flowchart TB
M["Istatistik basliyor:<br/>tanimlar + esitsizlikler"]
M --> E["beklenen deger:<br/>E[x] = toplam P_i x_i = m"]
M --> VAR["varyans:<br/>sigma^2 = E[(x-m)^2] = E[x^2] - m^2"]
M --> MK["Markov (x >= 0):<br/>P(x >= a) <= m/a"]
M --> CH["Chebyshev:<br/>P(|x-m| >= a) <= sigma^2/a^2<br/>(Markov dan kanit)"]
M --> OO["ortak olasilik:<br/>yapismamis vs yapisik paralar"]
MK --> CH
T["3 deney -> TENSOR (2x2x2)"]
V["covariance V = agirlikli<br/>dis-carpim toplami: simetrik PSD"]
D["bagimsiz -> kosegen V"]
OO --> T
OO --> V
V --> D
classDef center fill:#1f4e79,stroke:#163a5c,color:#ffffff,stroke-width:2px;
classDef branch fill:#2e75b6,stroke:#1f4e79,color:#ffffff,stroke-width:1px;
classDef side fill:#9dc3e6,stroke:#2e75b6,color:#11151c,stroke-width:1px;
class M center;
class E,VAR,MK,CH,OO branch;
class T,V,D side;
21 Tanımlar ve Eşitsizlikler — Mean, Variance, Covariance
İstatistik bloğu açılışı: Markov, Chebyshev ve covariance matrisi
NotBölüm bilgisi
Bu ders lineer cebir bloğunu kapatıp istatistik bloğunu açar: Strang’in Ders 20 videosu (≈55 dk) ve OCW Lecture 20 temel alınmıştır. Okuma süresi ≈34 dk; önkoşul Ders 19 (covariance önizlemesi).
21.1 Bu Derste Ne Var?
Lineer cebir bloğu kapandı; istatistik başlıyor. Bu ders olasılığın temel tanımlarını (beklenen değer, varyans) ve iki büyük eşitsizliği (Markov, Chebyshev) tazeler, sonra covariance matrisine ulaşır — derin öğrenmenin istatistiksel temeli.
Beş sonuç:
- Beklenen değer: \(E[x] = \sum_{i} P_{i}x_{i} = m\); varyans \(\sigma^{2} = E[(x-m)^{2}] = E[x^{2}] - m^{2}\).
- Markov eşitsizliği (\(x \geq 0\)): \(P(x \geq a) \leq \frac{m}{a}\).
- Chebyshev eşitsizliği: \(P(|x-m| \geq a) \leq \frac{\sigma^{2}}{a^{2}}\) — Markov’dan \(y = (x-m)^{2}\) ile kanıtlanır.
- Ortak olasılık: bağımsız (yapışmamış) vs bağımlı (yapışık) paralar; 3 deney → tensör (3-yollu dizi).
- Covariance matrisi: \(V = \sum P_{ij}\,(\text{sapma})(\text{sapma})^{\top}\); köşegen = varyanslar, köşegen-dışı = \(\sigma_{xy}\); bağımsız → köşegen; simetrik pozitif yarı-tanımlı.
“…part of deep learning as we get there.” — Strang, 0:28
Kavram haritası (Şekil 21.1) dersin akışını gösterir: merkezdeki “istatistik başlıyor” düğümünden beş dal (beklenen değer, varyans, Markov, Chebyshev, ortak olasılık) çıkar; Markov, Chebyshev’i besler (kanıt oku), ortak olasılık ise hem tensöre hem covariance matrisine açılır.
İpucuBuilder Notu — İstatistik Bloğunun Kapısı
Burası kitabın ikinci yarısının başlangıcı: 19 dersin lineer cebiri artık olasılığa hizmet ediyor. Covariance matrisi = veri yapısı — PCA (Ders 7), Mahalanobis mesafesi, Gauss dağılımı, Kalman filtresi (Ders 14) hep bu simetrik pozitif yarı-tanımlı matrise dayanır. Markov/Chebyshev = konsantrasyon eşitsizlikleri — ML genelleme sınırlarının (generalization bounds) ataları; “örneklem ortalaması gerçek ortalamaya ne kadar yakın?” sorusunu yanıtlar. Tensör — derin öğrenmenin temel veri yapısı (PyTorch/NumPy ndarray); 3+ yollu dizi ilk kez burada çıkıyor. Geriye köprü: Stat 110 (mean/variance/Markov/Chebyshev — §4.B), Ders 5 (pozitif tanımlı), Ders 19 (covariance önizleme).
21.2 1. Beklenen Değer (Mean)
İstatistik bloğu başlıyor — derin öğrenmenin de bir parçası.
“…part of deep learning as we get there.” — Strang, 0:28
Örneklem ortalaması (sample mean) veriden hesaplanır; beklenen değer ise olasılıklarla ağırlıklı ortalamadır. x değeri \(P_{1}\) olasılıkla \(x_{1}\), …, \(P_{n}\) olasılıkla \(x_{n}\) alıyorsa:
\[E[x] = P_{1}x_{1} + P_{2}x_{2} + \cdots + P_{n}x_{n} = m\]
E sembolü her yerde kullanılır — pratik bir kısaltma. Genel olarak herhangi bir \(f(x)\) fonksiyonunun beklenen değeri de olasılıklarla ağırlıklıdır:
\[E[f(x)] = \sum_{i} P_{i}\,f(x_{i})\]
İpucuBuilder Notu — Riskin Dili E Sembolü
Beklenen değer = olasılık-ağırlıklı ortalama; örneklem ortalaması bunun veriden tahminidir. ML köprüsü: bir kayıp fonksiyonunun beklenen değerini (risk) minimize etmek istatistiksel öğrenmenin tanımıdır; SGD (Ders 25) bu beklenen değeri mini-batch örneklem ortalamasıyla tahmin eder. \(E[\cdot]\) gösterimi tüm makine öğrenmesi teorisinin dili.
21.3 2. Varyans
Varyans, beklenen değerin özel bir hâli: ortalamadan uzaklığın karesinin beklenen değeri:
\[\sigma^{2} = E[(x - m)^{2}] = \sum_{i} P_{i}(x_{i} - m)^{2}\]
Kare şart — işaretten bağımsız bir yayılım ölçüsü verir. m = ortalama (mean). Varyans, dağılımın ortalama etrafında ne kadar saçıldığını ölçer.
Kod
v1, v2, m = variance_two_ways(DIE_XS, DIE_PS)
sigma = np.sqrt(v1)
fig, ax = plt.subplots(figsize=(7.5, 4))
ax.bar(DIE_XS, DIE_PS, color=COL_PRIMARY, width=0.6)
ax.axvline(m, color=COL_VEC3, linewidth=3, label="m = 3.5")
ax.text(m + 0.08, 0.235, "m = 3.5", color=COL_VEC3, fontsize=11, fontweight="bold", va="top")
ax.axvspan(m - sigma, m + sigma, color=COL_TEAL, alpha=0.12)
ax.text(m + sigma + 0.05, 0.05, "m +- sigma (sigma = 1.708)", color=COL_TEAL, fontsize=9.5, fontweight="bold", rotation=90, va="bottom")
ax.text(0.55, 0.215, "iki formul birebir:\nE[(x-m)^2] = E[x^2] - m^2 = 35/12 = 2.917",
color=COL_TEXT, fontsize=9.5,
bbox=dict(boxstyle="round,pad=0.4", facecolor=COL_BG, edgecolor=COL_STEEL_300))
apply_style(ax)
ax.set_xlabel("zar degeri"); ax.set_ylabel("olasilik")
ax.set_ylim(0, 0.25)
ax.set_title("Zar: beklenen deger m = 3.5, varyans iki formulle ayni (35/12 = 2.917, fark ~ 4e-16)",
color=COL_TEXT, fontsize=11, fontweight="bold")
plt.show()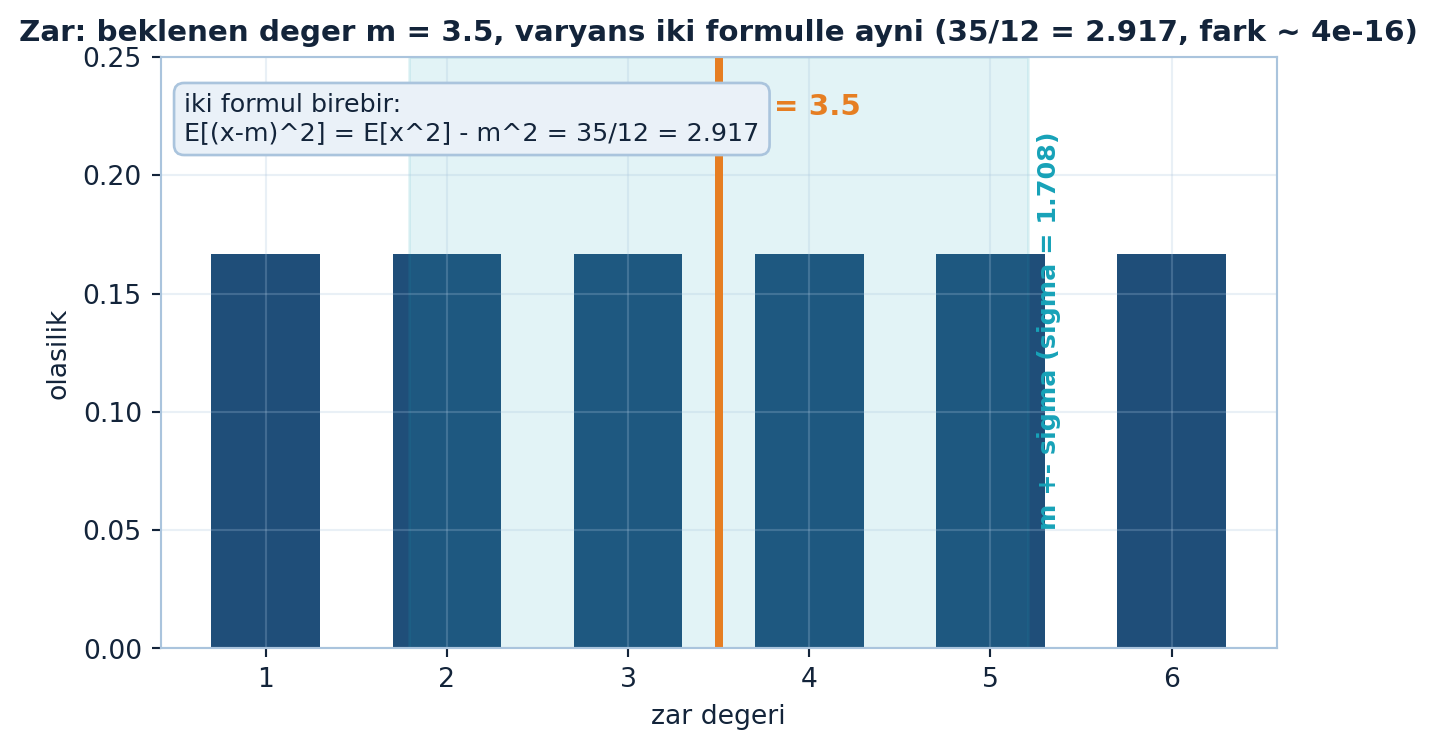
İpucuBuilder Notu — Saçılımın Karesi
Varyans = ortalamadan kare-uzaklığın ortalaması. ML köprüsü: bias-variance ayrışımı (model hatasının iki kaynağı), gradyan gürültüsünün varyansı (SGD yakınsama hızını belirler), ve PCA’da varyans-maksimizasyonu — hepsi bu tek tanıma dayanır. Yüksek varyans = aşırı-öğrenme sinyali.
21.4 3. Varyans için İkinci Formül
Kareyi açıp yeniden düzenleyerek varyansın çok kullanışlı (ve hesaplaması hızlı) ikinci biçimi çıkar:
\[\sigma^{2} = E[x^{2}] - m^{2}\]
“…the expected value of x squared minus m squared. It’s just algebra.” — Strang, 7:56
İspat lise cebiri: \(\sum P_{i}(x_{i}-m)^{2}\) açılınca \(\sum P_{i}x_{i}^{2} - 2m \sum P_{i}x_{i} + m^{2} \sum P_{i}\). Son terimde \(\sum P_{i} = 1\), orta terimde \(\sum P_{i}x_{i} = m\), yani \(-2m \cdot m + m^{2} = -m^{2}\). Geriye \(E[x^{2}] - m^{2}\) kalır.
Zar örneği (Şekil 21.2), bu iki formülün birebir aynı sonucu verdiğini sayısal olarak doğrular: \(m = 3.5\), her iki yoldan \(\sigma^{2} = 35/12 \approx 2.917\), aradaki fark yalnızca yuvarlama düzeyinde (\(\sim 4 \times 10^{-16}\)). \(m \pm \sigma\) bandı (\(\sigma \approx 1.708\)) dağılımın çoğunu kapsar.
İpucuBuilder Notu — Tek Geçişte Varyans
“Karelerin ortalaması eksi ortalamanın karesi” formülü tek geçişte (online) varyans hesaplamayı sağlar — \(\sum x^{2}\) ve \(\sum x\) biriktirip sonda birleştir. ML köprüsü: batch normalization ve running statistics (çalışan istatistikler) tam bu formülü kullanır; veri akışında ortalama ve varyansı tek geçişte günceller.
21.5 4. Markov Eşitsizliği
İstatistiğin iki büyük eşitsizliğinden ilki Markov’dan (1900’lerin büyük Rus olasılıkçısı):
“And the first one is due to Markov.” — Strang, 8:46
Negatif olmayan çıktılar için (tüm \(x_{i} \geq 0\)), x’in a’dan büyük olma olasılığını ortalama ile sınırlar:
\[P(x \geq a) \leq \frac{m}{a} \qquad (x \geq 0)\]
a büyüdükçe olasılık düşer (daha fazlasını istiyoruz). Örnek: m = 1, a = 3 → \(P(x \geq 3) \leq 1/3\). İspat sezgisi: \(x_{3}P_{3} + x_{4}P_{4} + \cdots \leq \sum x_{i}P_{i} = m\); tüm terimler negatif olmadığından ve toplam m olduğundan, “a’yı aşan” kısım m/a’yı geçemez.
Kod
fig, axs = plt.subplots(1, 2, figsize=(10, 4))
# Sol: a taramasi — gercek P(x >= a) vs Markov siniri m/a
xs1 = np.array([0., 1., 2., 3.])
ps1 = np.array([0.4, 0.35, 0.15, 0.1])
m1 = expectation(xs1, ps1) # = 0.95
a_scan = np.linspace(0.5, 3.5, 200)
gercek = [prob_tail(xs1, ps1, a) for a in a_scan]
sinir = [m1 / a for a in a_scan]
axs[0].step(a_scan, gercek, where="post", color=COL_PRIMARY, lw=2, label="gercek P(x >= a)")
axs[0].plot(a_scan, sinir, color=COL_VEC3, lw=2, label="Markov siniri m/a")
axs[0].fill_between(a_scan, gercek, sinir, color=COL_STEEL_300, alpha=0.25)
axs[0].set_xlabel("a"); axs[0].set_ylabel("olasilik")
axs[0].set_title("a taramasi: sinir HEP gercek olasiligin ustunde", fontsize=11)
axs[0].legend()
apply_style(axs[0])
# Sag: esitlik durumu — iki-noktali {0, 5} dagilim, a = 5
xs_eq = np.array([0., 5.])
ps_eq = np.array([0.6, 0.4])
a_eq = 5.0
gercek_eq, sinir_eq = markov_bound(xs_eq, ps_eq, a_eq) # 0.4 ve 0.4 AYNI
bars = axs[1].bar([0, 1], [gercek_eq, sinir_eq], width=0.5,
color=[COL_PRIMARY, COL_VEC3])
axs[1].set_xticks([0, 1]); axs[1].set_xticklabels(["gercek P(x >= 5)", "Markov siniri m/5"])
axs[1].set_ylabel("olasilik"); axs[1].set_ylim(0, 0.55)
axs[1].set_title("esitlik durumu: gercek = sinir = 0.4", fontsize=11)
for b, v in zip(bars, [gercek_eq, sinir_eq]):
axs[1].text(b.get_x() + b.get_width() / 2, v + 0.012, "%.2f" % v,
ha="center", va="bottom", color=COL_TEXT, fontweight="bold")
axs[1].annotate("esitlik: kutle yalniz {0, a} da", xy=(0.5, 0.4), xytext=(0.5, 0.5),
ha="center", color=COL_TEXT, fontsize=10,
arrowprops=dict(arrowstyle="->", color=COL_TEXT))
apply_style(axs[1])
fig.suptitle("Markov (x >= 0): P(x >= a) <= m/a — sabit dagilimda 200 esik (a) degerinde ihlal 0; esitlik yalniz iki-noktali {0, a} dagiliminda",
fontsize=11, color=COL_TEXT)
fig.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()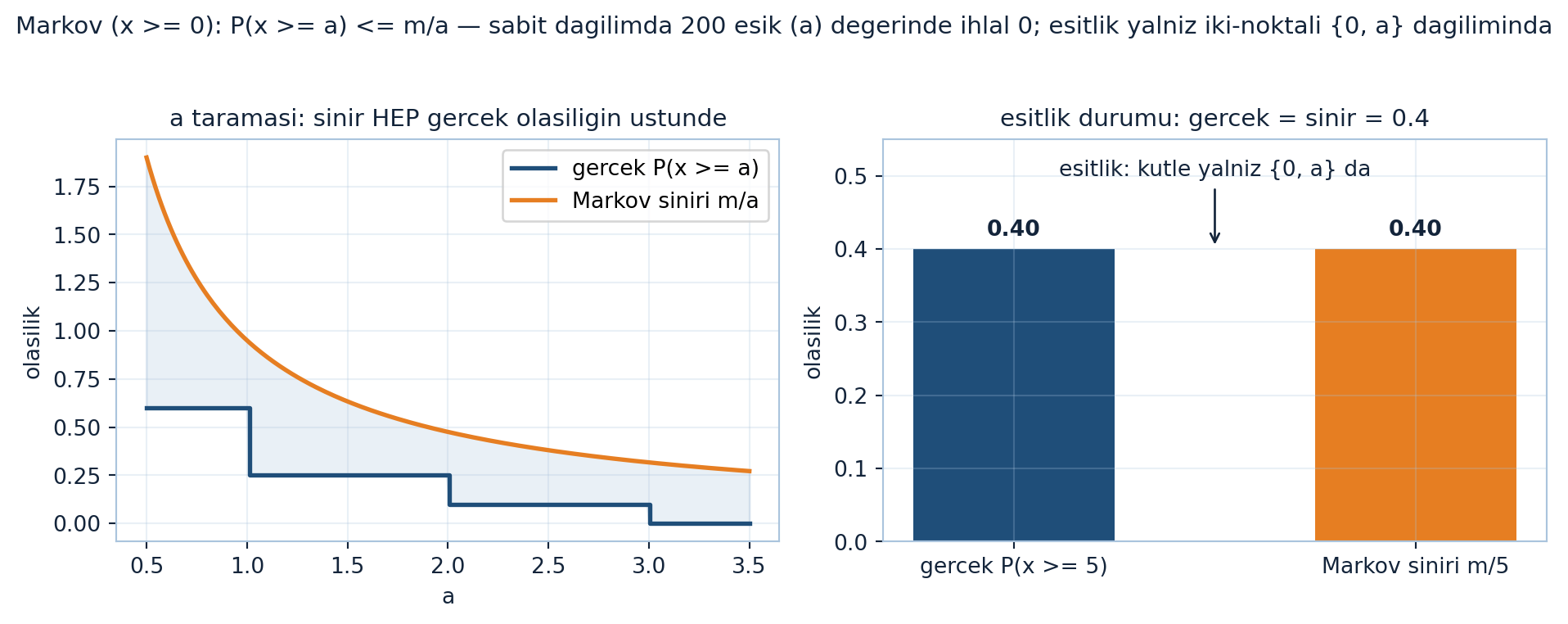
Markov’un iki yüzü (Şekil 21.3): solda sabit bir dört-noktalı dağılımda eşik a, \(0.5 \to 3.5\) boyunca (200 nokta) tarandıkça gerçek \(P(x \geq a)\) basamak eğrisi sınır \(m/a\) eğrisinin daima altında kalır — taranan 200 eşik değerinin hiçbirinde ihlal yok (ihlal sayısı 0). Sağda eşitliğin sağlandığı tek aile gösterilir: kütle yalnız \(\{0, a\}\) iki noktasına toplanırsa gerçek olasılık sınıra dokunur (\(a = 5\) için her ikisi de 0.40).
İpucuBuilder Notu — Az Varsayım Zayıf Sınır
Markov, en az varsayımla (sadece \(x \geq 0\)) en zayıf ama en genel sınırı verir. ML köprüsü: konsantrasyon eşitsizliklerinin (concentration inequalities) atası; genelleme sınırları, PAC öğrenme ve “kötü olay” olasılıklarını sınırlamak hep Markov-tipi argümanla başlar. Gauss gibi negatif değer alan dağılımlara uygulanamaz — sınırı orada Chebyshev devralır.
21.6 5. Chebyshev Eşitsizliği
İkinci büyük eşitsizlik Chebyshev’den (dönemin diğer büyük Rus olasılıkçısı). Markov’un \(x \geq 0\) varsayımını yapmaz:
“Chebyshev is the other great Russian probabilist of the time.” — Strang, 21:37
Ortalamadan uzaklığı (her iki yöne) sınırlar — varyans devreye girer:
\[P(|x - m| \geq a) \leq \frac{\sigma^{2}}{a^{2}}\]
Zekice olan: ispat doğrudan Markov’dan gelir.
“…the proof of Chebyshev comes directly from Markov.” — Strang, 25:05
Yeni bir çıktı tanımla: \(y = (x - m)^{2}\) (negatif olmayan! aynı olasılıklarla). Markov’u y’ye uygula: \(P(y \geq a^{2}) \leq E[y]/a^{2} = \sigma^{2}/a^{2}\). Ama \(y \geq a^{2}\) demek \(|x - m| \geq a\) demektir. Sonuç Chebyshev.
Kod
fig, axs = plt.subplots(1, 2, figsize=(10, 4))
# --- Sol: kanit gorseli (Chebyshev = Markov uygulandi) ---
xs_c = np.array([-2., 0., 1., 4.])
ps_c = np.array([0.2, 0.3, 0.3, 0.2])
a_scan = np.linspace(0.5, 4, 200)
gercek = [chebyshev_bound(xs_c, ps_c, a)[0] for a in a_scan]
cheb = [chebyshev_bound(xs_c, ps_c, a)[1] for a in a_scan]
mkv = [chebyshev_via_markov(xs_c, ps_c, a) for a in a_scan]
axs[0].step(a_scan, gercek, where="mid", color=COL_PRIMARY, lw=1.8, label="gercek P(|x-m| >= a)")
axs[0].plot(a_scan, cheb, color=COL_VEC3, lw=2.5, label="Chebyshev sigma^2/a^2")
axs[0].plot(a_scan, mkv, color=COL_TEAL, lw=2, linestyle="--", label="Markov(y=(x-m)^2) — AYNI egri (kanit)")
axs[0].set_xlabel("esik a"); axs[0].set_ylabel("olasilik / sinir")
axs[0].set_ylim(0, 2.2); axs[0].legend(fontsize=8.5, loc="upper right")
axs[0].set_title("Sol: iki sinir egrisi cakisir (kanit)", color=COL_TEXT, fontsize=11, fontweight="bold")
apply_style(axs[0])
# --- Sag: Gauss histogrami, |x|>=2 vurgu ---
rngg = np.random.default_rng(5)
g = rngg.standard_normal(200000)
axs[1].hist(g, bins=80, color=COL_STEEL_300, density=True, label="standart normal")
mask = np.abs(g) >= 2
axs[1].hist(g[mask], bins=80, color=COL_VEC3, density=False, weights=np.full(mask.sum(), 1.0 / (g.size * (g.max() - g.min()) / 80)), alpha=0.9, label="|x| >= 2 (kuyruk)")
axs[1].set_xlabel("x"); axs[1].set_ylabel("yogunluk")
axs[1].text(0.02, 0.97, "gercek P(|x|>=2) = 0.045\nvs Chebyshev 0.25\n(5.5 kat gevsek ama\nDAGILIM-BAGIMSIZ)",
transform=axs[1].transAxes, va="top", ha="left", fontsize=8.5,
bbox=dict(boxstyle="round", fc=COL_BG, ec=COL_ACCENT, alpha=0.95))
axs[1].set_title("Sag: Gauss ta sinir gevsek ama evrensel", color=COL_TEXT, fontsize=11, fontweight="bold")
apply_style(axs[1])
fig.suptitle("Chebyshev = Markov un (x-m)^2 ye uygulanmasi: iki sinir egrisi BIREBIR cakisir (1.6933 = 1.6933)",
color=COL_TEXT, fontsize=11.5, fontweight="bold")
fig.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()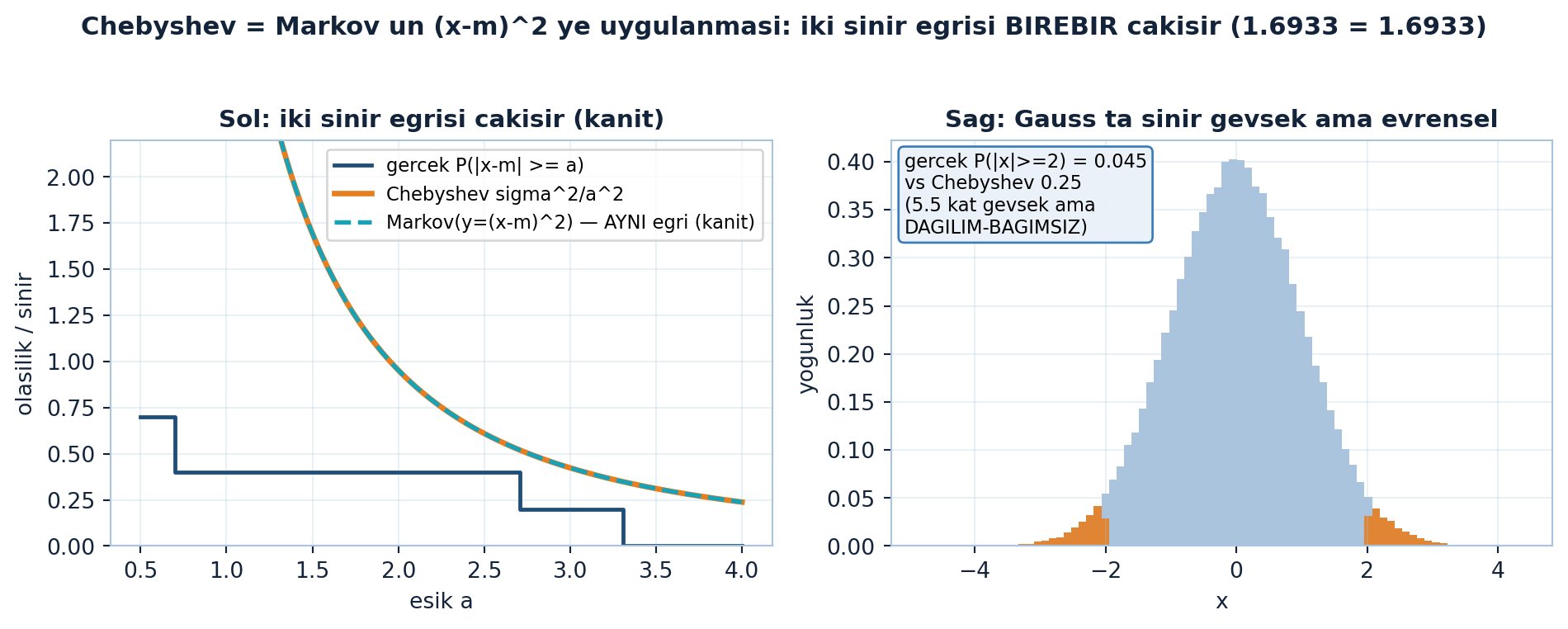
Kanıt görseli (Şekil 21.4) tam da bu hamleyi gösterir: solda Chebyshev sınırı \(\sigma^{2}/a^{2}\) (turuncu) ile “Markov’u \(y=(x-m)^{2}\)’ye uygula” eğrisi (teal kesik) birebir çakışır — sayısal tanık \(1.6933 = 1.6933\). Sağda standart normal için Chebyshev sınırı işler: gerçek \(P(|x| \geq 2) \approx 0.045\), sınır 0.25 (yaklaşık 5,5 kat gevşek). Bu gevşeklik bedel: Markov negatif değerli Gauss’a uygulanamaz, ama Chebyshev her dağılıma uygulanır.
İpucuBuilder Notu — Markov’u Kareye Uygula
Chebyshev mutlak değer/uzaklık ile çalışır, yani işaretsiz — varyans temelli. “Markov’u \((x-m)^{2}\)’ye uygula” hamlesi, negatif-olmayan bir dönüşüm bulup genel bir eşitsizliği özelden türetmenin klasik örneği. ML köprüsü: büyük sayılar yasasının (LLN) niceliksel hâli; örneklem ortalamasının gerçek ortalamaya yakınsama hızını (1/n) Chebyshev verir — SGD’nin neden işe yaradığının temeli.
21.7 6. Ortak Olasılık: Yapışmamış ve Yapışık Paralar
Covariance’a geçmeden önce ortak olasılık (joint probability). İki para at; sonuçları bir 2×2 matriste topla. Yapışmamış (bağımsız) paralar: her kombinasyon eşit olasılıklı:
\[P_{\text{unglued}} = \begin{bmatrix} 1/4 & 1/4 \\ 1/4 & 1/4 \end{bmatrix}\]
Yapışık (tam bağımlı) paralar: biri yazı gelirse diğeri de yazı; sadece YY veya TT mümkün:
\[P_{\text{glued}} = \begin{bmatrix} 1/2 & 0 \\ 0 & 1/2 \end{bmatrix}\]
Bir paranın sonucunu bilmek diğeri hakkında: bağımsızda hiçbir şey, bağımlıda her şeyi söyler. Üç deney (üç para) yaparsan, ortak olasılıklar artık bir matrise sığmaz — üç indis gerekir:
“…we’re seeing for the first time a tensor.” — Strang, 37:56
Üç para → 2×2×2 bir tensör (8 girdi); bağımsızsa her biri 1/8. Tensör = çok-yollu matris (satır, sütun, katman).
Kod
fig, axs = plt.subplots(1, 3, figsize=(10, 3.4))
heatmap(axs[0], P_UNGLUED, "yapismamis (bagimsiz): hepsi 1/4", fmt="{:.2f}")
heatmap(axs[1], P_GLUED, "yapisik: yalniz YY ve TT", fmt="{:.2f}")
T = tensor_three_coins()
heatmap(axs[2], np.hstack([T[:, :, 0], T[:, :, 1]]), "3 para -> 2x2x2 tensor (iki katman; hepsi 1/8)", fmt="{:.3f}")
fig.suptitle("Ortak olasilik: bagimsizda bilgi yok, yapisikta tam bilgi; uc deney matrise sigmaz -> ILK TENSOR", fontsize=11, color=COL_TEXT)
fig.tight_layout()
plt.show()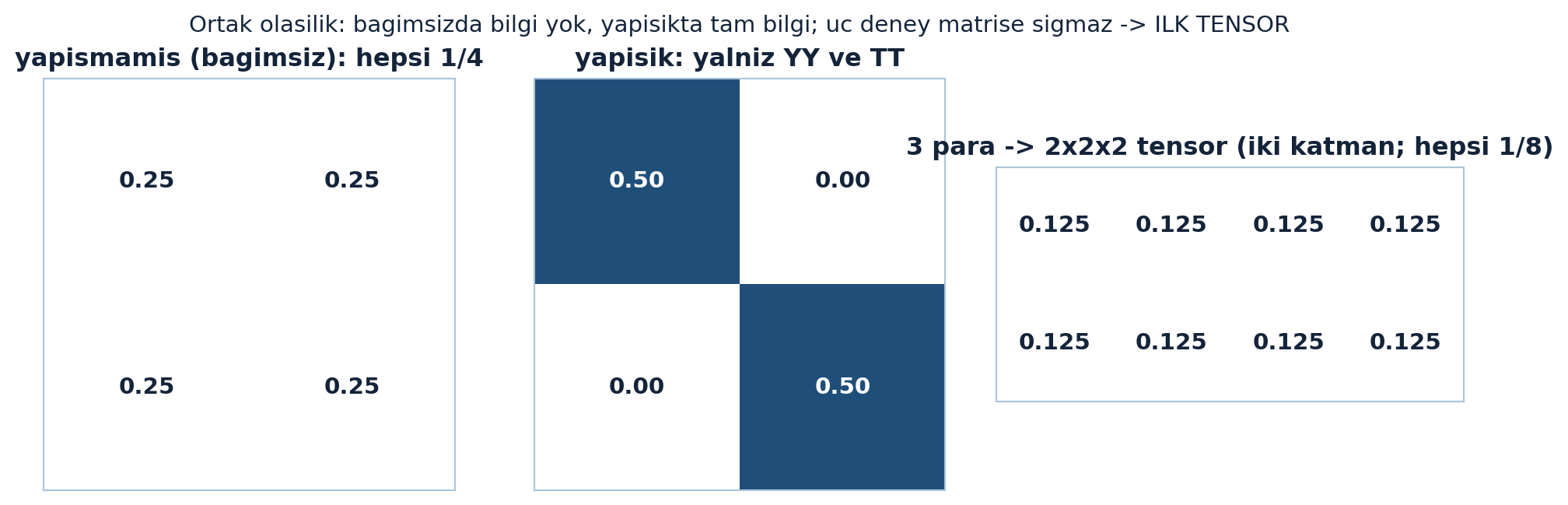
İki para matrisi ile ilk tensör (Şekil 21.5): solda yapışmamış paraların dört hücresi de 1/4, ortada yapışık paralarda kütle yalnız YY/TT köşegeninde (her biri 1/2), sağda üç para için 2×2×2 tensör iki katman olarak gösterilir (her hücre 1/8).
İpucuBuilder Notu — Köşegen-Dışı Bağımlılık Kodlar
Ortak olasılık matrisinin köşegen-dışı yapısı bağımlılığı kodlar: bağımsız = köşegen-baskın değil, eşit dağılım; bağımlı = sıfırlar belirir. ML köprüsü: tensör derin öğrenmenin temel veri yapısıdır (PyTorch/NumPy ndarray) — bir görüntü batch’i 4-yollu tensördür (batch×kanal×yükseklik×genişlik). Strang’ın “ilk kez tensör görüyoruz” anı, lineer cebirden çok-boyutlu dizilere geçişin kapısı.
21.8 7. Covariance Matrisi
Günün varış noktası:
“…what is the covariance matrix?” — Strang, 42:37
İki deney aynı anda koşar (deney 1 → x, deney 2 → y). Tüm olası \((x_{i}, y_{j})\) çiftleri üzerinde, ortak olasılık \(P_{ij}\) ile ağırlıklı, sapmaların dış-çarpımı (kolon × satır):
\[V = \sum_{i,j} P_{ij} \begin{bmatrix} x_{i} - m_{x} \\ y_{j} - m_{y} \end{bmatrix} \begin{bmatrix} x_{i} - m_{x} & y_{j} - m_{y} \end{bmatrix}\]
İki deney → 2×2 matris. (1,1) girdisi: \((x-m_{x})^{2}\) ağırlıklı toplam = x’in varyansı \(\sigma_{x}^{2}\). (2,2): \(\sigma_{y}^{2}\). Köşegen-dışı (1,2) = (2,1): kovaryans \(\sigma_{xy}\) (simetrik):
\[V = \begin{bmatrix} \sigma_{x}^{2} & \sigma_{xy} \\ \sigma_{xy} & \sigma_{y}^{2} \end{bmatrix}\]
Köşegen = ayrı ayrı varyanslar, köşegen-dışı = değişkenler arası ilişki. Dış-çarpım yapısı (Ders 1) covariance’ı doğal olarak simetrik kılar.
Kod
fig, axs = plt.subplots(1, 3, figsize=(10.5, 3.4))
Vu, _, _ = covariance_from_joint(P_UNGLUED)
Vg, _, _ = covariance_from_joint(P_GLUED)
heatmap(axs[0], Vu, "bağımsız: V = diag(1/4, 1/4)", fmt="{:.2f}")
heatmap(axs[1], Vg, "yapışık: TEKİL (det = 0)", fmt="{:.2f}")
for t in range(20):
P_r = random_joint(4, seed=t)
V_r, _, _ = covariance_from_joint(P_r, np.arange(4.), np.array([0., 2., 3., 7.]))
lams = np.linalg.eigvalsh(V_r)
axs[2].scatter(lams[0], lams[1], color=COL_PRIMARY, s=45, zorder=3)
axs[2].scatter(0, 0.5, color=COL_VEC3, marker="*", s=140, zorder=4)
axs[2].annotate("tekil sınır (yapışık)", xy=(0, 0.5), xytext=(0.6, 0.9),
color=COL_VEC3, fontsize=9,
arrowprops=dict(arrowstyle="->", color=COL_VEC3))
axs[2].axvline(0, color=COL_STEEL_300, linestyle="--", linewidth=1.2, zorder=1)
axs[2].set_xlabel("lambda_min")
axs[2].set_ylabel("lambda_max")
apply_style(axs[2])
fig.suptitle("Covariance = olasılık-ağırlıklı dış-çarpım toplamı -> HER ZAMAN simetrik PSD; bağımsız köşegen, tam bağımlı tekil")
fig.tight_layout()
plt.show()
Covariance’ın yapısı (Şekil 21.6): solda bağımsız paralarda \(V = \text{diag}(1/4, 1/4)\) (köşegen, \(\sigma_{xy} = 0\)), ortada yapışık paralarda \(V\)’nin tüm girdileri 1/4 olduğundan determinant sıfır — tekil/yarı-tanımlı. Sağda 20 rastgele ortak dağılımın özdeğer çiftleri \((\lambda_{\min}, \lambda_{\max})\) daima \(\lambda_{\min} > 0\) bölgesinde (en küçüğü 0.92), yapışık paranın noktası (0, 0.5) tam tekil sınırda.
İpucuBuilder Notu — Dış-Çarpımların Ağırlıklı Toplamı
Covariance matrisi = dış-çarpımların olasılık-ağırlıklı toplamı (Ders 1 \(uv^{\top}\) deseni). Köşegen-dışı terimler değişkenlerin birlikte nasıl değiştiğini söyler. ML köprüsü: veri matrisi A için \((1/n)A^{\top}A\) merkezlenmiş covariance’tır; özvektörleri ana bileşenler (PCA, Ders 7), özdeğerleri varyans miktarları. Gauss dağılımı, Mahalanobis mesafesi ve LDA hep V’ye dayanır.
21.9 8. Pozitif Yarı-Tanımlı ve Bağımsızlık
Dış-çarpım toplamı olduğundan covariance matrisi her zaman simetrik pozitif yarı-tanımlıdır (Ders 5): her sapma-dış-çarpımı pozitif yarı-tanımlı, toplamları da öyle. Bağımsız (yapışmamış) deneylerde kovaryans sıfırdır:
“…in that case, those are 0.” — Strang, 52:10
\[\text{independent} \;\Rightarrow\; \sigma_{xy} = 0 \;\Rightarrow\; V = \begin{bmatrix} \sigma_{x}^{2} & 0 \\ 0 & \sigma_{y}^{2} \end{bmatrix}\]
Bağımsızlıkta V köşegen — sadece ayrı varyanslar. Tam bağımlılıkta (yapışık) V tekildir (pozitif yarı-tanımlı, det = 0). Ek not: ortak olasılıkları bir indis üzerinden toplamak (\(\sum_{i} P_{ij} = P_{j}\)) marjinal olasılıkları verir.
İpucuBuilder Notu — Sıfır Özdeğer Tam Bağımlılık
“Bağımsız → köşegen covariance” ve “tam bağımlı → tekil (yarı-tanımlı)” ayrımı, covariance’ın özdeğerlerinin bağımlılık yapısını okuduğunu gösterir: sıfır özdeğer = mükemmel doğrusal bağımlılık. ML köprüsü: çoklu-doğrusallık (multicollinearity) tam budur — neredeyse-tekil covariance regresyonu kararsız kılar (Ders 10 kondisyon); PCA bu yönde varyansı sıfıra yakın bileşenleri atar.
21.10 Bu Dersin Özeti
- Beklenen değer: \(E[x] = \sum P_{i}x_{i} = m\); genel olarak \(E[f(x)] = \sum P_{i}f(x_{i})\).
- Varyans: \(\sigma^{2} = E[(x-m)^{2}] = E[x^{2}] - m^{2}\) (ikinci formül tek geçişte hesaplanır).
- Markov (\(x \geq 0\)): \(P(x \geq a) \leq m/a\). En genel, en zayıf sınır.
- Chebyshev: \(P(|x-m| \geq a) \leq \sigma^{2}/a^{2}\); Markov’u \(y = (x-m)^{2}\)’ye uygulayarak kanıtlanır.
- Ortak olasılık: bağımsız (köşegen-dışı bilgi yok) vs bağımlı; 3 deney → tensör (2×2×2).
- Covariance matrisi: \(V = \sum P_{ij}\,(\text{sapma})(\text{sapma})^{\top}\); köşegen = varyanslar, köşegen-dışı = \(\sigma_{xy}\); simetrik pozitif yarı-tanımlı.
- Bağımsızlık → köşegen V (\(\sigma_{xy} = 0\)); tam bağımlılık → tekil V.
ÖnemliTek Bir Cümle
Beklenen değer ve varyans olasılığın temel ölçüleridir; Markov (\(P(x \geq a) \leq m/a\)) ve Chebyshev (\(P(|x-m| \geq a) \leq \sigma^{2}/a^{2}\)) sapmaları sınırlar; covariance matrisi ise değişkenler arası ilişkiyi simetrik pozitif yarı-tanımlı bir matris olarak kodlar (köşegen = varyans, köşegen-dışı = kovaryans).
21.11 Kontrol Soruları
NotSoru 1: Varyansın iki formülü nedir ve ikincisi neden hesaplama açısından kullanışlı?
\(\sigma^{2} = E[(x-m)^{2}]\) (sapma-kare ortalaması) ve \(\sigma^{2} = E[x^{2}] - m^{2}\) (karelerin ortalaması eksi ortalamanın karesi). İkincisi kullanışlı çünkü \(\sum x^{2}\) ve \(\sum x\)’i tek veri geçişinde biriktirip sonda birleştirirsin — online/running varyans hesabı. İspatı lise cebiri: kareyi açıp \(\sum P_{i} = 1\) ve \(\sum P_{i}x_{i} = m\) kullan.
NotSoru 2: Markov ve Chebyshev eşitsizlikleri arasındaki fark nedir, ve Chebyshev nasıl kanıtlanır?
Markov yalnız \(x \geq 0\) için geçerli: \(P(x \geq a) \leq m/a\). Chebyshev bu varsayımı yapmaz; ortalamadan uzaklığı (her iki yön) sınırlar: \(P(|x-m| \geq a) \leq \sigma^{2}/a^{2}\). Chebyshev, Markov’u negatif-olmayan yeni değişken \(y = (x-m)^{2}\)’ye uygulayarak kanıtlanır: \(P(y \geq a^{2}) \leq E[y]/a^{2} = \sigma^{2}/a^{2}\), ve \(y \geq a^{2} \Leftrightarrow |x-m| \geq a\).
NotSoru 3: İki yazı-tura için yapışmamış (bağımsız) ve yapışık (bağımlı) ortak olasılık matrisleri nasıl farklıdır?
Yapışmamış: dört kombinasyon (YY, YT, TY, TT) eşit olasılıklı, her biri 1/4 — köşegen-dışı doludur, bilgi bağımsız. Yapışık: paralar birlikte hareket eder, sadece YY ve TT mümkün (her biri 1/2), YT ve TY sıfır — sadece köşegen dolu. Bir paranın sonucu, bağımsızda diğeri hakkında hiçbir şey, bağımlıda her şeyi söyler.
NotSoru 4: Covariance matrisi V neden simetrik pozitif yarı-tanımlıdır ve köşegen-dışı sıfır ne anlama gelir?
\(V = \sum P_{ij}\,(\text{sapma})(\text{sapma})^{\top}\), yani pozitif yarı-tanımlı dış-çarpımların olasılık-ağırlıklı toplamı (Ders 5) — dolayısıyla simetrik pozitif yarı-tanımlı. Köşegende varyanslar (\(\sigma_{x}^{2}\), \(\sigma_{y}^{2}\)), köşegen-dışında kovaryans \(\sigma_{xy}\) bulunur. Köşegen-dışı sıfır (\(\sigma_{xy} = 0\)) değişkenlerin bağımsız/ilişkisiz olduğu anlamına gelir; V köşegen matris olur.
21.12 Egzersizler
İki formül. Bir zar (1–6, eşit olasılık 1/6) için \(E[x] = m\)’yi ve hem \(\sigma^{2} = E[(x-m)^{2}]\) hem \(\sigma^{2} = E[x^{2}] - m^{2}\) ile varyansı hesapla; aynı çıktığını göster.
Markov sınırı. Ortalaması m = 2 olan negatif-olmayan bir x için \(P(x \geq 8)\) en fazla kaç olabilir? Markov sınırı gevşek mi sıkı mı, yorumla.
Chebyshev sınırı. m = 0, σ = 1 olan bir değişken için \(P(|x| \geq 2)\) Chebyshev’e göre en fazla kaçtır? (Gauss’ta gerçek değerle karşılaştır: ~0.046.)
Covariance hesabı. Yapışık paralar (YY: 1/2, TT: 1/2; Y=1, T=0). x ve y için \(m_{x} = m_{y} = 1/2\). \(\sigma_{xy}\) kovaryansını hesapla; \(\sigma_{x}^{2}\) ile karşılaştır. V matrisi tekil mi?
(Ders 21 habercisi) Bu derste beklenen değer/varyans gördük; bunlar bir kayıp fonksiyonunun “ortalama” davranışını tanımlar. Peki bir fonksiyonun minimumunu adım adım nasıl buluruz? Türev sıfır olduğunda mı, yoksa iteratif inişle mi? Bir tahmin yaz — Ders 21 “bir fonksiyonu adım adım minimize etmek” (Newton, gradient descent girişi) ile optimizasyon bloğunu açıyor.
21.13 Sonraki Ders İçin Hazırlık
Ders 21: Bir Fonksiyonu Adım Adım Minimize Etmek. İstatistikten optimizasyona geçiş: bir maliyet fonksiyonunun minimumunu nasıl buluruz? Strang Newton yöntemini (ikinci-derece, hızlı ama Hessian gerektirir) ve gradient descent’in (birinci-derece, ölçeklenebilir) temelini kurar — derin öğrenme eğitiminin (Ders 22+) çekirdek algoritması.
UyarıLineer cebirden optimizasyona
Bu ders istatistik bloğunun kapısıydı: beklenen değer, varyans, iki eşitsizlik ve covariance matrisi. Sıradaki blok optimizasyon — kayıp fonksiyonlarını minimize etme. Ders 21’e gelmeden önce gradyan (gradient) ve türev kavramlarını gözden geçir; gradient descent’in tek satırı “negatif gradyan yönünde adım at” olsa da arkasındaki sezgi tüm derin öğrenme eğitiminin temeli.
21.14 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Formül / Fikir | Strang (dk) |
|---|---|---|
| İstatistik başlıyor | olasılık = derin öğrenmenin parçası | 0m28 |
| Beklenen değer | \(E[x] = \sum P_{i}x_{i} = m\) | 0m28 |
| Varyans | \(\sigma^{2} = E[(x-m)^{2}] = E[x^{2}] - m^{2}\) | 7m56 |
| Markov eşitsizliği | \(P(x \geq a) \leq m/a\) (\(x \geq 0\)) | 8m46 |
| Chebyshev eşitsizliği | \(P(\lvert x-m \rvert \geq a) \leq \sigma^{2}/a^{2}\) | 21m37 |
| Chebyshev kanıtı | Markov’u \(y = (x-m)^{2}\)’ye uygula | 25m05 |
| Ortak olasılık / tensör | bağımsız vs bağımlı; 3 deney → 2×2×2 tensör | 37m56 |
| Covariance matrisi | \(V = \sum P_{ij}\,(\text{sapma})(\text{sapma})^{\top}\); simetrik PYT | 42m37 |
| Bağımsız → köşegen | \(\sigma_{xy} = 0 \Rightarrow V\) köşegen | 52m10 |
21.15 ML Bağlantıları Özeti
- Risk minimizasyonu: beklenen kayıp \(E[\text{loss}]\) minimize etmek = istatistiksel öğrenme; SGD (Ders 25) bunu mini-batch örneklem ortalamasıyla tahmin eder.
- Konsantrasyon eşitsizlikleri: Markov/Chebyshev → genelleme sınırları, PAC öğrenme; “örneklem ortalaması gerçek ortalamaya ne kadar yakın?” (LLN’in niceliksel hâli).
- Covariance / PCA: veri matrisi A → \((1/n)A^{\top}A\) covariance; özvektörleri ana bileşenler (Ders 7), özdeğerleri varyanslar; Gauss, Mahalanobis, LDA.
- Tensör: derin öğrenmenin temel veri yapısı (batch×kanal×H×W); çok-yollu dizi ilk kez burada.
- Batch normalization: \(E[x^{2}] - m^{2}\) formülü running statistics ile tek geçişte ortalama/varyans.
- Çoklu-doğrusallık: tekil (yarı-tanımlı) covariance → kararsız regresyon (Ders 10 kondisyon); PCA sıfıra yakın varyansı atar.
- Geriye köprü: Stat 110 §4.B (mean/variance/Markov/Chebyshev/covariance), Ders 5 (pozitif yarı-tanımlı), Ders 7 (PCA), Ders 14 (Kalman covariance), Ders 19 (covariance önizleme).
Kod
ns = [10, 100, 1000, 10000]
stds = sample_mean_concentration(DIE_XS, DIE_PS, ns, reps=2000)
sigma = np.sqrt(35.0 / 12.0)
fig, ax = plt.subplots(figsize=(7, 4.2))
ax.loglog(ns, stds, marker="o", ms=9, color=COL_PRIMARY, lw=2,
label="MC std(örneklem ort.) — 2000 tekrar")
ax.loglog(ns, sigma / np.sqrt(np.array(ns, dtype=float)), color=COL_VEC3, ls="--", lw=2,
label="teorik sigma/karekök(n)")
ax.legend()
apply_style(ax)
ax.set_xlabel("n (log)")
ax.set_ylabel("std (log)")
ax.set_title("Chebyshev/LLN niceliksel: örneklem ortalaması sapması sigma/karekök(n) gibi düşer "
"(MC/teorik oranları 0.97-1.04) — SGD'nin istatistiksel temeli",
fontsize=9)
plt.show()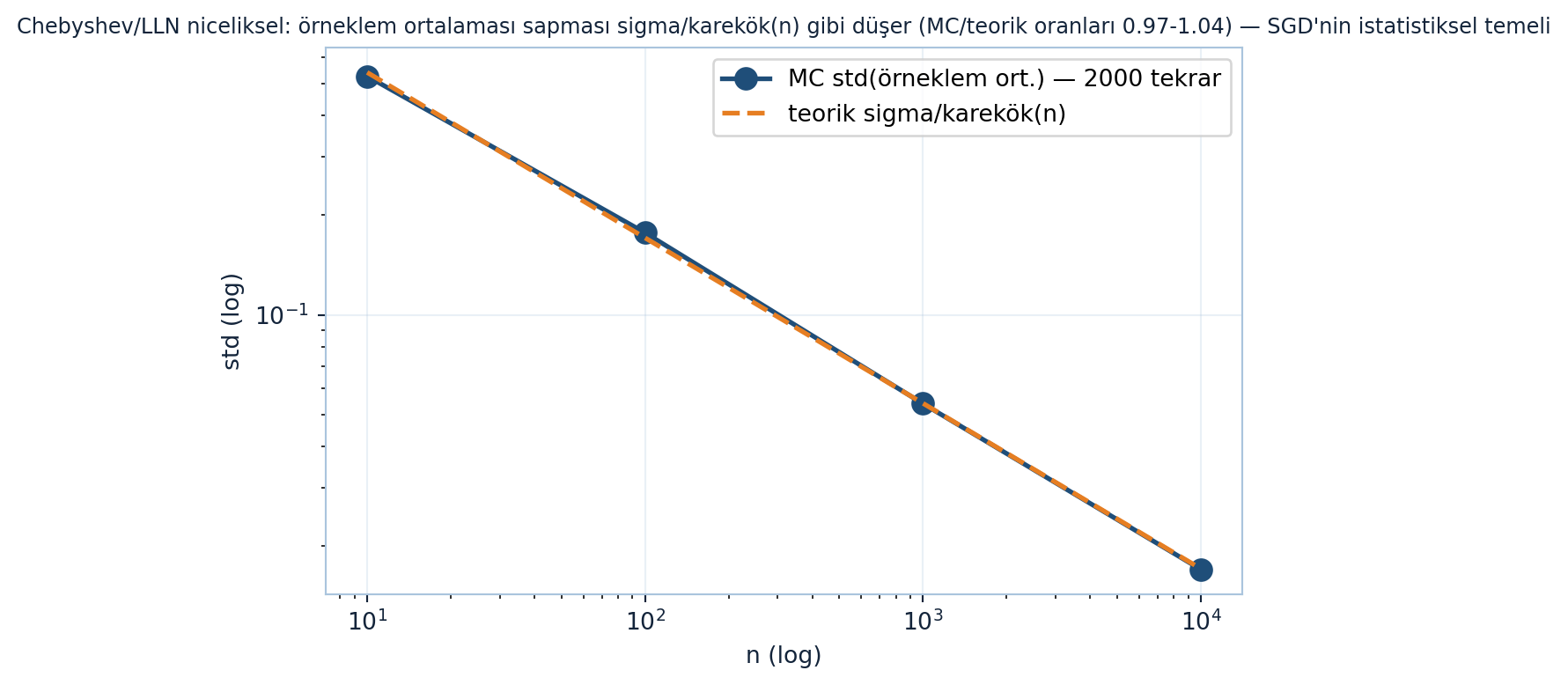
LLN’in niceliksel yüzü (Şekil 21.7): örneklem ortalamasının standart sapması teorik \(\sigma/\sqrt{n}\) eğrisini birebir takip eder (MC/teorik oranları 0.97–1.04 bandında); n 100 kat artınca std 10 kat düşer (std(10)/std(1000) = 9.77 ≈ 10). Bu, Chebyshev’in “örneklem ortalaması gerçek ortalamaya yakınsar” vaadinin sayısal kanıtı ve SGD’nin neden çalıştığının istatistiksel temeli.
Önemliİstatistik, lineer cebirin üzerine kurulur
“…part of deep learning as we get there.” — Strang, 0:28
Covariance bir matristir, özdeğerleri varyans yönlerini verir; beklenen değer ve varyans olasılığın iki temel ölçüsü, Markov ve Chebyshev sapmaları sınırlayan iki büyük eşitsizliktir. Bu blok lineer cebir ile optimizasyon ve derin öğrenme arasındaki köprü: covariance PCA’ya, konsantrasyon eşitsizlikleri genelleme sınırlarına, tensör ise derin öğrenmenin temel veri yapısına açılır.