flowchart TD
C["Ders 33: iki konu"]
C --> A["F(x,v): x = agirliklar (A_k, b_k),<br/>v = ozellik vektorleri"]
C --> B["uzaklik matrisleri:<br/>d_ij = |x_i - x_j|^2"]
A --> A1["katman: v_k = ReLU(A_k v_(k-1) + b_k);<br/>son katman ReLU suz"]
A --> A2["x underdetermined:<br/>agirlik sayisi >> ozellik sayisi"]
A --> A3["kayiplar: kare, L1, hinge,<br/>cross-entropy (NN icin en onemli)"]
B --> B1["G = X^T X =<br/>-1/2 (D - 1d^T - d1^T)"]
B --> B2["X kurtarma: ozdeger koku (simetrik)<br/>vs Cholesky (ucgen, hizli)"]
B --> B3["X ortogonal donusume kadar tek"]
K1["D26 NN ilk hali + D25 SGD"]
K2["D5-6 PSD / SVD"]
K3["D34 Procrustes (sonraki)"]
K4["Karpathy micrograd/makemore + NYU H1-2"]
K1 --> A
K2 --> B
B3 --> K3
A3 --> K4
classDef merkez fill:#1f4e79,stroke:#13243a,stroke-width:2px,color:#ffffff;
classDef dal fill:#2e75b6,stroke:#1f4e79,stroke-width:1.5px,color:#ffffff;
classDef vec fill:#ff8c42,stroke:#c25a16,stroke-width:1.5px,color:#1f2330;
classDef teal fill:#2ca6a4,stroke:#1f6f6e,stroke-width:1.5px,color:#ffffff;
class C merkez;
class A,A1,A2,A3,B,B1,B2,B3 dal;
class K1,K2 vec;
class K3,K4 teal;
32 Sinir Ağları ve Öğrenme Fonksiyonu
İki değişken kümesi F(x,v), dört kayıp fonksiyonu ve uzaklıklardan konum kurtarma
NotBölüm bilgisi
Bu ders iki ayrı konuyu birleştirir: önce Ders 26’nın sinir-ağı yapısını öğrenme fonksiyonu \(F(x, v)\) olarak yeniden kurar (kitapta section 7.1), sonra uzaklıklardan konum kurtaran uzaklık matrislerine geçer (section 4.9). Strang’in Ders 33 videosu (≈56 dk) ve OCW Lecture 33 temel alınmıştır. Okuma süresi ≈30 dk. Önkoşul Ders 26 (sinir-ağı yapısı, ilk hâli), Ders 25 (SGD/finite-sum kayıp) ve Ders 5-6 (PSD/SVD).
32.1 Bu Derste Ne Var?
Strang bu derste iki konu işliyor. İlki Ders 26’nın revize edilmiş sinir-ağı yapısı: öğrenme fonksiyonu \(F(x, v)\) — iki değişken kümesi. İkincisi uzaklık matrisleri: noktalar arası uzaklıklardan konumları geri kurma (Ders 34 Procrustes bloğunun girişi).
Beş sonuç:
- Öğrenme fonksiyonu \(F(x, v)\): \(x\) = ağırlıklar (\(A_k, b_k\)), \(v\) = özellik vektörleri (eğitim verisi). SGD \(x\)’i optimize eder; \(v\) veriden gelir, optimizasyona dahil değil.
- Ağ yapısı: her katman \(v_k = \text{ReLU}(A_k v_{k-1} + b_k)\); son katman ReLU’suz, \(v_\ell = A_\ell v_{\ell-1} + b_\ell\).
- \(x\) underdetermined: ağırlık sayısı çoğu zaman özellik sayısını çok aşar — çok sayıda çözüm (eksik-belirlenmiş sistem).
- Kayıp fonksiyonu \(L(x)\): tüm örnekler üzerinden toplam; kare (L2), L1 (Lasso), hinge (\(\pm 1\) sınıflama), cross-entropy (sinir ağları için en önemli).
- Uzaklık matrisleri: \(d_{ij} = \|x_i - x_j\|^2\); \(G = X^T X\)’i anahtar özdeşlikten bul; \(X\)’i \(G\)’den kurtar — özdeğer kökü \(Q\Lambda^{1/2}Q^T\) veya Cholesky \(D^{1/2}L^T\); \(X\) ortogonal dönüşüme kadar tektir.
Şekil 32.1 dersin iki konulu iskeletini gösterir: merkezdeki Ders 33: iki konu düğümünden A ve B dalları ayrılır. Dal A öğrenme fonksiyonu \(F(x,v)\) — \(x\) = ağırlıklar (\(A_k, b_k\)) optimize edilir, \(v\) = özellik vektörleri veriden akar; katman \(v_k = \text{ReLU}(A_k v_{k-1} + b_k)\), son katman ReLU’suz; \(x\) underdetermined (ağırlık sayısı ≫ özellik sayısı); kayıplar kare/L1/hinge/cross-entropy (NN için en önemli). Dal B uzaklık matrisleri — \(d_{ij} = \|x_i - x_j\|^2\), merkezleme özdeşliği \(G = X^T X = -\tfrac{1}{2}(D - \mathbf{1}d^T - d\mathbf{1}^T)\), \(X\) kurtarma (özdeğer kökü simetrik vs Cholesky üçgen-hızlı), \(X\) ortogonal dönüşüme kadar tek. Köprü düğümleri D26 (NN ilk hâli) + D25 (SGD), D5-6 (PSD/SVD), D34 Procrustes (sonraki) ve Karpathy micrograd/makemore + NYU H1-2 önceki/sonraki bloklara bağlar.
İpucuBuilder Notu — Ağın İki Yüzü
- \(F(x, v)\) ayrımı = param vs veri: ağırlıklar \(x\) optimize edilir (PyTorch
requires_grad=True), özellikler \(v\) edilmez. Her framework bu ayrımı yapar — bu, Strang’ın sinir ağına en temiz bakışı. - Kayıp seçimi göreve bağlı: regresyon → kare/L1, sınıflama → cross-entropy. Loss, \(F\)’in çıktısını gerçek etikete bağlar.
- Uzaklık matrisi = konum kurtarma: sensör ağı, NMR molekül şekli, manifold öğrenme — hepsi “uzaklıklardan konum” problemi. Cevap saf lineer cebir (Gram matrisi + PSD kök).
- Geriye köprü: Ders 26 (sinir ağı yapısı, ilk hali), Ders 25 (SGD/finite-sum loss), Ders 5-6 (PSD/SVD), Ders 18 (parametre sayımı). Paralel: Karpathy micrograd/makemore \(F\), fast.ai Learner, NYU H1-2.
Tek cümle: Bir sinir ağı, ağırlıklar \(x\) ile veri \(v\)’nin iki-değişkenli öğrenme fonksiyonu \(F(x,v)\)’dir (katmanlı ReLU + kayıp); uzaklık matrisi problemi ise tersini yapar — uzaklıklardan Gram matrisi \(G=X^TX\) üzerinden konumları (PSD kök ile, ortogonal dönüşüme kadar) geri kurar.
32.2 1. Öğrenme Fonksiyonu F(x,v): İki Değişken Kümesi
Strang, Ders 26’daki sinir-ağı bölümünü (kitapta section 7.1) yeniden yazdı. Anahtar fikir: ağ, iki ayrı değişken kümesinin fonksiyonudur.
“I now think of this as a function of two sets of variables, x and v.” — Strang, 2:05
\[F(x, v)\]
- \(x\) = ağırlıklar: çarptığın matrisler \(A_k\) ve eklediğin bias vektörleri \(b_k\). Gradyan inişiyle bunları optimize edersin.
- \(v\) = özellik vektörleri: eğitim verisinden gelen örnek vektörler (\(v_0\) = ham girdi, görüntüyse tüm pikseller). Bunlar verilidir, optimizasyonun parçası değildir.
Ders 25’teki gibi: SGD ile mini-batch boyutu 1 ise tek örnek, \(B\) ise \(B\) örnek, tüm epoch ise hepsi birden işlenir. Optimize edilen hep \(x\) (tüm \(A_k, b_k\)); \(v\) veriden gelir. Bu \(x/v\) ayrımı Ders 26’da net değildi — Strang burada düzeltti.
Şekil 32.2 (sonraki bölümde) bu \(x/v\) ayrımını ağ şeması üzerinde gösterir: navy kutular optimize edilen ağırlıkları (\(x\)), turuncu akış veriden gelen özellikleri (\(v\)) işaretler.
İpucuBuilder Notu — Parametre ile Verinin Ayrılığı
“Öğrenme fonksiyonu = ağırlıkların ve verinin ortak fonksiyonu” sinir ağının en temiz tanımı. ML köprüsü: PyTorch’ta ağırlıklar nn.Parameter (requires_grad=True), veri Tensor (grad’sız) — tam bu \(x/v\) ayrımı. Karpathy micrograd’da Value ağırlıkları ile girdi aynı grafikte ama yalnız ağırlıklar güncellenir; Strang’ın \(x/v\) ayrımı bunun matematiksel ifadesidir.
32.3 2. Ağın Yapısı: Katman Katman ReLU
Ağ, girdi \(v_0\)’dan başlar ve katman katman ilerler. Her katman iki adım: önce lineer (\(A_k\) ile çarp, \(b_k\) ekle), sonra nonlineer (ReLU her bileşene):
“You take the linear step using the first weights… Then you take a nonlinear step, and that gives you v1.” — Strang, 4:09
\[v_k = \text{ReLU}(A_k v_{k-1} + b_k), \quad k = 1, \dots, \ell\]
Son katmanda ReLU yok — yalnız lineer adım (ve çoğu zaman bias bile olmadan):
\[v_\ell = A_\ell v_{\ell-1} + b_\ell\]
Burada \(v_0\) girdi (bir eğitim örneği), \(v_\ell\) son katmanın çıktısı. Her gizli katman farklı sayıda nöron (bileşen) içerebilir — \(A_k\) matrisinin boyutu bunu belirler. Strang vurguluyor: elle çizilen bir resim, makine çizimine kıyasla zayıf kalır, ama yapı budur — lineer-sonra-ReLU zinciri.
Kod
from matplotlib.patches import Rectangle
fig, (axL, axR) = plt.subplots(1, 2, figsize=(11, 4.2))
# ---- SOL: ağ şeması (eksen kapalı) ----
axL.set_xlim(0, 10); axL.set_ylim(0, 10); axL.axis("off")
def box(ax, x, y, w, h, text, color, tcolor=COL_WHITE, fs=10):
ax.add_patch(Rectangle((x, y), w, h, facecolor=color, edgecolor=COL_TEXT, linewidth=1.2, zorder=3))
ax.text(x + w/2, y + h/2, text, ha="center", va="center", color=tcolor, fontsize=fs, fontweight="bold", zorder=4)
def arrow(ax, x0, x1, y):
ax.annotate("", xy=(x1, y), xytext=(x0, y), arrowprops=dict(arrowstyle="-|>", color=COL_TEXT, lw=1.4), zorder=2)
ycen = 5.6; h = 1.0
box(axL, 0.1, ycen-h/2, 1.1, h, "v0\n(girdi)", COL_VEC3)
arrow(axL, 1.2, 1.55, ycen)
box(axL, 1.55, ycen-h/2, 1.0, h, "A1, b1", COL_PRIMARY)
arrow(axL, 2.55, 2.85, ycen)
box(axL, 2.85, ycen-h/2+0.15, 0.75, h-0.3, "ReLU", COL_ACCENT, fs=8)
arrow(axL, 3.6, 3.9, ycen)
box(axL, 3.9, ycen-h/2, 0.85, h, "v1", COL_VEC3)
arrow(axL, 4.75, 5.05, ycen)
box(axL, 5.05, ycen-h/2, 1.0, h, "A2, b2", COL_PRIMARY)
arrow(axL, 6.05, 6.35, ycen)
box(axL, 6.35, ycen-h/2+0.15, 0.75, h-0.3, "ReLU", COL_ACCENT, fs=8)
arrow(axL, 7.1, 7.4, ycen)
box(axL, 7.4, ycen-h/2, 0.85, h, "v2", COL_VEC3)
arrow(axL, 8.25, 8.55, ycen)
box(axL, 8.55, ycen-h/2, 1.0, h, "A3, b3", COL_PRIMARY)
arrow(axL, 9.55, 9.78, ycen)
box(axL, 9.78, ycen-h/2, 0.95, h, "v_son", COL_VEC3, fs=9)
axL.text(10.25, ycen+1.0, "ReLU YOK", ha="center", va="center", color="#c0392b",
fontsize=9, fontweight="bold")
axL.annotate("", xy=(10.25, ycen+h/2), xytext=(10.25, ycen+0.85),
arrowprops=dict(arrowstyle="-|>", color="#c0392b", lw=1.2))
yA = ycen - h/2 - 0.55
axL.plot([1.55, 9.55], [yA, yA], color=COL_PRIMARY, lw=2.5, zorder=1)
axL.text(5.5, yA - 0.45, "x = optimize edilen (SGD)", ha="center", va="center",
color=COL_PRIMARY, fontsize=9.5, fontweight="bold")
yV = ycen + h/2 + 0.45
axL.plot([0.1, 10.73], [yV, yV], color=COL_VEC3, lw=2.5, zorder=1)
axL.text(4.0, yV + 0.45, "v = veriden gelen, sabit", ha="center", va="center",
color=COL_VEC3, fontsize=9.5, fontweight="bold")
# ---- SAĞ: Egz2 somut ----
A1 = np.array([[1., 0], [0, 1], [1, 1]])
v0 = np.array([1., -2])
lin = A1 @ v0 # (1, -2, -1)
rl = np.maximum(0, lin) # (1, 0, 0)
idx = np.arange(3)
axR.bar(idx - 0.18, lin, width=0.36, color=COL_ACCENT, label="A1 v0 (lineer)", zorder=3)
axR.bar(idx + 0.18, rl, width=0.36, color=COL_PRIMARY, label="ReLU(A1 v0)", zorder=3)
axR.axhline(0, color=COL_TEXT, lw=0.9)
axR.annotate("negatifler kirpildi", xy=(1 + 0.18, 0), xytext=(1.05, -1.6),
color="#c0392b", fontsize=9, fontweight="bold",
arrowprops=dict(arrowstyle="-|>", color="#c0392b", lw=1.2))
axR.set_xticks(idx); axR.set_xticklabels(["bilesen 1", "bilesen 2", "bilesen 3"])
axR.set_title("Egz2: lineer adim sonra ReLU", color=COL_TEXT, fontsize=12, fontweight="bold")
axR.legend(loc="upper right", fontsize=8.5)
apply_style(axR)
fig.suptitle("Ogrenme fonksiyonu F(x,v): agirliklar (x) optimize edilir, veri (v) sabit akar — katman = lineer adim + ReLU, son katman ReLU suz",
color=COL_TEXT, fontsize=10.5, fontweight="bold")
fig.tight_layout(rect=[0, 0, 1, 0.94])
plt.show()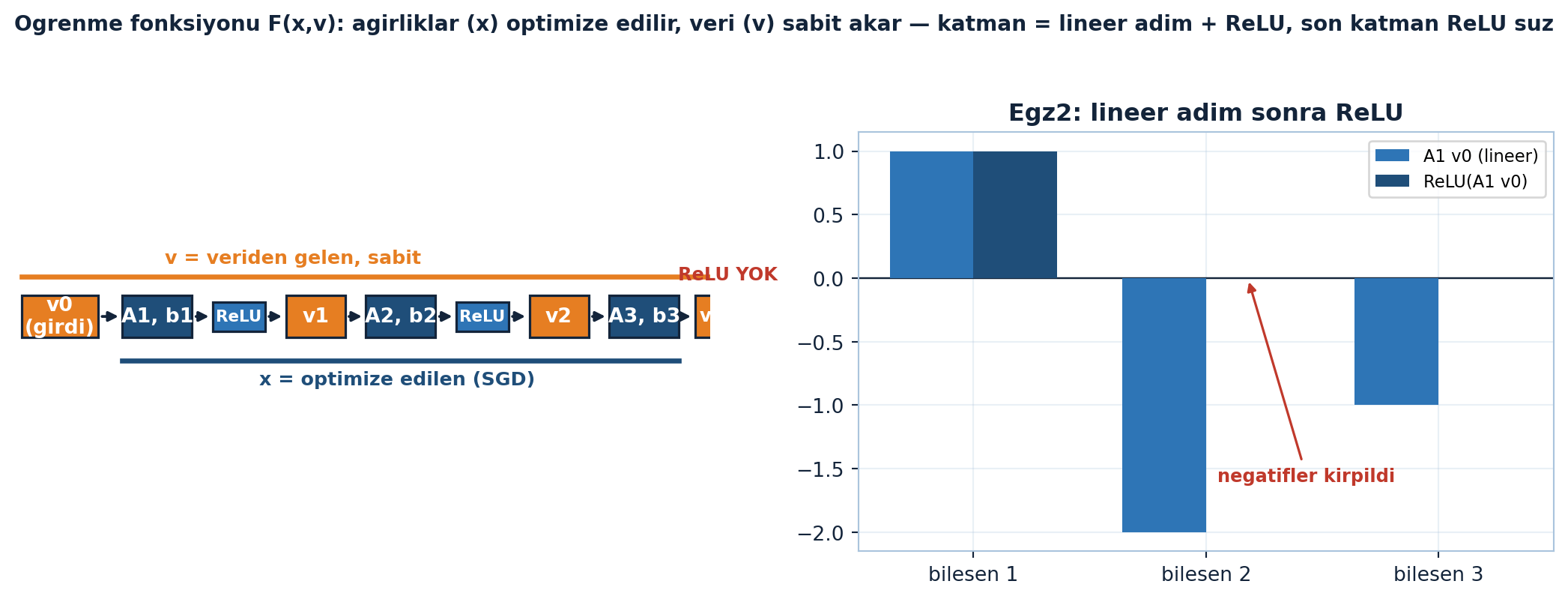
Şekil 32.2 ağ yapısını ve \(x/v\) ayrımını birlikte gösterir: solda girdi \(v_0\)’dan başlayan lineer-sonra-ReLU zinciri — navy kutular (\(A_1, b_1\), \(A_2, b_2\), \(A_3, b_3\)) optimize edilen ağırlıkları (\(x\), alttaki navy çizgi “SGD ile optimize edilen”), turuncu kutular (\(v_0, v_1, v_2, v_\text{son}\)) veriden akan özellikleri (\(v\), üstteki turuncu çizgi “veriden gelen, sabit”) kapsar; son katmanda kırmızı “ReLU YOK” vurgusu yer alır. Sağda Egz2 somutu: \(A_1 v_0 = (1, -2, -1)\) lineer adım (steel barlar) ve ReLU sonrası \((1, 0, 0)\) (navy barlar) yan yana — ikinci ve üçüncü bileşendeki negatifler kırpılır (motor-tanıklı), “negatifler kirpildi” annotation’ı bunu işaretler.
İpucuBuilder Notu — Lineer Adım Artı Kırpma
“Katman = lineer adım + ReLU” derin ağın yapı taşı. ML köprüsü: bu tam bir MLP’nin (çok-katmanlı algılayıcı) ileri geçişi; PyTorch’ta nn.Linear (\(A_k, b_k\)) + nn.ReLU() ardışık. Son katmanda ReLU olmaması kritik: regresyonda ham çıktı, sınıflamada softmax/logit gerekir — ReLU çıktıyı kırparak bilgiyi yok ederdi. Karpathy makemore’daki MLP tam bu zincir.
32.4 3. x Underdetermined: Ağırlıklar Özelliklerden Çok
Uygulamada kritik bir gözlem: ağırlık sayısı (\(A_k, b_k\)’deki tüm sayılar) çoğu zaman özellik sayısını (\(v\)’lerin bileşenleri) çok aşar.
“…the number of x’s exceeds, and often far exceeds, the number of v’s.” — Strang, 8:12
Sonuç: \(x\) eksik-belirlenmiş (underdetermined) — kaybı sıfırlayan tek bir \(x\) yoktur, sonsuz çözüm vardır. Strang bunu “interesting and unexpected” diye niteliyor. Ama bu, derin öğrenmenin kalbinde: aşırı-parametreli ağlar eğitim verisini tam ezberleyebilecek kadar serbestliğe sahiptir, yine de iyi genelleyebilir.
Kod
x_a, loss_a = train_tiny(1)
x_b, loss_b = train_tiny(9)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10.5, 4.2))
# Sol: kayip egrileri (semilogy)
ax1.semilogy(loss_a, color=COL_PRIMARY, lw=2, label="başlangıç A")
ax1.semilogy(loss_b, color=COL_VEC3, lw=2, label="başlangıç B")
ax1.legend()
ax1.set_xlabel("GD adımı"); ax1.set_ylabel("kayıp (log)")
ax1.set_title("iki farklı başlangıç: ikisi de kayıp ~0")
apply_style(ax1)
# Sag: 17 bilesen bar yan-yana
idx = np.arange(len(x_a))
ax2.bar(idx - 0.2, x_a, width=0.4, color=COL_PRIMARY, label="x_a (başlangıç A)")
ax2.bar(idx + 0.2, x_b, width=0.4, color=COL_VEC3, label="x_b (başlangıç B)")
ax2.legend()
ax2.annotate("norm(x_a - x_b) = 2.69 — AYNI sıfır kayıp, FARKLI çözüm",
xy=(0.5, 0.97), xycoords="axes fraction", ha="center", va="top",
fontsize=9, color=COL_TEXT,
bbox=dict(boxstyle="round,pad=0.3", fc=COL_BG, ec=COL_STEEL_300))
ax2.set_xlabel("ağırlık indeksi")
ax2.set_title("underdetermined: çözüm tek değil")
apply_style(ax2)
fig.suptitle("Ağırlık sayısı (17) >> özellik sayısı (2): kaybı sıfırlayan sonsuz x var — derin öğrenmenin temel gerilimi (implicit bias D10)", fontsize=10)
fig.tight_layout()
plt.show()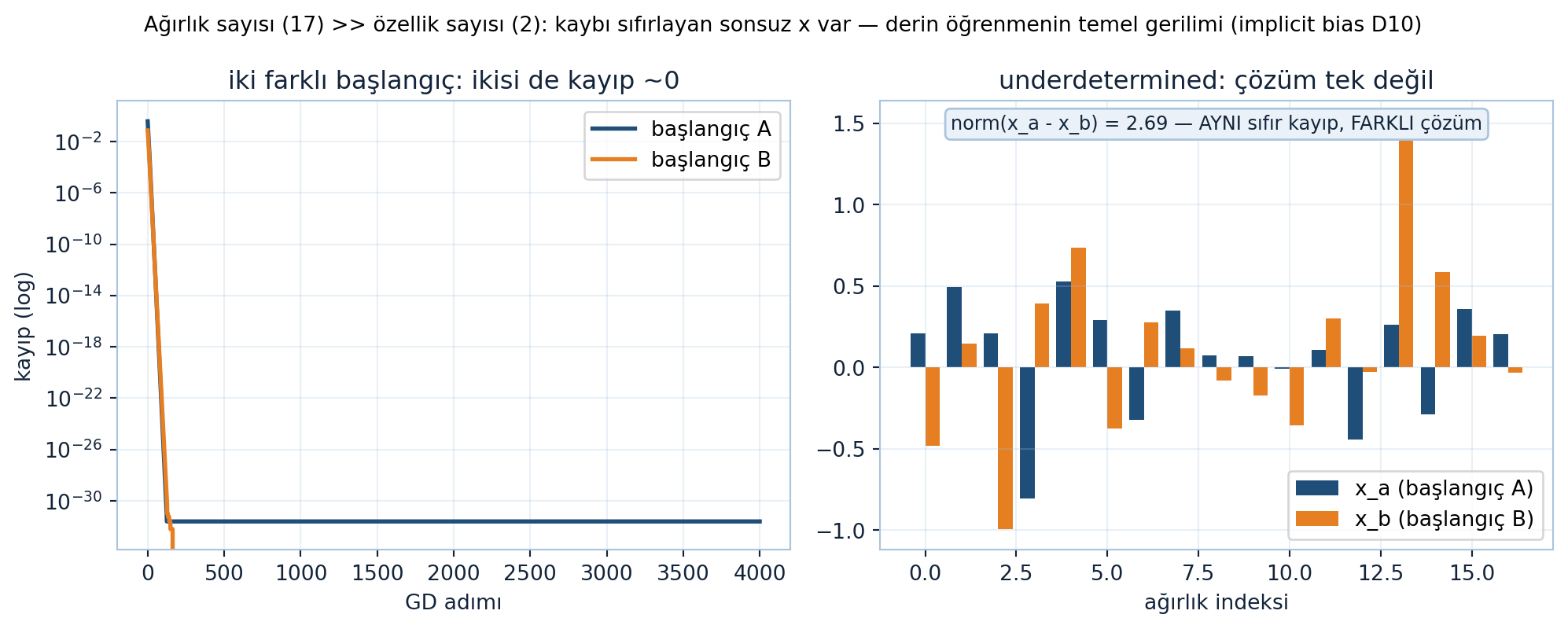
Şekil 32.3 eksik-belirlenmişliğin canlı sayısal kanıtıdır: aynı tek-örnek ağ (17 ağırlık) iki farklı seed ile eğitilir. Solda iki kayıp eğrisi (semilogy) — her iki başlangıç da kaybı \(\sim 0\)’a indirir (motorda 2.5e-32 ve 0.0). Sağda 17 ağırlık bileşeninin yan yana barı: çözüm vektörleri belirgin biçimde farklıdır — \(\|x_a - x_b\| = 2.69\) (tam değer 2.686). Aynı sıfır kayıp, farklı çözüm; kaybı sıfırlayan sonsuz \(x\)’in canlı örneği. Bu, ağırlık sayısının (17) özellik sayısını (2) çok aşmasının doğrudan sonucu.
İpucuBuilder Notu — Çözüm Bolluğu Sorun Değil
“Ağırlık sayısı ≫ örnek sayısı = eksik-belirlenmiş” modern derin öğrenmenin temel gerilimi. ML köprüsü: bugünün ağları milyonlarca-milyarlarca parametre, eğitim örneğinden kat kat fazla. Çok çözüm varsa SGD hangisini seçer? Genelde küçük-normlu / düz minimum (implicit regularization) — Ders 10 (implicit bias) + Ders 22-23 (gradyan inişi yolu) bunu hazırladı. Klasik istatistik “çok parametre = aşırı-öğrenme” derdi; derin öğrenme bu sezgiyi kırdı.
32.5 4. Kayıp Fonksiyonu L(x): Kare, L1, Hinge, Cross-Entropy
\(x\)’i, kaybı \(L(x)\) minimize ederek seçersin. Kayıp, tüm örnekler üzerinden bir toplamdır (Ders 25 finite-sum yapısı):
“…L is often a finite sum over all of F.” — Strang, 12:18
\[L(x) = \sum_{i=1}^{N} \ell\big(F(x, v_i),\, y_i\big)\]
Tam-ölçek gradyan inişi tüm \(i\) için hesaplar (pahalı); SGD bunlardan 1 ya da \(b\) tanesini (örn. 32, 128) seçer. Strang dört kayıp fonksiyonu sıralıyor:
- Kare kayıp (L2): \(\sum_i \|F(x, v_i) - y_i\|^2\) — en bilineni; regresyon için.
- L1 kayıp: hata mutlak değerlerinin toplamı; Lasso gibi problemlerde geçer, “ama derin öğrenmede değil” (Strang).
- Hinge kayıp: \(\pm 1\) sınıflama problemleri için (SVM’in kaybı).
- Cross-entropy (çapraz-entropi): sinir ağları için en çok kullanılan kayıp.
“…the most important for neural nets, is cross-entropy loss.” — Strang, 16:22
Kod
fig, ax = plt.subplots(figsize=(8, 4.6))
zz = np.linspace(-2, 3, 300)
sq, l1, hg, lg = margin_losses(zz)
ax.plot(zz, sq, color=COL_ACCENT, linestyle="--", label="kare (1-z)^2")
ax.plot(zz, l1, color=COL_TEAL, label="L1 |1-z|")
ax.plot(zz, hg, color=COL_VEC3, lw=2, label="hinge max(0, 1-z)")
ax.plot(zz, lg, color=COL_PRIMARY, lw=2.5, label="lojistik log(1+e^-z) — cross-entropy ikili formu")
ax.axvline(1.0, color="#888888", linestyle="--", alpha=0.7)
ax.text(1.05, 3.9, "margin sınırı", color=COL_TEXT, fontsize=9)
ax.set_xlabel("margin z = y * F")
ax.set_ylim(0, 4.2)
ax.set_title("Dört kayıp: z=0 da kare=L1=hinge=1, lojistik=log2 — NN için en önemlisi cross-entropy (Strang 16:22)", fontsize=9)
ax.legend()
apply_style(ax)
plt.show()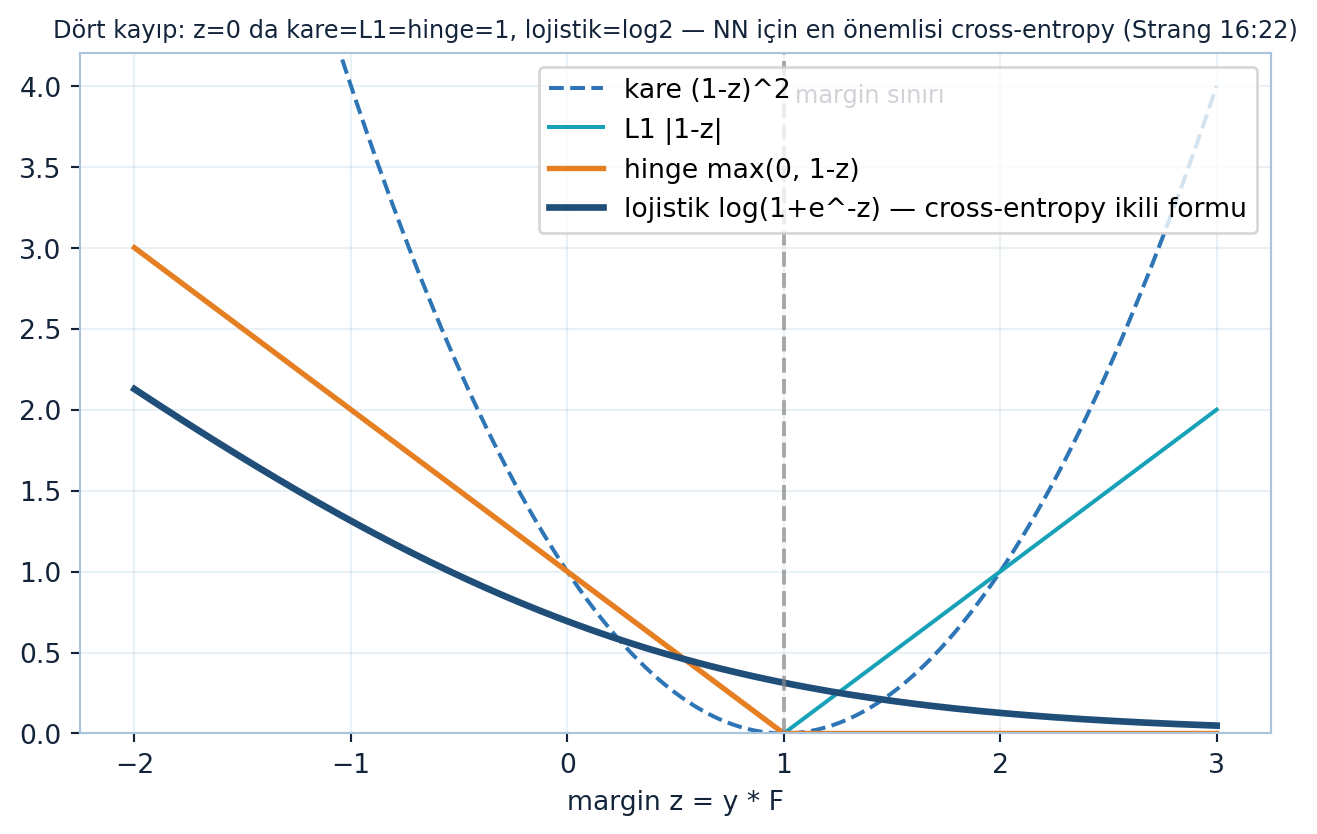
Şekil 32.4 dört kaybı tek panelde margin \(z = y \cdot F\) ekseninde karşılaştırır: \(z=0\)’da kare = L1 = hinge = 1, lojistik = \(\log 2 \approx 0.693\) (motor-dürüst). Hinge (\(\max(0, 1-z)\), turuncu) \(z \geq 1\)’de tam sıfırdır — margin aşıldıktan sonra ceza yok; lojistik (\(\log(1+e^{-z})\), navy — cross-entropy’nin ikili formu) hep azalır ama asla tam sıfır olmaz, doğru sınıflanmış örneklere bile küçük gradyan verir. Gri kesik çizgi \(z=1\) margin sınırını işaretler. Ayrı bir tanık olarak motorun çok-sınıf cross-entropy’si: logits \((2.0, 1.0, 0.1)\), target=0 → CE = 0.4170 (\(= -\log \text{softmax}[0]\)); yanlış sınıfa CE daha büyük çıkar.
İpucuBuilder Notu — Görev Kaybını Seçer
“Kayıp seçimi göreve göre” pratik bir karar. ML köprüsü: regresyon → kare kayıp (MSE); sınıflama → cross-entropy (PyTorch nn.CrossEntropyLoss; Karpathy makemore’un negatif log-olabilirlik kaybı tam budur). Hinge → SVM. L1 → seyreklik/özellik seçimi (Lasso). Strang’ın “L1 derin öğrenmede değil” notu yerinde — DL’de cross-entropy hâkimdir çünkü olasılık dağılımlarını doğal biçimde karşılaştırır.
32.6 5. Uzaklık Matrisleri: Uzaklıklardan Konumlar
Dersin ikinci yarısı tamamen yeni bir problem (kitapta section 4.9):
“We have a bunch of points in space… we know the distances between the points… what’s their position?” — Strang, 18:25
Uzaklık-kare matrisi \(D\) verili: \(d_{ij}\) = noktalar \(i\) ve \(j\) arası uzaklığın karesi. Soru: noktaların konumları \(x_i\) ne? Uygulamalar: sensör ağları (radar/seyahat süresiyle uzaklık ölç), NMR ile molekül şekli, ve makine öğrenmesinde manifold öğrenme (yüksek-boyutlu noktalar düşük-boyutlu eğri bir yüzeyde toplanır).
\[d_{ij} = \|x_i - x_j\|^2\]
Konumlar tek değildir: tüm noktaları öteleyebilir (translation) ya da katı döndürebilirsin (rigid rotation) — ikili uzaklıklar değişmez. Ağırlık merkezini (centroid) orijine koyarak en azından ötelemeyi sabitlersin.
“…positions are not unique, but I can come closer by saying, put the centroid at the origin.” — Strang, 30:49
Şekil 32.5 (sonraki bölümde) bu problemi 3-4-5 üçgeni üzerinde somutlaştırır: üç noktanın uzaklık-kare matrisi \(D\)’den iç-çarpım matrisi \(G\) kurtarılır.
İpucuBuilder Notu — Uzaklıktan Geometriye
“Uzaklıklardan konum = ters problem” geometrik bir kurtarma işi. ML köprüsü: bu, çok-boyutlu ölçekleme (MDS) ve manifold öğrenmenin (Isomap, t-SNE’nin atası) çekirdeğidir — yüksek-boyutlu veri düşük-boyutlu bir manifolda oturuyorsa, yalnız ikili uzaklıklardan o düşük-boyutlu gömmeyi kurtarırsın. Strang’ın deyişiyle bir geometricinin “manifold” diyeceği eğri yüzey; onu lineerleştirip boyutu düşürürsün (Ders 7 PCA ile akraba).
32.7 6. Anahtar Özdeşlik: Gram Matrisi G = XᵀX
Uzaklığın karesini aç (Strang 34:57):
\[d_{ij} = \|x_i - x_j\|^2 = x_i\cdot x_i - 2\,x_i\cdot x_j + x_j\cdot x_j\]
Sağdaki üç terim: \(x_i\cdot x_i\) (yalnız satıra bağlı → rank-1 parça), \(x_j\cdot x_j\) (yalnız sütuna bağlı → rank-1 parça) ve \(-2\,x_i\cdot x_j\) (çapraz çarpım = aradığımız iç-çarpımlar). İç-çarpım matrisini Gram matrisi \(G = X^T X\) olarak tanımla (\(G_{ij} = x_i\cdot x_j\)). Köşegen değerlerini \(d = (x_i\cdot x_i)\) vektörüyle gösterip özdeşliği matris dilinde yaz:
“…minus 1/2 of the D matrix plus 1/2 of the 1’s times the d… plus 1/2 of the d times the 1’s.” — Strang, 39:10
\[G = X^T X = -\tfrac{1}{2}\big(D - \mathbf{1}\,d^T - d\,\mathbf{1}^T\big)\]
Burada \(\mathbf{1}\) = hepsi-bir vektörü, \(d\) = köşegen \((x_i\cdot x_i)\) vektörü. İki rank-1 parça (\(\mathbf{1}d^T\) ve \(d\mathbf{1}^T\)) köşegen katkılarını temizler, geriye saf iç-çarpımlar (\(G\)) kalır. \(D\) verili olduğundan \(G\)’yi doğrudan hesaplarsın.
Kod
X = np.array([[0., 3, 0], [0, 0, 4]])
D = distance_matrix(X)
G = gram_from_D(D, [0, 9, 16])
G = G + 0.0 # -0 normalize: küçük negatif sıfırları temiz 0 göster
G[np.abs(G) < 1e-9] = 0.0
fig, axes = plt.subplots(1, 3, figsize=(12, 4))
# --- Sol: 3-4-5 üçgeni ---
ax = axes[0]
pts = X.T # satırlar nokta
ax.scatter(pts[:, 0], pts[:, 1], s=120, color=COL_PRIMARY, zorder=3)
labels = ["x1 (0,0)", "x2 (3,0)", "x3 (0,4)"]
offs = [(-0.15, -0.55), (0.1, -0.55), (0.1, 0.2)]
for (px, py), lab, (ox, oy) in zip(pts, labels, offs):
ax.annotate(lab, (px, py), xytext=(px + ox, py + oy), fontsize=10,
color=COL_TEXT, fontweight="bold")
# üç kenar çizgisi
edges = [(0, 1), (0, 2), (1, 2)]
edge_d = ["d=9", "d=16", "d=25"]
for (a, b), dlab in zip(edges, edge_d):
ax.plot([pts[a, 0], pts[b, 0]], [pts[a, 1], pts[b, 1]],
color=COL_ACCENT, lw=2, zorder=2)
mx = (pts[a, 0] + pts[b, 0]) / 2; my = (pts[a, 1] + pts[b, 1]) / 2
ax.annotate(dlab, (mx, my), fontsize=10, color=COL_VEC3, fontweight="bold",
ha="center", va="center",
bbox=dict(boxstyle="round,pad=0.15", fc=COL_WHITE, ec=COL_VEC3, lw=0.8))
ax.set_title("3-4-5 üçgeni", color=COL_TEXT, fontsize=12, fontweight="bold")
ax.set_aspect("equal")
ax.margins(0.25)
apply_style(ax)
# --- Orta: D heatmap ---
heatmap(axes[1], D, title="uzaklık-kare matrisi D", fmt="{:.0f}")
# --- Sağ: G heatmap ---
heatmap(axes[2], G, title="G = -1/2(D - 1d^T - d1^T) = X^T X", fmt="{:.0f}")
axes[2].annotate("G23 = -1/2(25-16-9) = 0 (dik!)", xy=(0.5, -0.18),
xycoords="axes fraction", ha="center", va="top",
fontsize=9.5, color=COL_TEXT, fontweight="bold")
fig.suptitle("Anahtar özdeşlik: iki rank-1 parçayı soyunca uzaklıklar iç-çarpımlara döner — Egz4 motor-tanıklı BİREBİR",
color=COL_TEXT, fontsize=11, fontweight="bold")
fig.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()
Şekil 32.5 özdeşliği 3-4-5 üçgeni üzerinde motor-tanıklı doğrular: solda üç nokta \(x_1=(0,0)\), \(x_2=(3,0)\), \(x_3=(0,4)\) düzlemde, kenar uzaklık-kareleri \(d=9\), \(d=16\), \(d=25\) (kareler!) ile etiketli. Ortada uzaklık-kare matrisi \(D = [[0,9,16],[9,0,25],[16,25,0]]\). Sağda \(G = -\tfrac{1}{2}(D - \mathbf{1}d^T - d\mathbf{1}^T) = \text{diag}(0, 9, 16)\) — köşegen \((0, 9, 16)\) tam olarak \(x_i \cdot x_i\) gerçek iç-çarpımlarıdır, yani \(G\) birebir \(X^T X\). Özellikle \(G_{23} = -\tfrac{1}{2}(25 - 16 - 9) = 0\): \(x_2\) ve \(x_3\) dik kenarlar olduğundan iç-çarpımları sıfır (dik!). Özdeşlik, \(d = (0, 9, 16)\) köşegeniyle uzaklıkları iç-çarpımlara çevirir.
İpucuBuilder Notu — İki Rank-Bir Parçayı Soyunca
“Uzaklık → Gram matrisi tek özdeşlikle” problemin can alıcı adımı. ML köprüsü: bu, çift-merkezleme (double centering) adımıdır — uzaklık-kare matrisinden iç-çarpım (kernel/Gram) matrisine geçiş; kernel yöntemleriyle akraba çünkü \(G\) bir Gram/kernel matrisidir. [tahmin] Klasik MDS literatürü bu dönüşüme “Gower / çift-merkezleme” der, ama Strang bu adı kullanmadı — özdeşliği terim terim elle türetti.
32.8 7. X’i Kurtarmak: Özdeğer Kökü vs Cholesky
Artık \(G = X^T X\) biliniyor; \(X\)’i bul. \(G\) simetrik ve pozitif yarı-tanımlı (PSD). \(X\)’i bulmak = \(G\)’nin bir “karekökünü” bulmaktır. \(X\) tek değildir: herhangi ortogonal \(Q\) için \(QX\) de işe yarar (çünkü \((QX)^T(QX) = X^T Q^T Q X = X^T X\)). İki yol var:
“…one way is to use eigenvalues… the other way would be to use elimination on X transpose X.” — Strang, 49:24
Yol 1 — Özdeğer kökü. Spektral teorem: \(G = Q\Lambda Q^T\) (PSD olduğundan tüm \(\lambda \geq 0\)). Aynı özvektörleri tut, özdeğerlerin karekökünü al:
\[G = Q\Lambda Q^T \;\Rightarrow\; X = Q\,\Lambda^{1/2}\,Q^T\]
Bu \(X\) simetrik PSD’dir; \(X^T X = Q\Lambda^{1/2}Q^T Q\Lambda^{1/2}Q^T = Q\Lambda Q^T = G\).
Yol 2 — Cholesky (eleme). Simetrik PSD matriste eleme, pozitif pivotlarla \(LDL^T\) verir (alt-üçgen × köşegen × üst-üçgen, simetride \(U = L^T\)):
\[G = L D L^T \;\Rightarrow\; X = D^{1/2} L^T\]
Bu \(X\) üçgenseldir; \(X^T X = L D^{1/2} D^{1/2} L^T = L D L^T = G\).
“…this is the Cholesky Factorization… much faster to compute than the eigenvalue square root.” — Strang, 53:31
Özdeğer kökü simetrik bir \(X\) verir (daha pahalı, özçözüm gerekir); Cholesky üçgen bir \(X\) verir (çok daha hızlı). İkisi de geçerli — aralarındaki fark yalnız bir ortogonal dönüşümdür.
Kod
rng = np.random.default_rng(33)
Xf = rng.uniform(-2, 2, (3, 3))
Gf = Xf.T @ Xf + 0.5 * np.eye(3)
Xe = recover_eig(Gf)
Xc = recover_chol(Gf)
fig, axes = plt.subplots(1, 3, figsize=(12, 4))
heatmap(axes[0], Xe, title="özdeğer kökü: SİMETRİK (defect 2.7e-15)", cmap=DIVERGE, fmt="{:.2f}")
heatmap(axes[1], Xc, title="Cholesky: ÜST-ÜÇGEN (hızlı)", cmap=DIVERGE, fmt="{:.2f}")
Qo = Xe @ np.linalg.inv(Xc)
heatmap(axes[2], np.abs(Qo.T @ Qo), title="fark ortogonal: Q^T Q = I", fmt="{:.0f}")
fig.suptitle("Aynı G nin iki karekökü: özdeğer (simetrik, pahalı) vs Cholesky (üçgen, O(n^3/3) hızlı) — aralarındaki fark YALNIZ ortogonal dönüşüm",
color=COL_TEXT, fontsize=10.5, fontweight="bold")
fig.tight_layout()
plt.show()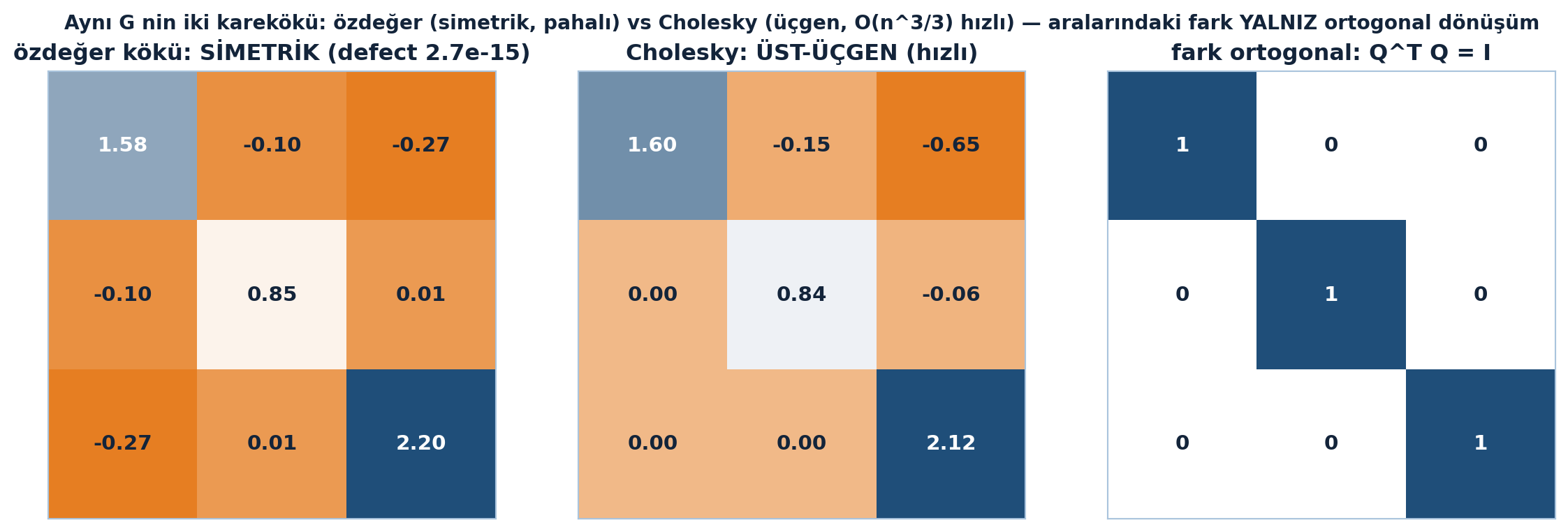
Şekil 32.6 aynı \(G\)’nin iki karekökünü yan yana koyar: solda özdeğer kökü \(X_\text{eig} = Q\Lambda^{1/2}Q^T\) simetriktir (\(X^T X - G\) defect 2.7e-15, özçözüm gerekir, pahalı), ortada Cholesky kökü \(X_\text{chol}\) üst-üçgendir (\(O(n^3/3)\), çok daha hızlı). Sağda ikisini bağlayan \(Q = X_\text{eig}\cdot X_\text{chol}^{-1}\) için \(|Q^T Q| = I\) — birim matris (motor-tanıklı): iki kök arasındaki fark yalnızca bir ortogonal dönüşümdür. “\(X\) ortogonal dönüşüme kadar tek” cümlesinin sayısal kanıtı budur.
İpucuBuilder Notu — Bir Matrisin İki Karekökü
“PSD matrisin iki karekökü: simetrik (özdeğer) vs üçgen (Cholesky)” temel bir hesaplama seçimi. ML köprüsü: Cholesky her yerde — Gauss süreçleri (GP), Kalman filtresi, ikinci-derece optimizasyon ve çok-değişkenli normalden örnek üretme hep PSD-kök ister; Cholesky \(O(n^3/3)\) ile en ucuzudur. Özdeğer kökü ise PCA/whitening’de tercih edilir. Ders 5-6 (PSD, SVD) bu kökleri zaten kurmuştu; burada uzaklık probleminin son adımı oldu.
Kod
Xo, Xr, defect = mds_demo()
fig, (axL, axR) = plt.subplots(1, 2, figsize=(10, 4.6))
axL.scatter(Xo[0], Xo[1], s=60, color=COL_PRIMARY, zorder=3, edgecolor=COL_WHITE, linewidth=0.8)
axL.set_title("orijinal konumlar (daire + 2 iç nokta)", color=COL_TEXT, fontsize=12, fontweight="bold")
apply_style(axL); axL.set_aspect("equal")
axR.scatter(Xr[0], Xr[1], s=60, color=COL_VEC3, zorder=3, edgecolor=COL_WHITE, linewidth=0.8)
axR.set_title("D'den kurtarılan (rank-2 MDS)", color=COL_TEXT, fontsize=12, fontweight="bold")
axR.annotate("uzaklıklar BİREBİR korundu (defect 2.8e-14) — ama döndürülmüş:\nortogonal dönüşüme kadar tek (D34 Procrustes hizalar)",
xy=(0.5, -0.02), xycoords="axes fraction", ha="center", va="top",
fontsize=8.5, color=COL_TEXT)
apply_style(axR); axR.set_aspect("equal")
fig.suptitle("MDS: yalnız ikili uzaklıklardan düşük-boyutlu gömme — Isomap/t-SNE'nin atası, sensör lokalizasyonu, NMR molekül şekli",
color=COL_TEXT, fontsize=11.5, fontweight="bold")
fig.tight_layout()
plt.show()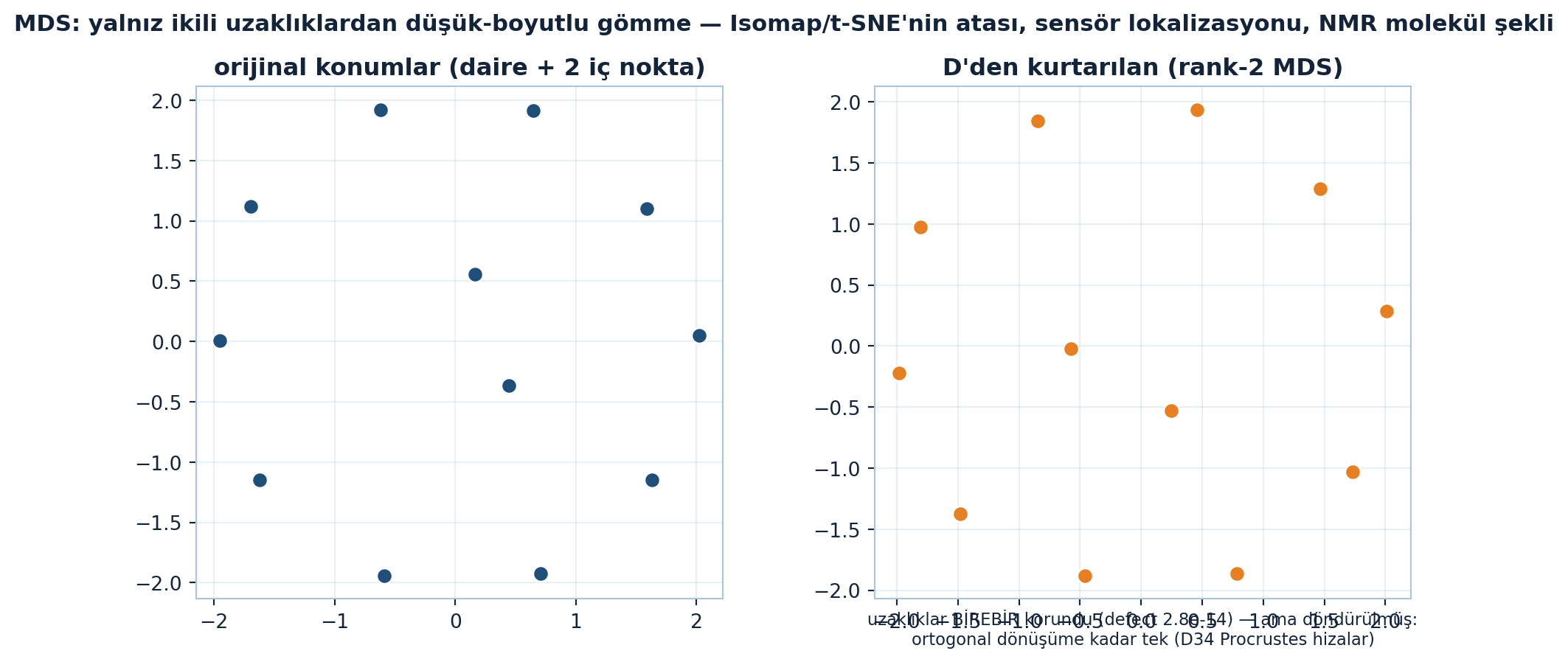
Şekil 32.7 özdeğer kökünü gerçek bir kurtarma probleminde çalıştırır ve D34’e köprü kurar: 12 noktalı 2B bulut → uzaklık-kare matrisi \(D\) → Gram \(G\) → rank-2 özdeğer gömmesi. Solda orijinal konumlar (daire + 2 iç nokta), sağda yalnız \(D\)’den kurtarılan konumlar. Uzaklıklar birebir korunur (D-koruma defekti 2.8e-14), ama kurtarılan bulut döndürülmüş görünür: ham kurtarma orijinalle çakışmaz, çünkü \(X\) ancak ortogonal dönüşüme kadar tektir. İşte sonraki dersin (D34 Procrustes) sorusu — döndürülmüş gömmeyi orijinale en iyi ortogonal \(Q\) ile nasıl hizalarsın.
32.9 Bu Dersin Özeti
- Öğrenme fonksiyonu F(x,v): \(x\) = ağırlıklar (\(A_k, b_k\)), \(v\) = özellik vektörleri; SGD \(x\)’i optimize eder, \(v\) veriden gelir (Ders 26’nın revize hali).
- Ağ yapısı: \(v_k = \text{ReLU}(A_k v_{k-1} + b_k)\); son katman ReLU’suz (\(v_\ell = A_\ell v_{\ell-1} + b_\ell\)).
- x underdetermined: #ağırlık ≫ #özellik → sonsuz çözüm (aşırı-parametreli ağların temeli, implicit bias Ders 10).
- Kayıp L(x): finite-sum; kare (L2), L1 (Lasso), hinge (\(\pm 1\) sınıflama), cross-entropy (NN için en önemli).
- Uzaklık matrisleri: \(d_{ij} = \|x_i - x_j\|^2\); \(G = X^T X = -\tfrac{1}{2}(D - \mathbf{1}d^T - d\mathbf{1}^T)\); \(X\)’i \(G\)’den özdeğer kökü (\(Q\Lambda^{1/2}Q^T\)) veya Cholesky (\(D^{1/2}L^T\)) ile bul; \(X\) ortogonal dönüşüme kadar tektir.
ÖnemliTek Bir Cümle
Bir sinir ağı, ağırlıklar \(x\) ve veri \(v\)’nin iki-değişkenli öğrenme fonksiyonu \(F(x,v)\)’dir (katmanlı ReLU + cross-entropy gibi bir kayıp); uzaklık matrisi problemi ise tersini yapar — uzaklık-kare matrisi \(D\)’den Gram matrisi \(G = X^T X = -\tfrac{1}{2}(D - \mathbf{1}d^T - d\mathbf{1}^T)\)’yi çıkarıp \(X\)’i (PSD kök ile, ortogonal dönüşüme kadar) geri kurar.
32.10 Kontrol Soruları
NotSoru 1 — Öğrenme fonksiyonu F(x,v)’de x ve v nedir; neden ayrı tutulur
\(x\) = ağırlıklar (tüm \(A_k\) matrisleri ve \(b_k\) bias vektörleri) — gradyan inişiyle optimize edilen değişkenler. \(v\) = özellik vektörleri (eğitim örnekleri, \(v_0\) = ham girdi) — veriden gelen, sabit değişkenler, optimize edilmez. Ayrım kritik: SGD yalnız \(x\)’i seçer; \(v\) eğitim setinden örneklenir. Bu, “ağırlık güncelle, veriyi güncelleme” ayrımının matematiksel ifadesidir.
NotSoru 2 — Neden son katmanda ReLU uygulanmaz
ReLU çıktıyı \([0,\infty)\) aralığına kırpar (negatifleri sıfırlar). Son katman çıktısı sonucu doğrudan verir: regresyonda negatif değerler gerekebilir, sınıflamada softmax/logit ham (kırpılmamış) skorlar ister. Son katmanda ReLU olsaydı bu bilgiyi yok ederdi. Bu yüzden son katman yalnız lineer: \(v_\ell = A_\ell v_{\ell-1} + b_\ell\).
NotSoru 3 — Uzaklık matrisi D’den Gram matrisi G=XᵀX’e nasıl ve neden geçilir
Uzaklığın karesini aç: \(d_{ij} = x_i\cdot x_i - 2\,x_i\cdot x_j + x_j\cdot x_j\). İlk ve son terim yalnız satıra/sütuna bağlı (iki rank-1 parça); orta terim \(-2\,x_i\cdot x_j\) aradığımız iç-çarpımları taşır. Köşegeni \(d=(x_i\cdot x_i)\) ile gösterip iki rank-1 parçayı çıkarınca özdeşlik: \(G = -\tfrac{1}{2}(D - \mathbf{1}d^T - d\mathbf{1}^T)\). Böylece verili \(D\)’den iç-çarpım (Gram) matrisini doğrudan elde edersin.
NotSoru 4 — G=XᵀX’ten X’i bulmanın iki yolu nedir; farkları
- Özdeğer kökü: \(G=Q\Lambda Q^T\), sonra \(X=Q\Lambda^{1/2}Q^T\) — simetrik bir \(X\), ama özçözüm gerektirir (pahalı). (2) Cholesky: \(G=LDL^T\), sonra \(X=D^{1/2}L^T\) — üçgen bir \(X\), çok daha hızlı. İkisi de \(X^T X=G\) sağlar. \(X\) tek değildir: herhangi ortogonal \(Q\) için \(QX\) de çözümdür (uzaklıklar rotasyonda değişmez), yani \(X\) ancak ortogonal dönüşüme kadar belirlidir.
32.11 Egzersizler
- Parametre sayımı. İki katmanlı bir ağ: \(v_0 \in \mathbb{R}^2\), \(A_1\) boyutu 3×2 + \(b_1 \in \mathbb{R}^3\), sonra \(A_2\) boyutu 1×3 + \(b_2 \in \mathbb{R}^1\). Ağırlık (\(x\)) toplam sayısını ve girdi özelliği (\(v_0\)) bileşen sayısını say. Hangisi büyük — sistem underdetermined mı? (Motor tanığı: \(A_1\) 3×2 + \(b_1\) 3 + \(A_2\) 1×3 + \(b_2\) 1 = 13 ağırlık vs \(v_0\) = 2 özellik → 13 ≫ 2, underdetermined.)
- ReLU ileri geçiş. \(A_1 = [[1,0],[0,1],[1,1]]\), \(b_1 = 0\), \(v_0 = (1, -2)\). Lineer adım \(A_1 v_0\)’ı hesapla, sonra \(v_1 = \text{ReLU}(A_1 v_0)\)’ı bul (her bileşene \(\max(0,\cdot)\)). (Motor tanığı: lineer adım \(A_1 v_0 = (1, -2, -1)\); ReLU sonrası \(v_1 = (1, 0, 0)\) — negatifler kırpılır.)
- Kayıp eşleştirme. Üç görev için uygun kaybı seç: (a) ev fiyatı tahmini, (b) kedi/köpek ikili sınıflama, (c) 10-sınıf rakam tanıma. Seçenekler: kare kayıp (L2), cross-entropy. Her eşleştirmeyi bir cümleyle gerekçelendir.
- Uzaklık → Gram. Düzlemde 3 nokta: \(x_1=(0,0)\), \(x_2=(3,0)\), \(x_3=(0,4)\). Uzaklık-kare matrisi \(D\)’yi (\(d_{ij}=\|x_i-x_j\|^2\)) yaz. Sonra köşegen \(d=(0,9,16)\) ile \(G=-\tfrac{1}{2}(D-\mathbf{1}d^T-d\mathbf{1}^T)\)’yi hesapla; \(G\)’nin gerçek iç-çarpımlarla (\(x_i\cdot x_j\)) eşleştiğini doğrula. (Motor tanığı: \(D = [[0,9,16],[9,0,25],[16,25,0]]\); \(G = \text{diag}(0,9,16) = X^T X\); \(G_{23} = -\tfrac{1}{2}(25-16-9) = 0\), dik kenarlar.)
- (Ders 34 habercisi) İki nokta kümen var; biri diğerinin döndürülüp ötelenmiş (ve hafif gürültülü) hali. En iyi ortogonal hizalamayı (rotasyon \(Q\)) nasıl bulursun? Bir tahmin yaz — Ders 34 “Procrustes problemi”ni (SVD ile en iyi \(Q\)) işliyor.
32.12 Sonraki Ders İçin Hazırlık
Ders 34: Uzaklık Matrisleri, Procrustes Problemi. Bu dersin uzaklık-matrisi çözümünü tamamlar ve Procrustes problemine geçer: iki nokta kümesini en iyi ortogonal dönüşümle (rotasyon) hizalama. Çözüm SVD’den gelir (en iyi \(Q = UV^T\)). Geometrik kurtarma + hizalama bloğunun devamı — sinyal/CNN/graf bloğunun ortası.
UyarıHazırlık
Bu dersin Egzersiz 5’inin sorduğu soruyu zihninde tut: iki nokta kümesi birbirinin döndürülüp ötelenmiş hâliyse, en iyi ortogonal hizalamayı (rotasyon \(Q\)) nasıl bulursun? Şekil 32.7’in gösterdiği gibi — uzaklıklardan kurtarılan konum döndürülmüş görünür; Ders 34 Procrustes problemini işler: SVD ile en iyi ortogonal \(Q = UV^T\). Bu derste açtığımız “uzaklıklardan konum” çözümünün hizalama ile tamamlanmasıdır.
32.13 Anahtar Kavramlar (Cheat Sheet)
| Kavram | Formül / Fikir | Strang (dk) |
|---|---|---|
| Öğrenme fonksiyonu | \(F(x,v)\); \(x\) = ağırlıklar, \(v\) = özellik vektörleri | 2m05 |
| Ağ katmanı | \(v_k = \text{ReLU}(A_k v_{k-1}+b_k)\); son katman ReLU’suz | 4m09 |
| x underdetermined | #ağırlık ≫ #özellik → sonsuz çözüm | 8m12 |
| Kayıp fonksiyonları | kare / L1 / hinge / cross-entropy (NN: cross-entropy) | 16m22 |
| Uzaklık problemi | \(d_{ij} = \|x_i-x_j\|^2\); uzaklıktan konum | 18m25 |
| Anahtar özdeşlik | \(G = X^T X = -\tfrac{1}{2}(D-\mathbf{1}d^T-d\mathbf{1}^T)\) | 39m10 |
| Özdeğer kökü | \(X = Q\Lambda^{1/2}Q^T\) (simetrik, pahalı) | 49m24 |
| Cholesky | \(X = D^{1/2}L^T\) (üçgen, hızlı) | 53m31 |
32.14 ML Bağlantıları Özeti
- F(x,v) = param vs veri: ağırlıklar optimize edilir, veri sabit; PyTorch
nn.ParametervsTensor; Karpathy micrograd/makemore’un öğrenme fonksiyonu. - Katmanlı ReLU: MLP ileri geçişi (
nn.Linear+nn.ReLU); son katman ham çıktı (regresyon) ya da softmax öncesi logit (sınıflama). - Underdetermined ağlar: aşırı-parametreli derin öğrenme; implicit bias SGD’yi düz/küçük-normlu minimuma çeker (Ders 10).
- Kayıplar: cross-entropy (sınıflama, makemore NLL), kare (regresyon/MSE), hinge (SVM), L1 (Lasso/seyreklik).
- Uzaklık matrisi → MDS/manifold: Isomap, t-SNE’nin atası; sensör lokalizasyonu, NMR molekül şekli; Gram matrisi = kernel matrisi.
- PSD kök (Cholesky / özdeğer): Gauss süreçleri, Kalman, çok-değişkenli normalden örnekleme; Cholesky \(O(n^3/3)\) en ucuz kök. Ders 5-6 (PSD/SVD) temeli.
- Geriye köprü: Ders 26 (NN ilk hali), Ders 25 (SGD/finite-sum kayıp), Ders 5-6 (PSD/SVD), Ders 18 (parametre sayımı), Ders 10 (implicit bias). Paralel: Karpathy micrograd/makemore \(F\), fast.ai Learner, NYU H1-2.
ÖnemliKapanış
“…most important was to get the structure of a neural net straight, separating the v’s, the sample vectors, from the x’s, the weights.” — Strang, 55:35
Bu ders iki yüzü gösterir: ileri yönde ağ, ağırlık (\(x\)) ve veriyi (\(v\)) \(F(x,v)\)’de birleştirir (öğrenme); ters yönde uzaklık matrisi, ölçülen uzaklıklardan geometriyi (konumları) PSD kökle geri kurar — derin öğrenme ile klasik geometrinin aynı lineer cebir diline yaslandığı yer.