flowchart TD
M["Neden bu kadar cok dusuk-rank matris?"] --> COMP["dusuk-rank = sikistirma: 2kn < n^2 (k < n/2)"]
M --> PAT["desenler: hizali (bayrak) veya simetrik (daire) iyi; kosegen/ucgen KOTU"]
M --> NUMR["sayisal rank: epsilon toleransiyla rank"]
M --> EY["Eckart-Young: sigma_(k+1) = en iyi rank-k hatasi"]
M --> SMOOTH["dunya puruzsuz (Reade 1983): gevsek"]
SYL["dunya Sylvester: AX - XB = C (C dusuk-rank)"]
ZOL["Zolotarev: E,F ayrik -> hizli dusus"]
GUEST["konuk: Alex Townsend (Cornell)"]
style M fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style SYL fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style ZOL fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style GUEST fill:#1f4e79,color:#fff,stroke:#13243a,stroke-width:2px
style COMP fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style PAT fill:#2e75b6,color:#fff,stroke:#13243a,stroke-width:2px
style NUMR fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
style EY fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
style SMOOTH fill:#6fa8dc,color:#13243a,stroke:#1f4e79,stroke-width:2px
18 Hızla Azalan Tekil Değerler
Konuk ders, Alex Townsend: düşük-rank dünyası, sayısal rank ve Sylvester denklemleri
NotBölüm bilgisi
Video: MIT 18.065 — Rapidly Decreasing Singular Values (konuk: Alex Townsend) · OCW: Lecture 17 · Okuma süresi: ≈35 dk · Konuk: Alex Townsend (Cornell) · Takdim: Gilbert Strang · Önkoşul: Ders 16 (tekil değer türevi).
Bu bir konuk dersidir. Cornell’den Prof. Alex Townsend (eskiden MIT’de 18.06 hocası), kendi araştırma alanı olan §4.3’ü anlatır. Ana içerik Townsend’e atfedilir; yalnız açılış takdimi Strang’a.
18.1 Bu Derste Ne Var?
Büyük soru: neden dünyada bu kadar çok düşük-rank matris var? Townsend bu hikayeyi anlatır. Önce düşük-rank’ın ne demek olduğunu (sıkıştırma), sonra sayısal rank kavramını ve son olarak iki derin açıklamayı (“dünya pürüzsüz” → “dünya Sylvester”) görürüz.
Beş sonuç:
- Düşük-rank = sıkıştırma: rank-k matris n² yerine 2kn sayıyla gönderilir; k < n/2 ise düşük-rank.
- Hangi matrisler: ızgaraya hizalı (bayrak) veya simetrik (daire) olanlar düşük-rank; köşegen/üçgensel desenler kötü.
- Sayısal rank (rank_ε): ε toleransı içinde; tam-rank matrisler bile tekil değerleri hızla düşüyorsa düşük sayısal rank’a sahip (Hilbert, Vandermonde).
- “Dünya pürüzsüz”: pürüzsüz fonksiyon örneklemesi polinomla yaklaşılabilir → düşük sayısal rank (Reade 1983) — ama Hilbert için zayıf (719 vs gerçek 28).
- “Dünya Sylvester”: AX − XB = C denklemini sağlayan matrisler; Zolotarev sayısı sınır verir (Hilbert: 34).
“Today I want to tell you a little about why there [are] so many matrices that are low rank in the world.” — Townsend, 1:15
Aşağıdaki kavram haritası dersin merkezini (“neden bu kadar çok düşük-rank matris?”) ana fikirlere bağlar: düşük-rank = sıkıştırma, hizalı/simetrik desenler iyi (köşegen/üçgen kötü), sayısal rank, Eckart-Young, dünyanın pürüzsüzlüğü (Reade gevşek) ve ayrı düğümlerde dünyanın Sylvester yapısı ile Zolotarev düşüşü — bir düğüm de bunun bir konuk dersi olduğunu (Alex Townsend, Cornell) işaretler (Şekil 18.1).
İpucuBuilder Notu — Sıkıştırılabilir Dünyanın Haritası
- Düşük-rank = sıkıştırma — görüntü sıkıştırma (Ders 7 Eckart-Young), model sıkıştırma, LoRA: hepsi “az parametreyle çok bilgi” fikrini kullanır.
- Sayısal rank — gerçek dünyada matrisler tam düşük-rank değil, sayısal düşük-rank; ML’de veri matrisleri ve ağırlıklar neredeyse hep böyle.
- Sylvester denklemi — bir matrisin neden sıkıştırılabilir olduğunu önceden söyler; sayısal lineer cebirin derin aracı.
- Geriye köprü: Ders 6 (SVD = ∑σᵢuᵢvᵢᵀ), Ders 7 (Eckart-Young, en iyi rank-k), Ders 16 (tekil değer türevi).
Tek cümle: Dünyada bu kadar çok (sayısal) düşük-rank matris vardır çünkü bunlar pürüzsüz fonksiyonlardan veya Sylvester denklemlerinden doğar; tekil değerlerin hızla düşmesi (Zolotarev sayısıyla sınırlı) onları sıkıştırılabilir kılar.
18.2 Strang’ın Takdimi
Strang konuğu tanıtır: Alex Townsend, MIT’de 18.06 dersini başarıyla vermiş, şimdi Cornell’de. §4.3 tamamen onun çalışması — yaratıcısından dinleme fırsatı.
“And now you get to hear from the creator himself.” — Strang, 1:00
Buradan sonra ana içerik Townsend’e aittir; quote’lar “— Townsend” diye atfedilir.
İpucuBuilder Notu — Yaratıcısından Birinci Ağızdan
Konuk ders formatı, bir konunun yaratıcısından birinci ağızdan dinlemenin değerini gösterir. Townsend’in açısı pratik/hesaplamalı: “neden gerçek dünyada bu kadar çok düşük-rank matris var?” — teorem değil, gözlem ve açıklama peşinde.
18.3 Neden Bu Kadar Çok Düşük-Rank Matris Var?
Townsend’in motivasyonu: hesaplamalı matematikçiler her yerde düşük-rank matrislerle karşılaşır. Neden? X bir n×n matris olsun. SVD’den (Ders 6) X’i rank-1 parçaların toplamı olarak yaz; X rank-k ise k tane parça:
“Today I want to tell you a little about why there [are] so many matrices that are low rank in the world.” — Townsend, 1:15
\[X = \sigma_{1}u_{1}v_{1}^{T} + \sigma_{2}u_{2}v_{2}^{T} + \cdots + \sigma_{k}u_{k}v_{k}^{T}\]
X rank-k demek: tekil değer dizisinde çok sayıda sıfır var (σ₍k+1₎ = ⋯ = 0), kolon uzayı = satır uzayı boyutu = k. Soru: hangi X’ler bu sıfırları üretir?
İpucuBuilder Notu — Rank-1 Parçaların Ekonomisi
“Rank-k = k rank-1 parçanın toplamı” Ders 6-7’nin tam tekrarı, ama Townsend bunu veri sıkıştırma merceğinden kullanıyor: az sayıda parça = az bilgi. Bu, görüntü/sinyal sıkıştırma ve model küçültmenin temel sezgisi.
18.4 Düşük-Rank = Sıkıştırma
Townsend’in düşük-rank tanımı somut: X’i bir resim gibi düşün (her eleman bir piksel). Arkadaşına iki türlü gönderebilirsin. Ya tüm elemanları — n² sayı. Ya da düşük-rank formda u₁,v₁,…,uₖ,vₖ vektörlerini — 2kn sayı (her vektör n uzunlukta, k çift).
“…a matrix is low rank if it’s more efficient to send x to our friend [in low-rank form].” — Townsend, 6:33
\[2kn < n^{2} \quad \Longleftrightarrow \quad k < \frac{n}{2}\]
Katı tanım: rank, boyutun yarısından küçükse matris düşük-rank. Pratikte daha fazlasını isteriz — k, n’den çok küçük olsun ki sıkıştırma kayda değer olsun.
İpucuBuilder Notu — Gönder Bakalım Kaç Sayı
“Göndermesi daha ucuzsa düşük-rank” tanımı bilgi-teorik: sıkıştırma = aynı bilgiyi daha az bitle taşımak. ML köprüsü: LoRA bir ağırlık güncellemesini ΔW = BAᵀ (düşük-rank) olarak saklar — milyonlarca parametre yerine 2kn. JPEG, PCA, otokodlayıcılar hep bu “2kn < n²” pazarlığını yapar.
18.5 Bayraklar: Hangi Desenler Düşük-Rank?
Townsend dünya bayraklarını örnek alır (her bayrak bir matris). Avusturya bayrağı (üç yatay şerit) rank-1 — arkadaşına sadece iki vektör (bir kolon, bir satır) gönderirsin:
“For example, the Austria flag– if you want to send that to your friend, that matrix is of rank 1.” — Townsend, 8:04
İngiltere bayrağı rank-2 (u₁,v₁,u₂,v₂). Japonya bayrağı (daire) düşük-rank ama o kadar küçük değil — n=60 için rank-11. İskoçya bayrağı (çapraz haç) ise rank-30 = n/2: tam burada \(2kn = 2\cdot30\cdot60 = 3600 = n^{2}\) olduğundan düşük-rank formda göndermenin sıkıştırma kazancı sıfırdır. Gözlem: matris satır/sütunlarla hizalı ise düşük-rank (Avusturya); köşegen/çapraz desenler kötü.
Aşağıdaki figür bayrakları matris olarak ve her birinin tekil değer profilini gösterir: Avusturya (1) ve İngiltere (2) neredeyse anında sayısal sıfıra düşer, Japonya k≈11’de uçurum yapar, İskoçya ise k≈30’a kadar ~1 kalıp orada düşer — köşegen desenin sıkışmaya direncini gözle gösterir (Şekil 18.2).
Kod
flags = [
(flag_austria(60), "Avusturya rank-1"),
(flag_england(60), "Ingiltere rank-2"),
(flag_japan(60), "Japonya rank-11"),
(flag_scotland(60), "Iskocya rank-30 = n/2"),
]
fig, axs = plt.subplots(2, 4, figsize=(12, 5.6))
for col, (M, title) in enumerate(flags):
ax_top = axs[0, col]
ax_top.imshow(M, cmap=NAVY_CMAP)
ax_top.set_title(title, color=COL_TEXT, fontsize=12, fontweight="bold")
ax_top.set_xticks([]); ax_top.set_yticks([])
ax_bot = axs[1, col]
prof = sigma_profile(M)[:40]
ax_bot.semilogy(range(1, len(prof) + 1), prof, color=COL_PRIMARY, lw=2)
ax_bot.set_xlabel("k"); ax_bot.set_ylabel(r"$\sigma_k / \sigma_1$")
apply_style(ax_bot)
fig.suptitle(
"Bayraklar matris olarak: hizali desen dusuk-rank (1, 2), simetrik daire dusuk (11), "
"capraz hac n/2 = 30 - sikistirma kazanci SIFIR (2kn = n^2)",
color=COL_TEXT, fontsize=11, fontweight="bold",
)
fig.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()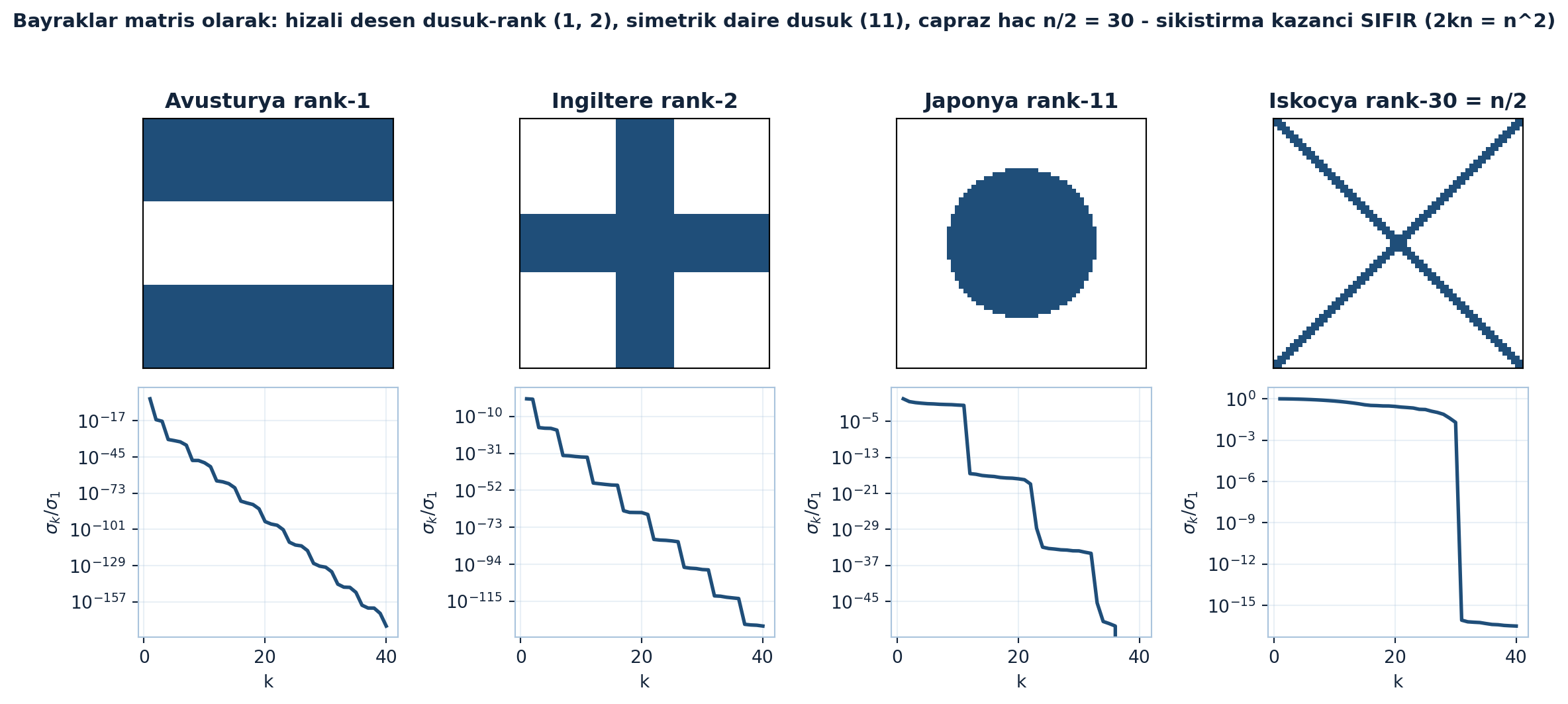
İpucuBuilder Notu — Bayrağına Bak Rankını Söyle
“Izgaraya hizalı → düşük-rank” sezgisi pratik bir tarama: bir veri matrisinin yapısı eksenlerle hizalıysa (bloklar, şeritler) sıkıştırılabilir. Ama Townsend birazdan bu sezginin yarı-doğru olduğunu gösterecek — daire (hizasız) da düşük-rank çıkar. Sezgiye körü körüne güvenme; tekil değerlere bak.
18.6 Üçgen Bayrak: Köşegen Neden Kötü
En kötü örneği incele: köşegen altı tamamen dolu (ones) üçgen matris L. Bu matrisin tersi, birinci-mertebe sonlu fark matrisine benzer; iki tersi çarpılınca Strang’ın favori −1, 2, −1 (ikinci fark) matrisi çıkar. Bu matrisin tekil değerleri çok iyi bilinir (Ders 4: AᵀA’nın özdeğerleri X’in tekil değerlerini verir). Sonuç:
\[\sigma_{1}(L) \approx \frac{2n}{\pi}, \qquad \sigma_{n}(L) \approx \frac{1}{2}\]
n=100 için motor σ₁ = 63.98 (≈ 2n/π = 63.66) ve σₙ = 0.5001 (≈ ½) verir; en küçük oran σₙ/σ₁ ≈ 7.8×10⁻³ ≈ π/(4n), yani düşmüyor. Tüm tekil değerler büyük — sıfıra yaklaşmıyorlar. Köşegen desenler düşük-rank için felaket:
“So triangular patterns are extremely bad for low rank.” — Townsend, 14:27
Aşağıdaki figür solda alt-üçgen ones matrisini, sağda hiç düşmeyen σ profilini gösterir — hiçbir σ sıfıra yaklaşmadığından sayısal rank tam 100 kalır (Şekil 18.3).
Kod
fig, axs = plt.subplots(1, 2, figsize=(9, 3.8))
# Sol: alt-üçgen ones (cumsum operatörü)
L = triangular_ones(100)
axs[0].imshow(L, cmap=NAVY_CMAP)
axs[0].set_xticks([]); axs[0].set_yticks([])
axs[0].set_title("alt-üçgen ones (cumsum operatörü)", color=COL_TEXT, fontsize=11, fontweight="bold")
# Sağ: σ profili — DÜŞMÜYOR
s = np.linalg.svd(L, compute_uv=False)
axs[1].semilogy(range(1, 101), s / s[0], color=COL_PRIMARY, lw=2)
axs[1].annotate(r"$\sigma_1 = 63.98$", xy=(1, 1.0), xytext=(12, 0.55),
fontsize=10, color=COL_TEXT)
axs[1].annotate(r"$\sigma_{100} = 0.50$", xy=(100, s[-1] / s[0]), xytext=(40, 1.4e-2),
fontsize=10, color=COL_TEXT,
arrowprops=dict(arrowstyle="->", color=COL_ACCENT, lw=1.2))
axs[1].set_xlabel("k", color=COL_TEXT)
axs[1].set_ylabel(r"$\sigma_k / \sigma_1$", color=COL_TEXT)
axs[1].set_title("σ profili: DÜŞMÜYOR", color=COL_TEXT, fontsize=11, fontweight="bold")
apply_style(axs[1])
fig.suptitle("Üçgen desen felaket: σ₁ = 64.0 ~ 2n/π, σₙ = 0.50 ~ 1/2 — hiçbir σ sıfıra yaklaşmıyor (tam sayısal rank 100)",
color=COL_TEXT, fontsize=10.5, fontweight="bold")
fig.tight_layout(rect=[0, 0, 1, 0.94])
plt.show()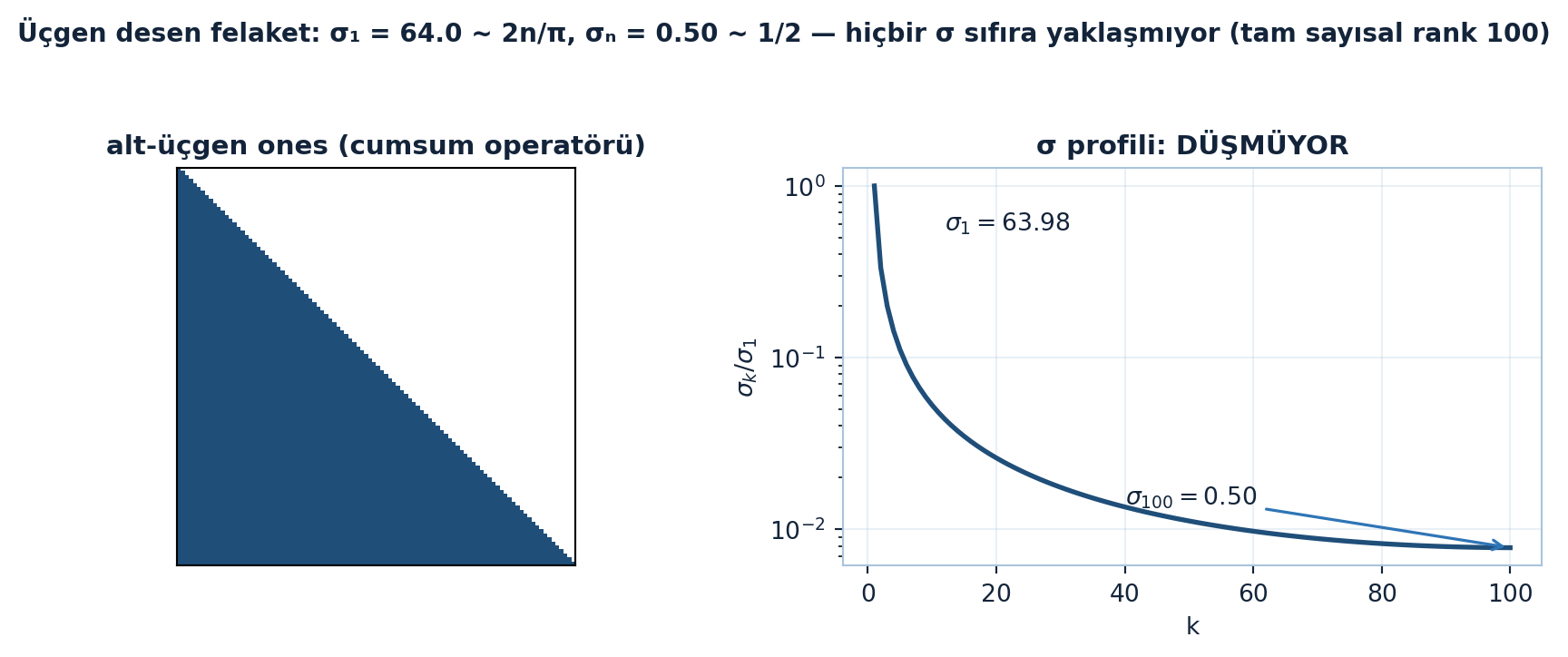
İpucuBuilder Notu — Geçmişi Unutmayan Sıkışmaz
Üçgen “ones” matrisinin tersinin sonlu farka, karesinin Strang’ın −1,2,−1 matrisine bağlanması, Phase 1 18.06’nın köşeyi tutan örneğidir — burada tekil değer analizini mümkün kılan köprü. ML köprüsü: kümülatif toplam (cumsum) operatörü tam bu üçgen matristir; tekil değerlerinin düşmemesi, “geçmişi unutmayan” işlemlerin neden sıkıştırılamadığını açıklar (uzun-bağlam dikkat mekanizmasının maliyeti).
18.7 Daire ve Simetri: Hizasız ama Düşük-Rank
Japonya bayrağı (ortada daire) ızgaraya hizalı değil — ama yine de düşük-rank. Neden? Simetri. Townsend daireyi parçalara böler: rank ≤ (ortadaki rank-1 kare) + (iç bölge). İç bölgeyi simetriyle tekrar tekrar yarıya böler — kolonların solu sağında, satırların üstü altında tekrarlandığından kolon/satır uzayı boyutu küçük kalır. Yarıçap r için sınır:
\[\text{rank} \lesssim \tfrac{1}{2}\,r + 1\]
Yani daire, çizgi-ızgara hizasının neredeyse zıttı olmasına rağmen düşük-rank. Ders: hizalama yeterli koşul değil; simetri de düşük-rank üretir.
İpucuBuilder Notu — Simetri de Sıkıştırır
“Simetri → düşük-rank” gözlemi, sezginin (ızgara hizası) tek açıklama olmadığını gösterir. ML köprüsü: evrişimsel ağlar (CNN, Ders 32) tam da uzaysal simetriyi (öteleme değişmezliği) sömürerek parametre paylaşır — simetri, az parametreyle çok şey ifade etmenin bir başka yoludur. Yapı (hizalama veya simetri) her zaman sıkıştırılabilirliğe yol açar.
18.8 Sayısal Rank: ε Kadar Esneklik
Gerçek matrisler nadiren tam düşük-rank’tır — ama sayısal düşük-rank olurlar. Townsend sayısal rank’ı tanımlar: tam rank tanımına biraz “esneme payı” (ε toleransı) ekle.
“…we allow ourselves a little bit of wiggle room when we define it…” — Townsend, 19:58
\[\text{rank}_{\varepsilon}(X) = k \quad \Longleftrightarrow \quad \sigma_{k+1} < \varepsilon\,\sigma_{1} \leq \sigma_{k}\]
Yani ε’dan (göreli) küçük tekil değerleri “sıfır say”. Pratikte bu daha önemli: arkadaşına bayrağı 16 hane hassasiyetle göndermek yeter — gözü farkı göremez. Bilgisayar zaten her sayıyı 16 haneye yuvarlar; ε = 10⁻¹⁵ ise X ile rank-k yaklaşımını ayırt edemez.
Aşağıdaki figür somut bir örnek verir: σ = (1, 0.1, 0.01, 0.001, 10⁻⁸, 10⁻¹²) ve ε = 10⁻⁶ için ilk 4 tekil değer eşiğin üstünde kalır, son 2’si altına düşer — matris tam rank 6 olsa bile rank_ε = 4 (Şekil 18.4).
Kod
sig = np.array([1, 0.1, 0.01, 0.001, 1e-8, 1e-12])
ks = np.arange(1, 7)
eps = 1e-6
above = sig >= eps # epsilon ustu (goreli sigma1=1)
fig, ax = plt.subplots(figsize=(7, 4.2))
# Tum noktalar: ilk 4 dolu navy + teal halka, son 2 soluk steel
for k, s, ab in zip(ks, sig, above):
if ab:
ax.semilogy([k], [s], marker="o", ms=10, color=COL_PRIMARY,
markeredgecolor=COL_TEAL, markeredgewidth=2.2, lw=0, zorder=3)
else:
ax.semilogy([k], [s], marker="o", ms=10, color=COL_STEEL_300,
markeredgecolor=COL_STEEL_300, lw=0, alpha=0.55, zorder=2)
# epsilon = 1e-6 yatay turuncu kesik cizgi + etiket
ax.axhline(eps, color=COL_VEC3, ls="--", lw=2, zorder=1)
ax.text(6.05, eps*1.6, "epsilon = 1e-6 (goreli)", color=COL_VEC3,
fontsize=10, fontweight="bold", ha="right", va="bottom")
# rank_epsilon = 4 annotate
ax.annotate(r"rank$_\varepsilon$ = 4", xy=(4, sig[3]), xytext=(4.5, 5e-2),
color=COL_PRIMARY, fontsize=12, fontweight="bold",
arrowprops=dict(arrowstyle="->", color=COL_PRIMARY, lw=1.6))
apply_style(ax)
ax.set_xlim(0.5, 6.5); ax.set_xticks(ks)
ax.set_xlabel("k"); ax.set_ylabel(r"$\sigma_k$ (log)")
ax.set_title("Sayisal rank: epsilon ustunde 4 tekil deger -> rank_epsilon = 4 (tam rank 6 olsa bile)",
fontsize=10.5, fontweight="bold")
fig.tight_layout()
plt.show()
İpucuBuilder Notu — Epsilon Kadar Esneklik
Sayısal rank, teorik rank’tan çok daha pratiktir: kayan-nokta aritmetiğinde “tam sıfır” diye bir şey yoktur, sadece “ε’dan küçük” vardır. ML köprüsü: bir sinir ağı ağırlık matrisinin etkin (effective) rank’ı tekil değerlerin nereye düştüğüyle ölçülür; budama (pruning) ve düşük-rank sıkıştırma tam bu ε-eşiğine dayanır. Modelin “gerçek boyutu” sayısal rank’tır, nominal boyut değil.
18.9 Eckart-Young Köprüsü: Hızlı Düşüş Yeter
Sayısal rank neden işe yarar? Çünkü Eckart-Young (Ders 7): (k+1)’inci tekil değer, X’in rank-k bir matrisle ne kadar iyi yaklaşılabileceğini söyler.
“…the singular values tell us how well we can approximate x by a low-rank matrix.” — Townsend, 21:58
\[\min_{\text{rank}(Y) \leq k}\|X - Y\| = \sigma_{k+1}\]
Sonuç çarpıcı: bir matris tam rank olabilir (hiçbir tekil değeri tam sıfır değil) ama tekil değerleri hızla sıfıra düşüyorsa düşük sayısal rank’a sahiptir. ε esnemesi sayesinde küçük tekil değerleri atarız ve devasa sıkıştırma kazanırız.
İpucuBuilder Notu — Tam Rank Ama Sayısal Küçük
“Tam rank ama hızla düşen σ → düşük sayısal rank” bu dersin kalbidir. ML köprüsü: gerçek veri matrisleri (görüntü, metin gömme, kullanıcı-ürün) neredeyse hiç tam düşük-rank değildir — ama σ hızla düştüğü için düşük sayısal rank’tırlar. Bütün PCA/SVD sıkıştırma pratiği bu olguya dayanır; “intrinsic dimension” (içsel boyut) kavramı budur.
18.10 Hilbert ve Vandermonde: Klasik Örnekler
İki ünlü örnek. Hilbert matrisi H₍jk₎ = 1/(j+k−1):
“…this is called the Hilbert matrix.” — Townsend, 24:38
\[H_{jk} = \frac{1}{j + k - 1}\]
1000×1000 Hilbert matrisi tam rank’tır (tüm σ pozitif), ama ε = 10⁻¹⁵ ile sayısal rank’ı sadece 28 — yani 15 haneyi feda ederek rank-28 ile yaklaşılır.
“…by a rank 28 matrix and only give up [15 digits].” — Townsend, 35:13
İkinci örnek Vandermonde matrisi V₍jk₎ = xⱼ^(k−1) (polinom interpolasyonunda çıkar). O da düşük sayısal rank’tır — ama bu kötü haber: düşük sayısal rank, tersini almayı çok zorlaştırır (kondisyon sayısı Ders 10 patlar). n=20 equispaced [0,1] noktalarında motor sayısal rank 19 (<20) ve kondisyon ≈ 1.2×10¹⁶ verir — tersini almak felaket. Sayısal düşük-rank her zaman lehine değildir.
Aşağıdaki figür solda Hilbert(1000) σ profilini (üçgen “ones” ile kontrastlı) gösterir: float64 gürültü tabanına (ε=10⁻¹⁵) k≈27’de çarpar — sağda ise sayısal rank n ile log-yavaş büyür (10 → 19 → 27) (Şekil 18.5).
Kod
fig, (axL, axR) = plt.subplots(1, 2, figsize=(10, 4))
# Sol: Hilbert(1000) sigma profili (ilk 40) VS ucgen profili (dusmuyor)
sH = np.linalg.svd(hilbert(1000), compute_uv=False)
profH = sH / sH[0]
axL.semilogy(range(1, 41), profH[:40], color=COL_PRIMARY, lw=2.5, label="Hilbert 1000×1000")
# Gercek-dusus bolgesinde (prof > 1e-15) egim: motordan hesapla (caption bu degere baglidir)
maskH = profH > 1e-15
kH = np.arange(1, len(profH) + 1)[maskH]
slopeH = np.polyfit(kH, np.log10(profH[maskH]), 1)[0] # ~ -0.57 dekat/adim
sL = sigma_profile(triangular_ones(100))
axL.semilogy(range(1, len(sL) + 1), sL, color=COL_VEC3, lw=2.0, ls="--", label="üçgen (düşmüyor)")
eps = 1e-15
axL.axhline(eps, color="#999999", ls="--", lw=1.2)
axL.axvline(27, color="#999999", ls=":", lw=1.0)
axL.annotate("sayısal rank ~ 28 (float64: 27)", xy=(27, eps), xytext=(8, 3e-13),
fontsize=8.5, color=COL_TEXT,
arrowprops=dict(arrowstyle="->", color="#999999", lw=1.0))
axL.annotate(f"eğim ≈ {slopeH:.2f} dekat/adım", xy=(14, profH[13]), xytext=(15, 1e-5),
fontsize=8.5, color=COL_TEXT,
arrowprops=dict(arrowstyle="->", color="#999999", lw=1.0))
axL.set_xlabel("k"); axL.set_ylabel(r"$\sigma_k/\sigma_1$ (log)")
axL.legend(fontsize=8.5, loc="lower left")
apply_style(axL)
# Sag: Hilbert sayisal rank buyumesi log-yavas (10/19/27)
ns = [10, 100, 1000]
nrc = hilbert_numrank_curve(ns)
axR.semilogx(ns, nrc, marker="o", ms=9, color=COL_PRIMARY, lw=2)
for x, y in zip(ns, nrc):
axR.annotate(str(int(y)), xy=(x, y), xytext=(0, 8), textcoords="offset points",
ha="center", fontsize=10, color=COL_TEXT, fontweight="bold")
axR.set_xlabel("n (log)"); axR.set_ylabel("sayısal rank (eps=1e-15)")
apply_style(axR)
fig.suptitle(f"Hilbert: TAM rank ama σ üstel düşer (eğim ≈ {slopeH:.2f} dekat/adım) → sayısal rank ~28; büyüme log-yavaş (10/19/27)",
color=COL_TEXT, fontsize=10, fontweight="bold")
fig.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()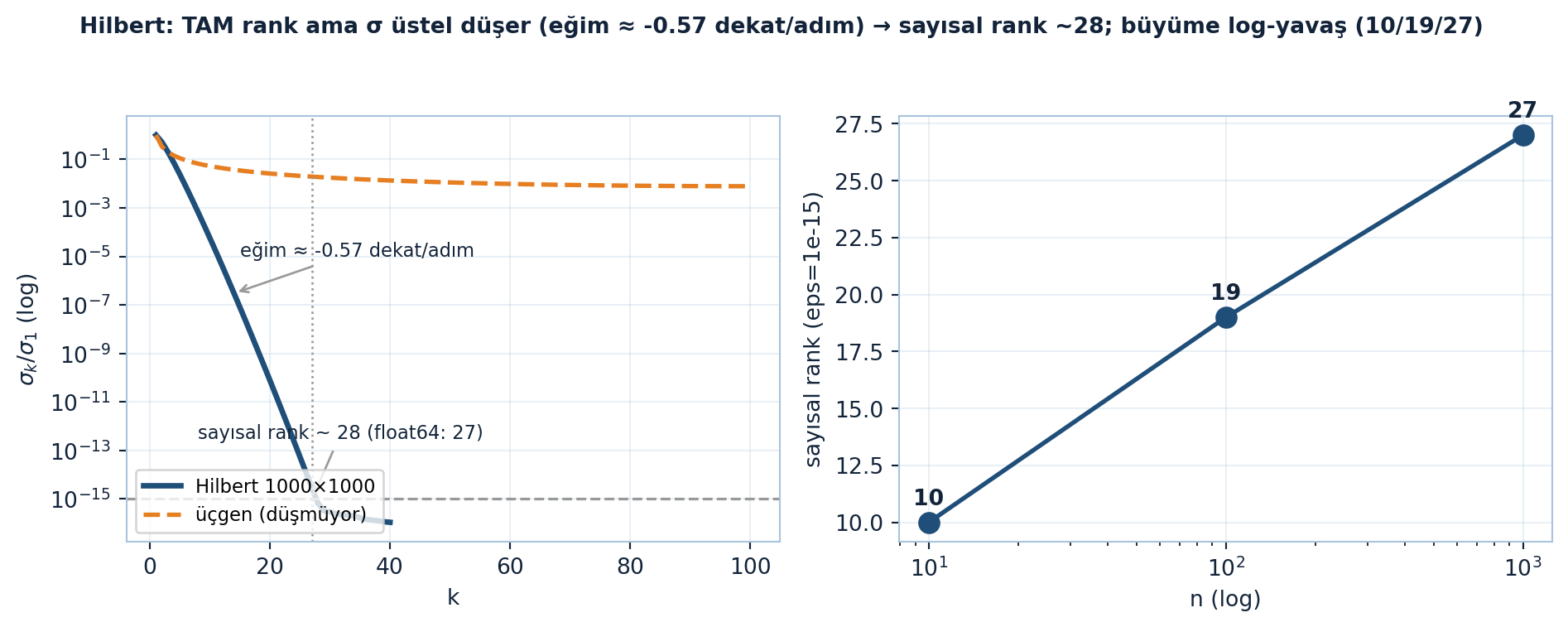
İpucuBuilder Notu — İyi Sıkışan Kötü Çözülür
Hilbert ve Vandermonde, “düşük sayısal rank iyi mi kötü mü?” ikiliğini gösterir: sıkıştırma için harika (Hilbert), ama denklem çözme için felaket (Vandermonde — neredeyse tekil, ters kararsız). ML köprüsü: polinom özellikleri (polynomial features) Vandermonde’dur — yüksek dereceli polinom regresyonun neden sayısal olarak kararsız olduğunun ve neden ortogonal polinom/spline tercih edildiğinin sebebi budur.
18.11 “Dünya Pürüzsüz” — Reade’in Açıklaması (1983)
Neden bu kadar çok düşük-rank matris var? Klasik cevap: dünya pürüzsüz.
“…so many low-rank matrices is because the world is smooth, as people say.” — Townsend, 27:16
Reade’in (1983) fikri: matris pürüzsüz bir fonksiyondan örnekleniyorsa, o fonksiyonu polinomla yaklaşabiliriz; iki değişkenli, her birinde derece m olan bir polinomu örneklemek en fazla m² rank verir (her terim bir rank-1 katkı). Pürüzsüz fonksiyon ≈ düşük dereceli polinom → düşük sayısal rank.
\[p(x,y) = \sum_{i,j} c_{ij}\,x^{i}y^{j} \;\Rightarrow\; \text{rank} \leq m^{2}\]
Sorun: Hilbert matrisi için Reade’in sınırı 719 çıkar — ama gerçek sayısal rank 28. Açıklama “doğru ama zayıf”; 719, “düşük sayısal rank” demek için çok büyük. Tatmin edici değil. (719 bir literatür değeridir; Townsend bunu Reade’e atıfla aktarır, motor-tanıklı 27-28 gerçek değerin yanında.)
İpucuBuilder Notu — Pürüzsüz Ama Gevşek
“Dünya pürüzsüz” sezgisel ve çoğu zaman doğru ama niceliksel olarak gevşek. ML köprüsü: aynı fikir kernel yöntemlerinde yaşar — pürüzsüz kernel’ler (RBF) düşük sayısal rank Gram matrisleri üretir, bu yüzden Nyström/rastlantısal özellikler (Ders 13) işe yarar. Ama “ne kadar düşük?” sorusuna pürüzsüzlük net cevap vermez — daha keskin bir araç gerek.
18.12 “Dünya Sylvester” — Daha Keskin Açıklama
Townsend’in tercih ettiği bakış: dünya Sylvester.
“…the world is Sylvester.” — Townsend, 36:50
Anlamı: birçok matris bir Sylvester denklemini sağlar.
“…the matrices satisfy a certain type of equation called the Sylvester equation…” — Townsend, 37:10
\[AX - XB = C\]
İş şu: X için öyle A, B, C bul ki bu denklem sağlansın ve C düşük-rank olsun (örneklerde rank 1). Hem Hilbert hem Vandermonde matrisi bir Sylvester denklemi sağlar — uygun köşegen A, B ve rank-1 C ile. Denklemin yapısı, X’in tekil değerlerinin ne kadar hızlı düşeceğini belirler.
Hilbert için bunu somutlaştır: \(A = \text{diag}(j-\tfrac{1}{2})\), \(B = -\text{diag}(k-\tfrac{1}{2})\) alınırsa AH − HB tam olarak tüm-birler (rank-1) matrisine eşit çıkar — motor n=5 ve n=8 için maxdiff 1.1×10⁻¹⁶ doğrular (Şekil 18.6).
Kod
lhs, C, md = sylvester_hilbert_check(5)
fig, axs = plt.subplots(1, 3, figsize=(10, 3.2))
heatmap(axs[0], lhs, "AH - HB", fmt="{:.2g}")
heatmap(axs[1], C, "C = tum-birler (rank-1)", fmt="{:.0f}")
heatmap(axs[2], lhs - C, "fark ~ 1e-16", fmt="{:.0e}")
fig.suptitle("Hilbert bir Sylvester denklemi saglar: A = diag(j-1/2), B = -diag(k-1/2) -> AH - HB = rank-1 ones (maxdiff 1e-16)", fontsize=10)
fig.tight_layout()
plt.show()
İpucuBuilder Notu — Denklemi Bul Sınırı Al
Sylvester denklemi (AX − XB = C) kontrol teorisi, sinyal işleme ve sayısal lineer cebirin temel denklemidir. Townsend’in içgörüsü: “neden düşük sayısal rank?” sorusunu “hangi Sylvester denklemini sağlıyor?” sorusuna çevirir — soyut ama güçlü, çünkü Sylvester denklemi hakkında çok şey biliniyor. ML köprüsü: Lyapunov denklemleri (Sylvester’ın özel hali) durum-uzay modellerinde (S4/Mamba, Ders 15 bağı) kovaryans ve kararlılık analizinde çıkar.
18.13 Zolotarev Sayısı ve Sınır
Sylvester denklemini sağlayan X için (A, B normal; rank(C) = r), tekil değerler için bir sınır kanıtlanmıştır:
\[\frac{\sigma_{1 + rk}(X)}{\sigma_{1}(X)} \leq Z_{k}(E, F)\]
Burada r = rank(C) (örneklerde 1), ve sağdaki “kötü görünümlü” sayı Zolotarev sayısıdır.
“This nasty guy here is called the Zolotarev number.” — Townsend, 44:55
E, A’nın özdeğerlerini; F, B’nin özdeğerlerini içeren kümeler. Bu sınırın değeri, Zolotarev sayısının 1870’lerden beri çok iyi çalışılmış olması. Anahtar nokta: E ve F ayrık (separated) ise Zolotarev sayısı k ile çok hızlı küçülür → tekil değerler hızla düşer → düşük sayısal rank.
“…the sets E and F are separated.” — Townsend, 46:41
Hilbert matrisi için bu analiz sayısal rank sınırını 34 verir — 719 değil, gerçek 28’e çok daha yakın:
“…a world record bound. For the Hilbert matrix is 34…” — Townsend, 48:43
Renkli bir kapanış: Zolotarev ve Penzl, bu sayı üzerinde çalışırken ikisi de 31 yaşında ölmüş (biri tren kazası, diğeri çığ) — Townsend kendi 31’ine yaklaştığını espriyle anar (“Zolotarev laneti”).
Aşağıdaki figür ayrıklığın etkisini gösterir: n=10, n=100 ve n=1000 Hilbert profilleri aynı üstel koridorda iner — E,F ayrıklığı boyuttan bağımsız hızlı düşüş verir (Şekil 18.7). (34 ve 719 literatür değerleridir, Townsend anlatımı; motor-tanıklı gerçek sayısal rank ~28.)
Kod
fig, ax = plt.subplots(figsize=(7.5, 4.5))
p10 = sigma_profile(hilbert(10))
p100 = sigma_profile(hilbert(100))[:35]
p1000 = sigma_profile(hilbert(1000))[:35]
ax.semilogy(np.arange(1, len(p10) + 1), p10, marker="o", color=COL_ACCENT, lw=1.6, label="n=10")
ax.semilogy(np.arange(1, len(p100) + 1), p100, marker="s", color=COL_TEAL, lw=1.6, label="n=100")
ax.semilogy(np.arange(1, len(p1000) + 1), p1000, marker="^", color=COL_PRIMARY, lw=2.5, label="n=1000")
ax.axhline(1e-15, color="#888888", ls="--", lw=1.2)
ax.text(len(p1000), 1e-15, " eps=1e-15", color="#888888", va="bottom", ha="right", fontsize=9)
ax.set_xlabel("k"); ax.set_ylabel("sigma_k/sigma_1 (log)")
ax.set_title("Ayrik spektrum -> ustel dusus her boyutta:\nZolotarev siniri Hilbert icin 34 (Townsend; gercek ~28, Reade 719 gevsekti)", fontsize=11)
apply_style(ax)
ax.legend()
plt.show()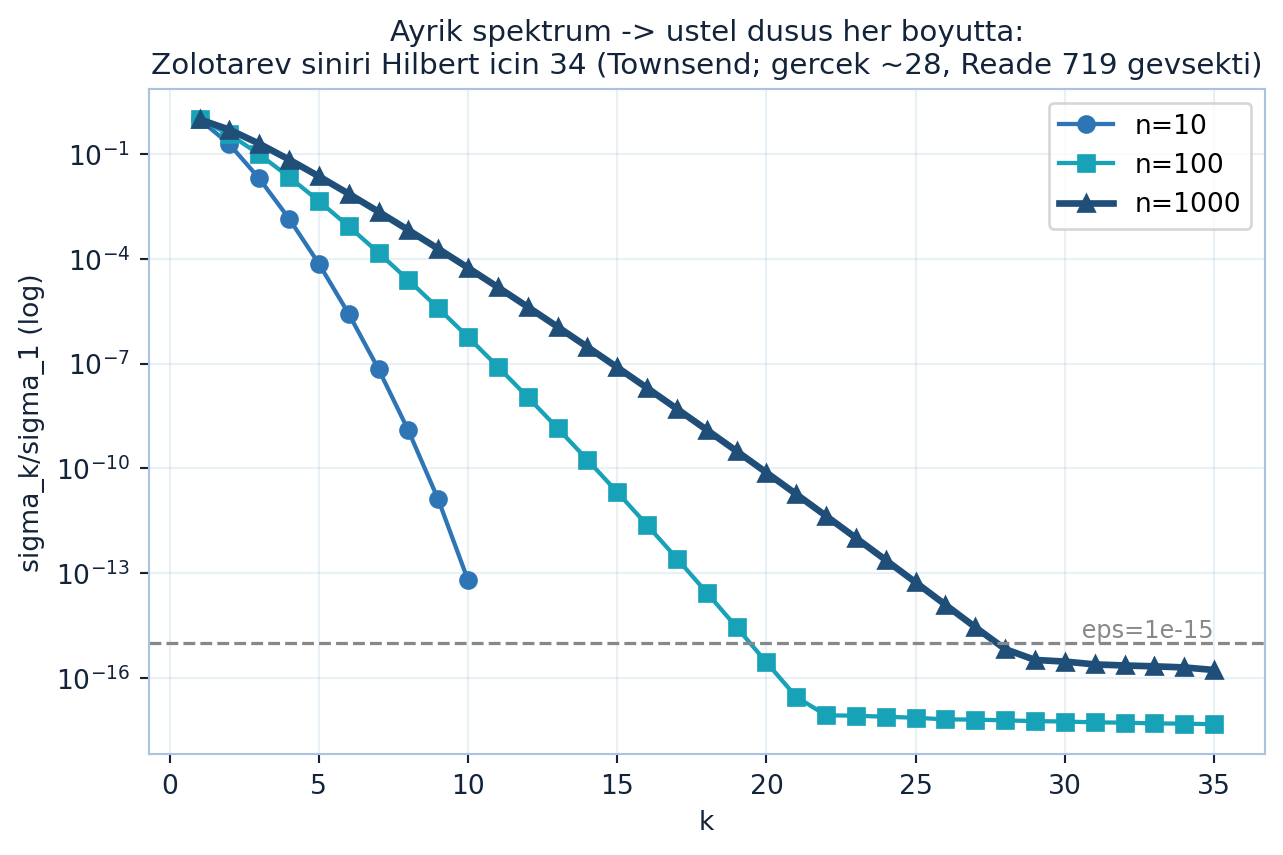
NotMotor Notu — Sayısal Rank ε-Duyarlıdır
[motor notu] Townsend Hilbert(1000) için sayısal rank 28 raporlar. Motor float64 SVD ile rank_ε(10⁻¹⁵) = 27 verir; çünkü σ₂₈/σ₁ = 6.7×10⁻¹⁶, eşiğin (10⁻¹⁵) tam altında ama gürültü tabanının ~3 katı. Eşik biraz gevşetilirse (ε = 5×10⁻¹⁶) sonuç 28 olur. Bu bir sapma değil — sayısal rank kavramının kendisi ε-duyarlıdır, ve tam bu kenar durumda kavramın inceliği canlı görünür: 27 ile 28 arasındaki fark, “kaç tekil değer gürültü tabanının üstünde sayılır?” sorusunun ε seçimine bağlı olmasıdır. Bu dersin tam konusu.
İpucuBuilder Notu — Yüz Elli Yıllık Sınır
Zolotarev sayısı, “soyut bir probleme çevir, sonra zengin literatürü kullan” stratejisinin güzel örneği: “tekil değerler ne kadar düşer?” sorusunu 150 yıllık bir matematik nesnesine bağlar. ML köprüsü: “ayrık spektrum → hızlı tekil değer düşüşü” ilkesi, iyi-koşullu vs kötü-koşullu problemleri ayırt etmenin derin sebebidir; düşük-rank yaklaşımın ne zaman işe yarayacağını önceden söyler.
18.14 Bu Dersin Özeti
- Düşük-rank = sıkıştırma: rank-k matris 2kn sayı (n² değil); k < n/2 ise düşük-rank, pratikte k ≪ n istenir.
- Hangi desenler: ızgaraya hizalı (bayrak, rank-1 Avusturya) veya simetrik (daire ≈ ½r+1); köşegen/üçgen kötü (σ düşmüyor: σ₁≈2n/π, σₙ≈½).
- Sayısal rank: rank_ε(X) = ε’dan büyük tekil değer sayısı; tam-rank ama hızla düşen σ → düşük sayısal rank (Eckart-Young: σ₍k+1₎ = en iyi rank-k hatası).
- Klasik örnekler: Hilbert H₍jk₎=1/(j+k−1) (1000×1000 → rank 28); Vandermonde (düşük sayısal rank → ters almak zor).
- “Dünya pürüzsüz” (Reade): pürüzsüz fonksiyon → polinom yaklaşım → rank ≤ m²; Hilbert için zayıf (719).
- “Dünya Sylvester”: AX − XB = C, C düşük-rank; Zolotarev sayısı sınırı (E, F ayrık → hızlı düşüş; Hilbert → 34).
ÖnemliTek Bir Cümle
Dünyada bu kadar çok sayısal düşük-rank matris vardır çünkü onlar pürüzsüz fonksiyonlardan veya düşük-rank C’li Sylvester denklemlerinden doğar; tekil değerlerin hızlı düşüşü (Zolotarev sayısıyla sınırlı) onları sıkıştırılabilir kılar.
18.15 Kontrol Soruları
NotSoru 1: Bir matris hangi koşulda düşük-rank sayılır ve kaç sayıyla gönderilir
rank-k bir n×n matris, k tane (uᵢ, vᵢ) çiftiyle, yani 2kn sayıyla gönderilir (tüm elemanlar için n² yerine). Katı tanım: 2kn < n², yani k < n/2 ise düşük-rank — düşük-rank formda göndermek daha verimli olduğunda. Pratikte k’nin n’den çok daha küçük olması istenir.
NotSoru 2: Üçgen matris neden kötüyken daire iyidir
Üçgen matrisin tekil değerleri sıfıra düşmez (σ₁≈2n/π, σₙ≈½ — hepsi büyük), çünkü köşegen deseni hiçbir simetri/hizalama sunmaz; sıkıştırılamaz. Daire ızgaraya hizalı olmasa da güçlü simetriye sahiptir; satır/sütun uzayları tekrar ettiğinden rank ≈ ½r+1 ile sınırlıdır — sıkıştırılabilir. Ders: hizalama veya simetri, ikisi de düşük-rank üretir.
NotSoru 3: Bir matris tam rank olduğu halde nasıl düşük sayısal rank olabilir
Tüm tekil değerleri pozitif (tam rank) olsa bile, σ değerleri hızla sıfıra düşüyorsa, ε toleransının altına düşenleri atarak düşük-rank bir matrisle çok iyi yaklaşılır. Eckart-Young’a göre σ₍k+1₎, en iyi rank-k yaklaşım hatasıdır; σ hızla düştüğünde küçük bir k yeter. Hilbert matrisi örnek: 1000×1000 tam rank, ama ε=10⁻¹⁵ ile sayısal rank 28.
NotSoru 4: Dünya Sylvester açıklaması dünya pürüzsüzden neden daha keskindir
“Dünya pürüzsüz” (Reade) doğru ama gevşek bir sınır verir (Hilbert için 719, gerçek 28). “Dünya Sylvester” matrisin AX − XB = C denklemini (C düşük-rank) sağladığını kullanır; bu, tekil değer düşüşünü Zolotarev sayısına bağlar. E (A’nın özdeğerleri) ve F (B’nin özdeğerleri) ayrıksa Zolotarev sayısı hızla küçülür ve Hilbert için 34 gibi çok daha keskin (gerçek 28’e yakın) bir sınır verir.
18.16 Egzersizler
Sıkıştırma hesabı. 1000×1000 bir matris rank-5 ise, tam formda kaç sayı, düşük-rank formda kaç sayı gönderirsin? Sıkıştırma oranı nedir? k < n/2 katı tanımını sağlıyor mu? (Motor: 10⁶ vs 10⁴, oran 100×; k=5 ≪ 500 = n/2 — fazlasıyla sağlar.)
Rank-1 bayrak. Üç yatay şeritli bir bayrağı (Avusturya: üst kırmızı, orta beyaz, alt kırmızı) matris olarak yaz. Bunun rank-1 = uvᵀ olduğunu, u ve v’yi açıkça vererek göster.
Sayısal rank. Tekil değerleri σ = (1, 0.1, 0.01, 0.001, 10⁻⁸, 10⁻¹²) olan bir matrisin ε = 10⁻⁶ (göreli) toleransındaki sayısal rank’ı kaçtır? (İpucu: σₖ/σ₁ > ε koşulu. Cevap: 4.)
Sylvester kontrolü. Hilbert matrisi H₍jk₎ = 1/(j+k−1) için, köşegen A = diag(j−½) ve B = diag(−(k−½)) seçimiyle AH − HB çarpımının her elemanının (j−½)+(k−½) = j+k−1 ile çarpıldığını, dolayısıyla paydanın sadeleşip C = (tüm-birler) rank-1 matrisi verdiğini göster. (Motor: n=5 ve n=8 için maxdiff 1.1×10⁻¹⁶.)
(Ders 18 habercisi) Bu derste düşük-rank’ın “kaç sayı” gerektirdiğini gördük (2kn). Peki bir SVD, LU veya QR ayrışımı toplam kaç bağımsız parametre içerir? Serbestlik derecelerini saymak ne öğretir? Bir tahmin yaz — Ders 18 “SVD, LU, QR’da parametre sayımı”nı işliyor.
18.17 Sonraki Ders İçin Hazırlık
Ders 18: SVD, LU, QR ve Eyer Noktalarında Parametre Sayımı. Townsend “2kn sayı” diyerek parametre saymaya başladı; Strang bunu sistematikleştirir: her matris ayrışımı (SVD, LU, QR, kutupsal) kaç bağımsız parametre içerir? Serbestlik derecesi sayımı, ayrışımların “neden bu boyutta” olduğunu ve eyer noktalarının yapısını açıklar.
UyarıDers 18 Öncesi Yapılacak
Bu dersin “2kn sayı” sayımını hatırla: rank-k bir n×n matris kaç bağımsız sayı içerir? Ders 18 aynı soruyu SVD (UΣVᵀ), LU ve QR için soracak — UΣVᵀ’de ortogonal U ve V kaç serbestlik derecesi taşır? Ortonormallik kısıtlarının (Ders 3) parametre sayısını nasıl düşürdüğünü düşün.
18.18 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Formül / Fikir | Konuşmacı (dk) |
|---|---|---|
| Strang takdimi | konuk Townsend: §4.3’ün yaratıcısı | Strang 1m00 |
| Neden düşük-rank | X = Σσᵢuᵢvᵢᵀ (k rank-1 parça) | Townsend 1m15 |
| Sıkıştırma | 2kn < n² ⟺ k < n/2 | Townsend 6m33 |
| Bayraklar | Avusturya rank-1; İskoçya tam rank | Townsend 8m04 |
| Üçgen kötü | σ₁ ≈ 2n/π, σₙ ≈ ½ (düşmez) | Townsend 14m27 |
| Sayısal rank | rank_ε = ε·σ₁ üstündeki σ sayısı | Townsend 19m58 |
| Eckart-Young | σ₍k+1₎ = en iyi rank-k yaklaşım hatası | Townsend 21m58 |
| Hilbert matrisi | H₍jk₎ = 1/(j+k−1); 1000×1000 → rank 28 | Townsend 24m38 |
| Dünya pürüzsüz | Reade: polinom → rank ≤ m² (719, zayıf) | Townsend 27m16 |
| Dünya Sylvester | AX − XB = C, C düşük-rank | Townsend 36m50 |
| Zolotarev sayısı | E, F ayrık → hızlı düşüş; Hilbert 34 | Townsend 44m55 |
18.19 ML Bağlantıları Özeti
- Sıkıştırma / LoRA: düşük-rank = 2kn parametre; LoRA (ΔW = BAᵀ), görüntü sıkıştırma, otokodlayıcılar bu pazarlığı yapar.
- Sayısal rank / etkin boyut: gerçek veri matrisleri ve ağ ağırlıkları tam değil sayısal düşük-rank’tır; budama (pruning) ve SVD sıkıştırma buna dayanır.
- Simetri → düşük-rank: CNN’ler (Ders 32) uzaysal simetriyle parametre paylaşır — “az parametre, çok bilgi”nin başka yolu.
- Pürüzsüzlük → kernel: pürüzsüz kernel’ler düşük sayısal rank Gram matrisi verir; Nyström/rastlantısal özellikler (Ders 13) bu yüzden çalışır.
- Kondisyon uyarısı: Vandermonde gibi düşük sayısal rank matrisler tersini almayı zorlaştırır (Ders 10); polinom özellikleri kararsız, ortogonal polinom/spline tercih edilir.
- Geriye köprü: Ders 6 (SVD = Σσᵢuᵢvᵢᵀ), Ders 7 (Eckart-Young, en iyi rank-k), Ders 16 (tekil değer türevi), Phase 1 18.06 (−1,2,−1 sonlu fark matrisi).
ÖnemliTownsend’in Sorusu, Townsend’in Cevabı
“Today I want to tell you a little about why there [are] so many matrices that are low rank in the world.” — Townsend, 1:15
Cevap: pürüzsüzlük ve Sylvester yapısı tekil değerleri hızla düşürür; gerçek dünyanın matrisleri bu yüzden sıkıştırılabilir.