flowchart TD
M["Pozitif Tanımlı (xᵀSx > 0)"] --> T["5 eşdeğer test (λ>0, det, pivot, enerji, AᵀA)"]
M --> E["enerji = kâse"]
E --> L["kâse = kayıp fonksiyonu"]
L --> GD["gradient descent"]
M --> IND["indefinite = eyer"]
M --> SEMI["yarı-tanımlı = sınır"]
style M fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style E fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style T fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style L fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style GD fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style IND fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
style SEMI fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
6 Pozitif Tanımlı ve Yarı-Tanımlı Matrisler
xᵀSx > 0: beş eşdeğer test, enerji-kâsesi ve gradient descent’in zemini
NotBölüm bilgisi
- Video: Positive Definite and Semidefinite Matrices — Gilbert Strang, MIT 18.065
- OCW: Lecture 5 — Positive Definite and Semidefinite Matrices
- Okuma süresi: ≈ 35 dk
- Önkoşul: Ders 4 (özdeğer/özvektör, spektral teorem \(S = Q\Lambda Q^{T}\), “simetrik → gerçek özdeğer / ortonormal özvektör”)
6.1 Bu Derste Ne Var?
Bu ders, lineer cebir “highlights” turunu kapatıyor (beş ders) ve hepsini birbirine bağlıyor: özdeğer, enerji, \(A^{T}A\), determinant, pivot — her biri aynı şeyin (pozitif tanımlılık) bir testidir. Strang ayrıca buradan derin öğrenmenin kalbine, gradient descent’e bir köprü atıyor.
Üç temel fikir:
- Pozitif tanımlı = simetrik + tüm özdeğerler > 0 — ve buna eşdeğer beş test (özdeğer, leading determinant, pivot, enerji \(x^{T}Sx\), \(A^{T}A\)).
- Enerji \(x^{T}Sx > 0\) = kâse (bowl) — pozitif tanımlı matris, yukarı açılan dışbükey bir yüzey verir; bu, bir kayıp fonksiyonudur.
- Gradient descent — kâsenin dibini bulmak: en dik iniş yönünü (gradyan) izle; dar vadi sorunu özdeğer oranından gelir.
“…positive definite matrices. These are the best of the symmetric matrices.” — Strang, 3:10
Bu üç fikrin nasıl tek bir merkezden (\(x^{T}Sx > 0\)) dallandığını Şekil 6.1 özetliyor: beş eşdeğer testten enerji-kâsesine, oradan kayıp fonksiyonu ve gradient descent’e, ve sınır durumlara (eyer, yarı-tanımlı) kadar dersin bütün hatları.
İpucuBuilder Notu — Optimizasyonun Zemini
- Enerji \(x^{T}Sx\) = kayıp fonksiyonu modeli: derin öğrenmenin büyük hesabı bir enerjiyi minimize etmektir; pozitif tanımlı Hessian = yerel dışbükey kâse.
- Gradient descent burada ilk kez tanıtılıyor (Ders 21-23’te derinleşir): birinci türevleri izle, ikinci türev (Hessian) hesaplama pahalı olduğundan kaçınılır.
- Özdeğer oranı (kondisyon sayısı) = kâsenin biçimi; dar vadi (büyük \(\lambda_{\max}/\lambda_{\min}\)) gradient descent’i yavaşlatır — momentum ve ön-koşullama (Ders 23) bunu düzeltir.
- \(A^{T}A\) her zaman pozitif yarı-tanımlı — kovaryans, Gram, kernel matrislerinin neden hep “kâse” verdiğinin sebebi.
Tek cümle: pozitif tanımlılık, bir simetrik matrisin “yukarı açılan kâse” olduğunun beş eşdeğer testidir — ve bu kâse, tüm optimizasyonun ve derin öğrenmenin zeminidir.
6.2 Pozitif Tanımlı: Beş Eşdeğer Test
Pozitif tanımlı (PD) matris, simetrik ve tüm özdeğerleri pozitif olan matristir. Bunlar simetrik matrislerin en iyileridir.
“…positive definite matrices. These are the best of the symmetric matrices.” — Strang, 3:10
Özdeğer hesabı zor olduğundan beş eşdeğer test vardır — herhangi biri geçerse hepsi geçer:
- Tüm özdeğerler \(\lambda_i > 0\).
- Tüm leading (sol-üst) alt-determinantlar \(> 0\).
- Tüm pivotlar \(> 0\).
- Enerji her \(x \neq 0\) için pozitif: \(x^{T}Sx > 0\).
- \(S = A^{T}A\) biçiminde, \(A\)’nın bağımsız kolonlarıyla yazılabilir.
Strang’e göre asıl tanım dördüncüsüdür (enerji):
\[ x^{T} S x > 0 \quad \text{(her } x \neq 0 \text{)} \]
\(S = \begin{pmatrix} 3 & 4 \\ 4 & 6 \end{pmatrix}\) için bu beş testi tek bir bakışta Şekil 6.2 gösteriyor: özdeğerler, leading minörler, pivotlar, enerji ve Cholesky — hepsi aynı kararı verir.
Kod
S = np.array([[3.0, 4.0], [4.0, 6.0]])
t = five_tests(S)
fig, (axL, axR) = plt.subplots(1, 2, figsize=(10.2, 4.4))
# SOL: özdeğerler > 0
bar_values(axL, t["eigenvalues"], [r"$\lambda_1$", r"$\lambda_2$"], "Özdeğerler > 0")
axL.set_ylim(0, t["eigenvalues"].max() * 1.25)
axL.set_ylabel("özdeğer değeri", color=COL_TEXT)
# SAĞ: diğer dört testin metin paneli
axR.axis("off")
m = t["leading_minors"]; p = t["pivots"]
notes = [
"Beş eşdeğer test (S = [[3, 4], [4, 6]]):",
"",
f"• özdeğerler: {t['eigenvalues'][0]:.2f}, {t['eigenvalues'][1]:.2f} (> 0)",
f"• leading minörler: {m[0]:.0f}, {m[1]:.0f} (> 0)",
f"• pivotlar: {p[0]:.0f}, 2/3 (> 0)",
"• enerji: 3x² + 8xy + 6y² > 0",
"• Cholesky OK (S = LLᵀ)",
"",
"⇒ 5 test de POZİTİF TANIMLI diyor",
]
axR.text(
0.04, 0.5, "\n".join(notes), transform=axR.transAxes,
ha="left", va="center", fontsize=12, color=COL_TEXT, fontweight="bold",
linespacing=1.5,
bbox=dict(boxstyle="round,pad=0.6", fc=COL_BG, ec=COL_ACCENT, lw=1.4),
)
fig.suptitle("Beş eşdeğer test: hepsi aynı şeyi söyler",
color=COL_TEXT, fontsize=13, fontweight="bold")
fig.tight_layout()
plt.show()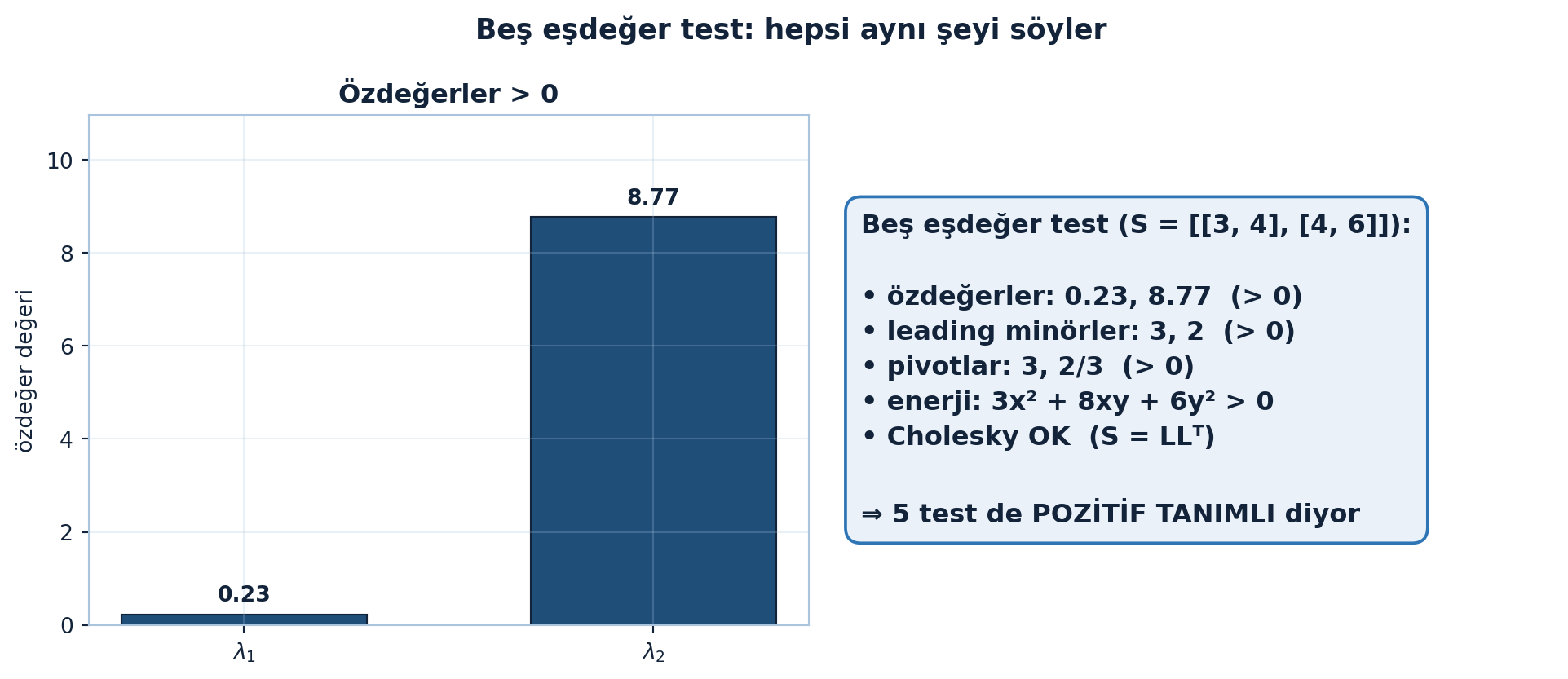
İpucuBuilder Notu — Beş Kapı, Tek Oda
Beş test, beş farklı kütüphane çağrısına karşılık gelir: eigvalsh (özdeğer), cholesky (pivot/\(A^{T}A\)), determinant. Pratikte pozitif tanımlılık Cholesky’nin başarısıyla test edilir — başarısızsa matris PD değildir, ucuz bir kontrol.
6.3 İndefinit Örnek
Hepsi pozitif sayılardan oluşan bir matris bile PD olmayabilir. Örnek:
\[ S = \begin{pmatrix} 3 & 4 \\ 4 & 5 \end{pmatrix}, \quad \det S = 15 - 16 = -1 \]
Determinant özdeğerlerin çarpımıdır; negatif olması bir özdeğerin negatif olduğunu söyler. Yani bir özdeğer pozitif, biri negatif — bu indefinit (belirsiz) matristir.
“This matrix is an indefinite matrix.” — Strang, 5:31
Köşegen girdiyi artırmak (\(5 \to 6\)) matrisi pozitif tanımlı yapar; köşegene değer eklemek daima “daha pozitif” yönüne iter.
İndefinit, pozitif tanımlı ve yarı-tanımlı yüzeylerin nasıl farklılaştığını Şekil 6.3 üç panelde yan yana koyuyor: kâse, eyer ve oluk.
Kod
fig, axes = plt.subplots(1, 3, figsize=(13, 4.4))
panels = [
([[2, 1], [1, 2]], "Pozitif tanımlı (kâse)"),
([[1, 2], [2, 1]], "İndefinit (eyer)"),
([[1, 1], [1, 1]], "Yarı-tanımlı (oluk)"),
]
xs = np.linspace(-3, 3, 120)
X, Y = np.meshgrid(xs, xs)
for ax, (M, baslik) in zip(axes, panels):
ax.contour(X, Y, quad_energy(M)(X, Y), levels=18, cmap=NAVY_CMAP)
style_square_axes(ax, 3, title=baslik)
fig.suptitle("Enerji yüzeyi şekli matrisin sınıfını gösterir",
color=COL_TEXT, fontsize=13, fontweight="bold")
fig.tight_layout()
plt.show()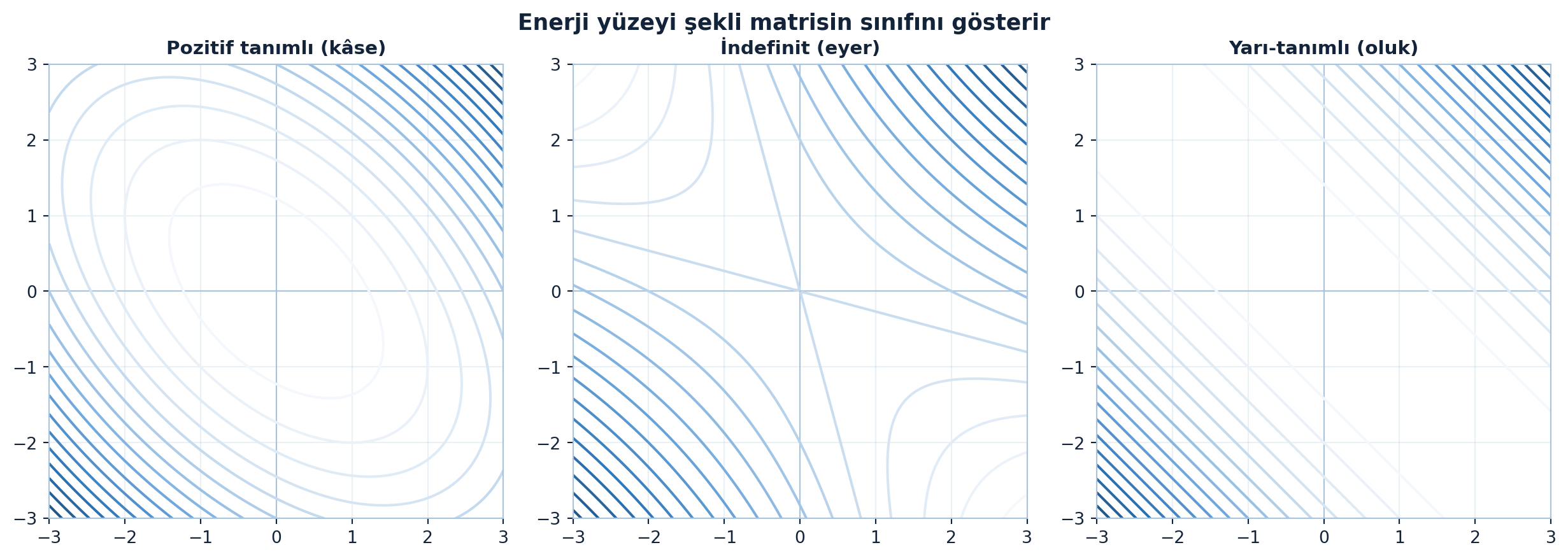
İpucuBuilder Notu — Eyer Tuzağı
İndefinit matris = eyer noktalı (saddle) yüzey: bazı yönlerde yukarı, bazılarında aşağı. Derin öğrenmede kayıp yüzeyinin eyer noktaları (Ders 19) tam da indefinit Hessian’a karşılık gelir — gradient descent’in takılabildiği yerler.
6.4 Leading Determinant Testi
İkinci test, sol-üst köşeden başlayan iç içe alt-matrislerin determinantlarına bakar. Pozitif tanımlı \(\begin{pmatrix} 3 & 4 \\ 4 & 6 \end{pmatrix}\) için:
\[ \det(3) = 3 > 0, \quad \det\begin{pmatrix} 3 & 4 \\ 4 & 6 \end{pmatrix} = 18 - 16 = 2 > 0 \]
Yalnızca tam determinanta bakmak yetmez: \(\begin{pmatrix} -3 & 4 \\ 4 & -6 \end{pmatrix}\) da determinantı \(2\) verir ama \(1 \times 1\) testini (\(-3 < 0\)) geçemez. Bu yüzden \(n\) özdeğer için \(n\) leading determinantın hepsi kontrol edilir.
İpucuBuilder Notu — Erken Uyarı
Leading minör testi, kovaryans matrislerinin geçerliliğini doğrulamada kullanılır. Negatif bir leading minör, tahmin edilen kovaryansın bozuk (PD değil) olduğunu erken yakalar — Gauss süreçleri ve Kalman filtrelerinde sayısal sağlık kontrolü.
6.5 Pivot Testi
Üçüncü test eliminasyon pivotlarına bakar. \(\begin{pmatrix} 3 & 4 \\ 4 & 6 \end{pmatrix}\) için ilk pivot \(3\)’tür; ikinci satırdan \(4/3\) çarpı birinci satırı çıkarınca ikinci pivot ortaya çıkar:
\[ \text{pivot}_1 = 3, \qquad \text{pivot}_2 = \frac{\det_2}{\det_1} = \frac{2}{3} \]
Her iki pivot da pozitif → matris PD. Güzel bağ: her pivot, ardışık leading determinantların oranıdır (\(2/3 = 2 \div 3\)).
“So the pivots… are the 3 and the 2/3.” — Strang, 8:43
İpucuBuilder Notu — Cholesky’nin Sırrı
Pivotların pozitifliği = Cholesky ayrışımının (\(S = LL^{T}\)) var olması. Cholesky, PD matrisleri çözmenin en hızlı ve kararlı yoludur; Bayesian çıkarım, Gauss süreçleri ve normal denklemler bunu kullanır. Bir pivot \(\leq 0\) çıkarsa Cholesky çöker — matris PD değildir.
6.6 Enerji Testi: xᵀSx > 0 (Kâse)
Strang’in asıl tanımı enerjidir. \(\begin{pmatrix} 3 & 4 \\ 4 & 6 \end{pmatrix}\) matrisinin enerjisini açalım:
\[ x^{T} S x = 3x^{2} + 8xy + 6y^{2} \]
Köşegen girdiler (\(3, 6\)) kareli terimleri (hep pozitif), köşegen-dışı (\(4+4 = 8\)) çapraz terimi verir. Çapraz terim negatife dönebilir ama kareli terimler onu bastırırsa fonksiyon her yerde pozitif kalır — grafik yukarı açılan bir kâsedir.
\[ f(x, y) = 3x^{2} + 8xy + 6y^{2} > 0 \quad \text{for } (x,y) \neq (0,0) \]
Bu yukarı açılan kâsenin üç boyutlu hâli Şekil 6.4’de görülüyor: tek bir minimum (orijin), her yöne tırmanan dışbükey bir yüzey.
Kod
f = quad_energy(np.array([[3, 4], [4, 6]]))
xs = np.linspace(-2, 2, 50)
X, Y = np.meshgrid(xs, xs)
Z = f(X, Y)
fig = plt.figure(figsize=(7, 5.5))
ax = fig.add_subplot(111, projection="3d")
apply_style_3d(ax)
ax.plot_surface(X, Y, Z, cmap=NAVY_CMAP, alpha=0.9, linewidth=0, antialiased=True)
ax.set_xlabel("x"); ax.set_ylabel("y"); ax.set_zlabel("Enerji $x^{T}Sx$")
ax.view_init(elev=30, azim=-60)
ax.set_title("Enerji $x^{T}Sx$: yukarı açılan dışbükey kâse (PD)", color=COL_TEXT, fontsize=12, fontweight="bold")
plt.show()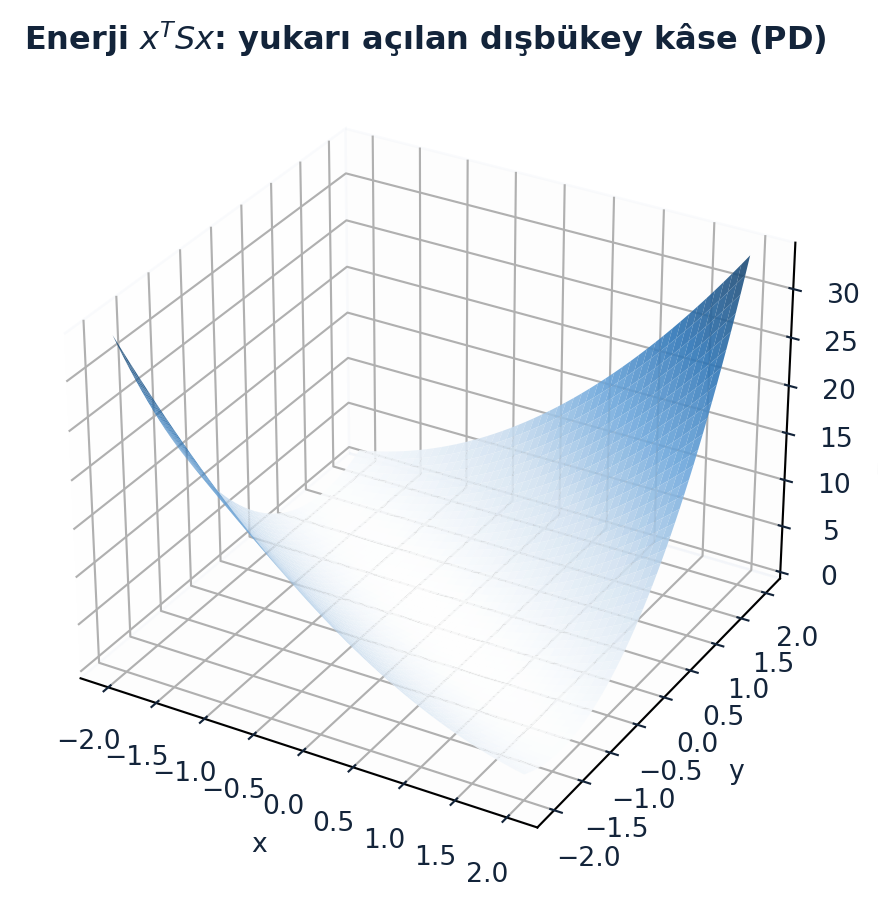
İpucuBuilder Notu — İdeal Kayıp
\(x^{T}Sx\) kuadratik formdur; PD ise grafiği dışbükey kâsedir, tek minimumu vardır (orijin). Bu kâse, ikinci-derece bir kayıp fonksiyonunun ta kendisidir — optimizasyonun “ideal” senaryosu.
6.7 Kâse = Kayıp Fonksiyonu
Strang burada lineer cebirden derin öğrenmeye köprü atıyor. O kâse, minimize edilen bir kayıp fonksiyonudur:
“This is what deep learning is about. This could be a loss function that you minimize.” — Strang, 14:25
Pratikte saf kareler olmaz; lineer terim (\(-x^{T}b\)) kâseyi merkezden kaydırır, lineer-olmayan terimler yüzeyi dalgalandırır. Ama temel model budur:
\[ f(x) = \tfrac{1}{2} x^{T} S x - x^{T} b \]
“…this is the model.” — Strang, 15:48
Bu fonksiyon dışbükey (convex): kuadratik için dışbükeylik = pozitif tanımlılık (veya sınırda yarı-tanımlılık). 100.000+ değişkenli kayıpların minimumunu bulmak, derin öğrenmenin en büyük hesabıdır.
İpucuBuilder Notu — Eğitim Bu
“Kayıp = kâse” modeli, eğitimin neden işe yaradığının çekirdeğidir. Kayıp yerel olarak PD Hessian’a sahipse (dışbükey kâse), gradient descent dibe iner. Gerçek derin ağlarda yüzey dışbükey değildir (eyer noktaları, çoklu minimum) — ama yerel kâse sezgisi hâlâ rehberdir.
6.8 Gradient Descent
Kâsenin dibini (minimum) nasıl bulursun? Bir başlangıç noktasından, en dik iniş yönünü — gradyanın tersini — izle:
\[ x_{k+1} = x_{k} - \eta \, \nabla f(x_{k}) \]
Gradyan \(\nabla f\) tüm birinci türevlerin vektörüdür ve o noktada en hızlı çıkış yönünü gösterir; eksisi en hızlı iniştir. Adım boyu (\(\eta\), learning rate) ve ne kadar gidileceği (line search) kritik kararlardır.
“…I would do a gradient descent.” — Strang, 22:09
Sorun: kâse dar bir vadiyse (bir özdeğer büyük, biri küçük), adımlar vadiyi enlemesine geçip karşı yamaca tırmanır; ileri-geri zikzak çizerek dibe çok yavaş yaklaşır.
“…if you’re going down a narrow valley…” — Strang, 26:30
Strang ikinci türev (Hessian) hesaplamaktan kaçınıldığını vurgular — 100.000+ değişkende çok pahalıdır; bu yüzden makine öğrenmesi çoğunlukla birinci türevle (gradyan) sınırlıdır.
Gradient descent’in dışbükey kâsenin dibine \(-\eta\nabla f\) adımlarıyla nasıl indiğini Şekil 6.5 gösteriyor: turuncu yol başlangıç noktasından \(x^{*} = S^{-1}b\) minimumuna yakınsar.
Kod
# Gradient descent yolu: f(x) = 1/2 xᵀSx − bᵀx, ∇f = Sx − b
Spd = np.array([[3.0, 1.0], [1.0, 2.0]]) # PD → dışbükey kâse
b = np.array([1.0, 1.0])
xstar = np.linalg.solve(Spd, b) # minimum: Sx = b → x* = S⁻¹b
path = gradient_descent(Spd, b, [3.0, -3.0], eta=0.18, steps=40)
f = quad_energy(Spd, b)
fig, ax = plt.subplots(figsize=(5.6, 5.6))
style_square_axes(ax, 4)
# Enerji yüzeyinin kontur çizgileri (kâse)
g = np.linspace(-4, 4, 240)
X, Y = np.meshgrid(g, g)
Z = f(X, Y)
ax.contour(X, Y, Z, levels=18, cmap=NAVY_CMAP, linewidths=1.0, zorder=1)
# GD yolu: x ← x − η∇f, kâsenin dibine doğru iner
ax.plot(path[:, 0], path[:, 1], "-o", color=COL_VEC3, ms=4, lw=1.6,
label="GD yolu (η=0.18, 40 adım)", zorder=3)
# Başlangıç noktası
ax.plot(path[0, 0], path[0, 1], "o", color=COL_VEC3, ms=8,
markeredgecolor=COL_TEXT, zorder=4)
ax.text(path[0, 0] + 0.12, path[0, 1] - 0.18, "x₀", color=COL_VEC3,
fontsize=10, fontweight="bold", ha="left", va="top")
# Minimum nokta x* = S⁻¹b (kâsenin dibi)
ax.plot(xstar[0], xstar[1], "*", color=COL_PRIMARY, ms=20,
markeredgecolor=COL_TEXT, markeredgewidth=0.8,
label="minimum x* = S⁻¹b", zorder=5)
ax.set_title("Gradient descent: x ← x − η·grad, kâsenin dibine iner",
color=COL_TEXT, fontsize=10.5, fontweight="bold")
ax.legend(loc="lower right", fontsize=8.5, framealpha=0.92)
plt.show()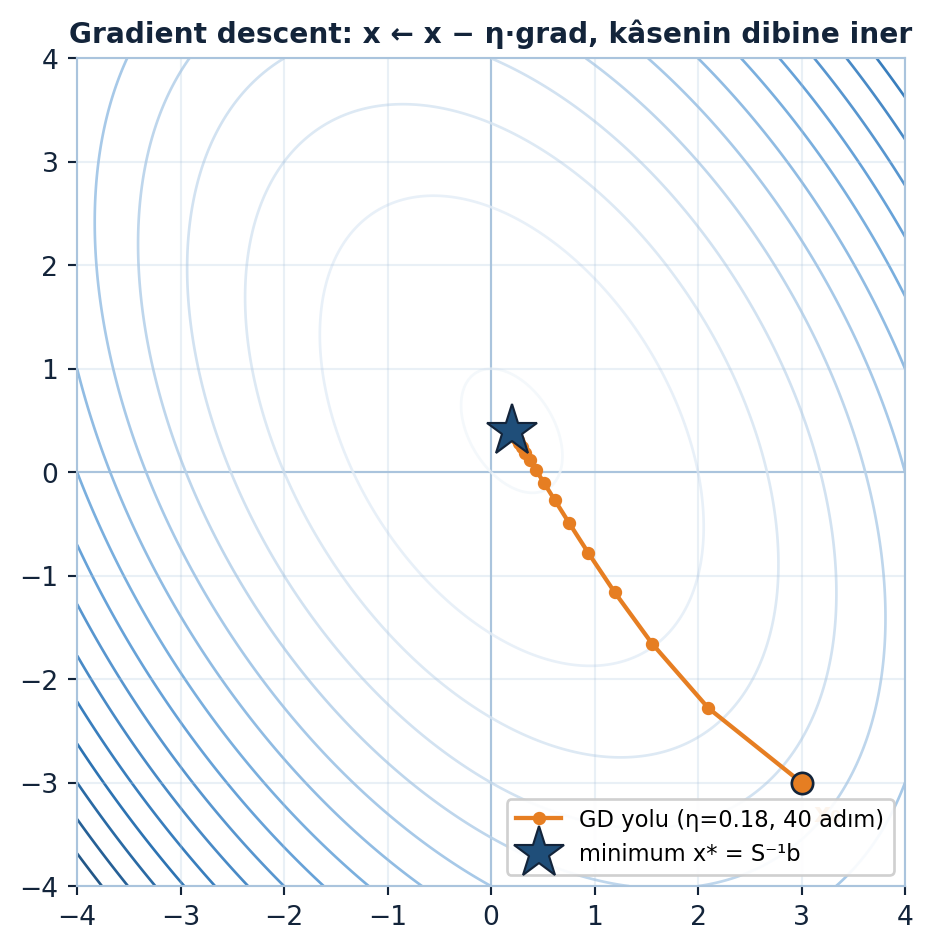
Bu zikzak sorununun kaynağı kondisyon sayısıdır: \(\kappa = \lambda_{\max}/\lambda_{\min}\) büyüdükçe iniş yavaşlar. Şekil 6.6 dengeli kâse ile dar vadiyi yan yana koyarak bunu somutlaştırıyor.
Kod
# --- Kondisyon sayısı: dengeli kâse vs dar vadi ---
fig, (axL, axR) = plt.subplots(1, 2, figsize=(11.5, 5.6))
# SOL: dengeli kâse (küçük κ)
SL = np.array([[3.0, 0.0], [0.0, 2.0]]); bL = np.array([0.0, 0.0])
kL = condition_number(SL)
pathL = gradient_descent(SL, bL, [3.0, 3.0], eta=0.25, steps=12)
limL = 3.6
gx = np.linspace(-limL, limL, 240); gy = np.linspace(-limL, limL, 240)
GX, GY = np.meshgrid(gx, gy)
ZL = quad_energy(SL, bL)(GX, GY)
axL.contour(GX, GY, ZL, levels=14, cmap=NAVY_CMAP, linewidths=1.0, zorder=1)
axL.plot(pathL[:, 0], pathL[:, 1], "-o", color=COL_VEC3, ms=4.5, lw=1.8,
markeredgecolor=COL_TEXT, markeredgewidth=0.5, zorder=3, label="GD yolu")
axL.plot(0, 0, "*", color=COL_PRIMARY, ms=16, markeredgecolor=COL_TEXT,
markeredgewidth=0.6, zorder=4, label="minimum")
style_square_axes(axL, limL)
axL.set_title(f"Dengeli kâse (küçük κ = {kL:.1f})", color=COL_TEXT, fontsize=11.5, fontweight="bold")
axL.legend(loc="lower right", fontsize=8.5, framealpha=0.92)
# SAĞ: dar vadi (büyük κ)
SR = np.array([[12.0, 0.0], [0.0, 1.0]]); bR = np.array([0.0, 0.0])
kR = condition_number(SR)
pathR = gradient_descent(SR, bR, [3.0, 3.0], eta=0.14, steps=40)
limR = 3.6
ZR = quad_energy(SR, bR)(GX, GY)
axR.contour(GX, GY, ZR, levels=20, cmap=NAVY_CMAP, linewidths=1.0, zorder=1)
axR.plot(pathR[:, 0], pathR[:, 1], "-o", color=COL_VEC3, ms=3.5, lw=1.4,
markeredgecolor=COL_TEXT, markeredgewidth=0.4, zorder=3, label="GD yolu (zikzak)")
axR.plot(0, 0, "*", color=COL_PRIMARY, ms=16, markeredgecolor=COL_TEXT,
markeredgewidth=0.6, zorder=4, label="minimum")
style_square_axes(axR, limR)
axR.set_title(f"Dar vadi (büyük κ = {kR:.0f})", color=COL_TEXT, fontsize=11.5, fontweight="bold")
axR.legend(loc="lower right", fontsize=8.5, framealpha=0.92)
fig.suptitle("Kondisyon sayısı κ: dengeli kâse hızlı, dar vadi zikzak",
color=COL_TEXT, fontsize=13, fontweight="bold", y=0.99)
fig.tight_layout(rect=[0, 0, 1, 0.96])
plt.show()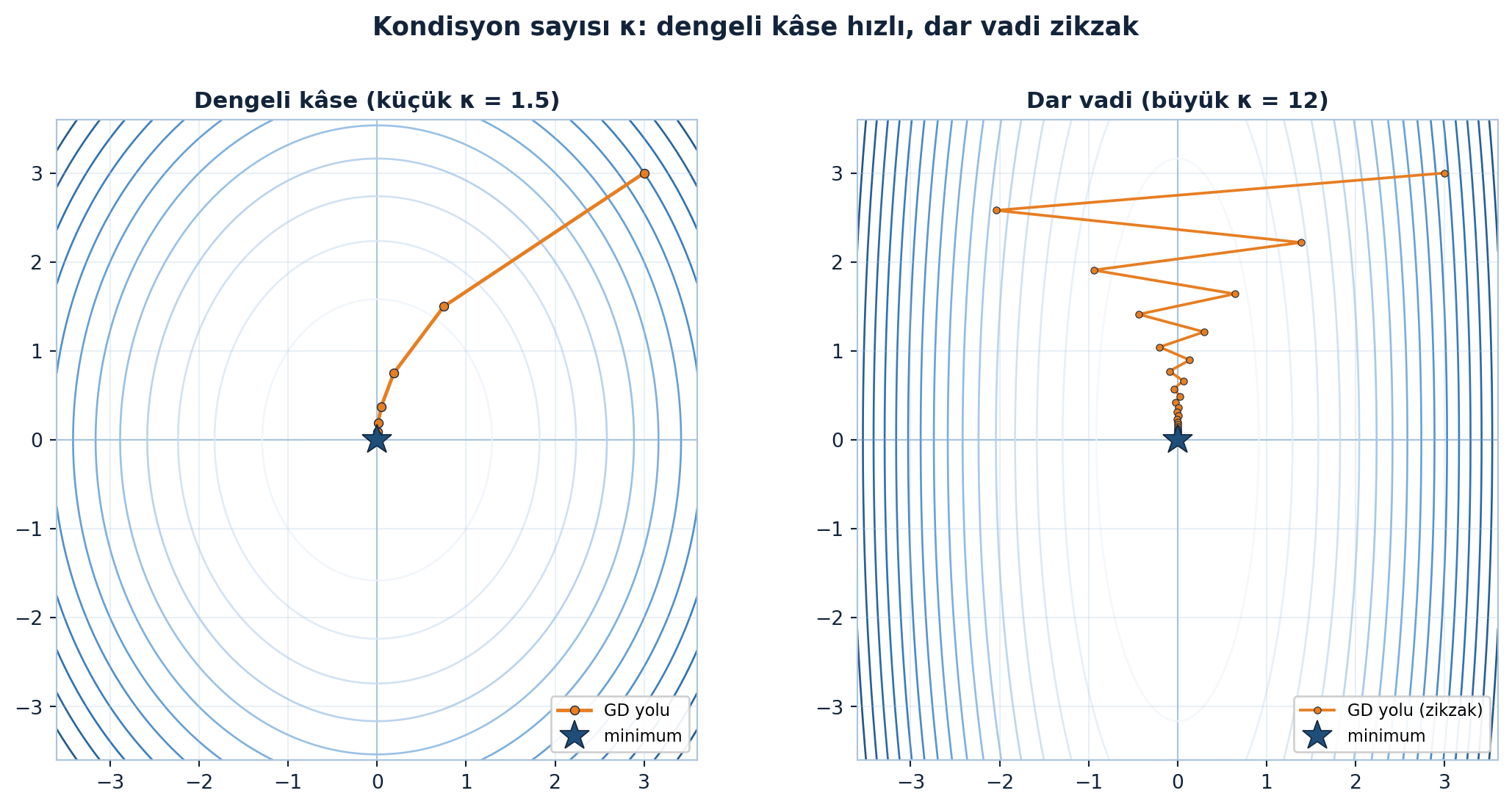
İpucuBuilder Notu — İnişin Merkezi
Bu, derin öğrenmenin merkezî algoritmasıdır (Ders 21-23’te momentum, SGD ile derinleşir). Dar vadi sorunu = yüksek kondisyon sayısı (\(\lambda_{\max}/\lambda_{\min}\)); momentum, Adam ve ön-koşullama (preconditioning) tam bu zikzakı azaltmak için icat edildi.
6.9 Pozitif Tanımlı Matrislerle İşlemler
Beş test, PD matrislerle yapılan işlemleri kolayca yanıtlar:
- S + T: İki PD matrisin toplamı PD mi? Enerji testiyle anında: her \(x\) için \(x^{T}(S+T)x = x^{T}Sx + x^{T}Tx > 0\). Evet.
\[ x^{T}(S+T)x = x^{T}Sx + x^{T}Tx > 0 \]
“What about S plus T?” — Strang, 30:44
- S⁻¹: PD’nin tersi PD mi? Özdeğer testiyle: \(S\)’nin özdeğerleri \(\lambda > 0\) ise \(S^{-1}\)’in özdeğerleri \(1/\lambda > 0\). Evet.
- QᵀSQ: \(Q\) ortogonal ise \(Q^{T}SQ\) PD mi? Hem benzerlik (aynı özdeğer) hem enerji (\(y = Qx\) ile \(y^{T}Sy > 0\)) ile: Evet.
İpucuBuilder Notu — Dışbükeyi Koru
“Doğru testi seç” becerisi ML’de işe yarar: \(S+T\)’nin PD’liği, iki dışbükey kaybın toplamının dışbükey olduğunu söyler (düzenlileştirme ekleme); \(S^{-1}\)’in PD’liği, ters kovaryans (precision matrix) matrisinin geçerliliğini garanti eder. Eigenvalue testi yerine enerji testi çoğu ispatı tek satıra indirir.
6.10 Yarı-Tanımlı (Semidefinite): Sınır Durum
Pozitif tanımlı ile indefinit arasındaki sınır yarı-tanımlıdır (positive semidefinite): özdeğerler \(\geq 0\), en az biri \(= 0\). \(\begin{pmatrix} 3 & 4 \\ 4 & 16/3 \end{pmatrix}\) tam sınırdadır:
\[ \det\begin{pmatrix} 3 & 4 \\ 4 & 16/3 \end{pmatrix} = 16 - 16 = 0 \]
“Semidefinite is the borderline.” — Strang, 38:06
Determinant \(0\) → bir özdeğer \(0\) (matris tekil); trace pozitif olduğundan diğeri pozitif. Klasik örnek hepsi-1 matrisi: rank 1 olduğundan özdeğerleri \(3, 0, 0\)’dır ve bir rank-1 yapı taşı olarak yazılır:
\[ \begin{pmatrix} 1 & 1 & 1 \\ 1 & 1 & 1 \\ 1 & 1 & 1 \end{pmatrix} = 3 \cdot \frac{1}{\sqrt{3}}\begin{pmatrix} 1 \\ 1 \\ 1 \end{pmatrix} \cdot \frac{1}{\sqrt{3}}\begin{pmatrix} 1 & 1 & 1 \end{pmatrix} \]
Yarı-tanımlılığın iki yüzünü — \(A^{T}A\)’nın daima \(\geq 0\) enerjisi ve hepsi-1 matrisinin rank-1 yapısı — Şekil 6.7 yan yana koyuyor.
Kod
A = np.array([[1, 0], [1, 1], [0, 1]])
AtA = A.T @ A
ones = np.ones((3, 3))
fig, axs = plt.subplots(1, 2, figsize=(10.5, 4.6))
heatmap(axs[0], AtA, title="AᵀA (PD, enerji=‖Ax‖² ≥ 0)", vmin=0, vmax=2)
heatmap(axs[1], ones, title="hepsi-1 (yarı-tanımlı, λ=3,0,0)", vmin=0, vmax=2)
fig.suptitle("AᵀA ve hepsi-1: λ ≥ 0 (yarı-tanımlı)",
color=COL_TEXT, fontsize=13, fontweight="bold")
fig.tight_layout(rect=(0, 0, 1, 0.95))
plt.show()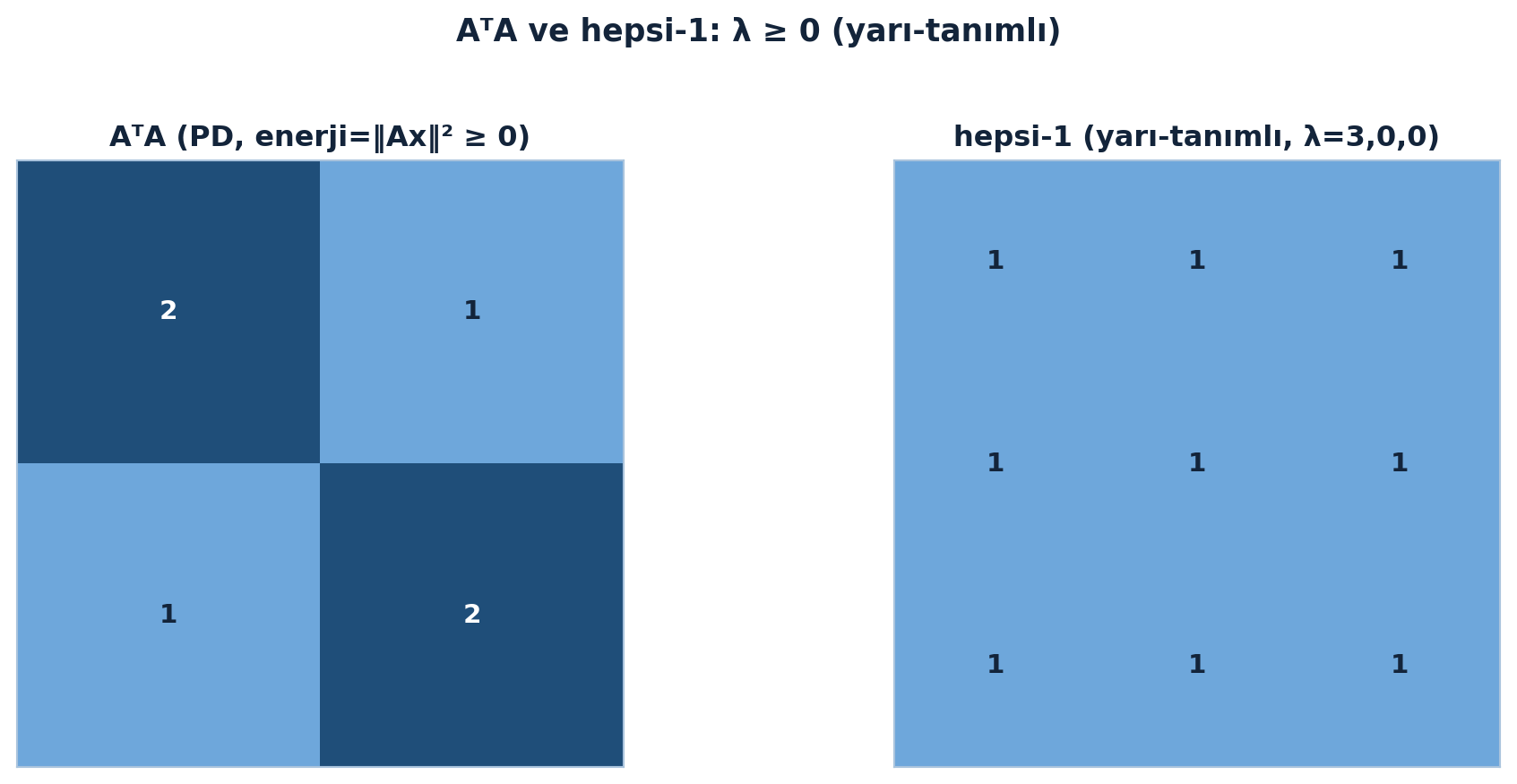
İpucuBuilder Notu — Sınırdaki Kovaryans
Yarı-tanımlılık ML’de her yerde: kovaryans ve Gram (\(A^{T}A\)) matrisleri her zaman en az yarı-tanımlıdır (özdeğerler \(\geq 0\)), çünkü bağımlı kolonlar \(0\) özdeğer üretir. Düzenlileştirme (\(S + \varepsilon I\)) bu \(0\) özdeğerleri pozitife çekip matrisi tam PD ve tersinir yapar.
6.11 Bu Dersin Özeti
- Pozitif tanımlı = simetrik + tüm özdeğerler \(> 0\).
- Beş eşdeğer test — özdeğer, leading determinant, pivot, enerji, \(A^{T}A\).
- İndefinit — \(\det < 0\) (karışık işaretli özdeğer); eyer noktası.
- Leading determinant testi — sol-üst minörlerin hepsi \(> 0\).
- Pivot testi — eliminasyon pivotları \(> 0\); pivot = ardışık determinant oranı.
- Enerji \(x^{T}Sx > 0\) — yukarı açılan dışbükey kâse; asıl tanım.
- Kâse = kayıp fonksiyonu — derin öğrenmenin minimize ettiği yüzey.
- Gradient descent — en dik iniş; dar vadi (özdeğer oranı) yavaşlatır.
- PD işlemleri — \(S+T\), \(S^{-1}\), \(Q^{T}SQ\) hepsi PD (doğru testle tek satır).
- Yarı-tanımlı — sınır durum: \(\lambda \geq 0\), \(\det = 0\) (örn. hepsi-1, rank 1).
ÖnemliTek Bir Cümle
Pozitif tanımlılık, bir simetrik matrisin “yukarı açılan kâse” (\(x^{T}Sx > 0\)) olduğunun beş eşdeğer testidir; bu kâse her optimizasyonun ve derin öğrenmenin kayıp yüzeyidir, gradient descent de o kâsenin dibini arar.
6.12 Kontrol Soruları
NotSoru 1: [[2, 1], [1, 2]] matrisi pozitif tanımlı mı? Üç testle göster.
\[ S = \begin{pmatrix} 2 & 1 \\ 1 & 2 \end{pmatrix} \]
Cevap:
Leading determinantlar: \(2 > 0\) ve \(\det = 4 - 1 = 3 > 0\) ✓. Özdeğerler: \(\lambda = 3, 1\) (ikisi de \(> 0\)) ✓. Enerji: \(x^{T}Sx = 2x^{2} + 2xy + 2y^{2} = (x + y)^{2} + x^{2} + y^{2} > 0\) ✓. Üç test de PD diyor.
NotSoru 2: [[1, 2], [2, 1]] pozitif tanımlı mı? Hepsi pozitif sayı olmasına rağmen.
\[ S = \begin{pmatrix} 1 & 2 \\ 2 & 1 \end{pmatrix} \]
Cevap:
\(\det = 1 - 4 = -3 < 0\) → özdeğerlerin çarpımı negatif → bir özdeğer negatif (\(\lambda = 3, -1\)). Bu indefinit. Pozitif girdiler PD garantisi vermez; önemli olan pozitif özdeğer/determinant/pivottur. Enerji \(x^{T}Sx = x^{2} + 4xy + y^{2}\), örneğin \((1, -1)\)’de \(1 - 4 + 1 = -2 < 0\).
NotSoru 3: [[1, 1], [1, 1]] matrisi hangi sınıfta? Enerjisini açıkça yaz.
\[ S = \begin{pmatrix} 1 & 1 \\ 1 & 1 \end{pmatrix} \]
Cevap:
\(\det = 0\) → tekil; özdeğerler \(2\) ve \(0\). Enerji: \(x^{T}Sx = x^{2} + 2xy + y^{2} = (x + y)^{2} \geq 0\), ama \((1, -1)\)’de tam \(0\). Negatif olmuyor ama sıfır olabiliyor → pozitif yarı-tanımlı (semidefinite). Rank 1 (hepsi-1 yapı taşı).
NotSoru 4: Yüksek kondisyon sayısı (λ_max/λ_min büyük) gradient descent’i neden yavaşlatır?
Cevap:
Enerji kâsesinin biçimi özdeğerlerle belirlenir: büyük özdeğer dik yön, küçük özdeğer sığ yön → uzun, dar bir vadi. Gradyan en dik yöne (dik duvara) işaret eder, vadinin uzun ekseni boyunca değil; bu yüzden adımlar vadiyi enlemesine geçip zikzak çizer, dibe çok yavaş yaklaşır.
\(\kappa = \lambda_{\max}/\lambda_{\min} = 1\) (çembersel kâse) ise tek adımda dibe iner. \(\kappa\) büyüdükçe yakınsama yavaşlar. Momentum, Adam ve ön-koşullama (Ders 23) bu zikzakı azaltır; eğitimde özellik ölçekleme/normalizasyon \(\kappa\)’yı küçük tutmak içindir.
6.13 Egzersizler
Cevapsız problemler. Çöz, sonra numpy ile kontrol et.
Egzersiz 1. \(\begin{pmatrix} 4 & 2 \\ 2 & 3 \end{pmatrix}\) matrisi pozitif tanımlı mı? Leading determinant, pivot ve enerji testlerinin üçüyle de göster.
Egzersiz 2. Hangi \(c\) değerleri için \(\begin{pmatrix} c & 2 \\ 2 & c \end{pmatrix}\) pozitif tanımlıdır? (Leading determinant testini kullan: \(c > 0\) ve \(c^{2} - 4 > 0\).)
\[ S = \begin{pmatrix} c & 2 \\ 2 & c \end{pmatrix} \]
Egzersiz 3. Herhangi bir \(A\) matrisi için \(A^{T}A\)’nın daima en az pozitif yarı-tanımlı olduğunu enerji testiyle göster. (İpucu: \(x^{T}(A^{T}A)x = (Ax)^{T}(Ax) = \lVert Ax \rVert^{2} \geq 0\).) \(A\)’nın kolonları bağımsızsa neden tam pozitif tanımlı olur?
Egzersiz 4. Python ile testleri uygula:
import numpy as np
S = np.array([[4.0, 2.0], [2.0, 3.0]])
print("özdeğerler:", np.linalg.eigvalsh(S)) # hepsi > 0 ?
try:
L = np.linalg.cholesky(S) # PD ise başarılı
print("Cholesky OK -> pozitif tanımlı")
except np.linalg.LinAlgError:
print("Cholesky başarısız -> PD değil")
# Enerji: rastgele x'lerde xᵀSx > 0 ?
for _ in range(3):
x = np.random.randn(2)
print("xᵀSx =", x @ S @ x)Egzersiz 5. (Ders 6 habercisi.) Ders 6 SVD’ye geçer. Aşağıdaki dikdörtgen \(A\) için \(A^{T}A\)’yı hesapla; simetrik ve yarı-tanımlı olduğunu doğrula. \(A^{T}A\)’nın özdeğerleri, \(A\)’nın tekil değerlerinin kareleridir (\(\sigma^{2}\)) — SVD’nin temeli.
\[ A = \begin{pmatrix} 1 & 0 \\ 1 & 1 \\ 0 & 1 \end{pmatrix} \]
6.14 Sonraki Ders İçin Hazırlık
Ders 6: Tekil Değer Ayrışımı (SVD)
Ders 5’i “ready for the SVD” diyerek kapattık. Ders 6, kursun ve tüm veri biliminin temel taşına geçer: SVD.
- Her matris (dikdörtgen dâhil) için \(A = U\Sigma V^{T}\)
- \(A^{T}A\) ve \(AA^{T}\)’nin özdeğerleri (\(= \sigma^{2}\)) ve özvektörleri (\(V\) ve \(U\))
- Tekil değerler \(\sigma \geq 0\); pozitif yarı-tanımlılıkla bağ
- Neden SVD = düşük-rank yaklaşımın, PCA’nın ve sıkıştırmanın merkezi
UyarıDers 6 Öncesi Yapılacak
- Bu dersin egzersizlerini çöz, özellikle Egzersiz 5’i (\(A^{T}A\) ve \(\sigma^{2}\)).
- Python’da
np.linalg.svdile birkaç dikdörtgen matrisi ayrıştır; \(\sigma\) değerlerini \(A^{T}A\)’nın özdeğerlerinin karekökleriyle karşılaştır. - Ana cümleyi tekrar oku: “Pozitif tanımlılık = yukarı açılan kâse (\(x^{T}Sx > 0\)).”
6.15 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Strang’de |
|---|---|---|
| Pozitif tanımlı | Simetrik + tüm özdeğerler \(> 0\); beş eşdeğer test | 3m10 |
| İndefinit | \(\det < 0\), karışık işaretli özdeğer; eyer noktası | 5m31 |
| Leading determinant | Sol-üst alt-determinantların hepsi \(> 0\) | 6m23 |
| Pivot testi | Eliminasyon pivotları \(> 0\); ardışık determinant oranı | 8m43 |
| Enerji \(x^{T}Sx > 0\) | Yukarı açılan dışbükey kâse; asıl tanım | 14m25 |
| Kâse = kayıp | Derin öğrenmenin minimize ettiği yüzey modeli | 15m48 |
| Gradient descent | En dik iniş; dar vadi (özdeğer oranı) yavaşlatır | 22m09 |
| \(S+T\), \(S^{-1}\), \(Q^{T}SQ\) | Hepsi pozitif tanımlı (doğru testle tek satır) | 30m44 |
| Yarı-tanımlı | Sınır durum: \(\lambda \geq 0\), \(\det = 0\) (örn. hepsi-1) | 38m06 |
| SVD’ye hazır | Sonraki büyük adım; \(A^{T}A\) özdeğerleri \(= \sigma^{2}\) | 45m08 |
6.16 ML Bağlantıları Özeti
- Enerji \(x^{T}Sx > 0\) = dışbükey kâse → ikinci-derece kayıp fonksiyonunun ideal biçimi; tek minimum.
- Kâse = kayıp → derin öğrenme bir enerjiyi minimize eder; PD Hessian = yerel dışbükeylik.
- Gradient descent → derin öğrenmenin merkezî algoritması; dar vadi → momentum/Adam (Ders 23).
- Kondisyon sayısı (\(\lambda_{\max}/\lambda_{\min}\)) → yakınsama hızını belirler; normalizasyon/ön-koşullama \(\kappa\)’yı küçültür.
- \(A^{T}A \geq 0\) (yarı-tanımlı) → kovaryans, Gram, kernel matrisleri hep kâse verir; düzenlileştirme (\(+\varepsilon I\)) tam PD yapar.
- \(S + T\) PD → dışbükey kayıpların toplamı dışbükey; düzenlileştirme terimi eklemenin gerekçesi.
- Cholesky (pivot \(> 0\)) → PD matrisleri çözmenin en hızlı/kararlı yolu; Bayesian çıkarım, GP.
ÖnemliTek bir şey alıp gideceksen
Pozitif tanımlılık, bir simetrik matrisin “yukarı açılan kâse” (\(x^{T}Sx > 0\)) olduğunun beş eşdeğer testidir. Bu kâse, optimizasyonun ve derin öğrenmenin kayıp yüzeyidir; gradient descent o kâsenin dibini arar ve kâse ne kadar dengeli (özdeğerler birbirine yakın) ise o kadar hızlı iner.