flowchart TD
M["5 Faktorizasyon"] --> LU["A = LU — eliminasyon"]
M --> QR["A = QR — ortonormallik"]
M --> S["S = QΛQᵀ — özdeğer"]
M --> SVD["A = UΣVᵀ — SVD (her matris)"]
M --> CR["A = CR — rank"]
style M fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style LU fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style QR fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style S fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
style SVD fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style CR fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
3 Beş Faktorizasyon — Matrisleri Çarpmak ve Çarpanlara Ayırmak
Her faktorizasyon farklı bir soruyu cevaplar
NotBölüm bilgisi
- Video: Multiplying and Factoring Matrices — Gilbert Strang, MIT 18.065
- OCW: Lecture 2 — Multiplying and Factoring Matrices
- Okuma süresi: ≈ 35 dk
- Önkoşul: 18.06 (lineer cebir) + Ders 1 (\(A = CR\) ve kolon görüşü)
3.1 Bu Derste Ne Var?
Ders 1’de \(A = CR\)’yi ve “matrise kolonları üstünden bakma” fikrini gördük. Ders 2 bunu beş büyük faktorizasyona genişletiyor ve matris çarpımının “kolon × satır” görüşünü derinleştiriyor; sonunda lineer cebirin temel teoremi (dört alt-uzay) geliyor.
Üç temel fikir:
- Beş faktorizasyon: \(A = LU\), \(A = QR\), \(S = Q\Lambda Q^{T}\), \(A = U\Sigma V^{T}\), \(A = CR\) — her biri bir soruyu cevaplar.
- Spektral teorem: simetrik \(S\), rank-1 parçaların toplamıdır (\(S = \sum_k \lambda_k q_k q_k^{T}\)); matris çarpımı = dış çarpımlar toplamı temasının devamı.
- Dört temel alt-uzay: \(C(A)\), \(C(A^{T})\), \(N(A)\), \(N(A^{T})\) — boyutları \(r\), \(r\), \(n-r\), \(m-r\).
Beş faktorizasyonun haritası Şekil 3.1’de: her dal bir matris ayrışımı, her ayrışım bir soru.
“…like LU or QR, would be the most used MATLAB commands in linear algebra.” — Strang, 1:29
İpucuBuilder Notu — Faktorizasyon Haritası
- Faktorizasyon = doğru soruyu sormak: LU eliminasyonu, QR ortonormalliği, \(Q\Lambda Q^{T}\) özdeğerleri, \(U\Sigma V^{T}\) tekil değerleri, CR rankı açığa çıkarır. NumPy ve PyTorch’un lineer cebir modülleri bu beşinin üstüne kuruludur.
- Spektral teorem → PCA: kovaryans matrisi simetriktir; \(S = \sum_k \lambda_k q_k q_k^{T}\) ayrışımı, ana bileşenlerin (en büyük \(\lambda\)’lar) tam tanımıdır.
- SVD = her matris için: dikdörtgen ağırlık matrisleri özdeğer ayrışımına sahip olmayabilir, ama SVD’si her zaman vardır — düşük-rank sıkıştırma, LoRA, PCA hepsi buradan.
- Dört alt-uzay → çözülebilirlik: \(Ax = b\) ne zaman çözülür (\(b \in C(A)\)), çözüm ne zaman tektir (\(N(A) = \{0\}\)) — least squares ve regularizasyonun geometrik temeli.
Tek cümle: bir matrisi “hangi faktorizasyon hangi soruyu cevaplıyor” diye görmek, sayısal lineer cebirin ve ML araç kutusunun haritasıdır.
3.2 Beş Büyük Faktorizasyon
Strang dersi, bir matrisin beş temel çarpanlamasını sıralayarak açıyor — her biri farklı bir soruyu cevaplar:
\[ A = LU, \quad A = QR, \quad S = Q\Lambda Q^{T}, \quad A = U\Sigma V^{T}, \quad A = CR \]
- \(A = LU\) — eliminasyon (alt üçgensel çarpı üst üçgensel)
- \(A = QR\) — ortonormallik (Gram-Schmidt; least squares)
- \(S = Q\Lambda Q^{T}\) — simetrik matrisin özdeğer ayrışımı (spektral teorem)
- \(A = U\Sigma V^{T}\) — tekil değer ayrışımı (SVD); her matris için
- \(A = CR\) — rank (Ders 1)
“I want to illustrate that by the five key factorizations of matrices.” — Strang, 1:12
İpucuBuilder Notu — numpy.linalg’in İskeleti
Bu beş satır, sayısal lineer cebirin tüm haritasıdır: numpy.linalg ve torch.linalg modüllerindeki her rutin (solve, lstsq, eig, svd, qr) bunlardan birine dayanır. Hangi problemde hangi faktorizasyonu çağıracağını bilmek, ML mühendisliğinin sessiz ama kritik bir becerisidir.
3.3 \(A = LU\) — Eliminasyon
İlk faktorizasyon en tanıdık olanı: \(Ax = b\) çözerken yaptığın satır işlemleri. Strang’in vurgusu, bu işlemlerin tam olarak bir matris çarpımına denk geldiği:
“all those row operations that you do are perfectly expressed by L times U.” — Strang, 17:20
\(L\) alt üçgensel (köşegende 1’ler, altında eliminasyon çarpanları), \(U\) üst üçgensel (köşegende pivotlar):
\[ A = LU \]
Bu, Phase 1 18.06 Ders 4’ün tam konusudur. 18.065’te aynı çarpanlamayı yeni bir gözle — kolon çarpı satır, yani rank-1 soyma olarak — Bölüm 8’de yeniden göreceğiz.
İpucuBuilder Notu — solve() Ne Yapar?
numpy.linalg.solve(A, b) arka planda \(A = LU\) yapar (LAPACK getrf), sonra iki üçgensel sistemi çözer. Aynı \(A\) ile çok sayıda \(b\) çözeceksen LU’yu bir kez hesaplayıp sakla: \(n^3\) yerine her \(b\) için \(n^2\) maliyet.
3.4 \(A = QR\) — Ortonormallik
İkinci faktorizasyon \(Q\)’nun ortonormal kolonlarına dayanır: kolonlar birbirine dik ve birim uzunlukta, yani \(Q^{T}Q = I\).
“Orthogonal. The columns are orthogonal. Often orthonormal.” — Strang, 2:31
\[ A = QR \]
\(Q\) ortonormal kolonları, \(R\) üst üçgensel matrisi taşır. Üretici algoritma Gram-Schmidt’tir (Phase 1 18.06 Ders 17). En büyük uygulaması least squares: normal denklemleri (\(A^{T}A\)) doğrudan çözmek yerine QR kullanmak sayısal olarak çok daha kararlıdır.
Gram-Schmidt’in bağımsız kolonları nasıl ortonormal \(Q\)’ya dönüştürdüğü Şekil 3.2’te görülüyor: ham kolonlardan izdüşüm çıkarılıp normalleştirilir, sonuç dik birim vektörlerdir.
Kod
from matplotlib.lines import Line2D
# Gram-Schmidt: bağımsız kolonlar a1=(2,1), a2=(1,2) -> ortonormal Q
A = np.array([[2.0, 1.0],
[1.0, 2.0]]) # kolonlar: a1=(2,1), a2=(1,2)
Q, R, steps = gram_schmidt(A)
a1 = A[:, 0]
a2 = A[:, 1]
q1 = Q[:, 0] # a1 normalize (navy)
q2 = Q[:, 1] # a2 - projeksiyon, normalize (çelik)
proj = R[0, 1] * q1 # a2'nin q1 üzerine izdüşümü
u2 = steps[1]["u"] # a2 - proj (ortogonalize, henüz normalize değil)
fig, ax = plt.subplots(figsize=(6.6, 6.4))
fig.patch.set_facecolor(COL_WHITE)
style_square_axes(ax, lim=2.6)
# --- ham kolonlar (soluk) ---
ax.quiver(0, 0, a1[0], a1[1], angles="xy", scale_units="xy", scale=1,
color=COL_STEEL_300, width=0.011, zorder=2)
ax.quiver(0, 0, a2[0], a2[1], angles="xy", scale_units="xy", scale=1,
color=COL_STEEL_300, width=0.011, zorder=2)
ax.text(a1[0] + 0.06, a1[1] - 0.18, r"$a_1$", color=COL_STEEL_300,
fontsize=13, fontweight="bold")
ax.text(a2[0] + 0.06, a2[1] + 0.04, r"$a_2$", color=COL_STEEL_300,
fontsize=13, fontweight="bold")
# --- projeksiyon-çıkarma: a2 ucundan u2 ucuna kesikli ok (orange) ---
# Gram-Schmidt çıkarma: a2'den q1 üzerine izdüşümü çıkar -> u2.
ax.annotate("", xy=(u2[0], u2[1]), xytext=(a2[0], a2[1]),
arrowprops=dict(arrowstyle="-|>", color=COL_VEC3,
lw=2.0, ls="--", shrinkA=0, shrinkB=0),
zorder=4)
# çıkarılan izdüşüm bileşenini gösteren ince yardımcı çizgi (proj vektörü)
ax.plot([0, proj[0]], [0, proj[1]], color=COL_VEC3, lw=1.2, ls=":", zorder=2)
ax.text(0.5 * (a2[0] + u2[0]) + 0.10, 0.5 * (a2[1] + u2[1]),
r"$-\,\mathrm{proj}_{q_1} a_2$", color=COL_VEC3,
fontsize=11, fontweight="bold")
# --- ortonormal vektörler q1 (navy), q2 (çelik) ---
ax.quiver(0, 0, q1[0], q1[1], angles="xy", scale_units="xy", scale=1,
color=COL_VEC1, width=0.016, zorder=5)
ax.quiver(0, 0, q2[0], q2[1], angles="xy", scale_units="xy", scale=1,
color=COL_VEC2, width=0.016, zorder=5)
ax.text(q1[0] + 0.08, q1[1] - 0.14, r"$q_1$", color=COL_VEC1,
fontsize=14, fontweight="bold")
ax.text(q2[0] - 0.34, q2[1] + 0.06, r"$q_2$", color=COL_VEC2,
fontsize=14, fontweight="bold")
# --- dik açı işareti (q1 ⊥ q2): orijinde küçük kare ---
d = 0.20
sq = np.array([q1 * d, q1 * d + q2 * d, q2 * d, [0, 0]])
ax.plot(np.append(sq[:, 0], sq[0, 0]), np.append(sq[:, 1], sq[0, 1]),
color=COL_TEXT, lw=1.3, zorder=6)
# legend (proxy)
handles = [
Line2D([0], [0], color=COL_STEEL_300, lw=3, label="ham kolonlar $a_1, a_2$"),
Line2D([0], [0], color=COL_VEC3, lw=2, ls="--",
label="izdüşüm çıkarma"),
Line2D([0], [0], color=COL_VEC1, lw=3, label="$q_1$ (ortonormal)"),
Line2D([0], [0], color=COL_VEC2, lw=3, label="$q_2$ (ortonormal)"),
]
ax.legend(handles=handles, loc="lower right", fontsize=9.5,
framealpha=0.92, edgecolor=COL_STEEL_300)
# adımları gösteren açıklama kutusu (steps kullanarak)
info = (f"ham: $a_2$ = ({a2[0]:.0f}, {a2[1]:.0f})\n"
f"ort: $u_2 = a_2 - (q_1^{{T}}a_2)\\,q_1$ = ({u2[0]:.1f}, {u2[1]:.1f})\n"
f"norm: $q_2 = u_2/\\|u_2\\|$ = ({q2[0]:.2f}, {q2[1]:.2f})")
ax.text(-2.5, -2.45, info, fontsize=8.6, color=COL_TEXT, va="bottom", ha="left",
bbox=dict(boxstyle="round,pad=0.4", fc=COL_BG, ec=COL_STEEL_300, lw=0.8))
ax.set_title("Gram-Schmidt: bağımsız kolonlar → ortonormal Q ($Q^{T}Q = I$)",
color=COL_PRIMARY, fontsize=13, fontweight="bold", pad=12)
plt.show()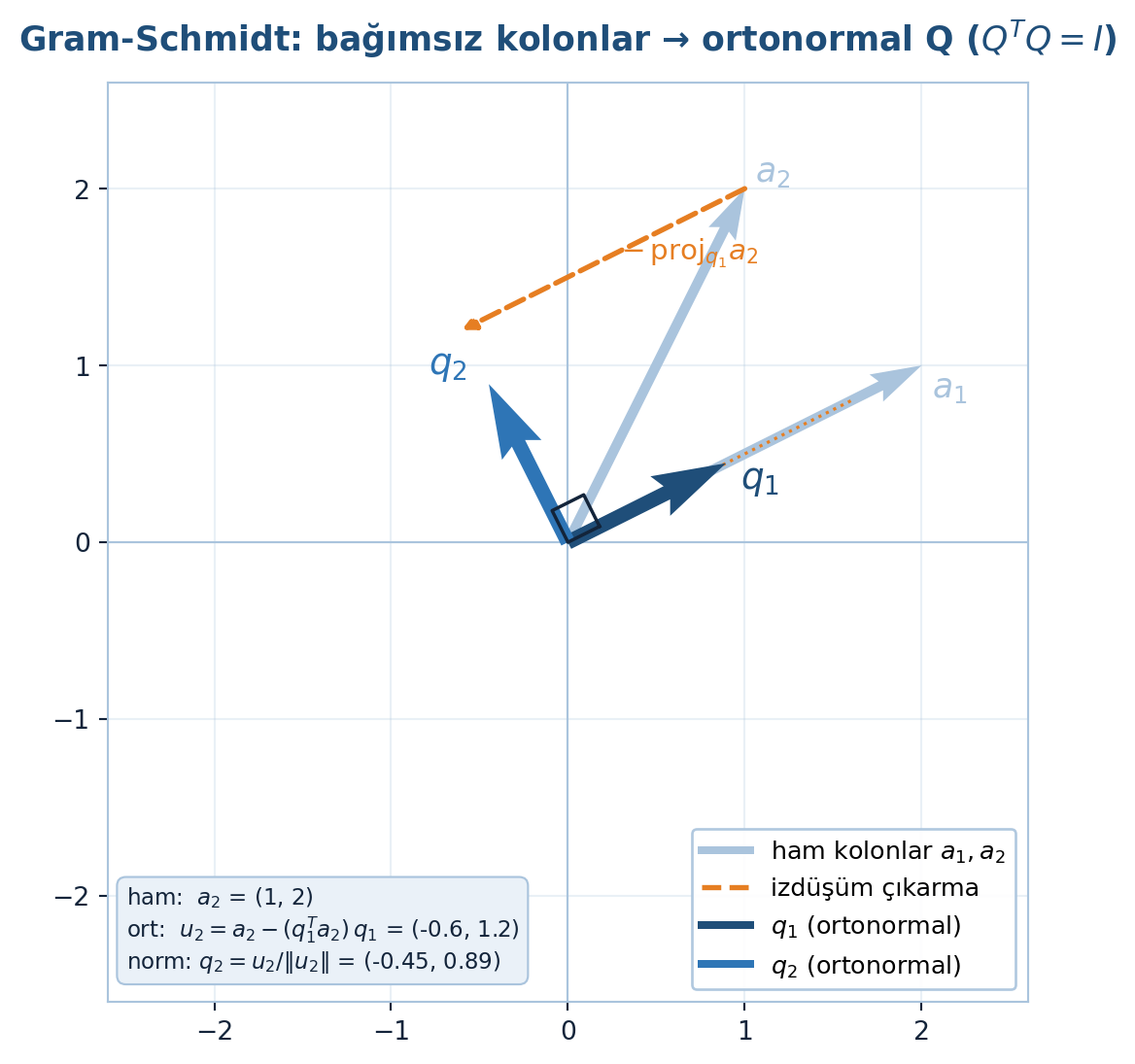
İpucuBuilder Notu — Kararlı Yol
QR, least squares’in (Ders 9) güvenilir yoludur. Derin öğrenmede ortonormal matrisler gradyan patlamasını/sönmesini önler (orthogonal initialization, ortonormal RNN ağırlıkları); QR ayrıca modern özdeğer algoritmalarının (QR iteration, Ders 12) çekirdeğidir.
3.5 \(S = Q\Lambda Q^{T}\) — Simetrik Matrisler ve Spektral Teorem
Üçüncü faktorizasyon simetrik matrisler içindir (\(S = S^{T}\)) ve Strang’e göre lineer cebirin en güzel sonucu:
\[ S = Q\Lambda Q^{T} \]
Burada \(\Lambda\) köşegen özdeğer matrisi, \(Q\) ise özvektörleri taşır. İki olağanüstü özellik:
- Özvektörler ortonormaldir — \(Q\) ortogonal matris, \(Q^{T}Q = I\).
- Özdeğerler gerçektir — \(\lambda\)’lar reel sayı.
“Orthogonal matrices are the queens, and symmetric matrices are the kings.” — Strang, 4:59 “They’re all real. So eigenvalues are real.” — Strang, 5:35
İpucuBuilder Notu — Simetrik Krallar
Simetrik matrisler ML’de her yerde: kovaryans matrisi, Gram matrisi (kernel), Hessian. Hepsi gerçek özdeğerli ve ortonormal özvektörlü — bu yüzden PCA, kernel yöntemleri ve ikinci-derece optimizasyon iyi tanımlıdır.
3.6 Spektral Teorem — Rank-1 Parçaların Toplamı
Ders 1’in “çarpım = dış çarpımlar toplamı” teması burada simetrik matrise uygulanıyor. \(S = Q\Lambda Q^{T}\)’yi kolon çarpı satır olarak açarsak, \(S\) bir rank-1 parçalar toplamına dönüşür:
“this is a sum of rank 1.” — Strang, 8:21
\[ S = \lambda_1 q_1 q_1^{T} + \lambda_2 q_2 q_2^{T} + \cdots + \lambda_n q_n q_n^{T} = \sum_{k=1}^{n} \lambda_k q_k q_k^{T} \]
Her parça \(\lambda_k q_k q_k^{T}\) simetrik bir rank-1 matristir. Doğruluğunu \(S\)’yi \(q_1\) ile çarparak görürüz: ortonormallik sayesinde \(q_k^{T} q_1 = 0\) (\(k \neq 1\)) ve \(q_1^{T} q_1 = 1\), yani tüm terimler düşer, geriye \(\lambda_1 q_1\) kalır:
\[ S q_1 = \lambda_1 q_1 (q_1^{T} q_1) + \lambda_2 q_2 (q_2^{T} q_1) + \cdots = \lambda_1 q_1 \]
“This is called the spectral theorem.” — Strang, 10:39
Spektral ayrışımın bileşenleri Şekil 3.3’de görselleştirilmiş: solda özdeğer çubukları (en büyüğü baskın), sağda rank-1 izdüşümler \(\lambda_1 q_1 q_1^{T} + \lambda_2 q_2 q_2^{T} = S\) olarak toplanıyor.
Kod
S = np.array([[2.0, 1.0], [1.0, 2.0]])
layers, cum, vals = spectral_layers(S)
fig = plt.figure(figsize=(11.0, 4.8))
gs = fig.add_gridspec(1, 2, width_ratios=[2, 3], wspace=0.30)
# ================= SOL PANEL: Özdeğerler =================
axL = fig.add_subplot(gs[0])
bar_values(axL, vals, ["λ₁", "λ₂"], title="Özdeğerler", highlight=[0])
axL.set_ylim(0, vals.max() * 1.18)
# ================= SAĞ PANEL: rank-1 toplam =================
gsR = gs[1].subgridspec(1, 3, wspace=0.42)
ax0 = fig.add_subplot(gsR[0])
ax1 = fig.add_subplot(gsR[1])
ax2 = fig.add_subplot(gsR[2])
# ortak renk ölçeği (üç heatmap aynı skalada okunsun)
all_M = np.concatenate([layers[0].ravel(), layers[1].ravel(), S.ravel()])
vmin = float(all_M.min())
vmax = float(all_M.max())
heatmap(ax0, layers[0], title="λ₁ q₁ q₁ᵀ", vmin=vmin, vmax=vmax,
fmt="{:.1f}", fontsize=12)
heatmap(ax1, layers[1], title="λ₂ q₂ q₂ᵀ", vmin=vmin, vmax=vmax,
fmt="{:.1f}", fontsize=12)
heatmap(ax2, S, title="S", vmin=vmin, vmax=vmax, fmt="{:.1f}", fontsize=12)
# "+" ve "=" işaretleri (heatmap'ler arası)
for axa, axb, sym in [(ax0, ax1, "+"), (ax1, ax2, "=")]:
x = 0.5 * (axa.get_position().x1 + axb.get_position().x0)
y = 0.5 * (axa.get_position().y0 + axa.get_position().y1)
fig.text(x, y, sym, ha="center", va="center",
fontsize=24, color=COL_PRIMARY, fontweight="bold")
fig.suptitle("Spektral teorem: S = Σ λₖ qₖ qₖᵀ (rank-1 parçalar)",
color=COL_PRIMARY, fontsize=15, fontweight="bold", y=1.04)
plt.show()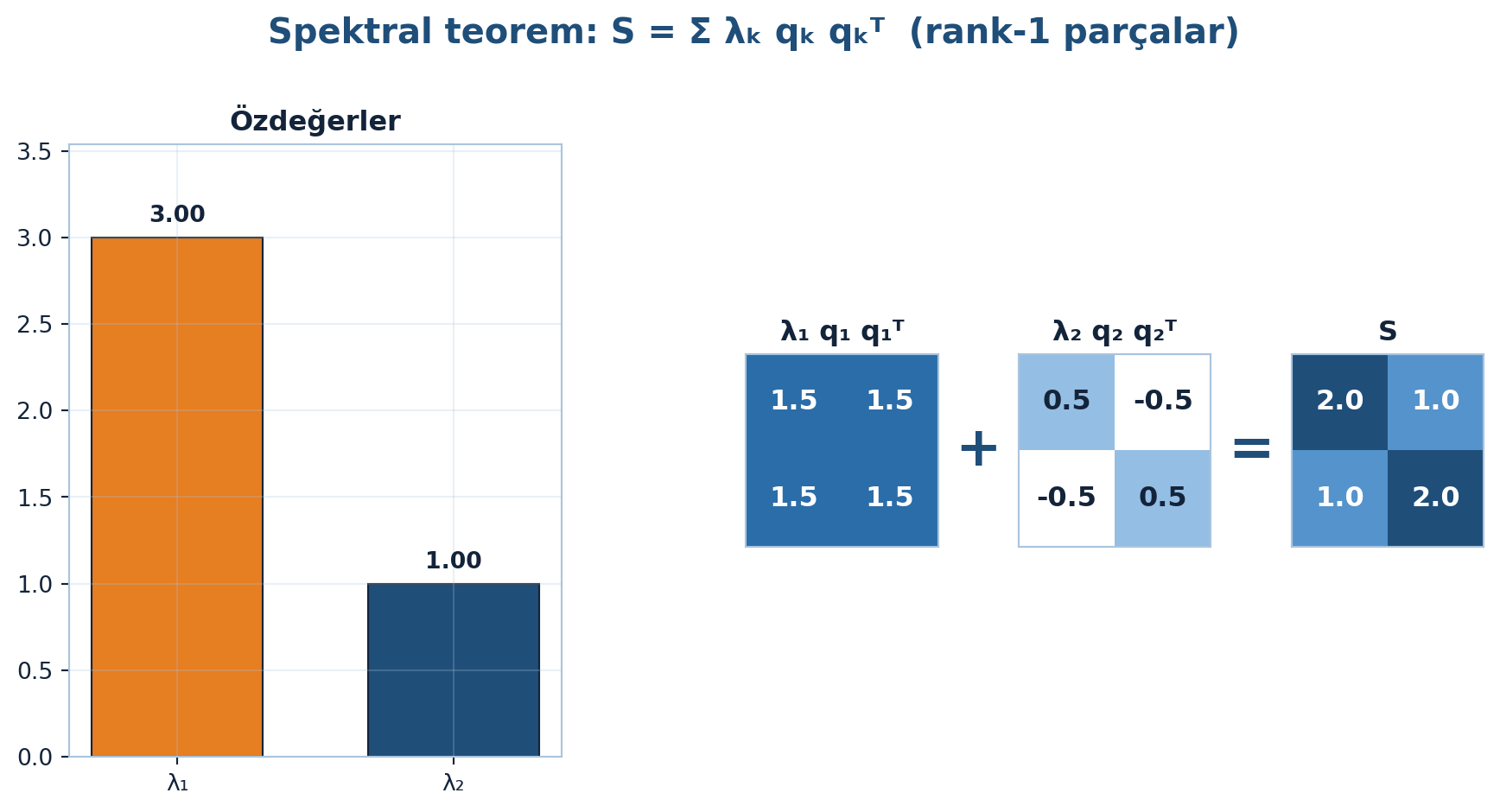
İpucuBuilder Notu — PCA’nın Ta Kendisi
\(S = \sum_k \lambda_k q_k q_k^{T}\) ayrışımı PCA’nın ta kendisidir: en büyük \(\lambda\)’lara karşılık gelen \(q_k\) yönleri verinin ana bileşenleridir. Birkaç büyük terimi tutmak = düşük-rank yaklaşım = boyut indirgeme. Aynı yapı Ders 7’de (Eckart-Young) SVD ile genelleşir.
3.7 \(A = U\Sigma V^{T}\) — SVD, Her Matris İçin
Dördüncü faktorizasyon, kursun ve tüm veri biliminin temel taşı:
\[ A = U\Sigma V^{T} \]
\(U\) ve \(V\) iki ayrı ortogonal matris, \(\Sigma\) köşegen tekil değer matrisi. Özdeğer ayrışımının aksine SVD dikdörtgen matrisler için de çalışır.
“it’s going to be a foundational factorization [for this course and for all of data science].” — Strang, 14:54 “The point is it works for every matrix.” — Strang, 16:04
Simetrik özdeğer ayrışımı \(Q\Lambda Q^{T}\) tek bir özvektör kümesi kullanır ve her matriste yeterli özvektör bulunmayabilir; SVD ise iki tekil vektör kümesi (\(U\) ve \(V\)) kullandığından bu sorun ortadan kalkar. Ayrıntısı Ders 6’da.
SVD’nin geometrisi Şekil 3.4’te üç adımla görülüyor: \(V^{T}\) döndürür, \(\Sigma\) gerer, \(U\) yeniden döndürür — birim çember eğik bir elipse dönüşür. Bu yapı en iyi düşük-rank yaklaşımı da verir; Şekil 3.5 tekil değer düşüşünü ve rank arttıkça hatanın düşmesini gösteriyor.
Kod
A = np.array([[3.0, 0.0], [4.0, 5.0]])
g = svd_unit_circle(A, 200)
U, s, Vt = g["U"], g["s"], g["Vt"]
V = Vt.T # sağ tekil vektörler (V kolonları)
lim = 7.0
fig, axes = plt.subplots(1, 4, figsize=(15, 4.2))
fig.patch.set_facecolor(COL_WHITE)
vec_cols = [COL_PRIMARY, COL_VEC3] # navy / orange
# --- Panel 1: birim çember + V eksenleri ---
ax = axes[0]
style_square_axes(ax, lim, title="birim çember")
plot_pointset(ax, g["circle"], color=COL_STEEL_300)
for i in range(2):
vx, vy = V[0, i], V[1, i]
ax.quiver(0, 0, vx, vy, angles="xy", scale_units="xy", scale=1,
color=vec_cols[i], width=0.012, zorder=5)
ax.text(vx * 1.25, vy * 1.25, f"v{i+1}", color=vec_cols[i],
fontsize=11, fontweight="bold", ha="center", va="center")
# --- Panel 2: Vᵀ döndür ---
ax = axes[1]
style_square_axes(ax, lim, title="Vᵀ (döndür)")
plot_pointset(ax, g["after_Vt"], color=COL_STEEL_300)
for i in range(2):
# Vᵀ uygulandıktan sonra vᵢ → standart eksenlere (eᵢ) döner
e = Vt @ V[:, i]
ax.quiver(0, 0, e[0], e[1], angles="xy", scale_units="xy", scale=1,
color=vec_cols[i], width=0.012, zorder=5)
ax.text(e[0] * 1.25, e[1] * 1.25, f"v{i+1}", color=vec_cols[i],
fontsize=11, fontweight="bold", ha="center", va="center")
# --- Panel 3: ΣVᵀ ger → elips (eksen-hizalı) ---
ax = axes[2]
style_square_axes(ax, lim, title="ΣVᵀ (ger → elips)")
plot_pointset(ax, g["after_SigVt"], color=COL_ACCENT)
for i in range(2):
e = Vt @ V[:, i]
ax.quiver(0, 0, s[i] * e[0], s[i] * e[1], angles="xy",
scale_units="xy", scale=1, color=vec_cols[i],
width=0.012, zorder=5)
ax.text(s[i] * e[0] * 1.12, s[i] * e[1] * 1.12, f"σ{i+1}",
color=vec_cols[i], fontsize=11, fontweight="bold",
ha="center", va="center")
# --- Panel 4: UΣVᵀ = A + tekil eksenler ---
ax = axes[3]
style_square_axes(ax, lim, title="UΣVᵀ = A")
plot_pointset(ax, g["after_A"], color=COL_ACCENT)
for i in range(2):
axis = U[:, i] * s[i] # i. tekil eksen: σᵢ uᵢ
ax.quiver(0, 0, axis[0], axis[1], angles="xy", scale_units="xy",
scale=1, color=vec_cols[i], width=0.012, zorder=5)
ax.text(axis[0] * 1.14, axis[1] * 1.14, f"σ{i+1}u{i+1}",
color=vec_cols[i], fontsize=10.5, fontweight="bold",
ha="center", va="center")
fig.suptitle("SVD geometrisi: döndür (Vᵀ) → ger (Σ) → döndür (U)",
fontsize=14, fontweight="bold", color=COL_PRIMARY, y=1.04)
fig.tight_layout()
plt.show()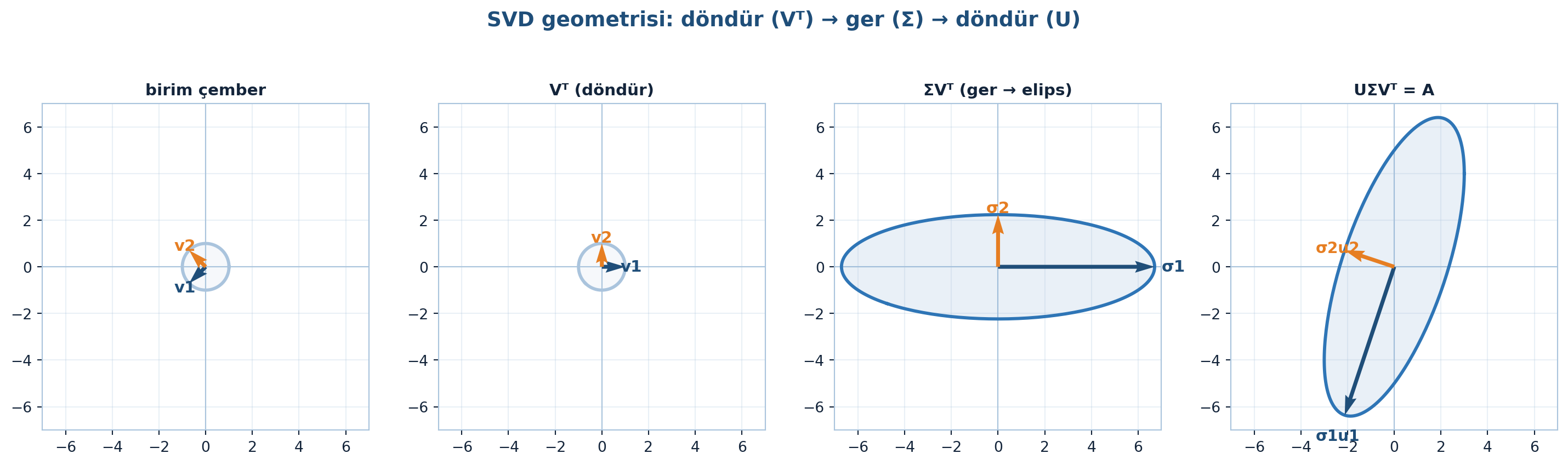
Kod
# Tekil değer düşüşlü 4×4 matris (Eckart-Young örneği)
A = np.outer([3, 2, 1, 1], [2, 2, 1, 1]) + 0.4 * np.outer([1, 0, 1, 0], [0, 1, 0, 1])
U, s, Vt = svd_full(A)
n = len(s)
# k=1..n için bağıl rekonstrüksiyon hatası
ks = list(range(1, n + 1))
errs = [rank_k_approx(A, k)[1] for k in ks]
fig, (axL, axR) = plt.subplots(1, 2, figsize=(11.0, 4.6))
# ---------------- SOL: tekil değerler (düşüş) ----------------
bar_values(axL, s,
labels=[f"σ{i+1}" for i in range(n)],
title="Tekil değerler σ (düşüş)",
highlight=[0])
# ---------------- SAĞ: rank-k bağıl hata eğrisi ----------------
axR.plot(ks, errs, color=COL_PRIMARY, lw=2.4, marker="o",
markersize=9, markerfacecolor=COL_ACCENT,
markeredgecolor=COL_PRIMARY, markeredgewidth=1.6, zorder=3)
for k, e in zip(ks, errs):
axR.annotate(f"{e:.3f}", xy=(k, e), xytext=(0, 11),
textcoords="offset points", ha="center",
fontsize=10, color=COL_TEXT, fontweight="bold")
axR.set_xticks(ks)
axR.set_xlabel("rank k", color=COL_TEXT, fontsize=11)
axR.set_ylabel("bağıl hata ‖A − Aₖ‖ / ‖A‖", color=COL_TEXT, fontsize=11)
axR.set_ylim(-0.04, max(errs) * 1.18)
apply_style(axR)
axR.set_title("En iyi rank-k yaklaşımın hatası (k ↑ → hata ↓)",
color=COL_TEXT, fontsize=12, fontweight="bold")
fig.suptitle("Eckart-Young: en iyi rank-k yaklaşım = ilk k tekil değer",
color=COL_PRIMARY, fontsize=14, fontweight="bold", y=1.02)
fig.tight_layout()
plt.show()
İpucuBuilder Notu — Her Matrisin Hakkı
SVD, ağırlık matrislerinin sıkıştırılması (düşük-rank yaklaşım, LoRA), gürültü giderme, pseudoinverse ve PCA için kullanılır. “Her matrisin SVD’si vardır” garantisi, dikdörtgen ML ağırlıklarına (örneğin embedding katmanları) onu doğrudan uygulanabilir kılar.
3.8 Matris Çarpımı = Kolon × Satır (Hatırlatma)
Spektral teoremde kullandığımız yapı taşı, Ders 1’in matris çarpımı görüşüdür: bir kolon çarpı bir satır, rank-1 bir matris verir.
\[ \begin{pmatrix} 1 \\ 2 \end{pmatrix} \begin{pmatrix} 3 & 4 \end{pmatrix} = \begin{pmatrix} 3 & 4 \\ 6 & 8 \end{pmatrix} \]
Tüm kolonlar \((1,2)\)’nin katı, tüm satırlar \((3,4)\)’ün katı — rankı 1.
“Its rank is 1.” — Strang, 7:34 “So those are the building blocks.” — Strang, 8:16
İki matrisin çarpımı \(AB\), bu rank-1 yapı taşlarının (\(A\)’nın kolonları çarpı \(B\)’nin satırları) toplamıdır. Spektral teorem ve LU’nun rank-1 soyma görüşü, hep bu tek fikrin uygulamalarıdır.
İpucuBuilder Notu — Ortak Dil
Kolon-çarpı-satır görüşü, GPU’da matris çarpımının (GEMM) ve attention’ın (\(QK^{T}\)) çalışma biçimidir. “Rank-1 yapı taşı” sezgisi SVD, PCA, LoRA ve spektral teoremin ortak dilidir.
3.9 \(A = LU\)’yu Rank-1 Soyarak Görmek
Strang LU’yu yeni bir gözle gösteriyor: eliminasyon, \(A\)’dan rank-1 parçaları sırayla soymaktır. \(2\times 2\) örnek:
\[ A = \begin{pmatrix} 2 & 3 \\ 4 & 7 \end{pmatrix} \]
Eliminasyon: satır 2’den 2 çarpı satır 1’i çıkar (çarpan \(\ell_{21} = 2\)), pivotlu \(U\) çıkar:
\[ U = \begin{pmatrix} 2 & 3 \\ 0 & 1 \end{pmatrix}, \quad L = \begin{pmatrix} 1 & 0 \\ 2 & 1 \end{pmatrix} \]
Şimdi \(A = LU\)’yu kolon çarpı satır olarak aç — birinci aşama, \(L\)’nin 1. kolonu çarpı \(U\)’nun 1. satırını soyar; geriye kalanı ikinci parça tamamlar:
\[ A = \begin{pmatrix} 1 \\ 2 \end{pmatrix}\begin{pmatrix} 2 & 3 \end{pmatrix} + \begin{pmatrix} 0 \\ 1 \end{pmatrix}\begin{pmatrix} 0 & 1 \end{pmatrix} = \begin{pmatrix} 2 & 3 \\ 4 & 6 \end{pmatrix} + \begin{pmatrix} 0 & 0 \\ 0 & 1 \end{pmatrix} \]
“[A is the first column of L times the first row of U, plus the rest] as the first column of l times the first row of u.” — Strang, 24:52
İlk rank-1 parça, \(A\)’nın ilk satır ve kolonunu doğru getirir; geriye bir boyut küçük bir problem (\(A_2\)) kalır. Bir sonraki eliminasyon adımı onu soyar. Böylece eliminasyon = ardışık rank-1 soyma. Bu soyma süreci Şekil 3.6’da gösteriliyor: üst sıra \(A = L \times U\), alt sıra rank-1 katmanların (\(\ell_1 u_1^{T} + \ell_2 u_2^{T}\)) toplamı.
Kod
# A = LU (pivotsuz, klasik eliminasyon — §2/§8 ardışık rank-1 soyma)
# scipy lu_factorization parça pivotlama yapar; bu pedagojik örnek pivotsuz LU.
A = np.array([[2., 3.], [4., 7.]])
L = np.array([[1., 0.], [2., 1.]])
U = np.array([[2., 3.], [0., 1.]])
# rank-1 parçalar: ℓ₁u₁ᵀ + ℓ₂u₂ᵀ = A
layer1 = np.outer(L[:, 0], U[0, :]) # [[2,3],[4,6]]
layer2 = np.outer(L[:, 1], U[1, :]) # [[0,0],[0,1]]
# Ortak renk ölçeği (tüm heatmap'ler aynı vmin/vmax)
allvals = np.concatenate([A.ravel(), L.ravel(), U.ravel(),
layer1.ravel(), layer2.ravel()])
vmin, vmax = float(allvals.min()), float(allvals.max())
fig, axes = plt.subplots(2, 3, figsize=(8.6, 6.0))
# --- Üst sıra: A = L × U ---
heatmap(axes[0, 0], A, title="A", vmin=vmin, vmax=vmax)
heatmap(axes[0, 1], L, title="L", vmin=vmin, vmax=vmax)
heatmap(axes[0, 2], U, title="U", vmin=vmin, vmax=vmax)
# "=" (A ile L arası) ve "×" (L ile U arası) işaretleri
fig.text(0.375, 0.74, "=", ha="center", va="center",
fontsize=26, fontweight="bold", color=COL_TEXT)
fig.text(0.645, 0.74, "×", ha="center", va="center",
fontsize=24, fontweight="bold", color=COL_TEXT)
# --- Alt sıra: ardışık rank-1 soyma ℓ₁u₁ᵀ + ℓ₂u₂ᵀ = A ---
heatmap(axes[1, 0], layer1, title=r"$\ell_1 u_1^{T}$", vmin=vmin, vmax=vmax)
heatmap(axes[1, 1], layer2, title=r"$\ell_2 u_2^{T}$", vmin=vmin, vmax=vmax)
heatmap(axes[1, 2], A, title="= A", vmin=vmin, vmax=vmax)
fig.text(0.375, 0.27, "+", ha="center", va="center",
fontsize=26, fontweight="bold", color=COL_TEXT)
fig.text(0.645, 0.27, "=", ha="center", va="center",
fontsize=26, fontweight="bold", color=COL_TEXT)
fig.suptitle("A = LU = ardışık rank-1 soyma",
fontsize=14, fontweight="bold", color=COL_PRIMARY, y=0.99)
fig.tight_layout(rect=(0, 0, 1, 0.96))
plt.show()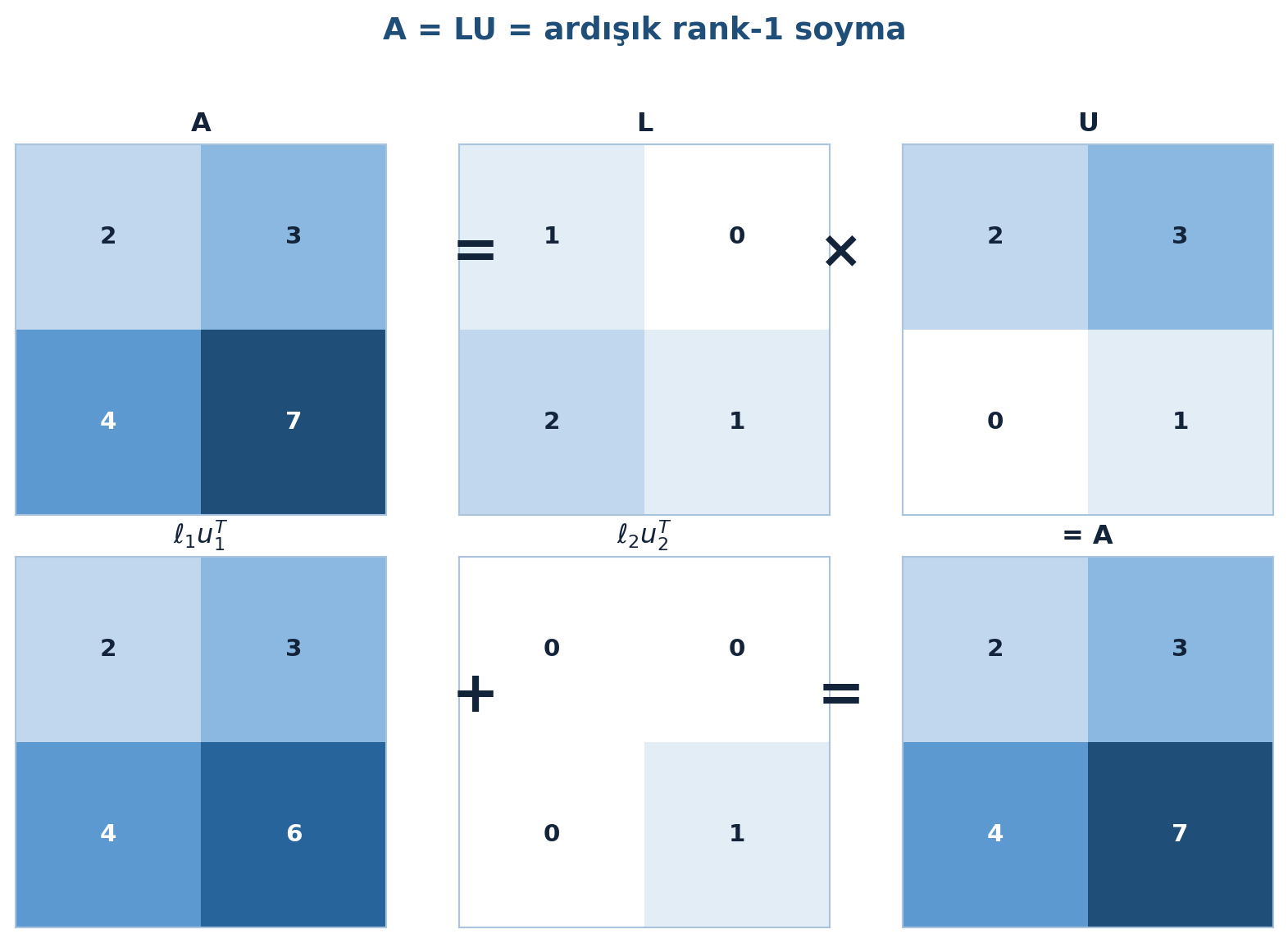
İpucuBuilder Notu — Soyarak Çözmek
Bu “rank-1 soyma” görüşü, blok-LU ve incremental/online matris ayrışımlarının temelidir. Aynı fikir SVD’de (en büyük tekil değerden başlayıp rank-1 parçaları soymak) düşük-rank yaklaşımı verir.
3.10 Dört Temel Alt-Uzay
Dersin sonunda Strang lineer cebirin temel teoremini veriyor: \(m\times n\), rank \(r\) bir \(A\) matrisinin dört temel alt-uzayı.
“I invented the name four fundamental subspaces.” — Strang, 29:09
- Kolon uzayı \(C(A)\) — \(A\)’nın kolonlarının kombinasyonları (\(\mathbf{R}^m\) içinde).
- Satır uzayı \(C(A^{T})\) — \(A\)’nın satırlarının kombinasyonları (\(\mathbf{R}^n\) içinde).
- Null uzayı \(N(A)\) — \(Ax = 0\) çözümleri (\(\mathbf{R}^n\) içinde).
- Sol null uzayı \(N(A^{T})\) — \(A^{T}y = 0\) çözümleri (\(\mathbf{R}^m\) içinde).
“It’s the set of solutions to Ax equal 0.” — Strang, 32:26
\(C(A)\) ve \(C(A^{T})\) doğrudan matrisin sayılarından okunur; \(N(A)\) ve \(N(A^{T})\) ise çözüm kümeleridir. Bir uzayda toplama ve sayıyla çarpma kapalıdır (lineer kombinasyon yine içindedir) — “uzay” olmanın tanımı budur.
Dört alt-uzayın büyük resmi Şekil 3.7’da: girdi uzayı \(\mathbf{R}^n\) (satır uzayı ⊥ null uzayı) ile çıktı uzayı \(\mathbf{R}^m\) (kolon uzayı ⊥ sol null uzayı) arasındaki \(A\) dönüşümü.
Kod
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
# Örnek matris: rank 2, 3×5 → four_subspace_dims = (r, r, n−r, m−r) = (2, 2, 3, 1)
A_example = np.array([
[1, 0, 2, 1, 3],
[0, 1, 1, 2, 1],
[1, 1, 3, 3, 4], # satır3 = satır1 + satır2 → rank 2
], dtype=float)
r_col, r_row, dimN, dimNT = four_subspace_dims(A_example) # (2, 2, 3, 1)
m, n = A_example.shape
fig, ax = plt.subplots(figsize=(9.5, 6.4))
# --- yardımcı: alt-uzay kutucuğu ---
def subspace_box(ax, x, y, w, h, label, dim, fc, ec):
box = FancyBboxPatch((x, y), w, h,
boxstyle="round,pad=0.02,rounding_size=0.06",
linewidth=2.0, edgecolor=ec, facecolor=fc, alpha=0.92,
mutation_aspect=1.0, zorder=2)
ax.add_patch(box)
ax.text(x + w / 2, y + h * 0.60, label, ha="center", va="center",
color=COL_WHITE, fontsize=13, fontweight="bold", zorder=3)
ax.text(x + w / 2, y + h * 0.26, dim, ha="center", va="center",
color=COL_WHITE, fontsize=10.5, zorder=3)
return (x + w / 2, y + h / 2)
ax.set_xlim(0, 10)
ax.set_ylim(0, 10)
# SOL büyük çerçeve: Rⁿ (n=5)
left_outer = FancyBboxPatch((0.35, 1.1), 3.5, 7.8,
boxstyle="round,pad=0.02,rounding_size=0.10",
linewidth=1.6, edgecolor=COL_STEEL_300,
facecolor=COL_BG, alpha=0.9, zorder=1)
ax.add_patch(left_outer)
ax.text(2.1, 9.25, f"$\\mathbf{{R}}^n$ (n = {n})", ha="center", va="center",
color=COL_TEXT, fontsize=14, fontweight="bold")
# SAĞ büyük çerçeve: Rᵐ (m=3)
right_outer = FancyBboxPatch((6.15, 1.1), 3.5, 7.8,
boxstyle="round,pad=0.02,rounding_size=0.10",
linewidth=1.6, edgecolor=COL_STEEL_300,
facecolor=COL_BG, alpha=0.9, zorder=1)
ax.add_patch(right_outer)
ax.text(7.9, 9.25, f"$\\mathbf{{R}}^m$ (m = {m})", ha="center", va="center",
color=COL_TEXT, fontsize=14, fontweight="bold")
# SOL: satır uzayı (üst, navy) + null uzayı (alt, steel)
row_c = subspace_box(ax, 0.75, 5.55, 2.7, 2.7,
r"satır uzayı $C(A^{T})$", f"boyut $r = {r_row}$",
COL_PRIMARY, COL_TEXT)
null_c = subspace_box(ax, 0.75, 1.75, 2.7, 2.7,
r"null uzayı $N(A)$", f"boyut $n-r = {dimN}$",
COL_ACCENT, COL_TEXT)
# SAĞ: kolon uzayı (üst, navy) + sol null uzayı (alt, steel)
col_c = subspace_box(ax, 6.55, 5.55, 2.7, 2.7,
r"kolon uzayı $C(A)$", f"boyut $r = {r_col}$",
COL_PRIMARY, COL_TEXT)
lnull_c = subspace_box(ax, 6.55, 1.75, 2.7, 1.55,
r"sol null $N(A^{T})$", f"boyut $m-r = {dimNT}$",
COL_ACCENT, COL_TEXT)
# Dik (⊥) tümleyen işaretleri — sol ve sağ çerçevenin ortasında
for cx in (2.1, 7.9):
ax.text(cx, 5.05, r"$\perp$", ha="center", va="center",
color=COL_TEXT, fontsize=15, fontweight="bold",
bbox=dict(boxstyle="circle,pad=0.18", fc=COL_WHITE,
ec=COL_STEEL_300, lw=1.2), zorder=4)
# Orta ok: satır uzayı → kolon uzayı (navy, "A")
a_arrow = FancyArrowPatch((row_c[0] + 1.35, row_c[1]),
(col_c[0] - 1.35, col_c[1]),
arrowstyle="-|>", mutation_scale=22,
linewidth=2.4, color=COL_PRIMARY, zorder=5,
connectionstyle="arc3,rad=-0.05")
ax.add_patch(a_arrow)
ax.text(5.0, row_c[1] + 0.45, r"$A$", ha="center", va="center",
color=COL_PRIMARY, fontsize=15, fontweight="bold")
ax.text(5.0, row_c[1] - 0.30, "x → Ax", ha="center", va="center",
color=COL_TEXT, fontsize=9.5, style="italic")
# Null uzayı → 0 oku (kesik): N(A) çarpımı sıfır
ax.text(5.0, null_c[1] + 0.55, "0", ha="center", va="center",
color=COL_TEXT, fontsize=14, fontweight="bold",
bbox=dict(boxstyle="circle,pad=0.22", fc=COL_WHITE,
ec=COL_TEXT, lw=1.4), zorder=5)
zero_arrow = FancyArrowPatch((null_c[0] + 1.35, null_c[1]),
(4.72, null_c[1] + 0.55),
arrowstyle="-|>", mutation_scale=18,
linewidth=2.0, color=COL_ACCENT, zorder=4,
linestyle="--",
connectionstyle="arc3,rad=0.12")
ax.add_patch(zero_arrow)
ax.text(3.95, null_c[1] + 0.70, r"$Ax = 0$", ha="center", va="center",
color=COL_ACCENT, fontsize=10.5, style="italic")
ax.set_title("Dört temel alt-uzay: boyutlar $r,\\ r,\\ n-r,\\ m-r$",
color=COL_TEXT, fontsize=15, fontweight="bold", pad=14)
ax.axis("off")
plt.show()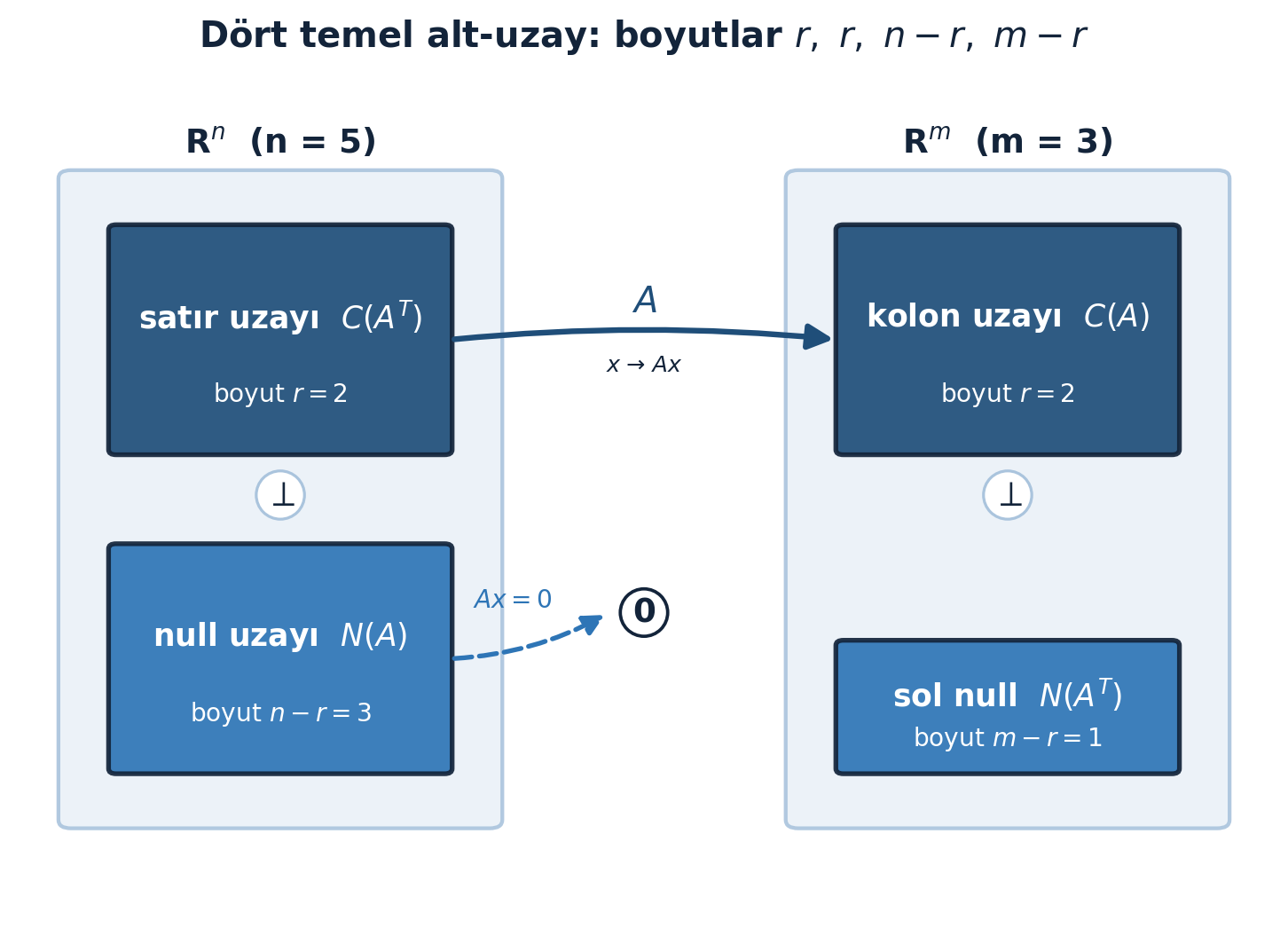
İpucuBuilder Notu — Çözülebilirliğin Geometrisi
Dört alt-uzay, \(Ax = b\)’nin geometrisidir: \(b \in C(A)\) ise çözüm vardır; \(N(A) \neq \{0\}\) ise çözüm tek değildir (sonsuz çözüm). Least squares (\(b \notin C(A)\) durumunda en yakın çözüm) ve minimum-norm çözüm (\(N(A)\) içinde seçim) bu geometriden doğar — Ders 9-11’in temeli.
3.11 Boyutlar ve Rank
Dört alt-uzayın boyutları tek bir sayı etrafında düzenlenir: rank \(r\).
\[ \dim C(A) = \dim C(A^{T}) = r, \quad \dim N(A) = n - r, \quad \dim N(A^{T}) = m - r \]
Kolon uzayı ve satır uzayının boyutunun aynı olması (her ikisi de \(r\)), Ders 1’in ilk büyük teoremidir — burada temel teoremin parçası olarak tekrar karşımıza çıkıyor.
“those have the same dimension, same dimension.” — Strang, 31:23
Rank, kolon ve satır sayısını aşamaz: \(r \leq \min(m, n)\). \(50\times 100\) bir matriste 100 kolonun bağımsız sayısı, 50 satırın bağımsız sayısına eşittir — sezgiye meydan okuyan ama her zaman doğru olan gerçek.
İpucuBuilder Notu — Serbestlik Derecesi
\(n - r\) (null uzay boyutu), bir lineer sistemin “serbestlik derecesi”dir: kaç parametre serbest kalır. Eksik-belirlenmiş (underdetermined) ML problemlerinde (parametre > veri) bu boyut büyüktür; regularizasyon (\(\ell^2\) veya minimum norm) bu serbestliği daraltıp tek çözüm seçer.
3.12 Bu Dersin Özeti
- Beş faktorizasyon — \(A = LU\) (eliminasyon), \(A = QR\) (ortonormallik), \(S = Q\Lambda Q^{T}\) (özdeğer), \(A = U\Sigma V^{T}\) (SVD), \(A = CR\) (rank).
- \(A = LU\) — satır işlemlerinin matris formu; alt çarpı üst üçgensel.
- \(A = QR\) — ortonormal kolonlar (\(Q^{T}Q = I\)); least squares’in kararlı yolu.
- \(S = Q\Lambda Q^{T}\) — simetrik matris: gerçek özdeğerler, ortonormal özvektörler.
- Spektral teorem — \(S = \sum_k \lambda_k q_k q_k^{T}\); rank-1 parçaların toplamı (PCA’nın temeli).
- \(A = U\Sigma V^{T}\) (SVD) — her matris için; iki ortogonal matris, dikdörtgende de çalışır.
- Matris çarpımı = kolon × satır — rank-1 yapı taşları (Ders 1 teması).
- \(A = LU\) = ardışık rank-1 soyma — eliminasyonun dış-çarpım görüşü.
- Dört temel alt-uzay — \(C(A)\), \(C(A^{T})\), \(N(A)\), \(N(A^{T})\).
- Boyutlar — \(r\), \(r\), \(n-r\), \(m-r\); kolon rank = satır rank.
ÖnemliTek Bir Cümle
Beş faktorizasyon (\(LU\), \(QR\), \(Q\Lambda Q^{T}\), \(U\Sigma V^{T}\), \(CR\)) bir matrisi beş farklı soruya göre çözer; hepsinin ortak dili “matris = rank-1 parçaların toplamı”dır ve dört temel alt-uzay (boyutları \(r\), \(r\), \(n-r\), \(m-r\)) bu yapının geometrisini verir.
3.13 Kontrol Soruları
NotSoru 1: Aşağıdaki simetrik matrisin spektral ayrışımını (S = QΛQᵀ) bul.
\[ S = \begin{pmatrix} 2 & 1 \\ 1 & 2 \end{pmatrix} \]
Cevap:
Karakteristik denklem: \(\det(S - \lambda I) = (2-\lambda)^2 - 1 = \lambda^2 - 4\lambda + 3 = (\lambda-3)(\lambda-1)\). Özdeğerler \(\lambda = 3\) ve \(\lambda = 1\) (ikisi de gerçek ✓).
\(\lambda = 3\) için özvektör \((1, 1)\); \(\lambda = 1\) için özvektör \((1, -1)\). Normalize edip \(Q\)’yu kur:
\[ Q = \frac{1}{\sqrt{2}}\begin{pmatrix} 1 & 1 \\ 1 & -1 \end{pmatrix}, \quad \Lambda = \begin{pmatrix} 3 & 0 \\ 0 & 1 \end{pmatrix} \]
Spektral toplam biçimi:
\[ S = 3 \cdot \frac{1}{2}\begin{pmatrix} 1 & 1 \\ 1 & 1 \end{pmatrix} + 1 \cdot \frac{1}{2}\begin{pmatrix} 1 & -1 \\ -1 & 1 \end{pmatrix} \]
Özvektörler ortogonal ✓ (dik), özdeğerler gerçek ✓ — simetrik matrisin iki garantisi.
NotSoru 2: Aşağıdaki matrisi bir kolon çarpı bir satır (rank-1 dış çarpım) olarak yaz ve rankını söyle.
\[ A = \begin{pmatrix} 3 & 4 \\ 6 & 8 \end{pmatrix} \]
Cevap:
Tüm kolonlar \((1,2)\)’nin katı, tüm satırlar \((3,4)\)’ün katı:
\[ A = \begin{pmatrix} 1 \\ 2 \end{pmatrix}\begin{pmatrix} 3 & 4 \end{pmatrix} \]
Rank 1. Bu, spektral teoremdeki ve LU soymadaki rank-1 yapı taşının aynısıdır.
NotSoru 3: Neden her kare matrisin özdeğer ayrışımı olmayabilir ama SVD’si her zaman vardır? Bir örnek ver.
Cevap:
Özdeğer ayrışımı \(A = Q\Lambda Q^{T}\) (veya genel \(A = S\Lambda S^{-1}\)) için yeterli sayıda bağımsız özvektör gerekir. Bazı matrislerde yoktur (defektif). Örnek:
\[ A = \begin{pmatrix} 0 & 1 \\ 0 & 0 \end{pmatrix} \]
Bu matrisin tek bir özdeğeri (0) ve tek bir bağımsız özvektörü var → diyagonalleştirilemez. Ayrıca dikdörtgen matrislerin (örneğin \(2\times 3\)) özdeğeri tanımlı bile değildir.
SVD (\(A = U\Sigma V^{T}\)) ise tek özvektör kümesi yerine iki tekil vektör kümesi (\(U\) ve \(V\)) kullanır; bu yüzden defektif ve dikdörtgen dahil her matris için vardır.
NotSoru 4: 3×5 boyutunda, rank 2 bir A matrisi için dört temel alt-uzayın boyutlarını ver. Ax = b her b için çözülebilir mi?
Cevap:
\(m = 3\), \(n = 5\), \(r = 2\):
\[ \dim C(A) = 2, \quad \dim C(A^{T}) = 2, \quad \dim N(A) = 5 - 2 = 3, \quad \dim N(A^{T}) = 3 - 2 = 1 \]
\(C(A)\), \(\mathbf{R}^3\) içinde 2 boyutlu bir alt-uzay (tüm \(\mathbf{R}^3\) değil) → \(Ax = b\) yalnızca \(b \in C(A)\) ise çözülür, her \(b\) için DEĞİL.
Çözülebildiğinde de çözüm tek değildir: \(N(A)\) 3 boyutlu olduğundan sonsuz çözüm vardır (genel çözüm = özel çözüm + \(N(A)\)). Bu, eksik-belirlenmiş sistemlerin tipik durumudur.
3.14 Egzersizler
Cevapsız problemler. Çöz, sonra numpy/scipy ile kontrol et.
Egzersiz 1. Aşağıdaki matrisin \(A = LU\) faktorizasyonunu bul (çarpanları kayıt et, \(L\)’yi doğrudan inşa et).
\[ A = \begin{pmatrix} 1 & 2 & 1 \\ 2 & 5 & 3 \\ 4 & 9 & 8 \end{pmatrix} \]
Egzersiz 2. İki aşamalı: (a) Aşağıdaki simetrik matrisin özdeğerlerini ve ortonormal özvektörlerini bul. (b) Spektral toplam \(S = \lambda_1 q_1 q_1^{T} + \lambda_2 q_2 q_2^{T}\) biçiminde yaz, \(S \cdot q_1 = \lambda_1 q_1\) olduğunu doğrula.
\[ S = \begin{pmatrix} 3 & 1 \\ 1 & 3 \end{pmatrix} \]
Egzersiz 3. Aşağıdaki dikdörtgen matrisin neden özdeğer ayrışımı tanımsız ama SVD’si var olduğunu açıkla. \(A^{T}A\) ve \(AA^{T}\)’nin boyutlarını yaz (tekil değerler bunların özdeğerlerinin karekökü).
\[ A = \begin{pmatrix} 1 & 0 & 2 \\ 0 & 1 & 1 \end{pmatrix} \]
Egzersiz 4. Python ile beş faktorizasyonu gör:
import numpy as np
from scipy.linalg import lu, qr
A = np.array([[4.0, 3.0], [6.0, 3.0]])
S = np.array([[3.0, 1.0], [1.0, 3.0]]) # simetrik
P, L, U = lu(A)
Q, R = qr(A)
lam, V = np.linalg.eigh(S) # simetrik için eigh
U2, sig, Vt = np.linalg.svd(A)
print("LU:", L, U, sep="\n")
print("QR:", Q, R, sep="\n")
print("eig(S):", lam, V, sep="\n") # ortonormal V, gerçek lam
print("SVD:", U2, sig, Vt, sep="\n")
# Spektral toplam kontrolü:
print("rebuild S:", (V * lam) @ V.T)Egzersiz 5. (Ders 3 habercisi.) Ders 3 \(Q\) matrislerine (\(Q^{T}Q = I\)) odaklanır. Aşağıdaki \(Q\) için \(Q^{T}Q = I\) olduğunu doğrula; kolonların hem birim uzunlukta hem birbirine dik olduğunu göster. Bu, Gram-Schmidt’in (Ders 3) üreteceği türden bir matristir.
\[ Q = \frac{1}{\sqrt{2}}\begin{pmatrix} 1 & 1 \\ 1 & -1 \end{pmatrix} \]
3.15 Sonraki Ders İçin Hazırlık
Ders 3: Q’nun Ortonormal Kolonları \(Q^{T}Q = I\) Verir
Ders 2’de beş faktorizasyonu tanıttık ve QR’a değindik. Ders 3, \(Q\) matrislerinin (ortonormal kolonlar) derinine iner — bu kursun ortogonallik temeli.
- Ortonormal kolonlar: \(Q^{T}Q = I\) ne demek, neden uzunluk ve açı korur
- Ortogonal matrisler (kare \(Q\)): döndürme ve yansıma
- Örnekler: Householder, Givens, Fourier, Hadamard matrisleri
- Neden ortonormallik sayısal kararlılık ve ML init için kritik
UyarıDers 3 Öncesi Yapılacak
- Bu dersin egzersizlerini çöz, özellikle Egzersiz 5’i (\(Q^{T}Q = I\) doğrulaması).
- Python’da
np.linalg.qrile birkaç matrisi ayrıştır, \(Q\)’nun ortonormalliğiniQ.T @ Qile kontrol et. - Ana cümleyi tekrar oku: “Beş faktorizasyon, matris = rank-1 parçaların toplamı.”
3.16 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Strang’de |
|---|---|---|
| Beş faktorizasyon | LU, QR, \(Q\Lambda Q^{T}\), \(U\Sigma V^{T}\), CR — her biri bir soruyu cevaplar | 1m12 |
| \(A = LU\) | Eliminasyon; alt üçgensel çarpı üst üçgensel | 17m20 |
| \(A = QR\) | Ortonormal kolonlar (\(Q^{T}Q = I\)); least squares | 2m31 |
| \(S = Q\Lambda Q^{T}\) | Simetrik: gerçek özdeğer, ortonormal özvektör | 4m59 |
| Özdeğerler gerçek | Simetrik matrisin garantisi | 5m35 |
| Spektral teorem | \(S = \sum_k \lambda_k q_k q_k^{T}\); rank-1 parçaların toplamı | 10m39 |
| \(A = U\Sigma V^{T}\) (SVD) | Her matris için; iki ortogonal matris | 16m04 |
| Rank-1 = kolon × satır | Dış çarpım; tüm çarpımların yapı taşı | 7m34 |
| \(A = LU\) rank-1 soyma | Eliminasyon = ardışık rank-1 parça soyma | 24m52 |
| Dört temel alt-uzay | \(C(A)\), \(C(A^{T})\), \(N(A)\), \(N(A^{T})\) | 29m09 |
| Boyutlar | \(r\), \(r\), \(n-r\), \(m-r\); kolon rank = satır rank | 31m23 |
3.17 ML Bağlantıları Özeti
- Beş faktorizasyon →
numpy.linalg/torch.linalgaraç kutusunun tamamı (solve, lstsq, eigh, svd, qr). - Spektral teorem → PCA; kovaryans matrisi \(S = \sum_k \lambda_k q_k q_k^{T}\) olarak ana bileşenlere ayrılır.
- SVD → her ağırlık matrisine uygulanır; düşük-rank sıkıştırma, LoRA, pseudoinverse.
- Rank-1 toplam → SVD, PCA, spektral teoremin ortak dili; GEMM ve attention’ın yapısı.
- QR → least squares’in kararlı çözümü; ortonormal ağırlık başlatması (orthogonal init).
- Dört alt-uzay → \(Ax = b\) çözülebilirliği (\(b \in C(A)\)) ve teklik (\(N(A) = \{0\}\)); least squares geometrisi.
- \(n-r\) serbestlik derecesi → eksik-belirlenmiş ML problemleri; regularizasyon bu serbestliği daraltıp tek çözüm seçer.
ÖnemliTek bir şey alıp gideceksen
Bir matrisi beş faktorizasyonla beş farklı soruya göre çözebilirsin — LU eliminasyonu, QR ortonormalliği, \(Q\Lambda Q^{T}\) özdeğerleri, \(U\Sigma V^{T}\) tekil değerleri, CR rankı açığa çıkarır. Hepsinin ortak dili “matris = rank-1 parçaların toplamı”dır; dört temel alt-uzay ise (boyutları \(r\), \(r\), \(n-r\), \(m-r\)) bu yapının geometrisini verir.