flowchart TD
M["Tekil deger turevleri + Weyl"] --> COMM["komutasyon tuzagi: d(A^2)/dt = A(dA/dt) + (dA/dt)A (2A dA/dt DEGIL)"]
M --> SIG["tekil deger turevi: dsigma/dt = u^T (dA/dt) v"]
M --> PROOF["ispat: sigma = u^T A v; iki yan terim AYRI AYRI iptal"]
M --> SVDEIG["SVD = ozdeger: simetrik + pozitif (yari-)tanimli"]
M --> MYST["Ders 15 gizemi: yeniden etiketleme"]
WEYL["Weyl: lambda_(i+j-1)(S+T) <= lambda_i(S) + lambda_j(T)"]
NUC["nuclear norm = sigma toplami -> matris tamamlama (Netflix)"]
style M fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style WEYL fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style NUC fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style COMM fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style SIG fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style PROOF fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
style SVDEIG fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
style MYST fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
17 Ters ve Tekil Değerlerin Türevleri
Tekil değer türevi, Weyl eşitsizliği ve nuclear norm ile matris tamamlama
NotBölüm bilgisi
Video: MIT 18.065 — Derivatives of Inverse and Singular Values · OCW: Lecture 16 · Okuma süresi: ≈32 dk · Eğitmen: Gilbert Strang · Önkoşul: Ders 15 (özdeğer türevi ve interlacing).
17.1 Bu Derste Ne Var?
Ders 15’i tamamlıyoruz. Orada özdeğer türevini (dλ/dt = yᵀ(dA/dt)x) bulduk; bu ders aynı hikayeyi tekil değer için yazar ve sonlu değişim eşitsizliklerini (interlacing → Weyl) genelleştirir.
Dört sonuç:
- Komütasyon tuzağı: d(A²)/dt = A(dA/dt) + (dA/dt)A — 2A(dA/dt) DEĞİL, çünkü matrisler değişmeli (commute) değil.
- Tekil değer türevi: dσ/dt = uᵀ (dA/dt) v — sol tekil vektör u, sağ tekil vektör v. Özdeğer formülünün tam ikizi.
- Ders 15 gizemi çözüldü: büyük itmede μ₂ λ₁’i “geçince” artık μ₁ olarak yeniden etiketlenir — çelişki yok.
- Weyl eşitsizliği: interlacing’in genel hali — herhangi rank değişim T için λᵢ₊ⱼ₋₁(S+T) ≤ λᵢ(S) + λⱼ(T). Sonda: nuclear norm + matris tamamlama (Netflix).
“Boy, you couldn’t ask for a nicer formula than that, right?” — Strang, 7:36 (tekil değer türevi için)
Aşağıdaki kavram haritası dersin merkezini (tekil değer türevleri + Weyl) ana fikirlere bağlar: komütasyon tuzağı, günün formülü tekil değer türevi, σ = uᵀAv ispatı, SVD’nin özdeğere ne zaman eşit olduğu, Ders 15’in gizemi ve ayrı düğümlerde Weyl eşitsizliği ile nuclear norm → matris tamamlama (Netflix) dalları (Şekil 17.1).
İpucuBuilder Notu — Türevden Netflix’e
- dσ/dt = uᵀ(dA/dt)v — PCA’nın kararlılığı: veri biraz değişirse ana bileşenlerin “önemi” (σ) ne kadar kayar; tekil vektör türevini gerektirmez.
- Komütasyon tuzağı — matris kalkülüsünde sıra korunur; backprop’ta (Ders 27) Jacobian’ların sırası bu yüzden önemli.
- Nuclear norm + matris tamamlama — Netflix öneri problemi; eksik matris hücrelerini doldurmak için ∑σᵢ’yi minimize et (düşük-rank çözüm). ℓ¹’in seyreklik (sparsity) etkisinin matris versiyonu.
- Geriye köprü: Ders 15 (özdeğer türevi paraleli), Ders 6 (SVD, Av=σu), Ders 7-8 (nuclear norm, Eckart-Young).
Tek cümle: Özdeğer türevi formülünün tam ikizi tekil değer için geçerlidir (dσ/dt = uᵀ(dA/dt)v), ve sonlu değişimlerde özdeğer/tekil değerleri Weyl eşitsizliği (interlacing’in genel hali) sınırlar.
17.2 Komütasyon Tuzağı: d(A²)/dt
Isınma sorusu: A² nin türevi nedir? İçgüdü “2A(dA/dt)” der — ama YANLIŞ. Neden? Türevi tanımdan kur: limit al.
\[\frac{d(A^{2})}{dt} = \lim_{\Delta t \to 0}\frac{(A + \Delta A)^{2} - A^{2}}{\Delta t}\]
(A + ΔA)² açılınca A² + AΔA + ΔA·A + ΔA². A² sadeleşir, ΔA² ihmal edilir. İki orta terim kalır — ve bunlar aynı değil:
“…one term is A delta A, and another term is delta A A.” — Strang, 5:01
\[\frac{d(A^{2})}{dt} = A\,\frac{dA}{dt} + \frac{dA}{dt}\,A\]
2A(dA/dt) olmamasının sebebi: matrisler genelde değişmeli (commute) değildir, A·(dA/dt) ≠ (dA/dt)·A. Skalerde iki terim birleşip 2A olurdu; matriste sıra korunur.
Aşağıdaki dört panel bunu sayısal olarak gösterir: doğru formül \(A\,\frac{dA}{dt} + \frac{dA}{dt}\,A\) ile merkez-fark \(d(A^{2})/dt\) birebir örtüşür (fark ~ 1e-10), oysa yanlış içgüdü \(2A\frac{dA}{dt}\) sapar (maxdiff ~ 2.0) — çünkü A(t) yolunda matrisler commute etmez (Şekil 17.2).
Kod
t0 = 0.4
A = a16_path(t0)
dA = a16_path_deriv(t0)
fig, axs = plt.subplots(1, 4, figsize=(12, 3))
heatmap(axs[0], dA2_correct(A, dA), "A (dA/dt) + (dA/dt) A")
heatmap(axs[1], dA2_numeric(a16_path, t0), "sayisal d(A^2)/dt")
heatmap(axs[2], dA2_correct(A, dA) - dA2_numeric(a16_path, t0), "fark ~ 1e-10", fmt="{:.0e}")
heatmap(axs[3], dA2_wrong(A, dA) - dA2_numeric(a16_path, t0), "YANLIS 2A(dA/dt) sapmasi", fmt="{:.2f}", cmap=DIVERGE)
fig.suptitle("Komutasyon tuzagi: dogru formul sayisalla birebir; 2A(dA/dt) sapar (maxdiff ~ 2.0) cunku matrisler commute etmez", color=COL_TEXT, fontsize=11)
fig.tight_layout()
plt.show()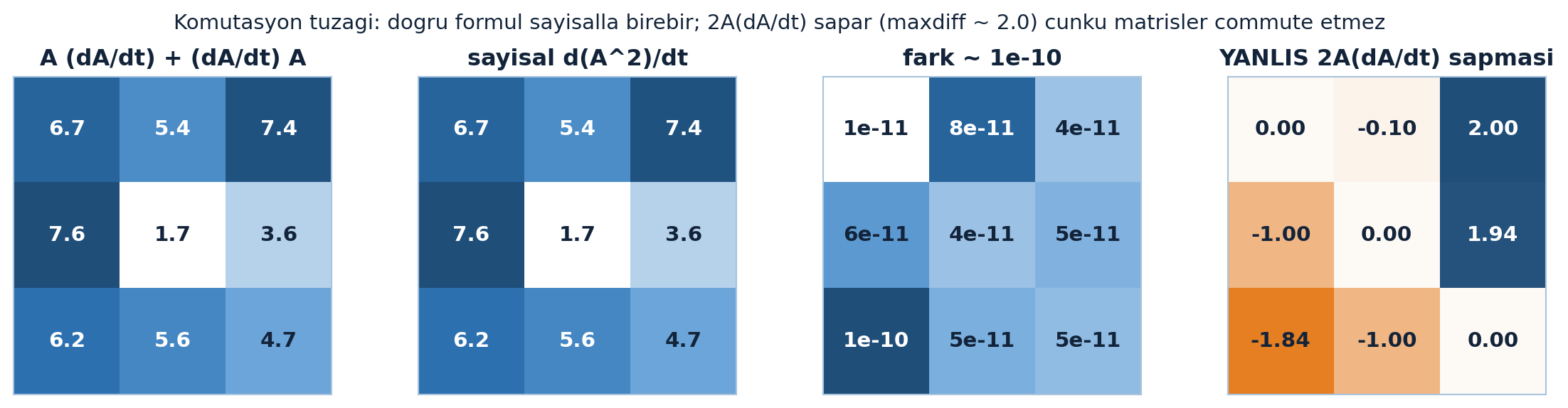
İpucuBuilder Notu — Sıra Bozulmaz Çünkü Commute Yok
“Matrisler commute etmez, sıra korunur” matris kalkülüsünün birinci kuralı. ML köprüsü: backprop’ta (Ders 27) zincir kuralı Jacobian’ları belirli sırada çarpar — sırayı bozmak yanlış gradyan verir. Çarpım kuralının skaler sezgisine körü körüne güvenmek en sık matris-kalkülüs hatasıdır.
17.3 Tekil Değer Türevi: dσ/dt = uᵀ(dA/dt)v
Ders 15 özdeğer türevini verdi: dλ/dt = yᵀ(dA/dt)x. Şimdi aynı soruyu tekil değer için sor: A değişirken σ nasıl değişir? Cevap, özdeğer formülünün tam ikizi:
\[\frac{d\sigma}{dt} = u^{T}\,\frac{dA}{dt}\,v\]
Burada u sol tekil vektör, v sağ tekil vektör (Ders 6’nın A = UΣVᵀ ayrışımından). Özdeğer formülünde sol/sağ özvektör (y, x) vardı; burada sol/sağ tekil vektör (u, v).
“Boy, you couldn’t ask for a nicer formula than that, right?” — Strang, 7:36
Soldaki panel A(t) yolu boyunca üç σᵢ(t) eğrisini çizer; t0=0.4’te her eğriye çizilen teğetin eğimi formülün verdiği türevdir ve teğet eğriye yapışır. Sağdaki panel formül değeri ile sayısal merkez farkı y=x üzerinde örtüştürür (maxdiff ~ 6e-11) (Şekil 17.3).
Kod
ts = np.linspace(0, 1, 81)
curves = sigma_curves(ts)
t0 = 0.4
s0, ds = dsigma_formula(a16_path(t0), a16_path_deriv(t0))
dn = dsigma_numeric(a16_path, t0)
fig, axs = plt.subplots(1, 2, figsize=(10, 4))
cols = [COL_PRIMARY, COL_ACCENT, COL_VEC3]
labels = [r"$\sigma_1(t)$", r"$\sigma_2(t)$", r"$\sigma_3(t)$"]
for i in range(3):
axs[0].plot(ts, curves[:, i], color=cols[i], lw=2.2, label=labels[i])
axs[0].plot(t0, s0[i], "o", color="#111111", ms=6, zorder=5)
tt = np.array([t0 - 0.3, t0 + 0.3])
tan = s0[i] + ds[i] * (tt - t0)
axs[0].plot(tt, tan, "--", color="#111111", lw=1.6, zorder=4)
apply_style(axs[0])
axs[0].set_xlabel("t")
axs[0].set_ylabel(r"tekil değerler $\sigma_i(t)$")
axs[0].set_title("σ eğrileri + t0=0.4 teğetleri (eğim = dσ/dt)", color=COL_TEXT, fontsize=11, fontweight="bold")
axs[0].legend(loc="best", framealpha=0.9, fontsize=9)
axs[1].scatter(ds, dn, color=COL_PRIMARY, s=70, zorder=5)
lo = min(ds.min(), dn.min()) - 0.2
hi = max(ds.max(), dn.max()) + 0.2
axs[1].plot([lo, hi], [lo, hi], "--", color="#888888", lw=1.4, zorder=2, label="y = x")
apply_style(axs[1])
axs[1].set_xlabel("formül: u^T (dA/dt) v")
axs[1].set_ylabel("sayısal merkez fark")
axs[1].set_title("formül = sayısal (maxdiff ~ 6e-11)", color=COL_TEXT, fontsize=11, fontweight="bold")
axs[1].legend(loc="best", framealpha=0.9, fontsize=9)
fig.suptitle("Özdeğer formülünün ikizi dσ/dt = u^T (dA/dt) v: teğetler σ eğrilerine yapışır (maxdiff ~ 6e-11)", fontsize=11, fontweight="bold", color=COL_TEXT)
fig.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()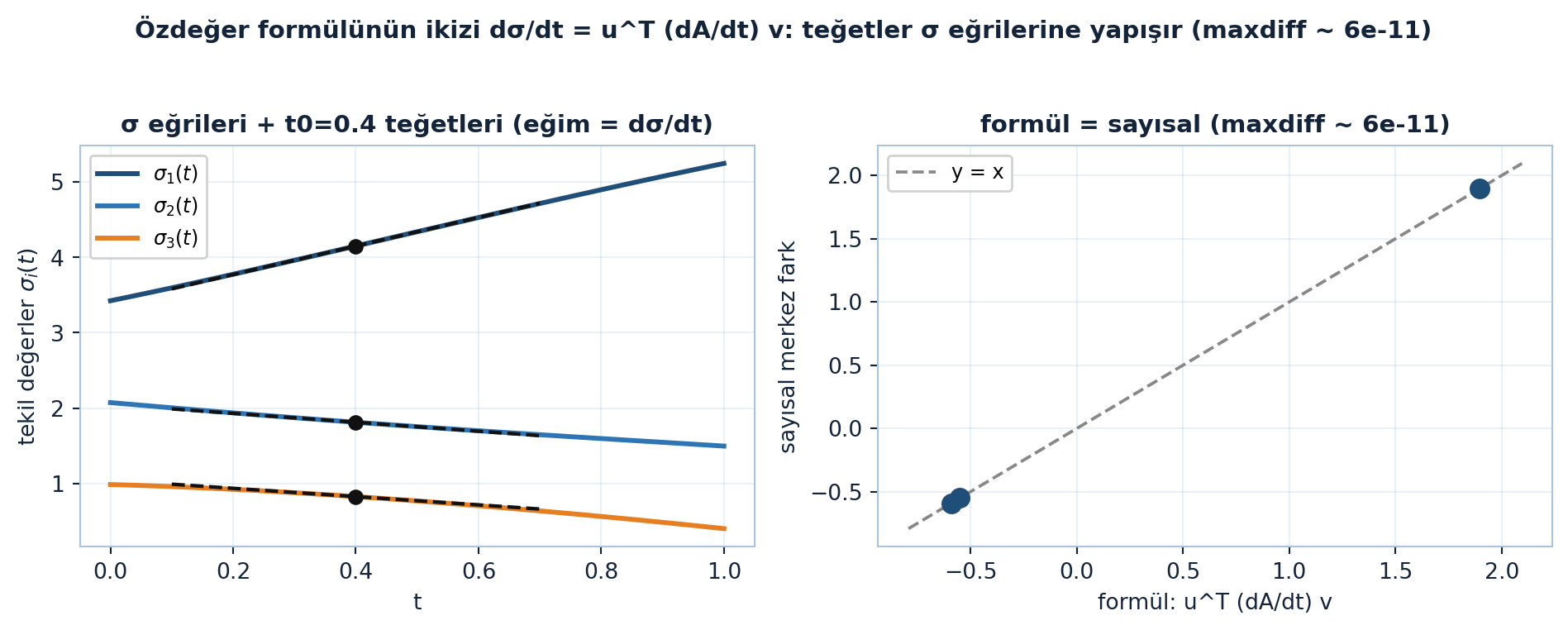
İpucuBuilder Notu — Özdeğer Formülünün İkizi
dσ/dt = uᵀ(dA/dt)v, PCA ve düşük-rank yaklaşımın kararlılık analizidir: veri matrisi biraz değişince ana bileşenlerin “ağırlığı” (σ) ne kadar kayar — tekil vektör türevini hesaplamadan. Öneri sistemleri ve gürültü gidermede, küçük veri güncellemelerinin sıralamayı bozup bozmadığını bu formül söyler.
17.4 İspat: σ = uᵀAv ve Ayrı Ayrı İptal
Önce σ için bir formül. SVD’den Av = σu (Ders 6). Soldan uᵀ ile çarp:
“So I believe that sigma is u transpose times A times v.” — Strang, 8:25
\[\sigma(t) = u^{T}(t)\,A(t)\,v(t)\]
Doğrula: uᵀAv = uᵀ(σu) = σ(uᵀu) = σ·1 = σ ✓ (çünkü uᵀu = 1). Şimdi türevini al — üç t-bağımlı çarpan, çarpım kuralı:
\[\frac{d\sigma}{dt} = \frac{du^{T}}{dt}Av + u^{T}\frac{dA}{dt}v + u^{T}A\frac{dv}{dt}\]
Orta terim cevap. Diğer ikisi sıfır — ama Ders 15’ten farklı olarak burada ayrı ayrı yok olurlar (özdeğerde birbirini götürüyorlardı). Birinci terim: Av = σu, yani (duᵀ/dt)Av = σ(duᵀ/dt)u. Bu, uᵀu = 1’in türevinin yarısı → 0. Üçüncü terim: Aᵀu = σv, yani uᵀA(dv/dt) = σvᵀ(dv/dt). Bu da vᵀv = 1’in türevinden → 0.
“Now, they disappear separately, leaving the right answer.” — Strang, 16:19
Geriye sade formül kalır: dσ/dt = uᵀ(dA/dt)v.
İpucuBuilder Notu — İki Kısıt İki Ayrı İptal
Özdeğer durumunda iki terim birlikte (d(yᵀx)/dt = 0 ile) iptal oluyordu; tekil değerde ayrı ayrı (uᵀu = 1 ve vᵀv = 1 iki ayrı kısıt). Sebep: SVD’nin u ve v’si ayrı ayrı birim uzunlukta, oysa özdeğerin y ve x’i sadece çiftleşik (yᵀx = 1). Bu fark, SVD’nin neden özdeğerden daha “kararlı” olduğunun ipucu.
17.5 SVD ve Özdeğer Ne Zaman Aynı?
λ = yᵀAx ve σ = uᵀAv neredeyse aynı görünüyor. Ne zaman birebir çakışırlar (tekil değerler = özdeğerler, tekil vektörler = özvektörler)? Cevap Strang’ın favori iki kelimesi:
“…write down positive definite in the answer to any question, because sigmas are by definition positive.” — Strang, 11:13
Simetrik ve pozitif (yarı-)tanımlı matrisler. Çünkü tekil değerler tanımı gereği ≥ 0; özdeğerlerle çakışmaları için özdeğerlerin de ≥ 0 (pozitif yarı-tanımlı) olması gerek. Simetrik ama işaretsiz bir matriste σ = |λ| olur (negatif özdeğerler mutlak değere döner).
Sol panel pozitif yarı-tanımlı bir S’de tekil değerlerin özdeğerlere birebir oturduğunu (maxdiff ~ 4e-15) gösterir; sağ panel diag(2, −3) gibi belirsiz (indefinit) bir matriste λ=[2, −3] iken σ=[3, 2] olduğunu — negatif özdeğerin mutlağa katlandığını ve sıranın da değiştiğini — gösterir (Şekil 17.4).
Kod
fig, axs = plt.subplots(1, 2, figsize=(9, 3.8))
# Sol: PSD — sigma = lambda
rng = np.random.default_rng(7)
B = rng.standard_normal((4, 4))
S_psd = B.T @ B
lam, sig = svd_vs_eig(S_psd)
x = np.arange(4)
ax = axs[0]
ax.bar(x - 0.18, lam, 0.36, color=COL_PRIMARY, label=r"$\lambda$")
ax.bar(x + 0.18, sig, 0.36, color=COL_VEC3, alpha=0.85, label=r"$\sigma$")
ax.set_title("PSD: sigma = lambda (maxdiff ~ 4e-15)", color=COL_TEXT, fontsize=11, fontweight="bold")
ax.set_xticks(x); ax.set_xticklabels([f"{i+1}" for i in x])
ax.set_xlabel("indeks i"); ax.set_ylabel("deger")
ax.legend(loc="upper right", framealpha=0.9)
apply_style(ax)
# Sag: indefinit — sigma = |lambda| (sira da degisir)
lam2, sig2 = svd_vs_eig(np.diag([2., -3.]))
x2 = np.arange(2)
ax = axs[1]
ax.bar(x2 - 0.18, lam2, 0.36, color=COL_PRIMARY, label=r"$\lambda$")
ax.bar(x2 + 0.18, sig2, 0.36, color=COL_VEC3, alpha=0.85, label=r"$\sigma$")
ax.axhline(0, color=COL_TEXT, lw=0.8, alpha=0.6)
ax.set_title("indefinit: sigma = |lambda| (sira da degisir)", color=COL_TEXT, fontsize=11, fontweight="bold")
ax.set_xticks(x2); ax.set_xticklabels([f"{i+1}" for i in x2])
ax.set_xlabel("indeks i"); ax.set_ylabel("deger")
ax.legend(loc="lower right", framealpha=0.9)
apply_style(ax)
fig.suptitle("SVD = ozdeger ancak simetrik + pozitif (yari-)tanimli matriste", color=COL_TEXT, fontsize=12, fontweight="bold")
fig.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()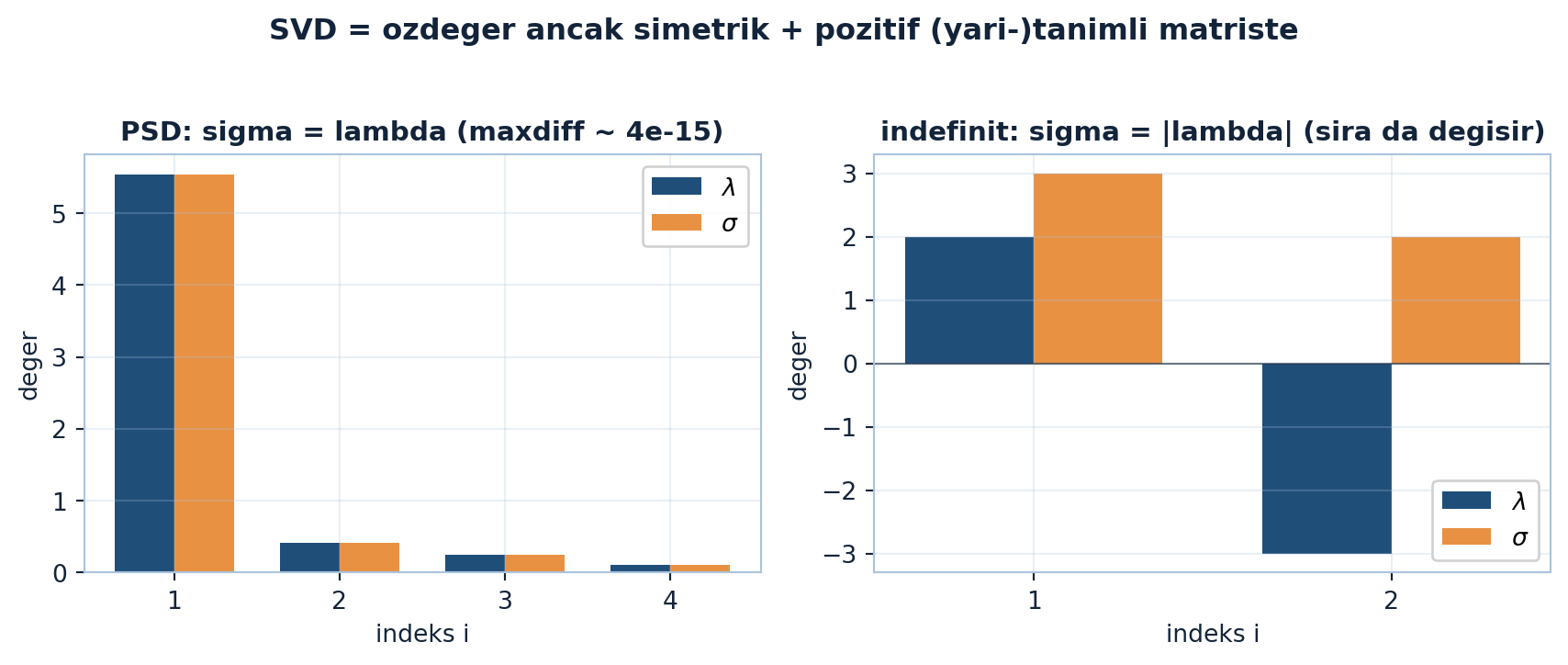
İpucuBuilder Notu — Emin Değilsen Pozitif Tanımlı Yaz
“Soruda emin değilsen ‘pozitif tanımlı’ yaz” Strang’ın esprili kuralı ama derin: pozitif tanımlılık (Ders 5) SVD ile özdeğer ayrışımını birleştiren köprüdür. ML’de Gram matrisi AᵀA, kovaryans matrisi ve kernel matrisleri hep pozitif yarı-tanımlıdır — bu yüzden onların SVD’si ve özdeğer ayrışımı aynıdır, hesap tek seferde iş görür.
17.6 Ders 15’in Gizemi Çözülüyor
Ders 15 bir bilmeceyle bitmişti: u = S’nin ikinci özvektörü ise, S + θuuᵀ o özvektörün özdeğerini λ₂ + θ yapar. θ büyükse (20, 200, 2000) bu değer λ₁’i geçer — interlacing’i bozar gibi görünür (μ₂ ≤ λ₁ olmalıydı). Çözüm:
“…if I increase theta beyond that, then this becomes not mu 2 any more, but mu 1.” — Strang, 25:20
İncelik şu: λ₂ + θ değeri λ₁’i geçtiği an, artık ikinci özdeğer (μ₂) değildir — birinci özdeğer (μ₁) olur. Özdeğerler azalan sırada etiketlenir; bir değer yukarı tırmanıp komşusunu geçince etiket de değişir. μ₂ tanım gereği λ₁’i asla geçmez, çünkü geçtiği anda adı μ₁ olur. Çelişki yok — sadece yeniden etiketleme.
Aşağıdaki figür bu çözümü etiket perspektifinden gösterir: μ₂ tanım gereği γ₁=4.38’i geçemez (θ≈3.35’te ona yapışır), θ ardından fırlayan değer artık μ₁ olarak devam eder. Ders 15’in fig-buyuk-itme’si KİMLİK perspektifiydi (belirli özvektörün özdeğeri komşusunu geçer, eğriler kesişir); bu figür ETİKET perspektifidir (sıralı μ_i eğrileri kesişMEZ, yapışır) (Şekil 17.5).
Kod
S = np.array([[4., 1., 0., .5], [1., 1., 1., 0.], [0., 1., -2., 1.], [.5, 0., 1., 0.]])
ths, mus, gam = mystery_label_curves(S, idx=1)
theta_star = gam[0] - gam[1]
fig, ax = plt.subplots(figsize=(7.5, 4.5))
apply_style(ax)
# Sıralı etiket eğrileri
ax.plot(ths, mus[:, 0], color=COL_VEC3, lw=2.5, label=r"$\mu_1$ (en büyük)")
ax.plot(ths, mus[:, 1], color=COL_PRIMARY, lw=2.5, label=r"$\mu_2$")
ax.plot(ths, mus[:, 2], color=COL_ACCENT, lw=1.2, label=r"$\mu_3$")
ax.plot(ths, mus[:, 3], color=COL_STEEL_300, lw=1.2, label=r"$\mu_4$")
# gamma_1 yatay kesik
ax.axhline(gam[0], color=COL_TEXT, lw=1.2, ls="--", alpha=0.8)
ax.text(ths[-1], gam[0] + 0.5, r"$\gamma_1 = 4.38$", color=COL_TEXT,
ha="right", va="bottom", fontsize=10, fontweight="bold")
# theta_star dikey ince çizgi
ax.axvline(theta_star, color=COL_TEXT, lw=1.0, ls=":", alpha=0.7)
ax.annotate("etiket takası", xy=(theta_star, gam[0]),
xytext=(theta_star + 4.0, gam[0] - 6.0),
color=COL_TEXT, fontsize=10, fontweight="bold",
arrowprops=dict(arrowstyle="->", color=COL_TEXT, lw=1.2))
ax.set_xlabel(r"$\theta$ ($S + \theta\,uu^{T}$, $u$ = ikinci özvektör)")
ax.set_ylabel(r"SIRALI özdeğerler $\mu_i$")
ax.set_title("Ders 15 gizemi çözüldü: $\\mu_2$ tanım gereği $\\gamma_1 = 4.38$ i GEÇEMEZ\n"
"— geçmeye kalkınca adı $\\mu_1$ olur (yeniden etiketleme)",
color=COL_TEXT, fontsize=11, fontweight="bold")
ax.legend(loc="upper left", framealpha=0.9, fontsize=9)
fig.tight_layout()
plt.show()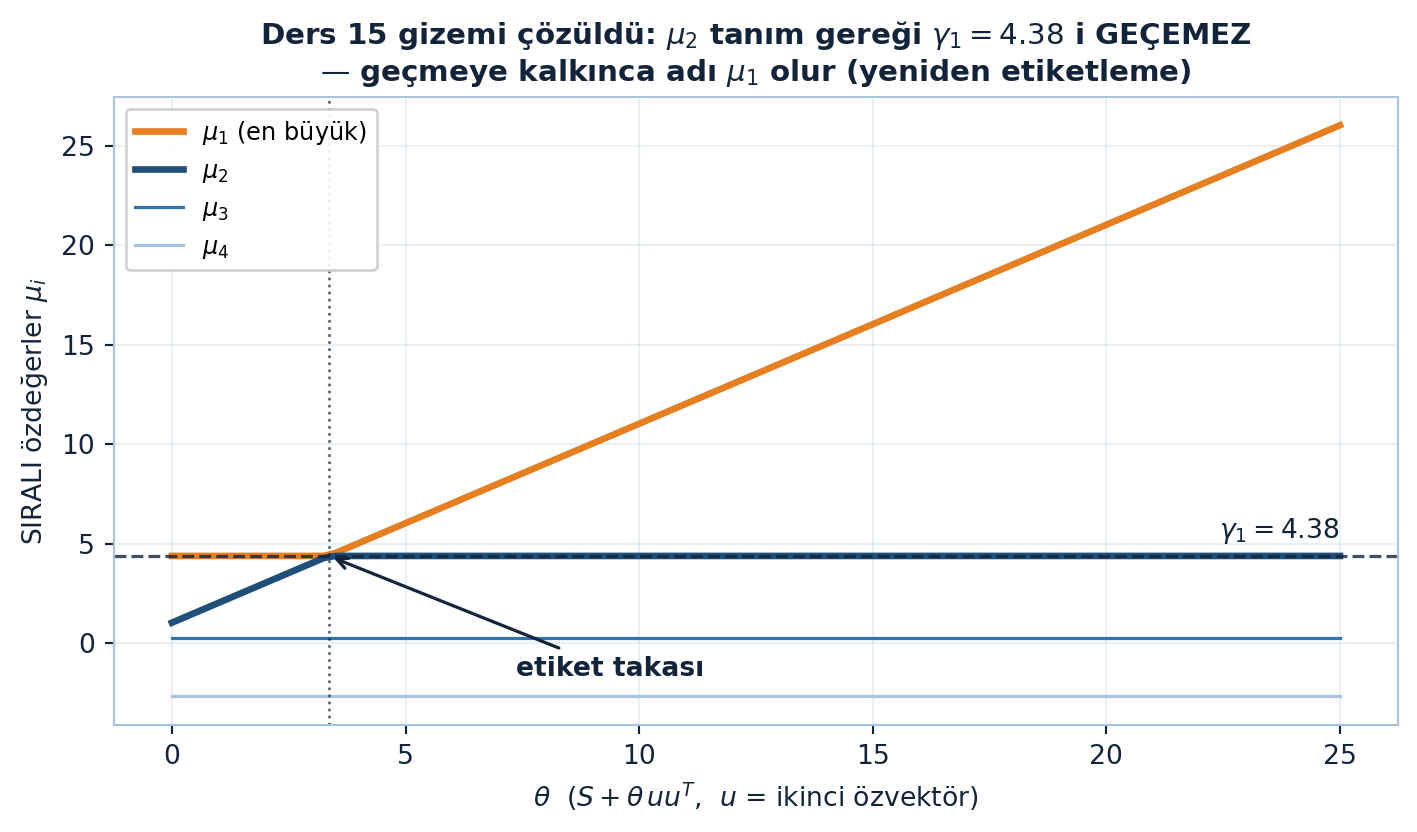
İpucuBuilder Notu — Etiket Kayar Kimlik Kalır
“Sıralı eşitsizlik etiket korur, kimlik değil” — interlacing bir özvektörü değil, sıralı konumu izler. ML köprüsü: online PCA’da bir bileşen başka bir bileşeni geçince “birinci ana bileşen” rolü el değiştirir; algoritmanın izlediği şey bileşen kimliği değil, varyans sırasıdır. Bu, takip (tracking) problemlerinde etiket karışmasının (label switching) kaynağıdır.
17.7 Weyl Eşitsizliği: Interlacing’in Genel Hali
Interlacing rank-1 değişim içindi. Genel rank için (S simetrik, T herhangi simetrik değişim) Weyl’in büyük eşitsizliği:
“…after the discoverer, Weyl’s inequality.” — Strang, 26:19
\[\lambda_{i+j-1}(S+T) \leq \lambda_{i}(S) + \lambda_{j}(T)\]
Tüm interlacing buradan düşer. j = 1 al: λᵢ(S+T) ≤ λᵢ(S) + λ_max(T) — T pozitifse özdeğerler yukarı çıkar ama en fazla T’nin en büyük özdeğeri kadar. Farklı i, j seçimleri komşu-olmayan özdeğerler hakkında da bilgi verir. Weyl aynı zamanda tekil değerleri keşfeden isimlerden; eşitsizliğin tekil değer versiyonu da geçerli.
\[\lambda_{i}(S+T) \leq \lambda_{i}(S) + \lambda_{\max}(T) \quad (j=1)\]
Notlarda iki ispat var: standart Weyl yaklaşımı ve Prof. Rao’nun grafik tabanlı argümanı.
Aşağıdaki figür j=1 halini gösterir: navy çubuklar S+T’nin sıralı özdeğerleri, turuncu yatay çizgiler λᵢ(S)+λ_max(T) üst sınırı — her çubuk kendi sınırının altında kalır. Motor bunu 50 rastgele simetrik (S, T) çifti üzerinde de tarar ve ihlal 0 sayar (Şekil 17.6).
Kod
# S = D15/motor matrisi (verify16 ile birebir)
S = np.array([[4.0, 1.0, 0.0, 0.5], [1.0, 1.0, 1.0, 0.0], [0.0, 1.0, -2.0, 1.0], [0.5, 0.0, 1.0, 0.0]])
rngT = np.random.default_rng(11)
T = rngT.standard_normal((4, 4)); T = (T + T.T) / 2
lS = np.sort(np.linalg.eigvalsh(S))[::-1]
lT = np.sort(np.linalg.eigvalsh(T))[::-1]
lST = np.sort(np.linalg.eigvalsh(S + T))[::-1]
bound = lS + lT[0]
fig, ax = plt.subplots(figsize=(7, 4))
x = np.arange(1, 5)
ax.bar(x, lST, 0.5, color=COL_PRIMARY, label=r"$\lambda_i(S+T)$")
for i in range(4):
lbl = r"$\lambda_i(S) + \lambda_{\max}(T)$" if i == 0 else None
ax.hlines(bound[i], x[i] - 0.3, x[i] + 0.3, color=COL_VEC3, lw=3, label=lbl)
apply_style(ax)
ax.legend()
ax.set_xticks(x)
ax.set_xlabel("i")
ax.set_title("Weyl (j=1): " + r"$\lambda_i(S+T) \leq \lambda_i(S) + \lambda_{\max}(T)$" +
"\nher özdeğer sınırın altında (verify: 50 rastgele çifte ihlal 0)",
color=COL_TEXT, fontsize=10, fontweight="bold")
plt.show()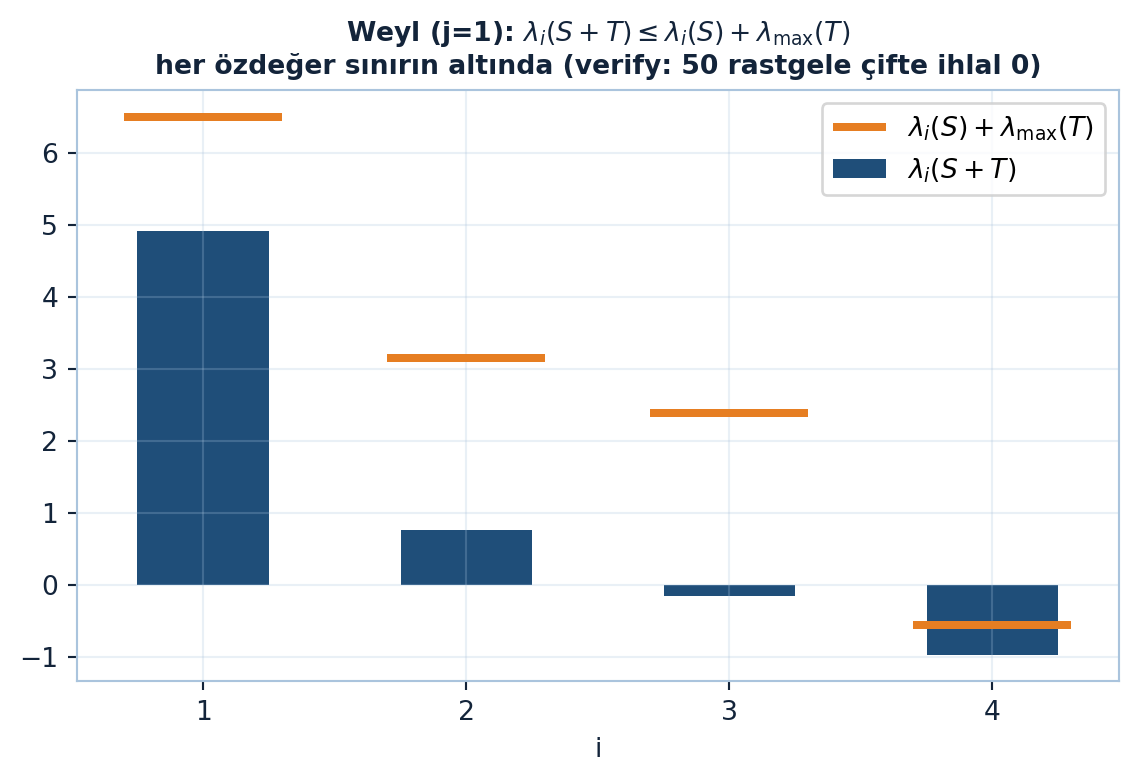
İpucuBuilder Notu — Gürültüye Karşı Spektral Sigorta
Weyl eşitsizliği perturbasyon teorisinin temel taşı: bir matrise gürültü/değişim T eklenince özdeğerlerin ne kadar kayabileceğini kesin sınırlar. ML köprüsü: gürültülü veride PCA’nın güvenilirliği, spektral kümelemenin (Ders 35) gürültüye dayanıklılığı ve düşük-rank yaklaşımın hata analizi hep Weyl-tipi sınırlara dayanır. “Küçük değişim → küçük özdeğer kayması” güvencesi olmadan spektral yöntemler kırılgan olurdu.
17.8 Nuclear Norm ve Matris Tamamlama (Önizleme)
Türevler bitti; ders yeni bir bölüme (compressed sensing) köprü kurar. Anahtar nesne nuclear norm:
“The nuclear norm a matrix is the sum of the singular values.” — Strang, 35:04
\[\|A\|_{*} = \sigma_{1} + \sigma_{2} + \cdots + \sigma_{r}\]
Bu, vektördeki ℓ¹ normun matris karşılığıdır (Ders 8). ℓ¹’in sihirli özelliği: bir kısıt altında minimize edilince seyrek (sparse) çözüm verir. Nuclear norm da matrisler için düşük-rank çözüm verir. Uygulaması matris tamamlama:
“And I’ll remember the words Netflix, which made the problem famous.” — Strang, 36:26
Netflix problemi: kullanıcı×film matrisinin çoğu hücresi boş (herkes her filmi izlemedi). Eksik hücreleri nasıl doldurursun? Fikir: nuclear normu minimize eden dolgu, en düşük-rank (en “açıklayıcı”) matristir. Neden nuclear norm? Çünkü asıl istediğimiz rank’i minimize etmek — ama rank bir norm değil (matrisi 2 ile çarpınca rank değişmez). rank, vektördeki ℓ⁰ normun (sıfır-olmayan eleman sayısı) matris eşi; ikisi de norm değil. Konveks gevşetme: ℓ⁰ → ℓ¹, rank → nuclear norm.
“…gradient descent finds the solution to the minimum problem in the nuclear norm.” — Strang, 42:02
Açık bir conjecture: derin öğrenmedeki gradient descent’in (Ders 22+) doğal olarak minimum-nuclear-norm (düşük-rank) çözümü bulduğu düşünülüyor — ama henüz kanıtlanmadı (implicit bias, Ders 10).
Aşağıdaki üç panel demoyu gösterir: gerçek rank-2 matris M, yarısı boş gözlem (66/144 hücre, %46) ve düşük-rank dolgu. Demo dolgusu rank-2 hard impute (dönüşümlü projeksiyon) kullanır — bu, nuclear-norm hedefinin “sert” halidir; küçük demoda kesin yöntemdir. Prose’da anlatılan nuclear norm minimizasyonu bu hedefin konveks gevşetmesidir. İki yöntem aynı düşük-rank çözüme götürür: dolgu gizli hücreleri 4.4e-08 hatayla TAM geri getirir ve nuclear norm eşitliği ‖X‖∗ = ‖M‖∗ = 29.30 tutar (Şekil 17.7).
Kod
M = make_lowrank(12, 12, r=2, seed=3)
mask = make_mask(12, 12, frac=0.5, seed=4)
X = lowrank_complete(M, mask, r=2)
fig, axs = plt.subplots(1, 3, figsize=(11, 3.6))
heatmap(axs[0], M, "gercek M (rank-2)", annotate=False)
axs[1].imshow(np.ma.masked_where(mask == 0, M), cmap=NAVY_CMAP, aspect="equal")
axs[1].set_title("gozlenen (66/144 hucre)", color=COL_TEXT, fontsize=12, fontweight="bold")
axs[1].set_xticks([]); axs[1].set_yticks([])
for sp in axs[1].spines.values(): sp.set_color(COL_STEEL_300)
heatmap(axs[2], X, "rank-2 dolgu (gizli hata 4e-08)", annotate=False)
fig.suptitle("Netflix: yarisi bos rank-2 matris dusuk-rank dolguyla TAM geri gelir — nuclear norm ayni hedefin konveks gevsetmesi (nuclear norm X = M = 29.30)", fontsize=10, color=COL_TEXT)
fig.tight_layout(rect=[0, 0, 1, 0.97])
plt.show()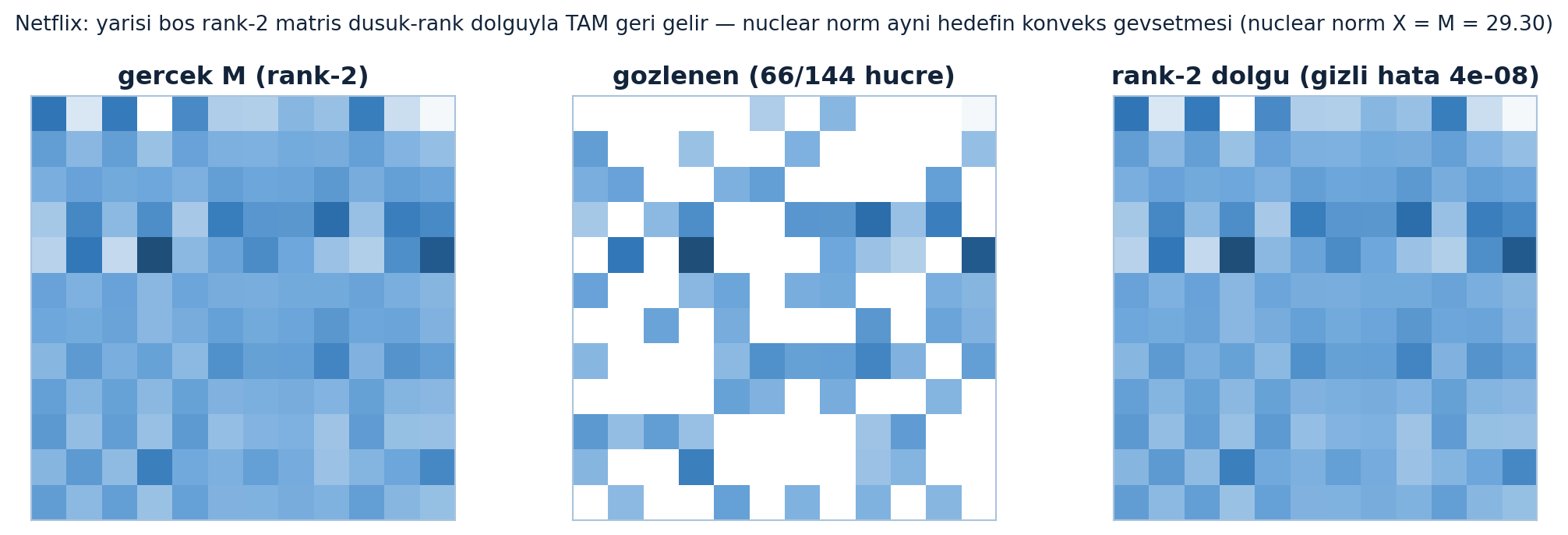
İpucuBuilder Notu — Rankın Konveks Gölgesi
rank → nuclear norm gevşetmesi modern ML’in temel hilesi: kombinatoryal (NP-zor) bir hedefi (rank minimize) konveks (çözülebilir) bir hedefe çevirir. Netflix Prize bu yöntemi ünlü etti. Köprü: LoRA (düşük-rank adaptasyon) aynı düşük-rank önyargısını fine-tuning’e taşır; “gradient descent düşük-rank bulur” conjecture’ı derin öğrenmenin neden genelleştirdiğini açıklama çabalarının merkezinde.
17.9 Bu Dersin Özeti
- Komütasyon tuzağı: d(A²)/dt = A(dA/dt) + (dA/dt)A, 2A(dA/dt) değil — matrisler değişmeli değil.
- Tekil değer türevi: dσ/dt = uᵀ(dA/dt)v (sol tekil vektör u, sağ tekil vektör v). Özdeğer formülünün ikizi.
- İspat: σ = uᵀAv (Av = σu, uᵀu = 1). Çarpım kuralı; iki yan terim ayrı ayrı sıfır (uᵀu = 1 ve vᵀv = 1 — özdeğerdeki gibi birlikte değil).
- SVD = özdeğer ne zaman: simetrik + pozitif (yarı-)tanımlı.
- Ders 15 gizemi: μ₂ büyüyüp λ₁’i geçince artık μ₁ olarak yeniden etiketlenir — çelişki yok, sadece sıralama etiketi kayar.
- Weyl eşitsizliği: λᵢ₊ⱼ₋₁(S+T) ≤ λᵢ(S) + λⱼ(T); interlacing’in genel hali (j=1 özel durum). Tekil değerler için de geçerli.
- Nuclear norm: ‖A‖∗ = Σσᵢ (matrisler için ℓ¹). rank → nuclear norm konveks gevşetmesi; matris tamamlama (Netflix), compressed sensing.
ÖnemliTek Bir Cümle
Özdeğer türevinin tam ikizi tekil değer için dσ/dt = uᵀ(dA/dt)v’dir (iki yan terim ayrı ayrı iptal); sonlu değişimleri Weyl eşitsizliği sınırlar, ve nuclear norm minimizasyonu düşük-rank matris tamamlamanın (Netflix) anahtarıdır.
17.10 Kontrol Soruları
NotSoru 1: d(A²)/dt neden 2A(dA/dt) değil
d(A²)/dt neden 2A(dA/dt) değildir? Doğru formül nedir?
Çünkü matrisler genelde değişmeli (commute) değildir: A·(dA/dt) ≠ (dA/dt)·A. (A+ΔA)² açılımında iki orta terim AΔA ve ΔA·A ayrıdır, birleşip 2AΔA olmazlar. Doğru formül: d(A²)/dt = A(dA/dt) + (dA/dt)A. Sıra korunmalıdır.
NotSoru 2: İki yan terim nasıl yok olur
dσ/dt = uᵀ(dA/dt)v ispatında iki yan terim özdeğer durumundan farklı olarak nasıl yok olur?
σ = uᵀAv’in türevinde üç terim çıkar. Birinci terim Av = σu kullanılınca σ(duᵀ/dt)u = (σ/2)·d(uᵀu)/dt; uᵀu = 1 sabit, türevi 0. Üçüncü terim Aᵀu = σv ile σvᵀ(dv/dt); vᵀv = 1, türevi 0. Yani iki terim ayrı ayrı (iki bağımsız birim-uzunluk kısıtından) sıfır olur — özdeğerde ise tek bir yᵀx = 1 kısıtından birlikte götürüyorlardı.
NotSoru 3: Interlacing neden bozulmaz
u = S’nin ikinci özvektörü ve S + 20uuᵀ ikinci özdeğeri çok yukarı itiyorsa, interlacing neden bozulmaz?
λ₂ + 20 değeri λ₁’i geçtiği anda, azalan-sıra etiketlemesi gereği artık ikinci özdeğer (μ₂) değil, birinci özdeğer (μ₁) olur. μ₂ tanım gereği λ₁’i geçemez — çünkü geçtiği an adı μ₁’e döner. Interlacing özvektör kimliğini değil, sıralı konumu izler; çelişki yoktur, sadece yeniden etiketleme vardır.
NotSoru 4: Neden rank yerine nuclear norm
Matris tamamlamada (Netflix) neden rank yerine nuclear norm minimize edilir?
Asıl hedef en düşük-rank dolguyu bulmak, ama rank bir norm değildir (matrisi 2 ile çarpınca rank değişmez) ve minimize etmesi NP-zordur. Nuclear norm (‖A‖∗ = Σσᵢ) rankın konveks gevşetmesidir — vektördeki ℓ⁰ → ℓ¹ geçişinin matris karşılığı. Konveks olduğu için verimli çözülür ve pratikte düşük-rank çözüm verir.
17.11 Egzersizler
Komütasyon kontrolü. A(t) = [[t, 1], [0, t]]. A²’yi hesapla, türevini doğrudan al. Sonra A(dA/dt) + (dA/dt)A formülüyle hesapla; eşit olduğunu, ama 2A(dA/dt)’nin farklı çıktığını göster.
[motor notu] Bu özel ailede dA/dt = I olduğundan ve I her matrisle değişir (commute), iki formül aynı çıkar — fark görünmez. Farkı görmek için dA/dt’nin A ile değişmediği bir aile gerekir (örn. motorun a16_path’i: sapma ~2.0).
Tekil değer türevi. A(t) = [[t, 0], [0, 2]] (t > 0). σ₁ = 2, σ₂ = t (t < 2 için). dA/dt = [[1,0],[0,0]]. σ₂ = t’nin türevi dσ₂/dt = uᵀ(dA/dt)v ile 1 çıkar mı? (İpucu: σ₂ tekil vektörleri e₁.)
Üçüncü terimi göster. dσ/dt ispatında üçüncü terim uᵀA(dv/dt)’nin Aᵀu = σv kullanılarak σvᵀ(dv/dt) olduğunu ve vᵀv = 1’den sıfırlandığını adım adım yaz.
Weyl → interlacing. Weyl eşitsizliğinde j = 1 ve T = θuuᵀ (rank-1, pozitif) al. λᵢ(S+T) ≤ λᵢ(S) + θ‖u‖² çıktığını ve bunun “özdeğerler en fazla θ‖u‖² kadar yukarı” interlacing ifadesini verdiğini göster.
(Ders 17 habercisi — konuk Townsend) Bu derste tekil değerlerin türevini gördük. Peki tekil değerler ne kadar hızlı küçülür? Bazı matrislerde σₖ üstel hızla düşer (etkin rank çok küçük). Hangi matrisler? Neden önemli? Bir tahmin yaz — Ders 17’de konuk Prof. Alex Townsend “hızla azalan tekil değerler”i işliyor.
17.12 Sonraki Ders İçin Hazırlık
Ders 17: Hızla Azalan Tekil Değerler (konuk: Alex Townsend). Strang’ın bahsettiği gibi Prof. Townsend §4.3’ü (kendi araştırma alanı) anlatır: hangi matrislerin tekil değerleri üstel hızla düşer, neden bu “sayısal düşük-rank” demektir ve Sylvester denklemleri/sınır değer problemleriyle bağı. Quote’lar konuşmacıya atfedilir (“— Townsend, X:XX”).
UyarıDers 17 Öncesi Yapılacak
Ders 17 Strang’ın değil, konuk Prof. Alex Townsend’in dersidir. Tekil değer kavramı (Ders 6) ve bu dersteki dσ/dt türevi tazeyken gir; “hızla azalan tekil değer = sayısal düşük-rank” fikrinin Eckart-Young (Ders 7) ile bağını düşün. Townsend’in tüm alıntıları ona atfedilecek (“— Townsend, X:XX”), Strang’a değil.
17.13 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Formül / Fikir | Strang (dk) |
|---|---|---|
| Komütasyon tuzağı | d(A²)/dt = A(dA/dt) + (dA/dt)A, 2A(dA/dt) değil | 5m01 |
| Tekil değer türevi | dσ/dt = uᵀ (dA/dt) v | 7m36 |
| σ formülü | σ = uᵀAv (Av = σu, uᵀu = 1) | 8m25 |
| SVD = özdeğer | simetrik + pozitif (yarı-)tanımlı | 11m13 |
| Ayrı ayrı iptal | uᵀu = 1 ve vᵀv = 1 → iki yan terim 0 | 16m19 |
| Gizem çözümü | μ₂ büyüyüp λ₁’i geçince μ₁ olur (yeniden etiket) | 25m20 |
| Weyl eşitsizliği | λᵢ₊ⱼ₋₁(S+T) ≤ λᵢ(S) + λⱼ(T) | 26m19 |
| Nuclear norm | ‖A‖∗ = Σσᵢ (matrisler için ℓ¹) | 35m04 |
| Matris tamamlama | Netflix; nuclear norm min → düşük-rank dolgu | 36m26 |
| GD conjecture | gradient descent düşük-rank çözüm bulur (kanıtsız) | 42m02 |
17.14 ML Bağlantıları Özeti
- PCA kararlılığı: dσ/dt = uᵀ(dA/dt)v — veri güncellemesinde ana bileşenlerin ağırlığı ne kadar kayar; tekil vektör türevi gerekmez.
- Matris kalkülüsü: komütasyon tuzağı (d(A²)/dt) — backprop’ta (Ders 27) Jacobian sırasının neden önemli olduğunun temeli.
- Matris tamamlama / öneri: Netflix problemi; nuclear norm minimizasyonu eksik matrisleri düşük-rank ile doldurur.
- Konveks gevşetme: rank → nuclear norm (ℓ⁰ → ℓ¹ matris versiyonu); NP-zor hedefi çözülebilir kılar.
- Implicit bias / LoRA: gradient descent’in düşük-rank bulma conjecture’ı + düşük-rank fine-tuning (LoRA); derin öğrenmenin genelleme gizemiyle bağlı.
- Perturbasyon sınırları: Weyl eşitsizliği — gürültülü veride spektral yöntemlerin (PCA, kümeleme) güvenilirlik garantisi.
- Geriye köprü: Ders 15 (özdeğer türevi paraleli + açık gizem), Ders 6 (SVD Av=σu), Ders 8 (nuclear/ℓ¹ norm), Ders 5 (pozitif tanımlı), Ders 10 (implicit bias).
ÖnemliTek Şey
“Boy, you couldn’t ask for a nicer formula than that, right?” — Strang, 7:36 — Tekil değer türevi dσ/dt = uᵀ(dA/dt)v, özdeğer formülünün ikizi; sonlu değişimleri Weyl sınırlar, ve nuclear norm düşük-rank dünyasının kapısını açar.