flowchart TD
M["Ax = b durumları"] --> SQ["iyi koşullu kare → eliminasyon"]
M --> OVER["fazla denklem → least squares"]
M --> UNDER["eksik denklem → minimum norm (derin öğrenme)"]
M --> ILLCOL["kötü kolon → QR"]
M --> SING["neredeyse tekil → ridge δ²I"]
M --> HUGE["devasa → iteratif/rastlantısal"]
M --> KAPPA["kondisyon κ=σ₁/σₙ"]
style M fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style KAPPA fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style SQ fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style OVER fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style UNDER fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style ILLCOL fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
style SING fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
style HUGE fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
11 Ax = b’nin Zorluklarına Genel Bakış
Bir lineer denklem doktoru — boyut, rank ve kondisyon sayısı hangi aleti seçeceğini söyler
NotBölüm bilgisi
Video: Survey of Difficulties with Ax = b · OCW: MIT 18.065 Lecture 10 · Okuma süresi: ~36 dk · Eğitmen: Gilbert Strang · Önkoşul: Ders 9 (least squares, pseudoinverse ve dört çözüm yolu).
11.1 Bu Derste Ne Var?
Bir lineer denklem doktoru: Ders 10, \(Ax = b\)’nin tüm olası durumlarını (boyut, rank, koşullanma) sistematik tarar ve her birinde ne yapılacağını reçete eder. Bu, önceki dokuz dersi tek bir haritada birleştiren bir özet.
Üç temel fikir:
- Durum haritası — kare/iyi koşullu (eliminasyon), fazla denklem (least squares), eksik denklem (minimum norm), neredeyse tekil (düzenlileştirme), çok büyük (iteratif/randomized).
- Kondisyon sayısı \(\kappa = \sigma_1/\sigma_n\) — bir matrisin “ne kadar zor” olduğunun ölçüsü; büyükse tehlike.
- Düzenlileştirme → pseudoinverse — ceza terimi \(\delta^{2}\|x\|^{2}\) ekle; \(\delta \to 0\) limitinde çözüm tam pseudoinverse’e gider.
Bütün bu durumların tek bir merkezden nasıl dallandığını Şekil 11.1 özetliyor: \(Ax = b\) tek bir problem değil, her biri kendi aletini isteyen bir problemler ailesidir.
“…the subject of today’s class, it’s Ax = b.” — Strang, 0:25
İpucuBuilder Notu — Lineer Denklem Doktoru
- Durum haritası = pratik karar ağacı: problemin boyut/rank/koşuluna göre doğru aletle (backslash, lstsq, pinv, conjugate gradient) eşleştir.
- Eksik-belirlenmiş = derin öğrenme: ağırlık > örnek; sonsuz çözüm, hangisini seçtiğin (implicit bias) genellemeyi belirler.
- Ridge düzenlileştirme — \(\delta^{2}I\) eklemek matrisi tersinir kılar; \(\delta \to 0\)’da pseudoinverse, istatistikte ridge regresyon/Tikhonov.
- Ölçeğe göre alet: küçük (doğrudan), büyük (iteratif/Krylov), devasa (rastlantısal LA — örnekleme).
Tek cümle: \(Ax = b\)’nin zorluğu boyut, rank ve kondisyon sayısıyla belirlenir; her durumun kendi çözüm aleti vardır ve düzenlileştirme (\(\delta^{2}I\)) neredeyse tekil problemleri pseudoinverse’e doğru yumuşatır.
11.2 1. Ax = b Sözlüğü: Durumlar Haritası
Strang bu dersi bir tanı kılavuzu gibi kuruyor: \(Ax = b\) farklı boyut, rank ve koşullarda çok farklı problemlerdir — her biri farklı bir çözüm ister.
“…the subject of today’s class, it’s Ax = b.” — Strang, 0:25
Kolaydan zora doğru durumlar: (0) pseudoinverse her zaman bir cevap verir; (1) iyi koşullu kare; (2) fazla denklem; (3) eksik denklem; (4) kötü kolonlar; (5) neredeyse tekil; (6) çok büyük; (7) devasa. Bu ders, semptoma göre reçeteyi eşleştiren bir sözlüktür.
Matrisin şekli ve rankı doğru aleti nasıl seçtiriyor, Şekil 11.2 bu tanı akışını gösteriyor: kare tam-rank → eliminasyon, tall → least squares, wide → minimum norm, neredeyse tekil → ridge.
Kod
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
fig, ax = plt.subplots(figsize=(10.0, 6.6))
ax.set_xlim(0, 10)
ax.set_ylim(0, 10)
# --- yardımcı: durum kutusu (başlık + alet) ---
def case_box(ax, x, y, w, h, baslik, alet):
box = FancyBboxPatch((x, y), w, h,
boxstyle="round,pad=0.03,rounding_size=0.10",
linewidth=2.2, edgecolor=COL_PRIMARY,
facecolor=COL_BG, alpha=0.95, zorder=2)
ax.add_patch(box)
ax.text(x + w / 2, y + h * 0.66, baslik, ha="center", va="center",
color=COL_PRIMARY, fontsize=11.5, fontweight="bold", zorder=3)
ax.text(x + w / 2, y + h * 0.28, alet, ha="center", va="center",
color=COL_TEXT, fontsize=10, style="italic", zorder=3)
return (x + w / 2, y + h / 2)
# Merkez düğüm: Ax = b
cx, cy = 5.0, 5.0
center = FancyBboxPatch((cx - 1.05, cy - 0.62), 2.1, 1.24,
boxstyle="round,pad=0.03,rounding_size=0.14",
linewidth=2.6, edgecolor=COL_PRIMARY,
facecolor=COL_PRIMARY, alpha=0.95, zorder=4)
ax.add_patch(center)
ax.text(cx, cy, r"$Ax = b$", ha="center", va="center",
color=COL_WHITE, fontsize=17, fontweight="bold", zorder=5)
# Dört köşe kutusu: şekil + rank + kondisyon → alet
bw, bh = 3.7, 1.85
tl = case_box(ax, 0.25, 7.65, bw, bh,
"Kare $m=n$ (tam-rank)", "eliminasyon / solve")
tr = case_box(ax, 6.05, 7.65, bw, bh,
"Tall $m>n$", "least squares (QR)")
bl = case_box(ax, 0.25, 0.55, bw, bh,
"Wide $m<n$", "minimum norm (pinv)")
br = case_box(ax, 6.05, 0.55, bw, bh,
"Neredeyse tekil (küçük $\\sigma$)", "ridge $\\delta^{2} I$")
# Merkezden 4 kutuya oklar
for tgt, off in [(tl, (-0.55, 0.40)), (tr, (0.55, 0.40)),
(bl, (-0.55, -0.40)), (br, (0.55, -0.40))]:
arrow = FancyArrowPatch((cx + off[0], cy + off[1]),
(tgt[0], tgt[1] + (-0.95 if off[1] > 0 else 0.95)),
arrowstyle="-|>", mutation_scale=20,
linewidth=2.0, color=COL_ACCENT, zorder=1,
connectionstyle="arc3,rad=0.0")
ax.add_patch(arrow)
ax.set_title("Durum haritası: şekil + rank + kondisyon $\\to$ doğru alet",
color=COL_TEXT, fontsize=13.5, fontweight="bold", pad=14)
ax.axis("off")
plt.show()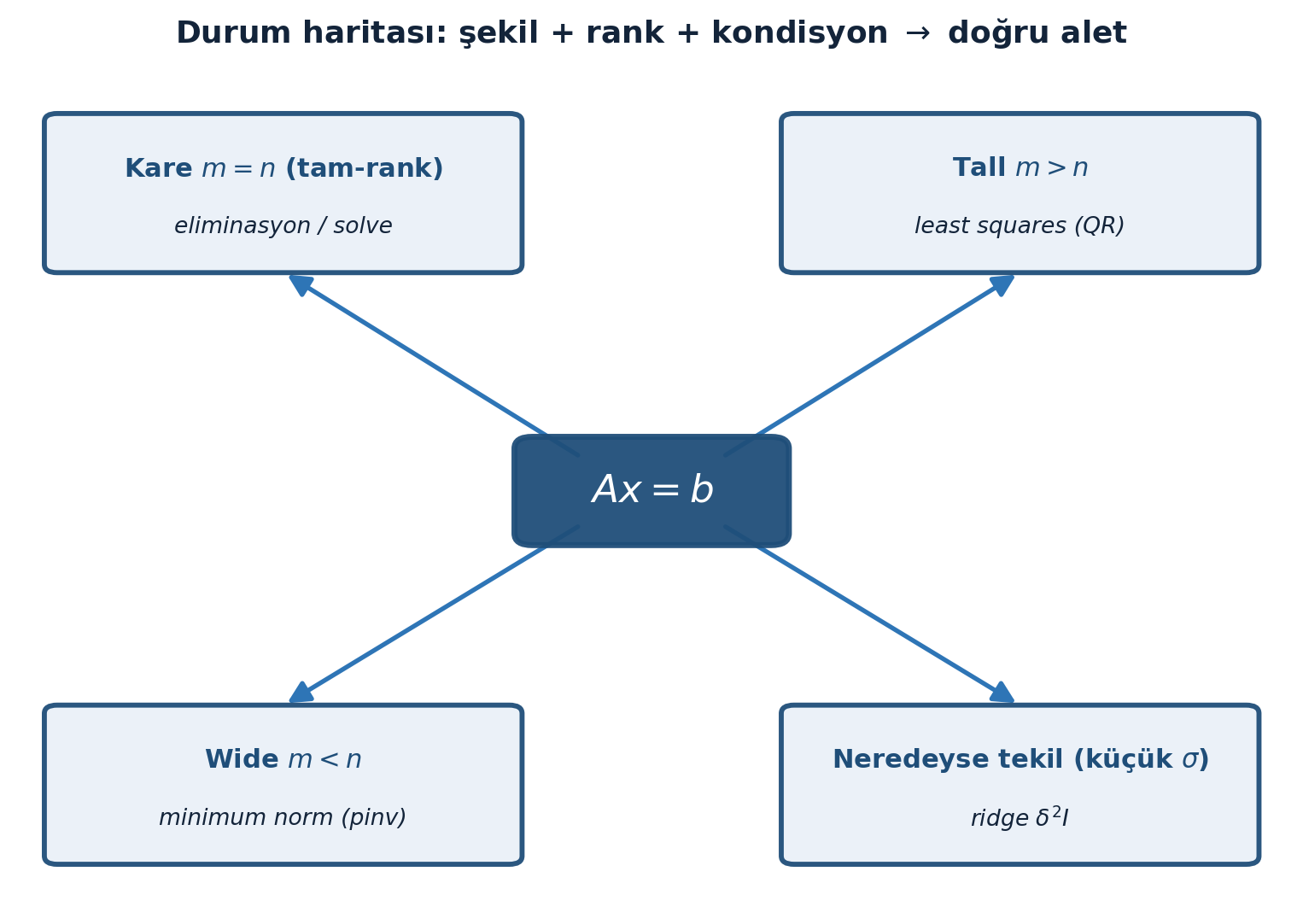
İpucuBuilder Notu — Tanı Kılavuzu
Bu harita pratik bir karar ağacıdır: problemin boyut/rank/koşuluna bakıp doğru aleti seç — solve (backslash), lstsq, pinv, conjugate gradient. ML mühendisliğinde “hangi çözücü” kararı sessizce buradan gelir.
11.3 2. Durum 0-1: Pseudoinverse ve İyi Koşullu Kare
Durum 0: Pseudoinverse (Ders 9) her durumda bir cevap verir — sıfır tekil değerlerin tersini sıfır alır. Her zaman çalışır ama bazen “kolaycılık”.
Durum 1 (iyi durum): \(A\) kare, makul boyutlu ve iyi koşullu. Sıradan eliminasyon (Matlab’de backslash) çalışır. “İyi koşullu” demek kondisyon sayısı makul demek:
\[\kappa = \frac{\sigma_1}{\sigma_n} \quad (\sigma_{\max} / \sigma_{\min})\]
“…the condition number… sigma 1 over sigma n.” — Strang, 2:27
\(\kappa\) büyükse (örneğin > 1000) matris zordur; küçükse rahat çözülür.
Birim çemberin bir matris altında nasıl bir elipse dönüştüğünü Şekil 11.3 gösteriyor: iyi koşullu matris çemberi neredeyse koruyor, kötü koşullu matris onu yassı bir elipse eziyor.
Kod
fig, axes = plt.subplots(1, 2, figsize=(9, 4.6))
# SOL: iyi koşullu (κ ≈ 1.1)
A1 = np.diag([2., 1.8])
circle1, ell1, s1a, sna = blowup_ellipse(A1)
k1 = s1a / sna
style_square_axes(axes[0], 3.2, title="iyi koşullu (κ ≈ %.1f)" % k1)
plot_pointset(axes[0], circle1, color=COL_STEEL_300, close=False)
plot_pointset(axes[0], ell1, color=COL_ACCENT, close=False)
# SAĞ: kötü koşullu (κ = 10)
A2 = np.diag([3., 0.3])
circle2, ell2, s1b, snb = blowup_ellipse(A2)
k2 = s1b / snb
style_square_axes(axes[1], 3.2, title="kötü koşullu (κ = %.0f)" % k2)
plot_pointset(axes[1], circle2, color=COL_STEEL_300, close=False)
plot_pointset(axes[1], ell2, color=COL_ACCENT, close=False)
fig.suptitle("Kondisyon κ=σ1/σn: yassı elips = kötü koşullu = zor problem",
color=COL_TEXT, fontsize=12, fontweight="bold")
fig.tight_layout()
plt.show()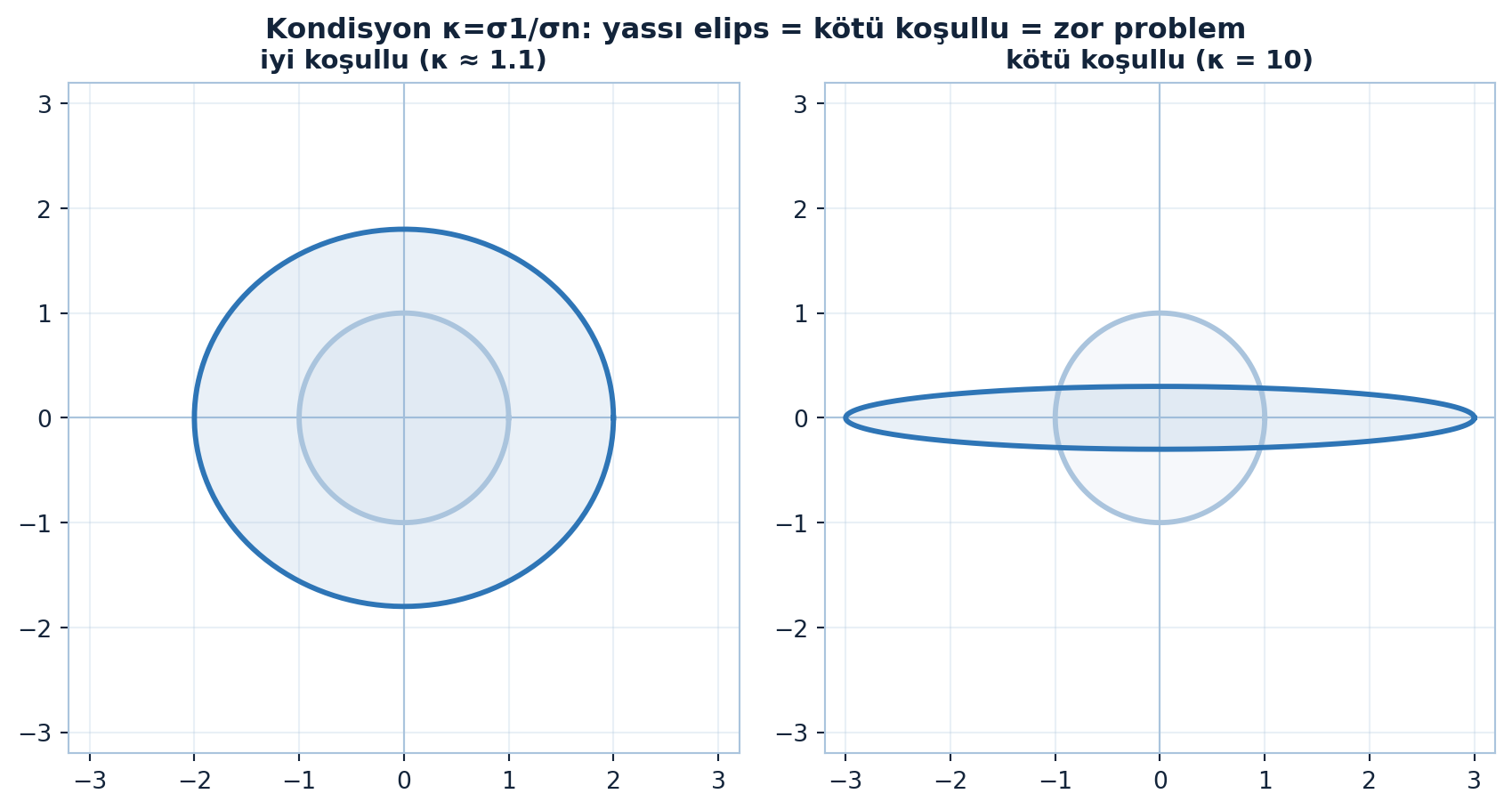
İpucuBuilder Notu — Zorluk Göstergesi
Kondisyon sayısı \(\kappa = \sigma_1/\sigma_n\), sayısal her şeyin “zorluk göstergesi”dir: büyük \(\kappa\) → yuvarlama hatası patlar, gradient descent yavaşlar (Ders 5 dar vadi). Normalizasyon, ön-koşullama ve batch norm hep \(\kappa\)’yı küçük tutmak içindir.
11.4 3. Durum 2: Fazla Denklem (Least Squares)
\(m > n\): denklem sayısı bilinmeyenden çok (overdetermined). İstatistikte sürekli karşılaşılır — çözüm yok, en iyiyi bul (least squares):
\[A^{T}A\,\hat{x} = A^{T}b\]
\(A\) makul boyutluysa \(A^{T}A\) tersinirdir ve backslash dikdörtgen \(A\) için bile bu çözümü verir (kare matris şart değil). Ders 9’da gördüğümüz normal denklemin ta kendisi.
İpucuBuilder Notu — Klasik Regresyon
Bu, gözetimli öğrenmenin en yaygın hâli: çok örnek (\(m\)), az parametre (\(n\)) → least squares regresyon. Tahmin modellerinin, baseline’ların ve son-katman lineer çözümlerin standart durumu; aşırı-belirlenmiş ve iyi davranışlı.
11.5 4. Durum 3: Eksik Denklem (Derin Öğrenme)
\(m < n\): yeterli denklem yok (underdetermined). Sonsuz çözüm var; birini seçmek gerekir. Bu, derin öğrenmenin tipik durumudur — ağda örnek sayısından çok daha fazla ağırlık vardır.
“…that’s typical of deep learning.” — Strang, 4:34
Hangi çözümü seçersin? Minimum-norm (\(\ell^2\), en kısa çözüm) ya da \(\ell^1\) (seyrek). Strang’in heyecanlandığı açık soru: stokastik gradient descent (Ders 25) hangi çözüme gider — minimum \(\ell^1\)’e mi? Bu, derin öğrenmenin neden çalıştığının kalbindeki sorudur.
Sonsuz çözüm doğrusunun üzerinde minimum-norm çözümün nasıl orijine en yakın nokta olduğunu Şekil 11.4 gösteriyor: gradyan inişi örtük yanlılıkla aynı \((1,1)\) noktasını seçer.
Kod
A = np.array([[1., 1.]]); b = np.array([2.])
xmn = min_norm_solution(A, b) # = (1, 1)
fig, ax = plt.subplots(figsize=(6.4, 6.0))
style_square_axes(ax, 3)
# çözüm doğrusu x + y = 2
t = np.linspace(-2, 4, 50)
ax.plot(t, 2 - t, color=COL_STEEL_300, lw=2, label="çözüm doğrusu x+y=2")
# birkaç başka çözüm (gri noktalar)
ax.scatter([0, 2], [2, 0], color=COL_STEEL_300, s=45, zorder=4,
edgecolors=COL_TEXT, linewidths=0.6, label="başka çözümler")
# minimum norm noktası
ax.scatter([1], [1], color=COL_VEC3, s=80, zorder=5, label="minimum norm (1,1)")
# orijinden minimum norm noktasına en kısa ok
draw_vec2d(ax, xmn, color=COL_PRIMARY)
ax.set_title("Eksik-belirlenmiş: sonsuz çözüm (doğru), minimum-norm seçilir (implicit bias)",
color=COL_TEXT, fontsize=10.5, fontweight="bold")
ax.legend(loc="upper right", fontsize=9)
plt.show()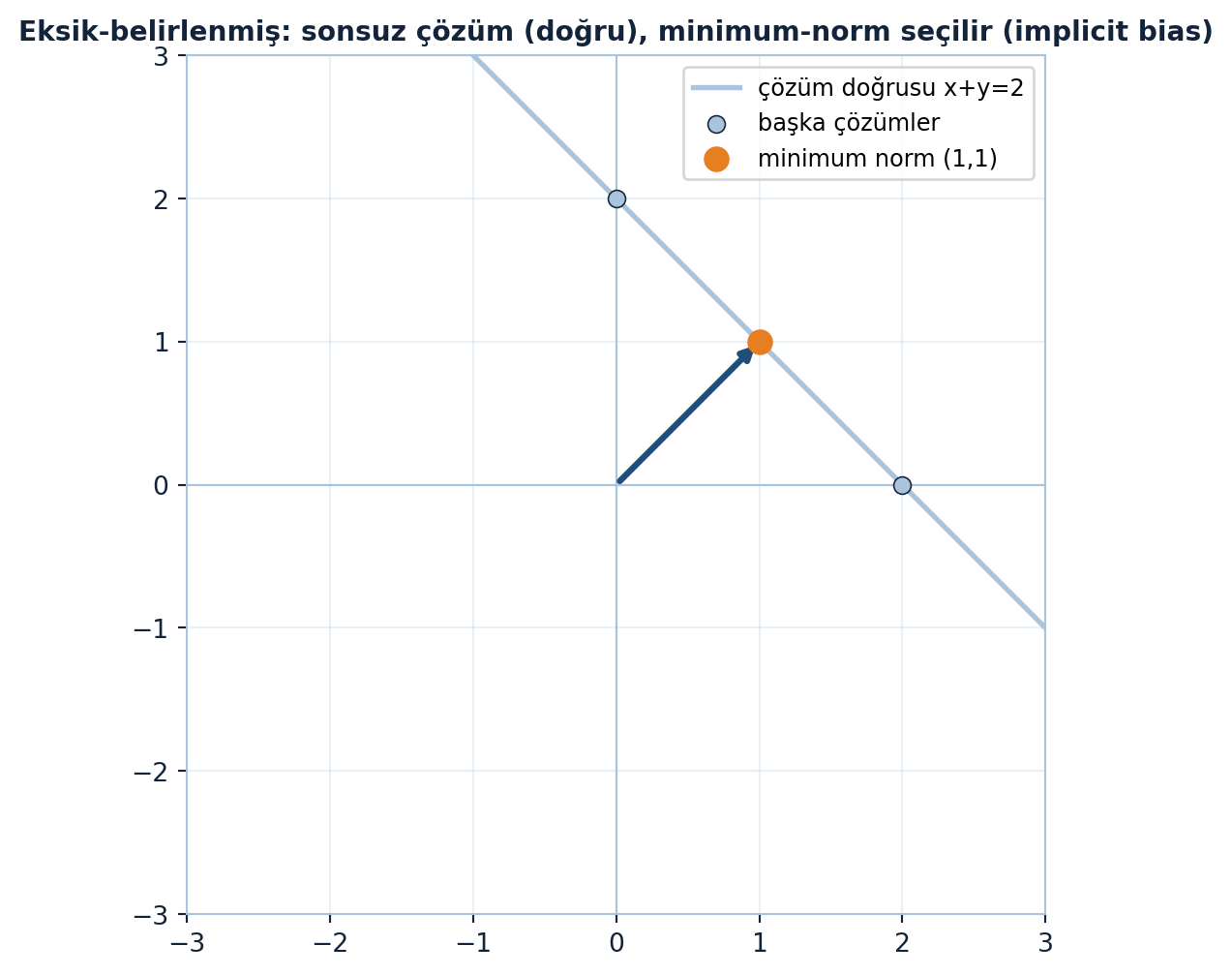
İpucuBuilder Notu — Derin Öğrenmenin Hâli
Eksik-belirlenmiş = fazla-parametreli (overparametrized) modern ağlar. Sonsuz sıfır-kayıp çözümü vardır; algoritmanın hangisini seçtiği (implicit bias) genellemeyi belirler. “Parametre > veri ama yine de çalışıyor” paradoksunun matematiksel zemini budur.
11.6 5. Durum 4: Kötü Kolonlar (Gram-Schmidt / QR)
Kolonlar neredeyse bağımlıysa (kötü koşullu taban) matris hâlâ tersinirdir ama tersi devasadır. Çözüm: kolonları ortogonalleştir.
“…You orthogonalize columns.” — Strang, 7:06
Verilen kolonlar yerine kolon uzayında ortonormal bir taban (\(Q_1 \ldots Q_n\)) bul; ikisi üst üçgensel \(R\) ile bağlıdır — bu \(A = QR\)’dir (Gram-Schmidt). Sayısal kararlılık için kolon pivotlama eklenir (kolonları daha iyi sırada al, tıpkı eliminasyondaki satır değişimi gibi).
\[A = QR \quad (Q: \text{ ortonormal}, \; R: \text{ upper triangular})\]
İpucuBuilder Notu — Kötü Tabanı Düzelt
QR + kolon pivotlama, rank-açığa-çıkaran faktorizasyonun temelidir: hangi kolonların gerçekten bağımsız olduğunu bulur. Özellik seçimi, kötü-koşullu tasarım matrislerini düzeltme ve sayısal kararlılıkta kritik (LAPACK’in geqp3).
11.7 6. Durum 5: Neredeyse Tekil → Düzenlileştirme
En ilginç durum: matris neredeyse tekil (sıfıra çok yakın tekil değerler). Tersi mantıksız büyüklükte; yuvarlama hatası her şeyi yok eder. Klasik kaynak: ters problemler (bir sistemin çıktısından parametrelerini geri bulmak — örneğin devre elemanlarını ölçümlerden kestirmek). Çare: bir ceza terimi ekle.
“…adding a penalty term.” — Strang, 14:49
Pseudoinverse “kolaycılık” sayılır; gerçek çözüm probleme düzenlileştirme katmaktır. \(\delta^{2}\|x\|^{2}\) cezası matrisi tersinir ve iyi koşullu yapar.
İpucuBuilder Notu — Gürültüye Karşı
Neredeyse tekil = küçük \(\sigma\)’lar = \(\kappa\) devasa. Ters problemler (tomografi, deconvolution, sistem kimliklendirme) bu sınıftadır; ham pseudoinverse gürültüyü patlatır. Düzenlileştirme (sonraki bölüm) bilgiyle gürültü arasında denge kurar.
11.8 7. Ceza Terimi: (AᵀA + δ²I)x = Aᵀb
Düzenlileştirme, least squares’e bir ceza ekler: çözümün hem veriye uyması hem küçük kalması istenir.
\[\min_x \;\|Ax - b\|^{2} + \delta^{2}\|x\|^{2}\]
Bunu minimize edince düzeltilmiş normal denklem çıkar — köşegene \(\delta^{2}\) eklenir:
\[(A^{T}A + \delta^{2} I)\,\hat{x} = A^{T}b\]
\(\delta > 0\) olduğu sürece \(A^{T}A + \delta^{2} I\) pozitif tanımlıdır (Ders 5) → her zaman tersinir, \(A\) ne kadar kötü olursa olsun. \(\delta\) büyüdükçe problem daha iyi koşullu olur ama veriden uzaklaşır. Bu, istatistikte ridge regresyon, mühendislikte Tikhonov düzenlileştirmesidir.
Kötü-koşullu bir matriste ridge çözümünün \(\delta\)’ya göre nasıl yol aldığını Şekil 11.5 gösteriyor: \(\delta\) küçüldükçe çözüm pseudoinverse’e yakınsar, \(\delta\) büyükken kararlı kalır.
Kod
A = np.array([[3., 0.], [0., 0.001]])
b = np.array([3., 0.001])
deltas = np.logspace(-4, 1, 40)
xs = np.array([ridge_solve(A, b, d) for d in deltas])
fig, ax = plt.subplots(figsize=(7.2, 4.6))
apply_style(ax)
ax.set_xscale("log")
ax.plot(deltas, xs[:, 0], color=COL_VEC1, lw=2.4, marker="o", ms=3, label="x₁")
ax.plot(deltas, xs[:, 1], color=COL_VEC2, lw=2.4, marker="s", ms=3, label="x₂")
ax.axhline(1, color=COL_VEC3, ls=":", lw=2.0, label="pseudoinverse çözüm (=1)")
ax.set_xlabel("δ (log)")
ax.set_ylabel("ridge çözüm bileşeni")
ax.legend(loc="best", framealpha=0.95)
ax.set_title("Ridge yolu: δ küçüldükçe çözüm pseudoinverse'e yakınsar;\nδ büyükken kararlı", color=COL_TEXT, fontsize=11, fontweight="bold")
plt.show()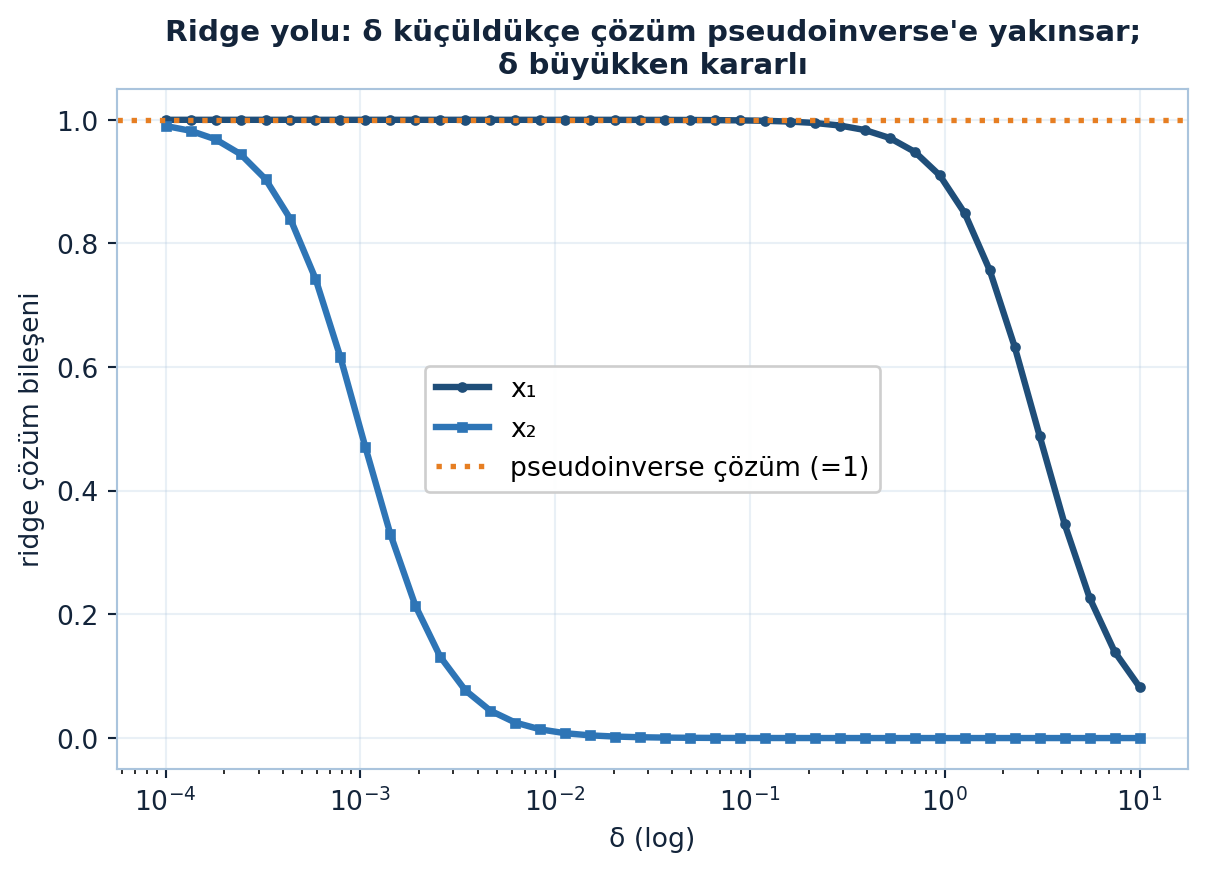
İpucuBuilder Notu — Ağırlık Zayıflatma
\(\delta^{2}\|x\|^{2}\) cezası = \(\ell^2\) ağırlık zayıflatma (weight decay): derin öğrenmede aşırı-uyumu önleyen en yaygın düzenlileştirici. Köşegene \(\delta^{2}\) eklemek hem sayısal kararlılık (tersinirlik) hem genelleme (küçük ağırlık) verir — tek hamlede iki kazanç.
11.9 8. δ → 0 Limiti = Pseudoinverse
\(\delta\)’yı sıfıra götürünce ne olur? \(1 \times 1\) örnek (\(A = \sigma\)) her şeyi gösterir. Çözüm:
\[x = \frac{\sigma}{\sigma^{2} + \delta^{2}}\,b \;\xrightarrow[\;\delta \to 0\;]{}\; \begin{cases} 1/\sigma & \sigma > 0 \\ 0 & \sigma = 0 \end{cases}\]
\(\sigma > 0\) ise \(1/\sigma\)’ya (gerçek ters), \(\sigma = 0\) ise \(0\)’a gider — tam olarak pseudoinverse’in yaptığı! Genel matriste de aynı:
\[(A^{T}A + \delta^{2} I)^{-1}A^{T} \;\xrightarrow[\;\delta \to 0\;]{}\; A^{+}\]
“…approaches the pseudo inverse, sigma plus.” — Strang, 46:41
Bu süreksiz, hassas bir limittir: \(\sigma\) büyüdükçe \(1/\sigma\) patlar ama \(\sigma = 0\)’da birden \(0\)’a düşer. İstatistikçiler pseudoinverse’i bu yoldan (ceza ekleyerek) bağımsız keşfetti.
Her tekil değer \(\sigma\) için ridge çözümünün \(\delta \to 0\) limitinde nasıl \(1/\sigma\) pseudoinverse eğrisine yakınsadığını Şekil 11.6 gösteriyor: \(\sigma > 0\) yönlerinde \(1/\sigma\)’ya gider, \(\sigma = 0\) yönünde \(0\) kalır.
Kod
fig, ax = plt.subplots(figsize=(7.2, 4.6))
apply_style(ax)
sig = np.linspace(0.01, 4, 200)
navy_tones = [COL_PRIMARY, COL_ACCENT, COL_SKY_400]
for d, c in zip([1.0, 0.5, 0.1], navy_tones):
ax.plot(sig, scalar_ridge(sig, d), color=c, lw=2.4, label="δ=" + str(d))
ax.plot(sig, 1 / sig, color=COL_VEC3, ls=":", lw=2, label="1/σ (δ→0)")
ax.set_ylim(0, 5)
ax.set_xlabel("tekil değer σ")
ax.set_ylabel("ridge çözüm σ/(σ²+δ²)")
ax.set_title("Ridge δ→0 → pseudoinverse: σ>0 ise 1/σ, σ=0 ise 0",
color=COL_TEXT, fontsize=11, fontweight="bold")
ax.legend()
plt.show()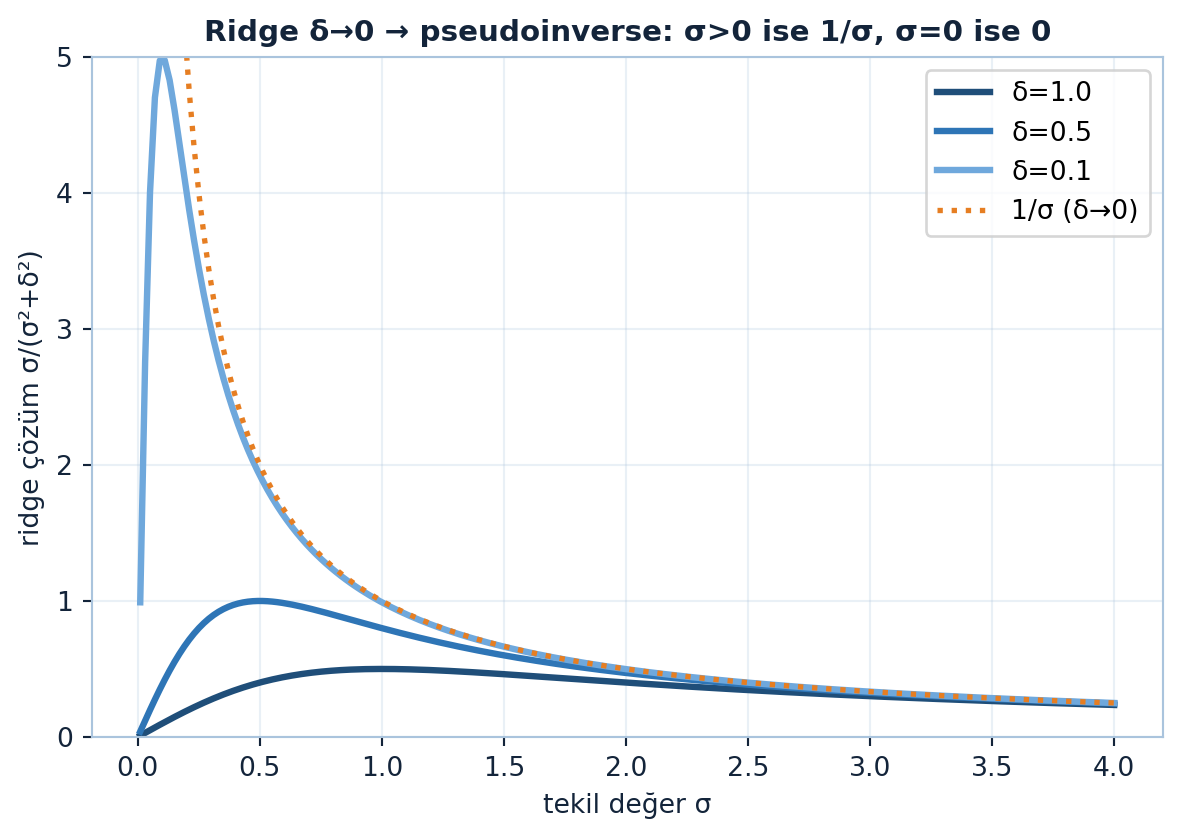
İpucuBuilder Notu — Ridge’in Sırrı
“Ridge → pseudoinverse” köprüsü, düzenlileştirmenin neden işe yaradığını açıklar: \(\delta\) küçük tekil değerlerin patlamasını engeller, yalnızca güvenilir (büyük \(\sigma\)) yönleri kullanır. Truncated SVD ve erken durdurma (early stopping) aynı sezginin akrabalarıdır.
11.10 9. Durum 6-7: İteratif ve Rastlantısal
Durum 6 (çok büyük): Matris büyükse doğrudan çözüm (\(A^{T}A\), QR) pahalıdır. İteratif yöntemler çözüme adım adım yaklaşır — kahramanı conjugate gradient.
“…like conjugate gradients, you get pretty close, pretty fast.” — Strang, 18:05 “…that name I erased is Krylov…” — Strang, 17:37
Bu yöntemler (Krylov ailesi) matrisi açıkça kurmaz, yalnızca \(A\) ile çarpım kullanır. Durum 7 (devasa): Matris belleğe bile sığmıyorsa rastlantısal lineer cebir devreye girer — matrisi olasılıkla örnekle, örnekten cevap çıkar.
“So randomized linear algebra has popped up…” — Strang, 18:46
Rastgele \(x\)’lerle \(Ax\) almak kolon uzayında rastgele vektörler verir; az sayıda örnek çoğu zaman kolon uzayını yeterince yakalar (Ders 13).
Ölçek büyüdükçe aletin nasıl değiştiğini Şekil 11.7 gösteriyor: küçük → doğrudan, büyük/seyrek → iteratif, devasa → rastlantısal.
Kod
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
fig, ax = plt.subplots(figsize=(11.0, 4.6))
ax.set_xlim(0, 13.2)
ax.set_ylim(0, 6.0)
# Üç ölçek üç alet: artan boyutta üç kutu, aralarında büyüyen-matris okları
boxes = [
{"x": 0.4, "w": 3.2, "h": 2.2, "fc": COL_PRIMARY,
"title": "Küçük",
"body": "doğrudan\n(solve, QR)"},
{"x": 4.7, "w": 3.5, "h": 2.9, "fc": COL_ACCENT,
"title": "Büyük / seyrek",
"body": "iteratif\n(conjugate gradient,\nKrylov)"},
{"x": 9.3, "w": 3.6, "h": 3.6, "fc": COL_PRIMARY,
"title": "Devasa",
"body": "rastlantısal\n(sketching,\nörnekleme)"},
]
centers = []
for bx in boxes:
y = (6.0 - bx["h"]) / 2.0 # dikey ortala (artan boyut taban+tavandan büyür)
box = FancyBboxPatch((bx["x"], y), bx["w"], bx["h"],
boxstyle="round,pad=0.02,rounding_size=0.10",
linewidth=2.0, edgecolor=COL_TEXT,
facecolor=bx["fc"], alpha=0.93, zorder=2)
ax.add_patch(box)
cx = bx["x"] + bx["w"] / 2.0
cy = y + bx["h"] / 2.0
ax.text(cx, cy + bx["h"] * 0.26, bx["title"], ha="center", va="center",
color=COL_WHITE, fontsize=13.5, fontweight="bold", zorder=3)
ax.text(cx, cy - bx["h"] * 0.10, bx["body"], ha="center", va="center",
color=COL_WHITE, fontsize=11, zorder=3)
centers.append((bx["x"], bx["x"] + bx["w"], y, y + bx["h"], cy))
# Büyüyen-matris okları (kutular arasında, ok kalınlığı/boyutu artar)
for i in range(len(boxes) - 1):
x0 = centers[i][1] + 0.15
x1 = centers[i + 1][0] - 0.15
ymid = 3.0
scale = 22 + i * 10
lw = 2.4 + i * 1.2
arr = FancyArrowPatch((x0, ymid), (x1, ymid),
arrowstyle="-|>", mutation_scale=scale,
linewidth=lw, color=COL_VEC3, zorder=4)
ax.add_patch(arr)
ax.text((x0 + x1) / 2.0, ymid + 0.45, "büyüyen matris",
ha="center", va="center", color=COL_VEC3,
fontsize=9.5, style="italic", zorder=4)
ax.set_title("Ölçeğe göre alet: doğrudan $\\to$ iteratif $\\to$ rastlantısal",
color=COL_TEXT, fontsize=13.5, fontweight="bold", pad=12)
ax.axis("off")
plt.show()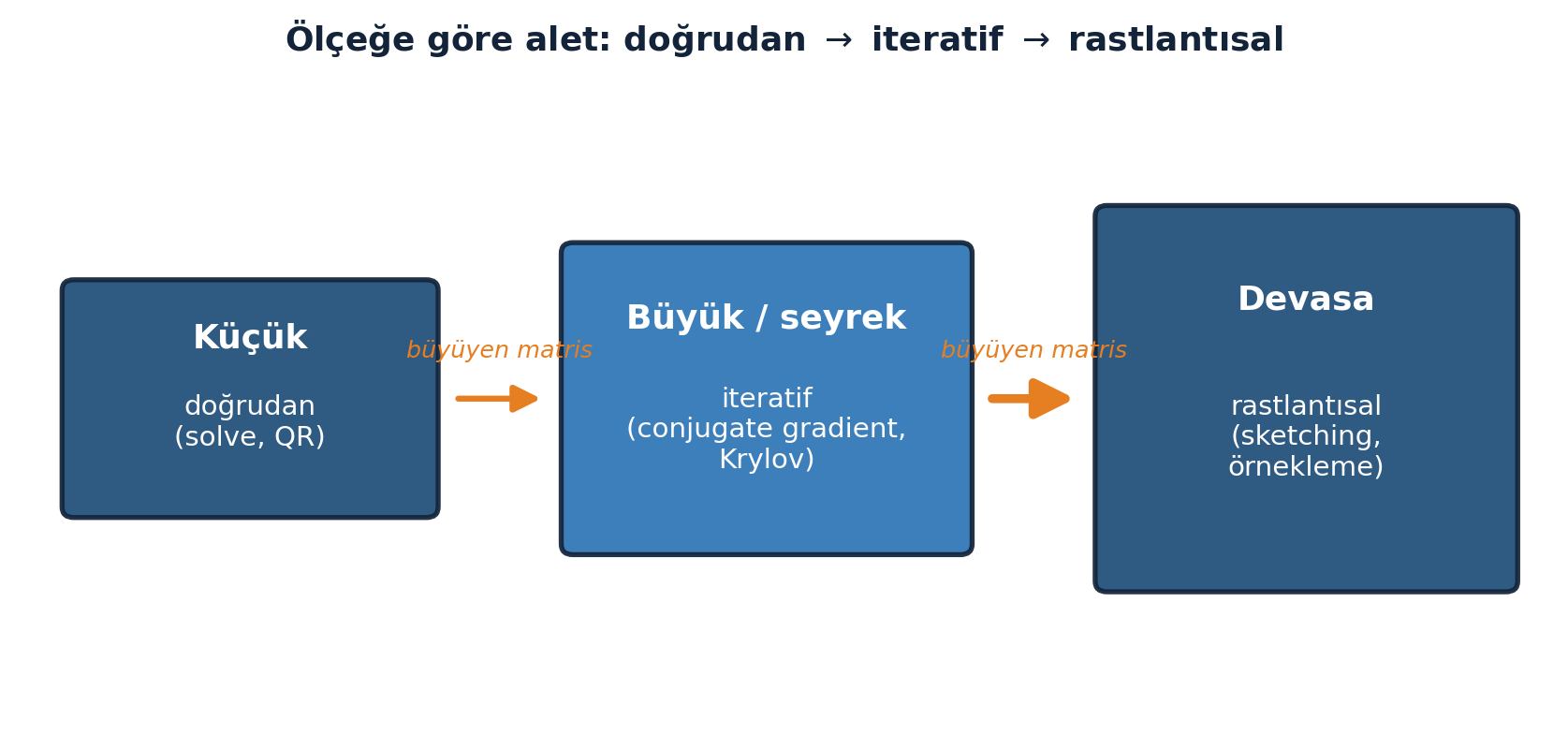
İpucuBuilder Notu — Ölçeğe Göre Alet
Ölçek arttıkça alet değişir: küçük → doğrudan, büyük/seyrek → iteratif (conjugate gradient, Krylov), devasa → rastlantısal (sketching). Büyük-ölçek ML ve bilimsel hesap bu üçünün üstünde durur; gradient descent (Ders 21-23) iteratif ailenin optimizasyon akrabasıdır.
11.11 10. Derin Öğrenmede Implicit Bias
Eksik-belirlenmiş derin öğrenmede sonsuz çözüm vardır — hepsi eğitim verisine tam uyar. Soru: hangisi test verisinde de iyi çalışır (genelleşir)?
“…It’s called implicit bias. How does that algorithm bias a solution toward a solution that generalizes…” — Strang, 23:02
Kritik gözlem: bir algoritma (örneğin gradient descent) çözümleri sessizce belli bir yöne yatırır — buna implicit bias denir. İyi algoritmalar genelleşen çözümlere; kötüleri test verisinde çuvallayan çözümlere gider. Bu, 2018’in açık matematik sorusudur ve kursun varış noktasıdır.
İpucuBuilder Notu — Neden Genelleşir
Implicit bias, modern derin öğrenme teorisinin merkezidir: açık düzenlileştirme olmadan bile GD küçük-norm/basit çözümlere yönelir (Srebro varsayımı, Ders 8). Fazla-parametreli ağların neden ezberlemeyip genelleştiğinin cevabı buradadır — algoritmanın seçtiği çözüm, çözüm uzayından daha önemlidir.
11.12 Bu Dersin Özeti
- Ax = b sözlüğü — boyut/rank/koşula göre durum haritası, her birine reçete.
- Durum 0-1 — pseudoinverse (her zaman); iyi koşullu kare → eliminasyon (backslash).
- Kondisyon sayısı \(\kappa = \sigma_1/\sigma_n\) — zorluk göstergesi; büyükse tehlike.
- Durum 2 — fazla denklem → least squares (\(A^{T}A\hat{x} = A^{T}b\)).
- Durum 3 — eksik denklem → minimum norm / \(\ell^1\); derin öğrenme.
- Durum 4 — kötü kolonlar → Gram-Schmidt/QR + pivotlama.
- Durum 5 — neredeyse tekil → düzenlileştirme (\(\delta^{2}I\)); ters problemler.
- Ceza terimi — \((A^{T}A + \delta^{2} I)\hat{x} = A^{T}b\); ridge/Tikhonov.
- \(\delta \to 0\) = pseudoinverse — ceza, \(\sigma > 0\)’da \(1/\sigma\)’ya, \(\sigma = 0\)’da \(0\)’a gider.
- Durum 6-7 — çok büyük → iteratif (Krylov/CG); devasa → rastlantısal LA.
- Implicit bias — hangi çözümün genelleştiği; GD’nin gizli tercihi.
ÖnemliTek Bir Cümle
\(Ax = b\)’nin zorluğu boyut, rank ve kondisyon sayısı \(\kappa = \sigma_1/\sigma_n\) ile belirlenir; her durumun kendi aleti vardır (eliminasyon, least squares, minimum norm, QR, iteratif, rastlantısal) ve \(\delta^{2}I\) düzenlileştirmesi neredeyse tekil problemleri pseudoinverse’e doğru yumuşatır.
11.13 Kontrol Soruları
NotSoru 1: Aşağıdaki üç sistem hangi durumdadır? Hangi yöntemi kullanırsın?
\[A_1 = \begin{pmatrix} 2 & 1 \\ 1 & 2 \end{pmatrix}, \quad A_2 = \begin{pmatrix} 1 \\ 1 \\ 1 \end{pmatrix}, \quad A_3 = \begin{pmatrix} 1 & 1 & 1 \end{pmatrix}\]
Cevap: \(A_1\): kare, tersinir (det = 3), iyi koşullu → doğrudan çözüm (backslash/eliminasyon). \(A_2\): \(3 \times 1\), fazla denklem (overdetermined) → least squares (\(A^{T}A\hat{x} = A^{T}b\)), tek bilinmeyen. \(A_3\): \(1 \times 3\), eksik denklem (underdetermined) → sonsuz çözüm, minimum-norm çözümü seç (pseudoinverse).
NotSoru 2: A = diag(100, 1) matrisinin kondisyon sayısını bul. Neden bu matris terslemede risklidir?
Cevap: Tekil değerler 100 ve 1 → \(\kappa = \sigma_1/\sigma_n = 100/1 = 100\). Ters \(A^{-1} = \text{diag}(0.01, 1)\); küçük yön (\(\sigma = 1\)) terste 1’e, büyük yön 0.01’e gider. \(\kappa = 100\) orta düzeyde kötü; girdideki küçük hata, çözümde 100 kata kadar büyüyebilir. \(\kappa \to \infty\) (\(\sigma_n \to 0\)) olunca matris terslenemez hâle gelir.
NotSoru 3: Ridge çözümü (AᵀA + δ²I)⁻¹Aᵀb, δ → 0’da σ = 0 ve σ > 0 için neye gider?
Cevap: \(1 \times 1\)’de çözüm \(\sigma/(\sigma^{2} + \delta^{2})\). \(\sigma > 0\) ise \(\delta \to 0\)’da \(1/\sigma\)’ya (gerçek ters) gider. \(\sigma = 0\) ise her \(\delta\) için 0, limitte de 0. Bu süreksiz davranış tam olarak pseudoinverse’tir: sıfır olmayan tekil değerleri tersler, sıfır olanları sıfır bırakır. Ceza terimi, \(\sigma = 0\) olsa bile son ana kadar problemi çözülebilir tutar.
NotSoru 4: Fazla-parametreli (underdetermined) bir ağ sonsuz çözüme sahipken neden genelleşebilir?
Cevap: Çözüm uzayı sonsuz olsa da, eğitim algoritması (gradient descent) hepsini eşit seçmez — implicit bias ile belli çözümlere (genelde minimum-norm/basit) yönelir. Bu çözümler test verisinde de iyi çalışır. Yani genelleme, çözüm uzayının kendisinden değil, algoritmanın o uzaydan hangisini seçtiğinden gelir. Bu, modern derin öğrenme teorisinin merkezî sorusudur (Srebro varsayımı ile bağlantılı).
11.14 Egzersizler
Cevapsız problemler. Çöz, sonra numpy ile kontrol et.
Egzersiz 1. Aşağıdaki sistemleri durum haritasında sınıfla (tersinir / least squares / minimum-norm) ve uygun yöntemi söyle: (a) \(4 \times 4\) tersinir \(A\); (b) \(1000 \times 3\) \(A\); (c) \(3 \times 1000\) \(A\); (d) \(\sigma\) değerleri 1, 0.001 olan \(2 \times 2\) \(A\).
Egzersiz 2. \(A = \begin{pmatrix} 3 & 0 \\ 0 & 0.01 \end{pmatrix}\) için kondisyon sayısını hesapla. \(A^{-1}\)’i yaz; küçük yöndeki büyütmeyi yorumla.
Egzersiz 3. \(A = \begin{pmatrix} 2 \end{pmatrix}\) (\(1 \times 1\)) ve \(b = 6\) için ridge çözümü \(x = \sigma/(\sigma^{2} + \delta^{2}) \cdot b\)’yi \(\delta = 1, 0.1, 0.01\) için hesapla; \(\delta \to 0\)’da \(1/\sigma \cdot b = 3\)’e yaklaştığını göster.
Egzersiz 4. Python ile düzenlileştirmeyi keşfet:
import numpy as np
A = np.array([[3.0, 0.0], [0.0, 0.001]])
print("kondisyon:", np.linalg.cond(A)) # σ1/σn = 3000
b = np.array([3.0, 0.001])
for delta in [1.0, 0.1, 0.01, 0.0]:
if delta > 0:
x = np.linalg.solve(A.T @ A + delta**2 * np.eye(2), A.T @ b)
else:
x = np.linalg.pinv(A) @ b # δ → 0 limiti
print(f"δ={delta}: x={x}")Egzersiz 5. (Ders 11 habercisi.) Ders 11, eksik-belirlenmiş sistemde (\(m < n\)) \(\|x\|\)’i minimize eden çözümü işler. \(A = \begin{pmatrix} 1 & 1 & 1 \end{pmatrix}\), \(b = 3\) için \(Ax = b\)’yi sağlayan minimum \(\ell^2\) norm çözümünü bul (pseudoinverse veya Lagrange ile). Cevabın \((1, 1, 1)\) olmasını bekle — neden?
11.15 Sonraki Ders İçin Hazırlık
Ders 11: \(Ax = b\) Koşuluyla \(\|x\|\)’i Minimize Etmek
Ders 10’da durum haritasını çıkardık; eksik-belirlenmiş durumda “hangi çözüm?” sorusunu açtık. Ders 11 bunu derinleştirir: kısıt altında minimum-norm çözümü.
- Minimum \(\ell^2\) norm çözümü (pseudoinverse’in verdiği)
- Minimum \(\ell^1\) norm (seyrek çözüm)
- Lagrange çarpanları ile kısıtlı minimizasyon
- Derin öğrenmede çözüm seçimiyle bağ
UyarıDers 11 Öncesi Yapılacak
- Bu dersin egzersizlerini çöz, özellikle Egzersiz 5’i (minimum-norm).
- Python’da
np.linalg.pinvile eksik-belirlenmiş sistemlerin minimum-norm çözümünü incele. - Ana cümleyi tekrar oku: “\(Ax = b\)’nin zorluğu \(\kappa = \sigma_1/\sigma_n\); düzenlileştirme pseudoinverse’e yumuşatır.”
11.16 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Strang’de |
|---|---|---|
| Ax = b sözlüğü | Durum haritası; her duruma ayrı reçete | 0m25 |
| Kondisyon sayısı | \(\kappa = \sigma_1/\sigma_n\); zorluk göstergesi | 2m27 |
| Durum 3: eksik | \(m < n\); minimum norm / \(\ell^1\); derin öğrenme | 4m34 |
| Gram-Schmidt / QR | Kötü kolonlar → ortonormal taban (\(A = QR\)) | 7m06 |
| Ceza / düzenlileştirme | \(\delta^{2}\|x\|^{2}\) ekle; \((A^{T}A + \delta^{2} I)\hat{x} = A^{T}b\) | 14m49 |
| \(\delta \to 0\) = pseudoinverse | Ridge/Tikhonov limiti; \(\sigma>0 \to 1/\sigma\), \(\sigma=0 \to 0\) | 46m41 |
| İteratif (conjugate gradient) | Çok büyük; Krylov ailesi, yalnız \(Ax\) çarpımı | 18m05 |
| Krylov | İteratif yöntemlerin adı (detay Ders 12) | 17m37 |
| Rastlantısal LA | Devasa matris; örnekleme (Ders 13) | 18m46 |
| Implicit bias | Algoritmanın hangi çözümü seçtiği; genelleme | 23m02 |
11.17 ML Bağlantıları Özeti
- Kondisyon sayısı \(\kappa\) → eğitim zorluğu; normalizasyon/ön-koşullama \(\kappa\)’yı küçültür.
- Eksik-belirlenmiş = derin öğrenme → fazla-parametre, sonsuz çözüm; seçim önemli.
- Minimum norm / \(\ell^1\) → düzenlileştirme; \(\ell^1\) seyrek, \(\ell^2\) düzgün.
- Gram-Schmidt/QR → kötü-koşullu tasarım matrislerini düzeltme; kararlı least squares.
- Ridge (\(\delta^{2}I\)) → pseudoinverse → weight decay, Tikhonov; sayısal kararlılık + genelleme.
- İteratif/rastlantısal → büyük-ölçek ML; conjugate gradient, randomized SVD, sketching.
- Implicit bias → fazla-parametreli ağların neden genelleştiği; GD’nin gizli düzenlileştirmesi.
ÖnemliEğer bu dersten tek bir şey alıp gidersen
\(Ax = b\) tek bir problem değil, bir problemler ailesidir — boyut, rank ve kondisyon sayısı \(\kappa = \sigma_1/\sigma_n\) hangisi olduğunu söyler. İyi koşulluda eliminasyon, fazla denklemde least squares, eksikte minimum norm, kötü kolonda QR, neredeyse tekilde düzenlileştirme (\(\delta^{2}I \to\) pseudoinverse), devasada iteratif/rastlantısal. Doğru tanı, doğru aleti seçtirir — ve eksik-belirlenmiş derin öğrenmede asıl soru, algoritmanın sonsuz çözümden hangisini (implicit bias) seçtiğidir.
ETAP 2 kapanışı (Ders 2-10): Bu on ders, lineer cebirin “highlights” turunu (faktorizasyonlar, ortogonallik, özdeğer/SVD, normlar) tamamlayıp veri bilimine (Eckart-Young, PCA, least squares, düzenlileştirme) ve derin öğrenmenin kapısına (gradient descent, implicit bias) bağladı. Sırada optimizasyon ve sinir ağları var.