flowchart TD
A["Ax = kolonların kombinasyonu"] --> B["Kolon uzayı C(A)"]
B --> C["rank = bağımsız kolon sayısı"]
C --> D["A = CR"]
D --> E["kolon rank = satır rank"]
C --> F["rank-1 = dış çarpım"]
F --> G["AB = Σ dış çarpımlar"]
style A fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style B fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style D fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style C fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style E fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style F fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
style G fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
2 Kolon Uzayı — A’nın Tüm Ax Vektörleri (A = CR)
Bir matrise bütün olarak bak: Ax kolonların kombinasyonudur, C(A) onların gerdiği uzaydır, A = CR bu yapıyı açığa çıkarır.
NotBölüm bilgisi
- Strang’in videosu: YouTube — The Column Space of A Contains All Vectors Ax (≈52 dk)
- OCW sayfası: MIT 18.065 — Video Lectures
- Okuma süresi: ≈35 dk
- Hoca: Gilbert Strang
- Önkoşul: 18.06 / Phase 1 Lineer Cebir (kolon uzayı, rank, baz)
2.1 Bu Derste Ne Var?
18.065’in ilk dersi. Strang kursu “veriden öğrenme” üzerine açıyor ve hemen lineer cebirin kalbine giriyor: bir matrise bir bütün olarak bakmak. Bu ders, Phase 1 18.06’da gördüğümüz kolon uzayı, rank ve baz kavramlarını veri ve faktorizasyon gözüyle yeniden çerçeveliyor.
Üç temel fikir:
- Ax = A’nın kolonlarının kombinasyonu — matris-vektör çarpımını “satır satır nokta çarpımı” olarak değil, “kolonların ağırlıklı toplamı” olarak görmek.
- Kolon uzayı \(C(A)\) ve \(A = CR\) faktorizasyonu — bağımsız kolonlar (C) çarpı bir kombinasyon reçetesi (R).
- Kolon rank = satır rank — lineer cebirin ilk büyük teoremi, doğrudan \(A = CR\)’den çıkıyor.
“this is a great adventure for me… teaching a course that involves learning from data.” — Strang, 0:23
Bu altı kavramın birbirine nasıl bağlandığını Şekil 2.1 özetliyor.
İpucuBuilder Notu — Veri-Odaklı Cebire Giriş Kapısı
Bu dersin kavramları ML altyapısında nereye bağlanıyor:
- Ax = kolonların kombinasyonu görüşü, GPU’daki matris çarpımının (GEMM) çalışma biçimidir: BLAS çarpımı satır-nokta-çarpımı yerine kolon ve blok kombinasyonları olarak yapar. “Matrise bütün olarak bakmak” performans sezgisidir.
- A = CR ve rank, düşük-rank yaklaşımın (Ders 7 Eckart-Young, PCA) ve LoRA gibi modern fine-tuning yöntemlerinin temelidir: büyük bir matrisi az sayıda bağımsız kolonla temsil etmek.
- Dış çarpım (kolon × satır) birikimi, tüm matris çarpımlarının atomik yapı taşıdır: \(AB = \sum_k a_k b_k^{T}\).
- Dev matrisi örnekleme (rastgele x ile Ax), Ders 13’teki rastlantısal lineer cebirin habercisidir.
Tek cümle: bir matrisi “kolonlarının ürettiği uzay” olarak görmek, sıkıştırmadan rastlantısal cebire kadar tüm veri-odaklı lineer cebirin giriş kapısıdır.
2.2 Matris × Vektör — Satır Yolu mu, Kolon Yolu mu?
Strang ilk dersi tanıdık bir işle açıyor: bir matrisi bir vektörle çarpmak. Ama esas soru, bunu nasıl gördüğün.
Strang’in matrisi:
\[ A = \begin{pmatrix} 2 & 1 & 3 \\ 3 & 1 & 4 \\ 5 & 7 & 12 \end{pmatrix} \]
\(Ax\) çarpımını iki şekilde okuyabilirsin.
Satır yolu (alışılmış, low-level): her satırı x ile nokta çarpımına sok. Birinci bileşen \(2x_1 + x_2 + 3x_3\), sonra ikinci, sonra üçüncü. Cevabı bileşen bileşen, parça parça verir.
Kolon yolu (Strang’in “doğru” yolu): sonucu kolonların ağırlıklı toplamı olarak gör.
\[ Ax = x_1 \begin{pmatrix} 2 \\ 3 \\ 5 \end{pmatrix} + x_2 \begin{pmatrix} 1 \\ 1 \\ 7 \end{pmatrix} + x_3 \begin{pmatrix} 3 \\ 4 \\ 12 \end{pmatrix} \]
Aynı sayılar çıkar, ama artık her şeyi bir kerede görüyorsun: \(Ax\), A’nın kolonlarının bir kombinasyonudur. Şekil 2.2 bu üç kolonu ve onların ağırlıklı toplamı olan \(Ax\)’i \(\mathbb{R}^3\) uzayında gösteriyor.
“But do you know it the right way? Do you think of the multiplication the right way?” — Strang, 4:29
“When I say Ax, you immediately think… it’s a combination of the columns of A.” — Strang, 7:32
Kod
A = EXAMPLE_A
c1 = A[:, 0] # (2, 3, 5)
c2 = A[:, 1] # (1, 1, 7)
c3 = A[:, 2] # (3, 4, 12) = c1 + c2
# Örnek x: düzlemde net bir Ax noktası (x3=0 → Ax sade)
x = np.array([0.6, 0.6, 0.0])
Ax = A @ x # = 0.6*c1 + 0.6*c2
fig = plt.figure(figsize=(8, 6))
ax = fig.add_subplot(111, projection="3d")
apply_style_3d(ax)
# Kolon okları
draw_vector_3d(ax, c1, color=COL_VEC1, label="c₁ = (2, 3, 5)", lw=2.6)
draw_vector_3d(ax, c2, color=COL_VEC2, label="c₂ = (1, 1, 7)", lw=2.6)
draw_vector_3d(ax, c3, color=COL_VEC3, label="c₃ = c₁ + c₂", lw=2.6)
# Ax = kolonların ağırlıklı toplamı
draw_vector_3d(ax, Ax, color=COL_TEAL, label="Ax = 0.6·c₁ + 0.6·c₂", lw=3.0)
# c3'ün c1+c2 olduğunu gösteren kesikli toplama yolu: c1 ucundan c2 kadar git
ax.plot([c1[0], c3[0]], [c1[1], c3[1]], [c1[2], c3[2]],
color=COL_VEC3, ls="--", lw=1.4, alpha=0.7)
ax.plot([c2[0], c3[0]], [c2[1], c3[1]], [c2[2], c3[2]],
color=COL_VEC3, ls="--", lw=1.4, alpha=0.7)
ax.set_xlabel("x ekseni")
ax.set_ylabel("y ekseni")
ax.set_zlabel("z ekseni")
ax.set_xlim(0, 4)
ax.set_ylim(0, 4.5)
ax.set_zlim(0, 13)
ax.set_title("Ax, A'nın kolonlarının kombinasyonudur",
fontsize=13, fontweight="bold", pad=12)
ax.view_init(elev=18, azim=-60)
fig.tight_layout()
plt.show()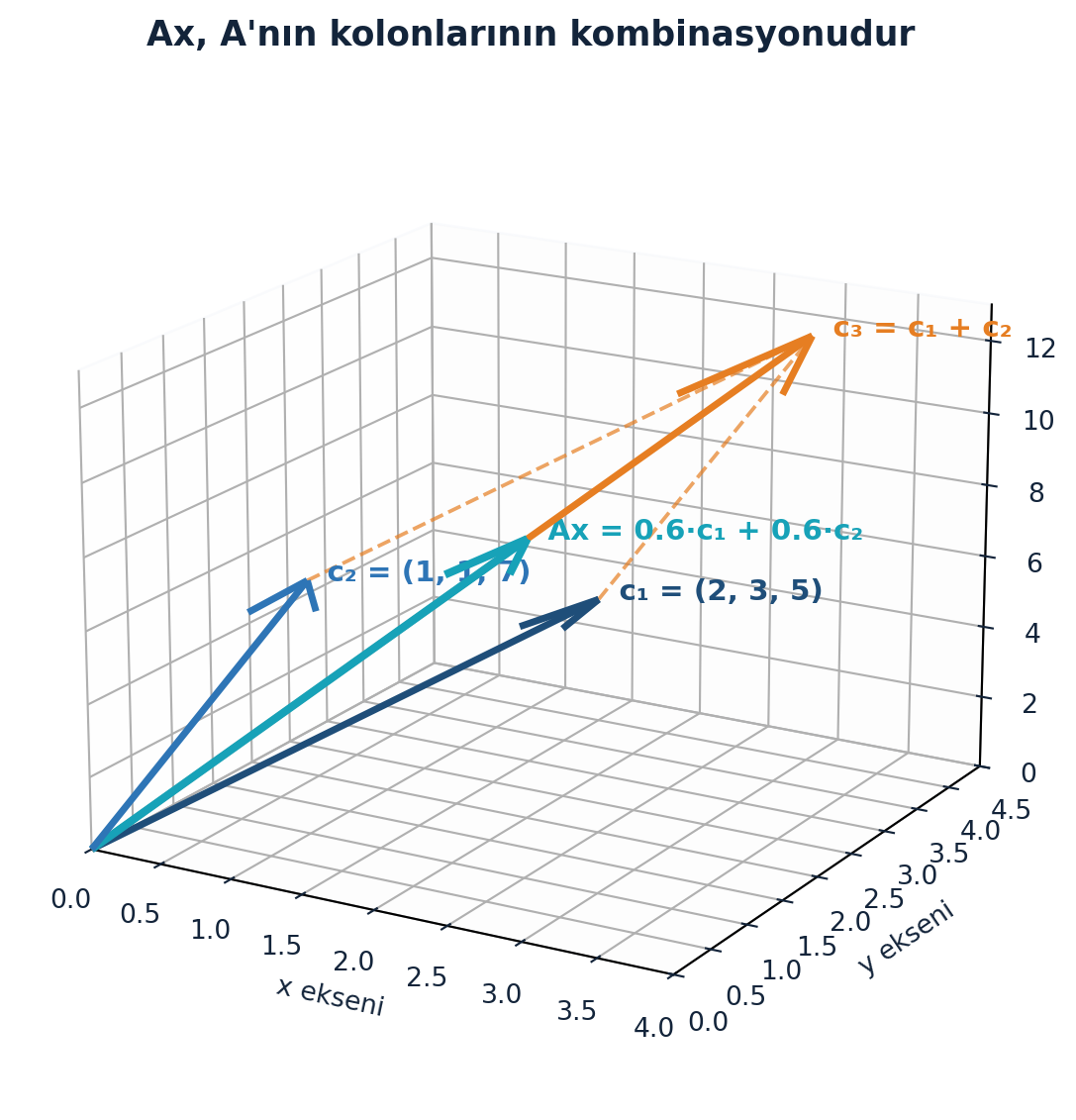
İpucuBuilder Notu — Karışım Reçetesi
Kolon görüşü ML’de neden önemli: bir nöron katmanının çıktısı \(Wx\), ağırlık matrisi W’nin kolonlarının girdiyle ölçeklenmiş toplamıdır. Her kolon, girdinin bir bileşeninin çıktıya “katkı yönü”dür. Bu görüş, embedding tablolarını (her kolon bir token’ın vektörü) ve GEMM’in kolon-blok yapısını anlamanın anahtarıdır.
2.3 Kolon Uzayı C(A)
Tek bir x al, tek bir \(Ax\) çıkar. Şimdi bütün x’leri al — çıkan \(Ax\)’lerin hepsini bir araya topla. Bu sonsuz vektör kümesi neye benzer?
Bütün \(Ax\)’lerin kümesine A’nın kolon uzayı denir, \(C(A)\) ile gösterilir. Tanım gereği bu, A’nın kolonlarının tüm kombinasyonlarının kümesidir — yani kolonların gerdiği uzay.
“And the beauty of linear algebra is that questions like this — you can answer them and you intuitively see it.” — Strang, 8:30
Bu A için kolon uzayı \(\mathbb{R}^3\)’ün tamamı mı? Hayır — bir düzlem. Çünkü üçüncü kolon ilk ikisinin toplamı; yeni bir yön getirmiyor. İlk iki kolon bir düzlem geriyor, üçüncü kolon o düzlemin içinde kalıyor. Bu düzlemi ve üzerine düşen rastgele \(Ax\) noktalarını Şekil 2.3 gösteriyor.
Eğer bir matrisin tüm kolonları aynı doğrultunun katlarıysa, kolon uzayı yalnızca bir doğru olur (rank 1). Rastgele bir 3×3 matriste ise kolonlar bağımsızdır, kolon uzayı tüm \(\mathbb{R}^3\)’tür ve matris tersinirdir.
Kod
c1 = EXAMPLE_A[:, 0]
c2 = EXAMPLE_A[:, 1]
c3 = EXAMPLE_A[:, 2] # c3 = c1 + c2 (bağımlı) → düzlemde yatar
fig = plt.figure(figsize=(7.2, 6.0))
ax = fig.add_subplot(111, projection="3d")
apply_style_3d(ax)
# C(A) düzlemi: c1, c2'nin gerdiği düzlem (rank 2)
# lim*||c|| vektör uçlarını içermeli (c'ler ~6-13 uzunlukta)
X, Y, Z = plane_mesh(c1, c2, lim=1.6, n=14)
ax.plot_surface(X, Y, Z, color=COL_SKY_400, alpha=0.22,
linewidth=0, antialiased=True, shade=False)
# Rastgele Ax noktaları — hepsi düzlemde yatar (rank 2 kanıtı)
pts = random_Ax_samples(EXAMPLE_A, k=60, seed=0, scale=0.35)
ax.scatter(pts[:, 0], pts[:, 1], pts[:, 2],
color=COL_TEAL, s=12, alpha=0.7, depthshade=False,
label="rastgele Ax (hep düzlemde)")
# Kolon vektörleri
draw_vector_3d(ax, c1, color=COL_VEC1, label="c₁")
draw_vector_3d(ax, c2, color=COL_VEC2, label="c₂")
draw_vector_3d(ax, c3, color=COL_VEC3, label="c₃ düzlemde")
ax.set_xlabel("x")
ax.set_ylabel("y")
ax.set_zlabel("z")
ax.set_title("C(A): tüm Ax'ler aynı düzlemde (rank 2)",
fontsize=12, fontweight="bold")
ax.view_init(elev=14, azim=-62)
ax.legend(loc="upper left", fontsize=9, framealpha=0.85)
plt.tight_layout()
plt.show()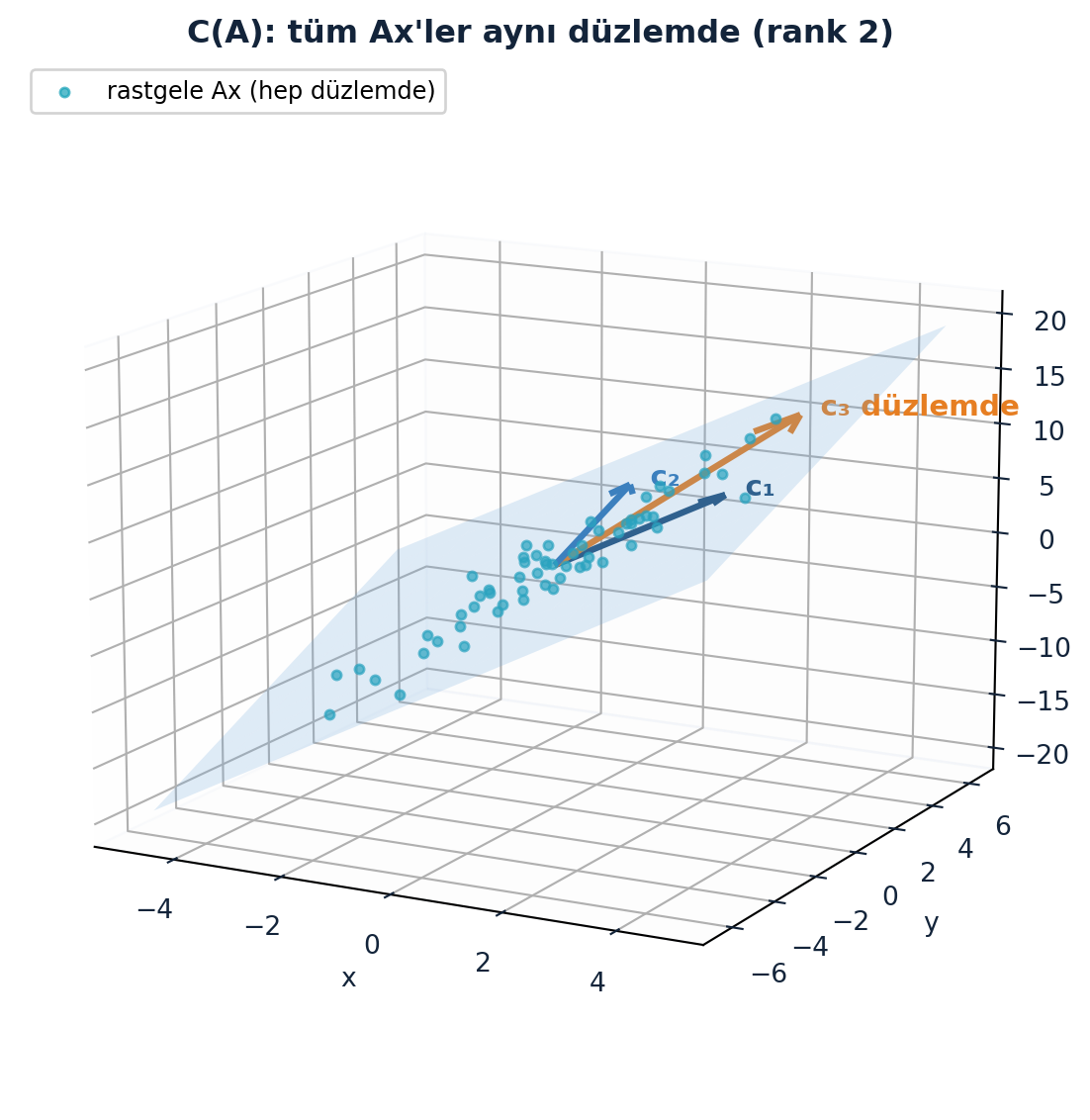
İpucuBuilder Notu — Erişilebilir Bölge
\(C(A)\), “bu matrisle hangi çıktılara ulaşabilirim?” sorusunun cevabıdır. \(Ax = b\) denkleminin çözümü olması için b’nin \(C(A)\) içinde olması gerekir (Ders 9-10’da least squares tam da bu yüzden devreye girer: b kolon uzayında değilse, en yakın noktaya projekte ederiz).
2.4 Rank ve Rank-1 Matrisler
Kolon uzayının boyutuna rank denir. Bizim A’mızın kolon uzayı bir düzlem (2 boyutlu), yani rank 2. Bir doğru olsaydı rank 1, tüm \(\mathbb{R}^3\) olsaydı rank 3 olurdu.
Üçüncü kolonun ilk ikisinin toplamı olması, yalnızca iki bağımsız kolon olduğunu söyler — ve rank, tam olarak bağımsız kolon sayısıdır.
Rank-1 matrisler lineer cebirin yapı taşıdır. Bir rank-1 matris, bir kolon vektörü çarpı bir satır vektörü olarak yazılır:
\[ \begin{pmatrix} 1 \\ 1 \\ 1 \end{pmatrix} \begin{pmatrix} 1 & 3 & 8 \end{pmatrix} = \begin{pmatrix} 1 & 3 & 8 \\ 1 & 3 & 8 \\ 1 & 3 & 8 \end{pmatrix} \]
3×1 çarpı 1×3 boyutu 3×3 verir; sonucun rankı 1’dir (tüm satırlar (1,3,8)’in katı, tüm kolonlar (1,1,1)’in katı). Şekil 2.4 bu dış çarpımı bir kolon ile bir satırın çarpımı olarak görselleştiriyor.
“matrices like this are really the building blocks of linear algebra, they’re the building blocks of data science. They’re rank one matrices.” — Strang, 13:56
Kod
col = RANK1_COL.reshape(3, 1) # kolon vektörü (3×1): (1,1,1)ᵀ
row = RANK1_ROW.reshape(1, 3) # satır vektörü (1×3): (1,3,8)
M = outer(RANK1_COL, RANK1_ROW) # dış çarpım = rank-1 matris (3×3)
# Ortak renk ölçeği: üç heatmap'in tonları karşılaştırılabilir olsun
vmin, vmax = 0.0, float(M.max())
fig = plt.figure(figsize=(7.4, 5.0))
fig.patch.set_facecolor(COL_WHITE)
# 2 satır × 4 sütun grid: üstte satır vektörü, altta kolon | × | matris | =
gs = fig.add_gridspec(
2, 4,
width_ratios=[1.0, 0.32, 3.0, 0.0001],
height_ratios=[1.0, 3.0],
wspace=0.35, hspace=0.30,
)
# Üst orta: satır vektörü (1×3) — matrisin tam üstünde
ax_row = fig.add_subplot(gs[0, 2])
heatmap(ax_row, row, title="satır (1, 3, 8)", vmin=vmin, vmax=vmax, fontsize=12)
# Alt sol: kolon vektörü (3×1) — matrisin tam solunda
ax_col = fig.add_subplot(gs[1, 0])
heatmap(ax_col, col, title="kolon (1, 1, 1)ᵀ", vmin=vmin, vmax=vmax, fontsize=12)
# Alt orta: rank-1 matris (3×3)
ax_mat = fig.add_subplot(gs[1, 2])
heatmap(ax_mat, M, title="rank-1 matris = dış çarpım", vmin=vmin, vmax=vmax, fontsize=13)
# "×" işareti: kolon ile matris arasında (alt sıra, ikinci sütun)
ax_times = fig.add_subplot(gs[1, 1])
ax_times.axis("off")
ax_times.text(0.5, 0.5, "×", ha="center", va="center",
fontsize=30, fontweight="bold", color=COL_ACCENT,
transform=ax_times.transAxes)
# "=" işareti: satır vektörü ile matris arasında (sol üst hücre köşesi)
fig.text(0.085, 0.40, "=", ha="center", va="center",
fontsize=26, fontweight="bold", color=COL_ACCENT)
# Açıklayıcı alt yazı: her satır (1,3,8), her kolon (1,1,1) katı
fig.text(
0.5, -0.02,
"rank-1: her satır (1, 3, 8)'in katı · her kolon (1, 1, 1)'in katı",
ha="center", va="top", fontsize=10.5, color=COL_TEXT,
)
fig.suptitle("Bir kolon × bir satır = rank-1 matris",
fontsize=14, fontweight="bold", color=COL_PRIMARY, y=1.02)
plt.show()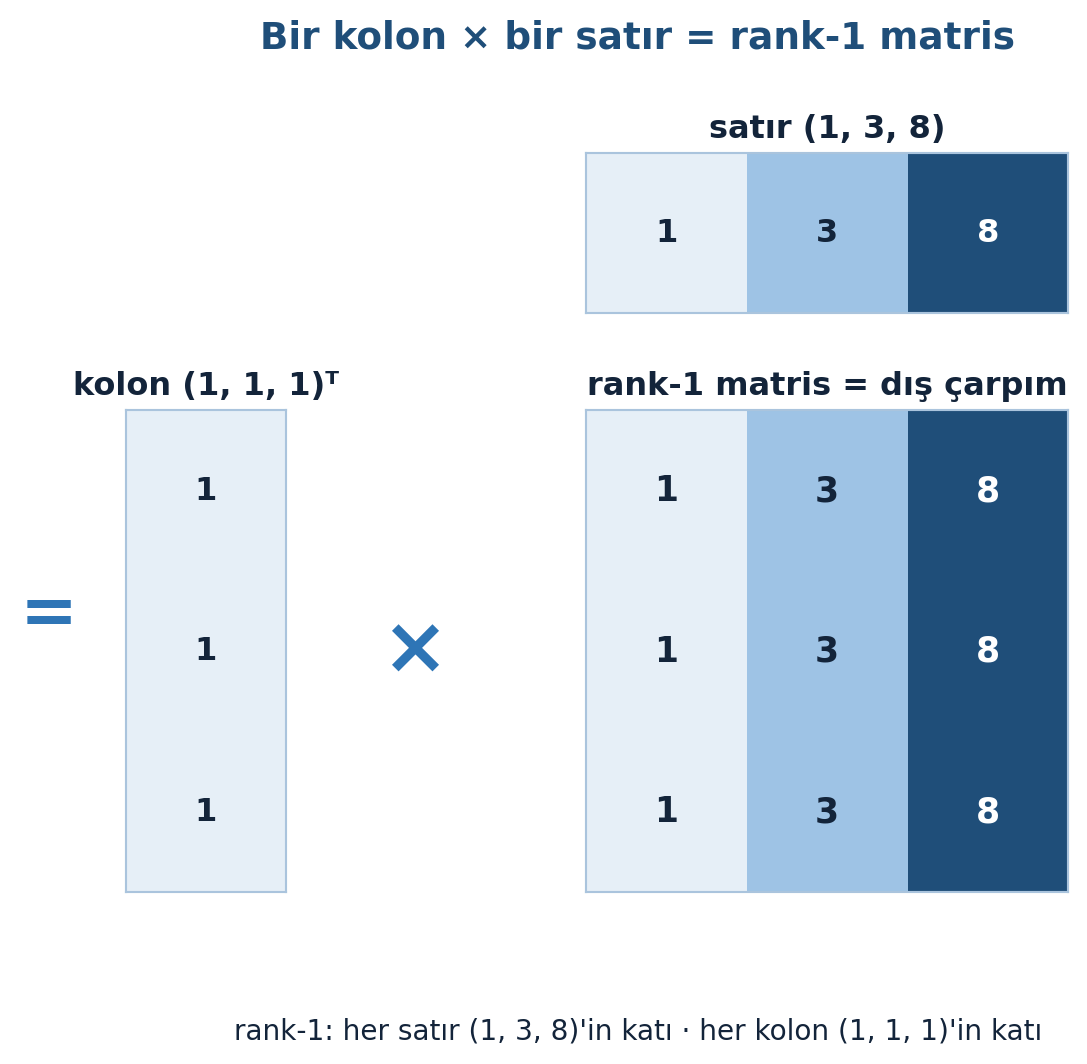
İpucuBuilder Notu — Atomik Birim
Rank-1 = kolon × satır = dış çarpım. SVD bir matrisi rank-1 dış çarpımların toplamı olarak yazar (Ders 6-7); en büyük birkaç terimi tutmak = düşük-rank sıkıştırma = PCA, LoRA, gömme sıkıştırma. “Rank-1 yapı taşı” sezgisi tüm kursun omurgasıdır.
2.5 Bağımsız Kolonlar ve Baz
Kolon uzayı için bir baz kuralım — en doğal yoldan, soldan sağa tarayarak.
Birinci kolon (2,3,5): sıfır değil, içeri al. İkinci kolon (1,1,7): birinciye bağlı değil, yeni bir yön — içeri al. Üçüncü kolon (3,4,12): ilk ikisinin toplamı, yeni bir şey katmıyor — alma. Geriye iki bağımsız kolon kaldı; bunlar kolon uzayının bir bazıdır.
“those two columns would be a basis for the column space.” — Strang, 15:51
Bu bağımsız kolonları yan yana koyup C matrisini oluştur:
\[ C = \begin{pmatrix} 2 & 1 \\ 3 & 1 \\ 5 & 7 \end{pmatrix} \]
C doğrudan A’dan alındı; sadece bağımsız kolonları, soldan sağa tutarak.
“I kept only independent columns and I worked from left to right.” — Strang, 19:51
İpucuBuilder Notu — Hangi Kolonlar Önemli?
Bu “soldan sağa, bağımsızsa tut” yordamı, sayısal lineer cebirdeki kolon pivotlu QR ve rank-açığa-çıkaran faktorizasyonların sezgisidir. CUR ve sütun-altküme seçimi gibi yöntemler tam da gerçek kolonları seçer — yorumlanabilirlik için (SVD’nin soyut tekil vektörlerinin aksine, C’nin kolonları gerçek veri sütunlarıdır).
2.6 A = CR Faktorizasyonu
C, A’nın bağımsız kolonlarını taşıyor (3×2). Şimdi bir R matrisi (2×3) kuralım: R, A’nın her kolonunun C’nin kolonlarından nasıl üretileceğini söylesin.
- A’nın 1. kolonu = 1·(C’nin 1. kolonu) + 0·(C’nin 2. kolonu) → R’nin 1. kolonu (1,0)
- A’nın 2. kolonu = 0·… + 1·… → R’nin 2. kolonu (0,1)
- A’nın 3. kolonu = 1·… + 1·… (çünkü \(c_3 = c_1 + c_2\)) → R’nin 3. kolonu (1,1)
\[ R = \begin{pmatrix} 1 & 0 & 1 \\ 0 & 1 & 1 \end{pmatrix} \]
Birleştirince \(A = CR\):
\[ A = CR = \begin{pmatrix} 2 & 1 \\ 3 & 1 \\ 5 & 7 \end{pmatrix} \begin{pmatrix} 1 & 0 & 1 \\ 0 & 1 & 1 \end{pmatrix} = \begin{pmatrix} 2 & 1 & 3 \\ 3 & 1 & 4 \\ 5 & 7 & 12 \end{pmatrix} \]
“this is a first matrix factorization. It’s not– well, it is a famous one, actually.” — Strang, 21:04
Bu eski bir öğretim aracı gibi görünse de, modern büyük ölçekli sayısal lineer cebirde C×R (gerçek kolonlar çarpı gerçek satırlar) ciddi bir araç haline geldi. Şekil 2.5 bu ayrışmayı A, C ve R ısı haritalarıyla yan yana gösteriyor.
“C times R, columns times rows has become very, very important in large scale [numerical linear algebra].” — Strang, 21:17
Kod
# fig-a-cr — A = C R faktorizasyonu (§5): 3 heatmap yan yana + "=" ve "×"
C, R, rank, piv = cr_factorization(EXAMPLE_A) # C 3×2, R 2×3 = [[1,0,1],[0,1,1]]
fig = plt.figure(figsize=(10.2, 3.6))
# Genişlik oranları: A(3) | "=" | C(2) | "×" | R(3); araya dar metin kolonları
gs = fig.add_gridspec(1, 5, width_ratios=[3, 0.7, 2, 0.7, 3], wspace=0.30)
axA = fig.add_subplot(gs[0, 0])
ax_eq = fig.add_subplot(gs[0, 1])
axC = fig.add_subplot(gs[0, 2])
ax_mul = fig.add_subplot(gs[0, 3])
axR = fig.add_subplot(gs[0, 4])
# Ortak renk ölçeği: üç matris de aynı NAVY_CMAP yoğunluk ekseninde okunur
allvals = np.concatenate([EXAMPLE_A.ravel(), C.ravel(), R.ravel()])
vmin, vmax = float(allvals.min()), float(allvals.max())
heatmap(axA, EXAMPLE_A, title="A", vmin=vmin, vmax=vmax)
heatmap(axC, C, title="C (bağımsız kolonlar)", vmin=vmin, vmax=vmax)
heatmap(axR, R, title="R (kombinasyon reçetesi)", vmin=vmin, vmax=vmax)
# "=" ve "×" anotasyon kolonları (eksen çerçevesi gizli, ortaya büyük sembol)
for ax, sym in ((ax_eq, "="), (ax_mul, "×")):
ax.axis("off")
ax.text(0.5, 0.5, sym, ha="center", va="center",
fontsize=30, fontweight="bold", color=COL_PRIMARY,
transform=ax.transAxes)
# R'nin son kolonunu (c3 = c1 + c2 reçetesi) turuncu çerçeveyle vurgula
nr, nc = R.shape
rect = plt.Rectangle((nc - 1 - 0.5, -0.5), 1, nr, fill=False,
edgecolor=COL_VEC3, linewidth=3.0, zorder=5)
axR.add_patch(rect)
axR.set_xlabel("son kolon (1,1) → c₃ = c₁ + c₂",
color=COL_VEC3, fontsize=9, fontweight="bold")
fig.suptitle("A = C × R — bağımsız kolonlar (C) çarpı reçete (R)",
color=COL_TEXT, fontsize=13, fontweight="bold", y=1.02)
plt.show()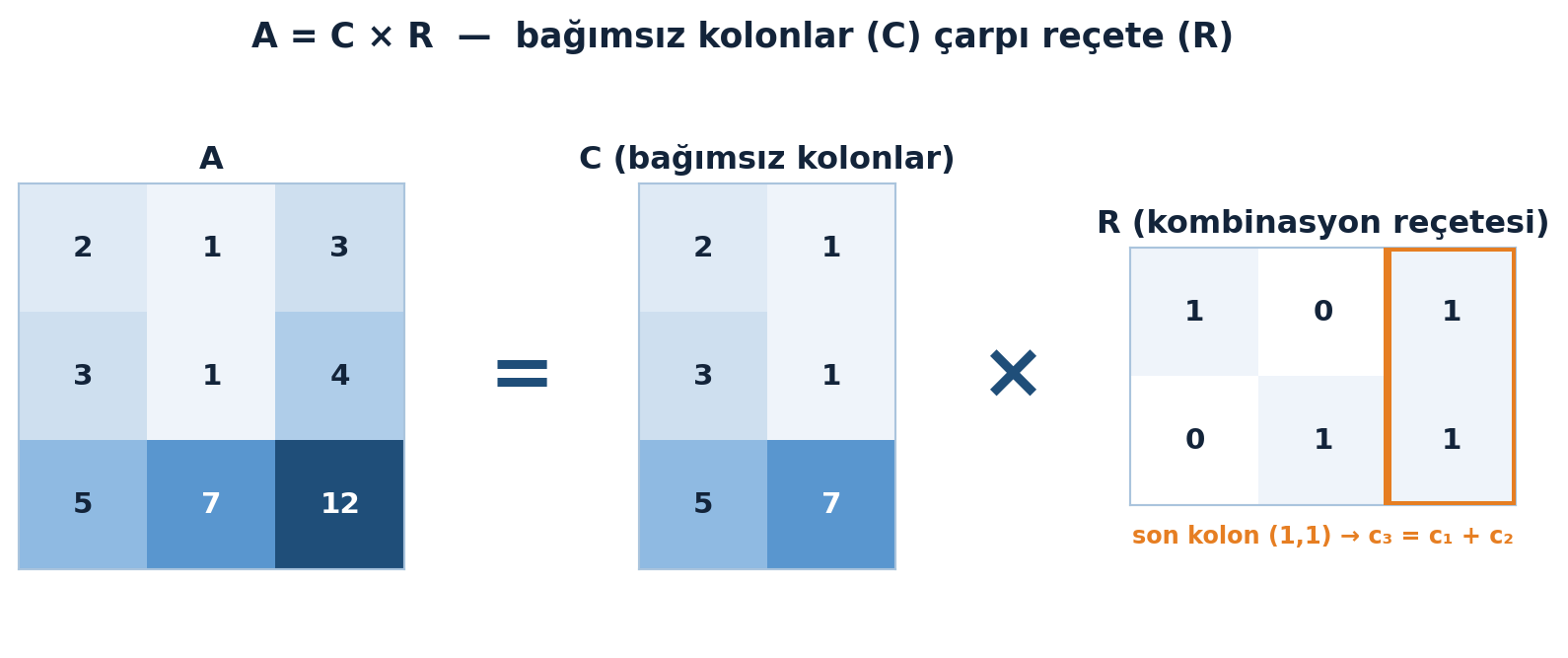
İpucuBuilder Notu — Tek Cümlede Lineer Cebir
\(A = CR\), yorumlanabilir düşük-rank temsilidir: C’nin kolonları A’nın gerçek kolonlarıdır (örneğin gerçek hastalar, gerçek kelimeler), R ise geri kalan her şeyin bu temsilcilerden nasıl kurulacağının reçetesidir. Bu, CUR ayrışımının ve öneri sistemlerinde/genomikte tercih edilen “örnek-tabanlı” sıkıştırmanın çekirdeğidir.
2.7 İlk Büyük Teorem — Kolon Rank = Satır Rank
Strang burada heyecanlanıyor: \(A = CR\) yazarken farkında olmadan lineer cebirin ilk büyük teoremini ispatlamış oluyoruz.
“[sitting here in front of me was] the first great theorem in linear algebra, the fact that the column rank equals the row rank.” — Strang, 23:44
Bizim A’mızda iki bağımsız kolon var (kolon rank = 2). Teorem diyor ki satır rank da 2 olmalı — yani satırlardan biri diğer ikisinin bir kombinasyonu. Matris kare ve tersinir değil (kolonlar bağımlı), o yüzden satırlar da bağımlı olmak zorunda.
“I believe that a combination of the rows gives 0.” — Strang, 24:10
İlk bakışta hangi satır kombinasyonunun sıfır verdiğini görmek zor — ama teorem garanti ediyor: bir matrisin bağımsız kolon sayısı, bağımsız satır sayısına her zaman eşittir. Neden eşit olduğunu bir sonraki bölümde \(A = CR\)’yi iki yönlü okuyarak göreceğiz. Şekil 2.6 bu iki yönlü okumayı — kolon okuması ve satır okuması — yan yana özetliyor.
Kod
C, R, rank, pivots = cr_factorization(EXAMPLE_A) # C:3x2, R:2x3, rank=2
fig = plt.figure(figsize=(11.0, 5.4))
gs = fig.add_gridspec(1, 2, wspace=0.28)
# ortak heatmap renk ölçeği (A,C,R aynı skalada okunsun)
vmax = float(max(EXAMPLE_A.max(), C.max(), R.max()))
vmin = 0.0
# ================= SOL PANEL: Kolon okuması =================
gsL = gs[0].subgridspec(1, 2, width_ratios=[3, 2], wspace=0.55)
axA1 = fig.add_subplot(gsL[0, 0])
axC = fig.add_subplot(gsL[0, 1])
heatmap(axA1, EXAMPLE_A, title="A (3×3)", vmin=vmin, vmax=vmax, fontsize=12)
heatmap(axC, C, title="C (3×2)", vmin=vmin, vmax=vmax, fontsize=12)
# C'nin 2 bağımsız kolonunu vurgula (her kolon bir bağımsız yön)
for j, col in enumerate([COL_VEC1, COL_VEC2]):
axC.add_patch(plt.Rectangle((j - 0.5, -0.5), 1, 3, fill=False,
edgecolor=col, lw=3.2, zorder=5))
# A'nın bağımlı 3. kolonunu (c3 = c1 + c2) turuncu vurgula
axA1.add_patch(plt.Rectangle((2 - 0.5, -0.5), 1, 3, fill=False,
edgecolor=COL_VEC3, lw=3.2, zorder=5))
axA1.annotate("", xy=(1.18, 0.5), xytext=(1.02, 0.5),
xycoords="axes fraction",
arrowprops=dict(arrowstyle="-|>", color=COL_PRIMARY, lw=2.4))
axA1.text(1.10, 0.62, "=", transform=axA1.transAxes,
ha="center", va="center", fontsize=18, color=COL_PRIMARY,
fontweight="bold")
axL = fig.add_subplot(gsL[0, :])
axL.axis("off")
axL.set_title("Kolon okuması", color=COL_PRIMARY, fontsize=14,
fontweight="bold", pad=18)
axL.text(0.5, -0.13,
"A'nın her kolonu = C'nin 2 kolonunun kombinasyonu\n→ kolon rank = 2",
transform=axL.transAxes, ha="center", va="top",
fontsize=11.5, color=COL_TEXT)
# ================= SAĞ PANEL: Satır okuması =================
gsR = gs[1].subgridspec(2, 1, height_ratios=[3, 2], hspace=0.55)
axA2 = fig.add_subplot(gsR[0, 0])
axR = fig.add_subplot(gsR[1, 0])
heatmap(axA2, EXAMPLE_A, title="A (3×3)", vmin=vmin, vmax=vmax, fontsize=12)
heatmap(axR, R, title="R (2×3)", vmin=vmin, vmax=vmax, fontsize=12)
# R'nin 2 satırını vurgula (her satır bağımsız bir satır yönü)
for i, col in enumerate([COL_VEC1, COL_VEC2]):
axR.add_patch(plt.Rectangle((-0.5, i - 0.5), 3, 1, fill=False,
edgecolor=col, lw=3.2, zorder=5))
# A'nın bağımlı 3. satırını (r3 = 16·r1 - 9·r2 yönünde) turuncu vurgula
axA2.add_patch(plt.Rectangle((-0.5, 2 - 0.5), 3, 1, fill=False,
edgecolor=COL_VEC3, lw=3.2, zorder=5))
axA2.annotate("", xy=(0.5, -0.30), xytext=(0.5, -0.10),
xycoords="axes fraction",
arrowprops=dict(arrowstyle="-|>", color=COL_PRIMARY, lw=2.4))
axRt = fig.add_subplot(gsR[:, 0])
axRt.axis("off")
axRt.set_title("Satır okuması", color=COL_PRIMARY, fontsize=14,
fontweight="bold", pad=18)
axRt.text(0.5, -0.10,
"A'nın her satırı = R'nin 2 satırının kombinasyonu\n→ satır rank ≤ 2",
transform=axRt.transAxes, ha="center", va="top",
fontsize=11.5, color=COL_TEXT)
# ================= ORTAK SONUÇ =================
fig.suptitle("A = CR · iki yönlü okuma → kolon rank = satır rank = 2",
color=COL_PRIMARY, fontsize=15, fontweight="bold", y=1.02)
plt.show()
İpucuBuilder Notu — İki Yol, Aynı Sayı
Rank, bir matrisin gerçek serbestlik derecesidir: m×n bir matris, rankı r ise aslında yalnızca \(r(m+n)\) civarı sayı içerir, \(mn\) değil. ML’de ağırlık ve veri matrislerinin “etkin rankı” ne kadar sıkıştırılabilir olduklarını belirler — düşük etkin rank, LoRA ve model budama (pruning) için açık kapıdır.
2.8 Satır Uzayı = C(Aᵀ)
Kolon uzayı kolonların kombinasyonlarıydı. Satır uzayı ise satırların tüm kombinasyonlarıdır. Strang yeni bir harf icat etmek yerine zarif bir numara yapıyor: satırları transpoz ile kolon hâline getir, sonra eski tanıma geri dön.
\[ \text{row space}(A) = C(A^{T}) \]
Yani satır uzayı = \(A^{T}\)’nin kolon uzayı. Böylece vektörleri hep kolon vektörü tutma alışkanlığını (NumPy, Julia, MATLAB konvansiyonu) bozmadan devam ediyoruz.
“So the row space of A is the column space of A transpose.” — Strang, 27:25
Strang araya önemli bir not düşüyor: bizim örneğimiz 3×3 kare olduğu için hem kolon uzayı hem satır uzayı \(\mathbb{R}^3\)’ün parçası. Ama gerçek veri kare gelmez — kolonlar örnekler (hastalar), satırlar öznitelikler (hastalıklar) olabilir; ikisi tamamen farklı boyutlu uzaylardadır.
İpucuBuilder Notu — Örnekler ve Öznitelikler
Bir veri matrisinde kolon uzayı “örneklerin gerebildiği yön kümesi”, satır uzayı ise “özniteliklerin gerebildiği yön kümesi”dir. PCA, kovaryans matrisi \(A^{T}A\) üzerinden tam da satır/kolon uzaylarının baskın yönlerini bulur. Kolon ve satır uzaylarının boyutunun eşit olması (rank), veri matrisinin gerçek bilgi içeriğinin tek bir sayıyla ölçülebilmesini sağlar.
2.9 İspat — CR’yi İki Yönlü Okumak
Kolon rank = satır rank neden doğru? İspat, \(A = CR\) çarpımına iki ayrı gözle bakmakta saklı.
“The proof is really to look at this multiplication, C times R, two ways.” — Strang, 32:54
Birinci okuma (kolon kombinasyonu): A’nın her kolonu, C’nin kolonlarının R tarafından verilen kombinasyonudur. C’nin r tane kolonu var → A’nın kolonları r boyutlu bir uzayı gerer → kolon rank = r.
İkinci okuma (satır kombinasyonu): Aynı çarpım, A’nın her satırının R’nin satırlarının (C’deki sayılarla ağırlıklı) kombinasyonu olduğunu söyler. R’nin r tane satırı var → A’nın satırları en çok r boyutlu bir uzayı gerer → satır rank ≤ r.
İki okuma birlikte: kolon rank = r ve satır rank ≤ r; simetri ile (aynı argümanı \(A^{T}\)’ye uygula) satır rank = r. Demek ki kolon rank = satır rank. Tek bir faktorizasyon, teoremi açığa çıkarıyor.
\[ A = CR \quad \Rightarrow \quad \text{col rank} = \text{row rank} = r \]
İpucuBuilder Notu — Bir Çarpım, İki Hikâye
“Aynı nesneyi iki yönlü oku” tekniği, ML matematiğinde tekrar tekrar karşına çıkar: bir Gram matrisini hem örnekler hem öznitelikler üzerinden okumak (kernel trick), bir dış çarpımı hem ileri hem geri geçişte kullanmak (backprop). Bir çarpımın yapısını iki perspektiften görebilmek, çoğu türetmenin anahtarıdır.
2.10 rref ve CUR Bağlantısı
Bulduğumuz R aslında tanıdık bir nesne: A’nın indirgenmiş satır echelon formu (row reduced echelon form, rref). İçinde birim matris bloğu ve kalan kolonların doğru kombinasyonları oturur.
“It’s called the row reduced echelon form of the matrix, and it’s a big goal in 18.06.” — Strang, 38:49
Yani Phase 1 18.06’nın büyük hedeflerinden biri (rref), burada \(A = CR\) faktorizasyonunun R parçası olarak yeniden karşımıza çıkıyor.
Strang bir alternatif daha gösteriyor: hem C’ye gerçek kolonları, hem de R’ye A’nın gerçek satırlarını koyarsan, ortada her şeyi düzelten küçük bir U matrisi gerekir. Bu, CUR faktorizasyonudur:
\[ A = C \, U \, R \]
“[I] wrote a page about CUR.” — Strang, 40:24
İpucuBuilder Notu — Pratik vs Klasik
CUR, SVD’ye yorumlanabilir bir alternatiftir: C ve R gerçek veri kolonları/satırları olduğundan (soyut tekil vektörler değil), sonuç insan-okunabilir kalır. Genomik, öneri sistemleri ve büyük seyrek matrislerde, “hangi gerçek özellikler önemli?” sorusuna SVD’den daha doğrudan cevap verir.
2.11 Dev Matrisleri Örnekleme
Strang dersin sonuna doğru ileriye bir köprü atıyor. Diyelim ki matrisin boyutu \(10^5 \times 10^5\) — hızlı belleğe sığmaz, tüm girdilerle uğraşmak imkânsız. Ne yaparsın? Örneklersin.
“if you have a giant matrix, like size 10 to the 5th… you sample it.” — Strang, 35:43
Doğal fikir: rastgele bir x vektörü seç, \(Ax\)’e bak. \(Ax\) nerede yaşar?
“Ax is in the column space.” — Strang, 37:02
Yani rastgele tek tek kolon seçmek yerine, rastgele x ile kolonların bir karışımını (\(Ax\)) alırsın; 100 rastgele x, kolon uzayının neye benzediği hakkında çoğu zaman yeterli fikir verir. Strang araya lineer cebirin altın kuralını sıkıştırıyor: \(ABCx\) çarpımı da A’nın kolon uzayındadır, çünkü o “A çarpı bir şey”dir.
“Putting parentheses in the right place is the key to linear algebra.” — Strang, 38:14
İpucuBuilder Notu — Petabyte’tan Megabyte’a
“Rastgele x ile \(Ax\) al” fikri, doğrudan Ders 13’teki rastlantısal lineer cebire (randomized SVD, matris taslaklama/sketching) açılır. Modern büyük-ölçek ML’de dev matrislerin tam SVD’si yerine rastgele projeksiyonlarla düşük-rank yaklaşımı hesaplanır — temelinde tam bu “örnekle ve kolon uzayını yakala” sezgisi yatar.
2.12 Matris × Matris = Dış Çarpımlar Toplamı
Aynı “kolon görüşü”nü matris-matris çarpımına taşı. Alışılmış yol: AB’nin (i,j) girdisi, A’nın i. satırı ile B’nin j. kolonunun nokta çarpımı — başlangıç için iyi, ama yüzeysel.
“the deeper way is columns times row.” — Strang, 46:36
Derin yol: AB’yi, A’nın kolonları çarpı B’nin satırlarının toplamı olarak gör. A’nın k. kolonu (m×1) çarpı B’nin k. satırı (1×p), bir rank-1 matris (m×p) verir; bunları k boyunca topla:
\[ AB = \sum_{k=1}^{n} a_k \, b_k^{T} \]
Burada \(a_k\) = A’nın k. kolonu, \(b_k^{T}\) = B’nin k. satırı. Her terim bir rank-1 dış çarpım; AB bu dış çarpımların toplamı.
“So it’s a sum of outer products.” — Strang, 48:48
Bu, Bölüm 1’deki \(Ax\) fikrinin matrise genellemesidir — ve rank-1 yapı taşı temasının doğal devamı. Şekil 2.7 bu toplamı rank-1 katmanlar olarak gösteriyor: \(a_1 b_1^{T} + a_2 b_2^{T} = AB\).
Kod
Amat = np.array([[1, 2], [3, 4], [5, 6]], dtype=float) # 3×2
Bmat = np.array([[1, 0, 2], [0, 1, 1]], dtype=float) # 2×3
layers, cumulative, prod = ab_outer_layers(Amat, Bmat)
# Ortak renk ölçeği — katmanlar ve çarpım kıyaslanabilir olsun
allM = np.concatenate([layers[0].ravel(), layers[1].ravel(), prod.ravel()])
vmin, vmax = float(allM.min()), float(allM.max())
fig, axes = plt.subplots(1, 3, figsize=(10.5, 4.0))
heatmap(axes[0], layers[0], title="a₁b₁ᵀ (rank-1)",
vmin=vmin, vmax=vmax)
heatmap(axes[1], layers[1], title="a₂b₂ᵀ (rank-1)",
vmin=vmin, vmax=vmax)
heatmap(axes[2], prod, title="AB = Σ dış çarpım",
vmin=vmin, vmax=vmax)
# "+" ve "=" anotasyonları (panel aralarına)
fig.text(0.375, 0.52, "+", ha="center", va="center",
fontsize=26, fontweight="bold", color=COL_PRIMARY)
fig.text(0.645, 0.52, "=", ha="center", va="center",
fontsize=26, fontweight="bold", color=COL_TEAL)
fig.suptitle("Matris çarpımı = rank-1 dış çarpımların toplamı",
color=COL_TEXT, fontsize=13, fontweight="bold", y=1.02)
fig.text(0.5, -0.04,
"Her terim aₖbₖᵀ rank-1'dir; tüm dış çarpımların toplamı AB matrisini verir.",
ha="center", va="center", color=COL_TEXT, fontsize=10)
plt.tight_layout()
plt.show()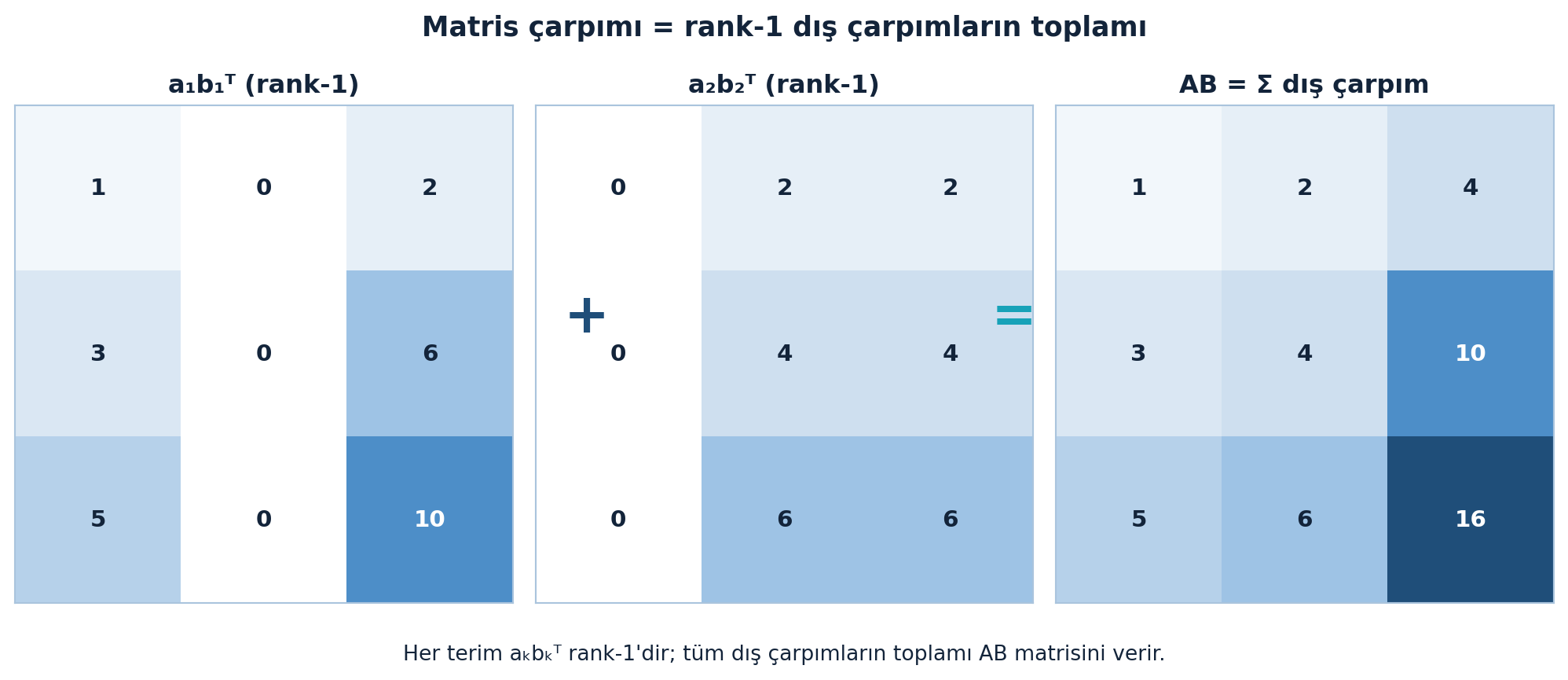
İpucuBuilder Notu — Tek Matrisi N Katmanda Görmek
Dış-çarpım görüşü ML’in her yerinde: attention skoru \(QK^{T}\) bir dış çarpımlar toplamıdır; LoRA güncellemesi \(\Delta W = BA\) tam da düşük sayıda dış çarpımdır; optimizer’larda rank-1 güncellemeler (örneğin BFGS) bu yapıyı kullanır. “Çarpım = dış çarpımlar toplamı” görüşü, hem matematiği hem bellek erişim desenini (GPU’da) anlamanın anahtarıdır.
2.13 Çarpım Maliyeti — mnp
Strang son bir dakikayı maliyete ayırıyor. m×n matris A çarpı n×p matris B kaç çarpma gerektirir?
Eski yol (nokta çarpımı): her girdi için n çarpma, ve sonuç m×p boyutunda → toplam \(n \cdot (mp)\) çarpma.
Yeni yol (dış çarpım): her dış çarpım \(mp\) çarpma, ve n tane dış çarpım var → toplam \((mp) \cdot n\) çarpma.
\[ n \cdot (mp) \;=\; mnp \;=\; (mp) \cdot n \]
İki yol da aynı sayıya, \(mnp\)’ye varır — hatta birebir aynı çarpmaları, sadece farklı sırada yapar.
“they’re exactly the same multiplications, just a different order.” — Strang, 51:56
İpucuBuilder Notu — Hızı Yön Belirler
\(mnp\), matris çarpımının FLOP sayısıdır — ve derin öğrenmenin maliyetinin neredeyse tamamı buradan gelir. GPU’ların TFLOPS değerleri tam da bu \(mnp\)’yi ne kadar hızlı yaptığını ölçer. Eğitim/çıkarım bütçesini tahmin etmek, hangi katmanın pahalı olduğunu görmek ve “aynı çarpmalar farklı sıra” (yani çarpımı yeniden sıralayıp bellek/önbellek verimini artırma — GEMM tiling) hepsi bu tek sayının üstünde durur.
2.14 Bu Dersin Özeti
- Ax = kolonların kombinasyonu — matris-vektör çarpımının “doğru” görüşü; satır-nokta-çarpımı değil.
- Kolon uzayı \(C(A)\) — tüm \(Ax\)’lerin kümesi; A’nın ulaşabildiği uzay.
- Rank = kolon uzayının boyutu = bağımsız kolon sayısı.
- Rank-1 matris = kolon × satır (dış çarpım) — lineer cebirin ve veri biliminin yapı taşı.
- A = CR faktorizasyonu — C bağımsız kolonları, R kombinasyon reçetesini (rref) taşır.
- Kolon rank = satır rank — ilk büyük teorem; \(A = CR\)’yi iki yönlü okuyarak kanıtlanır.
- Satır uzayı = \(C(A^{T})\) — yeni bir harf icat etmeye gerek yok.
- AB = dış çarpımlar toplamı, maliyeti \(mnp\); dev matrisler rastgele x ile (\(Ax\)) örneklenir.
ÖnemliTek Bir Cümle
\(A = CR\) — her matris, bağımsız kolonlarını (C) çarpı o kolonlardan geri kalan kolonları kuran reçeteyi (R) içerir; kolon rank = satır rank tam da bu yüzden doğrudur.
2.15 Kontrol Soruları
NotSoru 1: Aşağıdaki matrisin A = CR faktorizasyonunu bul (C bağımsız kolonlar, R kombinasyon reçetesi).
\[ A = \begin{pmatrix} 1 & 0 & 1 \\ 2 & 1 & 3 \\ 0 & 1 & 1 \end{pmatrix} \]
Cevap:
Kolon 1 = (1,2,0) ve kolon 2 = (0,1,1) bağımsız. Kolon 3 = (1,3,1) = kolon 1 + kolon 2 → bağımlı, alınmaz.
\[ C = \begin{pmatrix} 1 & 0 \\ 2 & 1 \\ 0 & 1 \end{pmatrix}, \quad R = \begin{pmatrix} 1 & 0 & 1 \\ 0 & 1 & 1 \end{pmatrix} \]
Doğrula: C·R = A ✓. Rank 2 (iki bağımsız kolon, kolon uzayı bir düzlem).
NotSoru 2: Bu matriste kolon rank’ı ve satır rank’ı ayrı ayrı bul. Eşit mi çıkıyor?
\[ A = \begin{pmatrix} 1 & 2 \\ 2 & 4 \\ 3 & 6 \end{pmatrix} \]
Cevap:
Kolon rank: ikinci kolon (2,4,6) = 2·(birinci kolon). Tek bağımsız kolon → kolon rank = 1.
Satır rank: tüm satırlar (1,2)’nin katı — (1,2), (2,4) = 2·(1,2), (3,6) = 3·(1,2). Tek bağımsız satır → satır rank = 1.
Eşit: kolon rank = satır rank = 1 ✓. (Genel kural: rank ≤ min(m,n); burada üst sınır min(3,2) = 2, gerçek rank 1.)
NotSoru 3: Aşağıdaki rank-1 matrisi bir kolon vektörü çarpı bir satır vektörü (dış çarpım) olarak yaz.
\[ A = \begin{pmatrix} 2 & 4 & 6 \\ 3 & 6 & 9 \end{pmatrix} \]
Cevap:
Tüm kolonlar (2,3)’ün katı, tüm satırlar (1,2,3)’ün katı. Demek ki:
\[ A = \begin{pmatrix} 2 \\ 3 \end{pmatrix} \begin{pmatrix} 1 & 2 & 3 \end{pmatrix} \]
2×1 çarpı 1×3 = 2×3, rank 1. Bu, SVD’nin tek bir rank-1 parçasının ta kendisidir (Ders 6-7’nin habercisi).
NotSoru 4: Bir m×n ağırlık matrisi rank r ise onu kaç sayıyla saklarsın? Bu neden LoRA’nın temeli?
Cevap:
Rank r matris \(A = CR\) biçiminde yazılır: C boyutu m×r, R boyutu r×n. Toplam saklanan sayı \(m \cdot r + r \cdot n = r(m+n)\).
Tam matris \(mn\) sayı tutar. \(r \ll \min(m,n)\) olduğunda \(r(m+n) \ll mn\) — büyük tasarruf.
Örnek: m = n = 1000, r = 8 → tam matris \(10^6\) sayı; düşük-rank temsil 8·2000 = 16.000 sayı (≈60× az).
LoRA tam da bunu yapar: ağırlık güncellemesini \(\Delta W = BA\) (düşük-rank) olarak saklar ve dev modeli çok az parametreyle fine-tune eder. “Rank = gerçek serbestlik derecesi” sezgisinin doğrudan uygulamasıdır.
2.16 Egzersizler
Cevapsız problemler. Çöz, sonra numpy ile kontrol et.
Egzersiz 1. Aşağıdaki 3×4 matrisin \(A = CR\) faktorizasyonunu bul. Bağımsız kolonları soldan sağa seç, sonra R’yi kur.
\[ A = \begin{pmatrix} 1 & 0 & 2 & 1 \\ 0 & 1 & 1 & 3 \\ 1 & 1 & 3 & 4 \end{pmatrix} \]
Egzersiz 2. İki aşamalı: (a) Aşağıdaki matrisin rankını bul. (b) Kolon uzayı için bir baz yaz. (c) \(A = CR\)’deki R matrisini kur.
\[ A = \begin{pmatrix} 2 & 4 & 1 \\ 1 & 2 & 0 \\ 3 & 6 & 2 \end{pmatrix} \]
Egzersiz 3. Yapısal soru: Bir matrisin tüm kolonları bağımsızsa (rank = kolon sayısı), \(A = CR\) faktorizasyonundaki R ne olur? Bir de: A’nın bir kolonu tamamen sıfırsa, o kolon C’ye girer mi, R’de nasıl görünür?
Egzersiz 4. Python ile doğrula:
import numpy as np
A = np.array([[1, 0, 2, 1],
[0, 1, 1, 3],
[1, 1, 3, 4]], dtype=float)
print("rank:", np.linalg.matrix_rank(A)) # bağımsız kolon sayısı
# Rastgele x ile Ax her zaman kolon uzayında:
x = np.random.randn(4)
b = A @ x
print("Ax (kolon uzayında bir vektör):", b)
# 3. ve 4. kolonun ilk ikisinden kuruluşunu kontrol et:
c1, c2 = A[:, 0], A[:, 1]
print("2*c1 + c2 == kolon 3 ?", np.allclose(2*c1 + c2, A[:, 2]))
print("c1 + 3*c2 == kolon 4 ?", np.allclose(c1 + 3*c2, A[:, 3]))Egzersiz 5. (Ders 2 habercisi.) Strang Ders 2’de matrisin beş büyük faktorizasyonunu tanıtıyor: A = LU (eliminasyon), A = QR (ortonormallik), \(A = Q\Lambda Q^{T}\) (özdeğerler), \(A = U\Sigma V^{T}\) (SVD) ve bu derste gördüğümüz A = CR (rank). Aşağıdaki matris için eliminasyon yapıp U üst üçgensel formunu bul; sonra \(A = CR\) ile A = LU’nun neyi açığa çıkardığını (biri rankı, diğeri eliminasyon adımlarını) bir cümleyle karşılaştır.
\[ A = \begin{pmatrix} 2 & 1 \\ 6 & 8 \end{pmatrix} \]
2.17 Sonraki Ders İçin Hazırlık
Ders 2: Matrisleri Çarpmak ve Çarpanlara Ayırmak
Ders 1’de tek bir faktorizasyon (\(A = CR\)) ve “matrise bütün olarak bakma” fikrini gördük. Ders 2 bunu genişletiyor: matris çarpımının farklı görünüşleri ve matrisin beş temel faktorizasyonu.
- Matris çarpımının dört farklı görünüşü (özellikle kolon × satır / dış çarpım)
- Beş büyük faktorizasyon: LU, QR, \(Q\Lambda Q^{T}\), SVD, CR
- Her faktorizasyonun hangi soruyu cevapladığı (eliminasyon, ortonormallik, özdeğer, tekil değer, rank)
UyarıDers 2 Öncesi Yapılacak
- Bu dersin egzersizlerini çöz, özellikle Egzersiz 5’i (LU önizlemesi).
- Python’da birkaç matrisin rankını
np.linalg.matrix_rankile bul; rank-1 ve rank-2 matrisleri gözle ayırt et. - Ana cümleyi tekrar oku: “A = CR — bağımsız kolonlar çarpı kombinasyon reçetesi; kolon rank = satır rank.”
2.18 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Strang’de |
|---|---|---|
| Ax = kolon kombinasyonu | \(Ax\), A’nın kolonlarının x ile ağırlıklı toplamıdır | 7m32 |
| Kolon uzayı \(C(A)\) | Tüm \(Ax\)’lerin kümesi; kolonların gerdiği uzay | 8m17 |
| Rank | Kolon uzayının boyutu, yani bağımsız kolon sayısı | 13m56 |
| Rank-1 = kolon × satır | Bir kolon çarpı bir satır; dış çarpım, yapı taşı | 13m56 |
| Baz | Bağımsız kolonlar; soldan sağa seçilir | 15m51 |
| A = CR | C bağımsız kolonlar, R kombinasyon reçetesi | 21m04 |
| Kolon rank = satır rank | İlk büyük teorem; bağımsız kolon sayısı = bağımsız satır sayısı | 23m44 |
| Satır uzayı = \(C(A^{T})\) | Satırların kombinasyonları; transpozun kolon uzayı | 27m25 |
| CR iki yönlü okuma | Kolon ve satır rankının eşitliğinin ispatı | 32m54 |
| R = rref | R, indirgenmiş satır echelon formudur; 18.06’nın hedefi | 38m49 |
| CUR | Gerçek kolonlar C, gerçek satırlar R, orta matris U | 40m24 |
| Dev matris örnekleme | Rastgele x ile \(Ax\) kolon uzayını yoklar (randomized LA) | 35m43 |
| AB = dış çarpımlar toplamı | AB, kolonₖ çarpı satırₖ rank-1 parçaların toplamı | 48m48 |
| Maliyet \(mnp\) | m×n çarpı n×p çarpımının çarpma sayısı | 51m56 |
2.19 ML Bağlantıları Özeti
- Ax = kolon kombinasyonu → GEMM/BLAS matris çarpımını kolon ve blok kombinasyonları olarak yapar; performans sezgisinin temeli.
- Rank-1 = dış çarpım → SVD, PCA ve LoRA hepsi rank-1 parçaların toplamı üstünde durur.
- A = CR / düşük-rank → yorumlanabilir sıkıştırma; CUR, öneri sistemleri, genomik gerçek kolon/satır seçer.
- Rank = serbestlik derecesi → ağırlık matrislerinin etkin rankı, model budama ve sıkıştırılabilirliği belirler.
- Kolon uzayı \(C(A)\) → \(Ax = b\) ne zaman çözülür (b ∈ \(C(A)\)); değilse least squares projeksiyonu (Ders 9-11).
- Dev matris örnekleme (rastgele x) → randomized SVD, matris taslaklama/sketching (Ders 13).
- AB = dış çarpımlar, maliyet \(mnp\) → GPU TFLOPS, attention \(QK^{T}\), eğitim/çıkarım maliyetinin fiziksel limiti.
ÖnemliTek bir şey alıp gideceksen
Bir matrise kolonları üstünden bak. \(Ax\) kolonların kombinasyonudur, \(C(A)\) onların gerdiği uzaydır, rank o uzayın boyutudur — ve \(A = CR\) bu yapıyı açığa çıkarıp kolon rank = satır rank teoremini bedavaya verir. Sıkıştırmadan rastlantısal cebire, LoRA’dan GPU’daki GEMM’e kadar tüm veri-odaklı lineer cebir bu tek görüşün üstünde durur.