flowchart TD
M["Ax = b çözümü"] --> NORM["norm min (özet)"]
M --> GS["Gram-Schmidt A = QR"]
M --> KRY["Krylov span{b, Ab, A²b}"]
M --> ORT["ortonormal → c = Qᵀx (iç çarpım)"]
NORM --> L1["ℓ1: seyrek"]
NORM --> L2["ℓ2: dik ayak"]
NORM --> LINF["ℓ∞: eşit bileşen"]
GS --> GSC["bileşeni çıkar + normalize"]
GSC --> MGS["modified GS"]
MGS --> PIV["kolon pivotlama"]
KRY --> CG["conjugate gradient"]
CG --> ARN["Arnoldi / Lanczos"]
style M fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style ORT fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style NORM fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style GS fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style KRY fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style L1 fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
style L2 fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
style LINF fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
style GSC fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
style MGS fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
style PIV fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
style CG fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
style ARN fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
12 Ax = b’nin Koşuluyla ‖x‖’i Minimize Etmek
Gram-Schmidt A = QR ve Krylov uzayı
NotBölüm bilgisi
Video: Minimizing ‖x‖ Subject to Ax = b · OCW: MIT 18.065 Lecture 11 · Okuma süresi: ~38 dk · Eğitmen: Gilbert Strang · Önkoşul: Ders 10 (Ax = b durum haritası, kondisyon sayısı, kötü kolonlar).
12.1 Bu Derste Ne Var?
Bu ders üç parçadan oluşur. Başlık kısa açılışı (\(\|x\|\) minimizasyonu) yansıtır ama dersin gövdesi Gram-Schmidt ve Krylov’dur. (Not: docx ders11 = OCW Lec 11; OCW başlığı açılış recap’ini vurgular, video asıl olarak Gram-Schmidt/QR + iteratif yöntemleri işler.)
Üç temel fikir:
- \(\|x\|\) minimizasyonu (recap) — \(Ax = b\) kısıtı altında en küçük normlu \(x\): \(\ell^1\) (elmas) seyrek, \(\ell^2\) (çember) dik ayak, \(\ell^\infty\) (kare) eşit bileşen.
- Gram-Schmidt: \(A = QR\) — bağımsız (belki kötü koşullu) kolonları ortonormal \(Q\)’ya çevir; \(R = Q^{T}A\); kolon pivotlama sayısal kararlılık için.
- Krylov + Arnoldi/Lanczos — büyük seyrek \(A\) için iteratif çözüm; Krylov uzayı \(\{b, Ab, A^{2}b, \ldots\}\), conjugate gradient, ve bazı ortonormalleştirme.
“Now, I’m coming to the topic of the day, which is Gram-Schmidt.” — Strang, 9:20
Dersin üç dalını ve aralarındaki bağı Şekil 12.1 özetliyor: merkezdeki \(Ax = b\) çözümünden norm minimizasyonu, Gram-Schmidt \(A = QR\) ve Krylov uzayına uzanan üç kol, hepsi ortonormal kolonların sağladığı iç çarpım kolaylığında (\(c = Q^{T}x\)) buluşur.
İpucuBuilder Notu — Sayısal Cebrin Omurgası
- Gram-Schmidt / QR — kötü koşullu tasarım matrislerini ortonormal tabana çevirir; least squares’in kararlı çözümü, özdeğer algoritmasının (Ders 12) temeli.
- Kolon pivotlama — rank-açığa-çıkaran QR; en bilgilendirici kolonu seçer (öznitelik seçimi, sayısal kararlılık).
- Krylov + conjugate gradient — büyük seyrek sistemlerin belkemiği; yalnız \(Ax\) çarpımı kullanır, matrisi açık kurmaz (büyük-ölçek ML/bilimsel hesap).
- Ortonormal baz → \(c = Q^{T}x\) — katsayılar tek bir transpozla; projeksiyon ve çözümün ucuz olduğu yer.
Tek cümle: kötü koşullu kolonları Gram-Schmidt ile ortonormalleştirmek (\(A = QR\)) sayısal lineer cebirin omurgasıdır; büyük sistemlerde aynı ortonormalleştirme Krylov/Arnoldi/Lanczos olarak iteratif çözümü mümkün kılar.
12.2 1. Önce Hatırlatma: ‖x‖ Minimizasyonu
Strang dersi, Ders 8’deki “kısıt altında norm minimizasyonu” resmini sayılarla somutlaştırarak açıyor. Kısıt tek bir doğru: \(3x_1 + 4x_2 = 1\). Bu doğru üzerinde hangi nokta en küçük normludur — norma göre değişir.
“Do you remember the day that we minimized different norms?” — Strang, 2:27
\[3x_1 + 4x_2 = 1 \quad (\text{constraint})\]
- \(\ell^2\): çember doğruya dik ayakta değer → kazanan \((3/25, 4/25)\).
- \(\ell^1\): elmas → kazanan \((0, 1/4)\).
- \(\ell^\infty\): kare → kazanan \((1/7, 1/7)\).
Aynı doğru üzerinde üç norm topunun farklı kazananlara değdiğini Şekil 12.2 gösteriyor: \(\ell^2\) çemberi dik ayakta, \(\ell^1\) elması köşesiyle eksen üstünde (seyrek), \(\ell^\infty\) karesi eşit bileşende değer.
Kod
a = np.array([3., 4.]); c = 1.0
fig, ax = plt.subplots(figsize=(5.6, 5.6))
style_square_axes(ax, 0.45)
xs, ys = line_points(a, c, 0.45)
ax.plot(xs, ys, color=COL_PRIMARY, lw=2, label="3x1+4x2=1")
w2 = min_norm_on_line(a, c, 2)
w1 = min_norm_on_line(a, c, 1)
winf = min_norm_on_line(a, c, np.inf)
# ℓ2 çember
plot_pointset(ax, norm_ball(2, np.linalg.norm(w2)), COL_ACCENT, close=False)
# ℓ1 elmas
plot_pointset(ax, norm_ball(1, np.abs(w1).sum()), COL_VEC3, close=False)
# ℓ∞ kare
plot_pointset(ax, norm_ball(np.inf, np.max(np.abs(winf))), COL_TEAL, close=False)
# üç kazanan
ax.scatter([w2[0]], [w2[1]], color=COL_ACCENT, s=70, zorder=5)
ax.scatter([w1[0]], [w1[1]], color=COL_VEC3, s=70, zorder=5)
ax.scatter([winf[0]], [winf[1]], color=COL_TEAL, s=70, zorder=5)
ax.text(w2[0], w2[1], " ℓ2", color=COL_ACCENT, fontsize=11, fontweight="bold", va="bottom")
ax.text(w1[0], w1[1], " ℓ1", color=COL_VEC3, fontsize=11, fontweight="bold", va="bottom")
ax.text(winf[0], winf[1], " ℓ∞", color=COL_TEAL, fontsize=11, fontweight="bold", va="top")
ax.legend(loc="lower left", fontsize=8)
ax.set_title("3x1+4x2=1 doğrusunda en küçük norm: ℓ2 dik ayak, ℓ1 köşe (seyrek), ℓ∞ eşit bileşen",
color=COL_TEXT, fontsize=10, fontweight="bold")
fig.tight_layout()
plt.show()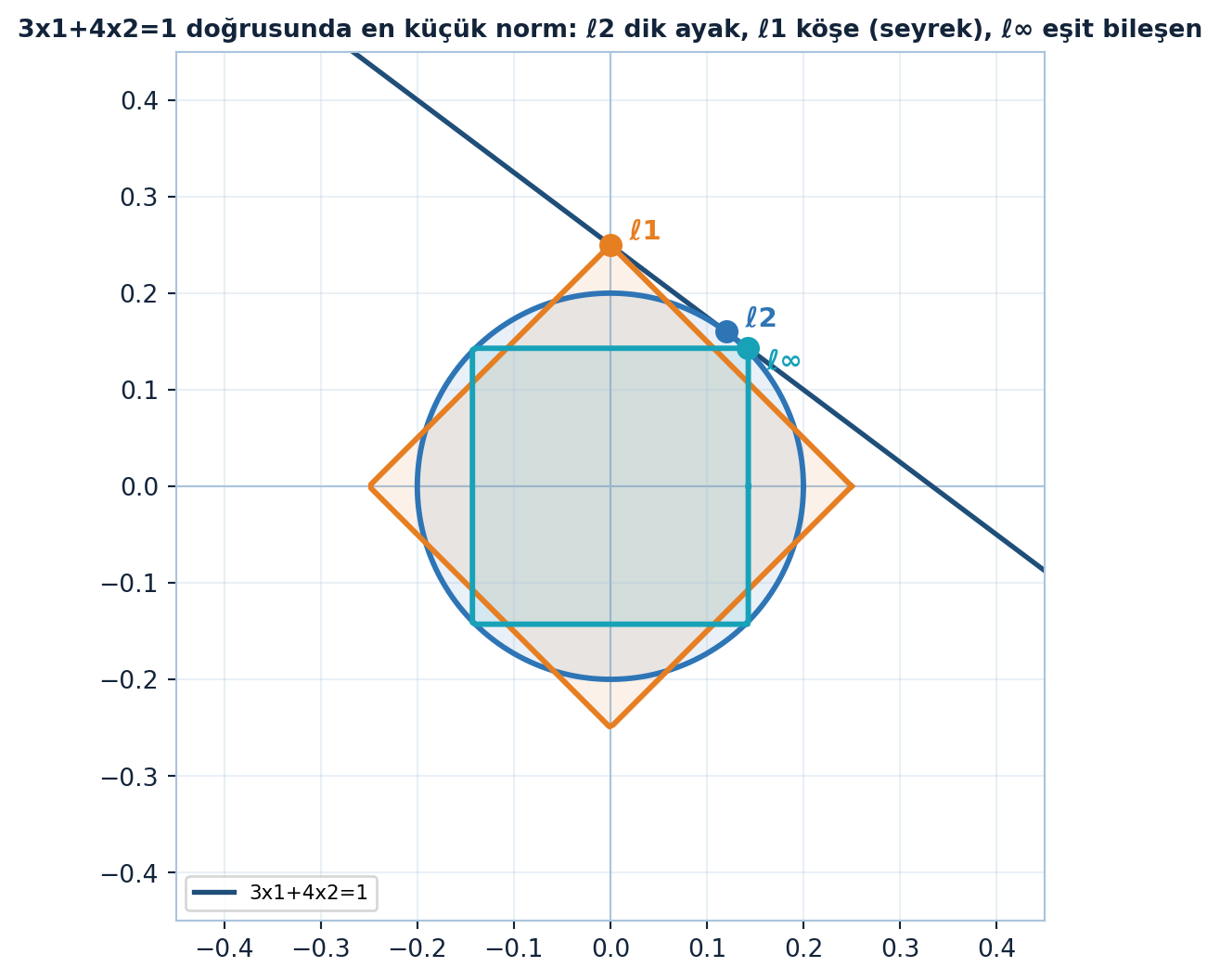
İpucuBuilder Notu — Norm Seçimi = Çözüm Seçimi
Bu üç kazanan, aynı kısıtta üç farklı düzenlileştirmenin (ridge, Lasso, max-norm) seçeceği üç farklı çözümdür. Norm seçimi = çözüm seçimi: aynı veri, farklı geometri, farklı sonuç.
12.3 2. \(\ell^1\) Seyrekliği
\(\ell^1\) kazananı neden özel? Çünkü elmasın köşesi eksende oturur — bir bileşeni tam sıfır olur.
“A diamond, right. A diamond. So the diamond that first touches the line is here.” — Strang, 5:02
\(3x_1 + 4x_2 = 1\) doğrusunda \(\ell^1\) kazananı \((0, 1/4)\): \(x_1 = 0\) (seyrek!). \(p\) arttıkça (\(1 \to 2 \to \infty\)) kazanan köşeden (seyrek) köşeye doğru kayar; çember ve karede seyreklik kaybolur. Yüksek boyutta bu, \(\ell^1\)’in neden seyrek çözüm verdiğinin kaynağıdır.
İki normun aynı doğrudaki kazananını yan yana koyan Şekil 12.3, elmasın köşeli geometrisinin neden sıfır bileşen ürettiğini gösteriyor: \(\ell^2\) çemberi iki bileşeni de sıfırdan farklı bırakır, \(\ell^1\) elması ise tam \(x_1 = 0\) verir.
Kod
a = np.array([3., 4.]); c = 1.0
fig, axs = plt.subplots(1, 2, figsize=(9, 4.2))
xs, ys = line_points(a, c, 0.4)
# ---- SOL: ℓ2 (çember) — dik ayak, iki bileşen de sıfırdan farklı ----
style_square_axes(axs[0], 0.4)
axs[0].plot(xs, ys, COL_PRIMARY, lw=2)
w2 = min_norm_on_line(a, c, 2)
plot_pointset(axs[0], norm_ball(2, np.linalg.norm(w2)), COL_ACCENT, close=False)
axs[0].scatter(*w2, color=COL_ACCENT, s=80, zorder=5)
axs[0].set_title("ℓ2 (çember): dik ayak, iki bileşen sıfırdan farklı",
color=COL_TEXT, fontsize=10, fontweight="bold")
# ---- SAĞ: ℓ1 (elmas) — köşe eksende -> x1=0 (seyrek) ----
style_square_axes(axs[1], 0.4)
axs[1].plot(xs, ys, COL_PRIMARY, lw=2)
w1 = min_norm_on_line(a, c, 1)
plot_pointset(axs[1], norm_ball(1, np.abs(w1).sum()), COL_VEC3, close=False)
axs[1].scatter(*w1, color=COL_VEC3, s=80, zorder=5)
axs[1].annotate("x1=0 (seyrek)", w1, color=COL_VEC3, fontsize=10, fontweight="bold",
xytext=(8, 8), textcoords="offset points")
axs[1].set_title("ℓ1 (elmas): köşe eksende → x1=0 (seyrek)",
color=COL_TEXT, fontsize=10, fontweight="bold")
fig.suptitle("ℓ1 seyrekliği: elmasın köşesi ekseni keser → bir bileşen tam sıfır (Lasso'nun sebebi)",
color=COL_TEXT, fontsize=11, fontweight="bold")
fig.tight_layout()
plt.show()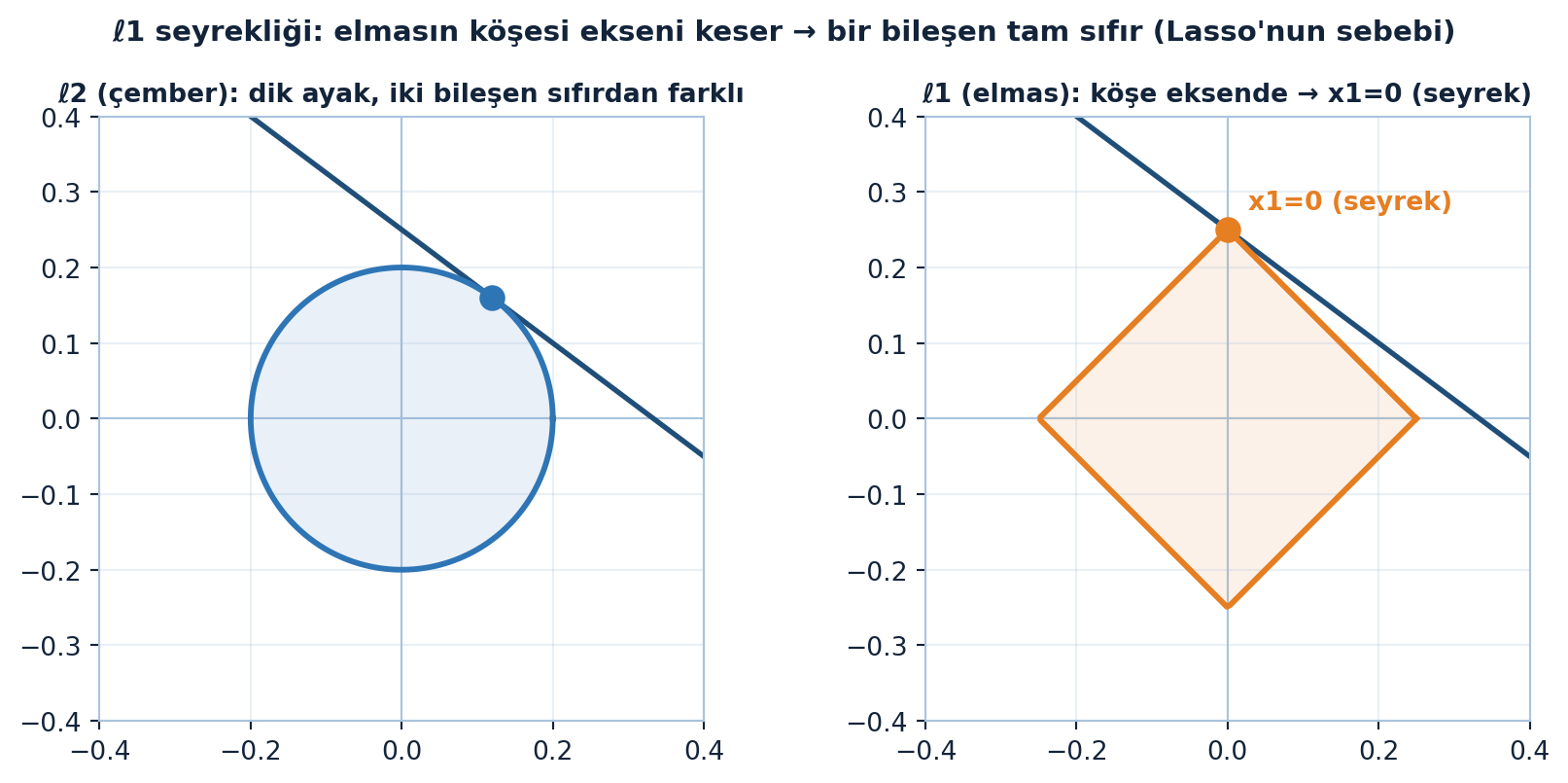
İpucuBuilder Notu — Sıfırın Geometrisi
“Elmas köşesi = sıfır bileşen” geometrisi Lasso’nun, compressed sensing’in ve seyrek modellerin matematiksel sebebidir. Kaç sıfır geleceği boyuta ve kısıt sayısına bağlıdır — Strang’in “ilginç proje” dediği açık soru.
12.4 3. Gram-Schmidt: A = QR
Dersin asıl konusu: kötü koşullu (neredeyse bağımlı) kolonları ortonormal bir tabana çevirmek.
“Now, I’m coming to the topic of the day, which is Gram-Schmidt.” — Strang, 9:20
Bağımsız ama belki barely-bağımsız kolonlu \(A\)’dan, ortonormal kolonlu \(Q\) üretilir; ikisi üst üçgensel \(R\) ile bağlıdır:
\[A = QR\]
\(R\), \(Q\)’nun kolonlarından \(A\)’nın kolonlarına geçiş reçetesidir. LU’da ileri gidip \(U\)’ya varırız; burada ileri gidip \(Q\)’ya varırız, sonra \(A\) ile \(Q\)’yu bağlayan \(R\)’yi yazarız.
“…the Matlab command is exactly QR.” — Strang, 12:15
\(A = QR\) ayrışımının üç matrisini Şekil 12.4 ısı haritasıyla yan yana koyuyor: soldaki \(A\) Gram-Schmidt’le ortada ortonormal kolonlu \(Q\)’ya geçer, sağda \(R = Q^{T}A\)’nın köşegen-altı tam sıfır (üst üçgen).
Kod
A = np.array([[1., 1., 1.], [0., 1., 1.], [0., 0., 1.]])
Q, R = gram_schmidt(A)
fig, axs = plt.subplots(1, 3, figsize=(10, 3.4))
heatmap(axs[0], A, "A")
heatmap(axs[1], Q, "Q (ortonormal kolon)")
heatmap(axs[2], R, "R = Q^T A (üst üçgen)")
fig.suptitle("A = QR: kolonlar ortonormal Q'ya, R = Q^T A üst üçgen (R_ij = q_i . a_j)",
color=COL_TEXT, fontsize=11, fontweight="bold")
fig.tight_layout()
plt.show()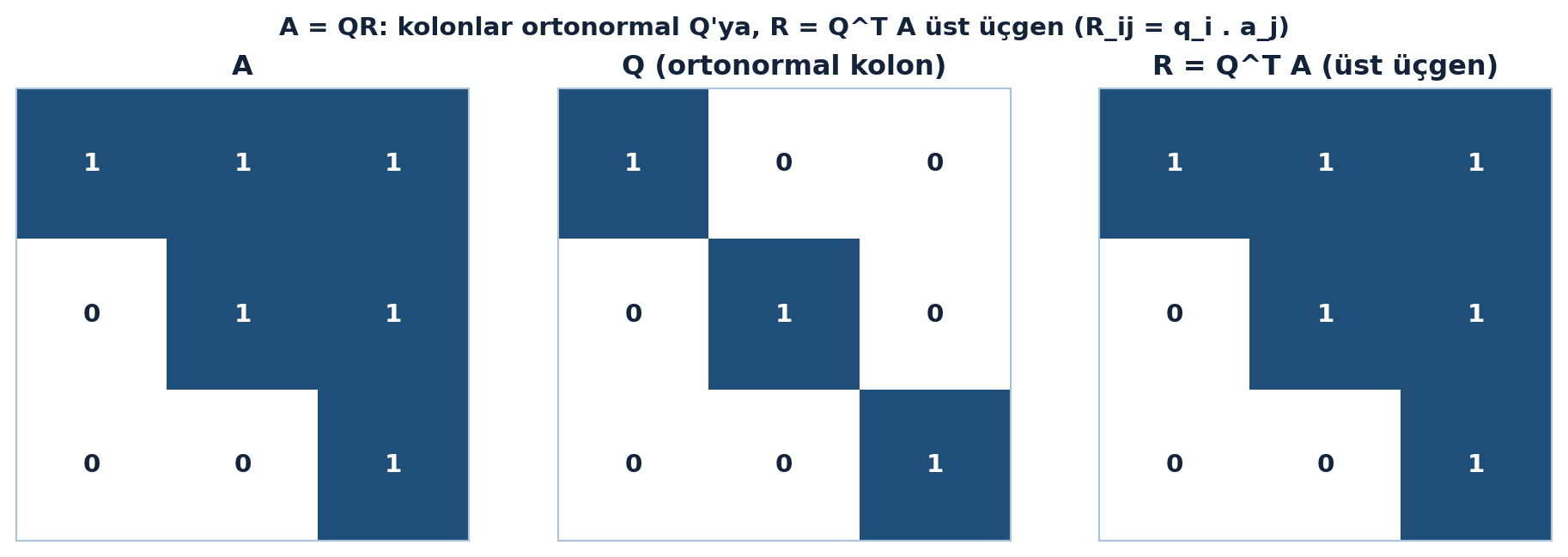
İpucuBuilder Notu — Günün Konusu
\(A = QR\), least squares’in kararlı çözüm yoludur (Ders 9-10) ve özdeğer algoritmasının (Ders 12 QR iterasyonu) çekirdeğidir. numpy.linalg.qr bunu verir; LU yerine QR, ortonormallik sayesinde kondisyonu karelemez.
12.5 4. \(R = Q^{T}A\) (İç Çarpımlar)
\(R\) gizemli görünür ama basittir. \(A = QR\)’de \(Q\) ortogonal olduğundan \(Q^{-1} = Q^{T}\); iki tarafı soldan \(Q^{T}\) ile çarp:
\[R = Q^{T}A\]
“…this mysterious R is Q transpose A.” — Strang, 13:13
\(R\)’nin \((i, j)\) girdisi, \(q_i\) satırı çarpı \(a_j\) kolonu — yani basitçe bir iç çarpım:
\[R_{ij} = q_i^{T} a_j\]
Demek ki \(R\), \(Q\)’ların \(A\)’larla nokta çarpımlarından ibarettir. Gizem yok: ortonormallik \(R\)’yi bu temiz forma indirir. (Yukarıdaki Şekil 12.4 aynı zamanda bu iç-çarpım yapısını görselleştirir: sağdaki \(R = Q^{T}A\) paneli.)
İpucuBuilder Notu — İç Çarpım Yeter
\(R = Q^{T}A\) olması, ortonormal bir tabanda koordinat bulmanın iç çarpımdan ibaret olduğunu gösterir (Bölüm 11). Bu, Fourier katsayıları, projeksiyon ve dikkat (attention) skorlarının da temelidir: dik tabanlarda her şey iç çarpımla okunur.
12.6 5. Gram-Schmidt’in Çift Adımı
Tüm Gram-Schmidt iki adımın tekrarıdır. İlk kolon kolaydır — sadece normalize et: \(q_1 = a_1/\|a_1\|\). Asıl fikir \(q_2\)’de:
“The whole idea of Gram-Schmidt is in q2.” — Strang, 16:05
\(a_2\)’nin \(q_1\) yönündeki bileşenini çıkar (ortogonal yap), sonra normalize et:
\[A_2 = a_2 - (a_2^{T}q_1)\,q_1, \qquad q_2 = \frac{A_2}{\|A_2\|}\]
Çıkarılan parça \((a_2^{T}q_1)q_1\); geriye kalan \(A_2\), \(q_1\)’e diktir (kontrol: \(q_1^{T}A_2 = a_2^{T}q_1 - (a_2^{T}q_1)(q_1^{T}q_1) = 0\)). Bu “çıkar + normalize” çifti tüm algoritmanın kalbidir.
Bu iki adımı somut sayılarla (\(a_1 = (1,1)\), \(a_2 = (2,0)\)) Şekil 12.5 gösteriyor: \(a_2\)’nin \(q_1\) üzerindeki projeksiyonu çıkarılır, dik kalan \(A_2\) normalize edilince \(q_2\) elde edilir ve kökteki kesik kare \(q_1 \perp q_2\) dikliğini işaretler.
Kod
fig, ax = plt.subplots(figsize=(7, 7))
style_square_axes(ax, 2.4)
# Başlangıç vektörleri
a1 = np.array([1., 1.])
a2 = np.array([2., 0.])
draw_vec2d(ax, a1, color=COL_STEEL_300, label="a1")
draw_vec2d(ax, a2, color=COL_STEEL_300, label="a2")
# Adım 1: q1 = a1 / ||a1||
q1 = a1 / np.linalg.norm(a1)
# Adım 2: a2'nin q1 bileşenini çıkar (projeksiyon)
proj = (a2 @ q1) * q1 # = (1, 1)
draw_vec2d(ax, proj, color=COL_PURPLE, ls=":", label="(a2.q1)q1")
# Kalan: A2 = a2 - proj (= (1, -1)), proj ucundan çiz
A2 = a2 - proj # = (1, -1)
draw_vec2d(ax, A2, origin=proj, color=COL_VEC3, label="A2 = a2 - proj")
# Ortonormal taban: q1, q2
draw_vec2d(ax, q1, color=COL_PRIMARY, lw=3, label="q1")
q2 = A2 / np.linalg.norm(A2)
draw_vec2d(ax, q2, color=COL_ACCENT, lw=3, label="q2")
# Dik açı işareti q1-q2 (kesikli)
d = 0.22
corner = d * q1 + d * q2
ax.plot([d*q1[0], corner[0]], [d*q1[1], corner[1]], color=COL_TEXT, lw=1.0, ls="--", alpha=0.7)
ax.plot([d*q2[0], corner[0]], [d*q2[1], corner[1]], color=COL_TEXT, lw=1.0, ls="--", alpha=0.7)
ax.set_title("Gram-Schmidt'in kalbi: a2'nin q1 bileşenini ÇIKAR (proj),\nkalan A2'yi NORMALIZE et → q2 (q1'e dik)",
color=COL_TEXT, fontsize=11, fontweight="bold")
fig.tight_layout()
plt.show()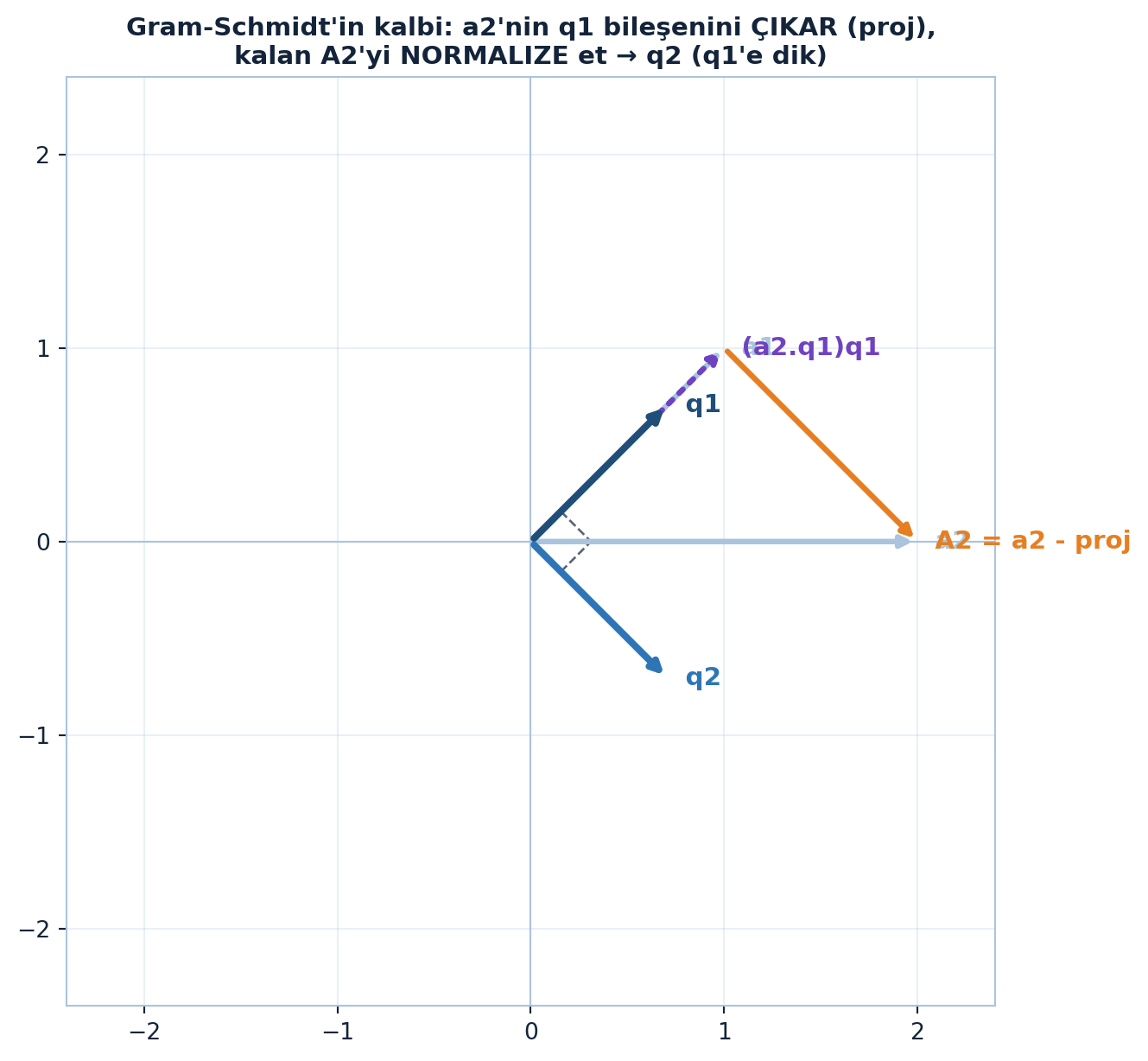
İpucuBuilder Notu — Çıkar ve Normalize
“Önceki yönlerin bileşenini çıkar, kalanı normalize et” — bu, dik bir taban kurmanın evrensel reçetesidir. Ortonormal RNN ağırlıkları, dik gömüler ve PCA sonrası dik eksenler aynı işlemi kullanır.
12.7 6. Modified Gram-Schmidt
Üçüncü vektörde iki bileşen çıkarılır (\(q_1\) ve \(q_2\)):
\[A_3 = a_3 - (a_3^{T}q_1)\,q_1 - (a_3^{T}q_2)\,q_2, \qquad q_3 = \frac{A_3}{\|A_3\|}\]
İki çıkarmayı ayrı ayrı (önce \(q_1\), sonra \(q_2\)) yapmak sayısal olarak daha kararlıdır — buna modified Gram-Schmidt denir.
“It’s called modified Gram-Schmidt.” — Strang, 20:43
Klasik (hepsini bir kerede çıkar) ile modified (sırayla çıkar) matematiksel olarak aynı sonucu verir ama yuvarlama hatasına karşı modified daha dayanıklıdır.
İpucuBuilder Notu — Kütüphanenin Tercihi
Modified Gram-Schmidt, kütüphanelerin tercih ettiği sürümdür: aynı işlem sayısı, daha iyi sayısal kararlılık. Householder QR (Ders 3) ise daha da kararlıdır; büyük problemlerde LAPACK Householder kullanır.
12.8 7. Kolon Pivotlama (Daha İyi Gram-Schmidt)
Standart Gram-Schmidt kolonları geldiği sırada alır — risklidir. Eğer \(a_2\) neredeyse \(a_1\) yönündeyse, çıkardıktan sonra geriye minik bir parça kalır; ona bölmek yuvarlama hatasını patlatır (tıpkı eliminasyonda küçük pivot gibi). Çözüm: her adımda kalan kolonların hepsinden \(q_1\) (ve sonraki \(q\)’lar) bileşenini çıkar, en büyüğünü seç.
“…I’m going to take the largest.” — Strang, 30:49
Bu, eliminasyondaki satır değişiminin (en büyük pivot) kolon karşılığıdır — kolon pivotlama. Strang’in vurgusu: ekstra iş yok, çünkü bu çıkarmaları zaten yapacaktın; sadece sırayı en büyük-kalan-kolon olarak seçiyorsun.
İpucuBuilder Notu — En Büyüğü Seç
Kolon pivotlu QR = rank-açığa-çıkaran faktorizasyon: hangi kolonların gerçekten bağımsız/bilgilendirici olduğunu bulur. Özellik seçimi, kötü-koşullu matris düzeltme ve sayısal kararlılıkta standart (LAPACK geqp3).
12.9 8. Krylov Uzayı
Dersin son parçası: \(A\) çok büyük ve seyrekse \(Ax = b\)’yi nasıl çözeriz? Büyük seyrek matrisle ucuz yapabileceğin tek şey matris-vektör çarpımı (\(Ax\)). O zaman \(b\)’den başlayıp ardışık çarpımlar üret:
\[\mathcal{K}_j = \text{span}\{\,b,\; Ab,\; A^{2}b,\; \ldots,\; A^{j-1}b\,\}\]
“…it’s called the Krylov space.” — Strang, 37:35
Bu vektörlerin kombinasyonları Krylov uzayıdır (boyut \(j\)). Önemli: \(A^2\) hiçbir zaman açıkça kurulmaz — \(A \cdot (A \cdot b)\) olarak ardışık çarpımla hesaplanır. Seyrek \(A\) için her çarpım ucuzdur.
Krylov vektörlerinin neden “kötü bir taban” olduğunu Şekil 12.6 gösteriyor: ardışık \(A^k b\) vektörleri giderek baskın özvektör yönüne döner, birbirine neredeyse bağımlı hale gelir — Arnoldi/Lanczos’un ortogonalleştirme ihtiyacının görsel sebebi.
Kod
M = np.array([[2., 1.], [1., 2.]]) # özvektör (1,1) λ=3 baskın
bk = np.array([1., -0.6])
K = krylov_space(M, bk, 4)
cols = [K[:, i] / np.linalg.norm(K[:, i]) for i in range(4)]
fig, ax = plt.subplots(figsize=(6.4, 6.4))
style_square_axes(ax, 1.3)
renkler = [COL_STEEL_300, COL_SKY_400, COL_ACCENT, COL_PRIMARY]
etiket = ["b", "Ab", "A2b", "A3b"]
for i in range(4):
draw_vec2d(ax, cols[i], color=renkler[i], label=etiket[i])
# baskın özvektör yönü (1,1)/√2
draw_vec2d(ax, np.array([1, 1]) / np.sqrt(2), color=COL_VEC3, ls=":", label="baskın özvektör")
ax.set_title("Krylov {b, Ab, A2b, ...}: vektörler baskın özvektöre döner\n(neredeyse bağımlı) → Arnoldi/Lanczos ortogonalleştirir",
color=COL_TEXT, fontsize=10.5, fontweight="bold")
plt.show()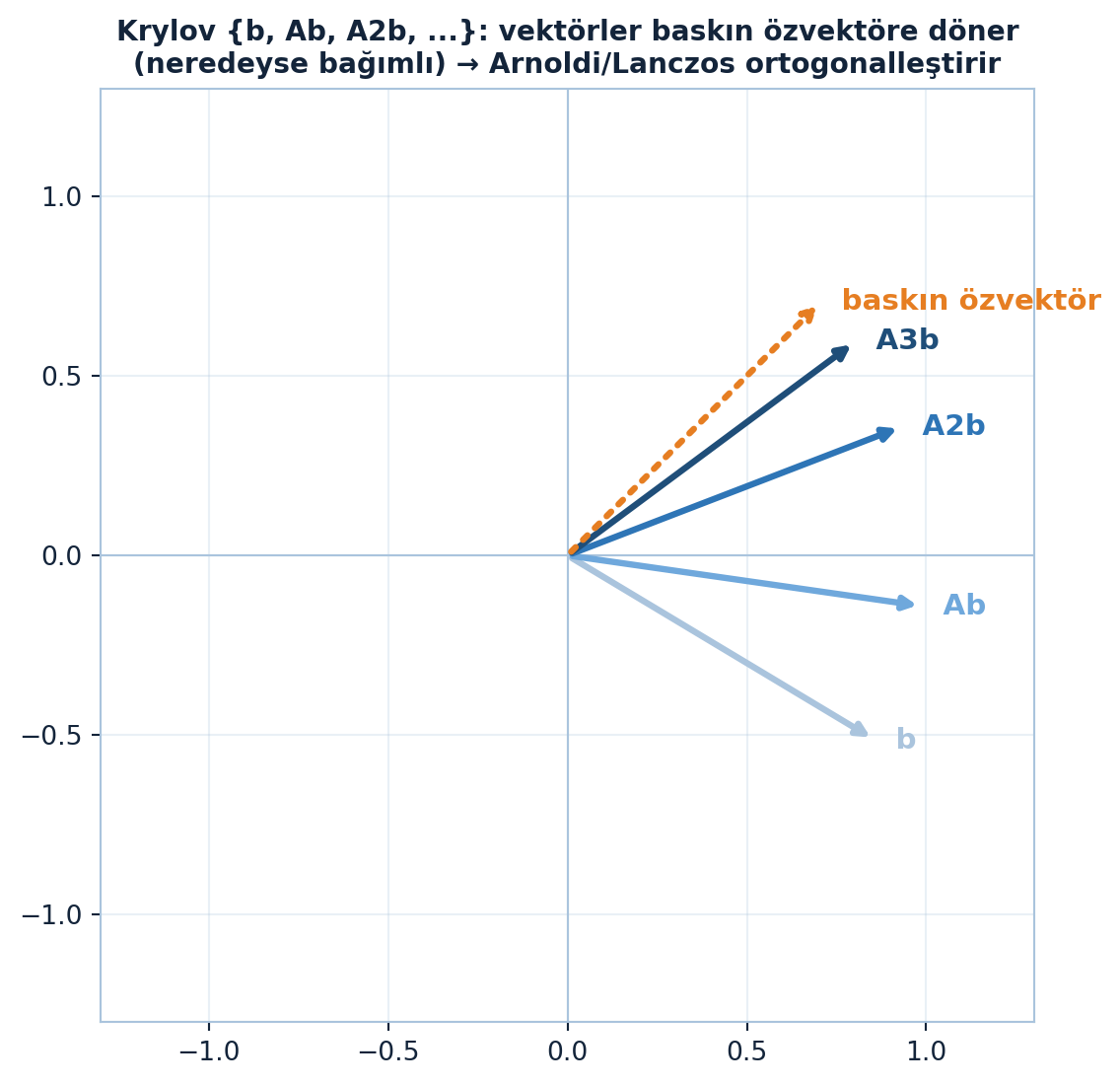
İpucuBuilder Notu — Yalnız Ax Çarpımı
Krylov uzayı, büyük-ölçek sayısal cebrin kalbidir: matrisi belleğe açmadan, yalnız \(Ax\) çarpımıyla çalışır. Conjugate gradient, GMRES, Lanczos hepsi Krylov tabanlıdır — devasa seyrek sistemler (PDE, ağ Laplacian’ları, öneri sistemleri) için tek pratik yol.
12.10 9. Conjugate Gradient
Krylov uzayında \(Ax = b\)’yi tam çözmeyiz; o uzaydaki en iyi (en yakın) çözümü buluruz.
“…xⱼ will be the best vector, or the closest vector [in the Krylov space].” — Strang, 39:19
\(j\) büyüdükçe Krylov uzayı genişler ve çözüm gerçek cevaba yakınsar. Bu yaklaşımın kahramanı conjugate gradient’tir: simetrik pozitif tanımlı sistemlerde Krylov uzayında hızla en iyi çözüme iner. Tam çözüm yerine “yeterince yakın, yeterince hızlı”.
Conjugate gradient’in gradient descent’e kıyasla ne kadar hızlı yakınsadığını Şekil 12.7 gösteriyor: aynı SPD sistemde CG, 20 adımda residual normunu ~\(10^{-3}\) düzeyine (sonlu-aritmetikte makine sıfırına ~27 adımda) indirirken, sabit-adım gradient descent çok daha yavaş ilerler ve aynı düzeye yaklaşamaz.
Kod
# --- CG vs GD yakınsama: SPD sistemde residual normu ---
np.random.seed(1)
B = np.random.randn(20, 20)
S = B @ B.T + 0.5 * np.eye(20)
bt = np.random.randn(20)
xcg, res = conjugate_gradient(S, bt, iters=20)
xgd, resgd = gradient_descent_spd(S, bt, 80)
fig, ax = plt.subplots(figsize=(7.2, 4.6))
apply_style(ax)
ax.semilogy(range(len(res)), res, color=COL_PRIMARY, marker="o", ms=4, label="conjugate gradient")
ax.semilogy(range(len(resgd)), resgd, color=COL_VEC3, label="gradient descent")
ax.set_xlabel("iterasyon")
ax.set_ylabel("residual norm (log)")
ax.legend()
ax.set_title(
"Conjugate gradient vs gradient descent: CG Krylov uzayında\n"
"çok daha hızlı yakınsar (SPD sistem)",
color=COL_TEXT, fontsize=11, fontweight="bold",
)
plt.show()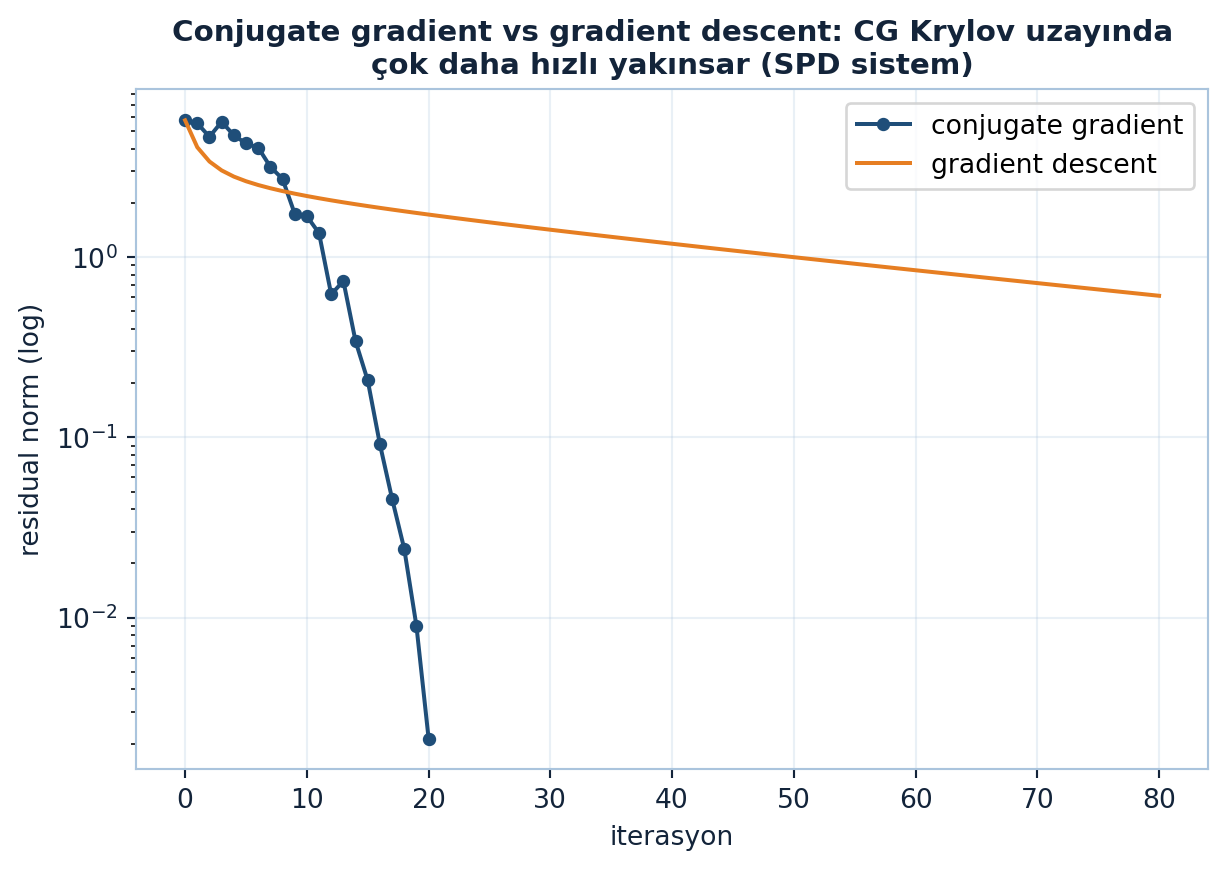
İpucuBuilder Notu — Akıllı Akraba
Conjugate gradient, gradient descent’in (Ders 21-23) akıllı akrabasıdır: SPD sistemlerde gradient descent’ten çok daha hızlı yakınsar (kondisyon sayısının karekökü kadar adım). Büyük lineer sistemleri ve ikinci-derece optimizasyonu çözmenin standart aracı; yalnız \(Ax\) gerektirir.
12.11 10. Arnoldi ve Lanczos
Krylov uzayının doğal bazı \(\{b, Ab, A^{2}b, \ldots\}\) büyük bir sorun taşır: bu vektörler genelde neredeyse bağımlıdır (hepsi baskın özvektör yönüne döner). Kötü bir tabandır. Çözüm: bu bazı ortogonalleştir.
“…that’s where Arnoldi comes in. And there’s also a Hungarian guy named Lanczos.” — Strang, 41:15
Arnoldi genel matrisler için, Lanczos simetrik matrisler için Krylov bazını ortonormalleştirir (Gram-Schmidt’in Krylov uzayına uygulanması). Ortonormal baz elde edilince, o uzaya projeksiyon (en iyi çözümü bulma) kolaylaşır.
İpucuBuilder Notu — Üç-Terimli Rekürans
Arnoldi/Lanczos, büyük seyrek matrislerin birkaç baskın özdeğerini/özvektörünü bulmanın standart yoludur (tam SVD yerine) — PCA, spektral kümeleme (NYU DL’deki spektral GCN), ve dev sistemlerin çözümünde kullanılır. Lanczos = simetrik durumda Arnoldi’nin ucuz hâli (üç-terimli rekürans).
12.12 11. Ortonormal Bazın Gücü
Neden ortonormal baz bu kadar değerli? Bir \(x\) vektörünü baz vektörleriyle yazmak istersen (\(x = Qc\)), katsayıları bulmak normalde \(Q^{-1}x\) çözmek demektir. Ama \(Q\) ortonormalse \(Q^{-1} = Q^{T}\), yani katsayılar bedava:
“…Q inverse is Q transpose. That’s the payoff.” — Strang, 43:32
\[x = Qc \;\Rightarrow\; c = Q^{T}x, \qquad c_i = q_i^{T}x\]
Her katsayı tek bir iç çarpımdır (\(c_i = q_i^{T}x\)) — çünkü \(q_i^{T}q_j = 0\) (\(i \neq j\)) diğer terimleri siler. Denklem çözmek yok; sadece nokta çarpımları. Tüm Gram-Schmidt/Krylov çabası bu kolaylık içindir.
İpucuBuilder Notu — Bedava Katsayılar
“\(c = Q^{T}x\)” — ortonormal tabanda projeksiyon = iç çarpım. Fourier dönüşümü, dalgacık katsayıları, PCA bileşenleri ve dikkat skorları hep bu ucuzluktan yararlanır. Ortonormallik, hesabı \(O(n^2)\) çözmeden \(O(n)\) iç çarpıma indirir.
12.13 Bu Dersin Özeti
- \(\|x\|\) minimizasyonu (recap) — \(Ax = b\) kısıtında \(\ell^1\) (elmas, seyrek), \(\ell^2\) (çember, dik ayak), \(\ell^\infty\) (kare).
- \(\ell^1\) seyrekliği — elmas köşesi eksende → bileşen sıfır.
- \(A = QR\) — Gram-Schmidt: kötü koşullu kolonları ortonormal \(Q\)’ya çevir.
- \(R = Q^{T}A\) — \(R_{ij} = q_i^{T}a_j\); iç çarpımlar.
- Çift adım — bileşeni çıkar, normalize et (Gram-Schmidt’in kalbi).
- Modified GS — çıkarmaları sırayla yap; sayısal kararlılık.
- Kolon pivotlama — en büyük kalan kolonu seç; rank-açığa-çıkaran.
- Krylov uzayı — \(\text{span}\{b, Ab, \ldots, A^{j-1}b\}\); yalnız \(Ax\) çarpımı.
- Conjugate gradient — Krylov uzayında en iyi/en yakın çözüm.
- Arnoldi/Lanczos — Krylov bazını ortonormalleştir; \(c = Q^{T}x\) ucuzluğu.
ÖnemliTek Bir Cümle
Kötü koşullu kolonları Gram-Schmidt ile ortonormalleştirmek (\(A = QR\)) sayısal lineer cebirin omurgasıdır; büyük seyrek sistemlerde aynı ortonormalleştirme (Krylov + Arnoldi/Lanczos) yalnız \(Ax\) çarpımıyla iteratif çözümü mümkün kılar — ve ortonormal tabanda her katsayı tek bir iç çarpımdır (\(c = Q^{T}x\)).
12.14 Kontrol Soruları
NotSoru 1: a₁ = (1, 1), a₂ = (2, 0) kolonlarına Gram-Schmidt uygula; q₁, q₂’yi bul.
Cevap: \(q_1 = a_1/\|a_1\| = (1, 1)/\sqrt{2}\). Çıkar: \(a_2^{T}q_1 = 2/\sqrt{2} = \sqrt{2}\), \(A_2 = a_2 - \sqrt{2}\cdot q_1 = (2, 0) - (1, 1) = (1, -1)\). Normalize: \(q_2 = (1, -1)/\sqrt{2}\).
\[q_1 = \frac{1}{\sqrt{2}}\begin{pmatrix} 1 \\ 1 \end{pmatrix}, \quad q_2 = \frac{1}{\sqrt{2}}\begin{pmatrix} 1 \\ -1 \end{pmatrix}\]
\(q_1^{T}q_2 = 0\) ✓ (ortonormal).
NotSoru 2: Soru 1’deki A = [a₁ a₂] için R = QᵀA matrisini bul. Üst üçgensel mi?
Cevap: \(R_{11} = \|a_1\| = \sqrt{2}\), \(R_{12} = q_1^{T}a_2 = \sqrt{2}\), \(R_{21} = q_2^{T}a_1 = 0\), \(R_{22} = \|A_2\| = \sqrt{2}\):
\[R = \begin{pmatrix} \sqrt{2} & \sqrt{2} \\ 0 & \sqrt{2} \end{pmatrix}\]
Üst üçgensel ✓ (\(R_{21} = 0\), çünkü \(q_2\) sonradan kuruldu ve \(a_1\)’e dik). \(A = QR\) doğrular.
NotSoru 3: Standart Gram-Schmidt kolonları sırayla alır. a₂ neredeyse a₁ yönündeyse risk nedir? Kolon pivotlama nasıl çözer?
Cevap: \(a_2 \approx a_1\) ise, \(q_1\) bileşenini çıkardıktan sonra \(A_2\) çok küçük olur; \(q_2 = A_2/\|A_2\|\)’de minik sayıya bölmek yuvarlama hatasını patlatır (eliminasyondaki küçük pivot gibi). Kolon pivotlama: her adımda kalan tüm kolonlardan mevcut \(q\)’ların bileşenini çıkar, en büyük kalanı seç → minik sayıya bölmekten kaçınır, sayısal kararlılık.
NotSoru 4: A 10⁶×10⁶ seyrek bir matris. Neden doğrudan QR/ters yerine Krylov + conjugate gradient kullanırsın?
Cevap: Bu boyutta \(A\)’yı açıkça tersine çevirmek/QR yapmak imkânsızdır (bellek ve \(O(n^3)\) maliyet). Seyrek \(A\) ile ucuz olan tek işlem matris-vektör çarpımıdır (\(Ax\)). Krylov uzayı \(\{b, Ab, A^{2}b, \ldots\}\) sadece ardışık \(Ax\) çarpımlarıyla kurulur; conjugate gradient bu uzayda hızla en iyi çözüme yakınsar (matrisi hiç açmadan). Büyük seyrek sistemler (PDE, ağ Laplacian, öneri) için tek pratik yol.
12.15 Egzersizler
Cevapsız problemler. Çöz, sonra numpy ile kontrol et.
Egzersiz 1. \(a_1 = (1, 0, 0)\), \(a_2 = (1, 1, 0)\), \(a_3 = (1, 1, 1)\) kolonlarına Gram-Schmidt uygula. \(q_1, q_2, q_3\)’ü bul ve ortonormal olduklarını doğrula.
Egzersiz 2. \(3x_1 + 4x_2 = 1\) doğrusunda \(\ell^2\), \(\ell^1\), \(\ell^\infty\) kazananlarını (sırasıyla \((3/25, 4/25)\), \((0, 1/4)\), \((1/7, 1/7)\)) sağla — her birinin kısıtı gerçekten sağladığını ve neden o normda en küçük olduğunu açıkla.
Egzersiz 3. \(A = \text{diag}(2, 3, 0, 0)\) ve \(b = (1, 1, 1, 1)\) için Krylov vektörlerini \(b, Ab, A^{2}b\) yaz. Bu Krylov uzayının boyutu kaçtır? (İpucu: sıfır özdeğerler hangi bileşenleri öldürür?)
Egzersiz 4. Python ile Gram-Schmidt ve QR:
import numpy as np
A = np.array([[1.0, 1.0, 1.0],
[0.0, 1.0, 1.0],
[0.0, 0.0, 1.0]])
Q, R = np.linalg.qr(A)
print("Q =\n", Q)
print("R =\n", R) # üst üçgensel
print("QᵀQ = I ?", np.allclose(Q.T @ Q, np.eye(3)))
print("QR = A ?", np.allclose(Q @ R, A))
# Krylov uzayı:
M = np.array([[2.0, 1.0], [1.0, 2.0]]); b = np.array([1.0, 0.0])
K = np.column_stack([b, M @ b, M @ (M @ b)])
print("Krylov rank:", np.linalg.matrix_rank(K))Egzersiz 5. (Ders 12 habercisi.) Ders 12, QR’ı özdeğer hesabına uygular: \(A_0 = QR\), sonra \(A_1 = RQ\) (ters sırada), tekrarla. \(A = \begin{pmatrix} 2 & 1 \\ 1 & 2 \end{pmatrix}\) için \(A_1 = RQ\)’yu hesapla; \(A_1\)’in özdeğerlerinin \(A\)’nınkiyle \((3, 1)\) aynı olduğunu doğrula (benzerlik).
12.16 Sonraki Ders İçin Hazırlık
Ders 12: Özdeğer ve Tekil Değerleri Hesaplamak
Ders 11’de Gram-Schmidt/QR ve Krylov’u kurduk. Ders 12 QR’ı beklenmedik bir yere uygular: özdeğer hesabı.
- QR iterasyonu: \(A = QR \to A_1 = RQ \to\) tekrarla; köşegene yakınsar
- Neden çalışır: her adım benzerlik (özdeğerler değişmez)
- Hızlandırma (shift) ve simetrik durumda Lanczos
- Tekil değerlerin hesabı (\(A^{T}A\) değil, doğrudan)
UyarıDers 12 Öncesi Yapılacak
- Bu dersin egzersizlerini çöz, özellikle Egzersiz 5’i (QR iterasyonu).
- Python’da
np.linalg.qrile birkaç matrise \(A \to RQ\) adımını birkaç kez uygula; köşegenin özdeğerlere yakınsamasını gözlemle. - Ana cümleyi tekrar oku: “\(A = QR\) ortonormalleştirir; Krylov + CG büyük sistemleri \(Ax\) çarpımıyla çözer.”
12.17 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Strang’de |
|---|---|---|
| \(\|x\|\) minimizasyonu | Kısıt altında en küçük norm; \(\ell^1/\ell^2/\ell^\infty\) farkı | 2m27 |
| \(\ell^1\) seyreklik | Elmas köşesi eksende → sıfır bileşen | 5m02 |
| Gram-Schmidt \(A = QR\) | Kötü koşullu kolonları ortonormal \(Q\)’ya çevir | 9m20 |
| \(R = Q^{T}A\) | \(R_{ij} = q_i^{T}a_j\); iç çarpımlar | 13m13 |
| GS çift adım | Bileşeni çıkar, sonra normalize et | 16m05 |
| Modified GS | Çıkarmaları sırayla yap; sayısal kararlılık | 20m43 |
| Kolon pivotlama | En büyük kalan kolonu seç; rank-açığa-çıkaran | 30m49 |
| Krylov uzayı | \(\text{span}\{b, Ab, A^{2}b, \ldots\}\); yalnız \(Ax\) çarpımı | 37m35 |
| Conjugate gradient | Krylov uzayında en iyi/en yakın çözüm | 39m19 |
| Arnoldi / Lanczos | Krylov bazını ortonormalleştir; \(c = Q^{T}x\) | 41m15 |
12.18 ML Bağlantıları Özeti
- \(A = QR\) → least squares’in kararlı çözümü; ortonormal ağırlık başlatması; özdeğer algoritması (Ders 12).
- \(R = Q^{T}A\) / \(c = Q^{T}x\) → ortonormal tabanda projeksiyon = iç çarpım; Fourier, dikkat skorları, PCA.
- \(\ell^1\) seyreklik → Lasso, compressed sensing; elmas köşesi.
- Kolon pivotlama → rank-açığa-çıkaran QR; öznitelik seçimi, kötü-koşullu düzeltme.
- Krylov + conjugate gradient → büyük seyrek sistemler; yalnız \(Ax\); PDE, ağ Laplacian, öneri.
- Arnoldi/Lanczos → baskın özdeğer/özvektör (tam SVD yerine); PCA, spektral GCN, spektral kümeleme.
- Ortonormallik → \(O(n^2)\) çözmeden \(O(n)\) iç çarpım; whitening, dik gömüler, hız.
ÖnemliEğer bu dersten tek bir şey alıp gidersen
Kötü koşullu kolonları Gram-Schmidt ile ortonormalleştirmek (\(A = QR\)) sayısal lineer cebirin omurgasıdır — least squares’i kararlı çözer, özdeğer algoritmasını besler, ve ortonormal tabanda her katsayı tek bir iç çarpıma (\(c = Q^{T}x\)) iner. Büyük seyrek sistemlerde aynı ortonormalleştirme Krylov uzayı + conjugate gradient + Arnoldi/Lanczos olarak yalnız \(Ax\) çarpımıyla iteratif çözümü mümkün kılar.