flowchart TD
M["Eckart-Young (en iyi rank-k)"] --> NORM["matris normları (spektral/Frobenius/nükleer)"]
M --> ORT["ortogonal değişmezlik (σ değişmez)"]
NORM --> L1["ℓ1 → seyreklik (Lasso)"]
NORM --> NUC["nükleer → matris tamamlama (Netflix)"]
M --> PCA["PCA (merkez + kovaryans)"]
style M fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style NORM fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style L1 fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style NUC fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style PCA fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style ORT fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
8 Eckart-Young — En Yakın Rank-k Matris
Matris normları, ℓ1 seyreklik ve PCA
NotBölüm bilgisi
Video: Eckart-Young: The Closest Rank k Matrix to A · OCW: MIT 18.065 Lecture 7 · Okuma süresi: ~36 dk · Eğitmen: Gilbert Strang · Önkoşul: Ders 6 (SVD).
8.1 Bu Derste Ne Var?
Ders 6’da SVD’yi kurduk. Ders 7 onun en güçlü sonucunu veriyor: bir matrisin en önemli bilgisi en büyük birkaç tekil değerdedir, ve Eckart-Young teoremi bunu kesinleştirir. Yanında matris normları ve PCA geliyor.
Üç temel fikir:
- Eckart-Young — SVD’nin ilk k parçası (\(A_k\)), A’ya en yakın rank-k matristir; her başka rank-k matris daha uzaktır.
- Matris normları — spektral (\(\sigma_1\)), Frobenius (\(\sqrt{\sum \sigma_i^2}\)), nükleer (\(\sum \sigma_i\)); üçü de yalnız tekil değerlere bağlı ve Eckart-Young hepsinde geçerli.
- PCA — veriyi merkezle, en iyi doğruyu bul; PCA least squares değildir (dik uzaklık, dikey değil).
“This lecture is about principal component analysis, PCA…” — Strang, 0:25
Şekil 8.1 bu dersin haritasını veriyor: merkezde Eckart-Young, ondan normlara, ℓ1 seyrekliğe, nükleer norm ile matris tamamlamaya, PCA’ya ve ortogonal değişmezliğe uzanan dallar.
İpucuBuilder Notu — Sıkıştırmanın Kalbi
- Eckart-Young = sıkıştırmanın garantisi: ilk k tekil parçayı tutmak en iyi rank-k yaklaşımdır — görüntü sıkıştırma, model budama, LoRA, gürültü giderme.
- ℓ1 normu → seyreklik: Lasso, compressed sensing, öznitelik seçimi — ℓ1 minimizasyonu çoğu bileşeni sıfır yapar (yorumlanabilirlik).
- Nükleer norm → matris tamamlama: Netflix yarışması, öneri sistemleri, eksik MRI verisi — düşük-rank tamamlama.
- PCA → boyut indirgeme: merkezlenmiş verinin SVD’si; ana bileşenler en yüksek varyans yönleridir.
Tek cümle: SVD’nin ilk k parçası (Eckart-Young) bir matrisin en iyi düşük-rank özetidir — ve bu, sıkıştırmadan öneri sistemlerine, PCA’dan LoRA’ya tüm veri biliminin temel hamlesidir.
8.2 1. PCA ve En Önemli k Parça
SVD, A’yı r tane rank-1 parçaya ayırır (her parça \(\sigma_i u_i v_i^{T}\), U ve V ortonormal). Ama büyük bir matriste tüm bilgi değil, önemli bilgi gerekir.
“This lecture is about principal component analysis, PCA…” — Strang, 0:25
Strang’in vurgusu: makine öğrenmesinde tüm eğitim verisini ezberlemek “öğrenmek” değildir. Önemli olan en büyük k tekil değerdeki bilgidir. Rank binlerce olabilir ama ilk 100 parça çoğu zaman yeter.
İpucuBuilder Notu — Önemli Bilgiyi Tut
“Önemli bilgi = en büyük tekil değerler” ilkesi, derin öğrenmenin sıkıştırma yönünü tanımlar: parametreleri ezberlemek yerine düşük-rank yapıyı yakalamak. LoRA, model budama ve damıtma (distillation) hep bu sezgidir.
8.3 2. Eckart-Young Teoremi
Dersin tek teoremi: SVD’nin ilk k parçası (\(A_k\)), A’ya en yakın rank-k matristir.
\[ A_k = \sum_{i=1}^{k} \sigma_i u_i v_i^{T} \]
“…is the best approximation to A of rank k.” — Strang, 2:33
Resmî ifade: rank’ı k olan herhangi başka bir B matrisi için, hata \(A_k\)’nin hatasından küçük olamaz:
\[ \|A - B\| \geq \|A - A_k\| \quad (\mathrm{rank}(B) \leq k) \]
“…it’s often called the Eckart-Young Theorem.” — Strang, 3:36
Bu, SVD’nin neden “mükemmel” olduğunu söyler: en iyi düşük-rank özeti doğrudan ilk k tekil parçadan gelir, ayrıca aramaya gerek yok.
Kod
A = np.diag([4, 3, 2, 1])
errs = eckart_young_errors(A)
fig, axes = plt.subplots(1, 2, figsize=(11, 4.4))
bar_values(axes[0], [4, 3, 2, 1], ["σ1", "σ2", "σ3", "σ4"], "Tekil değerler")
ax = axes[1]
ks = range(5)
spectral = [e[0] for e in errs]
frob = [e[1] for e in errs]
nuc = [e[2] for e in errs]
ax.plot(ks, spectral, "-o", color=COL_PRIMARY, lw=2.2, markersize=6, label="spektral")
ax.plot(ks, frob, "-o", color=COL_ACCENT, lw=2.2, markersize=6, label="Frobenius")
ax.plot(ks, nuc, "-o", color=COL_VEC3, lw=2.2, markersize=6, label="nükleer")
apply_style(ax)
ax.set_xticks(list(ks))
ax.set_xlabel("rank k")
ax.legend()
fig.suptitle("Eckart-Young: rank-k hata üç normda da k arttıkça düşer",
color=COL_TEXT, fontsize=13, fontweight="bold")
fig.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()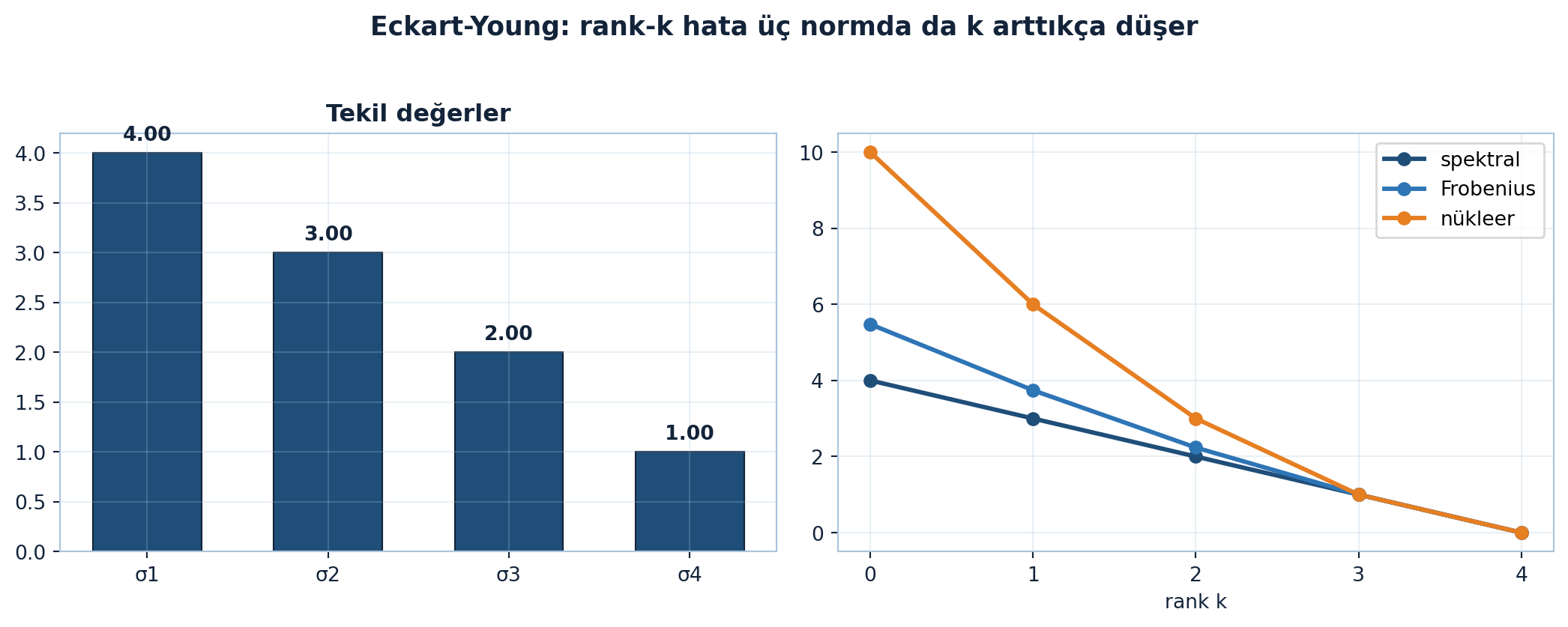
Şekil 8.2 bunu somutlaştırır: \(A=\mathrm{diag}(4,3,2,1)\) için her üç norm da rank k arttıkça monoton düşer ve tam rankta sıfıra iner.
İpucuBuilder Notu — En İyisi Garanti
Eckart-Young, sıkıştırmanın optimallik garantisidir: ilk k parçayı tutmak, tüm rank-k matrisler arasında en iyisidir. Görüntü sıkıştırma, gürültü giderme ve düşük-rank katman yaklaşımları bu teoreme dayanır — “en büyüğü tut” hamlesi kanıtlı en iyidir.
8.4 3. Vektör Normları (ℓ1, ℓ2, ℓ∞)
Teoremdeki çift çubuk \(\|\cdot\|\) bir norm — matrisin/vektörün büyüklüğünün ölçüsü.
“…the norm of the matrix.” — Strang, 4:13
Önce vektör normları. Üç temel norm:
\[ \|v\|_2 = \sqrt{v_1^2 + \cdots + v_n^2}, \quad \|v\|_1 = |v_1| + \cdots + |v_n|, \quad \|v\|_\infty = \max_i |v_i| \]
ℓ2 alışılmış uzunluk (Pythagoras hipotenüsü), ℓ1 mutlak değerlerin toplamı, ℓ∞ en büyük bileşen. İndeks (1, 2, ∞) hangi kuvvetin alınıp kök edildiğini söyler.
Kod
fig, axs = plt.subplots(1, 3, figsize=(9.6, 3.6))
specs = [
(1, "ℓ1 (elmas)"),
(2, "ℓ2 (çember)"),
(np.inf, "ℓ∞ (kare)"),
]
for ax, (p, title) in zip(axs, specs):
style_square_axes(ax, 1.4, title)
plot_pointset(ax, norm_ball(p), COL_ACCENT, close=False)
fig.suptitle("Birim toplar: ℓ1 elmas (köşeli), ℓ2 çember, ℓ∞ kare",
color=COL_TEXT, fontsize=13, fontweight="bold")
fig.tight_layout()
plt.show()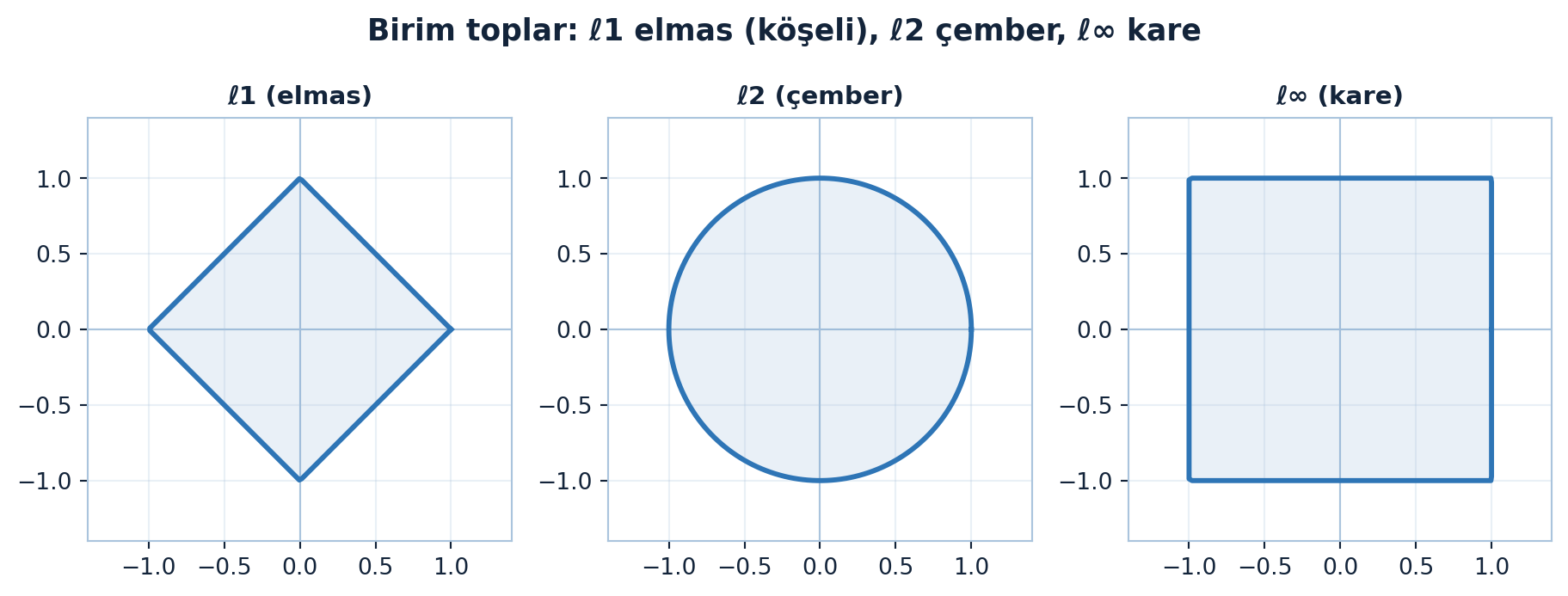
Şekil 8.3 üç birim topu yan yana koyar: ℓ1 elmas (köşeli), ℓ2 çember (pürüzsüz), ℓ∞ kare. Köşelerin yeri bir sonraki bölümün anahtarı.
İpucuBuilder Notu — Üç Uzunluk Ölçüsü
Bu üç norm ML’de farklı işler görür: ℓ2 (ridge, ağırlık zayıflatma), ℓ1 (Lasso, seyreklik), ℓ∞ (en kötü durum, sağlamlık/adversarial). Norm seçimi çözümün karakterini belirler.
8.5 4. ℓ1 ve Seyreklik
ℓ1 normu son yıllarda çok önemli hâle geldi çünkü onunla minimize edildiğinde kazanan vektör seyrek çıkar — çoğu bileşeni sıfır.
“…the minimizing vector turns out to be sparse.” — Strang, 8:16
ℓ2 (Gauss’un least squares’i) küçük ama çok sayıda sıfırdan-farklı bileşen verir (kareler küçükleri cezalandırmaz). ℓ1 ise birkaç sıfırdan-farklı bileşen verir — bu da yorumlanabilirdir: hangi bileşenlerin gerçekten önemli olduğunu görürsün.
Kod
fig, axes = plt.subplots(1, 2, figsize=(10, 5))
# Kısıt doğrusu: x + 2y = 2 -> x = 2 - 2y
ty = np.linspace(-1.2, 1.6, 50)
tx = 2 - 2*ty
# ---- SOL: ℓ2 (ridge) yoğun çözüm ----
ax = axes[0]
style_square_axes(ax, 2.2, title="ℓ2 (ridge): yoğun çözüm")
ax.plot(tx, ty, color=COL_TEXT, lw=1.6, ls="--", alpha=0.7, label="kısıt: x+2y=2", zorder=1)
# büyüyen ℓ2 çemberleri (artan r, soluk)
for r, al in [(0.5, 0.30), (0.7, 0.45), (0.894, 0.95)]:
b = norm_ball(2) * r
plot_pointset(ax, b, color=COL_ACCENT, lw=2.0 if al > 0.9 else 1.4, fill_alpha=0.05, close=False)
# teğet (projeksiyon) noktası: en küçük ||x||_2 doğru üzerinde -> (0.4, 0.8)
ax.scatter([0.4], [0.8], color=COL_VEC3, s=90, zorder=5, edgecolor=COL_TEXT, linewidth=0.8)
ax.text(0.4, 0.8, " (0.4, 0.8) ikisi de ≠0", color=COL_VEC3, fontsize=10, fontweight="bold", va="bottom")
ax.legend(loc="lower left", fontsize=9, framealpha=0.9)
# ---- SAĞ: ℓ1 (Lasso) seyrek çözüm ----
ax = axes[1]
style_square_axes(ax, 2.2, title="ℓ1 (Lasso): seyrek çözüm")
ax.plot(tx, ty, color=COL_TEXT, lw=1.6, ls="--", alpha=0.7, label="kısıt: x+2y=2", zorder=1)
# büyüyen ℓ1 elmasları (artan r, soluk)
for r, al in [(0.5, 0.30), (0.75, 0.45), (1.0, 0.95)]:
b = norm_ball(1) * r
plot_pointset(ax, b, color=COL_VEC3, lw=2.0 if al > 0.9 else 1.4, fill_alpha=0.05, close=False)
# köşe noktası eksende: (0, 1) -> bir bileşen = 0 (seyrek)
ax.scatter([0.0], [1.0], color=COL_VEC3, s=90, zorder=5, edgecolor=COL_TEXT, linewidth=0.8)
ax.text(0.0, 1.0, " (0, 1) bir bileşen=0", color=COL_VEC3, fontsize=10, fontweight="bold", va="bottom")
ax.legend(loc="lower left", fontsize=9, framealpha=0.9)
fig.suptitle("ℓ1 seyreklik üretir (köşede), ℓ2 üretmez (yoğun)",
color=COL_TEXT, fontsize=13, fontweight="bold")
fig.tight_layout()
plt.show()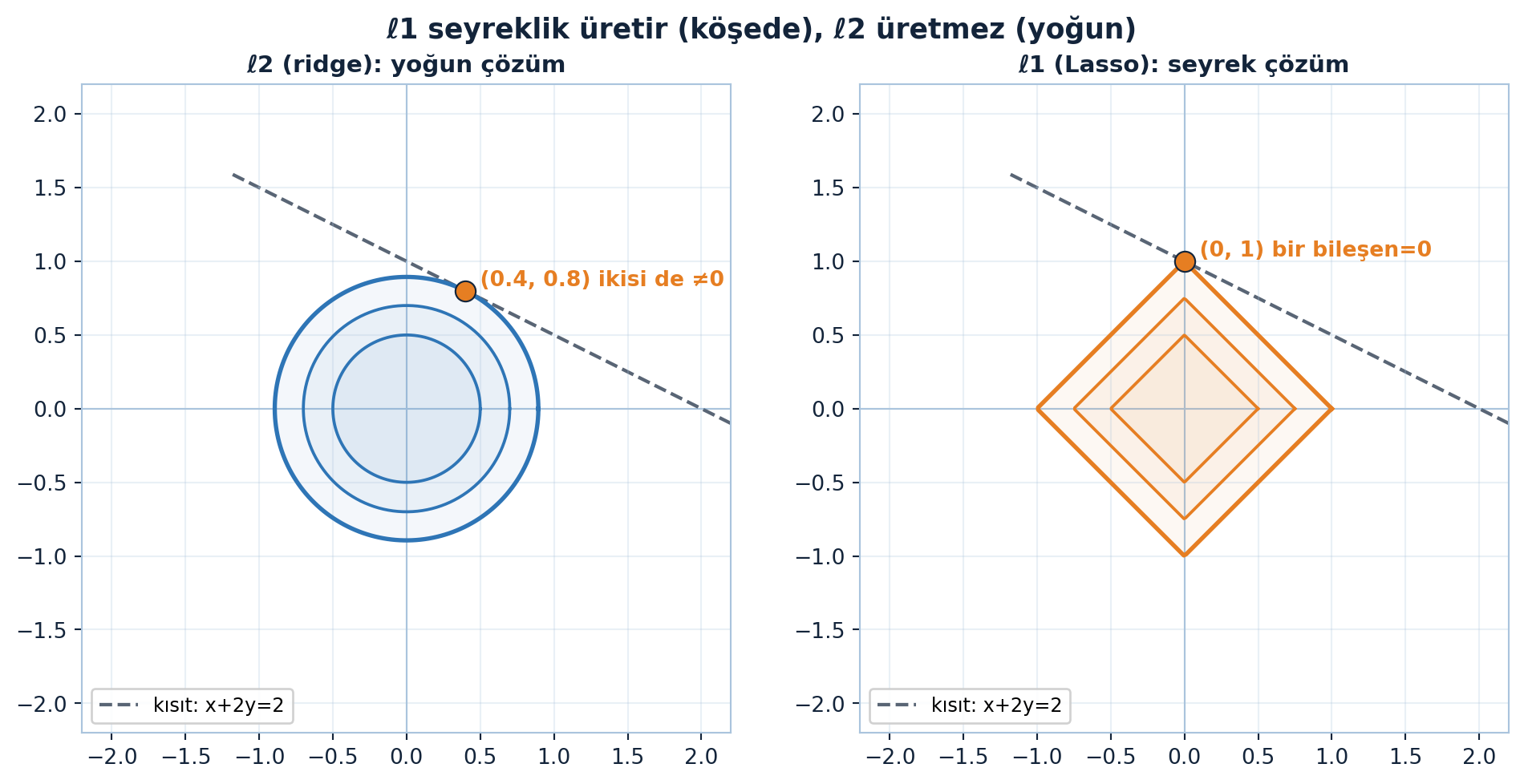
Şekil 12.3 geometriyi gösterir: ℓ2 topu doğruya eksen-dışı bir noktada teğet (yoğun çözüm), ℓ1 elması ise bir köşede değer — bu köşe seyrek çözümü üretir.
İpucuBuilder Notu — Sıfırların Gücü
ℓ1 → seyreklik, modern ML’in temel taşıdır: Lasso regresyonu (öznitelik seçimi), compressed sensing (az ölçümle sinyal kurtarma), seyrek kodlama. “ℓ1 seyreklik üretir” gerçeği, yorumlanabilir ve verimli modellerin matematiksel sebebidir.
8.6 5. Matris Normları (Spektral, Frobenius, Nükleer)
Vektör normları matrise üç şekilde taşınır — ve üçü de tekil değerlerle hesaplanır:
\[ \|A\|_2 = \sigma_1, \quad \|A\|_F = \sqrt{\sum_{i,j} a_{ij}^2} = \sqrt{\sigma_1^2 + \cdots + \sigma_r^2}, \quad \|A\|_N = \sigma_1 + \cdots + \sigma_r \]
Spektral norm (ℓ2) en büyük tekil değer \(\sigma_1\)’dir. Frobenius normu tüm girdilerin karelerinin toplamının kareköküdür (= tekil değerlerin karelerinin toplamının karekökü). Nükleer norm tekil değerlerin toplamıdır.
“…named after Frobenius.” — Strang, 11:54
“It’s called the nuclear norm.” — Strang, 13:05
Normların ortak özellikleri: homojenlik (\(\|cA\| = |c| \cdot \|A\|\)) ve üçgen eşitsizliği (\(\|A+B\| \leq \|A\| + \|B\|\)).
Kod
M = np.diag([3., 1.])
s = svd_full(M)[1]
sp, fr, nu = matrix_norms(M)
fig, ax = plt.subplots(figsize=(6.4, 4.6))
bar_values(ax, s, ["σ1", "σ2"], "Tekil degerler")
ax.text(0.97, 0.92, "spektral ||A||2 = σ1 = 3", transform=ax.transAxes,
ha="right", va="top", fontsize=11, fontweight="bold", color=COL_PRIMARY)
ax.text(0.97, 0.82, "Frobenius ||A||F = √Σσ² = √10 ≈ 3.16", transform=ax.transAxes,
ha="right", va="top", fontsize=11, fontweight="bold", color=COL_ACCENT)
ax.text(0.97, 0.72, "nukleer ||A||N = Σσ = 4", transform=ax.transAxes,
ha="right", va="top", fontsize=11, fontweight="bold", color=COL_VEC3)
ax.set_title("Matris normlari: ucu de yalniz σ funksiyonu", color=COL_TEXT, fontsize=12, fontweight="bold")
fig.tight_layout()
plt.show()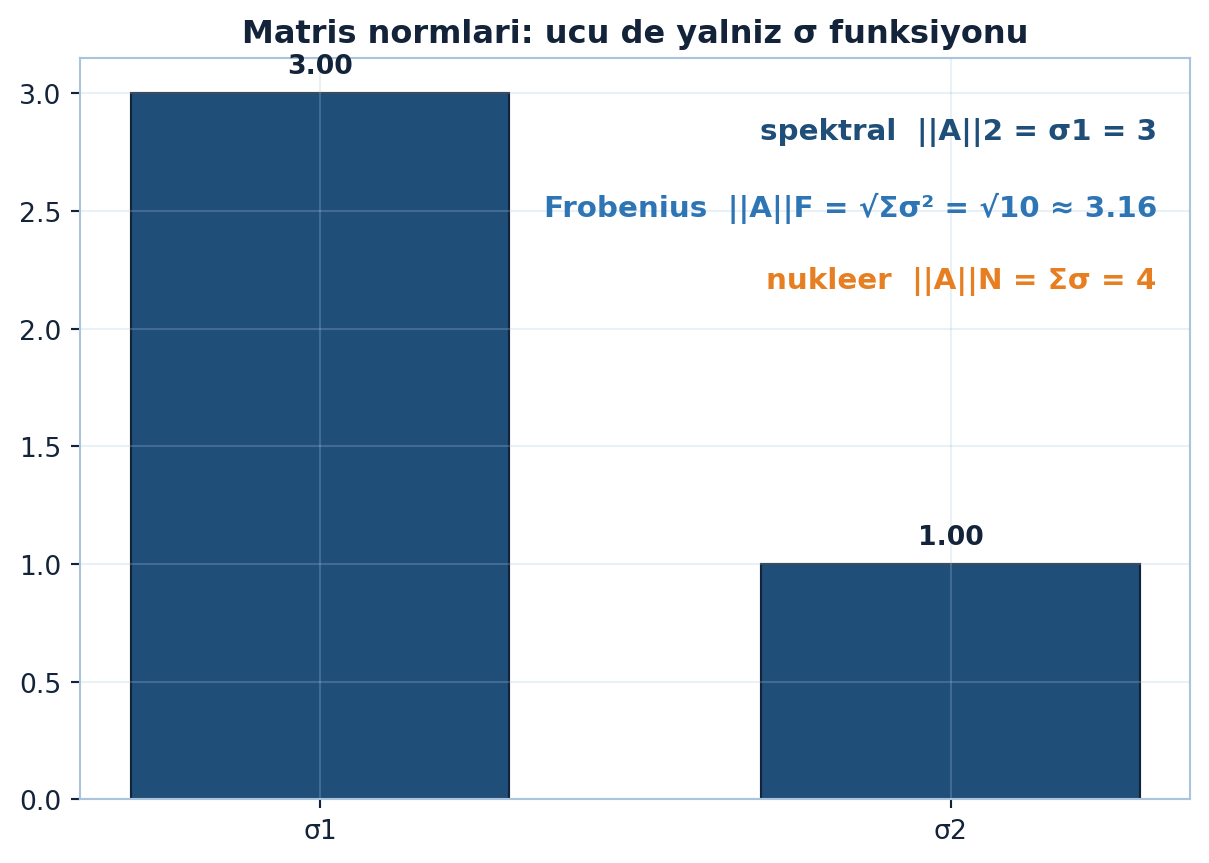
Şekil 8.5 üç normu \(M=\mathrm{diag}(3,1)\) üzerinde sayısallaştırır: spektral \(=3\), Frobenius \(=\sqrt{10}\approx 3.16\), nükleer \(=4\) — hepsi yalnız tekil değerlerden.
İpucuBuilder Notu — σ’nun Üç Dili
Üç norm üç rol oynar: spektral norm = Lipschitz sabiti (kararlılık, GAN); Frobenius = en yaygın matris “büyüklüğü” (ağırlık zayıflatma, \(\mathrm{trace}(A^{T}A)\)); nükleer = rankın dışbükey gevşemesi (düşük-rank optimizasyon, matris tamamlama).
8.7 6. Üç Norm da Yalnız Tekil Değerlere Bağlı
Eckart-Young teoremi tam olarak bu üç norm için doğrudur. Sebep: üçü de yalnızca tekil değerlere bağlıdır.
“These norms depend only on the singular values.” — Strang, 15:56
Spektral \(= \sigma_1\), Frobenius \(= \sqrt{\sum \sigma_i^2}\), nükleer \(= \sum \sigma_i\) — hepsi yalnız \(\sigma\)’ların fonksiyonu. Bu yüzden “en büyük k σ’yı tut” hamlesi her üçünde de en iyi sonucu verir; başka (σ’ya bağlı olmayan) bir norm uydurulsa Eckart-Young çalışmayabilirdi.
İpucuBuilder Notu — Neden SVD Çözer
“Tekil değere bağlı norm” sınıfı (unitarily invariant norms), düşük-rank optimizasyonun matematiksel zeminidir. Bir kayıp bu sınıftaysa, çözümü SVD ile bulunur — matris tamamlama ve robust PCA bu özelliği kullanır.
8.8 7. Nükleer Norm: Netflix, Matris Tamamlama, MRI
Nükleer norm (\(\sum \sigma_i\)), ℓ1’in matris karşılığıdır ve eksik veriyi tamamlamada parlar. Klasik örnek Netflix yarışması: kullanıcı × film puan matrisi, çoğu girdisi eksik (herkes her filmi izlemedi). Eksik girdileri doldurmak = matris tamamlama.
“It’s called the nuclear norm.” — Strang, 13:05
Nükleer normu minimize eden tamamlama, düşük-rank bir matris bulur (az sayıda gizli beğeni faktörü) — öneri sisteminin ta kendisi. Aynı yöntem MRI’da kullanılır: çocuk uzun süre durmadığında eksik kalan görüntü verisi, nükleer norm ile tamamlanır.
İpucuBuilder Notu — Eksiği Tamamla
Nükleer norm = rankın dışbükey gevşemesi: rank’ı doğrudan minimize etmek NP-zor, ama nükleer norm dışbükeydir ve düşük-rank çözümler üretir. Öneri sistemleri, robust PCA (gürültü + düşük-rank ayrıştırma) ve görüntü onarımı bunu kullanır.
8.9 8. Örnek ve Ortogonal Değişmezlik
Köşegen örnek: A = diag(4, 3, 2, 1), rank 4. En iyi rank-2 yaklaşım en büyük iki değeri tutar:
\[ A = \mathrm{diag}(4, 3, 2, 1) \;\Rightarrow\; A_2 = \mathrm{diag}(4, 3, 0, 0) \]
“Köşegende daha yakın” bir B (örn. 3.5’ler) denemek cazip ama düşük rank için ödenen köşegen-dışı bedel onu daha uzağa atar. Peki köşegen örnek özel mi? Hayır: \(A = U\Sigma V^{T}\) ile her iki yana ortogonal matris çarpsan bile tekil değerler değişmez (4, 3, 2, 1 kalır).
“…my whole problem is orthogonally invariant.” — Strang, 27:11
Çünkü Q ortogonal ise QA’nın SVD’si \((QU)\Sigma V^{T}\)’dir; QU yine ortogonal, Σ aynı. Normlar da değişmez (\(\|Qv\| = \|v\|\) gibi). Yani köşegen örnek tüm matrisleri temsil eder. Bu monoton düşüşün üç norm için sayısal kanıtını yukarıda Şekil 8.2’da görmüştük.
İpucuBuilder Notu — Tabandan Bağımsız
Ortogonal değişmezlik, normların ve Eckart-Young’un neden taban seçiminden bağımsız olduğunu söyler. Veriyi döndürmek (ortonormal dönüşüm) bilgisini değiştirmez — whitening, PCA eksenleri ve ortonormal gömülerin matematiksel güvencesi.
8.10 9. PCA: Veriyi Merkezle
PCA, veri matrisindeki en iyi doğrusal ilişkiyi bulur. Örnek: her sütun bir kişi, satır 1 boy, satır 2 yaş. İlk adım istatistikçinin yaptığıdır: her satırdan ortalamasını çıkarıp mean = 0 yap (veriyi merkezle).
\[ A_{\text{merkezli}} = A - (\text{satir ortalamalari}) \]
Merkezlenince noktalar orijin etrafında toplanır (küçük yaşlar negatif, büyükler pozitif olur). Artık en iyi doğru orijinden geçer ve aranan şey, bu bulutun ana yönüdür.
Kod
X = gen_correlated_data(160, seed=2)
Xc, C, vals, vecs = pca_2d(X)
fig, ax = plt.subplots(figsize=(6.4, 6.0))
apply_style(ax)
ax.scatter(Xc[0], Xc[1], s=12, color=COL_TEAL, alpha=0.6)
draw_vec2d(ax, vecs[:, 0] * np.sqrt(vals[0]) * 2.2, color=COL_VEC1, label="1. ana bileşen")
draw_vec2d(ax, vecs[:, 1] * np.sqrt(vals[1]) * 2.2, color=COL_VEC2, label="2.")
ax.set_aspect("equal")
ax.set_title("PCA: merkezli verinin ana eksenleri = kovaryans (AAt/(N-1)) özvektörleri",
color=COL_TEXT, fontsize=10, fontweight="bold")
fig.tight_layout()
plt.show()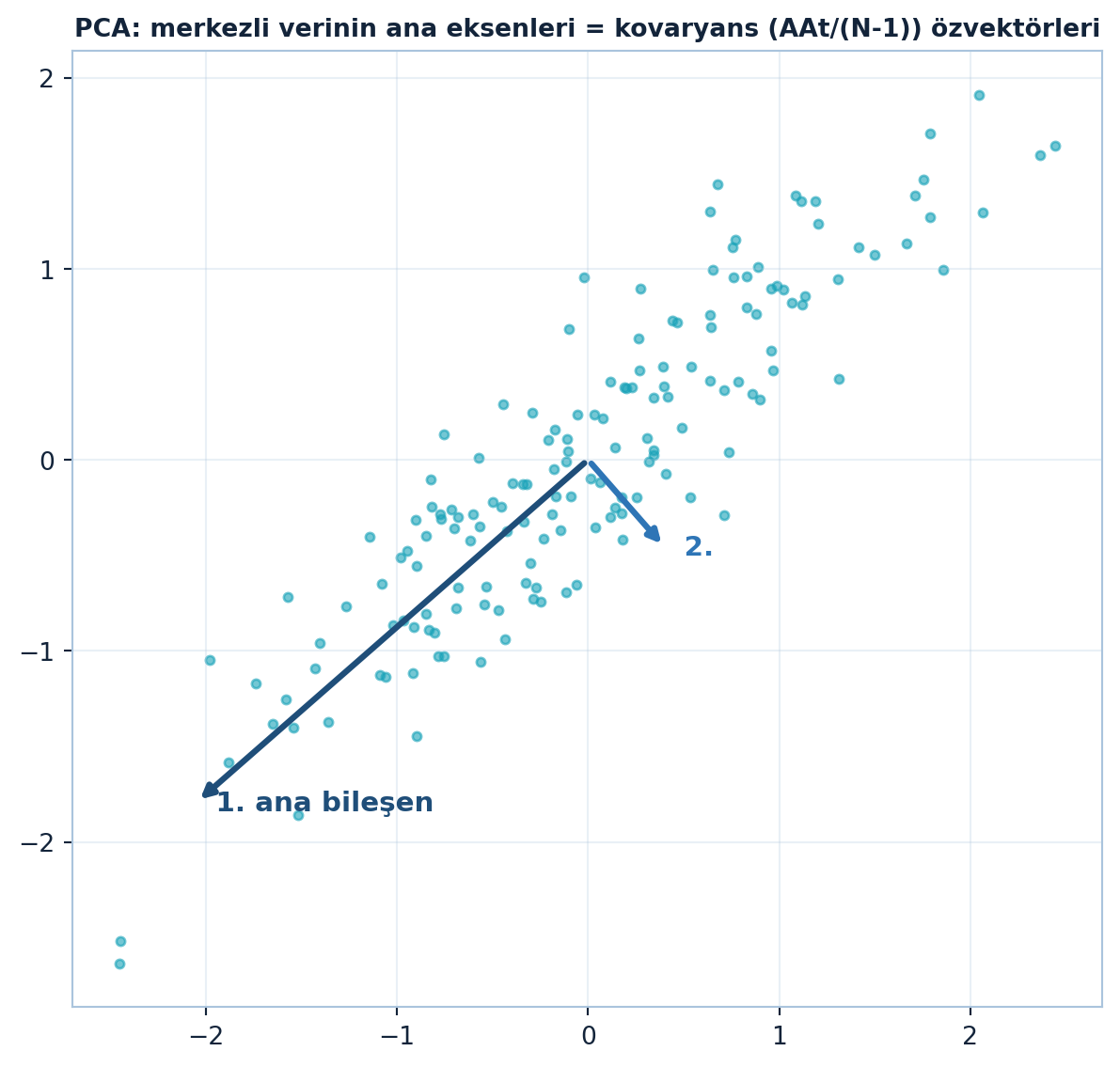
Şekil 8.6 merkezlenmiş bulutu ve onun ana eksenlerini gösterir: en uzun ok birinci ana bileşen (en büyük varyans yönü), kısa ok ona dik.
İpucuBuilder Notu — Sıfıra Çek
Merkezleme, PCA’nın zorunlu ön adımıdır: kovaryans, merkezlenmiş veriden hesaplanır. Sinir ağlarında girdi normalizasyonu (mean çıkarma, ölçekleme) aynı sezgidir — optimizasyonu kolaylaştırır, kâseyi merkezler (Ders 5).
8.11 10. PCA ≠ Least Squares
“En iyi doğru” deyince akla least squares gelir ama PCA farklıdır. Fark, hatanın nasıl ölçüldüğü:
“…in PCA, you’re measuring perpendicular to the line.” — Strang, 38:17
Least squares dikey hatayı (b − Ax) ölçer ve normal denklemleri çözer:
\[ A^{T}A\hat{x} = A^{T}b \quad (\text{least squares, dikey hata}) \]
PCA ise her noktanın doğruya dik uzaklığını ölçüp kareler toplamını minimize eder. İki farklı problem, iki farklı doğru — ve PCA’nın cevabı SVD’den (tekil vektörlerden) gelir, normal denklemlerden değil.
Kod
X = gen_correlated_data(120, seed=1)
pca_dir, a, b, mean = best_fit_lines(X)
fig, ax = plt.subplots(figsize=(8, 6.5))
apply_style(ax)
ax.scatter(X[0], X[1], s=12, color=COL_STEEL_300, alpha=0.7)
# Least Squares doğrusu (dikey hatayı minimize eder)
xs = np.linspace(X[0].min(), X[0].max(), 50)
ax.plot(xs, a*xs + b, color=COL_VEC3, lw=2.2, label="Least Squares (dikey hata)")
# PCA doğrusu (dik hatayı minimize eder)
t = np.linspace(-3, 3, 50)
ax.plot(mean[0] + t*pca_dir[0], mean[1] + t*pca_dir[1], color=COL_PRIMARY, lw=2.2, label="PCA (dik hata)")
# Birkaç nokta için DİK (PCA) ve DİKEY (LS) uzaklıkları kesik çizgi
idx = [5, 30, 70, 100, 115]
for i in idx:
px, py = X[0, i], X[1, i]
# DİKEY uzaklık (LS): noktadan y=ax+b doğrusuna dikey iz düşüm
ax.plot([px, px], [py, a*px + b], color=COL_VEC3, lw=1.1, ls="--", alpha=0.9)
# DİK uzaklık (PCA): noktadan PCA doğrusuna ortogonal iz düşüm
w = np.array([px - mean[0], py - mean[1]])
proj = mean + (w @ pca_dir) * pca_dir
ax.plot([px, proj[0]], [py, proj[1]], color=COL_PRIMARY, lw=1.1, ls="--", alpha=0.9)
ax.legend(loc="upper left")
ax.set_xlabel("x"); ax.set_ylabel("y")
ax.set_title("PCA dik uzaklığı, Least Squares dikey uzaklığı minimize eder → farklı doğrular",
color=COL_TEXT, fontsize=12, fontweight="bold")
fig.tight_layout()
plt.show()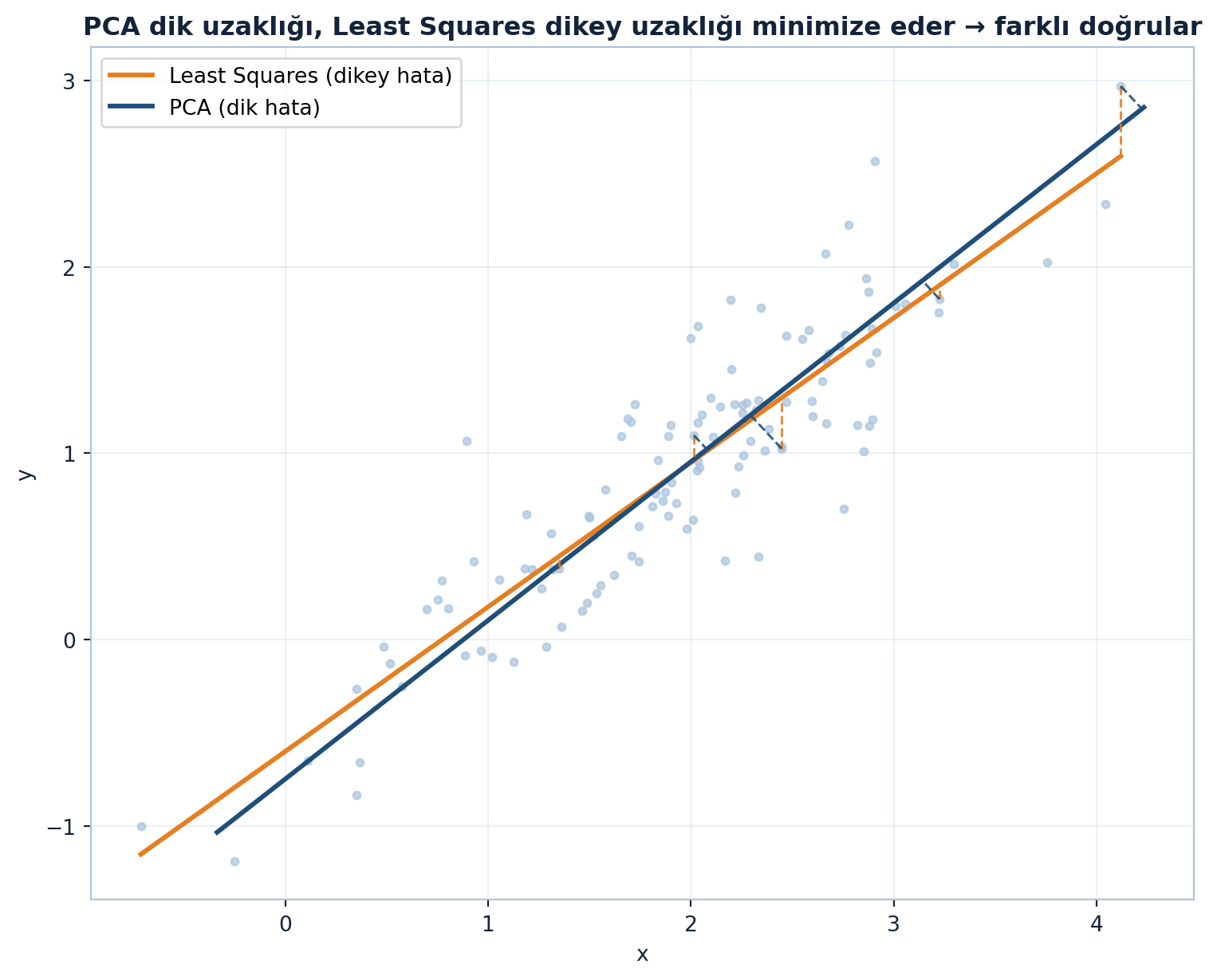
Şekil 8.7 aynı buluta iki doğru uydurur: PCA (lacivert) dik uzaklığı, Least Squares (turuncu) dikey uzaklığı minimize eder — farklı ölçüt, farklı doğru.
İpucuBuilder Notu — Dik mi Dikey mi
PCA (dik mesafe, simetrik) ile regresyon (dikey mesafe, y’yi x’ten tahmin) farklı sorulardır: regresyon tahmin için, PCA yapı/boyut indirgeme için. İkisini karıştırmak yaygın bir hatadır; PCA bir tahmin modeli değil, verinin ana eksenlerini bulan bir araçtır.
8.12 11. Kovaryans Matrisi ve En İyi Yön
Merkezlenmiş veriden sonra istatistikçi varyansa bakar. İki ölçüt (boy, yaş) olduğundan kovaryans matrisi 2×2’dir ve aralarındaki bağı içerir (burada \(A\) merkezlenmiş veridir):
\[ C = \frac{1}{N-1} A A^{T} \]
“…covariance matrix, and it will be 2 by 2.” — Strang, 42:06
Köşegen girdiler boy ve yaşın ayrı varyansları, köşegen-dışı ise aralarındaki kovaryans (birlikte değişim). En iyi doğrunun yönü, bu kovaryans matrisinin (yani \(AA^{T}\)’nin) en büyük özvektörü = A’nın birinci tekil vektörüdür. Böylece PCA SVD’ye bağlanır.
İpucuBuilder Notu — Verinin Ana Yönü
Kovaryans \(= \frac{1}{N-1} AA^{T}\) ve PCA = onun özvektörleri, istatistiğin ML ile buluştuğu yerdir. Birinci ana bileşen en yüksek varyans yönü; boyut indirgeme ilk birkaç bileşeni tutar. Aynı matris LDA, Gauss modelleri ve beyazlatmada görünür.
8.13 Bu Dersin Özeti
- PCA — bir veri matrisinin en önemli bilgisini en büyük tekil değerlerden çıkarma.
- Eckart-Young — \(A_k\) (ilk k SVD parçası) en iyi rank-k yaklaşımdır.
- Vektör normları — ℓ2 (uzunluk), ℓ1 (mutlak toplam, seyreklik), ℓ∞ (maksimum).
- ℓ1 → seyreklik — Lasso, compressed sensing; çoğu bileşen sıfır.
- Matris normları — spektral \(\sigma_1\), Frobenius \(\sqrt{\sum \sigma_i^2}\), nükleer \(\sum \sigma_i\).
- Üç norm da yalnız σ’ya bağlı — Eckart-Young hepsinde geçerli.
- Nükleer norm — Netflix, matris tamamlama, MRI (düşük-rank).
- Ortogonal değişmezlik — \(U\Sigma V^{T}\) tekil değerleri ve normları değiştirmez.
- PCA ≠ least squares — dik uzaklık, dikey değil.
- Kovaryans \(AA^{T}/(N-1)\) — en iyi yön = birinci tekil vektör.
ÖnemliTek Bir Cümle
Eckart-Young teoremi, SVD’nin ilk k parçasının bir matrisin en iyi rank-k özeti olduğunu (spektral, Frobenius ve nükleer normların üçünde de) söyler; PCA bunu merkezlenmiş veriye uygular ve en büyük tekil vektör verinin ana eksenini verir.
8.14 Kontrol Soruları
NotSoru 1: A = diag(5, 2) için en iyi rank-1 yaklaşımı ve hatasını (spektral norm) bul.
Cevap: Tekil değerler 5 ve 2. En iyi rank-1 = en büyüğü tut: \(A_1 = \mathrm{diag}(5, 0)\). Hata \(A - A_1 = \mathrm{diag}(0, 2)\), spektral normu \(\sigma_2 = 2\). Eckart-Young: başka hiçbir rank-1 matris 2’den yakın olamaz.
NotSoru 2: Tekil değerleri σ = 3, 1 olan bir A için spektral, Frobenius ve nükleer normları hesapla.
Cevap: Spektral: \(\|A\|_2 = \sigma_1 = 3\). Frobenius: \(\|A\|_F = \sqrt{\sigma_1^2 + \sigma_2^2} = \sqrt{9 + 1} = \sqrt{10} \approx 3.16\). Nükleer: \(\|A\|_N = \sigma_1 + \sigma_2 = 4\). Üçü de yalnız tekil değerlerin fonksiyonu — bu yüzden Eckart-Young üçünde de geçerli.
NotSoru 3: PCA ile least squares neden farklı doğrular bulur?
Cevap: Least squares dikey hatayı (y yönünde, b − Ax) minimize eder — y’yi x’ten tahmin etme problemi, asimetrik. PCA ise noktaların doğruya dik uzaklığını minimize eder — simetrik, x ve y’ye eşit davranır. Farklı hata ölçüsü → farklı doğru. PCA’nın cevabı SVD’nin birinci tekil vektörü; least squares’inki \(A^{T}A\hat{x} = A^{T}b\).
NotSoru 4: ℓ1 minimizasyonu neden seyrek çözüm verir, ℓ2 neden vermez? (Geometrik sezgi.)
Cevap: ℓ1 “topu” bir elmas (köşeleri eksenlerde); bir kısıt doğrusuna değdiğinde genelde bir köşede değer → bazı bileşenler tam sıfır (seyrek). ℓ2 topu bir çember (köşesiz); kısıta teğet noktası eksende olmak zorunda değildir → tüm bileşenler küçük ama sıfırdan farklı.
Bu yüzden Lasso (ℓ1) öznitelik seçer (sıfırlar üretir), ridge (ℓ2) ise tüm ağırlıkları küçültür ama sıfırlamaz. Seyreklik isteniyorsa ℓ1.
8.15 Egzersizler
Cevapsız problemler. Çöz, sonra numpy ile kontrol et.
Egzersiz 1. A = diag(6, 4, 1) için en iyi rank-1 ve rank-2 yaklaşımlarını yaz. Her birinin hatasını (spektral norm) bul.
Egzersiz 2. Aşağıdaki matrisin spektral, Frobenius ve nükleer normlarını hesapla.
\[ A = \begin{pmatrix} 3 & 0 \\ 0 & 4 \end{pmatrix} \]
Egzersiz 3. Simetrik pozitif tanımlı bir S için nükleer normun trace’e eşit olduğunu göster (\(\|S\|_N = \sum \sigma_i = \sum \lambda_i = \mathrm{trace}\, S\)). Neden bu yalnız PD matrisler için doğru?
Egzersiz 4. Python ile düşük-rank yaklaşımı keşfet:
import numpy as np
A = np.diag([4.0, 3.0, 2.0, 1.0])
U, s, Vt = np.linalg.svd(A)
k = 2
Ak = U[:, :k] @ np.diag(s[:k]) @ Vt[:k, :]
print("A_2 =\n", Ak)
print("hata (spektral) =", np.linalg.norm(A - Ak, 2)) # = σ_{k+1} = 2
print("hata (Frobenius) =", np.linalg.norm(A - Ak, 'fro')) # = √(σ3²+σ4²)
print("3 norm:", s[0], np.sqrt((s**2).sum()), s.sum()) # spektral, Frob, nükleerEgzersiz 5. (Ders 8 habercisi.) Ders 8 normları derinleştirir. Aşağıdaki matrisin spektral normunu (en büyük tekil değer) \(A^{T}A\)’nın en büyük özdeğerinin karekökü olarak bul.
\[ A = \begin{pmatrix} 2 & 0 \\ 1 & 2 \end{pmatrix} \]
8.16 Sonraki Ders İçin Hazırlık
Ders 8: Vektör ve Matris Normları
Ders 7’de üç normu tanıttık (Eckart-Young için). Ders 8 normları sistematik olarak ele alır.
- ℓp normları ve birim toplar (geometri)
- Matris normları: operatör (indüklenmiş) normlar vs Frobenius
- Spektral norm = en büyük tekil değer; nükleer norm = rankın dışbükey gevşemesi
- Norm seçiminin optimizasyon ve seyreklikteki rolü
UyarıDers 8 Öncesi Yapılacak
- Bu dersin egzersizlerini çöz, özellikle Egzersiz 5’i (spektral norm).
- Python’da
np.linalg.normile farklıorddeğerlerini (2, ‘fro’, ‘nuc’, 1, np.inf) dene. - Ana cümleyi tekrar oku: “Eckart-Young — SVD’nin ilk k parçası en iyi rank-k özettir.”
8.17 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Strang’de |
|---|---|---|
| PCA | En büyük tekil değerlerde önemli bilgi | 0m25 |
| Eckart-Young | \(A_k\) (ilk k SVD parçası) = en iyi rank-k yaklaşım | 2m33 |
| Matris normu | Matrisin büyüklüğünün ölçüsü \(\|A\|\) | 4m13 |
| Spektral norm (ℓ2) | En büyük tekil değer \(\sigma_1\) | 5m18 |
| ℓ1 → seyreklik | Minimize eden vektör seyrek (çoğu sıfır) | 8m16 |
| Frobenius normu | \(\sqrt{\sum a_{ij}^2} = \sqrt{\sum \sigma_i^2}\); en yaygın büyüklük | 11m54 |
| Nükleer norm | \(\sum \sigma_i\); matris tamamlama, rankın gevşemesi | 13m05 |
| Üç norm σ’ya bağlı | Eckart-Young üçünde de geçerli | 15m56 |
| Ortogonal değişmezlik | \(U\Sigma V^{T}\) tekil değerleri ve normları korur | 27m11 |
| PCA ≠ least squares | Dik uzaklık (PCA) vs dikey (LS) | 38m17 |
| Kovaryans \(AA^{T}/(N-1)\) | En iyi yön = birinci tekil vektör | 42m06 |
8.18 ML Bağlantıları Özeti
- Eckart-Young → görüntü/model sıkıştırma, LoRA, budama; “en büyüğü tut” kanıtlı en iyi.
- ℓ1 → seyreklik → Lasso, compressed sensing, öznitelik seçimi.
- Spektral norm (\(\sigma_1\)) → Lipschitz sabiti; spektral normalizasyon (GAN, sağlamlık).
- Frobenius → ağırlık zayıflatma, \(\mathrm{trace}(A^{T}A)\); en yaygın matris düzenlileştirmesi.
- Nükleer norm → matris tamamlama (Netflix, öneri), robust PCA, MRI onarımı.
- PCA → boyut indirgeme, görselleştirme, gürültü giderme; kovaryansın özvektörleri.
- Ortogonal değişmezlik → whitening, ortonormal gömüler; taban seçimi bilgisini değiştirmez.
ÖnemliEğer Bu Dersten Tek Bir Şey Alıp Gidersen
Eckart-Young teoremi, SVD’nin ilk k parçasının (en büyük k tekil değer) bir matrisin en iyi rank-k yaklaşımı olduğunu söyler — spektral, Frobenius ve nükleer normların üçünde de. PCA bunu merkezlenmiş veriye uygular: en büyük tekil vektör verinin ana eksenidir. Sıkıştırmadan öneri sistemlerine, Lasso’dan LoRA’ya tüm düşük-rank veri bilimi bu teoremin üstünde durur.