arrowprops=dict(arrowstyle="-|>", color=COL_VIOLET_M, lw=1.6,
connectionstyle="arc3,rad=-0.25"),
zorder=7,
)
ax.set_xlabel("y", fontsize=11)
ax.set_ylabel("enerji F(y)", fontsize=11)
ax.set_title("İyi enerji şekli — EBM (veride düşük, dışında yüksek)",
fontsize=13, color=COL_INK, fontweight="bold")
ax.set_xlim(-4, 4)
ax.set_ylim(F_min - 0.25, 1.25)
style_legend(ax, loc="upper left", fontsize=9)
```
::: {.callout-tip title="Builder Notu — Enerji ≠ Kayıp"}
**Geriye (Hafta 1):** "Veride düşük, dışında yüksek enerji" = Hafta 1'in manifold hipotezinin enerji diliyle ifadesi (veri manifoldu = enerji vadisi).
**İleriye:** "Dışarıyı yükseltme" sorunu, EBM eğitiminin merkezi zorluğudur — contrastive yöntemler (negatif örnek), score matching, ve modern SSL'in (Hafta 10) ayrımı buradan doğar.
:::
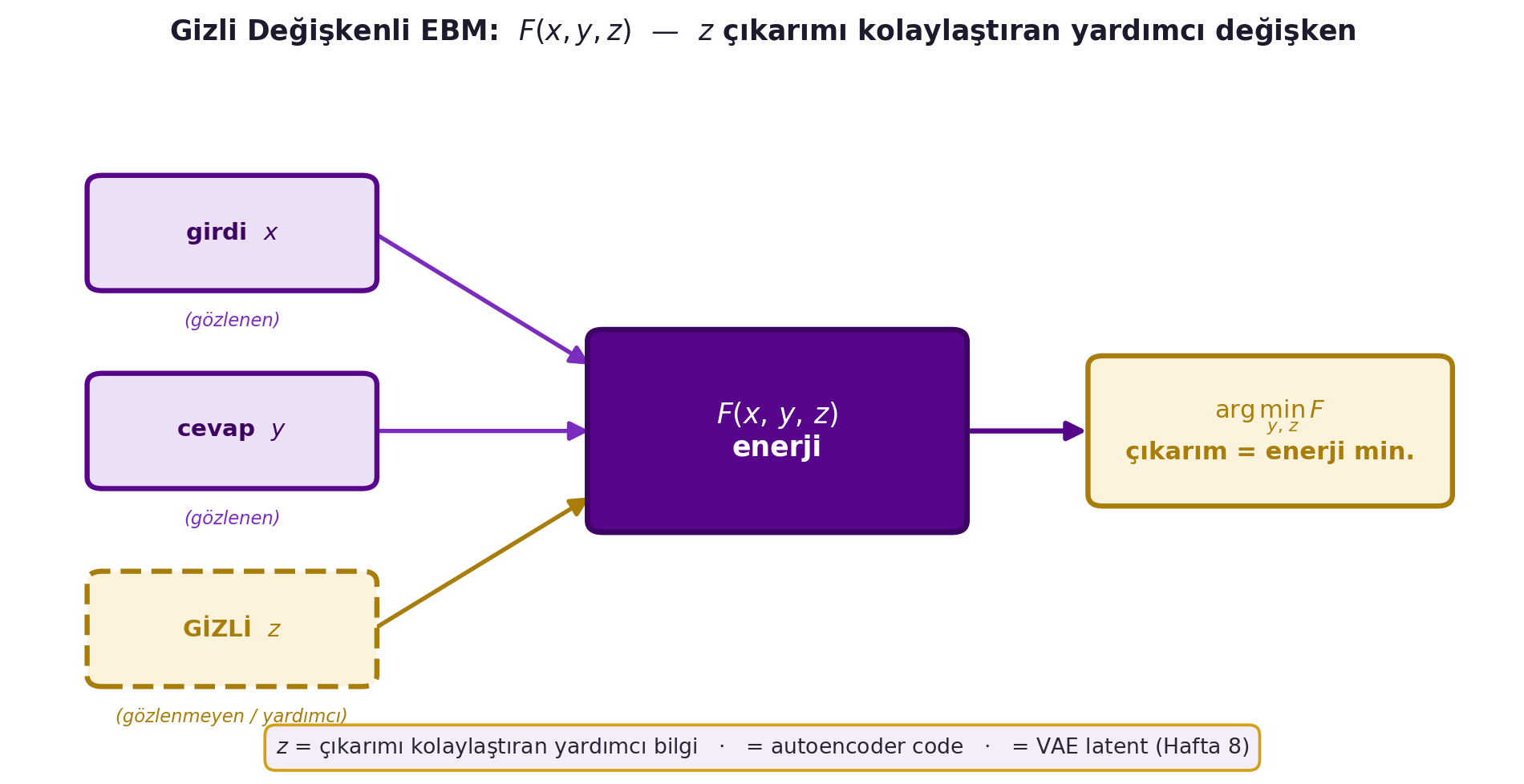
## (LeCun) Latent-Variable EBM {#sec-latent-ebm}
EBM'ler **gizli değişken (latent variable)** içerdiğinde gerçekten güçlenir. Bazen $y$'yi açıklamak için gözlenmeyen bir $z$ değişkeni gerekir; enerji artık $F(x, y, z)$ olur ve çıkarım hem $y$ hem $z$ üzerinden minimize edilir:
$$
\check{y} = \arg\min_{y,\, z} F(x, y, z)
$$
> "[latent-variable EBMs] are really where they start becoming interesting." — LeCun, 15:09
Gizli değişken, çıkarım problemini kolaylaştıran "yardımcı" bir bilgidir (örn. bir sahnedeki nesnenin hangi parçasının görünür olduğu). $z$'yi doğru seçersen $y$'yi bulmak kolaylaşır. @fig-latent-ebm bu şemayı gösterir: gözlenen $x$ ve $y$ ile gözlenmeyen $z$ birlikte $F(x, y, z)$'ye girer, çıkarım $\arg\min_{y,z} F$ olur. Bu, autoencoder'ın **code**'u (Canziani'nin latent space'i) ve VAE'nin (Hafta 8) latent $z$'siyle aynı fikirdir.
```{python}
#| label: fig-latent-ebm
#| fig-cap: "Gizli değişkenli enerji-temelli model (EBM). Gözlenen girdi $x$ ve cevap $y$ (violet) ile gözlenmeyen yardımcı gizli değişken $z$ (gold, kesikli kenar) birlikte $F(x,y,z)$ enerji fonksiyonuna girer; çıkarım $\\arg\\min_{y,z} F$ ile enerji minimizasyonudur. Gizli $z$, çıkarımı kolaylaştıran yardımcı bilgidir ve autoencoder code ile VAE latent (Hafta 8) ile aynı kavramdır."
fig, ax = plt.subplots(figsize=(10, 5.2))
ax.set_xlim(0, 10)
ax.set_ylim(0, 6)
ax.axis("off")
ax.set_title("Gizli Değişkenli EBM: $F(x, y, z)$ — $z$ çıkarımı kolaylaştıran yardımcı değişken",
color=COL_INK, fontsize=13, pad=14, fontweight="bold")
def add_box(x, y, w, h, label, *, fc, ec, lw=2.2, ls="solid", fontsize=11,
text_color=COL_TEXT, fontweight="normal"):
box = FancyBboxPatch(
(x - w / 2, y - h / 2), w, h,
boxstyle="round,pad=0.02,rounding_size=0.10",
fc=fc, ec=ec, lw=lw, linestyle=ls, zorder=2,
)
ax.add_patch(box)
ax.text(x, y, label, ha="center", va="center", fontsize=fontsize,
color=text_color, zorder=3, fontweight=fontweight)
return (x, y, w, h)
def arrow(p_from, p_to, *, color=COL_VIOLET_M, lw=2.0):
ax.add_patch(FancyArrowPatch(
p_from, p_to, arrowstyle="-|>", mutation_scale=18,
color=color, lw=lw, zorder=1,
shrinkA=2, shrinkB=2,
))
# --- Sol sütun: girdiler ---
bw, bh = 1.9, 0.95
x_in = 1.45
# girdi x (violet dolgulu — gözlenen)
add_box(x_in, 4.6, bw, bh, "girdi $x$",
fc="#ece0f7", ec=COL_VIOLET, lw=2.4, text_color=COL_VIOLET_D, fontweight="bold")
ax.text(x_in, 4.6 - bh / 2 - 0.28, "(gözlenen)", ha="center", va="center",
fontsize=8.5, color=COL_VIOLET_M, style="italic")
# cevap y (violet dolgulu — gözlenen)
add_box(x_in, 2.9, bw, bh, "cevap $y$",
fc="#ece0f7", ec=COL_VIOLET, lw=2.4, text_color=COL_VIOLET_D, fontweight="bold")
ax.text(x_in, 2.9 - bh / 2 - 0.28, "(gözlenen)", ha="center", va="center",
fontsize=8.5, color=COL_VIOLET_M, style="italic")
# gizli z (gold, kesikli kenar — gözlenmeyen / yardımcı)
add_box(x_in, 1.2, bw, bh, "GİZLİ $z$",
fc="#fbf3dc", ec=COL_GOLD_D, lw=2.4, ls=(0, (4, 2)),
text_color=COL_GOLD_D, fontweight="bold")
ax.text(x_in, 1.2 - bh / 2 - 0.28, "(gözlenmeyen / yardımcı)", ha="center", va="center",
fontsize=8.5, color=COL_GOLD_D, style="italic")
# --- Orta: enerji kutusu F(x,y,z) ---
x_F = 5.1
add_box(x_F, 2.9, 2.5, 1.7, "$F(x,\\, y,\\, z)$\nenerji",
fc=COL_VIOLET, ec=COL_VIOLET_D, lw=2.6, fontsize=13,
text_color=COL_WHITE, fontweight="bold")
# oklar: her girdi → F
arrow((x_in + bw / 2, 4.6), (x_F - 1.25 + 0.02, 2.9 + 0.55), color=COL_VIOLET_M, lw=2.0)
arrow((x_in + bw / 2, 2.9), (x_F - 1.25 + 0.02, 2.9), color=COL_VIOLET_M, lw=2.0)
arrow((x_in + bw / 2, 1.2), (x_F - 1.25 + 0.02, 2.9 - 0.55), color=COL_GOLD_D, lw=2.0)
# --- Sağ: argmin_{y,z} ---
x_arg = 8.4
add_box(x_arg, 2.9, 2.4, 1.25,
"$\\arg\\min_{y,\\,z}\\, F$\nçıkarım = enerji min.",
fc="#fbf3dc", ec=COL_GOLD_D, lw=2.4, fontsize=11.5,
text_color=COL_GOLD_D, fontweight="bold")
arrow((x_F + 1.25, 2.9), (x_arg - 1.2, 2.9), color=COL_VIOLET, lw=2.4)
# --- Alt annotation kutusu ---
ann = ("$z$ = çıkarımı kolaylaştıran yardımcı bilgi · = autoencoder code ·"
" = VAE latent (Hafta 8)")
ax.text(5.0, 0.18, ann, ha="center", va="center", fontsize=10,
color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.5", fc=COL_BG, ec=COL_GOLD, lw=1.4))
plt.tight_layout()
```
::: {.callout-tip title="Builder Notu — Latent = Yardımcı Bilgi"}
**Geriye (Stat 110):** Latent değişken = gözlenmeyen rastgele değişken; üzerinden minimize/marjinalize etmek Stat 110'un latent-değişken modellerinin (mixture, EM) çekirdeğidir.
**İleriye:** Latent $z$ → autoencoder code (bu hafta), VAE latent (Hafta 8), ve tüm üretken modellerin gizli uzayı.
:::
## Geçiş: LeCun'dan Canziani'ye {#sec-gecis-d7}
LeCun EBM'nin soyut çerçevesini kurdu: enerji = uyumluluk skoru, çıkarım = minimizasyon, latent değişkenler. Şimdi **Canziani** bunun en somut örneğini gösteriyor: **autoencoder**. Bir autoencoder, veriyi bir code'a sıkıştırıp geri kurar; ve Canziani'nin vurgulayacağı gibi, "yalnızca veri manifoldu üzerini iyi kurmak" = "manifold üzerine düşük enerji koymak". Canziani açıkça LeCun'a atıf yapıyor: "this is stuff Yann was covering yesterday" — yani autoencoder, dünün EBM'sinin pratik hâli.
## (Canziani) Autoencoder: Encoder → Code → Decoder {#sec-autoencoder}
Canziani autoencoder'ı tanıtıyor: bir **encoder** girdiyi küçük bir **code**'a (latent temsil) sıkıştırır; bir **decoder** code'dan girdiyi yeniden kurar. İlk akla gelen kullanım **sıkıştırma**dır (code girdiden küçükse). Ama Canziani uyarıyor:
> "[compression] is just one type, and it's kind of not the proper way of thinking about these guys." — Canziani, 19:28
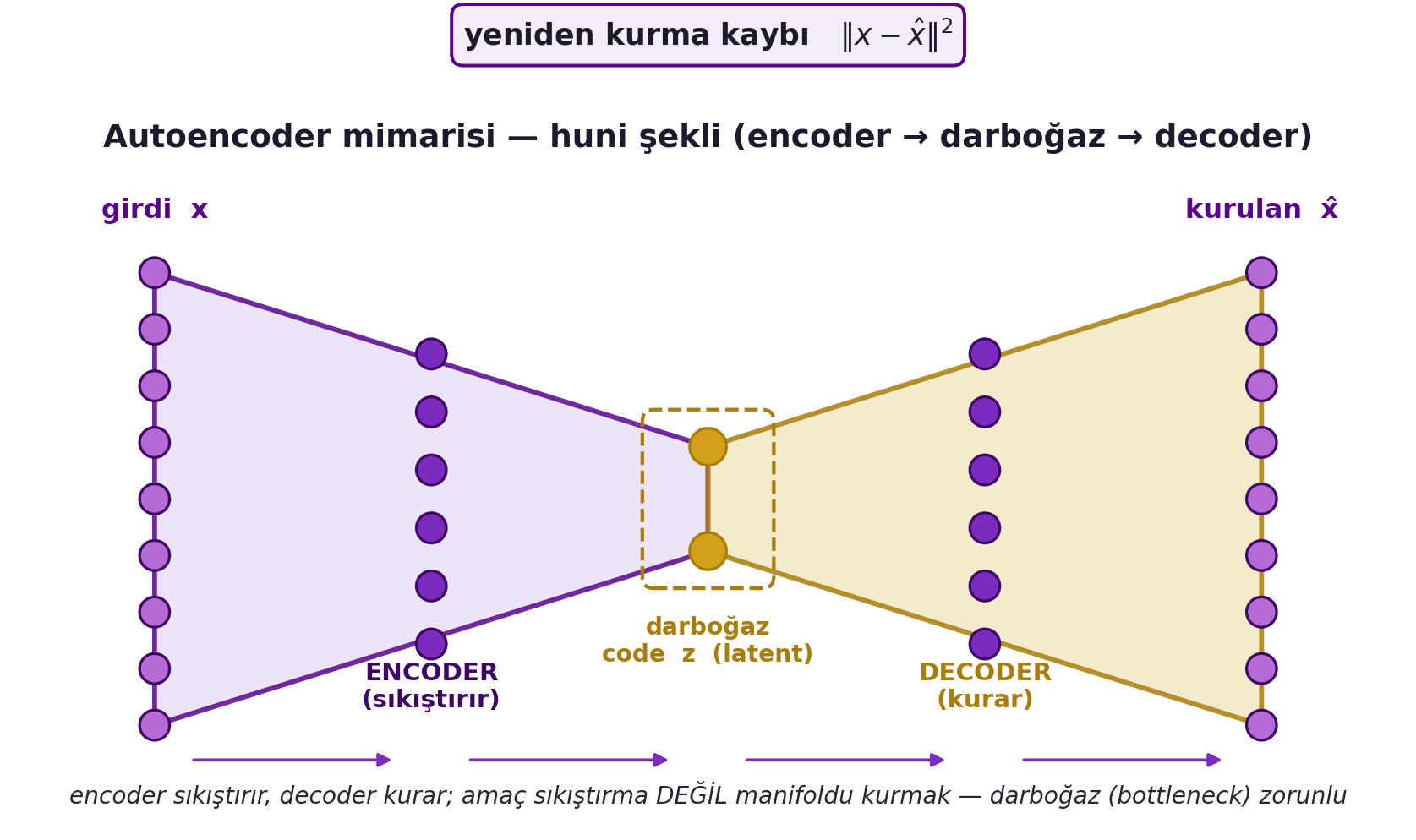
Latent space anlamlıdır: iki girdinin code'ları arasında yürürsen (interpolation), aradaki noktalar anlamlı görüntülere çözülür — yani latent uzay verinin **semantiğini** yakalar. @fig-autoencoder mimariyi huni şeklinde gösterir: geniş girdi $x$, daralan encoder, ortadaki gold darboğazda küçük code $z$, genişleyen decoder, kurulan $\hat{x}$ — ve üstte yeniden kurma kaybı $\lVert x - \hat{x} \rVert^2$.
```{python}
#| label: fig-autoencoder
#| fig-cap: "Autoencoder mimarisi (huni şekli): geniş girdi x, daralan encoder trapezi ile sıkıştırılır; ortadaki gold darboğazda küçük code/latent z kalır; genişleyen decoder bunu kurulan x̂'e açar. Üstteki yay yeniden kurma kaybını ‖x−x̂‖² gösterir. Amaç sıkıştırma değil veri manifoldunu kurmaktır — darboğaz (bottleneck) bu yüzden zorunludur: ağı, girdinin tüm bilgisini değil yalnızca manifold üzerindeki gerçek serbestlik derecelerini kodlamaya zorlar."
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch, Polygon, Circle
np.random.seed(0)
fig, ax = plt.subplots(figsize=(11, 5.2))
ax.set_xlim(0, 12)
ax.set_ylim(-0.4, 5.2)
ax.axis("off")
# Yardımcı: dikey nöron kolonu (ortada yc, yarı-yükseklik half_h, n nöron)
def neuron_column(xc, yc, half_h, n, color, ec, r=0.13, z=3):
ys = np.linspace(yc - half_h, yc + half_h, n)
for y in ys:
ax.add_patch(Circle((xc, y), r, fc=color, ec=ec, lw=1.2, zorder=z))
return ys
YC = 2.4 # dikey orta
# Geometri: girdi geniş -> encoder daralan -> darboğaz dar -> decoder genişleyen -> çıktı geniş
x_in, x_enc, x_code, x_dec, x_out = 1.2, 3.6, 6.0, 8.4, 10.8
H_WIDE = 1.95 # geniş kolon yarı-yüksekliği
H_CODE = 0.45 # darboğaz yarı-yüksekliği
# ENCODER trapezi (daralan) — violet
ax.add_patch(Polygon([
(x_in, YC - H_WIDE), (x_code, YC - H_CODE),
(x_code, YC + H_CODE), (x_in, YC + H_WIDE),
], closed=True, fc="#ece0f7", ec=COL_VIOLET, lw=2.2, zorder=1, alpha=0.85))
# DECODER trapezi (genişleyen) — gold
ax.add_patch(Polygon([
(x_code, YC - H_CODE), (x_out, YC - H_WIDE),
(x_out, YC + H_WIDE), (x_code, YC + H_CODE),
], closed=True, fc="#f3e8c4", ec=COL_GOLD_D, lw=2.2, zorder=1, alpha=0.85))
# Nöron kolonları
neuron_column(x_in, YC, H_WIDE, 9, COL_VIOLET_SOFT, COL_VIOLET_D) # girdi x
neuron_column(x_enc, YC, 1.25, 6, COL_VIOLET_M, COL_VIOLET_D) # encoder ara
neuron_column(x_code, YC, H_CODE, 2, COL_GOLD, COL_GOLD_D, r=0.16) # code z (darboğaz)
neuron_column(x_dec, YC, 1.25, 6, COL_VIOLET_M, COL_VIOLET_D) # decoder ara
neuron_column(x_out, YC, H_WIDE, 9, COL_VIOLET_SOFT, COL_VIOLET_D) # çıktı x̂
# Modül etiketleri (Türkçe)
ax.text((x_in + x_code) / 2, YC - 1.62, "ENCODER\n(sıkıştırır)", ha="center", va="center",
fontsize=11, fontweight="bold", color=COL_VIOLET_D, zorder=4)
ax.text((x_code + x_out) / 2, YC - 1.62, "DECODER\n(kurar)", ha="center", va="center",
fontsize=11, fontweight="bold", color=COL_GOLD_D, zorder=4)
# Girdi / çıktı etiketleri
ax.text(x_in, YC + H_WIDE + 0.42, "girdi x", ha="center", va="bottom",
fontsize=12, fontweight="bold", color=COL_VIOLET, zorder=4)
ax.text(x_out, YC + H_WIDE + 0.42, "kurulan x̂", ha="center", va="bottom",
fontsize=12, fontweight="bold", color=COL_VIOLET, zorder=4)
# Darboğaz (code / latent z) vurgu kutusu + etiket
ax.add_patch(FancyBboxPatch(
(x_code - 0.55, YC - H_CODE - 0.30), 1.10, 2 * H_CODE + 0.60,
boxstyle="round,pad=0.02,rounding_size=0.10",
fc="none", ec=COL_GOLD_D, lw=1.6, ls="--", zorder=2))
ax.text(x_code, YC - H_CODE - 0.55, "darboğaz\ncode z (latent)", ha="center", va="top",
fontsize=10.5, fontweight="bold", color=COL_GOLD_D, zorder=4)
# Yeniden kurma kaybı: ||x - x̂||^2 (girdi ile çıktı arası, üstte yay)
ax.add_patch(FancyArrowPatch(
(x_in, YC + H_WIDE + 0.95), (x_out, YC + H_WIDE + 0.95),
connectionstyle="arc3,rad=-0.28", arrowstyle="<|-|>",
mutation_scale=16, color=COL_TEXT, lw=1.8, zorder=4))
ax.text((x_in + x_out) / 2, YC + H_WIDE + 2.05,
r"yeniden kurma kaybı $\|x - \hat{x}\|^2$",
ha="center", va="center", fontsize=13, fontweight="bold",
color=COL_INK, zorder=5,
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG, ec=COL_VIOLET, lw=1.5))
# Akış okları (katmanlar arası)
for xa, xb in [(x_in, x_enc), (x_enc, x_code), (x_code, x_dec), (x_dec, x_out)]:
ax.add_patch(FancyArrowPatch(
(xa + 0.30, YC - H_WIDE - 0.30), (xb - 0.30, YC - H_WIDE - 0.30),
arrowstyle="-|>", mutation_scale=12, color=COL_VIOLET_M, lw=1.4, zorder=0))
# Alt mesaj (öğretim cümlesi)
ax.text(6.0, -0.15,
"encoder sıkıştırır, decoder kurar; amaç sıkıştırma DEĞİL manifoldu kurmak — darboğaz (bottleneck) zorunlu",
ha="center", va="center", fontsize=10.5, style="italic", color=COL_TEXT, zorder=4)
ax.set_title("Autoencoder mimarisi — huni şekli (encoder → darboğaz → decoder)",
fontsize=14, fontweight="bold", color=COL_INK, pad=12)
plt.show()
```
::: {.callout-tip title="Builder Notu — Code = Latent z"}
**Geriye (Hafta 4):** Encoder = boyut indiren afin+nonlinearite zinciri; code = düşük-boyutlu temsil (Hafta 4 SVD/boyut indirgeme akrabası). Latent interpolation, Hafta 1'in manifold sezgisinin pratiği.
**İleriye:** Latent space interpolation, üretken modellerin (VAE/GAN, Hafta 8-9) "latent traversal" demolarının temelidir.
:::
## (Canziani) Manifold: "Yalnızca Üzerini Yeniden Kur" {#sec-manifold-d7}
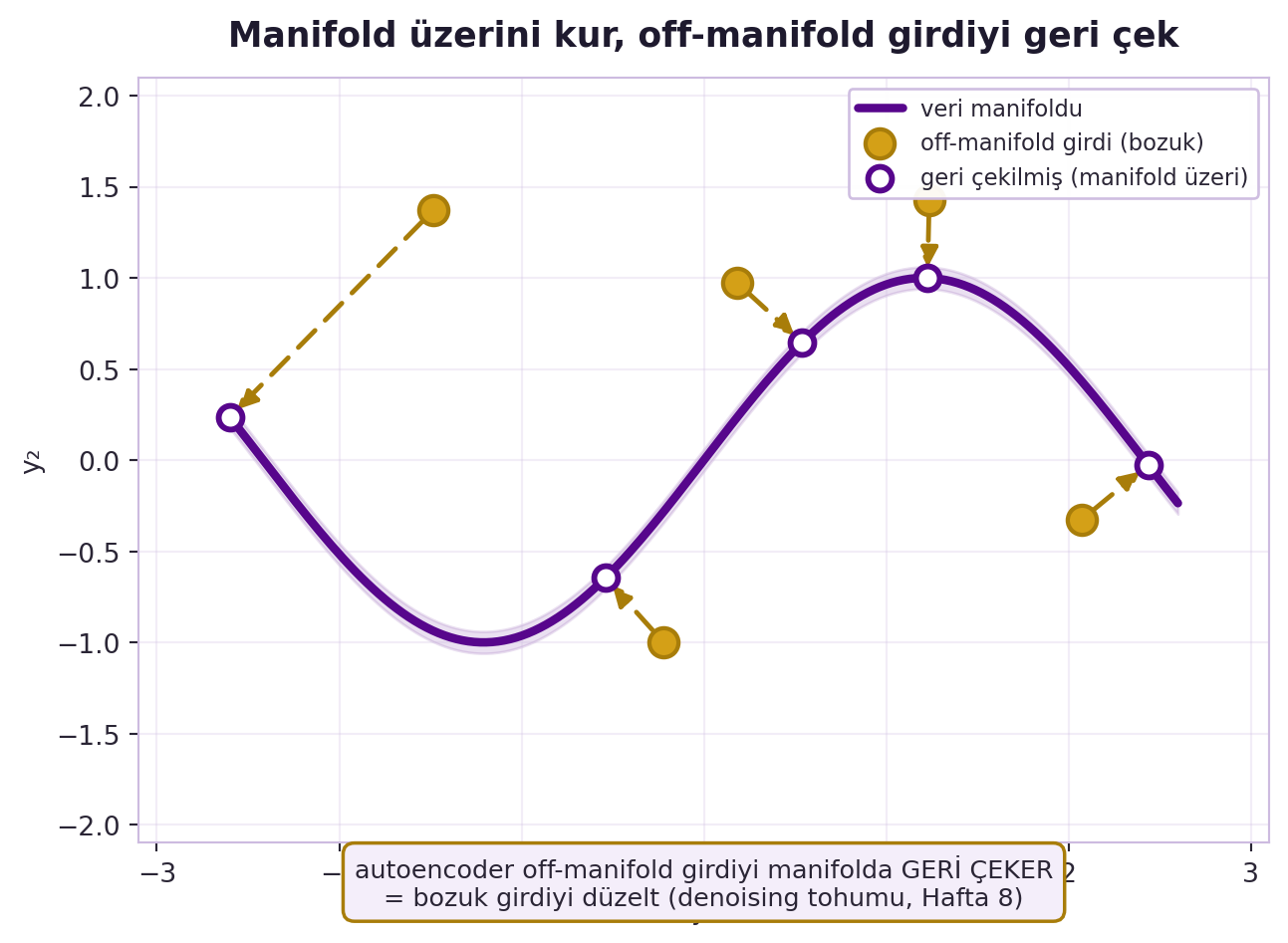
Canziani autoencoder'ın *doğru* amacını veriyor: sıkıştırma değil, **veri manifoldu üzerini yeniden kurmak**. Gerçek veri (yüzler, sahneler) yüksek-boyutlu uzayın küçük bir manifoldunda yaşar (Hafta 1). İyi bir autoencoder yalnızca bu manifold üzerindeki noktaları iyi kurar; manifold dışındaki bir noktayı verirsen, onu manifolda **geri çeker**.
> "the task of these autoencoders [is] only to reconstruct a small subset [that lives] on the manifold." — Canziani, 20:06
Örnek: bir yüze yama (patch) koyarsan görüntü manifolddan çıkar; manifold-üzeri kurma yapan autoencoder, yamayı kaldırıp en yakın gerçek yüzü kurar. @fig-manifold-reconstruct bunu somutlaştırır: violet eğri veri manifoldu, gold noktalar manifold dışına dağılmış bozuk girdiler, kesikli gold oklar her birini en yakın manifold noktasına geri çeker. Bu, "bozuk girdiyi düzelt" yeteneğidir (denoising'in tohumu, Hafta 8).
```{python}
#| label: fig-manifold-reconstruct
#| fig-cap: "Veri manifoldu (sinüs yayı, kalın violet eğri) ve manifold dışına dağılmış bozuk girdiler (gold). Her off-manifold nokta, en yakın manifold noktasına kesikli gold okla geri çekilir (project_to_manifold); varış noktaları (içi boş violet daireler) tam olarak manifold üzerine düşer. Autoencoder reconstruction sezgisi: off-manifold girdiyi manifolda geri çekmek = bozuk girdiyi düzeltmek, Hafta 8'deki denoising autoencoder'ın tohumu."
# Veri manifoldu: sinüs yayı (Hafta 1 manifold hipotezi)
M = make_manifold_curve(160)
# np.random.seed(0) ile manifold dışına dağılmış off-manifold noktalar
seed_pts = np.array([[-1.8, 1.3], [-0.4, -1.4], [0.9, 1.6],
[1.9, -0.3], [0.2, 0.9]])
off = seed_pts + np.random.normal(0, 0.18, seed_pts.shape)
# Autoencoder reconstruction: en yakın manifold noktasına geri çek
proj = project_to_manifold(off, M)
fig, ax = plt.subplots(figsize=(9.5, 5.2))
apply_style(ax)
# Veri manifoldu (kalın violet eğri)
ax.plot(M[:, 0], M[:, 1], color=COL_VIOLET, lw=3.2, zorder=2,
solid_capstyle="round", label="veri manifoldu")
ax.fill_between(M[:, 0], M[:, 1] - 0.06, M[:, 1] + 0.06,
color=COL_VIOLET, alpha=0.12, zorder=1)
# Geri çekme okları (off-manifold → manifold, kesikli ok)
for o, p in zip(off, proj):
ax.annotate("", xy=(p[0], p[1]), xytext=(o[0], o[1]),
arrowprops=dict(arrowstyle="-|>", color=COL_GOLD_D,
lw=1.8, ls=(0, (5, 3)),
mutation_scale=15,
shrinkA=6, shrinkB=4), zorder=3)
# Off-manifold noktalar (gold)
ax.scatter(off[:, 0], off[:, 1], s=120, c=COL_GOLD, edgecolors=COL_GOLD_D,
linewidths=1.6, zorder=5, label="off-manifold girdi (bozuk)")
# Varış noktaları manifold üzerinde (violet, manifold rengiyle uyumlu)
ax.scatter(proj[:, 0], proj[:, 1], s=80, c=COL_WHITE, edgecolors=COL_VIOLET,
linewidths=2.2, zorder=6, label="geri çekilmiş (manifold üzeri)")
ax.set_xlabel("y₁")
ax.set_ylabel("y₂")
ax.set_title("Manifold üzerini kur, off-manifold girdiyi geri çek",
color=COL_INK, fontsize=13, fontweight="bold", pad=12)
ax.set_aspect("equal", adjustable="box")
ax.set_xlim(M[:, 0].min() - 0.5, M[:, 0].max() + 0.5)
ax.set_ylim(-2.1, 2.1)
ax.annotate("autoencoder off-manifold girdiyi manifolda GERİ ÇEKER\n"
"= bozuk girdiyi düzelt (denoising tohumu, Hafta 8)",
xy=(0.5, -0.015), xycoords="axes fraction",
ha="center", va="top", fontsize=9.5, color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.45", fc=COL_BG,
ec=COL_GOLD_D, lw=1.3))
style_legend(ax, loc="upper right", fontsize=8.5)
```
::: {.callout-tip title="Builder Notu — Manifoldu Öğren"}
**Geriye (Hafta 1):** Bu, Hafta 1'in manifold hipotezinin doğrudan uygulamasıdır: anlamlı veri minik bir manifoldda; autoencoder o manifoldu öğrenir.
**İleriye:** "Off-manifold → manifolda geri çek" = denoising autoencoder (Hafta 8) ve diffusion modellerinin (Hafta 9) çekirdek sezgisi.
:::
## (Canziani) Reconstruction Loss, Bottleneck ve Autoencoder = EBM {#sec-recon-ebm}
Autoencoder bir **yeniden kurma kaybı (reconstruction loss)** ile eğitilir — girdi ile kurulan çıktı arasındaki fark:
$$
\mathcal{L} = \lVert x - \text{dec}(\text{enc}(x)) \rVert^2
$$
Manifoldu öğrenmeye zorlamak için bir **bilgi darboğazı (bottleneck)** gerekir. İki yol: **undercomplete** (code girdiden küçük → zorunlu sıkıştırma) veya **overcomplete** (code büyük ama ek bir kısıt/düzenlileştirme ile darboğaz yaratılır). Darboğaz olmadan autoencoder her şeyi ezberler (kimlik fonksiyonu) ve manifoldu öğrenmez.
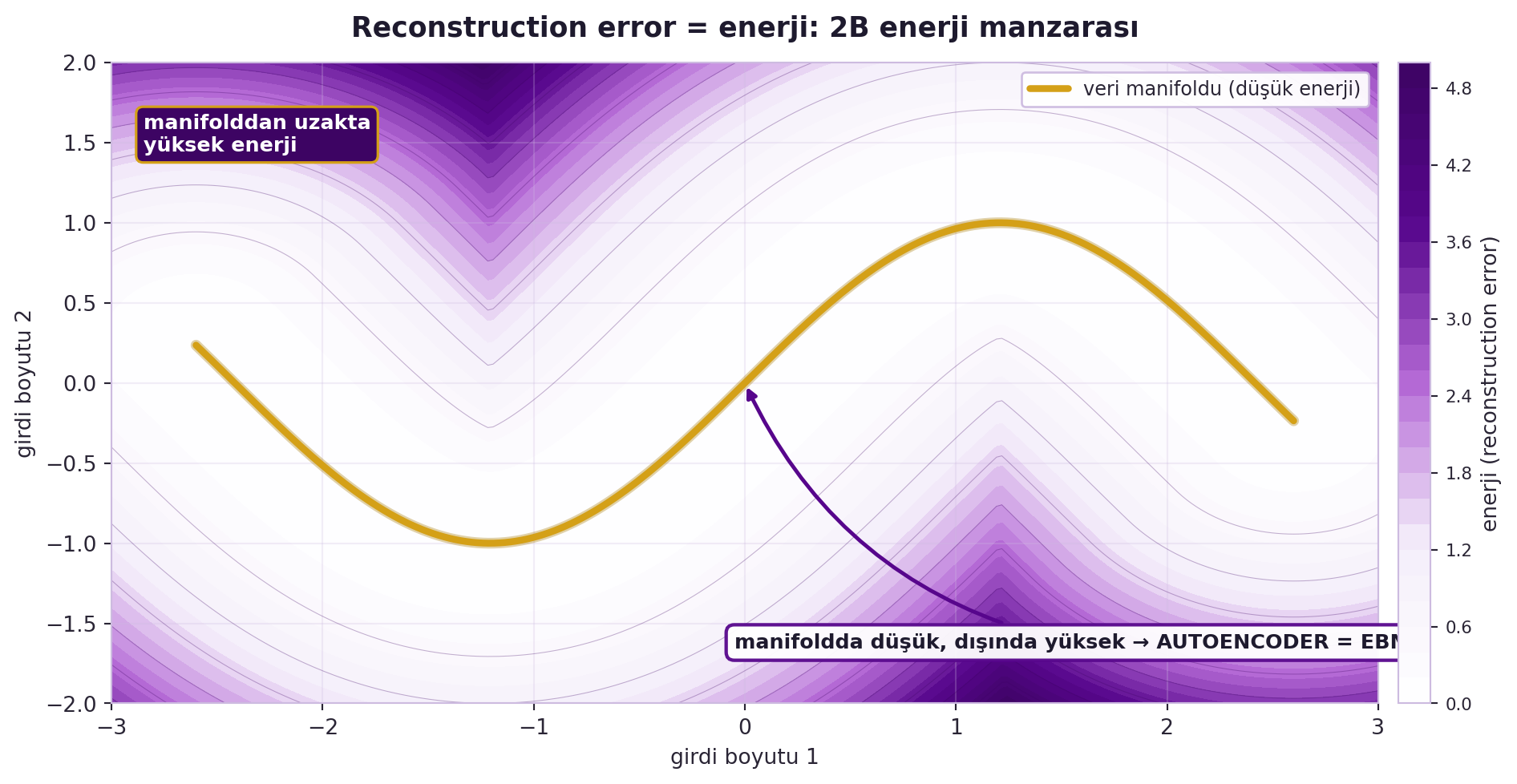
Ve işte EBM köprüsü: reconstruction loss bir **enerjidir**. Manifold üzerindeki noktalarda düşük (iyi kurulur), dışında yüksek (kötü kurulur). @fig-autoencoder-ebm bunu 2B bir enerji manzarası olarak gösterir: manifold (gold çizgi) düşük-enerji vadi tabanını oluşturur, uzaklaştıkça enerji yükselir. Yani autoencoder, LeCun'un dünkü EBM'sinin tam bir örneğidir — enerji = yeniden kurma hatası.
```{python}
#| label: fig-autoencoder-ebm
#| fig-cap: "Reconstruction error = enerji: bir autoencoder'ın öğrendiği veri manifoldu (sinüs yayı, gold çizgi) düşük-enerji vadi tabanını oluşturur; 2B girdi uzayında her noktanın manifolda en yakın kare mesafesi (reconstruction error) bir enerji manzarası tanımlar — manifoldda düşük, uzaklaştıkça yüksek. Bu yüzden autoencoder bir Enerji-Tabanlı Model (EBM) olarak okunabilir."
from matplotlib.colors import LinearSegmentedColormap
# Veri manifoldu: sinüs yayı üzerinde noktalar (autoencoder'ın "öğrendiği" alt-uzay)
M = make_manifold_curve(200)
# Enerji manzarası ızgarası: -3..3 × -2..2
gx = np.linspace(-3.0, 3.0, 240)
gy = np.linspace(-2.0, 2.0, 180)
xx, yy = np.meshgrid(gx, gy)
# Her ızgara noktası için manifolda EN YAKIN mesafe² = reconstruction error = enerji
# Vektörize: grid [G,2], manifold [N,2] → mesafe matrisi [G,N], min² al
grid = np.column_stack([xx.ravel(), yy.ravel()]) # [G,2]
diff = grid[:, None, :] - M[None, :, :] # [G,N,2]
d2 = (diff ** 2).sum(axis=2) # [G,N] kare mesafeler
E = d2.min(axis=1).reshape(xx.shape) # [H,W] en yakın mesafe² = enerji
# Tema renk haritası: açık (düşük enerji, vadi) → violet (yüksek enerji)
cmap = LinearSegmentedColormap.from_list(
"ebm_violet", [COL_WHITE, COL_BG, COL_VIOLET_SOFT, COL_VIOLET, COL_VIOLET_D]
)
fig, ax = plt.subplots(figsize=(10, 5.2))
cf = ax.contourf(xx, yy, E, levels=24, cmap=cmap)
ax.contour(xx, yy, E, levels=10, colors=COL_VIOLET_D, linewidths=0.4, alpha=0.30)
# Manifold eğrisi (düşük-enerji vadi tabanı) — gold çizgi
ax.plot(M[:, 0], M[:, 1], color=COL_GOLD, lw=3.2, zorder=5,
solid_capstyle="round", label="veri manifoldu (düşük enerji)")
ax.plot(M[:, 0], M[:, 1], color=COL_GOLD_D, lw=5.0, zorder=4, alpha=0.35,
solid_capstyle="round")
# Colorbar
cb = fig.colorbar(cf, ax=ax, pad=0.015, fraction=0.046)
cb.set_label("enerji (reconstruction error)", color=COL_TEXT, fontsize=10)
cb.ax.tick_params(colors=COL_TEXT, labelsize=8)
cb.outline.set_edgecolor(COL_GRID)
# Açıklama notu — manifoldun dışındaki yüksek-enerji bölgeyi işaretle
ax.annotate(
"manifolddan uzakta\nyüksek enerji",
xy=(-2.3, 1.55), xytext=(-2.85, 1.55),
ha="left", va="center", fontsize=9.5, color=COL_WHITE, weight="bold",
bbox=dict(boxstyle="round,pad=0.35", fc=COL_VIOLET_D, ec=COL_GOLD, lw=1.2),
)
ax.annotate(
"manifoldda düşük, dışında yüksek → AUTOENCODER = EBM",
xy=(0.0, np.sin(0.0)), xytext=(-0.05, -1.62),
ha="left", va="center", fontsize=9.5, color=COL_INK, weight="bold",
bbox=dict(boxstyle="round,pad=0.4", fc=COL_WHITE, ec=COL_VIOLET, lw=1.6, alpha=0.95),
arrowprops=dict(arrowstyle="-|>", color=COL_VIOLET, lw=1.8,
connectionstyle="arc3,rad=-0.25"),
)
apply_style(ax)
ax.set_xlim(-3.0, 3.0)
ax.set_ylim(-2.0, 2.0)
ax.set_xlabel("girdi boyutu 1", fontsize=10)
ax.set_ylabel("girdi boyutu 2", fontsize=10)
ax.set_title("Reconstruction error = enerji: 2B enerji manzarası",
fontsize=13, color=COL_INK, weight="bold", pad=12)
style_legend(ax, loc="upper right", fontsize=9)
fig.tight_layout()
```
::: {.callout-tip title="Builder Notu — Reconstruction = Enerji"}
**Geriye (LeCun bu hafta):** Reconstruction error = enerji fonksiyonu: veri manifoldunda düşük, dışında yüksek (LeCun Bölüm 3'teki "iyi enerji şekli"). Autoencoder, EBM'nin en sezgisel hâli.
**İleriye:** Bottleneck → VAE'nin olasılıksal latent'i (Hafta 8); reconstruction = enerji → score-based/diffusion modelleri (Hafta 9).
:::
## Bu Dersin Özeti {#sec-ozet-d7}
1. **EBM = her cevaba enerji** (uyumlu çift düşük, uyumsuz yüksek); olasılıksal modeller özel hâli.
2. **Çıkarım = enerji minimizasyonu:** $\check{y} = \arg\min_y F(x,y)$; birden çok cevap olabilir (örtük fonksiyon, gradient ile aranır).
3. **Enerji ≠ kayıp:** enerji çıkarımda; kayıp eğitimde enerji şeklini (veride düşük, dışında yüksek) kurmak için.
4. **Latent-variable EBM:** $F(x,y,z)$, $y$ ve $z$ üzerinden minimize; $z$ çıkarımı kolaylaştırır.
5. **Autoencoder (Canziani):** encoder→code→decoder; amaç sıkıştırma değil, veri manifoldu üzerini kurmak; off-manifold geri çekilir.
6. **Autoencoder = EBM:** reconstruction loss = enerji (manifoldda düşük, dışında yüksek); bottleneck (under/overcomplete) manifoldu öğrenmeye zorlar.
::: {.callout-important title="Tek Bir Cümle"}
Enerji-tabanlı model, her $(x, y)$ çiftine bir uyumluluk skoru (enerji) atayıp çıkarımı $\arg\min_y F(x,y)$ ile yapar — tek çıktı zorunluluğunu kaldırır; autoencoder bunun en somut hâlidir: veri manifoldu üzerine düşük enerji (iyi yeniden kurma) koyar, dışını manifolda geri çeker.
:::
## Kontrol Soruları {#sec-kontrol-d7}
::: {.callout-note collapse="true" title="Soru 1: EBM çıkarımı sıradan bir ağdan nasıl farklıdır? Çıkarım denklemini yaz. Neden \"birden çok cevap\" mümkündür?"}
**Cevap:** Sıradan ağ bir girdiye **tek** çıktı hesaplar (ileri geçiş). EBM ise her $(x, y)$ çiftine bir enerji $F(x, y)$ atar ve çıkarımı bir **arama/minimizasyon** yapar:
$$
\check{y} = \arg\min_y F(x, y)
$$
Enerji fonksiyonunun **birden çok minimumu** varsa, bir girdiye birden çok geçerli cevap verir (örn. bir cümlenin birçok çevirisi). Çıkarım, bu minimumu gradient descent ile ($y$ yönünde) arayabilir. Düşük enerji = uyumlu $(x, y)$; yüksek = uyumsuz (LeCun 7:52).
:::
::: {.callout-note collapse="true" title="Soru 2: \"Enerji ≠ kayıp\" ne demek? İyi bir enerji fonksiyonunun şekli nasıldır?"}
**Cevap:** **Enerji çıkarımda** kullanılır (verilen $x$ için hangi $y$?); **kayıp eğitimde** kullanılır (enerji fonksiyonunu doğru şekle sokmak için) — ikisi farklı şeyler (LeCun 7:27). İyi bir enerji fonksiyonu **veri noktalarında düşük (vadi), dışında yüksek (tepe)** olmalıdır. Eğitim, $F$'yi bu şekle getirir: gerçek çiftlere çukur, uyumsuzlara tepe. EBM eğitiminin merkezi zorluğu "dışarıyı nasıl yükseltirsin?" sorusudur (Hafta 8 contrastive). Bu şekil, Hafta 1'in manifold hipotezinin enerji dilidir.
:::
::: {.callout-note collapse="true" title="Soru 3: Bir autoencoder neden ve nasıl bir EBM'dir? \"Manifold üzerini kurmak\" ne demek?"}
**Cevap:** Autoencoder'ın **reconstruction loss**'u bir **enerjidir**: veri manifoldu üzerindeki noktalarda düşük (iyi kurulur), manifold dışında yüksek (kötü kurulur). Yani autoencoder, "veride düşük, dışında yüksek enerji" EBM şeklini öğrenir. "Manifold üzerini kurmak": autoencoder yalnızca gerçek verinin yaşadığı küçük manifoldu iyi kurar; manifold dışı (örn. yamalı yüz) bir girdiyi verirsen onu **manifolda geri çeker** (Canziani 20:06) — bu, bozuk girdiyi düzeltme (denoising) yeteneğidir. Darboğaz (under/overcomplete) olmadan autoencoder kimlik fonksiyonunu ezberler, manifoldu öğrenmez.
:::
::: {.callout-note collapse="true" title="Soru 4: (Builder) Latent-variable EBM ile autoencoder'ın \"code\"u nasıl aynı fikirdir? Çıkarım denklemini yaz."}
**Cevap:** Latent-variable EBM'de enerji $F(x, y, z)$ gözlenmeyen bir $z$ içerir; çıkarım hem $y$ hem $z$ üzerinden minimize edilir:
$$
\check{y} = \arg\min_{y,\, z} F(x, y, z)
$$
$z$, çıkarımı kolaylaştıran "yardımcı" bilgidir (LeCun 15:09). Autoencoder'ın **code**'u (Canziani'nin latent space'i) tam olarak bu $z$'dir: girdiyi açıklayan gizli temsil. VAE (Hafta 8) bu $z$'yi olasılıksal yapar. Yani autoencoder code = EBM latent değişken = üretken modellerin gizli uzayı — aynı fikrin farklı kılıkları.
:::
## Egzersizler {#sec-egzersiz-d7}
**Egzersiz 1 (Enerji şekli).** 1B bir örnekte, veri noktaları {−2, 0, 2} olsun. Bu üç noktada düşük, aralarda yüksek bir "enerji" $F(y)$ çiz (örn. üç çukurlu bir eğri). argmin hangi noktaları verir? Birden çok minimum = birden çok cevap fikrini gözlemle.
```python
import numpy as np
def energy_1d(y, data=(-2.0, 0.0, 2.0), width=0.35):
y = np.asarray(y, float)
F = np.ones_like(y)
for d in data: # her veri noktasi bir cukur
F = F - np.exp(-(y - d) ** 2 / (2 * width))
return F
y = np.linspace(-4, 4, 400)
F = energy_1d(y)
# Yerel minimumlar (cukur dipleri) = veri noktalari {-2, 0, 2}
mins = [y[i] for i in range(1, len(y) - 1)
if F[i] < F[i - 1] and F[i] < F[i + 1]]
print("yerel minimumlar:", np.round(mins, 2)) # ~[-2, 0, 2]
# COKLU minimum = COKLU gecerli cevap (tek f(x) degil)
```
**Egzersiz 2 (Autoencoder kur).** PyTorch'ta küçük bir undercomplete autoencoder (örn. 784 → 32 → 784) kur; MNIST'te reconstruction loss (MSE) ile eğit. Kurulan görüntüleri orijinalle karşılaştır. Code boyutunu 2'ye indirip latent uzayı 2B çiz.
```python
import torch
import torch.nn as nn
class Autoencoder(nn.Module):
def __init__(self, code_dim=32):
super().__init__()
self.encoder = nn.Sequential( # 784 -> code (sikistir)
nn.Linear(784, 128), nn.ReLU(),
nn.Linear(128, code_dim),
)
self.decoder = nn.Sequential( # code -> 784 (kur)
nn.Linear(code_dim, 128), nn.ReLU(),
nn.Linear(128, 784), nn.Sigmoid(),
)
def forward(self, x):
z = self.encoder(x) # latent code z
return self.decoder(z), z # x_hat, z
model = Autoencoder(code_dim=32)
loss_fn = nn.MSELoss() # ||x - x_hat||^2
opt = torch.optim.Adam(model.parameters(), lr=1e-3)
# egitim dongusu: x_hat, _ = model(x); loss = loss_fn(x_hat, x); loss.backward(); opt.step()
# code_dim=2 -> latent uzayi 2B scatter ile ciz (rakam siniflari kumelenir)
```
**Egzersiz 3 (Off-manifold).** Eğitilmiş autoencoder'a (a) gerçek bir rakam, (b) rastgele gürültü ver. Hangisi daha iyi kurulur (düşük reconstruction error/enerji)? Bu, autoencoder'ın EBM olduğunu nasıl gösterir?
```python
import torch
# Egitilmis model varsayalim (Egzersiz 2)
real_digit = mnist_sample # manifold UZERI (gercek rakam)
noise = torch.rand(1, 784) # manifold DISI (rastgele gurultu)
with torch.no_grad():
for name, x in [("gercek rakam", real_digit), ("rastgele gurultu", noise)]:
x_hat, _ = model(x)
energy = ((x - x_hat) ** 2).mean().item() # reconstruction error = ENERJI
print(f"{name:18s} enerji = {energy:.4f}")
# gercek rakam -> DUSUK enerji (manifoldda, iyi kurulur)
# gurultu -> YUKSEK enerji (manifold disi, kotu kurulur)
# => autoencoder veride dusuk/disinda yuksek enerji ogrenir = EBM
```
**Egzersiz 4 (Bottleneck).** Aynı autoencoder'ı code boyutu girdiye eşit (overcomplete, kısıtsız) yapıp eğit. Reconstruction mükemmel ama latent anlamsız — neden? (Kimlik fonksiyonu ezberi.) Darboğazın neden gerekli olduğunu açıkla.
```python
# undercomplete (code < girdi): darbogaz -> manifoldu OGRENMEK zorunda
under = Autoencoder(code_dim=32) # 784 -> 32 -> 784 (sikistirma zorunlu)
# overcomplete + kisitsiz (code >= girdi): darbogaz YOK
over = Autoencoder(code_dim=784) # 784 -> 784 -> 784
# Risk: encoder = I, decoder = I (kimlik fonksiyonu) ezberi
# -> reconstruction MUKEMMEL ama latent ANLAMSIZ (manifold ogrenilmez)
# Cozum: bottleneck (undercomplete) VEYA overcomplete + kisit/duzenlileme
# (sparse/denoising/contractive AE) -> manifoldu ogrenmeye zorla
```
**Egzersiz 5 (Hafta 8 habercisi — dışarıyı yükseltmek).** EBM eğitiminin zorluğu: veride enerjiyi düşürmek kolay, ama **dışarıyı yükseltmek** zor. (a) Yalnızca veride enerjiyi düşürürsen ne olur (enerji her yerde düşer, model çöker)? (b) Bir "negatif örnek" (uyumsuz çift) üretip onun enerjisini yükseltmek bu sorunu nasıl çözer? Bu, Hafta 8'in **contrastive yöntemlerine** girişi motive eder.
```python
# (a) SADECE veride enerjiyi dusur: F(veri) asagi cek
# -> ama hicbir sey disariyi YUKARI cekmez
# -> enerji HER YERDE duser (sabit/duz yuzey) -> model COKER (collapse)
# (b) contrastive: pozitif (veri) + negatif (uyumsuz) ornek ciftleri
# pozitif enerjiyi DUSUR, negatif enerjiyi YUKSELT
# -> veride cukur, disinda tepe = iyi enerji sekli (Bolum 3)
# loss ~ F(pozitif) - F(negatif) (margin/contrastive)
# negatif ornek nereden? -> Hafta 8: sampling, augmentation, vb.
print("non-contrastive: collapse riski | contrastive: disariyi yukselt")
```
## Sonraki Ders İçin Hazırlık {#sec-sonraki-d7}
::: {.callout-warning title="Sonraki Hafta — H8: Karşıtsal SSL, Sparse Coding ve VAE"}
**Enerji şeklini nasıl kurarsın?** Bu hafta EBM'nin merkezi zorluğunu sorduk ama çözmedik: enerji fonksiyonunu nasıl şekillendirirsin — veride düşük, dışında yüksek? Hafta 8 bunu çözüyor: LeCun **contrastive yöntemleri** (negatif örneklerle dışarıyı yükselt) ve regularize latent değişkenleri anlatacak; Canziani **VAE**'yi (olasılıksal autoencoder) gösterecek. Egzersiz 3 (off-manifold) ve Egzersiz 5 (dışarıyı yükseltme) tam bu derse hazırlar.
:::
**Hafta 8: Karşıtsal SSL, Sparse Coding ve VAE** — LeCun (Lecture) + Canziani (Practicum)
Hafta 8, EBM'nin merkezi zorluğunu çözüyor: enerji fonksiyonunu nasıl şekillendirirsin? LeCun **contrastive yöntemleri** (negatif örneklerle dışarıyı yükselt) ve regularize latent değişkenleri anlatacak; Canziani **VAE**'yi (olasılıksal autoencoder) gösterecek.
**Hafta 8 öncesi yapılacak:**
- Egzersiz 3 (off-manifold) ve Egzersiz 5 (dışarıyı yükseltme) çöz.
- "EBM çıkarımı = argmin_y F(x,y)" ve "autoencoder = EBM" cümlelerini kendi sözcüklerinle yaz.
- Hafta 1'in manifold hipotezini hatırla — EBM'nin "veride düşük enerji" şekli onunla aynı.
## Anahtar Kavramlar (Cheat Sheet) {#sec-cheat-d7}
| Kavram | Tanım | Hoca / timestamp |
|---|---|---|
| Enerji-tabanlı model (EBM) | Her $(x,y)$ çiftine uyumluluk skoru (enerji) | LeCun 0m00 |
| Enerji fonksiyonu $F(x,y)$ | Uyumlu çiftte düşük, uyumsuzda yüksek | LeCun 7m52 |
| Çıkarım = enerji minimizasyonu | $\check{y} = \arg\min_y F(x,y)$; birden çok cevap olabilir | LeCun 8m06 |
| Örtük (implicit) fonksiyon | $y$'yi doğrudan değil, $F$'yi minimize eden değer olarak tanımla | LeCun 4m47 |
| Enerji ≠ kayıp | Enerji çıkarımda; kayıp eğitimde (şekillendirme) | LeCun 7m27 |
| Latent-variable EBM | $F(x,y,z)$; $y$ ve $z$ üzerinden minimize | LeCun 15m09 |
| Autoencoder | encoder → code → decoder; girdiyi yeniden kur | Canziani 14m41 |
| Veri manifoldu | Anlamlı veri küçük bir altuzayda; AE onu kurar | Canziani 19m41 |
| Reconstruction loss | $\lVert x - \text{dec}(\text{enc}(x)) \rVert^2$ = enerji | Canziani 20m44 |
| Bottleneck (under/overcomplete) | Manifoldu öğrenmeye zorlayan kısıt | Canziani 23m01 |
## ML Builder Bağlantıları {#sec-koprular-d7}
**Geriye köprüler (önkoşul kurslar):**
1. **Enerji = −log olasılık** → Stat 110 (Boltzmann, Hafta 8-9'da derinleşir).
2. **Çıkarım = enerji minimizasyonu** → Calculus gradient descent ($y$ üzerinde) + örtük fonksiyon.
3. **Manifold (veride düşük enerji)** → Hafta 1 manifold hipotezi + 18.06 altuzay.
4. **Latent değişken** → Stat 110 latent-değişken modelleri (mixture, EM).
5. **Autoencoder = EBM** → bu haftanın iki yarısının birleşimi.
**İleriye köprüler (production / research):**
1. **EBM** → JEPA / I-JEPA / V-JEPA (post-2020 ileriye köprü, LeCun programı).
2. **Reconstruction = enerji** → score-based / diffusion modelleri (Hafta 9).
3. **Latent code** → VAE (Hafta 8), üretken modellerin gizli uzayı.
4. **Off-manifold geri çekme** → denoising AE (Hafta 8), diffusion.
::: {.callout-important title="Bu dersten tek bir şey alıp gideceksen"}
EBM sihir değildir — bir ağı "tek çıktı veren fonksiyon" olmaktan çıkarıp, her olası cevaba bir uyumluluk skoru (enerji) atayan ve çıkarımı $\arg\min_y F(x,y)$ ile yapan bir çerçeveye dönüştürür; böylece bir girdiye birden çok geçerli cevap verebilir. Autoencoder bunun en somut hâlidir: veri manifoldu üzerine düşük enerji koyup dışını geri çeker — LeCun enerji çerçevesini kurar, Canziani onu autoencoder'da gösterir, ve bu ikisi kursun geri kalanının (VAE, contrastive SSL, diffusion) teorik omurgasıdır.
:::