flowchart TD
M["Least Squares (min ‖Ax−b‖²)"] --> PINV["pseudoinverse A⁺=VΣ⁺Uᵀ (SVD)"]
M --> NORM["normal denklemler AᵀAx̂=Aᵀb"]
M --> QR["QR (kararlı)"]
M --> ITER["iteratif (büyük/seyrek)"]
M --> PROJ["projeksiyon: hata ⊥ kolon uzayı"]
style M fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style PINV fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style NORM fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style QR fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style ITER fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style PROJ fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
10 En Küçük Kareleri Çözmenin Dört Yolu
Pseudoinverse, normal denklemler, QR ve iteratif yöntemler — hepsi aynı projeksiyonda buluşur
NotBölüm bilgisi
Video: Four Ways to Solve Least Squares Problems · OCW: MIT 18.065 Lecture 9 · Okuma süresi: ~36 dk · Eğitmen: Gilbert Strang · Önkoşul: Ders 8 (vektör ve matris normları).
10.1 Bu Derste Ne Var?
\(Ax = b\) çoğu zaman çözülemez — ölçümler gürültülü, denklem sayısı bilinmeyenden çok. Least squares en iyi \(\hat{x}\)’i bulur. Ders 9 bunun dört yolunu işliyor; hepsi SVD ve dört temel alt-uzay üzerinde buluşuyor.
Üç temel fikir:
- Pseudoinverse \(A^{+} = V\Sigma^{+}U^{T}\) — SVD’den; satır/kolon uzayında gerçek ters, null uzaylarında sıfır. Her matris için tanımlı.
- Normal denklemler \(A^{T}A\hat{x} = A^{T}b\) — Gauss’un least squares’i; \(A\)’nın kolonları bağımsızsa çalışır; geometrik olarak \(b\)’nin kolon uzayına projeksiyonu.
- Dört yol — pseudoinverse (SVD), normal denklemler, QR/Gram-Schmidt, ve büyük/seyrek sistemler için iteratif yöntemler.
Bu dört yolun nasıl birbirine bağlandığını Şekil 10.1 özetliyor: hepsi tek bir least squares probleminden dallanır ve aynı dik izdüşümde buluşur.
“…what are these four ways…” — Strang, 5:21
İpucuBuilder Notu — Regresyonun Çekirdeği
- Least squares = regresyonun çekirdeği: lineer regresyon, en küçük kareler kaybı; ML’in en temel uyum problemi.
- Pseudoinverse \(A^{+}\) — rank-eksik ve dikdörtgen durumlarda “en iyi ters”; minimum-norm çözüm verir (Ders 11).
- \(A^{T}A\hat{x} = A^{T}b\) — pratikte en yaygın; ama \(A^{T}A\) kurmak kondisyonu kareler (Ders 6), o yüzden QR/SVD tercih edilir.
- Projeksiyon geometrisi — \(b\)’yi kolon uzayına düşür; hata \(b - A\hat{x}\) kolon uzayına diktir (ortogonallik ilkesi).
Tek cümle: çözülemeyen \(Ax = b\) için least squares, \(b\)’yi \(A\)’nın kolon uzayına projekte eder; bu projeksiyonu pseudoinverse, normal denklemler veya QR ile bulursun — hepsi aynı \(\hat{x}\)’e varır.
10.2 1. Least Squares Problemi
En küçük kareler problemi basittir: \(Ax = b\) denklemin çözümü yoktur (\(A\) dikdörtgen veya \(b\) kolon uzayında değil). Tipik durum: çok sayıda gürültülü ölçüm, az sayıda bilinmeyen.
“…the least squares problem is simply, you have an equation, Ax equals b.” — Strang, 23:05
Çözüm olmayınca ne yaparız? Gauss’un yolunu izleriz: hatanın \(\ell^2\) normunun karesini minimize et.
\[\min_x \;\|Ax - b\|^{2} = (Ax - b)^{T}(Ax - b)\]
Bu, çözülebilir bir problem verir ve Strang bunun dört çözüm yolunu işler.
“…what are these four ways…” — Strang, 5:21
İpucuBuilder Notu — En İyiyi Bul
Least squares, lineer regresyonun ve en temel uyum probleminin çekirdeğidir. \(\ell^2\) kaybı (kareli hata), derin öğrenmedeki MSE’nin atasıdır; “çözümü yok → en iyiyi bul” yaklaşımı tüm optimizasyonun zeminidir.
10.3 2. Pseudoinverse A⁺
İlk araç pseudoinverse’tir (sözde-ters). \(m \times n\) bir \(A\) için \(A^{+}\) matrisi \(n \times m\)’dir ve \(A^{+}A\)’yı mümkün olduğunca birim matrise yaklaştırır.
“…I’m going to get as near to the identity as I can. That’s the idea… of the pseudo inverse.” — Strang, 5:55
\(A\) tersinirse \(A^{+} = A^{-1}\) olur. Ama \(A\) dikdörtgense veya null uzayı varsa (kolonlar bağımlı), tam ters yoktur. Dört temel alt-uzay resmiyle: \(A\), satır uzayını kolon uzayına tersinir biçimde gönderir (üst yarı); \(A^{+}\) bunu geri getirir. Null uzayındaki vektörler \(0\)’a gider — geri getirilemez, \(A^{+}\) onları \(0\)’a gönderir.
Bu haritayı Şekil 10.2 gösteriyor: \(A\) satır uzayını kolon uzayına gönderir, \(A^{+}\) geri taşır, null uzayı sıfıra çöker.
Kod
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
fig, ax = plt.subplots(figsize=(9.5, 6.4))
ax.set_xlim(0, 10)
ax.set_ylim(0, 10)
# --- yardımcı: alt-uzay kutucuğu ---
def subspace_box(ax, x, y, w, h, label, fc):
box = FancyBboxPatch((x, y), w, h,
boxstyle="round,pad=0.02,rounding_size=0.06",
linewidth=2.0, edgecolor=COL_TEXT, facecolor=fc,
alpha=0.92, mutation_aspect=1.0, zorder=2)
ax.add_patch(box)
ax.text(x + w / 2, y + h / 2, label, ha="center", va="center",
color=COL_WHITE, fontsize=12.5, fontweight="bold", zorder=3)
return (x + w / 2, y + h / 2)
# SOL büyük çerçeve: Rⁿ
left_outer = FancyBboxPatch((0.35, 1.1), 3.5, 7.8,
boxstyle="round,pad=0.02,rounding_size=0.10",
linewidth=1.6, edgecolor=COL_STEEL_300,
facecolor=COL_BG, alpha=0.9, zorder=1)
ax.add_patch(left_outer)
ax.text(2.1, 9.25, r"$\mathbf{R}^n$", ha="center", va="center",
color=COL_TEXT, fontsize=15, fontweight="bold")
# SAĞ büyük çerçeve: Rᵐ
right_outer = FancyBboxPatch((6.15, 1.1), 3.5, 7.8,
boxstyle="round,pad=0.02,rounding_size=0.10",
linewidth=1.6, edgecolor=COL_STEEL_300,
facecolor=COL_BG, alpha=0.9, zorder=1)
ax.add_patch(right_outer)
ax.text(7.9, 9.25, r"$\mathbf{R}^m$", ha="center", va="center",
color=COL_TEXT, fontsize=15, fontweight="bold")
# SOL: satır uzayı (üst, navy) + null uzayı (alt, steel)
row_c = subspace_box(ax, 0.75, 5.55, 2.7, 2.7,
r"satır uzayı" + "\n" + r"$C(A^{T})$", COL_PRIMARY)
null_c = subspace_box(ax, 0.75, 1.75, 2.7, 2.7,
r"null uzayı" + "\n" + r"$N(A)$", COL_ACCENT)
# SAĞ: kolon uzayı (üst, navy) + sol null uzayı (alt, steel)
col_c = subspace_box(ax, 6.55, 5.55, 2.7, 2.7,
r"kolon uzayı" + "\n" + r"$C(A)$", COL_PRIMARY)
lnull_c = subspace_box(ax, 6.55, 1.75, 2.7, 2.7,
r"sol null" + "\n" + r"$N(A^{T})$", COL_ACCENT)
# Dik (⊥) tümleyen işaretleri — sol ve sağ çerçevenin ortasında
for cx in (2.1, 7.9):
ax.text(cx, 5.05, r"$\perp$", ha="center", va="center",
color=COL_TEXT, fontsize=15, fontweight="bold",
bbox=dict(boxstyle="circle,pad=0.18", fc=COL_WHITE,
ec=COL_STEEL_300, lw=1.2), zorder=4)
# A oku: satır uzayı → kolon uzayı (navy düz, üst yay)
a_arrow = FancyArrowPatch((row_c[0] + 1.35, row_c[1] + 0.35),
(col_c[0] - 1.35, col_c[1] + 0.35),
arrowstyle="-|>", mutation_scale=22,
linewidth=2.4, color=COL_PRIMARY, zorder=5,
connectionstyle="arc3,rad=-0.28")
ax.add_patch(a_arrow)
ax.text(5.0, row_c[1] + 1.45, r"$A$", ha="center", va="center",
color=COL_PRIMARY, fontsize=16, fontweight="bold")
# A⁺ oku: kolon uzayı → satır uzayı (orange, geri, alt yay)
ap_arrow = FancyArrowPatch((col_c[0] - 1.35, col_c[1] - 0.35),
(row_c[0] + 1.35, row_c[1] - 0.35),
arrowstyle="-|>", mutation_scale=22,
linewidth=2.4, color=COL_VEC3, zorder=5,
connectionstyle="arc3,rad=-0.28")
ax.add_patch(ap_arrow)
ax.text(5.0, row_c[1] - 1.40, r"$A^{+}$", ha="center", va="center",
color=COL_VEC3, fontsize=16, fontweight="bold")
# Null uzayı → 0 oku (kesik): N(A) çarpımı sıfır
ax.text(5.0, null_c[1], "0", ha="center", va="center",
color=COL_TEXT, fontsize=14, fontweight="bold",
bbox=dict(boxstyle="circle,pad=0.22", fc=COL_WHITE,
ec=COL_TEXT, lw=1.4), zorder=5)
zero_arrow = FancyArrowPatch((null_c[0] + 1.35, null_c[1]),
(4.72, null_c[1]),
arrowstyle="-|>", mutation_scale=18,
linewidth=2.0, color=COL_ACCENT, zorder=4,
linestyle="--",
connectionstyle="arc3,rad=0.0")
ax.add_patch(zero_arrow)
ax.text(3.95, null_c[1] + 0.42, r"$Ax = 0$", ha="center", va="center",
color=COL_ACCENT, fontsize=10.5, style="italic")
ax.set_title("$A$ satır uzayını kolon uzayına gönderir; $A^{+}$ geri getirir, null $\\to$ 0",
color=COL_TEXT, fontsize=13.5, fontweight="bold", pad=14)
ax.axis("off")
plt.show()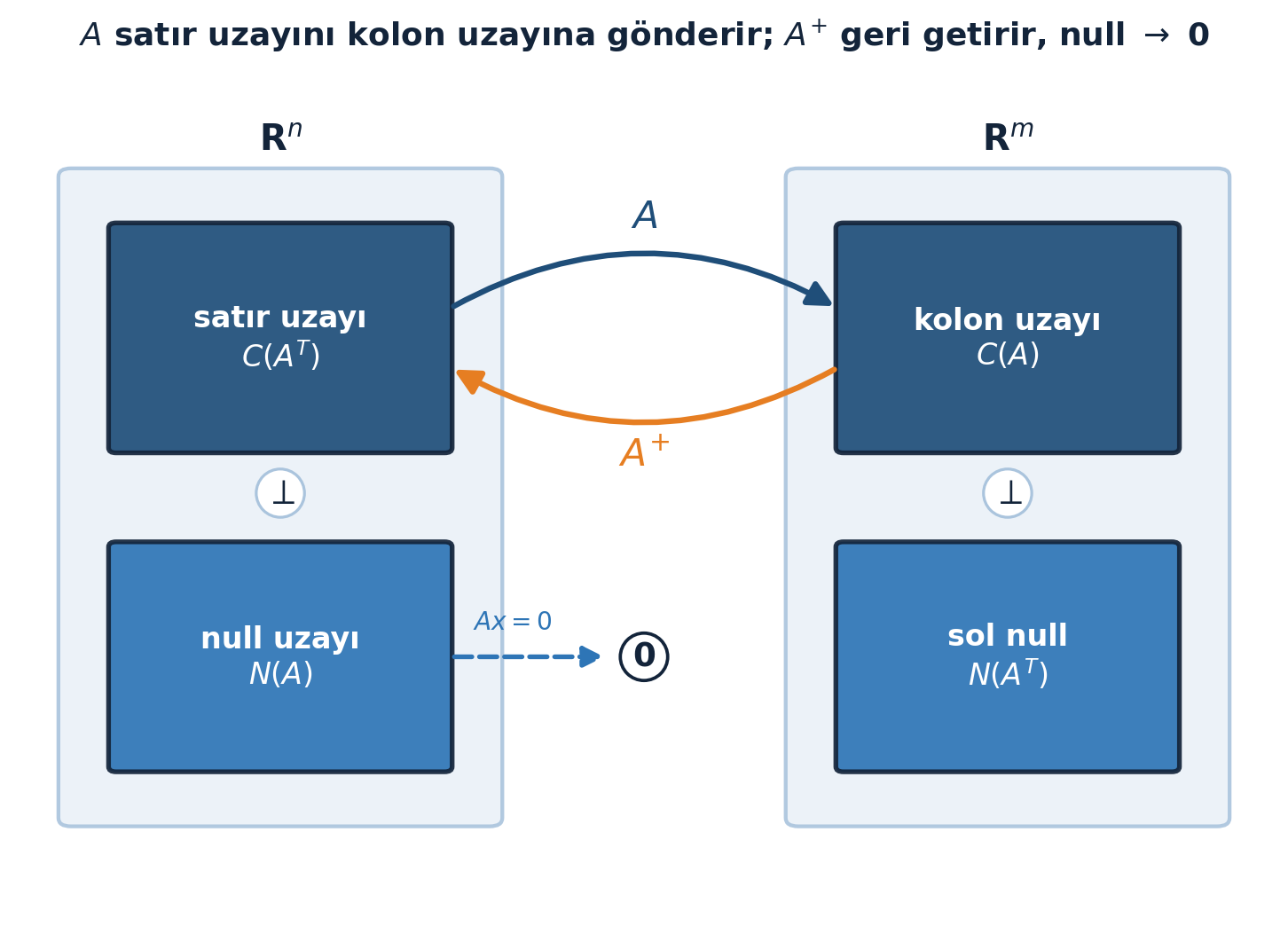
İpucuBuilder Notu — Tersi Olmayanın Tersi
\(A^{+}\), “tersi olmayan matrisin en iyi tersi”dir. ML’de rank-eksik tasarım matrisleri, eksik-belirlenmiş sistemler ve minimum-norm çözümlerde (Ders 11) kullanılır — regresyonun en genel hâli.
10.4 3. A⁺ = VΣ⁺Uᵀ (SVD ile)
Pseudoinverse için temiz formül SVD’den gelir, çünkü SVD her matris için vardır.
“…start with the SVD. Because the SVD works for any matrix.” — Strang, 14:34
\(A = U\Sigma V^{T}\) ise, üç çarpanı tersine çevir (ortogonal \(U\), \(V\) için ters = transpoz):
\[A^{+} = V \Sigma^{+} U^{T}\]
Buradaki \(\Sigma^{+}\), sıfırdan-farklı tekil değerleri ters çevirir, sıfırları sıfır bırakır:
\[\Sigma^{+} = \text{diag}\!\left(\tfrac{1}{\sigma_1}, \ldots, \tfrac{1}{\sigma_r}, 0, \ldots, 0\right)\]
\(\Sigma^{+}\Sigma\) çarpımı, ilk \(r\) köşegende 1, gerisi 0 olan bir projeksiyondur — yapabileceğimizin en iyisi. Bu tersleme kuralını Şekil 10.3 gösteriyor.
Kod
A = np.array([[3., 0., 0.], [0., 2., 0.]]) # 2x3, σ = 3, 2
s, sp = sigma_plus(A) # s = [3, 2], sp = [1/3, 1/2]
m, n = A.shape
Sig = np.zeros((m, n)); Sig[:len(s), :len(s)] = np.diag(s) # Σ (2×3)
Sigp = np.zeros((n, m)); Sigp[:len(sp), :len(sp)] = np.diag(sp) # Σ⁺ (3×2)
fig, axes = plt.subplots(1, 2, figsize=(11, 4.4))
heatmap(axes[0], Sig, title="Σ (2×3): σ = 3, 2", fmt="{:.2g}")
heatmap(axes[1], Sigp, title="Σ⁺ (3×2): 1/σ = 1/3, 1/2", fmt="{:.2g}")
fig.suptitle("Σ⁺: sıfırdan-farklı σ değerlerini tersler (1/σ), sıfırı bırakır → A⁺ = VΣ⁺Uᵀ",
color=COL_TEXT, fontsize=13, fontweight="bold")
fig.tight_layout()
plt.show()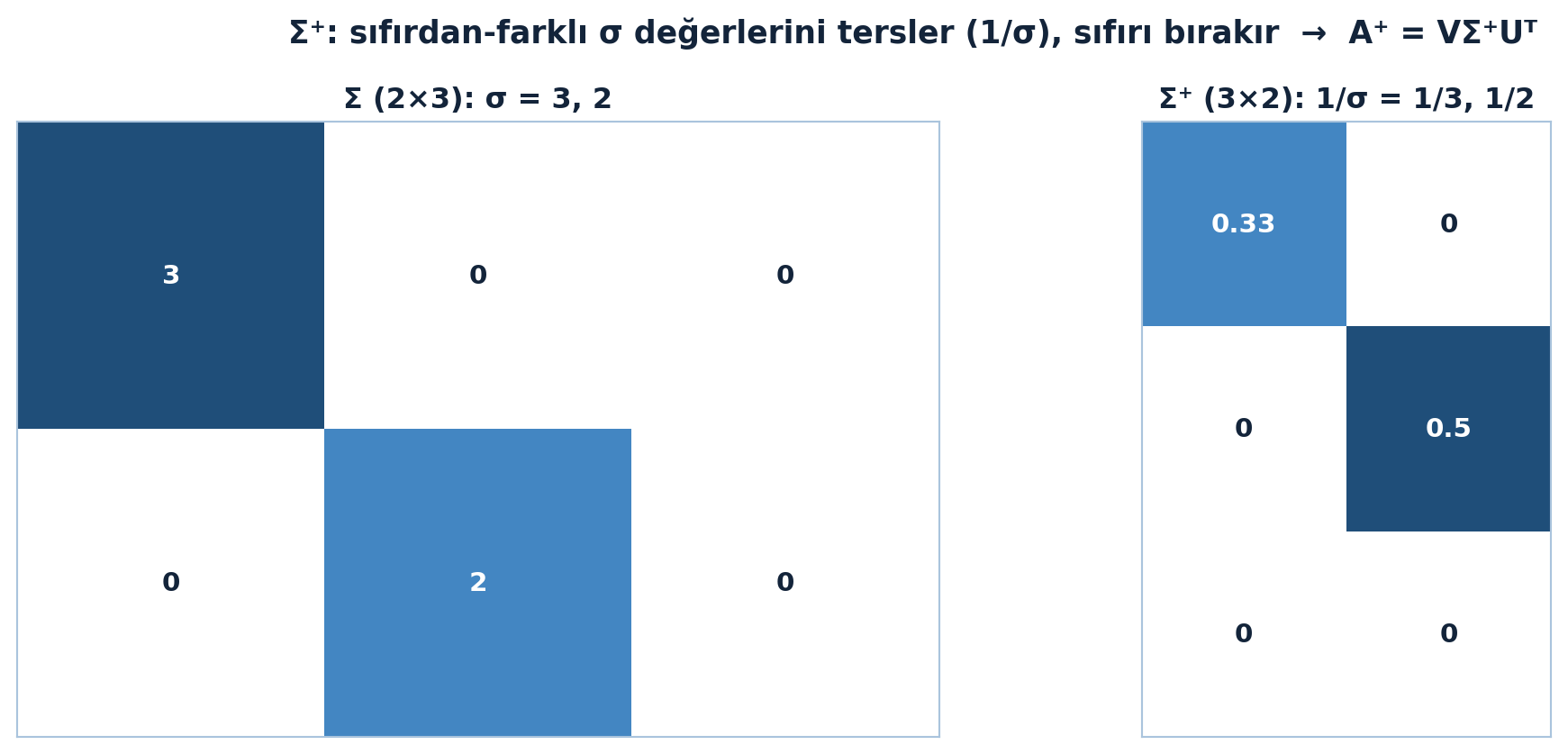
İpucuBuilder Notu — SVD Her Zaman Var
\(A^{+} = V\Sigma^{+}U^{T}\), np.linalg.pinv’in tam olarak hesapladığıdır. Küçük tekil değerleri (gürültü) eşikleyip atmak (truncated SVD), düzenlileştirilmiş bir pseudoinverse verir — ters problemlerde ve gürültülü regresyonda kararlılık sağlar.
10.5 4. Yol 1: x̂ = A⁺b
En genel çözüm doğrudan pseudoinverse ile gelir:
\[\hat{x} = A^{+} b = V \Sigma^{+} U^{T} b\]
Bu yol her durumda çalışır — \(A\) dikdörtgen, rank-eksik, null uzaylı olsa bile. Null uzayı varsa bu, sonsuz çözüm arasından minimum-norm olanı seçer (Ders 11). Diğer üç yol, \(A\)’nın bağımsız kolonlu olmasını gerektirir; pseudoinverse bu koşula ihtiyaç duymaz.
İpucuBuilder Notu — En Güvenli Çözüm
\(\hat{x} = A^{+}b\), np.linalg.lstsq/pinv’in döndürdüğü en güvenli çözümdür: rank-eksik durumlarda bile patlamaz, minimum-norm cevabı verir. Ters problemler, az-örnekli regresyon ve eksik-belirlenmiş sistemler için varsayılan.
10.6 5. Yol 2: Normal Denklemler
İkinci yol, \(A\)’nın bağımsız kolonları varsa en yaygın olanıdır. \(\|Ax - b\|^2\) minimize edilince türev sıfırlanır ve normal denklemler çıkar:
“We follow Gauss’s advice to get the best we can.” — Strang, 30:20
\[A^{T}A \, \hat{x} = A^{T}b\]
“A transpose A is going to come from there…” — Strang, 31:58
\(A\)’nın bağımsız kolonları varsa \(A^{T}A\) tersinirdir ve çözüm \(\hat{x} = (A^{T}A)^{-1}A^{T}b\) olur.
“If A has independent columns…” — Strang, 37:58
Bu, istatistikteki lineer regresyondur; çoğu pratik problemde matrisi kurup doğrudan çözersin. Ama bu basitliğin bir bedeli var: \(A^{T}A\) kurmak kondisyon sayısını karelendiriyor, ki bunu Şekil 10.4 net biçimde gösteriyor.
Kod
# Artan kondisyonlu birkaç A: diag(1, c)
cs = [2, 5, 10, 20]
kA_list = []; kAtA_list = []
for c in cs:
A = np.diag([1.0, float(c)])
kA, kAtA = cond_compare(A)
kA_list.append(kA); kAtA_list.append(kAtA)
kA_arr = np.array(kA_list); kAtA_arr = np.array(kAtA_list)
fig, ax = plt.subplots(figsize=(7.2, 5.2))
apply_style(ax)
# κ(A) referans doğrusu (y = x)
ax.plot(kA_arr, kA_arr, color=COL_PRIMARY, ls=":", lw=2.0, label=r"$\kappa(A)$ (referans)")
# κ² teorik eğri (çelik)
kgrid = np.linspace(kA_arr.min(), kA_arr.max(), 200)
ax.plot(kgrid, kgrid**2, color=COL_ACCENT, lw=2.2, label=r"$\kappa(A)^2$")
# ölçülen κ(AᵀA) (turuncu scatter)
ax.scatter(kA_arr, kAtA_arr, color=COL_VEC3, s=70, zorder=5, edgecolor=COL_TEXT, linewidth=0.8, label=r"$\kappa(A^{T}A)$")
ax.set_xscale("log"); ax.set_yscale("log")
ax.set_xlabel("κ(A)"); ax.set_ylabel("κ değeri")
ax.set_title("Normal denklem riski: κ(AᵀA) = κ(A)² (kondisyon karelenir -> QR/SVD tercih)",
color=COL_TEXT, fontsize=10.5, fontweight="bold")
ax.legend(loc="upper left", framealpha=0.9)
fig.tight_layout()
plt.show()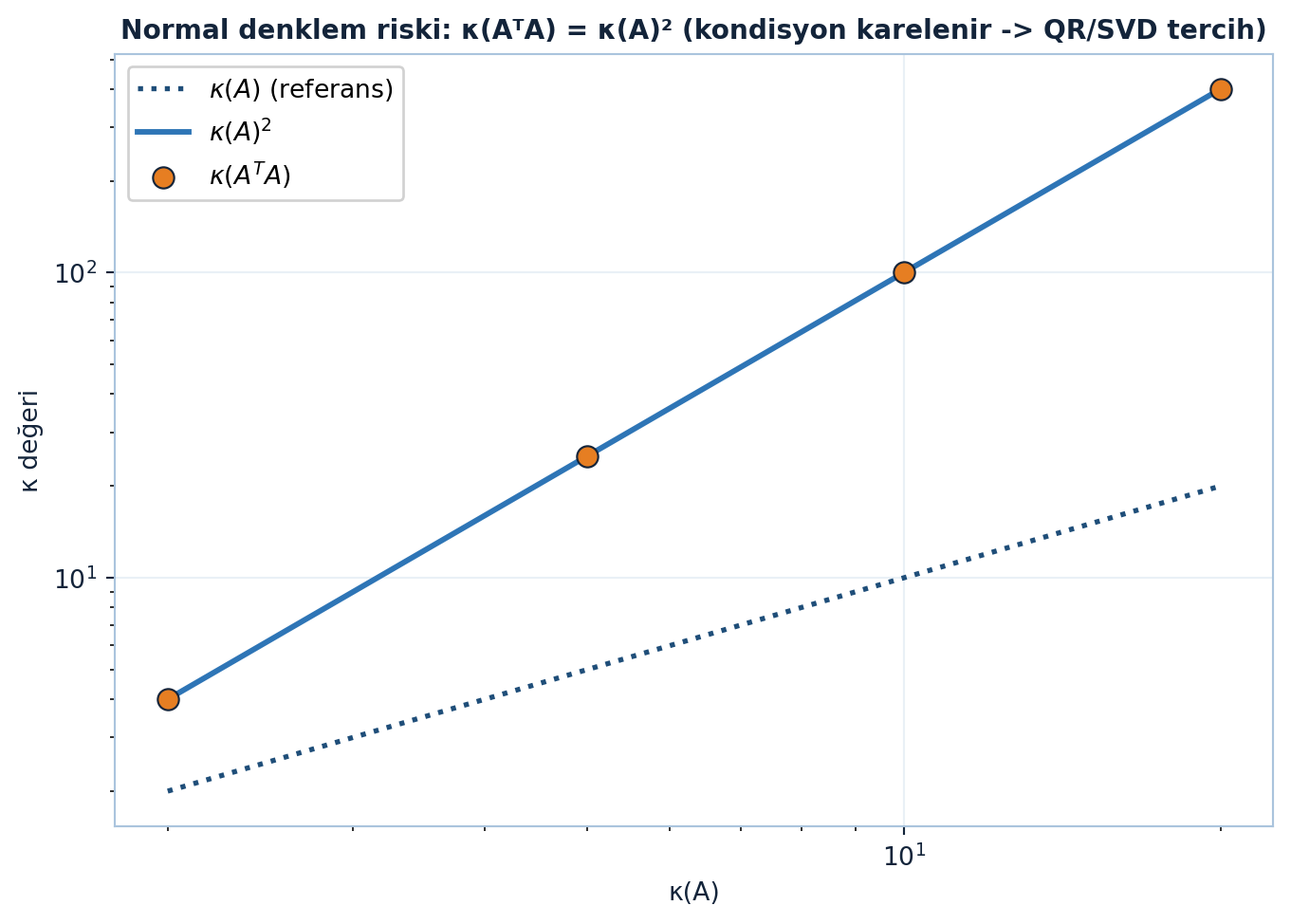
İpucuBuilder Notu — Gauss’un Yolu
Normal denklemler basit ama \(A^{T}A\) kondisyon sayısını kareler (Ders 6) — sayısal olarak riskli. Bu yüzden ciddi problemlerde QR (Yol 3) veya SVD (Yol 1) tercih edilir; lstsq arka planda normal denklem kurmaz, QR/SVD kullanır.
10.7 6. Geometri: Kolon Uzayına Projeksiyon
Normal denklemlerin geometrisi nettir. \(b\) genelde \(A\)’nın kolon uzayında değildir (o yüzden çözüm yok). En iyi \(A\hat{x}\), \(b\)’nin kolon uzayına dik izdüşümüdür:
“…It’s the projection.” — Strang, 35:41
\[A\hat{x} = \text{proj}_{C(A)}(b), \qquad (b - A\hat{x}) \perp C(A)\]
Hata vektörü \(b - A\hat{x}\), kolon uzayına diktir — bu da \(A^{T}(b - A\hat{x}) = 0\), yani \(A^{T}A\hat{x} = A^{T}b\) demektir. Geometri (diklik) ile cebir (normal denklem) aynı şeyi söyler. Bu ortogonallik ilkesi, least squares’in kalbidir. Şekil 10.5 bu izdüşümü üç boyutta gösteriyor: \(b\) düzlemin dışında, \(A\hat{x}\) düzlemin üzerinde, hata vektörü düzleme dik.
Kod
A = np.array([[1., 0.], [1., 1.], [1., 2.]])
b = np.array([6., 0., 0.])
p, r, xhat = projection(A, b)
fig = plt.figure(figsize=(7.2, 6.0))
ax = fig.add_subplot(111, projection="3d")
apply_style_3d(ax)
# C(A) düzlemi: A'nın iki kolonunun gerdiği düzlem
c1 = A[:, 0]
c2 = A[:, 1]
s = np.linspace(-1.5, 2.5, 16)
t = np.linspace(-1.5, 2.5, 16)
S, T = np.meshgrid(s, t)
X = S * c1[0] + T * c2[0]
Y = S * c1[1] + T * c2[1]
Z = S * c1[2] + T * c2[2]
ax.plot_surface(X, Y, Z, color=COL_SKY_400, alpha=0.2,
linewidth=0, antialiased=True, shade=False)
# b (gözlem) ve p = Ax̂ (izdüşüm)
draw_vec3d(ax, b, color=COL_VEC3, label="b")
draw_vec3d(ax, p, color=COL_PRIMARY, label="Ax̂ (proj)")
# Artık (hata) çizgisi: b'den p'ye, C(A)'ya dik
ax.plot([b[0], p[0]], [b[1], p[1]], [b[2], p[2]],
color=COL_TEAL, ls=":", lw=2.2, label="hata r ⊥ C(A)")
# quiver legendde görünmez → proxy artist'lerle açıklama
from matplotlib.lines import Line2D
proxies = [Line2D([0], [0], color=COL_VEC3, lw=2.4, label="b"),
Line2D([0], [0], color=COL_PRIMARY, lw=2.4, label="Ax̂ (proj)"),
Line2D([0], [0], color=COL_TEAL, lw=2.2, ls=":", label="hata r ⊥ C(A)")]
ax.set_xlabel("x")
ax.set_ylabel("y")
ax.set_zlabel("z")
ax.set_title("b'nin kolon uzayına dik izdüşümü: hata r=b-Ax̂ ⊥ C(A)",
color=COL_TEXT, fontsize=11, fontweight="bold")
ax.view_init(elev=30, azim=-40)
ax.legend(handles=proxies, loc="upper left", fontsize=9, framealpha=0.85)
plt.tight_layout()
plt.show()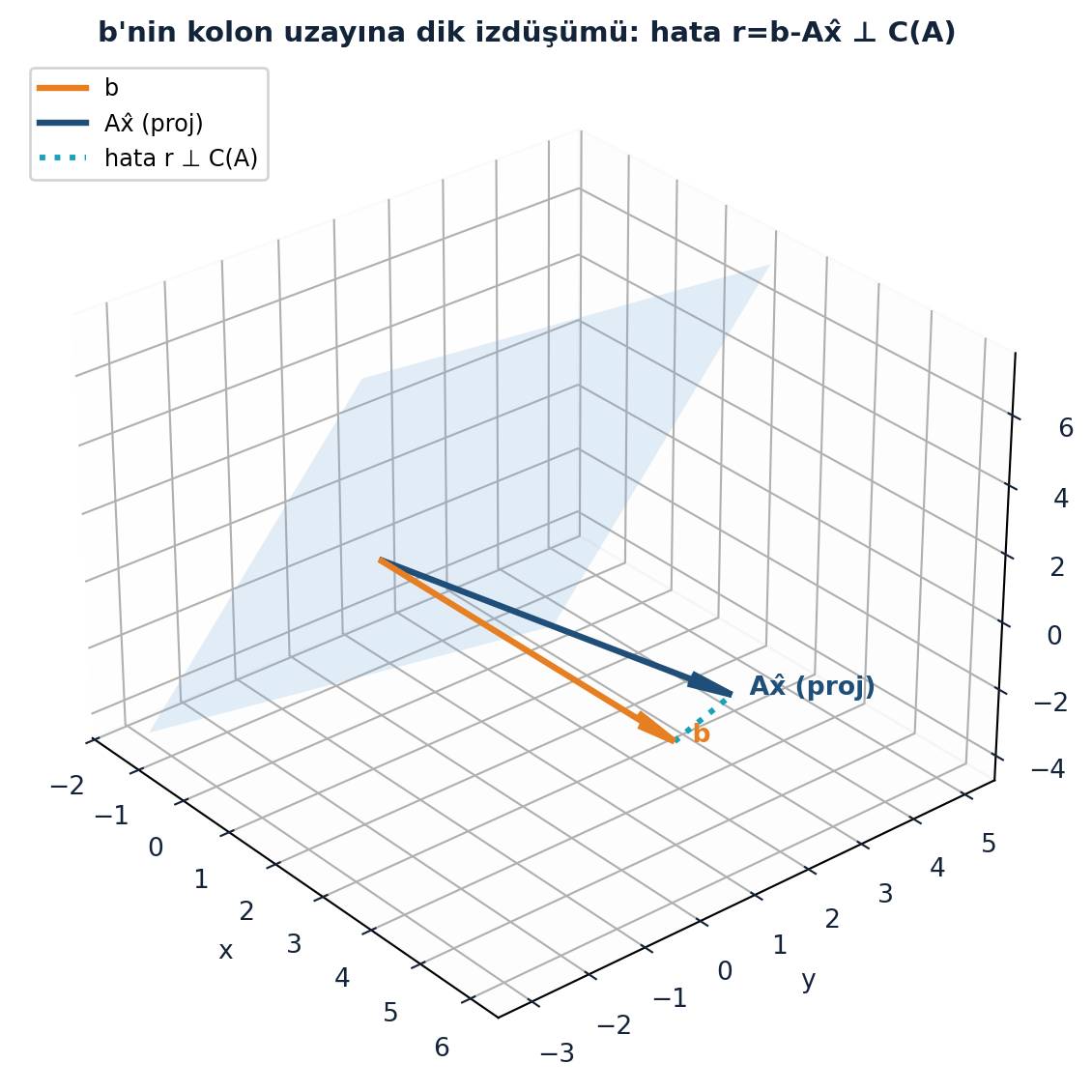
İpucuBuilder Notu — Diklik İlkesi
“Hata, kolon uzayına diktir” ilkesi her yerde: Kalman filtresi (yenilik artığı \(\perp\) geçmiş), Gauss-Markov teoremi, ve sinir ağı son katmanının lineer çözümü. Projeksiyon = en iyi tahmin = ortogonallik koşulu.
10.8 7. Doğru Uydurma Örneği
Least squares’in ünlü örneği: gürültülü noktalara en iyi doğruyu (\(C + Dx\)) uydurmak.
“…the famous example of least squares is fit a straight line to the b’s.” — Strang, 25:02
Her ölçüm \(x_i\) noktasında bir \(b_i\) değeri var; bilinmeyenler \(C\) ve \(D\) (iki sütun → rank 2). Sistem:
\[A = \begin{pmatrix} 1 & x_1 \\ 1 & x_2 \\ \vdots & \vdots \\ 1 & x_m \end{pmatrix}, \quad x = \begin{pmatrix} C \\ D \end{pmatrix}, \quad b = \begin{pmatrix} b_1 \\ \vdots \\ b_m \end{pmatrix}\]
\(m\) ölçüm, 2 bilinmeyen → çok fazla denklem, çözüm yok. Noktalar tam doğru üstündeyse çözüm vardır; gürültü varsa (gerçek hayat) yoktur → en iyi \(C\), \(D\)’yi least squares ile bul. Şekil 10.6 bunu gösteriyor: noktalar saçılı, en iyi doğru dikey hataların karelerini minimize ediyor.
Kod
xs = np.array([0, 1, 2, 3, 4.])
bs = np.array([1.0, 1.6, 1.3, 3.0, 2.7])
C, D, Af, bf, res = line_fit(xs, bs)
fig, ax = plt.subplots(figsize=(7, 4.5))
apply_style(ax)
ax.scatter(xs, bs, s=40, color=COL_STEEL_300, zorder=3, label="veri noktaları")
xx = np.linspace(0, 4, 40)
ax.plot(xx, C + D * xx, color=COL_VEC3, lw=2.2, label="en iyi doğru C+Dx")
for k, (xi, bi) in enumerate(zip(xs, bs)):
ax.plot([xi, xi], [bi, C + D * xi], color=COL_VEC1, ls=":", lw=1.2,
label="dikey artık (hata)" if k == 0 else None)
ax.set_xlabel("x"); ax.set_ylabel("b")
ax.legend()
ax.set_title("Least squares doğru uydurma: dikey hataların karesi min (C+Dx)",
color=COL_TEXT, fontsize=11, fontweight="bold")
plt.show()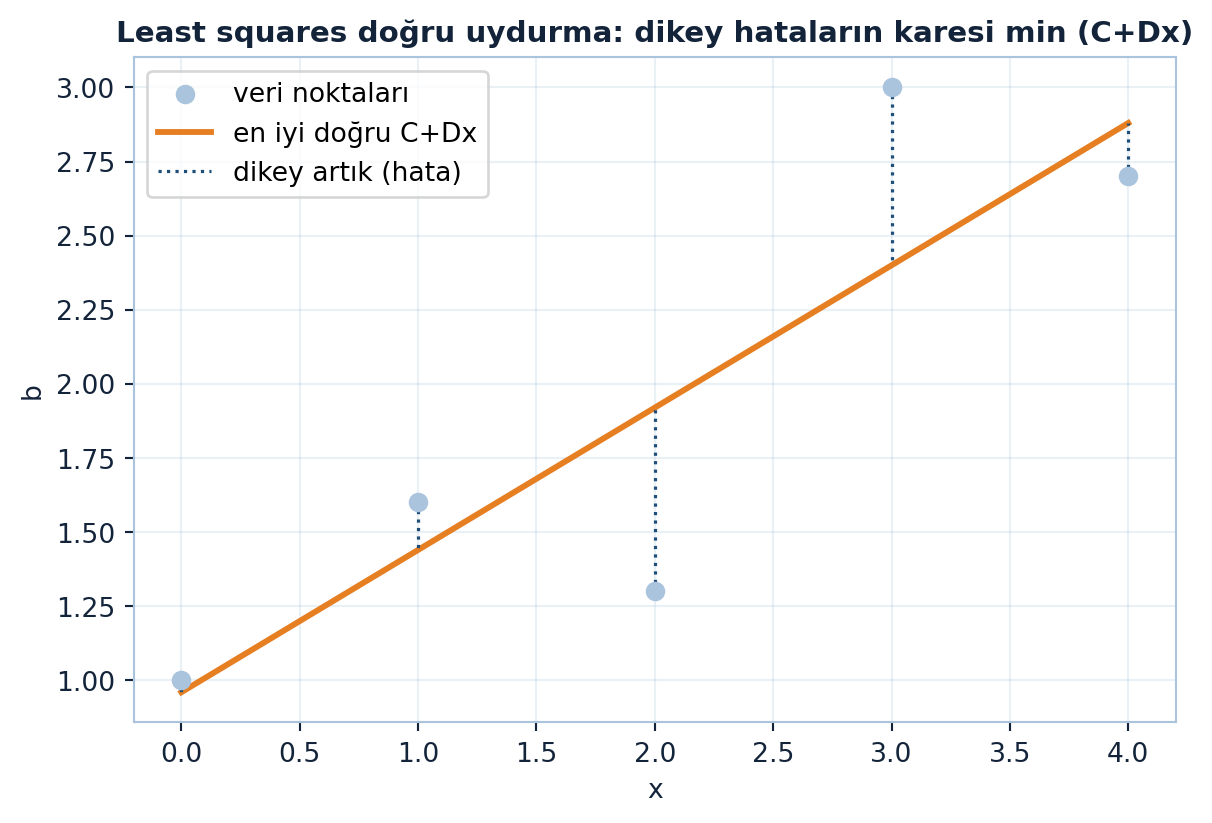
İpucuBuilder Notu — İlk Model
Bu, ML’deki en basit modeldir: tek özellikli lineer regresyon. Çok özellikli hâli (\(A\)’nın çok sütunu) aynı normal denklemle çözülür. Polinom uydurma, trend kestirimi ve baseline modeller hep bu yapıdır.
10.9 8. Yol 3: QR / Gram-Schmidt
Üçüncü yol, normal denklemin sayısal sorununu aşar: önce \(A\)’nın kolonlarını ortonormal yap (Gram-Schmidt), yani \(A = QR\).
“…Gram-Schmidt is a way… to get [orthogonal] columns.” — Strang, 47:11
\(A = QR\) yerine koyunca \(A^{T}A = R^{T}Q^{T}QR = R^{T}R\) olur (çünkü \(Q^{T}Q = I\)), ve normal denklem sadeleşir:
\[A = QR \;\Rightarrow\; R\hat{x} = Q^{T}b\]
\(R\) üst üçgensel olduğundan geri yerine koymayla çözülür; \(A^{T}A\) hiç kurulmaz, kondisyon karelenmez. Bu, pratik least squares’in standart yoludur.
İpucuBuilder Notu — Sayısal Güvenlik
QR, numpy.linalg.lstsq’in (ve LAPACK’in) varsayılan yoludur: kararlı, \(A^{T}A\)’dan kaçınır. Householder yansımaları (Ders 3) QR’ı kararlı üretir. Ortonormallik = sayısal güvenlik.
10.10 9. Pseudoinverse = Normal Denklem (Bağımsız Kolonlarda)
Dört yol aynı \(\hat{x}\)’e varır. \(A\)’nın bağımsız kolonları varsa (null uzay yok), pseudoinverse tam olarak normal denklem çözümüne eşittir:
\[A^{+} = (A^{T}A)^{-1}A^{T} \quad (\text{left inverse})\]
Bu \(A^{+}\), \(A\)’yı soldan tersler (\(A^{+}A = I\)) ama sağdan terslemez (\(AA^{+} \neq I\) — kolon uzayına projeksiyon). SVD formülü \(A^{+} = V\Sigma^{+}U^{T}\) ise hiçbir koşul gerektirmez ve rank-eksikte de geçerlidir; bağımsız kolonlarda ikisi çakışır. Dört yolun da aynı \(\hat{x}\)’e vardığını Şekil 10.7 sayısal olarak doğruluyor.
Kod
A = np.array([[1., 0.], [1., 1.], [1., 2.]])
b = np.array([6., 0., 0.])
w = four_ways(A, b)
methods = ["pseudoinverse", "normal", "QR", "lstsq"]
colors = [COL_VEC1, COL_VEC2, COL_TEAL, COL_VEC3]
fig, ax = plt.subplots(figsize=(8, 5))
apply_style(ax)
groups = np.arange(2) # x̂[0], x̂[1]
n = len(methods)
width = 0.18
for i, (m, c) in enumerate(zip(methods, colors)):
xhat = np.asarray(w[m], dtype=float)
offset = (i - (n - 1) / 2.0) * width
bars = ax.bar(groups + offset, xhat, width=width, color=c, edgecolor=COL_TEXT,
linewidth=0.8, label=m, zorder=3)
for x, v in zip(groups + offset, xhat):
ax.text(x, v + 0.18 * np.sign(v or 1), f"{v:.0f}", ha="center",
va="bottom" if v >= 0 else "top", fontsize=9, color=COL_TEXT, fontweight="bold")
ax.axhline(0, color=COL_STEEL_300, lw=0.9, zorder=1)
ax.set_xticks(groups)
ax.set_xticklabels(["$\\hat{x}[0]$", "$\\hat{x}[1]$"], fontsize=12)
ax.set_ylabel("Bileşen değeri", color=COL_TEXT)
ax.set_ylim(-4.5, 6.5)
ax.set_title("Dört yol → AYNI x̂ = (5, −3)", color=COL_TEXT, fontsize=12, fontweight="bold")
ax.legend(loc="upper right", framealpha=0.95, fontsize=9)
ax.text(0.5, -0.18, "pseudoinverse = normal = QR = lstsq",
transform=ax.transAxes, ha="center", va="top", fontsize=10,
color=COL_PRIMARY, fontstyle="italic")
fig.tight_layout()
plt.show()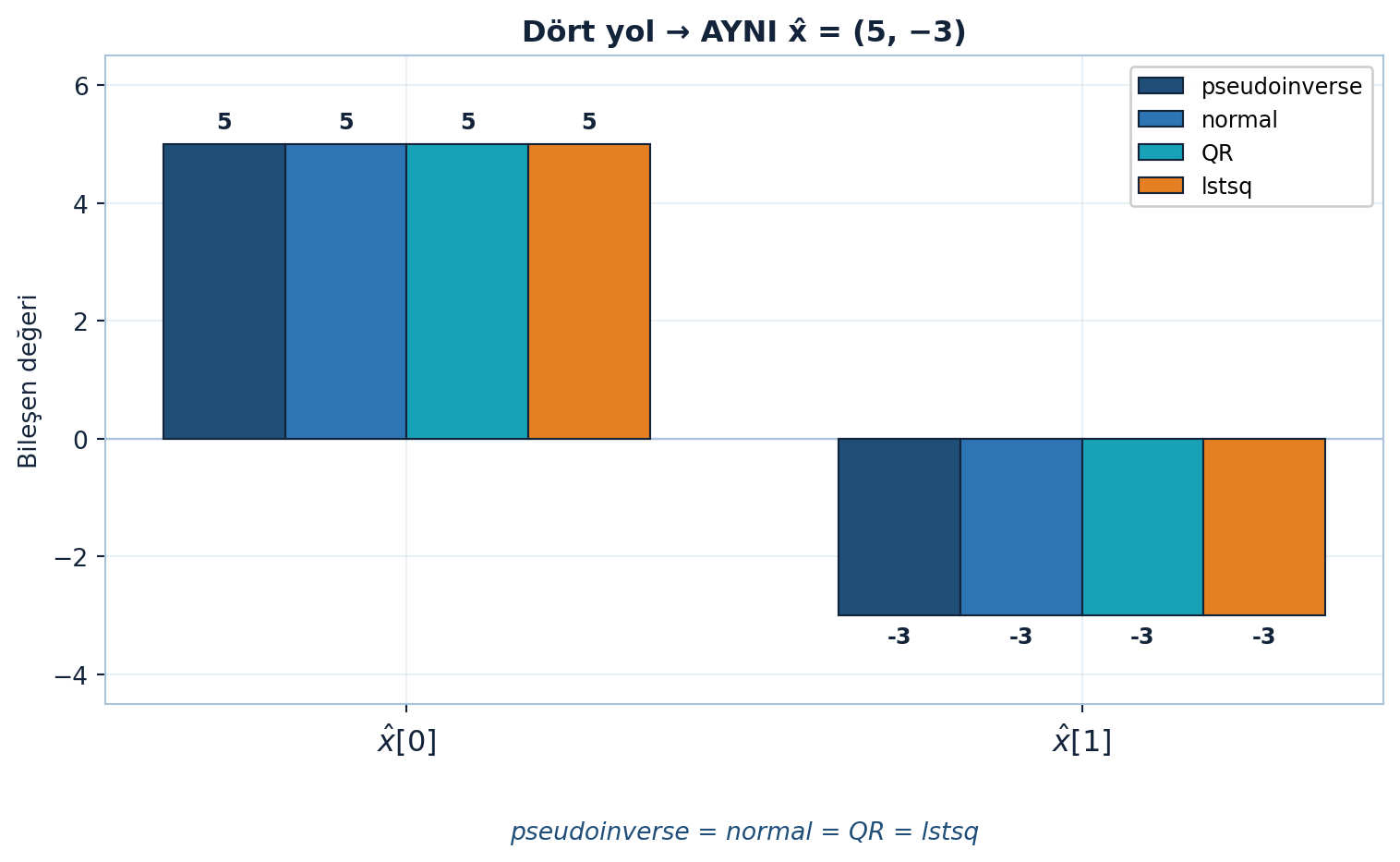
İpucuBuilder Notu — Sol Ters
“Sol ters var ama sağ ters yok” durumu, ince-uzun (tall) tasarım matrislerinin tipik hâlidir: çok örnek, az parametre. \(A^{+}A = I\) (parametreler kurtarılır) ama \(AA^{+}\) projeksiyon (veri tam kurtarılamaz, gürültü düşer) — regresyonun matematiksel imzası.
10.11 10. Yol 4: Büyük Sistemler İçin İteratif
Dördüncü yol, \(A\) çok büyük veya seyrek olduğunda devreye girer (Strang bu dersin sonunda zamana yetişemedi, ileri derslerde işlenir). Doğrudan \(A^{T}A\) veya QR çözmek pahalı/imkânsızsa, iteratif yöntemler (conjugate gradient ve benzeri) çözümü adım adım yaklaşır.
\[\text{Devasa/seyrek A} \;\rightarrow\; \text{iteratif (conjugate gradient)}\]
Bu yöntemler matrisi hiç açıkça kurmaz; yalnızca \(A\) ile çarpım (matrix-vector product) kullanır — milyon-boyutlu sistemlerde tek pratik seçenek.
İpucuBuilder Notu — Devasa Sistemler
İteratif çözücüler (conjugate gradient, LSQR), büyük-ölçek ML ve bilimsel hesabın belkemiğidir: yalnızca \(Ax\) çarpımı gerektirdiklerinden seyrek/yapısal matrislerde belleğe sığar. Gradient descent (Ders 21-23) bu ailenin optimizasyon akrabasıdır.
10.12 Bu Dersin Özeti
- Least squares — çözülemeyen \(Ax = b\) için \(\|Ax - b\|^2\)’yi minimize et.
- Pseudoinverse \(A^{+}\) — satır/kolon uzayında ters, null uzaylarında 0; her matris için.
- \(A^{+} = V\Sigma^{+}U^{T}\) — SVD’den; \(\Sigma^{+}\) sıfırdan-farklı \(\sigma\)’ları tersler, sıfırları bırakır.
- Yol 1: \(\hat{x} = A^{+}b\) — en genel; rank-eksikte minimum-norm çözüm.
- Yol 2: \(A^{T}A\hat{x} = A^{T}b\) — normal denklemler; bağımsız kolonlar gerekir.
- Geometri — \(A\hat{x} = b\)’nin kolon uzayına projeksiyonu; hata \(\perp\) kolon uzayı.
- Doğru uydurma — \(C + Dx\); \(m\) ölçüm, 2 bilinmeyen.
- Yol 3: QR — \(A = QR\), \(R\hat{x} = Q^{T}b\); \(A^{T}A\)’dan kaçınır, kararlı.
- \(A^{+} = (A^{T}A)^{-1}A^{T}\) — bağımsız kolonlarda pseudoinverse = normal denklem.
- Yol 4: iteratif — büyük/seyrek için conjugate gradient.
ÖnemliTek Bir Cümle
Çözülemeyen \(Ax = b\) için least squares, \(b\)’yi \(A\)’nın kolon uzayına dik olarak projekte eder (hata \(\perp\) kolon uzayı); bu \(\hat{x}\)’i pseudoinverse (SVD), normal denklemler veya QR ile bulursun — hepsi aynı en-iyi çözüme varır.
10.13 Kontrol Soruları
NotSoru 1: (1,1), (2,2), (3,2) noktalarına en iyi doğruyu (C + Dx) normal denklemlerle uydur.
\[A = \begin{pmatrix} 1 & 1 \\ 1 & 2 \\ 1 & 3 \end{pmatrix}, \quad b = \begin{pmatrix} 1 \\ 2 \\ 2 \end{pmatrix}\]
Cevap: \(A^{T}A = \begin{pmatrix} 3 & 6 \\ 6 & 14 \end{pmatrix}\), \(A^{T}b = (5, 11)\). Normal denklem: \(3C + 6D = 5\), \(6C + 14D = 11\). Çözüm: \(D = 1/2\), \(C = 2/3\). En iyi doğru: \(y = 2/3 + (1/2)x\). (Noktalar tam doğru üstünde değil, bu en küçük kareler uyumu.)
NotSoru 2: A = [[1, 2], [2, 4]] (rank 1) için pseudoinverse A⁺’ı bul.
\[A = \begin{pmatrix} 1 & 2 \\ 2 & 4 \end{pmatrix}\]
Cevap: \(A = c c^{T}\), \(c = (1, 2)\). Tek tekil değer \(\sigma_1 = \|c\|^2 = 5\), tekil vektör \(u = v = c/\sqrt{5}\). \(A^{+} = (1/\sigma_1) v u^{T} = (1/25) c c^{T} = A/25\):
\[A^{+} = \frac{1}{25}\begin{pmatrix} 1 & 2 \\ 2 & 4 \end{pmatrix}\]
Kontrol: \(A^{+}A\) satır uzayına projeksiyon (birim değil, çünkü rank 1).
NotSoru 3: Least squares çözümünde hata vektörü b − Ax̂ neden kolon uzayına diktir?
Cevap: \(A\hat{x}\), \(b\)’nin kolon uzayına en yakın noktasıdır (projeksiyon). En yakın nokta, hatanın uzaya dik olduğu noktadır (Pythagoras: dik olmayan her yön daha uzun hata verir). Diklik: kolon uzayının her vektörü \(Ay\) için \((Ay)^{T}(b - A\hat{x}) = 0 \to A^{T}(b - A\hat{x}) = 0 \to A^{T}A\hat{x} = A^{T}b\). Yani ortogonallik ilkesi doğrudan normal denklemleri verir.
NotSoru 4: Ne zaman pseudoinverse (A⁺), ne zaman normal denklem (AᵀA) kullanırsın?
Cevap: Normal denklem / QR: \(A\)’nın bağımsız kolonları varsa (tall, full-rank). QR sayısal olarak daha kararlı, pratik seçim. Pseudoinverse (SVD): \(A\) rank-eksik veya çok kötü koşullu ise — null uzayı varken sonsuz çözüm arasından minimum-norm olanı seçer, patlamaz. Çok büyük/seyrek \(A\) için ise iteratif yöntemler (Yol 4). Pratikte np.linalg.lstsq bu kararı senin için verir (QR/SVD tabanlı).
10.14 Egzersizler
Cevapsız problemler. Çöz, sonra numpy ile kontrol et.
Egzersiz 1. \((0, 6)\), \((1, 0)\), \((2, 0)\) noktalarına en iyi doğruyu (\(C + Dx\)) normal denklemlerle uydur. Hata vektörünü ve onun kolon uzayına dik olduğunu doğrula.
Egzersiz 2. Aşağıdaki matrisin pseudoinverse’ini SVD ile bul. \(A^{+}A\) ve \(AA^{+}\)’yı hesapla; hangisi birim, hangisi projeksiyon?
\[A = \begin{pmatrix} 1 & 0 \\ 0 & 1 \\ 0 & 0 \end{pmatrix}\]
Egzersiz 3. \(A\) bağımsız kolonluysa \(A^{+} = (A^{T}A)^{-1}A^{T}\) olduğunu göster. \(A^{+}A = I\) (sol ters) ama \(AA^{+} \neq I\) (projeksiyon) olduğunu açıkla.
Egzersiz 4. Python ile dört yolu karşılaştır:
import numpy as np
A = np.array([[1.0, 0.0], [1.0, 1.0], [1.0, 2.0]])
b = np.array([6.0, 0.0, 0.0])
x_normal = np.linalg.solve(A.T @ A, A.T @ b) # Yol 2
x_pinv = np.linalg.pinv(A) @ b # Yol 1
x_lstsq = np.linalg.lstsq(A, b, rcond=None)[0] # QR/SVD
print("normal:", x_normal, " pinv:", x_pinv, " lstsq:", x_lstsq) # aynı
# Hata kolon uzayına dik mi?
r = b - A @ x_lstsq
print("Aᵀ(b − Ax̂) =", A.T @ r) # ≈ 0Egzersiz 5. (Ders 10 habercisi.) Ders 10 \(Ax = b\)’nin tüm zorluklarını tarar (kare/dikdörtgen, tam/eksik rank, iyi/kötü koşullu). Aşağıdaki üç matris için hangi durumda olduğunu söyle: tersinir mi, least squares mi, minimum-norm mu gerekir?
\[A_1 = \begin{pmatrix} 2 & 1 \\ 1 & 2 \end{pmatrix}, \; A_2 = \begin{pmatrix} 1 \\ 1 \\ 1 \end{pmatrix}, \; A_3 = \begin{pmatrix} 1 & 1 & 1 \end{pmatrix}\]
10.15 Sonraki Ders İçin Hazırlık
Ders 10: Ax = b’nin Zorluklarına Genel Bakış
Ders 9’da least squares’i ve dört yolu işledik. Ders 10, \(Ax = b\)’nin tüm olası durumlarını sistematik tarar — hangi durumda hangi yöntemin gerektiğini.
- Kare/dikdörtgen, tam/eksik rank kombinasyonları
- Tersinir, least squares, minimum-norm, her ikisi
- İyi vs kötü koşullu sistemler
- Gram-Schmidt ve sayısal yöntemlere köprü
UyarıDers 10 Öncesi Yapılacak
- Bu dersin egzersizlerini çöz, özellikle Egzersiz 5’i (durum sınıflandırma).
- Python’da
np.linalg.matrix_rankile birkaç matrisin rankını ve durumunu incele. - Ana cümleyi tekrar oku: “Least squares = \(b\)’yi kolon uzayına projekte etmek; hata \(\perp\) kolon uzayı.”
10.16 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Tanım | Strang’de |
|---|---|---|
| Least squares | Çözülemeyen \(Ax = b\) için \(\min \|Ax - b\|^2\) | 23m05 |
| Pseudoinverse \(A^{+}\) | En iyi ters; satır/kolon uzayında, null \(\to\) 0 | 5m55 |
| \(A^{+} = V\Sigma^{+}U^{T}\) | SVD’den; \(\Sigma^{+}\) sıfırdan-farklı \(\sigma\)’ları tersler | 14m34 |
| Gauss least squares | \(\ell^2\) hatasını minimize et | 30m20 |
| Normal denklemler | \(A^{T}A\hat{x} = A^{T}b\); bağımsız kolonlar | 31m58 |
| Projeksiyon | \(A\hat{x} = b\)’nin kolon uzayına izdüşümü; hata \(\perp\) | 35m41 |
| Doğru uydurma | \(C + Dx\); \(m\) ölçüm, 2 bilinmeyen | 25m02 |
| Bağımsız kolon | \(A^{T}A\) tersinir, Gauss çalışır | 37m58 |
| Yol 3: QR | \(A = QR\), \(R\hat{x} = Q^{T}b\); \(A^{T}A\)’dan kaçınır | 47m11 |
| Dört yol | \(A^{+}\), normal denklem, QR, iteratif | 5m21 |
10.17 ML Bağlantıları Özeti
- Least squares → lineer regresyonun çekirdeği; MSE kaybının atası.
- Pseudoinverse \(A^{+}\) → rank-eksik/dikdörtgen regresyon; minimum-norm çözüm.
- Normal denklemler → klasik regresyon; ama \(A^{T}A\) kondisyonu kareler (dikkat).
- QR → kararlı least squares;
lstsq’in varsayılanı; ortonormal güvenlik. - Projeksiyon / ortogonallik → Kalman filtresi, Gauss-Markov, son katman lineer çözümü.
- Truncated SVD \(A^{+}\) → gürültülü/ters problemlerde düzenlileştirilmiş çözüm.
- İteratif (conjugate gradient) → büyük/seyrek sistemler; yalnız \(Ax\) çarpımı gerektirir.
ÖnemliEğer bu dersten tek bir şey alıp gidersen
Çözümü olmayan \(Ax = b\) için least squares, \(b\)’yi \(A\)’nın kolon uzayına dik olarak projekte eder — hata vektörü kolon uzayına diktir (ortogonallik ilkesi), ki bu doğrudan normal denklemleri (\(A^{T}A\hat{x} = A^{T}b\)) verir. Aynı en-iyi \(\hat{x}\)’e dört yoldan varılır: pseudoinverse (SVD, en genel), normal denklemler, QR (kararlı) ve büyük sistemler için iteratif.