flowchart TD
M["A = UΣVᵀ (SVD)"] --> ATA["AᵀA = VΣ²Vᵀ (V, σ²)"]
M --> AAT["AAᵀ → U"]
M --> AV["Av = σu"]
M --> GEO["geometri: döndür-ger-döndür"]
M --> R1["A = Σ σᵢuᵢvᵢᵀ (rank-1)"]
M --> POL["polar A = SQ"]
M --> PCA["en büyük σ = en önemli parça (PCA)"]
style M fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style R1 fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style ATA fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style AAT fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style AV fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style GEO fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
style POL fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
style PCA fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
7 Tekil Değer Ayrışımı (SVD)
A = UΣVᵀ: her matrise uygulanır — döndür, ger, yeniden döndür ve verinin en önemli parçası
NotBölüm bilgisi
- Video: Singular Value Decomposition (SVD) — Gilbert Strang, MIT 18.065
- OCW: Lecture 6 — Singular Value Decomposition (SVD)
- Okuma süresi: ≈ 38 dk
- Önkoşul: Ders 5 (pozitif tanımlılık, \(A^{T}A \geq 0\), “simetrik → gerçek özdeğer / ortonormal özvektör”, spektral teorem \(S = Q\Lambda Q^{T}\))
7.1 Bu Derste Ne Var?
Strang’in deyimiyle “büyük gün”: kursun ve tüm veri biliminin temel taşı SVD. Özdeğerler dikdörtgen matriste çalışmaz; SVD bunu iki tekil vektör kümesiyle çözer ve her matrise uygulanır.
Üç temel fikir:
- \(A = U\Sigma V^{T}\) — her matris (dikdörtgen dâhil) için; \(U\) sol tekil vektörler, \(V\) sağ tekil vektörler, \(\Sigma\) tekil değerler (\(\sigma \geq 0\)).
- \(A^{T}A\) anahtarı — \(V\), \(A^{T}A\)’nın özvektörleri; \(\sigma^{2}\), \(A^{T}A\)’nın özdeğerleri; \(U\) ise \(AA^{T}\)’nin özvektörleri (Ders 5’in pozitif yarı-tanımlılığı burada ödedi).
- Geometri — her matris bir döndürme × germe × döndürme’dir; çemberi elipse çevirir.
“…this is a big day mathematically speaking…” — Strang, 0:22
SVD’nin merkezî denkleminden (\(A = U\Sigma V^{T}\)) tüm hatların nasıl dallandığını Şekil 7.1 özetliyor: \(A^{T}A\) ve \(AA^{T}\) özvektörlerinden \(Av = \sigma u\) ilişkisine, döndür-ger-döndür geometrisine, rank-1 toplamına, polar ayrışıma ve PCA’ya kadar dersin bütün dalları.
İpucuBuilder Notu — Veri Biliminin Merkezi
- SVD = veri biliminin merkezi: en büyük birkaç \(\sigma\) ile rank-1 parça (\(\sigma_i u_i v_i^{T}\)) tutmak = düşük-rank yaklaşım = PCA, LoRA, sıkıştırma, gürültü giderme (Ders 7 Eckart-Young).
- Her matrise uygulanır: dikdörtgen ağırlık matrisleri (embedding, lineer katman) özdeğer ayrışımına sahip olmayabilir ama SVD’si her zaman vardır.
- \(A^{T}A\)’dan kaçın: pratik hesapta \(A^{T}A\) kurmak kondisyon sayısını kareler (yuvarlama hatası); gerçek SVD algoritmaları farklıdır.
- Polar ayrışım \(A = SQ\) — her matris simetrik × ortogonal; SVD’den türer (mühendislikte gerinim = germe + dönme).
Tek cümle: SVD her matrisi “döndür, ger, yeniden döndür” (\(U\Sigma V^{T}\)) olarak çözer ve en büyük tekil değerler verinin en önemli parçasını verir.
7.2 Neden SVD: Dikdörtgen Matris, İki Vektör Kümesi
Özdeğerler kare matrisler içindir. \(A\) dikdörtgense \(Ax\), \(x\)’ten farklı boyutta çıkar (\(\mathbb{R}^{n} \to \mathbb{R}^{m}\)), yani \(Ax = \lambda x\) imkânsızdır. Kare olsa bile genel bir matrisin özvektörleri kompleks veya dik olmayabilir. SVD bu sorunları iki ayrı vektör kümesiyle çözer.
“…this is a big day mathematically speaking…” — Strang, 0:22
Özdeğerlerde tek küme (\(Q\)) vardı; SVD’de \(m\) boyutunda sol tekil vektörler (\(U\)) ve \(n\) boyutunda sağ tekil vektörler (\(V\)) olmak üzere iki küme var.
“There are two sets of singular vectors, not one.” — Strang, 2:23
İpucuBuilder Notu — Her Ağırlığa Uygulanır
Bu “iki küme” fikri SVD’yi evrensel kılar: her ağırlık matrisi (dikdörtgen embedding, lineer katman) için tanımlıdır — özdeğer ayrışımının aksine hiçbir koşul gerektirmez.
7.3 A = UΣVᵀ
SVD, herhangi bir \(A\) matrisini üç çarpana ayırır:
\[ A = U \Sigma V^{T} \]
\(U\) (\(m \times m\)) ve \(V\) (\(n \times n\)) ortogonal matrisler (ortonormal kolonlar), \(\Sigma\) köşegen tekil değer matrisi. Köşegendeki değerler \(\sigma_1 \geq \sigma_2 \geq \cdots \geq 0\) hepsi negatif olmayan tekil değerlerdir. Bu, simetrik matrisin \(S = Q\Lambda Q^{T}\) ayrışımının her matrise genellenmiş hâlidir.
İpucuBuilder Notu — Tek Satır SVD
\(A = U\Sigma V^{T}\), NumPy/PyTorch’ta np.linalg.svd ile tek satırda gelir. Tekil değerlerin azalan sırada olması, “en önemli yön en başta” demektir — düşük-rank sıkıştırmanın temeli.
7.4 AᵀA Anahtarı: V ve σ²
SVD’nin matematiği \(A^{T}A\) üzerinden yürür. Bu matris simetrik ve pozitif yarı-tanımlıdır (Ders 5).
“…the key is that A transpose A is a great matrix.” — Strang, 4:09
\(A = U\Sigma V^{T}\) varsayıp \(A^{T}A\)’yı açarsak, ortadaki \(U^{T}U = I\) düşer:
\[ A^{T}A = (U\Sigma V^{T})^{T}(U\Sigma V^{T}) = V\Sigma^{T}U^{T}U\Sigma V^{T} = V\Sigma^{2}V^{T} \]
Bu tam olarak bir \(Q\Lambda Q^{T}\) biçimidir. Yani \(V\), \(A^{T}A\)’nın özvektörleri; \(\sigma^{2}\) (tekil değerlerin karesi), \(A^{T}A\)’nın özdeğerleridir.
“…the v’s are the eigenvectors of A transpose A.” — Strang, 15:20
Aynı simetrik özayrışımın diğer yönden (\(AA^{T}\)) \(U\)’yu nasıl verdiğini, ve \(\sigma^{2}\)’nin \(A^{T}A\)’nın özdeğerlerinden geldiğini Şekil 7.2 üç panelde gösteriyor: \(A^{T}A = V\Sigma^{2}V^{T}\), \(AA^{T} = U\Sigma\Sigma^{T}U^{T}\) ve \(\sigma^{2} = 3, 1\).
Kod
A = np.array([[1, 0], [1, 1], [0, 1]])
V, sig2, U = ata_aat_eig(A)
AtA = A.T @ A
AAt = A @ A.T
fig, axes = plt.subplots(1, 3, figsize=(13, 4.2))
heatmap(axes[0], AtA, title="AᵀA = VΣ²Vᵀ")
heatmap(axes[1], AAt, title="AAᵀ = UΣΣᵀUᵀ")
bar_values(axes[2], sorted(sig2, reverse=True), ["σ₁²", "σ₂²"],
title="σ² = eig(AᵀA) = 3, 1")
fig.suptitle("AᵀA ve AAᵀ: V, U ve σ² buradan gelir",
color=COL_TEXT, fontsize=14, fontweight="bold")
fig.tight_layout()
plt.show()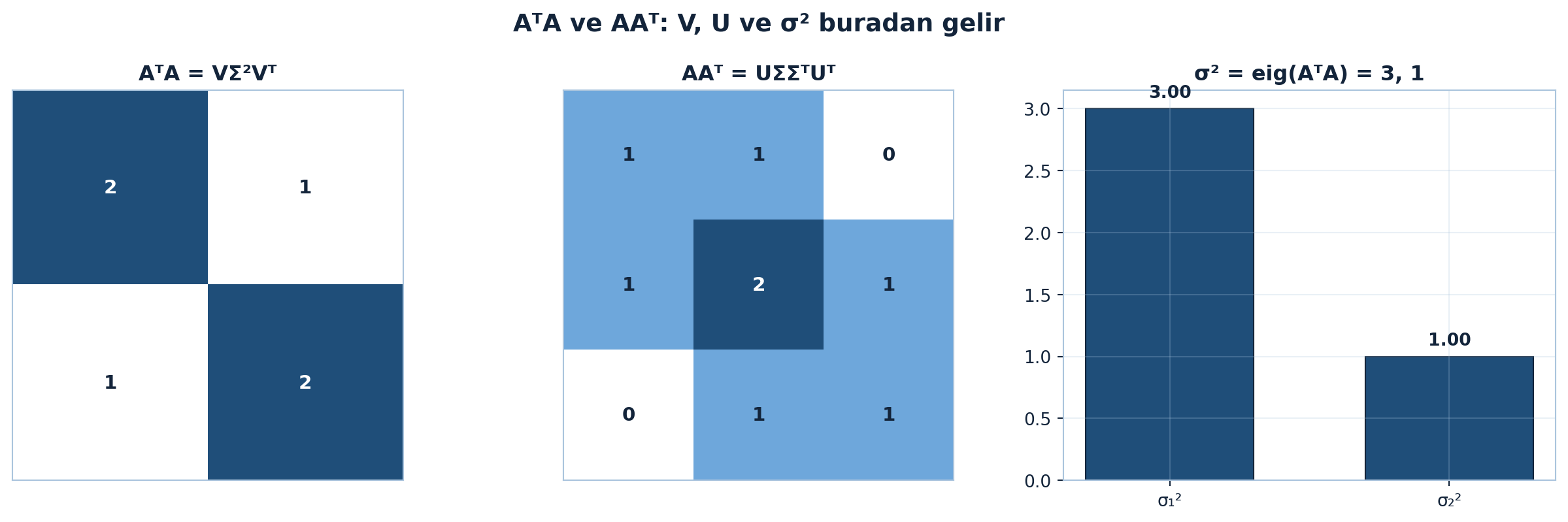
İpucuBuilder Notu — PCA’nın Özü
\(\sigma^{2} = A^{T}A\)’nın özdeğeri bağlantısı, Ders 5’in “\(A^{T}A \geq 0\)” sonucunu ödetir: özdeğerler \(\geq 0\) olduğundan karekökleri (\(\sigma\)) gerçektir. PCA bunu doğrudan kullanır: kovaryans = \((1/n)A^{T}A\), tekil değerler = standart sapma yönündeki ölçekler.
7.5 AAᵀ: U
Aynı numarayı diğer yönden yap. \(AA^{T}\)’yi açınca bu sefer \(V^{T}V = I\) düşer:
\[ AA^{T} = (U\Sigma V^{T})(U\Sigma V^{T})^{T} = U\Sigma V^{T}V\Sigma^{T}U^{T} = U\Sigma\Sigma^{T}U^{T} \]
Yani \(U\), \(AA^{T}\)’nin özvektörleridir. \(A^{T}A\) (\(n \times n\)) ve \(AA^{T}\) (\(m \times m\)) farklı boyutlarda ama aynı sıfırdan-farklı özdeğerlere sahiptir (Ders 4’teki \(AB/BA\) gerçeği) — eksik olanlar sıfırdır. Güzel simetri: \(V\) bir taraftan, \(U\) diğer taraftan gelir.
İpucuBuilder Notu — İki Yön, Aynı σ
\(A^{T}A\) ile \(AA^{T}\)’nin aynı sıfırdan-farklı özdeğerleri olması, hangisinin küçük olduğunu hesaplama özgürlüğü verir: \(10000 \times 50\) veride \(50 \times 50\) olan \(A^{T}A\)’yı çöz (kernel trick’in SVD karşılığı). Büyük veri matrislerinde muazzam tasarruf.
7.6 Av = σu ve Ortogonallik
SVD’nin tanımlayıcı ilişkisi, \(Ax = \lambda x\)’in yerini alır:
\[ A v_i = \sigma_i u_i, \qquad u_i = \frac{A v_i}{\sigma_i} \]
“A times one set of singular vectors gives me a number of times the other set of singular vectors.” — Strang, 9:02
Sihir şudur: \(A^{T}A\)’nın ortogonal özvektörleri (\(V\)) alınır, \(A\) ile çarpılır, ve çıkan \(Av\)’ler de ortogonaldir. Kanıt — \(u_1^{T}u_2\)’yi hesapla, ortada \(A^{T}A\) belirir, \(v_2\) onun özvektörü olduğundan \(\sigma_2^{2}v_2\) verir:
\[ u_1^{T}u_2 = \frac{(Av_1)^{T}(Av_2)}{\sigma_1\sigma_2} = \frac{v_1^{T}(A^{T}A)v_2}{\sigma_1\sigma_2} = \frac{\sigma_2^{2}\,(v_1^{T}v_2)}{\sigma_1\sigma_2} = 0 \]
Son adımda \(v_1^{T}v_2 = 0\) (ortonormallik). Demek ki satır uzayındaki ortogonal \(v\)’ler, kolon uzayında ortogonal \(Av\)’lere gider.
“…orthogonal v’s in the row space, orthogonal Av’s over in column space.” — Strang, 26:06
İpucuBuilder Notu — Kazanç Yönleri
“Bir ortogonal taban (\(V\)), \(A\) ile başka bir ortogonal tabana (\(U\)) gider” — SVD’nin kalbi budur. Veri matrisinde \(V\) girdi özelliklerinin, \(U\) çıktı örneklerinin doğal eksenleridir; \(\sigma\) ikisi arasındaki kazancı verir.
7.7 Hesaplama Uyarısı: AᵀA’dan Kaçın
\(A^{T}A\) ispat için harika ama pratikte tehlikeli. \(5000 \times 10000\) bir \(A\) için \(A^{T}A\) kurmak hem pahalıdır hem de hataları büyütür:
“…you would not go this A transpose A route.” — Strang, 26:58
Sebep: \(A^{T}A\) kurmak matrisin kondisyon sayısını kareler — yuvarlama hatasına karşı kırılganlık iki katına çıkar.
“…condition number gets squared.” — Strang, 28:02
Gerçek SVD algoritmaları \(A^{T}A\)’yı hiç kurmadan, doğrudan \(A\) üzerinde çalışır (bidiagonalizasyon + örtük QR).
İpucuBuilder Notu — Sayısal Altın Kural
“\(A^{T}A\) kurma” kuralı sayısal ML’nin altın kuralıdır: normal denklemler (\(A^{T}A\)) yerine QR veya SVD kullan; least squares’te lstsq bunu otomatik yapar. Kondisyon sayısının karelenmesi, küçük tekil değerlerin bilgisini yok eder.
7.8 Geometri: Döndürme × Germe × Döndürme
SVD’nin üç çarpanı üç geometrik işlemdir: \(V\) ortogonal (döndürme), \(\Sigma\) köşegen (germe), \(U\) ortogonal (döndürme). Yani her matris çarpımı şudur:
\[ A = U \Sigma V^{T} \]
Birim çember önce \(V^{T}\) ile döner (uzunluk değişmez), sonra \(\Sigma\) ile her eksende \(\sigma_i\) kadar gerilir (çember → elips), sonra \(U\) ile yeniden döner.
“…into a rotation times a stretch times a different rotation…” — Strang, 32:40
\(U\) ne zaman \(V\)’ye eşit olur? \(A\) simetrik pozitif tanımlı olduğunda — o zaman SVD tam olarak \(S = Q\Lambda Q^{T}\)’dir (\(Q = U = V\), \(\Lambda = \Sigma\)). Pozitif tanımlı matrisler bu yüzden “en iyileridir”: iki döndürme aynıdır.
Bu üç adımı — döndür, ger, döndür — Şekil 7.3 birim çember üzerinde tek tek izliyor: \(V^{T}\) döndürür, \(\Sigma\) elipse gerer, \(U\) yeniden döndürür; son panelde tekil eksenler \(\sigma_1 u_1\) ve \(\sigma_2 u_2\) elipsin ana ve yan eksenlerini gösterir.
Kod
B = np.array([[0, 2], [3, 0]])
g = svd_unit_circle(B)
fig, axes = plt.subplots(1, 4, figsize=(15, 4.2))
# Panel 1: birim çember
style_square_axes(axes[0], 3.4, "birim çember")
plot_pointset(axes[0], g["circle"], color=COL_ACCENT)
# Panel 2: Vᵀ (döndür)
style_square_axes(axes[1], 3.4, "Vᵀ (döndür)")
plot_pointset(axes[1], g["after_Vt"], color=COL_ACCENT)
# Panel 3: ΣVᵀ (ger → elips)
style_square_axes(axes[2], 3.4, "ΣVᵀ (ger → elips)")
plot_pointset(axes[2], g["after_SigVt"], color=COL_ACCENT)
# Panel 4: UΣVᵀ = A (accent) + tekil eksenler
style_square_axes(axes[3], 3.4, "UΣVᵀ = A")
plot_pointset(axes[3], g["after_A"], color=COL_VEC3)
draw_vec2d(axes[3], g["U"][:, 0] * g["s"][0], color=COL_PRIMARY, label="σ₁u₁")
draw_vec2d(axes[3], g["U"][:, 1] * g["s"][1], color=COL_VEC3, label="σ₂u₂")
fig.suptitle("SVD geometrisi: döndür (Vᵀ) → ger (Σ) → döndür (U); σ=3,2",
color=COL_TEXT, fontsize=13, fontweight="bold")
fig.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()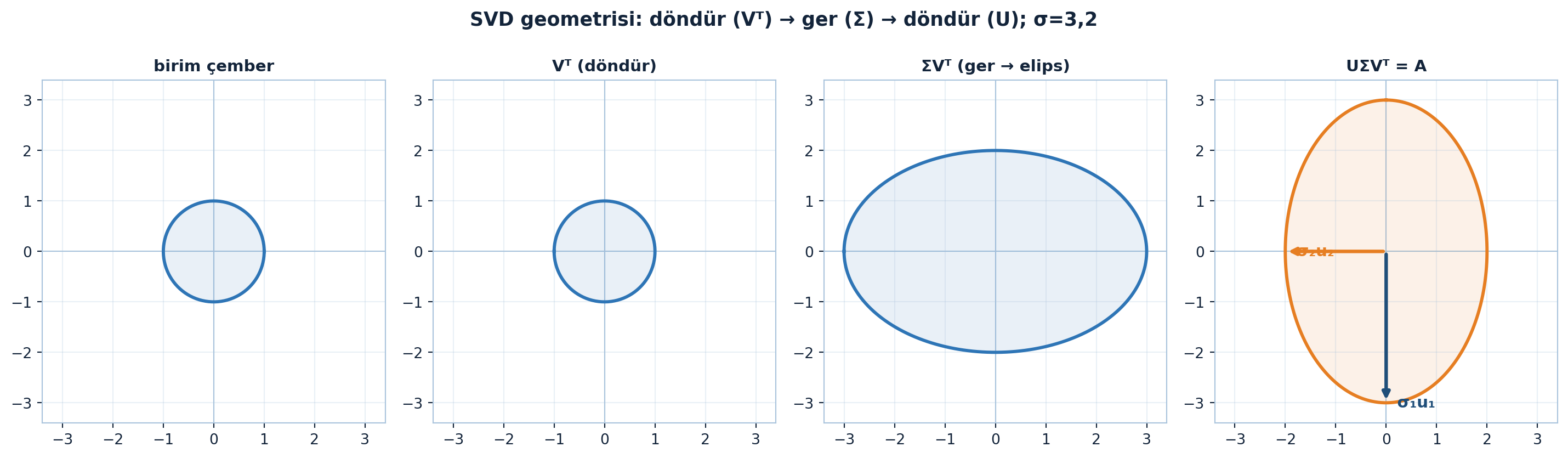
İpucuBuilder Notu — Katmanın Anatomisi
“Döndür-ger-döndür”, bir lineer katmanın geometrik anatomisidir. \(\Sigma\)’daki tekil değerler katmanın her yöndeki kazancını verir; en büyük \(\sigma\) Lipschitz sabitidir (spektral norm). Spektral normalizasyon \(\sigma_1\)’i sınırlayarak GAN ve sağlam ağları kararlı kılar.
7.9 Parametre Sayımı ve Determinant
Sayım güzel bir tutarlılık kontrolü verir. \(2 \times 2\) bir \(A\)’da 4 sayı (\(a, b, c, d\)) vardır; sağ tarafta da 4 olmalı: \(\Sigma\)’da 2 tekil değer + \(V\) döndürmesinde 1 açı + \(U\) döndürmesinde 1 açı = 4. \(3 \times 3\)’te \(9 = 3\) (\(\Sigma\)) + 3 (\(V\), roll-pitch-yaw) + 3 (\(U\)). Determinant da temiz: ortogonal matrislerin determinantı \(\pm 1\) olduğundan
\[ |\det A| = \sigma_1 \sigma_2 \cdots \sigma_n \]
Özdeğerlerin çarpımı gibi tekil değerlerin çarpımı da \(|\det|\)’i verir — ama tek tek \(\sigma \neq |\lambda|\) (tekil değerler özdeğerleri “dıştan sarar”).
İpucuBuilder Notu — Hacim Ölçeği
Tekil değerlerin çarpımı = hacim ölçeği (Jacobian determinantı). Normalizing flow’larda \(\log|\det| = \sum \log \sigma_i\) olasılık hesabına girer; düşük-rank katmanlarda küçük \(\sigma\)’lar hacmi (bilgiyi) sıkıştırır.
7.10 İndirgenmiş vs Tam SVD
SVD’nin iki boyu vardır. İndirgenmiş (reduced) form yalnızca \(r\) (rank) sıfırdan-farklı tekil değeri tutar: \(U\) (\(m \times r\)), \(\Sigma\) (\(r \times r\), hepsi \(> 0\)), \(V^{T}\) (\(r \times n\)). Tam (full) form \(U\)’yu \(m \times m\), \(V\)’yi \(n \times n\) ortogonal matrise tamamlar ve \(\Sigma\)’ya null uzayı için sıfırlar ekler.
\[ A = \sigma_1 u_1 v_1^{T} + \sigma_2 u_2 v_2^{T} + \cdots + \sigma_r u_r v_r^{T} \]
Bu rank-1 toplam, SVD’nin en kullanışlı yazılışıdır: \(A\), \(r\) tane rank-1 parçanın \(\sigma\)-ağırlıklı toplamıdır. Sıfırlar hiçbir şey katmaz; gerçek bilgi \(r\) parçadadır.
Bu \(\sigma\)-ağırlıklı rank-1 toplamı Şekil 7.4 somut bir \(3 \times 2\) matriste gösteriyor: \(\sigma_1 u_1 v_1^{T}\) en çok bilgiyi taşır, \(\sigma_2 u_2 v_2^{T}\) kalanı tamamlar, ikisinin toplamı tam olarak \(A\)’dır.
Kod
# A = σ₁u₁v₁ᵀ + σ₂u₂v₂ᵀ rank-1 parçaların σ-ağırlıklı toplamı
A = np.array([[1, 0], [1, 1], [0, 1]]) # 3×2, rank 2
layers, cum, s = svd_rank1_layers(A) # layers[0]=σ₁u₁v₁ᵀ, layers[1]=σ₂u₂v₂ᵀ
L1 = np.where(np.abs(layers[0]) < 1e-12, 0.0, layers[0]) # ~0 sayısal artıkları temizle
L2 = np.where(np.abs(layers[1]) < 1e-12, 0.0, layers[1])
# Ortak renk ölçeği: üç heatmap'in tonları karşılaştırılabilir olsun
allvals = np.concatenate([L1.ravel(), L2.ravel(), np.asarray(A, float).ravel()])
vmin = float(allvals.min()); vmax = float(allvals.max())
fig, axes = plt.subplots(1, 3, figsize=(8.6, 3.6))
fig.patch.set_facecolor(COL_WHITE)
heatmap(axes[0], L1, title="σ₁ u₁ v₁ᵀ", cmap=PM1_CMAP, vmin=vmin, vmax=vmax, fontsize=12)
heatmap(axes[1], L2, title="σ₂ u₂ v₂ᵀ", cmap=PM1_CMAP, vmin=vmin, vmax=vmax, fontsize=12)
heatmap(axes[2], A, title="A", cmap=PM1_CMAP, vmin=vmin, vmax=vmax, fontsize=12)
# "+" ve "=" anotasyonları (paneller arasında)
fig.text(0.365, 0.50, "+", ha="center", va="center", fontsize=30, fontweight="bold", color=COL_ACCENT)
fig.text(0.655, 0.50, "=", ha="center", va="center", fontsize=30, fontweight="bold", color=COL_ACCENT)
fig.suptitle("A = toplam σᵢ uᵢ vᵢᵀ (rank-1 parçaların σ-ağırlıklı toplamı)",
fontsize=13, fontweight="bold", color=COL_PRIMARY, y=1.04)
fig.tight_layout()
plt.show()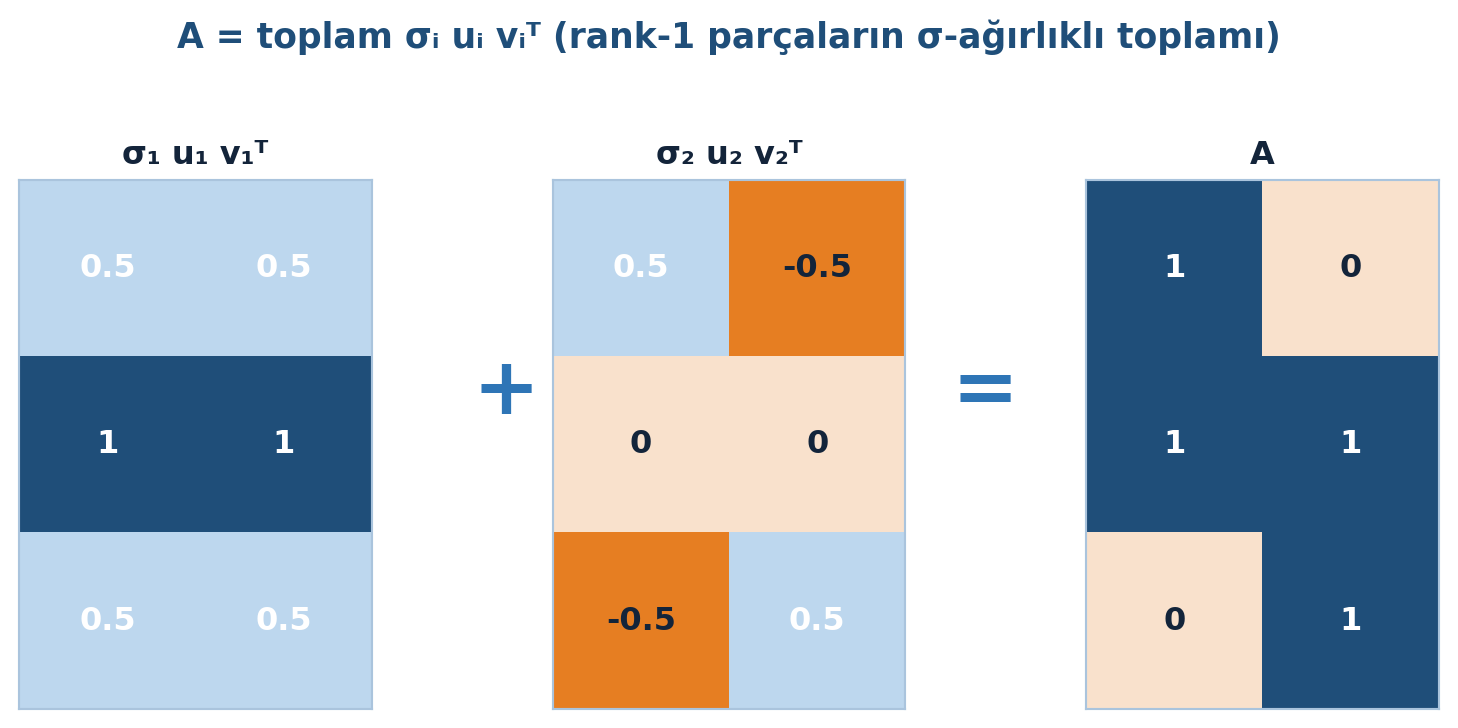
İpucuBuilder Notu — Depolama Tasarrufu
İndirgenmiş SVD = depolama tasarrufu: \(m \times n\) matris yerine \(r(m+n)\) sayı. Rank-1 toplam, düşük-rank yaklaşımın (en büyük \(k\) parçayı tut) ve LoRA’nın (\(\Delta W\) = düşük-rank) doğrudan formudur. np.linalg.svd(A, full_matrices=False) indirgenmiş formu verir.
7.11 Polar Ayrışım: A = SQ
SVD’den bedava çıkan ünlü bir ayrışım: polar ayrışım. Karmaşık sayının \(r \cdot e^{i\theta}\) formu gibi, her matris bir simetrik (\(r \leftrightarrow S\)) çarpı bir ortogonal (\(e^{i\theta} \leftrightarrow Q\)) olarak yazılır:
\[ A = U\Sigma V^{T} = (U\Sigma U^{T})(U V^{T}) = S Q \]
Araya \(U^{T}U = I\) sokup parantezleri kaydırdık: \(S = U\Sigma U^{T}\) simetrik pozitif yarı-tanımlı, \(Q = UV^{T}\) ortogonal.
“…It’s called the polar decomposition of a matrix.” — Strang, 46:17
Mühendislik dilinde: her gerinim (strain), bir simetrik germe çarpı bir iç döndürmedir.
Polar ayrışımın iki parçasını — simetrik germe \(S\) ve ortogonal döndürme \(Q\) — Şekil 7.5 somut bir matriste gösteriyor: \(A = SQ\), tıpkı karmaşık sayının yarıçap × dönüş ayrışımı gibi.
Kod
Bsq = np.array([[1, 1], [0, 1]])
S, Q = polar(Bsq)
vmin = float(min(Bsq.min(), S.min(), Q.min()))
vmax = float(max(Bsq.max(), S.max(), Q.max()))
fig, axs = plt.subplots(1, 3, figsize=(11, 4.2))
heatmap(axs[0], Bsq, title="A", cmap=PM1_CMAP, vmin=vmin, vmax=vmax)
heatmap(axs[1], S, title="S (simetrik PSD)", cmap=PM1_CMAP, vmin=vmin, vmax=vmax)
heatmap(axs[2], Q, title="Q (ortogonal)", cmap=PM1_CMAP, vmin=vmin, vmax=vmax)
fig.text(0.365, 0.55, "=", ha="center", va="center", fontsize=22, fontweight="bold", color=COL_TEXT)
fig.text(0.655, 0.55, "×", ha="center", va="center", fontsize=22, fontweight="bold", color=COL_TEXT)
fig.text(0.5, 0.05, "her matris = simetrik germe × ortogonal döndürme",
ha="center", va="center", fontsize=11, color=COL_TEXT)
fig.suptitle("Polar ayrışım A = S Q", color=COL_TEXT, fontsize=13, fontweight="bold")
fig.tight_layout(rect=(0, 0.07, 1, 0.94))
plt.show()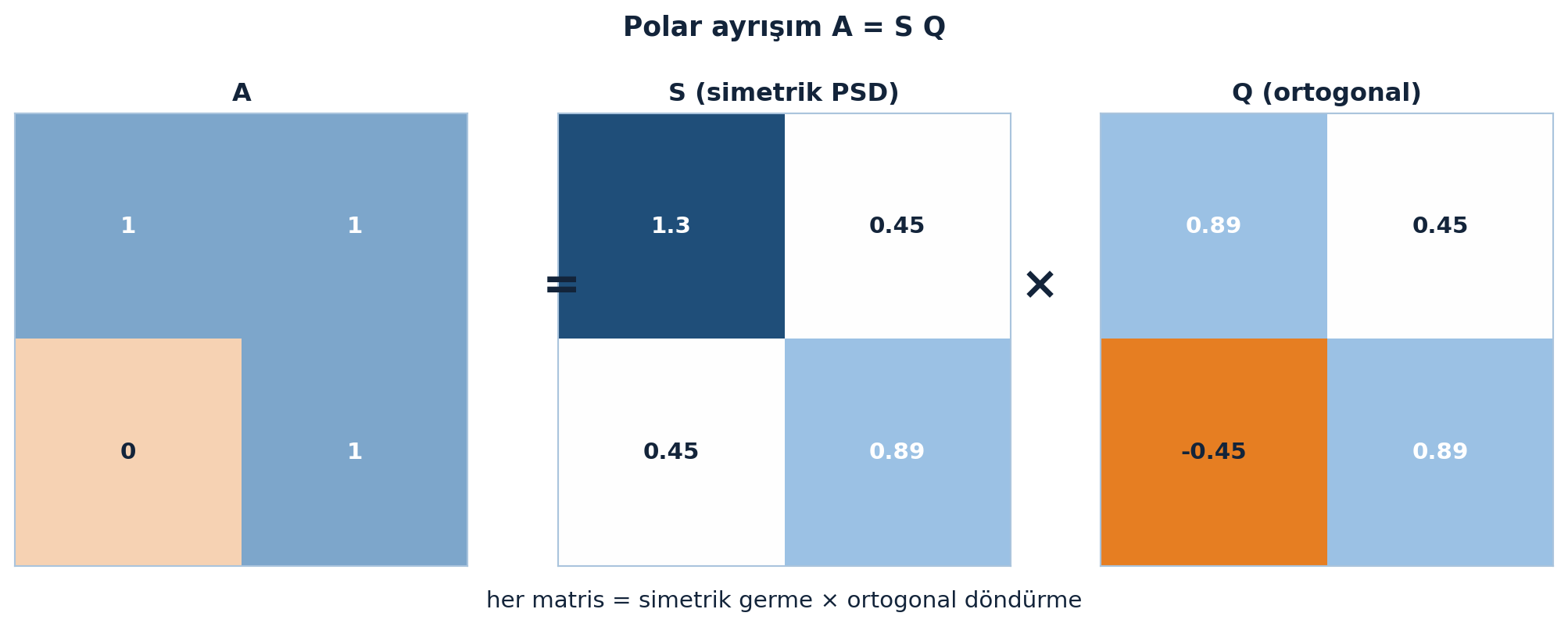
İpucuBuilder Notu — En Yakın Ortogonal
Polar ayrışım, en yakın ortogonal matrisi bulmanın yoludur (\(Q = UV^{T}\)) — Procrustes hizalaması (Ders 34), 3B poz/döndürme kestirimi ve ağırlıkları ortogonale yansıtma (ortogonal düzenlileştirme) bunu kullanır.
7.12 Veri: En Önemli Rank-1 Parça
Strang dersi veriye bağlayarak kapatıyor. Büyük bir veri matrisinde bir kısım sinyal, bir kısım gürültüdür. En önemli parça hangisi?
“…the most important part of the matrix.” — Strang, 50:42
Cevap, SVD’nin rank-1 toplamındaki en büyük tekil değerli parçadır:
\[ A \approx \sigma_1 u_1 v_1^{T} \quad (\text{largest single piece}) \]
\(\sigma\)’lar azalan sırada olduğundan \(\sigma_1 u_1 v_1^{T}\) matrisin en güçlü yönüdür. İlk \(k\) parçayı tutmak = en iyi rank-\(k\) yaklaşım = PCA. Bu, Ders 7’nin (Eckart-Young) tam konusudur.
Bunu Şekil 7.6 somut bir görüntü matrisinde gösteriyor: tam matristen başlayarak yalnızca ilk \(k\) tekil değer parçası tutulduğunda baskın yapı daha rank-3’te neredeyse tümüyle korunur. Tekil değerlerin hızlı düşüşünü ve kümülatif enerjinin ilk birkaç parçada nasıl toplandığını ise Şekil 7.7 ortaya koyuyor — en büyük \(\sigma\) sinyali taşır, küçük \(\sigma\)’lar gürültüdür.
Kod
M = structured_matrix(8)
vmin = float(M.min()); vmax = float(M.max())
fig, axes = plt.subplots(1, 4, figsize=(15, 4.2))
heatmap(axes[0], M, title="A (rank 8)", annotate=False, vmin=vmin, vmax=vmax)
for ax, k in zip(axes[1:], (1, 2, 3)):
Ak, e = rank_k_approx(M, k)
heatmap(ax, Ak, title="rank-" + str(k) + " (hata " + str(round(e, 2)) + ")",
annotate=False, vmin=vmin, vmax=vmax)
fig.suptitle("Eckart-Young: en iyi rank-k yaklaşım = ilk k tekil değer parçası",
color=COL_TEXT, fontsize=14, fontweight="bold")
fig.tight_layout(rect=(0, 0, 1, 0.93))
plt.show()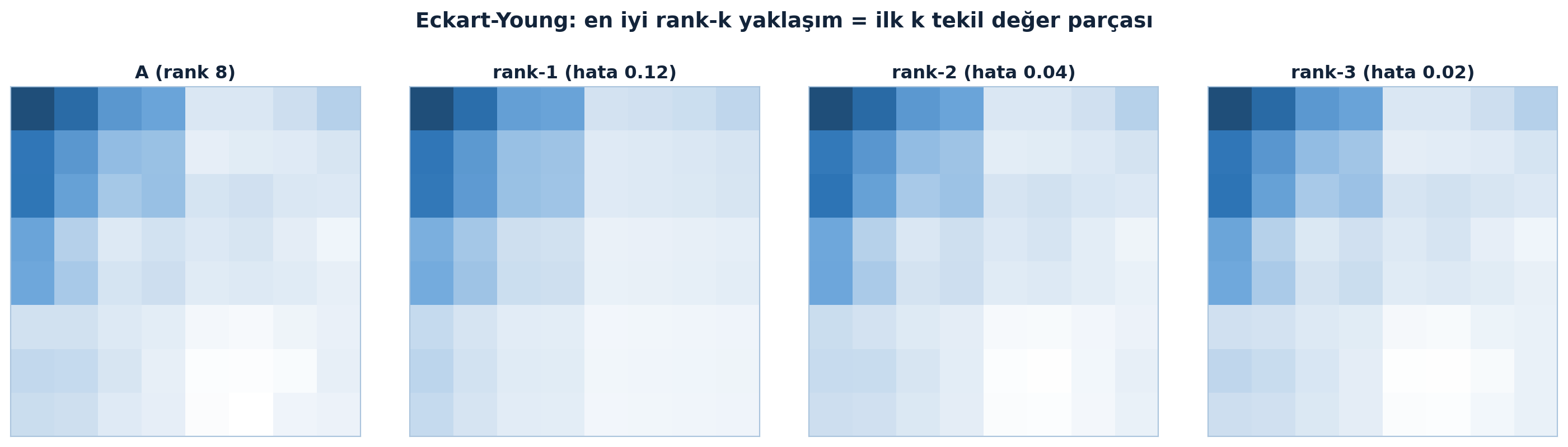
Kod
M = structured_matrix(8)
s = svd_full(M)[1]
fig, axes = plt.subplots(1, 2, figsize=(11, 4.4))
bar_values(axes[0], s, title="Tekil değerler σ (azalan)", highlight=[0])
ax = axes[1]
ks = np.arange(1, len(s) + 1)
energy = np.cumsum(s**2) / np.sum(s**2)
ax.plot(ks, energy, "-o", color=COL_PRIMARY, lw=2.2, markersize=6)
apply_style(ax)
ax.set_xticks(ks)
ax.set_ylabel("kümülatif enerji oranı")
ax.set_xlabel("parça sayısı k")
ax.set_title("Kümülatif enerji (ilk birkaç parça çoğunu taşır)", color=COL_TEXT, fontsize=12, fontweight="bold")
fig.suptitle("En büyük σ = en önemli parça (sinyal); küçük σ = gürültü",
color=COL_TEXT, fontsize=13, fontweight="bold")
fig.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()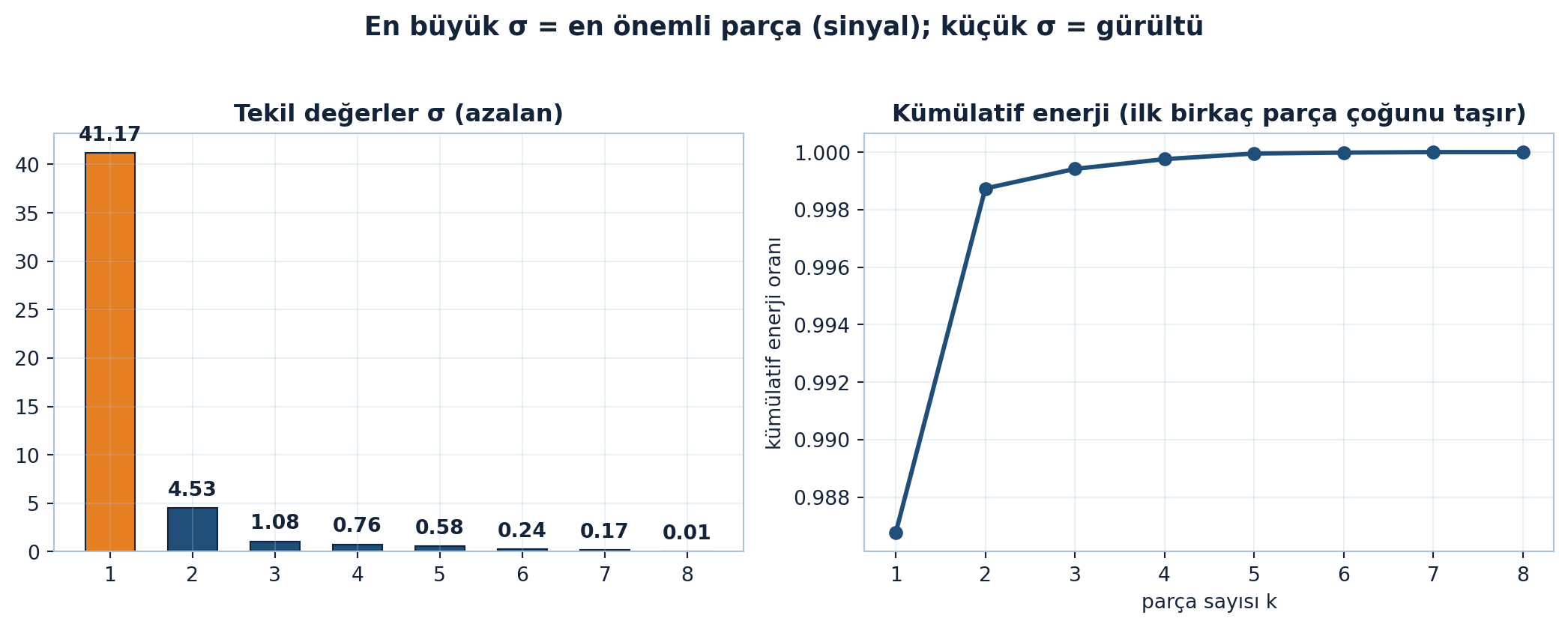
İpucuBuilder Notu — Sinyal vs Gürültü
“En büyük \(\sigma\) = en önemli yön” sezgisi, boyut indirgemenin (PCA), görüntü/model sıkıştırmanın ve gürültü gidermenin temelidir: küçük \(\sigma\)’lı parçalar genellikle gürültüdür, atılır. LoRA bunu fine-tuning’e uygular (düşük-rank güncelleme).
7.13 Bu Dersin Özeti
- SVD — özdeğerlerin dikdörtgen/genel matrise genellenmesi; iki tekil vektör kümesi.
- \(A = U\Sigma V^{T}\) — \(U\), \(V\) ortogonal; \(\Sigma\) köşegen, \(\sigma \geq 0\).
- \(A^{T}A = V\Sigma^{2}V^{T}\) — \(V\) özvektörler, \(\sigma^{2}\) özdeğerler.
- \(AA^{T} = U\Sigma\Sigma^{T}U^{T}\) — \(U\) özvektörler; aynı sıfırdan-farklı özdeğerler.
- \(Av = \sigma u\) — tanımlayıcı ilişki; ortogonal \(v\)’ler → ortogonal \(Av\)’ler.
- \(A^{T}A\)’dan kaçın — kondisyon sayısı karelenir; pratikte doğrudan \(A\).
- Geometri — döndürme × germe × döndürme; çember → elips.
- \(|\det A| = \prod \sigma\); parametre sayımı (\(2 \times 2 = 1 + 2 + 1\)).
- İndirgenmiş SVD — \(A = \sum \sigma_i u_i v_i^{T}\), \(r\) rank-1 parça.
- Polar ayrışım — \(A = SQ\) (simetrik × ortogonal).
- En büyük \(\sigma\) — verinin en önemli parçası (PCA habercisi).
ÖnemliTek Bir Cümle
SVD her matrisi \(A = U\Sigma V^{T}\) olarak “döndür, ger, yeniden döndür” diye çözer; \(V\) ve \(U\), \(A^{T}A\) ve \(AA^{T}\)’nin ortonormal özvektörleri, \(\sigma\)’lar da $^{2} = $ özdeğer ilişkisinden gelir — ve en büyük tekil değerler verinin en önemli (en düşük-rank) parçasını verir.
7.14 Kontrol Soruları
NotSoru 1: Aşağıdaki matrisin SVD’sini (U, Σ, V) bul. (İpucu: AᵀA köşegen.)
\[ A = \begin{pmatrix} 0 & 2 \\ 3 & 0 \end{pmatrix} \]
Cevap:
\(A^{T}A = \begin{pmatrix} 9 & 0 \\ 0 & 4 \end{pmatrix}\) → özdeğerler \(9, 4\) → \(\sigma_1 = 3\), \(\sigma_2 = 2\). \(V = I\) (özvektörler \(e_1, e_2\)). \(u_1 = Ae_1/\sigma_1 = (0, 3)/3 = (0, 1)\); \(u_2 = Ae_2/\sigma_2 = (2, 0)/2 = (1, 0)\).
\[ A = \begin{pmatrix} 0 & 1 \\ 1 & 0 \end{pmatrix}\begin{pmatrix} 3 & 0 \\ 0 & 2 \end{pmatrix}\begin{pmatrix} 1 & 0 \\ 0 & 1 \end{pmatrix} \]
Tekil değerler \(3, 2\) (pozitif), özdeğerler ise \(\pm\sqrt{6}\) idi — tekil değerler özdeğerlerden farklı.
NotSoru 2: A = [[1,0],[1,1],[0,1]] (3×2) için AᵀA’yı bul; tekil değerlerin σ² = AᵀA özdeğeri olduğunu doğrula.
\[ A^{T}A = \begin{pmatrix} 2 & 1 \\ 1 & 2 \end{pmatrix} \]
Cevap:
\(A^{T}A\)’nın özdeğerleri \(3\) ve \(1\) (det testi: \((2-\lambda)^{2}-1\)). Demek ki \(\sigma_1 = \sqrt{3}\), \(\sigma_2 = 1\). Tekil değerlerin kareleri (\(3, 1\)) tam olarak \(A^{T}A\)’nın özdeğerleridir ✓. \(V\), bu özvektörlerdir: \((1, 1)/\sqrt{2}\) ve \((1, -1)/\sqrt{2}\).
NotSoru 3: SVD ne zaman özdeğer ayrışımına (QΛQᵀ) eşit olur?
Cevap:
\(A\) simetrik pozitif tanımlı olduğunda. O zaman \(U = V = Q\) ve \(\Sigma = \Lambda\); iki döndürme aynıdır. Genel simetrikte (negatif özdeğerli) tekil değerler \(\sigma = |\lambda|\) olur ve \(U\) ile \(V\) işaretle ayrışır. Pozitif tanımlılık, \(\sigma = \lambda\) olmasını sağlayan koşuldur — bu yüzden “en iyi matrisler”dir.
NotSoru 4: Bir görüntü matrisini sıkıştırmak için neden en büyük tekil değerli parçalar tutulur?
Cevap:
\(A = \sum \sigma_i u_i v_i^{T}\) rank-1 parçaların \(\sigma\)-ağırlıklı toplamıdır. \(\sigma\)’lar azalan sırada olduğundan ilk \(k\) parça matrisin enerjisinin (Frobenius normunun) çoğunu taşır; küçük \(\sigma\)’lı parçalar genelde gürültü/ayrıntıdır.
İlk \(k\) parçayı tutmak (rank-\(k\) yaklaşım), \(m \times n\) yerine \(k(m+n)\) sayı saklar ve Eckart-Young teoremine (Ders 7) göre en iyi rank-\(k\) yaklaşımdır. JPEG benzeri sıkıştırma, PCA ve LoRA hep bu ilkeye dayanır.
7.15 Egzersizler
Cevapsız problemler. Çöz, sonra numpy ile kontrol et.
Egzersiz 1. Aşağıdaki matrisin SVD’sini bul (\(A^{T}A\) üzerinden \(V\) ve \(\sigma\), sonra \(u = Av/\sigma\)).
\[ A = \begin{pmatrix} 1 & 1 \\ 0 & 1 \end{pmatrix} \]
Egzersiz 2. \(A = \begin{pmatrix} 2 & 0 \\ 0 & 0 \end{pmatrix}\) matrisinin rank’ı kaçtır? İndirgenmiş SVD’sini (tek rank-1 parça) yaz. Tam SVD’de kaç sıfır tekil değer olur?
Egzersiz 3. Egzersiz 1’deki \(A\)’nın SVD’sinden polar ayrışımını \(A = SQ\) kur (\(S = U\Sigma U^{T}\), \(Q = UV^{T}\)). \(S\)’nin simetrik, \(Q\)’nun ortogonal olduğunu doğrula.
Egzersiz 4. Python ile SVD’yi keşfet:
import numpy as np
A = np.array([[1.0, 0.0], [1.0, 1.0], [0.0, 1.0]])
U, s, Vt = np.linalg.svd(A, full_matrices=False)
print("tekil değerler:", s)
print("σ² :", s**2)
print("eig(AᵀA):", np.linalg.eigvalsh(A.T @ A)) # σ² ile eşleşir
# Yeniden kur: A = U Σ Vᵀ
print("A rebuild:", U @ np.diag(s) @ Vt)
# En büyük rank-1 parça:
print("σ1 u1 v1ᵀ:", s[0] * np.outer(U[:, 0], Vt[0]))Egzersiz 5. (Ders 7 habercisi.) Ders 7 Eckart-Young teoremine geçer: en iyi rank-\(k\) yaklaşım, SVD’nin ilk \(k\) parçasıdır. Aşağıdaki matrisin SVD’sini bul ve en iyi rank-1 yaklaşımını (\(\sigma_1 u_1 v_1^{T}\)) yaz. Orijinalden ne kadar uzakta (Frobenius)?
\[ A = \begin{pmatrix} 3 & 0 \\ 0 & 1 \end{pmatrix} \]
7.16 Sonraki Ders İçin Hazırlık
Ders 7: Eckart-Young — A’ya En Yakın Rank-k Matris
Ders 6’da SVD’yi kurduk ve “en büyük \(\sigma\) = en önemli parça” sezgisini gördük. Ders 7 bunu teoreme dönüştürür.
- Eckart-Young: en iyi rank-\(k\) yaklaşım = SVD’nin ilk \(k\) parçası (her normda)
- PCA: merkezlenmiş verinin SVD’si; ana bileşenler
- Düşük-rank yaklaşımın hata ölçüsü (atılan \(\sigma\)’lar)
- Neden bu, sıkıştırma ve gürültü gidermenin matematiksel temeli
UyarıDers 7 Öncesi Yapılacak
- Bu dersin egzersizlerini çöz, özellikle Egzersiz 5’i (rank-1 yaklaşım).
- Python’da
np.linalg.svdile bir görüntüyü/matrisi farklı \(k\) değerleriyle yeniden kur; bilginin nasıl korunduğunu gözlemle. - Ana cümleyi tekrar oku: “SVD = döndür, ger, yeniden döndür (\(U\Sigma V^{T}\)).”
7.17 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Strang’de |
|---|---|---|
| SVD | Özdeğerlerin dikdörtgen/genel matrise genellenmesi | 0m22 |
| İki tekil vektör kümesi | \(U\) (sol, \(m\) boyut), \(V\) (sağ, \(n\) boyut) | 2m23 |
| \(A^{T}A\) anahtarı | SVD’nin matematiği; simetrik pozitif yarı-tanımlı | 4m09 |
| \(Av = \sigma u\) | Tanımlayıcı ilişki; \(Ax = \lambda x\)’in yerini alır | 9m02 |
| \(V = \text{eig}(A^{T}A)\), $^{2} = $ özdeğer | \(A^{T}A = V\Sigma^{2}V^{T}\); \(U\) ise \(\text{eig}(AA^{T})\) | 15m20 |
| Ortogonal \(v\) → ortogonal \(Av\) | SVD’nin kalbi; satır uzayından kolon uzayına | 26m06 |
| \(A^{T}A\)’dan kaçın | Kondisyon sayısı karelenir; doğrudan \(A\) kullan | 28m02 |
| Geometri | Döndürme × germe × döndürme; çember → elips | 32m40 |
| Polar ayrışım | \(A = SQ\); simetrik çarpı ortogonal | 46m17 |
| En önemli parça | En büyük \(\sigma\)’lı rank-1 parça (PCA habercisi) | 50m42 |
7.18 ML Bağlantıları Özeti
- \(A = U\Sigma V^{T}\) → her ağırlık/veri matrisine uygulanır; PCA, sıkıştırma, pseudoinverse.
- \(\sigma^{2} = \text{eig}(A^{T}A)\) → PCA’nın özü; kovaryans özdeğerleri = tekil değer kareleri.
- \(Av = \sigma u\) (ortogonal → ortogonal) → \(V\) girdi eksenleri, \(U\) çıktı eksenleri, \(\sigma\) kazanç.
- \(A^{T}A\)’dan kaçın → sayısal kararlılık; least squares’te QR/SVD, normal denklem değil.
- **$_1 = $ spektral norm** → Lipschitz sabiti; spektral normalizasyon (GAN, sağlamlık).
- Polar \(A = SQ\) → en yakın ortogonal matris; Procrustes, poz kestirimi, ortogonal düzenlileştirme.
- En büyük \(\sigma\) rank-1 parça → düşük-rank sıkıştırma, PCA, LoRA, gürültü giderme.
ÖnemliTek bir şey alıp gideceksen
SVD her matrisi \(A = U\Sigma V^{T}\) olarak çözer — \(V^{T}\) ile döndür, \(\Sigma\) ile ger, \(U\) ile yeniden döndür. \(V\) ve \(U\), \(A^{T}A\) ve \(AA^{T}\)’nin ortonormal özvektörleridir, \(\sigma\)’lar da $^{2} = $ özdeğer ilişkisinden gelir. En büyük tekil değerli rank-1 parçalar verinin en önemli kısmıdır — bu yüzden SVD, PCA’dan LoRA’ya tüm düşük-rank veri biliminin temel taşıdır.