flowchart TD
M["Rastlantısal matris çarpımı"] --> RANK["AB = Σ aⱼbⱼᵀ → rank-1 parçalar (Ders 1)"]
M --> SAMP["olasılıkla örnekle → yaklaşık AB"]
M --> MEAN["mean DOĞRU (yansız) ama variance var"]
M --> UNB["yansız tahmin: olasılığa böl"]
M --> NS["norm-kare örnekleme p ∝ ‖aⱼ‖‖bⱼ‖ → variance min"]
M --> LAG["Lagrange → norm-kare optimal"]
SGD["SGD = aynı kalıp (mini-batch)"]
style M fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style SGD fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style RANK fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style SAMP fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style MEAN fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style UNB fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
style NS fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
style LAG fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
14 Rastlantısal Matris Çarpımı
Mean, variance, norm-kare örnekleme — SGD’nin atası
NotBölüm bilgisi
Video: MIT 18.065 — Randomized Matrix Multiplication · OCW: Lecture 13 · Okuma süresi: ≈38 dk · Eğitmen: Gilbert Strang · Önkoşul: Ders 12 (büyük matrisler, iteratif yöntemler).
14.1 Bu Derste Ne Var?
Dev matrisler için \(AB\)’yi tüm terimlerle değil, örnekleyerek yaklaşık hesaplamak. Bu, kursun istatistik/olasılıkla ilk buluşması — mean, variance ve norm-kare örnekleme.
Üç temel fikir:
- \(AB = \sum\) dış çarpımı örnekle — \(AB = \sum_j a_j b_j^{T}\) (Ders 1); tüm terimler yerine olasılıkla seçilen birkaçını al, ortalaması \(AB\)’ye yakın.
- Mean doğru, variance sıfır değil — tahmin edici yansızdır (ortalama \(= AB\)) ama her örnek yanlış; iş, variance’ı küçültmek.
- Norm-kare örnekleme — olasılığı \(p_j \propto \|a_j\|\,\|b_j\|\) seçmek variance’ı minimize eder (Lagrange ile); büyük kolonlar daha sık.
Aşağıdaki kavram haritası bu dersin merkezindeki rastlantısal çarpımdan ana fikirlere uzanan dalları, ve aynı kalıbı tekrarlayan SGD düğümünü gösterir (Şekil 14.1).
“…the mean value of the random AB is correct AB. But there will be a variance.” — Strang, 2:28
İpucuBuilder Notu — SGD’nin Atası
- Yansız tahmin + variance — stokastik gradient descent’in (Ders 25) tam mantığı: mini-batch gradyanı gerçeğin yansız tahminidir, variance batch boyutuyla düşer.
- Norm-kare örnekleme — önemli (büyük) terimleri daha sık seçmek = importance sampling; randomized SVD ve büyük-ölçek çarpımın temeli.
- \(AB = \sum\) rank-1 — Ders 1’in dış-çarpım görüşü; her örnek bir rank-1 parça, toplamı \(AB\).
- Mean/variance — Stat 110 köprüsü; bu kursun ilk olasılık dersi, ileride olasılık bölümünde derinleşir.
Tek cümle: dev \(AB\)’yi rank-1 parçalarını olasılıkla örnekleyerek yaklaşık hesaplarız; doğru tahmin edici (yansız) mean’i \(AB\) yapar, norm-kare örnekleme ise variance’ı minimize eder — SGD’nin atası.
14.2 Rastlantısal LA: Neden
Matris çok çok büyükse (Ders 10’daki “devasa” durum) tam hesap imkânsızdır. Çözüm: olasılıkla örnekle.
“…randomized matrix multiplication. It’s a pretty cool idea…” — Strang, 0:33
Plan: \(AB\) çarpımında \(A\)’nın kolonlarını ve \(B\)’nin karşılık gelen satırlarını örnekle.
“…sample the columns of A and sample [the rows of B]…” — Strang, 0:53
Hepsini değil, olasılıkla seçilen birkaçını al, topla — sonuç \(AB\)’ye yakın olsun.
İpucuBuilder Notu — Devasaya Tek Çare
Rastlantısal LA, dev veri matrislerinin (\(10^6+\)) tek pratik yoludur: tam çarpım/SVD imkânsızken örnekleme makul bir yaklaşım verir. Randomized SVD, sketching ve stokastik gradient descent (Ders 25) hep bu sezgiye dayanır.
14.3 \(AB = \sum\) Dış Çarpımı Örnekle
Ders 1’in anahtarı: matris çarpımı, dış çarpımların (rank-1 parçaların) toplamıdır.
\[AB = \sum_{j} a_j b_j^{T}\]
Burada \(a_j = A\)’nın j. kolonu, \(b_j^{T} = B\)’nin j. satırı. Tüm \(r\) terimi toplamak yerine, terimleri olasılıkla örnekleriz — her örnek bir rank-1 parça. Tek örnek \(AB\)’den çok uzaktır (sadece rank-1), ama doğru olasılıklarla ortalama \(AB\)’ye varır.
Aşağıdaki figür çarpımı rank-1 parçalarına ayırır: ilk iki terim ve toplamları \(AB\)’nin yapısını görünür kılar (Şekil 14.2).
Kod
rng = np.random.default_rng(0)
A = rng.standard_normal((5, 4))
B = rng.standard_normal((4, 3))
terms = ab_outer_terms(A, B)
fig, axs = plt.subplots(1, 4, figsize=(11, 3))
heatmap(axs[0], A @ B, "AB")
heatmap(axs[1], terms[0], "a1 b1^T")
heatmap(axs[2], terms[1], "a2 b2^T")
heatmap(axs[3], terms[0] + terms[1], "ilk 2 terim toplamı")
fig.suptitle("AB = toplam a_j b_j^T: çarpım rank-1 parçaların toplamı (Ders 1) -> bazılarını örnekle",
color=COL_TEXT, fontsize=11, fontweight="bold")
fig.tight_layout()
plt.show()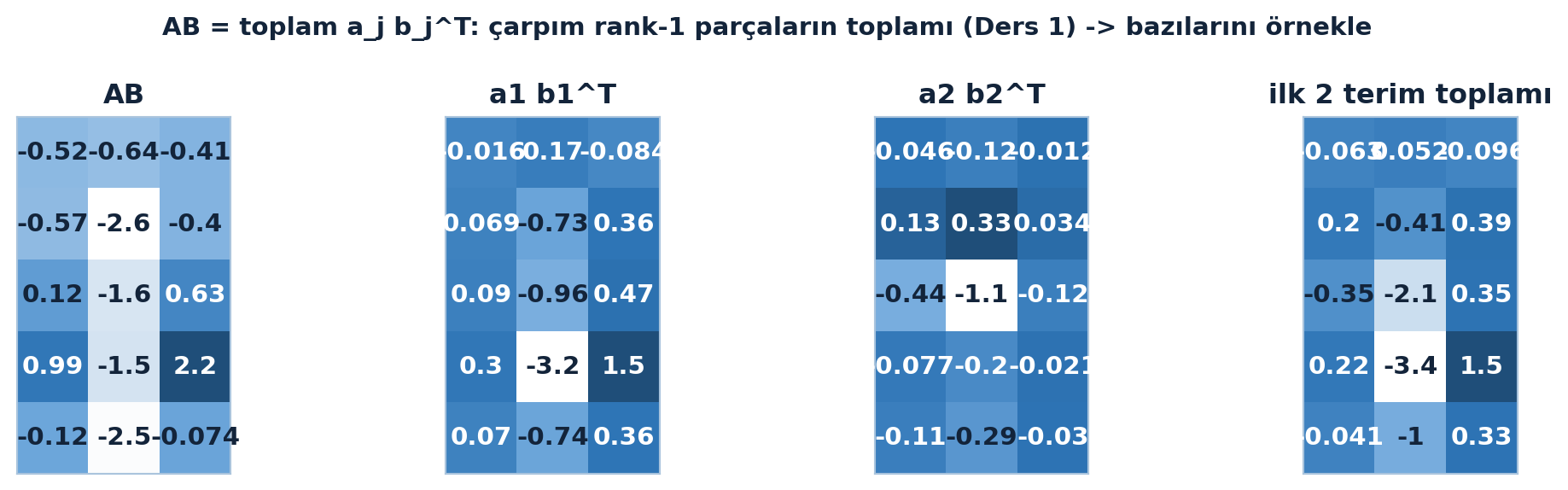
İpucuBuilder Notu — Rank-1 Parçalar
“Çarpım = rank-1 parçaların toplamı” görüşü, örneklemeyi mümkün kılar: her terim bağımsız bir katkıdır, bazılarını seçip ölçekleyerek toplamı kestirebilirsin. Aynı yapı SGD’de (gradyan = örnek gradyanların toplamı, mini-batch örnekle) ve Monte Carlo’da görülür.
14.4 Mean ve Variance (İstatistik Girişi)
Bu, kursun istatistikle ilk ciddi buluşması. İki kavram: mean (ortalama, beklenen değer) ve variance (yayılım). Olasılıklar 1’e toplanır; rastgele \(AB\)’nin mean’inin doğru \(AB\) olmasını umarız.
“…the mean value of the random AB is correct AB. But there will be a variance.” — Strang, 2:28
Ama variance sıfır değildir: hiçbir tek örnek doğru değil, sadece ortalamada doğru. İş, olasılıkları variance’ı minimize edecek şekilde seçmek (sonunda Lagrange çarpanlarıyla).
“…choose the probabilities that minimize the variance.” — Strang, 3:38
“…Lagrange multipliers will come in near the end.” — Strang, 4:32
İpucuBuilder Notu — Mean ve Variance
Mean (yansızlık) + variance (gürültü) ayrımı, stokastik optimizasyonun kalbidir: SGD’de gradyan tahmini yansızdır (mean \(=\) gerçek gradyan) ama variance vardır; öğrenme hızı ve batch boyutu bu variance’ı yönetir. Bu ders, Stat 110’un mean/variance’ını matrise taşır.
14.5 Pratik Örnek: 1×2 Matris, Mean Doğru
Strang basit bir örnekle ısınıyor: matris \([a \ \ b]\) (1×2). İki kolon var; her örnekte birini 1/2-1/2 olasılıkla seç, \(s = 2\) örnek al, ortalamasını çıkar. Örnekler \((a, 0)\) veya \((0, b)\). Mean’i hesapla:
\[\mu = 2 \cdot \tfrac{1}{2}\,(a, b) = (a, b)\]
Her örneğin mean’i \((1/2)(a, b)\); iki örnekle çarpınca \((a, b)\) — tam doğru.
“Mean is correct.” — Strang, 8:24
Süreç düzgün kurulduğu için (olasılık × ölçekleme) mean kesinlikle doğru çıkar. Aşağıdaki figür tek-örnek tahminlerin gerçekten uzakta olduğunu ama ortalamalarının hedefe yakınsadığını gösterir (Şekil 14.3).
Kod
hedef = np.array([2., 6.])
rng = np.random.default_rng(0)
samples = []
for _ in range(60):
if rng.random() < 0.5:
samples.append(np.array([4., 0.]))
else:
samples.append(np.array([0., 12.]))
samples = np.array(samples)
fig, ax = plt.subplots(figsize=(7, 5))
style_square_axes(ax, 14)
ax.scatter(samples[:, 0], samples[:, 1], color=COL_STEEL_300, alpha=0.5, s=30,
label="tek örnekler (1/p ölçekli)")
ax.scatter(*hedef, color=COL_PRIMARY, s=200, marker="*", zorder=5, label="gerçek (2,6)")
m = samples.mean(axis=0)
ax.scatter(*m, color=COL_VEC3, s=110, zorder=5, label="60 örnek ortalaması")
ax.legend(fontsize=8)
ax.set_title("Mean DOĞRU ama her örnek YANLIŞ: tek örnekler uzakta (gri), "
"ortalamaları gerçeğe (yıldız) yakınsıyor",
color=COL_TEXT, fontsize=10, fontweight="bold")
plt.show()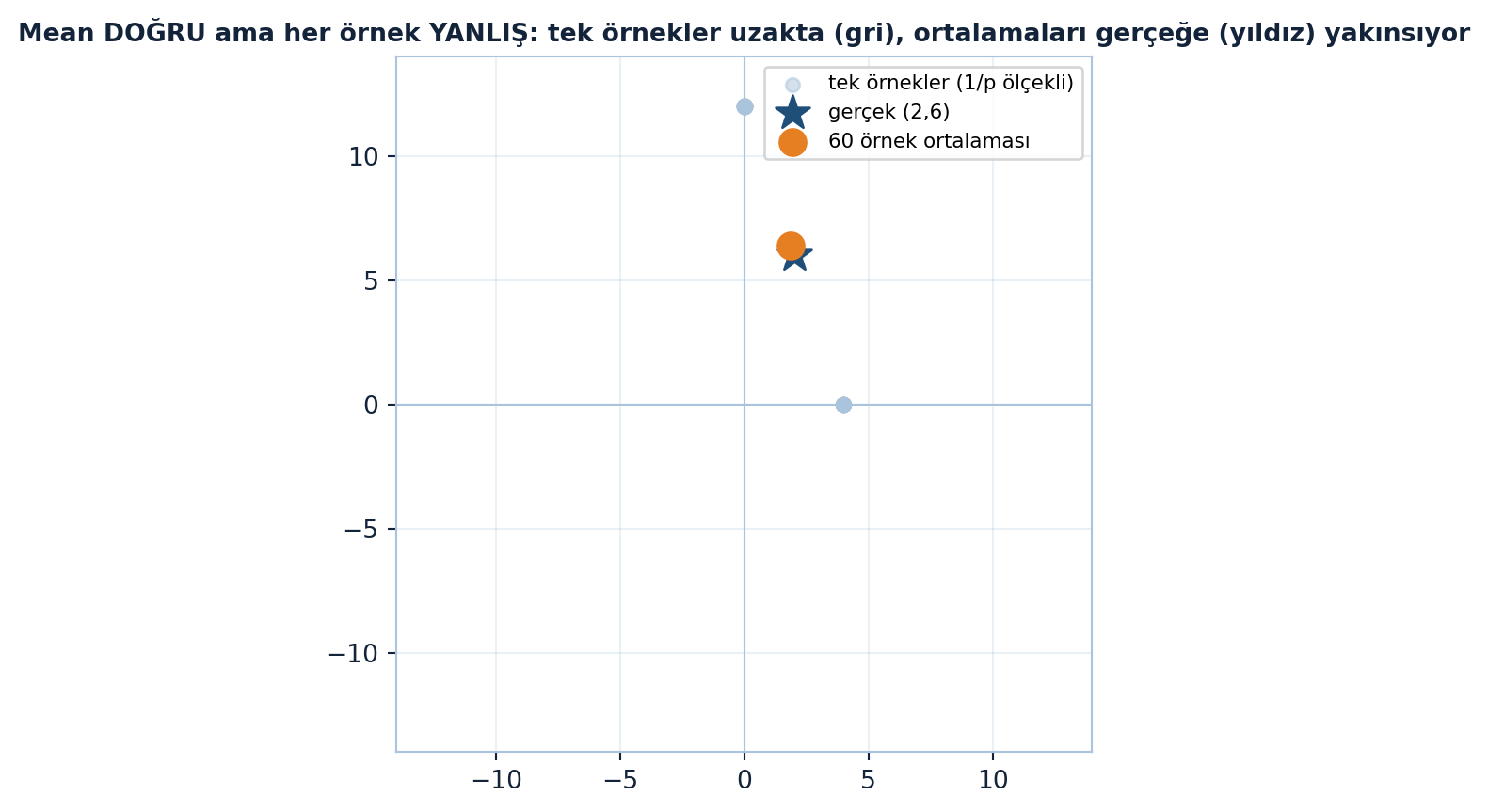
İpucuBuilder Notu — Yansızlığın Güvencesi
Yansız tahmin edici (mean \(=\) gerçek değer), Monte Carlo ve SGD’nin temel güvencesidir: yeterince örnek alırsan ortalama doğruya gider. Ama “mean doğru” tek başına yetmez — variance da küçük olmalı (sonraki bölümler).
14.6 Variance ≠ 0 (Her Örnek Yanlış)
Mean doğru ama her örnek yanlıştır. \((a, 0)\) örneği gerçek \((a, b)\)’den uzaktır; \((0, b)\) de öyle. Hiçbir tek örnek doğru değil — sadece ortalamada doğru.
Strang’in vurgusu: mean’in doğru olması, iyi cevap aldığın anlamına gelmez. \(-100\) ile \(+100\)’ün ortalaması \(0\) olabilir (doğru mean) ama her örnek 100 birim uzakta. Variance bu uzaklığı ölçer: doğru mean + büyük variance = işe yaramaz tahminler. O yüzden asıl iş variance’ı küçültmektir.
İpucuBuilder Notu — Doğru Mean Yetmez
“Doğru mean, büyük variance” tuzağı ML’de her yerde: yansız ama yüksek-varyanslı gradyan tahmini (küçük batch) eğitimi gürültülü yapar. Bias-variance dengesi, batch boyutu, momentum — hepsi variance’ı yönetmek için. Yansızlık gerekli ama yeterli değil.
14.7 İki Variance Formülü
Variance’ın iki eşdeğer formülü vardır. Birincisi mean’den uzaklığın karesi:
\[\sigma^{2} = \sum_i p_i\,(x_i - \mu)^{2}\]
İkincisi mean’i sona bırakır (cebirle aynı):
\[\sigma^{2} = \sum_i p_i\,x_i^{2} - \mu^{2}\]
“…the second formula for the same quantity…” — Strang, 19:34
İlk formül her çıktıdan mean’i çıkarır; ikincisi tüm karelerin ortalamasından \(\mu^2\)’yi çıkarır. Hangisi kolaysa onu kullan — sonuç aynı. Aşağıdaki figür her iki formülün özdeş variance verdiğini doğrular (Şekil 14.4).
Kod
xs = np.array([2., 6.]); ps = np.array([0.5, 0.5])
f1, f2, mu = variance_two_formulas(xs, ps)
fig, ax = plt.subplots(figsize=(6.5, 4.2))
apply_style(ax)
bars = ax.bar([0, 1], [f1, f2], color=[COL_PRIMARY, COL_ACCENT], width=0.5)
ax.set_xticks([0, 1])
ax.set_xticklabels(["toplam p(x-mu)^2", "toplam p x^2 - mu^2"])
ax.set_ylabel("variance")
for i, val in enumerate([f1, f2]):
ax.text(i, val + 0.1, f"{val:.1f}", ha="center", fontweight="bold", color=COL_TEXT)
ax.set_ylim(0, max(f1, f2) * 1.25)
ax.set_title(
f"Iki variance formulu ayni sonucu verir (mu={mu:.0f}, var={f1:.0f}): "
"ikincisi tek-gecisli (streaming istatistik)",
color=COL_TEXT, fontsize=10, fontweight="bold")
fig.tight_layout()
plt.show()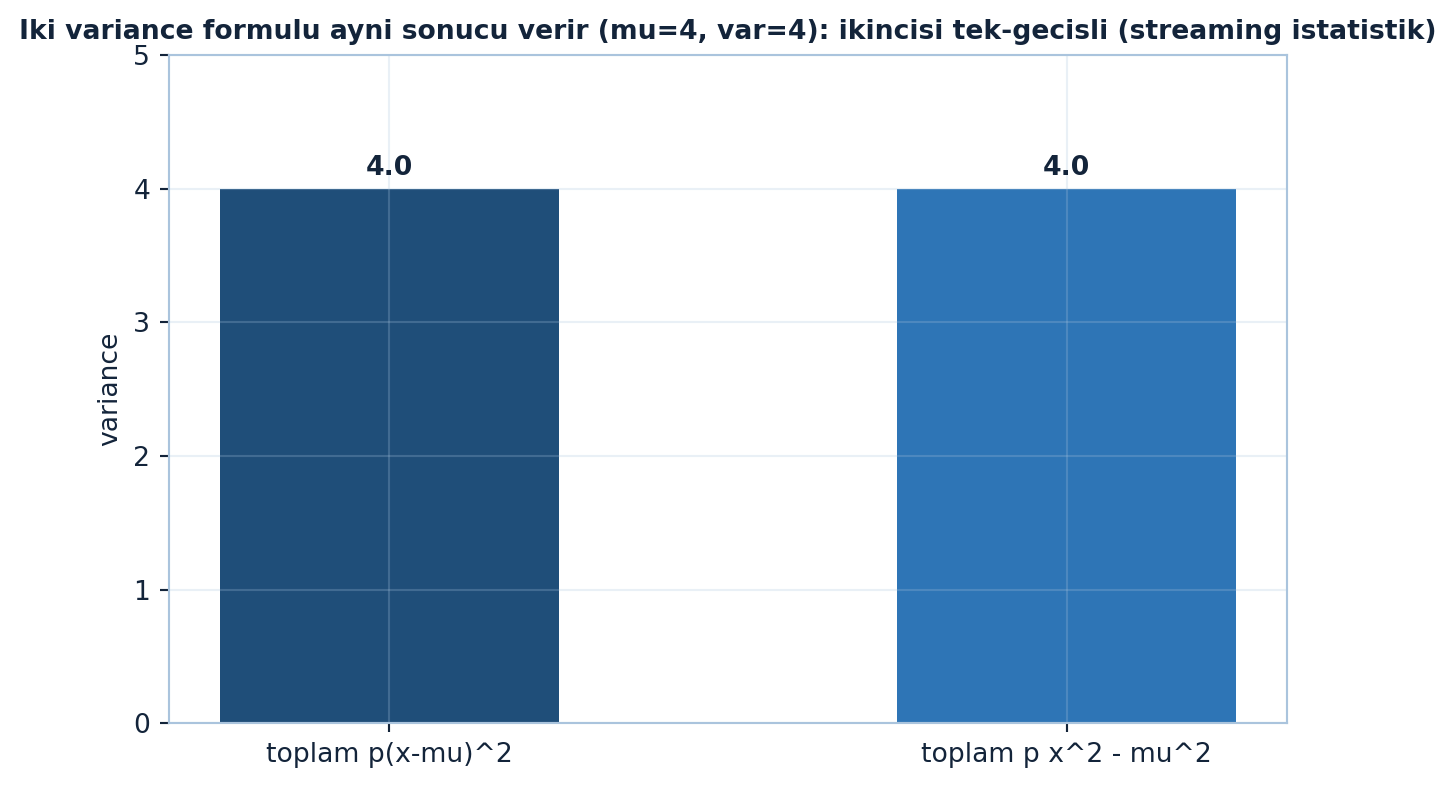
İpucuBuilder Notu — Tek Geçişte Variance
İkinci formül (\(E[x^2] - (E[x])^2\)) pratikte daha kullanışlıdır: tek geçişte hem \(\sum x\) hem \(\sum x^2\) biriktirip variance’ı hesaplarsın (online/streaming istatistik). Batch normalizasyonu ve running statistics bu formülü kullanır.
14.8 Norm-Kare Örnekleme
Eşit olasılık (1/2-1/2) en iyisi değil. Eğer bir kolon diğerinden çok büyükse, onu daha sık seçmek variance’ı düşürür. Optimal seçim norm-kare olasılıktır: bir terimin olasılığı, kolon ve satırının büyüklüğüyle orantılı.
“…norm squared probability.” — Strang, 18:02
\[p_j \propto \|a_j\|\,\|b_j\|, \qquad p_j = \frac{\|a_j\|\,\|b_j\|}{c}, \quad c = \sum_k \|a_k\|\,\|b_k\|\]
“…proportional to norm squared.” — Strang, 23:31
Bölü ile bölmek (\(c =\) toplam) olasılıkları 1’e toplar. Bir terimin \(\|a_j\|\,\|b_j\|\) büyüklüğü diğerinin iki katıysa, onu orantılı olarak (iki kat) daha sık seçersin. Büyük (önemli) terimler daha sık örneklenir. (“Norm-kare” adı Strang’in sözlü ifadesinden gelir; optimal olasılık ise norm çarpımının birinci kuvvetiyle orantılıdır — Drineas-Kannan-Mahoney.) Aşağıdaki figür (FLAGSHIP) norm-kare örneklemenin uniform örneklemeye kıyasla bağıl hatayı her örnek sayısında düşürdüğünü gösterir (Şekil 14.5).
Kod
# FLAGSHIP (§7): norm-kare örnekleme vs uniform örnekleme — bağıl hata vs örnek sayısı
rng = np.random.default_rng(0)
A = rng.standard_normal((5, 4)); A[:, 0] = A[:, 0] * 10 # kötü ölçek: 1 kolon büyük
B = rng.standard_normal((4, 3))
p_ns = norm_square_probs(A, B) # norm-kare örnekleme olasılıkları
p_un = np.ones(4) / 4 # uniform örnekleme
s_list = [2, 4, 8, 16, 32]
e_ns = rel_error_vs_s(A, B, p_ns, s_list, trials=60)
e_un = rel_error_vs_s(A, B, p_un, s_list, trials=60)
fig, ax = plt.subplots(figsize=(8.0, 4.6))
fig.patch.set_facecolor(COL_WHITE)
apply_style(ax)
ax.semilogy(s_list, e_ns, color=COL_PRIMARY, marker="o", ms=6, label="norm-kare örnekleme")
ax.semilogy(s_list, e_un, color=COL_VEC3, marker="s", ms=6, label="uniform örnekleme")
ax.set_xlabel("örnek sayısı s")
ax.set_ylabel("bağıl hata (log)")
ax.set_title("Norm-kare örnekleme variance'ı düşürür: büyük (önemli) terimleri daha sık seçer (importance sampling)",
fontsize=11, fontweight="bold", color=COL_PRIMARY)
ax.legend()
fig.tight_layout()
plt.show()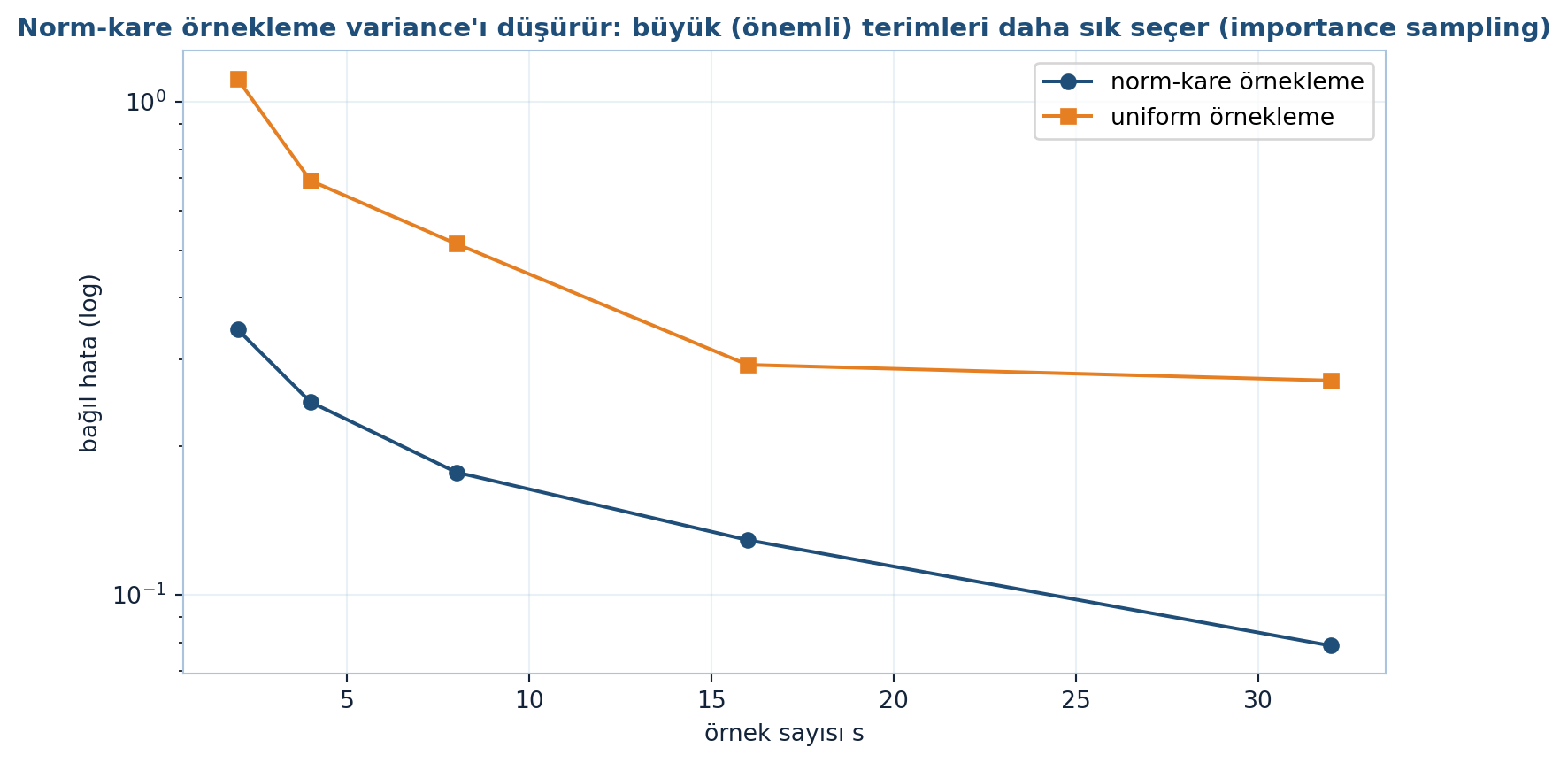
İpucuBuilder Notu — Önemliyi Sık Seç
Norm-kare örnekleme = importance sampling: önemli (büyük katkılı) terimleri daha sık seç. Randomized SVD, Monte Carlo integrasyonu ve önemli-örnekleme tabanlı SGD aynı ilkeyi kullanır — variance’ı, önemli olanı vurgulayarak düşür.
14.9 Yansız Tahmin Edici
Her örneği, seçim olasılığına bölerek ölçekleriz — bu, tahmini yansız (unbiased) yapar. \(s\) örnekle:
\[\widehat{AB} = \frac{1}{s}\sum_{i=1}^{s} \frac{a_{j_i} b_{j_i}^{T}}{p_{j_i}}\]
Mean’i hesapla: bir örnek \(j\), \(p_j\) olasılıkla seçilir ve \((a_j b_j^{T})/(s\,p_j)\) katkı verir; \(p_j\)’ler sadeleşir:
\[\text{mean} = s \cdot \sum_j p_j \cdot \frac{a_j b_j^{T}}{s\,p_j} = \sum_j a_j b_j^{T} = AB\]
\(p_j\)’lerin sadeleşmesi tam da yansızlığı verir — hangi olasılığı seçersen seç, mean daima \(AB\). Olasılık seçimi yalnızca variance’ı etkiler, mean’i değil. Aşağıdaki figür örnek sayısı arttıkça koşan ortalamanın \(AB\)’ye yakınsadığını (\(\sim 1/\sqrt{s}\)) gösterir (Şekil 14.6).
Kod
rng = np.random.default_rng(0)
A = rng.standard_normal((6, 5))
B = rng.standard_normal((5, 4))
p = norm_square_probs(A, B)
run = estimator_running_mean(A, B, p, 400, seed=2)
ks = np.arange(1, len(run) + 1)
fig, ax = plt.subplots(figsize=(7, 4.2))
apply_style(ax)
ax.loglog(ks, run, color=COL_PRIMARY, label="koşan ortalama bağıl hata")
ax.loglog(ks, run[0] / np.sqrt(ks), color=COL_STEEL_300, ls=":", label="~1/√s trend")
ax.set_xlabel("örnek sayısı (log)")
ax.set_ylabel("bağıl hata (log)")
ax.legend()
ax.set_title("Yansız tahmin: örnek sayısı arttıkça koşan ortalama AB ye yakınsar (~1/√s)",
color=COL_TEXT, fontsize=10.5, fontweight="bold")
plt.show()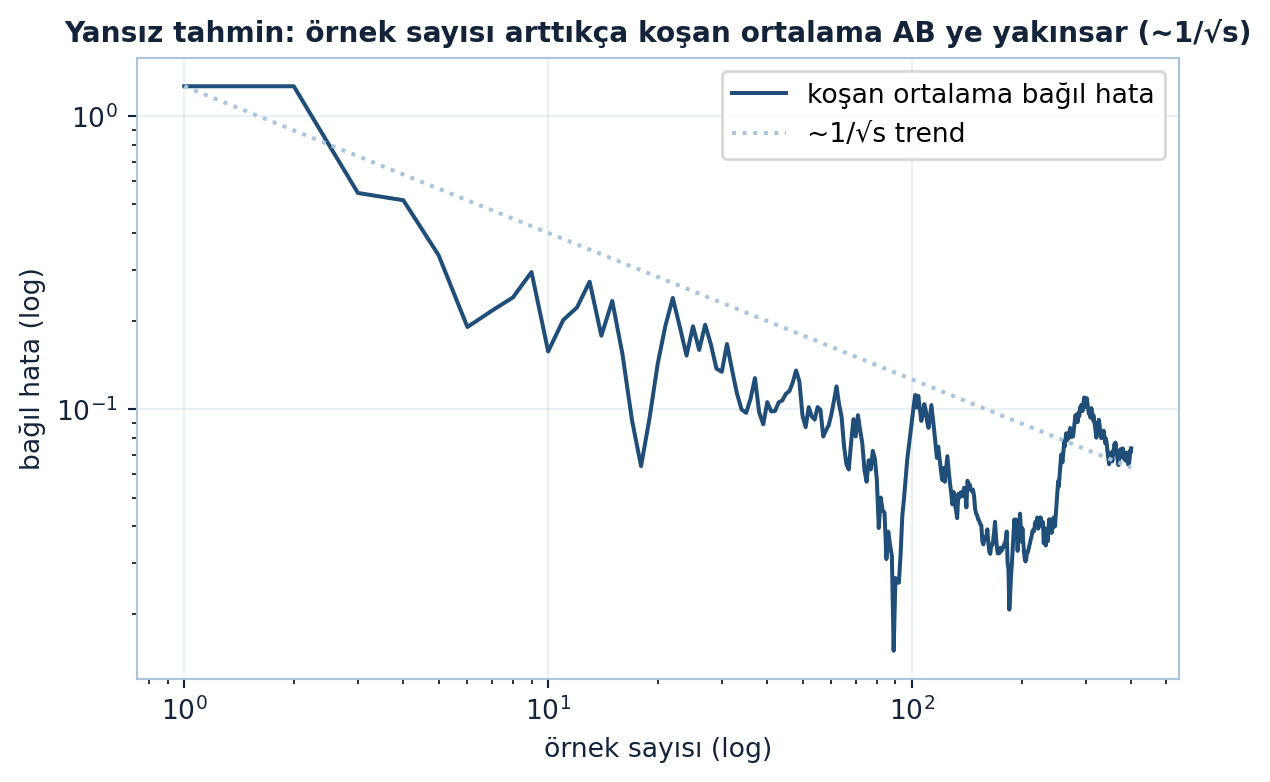
İpucuBuilder Notu — Olasılığa Böl
“Olasılığa böl → yansız” hilesi (importance weighting), off-policy RL, önem-örnekleme ve düzeltilmiş Monte Carlo’nun temelidir: nadir seçilen terimleri büyük ağırlıkla telafi et, böylece beklenen değer doğru kalır. SGD’de mini-batch ortalaması aynı yansızlığı sağlar.
14.10 Variance’ı Minimize Et (Lagrange → Norm-Kare)
Mean her olasılıkla doğru olduğundan, asıl optimizasyon variance’ı küçültmektir. Variance formülü \(p_j\)’lere bağlıdır; “olasılıklar 1’e toplanır” kısıtı altında variance’ı minimize etmek bir Lagrange çarpanı problemidir. Çözüm: \(p_j \propto \|a_j\|\,\|b_j\|\) — yani norm-kare örnekleme optimaldir.
\[\min_{p}\ \sigma^{2}(p) \quad \text{s.t.}\ \sum_j p_j = 1 \;\;\Rightarrow\;\; p_j \propto \|a_j\|\,\|b_j\|\]
Variance, ancak \(AB\) rank-1 ise sıfır olur (tek terim, hep doğru); genelde pozitiftir ama norm-kare seçimle en küçüğe iner.
İpucuBuilder Notu — Lagrange Optimali
Kısıt altında minimizasyon (Lagrange) → optimal örnekleme dağılımı: bu kalıp, varyans-azaltma tekniklerinin (control variates, stratified sampling) ve optimal importance sampling’in çekirdeğidir. “Önemliyi daha sık örnekle” sezgisinin matematiksel kanıtı.
14.11 SGD’ye Köprü ve Büyük Resim
Bu dersin kalıbı — yansız tahmin + variance azaltma — derin öğrenmenin merkezî algoritmasının (Ders 25, stokastik gradient descent) tam mantığıdır. SGD’de gerçek gradyan tüm verinin toplamıdır; biz bunu bir mini-batch örnekleyerek yaklaşık hesaplarız. Mini-batch gradyanı yansızdır (mean \(=\) gerçek gradyan) ama variance taşır; batch boyutu büyüdükçe variance düşer.
Aynı fikir randomized SVD’de (matrisi rastgele projeksiyonla küçült), Monte Carlo’da ve önem-örneklemede çalışır. Bu ders, “dev hesabı örnekleyerek yaklaşık yap, mean’i koru, variance’ı yönet” felsefesinin lineer cebir versiyonudur. Aşağıdaki figür (FLAGSHIP) mini-batch gradyan variance’ının batch boyutuyla \(1/B\) düştüğünü doğrular (Şekil 14.7).
Kod
rng = np.random.default_rng(0)
g = rng.standard_normal(200)
batch = [1, 2, 4, 8, 16, 32, 64]
v = minibatch_grad_variance(g, batch, trials=400, seed=3)
batch = np.array(batch)
fig, ax = plt.subplots(figsize=(7, 4.5))
apply_style(ax)
ax.loglog(batch, v, color=COL_PRIMARY, marker="o", ms=6, label="mini-batch gradyan variance")
ax.loglog(batch, v[0] / batch, color=COL_VEC3, ls=":", label="1/B trend")
ax.set_xlabel("batch boyutu B (log)")
ax.set_ylabel("variance (log)")
ax.set_title("SGD köprüsü: mini-batch gradyan variance'ı 1/B ile düşer (bu dersin kalıbı optimizasyonda)",
color=COL_TEXT, fontsize=11, fontweight="bold")
ax.legend()
plt.show()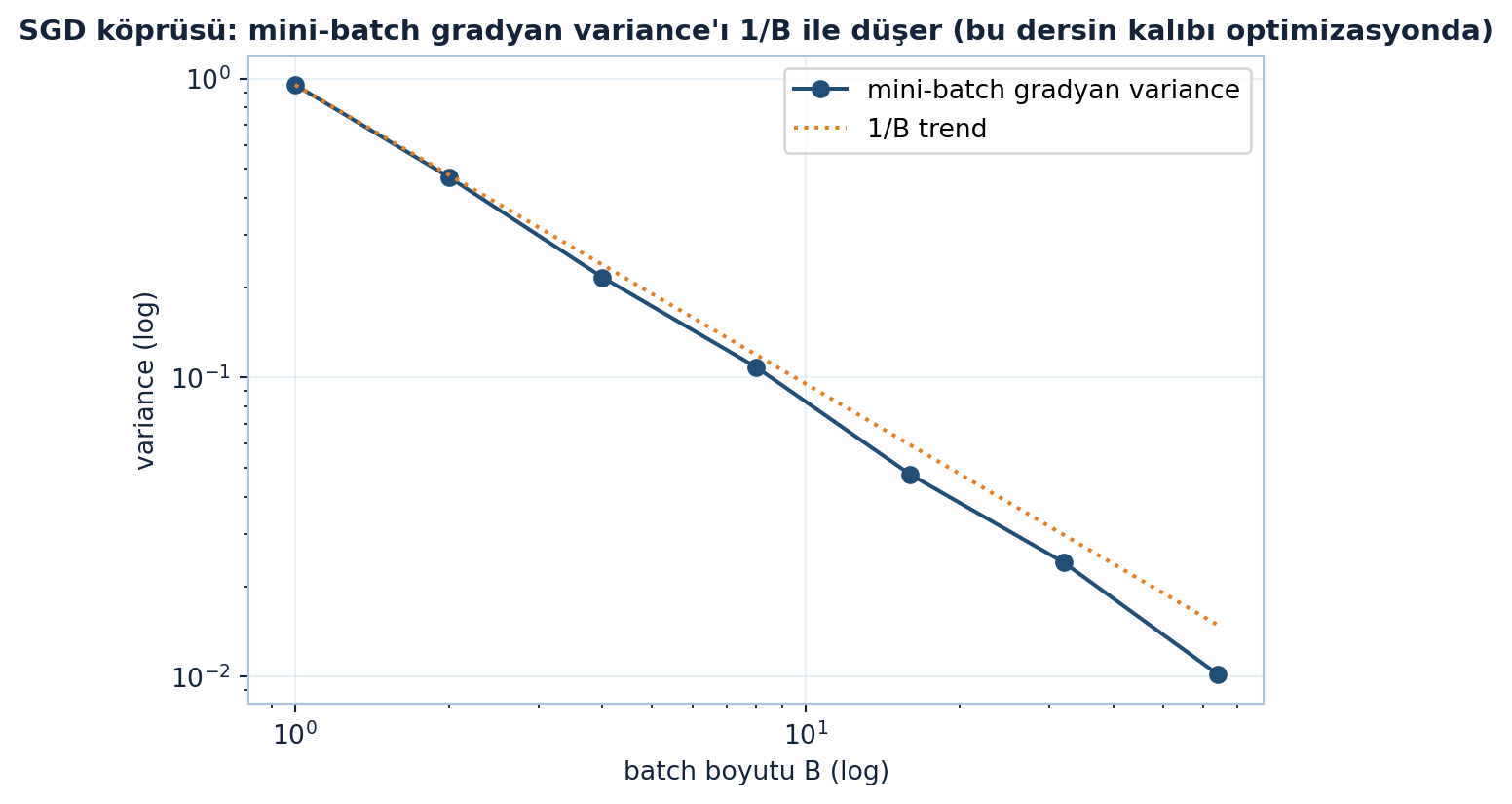
İpucuBuilder Notu — Mini-Batch’in Kalbi
SGD = bu dersin matris çarpımına uyguladığı örnekleme fikrinin optimizasyona taşınmış hâli: tam gradyan yerine örnek gradyan (yansız), variance’ı batch/öğrenme hızıyla yönet. Norm-kare örnekleme bile SGD’de karşılığını bulur (importance sampling SGD — büyük gradyanlı örnekleri daha sık seç).
14.12 Bu Dersin Özeti
- Rastlantısal LA — dev matrisler için örnekleme tabanlı yaklaşık hesap.
- \(AB = \sum a_j b_j^{T}\) örnekle — rank-1 parçaları olasılıkla seç, topla.
- Mean ve variance — kursun ilk istatistik kavramları.
- Pratik örnek — 1×2’de mean \(= (a, b)\) doğru çıkar.
- Variance ≠ 0 — her örnek yanlış; doğru mean yetmez, variance da küçük olmalı.
- İki variance formülü — \(\sum_i p_i(x_i-\mu)^2 = \sum_i p_i x_i^2 - \mu^2\).
- Norm-kare örnekleme — \(p_j \propto \|a_j\|\,\|b_j\|\); büyük terimler daha sık.
- Yansız tahmin edici — \((a_j b_j^{T})/(s\,p_j)\); \(p_j\) sadeleşir → mean \(= AB\).
- Variance’ı minimize — Lagrange → norm-kare optimal.
- SGD köprüsü — yansız tahmin + variance azaltma = stokastik optimizasyon.
ÖnemliTek Bir Cümle
Dev \(AB\)’yi, rank-1 parçalarını olasılıkla örnekleyerek yaklaşık hesaplarız; olasılığa bölen yansız tahmin edici mean’i daima \(AB\) yapar (seçimden bağımsız), norm-kare örnekleme ise variance’ı minimize eder — ve bu “yansız tahmin + variance azaltma” kalıbı stokastik gradient descent’in ta kendisidir.
14.13 Kontrol Soruları
NotSoru 1: 1×2 matriste mean
\([2 \ \ 6]\) matrisini kolonları 1/2-1/2 olasılıkla, 2 örnekle örnekle. Tahmin edicinin mean’ini hesapla.
Cevap: Örnekler \((2, 0)\) veya \((0, 6)\), her biri 1/2. Yansız tahmin edici örneği olasılığa böler: \((2,0)/(s\cdot\tfrac{1}{2})\) gibi. Bir örneğin mean’i \((\tfrac{1}{2})(2,6)\); \(s = 2\) örnekle çarp → mean \(= (2, 6) =\) orijinal matris. Yansız: mean tam doğru, seçimden bağımsız.
NotSoru 2: İki formülle variance
\([2 \ \ 6]\) örneğinde (eşit olasılık) variance’ı iki formülle de hesapla; aynı çıktığını gör.
Cevap: Çıktılar (her bileşeni mean’den uzaklık): \((2,0)\) ve \((0,6)\), mean \((1,3)\). Formül 1: \(\sigma^2 = \tfrac{1}{2}\|(2,0)-(1,3)\|^2 + \tfrac{1}{2}\|(0,6)-(1,3)\|^2 = \tfrac{1}{2}(1+9) + \tfrac{1}{2}(1+9) = 10\). Formül 2: \(\sigma^2 = \tfrac{1}{2}\|(2,0)\|^2 + \tfrac{1}{2}\|(0,6)\|^2 - \|(1,3)\|^2 = \tfrac{1}{2}\cdot 4 + \tfrac{1}{2}\cdot 36 - 10 = 20 - 10 = 10\). İkisi de 10 ✓.
NotSoru 3: Variance ne zaman sıfır
Rastlantısal matris çarpımında variance ne zaman tam sıfır olur?
Cevap: \(AB\) rank-1 olduğunda. O zaman seçilecek tek bir \(a_j b_j^{T}\) terimi vardır; her örnek aynı (doğru) sonucu verir, sapma yok → variance \(= 0\). Rank \(> 1\) ise her örnek farklı bir rank-1 parça seçer (hepsi tek başına yanlış), ortalamada doğru ama variance pozitif. Yani variance, \(AB\)’nin “kaç bağımsız parçadan oluştuğunu” yansıtır.
NotSoru 4: SGD bağlantısı
Bu dersin “yansız tahmin + variance azaltma” kalıbı SGD ile nasıl bağlantılı?
Cevap: SGD’de gerçek gradyan \(=\) tüm örneklerin gradyan toplamı (dev). Mini-batch gradyanı bunun örneklemesidir: yansız (mean \(=\) gerçek gradyan) ama variance taşır. Batch boyutu ↑ → variance ↓ (tıpkı \(s\) örnek ↑ → variance ↓). Norm-kare örnekleme bile karşılık bulur: büyük-gradyanlı örnekleri daha sık seçmek (importance sampling SGD) variance’ı düşürür. Aynı matematik, optimizasyona taşınmış hâli.
14.14 Egzersizler
Cevapsız problemler. Çöz, sonra numpy ile kontrol et.
Egzersiz 1. \([3 \ \ 9]\) (1×2) matrisini kolonları \(p_1, p_2\) olasılıkla örnekle. Yansız tahmin edicinin mean’inin her zaman \((3, 9)\) olduğunu (olasılıklardan bağımsız) göster.
Egzersiz 2. \(A\) (m×2) ve \(B\) (2×p) için norm-kare olasılıkları yaz: \(p_1 \propto \|a_1\|\,\|b_1\|\), \(p_2 \propto \|a_2\|\,\|b_2\|\). \(\|a_1\|\|b_1\| = 1\) ve \(\|a_2\|\|b_2\| = 3\) ise normalleştirilmiş \(p_1, p_2\) nedir?
Egzersiz 3. \(AB\) hangi durumda rank-1’dir ve bu neden variance \(= 0\) verir? (İpucu: \(A\)’nın tek kolonu veya \(B\)’nin tek satırı sıfırdan farklıysa ne olur?)
Egzersiz 4. Python ile rastlantısal matris çarpımı:
import numpy as np
rng = np.random.default_rng(0)
A = rng.standard_normal((100, 50))
B = rng.standard_normal((50, 80))
AB = A @ B
# norm-kare olasılıklar
w = np.linalg.norm(A, axis=0) * np.linalg.norm(B, axis=1)
p = w / w.sum()
s = 20 # örnek sayısı
est = np.zeros_like(AB)
for _ in range(s):
j = rng.choice(50, p=p)
est += np.outer(A[:, j], B[j, :]) / (s * p[j])
print("bağıl hata:", np.linalg.norm(est - AB) / np.linalg.norm(AB))Egzersiz 5. (Ders 14 habercisi.) Ders 14 düşük-rank değişimleri işler: \(A\) tersini biliyorsan, \(A\)’ya rank-1 bir değişim (\(A + uv^{T}\)) eklediğinde yeni tersi baştan hesaplamadan bulabilir misin? Bu, Sherman-Morrison formülüdür. 2×2 bir \(A\) ve \(u = v = (1, 0)^{T}\) için \((A + uv^{T})\)’yi yaz.
14.15 Sonraki Ders İçin Hazırlık
Ders 14: A ve Tersinde Düşük-Rank Değişimler
Ders 13’te örnekleme ve rank-1 parçaları gördük. Ders 14, \(A\)’ya rank-1 (veya düşük-rank) bir değişim eklendiğinde tersinin nasıl ucuzca güncellendiğini işler.
- Sherman-Morrison: \((A + uv^{T})^{-1}\) formülü
- Sherman-Morrison-Woodbury: düşük-rank genelleme
- Neden kritik: Kalman filtresi, ardışık güncellemeler, online öğrenme
- Matris determinant lemması
UyarıDers 14 Öncesi Yapılacak
- Bu dersin egzersizlerini çöz, özellikle Egzersiz 5’i (rank-1 değişim).
- Python’da bir matrise rank-1 ekleyip tersini doğrudan vs Sherman-Morrison ile hesapla, karşılaştır.
- Ana cümleyi tekrar oku: “Yansız tahmin + variance azaltma; norm-kare örnekleme = importance sampling = SGD’nin atası.”
14.16 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Strang’de |
|---|---|---|
| Rastlantısal LA | Dev matris için örnekleme tabanlı yaklaşık hesap | 0m33 |
| \(AB = \sum\) dış çarpım örnekle | Rank-1 parçaları (kolon×satır) olasılıkla seç | 0m53 |
| Mean ve variance | Mean doğru olmalı ama variance da var | 2m28 |
| Mean doğru (yansız) | Her olasılıkla mean \(= AB\); seçimden bağımsız | 8m24 |
| İki variance formülü | \(\sum p(x-\mu)^2 = \sum p\,x^2 - \mu^2\) | 19m34 |
| Norm-kare olasılık | Önemli (büyük) terimleri daha sık seç | 18m02 |
| \(p_j \propto \|a_j\|\,\|b_j\|\) | Norm-kare örnekleme; optimal olasılık | 23m31 |
| Variance minimize | Lagrange kısıtlı min → norm-kare optimal | 3m38 |
| Lagrange çarpanı | \(\sum_j p_j = 1\) kısıtı altında variance minimizasyonu | 4m32 |
14.17 ML Bağlantıları Özeti
- Yansız tahmin + variance → stokastik gradient descent (Ders 25); mini-batch gradyanı yansız, variance batch’le düşer.
- \(AB = \sum\) rank-1 örnekle → randomized SVD, sketching; dev çarpımı ucuzlatma.
- Norm-kare örnekleme → importance sampling; önemli terimleri/örnekleri vurgula.
- İki variance formülü (\(E[x^2]-\mu^2\)) → online/streaming istatistik, batch normalizasyon.
- Yansız tahmin edici (olasılığa böl) → importance weighting, off-policy RL.
- Lagrange ile optimal örnekleme → varyans-azaltma; control variates, stratified sampling.
- Mean ↔︎ variance ayrımı → bias-variance dengesi; eğitim gürültüsü yönetimi.
ÖnemliTek Şey
Eğer bu dersten tek bir şey alıp gidersen: Dev bir \(AB\) çarpımını, rank-1 parçalarını (\(a_j b_j^{T}\)) olasılıkla örnekleyip ölçekleyerek yaklaşık hesaplarsın. Olasılığa bölen tahmin edici yansızdır — mean daima \(AB\), seçilen olasılıktan bağımsız; olasılık seçimi yalnız variance’ı etkiler ve norm-kare örnekleme (büyük terimleri daha sık) onu minimize eder. Bu “yansız tahmin + variance azaltma” kalıbı, stokastik gradient descent ve tüm büyük-ölçek rastlantısal yöntemlerin temelidir.